---
title: "Konvolüsyonun Cebiri ve Optimizasyon (SGD, Momentum, Adam)"
subtitle: "NYU'nun bu haftaki iki sesi: Alfredo Canziani convolution'a lineer cebir gözüyle döner — convolution aslında *özel yapılı (Toeplitz) bir matrisle çarpımdır*, yani 'bir sürü sıfırı olan bir matris çarpımı'; sonra konuk araştırmacı Aaron Defazio (Facebook AI Research) sahneyi devralır ve o matrisleri (ağı) *nasıl* eğittiğimizin pratik motorunu anlatır — gradient descent'ten SGD'ye, momentum'a, ve modern adaptif yöntemlere (RMSprop, Adam)"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Canziani'nin Lecture videosu:** [YouTube — Convolution as linear algebra (Toeplitz)](https://www.youtube.com/watch?v=OrBEon3VlQg) (≈51 dk)
- **Konuk Lecture (Aaron Defazio):** [YouTube — Optimization for deep learning](https://www.youtube.com/watch?v=--NZb480zlg) (≈89 dk)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Alfredo Canziani (convolution cebiri) + **Aaron Defazio** (konuk, optimizasyon — FAIR)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈30 dk
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan build_toeplitz / conv1d / quad_loss / quad_grad / optimize_quad +
# COL_* + apply_style / draw_pipeline / style_legend / CLASS_COLORS
# isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Patch,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d4}
Bu hafta iki bağımsız ama tamamlayıcı parça var. Önce **Alfredo Canziani** convolution'a Hafta 3'te bıraktığımız soruyla geri döner: convolution aslında *nedir* — lineer cebir diliyle? Cevap zarif: convolution, **özel yapılı (Toeplitz) bir matrisle çarpmaktır** — yani "bir sürü sıfırı olan bir matris çarpımı". Sonra konuk bir optimizasyon araştırmacısı, **Aaron Defazio** (Facebook AI Research; PhD Australian National University) sahneyi devralır ve ağları *nasıl* eğittiğimizin pratik motorunu anlatır: gradient descent'ten SGD'ye, momentum'a, ve modern adaptif yöntemlere (RMSprop, Adam).
> ⚠️ **Atıf notu:** Bu haftanın optimizasyon dersi (Lecture) **LeCun değil, konuk Aaron Defazio** tarafından verilir (transkriptten doğrulandı: "research scientist at Facebook working on optimization, PhD ANU"). Quote'lar bu yüzden **— Defazio** ile işaretlenir.
Bu haftanın üç ana fikri:
1. **Convolution = Toeplitz matrisiyle çarpım.** Tam-bağlı katmanla aynı çatı; tek fark, matrisin paylaşımlı + seyrek (çoğu sıfır) olmasıdır.
2. **SGD + momentum, modern eğitimin belkemiğidir.** Tam-batch gradient descent neredeyse hiç kullanılmaz; momentum'u ($\beta \approx 0.9$) "neredeyse her zaman" açarsın.
3. **Adaptif yöntemler (Adam) per-weight öğrenme oranı verir** — ve en çok kullanılan yöntem olmasına rağmen teorisi tartışmalıdır ("optimization'ı tam anlamıyoruz").
```{mermaid}
%%| echo: false
flowchart TB
subgraph Cebir["(A) Convolution'ın cebiri (Canziani)"]
direction LR
FC["Tam-bağlı matris<br/>(her girdi her çıktıya)"]
Zorla["'Yerel + paylaşımlı'<br/>olmaya zorla"]
Toep["Toeplitz matrisi<br/>(seyrek: çoğu eleman sıfır)"]
Conv["Convolution<br/>= bir sürü sıfırlı çarpım"]
FC -- "kısıtla" --> Zorla
Zorla --> Toep
Toep --> Conv
end
subgraph Opt["(B) Optimizasyon merdiveni (Defazio)"]
direction LR
GD["Gradient Descent<br/>(κ kötüyse zikzak)"]
SGD["SGD<br/>(veri artıklığını sömür)"]
Mom["+ Momentum<br/>(salınımı söndür)"]
Adapt["+ Adaptif / RMSprop<br/>(per-weight ölçek)"]
Adam["Adam<br/>= RMSprop + Momentum"]
Zanaat["'Zanaat, teori değil'<br/>(tam anlamıyoruz)"]
GD --> SGD
SGD --> Mom
Mom --> Adapt
Adapt --> Adam
Adam --> Zanaat
end
Conv -. "bu matrisi (ağı) nasıl eğitiriz?" .-> GD
```
::: {.callout-tip title="Builder Notu — İki Yarı: Cebir ve Motor"}
**Geriye (önkoşul kurslar):**
- **Convolution = Toeplitz matris** → 18.06 matris-vektör çarpımı + Hafta 3 Egzersiz 5 (convolution = kısıtlı lineer katman) + Phase 2 18.065 yapılı matrisler.
- **Condition number $\kappa = L/\mu$** → 18.06 özdeğer (en büyük/en küçük) + 18.065 koşullanma.
- **Momentum** → Calculus ivme (ikinci türev sezgisi) + fizik (Newton).
**İleriye (production / research):**
- Toeplitz görüşü → convolution'ın FFT ile hızlı hesabı, structured matrices.
- SGD+momentum / Adam → her modern eğitim hattının optimizer seçimi; LR schedule, warmup.
**Tek cümleyle:** Convolution özel yapılı bir matris çarpımıdır; ve o matrisi (ağı) eğitmek, gradient descent'i SGD + momentum + adaptif ölçeklemeyle pratiğe döken — ama teorisi hâlâ tam oturmamış — bir optimizasyon zanaatıdır.
:::
## (Canziani) Lineer Cebir Recap: Matris × Vektör'ün İki Görüşü {#sec-iki-gorus}
Canziani convolution'ı kurmadan önce matris-vektör çarpımını iki farklı gözle okutuyor. Afin dönüşüm $z = Ax$ (bias'ı matrisin içine gömerek). Bu çarpıma iki türlü bakılır:
1. **Satır görüşü:** çıktının her elemanı, $A$'nın bir **satırı** ile girdinin iç çarpımıdır — yani "girdinin o satırla ne kadar hizalı olduğu". Canziani'nin vurgusu: bir lineer katmanda **kernel, matrisin tam bir satırıdır**.
> "whenever you have a linear layer, your kernel is going to be the whole row of the matrix." — Canziani, 13:31
2. **Sütun görüşü:** çıktı, $A$'nın **sütunlarının** girdi katsayılarıyla ağırlıklı toplamıdır:
$$
A\mathbf{x} = \sum_{j} x_j\, \mathbf{a}_j
$$
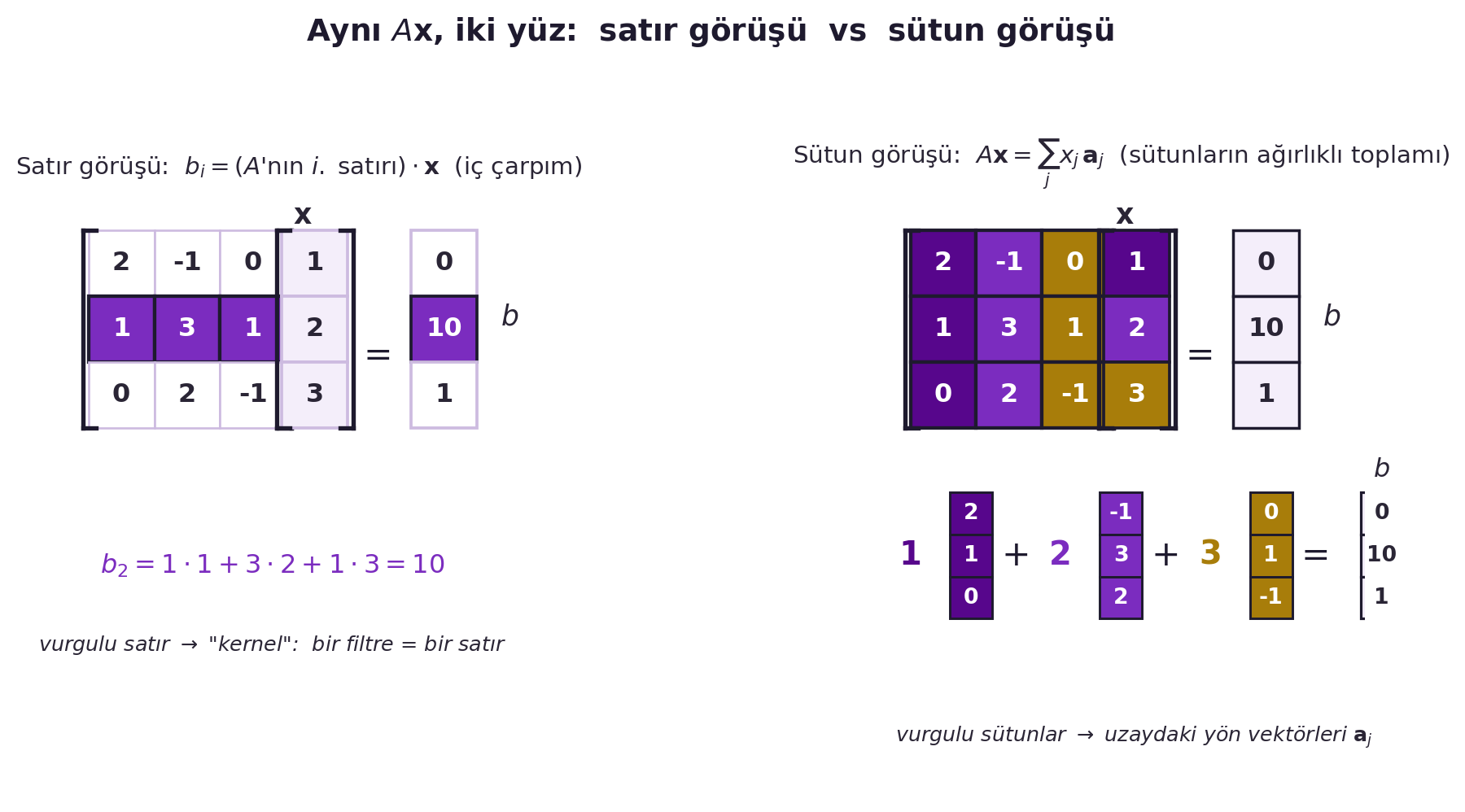
Bu iki görüş aynı işlemin iki yüzü; convolution'ı anlamak için birincisi (satır = kernel) kritiktir. @fig-row-column-view aynı 3×3 sayısal $A\mathbf{x}$ çarpımını iki panelde yan yana koyar: solda satır·girdi iç çarpımı (vurgulu satır = kernel), sağda sütunların $\mathbf{x}$ katsayılarıyla ağırlıklı toplamı.
```{python}
#| label: fig-row-column-view
#| fig-cap: "Aynı $A\\mathbf{x}$ çarpımının iki yüzü. SOL (satır görüşü): çıktının her elemanı $b_i$, $A$'nın $i.$ satırı ile $\\mathbf{x}$'in iç çarpımıdır; vurgulu satır convolution'daki \"kernel\" rolündedir — bir filtre tam olarak bir satıra karşılık gelir. SAĞ (sütun görüşü): $A\\mathbf{x}=\\sum_j x_j\\,\\mathbf{a}_j$, yani $A$'nın sütunlarının $\\mathbf{x}$ ağırlıklarıyla toplamıdır; sütunlar uzaydaki yön vektörleridir. Aynı sonuç ($b=[0,10,1]$), iki farklı okuma — convolution sezgisi için \"kernel = satır\" yorumu kritiktir."
