flowchart LR
A["Unicode -> UTF-8 byte<br/>256 taban"] --> B["BPE: en sik cifti birlestir<br/>get_stats + merge"]
B --> C["encode / decode<br/>merges sozlugu"]
C --> D["GPT-2 regex split<br/>kategori-bilincli"]
D --> E["tiktoken / sentencepiece<br/>+ ozel tokenlar"]
E --> F["vocab-size dengesi<br/>kisa dizi vs buyuk tablo"]
F --> G["Tuhafliklar<br/>strawberry, token vergisi"]
style B fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style G fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
10 GPT Tokenizer’ı Sıfırdan — Byte-Pair Encoding (BPE)
Tokenizer, metni ağa girmeden önce öğrenilmiş alt-kelime parçalarına (token) bölen ağ-dışı bir ön-işleme adımıdır; BPE bu sözlüğü UTF-8 byte’larından en sık çiftleri birleştirerek kurar — ve LLM’lerin yazım, sayma, dil tuhaflıklarının çoğu, model karakterleri değil token’ları gördüğü için bu adımdan doğar
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — Let’s build the GPT Tokenizer (≈134 dk)
- Seri: Neural Networks: Zero to Hero — Ders 9
- Hoca: Andrej Karpathy
- Kaynak repo: github.com/karpathy/minbpe
- Okuma süresi: ≈34 dk
10.1 Bu Derste Ne Var?
Ders 7’de bir GPT kurarken naif bir karakter tokenizer kullanmıştık (\(65\) karakter → \(65\) id). Gerçek GPT’ler böyle yapmaz: byte-pair encoding (BPE) kullanırlar. Bu derste o tokenizer’ı sıfırdan kuruyoruz — ve LLM’lerin pek çok tuhaf davranışının (neden “strawberry”deki r’leri sayamaz, neden basit aritmetik/yazım zorlar) kökeninin tokenization olduğunu görüyoruz.
“Tokenization is my least favorite part of working with large language models, but unfortunately it is necessary to understand in some detail.” — Karpathy, 0:06
“Tokens are the fundamental unit — the atom of large language models. Everything is in units of tokens.” — Karpathy, 3:34
Büyük fikir: metni karakter değil, kelime de değil, öğrenilmiş alt-kelime parçalarına (token) bölmek. BPE, UTF-8 byte’larından başlayıp en sık geçen çiftleri tekrar tekrar birleştirerek bu sözlüğü kurar.
Dersin üç büyük fikri:
- Unicode → UTF-8 byte — metni byte dizisine çevirmek (tokenizer’ın ham girdisi).
- BPE algoritması — en sık byte/token çiftini birleştir, yeni token yarat, tekrarla (train/encode/decode).
- Production tokenizer’ları — GPT-2/GPT-4 regex split, tiktoken, sentencepiece, özel token’lar ve tokenization tuhaflıkları.
İpucuBuilder Notu — Geriye Ders 2 ve 7, İleriye Ders 10
Geriye (Ders 2, 7):
- Naif tokenizer = Ders 7. Ders 7’de karakter tokenizer (s2i/i2s, Ders 2’den) kurmuştuk; bu ders onu gerçek BPE ile değiştirir.
- Ağ-dışı adım. Tokenizer, sinir ağının dışında ayrı bir ön-işleme adımıdır — autograd/backprop YOK. Metin → token id’leri → (sonra) ağa girer.
İleriye: Tokenizer seçimi, modelin verimliliğini (sıkıştırma oranı), dil-adaletini (İngilizce-dışı diller daha çok token) ve tuhaf hatalarını (yazım, aritmetik) doğrudan belirler. Ders 10’da GPT-2’nin tokenizer’ını kullanacağız.
Tek cümleyle: Tokenizer, metni ağa girmeden önce öğrenilmiş alt-kelime parçalarına (token) bölen, ağ-dışı bir ön-işleme adımıdır; BPE bu sözlüğü UTF-8 byte’larından en sık çiftleri birleştirerek kurar — ve LLM’lerin pek çok tuhaflığı bu adımdan doğar.
10.2 Tokenization Neden Önemli?
Karpathy açıkça sevmediğini söyler ama şart olduğunu vurgular. Neden? Çünkü LLM’lerin pek çok “aptalık”ı tokenization’dan gelir:
“[LLMs are] not able to do spelling tasks very easily — that’s usually due to tokenization.” — Karpathy, 4:54
Neden bir LLM “strawberry”deki r’leri sayamaz? Çünkü model karakterleri görmez — metni token’lar hâlinde görür. “strawberry” birkaç token’a bölünür; model tek tek harfleri ayırt edemez. Aynı şekilde basit aritmetik, İngilizce-dışı diller, kod girintileri — hepsinde tokenization sorun çıkarır. Bu yüzden tokenizer’ı anlamak, LLM davranışını anlamaktır.
İpucuBuilder Notu — Model Token Görür, Karakter Değil
İleriye: “Modelin gördüğü şey token, karakter değil” — bir LLM uygulamacısının bilmesi gereken en pratik gerçeklerden. Yazım/sayma/format hatalarını teşhis ederken ilk bakılacak yer tokenization.
10.3 tiktokenizer ile Sezgi
Karpathy önce sezgi için bir web aracı gösterir: tiktokenizer. Bir metin yazıp hangi token’lara bölündüğünü görsel olarak görürsün. Gözlemler:
- Sık kelimeler tek token; nadir kelimeler parçalanır.
- Baştaki boşluk token’ın parçasıdır (
" token"ile"token"farklı id). - Sayılar tutarsız bölünür (
"127"tek token,"677"iki token olabilir) — aritmetik zorluğunun kökü. - İngilizce-dışı metin daha çok token’a bölünür (aynı anlam, daha çok token = daha pahalı, daha kısa etkin bağlam).
Bu görsel araç, “model neden böyle davranıyor” sorularının çoğunu açıklar.
İpucuBuilder Notu — Token Sayısı = Maliyet
İleriye: Bir prompt’un kaç token olduğu, hem maliyeti (API token başı ücret) hem etkin bağlamı belirler. İngilizce-dışı dillerin daha çok token’a bölünmesi (“token vergisi”), çok dilli adalet sorunudur; Türkçe de bundan etkilenir.
10.4 String, Unicode ve UTF-8 Byte
Tokenizer’ın ham girdisi metindir; ama bilgisayar metni byte olarak görür. Python’da bir string, Unicode kod noktalarından (code point) oluşur; ord ile her karakterin kod noktasını alırız. Modeli evrensel kılmak için metni UTF-8 ile byte dizisine çeviririz (her karakter 1-4 byte).
ord('h') # 104 (Unicode kod noktasi)
ord('😀') # 128512
list('hi 😀'.encode('utf-8')) # [104, 105, 32, 240, 159, 152, 128] byte'lar (0-255)UTF-8 neden? Çünkü \(256\) olası byte değeri (\(0\)-\(255\)) ile her dilden her karakteri temsil edebilir — Türkçe, Çince, emoji dahil. Tokenizer byte’lardan başlar: başlangıç sözlüğü = \(256\) byte. Sorun: byte-düzeyi diziler çok uzun (her karakter birkaç byte). Çözüm: en sık byte çiftlerini birleştirip sözlüğü büyütmek — BPE.
