flowchart LR
A["Türev<br/>(küçük-h ile dürt)"] --> B["Value nesnesi<br/>data · grad · _prev · _op"]
B --> C["İfade grafiği<br/>(DAG, forward)"]
C --> D["Geri yayılım<br/>zincir kuralı, backward"]
D --> E["_backward + topolojik sıra<br/>otomatik backward()"]
E --> F["Neuron · Layer · MLP"]
F --> G["MSE kaybı<br/>L = Σ (ypred − ygt)²"]
G --> H["Eğitim döngüsü<br/>forward → zero_grad → backward → adım"]
style A fill:#f1f5f9,stroke:#475569,stroke-width:2px
style D fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style H fill:#e0e7ff,stroke:#4f46e5,stroke-width:3px
2 Sıfırdan Autograd ve Geri Yayılım (micrograd)
Bir sinir ağını eğiten makineyi 100 satırda kur: Value, ifade grafiği, backprop ve gradient descent
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — The spelled-out intro to neural networks and backpropagation: building micrograd (≈146 dk)
- Seri: Neural Networks: Zero to Hero — Ders 1
- Hoca: Andrej Karpathy
- Kaynak repo: github.com/karpathy/micrograd
- Okuma süresi: ≈35 dk
2.1 Bu Derste Ne Var?
Bu, Karpathy’nin Neural Networks: Zero to Hero serisinin ilk dersi — ve serinin geri kalanının üstüne kurulacağı temel. Karpathy boş bir Jupyter notebook açıp, bir sinir ağını eğiten makinenin tam olarak nasıl çalıştığını sıfırdan kurar: parça parça, her satırı yorumlayarak. Ortaya çıkan şey micrograd — yaklaşık 100 satırlık küçük bir autograd (otomatik gradyan) motoru.
Dersin sürpriz iddiası şu: bir sinir ağını eğitmek için gereken matematiğin tamamı bu küçük motorda. Gerisi — tensörler, GPU, milyar parametre — yalnızca verimliliktir.
“Okay so here’s the fun part. My claim is that micrograd is what you need to train your networks, and everything else is just efficiency.” — Karpathy, 6:44
Dersin üç büyük fikri:
- Türev ve gradyan — bir sayının çıktıyı ne kadar etkilediğini ölçmek (sayısal sezgiyle başlayıp analitik backprop’a geçeriz).
- İfade grafiği + geri yayılım — her hesabı düğümlerden oluşan bir grafiğe dökmek, sonra zincir kuralını grafikte geriye doğru uygulamak.
- Sinir ağı = ifade grafiğinin özel hâli — Neuron / Layer / MLP’yi bu motorun üstüne kurup, bir loss’u gradient descent ile minimize ederek eğitmek.
İpucuBuilder Notu — ML Köprüleri
Bu ders neredeyse tamamen önceki üç kursun (calculus, lineer cebir, olasılık) matematik temeli üstünde durur — köprüler zorlama değil, dersin kendi dili:
- Geri yayılım = Calculus zincir kuralı. Karpathy’nin kendi sözüyle “nothing more than the chain rule” (Calculus Ders 4).
- Sayısal türev = Calculus türev tanımı. Küçük bir \(h\) ile \((f(x+h) - f(x))/h\), türevin limit tanımının ta kendisi (Calculus Ders 2).
- Nöron = 18.06 dot product. \(\mathbf{w}\cdot\mathbf{x} + b\) tam olarak matris-vektör çarpımı + öteleme (18.06 Ders 30).
- İfade grafiği = yönlü çevrimsiz grafik (DAG). Topolojik sıralama bir graf teorisi kavramıdır.
İleriye (production) köprüler de derse içkin: micrograd’ın backward()’ı PyTorch autograd’ın skaler prototipidir; Neuron/Layer/MLP API’si torch.nn.Module ile birebir hizalanır; skalerden tensöre geçiş GPU GEMM ve paralellik demektir.
Tek cümleyle: Bir sinir ağını eğitmek = bir ifade grafiğinde ileri geçişle loss’u hesaplamak, sonra zincir kuralını geriye uygulayıp (backprop) her parametrenin gradyanını bulmak ve gradyanın tersine küçük adım atmak — micrograd bu çekirdeği 100 satırda gösterir.
2.2 micrograd Nedir?
Karpathy işe tanımla başlıyor: micrograd bir autograd motorudur. “Autograd”, automatic gradient (otomatik gradyan) kısaltması. Görevi: bir matematiksel ifadeyi otomatik olarak türevlemek — yani her girdinin çıktıyı ne kadar etkilediğini (gradyanını) hesaplamak.
“Micrograd is basically an autograd engine. Autograd is short for automatic gradient.” — Karpathy, 0:47
Micrograd iki dosyadan ibarettir: engine.py (autograd çekirdeği) ve nn.py (üstüne kurulan minik sinir ağı kütüphanesi). engine.py’nin temel yapı taşı Value nesnesidir — tek bir skaleri (sayıyı) saran, onu hangi işlemden ve hangi başka Value’lardan üretildiğini hatırlayan bir kutu. Value’lar üzerinde toplama, çarpma gibi işlemler yaptıkça, arka planda bir ifade grafiği (expression graph) örülür.
İki yön var. İleri geçiş (forward pass): girdilerden çıktıyı hesaplamak — düz, sıradan aritmetik. Geri geçiş (backward pass): çıktıdan başlayıp her girdinin çıktıya etkisini (gradyanı) grafikte geriye doğru taşımak. İşte tüm zorluk ve tüm güç, bu ikinci yöndedir.
Önemli bir basitleştirme: micrograd skaler değerlerle çalışır (tek tek sayılar), tensörlerle değil. Bu kasıtlı — Karpathy önce mekanizmayı en sade hâlinde gösteriyor; PyTorch’un tensörleri yalnızca aynı işlemleri paralel yapan bir verimlilik katmanıdır.
İpucuBuilder Notu — PyTorch autograd
İleriye: engine.py’deki Value + backward(), PyTorch’taki torch.Tensor + loss.backward()’ın birebir kavramsal karşılığıdır. Fark: PyTorch tensör (çok boyutlu dizi) üzerinde çalışıp işlemleri GPU’da paralelleştirir; micrograd ise tek skalerle çalışır. “Gerisi sadece verimlilik” derken Karpathy tam da bunu kastediyor — algoritma aynı, ölçek farklı.
2.3 Türev Nedir? Tek Girişli Fonksiyonun Eğimi
Karpathy backprop’a girmeden önce, türevin ne olduğuna dair sezgiyi sağlamlaştırmak istiyor. Çünkü gradyan = türev, ve backprop = türevlerin zincirlenmesi.
“I’d like to make sure that you have a very good understanding intuitively of what a derivative is and exactly what information it gives you.” — Karpathy, 8:09
Uydurma bir skaler fonksiyon alalım:
\[ f(x) = 3x^2 - 4x + 5 \]
Türev, “x’i azıcık değiştirsem f ne kadar değişir?” sorusunun cevabıdır — yani fonksiyonun o noktadaki duyarlılığı (eğimi). Karpathy bunu sembolik formülle değil, sayısal olarak gösteriyor: çok küçük bir h al, fark oranını hesapla.
\[ \frac{df}{dx} = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h} \]
Pratikte h’yi 0 yapamayız ama 0,0001 gibi küçük bir değer alıp oranı hesaplayabiliriz — bu da gerçek türeve çok yaklaşır. Örneğin \(x = 3\)’te eğim pozitif (f artıyor), \(x = -3\)’te negatif (f azalıyor), eğimin sıfır olduğu noktada ise fonksiyon tepe/dip yapar.
def f(x):
return 3*x**2 - 4*x + 5
h = 0.0001
x = 3.0
# sayisal turev: fark orani (difference quotient)
slope = (f(x + h) - f(x)) / h
print(slope) # ~14 (analitik: 6x - 4 = 14)Bu “küçük h ile dürt, ne değişti bak” fikri dersin tamamının çekirdeği: birazdan her girdiyi tek tek dürtüp gradyanı sayısal olarak okuyacağız, sonra aynı sonucu analitik olarak (zincir kuralıyla) üretip ikisinin eşleştiğini doğrulayacağız (buna gradyan kontrolü denir).
Kod
import numpy as np
import matplotlib.pyplot as plt
# --- saf fonksiyon: motor (Value) KULLANMAZ; yalnız viz stil sabitleri ---
def f(x):
return 3 * x**2 - 4 * x + 5
x0 = 3.0 # teğet noktası
h = 1e-3 # küçük-h (sayısal türev için)
# analitik türev: f'(x) = 6x - 4 -> x=3'te 14
egim_analitik = 6 * x0 - 4
# sayısal türev (fark oranı): (f(x+h) - f(x)) / h ≈ 14
egim_sayisal = (f(x0 + h) - f(x0)) / h
fig, ax = plt.subplots(figsize=(9, 5))
apply_style(ax)
# parabol eğrisi (slate)
xs = np.linspace(-1.0, 6.0, 400)
ax.plot(xs, f(xs), color=LINE_PRIMARY, linewidth=2.6,
label=r"$f(x) = 3x^2 - 4x + 5$", zorder=2)
# x=3'teki teğet doğru: y = f(x0) + egim·(x - x0) (indigo)
xt = np.linspace(x0 - 2.2, x0 + 2.2, 100)
yt = f(x0) + egim_analitik * (xt - x0)
ax.plot(xt, yt, color=LINE_ACCENT, linewidth=2.2, linestyle="--",
label=rf"$x=3$'te teğet (eğim ${int(egim_analitik)}$)", zorder=3)
# teğet noktası işareti
ax.scatter([x0], [f(x0)], s=80, color=LINE_ACCENT, zorder=5,
edgecolor=COL_WHITE, linewidth=1.5)
ax.annotate(rf"$(3,\ {int(f(x0))})$", xy=(x0, f(x0)),
xytext=(x0 - 1.35, f(x0) + 1.0), fontsize=11, color=COL_TEXT)
# --- küçük-h sekant oku: (x0, f(x0)) -> (x0+H, f(x0+H)) ---
# görselde h'yi büyütüp gösteriyoruz (gerçek hesap yukarıda h=0,001 ile yapıldı)
H = 1.2
px, py = x0, f(x0)
qx, qy = x0 + H, f(x0 + H)
ax.scatter([qx], [qy], s=55, color=COL_INDIGO_400, zorder=5,
edgecolor=COL_WHITE, linewidth=1.2)
# yatay bacak (Δx = h)
ax.annotate("", xy=(qx, py), xytext=(px, py),
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=1.6))
ax.text((px + qx) / 2, py - 2.2, r"$h$", ha="center", va="top",
fontsize=12, color=COL_PRIMARY)
# dikey bacak (Δf = f(x+h) - f(x))
ax.annotate("", xy=(qx, qy), xytext=(qx, py),
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=1.6))
ax.text(qx + 0.12, (py + qy) / 2, r"$f(x{+}h)-f(x)$", ha="left", va="center",
fontsize=10.5, color=COL_PRIMARY)
# sekant doğrusu (nokta P'den Q'ya)
ax.plot([px, qx], [py, qy], color=COL_INDIGO_400, linewidth=1.8,
linestyle=":", zorder=4)
# sayısal türev sezgisi kutusu
ax.text(0.03, 0.97,
"Sayısal türev (fark oranı):\n"
rf"$\dfrac{{f(3+h)-f(3)}}{{h}} \approx {egim_sayisal:.2f}$"
"\n"
rf"analitik $f'(3)=6\cdot 3-4={int(egim_analitik)}$",
transform=ax.transAxes, ha="left", va="top", fontsize=10.5,
color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.4))
ax.set_xlabel("x", fontsize=12)
ax.set_ylabel("f(x)", fontsize=12)
ax.set_title("Türev sezgisi: küçük bir $h$ ile dürt, eğimi oku", fontsize=12)
ax.legend(loc="lower right", fontsize=10, framealpha=0.95)
ax.set_xlim(-1.0, 6.0)
plt.tight_layout()
plt.show()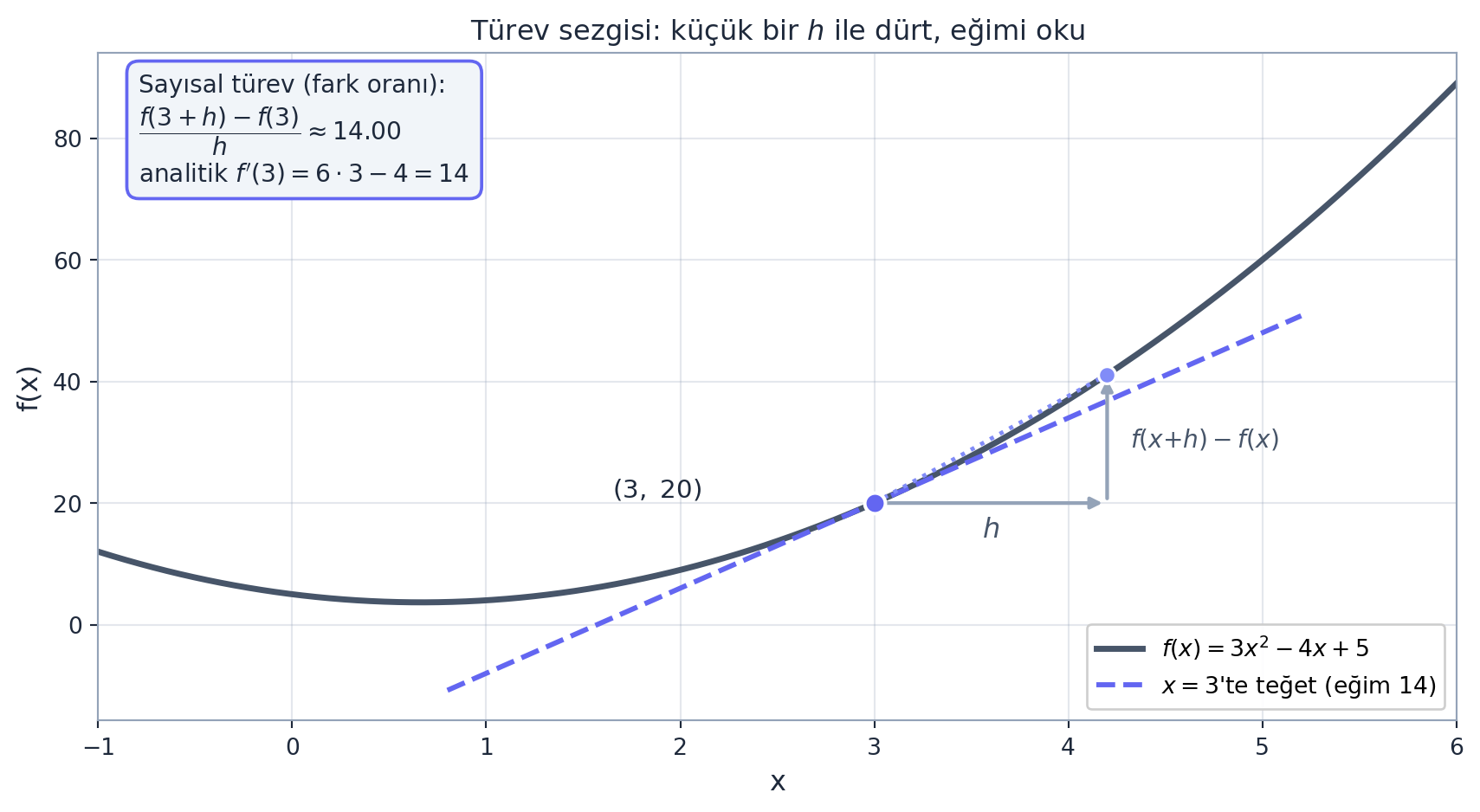
İpucuBuilder Notu — Gradient Check
Geriye (Calculus): Bu bölüm doğrudan Calculus Ders 2’nin türev tanımı. “Anlık değişim oranı” yerine Grant’ın (3Blue1Brown) tercih ettiği “en iyi sabit yaklaşım” sezgisi de aynı şeyi söyler: türev, fonksiyonu o noktada en iyi yaklaşan doğrunun eğimidir. \(h \to 0\) limiti ise fark oranının (difference quotient) gerçek türeve yakınsamasıdır.
