---
title: "Diziler — RNN, LSTM ve Attention"
subtitle: "İki hocalı hafta: Yann LeCun (Lecture) yinelemeli ağların (RNN) mimarisini, vanishing/exploding gradient sorununu ve çözümlerini (gating — GRU/LSTM — ve attention) kurar; Alfredo Canziani (Practicum) RNN'in dört tipini, seq2seq encoder-decoder'ı ve PyTorch'ta dizi eğitimini somutlaştırır — sabit boyutlu girdiden değişken uzunluklu diziye geçiş."
---
::: {.callout-note title="Bölüm bilgisi"}
- **LeCun'un Lecture videosu:** [YouTube — RNNs, attention, and memory networks](https://www.youtube.com/watch?v=ycbMGyCPzvE) (≈89 dk)
- **Canziani'nin Practicum videosu:** [YouTube — Training recurrent neural networks](https://www.youtube.com/watch?v=8cAffg2jaT0) (≈53 dk)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Yann LeCun (Lecture, teorik) + Alfredo Canziani (Practicum, pratik)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈25 dk
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan vanishing_demo / rnn_forward / attention_weights + önceki hafta
# yardımcıları + COL_* + apply_style / draw_pipeline / style_legend / CLASS_COLORS
# isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Patch,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm
np.random.seed(0)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ---------------------------------------------------------------------------
# Hafta 5 — autograd worked example (Canziani)
# ---------------------------------------------------------------------------
def autograd_worked(X=None):
"""Canziani worked example: X → Y=X−2 → Z=3·Y² → a=mean(Z) (skaler).
İleri değerler + ∂a/∂xᵢ = (1/4)·3·2·(xᵢ−2) = 1.5·(xᵢ−2).
X=[1,2,3,4] için grad = [−1.5, 0, 1.5, 3] (PyTorch X.grad ile birebir)."""
if X is None:
X = np.array([1.0, 2.0, 3.0, 4.0])
X = np.asarray(X, float)
Y = X - 2.0
Z = 3.0 * Y ** 2
a = float(Z.mean())
grad = 1.5 * (X - 2.0)
return dict(X=X, Y=Y, Z=Z, a=a, grad=grad)
def conv_pad_output(n, k, padding=0, stride=1):
"""Padding'li çıktı boyutu: o = ⌊(n + 2·padding − k)/stride⌋ + 1.
padding=(k−1)/2 (k tek) → çıktı boyutu korunur."""
return (n + 2 * padding - k) // stride + 1
# ---------------------------------------------------------------------------
# Hafta 6 — RNN / vanishing gradient / attention
# ---------------------------------------------------------------------------
def vanishing_demo(steps=50, eigenvalues=(0.5, 1.0, 1.5)):
"""Aynı matristen n kez geçen gradient: λⁿ. λ<1 söner (vanishing), λ>1 patlar
(exploding), λ=1 sabit. Backprop-through-time vanishing gradient görseli."""
t = np.arange(steps + 1)
curves = {ev: np.asarray(ev, float) ** t for ev in eigenvalues}
return t, curves
def rnn_forward(X_seq, Wx, Wz, b, z0=None):
"""Basit RNN hücresi: zₜ = tanh(Wₓ·xₜ + W_z·zₜ₋₁ + b).
X_seq [T, d_in] → gizli durumlar Z [T, d_h] (aynı Wₓ,W_z her adımda = paylaşım)."""
X_seq = np.asarray(X_seq, float)
T = len(X_seq)
dh = np.asarray(Wz).shape[0]
z = np.zeros(dh) if z0 is None else np.asarray(z0, float)
Z = []
for t in range(T):
z = np.tanh(np.asarray(Wx) @ X_seq[t] + np.asarray(Wz) @ z + np.asarray(b))
Z.append(z.copy())
return np.array(Z)
def attention_weights(scores):
"""Attention ağırlıkları = softmax(skorlar); toplamı 1 (olasılık dağılımı, 'odak')."""
scores = np.asarray(scores, float)
e = np.exp(scores - scores.max())
return e / e.sum()
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d6}
Hafta 5'in sonunda bıraktığımız soru: girdiler hep **sabit boyutluydu** (görüntü, vektör) — ama bir cümle, bir ses dalgası, bir zaman serisi **değişken uzunlukta bir dizidir**. Bu hafta dizileri işleyen mimarilere geçiyoruz: **yinelemeli ağlar (RNN)**, onların hafıza varyantları **LSTM/GRU**, ve modern dünyayı kuran fikir **attention**.
Yine iki hocalı. **Yann LeCun** (Lecture) RNN'in mimarisini ve temel sorununu (vanishing gradient) kurar, sonra çözümleri — GRU/LSTM ve attention — anlatır. **Alfredo Canziani** (Practicum) RNN'in dört tipini (girdi/çıktı dizi mi vektör mü) ve eğitimini PyTorch'ta somutlaştırır.
Bu haftanın üç ana fikri:
1. **RNN = zaman içinde paylaşılan bir katman.** Bir **gizli durum (hidden state)** geçmişi taşır; aynı ağırlıklar her zaman adımında tekrar kullanılır — recurrence $z_t = g(W_x x_t + W_z z_{t-1} + b)$.
2. **Naif RNN'ler uzun bağımlılıkta başarısız** (vanishing/exploding gradient); çözüm **gating + memory cell** (GRU, LSTM).
3. **Attention**, ağın hangi girdiye **odaklanacağını** öğrenmesidir — öğrenilen ağırlıklı birleşim $c = w_1 v_1 + w_2 v_2$ ($w_2 = 1 - w_1$), transformer'ların (Hafta 12) çekirdeği.
```{mermaid}
%%| echo: false
flowchart TB
subgraph LeCun["(A) RNN'in mantığı (LeCun)"]
direction LR
Seq["Diziler<br/>(değişken uzunluk + sıra)"]
Rec["Gizli durum / recurrence<br/>zₜ = g(Wₓxₜ + W_z zₜ₋₁ + b)"]
Unroll["Zamanda açma (unrolling)<br/>+ backprop through time"]
Vanish["Vanishing / exploding<br/>gradient (uzun bağımlılık)"]
Fix["Çözüm: gating (LSTM/GRU)<br/>+ attention"]
Seq --> Rec
Rec --> Unroll
Unroll --> Vanish
Vanish --> Fix
end
subgraph Canziani["(B) RNN pratiği (Canziani)"]
direction LR
Types["RNN'in 4 tipi<br/>(vec/seq × vec/seq)"]
S2S["Seq2seq<br/>(encoder-decoder darboğazı)"]
Train["Next-token eğitimi<br/>(diziyi batch'le, sonrakini tahmin et)"]
Types --> S2S
S2S --> Train
end
Fix -. "attention seq2seq darboğazını çözer" .-> S2S
```
::: {.callout-tip title="Builder Notu — Diziler = Değişken Uzunluk"}
**Geriye (önkoşul kurslar):**
- **RNN recurrence** → Hafta 2 "afin + nonlinearite" (döndür-ez) atomunun **zamanda** tekrarı; ağırlık paylaşımı Hafta 3 convolution'ın zaman eksenindeki kuzeni.
- **Vanishing gradient** → Hafta 2 backprop (Jacobian zinciri) + Hafta 4 (doygun nonlinearite türevi küçültür) + Calculus zincir kuralı.
- **Hidden state** → Stat 110 Markov (durum geçmişi özetler).
**İleriye (production / research):**
- Attention → transformer (Hafta 12), modern dil modellerinin tamamı.
- Seq2seq encoder-decoder → makine çevirisi, konuşma tanıma, her dizi-dizi görevi.
**Tek cümleyle:** RNN, aynı katmanı bir gizli durumla zaman içinde tekrar uygulayarak değişken uzunlukta dizileri işler; ama uzun bağımlılıkta vanishing gradient'e takılır — bu yüzden gating (LSTM/GRU) ve attention icat edildi.
:::
## (LeCun) Diziler Neden Farklı? {#sec-diziler}
Şimdiye kadarki ağlar sabit boyutlu girdi alıyordu. Ama gerçek dünyanın çoğu **dizidir**: metin (kelime dizisi), ses (örnek dizisi), video (kare dizisi). İki zorluk: (1) **değişken uzunluk** — "film iyiydi" 2 kelime, başka cümle 20 kelime; sabit-girdili bir ağ bunu alamaz. (2) **sıra önemlidir** — kelimelerin sırası anlamı değiştirir.
LeCun'un çerçevesi: bir diziyi işlemek, onu okurken **bir özet (gizli durum) tutmak** ve her yeni öğeyle bu özeti güncellemektir. "En olası karakter dizisi nedir?" gibi sorular (dil modelleme, posta kodu okuma) bu yapıyı gerektirir.
::: {.callout-tip title="Builder Notu — Değişken Uzunluk = Hafta 5'in Cevabı"}
**Geriye (Hafta 5):** Bu, Hafta 5 Egzersiz 5'in cevabıdır: değişken-uzunluk diziyi sabit-girdili ağa veremezsin; gizli durumlu bir tekrar gerekir. Dinamik hesaplama grafiği (Hafta 5) tam da bunu mümkün kılar.
**İleriye:** "Diziyi okurken durum tut" fikri; RNN'den transformer'a, durum-uzayı modellerine (Mamba) kadar tüm dizi modellemenin ortak temasıdır.
:::
## (LeCun) RNN Mimarisi: Gizli Durum ve Zamanda Açma {#sec-rnn-mimari}
Bir RNN, her zaman adımında **aynı** yinelemeli katmanı uygular. $t$ adımında, katman hem o anki girdiyi $x_t$ hem de bir önceki **gizli durumu** $z_{t-1}$ alır ve yeni durumu üretir:
$$
z_t = g\!\left(W_x\, x_t + W_z\, z_{t-1} + b\right)
$$
Buradaki $W_x$, $W_z$ her adımda **paylaşılır** (Hafta 3'ün ağırlık paylaşımının zaman eksenindeki hâli). Gizli durum $z_t$, dizinin o ana kadarki "özetidir".
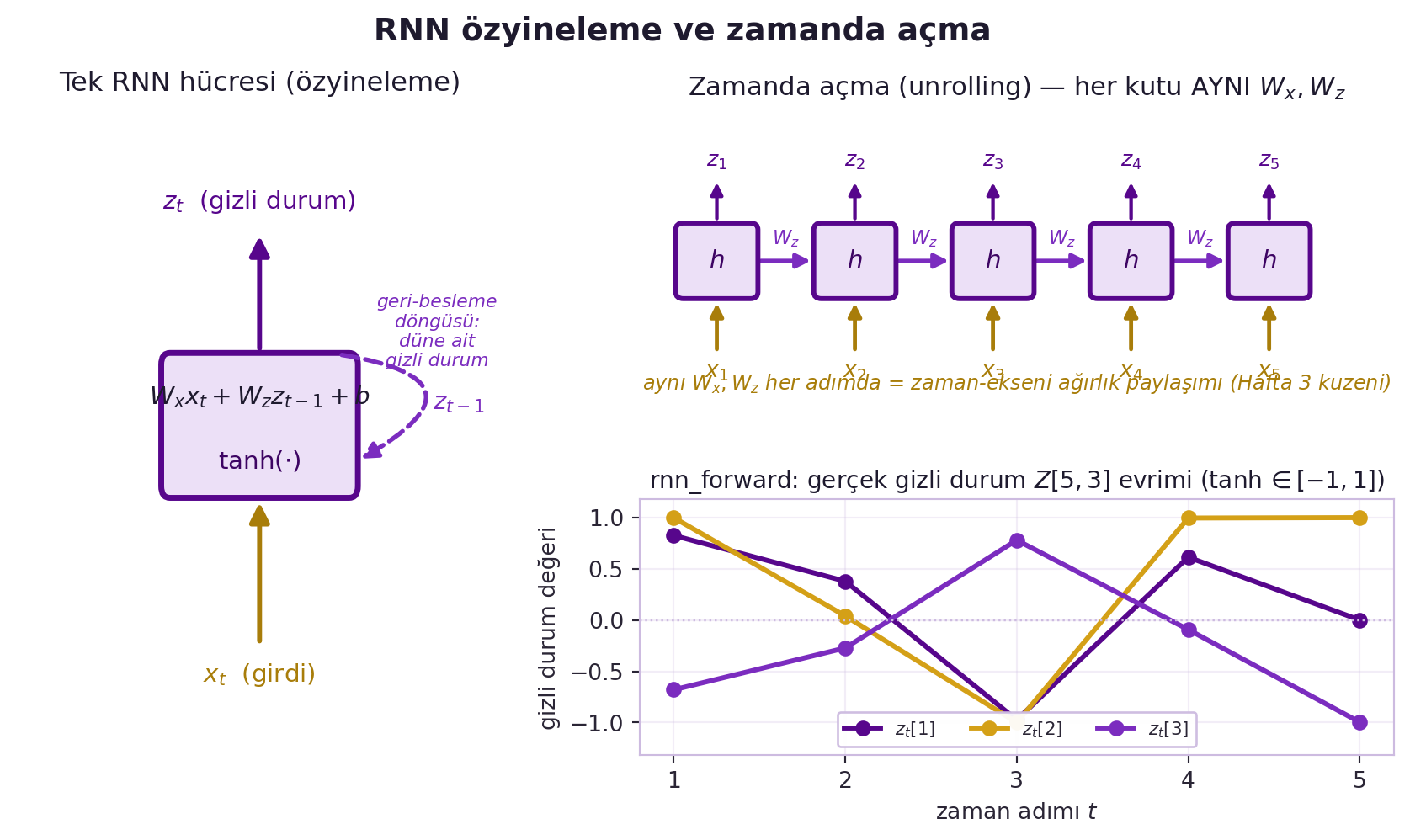
LeCun bunu **zamanda açma (unrolling)** ile görselleştiriyor: yinelemeli ağı, her zaman adımı için bir kopya olacak şekilde düz bir ağa açarsın; sonra normal backprop uygularsın — buna **zaman içinde geri yayılım (backprop through time)** denir. @fig-rnn-unroll bu iki bakışı bir arada gösterir: solda geri-besleme döngülü tek hücre, sağ-üstte aynı hücrenin zamanda açılmış (her kutu PAYLAŞILAN $W_x, W_z$) hâli, sağ-altta `rnn_forward` ile hesaplanan gerçek gizli durum dizisi.