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
fig, ax = plt.subplots(figsize=(10, 4.5))
ax.set_xlim(0, 12); ax.set_ylim(0, 5); ax.axis("off")
x = 0.6
for (ch, cp, bs) in BYTES_DEMO:
disp = "␣" if ch == " " else ch
multi = len(bs) > 1
cw = max(1.0, 0.55 * len(bs) + 0.5)
# karakter kutusu (ust)
ax.add_patch(FancyBboxPatch((x, 3.3), cw, 0.9, boxstyle="round,pad=0.02,rounding_size=0.1",
fc="#eef2ff", ec=COL_INDIGO_600 if multi else COL_PRIMARY, lw=2.0))
ax.text(x + cw/2, 3.75, f"{disp}", ha="center", va="center", fontsize=15, weight="bold", color=COL_TEXT)
ax.text(x + cw/2, 2.95, f"cp {cp}", ha="center", va="top", fontsize=8, color=COL_SLATE_400)
# byte kutulari (alt)
bx = x
bw = cw / len(bs)
for b in bs:
ax.add_patch(FancyBboxPatch((bx + 0.03, 1.4), bw - 0.06, 0.8, boxstyle="round,pad=0.01,rounding_size=0.06",
fc="#ffffff", ec=COL_ACCENT if multi else COL_SLATE_400, lw=1.6))
ax.text(bx + bw/2, 1.8, str(b), ha="center", va="center", fontsize=9, color=COL_TEXT, weight="bold")
bx += bw
ax.add_patch(FancyArrowPatch((x + cw/2, 3.25), (x + cw/2, 2.25), arrowstyle="-|>",
mutation_scale=12, color=COL_SLATE_400, lw=1.4))
x += cw + 0.5
ax.text(0.6, 4.6, "karakter (Unicode kod noktası)", ha="left", color=COL_TEXT, fontsize=10, weight="bold")
ax.text(0.6, 0.8, "UTF-8 byte (0-255) — emoji 4 byte (indigo)", ha="left", color=COL_TEXT, fontsize=10, weight="bold")
plt.tight_layout()
plt.show()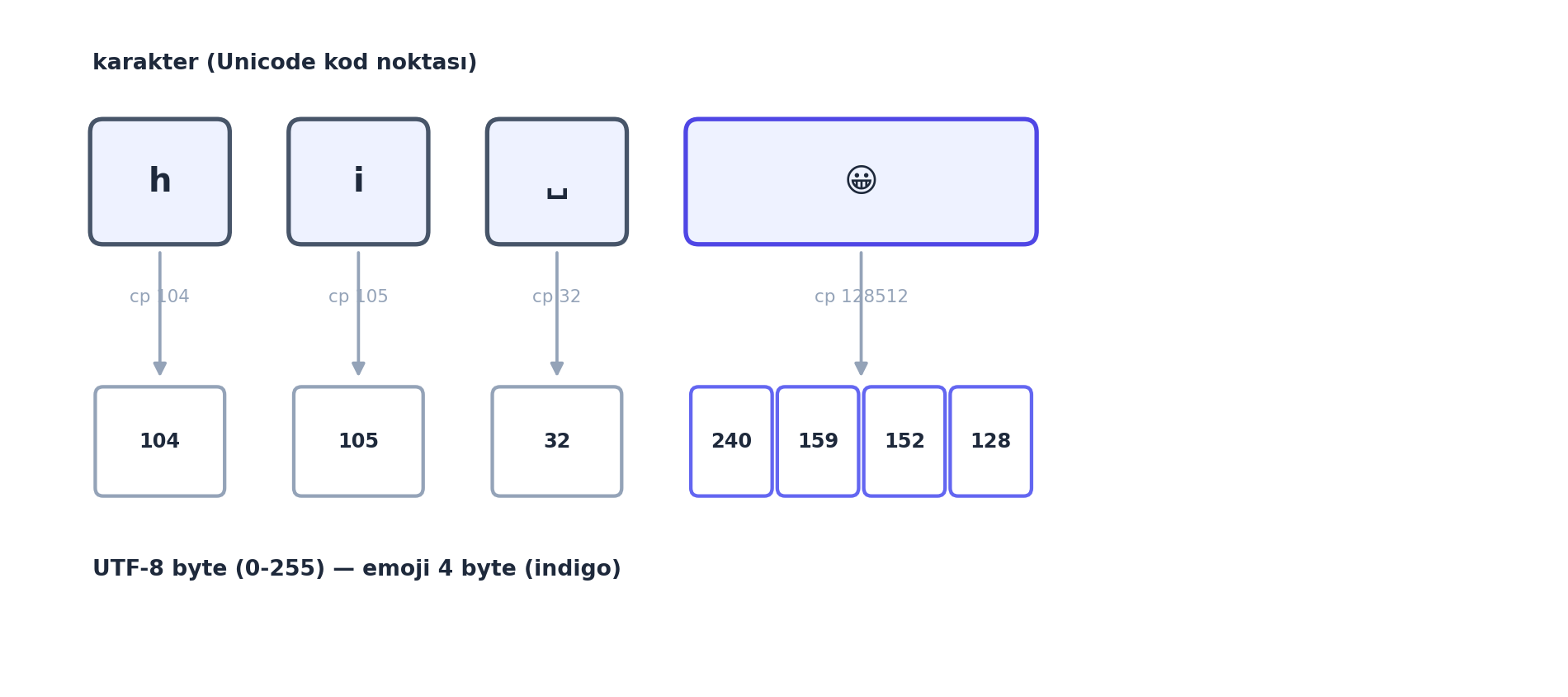
'hi 😀'). Tokenizer’ın ham girdisi byte’lardır. ASCII karakterler (\(h, i\), boşluk) tek byte; ama emoji 😀 (kod noktası \(128512\)) dört byte’a açılır (\([240, 159, 152, 128]\)). UTF-8’in \(256\) olası byte değeriyle her dilden her karakter temsil edilebilir — bu yüzden BPE byte’lardan başlar (hiçbir metin “bilinmeyen” olmaz). Sorun: byte dizileri uzun; BPE bu yüzden en sık çiftleri birleştirip kısaltır.
İpucuBuilder Notu — Byte-Level: Hiçbir Şey ‘Bilinmeyen’ Değil
İleriye: “Byte-level” başlangıç, modern tokenizer’ların (GPT-2/4) standardı: hiçbir metin “bilinmeyen” (unknown) olmaz, çünkü en kötü ihtimalle byte’lara iner. UTF-8’in \(256\)-byte tabanı, çok dilli evrenselliği sağlar — ama İngilizce-dışı diller daha çok byte/token harcar.
10.5 BPE Algoritması
Byte-pair encoding (BPE) fikri basit: byte dizisinde en sık geçen ardışık çifti bul, onu yeni bir token ile değiştir, tekrarla. Her birleştirme sözlüğü \(1\) büyütür (\(256, 257, 258, \ldots\)) ve diziyi kısaltır.
