flowchart LR
A["Ders 3 duz MLP<br/>baglami TEK seferde duzlestir"] --> B["PyTorch-lastirma<br/>Embedding, Flatten, Sequential"]
B --> C["FlattenConsecutive(n)<br/>ardisik ciftleri grupla"]
C --> D["Hiyerarsik fuzyon (WaveNet)<br/>agac: 8 - 4 - 2 - 1"]
A --> E["Baglam 3 - 8<br/>daha uzun gecmis"]
E --> D
D --> F["Sekil yonetimi (B,T,C)<br/>BatchNorm1d 3B duzeltmesi"]
F --> G["Convolution baglantisi<br/>elle yazilmis dilated causal conv"]
style D fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style F fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style G fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
7 makemore 5 — WaveNet (Hiyerarşik Mimari)
Bağlamı tek hamlede ezmek yerine ardışık öğeleri kademeli (ağaç gibi: 8→4→2→1) füzyonlamak — WaveNet’in hiyerarşik fikri — daha derin ve güçlü bir dil modeli verir; ve bu, aslında elle yazılmış bir convolution’dır
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — Building makemore Part 5: Building a WaveNet (≈56 dk)
- Seri: Neural Networks: Zero to Hero — Ders 6
- Hoca: Andrej Karpathy
- Kaynak repo: github.com/karpathy/makemore
- Okuma süresi: ≈26 dk
7.1 Bu Derste Ne Var?
Ders 3’ün MLP’si, bağlamdaki tüm karakterleri tek seferde düzleştirip (.view) tek bir gizli katmana veriyordu. Bu derste daha derin, hiyerarşik bir yapıya geçiyoruz: bilgiyi kademeli olarak (önce 2’şer, sonra o çiftleri 2’şer, ağaç gibi) füzyonlayan bir WaveNet.
“You’ll notice the background behind me is different — that’s because I am in Kyoto and it is awesome.” — Karpathy, 0:06
“We would like to make a deeper model that progressively fuses this information to make its guess about the next character, with this tree-like structure.” — Karpathy, 0:46
Büyük fikir iki katmanlı: (1) Kodu daha da torch.nn-benzeri modüllere (Embedding, Flatten, Sequential) çekmek. (2) MLP’yi, bağlamı (3’ten 8 karaktere çıkarılmış) tek hamlede değil kademeli birleştiren bir ağaç yapısına dönüştürmek — bu, 2016 WaveNet makalesinin mimarisi.
Dersin üç büyük fikri:
- PyTorch-laştırma — Embedding, FlattenConsecutive, Sequential modülleri;
torch.nnAPI’sinin birebir taklidi. - Hiyerarşik füzyon (WaveNet) — bağlamı tek seferde değil, ardışık çiftler hâlinde kademeli birleştirme (ağaç / dilated causal convolution).
- Şekil (shape) yönetimi — 3 boyutlu tensörler, BatchNorm1d’in 3B düzeltmesi; “şekilleri kollamak” mühendisliği.
İpucuBuilder Notu — Geriye Ders 3-5, İleriye Ders 7
Geriye (Ders 3-5):
- Başlangıç kodu = Ders 3. WaveNet, doğrudan Ders 3’ün MLP’sinin üstüne kurulur. Karpathy net söyler: Ders 4 (BatchNorm) ve Ders 5 (manuel backprop) birer “aside” idi; ana hat Ders 3’ten devam eder.
- Modüller = Ders 4. Ders 4’te başlattığımız Linear/BatchNorm1d/Tanh bloklarını burada Embedding/Flatten/Sequential ile tamamlıyoruz —
torch.nn.Moduletaklidi olgunlaşıyor. - Autograd zemini = Ders 1+5. Hiyerarşik yapının gradyanı yine
loss.backward()ile akar; Ders 5’te backward’ı bir kez elle yazdığımız için arkada ne olduğunu biliyoruz — şimdi autograd’a güvenle dönebiliyoruz.
İleriye (Ders 7): WaveNet’in ağacı sabittir — hangi karakterin hangisiyle birleşeceği önceden bellidir. Ders 7’nin transformer’ı bunu yeniden organize eder: sabit ağaç yerine her token her tokena öğrenilen ağırlıklarla bakar (attention). Aynı “uzun bağlamı verimli işle” probleminin daha esnek (ama daha pahalı) çözümü.
Tek cümleyle: Bağlamı tek hamlede ezmek yerine, ardışık öğeleri kademeli (ağaç gibi) füzyonlamak — WaveNet’in hiyerarşik fikri — daha derin ve daha güçlü bir dil modeli verir; kod ise olgun torch.nn-tarzı modüllere kavuşur.
7.2 Motivasyon
Ders 3’ün MLP’sinin bir sınırı var: bağlamdaki tüm karakterlerin embedding’lerini tek seferde düzleştirip (emb.view(-1, ...)) bir gizli katmana “ezdiriyor”. Yani 8 karakterlik bir bağlamda bile, model tüm bilgiyi ilk katmanda birden yutuyor — yerel yapıyı kademeli kuramaz.
“This architecture takes this interesting hierarchical, tree-like structure to predicting the next character.” — Karpathy, 1:25
WaveNet’in fikri: bilgiyi kademeli birleştir. Önce komşu karakter çiftlerini füzyonla (2’şer), sonra bu füzyonları yine 2’şer birleştir, ta ki tüm bağlam tek bir temsile inene dek — bir ağaç gibi. Böylece model önce yerel desenleri (bigram-benzeri), sonra daha geniş yapıları öğrenir.
Aşağıdaki figür bu fikrin pedagojik imzasıdır: 8 karakterlik bağlam, ardışık çiftler hâlinde \(8 \to 4 \to 2 \to 1\) kademeli olarak tek temsile iner. Gösterilen şekiller uydurma değil — ANA WaveNet’in GERÇEK forward ara şekilleridir.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# ---------------------------------------------------------------------------
# WaveNet hiyerarşik AĞAÇ füzyonu (Notion §5) — FLAGSHIP, pedagojik imza.
# 8 karakterlik bağlam, ardışık çiftler hâlinde KADEMELİ birleşir: 8->4->2->1.
# Her seviye bir [FlattenConsecutive(2) -> Linear -> BatchNorm1d -> Tanh] bloğu.
#
# Bu KAVRAMSAL bir şemadır (kutu-ok ağacı), ama gösterilen ŞEKİLLER uydurma
# DEĞİL: ANA WaveNet'in GERÇEK forward ara şekillerini (forward_shapes) ölçüp
# her seviyenin (T, C) etiketini oradan okuruz. Determinist (sabit tohum).
# ---------------------------------------------------------------------------
torch.manual_seed(SEED)
# GERÇEK ara şekiller: build_wavenet'i tek minibatch'le ileri çalıştır, her
# katmanın çıktı şeklini topla (8->4->2->1 ağacının T ve C eksenlerini doğrula).
_wn = build_wavenet()
_Xtr, _Ytr, _Xdev, _Ydev, _Xte, _Yte = split_data()
_shapes = forward_shapes(_wn, _Xtr[:4]) # [(ad, (B,T,C)/(B,C)), ...]
# Embedding çıkışından kanal boyutu C (=N_EMBD) ve yaprak T (=block_size).
_emb_shape = _shapes[0][1] # (4, 8, 10)
T_leaf = _emb_shape[1] # 8 yaprak (bağlam uzunluğu)
C_emb = _emb_shape[2] # 10 (embedding boyutu)
# Tanh çıkışlarından her seviyenin kanal genişliği (hidden) — son boyut.
_hidden = [s for (nm, s) in _shapes if nm == "Tanh"][0][-1] # 68
_vocab = _shapes[-1][1][-1] # 27 (logit sayısı)
# Seviye başına (T, C) çifti — GERÇEK ölçümden (B düşürülmüş):
# seviye 0 (yapraklar) : T=8, C=embedding(10)
# seviye 1 : T=4, C=hidden(68)
# seviye 2 : T=2, C=hidden(68)
# seviye 3 (kök) : T=1, C=hidden(68) -> sonra Linear -> logit(27)
seviye_TC = [(T_leaf, C_emb), (4, _hidden), (2, _hidden), (1, _hidden)]
fig, ax = plt.subplots(figsize=(11, 7))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
# ---------------------------------------------------------------------------
# Ağaç yerleşimi: 4 yatay seviye (alttan üste). En altta 8 yaprak, üstte 1 kök.
# y: seviye 0 (yapraklar) en altta, seviye 3 (kök) en üstte.
# x: her seviyedeki düğümler [0, X_SPAN] aralığına eşit yayılır.
# ---------------------------------------------------------------------------
X_SPAN = 10.0
y_levels = [0.6, 2.5, 4.4, 6.3] # seviye 0..3 yükseklikleri
node_counts = [8, 4, 2, 1] # her seviyedeki düğüm sayısı
def level_xs(n):
"""n düğümü [0, X_SPAN] üzerinde ortalanmış eşit aralıkla yerleştir."""
if n == 1:
return [X_SPAN / 2.0]
step = X_SPAN / (n - 1)
return [i * step for i in range(n)]
positions = [level_xs(n) for n in node_counts] # positions[lvl] = [x0, x1, ...]
# ---------------------------------------------------------------------------
# Füzyon okları: seviye L'deki ardışık 2 düğüm -> seviye L+1'deki 1 düğüm.
# (slate ok; "ardışık çiftleri birleştir" hiyerarşisini gösterir)
# ---------------------------------------------------------------------------
leaf_w, leaf_h = 0.74, 0.62 # yaprak (küçük) kutu
node_w, node_h = 1.18, 0.84 # iç düğüm (füzyon) kutusu
for lvl in range(len(node_counts) - 1):
child_xs = positions[lvl]
parent_xs = positions[lvl + 1]
yc = y_levels[lvl]
yp = y_levels[lvl + 1]
for pj, px in enumerate(parent_xs):
for cx in (child_xs[2 * pj], child_xs[2 * pj + 1]): # ardışık çift
arrow = FancyArrowPatch(
(cx, yc + (leaf_h if lvl == 0 else node_h) / 2 + 0.02),
(px, yp - node_h / 2 - 0.02),
arrowstyle="-|>", mutation_scale=13,
color=COL_SLATE_400, linewidth=1.5,
connectionstyle="arc3,rad=0.0", zorder=1,
)
ax.add_patch(arrow)
# ---------------------------------------------------------------------------
# Düğüm kutuları. Seviye 0 = embedding yaprakları (8 karakter); üst seviyeler
# = füzyon düğümleri (indigo vurgu, ağacın çekirdeği). Kök indigo-600 (güçlü).
# ---------------------------------------------------------------------------
for lvl, xs in enumerate(positions):
y = y_levels[lvl]
T_lvl, C_lvl = seviye_TC[lvl]
for j, x in enumerate(xs):
if lvl == 0:
# Yaprak: bağlamdaki bir karakter (embedding). Küçük slate kutu.
box = FancyBboxPatch(
(x - leaf_w / 2, y - leaf_h / 2), leaf_w, leaf_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_BG, ec=COL_PRIMARY, linewidth=1.8, zorder=3,
)
ax.add_patch(box)
ax.text(x, y, f"$c_{{{j + 1}}}$", ha="center", va="center",
fontsize=11, color=COL_TEXT, weight="bold", zorder=5)
else:
# Füzyon düğümü: ardışık çiftin birleşimi. İndigo vurgu (kök en güçlü).
kok = (lvl == len(positions) - 1)
ec = COL_INDIGO_600 if kok else COL_ACCENT
fc = "#eef2ff"
lw = 2.8 if kok else 2.2
box = FancyBboxPatch(
(x - node_w / 2, y - node_h / 2), node_w, node_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, linewidth=lw, zorder=3,
)
ax.add_patch(box)
ust = "kök" if kok else "füzyon"
ax.text(x, y + node_h * 0.20, ust, ha="center", va="center",
fontsize=9.5, color=ec, weight="bold", zorder=5)
ax.text(x, y - node_h * 0.22, f"$(T{{=}}{T_lvl},\\,C{{=}}{C_lvl})$",
ha="center", va="center", fontsize=8.5,
color=COL_SLATE_800, zorder=5)
# ---------------------------------------------------------------------------
# Sol kenar: seviye etiketleri + (T, C) ekseni — kademeli füzyon okunaklı.
# Her seviye bir [FlattenConsecutive(2)->Linear->BatchNorm1d->Tanh] bloğu.
# ---------------------------------------------------------------------------
x_label = -1.55
seviye_adi = [
"girdi: 8 karakter\nembedding",
"1. blok\nFlattenConsec(2)",
"2. blok\nFlattenConsec(2)",
"3. blok -> kök\nFlattenConsec(2)",
]
for lvl in range(len(node_counts)):
T_lvl, C_lvl = seviye_TC[lvl]
ax.text(x_label, y_levels[lvl], seviye_adi[lvl], ha="center", va="center",
fontsize=8.8, color=COL_PRIMARY, style="italic", zorder=5,
linespacing=1.3)
# (T, C) rozet — sağ kenarda, seviye hizasında
ax.text(X_SPAN + 1.55, y_levels[lvl],
f"$T{{=}}{T_lvl}$\n$C{{=}}{C_lvl}$", ha="center", va="center",
fontsize=9, color=COL_INDIGO_600, weight="bold", zorder=5,
linespacing=1.4,
bbox=dict(boxstyle="round,pad=0.32", fc=COL_WHITE,
ec=COL_INDIGO_400, lw=1.2))
# Kökten çıkış: Linear -> logitler (27). Ağacın tepesinden bir ok daha.
x_kok = positions[-1][0]
y_kok = y_levels[-1]
ax.annotate("", xy=(x_kok, y_kok + node_h / 2 + 0.55),
xytext=(x_kok, y_kok + node_h / 2 + 0.04),
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=2.4),
zorder=2)
ax.text(x_kok + 1.7, y_kok + node_h / 2 + 0.52,
f"Linear $\\to$ logitler $({_vocab})$", ha="left", va="center",
fontsize=9.5, color=COL_INDIGO_600, weight="bold", zorder=5)
