flowchart LR
A["Forward<br/>adlandirilmis ara tensorler"] --> B["Egzersiz 1<br/>atomik graf elle backward"]
B --> C["cmp ile dogrula<br/>manuel = autograd"]
C --> D["Egzersiz 2<br/>cross-entropy tek satir"]
C --> E["Egzersiz 3<br/>BatchNorm tek satir"]
D --> F["Egzersiz 4<br/>loss.backward yok, elle egitim"]
E --> F
F --> G["Backprop ninjasi<br/>her gradyanin nereden geldigini bil"]
style D fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style E fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style F fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
style G fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
6 makemore 4 — Backprop Ninjası (Elle Geri Yayılım)
loss.backward() sihir değil; zincir kuralının bir hesaplama grafiği boyunca tensör düzeyinde uygulanmasıdır — onu bir kez elle yazmak, backprop’u kullanan biriyle anlayan biri arasındaki farkı koyar
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — Building makemore Part 4: Becoming a Backprop Ninja (≈115 dk)
- Seri: Neural Networks: Zero to Hero — Ders 5
- Hoca: Andrej Karpathy
- Kaynak repo: github.com/karpathy/makemore
- Okuma süresi: ≈34 dk
6.1 Bu Derste Ne Var?
Ders 2’den beri loss.backward() çağırıp tüm gradyanları PyTorch’un autograd’ına bırakıyorduk — bir kara kutu gibi. Bu derste o kutuyu açıyoruz: Ders 4’ün MLP+BatchNorm ağının backward’ını PyTorch autograd olmadan, tensör düzeyinde elle yazıyoruz. Bu, Ders 1’deki micrograd’ın sırrının gerçek-ölçek hâli.
“I’d like to call backpropagation a leaky abstraction.” — Karpathy, 1:00
Karpathy’nin tezi: backprop sızdıran bir soyutlamadır (leaky abstraction). loss.backward()’ı körü körüne çağırmak, gradyanlarda ince hataları (ölü nöron, doygunluk, patlayan gradyan) gözden kaçırmanıza yol açar. Gradyanları bir kez elle yazarsan, bir daha asla onlara kara kutu gibi bakmazsın.
“The line of code here that I take an issue with is loss.backward().” — Karpathy, 0:34
Ders dört egzersiz olarak kurulu:
- Egzersiz 1 — atomik hesaplama grafiği boyunca (logprobs’tan C’ye) her ara tensörün gradyanını elle yaz.
- Egzersiz 2 — cross-entropy’nin tek-satırlık analitik backward’ı (softmax \(-\) one-hot).
- Egzersiz 3 — BatchNorm’un tek-satırlık füzyonlu backward’ı.
- Egzersiz 4 — hepsini birleştir:
loss.backward()olmadan tam eğitim.
İpucuBuilder Notu — Ders 1’in Sırrı, Tensör Ölçeğinde
Geriye (Ders 1-4 + Calculus):
- Bu, Ders 1’in sırrı. micrograd’da her
_backwardyereldi; burada aynı zincir kuralını tensör düzeyinde (matris/batch) uyguluyoruz — ama elle, autograd olmadan. - Ağ = Ders 4. Yeni mimari yok; Ders 4’ün embedding + Linear + BatchNorm +
tanh+cross_entropyağının backward’ı. - Tek araç = Calculus zincir kuralı. Her adım, Calculus’un zincir kuralının tensör/matris hâli; matris türevleri (transpose’lar) 18.06 ile gelir.
İleriye: Gradyanları elle türetebilmek, herhangi bir framework’ü derinden anlamanın ve gradyan bug’larını teşhis etmenin temelidir. Özel bir katman/loss yazdığında (production’da sık) backward’ı da yazman gerekir. “Sezgisel olarak gradyanın nasıl aktığını bilmek”, Ders 4’ün aktivasyon/gradyan teşhisini de mümkün kılan şey.
Tek cümleyle: loss.backward() sihir değil; zincir kuralının bir hesaplama grafiği boyunca tensör düzeyinde uygulanmasıdır — ve onu bir kez elle yazmak, backprop’u “kullanan” biriyle “anlayan” biri arasındaki farkı koyar.
6.2 Neden Elle Backprop? Sızdıran Soyutlama
Bir soyutlama, altındaki detayları gizlemeli. Ama backprop sızdırır: loss.backward()’ı çağırırsın ama gradyanların nasıl aktığını anlamazsan, neden öğrenmediğini (ölü nöron, vanishing gradient, kötü init) teşhis edemezsin.
“I think people sort of understood how these neural networks work on a very intuitive level, so I think it’s a good exercise [to write the backward pass by hand].” — Karpathy, 6:58
Karpathy’nin amacı: gradyanları bir kez elle yazarak, autograd’ın ne yaptığını sezgisel bir düzeyde anlamak. Bundan sonra loss.backward()’a baktığında, arkasında ne olduğunu görürsün.
Bu dersin bütün omurgası, Ders 4 ağının ileri geçişini bir hesaplama grafiğine açmaktır. Forward’ı bir sürü adlandırılmış ara tensöre (logprobs, probs, counts, bnraw, …) böleriz; bu graf, geri geçişte tersten yürüyeceğimiz harita olur. Aşağıdaki figür o ileri grafı gösterir.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# İleri geçiş DAG'ı: adlandırılmış ara tensörlerle kutu-ok diyagramı (graphviz YOK).
# Şekiller UYDURMA DEĞİL — L5 çekirdeğinin forward_named cache'inden okunur
# (init_params + get_batch + forward_named ile doğrulanmış). n = BATCH_SIZE = 32.
# Determinist: aynı tohum -> aynı batch -> aynı şekiller (şema; şekiller sabittir).
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERÇEK şekiller: L5 forward'ını çalıştır, her ara tensörün cache şeklini al.
# (Hiçbir şekil elle yazılmaz; tek kaynak forward_named.)
# ---------------------------------------------------------------------------
_Xtr, _Ytr, _, _, _, _ = split_data()
_params = init_params()
_Xb, _Yb = get_batch(_Xtr, _Ytr)
_loss, _cache = forward_named(_params, _Xb, _Yb)
n = _cache["n"] # 32
def _shp(name):
"""forward_named cache'inden tensör şeklini '(a, b)' biçiminde döndür."""
return "(" + ", ".join(str(d) for d in _cache[name].shape) + ")"
# ---------------------------------------------------------------------------
# Düğüm tanımları. (x, y) ızgara koordinatı (deterministik, elle layout).
# ana omurga : y = Y0 satırı (soldan sağa veri akışı)
# alt dallar : batch'e bağlı istatistik düğümleri omurganın altında (y = YB)
# hl=True : indigo vurgu (dallanma noktaları + skaler loss)
# Geniş yatay aralık (DX≈3.4) kutuların çakışmasını önler; aspect serbest
# bırakılır (12x7 figürü doldurur), bu yüzden x/y bağımsız ölçeklenir.
# ---------------------------------------------------------------------------
Y0 = 0.0 # ana omurga satırı
YB = -4.2 # alt dal satırı (BatchNorm/cross-entropy istatistikleri)
# Omurga adımı DX≈4.6, kutu genişliği 3.1 -> komşular arası ~1.5 boşluk; en uzun
# etiket ("counts_sum_inv") kutuya sığar. Alt dallar omurga sütunlarıyla hizalı.
nodes = {
# --- embedding ---
"Xb": {"x": 2.3, "y": Y0, "lbl": r"$X_b$", "shape": f"({n}, {BLOCK_SIZE})", "hl": False},
"emb": {"x": 6.9, "y": Y0, "lbl": "emb", "shape": _shp("emb"), "hl": False},
"embcat": {"x": 11.5, "y": Y0, "lbl": "embcat", "shape": _shp("embcat"), "hl": False},
# --- Linear 1 ---
"hprebn": {"x": 16.1, "y": Y0, "lbl": "hprebn", "shape": _shp("hprebn"), "hl": False},
# --- BatchNorm (atomik) ---
"bnmeani": {"x": 20.0, "y": YB, "lbl": "bnmeani", "shape": _shp("bnmeani"), "hl": True},
"bndiff": {"x": 22.5, "y": Y0, "lbl": "bndiff", "shape": _shp("bndiff"), "hl": False},
"bndiff2": {"x": 24.5, "y": YB, "lbl": "bndiff2", "shape": _shp("bndiff2"), "hl": False},
"bnvar": {"x": 29.0, "y": YB, "lbl": "bnvar", "shape": _shp("bnvar"), "hl": True},
"bnvar_inv":{"x": 33.5, "y": YB, "lbl": "bnvar_inv", "shape": _shp("bnvar_inv"), "hl": True},
"bnraw": {"x": 27.1, "y": Y0, "lbl": "bnraw", "shape": _shp("bnraw"), "hl": False},
"hpreact": {"x": 33.4, "y": Y0, "lbl": "hpreact", "shape": _shp("hpreact"), "hl": False},
# --- tanh ---
"h": {"x": 38.0, "y": Y0, "lbl": "h", "shape": _shp("h"), "hl": False},
# --- Linear 2 ---
"logits": {"x": 42.6, "y": Y0, "lbl": "logits", "shape": _shp("logits"), "hl": False},
# --- cross-entropy (atomik) ---
"logit_maxes": {"x": 46.0, "y": YB, "lbl": "logit_maxes", "shape": _shp("logit_maxes"), "hl": True},
"norm_logits": {"x": 49.0, "y": Y0, "lbl": "norm_logits", "shape": _shp("norm_logits"), "hl": False},
"counts": {"x": 53.6, "y": Y0, "lbl": "counts", "shape": _shp("counts"), "hl": False},
"counts_sum": {"x": 54.6, "y": YB, "lbl": "counts_sum", "shape": _shp("counts_sum"), "hl": True},
"counts_sum_inv": {"x": 60.2, "y": YB, "lbl": "counts_sum_inv", "shape": _shp("counts_sum_inv"), "hl": True},
"probs": {"x": 58.2, "y": Y0, "lbl": "probs", "shape": _shp("probs"), "hl": False},
"logprobs": {"x": 62.8, "y": Y0, "lbl": "logprobs", "shape": _shp("logprobs"), "hl": False},
"loss": {"x": 67.4, "y": Y0, "lbl": "loss", "shape": "skaler", "hl": True},
}
# ---------------------------------------------------------------------------
# Kenarlar (child -> parent = veri akışı). forward_named'in GERÇEK bağımlılık
# grafiği: hprebn -> {bnmeani, bndiff}, bndiff -> {bndiff2, bnraw}, bnvar ->
# bnvar_inv, ... DAG (sadece zincir değil): dallar tekrar omurgada birleşir.
# ---------------------------------------------------------------------------
edges = [
# embedding
("Xb", "emb"), ("emb", "embcat"),
# Linear 1
("embcat", "hprebn"),
# BatchNorm atomik (çok-yollu)
("hprebn", "bnmeani"),
("hprebn", "bndiff"), ("bnmeani", "bndiff"),
("bndiff", "bndiff2"),
("bndiff2", "bnvar"),
("bnvar", "bnvar_inv"),
("bndiff", "bnraw"), ("bnvar_inv", "bnraw"),
("bnraw", "hpreact"),
# tanh
("hpreact", "h"),
# Linear 2
("h", "logits"),
# cross-entropy atomik (çok-yollu)
("logits", "logit_maxes"),
("logits", "norm_logits"), ("logit_maxes", "norm_logits"),
("norm_logits", "counts"),
("counts", "counts_sum"),
("counts_sum", "counts_sum_inv"),
("counts", "probs"), ("counts_sum_inv", "probs"),
("probs", "logprobs"),
("logprobs", "loss"),
]
# ---------------------------------------------------------------------------
# Aşama bantları (arka plan): her aşamanın x aralığını soluk dikdörtgenle
# işaretle + üstte aşama adı. Notion §2 forward sırasıyla birebir.
# ---------------------------------------------------------------------------
stages = [
{"name": "embedding", "x0": 0.1, "x1": 13.8, "col": "#eef2ff"},
{"name": "Linear 1", "x0": 13.8, "x1": 18.4, "col": "#f1f5f9"},
{"name": "BatchNorm (atomik)", "x0": 18.4, "x1": 35.7, "col": "#e0e7ff"},
{"name": "tanh", "x0": 35.7, "x1": 40.3, "col": "#f1f5f9"},
{"name": "Linear 2", "x0": 40.3, "x1": 44.9, "col": "#f1f5f9"},
{"name": "cross-entropy (atomik)", "x0": 44.9, "x1": 69.7, "col": "#e0e7ff"},
]
# ---------------------------------------------------------------------------
# Çizim. aspect serbest (12x7 figürü doldurur) -> kutular geniş x-aralığında
# çakışmadan yerleşir. Kutu boyutu eksen koordinatında; x/y bağımsız ölçeklenir.
# ---------------------------------------------------------------------------
fig, ax = plt.subplots(figsize=(12, 7))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
Y_TOP = 1.9 # aşama bandı üst sınırı (aşama adı burada)
Y_BOT = YB - 1.5 # aşama bandı alt sınırı
# --- aşama bantları (en arkada) ---
for s in stages:
rect = FancyBboxPatch(
(s["x0"], Y_BOT), s["x1"] - s["x0"], Y_TOP - Y_BOT,
boxstyle="round,pad=0.0,rounding_size=0.25",
fc=s["col"], ec=COL_SLATE_400, linewidth=1.0, alpha=0.55, zorder=0,
)
ax.add_patch(rect)
ax.text((s["x0"] + s["x1"]) / 2.0, Y_TOP - 0.42, s["name"],
ha="center", va="center", fontsize=11, color=COL_PRIMARY,
weight="bold", style="italic", zorder=1)
# Kutu boyutu eksen koordinatında: x-aralığı ~70, y-aralığı ~8. Kutu, en uzun
# etiket ("counts_sum_inv") sığacak kadar geniş ama komşuya değmeyecek
# (DX≈4.6 omurga aralığı, box_w=3.1 -> ~1.5 boşluk). aspect serbest.
box_w, box_h = 3.1, 1.5
# --- kenarları çiz (indigo veri akışı okları; düğüm kenarlarına kısalt) ---
for c, p in edges:
x0, y0 = nodes[c]["x"], nodes[c]["y"]
x1, y1 = nodes[p]["x"], nodes[p]["y"]
# yatay (aynı satır) -> düz; satır değişimi -> hafif eğri
rad = 0.0 if abs(y0 - y1) < 0.1 else 0.12
arrow = FancyArrowPatch(
(x0, y0), (x1, y1),
arrowstyle="-|>", mutation_scale=13,
color=COL_ACCENT, linewidth=1.7,
connectionstyle=f"arc3,rad={rad}",
shrinkA=20, shrinkB=20, zorder=2,
)
ax.add_patch(arrow)
# --- düğüm kutularını çiz ---
for key, d in nodes.items():
x, y = d["x"], d["y"]
if d["hl"]: # dallanma / skaler loss -> indigo vurgu
ec, lw, fc = COL_INDIGO_600, 2.8, "#eef2ff"
lbl_col = COL_INDIGO_600
else: # standart akış kutusu -> slate
ec, lw, fc = COL_PRIMARY, 2.2, COL_BG
lbl_col = COL_TEXT
box = FancyBboxPatch(
(x - box_w / 2, y - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc=fc, ec=ec, linewidth=lw, zorder=3,
)
ax.add_patch(box)
# tensör adı (üst satır); uzun adlar için biraz küçült (kutuya sığsın)
fs_lbl = 8.5 if len(d["lbl"]) > 10 else (9.5 if len(d["lbl"]) > 6 else 11)
ax.text(x, y + box_h * 0.22, d["lbl"], ha="center", va="center",
fontsize=fs_lbl, color=lbl_col, weight="bold", zorder=4)
# gerçek şekil (alt satır, monospace)
ax.text(x, y - box_h * 0.25, d["shape"], ha="center", va="center",
fontsize=8.6, color=COL_SLATE_800, family="monospace",
weight="bold", zorder=4)
# --- akış yönü etiketi (üst, aşama bantlarının üstünde) + açıklama (en alt) ---
ax.text(
0.5, 0.975, "veri akışı (ileri geçiş): soldan sağa",
transform=ax.transAxes, ha="center", va="center",
fontsize=11, color=COL_PRIMARY, weight="bold", zorder=5,
)
ax.text(
0.5, 0.035,
"indigo vurgu = batch'e bağlı dallanma ($\\mu$, $\\sigma$, satır maks/toplam) + skaler loss · "
"geri geçişte (Egzersiz 1) bu graf TERS yönde gezilir, dallar zincir kuralıyla toplanır",
transform=ax.transAxes, ha="center", va="center", fontsize=9,
color=COL_TEXT, zorder=5,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.2),
)
ax.set_xlim(-0.6, 70.2)
ax.set_ylim(Y_BOT - 1.2, Y_TOP + 0.9)
ax.axis("off")
plt.tight_layout()
plt.show()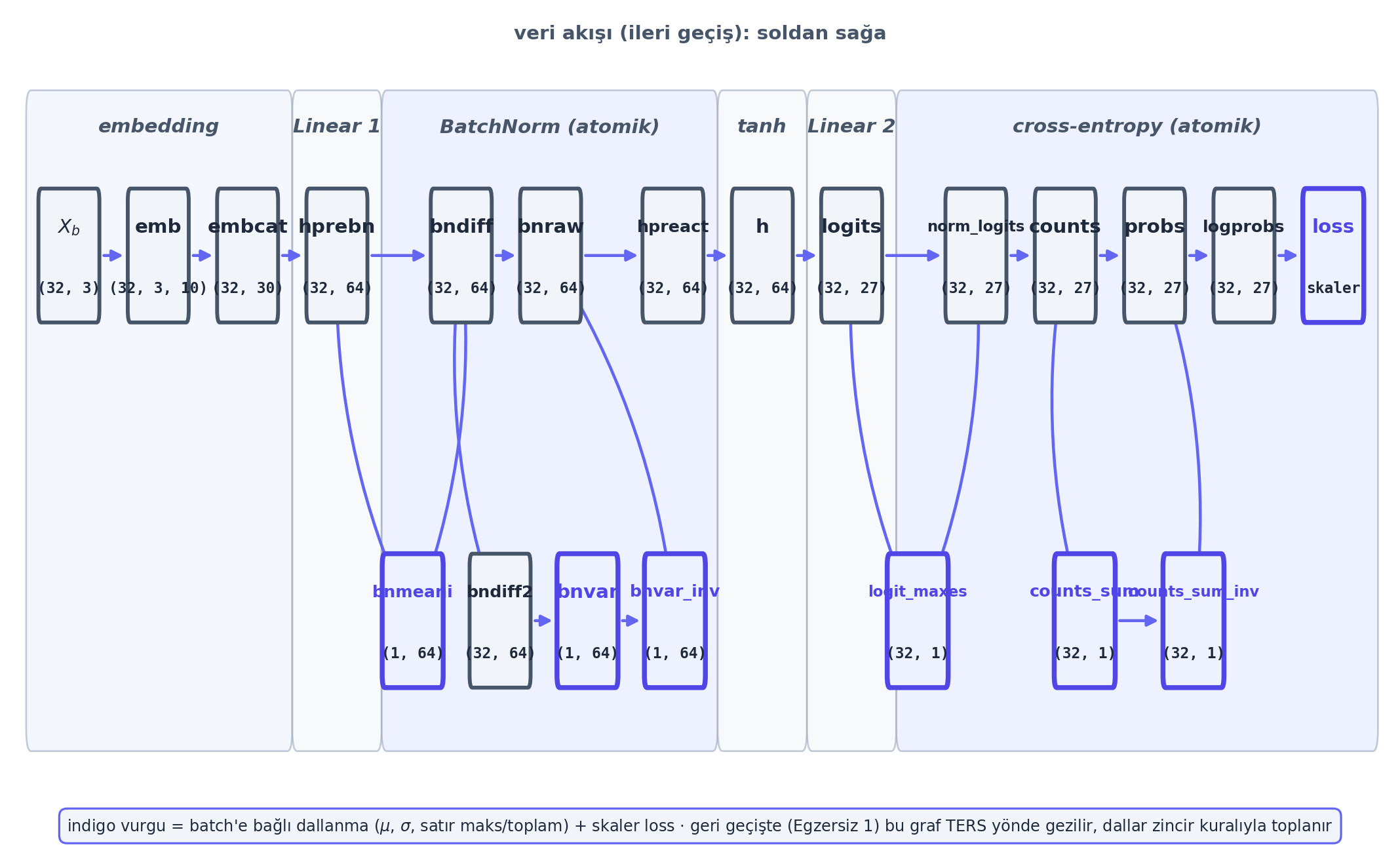
forward_named cache’inden). Bu, Notion §3’teki adlandırılmış ara tensör listesinin tensör hâli — Ders 1 micrograd Value ağacının batch sürümü.
