---
title: "Aktivasyon/Kayıp Fonksiyonları ve PPUU"
subtitle: "İki parçalı hafta — Yann LeCun (Lecture) aktivasyon ve kayıp fonksiyonlarının sistematik turunu yapar ve kritik olarak kayıpları EBM çerçevesinde (enerji manzarasını şekillendirme) toparlar: bir kayıp fonksiyonu seçmek aslında doğru cevabın enerjisini bastırırken yanlışları bir marjla yukarı iten bir enerji manzarası tasarlamaktır, marj yoksa sistem çöker (her cevaba aynı enerji); aktivasyon tarafında ise tek-kıvrımlı (ReLU türü) fonksiyonlar ölçeğe duyarsız oldukları için derin ağlarda normalleştirmeyle uyumludur, sigmoid/tanh ise gömülü bir ölçek taşır ve doyumda gradyanı yok eder. Ardından Alfredo Canziani (Practicum) Hafta 9-10'un dünya modelini sonuna kadar götürüp PPUU'yu (belirsizlik düzenlileştirmeli öngörülü politika öğrenme) — yoğun trafikte otonom sürüş — baştan sona kurar: deterministik MSE dünya modeli çoklu-geleceği ortalamaya indirip bulanıklaşır, latent değişken eksik bilgiyi taşıyıp keskin çoklu-gelecek üretir, latent dropout eylem-körlüğü sızıntısını keser ve belirsizlik düzenlileştirmesi (varyans cezası) politikayı güvenli eğitim manifoldunda tutar."
---
::: {.callout-note title="Bölüm bilgisi"}
- **LeCun'un Lecture videosu:** [YouTube — Activation and loss functions, EBM](https://www.youtube.com/watch?v=bj1fh3BvqSU) (Hafta 11 Lecture)
- **Canziani'nin Practicum videosu:** [YouTube — PPUU (prediction and policy learning under uncertainty)](https://www.youtube.com/watch?v=A3klBqEWR-I)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Yann LeCun (Lecture, teorik) + Alfredo Canziani (Practicum, PPUU)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈28 dk
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan activation_fns / softplus_scaled / margin_losses /
# uncertainty_demo + önceki hafta yardımcıları + COL_* + apply_style /
# draw_pipeline / style_legend / CLASS_COLORS isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Ellipse, Polygon, Patch,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm, LinearSegmentedColormap
np.random.seed(0)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ---------------------------------------------------------------------------
# Hafta 5 — autograd worked example (Canziani)
# ---------------------------------------------------------------------------
def autograd_worked(X=None):
"""Canziani worked example: X → Y=X−2 → Z=3·Y² → a=mean(Z) (skaler).
İleri değerler + ∂a/∂xᵢ = (1/4)·3·2·(xᵢ−2) = 1.5·(xᵢ−2).
X=[1,2,3,4] için grad = [−1.5, 0, 1.5, 3] (PyTorch X.grad ile birebir)."""
if X is None:
X = np.array([1.0, 2.0, 3.0, 4.0])
X = np.asarray(X, float)
Y = X - 2.0
Z = 3.0 * Y ** 2
a = float(Z.mean())
grad = 1.5 * (X - 2.0)
return dict(X=X, Y=Y, Z=Z, a=a, grad=grad)
def conv_pad_output(n, k, padding=0, stride=1):
"""Padding'li çıktı boyutu: o = ⌊(n + 2·padding − k)/stride⌋ + 1.
padding=(k−1)/2 (k tek) → çıktı boyutu korunur."""
return (n + 2 * padding - k) // stride + 1
# ---------------------------------------------------------------------------
# Hafta 6 — RNN / vanishing gradient / attention
# ---------------------------------------------------------------------------
def vanishing_demo(steps=50, eigenvalues=(0.5, 1.0, 1.5)):
"""Aynı matristen n kez geçen gradient: λⁿ. λ<1 söner (vanishing), λ>1 patlar
(exploding), λ=1 sabit. Backprop-through-time vanishing gradient görseli."""
t = np.arange(steps + 1)
curves = {ev: np.asarray(ev, float) ** t for ev in eigenvalues}
return t, curves
def rnn_forward(X_seq, Wx, Wz, b, z0=None):
"""Basit RNN hücresi: zₜ = tanh(Wₓ·xₜ + W_z·zₜ₋₁ + b).
X_seq [T, d_in] → gizli durumlar Z [T, d_h] (aynı Wₓ,W_z her adımda = paylaşım)."""
X_seq = np.asarray(X_seq, float)
T = len(X_seq)
dh = np.asarray(Wz).shape[0]
z = np.zeros(dh) if z0 is None else np.asarray(z0, float)
Z = []
for t in range(T):
z = np.tanh(np.asarray(Wx) @ X_seq[t] + np.asarray(Wz) @ z + np.asarray(b))
Z.append(z.copy())
return np.array(Z)
def attention_weights(scores):
"""Attention ağırlıkları = softmax(skorlar); toplamı 1 (olasılık dağılımı, 'odak')."""
scores = np.asarray(scores, float)
e = np.exp(scores - scores.max())
return e / e.sum()
# ---------------------------------------------------------------------------
# Hafta 7 — EBM / autoencoder / manifold
# ---------------------------------------------------------------------------
def energy_1d(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""1B enerji F(y): veri noktalarında düşük (çukur), aralarda yüksek (tepe).
'İyi enerji şekli' = veride düşük, dışında yüksek (EBM); çoklu minimum = çoklu cevap."""
y = np.asarray(y, float)
F = np.ones_like(y)
for d in data_points:
F = F - np.exp(-(y - d) ** 2 / (2 * width))
return F
def energy_1d_grad(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""energy_1d'nin türevi (çıkarım = enerji minimizasyonu, gradient ile arama)."""
y = np.asarray(y, float)
g = np.zeros_like(y)
for d in data_points:
g = g + (y - d) / width * np.exp(-(y - d) ** 2 / (2 * width))
return g
def make_manifold_curve(n=160, noise=0.0, seed=0):
"""2B veri manifoldu: bir eğri (sinüs yayı) üzerinde noktalar (Hafta 1 manifold hipotezi)."""
t = np.linspace(-2.6, 2.6, n)
M = np.column_stack([t, np.sin(1.3 * t)])
if noise:
M = M + np.random.default_rng(seed).normal(0, noise, M.shape)
return M
def project_to_manifold(points, manifold):
"""Her noktayı manifoldun EN YAKIN noktasına çeker (autoencoder reconstruction sezgisi:
off-manifold girdiyi manifolda geri çek → düşük enerji)."""
points = np.asarray(points, float)
proj = np.array([manifold[np.linalg.norm(manifold - p, axis=1).argmin()] for p in points])
return proj
# ---------------------------------------------------------------------------
# Hafta 8 — contrastive / VAE
# ---------------------------------------------------------------------------
def vae_reparam(mu, sigma, n=400, seed=0):
"""Reparameterization trick: z = μ + σ⊙ε, ε~N(0,I). Düzenli (sürekli, dolu)
Gaussian latent örnekleri — VAE'nin üretken latent uzayı."""
mu = np.atleast_1d(np.asarray(mu, float))
sigma = np.atleast_1d(np.asarray(sigma, float))
rng = np.random.default_rng(seed)
eps = rng.normal(0, 1, (n, len(mu)))
return mu + sigma * eps
def ae_latent_clusters(n=400, seed=0):
"""Sıradan AE latent'i: dağınık, boşluklu kümeler (düzensiz uzay — VAE kontrastı)."""
rng = np.random.default_rng(seed)
centers = np.array([[-2.2, 1.8], [2.0, 2.1], [0.3, -2.3], [-1.8, -1.5]])
pts = []
for c in centers:
pts.append(c + rng.normal(0, 0.28, (n // len(centers), 2)))
return np.vstack(pts)
# ---------------------------------------------------------------------------
# Hafta 9 — sparse coding / GAN (EBM)
# ---------------------------------------------------------------------------
def sparse_code_demo(n=24, n_active=5, seed=0):
"""Yoğun (dense) vs seyrek (sparse) code: L1 düzenlileştirme çoğu bileşeni
sıfıra iter — yalnızca birkaç birim aktif kalır (sparse coding)."""
rng = np.random.default_rng(seed)
dense = rng.normal(0, 1, n)
idx = np.argsort(-np.abs(dense)) # en büyük |değer| → aktif kalanlar
sparse = np.zeros(n)
sparse[idx[:n_active]] = dense[idx[:n_active]]
return dense, sparse
def rotate_image_4way(img):
"""0/90/180/270° döndürülmüş 4 versiyon — rotation pretext görevi (Hafta 10 SSL):
ağ 'kaç derece döndürüldü?' sorusunu çözer (4-yönlü sınıflandırma)."""
img = np.asarray(img, float)
return [np.rot90(img, k) for k in range(4)]
def gan_samples(seed=0, n=200):
"""GAN sezgisi: gerçek veri (manifold/halka) vs generator'ın ürettiği sahte örnekler.
İlk başta sahteler dağınık (eğitilmemiş generator), gerçeğe yakınsar."""
rng = np.random.default_rng(seed)
th = rng.uniform(0, 2 * np.pi, n)
real = np.column_stack([np.cos(th), np.sin(th)]) + rng.normal(0, 0.06, (n, 2)) # gerçek = birim halka
fake_early = rng.normal(0, 1.1, (n, 2)) # eğitilmemiş gen (dağınık)
th2 = rng.uniform(0, 2 * np.pi, n)
fake_late = np.column_stack([np.cos(th2), np.sin(th2)]) + rng.normal(0, 0.18, (n, 2)) # eğitilmiş gen (halkaya yakın)
return real, fake_early, fake_late
# ---------------------------------------------------------------------------
# Hafta 11 — aktivasyon / kayıp (EBM) / belirsizlik
# ---------------------------------------------------------------------------
def _sig(x):
return 1.0 / (1.0 + np.exp(-np.clip(x, -50, 50)))
def activation_fns():
"""Aktivasyon fonksiyonu zoo'su + türevleri (Hafta 11). {ad: (f, f')}."""
return {
"ReLU": (lambda x: np.maximum(0, x), lambda x: (np.asarray(x) > 0).astype(float)),
"Leaky ReLU": (lambda x: np.where(x > 0, x, 0.1 * x), lambda x: np.where(np.asarray(x) > 0, 1.0, 0.1)),
"sigmoid": (_sig, lambda x: _sig(x) * (1 - _sig(x))),
"tanh": (np.tanh, lambda x: 1 - np.tanh(x) ** 2),
"softplus": (lambda x: np.log1p(np.exp(-np.abs(x))) + np.maximum(x, 0), _sig),
"ELU": (lambda x: np.where(x > 0, x, np.exp(np.clip(x, -50, 50)) - 1),
lambda x: np.where(np.asarray(x) > 0, 1.0, np.exp(np.clip(x, -50, 50)))),
}
def softplus_scaled(x, beta=1.0):
"""β-ölçekli softplus: (1/β)·log(1+e^(βx)). β büyük → ReLU'ya yaklaşır (ölçek-bağımlı)."""
x = np.asarray(x, float)
return (1.0 / beta) * (np.log1p(np.exp(-np.abs(beta * x))) + np.maximum(beta * x, 0))
def margin_losses(gap, m=1.0):
"""EBM kayıpları. gap = E(ȳ) − E(y) (doğru-yanlış enerji farkı; pozitif=doğru daha düşük).
hinge marj m (gap≥m'de 0), perceptron marjsız (gap≥0'da 0 → collapse'a açık)."""
gap = np.asarray(gap, float)
hinge = np.maximum(0.0, m - gap)
perceptron = np.maximum(0.0, -gap)
return hinge, perceptron
def uncertainty_demo(x_train, x_grid, bandwidth=0.6):
"""Belirsizlik (epistemik varyans proxy) ~ eğitim verisinden uzaklık: eğitim
noktalarına yakın DÜŞÜK, uzakta YÜKSEK (PPUU 'U' düzenlileştirmesi)."""
x_train = np.atleast_1d(np.asarray(x_train, float))
x_grid = np.atleast_1d(np.asarray(x_grid, float))
d = np.abs(x_grid[:, None] - x_train[None, :]).min(axis=1)
return 1.0 - np.exp(-(d / bandwidth) ** 2)
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d11}
Bu hafta iki parça: **Yann LeCun** (Lecture) aktivasyon ve **kayıp fonksiyonlarının** sistematik turunu yapıyor — ve kritik olarak kayıpları **EBM çerçevesinde** (enerjiyi şekillendirme) toparlıyor; **Alfredo Canziani** (Practicum) ise Hafta 9-10'da tanıttığı dünya modelini sonuna kadar götürüp **PPUU**'yu (belirsizlik düzenlileştirmeli öngörülü politika öğrenme) — yoğun trafikte sürüş — baştan sona kuruyor.
LeCun'un büyük fikri: bir kayıp fonksiyonu seçmek, aslında **enerji manzarasını nasıl şekillendireceğini** seçmektir. "İyi" bir kayıp, doğru cevabın enerjisini bastırırken yanlışları bir **marjla** yukarı iter; marj yoksa sistem **çöker** (her cevaba aynı enerjiyi verir). Canziani ise Hafta 7-9'un EBM/latent-değişken fikirlerinin gerçek bir mühendislik probleminde (otonom sürüş) nasıl birleştiğini gösterir.
Bu haftanın üç ana fikri:
1. **Aktivasyon = ölçek-değişmezliği.** Tek-kıvrımlı (ReLU türü) fonksiyonlar derin ağlarda daha iyidir çünkü ölçeğe duyarsızdır; çok-kıvrımlı/yumuşak (sigmoid) fonksiyonlar gömülü bir ölçek taşır ve normalleştirmeyle çatışır.
2. **Kayıp = enerji şekillendirme.** Her kayıp (MSE, L1, cross-entropy, hinge) doğru cevabı aşağı iter; "iyi" olanlar yanlışları **marjla** yukarı da iter — yoksa enerji çöker (Hafta 8-9 collapse problemi).
3. **PPUU:** dünya modeli + politika + **belirsizlik düzenlileştirmesi**; latent değişken çoklu-geleceğin bulanıklığını çözer, varyans cezası politikayı eğitim manifoldunda tutar.