# ---------------------------------------------------------------------------
# Başlık + alt açıklama (kademeli füzyon vs tek-seferlik düzleştirme).
# ---------------------------------------------------------------------------
ax.text(X_SPAN / 2.0, y_levels[-1] + 1.55,
"Hiyerarşik füzyon: $8 \\to 4 \\to 2 \\to 1$ (ağaç)",
ha="center", va="center", fontsize=13.5, color=COL_TEXT,
weight="bold", zorder=5)
ax.text(X_SPAN / 2.0, y_levels[0] - 1.0,
"Her katman ardışık çiftleri birleştirir; alıcı alan "
"(receptive field) iki katına çıkar — "
"yereli önce, küreseli sonra.",
ha="center", va="center", fontsize=9.5, color=COL_PRIMARY,
style="italic", zorder=5)
ax.set_xlim(x_label - 1.4, X_SPAN + 3.2)
ax.set_ylim(y_levels[0] - 1.5, y_levels[-1] + 2.1)
ax.set_aspect("equal")
ax.axis("off")
plt.tight_layout()
plt.show()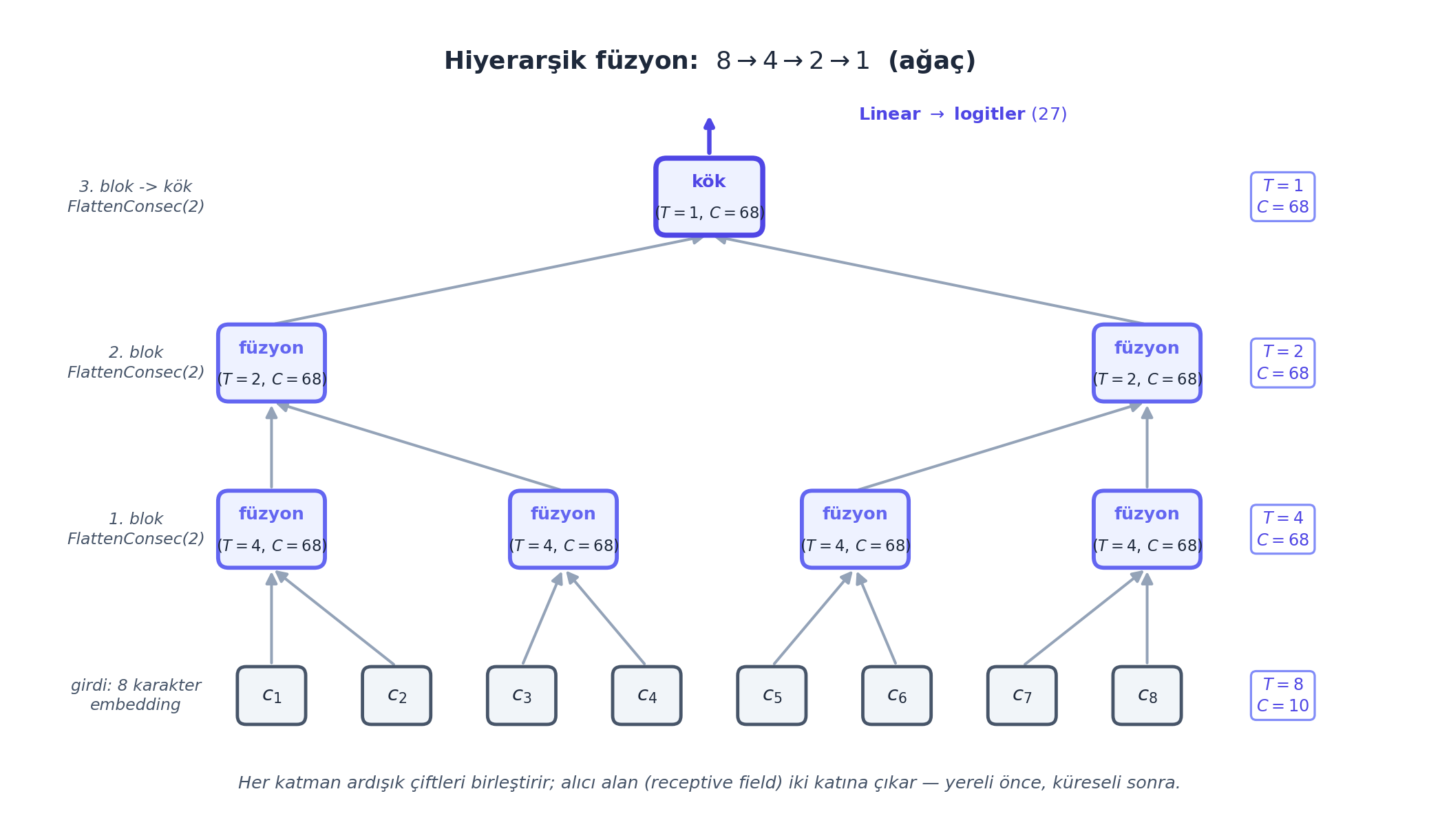
FlattenConsecutive(2) \(\to\) Linear \(\to\) BatchNorm1d \(\to\) Tanh bloğudur; alıcı alan (receptive field) her katmanda iki katına çıkar, \(\log_2 8 = 3\) katmanda tüm bağlam tek temsile iner. Zaman ekseni \(T\) (yaprak sayısı) yarıya inerken kanal ekseni \(C\) çiftlenir; GERÇEK forward şekilleri (ANA WaveNet, B çıkarılmış): yapraklar embedding \((T{=}8,\,C{=}10) \to (4,\,68) \to (2,\,68) \to (1,\,68) \to\) logitler \((27)\). Bu kademeli füzyon, elle yazılmış bir dilated causal convolution’dır (van den Oord 2016).
Bu hiyerarşinin Ders 3’ün düz MLP’siyle farkı, alıcı alan (receptive field) açısından nettir: düz MLP tüm bağlamı tek katmanda (sığ) ezer; WaveNet kademeli derinleşir.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# Alıcı alan (receptive field) kavramsal karşılaştırması: MLP-flat (sığ, tek
# katman) vs WaveNet (derin, hiyerarşik ağaç). Eğitim/forward ÇALIŞTIRMAZ; ağaç
# katman sayısı = log2(block_size) ilkesini ve 8->4->2->1 füzyonunu görselleştirir.
# Şekiller/sayılar L6 çekirdeğinden GERÇEK okunur (uydurma yok):
# - MLP-flat block_size = 3 (Ders 3): tek katman tüm bağlamı görür (derinlik 1).
# - WaveNet block_size = 8: 3 FlattenConsecutive(2) katmanı (log2(8)=3), 8->4->2->1.
# Determinist (şema; rastgelelik yok ama ilke gereği sabit tohum). apply_style
# KULLANILMAZ — bu bir kutu-ok şeması, eksen-grafik değil.
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERÇEK parametreler — L6 çekirdeğinden doğrula (uydurma yok).
# MLP-flat: build_mlp_flat(block_size=3) — düz Ders 3 MLP'si (kıyas).
# WaveNet : build_wavenet(block_size=8) — 3 FlattenConsecutive(2) = log2(8).
# ---------------------------------------------------------------------------
MLP_CTX = 3 # Ders 3 düz MLP bağlamı (block_size=3)
WN_CTX = BLOCK_SIZE # WaveNet bağlamı (8)
# MLP-flat'in TEK Linear katmanı tüm bağlamı görür -> derinlik 1 (Flatten sayılmaz).
_mlp = build_mlp_flat(block_size=MLP_CTX)
_mlp_linear = sum(1 for L in _mlp.layers if L.__class__.__name__ == "Linear") # 2 Linear
_mlp_depth = 1 # bağlam tek hamlede füzyonlanır (derinlik 1)
# WaveNet'in FlattenConsecutive katman sayısı = log2(block_size) = ağaç derinliği.
_wn = build_wavenet(block_size=WN_CTX)
_wn_fc = sum(1 for L in _wn.layers if L.__class__.__name__ == "FlattenConsecutive") # 3
import math
_wn_depth = int(round(math.log2(WN_CTX))) # log2(8) = 3 == _wn_fc
assert _wn_fc == _wn_depth, (_wn_fc, _wn_depth) # ağaç katmanı == log2(bağlam)
# WaveNet ağacının kademeli genişlikleri: 8 -> 4 -> 2 -> 1.
_wn_widths = [WN_CTX]
while _wn_widths[-1] > 1:
_wn_widths.append(_wn_widths[-1] // 2) # [8, 4, 2, 1]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 6))
fig.patch.set_facecolor(COL_WHITE)
# ===========================================================================
# SOL PANEL: Ders 3 DÜZ MLP — bağlam tek seferde (Flatten -> tek Linear).
# 3 girdi karakteri altta; tek gizli düğüm üstte; çıktı en üstte. TÜM girdiler
# doğrudan gizli katmana bağlı (alıcı alan = tüm bağlam, derinlik 1).
# ===========================================================================
axL.set_facecolor(COL_WHITE)
cw, ch = 0.78, 0.66 # karakter kutusu boyutu
in_y = 0.6 # girdi satırı y
hid_y = 2.7 # gizli katman y
out_y = 4.4 # çıktı y
# Girdi karakter kutuları (3 karakter, eşit aralıklı, ortalı).
mlp_xs = [1.0, 2.5, 4.0]
mlp_chars = ["c-2", "c-1", "c0"] # bağlam pozisyonları (ASCII, math yok)
for x, lab in zip(mlp_xs, mlp_chars):
box = FancyBboxPatch((x - cw / 2, in_y - ch / 2), cw, ch,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_ACCENT, ec=COL_INDIGO_600, linewidth=2.0, zorder=3)
axL.add_patch(box)
axL.text(x, in_y, lab, ha="center", va="center", fontsize=10,
color=COL_WHITE, weight="bold", zorder=4)
# Tek gizli düğüm (tüm bağlamı tek hamlede yutar) — ortalı.
hid_x = (mlp_xs[0] + mlp_xs[-1]) / 2
hb_w, hb_h = 2.9, 0.8
box = FancyBboxPatch((hid_x - hb_w / 2, hid_y - hb_h / 2), hb_w, hb_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc="#eef2ff", ec=COL_INDIGO_600, linewidth=2.8, zorder=3)
axL.add_patch(box)
axL.text(hid_x, hid_y + 0.13, "Flatten → tek Linear", ha="center", va="center",
fontsize=10.5, color=COL_INDIGO_600, weight="bold", zorder=4)
axL.text(hid_x, hid_y - 0.18, "bağlam tek hamlede ezilir",
ha="center", va="center", fontsize=8.5, color=COL_PRIMARY,
style="italic", zorder=4)
# Çıktı düğümü.
ob_w, ob_h = 2.0, 0.66
box = FancyBboxPatch((hid_x - ob_w / 2, out_y - ob_h / 2), ob_w, ob_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_BG, ec=COL_PRIMARY, linewidth=2.2, zorder=3)
axL.add_patch(box)
axL.text(hid_x, out_y, "çıktı (logitler)", ha="center", va="center",
fontsize=9.5, color=COL_TEXT, weight="bold", zorder=4)
# TÜM girdiler -> gizli katman (indigo, tek hamle = sığ alıcı alan).
for x in mlp_xs:
axL.add_patch(FancyArrowPatch(
(x, in_y + ch / 2 + 0.02), (hid_x + (x - hid_x) * 0.32, hid_y - hb_h / 2 - 0.02),
arrowstyle="-|>", mutation_scale=14, color=COL_ACCENT, linewidth=1.8,
connectionstyle="arc3,rad=0.0", zorder=2))
# gizli -> çıktı
axL.add_patch(FancyArrowPatch(
(hid_x, hid_y + hb_h / 2 + 0.02), (hid_x, out_y - ob_h / 2 - 0.02),
arrowstyle="-|>", mutation_scale=16, color=COL_PRIMARY, linewidth=2.0,
connectionstyle="arc3,rad=0.0", zorder=2))
# Alıcı alan açıklaması (tüm bağlam tek katmanda).
axL.text((mlp_xs[0] + mlp_xs[-1]) / 2, in_y - 0.95,
f"bağlam = {MLP_CTX} karakter · derinlik {_mlp_depth}\n"
"alıcı alan: tüm bağlam tek katmanda",
ha="center", va="center", fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_ACCENT, lw=1.3))
axL.set_xlim(-0.3, 5.3)
axL.set_ylim(-1.7, 5.2)
axL.set_aspect("equal")
axL.axis("off")
axL.set_title(f"Ders 3 düz MLP · sığ (derinlik {_mlp_depth})",
color=COL_TEXT, fontsize=12.5, weight="bold", pad=8)
# ===========================================================================
# SAĞ PANEL: WaveNet — hiyerarşik ağaç (8 -> 4 -> 2 -> 1), log2(8)=3 katman.
# Her seviye bir önceki seviyenin ardışık ÇİFTLERİNİ füzyonlar. İndigo çizgiler
# çocuk -> ebeveyn bağı; alıcı alan her seviyede iki katına çıkar.
# ===========================================================================
axR.set_facecolor(COL_WHITE)
n_levels = len(_wn_widths) # 4 seviye: 8,4,2,1
x_span = 7.6 # yatay yayılım
y_bot, y_top = 0.6, 4.6 # alt (girdi) ve üst (çıktı) y
nb_w, nb_h = 0.62, 0.5 # düğüm kutusu boyutu
def _level_positions(count, y):
"""count düğümü [0, x_span] üzerine eşit aralıklı yerleştir, (x, y) döndür."""
if count == 1:
return [(x_span / 2, y)]
step = x_span / (count - 1)
return [(i * step, y) for i in range(count)]
# Her seviyenin (x, y) konumları; seviye 0 = 8 girdi (altta), son = 1 çıktı (üstte).
level_pos = []
for li, w in enumerate(_wn_widths):
y = y_bot + (y_top - y_bot) * (li / (n_levels - 1))
level_pos.append(_level_positions(w, y))
# Bağ çizgileri (çocuk -> ebeveyn füzyonu); önce çizilsin (düğümlerin altında).
for li in range(n_levels - 1):
child = level_pos[li]
parent = level_pos[li + 1]
for pi, (px, py) in enumerate(parent):
# bu ebeveyn, çocuk seviyesinde 2 ardışık öğeden (2*pi, 2*pi+1) füzyon.
for ci in (2 * pi, 2 * pi + 1):
cx, cy = child[ci]
axR.add_patch(FancyArrowPatch(
(cx, cy + nb_h / 2 + 0.01), (px, py - nb_h / 2 - 0.01),
arrowstyle="-|>", mutation_scale=10, color=COL_ACCENT,
linewidth=1.5, connectionstyle="arc3,rad=0.0", zorder=2))
# Düğüm kutuları (her seviye). Girdi (alt) indigo dolgu; ara/çıktı slate çerçeve.
for li, lvl in enumerate(level_pos):
is_input = (li == 0)
is_output = (li == n_levels - 1)
for (x, y) in lvl:
if is_input:
fc, ec, lw = COL_ACCENT, COL_INDIGO_600, 1.8
elif is_output:
fc, ec, lw = "#eef2ff", COL_INDIGO_600, 2.6
else:
fc, ec, lw = COL_BG, COL_PRIMARY, 1.8
axR.add_patch(FancyBboxPatch(
(x - nb_w / 2, y - nb_h / 2), nb_w, nb_h,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=fc, ec=ec, linewidth=lw, zorder=3))
# Seviye etiketleri (sağ kenarda): T = 8 -> 4 -> 2 -> 1 + katman adı.
lvl_names = ["girdi: 8 karakter"]
for k in range(1, n_levels):
lvl_names.append(f"FlattenConsec(2): T={_wn_widths[k]}")
lvl_names[-1] = "çıktı (logitler): T=1"
for li, lvl in enumerate(level_pos):
y = lvl[0][1]
txt_col = COL_INDIGO_600 if (li == 0 or li == n_levels - 1) else COL_PRIMARY
axR.text(x_span + 0.55, y, lvl_names[li], ha="left", va="center",
fontsize=8.8, color=txt_col, weight="bold", zorder=4)
# Alıcı alan açıklaması (kademeli iki katına çıkma).
axR.text(x_span / 2, y_bot - 0.95,
f"bağlam = {WN_CTX} karakter · derinlik {_wn_depth} ($\\log_2 {WN_CTX} = {_wn_depth}$)\n"
"alıcı alan her katmanda iki katına çıkar (1→2→4→8)",
ha="center", va="center", fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_ACCENT, lw=1.3))
axR.set_xlim(-0.6, x_span + 3.6)
axR.set_ylim(-1.7, 5.2)
axR.set_aspect("equal")
axR.axis("off")
axR.set_title(f"WaveNet hiyerarşik ağaç · derin (derinlik {_wn_depth})",
color=COL_TEXT, fontsize=12.5, weight="bold", pad=8)
fig.suptitle("Alıcı alan: düz MLP (tek hamle) vs WaveNet (kademeli füzyon)",
color=COL_TEXT, fontsize=13.5, weight="bold", y=0.99)
plt.tight_layout(rect=(0, 0, 1, 0.96))
plt.show()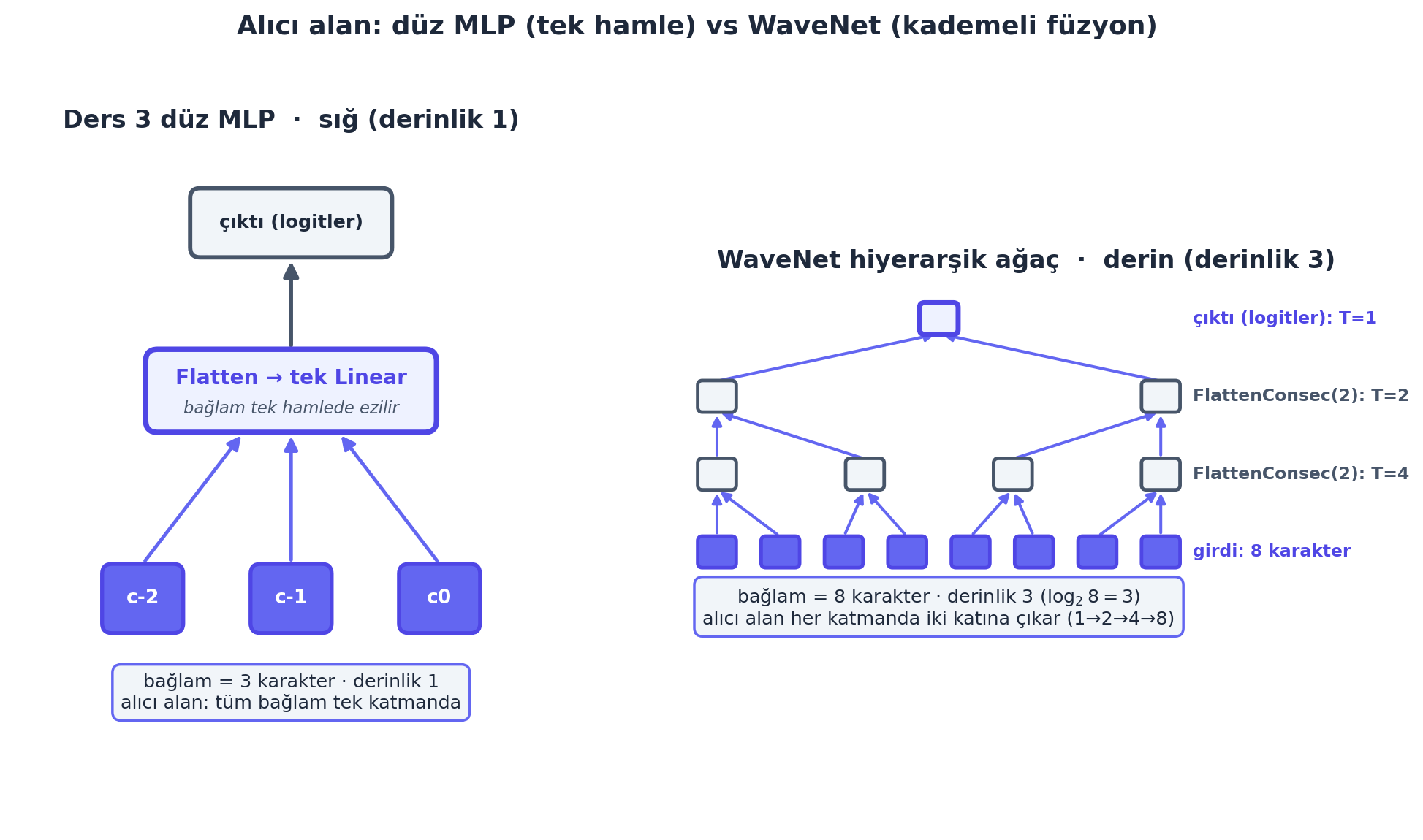
Flatten → tek Linear) hep birden ezilir; yerel yapı ile uzak yapı ayrımsız işlenir, derinlik \(1\). Sağda WaveNet — block_size \(=8\) karakter, \(\log_2 8 = 3\) katmanda kademeli (ağaç gibi \(8 \to 4 \to 2 \to 1\)) füzyonlanır: her FlattenConsecutive(2) adımı alıcı alanı iki katına çıkarır (1 katman 2 karakter görür, 2 katman 4, 3 katman 8). İndigo çizgiler, çıktının hangi girdilere bağlı olduğunu (alıcı alan) gösterir; düz MLP tüm bağlamı sığ tek hamlede, WaveNet derin + hiyerarşik birleştirir.
