---
title: "1B/2B Convolution ve Otomatik Türev (autograd)"
subtitle: "NYU'nun bu haftaki tek sesi: Alfredo Canziani'nin Practicum'u (bu hafta ayrı Lecture yok). İki konu işliyoruz, ikisi de 'elle anladığımız' şeyleri PyTorch'ta somutlaştırmak: (1) convolution'ı bir *projeksiyon* olarak okumak, boyut aritmetiğini ($o = n - k + 1$, 4-boyutlu 2B kernel) koda dökmek; (2) *otomatik türev (autograd)* — yani önceki haftalarda elle kurduğumuz backprop'un (zincir kuralı + hesaplama grafiği) PyTorch tarafından `requires_grad` + `.backward()` ile otomatik hesaplanması"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Canziani'nin Practicum videosu:** [YouTube — 1D/2D convolutions and autograd](https://www.youtube.com/watch?v=eEzCZnOFU1w) (≈45 dk)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hoca:** Alfredo Canziani (yalnızca Practicum — **bu hafta ayrı Lecture yok**)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈22 dk
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan conv1d / conv_output_size / conv_pad_output / autograd_worked +
# COL_* + apply_style / draw_pipeline / style_legend / CLASS_COLORS
# isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Patch,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm
np.random.seed(0)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ---------------------------------------------------------------------------
# Hafta 5 — autograd worked example (Canziani)
# ---------------------------------------------------------------------------
def autograd_worked(X=None):
"""Canziani worked example: X → Y=X−2 → Z=3·Y² → a=mean(Z) (skaler).
İleri değerler + ∂a/∂xᵢ = (1/4)·3·2·(xᵢ−2) = 1.5·(xᵢ−2).
X=[1,2,3,4] için grad = [−1.5, 0, 1.5, 3] (PyTorch X.grad ile birebir)."""
if X is None:
X = np.array([1.0, 2.0, 3.0, 4.0])
X = np.asarray(X, float)
Y = X - 2.0
Z = 3.0 * Y ** 2
a = float(Z.mean())
grad = 1.5 * (X - 2.0)
return dict(X=X, Y=Y, Z=Z, a=a, grad=grad)
def conv_pad_output(n, k, padding=0, stride=1):
"""Padding'li çıktı boyutu: o = ⌊(n + 2·padding − k)/stride⌋ + 1.
padding=(k−1)/2 (k tek) → çıktı boyutu korunur."""
return (n + 2 * padding - k) // stride + 1
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d5}
Bu hafta tek hocalı: yalnızca **Alfredo Canziani**'nin Practicum'u var (bu hafta ayrı bir Lecture yok). İki konu işliyoruz, ikisi de "elle anladığımız" şeyleri **PyTorch'ta somutlaştırmak**: (1) convolution'ın 1B/2B boyutlarını ve çıktı genişliğini koda dökmek; (2) **otomatik türev (autograd)** — yani Hafta 2'de LeCun'un elle kurduğu, Hafta 4'te Defazio'nun kullandığı gradient'lerin PyTorch tarafından otomatik hesaplanması.
Canziani'nin köprüsü açık: convolution bir **projeksiyon**dur (sinyalin kernel'e hizası), ve autograd, Hafta 2'nin backprop'unun (zincir kuralı + Jacobian) "düğmeye basınca çalışan" hâlidir. Bu hafta yeni bir teori değil; önceki üç haftanın **çalışan koda** dönüşmesi.
Bu haftanın üç ana fikri:
1. **Convolution boyutları kuralı:** her convolution çıktıyı $(k - 1)$ kadar kısaltır ($o = n - k + 1$); 2B kernel topluluğu 4 boyutludur.
2. **autograd = otomatik backprop.** `requires_grad=True` ile PyTorch tüm işlemleri bir **hesaplama grafiğinde** izler; `.backward()` gradient'leri zincir kuralıyla hesaplar, `.grad`'a yazar.
3. **Dinamik grafik (define-by-run):** PyTorch grafiği çalışma anında kurar — döngüler, koşullar serbestçe kullanılır.
```{mermaid}
%%| echo: false
flowchart TB
subgraph Conv["(A) Convolution boyut aritmetiği (Canziani)"]
direction LR
Proj["Convolution = projeksiyon<br/>(sinyalin kernel'e hizası)"]
Dim["Boyut cebiri<br/>(1B = 3 boyut · 2B = 4 boyut)"]
Width["Output width<br/>o = n − k + 1 · padding telafi"]
Torch["nn.Conv1d / nn.Conv2d<br/>(batch boyutu zorunlu)"]
Proj --> Dim
Dim --> Width
Width --> Torch
end
subgraph Auto["(B) Otomatik türev — autograd (Canziani)"]
direction LR
Req["requires_grad = True<br/>(işlemleri izle)"]
Graph["Hesaplama grafiği<br/>(grad_fn = üretici işlem)"]
Back[".backward()<br/>(zincir kuralı = backprop)"]
Grad[".grad<br/>(∂a/∂xᵢ sonucu)"]
Dyn["Dinamik grafik<br/>(define-by-run)"]
Req --> Graph
Graph --> Back
Back --> Grad
Grad --> Dyn
end
Torch -. "convolution katmanını nasıl eğitiriz?" .-> Req
```
::: {.callout-tip title="Builder Notu — Çalışan Koda Dönüşüm"}
**Geriye (önkoşul kurslar):**
- **Convolution = projeksiyon** → 18.06 iç çarpım/projeksiyon + Hafta 4 (Toeplitz, satır = kernel).
- **autograd = zincir kuralı** → Hafta 2 backprop (Jacobian zinciri) + Calculus Ders 4 + Karpathy micrograd (`_backward`).
- **Output width $o = n - k + 1$** → basit sayma; Hafta 3 stride formülünün stride=1 hâli.
**İleriye (production / research):**
- autograd → tüm PyTorch eğitiminin motoru (`torch.autograd`); dinamik grafik, define-by-run paradigması.
- Convolution boyut yönetimi → padding/stride ile mimari tasarımı, receptive field hesabı.
**Tek cümleyle:** Bu hafta convolution'ın boyut aritmetiğini ve PyTorch'un otomatik türev motorunu (autograd) öğreniyoruz — yani önceki haftaların elle kurduğu backprop'un, `requires_grad` + `.backward()` ile nasıl tek satıra indiğini.
:::
## (Canziani) Convolution = Projeksiyon {#sec-projeksiyon}
Canziani convolution'a Hafta 4'ün diliyle başlıyor: her convolution adımı, sinyalin bir parçasının kernel üzerine **projeksiyonudur** (normalize edilmemiş bir kosinüs/hiza değeri).
> "this is going to be my projection of my input signal onto the kernel... what is the alignment of this part of the signal onto this specific subspace?" — Canziani, 1:20
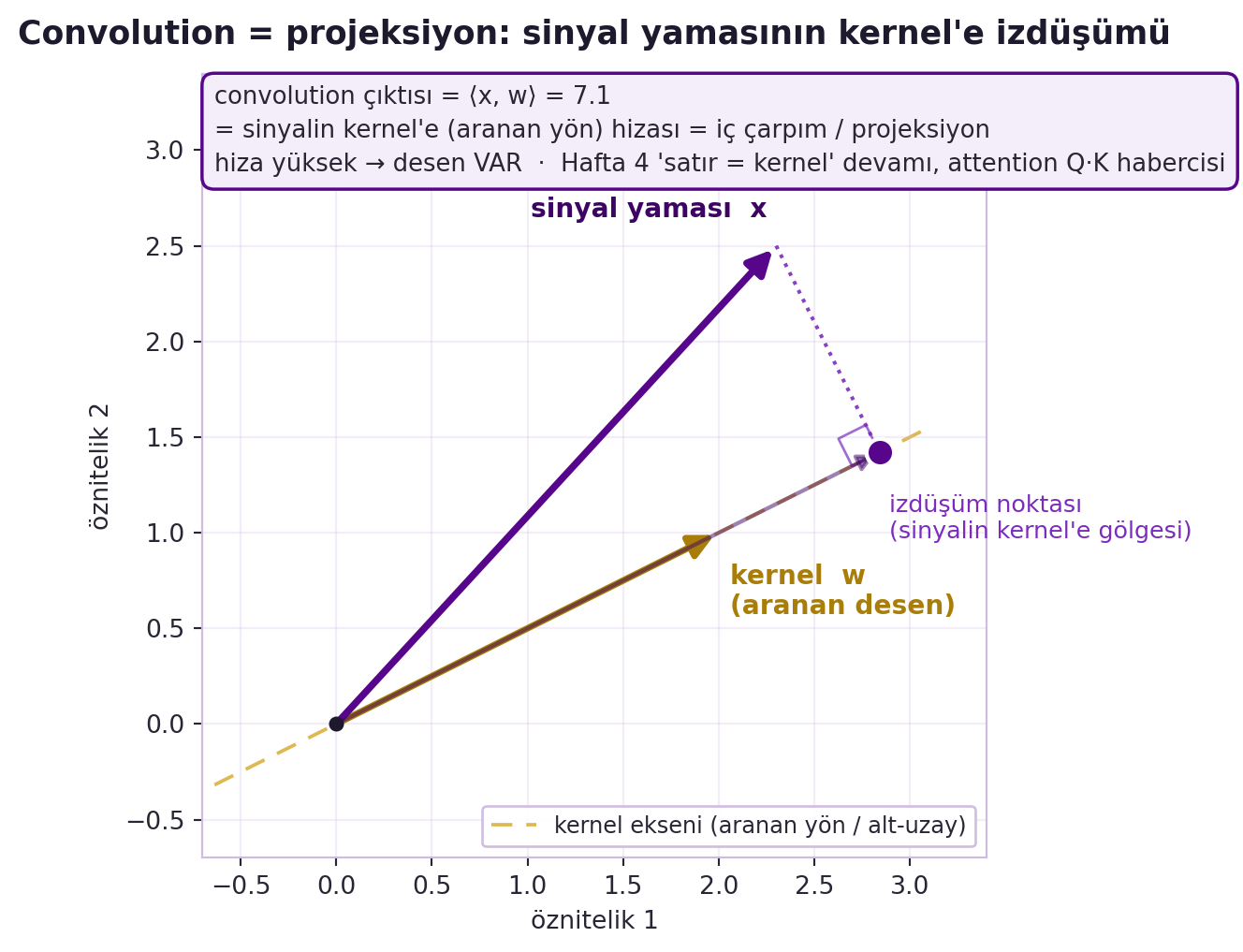
Yani kernel bir "yön" (alt-uzay) tanımlar; convolution çıktısı, sinyalin o yöne ne kadar hizalı olduğunu ölçer. Çıktı yüksekse, kernel'in aradığı desen o konumda güçlüdür. Bu, Hafta 3'ün "öznitelik dedektörü" ve Hafta 4'ün "satır = kernel, çıktı = iç çarpım" görüşünün aynı fikrin devamıdır. @fig-conv-projection bu projeksiyonu somut bir 2B çizimde gösterir: gold ok kernel'in tanımladığı yönü (aranan desen / alt-uzay eksenini), violet ok sinyal yamasını çizer; kesikli dikme sinyali kernel eksenine indirir ve izdüşüm noktası — sinyalin kernel'e gölgesi — convolution çıktısının ta kendisidir.
