flowchart LR
A["names.txt<br/>32033 isim"] --> B["Bigram'ları say<br/>27×27 tensör N"]
B --> C["Normalize<br/>P = N / satır toplamı"]
C --> D["torch.multinomial<br/>isim örnekle"]
B --> E["one-hot girdi<br/>xenc = F.one_hot(xs)"]
E --> F["xenc @ W<br/>logits = log-counts"]
F --> G["softmax<br/>exp + normalize"]
G --> H["NLL + gradient descent<br/>aynı modele yakınsar"]
C -.eşdeğer.-> H
style C fill:#f1f5f9,stroke:#475569,stroke-width:2px
style G fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style H fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
3 makemore 1 — Bigram Karakter Dil Modeli
Aynı modeli iki kez kur: önce bigram’ları say-normalize et, sonra birebir aynısını tek katmanlı bir sinir ağı olarak softmax + gradient descent ile eğit
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — The spelled-out intro to language modeling: building makemore (≈118 dk)
- Seri: Neural Networks: Zero to Hero — Ders 2
- Hoca: Andrej Karpathy
- Kaynak repo: github.com/karpathy/makemore
- Okuma süresi: ≈32 dk
3.1 Bu Derste Ne Var?
Ders 1’de skaler bir sinir ağını (micrograd) elle eğittik. Bu derste makemore projesine geçiyoruz: 32 binden fazla gerçek ismi (names.txt) öğrenip yeni, isme-benzer diziler üreten bir karakter-düzeyli dil modeli. Karpathy serinin geri kalanını da haber veriyor: bigram’dan başlayıp adım adım GPT-2 eşdeğeri bir transformer’a kadar tırmanacağız.
“Like micrograd before it, makemore is a repository that I have on my GitHub webpage. Just like with micrograd, I’m going to build it out step by step and I’m going to spell everything out.” — Karpathy, 0:06
Dersin büyük fikri şu: aynı modeli iki kez kuracağız. Önce saf sayımla (her karakter çiftinin kaç kez geçtiğini sayarak), sonra birebir aynı modeli tek katmanlı bir sinir ağı olarak (gradient descent ile eğitilen). İkisinin aynı sonucu vermesi, Ders 1’deki mekaniğin gerçek bir probleme nasıl oturduğunu gösterir.
Dersin üç büyük fikri:
- Bigram dil modeli — bir sonraki karakteri yalnızca önceki tek karaktere bakarak tahmin etmek; sayım + normalize ile bir olasılık tablosu kurmak.
- Negatif log olabilirlik (NLL) — modelin ne kadar iyi olduğunu ölçen tek sayı; Ders 1’deki MSE’nin dil modeli karşılığı.
- Aynı model = tek katmanlı sinir ağı — one-hot girdi,
xenc @ W, softmax, sonra Ders 1’deki forward/backward/update döngüsüyle eğitim.
İpucuBuilder Notu — İki Yol, Tek Model
Geriye (Ders 1 + Stat 110):
- Sayım → olasılık = Stat 110. Bigram sıklıklarını toplayıp normalize etmek, frekanstan olasılığa geçiştir; NLL’i minimize etmek maximum likelihood’dur (Stat 110, MLE).
- Eğitim döngüsü = Ders 1 micrograd. Bu dersin sinir ağı kısmı, micrograd’da gördüğümüz
forward → backward → updatedöngüsünün birebir aynısı; Karpathy bunu derste micrograd notebook’unu açarak gösterir. - MSE → NLL. Ders 1’de regresyon için MSE kullandık; burada çıktı bir olasılık dağılımı olduğu için kayıp NLL olur (sınıflandırmanın doğal kaybı).
İleriye: Bu bigram yalnızca tek karaktere bakıyor — bağlam yok. Ders 3’te embedding tablosu + MLP ile birkaç karakterlik bağlam ekleyeceğiz; sonunda transformer (Ders 7) ile uzun bağlam. Ama çerçeve hep aynı: “bir sonraki token’ı tahmin et, NLL’i düşür”. torch.multinomial, broadcasting, softmax burada öğreneceğin ve tüm seri boyunca kullanacağın production araçları.
Tek cümleyle: Bir dil modeli, “bir sonraki karakterin olasılık dağılımını” üreten bir fonksiyondur; bigram bunu en basit hâliyle (tek karakter bağlamı) yapar ve ister say, ister gradient descent ile eğit — aynı modele ulaşırsın.
3.2 makemore Nedir? Veri Seti
makemore, adının söylediğini yapar: kendisine verilen şeylerden daha fazlasını üretir. Bu derste girdi names.txt — 32 binden fazla gerçek isim (emma, olivia, ava, …). Model bu isimleri “öğrenip” yeni, isme-benzer ama var olmayan diziler üretecek.
Karakter-düzeyli bir model kuruyoruz: İsmi bir karakter dizisi olarak görür, bir sonraki karakteri bir öncekilerden tahmin eder. Önce veriyi yükleyip tanıyalım.
words = open('names.txt', 'r').read().splitlines()
len(words) # 32033
min(len(w) for w in words) # 2 (en kisa isim)
max(len(w) for w in words) # 15 (en uzun isim)
words[:3] # ['emma', 'olivia', 'ava']Kritik sezgi: tek bir “emma” kelimesi bile bir sürü eğitim örneği taşır. “e’den sonra m gelir”, “m’den sonra m gelir”, “m’den sonra a gelir”, artı ismin nerede başlayıp nerede bittiği bilgisi. Bir karakter-düzeyli model, kelimeyi bu küçük “şu karakterden sonra şu gelir” kararlarına böler.
İpucuBuilder Notu — Diziyi Tahmin Problemine Çevirmek
İleriye: Bu “bir diziyi, bir sonraki öğeyi tahmin etme problemine çevirme” fikri, tüm dil modellemenin temelidir — GPT de tam olarak bunu yapar, yalnızca karakter yerine token ve tek karakter bağlamı yerine binlerce token bağlamıyla (Ders 9: tokenizer, Ders 7/10: GPT). 32033 isim küçük görünür ama yüz binlerce bigram örneği taşır; veri bolluğu, sayım yerine öğrenmeye geçince anlam kazanır.
3.3 Bigram’ları Saymak
Bigram, ardışık iki karakterdir. Bigram modeli son derece zayıftır: yalnızca tek önceki karaktere bakar, ondan öncesini unutur. Ama başlamak için mükemmel.
Her kelimedeki ardışık çiftleri zip(w, w[1:]) ile gezeriz. Bir de ismin başını ve sonunu işaretlemek gerek; Karpathy önce ayrı <S> / <E> token’ları kullanır, sonra ikisini tek bir nokta token’ına (.) sadeleştirir. Çiftleri bir Python sözlüğünde sayarız:
b = {}
for w in words:
chs = ['.'] + list(w) + ['.'] # basla/bitir token'i
for ch1, ch2 in zip(chs, chs[1:]): # ardisik ciftler
bigram = (ch1, ch2)
b[bigram] = b.get(bigram, 0) + 1 # say
# en sik bigram'lar
sorted(b.items(), key=lambda kv: -kv[1])[:3]b.get(bigram, 0) + 1 deyimi önemli: sözlükte yoksa varsayılan 0 döner, varsa mevcut sayıyı alır — böylece her çifti güvenle artırırız. Sonuç: hangi karakter çiftinin kaç kez geçtiğini gösteren bir tablo. Bir sonraki adımda bunu bir sözlük yerine bir tensöre taşıyacağız — çünkü tensör hem hızlı hem de PyTorch’un tüm gücünü açar.
İpucuBuilder Notu — Sayım Neden Ölçeklenmez
İleriye: Sayım, bir modeli eğitmenin en sade yoludur — “veriden istatistik çıkar”. Ama ölçeklenmez: bigram (tek karakter) için \(27 \times 27\) tablo yeter, ama iki karakter bağlamı \(27 \times 27 \times 27\), on karakter için astronomik olur. Bu yüzden Ders 3’ten itibaren sayım yerine öğrenilen parametreler (sinir ağı) kullanılır. Bu sayım-patlaması, dersin sonundaki Egzersiz 5’in tam çekirdeği.
3.4 Sayımları 2B Tensöre: N ve s2i / i2s
Python sözlüğü yerine sayımları bir 2 boyutlu tensörde tutalım. 27 karakter var (26 harf + nokta token’ı), yani \(27 \times 27\)’lik bir tamsayı tensörü N: satır = ilk karakter, kolon = ikinci karakter, hücre = o çiftin sayısı.
Önce karakterleri tamsayıya çeviren bir arama tablosu gerekir (s2i = string-to-integer) ve tersi (i2s). Karpathy noktayı (.) 0 indeksine, harfleri 1-26’ya yerleştirir:
import torch
chars = sorted(list(set(''.join(words)))) # a..z
s2i = {ch: i + 1 for i, ch in enumerate(chars)} # a->1 .. z->26
s2i['.'] = 0 # nokta -> 0
i2s = {i: ch for ch, i in s2i.items()} # ters tablo
N = torch.zeros((27, 27), dtype=torch.int32)
for w in words:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
N[s2i[ch1], s2i[ch2]] += 1 # ilgili hucreyi artirArtık tüm bigram istatistiği tek bir tensörde. dtype=torch.int32 ile tamsayı tutuyoruz (sayımlar tam sayı). Bir sonraki adımda bu sayımları olasılığa çevirip örnekleme yapacağız.
İpucuBuilder Notu — N Bir Matris, s2i Bir Tokenizer
Geriye (18.06): N bir matristir; satır/kolon indeksleme tam olarak lineer cebirdeki matris elemanı erişimidir. Birazdan bu matrisi satır-satır normalize edip her satırı bir olasılık dağılımına çevireceğiz.
İleriye: s2i / i2s arama tabloları, her dil modelinin tokenizer’ının çekirdeğidir — karakter/token ile tamsayı id arasındaki çeviri (Ders 9’da bunun gerçek, byte-pair encoding hâlini kuracağız).
3.5 Görselleştirme ve Tek ‘.’ Token
Karpathy matplotlib ile N’i etiketli bir ızgara olarak çizer — her hücrede bigram ve sayısı görünür. Görselleştirme, modelin ne öğrendiğini gözle görmeyi sağlar: örneğin satır . (başlangıç) en çok hangi harfle başlandığını, kolon . ise isimlerin en çok hangi harfle bittiğini gösterir.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
torch.manual_seed(SEED) # determinizm (figür yalnız sayıma dayanır; rastgelelik yok)
# Slate -> Indigo özel colormap: düşük sayım açık slate (COL_BG),
# yüksek sayım indigo (COL_ACCENT). apply_style KULLANILMAZ (imshow).
cmap_bigram = LinearSegmentedColormap.from_list("slate_indigo", [COL_BG, COL_ACCENT])
fig, ax = plt.subplots(figsize=(11, 11))
fig.patch.set_facecolor(COL_WHITE)
Nnp = N.numpy() # 27x27 int sayım matrisi
ax.imshow(Nnp, cmap=cmap_bigram)
# Her hücreye iki satır metin: üstte bigram etiketi (i2s[i]+i2s[j], '.' dahil),
# altta sayı (N[i,j]). Arka plan koyulaştıkça metin beyaza döner (kontrast).
vmax = Nnp.max()
for i in range(VOCAB):
for j in range(VOCAB):
bigram = i2s[i] + i2s[j]
sayi = int(Nnp[i, j])
txt_col = COL_WHITE if Nnp[i, j] > vmax * 0.5 else COL_TEXT
ax.text(j, i, bigram, ha="center", va="bottom", fontsize=6, color=txt_col)
ax.text(j, i, str(sayi), ha="center", va="top", fontsize=6, color=txt_col)