```{mermaid}
%%| echo: false
flowchart TB
Hafta["Hafta 11 = iki parça<br/>(LeCun: aktivasyon/kayıp · Canziani: PPUU)"]
subgraph A["(A) Aktivasyon + Kayıp = Enerji — LeCun"]
direction TB
Aktivasyon["Aktivasyon = ÖLÇEK-değişmezliği<br/>(tek-kıvrım iyi · sigmoid gömülü ölçek)"]
Kayip["Kayıp = ENERJİ şekillendirme<br/>(MSE bulanık · CE=logsoftmax+NLL · hinge=marj)"]
Collapse["Collapse vs Margin<br/>(marjsız enerji ÇÖKER · hinge marj ZORLAR)"]
Negatif["Negatif (ȳ) seçimi<br/>(sürekli uzayda ZOR · MoCo vs SimCLR)"]
Post["post-2020 (BYOL/VICReg/JEPA)<br/>— KURSTA YOK —"]
Aktivasyon --> Kayip
Kayip --> Collapse
Collapse --> Negatif
Negatif --> Post
end
subgraph B["(B) PPUU — Canziani"]
direction TB
Dunya["Dünya modeli<br/>(NGSIM trafik · sₜ=(pₜ,vₜ,iₜ))"]
Latent["+ Latent z (çoklu-gelecek)<br/>(MSE bulanıklığını çözer · Hafta 8 VAE)"]
Belirsizlik["+ Belirsizlik 'U'<br/>(varyans minimize → güvenli manifold)"]
Dunya --> Latent
Latent --> Belirsizlik
end
Hafta --> Aktivasyon
Hafta --> Dunya
```
::: {.callout-tip title="Builder Notu — İki Parça, Tek Çatı: Enerjiyi Doğru Verinin Etrafında Şekillendir"}
**Geriye (önkoşul + kurs):**
- **Aktivasyon ölçeği** → Hafta 2-3 ağırlık matrisleri + normalleştirme (BatchNorm).
- **EBM kayıpları** → Hafta 7 (EBM), Hafta 8 (contrastive push-down/up), Hafta 9 (collapse'ı önle).
- **PPUU** → Hafta 9 dünya modeli + Hafta 10 PPUU girişi (emulator/controller); latent+KL = Hafta 8 VAE.
**İleriye (production / research):**
- Kayıp seçimi = enerji tasarımı → modern temsil öğrenmenin tasarım dili.
- PPUU belirsizlik + dünya modeli → LeCun'un **JEPA** programı (post-2020, Bölüm 4).
**Tek cümleyle:** Bir kayıp fonksiyonu seçmek, doğru cevabı bastırıp yanlışları marjla iten bir enerji manzarası tasarlamaktır (LeCun); PPUU ise bir dünya modeli öğrenip latent değişkenle çoklu-geleceği, belirsizlik cezasıyla da güvenli sürüşü çözerek bu fikirleri otonom sürüşe döker (Canziani).
:::
## (LeCun) Aktivasyon Fonksiyonları Zoo'su ve Ölçek-Değişmezliği {#sec-aktivasyon}
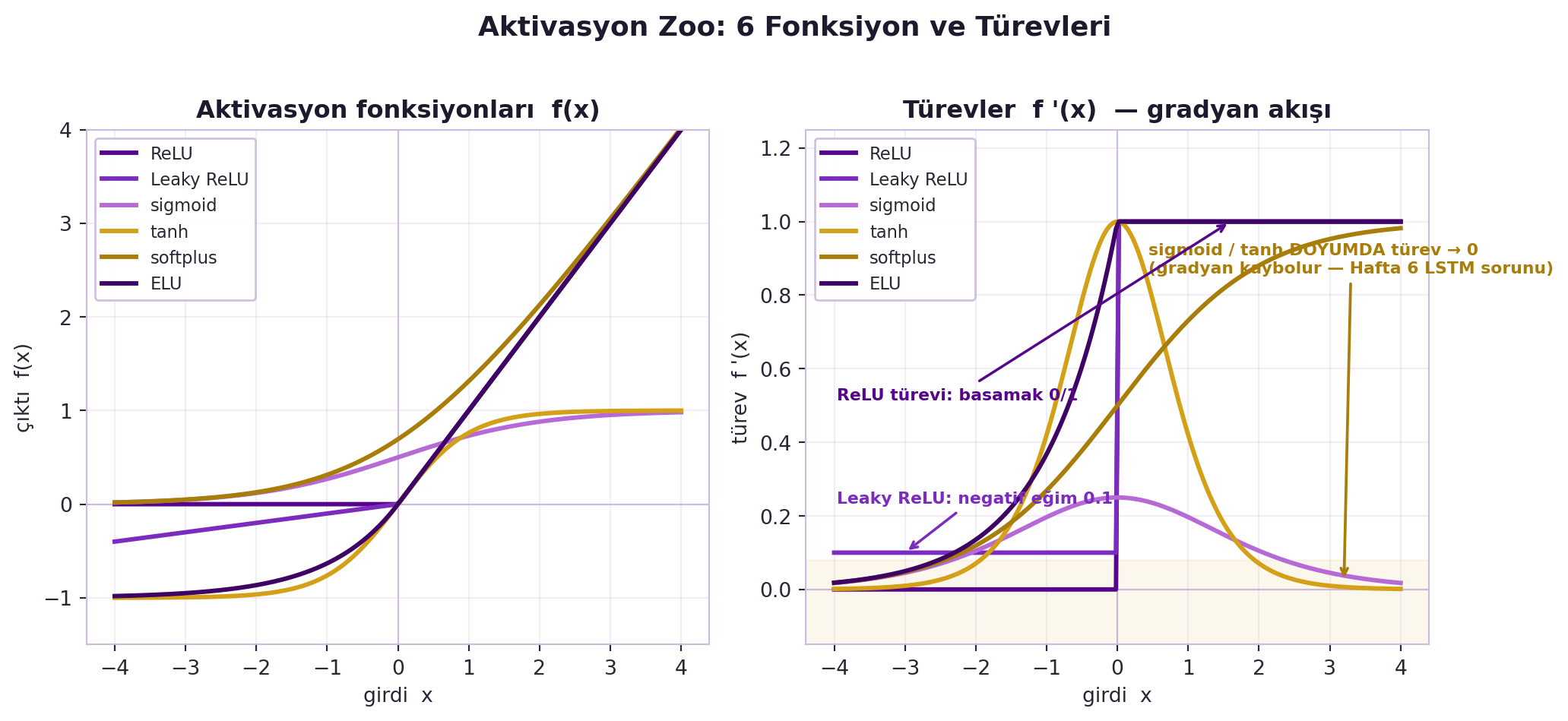
LeCun PyTorch'taki aktivasyon fonksiyonlarının "menajerisini" geziyor: ReLU ve varyantları (leaky/PReLU/RReLU — alt kısma negatif eğim vererek **ölü ReLU**'nun gradyan almasını sağlar), softplus (ReLU'nun yumuşak, β-ölçekli hâli), ELU/SELU (negatife inerek çıkışı sıfır-ortalamalı yapar → daha hızlı yakınsama), sigmoid/tanh (doyuma girince **gradyan kaybolur**; tanh sıfır-merkezli olduğu için daha iyi), hardtanh (basit rampa, küçük ağırlıklarla şaşırtıcı iyi çalışır), softshrink/hardshrink (sparse coding'in ISTA adımı — L1 gradyan adımı). @fig-activation-zoo bu altı fonksiyonu ve türevlerini yan yana koyar: sağ panel doyum bölgesinde sigmoid/tanh türevinin nasıl sıfıra çöktüğünü (gradyan kaybı = Hafta 6 LSTM sorunu) doğrudan gösterir.
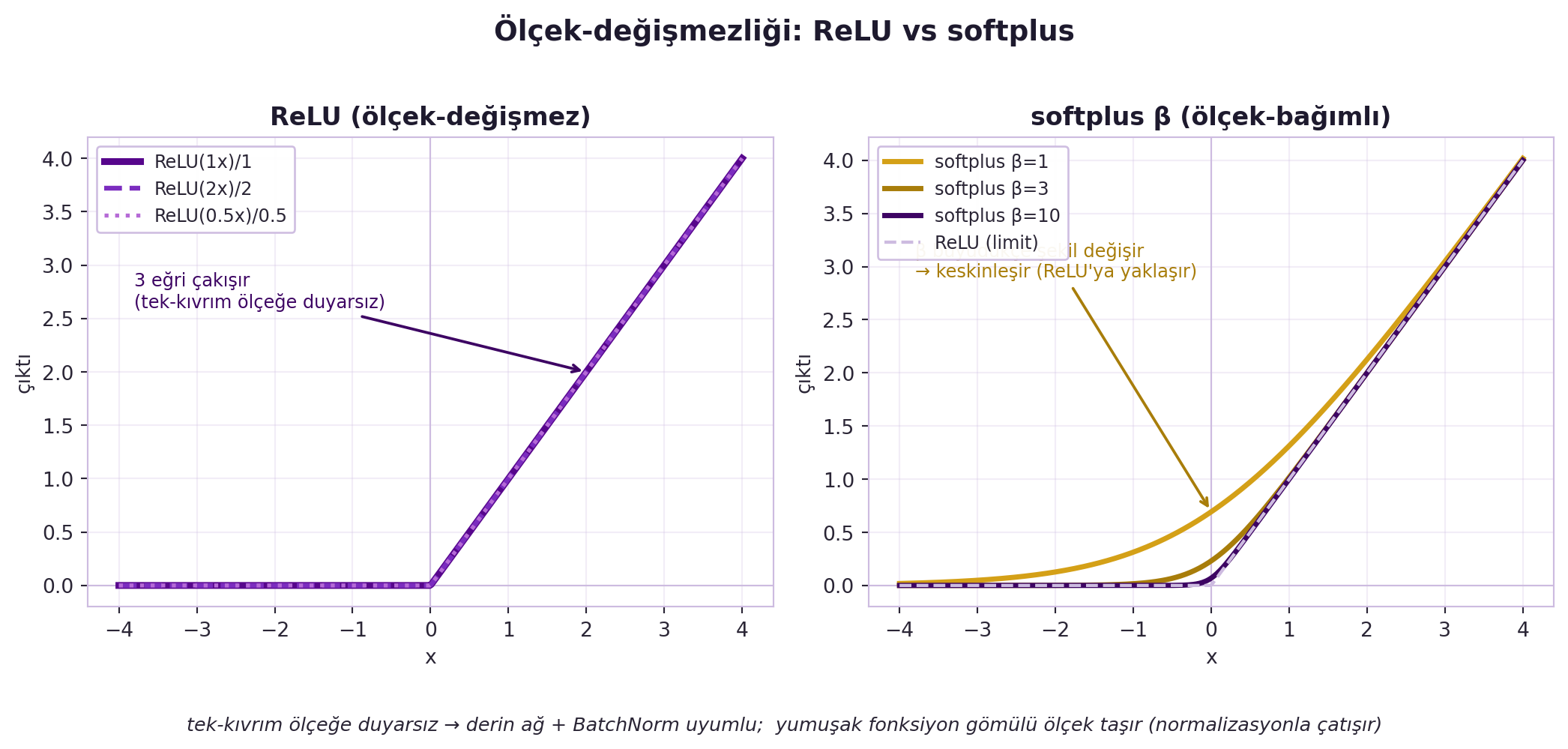
En derin içgörü **ölçek-değişmezliği**: tek keskin kıvrımlı bir fonksiyonda girişi 2 ile çarparsan çıkış da 2 ile çarpılır (yapı değişmez); ama yumuşak/çift-kıvrımlı fonksiyonda **gömülü bir ölçek** vardır — girişi büyütünce fonksiyonun davranışı tamamen değişir.
> "if you have a non-linearity that does care about scale, then your network doesn't have a choice of what size weight matrix it can use in the first layer, because that will completely change the behavior." — LeCun, 27:04
Bu yüzden **tek-kıvrımlı fonksiyonlar derin ağlarda daha iyidir** ve grup/batch normalleştirmeyle **uyumsuzdur**: normalleştirme ölçeği sabitlerse, sigmoid'in hangi bölgesinin kullanılacağı seçimi kaybolur. @fig-scale-invariance bu iki rejimi karşılaştırır: ReLU üç ölçek için çakışırken (ölçeğe duyarsız) softplus β büyüdükçe şekil değiştirir (gömülü ölçek). Softmax sıcaklığı β bir **ters sıcaklıktır** (annealing: düşük β yumuşak → yüksek β sert kararlar; mixture-of-experts/attention'da işe yarar).