```{python}
#| label: fig-conv-projection
#| fig-cap: "Convolution = projeksiyon: tek bir convolution çıktısı, sinyal yamasının kernel yönüne (aranan desene) izdüşümüdür. Gold ok kernel'i ve aradığı alt-uzay eksenini, violet ok sinyal yamasını gösterir; kesikli dikme sinyali kernel eksenine indirir ve izdüşüm noktası (sinyalin kernel'e gölgesi) çıkar. Çıktı = ⟨x, w⟩ iç çarpımı = hiza; hiza yüksekse desen vardır. Hafta 4'teki 'satır = kernel' okumasının devamı ve attention Q·K skorunun habercisi."
k_vec = np.array([2.0, 1.0]) # kernel yönü (aranan desen)
s_vec = np.array([2.3, 2.5]) # sinyal yaması
dot_val = float(conv1d(s_vec, k_vec)[0]) # = s·k (tek pencere)
k_hat = k_vec / np.linalg.norm(k_vec) # birim kernel yönü
proj_scalar = float(s_vec @ k_hat) # izdüşüm uzunluğu (skaler hiza)
proj_pt = proj_scalar * k_hat # izdüşüm noktası (sinyalin gölgesi)
fig, ax = plt.subplots(figsize=(9.2, 5.4))
apply_style(ax)
# Kernel ekseni (aranan yön) — gold ışın, alt-uzay çizgisi
t = np.linspace(-0.4, 1.55, 50)
axis_line = np.outer(t, k_hat) * np.linalg.norm(k_vec)
ax.plot(axis_line[:, 0], axis_line[:, 1], color=COL_GOLD, lw=1.4,
ls=(0, (6, 4)), alpha=0.75, zorder=1,
label="kernel ekseni (aranan yön / alt-uzay)")
# Kernel yön oku (gold)
ax.add_patch(FancyArrowPatch((0, 0), tuple(k_vec), arrowstyle="-|>",
mutation_scale=20, color=COL_GOLD_D, lw=2.6, zorder=4))
ax.text(k_vec[0] + 0.06, k_vec[1] - 0.16, "kernel w\n(aranan desen)",
color=COL_GOLD_D, fontsize=10.5, fontweight="bold", va="top")
# Sinyal yaması oku (violet)
ax.add_patch(FancyArrowPatch((0, 0), tuple(s_vec), arrowstyle="-|>",
mutation_scale=20, color=COL_VIOLET, lw=2.8, zorder=4))
ax.text(s_vec[0] - 0.05, s_vec[1] + 0.12, "sinyal yaması x",
color=COL_VIOLET_D, fontsize=10.5, fontweight="bold", va="bottom", ha="right")
# İzdüşüm dikmesi (sinyalden eksene kesikli çizgi)
ax.plot([s_vec[0], proj_pt[0]], [s_vec[1], proj_pt[1]],
color=COL_VIOLET_M, lw=1.5, ls=":", alpha=0.9, zorder=3)
# İzdüşüm noktası (sinyalin kernel ekseni üzerindeki gölgesi)
ax.plot(proj_pt[0], proj_pt[1], "o", ms=11, color=COL_VIOLET,
mec=COL_WHITE, mew=1.6, zorder=5)
ax.text(proj_pt[0] + 0.05, proj_pt[1] - 0.22,
"izdüşüm noktası\n(sinyalin kernel'e gölgesi)",
color=COL_VIOLET_M, fontsize=9.5, va="top")
# İzdüşüm bileşeni vurgu oku (orijinden gölgeye, koyu violet, ince)
ax.add_patch(FancyArrowPatch((0, 0), tuple(proj_pt), arrowstyle="-|>",
mutation_scale=14, color=COL_VIOLET_D, lw=1.6, zorder=4,
alpha=0.5))
# Dik açı işareti (küçük kare) izdüşüm ayağında
perp = np.array([-k_hat[1], k_hat[0]]) * 0.16
sq = np.array([proj_pt, proj_pt + perp,
proj_pt + perp + (-k_hat) * 0.16, proj_pt + (-k_hat) * 0.16])
ax.plot(np.append(sq[:, 0], sq[0, 0]), np.append(sq[:, 1], sq[0, 1]),
color=COL_VIOLET_M, lw=1.0, alpha=0.7, zorder=3)
# Açıklama kutusu (annotation) — iç çarpım = projeksiyon mesajı
note = (f"convolution çıktısı = ⟨x, w⟩ = {dot_val:.1f}\n"
f"= sinyalin kernel'e (aranan yön) hizası = iç çarpım / projeksiyon\n"
f"hiza yüksek → desen VAR · Hafta 4 'satır = kernel' devamı, "
f"attention Q·K habercisi")
ax.text(0.015, 0.985, note, transform=ax.transAxes, va="top", ha="left",
fontsize=9.7, color=COL_TEXT, linespacing=1.5,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_VIOLET, lw=1.3))
# Orijin
ax.plot(0, 0, "o", ms=5, color=COL_INK, zorder=6)
ax.set_xlim(-0.7, 3.4)
ax.set_ylim(-0.7, 3.4)
ax.set_aspect("equal")
ax.set_xlabel("öznitelik 1")
ax.set_ylabel("öznitelik 2")
ax.set_title("Convolution = projeksiyon: sinyal yamasının kernel'e izdüşümü",
color=COL_INK, fontsize=13, fontweight="bold", pad=12)
style_legend(ax, loc="lower right", fontsize=9)
fig.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Projeksiyon = Hiza"}
**Geriye (18.06 + Hafta 4):** Projeksiyon = iç çarpım / kosinüs benzerliği (18.06); Hafta 4'ün "kernel = matrisin satırı, çıktı = satır·girdi" görüşü tam olarak bu projeksiyondur.
**İleriye:** "Kernel = aranan yön" görüşü, attention'daki sorgu-anahtar hizasının ($Q \cdot K^\top$) habercisidir (Hafta 6 ve sonrası).
:::
## (Canziani) 1B/2B Convolution ve Çok-Kanallı Kernel'ler {#sec-boyut}
Canziani convolution kernel'lerinin **boyut aritmetiğini** açıyor. Tek bir kernel küçük bir ağırlık penceresidir; bir katman birden çok kernel tutar ve onları istifleyerek/kaydırarak uygular. Çok-kanallı durumda kernel'in bir **kalınlığı (thickness)** vardır = girdi kanal sayısı.
- **1B convolution:** sinyal bir boyutlu (örn. ses). $m$ kernel, her biri (kalınlık × kernel_boyutu). Kernel topluluğu **3 boyutlu** bir tensördür: (kernel sayısı × girdi kanalı × kernel boyutu).
- **2B convolution:** sinyal iki boyutlu (görüntü). Kernel topluluğu **4 boyutlu**dur: (kernel sayısı × girdi kanalı × yükseklik × genişlik).
> "what is the dimensionality of the collection of kernels used for two-dimensional data? Four." — Canziani, 26:05
Her kernel girdinin tüm kanallarına bakar (kalınlık = girdi kanalı) ve tek bir öznitelik haritası üretir; kernel sayısı = çıktı kanal sayısı. Bu, Hafta 3'teki "her kernel bir feature map" kuralının boyutsal kesin ifadesidir. @fig-kernel-dims iki paneli yan yana koyar: solda 1B kernel topluluğunun 3-eksenli tensörü, sağda 2B'nin 4-eksenli tensörü ve `nn.Conv2d(20, 16, (3, 5)).weight.shape = (16, 20, 3, 5)` somutlaması.
```{python}
#| label: fig-kernel-dims
#| fig-cap: "Kernel boyut cebiri: 1B konvolüsyonda kernel tensörü 3 boyutludur (kernel sayısı × girdi kanalı × boyut), 2B konvolüsyonda 4 boyutludur (kernel sayısı × girdi kanalı × yükseklik × genişlik). Her iki durumda da kernel sayısı çıktı kanalı sayısına, kalınlık ise girdi kanalı sayısına eşittir. PyTorch'ta nn.Conv2d(20, 16, (3, 5)) ağırlık tensörünün şekli (16, 20, 3, 5) olur — yani (çıktı kanalı, girdi kanalı, H, W)."
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5))
def cube_stack(ax, x0, y0, n_boxes, box_w, box_h, depth, fc, ec,
row_labels=None, dx=0.10, dy=0.06):
"""n_boxes adet 'kalın' kutuyu (girdi kanalı kalınlığı sezgisi) dikey yığar."""
