---
title: "Derin Öğrenmeye Giriş ve Lineer Cebir Motivasyonu"
subtitle: "NYU'nun iki hocalı ritmi: LeCun cebirle 'temsili veriden öğren' der, Canziani geometriyle 'ağ uzayın kumaşını gerer' diye gösterir — aynı gerçeğin iki dili"
---
::: {.callout-note title="Bölüm bilgisi"}
- **LeCun'un Lecture videosu:** [YouTube — Lecture 01: History, motivation, and evolution of Deep Learning](https://www.youtube.com/watch?v=0bMe_vCZo30) (≈99 dk)
- **Canziani'nin Practicum videosu:** [YouTube — Practicum 01: Classification, linear algebra, visualization](https://www.youtube.com/watch?v=5_qrxVq1kvc) (≈52 dk)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Yann LeCun (Lecture, teorik) + Alfredo Canziani (Practicum, pratik)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈35 dk
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU H1 sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan affine_transform / make_spiral / svd_demo / linear_transforms /
# energy_landscape / make_moons_np / mlp_train + COL_* + apply_style /
# draw_pipeline / style_legend isimlerini kullanır. _engine.py saf numpy
# (torch YOK); _viz.py NYU Violet+gold paleti. İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri ayırır)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
return dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d1}
Bu, NYU Deep Learning'in ilk haftası — ve kursun **iki hocalı ritmini** ilk kez görüyorsun. Önce **Yann LeCun** (Lecture, Pazartesi akşamı) büyük resmi çizer: derin öğrenme nedir, nereden geldi, neden şimdi patladı. Sonra **Alfredo Canziani** (Practicum, Salı akşamı) aynı fikirleri somut lineer cebire ve PyTorch'a oturtur. LeCun "neden"i, Canziani "nasıl"ı anlatır.
LeCun'un büyük fikri tek cümlede: geleneksel örüntü tanıma (pattern recognition) bir görevi çözmek için **insan eliyle tasarlanmış öznitelik çıkarıcısı** (feature extractor) ister; derin öğrenme bu temsili (representation) **doğrudan veriden** — uçtan uca, katman katman — öğrenir. Canziani ise bunun geometrisini gösterir: bir görüntü, milyonlarca boyutlu bir uzayda tek bir **nokta**dır; bir sinir ağı, bu uzayın "kumaşını" gere gere benzer noktaları ayrılabilir hale getiren bir dönüşümdür.
Bu haftanın üç ana fikri:
1. **Derin öğrenme = temsili veriden öğrenmek.** Elle öznitelik tasarlamak yerine, ağ kendi özniteliklerini katman katman kurar.
2. **"Derin" kelimesi çok katmanlılıktan gelir** — başka bir gizem yok. Her katman ayarlanabilir parametreler + bir **doğrusal-olmama** (nonlinearity) içerir.
3. **Doğrusal-olmama şart.** İki ardışık doğrusal katman tek bir doğrusal katmana çöker (LeCun ve Canziani aynı noktayı ayrı ayrı vurgular).
```{mermaid}
%%| echo: false
flowchart TB
AI["Yapay Zekâ (AI)"]
ML["Makine Öğrenmesi (ML)"]
DL["Derin Öğrenme (DL):<br/>çok katmanlı sinir ağı"]
AI --> ML --> DL
DL --> LeCun["LeCun (cebir):<br/>iki doğrusal = tek doğrusal"]
DL --> Canziani["Canziani (geometri):<br/>tek katman sadece döner/ölçekler"]
LeCun --> Sonuc["Doğrusal-olmama şart:<br/>derinlik ancak bükmeyle gelir"]
Canziani --> Sonuc
```
::: {.callout-tip title="Builder Notu — İki Yön: Geriye ve İleriye"}
**Geriye (önkoşul kurslar):**
- **Perceptron = Wx + b** → Phase 1 DL Ders 1 perceptron + 18.06 matris-vektör çarpımı. Canziani'nin "ağ = matrisler + doğrusal-olmama" çerçevesi doğrudan lineer cebirdir.
- **Lineer dönüşüm tipleri (rotation/scaling/shearing/reflection) + SVD** → 18.06 (Ders 21 özdeğer, Ders 29 SVD) + Phase 2 18.065 ileri.
- **Görüntü = yüksek-boyutlu uzayda nokta, veri düşük-boyutlu altuzayda** → **manifold hipotezi**; 18.06 altuzay + Stat 110 çok-değişkenli dağılım.
**İleriye (production / research):**
- LeCun'un "en sevdiği konu" olarak açtığı **enerji-tabanlı modeller (EBM)** — bu kursun omurgası; Hafta 7'de başlar, bugün JEPA'ya uzanır (ileriye köprü, post-2020).
- Öznitelik öğrenme hiyerarşisi → **öz-denetimli öğrenme (SSL)** (Hafta 8-10) ve **graf ağları (GCN)** (Hafta 13).
- Manifold sezgisi → temsil öğrenme (representation learning) ve boyut indirgemenin tüm modern kullanımları.
:::
::: {.callout-important title="Tek Bir Cümle"}
Derin öğrenme, elle tasarlanan öznitelik çıkarıcısını çöpe atar ve temsili doğrudan veriden öğrenir; ve bu öğrenme, geometrik olarak veri uzayını doğrusal dönüşümler + doğrusal-olmamalarla yeniden şekillendirmekten ibarettir.
:::
## (LeCun) Derin Öğrenme Nedir? Temsili Veriden Öğrenmek {#sec-dl-nedir}
LeCun ilk dersi kasıtlı olarak yüzeysel ve geniş tutuyor: "bu ilk ders gerçekten geniş bir giriş olacak — derin öğrenmenin ne olduğu, ne yapabildiği ve ne yapamadığı." Tüm kursun yayını burada çiziliyor, sonra her konuya tek tek dönülecek.
Çekirdek fikir şu: yapay zekâ (AI) ⊃ makine öğrenmesi (ML) ⊃ derin öğrenme (DL). DL, ML'in **çok katmanlı sinir ağı** kullanan alt-kümesidir. Ama LeCun'un asıl vurgusu mimari değil, bir *düşünce değişimi*: geleneksel sistemde bir görevi çözmek için **temsili (representation) insan eliyle** tasarlarsın; derin öğrenmede bu temsili **veriden öğrenirsin**.
Bunu somutlaştırmak için LeCun klasik **örüntü tanıma (pattern recognition)** şemasını çiziyor (Bölüm 3'te ayrıntılı). Şimdilik tek cümle: derin öğrenmenin tüm vaadi, "iyi öznitelikler (features) nelerdir?" sorusunu mühendisten alıp **öğrenme algoritmasına** devretmektir.
::: {.callout-tip title="Builder Notu — Temsil Öğrenme Nereye Bağlanır"}
**Geriye (Phase 1 DL):** "Temsili veriden öğrenmek" fikri MIT 6.S191 Ders 1'in de açılışıydı (elle mühendislik vs öğrenilen hiyerarşi). NYU bu fikri çok daha teorik bir zemine — enerji-tabanlı modeller ve öz-denetimli öğrenmeye — taşıyacak.
**İleriye:** "Hangi temsil iyi?" sorusu, modern **representation learning** ve **foundation model** çağının tam kalbidir. Bugün bir modelin değeri, büyük ölçüde öğrendiği temsilin kalitesiyle ölçülür.
:::
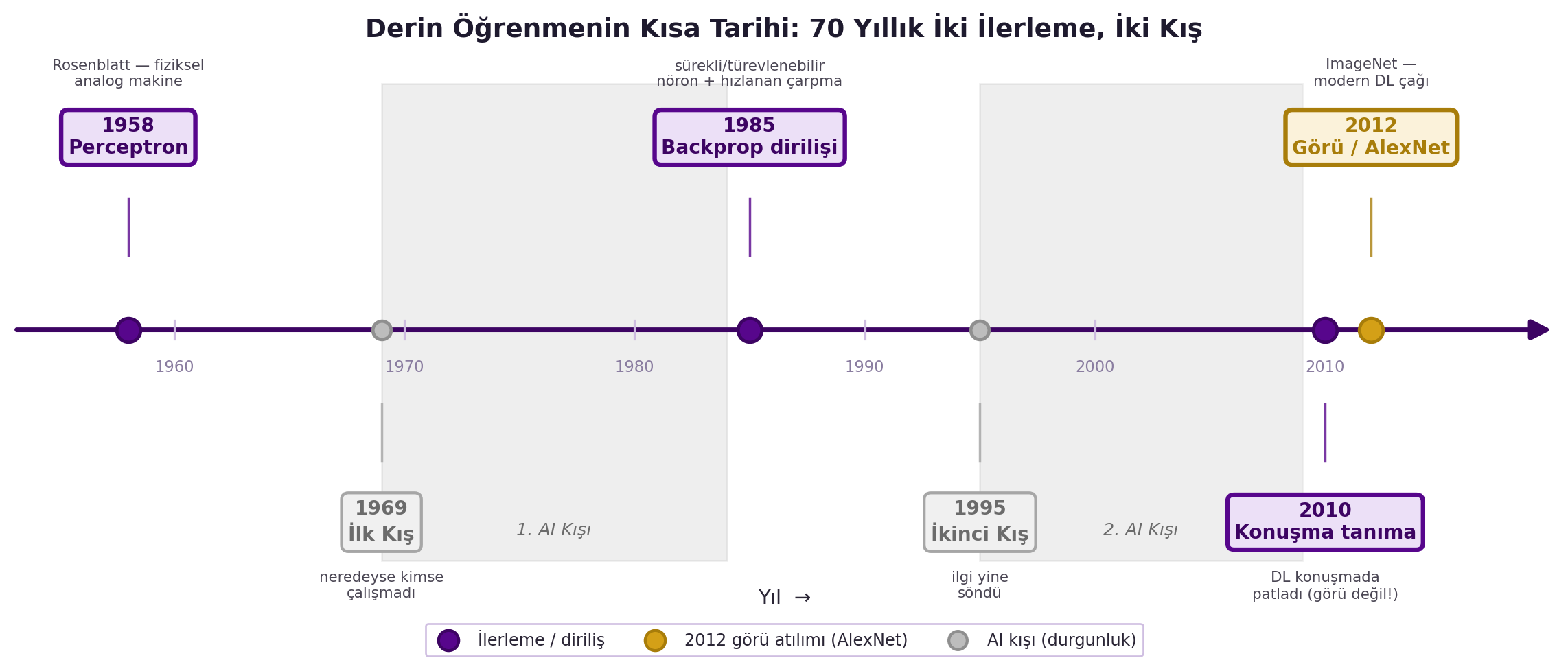
## (LeCun) Kısa Tarih: Rosenblatt'ın Perceptron'undan Bugüne {#sec-tarih}
LeCun derin öğrenmenin 70 yıllık inişli çıkışlı tarihini anlatıyor — ve bu tarih, alanın neden "şimdi" patladığını açıklıyor.
```{python}
#| label: fig-history-timeline
#| fig-cap: "Derin öğrenmenin yaklaşık 70 yıllık tarihi: 1958 Perceptron'dan 2012 AlexNet'e iki büyük ilerleme (violet/gold vurgulu) ve aralarındaki iki AI kışı (soluk gri) yatay zaman ekseni üzerinde."
np.random.seed(0)