A = np.array([[2.0, -1.0, 0.0],
[1.0, 3.0, 1.0],
[0.0, 2.0, -1.0]])
x = np.array([1.0, 2.0, 3.0])
b = A @ x # [0, 10, 1] — satır görüşü = sütun görüşü, aynı sonuç
ROW_COLORS = [COL_VIOLET, COL_VIOLET_M, COL_GOLD_D]
COL_COLORS = [COL_VIOLET, COL_VIOLET_M, COL_GOLD_D]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11.5, 5.2))
fig.suptitle("Aynı $A\\mathbf{x}$, iki yüz: satır görüşü vs sütun görüşü",
color=COL_INK, fontsize=14, fontweight="bold", y=0.99)
def draw_matrix(ax, M, x0, y0, cell, highlight_rows=None, highlight_cols=None,
row_colors=None, col_colors=None, fmt="{:.0f}"):
nr, nc = M.shape
for i in range(nr):
for j in range(nc):
fc, ec, lw = COL_WHITE, COL_GRID, 1.0
if highlight_rows is not None and i in highlight_rows:
fc = row_colors[i] if row_colors else COL_BG
ec, lw = COL_INK, 1.6
if highlight_cols is not None and j in highlight_cols:
fc = col_colors[j] if col_colors else COL_BG
ec, lw = COL_INK, 1.6
rx, ry = x0 + j * cell, y0 - i * cell
ax.add_patch(Rectangle((rx, ry), cell, cell, fc=fc, ec=ec, lw=lw, zorder=2))
tcol = COL_WHITE if (fc not in (COL_WHITE, COL_BG)) else COL_TEXT
ax.text(rx + cell / 2, ry + cell / 2, fmt.format(M[i, j]),
ha="center", va="center", fontsize=12, color=tcol,
fontweight="bold", zorder=3)
ax.plot([x0 - 0.04, x0 - 0.04], [y0 - (nr - 1) * cell, y0 + cell], color=COL_INK, lw=2)
ax.plot([x0 - 0.04, x0 + 0.06], [y0 + cell, y0 + cell], color=COL_INK, lw=2)
ax.plot([x0 - 0.04, x0 + 0.06], [y0 - (nr - 1) * cell, y0 - (nr - 1) * cell], color=COL_INK, lw=2)
rxend = x0 + nc * cell
ax.plot([rxend + 0.04, rxend + 0.04], [y0 - (nr - 1) * cell, y0 + cell], color=COL_INK, lw=2)
ax.plot([rxend + 0.04, rxend - 0.06], [y0 + cell, y0 + cell], color=COL_INK, lw=2)
ax.plot([rxend + 0.04, rxend - 0.06], [y0 - (nr - 1) * cell, y0 - (nr - 1) * cell], color=COL_INK, lw=2)
def draw_vector(ax, vec, x0, y0, cell, colors=None, fmt="{:.0f}", default_fc=COL_WHITE):
n = len(vec)
for i in range(n):
fc = colors[i] if colors else default_fc
ec = COL_INK if colors else COL_GRID
ry = y0 - i * cell
ax.add_patch(Rectangle((x0, ry), cell, cell, fc=fc, ec=ec, lw=1.4, zorder=2))
tcol = COL_WHITE if (colors and fc not in (COL_WHITE, COL_BG)) else COL_TEXT
ax.text(x0 + cell / 2, ry + cell / 2, fmt.format(vec[i]),
ha="center", va="center", fontsize=12, color=tcol,
fontweight="bold", zorder=3)
ax.plot([x0 - 0.04, x0 - 0.04], [y0 - (n - 1) * cell, y0 + cell], color=COL_INK, lw=2)
ax.plot([x0 - 0.04, x0 + 0.06], [y0 + cell, y0 + cell], color=COL_INK, lw=2)
ax.plot([x0 - 0.04, x0 + 0.06], [y0 - (n - 1) * cell, y0 - (n - 1) * cell], color=COL_INK, lw=2)
rxend = x0 + cell
ax.plot([rxend + 0.04, rxend + 0.04], [y0 - (n - 1) * cell, y0 + cell], color=COL_INK, lw=2)
ax.plot([rxend + 0.04, rxend - 0.06], [y0 + cell, y0 + cell], color=COL_INK, lw=2)
ax.plot([rxend + 0.04, rxend - 0.06], [y0 - (n - 1) * cell, y0 - (n - 1) * cell], color=COL_INK, lw=2)
cell = 0.5
# ---------- SOL: Satır görüşü ----------
axL.set_title("Satır görüşü: $b_i = (A$'nın $i.$ satırı$)\\cdot\\mathbf{x}$ (iç çarpım)",
color=COL_TEXT, fontsize=11, pad=8)
hi_row = 1
Ly0 = 4.6
draw_matrix(axL, A, x0=0.15, y0=Ly0, cell=cell,
highlight_rows=[hi_row], row_colors=ROW_COLORS)
axL.text(1.78, Ly0 + 0.55, "$\\mathbf{x}$", color=COL_TEXT, fontsize=13, ha="center")
draw_vector(axL, x, x0=1.62, y0=Ly0, cell=cell, default_fc=COL_BG)
axL.text(2.35, Ly0 - 0.45, "=", color=COL_INK, fontsize=16, ha="center", va="center")
for i in range(3):
fc = ROW_COLORS[i] if i == hi_row else COL_WHITE
ec = COL_INK if i == hi_row else COL_GRID
ry = Ly0 - i * cell
axL.add_patch(Rectangle((2.6, ry), cell, cell, fc=fc, ec=ec, lw=1.4, zorder=2))
tc = COL_WHITE if i == hi_row else COL_TEXT
axL.text(2.6 + cell / 2, ry + cell / 2, "{:.0f}".format(b[i]),
ha="center", va="center", fontsize=12, color=tc, fontweight="bold", zorder=3)
axL.text(2.6 + cell + 0.18, Ly0 - 0.22, "$b$", color=COL_TEXT, fontsize=13, ha="left")
rowvals = A[hi_row]
expr = "$b_2 = {:.0f}\\cdot{:.0f} + {:.0f}\\cdot{:.0f} + {:.0f}\\cdot{:.0f} = {:.0f}$".format(
rowvals[0], x[0], rowvals[1], x[1], rowvals[2], x[2], b[hi_row])
axL.text(1.55, 2.55, expr, ha="center", va="center", fontsize=12,
color=ROW_COLORS[hi_row], fontweight="bold")
axL.text(1.55, 1.95, "vurgulu satır $\\to$ \"kernel\": bir filtre = bir satır",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, style="italic")
axL.set_xlim(-0.1, 3.6); axL.set_ylim(0.8, 5.4)
axL.axis("off"); axL.set_aspect("equal")
# ---------- SAĞ: Sütun görüşü ----------
axR.set_title("Sütun görüşü: $A\\mathbf{x} = \\sum_j x_j\\,\\mathbf{a}_j$ (sütunların ağırlıklı toplamı)",
color=COL_TEXT, fontsize=11, pad=8)
my0 = 4.6
draw_matrix(axR, A, x0=0.15, y0=my0, cell=cell,
highlight_cols=[0, 1, 2], col_colors=COL_COLORS)
axR.text(1.78, my0 + 0.55, "$\\mathbf{x}$", color=COL_TEXT, fontsize=13, ha="center")
draw_vector(axR, x, x0=1.62, y0=my0, cell=cell, colors=COL_COLORS)
axR.text(2.35, my0 - 0.45, "=", color=COL_INK, fontsize=16, ha="center", va="center")
for i in range(3):
ry = my0 - i * cell
axR.add_patch(Rectangle((2.6, ry), cell, cell, fc=COL_BG, ec=COL_INK, lw=1.3, zorder=2))
axR.text(2.6 + cell / 2, ry + cell / 2, "{:.0f}".format(b[i]),
ha="center", va="center", fontsize=12, color=COL_TEXT, fontweight="bold", zorder=3)
axR.text(2.6 + cell + 0.18, my0 - 0.22, "$b$", color=COL_TEXT, fontsize=13, ha="left")
# alt bant: x1*a1 + x2*a2 + x3*a3 = b
mc = 0.32
y_top = 2.15
xpos = 0.15
mid_y = y_top + 1.5 * mc
for j in range(3):
axR.text(xpos, mid_y, "{:.0f}".format(x[j]), color=COL_COLORS[j],
fontsize=15, fontweight="bold", ha="center", va="center")
xpos += 0.30
for i in range(3):
ry = y_top + (2 - i) * mc
axR.add_patch(Rectangle((xpos, ry), mc, mc, fc=COL_COLORS[j],
ec=COL_INK, lw=1.1, zorder=2))
axR.text(xpos + mc / 2, ry + mc / 2, "{:.0f}".format(A[i, j]),
ha="center", va="center", fontsize=10, color=COL_WHITE,
fontweight="bold", zorder=3)
xpos += mc + 0.18
if j < 2:
axR.text(xpos, mid_y, "+", color=COL_INK, fontsize=16, ha="center", va="center")
xpos += 0.34
axR.text(xpos, mid_y, "=", color=COL_INK, fontsize=16, ha="center", va="center")
xpos += 0.34
for i in range(3):
ry = y_top + (2 - i) * mc
axR.add_patch(Rectangle((xpos, ry), mc, mc, fc=COL_BG, ec=COL_INK, lw=1.2, zorder=2))
axR.text(xpos + mc / 2, ry + mc / 2, "{:.0f}".format(b[i]),
ha="center", va="center", fontsize=10, color=COL_TEXT, fontweight="bold", zorder=3)
axR.text(xpos + mc / 2, y_top + 3 * mc + 0.12, "$b$", color=COL_TEXT, fontsize=12, ha="center")
axR.text(1.85, 1.25, "vurgulu sütunlar $\\to$ uzaydaki yön vektörleri $\\mathbf{a}_j$",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, style="italic")
axR.set_xlim(-0.1, 3.6); axR.set_ylim(0.8, 5.4)
axR.axis("off"); axR.set_aspect("equal")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
```
::: {.callout-tip title="Builder Notu — Satır = Kernel"}
**Geriye (18.06):** Bu, 18.06'nın "matris çarpımının satır vs sütun yorumu" dersidir. Satır görüşü = iç çarpım/projeksiyon; sütun görüşü = sütun uzayı (column space). İkisi de aynı $A\mathbf{x}$.
**İleriye:** "Kernel = satır" görüşü, convolution'ı tam-bağlı katmanın özel bir hâli olarak görmenin anahtarıdır (Bölüm 3).
:::
## (Canziani) Convolution = Toeplitz Matrisi {#sec-toeplitz}
Şimdi convolution'ı bir matrise çeviriyoruz. Diyelim küçük bir kernel (boyut 3) ile çok uzun bir sinyali convolve edeceğiz. Bunu bir matris çarpımı olarak yazmak istersek, kernel'i her satırda **bir konum kaydırarak** yerleştiririz; geri kalan her yer **sıfırdır**. Ortaya çıkan matrisin özel bir adı var:
> "this is going to be called a Toeplitz matrix." — Canziani, 23:36
**Toeplitz matrisi:** her köşegeni sabit olan, kernel'in kaydırılarak tekrarlandığı matris. İki temel özelliği:
- **Seyrek (sparse):** her satırda yalnızca kernel boyutu kadar sıfır-olmayan eleman var (gerisi sıfır) — bu, **locality** (Hafta 3) demektir.
- **Paylaşımlı:** her satır aynı kernel'i içerir, sadece kaydırılmış — bu, **stationarity / parameter sharing** demektir.
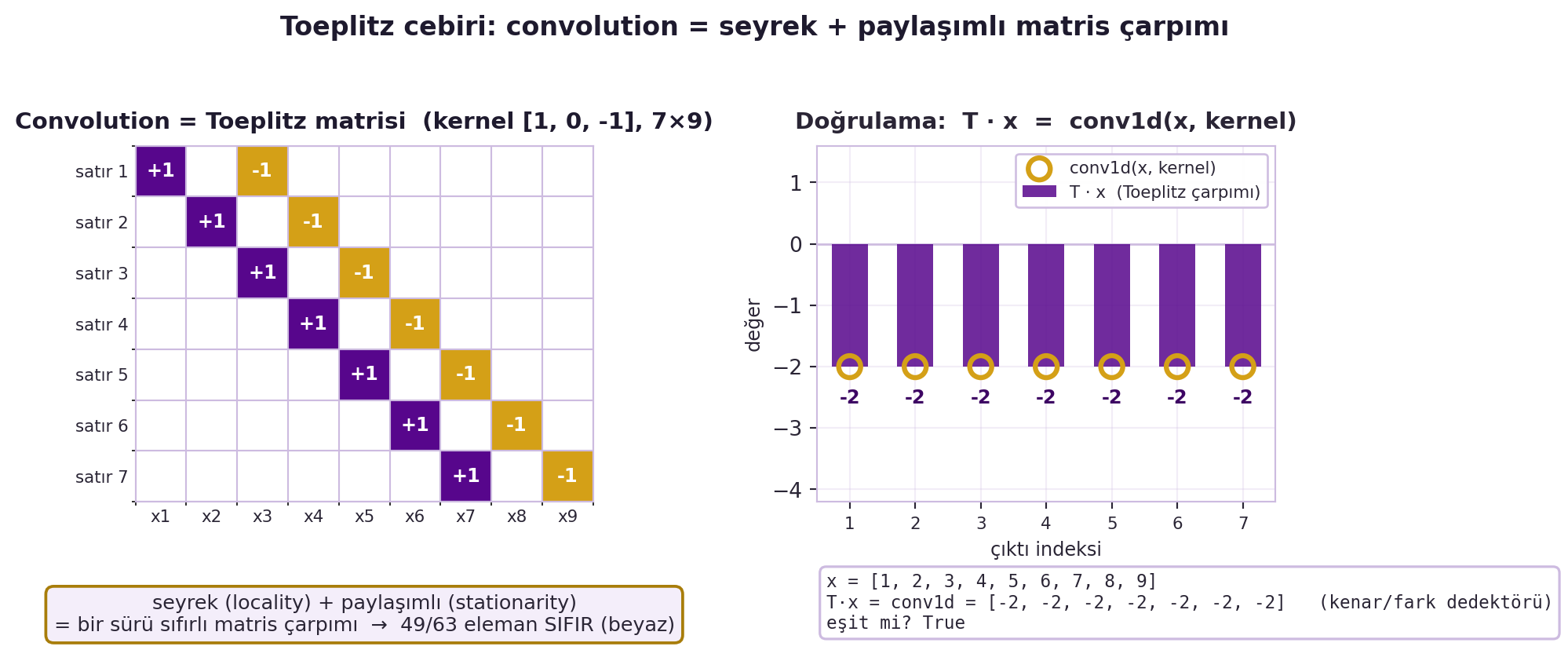
Yani convolution'ı icat etmemize gerek yok: tam-bağlı bir katman alıp matrisini "yerel + paylaşımlı" olmaya zorlarsan, kendiliğinden convolution'ı yeniden keşfedersin. @fig-toeplitz bu fikri somutlaştırır: solda kernel $[1, 0, -1]$'in $7 \times 9$ Toeplitz matrisi (elemanların çoğu sıfır = beyaz), sağda $T\mathbf{x}$ ile doğrudan `conv1d`'nin birebir aynı kenar/fark çıktısını verdiği doğrulama.