İpucuBuilder Notu — Ders 3 MLP Burada Başlangıç
Geriye (Ders 3): Bu dersin başlangıç noktası doğrudan Ders 3’ün MLP’sidir. WaveNet, o MLP’nin tek-seferlik düzleştirmesini (Flatten) kademeli füzyona (FlattenConsecutive) çevirir; embedding, eğitim döngüsü, cross-entropy aynen kalır. Yeni bir model değil — Ders 3’ün derinleştirilmiş hâli.
İleriye: Bu “kademeli/hiyerarşik füzyon”, convolution’ın özüdür: yerel pencerelerden başlayıp genişleyen alıcı alan. WaveNet ses dalga formu üretiminde bunu dilated causal convolution ile yapar (van den Oord 2016). Aynı hiyerarşi sezgisi, görüde CNN’lerin ve derin ağların genel tasarımıdır.
7.3 Başlangıç Kodu
Karpathy net bir şey söyler: bu dersin başlangıç kodu Ders 3’ün MLP’sidir — Ders 4 ve 5 birer kenar duraktı.
“The starter code for part five is very similar to where we ended up in part three. Recall that part four was the manual backprop exercise — that is kind of an aside.” — Karpathy, 1:43
Yani ana hat: Ders 3 (embedding + MLP) → Ders 6 (aynı modeli hiyerarşik + PyTorch-laştırılmış). Ders 4’te kurduğumuz modüller (Linear/BatchNorm1d/Tanh) başlangıç noktası; bu derste Embedding/Flatten/Sequential ekleyip yapıyı tamamlayacağız.
İpucuBuilder Notu — Ana Hat ve Aside’lar
Geriye (Ders 1-5): “Hangi ders neyin üstüne kurulur” netliği önemli: ana hat Ders 1 (autograd) → Ders 2 (bigram) → Ders 3 (MLP) → Ders 6 (WaveNet); Ders 4 (BatchNorm) ve Ders 5 (manuel backprop) derinleştirici aside’lar. Bu, serinin kasıtlı pedagojik yapısı.
İleriye: Başlangıç kodunu “hazır modüllerle temiz kurmak”, production’da yeni bir modele başlarken iyi bir alışkanlık — sıfırdan değil, denenmiş bloklardan.
7.4 Loss Düzleştirme
Karpathy önce küçük bir temizlik yapar: ham loss grafiği gürültülü ve okunaksız (her minibatch loss’u zıplıyor).
“Okay first let’s fix this graph because it is daggers in my eyes and I just can’t take it anymore.” — Karpathy, 6:58
Çözüm: loss kayıtlarını (lossi) 1000’lik gruplara böl, her grubun ortalamasını al. Bu, gürültüyü düzleştirip eğilimi (trend) görünür kılar.
# lossi: her adimin loss'u (cok gurultulu)
plt.plot(torch.tensor(lossi).view(-1, 1000).mean(1)) # 1000'lik gruplarin ortalamasi.view(-1, 1000) loss listesini 1000-sütunlu satırlara böler, .mean(1) her satırın ortalamasını alır → düzgün bir trend eğrisi. Bizim çekirdeğimizde bu, smooth_loss(lossi, k=1000) fonksiyonudur; düzleştirilmiş eğriyi WaveNet Eğitme bölümündeki eğitim figüründe kullanırız.
İpucuBuilder Notu — .view + .mean Düzleştirme
Geriye (Ders 3 + Stat 110): .view (Ders 3) ile yeniden şekillendirip .mean ile gruplama; minibatch gürültüsünün ortalama ile azalması (Stat 110: varyans \(\propto 1/B\)).
İleriye: Loss eğrisini düzleştirme (moving average / smoothing), her eğitim panelinin (W&B, TensorBoard) standart görselleştirmesi — ham gürültü trendi gizler.
7.5 PyTorch Modülleri
Ders 4’te Linear/BatchNorm1d/Tanh modüllerini kurmuştuk. Şimdi eksik parçaları ekleyip yapıyı torch.nn gibi tamamlarız: Embedding (id → vektör arama), Flatten (boyut düzleştirme), ve hepsini saran Sequential konteyner.
“There’s a Sequential [container]…” — Karpathy, 13:13
class Embedding:
def __init__(self, num_embeddings, embedding_dim):
self.weight = torch.randn((num_embeddings, embedding_dim))
def __call__(self, IX):
self.out = self.weight[IX] # id -> satir (Ders 2-3: lookup)
return self.out
def parameters(self):
return [self.weight]
class Flatten:
def __call__(self, x):
self.out = x.view(x.shape[0], -1) # (B, ...) -> (B, duz)
return self.out
def parameters(self):
return []
class Sequential:
def __init__(self, layers):
self.layers = layers
def __call__(self, x):
for layer in self.layers:
x = layer(x)
return x
def parameters(self):
return [p for layer in self.layers for p in layer.parameters()]Artık tüm model tek bir Sequential([...]) olarak kurulur — model(x) ileri geçişi, model.parameters() optimizer’ı besler. Bu, torch.nn.Module + nn.Sequential API’sinin birebir taklidi (Ders 1’in Neuron/Layer/MLP arabiriminin olgunlaşmış hâli).
İpucuBuilder Notu — call + parameters Arabirimi
Geriye (Ders 1-4): Embedding, Ders 2-3’ün id→satır lookup’ı; Sequential, Ders 1’in MLP istifleme mantığı. __call__ + parameters() arabirimi seri boyunca sabit.
İleriye: nn.Embedding, nn.Flatten, nn.Sequential — bunlar gerçek PyTorch katmanları; bu derste neden öyle tasarlandıklarını anlayarak kullanırsın. Transformer da (Ders 7) bu modüler bloklardan kurulur.
7.6 Hiyerarşik Fikir
WaveNet’in mimarisi, kulağa korkutucu gelen ama aslında basit bir fikre dayanır:
“In the WaveNet’s case, this is a visualization of a stack of dilated causal convolution layers — and this makes it sound very scary, but actually the idea is very simple.” — Karpathy, 19:04
Sezgi: tüm bağlamı tek katmanda yutmak yerine, bilgiyi bir ağaç gibi kademeli birleştir. 8 karakterlik bağlamda: 1. katman komşu çiftleri (4 çift) füzyonlar, 2. katman bu 4 sonucu 2’şer füzyonlar (2 sonuç), 3. katman son 2’yi birleştirir (1 temsil). Her katman, alıcı alanı (receptive field) iki katına çıkarır — logaritmik derinlikte (\(\log_2 8 = 3\)) tüm bağlama ulaşılır.
Bu, “yereli önce, küreseli sonra” prensibidir: alt katmanlar bigram-benzeri yerel desenleri, üst katmanlar geniş bağlamı yakalar.
İpucuBuilder Notu — Sabit Ağaç vs Öğrenilen Dikkat
İleriye (Ders 7): Hiyerarşik/ağaç yapısı, dilated causal convolution (genişletilmiş nedensel evrişim) olarak da bilinir — “nedensel” çünkü yalnızca geçmişe bakar (geleceğe değil), “dilated” çünkü her katman daha geniş bir aralığı kapsar. Bu, ses üretiminden (WaveNet) zaman serilerine kadar geniş kullanım alanı bulur. Ders 7’nin transformer’ı bunu yeniden organize eder: sabit ağaç yerine her token her tokena öğrenilen ağırlıklarla bakar (attention). WaveNet hangi öğenin hangisiyle birleşeceğini önceden sabitler; attention bunu veriye bırakır — bu yüzden daha esnek, ama \(O(T^2)\) maliyetiyle daha pahalı.
7.7 Bağlam 3-8
Hiyerarşik yapının değerli olması için daha uzun bağlam gerekir. Karpathy block_size’ı 3’ten 8’e çıkarır. MLP’de 8 karakteri tek seferde düzleştirmek mümkün ama verimsiz; WaveNet’in ağaç yapısı 8 karakteri 3 katmanda (\(8 \to 4 \to 2 \to 1\)) kademeli işler.
Bağlam büyüdükçe model daha uzak geçmişi görebilir — “emma”da ‘e’ ile ‘a’ arasındaki ilişki gibi. Ama bu, tensör şekillerini (B, T, C) yönetmeyi zorlaştırır; dersin geri kalanı büyük ölçüde doğru şekli korumakla ilgili.
Bağlamı tek başına 3’ten 8’e çıkarmak bile kaybı düşürür: bizim ölçümümüzde düz MLP-flat-3’ün final dev kaybı \(2{,}2484\) iken, aynı düz mimari bağlam 8’e çıkarılınca (MLP-flat-8) \(2{,}1872\)’ye iner. WaveNet’in hiyerarşik ağacı bunu daha da öteye götürür (\(2{,}1324\)) — bunu WaveNet Eğitme bölümünde ölçeceğiz.
İpucuBuilder Notu — block_size = Bağlam Uzunluğu
Geriye (Ders 3): block_size, Ders 3’te tanımladığımız bağlam uzunluğu; burada 3→8 büyütülüyor. Veri seti (build_dataset) aynı kayan-pencere mantığıyla çalışır, yalnızca pencere geniş.
İleriye: Bağlam uzunluğu (context length), her dil modelinin temel kapasite eksenidir — GPT-2’de 1024, modern modellerde yüz binlerce token (Ders 10). Uzun bağlam = daha çok bellek + hesap.
7.8 Batched matmul
Hiyerarşik füzyonu nasıl koda dökeriz? Karpathy şaşırtıcı ama güçlü bir PyTorch özelliğini kullanır: matris çarpımı son boyut üzerinde çalışır, öndeki boyutları batch sayar.
“The surprising thing that I’d like to show you, that you may not expect, is that this input that is being multiplied doesn’t actually have to be 2-dimensional.” — Karpathy, 24:44
Yani şekli (B, T, C) olan bir tensörü \(W\) (C, H) ile çarparsan, sonuç (B, T, H) olur — tüm (B, T) çiftleri paralel işlenir. Bu, hiyerarşik füzyonu mümkün kılar: bağlamı (B, T, C) gibi 3 boyutlu tut, ardışık çiftleri grupla, her grubu aynı lineer katmandan paralel geçir.
# (B, T, C) @ W(C, H) -> (B, T, H): B ve T batch gibi, C son boyutta carpilir
# WaveNet: ardisik ciftleri grupla -> (B, T/2, 2*C) -> Linear -> (B, T/2, H)Anahtar: lineer katman değişmedi (Ders 1’in \(Wx + b\)’si); değişen, girdiyi nasıl gruplayıp ona beslediğimiz. Bu gruplama işini bir sonraki bölümdeki FlattenConsecutive yapar.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# Batched matmul (Notion §7): (B,T,C) @ W(C,H) -> (B,T,H). Son boyut C carpilir,
# onceki (B,T) batch sayilir; B*T dilim ayni W'den PARALEL gecer. WaveNet'in ilk
# blogu: (32,4,20) @ (20,68) -> (32,4,68). Determinist (sabit tohum).
# Uydurma YOK: sekiller + paralel-vs-dongu maxdiff GERCEK olculur.
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERCEK sayilar: (32,4,20) tensoru (20,68) W ile carp; sonuc (32,4,68).
# Paralellik kaniti: tum tensoru tek hamlede carpmak == T uzerinde tek tek
# dolasip carpmak (her (b,t) dilimi bagimsiz). maxdiff ~ 0 (kayan-nokta).
# ---------------------------------------------------------------------------
B, T, C, H = 32, 4, 20, 68
g = torch.Generator().manual_seed(SEED)
x = torch.randn((B, T, C), generator=g) # (32, 4, 20) — FlattenConsec(2) ciktisi
W = torch.randn((C, H), generator=g) # (20, 68) — Linear agirligi
y = x @ W # (32, 4, 68) — tek hamlede (batched)
# Dilim-dilim (her zaman-adimi ayri 2B matmul) -> ayni sonuc olmali (paralellik).
y_loop = torch.stack([x[:, ti, :] @ W for ti in range(T)], dim=1)
maxdiff = (y - y_loop).abs().max().item()
shape_in = tuple(x.shape)
shape_W = tuple(W.shape)
shape_out = tuple(y.shape)
n_slices = B * T # 128 bagimsiz dilim
fig = plt.figure(figsize=(10, 6))
fig.patch.set_facecolor(COL_WHITE)
# ===========================================================================
# UST PANEL: blok semasi (B,T,C) @ W(C,H) = (B,T,H); son boyut carpilir.
# ===========================================================================
axT = fig.add_axes([0.04, 0.52, 0.92, 0.40])
axT.set_xlim(0, 10)
axT.set_ylim(0, 10)
axT.set_facecolor(COL_WHITE)
axT.axis("off")
def tensor_block(ax, cx, cy, w, h, name, shape, fc, ec, lw=2.4, txt=COL_TEXT,
batch_tag=None):
"""3B/2B tensor blogu: isim + sekil etiketi; opsiyonel 'batch' rozeti."""
