---
title: "Transfer Learning ve PyTorch Lightning"
subtitle: "Kursun bonus dersi ve finali — konuk hoca William Falcon (PyTorch Lightning'in yaratıcısı) Canziani ile birlikte transfer learning'i hem denetimli hem öz-denetimli canlı kodla anlatır ve önceki haftaların tüm pre-train sonra fine-tune ipliklerini pratiğe döker. Falcon'un büyük pratik mesajı şudur: sıfırdan eğitmek yerine birinin başka veride eğittiği bir modeli al (önceden eğitilmiş omurga), üstüne yeni bir sınıflandırıcı tak, kendi az verinde ince ayar yap; ama kritik koşul, önceden eğitilmiş modelin verisinin seninkine benzemesidir (ImageNet doğal nesnelerde iyi prior verir ama röntgen veya kanser görüntülerine transfer etmez, çünkü sinir ağının sihri körlemesine işlemez). Transfer iki parçadır: önceden eğitilmiş omurga ve üstüne eklenen yeni kafa; omurgayı dondurup öznitelik çıkarıcı gibi kullanabilir (donuk omurga üstüne herhangi bir sınıflandırıcı, öznitelikler lineer ayrılabilir olmalı) ya da birkaç epoch sonra çözüp daha düşük öğrenme oranıyla tüm ağı ince ayar yapabilirsin; az veri dondurmayı, çok veri ince ayarı ister. PyTorch Lightning bütün bu eğitim mantığını boilerplate olmadan yapar: yalnız iki şey bilmen yeter, eğitim mantığını içeren LightningModule ve epoch ile geri yayılımı otomatik yürüten Trainer, böylece çok-GPU veya TPU bedava gelir. Ve dersin doruğu öz-denetimli transferdir: denetimli omurga yerine SwAV gibi etiketsiz öz-denetimli bir omurga kullanılır, kendi etiketsiz verinde önceden eğitilebildiği için ve sınıflandırma için eğitilmediği için başka görevlere daha iyi transfer eder, az-etiket deneyinde denetimli ön-eğitimin yaklaşık iki katını verir, çünkü etiketler pahalıdır ve öz-denetim onları atlar. Böylece kurs kapanır: bu pratik zafer, kursun Hafta 10'dan beri savunduğu öz-denetim tezinin somut kanıtıdır ve post-2020 foundation models çağının doğrudan tohumudur."
---
::: {.callout-note title="Bölüm bilgisi (KONUK William Falcon + Canziani — BONUS, Kurs Finali)"}
- **Bonus dersi (William Falcon, KONUK):** [YouTube — Transfer Learning & PyTorch Lightning](https://www.youtube.com/watch?v=Rl3Poc12sB0) (Hafta 15 — bonus, kurs finali)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** William Falcon (KONUK — PyTorch Lightning'in yaratıcısı; transfer learning, supervised + self-supervised, Lightning soyutlaması) + Alfredo Canziani (eşlik eden hoca — pratik püfler, az-etiket deneyinin yorumu)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈30 dk
> ⚠️ **Atıf notu (KONUK):** Bu bonus ders **LeCun değildir** — bonusu **konuk hoca William Falcon** (PyTorch Lightning'in yaratıcısı) verir, **Canziani** eşlik eder. Bölüm 1-4 quote'ları **— Falcon** veya **— Canziani**; **`## (LeCun)` başlığı bu derste hiç yoktur**.
> ⚠️ **Tarih notu:** Bu bonus, ana kurstan (Mart 2020) biraz **sonra** (~Haz/Tem 2020) çekilmiştir — bu yüzden ana derslerin "post-2020, kursta yok" diye işaretlediği **SwAV/BYOL** gibi yöntemleri fiilen **kullanır** (her ikisi de Haziran 2020'de doğdu). Bu çelişki bilinçlidir ve korunmuştur.
:::
```{python}
#| echo: false
import networkx as nx
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan few_label_curve + önceki hafta yardımcıları + COL_* +
# apply_style / draw_pipeline / style_legend isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# Graf/şema çizimleri için networkx kullanılır (üst satırda import edilir).
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib as mpl
import matplotlib.patches as mpatches
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Ellipse, Polygon, Patch, Arc,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm, LinearSegmentedColormap
np.random.seed(0)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
import numpy as np
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ---------------------------------------------------------------------------
# Hafta 5 — autograd worked example (Canziani)
# ---------------------------------------------------------------------------
def autograd_worked(X=None):
"""Canziani worked example: X → Y=X−2 → Z=3·Y² → a=mean(Z) (skaler).
İleri değerler + ∂a/∂xᵢ = (1/4)·3·2·(xᵢ−2) = 1.5·(xᵢ−2).
X=[1,2,3,4] için grad = [−1.5, 0, 1.5, 3] (PyTorch X.grad ile birebir)."""
if X is None:
X = np.array([1.0, 2.0, 3.0, 4.0])
X = np.asarray(X, float)
Y = X - 2.0
Z = 3.0 * Y ** 2
a = float(Z.mean())
grad = 1.5 * (X - 2.0)
return dict(X=X, Y=Y, Z=Z, a=a, grad=grad)
def conv_pad_output(n, k, padding=0, stride=1):
"""Padding'li çıktı boyutu: o = ⌊(n + 2·padding − k)/stride⌋ + 1.
padding=(k−1)/2 (k tek) → çıktı boyutu korunur."""
return (n + 2 * padding - k) // stride + 1
# ---------------------------------------------------------------------------
# Hafta 6 — RNN / vanishing gradient / attention
# ---------------------------------------------------------------------------
def vanishing_demo(steps=50, eigenvalues=(0.5, 1.0, 1.5)):
"""Aynı matristen n kez geçen gradient: λⁿ. λ<1 söner (vanishing), λ>1 patlar
(exploding), λ=1 sabit. Backprop-through-time vanishing gradient görseli."""
t = np.arange(steps + 1)
curves = {ev: np.asarray(ev, float) ** t for ev in eigenvalues}
return t, curves
def rnn_forward(X_seq, Wx, Wz, b, z0=None):
"""Basit RNN hücresi: zₜ = tanh(Wₓ·xₜ + W_z·zₜ₋₁ + b).
X_seq [T, d_in] → gizli durumlar Z [T, d_h] (aynı Wₓ,W_z her adımda = paylaşım)."""
X_seq = np.asarray(X_seq, float)
T = len(X_seq)
dh = np.asarray(Wz).shape[0]
z = np.zeros(dh) if z0 is None else np.asarray(z0, float)
Z = []
for t in range(T):
z = np.tanh(np.asarray(Wx) @ X_seq[t] + np.asarray(Wz) @ z + np.asarray(b))
Z.append(z.copy())
return np.array(Z)
def attention_weights(scores):
"""Attention ağırlıkları = softmax(skorlar); toplamı 1 (olasılık dağılımı, 'odak')."""
scores = np.asarray(scores, float)
e = np.exp(scores - scores.max())
return e / e.sum()
# ---------------------------------------------------------------------------
# Hafta 7 — EBM / autoencoder / manifold
# ---------------------------------------------------------------------------
def energy_1d(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""1B enerji F(y): veri noktalarında düşük (çukur), aralarda yüksek (tepe).
'İyi enerji şekli' = veride düşük, dışında yüksek (EBM); çoklu minimum = çoklu cevap."""
y = np.asarray(y, float)
F = np.ones_like(y)
for d in data_points:
F = F - np.exp(-(y - d) ** 2 / (2 * width))
return F
def energy_1d_grad(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""energy_1d'nin türevi (çıkarım = enerji minimizasyonu, gradient ile arama)."""
y = np.asarray(y, float)
g = np.zeros_like(y)
for d in data_points:
g = g + (y - d) / width * np.exp(-(y - d) ** 2 / (2 * width))
return g
def make_manifold_curve(n=160, noise=0.0, seed=0):
"""2B veri manifoldu: bir eğri (sinüs yayı) üzerinde noktalar (Hafta 1 manifold hipotezi)."""
t = np.linspace(-2.6, 2.6, n)
M = np.column_stack([t, np.sin(1.3 * t)])
if noise:
M = M + np.random.default_rng(seed).normal(0, noise, M.shape)
return M
def project_to_manifold(points, manifold):
"""Her noktayı manifoldun EN YAKIN noktasına çeker (autoencoder reconstruction sezgisi:
off-manifold girdiyi manifolda geri çek → düşük enerji)."""
points = np.asarray(points, float)
proj = np.array([manifold[np.linalg.norm(manifold - p, axis=1).argmin()] for p in points])
return proj
# ---------------------------------------------------------------------------
# Hafta 8 — contrastive / VAE
# ---------------------------------------------------------------------------
def vae_reparam(mu, sigma, n=400, seed=0):
"""Reparameterization trick: z = μ + σ⊙ε, ε~N(0,I). Düzenli (sürekli, dolu)
Gaussian latent örnekleri — VAE'nin üretken latent uzayı."""
mu = np.atleast_1d(np.asarray(mu, float))
sigma = np.atleast_1d(np.asarray(sigma, float))
rng = np.random.default_rng(seed)
eps = rng.normal(0, 1, (n, len(mu)))
return mu + sigma * eps
def ae_latent_clusters(n=400, seed=0):
"""Sıradan AE latent'i: dağınık, boşluklu kümeler (düzensiz uzay — VAE kontrastı)."""
rng = np.random.default_rng(seed)
centers = np.array([[-2.2, 1.8], [2.0, 2.1], [0.3, -2.3], [-1.8, -1.5]])
pts = []
for c in centers:
pts.append(c + rng.normal(0, 0.28, (n // len(centers), 2)))
return np.vstack(pts)
# ---------------------------------------------------------------------------
# Hafta 9 — sparse coding / GAN (EBM)
# ---------------------------------------------------------------------------
def sparse_code_demo(n=24, n_active=5, seed=0):
"""Yoğun (dense) vs seyrek (sparse) code: L1 düzenlileştirme çoğu bileşeni
sıfıra iter — yalnızca birkaç birim aktif kalır (sparse coding)."""
rng = np.random.default_rng(seed)
dense = rng.normal(0, 1, n)
idx = np.argsort(-np.abs(dense)) # en büyük |değer| → aktif kalanlar
sparse = np.zeros(n)
sparse[idx[:n_active]] = dense[idx[:n_active]]
return dense, sparse
def rotate_image_4way(img):
"""0/90/180/270° döndürülmüş 4 versiyon — rotation pretext görevi (Hafta 10 SSL):
ağ 'kaç derece döndürüldü?' sorusunu çözer (4-yönlü sınıflandırma)."""
img = np.asarray(img, float)
return [np.rot90(img, k) for k in range(4)]
# ---------------------------------------------------------------------------
# Hafta 11 — aktivasyon / kayıp (EBM) / belirsizlik
# ---------------------------------------------------------------------------
def _sig(x):
return 1.0 / (1.0 + np.exp(-np.clip(x, -50, 50)))
def activation_fns():
"""Aktivasyon fonksiyonu zoo'su + türevleri (Hafta 11). {ad: (f, f')}."""
return {
"ReLU": (lambda x: np.maximum(0, x), lambda x: (np.asarray(x) > 0).astype(float)),
"Leaky ReLU": (lambda x: np.where(x > 0, x, 0.1 * x), lambda x: np.where(np.asarray(x) > 0, 1.0, 0.1)),
"sigmoid": (_sig, lambda x: _sig(x) * (1 - _sig(x))),
"tanh": (np.tanh, lambda x: 1 - np.tanh(x) ** 2),
"softplus": (lambda x: np.log1p(np.exp(-np.abs(x))) + np.maximum(x, 0), _sig),
"ELU": (lambda x: np.where(x > 0, x, np.exp(np.clip(x, -50, 50)) - 1),
lambda x: np.where(np.asarray(x) > 0, 1.0, np.exp(np.clip(x, -50, 50)))),
}
def softplus_scaled(x, beta=1.0):
"""β-ölçekli softplus: (1/β)·log(1+e^(βx)). β büyük → ReLU'ya yaklaşır (ölçek-bağımlı)."""
x = np.asarray(x, float)
return (1.0 / beta) * (np.log1p(np.exp(-np.abs(beta * x))) + np.maximum(beta * x, 0))
def margin_losses(gap, m=1.0):
"""EBM kayıpları. gap = E(ȳ) − E(y) (doğru-yanlış enerji farkı; pozitif=doğru daha düşük).
hinge marj m (gap≥m'de 0), perceptron marjsız (gap≥0'da 0 → collapse'a açık)."""
gap = np.asarray(gap, float)
hinge = np.maximum(0.0, m - gap)
perceptron = np.maximum(0.0, -gap)
return hinge, perceptron
def uncertainty_demo(x_train, x_grid, bandwidth=0.6):
"""Belirsizlik (epistemik varyans proxy) ~ eğitim verisinden uzaklık: eğitim
noktalarına yakın DÜŞÜK, uzakta YÜKSEK (PPUU 'U' düzenlileştirmesi)."""
x_train = np.atleast_1d(np.asarray(x_train, float))
x_grid = np.atleast_1d(np.asarray(x_grid, float))
d = np.abs(x_grid[:, None] - x_train[None, :]).min(axis=1)
return 1.0 - np.exp(-(d / bandwidth) ** 2)
def gan_samples(seed=0, n=200):
"""GAN sezgisi: gerçek veri (manifold/halka) vs generator'ın ürettiği sahte örnekler.
İlk başta sahteler dağınık (eğitilmemiş generator), gerçeğe yakınsar."""
rng = np.random.default_rng(seed)
th = rng.uniform(0, 2 * np.pi, n)
real = np.column_stack([np.cos(th), np.sin(th)]) + rng.normal(0, 0.06, (n, 2)) # gerçek = birim halka
fake_early = rng.normal(0, 1.1, (n, 2)) # eğitilmemiş gen (dağınık)
th2 = rng.uniform(0, 2 * np.pi, n)
fake_late = np.column_stack([np.cos(th2), np.sin(th2)]) + rng.normal(0, 0.18, (n, 2)) # eğitilmiş gen (halkaya yakın)
return real, fake_early, fake_late
# ---------------------------------------------------------------------------
# Hafta 12 — Attention / Transformer (NLP, Lewis + Canziani)
# ---------------------------------------------------------------------------
def _softmax_rows(M):
"""Satır-bazlı kararlı softmax (her satır toplamı 1)."""
M = np.asarray(M, float)
e = np.exp(M - M.max(axis=-1, keepdims=True))
return e / e.sum(axis=-1, keepdims=True)
def self_attention_matrix(X, scale=True):
"""Self-attention ağırlık matrisi A = softmax(XXᵀ/√d) (Canziani: küme→küme).
X [T, d] token kümesi → A [T, T]: A[i,j] = token i'nin token j'ye verdiği dikkat (satır toplamı 1).
scale=True → β=1/√d ölçekleme (Canziani 20:44: vektör büyüklüğü √d ile büyür, sıcaklık sabit)."""
X = np.asarray(X, float)
d = X.shape[1]
scores = X @ X.T
if scale:
scores = scores / np.sqrt(d)
return _softmax_rows(scores)
def causal_mask_demo(scores):
"""Causal (look-ahead) maske gösterimi (Lewis 27:08).
scores [T, T] → (A_acik, A_maskeli): maskesiz softmax vs üst-üçgen −∞ maskeli softmax.
Maskeli: her token yalnız kendine + soluna bakar (geleceği göremez = hile yok)."""
scores = np.asarray(scores, float)
T = scores.shape[0]
A_open = _softmax_rows(scores)
mask = np.triu(np.full((T, T), -np.inf), k=1) # üst-üçgen (gelecek) = −∞
A_masked = _softmax_rows(scores + mask)
return A_open, A_masked
def softmax_temperature(scores, betas):
"""Sıcaklık β'nın softmax üzerindeki etkisi (Hafta 11 köprüsü; soft↔hard attention).
scores [n] tek satır → her β için softmax(β·scores) [len(betas), n].
β→0 düzleşir (uniform), β→∞ sivrilir (one-hot=hard attention)."""
scores = np.asarray(scores, float)
out = []
for b in betas:
s = b * scores
e = np.exp(s - s.max())
out.append(e / e.sum())
return np.array(out)
def positional_encoding(seq_len, d, base=10000.0):
"""Sinüzoidal positional encoding (Vaswani 2017; Lewis: küme→sıra).
PE[pos,2i]=sin(pos/base^(2i/d)), PE[pos,2i+1]=cos(...). → [seq_len, d] matris.
Attention girdiyi sırasız küme görür; konum bilgisini bu eklenen embedding taşır."""
pos = np.arange(seq_len)[:, None]
i = np.arange(d)[None, :]
angle = pos / np.power(base, (2 * (i // 2)) / d)
PE = np.where(i % 2 == 0, np.sin(angle), np.cos(angle))
return PE
def topk_truncate(probs, k):
"""Top-k sampling kırpması (Lewis 49:54; Angela Fan).
probs [V] olasılık dağılımı → en iyi k dışındaki kütleyi 0'la, yeniden normalize et.
Greedy=k1; beam farklı (hipotez tutar); top-k=çeşitlilik + manifolddan düşmeme."""
probs = np.asarray(probs, float)
out = np.zeros_like(probs)
idx = np.argsort(probs)[::-1][:k] # en yüksek k indeks
out[idx] = probs[idx]
return out / out.sum()
# ---------------------------------------------------------------------------
# Hafta 13 — Graph Convolutional Networks (Bresson + Canziani)
# ---------------------------------------------------------------------------
def path_graph_adj(n):
"""Yol grafı (zincir 0-1-2-...-n-1) adjacency [n,n]. Fourier modları = kosinüsler (1D DCT)."""