```{python}
#| label: fig-toeplitz
#| fig-cap: "1B convolution'ın Toeplitz matrisi olarak yazılışı. Solda kernel [1, 0, −1]'in n=9 girdi için ürettiği 7×9 Toeplitz matrisi: her satır kernel'i bir kaydırılmış kopyasıdır (violet +1, gold −1), 63 elemanın 49'u sıfır (beyaz). Bu seyreklik (locality, yereldelik) ve satır-paylaşımı (stationarity, durağanlık) convolution'ı çok sayıda sıfır içeren bir matris çarpımına indirger. Sağda doğrulama: T·x ile conv1d(x, kernel) birebir aynı kenar/fark çıktısını ([−2]×7) verir."
kernel = [1, 0, -1]
n = 9
T = build_toeplitz(kernel, n) # (7, 9) Toeplitz matrisi
x = np.arange(1, n + 1, dtype=float) # [1,2,3,4,5,6,7,8,9]
y_T = T @ x # Toeplitz çarpımı
y_conv = conv1d(x, kernel) # doğrudan convolution
n_zeros = int(np.sum(T == 0))
n_total = T.size
# --- Figür: solda Toeplitz seyrekliği (imshow), sağda T@x == conv doğrulaması ---
fig, (axM, axV) = plt.subplots(
1, 2, figsize=(11, 4.8), gridspec_kw={"width_ratios": [1.55, 1.0]}
)
# === Sol: Toeplitz matrisi (seyreklik) ===
# Renk: non-zero → işaret bazlı (pozitif violet, negatif gold); zero → beyaz
disp = np.zeros_like(T)
disp[T > 0] = 1.0 # +1 katsayı
disp[T < 0] = -1.0 # -1 katsayı
cmap = ListedColormap([COL_GOLD, COL_WHITE, COL_VIOLET]) # -1, 0, +1
norm = BoundaryNorm([-1.5, -0.5, 0.5, 1.5], cmap.N)
axM.imshow(disp, cmap=cmap, norm=norm, aspect="equal")
# her hücreye katsayıyı yaz
oh, ncol = T.shape
for i in range(oh):
for j in range(ncol):
val = T[i, j]
if val != 0:
axM.text(j, i, f"{int(val):+d}", ha="center", va="center",
fontsize=9, color=COL_WHITE, fontweight="bold", zorder=3)
# ızgara çizgileri (hücre sınırları)
axM.set_xticks(np.arange(-0.5, ncol, 1), minor=True)
axM.set_yticks(np.arange(-0.5, oh, 1), minor=True)
axM.grid(which="minor", color=COL_GRID, linewidth=0.8)
axM.set_xticks(range(ncol))
axM.set_yticks(range(oh))
axM.set_xticklabels([f"x{k+1}" for k in range(ncol)], fontsize=8, color=COL_TEXT)
axM.set_yticklabels([f"satır {k+1}" for k in range(oh)], fontsize=8, color=COL_TEXT)
axM.set_title(f"Convolution = Toeplitz matrisi (kernel {kernel}, {oh}×{ncol})",
fontsize=11, color=COL_INK, fontweight="bold", pad=8)
axM.tick_params(length=0)
for sp in axM.spines.values():
sp.set_color(COL_GRID)
# seyreklik annotation
axM.text(
0.5, -0.26,
f"seyrek (locality) + paylaşımlı (stationarity)\n"
f"= bir sürü sıfırlı matris çarpımı → {n_zeros}/{n_total} eleman SIFIR (beyaz)",
transform=axM.transAxes, ha="center", va="top", fontsize=9.5,
color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_GOLD_D, lw=1.4),
)
# === Sağ: T @ x == conv1d(x, kernel) doğrulaması ===
axV.axis("off")
axV.set_title("Doğrulama: T · x = conv1d(x, kernel)",
fontsize=11, color=COL_INK, fontweight="bold", pad=8)
idx = np.arange(oh)
axV.set_xlim(-0.5, oh - 0.5)
axV.set_ylim(min(y_T.min(), -3) - 1.2, max(y_T.max(), 1) + 0.6)
# T@x noktaları (violet) ve conv1d (gold halka) — üst üste düşer
axV.bar(idx, y_T, width=0.55, color=COL_VIOLET, alpha=0.85,
label="T · x (Toeplitz çarpımı)", zorder=2)
axV.scatter(idx, y_conv, s=110, facecolors="none", edgecolors=COL_GOLD,
linewidths=2.4, label="conv1d(x, kernel)", zorder=4)
axV.axhline(0, color=COL_GRID, lw=1.0, zorder=1)
for i in idx:
axV.text(i, y_T[i] - 0.35, f"{int(y_T[i])}", ha="center", va="top",
fontsize=9, color=COL_VIOLET_D, fontweight="bold")
axV.set_xticks(idx)
axV.set_xticklabels([f"{k+1}" for k in idx], fontsize=8, color=COL_TEXT)
axV.set_xlabel("çıktı indeksi", fontsize=9, color=COL_TEXT)
axV.set_ylabel("değer", fontsize=9, color=COL_TEXT)
apply_style(axV)
axV.axis("on")
for sp in axV.spines.values():
sp.set_color(COL_GRID)
style_legend(axV, loc="upper right", fontsize=8)
# x girdi vektörünü ve eşitliği yaz
axV.text(
0.02, -0.20,
f"x = {x.astype(int).tolist()}\n"
f"T·x = conv1d = {y_T.astype(int).tolist()} (kenar/fark dedektörü)\n"
f"eşit mi? {np.allclose(y_T, y_conv)}",
transform=axV.transAxes, ha="left", va="top", fontsize=8.5,
color=COL_TEXT, family="monospace",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_WHITE, ec=COL_GRID, lw=1.2),
)
fig.suptitle("Toeplitz cebiri: convolution = seyrek + paylaşımlı matris çarpımı",
fontsize=12.5, color=COL_INK, fontweight="bold", y=1.00)
fig.tight_layout(rect=[0, 0.04, 1, 0.97])
plt.show()
```
::: {.callout-tip title="Builder Notu — Toeplitz = Kısıtlı Matris"}
**Geriye (Hafta 3 + 18.06):** Bu, Hafta 3 Egzersiz 5'in cevabıdır: convolution = Toeplitz (yapısı kısıtlanmış) matris. Hafta 3'ün "locality → sparsity, stationarity → parameter sharing" eşlemesi, Toeplitz matrisin sıfır deseni + tekrar deseni olarak somutlaşır.
**İleriye:** Toeplitz/dolaşım (circulant) matrisler **Fourier dönüşümüyle köşegenleşir** — convolution'ın FFT ile $O(n \log n)$ hesabının temeli budur (18.065 spectral köprüsü, Hafta 13).
:::
## (Canziani) "Bir Sürü Sıfırlı Matris Çarpımı" {#sec-sifirli-carpim}
Canziani'nin özlü kapanışı:
> "a convolution is just a matrix multiplication with a lot of zeros — that's it." — Canziani, 27:55
Tam-bağlı katman ile convolution katmanı **aynı çatıdadır** (ikisi de $A\mathbf{x}$). Tek fark:
- **Tam-bağlı:** kernel = matrisin **tam satırı** (her girdiye bağlı, paylaşım yok) → çok parametre.
- **Convolution:** kernel = küçük, kaydırılan pencere (Toeplitz) → seyrek + paylaşımlı → az parametre.
Canziani "listening to convolutions" demosunda bir ses sinyalini bir kernel'le convolve edip sonucu dinletir — convolution'ın somut, işitilebilir etkisini gösterir. Özet: compositionality + locality + stationarity sayesinde matris-vektör çarpımını seyrek, yerel, paylaşımlı bir Toeplitz matrise indirgeyerek **convolution operatörünü yeniden keşfederiz**.
::: {.callout-tip title="Builder Notu — Sıfırlı Matris Çarpımı"}
**Geriye (Hafta 2-3):** Convolution bir modül olduğundan (Hafta 2), backprop onun için de otomatik çalışır; Toeplitz görüşü, convolution'ın geri geçişinin de yine bir convolution (transpoze kernel) olduğunu açıklar — "forward $W$, backward $W^\top$" (Hafta 2) convolution'a taşınır.
**İleriye:** "Convolution = yapılı matris" görüşü, donanımda neden convolution'ın özel kernel'lerle (im2col + GEMM, ya da Winograd/FFT) hızlandırıldığını açıklar.
:::
## Geçiş: Canziani'den Defazio'ya (Konuk Optimizasyon Dersi) {#sec-gecis-d4}
Convolution'ın *ne* olduğunu (yapılı matris) gördük. Şimdi konu değişiyor: bu matrisleri (ağı) **nasıl eğitiriz**? Bu haftanın ikinci yarısı, konuk bir optimizasyon araştırmacısı **Aaron Defazio**'ya ait. Hafta 2'de SGD'yi tanımıştık; Defazio onu derinleştirip pratikte gerçekten kullandığımız yöntemlere (momentum, Adam) götürüyor. Üslubu açıkça pratik:
> "optimization is at the heart of machine learning... I'm going to focus on the application of these methods rather than the theory, part of the reason is that we don't fully understand all of these methods." — Defazio, 0:45
## (Defazio) Gradient Descent ve Condition Number {#sec-condition-number}
Defazio gradient descent'i hatırlatıp asıl sorunu gösteriyor: yakınsama hızı, problemin **koşullanmasına (conditioning)** bağlıdır. Kuadratik bir problemde bu, Hessian'ın en büyük ($L$) ve en küçük ($\mu$) özdeğerlerinin oranıyla ölçülür — **condition number**:
$$
\kappa = \frac{L}{\mu}
$$
$\kappa$ büyükse ($\kappa = \frac{L}{\mu}$ kötü koşullanmış) gradient descent zikzak çizer ve yavaşlar. Learning rate seçimi de bir gerilimdir: mümkün olduğunca büyük istersin (hızlı öğrenme) ama çok büyükse ıraksar — yani sürekli "ıraksamanın eşiğinde" çalışırsın.
> "we want to use learning rates as large as possible to get as quick learning as possible, so we're always at the edge of divergence." — Defazio, 13:42
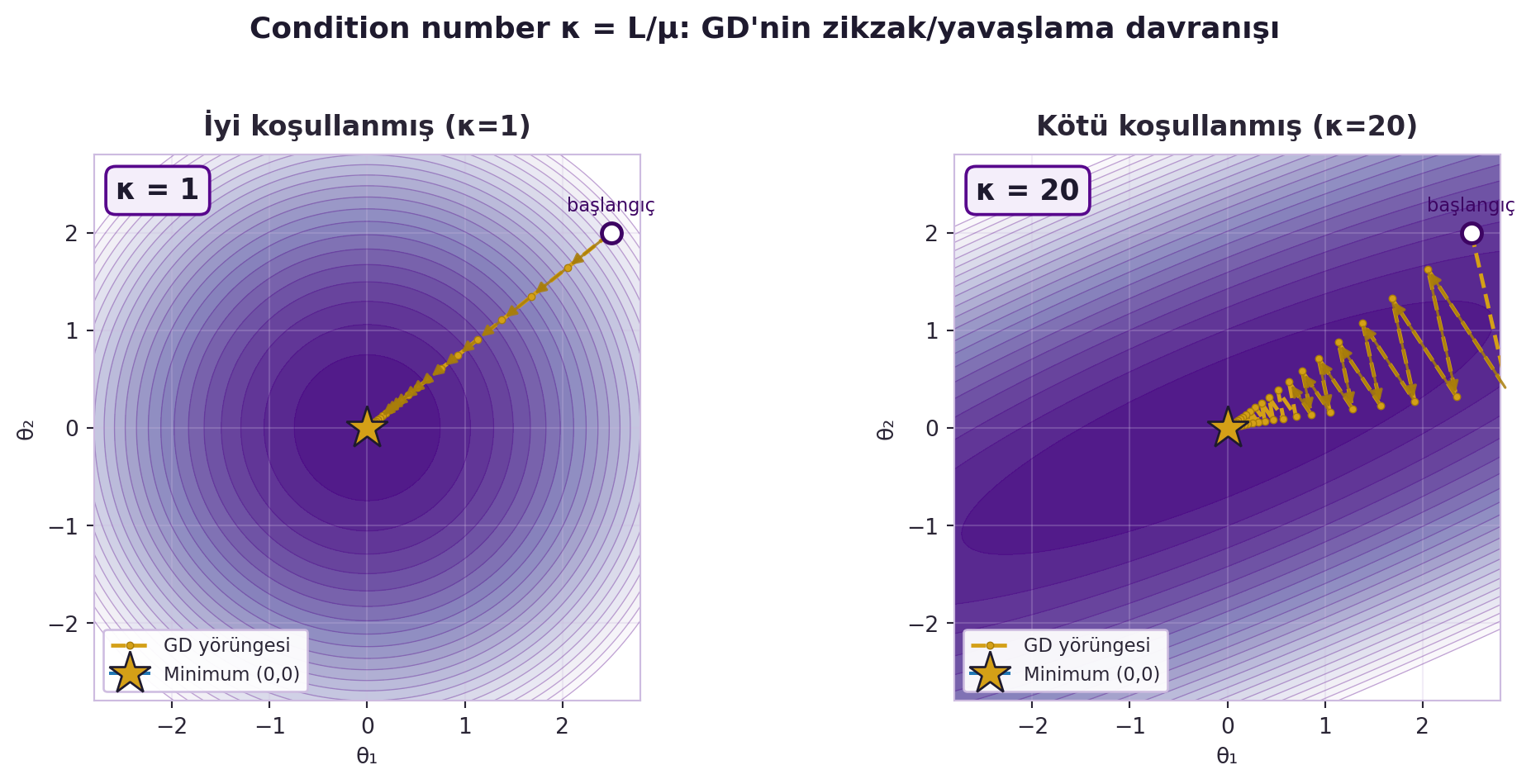
İlginç bir gözlem: "güzel davranan" (salınmayan) düşük bir learning rate, çoğu zaman çözümden daha *uzakta* bırakır; iyi sonuç için rahatsız edici derecede yüksek oranlarla yaşamak gerekir. @fig-condition-number iki uçta aynı GD'yi gösterir: solda $\kappa=1$ (yuvarlak çukur, düz iniş), sağda $\kappa=20$ (uzun ince vadi, zikzak).
```{python}
#| label: fig-condition-number
#| fig-cap: "Condition number κ = L/μ ve gradient descent davranışı. SOL panel (κ=1, iyi koşullanmış): kayıp yüzeyi yuvarlak bir çukurdur; GD yörüngesi başlangıçtan (2,5, 2,0) minimuma (0,0) neredeyse düz iner — her adım doğru yöne bakar. SAĞ panel (κ=20, kötü koşullanmış): aynı kayıp uzun ve ince bir vadiye dönüşür; GD vadinin dik duvarları arasında zikzak çizerek minimuma yavaş yaklaşır. Mesaj: κ büyüdükçe (öz değerlerin oranı bozuldukça) düz gradient descent zikzaklaşır ve yavaşlar — Defazio'nun momentum/adaptif yöntemleri motive eden temel gözlemi."
np.random.seed(0)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.8))
lim = 2.8
gx = np.linspace(-lim, lim, 320)
gy = np.linspace(-lim, lim, 320)
XX, YY = np.meshgrid(gx, gy)
def _panel(ax, kappa, lr, title):
Z = quad_loss(XX, YY, kappa=kappa)
levels = np.linspace(Z.min(), np.percentile(Z, 96), 22)
ax.contourf(XX, YY, Z, levels=levels, cmap="Purples_r", alpha=0.92)
ax.contour(XX, YY, Z, levels=levels, colors=COL_VIOLET, linewidths=0.5, alpha=0.35)
path, _ = optimize_quad("gd", [2.5, 2.0], lr=lr, steps=60, kappa=kappa)
ax.plot(path[:, 0], path[:, 1], color=COL_GOLD, lw=1.8, ls="--",
marker="o", ms=3.2, mfc=COL_GOLD, mec=COL_GOLD_D, mew=0.5,
zorder=5, label="GD yörüngesi")
for i in range(min(14, len(path) - 1)):
p0, p1 = path[i], path[i + 1]
ax.annotate("", xy=(p1[0], p1[1]), xytext=(p0[0], p0[1]),
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D,
lw=1.2, alpha=0.85), zorder=6)
ax.plot(0, 0, marker="*", ms=20, mfc=COL_GOLD, mec=COL_INK, mew=1.0,
zorder=8, label="Minimum (0,0)")
ax.plot(2.5, 2.0, marker="o", ms=9, mfc=COL_WHITE, mec=COL_VIOLET_D,
mew=1.8, zorder=7)
ax.text(2.5, 2.18, "başlangıç", ha="center", va="bottom",
fontsize=8.5, color=COL_VIOLET_D, zorder=9)
ax.text(0.04, 0.96, f"κ = {kappa:g}", transform=ax.transAxes,
ha="left", va="top", fontsize=13, color=COL_INK, weight="bold",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BG, ec=COL_VIOLET, lw=1.4),
zorder=10)
ax.set_title(title, color=COL_INK, fontsize=12.5, weight="bold", pad=9)
ax.set_xlim(-lim, lim)
ax.set_ylim(-lim, lim)
ax.set_aspect("equal")
ax.set_xlabel("θ₁", color=COL_TEXT, fontsize=10)
ax.set_ylabel("θ₂", color=COL_TEXT, fontsize=10)
apply_style(ax)
style_legend(ax, loc="lower left", fontsize=8.5)
_panel(axL, kappa=1.0, lr=0.18, title="İyi koşullanmış (κ=1)")
_panel(axR, kappa=20.0, lr=0.095, title="Kötü koşullanmış (κ=20)")
fig.suptitle("Condition number κ = L/μ: GD'nin zikzak/yavaşlama davranışı",
color=COL_INK, fontsize=13.5, weight="bold", y=1.02)
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — κ = Koşullanma"}
**Geriye (18.06 + 18.065):** Condition number $\kappa = L/\mu$ doğrudan 18.06 özdeğer dünyasıdır; kötü koşullanma, özdeğerlerin çok farklı ölçeklerde olması demektir (uzun, ince vadi). 18.065 (Matrix Methods) bunu ML bağlamında ele alır.