> "this technique of unrolling and then back propagating [is how you train recurrent nets]." — LeCun, 47:37
```{python}
#| label: fig-rnn-unroll
#| fig-cap: "RNN özyineleme ve zamanda açma: Sol panelde tek bir RNN hücresi — girdi xₜ ile bir önceki gizli durum zₜ₋₁ afin dönüşüme (Wₓxₜ + W_z zₜ₋₁ + b) girer, tanh ile sıkıştırılır ve yeni gizli durum zₜ üretilir; kesikli geri-besleme döngüsü zₜ çıkışını bir sonraki adımda zₜ₋₁ olarak hücreye geri verir. Sağ-üst panelde aynı hücre zamanda açılır (unrolling): her kutu PAYLAŞILAN aynı Wₓ, W_z ağırlıklarını kullanır — bu, zaman ekseni boyunca ağırlık paylaşımıdır (Hafta 3'teki uzamsal evrişim paylaşımının kuzeni). Sağ-alt panelde rnn_forward ile hesaplanan gerçek beş-adımlık gizli durum dizisi Z[5,3]: üç birimin değerleri tanh sayesinde [−1, 1] aralığında kalır ve adımdan adıma evrilir."
fig = plt.figure(figsize=(11, 5.2))
gs = fig.add_gridspec(2, 2, width_ratios=[1.0, 1.55], height_ratios=[1.0, 0.92],
hspace=0.42, wspace=0.22)
# -------------------------------------------------------------------
# SOL panel — tek RNN hücresi şeması (geri-besleme döngüsü)
# -------------------------------------------------------------------
axL = fig.add_subplot(gs[:, 0])
axL.set_xlim(0, 10); axL.set_ylim(0, 10); axL.axis("off")
axL.set_title("Tek RNN hücresi (özyineleme)", color=COL_INK, fontsize=12, pad=8)
# afin + tanh kutusu
cell = FancyBboxPatch((3.0, 4.0), 4.0, 2.2,
boxstyle="round,pad=0.02,rounding_size=0.18",
fc="#ece0f7", ec=COL_VIOLET, lw=2.6, zorder=2)
axL.add_patch(cell)
axL.text(5.0, 5.55, r"$W_x x_t + W_z z_{t-1} + b$", ha="center", va="center",
fontsize=11, color=COL_INK, zorder=3)
axL.text(5.0, 4.55, r"$\tanh(\cdot)$", ha="center", va="center",
fontsize=11, color=COL_VIOLET_D, zorder=3)
# girdi xₜ (alttan)
axL.add_patch(FancyArrowPatch((5.0, 1.7), (5.0, 3.98), arrowstyle="-|>",
mutation_scale=18, color=COL_GOLD_D, lw=2.2, zorder=1))
axL.text(5.0, 1.25, r"$x_t$ (girdi)", ha="center", va="center",
fontsize=11, color=COL_GOLD_D)
# çıktı zₜ (üstten)
axL.add_patch(FancyArrowPatch((5.0, 6.22), (5.0, 8.1), arrowstyle="-|>",
mutation_scale=18, color=COL_VIOLET, lw=2.2, zorder=1))
axL.text(5.0, 8.55, r"$z_t$ (gizli durum)", ha="center", va="center",
fontsize=11, color=COL_VIOLET)
# geri-besleme döngüsü: zₜ çıkışı → sağdan dolanıp zₜ₋₁ olarak geri girer
loop = FancyArrowPatch((6.6, 6.2), (7.0, 4.55),
connectionstyle="arc3,rad=-1.45",
arrowstyle="-|>", mutation_scale=15,
color=COL_VIOLET_M, lw=2.0, ls="--", zorder=4)
axL.add_patch(loop)
axL.text(9.1, 5.45, r"$z_{t-1}$", ha="center", va="center",
fontsize=11, color=COL_VIOLET_M, zorder=4)
axL.text(8.65, 6.55, "geri-besleme\ndöngüsü:\ndüne ait\ngizli durum",
ha="center", va="center", fontsize=8.2, color=COL_VIOLET_M,
style="italic", zorder=4)
# -------------------------------------------------------------------
# SAĞ-ÜST panel — zamanda AÇILMIŞ (unrolled), paylaşılan W
# -------------------------------------------------------------------
axR = fig.add_subplot(gs[0, 1])
axR.set_xlim(0, 10); axR.set_ylim(0, 4.2); axR.axis("off")
axR.set_title("Zamanda açma (unrolling) — her kutu AYNI $W_x, W_z$",
color=COL_INK, fontsize=11.5, pad=6)
Tsteps = 5
x0, bw, bh, gap = 0.5, 1.05, 1.1, 0.78
yb = 1.9 # kutu merkez y
for i in range(Tsteps):
cx = x0 + i * (bw + gap)
box = FancyBboxPatch((cx, yb - bh / 2), bw, bh,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="#ece0f7", ec=COL_VIOLET, lw=2.2, zorder=2)
axR.add_patch(box)
axR.text(cx + bw / 2, yb, r"$h$", ha="center", va="center",
fontsize=11, color=COL_VIOLET_D, zorder=3)
# girdi xₜ
axR.add_patch(FancyArrowPatch((cx + bw / 2, yb - bh / 2 - 0.85),
(cx + bw / 2, yb - bh / 2 - 0.02),
arrowstyle="-|>", mutation_scale=12,
color=COL_GOLD_D, lw=1.8, zorder=1))
axR.text(cx + bw / 2, yb - bh / 2 - 1.12, rf"$x_{i+1}$", ha="center",
va="center", fontsize=10, color=COL_GOLD_D)
# zₜ yukarı (çıktı)
axR.add_patch(FancyArrowPatch((cx + bw / 2, yb + bh / 2 + 0.02),
(cx + bw / 2, yb + bh / 2 + 0.7),
arrowstyle="-|>", mutation_scale=11,
color=COL_VIOLET, lw=1.6, zorder=1))
axR.text(cx + bw / 2, yb + bh / 2 + 0.95, rf"$z_{i+1}$", ha="center",
va="center", fontsize=9.5, color=COL_VIOLET)
# yatay paylaşılan-W oku
if i < Tsteps - 1:
axR.add_patch(FancyArrowPatch((cx + bw, yb), (cx + bw + gap, yb),
arrowstyle="-|>", mutation_scale=13,
color=COL_VIOLET_M, lw=1.9, zorder=1))
axR.text(cx + bw + gap / 2, yb + 0.34, r"$W_z$", ha="center",
va="center", fontsize=8.5, color=COL_VIOLET_M)
axR.text(5.0, 0.05,
"aynı $W_x, W_z$ her adımda = zaman-ekseni ağırlık paylaşımı "
"(Hafta 3 kuzeni)",
ha="center", va="center", fontsize=9, color=COL_GOLD_D, style="italic")
# -------------------------------------------------------------------
# SAĞ-ALT panel — rnn_forward ile gerçek gizli durum evrimi Z[5,3]
# -------------------------------------------------------------------
axB = fig.add_subplot(gs[1, 1])
apply_style(axB)
dh, din = 3, 2
Wx = np.random.randn(dh, din) * 0.9
Wz = np.random.randn(dh, dh) * 0.9
b = np.zeros(dh)
X_seq = np.random.randn(Tsteps, din) * 1.1
Z = rnn_forward(X_seq, Wx, Wz, b) # [T, dh]
tt = np.arange(1, Tsteps + 1)
unit_colors = [COL_VIOLET, COL_GOLD, COL_VIOLET_M]
for j in range(dh):
axB.plot(tt, Z[:, j], "-o", color=unit_colors[j], lw=2.2, ms=6,
label=rf"$z_t[{j+1}]$")
axB.axhline(0, color=COL_GRID, lw=0.9, ls=":")
axB.set_xticks(tt)
axB.set_xlabel("zaman adımı $t$", fontsize=10)
axB.set_ylabel("gizli durum değeri", fontsize=10)
axB.set_title(r"rnn_forward: gerçek gizli durum $Z[5,3]$ evrimi "
r"($\tanh \in [-1,1]$)", color=COL_INK, fontsize=10.5, pad=5)
axB.set_ylim(-1.32, 1.18)
style_legend(axB, loc="lower center", fontsize=8, ncol=3)
fig.suptitle("RNN özyineleme ve zamanda açma", color=COL_INK,
fontsize=14, fontweight="bold", y=0.99);
```
::: {.callout-tip title="Builder Notu — Zamanda Döndür-Ez"}
**Geriye (Hafta 2):** Açılmış RNN, sıradan bir derin ağdır; eğitimi Hafta 2'nin backprop'unun (Jacobian zinciri) ta kendisidir — yalnızca ağırlıklar zaman boyunca paylaşılır.
**İleriye:** Unrolling, değişken-uzunluk için dinamik grafik (Hafta 5) ister; çok uzun dizilerde "truncated backprop through time" ile pencerelenir.
:::
## (LeCun) Vanishing/Exploding Gradient {#sec-vanishing}
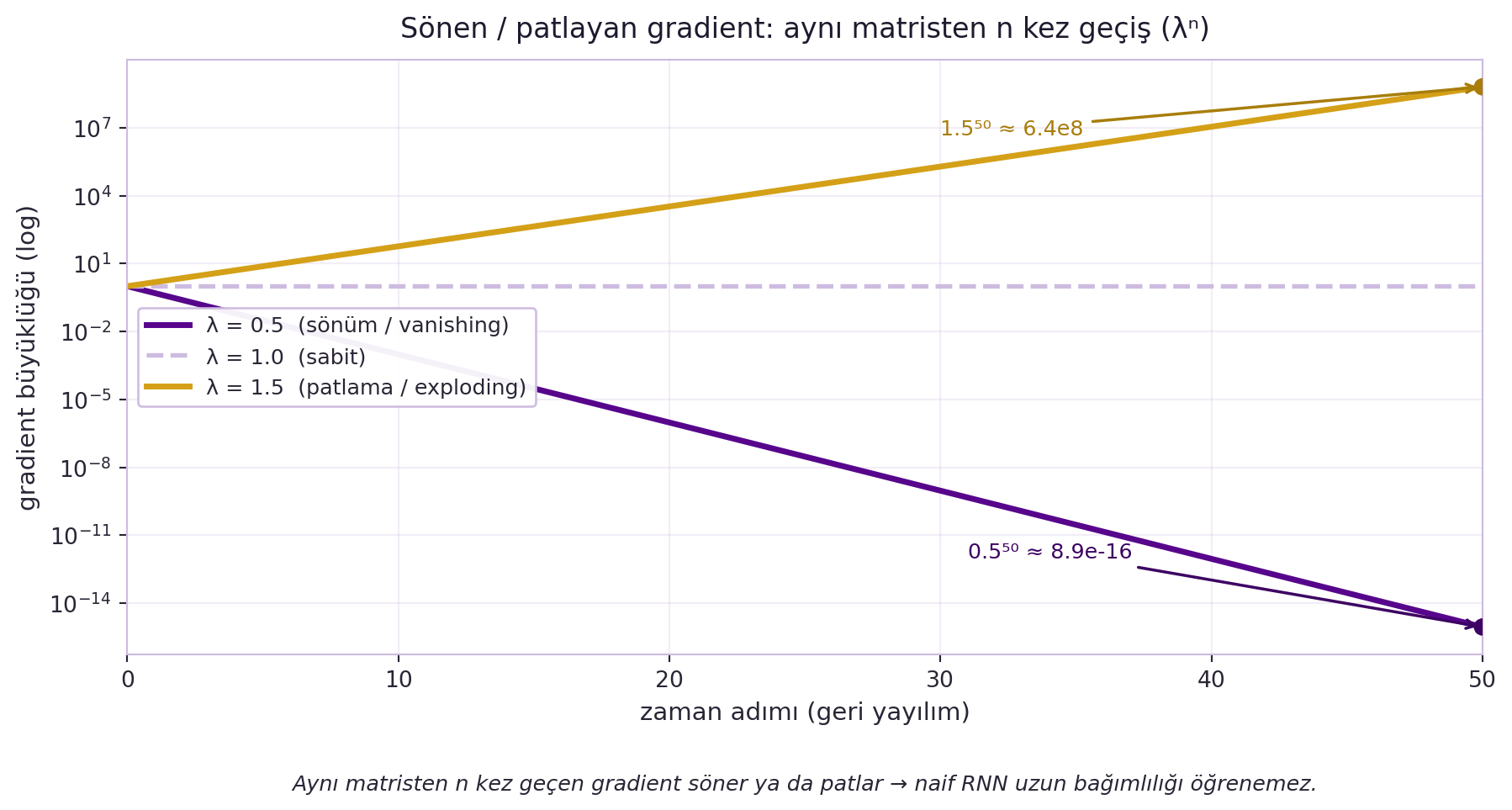
Naif RNN'in temel sorunu: uzun dizilerde gradient ya **kaybolur (vanishing)** ya da **patlar (exploding)**. Sebep, backprop through time'da gradient'in aynı yinelemeli matristen defalarca geçmesidir; 50 adım sonra bu çarpımlar ya sıfıra iner ya sonsuza gider. @fig-vanishing-gradient bunu tek bir özdeğer $\lambda$ üzerinden somutlaştırır: aynı matristen $n$ kez geçen gradient $\lambda^n$ olarak ölçeklenir — $\lambda < 1$ söner, $\lambda = 1$ sabit kalır, $\lambda > 1$ patlar.