```{python}
#| label: fig-activation-zoo
#| fig-cap: "Aktivasyon zoo (Hafta 11): altı aktivasyon fonksiyonu f(x) ve türevleri f'(x). Sol panel fonksiyonları, sağ panel türevleri (gradyan akışını belirleyen kısım) gösterir. Sigmoid ve tanh doygunluk bölgesinde türevleri sıfıra çöker (gold bant) — geriye yayılımda gradyan kaybolur (Hafta 6 LSTM sorununun kökeni). ReLU türevi 0/1 basamak fonksiyonudur; Leaky ReLU negatif tarafta 0.1 eğimle gradyanı canlı tutar; softplus ve ELU yumuşak geçişlerle ReLU'nun ölü-nöron sorununu hafifletir."
fns = activation_fns()
x = np.linspace(-4, 4, 200)
fig, (ax_f, ax_d) = plt.subplots(1, 2, figsize=(11, 4.8))
names = ["ReLU", "Leaky ReLU", "sigmoid", "tanh", "softplus", "ELU"]
for name, color in zip(names, CLASS_COLORS + [COL_VIOLET_D]):
f, df = fns[name]
ax_f.plot(x, f(x), color=color, lw=2.2, label=name)
ax_d.plot(x, df(x), color=color, lw=2.2, label=name)
# Sol panel — f(x)
apply_style(ax_f)
ax_f.axhline(0, color=COL_GRID, lw=0.8, zorder=0)
ax_f.axvline(0, color=COL_GRID, lw=0.8, zorder=0)
ax_f.set_title("Aktivasyon fonksiyonları f(x)", color=COL_INK, fontsize=12, fontweight="bold")
ax_f.set_xlabel("girdi x")
ax_f.set_ylabel("çıktı f(x)")
ax_f.set_ylim(-1.5, 4.0)
style_legend(ax_f, loc="upper left", fontsize=8.5)
# Sağ panel — f'(x)
apply_style(ax_d)
ax_d.axhline(0, color=COL_GRID, lw=0.8, zorder=0)
ax_d.axvline(0, color=COL_GRID, lw=0.8, zorder=0)
ax_d.set_title("Türevler f '(x) — gradyan akışı", color=COL_INK, fontsize=12, fontweight="bold")
ax_d.set_xlabel("girdi x")
ax_d.set_ylabel("türev f '(x)")
ax_d.set_ylim(-0.15, 1.25)
style_legend(ax_d, loc="upper left", fontsize=8.5)
# Doyum bölgesi vurgusu (sigmoid/tanh türevi → 0)
ax_d.axhspan(-0.15, 0.08, color=COL_GOLD, alpha=0.08, zorder=0)
ax_d.annotate(
"sigmoid / tanh DOYUMDA türev → 0\n(gradyan kaybolur — Hafta 6 LSTM sorunu)",
xy=(3.2, 0.02), xytext=(0.55, 0.78), textcoords=ax_d.transAxes,
fontsize=8.2, color=COL_GOLD_D, fontweight="bold", ha="left", va="top",
arrowprops=dict(arrowstyle="->", color=COL_GOLD_D, lw=1.4),
)
ax_d.annotate(
"ReLU türevi: basamak 0/1",
xy=(1.6, 1.0), xytext=(0.05, 0.50), textcoords=ax_d.transAxes,
fontsize=8.2, color=COL_VIOLET, fontweight="bold", ha="left", va="top",
arrowprops=dict(arrowstyle="->", color=COL_VIOLET, lw=1.3),
)
ax_d.annotate(
"Leaky ReLU: negatif eğim 0.1",
xy=(-3.0, 0.1), xytext=(0.05, 0.30), textcoords=ax_d.transAxes,
fontsize=8.2, color=COL_VIOLET_M, fontweight="bold", ha="left", va="top",
arrowprops=dict(arrowstyle="->", color=COL_VIOLET_M, lw=1.3),
)
fig.suptitle("Aktivasyon Zoo: 6 Fonksiyon ve Türevleri",
color=COL_INK, fontsize=13.5, fontweight="bold", y=1.02)
fig.tight_layout()
```
```{python}
#| label: fig-scale-invariance
#| fig-cap: "Ölçek-değişmezliği: ReLU vs softplus. SOL — ReLU(c·x)/c üç farklı ölçek (c=1, 2, 0.5) için üst üste çakışır: tek-kıvrımlı, parçalı-lineer fonksiyon ölçeğe duyarsızdır (pozitif homojenlik). SAĞ — β-ölçekli softplus β=1, 3, 10 için şekil değiştirir; β büyüdükçe geçiş bölgesi keskinleşir ve fonksiyon ReLU limitine yaklaşır. Yumuşak aktivasyon gömülü bir ölçek (β) taşır, bu da normalizasyon katmanlarıyla (BatchNorm) çatışabilir; ReLU'nun ölçek-değişmezliği derin ağlarda normalizasyonla uyumludur."
x = np.linspace(-4, 4, 400)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.6))
# SOL — ReLU (ölçek-değişmez): relu(c·x)/c hep aynı şekil
relu = activation_fns()["ReLU"][0]
scales = [1.0, 2.0, 0.5]
violets = [COL_VIOLET, COL_VIOLET_M, COL_VIOLET_SOFT]
styles = ["-", "--", ":"]
lws = [3.4, 2.4, 2.0]
for c, col, ls, lw in zip(scales, violets, styles, lws):
axL.plot(x, relu(c * x) / c, color=col, ls=ls, lw=lw,
label=f"ReLU(%gx)/%g" % (c, c))
apply_style(axL)
axL.set_title("ReLU (ölçek-değişmez)", color=COL_INK, fontsize=12.5, fontweight="bold")
axL.set_xlabel("x")
axL.set_ylabel("çıktı")
axL.axhline(0, color=COL_GRID, lw=0.8, zorder=0)
axL.axvline(0, color=COL_GRID, lw=0.8, zorder=0)
style_legend(axL, loc="upper left", fontsize=9)
axL.annotate("3 eğri çakışır\n(tek-kıvrım ölçeğe duyarsız)",
xy=(2.0, relu(2.0)), xytext=(-3.8, 2.6),
fontsize=9, color=COL_VIOLET_D,
arrowprops=dict(arrowstyle="->", color=COL_VIOLET_D, lw=1.4))
# SAĞ — softplus β (ölçek-bağımlı): β büyük → keskinleşir (ReLU'ya yaklaşır)
betas = [1.0, 3.0, 10.0]
golds = [COL_GOLD, COL_GOLD_D, COL_VIOLET_D]
for b, col, lw in zip(betas, golds, [2.6, 2.6, 2.6]):
axR.plot(x, softplus_scaled(x, b), color=col, lw=lw, label=f"softplus β={b:g}")
axR.plot(x, relu(x), color=COL_GRID, ls="--", lw=1.6, label="ReLU (limit)")
apply_style(axR)
axR.set_title("softplus β (ölçek-bağımlı)", color=COL_INK, fontsize=12.5, fontweight="bold")
axR.set_xlabel("x")
axR.set_ylabel("çıktı")
axR.axhline(0, color=COL_GRID, lw=0.8, zorder=0)
axR.axvline(0, color=COL_GRID, lw=0.8, zorder=0)
style_legend(axR, loc="upper left", fontsize=9)
axR.annotate("β büyüdükçe şekil değişir\n→ keskinleşir (ReLU'ya yaklaşır)",
xy=(0.0, softplus_scaled(0.0, 1.0)), xytext=(-3.8, 2.9),
fontsize=9, color=COL_GOLD_D,
arrowprops=dict(arrowstyle="->", color=COL_GOLD_D, lw=1.4))
fig.suptitle("Ölçek-değişmezliği: ReLU vs softplus", color=COL_INK,
fontsize=14, fontweight="bold", y=1.02)
fig.text(0.5, -0.04,
"tek-kıvrım ölçeğe duyarsız → derin ağ + BatchNorm uyumlu; "
"yumuşak fonksiyon gömülü ölçek taşır (normalizasyonla çatışır)",
ha="center", va="top", fontsize=9.5, color=COL_TEXT, style="italic")
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Aktivasyon = Ölçek"}
**Geriye (Hafta 2-3):** Ölçek-değişmezliği = ağırlık matrislerini serbestçe yeniden ölçekleyebilme (lineer katman ikiliği); normalleştirme = Hafta 3 BatchNorm. Doyum/gradyan kaybolması = Hafta 6'da LSTM'in çözdüğü sorun.
**İleriye:** "Hangi aktivasyon?" sorusunun genel cevabı yoktur (LeCun); ama tek-kıvrım + normalleştirme, derin ağ tasarımının fiilî standardıdır.
:::
## (LeCun) Kayıp Fonksiyonları I: MSE Neden Bulanıklaştırır, Cross-Entropy Neden Birleştirilir {#sec-kayip-1}
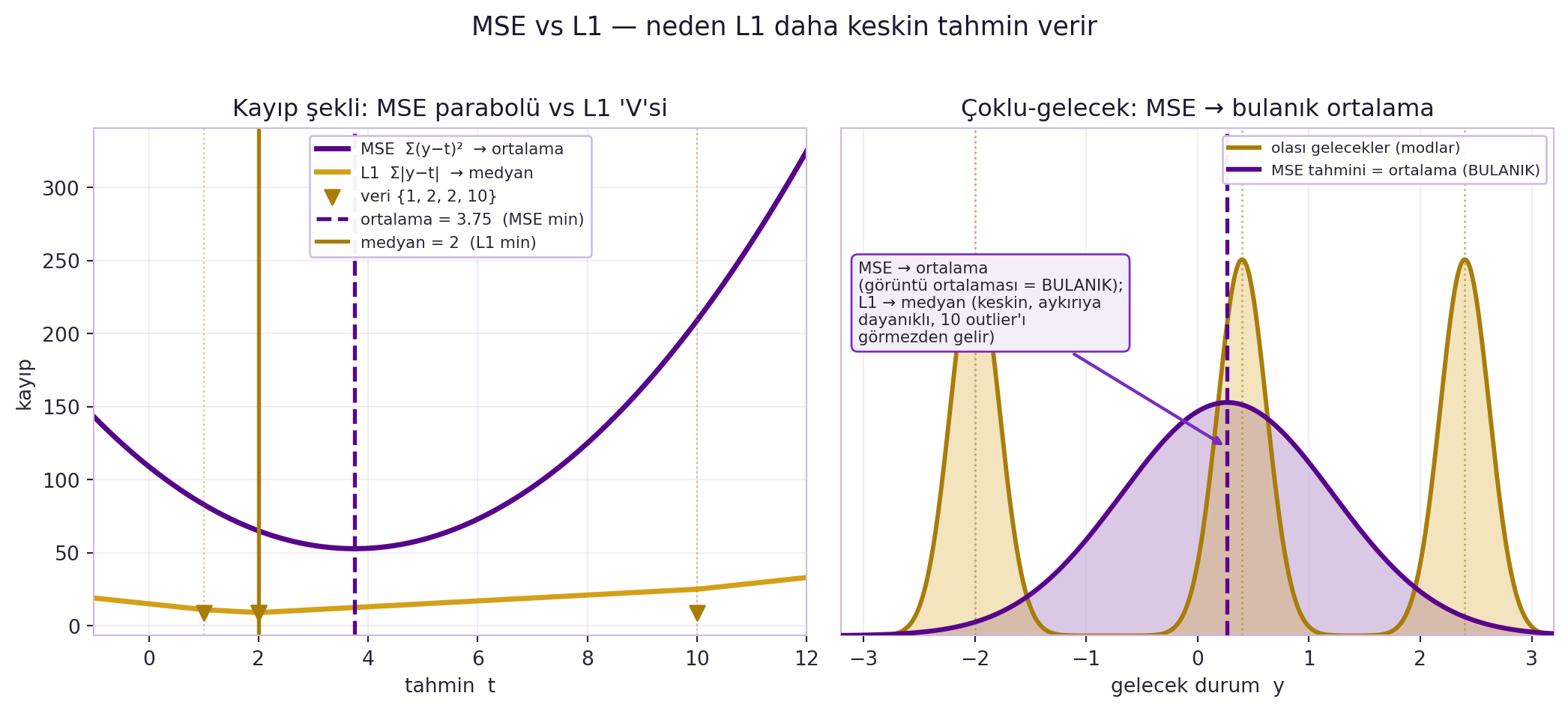
LeCun kayıplara geçiyor ve hemen mühendislik sezgisi veriyor. **MSE (L2)** doğru cevabı ortalamaya çeker; bir girişe karşılık birden çok olası çıkış varsa, sistem hepsinin **ortalamasını** üretir — ve görüntülerin ortalaması **bulanık** bir görüntüdür.
> "the average of a bunch of images is a blurry image, okay, that's why you get those blur effects." — LeCun, 37:50
**L1 (mutlak değer)** ise medyanı verir (bulanık değil) ve aykırı değerlere **dayanıklıdır**, ama tabanda türevlenemez (softshrink ile çözülür). Huber/SmoothL1 ikisini birleştirir (uzakta L1, yakında L2; Fast R-CNN). @fig-mse-vs-l1 bu farkı sayısal olarak gösterir: {1, 2, 2, 10} verisinde MSE minimumu ortalamaya (3,75) düşerken L1 minimumu medyanda (2) kalıp aykırı değeri görmezden gelir — ve aynı "ortalama = bulanık" sezgisi sağ panelde çoklu-gelecek olarak resmedilir.
Sınıflandırmada **NLL** doğru sınıfın skorunu büyütür. **Cross-entropy = logsoftmax + NLL** birleşik modülüdür — ve birleştirmenin sebebi **sayısal kararlılıktır**: ayrı ayrı hesaplanırsa ara gradyanlar sonsuza gidip kararsızlık yaratır.
> "you don't want to separate log and softmax, you want to do logsoftmax in one go... it makes the whole thing much more stable numerically." — LeCun, 47:22
Cross-entropy aslında sistemin dağılımı ile one-hot hedef dağılım arasındaki **KL ıraksamasıdır**. (LeCun ayrıca pratik bir uyarı veriyor: dengesiz sınıflarda ağırlık vermek yerine **örnekleme frekansını eşitle** — tıp fakültesi analojisi: nadir hastalıkları da eşit çalış ki öznitelikleri öğrenesin, frekansı en sona düzelt.)
```{python}
#| label: fig-mse-vs-l1
#| fig-cap: "MSE vs L1 kayıpları: neden L1 daha keskin tahmin verir. SOL panel — veri {1, 2, 2, 10} üzerinde MSE kaybı Σ(y−t)² bir parabol çizer ve minimumu ortalamadadır (3,75; violet kesikli çizgi), L1 kaybı Σ|y−t| ise bir 'V' çizer ve minimumu medyandadır (2; gold çizgi). L1 minimumu 10 değerindeki aykırı noktayı görmezden gelerek 2'de kalır, MSE ise aykırı nokta tarafından 3,75'e çekilir. SAĞ panel — çoklu-gelecek sezgisi: birbirinden ayrı üç olası gelecek modu (gold) varken MSE tek bir tahmin olarak bunların ortalamasını üretir (violet); bu ortalama hiçbir moda denk gelmez, ortada ve BULANIK kalır. Sezgi: MSE → ortalama (görüntü/gelecek ortalaması = bulanık), L1 → medyan (keskin, aykırıya dayanıklı)."