# Derin öğrenmenin ~70 yıllık tarihi: yatay zaman ekseni üstünde olaylar.
# Her olay: (yıl, başlık, alt-açıklama, tür)
# tür "dirilis" -> NYU violet/gold vurgulu nokta
# tür "kis" -> soluk gri dönem (AI kışı)
events = [
(1958, "Perceptron", "Rosenblatt — fiziksel\nanalog makine", "dirilis"),
(1969, "İlk Kış", "neredeyse kimse\nçalışmadı", "kis"),
(1985, "Backprop dirilişi", "sürekli/türevlenebilir\nnöron + hızlanan çarpma", "dirilis"),
(1995, "İkinci Kış", "ilgi yine\nsöndü", "kis"),
(2010, "Konuşma tanıma", "DL konuşmada\npatladı (görü değil!)", "dirilis"),
(2012, "Görü / AlexNet", "ImageNet —\nmodern DL çağı", "dirilis"),
]
# Kış dönemleri (soluk gri bantlar): (başlangıç, bitiş, etiket)
winters = [
(1969, 1984, "1. AI Kışı"),
(1995, 2009, "2. AI Kışı"),
]
t0, t1 = 1953, 2020
fig, ax = plt.subplots(figsize=(12.0, 5.2))
apply_style(ax)
ax.set_xlim(t0, t1)
ax.set_ylim(-3.2, 3.4)
# --- Kış dönemlerini soluk gri bant olarak çiz ---
for ws, we, wlbl in winters:
ax.axvspan(ws, we, ymin=0.04, ymax=0.96, color="#9a9a9a", alpha=0.16, zorder=0)
ax.text((ws + we) / 2, -2.55, wlbl, ha="center", va="center",
fontsize=9.5, style="italic", color="#6b6b6b", zorder=1)
# --- Ana zaman ekseni: yatay ok ---
ax.annotate(
"", xy=(t1, 0), xytext=(t0, 0),
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_D, lw=2.6,
mutation_scale=22), zorder=2,
)
# Onyıl işaretleri
for yr in range(1960, 2011, 10):
ax.plot([yr, yr], [-0.12, 0.12], color=COL_GRID, lw=1.2, zorder=2)
ax.text(yr, -0.38, str(yr), ha="center", va="top",
fontsize=8.5, color="#8a7da0", zorder=2)
# --- Olayları üst/alt dönüşümlü yerleştir (okunabilirlik) ---
# 2010 konuşma aşağı, 2012 görü yukarı -> sağ uçta çakışma olmasın
ups = [1, -1, 1, -1, -1, 1] # her olayın hangi tarafa gideceği
y_stub = 0.0
for (yr, title, sub, kind), up in zip(events, ups):
if kind == "dirilis":
# 2012 görü -> gold vurgu; diğer diriliş -> violet
is_vision = (yr == 2012)
dot_c = COL_GOLD if is_vision else COL_VIOLET
dot_edge = COL_GOLD_D if is_vision else COL_VIOLET_D
box_fc = "#fbf2da" if is_vision else "#ece0f7"
box_ec = COL_GOLD_D if is_vision else COL_VIOLET
title_c = COL_GOLD_D if is_vision else COL_VIOLET_D
ms, lw = 13, 2.4
else: # kış noktası: soluk gri
dot_c = "#bdbdbd"
dot_edge = "#8f8f8f"
box_fc = "#f0f0f0"
box_ec = "#a6a6a6"
title_c = "#6b6b6b"
ms, lw = 10, 1.6
# eksen üstündeki olay noktası
ax.plot(yr, y_stub, "o", ms=ms, mfc=dot_c, mec=dot_edge,
mew=1.8, zorder=4)
# bağlantı çizgisi (eksen -> kutu)
ytip = up * 0.95
yhead = up * 2.45
ax.plot([yr, yr], [ytip, yhead - up * 0.78],
color=box_ec, lw=1.3, ls="-", zorder=3, alpha=0.8)
# etiket kutusu
va = "bottom" if up > 0 else "top"
ax.text(
yr, yhead, f"{yr}\n{title}",
ha="center", va="center", zorder=5,
fontsize=10.5, fontweight="bold", color=title_c,
bbox=dict(boxstyle="round,pad=0.35", fc=box_fc, ec=box_ec, lw=lw),
)
# alt-açıklama (kutunun biraz dışında)
yo = yhead + up * 0.62
ax.text(yr, yo, sub, ha="center", va=va,
fontsize=8.0, color=COL_TEXT, zorder=5, alpha=0.85)
# --- Başlık + eksen etiketi ---
ax.set_title("Derin Öğrenmenin Kısa Tarihi: 70 Yıllık İki İlerleme, İki Kış",
fontsize=14, fontweight="bold", color=COL_INK, pad=14)
ax.set_xlabel("Yıl →", fontsize=11, color=COL_TEXT)
ax.set_yticks([])
ax.set_xticks([]) # kendi onyıl işaretlerimi çiziyorum; çift tick satırı olmasın
ax.grid(False)
for sp in ["left", "right", "top", "bottom"]:
ax.spines[sp].set_visible(False)
# --- Lejant: diriliş vs kış ---
Line2D = matplotlib.lines.Line2D
legend_items = [
Line2D([0], [0], marker="o", color="none", mfc=COL_VIOLET, mec=COL_VIOLET_D,
mew=1.6, ms=11, label="İlerleme / diriliş"),
Line2D([0], [0], marker="o", color="none", mfc=COL_GOLD, mec=COL_GOLD_D,
mew=1.6, ms=11, label="2012 görü atılımı (AlexNet)"),
Line2D([0], [0], marker="o", color="none", mfc="#bdbdbd", mec="#8f8f8f",
mew=1.6, ms=10, label="AI kışı (durgunluk)"),
]
leg = ax.legend(handles=legend_items, loc="lower center",
bbox_to_anchor=(0.5, -0.16), ncol=3,
frameon=True, framealpha=0.95, edgecolor=COL_GRID,
fontsize=9.0)
leg.get_frame().set_facecolor(COL_WHITE)
for tx in leg.get_texts():
tx.set_color(COL_TEXT)
fig.tight_layout()
```
**1950'ler — Perceptron.** Frank Rosenblatt, ağırlıkları öğrenmeyle değişen basit sinir ağlarını hayal etti. İlk perceptron bir yazılım değildi:
> "this was a physical analog computer, it was not a three-line Python program... it was a gigantic machine with wires and optical sensors... the weights were potentiometers, potentiometers had motors on them so they could rotate for the learning algorithm." — LeCun, 17:18
Yani ağırlıklar, motorla dönen fiziksel potansiyometrelerdi. Sinir ağı fikri 1940'larda doğdu, 1950'lerin sonunda yükseldi.
**1969-1984 — İlk kış.** Dönemin algoritmaları yalnızca çok basit örüntü tanıma yapabiliyordu. LeCun'un deyişiyle, kabaca 1969 ile 1984 arasında dünyada neredeyse hiç kimse sinir ağları üzerinde çalışmadı — birkaç izole araştırmacı dışında, çoğu Japonya'da (kendi içine kapalı bir araştırma ekosistemi olduğu için modalara kapılmadılar).
**1985 — Backprop ile diriliş.** Çok katmanlı ağları eğiten **backpropagation** ortaya çıktı. Peki neden daha önce değil? LeCun iki sebep veriyor:
1. **Yanlış nöronlar.** 60'larda kullanılan McCulloch-Pitts nöronları ikiliydi (binary). Gradient descent için **sürekli, türevlenebilir** bir aktivasyon gerekir; bu fikre kimse varmamıştı.
2. **Çarpma pahalıydı.** İkili nöronlar çarpma gerektirmez (yalnızca toplama). Sürekli nöronlar ağırlık × aktivasyon çarpımı ister; 1980'lerden önce kayan-nokta çarpımı çok yavaştı. Donanım ancak 80'lerin ortasında yeterince hızlandı.
**1995-2010 — İkinci kış ve diriliş.** 1985-1995 dalgası 1995'te söndü. Asıl geri dönüş **2010 civarı konuşma tanımayla** oldu (ImageNet'le değil!): "it didn't start with ImageNet, it started with speech recognition around 2010." 18 ay içinde her büyük oyuncu sinir ağlı konuşma tanıma sistemleri kurdu. 2012-2013'te aynı devrim **bilgisayarlı görüde** (AlexNet) yaşandı.
::: {.callout-tip title="Builder Notu — Türevlenebilirlik ve Donanım"}
**Geriye:** Backprop'un neden 1985'i beklediği — "sürekli, türevlenebilir aktivasyon" — doğrudan Calculus türev/zincir kuralıdır (Phase 1 Calculus Ders 4). İkili → sürekli nöron geçişi, gradient descent'in ön koşuludur.
**İleriye:** "Donanım yeterince hızlanınca alan patladı" gözlemi bir builder gerçeğidir: GPU/TPU throughput, modern DL'in motorudur. Aynı kalıp bugün de geçerli — ölçek (compute) çoğu sıçramanın arkasındadır (scaling laws).
:::
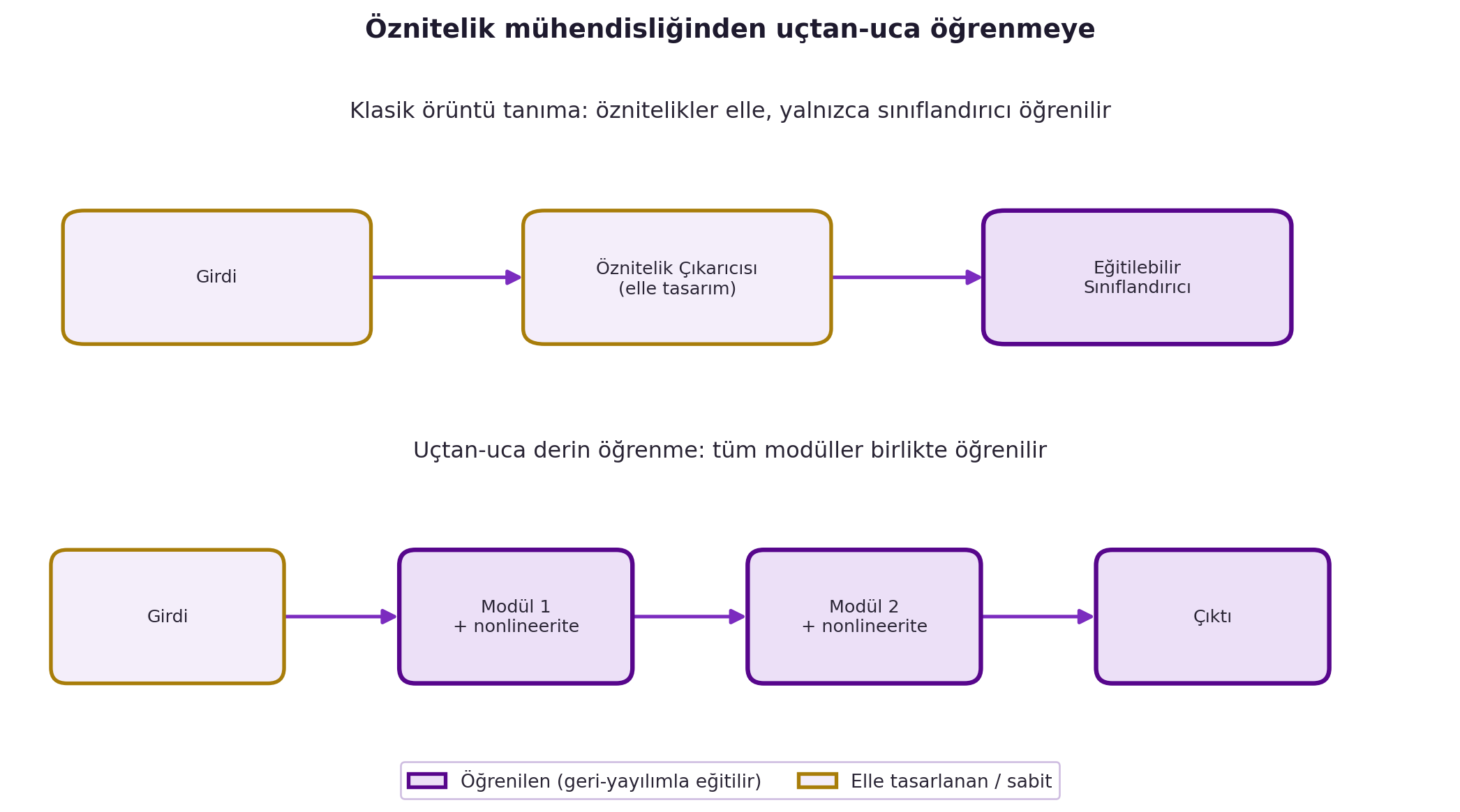
## (LeCun) Örüntü Tanıma ve Öznitelik Çıkarıcısı (Feature Extractor) {#sec-feature-extractor}
LeCun, derin öğrenme öncesi dünyayı anlatıyor — çünkü derin öğrenmenin ne yıktığını ancak böyle görürsün. Kabaca dört on yıl boyunca örüntü tanımanın standart şeması iki aşamalıydı:
**girdi → öznitelik çıkarıcısı (feature extractor) → eğitilebilir sınıflandırıcı (classifier)**
Öznitelik çıkarıcısı, girdiden görevle ilgili karakteristikleri çeker ve bir **öznitelik vektörü** üretir (sayılardan oluşan bir liste). Bu vektör, eğitilebilir bir sınıflandırıcıya verilir. Perceptron durumunda sınıflandırıcı basitçe bir **ağırlıklı toplam + eşik** hesaplar:
$\hat{y} = g\!\left(\mathbf{w}^\top \mathbf{x} + b\right)$
Buradaki kritik sorun şu: öznitelik çıkarıcısını **elle tasarlaman** gerekir. Bir yüzü tanımak istiyorsan "göz nasıl tespit edilir? — herhalde bir yerde koyu bir daire vardır" gibi kuralları sen yazarsın.
> "the entire literature of pattern recognition... was focused on this part, the feature extractor: how do you design a feature extractor for a particular problem?" — LeCun, 26:46
LeCun'un vurgusu: on yıllar boyunca tüm emek bu elle-tasarım aşamasına gitti, sınıflandırıcıya çok az.
```{python}
#| label: fig-pattern-vs-e2e
#| fig-cap: "Klasik örüntü tanıma (elle tasarlanan öznitelik çıkarıcısı + eğitilebilir sınıflandırıcı) ile uçtan-uca derin öğrenme (tüm modüllerin geri-yayılımla birlikte öğrenildiği) boru hatlarının karşılaştırması."
np.random.seed(0)
fig, (ax_top, ax_bot) = plt.subplots(2, 1, figsize=(11, 5.6))
# ÜST: Klasik örüntü tanıma — öznitelik çıkarıcı ELLE (gold), sınıflandırıcı ÖĞRENİLEN (violet)
draw_pipeline(
ax_top,
[
("Girdi", False),
("Öznitelik Çıkarıcısı\n(elle tasarım)", False),
("Eğitilebilir\nSınıflandırıcı", True),
],
title="Klasik örüntü tanıma: öznitelikler elle, yalnızca sınıflandırıcı öğrenilir",
)
# ALT: Uçtan-uca derin öğrenme — TÜM modüller ÖĞRENİLEN (violet)
draw_pipeline(
ax_bot,
[
("Girdi", False),
("Modül 1\n+ nonlineerite", True),
("Modül 2\n+ nonlineerite", True),
("Çıktı", True),
],
title="Uçtan-uca derin öğrenme: tüm modüller birlikte öğrenilir",
)
# Tema-uyumlu açıklama (legend) — proxy patch'lerle
legend_handles = [
plt.Rectangle((0, 0), 1, 1, facecolor="#ece0f7", edgecolor=COL_VIOLET, linewidth=2.0, label="Öğrenilen (geri-yayılımla eğitilir)"),
plt.Rectangle((0, 0), 1, 1, facecolor=COL_BG, edgecolor=COL_GOLD_D, linewidth=2.0, label="Elle tasarlanan / sabit"),
]
fig.legend(
handles=legend_handles, loc="lower center", ncol=2,
frameon=True, framealpha=0.95, edgecolor=COL_GRID,
bbox_to_anchor=(0.5, -0.04), fontsize=10,
)
for t in fig.legends[0].get_texts():
t.set_color(COL_TEXT)
fig.suptitle(
"Öznitelik mühendisliğinden uçtan-uca öğrenmeye",
color=COL_INK, fontsize=14, fontweight="bold", y=1.02,
)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Wx+b: Perceptron Cebiri"}
**Geriye (18.06):** Perceptron'un çekirdeği `wᵀx + b` — bir **nokta çarpımı + öteleme**, yani 18.06'nın temel işlemi. Bir katmanda bu, matris-vektör çarpımına (Wx + b) genişler.