“Byte Pair Encoding (BPE) algorithm walkthrough.” — Karpathy, 23:49
Oyuncak örnek: "aaabdaaabac" dizisinde en sık çift "aa". Onu Z ile değiştir → "ZabdZabac". Sonra en sık "ab" → Y: "ZYdZYac". Diziler kısalır, sözlük büyür. Gerçek metinde de aynısı olur — aşağıda tiny Shakespeare üzerinde eğittiğimiz tokenizer’ın ilk birleştirmeleri (en sık İngilizce desenler tek token oluyor):
Kod
import matplotlib.pyplot as plt
top = TRACE[:10]
labels = []
counts = []
for (pair, idx, cnt, b) in top:
s = b.decode("utf-8", errors="replace").replace(" ", "␣")
labels.append(f"{idx}: '{s}'")
counts.append(cnt)
labels = labels[::-1]; counts = counts[::-1] # en sık üstte
fig, ax = plt.subplots(figsize=(10, 5.5))
bars = ax.barh(range(len(counts)), counts, color=COL_INDIGO_500 if False else COL_ACCENT, zorder=3)
# kademeli renk: en sık koyu
for i, b in enumerate(bars):
b.set_color([COL_INDIGO_600, COL_ACCENT, COL_INDIGO_400][i % 3])
ax.set_yticks(range(len(labels)))
ax.set_yticklabels(labels, fontsize=9.5, family="monospace")
apply_style(ax)
ax.set_xlabel("birleştirme sayısı (en sık ardışık çift)")
ax.set_title("İlk 10 BPE birleştirmesi — yeni id: birleşen bytes (adet)", color=COL_TEXT)
for i, (b, c) in enumerate(zip(bars, counts)):
ax.text(c + 4, i, str(c), va="center", color=COL_TEXT, fontsize=9, weight="bold")
ax.set_xlim(0, max(counts) * 1.15)
plt.tight_layout()
plt.show()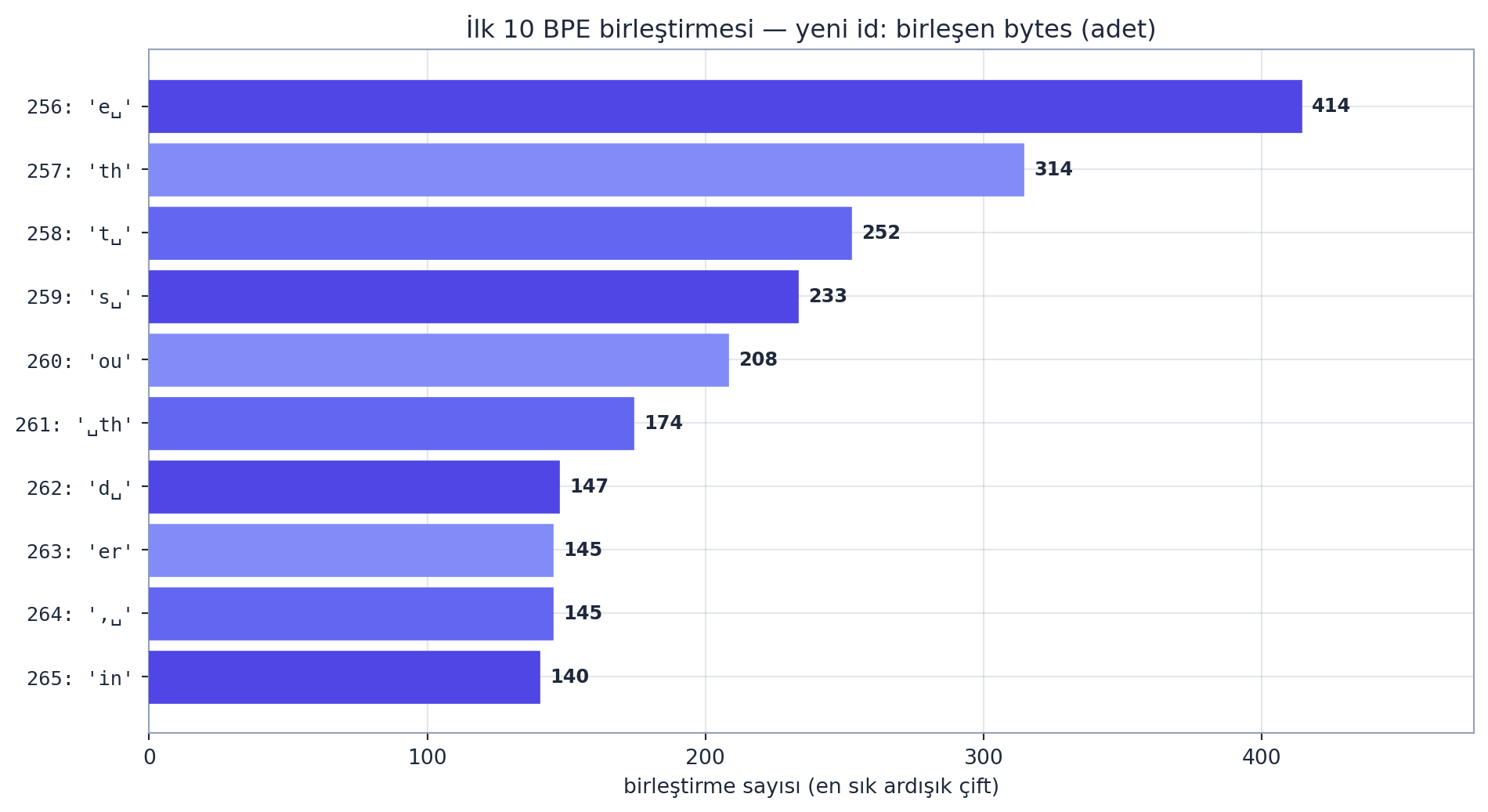
'e ' (414 kez — “e”+boşluk), sonra 'th' (314), 't ' (252), 's ' (233), 'ou' (208)… Klasik İngilizce desenler tek token oluyor; sık desenler sıkışır, nadir olanlar parçalı kalır. Her birleştirme sözlüğü 1 büyütür (\(256 \to 257 \to \ldots\)) ve diziyi kısaltır.
İpucuBuilder Notu — BPE = Sıkıştırma
İleriye: BPE aslında bir sıkıştırma algoritmasıdır (veri sıkıştırmadan ödünç). Sözlük büyüklüğü bir denge: büyük sözlük = kısa diziler (verimli) ama büyük embedding tablosu + seyrek token’lar. GPT-2: \(\approx 50\)K, GPT-4: \(\approx 100\)K token.
10.6 BPE İmplementasyonu: get_stats, merge, Eğitim
BPE üç parçadan oluşur. get_stats: ardışık çiftleri say. merge: bir çifti yeni id ile değiştir. Eğitim döngüsü: en sık çifti bul, birleştir, tekrarla.
def get_stats(ids):
counts = {}
for pair in zip(ids, ids[1:]): # ardisik ciftler
counts[pair] = counts.get(pair, 0) + 1
return counts
def merge(ids, pair, idx):
newids = []
i = 0
while i < len(ids):
if i < len(ids) - 1 and ids[i] == pair[0] and ids[i+1] == pair[1]:
newids.append(idx) # cifti yeni token ile degistir
i += 2
else:
newids.append(ids[i])
i += 1
return newids“Implement first the function that finds the most common pair.” — Karpathy, 28:32
vocab_size = 276 # hedef sozluk (256 byte + 20 birlestirme)
num_merges = vocab_size - 256
ids = list(tokens) # baslangic: byte id'leri
merges = {} # (cift) -> yeni id
for i in range(num_merges):
stats = get_stats(ids)
pair = max(stats, key=stats.get) # en sik cift
idx = 256 + i
ids = merge(ids, pair, idx)
merges[pair] = idx # birlestirme kaydimerges sözlüğü, eğitilen tokenizer’ın “modeli”dir: hangi çiftin hangi yeni token’a birleştiğini tutar. encode/decode bunu kullanır.
İpucuBuilder Notu — get_stats = Ders 2 Bigram Sayımı
Geriye (Ders 2): get_stats, Ders 2’deki bigram sayımının (çiftleri say) ta kendisi — ama amacı farklı (en sık çifti birleştirmek). merges sözlüğü, Ders 2’nin s2i’sinin BPE karşılığı.
İleriye: Bu \(\approx 30\) satır, minbpe’nin çekirdeği. Production’da (tiktoken) aynı algoritma C/Rust’ta hızlandırılır; ama mantık birebir budur.
10.7 encode ve decode
Tokenizer, modelin dışında ve ondan ayrı eğitilir. Eğitilen merges ile iki yönlü çeviri yaparız: decode (id’ler → metin) ve encode (metin → id’ler).