A = np.zeros((n, n))
for i in range(n - 1):
A[i, i + 1] = A[i + 1, i] = 1.0
return A
def community_graph_adj():
"""İki topluluk grafı (8 düğüm: 0-3 ve 4-7 iki klik, 3-4 köprü kenarı).
Karate Club benzeri yarı-denetimli/K-hop demoları için (seyreklik = yapı)."""
A = np.zeros((8, 8))
edges = [(0,1),(0,2),(1,2),(1,3),(2,3), # topluluk A (0-3)
(4,5),(4,6),(5,6),(5,7),(6,7), # topluluk B (4-7)
(3,4)] # köprü
for i, j in edges:
A[i, j] = A[j, i] = 1.0
return A
def graph_laplacian(A):
"""Normalize graf Laplacian Δ = I − D⁻¹ᐟ²AD⁻¹ᐟ² (Bresson 26:45; pürüzsüzlük operatörü).
Simetrik, özdeğerler [0,2]. Δh = h_i ile komşu ortalaması farkı (yüksek frekans büyük)."""
A = np.asarray(A, float)
n = A.shape[0]
d = A.sum(axis=1)
dinv = np.where(d > 0, 1.0 / np.sqrt(d), 0.0)
Dinv = np.diag(dinv)
return np.eye(n) - Dinv @ A @ Dinv
def graph_fourier(A):
"""Graf Fourier: Δ = ΦΛΦᵀ özayrışım (Bresson 30:03). Özvektörler Φ = Fourier fonksiyonları.
Döner (eigvals artan, eigvecs): düşük özdeğer=pürüzsüz mod, yüksek=salınan mod."""
Delta = graph_laplacian(A)
w, V = np.linalg.eigh(Delta) # eigh: simetrik, özdeğerler artan
return w, V
def laplacian_smoothness(A, h):
"""Pürüzsüzlük ölçüsü: Δh ve kuadratik form hᵀΔh (Bresson).
Pürüzsüz sinyal → küçük; salınan sinyal → büyük (Egzersiz 2)."""
Delta = graph_laplacian(A)
h = np.asarray(h, float)
Dh = Delta @ h
return Dh, float(h @ Delta @ h)
def khop_diffusion(A, source, K):
"""K-hop yerelleştirme (ChebNet sezgisi, Bresson 56:42): kaynağa Δ'yı k kez uygula.
Δᵏ·e_source desteği TAM k-hop genişler → [|Δ⁰e|, |Δ¹e|, ..., |Δᴷe|] büyüklük desenleri."""
Delta = graph_laplacian(A)
n = A.shape[0]
e = np.zeros(n); e[source] = 1.0
out = [np.abs(e.copy())]
cur = e.copy()
for _ in range(K):
cur = Delta @ cur
out.append(np.abs(cur))
return out
def gcn_message_pass(A, X, W, U):
"""İzotropik GCN katmanı (Canziani 29:04): hᵢ = ReLU(U·xᵢ + (1/dᵢ)Σ_{j∈N(i)} W·xⱼ).
a = adjacency (verili, attention'ın hesaplanan softmax'i değil). X[n,din]→H[n,dout]."""
A = np.asarray(A, float); X = np.asarray(X, float)
W = np.asarray(W, float); U = np.asarray(U, float)
d = A.sum(axis=1); dinv = np.where(d > 0, 1.0 / d, 0.0)
neigh = (np.diag(dinv) @ A) @ X @ W.T # (1/dᵢ)Σ W·xⱼ komşuluk ortalaması
self_term = X @ U.T # U·xᵢ self-connection
return np.maximum(0.0, self_term + neigh)
def gate_eta(edge_feats):
"""Residual Gated GCN kapısı (Canziani 27:53): ηᵢⱼ = σ(eᵢⱼ)/Σ_k σ(eᵢₖ).
İzotropik (1/d eşit) ortalamayı anizotropik ağırlıklı toplama çevirir. edge_feats[d]→η[d]."""
e = np.asarray(edge_feats, float)
s = 1.0 / (1.0 + np.exp(-e)) # sigmoid
return s / s.sum()
# ---------------------------------------------------------------------------
# Hafta 14 — Yapılandırılmış Tahmin + Düzenlileştirme (LeCun son ders + Canziani)
# ---------------------------------------------------------------------------
def trellis_shortest_path(unaries, pair_cost):
"""Faktör grafiği = trellis en-kısa-yol (LeCun 22:52; dinamik programlama).
unaries [T, S] her adımda S durumun tekil enerjisi; pair_cost [S, S] geçiş enerjisi.
Döner (path, min_energy, brute_count, dp_count): DP üsteli (S^T) lineere (T·S²) indirir."""
unaries = np.asarray(unaries, float)
T, S = unaries.shape
dp = unaries[0].copy()
back = np.zeros((T, S), int)
for t in range(1, T):
for s in range(S):
cand = dp + pair_cost[:, s] + unaries[t, s]
back[t, s] = int(np.argmin(cand))
dp[s] = cand[back[t, s]]
end = int(np.argmin(dp)); min_e = float(dp[end])
path = [end]
for t in range(T - 1, 0, -1):
end = back[t, end]; path.append(end)
path.reverse()
return path, min_e, S ** T, T * S * S # kaba kuvvet vs DP degerlendirme sayisi
def free_energy_curve(q_stds, T=1.0):
"""Varyasyonel serbest enerji F = ⟨E⟩ − T·H (LeCun 2:02; VAE = bu).
q = N(0,σ) latent dağılımı; enerji E(z)=½z² (kuadratik kuyu). σ tarandıkça:
⟨E⟩=½σ² artar, H=½ln(2πeσ²) artar → F'nin bir minimumu var (denge = VAE recon+KL)."""
q_stds = np.asarray(q_stds, float)
avg_E = 0.5 * q_stds ** 2 # ⟨E⟩ = ½σ² (Gauss, E=½z²)
H = 0.5 * np.log(2 * np.pi * np.e * q_stds ** 2) # Gauss diferansiyel entropi
F = avg_E - T * H
return avg_E, H, F
def overfit_regimes(seed=0, n=14, degrees=(1, 2, 11)):
"""Underfit / doğru / overfit (Canziani 5:39): gürültülü parabole polinom fit.
Döner (x, y, x_grid, fits[deg]): düşük derece=underfit, eşit=doğru, yüksek=overfit (gürültü ezber)."""
rng = np.random.default_rng(seed)
x = np.linspace(-3, 3, n)
y_true = 0.4 * x ** 2 - 0.5 # gercek parabol
y = y_true + rng.normal(0, 0.8, n) # + gurultu (overfit'in kaynagi)
x_grid = np.linspace(-3.2, 3.2, 200)
fits = {}
for d in degrees:
c = np.polyfit(x, y, d)
fits[d] = np.polyval(c, x_grid)
return x, y, x_grid, fits
def l1_l2_weights(seed=0, n=400, lam=0.1):
"""L1 (seyreklik, eksen öldür) vs L2 (uzunluk kısalt) ağırlık dağılımı (Canziani 27:03).
Gradyan inişiyle yakınsamış ağırlıkların histogramı: L1→0'da yığılma+seyrek, L2→küçük Gauss."""
rng = np.random.default_rng(seed)
w0 = rng.normal(0, 1.0, n) # baslangic agirliklari
# proximal/gradyan: L2 ağırlıkları orantılı küçültür; L1 sabit miktar çeker (eksen öldürür)
w_l2 = w0 / (1.0 + lam) # ridge: uzunluk kisalt
w_l1 = np.sign(w0) * np.maximum(np.abs(w0) - lam, 0.0) # soft-threshold: kucukleri 0'la
return w_l1, w_l2
def mc_dropout_variance(seed=0, n_models=60, p=0.35):
"""MC Dropout belirsizliği = PPUU (Canziani 1:02; Hafta 11 halkası).
Her model eğitim verisine bir öznitelik-dropout maskesiyle FIT edilir → eğitim
bölgesi [-2,2]'de hepsi veriye sabitlenir (uyumlu), dışında ıraksar → varyans↑.
Döner (x_grid, mean, std, xt, yt): std eğitim içinde küçük, dışında büyük (= belirsizlik)."""
rng = np.random.default_rng(seed)
xt = np.linspace(-2, 2, 14)
yt = np.sin(xt) # egitim verisi
Phi = lambda x: np.stack([np.ones_like(x), x, x**2, x**3,
np.sin(x), np.cos(x), np.sin(2*x), np.cos(2*x)], 1)
A = Phi(xt); F = A.shape[1]
xg = np.linspace(-5, 5, 240)
preds = []
for _ in range(n_models):
keep = rng.random(F) > p # oznitelik dropout maskesi
if not keep.any():
keep[rng.integers(F)] = True
ck, *_ = np.linalg.lstsq(A[:, keep], yt, rcond=None) # KALAN ozniteliklerle veriye FIT
full = np.zeros(F); full[keep] = ck
preds.append(Phi(xg) @ full)
preds = np.array(preds)
return xg, preds.mean(0), preds.std(0), xt, yt
# ---------------------------------------------------------------------------
# Hafta 15 (Bonus) — Transfer Learning (Falcon + Canziani)
# ---------------------------------------------------------------------------
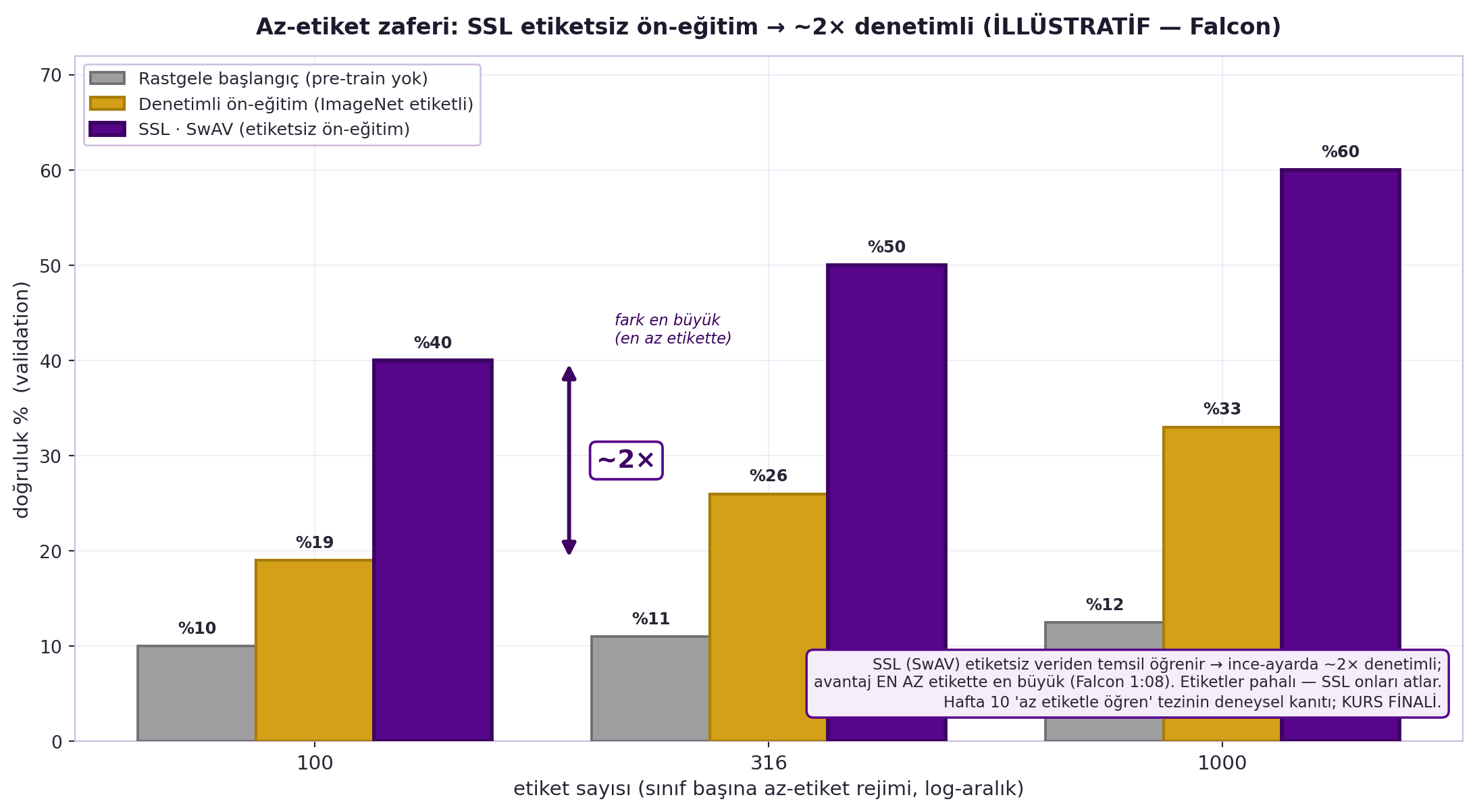
def few_label_curve():
"""Az-etiket zaferi (Falcon 1:08; İLLÜSTRATİF — Falcon'un bildirdiği değerler).
100/316/1000 etiketle 3 backbone validation doğruluğu: rastgele ~%10 < supervised
~%20-30 < SSL(SwAV) ~2× supervised. SSL avantajı az-etikette EN BÜYÜK (Hafta 10 tezi).
Döner (n_labels, random, supervised, ssl) — yüzde."""
n_labels = np.array([100, 316, 1000])
random_acc = np.array([10.0, 11.0, 12.5]) # rastgele backbone (~%10)
supervised = np.array([19.0, 26.0, 33.0]) # ImageNet supervised pre-train
ssl_swav = np.array([40.0, 50.0, 60.0]) # SwAV SSL pre-train (~2× supervised)
return n_labels, random_acc, supervised, ssl_swav
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri
# ===========================================================================
# NYU Violet + gold paleti
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d15}
Kursun **bonus** dersi ve **finali**: **konuk hoca William Falcon** (PyTorch Lightning'in yaratıcısı), **Canziani** ile birlikte transfer learning'i — denetimli ve öz-denetimli — canlı kodla anlatır. Önceki haftaların tüm pre-train→fine-tune ipliklerini (Hafta 10 SSL, Hafta 12 BERT, Hafta 14 transfer) pratiğe döker.
Falcon'un büyük pratik mesajı: sıfırdan eğitmek yerine, **birinin başka veride eğittiği bir modeli al** (önceden eğitilmiş omurga), üstüne yeni sınıflandırıcı tak, kendi (az) verinde ince ayar yap. Kritik uyarı: önceden eğitilmiş modelin verisi seninkine **benzemeli** (ImageNet, röntgen/kanser görüntülerine transfer etmez). Ve öz-denetimli ön-eğitim, etiketli ön-eğitimi — özellikle az etiketle — geçer.
**Üç ana fikir:**
1. **Transfer learning = önceden eğitilmiş omurga + yeni kafa.** Omurgayı dondur (öznitelik çıkarıcı) ya da ince ayar yap; veri dağılımı eşleşmeli.
2. **PyTorch Lightning = boilerplate'i soyutla.** LightningModule (`training_step` + `configure_optimizers`) + Trainer (epoch/optimizer/backward otomatik); çok-GPU/TPU bedava.
3. **Öz-denetimli transfer (SwAV) az-etiketle kazanır.** Kendi etiketsiz verinde omurgayı ön-eğit; sonra az etiketle sınıflandırıcıyı eğit → denetimli ön-eğitimin yaklaşık 2 katı.