box = FancyBboxPatch(
(cx - w / 2, cy - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=fc, ec=ec, linewidth=lw, zorder=3,
)
ax.add_patch(box)
ax.text(cx, cy + h * 0.20, name, ha="center", va="center",
fontsize=14, color=txt, weight="bold", zorder=5)
ax.text(cx, cy - h * 0.24, shape, ha="center", va="center",
fontsize=9.5, color=COL_PRIMARY, family="monospace", zorder=5)
if batch_tag is not None:
ax.text(cx, cy - h * 0.5 - 0.30, batch_tag, ha="center", va="top",
fontsize=8.5, color=COL_SLATE_800, zorder=5)
def op_sym(ax, x, y, sym, col=COL_PRIMARY, fs=20):
ax.text(x, y, sym, ha="center", va="center", fontsize=fs,
color=col, weight="bold", zorder=4)
yc = 5.6
# (B, T, C) girdi — onceki (B,T) batch, son C carpilir.
tensor_block(axT, 1.7, yc, 2.5, 3.2, "$X$", "(32, 4, 20)",
COL_BG, COL_PRIMARY,
batch_tag="(B, T) batch $\\cdot$ C son boyut")
op_sym(axT, 3.4, yc, r"$@$")
# W (C, H) — paylasilan Linear agirligi.
tensor_block(axT, 5.0, yc, 1.9, 2.4, "$W$", "(20, 68)",
"#eef2ff", COL_ACCENT, txt=COL_ACCENT,
batch_tag="C $\\to$ H")
op_sym(axT, 6.55, yc, r"$=$")
# (B, T, H) cikti.
tensor_block(axT, 8.3, yc, 2.6, 3.2, "$Y$", "(32, 4, 68)",
"#eef2ff", COL_INDIGO_600, lw=2.8, txt=COL_INDIGO_600,
batch_tag="(B, T) korunur $\\cdot$ H yeni son boyut")
# Ic boyut uyumu vurgusu (C=20 ortak).
axT.text(4.2, yc + 2.35, r"iç boyut $C = 20$ uyuşur",
ha="center", va="bottom", fontsize=9, color=COL_SLATE_800, weight="bold")
axT.text(5.0, 9.55,
r"Son boyut çarpılır, öndeki $(B, T)$ boyutları batch sayılır",
ha="center", va="center", fontsize=12, color=COL_TEXT, weight="bold")
# ===========================================================================
# ALT PANEL: paralellik — B*T=128 dilim ayni W'den gecer (3 ornek dilim + GERCEK).
# ===========================================================================
axB = fig.add_axes([0.04, 0.05, 0.92, 0.40])
axB.set_xlim(0, 10)
axB.set_ylim(0, 10)
axB.set_facecolor(COL_WHITE)
axB.axis("off")
axB.text(0.2, 9.0, f"Paralellik: {n_slices} dilim, tek $W$",
ha="left", va="center", fontsize=10.5, color=COL_INDIGO_600, weight="bold")
# Uc ornek (b,t) dilim -> hepsi ayni W -> 68B cikti (yan yana, paralel oklar).
slice_labels = ["$(b, t) = (0, 0)$", "$(b, t) = (0, 1)$", r"$\vdots$"]
ys_slices = [6.4, 3.8, 1.4]
for lbl, ys in zip(slice_labels, ys_slices):
if lbl == r"$\vdots$":
axB.text(1.3, ys, lbl, ha="center", va="center", fontsize=14,
color=COL_PRIMARY)
axB.text(4.9, ys, lbl, ha="center", va="center", fontsize=14,
color=COL_ACCENT)
axB.text(8.4, ys, lbl, ha="center", va="center", fontsize=14,
color=COL_INDIGO_600)
continue
# 20B girdi dilimi
box_in = FancyBboxPatch((0.5, ys - 0.55), 1.6, 1.1,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=COL_BG, ec=COL_PRIMARY, linewidth=1.6, zorder=3)
axB.add_patch(box_in)
axB.text(1.3, ys, "20B", ha="center", va="center", fontsize=9.5,
color=COL_TEXT, family="monospace", zorder=5)
# ok -> W
arr1 = FancyArrowPatch((2.2, ys), (4.0, ys), arrowstyle="-|>",
mutation_scale=14, color=COL_SLATE_400,
linewidth=1.5, zorder=2)
axB.add_patch(arr1)
# paylasilan W (orta)
box_W = FancyBboxPatch((4.0, ys - 0.55), 1.8, 1.1,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc="#eef2ff", ec=COL_ACCENT, linewidth=1.8, zorder=3)
axB.add_patch(box_W)
axB.text(4.9, ys, "$W$ (20,68)", ha="center", va="center", fontsize=8.5,
color=COL_ACCENT, family="monospace", weight="bold", zorder=5)
# ok -> cikti
arr2 = FancyArrowPatch((5.9, ys), (7.6, ys), arrowstyle="-|>",
mutation_scale=14, color=COL_INDIGO_600,
linewidth=1.5, zorder=2)
axB.add_patch(arr2)
# 68B cikti dilimi
box_out = FancyBboxPatch((7.6, ys - 0.55), 1.6, 1.1,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc="#eef2ff", ec=COL_INDIGO_600, linewidth=1.8, zorder=3)
axB.add_patch(box_out)
axB.text(8.4, ys, "68B", ha="center", va="center", fontsize=9.5,
color=COL_INDIGO_600, family="monospace", zorder=5)
# dilim etiketi (sol)
axB.text(0.5, ys + 0.85, lbl, ha="left", va="center", fontsize=8,
color=COL_SLATE_800, zorder=5)
# GERCEK dogrulama rozeti (paralel == dongu).
md_txt = ("0,0" if maxdiff == 0.0
else f"{maxdiff:.1e}".replace(".", ",").replace("e-0", " x 10^-"))
axB.text(9.9, 9.0,
f"GERÇEK: batched $=$ döngü\nmaxdiff $= {md_txt}$",
ha="right", va="center", fontsize=8.5, color=COL_TEXT,
family="monospace", linespacing=1.5, zorder=5,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_PRIMARY, lw=1.4))
fig.suptitle("Batched matmul", fontsize=14, color=COL_TEXT, weight="bold", y=0.99)
plt.show()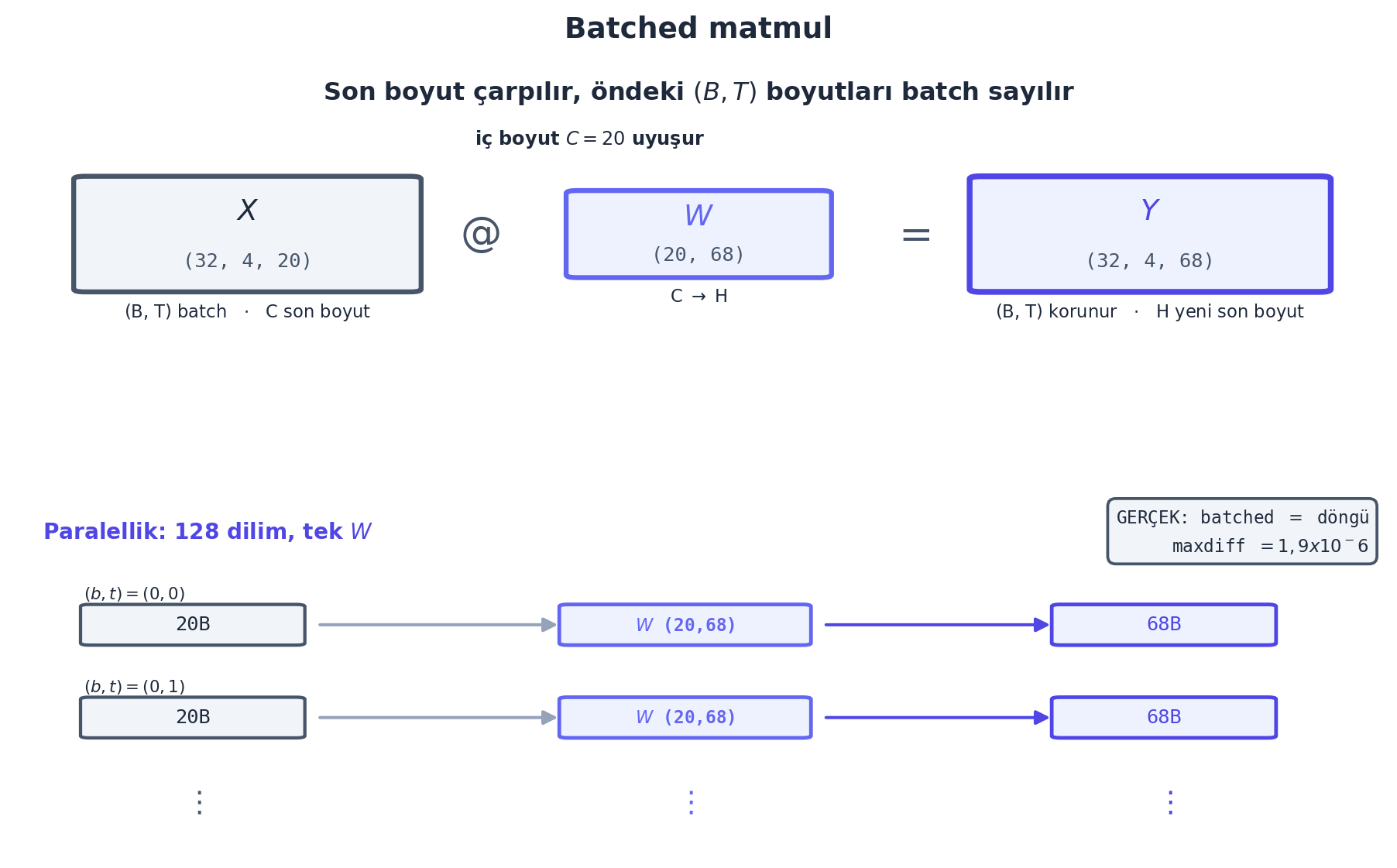
(B, T, C) @ W son boyutu \(C\) çarpar, öndeki (B, T) boyutlarını batch sayar — sonuç (B, T, H). GERÇEK (\(B=32\), \(T=4\), \(C=20\), \(H=68\)): WaveNet’in ilk bloğunda \((32, 4, 20) @ (20, 68) \to (32, 4, 68)\). Aynı \(W\) (Linear katmanı), \(B \cdot T = 128\) dilime paralel uygulanır: her \((b, t)\) konumundaki \(20\)-boyutlu vektör tek başına \(W\) ile çarpılır. Doğrulama: tüm tensörü tek hamlede çarpmak ile \(T\) ekseni üzerinde tek tek dolaşıp çarpmak aynı sonucu verir (maxdiff \(= 1{,}9 \times 10^{-6}\), kayan-nokta gürültüsü). Anahtar: Linear değişmedi (Ders 1’in \(Wx\)’i); değişen, girdiyi nasıl gruplayıp ona beslediğimiz.
İpucuBuilder Notu — Batched matmul = Linear’ın Çok-Boyutlu Hâli
Geriye (Ders 1 + 18.06): Batched matmul, Ders 1’in lineer katmanının çok-boyutlu hâli (18.06 matris çarpımı, son eksende). “Öndeki boyutlar batch” kuralı, tensör hesabının her yerinde geçerli.
İleriye: Bu batched-matmul deseni, transformer’da (Ders 7) attention’ın çok başlı (multi-head) hesabının da temeli: (B, head, T, d) şekilli tensörlerde son boyutlarda matmul, öndekiler batch. GPU bu paralelliği sever (yüksek throughput).
7.9 FlattenConsecutive
Hiyerarşik füzyonun çekirdeği: ardışık öğeleri gruplama. Karpathy FlattenConsecutive(n) adlı bir modül yazar — şekli (B, T, C) olan bir tensörü alıp ardışık \(n\) öğeyi birleştirir: (B, T, C) → (B, T/n, C·n).
class FlattenConsecutive:
def __init__(self, n):
self.n = n
def __call__(self, x):
B, T, C = x.shape
x = x.view(B, T // self.n, C * self.n) # ardisik n ogeyi birlestir
if x.shape[1] == 1:
x = x.squeeze(1) # T/n == 1 ise o boyutu kaldir
self.out = x
return self.out
def parameters(self):
return []Örneğin \(n=2\) ile (4, 8, 10) → (4, 4, 20): 8 zaman-adımı 4 çifte iner, her çiftin 10-boyutlu embedding’leri yan yana gelip 20-boyut olur. Sonra bir Linear bu 20’yi işler. Bunu üst üste istifleyince (FlattenConsecutive(2) → Linear → BatchNorm → Tanh blokları) ağaç yapısı oluşur: \(8 \to 4 \to 2 \to 1\). squeeze(1), son katmanda \(T/n=1\) olunca gereksiz boyutu temizler.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, ConnectionPatch
# FlattenConsecutive(2) operasyonu (Notion §8): bir tek örneğin (b=0) zaman x kanal
# izgarası, ardışik 2 zaman-adimini yan yana birlestirerek nasil yeniden
# sekillendigini gosterir. 4 asama: (4,8,10) -> (4,4,20) -> (4,2,40) -> (4,80).
# Determinist (sabit tohum). Uydurma YOK: tum sekiller GERCEK tensorle olculur.
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERCEK sekiller: bir (4, 8, 10) tensor uzerinde FlattenConsecutive(2)'yi
# kademeli uygula ve her asamanin seklini OLC (forward_shapes mantigi).
# ---------------------------------------------------------------------------
B0, T0, C0 = 4, 8, 10
x = torch.randn((B0, T0, C0))
fc = FlattenConsecutive(2)
stages = [tuple(x.shape)] # (4, 8, 10)
x1 = fc(x.clone()); stages.append(tuple(x1.shape)) # (4, 4, 20)
x2 = fc(x1.clone()); stages.append(tuple(x2.shape)) # (4, 2, 40)
x3 = fc(x2.clone()); stages.append(tuple(x3.shape)) # (4, 80) — squeeze(1)
# Izgara cizimi icin (T, C) ciftleri (ilk uc asama 3B, son asama squeeze sonrasi).
TC = [(T0, C0), # (8, 10)
(T0 // 2, C0 * 2), # (4, 20)
(T0 // 4, C0 * 4), # (2, 40)
(1, C0 * 8)] # (1, 80) -> squeeze -> (4, 80)
fig, axes = plt.subplots(1, 4, figsize=(10, 6))
fig.patch.set_facecolor(COL_WHITE)
# Her asamada kullanilan renk: kademeli koyulasan indigo (yereli->kuresel fuzyon).
stage_cols = [COL_SLATE_400, COL_INDIGO_400, COL_ACCENT, COL_INDIGO_600]
# Cift renklendirme: ardisik 2 zaman-adimi tek renge boyanir (fuzyon vurgusu).
pair_a, pair_b = "#e0e7ff", "#c7d2fe" # acik indigo tonlari (cift ayrimi)
stage_titles = [
"Girdi\n(embedding)",
r"$1.$ FlattenConsec(2)",
r"$2.$ FlattenConsec(2)",
r"$3.$ + squeeze(1)",
]
stage_caps = [
"(4, 8, 10)",
"(4, 4, 20)",
"(4, 2, 40)",
"(4, 80)",
]