for i in range(n_boxes):
yy = y0 - i * (box_h + 0.14)
for d in range(depth, 0, -1):
box = FancyBboxPatch(
(x0 + d * dx, yy + d * dy), box_w, box_h,
boxstyle="round,pad=0.01,rounding_size=0.04",
fc=fc, ec=ec, lw=1.0, alpha=0.30 + 0.10 * (depth - d), zorder=2 + d,
)
ax.add_patch(box)
front = FancyBboxPatch(
(x0, yy), box_w, box_h,
boxstyle="round,pad=0.01,rounding_size=0.04",
fc=fc, ec=ec, lw=1.8, zorder=20,
)
ax.add_patch(front)
if row_labels and i < len(row_labels):
ax.text(x0 + box_w / 2, yy + box_h / 2, row_labels[i],
ha="center", va="center", fontsize=8.5,
color=COL_INK, zorder=21)
# SOL PANEL — 1B: 3 boyutlu kernel tensörü
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.axis("off")
axL.set_title("1B konvolüsyon: 3 boyutlu kernel tensörü",
color=COL_INK, fontsize=12, fontweight="bold", pad=12)
cube_stack(axL, x0=2.4, y0=7.6, n_boxes=3, box_w=2.6, box_h=1.2, depth=3,
fc="#ece0f7", ec=COL_VIOLET,
row_labels=["kernel 1", "kernel 2", "kernel 3"])
axL.annotate("kernel sayısı\n(= çıktı kanalı)", xy=(2.1, 5.6), xytext=(0.2, 4.0),
ha="center", fontsize=9.5, color=COL_GOLD_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6))
axL.annotate("girdi kanalı\n(kalınlık)", xy=(6.0, 7.9), xytext=(7.3, 9.0),
ha="center", fontsize=9.5, color=COL_GOLD_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6))
axL.annotate("boyut\n(çekirdek genişliği)", xy=(5.0, 6.4), xytext=(6.6, 4.6),
ha="center", fontsize=9.5, color=COL_GOLD_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6))
axL.text(5.0, 1.6, "şekil = (kernel sayısı × girdi kanalı × boyut)",
ha="center", fontsize=10, color=COL_VIOLET_D, fontweight="bold")
axL.text(5.0, 0.7, "3 eksen → 3 boyutlu tensör",
ha="center", fontsize=9, color=COL_TEXT, style="italic")
# SAĞ PANEL — 2B: 4 boyutlu kernel tensörü
axR.set_xlim(0, 10)
axR.set_ylim(0, 10)
axR.axis("off")
axR.set_title("2B konvolüsyon: 4 boyutlu kernel tensörü",
color=COL_INK, fontsize=12, fontweight="bold", pad=12)
cube_stack(axR, x0=2.4, y0=7.9, n_boxes=3, box_w=2.0, box_h=1.5, depth=3,
fc="#ece0f7", ec=COL_VIOLET,
row_labels=["H×W", "H×W", "H×W"])
axR.annotate("kernel sayısı\n(= çıktı kanalı)", xy=(2.1, 6.0), xytext=(0.2, 4.4),
ha="center", fontsize=9.5, color=COL_GOLD_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6))
axR.annotate("girdi kanalı\n(kalınlık)", xy=(5.6, 8.4), xytext=(7.2, 9.2),
ha="center", fontsize=9.5, color=COL_GOLD_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6))
axR.annotate("yükseklik × genişlik", xy=(4.4, 6.9), xytext=(6.6, 5.0),
ha="center", fontsize=9.5, color=COL_GOLD_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6))
annot = FancyBboxPatch(
(0.6, 2.0), 8.8, 1.55,
boxstyle="round,pad=0.06,rounding_size=0.12",
fc=COL_BG, ec=COL_GOLD, lw=2.0, zorder=5,
)
axR.add_patch(annot)
axR.text(5.0, 3.05, "nn.Conv2d(20, 16, (3, 5)).weight.shape",
ha="center", fontsize=10.5, color=COL_INK, fontweight="bold",
family="monospace", zorder=6)
axR.text(5.0, 2.45, "= (16, 20, 3, 5) → (çıktı kanalı, girdi kanalı, H, W)",
ha="center", fontsize=9.5, color=COL_VIOLET_D, zorder=6)
axR.text(5.0, 1.0, "4 eksen → 4 boyutlu tensör",
ha="center", fontsize=9, color=COL_TEXT, style="italic")
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Kernel Boyut Cebiri"}
**Geriye (Hafta 3):** "Her kernel girdinin tüm kanallarına bakar, bir harita üretir" — Hafta 3'ün multi-channel kernel açıklamasının boyut-cebiri hâli.
**İleriye:** Bu boyutları doğru saymak, `nn.Conv2d` parametre sayımının ve bellek bütçesinin temelidir; mimari tasarımda kanal sayısı en kritik kapasite eksenidir.
:::
## (Canziani) Output Width: Her Convolution Boyut Kaybeder {#sec-output}
Convolution'ın temel boyut kuralı: kernel'i kaydırırken kenarlarda yer kalmaz, dolayısıyla çıktı girdiden küçüktür. Stride 1 için, girdi boyutu $n$ ve kernel boyutu $k$ ise çıktı:
$$
o = n - k + 1
$$
Yani her convolution boyutu **$(k - 1)$** kadar kısaltır. Canziani somut sayar: $n = 5$, $k = 2$ → çıktı 4; $n = 5$, $k = 3$ → çıktı 3.
> "every time you perform a convolution you lose the dimension of the kernel minus one." — Canziani, 17:17
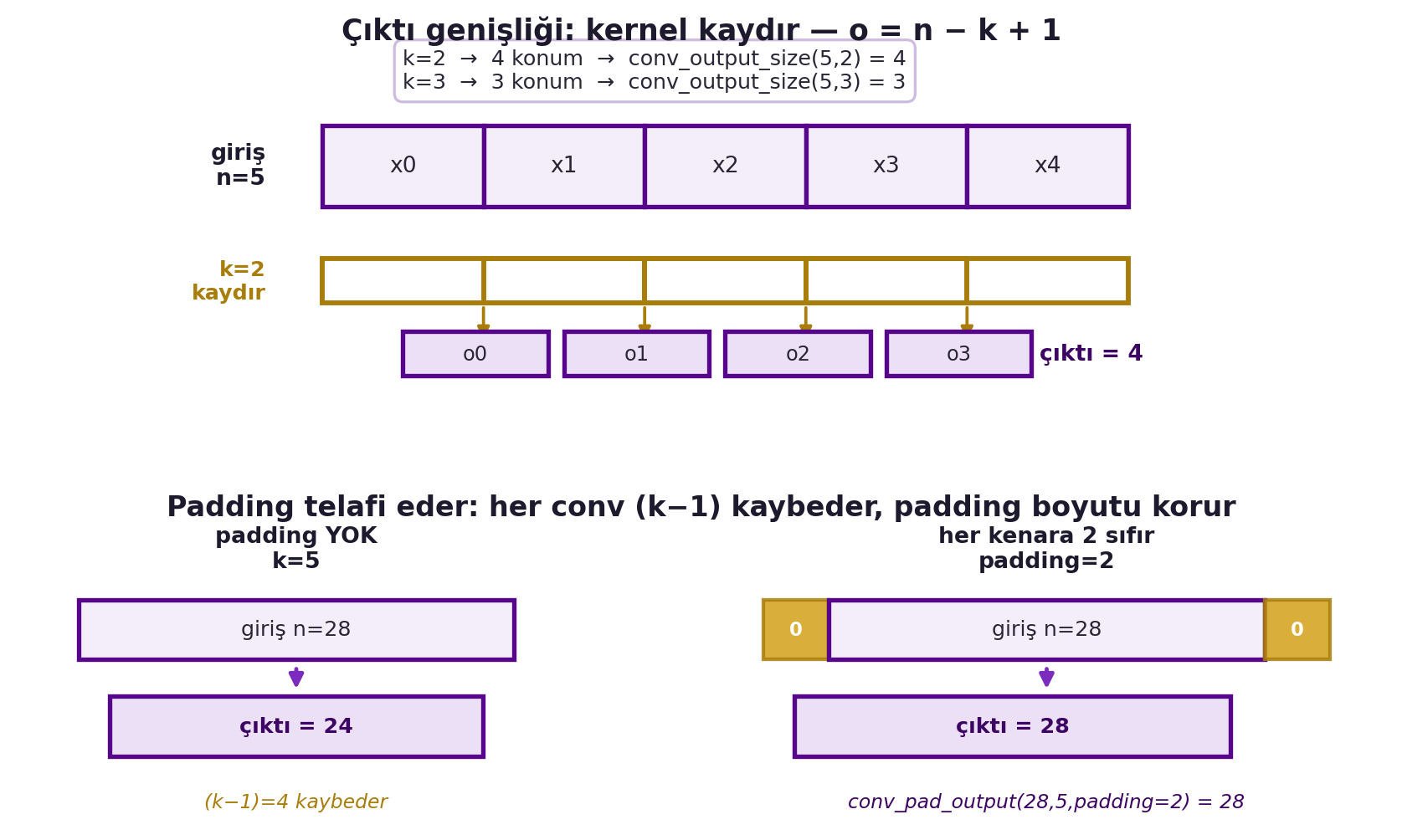
Bu kayıp istenmiyorsa **padding** (kenarlara sıfır ekleme) ile telafi edilir — örneğin her kenara $(k-1)/2$ sıfır ekleyerek çıktı boyutu korunur. (Bu, Hafta 3'teki genel stride formülünün — $\lfloor(n-k)/s\rfloor + 1$ — stride = 1 hâlidir.) @fig-output-width üstte kernel kaydırmasıyla $o = n - k + 1$ kuralını, altta padding'in $n = 28$, $k = 5$ için boyutu nasıl koruduğunu somutlaştırır.
```{python}
#| label: fig-output-width
#| fig-cap: "Konvolüsyonda çıktı genişliği. ÜST: n=5 girişte kernel kaydırma — k=2 dört konum üretir (çıktı 4), k=3 üç konum (çıktı 3); genel kural o = n − k + 1, conv_output_size(5,2)=4 ve (5,3)=3 ile doğrulanır. ALT: padding telafisi — n=28, k=5 için padding olmadan çıktı 24'e düşer (k−1=4 kayıp); her kenara 2 sıfır eklenince conv_pad_output(28,5,padding=2)=28 ile boyut korunur."