**İleriye:** "Öznitelik mühendisliği" bugün hâlâ klasik ML'de (tablo verisi, XGBoost) yaşıyor; ama görü/dil/ses gibi yüksek-boyutlu alanlarda derin öğrenme onu tamamen değiştirdi. Bu ayrım, bir problemde "deep mi, klasik ML mi?" kararının temelidir.
:::
## (LeCun) Derin Öğrenme = Uçtan Uca Öğrenme (ve Neden Doğrusal-Olmama Şart) {#sec-uctan-uca}
Derin öğrenmenin getirdiği fikir: iki aşamalı (biri elle kurulmuş) süreci bırak, **tüm görevi uçtan uca öğren**. Sistemi bir **modüller dizisi (cascade)** olarak kur; her modülün ayarlanabilir parametreleri ve bir **doğrusal-olmaması (nonlinearity)** vardır; bu katmanları üst üste istifle.
> "the only reason for the deep word in deep learning is the fact that there are multiple layers — there is nothing more to that." — LeCun, 28:14
İlk modülün parametrelerini, çıktıyı istediğin yöne yaklaştıracak biçimde nasıl ayarlarsın? İşte **backpropagation** bunu yapar (Hafta 2).
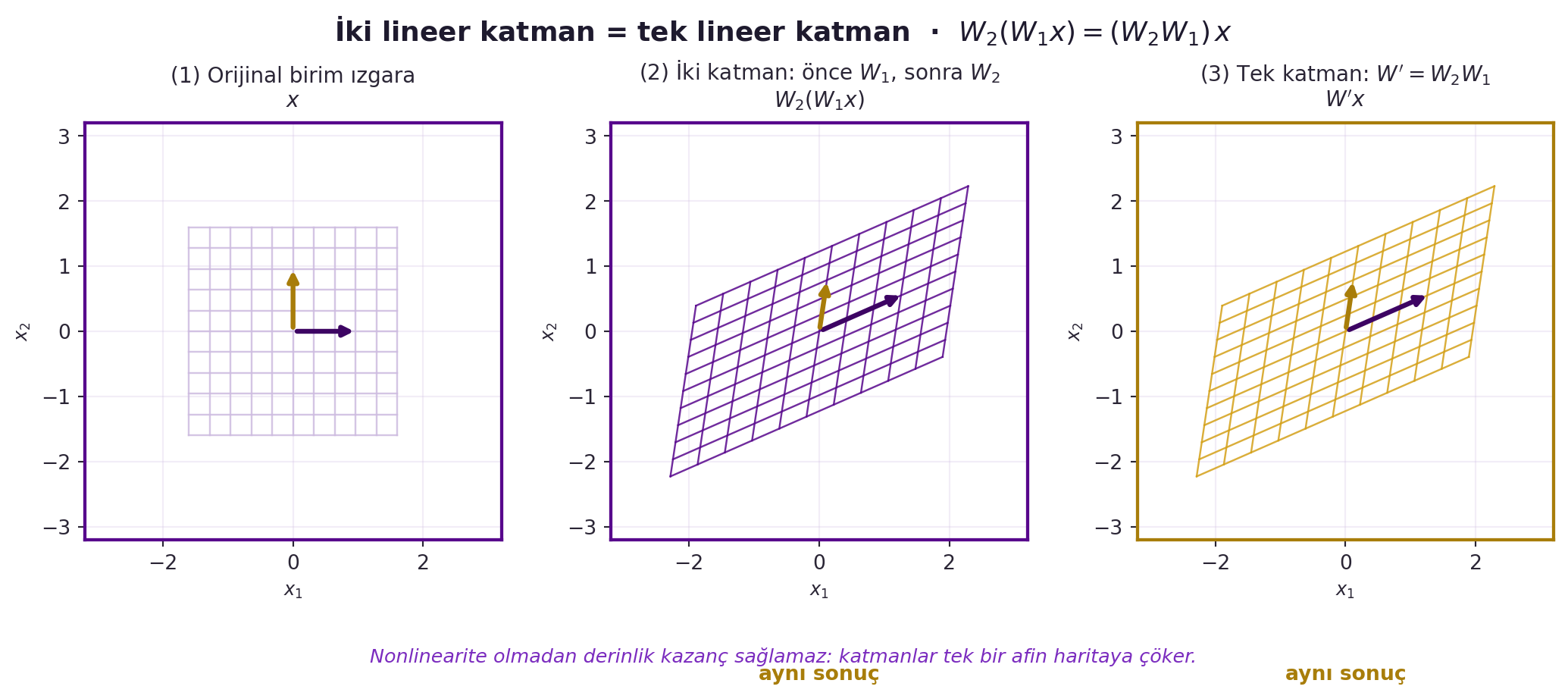
Peki neden her modül **doğrusal-olmayan** olmak zorunda? LeCun'un cevabı kesin: iki ardışık doğrusal modül tek bir doğrusal modüle çöker. İki doğrusal fonksiyonun bileşkesi yine doğrusaldır:
$W_2 \left(W_1 \mathbf{x}\right) = \left(W_2 W_1\right) \mathbf{x} = W' \mathbf{x}$
> "if you have two successive modules and they're both linear, you can collapse them into a single linear... there's no point having multiple layers if those layers are linear." — LeCun, 28:48
Yani derinlik ancak katmanlar arasına doğrusal-olmama girerse anlam kazanır. **Bu noktayı aklında tut** — Canziani aynı fikri Practicum'da uzay-germe animasyonuyla *gösterecek* (Bölüm 9). İki hoca, aynı gerçeği iki dilde anlatıyor: LeCun cebirle, Canziani geometriyle. @fig-linear-collapse bunu birim ızgara üzerinde gösterir: önce $W_1$ sonra $W_2$ uygulamak ile tek matris $W' = W_2 W_1$ uygulamak aynı sonucu verir.
```{python}
#| label: fig-linear-collapse
#| fig-cap: "İki ardışık lineer katmanın tek bir matrise çökmesi: W₂(W₁x) ile (W₂W₁)x aynı dönüşümü verir, bu yüzden nonlinearite olmadan derinlik kazanç sağlamaz."
np.random.seed(0)
T = linear_transforms()
W1 = T["rotation"] # 1. katman: dönme
W2 = T["shearing"] # 2. katman: kayma (shear)
Wp = W2 @ W1 # çökmüş tek matris W' = W2·W1
grid = unit_grid(n=11, lim=1.6, fine=61)
def draw_grid(ax, lines, transforms, color):
"""Izgara çizgilerine sırayla transforms uygular ve çizer."""
for ln in lines:
Y = ln
for W in transforms:
Y = affine_transform(Y, W)
ax.plot(Y[:, 0], Y[:, 1], color=color, lw=0.9, alpha=0.85)
panels = [
("(1) Orijinal birim ızgara\n$x$", [], COL_GRID, COL_VIOLET),
("(2) İki katman: önce $W_1$, sonra $W_2$\n$W_2(W_1 x)$", [W1, W2], COL_VIOLET, COL_VIOLET),
("(3) Tek katman: $W' = W_2 W_1$\n$W' x$", [Wp], COL_GOLD, COL_GOLD_D),
]
fig, axes = plt.subplots(1, 3, figsize=(11, 4.2))
for ax, (ttl, tfs, gcol, frame) in zip(axes, panels):
draw_grid(ax, grid, tfs, gcol)
# birim vektörler (i, j) — dönüşümü vurgulamak için
for vec, vcol, vlab in [(np.array([[1.0, 0.0]]), COL_VIOLET_D, r"$\hat{e}_1$"),
(np.array([[0.0, 1.0]]), COL_GOLD_D, r"$\hat{e}_2$")]:
Yv = vec
for W in tfs:
Yv = affine_transform(Yv, W)
ax.annotate("", xy=(Yv[0, 0], Yv[0, 1]), xytext=(0, 0),
arrowprops=dict(arrowstyle="-|>", color=vcol, lw=2.4))
apply_style(ax)
ax.set_title(ttl, fontsize=10.5, color=COL_TEXT, pad=8)
ax.set_aspect("equal")
ax.set_xlim(-3.2, 3.2)
ax.set_ylim(-3.2, 3.2)
ax.set_xlabel("$x_1$", fontsize=9)
ax.set_ylabel("$x_2$", fontsize=9)
for sp in ax.spines.values():
sp.set_color(frame)
sp.set_linewidth(1.6)
# Panel 2 ↔ 3 aynılığını vurgula
axes[1].text(0.5, -0.30, "aynı sonuç", transform=axes[1].transAxes,
ha="center", va="top", fontsize=10, color=COL_GOLD_D, fontweight="bold")
axes[2].text(0.5, -0.30, "aynı sonuç", transform=axes[2].transAxes,
ha="center", va="top", fontsize=10, color=COL_GOLD_D, fontweight="bold")
fig.suptitle("İki lineer katman = tek lineer katman · $W_2(W_1 x) = (W_2 W_1)\\,x$",
fontsize=13.5, color=COL_INK, fontweight="bold", y=1.02)
fig.text(0.5, -0.04,
"Nonlinearite olmadan derinlik kazanç sağlamaz: katmanlar tek bir afin haritaya çöker.",
ha="center", fontsize=9.5, color=COL_VIOLET_M, style="italic")
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Doğrusal Çöküş ve Uçtan Uca"}
**Geriye (18.06 + Phase 1 DL):** "Doğrusal ∘ doğrusal = doğrusal" tam olarak 18.06'nın bileşke lineer dönüşüm kuralıdır. Phase 1 DL Ders 1 de aynı çöküşü göstermişti — NYU bunu hem LeCun hem Canziani ile pekiştiriyor.
**İleriye:** Uçtan uca öğrenme (end-to-end), modern sistemlerin varsayılanıdır: ham pikselden/token'dan çıktıya tek bir türevlenebilir hat. "Modül + nonlinearity + istifle" reçetesi, bütün mimarilerin (CNN, transformer, GNN) ortak iskeletidir.
:::
## (LeCun) Optimizasyon, "Kimse Anlamıyor" ve Enerji-Tabanlı Modeller {#sec-ebm}
LeCun derin öğrenmenin nasıl çalıştığına geçiyor: öğrenme neredeyse her zaman **optimizasyon**dur, derin öğrenme ise neredeyse her zaman **gradient-tabanlı** optimizasyondur. Convex (dışbükey) durumda optimizasyon kuralları iyi anlaşılmıştır; ama derin öğrenmede maliyet fonksiyonu **convex değildir** — yerel minimumları, eyer noktaları vardır. Bu yüzden hedef fonksiyonun geometrisini anlamak önemlidir. Sonra LeCun'un en sevdiği itiraf geliyor:
> "it's important to understand the geometry of the objective function... but the big secret here is that nobody actually understands. So it's important to understand that nobody understands." — LeCun, 7:02
Yani alan, işe yarayan ama tam teorik temeli olmayan **sezgi + biraz teori + bol ampirik arayış** karışımı tricklerle ilerliyor: initialization, normalization, regularization (dropout), gradient clipping, momentum, ve egzotik bir konu olan **Lagrangian backprop** (Hafta 14'te döner).