decode: her id’yi byte’larına çevir, birleştir, UTF-8 çöz. Geçersiz byte dizilerinde errors='replace' kullanılır:
vocab = {idx: bytes([idx]) for idx in range(256)}
for (p0, p1), idx in merges.items():
vocab[idx] = vocab[p0] + vocab[p1] # birlestirilen token'in byte'lari
def decode(ids):
tokens = b''.join(vocab[idx] for idx in ids)
return tokens.decode('utf-8', errors='replace') # gecersiz byte -> replacementencode: metni byte’lara çevir, sonra merges’i (en erken öğrenilen birleştirmeden başlayarak) açgözlü uygula:
def encode(text):
tokens = list(text.encode('utf-8'))
while len(tokens) >= 2:
stats = get_stats(tokens)
pair = min(stats, key=lambda p: merges.get(p, float('inf'))) # en erken merge
if pair not in merges:
break
tokens = merge(tokens, pair, merges[pair])
return tokenserrors='replace' kritik: model rastgele token üretebilir, bunlar geçerli UTF-8 olmayabilir; replace çökme yerine replacement karakteri verir. Eğittiğimiz tokenizer kayıpsızdır (decode(encode(text)) == text) ve metni belirgin biçimde sıkıştırır:
Kod
import matplotlib.pyplot as plt
names = ["Karakter\n(Ders 7)", "Byte\n(UTF-8)", "BPE\n(vocab 512)"]
vals = [CV["chars"], CV["bytes"], CV["bpe"]]
cols = [COL_SLATE_400, COL_INDIGO_400, COL_INDIGO_600]
fig, ax = plt.subplots(figsize=(9, 5))
bars = ax.bar(names, vals, color=cols, width=0.6, zorder=3)
apply_style(ax)
ax.set_ylabel("dizi uzunluğu (token sayısı)")
ax.set_title(f"Dizi uzunluğu: BPE ≈ {CV['compression_vs_bytes']:.2f}× daha kısa".replace(".", ","), color=COL_TEXT)
for b, v in zip(bars, vals):
ax.text(b.get_x() + b.get_width() / 2, v + 200, f"{v}", ha="center", va="bottom",
color=COL_TEXT, fontsize=11, weight="bold")
ax.set_ylim(0, max(vals) * 1.12)
ax.annotate("", xy=(2, CV["bpe"]), xytext=(1, CV["bytes"]),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0))
ax.text(1.5, (CV["bytes"] + CV["bpe"]) / 2 + 700, "sıkıştır", color=COL_ACCENT,
fontsize=10, style="italic", ha="center")
plt.tight_layout()
plt.show()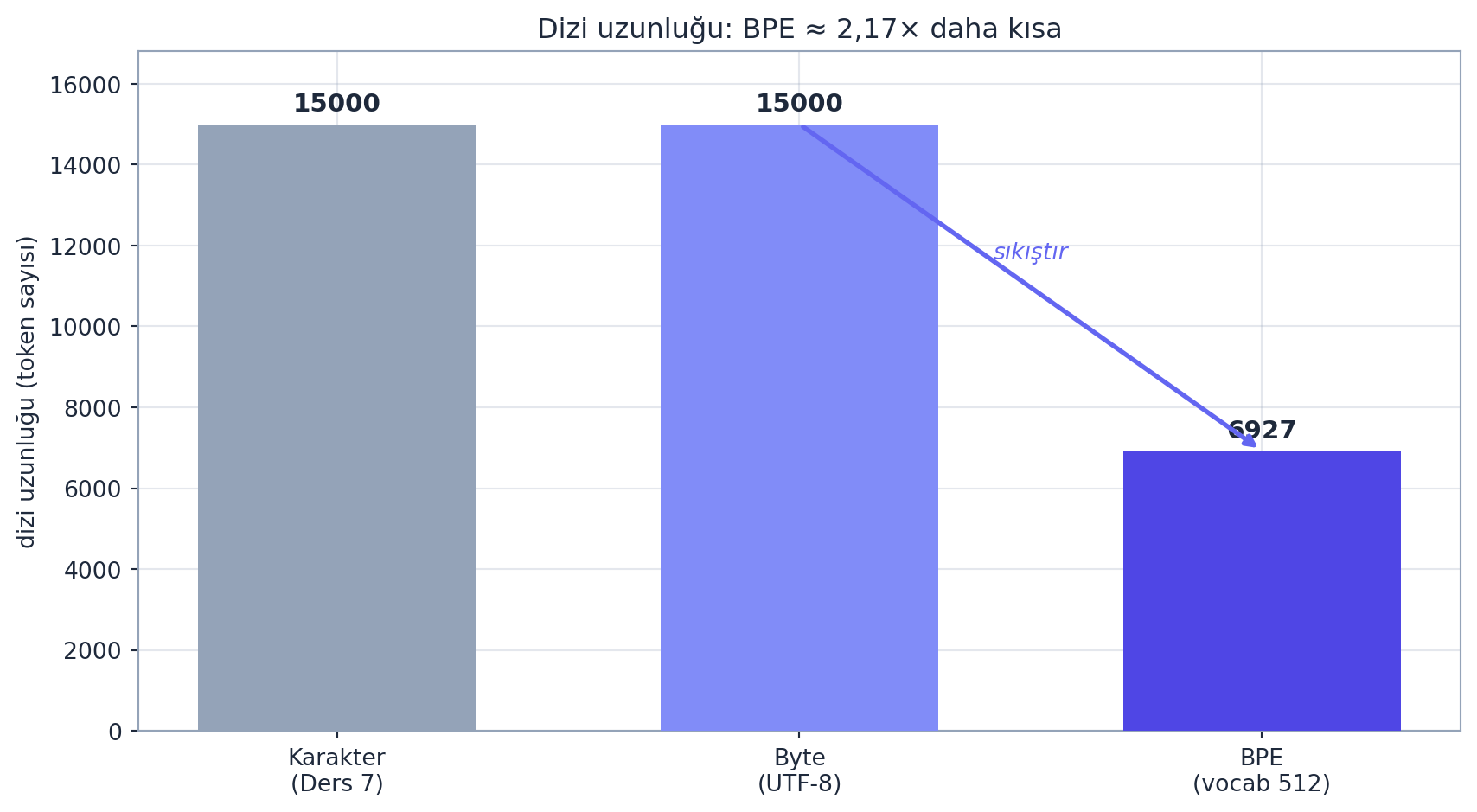
İpucuBuilder Notu — Tokenizer Ayrı Eğitilir
İleriye: “Tokenizer ayrı eğitilir” gerçeği önemli: tokenizer’ın eğitim verisi modelinkinden farklı olabilir (örn. çoğu İngilizce tokenizer, az kod görmüş → kodu verimsiz tokenize eder). errors='replace' (geçersiz start byte sorunu), gerçek dünyada sık karşılaşılan bir tuzak.
10.8 GPT-2 Regex Split Deseni
Naif BPE bir sorun yaratır: birleştirmeler kategori sınırlarını aşabilir (örn. “dog” + “.” → “dog.” tek token, ya da harf+boşluk birleşir). GPT-2, bunu önlemek için metni önce bir regex ile parçalara böler, BPE’yi her parça içinde ayrı çalıştırır (parçalar arası birleşme olmaz).
“Regex patterns to force splits across categories.” — Karpathy, 57:31
GPT-2’nin meşhur deseni (harf grupları, sayı grupları, noktalama, boşluklar ayrı tutulur):
import regex as re # 're' degil 'regex' (Unicode ozellik siniflari icin)
gpt2pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
re.findall(gpt2pat, "Hello world123 how's it going")\p{L} (harfler), \p{N} (sayılar) Unicode özellik sınıflarıdır — bu yüzden standart re değil, regex modülü gerekir. Böylece “dog.” → ["dog", "."] (nokta harfe yapışmaz):
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch
fig, ax = plt.subplots(figsize=(11, 3.6))
ax.set_xlim(0, 12); ax.set_ylim(0, 4); ax.axis("off")
ax.text(0.3, 3.5, "\"Hello world123 how's it going\" → GPT-2 regex parçaları:", ha="left",
color=COL_TEXT, fontsize=12, weight="bold")
cols = [COL_INDIGO_600, COL_INDIGO_400, COL_ACCENT, COL_PRIMARY]
x = 0.3
for i, ch in enumerate(REGEX_CHUNKS):
disp = ch.replace(" ", "␣")
w = 0.5 + 0.42 * len(ch)
ax.add_patch(FancyBboxPatch((x, 1.6), w, 1.1, boxstyle="round,pad=0.02,rounding_size=0.1",
fc="#eef2ff", ec=cols[i % 4], lw=2.0))
ax.text(x + w/2, 2.15, f"'{disp}'", ha="center", va="center", fontsize=11, color=COL_TEXT, family="monospace")
x += w + 0.3
ax.text(0.3, 0.8, "Sayı grubu (123) ayrı · kısaltma ('s) ayrı · öndeki boşluk parçaya dahil (␣world) · birleştirmeler sınır aşmaz",
ha="left", color=COL_SLATE_400, fontsize=9, style="italic")
plt.tight_layout()
plt.show()
regex modülü). Naif BPE birleştirmeleri kategori sınırlarını aşabilir (harf+noktalama, harf+boşluk birleşir). GPT-2 bunu önlemek için metni önce regex ile parçalara böler, BPE’yi her parça içinde ayrı çalıştırır. "Hello world123 how's it going" → görülen parçalar: harf grupları, sayı grubu (123 ayrı), kısaltma ('s), öndeki boşluk parçaya dahil (world). Bu desen, sayıların tutarsız bölünmesinin (aritmetik zorluğu) ve boşluk davranışının kökenidir.