İleriye: Sayısal gradyan, üretimde gradient check olarak yaşar: elle yazdığın (veya optimize ettiğin) analitik gradyanın doğru olduğunu, küçük bir \(h\) ile sayısal gradyana karşı test ederek doğrularsın. Karpathy bu derste tam olarak bunu yapacak.
2.4 Çok Girişli Fonksiyonda Kısmi Türevler
Tek girişli fonksiyondan, birden çok girişe geçelim — çünkü sinir ağları yüzlerce/milyonlarca girişe sahip. Karpathy basit bir örnek alır:
\[ d = a \cdot b + c \]
Üç girişimiz var: \(a = 2\), \(b = -3\), \(c = 10\). Şimdi her birini ayrı ayrı küçük bir h ile dürtüp d’nin nasıl değiştiğine bakarız — bu, her girişin kısmi türevidir (partial derivative). Sonuçlar analitik olarak da doğrulanabilir:
\[ \frac{\partial d}{\partial a} = b = -3, \qquad \frac{\partial d}{\partial b} = a = 2, \qquad \frac{\partial d}{\partial c} = 1 \]
Dikkat: a’nın kısmi türevi b’ye, b’ninki a’ya eşit — yani çarpma, her girişe diğer girişin değerini gradyan olarak geçirir. Toplama ise (c terimi) gradyanı 1 katsayısıyla, yani değiştirmeden geçirir. Bu iki kural — “çarpma diğerini geçirir, toplama aynen geçirir” — birazdan tüm geri yayılımın temeli olacak.
İpucuBuilder Notu — Gradyan Vektörü
Geriye (Calculus + 18.06): Kısmi türev, çok değişkenli fonksiyonun tek bir değişkene göre türevidir (Calculus Ders 6). Tüm kısmi türevleri bir vektörde toplarsak gradyan (\(\nabla\)) elde edilir. Bir sinir ağında “her parametrenin loss’a kısmi türevi” tam olarak budur — milyonlarca kısmi türevden oluşan dev bir gradyan vektörü.
2.5 Value Nesnesi ve İfade Grafiği
Şimdi bu sayıları ve işlemleri koda dökelim. Karpathy ilk olarak Value nesnesini yazar:
“First, a very simple Value object. Class Value takes a single scalar value that it wraps and keeps track of, and that’s it.” — Karpathy, 19:30
Value, tek bir skaleri saran bir kutudur. Üstüne __add__ ve __mul__ gibi Python operatör metotlarını ekleriz; böylece a + b veya a * b yazdığımızda, sonuç yeni bir Value olur ve bu yeni Value, kendisini hangi çocuk düğümlerden (_prev) ve hangi işlemden (_op) üretildiğini hatırlar.
class Value:
def __init__(self, data, _children=(), _op=''):
self.data = data
self.grad = 0.0 # baslangicta gradyan sifir
self._prev = set(_children) # bu degeri ureten cocuk dugumler
self._op = _op # ureten islem etiketi: + veya *
def __add__(self, other):
return Value(self.data + other.data, (self, other), '+')
def __mul__(self, other):
return Value(self.data * other.data, (self, other), '*')
def __repr__(self):
return f"Value(data={self.data})"_prev ve _op sayesinde, art arda yapılan işlemler bir ifade grafiği (expression graph) örer: yapraklar girdiler, iç düğümler ara sonuçlar, kök ise nihai çıktı. Karpathy bu grafiği draw_dot adlı bir Graphviz yardımcısıyla görselleştirir — her Value bir kutu (veri + gradyan), her işlem ayrı bir düğüm olarak çizilir. Grafiği görmek, geri yayılımın neden “grafikte geriye yürümek” olduğunu sezgisel kılar.
Aşağıda Karpathy’nin klasik örneğini — \(L = (a \cdot b + c) \cdot f\) — kendi motorumuzla kurup ifade grafiğini çiziyoruz. İleri geçişte değerler otomatik akar: \(e = -6\), \(d = 4\), \(L = -8\).
Kod
import matplotlib.pyplot as plt
# L = (a·b + c)·f ifade grafiğini Value motoruyla kur (Karpathy'nin klasik örneği).
# İleri geçiş değerleri otomatik hesaplanır: e = -6, d = 4, L = -8.
a = Value(2.0, label="a")
b = Value(-3.0, label="b")
c = Value(10.0, label="c")
f = Value(-2.0, label="f")
e = a * b # e = a·b = -6
e.label = "e"
d = e + c # d = e + c = 4
d.label = "d"
L = d * f # L = d·f = -8
L.label = "L"
# fig-backward-flow ile BİREBİR aynı layout: aynı düğümler, aynı label/op,
# aynı draw_graph çağrısı. Burada mode='forward' — data vurgulu, oklar girişten çıktıya.
fig, ax = plt.subplots(figsize=(11, 5))
draw_graph(
L, ax=ax, mode="forward",
title="İleri geçiş: L = (a·b + c)·f → data düğümlerde (indigo vurgulu)",
)
plt.show()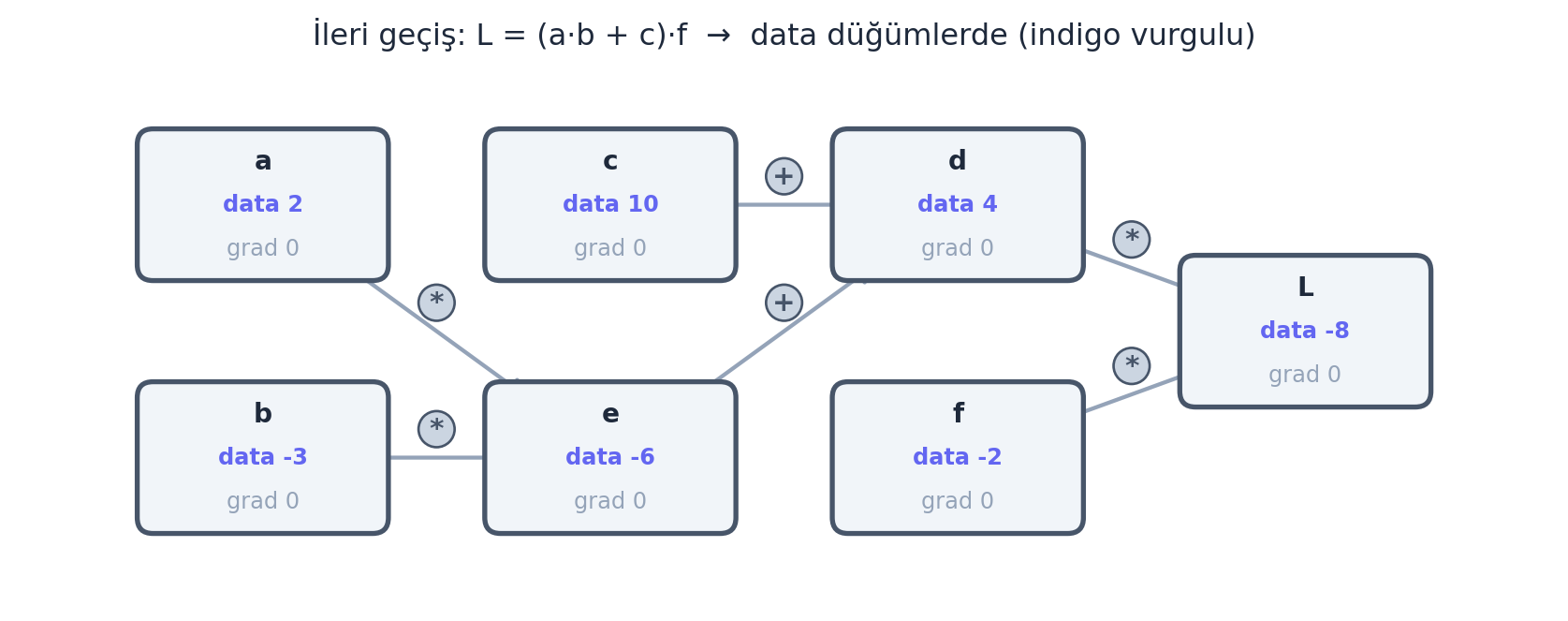
İpucuBuilder Notu — Computation Graph
Geriye (18.06 / graf teorisi): İfade grafiği bir yönlü çevrimsiz grafiktir (DAG): kenarlar hep girdiden çıktıya akar, döngü yoktur. Bu yapı, birazdan göreceğimiz topolojik sıralamanın ön koşuludur.
İleriye: Bu Value + _prev + _op üçlüsü, PyTorch’un computation graph’ının skaler prototipidir. PyTorch da her tensör işleminde “bu tensör hangi işlemden, hangi girdilerden üretildi” bilgisini (grad_fn) saklar — loss.backward() tam olarak bu grafiği geriye yürür.