```{mermaid}
%%| echo: false
flowchart TB
Hafta["Hafta 15 (BONUS) — Transfer Learning ve PyTorch Lightning<br/>(KONUK William Falcon + Canziani — Kurs Finali)"]
subgraph A["(A) Falcon: transfer learning + Lightning + öz-denetimli transfer"]
direction TB
NeZaman["Ne zaman transfer?<br/>(çok veri → sıfırdan · az veri → önceden eğitilmiş; dağılım eşleşmeli)"]
Backbone["Omurga + kafa<br/>(önceden eğitilmiş omurga + üstüne yeni sınıflandırıcı)"]
Freeze["Dondur (linear probe) vs ince ayar<br/>(donuk öznitelik çıkarıcı · çözülü düşük öğrenme oranı)"]
Lightning["PyTorch Lightning<br/>(LightningModule + Trainer = boilerplate yok)"]
SSL["Öz-denetimli transfer<br/>(SwAV etiketsiz ön-eğitim)"]
Zafer["Az-etiket zaferi<br/>(SSL ~2 katı denetimli; etiket pahalı)"]
NeZaman --> Backbone
Backbone --> Freeze
Freeze --> Lightning
Lightning --> SSL
SSL --> Zafer
end
subgraph B["(B) Kapanış: öz-denetim = kursun pratiği"]
direction TB
Kok["SSL = Hafta 7-9 EBM + Hafta 10 pretext +<br/>Hafta 12 BERT + Hafta 14 serbest enerji'nin pratiği"]
Foundation["→ foundation models<br/>(post-2020, kursun ipliğinin vardığı yer)"]
Kok --> Foundation
end
Hafta --> NeZaman
Zafer --> Kok
```
::: {.callout-tip title="Builder Notu — Giriş: Pre-train→Fine-tune İpliğinin Pratik Hâli"}
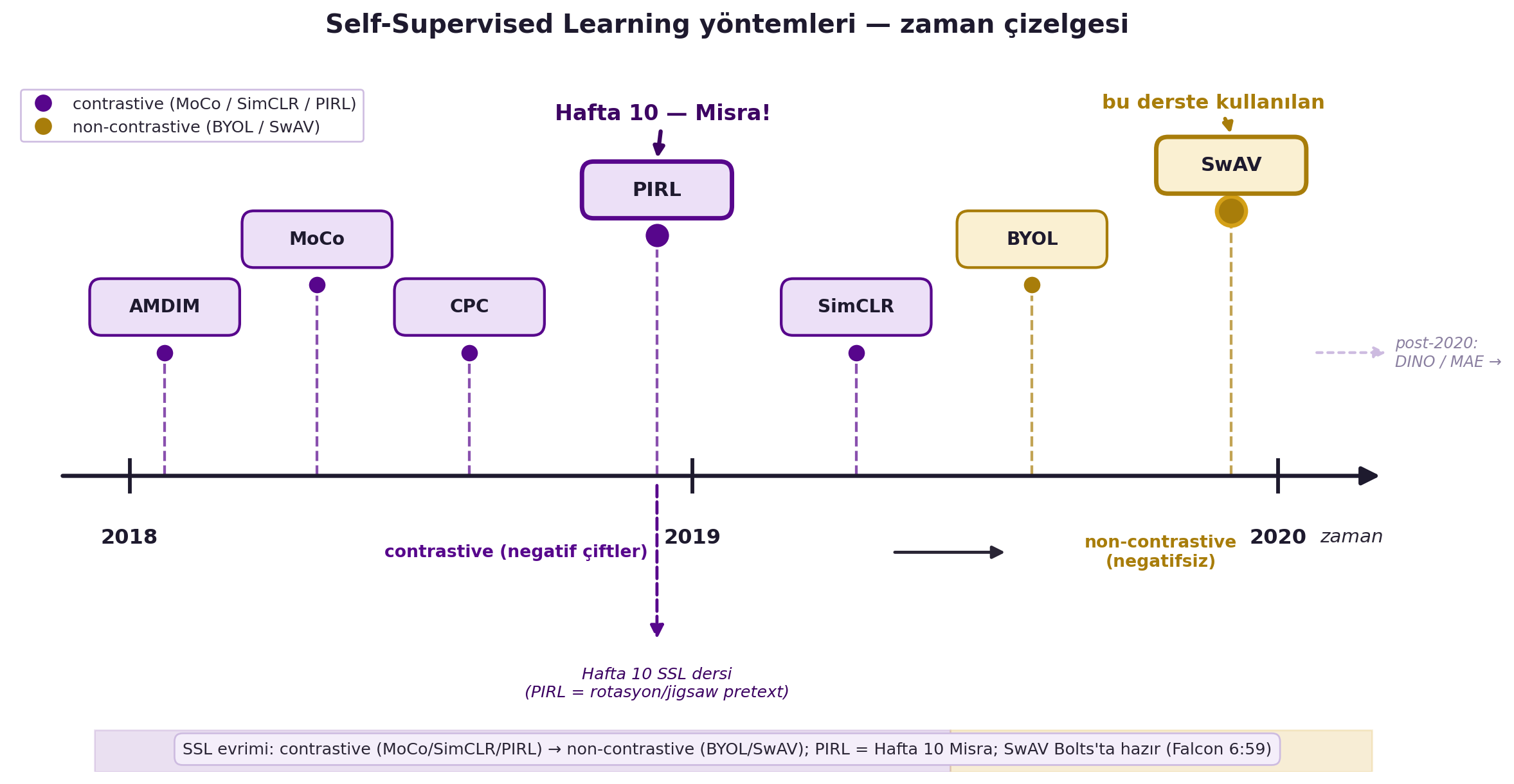
**Geriye:** Pre-train→fine-tune → Hafta 10 (SSL/Misra) + 12 (BERT) + 14 (transfer); SSL yöntemleri (PIRL/MoCo/SimCLR) → Hafta 8-9 + 10 (PIRL); ResNet/freeze → Hafta 3/9; linear probe → Hafta 10.
**İleriye:** SSL omurga + az etiket → foundation models, etiketleme tasarrufu; SwAV/BYOL → post-2020 SSL patlaması (DINO/MAE, §[İleriye Köprü](#sec-ileriye-kopru-d15)).
**Tek cümleyle:** Transfer learning, başka veride eğitilmiş bir omurgayı alıp (dondur ya da ince ayar yap) kendi az verinde yeniden kullanmaktır; PyTorch Lightning bunu boilerplate'siz yapar; ve öz-denetimli ön-eğitim (SwAV) — kendi etiketsiz verinde eğitilebildiği için — etiketli ön-eğitimi özellikle az-etiket rejiminde geçer.
:::
## (Falcon — Konuk) Ne Zaman Transfer Learning? Karar Ağacı {#sec-ne-zaman}
Falcon basit karar ağacıyla başlar: **Çok veri + zaman/compute var mı?** Evetse, ince ayara gerek yok — kendi verinde sıfırdan eğit. **Az veri varsa**, veri dağılımına **uyan** önceden eğitilmiş model bul.
> "if you don't have a lot of data then you should try to find a pre-trained model that matches your data distribution... most vision models are trained on ImageNet, so if you want to do cancer detection or x-rays, that's unlikely to transfer." — Falcon, 4:58
Bu kritik: "sinir ağının sihri körlemesine işlemez." ImageNet doğal nesnelerde (kedi, köpek, kuş) iyi prior verir; tıbbi görüntülerin istatistiği tamamen farklıdır. @fig-transfer-decision-tree bu karar ağacını bütün dallarıyla gösterir: kök soru çok veri/az veri ayrımını yapar, az-veri dalı dağılıma uyan önceden eğitilmiş modele iner, oradan supervised ve self-supervised ön-eğitim seçeneklerine ayrılır; alttaki kırmızı uyarı kutusu "ImageNet ≠ röntgen/kanser" eşleşmezliğini vurgular. Transfer learning iki parçadır:
> "when you think about transfer learning we have two parts: the pre-trained model that was trained on something else, and the stuff you're going to add on top to transfer that." — Falcon, 5:35
İki seçenek: **supervised** ön-eğitim (ImageNet sınıflandırma — ama sınıflandırma için **bias** yükler; segmentasyon/tespit garantisi yok) veya **self-supervised** ön-eğitim (sınıflandırma için eğitilmediğinden başka görevlere daha iyi transfer **edebilir**).
```{python}
#| label: fig-transfer-decision-tree
#| fig-cap: "Transfer öğrenme karar ağacı (kursu kapatan sentez, H15 bonus). Kök 'Çok veri + zaman/compute var mı?' sorusundan EVET dalı sıfırdan eğitime (ince ayar gereksiz), HAYIR (az veri) dalı dağılıma uyan önceden eğitilmiş modele iner; oradan iki alt-dal: supervised ön-eğitim (ImageNet, bias yükler) ve self-supervised ön-eğitim (SwAV, daha iyi transfer, ★ tercih edilen). Alttaki kırmızı uyarı kutusu 'ImageNet ≠ röntgen/kanser → transfer ETMEZ (dağılım eşleşmeli)' der. Sinir ağının sihri körlemesine işlemez (Falcon 4:58); transfer = omurga + yeni kafa (5:35)."
np.random.seed(0)
fig, ax = plt.subplots(figsize=(11.5, 7.0))
ax.set_xlim(0, 12)
ax.set_ylim(0, 10)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
fig.patch.set_facecolor(COL_WHITE)
def node_box(ax, cx, cy, w, h, text, fc, ec, lw=2.2, fontsize=10.5,
textcolor=COL_INK, fontweight="normal", rounding=0.12):
box = FancyBboxPatch(
(cx - w / 2, cy - h / 2), w, h,
boxstyle=f"round,pad=0.02,rounding_size={rounding}",
fc=fc, ec=ec, lw=lw, zorder=3,
)
ax.add_patch(box)
ax.text(cx, cy, text, ha="center", va="center", fontsize=fontsize,
color=textcolor, zorder=4, wrap=True, fontweight=fontweight)
def arrow(ax, p0, p1, color, lw=2.2, ls="-"):
ax.add_patch(FancyArrowPatch(
p0, p1, arrowstyle="-|>", mutation_scale=20,
color=color, lw=lw, zorder=2, linestyle=ls,
shrinkA=2, shrinkB=2,
))
# Renk kısayolları (NYU violet/gold birincil; gri/yeşil/kırmızı/turuncu ikincil)
GREEN = "#2e8b57" # EVET dalı (sıfırdan eğit)
ORANGE = "#e07b1a" # HAYIR/az veri dalı
RED = "#c0392b" # uyarı çerçevesi
# --- Kök kutu: karar sorusu ---
node_box(ax, 6.0, 9.1, 6.6, 1.05,
"Çok veri + zaman/compute var mı?",
fc=COL_VIOLET, ec=COL_VIOLET_D, lw=2.6,
fontsize=12.5, textcolor=COL_WHITE, fontweight="bold", rounding=0.14)
# --- EVET dalı (yeşil ok, sola) ---
arrow(ax, (4.2, 8.62), (2.55, 7.55), GREEN, lw=2.6)
ax.text(2.85, 8.25, "EVET", ha="center", va="center", fontsize=11,
color=GREEN, fontweight="bold", zorder=5)
node_box(ax, 2.35, 6.95, 4.0, 1.15,
"Sıfırdan eğit\n(fine-tune gereksiz)",
fc="#e8f5ee", ec=GREEN, lw=2.3, fontsize=10.5, textcolor="#1d5b3a")
# --- HAYIR / az veri dalı (turuncu ok, sağa) ---
arrow(ax, (7.8, 8.62), (9.0, 7.7), ORANGE, lw=2.6)
ax.text(9.05, 8.25, "HAYIR\n(az veri)", ha="center", va="center", fontsize=10.5,
color=ORANGE, fontweight="bold", zorder=5)
node_box(ax, 8.85, 7.05, 5.3, 1.15,
"Dağılıma uyan\npre-trained model bul",
fc=COL_BG, ec=ORANGE, lw=2.3, fontsize=10.5, textcolor=COL_INK,
fontweight="bold")
# --- 2 alt-dal: supervised vs self-supervised ---
arrow(ax, (7.6, 6.55), (5.55, 5.35), COL_VIOLET_M, lw=2.1)
arrow(ax, (10.0, 6.55), (10.05, 5.45), COL_VIOLET_M, lw=2.1)
node_box(ax, 4.55, 4.55, 5.0, 1.45,
"Supervised pre-train\n(ImageNet)\nbias yükler",
fc="#f1e9f8", ec=COL_VIOLET_M, lw=2.2, fontsize=10.0, textcolor=COL_VIOLET_D)
node_box(ax, 10.0, 4.55, 5.0, 1.45,
"Self-supervised pre-train\n(SwAV)\ndaha iyi transfer",
fc="#fbf3df", ec=COL_GOLD_D, lw=2.4, fontsize=10.0, textcolor=COL_GOLD_D,
fontweight="bold")
# gold "tercih" rozeti SSL kutusunda
ax.text(10.0, 3.55, "★ tercih edilen", ha="center", va="center", fontsize=9.0,
color=COL_GOLD_D, fontweight="bold", zorder=5, style="italic")
# --- Alt uyarı kutusu (kırmızı çerçeve) ---
node_box(ax, 6.0, 1.7, 9.6, 1.45,
"⚠ ImageNet ≠ röntgen / kanser → transfer ETMEZ\n(dağılım eşleşmeli — yanlış dağılım fayda sağlamaz)",
fc="#fdecea", ec=RED, lw=2.6, fontsize=11.0, textcolor="#7d1f15",
fontweight="bold", rounding=0.10)
# iki pre-train kutusundan uyarıya ince oklar
arrow(ax, (4.55, 3.82), (4.9, 2.45), COL_GRID, lw=1.5, ls=(0, (4, 3)))
arrow(ax, (10.0, 3.82), (7.6, 2.45), COL_GRID, lw=1.5, ls=(0, (4, 3)))
# --- Falcon annotation (alt köşe) ---
ax.text(0.15, 0.18,
"Sinir ağının sihri körlemesine işlemez (Falcon 4:58); "
"transfer = backbone + yeni kafa (5:35).",
ha="left", va="bottom", fontsize=9.5, color=COL_TEXT, style="italic",
transform=ax.transData, wrap=True)
# --- Başlık ---
ax.text(6.0, 9.85, "Transfer Öğrenme Karar Ağacı — Kursu Kapatan Sentez (H15 bonus)",
ha="center", va="center", fontsize=13.5, color=COL_INK, fontweight="bold")
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Ne Zaman Transfer: Dağılım Eşleşmesi Ön Koşuldur"}
**Geriye (Hafta 10 + 14):** Pre-train→fine-tune = Hafta 10 (SSL) + Hafta 14 (Canziani transfer vs fine-tune); veri-dağılımı eşleşmesi = transfer ön koşulu.
**İleriye:** "Önce uygun omurga bul" = foundation-model çağının ilk kuralı; alan-eşleşmesi hâlâ kritik.
:::
## (Falcon — Konuk) Supervised Transfer: ResNet-50, Freeze vs Fine-tune {#sec-supervised-transfer}
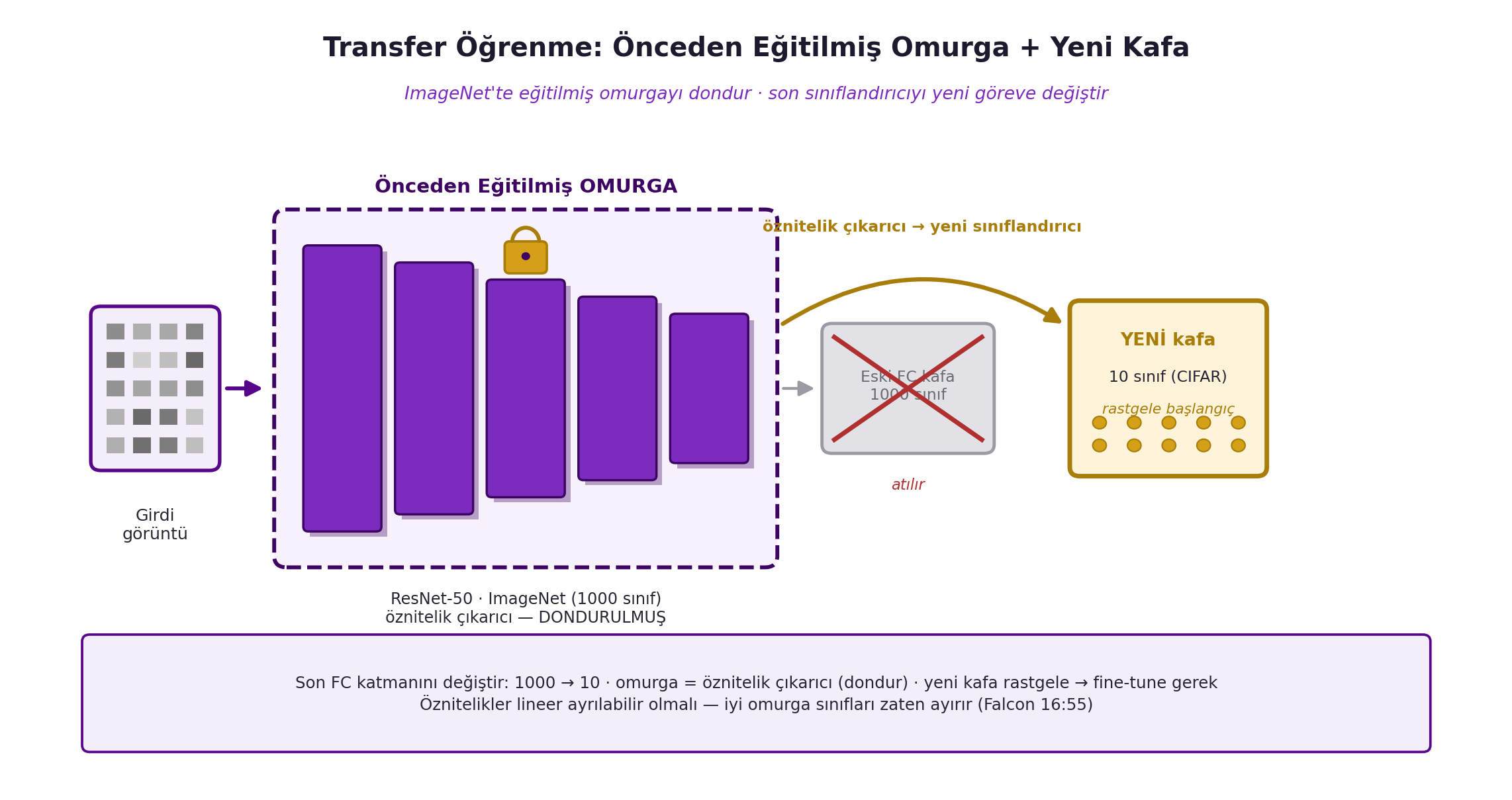
Somut örnek: ImageNet'te (1M görüntü, 1000 sınıf) önceden eğitilmiş **ResNet-50** omurgayı al; CIFAR-10 (10 sınıf) için **son fully-connected katmanı değiştir** (1000→10). Ama yeni kafa rastgele olduğundan tahminler tutmaz → **ince ayar** gerekir. @fig-backbone-head bu yapıyı gösterir: önceden eğitilmiş ResNet-50 omurga (kilitli, öznitelik çıkarıcı), atılan eski 1000-sınıf FC kafa (üstü çizili) ve gold renkli yeni 10-sınıf kafa (rastgele başlangıç) — akış "öznitelik çıkarıcı → yeni sınıflandırıcı" şeklindedir. İki mod vardır:
- **Omurgayı dondur (freeze):** omurgaya backprop yapma; üstüne herhangi bir sınıflandırıcı (linear, SVM, logistic, random forest) tak. Ağ işini yaptıysa öznitelikler **lineer ayrılabilir** olmalı.