fig = plt.figure(figsize=(11, 6.2))
gs = fig.add_gridspec(2, 1, height_ratios=[1.15, 1.0], hspace=0.42)
# ÜST: 1B sinyal n=5, kernel kaydır (k=2 → 4 konum, k=3 → 3 konum)
ax1 = fig.add_subplot(gs[0])
ax1.axis("off")
n = 5
cell = 1.0
sig_y = 2.55
for i in range(n):
x = i * cell
ax1.add_patch(Rectangle((x, sig_y), cell, cell, facecolor=COL_BG,
edgecolor=COL_VIOLET, lw=2.0, zorder=2))
ax1.text(x + cell / 2, sig_y + cell / 2, f"x{i}", ha="center", va="center",
fontsize=10, color=COL_TEXT, zorder=3)
ax1.text(-0.35, sig_y + cell / 2, "giriş\nn=5", ha="right", va="center",
fontsize=10, color=COL_INK, fontweight="bold")
o2 = conv_output_size(n, 2) # 4
win_y2 = 1.35
for i in range(o2):
x = i * cell
ax1.add_patch(Rectangle((x, win_y2), 2 * cell, cell * 0.55, facecolor="none",
edgecolor=COL_GOLD_D, lw=2.2, zorder=4))
ax1.add_patch(FancyArrowPatch((x + cell, win_y2), (x + cell, win_y2 - 0.5),
arrowstyle="-|>", mutation_scale=11, color=COL_GOLD_D, lw=1.4, zorder=1))
ax1.text(-0.35, win_y2 + cell * 0.275, "k=2\nkaydır", ha="right", va="center",
fontsize=9.5, color=COL_GOLD_D, fontweight="bold")
out_y2 = 0.45
for i in range(o2):
x = i * cell + cell * 0.5
ax1.add_patch(Rectangle((x, out_y2), cell * 0.9, cell * 0.55, facecolor="#ece0f7",
edgecolor=COL_VIOLET, lw=2.0, zorder=2))
ax1.text(x + cell * 0.45, out_y2 + cell * 0.275, f"o{i}", ha="center", va="center",
fontsize=9, color=COL_TEXT, zorder=3)
ax1.text(o2 * cell + 0.45, out_y2 + cell * 0.275, f"çıktı = {o2}", ha="left", va="center",
fontsize=10, color=COL_VIOLET_D, fontweight="bold")
ax1.set_title("Çıktı genişliği: kernel kaydır — o = n − k + 1",
fontsize=13, color=COL_INK, fontweight="bold", pad=8)
ax1.text(0.5, 3.95,
"k=2 → 4 konum → conv_output_size(5,2) = 4\n"
"k=3 → 3 konum → conv_output_size(5,3) = 3",
ha="left", va="bottom", fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.4", facecolor=COL_WHITE, edgecolor=COL_GRID, lw=1.2))
ax1.set_xlim(-1.9, n * cell + 1.6)
ax1.set_ylim(0.2, 4.4)
# ALT: padding — n=28, k=5 → 24; her kenara 2 sıfır → korunur (28)
ax2 = fig.add_subplot(gs[1])
ax2.axis("off")
o_nopad = conv_output_size(28, 5) # 24
pad = 2
o_pad = conv_pad_output(28, 5, padding=pad) # 28
gx0 = 0.0
bar_h = 0.62
ax2.add_patch(Rectangle((gx0, 1.55), 2.8, bar_h, facecolor=COL_BG, edgecolor=COL_VIOLET, lw=2.0))
ax2.text(gx0 + 1.4, 1.55 + bar_h / 2, "giriş n=28", ha="center", va="center",
fontsize=9.5, color=COL_TEXT)
out_w_nopad = 2.8 * o_nopad / 28
ax2.add_patch(Rectangle((gx0 + 0.2, 0.55), out_w_nopad, bar_h, facecolor="#ece0f7",
edgecolor=COL_VIOLET, lw=2.0))
ax2.text(gx0 + 0.2 + out_w_nopad / 2, 0.55 + bar_h / 2, f"çıktı = {o_nopad}",
ha="center", va="center", fontsize=9.5, color=COL_VIOLET_D, fontweight="bold")
ax2.add_patch(FancyArrowPatch((gx0 + 1.4, 1.5), (gx0 + 1.4, 1.2),
arrowstyle="-|>", mutation_scale=13, color=COL_VIOLET_M, lw=1.8))
ax2.text(gx0 + 1.4, 2.45, "padding YOK\nk=5", ha="center", va="bottom",
fontsize=10, color=COL_INK, fontweight="bold")
ax2.text(gx0 + 1.4, 0.18, "(k−1)=4 kaybeder", ha="center", va="top",
fontsize=8.8, color=COL_GOLD_D, style="italic")
gx1 = 4.4
pad_w = 0.42
ax2.add_patch(Rectangle((gx1, 1.55), pad_w, bar_h, facecolor=COL_GOLD,
edgecolor=COL_GOLD_D, lw=1.6, alpha=0.85))
ax2.add_patch(Rectangle((gx1 + pad_w, 1.55), 2.8, bar_h, facecolor=COL_BG,
edgecolor=COL_VIOLET, lw=2.0))
ax2.add_patch(Rectangle((gx1 + pad_w + 2.8, 1.55), pad_w, bar_h, facecolor=COL_GOLD,
edgecolor=COL_GOLD_D, lw=1.6, alpha=0.85))
ax2.text(gx1 + pad_w / 2, 1.55 + bar_h / 2, "0", ha="center", va="center",
fontsize=8.5, color=COL_WHITE, fontweight="bold")
ax2.text(gx1 + pad_w + 2.8 + pad_w / 2, 1.55 + bar_h / 2, "0", ha="center", va="center",
fontsize=8.5, color=COL_WHITE, fontweight="bold")
ax2.text(gx1 + pad_w + 1.4, 1.55 + bar_h / 2, "giriş n=28", ha="center", va="center",
fontsize=9.5, color=COL_TEXT)
ax2.add_patch(Rectangle((gx1 + 0.2, 0.55), 2.8, bar_h, facecolor="#ece0f7",
edgecolor=COL_VIOLET, lw=2.0))
ax2.text(gx1 + 0.2 + 1.4, 0.55 + bar_h / 2, f"çıktı = {o_pad}",
ha="center", va="center", fontsize=9.5, color=COL_VIOLET_D, fontweight="bold")
ax2.add_patch(FancyArrowPatch((gx1 + pad_w + 1.4, 1.5), (gx1 + pad_w + 1.4, 1.2),
arrowstyle="-|>", mutation_scale=13, color=COL_VIOLET_M, lw=1.8))
ax2.text(gx1 + pad_w + 1.4, 2.45, "her kenara 2 sıfır\npadding=2", ha="center", va="bottom",
fontsize=10, color=COL_INK, fontweight="bold")
ax2.text(gx1 + pad_w + 1.4, 0.18, "conv_pad_output(28,5,padding=2) = 28",
ha="center", va="top", fontsize=8.8, color=COL_VIOLET_D, style="italic")
ax2.set_title("Padding telafi eder: her conv (k−1) kaybeder, padding boyutu korur",
fontsize=12.5, color=COL_INK, fontweight="bold", pad=6)
ax2.set_xlim(-0.4, 8.4)
ax2.set_ylim(-0.15, 2.9)
plt.show()
```
::: {.callout-tip title="Builder Notu — Boyut Kaybı + Padding"}
**Geriye (Hafta 3):** Hafta 3'ün stride'lı çıktı formülünün özel hâli (s=1). Boyut kaybı, convolution'ın "kenar etkisi"dir.
**İleriye:** Derin ağlarda her katmanın boyut kaybı birikir; `padding` ile boyut korumak veya kasıtlı küçültmek (stride/pooling) mimari tasarımın günlük aritmetiğidir. Receptive field hesabı da bu aritmetiğe dayanır.
:::
## (Canziani) PyTorch'ta Convolution Boyutları {#sec-pytorch-d5}
Canziani teoriyi `nn.Conv1d` / `nn.Conv2d` ile somutlaştırıyor. Bir convolution katmanı tanımlarken: girdi kanalı, çıktı kanalı (kernel sayısı), kernel boyutu, stride, padding verilir.
```python
import torch
import torch.nn as nn
# 1B: 20 girdi kanali, 16 kernel (cikti kanali), kernel boyutu 3
conv1d = nn.Conv1d(in_channels=20, out_channels=16, kernel_size=3, stride=1)
print(conv1d.weight.shape) # (16, 20, 3) -> 3 boyutlu kernel toplulugu
print(conv1d.bias.shape) # (16,)
# 2B: 20 girdi kanali, 16 kernel, 3x5 kernel, padding ile boyut koru
conv2d = nn.Conv2d(in_channels=20, out_channels=16, kernel_size=(3, 5),
stride=1, padding=(1, 2))
x = torch.randn(1, 20, 64, 224) # (batch, kanal, yukseklik, genislik)
y = conv2d(x) # padding sayesinde 64x224 korunur
```
Kritik noktalar: kernel ağırlığı 2B convolution'da **4 boyutludur** ($16 \times 20 \times 3 \times 5$); PyTorch her zaman bir **batch boyutu** bekler (tek sinyal göndersen bile (1, kanal, ...) şeklinde), yoksa hata verir; `padding`, "her convolution boyut kaybeder" kuralını telafi etmenin yoludur.
::: {.callout-tip title="Builder Notu — Batch-First Tensör"}
**Geriye (Hafta 4):** `conv1d.weight.shape = (16, 20, 3)` tam olarak Hafta 4'ün "kernel = yapılı matris satırı" görüşünün tensör hâli; bias = afin terimi.
**İleriye:** "Batch boyutu zorunlu" kuralı, tüm PyTorch tensör akışının (batch-first) temelidir; `padding`/`stride`/`dilation` üçlüsü, receptive field ve çözünürlüğü ayarlamanın pratik kollarıdır.
:::
## (Canziani) Otomatik Türev (autograd): requires_grad ve Hesaplama Grafiği {#sec-autograd}
Practicum'un ikinci yarısı **autograd**. Canziani şakayla başlıyor: 90'larda LSTM gradient'lerini elle türetmek zorundaydılar (sayfalar dolusu); bugün PyTorch bunu otomatik yapar.
Bir tensöre `requires_grad=True` verirsen, PyTorch o tensör üzerindeki **tüm işlemleri bir hesaplama grafiğinde izler**, böylece kısmi türevleri hesaplayabilir.