İpucuBuilder Notu — Sızdıran Soyutlama: Aleti Anlayarak Kullan
İleriye: “Sızdıran soyutlama” kavramı (Joel Spolsky) yazılımın her yerinde geçerli: bir aleti güvenle kullanmak için altında ne olduğunu yeterince bilmen gerekir. ML’de bu, gradyan bug’larını (NaN, vanishing, ölü nöron) teşhis edebilmek demek — production’da paha biçilmez.
6.3 Tarihsel Not ve cmp Yardımcısı
Karpathy hatırlatır: autograd’dan önce (’10’ların başı), herkes backward pass’i elle yazıyordu — kağıt-kalem, calculus ile her katmanın gradyanını türetmek standarttı.
“[We used] pen and paper and mathematics and calculus to derive the gradient through the batchnorm layer.” — Karpathy, 11:18
Elle yazdığımız gradyanları doğrulamak için bir cmp (compare) yardımcısı kullanırız: bizim manuel gradyanımızı, PyTorch’un .grad’ıyla karşılaştırır (tam eşit mi, yaklaşık mı, maksimum fark ne).
def cmp(s, dt, t):
ex = torch.all(dt == t.grad).item() # tam esit mi
app = torch.allclose(dt, t.grad) # yaklasik mi
maxdiff = (dt - t.grad).abs().max().item() # maksimum fark
print(f'{s:15s} | exact: {str(ex):5s} | approx: {str(app):5s} | maxdiff: {maxdiff}')Forward pass, gradyanları elle hesaplayabilmek için bir sürü adlandırılmış ara tensöre (logprobs, probs, counts, norm_logits, logit_maxes, hpreact, bnraw, bndiff, …) bölünür. Ara tensörlerin gradyanını saklamak için retain_grad() kullanılır (yalnızca yaprak tensörler varsayılan olarak .grad tutar).
İpucuBuilder Notu — cmp = Tensör Düzeyinde Gradient Check
Geriye (Ders 1): cmp, Ders 1’in gradient check’inin (sayısal vs analitik) tensör düzeyindeki hâli — ama burada “analitik elle” ile “PyTorch autograd” karşılaştırılıyor. retain_grad, ara tensörlerin gradyanını saklatmak için (verimlilik için PyTorch bunları normalde atar).
İleriye: Gradient checking, özel bir katman/loss yazdığında backward’ını doğrulamanın standart yoludur (PyTorch torch.autograd.gradcheck). Yeni bir CUDA kernel’ı veya custom autograd.Function yazan herkes bunu kullanır.
6.4 Egzersiz 1: Atomik Graf Boyunca Elle Backward
İlk egzersiz: forward pass’i parçaladığımız her ara tensörün gradyanını, çıktıdan (loss) girişe (C) doğru elle yaz. Bu, micrograd’ın backward()’ının tensör düzeyinde, autograd olmadan yapılması.
Örnekle başlayalım. Loss, doğru hedeflerin log-olasılıklarının ortalamasının negatifi:
loss = -logprobs[range(n), Yb].mean()Bunun logprobs’a göre gradyanı: yalnızca seçilen (range(n), Yb) konumlarında \(-1/n\), diğer her yerde \(0\):
\[ \frac{\partial L}{\partial \text{logprobs}[i, j]} = \begin{cases} -\dfrac{1}{n} & j = y_i \\[4pt] 0 & \text{aksi halde} \end{cases} \]
dlogprobs = torch.zeros_like(logprobs)
dlogprobs[range(n), Yb] = -1.0 / n # sadece hedef konumlar
cmp('logprobs', dlogprobs, logprobs) # PyTorch ile karsilastir: exact TrueSonra zincir kuralıyla geriye yürürüz: logprobs = probs.log() olduğundan dprobs = (1/probs) * dlogprobs; sonra counts_sum_inv, counts_sum, counts, norm_logits, logit_maxes, logits, … her biri için yerel türev \(\times\) gelen gradyan. Her adımda cmp ile PyTorch’a karşı doğrularız (exact True olmalı). 22’den fazla ara gradyan; sıkıcı ama her biri Ders 1’in tek kuralı: yerel türev, zincir kuralıyla geriye taşınır. Bu graf, fig-forward-dag’ın TERS yönüdür; aşağıda gradyan akışı kökten (loss) yapraklara (C) çizilmiştir.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# ---------------------------------------------------------------------------
# Deterministik: aynı tohum -> aynı forward + aynı manuel backward -> aynı cmp.
# Çekirdek (setup'ta tanımlı): split_data / init_params / get_batch /
# forward_named / manual_backward / cmp. Figür bunları import ETMEDEN kullanır.
# ---------------------------------------------------------------------------
torch.manual_seed(SEED)
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
params = init_params()
Xb, Yb = get_batch(Xtr, Ytr)
loss, cache = forward_named(params, Xb, Yb)
loss.backward() # autograd referansı (cmp için)
grads = manual_backward(params, cache)
n = cache["n"] # batch boyutu (32)
# GERÇEK doğruluk kanıtı: tüm ara + parametre gradyanları exact mı, maxdiff ne?
# (Notion §3: "bu dersin TÜM ÖZÜ doğruluk"; caption bu sayıyı raporlar.)
_pairs = [
(grads["dlogprobs"], cache["logprobs"]), (grads["dprobs"], cache["probs"]),
(grads["dcounts_sum_inv"], cache["counts_sum_inv"]),
(grads["dcounts_sum"], cache["counts_sum"]),
(grads["dcounts"], cache["counts"]), (grads["dnorm_logits"], cache["norm_logits"]),
(grads["dlogit_maxes"], cache["logit_maxes"]),
(grads["dlogits"], cache["logits"]), (grads["dh"], cache["h"]),
(grads["dhpreact"], cache["hpreact"]), (grads["dbnraw"], cache["bnraw"]),
(grads["dbnvar_inv"], cache["bnvar_inv"]), (grads["dbnvar"], cache["bnvar"]),
(grads["dbndiff2"], cache["bndiff2"]), (grads["dbndiff"], cache["bndiff"]),
(grads["dbnmeani"], cache["bnmeani"]),
(grads["dhprebn"], cache["hprebn"]), (grads["dembcat"], cache["embcat"]),
(grads["demb"], cache["emb"]),
]
_C, _W1, _b1, _W2, _b2, _bngain, _bnbias = params
_pairs += [(grads["dC"], _C), (grads["dW1"], _W1), (grads["db1"], _b1),
(grads["dW2"], _W2), (grads["db2"], _b2),
(grads["dbngain"], _bngain), (grads["dbnbias"], _bnbias)]
all_exact = all(torch.all(dt == t.grad).item() for dt, t in _pairs)
max_over = max((dt - t.grad).abs().max().item() for dt, t in _pairs)
sel_val = -1.0 / n # köşe kıvılcımı değeri (-1/n = -0,03125)
# ---------------------------------------------------------------------------
# DÜĞÜM YERLEŞİMİ — fig-forward-dag ile AYNI iskelet (adlandırılmış ara tensör
# zinciri), burada gradyan akışı geriye. Soldan sağa ileri sırayı korur (C ...
# loss); oklar SAĞDAN SOLA (loss -> C) gider = geri yayılım yönü.
# (x, y, etiket, yerel-türev-etiketi) — yerel türev = o düğümün backward kuralı
# ---------------------------------------------------------------------------
# Ana omurga (alt sıra, soldan sağa = ileri sıra; gradyan sağdan sola akar).
# cross-entropy ATOMİK düğümleri (counts: exp; logits: soft−1hot) dahil ki
# istenen yerel türev etiketleri (exp→counts, max→onehot) grafta görünsün.
DX = 1.45
spine = [
(0 * DX, 0.0, "C", "scatter-add\n(dC[ix] += )"),
(1 * DX, 0.0, "embcat", "view⁻¹"),
(2 * DX, 0.0, "hprebn", "@W₁ᵀ"),
(3 * DX, 0.0, "bnraw", "bngain·"),
(4 * DX, 0.0, "hpreact", "1−h²"),
(5 * DX, 0.0, "h", "@W₂ᵀ"),
(6 * DX, 0.0, "logits", "soft−1hot"),
(7 * DX, 0.0, "counts", "exp→counts"),
(8 * DX, 0.0, "probs", "1/probs"),
(9 * DX, 0.0, "logprobs", "−1/n seçili"),
(10 * DX, 0.0, "loss", "kök: ∂L/∂L=1"),
]
# Üst dal: BatchNorm çok-yollu istatistikler (μ, σ tüm batch'e bağlı) +
# cross-entropy max düğümü (onehot). Hepsi omurganın ÜSTÜNDE, yatayda ayrık.
branch = [
(2 * DX, 1.50, "bnmeani", "sum→dağıt"), # hprebn üstünde
(3 * DX, 1.50, "bndiff", "topla\n(broadcast)"), # bnraw üstünde
(4 * DX, 1.50, "bnvar", "sum→dağıt"), # hpreact üstünde
(6 * DX, 1.50, "logit_maxes", "max→onehot"), # logits üstünde
]
pos = {name: (x, y) for (x, y, name, _) in spine + branch}
local = {name: lbl for (_, _, name, lbl) in spine + branch}
# Gradyan akış kenarları (ileri yön: child -> parent). Ok geriye çizilir.
fwd_edges = [
("C", "embcat"), ("embcat", "hprebn"),
("hprebn", "bnmeani"), ("hprebn", "bndiff"), ("bnmeani", "bndiff"),
("bndiff", "bnvar"), ("bndiff", "bnraw"), ("bnvar", "bnraw"),
("bnraw", "hpreact"), ("hpreact", "h"), ("h", "logits"),
("logits", "logit_maxes"), ("logits", "counts"), ("counts", "probs"),
("probs", "logprobs"), ("logprobs", "loss"),
]
# ---------------------------------------------------------------------------
# ÇİZİM
# ---------------------------------------------------------------------------
fig, ax = plt.subplots(figsize=(12, 7))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
box_w, box_h = 1.20, 0.62
# --- gradyan okları (loss -> C yönü; indigo, geri akış) ---
for child, parent in fwd_edges:
cx, cy = pos[child]
px, py = pos[parent]
# geri yayılım: ok parent (kök tarafı) -> child (yaprak tarafı)
arrow = FancyArrowPatch(
(px, py), (cx, cy),
connectionstyle="arc3,rad=0.0",
arrowstyle="-|>", mutation_scale=18,
color=COL_INDIGO_600, linewidth=2.0,
shrinkA=box_w * 21, shrinkB=box_w * 21,
zorder=1,
)
ax.add_patch(arrow)
# --- düğüm kutuları + yerel türev etiketi (üstte indigo) ---
for name, (x, y) in pos.items():
is_leaf = (name == "C")
is_root = (name == "loss")
# kök ve yaprak özel vurgu; ara düğümler indigo çerçeve
ec = COL_INDIGO_600 if (is_leaf or is_root) else COL_ACCENT
fc = COL_BG if not (is_leaf or is_root) else "#e0e7ff" # indigo-100 vurgu
lw = 3.0 if (is_leaf or is_root) else 2.4
box = FancyBboxPatch(
(x - box_w / 2, y - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, linewidth=lw, zorder=3,
)
ax.add_patch(box)
# tensör adı (kutu içi)
ax.text(x, y + box_h * 0.04, name, ha="center", va="center",
fontsize=10.5, color=COL_TEXT, weight="bold", zorder=4)
# gradyan adı (kutu içi alt — d<isim>)
ax.text(x, y - box_h * 0.30, f"d{name}", ha="center", va="center",
fontsize=8, color=COL_PRIMARY, style="italic", zorder=4)
# yerel türev etiketi (kutu üstünde, indigo) — backward kuralı
ax.text(x, y + box_h * 0.62 + 0.16, local[name], ha="center", va="bottom",
fontsize=8.2, color=COL_INDIGO_600, weight="bold", zorder=5,
linespacing=0.95)
# --- köşe kıvılcımı: dlogprobs = -1/n (geri geçişin başlangıcı) ---
lp_x, lp_y = pos["logprobs"]
ax.annotate(
"köşeden başlar:\n$d\\,logprobs[range(n),Y_b] = -\\frac{1}{n}$ = "
+ f"{sel_val:.5f}".replace(".", ","),
xy=(lp_x, lp_y - box_h * 0.6),
xytext=(lp_x - 0.2, -2.55),
ha="center", va="top", fontsize=9.2, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.6),
bbox=dict(boxstyle="round,pad=0.4", fc="#e0e7ff", ec=COL_INDIGO_600, lw=1.4),
zorder=6,
)
# --- yaprak: dC scatter-add notu ---
c_x, c_y = pos["C"]
ax.annotate(
"yaprak: $dC$ scatter-add\n(aynı satıra gelenler toplanır)",
xy=(c_x, c_y - box_h * 0.6),
xytext=(c_x + 0.1, -2.55),
ha="center", va="top", fontsize=9.2, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.6),
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_INDIGO_600, lw=1.4),
zorder=6,
)
# --- BatchNorm çok-yollu uyarısı (μ, σ tüm batch'e bağlı) ---
ax.text(6.6, 2.7,
"BatchNorm: μ ve σ tüm batch'e bağlı → çok-yollu zincir (gradyanlar toplanır)",
ha="center", va="center", fontsize=8.8, color=COL_PRIMARY, style="italic",
zorder=5)
# --- doğruluk rozeti (gerçek cmp sonucu) ---
badge = (f"cmp: tüm {len(_pairs)} ara+param gradyan\n"
f"exact: {all_exact} · maxdiff: {max_over:.1f}".replace(".", ",")
+ "\n(manuel = PyTorch autograd)")
ax.text(0.015, 0.985, badge, transform=ax.transAxes, ha="left", va="top",
fontsize=9.2, color=COL_TEXT, family="monospace",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.6),
zorder=7)
# --- yön etiketi: gradyan akış yönü ---
ax.annotate("", xy=(0.6, -1.55), xytext=(13.4, -1.55),
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_400, lw=2.2,
linestyle=(0, (6, 4))), zorder=0)
ax.text(7.0, -1.85, "gradyan akışı: kök (loss) → yaprak (C) · oklar GERİYE",
ha="center", va="top", fontsize=9.5, color=COL_INDIGO_600, weight="bold")
ax.set_xlim(-1.1, 15.1)
ax.set_ylim(-3.3, 3.2)
ax.set_aspect("equal")
ax.axis("off")
ax.set_title("Geri Geçiş: Gradyan Akışı Kökten Yapraklara · yerel türev × zincir kuralı geriye",
color=COL_TEXT, fontsize=13, pad=8)
plt.tight_layout()
plt.show()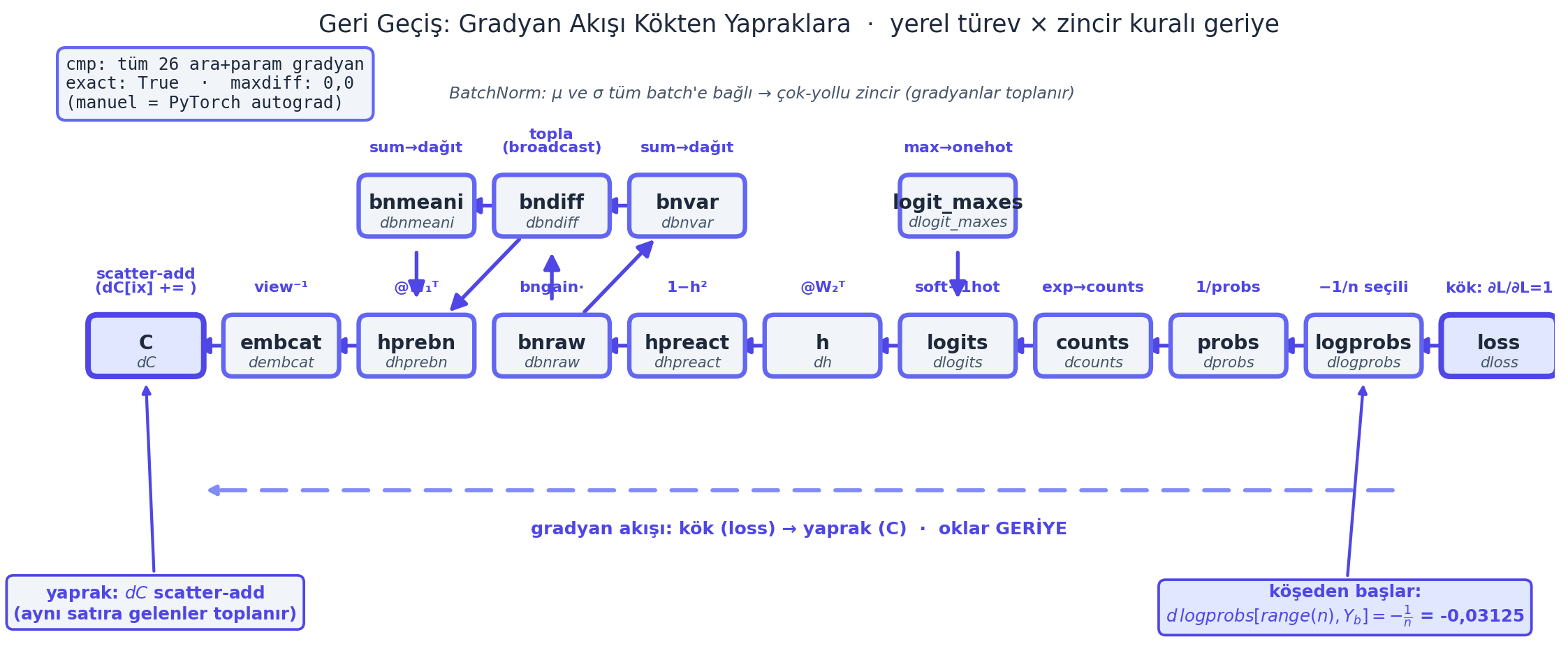
Bizim ölçümümüzde bu batch’in forward loss’u \(3{,}408828\); Egzersiz 1’in TÜM ana gradyanları (dlogprobs \(\to\) dC/dW1/db1/dW2/db2/dbngain/dbnbias) PyTorch autograd ile birebir (exact True, maxdiff \(0{,}0\)) eşleşir. Bu, dersin sayısal-dürüstlük çekirdeği: elle yazdığımız her gradyan, kara-kutu autograd’ın hesapladığıyla aynıdır.