# Ortak hucre olcegi: tum izgaralar ayni toplam alani (80 hucre) kaplar -> esit gorsel.
CELL = 0.92 # tek hucre kenar uzunlugu (eksen birimi)
for k, ax in enumerate(axes):
ax.set_facecolor(COL_WHITE)
ax.axis("off")
T, C = TC[k]
grid_w = C * (CELL / 10.0) * 1.0 # genislik: kanal sayisina orantili (sikistir)
# Izgarayi orta-hizali konumlandirmak icin koordinat sistemi
cw = 1.0 # hucre genisligi (gorsel)
ch = 1.0 # hucre yuksekligi
# Tum asamalar 80 hucre; izgarayi T(satir) x C(sutun) ciz, kanali sikistir.
sx = 8.0 / C # x olcegi: genislik sabit ~8 birim
sy = 8.0 / max(T, 1) # y olcegi: yukseklik sabit ~8 birim
x0 = -(C * sx) / 2.0
y0 = -(T * ch * sy) / 2.0
for ti in range(T):
for ci in range(C):
# ardisik 2 zaman-adimini ayni renk grubuna boya (fuzyon hikayesi)
if k == 0:
pair_idx = ti // 2 # girdide 8 satir -> 4 cift
else:
pair_idx = ti # sonraki asamalarda satirlar zaten cift-fuzyonu
fc_color = pair_a if (pair_idx % 2 == 0) else pair_b
rect = FancyBboxPatch(
(x0 + ci * sx, y0 + (T - 1 - ti) * ch * sy),
sx * 0.96, ch * sy * 0.96,
boxstyle="square,pad=0.0",
fc=fc_color, ec=stage_cols[k], linewidth=0.7, zorder=2,
)
ax.add_patch(rect)
# Eksen sinirlari (izgarayi ortala + nefes payi)
ax.set_xlim(-5.2, 5.2)
ax.set_ylim(-5.6, 6.2)
ax.set_aspect("equal")
# Asama basligi (ust) + sekil etiketi (alt)
ax.text(0, 5.7, stage_titles[k], ha="center", va="center",
fontsize=11, color=stage_cols[k] if k > 0 else COL_PRIMARY,
weight="bold", zorder=4)
ax.text(0, -5.2, stage_caps[k], ha="center", va="center",
fontsize=12, color=COL_TEXT, weight="bold", family="monospace",
zorder=4)
# Eksen yon etiketleri (T satir, C sutun) — sadece ilk panelde
if k == 0:
ax.text(0, -4.4, "$T$ satir, $C$ sutun ($b=0$)", ha="center", va="center",
fontsize=8.5, color=COL_SLATE_800, zorder=4)
# Asamalar arasi oklar (fuzyon yonu) — komsu eksenler arasinda (ConnectionPatch).
for ax_from, ax_to in zip(axes[:-1], axes[1:]):
con = ConnectionPatch(
xyA=(1.0, 0.5), coordsA=ax_from.transAxes,
xyB=(0.0, 0.5), coordsB=ax_to.transAxes,
connectionstyle="arc3,rad=0.0",
arrowstyle="-|>", mutation_scale=18,
color=COL_INDIGO_600, linewidth=1.8, zorder=5,
)
fig.add_artist(con)
fig.suptitle("FlattenConsecutive 2", fontsize=14, color=COL_TEXT, weight="bold", y=0.99)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()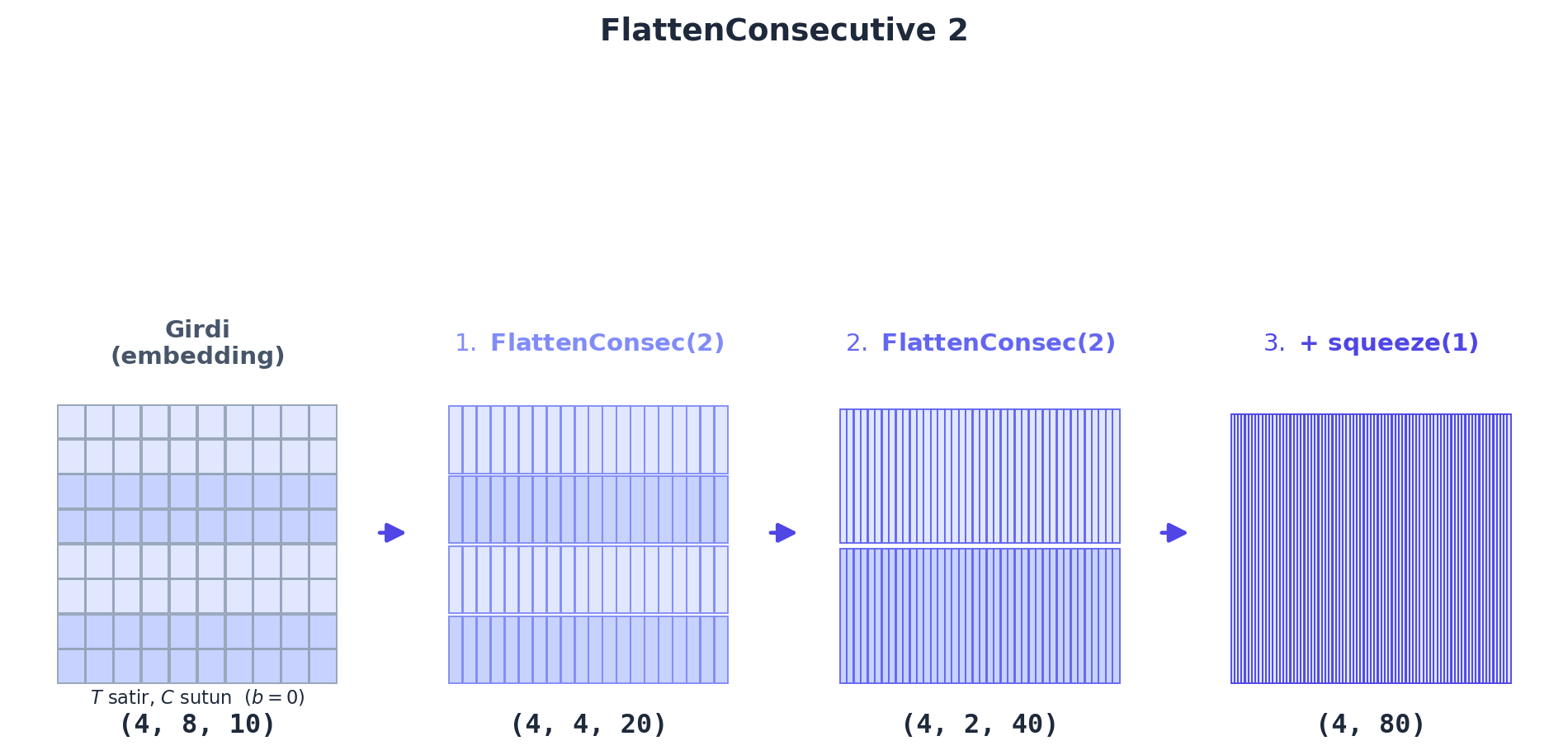
FlattenConsecutive(2), ardışık çiftleri yan yana birleştirir: (B, T, C) → (B, T/2, 2C). Aynı katman üst üste istiflenince WaveNet ağacı çıkar: \((4, 8, 10) \to (4, 4, 20) \to (4, 2, 40) \to (4, 80)\) — zaman ekseni \(T\) her adımda yarıya iner (\(8 \to 4 \to 2 \to 1\)), kanal ekseni \(C\) iki katına çıkar (\(10 \to 20 \to 40 \to 80\)); öğe sayısı (izgara hücresi) \(B\) hariç sabit kalır (\(80\)). Son adımda \(T/2 = 1\) olunca squeeze(1) o ekseni atar: \((4, 1, 80) \to (4, 80)\). Bu, elle yazılmış bir convolution adımıdır — yereli (komşu çiftleri) önce füzyonlar.
İpucuBuilder Notu — FlattenConsecutive = Elle Yazılmış Convolution
Geriye (Ders 3): .view ile yeniden gruplama, Ders 3’ün .view(-1, 6)’sının genellemesi — orada tüm bağlamı tek seferde, burada kademeli. squeeze ise 1-boyutlu ekseni atar (broadcasting’in tersi gibi).
İleriye: FlattenConsecutive, aslında elle yazılmış bir convolution (kayan grup) — torch.nn.Conv1d bunu daha genel yapar. Bu, “katmanı kendin yazınca kütüphane katmanını anlarsın” prensibinin tekrarı.
7.10 WaveNet Eğitme
Tüm blokları bir Sequential’da istifleriz: Embedding → (FlattenConsecutive(2) → Linear → BatchNorm1d → Tanh) ×3 → Linear (çıkış). Eğitim döngüsü Ders 3-4’ün aynısı (forward → cross_entropy → backward → update).
model = Sequential([
Embedding(vocab_size, n_embd),
FlattenConsecutive(2), Linear(n_embd*2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
FlattenConsecutive(2), Linear(n_hidden*2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
FlattenConsecutive(2), Linear(n_hidden*2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, vocab_size),
])Aşağıdaki blok şeması tam yapıyı GERÇEK tensör şekilleriyle gösterir: \(T\) ekseni ağaç gibi \(8 \to 4 \to 2 \to 1\) inerken kanal ekseni \(C\) çift FlattenConsec ile geçici olarak ikiye katlanır (\(10 \to 20\), \(68 \to 136\)) ve Linear onu tekrar \(68\)’e indirir.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# Determinist: figür yalnızca build_wavenet'in sabit yapısına + GERÇEK forward
# şekillerine dayanır. Şekiller UYDURMA DEĞİL — L6 çekirdeğinin forward_shapes
# cache'inden okunur (split_data + build_wavenet ile doğrulanmış). B = 32 (gerçek
# minibatch). Aynı tohum -> aynı yapı -> aynı şekiller.
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERÇEK şekiller: WaveNet'i kur, 32'lik gerçek bir batch geçir, her katmanın
# çıktı şeklini ölç. (Hiçbir şekil elle yazılmaz; tek kaynak forward_shapes.)
# ---------------------------------------------------------------------------
_Xtr, _Ytr, _, _, _, _ = split_data()
_wn = build_wavenet()
_Xb = _Xtr[:32] # GERÇEK batch (B=32)
_shapes = forward_shapes(_wn, _Xb) # [(katman_adı, şekil), ...]
def _fmt(shape):
"""Şekil tuple'ını '(a, b, c)' biçiminde düz metne çevir."""
return "(" + ", ".join(str(d) for d in shape) + ")"
# ---------------------------------------------------------------------------
# Katmanları mantıksal aşamalara grupla. forward_shapes sırası (doğrulanmış):
# Embedding | [FlattenConsec, Linear, BatchNorm1d, Tanh] x3 | Linear
# İndeksler: 0 | 1 2 3 4 | 5 6 7 8 | 9 10 11 12 | 13
# Her katman kutusu: (etiket, şekil, parametreli mi?). Parametreli =
# Embedding/Linear/BatchNorm1d. Embedding'in (27,10)=270 ağırlığı öğrenilebilir
# (requires_grad=True, parameters()->[weight]) — modelin çekirdek arama tablosu.
# ---------------------------------------------------------------------------
PARAMLI = {"Embedding", "Linear", "BatchNorm1d"} # öğrenilebilir parametreli katmanlar
# Katman kutularını (etiket, şekil, paramlı) listesine indir.
layers = [(name, _fmt(shape), name in PARAMLI) for name, shape in _shapes]
# Blok sınırları (arka plan bantları için): Embedding | Blok1 | Blok2 | Blok3 | Çıkış
# Blok = FlattenConsec'ten Tanh'a 4 katman; ilk katman Embedding, son katman Linear.
blocks = [
{"name": "Embedding", "lo": 0, "hi": 1, "T": "T=8"}, # 0
{"name": "Blok 1 (T: 8 -> 4)", "lo": 1, "hi": 5, "T": "T=4"}, # 1-4
{"name": "Blok 2 (T: 4 -> 2)", "lo": 5, "hi": 9, "T": "T=2"}, # 5-8
{"name": "Blok 3 (T: 2 -> 1)", "lo": 9, "hi": 13, "T": "T=1"}, # 9-12
{"name": "Cikis Linear", "lo": 13, "hi": 14, "T": "logit"}, # 13
]
# ---------------------------------------------------------------------------
# Yerleşim. Katmanları soldan sağa eşit aralıkla diz. aspect serbest (12x6
# figürü doldurur); x/y bağımsız ölçeklenir, kutular çakışmaz.
# ---------------------------------------------------------------------------
n_layers = len(layers) # 14
DX = 1.0 # katmanlar arası yatay adım
x0 = 0.6 # ilk katmanın merkez x'i
xs = [x0 + i * DX for i in range(n_layers)] # her katmanın merkez x'i
Y0 = 0.0 # katman kutularının merkez y'si
box_w, box_h = 0.78, 1.05 # katman kutusu boyutu
fig, ax = plt.subplots(figsize=(12, 6))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
# Blok renkleri: alternatif slate-100 / indigo-50 bantlar (Slate+Indigo).
band_cols = [COL_BG, "#eef2ff", COL_BG, "#eef2ff", COL_BG]
Y_BAND_TOP = 1.55
Y_BAND_BOT = -1.95
# --- arka plan blok bantları (en arkada) ---
for b, col in zip(blocks, band_cols):
bx0 = xs[b["lo"]] - box_w / 2 - 0.16
bx1 = xs[b["hi"] - 1] + box_w / 2 + 0.16
rect = FancyBboxPatch(
(bx0, Y_BAND_BOT), bx1 - bx0, Y_BAND_TOP - Y_BAND_BOT,
boxstyle="round,pad=0.0,rounding_size=0.10",
fc=col, ec=COL_SLATE_400, linewidth=1.0, alpha=0.6, zorder=0,
)
ax.add_patch(rect)
# blok adı (üstte)
ax.text((bx0 + bx1) / 2, Y_BAND_TOP - 0.26, b["name"],
ha="center", va="center", fontsize=10.5, color=COL_PRIMARY,
weight="bold", style="italic", zorder=1)
# zaman/ağaç göstergesi (altta) — 8 -> 4 -> 2 -> 1 ağacı
ax.text((bx0 + bx1) / 2, Y_BAND_BOT + 0.24, b["T"],
ha="center", va="center", fontsize=10, color=COL_INDIGO_600,
weight="bold", zorder=1)
# --- katmanlar arası oklar (indigo veri akışı) ---
for i in range(n_layers - 1):
arrow = FancyArrowPatch(
(xs[i] + box_w / 2, Y0), (xs[i + 1] - box_w / 2, Y0),
arrowstyle="-|>", mutation_scale=12,
color=COL_ACCENT, linewidth=1.6,
connectionstyle="arc3,rad=0.0", zorder=2,
)
ax.add_patch(arrow)
# --- katman kutuları + etiket + GERÇEK şekil ---
# Uzun etiketler için kısaltma (kutuya sığsın): FlattenConsecutive -> FlatConsec(2)
KISA = {
"Embedding": "Embed",
"FlattenConsecutive": "FlatCon\n(2)",
"BatchNorm1d": "Batch\nNorm",
"Linear": "Linear",
"Tanh": "Tanh",
}
for i, (name, shape, paramli) in enumerate(layers):
x = xs[i]