# Bölüm 2 — MSE vs L1: MSE → ortalama (bulanık), L1 → medyan (keskin)
veri = np.array([1.0, 2.0, 2.0, 10.0])
ortalama = float(np.mean(veri)) # MSE minimumu = 3.75
medyan = float(np.median(veri)) # L1 minimumu = 2.0
t = np.linspace(-1, 12, 400)
mse = np.array([np.sum((veri - ti) ** 2) for ti in t]) # Σ(y−t)² parabol
l1 = np.array([np.sum(np.abs(veri - ti)) for ti in t]) # Σ|y−t| V-şekli
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.8))
# --- SOL panel: kayıp fonksiyonları + veri noktaları ---
apply_style(axL)
axL.plot(t, mse, color=COL_VIOLET, lw=2.6, label="MSE Σ(y−t)² → ortalama")
axL.plot(t, l1, color=COL_GOLD, lw=2.6, label="L1 Σ|y−t| → medyan")
# veri noktaları (gold dikey işaretler)
for v in np.unique(veri):
axL.axvline(v, color=COL_GOLD_D, lw=0.9, ls=":", alpha=0.45)
yfloor = min(l1.min(), mse.min())
axL.scatter(veri, np.full_like(veri, yfloor), color=COL_GOLD_D, s=55,
zorder=5, marker="v", clip_on=False, label="veri {1, 2, 2, 10}")
# minimumlar: ortalama (violet kesikli) + medyan (gold düz)
axL.axvline(ortalama, color=COL_VIOLET, lw=2.0, ls="--",
label=f"ortalama = {ortalama:.2f} (MSE min)")
axL.axvline(medyan, color=COL_GOLD_D, lw=2.0, ls="-",
label=f"medyan = {medyan:.0f} (L1 min)")
axL.set_xlim(-1, 12)
axL.set_xlabel("tahmin t", fontsize=10)
axL.set_ylabel("kayıp", fontsize=10)
axL.set_title("Kayıp şekli: MSE parabolü vs L1 'V'si", color=COL_INK, fontsize=12)
style_legend(axL, loc="upper center", fontsize=8.0)
# --- SAĞ panel: çoklu-gelecek sezgisi ---
apply_style(axR)
axR.set_xlim(-3.2, 3.2)
axR.set_ylim(0, 1.35)
axR.set_yticks([])
# olası gelecekler (modlar) — gold
modlar = [-2.0, 0.4, 2.4]
xg = np.linspace(-3.2, 3.2, 500)
yoğunluk = np.zeros_like(xg)
for m in modlar:
yoğunluk += np.exp(-((xg - m) ** 2) / (2 * 0.22 ** 2))
yoğunluk /= yoğunluk.max()
axR.fill_between(xg, 0, yoğunluk, color=COL_GOLD, alpha=0.28, zorder=1)
axR.plot(xg, yoğunluk, color=COL_GOLD_D, lw=2.2, zorder=2,
label="olası gelecekler (modlar)")
for m in modlar:
axR.axvline(m, color=COL_GOLD_D, lw=1.0, ls=":", alpha=0.6)
# MSE'nin ürettiği ortalama — bulanık, ortada, hiçbir moda değmiyor
mse_ort = float(np.mean(modlar))
bulanik = 0.62 * np.exp(-((xg - mse_ort) ** 2) / (2 * 0.95 ** 2))
axR.fill_between(xg, 0, bulanik, color=COL_VIOLET, alpha=0.22, zorder=0)
axR.plot(xg, bulanik, color=COL_VIOLET, lw=2.4, zorder=3,
label="MSE tahmini = ortalama (BULANIK)")
axR.axvline(mse_ort, color=COL_VIOLET, lw=2.0, ls="--", zorder=4)
axR.set_xlabel("gelecek durum y", fontsize=10)
axR.set_title("Çoklu-gelecek: MSE → bulanık ortalama", color=COL_INK, fontsize=12)
style_legend(axR, loc="upper right", fontsize=7.6)
axR.annotate(
"MSE → ortalama\n(görüntü ortalaması = BULANIK);\n"
"L1 → medyan (keskin, aykırıya\ndayanıklı, 10 outlier'ı\ngörmezden gelir)",
xy=(mse_ort, 0.50), xytext=(-3.05, 0.78),
fontsize=8.0, color=COL_TEXT,
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_M, lw=1.6),
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_VIOLET_M, lw=1.0))
fig.suptitle("MSE vs L1 — neden L1 daha keskin tahmin verir",
color=COL_INK, fontsize=13, y=1.02)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — MSE Bulanıklaştırır"}
**Geriye (Hafta 2):** Cross-entropy = Hafta 2'nin temel sınıflandırma kaybı; softmax = enerji yorumuyla (eksi işaret → skorlar enerji olur) Hafta 7 EBM'e köprü. KL = dağılımlar arası fark.
**İleriye:** MSE bulanıklığı, üretici modellerin (görüntü/video tahmini) merkezî sorunudur — ve bu hafta Canziani'nin latent-değişkenle çözdüğü tam problemdir.
:::
## (LeCun) Kayıp Fonksiyonları II: Margin, Hinge ve EBM Kayıpları {#sec-kayip-2}
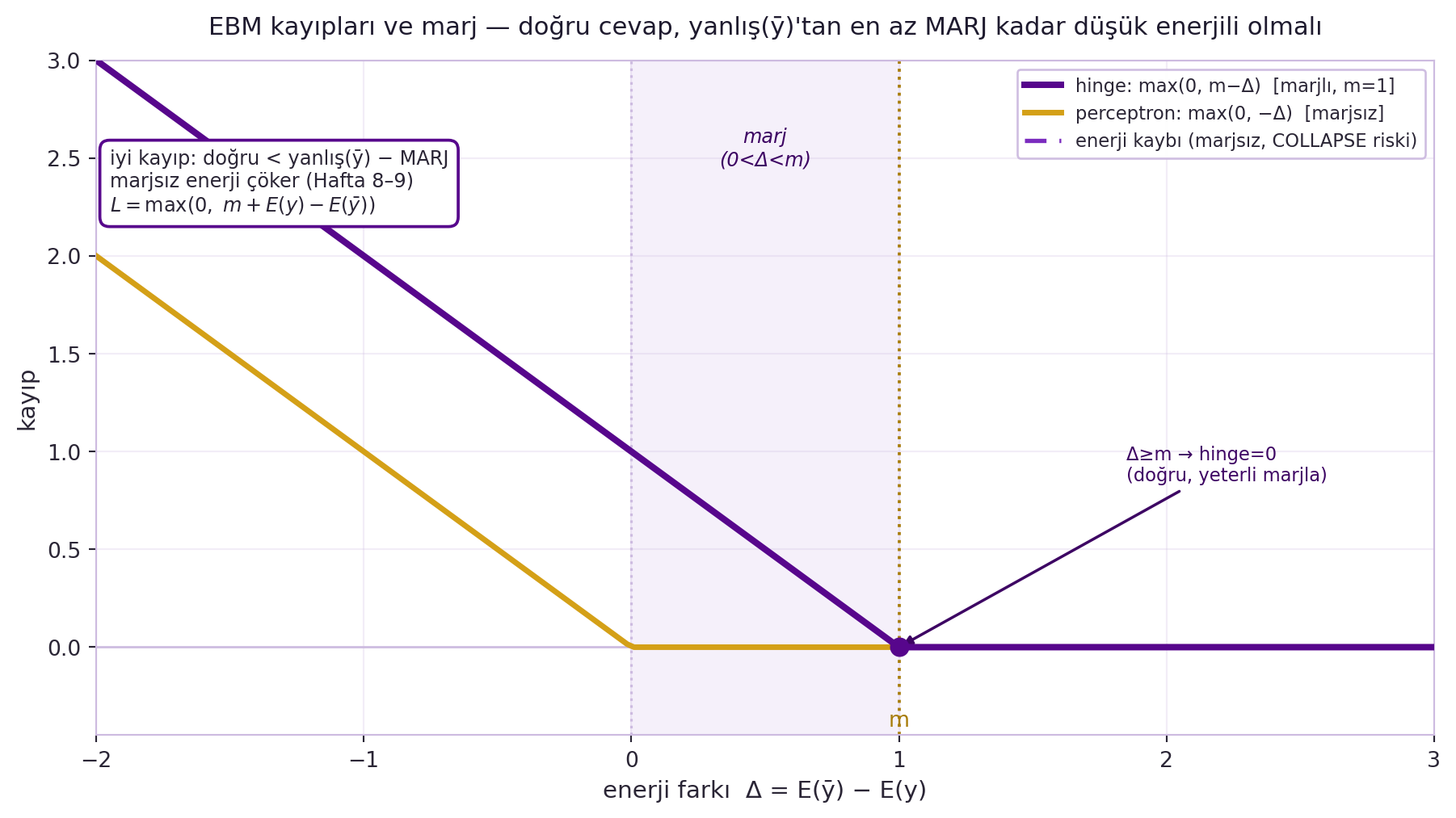
Asıl hafta burada Hafta 7-9 EBM omurgasına bağlanıyor. LeCun kayıpları genel bir **kayıp fonksiyoneli** olarak kuruyor: amaç, doğru cevabın enerjisini küçük, yanlışlarınkini büyük yapmak. Ama nasıl?
**Enerji kaybı** (sadece doğru cevabı aşağı it) tehlikelidir — yanlışları yukarı itmediği için enerji **her yerde düzleşip çökebilir**:
> "you're just trying to make the energy of the correct answer small, you're not telling the system the energy of everything else should be higher, and so the system might just collapse." — LeCun, 1:20:13
Bu, tam olarak Hafta 8-9'un **collapse** problemidir. **Perceptron kaybı** doğru cevabı aşağı, en-düşük-enerjili cevabı yukarı iter ama **marj** içermez → sistem her cevaba aynı enerjiyi verebilir (yalnız lineer modellerde iyi). Çözüm **marjlı kayıplar** (hinge):
> "as long as your objective function ensures that the energy of the correct answer is smaller than the energy of the most offending incorrect answer by at least a nonzero margin, then your loss function is good." — LeCun, 1:25:47
"En çok suç işleyen yanlış cevap" (most offending incorrect answer, ȳ) = yanlış olduğu hâlde en düşük enerjili cevap. Hinge bu farkı bir marja zorlar:
$$
L = \max(0,\; m + E(x, y) - E(x, \bar{y}))
$$
@fig-loss-margin bu üç kaybı tek bir enerji-farkı ekseninde (Δ = E(ȳ) − E(y)) yan yana koyar: hinge Δ ≥ m olunca sıfırlanır (marj zorunlu), perceptron yalnızca Δ ≥ 0 ister (marjsız), marjsız enerji kaybı ise perceptron'la aynı biçimi paylaşıp **collapse**'a açıktır. Soft-hinge (sonsuz marj, üstel sönüm), square-square (Siamese ağlar, DeepFace yüz tanıma) bu ailenin üyeleridir. **Kritik nüans:** ȳ'yi seçmek sınıflandırmada kolay, ama sürekli/yüksek-boyutlu uzayda zordur — negatif örnekleme problemi:
> "that's why what makes the difference between MoCo [and] SimCLR etc is how you pick those negative samples." — LeCun, 1:36:09
Yani Hafta 8'in contrastive yöntemi ile Hafta 10'un SSL'i, aynı "negatif nasıl seçilir?" sorusunun farklı cevaplarıdır.
```{python}
#| label: fig-loss-margin
#| fig-cap: "EBM kayıpları ve marj: doğru cevabın enerjisi, yanlış cevap ȳ'nin enerjisinden en az bir MARJ (m) kadar düşük olmalıdır. Yatay eksen enerji farkı Δ = E(ȳ) − E(y) (pozitif = doğru cevap daha düşük enerjili). Hinge kaybı (violet, max(0, m−Δ)) Δ≥m olunca sıfırlanır — pozitif marj zorunlu kılar. Perceptron kaybı (gold, max(0, −Δ)) yalnızca Δ≥0 ister; marjsızdır. Marjsız enerji kaybı (kesik violet) ile perceptron aynı biçimi paylaşır ve enerji manzarasının düz çökmesine (collapse, Hafta 8–9) açıktır. Gölgeli bölge 0<Δ<m marj aralığını gösterir. Genel EBM kaybı L = max(0, m + E(y) − E(ȳ))."
gap = np.linspace(-2.0, 3.0, 200)
m = 1.0
hinge, perceptron = margin_losses(gap, m)
energy = np.maximum(0.0, -gap) + 0.0 # marjsiz enerji kaybi (perceptron ile ayni biçim, COLLAPSE riski)
fig, ax = plt.subplots(figsize=(9.5, 5.4))
apply_style(ax)
# Marj bölgesi (0 < gap < 1) gölgeli
ax.axvspan(0.0, m, color=COL_BG, alpha=0.85, zorder=0)
ax.text(0.5, 2.55, "marj\n(0<Δ<m)", ha="center", va="center",
fontsize=9, color=COL_VIOLET_D, style="italic", zorder=4)
# Hinge (violet) — marjlı
ax.plot(gap, hinge, color=COL_VIOLET, lw=3.0, zorder=5,
label="hinge: max(0, m−Δ) [marjlı, m=1]")
# Perceptron (gold) — marjsız
ax.plot(gap, perceptron, color=COL_GOLD, lw=2.6, zorder=4,
label="perceptron: max(0, −Δ) [marjsız]")
# Üçüncü çizgi: marjsız enerji kaybı (COLLAPSE riski) — kesik koyu violet
ax.plot(gap, energy, color=COL_VIOLET_M, lw=2.0, ls="--", dashes=(5, 3), zorder=3,
label="enerji kaybı (marjsız, COLLAPSE riski)")
# Marj eşik çizgileri
ax.axvline(0.0, color=COL_GRID, lw=1.2, ls=":", zorder=1)
ax.axvline(m, color=COL_GOLD_D, lw=1.4, ls=":", zorder=2)
ax.text(m, -0.32, "m", ha="center", va="top", fontsize=10, color=COL_GOLD_D)
ax.axhline(0.0, color=COL_GRID, lw=1.0, zorder=1)
# hinge'in m'de sıfıra indiğini işaretle
ax.plot([m], [0.0], "o", color=COL_VIOLET, ms=8, zorder=6)
ax.annotate("Δ≥m → hinge=0\n(doğru, yeterli marjla)",
xy=(m, 0.0), xytext=(1.85, 0.85),
fontsize=8.5, color=COL_VIOLET_D,
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_D, lw=1.3))
# Ana açıklama kutusu
ax.text(-1.95, 2.55,
"iyi kayıp: doğru < yanlış(ȳ) − MARJ\n"
"marjsız enerji çöker (Hafta 8–9)\n"
r"$L=\max(0,\ m+E(y)-E(\bar y))$",
ha="left", va="top", fontsize=9.0, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_WHITE, ec=COL_VIOLET, lw=1.4),
zorder=7)
ax.set_xlim(-2.0, 3.0)
ax.set_ylim(-0.45, 3.0)
ax.set_xlabel("enerji farkı Δ = E(ȳ) − E(y)", fontsize=11)
ax.set_ylabel("kayıp", fontsize=11)
ax.set_title("EBM kayıpları ve marj — doğru cevap, yanlış(ȳ)'tan en az MARJ kadar düşük enerjili olmalı",
fontsize=11.5, color=COL_INK, pad=12)
style_legend(ax, loc="upper right", fontsize=8.5)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Collapse vs Hinge"}
**Geriye (Hafta 7-8-9):** Enerji kaybı collapse'ı = Hafta 8-9 (yanlışları itmezsen enerji düzleşir); margin/hinge = Hafta 8 contrastive push-down/up; ȳ seçimi = Hafta 8 NCE + Hafta 10 hard-negative.