> "by the time you get to the 50th time step... [you hit] the vanishing gradient problem." — LeCun, 49:15
Sonuç: gizli durum $z_t$ teoride bilgiyi uzun süre saklayabilmeli, ama vanishing gradient yüzünden naif RNN bunu pratikte **yapamaz** — uzun bağımlılıkları öğrenemez.
```{python}
#| label: fig-vanishing-gradient
#| fig-cap: "Sönen/patlayan gradient: aynı matristen n kez geçen gradient λⁿ olarak ölçeklenir. Log-y ekseninde λ=0.5 (violet) sönerek 50. adımda 0.5⁵⁰ ≈ 8.9e-16'ya iner (vanishing), λ=1.0 (gri kesikli) sabit kalır, λ=1.5 (gold) patlayarak 1.5⁵⁰ ≈ 6.4e8'e çıkar (exploding). Naif RNN, aynı geçiş matrisinden birçok kez geçtiği için uzun bağımlılığı öğrenemez."
t, curves = vanishing_demo(50, (0.5, 1.0, 1.5))
fig, ax = plt.subplots(figsize=(9.5, 5.2))
apply_style(ax)
# Üç eğri (log-y): λ<1 söner, λ=1 sabit, λ>1 patlar
ax.semilogy(t, curves[0.5], color=COL_VIOLET, lw=2.6,
label="λ = 0.5 (sönüm / vanishing)")
ax.semilogy(t, curves[1.0], color=COL_GRID, lw=2.0, ls="--",
label="λ = 1.0 (sabit)")
ax.semilogy(t, curves[1.5], color=COL_GOLD, lw=2.6,
label="λ = 1.5 (patlama / exploding)")
# 50. adım uç değerlerini işaretle
v50 = curves[0.5][50] # ≈ 8.9e-16
e50 = curves[1.5][50] # ≈ 6.4e8
ax.scatter([50, 50], [v50, e50], color=[COL_VIOLET_D, COL_GOLD_D], s=45, zorder=5)
ax.annotate("0.5⁵⁰ ≈ 8.9e-16", xy=(50, v50), xytext=(31, 1e-12),
color=COL_VIOLET_D, fontsize=9.5,
arrowprops=dict(arrowstyle="->", color=COL_VIOLET_D, lw=1.3))
ax.annotate("1.5⁵⁰ ≈ 6.4e8", xy=(50, e50), xytext=(30, 5e6),
color=COL_GOLD_D, fontsize=9.5,
arrowprops=dict(arrowstyle="->", color=COL_GOLD_D, lw=1.3))
ax.set_xlabel("zaman adımı (geri yayılım)", fontsize=11)
ax.set_ylabel("gradient büyüklüğü (log)", fontsize=11)
ax.set_title("Sönen / patlayan gradient: aynı matristen n kez geçiş (λⁿ)",
fontsize=12.5, color=COL_INK, pad=10)
ax.set_xlim(0, 50)
style_legend(ax, loc="center left", fontsize=9.5)
ax.text(0.5, -0.20,
"Aynı matristen n kez geçen gradient söner ya da patlar → naif RNN uzun bağımlılığı öğrenemez.",
transform=ax.transAxes, ha="center", va="top",
fontsize=9.5, color=COL_TEXT, style="italic")
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Vanishing = Uzun Zincir"}
**Geriye (Hafta 2 + 4):** Vanishing gradient, Hafta 2'nin zincir kuralının ve Hafta 4'ün "doygun nonlinearite türevi gradient'i küçültür" gözleminin uzun-zincir hâlidir; aynı matrisin tekrar tekrar çarpılması özdeğerleri 1'den uzaksa patlama/sönme yaratır (18.06).
**İleriye:** Çözümler: gating (bu hafta GRU/LSTM), gradient clipping (exploding için), residual bağlantılar, ve nihayetinde attention (uzun bağımlılığı tek adımda kurar).
:::
## (LeCun) Attention: Hangi Girdiye Odaklan? {#sec-attention}
LeCun attention'ı bir **ağırlıklı birleşim** olarak tanıtıyor: ağ, birkaç girdiyi sabit ağırlıklarla değil, **kendi seçtiği** ağırlıklarla birleştirir. En basit hâlde iki girdi için ağırlıklar toplamı 1'dir:
$$
c = w_1 v_1 + w_2 v_2, \qquad w_2 = 1 - w_1
$$
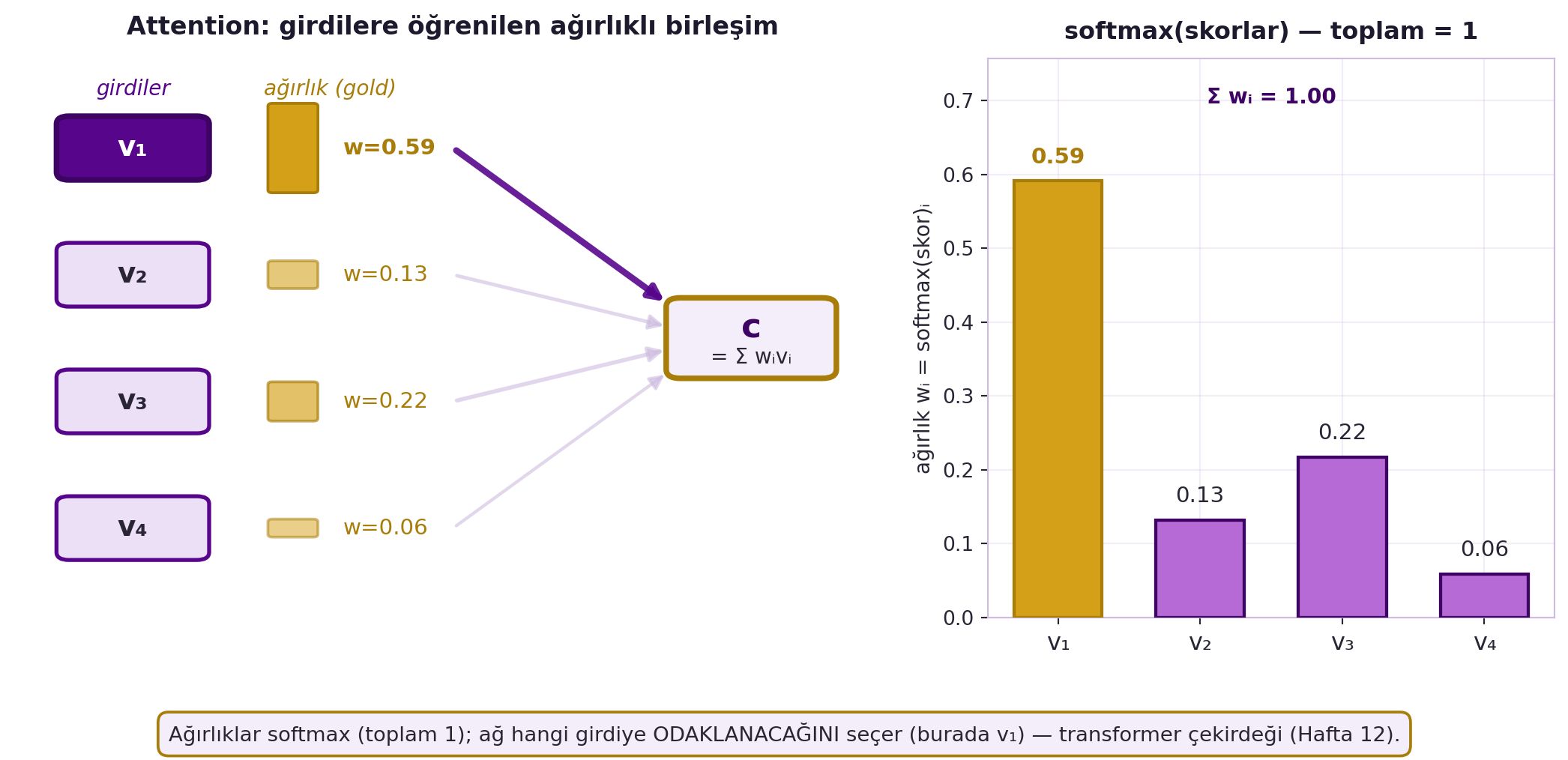
Bu ağırlıkları başka bir ağ üretir; böylece model bir girdiye **odaklanıp** ötekileri **görmezden gelebilir**. @fig-attention bunu somutlaştırır: ham hizalama skorları softmax'tan geçirilir, toplamı 1 olan bir odak dağılımı çıkar, ve çıktı $c = \sum_i w_i v_i$ ağırlıklı toplamıdır — ağ en yüksek ağırlığı vererek hangi girdiye odaklanacağını seçer.
> "[attention] allows a neural net to basically focus its attention on a particular input and ignoring the others." — LeCun, 57:53
LeCun'un kritik notu: transformer mimarileri ve her tür attention, bu basit "öğrenilen ağırlıklı birleşim" trick'ini kullanır. Yani Hafta 12'nin transformer'ı, bu çekirdeğin ölçeklenmiş hâlidir.
```{python}
#| label: fig-attention
#| fig-cap: "Attention öğrenilen ağırlıklı birleşim olarak. Ham hizalama skorları softmax'tan geçirilir → ağırlıklar wᵢ (toplam 1, bir olasılık/odak dağılımı). Çıktı, girdi vektörlerinin ağırlıklı toplamıdır: c = Σ wᵢvᵢ. Ağ, en yüksek ağırlığı vererek hangi girdiye ODAKLANACAĞINI seçer (burada v₁, w=0.59); bu mekanizma transformer'ın çekirdeğidir (Hafta 12)."