2.6 Elle Geri Yayılım #1: L = (a·b + c)·f
Şimdi grafiğin kökünden başlayıp, her düğümün gradyanını elle hesaplayalım. Karpathy’nin klasik örneği:
\[ e = a \cdot b, \qquad d = e + c, \qquad L = d \cdot f \]
Değerler: \(a = 2\), \(b = -3\), \(c = 10\), \(f = -2\). İleri geçiş: \(e = -6\), \(d = 4\), \(L = -8\). Amacımız her girişin L’ye etkisini, yani \(\partial L/\partial a\), \(\partial L/\partial b\), \(\partial L/\partial c\), \(\partial L/\partial f\)’i bulmak.
Köke kendi gradyanını veririz: \(\partial L/\partial L = 1\). Sonra geriye yürürüz. \(L = d \cdot f\) bir çarpma olduğundan, her operanda diğerini geçirir:
\[ \frac{\partial L}{\partial d} = f = -2, \qquad \frac{\partial L}{\partial f} = d = 4 \]
“Now we’re getting to the crux of backpropagation, so this will be the most important node to understand. Because if you understand the gradient for this node, you understand all of backpropagation and all of training of neural nets basically.” — Karpathy, 38:03
Şimdi en kritik adım: \(d = e + c\) bir toplama. Toplama gradyanı değiştirmeden geçirir (yerel türev 1). Yani zincir kuralıyla:
\[ \frac{\partial L}{\partial c} = \frac{\partial L}{\partial d} \cdot \frac{\partial d}{\partial c} = (-2) \cdot 1 = -2 \]
\[ \frac{\partial L}{\partial e} = \frac{\partial L}{\partial d} \cdot \frac{\partial d}{\partial e} = (-2) \cdot 1 = -2 \]
Bir adım daha geriye, \(e = a \cdot b\) çarpımına: gradyanı diğer operandla çarparak geçiririz:
\[ \frac{\partial L}{\partial a} = \frac{\partial L}{\partial e} \cdot b = (-2)(-3) = 6, \qquad \frac{\partial L}{\partial b} = \frac{\partial L}{\partial e} \cdot a = (-2)(2) = -4 \]
İşte geri yayılımın özü: kökten başla, her düğümde yerel türevi hesapla, gelen gradyanla çarp (zincir kuralı), bir önceki düğüme aktar. Her gradyanı küçük bir h ile sayısal olarak doğrulayabiliriz (gradient check) — analitik ile sayısal eşleşmeli. Aşağıdaki figür, motorumuzun L.backward() ile otomatik bulduğu gradyanların elle hesabımızla birebir aynı çıktığını gösteriyor.
Kod
# fig-expression-graph ile AYNI ifade grafiği, AYNI etiketler -> AYNI layout.
# L = (a*b + c) * f ; a=2, b=-3, c=10, f=-2 -> e=-6, d=4, L=-8
a = Value(2.0, label="a")
b = Value(-3.0, label="b")
c = Value(10.0, label="c")
f = Value(-2.0, label="f")
e = a * b
e.label = "e"
d = e + c
d.label = "d"
L = d * f
L.label = "L"
# Geri yayılım: ters topolojik sırada gradyanları kökten yapraklara taşı.
# Sonuç (Bölüm 5): a.grad=6, b.grad=-4, c.grad=-2, e.grad=-2, d.grad=-2, f.grad=4, L.grad=1
L.backward()
fig, ax = plt.subplots(figsize=(11, 5))
fig.patch.set_facecolor(COL_WHITE)
draw_graph(
L, ax=ax, mode="backward",
title="Gradyan akışı (backward): ∂L/∂· kökten yapraklara taşınır",
)
# Köke ∂L/∂L = 1 başlangıç gradyanını açıkça not düş (geri geçişin kıvılcımı).
xlim = ax.get_xlim()
ylim = ax.get_ylim()
ax.annotate(
r"başlangıç: $\partial L/\partial L = 1$",
xy=(xlim[1] - 0.05, ylim[1] - 0.18),
ha="right", va="top", fontsize=9.5, color=COL_INDIGO_600, weight="bold",
)
ax.annotate(
"oklar geriye akar (kök → yaprak) · indigo = gradyan vurgusu",
xy=((xlim[0] + xlim[1]) / 2.0, ylim[0] + 0.12),
ha="center", va="bottom", fontsize=9, color=COL_PRIMARY,
)
plt.tight_layout()
plt.show()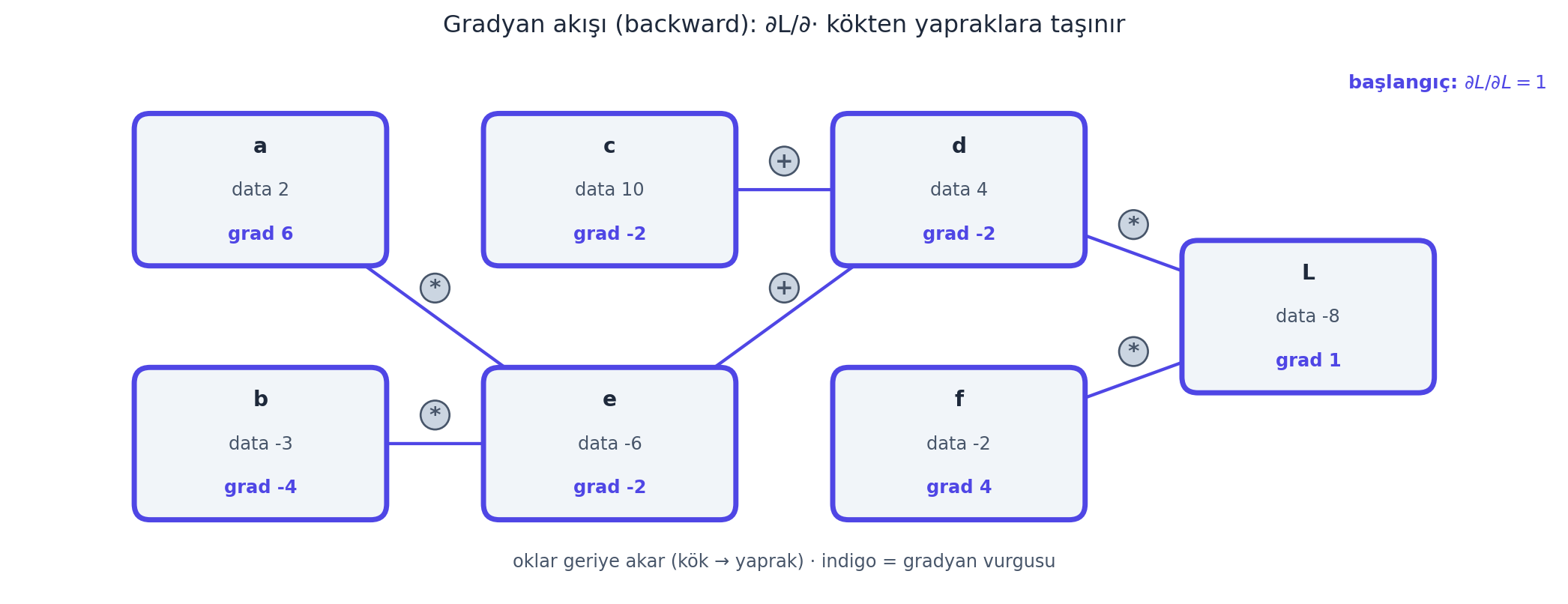
İpucuBuilder Notu — Zincir Kuralı
Geriye (Calculus): Buradaki tek araç zincir kuralıdır (Calculus Ders 4): bileşik bir fonksiyonun türevi, dış türev × iç türev. “Toplama gradyanı aynen geçirir, çarpma diğerini geçirir” kuralları, +/× işlemlerinin yerel türevlerinin \((1, 1)\) ve \((b, a)\) olmasından çıkar.
İleriye: Bu elle yaptığımız işlem, PyTorch’ta loss.backward() çağrısının her ara tensör için otomatik yaptığı şeydir. Manuel yapmak — “motoru kapağı açıkken görmek” — tam olarak Karpathy’nin amacı: kütüphane bir kara kutu olmaktan çıkar.
2.7 Zincir Kuralı ve Özyinelemeli Sezgi
Az önce sezgisel yaptığımız şeyin resmî adı zincir kuralıdır. Karpathy Wikipedia’dan açıp, en sevdiği ifadeyi paylaşır:
“This is the way I learned chain rule and it was very confusing. I like this expression much better.” — Karpathy, 42:03
Sezgi, klasik araba örneğiyle gelir: bir araba bisikletten iki kat, bisiklet de yürüyen bir insandan dört kat hızlıysa, araba insandan \(2 \times 4 = 8\) kat hızlıdır. “Oranlar çarpılır.” Matematikte z, y’ye; y de x’e bağlıysa:
\[ \frac{dz}{dx} = \frac{dz}{dy} \cdot \frac{dy}{dx} \]
İşte geri yayılımın özyinelemeli (recursive) doğası burada: bir düğümün loss’a etkisi = (bir sonraki düğümün loss’a etkisi) × (kendi yerel türevi). Bu çarpımı grafikte kökten yapraklara doğru zincirleyerek taşırız. Toplama düğümü gradyanı 1 ile çarpıp aynen “yönlendirir” (router gibi); çarpma düğümü diğer operandla çarpar.
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# Zincir kuralının özyinelemeli sezgisi: z, y'ye; y de x'e bağlı.
# Karpathy'nin araba/bisiklet/insan örneği: araba bisikletten 2x, bisiklet
# insandan 4x hızlı -> araba insandan 2*4 = 8x hızlı. "Oranlar çarpılır."
# Motor kullanmaz; kavramsal şema (Slate kutular, indigo oran etiketleri).
fig, ax = plt.subplots(figsize=(9, 4))
# Üç düğüm: z (araba) -> y (bisiklet) -> x (insan), soldan sağa zincir.
dugumler = [
{"x": 1.4, "etiket": "z", "alt": "araba"},
{"x": 4.5, "etiket": "y", "alt": "bisiklet"},
{"x": 7.6, "etiket": "x", "alt": "insan"},
]
box_w, box_h, y0 = 1.7, 1.05, 2.55
for d in dugumler:
box = FancyBboxPatch(
(d["x"] - box_w / 2, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=COL_BG, ec=COL_PRIMARY, linewidth=2.2, zorder=2,
)
ax.add_patch(box)
ax.text(d["x"], y0 + 0.16, f"${d['etiket']}$", ha="center", va="center",
fontsize=20, color=COL_TEXT, weight="bold", zorder=4)
ax.text(d["x"], y0 - 0.27, d["alt"], ha="center", va="center",
fontsize=11, color=COL_PRIMARY, style="italic", zorder=4)