**İleriye:** "Kayıp = enerji şekillendirme + marj" çerçevesi, contrastive/non-contrastive tüm temsil öğrenmenin ortak dilidir.
:::
## (İleriye Köprü) Negatif Seçiminden Non-Contrastive'e ve JEPA — KURSTA YOK {#sec-jepa-kopru}
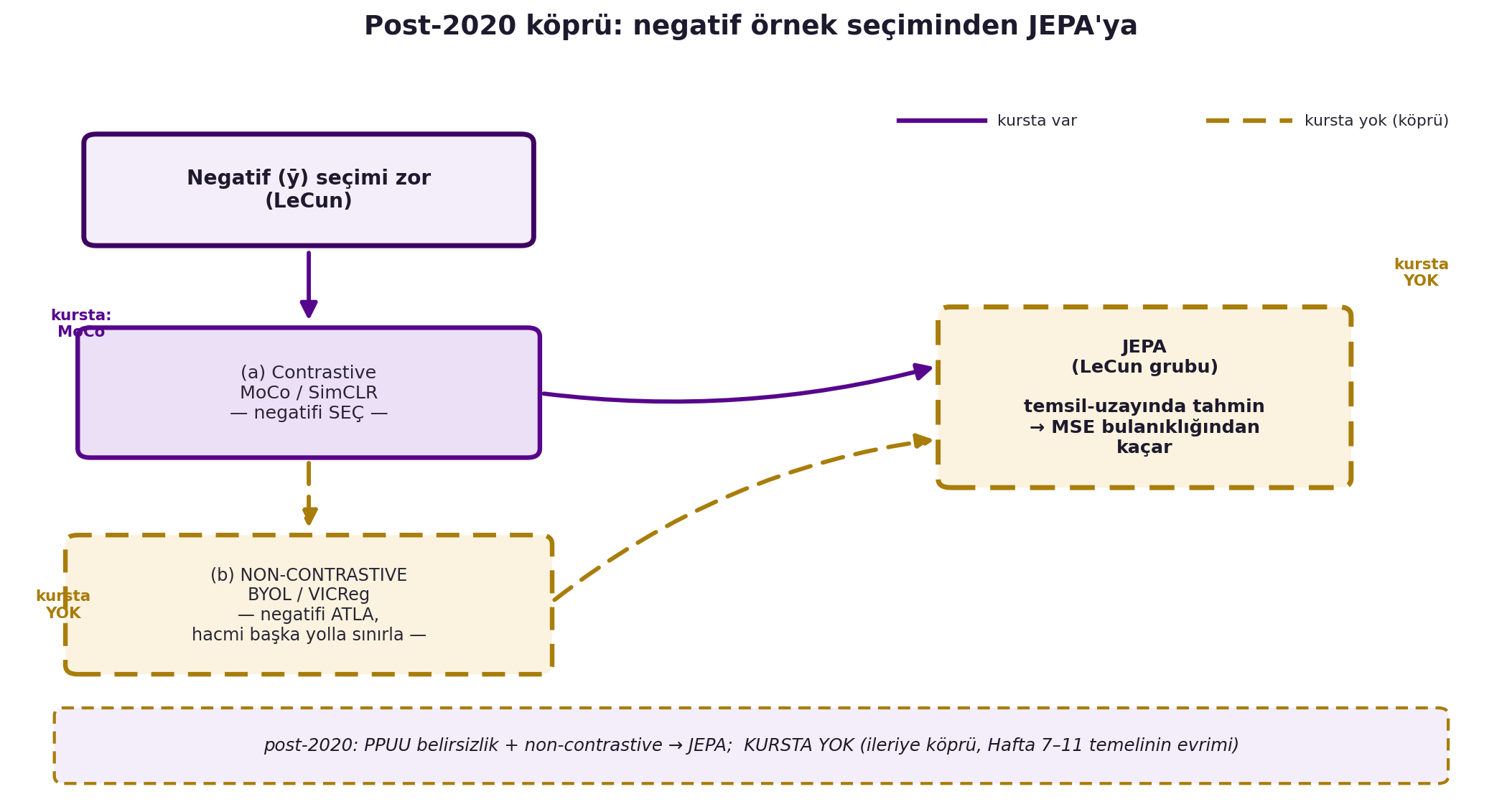
LeCun'un "ȳ'yi (negatifi) seçmek zordur" tespiti ve Canziani'nin birazdan göreceğimiz **belirsizlik düzenlileştirmesi**, DLSP20'den **sonra** olgunlaşan bir programa işaret eder. @fig-jepa-bridge bu evrimi şematize eder: "negatif seçimi zor" kutusundan iki yol (contrastive vs non-contrastive) çıkar ve ikisi de JEPA'da buluşur. Aşağıdakiler bu kursta **YOKTUR** (yalnızca ileriye köprü):
::: {.callout-warning title="⚠️ İleriye Köprü Notu (post-2020 — KURSTA YOK)"}
- **BYOL** (Haz 2020), **VICReg** (2021) — **negatif örneksiz** (non-contrastive) SSL: LeCun'un "negatif seçmek zor" sorununu, negatifleri tamamen atıp enerji hacmini başka yolla sınırlayarak çözer. Canziani'nin varyans/belirsizlik cezası bu fikrin erken bir akrabasıdır.
- **JEPA / I-JEPA / V-JEPA** (LeCun grubu, 2022-2024) — joint-embedding predictive architecture: PPUU'nun "dünya modeli öğren + belirsizlikle planla" fikrinin bugünkü zirvesi; gözlemi piksel yerine **temsil uzayında** öngörür (MSE bulanıklığından tamamen kaçar).
Bunlar kurs terimi gibi eklenmez; Hafta 7-11'de kurulan EBM + dünya-modeli temelinin nereye evrildiğini göstermek için anılır.
:::
```{python}
#| label: fig-jepa-bridge
#| fig-cap: "Post-2020 köprü: negatif örnek seçiminden JEPA'ya. 'Negatif (ȳ) seçimi zor (LeCun)' kutusundan iki yol çıkar: (a) Contrastive (MoCo/SimCLR — kursta MoCo, violet düz çizgi) negatifi seçer; (b) NON-CONTRASTIVE (BYOL/VICReg — kursta yok, gold kesikli) negatifi atlar ve hacmi başka yolla sınırlar. Her iki yol da JEPA'ya (LeCun grubu, kursta yok, kesikli) varır: temsil-uzayında tahmin yaparak MSE bulanıklığından kaçar. Bu şema Hafta 7–11 temelinin (EBM, belirsizlik, contrastive/non-contrastive) post-2020 evrimine ileriye köprüdür."
fig, ax = plt.subplots(figsize=(11, 6))
ax.set_xlim(0, 12)
ax.set_ylim(0, 8)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
ax.set_title("Post-2020 köprü: negatif örnek seçiminden JEPA'ya",
color=COL_INK, fontsize=14, fontweight="bold", pad=14)
def box(x, y, w, h, label, fc, ec, lw=2.2, dashed=False, fs=9.5,
fontweight="normal", tc=COL_TEXT):
style = "round,pad=0.03,rounding_size=0.10"
ls = (0, (5, 3)) if dashed else "solid"
b = FancyBboxPatch((x - w / 2, y - h / 2), w, h, boxstyle=style,
fc=fc, ec=ec, lw=lw, linestyle=ls, zorder=2)
ax.add_patch(b)
ax.text(x, y, label, ha="center", va="center", fontsize=fs,
color=tc, zorder=3, wrap=True, fontweight=fontweight)
def arrow(p0, p1, color=COL_VIOLET_M, lw=2.0, dashed=False, rad=0.0):
ls = (0, (5, 3)) if dashed else "solid"
cs = f"arc3,rad={rad}"
ax.add_patch(FancyArrowPatch(p0, p1, arrowstyle="-|>", mutation_scale=18,
color=color, lw=lw, linestyle=ls,
connectionstyle=cs, zorder=1,
shrinkA=4, shrinkB=4))
# --- Kaynak kutu: negatif seçimi zor (LeCun) ---
box(2.4, 6.6, 3.6, 1.15,
"Negatif (ȳ) seçimi zor\n(LeCun)",
fc=COL_BG, ec=COL_VIOLET_D, lw=2.6, fs=10.5, fontweight="bold",
tc=COL_INK)
# --- İKİ YOL ---
# (a) Contrastive (kursta MoCo) — violet, solid
box(2.4, 4.4, 3.7, 1.35,
"(a) Contrastive\nMoCo / SimCLR\n— negatifi SEÇ —",
fc="#ece0f7", ec=COL_VIOLET, lw=2.4, fs=9.5)
ax.text(0.55, 5.15, "kursta:\nMoCo", ha="center", va="center",
fontsize=8, color=COL_VIOLET, fontweight="bold", zorder=3)
# (b) Non-contrastive (KURSTA YOK) — gold, dashed
box(2.4, 2.1, 3.9, 1.45,
"(b) NON-CONTRASTIVE\nBYOL / VICReg\n— negatifi ATLA,\nhacmi başka yolla sınırla —",
fc="#fbf3df", ec=COL_GOLD_D, lw=2.4, dashed=True, fs=9.0)
ax.text(0.4, 2.1, "kursta\nYOK", ha="center", va="center",
fontsize=8, color=COL_GOLD_D, fontweight="bold", zorder=3)
# --- JEPA (KURSTA YOK) — gold dashed, sağda merkezde ---
box(9.2, 4.35, 3.3, 1.9,
"JEPA\n(LeCun grubu)\n\ntemsil-uzayında tahmin\n→ MSE bulanıklığından\nkaçar",
fc="#fbf3df", ec=COL_GOLD_D, lw=2.6, dashed=True, fs=9.5,
fontweight="bold", tc=COL_INK)
ax.text(11.45, 5.7, "kursta\nYOK", ha="center", va="center",
fontsize=8, color=COL_GOLD_D, fontweight="bold", zorder=3)
# --- Oklar ---
# kaynak → iki yol
arrow((2.4, 6.0), (2.4, 5.10), color=COL_VIOLET, lw=2.2)
arrow((2.4, 3.72), (2.4, 2.85), color=COL_GOLD_D, lw=2.2, dashed=True)
# iki yol → JEPA
arrow((4.25, 4.4), (7.55, 4.7), color=COL_VIOLET, lw=2.2, rad=0.10)
arrow((4.35, 2.1), (7.55, 3.9), color=COL_GOLD_D, lw=2.2, dashed=True, rad=-0.14)
# --- Alt annotation kutusu ---
ann = ("post-2020: PPUU belirsizlik + non-contrastive → JEPA; "
"KURSTA YOK (ileriye köprü, Hafta 7–11 temelinin evrimi)")
ax.add_patch(FancyBboxPatch((0.35, 0.18), 11.3, 0.78,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=COL_BG, ec=COL_GOLD_D, lw=1.6, linestyle=(0, (4, 2.5)),
zorder=2))
ax.text(6.0, 0.57, ann, ha="center", va="center", fontsize=9.2,
color=COL_INK, zorder=3, fontstyle="italic")
# --- Mini lejant (çizgi tipi açıklaması) ---
ax.plot([7.2, 7.9], [7.35, 7.35], color=COL_VIOLET, lw=2.4, zorder=3)
ax.text(8.0, 7.35, "kursta var", ha="left", va="center", fontsize=8.2,
color=COL_TEXT, zorder=3)
ax.plot([9.7, 10.4], [7.35, 7.35], color=COL_GOLD_D, lw=2.4,
linestyle=(0, (5, 3)), zorder=3)
ax.text(10.5, 7.35, "kursta yok (köprü)", ha="left", va="center",
fontsize=8.2, color=COL_TEXT, zorder=3)
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — Negatif Seçimi"}
**Geriye (Hafta 8-9-11):** Non-contrastive = Hafta 9 "düşük-enerji hacmini sınırla" + bu haftanın "marjsız enerji kaybı collapse eder" uyarısının çözümü.
**İleriye:** JEPA, LeCun'un tüm kurs boyunca tohumladığı (EBM + world model + non-contrastive) fikirlerin sentezidir.
:::
## Geçiş: LeCun'dan Canziani'ye {#sec-gecis-d11}
LeCun kayıpların enerji manzarasını nasıl şekillendirdiğini anlattı ve "çoklu-gelecek varsa MSE bulanıklaştırır" tespitini bıraktı. Şimdi **Canziani** tam bu sorunu gerçek bir sistemde — yoğun trafikte otonom sürüş — çözüyor: Hafta 9-10'un dünya modelini latent değişken ve **belirsizlik düzenlileştirmesiyle** tamamlayarak **PPUU**'yu baştan sona kuruyor.
## (Canziani) PPUU: Dünya Modeli, Maliyet ve Model-Free'nin Sorunu {#sec-ppuu-dunya}
Canziani problemi koyuyor: bir aracı yoğun trafikte sürmeyi öğret. **Model-free RL** kaza yaparak öğrenir — kötü fikir:
> "you have to die a few times before actually learning not to die, but that's arguably not the way you learn how to drive." — Canziani, 1:43
Bunun yerine bir **dünya modeli** öğrenip onun içinde planla (yemek yaparken elini yakmadan önce zihninde dene). **Veri:** NGSIM I-80 otoyolu — bir binanın tepesindeki kameralardan tepeden-görünüm, bounding box + takip. Her araç için durum sₜ = (pₜ konum, vₜ hız, iₜ bağlam görüntüsü). Görüntü iₜ bir **doluluk ızgarasıdır** (mavi=ben, kırmızı=şerit, yeşil=diğerleri) — değişken sayıda aracı sabit boyutlu temsille kodlamanın "şirin" yolu. Eylemler, **kinematiği tersine çevirerek** kurtarılır (düzgün doğrusal hareketten sapma = eylem).
**Maliyet** = şerit maliyeti (şeritten çıkma) + yakınlık maliyeti (hıza göre uzayan boylamsal potansiyel × enlemsel potansiyel) — ikisi de **türevlenebilir**, böylece çarpışmayı azaltmak için gradyan akıtılabilir.