# Eksen tick'leri yok — hücre içi etiketler kullanılır.
ax.set_xticks([])
ax.set_yticks([])
ax.set_title(
"27×27 bigram sayım matrisi N — satır = mevcut karakter, kolon = sonraki",
color=COL_TEXT, fontsize=13, pad=12,
)
plt.tight_layout()
plt.show()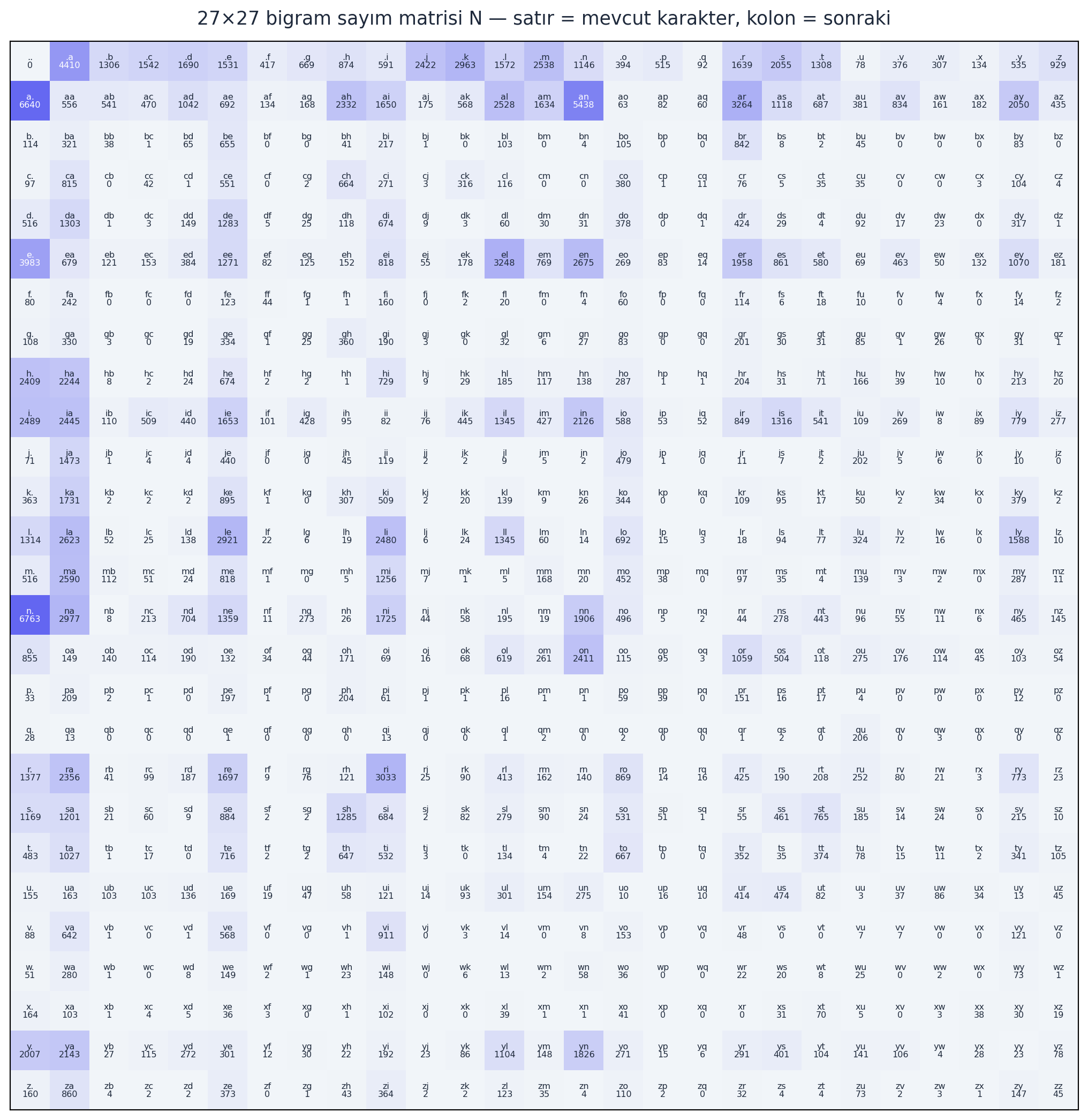
em), altta o çiftin sayısı. Renk Slate→Indigo: açık = az, indigo = çok. 0. satır (.) isimlerin hangi harfle başladığını, 0. kolon (.) hangi harfle bittiğini gösterir.
Başlangıçta ayrı <S> ve <E> token’ları kullanmak iki sorun yaratır: tablo gereksiz büyür ve bazı satır/kolonlar hep sıfır kalır. Çözüm: tek bir . token’ı hem başlangıç hem bitiş için (indeks 0). Bu, tabloyu temiz \(27 \times 27\)’ye indirir.
İpucuBuilder Notu — Modeli Görselleştir
İleriye: “Modeli görselleştir, ne öğrendiğine bak” alışkanlığı production’da kritiktir — attention matrisleri, embedding uzayları, aktivasyon istatistikleri hep görselleştirilir (Ders 4’te aktivasyon/gradyan histogramları, Ders 7’de attention desenleri). Yukarıdaki ısı haritası, bir modeli “okumanın” en sade hâli: koyu hücreler sık geçişler, açık hücreler nadir veya hiç görülmemiş çiftler.
3.6 Olasılığa Çevirip Örnekleme
Modelden isim üretmek için: bir karakterden başla (.), o satırın sayımlarını olasılığa çevir, bu dağılımdan bir sonraki karakteri çek, tekrarla — ta ki . (bitiş) gelene dek.
Bir satırı olasılığa çevirmek = sayıları toplamlarına bölmek (normalize). Sonra torch.multinomial ile bu dağılımdan örnek çekeriz. Tekrarlanabilirlik için tohumlu bir torch.Generator kullanılır.
“To sample from these distributions we’re going to use torch.multinomial.” — Karpathy, 26:29
g = torch.Generator().manual_seed(2147483647) # tohumlu -> tekrarlanabilir
for _ in range(5):
out = []
ix = 0 # '.' ile basla
while True:
p = N[ix].float()
p = p / p.sum() # satiri olasiliga cevir (normalize)
ix = torch.multinomial(p, num_samples=1, replacement=True,
generator=g).item()
if ix == 0: # '.' bitis -> dur
break
out.append(i2s[ix])
print(''.join(out))Aşağıda, sayım modeliyle (P) üretilen isimleri, her satırı eşit (\(1/27\)) olan bir uniform modelin ürettikleriyle yan yana koyuyoruz — aynı tohum, aynı örnekleme.
Kod
import torch
import matplotlib.pyplot as plt
# Determinizm: aynı tohumla aynı örnekler (Karpathy'nin meşhur tohumu).
torch.manual_seed(SEED)
# Sol panel: bigram SAYIM modeli (P) ile 8 isim.
count_isimler = sample_names(P, n=8, seed=SEED)
# Sağ panel: UNIFORM model (her satır 1/27 eşit) ile 8 isim.
P_uniform = torch.full((VOCAB, VOCAB), 1.0 / VOCAB)
uniform_isimler = sample_names(P_uniform, n=8, seed=SEED)
# Loss kıyası: sayım modeli ölçülebilir biçimde uniform'dan daha iyi.
count_nll = count_model_nll(P) # ~2.45
uniform_nll = count_model_nll(P_uniform) # ~3.30 = log(27)
fig, ax = plt.subplots(figsize=(10, 5))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
ax.axis("off")
# Üst başlık: NLL kıyası (sayım vs uniform).
ax.set_title(
f"Sayım modeli (NLL = {count_nll:.2f}) vs uniform model (NLL = {uniform_nll:.2f})\n"
"aynı tohum, aynı örnekleme; bigram uniform'dan ölçülebilir biçimde iyi",
fontsize=12, color=COL_TEXT, pad=14,
)
# İki sütun: sol = sayım modeli (indigo vurgulu metin), sağ = uniform (soluk slate).
sutun_x = [0.25, 0.75]
basliklar = [
f"Sayım modeli · NLL = {count_nll:.2f}",
f"Uniform model · NLL = {uniform_nll:.2f}",
]
baslik_renk = [COL_INDIGO_600, COL_SLATE_400]
isim_renk = [COL_TEXT, COL_SLATE_400]
listeler = [count_isimler, uniform_isimler]
for sx, baslik, brenk, irenk, isimler in zip(
sutun_x, basliklar, baslik_renk, isim_renk, listeler
):
# Sütun başlığı
ax.text(sx, 0.92, baslik, ha="center", va="top",
fontsize=12, color=brenk, weight="bold",
transform=ax.transAxes)
# İsim listesi (tek tek, eşit dikey aralık).
# Uniform model çok uzun çöp diziler üretebilir; panele sığması için kırp.
y = 0.80
for isim in isimler:
gosterim = isim if isim else "(boş)"
if len(gosterim) > 22:
gosterim = gosterim[:21] + "…"
ax.text(sx, y, gosterim, ha="center", va="top",
fontsize=13, color=irenk, family="monospace",
transform=ax.transAxes)
y -= 0.085
# Sütunları ayıran ince slate çizgi
ax.axvline(0.5, color=COL_SLATE_400, linewidth=1.0, alpha=0.5)
# Alt not: düşük NLL = daha iyi model (sezgi köprüsü).
ax.text(0.5, 0.04,
f"Daha düşük NLL = daha iyi model (uniform NLL = log(27) ≈ {uniform_nll:.2f})",
ha="center", va="bottom", fontsize=10, color=COL_PRIMARY,
style="italic", transform=ax.transAxes)
plt.tight_layout()
plt.show()
Üretilen isimler korkunç görünür (“cexze”, “ka”, …) — ama Karpathy önemli bir noktayı vurgular: bu model rastgele (uniform) bir modelden ölçülebilir biçimde daha iyidir. Sayım modelinin ortalama NLL’i ≈2,45, uniform modelinki \(\log 27 \approx 3{,}30\); bigram bile veriden bir şey öğrenmiştir; sadece tek karakter bağlamı çok zayıf olduğu için sonuç zayıf.
İpucuBuilder Notu — Dağılımdan Örnekle
Geriye (Stat 110): torch.multinomial, bir olasılık dağılımından örnek çeker — Stat 110’daki multinomial/kategorik örneklemenin ta kendisi. Tohumlu Generator ise determinizm için (aynı tohum = aynı sonuç), production’da reproducibility’nin temeli.
İleriye: “Bir olasılık dağılımı üret, ondan örnekle” döngüsü, her üretken modelin (GPT dahil) çekirdeğidir. GPT de her adımda bir sonraki token için dağılım üretip ondan örnekler (sampling, temperature, top-k — hepsi bu multinomial adımının varyasyonları).
3.7 Vektörel Normalizasyon ve Broadcasting
Her örnekte satırı tek tek normalize etmek yavaş. Bunun yerine tüm satırları bir kerede normalize edip bir olasılık matrisi P önceden hesaplarız. İşte burada PyTorch’un broadcasting (yayım) kuralları devreye girer — ve Karpathy en sık yapılan hatayı kasten gösterir.
P = N.float()
P = P / P.sum(1, keepdim=True) # her satiri kendi toplamina bolİncelik keepdim argümanında. N.sum(1) satır toplamlarını verir ama şekli (27,) — bu, broadcasting’de bir satır vektörü gibi hizalanır ve yanlışlıkla her kolonu böler. N.sum(1, keepdim=True) ise şekli (27, 1) tutar — bu, her satır boyunca yayılır ve doğru olanı (satır normalizasyonu) yapar.
“I’ll be honest with you, this doesn’t look right, so I spent a few minutes to convince myself that it actually is right.” — Karpathy, 34:14
Aşağıdaki figür ikisini yan yana koyuyor: keepdim=True ile satır toplamları tam \(1\) (doğru), keepdim=False ile satır toplamları \(1\) değil (yanlış — kod hata fırlatmadan sessizce yanlış eksende böler).