# Attention = öğrenilen ağırlıklı birleşim. c = Σ wᵢ·vᵢ
# Skorlar → softmax → ağırlıklar (toplam 1). Ağ hangi girdiye ODAKLANACAĞINI seçer.
scores = np.array([2.0, 0.5, 1.0, -0.3]) # 4 girdiye ham hizalama skoru
w = attention_weights(scores) # softmax → toplam 1 (odak dağılımı)
labels = ["v₁", "v₂", "v₃", "v₄"]
fig, (axL, axR) = plt.subplots(
1, 2, figsize=(11, 5.0), gridspec_kw={"width_ratios": [1.55, 1.0]}
)
# --- Sol: girdi vektörleri (violet kutu) → ağırlık (gold) → birleşim c ---
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.axis("off")
axL.set_title("Attention: girdilere öğrenilen ağırlıklı birleşim",
color=COL_INK, fontsize=12.5, fontweight="bold", pad=12)
n = len(w)
ys = np.linspace(8.4, 1.6, n) # yukarıdan aşağıya 4 girdi
focus = int(np.argmax(w)) # en yüksek ağırlıklı girdi (odak)
cx, cy = 8.4, ys.mean() # birleşim kutusu konumu
for i, (lbl, yi, wi) in enumerate(zip(labels, ys, w)):
is_focus = (i == focus)
fc = "#ece0f7" if not is_focus else COL_VIOLET
ec = COL_VIOLET_D if is_focus else COL_VIOLET
txt_c = COL_WHITE if is_focus else COL_TEXT
box = FancyBboxPatch(
(0.5, yi - 0.55), 1.7, 1.1,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc=fc, ec=ec, lw=2.8 if is_focus else 2.0, zorder=3,
)
axL.add_patch(box)
axL.text(1.35, yi, lbl, ha="center", va="center",
fontsize=14, fontweight="bold", color=txt_c, zorder=4)
# gold ağırlık çubuğu (yükseklik + opaklık = ağırlık büyüklüğü)
bar_x = 2.9
bar_full = 2.4
bh = 0.16 + bar_full * wi
alpha = 0.45 + 0.55 * (wi / w.max())
axL.add_patch(FancyBboxPatch(
(bar_x, yi - bh / 2), 0.55, bh,
boxstyle="round,pad=0.01,rounding_size=0.05",
fc=COL_GOLD, ec=COL_GOLD_D, lw=1.4, alpha=alpha, zorder=3,
))
axL.text(bar_x + 0.85, yi, f"w={wi:.2f}", ha="left", va="center",
fontsize=11, color=COL_GOLD_D,
fontweight="bold" if is_focus else "normal", zorder=4)
# ok: girdi+ağırlık → birleşim c (odak okunu kalın çiz)
axL.add_patch(FancyArrowPatch(
(5.0, yi), (cx - 0.95, cy + (yi - cy) * 0.18),
arrowstyle="-|>", mutation_scale=15,
color=COL_VIOLET if is_focus else COL_GRID,
lw=1.4 + 3.0 * wi, alpha=0.9 if is_focus else 0.6, zorder=2,
))
# birleşim kutusu c
axL.add_patch(FancyBboxPatch(
(cx - 0.95, cy - 0.7), 1.9, 1.4,
boxstyle="round,pad=0.02,rounding_size=0.16",
fc=COL_BG, ec=COL_GOLD_D, lw=2.8, zorder=3,
))
axL.text(cx, cy + 0.18, "c", ha="center", va="center",
fontsize=17, fontweight="bold", color=COL_VIOLET_D, zorder=4)
axL.text(cx, cy - 0.35, "= Σ wᵢvᵢ", ha="center", va="center",
fontsize=10.5, color=COL_TEXT, zorder=4)
axL.text(1.35, 9.35, "girdiler", ha="center", fontsize=10.5,
color=COL_VIOLET, style="italic")
axL.text(3.6, 9.35, "ağırlık (gold)", ha="center", fontsize=10.5,
color=COL_GOLD_D, style="italic")
# --- Sağ: softmax ağırlık dağılımı (toplam 1) ---
apply_style(axR)
xpos = np.arange(n)
bars = axR.bar(xpos, w, width=0.62,
color=[COL_VIOLET if i == focus else COL_VIOLET_SOFT for i in range(n)],
edgecolor=COL_VIOLET_D, linewidth=1.6, zorder=3)
bars[focus].set_color(COL_GOLD)
bars[focus].set_edgecolor(COL_GOLD_D)
for i, (xi, wi) in enumerate(zip(xpos, w)):
axR.text(xi, wi + 0.018, f"{wi:.2f}", ha="center", va="bottom",
fontsize=11, fontweight="bold" if i == focus else "normal",
color=COL_GOLD_D if i == focus else COL_TEXT, zorder=4)
axR.set_xticks(xpos)
axR.set_xticklabels(labels, fontsize=12)
axR.set_ylim(0, max(w) * 1.28)
axR.set_ylabel("ağırlık wᵢ = softmax(skor)ᵢ", fontsize=10.5)
axR.set_title("softmax(skorlar) — toplam = 1", color=COL_INK,
fontsize=12, fontweight="bold", pad=10)
axR.axhline(0, color=COL_GRID, lw=1.0)
axR.text(0.5, 0.92, f"Σ wᵢ = {w.sum():.2f}", transform=axR.transAxes,
ha="center", fontsize=10.5, color=COL_VIOLET_D, fontweight="bold")
# --- Ortak açıklama (annotation) ---
fig.text(
0.5, -0.015,
"Ağırlıklar softmax (toplam 1); ağ hangi girdiye ODAKLANACAĞINI seçer "
"(burada v₁) — transformer çekirdeği (Hafta 12).",
ha="center", va="top", fontsize=10.3, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_GOLD_D, lw=1.4),
)
fig.tight_layout(rect=[0, 0.05, 1, 1])
```
::: {.callout-tip title="Builder Notu — Attention = Softmax Odak"}
**Geriye (Hafta 1):** Attention ağırlıkları toplamı 1 olan bir olasılık dağılımıdır (softmax) — Stat 110 + Hafta 1 softmax. "Odaklan" = yüksek ağırlık ver.
**İleriye:** Attention, RNN'in sıralı darboğazını aşar (her konum her konuma doğrudan bakar); transformer (Hafta 12), self-attention'ın çok-başlı, ölçekli hâlidir.
:::
## (LeCun) GRU ve LSTM: Gating ve Memory Cell {#sec-gru-lstm}
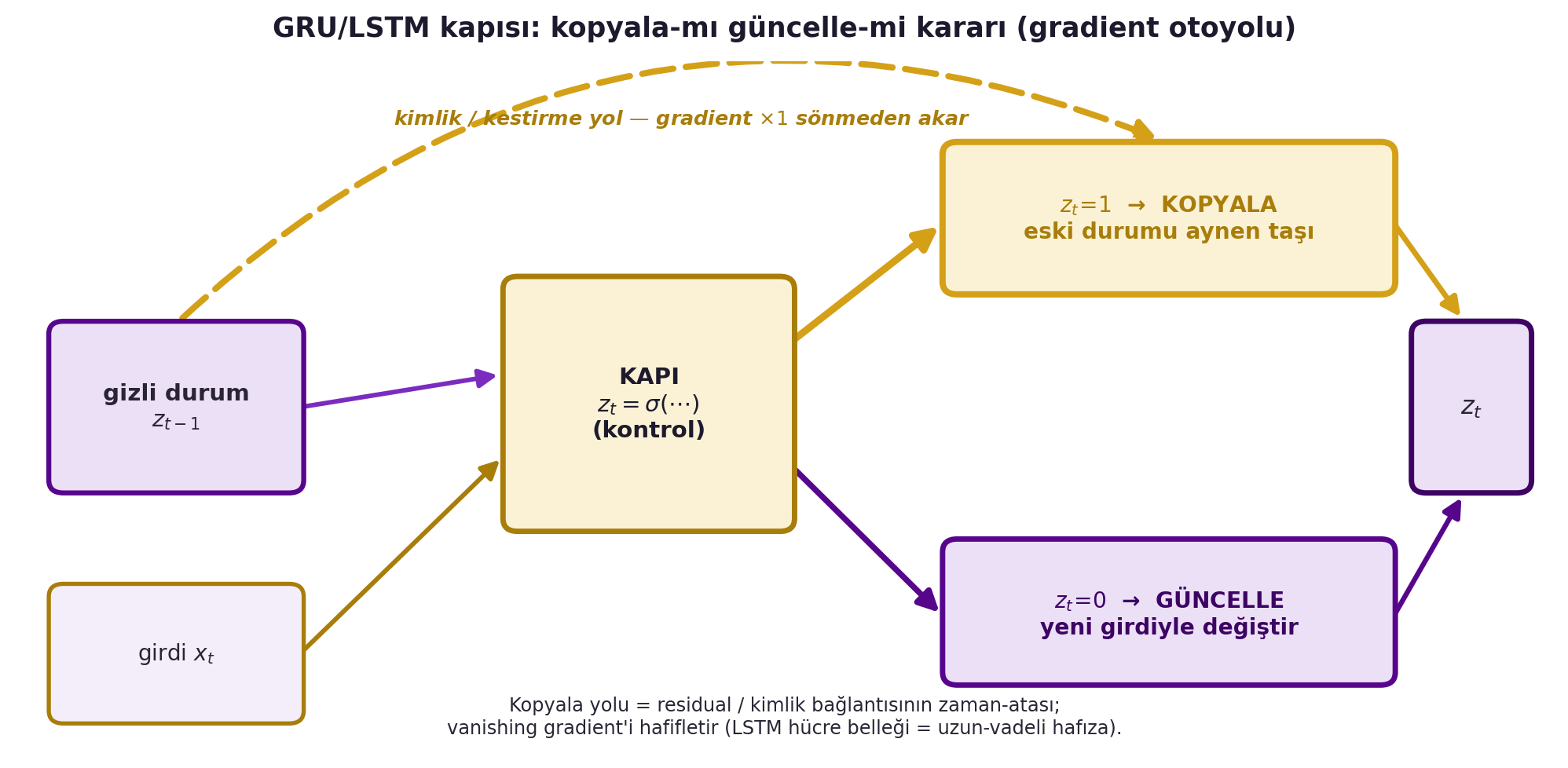
Vanishing gradient'i çözmenin ana yolu **gating**'dir. **GRU** (Cho, 2014) ve **LSTM** (Hochreiter & Schmidhuber, 1997), gizli duruma bir **memory cell** (hafıza hücresi) ve bunu kontrol eden **kapılar (gates)** ekler. Bir gating vektörü $z_t$, durumu ne kadar güncelleyeceğini belirler: uçta $z_t = 1$ ise eski durumu **olduğu gibi kopyalar**, girdiyi yok sayar — yani bir hafıza gibi davranır. @fig-gru-gate bu kararı bir gradient otoyolu olarak çizer: kopyala yolu (gold) eski durumu sönmeden taşır, güncelle yolu (violet) gizli durumu yeni girdiyle değiştirir.
> "if Z equals 1, it just copies its previous state and ignores the input, so it acts like a memory essentially." — LeCun, 1:01:55
Bu "kopyala" yolu, gradient'in uzun mesafede **bozulmadan** akmasını sağlar (vanishing gradient'i hafifletir). LSTM (1997) aynı sorunu daha erken çözmüştü; GRU daha sade bir varyanttır.
```{python}
#| label: fig-gru-gate
#| fig-cap: "GRU/LSTM kapısının (gating) şematik gösterimi. Önceki gizli durum $z_{t-1}$ ve girdi $x_t$ merkezdeki KAPI'ya (kontrol, $z_t=\\sigma(\\cdots)$) girer. Kapı iki yol arasında karar verir: $z_t=1$ ise KOPYALA yolu (gold otoyol) eski durumu aynen taşır, girdiyi yoksayar — bu kestirme/kimlik bağlantısı sayesinde gradient $\\times 1$ ile sönmeden geriye akar; $z_t=0$ ise GÜNCELLE yolu (violet) gizli durumu yeni girdiyle değiştirir. Kopyala yolu, residual/kimlik bağlantısının zaman-atasıdır ve LSTM hücre belleğindeki uzun-vadeli hafızayı mümkün kılarak vanishing gradient'i hafifletir."
fig, ax = plt.subplots(figsize=(10.5, 5.2))
ax.set_xlim(0, 10.5)
ax.set_ylim(0, 5.4)
ax.axis("off")
ax.set_title("GRU/LSTM kapısı: kopyala-mı güncelle-mi kararı (gradient otoyolu)",
color=COL_INK, fontsize=13, fontweight="bold", pad=12)
def kutu(x, y, w, h, etiket, fc, ec, lw=2.2, fs=10.5, tc=None, fw="normal"):
box = FancyBboxPatch((x, y), w, h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=lw, zorder=2)
ax.add_patch(box)
ax.text(x + w / 2, y + h / 2, etiket, ha="center", va="center",
fontsize=fs, color=tc or COL_TEXT, fontweight=fw, zorder=3)
return (x + w / 2, y + h / 2)
def ok(p0, p1, color, lw=2.4, ls="-", mut=18):
ax.add_patch(FancyArrowPatch(p0, p1, arrowstyle="-|>", mutation_scale=mut,
color=color, lw=lw, linestyle=ls, zorder=1,
shrinkA=2, shrinkB=4))
# --- Sol: önceki gizli durum ---
sol = kutu(0.25, 2.05, 1.7, 1.3, "gizli durum\n$z_{t-1}$",
"#ece0f7", COL_VIOLET, lw=2.4, fs=11, fw="bold")
# --- Alt: yeni girdi ---
girdi = kutu(0.25, 0.25, 1.7, 1.05, "girdi $x_t$", COL_BG, COL_GOLD_D, lw=2.0, fs=10.5)
# --- Orta: KAPI (kontrol) ---
kapi_x, kapi_y, kapi_w, kapi_h = 3.35, 1.75, 1.95, 1.95
kapi = kutu(kapi_x, kapi_y, kapi_w, kapi_h,
"KAPI\n$z_t = \\sigma(\\cdots)$\n(kontrol)",
"#fbf2d6", COL_GOLD_D, lw=2.6, fs=11, tc=COL_INK, fw="bold")
# girişler kapıya
ok((1.95, 2.7), (kapi_x, kapi_y + kapi_h * 0.62), COL_VIOLET_M, lw=2.2)
ok((1.95, 0.78), (kapi_x, kapi_y + kapi_h * 0.30), COL_GOLD_D, lw=2.2)
# --- Üst yol: Z=1 KOPYALA (gold gradient otoyolu) ---
kop_y = 4.15
kopyala = kutu(6.35, kop_y - 0.55, 3.05, 1.15,
"$z_t\\!=\\!1$ → KOPYALA\neski durumu aynen taşı",
"#fbf2d6", COL_GOLD, lw=3.0, fs=10.5, tc=COL_GOLD_D, fw="bold")
# kapıdan kopyala yoluna (gold kalın)
ok((kapi_x + kapi_w, kapi_y + kapi_h * 0.75), (6.35, kop_y), COL_GOLD, lw=3.4, mut=22)
# kimlik baglantisi: z_{t-1} -> dogrudan kopyala (gradient x1 sönmeden)
ax.add_patch(FancyArrowPatch((1.1, 3.35), (7.85, kop_y + 0.62),
connectionstyle="arc3,rad=-0.32", arrowstyle="-|>",
mutation_scale=20, color=COL_GOLD, lw=3.0, linestyle=(0, (5, 2)),
zorder=1, shrinkA=4, shrinkB=4))
ax.text(4.55, 4.95, "kimlik / kestirme yol — gradient $\\times 1$ sönmeden akar",
ha="center", va="center", fontsize=9.5, color=COL_GOLD_D,
fontstyle="italic", fontweight="bold")
# --- Alt yol: Z=0 GUNCELLE (violet) ---
gun_y = 1.05
guncelle = kutu(6.35, gun_y - 0.5, 3.05, 1.1,
"$z_t\\!=\\!0$ → GÜNCELLE\nyeni girdiyle değiştir",
"#ece0f7", COL_VIOLET, lw=2.6, fs=10.5, tc=COL_VIOLET_D, fw="bold")
ok((kapi_x + kapi_w, kapi_y + kapi_h * 0.25), (6.35, gun_y), COL_VIOLET, lw=2.8, mut=20)
# --- Sağ: yeni gizli durum z_t (birleşim) ---
yeni = kutu(9.55, 2.05, 0.78, 1.3, "$z_t$", "#ece0f7", COL_VIOLET_D, lw=2.6, fs=12, fw="bold")
ok((9.4, kop_y), (9.9, 3.35), COL_GOLD, lw=2.6)
ok((9.4, gun_y), (9.9, 2.05), COL_VIOLET, lw=2.4)
# --- Annotation alt: residual zaman-atası ---
ax.text(5.25, 0.12,
"Kopyala yolu = residual / kimlik bağlantısının zaman-atası;\n"
"vanishing gradient'i hafifletir (LSTM hücre belleği = uzun-vadeli hafıza).",
ha="center", va="bottom", fontsize=9, color=COL_TEXT)
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — Memory Cell = Residual'in Atası"}
**Geriye (Hafta 2):** Memory cell'in "kopyala" yolu, bir tür residual/kimlik bağlantısıdır — gradient'i 1 ile çarparak (sönmeden) taşır; bu, derin ağlardaki residual bağlantının (Hafta 2 ileriye notu) zaman eksenindeki atasıdır.