**İleriye:** Learning rate, en kritik hyperparameter'dır; warmup + decay schedule, "ıraksama eşiği"nde güvenli kalmanın pratiğidir.
:::
## (Defazio) SGD: "Gradient Descent Kullanma" {#sec-sgd-d4}
Hafta 2'de SGD'yi tanımıştık; Defazio çok daha keskin: pratikte tam-batch gradient descent neredeyse hiç kullanılmaz.
> "it's hard to come up with a compelling reason to use gradient descent given the success of stochastic gradient descent... if you need to do full batch optimization, do not use gradient descent — I can't emphasize it enough." — Defazio, 19:03 / 21:48
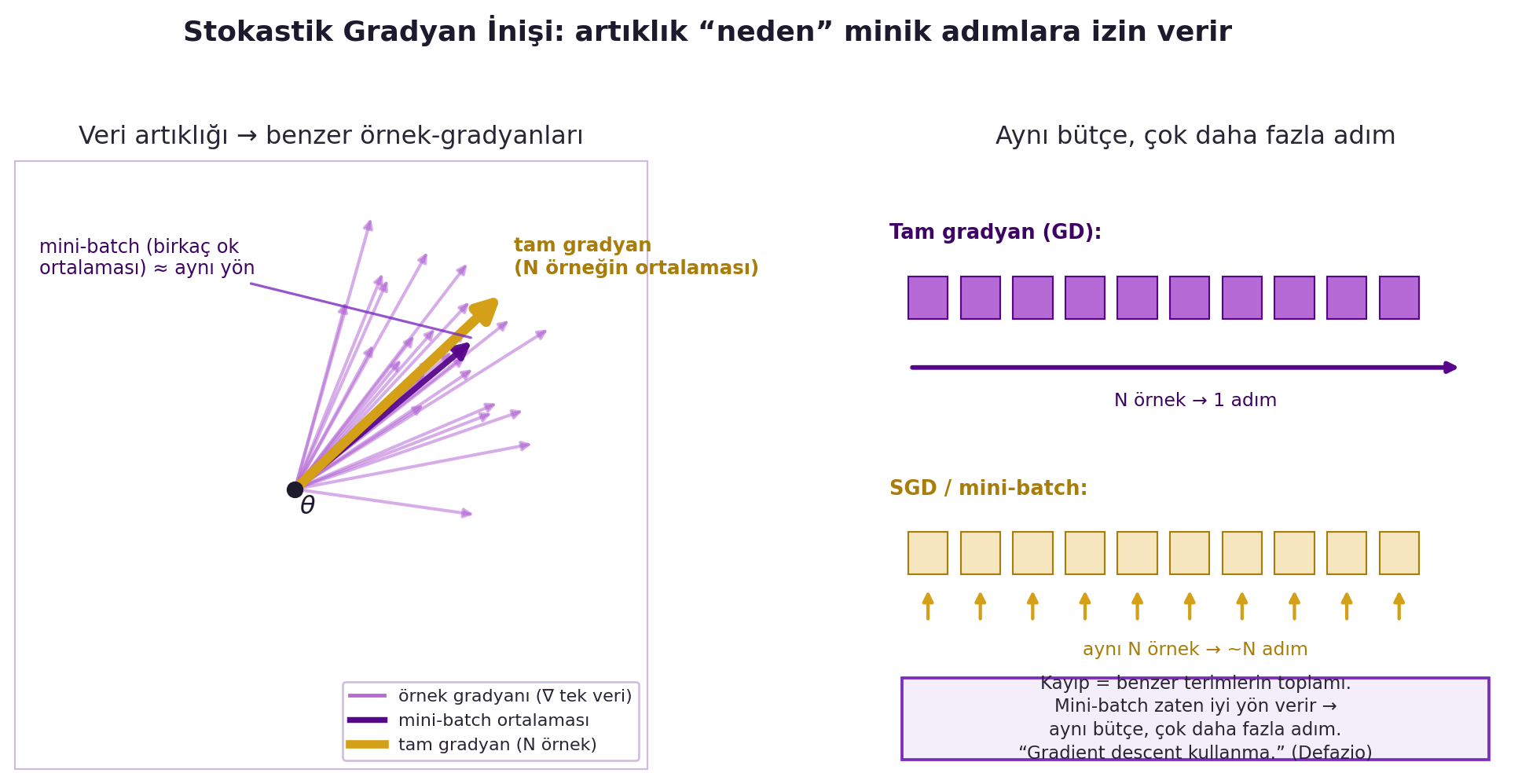
Neden? Çünkü makine öğrenmesi kaybı, **çok sayıda benzer terimin toplamıdır** (her veri noktası bir terim). Bu yapıda veri **artıklığı (redundancy)** vardır — yüzlerce benzer örnek aynı yönü gösterir; hepsini taramak israftır. SGD bu artıklığı sömürür: küçük bir mini-batch zaten iyi bir yön verir, ve aynı bütçeyle çok daha fazla adım atarsın. Defazio'nun inceliği: SGD "gürültülü gradient descent" değildir; gürültünün kendine has bir dinamiği vardır (vadi tabanında "zıplama"). @fig-sgd-redundancy bunu görselleştirir: solda çok sayıda benzer örnek-gradyanı ve ortalaması, sağda aynı bütçenin GD'de 1 adıma karşı SGD'de ~N adıma dönüşmesi.
```{python}
#| label: fig-sgd-redundancy
#| fig-cap: "Stokastik gradyan inişinin sezgisi: veri artıklığı. Sol panelde tek-veri örnek-gradyanları (soluk violet oklar) birbirine yakın yönleri gösterir; bunların ortalaması tam gradyandır (kalın gold ok), birkaç okun ortalaması olan mini-batch ise zaten neredeyse aynı yönü verir (orta violet ok). Sağ panel aynı örnek-okuma bütçesinin GD'de tek bir adıma karşılık SGD/mini-batch'te ~N adıma dönüştüğünü gösterir. Defazio: kayıp benzer terimlerin toplamı olduğundan mini-batch erkenden iyi yön verir — aynı bütçeyle çok daha fazla adım atılır."
fig, (axL, axR) = plt.subplots(
1, 2, figsize=(11.0, 5.2),
gridspec_kw={"width_ratios": [1.35, 1.0]}
)
# ---------------------------------------------------------------------------
# SOL PANEL — veri artıklığı: çok sayıda benzer gradyan oku + ortalaması
# ---------------------------------------------------------------------------
apply_style(axL)
axL.set_xlim(-1.15, 1.45)
axL.set_ylim(-1.15, 1.35)
axL.set_aspect("equal")
axL.set_xticks([])
axL.set_yticks([])
origin = np.array([0.0, 0.0])
# Tam gradyan = N benzer örnek-gradyanının ortalaması.
# Ortak ana yön (sağ-üst) + her örneğe küçük açısal sapma → "birbirine yakın yönler bulutu".
base_dir = np.array([0.86, 0.62])
base_dir = base_dir / np.linalg.norm(base_dir)
n_grads = 26
angles = np.random.normal(0.0, 0.30, n_grads) # küçük açısal dağılım (~17°)
mags = np.random.normal(1.0, 0.16, n_grads) # benzer büyüklükler
sample_vecs = []
for ang, mag in zip(angles, mags):
c, s = np.cos(ang), np.sin(ang)
R = np.array([[c, -s], [s, c]])
v = (R @ base_dir) * mag * 0.95
sample_vecs.append(v)
axL.add_patch(FancyArrowPatch(
origin, v, arrowstyle="-|>", mutation_scale=9,
color=COL_VIOLET_SOFT, lw=1.5, alpha=0.55, zorder=2,
))
sample_vecs = np.array(sample_vecs)
# Mini-batch = birkaç okun ortalaması ≈ aynı yön (orta violet, daha kalın)
mb_idx = [2, 5, 9, 14]
mb_avg = sample_vecs[mb_idx].mean(axis=0)
axL.add_patch(FancyArrowPatch(
origin, mb_avg, arrowstyle="-|>", mutation_scale=15,
color=COL_VIOLET, lw=2.8, alpha=0.95, zorder=4,
))
axL.annotate(
"mini-batch (birkaç ok\nortalaması) ≈ aynı yön",
xy=mb_avg, xytext=(-1.05, 0.95),
fontsize=9.0, color=COL_VIOLET_D, va="center", ha="left",
arrowprops=dict(arrowstyle="-", color=COL_VIOLET_M, lw=1.2, alpha=0.8),
zorder=6,
)
# Tam gradyan = TÜM okların ortalaması (kalın gold ok)
full_avg = sample_vecs.mean(axis=0)
full_dir = full_avg / np.linalg.norm(full_avg) * 1.18
axL.add_patch(FancyArrowPatch(
origin, full_dir, arrowstyle="-|>", mutation_scale=22,
color=COL_GOLD, lw=4.6, zorder=5,
))
axL.add_patch(FancyArrowPatch(
origin, full_dir, arrowstyle="-|>", mutation_scale=22,
color=COL_GOLD_D, lw=4.6, zorder=4.5, alpha=0.35,
))
axL.text(
full_dir[0] + 0.04, full_dir[1] + 0.06,
"tam gradyan\n(N örneğin ortalaması)",
fontsize=9.2, color=COL_GOLD_D, fontweight="bold",
va="bottom", ha="left", zorder=6,
)
# Başlangıç noktası işareti
axL.plot([0], [0], "o", ms=7, color=COL_INK, zorder=7)
axL.text(0.02, -0.10, "θ", fontsize=12, color=COL_INK, style="italic", zorder=7)
axL.set_title(
"Veri artıklığı → benzer örnek-gradyanları",
color=COL_TEXT, fontsize=12, pad=8,
)
# Manuel legend (renk anlamı)
handles = [
Line2D([0], [0], color=COL_VIOLET_SOFT, lw=1.8, label="örnek gradyanı (∇ tek veri)"),
Line2D([0], [0], color=COL_VIOLET, lw=2.8, label="mini-batch ortalaması"),
Line2D([0], [0], color=COL_GOLD, lw=4.0, label="tam gradyan (N örnek)"),
]
leg = axL.legend(handles=handles, loc="lower right", frameon=True,
framealpha=0.95, edgecolor=COL_GRID, fontsize=8.3)
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
# ---------------------------------------------------------------------------
# SAĞ PANEL — bütçe karşılaştırması: aynı maliyet, çok daha fazla adım
# ---------------------------------------------------------------------------
axR.set_xlim(0, 1)
axR.set_ylim(0, 1)
axR.axis("off")
axR.set_title("Aynı bütçe, çok daha fazla adım", color=COL_TEXT, fontsize=12, pad=8)
# Üst şerit: tam gradyan = 1 adım için N örnek okunur
axR.text(0.02, 0.88, "Tam gradyan (GD):", fontsize=9.6, color=COL_VIOLET_D,
fontweight="bold", va="center")
for i in range(10):
axR.add_patch(plt.Rectangle((0.05 + i * 0.082, 0.74), 0.062, 0.07,
fc=COL_VIOLET_SOFT, ec=COL_VIOLET, lw=0.8))
axR.annotate("", xy=(0.92, 0.66), xytext=(0.05, 0.66),
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET, lw=2.2))
axR.text(0.5, 0.605, "N örnek → 1 adım", fontsize=8.8, color=COL_VIOLET_D,
ha="center", va="center")
# Alt şerit: SGD/mini-batch = aynı N örnek bütçesi ile birçok adım
axR.text(0.02, 0.46, "SGD / mini-batch:", fontsize=9.6, color=COL_GOLD_D,
fontweight="bold", va="center")
for i in range(10):
axR.add_patch(plt.Rectangle((0.05 + i * 0.082, 0.32), 0.062, 0.07,
fc="#f5e6bf", ec=COL_GOLD_D, lw=0.8))
# her örnek bütçe diliminden bir adım oku
axR.annotate("", xy=(0.081 + i * 0.082, 0.30), xytext=(0.081 + i * 0.082, 0.24),
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD, lw=1.6))
axR.text(0.5, 0.195, "aynı N örnek → ~N adım", fontsize=8.8, color=COL_GOLD_D,
ha="center", va="center")
# Defazio kapanış mesajı (kutu)
msg = ("Kayıp = benzer terimlerin toplamı.\n"
"Mini-batch zaten iyi yön verir →\n"
"aynı bütçe, çok daha fazla adım.\n"
"“Gradient descent kullanma.” (Defazio)")
axR.add_patch(plt.Rectangle((0.04, 0.015), 0.92, 0.135, fc=COL_BG,
ec=COL_VIOLET_M, lw=1.4))
axR.text(0.5, 0.083, msg, fontsize=8.6, color=COL_TEXT, ha="center", va="center",
linespacing=1.35)
fig.suptitle(
"Stokastik Gradyan İnişi: artıklık “neden” minik adımlara izin verir",
color=COL_INK, fontsize=13.5, fontweight="bold", y=0.99,
)
fig.tight_layout(rect=[0, 0, 1, 0.95])
```
::: {.callout-tip title="Builder Notu — Artıklık → SGD"}
**Geriye (Hafta 2 + Stat 110):** Bu, Hafta 2'deki "SGD = gradient'in tarafsız tahmincisi" fikrinin pratik sonucudur. Veri artıklığı = örneklerin istatistiksel benzerliği (Stat 110).