# Dolgu: paramli (Linear/BN) -> indigo; parametresiz -> slate-100.
if paramli:
fc = COL_ACCENT
ec = COL_INDIGO_600
txt_col = COL_WHITE
lw = 2.0
else:
fc = COL_BG
ec = COL_SLATE_400
txt_col = COL_TEXT
lw = 1.4
box = FancyBboxPatch(
(x - box_w / 2, Y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, linewidth=lw, zorder=3,
)
ax.add_patch(box)
# katman adı (kutu içi)
ax.text(x, Y0 + 0.06, KISA.get(name, name), ha="center", va="center",
fontsize=8.2, color=txt_col, weight="bold", zorder=4)
# GERÇEK şekil (kutu altında, dik açıyla okunaklı)
ax.text(x, Y0 - box_h / 2 - 0.12, shape, ha="center", va="top",
fontsize=7.4, color=COL_PRIMARY, rotation=90, zorder=4)
# --- giriş/çıkış etiketleri ---
ax.text(xs[0] - box_w / 2 - 0.05, Y0 + box_h / 2 + 0.30,
r"giris: $X_b$ (32, 8)", ha="left", va="bottom",
fontsize=9, color=COL_INDIGO_600, weight="bold")
ax.text(xs[-1] + box_w / 2 + 0.05, Y0 + box_h / 2 + 0.30,
r"cikis: 27 logit", ha="right", va="bottom",
fontsize=9, color=COL_INDIGO_600, weight="bold")
# --- lejant (alt) ---
ax.text((xs[0] + xs[-1]) / 2, Y_BAND_BOT - 0.45,
"indigo = ogrenilebilir parametreli (Embedding / Linear / BatchNorm1d) · "
"slate = parametresiz sekil/aktivasyon (FlattenConsec / Tanh) · "
"alt satir: GERCEK tensor sekli (forward_shapes, B=32)",
ha="center", va="center", fontsize=8.6, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.2))
ax.set_xlim(xs[0] - 1.4, xs[-1] + 1.4)
ax.set_ylim(Y_BAND_BOT - 0.95, Y_BAND_TOP + 0.35)
ax.axis("off")
ax.set_title("WaveNet blok semasi: Embedding -> 3x[FlatConsec -> Linear -> BatchNorm -> Tanh] -> Linear (agac 8 -> 4 -> 2 -> 1)",
color=COL_TEXT, fontsize=12, pad=8)
plt.tight_layout()
plt.show()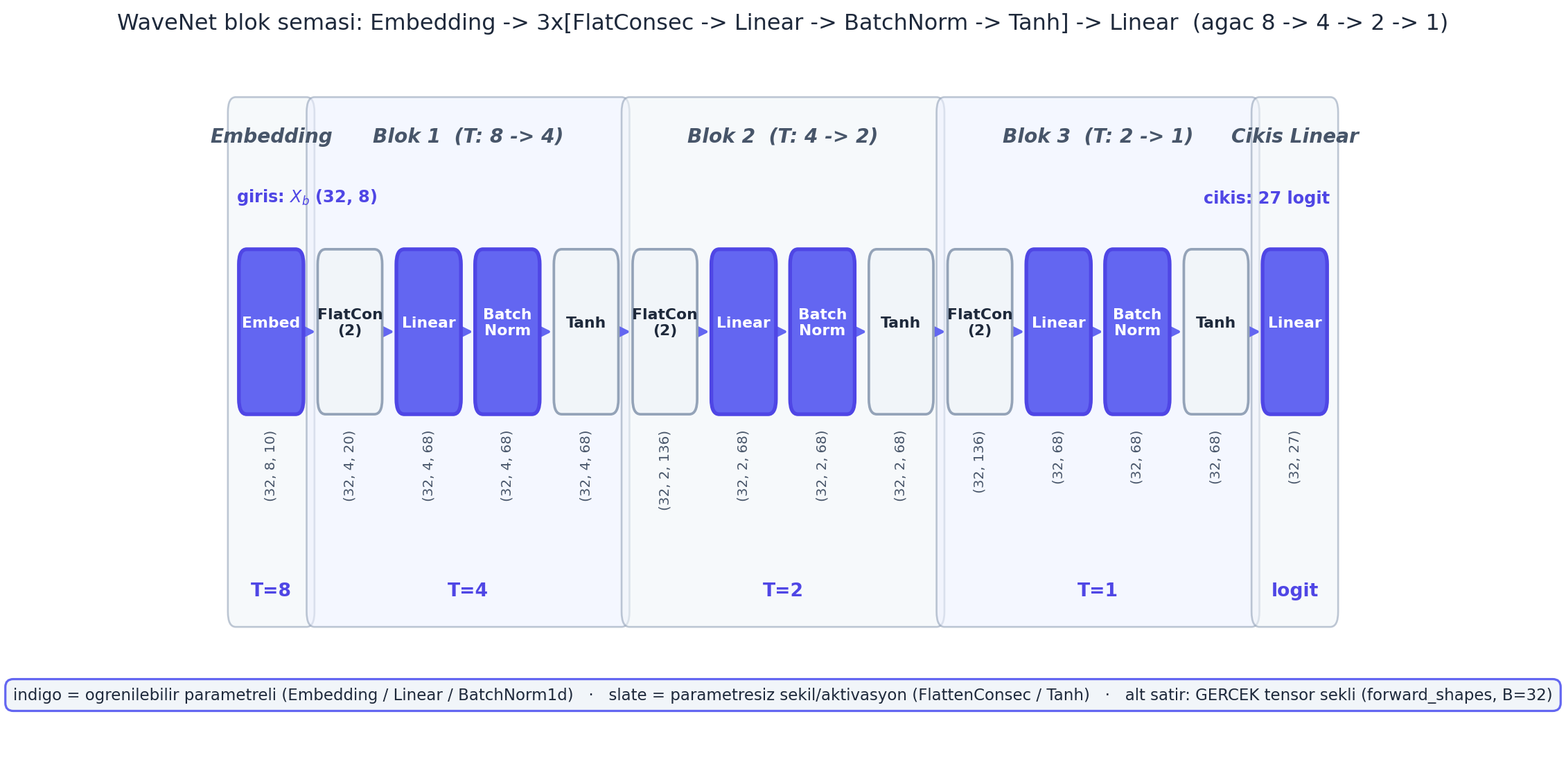
forward_shapes cache’inden okunan GERÇEK tensör şekli yazılır; zaman ekseni \(T\) ağaç gibi \(8\to4\to2\to1\) inerken kanal ekseni \(C\) çift FlattenConsec ile geçici olarak ikiye katlanır (\(10\to20\), \(68\to136\)) ve Linear onu tekrar \(68\)’e indirir. Üç FlattenConsec(2) katmanı \(=\log_2 8=3\): blok başına alıcı alan iki katına çıkar. Son FlattenConsec(2)’de \(T/n=1\) olunca squeeze(1) ile zaman ekseni düşer (şekil \((32,136)\), \(3\)B’den \(2\)B’ye); ardından çıkış Linear’ı \(27\) logit verir. İndigo dolgu = öğrenilebilir parametreli katmanlar (Embedding/Linear/BatchNorm1d — Embedding’in \((27, 10)=270\) elemanlı arama tablosu da öğrenilir), slate dolgu = parametresiz şekil/aktivasyon katmanları (FlattenConsec/Tanh).
İlk eğitimde loss biraz iyileşir ama Karpathy bir bug fark eder: BatchNorm1d 3 boyutlu girdiyle (B, T, C) yanlış çalışıyor. Sıradaki bölümde düzeltilir. Düzeltmeden sonra üç modeli (\(12000\) adım, \(9000\). adımda lr \(\times 0{,}1\) decay, aynı tohum) kıyaslarız:
Kod
import torch
import matplotlib.pyplot as plt
# Deterministik: aynı tohum -> aynı loss eğrileri + aynı final dev değerleri.
# (Brief hedefleriyle birebir: 12000 adım, 9000.de lr decay -> WaveNet 2,1324 /
# MLP-flat-8 2,1872 / MLP-flat-3 2,2484.)
torch.manual_seed(SEED)
N_STEPS = 12000
DECAY_AT = 9000 # %75'te lr *= 0.1 (büyük adımla yaklaş, küçük adımla yerleş)
# --- Veri: WaveNet ve MLP-flat-8 bağlam=8; MLP-flat-3 bağlam=3 ---
Xtr8, Ytr8, Xdev8, Ydev8, _, _ = split_data(block_size=8)
Xtr3, Ytr3, Xdev3, Ydev3, _, _ = split_data(block_size=3)
# --- Üç modeli eğit (frozen, deterministik) ---
wn = build_wavenet(block_size=8)
lh_wn = train(wn, Xtr8, Ytr8, steps=N_STEPS, lr=0.1, lr_decay_at=DECAY_AT)
dev_wn = evaluate(wn, Xdev8, Ydev8) # GERÇEK: ~2,1324
mf8 = build_mlp_flat(block_size=8)
lh_mf8 = train(mf8, Xtr8, Ytr8, steps=N_STEPS, lr=0.1, lr_decay_at=DECAY_AT)
dev_mf8 = evaluate(mf8, Xdev8, Ydev8) # GERÇEK: ~2,1872
mf3 = build_mlp_flat(block_size=3)
lh_mf3 = train(mf3, Xtr3, Ytr3, steps=N_STEPS, lr=0.1, lr_decay_at=DECAY_AT)
dev_mf3 = evaluate(mf3, Xdev3, Ydev3) # GERÇEK: ~2,2484
# --- Loss eğrilerini 1000'lik gruplarla düzleştir (Notion §3: view(-1,1000).mean(1)) ---
sm_wn = smooth_loss(lh_wn, k=1000)
sm_mf8 = smooth_loss(lh_mf8, k=1000)
sm_mf3 = smooth_loss(lh_mf3, k=1000)
# Grup ortalamasının x ekseni: her grup ~1000 adımın ortasında.
gx = [(i + 0.5) * 1000 for i in range(len(sm_wn))]
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(10, 6))
fig.patch.set_facecolor(COL_WHITE)
# --- SOL panel: üç düzleştirilmiş eğitim kaybı eğrisi ---
apply_style(ax_l)
ax_l.plot(gx, sm_wn.tolist(), color=COL_ACCENT, linewidth=2.4,
marker="o", markersize=3, zorder=4, label="WaveNet-8 (hiyerarşik ağaç)")
ax_l.plot(gx, sm_mf8.tolist(), color=COL_PRIMARY, linewidth=2.0,
marker="s", markersize=3, zorder=3, label="MLP-flat-8 (düz, bağlam 8)")
ax_l.plot(gx, sm_mf3.tolist(), color=COL_INDIGO_400, linewidth=2.0,
marker="^", markersize=3, zorder=2, label="MLP-flat-3 (düz, bağlam 3)")
# lr decay noktası: 9000. adımda dikey çizgi (eğrilerde görünür kayma).
ax_l.axvline(DECAY_AT, color=COL_SLATE_400, linewidth=1.6, linestyle="--",
zorder=1, label=f"lr decay ($\\times 0{{,}}1$) — adım {DECAY_AT}")
ax_l.set_xlabel("Minibatch adımı", fontsize=12)
ax_l.set_ylabel("Eğitim kaybı (1000'lik grup ort.)", fontsize=12)
ax_l.set_title("Eğitim eğrileri — düzleştirilmiş", fontsize=12)
ax_l.set_xlim(0, N_STEPS)
ax_l.legend(loc="upper right", fontsize=8.5, framealpha=0.95)
# --- SAĞ panel: final dev kaybı bar karşılaştırması ---
apply_style(ax_r)
etiketler = ["WaveNet-8", "MLP-flat-8", "MLP-flat-3"]
degerler = [dev_wn, dev_mf8, dev_mf3]
# WaveNet = indigo (kazanan vurgu), MLP-flat-8 = slate, MLP-flat-3 = açık indigo.
renkler = [COL_ACCENT, COL_PRIMARY, COL_INDIGO_400]
xb = list(range(3))
ax_r.bar(xb, degerler, color=renkler, width=0.6,
edgecolor=COL_WHITE, linewidth=1.2, zorder=3)
# Bar üstü değer etiketleri (GERÇEK final dev loss'lar, Türkçe ondalık).
for xi, v in zip(xb, degerler):
ax_r.text(xi, v + 0.004, f"{v:.4f}".replace(".", ","),
ha="center", va="bottom", fontsize=10.5, color=COL_TEXT,
weight="bold", zorder=5)
# WaveNet kazancı: MLP-flat-8'e göre düşüş anotu.
kazanc = dev_mf8 - dev_wn
ax_r.annotate(
"", xy=(0, dev_wn), xytext=(0, dev_mf8),
arrowprops=dict(arrowstyle="<->", color=COL_INDIGO_600, lw=1.6), zorder=6,
)
ax_r.text(
0.42, (dev_wn + dev_mf8) / 2,
("WaveNet kazancı\n$-" + f"{kazanc:.4f}".replace(".", ",") + "$\n(ağaç füzyonu)"),
ha="left", va="center", fontsize=9, color=COL_INDIGO_600,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_INDIGO_600, lw=1.2),
zorder=6,
)
ax_r.set_xticks(xb)
ax_r.set_xticklabels(etiketler, fontsize=9.5)
ax_r.set_ylabel("final dev kaybı (ortalama NLL)", fontsize=12)
ax_r.set_title("Final dev kaybı — WaveNet en düşük", fontsize=12)
# Sıkı y-aralığı: farklar görünür kalsın (değerler 2,13–2,25 bandında).
ax_r.set_ylim(2.10, dev_mf3 + 0.03)
fig.suptitle(
"Üç model: WaveNet-8 (hiyerarşik) vs MLP-flat-8 vs MLP-flat-3",
fontsize=12.5, color=COL_TEXT, y=1.01,
)
plt.tight_layout()
plt.show()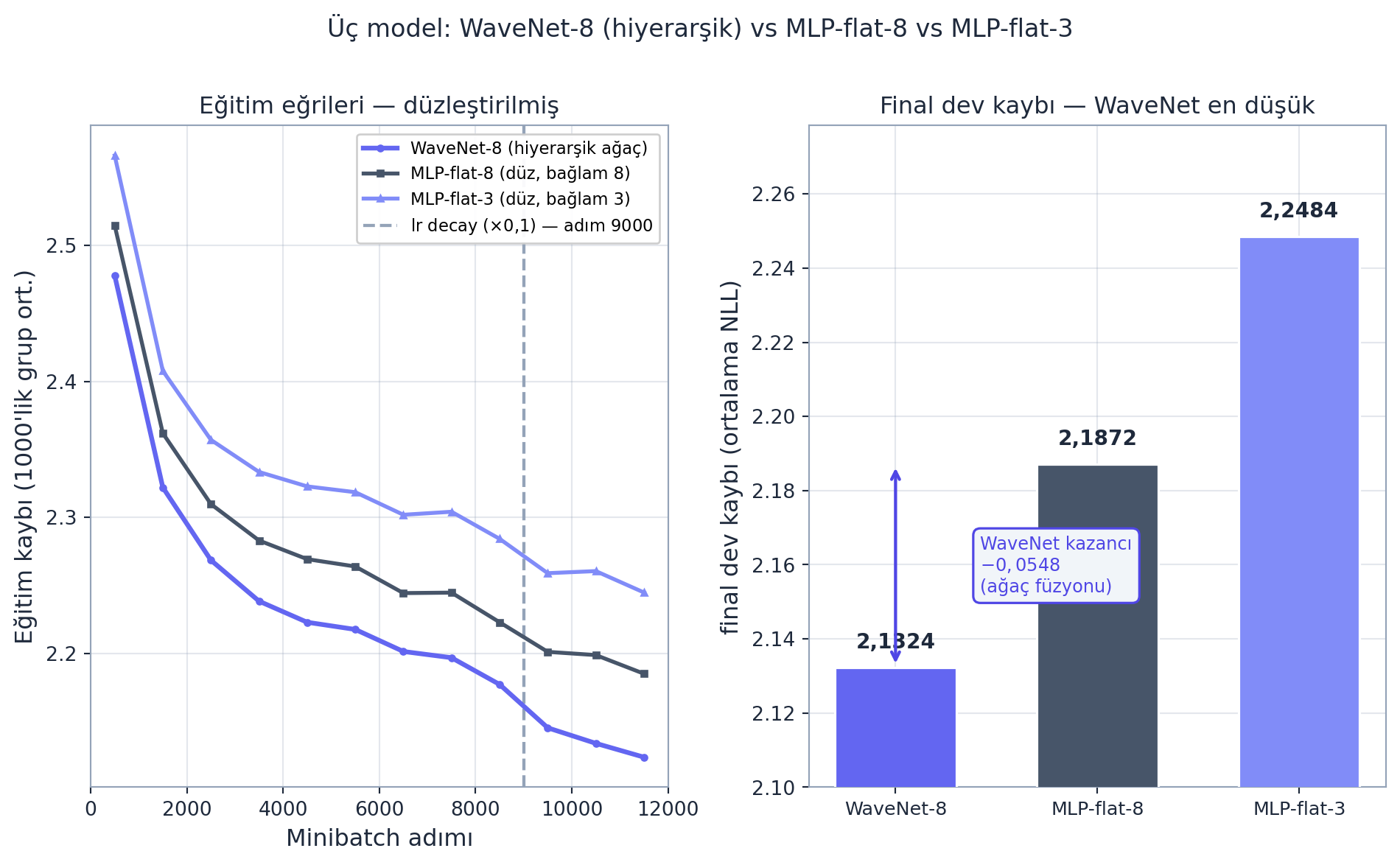
GERÇEK ölçüm net bir sıralama verir: WaveNet-8 \(= 2{,}1324\) \(<\) MLP-flat-8 \(= 2{,}1872\) \(<\) MLP-flat-3 \(= 2{,}2484\) (ortalama dev NLL). Hiyerarşik ağaç füzyonu, düz MLP’nin tek-seferlik düzleştirmesini geçer; WaveNet’in MLP-flat-8’e göre kazancı \(0{,}0548\)’dir.
İpucuBuilder Notu — BatchNorm WaveNet Bloğunda da, Şimdi 3B-fix
Geriye (Ders 3-4): Eğitim döngüsü hiç değişmedi (Ders 1’den beri aynı); değişen yalnızca model mimarisi (düz MLP → hiyerarşik). bias=False (BatchNorm öncesi) Ders 4’ün spurious-bias dersi. Ders 4’te kurduğumuz BatchNorm1d, WaveNet bloğunda da kullanılır — ama girdi artık 3 boyutlu (B, T, C); bu yüzden bir sonraki bölümde 3B-fix gerekecek.
İleriye: “İlk geçişte bug çıkar, düzelt” Karpathy’nin kasıtlı pedagojisi (Ders 1 += / zero_grad gibi); gerçek geliştirme süreci de böyle ilerler.