Kod
import torch
import matplotlib.pyplot as plt
# §6 broadcasting tuzağı: aynı sayım tensörü N, iki farklı normalizasyon.
# DOĞRU : keepdim=True -> bölen (27,1) -> her SATIR kendi toplamına bölünür.
# YANLIŞ : keepdim=False -> bölen (27,) -> vektör KOLONLARA hizalanır (sessiz bug).
torch.manual_seed(2147483647) # determinizm (figür rastgelelik kullanmaz; ilke gereği sabit)
Nf = N.float()
# DOĞRU normalizasyon: bölen şekli (27, 1)
P_dogru = Nf / Nf.sum(1, keepdim=True)
# YANLIŞ normalizasyon: bölen şekli (27,)
P_yanlis = Nf / Nf.sum(1)
# İlk 6 satırın gerçek satır toplamları (.sum(1))
k = 6
satir_top_dogru = P_dogru.sum(1)[:k].tolist()
satir_top_yanlis = P_yanlis.sum(1)[:k].tolist()
# Satır etiketleri: ilgili satırın başlangıç karakteri (i2s)
satir_etiket = [f"'{i2s[i]}'" for i in range(k)]
x = list(range(k))
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11, 5))
# --- SOL panel: DOĞRU (keepdim=True) ---
apply_style(ax_l)
ax_l.bar(x, satir_top_dogru, color=COL_PRIMARY, width=0.62,
edgecolor=COL_WHITE, linewidth=1.0, zorder=3)
ax_l.axhline(1.0, color=COL_ACCENT, linewidth=2.2, linestyle="--", zorder=4,
label="referans $y = 1$")
ax_l.set_title("DOĞRU — bölen $(27, 1)$ → satır normalizasyonu",
fontsize=12, color=COL_TEXT)
ax_l.set_xlabel("satır (başlangıç karakteri)", fontsize=11)
ax_l.set_ylabel("satır toplamı $\\sum_j P[i, j]$", fontsize=11)
ax_l.set_xticks(x)
ax_l.set_xticklabels(satir_etiket)
ax_l.set_ylim(0, 1.25)
ax_l.legend(loc="upper right", fontsize=9.5, framealpha=0.95)
for xi, yi in zip(x, satir_top_dogru):
ax_l.text(xi, yi + 0.03, f"{yi:.2f}", ha="center", va="bottom",
fontsize=9, color=COL_TEXT, weight="bold", zorder=5)
# --- SAĞ panel: YANLIŞ (keepdim=False) ---
apply_style(ax_r)
ax_r.bar(x, satir_top_yanlis, color=COL_INDIGO_400, width=0.62,
edgecolor=COL_WHITE, linewidth=1.0, zorder=3)
ax_r.axhline(1.0, color=COL_ACCENT, linewidth=2.2, linestyle="--", zorder=4,
label="hedef $y = 1$ (tutmaz)")
ax_r.set_title("YANLIŞ — bölen $(27,)$ → kolon böler",
fontsize=12, color=COL_TEXT)
ax_r.set_xlabel("satır (başlangıç karakteri)", fontsize=11)
ax_r.set_ylabel("satır toplamı $\\sum_j P[i, j]$", fontsize=11)
ax_r.set_xticks(x)
ax_r.set_xticklabels(satir_etiket)
ymax = max(satir_top_yanlis) * 1.18
ax_r.set_ylim(0, ymax)
ax_r.legend(loc="upper right", fontsize=9.5, framealpha=0.95)
for xi, yi in zip(x, satir_top_yanlis):
ax_r.text(xi, yi + ymax * 0.018, f"{yi:.2f}", ha="center", va="bottom",
fontsize=9, color=COL_TEXT, weight="bold", zorder=5)
# Tüm veri min/max notu (sessiz buga dikkat — hata fırlatmaz, kod çalışır)
tum_min = P_yanlis.sum(1).min().item()
tum_max = P_yanlis.sum(1).max().item()
ax_r.text(0.03, 0.97,
"tüm satırlar:\n"
f"min $= {tum_min:.4f}$\n"
f"max $= {tum_max:.4f}$",
transform=ax_r.transAxes, ha="left", va="top", fontsize=9.5,
color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG,
ec=COL_INDIGO_600, lw=1.3))
fig.suptitle("`keepdim=True` (DOĞRU) vs `keepdim=False` (YANLIŞ): satır toplamları 1 mi?",
fontsize=12.5, color=COL_TEXT, y=1.01)
plt.tight_layout()
plt.show()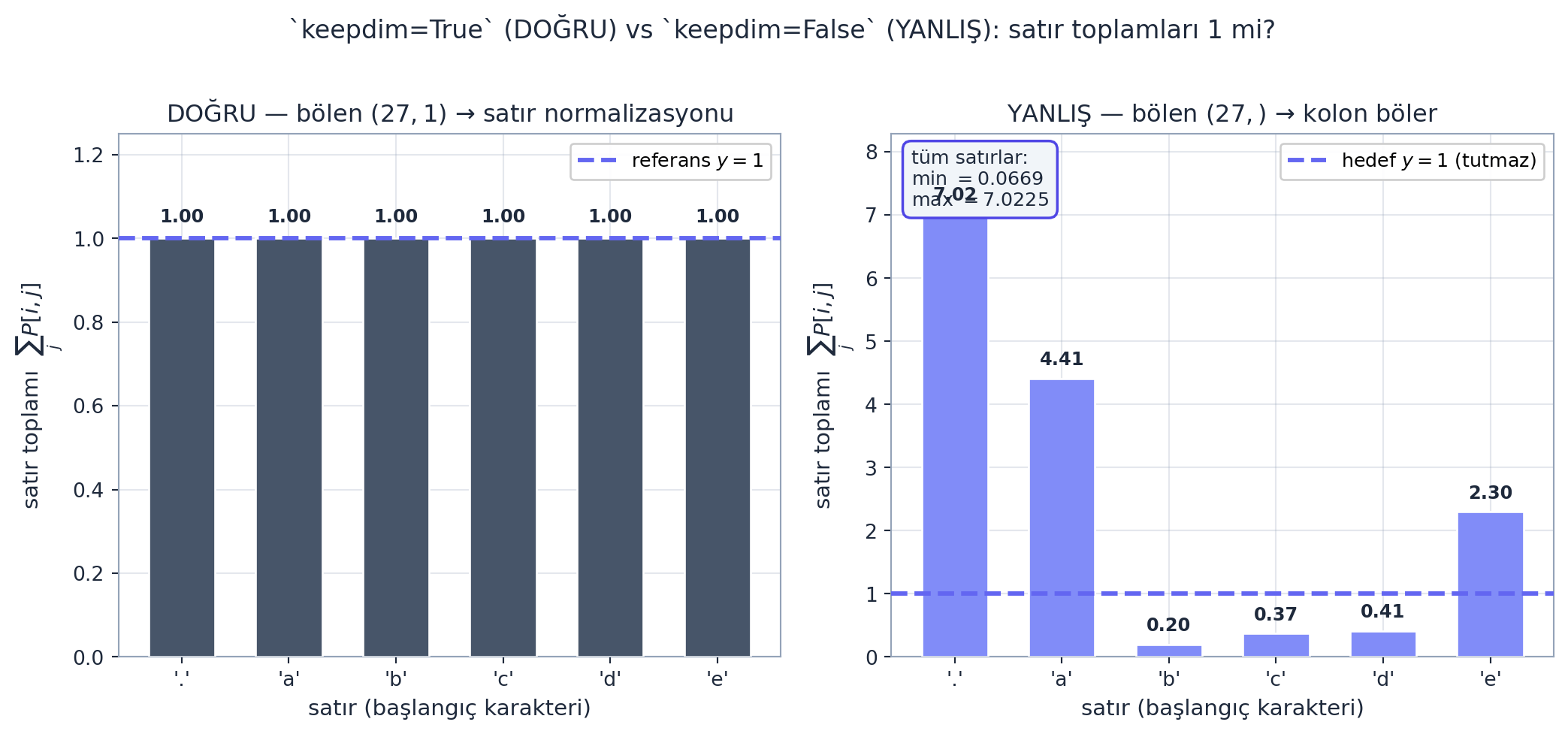
keepdim=True bölen şekli \((27, 1)\) — her satır kendi toplamına bölünür, satır toplamları tam \(1\) (DOĞRU); sağda keepdim=False bölen şekli \((27,)\) — vektör kolonlara hizalanır, satır toplamları \(1\) değil (YANLIŞ; \(\min/\max = 0{,}0669/7{,}0225\)). İlk altı satırın .sum(1) değerleri bar olarak; indigo yatay çizgi \(y=1\) referansı.
Karpathy broadcasting’e saygı duyulması gerektiğini özellikle vurgular; sessizce yanlış sonuç veren ama hata fırlatmayan bu tür buglar en tehlikelisidir:
“Now I would like to scare you a little bit… I encourage you to treat this with respect, and it’s not something to play fast and loose with.” — Karpathy, 44:19
İpucuBuilder Notu — Sessiz Şekil Hataları
İleriye: Broadcasting, tüm tensör kodunun (NumPy, PyTorch, JAX) temelidir ve sessiz hata kaynağı bir numara: şekiller “uyduğu” için kod çalışır ama yanlış eksende işlem yapar. Kural: kritik işlemlerden sonra .shape yazdır (Ders 1’deki print(x.shape) debug alışkanlığı). Bu bug sınıfı production’da modelinizi sessizce bozabilir — yukarıdaki sağ panelde satır toplamları \(0{,}0669\) ile \(7{,}0225\) arasında savrulur, yani hiçbiri olasılık dağılımı değildir.
3.8 Loss: Negatif Log Olabilirlik (NLL)
Model “iyi mi”? Tek bir sayıya ihtiyacımız var. Sezgi: iyi bir model, veride gerçekten görülen bigram’lara yüksek olasılık atamalı. Tüm bu olasılıkların çarpımı (likelihood) modelin veriyi ne kadar iyi açıkladığını ölçer — ama çarpım çok küçük sayılara iner, bu yüzden logaritmasını alırız (çarpım → toplam):
\[ \text{likelihood} = \prod_{i} P(x_i), \qquad \log(\text{likelihood}) = \sum_{i} \log P(x_i) \]
Loss’u “düşük = iyi” yapmak için negatifini alır ve örnek sayısına böleriz — ortalama negatif log olabilirlik:
\[ \text{NLL} = -\frac{1}{n} \sum_{i} \log P(x_i) \]
“The loss function: the negative log likelihood of the data under our model.” — Karpathy, 50:09
Aşağıdaki figür sezgiyi somutlaştırır: yüksek olasılıklı bir bigram düşük \(-\log P\) (düşük kayıp) verir; nadir bir çift çok yüksek kayıp verir.