**İleriye:** "Kayıp = benzer terimlerin toplamı" yapısı, SGD'nin neden ML'e özgü kadar iyi çalıştığını açıklar; bu yapı yoksa (örn. tek bir karmaşık fonksiyon) L-BFGS gibi yöntemler daha uygun olabilir.
:::
## (Defazio) Momentum: "Neredeyse Her Zaman Kullan" {#sec-momentum}
Defazio momentum'u SGD'nin üstüne eklenen, "neredeyse her zaman açman gereken" bir trick olarak sunuyor.
> "momentum is a trick that you should pretty much always be using when you're using stochastic gradient descent." — Defazio, 27:52
Fizikten gelen sezgi: momentum, bir nesnenin gittiği yönde gitmeye devam etme eğilimidir (Newton). Pratikte bir **hız tamponu (heavy ball)** tutarsın: gradient'leri biriktirip adımı bu birikmiş hızla atarsın.
$$
p \leftarrow \beta p + \nabla \mathcal{L}(\theta), \qquad \theta \leftarrow \theta - \eta\, p
$$
Tipik $\beta = 0.9$. Momentum neden işe yarar? Defazio iki sebep veriyor: (1) **salınım sönümleme / acceleration** — gradient descent'in vadi duvarlarındaki zikzakını bastırır; (2) **noise smoothing** — gradient'lerin hareketli ortalamasını alarak SGD gürültüsünü yumuşatır, böylece son nokta çözümün iyi bir tahmini olur (saf SGD'de bir sürü son noktayı ortalaman gerekirdi). Heavy-ball kuralı $p\leftarrow\beta p+\nabla\mathcal{L}(\theta)$, geçmiş gradyanları üstel sönümle biriktirir.
> "momentum adds smoothing to the optimization, so the last point you visit is still a good approximation to the solution." — Defazio, 42:09
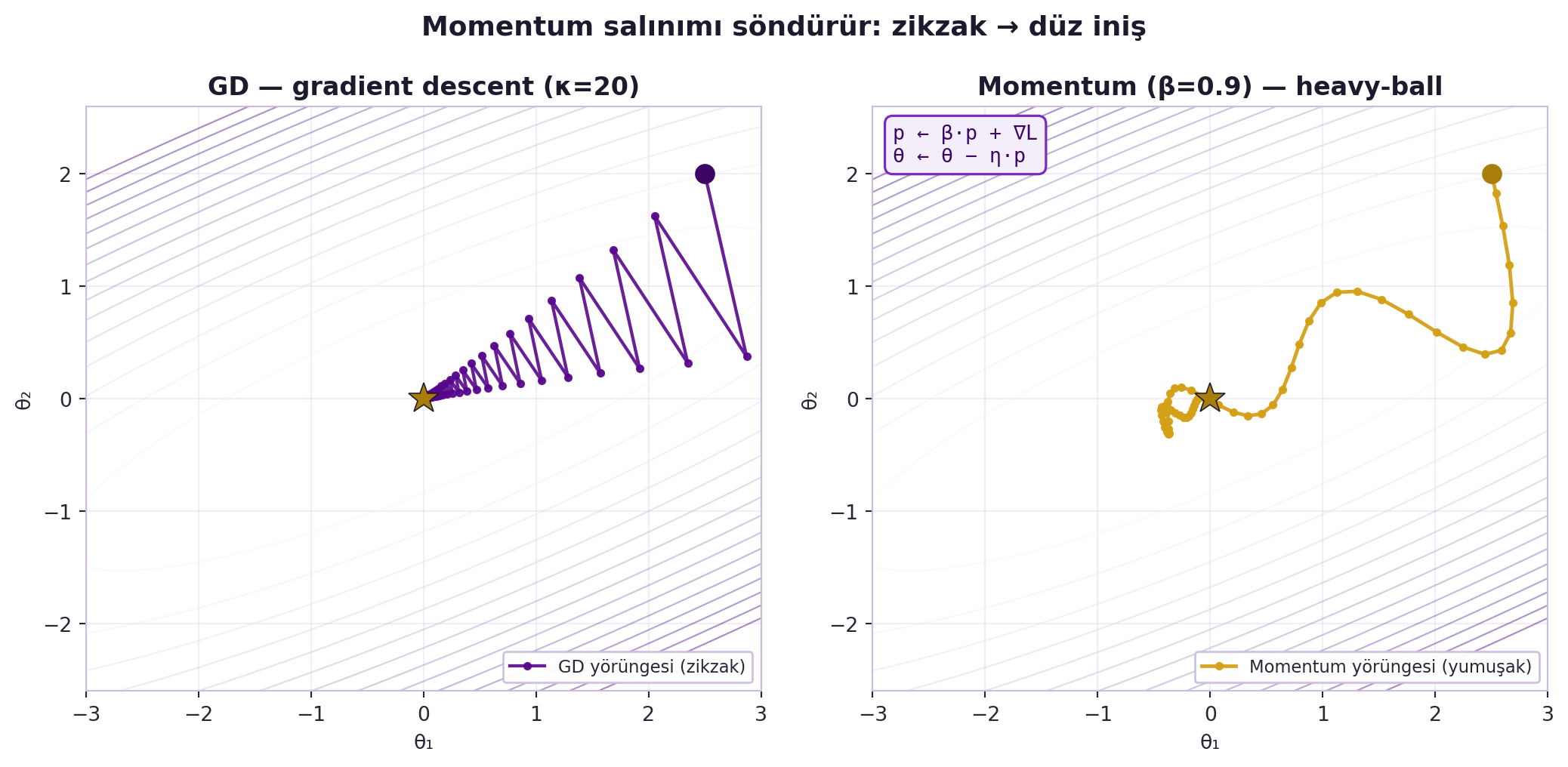
(Bir uyarı: Nesterov acceleration teorik olarak convex problemlerde yakınsamayı hızlandırır ama sinir ağlarında ve gürültüde bu etki büyük ölçüde kaybolur — pratikte momentum'un asıl faydası noise smoothing'dir.) @fig-momentum aynı $\kappa=20$ vadide GD'nin zikzakı ile momentum'un yumuşak inişini yan yana koyar.
```{python}
#| label: fig-momentum
#| fig-cap: "Momentum salınımı söndürür. Aynı κ=20 koşullanmalı dar kuadratik vadide (soluk Purples kontur) iki optimizer karşılaştırılır. SOL panel — GD (η=0.095): yörünge vadinin dik duvarları arasında zikzak çizerek minimuma yaklaşır; her adım eğimin tersine sıçrayıp salınır (Defazio'nun \"koşullanma kötüyse gradient descent zikzak çizer\" gözlemi). SAĞ panel — Momentum/heavy-ball (η=0.010, β=0.9): p←β·p+∇L birikimli hız, dik yönlerdeki zıt-işaretli gradyanları birbirine söndürür; yörünge düz/yumuşak bir eğri olarak vadinin dibini takip eder. Mesaj: momentum salınımı sönümler ve gürültüyü yumuşatır."
kappa = 20.0
theta0 = [2.5, 2.0]
steps = 60
# Vadi konturu (soluk arka plan, her iki panelde aynı)
gx = np.linspace(-3.0, 3.0, 240)
gy = np.linspace(-2.6, 2.6, 240)
GX, GY = np.meshgrid(gx, gy)
Z = quad_loss(GX, GY, kappa)
levels = np.linspace(Z.min(), Z.max() * 0.7, 16)
# Yörüngeler
path_gd, _ = optimize_quad("gd", theta0, lr=0.095, steps=steps, kappa=kappa)
path_mom, _ = optimize_quad("momentum", theta0, lr=0.010, steps=steps, kappa=kappa, beta=0.9)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5))
for ax in (axL, axR):
apply_style(ax)
ax.contour(GX, GY, Z, levels=levels, cmap="Purples", alpha=0.45, linewidths=0.8)
ax.plot(0, 0, marker="*", color=COL_GOLD_D, markersize=16,
markeredgecolor=COL_INK, markeredgewidth=0.6, zorder=5)
ax.set_xlim(-3.0, 3.0)
ax.set_ylim(-2.6, 2.6)
ax.set_xlabel("θ₁")
ax.set_ylabel("θ₂")
ax.set_aspect("equal", adjustable="box")
# SOL — GD (zikzak, violet)
axL.plot(path_gd[:, 0], path_gd[:, 1], "-o", color=COL_VIOLET,
markersize=3.2, linewidth=1.6, alpha=0.9, zorder=4,
label="GD yörüngesi (zikzak)")
axL.plot(theta0[0], theta0[1], marker="o", color=COL_VIOLET_D,
markersize=9, zorder=6)
axL.set_title("GD — gradient descent (κ=20)", color=COL_INK,
fontsize=12.5, fontweight="bold")
style_legend(axL, loc="lower right", fontsize=8.5)
# SAĞ — Momentum (düz/yumuşak, gold)
axR.plot(path_mom[:, 0], path_mom[:, 1], "-o", color=COL_GOLD,
markersize=3.2, linewidth=1.8, alpha=0.95, zorder=4,
label="Momentum yörüngesi (yumuşak)")
axR.plot(theta0[0], theta0[1], marker="o", color=COL_GOLD_D,
markersize=9, zorder=6)
axR.set_title("Momentum (β=0.9) — heavy-ball", color=COL_INK,
fontsize=12.5, fontweight="bold")
style_legend(axR, loc="lower right", fontsize=8.5)
# Heavy-ball güncelleme kuralı anotasyonu (sağ panel)
axR.text(0.03, 0.97,
"p ← β·p + ∇L\nθ ← θ − η·p",
transform=axR.transAxes, ha="left", va="top", fontsize=10,
color=COL_VIOLET_D, family="monospace",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG,
ec=COL_VIOLET_M, lw=1.2))
fig.suptitle("Momentum salınımı söndürür: zikzak → düz iniş",
color=COL_INK, fontsize=13.5, fontweight="bold", y=1.00)
fig.tight_layout(rect=[0, 0, 1, 0.97])
```
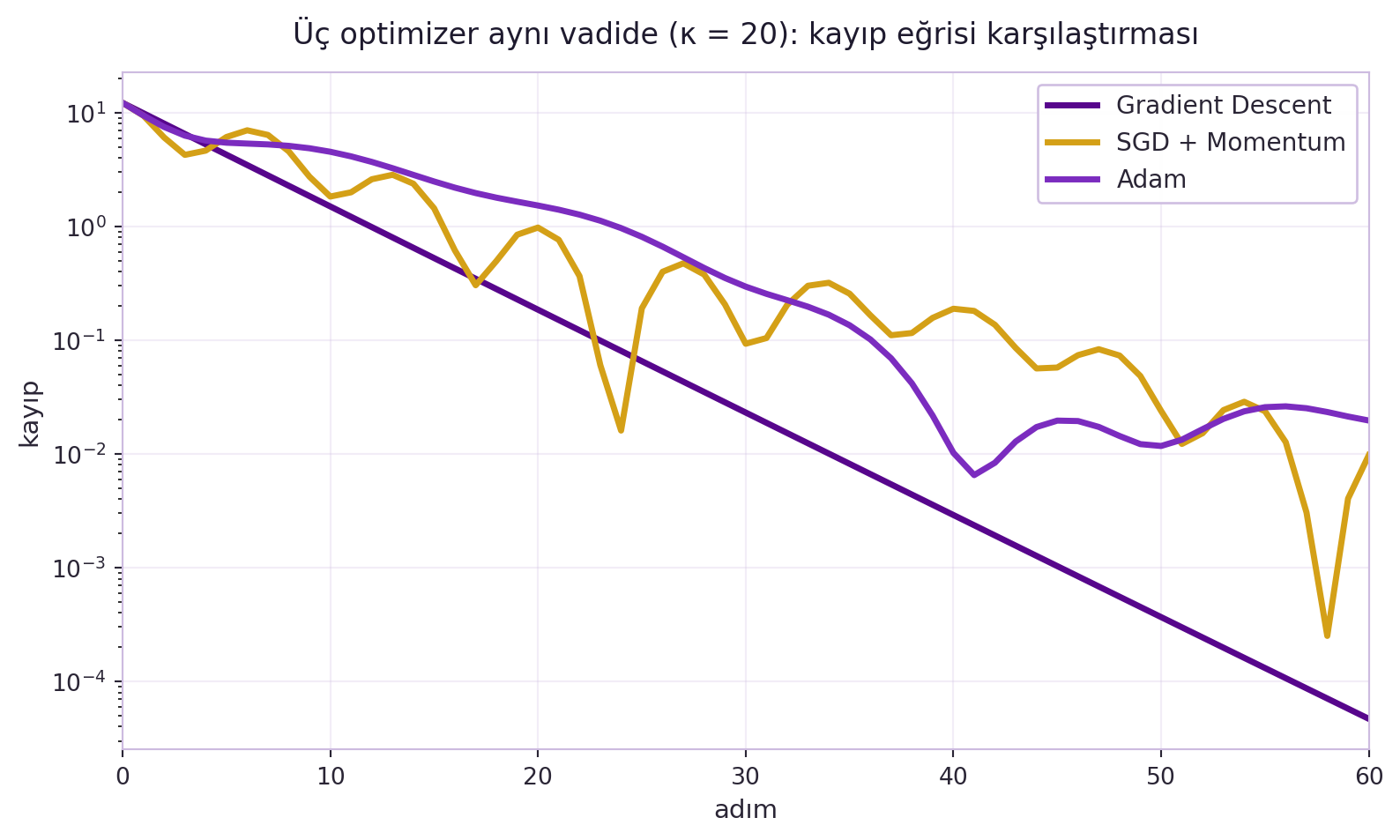
Üç optimizer'ı tek bir kayıp eğrisinde de görmek aydınlatıcıdır: @fig-optimizer-compare GD, SGD+Momentum ve Adam'ı aynı $\kappa=20$ vadide logaritmik ölçekte karşılaştırır — Defazio'nun "zikzak / sönümleme / adaptif" üçlü anlatısının doğrudan görsel özeti.