İpucuBuilder Notu — Regex = GPT-2 Sözleşmesi
İleriye: Bu regex, GPT-2 tokenizer’ının sözleşmesidir; metni “neyin neyle birleşebileceği” açısından böler. Sayıların tutarsız bölünmesi (aritmetik zorluğu) ve boşluk davranışı bu desenden gelir. GPT-4 farklı (daha iyi) bir regex kullanır.
10.9 tiktoken: GPT-2 vs GPT-4
OpenAI’nin tiktoken kütüphanesi, GPT-2/GPT-4 tokenizer’larını (hızlı, Rust ile) sağlar. (Bu derste tiktoken’ı kavramsal anlatıyoruz; demolar kendi BPE’mizle yapıldı — algoritma birebir aynı.)
import tiktoken
enc = tiktoken.get_encoding('gpt2') # GPT-2 tokenizer
enc = tiktoken.get_encoding('cl100k_base') # GPT-4 tokenizer
enc.encode("hello world")Farklar: (1) GPT-4 sözlüğü daha büyük (\(\approx 100\)K vs GPT-2 \(\approx 50\)K) → daha kısa diziler. (2) GPT-4 regex’i geliştirildi: sayıları en fazla 3 haneye böler, büyük/küçük harfi daha iyi ele alır. (3) GPT-4 kod girintilerini (ardışık boşluklar) daha verimli tokenize eder. tiktoken yalnızca encode/decode yapar (eğitim yok); merges’i hazır gelir.
İpucuBuilder Notu — tiktoken = Maliyet Hesabı
İleriye: tiktoken, production’da token sayma/maliyet hesabı için standart araç (OpenAI API). Tokenizer şeması (cl100k vs o200k), modelin verimliliğini ve dil-adaletini belirler; yeni modeller genelde daha büyük, daha dengeli sözlükler kullanır.
10.10 OpenAI gpt2 encoder.py
Karpathy OpenAI’nin yayımladığı gerçek GPT-2 tokenizer kodunu (encoder.py) gezer. İçinde bizim kurduğumuzla aynı parçalar var: bir encoder (token → id, bizim vocab’ımız), bir bpe_merges listesi (bizim merges), ve bir regex. Ek olarak bir byte_encoder katmanı vardır — byte’ları “görünür” karakterlere eşleyen kozmetik bir eşleme (örneğin boşluğu Ġ olarak gösterir).
Mesaj: kurduğumuz minik BPE, OpenAI’nin production kodunun çekirdeğiyle aynı — yalnızca birkaç pratik detay (byte_encoder, dosya formatı) eklenmiş.
İpucuBuilder Notu — Sıfırdan Kur, Sonra Karşılaştır
Geriye (Ders 1, 7): “Sıfırdan kur, sonra gerçek kodla karşılaştır” deseni (Ders 1 micrograd vs PyTorch, Ders 4 nn.Linear) burada da: kendi BPE’miz vs OpenAI encoder.py. Artık production tokenizer’ı bir kara kutu değil.
10.11 Özel Token’lar
Normal token’lar BPE ile veriden öğrenilir. Ama bazı token’lar elle eklenir ve özel anlam taşır — bunlar veride geçmez, dışarıdan enjekte edilir:
<|endoftext|>: belgeler arası sınır (pretraining’de, Ders 8). Model “burada yeni bir belge başlıyor” bilgisini alır.- FIM (fill-in-the-middle): kod tamamlamada ortayı doldurmak için özel token’lar.
- Sohbet sınırları:
<|im_start|>/<|im_end|>— kullanıcı/asistan dönüşlerini ayırır (ChatGPT formatı).
Özel token eklemek model cerrahisi gerektirir: token embedding tablosuna (Ders 3-7 wte) ve LM head’e (çıkış katmanı) yeni satırlar eklenir, bunlar eğitilir. Yani tokenizer değişikliği modele de dokunur.
İpucuBuilder Notu — Özel Token = Ders 8 Altyapısı
Geriye (Ders 7-8): <|endoftext|> = Ders 8’deki pretraining belge-ayracı; sohbet token’ları = Ders 8’deki asistan formatının (SFT) altyapısı. wte genişletme = Ders 7’nin token embedding tablosuna ekleme.
İleriye: Özel token’lar, chat template’lerin (Claude/GPT mesaj formatı), tool-use işaretçilerinin ve FIM kod modellerinin temelidir. Yanlış kullanımları (prompt injection ile özel token enjekte etme) bir güvenlik açığıdır.
10.12 minbpe ve sentencepiece
Karpathy iki gerçek araç gösterir. minbpe — kendi temiz BPE implementasyonu (bu dersin kodu). sentencepiece — Google’ın kütüphanesi, Llama 2’nin sözlüğünü eğitmekte kullanılmış.
“sentencepiece library intro, used to train Llama 2 vocabulary.” — Karpathy, 1:28:41
Önemli fark: tiktoken byte-level BPE (önce UTF-8 byte, sonra merge); sentencepiece ise doğrudan Unicode kod noktaları üzerinde çalışır, nadir karakterler için byte_fallback’e iner. sentencepiece’in çok sayıda ayarı vardır (add_dummy_prefix, character_coverage, <unk>); bunlar tarihsel ve karmaşıktır — Karpathy dikkatli olmayı önerir.
İpucuBuilder Notu — İki Yaklaşım Yan Yana Yaşar
İleriye: İki yaklaşım (tiktoken byte-level vs sentencepiece code-point + byte_fallback) sektörde yan yana yaşar. Kendi modelini eğitirken tokenizer kütüphanesi seçimi (ve onlarca ayarı) erken ve kalıcı bir karardır; yanlış ayar (örn. düşük character_coverage) bir dili sakatlayabilir.