# Yerel oran okları (z<-y, y<-x): zincir kuralı çıktıdan girişe yürür.
# Her kenarda yerel oran (indigo etiket).
kenarlar = [
{"sag": dugumler[0]["x"], "sol": dugumler[1]["x"],
"oran": r"$\dfrac{dz}{dy} = 2$", "kat": "2 kat hızlı"},
{"sag": dugumler[1]["x"], "sol": dugumler[2]["x"],
"oran": r"$\dfrac{dy}{dx} = 4$", "kat": "4 kat hızlı"},
]
for k in kenarlar:
start = (k["sol"] - box_w / 2 - 0.05, y0) # soldaki kutudan
end = (k["sag"] + box_w / 2 + 0.05, y0) # sağdaki kutuya (oran akışı)
arrow = FancyArrowPatch(
start, end,
arrowstyle="-|>", mutation_scale=20,
color=COL_INDIGO_600, linewidth=2.2,
connectionstyle="arc3,rad=0.0", zorder=1,
)
ax.add_patch(arrow)
mx = (k["sol"] + k["sag"]) / 2.0
# Yerel oran etiketi (indigo) — okun üstünde
ax.text(mx, y0 + 0.62, k["oran"], ha="center", va="center",
fontsize=15, color=COL_INDIGO_600, weight="bold", zorder=5,
bbox=dict(boxstyle="round,pad=0.28", fc=COL_WHITE,
ec=COL_INDIGO_400, lw=1.2))
# Sözel açıklama — okun altında
ax.text(mx, y0 - 0.66, k["kat"], ha="center", va="center",
fontsize=10.5, color=COL_SLATE_400, style="italic", zorder=5)
# Toplam oran: kökten yaprağa çarpım dz/dx = dz/dy * dy/dx = 2*4 = 8
ax.annotate(
"", xy=(dugumler[0]["x"], y0 - box_h / 2 - 0.30),
xytext=(dugumler[2]["x"], y0 - box_h / 2 - 0.30),
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=2.0,
connectionstyle="arc3,rad=-0.22"), zorder=1,
)
mx_total = (dugumler[0]["x"] + dugumler[2]["x"]) / 2.0
ax.text(mx_total, y0 - 1.55,
r"$\dfrac{dz}{dx} = \dfrac{dz}{dy} \cdot \dfrac{dy}{dx} = 2 \cdot 4 = 8$",
ha="center", va="center", fontsize=16, color=COL_TEXT, weight="bold",
zorder=5,
bbox=dict(boxstyle="round,pad=0.40", fc=COL_BG,
ec=COL_PRIMARY, lw=2.0))
ax.text(mx_total, y0 - 2.30, "toplam oran = yerel oranların çarpımı",
ha="center", va="center", fontsize=11, color=COL_PRIMARY,
style="italic", zorder=5)
# Başlık
ax.text(mx_total, y0 + 1.55,
"Zincir kuralı: oranlar çarpılır",
ha="center", va="center", fontsize=13.5, color=COL_TEXT,
weight="bold", zorder=5)
ax.set_xlim(0.1, 8.9)
ax.set_ylim(-0.2, 4.7)
ax.set_aspect("equal")
ax.axis("off")
plt.tight_layout()
plt.show()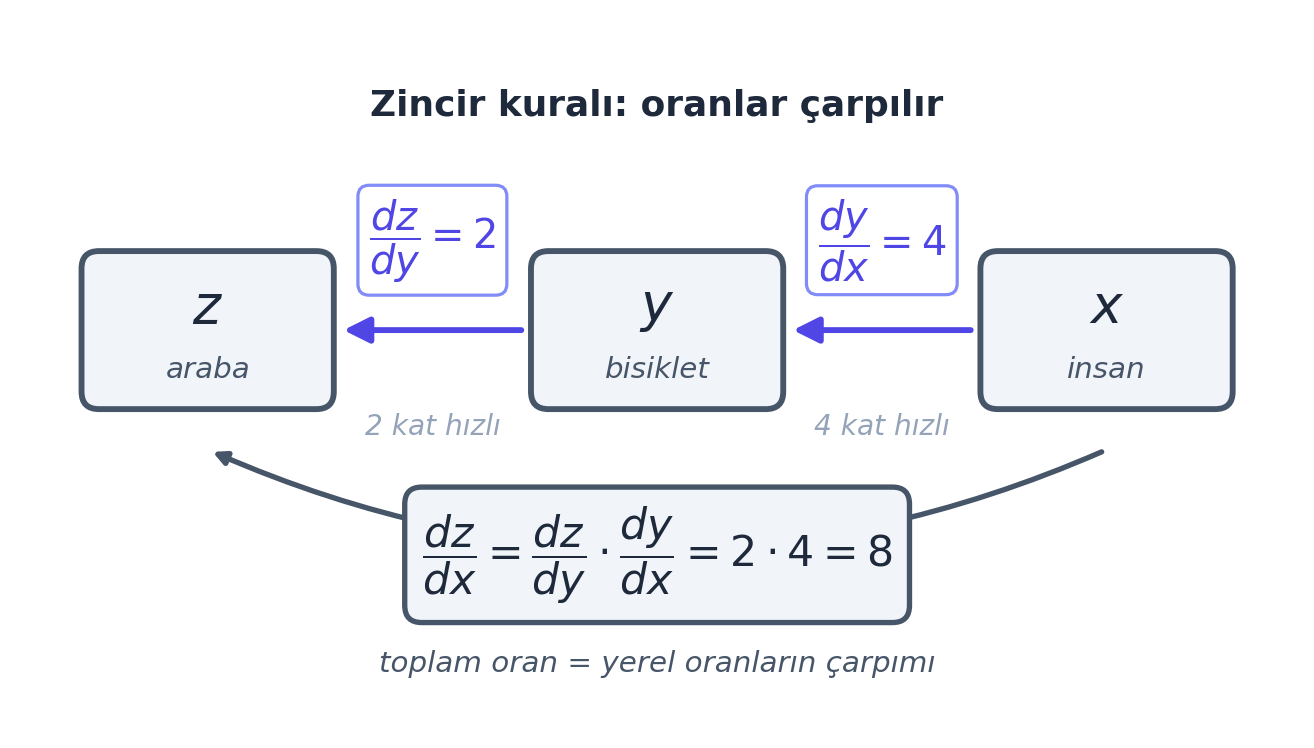
İpucuBuilder Notu — Reverse-Mode Autodiff
Geriye (Calculus Ders 4): Karpathy’nin dersin ilerleyen bölümünde söyleyeceği gibi, backprop “nothing more than the chain rule” — zincir kuralının bir grafik boyunca tekrar tekrar uygulanması. Calculus’ta gördüğün “dış türev çarpı iç türev” buraya birebir oturur.
İleriye: Bu özyinelemeli yapı, reverse-mode autodiff (ters-mod otomatik türev) adını alır. Gradyanı çıktıdan girişe doğru biriktirmek, ara türevleri yeniden hesaplamadan zincirler — bu yüzden derin ağlarda verimlidir (ileri-mod yerine ters-mod seçilmesinin sebebi).
2.8 Tek Optimizasyon Adımı (Önizleme)
Gradyanlar elimizde; peki ne işe yarar? Karpathy kısa bir önizleme yapar: girişleri gradyan yönünde azıcık iterek (nudge) L’yi yükseltmeye çalışır.
“What we’re going to do is we’re going to nudge our inputs to try to make L go up.” — Karpathy, 51:10
Mantık basit: \(\partial L/\partial a\), a’yı artırırsak L’nin ne yönde değişeceğini söyler. L’yi yükseltmek istiyorsak her girişi kendi gradyanı yönünde küçük bir adım kaydırırız; sonra ileri geçişi tekrar koşar ve L’nin gerçekten arttığını görürüz. Sinir ağı eğitiminde tam tersini yapacağız — loss’u düşürmek için gradyanın negatif yönünde adım atacağız (gradient descent). Ama mekanizma birebir aynı.
Kod
import numpy as np
import matplotlib.pyplot as plt
# Kavramsal loss yüzeyi: hafif basık bir çukur (eliptik paraboloit).
# GERÇEK eğitim DEĞİL — burada sadece "gradyanın tersine adım at" sezgisi
# görselleştirilir (§7 önizleme + §15 update kuralı).
# L(p1, p2) = a·(p1 − c1)² + b·(p2 − c2)²
# Gradyan analitik: ∇L = [2a(p1 − c1), 2b(p2 − c2)]
a, b = 1.0, 1.8 # iki eksende farklı eğrilik (basık çukur)
c1, c2 = 0.0, 0.0 # minimum (çukurun dibi)
def loss(p1, p2):
return a * (p1 - c1) ** 2 + b * (p2 - c2) ** 2
def grad(p1, p2):
return np.array([2 * a * (p1 - c1), 2 * b * (p2 - c2)])
# Deterministik başlangıç ve adımlar (her şey analitik; rastgelelik yok).
eta = 0.18 # öğrenme oranı η (adım boyu)
p = np.array([-2.6, 1.55])
yol = [p.copy()]
for _ in range(7):
p = p - eta * grad(p[0], p[1]) # p ← p − η·grad (gradient descent)
yol.append(p.copy())
yol = np.array(yol)
fig, ax = plt.subplots(figsize=(9, 5))
apply_style(ax)
# Loss yüzeyi: slate eş-yükselti (contour) çizgileri + hafif dolgu.
g1 = np.linspace(-3.2, 3.2, 400)
g2 = np.linspace(-2.4, 2.4, 400)
G1, G2 = np.meshgrid(g1, g2)
Z = loss(G1, G2)
levels = np.linspace(Z.min(), Z.max(), 14)
ax.contourf(G1, G2, Z, levels=levels, cmap="Blues", alpha=0.28)
ax.contour(G1, G2, Z, levels=levels, colors=COL_SLATE_400, linewidths=0.9, alpha=0.9)
# Minimum işareti (çukurun dibi).
ax.plot(c1, c2, marker="*", markersize=20, color=COL_PRIMARY,
markeredgecolor=COL_TEXT, markeredgewidth=0.8, zorder=6)
ax.annotate("minimum\n(loss en düşük)", (c1, c2), xytext=(c1 + 0.35, c2 - 0.75),
fontsize=9, color=COL_TEXT, ha="left", va="top",
fontweight="bold", zorder=7)
# İndigo adım okları: her adım gradyanın TERSİ yönünde (p ← p − η·grad).
for i in range(len(yol) - 1):
x0, y0 = yol[i]
x1, y1 = yol[i + 1]
ax.annotate(
"", xy=(x1, y1), xytext=(x0, y0),
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600,
lw=2.2, mutation_scale=18, shrinkA=2, shrinkB=2),
zorder=5,
)
# Adım noktaları.
ax.plot(yol[:, 0], yol[:, 1], "o", color=COL_ACCENT,
markeredgecolor=COL_INDIGO_600, markeredgewidth=1.2,
markersize=7, zorder=6)
# Başlangıç noktası etiketi.
ax.annotate(r"başlangıç $p_0$", (yol[0, 0], yol[0, 1]),
xytext=(yol[0, 0] - 0.05, yol[0, 1] + 0.42),
fontsize=9.5, color=COL_TEXT, ha="center", fontweight="bold", zorder=7)
# İlk adımda gradyan yönünü (yokuş yukarı) soluk slate kesikli okla göster:
# atılan adım bunun TERSİ yönündedir.
p0 = yol[0]
g0 = grad(p0[0], p0[1])
g0n = g0 / np.linalg.norm(g0) * 0.85 # görsel için normalize edilmiş ok
ax.annotate(
"", xy=(p0[0] + g0n[0], p0[1] + g0n[1]), xytext=(p0[0], p0[1]),
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=1.8,
mutation_scale=15, linestyle="--"),
zorder=4,
)
ax.text(p0[0] + g0n[0] + 0.05, p0[1] + g0n[1] + 0.10, r"$\nabla L$ (yokuş yukarı)",
fontsize=8.5, color=COL_SLATE_400, ha="left", va="bottom",
fontstyle="italic", zorder=7)
# Güncelleme kuralını köşeye yaz (kavramın özü).
ax.text(0.985, 0.04, r"$p \leftarrow p - \eta\,\nabla L$",
transform=ax.transAxes, ha="right", va="bottom",
fontsize=14, color=COL_INDIGO_600, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_INDIGO_600, lw=1.4),
zorder=8)
ax.set_xlabel(r"parametre $p_1$", fontsize=10.5)
ax.set_ylabel(r"parametre $p_2$", fontsize=10.5)
ax.set_title(r"Tek optimizasyon adımı: gradyanın tersine küçük bir kayma ($\eta = 0{,}18$)",
fontsize=12)
ax.set_xlim(-3.2, 3.2)
ax.set_ylim(-2.4, 2.4)
ax.set_aspect("auto")
plt.tight_layout()
plt.show()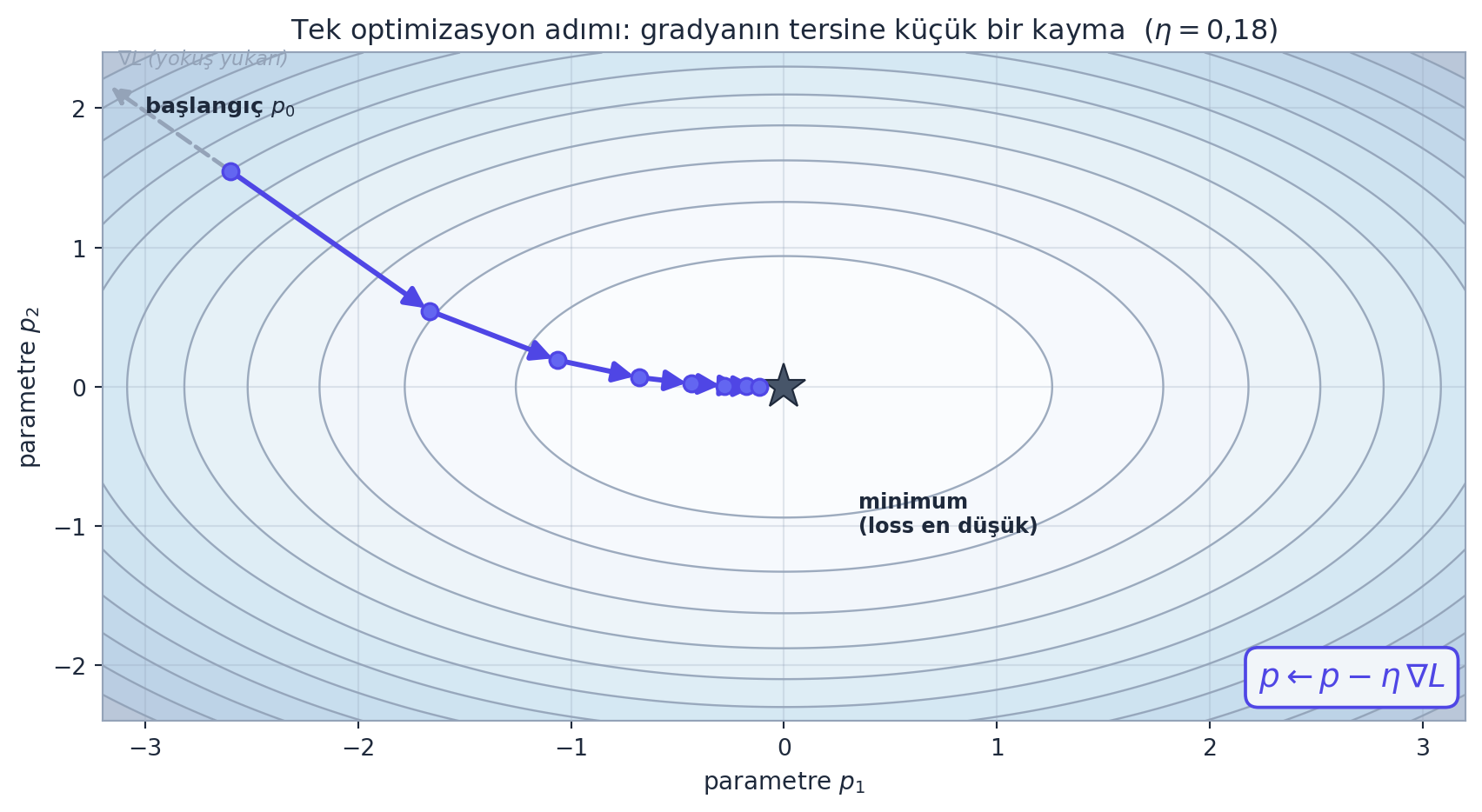
İpucuBuilder Notu — Gradient Descent Adımı
İleriye: Bu “gradyan yönünde küçük adım” tek hücresi, optimizer’ın ta kendisidir. Eğitimde formül \(p \leftarrow p - \eta \cdot \text{gradyan}\) olur; \(\eta\) (learning rate) adım boyudur. Karpathy burada işaretini artı yapıp L’yi yükseltiyor — Bölüm 16’da işareti eksiye çevirip loss’u düşüreceğiz.