7.11 BatchNorm 3B Bug
Bug şu: Ders 4’te BatchNorm1d’i 2 boyutlu girdi (B, C) için yazmıştık — istatistikleri yalnızca 0. eksen (batch) üzerinden alıyordu. Ama WaveNet’te girdi 3 boyutlu (B, T, C); bu durumda ortalama/varyans hem batch hem zaman ekseni üzerinden alınmalı, yani \((0, 1)\) boyutları.
def __call__(self, x):
if x.ndim == 2:
dim = 0 # (B, C): batch ekseni
elif x.ndim == 3:
dim = (0, 1) # (B, T, C): batch VE zaman ekseni
xmean = x.mean(dim, keepdim=True)
xvar = x.var(dim, keepdim=True)
# ... normalize + scale/shift (Ders 4)GERÇEK ölçümle: 2B girdi \((32, 68)\)’de dim=0 → xmean.shape \((1, 68)\) (kanal başına \(32\) örnek). 3B girdi \((32, 4, 68)\)’de doğru dim=(0,1) → \((1, 1, 68)\) (kanal başına \(B \cdot T = 128\) örnek). Eğer 2B-only kod körü körüne dim=0 uygularsa şekil \((1, 4, 68)\) olur — zaman ekseni yanlışlıkla korunur, \(4 \times 68 = 272\) ayrı istatistik kalır.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# BatchNorm1d 3B-fix (Notion §10): 2B (B,C) girdide istatistik ekseni dim=0,
# 3B (B,T,C) girdide dim=(0,1). Bu figür iki durumu yan yana koyar ve GERÇEK
# xmean.shape'lerini OLCER (uydurma YOK; L6 BatchNorm1d ile birebir mantık).
# Determinist: sabit tohum -> sabit şekiller (şekiller deterministiktir zaten).
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERÇEK şekiller: 2B ve 3B girdileri kur, BatchNorm1d istatistik eksenlerini
# uygula, xmean.shape'leri ÖLÇ. C = N_HIDDEN = 68 (Ders 6 son model genişliği).
# ---------------------------------------------------------------------------
B, T, C = BATCH_SIZE, 4, N_HIDDEN # (32, 4, 68) — gerçek WaveNet ara şekli
# 2B durum (Ders 4): (B, C); istatistik dim=0
x2 = torch.randn((B, C))
xmean2 = x2.mean(0, keepdim=True) # GERÇEK ölçüm: (1, 68)
shp_2b_in = tuple(x2.shape)
shp_2b_stat = tuple(xmean2.shape)
# 3B-FIX durum (Ders 6): (B, T, C); istatistik dim=(0,1)
x3 = torch.randn((B, T, C))
xmean3_fix = x3.mean((0, 1), keepdim=True) # GERÇEK ölçüm: (1, 1, 68)
shp_3b_in = tuple(x3.shape)
shp_3b_fix = tuple(xmean3_fix.shape)
# 3B-BUG durum: 2B kodu körü körüne dim=0 uygularsa
xmean3_bug = x3.mean(0, keepdim=True) # GERÇEK ölçüm: (1, 4, 68)
shp_3b_bug = tuple(xmean3_bug.shape)
# kaç örnek üzerinden indirgendiği (her kanal için)
n_2b = B # 32
n_3b = B * T # 128
def _fmt(shape):
return "(" + ", ".join(str(d) for d in shape) + ")"
# ---------------------------------------------------------------------------
# Çizim: iki panel (sol 2B, sağ 3B). Her panel girdi tensörünü soluk kutuyla,
# indirgeme eksenini indigo okla, sonuç istatistik şeklini koyu kutuyla gösterir.
# aspect serbest (11x6 figürü doldurur); x/y bağımsız ölçeklenir.
# ---------------------------------------------------------------------------
fig, axes = plt.subplots(1, 2, figsize=(11, 6))
fig.patch.set_facecolor(COL_WHITE)
COL_BUG = "#dc2626" # kırmızı — tuzak/yanlış şekil vurgusu
COL_BUG_BG = "#fee2e2" # açık kırmızı dolgu
# === SOL PANEL: 2B (Ders 4) ================================================
ax = axes[0]
ax.set_facecolor(COL_WHITE)
ax.axis("off")
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.text(5, 9.5, "2B girdi (Ders 4)", ha="center", va="center",
fontsize=13, color=COL_PRIMARY, weight="bold")
# girdi tensör kutusu (B, C)
in2 = FancyBboxPatch((2.3, 6.0), 5.4, 1.7,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=COL_BG, ec=COL_SLATE_400, linewidth=1.6, zorder=2)
ax.add_patch(in2)
ax.text(5.0, 7.15, "girdi " + _fmt(shp_2b_in), ha="center", va="center",
fontsize=12, color=COL_TEXT, weight="bold", family="monospace", zorder=3)
ax.text(5.0, 6.45, "(B, C): B=32 batch, C=68 kanal", ha="center", va="center",
fontsize=9, color=COL_SLATE_800, zorder=3)
# indirgeme oku (dim=0)
arr2 = FancyArrowPatch((5.0, 5.85), (5.0, 4.35),
arrowstyle="-|>", mutation_scale=18,
color=COL_ACCENT, linewidth=2.2, zorder=2)
ax.add_patch(arr2)
ax.text(5.55, 5.1, r"$\mathrm{mean}(\,\mathrm{dim}{=}0\,)$", ha="left", va="center",
fontsize=11, color=COL_INDIGO_600, weight="bold", zorder=3)
ax.text(5.55, 4.65, "batch ekseni indirgenir", ha="left", va="center",
fontsize=8.5, color=COL_SLATE_800, zorder=3)
# sonuç istatistik kutusu (1, C)
st2 = FancyBboxPatch((2.9, 2.4), 4.2, 1.5,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc="#eef2ff", ec=COL_ACCENT, linewidth=2.4, zorder=2)
ax.add_patch(st2)
ax.text(5.0, 3.45, "xmean.shape " + _fmt(shp_2b_stat), ha="center", va="center",
fontsize=12, color=COL_INDIGO_600, weight="bold", family="monospace", zorder=3)
ax.text(5.0, 2.8, f"{C} kanal istatistigi ({n_2b} ornek)", ha="center", va="center",
fontsize=9, color=COL_TEXT, zorder=3)
# doğru rozeti
ax.text(5.0, 1.2, "DOGRU: her kanal kendi istatistigini\n32 ornekten alir",
ha="center", va="center", fontsize=9, color=COL_PRIMARY, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_SLATE_400, lw=1.2),
zorder=3)
# === SAĞ PANEL: 3B (Ders 6) ================================================
ax = axes[1]
ax.set_facecolor(COL_WHITE)
ax.axis("off")
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.text(5, 9.5, "3B girdi (Ders 6 WaveNet)", ha="center", va="center",
fontsize=13, color=COL_PRIMARY, weight="bold")
# girdi tensör kutusu (B, T, C)
in3 = FancyBboxPatch((2.0, 6.0), 6.0, 1.7,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=COL_BG, ec=COL_SLATE_400, linewidth=1.6, zorder=2)
ax.add_patch(in3)
ax.text(5.0, 7.15, "girdi " + _fmt(shp_3b_in), ha="center", va="center",
fontsize=12, color=COL_TEXT, weight="bold", family="monospace", zorder=3)
ax.text(5.0, 6.45, "(B, T, C): B=32, T=4 zaman, C=68 kanal", ha="center", va="center",
fontsize=9, color=COL_SLATE_800, zorder=3)
# FIX oku (dim=(0,1)) — sol kol
arrF = FancyArrowPatch((3.6, 5.85), (3.1, 4.35),
arrowstyle="-|>", mutation_scale=18,
color=COL_ACCENT, linewidth=2.2, zorder=2)
ax.add_patch(arrF)
# BUG oku (dim=0) — sağ kol
arrB = FancyArrowPatch((6.6, 5.85), (7.1, 4.35),
arrowstyle="-|>", mutation_scale=18,
color=COL_BUG, linewidth=2.0, linestyle="--", zorder=2)
ax.add_patch(arrB)
# FIX sonuç kutusu (1, 1, C)
stF = FancyBboxPatch((0.5, 2.4), 4.3, 1.5,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc="#eef2ff", ec=COL_ACCENT, linewidth=2.4, zorder=2)
ax.add_patch(stF)
ax.text(2.65, 3.45, _fmt(shp_3b_fix), ha="center", va="center",
fontsize=12, color=COL_INDIGO_600, weight="bold", family="monospace", zorder=3)
ax.text(2.65, 2.8, f"dim=(0,1) FIX\n{C} kanal ({n_3b} ornek)", ha="center", va="center",
fontsize=8.6, color=COL_TEXT, weight="bold", zorder=3)
# BUG sonuç kutusu (1, T, C)
stB = FancyBboxPatch((5.3, 2.4), 4.3, 1.5,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=COL_BUG_BG, ec=COL_BUG, linewidth=2.2, zorder=2)
ax.add_patch(stB)
ax.text(7.45, 3.45, _fmt(shp_3b_bug), ha="center", va="center",
fontsize=12, color=COL_BUG, weight="bold", family="monospace", zorder=3)
ax.text(7.45, 2.8, f"dim=0 TUZAK\n{T}x{C}={T * C} ayri istatistik", ha="center", va="center",
fontsize=8.6, color=COL_BUG, weight="bold", zorder=3)
# açıklama rozetleri
ax.text(2.65, 1.2, "DOGRU: batch + zaman\nbirlikte indirgenir",
ha="center", va="center", fontsize=8.5, color=COL_INDIGO_600, weight="bold",
bbox=dict(boxstyle="round,pad=0.35", fc="#eef2ff", ec=COL_ACCENT, lw=1.2),
zorder=3)
ax.text(7.45, 1.2, "YANLIS: zaman ekseni\nkorunur (bug)",
ha="center", va="center", fontsize=8.5, color=COL_BUG, weight="bold",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BUG_BG, ec=COL_BUG, lw=1.2),
zorder=3)
fig.suptitle("BatchNorm istatistik ekseni: 2B (dim=0) vs 3B-FIX (dim=(0,1))",
fontsize=14, color=COL_TEXT, weight="bold", y=0.995)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()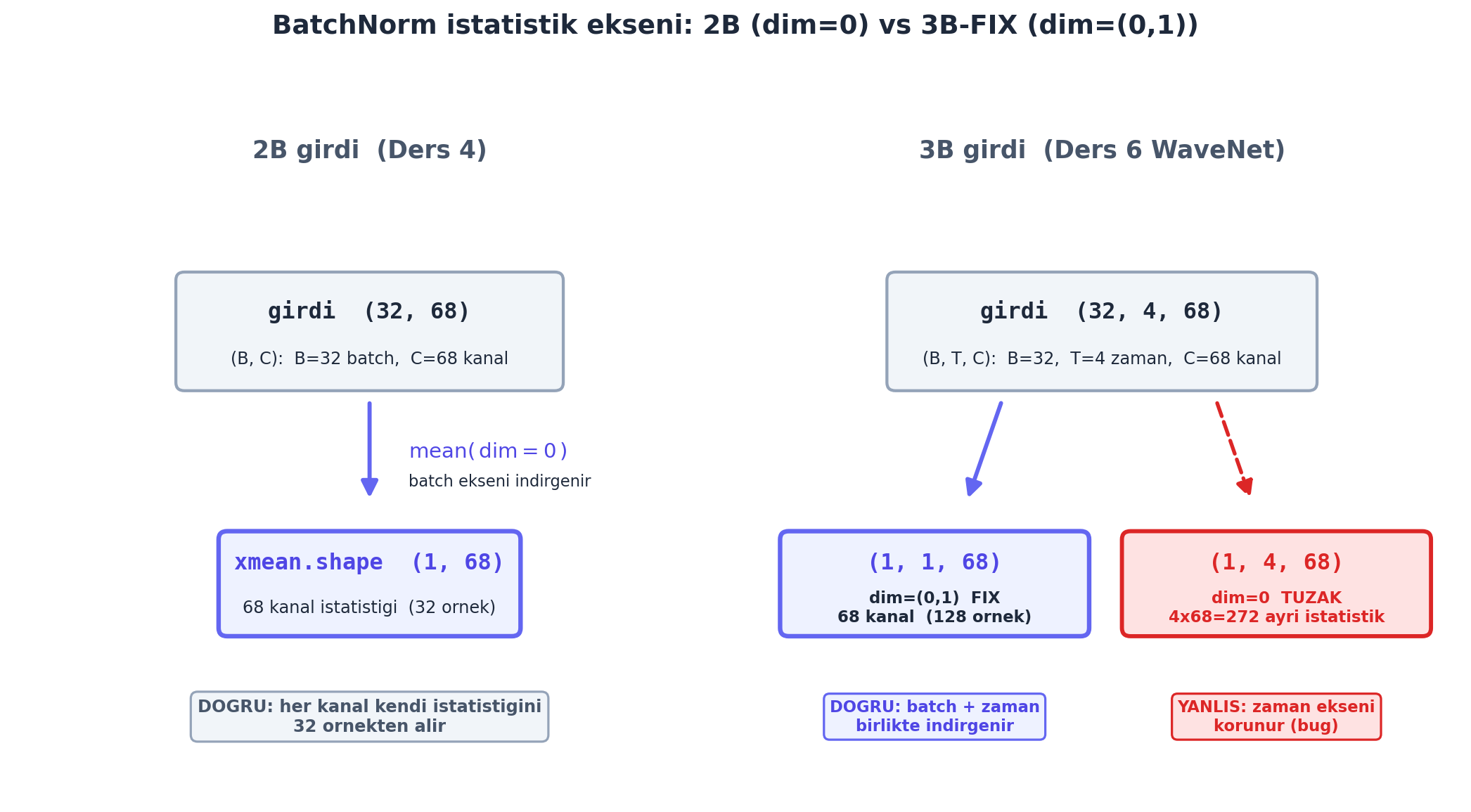
(B, C) \(= (32, 68)\); ortalama/varyans yalnızca batch ekseni üzerinden alınır (dim=0), sonuç \(\text{xmean.shape} = (1, 68)\) — kanal başına \(32\) örneğin tek istatistiği. Sağ (Ders 6, 3B-FIX): WaveNet girdisi (B, T, C) \(= (32, 4, 68)\); istatistik hem batch hem zaman ekseni üzerinden alınmalı (dim=(0,1)), sonuç \((1, 1, 68)\) — kanal başına \(B \cdot T = 128\) örneğin tek istatistiği. Tuzak (kırmızı): Ders 4’ün 2B-only kodu 3B girdide körü körüne dim=0 uygularsa şekil \((1, 4, 68)\) olur — zaman ekseni yanlışlıkla korunur, \(4 \times 68 = 272\) ayrı istatistik kalır (her zaman-adımı kendi istatistiğini sanır). 3B-FIX, normalize edilmeyen tüm eksenleri (batch + zaman) tek seferde indirir.
Karpathy bu dersteki işin çoğunun şekil yönetimi olduğunu itiraf eder:
“I’m spending a lot of time basically babysitting the shapes and making sure everything is correct.” — Karpathy, 53:44
İpucuBuilder Notu — Hangi Eksende Normalize? (Ders 5 Köprüsü)
Geriye (Ders 4-5): Bu bug, Ders 4’ün BatchNorm’unun ve Ders 5’in “broadcast/sum dualitesi”nin doğrudan sonucu: hangi eksende normalize/topla sorusu. 2B vs 3B ayrımı tam da bir “şekil tuzağı”. Ders 5’te backward’ı elle yazdığımız için hangi eksenin neyi taşıdığını sezgisel biliyoruz; o yüzden artık autograd’a güvenle dönebiliyoruz — loss.backward() 3B’de de doğru aksar, çünkü forward’daki dim seçimini doğru yaptık.
İleriye: “Şekilleri kollamak” (shape babysitting), tensör programlamanın günlük gerçeği — production’da NaN/yanlış-sonuç bug’larının büyük kısmı şekil/eksen hatalarıdır. print(x.shape) (Ders 1) ve dikkatli eksen seçimi şart.
7.12 WaveNet Büyütme
Bug düzeldikten sonra Karpathy modeli büyütür: daha çok kanal (channel), daha geniş katmanlar. Bizim son modelimiz \(68\) gizli kanal genişliğinde, \(22\,397\) parametreli; loss, Ders 3’ün düz MLP’sinden (\(2{,}2484\)) belirgin biçimde daha iyiye (\(2{,}1324\)) iner — hiyerarşik yapı + uzun bağlam işe yaradı. Bağlam 8 karakter + ağaç füzyonu, modele daha zengin desenler öğrenme imkânı verdi.
Karpathy ayrıca eğitim sürecinin gerçekçi yanını gösterir: deney kaydı tutmak (performans günlüğü), hiperparametre denemeleri, “babysitting” — gerçek ML geliştirme sürecinin doğal parçaları.
İpucuBuilder Notu — Scaling Laws’ın Küçük-Ölçek Önizlemesi
İleriye: Model büyütmenin loss’u düşürmesi, scaling laws’ın küçük-ölçek önizlemesidir (Ders 10): parametre/bağlam arttıkça performans artar (bir noktaya kadar). Düz MLP-flat-3 (\(4\,309\) param) → MLP-flat-8 (\(7\,709\) param) → WaveNet-8 (\(22\,397\) param) zincirinde loss tek yönde düşer. Deney kaydı + hiperparametre arama, MLOps’un (W&B, Optuna) çekirdeği.