10.13 Vocab-Size Dengeleri, Genişletme ve Multimodal
Sözlük büyüklüğü (vocab size) bir dengedir. Büyük sözlük: diziler kısalır (her token daha çok bilgi, daha verimli bağlam) — ama (a) embedding tablosu ve çıkış softmax’ı büyür, (b) her token daha az eğitim örneği görür (seyrekleşir). Küçük sözlük: tersine. Aşağıda kendi metnimizde bu dengeyi GERÇEK ölçtük:
Kod
import matplotlib.pyplot as plt
xs = [vs for (vs, n) in CURVE]
ys = [n for (vs, n) in CURVE]
fig, ax = plt.subplots(figsize=(9, 5))
ax.plot(xs, ys, "-o", color=COL_INDIGO_600, lw=2.4, markersize=7, zorder=3)
apply_style(ax)
ax.set_xlabel("sözlük büyüklüğü (vocab size)")
ax.set_ylabel("dizi uzunluğu (token sayısı)")
ax.set_title("Vocab ↑ → dizi ↓ (azalan verim)", color=COL_TEXT)
for x, y in zip(xs, ys):
ax.annotate(str(y), (x, y), textcoords="offset points", xytext=(6, 8),
fontsize=8.5, color=COL_TEXT, weight="bold")
ax.axhline(ys[0], color=COL_SLATE_400, ls="--", lw=1.2)
ax.text(xs[-1], ys[0], " saf byte (256)", va="bottom", ha="right", color=COL_SLATE_400, fontsize=8.5)
plt.tight_layout()
plt.show()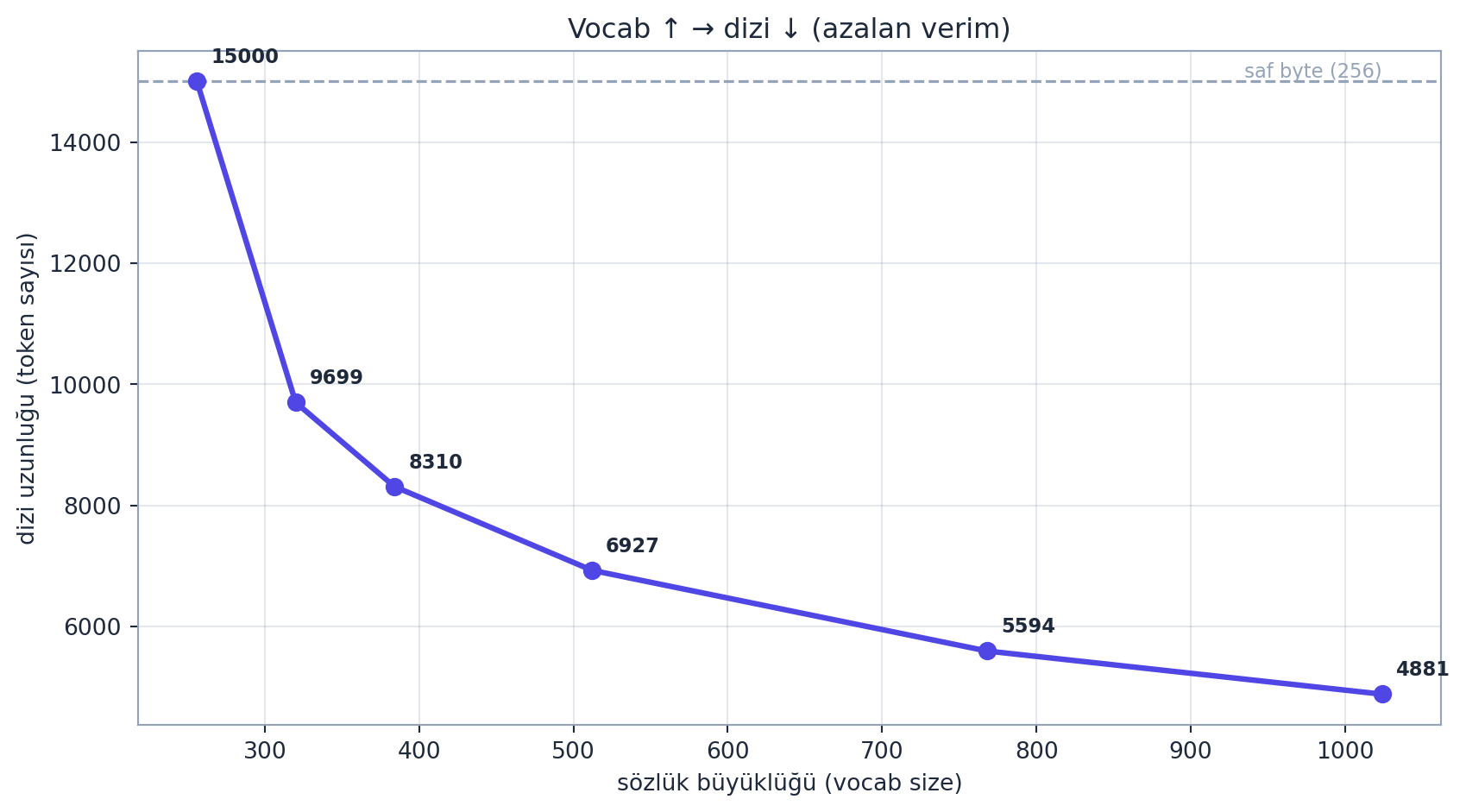
Sözlük genişletme: var olan bir modele yeni token eklemek (özel token’lar) mümkün — embedding + LM head’e satır ekle, yalnızca onları eğit (model cerrahisi). Multimodal: tokenizer fikri metne özel değil. Görüntü/ses de “token”a çevrilebilir — örneğin Sora, videoyu görsel yamalara böler, her yamayı bir token gibi işler. Aynı transformer, farklı modalitelerin token’larını işleyebilir.
İpucuBuilder Notu — Vocab Size = Scaling Kararı
İleriye: Vocab size, scaling/maliyet kararının parçası (Ders 10). Multimodal tokenization (görüntü→patch, ses→kod), GPT-4o/Gemini gibi modellerin temeli: tek transformer, çok modalite — hepsi “token dizisi” olarak.
10.14 Tokenization Tuhaflıkları
Karpathy, LLM’lerin meşhur “aptallıkları”nın tokenization kökenini sıralar:
- Yazım/sayma (strawberry’deki r’ler): model karakterleri değil token’ları görür.
- Sondaki boşluk (trailing whitespace):
" "ayrı token; promptu boşlukla bitirmek modeli şaşırtır. - SolidGoldMagikarp: eğitim verisinde geçen ama model eğitiminde hiç görülmeyen token’lar (örn. bir Reddit kullanıcı adı) → model onlarla karşılaşınca “bozulur” (eğitilmemiş embedding).
- İngilizce-dışı / kod: daha çok token = daha pahalı, daha kötü performans.
Aşağıda iki tuhaflığı kendi BPE’mizle GERÇEK gösteriyoruz — “strawberry”nin token bölünmesi ve Türkçe’nin “token vergisi”:
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5))
# Sol: strawberry token bölünmesi
axL.set_xlim(0, 10); axL.set_ylim(0, 6); axL.axis("off")
axL.text(5, 5.5, "\"strawberry\" → " + str(len(SB_TOKENS)) + " token", ha="center",
color=COL_TEXT, fontsize=13, weight="bold")
x = 0.4
cols = [COL_INDIGO_600, COL_INDIGO_400, COL_ACCENT]
for i, tk in enumerate(SB_TOKENS):
w = 0.55 + 0.42 * len(tk)
axL.add_patch(FancyBboxPatch((x, 2.6), w, 1.2, boxstyle="round,pad=0.02,rounding_size=0.1",
fc="#eef2ff", ec=cols[i % 3], lw=2.2))
axL.text(x + w/2, 3.2, tk, ha="center", va="center", fontsize=13, weight="bold", color=COL_TEXT, family="monospace")
x += w + 0.25
axL.text(5, 1.5, "model her kutuyu atomik görür →\n'r' harflerini tek tek sayamaz",
ha="center", va="center", color=COL_SLATE_400, fontsize=9.5, style="italic")
# Sag: token vergisi
labels = [t[0] for t in TAX]
ntok = [t[2] for t in TAX]
nchar = [t[1] for t in TAX]
bars = axR.bar(labels, ntok, color=[COL_INDIGO_400, COL_ACCENT], width=0.5, zorder=3)
apply_style(axR)
axR.set_ylabel("BPE token sayısı")
axR.set_title("Token vergisi — aynı anlam, farklı maliyet", color=COL_TEXT)
for b, nt, nc in zip(bars, ntok, nchar):
axR.text(b.get_x() + b.get_width()/2, nt + 0.6, f"{nt} token\n({nc} karakter)", ha="center", va="bottom",
color=COL_TEXT, fontsize=9.5, weight="bold")
axR.set_ylim(0, max(ntok) * 1.25)
plt.tight_layout()
plt.show()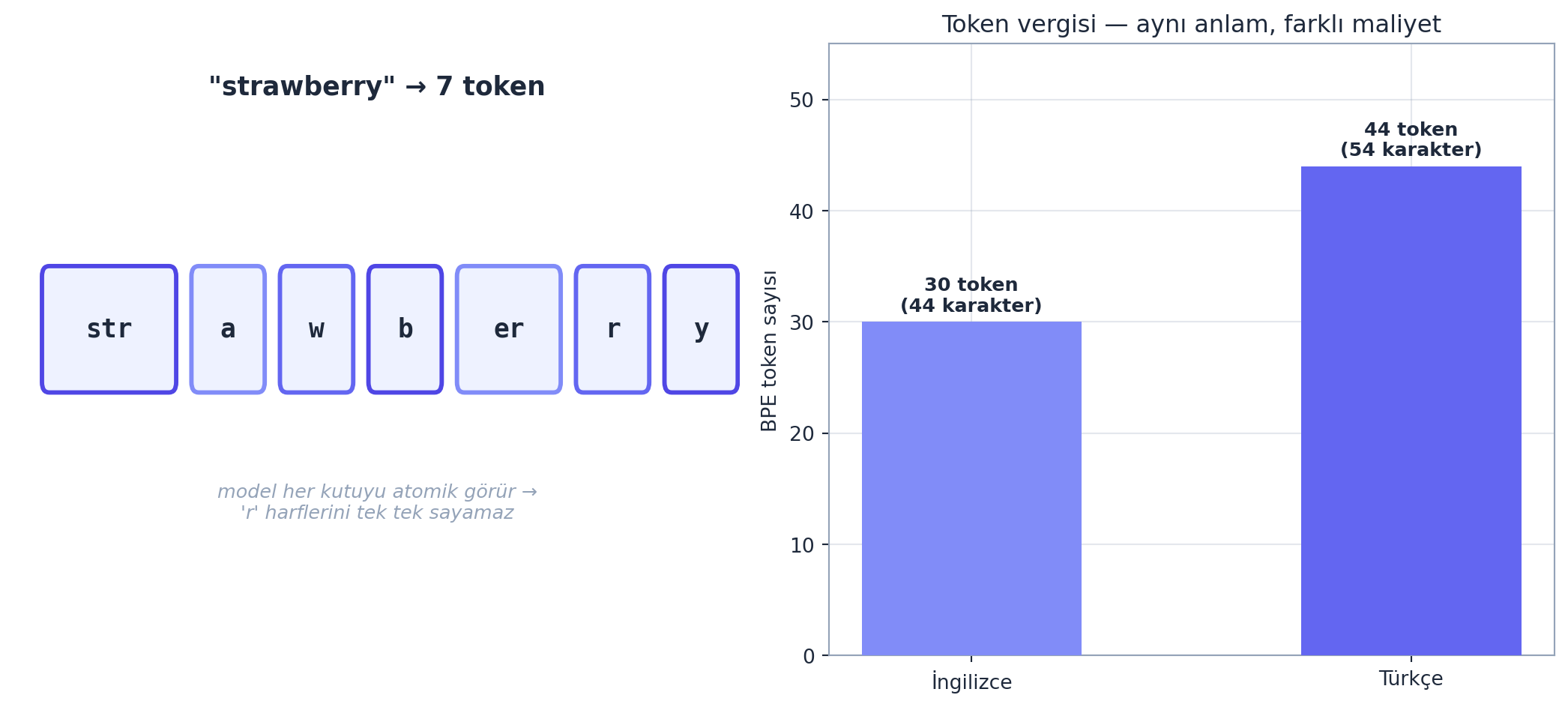