> "you're using the neural network to extract features, and then using some other classifier... if the network did its job, they should be linearly separable." — Falcon, 16:55
- **İnce ayar yap (fine-tune):** birkaç epoch sonra omurgayı **çöz (unfreeze)**, daha **düşük öğrenme oranı** ile tüm ağı ayarla → zamanla daha iyi performans.
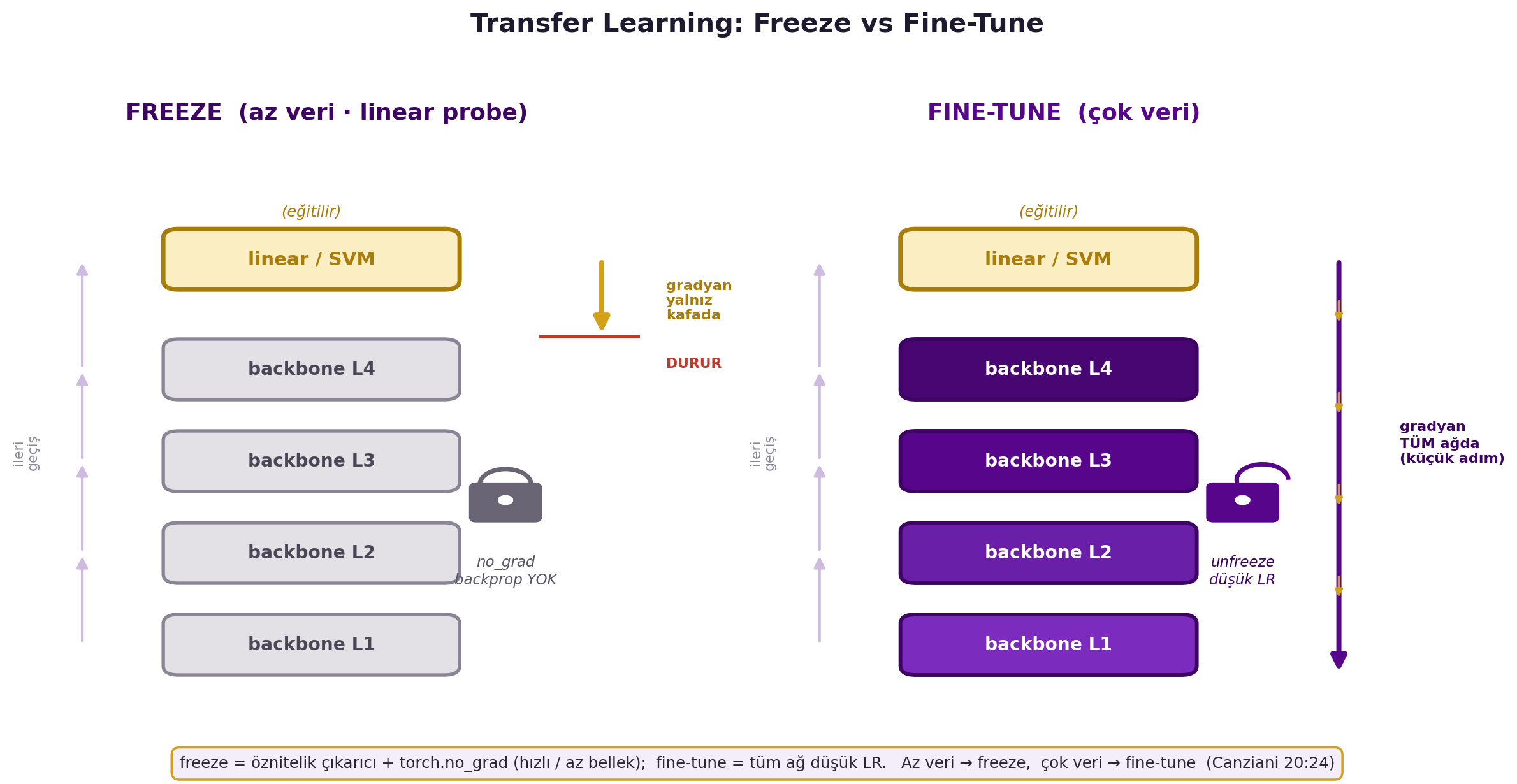
Pratik püf (Canziani ekler): dondurulmuş omurga için `torch.no_grad()` kullan — hesaplama grafiği tutulmaz, daha hızlı + az bellek. @fig-freeze-vs-finetune iki modu yan yana koyar: solda freeze (omurga kilitli, gradyan yalnız kafada durur), sağda fine-tune (omurga çözülü, gradyan tüm ağda küçük adımlarla akar).
```{python}
#| label: fig-backbone-head
#| fig-cap: "Transfer öğrenme: önceden eğitilmiş omurga + yeni kafa (Hafta 15 bonus, Falcon + Canziani). Soldan: girdi görüntü → ResNet-50 omurga (ImageNet 1000-sınıf, violet conv blokları, KİLİTLİ ikonu = dondurulmuş öznitelik çıkarıcı) → eski 1000-sınıf FC kafa (üstü çizili, atılır) → yeni 10-sınıf CIFAR kafa (gold, rastgele başlangıç). Son FC katmanı değiştir (1000→10); omurga öznitelik çıkarıcı; yeni kafa rastgele → fine-tune gerek; öznitelikler lineer ayrılabilir olmalı (Falcon 16:55)."
np.random.seed(0)
fig, ax = plt.subplots(figsize=(12, 6.4))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.8)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
fig.patch.set_facecolor(COL_WHITE)
# --- Başlık ---
ax.text(6.0, 6.5, "Transfer Öğrenme: Önceden Eğitilmiş Omurga + Yeni Kafa",
ha="center", va="center", fontsize=15, fontweight="bold", color=COL_INK)
ax.text(6.0, 6.08, "ImageNet'te eğitilmiş omurgayı dondur · son sınıflandırıcıyı yeni göreve değiştir",
ha="center", va="center", fontsize=10, color=COL_VIOLET_M, style="italic")
cy = 3.5 # ana dikey eksen
# --- 1) Girdi görüntü ---
img_x = 0.65
img = FancyBboxPatch((img_x, cy - 0.7), 1.0, 1.4,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=COL_BG, ec=COL_VIOLET, lw=2.0, zorder=3)
ax.add_patch(img)
# minik "görüntü" deseni (ızgara)
for gx in np.linspace(img_x + 0.18, img_x + 0.82, 4):
for gy in np.linspace(cy - 0.5, cy + 0.5, 5):
shade = (np.sin(gx * 7) * np.cos(gy * 5) + 1) / 2
ax.add_patch(plt.Rectangle((gx - 0.07, gy - 0.07), 0.14, 0.14,
fc=str(0.35 + 0.5 * shade), ec="none", zorder=4))
ax.text(img_x + 0.5, cy - 1.05, "Girdi\ngörüntü", ha="center", va="top",
fontsize=9.5, color=COL_TEXT)
# --- 2) Pre-trained BACKBONE (4-5 violet conv blok üst üste) — KİLİTLİ ---
bb_x0 = 2.35
n_blocks = 5
bw = 0.62
gap_b = 0.12
# arka çerçeve (donmuş bölge)
bb_total = n_blocks * bw + (n_blocks - 1) * gap_b
frame = FancyBboxPatch((bb_x0 - 0.22, cy - 1.55), bb_total + 0.44, 3.1,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="#f7f1fc", ec=COL_VIOLET_D, lw=2.2, ls="--", zorder=2)
ax.add_patch(frame)
block_heights = [2.5, 2.2, 1.9, 1.6, 1.3]
for i in range(n_blocks):
bx = bb_x0 + i * (bw + gap_b)
bh = block_heights[i]
# 3B blok hissi: gölge + ön yüz
ax.add_patch(plt.Rectangle((bx + 0.05, cy - bh/2 - 0.05), bw, bh,
fc=COL_VIOLET_D, ec="none", alpha=0.35, zorder=3))
ax.add_patch(FancyBboxPatch((bx, cy - bh/2), bw, bh,
boxstyle="round,pad=0.005,rounding_size=0.04",
fc=COL_VIOLET_M, ec=COL_VIOLET_D, lw=1.3, zorder=4))
ax.text(bb_x0 + bb_total/2, cy + 1.78, "Önceden Eğitilmiş OMURGA",
ha="center", va="center", fontsize=11, fontweight="bold", color=COL_VIOLET_D)
ax.text(bb_x0 + bb_total/2, cy - 1.78, "ResNet-50 · ImageNet (1000 sınıf)\nöznitelik çıkarıcı — DONDURULMUŞ",
ha="center", va="top", fontsize=9, color=COL_TEXT)
# KİLİT ikonu (omurganın üstünde)
lock_x, lock_y = bb_x0 + bb_total/2, cy + 1.18
ax.add_patch(FancyBboxPatch((lock_x - 0.16, lock_y - 0.16), 0.32, 0.26,
boxstyle="round,pad=0.01,rounding_size=0.04",
fc=COL_GOLD, ec=COL_GOLD_D, lw=1.4, zorder=6))
# kilit kemeri
arc = matplotlib.patches.Arc((lock_x, lock_y + 0.10), 0.22, 0.26, theta1=0, theta2=180,
color=COL_GOLD_D, lw=2.2, zorder=6)
ax.add_patch(arc)
ax.add_patch(Circle((lock_x, lock_y - 0.02), 0.035, fc=COL_VIOLET_D, ec="none", zorder=7))
# --- 3) Eski FC kafa (1000-sınıf, gri, ÜSTÜ ÇİZİLİ / X) ---
old_x = 6.55
old_box = FancyBboxPatch((old_x, cy - 0.55), 1.35, 1.1,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc="#e2e2e6", ec="#9a9aa2", lw=1.8, zorder=3)
ax.add_patch(old_box)
ax.text(old_x + 0.675, cy + 0.02, "Eski FC kafa\n1000 sınıf",
ha="center", va="center", fontsize=8.8, color="#6a6a72")
# ÜSTÜ ÇİZİLİ (kırmızımsı X — "atılır")
xc, yc = old_x + 0.675, cy
ax.plot([old_x + 0.08, old_x + 1.27], [cy - 0.45, cy + 0.45],
color="#b03030", lw=2.6, zorder=5)
ax.plot([old_x + 0.08, old_x + 1.27], [cy + 0.45, cy - 0.45],
color="#b03030", lw=2.6, zorder=5)
ax.text(old_x + 0.675, cy - 0.78, "atılır", ha="center", va="top",
fontsize=8.5, color="#b03030", style="italic")
# --- 4) YENİ kafa (10-sınıf CIFAR, gold, rastgele başlangıç) ---
new_x = 8.55
new_box = FancyBboxPatch((new_x, cy - 0.75), 1.55, 1.5,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc="#fdf3d8", ec=COL_GOLD_D, lw=2.6, zorder=3)
ax.add_patch(new_box)
ax.text(new_x + 0.775, cy + 0.42, "YENİ kafa",
ha="center", va="center", fontsize=10, fontweight="bold", color=COL_GOLD_D)
ax.text(new_x + 0.775, cy + 0.10, "10 sınıf (CIFAR)",
ha="center", va="center", fontsize=8.8, color=COL_TEXT)
ax.text(new_x + 0.775, cy - 0.18, "rastgele başlangıç",
ha="center", va="center", fontsize=8.2, color=COL_GOLD_D, style="italic")
# 10 küçük çıktı nöronu (gold noktalar)
for j in range(10):
nx_dot = new_x + 0.22 + (j % 5) * 0.28
ny_dot = cy - 0.40 + (j // 5) * (-0.20) + 0.10
ax.add_patch(Circle((nx_dot, ny_dot), 0.055, fc=COL_GOLD, ec=COL_GOLD_D, lw=0.8, zorder=5))
# --- Oklar (akış) ---
def arrow(x0, x1, y, color=COL_VIOLET, lw=2.2, style="-|>"):
ax.add_patch(FancyArrowPatch((x0, y), (x1, y), arrowstyle=style,
mutation_scale=18, color=color, lw=lw, zorder=2))
arrow(img_x + 1.05, bb_x0 - 0.30, cy) # görüntü → omurga
arrow(bb_x0 + bb_total + 0.26, old_x - 0.05, cy, color="#9a9aa2", lw=1.6) # omurga → eski (soluk)
# omurga → yeni kafa (gerçek akış, üstten kavis)
ax.add_patch(FancyArrowPatch((bb_x0 + bb_total + 0.26, cy + 0.55),
(new_x - 0.05, cy + 0.55),
connectionstyle="arc3,rad=-0.32", arrowstyle="-|>",
mutation_scale=18, color=COL_GOLD_D, lw=2.4, zorder=2))
ax.text((bb_x0 + bb_total + new_x) / 2 + 0.1, cy + 1.42,
"öznitelik çıkarıcı → yeni sınıflandırıcı",
ha="center", va="center", fontsize=8.8, color=COL_GOLD_D, fontweight="bold")
# --- Alt annotation kutusu ---
note = ("Son FC katmanını değiştir: 1000 → 10 · omurga = öznitelik çıkarıcı (dondur) · "
"yeni kafa rastgele → fine-tune gerek\n"
"Öznitelikler lineer ayrılabilir olmalı — iyi omurga sınıfları zaten ayırır (Falcon 16:55)")
ax.add_patch(FancyBboxPatch((0.6, 0.35), 10.8, 0.95,
boxstyle="round,pad=0.04,rounding_size=0.06",
fc=COL_BG, ec=COL_VIOLET, lw=1.4, zorder=1))
ax.text(6.0, 0.82, note, ha="center", va="center", fontsize=9.2, color=COL_TEXT)
plt.tight_layout()
plt.show()
```
```{python}
#| label: fig-freeze-vs-finetune
#| fig-cap: "Transfer learning: freeze vs fine-tune iki mod (Falcon + Canziani). SOL panel FREEZE (az veri, linear probe): omurga KİLİTLİ (no_grad, gri bloklar, backprop YOK), üstüne linear/SVM kafa eğitilir; gradyan yalnız kafada akar, omurga sınırında DURUR. SAĞ panel FINE-TUNE (çok veri): omurga ÇÖZÜLÜ (unfreeze, violet bloklar, düşük öğrenme oranı), gradyan tüm ağda küçük adımlarla en alta kadar akar. Freeze = öznitelik çıkarıcı + torch.no_grad (hızlı/az bellek); fine-tune = tüm ağ düşük öğrenme oranı; az veri → freeze, çok veri → fine-tune (Canziani 20:24)."
np.random.seed(0)
def draw_padlock(ax, cx, cy, color, locked=True, scale=1.0):
"""Asma kilit ikonu (gövde + kavis): locked=True kapalı, False açık (kavis kayık)."""
bw, bh = 0.34 * scale, 0.30 * scale # gövde
body = FancyBboxPatch(
(cx - bw / 2, cy - bh / 2), bw, bh,
boxstyle="round,pad=0.01,rounding_size=0.04",
fc=color, ec=color, lw=1.4, zorder=6,
)
ax.add_patch(body)
# kilit dili (gövde içi nokta)
ax.add_patch(plt.Circle((cx, cy + 0.02 * scale), 0.035 * scale,
fc=COL_WHITE, ec=COL_WHITE, zorder=7))
# kavis (shackle)
r = 0.13 * scale
top = cy + bh / 2
if locked:
ax.add_patch(Arc((cx, top), 2 * r, 2 * r, theta1=0, theta2=180,
color=color, lw=2.6, zorder=6))
ax.plot([cx - r, cx - r], [top, top - 0.02 * scale], color=color, lw=2.6, zorder=6)
ax.plot([cx + r, cx + r], [top, top - 0.02 * scale], color=color, lw=2.6, zorder=6)
else:
# açık: kavis bir tarafta yukarı kalkık
ax.add_patch(Arc((cx + 0.10 * scale, top + 0.04 * scale), 2 * r, 2 * r,
theta1=0, theta2=200, color=color, lw=2.6, zorder=6))
ax.plot([cx - r + 0.10 * scale, cx - r + 0.10 * scale],
[top + 0.04 * scale, top - 0.06 * scale], color=color, lw=2.6, zorder=6)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12.5, 6.4))
# ---------------------------------------------------------------------------
# Ortak çizim yardımcıları
# ---------------------------------------------------------------------------
BLOCK_W, BLOCK_H = 1.9, 0.62
X_C = 1.55 # blok merkez x
Y_BACK = [0.55, 1.55, 2.55, 3.55] # backbone 4 katman (alttan üste)
Y_HEAD = 4.75 # kafa (linear/SVM)
def draw_block(ax, yc, label, fc, ec, lw=2.2, text_color=COL_INK, hatch=None, fontsize=10.5):
box = FancyBboxPatch(
(X_C - BLOCK_W / 2, yc - BLOCK_H / 2), BLOCK_W, BLOCK_H,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=lw, zorder=3, hatch=hatch,
)
ax.add_patch(box)
ax.text(X_C, yc, label, ha="center", va="center",
fontsize=fontsize, color=text_color, zorder=4, fontweight="bold")
def forward_arrows(ax, ys):
"""İleri geçiş okları (açık gri, ince) — alttan üste veri akışı."""