> "I'm asking torch: please track all the gradient computations over the tensor, such that we can perform computation of partial derivatives." — Canziani, 28:53
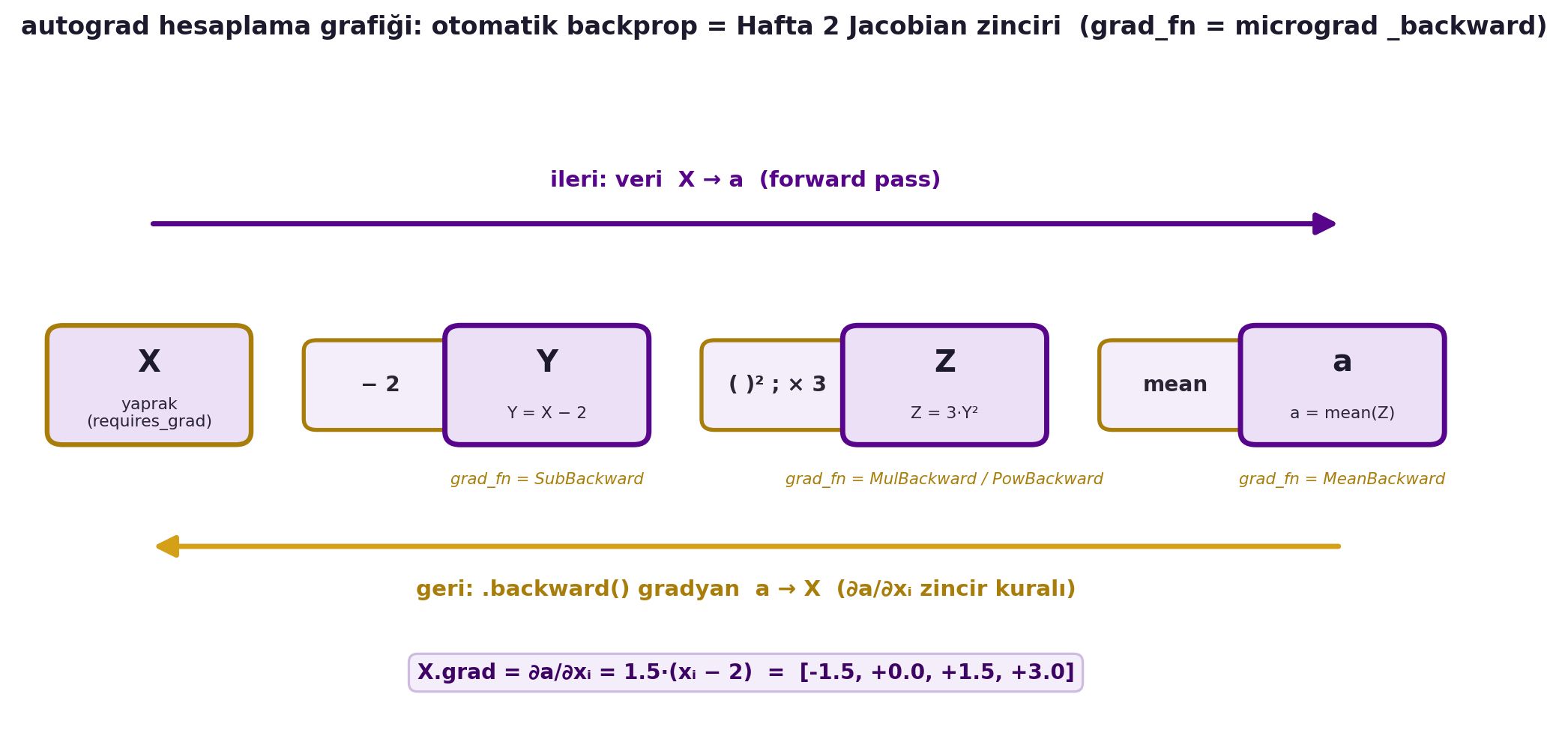
Her türetilmiş tensörün bir `grad_fn`'i (grad function) vardır: onu hangi işlemin ürettiğini söyler. Örneğin $Y = X - 2$ için $Y$'nin `grad_fn`'i bir "SubBackward"dır. Bu, Hafta 2'de LeCun'un "her modülün bir backward'ı var" dediği şeyin ta kendisidir — ve Hafta 6'da göreceğimiz RNN gradient'leri de bu motorla otomatik akar. @fig-autograd-graph bu hesaplama grafiğini bir DAG olarak çizer: üstte ileri geçiş (veri $X \to a$), altta geri geçiş (`.backward()` ile gradyan $a \to X$), her düğümün altında `grad_fn` etiketi.
```{python}
#| label: fig-autograd-graph
#| fig-cap: "autograd hesaplama grafiği (DAG): X → [−2] → Y → [( )²; ×3] → Z → [mean] → a. Üst violet ok ileri geçişi (veri X→a), alt gold ok geri geçişi (.backward() ile gradyan a→X) gösterir. Her ara düğümün altındaki grad_fn etiketi (SubBackward, MulBackward/PowBackward, MeanBackward) o düğümün yerel geri-yayılım kuralını tutar — yani autograd, Hafta 2'deki Jacobian zincir kuralının otomatikleştirilmiş hâlidir ve grad_fn, micrograd'daki _backward closure'unun PyTorch karşılığıdır. Sonuç: X.grad = ∂a/∂xᵢ = 1.5·(xᵢ−2) = [−1.5, 0, +1.5, +3]."
res = autograd_worked(np.array([1.0, 2.0, 3.0, 4.0]))
X, Y, Z, a, grad = res["X"], res["Y"], res["Z"], res["a"], res["grad"]
fig, ax = plt.subplots(figsize=(11, 5.2))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6)
ax.axis("off")
# --- düğüm (tensör) ve operasyon kutuları ---
node_w, node_h = 1.55, 1.05
op_w, op_h = 1.15, 0.78
y_node = 3.05 # tensör düğüm satırı (orta)
y_op = 3.05 # operasyon kutuları aynı hizada (düğümler arası)
# tensör düğümleri: konum + etiket + grad_fn
nodes = [
(1.05, "X", "yaprak\n(requires_grad)", None),
(4.15, "Y", "Y = X − 2", "SubBackward"),
(7.25, "Z", "Z = 3·Y²", "MulBackward / PowBackward"),
(10.35, "a", "a = mean(Z)", "MeanBackward"),
]
# operasyonlar (düğümler arasında)
ops = [
(2.85, "− 2"),
(5.95, "( )² ; × 3"),
(9.05, "mean"),
]
# operasyon kutularını çiz (gold kenarlı)
for xc, lbl in ops:
box = FancyBboxPatch(
(xc - op_w / 2, y_op - op_h / 2), op_w, op_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_BG, ec=COL_GOLD_D, lw=2.0, zorder=2,
)
ax.add_patch(box)
ax.text(xc, y_op, lbl, ha="center", va="center",
fontsize=10.5, color=COL_TEXT, zorder=3, fontweight="bold")
# tensör düğümlerini çiz (violet dolgulu)
for xc, name, sub, gfn in nodes:
leaf = gfn is None
fc = "#ece0f7"
ec = COL_VIOLET if not leaf else COL_GOLD_D
lw = 2.6 if not leaf else 2.4
box = FancyBboxPatch(
(xc - node_w / 2, y_node - node_h / 2), node_w, node_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(xc, y_node + 0.20, name, ha="center", va="center",
fontsize=15, color=COL_INK, zorder=3, fontweight="bold")
ax.text(xc, y_node - 0.26, sub, ha="center", va="center",
fontsize=8.2, color=COL_TEXT, zorder=3)
# grad_fn etiketi (düğümün altında, gold)
if gfn is not None:
ax.text(xc, y_node - node_h / 2 - 0.34, f"grad_fn = {gfn}",
ha="center", va="center", fontsize=8.0, color=COL_GOLD_D,
zorder=3, fontstyle="italic")
# --- ileri ok (üst, violet): veri X -> a ---
y_fwd = y_node + node_h / 2 + 0.95
ax.add_patch(FancyArrowPatch(
(1.05, y_fwd), (10.35, y_fwd),
arrowstyle="-|>", mutation_scale=22,
color=COL_VIOLET, lw=2.6, zorder=1,
connectionstyle="arc3,rad=0.0",
))
ax.text(5.7, y_fwd + 0.30, "ileri: veri X → a (forward pass)",
ha="center", va="bottom", fontsize=11, color=COL_VIOLET,
fontweight="bold")
# --- geri ok (alt, gold): gradyan a -> X ---
y_bwd = y_node - node_h / 2 - 0.95
ax.add_patch(FancyArrowPatch(
(10.35, y_bwd), (1.05, y_bwd),
arrowstyle="-|>", mutation_scale=22,
color=COL_GOLD, lw=2.6, zorder=1,
connectionstyle="arc3,rad=0.0",
))
ax.text(5.7, y_bwd - 0.30, "geri: .backward() gradyan a → X (∂a/∂xᵢ zincir kuralı)",
ha="center", va="top", fontsize=11, color=COL_GOLD_D,
fontweight="bold")
# --- alt açıklama şeridi: hesaplanan grad ---
grad_txt = "X.grad = ∂a/∂xᵢ = 1.5·(xᵢ − 2) = [" + ", ".join(f"{g:+.1f}" for g in grad) + "]"
ax.text(5.7, 0.42, grad_txt, ha="center", va="center", fontsize=10.5,
color=COL_VIOLET_D, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_GRID, lw=1.2))
# başlık
ax.set_title(
"autograd hesaplama grafiği: otomatik backprop = Hafta 2 Jacobian zinciri "
"(grad_fn = micrograd _backward)",
color=COL_INK, fontsize=12.5, pad=14, fontweight="bold")
fig.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — grad_fn = micrograd _backward"}
**Geriye (Hafta 2 + Karpathy):** `grad_fn`, Karpathy'nin micrograd'daki `_backward` kapanışının PyTorch karşılığıdır; hesaplama grafiği, LeCun'un "modüllerin DAG'ı" (Hafta 2) görüşüdür.
**İleriye:** `torch.autograd`, tüm derin öğrenme eğitiminin sessiz motorudur; `grad_fn` zincirini anlamak, bellek (retain_graph), gradient checkpointing ve hata ayıklamanın anahtarıdır.
:::
## (Canziani) Worked Example: a.backward() ve .grad {#sec-worked}
Canziani somut bir örnek yürütüyor. $X = [1, 2, 3, 4]$ (`requires_grad=True`), sonra:
- $Y = X - 2$
- $Z = 3 \cdot Y^2$
- $a = \text{mean}(Z)$ (skaler)
`a.backward()` çağrısı, $a$'nın $X$'e göre gradient'ini zincir kuralıyla hesaplar (backprop). Elle:
$$
\frac{\partial a}{\partial x_i} = \frac{1}{4}\cdot 3\cdot 2\,(x_i - 2) = \frac{3}{2}(x_i - 2)
$$
$X = [1, 2, 3, 4]$ için bu $[-1.5, 0, 1.5, 3]$ verir — ve `X.grad` tam bunu içerir.