::: {.callout-tip title="Builder Notu — Dünya Modeli + Maliyet"}
**Geriye (Hafta 9-10):** Dünya modeli = Hafta 9; emulator/controller ayrımı = Hafta 10 PPUU girişi. Doluluk ızgarası = değişken-uzunluk problemini görüntüyle çözmek (attention'a alternatif).
**İleriye:** "Önce dünya modeli, sonra içinde planla" = model-based RL ve MPC'nin (model predictive control) çekirdeği.
:::
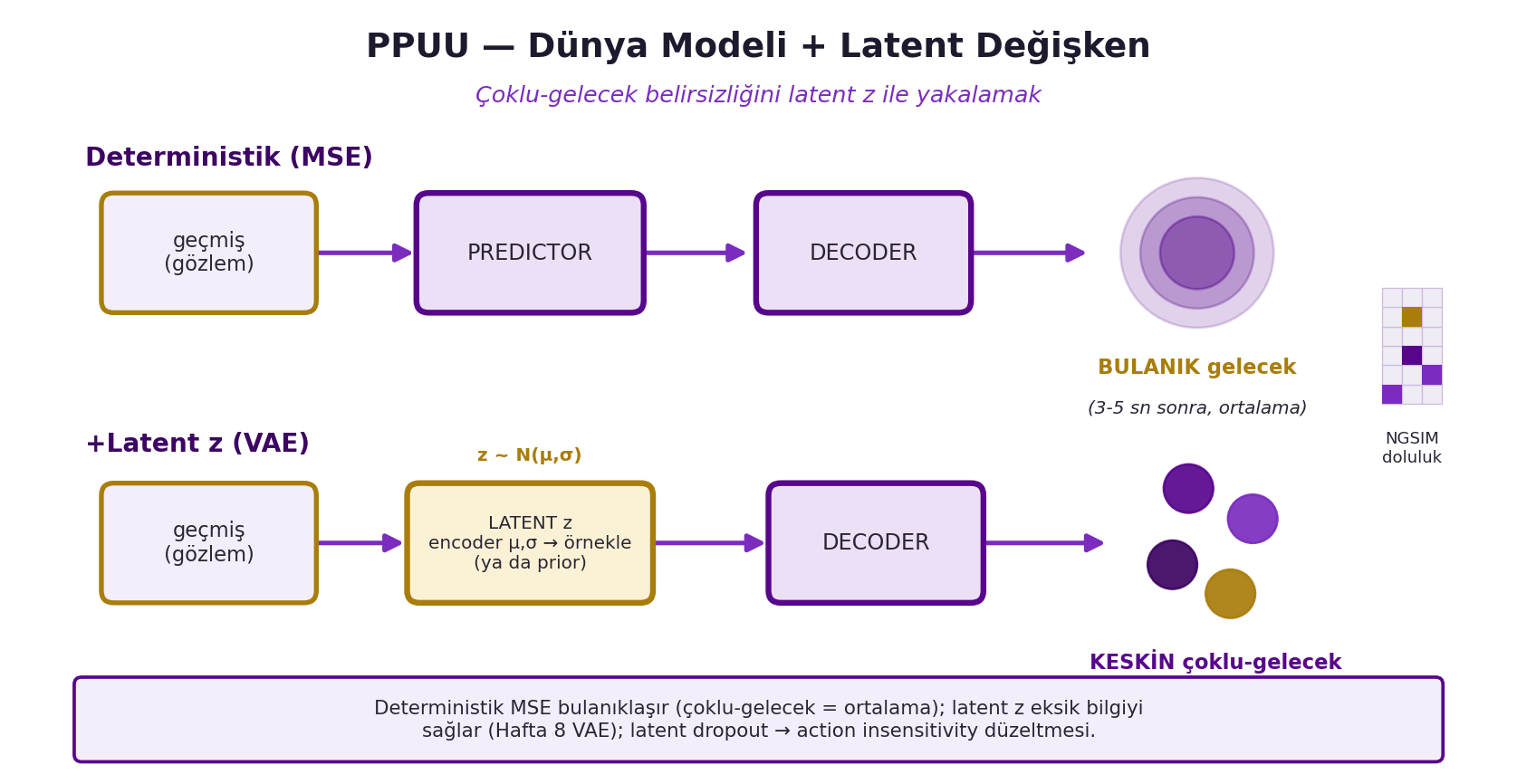
## (Canziani) MSE Bulanıklığı ve Latent Değişken Çözümü {#sec-latent}
İlk deneme **deterministik** dünya modeli: predictor (geçmiş → geleceğin gizli temsili) + decoder (gizli → gerçek gelecek), MSE ile eğit. **Başarısız** — tahminler 3-5 saniye sonra bulanıklaşır. Sebep tam olarak LeCun'un dediği: çoklu-gelecek varken MSE **ortalamayı** üretir. @fig-ppuu-latent iki yolu yan yana koyar: üstte deterministik (MSE) yol bulanık gelecek, altta +latent z (VAE) yolu keskin çoklu-gelecek üretir. Canziani'nin düşen-kalem örneği:
> "the average final location is like the pen never fell, and it's really wrong." — Canziani, 28:59
Çözüm: düşük-boyutlu (16-boyutlu) bir **latent değişken** zₜ ekle. zₜ, MSE'yi sıfırlayacak şekilde ya **çıkarımla** (latent uzayda gradyan inişi) ya da geleceği gören bir **variational encoder** ile (ortalama+varyans, örnekle) bulunur. **KL terimi** posterior'u N(0, I) prior'a yaklaştırır; böylece test anında prior'dan örnekleyerek gelecek **üretebilirsin** (Hafta 8 VAE = non-contrastive EBM):
> "you add latent variables in order to provide the missing information that would be required for you to make a proper prediction." — Canziani, 1:10:47
**İncelikli tuzak — action insensitivity (bilgi sızıntısı):** encoder geleceği gördüğü için "döndük" bilgisini latent'e sızdırır → forward model **direksiyonu (eylemi) yok sayar**. Çözüm **latent dropout**: bazı zamanlar zₜ'yi encoder yerine prior'dan örnekle, böylece dönme latent'e kodlanamaz ve ağ eylemi kullanmak **zorunda** kalır.
> "we fix this problem by simply dropping out this latent and sampling from the prior... in this way you can't encode the rotation anymore in the latent variable." — Canziani, 52:52
```{python}
#| label: fig-ppuu-latent
#| fig-cap: "PPUU dünya modeli ve latent değişken: üstte deterministik (MSE) yol geçmiş → PREDICTOR → DECODER zinciriyle 3-5 saniye sonrası için bulanık (ortalama) gelecek üretir; altta +Latent z (VAE) yolu encoder μ,σ'dan örneklenen (ya da prior'dan gelen) z'yi DECODER'a enjekte ederek keskin, çoklu-gelecek tahmini sağlar. Sağda NGSIM doluluk ızgarası ikonu (violet=ben, gold=şerit, orta-violet=diğer araçlar). Deterministik MSE çoklu-gelecek belirsizliğini ortalamaya indirip bulanıklaşırken latent z eksik bilgiyi taşır (Hafta 8 VAE bağı) ve latent dropout action insensitivity sorununu düzeltir."
fig, ax = plt.subplots(figsize=(11, 5.6))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.2)
ax.axis("off")
ax.text(6, 5.95, "PPUU — Dünya Modeli + Latent Değişken",
ha="center", va="center", fontsize=14, fontweight="bold", color=COL_INK)
ax.text(6, 5.55, "Çoklu-gelecek belirsizliğini latent z ile yakalamak",
ha="center", va="center", fontsize=9.5, color=COL_VIOLET_M, style="italic")
# Kutu çizici yardımcı
def box(x, y, w, h, label, fc, ec, lw=2.0, fs=9.0, tc=None):
p = FancyBboxPatch((x - w / 2, y - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=lw, zorder=3)
ax.add_patch(p)
ax.text(x, y, label, ha="center", va="center", fontsize=fs,
color=tc or COL_TEXT, zorder=4, wrap=True)
def arrow(x0, y0, x1, y1, color=COL_VIOLET_M, lw=1.9, style="-|>"):
ax.add_patch(FancyArrowPatch((x0, y0), (x1, y1), arrowstyle=style,
mutation_scale=15, color=color, lw=lw, zorder=2))
# --------- ÜST YOL: Deterministik (MSE) ---------
yU = 4.25
ax.text(0.55, yU + 0.78, "Deterministik (MSE)", ha="left", va="center",
fontsize=10.5, fontweight="bold", color=COL_VIOLET_D)
box(1.55, yU, 1.7, 0.95, "geçmiş\n(gözlem)", COL_BG, COL_GOLD_D, fs=8.5)
box(4.15, yU, 1.8, 0.95, "PREDICTOR", "#ece0f7", COL_VIOLET, lw=2.4, fs=9.0)
box(6.85, yU, 1.7, 0.95, "DECODER", "#ece0f7", COL_VIOLET, lw=2.4, fs=9.0)
arrow(2.4, yU, 3.25, yU)
arrow(5.05, yU, 5.95, yU)
# Bulanık gelecek çıktısı (üst)
xb, yb = 9.55, yU
for r, a in [(0.62, 0.18), (0.46, 0.28), (0.30, 0.42)]:
ax.add_patch(plt.Circle((xb, yb), r, color=COL_VIOLET, alpha=a, zorder=3))
arrow(7.7, yU, 8.7, yU)
ax.text(xb, yb - 0.95, "BULANIK gelecek", ha="center", va="center",
fontsize=8.5, color=COL_GOLD_D, fontweight="bold")
ax.text(xb, yb - 1.28, "(3-5 sn sonra, ortalama)", ha="center", va="center",
fontsize=7.5, color=COL_TEXT, style="italic")
# --------- ALT YOL: +Latent z (VAE) ---------
yL = 1.85
ax.text(0.55, yL + 0.82, "+Latent z (VAE)", ha="left", va="center",
fontsize=10.5, fontweight="bold", color=COL_VIOLET_D)
box(1.55, yL, 1.7, 0.95, "geçmiş\n(gözlem)", COL_BG, COL_GOLD_D, fs=8.5)
# Latent z bloğu (gold vurgulu)
box(4.15, yL, 1.95, 0.95, "LATENT z\nencoder μ,σ → örnekle\n(ya da prior)",
"#fbf2d6", COL_GOLD_D, lw=2.4, fs=7.5, tc=COL_TEXT)
box(6.95, yL, 1.7, 0.95, "DECODER", "#ece0f7", COL_VIOLET, lw=2.4, fs=9.0)
arrow(2.4, yL, 3.17, yL)
arrow(5.13, yL, 6.1, yL)
# z enjeksiyon etiketi (gold)
ax.text(4.15, yL + 0.72, "z ~ N(μ,σ)", ha="center", va="center",
fontsize=7.5, color=COL_GOLD_D, fontweight="bold")
# Keskin çoklu-gelecek (alt) — birkaç ayrı keskin daire
xk, yk = 9.7, yL
sharp = [(-0.22, 0.45, COL_VIOLET), (0.30, 0.20, COL_VIOLET_M),
(0.12, -0.42, COL_GOLD_D), (-0.35, -0.18, COL_VIOLET_D)]
for dx, dy, c in sharp:
ax.add_patch(plt.Circle((xk + dx, yk + dy), 0.20, color=c, alpha=0.92, zorder=4))
arrow(7.8, yL, 8.85, yL)
ax.text(xk, yk - 0.98, "KESKİN çoklu-gelecek", ha="center", va="center",
fontsize=8.5, color=COL_VIOLET, fontweight="bold")
# --------- Yan: NGSIM doluluk ızgarası ikonu ---------
gx0, gy0 = 11.05, 3.0
cell = 0.16
ng = 6
for i in range(ng):
for j in range(3):
ax.add_patch(plt.Rectangle((gx0 + j * cell, gy0 + i * cell), cell, cell,
fc="#f0ecf6", ec=COL_GRID, lw=0.5, zorder=2))
# ben (violet), şerit (gold_d), diğer araçlar (violet_m)
ax.add_patch(plt.Rectangle((gx0 + 1 * cell, gy0 + 2 * cell), cell, cell, fc=COL_VIOLET, zorder=3)) # ben
ax.add_patch(plt.Rectangle((gx0 + 1 * cell, gy0 + 4 * cell), cell, cell, fc=COL_GOLD_D, zorder=3)) # şerit önü
ax.add_patch(plt.Rectangle((gx0 + 0 * cell, gy0 + 0 * cell), cell, cell, fc=COL_VIOLET_M, zorder=3)) # diğer
ax.add_patch(plt.Rectangle((gx0 + 2 * cell, gy0 + 1 * cell), cell, cell, fc=COL_VIOLET_M, zorder=3)) # diğer
ax.text(gx0 + 1.5 * cell, gy0 - 0.22, "NGSIM\ndoluluk", ha="center", va="top",
fontsize=6.8, color=COL_TEXT)
# --------- Annotation kutusu ---------
note = ("Deterministik MSE bulanıklaşır (çoklu-gelecek = ortalama); latent z eksik bilgiyi\n"
"sağlar (Hafta 8 VAE); latent dropout → action insensitivity düzeltmesi.")
ax.add_patch(FancyBboxPatch((0.5, 0.08), 11.0, 0.62,
boxstyle="round,pad=0.04,rounding_size=0.06",
fc=COL_BG, ec=COL_VIOLET, lw=1.4, zorder=2))
ax.text(6, 0.39, note, ha="center", va="center", fontsize=8.0,
color=COL_TEXT, zorder=3);
```
::: {.callout-tip title="Builder Notu — Latent = Eksik Bilgi"}
**Geriye (Hafta 8 + 2):** MSE-ortalama = bu haftanın LeCun bulanıklık tespiti; latent+KL = Hafta 8 VAE; "missing info" latent = Hafta 8 gizli değişken yorumu. Latent dropout = bilgi sızıntısını kesen düzenlileştirme.
**İleriye:** Çoklu-geleceği latent'le modelleme = koşullu üretici modellerin (CVAE, diffusion) temel kalıbı; piksel-MSE'den kaçış → JEPA (temsil uzayında tahmin).