for y0, y1 in zip(ys[:-1], ys[1:]):
ax.add_patch(FancyArrowPatch(
(X_C - BLOCK_W / 2 - 0.55, y0), (X_C - BLOCK_W / 2 - 0.55, y1),
arrowstyle="-|>", mutation_scale=13,
color=COL_GRID, lw=1.6, zorder=1,
connectionstyle="arc3,rad=0",
))
def setup_axis(ax, title, title_color):
ax.set_xlim(-0.4, 3.7)
ax.set_ylim(-0.25, 6.05)
ax.axis("off")
ax.set_title(title, color=title_color, fontsize=13.5, fontweight="bold", pad=12)
# ===========================================================================
# SOL PANEL — FREEZE (az veri, linear probe)
# ===========================================================================
setup_axis(axL, "FREEZE (az veri · linear probe)", COL_VIOLET_D)
# backbone — KİLİTLİ (gri bloklar)
for i, y in enumerate(Y_BACK):
draw_block(axL, y, f"backbone L{i+1}", fc="#e3e0e6", ec="#8a8595", lw=2.0,
text_color="#4a4655")
# kilit ikonu (KAPALI) + no_grad etiketi
draw_padlock(axL, X_C + BLOCK_W / 2 + 0.32, 2.10, "#6a6575", locked=True, scale=1.3)
axL.text(X_C + BLOCK_W / 2 + 0.32, 1.35, "no_grad\nbackprop YOK", ha="center", va="center",
fontsize=8.6, color="#5a5565", style="italic", zorder=5,
linespacing=1.25)
# kafa — EĞİTİLİR (gold)
draw_block(axL, Y_HEAD, "linear / SVM", fc="#fbeec2", ec=COL_GOLD_D, lw=2.6,
text_color=COL_GOLD_D, fontsize=11)
axL.text(X_C, Y_HEAD + 0.52, "(eğitilir)", ha="center", va="center",
fontsize=9, color=COL_GOLD_D, style="italic", zorder=4)
# ileri geçiş (tüm yığın boyunca, açık gri)
forward_arrows(axL, Y_BACK + [Y_HEAD])
axL.text(X_C - BLOCK_W / 2 - 0.92, 2.65, "ileri\ngeçiş", ha="center", va="center",
fontsize=8.2, color="#8a8595", rotation=90, linespacing=1.15)
# geri-yayılım oku — SADECE kafada (kafadan başlar, backbone'da DURUR)
axR_back_x = X_C + BLOCK_W / 2 + 0.95
axL.add_patch(FancyArrowPatch(
(axR_back_x, Y_HEAD), (axR_back_x, Y_BACK[-1] + BLOCK_H / 2 + 0.05),
arrowstyle="-|>", mutation_scale=18,
color=COL_GOLD, lw=3.0, zorder=6,
))
# durma çizgisi (backbone üst sınırı)
axL.plot([X_C + BLOCK_W / 2 + 0.55, axR_back_x + 0.32],
[Y_BACK[-1] + BLOCK_H / 2 + 0.05, Y_BACK[-1] + BLOCK_H / 2 + 0.05],
color="#c0392b", lw=2.2, zorder=6)
axL.text(axR_back_x + 0.42, (Y_HEAD + Y_BACK[-1]) / 2 + 0.15, "gradyan\nyalnız\nkafada",
ha="left", va="center", fontsize=8.4, color=COL_GOLD_D,
fontweight="bold", linespacing=1.18, zorder=6)
axL.text(axR_back_x + 0.42, Y_BACK[-1] + BLOCK_H / 2 - 0.25, "DURUR",
ha="left", va="center", fontsize=8.2, color="#c0392b",
fontweight="bold", zorder=6)
# ===========================================================================
# SAĞ PANEL — FINE-TUNE (çok veri)
# ===========================================================================
setup_axis(axR, "FINE-TUNE (çok veri)", COL_VIOLET)
# backbone — ÇÖZÜLÜ (violet bloklar)
violet_shades = ["#7b2cbf", "#6a1fa8", "#57068c", "#480672"]
for i, y in enumerate(Y_BACK):
draw_block(axR, y, f"backbone L{i+1}", fc=violet_shades[i], ec=COL_VIOLET_D, lw=2.2,
text_color=COL_WHITE)
draw_padlock(axR, X_C + BLOCK_W / 2 + 0.32, 2.10, COL_VIOLET, locked=False, scale=1.3)
axR.text(X_C + BLOCK_W / 2 + 0.32, 1.35, "unfreeze\ndüşük LR", ha="center", va="center",
fontsize=8.6, color=COL_VIOLET_D, style="italic", zorder=5,
linespacing=1.25)
# kafa
draw_block(axR, Y_HEAD, "linear / SVM", fc="#fbeec2", ec=COL_GOLD_D, lw=2.6,
text_color=COL_GOLD_D, fontsize=11)
axR.text(X_C, Y_HEAD + 0.52, "(eğitilir)", ha="center", va="center",
fontsize=9, color=COL_GOLD_D, style="italic", zorder=4)
# ileri geçiş
forward_arrows(axR, Y_BACK + [Y_HEAD])
axR.text(X_C - BLOCK_W / 2 - 0.92, 2.65, "ileri\ngeçiş", ha="center", va="center",
fontsize=8.2, color="#8a8595", rotation=90, linespacing=1.15)
# geri-yayılım oku — TÜM AĞ BOYUNCA (kafadan en alta, küçük adım)
bp_x = X_C + BLOCK_W / 2 + 0.95
axR.add_patch(FancyArrowPatch(
(bp_x, Y_HEAD), (bp_x, Y_BACK[0] - BLOCK_H / 2 - 0.02),
arrowstyle="-|>", mutation_scale=18,
color=COL_VIOLET, lw=3.0, zorder=6,
))
axR.text(bp_x + 0.40, (Y_HEAD + Y_BACK[0]) / 2 + 0.10, "gradyan\nTÜM ağda\n(küçük adım)",
ha="left", va="center", fontsize=8.4, color=COL_VIOLET_D,
fontweight="bold", linespacing=1.18, zorder=6)
# küçük "düşük LR" adım işaretleri ok boyunca
for y in [4.15, 3.15, 2.15, 1.15]:
axR.add_patch(FancyArrowPatch(
(bp_x, y + 0.18), (bp_x, y - 0.12),
arrowstyle="-|>", mutation_scale=9,
color=COL_GOLD, lw=1.4, zorder=7,
))
# ---------------------------------------------------------------------------
# Alt açıklama bandı (her iki panelin altında, fig koordinatı)
# ---------------------------------------------------------------------------
fig.text(
0.5, 0.015,
"freeze = öznitelik çıkarıcı + torch.no_grad (hızlı / az bellek); "
"fine-tune = tüm ağ düşük LR. Az veri → freeze, çok veri → fine-tune (Canziani 20:24)",
ha="center", va="bottom", fontsize=9.2, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_GOLD, lw=1.3),
)
fig.suptitle("Transfer Learning: Freeze vs Fine-Tune",
fontsize=15.5, fontweight="bold", color=COL_INK, y=0.985)
plt.tight_layout(rect=[0, 0.06, 1, 0.95])
plt.show()
```
::: {.callout-tip title="Builder Notu — Freeze vs Fine-tune: Transfer'in Temel Kararı"}
**Geriye (Hafta 3 + 10):** ResNet = Hafta 3/9 residual; freeze + linear sınıflandırıcı = Hafta 10 linear probe; öznitelik çıkarıcı = Hafta 1 temsil öğrenme.
**İleriye:** Freeze (az veri) vs fine-tune (çok veri) = transfer'in temel kararı; `torch.no_grad()` = pratik verimlilik standardı.
:::
## (Falcon — Konuk) PyTorch Lightning: Boilerplate'i Soyutlamak {#sec-lightning}
Falcon **PyTorch Lightning**'i tanıtır: PyTorch kodunu organize eden hafif sarmalayıcı — çok-GPU, TPU, dağıtık eğitim gibi uzmanlık gerektiren şeyleri sana yaptırır.
> "lightning is a lightweight wrapper for PyTorch... it organizes your PyTorch code so you can leverage multiple GPU training, TPUs and different things that require a lot of expertise." — Falcon, 1:22
Lightning'de yalnız **iki şey** bilmen yeter:
- **LightningModule:** `nn.Module` gibi ama eğitim mantığını içerir. `training_step` (bir batch verildiğinde kaybı hesapla — forward değil, **tüm sistem**: BERT/GAN/VAE mantığı burada) + `configure_optimizers`; `forward` opsiyonel.
- **Trainer:** epoch/batch döngüsü, `backward`, `optimizer.step`, `zero_grad`'ı **otomatik** yapar. `self.log` metrikleri kaydeder + GPU'lar arası senkronize eder. `fast_dev_run` = tek batch hızlı hata-ayıklama.
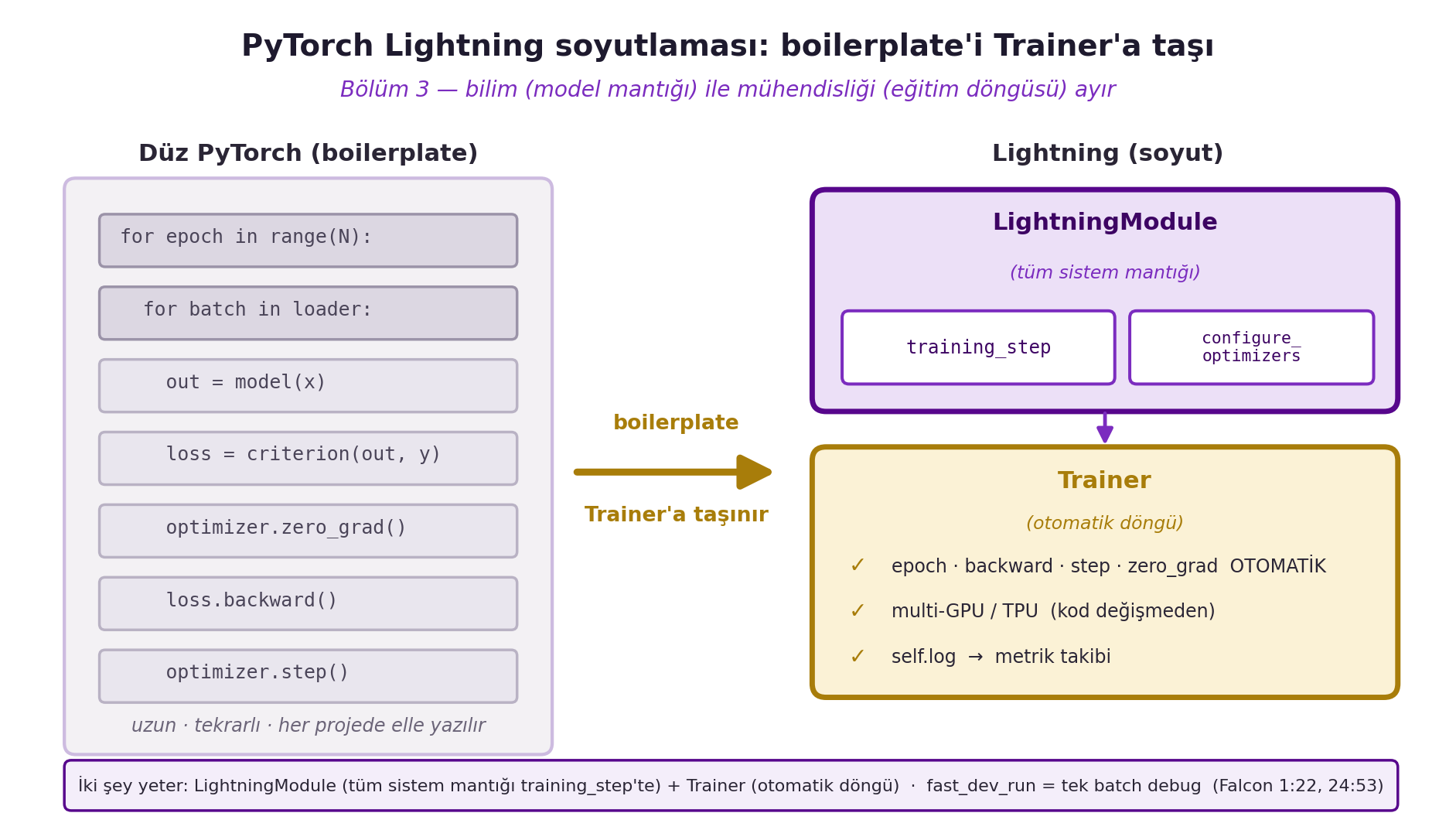
Böylece eğitim döngüsü modelin **içine** taşınır, kod self-contained ve az-boilerplate olur. @fig-lightning-abstraction bu soyutlamayı gösterir: solda düz PyTorch'un elle yazılan tekrarlı döngüsü (`for epoch` → `forward` → `loss` → `backward` → `optimizer.step` → `zero_grad`), sağda Lightning'in iki kutusu — LightningModule (`training_step` + `configure_optimizers`) ve boilerplate'i otomatik üstlenen Trainer (multi-GPU/TPU + `self.log`).
```{python}
#| label: fig-lightning-abstraction
#| fig-cap: "PyTorch Lightning soyutlaması: boilerplate'i Trainer'a taşı (Bölüm 3). SOL: düz PyTorch'un elle yazılan, tekrarlı döngü kutuları (for epoch → for batch → forward → loss → zero_grad → backward → optimizer.step — uzun, her projede elle yazılır). SAĞ: Lightning'in iki bileşeni — LightningModule (violet; training_step + configure_optimizers, tüm sistem mantığı) ve Trainer (gold; epoch/backward/step/zero_grad OTOMATİK + multi-GPU/TPU + self.log). İki şey yeter; fast_dev_run = tek batch debug (Falcon 1:22, 24:53)."