```{python}
#| label: fig-optimizer-compare
#| fig-cap: "Üç optimizer aynı eğik kuadratik vadide (κ = 20, θ₀ = [2.5, 2.0], 60 adım) karşılaştırılır; kayıp logaritmik ölçekte gösterilir. Gradient Descent (lr = 0.095, mor) düz bir doğru boyunca tek-yönlü iner; SGD + Momentum (lr = 0.010, β = 0.9, altın) heavy-ball ataletiyle salınarak ilerler; Adam (lr = 0.15, mor-orta) adaptif öğrenme hızıyla her boyutu ayrı ölçekler. Eğrilerin biçimi Defazio'nun \"zikzak / sönümleme / adaptif\" üçlü anlatısını görselleştirir."
kappa = 20.0
theta0 = [2.5, 2.0]
steps = 60
# Uc optimizer — ayni kuadratik vadi (kappa=20), ayni baslangic
_, loss_gd = optimize_quad("gd", theta0, lr=0.095, steps=steps, kappa=kappa)
_, loss_mom = optimize_quad("momentum", theta0, lr=0.010, steps=steps, kappa=kappa, beta=0.9)
_, loss_adam = optimize_quad("adam", theta0, lr=0.15, steps=steps, kappa=kappa)
fig, ax = plt.subplots(figsize=(9.5, 5.2))
apply_style(ax)
it = np.arange(steps + 1)
ax.semilogy(it, loss_gd, color=COL_VIOLET, lw=2.6, label="Gradient Descent")
ax.semilogy(it, loss_mom, color=COL_GOLD, lw=2.6, label="SGD + Momentum")
ax.semilogy(it, loss_adam, color=COL_VIOLET_M, lw=2.6, label="Adam")
ax.set_xlabel("adım", fontsize=11)
ax.set_ylabel("kayıp", fontsize=11)
ax.set_title("Üç optimizer aynı vadide (κ = 20): kayıp eğrisi karşılaştırması",
fontsize=12.5, color=COL_INK, pad=12)
ax.set_xlim(0, steps)
style_legend(ax, loc="upper right", fontsize=10.5)
```
::: {.callout-tip title="Builder Notu — Heavy Ball Sönümleme"}
**Geriye (Calculus + fizik):** Momentum = ivme (Calculus ikinci türev) + Newton'un birinci yasası; "heavy ball" fiziksel benzetmesi. Hareketli ortalama = geçmiş gradient'lerin üstel ağırlıklı toplamı.
**İleriye:** SGD + momentum ($\beta=0.9$) hâlâ pek çok görü probleminde state-of-the-art; üstüne LR schedule biner.
:::
## (Defazio) Adaptif Yöntemler: Her Ağırlığa Ayrı Öğrenme Oranı {#sec-adaptif}
Kötü koşullanmış problemler için Defazio **adaptif yöntemleri** tanıtıyor. Buradaki "adaptif", her ağırlık için **ayrı (individual) bir öğrenme oranı** demektir — global tek bir $\eta$ yerine.
> "for adaptive methods, we want to adapt a learning rate for every weight individually, using information we get from gradients for each weight." — Defazio, 44:36
Neden gerekli? Çünkü ağın farklı kısımları çok farklı yapıdadır: erken katmanlar büyük görüntülerde sığ convolution'lar yapar; geç katmanlar küçük görüntülerde çok kanallı convolution'lar. Bir kısım için iyi olan learning rate, diğeri için kötü olabilir. Özellikle çıktıya doğrudan etki eden son katman ağırlıkları küçük learning rate ister. Defazio'nun dürüstlüğü: "neden gerektiğini tam bilmiyoruz; iyi koşullanmış bir ağda gerekmeyebilir bile."
::: {.callout-tip title="Builder Notu — Per-Weight LR"}
**Geriye (18.06):** Per-weight learning rate, kötü koşullanmayı (özdeğer ölçek farkı) ağırlık bazında telafi etme girişimidir — bir tür diyagonal ön-koşullama (preconditioning).
**İleriye:** Per-parameter ölçekleme, büyük modellerde (transformer) eğitim kararlılığının anahtarıdır; LAMB, Adafactor gibi yöntemler bunu bellek-verimli yapar.
:::
## (Defazio) RMSprop ve Adam {#sec-rmsprop-adam}
**RMSprop** (root mean squared propagation, Hinton'ın ders slaytlarından): kare gradient'in **üstel hareketli ortalamasını** ($v$ tamponu) tutar; sonra gradient'i bu ortalamanın kareköküne böler (eleman-bazlı). Böylece büyük-gradient'li yönlerde adım küçülür, küçük-gradient'li yönlerde büyür — otomatik per-weight ölçekleme. Sıfıra bölmeyi önlemek için bir $\epsilon$ ($\approx 10^{-7}$) eklenir.
$$
\theta \leftarrow \theta - \frac{\eta}{\sqrt{v} + \epsilon}\, g
$$
**Adam** (adaptive moment estimation) = **RMSprop + momentum**. Hem gradient'in (birinci moment) hem kare gradient'in (ikinci moment) üstel hareketli ortalamasını tutar; momentum'lu gradient'i RMSprop ölçeklemesiyle ($\theta\leftarrow\theta-\frac{\eta}{\sqrt{v}+\epsilon}\,g$) böler.
> "Adam is RMSprop with momentum... I'd generally recommend using either SGD with momentum or Adam as your go-to methods." — Defazio, 54:54 / 59:09
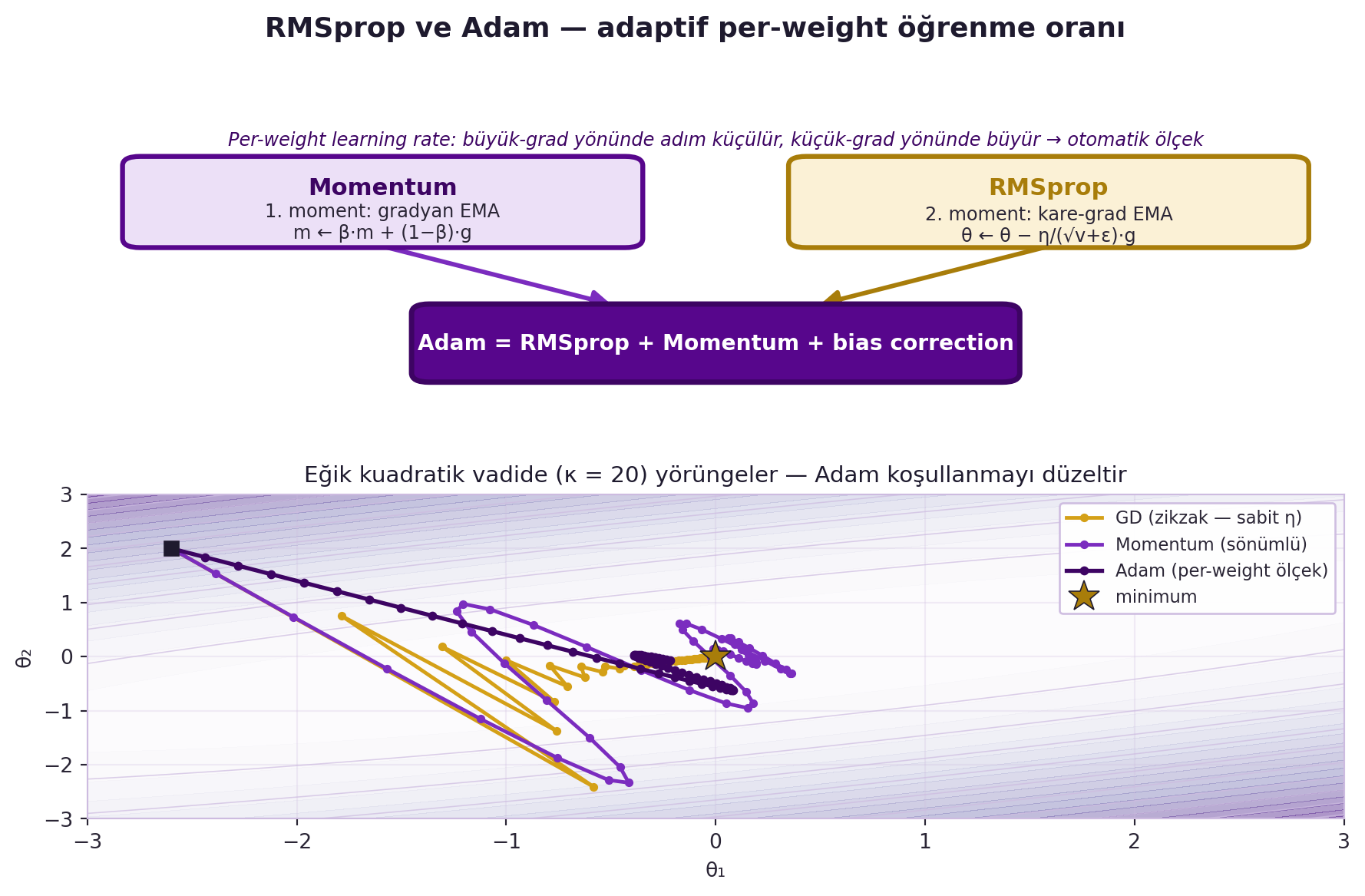
Adam'ın bir ek detayı **bias correction**: tamponlar sıfırdan başladığı için ilk adımlarda küçük kalırlar; bias correction bunu düzeltir (erken adımları ölçekler). @fig-rmsprop-adam üstte kavramsal şemayı (Momentum + RMSprop → Adam), altta motor kanıtını (aynı vadide GD/Momentum/Adam yörüngeleri) verir.
```{python}
#| label: fig-rmsprop-adam
#| fig-cap: "RMSprop ve Adam — adaptif per-weight öğrenme oranı. Üst panel kavramsal şema: iki kaynak modül — Momentum (1. moment, gradyan EMA, violet) ve RMSprop (2. moment, kare-grad EMA, θ←θ−η/(√v+ε)·g, gold) — birleşim oklarıyla Adam = RMSprop + Momentum + bias correction kutusunda birleşir. Annotation: büyük-grad yönünde adım küçülür, küçük-grad yönünde büyür → otomatik per-weight ölçek. Alt panel motor kanıtı: κ=20 eğik kuadratik vadide GD sabit-η ile zikzak çizip aşar, Momentum sönümlü salınır, Adam ise per-weight ölçekle koşullanmayı düzeltip minimuma düzgün iner (optimize_quad)."
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
np.random.seed(0)
# ---------------------------------------------------------------------------
# Üst panel: kavramsal şema (Momentum + RMSprop -> Adam)
# Alt panel: motor kanıtı — eğik kuadratik vadide GD/Momentum/Adam yörüngeleri
# ---------------------------------------------------------------------------
fig = plt.figure(figsize=(11, 6.2))
gs = fig.add_gridspec(2, 1, height_ratios=[1.0, 1.15], hspace=0.32)
# ===== ÜST: şema =====
ax = fig.add_subplot(gs[0])
ax.set_xlim(0, 10)
ax.set_ylim(0, 4.3)
ax.axis("off")
# İki kaynak kutu
mom = FancyBboxPatch((0.3, 2.3), 4.1, 1.35,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc="#ece0f7", ec=COL_VIOLET, lw=2.4, zorder=2)
ax.add_patch(mom)
ax.text(2.35, 3.18, "Momentum", ha="center", va="center",
fontsize=11.5, fontweight="bold", color=COL_VIOLET_D, zorder=3)
ax.text(2.35, 2.66, "1. moment: gradyan EMA\nm ← β·m + (1−β)·g",
ha="center", va="center", fontsize=9, color=COL_TEXT, zorder=3)
rms = FancyBboxPatch((5.6, 2.3), 4.1, 1.35,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc="#fbf1d6", ec=COL_GOLD_D, lw=2.4, zorder=2)
ax.add_patch(rms)
ax.text(7.65, 3.18, "RMSprop", ha="center", va="center",
fontsize=11.5, fontweight="bold", color=COL_GOLD_D, zorder=3)
ax.text(7.65, 2.62, "2. moment: kare-grad EMA\nθ ← θ − η/(√v+ε)·g",
ha="center", va="center", fontsize=9, color=COL_TEXT, zorder=3)
# Birleşim okları -> Adam kutusu
adam = FancyBboxPatch((2.6, 0.25), 4.8, 1.15,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc=COL_VIOLET, ec=COL_VIOLET_D, lw=2.6, zorder=2)
ax.add_patch(adam)
ax.text(5.0, 0.82, "Adam = RMSprop + Momentum + bias correction",
ha="center", va="center", fontsize=10.5, fontweight="bold",
color=COL_WHITE, zorder=3)
ax.add_patch(FancyArrowPatch((2.35, 2.3), (4.2, 1.4),
arrowstyle="-|>", mutation_scale=18,
color=COL_VIOLET_M, lw=2.2, zorder=1))
ax.add_patch(FancyArrowPatch((7.65, 2.3), (5.8, 1.4),
arrowstyle="-|>", mutation_scale=18,
color=COL_GOLD_D, lw=2.2, zorder=1))
# Annotation: otomatik per-weight ölçek
ax.text(5.0, 3.92,
"Per-weight learning rate: büyük-grad yönünde adım küçülür, "
"küçük-grad yönünde büyür → otomatik ölçek",
ha="center", va="center", fontsize=9, style="italic",
color=COL_VIOLET_D, zorder=3)
# ===== ALT: motor kanıtı — yörüngeler =====
ax2 = fig.add_subplot(gs[1])
apply_style(ax2)
kappa = 20.0
theta0 = [-2.6, 2.0] # dik vadi eksenini keser → GD zikzakı görünür
# Kayıp yüzeyi kontur (eğik ince vadi)
gx = np.linspace(-3.0, 3.0, 220)
gy = np.linspace(-3.0, 3.0, 220)
GX, GY = np.meshgrid(gx, gy)
Z = quad_loss(GX, GY, kappa)
ax2.contourf(GX, GY, Z, levels=22, cmap="Purples", alpha=0.45)
ax2.contour(GX, GY, Z, levels=12, colors=COL_GRID, linewidths=0.6, alpha=0.7)
# Üç optimizer
p_gd, _ = optimize_quad("gd", theta0, lr=0.085, steps=60, kappa=kappa)
p_mom, _ = optimize_quad("momentum", theta0, lr=0.009, steps=60, kappa=kappa,
beta=0.9)
p_adam, _ = optimize_quad("adam", theta0, lr=0.16, steps=60, kappa=kappa,
beta=0.9, beta2=0.999, eps=1e-8)
ax2.plot(p_gd[:, 0], p_gd[:, 1], "-o", color=COL_GOLD, lw=1.8, ms=3.2,
label="GD (zikzak — sabit η)", zorder=4)
ax2.plot(p_mom[:, 0], p_mom[:, 1], "-o", color=COL_VIOLET_M, lw=1.8, ms=3.2,
label="Momentum (sönümlü)", zorder=5)
ax2.plot(p_adam[:, 0], p_adam[:, 1], "-o", color=COL_VIOLET_D, lw=2.0, ms=3.4,
label="Adam (per-weight ölçek)", zorder=6)
ax2.plot(0, 0, "*", color=COL_GOLD_D, ms=16, mec=COL_INK, mew=0.6,
label="minimum", zorder=7)
ax2.plot(*theta0, "s", color=COL_INK, ms=7, zorder=7)
ax2.set_xlim(-3.0, 3.0)
ax2.set_ylim(-3.0, 3.0)
ax2.set_xlabel("θ₁", color=COL_TEXT)
ax2.set_ylabel("θ₂", color=COL_TEXT)
ax2.set_title("Eğik kuadratik vadide (κ = 20) yörüngeler — Adam koşullanmayı düzeltir",
fontsize=11, color=COL_INK)
style_legend(ax2, loc="upper right", fontsize=8.5)
fig.suptitle("RMSprop ve Adam — adaptif per-weight öğrenme oranı",
fontsize=13.5, fontweight="bold", color=COL_INK, y=0.99);
```
::: {.callout-tip title="Builder Notu — Adam = RMSprop + Momentum"}
**Geriye (Stat 110):** Üstel hareketli ortalama = geçmişi üstel sönümleyen ağırlıklı ortalama; ikinci moment = kare beklentisi (Stat 110 varyans/moment). Bias correction = tarafsız tahminci kurma (beklenti = gradient).