2.9 Elle Geri Yayılım #2: tanh’lı Tek Nöron
Şimdi daha gerçekçi bir örnek: tek bir nöron. Karpathy iki girişli bir nöron kurar.
“So now I would like to do one more example of manual backpropagation using a bit more complex and useful example. We are going to backpropagate through a neuron.” — Karpathy, 52:52
Nöron, girişleri ağırlıklarla çarpıp toplar, bias ekler (ham toplam n), sonra bir aktivasyon fonksiyonundan geçirir. Karpathy aktivasyon olarak tanh seçer:
\[ n = x_1 w_1 + x_2 w_2 + b, \qquad o = \tanh(n) \]
tanh’ın geri yayılımda işimizi kolaylaştıran güzel bir türevi vardır:
\[ \frac{\partial o}{\partial n} = 1 - \tanh^2(n) = 1 - o^2 \]
Yani \(o = \tanh(n)\) düğümünün yerel türevini, çıktının kendisinden (o) hesaplayabiliriz — n’i yeniden tanh’lamaya gerek yok. Geri geçişte: o.grad = 1’den başlar, n.grad = (1 − o²)·o.grad olur, oradan çarpma ve toplama düğümlerinden geçerek \(x_1, w_1, x_2, w_2, b\) gradyanlarına ulaşırız — Bölüm 5’teki aynı iki kuralla (toplama aynen geçirir, çarpma diğerini geçirir).
Kod
import numpy as np
import matplotlib.pyplot as plt
# x ekseni: tanh'ın doyduğu aralığı kapsasın
x = np.linspace(-4.0, 4.0, 400)
o = np.tanh(x) # aktivasyon çıktısı o = tanh(x)
yerel_turev = 1 - o**2 # yerel türev 1 - tanh^2(x) = 1 - o^2
fig, ax = plt.subplots(figsize=(9, 5))
apply_style(ax)
# tanh(x) — slate/indigo birincil eğri
ax.plot(x, o, color=COL_PRIMARY, linewidth=2.6,
label=r"$o = \tanh(x)$ (aktivasyon)")
# 1 - tanh^2(x) — açık indigo türev eğrisi
ax.plot(x, yerel_turev, color=COL_INDIGO_400, linewidth=2.6, linestyle="--",
label=r"$1 - \tanh^2(x) = 1 - o^2$ (yerel türev)")
# Eksen referans çizgileri
ax.axhline(0.0, color=COL_SLATE_400, linewidth=1.0, alpha=0.7)
ax.axvline(0.0, color=COL_SLATE_400, linewidth=1.0, alpha=0.7)
# Doyma bölgesi vurgusu: |x| büyükken türev sıfıra iner (gradyan kaybolur)
ax.annotate(
"doyma: türev → 0\n(gradyan kaybolur)",
xy=(3.2, 1 - np.tanh(3.2) ** 2), xytext=(1.3, 0.62),
fontsize=9.5, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.4),
)
# Orijinde maksimum eğim: 1 - 0^2 = 1
ax.annotate(
"merkez: yerel türev = 1\n(en dik eğim)",
xy=(0.0, 1.0), xytext=(-3.9, 0.30),
fontsize=9.5, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.4),
)
# Spot doğrulama (motor ile): n bir noktada Value.tanh()'ın yerel türevi 1 - o^2 mi?
n_nokta = 0.8
n = Value(n_nokta, label="n")
o_val = n.tanh()
o_val.backward() # n.grad = (1 - o^2) * 1
analitik = 1 - np.tanh(n_nokta) ** 2
assert abs(n.grad - analitik) < 1e-9, (n.grad, analitik)
# Grafikte spot noktayı işaretle
ax.plot([n_nokta], [analitik], "o", color=COL_INDIGO_600, markersize=8, zorder=5)
ax.annotate(
rf"$x={n_nokta}$: motor $\partial o/\partial n={n.grad:.3f}$",
xy=(n_nokta, analitik), xytext=(0.95, 0.05),
fontsize=9, color=COL_INDIGO_600,
arrowprops=dict(arrowstyle="->", color=COL_INDIGO_600, lw=1.2),
)
ax.set_xlabel("girdi $x$ (nöronun ham toplamı $n$)", fontsize=12)
ax.set_ylabel("değer", fontsize=12)
ax.set_title("tanh aktivasyonu ve yerel türevi: " r"$1 - \tanh^2(x) = 1 - o^2$",
fontsize=12.5)
ax.set_xlim(-4.0, 4.0)
ax.set_ylim(-1.15, 1.15)
ax.legend(loc="lower right", fontsize=10, framealpha=0.95)
plt.tight_layout()
plt.show()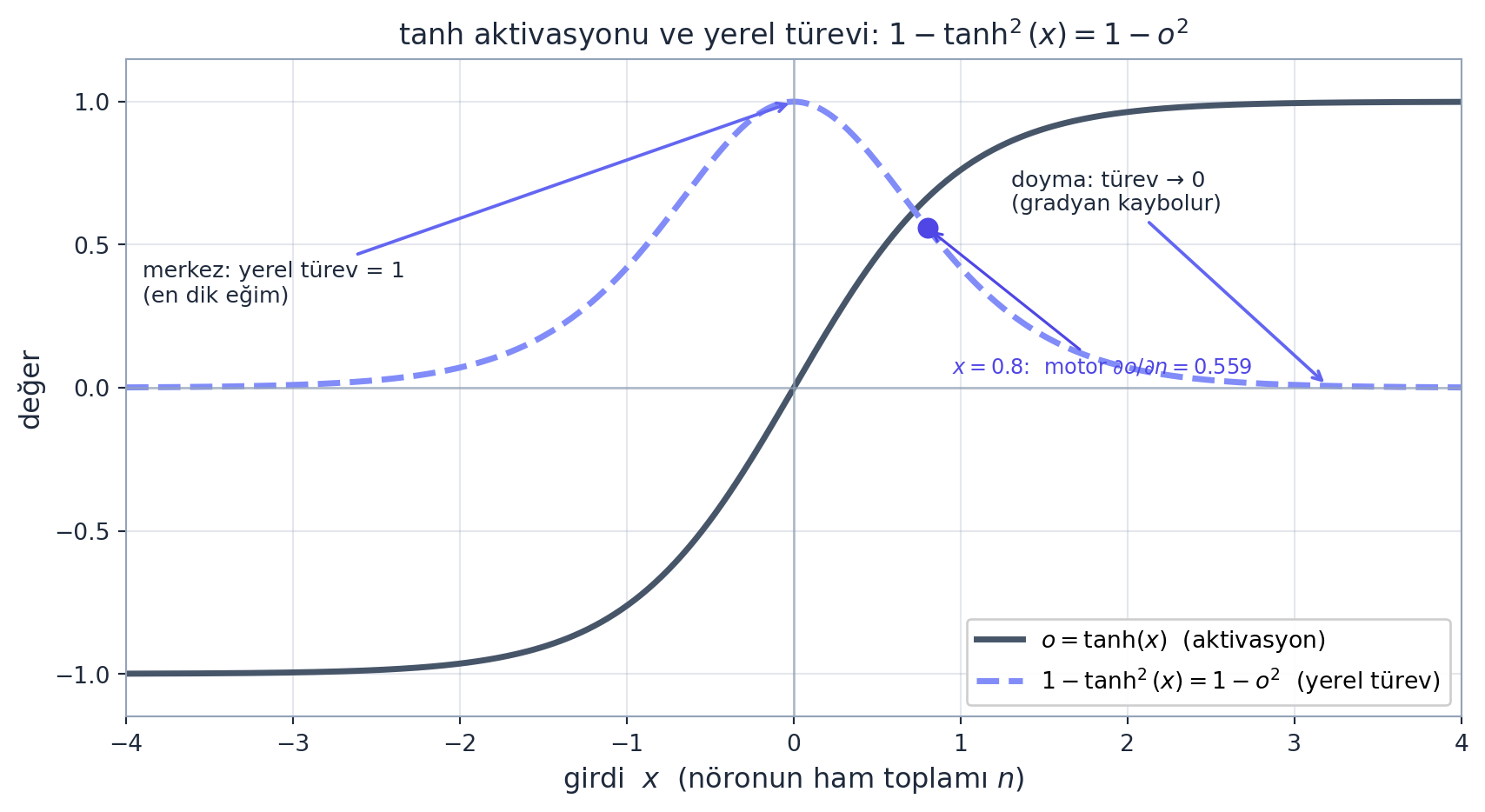
İpucuBuilder Notu — tanh ve ReLU Türevi
Geriye (18.06 + Calculus): Nöronun çekirdeği \(x_1 w_1 + x_2 w_2 + b\), tam olarak dot product + bias (18.06 Ders 30) — bir katmanda bu \(\mathbf{W}\mathbf{x} + \mathbf{b}\) matris çarpımına genişler. tanh’ın \(1 - \tanh^2\) türevi ise Calculus’tan; sigmoid’in türevinin \(g(1-g)\) olmasına akrabadır.
İleriye: GitHub’daki güncel micrograd, tanh yerine ReLU kullanır (\(\max(0, x)\); türevi 0 veya 1). Karpathy derste bilinçli tanh seçer — türevi daha “zengin” olduğu için backprop’u daha öğretici kılar. Modern derin ağlarda varsayılan çoğunlukla ReLU/GELU’dur.