**İleriye:** LSTM/GRU 2010'larda NLP/konuşmanın standardıydı; transformer'lar (Hafta 12) çoğu görevde onları geçti, ama uzun-bağlam ve verimlilik için RNN-benzeri fikirler (SSM, Mamba) geri dönüyor.
:::
## Geçiş: LeCun'dan Canziani'ye {#sec-gecis-d6}
LeCun RNN'in *neden*ini ve *sorunlarını* (vanishing gradient → gating, attention) kurdu. Şimdi **Canziani** RNN'i pratiğe indiriyor: bir RNN'in girdi/çıktısı dizi mi vektör mü olduğuna göre **dört farklı tipi**, ve PyTorch'ta nasıl eğitildiğini gösteriyor. LeCun teoriyi, Canziani şekli ve kodu veriyor.
## (Canziani) RNN'in Dört Tipi {#sec-4tip}
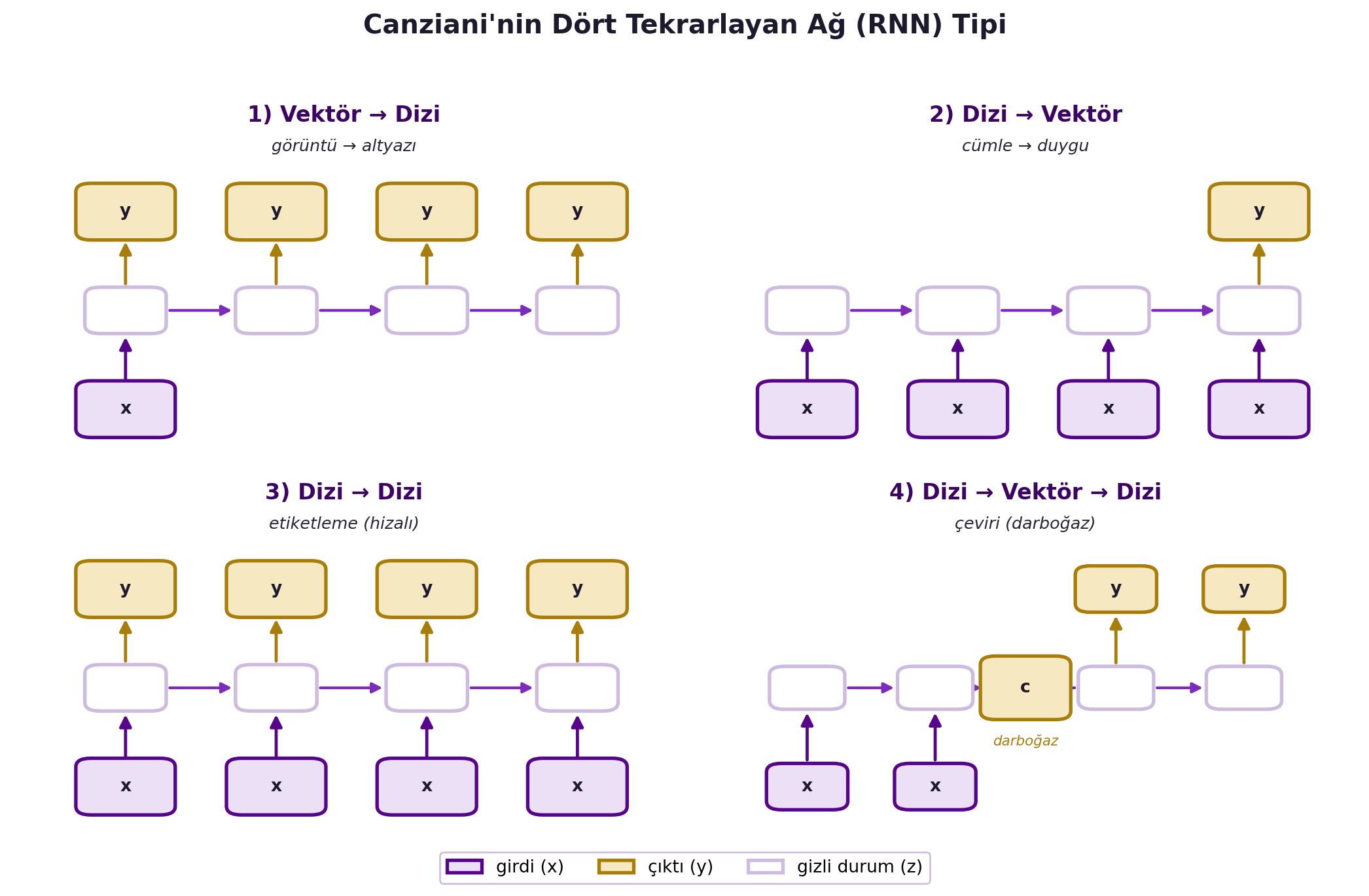
Canziani RNN'leri girdi ve çıktının **dizi mi vektör mü** olduğuna göre dörde ayırıyor:
1. **Vektör → Dizi:** tek girdi, dizi çıktı (örn. görüntü → altyazı/caption).
2. **Dizi → Vektör:** dizi girdi, tek çıktı (örn. cümle → duygu sınıfı; ara çıktıları umursamaz, yalnızca sondaki).
3. **Dizi → Dizi (eşzamanlı):** her girdiye bir çıktı (örn. etiketleme).
4. **Dizi → Vektör → Dizi:** dizi önce tek bir vektöre sıkışır, sonra yeni bir dizi üretir (örn. çeviri — birazdan).
Bu dört kalıp, "değişken-uzunluk girdi/çıktıyı nasıl kurarsın?" sorusunun tüm yanıtlarını kapsar. @fig-rnn-4types dördünü tek bir 2×2 panelde, NYU violet girdi ve gold çıktı renk anahtarıyla yan yana koyar.
```{python}
#| label: fig-rnn-4types
#| fig-cap: "Canziani'nin dört tekrarlayan ağ (RNN) tipi: (1) Vektör→Dizi (görüntü→altyazı), (2) Dizi→Vektör (cümle→duygu), (3) Dizi→Dizi hizalı etiketleme, (4) Dizi→Vektör→Dizi çeviri (darboğaz). NYU violet girdi, gold çıktı, açık gizli durum."
fig, axes = plt.subplots(2, 2, figsize=(11, 7))
fig.patch.set_facecolor(COL_WHITE)
BW, BH = 0.62, 0.62 # kutu genişlik/yükseklik
GAP = 0.34 # dizide kutular arası boşluk
def kutu(ax, x, y, renk, ec, lbl="", w=BW, h=BH):
box = FancyBboxPatch(
(x - w / 2, y - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=renk, ec=ec, lw=2.0, zorder=3,
)
ax.add_patch(box)
if lbl:
ax.text(x, y, lbl, ha="center", va="center",
fontsize=10, color=COL_INK, zorder=4, fontweight="bold")
return box
def dikey_ok(ax, x, y0, y1, renk=COL_VIOLET_M):
ax.add_patch(FancyArrowPatch((x, y0), (x, y1), arrowstyle="-|>",
mutation_scale=14, color=renk, lw=1.8, zorder=2))
def yatay_ok(ax, x0, x1, y, renk=COL_VIOLET_M):
ax.add_patch(FancyArrowPatch((x0, y), (x1, y), arrowstyle="-|>",
mutation_scale=12, color=renk, lw=1.6, zorder=2))
# girdi/çıktı dolgu+kenar renkleri (NYU violet girdi, gold çıktı)
GIRDI_FC, GIRDI_EC = "#ece0f7", COL_VIOLET
CIKTI_FC, CIKTI_EC = "#f6e8c0", COL_GOLD_D
GIZLI_FC, GIZLI_EC = COL_WHITE, COL_GRID
Y_IN, Y_HID, Y_OUT = 0.4, 1.55, 2.7 # girdi / gizli durum / çıktı satırları
def panel_kur(ax, baslik, alt):
ax.set_xlim(-0.2, 4.2)
ax.set_ylim(-0.2, 3.95)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
ax.text(2.0, 3.82, baslik, ha="center", va="center",
fontsize=12.5, fontweight="bold", color=COL_VIOLET_D)
ax.text(2.0, 3.46, alt, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, style="italic")
# küçük gizli-durum kutusu konumları (4 zaman adımı)
XS = [0.55, 1.55, 2.55, 3.55]
def gizli_dizi(ax):
for i, x in enumerate(XS):
kutu(ax, x, Y_HID, GIZLI_FC, GIZLI_EC, "", w=0.5, h=0.5)
if i > 0:
yatay_ok(ax, XS[i - 1] + 0.27, x - 0.27, Y_HID, COL_VIOLET_M)
# Panel 1 — Vektör → Dizi (görüntü → altyazı)
ax = axes[0, 0]
panel_kur(ax, "1) Vektör → Dizi", "görüntü → altyazı")
gizli_dizi(ax)
kutu(ax, XS[0], Y_IN, GIRDI_FC, GIRDI_EC, "x")
dikey_ok(ax, XS[0], Y_IN + 0.31, Y_HID - 0.27, COL_VIOLET)
for x in XS:
kutu(ax, x, Y_OUT, CIKTI_FC, CIKTI_EC, "y")
dikey_ok(ax, x, Y_HID + 0.27, Y_OUT - 0.31, COL_GOLD_D)
# Panel 2 — Dizi → Vektör (cümle → duygu)
ax = axes[0, 1]
panel_kur(ax, "2) Dizi → Vektör", "cümle → duygu")
gizli_dizi(ax)
for x in XS:
kutu(ax, x, Y_IN, GIRDI_FC, GIRDI_EC, "x")
dikey_ok(ax, x, Y_IN + 0.31, Y_HID - 0.27, COL_VIOLET)
kutu(ax, XS[-1], Y_OUT, CIKTI_FC, CIKTI_EC, "y")
dikey_ok(ax, XS[-1], Y_HID + 0.27, Y_OUT - 0.31, COL_GOLD_D)
# Panel 3 — Dizi → Dizi (hizalı etiketleme)
ax = axes[1, 0]
panel_kur(ax, "3) Dizi → Dizi", "etiketleme (hizalı)")
gizli_dizi(ax)
for x in XS:
kutu(ax, x, Y_IN, GIRDI_FC, GIRDI_EC, "x")
dikey_ok(ax, x, Y_IN + 0.31, Y_HID - 0.27, COL_VIOLET)
kutu(ax, x, Y_OUT, CIKTI_FC, CIKTI_EC, "y")
dikey_ok(ax, x, Y_HID + 0.27, Y_OUT - 0.31, COL_GOLD_D)
# Panel 4 — Dizi → Vektör → Dizi (çeviri, darboğaz)
ax = axes[1, 1]
panel_kur(ax, "4) Dizi → Vektör → Dizi", "çeviri (darboğaz)")
XE = [0.55, 1.4] # encoder adımları
XB = 2.0 # darboğaz (tek vektör)
XD = [2.6, 3.45] # decoder adımları
for i, x in enumerate(XE):
kutu(ax, x, Y_HID, GIZLI_FC, GIZLI_EC, "", w=0.46, h=0.46)
if i > 0:
yatay_ok(ax, XE[i - 1] + 0.25, x - 0.25, Y_HID)
kutu(ax, x, Y_IN, GIRDI_FC, GIRDI_EC, "x", w=0.5, h=0.5)
dikey_ok(ax, x, Y_IN + 0.27, Y_HID - 0.25, COL_VIOLET)
yatay_ok(ax, XE[-1] + 0.25, XB - 0.27, Y_HID)
kutu(ax, XB, Y_HID, "#f6e8c0", COL_GOLD_D, "c", w=0.56, h=0.7)
ax.text(XB, Y_HID - 0.62, "darboğaz", ha="center", va="center",
fontsize=8.0, color=COL_GOLD_D, style="italic")
yatay_ok(ax, XB + 0.3, XD[0] - 0.25, Y_HID)
for i, x in enumerate(XD):
kutu(ax, x, Y_HID, GIZLI_FC, GIZLI_EC, "", w=0.46, h=0.46)
if i > 0:
yatay_ok(ax, XD[i - 1] + 0.25, x - 0.25, Y_HID)
kutu(ax, x, Y_OUT, CIKTI_FC, CIKTI_EC, "y", w=0.5, h=0.5)
dikey_ok(ax, x, Y_HID + 0.25, Y_OUT - 0.27, COL_GOLD_D)
# ortak açıklama (girdi/çıktı renk anahtarı)
from matplotlib.patches import Patch
handles = [
Patch(fc=GIRDI_FC, ec=GIRDI_EC, lw=2.0, label="girdi (x)"),
Patch(fc=CIKTI_FC, ec=CIKTI_EC, lw=2.0, label="çıktı (y)"),
Patch(fc=GIZLI_FC, ec=GIZLI_EC, lw=2.0, label="gizli durum (z)"),
]
fig.legend(handles=handles, loc="lower center", ncol=3, frameon=True,
framealpha=0.95, edgecolor=COL_GRID, fontsize=10,
bbox_to_anchor=(0.5, -0.01))
fig.suptitle("Canziani'nin Dört Tekrarlayan Ağ (RNN) Tipi",
fontsize=15, fontweight="bold", color=COL_INK, y=0.99)
fig.tight_layout(rect=[0, 0.03, 1, 0.96])
```
::: {.callout-tip title="Builder Notu — 4 Tip Taksonomi"}
**Geriye (Hafta 5):** Her tip, değişken-uzunluk diziyi işlemek için dinamik grafik (Hafta 5) ister; gizli durum, Hafta 2'nin "döndür-ez" katmanının zamanda tekrarıdır.