np.random.seed(0)
fig, ax = plt.subplots(figsize=(12.4, 7.0))
ax.set_xlim(0, 12.4)
ax.set_ylim(0, 7.0)
ax.axis("off")
# ---------------------------------------------------------------------------
# Başlık
# ---------------------------------------------------------------------------
ax.text(6.2, 6.72, "PyTorch Lightning soyutlaması: boilerplate'i Trainer'a taşı",
ha="center", va="center", fontsize=14.5, fontweight="bold", color=COL_INK)
ax.text(6.2, 6.34, "Bölüm 3 — bilim (model mantığı) ile mühendisliği (eğitim döngüsü) ayır",
ha="center", va="center", fontsize=10.5, color=COL_VIOLET_M, style="italic")
# ===========================================================================
# SOL: Düz PyTorch (boilerplate) — dikey elle döngü kutuları
# ===========================================================================
ax.text(2.55, 5.78, "Düz PyTorch (boilerplate)", ha="center", va="center",
fontsize=11.5, fontweight="bold", color=COL_TEXT)
# çerçeve
frame_l = FancyBboxPatch((0.45, 0.55), 4.2, 5.0,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="#f3f1f4", ec=COL_GRID, lw=1.6, zorder=1)
ax.add_patch(frame_l)
# elle döngü adımları (tekrarlı, gri kutular)
steps_l = [
"for epoch in range(N):",
" for batch in loader:",
" out = model(x)",
" loss = criterion(out, y)",
" optimizer.zero_grad()",
" loss.backward()",
" optimizer.step()",
]
y_top = 5.30
box_h = 0.55
gap = 0.085
box_w = 3.6
x_l = 0.75
for i, s in enumerate(steps_l):
y = y_top - i * (box_h + gap)
# ilk iki satır döngü başlığı (koyu gri), gerisi gövde
is_loop = i < 2
fc = "#dcd7e2" if is_loop else "#e9e6ee"
ec = "#9b93a8" if is_loop else "#b9b2c4"
box = FancyBboxPatch((x_l, y - box_h + 0.06), box_w, box_h - 0.12,
boxstyle="round,pad=0.015,rounding_size=0.05",
fc=fc, ec=ec, lw=1.3, zorder=2)
ax.add_patch(box)
ax.text(x_l + 0.16, y - box_h / 2 + 0.03, s, ha="left", va="center",
fontsize=9.3, family="monospace", color="#4a4458", zorder=3)
ax.text(2.55, 0.78, "uzun · tekrarlı · her projede elle yazılır",
ha="center", va="center", fontsize=9.0, color="#6b6478", style="italic")
# ===========================================================================
# Büyük ok: "boilerplate Trainer'a taşınır"
# ===========================================================================
ax.add_patch(FancyArrowPatch((4.85, 3.0), (6.65, 3.0),
arrowstyle="-|>", mutation_scale=34,
color=COL_GOLD_D, lw=3.4, zorder=4))
ax.text(5.75, 3.42, "boilerplate", ha="center", va="center",
fontsize=10.0, fontweight="bold", color=COL_GOLD_D)
ax.text(5.75, 2.62, "Trainer'a taşınır", ha="center", va="center",
fontsize=10.0, fontweight="bold", color=COL_GOLD_D)
# ===========================================================================
# SAĞ: Lightning (soyut) — iki kutu
# ===========================================================================
ax.text(9.5, 5.78, "Lightning (soyut)", ha="center", va="center",
fontsize=11.5, fontweight="bold", color=COL_TEXT)
# --- LightningModule (violet) ---
lm = FancyBboxPatch((6.95, 3.55), 5.05, 1.9,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc="#ece0f7", ec=COL_VIOLET, lw=2.6, zorder=2)
ax.add_patch(lm)
ax.text(9.475, 5.18, "LightningModule", ha="center", va="center",
fontsize=11.5, fontweight="bold", color=COL_VIOLET_D)
ax.text(9.475, 4.74, "(tüm sistem mantığı)", ha="center", va="center",
fontsize=8.8, color=COL_VIOLET_M, style="italic")
# içerideki iki method kutusu
m1 = FancyBboxPatch((7.20, 3.78), 2.35, 0.62,
boxstyle="round,pad=0.01,rounding_size=0.06",
fc=COL_WHITE, ec=COL_VIOLET_M, lw=1.5, zorder=3)
ax.add_patch(m1)
ax.text(8.375, 4.09, "training_step", ha="center", va="center",
fontsize=9.0, family="monospace", color=COL_VIOLET_D, zorder=4)
m2 = FancyBboxPatch((9.70, 3.78), 2.10, 0.62,
boxstyle="round,pad=0.01,rounding_size=0.06",
fc=COL_WHITE, ec=COL_VIOLET_M, lw=1.5, zorder=3)
ax.add_patch(m2)
ax.text(10.75, 4.09, "configure_\noptimizers", ha="center", va="center",
fontsize=8.0, family="monospace", color=COL_VIOLET_D, zorder=4)
# --- Trainer (gold) ---
tr = FancyBboxPatch((6.95, 1.05), 5.05, 2.15,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc="#fbf2d6", ec=COL_GOLD_D, lw=2.6, zorder=2)
ax.add_patch(tr)
ax.text(9.475, 2.92, "Trainer", ha="center", va="center",
fontsize=11.5, fontweight="bold", color=COL_GOLD_D)
ax.text(9.475, 2.55, "(otomatik döngü)", ha="center", va="center",
fontsize=8.8, color=COL_GOLD_D, style="italic")
auto_items = [
"epoch · backward · step · zero_grad OTOMATİK",
"multi-GPU / TPU (kod değişmeden)",
"self.log → metrik takibi",
]
for i, it in enumerate(auto_items):
yy = 2.18 - i * 0.40
ax.text(7.25, yy, "✓", ha="left", va="center",
fontsize=10.5, fontweight="bold", color=COL_GOLD_D, zorder=4)
ax.text(7.62, yy, it, ha="left", va="center",
fontsize=8.9, color=COL_TEXT, zorder=4)
# ok: LightningModule → Trainer (mantığı Trainer kullanır)
ax.add_patch(FancyArrowPatch((9.475, 3.55), (9.475, 3.20),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.8, zorder=3))
# ===========================================================================
# Alt annotation kutusu
# ===========================================================================
note = FancyBboxPatch((0.45, 0.06), 11.55, 0.40,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=COL_BG, ec=COL_VIOLET, lw=1.3, zorder=2)
ax.add_patch(note)
ax.text(6.225, 0.26,
"İki şey yeter: LightningModule (tüm sistem mantığı training_step'te) + Trainer (otomatik döngü) · "
"fast_dev_run = tek batch debug (Falcon 1:22, 24:53)",
ha="center", va="center", fontsize=8.3, color=COL_TEXT, zorder=3)
plt.show()
```
::: {.callout-tip title="Builder Notu — Lightning Soyutlama: Eğitim Döngüsünün Modele Taşınması"}
**Geriye (Hafta 5):** `training_step` = Hafta 5 autograd döngüsünün (forward→loss→backward→step) organize hâli; Trainer = o döngünün soyutlanması.
**İleriye:** Lightning/Bolts = araştırma-üretim köprüsü; SSL modelleri (SwAV/SimCLR/BYOL) Bolts'ta hazır.
:::
## (Falcon — Konuk) Self-Supervised Transfer (SwAV) ve Az-Etiket Zaferi {#sec-ssl-transfer}
Şimdi supervised ResNet yerine **SwAV** (FAIR'in 2020 SSL yöntemlerinden, Bolts'ta hazır) omurga kullanılır — ImageNet'te **etiketsiz** ön-eğitim (3000 öznitelik). SSL omurgasının büyük avantajı:
> "you can pre-train your SwAV model on your own data, which you don't have many labels for, and then just train the classifier with the few labels you have." — Canziani, 48:28
Etiketler pahalıdır; SSL ile **kendi etiketsiz verinde** omurgayı eğitebilir, sonra **az etiketle** sadece sınıflandırıcıyı eğitebilirsin. Az-etiket deneyi çarpıcı: 100/316/1000 örnekle üç modeli (rastgele, supervised-pretrain, SSL-pretrain) karşılaştır:
> "when they're trained without labels, we get double the performance of the models that were trained with the labels." — Falcon, 1:08:13
Rastgele model ~%10'larda; supervised-pretrain ~%20-30; **SSL-pretrain (SwAV) bunun ~2 katı**. SSL ayrıca daha **hızlı** yakınsar. @fig-few-label-victory bu deneyi gerçek bir grafikle gösterir: üç omurganın 100/316/1000 etiketteki validation doğruluğu, SwAV (violet) çubukları denetimli (gold) çubukların yaklaşık iki katı, ve fark en az etikette (100) en büyük. Falcon listeler: AMDIM, MoCo, CPC, PIRL, SimCLR, BYOL, SwAV (en yenisi) — @fig-ssl-methods-timeline bu yöntemleri zaman ekseninde sıralar ve PIRL'in Hafta 10 (Misra) köprüsünü işaretler.
```{python}
#| label: fig-few-label-victory
#| fig-cap: "Az-etiket zaferi (FLAGSHIP, İLLÜSTRATİF — Falcon'un bildirdiği değerler, few_label_curve motoru). 100/316/1000 etiketle üç omurganın validation doğruluğu: rastgele başlangıç ~%10 (gri), denetimli ön-eğitim (ImageNet etiketli) ~%20-33 (gold), SSL · SwAV (etiketsiz ön-eğitim) ~%40-60 (violet, ~2× denetimli). SSL-denetimli farkı EN AZ etikette (100) en büyük (~2× işaretli). SSL etiketsiz veriden temsil öğrenir; etiketler pahalı, SSL onları atlar (Falcon 1:08); Hafta 10 'az etiketle öğren' tezinin deneysel kanıtı — KURS FİNALİ."
n_labels, random_acc, supervised, ssl_swav = few_label_curve()
fig, ax = plt.subplots(figsize=(11.5, 6.4))
apply_style(ax)
x = np.arange(len(n_labels)) # kategorik eksen: 100 / 316 / 1000
width = 0.26
# Üç backbone: rastgele (gri) < supervised (gold) < SSL/SwAV (violet kalın)
b_rand = ax.bar(x - width, random_acc, width,
color="#9e9e9e", edgecolor="#6e6e6e", lw=1.4,
label="Rastgele başlangıç (pre-train yok)", zorder=3)
b_sup = ax.bar(x, supervised, width,
color=COL_GOLD, edgecolor=COL_GOLD_D, lw=1.6,
label="Denetimli ön-eğitim (ImageNet etiketli)", zorder=3)
b_ssl = ax.bar(x + width, ssl_swav, width,
color=COL_VIOLET, edgecolor=COL_VIOLET_D, lw=2.2,
label="SSL · SwAV (etiketsiz ön-eğitim)", zorder=3)
# Bar üstü değer etiketleri
for bars, vals in [(b_rand, random_acc), (b_sup, supervised), (b_ssl, ssl_swav)]:
for rect, v in zip(bars, vals):
ax.text(rect.get_x() + rect.get_width() / 2, v + 1.0, f"%{v:.0f}",
ha="center", va="bottom", fontsize=9, color=COL_TEXT, fontweight="bold")
# SSL vs supervised farkı EN BÜYÜK etiket=100'de → dikey çift-ok + '~2×'
i0 = 0
y_sup0 = supervised[i0]
y_ssl0 = ssl_swav[i0]
x_arrow = x[i0] + width + 0.30
ax.add_patch(FancyArrowPatch((x_arrow, y_sup0), (x_arrow, y_ssl0),
arrowstyle="<|-|>", mutation_scale=15,
color=COL_VIOLET_D, lw=2.2, zorder=5))
ax.text(x_arrow + 0.06, (y_sup0 + y_ssl0) / 2, "~2×",
ha="left", va="center", fontsize=14, fontweight="bold",
color=COL_VIOLET_D, zorder=6,
bbox=dict(boxstyle="round,pad=0.25", fc=COL_WHITE, ec=COL_VIOLET, lw=1.4))
ax.text(x_arrow + 0.10, y_ssl0 + 1.5, "fark en büyük\n(en az etikette)",
ha="left", va="bottom", fontsize=8.5, color=COL_VIOLET_D, zorder=6, style="italic")
# Eksen + başlık (Türkçe ZORUNLU)
ax.set_xticks(x)
ax.set_xticklabels([f"{n}" for n in n_labels], fontsize=11)
ax.set_xlabel("etiket sayısı (sınıf başına az-etiket rejimi, log-aralık)", fontsize=11)
ax.set_ylabel("doğruluk % (validation)", fontsize=11)
ax.set_ylim(0, 72)
ax.set_title("Az-etiket zaferi: SSL etiketsiz ön-eğitim → ~2× denetimli (İLLÜSTRATİF — Falcon)",
fontsize=12.5, fontweight="bold", color=COL_INK, pad=12)
style_legend(ax, loc="upper left", fontsize=9.5)
# Açıklama kutusu (annotation)
note = ("SSL (SwAV) etiketsiz veriden temsil öğrenir → ince-ayarda ~2× denetimli;\n"
"avantaj EN AZ etikette en büyük (Falcon 1:08). Etiketler pahalı — SSL onları atlar.\n"
"Hafta 10 'az etiketle öğren' tezinin deneysel kanıtı; KURS FİNALİ.")
ax.text(0.985, 0.045, note, transform=ax.transAxes, ha="right", va="bottom",
fontsize=8.6, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_VIOLET, lw=1.3))
fig.tight_layout()
plt.show()
```
```{python}
#| label: fig-ssl-methods-timeline
#| fig-cap: "Self-Supervised Learning yöntemleri — zaman çizelgesi (Bölüm 4). Yatay zaman ekseni 2018→2020: AMDIM → MoCo → CPC → PIRL (2019, 'Hafta 10 — Misra!' vurgusu + aşağı köprü oku) → SimCLR → BYOL → SwAV (2020, en yeni, 'bu derste kullanılan'). Contrastive yöntemler (negatif çiftler, violet) → non-contrastive (negatifsiz, gold) geçişi; sağda soluk post-2020 (DINO/MAE) oku. SSL evrimi: contrastive (MoCo/SimCLR/PIRL) → non-contrastive (BYOL/SwAV); PIRL = Hafta 10 Misra; SwAV Bolts'ta hazır (Falcon 6:59)."
np.random.seed(0)
fig, ax = plt.subplots(figsize=(12.4, 6.4))
ax.set_xlim(-0.6, 11.4)
ax.set_ylim(-2.4, 3.2)
ax.axis("off")
# --- Zaman ekseni (yatay) ---
axis_y = 0.0
ax.add_patch(FancyArrowPatch((-0.2, axis_y), (11.1, axis_y),
arrowstyle="-|>", mutation_scale=22,
color=COL_INK, lw=2.4, zorder=2))
ax.text(11.1, axis_y - 0.42, "zaman", ha="right", va="top",
fontsize=11, style="italic", color=COL_TEXT)
# Yıl işaretleri
for yx, yr in [(0.4, "2018"), (5.2, "2019"), (10.2, "2020")]:
ax.plot([yx, yx], [axis_y - 0.13, axis_y + 0.13], color=COL_INK, lw=2.2, zorder=3)
ax.text(yx, axis_y - 0.42, yr, ha="center", va="top",
fontsize=12, fontweight="bold", color=COL_INK)
# --- Yöntemler: (x, ad, yıl_etiketi, tür) ---
# tür: "contrastive" -> violet, "non" -> gold (non-contrastive)
methods = [
(0.7, "AMDIM", "2018", "contrastive", 1.0),
(2.0, "MoCo", "2019", "contrastive", 1.55),
(3.3, "CPC", "2019", "contrastive", 1.0),
(4.9, "PIRL", "2019", "contrastive", 1.95), # Hafta 10 Misra köprüsü
(6.6, "SimCLR", "2020", "contrastive", 1.0),
(8.1, "BYOL", "2020", "non", 1.55),
(9.8, "SwAV", "2020", "non", 2.15), # bu derste kullanılan, vurgu
]
for (mx, name, yr, kind, stem) in methods:
is_swav = (name == "SwAV")
is_pirl = (name == "PIRL")
col = COL_VIOLET if kind == "contrastive" else COL_GOLD_D
fc = "#ece0f7" if kind == "contrastive" else "#faf0d2"
# Sap çizgisi (eksen → nokta)
ax.plot([mx, mx], [axis_y, stem], color=col, lw=1.6, ls="--", alpha=0.7, zorder=1)
# Nokta
msz = 17 if is_swav else (15 if is_pirl else 11)
ax.plot(mx, stem, "o", ms=msz, color=col,
mec=COL_GOLD if is_swav else COL_WHITE, mew=2.4 if is_swav else 1.4, zorder=4)
# Etiket kutusu
lw_box = 2.6 if (is_swav or is_pirl) else 1.6
box = FancyBboxPatch((mx - 0.62, stem + 0.16), 1.24, 0.42,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=col, lw=lw_box, zorder=5)
ax.add_patch(box)
ax.text(mx, stem + 0.37, name, ha="center", va="center",
fontsize=11.5 if (is_swav or is_pirl) else 10.5,
fontweight="bold", color=COL_INK, zorder=6)
# --- PIRL kalın "Hafta 10 Misra!" etiketi + ok ---
pirl_x, pirl_y = 4.9, 1.95
ax.annotate("Hafta 10 — Misra!",
xy=(pirl_x, pirl_y + 0.60), xytext=(pirl_x + 0.05, 2.85),
ha="center", va="bottom",
fontsize=12.5, fontweight="bold", color=COL_VIOLET_D,
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_D, lw=2.4,
connectionstyle="arc3,rad=0.0"), zorder=7)
# --- SwAV "bu derste kullanılan" vurgusu ---
swav_x, swav_y = 9.8, 2.15
ax.annotate("bu derste kullanılan",
xy=(swav_x, swav_y + 0.60), xytext=(swav_x - 0.15, 2.95),
ha="center", va="bottom",
fontsize=11.5, fontweight="bold", color=COL_GOLD_D,
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=2.2,
connectionstyle="arc3,rad=-0.15"), zorder=7)
# --- PIRL'den Hafta 10 köprü oku (kesikli, aşağıya) ---
ax.add_patch(FancyArrowPatch((pirl_x, axis_y - 0.05), (pirl_x, -1.35),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET, lw=1.8, ls="--", zorder=3))
ax.text(pirl_x, -1.55, "Hafta 10 SSL dersi\n(PIRL = rotasyon/jigsaw pretext)",
ha="center", va="top", fontsize=9.5, color=COL_VIOLET_D, style="italic")
# --- Sağ uca soluk post-2020 kesikli ---
ax.add_patch(FancyArrowPatch((10.5, 1.0), (11.15, 1.0),
arrowstyle="-|>", mutation_scale=14,
color=COL_GRID, lw=1.6, ls=(0, (2, 2)), zorder=2))
ax.text(11.2, 1.0, "post-2020:\nDINO / MAE →", ha="left", va="center",
fontsize=9.0, color="#8a7fa0", style="italic")
# --- Tür ayrımı: contrastive (violet) vs non-contrastive (gold) açıklama bandı ---
# contrastive bölge gölgesi
ax.axvspan(0.1, 7.4, ymin=0.0, ymax=0.06, color=COL_VIOLET, alpha=0.12, zorder=0)
ax.axvspan(7.4, 11.0, ymin=0.0, ymax=0.06, color=COL_GOLD, alpha=0.18, zorder=0)
ax.text(3.7, -0.62, "contrastive (negatif çiftler)", ha="center", va="center",
fontsize=10, fontweight="bold", color=COL_VIOLET, zorder=4)
ax.text(9.2, -0.62, "non-contrastive\n(negatifsiz)", ha="center", va="center",
fontsize=10, fontweight="bold", color=COL_GOLD_D, zorder=4)
# Geçiş oku contrastive → non
ax.add_patch(FancyArrowPatch((6.9, -0.62), (7.9, -0.62),
arrowstyle="-|>", mutation_scale=15,
color=COL_TEXT, lw=1.8, zorder=4))
# --- Başlık ---
ax.text(5.5, 3.55, "Self-Supervised Learning yöntemleri — zaman çizelgesi",
ha="center", va="bottom", fontsize=15, fontweight="bold", color=COL_INK)
# --- Legend (sol üst) ---
legend_elems = [
Line2D([0], [0], marker="o", color="w", markerfacecolor=COL_VIOLET,
markersize=11, label="contrastive (MoCo / SimCLR / PIRL)"),
Line2D([0], [0], marker="o", color="w", markerfacecolor=COL_GOLD_D,
markersize=11, label="non-contrastive (BYOL / SwAV)"),
]
leg = ax.legend(handles=legend_elems, loc="upper left",
bbox_to_anchor=(0.0, 1.0), frameon=True, framealpha=0.96,
edgecolor=COL_GRID, fontsize=9.5)
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
# --- Alt açıklama (annotation) ---
ax.text(5.5, -2.28,
"SSL evrimi: contrastive (MoCo/SimCLR/PIRL) → non-contrastive (BYOL/SwAV); "
"PIRL = Hafta 10 Misra; SwAV Bolts'ta hazır (Falcon 6:59)",
ha="center", va="bottom", fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_GRID, lw=1.0))
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — SwAV Az-Etiket Zaferi: Hafta 10 Tezinin Deneysel Kanıtı"}
**Geriye (Hafta 8-10):** SSL yöntemleri = Hafta 8-9 contrastive + Hafta 10 PIRL (Misra'nın yöntemi!) + MoCo; az-etiket avantajı = Hafta 10'un "az etiketle öğren" tezinin deneysel kanıtı.