**İleriye:** AdamW (weight decay düzeltmeli Adam) bugün LLM eğitiminin varsayılan optimizer'ıdır; $\epsilon$, $\beta_1$, $\beta_2$ ayarları pratik kararlardır.
:::
## (Defazio) "Optimization'ın Ölümü": En Çok Kullanılan Yöntemin Teorisi Yanlış {#sec-zanaat}
Defazio bir optimizasyon araştırmacısı olarak çarpıcı bir itirafta bulunuyor — bu, LeCun'un Hafta 1'deki "kimse anlamıyor" temasının optimizasyon versiyonudur:
> "I hate Adam because I'm an optimization researcher and the theory in their paper is wrong — this has been shown recently; the method in fact does not converge, and you can show this on very simple test problems." — Defazio, 59:14
Yani modern ML'in en yoğun kullanılan yöntemlerinden biri, basit test problemlerinde bile yakınsamayabilir. Üstelik Adam, özellikle **görüntü problemlerinde SGD'den daha kötü genelleme (generalization)** verebilir — belki o "küçük, kötü yerel minimumlara" daha kolay düştüğü için. Yine de **dil modelleri için Adam zorunludur** (SGD ile eğitilemiyorlar). Defazio'nun pratik tavsiyesi nettir: **SGD+momentum veya Adam dene**; görüde genelde SGD+momentum, dilde Adam.
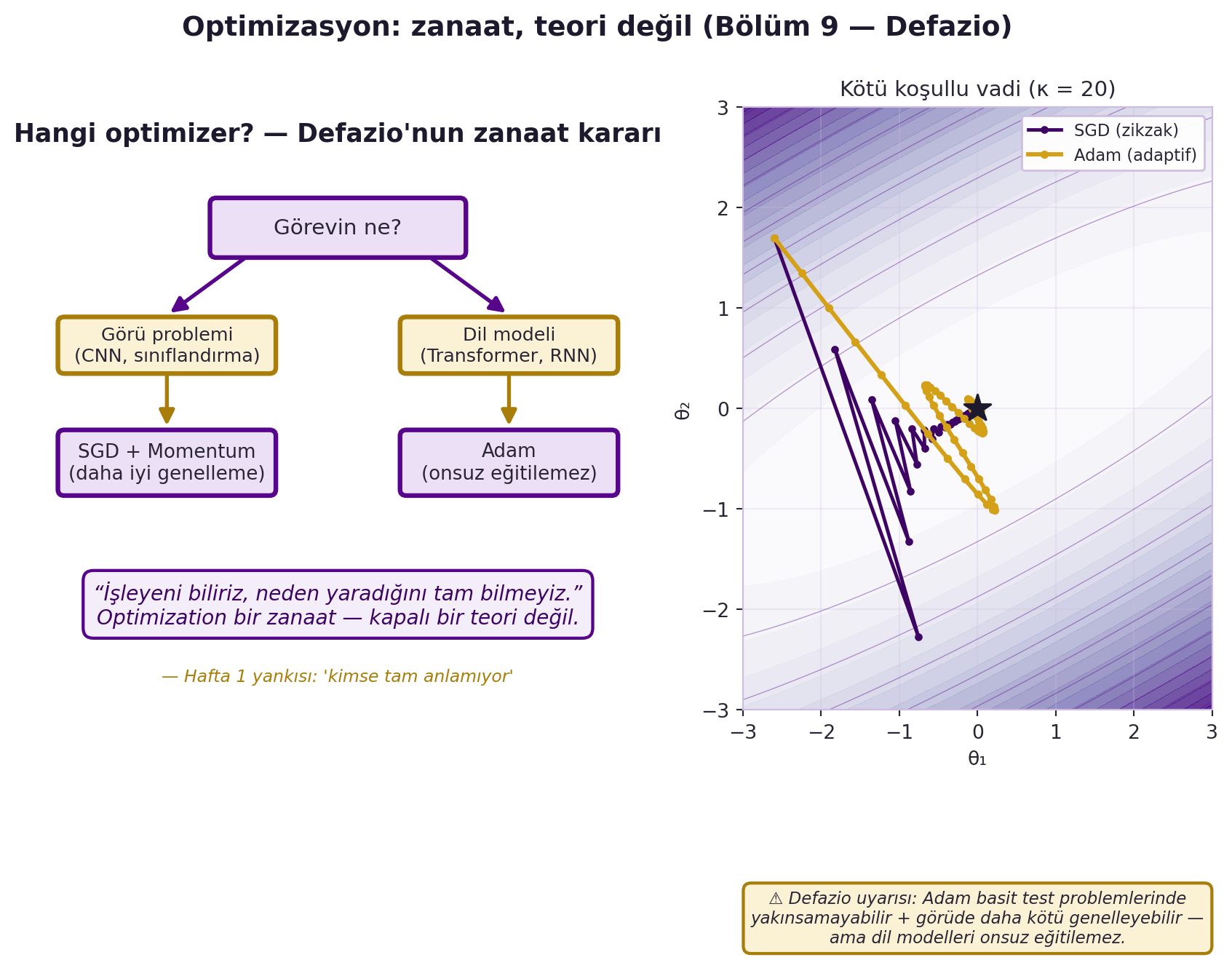
Bu bölüm dersin omurgasını özetler: optimizasyon bir teori değil, bir **zanaattir** — işe yarayanı biliyoruz, neden yaradığını tam bilmiyoruz. @fig-adam-craft bu zanaat kararını (görü → SGD+Momentum, dil → Adam) ve Defazio'nun dürüst uyarısını tek figürde toplar.
```{python}
#| label: fig-adam-craft
#| fig-cap: "Optimizasyon bir zanaattır, kapalı bir teori değil (Bölüm 9 — Defazio). Sol panel karar şeması: görü problemleri (CNN, sınıflandırma) için SGD + Momentum daha iyi genelleme verir; dil modelleri (Transformer, RNN) için Adam pratikte zorunludur. Sağ panel kötü koşullu kuadratik vadide (κ = 20) kanıt sunar: saf SGD vadinin dik ekseninde zikzak çizerken Adam adaptif adımıyla minimuma (★) daha düzgün ilerler. Defazio'nun dürüst uyarısı altta: Adam basit test problemlerinde yakınsamayabilir ve görüde daha kötü genelleyebilir — yine de büyük dil modelleri onsuz eğitilemez. 'İşleyeni biliriz, neden yaradığını tam bilmeyiz' (Hafta 1 'kimse tam anlamıyor' yankısı)."
fig = plt.figure(figsize=(11, 5.6))
gs = fig.add_gridspec(1, 2, width_ratios=[1.35, 1.0], wspace=0.16)
# --------------------------------------------------------------------------
# SOL PANEL — Optimizer karar şeması (iki dal) + alttaki dürüst not
# --------------------------------------------------------------------------
axL = fig.add_subplot(gs[0, 0])
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.axis("off")
axL.text(5.0, 9.55, "Hangi optimizer? — Defazio'nun zanaat kararı",
ha="center", va="center", fontsize=13, fontweight="bold", color=COL_INK)
# Kök kutu: problem
def box(ax, cx, cy, w, h, label, learned=True, fs=10.5, gold=False):
fc = "#ece0f7" if learned else COL_BG
ec = COL_GOLD_D if gold else COL_VIOLET
lw = 2.4
if gold:
fc = "#fbf2d6"
b = FancyBboxPatch((cx - w / 2, cy - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=lw, zorder=2)
ax.add_patch(b)
ax.text(cx, cy, label, ha="center", va="center", fontsize=fs,
color=COL_TEXT, zorder=3, wrap=True)
def arrow(ax, p0, p1, color=COL_VIOLET_M, lw=2.0):
ax.add_patch(FancyArrowPatch(p0, p1, arrowstyle="-|>", mutation_scale=16,
color=color, lw=lw, zorder=1))
# Karar düğümü
box(axL, 5.0, 8.0, 4.0, 0.95, "Görevin ne?", learned=True, fs=11)
# Sol dal — görü
arrow(axL, (3.6, 7.55), (2.3, 6.55), color=COL_VIOLET)
box(axL, 2.3, 6.05, 3.4, 0.9, "Görü problemi\n(CNN, sınıflandırma)", learned=False, gold=True, fs=9.5)
arrow(axL, (2.3, 5.6), (2.3, 4.65), color=COL_GOLD_D)
box(axL, 2.3, 4.1, 3.4, 1.05, "SGD + Momentum\n(daha iyi genelleme)", learned=True, fs=9.8)
# Sağ dal — dil
arrow(axL, (6.4, 7.55), (7.7, 6.55), color=COL_VIOLET)
box(axL, 7.7, 6.05, 3.4, 0.9, "Dil modeli\n(Transformer, RNN)", learned=False, gold=True, fs=9.5)
arrow(axL, (7.7, 5.6), (7.7, 4.65), color=COL_GOLD_D)
box(axL, 7.7, 4.1, 3.4, 1.05, "Adam\n(onsuz eğitilemez)", learned=True, fs=9.8)
# Alt dürüst not (quote, italik)
note = ("“İşleyeni biliriz, neden yaradığını tam bilmeyiz.”\n"
"Optimization bir zanaat — kapalı bir teori değil.")
axL.text(5.0, 1.75, note, ha="center", va="center", fontsize=10.5,
color=COL_VIOLET_D, style="italic",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_VIOLET, lw=1.6))
axL.text(5.0, 0.55, "— Hafta 1 yankısı: 'kimse tam anlamıyor'",
ha="center", va="center", fontsize=8.8, color=COL_GOLD_D, style="italic")
# --------------------------------------------------------------------------
# SAĞ PANEL — engine semasi: κ kötü vadide GD zikzak vs Adam (kanıt)
# --------------------------------------------------------------------------
axR = fig.add_subplot(gs[0, 1])
kappa = 20.0
theta0 = [-2.6, 1.7]
g = np.linspace(-3.0, 3.0, 220)
GX, GY = np.meshgrid(g, g)
Z = quad_loss(GX, GY, kappa)
axR.contourf(GX, GY, Z, levels=22, cmap="Purples", alpha=0.85)
axR.contour(GX, GY, Z, levels=12, colors=COL_VIOLET, linewidths=0.5, alpha=0.4)
gd_p, _ = optimize_quad("gd", theta0, lr=0.085, steps=60, kappa=kappa)
ad_p, _ = optimize_quad("adam", theta0, lr=0.35, steps=60, kappa=kappa,
beta=0.9, beta2=0.999, eps=1e-8)
axR.plot(gd_p[:, 0], gd_p[:, 1], "-o", color=COL_VIOLET_D, lw=1.8, ms=3.0,
label="SGD (zikzak)", zorder=4)
axR.plot(ad_p[:, 0], ad_p[:, 1], "-o", color=COL_GOLD, lw=2.2, ms=3.2,
label="Adam (adaptif)", zorder=5)
axR.plot(0, 0, marker="*", color=COL_INK, ms=15, zorder=6)
apply_style(axR)
axR.set_title(f"Kötü koşullu vadi (κ = {int(kappa)})", color=COL_TEXT, fontsize=11)
axR.set_xlabel("θ₁")
axR.set_ylabel("θ₂")
axR.set_xlim(-3.0, 3.0)
axR.set_ylim(-3.0, 3.0)
style_legend(axR, loc="upper right", fontsize=8.5)
# Defazio uyarı kutusu (sağ panel altında)
warn = ("⚠ Defazio uyarısı: Adam basit test problemlerinde\n"
"yakınsamayabilir + görüde daha kötü genelleyebilir —\n"
"ama dil modelleri onsuz eğitilemez.")
axR.text(0.5, -0.30, warn, transform=axR.transAxes, ha="center", va="top",
fontsize=8.6, color=COL_TEXT, style="italic",
bbox=dict(boxstyle="round,pad=0.45", fc="#fbf2d6", ec=COL_GOLD_D, lw=1.6))
fig.suptitle("Optimizasyon: zanaat, teori değil (Bölüm 9 — Defazio)",
fontsize=14, fontweight="bold", color=COL_INK, y=1.0);
```
::: {.callout-tip title="Builder Notu — Zanaat, Teori Değil"}
**Geriye (Hafta 1):** Bu, LeCun'un "it's important to understand that nobody understands" (Hafta 1) cümlesinin optimizasyondaki tam karşılığıdır. Alan, kanıttan çok ampirik başarıyla ilerler.
**İleriye:** Adam'ın yakınsama sorunu → AMSGrad, AdamW gibi düzeltmeler; generalization farkı → "flat vs sharp minima" araştırması. Bunlar hâlâ açık problemler.
:::
## Bu Dersin Özeti {#sec-ozet-d4}
1. **Convolution = Toeplitz matrisiyle çarpım** (Canziani): kernel kaydırılarak tekrarlanır, gerisi sıfır — seyrek (locality) + paylaşımlı (stationarity). "Bir sürü sıfırlı matris çarpımı."
2. **Tam-bağlı vs convolution:** ikisi de $A\mathbf{x}$; FC'de kernel = tam satır, conv'da kernel = kaydırılan küçük pencere.