Kod
import torch
import numpy as np
import matplotlib.pyplot as plt
# Olasılık matrisi P (satır-normalize, keepdim=True) — L2 çekirdeğinden.
P = make_P(N)
# Üç tipik bigram + bir nadir çift. Nadir çift 'h->q' veride YALNIZCA 1 kez
# geçer (count=1): çok küçük olasılık -> çok yüksek -log P (yüksek loss).
ciftler = [(".", "a"), ("a", "n"), ("n", "."), ("h", "q")]
etiketler = [f"{a}→{b}" for a, b in ciftler] # . -> a vb.
probs = np.array([P[s2i[a], s2i[b]].item() for a, b in ciftler])
nll = -np.log(probs) # -log P = o çiftin loss'u
# Tüm veri üzerinde sayım modelinin ortalama NLL'i (vurgu metni ~2.45).
ort_nll = count_model_nll(P)
x = np.arange(len(ciftler))
fig, (ax_p, ax_n) = plt.subplots(1, 2, figsize=(9, 5))
# --- Sol panel: olasılık (slate, COL_PRIMARY) ---
apply_style(ax_p)
ax_p.bar(x, probs, color=COL_PRIMARY, edgecolor=COL_WHITE, linewidth=0.6, zorder=3)
ax_p.set_xticks(x)
ax_p.set_xticklabels(etiketler, fontsize=11)
ax_p.set_ylabel("olasılık $P(\\mathrm{ch2} \\mid \\mathrm{ch1})$", fontsize=11)
ax_p.set_title("Yüksek olasılık = iyi tahmin", fontsize=11)
ax_p.set_ylim(0, max(probs) * 1.25)
for xi, p in zip(x, probs):
ax_p.text(xi, p + max(probs) * 0.02, f"{p:.4f}", ha="center", va="bottom",
fontsize=9, color=COL_TEXT)
# --- Sağ panel: -log P = loss (indigo, COL_ACCENT) ---
apply_style(ax_n)
ax_n.bar(x, nll, color=COL_ACCENT, edgecolor=COL_WHITE, linewidth=0.6, zorder=3)
ax_n.set_xticks(x)
ax_n.set_xticklabels(etiketler, fontsize=11)
ax_n.set_ylabel("$-\\log P$ (kayıp)", fontsize=11)
ax_n.set_title("Düşük olasılık = yüksek kayıp", fontsize=11)
ax_n.set_ylim(0, max(nll) * 1.18)
for xi, v in zip(x, nll):
ax_n.text(xi, v + max(nll) * 0.02, f"{v:.2f}", ha="center", va="bottom",
fontsize=9, color=COL_INDIGO_600, weight="bold")
# Ortalama NLL referans çizgisi + vurgu metni (sağ panel).
ax_n.axhline(ort_nll, color=COL_PRIMARY, linestyle="--", linewidth=1.6, zorder=4)
ax_n.text(
len(ciftler) - 1, ort_nll + max(nll) * 0.03,
f"ortalama NLL = {ort_nll:.2f}", ha="right", va="bottom",
fontsize=10.5, color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_PRIMARY, lw=1.2),
)
fig.suptitle(
"NLL sezgisi: olasılık $\\rightarrow$ $-\\log P$ (yüksek olasılık = düşük loss)",
fontsize=12, color=COL_TEXT,
)
plt.tight_layout(rect=(0, 0, 1, 0.96))
plt.show()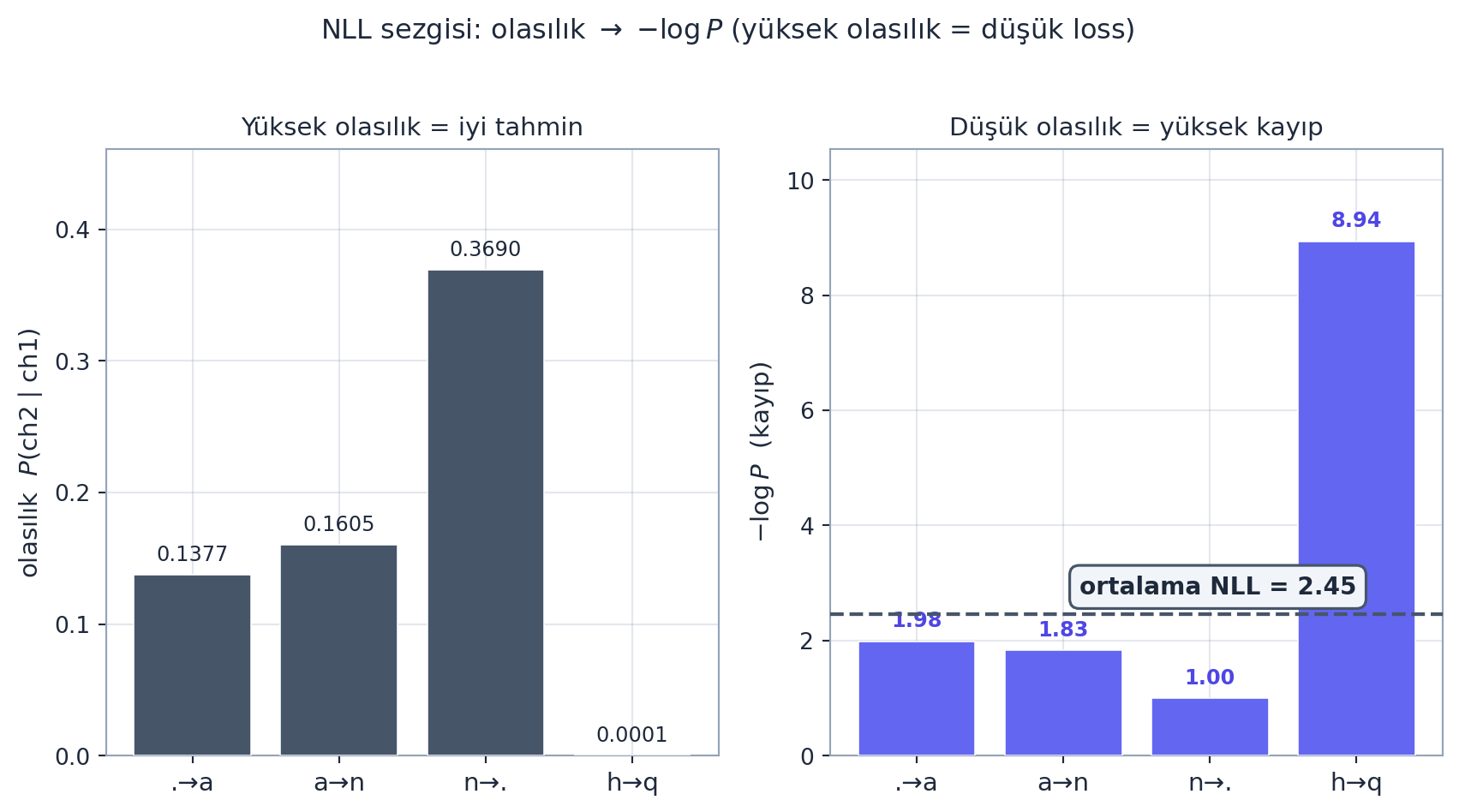
Bigram modeli için bu ≈2,45 çıkar. Karpathy maximum likelihood ile bağını net kurar:
“Our goal is to maximize likelihood, the product of all the probabilities assigned by the model… maximizing the likelihood is equivalent to maximizing the log likelihood because log is a monotonic [function].” — Karpathy, 59:08
İpucuBuilder Notu — NLL = Maximum Likelihood = Cross-Entropy
Geriye (Stat 110 + Ders 1): NLL’i minimize etmek = log-likelihood’u maksimize etmek = maximum likelihood estimation (Stat 110). Log’un monotonluğu, çarpım yerine toplamla çalışmayı (sayısal kararlılık + türevlenebilirlik) sağlar. Bu, Ders 1’deki cross-entropy’nin ta kendisidir — orada Bernoulli, burada karakterler üzerinden multinomial.
İleriye: NLL / cross-entropy, neredeyse tüm sınıflandırma ve dil modellerinin standart kaybıdır. GPT’nin eğitildiği loss da budur: bir sonraki token’a atanan olasılığın negatif log’u.
3.9 Model Yumuşatma (Fake Counts)
Bir sorun: veride hiç görülmemiş bir bigram’a model sıfır olasılık atar; o bigram bir isimde geçerse \(\log(0) = -\infty\) olur, NLL patlar. Çözüm basit ve klasik: her sayıma küçük bir sahte sayı ekle (örn. +1), böylece hiçbir olasılık sıfır olmaz.
P = (N + 1).float() # +1 = yumusatma (smoothing)
P = P / P.sum(1, keepdim=True)Ne kadar çok eklersen model o kadar “düzleşir” (her şey eşit olasılığa yaklaşır); ne kadar az, gerçek sayımlara o kadar sadık kalır. Bu, modeli aşırı keskinlikten koruyan bir denge ayarıdır. Pratikte +1 yumuşatma, sayım NLL’ini neredeyse hiç bozmaz (2,4540’tan 2,4546’ya), ama \(-\infty\) riskini ortadan kaldırır.
İpucuBuilder Notu — Smoothing = Laplace = Uniform Prior
Geriye (Stat 110): Sahte sayı eklemek, Stat 110’daki Laplace ardışıklık kuralının (Laplace smoothing) ta kendisidir: uniform bir prior eklemek gibi. Birazdan göreceğiz ki bu, sinir ağı versiyonunda L2 düzenlileştirme (regularization) ile birebir aynı işi yapar (§14).
İleriye: “Görülmemiş duruma sıfır verme” problemi her olasılıksal modelde vardır; smoothing/regularization, modelin eğitim verisine aşırı güvenmesini (overfitting) engelleyen genel bir araçtır.
3.10 Bölüm 2: Bigram’ı Sinir Ağı Olarak Görmek
Şimdi dersin asıl güzelliği: tam olarak aynı bigram modelini bir sinir ağı olarak yeniden kuralım. Sayım yerine, modeli gradient descent ile eğiteceğiz (Ders 1 micrograd mekaniği).
Yeni çerçeve: ağ bir karakter alır (girdi), bir ağırlık matrisi W vardır, çıktı olarak bir sonraki karakterin olasılık dağılımını üretir. Eğitim = NLL kaybını gradient descent ile minimize etmek. Sonuçta öğrenilen W, sayım tablosuyla aynı modeli verecek — ama bu kez yöntem her ölçeğe genişleyebilir.
İpucuBuilder Notu — Aynı Fikir, Tensör Hâli
Geriye (Ders 1): Bu, micrograd’da kurduğumuz “parametreleri loss’u düşürecek şekilde ayarla” fikrinin gerçek bir probleme uygulanması. Tek fark: skaler yerine tensör, elle yazılmış MLP yerine PyTorch.
İleriye: “Girdi → ağırlıklar → olasılık dağılımı → NLL ile eğit” şablonu, tüm dil modellerinin iskeletidir. Ders 3’te W’nin yerini embedding + gizli katman alır; GPT’de devasa bir transformer — ama çerçeve sabit.
3.11 Bigram Veri Seti ve One-Hot Kodlama
Önce eğitim verisini hazırlarız: her bigram bir (girdi, hedef) çiftidir. xs girdi karakterlerinin tamsayı id’leri, ys hedef (bir sonraki) karakterlerin id’leri.
xs, ys = [], []
for w in words:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
xs.append(s2i[ch1]) # girdi karakter id
ys.append(s2i[ch2]) # hedef (sonraki) karakter id
xs = torch.tensor(xs) # KUCUK harf torch.tensor (dtype korur)
ys = torch.tensor(ys)Karpathy bir tuzağa dikkat çeker: torch.tensor (küçük t) girdinin dtype’ını korur (tamsayı kalır); torch.Tensor (büyük T) float32’e çevirir. Küçük harf tercih edilir.
Bir tamsayı id’sini doğrudan sinir ağına besleyemezsin (ağ sayılarla aritmetik yapar, “13” karakterin sırası değil sayısal değeri olur). Çözüm one-hot kodlama: id’yi, yalnızca o indekste 1 olan bir sıfır vektörüne çevir.
import torch.nn.functional as F
xenc = F.one_hot(xs, num_classes=27).float() # (n, 27), float'a cevirxenc’in her satırı tek bir 1 içeren 27-uzunlukta bir vektör. .float() şart: ağ ondalık aritmetik yapacak.
İpucuBuilder Notu — One-Hot = Baz Vektörü
Geriye (18.06): One-hot vektör, standart baz vektörüdür (\(e_i\)) — yalnızca \(i\)’inci bileşeni 1. Birazdan göreceğin gibi, bir baz vektörüyle matris çarpımı, matrisin tam o satırını/kolonunu seçer (18.06 Ders 30).