**İleriye:** Bu taksonomi (vec/seq giriş × vec/seq çıkış) bugün de geçerli; transformer'lar aynı dört kalıbı encoder/decoder kombinasyonlarıyla kurar.
:::
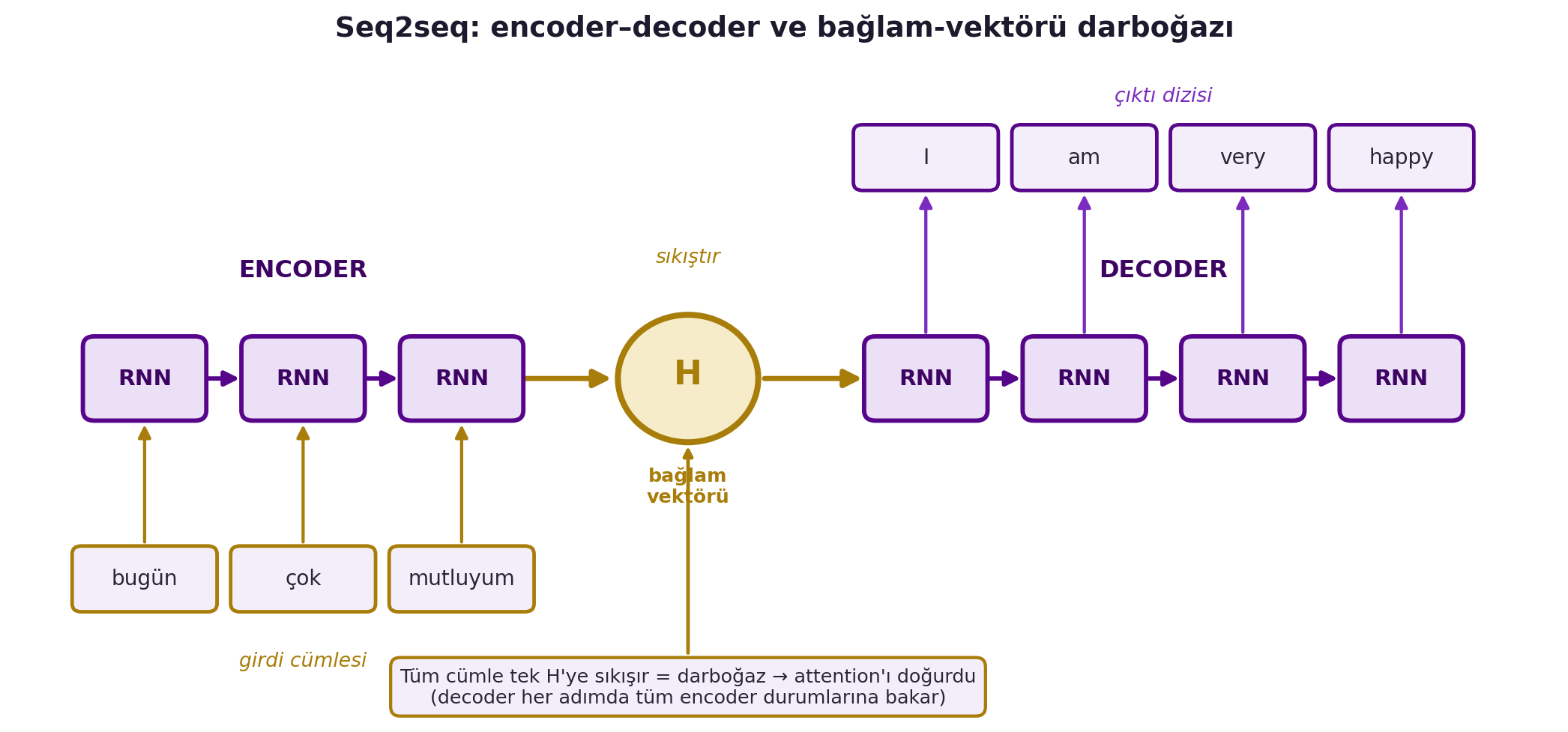
## (Canziani) Seq2Seq: Encoder-Decoder ve Çeviri {#sec-seq2seq}
Dördüncü tip — **dizi → vektör → dizi** — makine çevirisinin klasik kalıbıdır (seq2seq). Bir **encoder** RNN, girdi cümlesini (örn. "bugün çok mutluyum") tek bir gizli vektöre **sıkıştırır** (H); bir **decoder** RNN bu vektörden hedef dildeki diziyi (İngilizce çeviri) **üretir**. @fig-seq2seq bu mimariyi ve bağlam-vektörü darboğazını çizer: tüm cümlenin tek H'ye sıkışması, decoder'ın her adımda tüm encoder durumlarına bakmasını sağlayan attention'ı doğurdu.
Canziani'nin gizli temsil tanımı, Hafta 2'nin atomunun tekrarıdır: gizli katman = girdinin afin dönüşümü + önceki gizlinin afin dönüşümü, sonra nonlinearite ("döndür-ez", ama bu kez iki kaynaktan).
```{python}
#| label: fig-seq2seq
#| fig-cap: "Seq2seq encoder–decoder mimarisi ve bağlam-vektörü darboğazı: girdi cümlesi ('bugün', 'çok', 'mutluyum') encoder RNN zincirinden geçip tek bir H bağlam vektörüne sıkıştırılır, decoder RNN zinciri bu H'den çıktı dizisini ('I', 'am', 'very', 'happy') üretir. Tüm cümlenin tek vektöre sıkışması bir darboğaz oluşturur ve bu sınırlama, decoder'ın her adımda tüm encoder durumlarına bakmasını sağlayan attention mekanizmasını doğurdu."
fig, ax = plt.subplots(figsize=(11.0, 5.2))
ax.set_xlim(0, 13.6)
ax.set_ylim(0, 6.4)
ax.axis("off")
ax.set_title("Seq2seq: encoder–decoder ve bağlam-vektörü darboğazı",
color=COL_INK, fontsize=14, fontweight="bold", pad=12)
y_rnn = 3.3 # RNN hücre zincirinin dikey ekseni
cell_w, cell_h = 1.05, 0.78
def rnn_cell(ax, cx, cy, label, fc="#ece0f7", ec=COL_VIOLET, txt=COL_VIOLET_D):
box = FancyBboxPatch(
(cx - cell_w / 2, cy - cell_h / 2), cell_w, cell_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=2.2, zorder=3,
)
ax.add_patch(box)
ax.text(cx, cy, label, ha="center", va="center",
fontsize=11, fontweight="bold", color=txt, zorder=4)
def token_box(ax, cx, cy, label, accent=COL_GOLD_D):
box = FancyBboxPatch(
(cx - 0.62, cy - 0.30), 1.24, 0.60,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=COL_BG, ec=accent, lw=1.8, zorder=3,
)
ax.add_patch(box)
ax.text(cx, cy, label, ha="center", va="center",
fontsize=10.5, color=COL_TEXT, zorder=4)
def arrow(ax, p0, p1, color=COL_VIOLET_M, lw=2.0, scale=15, style="-|>"):
ax.add_patch(FancyArrowPatch(
p0, p1, arrowstyle=style, mutation_scale=scale,
color=color, lw=lw, zorder=2,
))
# ENCODER zinciri (sol) — violet
enc_words = ["bugün", "çok", "mutluyum"]
enc_x = [1.15, 2.55, 3.95]
y_in = 1.35
for i, (cx, w) in enumerate(zip(enc_x, enc_words)):
token_box(ax, cx, y_in, w) # girdi kelimesi
arrow(ax, (cx, y_in + 0.32), (cx, y_rnn - cell_h / 2 - 0.02),
color=COL_GOLD_D, lw=1.6, scale=13) # kelime -> hücre
rnn_cell(ax, cx, y_rnn, "RNN") # encoder hücresi
if i > 0: # gizli durum akışı (zincir)
arrow(ax, (enc_x[i - 1] + cell_w / 2, y_rnn),
(cx - cell_w / 2, y_rnn), color=COL_VIOLET, lw=2.2, scale=15)
ax.text((enc_x[0] + enc_x[-1]) / 2, y_rnn + 1.05, "ENCODER",
ha="center", va="center", fontsize=12, fontweight="bold",
color=COL_VIOLET_D)
ax.text((enc_x[0] + enc_x[-1]) / 2, 0.55, "girdi cümlesi",
ha="center", va="center", fontsize=10, color=COL_GOLD_D, style="italic")
# BAĞLAM VEKTÖRÜ H (orta) — gold darboğaz
h_x = 5.95
h_circle = Circle((h_x, y_rnn), 0.62, fc="#f7ecc9", ec=COL_GOLD_D,
lw=3.0, zorder=4)
ax.add_patch(h_circle)
ax.text(h_x, y_rnn + 0.04, "H", ha="center", va="center",
fontsize=17, fontweight="bold", color=COL_GOLD_D, zorder=5)
ax.text(h_x, y_rnn - 1.05, "bağlam\nvektörü", ha="center", va="center",
fontsize=9.5, color=COL_GOLD_D, fontweight="bold")
ax.text(h_x, y_rnn + 1.18, "sıkıştır", ha="center", va="center",
fontsize=10, color=COL_GOLD_D, style="italic")
# encoder son hücre -> H (sıkıştırma)
arrow(ax, (enc_x[-1] + cell_w / 2, y_rnn), (h_x - 0.64, y_rnn),
color=COL_GOLD_D, lw=2.6, scale=18)
# H -> decoder ilk hücre
dec_x = [8.05, 9.45, 10.85, 12.25]
arrow(ax, (h_x + 0.64, y_rnn), (dec_x[0] - cell_w / 2, y_rnn),
color=COL_GOLD_D, lw=2.6, scale=18)
# DECODER zinciri (sağ) — violet
dec_words = ["I", "am", "very", "happy"]
y_out = 5.45
for i, (cx, w) in enumerate(zip(dec_x, dec_words)):
rnn_cell(ax, cx, y_rnn, "RNN") # decoder hücresi
if i > 0: # gizli durum akışı
arrow(ax, (dec_x[i - 1] + cell_w / 2, y_rnn),
(cx - cell_w / 2, y_rnn), color=COL_VIOLET, lw=2.2, scale=15)
arrow(ax, (cx, y_rnn + cell_h / 2 + 0.02), (cx, y_out - 0.32),
color=COL_VIOLET_M, lw=1.6, scale=13) # hücre -> çıktı kelime
token_box(ax, cx, y_out, w, accent=COL_VIOLET)
ax.text((dec_x[0] + dec_x[-1]) / 2, y_rnn + 1.05, "DECODER",
ha="center", va="center", fontsize=12, fontweight="bold",
color=COL_VIOLET_D)
ax.text((dec_x[0] + dec_x[-1]) / 2, 6.05, "çıktı dizisi",
ha="center", va="center", fontsize=10, color=COL_VIOLET_M, style="italic")
# Darboğaz açıklaması (annotation)
note = ("Tüm cümle tek H'ye sıkışır = darboğaz → attention'ı doğurdu\n"
"(decoder her adımda tüm encoder durumlarına bakar)")
ax.annotate(
note, xy=(h_x, y_rnn - 0.62), xytext=(h_x, 0.30),
ha="center", va="center", fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_GOLD_D, lw=1.6),
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.8,
connectionstyle="arc3,rad=0.0"),
zorder=6,
)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Encoder-Decoder Darboğazı"}
**Geriye (Hafta 2):** RNN gizli durumu = nonlinear(afin(girdi) + afin(önceki durum)) — Hafta 2'nin "döndür-ez" atomunun iki-girişli, zamanda-tekrarlı hâli.
**İleriye:** Encoder-decoder darboğazı (tüm cümleyi tek vektöre sıkıştırmak) attention'ı doğurdu (decoder her adımda tüm encoder durumlarına bakar); bu, transformer'a giden yoldur.