3. **Condition number $\kappa = L/\mu$** (Defazio) yakınsama hızını belirler; learning rate "ıraksamanın eşiğinde" seçilir.
4. **SGD'yi kullan, gradient descent'i değil** — veri artıklığını sömürür.
5. **Momentum'u neredeyse her zaman aç** ($\beta \approx 0.9$): salınım sönümleme + noise smoothing.
6. **Adaptif yöntemler** per-weight learning rate verir; **RMSprop** (kare-grad EMA ile böl) → **Adam** = RMSprop + momentum (+ bias correction).
7. **Pratik tavsiye:** SGD+momentum veya Adam. Ama Adam'ın teorisi tartışmalı (yakınsama + generalization) — "optimization'ı tam anlamıyoruz".
::: {.callout-important title="Tek Bir Cümle"}
Convolution, yerel ve paylaşımlı bir Toeplitz matrisiyle çarpımdan ibarettir (Canziani); ve o ağı eğitmek, gradient descent'i veri artıklığı için SGD'ye, salınım+gürültü için momentum'a, kötü koşullanma için adaptif ölçeklemeye (RMSprop/Adam) çeviren — teorisi hâlâ eksik ama pratikte çalışan — bir zanaattir (Defazio).
:::
## Kontrol Soruları {#sec-kontrol-d4}
::: {.callout-note collapse="true" title="Soru 1: Convolution'ı bir matris çarpımı olarak nasıl yazarsın? Bu matrisin adı ve iki özelliği nedir? Tam-bağlı katmandan farkı?"}
**Cevap:** Kernel'i her satırda bir konum kaydırarak, geri kalanı sıfır bırakarak bir **Toeplitz matrisi** kurarsın; convolution = bu matrisle çarpım ("a matrix multiplication with a lot of zeros", Canziani 27:55). İki özelliği: **seyrek** (her satırda yalnızca kernel kadar sıfır-olmayan eleman = locality) ve **paylaşımlı** (her satır aynı kaydırılmış kernel = stationarity/parameter sharing). Tam-bağlı katmanda kernel matrisin **tam bir satırıdır** (her girdiye bağlı, paylaşım yok); convolution'da kernel küçük, kaydırılan, paylaşılan bir penceredir — yani convolution, yapısı kısıtlanmış bir lineer katmandır.
:::
::: {.callout-note collapse="true" title="Soru 2: Condition number nedir, neyi belirler? Defazio neden 'gradient descent kullanma' diyor?"}
**Cevap:** Condition number, kuadratik bir problemde Hessian'ın en büyük ($L$) ve en küçük ($\mu$) özdeğerlerinin oranıdır:
$$
\kappa = \frac{L}{\mu}
$$
$\kappa$ büyükse problem kötü koşullanmıştır (uzun ince vadi); gradient descent zikzak çizer, yavaşlar. Defazio "gradient descent kullanma" der çünkü ML kaybı çok sayıda benzer terimin toplamıdır (her veri noktası bir terim) ve bu yapıda **artıklık (redundancy)** vardır — küçük bir mini-batch zaten iyi bir yön verir, ve SGD aynı bütçeyle çok daha fazla adım atar. Tam-batch gradient descent bu artıklığı israf eder.
:::
::: {.callout-note collapse="true" title="Soru 3: Momentum neden işe yarar (iki sebep)? Heavy-ball güncellemesini yaz. Tipik β kaçtır?"}
**Cevap:** İki sebep: (1) **salınım sönümleme / acceleration** — vadi duvarlarındaki zikzakı bastırır; (2) **noise smoothing** — gradient'lerin hareketli ortalamasını alıp SGD gürültüsünü yumuşatır, böylece son nokta çözümün iyi bir tahmini olur. Heavy-ball güncellemesi:
$$
p \leftarrow \beta p + \nabla \mathcal{L}(\theta), \qquad \theta \leftarrow \theta - \eta\, p
$$
Tipik $\beta = 0.9$. Defazio: "momentum'u neredeyse her zaman kullan" (27:52). (Nesterov acceleration teorik olarak convex problemlerde hızlandırır ama gürültü onu büyük ölçüde öldürür; pratikte asıl fayda noise smoothing'dir.)
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) Adam nedir, hangi iki yöntemi birleştirir? Defazio neden onu hem önerir hem eleştirir?"}
**Cevap:** **Adam (adaptive moment estimation) = RMSprop + momentum.** RMSprop, kare gradient'in üstel hareketli ortalamasının kareköküne bölerek (eleman-bazlı, $+\epsilon$) per-weight ölçekleme yapar:
$$
\theta \leftarrow \theta - \frac{\eta}{\sqrt{v} + \epsilon}\, g
$$
Adam buna gradient'in hareketli ortalamasını (momentum) ve bias correction'ı ekler. Defazio **önerir** çünkü pratikte çok iyi çalışır ve bazı ağlar (dil modelleri) onsuz eğitilemez; ama **eleştirir** çünkü orijinal yakınsama teoremi yanlıştır ("does not converge", 59:14) ve görü problemlerinde SGD'den daha kötü genelleme verebilir. Pratik tavsiye: SGD+momentum (görü) veya Adam (dil) — "optimization'ı tam anlamıyoruz".
:::
## Egzersizler {#sec-egzersiz-d4}
**Egzersiz 1 (Convolution = Toeplitz).** 1B kernel $w = [1, 0, -1]$ ve girdi $x = [1, 2, 3, 4, 5]$ için convolution'ı, uygun bir Toeplitz matrisi $T$ kurup $T \cdot x$ ile hesapla. Sonucu `torch.nn.functional.conv1d` ile karşılaştır. Matrisin kaç sıfır içerdiğini say (sparsity).
```python
import torch
import torch.nn.functional as F
import numpy as np
w = [1, 0, -1]
x = np.array([1., 2., 3., 4., 5.])
k, n = len(w), len(x)
oh = n - k + 1
T = np.zeros((oh, n)) # Toeplitz matrisi
for i in range(oh):
T[i, i:i + k] = w
y_toeplitz = T @ x # -> [-2, -2, -2]
xt = torch.tensor(x, dtype=torch.float).view(1, 1, -1)
wt = torch.tensor(w, dtype=torch.float).view(1, 1, -1)
y_conv = F.conv1d(xt, wt).flatten() # -> [-2, -2, -2]
print(y_toeplitz, y_conv, int((T == 0).sum())) # eşit + sıfır sayısı
```
**Egzersiz 2 (İki görüş).** Bir 3×2 matris $A$ ve vektör $x$ için $Ax$'i (a) satır·$x$ iç çarpımları, (b) sütunların ağırlıklı toplamı ($A\mathbf{x}=\sum_j x_j\mathbf{a}_j$) olarak ayrı ayrı hesapla; ikisinin aynı çıktığını doğrula.
```python
import numpy as np
A = np.array([[2., -1.], [1., 3.], [0., 2.]]) # 3x2
x = np.array([4., -1.])
row_view = np.array([A[i] @ x for i in range(A.shape[0])]) # satır·x
col_view = x[0] * A[:, 0] + x[1] * A[:, 1] # sütun toplamı
print(row_view, col_view, np.allclose(row_view, col_view))
```
**Egzersiz 3 (Learning rate süpürmesi).** Basit bir kuadratik $L(w) = (w-3)^2$ üzerinde gradient descent'i $\eta \in \{0.01, 0.1, 0.5, 1.0, 1.01\}$ için koştur (Hafta 2 Egz 5). Hangi $\eta$ ıraksıyor? "Edge of divergence" gözlemini Defazio'nun yorumuyla ilişkilendir.
```python
import numpy as np
def run(lr, steps=50, w0=10.0):
w = w0
for _ in range(steps):
w = w - lr * 2 * (w - 3) # ∇L = 2(w-3)
return w
for lr in [0.01, 0.1, 0.5, 1.0, 1.01]:
print(lr, run(lr)) # lr=1.01 -> ıraksar (|1-2lr|>1)
```
**Egzersiz 4 (Optimizer karşılaştırması).** Hafta 2'nin spiral ağını üç optimizer ile eğit: (a) SGD, (b) SGD+momentum(0.9), (c) Adam. Kayıp eğrilerini karşılaştır. Hangisi en hızlı, hangisi en kararlı? Momentum'un salınımı nasıl etkilediğini gözlemle.
```python
import torch
import torch.nn as nn
net = nn.Sequential(nn.Linear(2, 32), nn.ReLU(), nn.Linear(32, 5))
opts = {
"sgd": torch.optim.SGD(net.parameters(), lr=0.1),
"momentum": torch.optim.SGD(net.parameters(), lr=0.1, momentum=0.9),
"adam": torch.optim.Adam(net.parameters(), lr=1e-3),
}
# her opt icin: forward -> loss -> backward -> step (Hafta 2 dongusu)
# loss egrilerini kaydet ve karsilastir
```
**Egzersiz 5 (Hafta 5 habercisi).** Hafta 5 yalnızca Canziani'nin Practicum'u olacak: 1D/2D convolution'ın PyTorch'ta uygulanması ve **otomatik türev (autograd)**. (a) `torch.nn.functional.conv2d` ile küçük bir görüntüye bir kenar dedektörü kernel'i uygula. (b) Bir tensöre `requires_grad=True` verip basit bir fonksiyonun `.backward()`'ını çağır; `.grad`'ı elle hesapladığınla karşılaştır. Bu, Hafta 2'nin backprop'unun PyTorch'taki otomatik hâlidir — neden "autograd" Hafta 2'nin doğal devamı?
```python
import torch
x = torch.tensor(2.0, requires_grad=True)
y = x ** 3 + 2 * x # f(x) = x^3 + 2x
y.backward() # otomatik turev
print(x.grad) # 3x^2 + 2 = 14 (elle ile karsilastir)
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d4}
::: {.callout-warning title="Sonraki Hafta — H5: 1D/2D Convolution ve Otomatik Türev (autograd) — yalnız Canziani"}
**Convolution'dan autograd'a.** Bu hafta convolution'ın cebirini (Toeplitz) ve ağı eğiten optimizasyon motorunu (SGD/momentum/Adam) gördük. Hafta 5'te lecture yok; **yalnızca Canziani'nin Practicum'u** convolution'ı PyTorch'ta somutlaştırır (`conv1d`/`conv2d`, boyutlar) ve **autograd**'ı gösterir — Hafta 2'de LeCun'un elle kurduğu Jacobian zincirinin PyTorch'taki otomatik karşılığı. Egzersiz 1 (Toeplitz) ve Egzersiz 5 (conv2d + autograd) tam bu derse hazırlar.
:::
**Hafta 5: 1D/2D Convolution ve Otomatik Türev (autograd)** — yalnızca Canziani (Practicum)
Hafta 5'te lecture yok; Canziani convolution'ı PyTorch'ta somutlaştırır (`conv1d`/`conv2d`, boyutlar) ve **autograd**'ı gösterir — Hafta 2'de LeCun'un elle kurduğu Jacobian zincirinin PyTorch'taki otomatik karşılığı.
**Hafta 5 öncesi yapılacak:**
- Egzersiz 1 (Toeplitz) ve Egzersiz 5 (conv2d + autograd) çöz.
- "Convolution = bir sürü sıfırlı matris çarpımı" cümlesini kendi sözcüklerinle yaz.
- Hafta 2'nin `loss.backward()`'ını hatırla — Hafta 5'te onun nasıl çalıştığını PyTorch içinden göreceğiz.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d4}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Matris × vektör — satır görüşü | Çıktı elemanı = satır·girdi; kernel = matris satırı | Canziani 13m31 |
| Matris × vektör — sütun görüşü | Çıktı = sütunların ağırlıklı toplamı | Canziani 16m22 |
| Toeplitz matrisi | Kernel kaydırılarak tekrarlanmış seyrek matris | Canziani 23m36 |
| Convolution = matris çarpımı | "Bir sürü sıfırlı matris çarpımı"; seyrek + paylaşımlı | Canziani 27m55 |
| Condition number κ | L/μ (en büyük/en küçük özdeğer); yakınsama hızı | Defazio 11m36 |
| Edge of divergence | En büyük güvenli learning rate; hız için ıraksama eşiği | Defazio 13m42 |
| SGD vs full-batch | Veri artıklığını sömür; "gradient descent kullanma" | Defazio 19m03 |
| Momentum (heavy ball) | Hız tamponu; salınım sönümleme + noise smoothing; β=0.9 | Defazio 27m52 |
| Adaptif yöntem | Her ağırlığa ayrı learning rate | Defazio 44m36 |
| RMSprop | Kare-grad EMA'nın köküne böl (+ε); per-weight ölçek | Defazio 50m43 |
| Adam | RMSprop + momentum + bias correction | Defazio 54m54 |
| Optimization'ı anlamıyoruz | Adam teorisi yanlış (yakınsamıyor); ama pratikte çalışır | Defazio 59m14 |
## ML Builder Bağlantıları {#sec-koprular-d4}
**Geriye köprüler (önkoşul kurslar):**
1. **Convolution = Toeplitz matris** → 18.06 matris-vektör + Hafta 3 (locality/stationarity) + 18.065 yapılı matrisler.
2. **Condition number $\kappa = L/\mu$** → 18.06 özdeğer + 18.065 koşullanma.
3. **Momentum = ivme** → Calculus ikinci türev + fizik (Newton).
4. **EMA / ikinci moment** → Stat 110 ağırlıklı ortalama, varyans/moment.
5. **SGD artıklık** → Hafta 2 tarafsız tahminci + Stat 110 örneklem.
**İleriye köprüler (production / research):**
1. **Toeplitz/circulant** → FFT ile hızlı convolution; im2col+GEMM, Winograd.
2. **SGD+momentum / Adam** → AdamW (LLM varsayılanı), LAMB, Adafactor.
3. **Edge of divergence** → LR warmup + cosine decay schedule.
4. **Adam yakınsama/generalization sorunu** → AMSGrad, flat vs sharp minima araştırması.
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Convolution gizemli bir işlem değil — yerel ve paylaşımlı bir Toeplitz matrisiyle çarpımdır (Canziani: "bir sürü sıfırlı matris çarpımı"); ve o ağı eğitmek, gradient descent'i veri artıklığı için SGD'ye, salınım ve gürültü için momentum'a, kötü koşullanma için adaptif ölçeklemeye (Adam) çeviren bir zanaattir — işe yarayanı biliriz, ama Defazio'nun dürüstçe itiraf ettiği gibi, neden yaradığını hâlâ tam anlamıyoruz.
:::