İleriye: One-hot, küçük sözlükler için iyidir ama 50.000 token’lık bir sözlükte 50.000-uzunlukta seyrek vektör israftır. Ders 3’te bunun yerini embedding tablosu alır (doğrudan id ile satır seçimi) — ama Karpathy birazdan one-hot @ W’nin zaten bir satır seçimi olduğunu gösterecek (§14), yani embedding’in habercisi.
3.12 Tek Lineer Katman + Softmax
Ağırlık matrisini rastgele başlatırız: W = torch.randn((27, 27)). Girdiyi (one-hot) W ile çarparız: xenc @ W. Bu, 27 nöronun aynı girdiye paralel ateşlemesidir — çıktı her olası sonraki karakter için bir ham sayı.
Bu 27 ham sayı logit (log-counts) olarak yorumlanır:
“These 27 numbers are giving us log counts basically. So instead of giving us counts directly… and to get the counts we’re going to exponentiate them.” — Karpathy, 1:20:42
Yani: logitleri üstel alıp (pozitif “fake counts” elde et), sonra normalize et → olasılık dağılımı. Bu iki adım (exp + normalize) tam olarak softmax’tır:
\[ z = x_{enc} \, W, \qquad P = \frac{e^{z}}{\sum_{j} e^{z_j}} \]
W = torch.randn((27, 27), requires_grad=True) # ogrenilecek parametre
xenc = F.one_hot(xs, num_classes=27).float()
logits = xenc @ W # ham log-counts (n, 27)
counts = logits.exp() # fake counts (pozitif)
probs = counts / counts.sum(1, keepdim=True) # softmax -> olasiliklogits.exp() neden? Çünkü ham logitler negatif olabilir, ama sayım/olasılık pozitif olmalı; üstel her şeyi pozitife taşır. counts.sum(1, keepdim=True) — yine §6’daki broadcasting kuralı (satır normalizasyonu için keepdim=True). Aşağıdaki figür, tek bir örnek satır için softmax’ın üç aşamasını gösterir.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyArrowPatch
# Tek bir örnek satır: W'nin bir satırı (tohumlu -> deterministik).
# Tam 27x27 W'nin ilk satırını alıp ilk 7 sınıfa kısaltıyoruz (okunur görünüm).
torch.manual_seed(SEED)
g = torch.Generator().manual_seed(SEED)
W_row = torch.randn(VOCAB, generator=g) # bir satır (27 logit)
K = 7 # gösterilen sınıf sayısı (kısaltılmış görünüm)
etiketler = [i2s[i] for i in range(K)] # '.', a, b, c, d, e, f
logits = W_row[:K] # ham çıktı (negatif/pozitif olabilir)
counts = logits.exp() # exp -> hepsi pozitif (fake counts)
probs = counts / counts.sum() # normalize -> olasılık (toplam 1)
idx = list(range(K))
fig, axes = plt.subplots(1, 3, figsize=(11, 4))
# --- Panel 1: logits (ham çıktı; negatif/pozitif) ---
ax = axes[0]
apply_style(ax)
ax.bar(idx, logits.tolist(), color=COL_PRIMARY, edgecolor=COL_WHITE, linewidth=0.8)
ax.axhline(0, color=COL_SLATE_400, linewidth=1.2, zorder=1) # sıfır referans çizgisi
ax.set_title("logits (ham çıktı)", fontsize=11)
ax.set_xticks(idx)
ax.set_xticklabels(etiketler)
ax.set_ylabel("değer (±)", fontsize=10)
# --- Panel 2: counts = logits.exp() (hepsi pozitif) ---
ax = axes[1]
apply_style(ax)
ax.bar(idx, counts.tolist(), color=COL_INDIGO_400, edgecolor=COL_WHITE, linewidth=0.8)
ax.set_title("counts = $e^{z}$ (pozitif)", fontsize=11)
ax.set_xticks(idx)
ax.set_xticklabels(etiketler)
ax.set_ylabel("sahte sayım", fontsize=10)
# --- Panel 3: probs = counts / counts.sum() (toplam 1) ---
ax = axes[2]
apply_style(ax)
ax.bar(idx, probs.tolist(), color=COL_ACCENT, edgecolor=COL_WHITE, linewidth=0.8)
ax.set_title(f"olasılık (toplam = {probs.sum().item():.2f})", fontsize=11)
ax.set_xticks(idx)
ax.set_xticklabels(etiketler)
ax.set_ylabel("P(sonraki)", fontsize=10)
# --- Paneller arası ok + etiket: 'exp' ve 'normalize' ---
fig.canvas.draw() # tight layout öncesi konumlar için
plt.tight_layout(w_pad=4.0)
asama_etiketleri = ["exp", "normalize"]
for k, sol_ax, sag_ax in [(0, axes[0], axes[1]), (1, axes[1], axes[2])]:
# iki panelin ekseni arasındaki orta boşlukta yatay ok (figür koordinatı)
p_sol = sol_ax.get_position()
p_sag = sag_ax.get_position()
x0 = p_sol.x1 + 0.005
x1 = p_sag.x0 - 0.005
ymid = (p_sol.y0 + p_sol.y1) / 2.0
ok = FancyArrowPatch(
(x0, ymid), (x1, ymid),
transform=fig.transFigure,
arrowstyle="-|>", mutation_scale=20,
color=COL_INDIGO_600, linewidth=2.2, zorder=10,
)
fig.add_artist(ok)
fig.text((x0 + x1) / 2.0, ymid + 0.06, asama_etiketleri[k],
ha="center", va="center", fontsize=11, color=COL_INDIGO_600,
weight="bold",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_WHITE,
ec=COL_INDIGO_400, lw=1.2))
plt.show()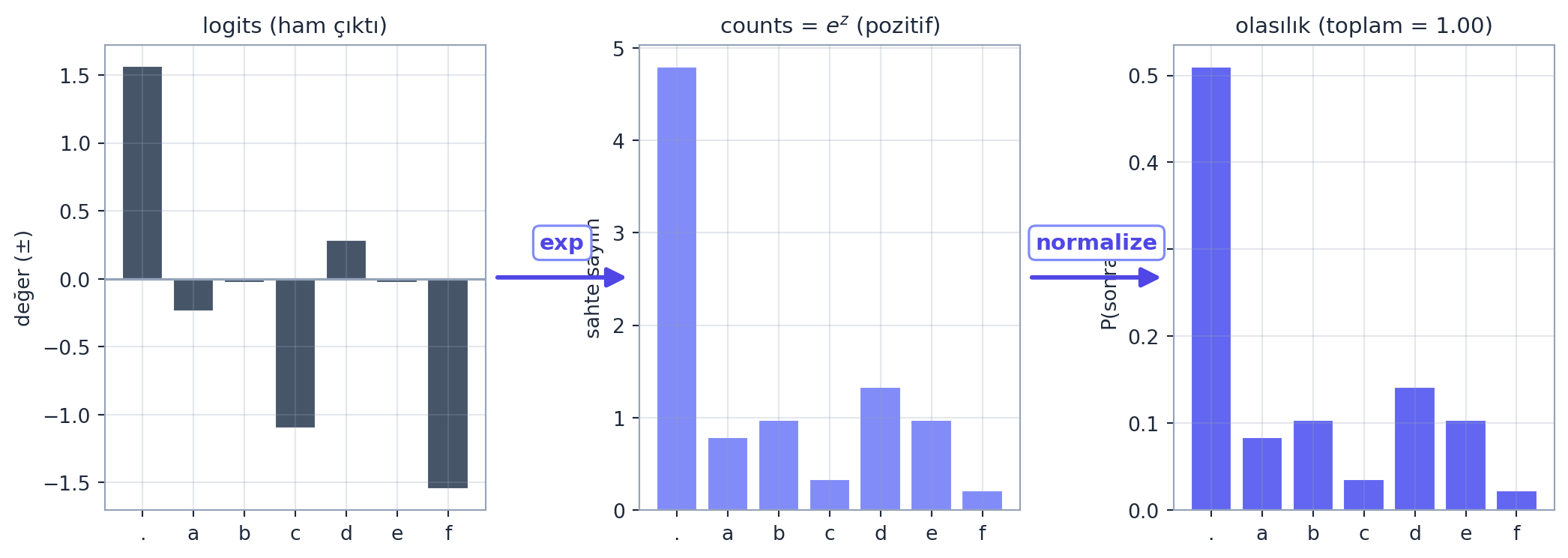
İpucuBuilder Notu — Softmax = exp + normalize
Geriye (18.06 + Calculus + Ders 1): xenc @ W, bir one-hot (baz vektörü) ile matris çarpımı olduğundan W’nin ilgili satırını seçer (18.06). exp ise Calculus Ders 5’in \(e^x\)’i. Softmax = exp + normalize, Ders 1’deki sigmoid’in çok-sınıflı genellemesidir.
İleriye: Softmax, her çok-sınıflı sınıflandırıcının ve her dil modelinin son katmanıdır. GPT de son katmanda sözlük-boyutu kadar logit üretip softmax’tan geçirir. “Logit = log-counts” sezgisi tüm seride geçerli kalır.
3.13 Forward / Backward / Update
Şimdi modeli eğitelim. Loss = doğru hedeflere atanan olasılıkların ortalama negatif log’u. Vektörel olarak: her örnek için probs[satır, ys] ile doğru karakterin olasılığını seç, log’unu al, ortalamasının negatifini hesapla:
loss = -probs[torch.arange(len(xs)), ys].log().mean() # ortalama NLLSonra Ders 1’deki micrograd döngüsünün birebir aynısı: gradyanları sıfırla, geri yayılım, gradyanın tersine adım.
W.grad = None # zero_grad (Ders 1: gradyanlar birikir!)
loss.backward() # autograd -> W.grad doldurulur
W.data += -50 * W.grad # gradient descent adimiKarpathy neden rastgele deneme değil de gradient descent kullandığımızı net söyler:
“What I’m doing here, which is just guess and check of randomly assigning parameters and seeing if the network is good — that is amateur hour. That’s not how you optimize a neural net.” — Karpathy, 1:32:29
Ve eğitim döngüsünün Ders 1 ile aynı olduğunu göstermek için micrograd notebook’unu açar:
“Identical to what we had with micrograd. So here I pulled up the lecture from micrograd… we had something very very similar.” — Karpathy, 1:33:14
İpucuBuilder Notu — Dört Adım, Tensör Üzerinde
Geriye (Ders 1): loss.backward() + W.data += -lr * W.grad, micrograd’daki backward() + güncelleme döngüsünün tensör versiyonu. W.grad = None ise Ders 1’in zero_grad dersi (gradyanlar birikir, sıfırlamazsan bozulur). Tek fark: PyTorch tüm gradyanları tensör üzerinde otomatik hesaplar.
İleriye: Bu dört adım (forward → loss → backward → update) her PyTorch eğitiminin çekirdeği. Öğrenme oranı (≈50) burada elle ayarlanır; Ders 4’te bunun nasıl prensipli seçileceğini (init + LR taraması), Ders 10’da production schedule’larını göreceğiz.
3.14 Tam Veri Seti ve Eşdeğerlik
Modeli tüm veri setine ölçeklendiririz: 228 binden fazla bigram örneği. Öğrenme oranını yükseltip (≈50) yeterince adım koşunca eğitim eğrisindeki loss (L2 reg dahil) ≈2,49’a iner; sayım modeliyle adil kıyas için reg’siz ölçülen saf NLL ≈2,47, sayım modelinin ≈2,45’ine çok yakındır.