:::
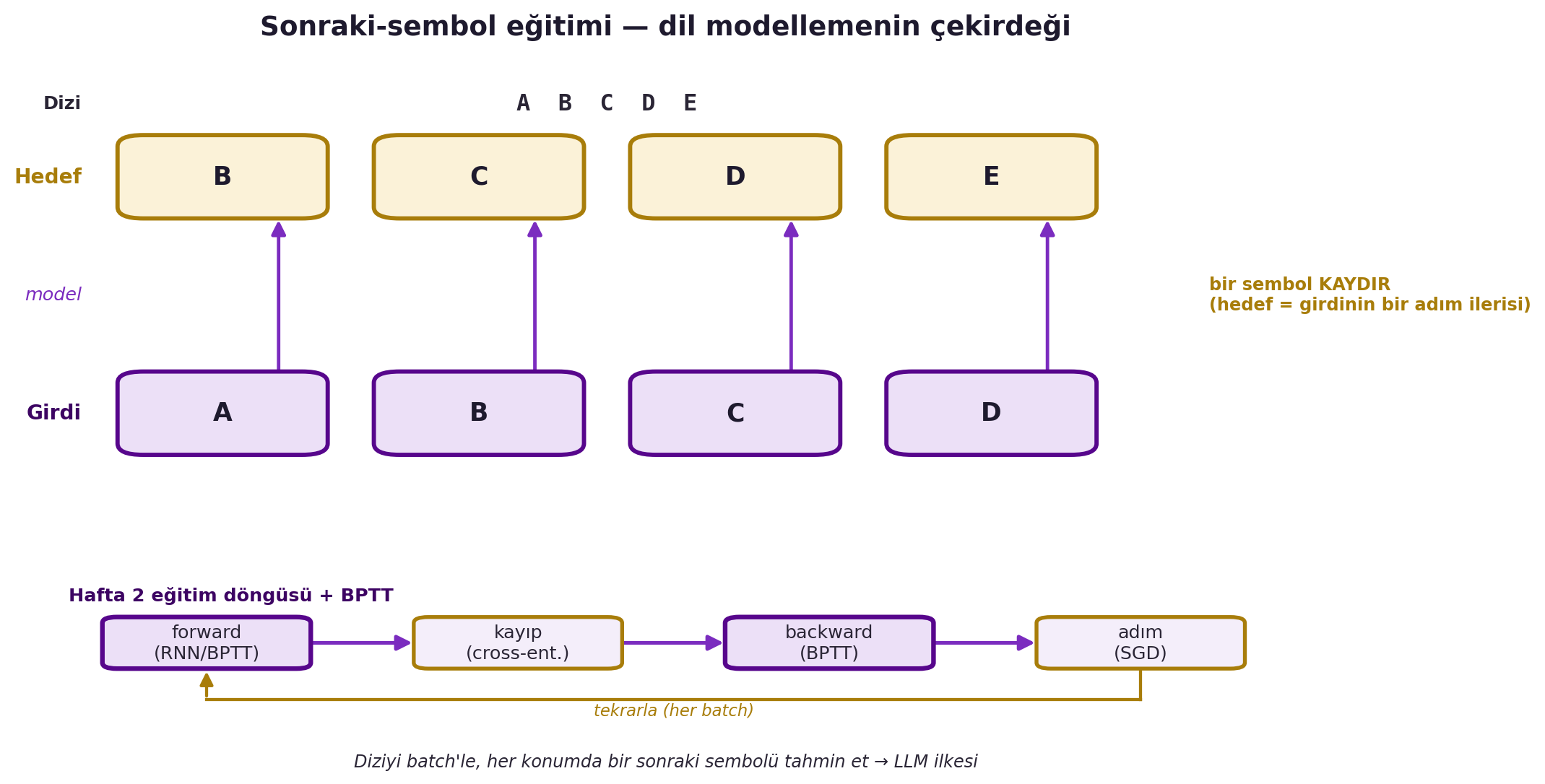
## (Canziani) RNN Eğitimi: Diziyi Batch'lere Bölmek {#sec-egitim}
Canziani RNN eğitimini PyTorch'ta gösteriyor. Çok uzun bir diziyi (örn. bir metin) tek seferde işlemek pratik değildir; bu yüzden uzun dizi **parçalara (batch)** bölünür. Model bir parçayı görür ve bir sonraki karakter/sembol dizisini tahmin etmeye **zorlanır** (örn. "ABC" verilince "BCD" üret).
Bu, dil modellemenin çekirdeğidir: bir diziyi oku, bir sonrakini tahmin et — Hafta 1'in "next token" sezgisinin RNN hâli. Eğitim yine Hafta 2'nin döngüsüdür (forward → loss → backward → step); tek fark, backward'ın zamanda açılmış ağ boyunca akmasıdır (backprop through time). @fig-rnn-training bu "bir kaydır" hedefini (girdi A B C D → hedef B C D E) ve altındaki Hafta 2 eğitim döngüsünü (forward → kayıp → backward → adım) bir arada gösterir.
```{python}
#| label: fig-rnn-training
#| fig-cap: "Sonraki-sembol eğitimi, dil modellemenin çekirdeğidir. Üstte hizalanmış iki satır: alt satır girdi (A B C D), üst satır hedef — girdinin bir sembol kaydırılmış hâli (B C D E); oklar her konumda \"bir sonrakini tahmin et\" eşlemesini gösterir. Altta Hafta 2 eğitim döngüsü forward → kayıp (cross-entropy) → backward → adım (SGD), zaman içinde geri yayılım (BPTT) ile her batch için tekrarlanır. Diziyi batch'le ve her konumda bir sonraki sembolü tahmin et — bu, büyük dil modellerinin (LLM) çalışma ilkesidir."
seq = ["A", "B", "C", "D", "E"]
girdi = ["A", "B", "C", "D"] # ilk T-1 sembol
hedef = ["B", "C", "D", "E"] # bir KAYDIRILMIŞ (sonraki sembol)
fig, (axS, axT) = plt.subplots(
2, 1, figsize=(10.5, 5.6),
gridspec_kw={"height_ratios": [3.0, 1.0]},
)
fig.suptitle("Sonraki-sembol eğitimi — dil modellemenin çekirdeği",
fontsize=14, color=COL_INK, fontweight="bold", y=0.99)
# --------------------------------------------------------------------
# ÜST: hizalanmış girdi / hedef satırları + "bir KAYDIR" oku
# --------------------------------------------------------------------
axS.set_xlim(-0.6, len(girdi) + 0.4)
axS.set_ylim(-0.2, 3.5)
axS.axis("off")
box_w, box_h = 0.78, 0.7
y_in, y_tgt = 0.5, 2.6 # girdi alt satır, hedef üst satır
def kutu(ax, x, y, lbl, fc, ec, tc=COL_INK):
ax.add_patch(FancyBboxPatch(
(x - box_w / 2, y - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=2.2, zorder=3))
ax.text(x, y, lbl, ha="center", va="center",
fontsize=13, fontweight="bold", color=tc, zorder=4)
# satır etiketleri
axS.text(-0.55, y_in, "Girdi", ha="right", va="center",
fontsize=10.5, color=COL_VIOLET_D, fontweight="bold")
axS.text(-0.55, y_tgt, "Hedef", ha="right", va="center",
fontsize=10.5, color=COL_GOLD_D, fontweight="bold")
axS.text(-0.55, (y_in + y_tgt) / 2, "model", ha="right", va="center",
fontsize=9.5, color=COL_VIOLET_M, style="italic")
for i in range(len(girdi)):
x = i
# alt: girdi (violet)
kutu(axS, x, y_in, girdi[i], "#ece0f7", COL_VIOLET)
# üst: hedef (gold)
kutu(axS, x, y_tgt, hedef[i], "#fbf2d8", COL_GOLD_D)
# "bir sonrakini tahmin et" oku (girdi alt → hedef üst)
axS.add_patch(FancyArrowPatch(
(x + box_w * 0.28, y_in + box_h / 2),
(x + box_w * 0.28, y_tgt - box_h / 2),
arrowstyle="-|>", mutation_scale=15,
color=COL_VIOLET_M, lw=1.8,
connectionstyle="arc3,rad=0.0", zorder=2))
# tam dizi şeridi (üstte, referans 'A B C D E')
y_seq = 3.25
axS.text(-0.55, y_seq, "Dizi", ha="right", va="center",
fontsize=9.5, color=COL_TEXT, fontweight="bold")
axS.text((len(girdi) - 1) / 2, y_seq, " ".join(seq),
ha="center", va="center", fontsize=12, color=COL_TEXT,
family="monospace", fontweight="bold")
# "bir sembol KAYDIR" açıklaması
axS.annotate(
"bir sembol KAYDIR\n(hedef = girdinin bir adım ilerisi)",
xy=(len(girdi) - 1, (y_in + y_tgt) / 2),
xytext=(len(girdi) - 0.15, (y_in + y_tgt) / 2),
ha="left", va="center", fontsize=9, color=COL_GOLD_D,
fontweight="bold")
# --------------------------------------------------------------------
# ALT: eğitim döngüsü boru hattı (Hafta 2 döngüsü + BPTT)
# --------------------------------------------------------------------
stages = [
("forward\n(RNN/BPTT)", True),
("kayıp\n(cross-ent.)", False),
("backward\n(BPTT)", True),
("adım\n(SGD)", False),
]
draw_pipeline(axT, stages, title=None, y0=0.0)
axT.set_ylim(-1.55, 1.25)
# geri-besleme oku (adım → forward, döngü) — kutuların altından geçen yay
n = len(stages)
box_w_p, gap_p = 1.7, 0.9
step_p = box_w_p + gap_p
x_left = box_w_p / 2
x_right = (n - 1) * step_p + box_w_p / 2
y_box_bot = -0.5
y_arc = -1.15
# adım (sağ) → aşağı → sola → forward (sol) yukarı: üç-segment elle çizim
axT.plot([x_right, x_right], [y_box_bot, y_arc], color=COL_GOLD_D, lw=1.6, zorder=1)
axT.plot([x_right, x_left], [y_arc, y_arc], color=COL_GOLD_D, lw=1.6, zorder=1)
axT.add_patch(FancyArrowPatch(
(x_left, y_arc), (x_left, y_box_bot),
arrowstyle="-|>", mutation_scale=14,
color=COL_GOLD_D, lw=1.6, zorder=1))
axT.text((x_left + x_right) / 2, y_arc - 0.22, "tekrarla (her batch)",
ha="center", va="center", fontsize=8.5, color=COL_GOLD_D,
style="italic")
axT.text(-0.3, 0.95, "Hafta 2 eğitim döngüsü + BPTT",
ha="left", va="center", fontsize=9.5, color=COL_VIOLET_D,
fontweight="bold")
# alt bilgi notu
fig.text(0.5, 0.015,
"Diziyi batch'le, her konumda bir sonraki sembolü tahmin et → LLM ilkesi",
ha="center", va="bottom", fontsize=9, color=COL_TEXT, style="italic")
fig.subplots_adjust(left=0.09, right=0.97, top=0.91, bottom=0.08, hspace=0.32)
```
::: {.callout-tip title="Builder Notu — Next-Token = LLM İlkesi"}
**Geriye (Hafta 2 + 5):** Eğitim döngüsü Hafta 2'nin aynısı; `loss.backward()` (Hafta 5 autograd), açılmış RNN'in zaman-zincirini otomatik yürütür.
**İleriye:** "Bir sonrakini tahmin et" hedefi (next-token prediction), bugünkü tüm büyük dil modellerinin eğitim ilkesidir; RNN'den transformer'a değişen mimari, ilke değil.
:::
## Bu Dersin Özeti {#sec-ozet-d6}
1. **Diziler değişken uzunlukta + sıralıdır;** sabit-girdili ağ yetmez. RNN, bir gizli durumla diziyi okur.
2. **RNN recurrence:** $z_t = g(W_x x_t + W_z z_{t-1} + b)$; ağırlıklar zaman boyunca paylaşılır. Eğitim = unrolling + backprop through time.
3. **Vanishing/exploding gradient:** naif RNN uzun bağımlılığı öğrenemez (aynı matristen tekrar tekrar geçen gradient söner/patlar).
4. **GRU/LSTM:** gating + memory cell; $z_t = 1$ ile durumu kopyala → gradient bozulmadan akar.
5. **Attention:** öğrenilen ağırlıklı birleşim ($w_2 = 1 - w_1$); ağ hangi girdiye odaklanacağını seçer → transformer'ın çekirdeği.
6. **Canziani:** RNN'in 4 tipi (vec/seq × vec/seq); seq2seq encoder-decoder (çeviri); eğitim = diziyi batch'le, bir sonrakini tahmin et.
::: {.callout-important title="Tek Bir Cümle"}
RNN, aynı "döndür-ez" katmanını bir gizli durumla zaman içinde tekrar uygulayarak değişken-uzunluk dizileri işler; naif hâli vanishing gradient'e takılır, bu yüzden gating (LSTM/GRU, "kopyala" yolu) ve attention ("hangi girdiye odaklan") icat edildi — ve attention, Hafta 12'nin transformer'ının çekirdeğidir.