Karpathy’nin önerisi: mümkünse hazır, iyi-test edilmiş bir tokenizer (tiktoken cl100k) kullan; kendi eğiteceksen sentencepiece’i dikkatle ayarla. Ve tokenizasyonu bir gün ortadan kaldırmayı diler:
“Eternal glory goes to anyone who can get rid of it.” — Karpathy, 2:10:21
İpucuBuilder Notu — Debug Çantasının İlk Maddesi
İleriye: Bu tuhaflıklar, bir LLM uygulamacısının debug çantasının ilk maddesi: “model neden bunu yapamıyor” → önce tokenization’a bak. SolidGoldMagikarp türü açıklar, güvenlik (adversarial token) açısından da önemli.
10.15 Bu Dersin Özeti
- Tokenizer, metni ağa girmeden önce token’lara bölen, ağ-dışı bir ön-işleme adımıdır (autograd yok). LLM tuhaflıklarının çoğu buradan doğar.
- Unicode → UTF-8 byte: metni \(256\)-byte tabanına çevir (her dil/karakter temsil edilebilir); ama byte dizileri uzun.
- BPE: en sık ardışık çifti bul, yeni token’a birleştir, tekrarla — sözlüğü büyüt, diziyi kısalt (sıkıştırma; bizde \(15.000\) byte → \(6.927\) token, \(\approx 2{,}17\times\)).
- İmplementasyon:
get_stats(çiftleri say) +merge(çifti değiştir) + eğitim döngüsü;mergessözlüğü tokenizer’ın modelidir. - encode/decode: metin → byte → açgözlü merge; id → byte → UTF-8 (
errors='replace'); kayıpsız roundtrip. - GPT-2 regex split: metni kategorilere böl (harf/sayı/noktalama/boşluk ayrı) ki birleştirmeler sınır aşmasın (
\p{L},\p{N}→regexmodülü). - tiktoken (GPT-2/GPT-4, cl100k_base) vs sentencepiece (Llama 2, byte_fallback); özel token’lar (
<|endoftext|>, FIM, chat) model cerrahisiyle eklenir. - Vocab size bir denge (kısa dizi vs büyük tablo/seyrek token); multimodal tokenization (Sora görsel yamalar) aynı fikrin uzantısı.
- Tuhaflıklar: yazım/sayma, trailing whitespace, SolidGoldMagikarp, İngilizce-dışı maliyet — hepsi tokenization kökenli.
ÖnemliTek Bir Cümle
Tokenizer, metni ağ-dışı bir adımda öğrenilmiş alt-kelime parçalarına (token) bölen bir ön-işlemedir; BPE bu sözlüğü UTF-8 byte’larından en sık çiftleri birleştirerek kurar — ve LLM’lerin yazım/sayma/dil tuhaflıklarının çoğu, “model karakterleri değil token’ları görür” gerçeğinden doğar.
10.16 Kontrol Soruları
NotSoru 1: ‘aaabdaaabac’ dizisinde BPE’nin ilk birleştirmesi ne olur? Sonraki adım ne olabilir?
Cevap: En sık ardışık çift "aa"’dır; onu yeni bir token Z ile değiştir → "ZabdZabac". İlk birleştirme: (a, a) → Z. Sonra yeni dizide en sık çift "ab"; onu Y ile değiştir → "ZYdZYac". Her adım sözlüğü \(1\) büyütür (yeni token), diziyi kısaltır. Metinde de aynısı: en sık byte çiftleri (örn. bizim ölçümümüzde "e " \(414\) kez, "th" \(314\) kez) tek token olur — sık desenler sıkışır.
NotSoru 2: Ders 7’deki karakter tokenizer ile BPE arasındaki temel denge nedir?
Cevap: Karakter tokenizer (Ders 7): küçük sözlük (\(65\)), ama çok uzun diziler — her karakter bir token, bağlam hızla dolar. BPE: sık desenleri (alt-kelimeler) tek token yapar → çok daha kısa diziler (bizde \(15.000\) karakter → \(6.927\) token), ama sözlük büyük (\(50\)K-\(100\)K) → büyük embedding tablosu + softmax. BPE ayrıca “bilinmeyen” sorununu çözer (en kötü byte’a iner). Denge: BPE, dizi-uzunluğu ile sözlük-boyutu arasında karakterden çok daha iyi bir orta nokta bulur — bu yüzden tüm gerçek GPT’ler BPE kullanır.
NotSoru 3: Bir LLM neden ‘strawberry’ kelimesindeki ‘r’ harflerini güvenilir sayamaz?
Cevap: Model metni karakter olarak görmez — token olarak görür. “strawberry” tek tek harflere değil, birkaç token’a bölünür (bizim BPE’mizde \(7\) token: ['str','a','w','b','er','r','y']). Model bu token’ları birer atomik birim olarak işler; içlerindeki tek tek ‘r’ harflerini “göremez” (token’ın iç karakter yapısı modele şeffaf değil). Karakter-düzeyli bir işlem (sayma, ters çevirme, yazım) bu yüzden zordur. Aynı sebep: aritmetik, kafiye, anagram. Çözüm yolları: karakterleri açıkça ayır (boşlukla), veya araç kullandır.
NotSoru 4: (Builder) Sözlük büyüklüğünü (vocab size) artırmanın artıları ve eksileri nelerdir?