Kritik gözlem: bu, saf sayım yöntemiyle aldığımız ≈2,45 ile neredeyse aynı. Yani iki yöntem — sayım+normalize ve gradient descent — aynı modele ulaşır. Sayım yöntemi bigram için doğrudan optimal çözümü verir; gradient descent ise onu yinelemeli olarak bulur. Eğitim eğrisinde okunan ≈2,49 değeri 0.01 * (W**2).mean() L2 reg cezasını da içerir; sayım modelinin reg’i olmadığından adil kıyas, ağın reg’siz saf NLL’idir (≈2,47) — bu da sayımın ≈2,45’ine 0,02 farkla yakındır. Fark: gradient descent her ölçeğe (çok daha karmaşık modellere) genişler, sayım yöntemi genişlemez.
Kod
import matplotlib.pyplot as plt
# Deterministik eğitim: aynı tohum -> aynı loss eğrisi (Karpathy SEED).
# train_nn: one-hot -> xenc@W -> softmax -> NLL + L2 reg -> backward -> GD adımı.
W, loss_gecmisi = train_nn(steps=100, lr=50.0, seed=SEED, reg=0.01)
# Sayım modelinin tüm veri üzerindeki ortalama NLL'i (eşdeğerlik referansı, ~2.45).
count_nll = count_model_nll(P)
fig, ax = plt.subplots(figsize=(9, 5))
apply_style(ax)
adim_no = list(range(1, len(loss_gecmisi) + 1))
ax.plot(adim_no, loss_gecmisi,
color=COL_PRIMARY, linewidth=2.4, zorder=2,
label="NN eğitim kaybı (NLL + L2)")
ax.scatter(adim_no, loss_gecmisi,
color=COL_ACCENT, s=28, zorder=3, edgecolor=COL_WHITE, linewidth=0.8)
# Sayım modeli referans çizgisi: NN bu değere yakınsar (aynı model = eşdeğerlik).
ax.axhline(count_nll, color=COL_INDIGO_600, linewidth=2.0, linestyle="--",
zorder=2, label=f"sayım modeli $\\approx$ {count_nll:.2f}")
# İlk ve son kaybı anotla (yakınsamayı vurgula).
ax.annotate(f"ilk: {loss_gecmisi[0]:.2f}",
xy=(adim_no[0], loss_gecmisi[0]),
xytext=(adim_no[0] + 6, loss_gecmisi[0] - 0.05),
color=COL_TEXT, fontsize=10, va="center",
arrowprops=dict(arrowstyle="->", color=COL_SLATE_400, lw=1.2))
ax.annotate(f"son: {loss_gecmisi[-1]:.2f}",
xy=(adim_no[-1], loss_gecmisi[-1]),
xytext=(adim_no[-1] - 32, loss_gecmisi[-1] + 0.35),
color=COL_INDIGO_600, fontsize=10, va="center",
arrowprops=dict(arrowstyle="->", color=COL_INDIGO_600, lw=1.2))
ax.set_xlabel("Eğitim adımı", fontsize=12)
ax.set_ylabel("Kayıp (loss) = ortalama NLL", fontsize=12)
ax.set_title("NN eğitimi sayım modeline yakınsar (eşdeğerlik)", fontsize=12)
ax.set_xlim(left=0)
ax.legend(loc="upper right", fontsize=10, framealpha=0.95)
plt.tight_layout()
plt.show()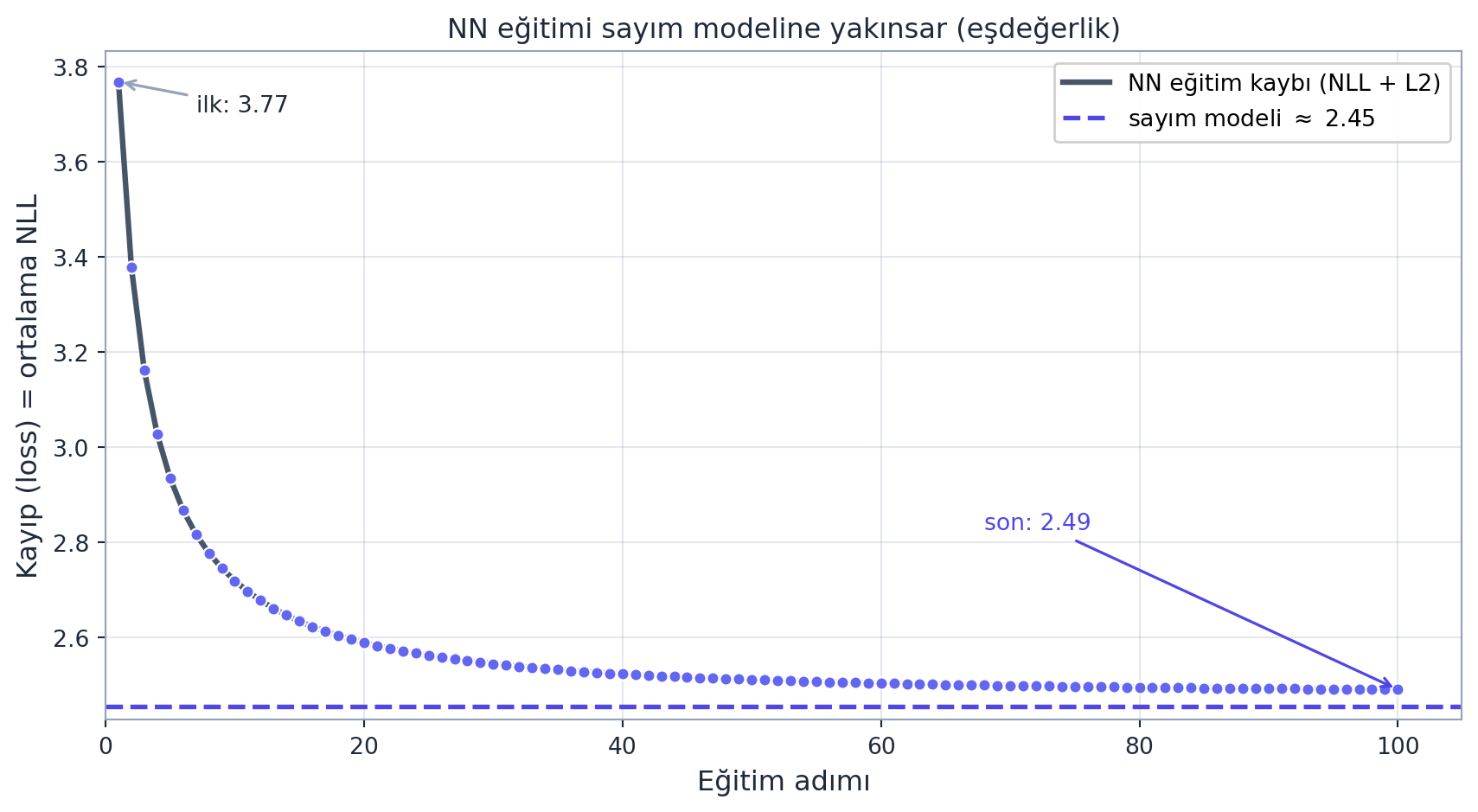
train_nn, 100 adım, lr=50, seed sabit) ortalama NLL kaybı: ilk adım \(\approx 3{,}77\), son adım \(\approx 2{,}49\). Slate çizgi + indigo işaretçiler. Kesikli indigo yatay çizgi, sayım modelinin tüm veri üzerindeki NLL’i (\(\approx 2{,}45\)); gradient descent ile eğitilen ağ bu değere yakınsar — yani sayım yöntemiyle gradient descent aynı modele ulaşır (eşdeğerlik). x = eğitim adımı, y = kayıp (loss).
İpucuBuilder Notu — İki Yöntem, Tek Optimum
İleriye: “İki farklı yöntem aynı sonuca ulaşıyor” — bu, gradient descent’in doğruluğuna güven verir. Bigram’da sayımla doğrulayabildik; ama gerçek modellerde (GPT) kapalı-form çözüm YOKTUR, yalnızca gradient descent kalır. Bu ders, o güveni küçük, doğrulanabilir bir örnekte inşa eder.
3.15 İki Not: One-Hot = Satır Seçimi, L2 = Yumuşatma
Karpathy iki güzel bağlantıyla kapatır:
One-hot @ W = satır seçimi. Bir one-hot vektörünü W ile çarpmak, aslında W’nin tam o indeksteki satırını çekip almaktır (çarpma masrafı boşa). Yani W’nin satırları, sayım tablosundaki log-sayımların öğrenilmiş hâlidir. Bu gözlem, Ders 3’teki embedding tablosunun doğrudan habercisi: id ile satır seçimi, matris çarpımı olmadan.
Kod
import torch
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# Deterministik küçük W (Karpathy'nin meşhur tohumu) — figür her render'da aynı.
g = torch.Generator().manual_seed(SEED)
W = torch.randn((VOCAB, VOCAB), generator=g)
# Hangi satırı seçiyoruz? 'a' karakteri -> s2i['a'] = 1 (baz vektörü e_1).
i = s2i["a"]
# one-hot girdi vektörü (1 x 27): yalnız i. hücre 1, gerisi 0.
xenc = torch.zeros(VOCAB)