**İleriye:** "Kendi etiketsiz verinde SSL ön-eğit + az etiketle fine-tune" = foundation-model çağının endüstri reçetesi.
:::
## (İleriye Köprü) SSL Patlaması ve Foundation Models — Kursun Kapanış Köprüsü {#sec-ileriye-kopru-d15}
Bu bonus (~Haz/Tem 2020), SwAV ve BYOL'u **fiilen kullanır** — ana kursun (Mart 2020) "post-2020, kursta yok" dediği yöntemler. Yani bonus, kursun tam **eşiğindeki** son gelişmeleri yakalar. Buradan sonrası kursta **YOKTUR** ama tüm kursun (Hafta 10, 12, 14) işaret ettiği yöndür:
::: {.callout-warning title="İleriye Köprü Notu (post-2020 — KURSTA YOK)"}
- **DINO** (2021), **MAE** (2021), **DINOv2** (2023) — SwAV/BYOL/SimCLR'dan sonra gelen, görü SSL'inin olgun nesli; bu bonusun "etiketsiz ön-eğit" fikrinin zirvesi.
- **Foundation models** (GPT-3/CLIP/SAM, 2020+) — "büyük omurgayı bir kez ön-eğit, her göreve transfer et" paradigmasının evrenselleşmesi; bu dersin "ön-eğit omurga + fine-tune kafa" reçetesinin dev ölçekli hâli.
Kurs terimi gibi eklenmez; bu bonusun (ve tüm kursun) öz-denetimli temelinin nereye vardığını göstermek için anılır.
:::
::: {.callout-tip title="Builder Notu — Kursun Kapanışı: Öz-Denetimli Temelin Vardığı Yer"}
**Geriye (tüm kurs):** SSL patlaması = Hafta 7-9 (EBM) + 10 (pretext) + 12 (BERT) + 14 (serbest enerji) temelinin doğrudan ürünü.
**İleriye:** Foundation model + transfer = 2020-sonrası makine öğrenmesinin tanımı; bu kursun bütün ipliklerinin birleştiği nokta.
:::
## Bu Dersin Özeti {#sec-ozet-d15}
1. **Ne zaman transfer (Falcon):** çok veri → sıfırdan; az veri → dağılımı eşleşen önceden eğitilmiş model (ImageNet ≠ röntgen).
2. **Supervised transfer (Falcon):** ResNet-50 + son katmanı değiştir; freeze (öznitelik çıkarıcı + linear probe) vs fine-tune (unfreeze, düşük öğrenme oranı); `torch.no_grad()`.
3. **PyTorch Lightning (Falcon):** LightningModule (`training_step` + `configure_optimizers`) + Trainer (otomatik döngü/log/multi-GPU); az boilerplate.
4. **Self-supervised transfer (Falcon/Canziani):** SwAV (etiketsiz ön-eğitim); kendi etiketsiz verinde eğit + az etiketle sınıflandır; SSL ~2× supervised, daha hızlı.
5. **Az-etiket zaferi:** rastgele ~%10 < supervised ~%20-30 < SSL ~2×; etiket pahalı, SSL onu atlar.
6. **Post-2020 (KURSTA YOK):** DINO/MAE/DINOv2, foundation models — kursun bütün ipliklerinin vardığı yer.
::: {.callout-important title="Tek Bir Cümle"}
Transfer learning, başka (büyük) veride eğitilmiş bir omurgayı alıp kendi az verinde yeniden kullanmaktır — omurgayı dondur (linear probe) ya da ince ayar yap, ama veri dağılımı eşleşsin; PyTorch Lightning bunu boilerplate'siz yapar; ve öz-denetimli ön-eğitim (SwAV), kendi etiketsiz verinde eğitilebildiği için, etiketli ön-eğitimi özellikle az-etiket rejiminde ~2 kat geçer — ki bu, kursun Hafta 10'dan beri savunduğu "öz-denetim dilin/görünün motorudur" tezinin pratik zaferidir.
:::
## Kontrol Soruları {#sec-kontrol-d15}
::: {.callout-note collapse="true" title="Soru 1: Ne zaman transfer learning yaparsın, ne zaman yapmazsın? \"Veri dağılımı eşleşmesi\" neden kritik?"}
**Cevap:** **Çok veriniz + zaman/compute** varsa fine-tune'a gerek yok — sıfırdan eğitin. **Az veriniz** varsa, veri dağılımına **uyan** önceden eğitilmiş model bulun (Falcon 4:58). Dağılım eşleşmesi kritiktir çünkü "sinir ağının sihri körlemesine işlemez": ImageNet doğal nesnelerde (kedi/köpek) iyi prior verir ama tıbbi görüntülerin (röntgen, kanser) istatistiği tamamen farklıdır → transfer etmez. Transfer iki parçadır: **önceden eğitilmiş omurga** + üstüne **yeni kafa** (Falcon 5:35).
:::
::: {.callout-note collapse="true" title="Soru 2: \"Freeze\" ve \"fine-tune\" transfer modları nasıl farklıdır? torch.no_grad() neden kullanılır?"}
**Cevap:** **Freeze:** omurgaya backprop yapılmaz, **öznitelik çıkarıcı** olarak kullanılır; üstüne herhangi bir sınıflandırıcı (linear/SVM/logistic) takılır — ağ işini yaptıysa öznitelikler **lineer ayrılabilir** olmalı (Falcon 16:55). **Fine-tune:** birkaç epoch sonra omurga **çözülür**, daha düşük öğrenme oranıyla tüm ağ ayarlanır (çok veri varsa daha iyi). Dondurulmuş omurga için **`torch.no_grad()`** hesaplama grafiğini tutmaz → daha hızlı + az bellek. Az veri → freeze; çok veri → fine-tune.
:::
::: {.callout-note collapse="true" title="Soru 3: PyTorch Lightning'in iki ana bileşeni nedir? training_step ne döndürür ve neyi soyutlar?"}
**Cevap:** İki bileşen: **LightningModule** (`training_step` + `configure_optimizers`; `forward` opsiyonel) ve **Trainer** (epoch/batch döngüsü, backward, optimizer.step, zero_grad'ı **otomatik**). `training_step`, bir batch verildiğinde **kaybı** döndürür — ama yalnız forward değil, **tüm sistem** mantığı (BERT/GAN/VAE) burada yaşar (Falcon 1:22, 24:53). Eğitim döngüsü modelin içine taşınır; çok-GPU/TPU, log senkronizasyonu (`self.log`) Trainer'a bırakılır → az boilerplate.
:::
::: {.callout-note collapse="true" title="Soru 4: Self-supervised transfer (SwAV), supervised'a göre hangi avantajı sağlar? Az-etiket deneyi ne gösterdi?"}
**Cevap:** SwAV omurgası ImageNet'te **etiketsiz** ön-eğitilmiştir. Avantaj: sınıflandırma için eğitilmediğinden başka görevlere daha iyi transfer edebilir; ve kritik olarak **kendi etiketsiz verinde** ön-eğitip **az etiketle** sınıflandırıcıyı eğitebilirsin (Canziani 48:28) — etiketler pahalı. Az-etiket deneyi (100/316/1000): rastgele ~%10, supervised ~%20-30, **SSL ~2 katı** (Falcon 1:08:13); SSL daha hızlı yakınsar. Hafta 10'un "az etiketle öğren" tezinin deneysel kanıtı.
:::
::: {.callout-note collapse="true" title="Soru 5: Bu bonus neden SwAV/BYOL \"kullanır\" ama ana kurs onları \"post-2020 yok\" der? Kursun bütün ipliği nereye varır?"}
**Cevap:** Çünkü bu bonus ana kurstan (Mart 2020) **biraz sonra** (~Haz/Tem 2020) çekilmiştir; SwAV/BYOL Haziran 2020'de doğmuştur, yani bonusun çekildiği anda **henüz yeni** ama mevcut (atıf notunda işaretlendi). Ana derslerin "kursta yok" dedikleri Mart-2020 tarihine göredir. Kursun bütün ipliği — Hafta 7-9 (EBM), 10 (SSL pretext), 12 (BERT pre-train→fine-tune), 14 (serbest enerji) — buraya, **öz-denetimli ön-eğitim + transfer** paradigmasına varır; ve post-2020'de DINO/MAE/DINOv2 + foundation models (CLIP/SAM/GPT) ile evrenselleşir.
:::
## Egzersizler {#sec-egzersiz-d15}
**Egzersiz 1 (Karar ağacı).** Üç senaryo için "sıfırdan eğit / supervised transfer / self-supervised transfer" seç ve gerekçelendir: (a) 50 etiketli röntgen, (b) 1M etiketli doğal görüntü, (c) 500K etiketsiz + 200 etiketli kendi şirket verisi. Veri-dağılımı eşleşmesi her birinde neden belirleyici?
```python
import numpy as np
# Karar agaci: (veri_miktari, etiketli_mi, dagilim_eslesiyor_mu) -> oneri
senaryolar = {
"(a) 50 etiketli rontgen": dict(az_veri=True, ImageNet_eslesir=False, etiketsiz_var=False),
"(b) 1M etiketli dogal goruntu": dict(az_veri=False, ImageNet_eslesir=True, etiketsiz_var=False),
"(c) 500K etiketsiz + 200 etiketli sirket": dict(az_veri=True, ImageNet_eslesir=False, etiketsiz_var=True),
}
def oner(az_veri, ImageNet_eslesir, etiketsiz_var):
if not az_veri:
return "SIFIRDAN EGIT (cok veri -> transfer gereksiz)"
if etiketsiz_var:
return "SELF-SUPERVISED TRANSFER (kendi etiketsiz verinde SwAV on-egit + az etiketle siniflandir)"
if ImageNet_eslesir:
return "SUPERVISED TRANSFER (ImageNet omurga dondur + linear probe)"
return "DIKKAT: dagilim eslesmiyor (ImageNet != rontgen); domain-eslesen on-egitim ara / self-supervised dene"
for ad, kw in senaryolar.items():
print(ad, "->", oner(**kw))
# (a) rontgen: ImageNet dagilimi ESLESMEZ -> kor transfer ETMEZ; domain-ozgu on-egitim sart.
# (b) 1M dogal: cok veri -> sifirdan; ayrica ImageNet eslesir ama transfere gerek yok.
# (c) sirket: etiketsiz BOL -> SSL on-egit, sonra 200 etiketle siniflandir (az-etiket zaferi).
```
**Egzersiz 2 (Freeze vs fine-tune).** CIFAR-10'da pre-trained ResNet-50 ile (a) backbone-dondurulmuş linear probe ve (b) tam fine-tune (düşük öğrenme oranı) eğit. Az veri (100) vs çok veri (50K) senaryolarında hangisi kazanır, neden? `torch.no_grad()` (a)'da neyi hızlandırır?
```python
import numpy as np
# Illustratif: az veri (100) vs cok veri (50K) -> freeze vs fine-tune dogrulugu
veri = {"az (100)": dict(freeze=0.62, finetune=0.55), # az veri: freeze KAZANIR (az parametre, az overfit)
"cok (50K)": dict(freeze=0.78, finetune=0.91)} # cok veri: fine-tune KAZANIR (tum ag ayarlanir)
for rejim, d in veri.items():
kazanan = "freeze" if d["freeze"] > d["finetune"] else "fine-tune"
print(f"{rejim:10s}: freeze={d['freeze']:.2f} fine-tune={d['finetune']:.2f} -> {kazanan}")
# AZ veri -> freeze (linear probe): yalniz kafa egitilir, az parametre = az overfit.
# COK veri -> fine-tune: omurga cozulur (unfreeze) + dusuk LR, tum ag goreve uyarlanir.
# torch.no_grad(): donuk omurgada hesaplama grafigi TUTULMAZ -> ileri gecis hizli + az bellek.
```
**Egzersiz 3 (Lightning'e çevir).** Düz PyTorch eğitim döngüsünü (forward→loss→backward→step→zero_grad) bir LightningModule'e (`training_step` + `configure_optimizers`) çevir. Trainer hangi 4 işlemi senin yerine yapar? `fast_dev_run` ne işe yarar?
```python
# Duz PyTorch (boilerplate) vs Lightning (soyut) — kavramsal cevrim (statik, calistirmak gerekmez)
# --- DUZ PYTORCH: elle dongu ---
# for epoch in range(N):
# for x, y in loader:
# optimizer.zero_grad() # 1) gradyani sifirla
# out = model(x) # ileri gecis
# loss = criterion(out, y) # kayip
# loss.backward() # 2) geri yayilim
# optimizer.step() # 3) parametre guncelle
# # 4) epoch/batch dongusu = elle
# --- LIGHTNING: yalniz iki sey ---
# class Net(pl.LightningModule):
# def training_step(self, batch, idx): # bir batch -> KAYIP dondur (tum sistem mantigi)
# x, y = batch
# loss = criterion(self(x), y)
# self.log("train_loss", loss) # metrik + multi-GPU senkron
# return loss
# def configure_optimizers(self):
# return torch.optim.Adam(self.parameters())
# trainer = pl.Trainer(fast_dev_run=True) # tek batch hizli debug
# trainer.fit(net, loader)
print("Trainer'in OTOMATIK yaptigi 4 islem: zero_grad, backward, optimizer.step, epoch/batch dongusu")
print("fast_dev_run=True: tek batch ileri+geri gecis -> kodu saniyede dogrula (tam egitim oncesi debug)")
# Egitim dongusu modelin ICINE tasinir; multi-GPU/TPU kod degismeden gelir.
```
**Egzersiz 4 (Az-etiket eğrisi).** SwAV-pretrain, supervised-pretrain ve rastgele backbone'u 100/316/1000 etiketle eğitip validation doğruluğunu çiz. SSL'in avantajı etiket sayısı azaldıkça neden **artar**? Hafta 10 Misra ile ilişkilendir.
```python
import numpy as np
n_labels = np.array([100, 316, 1000])
random_acc = np.array([10.0, 11.0, 12.5]) # rastgele backbone (~%10)
supervised = np.array([19.0, 26.0, 33.0]) # ImageNet supervised pre-train
ssl_swav = np.array([40.0, 50.0, 60.0]) # SwAV SSL pre-train (~2x supervised)
oran = ssl_swav / supervised # SSL / supervised orani
for n, s, ss, o in zip(n_labels, supervised, ssl_swav, oran):
print(f"{n:5d} etiket: supervised {s:.0f}% SSL {ss:.0f}% oran x{o:.2f}")
print("SSL avantaji en AZ etikette en buyuk:", n_labels[np.argmax(oran)], "etikette x", round(float(oran.max()),2))
# SSL etiketsiz veriden temsil ogrendigi icin az-etikette siniflandirici zaten iyi ozniteliklerle baslar.
# Etiket azaldikca supervised omurga cokerken SSL omurga ayakta kalir -> fark BUYUR.
# Hafta 10 (Misra/PIRL): "az etiketle ogren" pretext gorevlerinin TAM bu deneysel kaniti.
```
**Egzersiz 5 (Kurs sentezi — KAPANIŞ).** Tüm kursu tek cümlede birleştir: Hafta 1 (manifold) → Hafta 7-9 (EBM) → Hafta 10-12 (SSL/Transformer) → Hafta 13 (GCN) → Hafta 14 (serbest enerji) → Hafta 15 (transfer). LeCun'un "enerji + öz-denetim" programının bu 15 haftadaki izini sür; bugünkü foundation models bu programın neresinde durur?