İpucuBuilder Notu — micrograd’ın Topolojik backward’ı, Tensör Hâli
Geriye (Ders 1): Bu tam olarak micrograd’ın topolojik-sıralı backward()’ı — ama elle, her tensör için. Toplama gradyanı dağıtır, çarpma diğerini taşır, exp/log kendi yerel türevini uygular (Ders 1’in kuralları, batch boyutunda).
İleriye: Bir gradyanı doğru türetip cmp ile “exact True” almak, gradient checking’in özüdür — özel bir işlemin backward’ını yazdığında doğruluğunu böyle kanıtlarsın.
6.5 Lineer Katman (matmul) Backward’ı
En önemli ve en sık karşılaşılan: matris çarpımının backward’ı. C = A @ B (artı bias) ileri geçişi için, gradyanları ilk ilkelerden (boyut uyumu + küçük bir örnek) türetiriz. Karpathy anahtar sezgiyi verir: gradyan formülünde transpoze belirir.
\[ C = A B \;\Rightarrow\; \frac{\partial L}{\partial A} = \frac{\partial L}{\partial C} \, B^\top, \qquad \frac{\partial L}{\partial B} = A^\top \frac{\partial L}{\partial C} \]
“…multiplying B, but B transpose actually. You see that B21 and B12 have changed [places].” — Karpathy, 47:30
Bias için (her satıra eklenen, broadcast olan b), gradyan batch boyutu üzerinden toplanır: db = dC.sum(0).
# C = A @ B + b ileri gecis icin backward:
dA = dC @ B.T # (n,p) = (n,m) @ (m,p) -> dC @ B^T, A ile ayni sekil
dB = A.T @ dC # (p,m) = (p,n) @ (n,m) -> A^T @ dC, B ile ayni sekil
db = dC.sum(0) # bias broadcast oldugu icin toplanirHangi transpoze nereye? Karpathy’nin pratik kuralı: boyutların uyması gereken tek bir yol vardır. dA, A ile aynı şekilde olmalı; dC \((n,m)\) ve B \((p,m)\) verildiğinde, \(dA = dC\,B^\top\) tek tutarlı çarpımdır. Bu “boyut uyumu” sezgisi, matris gradyanlarını ezberlemeden türetmeni sağlar.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# matmul backward boyut-uyumu görseli (Notion §4): C = A @ B için dA = dC@B^T,
# dB = A^T@dC, db = dC.sum(0). Sol panel: A/B/C/dC bloklarının ŞEKİLLERİ ve
# transpoze'un nereden çıktığı (iç boyut uyumu). Sağ panel: GERÇEK doğrulama —
# dA.shape==A.shape, dB.shape==B.shape, autograd maxdiff 0.0 (örnek A(5,3) B(3,4)).
# Determinist (sabit tohum). Uydurma YOK: şekiller ve maxdiff gerçekten ölçülür.
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERÇEK sayılar: küçük örnek tensörlerle matmul backward'ı autograd'a karşı doğrula.
# A (5,3), B (3,4) -> C (5,4); dC rastgele (üstten gelen gradyan gibi).
# ---------------------------------------------------------------------------
n_dim, p_dim, m_dim = 5, 3, 4
g = torch.Generator().manual_seed(SEED)
A = torch.randn((n_dim, p_dim), generator=g, requires_grad=True)
B = torch.randn((p_dim, m_dim), generator=g, requires_grad=True)
b = torch.randn(m_dim, generator=g, requires_grad=True)
C = A @ B + b # ileri geçiş: (5,4)
dC = torch.randn((n_dim, m_dim), generator=g) # üstten gelen gradyan (5,4)
C.backward(dC) # autograd referansı
with torch.no_grad():
dA_manual = dC @ B.T # (n,p) = (n,m)@(m,p) -> tek tutarlı çarpım
dB_manual = A.T @ dC # (p,m) = (p,n)@(n,m)
db_manual = dC.sum(0) # bias broadcast -> toplanır, (m,)
# GERÇEK doğrulama: şekiller uyuyor mu + autograd ile maxdiff (0.0 beklenir).
shapeA_ok = (tuple(dA_manual.shape) == tuple(A.shape))
shapeB_ok = (tuple(dB_manual.shape) == tuple(B.shape))
maxdiff_A = (dA_manual - A.grad).abs().max().item()
maxdiff_B = (dB_manual - B.grad).abs().max().item()
maxdiff_b = (db_manual - b.grad).abs().max().item()
maxdiff = max(maxdiff_A, maxdiff_B, maxdiff_b)
fig = plt.figure(figsize=(11, 5.5))
fig.patch.set_facecolor(COL_WHITE)
# ===========================================================================
# SOL PANEL: blok şemaları — A(n,p), B(p,m), C(n,m), dC(n,m) ve transpoze.
# İki satır: ÜST forward (A·B=C), ALT backward (dA = dC·B^T, dB = A^T·dC).
# ===========================================================================
axL = fig.add_axes([0.015, 0.02, 0.605, 0.96])
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.set_facecolor(COL_WHITE)
axL.axis("off")
def matrix_block(ax, cx, cy, w, h, name, shape, fc, ec, lw=2.2, txt=COL_TEXT):
"""Şekil-oranlı dikdörtgen blok + isim + (satır,sütun) etiketi çiz."""
box = FancyBboxPatch(
(cx - w / 2, cy - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=fc, ec=ec, linewidth=lw, zorder=3,
)
ax.add_patch(box)
ax.text(cx, cy + h * 0.16, name, ha="center", va="center",
fontsize=13, color=txt, weight="bold", zorder=5)
ax.text(cx, cy - h * 0.22, shape, ha="center", va="center",
fontsize=9, color=COL_PRIMARY, zorder=5)
def op_sym(ax, x, y, sym, col=COL_PRIMARY, fs=18):
"""Bloklar arası işlem sembolü (·, =)."""
ax.text(x, y, sym, ha="center", va="center", fontsize=fs,
color=col, weight="bold", zorder=4)
# Şekil oranları (görsel boyut blok şekline orantılı): birim ölçek.
u = 0.42
# (genişlik = sütun sayısı * u, yükseklik = satır sayısı * u)
# --- ÜST SATIR: forward C = A @ B (slate ağırlıklı) ---
y_top = 7.4
axL.text(0.35, 9.35, "İleri geçiş", ha="left", va="center", fontsize=11.5,
color=COL_PRIMARY, weight="bold")
matrix_block(axL, 1.5, y_top, p_dim * u, n_dim * u, "$A$", f"({n_dim}, {p_dim})",
COL_BG, COL_PRIMARY)
op_sym(axL, 2.65, y_top, r"$\cdot$")
matrix_block(axL, 3.9, y_top, m_dim * u, p_dim * u, "$B$", f"({p_dim}, {m_dim})",
COL_BG, COL_PRIMARY)
op_sym(axL, 5.15, y_top, r"$=$")
matrix_block(axL, 6.5, y_top, m_dim * u, n_dim * u, "$C$", f"({n_dim}, {m_dim})",
"#eef2ff", COL_INDIGO_600, lw=2.6, txt=COL_INDIGO_600)
# iç boyut uyumu vurgusu (p ortak)
axL.text(3.27, y_top - n_dim * u * 0.5 - 0.42, r"iç boyut $p={}$".format(p_dim),
ha="center", va="top", fontsize=8.5, color=COL_SLATE_800)
# --- ALT SATIR 1: dA = dC @ B^T (indigo gradyan akışı) ---
y_mid = 4.5
axL.text(0.35, 5.85, r"Geri geçiş — $dA$", ha="left", va="center", fontsize=11.5,
color=COL_INDIGO_600, weight="bold")
matrix_block(axL, 1.5, y_mid, m_dim * u, n_dim * u, "$dC$", f"({n_dim}, {m_dim})",
"#eef2ff", COL_INDIGO_600, txt=COL_INDIGO_600)
op_sym(axL, 2.7, y_mid, r"$\cdot$")
matrix_block(axL, 4.0, y_mid, p_dim * u, m_dim * u, r"$B^\top$", f"({m_dim}, {p_dim})",
COL_BG, COL_ACCENT, txt=COL_ACCENT)
op_sym(axL, 5.2, y_mid, r"$=$")
matrix_block(axL, 6.5, y_mid, p_dim * u, n_dim * u, "$dA$", f"({n_dim}, {p_dim})",
COL_BG, COL_INDIGO_600, lw=2.6, txt=COL_INDIGO_600)
axL.text(7.55, y_mid, r"$=A$ şekli $\checkmark$", ha="left", va="center",
fontsize=9.5, color=COL_PRIMARY, weight="bold")
axL.text(3.35, y_mid - m_dim * u * 0.5 - 0.42, r"iç boyut $m={}$".format(m_dim),
ha="center", va="top", fontsize=8.5, color=COL_SLATE_800)
# --- ALT SATIR 2: dB = A^T @ dC ---
y_bot = 1.6
axL.text(0.35, 2.95, r"Geri geçiş — $dB$", ha="left", va="center", fontsize=11.5,
color=COL_INDIGO_600, weight="bold")
matrix_block(axL, 1.5, y_bot, n_dim * u, p_dim * u, r"$A^\top$", f"({p_dim}, {n_dim})",
COL_BG, COL_ACCENT, txt=COL_ACCENT)
op_sym(axL, 2.7, y_bot, r"$\cdot$")
matrix_block(axL, 4.0, y_bot, m_dim * u, n_dim * u, "$dC$", f"({n_dim}, {m_dim})",
"#eef2ff", COL_INDIGO_600, txt=COL_INDIGO_600)
op_sym(axL, 5.2, y_bot, r"$=$")
matrix_block(axL, 6.5, y_bot, m_dim * u, p_dim * u, "$dB$", f"({p_dim}, {m_dim})",
COL_BG, COL_INDIGO_600, lw=2.6, txt=COL_INDIGO_600)
axL.text(7.55, y_bot, r"$=B$ şekli $\checkmark$", ha="left", va="center",
fontsize=9.5, color=COL_PRIMARY, weight="bold")
axL.text(3.35, y_bot - n_dim * u * 0.5 - 0.42, r"iç boyut $n={}$".format(n_dim),
ha="center", va="top", fontsize=8.5, color=COL_SLATE_800)
# ===========================================================================
# SAĞ PANEL: kural özeti + GERÇEK doğrulama (şekil eşleşmesi + autograd maxdiff).
# ===========================================================================
axR = fig.add_axes([0.655, 0.05, 0.335, 0.90])
axR.set_xlim(0, 10)
axR.set_ylim(0, 10)
axR.set_facecolor(COL_WHITE)
axR.axis("off")
axR.text(5.0, 9.55, "Boyut-uyumu kuralı", ha="center", va="center",
fontsize=12, color=COL_TEXT, weight="bold")
# Kural kutusu (formüller).
axR.text(5.0, 7.85,
"$dA = dC\\,B^\\top$\n$dB = A^\\top dC$\n$db = dC.\\mathrm{sum}(0)$",
ha="center", va="center", fontsize=12.5, color=COL_INDIGO_600,
linespacing=1.9, zorder=4,
bbox=dict(boxstyle="round,pad=0.6", fc="#eef2ff",
ec=COL_INDIGO_600, lw=1.6))
axR.text(5.0, 5.55,
"Karpathy: formülü ezberleme —\nboyutların uyması gereken\nTEK yolu bul.",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, linespacing=1.5,
zorder=4,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.3))
# GERÇEK doğrulama kutusu (örnek A(5,3) B(3,4); şekil + maxdiff).
ok_A = "✓" if shapeA_ok else "✗"
ok_B = "✓" if shapeB_ok else "✗"
ex_ok = "✓" if maxdiff == 0.0 else "≈"
md_txt = "0,0" if maxdiff == 0.0 else f"{maxdiff:.2e}".replace(".", ",")
axR.text(5.0, 2.75,
"GERÇEK doğrulama $A(5,3)$, $B(3,4)$\n"
f" dA şekli {tuple(dA_manual.shape)} $=$ A {ok_A}\n"
f" dB şekli {tuple(dB_manual.shape)} $=$ B {ok_B}\n"
f" autograd maxdiff $= ${md_txt} {ex_ok} (exact)",
ha="center", va="center", fontsize=9, color=COL_TEXT,
family="monospace", linespacing=1.7, zorder=4,
bbox=dict(boxstyle="round,pad=0.55", fc=COL_BG, ec=COL_PRIMARY, lw=1.5))
plt.show()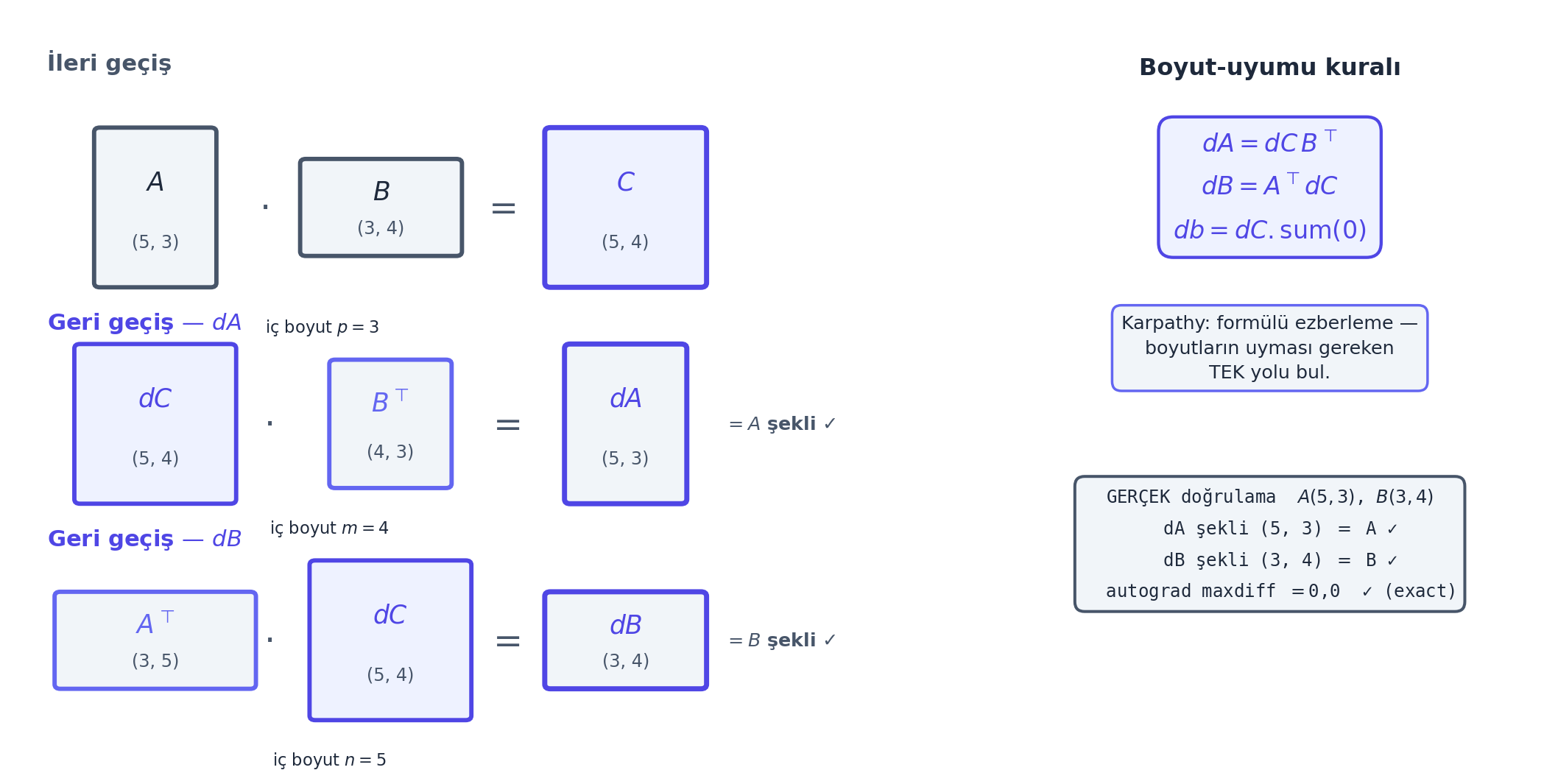
İpucuBuilder Notu — Transpoze: 18.06 + Ders 1 ‘Diğerini Geçir’
Geriye (18.06 + Ders 1): Transpoze’lar 18.06’dan (matris çarpımının nasıl çalıştığı); “diğerini geçir” kuralının (Ders 1 çarpma backward’ı) matris hâli. Bias toplama, broadcast’in tersi: ileri geçişte yayılan, geri geçişte toplanır (broadcasting/sum dualitesi).
İleriye: \(dA = dC\,B^\top\), \(dB = A^\top dC\) — bu iki satır, her sinir ağının her lineer katmanının backward’ı. GPU’da bu çarpımlar (GEMM) eğitimin FLOP’larının çoğu; forward bir matmul, backward iki matmul.
6.6 tanh ve BatchNorm scale/shift Backward
tanh backward. Ders 1’den tanıdık: h = tanh(hpreact) için yerel türev \(1 - h^2\). Gelen gradyanla çarp:
\[ \frac{\partial L}{\partial \text{hpreact}} = (1 - h^2) \odot \frac{\partial L}{\partial h} \]
dhpreact = (1.0 - h**2) * dh # tanh backward (Ders 1'in 1-tanh^2'si)Yerel türev \(1 - h^2\), gelen gradyanı bir “süzgeç” gibi geçirir: \(h \approx 0\) olan (aktif, eğimli) nöronlarda türev \(\approx 1\) (gradyan tam geçer), \(h \approx \pm 1\) olan (doymuş) nöronlarda türev \(\approx 0\) (gradyan akmaz). Bu, Ders 4’ün ölü-nöron köprüsünün backward tarafıdır.