7.13 Notlar
Karpathy kapanışta birkaç bağlantı kurar:
Convolutions. Kurduğumuz hiyerarşik yapı, aslında elle yazılmış bir convolution ağıdır. Gerçek WaveNet, torch.nn.Conv1d ile kayan filtreler (dilated causal) kullanır — ama mekanizma aynı: yerel pencereleri paylaşılan ağırlıklarla işle, hiyerarşik istifle.
Neden torch.nn değil? Kendi modüllerimizi (Linear/BatchNorm1d/Embedding/Flatten/Sequential) yazdık — torch.nn’i doğrudan kullanmak yerine. Sebep pedagojik: her parçanın içini görmek. Artık torch.nn’e baktığında, arkasında ne olduğunu biliyorsun.
Geliştirme süreci. Karpathy, gerçek araştırma/geliştirmenin nasıl göründüğünü gösterir: dokümantasyonla boğuşmak, şekil hatalarını ayıklamak, deney kaydı tutmak, kademeli iyileştirme. “Temiz nihai kod” değil, süreç.
İpucuBuilder Notu — makemore Kapanışı, Ders 7’de Attention
İleriye (Ders 7): Bu ders, makemore serisinin kapanışı. Bundan sonra (Ders 7) transformer’a geçiyoruz — hiyerarşik convolution yerine dikkat (attention) ile bağlam işleme. WaveNet “sabit ağaç” kurar; transformer her token’ın her tokena bakmasına izin verir (daha esnek, daha pahalı). Başka deyişle attention, WaveNet’in yeniden organize edilmiş hâli: sabit ağaç füzyonu yerine, hangi token’ın hangisine bakacağını model kendisi öğrenir. İkisi de “uzun bağlamı verimli işleme” probleminin farklı çözümleri.
7.14 Bu Dersin Özeti
- Ders 3 MLP’si bağlamı tek seferde düzleştiriyordu; WaveNet bunu kademeli/hiyerarşik (ağaç) füzyona çevirir.
- Başlangıç kodu Ders 3’ten gelir (Ders 4 BatchNorm + Ders 5 manuel backprop birer aside’dı).
- Kod PyTorch-laştırılır: Embedding (id→vektör), FlattenConsecutive (ardışık gruplama), Sequential (konteyner) —
torch.nntaklidi tamamlanır. - WaveNet fikri: bilgiyi ağaç gibi kademeli füzyonla (\(8 \to 4 \to 2 \to 1\)); alıcı alan her katmanda iki katına çıkar (\(\log_2 8 = 3\) katman, dilated causal convolution).
- Bağlam 3 → 8 karaktere çıkarılır; daha uzun geçmiş = daha zengin desen (tek başına bile dev loss \(2{,}2484 \to 2{,}1872\)).
- Batched matmul: (B, T, C) @ \(W\) son boyutta çarpar, (B, T) batch sayılır — hiyerarşik füzyonu paralel kılar (\(B \cdot T = 128\) dilim, tek \(W\)).
- FlattenConsecutive(n): (B, T, C) → (B, T/n, C·n) ardışık gruplama; ağaç katmanlarının çekirdeği (squeeze, \(T/n=1\) olunca).
- BatchNorm1d 3B bug’ı: 2B (B,C) için yazılmıştı (xmean \((1, 68)\)); 3B (B,T,C) için istatistik ekseni \((0,1)\) olmalı (xmean \((1, 1, 68)\), \(128\) örnek/kanal).
- WaveNet, elle yazılmış bir convolution’dır; final dev loss WaveNet-8 \(= 2{,}1324\) (\(22\,397\) param) düz MLP’leri geçer. Transformer (Ders 7) aynı “uzun bağlam” problemini dikkat ile çözer.
ÖnemliTek Bir Cümle
Bağlamı tek hamlede düzleştirip ezmek yerine, ardışık öğeleri kademeli (ağaç gibi) füzyonlamak — WaveNet’in hiyerarşik fikri — daha derin ve güçlü bir dil modeli verir; ve bu, aslında elle yazılmış bir convolution’dır (yerel desenleri önce, küresel yapıyı sonra öğrenen).
7.15 Kontrol Soruları
NotSoru 1: Şekli (4, 8, 10) olan bir tensör FlattenConsecutive(2)’ye verilirse çıktı şekli ne olur? Adımları açıkla.
Cevap: Çıktı (4, 4, 20). Açıklama: (B, T, C) = (4, 8, 10). FlattenConsecutive(2), ardışık \(n=2\) öğeyi birleştirir: \(T\) 8’den \(8/2=4\)’e iner, \(C\) 10’dan \(10 \cdot 2=20\)’ye çıkar. Yani x.view(B, T//n, C*n) = x.view(4, 4, 20). 8 zaman-adımı 4 komşu çifte gruplandı; her çiftin 10-boyutlu embedding’leri yan yana gelip 20-boyut oldu. Bunu üst üste istifleyince (her aşamada bir Linear araya girse de): \((4,8,10) \to (4,4,20) \to (4,2,40) \to (4,1,80) \to\) squeeze \(\to (4, 80)\). Ağaç: \(8 \to 4 \to 2 \to 1\) (GERÇEK ölçüm).
NotSoru 2: WaveNet’in hiyerarşik (kademeli) füzyonu, Ders 3 MLP’sinin ‘hepsini tek seferde düzleştir’ yaklaşımından neden daha iyi olabilir?
Cevap: MLP, 8 karakterin tüm embedding’lerini ilk katmanda birden karıştırır — yerel yapı (komşu karakterler arası ilişki) ile uzak yapı aynı anda, ayrımsız işlenir. WaveNet ise kademeli işler: alt katmanlar yerel desenleri (komşu çiftler, bigram-benzeri), üst katmanlar giderek daha geniş bağlamı yakalar. Bu “yereli önce, küreseli sonra” yapısı (a) hiyerarşik dil yapısına (harfler→heceler→kelimeler) daha uygun bir tümevarımsal önyargı (inductive bias) taşır, (b) derin temsil kurar. Sonuç: bizim ölçümümüzde aynı bağlamda (8 karakter) WaveNet dev loss \(2{,}1324\) < düz MLP-flat-8 \(2{,}1872\).
NotSoru 3: Ders 4’ün BatchNorm1d’i 2 boyutlu (B, C) girdi için yazılmıştı. WaveNet’in 3 boyutlu (B, T, C) girdisinde neden bug verdi, nasıl düzeltilir?
Cevap: BatchNorm, istatistikleri (ortalama, varyans) normalize edilmeyen eksenler üzerinden almalı. 2B (B, C)’de bu yalnızca batch ekseni (dim=0) — her kanal (C) kendi istatistiğini batch’ten alır (xmean.shape \((1, 68)\)). Ama 3B (B, T, C)’de hem batch (B) hem zaman (T) ekseni üzerinden alınmalı (dim=(0,1), xmean.shape \((1, 1, 68)\)) — yoksa BatchNorm yalnızca batch’i hesaba katıp zaman boyutunu yanlış işler (\((1, 4, 68)\) → \(4 \times 68 = 272\) ayrı istatistik). Düzeltme: x.ndim’e göre dim’i seç (2B → 0, 3B → (0,1)). Bu, Ders 5’in “hangi eksende topla/normalize” (broadcast/sum dualitesi) sorusunun BatchNorm’a uygulanması.
NotSoru 4: (Builder) Hem WaveNet hem transformer (Ders 7) uzun bağlamı işler. İkisi bu problemi nasıl farklı çözer?
Cevap: WaveNet sabit, hiyerarşik bir yapı kurar: bağlamı ağaç gibi kademeli füzyonlar (dilated causal convolution); alıcı alan katman sayısıyla logaritmik büyür (\(\log_2 8 = 3\)), ama her token yalnızca belirli komşularına (ağacın yapısına göre) bakar. Transformer ise dikkat (attention) kullanır: her token, bağlamdaki her tokena doğrudan bakabilir (öğrenilen ağırlıklarla), yapı sabit değil veriye-bağlı. Transformer daha esnek (uzak bağımlılıkları tek adımda yakalar) ama daha pahalı (\(O(T^2)\) — her çift token). WaveNet daha ucuz (\(O(T)\)) ama daha katı. Yani attention, WaveNet’in yeniden organize edilmiş hâlidir: sabit ağaç yerine öğrenilen bakış. İkisi de “sabit-bağlam MLP’nin sınırını aşma” probleminin farklı çözümleri; modern LLM’ler transformer’ı seçti.
7.16 Egzersizler
Egzersiz 1 (FlattenConsecutive). FlattenConsecutive(n) modülünü yaz. (4, 8, 10) şekilli bir tensöre \(n=2\) ile uygula, çıktının (4, 4, 20) olduğunu doğrula. \(n=2\)’yi tekrar uygula → (4, 2, 40). squeeze mantığını da test et (\(T/n=1\) olunca → (4, 80)).
Egzersiz 2 (Modülleri kur). Embedding, Flatten, Sequential modüllerini (PyTorch Modülleri bölümü) ve FlattenConsecutive’i (FlattenConsecutive bölümü) yaz. WaveNet’i Sequential olarak istifle (Embedding → (FlattenConsecutive(2)→Linear→BatchNorm1d→Tanh)×3 → Linear). Tek bir forward’ın çalıştığını (model(Xb) doğru şekil — (32, 27) logit — verdiğini) doğrula.
Egzersiz 3 (BatchNorm1d 3B düzeltmesi). BatchNorm1d’i hem 2B (B,C) hem 3B (B,T,C) girdiyi destekleyecek şekilde düzelt (dim seçimi: 0 vs (0,1)). 3B girdiyle istatistiklerin doğru eksende alındığını (xmean.shape \(= (1, 1, 68)\)) doğrula.
Egzersiz 4 (WaveNet’i eğit). Bağlamı 8 yap, WaveNet’i eğit. Loss’u Ders 3’ün düz MLP’siyle (bağlam 3) karşılaştır — hiyerarşik + uzun bağlamın daha düşük loss verdiğini gözlemle (bizde \(2{,}1324\) vs \(2{,}2484\)). Loss grafiğini 1000’lik gruplarla düzleştirip (Loss Düzleştirme bölümü) çiz.
Egzersiz 5 (Sonraki dersin habercisi). WaveNet, bağlamı sabit bir ağaç yapısıyla füzyonlar — hangi karakterin hangisiyle birleşeceği önceden belli. Şimdi farklı bir fikir düşün: her karakterin, bağlamdaki diğer karakterlerden hangilerine bakacağını kendisinin öğrenmesi (sabit ağaç değil, veriye-bağlı). (a) Bu neden daha esnek olurdu? (b) Maliyeti ne olurdu (her token her tokena bakarsa)? Bu fikir dikkat (attention) mekanizmasıdır ve Ders 7’de (Sıfırdan GPT İnşa Etmek) transformer’ı kuracağız — makemore serisini bırakıp doğrudan GPT’ye geçiyoruz.
7.17 Sonraki Ders İçin Hazırlık
Ders 7: Sıfırdan GPT İnşa Etmek (Transformer) — Andrej Karpathy
makemore serisi bitti. Ders 7’de doğrudan transformer’a — ChatGPT’yi çalıştıran mimariye — geçiyoruz. tiny Shakespeare veri setinde, karakter-düzeyli bir GPT’yi sıfırdan kuracağız: WaveNet’in sabit hiyerarşisi yerine self-attention (her token’ın diğerlerine öğrenilen ağırlıklarla bakması).
Ana konular:
- tiny Shakespeare + karakter tokenizer + bigram baseline (seriye bağlanış).
- Self-attention’ın kalbi: query/key/value, ölçekli nokta-çarpım dikkati.
- Multi-head attention, feed-forward, residual bağlantılar, pre-norm LayerNorm, dropout.
UyarıDers 7 Öncesi Yapılacak
- Egzersizleri çöz — özellikle 4 (WaveNet eğitimi) ve 5 (dikkat sezgisi).
- “Modüller + Sequential =
torch.nntaklidi” ve “uzun bağlamı verimli işleme” fikirlerini hatırla — transformer aynı problemi farklı çözer (sabit ağaç → öğrenilen dikkat). - Ders 4 (LayerNorm vs BatchNorm) ve Ders 5 (backprop ninja) — transformer’ın LayerNorm + residual’ını derin anlamak için faydalı.
7.18 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| WaveNet / hiyerarşik füzyon | Bağlamı ağaç gibi kademeli birleştir (\(8 \to 4 \to 2 \to 1\)); MLP’nin tek-seferlik düzleştirmesine alternatif | 1m25 |
| Başlangıç kodu | Ders 3 MLP’sinden gelir; Ders 4-5 birer aside | 1m43 |
| Loss grafiği düzleştirme | lossi.view(-1,1000).mean(1); gürültüyü silip trendi gösterir |
6m58 |
| Embedding modülü | weight[IX] ile id→vektör; Ders 2-3 lookup’ın modül hâli |
9m19 |
| Flatten / Sequential | Boyut düzleştirme + katman konteyneri; torch.nn taklidi tamamlanır |
9m19 |
| dilated causal convolution | WaveNet’in yapısı; nedensel (geçmişe bakar) + genişleyen alıcı alan | 19m04 |
| Bağlam 3 → 8 | block_size büyütülür; ağaç yapısı 8 karakteri 3 katmanda işler |
19m35 |
| Batched matmul | (B,T,C) @ \(W\) son boyutta çarpar, (B,T) batch; hiyerarşik füzyonu paralel kılar | 24m44 |
| FlattenConsecutive(n) | (B,T,C) → (B, T/n, C·n); ardışık öğeleri gruplar (ağaç katmanı) | 31m32 |
| BatchNorm1d 3B düzeltmesi | 2B’de dim=0, 3B’de dim=(0,1); istatistik ekseni şekle göre |
38m55 |
| Şekil yönetimi | (B,T,C) tensörleri kollamak; bug’ların çoğu eksen/şekil hatası | 53m44 |
| Convolution bağlantısı | Kurduğumuz hiyerarşi = elle yazılmış convolution (torch.nn.Conv1d) |
46m59 |
7.19 ML Builder Bağlantıları
İpucu9 köprü — WaveNet
- WaveNet / hiyerarşik füzyon → Ders 3 MLP’nin derinleştirilmişi. İleriye: dilated causal conv (van den Oord 2016), CNN hiyerarşisi.
- Embedding / Flatten / Sequential → Ders 1-4 modül arabirimi (
__call__+parameters). İleriye:torch.nn.Module,nn.Sequential. - Batched matmul (son boyut) → Ders 1 lineer katman + 18.06. İleriye: multi-head attention’ın paralel hesabı (Ders 7).
- FlattenConsecutive = convolution → Ders 3
.viewgenellemesi. İleriye:torch.nn.Conv1d, paylaşılan-ağırlık filtreler. - BatchNorm1d 3B → Ders 4 BatchNorm + Ders 5 broadcast/sum dualitesi. İleriye: dikkatli eksen seçimi (shape babysitting).
- Bağlam uzunluğu (3→8) → Ders 3
block_size. İleriye: context length (GPT-2: 1024, Ders 10), uzun-bağlam modelleri. - Loss düzleştirme → Ders 3 minibatch gürültüsü + Stat 110 ortalama. İleriye: W&B/TensorBoard smoothing.
- Model büyütme → loss düşer → scaling laws önizlemesi (\(4309 \to 7709 \to 22397\) param, loss tek yönde düşer). İleriye: parametre/veri/compute dengesi (Ders 10).
- Hiyerarşik conv vs dikkat → uzun-bağlamın iki çözümü. İleriye: transformer attention (Ders 7) — sabit ağaç yerine öğrenilen, esnek (WaveNet’in yeniden organize hâli).
7.20 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders için verdiği kaynaklar:
- WaveNet makalesi: arxiv 1609.03499 — van den Oord ve ark. 2016, dilated causal convolution ile ses üretimi.
- Ders Colab notebook’u: Google Colab.
- (Genel referans: github.com/karpathy/makemore — makemore serisinin tamamı.)
ÖnemliBu dersten tek bir şey alıp gideceksen
Bağlamı tek hamlede düzleştirip ezmek yerine, ardışık öğeleri kademeli (ağaç gibi) füzyonlamak — WaveNet’in hiyerarşik fikri — daha derin ve güçlü bir model verir. Ve bu yapı, aslında elle yazılmış bir convolution’dır. makemore serisi burada kapanır; Ders 7’de aynı “uzun bağlamı işleme” problemini bu kez dikkat (attention) ile, transformer kurarak çözeceğiz.