:::
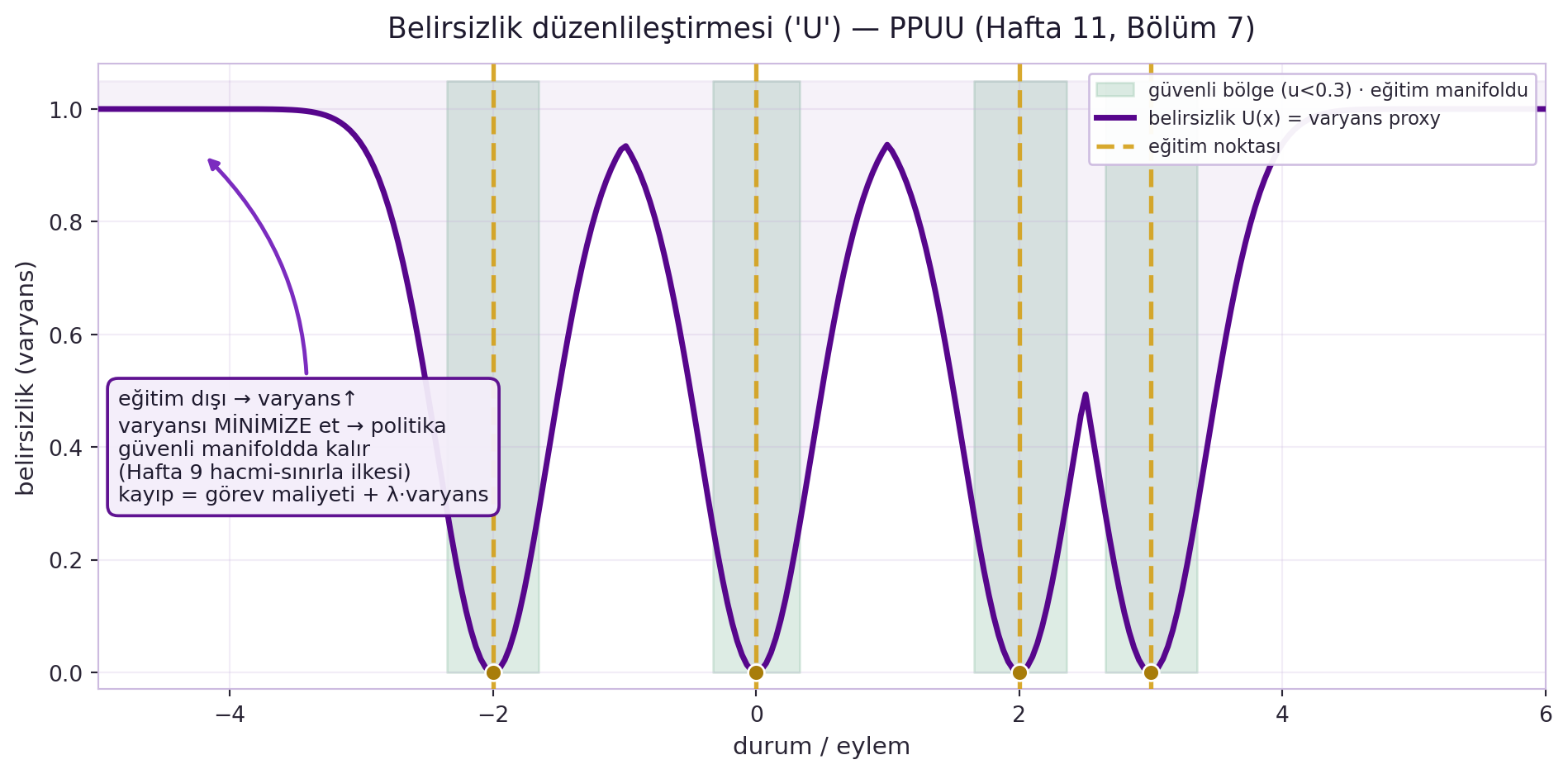
## (Canziani) Belirsizlik Düzenlileştirmesi — PPUU'nun "U"su {#sec-belirsizlik-d11}
Politikayı eğitmek: politika(durum) → eylem → dünya modeli → tahmin → maliyet (yakınlık+şerit), zinciri açıp **backprop** ile politikayı eğit (dünya modeli donuk). **Başarısız** — politika hile yapıp **manifold dışına** çıkar (her şeyi siyah/sıfır-maliyet tahmin ettirir → yola çıkar, çarpışır).
Birinci yama **uzman düzenleyici** (taklit öğrenme — politikayı uzman eylemine yaklaştır) işe yarar. Asıl fikir ikinci yama, **belirsizlik düzenlileştirmesi** ("U"): eğitim bölgesi dışında dünya modelinin **varyansı** artar; varyans türevlenebilir, öyleyse onu minimize et — politika güvenli, eğitim manifolduna yakın eylemler seçsin. @fig-uncertainty-reg bu varyans-proxy'sini gösterir: eğitim noktalarına yakın çukurlaşır (~0), uzakta doygunluğa (~1) ulaşır; yeşil bant düşük-belirsizlik (güvenli) bölgesini işaretler.
> "as you go away from the training interval the variance will increase... your variance now is your loss, you do gradient descent in action space for variance minimization." — Canziani, 1:18:00
Birden çok tahmin için çıkarımda **dropout açık** bırakılır (varyansı ölçmek için). Nihai kayıp = görev maliyeti + λ·belirsizlik. Sonuç: araç yoğun trafikte hayatta kalır. Bu, Hafta 9'un "düşük-enerji hacmini sınırla" non-contrastive ilkesinin somut bir mühendislik hâlidir — varyans cezası, enerjiyi eğitim verisinin etrafında tutan bir düzenleyicidir.
```{python}
#| label: fig-uncertainty-reg
#| fig-cap: "Belirsizlik düzenlileştirmesi ('U' — PPUU, Hafta 11): epistemik varyans proxy'si eğitim noktalarına (gold dikey işaretler, x=-2,0,2,3) yakın çukurlaşır (~0), eğitim manifoldundan uzaklaştıkça doygunluğa (~1) ulaşır. Yeşil gölgeli güvenli bölge (u<0.3) eğitim manifoldunu işaretler. PPUU'da kayıp = görev maliyeti + λ·varyans olarak kurulur; varyansı minimize etmek politikayı düşük-belirsizlik (gözlenmiş) bölgesinde tutar — Hafta 9'un 'hacmi sınırla' EBM ilkesinin kontrol karşılığı."
x_train = np.array([-2.0, 0.0, 2.0, 3.0])
x_grid = np.linspace(-5, 6, 300)
u = uncertainty_demo(x_train, x_grid)
fig, ax = plt.subplots(figsize=(10, 5))
apply_style(ax)
# Düşük-belirsizlik bandı (u < 0.3) — güvenli/eğitim manifoldu (yeşil gölge)
safe = u < 0.3
ax.fill_between(x_grid, 0, 1.05, where=safe, color="#2e8b57", alpha=0.16,
step="mid", label="güvenli bölge (u<0.3) · eğitim manifoldu", zorder=1)
# Belirsizlik eğrisi (violet)
ax.plot(x_grid, u, color=COL_VIOLET, lw=2.6, zorder=4,
label="belirsizlik U(x) = varyans proxy")
ax.fill_between(x_grid, u, 1.05, color=COL_VIOLET, alpha=0.05, zorder=2)
# Eğitim noktaları (gold dikey işaretler)
for i, xt in enumerate(x_train):
ax.axvline(xt, color=COL_GOLD, lw=2.0, ls=(0, (4, 2)), alpha=0.9, zorder=3,
label="eğitim noktası" if i == 0 else None)
ax.scatter([xt], [0.0], color=COL_GOLD_D, s=55, zorder=6,
edgecolor=COL_WHITE, linewidth=1.0)
# Annotation — politika / kayıp formülü
ax.annotate(
"eğitim dışı → varyans↑\n"
"varyansı MİNİMİZE et → politika\n"
"güvenli manifoldda kalır\n"
"(Hafta 9 hacmi-sınırla ilkesi)\n"
r"kayıp = görev maliyeti + λ·varyans",
xy=(-4.2, 0.92), xycoords="data",
xytext=(-4.85, 0.40), textcoords="data",
fontsize=9.5, color=COL_INK, va="center", ha="left",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_VIOLET, lw=1.4, alpha=0.95),
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_M, lw=1.8,
connectionstyle="arc3,rad=0.25"),
zorder=7,
)
ax.set_xlim(-5, 6)
ax.set_ylim(-0.03, 1.08)
ax.set_xlabel("durum / eylem", fontsize=11)
ax.set_ylabel("belirsizlik (varyans)", fontsize=11)
ax.set_title("Belirsizlik düzenlileştirmesi ('U') — PPUU (Hafta 11, Bölüm 7)",
fontsize=13, color=COL_INK, pad=12)
style_legend(ax, loc="upper right", fontsize=8.5)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Belirsizlik 'U'su"}
**Geriye (Hafta 5-6-9):** Zincir-backprop = Hafta 5 autograd + Hafta 6 BPTT; belirsizlik cezası = Hafta 9 non-contrastive "hacmi sınırla"; manifold-dışı çökme = Hafta 9 collapse'ın politika hâli.
**İleriye:** Belirsizlik-bilinçli planlama = model-based RL'in güvenlik anahtarı; epistemik belirsizlik (ensemble/dropout varyansı) tüm risk-duyarlı kontrolün temeli.
:::
## Bu Dersin Özeti {#sec-ozet-d11}
1. **Aktivasyon = ölçek-değişmezliği (LeCun):** tek-kıvrımlı (ReLU) fonksiyonlar derin ağlarda daha iyi, normalleştirmeyle uyumlu; sigmoid/tanh gömülü ölçek taşır + doyumda gradyan kaybolur.
2. **MSE → bulanık (LeCun/Canziani):** çoklu-gelecekte MSE ortalama üretir (görüntü ortalaması = bulanık); L1 → medyan (keskin, dayanıklı).
3. **Cross-entropy = logsoftmax + NLL:** sayısal kararlılık için birleşik; KL ıraksaması (sistem dağılımı vs one-hot).
4. **Kayıp = enerji şekillendirme + marj (LeCun):** enerji kaybı marjsız → collapse; hinge/margin doğru cevabı yanlıştan marjla ayırır → iyi; ȳ (negatif) seçimi sürekli uzayda zor (MoCo vs SimCLR).
5. **PPUU (Canziani):** dünya modeli + latent değişken (çoklu-gelecek) + KL + latent dropout (action insensitivity) + **belirsizlik düzenlileştirmesi** (varyans minimizasyonu = güvenli manifold).
6. **Post-2020 (KURSTA YOK):** non-contrastive (BYOL/VICReg) = negatif seçimini atlar; JEPA = PPUU + temsil-uzayı tahmini.
::: {.callout-important title="Tek Bir Cümle"}
Bir kayıp fonksiyonu seçmek, doğru cevabın enerjisini bastırıp yanlışları bir **marjla** iten bir enerji manzarası tasarlamaktır — marj yoksa enerji çöker (LeCun); ve PPUU, Hafta 9-10'un dünya modelini latent değişkenle (çoklu-geleceğin bulanıklığını çözer) ve **belirsizlik düzenlileştirmesiyle** (politikayı güvenli manifoldda tutar) tamamlayarak EBM/world-model fikirlerini otonom sürüşe döker (Canziani).
:::
## Kontrol Soruları {#sec-kontrol-d11}
::: {.callout-note collapse="true" title="Soru 1: Neden tek-kıvrımlı (ReLU) fonksiyonlar derin ağlarda sigmoid'den daha iyidir? \"Ölçek-değişmezliği\" ne demek?"}
**Cevap:** Tek keskin kıvrımlı bir fonksiyon **ölçeğe duyarsızdır**: girişi 2 ile çarparsan çıkış da 2 ile çarpılır, davranış (kıvrımın yeri) değişmez. Sigmoid/softplus gibi yumuşak fonksiyonlarda **gömülü bir ölçek** vardır — girişi büyütünce fonksiyonun "sert mi yumuşak mı" davranışı değişir. Derin ağda ardışık katmanların ağırlık ölçeği serbestçe yeniden dağıtılabildiği için (LeCun 27:04), ölçeğe duyarlı bir aktivasyon ağı kısıtlar ve doyuma sokup gradyan kaybına yol açar. Ayrıca sigmoid, batch/grup normalleştirmeyle **uyumsuzdur**: normalleştirme ölçeği sabitlerse, sigmoid'in hangi bölgesinin kullanılacağı seçimi kaybolur.
:::
::: {.callout-note collapse="true" title="Soru 2: MSE neden bulanık tahminler üretir? L1 farkı nedir? Bu Canziani'nin PPUU'sundaki hangi sorunla aynıdır?"}
**Cevap:** Bir girişe karşılık birden çok olası çıkış varsa, MSE'yi minimize eden değer hepsinin **ortalamasıdır**; görüntülerin ortalaması bulanıktır (LeCun 37:50). Düşen-kalem örneği: kalemin düşeceği yönlerin ortalaması "kalem hiç düşmedi" konumudur — yanlış (Canziani 28:59). L1 ise **medyanı** verir (bulanık değil) ve aykırı değerlere dayanıklıdır, ama tabanda türevlenemez. PPUU'da deterministik dünya modeli tam bu yüzden 3-5 saniye sonra bulanıklaşır; çözüm, çoklu-geleceği yakalayan bir **latent değişkendir**.
:::
::: {.callout-note collapse="true" title="Soru 3: \"Enerji kaybı\" neden tehlikelidir? \"İyi\" bir EBM kaybını ne yapar? \"Most offending incorrect answer\" (ȳ) nedir?"}
**Cevap:** Sadece doğru cevabın enerjisini bastıran **enerji kaybı**, yanlışları yukarı itmediği için enerjiyi her yerde düzleştirebilir — sistem **çöker** (LeCun 1:20:13; Hafta 8-9 collapse). İyi bir kayıp, doğru cevabın enerjisini en-çok-suç-işleyen yanlış cevabın (**ȳ**: yanlış olduğu hâlde en düşük enerjili) enerjisinden **en az bir marj** kadar küçük tutar (LeCun 1:25:47):
$$
L = \max(0,\; m + E(x, y) - E(x, \bar{y}))
$$
ȳ'yi seçmek sınıflandırmada kolay, sürekli/yüksek-boyutlu uzayda zordur — "negatif nasıl seçilir?" sorusu MoCo ile SimCLR'ı ayıran şeydir (LeCun 1:36:09).