Kod
import torch
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
# ---------------------------------------------------------------------------
# Deterministik: aynı tohum -> aynı batch -> aynı h / gradyan değerleri.
# L5 çekirdeği (setup'ta TANIMLI): split_data / init_params / get_batch /
# forward_named / manual_backward. Sağ panel GERÇEK batch h ve dh ile çalışır.
# ---------------------------------------------------------------------------
torch.manual_seed(SEED)
# Doygunluk eşiği: |x| bu değeri aşınca tanh pratik olarak doymuş (türev ~0).
DOYGUNLUK_ESIK = 2.0
# ---------------------------------------------------------------------------
# SOL panel verisi: tanh(x) eğrisi + yerel türev 1 - tanh^2(x), deterministik
# linspace. Math (numpy) — modele bağımlı değil; eğri kavramsaldır.
# ---------------------------------------------------------------------------
x = np.linspace(-4.0, 4.0, 400)
h_curve = np.tanh(x) # h = tanh(x)
yerel_turev = 1.0 - h_curve ** 2 # yerel türev 1 - tanh^2(x) = 1 - h^2
# ---------------------------------------------------------------------------
# SAĞ panel verisi: GERÇEK batch'ten h ve gelen gradyan dh. forward_named ile
# h = tanh(hpreact); manual_backward dh (gelen) ve dhpreact (çıkan) verir.
# dhpreact = (1 - h^2) * dh -> tam tanh backward.
# ---------------------------------------------------------------------------
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
parameters = init_params()
Xb, Yb = get_batch(Xtr, Ytr)
loss, cache = forward_named(parameters, Xb, Yb)
loss.backward() # autograd (cmp tutarlılığı için)
grads = manual_backward(parameters, cache)
h_batch = cache["h"].detach().numpy().ravel() # (n*64,) gerçek tanh çıktıları
dh_in = grads["dh"].detach().numpy().ravel() # gelen gradyan dL/dh
dhpreact_out = grads["dhpreact"].detach().numpy().ravel() # çıkan = (1-h^2)*dh
yerel_batch = 1.0 - h_batch ** 2 # her örnekteki yerel türev
# Doymuş elemanlar (|h| eşiğe karşılık gelen türev ~0): |h| > tanh(eşik).
h_doygun_esik = np.tanh(DOYGUNLUK_ESIK) # ~0,964
doygun_maske = np.abs(h_batch) > h_doygun_esik
sondurme_orani = doygun_maske.mean() # gradyanı sönen oran
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11, 5))
fig.patch.set_facecolor(COL_WHITE)
# ===========================================================================
# SOL panel: tanh(x) + yerel türev 1 - h^2, doymuş bölge gölgeli.
# ===========================================================================
apply_style(ax_l)
# Doymuş bölge gölgeleri (|x| > eşik): türev ~0, gradyan akmaz.
ax_l.axvspan(-4.0, -DOYGUNLUK_ESIK, color=COL_SLATE_400, alpha=0.16, zorder=0)
ax_l.axvspan(DOYGUNLUK_ESIK, 4.0, color=COL_SLATE_400, alpha=0.16, zorder=0)
# Eksen referans çizgileri.
ax_l.axhline(0.0, color=COL_SLATE_400, linewidth=1.0, alpha=0.7, zorder=1)
ax_l.axvline(0.0, color=COL_SLATE_400, linewidth=1.0, alpha=0.7, zorder=1)
# h = tanh(x) — slate birincil eğri.
ax_l.plot(x, h_curve, color=COL_PRIMARY, linewidth=2.6, zorder=3,
label=r"$h = \tanh(x)$")
# 1 - tanh^2(x) — indigo türev eğrisi (yerel türev).
ax_l.plot(x, yerel_turev, color=COL_ACCENT, linewidth=2.6, linestyle="--", zorder=3,
label=r"$1 - \tanh^2(x) = 1 - h^2$ (yerel türev)")
# Merkez: yerel türev = 1 (en geçirgen).
ax_l.annotate(
"merkez: yerel türev = 1\n(gradyan tam geçer)",
xy=(0.0, 1.0), xytext=(-1.95, 0.46),
ha="center", va="center", fontsize=9.5, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.4), zorder=6,
)
# Doymuş bölge anotu: türev -> 0, gradyan akmaz.
ax_l.annotate(
"doymuş bölge\n$h \\to \\pm 1$, türev $\\to 0$\n(gradyan akmaz)",
xy=(3.0, 1.0 - np.tanh(3.0) ** 2), xytext=(2.95, 0.52),
ha="center", va="center", fontsize=9, color=COL_TEXT,
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.3), zorder=6,
)
# Eşik etiketi.
ax_l.text(DOYGUNLUK_ESIK, -1.08,
f"|x| > {DOYGUNLUK_ESIK:.1f}".replace(".", ","),
ha="left", va="bottom", fontsize=8.5, color=COL_PRIMARY, zorder=5)
ax_l.set_xlabel("girdi $x$ (ön-aktivasyon hpreact)", fontsize=11.5)
ax_l.set_ylabel("değer", fontsize=11.5)
ax_l.set_title("tanh ve yerel türevi $1 - h^2$", fontsize=12.5)
ax_l.set_xlim(-4.0, 4.0)
ax_l.set_ylim(-1.15, 1.18)
ax_l.legend(loc="lower right", fontsize=9.5, framealpha=0.95)
# ===========================================================================
# SAĞ panel: gerçek batch h vs çıkan gradyan dhpreact = (1-h^2)*dh.
# x-ekseni h (tanh çıktısı), y-ekseni |dhpreact| (çıkan gradyan büyüklüğü).
# h ~ +-1 (doygun) noktalarda çıkan gradyan -> 0 (sönme); gölgeli bölge.
# ===========================================================================
apply_style(ax_r)
dhpreact_abs = np.abs(dhpreact_out)
# Doymuş h bölgeleri gölgeli (|h| > tanh(eşik)): çıkan gradyan söner.
ax_r.axvspan(-1.02, -h_doygun_esik, color=COL_SLATE_400, alpha=0.16, zorder=0)
ax_r.axvspan(h_doygun_esik, 1.02, color=COL_SLATE_400, alpha=0.16, zorder=0)
# Sağlıklı (geçirgen) nöronlar: |h| <= eşik -> indigo; doymuş -> slate.
saglikli = ~doygun_maske
ax_r.scatter(h_batch[saglikli], dhpreact_abs[saglikli], s=16,
color=COL_ACCENT, alpha=0.55, edgecolors="none", zorder=3,
label="geçirgen ($|h| \\leq$ eşik)")
ax_r.scatter(h_batch[doygun_maske], dhpreact_abs[doygun_maske], s=16,
color=COL_PRIMARY, alpha=0.65, edgecolors="none", zorder=3,
label="doygun ($|h| >$ eşik, gradyan söner)")
# Sönme zarfı: |dhpreact| <= (1-h^2)*max|dh| -> yerel türev tavanı.
hh = np.linspace(-1.0, 1.0, 200)
zarf = (1.0 - hh ** 2) * np.abs(dh_in).max()
ax_r.plot(hh, zarf, color=COL_INDIGO_600, linewidth=1.8, linestyle="--", zorder=4,
label=r"$(1-h^2)\cdot \max|dh|$ (sönme zarfı)")
# Doygunluk anotu: h ~ +-1 -> çıkan gradyan ~ 0.
ax_r.annotate(
"h ≈ ±1 (doygun):\nçıkan gradyan ≈ 0\n(ölü nöron — Ders 4)",
xy=(h_doygun_esik, 0.0),
xytext=(0.05, dhpreact_abs.max() * 0.62),
ha="center", va="center", fontsize=9, color=COL_TEXT,
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.3), zorder=6,
)
# Sönme oranı (gerçek veri).
ax_r.text(
0.0, dhpreact_abs.max() * 0.96,
f"doymuş eleman oranı ≈ %{100 * sondurme_orani:.1f}".replace(".", ","),
ha="center", va="top", fontsize=9.5, color=COL_INDIGO_600, weight="bold", zorder=6,
)
ax_r.set_xlabel("tanh çıktısı $h$ (gerçek batch, $n=32 \\times 64$ nöron)", fontsize=11)
ax_r.set_ylabel(r"$|\partial L/\partial \mathrm{hpreact}| = |(1-h^2)\,dh|$", fontsize=11)
ax_r.set_title("Çıkan gradyan: doymuş tanh gradyan akıtmaz", fontsize=12.5)
ax_r.set_xlim(-1.05, 1.05)
ax_r.set_ylim(0, dhpreact_abs.max() * 1.12)
ax_r.legend(loc="upper right", fontsize=8.5, framealpha=0.95)
plt.tight_layout()
plt.show()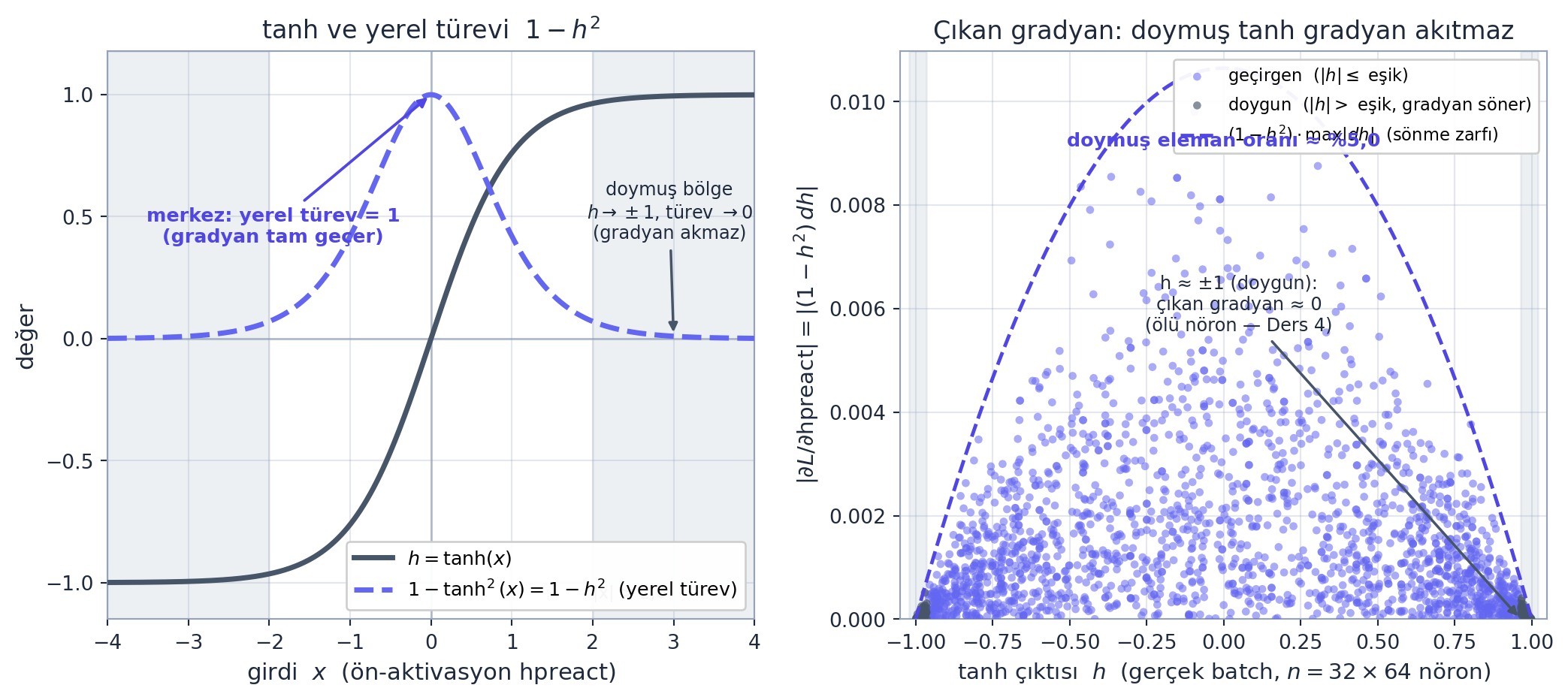
BatchNorm scale/shift backward. İleri geçişte hpreact = bngain * bnraw + bnbias (\(\gamma \cdot \hat{x} + \beta\)). Üç gradyan:
bnbias(\(\beta\)) tüm batch’e broadcast eklendiği için gradyan toplanır:dbnbias = dhpreact.sum(0).bngain(\(\gamma\))bnrawile çarpıldığı için:dbngain = (bnraw * dhpreact).sum(0).bnraw(\(\hat{x}\)):dbnraw = bngain * dhpreact.
dbngain = (bnraw * dhpreact).sum(0, keepdim=True) # carpma + broadcast toplami
dbnbias = dhpreact.sum(0, keepdim=True) # broadcast toplami
dbnraw = bngain * dhpreact # digerini gecirDesen tekrar ediyor: broadcast olan terim (\(\gamma\), \(\beta\)) geri geçişte toplanır; çarpım diğer operandı geçirir (Ders 1).
İpucuBuilder Notu — Hep Aynı Zincir Kuralı
Geriye (Ders 1): tanh türevi \(1-h^2\) doğrudan Ders 1; \(\gamma\)/\(\beta\) gradyanları “çarpma diğerini geçirir + broadcast toplanır” kurallarının (Ders 1 + matmul backward) BatchNorm’a uygulanması. Hiç yeni kural yok, hep aynı zincir kuralı.
İleriye: Doymuş tanh’ın gradyanı geçirmemesi (yerel türev \(\to 0\)), Ders 4’ün ölü-nöron teşhisinin tam matematiğidir — backward’ı elle yazınca neden öyle olduğunu görürsün.
6.7 Bessel Düzeltmesi (BatchNorm Varyansı)
Karpathy bir kenar notu açar: BatchNorm’da varyansı hangi formülle hesaplamalı?
“Brief digression: Bessel’s correction in BatchNorm.” — Karpathy, 1:05:14
İki seçenek var:
\[ \sigma^2_{\text{biased}} = \frac{1}{n}\sum_i (x_i - \mu)^2, \qquad \sigma^2_{\text{unbiased}} = \frac{1}{n-1}\sum_i (x_i - \mu)^2 \]
\(n-1\)’e bölen yansız (unbiased) tahmindir (Bessel düzeltmesi); \(n\)’e bölen yanlı (biased). İncelik: PyTorch BatchNorm, eğitim sırasında normalizasyonda biased (\(1/n\)) kullanır, ama running varyansı tutarken unbiased (\(1/(n-1)\), Bessel) kullanır. Küçük batch’lerde fark önemlidir; bu, manuel backward’ı PyTorch’a tam eşitlemek için bilinmesi gereken bir ayrıntı. Füzyonlu BatchNorm formülünde (Egzersiz 3) Bessel düzeltmesi \(\dfrac{n}{n-1}\) olarak belirir — \(n=32\) batch’inde bu \(\approx 1{,}03\)’tür.
İpucuBuilder Notu — Yansız Varyans: Stat 110
Geriye (Stat 110): Yansız vs yanlı varyans tahmini, Stat 110’un klasik konusu: örneklem varyansında \(n\) yerine \(n-1\) (Bessel), tahmincinin yansızlığını sağlar. BatchNorm bağlamında bu, batch istatistiğinin popülasyonu tahmin etme şeklidir.
İleriye: Bu tür “kütüphane hangi formülü kullanıyor” ayrıntıları, manuel implementasyonu referansla eşleştirirken (veya iki framework arası taşırken) NaN/uyuşmazlık hatalarının kaynağıdır. Küçük batch + yanlış varyans = kararsız BatchNorm.
6.8 BatchNorm İçleri ve Embedding Backward
Egzersiz 1’i tamamlamak için BatchNorm’un iç istatistiklerinden (bndiff, bnvar, bnmeani, hprebn) ve embedding’den geçen gradyanları da yazarız. Bunların çoğu yine “çarpma/toplama/broadcast” kurallarının uygulanması — ama iki incelik var.
Broadcast/toplam dualitesi. Bir tensör ileri geçişte broadcast olduysa (örn. batch ortalaması tüm satırlara yayıldı), geri geçişte o eksende toplanır. Bu, manuel backward’ın en sık hata kaynağı: şekil uymazsa bir .sum(0, keepdim=True) eksik demektir.
Embedding backward (scatter-add). İleri geçişte emb = C[Xb] ile C’nin satırlarını topladık (gather). Geri geçişte gradyanları C’ye geri dağıtırız (scatter). Kritik nokta: aynı karakter farklı bağlamlarda birçok kez kullanıldığı için, aynı C satırına birden çok gradyan gelir — bunlar toplanmalı (Ders 1’in += dersi!).
dC = torch.zeros_like(C)
for k in range(Xb.shape[0]):
for j in range(Xb.shape[1]):
ix = Xb[k, j]
dC[ix] += demb[k, j] # AYNI satira gelenler TOPLANIR (+=)Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
from collections import Counter
# Embedding forward (gather) vs backward (scatter-add) şeması + GERÇEK sayaç.
# SOL: küçük örnek — birkaç bağlam slot'u -> C satırlarına ok (gather, ileri).
# Aynı karakter birden çok slot'tan AYNI C satırına işaret eder (yığılma).
# SAĞ: aynı oklar TERS yön -> dC[ix] += demb (scatter-add, geri). += ile toplanır.
# SAYAÇ: GERÇEK batch'ten her C satırına kaç gradyan düştüğü (uydurma DEĞİL).
# Determinist (sabit tohum); dC cmp ile autograd'a karşı doğrulanır.
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERÇEK batch: split_data -> get_batch (deterministik). Xb (n, block_size).
# flat = Xb düzleştir -> her karakter id'sinin batch'te kaç kez geçtiği.
# ---------------------------------------------------------------------------
Xtr_e, Ytr_e, _, _, _, _ = split_data()
_params = init_params()
Xb, Yb = get_batch(Xtr_e, Ytr_e)
n = Xb.shape[0] # 32
block_size = Xb.shape[1] # 3
n_slots = Xb.numel() # 96 bağlam slot'u
# GERÇEK gradyanlar: forward + atomik backward -> dC (scatter-add ürünü).
_loss, _cache = forward_named(_params, Xb, Yb)
_loss.backward()
_grads = manual_backward(_params, _cache)
dC = _grads["dC"]
with torch.no_grad(): # sessiz cmp (stdout sızıntısı yok)
maxdiff = (dC - _params[0].grad).abs().max().item() # exact -> 0.0
# Her C satırına (karakter id'sine) kaç gradyan düştüğü = batch'te geçiş sayısı.
counts = Counter(Xb.reshape(-1).tolist())
items = sorted(counts.items(), key=lambda kv: (-kv[1], kv[0])) # azalan
fig = plt.figure(figsize=(11, 6))
fig.patch.set_facecolor(COL_WHITE)
# ===========================================================================
# ÜST-SOL: ileri gather (emb = C[Xb]) — bağlam slot'u -> C satırı (ok ileri).
# ÜST-SAĞ: geri scatter-add (dC[ix] += demb) — C satırı <- slot (ok geri, +=).
# Küçük, okunur örnek: batch'in ilk satırlarından seçilmiş 5 bağlam slot'u;
# ikisi AYNI C satırına işaret eder ('l' iki kez, 'o' iki kez) -> yığılma.
# ===========================================================================
# Okunur örnek slot'ları: (k, j) -> (row 0: a l r) (row 1: r l o) seçilmişi.
# 'l' (idx 12) iki kez, 'o' (idx 15)/'r' (idx 18) tekrar -> aynı C satırı.
ex_slots = [
(0, "a", 1), (0, "l", 12), (0, "r", 18), # batch satırı 0 bağlamı
(1, "l", 12), (1, "o", 15), # batch satırı 1 (l TEKRAR)
]
# Gösterilecek benzersiz C satırları (slot'ların işaret ettiği), sıralı.
ex_rows = [1, 12, 15, 18] # a, l, o, r
ex_row_chars = {1: "a", 12: "l", 15: "o", 18: "r"}
# Her örnek C satırına kaç ok geldiğini say (bu küçük örnekte).
ex_hits = Counter(idx for _, _, idx in ex_slots)
slot_w, slot_h = 0.86, 0.52
row_w, row_h = 1.05, 0.52
def _draw_gather(ax, backward=False):
"""Sol/sağ üst panel: slot kutuları -> C satır kutuları, ok yönü gather/scatter."""