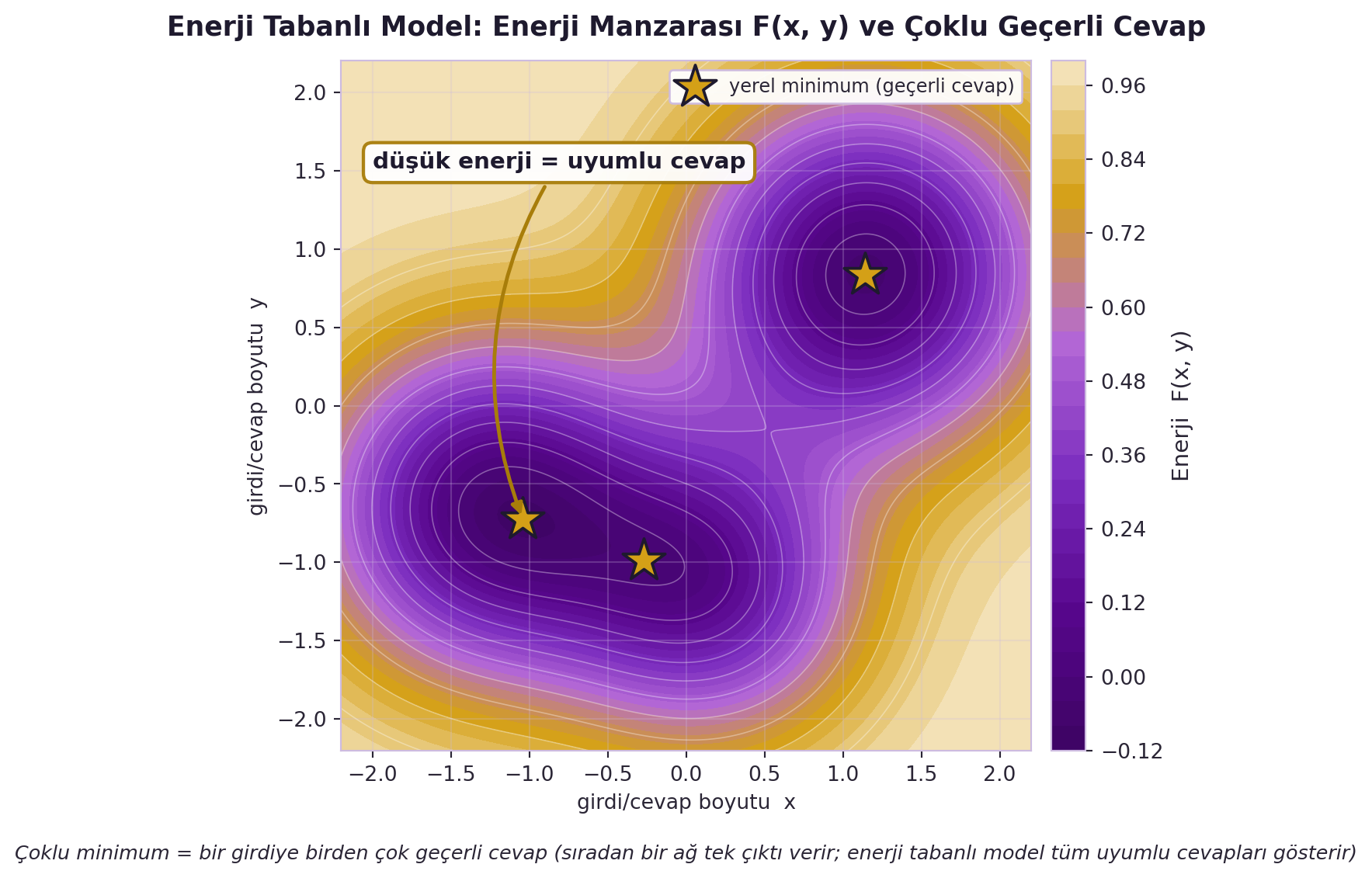
Sonra LeCun kursun omurgasını açıyor — en sevdiği konu, **enerji-tabanlı modeller (EBM)**:
> "energy based models — this is sort of a general formulation of a lot of different approaches to learning, whether they are supervised, unsupervised, self-supervised." — LeCun, 7:50
Fikir şu: bir sinir ağını "girdiyi çıktıya çeviren fonksiyon" olarak görmek kısıtlayıcıdır — bir girdiye yalnızca tek çıktı üretir. Oysa çoğu problemde bir girdiye **birden çok geçerli cevap** vardır. EBM bunu çözer: cevapları bir **enerji fonksiyonunun minimumları** yap; çıkarım (inference) bu enerjiyi minimize eden değerleri *arar*. Bu, sinir ağlarıyla "akıl yürütme"yi (reasoning) modellemenin bir yoludur.
```{python}
#| label: fig-ebm-energy
#| fig-cap: "Enerji tabanlı modelin F(x, y) enerji manzarası: koyu violet kuyular düşük enerjili yerel minimumları (gold yıldız) işaretler ve çoklu minimum bir girdiye birden çok geçerli cevabın karşılığıdır."
np.random.seed(0)
# F(x,y) enerji manzarasi: birkac Gauss kuyusu -> coklu yerel minimum
lim = 2.2
gx = np.linspace(-lim, lim, 320)
gy = np.linspace(-lim, lim, 320)
xx, yy = np.meshgrid(gx, gy)
F = energy_landscape(xx, yy)
# tema-uyumlu violet -> gold -> off-white kolormap (dusuk enerji = koyu violet)
from matplotlib.colors import LinearSegmentedColormap
ebm_cmap = LinearSegmentedColormap.from_list(
"ebm_violet_gold",
[COL_VIOLET_D, COL_VIOLET, COL_VIOLET_M, COL_VIOLET_SOFT, COL_GOLD, "#f6e7c4"],
)
fig, ax = plt.subplots(figsize=(9.0, 6.0))
apply_style(ax)
cf = ax.contourf(xx, yy, F, levels=28, cmap=ebm_cmap)
cl = ax.contour(xx, yy, F, levels=12, colors=COL_WHITE, linewidths=0.6, alpha=0.35)
cb = fig.colorbar(cf, ax=ax, pad=0.02, fraction=0.046)
cb.set_label("Enerji F(x, y)", color=COL_TEXT, fontsize=11)
cb.ax.tick_params(colors=COL_TEXT)
cb.outline.set_edgecolor(COL_GRID)
# Yerel minimumlari sayisal olarak izgaradan bul (kuyu merkezleri yakini)
wells = [(-1.25, -0.65), (1.15, 0.85), (0.15, -1.15)]
mins = []
for cx, cy in wells:
sel = ((xx - cx) ** 2 + (yy - cy) ** 2) < 0.45 ** 2
idx = np.argmin(np.where(sel, F, np.inf))
r, c = np.unravel_index(idx, F.shape)
mins.append((xx[r, c], yy[r, c]))
mx = [m[0] for m in mins]
my = [m[1] for m in mins]
ax.scatter(mx, my, marker="*", s=460, c=COL_GOLD, edgecolors=COL_INK,
linewidths=1.4, zorder=6, label="yerel minimum (geçerli cevap)")
# Annotation: dusuk enerji = uyumlu cevap
ax.annotate(
"düşük enerji = uyumlu cevap",
xy=mins[0], xycoords="data",
xytext=(-2.0, 1.55), textcoords="data",
fontsize=11, color=COL_INK, fontweight="bold",
ha="left", va="center",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_WHITE, ec=COL_GOLD_D, lw=1.6, alpha=0.95),
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.8,
connectionstyle="arc3,rad=0.25"),
zorder=7,
)
# Pedagojik mesaj: coklu minimum = bir girdiye BIRDEN COK gecerli cevap
ax.text(
0.5, -0.135,
"Çoklu minimum = bir girdiye birden çok geçerli cevap "
"(sıradan bir ağ tek çıktı verir; enerji tabanlı model tüm uyumlu cevapları gösterir)",
transform=ax.transAxes, ha="center", va="top",
fontsize=9.5, color=COL_TEXT, style="italic",
)
ax.set_title("Enerji Tabanlı Model: Enerji Manzarası F(x, y) ve Çoklu Geçerli Cevap",
color=COL_INK, fontsize=13, fontweight="bold", pad=12)
ax.set_xlabel("girdi/cevap boyutu x")
ax.set_ylabel("girdi/cevap boyutu y")
ax.set_xlim(-lim, lim)
ax.set_ylim(-lim, lim)
ax.set_aspect("equal")
style_legend(ax, loc="upper right", fontsize=9)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Enerji, Olasılık ve JEPA Köprüsü"}
**Geriye (Stat 110 + Calculus):** EBM'nin enerji → olasılık köprüsü Boltzmann dağılımıdır (P(y) ∝ exp(−βE)); energy = −log p (Stat 110). "Non-convex geometri" ise Calculus ikinci türev/Hessian dünyasıdır. Bu kavramlar Hafta 7'de derinleşecek (Yazım Kılavuzu §4.J kurs terimleri).
**İleriye:** EBM, LeCun'un bugünkü araştırma programının (JEPA, I-JEPA, V-JEPA — post-2020 ileriye köprü) tohumu. "Çıkarım = enerji minimizasyonu" fikri, modern dünya-modeli ve planlama yaklaşımlarının temelidir.
:::
## Geçiş: LeCun'dan Canziani'ye {#sec-gecis-d1}
LeCun büyük resmi çizdi — derin öğrenme temsili veriden öğrenir, katmanlar doğrusal-olmamayla anlam kazanır, ve tüm bunlar bir optimizasyon problemidir. Şimdi **Alfredo Canziani** Practicum'da sahneye çıkıyor ve aynı fikirleri **somut lineer cebire** indiriyor. LeCun'un soyut "temsil öğrenme"si, Canziani'nin elinde gözle görülür bir şeye dönüşüyor: **uzayda noktaları hareket ettirmek.** Üslup da değişiyor — Canziani interaktif, esprili, İtalyan:
> "I have a very strong Italian accent, you know — 'mamma mia!'... if you do not understand something, it's almost 99.9% my fault." — Canziani, 0:33
## (Canziani) Sınıflandırma: Görüntü = Yüksek-Boyutlu Uzayda Bir Nokta {#sec-yuksek-boyut}
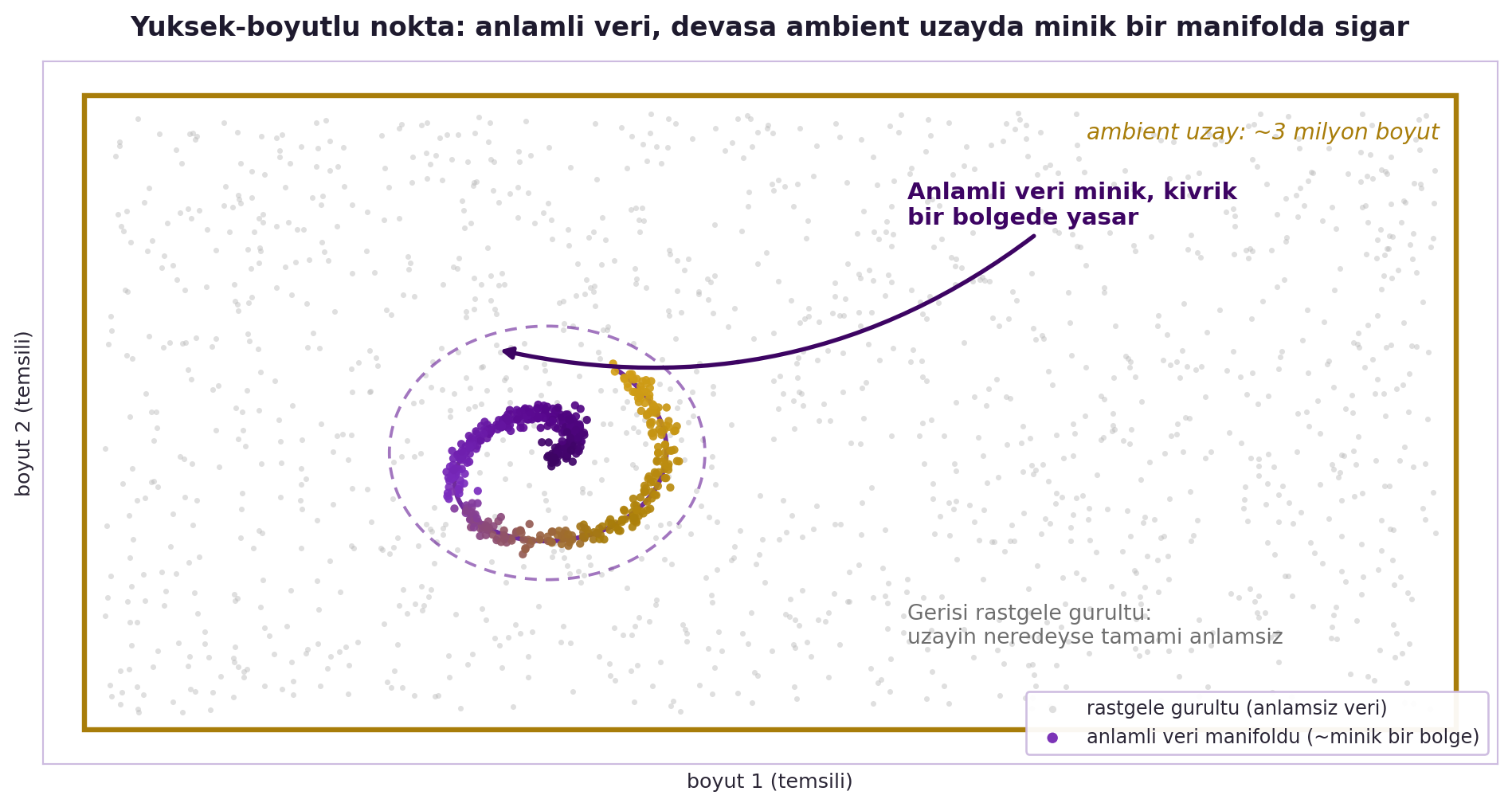
Canziani sınıflandırmayı (classification) geometriyle anlatıyor. Bir megapiksellik (1000 × 1000) renkli bir fotoğraf düşün: her piksel RGB olduğundan toplam 1000 × 1000 × 3 = **3 milyon sayı**. Yani bu görüntü, **3 milyon boyutlu bir uzayda tek bir nokta**dır.