> "backpropagation is how you compute the gradients; how do we train the networks — with gradients. Keep them separate!" — Canziani, 32:04
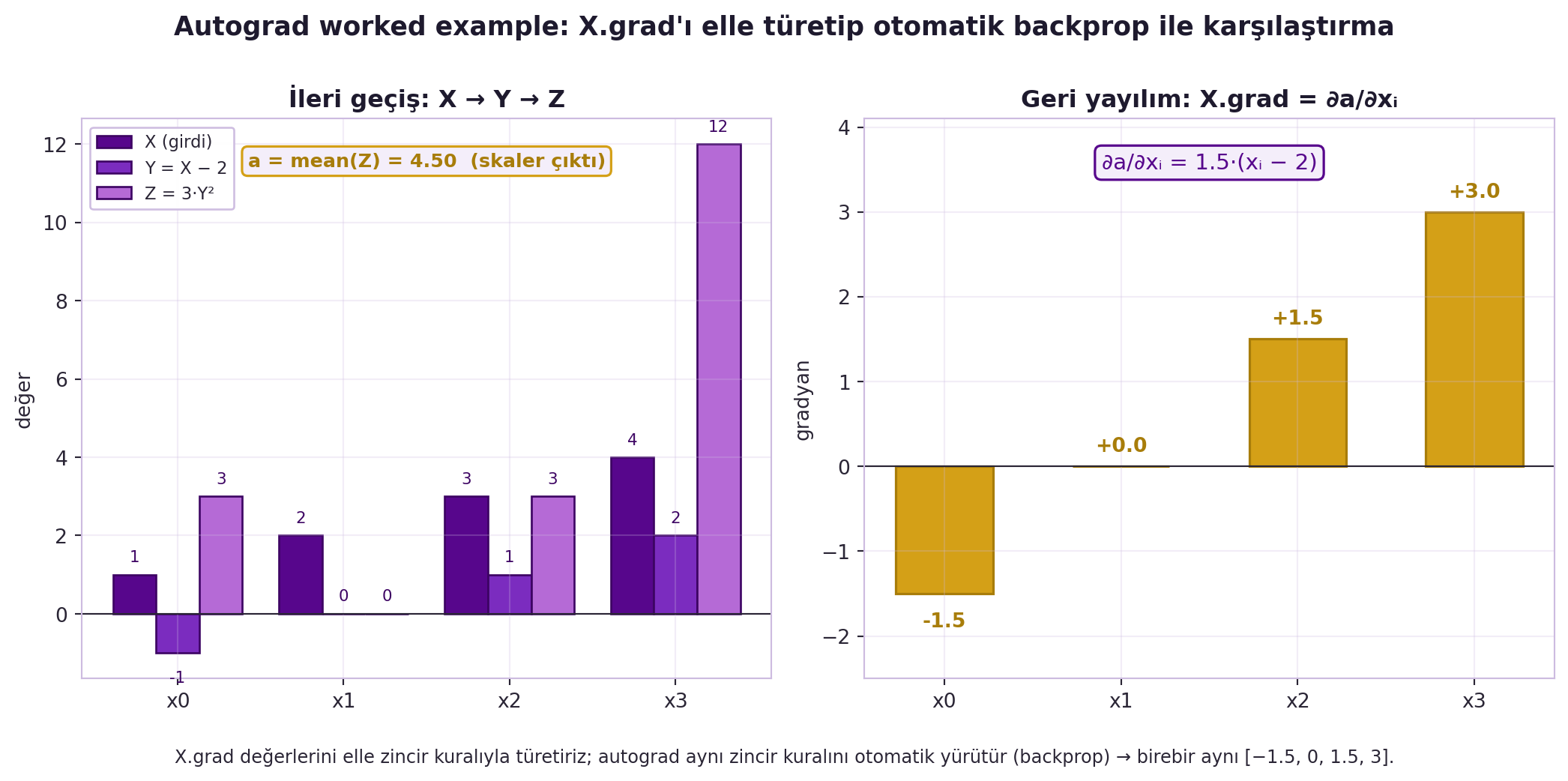
Canziani'nin uyarısı kritik: **backprop = gradient hesaplama**, **eğitim = gradient kullanma** — ikisini karıştırma. (Bir teknik not: PyTorch `.grad`'ı girdiyle **aynı şekilde** tutar; teorik Jacobian/gradient transpoze farkını pratiklik için göz ardı eder.) @fig-autograd-worked bu örneği gerçek değerlerle çizer: solda ileri geçiş ($X \to Y \to Z$, $a = 4.5$), sağda elle türetilen `X.grad` ve autograd'ın birebir aynı $[-1.5, 0, 1.5, 3]$ sonucu.
```{python}
#| label: fig-autograd-worked
#| fig-cap: "Autograd worked example (Canziani, Bölüm 6): X=[1,2,3,4] üzerinde ileri geçiş Y=X−2 → Z=3·Y² → a=mean(Z)=4.5 ve geri yayılımla elde edilen X.grad=[−1.5, 0, 1.5, 3]. Sol panel ileri geçiş değerlerini (violet), sağ panel ∂a/∂xᵢ gradyanlarını (gold) gösterir. Gradyan elle ∂a/∂xᵢ = 1.5·(xᵢ−2) zincir kuralıyla türetilir; PyTorch autograd aynı zincir kuralını otomatik yürütür (backprop) ve birebir aynı sonucu verir."
w = autograd_worked()
X, Y, Z, a, grad = w["X"], w["Y"], w["Z"], w["a"], w["grad"]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5))
idx = np.arange(len(X))
labels = [f"x{i}" for i in range(len(X))]
width = 0.26
# --- SOL panel: ileri geçiş değerleri (X, Y, Z) ---
axL.bar(idx - width, X, width, label="X (girdi)", color=COL_VIOLET, edgecolor=COL_VIOLET_D, lw=1.0)
axL.bar(idx, Y, width, label="Y = X − 2", color=COL_VIOLET_M, edgecolor=COL_VIOLET_D, lw=1.0)
axL.bar(idx + width, Z, width, label="Z = 3·Y²", color=COL_VIOLET_SOFT, edgecolor=COL_VIOLET_D, lw=1.0)
apply_style(axL)
axL.axhline(0, color=COL_TEXT, lw=0.8)
axL.set_xticks(idx)
axL.set_xticklabels(labels)
axL.set_title("İleri geçiş: X → Y → Z", color=COL_INK, fontsize=12, fontweight="bold")
axL.set_ylabel("değer")
style_legend(axL, loc="upper left", fontsize=8.5)
for i in range(len(X)):
axL.text(i - width, X[i] + 0.25, f"{X[i]:.0f}", ha="center", va="bottom", fontsize=8, color=COL_VIOLET_D)
axL.text(i, Y[i] + (0.25 if Y[i] >= 0 else -0.45), f"{Y[i]:.0f}", ha="center",
va="bottom" if Y[i] >= 0 else "top", fontsize=8, color=COL_VIOLET_D)
axL.text(i + width, Z[i] + 0.25, f"{Z[i]:.0f}", ha="center", va="bottom", fontsize=8, color=COL_VIOLET_D)
axL.text(0.5, 0.94, f"a = mean(Z) = {a:.2f} (skaler çıktı)", transform=axL.transAxes,
ha="center", va="top", fontsize=9.5, color=COL_GOLD_D, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_GOLD, lw=1.2))
# --- SAĞ panel: X.grad (geri yayılım) ---
axR.bar(idx, grad, 0.55, color=COL_GOLD, edgecolor=COL_GOLD_D, lw=1.2)
apply_style(axR)
axR.axhline(0, color=COL_TEXT, lw=0.8)
axR.set_xticks(idx)
axR.set_xticklabels(labels)
axR.set_title("Geri yayılım: X.grad = ∂a/∂xᵢ", color=COL_INK, fontsize=12, fontweight="bold")
axR.set_ylabel("gradyan")
for i in range(len(X)):
axR.text(i, grad[i] + (0.12 if grad[i] >= 0 else -0.22), f"{grad[i]:+.1f}",
ha="center", va="bottom" if grad[i] >= 0 else "top",
fontsize=10, color=COL_GOLD_D, fontweight="bold")
axR.text(0.5, 0.94, "∂a/∂xᵢ = 1.5·(xᵢ − 2)", transform=axR.transAxes,
ha="center", va="top", fontsize=11, color=COL_VIOLET,
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_VIOLET, lw=1.2))
axR.set_ylim(min(grad.min() - 1.0, -2.0), grad.max() + 1.1)
fig.suptitle("Autograd worked example: X.grad'ı elle türetip otomatik backprop ile karşılaştırma",
color=COL_INK, fontsize=13, fontweight="bold", y=1.00)
fig.text(0.5, -0.02,
"X.grad değerlerini elle zincir kuralıyla türetiriz; autograd aynı zincir kuralını "
"otomatik yürütür (backprop) → birebir aynı [−1.5, 0, 1.5, 3].",
ha="center", va="top", fontsize=9, color=COL_TEXT, wrap=True)
fig.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — backprop ≠ Eğitim"}
**Geriye (Hafta 2 + 4):** `a.backward()` = Hafta 2'nin Jacobian zinciri; "backprop ≠ eğitim" ayrımı, Hafta 4'te Defazio'nun da vurguladığı şeydir (Canziani "Aaron'un dün dediği gibi" der — Hafta 4 Defazio dersine atıf).
**İleriye:** `.backward()` + optimizer (`step()`) = Hafta 2'nin dört satırlık eğitim döngüsü; `.grad`'ın şekli ve birikimi (`zero_grad`) günlük hata kaynaklarıdır.
:::
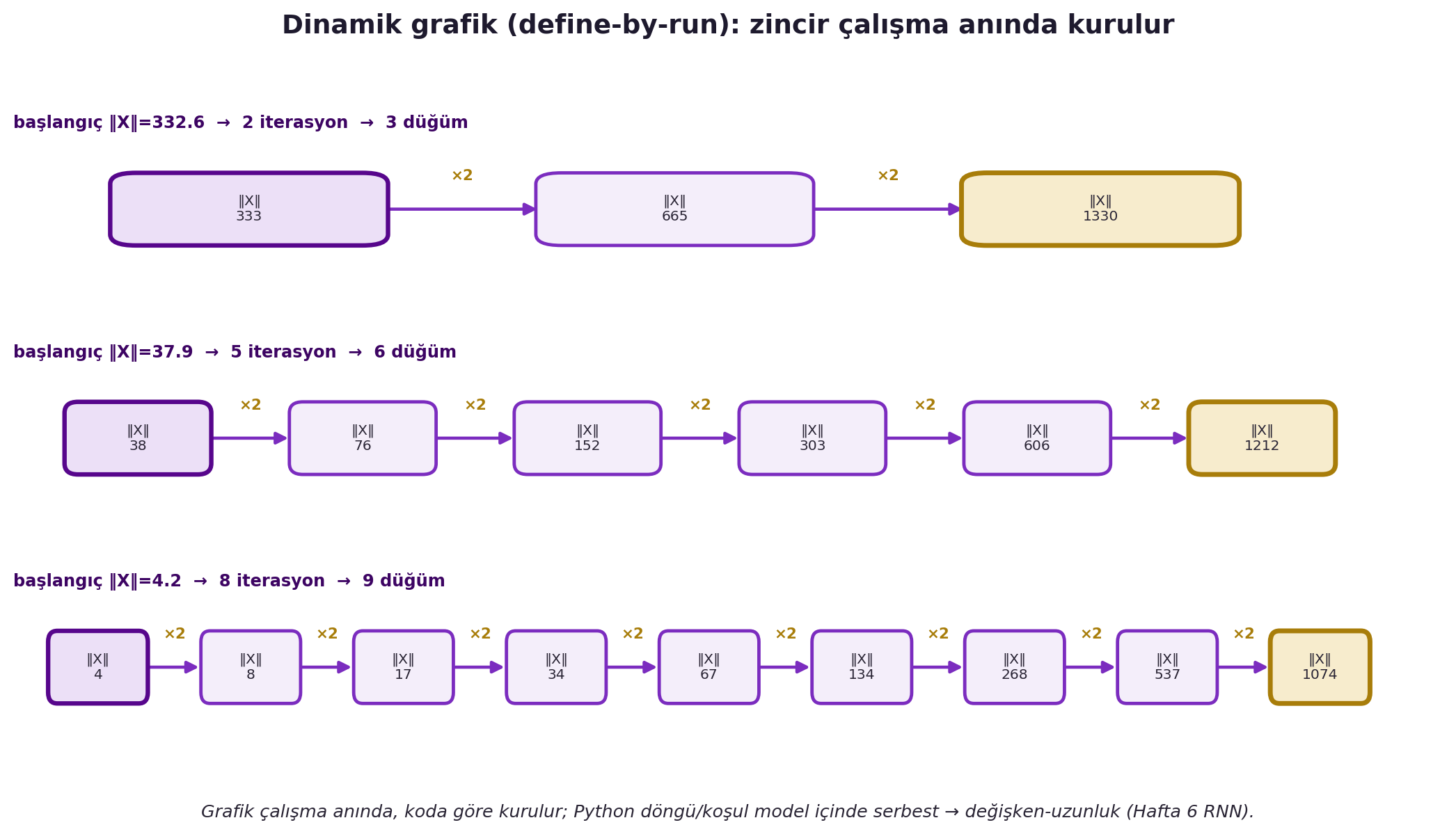
## (Canziani) Dinamik Hesaplama Grafiği (Define-by-Run) {#sec-dinamik}
Canziani PyTorch'un ayırt edici özelliğini gösteriyor: grafik **statik değil, dinamiktir**. Bir örnek: $X$'i, normu 1000'i aşana kadar bir `while` döngüsünde ikiye katla. Kaç iterasyon döneceği rastgele başlangıca bağlıdır — yani **hesaplama grafiği çalışma anında, koda göre kurulur** (define-by-run).