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) PPUU'da \"action insensitivity\" (bilgi sızıntısı) sorunu nedir, latent dropout nasıl çözer?"}
**Cevap:** Variational encoder geleceği gördüğü için "döndük" bilgisini latent değişkene **sızdırır**; o zaman forward model direksiyonu (eylemi) yok sayar — küçük bir direksiyon değişikliği büyük bir MSE değişikliği yarattığından, ağ bu bilgiyi eylem yerine latent'ten alır. Çözüm **latent dropout**: eğitimin bir kısmında zₜ'yi encoder yerine prior'dan örnekle (Canziani 52:52). Böylece dönme latent'e kodlanamaz (bazen yok olur), ağ eylemi kullanmak zorunda kalır → eylem-gelecek bağı kurulur.
:::
::: {.callout-note collapse="true" title="Soru 5: Belirsizlik düzenlileştirmesi (\"U\") politikayı nasıl güvende tutar? Hangi Hafta-9 ilkesinin somut hâlidir?"}
**Cevap:** Politika tek başına dünya modelini "kandırıp" manifold dışına çıkar (sıfır-maliyet hayalleri görür). Dünya modelinin **varyansı** eğitim bölgesi dışında artar (ensemble/dropout ile ölçülür); varyans türevlenebilir, böylece onu da minimize edersin (Canziani 1:18:00). Nihai kayıp = görev maliyeti + λ·varyans. Bu, politikayı eğitim verisinin etrafında (güvenli) tutar — Hafta 9'un **"düşük-enerji hacmini sınırla"** non-contrastive ilkesinin mühendislik hâlidir.
:::
## Egzersizler {#sec-egzersiz-d11}
**Egzersiz 1 (Aktivasyon ölçeği).** Tek-kıvrımlı (ReLU) ve yumuşak (softplus, β=1 ve β=10) bir fonksiyonu çiz. Girişi 0.1, 1, 10 ile ölçekleyince ReLU'nun şeklinin değişmediğini ama softplus'ın "sertleştiğini" göster. Bu, neden derin ağlarda ReLU + BatchNorm'un tercih edildiğini nasıl açıklar?
```python
import numpy as np
# ReLU OLCEK-DEGISMEZ: relu(c*x)/c hep ayni sekil (pozitif homojenlik).
# softplus OLCEK-BAGIMLI: beta buyudukce sekil degisir (gomulu olcek).
def relu(x):
return np.maximum(0.0, x)
def softplus_scaled(x, beta=1.0):
# (1/beta) * log(1 + e^(beta*x)) -> beta buyuk: ReLU'ya yaklasir
return (1.0 / beta) * np.log1p(np.exp(-np.abs(beta * x))) + np.maximum(x, 0.0)
x = np.linspace(-3, 3, 7)
for c in [0.1, 1.0, 10.0]:
print(f"ReLU(c*x)/c, c={c:>4}: {np.round(relu(c * x) / c, 2)}") # AYNI sekil
for beta in [1.0, 10.0]:
print(f"softplus beta={beta:>4}: {np.round(softplus_scaled(x, beta), 2)}") # DEGISIR
# ReLU normalizasyonla uyumlu (olcek serbest); softplus gomulu olcek tasir -> catisir
```
**Egzersiz 2 (MSE vs L1).** Tek bir x için y değerleri {1, 2, 2, 10} (bir aykırı) gözlemlensin. MSE'yi minimize eden tahmin (ortalama = 3.75) ile L1'i minimize edeni (medyan = 2) karşılaştır. Görüntü tahmininde bu fark neden "bulanık vs keskin"e dönüşür?
```python
import numpy as np
# MSE-min = ORTALAMA (aykiri tarafindan cekilir, "bulanik");
# L1-min = MEDYAN (aykiriyi gormezden gelir, "keskin").
veri = np.array([1.0, 2.0, 2.0, 10.0])
print(f"MSE minimumu (ortalama) = {veri.mean():.2f}") # 3.75 <- 10 aykirisi ceker
print(f"L1 minimumu (medyan) = {np.median(veri):.2f}") # 2.00 <- aykiri etkisiz
# Goruntude: cok-gelecek varsa MSE hepsinin ORTALAMASINI cizer -> bulanik;
# L1 medyani sectigi icin tek bir keskin moda yakin kalir.
for t in [2.0, 3.75]:
mse = np.sum((veri - t) ** 2)
l1 = np.sum(np.abs(veri - t))
print(f"t={t:>4}: MSE={mse:6.2f} L1={l1:5.2f}")
# MSE t=3.75'te minimum, L1 t=2'de minimum -> farkli "en iyi tahmin"
```
**Egzersiz 3 (EBM kaybı tasarla).** İki skor (doğru, yanlış) veren bir model için (a) enerji kaybı, (b) perceptron kaybı, (c) hinge (marj m) kaybını yaz. Hangisi collapse'a açıktır, neden? Marj m'yi büyütmek/küçültmek ne yapar (ipucu: son katman ağırlıklarının ölçeği)?
```python
import numpy as np
# E_pos = dogru cevabin enerjisi (DUSUK olmali);
# E_neg = en-cok-suc-isleyen yanlis (ybar) enerjisi (YUKSEK olmali).
def energy_loss(E_pos, E_neg):
return E_pos # (a) sadece dogruyu bas -> COLLAPSE riski
def perceptron_loss(E_pos, E_neg):
return np.maximum(0.0, E_pos - E_neg) # (b) marjsiz -> collapse'a acik
def hinge_loss(E_pos, E_neg, m=1.0):
return np.maximum(0.0, m + E_pos - E_neg) # (c) marj m ZORLAR -> iyi
E_pos, E_neg = 0.2, 1.5
print(f"enerji = {energy_loss(E_pos, E_neg):.2f} (yanlisi itmez -> COLLAPSE)")
print(f"perceptron= {perceptron_loss(E_pos, E_neg):.2f} (marjsiz)")
for m in [0.5, 1.0, 2.0]:
print(f"hinge m={m}: {hinge_loss(E_pos, E_neg, m):.2f}")
# (a) ve (b) collapse'a acik (marj yok); m buyumesi daha buyuk enerji-farki
# (dolayli olarak son katman agirligi olcegi) zorlar -> daha guclu ayrim
```
**Egzersiz 4 (PPUU latent dropout).** Bir koşullu predictor'da encoder'dan gelen latent'i %50 olasılıkla prior örneğiyle değiştir. "Eğitim sırasında her zaman görülen tek sinyal eylemdir" cümlesini bu mekanizmayla açıkla. Latent dropout olmazsa hangi yanlış kestirme (shortcut) öğrenilir?
```python
import numpy as np
# Latent dropout: bazi adimlarda z'yi ENCODER yerine PRIOR'dan ornekle.
# Boylece "donme/gelecek" bilgisi latent'e GUVENILIR sekilde kodlanamaz
# -> ag bu bilgiyi EYLEM'den almak ZORUNDA kalir (action insensitivity fix).
def sample_latent(encoder_mu, encoder_sigma, p_drop=0.5, rng=None):
rng = rng or np.random.default_rng(0)
if rng.random() < p_drop:
return rng.normal(0.0, 1.0, size=encoder_mu.shape) # PRIOR (bilgi yok)
return encoder_mu + encoder_sigma * rng.normal(0.0, 1.0, size=encoder_mu.shape)
rng = np.random.default_rng(0)
mu, sigma = np.zeros(4), np.ones(4)
drops = [np.allclose(sample_latent(mu, sigma, 0.5, rng), 0, atol=5) for _ in range(6)]
print("bazi adimlarda latent = prior (bilgi tasimaz):", "evet" if any(drops) else "hayir")
# Latent dropout YOKSA: encoder gelecegi latent'e sizdirir -> forward model
# direksiyonu (eylemi) YOK SAYAR (shortcut). Tek tutarli sinyal = eylem.
```
**Egzersiz 5 (Hafta 12 habercisi — NLP & Transformer).** Hafta 12'de **konuk Mike Lewis** (FAIR) NLP/seq2seq/decoding'i anlatacak; Canziani attention ve Transformer'ı kuracak. (a) Bu haftaki softmax tartışmasını (β sıcaklık, "0'a yakın katsayı için giriş −∞ olmalı") attention katsayılarıyla nasıl ilişkilendirirsin? (b) Hafta 6'nın attention/seq2seq'i ile Transformer'ın "set→set" görüşü arasında ne fark beklersin?
```python
import numpy as np
# (a) softmax sicakligi beta = "ters sicaklik": dusuk beta -> yumusak/duz dagilim,
# yuksek beta -> sert/odakli (tek anahtara yaklasir). Attention katsayilari
# da softmax(skor/sqrt(d))'dir -> ayni "0'a yakin agirlik icin skor -> -inf".
def softmax(z, beta=1.0):
z = beta * (z - z.max())
e = np.exp(z)
return e / e.sum()
skorlar = np.array([2.0, 1.0, 0.1])
for beta in [0.3, 1.0, 5.0]:
w = softmax(skorlar, beta)
print(f"beta={beta}: attention agirliklari = {np.round(w, 3)}") # beta buyur -> odak
# (b) Hafta 6: seq2seq = TEKRARLAMALI (zaman zinciri); Transformer = set->set
# (tum konumlar paralel, recurrence YOK) -> Hafta 12'de Canziani kuracak.
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d11}
::: {.callout-warning title="Sonraki Hafta — H12: NLP, Decoding ve Attention/Transformer (Konuk: Mike Lewis)"}
**Kayıp = enerji çerçevesini dile taşıyoruz.** Bu hafta aktivasyonları (ölçek-değişmezliği), kayıpları (MSE bulanık, cross-entropy = logsoftmax+NLL, hinge = marj), EBM collapse vs margin'i ve PPUU'yu (dünya modeli + latent + belirsizlik) kapattık. Hafta 12'de konuk **Mike Lewis** (FAIR) NLP/seq2seq/decoding'i (beam search) anlatacak; **Canziani** attention'ı ve Transformer'ı ("sets to sets") kuracak. Egzersiz 3 (EBM kaybı) ve Egzersiz 5 (softmax → attention) tam bu derse hazırlar.
:::
**Hafta 12: NLP, Decoding ve Attention/Transformer** — Mike Lewis (Konuk Lecture) + Canziani (Practicum)
Hafta 12'de konuk **Mike Lewis** (FAIR) doğal dil işleme, seq2seq, decoding (beam search) ve çeviriyi; **Canziani** ise attention'ı ve Transformer'ı ("sets to sets") anlatacak.
**Hafta 12 öncesi yapılacak:**
- Egzersiz 3 (EBM kaybı) ve Egzersiz 5 (softmax → attention) çöz.
- "Kayıp = enerji + marj" ve "latent = eksik bilgi" cümlelerini kendi sözcüklerinle yaz.
- Hafta 6 attention/seq2seq'i hatırla — Transformer onun "tekrarlamasız" hâlidir.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d11}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Ölçek-değişmezliği | Tek-kıvrım: giriş×2 → çıkış×2 (şekil sabit); derin ağda iyi | LeCun 27m04 |
| Softmax sıcaklığı β | Ters sıcaklık; annealing (yumuşak→sert), mixture-of-experts | LeCun 29m45 |
| MSE → bulanık | Çoklu-gelecekte ortalama; görüntü ortalaması = bulanık | LeCun 37m50 |
| L1 → medyan | Keskin, aykırıya dayanıklı; tabanda türevsiz | LeCun 38m06 |
| Cross-entropy = logsoftmax+NLL | Sayısal kararlılık; KL ıraksaması (sistem vs one-hot) | LeCun 47m22 |
| Enerji kaybı → collapse | Marjsız → enerji düzleşir; tehlikeli | LeCun 1h20 |
| Margin/hinge kaybı | Doğru < yanlış (ȳ) − marj; "iyi" kayıp | LeCun 1h25 |
| ȳ (most offending) | En düşük enerjili yanlış cevap; seçimi sürekli uzayda zor | LeCun 1h36 |
| PPUU dünya modeli | sₜ=(pₜ,vₜ,iₜ); doluluk ızgarası; kinematik tersi=eylem | Canziani 8m26 |
| Latent + KL | 16-boyut z; çoklu-gelecek; prior'dan örnekle (VAE) | Canziani 35m22 |
| Action insensitivity / latent dropout | Sızıntıyı kes; ağ eylemi kullansın | Canziani 52m52 |
| Belirsizlik düzenlileştirmesi (U) | Varyans minimizasyonu → güvenli manifold | Canziani 1h18 |
## ML Builder Bağlantıları {#sec-koprular-d11}
**Geriye köprüler (önkoşul + kurs):**
1. **Aktivasyon ölçeği** → Hafta 2-3 ağırlık ölçeği + BatchNorm.
2. **Cross-entropy / softmax** → Hafta 2 sınıflandırma + Hafta 7 enerji yorumu.
3. **EBM kayıpları (collapse, margin, ȳ)** → Hafta 7 EBM + Hafta 8 contrastive + Hafta 9 collapse/non-contrastive + Hafta 10 hard-negative.
4. **PPUU dünya modeli** → Hafta 9 (world model) + Hafta 10 (emulator/controller).
5. **Latent + KL + zincir-backprop** → Hafta 8 VAE + Hafta 5 autograd + Hafta 6 BPTT.
**İleriye köprüler (production / research):**
1. **Kayıp = enerji tasarımı** → contrastive/non-contrastive temsil öğrenmenin dili.
2. **Negatif seçimi** → MoCo/SimCLR → **non-contrastive BYOL/VICReg (post-2020, KURSTA YOK)**.
3. **PPUU + belirsizlik + dünya modeli** → model-based RL, MPC, **JEPA (post-2020)**.
4. **Latent çoklu-gelecek** → CVAE, diffusion, koşullu üretici modeller.
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Bir kayıp fonksiyonu seçmek aslında bir **enerji manzarası tasarlamaktır** — doğru cevabı aşağı itip yanlışları bir **marjla** yukarı it; marj yoksa enerji çöker (LeCun'un enerji-kaybı uyarısı = Hafta 8-9 collapse). Ve PPUU, Hafta 9-10'un dünya modelini üç ekle tamamlar: **latent değişken** (çoklu-geleceğin bulanıklığını çözer, Hafta 8 VAE), **latent dropout** (eylem-körlüğü sızıntısını keser) ve **belirsizlik düzenlileştirmesi** (varyansı minimize ederek politikayı güvenli manifoldda tutar — Hafta 9'un "hacmi sınırla" ilkesi). İkisi de aynı temele oturur: enerjiyi/belirsizliği doğru verinin etrafında şekillendirmek — ve bu temelin post-2020 zirvesi (non-contrastive SSL, JEPA) kursta yoktur ama LeCun'un bugünkü programının doğrudan devamıdır.
:::