2.10 Her İşlem İçin _backward {#sec-backward-kapanis}
Elle backprop yapmak öğretici ama dayanılmaz. Karpathy bunu otomatikleştirmeye geçer:
“Okay so doing the backpropagation manually is obviously ridiculous, so we are now going to put an end to this suffering and we’re going to see how we can implement the backward pass a bit more automatically.” — Karpathy, 1:08:59
Fikir şu: her işlem, kendi yerel gradyan kuralını bilir. O hâlde her Value’ya, çıkışının gradyanını (out.grad) alıp girişlerine dağıtan bir _backward fonksiyonu (closure) iliştirelim. Toplama aynen geçirir, çarpma diğerini geçirir, tanh ise \((1 - o^2)\) ile çarpar:
import math
def __add__(self, other):
out = Value(self.data + other.data, (self, other), '+')
def _backward():
self.grad = 1.0 * out.grad # toplama: gradyani aynen gecir
other.grad = 1.0 * out.grad
out._backward = _backward
return out
def __mul__(self, other):
out = Value(self.data * other.data, (self, other), '*')
def _backward():
self.grad = other.data * out.grad # carpma: digerini gecir
other.grad = self.data * out.grad
out._backward = _backward
return out
def tanh(self):
t = math.tanh(self.data)
out = Value(t, (self,), 'tanh')
def _backward():
self.grad = (1 - t**2) * out.grad # tanh: (1 - o^2) ile carp
out._backward = _backward
return outArtık elle çarpmak yerine, doğru sırada her düğümün _backward()’ını çağırmamız yeter. Ama “doğru sıra” ne? Bir düğümün gradyanını dağıtmadan önce, kendi gradyanının tamamlanmış olması gerekir — yani çıkışındaki tüm düğümler işlenmiş olmalı. İşte bu sırayı bir sonraki bölümde topolojik sıralamayla çözeceğiz.
İpucuBuilder Notu — torch.autograd.Function
İleriye: Her işleme kendi yerel gradyanını gömmek, PyTorch’taki torch.autograd.Function’ın forward/backward çiftinin tam karşılığıdır. Yeni bir özel işlem tanımladığında PyTorch’ta da yaptığın şey budur: ileri hesabı ve onun yerel gradyanını yazmak; gerisini motor halleder.
2.11 Topolojik Sıralama ve Otomatik backward()
_backward’ları doğru sırada çağırmak için grafiği topolojik olarak sıralarız.
“This can be achieved using something called topological sort. Topological sort is basically a laying out of a graph such that all the edges go only from left to right.” — Karpathy, 1:18:14
Topolojik sıralama, bir düğümü ancak tüm çocukları listeye eklendikten sonra ekleyen özyinelemeli bir gezintidir. Sonuç: kenarların hep soldan sağa aktığı bir dizilim. Geri yayılım için bu dizilimi tersten gezeriz: önce köke grad = 1 veririz, sonra ters topolojik sırada her düğümün _backward()’ını çağırırız. Böylece her düğüm işlenirken, gradyanı çoktan tamamlanmış olur.
def backward(self):
topo = []
visited = set()
def build_topo(v):
if v not in visited:
visited.add(v)
for child in v._prev:
build_topo(child) # once cocuklar
topo.append(v) # sonra dugumun kendisi
build_topo(self)
self.grad = 1.0 # kok dugumun gradyani 1
for node in reversed(topo): # ters topolojik sira
node._backward()Tek bir o.backward() çağrısı, artık tüm grafiğin gradyanlarını otomatik hesaplar. Bu, micrograd’ın kalbidir — ve PyTorch’taki loss.backward() ile aynı fikir. (Bölüm 5’teki Şekil 2.4 figürü, tam olarak bu backward() çağrısının ürettiği gradyanları çiziyordu.)
İpucuBuilder Notu — Topolojik Sıralama
Geriye (graf teorisi): Topolojik sıralama yalnızca DAG’larda (yönlü çevrimsiz grafik) tanımlıdır — ifade grafiğimiz tam da öyle. Döngü olsaydı sıralama mümkün olmazdı (ve gradyan da tanımsız olurdu).
İleriye: PyTorch da backward() çağrısında dahili computation graph’ı ters topolojik sırada gezer. Sıralama mantığı birebir aynı; tek fark, PyTorch’un bunu C++ seviyesinde ve tensörler üzerinde yapması.
2.12 Gradyan Biriktirme (+=) Hatası
Karpathy şimdi ince ama kritik bir bug gösterir — kasten. Bir değişken grafikte birden çok kez kullanılırsa ne olur? Örneğin \(b = a + a\), ya da bir nöronun aynı girdiyi iki yola beslemesi.
_backward içinde self.grad = ... (atama) yazdık. Ama a iki kez kullanılırsa, ikinci _backward çağrısı birincinin yazdığı gradyanı ezer — oysa çok değişkenli zincir kuralına göre, bir değişken birden çok yola katkı veriyorsa gradyanları toplanmalıdır.
“But then we come back to d and call backward, and it overwrites those gradients at a and b. So that’s obviously a problem.” — Karpathy, 1:25:05
Çözüm tek karakter: = yerine +=. Her _backward, mevcut gradyanın üstüne ekler, ezmez:
def _backward():
self.grad += 1.0 * out.grad # ATAMA degil, BIRIKTIRME (+=)
other.grad += 1.0 * out.gradBu yüzden backward()’tan önce tüm gradyanların 0 olması gerekir (birikim sıfırdan başlasın diye) — bu da Bölüm 16’daki zero_grad dersinin tohumu.
İpucuBuilder Notu — zero_grad
Geriye (Calculus): Bu, çok değişkenli zincir kuralının doğrudan sonucudur: bir değişken çıktıya birden çok yoldan etki ediyorsa, toplam türev bu yolların türevlerinin toplamıdır. += tam olarak bu toplamı uygular.
İleriye: Aynı mantık PyTorch’ta da geçerlidir — gradyanlar varsayılan olarak birikir. Bu yüzden her eğitim adımından önce optimizer.zero_grad() çağırırsın. Karpathy’nin burada gösterdiği bug, üretimde “zero_grad’ı unuttum” hatasının ta kendisidir (Bölüm 16).
2.13 tanh’ı Atomlara Ayırma (exp, pow, bölme)
Şimdiye dek tanh’ı tek parça (kompozit) bir işlem olarak yazdık — yerel türevi \(1 - o^2\) olduğu sürece bu meşru. Karpathy burada güzel bir nokta gösterir: bir işlemi ne kadar “atomik” tutacağın sana kalmış; yeter ki her parçanın yerel türevini bilesin. tanh’ı atomlarından kurmak için yeni işlemler ekler: exp, __pow__ (kuvvet), bölme ve çıkarma.
\[ \tanh(n) = \frac{e^{2n} - 1}{e^{2n} + 1} \]
Bunu yazabilmek için \(e^x\)’in türevinin yine kendisi olduğunu (\(d(e^x)/dx = e^x\)) ve kuvvet kuralını kullanırız:
\[ \frac{d}{dx} x^k = k \, x^{k-1} \]
Bölme de ayrı bir işlem değil — a / b, \(a \cdot b^{-1}\) olarak yazılır (kuvvet kuralının −1 özel hâli):
“A value raised to the power of negative one — we have now defined that.” — Karpathy, 1:33:00
def exp(self):
out = Value(math.exp(self.data), (self,), 'exp')
def _backward():
self.grad += out.data * out.grad # d(e^x)/dx = e^x
out._backward = _backward
return out
def __pow__(self, k): # k: int veya float
out = Value(self.data ** k, (self,), f'**{k}')
def _backward():
self.grad += k * self.data**(k - 1) * out.grad # kuvvet kurali
out._backward = _backward
return out
def __truediv__(self, other): # a / b = a * b**-1
return self * other**-1tanh’ı bu atomlardan kurup, hem ileri geçişin hem de gradyanların birebir aynı çıktığını görürüz. Ayrıca 2 * a gibi durumlarda Python’un sağdan çağırdığı __rmul__ / __radd__ yedek operatörleri ve skaler sarmalama da eklenir (örn. 1 + a).
İpucuBuilder Notu — Fused Kernel
Geriye (Calculus): Burada üç Calculus aracı bir arada: \(e^x\)’in türevi (Ders 5), kuvvet kuralı (Ders 2), ve bölmenin negatif kuvvet olarak yazılması. Hepsi yerel türev olarak _backward’a girer.
İleriye: “Soyutlama seviyesini sen seçersin” fikri PyTorch’ta da geçerli: tanh’ı tek torch.tanh çağrısı olarak da, atomlarından da yazabilirsin — motor her iki durumda da doğru gradyanı üretir. Performans için kütüphaneler bunları tek bir fused kernel’de birleştirir.
2.14 Aynı Şeyi PyTorch ile
Karpathy şimdi tam olarak aynı nöronu PyTorch ile kurar ve micrograd’ın doğruluğunu kanıtlar. Tek fark: PyTorch tensörlerle çalışır (micrograd skalerle). Yapraklarda requires_grad = True açılır (PyTorch verimlilik için gradyanı varsayılan kapalı tutar), o.backward() çağrılır ve gradyanlar micrograd ile birebir eşleşir.
import torch
x1 = torch.tensor([2.0]).double(); x1.requires_grad = True
x2 = torch.tensor([0.0]).double(); x2.requires_grad = True
w1 = torch.tensor([-3.0]).double(); w1.requires_grad = True
w2 = torch.tensor([1.0]).double(); w2.requires_grad = True
b = torch.tensor([6.8813735870195432]).double(); b.requires_grad = True
n = x1*w1 + x2*w2 + b
o = torch.tanh(n)
o.backward()
print(x1.grad.item(), w1.grad.item()) # micrograd ile ayni cikarMesaj net: micrograd ile PyTorch aynı algoritmayı çalıştırır. PyTorch yalnızca (a) tensörlerle paralel hesap yapar, (b) bunu GPU’da hızlandırır. “Gerisi sadece verimlilik” iddiası burada kanıtlanır.
İpucuBuilder Notu — torch.Tensor API
İleriye: requires_grad, .backward(), .grad — bunlar her PyTorch eğitim döngüsünde her gün kullandığın API’nin ta kendisi. Tensörlerin .double() ile float64’e çevrilmesi yalnızca micrograd’la birebir sayısal karşılaştırma içindir; gerçek eğitimde float32 (hatta bf16) kullanılır (bkz. Ders 10, mixed precision).
2.15 Sinir Ağı Kütüphanesi: Neuron, Layer, MLP
Elimizde karmaşık ifadeler kurup türevleyebilen bir motor var. Karpathy artık sinir ağı katmanını (nn.py) kurar:
“Okay so now that we have some machinery to build out pretty complicated mathematical expressions, we can also start building out neural nets. And as I mentioned, neural nets are just a specific class of mathematical expressions.” — Karpathy, 1:43:55
Üç sınıf, üst üste: Neuron (rastgele ağırlıklar + bias, dot product + tanh), Layer (nöron listesi), MLP (katman dizisi). Her birinde parameters() metodu, tüm öğrenilebilir Value’ları tek listede toplar.
import random
class Neuron:
def __init__(self, nin):
self.w = [Value(random.uniform(-1, 1)) for _ in range(nin)]
self.b = Value(random.uniform(-1, 1))
def __call__(self, x):
act = sum((wi*xi for wi, xi in zip(self.w, x)), self.b) # w.x + b
return act.tanh()
def parameters(self):
return self.w + [self.b]
class Layer:
def __init__(self, nin, nout):
self.neurons = [Neuron(nin) for _ in range(nout)]
def __call__(self, x):
outs = [n(x) for n in self.neurons]
return outs[0] if len(outs) == 1 else outs
def parameters(self):
return [p for n in self.neurons for p in n.parameters()]
class MLP:
def __init__(self, nin, nouts):
sz = [nin] + nouts
self.layers = [Layer(sz[i], sz[i+1]) for i in range(len(nouts))]
def __call__(self, x):
for layer in self.layers:
x = layer(x)
return x
def parameters(self):
return [p for layer in self.layers for p in layer.parameters()]
# 3 girisli, iki gizli katman (4,4) ve 1 cikisli bir MLP
model = MLP(3, [4, 4, 1])
İpucuBuilder Notu — torch.nn.Module
Geriye (18.06): Bir Layer = nöron listesi; her nöron \(\mathbf{w}\cdot\mathbf{x} + b\) (dot product + öteleme). Tüm katmanın ileri geçişi aslında bir matris-vektör çarpımıdır (18.06 Ders 30) — micrograd bunu skaler tek tek yapar, PyTorch tek nn.Linear çağrısında.
İleriye: MLP.parameters() ve __call__ arabirimi, torch.nn.Module API’siyle birebir hizalanır: PyTorch’ta da model.parameters() optimizer’a verilir, model(x) ileri geçişi koşar. Karpathy bunu kasten aynı yapar — micrograd’dan PyTorch’a geçiş sıfır sürtünmeli olsun diye.