Bu, normal Python kontrol akışını (döngü, koşul) modelin içinde serbestçe kullanabilmen demektir; autograd yine de doğru gradient'i hesaplar çünkü grafiği sen çalıştırdıkça örer. @fig-dynamic-graph üç farklı rastgele başlangıç için döngünün farklı sayıda iterasyon döndüğünü ve böylece farklı uzunlukta grafik zincirleri doğduğunu gösterir.
```{python}
#| label: fig-dynamic-graph
#| fig-cap: "Dinamik grafik (define-by-run): hesap grafiği çalışma anında, kodun akışına göre kurulur. `while X.norm() < 1000: X = X * 2` döngüsü üç farklı rastgele başlangıç için (‖X‖ = 332.6, 37.9, 4.2) farklı sayıda iterasyonda 1000 eşiğini aşar — sırasıyla 2, 5 ve 8 kez ikiye katlama — ve bu yüzden farklı uzunlukta (3, 6, 9 düğümlü) grafik zincirleri doğar. Her kutu o adımdaki ‖X‖ değerini, her ok ×2 işlemini, gold kutu eşiği aşan son düğümü gösterir. Python döngü/koşulun model içinde serbestçe çalışabilmesi tam da değişken-uzunluklu hesaba (Hafta 6 RNN) kapı açar; statik grafikte (define-then-run) bu mümkün değildir."
def build_chain(x0):
"""X.norm() < 1000 olduğu sürece X = X * 2; her adımda zincire bir kutu ekle."""
x = float(abs(x0))
norms = [x]
while norms[-1] < 1000.0:
x = x * 2.0
norms.append(x)
return norms # uzunluk = iterasyon sayısı + 1 (başlangıç dahil)
# 3 FARKLI rastgele başlangıç → 3 farklı zincir uzunluğu.
# Her başlangıç ayrı bir büyüklük bandından rastgele çekilir; bantlar yeterince
# ayrık → küçük başlangıç çok iterasyon, büyük başlangıç az iterasyon ile 1000
# eşiğini aşar → zincirler garanti farklı uzunlukta (define-by-run'ın özü).
bands = [(2.0, 6.0), (20.0, 45.0), (200.0, 420.0)]
starts = np.array([np.random.uniform(lo, hi) for lo, hi in bands])[::-1] # büyükten küçüğe
chains = [build_chain(s) for s in starts]
fig, axes = plt.subplots(3, 1, figsize=(11, 6.2))
fig.suptitle("Dinamik grafik (define-by-run): zincir çalışma anında kurulur",
color=COL_INK, fontsize=14, fontweight="bold", y=0.99)
box_w, box_h, gap = 1.05, 0.62, 0.62
step = box_w + gap
for row, (ax, norms, s) in enumerate(zip(axes, chains, starts)):
n = len(norms)
ax.set_xlim(-0.4, n * step + 0.2)
ax.set_ylim(-0.95, 0.95)
ax.axis("off")
for i, val in enumerate(norms):
x = i * step
is_start = (i == 0)
is_last = (i == n - 1)
# başlangıç violet dolgulu, son (eşik aşan) gold vurgulu, ara düğümler açık violet
if is_last:
fc, ec, lw = "#f7eccd", COL_GOLD_D, 2.6
elif is_start:
fc, ec, lw = "#ece0f7", COL_VIOLET, 2.4
else:
fc, ec, lw = COL_BG, COL_VIOLET_M, 1.8
box = FancyBboxPatch(
(x, -box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
lbl = f"‖X‖\n{val:.0f}" if val < 100000 else f"‖X‖\n{val:.0e}"
ax.text(x + box_w / 2, 0.0, lbl, ha="center", va="center",
fontsize=7.6, color=COL_TEXT, zorder=3)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, 0.0), (x, 0.0),
arrowstyle="-|>", mutation_scale=13,
color=COL_VIOLET_M, lw=1.7, zorder=1,
))
# ok üstüne ×2 işlemi
ax.text(x - gap / 2, 0.30, "×2", ha="center", va="center",
fontsize=8.0, color=COL_GOLD_D, fontweight="bold", zorder=3)
iters = n - 1
ax.text(-0.4, 0.78,
f"başlangıç ‖X‖={s:.1f} → {iters} iterasyon → {n} düğüm",
ha="left", va="center", fontsize=9.0, color=COL_VIOLET_D,
fontweight="bold")
# alt açıklama
fig.text(0.5, 0.015,
"Grafik çalışma anında, koda göre kurulur; Python döngü/koşul model içinde "
"serbest → değişken-uzunluk (Hafta 6 RNN).",
ha="center", va="bottom", fontsize=9.5, color=COL_TEXT, style="italic")
fig.tight_layout(rect=[0, 0.05, 1, 0.96])
plt.show()
```
::: {.callout-tip title="Builder Notu — Define-by-Run"}
**Geriye (Hafta 2):** Hafta 2'de LeCun "döngü varsa grafik üretimi karmaşıklaşır" demişti; PyTorch'un dinamik grafiği bunu doğal çözer — her ileri geçişte grafiği yeniden kurar.
**İleriye:** Define-by-run, PyTorch'u araştırmada esnek kılan şeydir (RNN'ler, değişken-uzunluk diziler — Hafta 6); buna karşılık statik grafikler (eski TensorFlow, `torch.compile`/`torch.jit`) hız/optimizasyon için grafiği önceden dondurur.
:::
## Bu Dersin Özeti {#sec-ozet-d5}
1. **Convolution = projeksiyon:** sinyalin kernel'e (aranan yöne) hizası.
2. **Boyut aritmetiği:** 1B kernel topluluğu 3 boyutlu, 2B 4 boyutlu (kernel sayısı × girdi kanalı × [yükseklik ×] genişlik); kernel sayısı = çıktı kanalı.
3. **Output width:** $o = n - k + 1$ (stride 1); her convolution $(k-1)$ boyut kaybeder; padding telafi eder.
4. **PyTorch:** `nn.Conv1d/2d(in, out, kernel_size, stride, padding)`; batch boyutu zorunlu.
5. **autograd:** `requires_grad=True` ile işlemler hesaplama grafiğinde izlenir; `grad_fn` üretici işlemi tutar.
6. **`.backward()` = backprop:** gradient'i zincir kuralıyla hesaplar, `.grad`'a yazar. backprop ≠ eğitim.
7. **Dinamik grafik (define-by-run):** grafik çalışma anında kurulur; döngü/koşul serbest.
::: {.callout-important title="Tek Bir Cümle"}
Bu hafta convolution'ın boyut aritmetiğini ($o = n - k + 1$, 4-boyutlu 2B kernel) ve PyTorch'un autograd motorunu öğrendik — `requires_grad` + `.backward()`, Hafta 2'de LeCun'un elle kurduğu Jacobian zincirini tek satıra indirir, ve dinamik grafik sayesinde bunu döngü/koşul içeren her kodda yapar.
:::
## Kontrol Soruları {#sec-kontrol-d5}
::: {.callout-note collapse="true" title="Soru 1: Stride 1'de, girdi boyutu 28 ve kernel boyutu 5 olan bir convolution'ın çıktısı kaç olur? Genel kural nedir? Boyutu korumak için ne yaparsın?"}
**Cevap:** Çıktı boyutu:
$$
o = n - k + 1 = 28 - 5 + 1 = 24
$$
Genel kural: her convolution çıktıyı $(k - 1)$ kadar kısaltır (Canziani 17:17). Boyutu korumak için **padding** eklersin — her kenara $(k-1)/2 = 2$ sıfır eklersen çıktı yine 28 olur. (Bu, Hafta 3'ün $\lfloor(n-k)/s\rfloor+1$ formülünün s=1 hâlidir.)
:::
::: {.callout-note collapse="true" title="Soru 2: 2B convolution kernel topluluğu kaç boyutludur ve bu boyutlar neyi temsil eder?"}
**Cevap:** **4 boyutlu** (Canziani 26:05): (kernel sayısı × girdi kanalı × yükseklik × genişlik). Kernel sayısı = çıktı kanal sayısı; girdi kanalı = kernel'in "kalınlığı" (her kernel girdinin tüm kanallarına bakar); yükseklik × genişlik = uzamsal pencere. PyTorch'ta `nn.Conv2d(20, 16, (3,5)).weight.shape = (16, 20, 3, 5)`. Ayrıca PyTorch her zaman bir batch boyutu bekler (girdi: batch × kanal × H × W).