```python
# KURS SENTEZI (KAPANIS) — 15 haftanin tek iplikte ozeti (statik)
program = [
("Hafta 1", "manifold hipotezi", "veri dusuk-boyutlu manifoldda yasar (temsil)"),
("Hafta 2-5", "backprop / autograd", "gradyanla enerji minimizasyonu"),
("Hafta 6", "RNN / attention", "dizi + odak"),
("Hafta 7-9", "EBM OMURGA (AE/VAE/GAN)", "enerji tasarla: dogruyu bastir, yanlisi it"),
("Hafta 10", "SSL pretext", "etiketsiz veriden ogren"),
("Hafta 11", "aktivasyon/kayip/PPUU", "marj + belirsizlik"),
("Hafta 12", "Transformer (BERT)", "pre-train -> fine-tune"),
("Hafta 13", "GCN", "graf uzerinde mesaj gecisi"),
("Hafta 14", "serbest enerji = VAE", "gizliyi marjinalleştir (F = <E> - T*H)"),
("Hafta 15", "transfer learning", "omurga yeniden kullan + SSL az-etiket zaferi"),
]
for h, konu, ozet in program:
print(f"{h:9s} {konu:26s} {ozet}")
print()
print("TEK PROGRAM: bir enerji tasarla, dogruyu bastir, yanlisi marjla it, gizliyi marjinalleştir,")
print(" ve ETIKETSIZ veriden ogren.")
print("Foundation models (CLIP/SAM/GPT, post-2020) = bu programin dev-olcekli, evrensel hali (KURSTA YOK).")
```
## Kurs Tamamlandı 🎓 {#sec-kurs-tamamlandi}
::: {.callout-important title="🎓 NYU Deep Learning (DLSP20) — 15/15 Hafta Tamamlandı"}
**Bu bonus dersle birlikte, LeCun ve Canziani'nin tüm kursu Türkçe öğretim setine dönüştü:** manifold geometriden (Hafta 1) enerji-tabanlı modellere (Hafta 7-9), attention/Transformer'dan (Hafta 12) graph neural net'lere (Hafta 13), varyasyonel serbest enerjiden (Hafta 14) transfer learning'e (Hafta 15).
**Kurs sonrası yapılacak:** Egzersiz 5 (kurs sentezi) ile 15 haftayı tek iplikte topla; "Enerji tasarla, doğruyu bastır, yanlışı marjla it, gizliyi marjinalleştir" cümlesini her hafta için örnekle; post-2020 köprülerini (JEPA, diffusion, DINO/MAE, foundation models) kursun hangi temeline oturduğunu yaz.
:::
@fig-course-synthesis-map tüm kursu tek bir haritada toplar: Hafta 1 (manifold) → Hafta 7-9 (EBM omurga) → Hafta 10-12 (SSL/Transformer) → Hafta 13-15 (graf/sentez/transfer), merkezde **enerji + öz-denetim** birleştirici çatısı (LeCun programı) ve sağ altta post-2020 (JEPA/diffusion/DINO/foundation) bu 15 haftanın ürünü olarak işaretli.
```{python}
#| label: fig-course-synthesis-map
#| fig-cap: "Kurs sentez haritası — 15 haftada tek program (H1 → H15, KURSU KAPATAN FLAGSHIP). Üst sıra temeller (H1 manifold → H2 backprop → H3 ConvNet → H5 autograd → H6 RNN/attention, violet açık); orta katman EBM omurga (H7-H9 autoencoder · VAE · GAN, violet koyu) + SSL/Transformer (H10 pretext, H11 aktivasyon/PPUU, H12 Transformer, gold); alt sıra graf/sentez/transfer (H13 GCN → H14 serbest enerji = VAE → H15 transfer, violet-gold). Merkezde 'ENERJİ + ÖZ-DENETİM' (LeCun programı); sağ altta post-2020 (JEPA/diffusion/DINO/foundation, KURSTA YOK). Tek program: enerji tasarla, doğruyu bastır, yanlışı marjla it, gizliyi marjinalleştir, etiketsiz veriden öğren."
np.random.seed(0)
fig, ax = plt.subplots(figsize=(13, 7.2))
ax.set_xlim(0, 13)
ax.set_ylim(0, 7.4)
ax.axis("off")
fig.patch.set_facecolor(COL_WHITE)
# Renk grupları
C_TEMEL = "#9b5fc7" # temeller H1-H6 (violet açık)
C_TEMEL_FC = "#efe5f8"
C_OMURGA = COL_VIOLET_D # EBM omurga H7-9 (violet koyu)
C_OMURGA_FC = "#e0cdf0"
C_SSL = COL_GOLD_D # SSL/transformer H10-12 (gold)
C_SSL_FC = "#f8edcf"
C_SENTEZ = COL_VIOLET # graf/sentez/transfer H13-15 (violet-gold)
C_SENTEZ_FC = "#e8d8f4"
# Düğüm tanımları: (id, etiket, x, y, grup_renk, dolgu)
nodes = {
"H1": ("H1\nmanifold", 1.15, 6.35, C_TEMEL, C_TEMEL_FC),
"H2": ("H2\nbackprop", 3.15, 6.35, C_TEMEL, C_TEMEL_FC),
"H3": ("H3\nConvNet", 5.15, 6.35, C_TEMEL, C_TEMEL_FC),
"H5": ("H5\nautograd", 7.15, 6.35, C_TEMEL, C_TEMEL_FC),
"H6": ("H6\nRNN/attention", 9.35, 6.35, C_TEMEL, C_TEMEL_FC),
# EBM omurga (gruplanmış kutu içinde)
"H79": ("H7–H9 EBM OMURGA\nautoencoder · VAE · GAN", 2.55, 4.15, C_OMURGA, C_OMURGA_FC),
# SSL / transformer
"H10": ("H10\nSSL pretext", 6.35, 4.25, C_SSL, C_SSL_FC),
"H11": ("H11\naktivasyon/PPUU", 8.55, 4.25, C_SSL, C_SSL_FC),
"H12": ("H12\nTransformer", 10.75, 4.25, C_SSL, C_SSL_FC),
# graf / sentez / transfer
"H13": ("H13\nGCN", 2.4, 1.7, C_SENTEZ, C_SENTEZ_FC),
"H14": ("H14\nserbest enerji = VAE", 5.4, 1.7, C_SENTEZ, C_SENTEZ_FC),
"H15": ("H15\ntransfer learning", 8.45, 1.7, C_SENTEZ, C_SENTEZ_FC),
}
bw, bh = 1.55, 0.92
omurga_w, omurga_h = 3.4, 1.05
node_box = {} # id -> (cx, cy, w, h) bağlantı için
for nid, (lbl, x, y, ec, fc) in nodes.items():
if nid == "H79":
w, h = omurga_w, omurga_h
lw = 3.0
elif nid == "H14":
w, h = 2.05, bh
lw = 2.3
else:
w, h = bw, bh
lw = 2.3
box = FancyBboxPatch(
(x - w / 2, y - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=lw, zorder=3,
)
ax.add_patch(box)
fs = 10.5 if nid == "H79" else 9.0
fw = "bold" if nid == "H79" else "normal"
ax.text(x, y, lbl, ha="center", va="center", fontsize=fs,
color=COL_INK if nid == "H79" else COL_TEXT,
fontweight=fw, zorder=4)
node_box[nid] = (x, y, w, h)
def arrow(a, b, color=COL_VIOLET_M, lw=2.0, style="-|>", rad=0.0, zorder=2, alpha=1.0):
xa, ya, wa, ha_ = node_box[a]
xb, yb, wb, hb = node_box[b]
# bağlantı noktalarını kutu kenarına yaklaştır
dx, dy = xb - xa, yb - ya
# kaynak kenarı
pa = (xa + np.clip(dx, -wa / 2, wa / 2) * 0.95,
ya + np.clip(dy, -ha_ / 2, ha_ / 2) * 0.95)
pb = (xb - np.clip(dx, -wb / 2, wb / 2) * 0.95,
yb - np.clip(dy, -hb / 2, hb / 2) * 0.95)
ax.add_patch(FancyArrowPatch(
pa, pb, arrowstyle=style, mutation_scale=15,
color=color, lw=lw, zorder=zorder, alpha=alpha,
connectionstyle=f"arc3,rad={rad}",
))
# Üst sıra zinciri (temeller)
arrow("H1", "H2"); arrow("H2", "H3"); arrow("H3", "H5"); arrow("H5", "H6")
# Temellerden EBM omurgaya iniş
arrow("H2", "H79", color=COL_VIOLET, lw=2.2, rad=0.12)
arrow("H6", "H79", color=COL_VIOLET, lw=2.0, rad=-0.18)
# EBM omurgadan SSL/transformer sırasına
arrow("H79", "H10", color=COL_GOLD_D, lw=2.2, rad=-0.08)
arrow("H10", "H11", color=COL_GOLD_D, lw=2.0)
arrow("H11", "H12", color=COL_GOLD_D, lw=2.0)
# Alt sıra sentez/transfer
arrow("H79", "H13", color=COL_VIOLET, lw=2.0, rad=0.15)
arrow("H13", "H14", color=C_SENTEZ, lw=2.0)
arrow("H14", "H15", color=C_SENTEZ, lw=2.0)
arrow("H12", "H15", color=COL_GOLD_D, lw=2.0, rad=0.15)
# H14 serbest enerji ← EBM omurga halkası
arrow("H79", "H14", color=COL_VIOLET_D, lw=1.8, rad=-0.3, alpha=0.85)
# ---------------------------------------------------------------------------
# MERKEZ büyük kutu: ENERJİ + ÖZ-DENETİM (LeCun programı)
# ---------------------------------------------------------------------------
cx, cy, cw, ch = 6.55, 3.05, 3.5, 0.0 # yalnız ölçek referansı
center = FancyBboxPatch(
(4.55, 2.55), 4.0, 0.95,
boxstyle="round,pad=0.03,rounding_size=0.14",
fc=COL_VIOLET, ec=COL_GOLD, lw=3.2, zorder=6,
)
ax.add_patch(center)
ax.text(6.55, 3.02, "ENERJİ + ÖZ-DENETİM", ha="center", va="center",
fontsize=13.5, color=COL_WHITE, fontweight="bold", zorder=7)
ax.text(6.55, 2.72, "(LeCun programı)", ha="center", va="center",
fontsize=9.5, color=COL_GOLD, fontstyle="italic", zorder=7)
# Merkeze yumuşak bağlar (omurga + SSL + sentez → merkez)
for nid in ("H79", "H10", "H14"):
xn, yn, wn, hn = node_box[nid]
ax.add_patch(FancyArrowPatch(
(xn, yn), (6.55, 3.02),
arrowstyle="-", mutation_scale=1,
color=COL_GRID, lw=1.2, ls=(0, (4, 3)), zorder=1, alpha=0.6,
connectionstyle="arc3,rad=0.0",
))
# ---------------------------------------------------------------------------
# Sağ alt: post-2020 soluk kesikli kutu
# ---------------------------------------------------------------------------
post = FancyBboxPatch(
(10.0, 0.55, ), 2.7, 1.15,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="#faf6fe", ec=COL_VIOLET_M, lw=1.6, ls=(0, (5, 3)), zorder=2, alpha=0.95,
)
ax.add_patch(post)
ax.text(11.35, 1.32, "post-2020", ha="center", va="center", fontsize=9.5,
color=COL_VIOLET_M, fontweight="bold", zorder=3, fontstyle="italic")
ax.text(11.35, 0.95, "JEPA · diffusion\nDINO · foundation", ha="center", va="center",
fontsize=8.3, color=COL_TEXT, zorder=3)
# H15'ten post-2020'ye soluk ok
ax.add_patch(FancyArrowPatch(
(9.35, 1.55), (10.0, 1.25),
arrowstyle="-|>", mutation_scale=13,
color=COL_VIOLET_M, lw=1.6, ls=(0, (4, 2)), zorder=2, alpha=0.8,
connectionstyle="arc3,rad=-0.15",
))
# ---------------------------------------------------------------------------
# Grup renk lejantı (sol üst köşe)
# ---------------------------------------------------------------------------
leg_items = [
("temeller H1–H6", C_TEMEL, C_TEMEL_FC),
("EBM omurga H7–H9", C_OMURGA, C_OMURGA_FC),
("SSL/Transformer H10–H12", C_SSL, C_SSL_FC),
("graf/sentez/transfer H13–H15", C_SENTEZ, C_SENTEZ_FC),
]
# Yatay lejant — temeller sırası ile EBM omurga arasındaki temiz banda yerleştir
ly0 = 5.05
lx0 = 0.45
col_w = 3.15
for i, (txt, ec, fc) in enumerate(leg_items):
xx = lx0 + i * col_w
ax.add_patch(FancyBboxPatch(
(xx, ly0 - 0.12), 0.30, 0.24,
boxstyle="round,pad=0.0,rounding_size=0.05",
fc=fc, ec=ec, lw=1.8, zorder=5,
))
ax.text(xx + 0.42, ly0, txt, ha="left", va="center", fontsize=8.0,
color=COL_TEXT, zorder=5)
# ---------------------------------------------------------------------------
# Başlık + kapanış annotation
# ---------------------------------------------------------------------------
ax.text(6.5, 7.15, "Kurs Sentez Haritası — 15 Haftada Tek Program (H1 → H15)",
ha="center", va="center", fontsize=14.5, color=COL_INK, fontweight="bold")
annot = ("Tek program: enerji tasarla, doğruyu bastır, yanlışı marjla it, "
"gizliyi marjinalleştir, etiketsiz veriden öğren.\n"
"post-2020 (JEPA · diffusion · DINO · foundation) bu 15 haftanın ürünü.")
ax.add_patch(FancyBboxPatch(
(0.3, 0.18), 9.4, 0.62,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=COL_BG, ec=COL_GOLD_D, lw=1.5, zorder=2,
))
ax.text(0.5, 0.49, annot, ha="left", va="center", fontsize=8.6,
color=COL_TEXT, zorder=3, linespacing=1.4)
plt.tight_layout()
plt.show()
```
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d15}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Ne zaman transfer | Az veri → pre-trained; dağılım eşleşmeli | Falcon 4:58 |
| Transfer = omurga + kafa | Önceden eğitilmiş omurga + üstüne yeni sınıflandırıcı | Falcon 5:35 |
| Freeze (linear probe) | Omurga dondur; öznitelik çıkarıcı; lineer ayrılabilir | Falcon 16:55 |
| Fine-tune | Omurga çöz, düşük öğrenme oranı; çok veri | Falcon 40:22 |
| torch.no_grad | Graf tutma; hızlı + az bellek | Canziani 20:24 |
| LightningModule | training_step + configure_optimizers | Falcon 24:53 |
| Trainer | epoch/backward/step/zero_grad otomatik | Falcon 31:08 |
| fast_dev_run | Tek batch hata-ayıklama | Falcon 42:20 |
| SwAV (SSL omurga) | Etiketsiz ön-eğitim; 3000 öznitelik | Falcon 46:03 |
| SSL kendi-veri avantajı | Etiketsiz kendi veride ön-eğit + az etiket | Canziani 48:28 |
| Az-etiket zaferi | SSL ~2× supervised; daha hızlı | Falcon 1:08 |
| SSL yöntemleri | MoCo/PIRL/SimCLR/BYOL/SwAV | Falcon 6:59 |
## ML Builder Bağlantıları {#sec-koprular-d15}
**Geriye köprüler:**
1. **Pre-train → fine-tune** → Hafta 10 (SSL) + 12 (BERT) + 14 (transfer vs fine-tune).
2. **SSL yöntemleri (PIRL/MoCo/SimCLR)** → Hafta 8-9 (contrastive) + 10 (PIRL=Misra).
3. **ResNet / freeze / linear probe** → Hafta 3/9 (residual) + 10 (linear probe).
4. **training_step döngüsü** → Hafta 5 (autograd: forward→loss→backward→step).
5. **Az-etiket SSL avantajı** → Hafta 10 (az etiketle öğren tezi).
**İleriye köprüler:**
1. **SwAV/BYOL** → **DINO/MAE/DINOv2 (post-2020, KURSTA YOK)**.
2. **Omurga + transfer** → **foundation models (CLIP/SAM/GPT, post-2020)**.
3. **Lightning/Bolts** → araştırma-üretim köprüsü; reproducible SSL.
4. **Kendi-veri SSL** → endüstride etiket-tasarrufu, alan-uyarlama.
::: {.callout-important title="Bu dersten — ve bu kurstan — tek bir şey alıp gideceksen"}
Transfer learning, başka (büyük) veride eğitilmiş bir omurgayı alıp kendi az verinde yeniden kullanmaktır — dağılımlar eşleştiği sürece omurgayı dondurup (linear probe) ya da ince ayar yaparak; ve PyTorch Lightning bunu boilerplate'siz, çok-GPU'lu yapar. Asıl ders şu: **öz-denetimli ön-eğitim (SwAV), etiketli ön-eğitimi — özellikle az-etiket rejiminde ~2 kat — geçer**, çünkü kendi etiketsiz verinde eğitilebilir. Bu, kursun Hafta 10'dan beri savunduğu tezin pratik zaferidir: öz-denetim, pahalı etiketleri atlayıp verinin kendi yapısından öğrenir. Ve böylece kurs kapanır — manifold geometriden (Hafta 1) enerji-tabanlı modellere (Hafta 7-9), Transformer'dan (Hafta 12) graph net'lere (Hafta 13), serbest enerjiden (Hafta 14) transfer'e (Hafta 15): hepsi tek bir programın parçaları — **bir enerji tasarla, doğruyu bastır, yanlışı marjla it, gizliyi marjinalleştir, ve etiketsiz veriden öğren**. Bu temelin post-2020 zirvesi (DINO, MAE, diffusion, foundation models, JEPA) kursta yoktur ama bu 15 haftanın tohumlarının doğrudan ürünüdür.
:::