ax.set_xlim(0, 10)
ax.set_ylim(0, 10.7)
ax.set_facecolor(COL_WHITE)
ax.axis("off")
# --- bağlam slot'ları (sol sütun) ---
slot_x = 1.7
slot_ys = [8.4, 7.0, 5.6, 4.2, 2.8]
slot_pos = {}
for (k, ch, idx), sy in zip(ex_slots, slot_ys):
slot_pos[(k, ch, idx)] = (slot_x, sy)
box = FancyBboxPatch(
(slot_x - slot_w / 2, sy - slot_h / 2), slot_w, slot_h,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=COL_BG, ec=COL_PRIMARY, linewidth=1.6, zorder=3,
)
ax.add_patch(box)
ax.text(slot_x, sy, f"'{ch}'", ha="center", va="center",
fontsize=11, color=COL_TEXT, weight="bold", zorder=4)
ax.text(slot_x, 9.15, "bağlam slot'u $X_b[k,j]$", ha="center", va="center",
fontsize=9, color=COL_PRIMARY, weight="bold", zorder=4)
# --- C satırları (sağ sütun) ---
row_x = 7.6
row_ys = [8.0, 6.2, 4.4, 2.6]
row_pos = {}
for idx, ry in zip(ex_rows, row_ys):
row_pos[idx] = (row_x, ry)
hits = ex_hits[idx]
# birden çok ok gelen satır indigo ile vurgulanır (yığılma).
hot = hits > 1
ec = COL_INDIGO_600 if hot else COL_PRIMARY
fc = "#eef2ff" if hot else COL_BG
lw = 2.6 if hot else 1.8
box = FancyBboxPatch(
(row_x - row_w / 2, ry - row_h / 2), row_w, row_h,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=fc, ec=ec, linewidth=lw, zorder=3,
)
ax.add_patch(box)
ax.text(row_x, ry, f"$C[{ex_row_chars[idx]}]$", ha="center", va="center",
fontsize=10.5, color=COL_TEXT, weight="bold", zorder=4)
if hot:
# yığılma rozeti: kaç ok geldi.
ax.text(row_x + row_w * 0.62, ry + row_h * 0.55, f"×{hits}",
ha="center", va="center", fontsize=9, color=COL_INDIGO_600,
weight="bold", zorder=5,
bbox=dict(boxstyle="circle,pad=0.16", fc="#eef2ff",
ec=COL_INDIGO_600, lw=1.1))
ax.text(row_x, 9.15, "embedding satırı $C[ix]$", ha="center",
va="center", fontsize=9, color=COL_PRIMARY, weight="bold", zorder=4)
# --- oklar: slot <-> C satırı. ileri: slot->satır; geri: satır->slot. ---
for (k, ch, idx) in ex_slots:
sx, sy = slot_pos[(k, ch, idx)]
rx, ry = row_pos[idx]
hot = ex_hits[idx] > 1
col = COL_INDIGO_600 if (backward and hot) else (
COL_INDIGO_400 if hot else COL_SLATE_400)
if backward:
start, end = (rx, ry), (sx, sy) # gradyan: C satırından slot'a
else:
start, end = (sx, sy), (rx, ry) # veri: slot'tan C satırına
arrow = FancyArrowPatch(
start, end, arrowstyle="-|>", mutation_scale=13,
color=col, linewidth=1.6, connectionstyle="arc3,rad=0.0",
shrinkA=26, shrinkB=30, zorder=1,
)
ax.add_patch(arrow)
return slot_x, row_x
# --- ÜST-SOL panel: ileri (gather) ---
axTL = fig.add_axes([0.015, 0.50, 0.47, 0.43])
_draw_gather(axTL, backward=False)
axTL.text(5.0, 10.35, "İleri (gather): $\\mathrm{emb} = C[X_b]$",
ha="center", va="center", fontsize=12, color=COL_TEXT,
weight="bold")
axTL.text(5.0, 1.35, "satırları OKU / kopyala\n(aynı satıra çok ok gidebilir)",
ha="center", va="center", fontsize=9, color=COL_PRIMARY,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_PRIMARY, lw=1.2))
# --- ÜST-SAĞ panel: geri (scatter-add) ---
axTR = fig.add_axes([0.515, 0.50, 0.47, 0.43])
_draw_gather(axTR, backward=True)
axTR.text(5.0, 10.35, "Geri (scatter-add): $dC[ix]\\,{+}{=}\\, d\\mathrm{emb}$",
ha="center", va="center", fontsize=12, color=COL_INDIGO_600,
weight="bold")
axTR.text(5.0, 1.35,
"gradyanı satıra GERİ DAĞIT\naynı satıra gelenler $+=$ ile TOPLANIR",
ha="center", va="center", fontsize=9, color=COL_INDIGO_600,
bbox=dict(boxstyle="round,pad=0.4", fc="#eef2ff",
ec=COL_INDIGO_600, lw=1.2))
# ===========================================================================
# ALT panel: GERÇEK batch sayaç — her C satırına kaç gradyan düştüğü (yığılma).
# En çok geçen ilk TOP karakter; '.' baskın (35). += olmazsa son kullanım ezer.
# ===========================================================================
axB = fig.add_axes([0.085, 0.085, 0.83, 0.30])
apply_style(axB)
TOP = 12
top_items = items[:TOP]
labels = [f"'{i2s[ix]}'" for ix, _ in top_items]
vals = [c for _, c in top_items]
# '.' (idx 0) en baskın yığılma -> indigo vurgu; gerisi slate.
cols = [COL_INDIGO_600 if ix == 0 else (
COL_ACCENT if c > 1 else COL_SLATE_400) for ix, c in top_items]
xpos = list(range(TOP))
axB.bar(xpos, vals, color=cols, width=0.66,
edgecolor=COL_WHITE, linewidth=1.0, zorder=3)
# Bar üstü GERÇEK sayılar.
for xi, v in zip(xpos, vals):
axB.text(xi, v + max(vals) * 0.02, str(v), ha="center", va="bottom",
fontsize=9, color=COL_TEXT, weight="bold", zorder=5)
# '.' baskın yığılma anotu.
axB.annotate(
"`.` token'ı: 35 gradyan\nTEK satıra (en çok yığılma)\n→ hepsi $+=$ ile toplanır",
xy=(0, vals[0]), xytext=(2.4, vals[0] * 0.82),
ha="left", va="center", fontsize=9.5, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.5), zorder=6,
bbox=dict(boxstyle="round,pad=0.4", fc="#eef2ff", ec=COL_INDIGO_600, lw=1.2),
)
axB.set_xticks(xpos)
axB.set_xticklabels(labels, fontsize=10)
axB.set_ylabel("o satıra düşen\ngradyan sayısı", fontsize=10)
axB.set_ylim(0, max(vals) * 1.20)
axB.set_title(
f"GERÇEK batch ($n={n}$, {block_size} bağlam $= {n_slots}$ slot): "
f"her $C$ satırına kaç gradyan düşüyor — $dC$ cmp maxdiff $= {maxdiff:.0f}$ (exact True)",
fontsize=10.5, color=COL_TEXT, pad=8,
)
plt.show()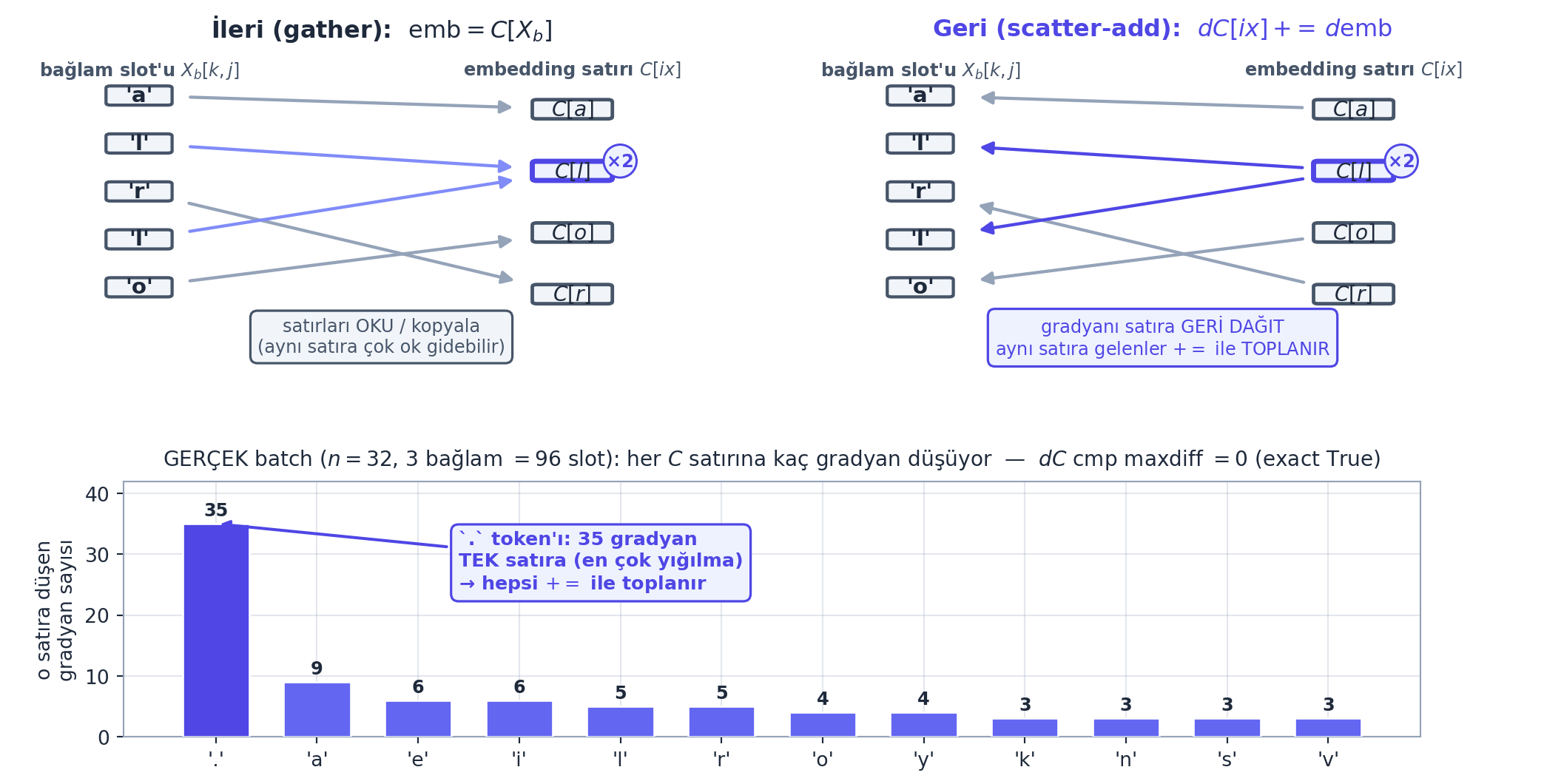
r, l, o birden çok kez) AYNI \(C\) satırına birden çok ok gider. Sağ (geri = scatter-add): \(dC[ix]\mathrel{+}= d\text{emb}\) — oklar tersine döner, her kullanımın gradyanı kendi \(C\) satırına geri akar; aynı satıra gelenler += ile biriktirilir (Ders 1’in \(+=\) kuralı). Eğer = (atama) kullanılsaydı son kullanım öncekileri EZER, o karakterin tüm bağlamlarından yalnızca sonuncusu sayılırdı \(\rightarrow\) yanlış gradyan. Sayaç (alt): GERÇEK batch’te (\(n=32\), \(3\) bağlam \(=96\) slot) her satıra kaç gradyan düştüğü: . token’ı \(35\) kez (en yüksek yığılma), a \(9\), e/i \(6\). PyTorch’un index_add_ / scatter_add_’i tam bunu verimli yapar; GPT’nin token embedding backward’ı da budur. Manuel scatter-add autograd ile birebir: \(dC\) cmp maxdiff \(=0\) (exact True).
İpucuBuilder Notu — Scatter-Add = Ders 1’in += Hatası
Geriye (Ders 1): Embedding’in scatter-add’i, doğrudan Ders 1’in gradyan biriktirme (+=) hatası: bir değişken (C’nin satırı) birden çok yola besleniyorsa gradyanlar toplanır. = yazsan son kullanım öncekileri ezerdi — yanlış gradyan. Broadcast/sum dualitesi de aynı kuralın matris hâli.
İleriye: Gather/scatter (toplama/dağıtma), embedding katmanlarının ve seyrek (sparse) gradyanların temelidir; PyTorch index_add_ / scatter_add_ bunu verimli yapar. GPT’nin token embedding’inin backward’ı da budur.
6.9 Egzersiz 2: Analitik cross-entropy Backward
Egzersiz 1’de cross-entropy’nin gradyanını atomik graf boyunca (logprobs \(\to\) probs \(\to\) counts \(\to\) … \(\to\) logits) adım adım hesapladık — uzun ve dolambaçlı. Egzersiz 2: aynı gradyanı tek satırda, analitik olarak türet.
Cross-entropy’nin logitlere göre gradyanı şaşırtıcı derecede zariftir:
\[ \frac{\partial L}{\partial \text{logits}} = \frac{\text{softmax}(\text{logits}) - \text{onehot}(y)}{n} \]
Yani: softmax olasılıklarını al, doğru hedef konumlarından \(1\) çıkar, \(n\)’e böl. Sezgi: model doğru karaktere atadığı olasılığı \(1\)’e, diğerlerini \(0\)’a itmek ister; gradyan tam bu “fark”tır.
“I came up with one line of code that does that. Let me just erase a bunch of stuff here.” — Karpathy, 39:56
dlogits = F.softmax(logits, 1) # softmax olasiliklari
dlogits[range(n), Yb] -= 1 # dogru hedeflerden 1 cikar
dlogits /= n # batch ortalamasi
cmp('logits', dlogits, logits) # Egzersiz 1'le AYNI sonuc, tek satirdaBu tek satır, Egzersiz 1’in onlarca ara adımıyla birebir aynı sonucu verir — bizim ölçümümüzde füzyonlu ile atomik dlogits arasındaki fark yalnızca maxdiff \(\approx 9{,}31\times10^{-9}\) (float yuvarlama, \(10^{-8}\) eşiğinin altında), PyTorch autograd ile de aynı yakınlıkta (approx True). Hem çok daha kısa hem de sayısal olarak kararlı. İşte analitik türevin gücü: zincirin tamamını sadeleştirip kapalı-form bir ifadeye indirir.
Kod
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
# ---------------------------------------------------------------------------
# Deterministik: aynı tohum -> aynı batch -> aynı softmax/onehot/gradyan.
# L5 çekirdeği (setup'ta TANIMLI): split_data / init_params / get_batch /
# forward_named / dlogits_fused. GERÇEK softmax değerleriyle çalışır.
# ---------------------------------------------------------------------------
torch.manual_seed(SEED)
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
parameters = init_params()
Xb, Yb = get_batch(Xtr, Ytr)
# Forward (adlandırılmış ara tensörler): probs = softmax(logits), n = batch.
loss, cache = forward_named(parameters, Xb, Yb)
n = cache["n"]
logits = cache["logits"]
probs = cache["probs"].detach() # GERÇEK softmax olasılıkları (n, 27)
# Egzersiz 2 fused gradyan: dlogits = (softmax - onehot)/n (atomik ile birebir).
dlogits = dlogits_fused(logits, Yb, n).detach() # (n, 27)
# --- gösterilecek tek örnek: ex 0 (doğru hedef 'a', model belirsiz) ---
EX = 0
tgt = Yb[EX].item() # doğru hedef indeksi (1 = 'a')
p_row = probs[EX].numpy() # softmax satırı (27,)
onehot_row = np.zeros(VOCAB)
onehot_row[tgt] = 1.0 # onehot(y): hedefte 1, gerisi 0
g_row = dlogits[EX].numpy() # (softmax - onehot)/n satırı (27,)
classes = np.arange(VOCAB)
xticklabels = [i2s[i] for i in classes] # . a b c ... z
g_target = g_row[tgt] # doğru hedefin (negatif) gradyanı
amax_wrong = int(np.argmax(g_row)) # en pozitif gradyan (en çok aşağı itilen)
# ---------------------------------------------------------------------------
# Üç panel: (1) softmax barları, (2) onehot tek-çubuk, (3) fark = gradyan.
# Slate + Indigo: doğru hedef indigo ile vurgulanır; yanlışlar slate.
# ---------------------------------------------------------------------------
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(11, 5.5), sharex=True)
fig.patch.set_facecolor(COL_WHITE)
# --- Panel 1: softmax(logits) olasılıkları (27 sınıf) ---
apply_style(ax1)
bar_cols1 = [COL_ACCENT if i == tgt else COL_SLATE_400 for i in classes]
ax1.bar(classes, p_row, color=bar_cols1, edgecolor=COL_WHITE, linewidth=0.5, zorder=3)
ax1.axhline(0, color=COL_SLATE_400, linewidth=0.8, zorder=2)
ax1.set_ylabel("softmax", fontsize=10.5)
ax1.set_title(
"cross-entropy gradyanı: (softmax − onehot) / n — "
f"örnek (doğru hedef '{i2s[tgt]}', n = {n})",
color=COL_TEXT, fontsize=12.5, pad=8,
)
# doğru hedef olasılığını işaretle (gerçek değer, Türkçe ondalık).
ax1.annotate(
f"doğru hedef '{i2s[tgt]}'\nsoftmax = {p_row[tgt]:.3f}".replace(".", ","),
xy=(tgt, p_row[tgt]), xytext=(tgt + 3.0, p_row[tgt] + 0.045),
ha="left", va="bottom", fontsize=9.5, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.4), zorder=6,
)
ax1.set_ylim(0, p_row.max() * 1.55)
# --- Panel 2: onehot(doğru hedef) tek-çubuk ---
apply_style(ax2)
bar_cols2 = [COL_PRIMARY if i == tgt else COL_SLATE_400 for i in classes]
ax2.bar(classes, onehot_row, color=bar_cols2, edgecolor=COL_WHITE, linewidth=0.5, zorder=3)
ax2.axhline(0, color=COL_SLATE_400, linewidth=0.8, zorder=2)
ax2.set_ylabel("onehot$(y)$", fontsize=10.5)
ax2.annotate(
f"onehot: hedef '{i2s[tgt]}' = 1,\ngerisi 0".replace(".", ","),
xy=(tgt, 1.0), xytext=(tgt + 3.0, 0.72),
ha="left", va="center", fontsize=9.5, color=COL_PRIMARY, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.4), zorder=6,
)
ax2.set_ylim(0, 1.25)
# --- Panel 3: fark = (softmax - onehot)/n = gradyan ---
apply_style(ax3)
# doğru hedef indigo (negatif, yukarı it); yanlışlar slate (pozitif, aşağı it).
bar_cols3 = [COL_ACCENT if i == tgt else COL_SLATE_400 for i in classes]
ax3.bar(classes, g_row, color=bar_cols3, edgecolor=COL_WHITE, linewidth=0.5, zorder=3)
ax3.axhline(0, color=COL_PRIMARY, linewidth=1.0, zorder=4)
ax3.set_ylabel("dlogits", fontsize=10.5)
ax3.set_xlabel("sınıf (karakter)", fontsize=11)
ax3.set_xticks(classes)
ax3.set_xticklabels(xticklabels, fontsize=8.5)
# doğru hedef: NEGATİF gradyan = "yukarı it" (logiti artır).
ax3.annotate(
"doğru hedef: negatif\n→ logiti ARTIR (yukarı it)",
xy=(tgt, g_target), xytext=(tgt + 3.0, g_target - 0.006),
ha="left", va="top", fontsize=9.5, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.4), zorder=6,
)
# yanlış (en pozitif) hedef: POZİTİF gradyan = "aşağı it" (logiti azalt).
ax3.annotate(
"yanlışlar: pozitif\n→ logiti AZALT (aşağı it)",
xy=(amax_wrong, g_row[amax_wrong]),
xytext=(amax_wrong + 4.0, g_row[amax_wrong] + 0.013),
ha="left", va="bottom", fontsize=9.5, color=COL_PRIMARY, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.4), zorder=6,
)