Cevap: Artı: Büyük sözlük → diziler kısalır (her token daha çok bilgi taşır) → aynı bağlam penceresine daha çok “metin” sığar, hesap daha verimli (bizde vocab \(256 \to 1024\)’te dizi \(15.000 \to 4.881\)). Eksi: (1) Embedding tablosu (Ders 3-7 wte) ve çıkış softmax’ı büyür → daha çok parametre + bellek; (2) her token daha az eğitim örneği görür → seyrekleşir, nadir token’lar az-eğitilmiş kalır (SolidGoldMagikarp riski); (3) çok büyük softmax yavaşlar. Bu yüzden bir orta nokta seçilir (GPT-2 \(\approx 50\)K, GPT-4 \(\approx 100\)K). Karar, model boyutu/veri/dil dağılımına bağlı bir denge — scaling kararının parçası (Ders 10).
10.17 Egzersizler
Egzersiz 1 (BPE eğitimi). get_stats ve merge’i yaz. Bir paragraf metni UTF-8 byte’larına çevir, vocab_size=276 (\(20\) birleştirme) ile BPE eğit. merges sözlüğünü incele — hangi çiftler birleşti (sık desenler: " th", "in")?
Egzersiz 2 (encode/decode roundtrip). encode ve decode’u yaz. Rastgele bir metin için decode(encode(text)) == text olduğunu doğrula (kayıpsız roundtrip). Sonra decode’a rastgele id’ler ver — errors='replace' sayesinde çökmediğini gözlemle.
Egzersiz 3 (Geçersiz byte). Geçerli UTF-8 olmayan bir byte dizisi (örn. tek başına 0x80) decode et. errors='replace' ile replacement karakteri (�) döndüğünü, errors='strict' ile hata fırlattığını karşılaştır. Bu, modelin geçersiz token üretmesine karşı neden gerekli?
Egzersiz 4 (Token vergisi). Aynı anlamı taşıyan bir İngilizce ve Türkçe cümleyi tokenize et. Türkçe’nin daha çok token’a bölündüğünü (token vergisi) say ve gözlemle. “strawberry”yi tokenize edip kaç token olduğunu, harflerin nasıl bölündüğünü gör.
Egzersiz 5 (Sonraki dersin habercisi). Artık iki büyük parçaya sahibiz: mimari (Ders 7, transformer) ve tokenizer (Ders 9, BPE). Gerçek bir GPT-2 (\(124\)M) üretmek için daha ne gerekir? (a) Ölçek (kaç parametre, kaç token), (b) gerçek veri (internet metni), (c) eğitim hızı (GPU, mixed precision), (d) eğitim teknikleri (LR schedule, gradient clipping, dağıtık eğitim). Bu sorular, Ders 10’da (GPT-2’yi Yeniden Üretmek) tüm seriyi production-ölçek tek bir modelde birleştirmeyi motive eder.
10.18 Sonraki Ders İçin Hazırlık
Ders 10: GPT-2’yi (\(124\)M) Yeniden Üretmek (nanoGPT) — Andrej Karpathy
Serinin finali. Ders 7’nin transformer’ı + Ders 9’un tokenizer’ı + Ders 8’in pipeline kavramları, gerçek bir GPT-2 124M modelinde birleşir. Karpathy OpenAI’nin GPT-2’sini sıfırdan yeniden üretir: gerçek mimari (HuggingFace ağırlıklarıyla uyumlu), production eğitim hızı (TF32/bf16/torch.compile, FlashAttention), ve ciddi eğitim altyapısı (LR schedule, gradient clipping, weight decay, gradient accumulation, dağıtık eğitim — DDP).
Ana konular:
- GPT-2
nn.Module+ HuggingFace ağırlık yükleme + weight tying. - Eğitimi hızlandırma: TF32, bfloat16, torch.compile, FlashAttention.
- Hiperparametreler, gradient clipping, LR schedule, weight decay, gradient accumulation, DDP; FineWeb-EDU verisi + HellaSwag değerlendirmesi.
UyarıDers 10 Öncesi Yapılacak
- Egzersizleri çöz — özellikle 4 (token vergisi) ve 5 (GPT-2 için ne gerekir).
- Ders 7 (transformer mimarisi) ve Ders 9 (BPE tokenizer) kodlarını hazır tut; Ders 10 ikisini birleştirir.
- Ders 4 (init/mixed precision notları), Ders 8 (scaling/pipeline) — Ders 10’un production teknikleri için zemin.
10.19 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| Tokenization önemi | LLM tuhaflıkları (yazım, sayma, dil) çoğu buradan; model token görür, karakter değil | 0m06 |
| tiktokenizer | Web aracı: metnin token’lara nasıl bölündüğünü görselleştirir | 5m49 |
| Unicode / UTF-8 byte | Metin → kod noktaları → UTF-8 byte (\(256\) taban); tokenizer’ın ham girdisi | 14m56 |
| BPE algoritması | En sık ardışık çifti yeni token’a birleştir, tekrarla; sözlük büyür, dizi kısalır | 23m49 |
| get_stats + merge | Çiftleri say + en sık çifti yeni id ile değiştir; merges sözlüğü = tokenizer modeli |
26m56 |
| encode / decode | metin → byte → açgözlü merge; id → byte → UTF-8 (errors='replace') |
39m20 |
| GPT-2 regex split | Metni kategorilere böl (harf/sayı/noktalama/boşluk); birleştirmeler sınır aşmaz | 57m35 |
| tiktoken (cl100k) | OpenAI GPT-2/GPT-4 tokenizer’ı; encode/decode (eğitim yok), Rust-hızlı | 1h11m |
| Özel token’lar | endoftext, FIM, sohbet sınırları; elle eklenir (model cerrahisi) | 1h18m |
| minbpe / sentencepiece | minbpe (byte-level BPE); sentencepiece (Llama 2, code-point + byte_fallback) | 1h25m |
| Vocab size dengesi | Büyük: kısa dizi ama büyük tablo/seyrek; küçük: tersine (GPT-2 \(\approx 50\)K, GPT-4 \(\approx 100\)K) | 2h23m |
| Tokenization tuhaflıkları | strawberry sayma, trailing whitespace, SolidGoldMagikarp, İngilizce-dışı maliyet | 2h31m |
10.20 ML Builder Bağlantıları
İpucu8 köprü — Tokenizer
- Tokenizer = ağ-dışı adım → Ders 7 naif char tokenizer’ın gerçek hâli. İleriye: GPT-2 tokenizer (Ders 10).
- Unicode/UTF-8 byte → temel veri temsili. İleriye: byte-level BPE, çok dilli evrensellik + token vergisi.
- BPE (get_stats) → Ders 2 bigram sayımının çift-birleştirme amaçlı kullanımı. İleriye: tiktoken/sentencepiece production.
- encode/decode + merges → Ders 2 s2i/i2s’in BPE karşılığı. İleriye:
errors='replace'(geçersiz byte dayanıklılığı). - GPT-2 regex → kategori-bilinçli bölme. İleriye: aritmetik/kod/dil davranışının kökeni.
- Özel token’lar → Ders 8 pretraining (endoftext) + asistan formatı (sohbet token’ları). İleriye: chat template, FIM, tool işaretçileri.
- Vocab size → embedding tablosu (Ders 3-7
wte) + softmax boyutu dengesi. İleriye: scaling kararı (Ders 10). - Tokenization tuhaflıkları → “model token görür” gerçeği. İleriye: LLM debug çantasının ilk maddesi; adversarial token güvenliği.
10.21 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders için verdiği kaynaklar:
- minbpe repo: github.com/karpathy/minbpe — dersin kodu + adım adım egzersiz.
- tiktokenizer (web): tiktokenizer.vercel.app — token görselleştirme aracı.
- tiktoken: github.com/openai/tiktoken — OpenAI BPE kütüphanesi.
- sentencepiece: github.com/google/sentencepiece — Google tokenizer (Llama 2).
ÖnemliBu dersten tek bir şey alıp gideceksen
Tokenizer, metni ağa girmeden önce öğrenilmiş alt-kelime parçalarına (token) bölen, ağ-dışı bir ön-işleme adımıdır — BPE bu sözlüğü UTF-8 byte’larından en sık çiftleri birleştirerek kurar. Ve LLM’lerin yazım/sayma/dil tuhaflıklarının çoğu tek bir gerçekten doğar: model karakterleri değil, token’ları görür.