Bu uzay akıl almaz büyüklükte. İçinde rastgele dolaşırsan hiçbir anlamlı şey görmezsin. Bir köpek fotoğrafı bir noktada, bir kedi fotoğrafı başka bir noktada durur — ve Canziani sınıfa soruyor: kedi noktası köpek noktasına yakın mı, uzak mı? Cevap: **çok yakın.**
> "everything that actually makes sense is here (closes hand) — everything else is just trash." — Canziani, 5:45
Yani anlamlı görüntüler (kediler, köpekler, gerçek sahneler) bu devasa uzayın **minik bir bölgesinde** toplanmıştır; geri kalan her yer rastgele gürültüdür. Sınıflandırma problemi şudur: bu sıkışık noktaları al, uzayda **ayrıştırılabilir** hale gelecek biçimde hareket ettir, sonra aralarına bir sınır çiz.
```{python}
#| label: fig-high-dim-manifold
#| fig-cap: "Yuksek-boyutlu nokta: devasa ambient uzayda (~3 milyon boyut) anlamli veri yalnizca minik, kivrik bir manifolda sigarken uzayin geri kalani rastgele gurultudur."
np.random.seed(0)
fig, ax = plt.subplots(figsize=(10, 5.4))
# Ambient uzay sinirlari (buyuk acik dikdortgen)
AX0, AX1 = -10.0, 10.0
AY0, AY1 = -5.5, 5.5
# --- 1) 'Trash': ambient uzaya yayilmis soluk gri rastgele gurultu ---
n_trash = 1400
gx = np.random.uniform(AX0 + 0.3, AX1 - 0.3, n_trash)
gy = np.random.uniform(AY0 + 0.3, AY1 - 0.3, n_trash)
ax.scatter(gx, gy, s=7, c="#b9b9b9", alpha=0.45, linewidths=0,
zorder=1, label="rastgele gurultu (anlamsiz veri)")
# --- 2) Anlamli veri manifoldu: minik, kivrik NYU-violet serit ---
# Parametrik kivrik egri (spiral kol + sinus kivrimi), kucuk bir bolgede
t = np.linspace(0, 1, 600)
cx_base, cy_base = -3.4, -0.8 # manifoldun ambient icindeki konumu
rad = 0.18 + 1.55 * t # disari acilan spiral kol
ang = 2.0 * np.pi * 1.15 * t
mx = cx_base + rad * np.cos(ang) + 0.35 * np.sin(9 * t)
my = cy_base + rad * np.sin(ang) + 0.22 * np.sin(7 * t)
# Manifold uzerinde yogun renkli noktalar (serit boyunca kucuk dik yayilim)
n_man = 520
ti = np.random.uniform(0, 1, n_man)
ri = 0.18 + 1.55 * ti
ai = 2.0 * np.pi * 1.15 * ti
mxi = cx_base + ri * np.cos(ai) + 0.35 * np.sin(9 * ti)
myi = cy_base + ri * np.sin(ai) + 0.22 * np.sin(7 * ti)
# serit kalinligi (manifold ince ama sifir-kalinlik degil)
mxi = mxi + np.random.normal(0, 0.10, n_man)
myi = myi + np.random.normal(0, 0.10, n_man)
# renk parametre boyunca violet->gold gecisi (sadece NYU marka renkleri)
from matplotlib.colors import LinearSegmentedColormap
nyu_cmap = LinearSegmentedColormap.from_list(
"nyu_vg", [COL_VIOLET_D, COL_VIOLET, COL_VIOLET_M, COL_GOLD_D, COL_GOLD])
ax.scatter(mxi, myi, s=15, c=ti, cmap=nyu_cmap, alpha=0.92,
linewidths=0, zorder=4,
label="anlamli veri manifoldu (~minik bir bolge)")
# kivrik serit konturu (violet egri)
ax.plot(mx, my, color=COL_VIOLET, lw=2.2, alpha=0.85, zorder=3, solid_capstyle="round")
# Manifoldu cevreleyen soluk halka (bolgeyi vurgula)
from matplotlib.patches import Ellipse
halo = Ellipse((cx_base + 0.15, cy_base + 0.1), 4.6, 4.4,
fc="none", ec=COL_VIOLET, lw=1.4, ls=(0, (4, 3)),
alpha=0.55, zorder=2)
ax.add_patch(halo)
# --- Ambient uzay cercevesi (buyuk acik dikdortgen) ---
ax.add_patch(plt.Rectangle((AX0, AY0), AX1 - AX0, AY1 - AY0,
fc="none", ec=COL_GOLD_D, lw=2.4, zorder=5))
ax.text(AX1 - 0.25, AY1 - 0.45, "ambient uzay: ~3 milyon boyut",
ha="right", va="top", fontsize=10.5, color=COL_GOLD_D,
style="italic", zorder=6)
# --- Aciklama oku: manifolda isaret et ---
ax.annotate(
"Anlamli veri minik, kivrik\nbir bolgede yasar",
xy=(cx_base - 0.6, cy_base + 1.9),
xytext=(2.0, 3.6),
fontsize=11, color=COL_VIOLET_D, fontweight="bold",
ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_D, lw=2.0,
connectionstyle="arc3,rad=-0.25"),
zorder=7,
)
ax.text(2.0, -3.7,
"Gerisi rastgele gurultu:\nuzayin neredeyse tamami anlamsiz",
fontsize=10, color="#6e6e6e", ha="left", va="center", zorder=7)
apply_style(ax)
ax.set_xlim(AX0 - 0.6, AX1 + 0.6)
ax.set_ylim(AY0 - 0.6, AY1 + 0.6)
ax.set_xticks([]); ax.set_yticks([])
ax.set_title("Yuksek-boyutlu nokta: anlamli veri, devasa ambient uzayda minik bir manifolda sigar",
fontsize=12.5, color=COL_INK, pad=12, fontweight="bold")
ax.set_xlabel("boyut 1 (temsili)", fontsize=9.5)
ax.set_ylabel("boyut 2 (temsili)", fontsize=9.5)
style_legend(ax, loc="lower right", fontsize=9, markerscale=1.3)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Vektör Uzayı ve Manifold"}
**Geriye (18.06 + Stat 110):** "3 milyon boyutlu uzayda nokta" doğrudan 18.06'nın vektör uzayıdır; "anlamlı veri minik bir bölgede" gözlemi ise **manifold hipotezi**nin (Bölüm 7) sezgisel ifadesidir. Yüksek boyutta noktaların dağılımı Stat 110 çok-değişkenli dağılımla bağlanır.
**İleriye:** "Veri, ambient uzayın küçük bir manifoldunda yaşar" fikri; boyut indirgeme, autoencoder (Hafta 7), ve üretken modellerin (VAE/GAN, Hafta 8-9) hepsinin dayandığı temel varsayımdır.
:::
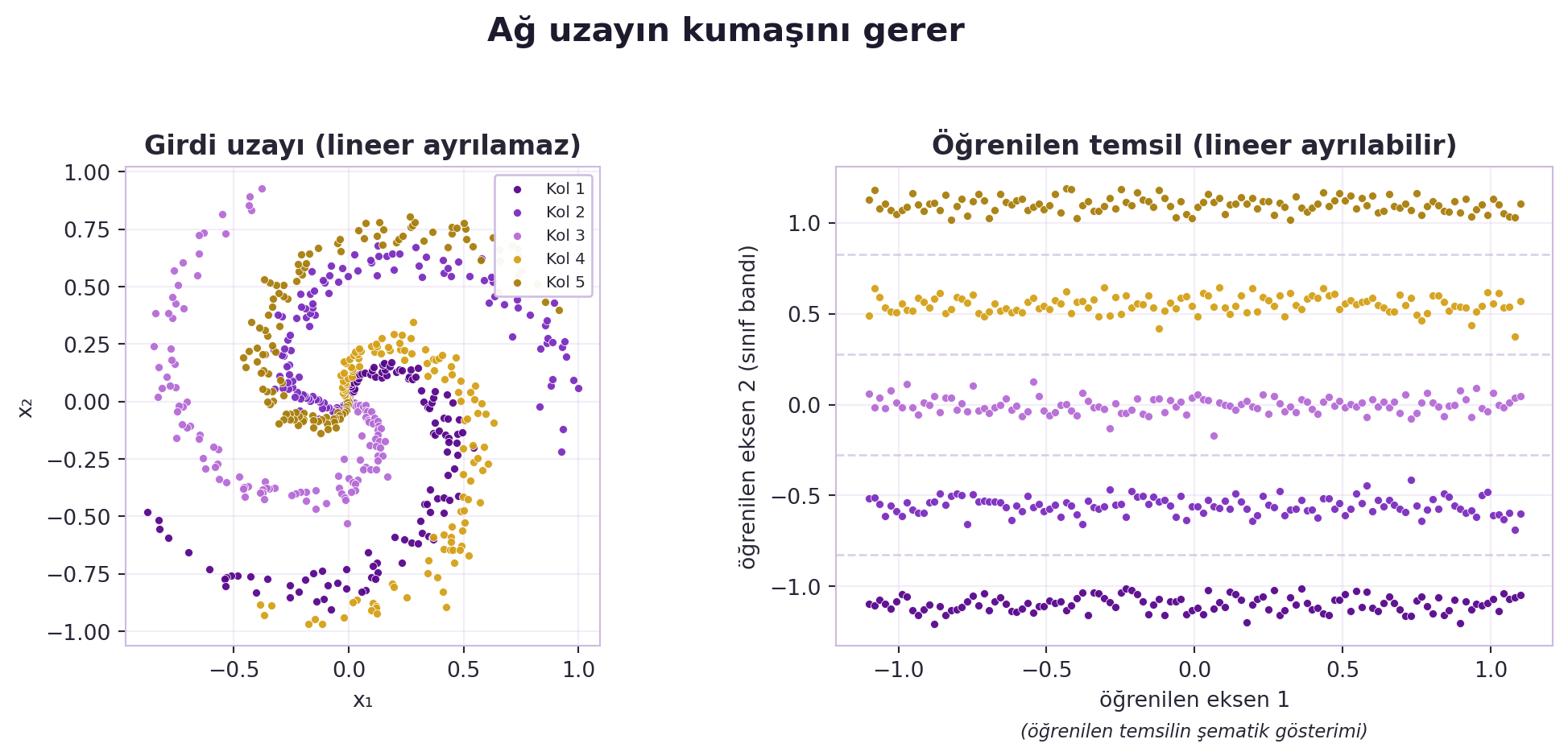
## (Canziani) Manifold Sezgisi: Uzayın Kumaşını Germek {#sec-manifold-d1}
Canziani spiral demosunu açıyor: bir spiralin beş kolu, her kol farklı renkte (sınıf). Girdi sadece (x, y) koordinatları — renk yok. Ağdan istenen: noktaları renge göre ayırmak. Ekrandaki animasyonda ağ, uzayı *fiziksel olarak gerip büküyor*:
> "it takes the space... and it performs like a stretching of the space fabric." — Canziani, 15:11
Ağ, uzayın kumaşını öyle bir geriyor ki sonunda aynı renkten noktalar aynı alt-bölgede toplanıyor — yani **lineer olarak ayrılabilir** hale geliyorlar. O noktada basit bir lojistik regresyon (düz bir sınır) işi bitiriyor. Bu, LeCun'un "temsili öğrenmek" dediği şeyin gözle görülür hâlidir: iyi bir temsil, problemi kolay (ayrılabilir) yapan bir uzaydır.
```{python}
#| label: fig-spiral-stretching
#| fig-cap: "5-kollu spiral girdi uzayı (solda, lineer ayrılamaz) ile ağın öğrendiği temsil (sağda, paralel sınıf bantlarına açılmış, lineer ayrılabilir) yan yana — ağın manifoldu nasıl 'gerdiğini' gösteren şematik karşılaştırma."
np.random.seed(0)
X, y = make_spiral(n_per=120, k=5, seed=0)
Z = unroll_spiral(X, y, k=5, seed=0)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5))
# SOL — girdi uzayi (lineer ayrilamaz spiral)
for j in range(5):
m = (y == j)
axL.scatter(X[m, 0], X[m, 1], s=14, color=CLASS_COLORS[j],
edgecolor=COL_WHITE, linewidth=0.3, alpha=0.95,
label=f"Kol {j + 1}", zorder=3)
apply_style(axL)
axL.set_title("Girdi uzayı (lineer ayrılamaz)", fontsize=12.5, fontweight="bold")
axL.set_xlabel("x₁")
axL.set_ylabel("x₂")
axL.set_aspect("equal")
style_legend(axL, loc="upper right", fontsize=7.5, ncol=1)
# SAG — ogrenilen temsil (paralel yatay bantlar -> lineer ayrilabilir)
band_centers = sorted(set(np.round((np.arange(5) - 2) * 0.55, 4)))
for c0, c1 in zip(band_centers[:-1], band_centers[1:]):
axR.axhline((c0 + c1) / 2.0, color=COL_GRID, linewidth=1.0,
linestyle="--", alpha=0.7, zorder=1)
for j in range(5):
m = (y == j)
axR.scatter(Z[m, 0], Z[m, 1], s=14, color=CLASS_COLORS[j],
edgecolor=COL_WHITE, linewidth=0.3, alpha=0.95,
label=f"Kol {j + 1}", zorder=3)
apply_style(axR)
axR.set_title("Öğrenilen temsil (lineer ayrılabilir)", fontsize=12.5, fontweight="bold")
axR.set_xlabel("öğrenilen eksen 1")
axR.set_ylabel("öğrenilen eksen 2 (sınıf bandı)")
axR.text(0.5, -0.16, "(öğrenilen temsilin şematik gösterimi)",
transform=axR.transAxes, ha="center", va="top",
fontsize=8.5, style="italic", color=COL_TEXT)
fig.suptitle("Ağ uzayın kumaşını gerer", fontsize=15.5,
fontweight="bold", color=COL_INK, y=1.01)
fig.tight_layout(rect=(0, 0.02, 1, 0.97))
```
@fig-spiral-stretching solda iç içe geçmiş 5-kollu spirali (lineer ayrılamaz), sağda ağın açtığı paralel sınıf bantlarını (lineer ayrılabilir) yan yana koyar. Bu, **manifold hipotezi**nin canlı gösterimi: veri, yüksek-boyutlu uzayda kıvrılmış düşük-boyutlu bir yüzey (manifold) üzerinde yaşar; öğrenme, bu manifoldu açıp düzleştirmektir. (LeCun de dersini manifold ile kapatır: bir çembere topolojik olarak denk, kıvrık bir manifoldu PCA gibi doğrusal bir yöntem **bulamaz** — çünkü düz değildir.)