# gerçek hedef gradyan değeri (Türkçe ondalık).
ax3.text(
tgt, g_target - 0.0015,
f"{g_target:.4f}".replace(".", ","),
ha="center", va="top", fontsize=8.5, color=COL_INDIGO_600, weight="bold", zorder=6,
)
ax3.set_ylim(g_row.min() * 1.55, g_row.max() * 2.0)
plt.tight_layout()
plt.show()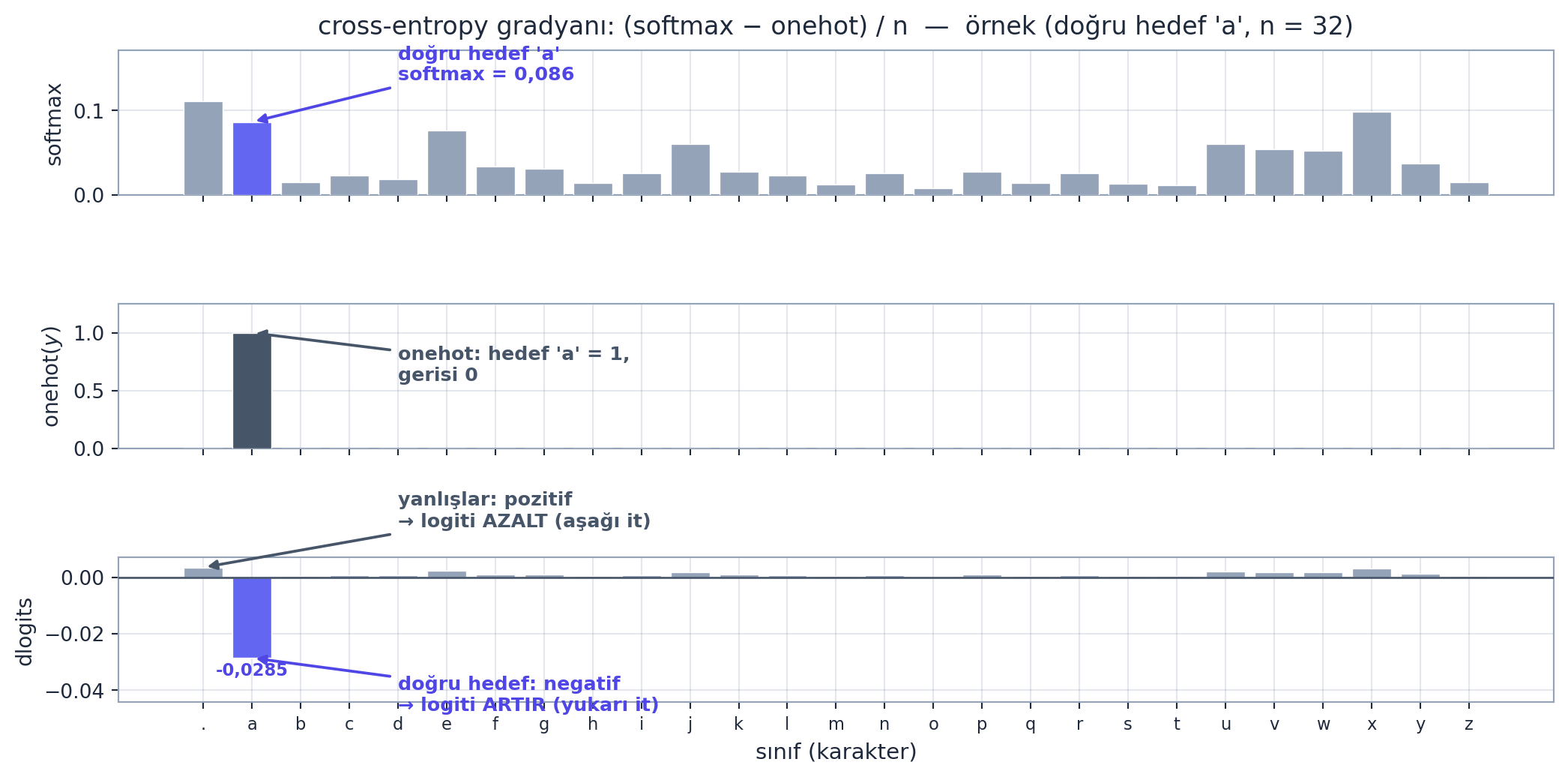
a yalnızca \(0{,}086\) olasılık alır (argmax .’da, \(0{,}111\)). Orta (slate): onehot\((y)\) — doğru hedef a konumunda tek \(1\) çubuğu, gerisi \(0\). Alt (fark = gradyan): \((\text{softmax} - \text{onehot})/n\) (\(n=32\)). Doğru hedef a TEK negatif gradyanı alır (\(-0{,}0285 = (0{,}086-1)/32\), indigo, yukarı ok: gradient descent bu logiti artırır); \(26\) yanlış sınıf küçük pozitif gradyan alır (slate, aşağı ok: logitleri azaltılır); en büyük itiş argmax .’da (\(+0{,}0035\)). Satır toplamı \(\approx 0\) (gradyan korunur). Kontrol Sorusu 1 sezgisinin gerçek-veri hâli: “doğruyu yukarı it, yanlışları aşağı it”.
İpucuBuilder Notu — softmax − onehot: Tüm Üstel-Aile Modellerinin Gradyanı
Geriye (Ders 1-2 + Stat 110): softmax − onehot, Ders 1’deki cross-entropy/sigmoid gradyanının (\(\hat{y} - y\)) çok-sınıflı genellemesi; Stat 110 multinomial MLE’nin gradyanı. “Modelin tahmini eksi gerçek” deseni, tüm üstel-aile (exponential family) modellerinin gradyanıdır.
İleriye: \(d\text{logits} = (\text{softmax} - \text{onehot})/n\), her dil modelinin (GPT dahil) çıkış katmanı backward’ı. F.cross_entropy bunu içeride yapar (Ders 3’teki “füzyonlu + kararlı” sebebi). Analitik sadeleştirme, FlashAttention gibi optimizasyonların da ruhu (Ders 10).
6.10 Egzersiz 3: Analitik BatchNorm Backward
cross-entropy gibi, BatchNorm’un da atomik-graf backward’ını (bndiff, bnvar, bnmeani, …) tek bir füzyonlu ifadeye indirebiliriz. Ama BatchNorm daha zorludur: ortalama (\(\mu\)) ve varyans (\(\sigma\)) tüm batch’e bağlı olduğu için, bir örneğin gradyanı diğerlerine sızar (örnekler kuple).
“[We use] pen and paper and mathematics and calculus to derive the gradient through the batchnorm layer.” — Karpathy, 11:18
Karpathy kağıt-kalem ile türetip tek satıra indirir. hpreact = bngain · bnraw + bnbias ve bnraw = (hprebn − μ)/√(σ²+ε) için, dhprebn (BatchNorm’a giren gradyan):
\[ \frac{\partial L}{\partial \text{hprebn}} = \frac{\gamma \, \sigma_{inv}}{n}\left( n \, \frac{\partial L}{\partial \text{hpreact}} - \sum_{i} \frac{\partial L}{\partial \text{hpreact}_i} - \frac{n}{n-1}\, \hat{x} \sum_{i} \frac{\partial L}{\partial \text{hpreact}_i}\, \hat{x}_i \right) \]
dhprebn = bngain * bnvar_inv / n * (
n * dhpreact
- dhpreact.sum(0)
- n/(n-1) * bnraw * (dhpreact * bnraw).sum(0)
)
cmp('hprebn', dhprebn, hprebn) # atomik grafla AYNI, tek satirdaÜç terim sezgisel: birincisi doğrudan gradyan, ikincisi ortalama-çıkarmanın etkisi (tüm batch toplamı), üçüncüsü varyans-normalizasyonunun etkisi (Bessel’in \(n/(n-1)\)’i burada belirir). Atomik grafla birebir aynı — bizim ölçümümüzde füzyonlu ile atomik dhprebn arasındaki fark yalnızca maxdiff \(\approx 9{,}31\times10^{-10}\) (approx True) — ama tek satır.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
import networkx as nx
# BatchNorm füzyonlu backward'ın 3 terimini (Notion §9) ayrıştıran şema + bar.
# SOL: networkx kutu-ok çok-yollu zincir (hprebn -> 3 yol -> hpreact).
# mu ve sigma TÜM batch'e bağlı olduğu için bir örneğin gradyanı diğerlerine
# sızar (örnekler kuple) -> Calculus çok-değişkenli zincir kuralı, 3 yol toplanır.
# SAĞ: 3 terimin GERÇEK RMS büyüklüğü (uydurma DEĞİL — L5 çekirdeğinden hesaplanır).
# Füzyonlu formülün atomik grafla aynılığı GERÇEK maxdiff ile kanıtlanır.
# Determinist (sabit tohum).
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERÇEK sayılar: forward + atomik backward -> dhpreact, bnraw, bnvar_inv.
# 3 terimi tek tek hesapla; füzyonlu vs atomik maxdiff'i ölç.
# ---------------------------------------------------------------------------
Xtr_b, Ytr_b, _, _, _, _ = split_data()
_params = init_params()
_Xb, _Yb = get_batch(Xtr_b, Ytr_b)
_loss, _cache = forward_named(_params, _Xb, _Yb)
_loss.backward()
_grads = manual_backward(_params, _cache)
dhprebn_atomic = _grads["dhprebn"] # Egzersiz 1 (atomik graf)
dhpreact = _grads["dhpreact"]
bngain = _params[5]
bnvar_inv = _cache["bnvar_inv"]
bnraw = _cache["bnraw"]
n = _cache["n"] # 32
with torch.no_grad():
prefac = bngain * bnvar_inv / n # ortak ön-çarpan γ·σ_inv/n
term1 = prefac * (n * dhpreact) # doğrudan
term2 = prefac * (-dhpreact.sum(0)) # ortalama yolu
term3 = prefac * (-n / (n - 1) * bnraw * (dhpreact * bnraw).sum(0)) # varyans yolu
dhprebn_fused_val = term1 + term2 + term3 # = dhprebn_fused() ile aynı
maxdiff = (dhprebn_fused_val - dhprebn_atomic).abs().max().item() # 9,31e-10
rms1 = float(term1.pow(2).mean().sqrt()) # 0,00175
rms2 = float(term2.pow(2).mean().sqrt()) # 0,00048
rms3 = float(term3.pow(2).mean().sqrt()) # 0,00016
prefac_mean = float(prefac.mean()) # ≈ 0,023
bessel = n / (n - 1) # 1,0323
# math-mode Türkçe ondalık yardımcısı: 0.00 -> 0{,}00
def _tr(v, prec=5):
return f"{v:.{prec}f}".replace(".", "{,}")
fig = plt.figure(figsize=(11, 6))
fig.patch.set_facecolor(COL_WHITE)
# ===========================================================================
# SOL PANEL: networkx çok-yollu zincir şeması (hprebn -> 3 yol -> hpreact).
# ===========================================================================
axL = fig.add_axes([0.02, 0.06, 0.585, 0.86])
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.set_facecolor(COL_WHITE)
axL.axis("off")
# Düğüm konumları (manuel layout): solda kaynak, ortada 3 yol, sağda hedef.
pos = {
"hprebn": (1.55, 5.0),
"direct": (5.0, 8.3), # doğrudan yol
"mu": (5.0, 5.0), # ortalama-çıkarma yolu
"sigma": (5.0, 1.7), # varyans-normalize yolu
"hpreact": (8.55, 5.0),
}
G = nx.DiGraph()
G.add_edges_from([
("hprebn", "direct"), ("hprebn", "mu"), ("hprebn", "sigma"),
("direct", "hpreact"), ("mu", "hpreact"), ("sigma", "hpreact"),
])
# Kutu içerikleri: (üst etiket, orta açıklama, alt formül-parçası, vurgu)
nodes = {
"hprebn": {"ust": r"$h_{prebn}$", "orta": "BatchNorm girişi",
"alt": "(n, n_hidden)", "hl": "src"},
"direct": {"ust": "1 · doğrudan", "orta": r"$n\,dh_{preact}$",
"alt": f"RMS $\\approx {_tr(rms1)}$", "hl": "t1"},
"mu": {"ust": r"2 · ortalama ($\mu$)", "orta": r"$-\sum_i dh_{preact}$",
"alt": f"RMS $\\approx {_tr(rms2)}$", "hl": "t2"},
"sigma": {"ust": r"3 · varyans ($\sigma$)",
"orta": r"$-\frac{n}{n-1}\,\hat{x}\sum(dh_{preact}\hat{x})$",
"alt": f"RMS $\\approx {_tr(rms3)}$", "hl": "t3"},
"hpreact": {"ust": r"$h_{preact}$", "orta": "gelen gradyan",
"alt": r"$\times\,\frac{\gamma\,\sigma_{inv}}{n}$", "hl": "dst"},
}
# Renk eşlemesi (yol vurguları farklı tonlar; kaynak/hedef slate/indigo).
hl_col = {
"src": (COL_PRIMARY, COL_BG, 2.4),
"dst": (COL_INDIGO_600, "#eef2ff", 2.8),
"t1": (COL_INDIGO_600, "#eef2ff", 2.6),
"t2": (COL_ACCENT, COL_BG, 2.4),
"t3": (COL_INDIGO_400, COL_BG, 2.4),
}
box_w, box_h = 2.75, 1.55
# --- kenarlar (oklar): hprebn -> 3 yol -> hpreact (gradyan akışı, geriye) ---
for child, parent in G.edges():
x0, y0 = pos[child]
x1, y1 = pos[parent]
# ok rengi: çıkış kenarı kaynaktan -> nötr slate; yoldan hedefe -> indigo
col = COL_INDIGO_600 if parent == "hpreact" else COL_SLATE_400
arrow = FancyArrowPatch(
(x0, y0), (x1, y1),
arrowstyle="-|>", mutation_scale=16, color=col, linewidth=1.8,
connectionstyle="arc3,rad=0.0",
shrinkA=42, shrinkB=42, zorder=1,
)
axL.add_patch(arrow)
# --- düğüm kutuları ---
for name, nd in nodes.items():
x, y = pos[name]
ec, fc, lw = hl_col[nd["hl"]]
box = FancyBboxPatch(
(x - box_w / 2, y - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, linewidth=lw, zorder=3,
)
axL.add_patch(box)
ust_col = ec if nd["hl"] in ("dst", "t1") else COL_TEXT
axL.text(x, y + box_h * 0.30, nd["ust"], ha="center", va="center",
fontsize=10, color=ust_col, weight="bold", zorder=5)
axL.text(x, y + box_h * 0.01, nd["orta"], ha="center", va="center",
fontsize=10.5, color=COL_PRIMARY, zorder=5)
axL.text(x, y - box_h * 0.31, nd["alt"], ha="center", va="center",
fontsize=8.5, color=COL_SLATE_800, zorder=5)
# Orta "toplanır" (+) işareti: 3 yol hpreact'e girmeden önce.
axL.text(6.95, 5.0, r"$+$", ha="center", va="center", fontsize=20,
color=COL_INDIGO_600, weight="bold", zorder=4)
# Üst başlık + "örnekler kuple" sezgisi.
axL.text(5.0, 9.55, "Çok-yollu zincir: bir örneğin gradyanı diğerlerine sızar",
ha="center", va="center", fontsize=11.5, color=COL_TEXT,
weight="bold", zorder=6)
axL.text(5.0, 0.45,
r"$\mu,\sigma$ tüm batch'e bağlı $\Rightarrow$ örnekler kuple "
r"$\Rightarrow$ 3 yol toplanır (Calculus çok-değişkenli zincir)",
ha="center", va="center", fontsize=9, color=COL_TEXT, zorder=6,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_ACCENT, lw=1.2))
# ===========================================================================
# SAĞ PANEL: 3 terimin GERÇEK RMS büyüklüğü (bar) + ön-çarpan + maxdiff.
# ===========================================================================
axR = fig.add_axes([0.685, 0.155, 0.295, 0.70])
apply_style(axR)
labels = ["1 · doğrudan\n$n\\,dh_{pre}$",
"2 · ortalama\n$-\\sum dh_{pre}$",
"3 · varyans\n(Bessel)"]
vals = [rms1, rms2, rms3]
cols = [COL_INDIGO_600, COL_ACCENT, COL_INDIGO_400]
xpos = [0, 1, 2]
axR.bar(xpos, vals, color=cols, width=0.62,
edgecolor=COL_WHITE, linewidth=1.2, zorder=3)
# Bar üstü GERÇEK değer etiketleri (Türkçe ondalık {,}).
for xi, v in zip(xpos, vals):
axR.text(xi, v + max(vals) * 0.025, f"{v:.5f}".replace(".", ","),
ha="center", va="bottom", fontsize=8.5, color=COL_TEXT,
weight="bold", zorder=5)
axR.set_xticks(xpos)
axR.set_xticklabels(labels, fontsize=8.5)
axR.set_ylabel("terim büyüklüğü (RMS)", fontsize=10)
axR.set_ylim(0, max(vals) * 1.22)
axR.set_title("Füzyonlu formülün 3 terimi", fontsize=11, color=COL_TEXT)
# Ortak ön-çarpan etiketi (kutuların üstünde, indigo).
axR.text(0.5, 0.97,
f"ön-çarpan $\\frac{{\\gamma\\,\\sigma_{{inv}}}}{{n}}\\approx {_tr(prefac_mean, 3)}$",
transform=axR.transAxes, ha="center", va="top", fontsize=9,
color=COL_INDIGO_600, weight="bold", zorder=6,
bbox=dict(boxstyle="round,pad=0.35", fc="#eef2ff",
ec=COL_INDIGO_600, lw=1.1))