:::
::: {.callout-note collapse="true" title="Soru 3: requires_grad=True ne yapar? grad_fn nedir? .backward() ile eğitim arasındaki fark nedir?"}
**Cevap:** `requires_grad=True`, PyTorch'a o tensör üzerindeki tüm işlemleri bir **hesaplama grafiğinde izlemesini** söyler, böylece kısmi türevler hesaplanabilir (Canziani 28:53). `grad_fn`, türetilmiş bir tensörü hangi işlemin ürettiğini tutar (örn. $Y = X - 2$ için SubBackward) — Karpathy micrograd'ın `_backward`'ının karşılığı. **`.backward()` = backprop = gradient'leri hesaplama** (zincir kuralı, `.grad`'a yazar); **eğitim = bu gradient'leri kullanıp parametreyi güncelleme** (optimizer.step). Canziani: "ikisini karıştırma" (32:04).
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) X = [1,2,3,4] (requires_grad), Y = X−2, Z = 3Y², a = mean(Z). a.backward() sonrası X.grad nedir? Elle türet."}
**Cevap:** $a = (1/4)\sum 3(x_i - 2)^2$. Zincir kuralı:
$$
\frac{\partial a}{\partial x_i} = \frac{1}{4}\cdot 3\cdot 2\,(x_i - 2) = \frac{3}{2}(x_i - 2)
$$
$X = [1,2,3,4]$ için: $[1.5\cdot(-1),\ 1.5\cdot 0,\ 1.5\cdot 1,\ 1.5\cdot 2] = $ **[−1.5, 0, 1.5, 3]**. `X.grad` tam bunu içerir — autograd, elle yaptığımız zincir kuralını otomatik yürütür. (PyTorch `.grad`'ı girdiyle aynı şekilde tutar.)
:::
## Egzersizler {#sec-egzersiz-d5}
**Egzersiz 1 (Boyut aritmetiği).** Bir 32×32 görüntüye art arda üç `nn.Conv2d(kernel_size=3, padding=0)` uygula. Her katmandan sonra uzamsal boyut ne olur? `padding=1` ile tekrar dene — fark nedir? Formül $o = n - k + 1$ ile önceden tahmin et.
```python
import torch
import torch.nn as nn
x = torch.randn(1, 3, 32, 32) # (batch, kanal, H, W)
net_nopad = nn.Sequential(
nn.Conv2d(3, 8, 3), nn.Conv2d(8, 8, 3), nn.Conv2d(8, 8, 3))
net_pad = nn.Sequential(
nn.Conv2d(3, 8, 3, padding=1),
nn.Conv2d(8, 8, 3, padding=1),
nn.Conv2d(8, 8, 3, padding=1))
print(net_nopad(x).shape) # 32 -> 30 -> 28 -> 26
print(net_pad(x).shape) # padding=1 -> 32 korunur
```
**Egzersiz 2 (Kernel şekli).** `nn.Conv2d(3, 64, kernel_size=7)` katmanının `.weight.shape` ve `.bias.shape`'ini önce tahmin et, sonra yazdırıp doğrula. Toplam parametre sayısını hesapla.
```python
import torch
import torch.nn as nn
conv = nn.Conv2d(3, 64, kernel_size=7)
print(conv.weight.shape) # (64, 3, 7, 7)
print(conv.bias.shape) # (64,)
params = 64 * 3 * 7 * 7 + 64 # ağırlık + bias
print(params) # 9472
```
**Egzersiz 3 (autograd worked example).** `X = torch.tensor([1.,2.,3.,4.], requires_grad=True)` ile Y=X−2, Z=3*Y**2, a=Z.mean(); `a.backward()` çağır ve `X.grad`'ı yazdır. [−1.5, 0, 1.5, 3] çıktığını ve elle türevle eştiğini doğrula.
```python
import torch
X = torch.tensor([1., 2., 3., 4.], requires_grad=True)
Y = X - 2
Z = 3 * Y ** 2
a = Z.mean()
a.backward()
print(X.grad) # tensor([-1.5000, 0.0000, 1.5000, 3.0000])
# elle: da/dxi = (1/4)*3*2*(xi-2) = 1.5*(xi-2)
```
**Egzersiz 4 (grad_fn zinciri).** Yukarıdaki Y, Z, a tensörlerinin `.grad_fn`'lerini yazdır. Hangi işlemleri görüyorsun (Sub, Mul, Mean)? Bu zincirin Hafta 2'nin Jacobian zinciriyle ilişkisini açıkla.
```python
import torch
X = torch.tensor([1., 2., 3., 4.], requires_grad=True)
Y = X - 2; Z = 3 * Y ** 2; a = Z.mean()
print(Y.grad_fn) # <SubBackward0>
print(Z.grad_fn) # <MulBackward0>
print(a.grad_fn) # <MeanBackward0>
# her grad_fn = o işlemin yerel Jacobian'i (Hafta 2 zincir kurali halkasi)
```
**Egzersiz 5 (Hafta 6 habercisi — diziler).** Şimdiye kadar girdiler sabit boyutluydu (görüntü, vektör). Bir cümle ise **değişken uzunlukta bir dizidir** ("film iyiydi" 2 kelime, "film başından sonuna kadar harikaydı" 5 kelime). (a) Sabit-girdili bir ağa değişken uzunlukta diziyi nasıl verirsin — naif bir fikir öner ve neden yetersiz olduğunu açıkla. (b) Dinamik hesaplama grafiği (Bölüm 7), değişken-uzunluk dizileri işlemek için neden uygundur? Bu, Hafta 6'da **RNN ve attention**'a geçişi motive eder.
```python
# (a) naif fikir: tum cumleleri sabit L uzunluga pad/truncate et
# -> kisa cumlede bos token israfi, uzun cumlede bilgi kaybi
# (b) dinamik grafik: her cumle icin grafik o cumlenin uzunluguna gore
# calisma aninda kurulur -> degisken-uzunluk dogal (Hafta 6 RNN/attention)
sentences = [["film", "iyiydi"],
["film", "basindan", "sonuna", "kadar", "harikaydi"]]
for s in sentences:
print(len(s)) # 2, 5 -> farkli uzunluk
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d5}
::: {.callout-warning title="Sonraki Hafta — H6: Diziler — RNN, LSTM ve Attention"}
**Sabit boyuttan değişken uzunluğa.** Bu haftaya kadar sabit boyutlu girdilerle (görüntü, vektör) çalıştık. Hafta 6'da değişken uzunlukta **dizilere** (metin, ses, zaman serisi) geçiyoruz: LeCun RNN ve attention'ı, Canziani PyTorch'ta dizi eğitimini gösterecek. Bu haftanın dinamik hesaplama grafiği (define-by-run) tam da bu değişken-uzunluk dünyasının altyapısıdır — Egzersiz 3-4 (autograd) ve Egzersiz 5 (dizi problemi) tam bu derse hazırlar.
:::
**Hafta 6: Diziler — RNN, LSTM ve Attention** — LeCun (Lecture) + Canziani (Practicum)
Bu haftaya kadar sabit boyutlu girdilerle (görüntü, vektör) çalıştık. Hafta 6'da değişken uzunlukta **dizilere** (metin, ses, zaman serisi) geçiyoruz: LeCun RNN ve attention'ı, Canziani PyTorch'ta dizi eğitimini gösterecek. Dinamik hesaplama grafiği (bu hafta) tam da bu değişken-uzunluk dünyasının altyapısıdır.
**Hafta 6 öncesi yapılacak:**
- Egzersiz 3-4 (autograd) ve Egzersiz 5 (dizi problemi sezgisi) çöz.
- "autograd = otomatik backprop (zincir kuralı + hesaplama grafiği)" cümlesini kendi sözcüklerinle yaz.
- Hafta 2-4-5 üçlüsünü bağla: backprop'u elle kurduk (2), kullandık (4), otomatikleştirdik (5).
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d5}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Convolution = projeksiyon | Sinyalin kernel'e (aranan yöne) hizası | Canziani 1m20 |
| 1B kernel topluluğu | 3 boyutlu: kernel sayısı × girdi kanalı × boyut | Canziani 12m37 |
| 2B kernel topluluğu | 4 boyutlu: kernel × kanal × yükseklik × genişlik | Canziani 26m05 |
| Output width | $o = n - k + 1$; her conv $(k-1)$ kaybeder | Canziani 17m17 |
| Padding | Kenara sıfır ekleyip boyut koruma | Canziani 25m20 |
| Batch boyutu zorunlu | PyTorch girdisi batch × kanal × uzamsal | Canziani 26m50 |
| requires_grad | İşlemleri hesaplama grafiğinde izle | Canziani 28m53 |
| grad_fn | Tensörü üreten işlem (örn. SubBackward) | Canziani 29m22 |
| .backward() | Backprop = gradient hesapla; .grad'a yaz | Canziani 32m04 |
| backprop ≠ eğitim | Backprop gradient hesaplar; eğitim onu kullanır | Canziani 32m16 |
| Dinamik grafik | Define-by-run; grafik çalışma anında kurulur | Canziani 37m43 |
## ML Builder Bağlantıları {#sec-koprular-d5}
**Geriye köprüler (önkoşul kurslar):**
1. **Convolution = projeksiyon** → 18.06 iç çarpım + Hafta 4 (satır = kernel).
2. **autograd = zincir kuralı** → Hafta 2 backprop (Jacobian) + Calculus Ders 4 + Karpathy `_backward`.
3. **grad_fn = modül backward** → Hafta 2 "her modülün bir backward'ı var".
4. **Output width** → Hafta 3 stride formülü (s=1).
5. **backprop ≠ eğitim** → Hafta 4 Defazio (aynı uyarı).
**İleriye köprüler (production / research):**
1. **autograd** → torch.autograd, retain_graph, gradient checkpointing.
2. **Dinamik grafik** → RNN/değişken-uzunluk (Hafta 6); torch.compile (statik optimizasyon).
3. **Convolution boyut yönetimi** → padding/stride/dilation, receptive field hesabı.
4. **Batch-first tensör** → tüm PyTorch veri hattı.
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
PyTorch'un autograd'ı sihir değildir — `requires_grad=True` tüm işlemleri bir hesaplama grafiğinde izler, `.backward()` ise Hafta 2'de LeCun'un elle kurduğu zincir kuralını (Jacobian zinciri) otomatik yürütüp `.grad`'a yazar; convolution boyutları ise basit bir aritmetiktir ($o = n - k + 1$). Backprop'u önce elle anladık (Hafta 2), sonra kullandık (Hafta 4), şimdi de PyTorch'a otomatik yaptırıyoruz — ve dinamik grafik, bunu döngü/koşul içeren her kodda mümkün kılarak bizi değişken-uzunluk dizilere (Hafta 6) hazırlıyor.
:::