::: {.callout-tip title="Builder Notu — Germe = Lineer Dönüşüm + Bükme"}
**Geriye (18.06):** "Uzayı germek/bükmek" bir dizi **lineer dönüşüm** (matris) + doğrusal-olmamadır (Bölüm 8). PCA'nin kıvrık manifoldu bulamaması, doğrusal yöntemlerin sınırını gösterir — 18.06 SVD'nin (Ders 29) neden tek başına yetmediğinin sezgisi.
**İleriye:** Bu "açıp düzleştirme" görüşü; representation learning, t-SNE/UMAP görselleştirme ve autoencoder'ların ortak dilidir.
:::
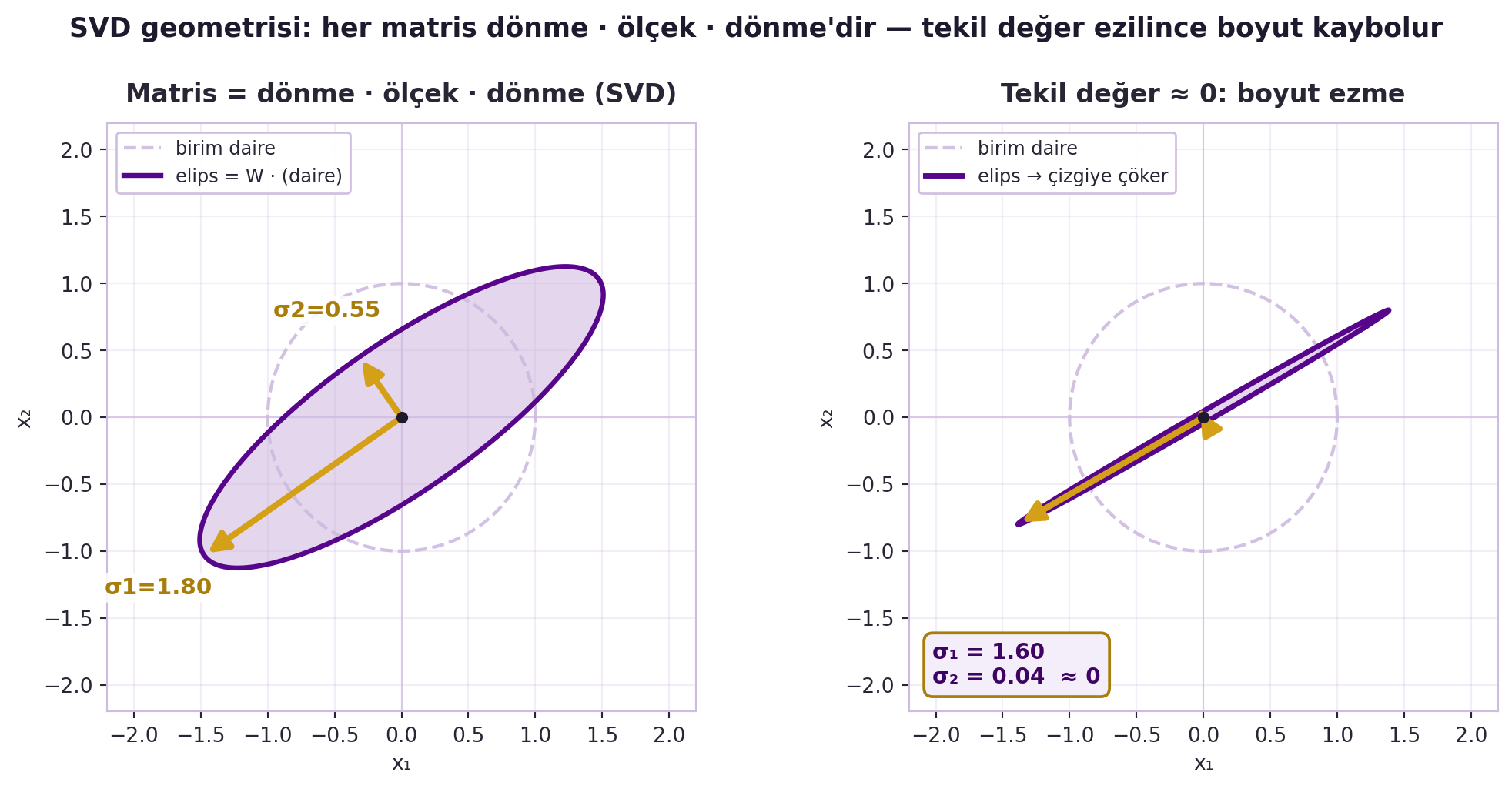
## (Canziani) Lineer Dönüşümler ve SVD {#sec-svd}
Peki uzayda noktaları nasıl hareket ettiririz? Canziani lineer cebiri interaktif soruyor: matris çarpımı ne yapar? Cevap — bir **lineer dönüşüm**. Dört temel tip var (@fig-linear-transforms):
1. **Rotation (döndürme)** — matris ortonormalse.
2. **Scaling / stretching (ölçekleme)** — köşegen matrisle.
3. **Shearing (kaydırma)** — eksenleri eğer.
4. **Reflection (yansıma)** — determinant negatifse.
Bir uyarı: **öteleme (translation) lineer DEĞİLDİR.** Canziani'nin testi: bir dönüşüm lineerse 0'ı 0'a götürmeli; öteleme bunu yapmaz. Öteleme eklersek dönüşüm **afin (affine)** olur. Bir sinir ağı katmanı tam olarak budur — matris çarpımı (lineer) + öteleme (bias):
$$
\mathbf{y} = W\mathbf{x} + \mathbf{b}
$$
```{python}
#| label: fig-linear-transforms
#| fig-cap: "Dört temel lineer dönüşümün (donme, olcekleme, kaydirma, yansima) birim ızgara ve birim kare üzerindeki geometrik etkisi; determinant işareti yansımanın yönelimi tersine çevirdiğini gösterir."
np.random.seed(0)
T = linear_transforms()
grid = unit_grid(n=9, lim=1.6, fine=61)
# birim kare (kapali koselerin sirasi)
square = np.array([[-1, -1], [1, -1], [1, 1], [-1, 1], [-1, -1]], float)
panels = [
("rotation", "Donme (rotation)"),
("scaling", "Olcekleme (scaling)"),
("shearing", "Kaydirma (shearing)"),
("reflection", "Yansima (reflection, det<0)"),
]
fig, axes = plt.subplots(2, 2, figsize=(9.5, 9.0))
axes = axes.ravel()
for ax, (key, title) in zip(axes, panels):
W = T[key]
apply_style(ax)
# Orijinal izgara (soluk gri)
for ln in grid:
ax.plot(ln[:, 0], ln[:, 1], color=COL_GRID, lw=0.8, alpha=0.7, zorder=1)
# Orijinal birim kare (soluk gri)
ax.plot(square[:, 0], square[:, 1], color="#9a9a9a", lw=1.6, alpha=0.8, zorder=2)
# Donmus izgara (NYU violet)
for ln in grid:
Y = affine_transform(ln, W)
ax.plot(Y[:, 0], Y[:, 1], color=COL_VIOLET, lw=0.9, alpha=0.55, zorder=3)
# Donmus birim kare (koyu violet + gold dolgu)
Sq = affine_transform(square, W)
ax.fill(Sq[:, 0], Sq[:, 1], color=COL_GOLD, alpha=0.18, zorder=4)
ax.plot(Sq[:, 0], Sq[:, 1], color=COL_VIOLET_D, lw=2.4, zorder=5)
# det bilgisi annotation
det = np.linalg.det(W)
ax.annotate(f"det(W) = {det:+.2f}", xy=(0.5, 0.015), xycoords="axes fraction",
ha="center", va="bottom", fontsize=9, color=COL_GOLD_D,
fontweight="bold", zorder=6)
ax.set_title(title, fontsize=12, color=COL_INK, fontweight="bold", pad=8)
ax.set_xlabel("x₁")
ax.set_ylabel("x₂")
ax.set_aspect("equal")
ax.set_xlim(-2.6, 2.6)
ax.set_ylim(-2.6, 2.6)
# Tema-uyumlu ortak legend (figur seviyesinde)
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
handles = [
Line2D([0], [0], color="#9a9a9a", lw=1.6, label="Orijinal uzay (birim ızgara + kare)"),
Line2D([0], [0], color=COL_VIOLET, lw=1.6, label="Dönüşmüş ızgara y = W·x"),
Patch(facecolor=COL_GOLD, alpha=0.25, edgecolor=COL_VIOLET_D,
label="Dönüşmüş birim kare"),
]
leg = fig.legend(handles=handles, loc="lower center", ncol=3, frameon=True,
framealpha=0.95, edgecolor=COL_GRID, fontsize=9.5,
bbox_to_anchor=(0.5, -0.015))
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
fig.suptitle("Lineer dönüşümler: 2×2 matris uzayın kumaşını nasıl büker",
fontsize=14, color=COL_INK, fontweight="bold", y=0.995)
fig.tight_layout(rect=(0, 0.04, 1, 0.97))
```
Noktaları ayırmak için Canziani'nin reçetesi: önce öteleme ile aşağı indir, sonra köşegen matrisle (uygun **tekil değerlerle**, singular values) ger. Matrisi köşegenleştirmek için araç **SVD (singular value decomposition)**: bir matris = rotation · scaling · rotation. Tekil değerlerden biri sıfıra yakınsa matris bir boyutu neredeyse "öldürür" (ezme). @fig-svd-geometry bunu gösterir: solda birim daire bir elipse ("patatese") döner (ana eksenler = tekil değerler), sağda bir tekil değer sıfıra yaklaşınca elips bir çizgiye çöker.
```{python}
#| label: fig-svd-geometry
#| fig-cap: "Birim dairenin bir matrisle çarpılınca bir elipse ('patates') dönüşmesi ve SVD'nin geometrik okuması: her matris bir dönme·ölçek·dönme bileşimidir; sağ panelde bir tekil değer sıfıra yaklaşınca elips bir çizgiye çöker ve bir boyut ezilir."
np.random.seed(0)
circle = unit_circle(240)
# --- SOL panel: genel 2x2 matris = donme . olcek . donme (SVD) ---
T = linear_transforms()
W = T["rotation"] @ T["scaling"] # genel 2x2: donme @ olcek (egik elips)
ellipse = circle @ W.T # birim daire -> elips ('patates')
U, s, Vt = svd_demo(W) # W = U diag(s) Vt
# --- SAG panel: tekil deger ~ 0 -> bir boyut ezilir ---
M = near_singular_matrix()
ellipse2 = circle @ M.T # elips bir cizgiye coker
U2, s2, Vt2 = svd_demo(M)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11.0, 5.2))
# ============ SOL ============
axL.plot(circle[:, 0], circle[:, 1], color=COL_GRID, lw=1.6,
ls="--", alpha=0.9, label="birim daire", zorder=2)
axL.fill(ellipse[:, 0], ellipse[:, 1], color=COL_VIOLET, alpha=0.16, zorder=1)
axL.plot(ellipse[:, 0], ellipse[:, 1], color=COL_VIOLET, lw=2.4,
label="elips = W · (daire)", zorder=3)
# Ana eksenler: U sutunlari * tekil degerler (gold oklar)
for i in range(2):
vec = U[:, i] * s[i]
axL.annotate("", xy=(vec[0], vec[1]), xytext=(0, 0),
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD,
lw=3.0, mutation_scale=20), zorder=5)
nrm = np.linalg.norm(vec) + 1e-9
off = vec / nrm * 0.42
axL.text(vec[0] + off[0], vec[1] + off[1], f"σ{i+1}={s[i]:.2f}",
color=COL_GOLD_D, fontsize=11, fontweight="bold",
ha="center", va="center", zorder=6,
bbox=dict(boxstyle="round,pad=0.18", fc=COL_WHITE, ec="none", alpha=0.85))
axL.scatter([0], [0], color=COL_INK, s=22, zorder=6)
axL.set_title("Matris = dönme · ölçek · dönme (SVD)",
fontsize=12.5, color=COL_INK, fontweight="bold", pad=10)
axL.set_xlabel("x₁"); axL.set_ylabel("x₂")
axL.set_aspect("equal", "box")
lim = 2.2
axL.set_xlim(-lim, lim); axL.set_ylim(-lim, lim)
axL.axhline(0, color=COL_GRID, lw=0.8, alpha=0.7)
axL.axvline(0, color=COL_GRID, lw=0.8, alpha=0.7)
apply_style(axL)
style_legend(axL, loc="upper left", fontsize=9)
# ============ SAG ============
axR.plot(circle[:, 0], circle[:, 1], color=COL_GRID, lw=1.6,
ls="--", alpha=0.9, label="birim daire", zorder=2)
axR.fill(ellipse2[:, 0], ellipse2[:, 1], color=COL_VIOLET, alpha=0.16, zorder=1)
axR.plot(ellipse2[:, 0], ellipse2[:, 1], color=COL_VIOLET, lw=2.6,
label="elips → çizgiye çöker", zorder=3)
# Ana eksenler (gold) — ikinci eksen neredeyse yok
for i in range(2):
vec = U2[:, i] * s2[i]
axR.annotate("", xy=(vec[0], vec[1]), xytext=(0, 0),
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD,
lw=3.0, mutation_scale=20), zorder=5)
axR.scatter([0], [0], color=COL_INK, s=22, zorder=6)
axR.set_title("Tekil değer ≈ 0: boyut ezme",
fontsize=12.5, color=COL_INK, fontweight="bold", pad=10)
axR.set_xlabel("x₁"); axR.set_ylabel("x₂")
axR.set_aspect("equal", "box")
axR.set_xlim(-lim, lim); axR.set_ylim(-lim, lim)
axR.axhline(0, color=COL_GRID, lw=0.8, alpha=0.7)
axR.axvline(0, color=COL_GRID, lw=0.8, alpha=0.7)
# s degerlerini annotation kutusunda yaz
txt = f"σ₁ = {s2[0]:.2f}\nσ₂ = {s2[1]:.2f} ≈ 0"
axR.text(0.04, 0.04, txt, transform=axR.transAxes, fontsize=10.5,
color=COL_VIOLET_D, fontweight="bold", ha="left", va="bottom",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_GOLD_D, lw=1.4))
apply_style(axR)
style_legend(axR, loc="upper left", fontsize=9)
fig.suptitle("SVD geometrisi: her matris dönme · ölçek · dönme'dir — tekil değer ezilince boyut kaybolur",
fontsize=13, color=COL_INK, fontweight="bold", y=1.005)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — SVD, Düşük-Rank ve LoRA"}
**Geriye (18.06 + 18.065):** Lineer dönüşüm tipleri 18.06'nın çekirdeğidir; SVD = Ders 29. "Bir matris = rotation · scaling · rotation" tam olarak SVD'nin geometrik okumasıdır. Tekil değer ≈ 0 → matris tekil (singular), boyut kaybı. Bu, Phase 2 18.065'in (Matrix Methods) ML-uygulamalı tam konusudur — atıf: (Phase 1 18.06 Ders 29 + Phase 2 18.065 ileri).