xenc[i] = 1.0
# satır seçimi sonucu = W'nin i. satırı (xenc @ W ile birebir aynı).
secilen_satir = (xenc @ W).numpy() # (27,)
W_np = W.numpy()
fig, ax = plt.subplots(figsize=(11, 5))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
# ---------------------------------------------------------------------------
# Yerleşim koordinatları (eksen birimleri). Soldan sağa: one-hot | @ | W | = | sonuç
# ---------------------------------------------------------------------------
hucre = 0.30 # bir hücre kenarı (one-hot/sonuç sütun yüksekliği)
oh_x = 0.6 # one-hot vektörün x konumu (dikey 27'lik sütun)
W_x0 = 2.4 # W ızgarasının sol kenarı
W_x1 = W_x0 + VOCAB * hucre # W ızgarasının sağ kenarı
res_x = W_x1 + 1.8 # sonuç vektörünün x konumu (dikey 27'lik sütun)
y_top = VOCAB * hucre # sütunların üst kenarı (0..27 hücre)
# ---------------------------------------------------------------------------
# SOL: one-hot vektör (1 x 27, dikey çizilir) — baz vektörü e_i
# ---------------------------------------------------------------------------
for r in range(VOCAB):
y = y_top - (r + 1) * hucre
dolu = (r == i)
ax.add_patch(Rectangle(
(oh_x, y), hucre, hucre,
facecolor=COL_ACCENT if dolu else COL_BG,
edgecolor=COL_SLATE_400, linewidth=0.7, zorder=2,
))
if dolu:
ax.text(oh_x + hucre / 2, y + hucre / 2, "1", ha="center", va="center",
fontsize=8, color=COL_WHITE, weight="bold", zorder=3)
ax.text(oh_x + hucre / 2, y_top + 0.32, "one-hot", ha="center", va="bottom",
fontsize=11, color=COL_TEXT, weight="bold")
ax.text(oh_x + hucre / 2, y_top + 0.05, r"$e_i$ (1×27)", ha="center", va="bottom",
fontsize=9.5, color=COL_PRIMARY)
# i. hücrenin etiketi (sol tarafta)
y_i = y_top - (i + 1) * hucre
ax.annotate(f"i = s2i['a'] = {i}", xy=(oh_x, y_i + hucre / 2),
xytext=(oh_x - 0.45, y_i + hucre / 2), ha="right", va="center",
fontsize=9.5, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.4))
# @ işareti (one-hot ile W arası)
ax.text((oh_x + hucre + W_x0) / 2, y_top / 2, r"$@$", ha="center", va="center",
fontsize=24, color=COL_PRIMARY, weight="bold")
# ---------------------------------------------------------------------------
# ORTA: 27 x 27 W ızgarası (imshow), i. satır indigo çerçeveyle vurgulu
# ---------------------------------------------------------------------------
extent = [W_x0, W_x1, y_top - VOCAB * hucre, y_top] # [sol, sağ, alt, üst]
ax.imshow(W_np, cmap="Greys", extent=extent, aspect="auto",
origin="upper", alpha=0.85, zorder=2,
vmin=-3, vmax=3)
# ızgara dış çerçevesi
ax.add_patch(Rectangle((W_x0, y_top - VOCAB * hucre), VOCAB * hucre, VOCAB * hucre,
facecolor="none", edgecolor=COL_SLATE_400, linewidth=1.0, zorder=3))
# i. satırı indigo dikdörtgenle vurgula (üstten i. sıra)
row_y = y_top - (i + 1) * hucre
ax.add_patch(Rectangle((W_x0, row_y), VOCAB * hucre, hucre,
facecolor="none", edgecolor=COL_INDIGO_600, linewidth=2.6, zorder=4))
ax.text((W_x0 + W_x1) / 2, y_top + 0.32, "ağırlık matrisi", ha="center", va="bottom",
fontsize=11, color=COL_TEXT, weight="bold")
ax.text((W_x0 + W_x1) / 2, y_top + 0.05, r"$W$ (27×27)", ha="center", va="bottom",
fontsize=9.5, color=COL_PRIMARY)
ax.annotate("i. satır", xy=(W_x1, row_y + hucre / 2),
xytext=(W_x1 + 0.15, row_y + hucre / 2 + 0.55), ha="left", va="center",
fontsize=9.5, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.4))
# = işareti (W ile sonuç arası)
ax.text((W_x1 + res_x) / 2, y_top / 2, r"$=$", ha="center", va="center",
fontsize=24, color=COL_PRIMARY, weight="bold")
# ---------------------------------------------------------------------------
# SAĞ: sonuç vektörü (1 x 27, dikey) = W'nin i. satırı (indigo çerçeve)
# ---------------------------------------------------------------------------
vmin, vmax = float(secilen_satir.min()), float(secilen_satir.max())
rng = (vmax - vmin) if vmax > vmin else 1.0
for r in range(VOCAB):
y = y_top - (r + 1) * hucre
t = (secilen_satir[r] - vmin) / rng # 0..1 gri tonu
gri = 0.92 - 0.62 * t # koyu = yüksek değer
ax.add_patch(Rectangle(
(res_x, y), hucre, hucre,
facecolor=(gri, gri, gri),
edgecolor=COL_SLATE_400, linewidth=0.7, zorder=2,
))
ax.add_patch(Rectangle((res_x, y_top - VOCAB * hucre), hucre, VOCAB * hucre,
facecolor="none", edgecolor=COL_INDIGO_600, linewidth=2.2, zorder=4))
ax.text(res_x + hucre / 2, y_top + 0.32, "sonuç", ha="center", va="bottom",
fontsize=11, color=COL_TEXT, weight="bold")
ax.text(res_x + hucre / 2, y_top + 0.05, r"$W$'nin i. satırı", ha="center", va="bottom",
fontsize=9.5, color=COL_INDIGO_600)
# Alt açıklama: çarpma değil, satır çekme.
ax.text((oh_x + res_x) / 2, -0.85,
r"$e_i \, @ \, W$ = $W$'nin $i$. satırı — baz vektörüyle satır seçimi (18.06), embedding'in habercisi",
ha="center", va="center", fontsize=10.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.4))
ax.set_xlim(-0.9, res_x + hucre + 1.4)
ax.set_ylim(-1.5, y_top + 0.9)
ax.set_aspect("equal")
ax.axis("off")
ax.set_title("one-hot $@\\, W$ = satır seçimi", color=COL_TEXT, fontsize=12)
plt.tight_layout()
plt.show()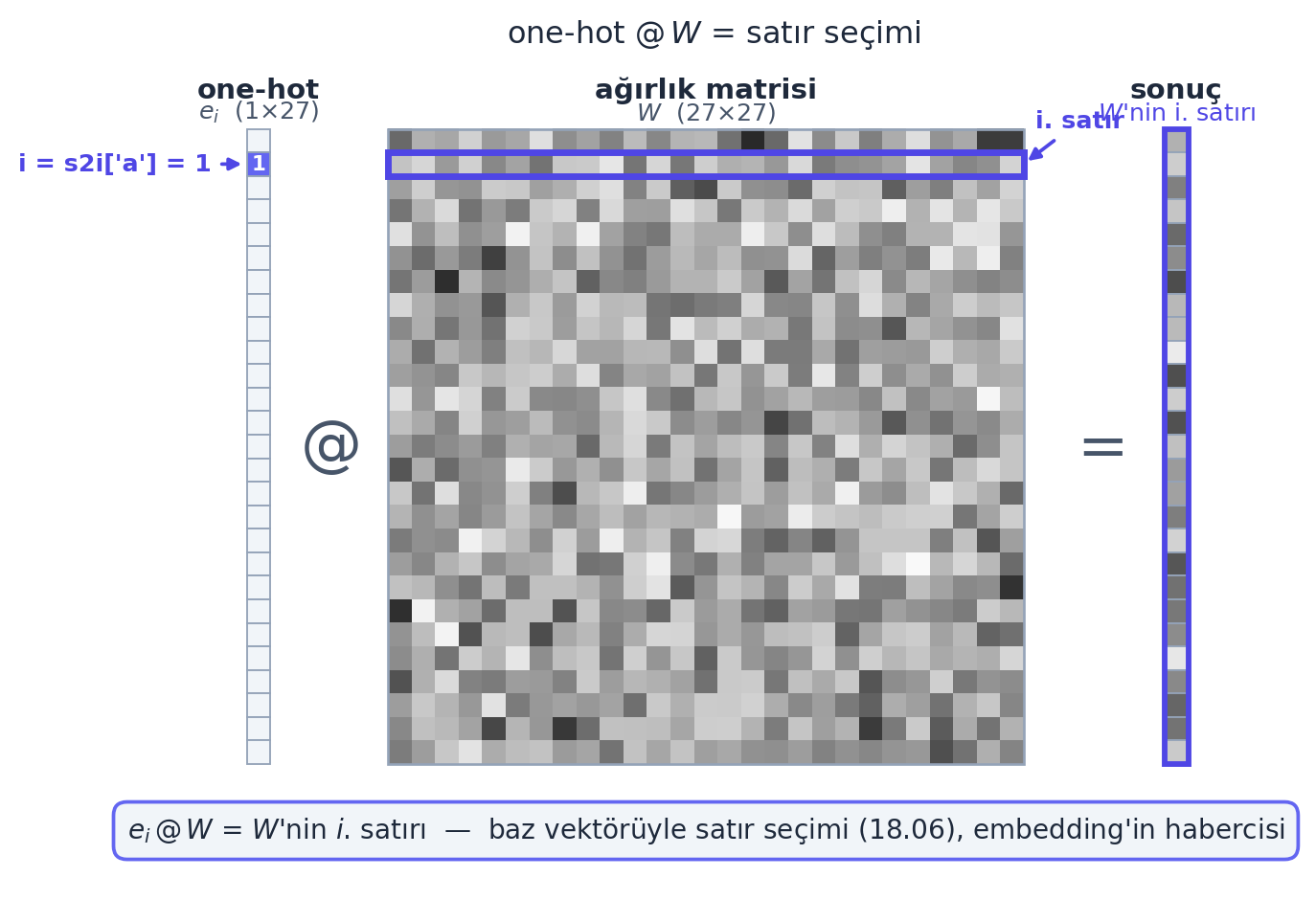
s2i['a'] \(= 1\); yalnız 1. hücre dolu, gerisi 0). Bunu \(27 \times 27\) ağırlık matrisi \(W\) ile çarpmak, \(W\)’nin tam \(i\). satırını çekip alır — 27 çarpma-toplama boşa, sonuç sadece o satır. Bu, 18.06’daki baz vektörüyle satır seçiminin ta kendisi ve Ders 3’teki embedding tablosunun habercisidir.
L2 düzenlileştirme = yumuşatma. Loss’a (W**2).mean() * strength eklemek, W’yi sıfıra doğru iter; \(W = 0\) ise tüm logitler eşit, yani uniform dağılım. Bu, §8’deki sahte sayı eklemenin (smoothing) birebir sinir ağı karşılığıdır — ne kadar güçlü, o kadar düz model.
loss = -probs[torch.arange(len(xs)), ys].log().mean() + 0.01 * (W**2).mean()Ağdan örneklenen isimler, sayım modelinden örneklenenlerle aynı çıkar — çünkü aynı model. Karpathy sonra bir sonraki adımı haber verir:
“We can expand this approach and complexify the neural net. So currently we’re just taking a single character and feeding it into a neural net… but we’re about to iterate on this substantially.” — Karpathy, 1:46:09
İpucuBuilder Notu — İki İleri Kavram, Aslında Tanıdık
Geriye (Stat 110 + 18.06): L2 regularization = Laplace smoothing = uniform prior eklemek (Stat 110). One-hot @ W = baz vektörüyle satır seçimi (18.06). İki “ileri seviye” kavram, aslında daha önce gördüğün basit şeyler.
İleriye: “Karmaşıklaştır” sözü serinin yol haritası: tek karakter → çok karakter bağlam (Ders 3 MLP), sonra dikkat mekanizması (Ders 7 transformer). Her adımda model büyür ama loss/eğitim çerçevesi aynı kalır.
3.16 Bu Dersin Özeti
- makemore, karakter-düzeyli bir dil modelidir:
names.txt’ten öğrenip yeni isimler üretir. Bigram modeli sonraki karakteri yalnızca önceki tek karakterden tahmin eder. - Bigram’ları sayıp (\(27 \times 27\) tensör
N), satır-satır normalize ederek bir olasılık matrisi elde ederiz. - Örnekleme: bir satırı olasılığa çevir,
torch.multinomial(tohumluGenerator) ile sonraki karakteri çek,.gelene dek tekrarla. - Broadcasting kurallarına saygı (özellikle
keepdim=True) — sessiz satır/kolon hatasından kaçın. - Loss = ortalama NLL \(= -\frac{1}{n} \sum_i \log P(x_i)\); minimize etmek = maximum likelihood (Stat 110). Bigram için ≈2,45.
- Yumuşatma (sahte sayı +1) sıfır olasılığı önler (\(\log(0) = -\infty\) patlamasını).
- Aynı model = tek katmanlı sinir ağı: one-hot girdi →
xenc @ W(logit/log-counts) → exp → normalize (softmax) → olasılık. - Eğitim = Ders 1 micrograd döngüsü: forward → NLL →
loss.backward()→W.data += -lr * W.grad(zero_grad’ı unutma). - Gradient descent ≈2,47’ye (reg’siz saf NLL; eğitim eğrisi reg dahil ≈2,49) yakınsar — sayımın ≈2,45’iyle aynı model. One-hot @ W = satır seçimi (embedding habercisi); L2 reg = yumuşatma.
ÖnemliTek Bir Cümle
Bir dil modeli, “bir sonraki karakterin olasılık dağılımını” üreten bir fonksiyondur; bigram bunu tek karakter bağlamıyla yapar ve ister say-normalize et ister one-hot + softmax + gradient descent ile eğit — aynı modele ulaşırsın, ama yalnızca ikincisi GPT ölçeğine genişler.
3.17 Kontrol Soruları
NotSoru 1: Bigram modelinde N[., a] = 4000 ve ‘.’ satırının toplamı 32000 olsun. P(a | .) nedir? Bu bigram’ın -log P katkısı yaklaşık kaçtır?