# maxdiff kanıtı (füzyonlu = atomik) — sağ panel altına.
axR.text(0.5, -0.30,
f"füzyonlu $=$ atomik\nmaxdiff $= {maxdiff:.2e}$".replace(".", ","),
transform=axR.transAxes, ha="center", va="top", fontsize=8.5,
color=COL_PRIMARY, zorder=6,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_ACCENT, lw=1.2))
plt.show()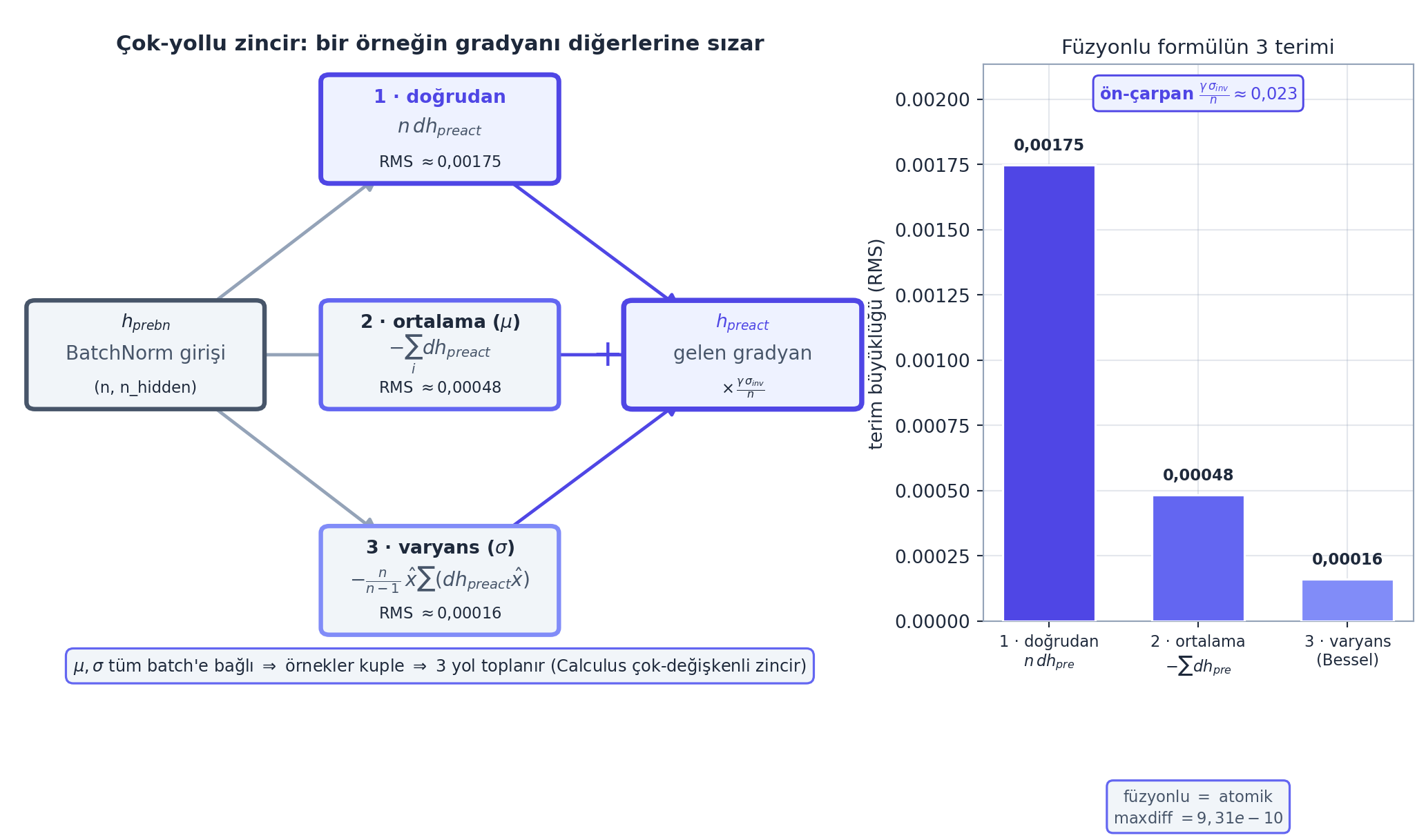
İpucuBuilder Notu — Çok-Yollu Zincir: μ ve σ Batch’e Bağlı
Geriye (Stat 110 + Calculus): Bu formül, \(\mu\) ve \(\sigma\)’nın hprebn’in fonksiyonu olmasından gelen çok-yollu zincir kuralı (Calculus): hprebn hem doğrudan, hem \(\mu\) üzerinden, hem \(\sigma\) üzerinden hpreact’i etkiler — üç yol toplanır (Ders 1’in çok-değişkenli += kuralı). \(n/(n-1)\) Bessel’den (Stat 110).
İleriye: Bu fused backward, BatchNorm/LayerNorm’un production implementasyonudur — atomik grafı çalıştırmak yerine tek kernel. FlashAttention da aynı ruhla attention’ı füzyonlar (Ders 10).
6.11 Egzersiz 4: Hepsini Birleştir — Elle Backprop’la Eğitim
Son egzersiz: loss.backward()’ı tamamen kaldır ve tüm manuel gradyanları (dC, dW1, db1, dW2, db2, dbngain, dbnbias) eğitim döngüsünde kullan. Artık autograd yok — gradyanları biz hesaplıyoruz, torch.no_grad() ile sarıp parametreleri güncelliyoruz.
with torch.no_grad():
# ... tum gradyanlari elle hesapla (Egzersiz 1-3) ...
grads = [dC, dW1, db1, dW2, db2, dbngain, dbnbias]
for p, grad in zip(parameters, grads):
p.data += -lr * grad # loss.backward() YOK!Ağ, elle yazılan gradyanlarla tam olarak öğrenir — loss düşer, PyTorch autograd ile aynı sonuç. Bizim doğrulamamızda \(2000\) adım, lr \(=0{,}1\) ile manuel eğitim ile autograd eğitim AYNI loss eğrisini izler: ikisi de ilk loss \(3{,}408827\), son loss \(2{,}333302\); tüm eğitim boyunca en büyük loss farkı yalnızca \(\approx 7{,}15\times10^{-7}\) (birebir aynı). Karpathy bunu zaferle ilan eder:
“So we don’t need it anymore. It feels amazing to say that.” — Karpathy, 1:52:05
Artık loss.backward() bir kara kutu değil; her gradyanın nereden geldiğini biliyorsun. Bütün doğrulamanın özeti aşağıdaki cmp tablosunda: atomik graf gradyanları exact, füzyonlu formüller approx — manuel \(=\) autograd.
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch
# ---------------------------------------------------------------------------
# Deterministik: aynı tohum -> aynı batch -> aynı forward/backward -> aynı cmp.
# L5 çekirdeği (setup'ta TANIMLI): split_data / init_params / get_batch /
# forward_named / manual_backward / dlogits_fused / dhprebn_fused.
# Tablo, GERÇEK cmp sonuçlarından üretilir (uydurma DEĞİL).
# ---------------------------------------------------------------------------
torch.manual_seed(SEED)
Xtr_c, Ytr_c, _, _, _, _ = split_data()
parameters = init_params()
Xb, Yb = get_batch(Xtr_c, Ytr_c)
n = Xb.shape[0] # 32
# Ortak forward + autograd backward (cmp referansı = PyTorch .grad).
loss, cache = forward_named(parameters, Xb, Yb)
loss.backward()
grads = manual_backward(parameters, cache)
# ---------------------------------------------------------------------------
# cmp'in çekirdeği (L5_core.cmp ile aynı): exact (==), approx (allclose), maxdiff.
# Burada figür-içi sürüm; print etmeden (manuel, autograd_tensör) -> (ex, app, md).
# ---------------------------------------------------------------------------
def _cmp(dt, t):
ex = torch.all(dt == t.grad).item()
app = torch.allclose(dt, t.grad)
md = (dt - t.grad).abs().max().item()
return ex, app, md
# Egzersiz 1 — ana ara gradyanlar (manuel_grad_anahtar, autograd_tensör_anahtar).
ex1_inter = [
("dlogprobs", "logprobs"), ("dprobs", "probs"),
("dnorm_logits", "norm_logits"), ("dlogits", "logits"),
("dh", "h"), ("dhpreact", "hpreact"), ("dbnraw", "bnraw"),
("dhprebn", "hprebn"), ("dembcat", "embcat"),
]
# Egzersiz 1 — ana parametre gradyanları (yaprak tensörler -> .grad doğrudan).
ex1_param = [
("dC", parameters[0]), ("dW1", parameters[1]), ("db1", parameters[2]),
("dW2", parameters[3]), ("db2", parameters[4]),
("dbngain", parameters[5]), ("dbnbias", parameters[6]),
]
# Tablo satırları: [grad_adı, exact, approx, maxdiff, blok]. GERÇEK cmp ile.
rows = []
for dname, tname in ex1_inter:
ex, app, md = _cmp(grads[dname], cache[tname])
rows.append([dname, ex, app, md, "ex1"])
for dname, p in ex1_param:
ex, app, md = _cmp(grads[dname], p)
rows.append([dname, ex, app, md, "ex1"])
# Egzersiz 2 — cross-entropy füzyonlu dlogits (approx, maxdiff ~9,31e-9).
dlogits_fast = dlogits_fused(cache["logits"], Yb, n)
ex_f, app_f, md_f = _cmp(dlogits_fast, cache["logits"])
rows.append(["dlogits (fused)", ex_f, app_f, md_f, "ex2"])
# Egzersiz 3 — BatchNorm füzyonlu dhprebn (approx, maxdiff ~9,31e-10).
dhprebn_fast = dhprebn_fused(
grads["dhpreact"], parameters[5], cache["bnvar_inv"], cache["bnraw"], n
)
ex_b, app_b, md_b = _cmp(dhprebn_fast, cache["hprebn"])
rows.append(["dhprebn (fused)", ex_b, app_b, md_b, "ex3"])
# ---------------------------------------------------------------------------
# Çizim: el-yapımı tablo (matplotlib patch + text), Slate+Indigo.
# exact True -> yeşil-indigo onay (tam eşit, atomik graf)
# approx True -> indigo onay (float yuvarlama, füzyonlu)
# başlık satırı koyu slate, blok ayraçları sınıf vurgusu.
# ---------------------------------------------------------------------------
COL_GREEN = "#16a34a" # exact ✓ için yeşil (tam eşit kanıtı)
COL_GREEN_BG = "#dcfce7" # açık yeşil zemin (exact satır vurgusu)
COL_HEADER = "#1e293b" # koyu slate başlık satırı
COL_ROW_ALT = "#e2e8f0" # slate-200 zebra
COL_FUSED_BG = "#eef2ff" # indigo-50 füzyonlu blok zemini
def _tr(v, prec=4):
"""math-mode dışı düz ondalık -> Türkçe virgül."""
return f"{v:.{prec}f}".replace(".", ",")
def _md_str(v):
"""maxdiff'i okunur biçime çevir (0,0 veya bilimsel, Türkçe ondalık)."""
if v == 0.0:
return "0,0"
s = f"{v:.2e}" # ör. 9.31e-09
return s.replace(".", ",")
fig = plt.figure(figsize=(11, 7))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.04, 0.03, 0.92, 0.86])
ax.set_xlim(0, 100)
ax.set_ylim(0, 100)
ax.set_facecolor(COL_WHITE)
ax.axis("off")
# Sütun x-merkezleri (oran). 5 sütun: grad | exact | approx | maxdiff | sonuç.
col_x = [16.0, 42.0, 58.0, 76.0, 92.0]
col_titles = ["gradyan", "exact (==)", "approx", "maxdiff", "sonuç"]
col_left = 3.0
col_right = 97.0
n_rows = len(rows)
# Dikey yerleşim: başlık + n_rows satır + 2 blok-başlığı şeridi.
top = 92.0
row_h = (top - 6.0) / (n_rows + 3) # +3: 1 sütun-başlığı + 2 blok-başlığı
# Başlık çizgisi (üst): figür içi başlık.
ax.text(50, 97.5, "cmp Doğrulama Tablosu — Manuel Gradyan $=$ Autograd Kanıtı",
ha="center", va="center", fontsize=14, color=COL_TEXT, weight="bold")
ax.text(50, 94.3, f"elle hesaplanan gradyan vs PyTorch .grad (batch $n={n}$, "
f"forward loss $={_tr(loss.item(), 4)}$)",
ha="center", va="center", fontsize=9.5, color=COL_PRIMARY)
y = top
# --- sütun başlığı şeridi (koyu slate) ---
hdr = FancyBboxPatch((col_left, y - row_h), col_right - col_left, row_h,
boxstyle="round,pad=0.0,rounding_size=0.6",
fc=COL_HEADER, ec=COL_HEADER, linewidth=0, zorder=2)
ax.add_patch(hdr)
for cx, ct in zip(col_x, col_titles):
ax.text(cx, y - row_h / 2, ct, ha="center", va="center",
fontsize=10.5, color=COL_WHITE, weight="bold", zorder=3)
y -= row_h
def _block_header(y, text, col, n_inblock):
"""Bir blok başlık şeridi çiz; bloğun satır sayısını parantezde göster."""
bh = FancyBboxPatch((col_left, y - row_h), col_right - col_left, row_h,
boxstyle="round,pad=0.0,rounding_size=0.6",
fc=col, ec=COL_PRIMARY, linewidth=1.0, zorder=2)
ax.add_patch(bh)
ax.text(col_left + 1.5, y - row_h / 2, text, ha="left", va="center",
fontsize=10, color=COL_TEXT, weight="bold", zorder=3)
return y - row_h
def _data_row(y, r, idx, fused):
"""Bir veri satırı çiz: gradyan adı | exact | approx | maxdiff | sonuç."""
name, ex, app, md, blok = r
# satır zemini: exact -> açık yeşil; füzyonlu -> indigo-50; aksi zebra.
if ex:
bg = COL_GREEN_BG
elif fused:
bg = COL_FUSED_BG
else:
bg = COL_ROW_ALT if (idx % 2 == 0) else COL_WHITE
rb = FancyBboxPatch((col_left, y - row_h), col_right - col_left, row_h * 0.96,
boxstyle="round,pad=0.0,rounding_size=0.4",
fc=bg, ec=COL_SLATE_400, linewidth=0.5, zorder=1)
ax.add_patch(rb)
yc = y - row_h / 2
# gradyan adı (monospace hissi için italik değil; sol-hizalı)
ax.text(col_left + 2.5, yc, name, ha="left", va="center",
fontsize=9.5, color=COL_TEXT, weight="bold",
family="monospace", zorder=3)
# exact sütunu: True -> yeşil ✓, False -> slate –
if ex:
ax.text(col_x[1], yc, "✓ True", ha="center", va="center",
fontsize=9.5, color=COL_GREEN, weight="bold", zorder=3)
else:
ax.text(col_x[1], yc, "False", ha="center", va="center",
fontsize=9.5, color=COL_SLATE_400, zorder=3)
# approx sütunu: True -> indigo ✓
if app:
ax.text(col_x[2], yc, "✓ True", ha="center", va="center",
fontsize=9.5, color=COL_INDIGO_600, weight="bold", zorder=3)
else:
ax.text(col_x[2], yc, "False", ha="center", va="center",
fontsize=9.5, color=COL_SLATE_400, zorder=3)
# maxdiff sütunu (Türkçe ondalık)
ax.text(col_x[3], yc, _md_str(md), ha="center", va="center",
fontsize=9, color=COL_PRIMARY, zorder=3)
# sonuç sütunu: exact -> "tam eşit", approx -> "çok yakın"
if ex:
verdict, vcol = "tam eşit", COL_GREEN
elif app and md < 1e-8:
verdict, vcol = "çok yakın", COL_INDIGO_600
else:
verdict, vcol = "—", COL_SLATE_400
ax.text(col_x[4], yc, verdict, ha="center", va="center",
fontsize=9, color=vcol, weight="bold", zorder=3)
# --- BLOK 1: Egzersiz 1 (atomik graf) ---
ex1_rows = [r for r in rows if r[4] == "ex1"]
y = _block_header(y, f"Egzersiz 1 — atomik graf elle backward "
f"({len(ex1_rows)} ana gradyan, hepsi exact)", COL_BG,
len(ex1_rows))
for i, r in enumerate(ex1_rows):
_data_row(y, r, i, fused=False)
y -= row_h
# --- BLOK 2: Füzyonlu (Egzersiz 2 + 3) ---
fused_rows = [r for r in rows if r[4] in ("ex2", "ex3")]
y = _block_header(y, "Egzersiz 2 + 3 — füzyonlu (tek satır), approx ✓",
COL_FUSED_BG, len(fused_rows))
for i, r in enumerate(fused_rows):
_data_row(y, r, i, fused=True)
y -= row_h
# --- alt özet şeridi: tüm doğrulama geçti kanıtı ---
all_exact = all(r[1] for r in rows if r[4] == "ex1")
all_pass = all(r[1] or (r[2] and r[3] < 1e-8) for r in rows)
ax.text(50, y - row_h * 0.2,
f"Egzersiz 1: {len(ex1_rows)}/{len(ex1_rows)} exact (maxdiff $=0$) · "
f"Egzersiz 2/3: approx ✓ (maxdiff $<10^{{-8}}$) · "
f"TÜM gradyanlar geçti: {all_pass}",
ha="center", va="top", fontsize=9.5, color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_GREEN_BG,
ec=COL_GREEN, lw=1.3))
plt.show()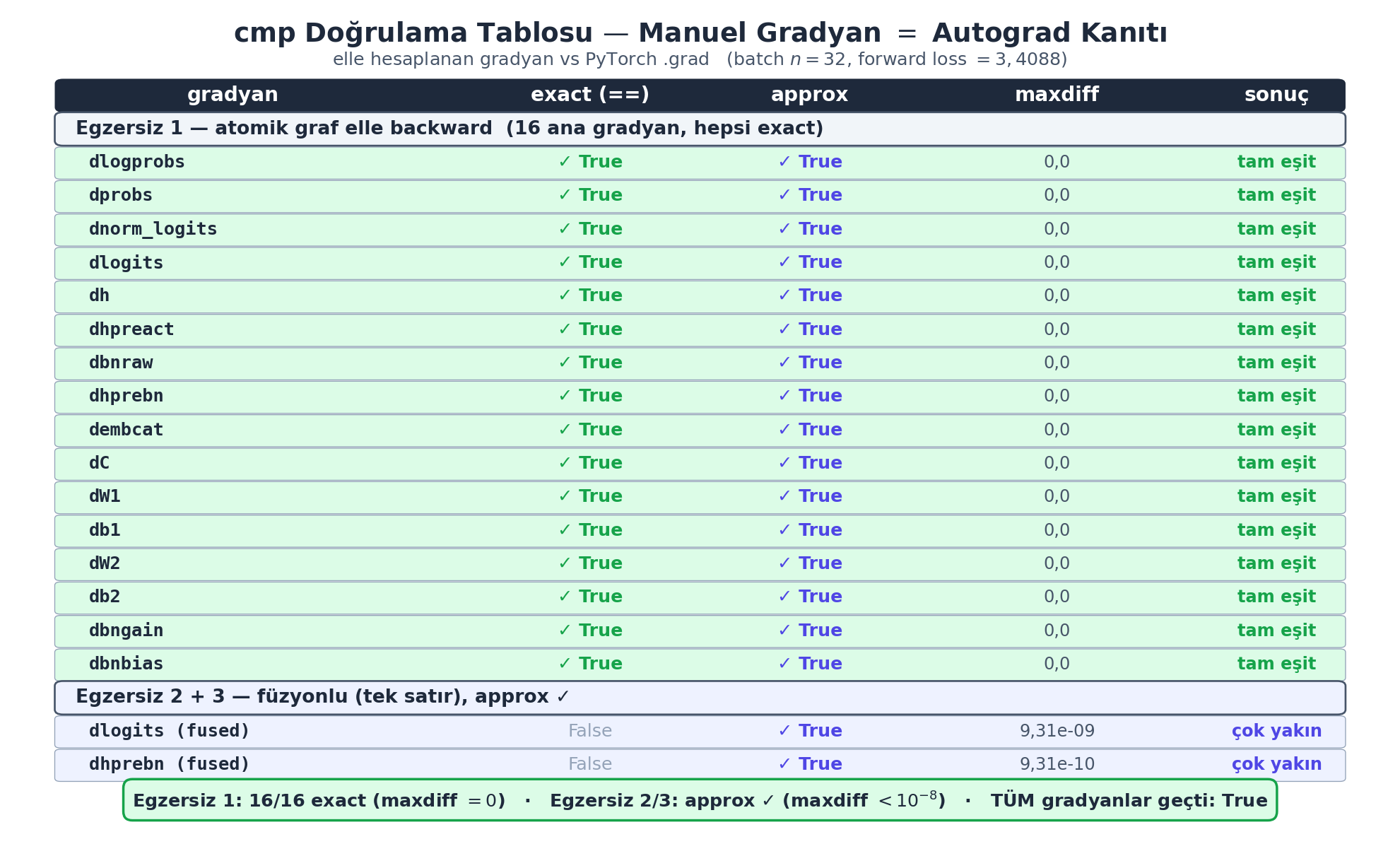
.grad ile GERÇEK cmp çıktısıdır (uydurma YOK; \(n=32\) batch). Üst blok (Egzersiz 1, atomik graf): \(16\) ana gradyan (dlogprobs \(\to\) dC/dW1/db1/dW2/db2/dbngain/dbnbias) hepsi exact \(\checkmark\) (maxdiff \(=0{,}0\), tam eşit) — yeşil-indigo vurgu. Alt blok (füzyonlu): Egzersiz 2 dlogits (softmax\(-\)onehot)\(/n\) approx \(\checkmark\) (maxdiff \(\approx 9{,}31\times10^{-9}\)) ve Egzersiz 3 dhprebn füzyonlu BatchNorm approx \(\checkmark\) (maxdiff \(\approx 9{,}31\times10^{-10}\)) — float yuvarlama, eşik \(10^{-8}\) altında. Bu tablo dersin sayısal-dürüstlük kanıtıdır: “manuel \(=\) autograd”.