**İleriye:** SVD ve düşük-rank yaklaşım; PCA, model sıkıştırma, ve LoRA (düşük-rank fine-tune) gibi tekniklerin matematiksel temelidir.
:::
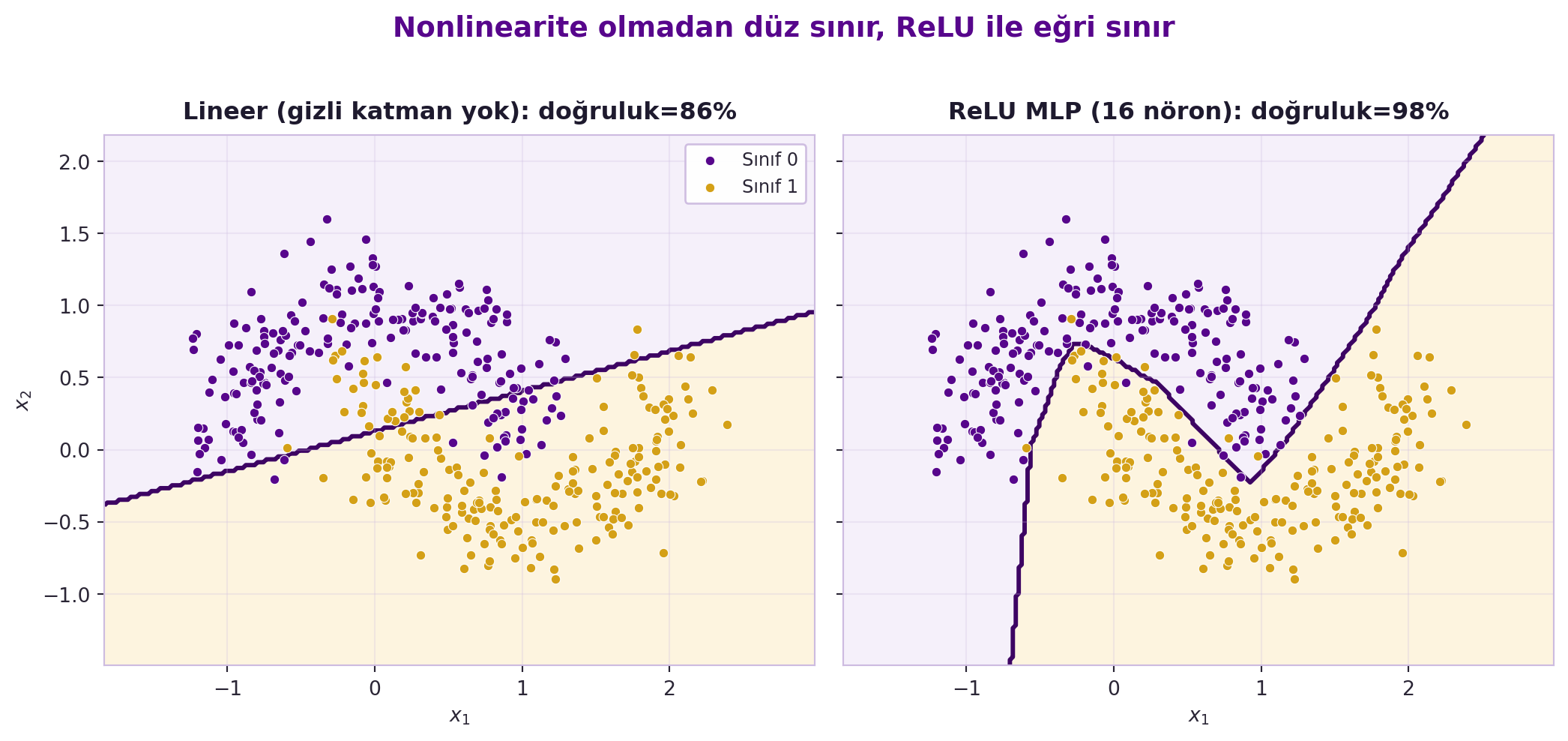
## (Canziani) Neden Doğrusal-Olmama? (LeCun ile Buluşma) {#sec-nonlinearity}
Canziani ağı iki matrisli bir örnekle kuruyor: girdi 2 boyut → ara katman 100 boyut (bir nonlinearity) → çıktı. Sonra kritik soruyu soruyor: neden birden çok matris, neden doğrusal-olmama? Cevabı, LeCun'un cebirle söylediğiyle **birebir aynı** — ama bu kez geometrik:
> "without nonlinearity it would look like a single layer neural network — and a single layer neural network, what can it do? Scaling, translation, rotation, reflection, shearing." — Canziani, 20:21
Yani doğrusal-olmama olmadan, kaç matris istiflersen istifle, ağ yalnızca o dört-beş temel dönüşümü (Bölüm 8) yapabilir; hepsi tek bir matrise çöker. Spiral noktalarını ancak doğru bir sınırla ayıramazsın — uzayı *bükmen* gerekir, ve bükme yalnızca doğrusal-olmamadan gelir. İşte LeCun'un "linear ∘ linear = linear" cebri ile Canziani'nin "tek katman sadece germe/döndürme yapar" geometrisi aynı madalyonun iki yüzü. @fig-nonlinearity-moons bu farkı somutlaştırır: aynı iki-hilal verisinde lineer sınıflandırıcı düz bir sınırla takılırken, ReLU'lu ağ eğri bir sınır öğrenip sınıfları ayırır.
```{python}
#| label: fig-nonlinearity-moons
#| fig-cap: "Aynı iki-hilal verisinde lineer sınıflandırıcı düz bir karar sınırı üretip hilalleri ayıramazken (doğruluk %86), 16 nöronlu ReLU MLP eğri bir sınır öğrenip sınıfları ayırır (doğruluk %98) — nonlinearitenin neden gerekli olduğunu gösterir."
np.random.seed(0)
# Ortak veri: dogrusal ayrilamaz iki hilal
X, y = make_moons_np(n=400, noise=0.20, seed=0)
xx, yy, grid = decision_grid(X, pad=0.6, h=0.02)
# SOL: lineer (gizli katmansiz) softmax -> DUZ sinir
lin = logreg_train(X, y, steps=500, lr=1.0, seed=0)
acc_lin = accuracy(logreg_forward, lin, X, y)
Z_lin = logreg_forward(lin, grid).argmax(axis=1).reshape(xx.shape)
# SAG: ReLU MLP -> EGRI sinir (hilalleri ayirir)
mlp = mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0)
acc_mlp = accuracy(mlp_forward, mlp, X, y)
Z_mlp = mlp_forward(mlp, grid).argmax(axis=1).reshape(xx.shape)
region_cmap = matplotlib.colors.ListedColormap([COL_BG, "#fdf3da"]) # soluk violet / soluk gold
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5), sharex=True, sharey=True)
for ax, Z, acc, title in [
(axL, Z_lin, acc_lin, f"Lineer (gizli katman yok): doğruluk={acc_lin:.0%}"),
(axR, Z_mlp, acc_mlp, f"ReLU MLP (16 nöron): doğruluk={acc_mlp:.0%}"),
]:
ax.contourf(xx, yy, Z, levels=[-0.5, 0.5, 1.5], cmap=region_cmap, alpha=0.85, zorder=0)
ax.contour(xx, yy, Z, levels=[0.5], colors=[COL_VIOLET_D], linewidths=2.2, zorder=1)
ax.scatter(X[y == 0, 0], X[y == 0, 1], s=22, c=CLASS_COLORS[0],
edgecolors="white", linewidths=0.4, label="Sınıf 0", zorder=2)
ax.scatter(X[y == 1, 0], X[y == 1, 1], s=22, c=CLASS_COLORS[3],
edgecolors="white", linewidths=0.4, label="Sınıf 1", zorder=2)
apply_style(ax)
ax.set_title(title, fontsize=12, color=COL_INK, fontweight="bold", pad=8)
ax.set_xlabel("$x_1$")
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
axL.set_ylabel("$x_2$")
style_legend(axL, loc="upper right", fontsize=9)
fig.suptitle("Nonlinearite olmadan düz sınır, ReLU ile eğri sınır",
fontsize=14, color=COL_VIOLET, fontweight="bold", y=1.02)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — İki Hocanın Aynı Teoremi"}
**Geriye (Bölüm 4 + 18.06):** Bu, dersin en güçlü çapraz-doğrulamasıdır: aynı teorem (doğrusal katmanların çökmesi) hem LeCun (Lecture, cebir) hem Canziani (Practicum, geometri) tarafından bağımsız anlatılıyor. İki hoca = iki kanıt yolu.
**İleriye:** ReLU/GELU gibi doğrusal-olmamaların seçimi, derin ağların ifade gücünü ve eğitim kararlılığını belirler — modern mimarilerin temel tasarım kararı.
:::
## (Canziani) PyTorch İlk Dokunuş: nn.Linear, ReLU ve Rastgele Projeksiyonlar {#sec-pytorch-d1}
Canziani teoriyi koda döküyor. PyTorch'ta bir katman `nn.Linear` (matris çarpımı + bias = afine); doğrusal-olmama `nn.ReLU` (pozitif kısım) veya `tanh`. Eğitilmemiş bir ağ bile uzayı ilginç biçimde büker:
```python
import torch
import torch.nn as nn
# bir sinir agi = afine donusum + dogrusal-olmama
model = nn.Sequential(
nn.Linear(2, 5), # 2 -> 5: matris + bias (affine)
nn.ReLU(), # pozitif kisim: dogrusal-olmama
nn.Linear(5, 2), # 5 -> 2: ekranda gosterebilmek icin
)
x = torch.randn(1000, 2) # 1000 nokta, standart normal bulut
y = model(x) # uzayi ger, bukle, yansit
```
Canziani'nin **rastgele projeksiyon** notebook'u tam da bunu görselleştirir: 1000 noktalık dairesel bir bulutu bir matrisle çarpınca bulut bir "patatese" (elips) döner; tekil değerlerden biri ≈ 0 ise bir boyut ezilir. Üstüne `tanh` koyunca (kink ≈ ±2.5) veri bir kutuya sıkışır; `ReLU` koyunca köşeli, ayrıştırılabilir kümeler oluşur. Canziani'nin uyarısı: bu sihir değil, sadece görselleştirme —
> "this is just visualization using matplotlib... this is not magic." — Canziani, 23:18
Son olarak donanım: tensörler CPU yerine GPU belleğinde tutulursa paralel hesap çok hızlanır. Tek satır yeter:
```python
# CUDA varsa tensorleri GPU bellegine koy, yoksa CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
```
Canziani'nin esprili özeti: CPU tek seferde bir şey yapar (çok hızlı ama sıralı); GPU çok daha yavaş ama aynı anda binlerce işlem yapar — bu yüzden büyük matris işlerinde kazanır.
::: {.callout-tip title="Builder Notu — nn.Linear, Device ve Init"}
**Geriye (18.06):** `nn.Linear(2, 5)` tam olarak 5×2 boyutlu bir matris + 5-boyutlu bias; rastgele projeksiyon = bir matrisle çarpmanın geometrik etkisi (SVD ile okunur, Bölüm 8).