Satırı normalize ederiz:
\[ P(a \mid .) = \frac{N[., a]}{\sum_j N[., j]} = \frac{4000}{32000} = 0{,}125 \]
NLL katkısı bu olasılığın negatif log’udur:
\[ -\log P(a \mid .) = -\log(0{,}125) \approx 2{,}08 \]
Cevap: \(P(a \mid .) = 0{,}125\) (yani %12,5 olasılıkla isimler ‘a’ ile başlar). \(-\log(0{,}125) \approx 2{,}08\). Model bu karaktere ne kadar yüksek olasılık atarsa, \(-\log\) o kadar küçük (loss o kadar iyi) olur; olasılık 1’e giderse katkı 0’a, 0’a giderse \(+\infty\)’a gider.
NotSoru 2: Sayım ≈2,45, gradient descent (reg’siz) ≈2,47 loss veriyor — neredeyse aynı. Bu neden beklenir? Neden yine de gradient descent öğreniriz?
Cevap: İkisi de aynı amacı optimize eder: bigram olasılıklarını veriye en iyi uyduran değerler. Sayım+normalize, bigram için bu optimumun kapalı-form (doğrudan) çözümüdür; gradient descent ise aynı optimuma yinelemeli yaklaşır — bu yüzden neredeyse aynı loss’a varırlar (sayım ≈2,45, ağın reg’siz saf NLL’i ≈2,47, fark 0,02). Bir incelik: ağın eğitim eğrisinde okunan değer (≈2,49) 0.01 * (W**2).mean() L2 reg cezasını da içerir; sayım modelinin reg’i olmadığından adil kıyas, ağın reg’siz saf NLL’idir (≈2,47). Yani ağın biraz daha yüksek görünmesinin bir kısmı yinelemeli yaklaşım, bir kısmı da reg terimidir. Gradient descent’i öğrenmemizin sebebi: bigram’dan daha karmaşık modellerde (MLP, transformer) kapalı-form çözüm yoktur — sayamazsın. Gradient descent her ölçeğe genişleyen tek yöntemdir. Bigram, gradient descent’i sayımla doğrulayabildiğimiz son basit duraktır.
NotSoru 3: P = N.float() / N.sum(1, keepdim=True) ile P = N.float() / N.sum(1) farkı nedir? Hangisi satırları doğru normalize eder, neden?
Cevap: N.sum(1) her satırın toplamını verir ama şekli (27,) — broadcasting’de bir satır vektörü gibi hizalanır ve \((27, 27)\) matrisin her kolonunu bu vektöre böler (YANLIŞ — kolon normalizasyonu). N.sum(1, keepdim=True) şekli (27, 1) tutar; bu, her satır boyunca yayılır ve her satırı kendi toplamına böler (DOĞRU — satır normalizasyonu, her satır toplamı 1 olur). Tehlikeli olan: ikisi de hata fırlatmaz, kod çalışır — ama keepdim=False sessizce yanlış eksende normalize eder (satır toplamları \(0{,}0669\)–\(7{,}0225\) arası savrulur). Kural: şekilleri .shape ile kontrol et.
NotSoru 4: (Builder) xenc @ W işleminde xenc bir one-hot vektörse, sonuç neden W’nin tam bir satırına eşittir? 18.06 ile bağla.
Cevap: One-hot vektör, standart baz vektörüdür \(e_i\) — yalnızca \(i\)’inci bileşeni 1, gerisi 0. Bir baz vektörü \(e_i\) ile matris çarpımı (\(e_i \cdot W\)), \(W\)’nin \(i\)’inci satırını seçip döndürür (18.06 Ders 30: matris-vektör çarpımı, satırların/kolonların seçilmesi). Yani 27 çarpma-toplama yapıyor gibi görünse de, aslında W’nin bir satırını “çekip alıyoruz”. Bu yüzden W’nin her satırı, o girdi karakteri için 27 log-count’tur — tıpkı sayım tablosunun bir satırı gibi. Bu gözlem, Ders 3’teki embedding tablosunun temelidir: id ile doğrudan satır seçimi (one-hot + matris çarpımı israfı olmadan).
3.18 Egzersizler
Egzersiz 1 (Sayım modelini kur). names.txt’i indir (github.com/karpathy/makemore), bigram sayım tensörü N’i (\(27 \times 27\)) doldur, olasılık matrisi P’yi (satır normalize, keepdim=True) hesapla. Tohumlu torch.multinomial ile 10 isim örnekle. Üretilen isimleri gözlemle.
Egzersiz 2 (NLL’i hesapla). Sayım modelinin tüm veri seti üzerindeki ortalama negatif log olabilirliğini hesapla (her bigram için \(-\log P(\text{ch2} \mid \text{ch1})\), ortalamasını al). ≈2,45 çıkmalı. Sonra +1 yumuşatma ekleyip nasıl değiştiğine bak.
Egzersiz 3 (keepdim bug’ını gör). P = N / N.sum(1, keepdim=True) ile P = N / N.sum(1) çıktılarını karşılaştır. İkincide her satırın toplamının 1 olmadığını (yanlış normalizasyon) P.sum(1) ile doğrula. Şekilleri (N.sum(1).shape vs N.sum(1, keepdim=True).shape) yazdır.
Egzersiz 4 (Sinir ağı = sayım, doğrula). W = torch.randn((27,27), requires_grad=True) ile sinir ağı versiyonunu kur (one-hot → xenc @ W → exp → normalize → NLL). Gradient descent ile eğit (lr≈50); reg’siz saf NLL’in ≈2,47’ye — yani sayım modelinin ≈2,45’ine — indiğini gözlemle. 0.01 * (W**2).mean() regularization ekleyip etkisine bak: eğitim eğrisinde okunan değer reg cezası dahil ≈2,49 olur.
Egzersiz 5 (Sonraki dersin habercisi). Bigram yalnızca tek karaktere bakıyor. Bağlamı 3 karaktere çıkarmak istesen, sayım tablosu kaç hücre olur? (a) \(27^3 = ?\) hesapla; 10 karakter bağlam için \(27^{10}\)’un neden imkânsız olduğunu açıkla. (b) Bir sinir ağı (her karakteri küçük bir vektöre — embedding — gömüp birleştiren) bu patlamayı nasıl önler? Bu iki gözlem, Ders 3’te (makemore 2: MLP, Bengio 2003) sayım yerine neden öğrenilen embedding + gizli katmana geçtiğimizi motive eder.
3.19 Sonraki Ders İçin Hazırlık
Ders 3: makemore 2 — MLP (Bengio 2003) — Andrej Karpathy
Bigram tek karakter bağlamıyla sınırlıydı ve sayım tablosu bağlamla üstel büyüyor. Ders 3’te 2003 tarihli ünlü Bengio makalesini izleyip bir çok katmanlı algılayıcı (MLP) kuracağız: birkaç karakterlik bağlamı embedding tablosuyla küçük vektörlere gömüp, bir gizli tanh katmanından geçirip F.cross_entropy ile eğiteceğiz. Bu, bigram’ın sayım-patlamasını öğrenilen parametrelerle aşar.
Ana konular:
- Embedding arama tablosu C (bu dersin “one-hot @ W = satır seçimi” gözlemi somutlaşır).
- Bağlam penceresi (
block_size), gizlitanhkatmanı,F.cross_entropy. - Minibatch SGD, öğrenme oranı taraması, train/dev/test bölmesi.
UyarıDers 3 Öncesi Yapılacak
- Egzersizleri çöz — özellikle 4 (NN = sayım doğrulaması) ve 5 (bağlam patlaması sezgisi).
- “One-hot @ W = W’nin bir satırını seçer” gözlemini kendi cümlenle yaz (Ders 3’te embedding tam budur).
- Ana cümleyi tekrar oku: “Bir dil modeli, bir sonraki karakterin olasılık dağılımını üreten bir fonksiyondur.”
3.20 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| makemore / bigram | Karakter-düzeyli dil modeli; sonraki karakteri önceki tek karakterden tahmin eder | 0m06 |
| ‘.’ token | Başlangıç ve bitişi işaretleyen tek özel token (indeks 0) | 18m19 |
| s2i / i2s | Karakter ile tamsayı id arasındaki arama tabloları (tokenizer çekirdeği) | 12m45 |
| Sayım tensörü N | \(27 \times 27\) tamsayı tensör; N[i,j] = i’den sonra j’nin geçiş sayısı | 12m45 |
| Normalize + keepdim | P = N / N.sum(1, keepdim=True); satır normalizasyonu, broadcasting tuzağı | 36m17 |
| torch.multinomial | Olasılık dağılımından örnek çekme; tohumlu Generator ile tekrarlanabilir | 26m29 |
| Negatif log olabilirlik | Loss \(= -\frac{1}{n} \sum_i \log P(x_i)\); minimize = maximum likelihood; bigram ≈2,45 | 50m09 |
| Yumuşatma (smoothing) | Sahte sayı (+1) ekleyip sıfır olasılığı (\(\log(0) = -\infty\)) önleme | 1h00m |
| One-hot kodlama | Tamsayı id’yi tek-1’li sıfır vektörüne çevirme (F.one_hot); baz vektörü | 1h05m |
| logits / softmax | xenc@W ham çıktı = log-counts; exp + normalize = olasılık | 1h20m |
| Eğitim döngüsü | forward → NLL → loss.backward() → W.data += -lr·W.grad (zero_grad) | 1h35m |
| Count = gradient eşdeğerliği | Sayım (≈2,45) ile gradient descent (reg’siz ≈2,47; eğitim eğrisi ≈2,49) aynı modele varır | 1h42m |
| L2 reg = smoothing | \((W^2)\).mean() cezası W’yi 0’a iter (uniform); sahte sayımın NN karşılığı | 1h47m |
3.21 ML Builder Bağlantıları
İpucu9 köprü
- NLL / cross-entropy → Stat 110 maximum likelihood + Ders 1 cross-entropy (Bernoulli’nin multinomial genellemesi). İleriye: GPT’nin eğitim kaybı.
- softmax (exp + normalize) → Calculus \(e^x\) (Ders 5) + Stat 110 multinomial. İleriye: her sınıflandırıcının/dil modelinin son katmanı.
- one-hot @ W = satır seçimi → 18.06 baz vektörü/matris-vektör çarpımı (Ders 30). İleriye: Ders 3 embedding tablosu.
- forward/backward/update + zero_grad → Ders 1 micrograd döngüsünün tensör hâli. İleriye: tüm PyTorch eğitimi.
- torch.multinomial (tohumlu) → Stat 110 kategorik örnekleme + reproducibility. İleriye: GPT sampling (temperature, top-k).
- broadcasting / keepdim → tensör mekaniği. İleriye: sessiz şekil hatalarından kaçınma (production debug).
- L2 regularization = smoothing → Stat 110 Laplace/uniform prior. İleriye: weight decay (Ders 4, AdamW).
- sayım = gradient eşdeğerliği → bigram’da kapalı-form var; GPT’de YOK, yalnızca gradient descent kalır.
- “sonraki token’ı tahmin et” çerçevesi → tüm dil modellemenin çekirdeği; bigram → MLP → transformer hep aynı amaç.
3.22 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders için verdiği kaynaklar:
- makemore repo: github.com/karpathy/makemore —
names.txtve tam proje. - Ders notebook’u: makemore_part1_bigrams.ipynb — dersin adım adım kodu.
- Ders Colab notebook’u: Google Colab — çalıştırılabilir ortam.
ÖnemliTek bir şey alıp gideceksen
Bir dil modeli, “bir sonraki karakterin olasılık dağılımını” üreten bir fonksiyondur. Bigram bunu en sade hâliyle kurar — ve ister say-normalize et ister one-hot + softmax + gradient descent ile eğit, aynı modele ulaşırsın. Fark şu: yalnızca gradient descent yaklaşımı, bağlamı büyüttükçe (Ders 3 MLP, Ders 7 transformer) ölçeklenir. “That is amateur hour” — Karpathy, rastgele değil, gradient’le optimize et.