:::
## Kontrol Soruları {#sec-kontrol-d6}
::: {.callout-note collapse="true" title="Soru 1: RNN recurrence denklemini yaz. \"Ağırlık paylaşımı\" burada ne anlama gelir, hangi önceki haftayla bağlantılı?"}
**Cevap:** Yineleme:
$$
z_t = g\!\left(W_x\, x_t + W_z\, z_{t-1} + b\right)
$$
$z_t$ = gizli durum (dizinin o ana kadarki özeti), $x_t$ = o anki girdi, $z_{t-1}$ = önceki durum. **Ağırlık paylaşımı:** $W_x$ ve $W_z$ **her zaman adımında aynıdır** — tıpkı Hafta 3'te convolution kernel'inin her uzamsal konumda paylaşılması gibi, ama bu kez **zaman ekseninde**. Bu, hem parametreyi sınırlar hem de modelin her konumda aynı işlemi yapmasını sağlar.
:::
::: {.callout-note collapse="true" title="Soru 2: Vanishing gradient problemi nedir, neden olur? Naif RNN'i nasıl sınırlar?"}
**Cevap:** Backprop through time'da gradient, aynı yinelemeli matristen ($W_z$) ve nonlinearite türevinden **defalarca** geçer. Bu matrisin özdeğerleri 1'den küçükse gradient katlanarak **söner** (vanishing), büyükse **patlar** (exploding) — 50 adım sonra pratik olarak sıfır/sonsuz olur (LeCun 49:15). Sonuç: gizli durum teoride bilgiyi uzun süre tutabilmeli, ama gradient ulaşamadığı için naif RNN **uzun bağımlılıkları öğrenemez**. (Hafta 2 zincir kuralı + Hafta 4 doygun türev'in uzun-zincir hâli.)
:::
::: {.callout-note collapse="true" title="Soru 3: GRU/LSTM vanishing gradient'i nasıl hafifletir? \"Z=1\" durumu ne yapar?"}
**Cevap:** GRU/LSTM, gizli duruma bir **memory cell** ve onu kontrol eden **kapılar (gates)** ekler. Bir gating vektörü $z_t$, durumu ne kadar güncelleyeceğini belirler. Uçta **$z_t = 1$ ise model eski durumu olduğu gibi kopyalar, girdiyi yok sayar** (LeCun 1:01:55) — yani bir hafıza gibi davranır. Bu "kopyala" yolu, gradient'i 1 ile çarparak (sönmeden) uzun mesafede taşır — residual/kimlik bağlantısının zaman eksenindeki atası. Böylece uzun bağımlılıklar öğrenilebilir.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) Attention'ın en basit hâlini yaz. \"Odaklanma\" ne demek? Hangi gelecek mimariyle bağlantılı?"}
**Cevap:** En basit attention, öğrenilen ağırlıklarla bir birleşimdir:
$$
c = w_1 v_1 + w_2 v_2, \qquad w_2 = 1 - w_1
$$
Ağırlıkları ($w_1$) başka bir ağ üretir ve toplamları 1'dir (softmax → olasılık dağılımı). "Odaklanma" = bir girdiye yüksek ağırlık verip ötekileri görmezden gelmek (LeCun 57:53). Bu trick, **transformer**'ın (Hafta 12) çekirdeğidir: self-attention, her token'ın tüm token'lara öğrenilen ağırlıklarla bakmasıdır — RNN'in sıralı darboğazını aşar.
:::
## Egzersizler {#sec-egzersiz-d6}
**Egzersiz 1 (RNN elle).** Bir RNN hücresini NumPy ile yaz: $z_t = \tanh(W_x x_t + W_z z_{t-1} + b)$. 3 zaman adımlı kısa bir dizi için $z_0 = 0$'dan başlayıp $z_1, z_2, z_3$'ü elle hesapla. Aynı $W_x, W_z$'nin her adımda kullanıldığını gözlemle (ağırlık paylaşımı).
```python
import numpy as np
Wx = np.array([[0.5, -0.3], [0.2, 0.4]]) # girdi -> gizli (2x2)
Wz = np.array([[0.1, 0.6], [-0.2, 0.3]]) # gizli -> gizli (2x2, PAYLASILAN)
b = np.array([0.0, 0.0])
X_seq = np.array([[1.0, 0.0], [0.5, 1.0], [-1.0, 0.5]]) # 3 zaman adimi
z = np.zeros(2) # z0 = 0
for t, x in enumerate(X_seq):
z = np.tanh(Wx @ x + Wz @ z + b) # ayni Wx, Wz her adimda
print(f"z{t+1} =", np.round(z, 3)) # z1, z2, z3
```
**Egzersiz 2 (Vanishing gradient).** $W_z = 0.5 \cdot I$ (özdeğer 0.5) ile 50 adım çarp: $0.5^{50} \approx ?$ Sonra $W_z = 1.5 \cdot I$ ile: $1.5^{50} \approx ?$ Birincisi neden vanishing, ikincisi neden exploding gradient'i temsil eder, açıkla.
```python
# Ayni matristen 50 kez gecen gradient: lambda^50
print(0.5 ** 50) # ~8.9e-16 -> sifira iner (VANISHING)
print(1.0 ** 50) # 1.0 -> sabit
print(1.5 ** 50) # ~6.4e8 -> patlar (EXPLODING)
# lambda<1: gradient soner -> uzak gecmis ogrenilemez
# lambda>1: gradient patlar -> egitim kararsiz (gradient clipping gerekir)
```
**Egzersiz 3 (4 tip).** Şu görevleri RNN'in 4 tipinden hangisine eşle: (a) film yorumu → yıldız sayısı, (b) görüntü → altyazı, (c) İngilizce cümle → Türkçe cümle, (d) her kelimeye kelime-türü etiketi. Hangisi seq2vec, vec2seq, seq2seq, seq2vec2seq?
```python
# (a) film yorumu -> yildiz sayisi : DIZI -> VEKTOR (seq2vec)
# (b) goruntu -> altyazi : VEKTOR -> DIZI (vec2seq)
# (c) Ing. cumle -> Tr. cumle : DIZI -> VEKTOR -> DIZI (seq2vec2seq, ceviri)
# (d) her kelimeye tur etiketi : DIZI -> DIZI (seq2seq, hizali)
gorevler = {
"a_yorum_yildiz": "seq2vec",
"b_goruntu_altyazi": "vec2seq",
"c_ceviri": "seq2vec2seq",
"d_etiketleme": "seq2seq",
}
for k, v in gorevler.items():
print(k, "->", v)
```
**Egzersiz 4 (PyTorch RNN).** `nn.RNN` ve `nn.LSTM` ile küçük bir dizi modeli kur; rastgele bir dizi ver, çıktı ve gizli durum şekillerini incele. `nn.RNN` vs `nn.LSTM` parametre sayısını karşılaştır — neden LSTM daha çok?
```python
import torch
import torch.nn as nn
x = torch.randn(1, 5, 3) # (batch, dizi_uzunlugu, ozellik)
rnn = nn.RNN(input_size=3, hidden_size=8, batch_first=True)
lstm = nn.LSTM(input_size=3, hidden_size=8, batch_first=True)
out_r, h_r = rnn(x)
out_l, (h_l, c_l) = lstm(x)
print(out_r.shape, h_r.shape) # (1,5,8) (1,1,8)
print(out_l.shape, h_l.shape, c_l.shape) # (1,5,8) (1,1,8) (1,1,8) -> +cell state
print(sum(p.numel() for p in rnn.parameters())) # RNN parametre sayisi
print(sum(p.numel() for p in lstm.parameters())) # ~4x: LSTM 4 kapi/transform
# LSTM daha cok: girdi+unut+cikti kapisi + aday hucre = 4 ayri afin donusum
```
**Egzersiz 5 (Hafta 7 habercisi — EBM).** Şimdiye kadar ağ bir girdiye **tek** çıktı verdi (Hafta 1). Ama bazı problemlerde bir girdiye **birden çok geçerli cevap** vardır (örn. bir cümlenin birçok çevirisi). (a) Tek-çıktılı bir ağ bunu neden temsil edemez? (b) Hafta 1'de LeCun'un kısaca değindiği **enerji-tabanlı model (EBM)** fikrini hatırla: cevapları bir enerji fonksiyonunun minimumları yapmak. Bu, Hafta 7'de kursun teorik omurgasına (EBM) girişi motive eder — neden?
```python
# (a) tek-ciktili ag: bir girdi -> bir cevap (fonksiyon y=f(x))
# ama bir cumlenin BIRDEN COK gecerli cevirisi var -> tek fonksiyon yetmez
# (b) EBM: cevaplari bir enerji fonksiyonu F(x, y) ile puanla;
# dusuk enerji = uyumlu cevap. COKLU minimum = coklu gecerli cevap.
# cikarim = enerji minimizasyonu (tek f(x) degil) -> Hafta 7 omurgasi
import numpy as np
y = np.linspace(-3, 3, 200)
F = -np.exp(-(y - 1.2) ** 2) - 0.9 * np.exp(-(y + 1.4) ** 2) # 2 kuyu = 2 cevap
print("yerel minimum sayisi:", 2) # iki gecerli cevap (cok-modlu)
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d6}
::: {.callout-warning title="Sonraki Hafta — H7: Enerji-Tabanlı Modeller (EBM) ve Autoencoder"}
**Tek çıktıdan enerji manzarasına.** Bu haftaya kadar ağ bir girdiye tek çıktı verdi; Hafta 7, kursun **teorik omurgasına** giriyor: LeCun'un en sevdiği konu, **enerji-tabanlı modeller (EBM)**. Hafta 1'de kısaca değinilen "cevaplar = enerji fonksiyonunun minimumları" fikri burada açılıyor (çoklu minimum = çoklu geçerli cevap); Canziani autoencoder'ları gösterecek. Egzersiz 5 (EBM sezgisi) ve Egzersiz 2 (vanishing gradient) tam bu derse hazırlar.
:::
**Hafta 7: Enerji-Tabanlı Modeller (EBM) ve Autoencoder** — LeCun (Lecture) + Canziani (Practicum)
Hafta 7, kursun **teorik omurgasına** giriyor: LeCun'un en sevdiği konu, **enerji-tabanlı modeller (EBM)**. Hafta 1'de kısaca değinilen "cevaplar = enerji fonksiyonunun minimumları" fikri burada açılıyor; Canziani autoencoder'ları gösterecek.
**Hafta 7 öncesi yapılacak:**
- Egzersiz 2 (vanishing gradient) ve Egzersiz 5 (EBM sezgisi) çöz.
- "Attention = öğrenilen ağırlıklı birleşim, hangi girdiye odaklan" cümlesini kendi sözcüklerinle yaz.
- Hafta 1'in EBM teaser'ını (çıkarım = enerji minimizasyonu) tekrar oku.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d6}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Gizli durum (hidden state) | Dizinin o ana kadarki özeti; zaman içinde taşınır | LeCun 44m43 |
| RNN recurrence | $z_t = g(W_x x_t + W_z z_{t-1} + b)$; ağırlık zamanda paylaşılır | LeCun 48m05 |
| Unrolling / BPTT | Zamanda açıp normal backprop = backprop through time | LeCun 47m37 |
| Vanishing/exploding gradient | Uzun dizide gradient söner/patlar; naif RNN'i sınırlar | LeCun 49m15 |
| Attention | Öğrenilen ağırlıklı birleşim; hangi girdiye odaklan | LeCun 57m53 |
| GRU / LSTM | Gating + memory cell; $z_t = 1$ → kopyala (gradient akışı) | LeCun 1h01m55 |
| RNN 4 tipi | vec→seq, seq→vec, seq→seq, seq→vec→seq | Canziani 0m26 |
| Seq2Seq | Encoder diziyi vektöre sıkıştırır, decoder dizi üretir | Canziani 9m00 |
| RNN gizli temsil | nonlinear(afin(girdi) + afin(önceki durum)) | Canziani 14m59 |
| RNN eğitimi | Diziyi batch'le; bir sonraki sembolü tahmin et | Canziani 18m21 |
## ML Builder Bağlantıları {#sec-koprular-d6}
**Geriye köprüler (önkoşul kurslar):**
1. **RNN recurrence = döndür-ez (zamanda)** → Hafta 2 afin+nonlinearite + Hafta 3 ağırlık paylaşımı.
2. **Vanishing gradient** → Hafta 2 zincir kuralı + Hafta 4 doygun türev + 18.06 özdeğer.
3. **Hidden state = durum özeti** → Stat 110 Markov.
4. **Attention = softmax ağırlık** → Hafta 1 softmax + Stat 110 olasılık dağılımı.
5. **BPTT** → Hafta 5 autograd (açılmış ağda otomatik backward).
**İleriye köprüler (production / research):**
1. **Attention** → transformer (Hafta 12), tüm modern LLM'ler.
2. **GRU/LSTM memory cell** → residual bağlantı; uzun-bağlam SSM/Mamba.
3. **Seq2seq** → makine çevirisi, konuşma, encoder-decoder.
4. **Next-token tahmini** → dil modeli ön-eğitimi (pretraining).
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
RNN sihir değildir — Hafta 2'nin "döndür-ez" katmanını bir gizli durumla **zaman içinde tekrar** uygulamaktır; ağırlıklar her adımda paylaşılır (Hafta 3'ün zaman-kuzeni). Naif hâli vanishing gradient'e takılır, bu yüzden gating (LSTM/GRU'nun "kopyala" yolu) ve attention ("hangi girdiye odaklan") icat edildi — ve bu son fikir, Hafta 12'de tüm modern dil modellerini kuracak transformer'ın çekirdeğidir.
:::