2.16 Veri Seti, MSE Kaybı ve Elle Eğitim
Ağı kurduk; şimdi eğitelim. Karpathy 4 örnekten oluşan oyuncak bir veri seti tanımlar: dört giriş vektörü (xs) ve dört hedef (ys, +1 veya −1). Ağın tahminleri (ypred) ile hedefler arasındaki farkı tek bir sayıda toplamak için ortalama karesel hata (MSE) kullanır:
\[ L = \sum_{i} \left( y_i^{\text{pred}} - y_i^{\text{gt}} \right)^2 \]
Her tahmin hedefe ne kadar yakınsa kare-fark o kadar küçük; toplam loss sıfıra yaklaştıkça ağ “doğru öğrenmiş” demektir. Önemli olan şu: loss da bir Value’dur — yani devasa bir ifade grafiğinin köküdür. loss.backward() çağırınca, tüm ağırlıkların gradyanı otomatik hesaplanır (Bölüm 10’daki motor). Sonra her parametreyi gradyanın tersine küçük bir adım kaydırırız (loss’u düşürmek için):
\[ p \leftarrow p - \eta \, \frac{\partial L}{\partial p} \]
Karpathy bunu önce elle birkaç kez yapar: forward → backward → update. Loss’un adım adım düştüğünü, tahminlerin hedeflere yaklaştığını izleriz.
İpucuBuilder Notu — MSE ve Learning Rate
Geriye (istatistik): MSE, tahminlerin hedeflerden ortalama karesel uzaklığıdır; Gauss gürültü varsayımı altında maximum likelihood’a denktir. (Sınıflandırmada yerini cross-entropy alır — bkz. Ders 2, makemore.)
İleriye: model.parameters() + loss + backward() + güncelleme, her PyTorch eğitim döngüsünün dört temel adımıdır. \(\eta\) (learning rate) burada elle 0,05 seçilir; gerçek eğitimde en kritik hyperparameter’lardandır.
2.17 Eğitim Döngüsü, zero_grad Hatası ve Özet
Elle tekrar etmek yerine düzgün bir eğitim döngüsü yazalım:
“Okay let’s make this a tiny bit more respectable and implement an actual training loop.” — Karpathy, 2:08:35
Ve burada Karpathy en meşhur hatasını gösterir — yine kasten. Gradyanların += ile biriktiğini (Bölüm 11) hatırla. Eğer her adımda backward()’tan önce gradyanları sıfırlamazsan, önceki adımların gradyanları üst üste birikir; adımlar bozulur, eğitim kararsızlaşır. Çözüm: her iterasyonda önce p.grad = 0.0 (zero_grad), sonra backward.
for k in range(20):
# 1) ileri gecis: tahmin + loss
ypred = [model(x) for x in xs]
loss = sum((yout - ygt)**2 for ygt, yout in zip(ys, ypred))
# 2) ZERO_GRAD: gradyanlari sifirla (yoksa birikir!)
for p in model.parameters():
p.grad = 0.0
# 3) geri gecis: tum gradyanlari hesapla
loss.backward()
# 4) guncelleme: gradyanin tersine kucuk adim
for p in model.parameters():
p.data += -0.05 * p.grad
print(k, loss.data) # loss adim adim dusmeliBu döngü, GPT ölçeğindeki ağlara aynen ölçeklenir: yapı taşı değişmez, yalnızca skaler yerine tensör, CPU yerine GPU, dört örnek yerine milyarlarca token gelir. Aşağıdaki figür, tam olarak bu döngüyü kendi motorumuzla 20 adım koşturup MSE kaybının monoton düştüğünü gösteriyor.
Kod
import random
import matplotlib.pyplot as plt
# Deterministik kurulum: aynı ağırlıklar her koşuda (seed sabit)
random.seed(1337)
model = MLP(3, [4, 4, 1])
# 4 örnekli oyuncak veri seti (Karpathy Bölüm 15)
xs = [
[2.0, 3.0, -1.0],
[3.0, -1.0, 0.5],
[0.5, 1.0, 1.0],
[1.0, 1.0, -1.0],
]
ys = [1.0, -1.0, -1.0, 1.0] # hedefler (+1 / -1)
eta = 0.05 # learning rate (Karpathy'nin elle seçtiği adım)
adimlar = 20
loss_gecmisi = []
for k in range(adimlar):
# 1) ileri geçiş: tahmin + MSE loss (loss da bir Value, grafiğin köküdür)
ypred = [model(x) for x in xs]
loss = sum((yout - ygt) ** 2 for ygt, yout in zip(ys, ypred))
# 2) zero_grad: gradyanları sıfırla (yoksa += ile birikir)
for p in model.parameters():
p.grad = 0.0
# 3) geri geçiş: tüm gradyanları otomatik hesapla
loss.backward()
# 4) güncelleme: gradyanın TERSİNE küçük adım (gradient descent)
for p in model.parameters():
p.data += -eta * p.grad
loss_gecmisi.append(loss.data)
fig, ax = plt.subplots(figsize=(9, 5))
apply_style(ax)
adim_no = list(range(1, adimlar + 1))
ax.plot(adim_no, loss_gecmisi,
color=COL_PRIMARY, linewidth=2.4, zorder=2,
label="Eğitim kaybı $L = \\sum_i (y_i^{\\text{pred}} - y_i^{\\text{gt}})^2$")
ax.scatter(adim_no, loss_gecmisi,
color=COL_ACCENT, s=55, zorder=3, edgecolor=COL_WHITE, linewidth=1.0)
# İlk ve son kaybı anotla (monoton düşüşü vurgula)
ax.annotate(f"başlangıç: {loss_gecmisi[0]:.3f}",
xy=(adim_no[0], loss_gecmisi[0]),
xytext=(adim_no[0] + 1.8, loss_gecmisi[0]),
color=COL_TEXT, fontsize=10, va="center",
arrowprops=dict(arrowstyle="->", color=COL_SLATE_400, lw=1.2))
ax.annotate(f"son: {loss_gecmisi[-1]:.3f}",
xy=(adim_no[-1], loss_gecmisi[-1]),
xytext=(adim_no[-1] - 5.5, loss_gecmisi[-1] + 0.8),
color=COL_INDIGO_600, fontsize=10, va="center",
arrowprops=dict(arrowstyle="->", color=COL_INDIGO_600, lw=1.2))
ax.set_xlabel("Eğitim adımı $k$", fontsize=12)
ax.set_ylabel("Kayıp (loss) $L$", fontsize=12)
ax.set_title("MLP(3, [4, 4, 1]) gerçek eğitimi — 20 adımda kayıp düşüşü",
fontsize=12)
ax.set_xticks(range(0, adimlar + 1, 2))
ax.set_ylim(bottom=0)
ax.legend(loc="upper right", fontsize=10, framealpha=0.95)
plt.tight_layout()
plt.show()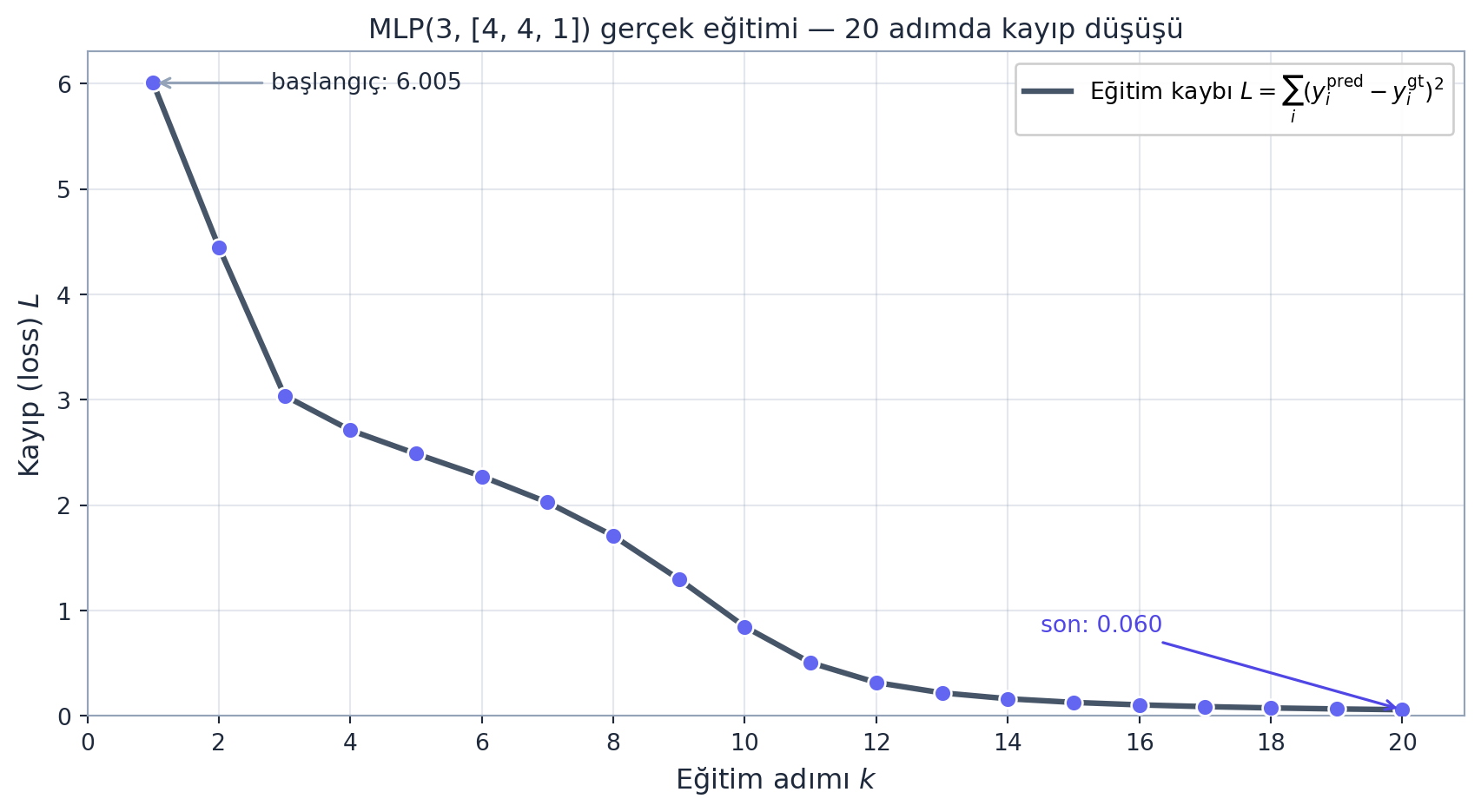
random.seed(1337) ile deterministik 20 adımda kayıp eğrisi. Her adım forward → zero_grad → backward → güncelleme; MSE kaybı \(L = \sum_i (y_i^{\text{pred}} - y_i^{\text{gt}})^2\) monoton düşer (başlangıç 6,005 → son 0,060). Slate çizgi, indigo işaretçiler.
İpucuBuilder Notu — Eğitim Döngüsü
İleriye: “zero_grad’ı unutma” hatası üretimde gerçektir — PyTorch’ta her adımda optimizer.zero_grad() çağırırsın, tam olarak bu yüzden. Karpathy’nin döngüsü (forward → zero_grad → backward → update) PyTorch eğitim döngüsünün birebir iskeletidir; tek fark optimizer.step()’in güncellemeyi senin yerine yapması.
2.18 Bu Dersin Özeti
- micrograd, bir autograd (otomatik gradyan) motorudur — yaklaşık 100 satırda backpropagation’ı gösterir. “Gerisi sadece verimlilik.”
- Türev, bir girişi azıcık dürtünce çıktının ne kadar değiştiğidir; küçük bir h ile sayısal olarak okunabilir (gradient check).
- Value nesnesi bir skaleri sarar, hangi işlemden (
_op) ve hangi çocuklardan (_prev) üretildiğini tutar; işlemler bir ifade grafiği (DAG) örer. - Geri yayılım, kökten yapraklara zincir kuralını uygulamaktır: toplama gradyanı aynen geçirir, çarpma diğer operandı geçirir, tanh ise \((1 - o^2)\) ile çarpar.
- Her işleme bir
_backwardkapanışı iliştirilir; topolojik sıralamanın tersinde çağrılınca tekbackward()tüm gradyanları hesaplar. - Bir değişken birden çok yola besleniyorsa gradyanlar toplanır (
+=) — yoksa ezilir (Bölüm 11 bug’ı). - Neuron / Layer / MLP, motorun üstüne kurulan sinir ağıdır;
parameters()tüm ağırlıkları toplar (PyTorchnn.Modulegibi). - Eğitim = döngüde forward → zero_grad → backward → gradyanın tersine adım (gradient descent). zero_grad’ı atlamak en meşhur hatadır.
- micrograd ile PyTorch aynı algoritmayı çalıştırır; fark yalnızca tensör + GPU + ölçek.
ÖnemliTek Bir Cümle
Bir sinir ağını eğitmek sihir değildir: her hesabı bir ifade grafiğine dök, ileri geçişle loss’u hesapla, zincir kuralını grafikte geriye uygulayıp (backprop) her parametrenin gradyanını bul, sonra gradyanın tersine küçük bir adım at — micrograd bu çekirdeği 100 satırda gösterir, GPT bunu yalnızca devasa ölçekte tekrarlar.