**İleriye:** "Tensörleri doğru cihaza (device) koy" tek satırı, tüm modern eğitim hattının (GPU/TPU throughput, mixed precision, DDP) giriş kapısıdır. Eğitilmemiş ağın bile yapı kurması, **weight initialization**'ın neden önemli olduğunu önceler (Hafta 4'te BatchNorm/init).
:::
## Özet {#sec-ozet-d1}
1. **Derin öğrenme = temsili veriden öğrenmek.** Geleneksel örüntü tanıma elle tasarlanmış öznitelik çıkarıcısı + sınıflandırıcıdır; derin öğrenme bu iki aşamayı uçtan uca, öğrenilen modüllerle değiştirir.
2. **"Derin" = çok katmanlı.** Her katman ayarlanabilir parametre + doğrusal-olmama içerir; başka gizem yok.
3. **Doğrusal-olmama şart** — iki ardışık doğrusal katman tek bir doğrusala çöker (LeCun cebirle, Canziani geometriyle gösterir).
4. **Tarih neden önemli:** perceptron (Rosenblatt, fiziksel analog), 1969-1984 kışı, 1985 backprop (sürekli nöron + hızlanan çarpma), 2010 konuşma + 2012 görü dirilişi.
5. **Optimizasyon non-convex** ve "kimse tam anlamıyor"; alan tricklerle (init, norm, dropout) ilerler.
6. **EBM** (LeCun'un en sevdiği konu, kursun omurgası): cevaplar bir enerji fonksiyonunun minimumlarıdır; çıkarım = enerji minimizasyonu.
7. **Geometri (Canziani):** görüntü = yüksek-boyutlu uzayda nokta; anlamlı veri minik bir manifoldda yaşar; ağ bu uzayın kumaşını gerip noktaları ayrıştırılabilir yapar.
8. **Lineer cebir:** matris çarpımı = rotation/scaling/shearing/reflection; öteleme afin yapar (Wx + b); SVD = rotation · scaling · rotation.
::: {.callout-important title="Tek Bir Cümle"}
Derin öğrenme, elle tasarlanan öznitelik çıkarıcısını çöpe atıp temsili doğrudan veriden öğrenir; geometrik olarak bu, veri uzayını doğrusal dönüşümler (Wx + b) ve doğrusal-olmamalarla yeniden şekillendirip, kıvrık veri manifoldunu ayrıştırılabilir hale getirmektir.
:::
## Kontrol Soruları {#sec-kontrol-d1}
::: {.callout-note collapse="true" title="Soru 1: Bir ağda tüm doğrusal-olmamaları kaldırırsan (her katman sadece matris çarpımı olursa) ne olur? Neden işe yaramaz?"}
**Cevap:** Ağ ardışık matris çarpımlarına iner ve hepsi tek bir matrise çöker. İki katman için:
$$
W_2 \left(W_1 \mathbf{x}\right) = \left(W_2 W_1\right) \mathbf{x} = W' \mathbf{x}
$$
Kaç katman istiflersen istifle, sonuç tek bir doğrusal dönüşüm (W′x) kalır — yalnızca rotation/scaling/shearing/reflection yapabilir, veriyi *bükemez*. Spiral gibi doğrusal ayrılamayan veriyi asla ayıramaz. LeCun bunu cebirle ("composition of two linear functions is linear", 28:48), Canziani geometriyle ("single layer only scales/rotates", 20:21) söyler. Derinliği anlamlı kılan tek şey katmanlar arasındaki doğrusal-olmamadır.
:::
::: {.callout-note collapse="true" title="Soru 2: Bir megapiksellik (1000 × 1000) RGB görüntü kaç boyutlu uzayda bir noktadır? 'Manifold hipotezi' bu uzay hakkında ne söyler?"}
**Cevap:** 1000 × 1000 × 3 = **3.000.000 boyut**. Görüntü, bu 3 milyon boyutlu uzayda tek bir noktadır. Manifold hipotezi: anlamlı görüntüler (kediler, sahneler) bu devasa uzayın **minik, düşük-boyutlu, kıvrık bir alt-yüzeyinde (manifold)** toplanmıştır; geri kalan neredeyse her nokta rastgele gürültüdür ("everything else is just trash", Canziani 5:45). Öğrenme, bu manifoldu açıp ayrıştırılabilir hale getirmektir. Doğrusal bir yöntem (PCA) kıvrık manifoldu bulamaz — LeCun'un kapanış örneği.
:::
::: {.callout-note collapse="true" title="Soru 3: Öteleme (translation) neden bir lineer dönüşüm değildir? Sinir ağı katmanını 'afin' yapan nedir?"}
**Cevap:** Bir dönüşümün lineer olması için sıfırı sıfıra götürmesi gerekir (T(0) = 0). Öteleme sıfırı b'ye taşır, dolayısıyla lineer değildir (Canziani'nin testi, 10:10). Matris çarpımına (lineer) bir öteleme (bias) eklersek dönüşüm **afin (affine)** olur — bir sinir ağı katmanı tam olarak budur:
$$
\mathbf{y} = W\mathbf{x} + \mathbf{b}
$$
Yani `nn.Linear(..., bias=True)` afin, `bias=False` ise saf lineer (matris) dönüşümdür.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) EBM'de 'çıkarım = enerji minimizasyonu', sıradan bir ağın 'girdi → çıktı' çıkarımından nasıl farklıdır? Stat 110 ile bağla."}
**Cevap:** Sıradan bir ağ bir girdiye **tek** çıktı üretir (ileri geçiş). EBM ise bir enerji fonksiyonu F(x, y) tanımlar ve çıkarımı bir **arama/optimizasyon** yapar: verilen x için enerjiyi minimize eden y'yi (veya y'leri) bulur. Birden çok minimum varsa, bir girdiye **birden çok geçerli cevap** verebilir — LeCun'un "akıl yürütme" dediği budur (7:50). Stat 110 köprüsü: enerji ile olasılık, Boltzmann dağılımıyla bağlanır — P(y) ∝ exp(−βE), yani energy = −log p (sabite kadar). Düşük enerji = yüksek olasılık. Bu, Hafta 7'nin (EBM) çekirdeğidir.
:::
## Egzersizler {#sec-egzersiz-d1}
**Egzersiz 1 (Perceptron'u elle kur).** Tek bir perceptron'un ileri geçişini NumPy ile yaz (nokta çarpımı + bias + aktivasyon), sonra `nn.Linear` + aktivasyonla aynı sonucu al.
```python
import numpy as np
def perceptron(x, w, b, g=lambda z: 1/(1+np.exp(-z))):
z = np.dot(x, w) + b # nokta carpimi + bias
return g(z) # aktivasyon
x = np.array([3.0, 1.0]); w = np.array([1.0, -1.0]); b = 0.0
print(perceptron(x, w, b)) # ~0.88
```
**Egzersiz 2 (Doğrusal çöküşü göster).** Aktivasyonsuz iki `nn.Linear` katmanı zincirle. Bunların tek bir matrise (W₂W₁) eşit olduğunu sayısal olarak doğrula — derinliğin aktivasyonsuz anlamsız olduğunu kendin gör.
```python
import torch, torch.nn as nn
W1 = nn.Linear(2, 5, bias=False); W2 = nn.Linear(5, 2, bias=False)
x = torch.randn(10, 2)
chained = W2(W1(x))
collapsed = x @ W1.weight.T @ W2.weight.T # tek matris (W2 W1)
print(torch.allclose(chained, collapsed, atol=1e-5)) # True
```
**Egzersiz 3 (Rastgele projeksiyon + SVD).** 1000 noktalık standart normal bir bulut üret, rastgele bir 2×2 matrisle çarp, `torch.linalg.svd` ile tekil değerleri incele. Bir tekil değeri çok küçük yapıp bir boyutun nasıl "ezildiğini" çiz (Canziani'nin patatesi).
**Egzersiz 4 (Doğrusal-olmama neden şart).** `sklearn.datasets.make_moons` ile doğrusal ayrılamayan veri üret. (a) Aktivasyonsuz, (b) `nn.ReLU`'lu bir ağ kur; karar sınırlarını çiz. Aktivasyonsuz ağın neden yalnızca düz çizgi çizebildiğini gözlemle.
**Egzersiz 5 (Hafta 2 habercisi — gradient descent + backprop).** Bu hafta ağ kurduk ama *eğitmedik*. Basit bir kuadratik kayıp L(w) = (w − 3)² üzerinde gradient descent'i elle uygula (gradient = 2(w − 3)). Sonra `x → nöron → ŷ → L` minik ağı için ∂L/∂w'yi zincir kuralıyla yaz. Bu iki gözlem, Hafta 2'de **backpropagation**'a (LeCun: backprop = zincir kuralının katmanlara uygulanması) neden ihtiyaç duyduğumuzu motive eder.
```python
def gd(eta, steps=50, w0=10.0):
w = w0
for _ in range(steps):
grad = 2*(w - 3) # dL/dw
w = w - eta*grad # gradient descent adimi
return w
for eta in [0.01, 0.1, 0.5, 1.0]:
print(eta, round(gd(eta), 4))
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d1}
::: {.callout-warning title="Sonraki Hafta — H2: Gradient Descent ve Backprop"}
**Manifold geometrisinden optimizasyon dinamiğine.** Bu hafta ağı *kurduk*; Hafta 2 onu **eğitir**: gradient descent, learning rate, loss landscape (kayıp manzarası) ve backpropagation = zincir kuralının katmanlara uygulanması. Bu haftaki spiral noktalarını gerçekten ayıracağız.
:::
**Hafta 2: Gradient Descent, Backprop ve Yapay Sinir Ağları** — LeCun (Lecture) + Canziani (Practicum)
Bu hafta ağı *kurduk* ama nasıl *öğrendiğini* görmedik. Hafta 2'de LeCun gradient descent ve backpropagation'ı (zincir kuralının katmanlara uygulanması) anlatacak; Canziani PyTorch'ta sinir ağı eğitimini gösterecek — bu haftaki spiral noktalarını gerçekten ayıracağız.
**Hafta 2 öncesi yapılacak:**
- Egzersiz 2'yi (doğrusal çöküş) ve Egzersiz 5'i (gradient descent) çöz.
- "İki ardışık doğrusal katman tek katmana çöker" cümlesini kendi sözcüklerinle yaz (hem cebir hem geometri).
- Calculus zincir kuralını (Phase 1 Calculus Ders 4) gözden geçir — backprop tam olarak budur.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d1}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Representation learning | Temsili elle tasarlamak yerine veriden öğrenmek | LeCun |
| Feature extractor | Klasik örüntü tanımada elle tasarlanan öznitelik aşaması | LeCun 26m46 |
| Perceptron | Ağırlıklı toplam + eşik; Rosenblatt'ın fiziksel analog makinesi | LeCun 17m18 |
| Deep = çok katman | "Derin"in tek anlamı: birden çok katman | LeCun 28m14 |
| Doğrusal çöküş | linear ∘ linear = linear; nonlinearity şart | LeCun 28m48 / Canziani 20m21 |
| EBM | Cevaplar = enerji fonksiyonunun minimumları; çıkarım = minimize | LeCun 7m50 |
| Yüksek-boyutlu nokta | 1MP RGB görüntü = 3 milyon boyutlu uzayda bir nokta | Canziani 4m45 |
| Manifold hipotezi | Anlamlı veri minik, kıvrık bir alt-manifoldda yaşar | Canziani 5m45 |
| Uzay germe | Ağ = uzayın kumaşını gerip noktaları ayrıştırma | Canziani 15m11 |
| Lineer dönüşüm | rotation / scaling / shearing / reflection (det < 0) | Canziani 8m14 |
| Afin dönüşüm | Wx + b; öteleme lineer değil (0 ↛ 0) | Canziani 10m10 |
| SVD | Matris = rotation · scaling · rotation; tekil değer ≈ 0 → boyut ezme | Canziani 40m02 |
## ML Builder Bağlantıları {#sec-koprular-d1}
**Geriye köprüler (önkoşul kurslar):**
1. **Perceptron / afin katman (Wx + b)** → 18.06 matris-vektör çarpımı + Phase 1 DL Ders 1.
2. **Lineer dönüşüm tipleri + SVD** → 18.06 (Ders 29 SVD) + Phase 2 18.065 (Matrix Methods) ileri.
3. **EBM enerji → olasılık** → Stat 110 Boltzmann, energy = −log p.
4. **Backprop için sürekli/türevlenebilir nöron** → Calculus türev + zincir kuralı (Ders 4).
5. **Manifold hipotezi** → 18.06 altuzay + Stat 110 çok-değişkenli dağılım geometrisi.
**İleriye köprüler (production / research):**
1. **EBM** → JEPA / I-JEPA / V-JEPA (post-2020 ileriye köprü, LeCun'un bugünkü programı).
2. **Representation learning** → foundation models, transfer learning (Hafta 15 bonus).
3. **GPU device yerleşimi** → throughput, mixed precision, DDP.
4. **Donanım hızlanması alanı patlattı** → scaling laws.
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Derin öğrenme sihir değildir — elle tasarlanan öznitelikleri çöpe atıp, veri uzayını doğrusal dönüşümler (Wx + b) ve doğrusal-olmamalarla gere büke yeniden şekillendirir; kıvrık veri manifoldunu ayrıştırılabilir hale getirir. LeCun bunu cebirle anlatır, Canziani geometriyle gösterir — aynı gerçeğin iki dili.
:::