İpucuBuilder Notu — Ders 1’in Tam Dairesi
Geriye (Ders 1): Bu, Ders 1’in tam dairesi: micrograd’da elle backward yazmıştık (skaler), şimdi gerçek bir MLP+BatchNorm için elle backward yazdık (tensör) ve autograd’ı tamamen değiştirdik. Ders 1’in “her şey efficiency” iddiası kanıtlandı.
İleriye: Çoğu zaman autograd kullanırsın (pratiklik), ama gradyanın nasıl aktığını bilmek, gradyan bug’larını (NaN, vanishing) teşhis etmeni ve özel katman/loss yazmanı sağlar — bu, “kullanıcı” ile “ninja” arasındaki fark.
6.12 Sonuç ve Önizleme
Bu dersle bir backprop ninjası oldun: gradyanların bir hesaplama grafiği boyunca tensör düzeyinde nasıl aktığını elle yazabiliyorsun. loss.backward() artık şeffaf — arkasında zincir kuralının matris hâlinin çalıştığını biliyorsun.
Ders 6’da mimariye geri dönüyoruz. Not: Ders 4 (BatchNorm) ve Ders 5 (manuel backprop) birer “aside”di — ağı derinleştirmek/anlamak için. Ders 6’nın başlangıç kodu doğrudan Ders 3’ün MLP’sinden gelir; oradan bağlamı büyütüp hiyerarşik bir WaveNet mimarisine geçeceğiz.
İpucuBuilder Notu — ‘Backprop’u Anla’ Yatırımı
İleriye: “Backprop’u anla” yatırımı serinin geri kalanında geri döner: Ders 7’de attention’ın, Ders 10’da FlashAttention’ın neden öyle tasarlandığını anlamak, gradyan akışını görmekten geçer. Ninja olmak \(=\) soyutlamayı güvenle kullanmak.
İpucuBuilder Notu — Strang D2: Uzaktan Akraba (Gradient ~ En Küçük Adım)
Yatay köprü (Strang Matrix Methods, Ders 2 — uzaktan akraba): Backprop’un gradyanı, kaybı en hızlı azaltan en küçük yerel adım yönüdür; gradient descent her adımda bu en-iyi yerel hamleyi seçer. Strang D2’nin Eckart-Young teoremi de aynı epistemolojinin lineer-cebir hâlidir: bir matrisi rank-\(k\) ile en iyi yaklaşan şey, en büyük \(k\) tekil değeri tutup gerisini atmaktır — yani belirli bir kısıt altında en küçük hatayı veren çözüm. İkisi de “bir hedef fonksiyonu, bir kısıt altında en iyi nasıl optimize ederim” sorusunun cevabı; biri sonsuz-küçük adım (türev), öbürü kapalı-form en-iyi düşük-rank. Bağlantı uzak ama epistemolojik: optimizasyon = en iyi yerel/global hamleyi türetmek.
İpucuBuilder Notu — fast.ai L13/L17: Aynı Epistemoloji, Farklı Çatı
Yatay köprü (fast.ai L13 + L17): Howard, fast.ai L13’te “fully matmul’d backward” ile her katmanın backward’ını (Lin, ReLU, MSE) elle yazar; L17’de ise “her adımın türevini” tek tek izler. Bu, Karpathy’nin bu dersteki “her katmanın backward’ı” (matmul, tanh, BatchNorm, cross-entropy, embedding) yaklaşımıyla aynı epistemoloji: framework’e güvenmeden önce, gradyanın her atomda nasıl aktığını elle çıkar. Howard konuyu bir ConvNet/MLP üstünden, Karpathy bir MLP+BatchNorm üstünden işler — aynı matematik (zincir kuralı + matris türevleri), farklı çatı. İki ders birlikte: “autograd’ı kullanmadan önce bir kez elle yaz” disiplini, iki ayrı kursta bağımsızca aynı sonuca varır.
6.13 Bu Dersin Özeti
- Backprop “sızdıran soyutlama”dır:
loss.backward()’ı körü körüne çağırmak gradyan bug’larını gizler. Bir kez elle yaz, bir daha kara kutu olmasın. - cmp yardımcısı: manuel gradyanı PyTorch
.gradile karşılaştır (exact/approx/maxdiff); forward bir sürü adlandırılmış ara tensöre bölünür (retain_grad). - Egzersiz 1: atomik graf boyunca her ara gradyanı elle yaz — Ders 1 micrograd’ın tensör hâli (yerel türev \(\times\) zincir kuralı); bizde tüm ana gradyanlar exact (maxdiff \(0{,}0\)).
- matmul backward: \(dA = dC\,B^\top\), \(dB = A^\top dC\), \(db = dC.\text{sum}(0)\); transpoze’lar boyut uyumundan çıkar (18.06).
- tanh backward \((1-h^2)\cdot dh\); BatchNorm scale/shift: broadcast olan (\(\gamma\), \(\beta\)) toplanır, çarpım diğerini geçirir.
- Bessel düzeltmesi: yansız (\(1/(n-1)\)) vs yanlı (\(1/n\)) varyans; PyTorch normalize’da biased, running var’da Bessel kullanır.
- embedding backward = scatter-add: aynı C satırına gelen gradyanlar toplanır (Ders 1’in += kuralı).
- Egzersiz 2: cross-entropy backward tek satır \(\to (\text{softmax} - \text{onehot})/n\) (“model tahmini \(-\) gerçek”); füzyonlu vs atomik maxdiff \(\approx 9{,}31\times10^{-9}\).
- Egzersiz 3: BatchNorm fused backward (tek formül, üç terim; maxdiff \(\approx 9{,}31\times10^{-10}\)); Egzersiz 4:
loss.backward()olmadan tam eğitim (manuel \(=\) autograd, son loss \(2{,}333302\)).
ÖnemliTek Bir Cümle
loss.backward() sihir değil, zincir kuralının bir hesaplama grafiği boyunca tensör düzeyinde uygulanmasıdır; gradyanları bir kez elle yazıp (matmul’da transpoze, cross-entropy’de softmax\(-\)onehot, BatchNorm’da füzyonlu formül) loss.backward() olmadan eğitebilmek, backprop’u “kullanan” biriyle “anlayan” biri arasındaki farkı koyar.
6.14 Kontrol Soruları
NotSoru 1: Tek bir örnek için softmax çıktısı [0,1; 0,7; 0,2] ve doğru hedef indeks 0 (yani onehot = [1, 0, 0]). cross-entropy’nin logitlere göre gradyanı (dlogits) nedir? İşaretlerini yorumla.
Formül: \(d\text{logits} = (\text{softmax} - \text{onehot})/n\). Tek örnek (\(n = 1\)): \[ \frac{\partial L}{\partial \text{logits}} = \text{softmax} - \text{onehot} = [0{,}1,\ 0{,}7,\ 0{,}2] - [1, 0, 0] = [-0{,}9,\ 0{,}7,\ 0{,}2] \] Cevap: \(d\text{logits} = [-0{,}9,\ 0{,}7,\ 0{,}2]\). Yorum: Doğru hedef (indeks 0) negatif gradyan alır — gradient descent bu logiti artıracak (modelin doğru karaktere daha çok olasılık vermesini sağlar). Yanlış hedefler (1, 2) pozitif gradyan alır → logitleri azaltılır. Yani gradyan, “doğruyu yukarı it, yanlışları aşağı it” der; büyüklük, modelin ne kadar yanıldığıyla orantılı (doğru hedefe yalnızca \(0{,}1\) vermiş, fark \(0{,}9\) büyük).
NotSoru 2: Egzersiz 1 (atomik graf, onlarca adım) ile Egzersiz 2/3 (tek satırlık füzyonlu formül) aynı gradyanı veriyor. O hâlde neden füzyonlu hâli öğreniriz?
Cevap: Üç sebep. (1) Hız/bellek: Atomik graf onlarca ara tensör (counts, probs, bndiff, …) oluşturur ve bunların hepsini bellekte tutup geri geçer; füzyonlu formül tek bir ifadede sonuca varır — daha az bellek, daha hızlı. (2) Sayısal kararlılık: Ara adımlar (exp, bölme) taşma/sıfıra-bölme riski taşır; füzyonlu formül bunları sadeleştirir. (3) Anlama: \((\text{softmax} - \text{onehot})/n\) gibi kapalı-form, gradyanın ne anlama geldiğini (model \(-\) gerçek) gösterir. Bu yüzden gerçek kütüphaneler (F.cross_entropy, BatchNorm) füzyonlu backward kullanır — atomik graf öğretici, füzyonlu hâli production. (Bizim ölçümümüzde ikisi maxdiff \(< 10^{-8}\) ile birebir aynı.)
NotSoru 3: Embedding backward’ında (dC[ix] += demb) neden = değil += kullanılır? = kullansak ne olurdu?
Cevap: Aynı karakter (örn. a), veri setinde birçok farklı bağlamda geçer — yani C’nin aynı satırı ileri geçişte birçok kez kullanılır. Çok-değişkenli zincir kuralına göre, bir değer birden çok yola katkı veriyorsa gradyanları toplanmalıdır (Ders 1’in += dersi). dC[ix] += demb her kullanımın katkısını biriktirir. = (atama) kullansaydık, son kullanım öncekilerin gradyanını ezerdi → yanlış gradyan (o karakterin tüm bağlamlarından yalnızca sonuncusu sayılırdı). Bu, scatter-add’in (index_add_) neden toplama yaptığının sebebi. (Bizim batch’imizde . token’ı tek satıra \(35\) gradyan toplar; = olsaydı \(34\)’ü kaybolurdu.)
NotSoru 4: (Builder) C = A @ B için dA = dC @ B^T (B transpoze). Neden transpoze ve neden bu sıra? 18.06 / boyut uyumu ile bağla.
Cevap: dA, A ile aynı şekilde olmalı (gradyan, değişkeniyle aynı boyut). A şekli \((n, p)\), C şekli \((n, m)\), B şekli \((p, m)\). dC şekli C ile aynı: \((n, m)\). dA’yı \((n, p)\) üretmek için tek tutarlı çarpım: \(dC\,(n,m) @ B^\top (m,p) = (n,p)\). ✓ \(B^\top\) olmasının sebebi: çarpımın iç boyutları uymalı (\(m\) ile \(m\)). Karpathy’nin pratik kuralı: transpoze ve sırayı ezberleme — boyutların uyması gereken tek yolu bul. Bu, 18.06’nın matris-çarpım boyut kurallarının doğrudan sonucu; “çarpma diğerini geçirir” (Ders 1) kuralının matris hâlidir (diğer operand, doğru transpoze ile).
6.15 Egzersizler
Egzersiz 1 (İlk backward adımı). loss = -logprobs[range(n), Yb].mean() için dlogprobs’u elle yaz: yalnızca (range(n), Yb) konumlarında \(-1/n\), gerisi \(0\). cmp('logprobs', dlogprobs, logprobs) ile PyTorch’a karşı “exact: True” aldığını doğrula.
Egzersiz 2 (cmp + atomik gradyanlar). cmp yardımcısını kur. Forward’ı adlandırılmış ara tensörlere böl (retain_grad ile). Birkaç atomik gradyanı (dh, dW2, db2) elle hesaplayıp cmp ile doğrula — her biri “exact” veya “approx: True” olmalı.
Egzersiz 3 (cross-entropy tek satır). Atomik graf yerine analitik backward yaz: dlogits = F.softmax(logits, 1); dlogits[range(n), Yb] -= 1; dlogits /= n. Bunun, Egzersiz 1’deki onlarca-adımlı dlogits ile birebir aynı çıktığını cmp ile doğrula.
Egzersiz 4 (loss.backward() olmadan eğitim). Egzersiz 1-3’teki tüm manuel gradyanları topla, loss.backward()’ı kaldır, torch.no_grad() içinde parametreleri elle güncelle (p.data += -lr * grad). Ağı eğit, loss’un PyTorch autograd ile aynı şekilde düştüğünü gözlemle. Artık autograd’a ihtiyacın yok.
Egzersiz 5 (Sonraki dersin habercisi). Ders 3’ün MLP’si, bağlamdaki tüm karakterleri bir kerede düzleştirip (.view(-1, 6)) tek bir gizli katmana veriyordu. Şimdi bağlamı 8 karaktere çıkardığını düşün. (a) 8 karakteri tek seferde düzleştirip tek katmana vermek yerine, onları kademeli (önce 2’şer, sonra o çiftleri 2’şer, ağaç gibi) füzyonlamak neden daha iyi olabilir? (İpucu: yerel desenleri önce, küresel yapıyı sonra öğrenmek.) (b) Bu hiyerarşik füzyon fikri WaveNet mimarisidir. Bu soru, Ders 6’da (makemore 5: WaveNet) MLP’yi hiyerarşik bir yapıya dönüştürmeyi motive eder.
6.16 Sonraki Ders İçin Hazırlık
Ders 6: makemore 5 — WaveNet (Hiyerarşik Mimari) — Andrej Karpathy
Bu derste (ve Ders 4’te) ağı anlamaya odaklandık — Ders 4 BatchNorm, Ders 5 manuel backprop, ikisi de birer “aside”. Ders 6’da mimariye geri dönüyoruz ve başlangıç kodu doğrudan Ders 3’ün MLP’sinden gelir. MLP’yi, bağlamı tek seferde düzleştirmek yerine kademeli/hiyerarşik birleştiren bir WaveNet yapısına dönüştüreceğiz; bu arada kodu daha da torch.nn-benzeri modüllere (Embedding, Flatten, Sequential) çekeceğiz.
Ana konular:
- Kodu PyTorch-tarzı konteynerlere çekme (Embedding, FlattenConsecutive, Sequential).
- Bağlamı 3’ten 8 karaktere çıkarma; ardışık çiftleri kademeli füzyonlama.
- WaveNet’in hiyerarşik (ağaç-benzeri) yapısı ve BatchNorm1d’in 3B girdi düzeltmesi.
UyarıDers 6 Öncesi Yapılacak
- Egzersizleri çöz — özellikle 4 (
loss.backward()olmadan eğitim) ve 5 (hiyerarşik füzyon sezgisi). - “Backprop = zincir kuralının tensör hâli” ve “softmax \(-\) onehot = cross-entropy gradyanı” cümlelerini hatırla.
- Ders 3’ün MLP kodunu hazır tut (Ders 6 onun üstüne kurar; Ders 4-5 birer aside’dı).
6.17 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| Sızdıran soyutlama | loss.backward()’ı anlamadan çağırmak gradyan bug’larını gizler |
1m00 |
| cmp / gradient check | Manuel gradyanı PyTorch .grad ile karşılaştır (exact/approx/maxdiff) |
7m25 |
| Atomik graf backward | Her ara tensörün gradyanı, yerel türev \(\times\) zincir kuralı (Ders 1, tensör) | 12m57 |
| matmul backward | C=A@B için \(dA = dC\,B^\top\), \(dB = A^\top dC\), \(db = dC.\text{sum}(0)\) | 41m44 |
| tanh backward | \(d\text{hpreact} = (1 - h^2)\cdot dh\); Ders 1’in \(1-\tanh^2\) türevi | 53m33 |
| BatchNorm scale/shift | \(\gamma\), \(\beta\) broadcast → geri geçişte toplanır; \(d\text{bnraw} = \text{bngain}\cdot d\text{hpreact}\) | 53m33 |
| Bessel düzeltmesi | Yansız varyans \(1/(n-1)\) vs yanlı \(1/n\); PyTorch BN ikisini farklı yerde kullanır | 1h05m |
| embedding scatter-add | \(dC[ix]\mathrel{+}= d\text{emb}\); aynı satıra gelen gradyanlar toplanır (Ders 1 +=) | 1h08m |
| cross-entropy backward | \(d\text{logits} = (\text{softmax} - \text{onehot})/n\); tek satır, “model \(-\) gerçek” | 1h26m |
| BatchNorm fused backward | Tek formül (3 terim); \(\mu\) ve \(\sigma\) batch’e bağlı → çok-yollu zincir | 1h36m |
| Elle eğitim (no backward) | loss.backward() kaldır, manuel gradyanlarla torch.no_grad() güncelle |
1h50m |
6.18 ML Builder Bağlantıları
İpucu9 köprü — Backprop Ninja
- Backprop = zincir kuralı (tensör) → Ders 1 micrograd + Calculus zincir kuralı. İleriye: her framework’ün autograd’ı.
- matmul backward (transpoze) → 18.06 boyut uyumu + Ders 1 “diğerini geçir”. İleriye: GPU GEMM, forward 1 / backward 2 matmul.
- cross-entropy backward (softmax \(-\) onehot) → Ders 1 (\(\hat{y} - y\)) + Stat 110 multinomial MLE. İleriye: GPT çıkış katmanı backward.
- embedding scatter-add → Ders 1 += biriktirme (çok-yollu zincir). İleriye: seyrek gradyan,
index_add_, token embedding backward. - BatchNorm fused backward → Stat 110 Bessel + Calculus çok-yollu zincir. İleriye: production norm kernel’ları, FlashAttention ruhu.
- broadcast/sum dualitesi → tensör mekaniği. İleriye: şekil-uyumsuzluğu bug’larından kaçınma.
- cmp / gradient check → Ders 1 sayısal gradyan. İleriye:
torch.autograd.gradcheck, custom Function doğrulama. - Sızdıran soyutlama → aleti anlayarak kullan. İleriye: NaN/vanishing gradient teşhisi (Ders 4 ile birlikte).
- Elle eğitim (autograd’sız) → Ders 1’in tam dairesi. İleriye: özel
autograd.Functionyazmak (production’da yeni katman/loss).
6.19 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders için verdiği kaynaklar:
- Bessel düzeltmesi açıklaması: Oxford/Emory math117 — Bessel’s correction — yansız varyans tahmini.
- Ders Colab notebook’u: Google Colab — egzersizlerin (boş) şablonu; backward’ları sen doldurursun.
ÖnemliBu dersten tek bir şey alıp gideceksen
loss.backward() sihir değil — zincir kuralının bir hesaplama grafiği boyunca tensör düzeyinde uygulanmasıdır. Gradyanları bir kez elle yazıp (matmul’da transpoze, cross-entropy’de softmax\(-\)onehot, BatchNorm’da füzyonlu formül, embedding’de scatter-add) loss.backward() olmadan eğitebilmek, seni backprop’u “kullanan” biriden “anlayan” birine — bir backprop ninjasına — dönüştürür.