2.19 Kontrol Soruları
NotSoru 1: a = 3, b = 2 için şu grafiği düşün: e = a·b, d = e + 5, L = d·2. Tüm gradyanları elle hesapla.
Cevap: İleri geçiş: \(e = 6\), \(d = 11\), \(L = 22\). Kökten geriye yürüyelim (\(\partial L/\partial L = 1\)). \(L = d \cdot 2\) bir çarpma (diğerini geçirir), \(d = e + 5\) bir toplama (aynen geçirir), \(e = a \cdot b\) bir çarpma:
\[ \frac{\partial L}{\partial d} = 2, \qquad \frac{\partial L}{\partial e} = 2 \cdot 1 = 2 \]
\[ \frac{\partial L}{\partial a} = \frac{\partial L}{\partial e} \cdot b = 2 \cdot 2 = 4, \qquad \frac{\partial L}{\partial b} = \frac{\partial L}{\partial e} \cdot a = 2 \cdot 3 = 6 \]
Cevap: \(\partial L/\partial d = 2\), \(\partial L/\partial e = 2\), \(\partial L/\partial a = 4\), \(\partial L/\partial b = 6\). Doğrulamak için a’yı 0,0001 dürt: \(L \approx 22 + 4 \cdot 0{,}0001\) olmalı (sayısal gradyan \(\approx 4\)).
NotSoru 2: _backward içinde neden self.grad = … değil self.grad += … kullanırız? Hangi durumda fark yaratır, hangi durumda yaratmaz?
Cevap: Bir değişken grafikte birden çok kez kullanılırsa (örn. \(b = a + a\), ya da aynı girdinin iki nörona beslenmesi), o değişkenin _backward’ı birden çok kez çağrılır. = (atama) kullanırsak ikinci çağrı birincinin yazdığını ezer; oysa çok değişkenli zincir kuralı, farklı yollardan gelen katkıların toplanmasını gerektirir. += bu toplamayı yapar. Bir değişken yalnızca bir kez kullanılıyorsa = ile += aynı sonucu verir — fark yalnızca çoklu kullanımda ortaya çıkar. Bu yüzden backward()’tan önce tüm gradyanların 0 olması gerekir (birikim sıfırdan başlasın diye).
NotSoru 3: tanh’ı hem tek kompozit işlem hem de exp/pow/bölme atomlarından kurabiliyoruz ve ikisi de aynı gradyanı veriyor. Bu nasıl mümkün? Hangisini seçmek neyi değiştirir?
Cevap: Geri yayılım yalnızca her düğümün yerel türevinin doğru olmasını ister. tanh’ı tek işlem yazarsan yerel türev \(1 - o^2\)’dir; atomlarına ayırırsan her atom (exp, pow, toplama, bölme) kendi yerel türevini taşır ve zincir kuralı bunları çarparak aynı sonuca ulaşır. Yani matematiksel sonuç (doğruluk) değişmez. Değişen şey grafiğin granülerliğidir: atomik graf daha çok düğüm/bellek demektir ama daha esnektir; tek-parça işlem daha az düğüm ve pratikte daha hızlıdır. Üretimde kütüphaneler bu atomları tek bir fused kernel’de birleştirip hızlandırır — soyutlama seviyesi bir performans kararıdır, doğruluk kararı değil.
NotSoru 4: (Builder) backward() neden düğümleri ters topolojik sırada çağırmak zorunda? Calculus zincir kuralıyla bağla.
Cevap: Bir düğümün gradyanını çocuklarına dağıtmadan önce, o düğümün kendi gradyanının tamamlanmış olması gerekir — yani çıkışındaki tüm düğümler çoktan işlenmiş olmalı. Zincir kuralı \(\partial L/\partial x = \partial L/\partial y \cdot \partial y/\partial x\) der; burada \(\partial L/\partial y\) (sonraki düğümün gradyanı) önce bilinmeli ki \(\partial L/\partial x\)’i hesaplayabilelim. Topolojik sıralama tüm kenarları soldan sağa dizer; bunu tersten gezmek, her düğüm işlenirken gradyanının hazır olmasını garanti eder. Döngü olsaydı (DAG değilse) ne sıralama ne de gradyan tanımlı olurdu — bu yüzden ifade grafiği çevrimsizdir.
2.20 Egzersizler
Egzersiz 1 (Value’yu sıfırdan kur). Value sınıfını baştan yaz: data, grad, _prev, _op ve __add__ / __mul__. Sonra a = Value(2.0), b = Value(-3.0), c = Value(10.0) ile L = (a*b + c) * Value(-2.0) ifadesini kur. İleri geçişin Bölüm 5’teki \(L = -8\) ile aynı çıktığını doğrula.
Egzersiz 2 (Elle backprop + gradient check). Egzersiz 1’in grafiğinde, her düğümün gradyanını elle hesapla (\(\partial L/\partial a = 6\), \(\partial L/\partial b = -4\) vb. çıkmalı). Sonra her girişi küçük bir \(h = 0{,}0001\) ile dürtüp sayısal gradyanı hesapla ve analitik sonuçla karşılaştır. İki değer yaklaşık eşleşmeli (gradient check).
def numerical_grad(f, x, h=1e-4):
# f: tek girisli fonksiyon, x: nokta -> sayisal turev
return (f(x + h) - f(x - h)) / (2 * h) # merkezi fark daha hassasEgzersiz 3 (Edge case — += hatası). a = Value(3.0) için b = a + a kur ve b.backward() çağır. a.grad ne çıkmalı? _backward’ı = (atama) ile yazarsan ne çıkar, += (biriktirme) ile ne çıkar? Doğru cevabın (\(\partial b/\partial a = 2\)) neden yalnızca += ile geldiğini açıkla.
Egzersiz 4 (MLP’yi eğit). Bölüm 14-16’daki MLP(3, [4, 4, 1]) ile 4 örnekli oyuncak veri setini eğit. Eğitim döngüsünü (forward → zero_grad → backward → update) 20 adım koştur, her adımda loss’u yazdır. Loss’un düştüğünü gözlemle. Sonra bilerek zero_grad’ı kaldır ve eğitimin nasıl bozulduğunu gör.
Egzersiz 5 (Sonraki dersin habercisi). micrograd skaler değerlerle çalışıyor ve örneklerimiz sayısaldı. Şimdi farklı bir problem düşün: bir isim üretmek (örn. “emma”, “olivia”). Bir karakteri tahmin etmek için önceki karaktere bakan basit bir model nasıl kurulur? (a) Karakterleri sayıya nasıl çevirirsin (bir karakter = bir giriş)? (b) Çıktı neden bir olasılık dağılımı olmalı (tek bir sayı değil)? (c) micrograd’daki MSE yerine, “doğru karaktere yüksek olasılık ver” diyen bir kayıp nasıl tanımlanır? Bu üç soru, Ders 2’de (makemore, bigram dil modeli) kuracağımız modeli motive eder.
2.21 Sonraki Ders İçin Hazırlık
Ders 2: makemore 1 — Bigram Karakter Dil Modeli — Andrej Karpathy
Bu derste skaler bir MLP’yi elle eğittik. Ders 2’de makemore projesine geçiyoruz: 32 binden fazla gerçek ismi öğrenip yeni isimler üreten bir karakter-düzeyli dil modeli. Önce bigram’ları (ardışık karakter çiftlerini) sayarak, sonra tam olarak aynı modeli tek katmanlı bir sinir ağı olarak yeniden kurarak — micrograd’da gördüğümüz forward/backward/update döngüsünün birebir aynısıyla.
Ana konular:
- Karakter-düzeyli dil modeli: bir karaktere bakıp sonrakini tahmin etmek.
- Bigram sayımı, olasılık matrisi ve
torch.multinomialile örnekleme. - Negatif log olabilirlik (NLL) kaybı — micrograd’daki MSE’nin dil modeli karşılığı.
- Aynı modelin sinir ağı hâli: one-hot girdi, softmax, gradient descent.
UyarıDers 2 Öncesi Yapılacak
- Egzersizleri çöz — özellikle 4 (MLP eğitimi) ve 5 (dil modeli sezgisi).
- micrograd’ın
engine.pyvenn.py’sini github.com/karpathy/micrograd üzerinden oku; 100 satırın tamamını gör. - Ana cümleyi tekrar oku: “Bir sinir ağını eğitmek = ifade grafiğinde forward, sonra backprop (zincir kuralı), sonra gradyanın tersine adım.”
2.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| micrograd / autograd | ≈100 satırlık otomatik gradyan motoru; backprop’u skaler düzeyde gösterir | 0m47 |
| Türev / sayısal gradyan | Girişi h ile dürtünce çıktının değişimi; \((f(x+h)-f(x))/h\) ile sayısal okunur | 8m09 |
| Value nesnesi | Skaleri saran kutu; data, grad, _prev, _op, _backward tutar | 19m30 |
| İfade grafiği (DAG) | İşlemlerin ördüğü yönlü çevrimsiz grafik; yapraklar girdi, kök çıktı | 19m30 |
| Yerel türev kuralları | Toplama gradyanı aynen geçirir; çarpma diğer operandı geçirir | 38m03 |
| Zincir kuralı (backprop) | \(\partial L/\partial x = \partial L/\partial y \cdot \partial y/\partial x\); grafikte kökten yapraklara çarpılarak taşınır | 42m03 |
| tanh aktivasyonu | Nöronun doğrusal-olmama katmanı; yerel türevi \(1 - o^2\) | 52m52 |
| **_backward kapanışı** | Her işleme iliştirilen, yerel gradyanı girişlere dağıtan fonksiyon | 1h09m |
| Topolojik sıralama | Düğümleri bağımlılık sırasına dizer; backward ters sırada gezer | 1h18m |
| Gradyan biriktirme (+=) | Birden çok kez kullanılan düğümün gradyanları toplanır, ezilmez | 1h25m |
| Neuron / Layer / MLP | Motorun üstüne kurulan ağ; parameters() tüm ağırlıkları toplar | 1h44m |
| MSE kaybı | \(\sum (\text{tahmin} - \text{hedef})^2\); eğitilen loss, ifade grafiğinin köküdür | 1h51m |
| zero_grad + eğitim döngüsü | forward → zero_grad → backward → gradyanın tersine adım | 2h08m |
2.23 ML Builder Bağlantıları
İpucu9 köprü
Bu ders, modern derin öğrenme altyapısının skaler prototipidir — köprülerin özeti:
- Value + backward() → PyTorch
torch.Tensor+loss.backward()(autograd). İleriye: tensör + GPU. - İfade grafiği → PyTorch computation graph (
grad_fn); aynı “neyden üretildim” bilgisi. - **İşleme gömülü _backward** → PyTorch
torch.autograd.Function’ın forward/backward çifti. - Topolojik sıralama → reverse-mode autodiff; gradyanı çıktıdan girişe biriktirme (derin ağlarda neden verimli).
- Neuron / Layer / MLP + parameters() →
torch.nn.ModuleAPI’si;model.parameters()optimizer’a verilir. - \(\mathbf{w}\cdot\mathbf{x} + b\) → 18.06 dot product / matris çarpımı (Ders 30). İleriye: GPU GEMM, throughput.
- backprop = zincir kuralı → Calculus Ders 4; Karpathy’nin kendi sözüyle “nothing more than the chain rule”.
- zero_grad + gradyan biriktirme (+=) → PyTorch
optimizer.zero_grad(); “unutursan bug” hatasının kaynağı. - “Gerisi sadece verimlilik” → skalerden tensöre, oradan GPT ölçeğine (Ders 7 ve 10) aynı çekirdek.
2.24 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders için verdiği kaynaklar:
- micrograd repo: github.com/karpathy/micrograd — dersin kurduğu kütüphanenin tamamı (engine.py + nn.py).
- Ders deposu: nn-zero-to-hero / lectures / micrograd — ders notebook’ları.
- Ders Colab notebook’u: Google Colab — dersi adım adım çalıştırabileceğin ortam.
ÖnemliTek bir şey alıp gideceksen
Bir sinir ağı sihir değildir — “dot product + bias + doğrusal-olmama” yapı taşının istiflenmesidir ve onu eğitmek, bir loss’u gradient descent ile minimize edip gradyanı backpropagation (zincir kuralı) ile hesaplamaktan ibarettir. micrograd bu çekirdeği 100 satırda gösterir; GPT yalnızca aynı şeyi devasa ölçekte tekrarlar. “Micrograd is what you need to train your networks, and everything else is just efficiency.”