flowchart LR
A["Pretraining<br/>base model (Ders 7, dev olcek)"] --> B["SFT<br/>asistan formati"]
B --> C["Odul Modeli<br/>insan tercihi"]
C --> D["RLHF<br/>asistan (ChatGPT)"]
D --> E["Token simulatoru<br/>dusunmek icin token"]
E --> F["Prompt muhendisligi<br/>CoT, self-consistency"]
F --> G["Tool use + RAG<br/>eksigi disardan tamamla"]
style D fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style F fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style G fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
9 GPT’nin Hâli — Pretrain’den ChatGPT’ye (State of GPT)
Ham bir pretrain edilmiş GPT, internet metnini taklit eden bir token simülatörüdür; onu yardımcı bir asistana çevirmek insan örnekleri (SFT) ve insan tercihleri (ödül modeli + RLHF) ile ek eğitim, etkili kullanmak ise modele düşünmek için token verip istediğini açıkça istemek (prompt mühendisliği) gerektirir
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — State of GPT (≈41 dk)
- Seri: Neural Networks: Zero to Hero — Ders 8
- Hoca: Andrej Karpathy
- Kaynak: Microsoft Build 2023 konferans konuşması
- Okuma süresi: ≈24 dk
ÖnemliBu ders farklı: kavramsal kuş bakışı, canlı kod yok
Ders 8, serinin diğer derslerinden farklı olarak canlı kodlama içermez. Bir konferans konuşması: kavramsal, kuş bakışı. Bu yüzden “live coding adımları” yerine kavramsal açıklama bölümleri var; kod bloğu yok (yalnızca kavram, diyagram ve örnek prompt’lar). Ders 9 (tokenizer) ve Ders 10 (GPT-2) yine koda döner.
9.1 Bu Derste Ne Var?
Ders 7’de bir GPT’yi mimari olarak kurup pretrain ettik (“bir sonraki token’ı tahmin et”). Ama ChatGPT yalnızca metni sürdürmez — talimatları izler, yardımcı olur. Bu ders, ham bir pretrain edilmiş GPT’nin nasıl bir asistana dönüştürüldüğünü (4-aşamalı hat) ve bu asistanların nasıl etkili kullanılacağını (prompt mühendisliği) kuş bakışı anlatır.
Konuşma iki parça: (1) GPT asistanları nasıl eğitilir (pretraining → SFT → ödül modeli → RLHF) ve (2) bu asistanlar nasıl kullanılır (prompt mühendisliği, tool use, RAG).
Dersin üç büyük fikri:
- Dört aşamalı eğitim hattı — her aşama bir öncekinin üstüne: pretraining (bilgi), SFT (asistan formatı), ödül modeli (insan tercihi), RLHF (tercihe göre optimize).
- “Token simülatörü” zihniyeti — LLM başarmak değil taklit etmek ister; istediğin davranışı açıkça iste.
- Prompt mühendisliği — “düşünmek için token” (chain-of-thought), self-consistency, tool use, RAG: modelin Sistem 2’sini dışarıdan kurmak.
İpucuBuilder Notu — Geriye Ders 2-7, İleriye Ders 9-10
Geriye (Ders 2-7):
- Pretraining = Ders 2-7. Konuşmanın 1. aşaması (pretraining: “bir sonraki token’ı tahmin et”), tüm makemore + GPT serisinin yaptığı şeyin ta kendisi — yalnızca dev ölçekte (internet metni, milyarlarca parametre).
- Base model = Ders 7 GPT. Ders 7’de kurduğumuz pretrain edilmiş GPT, bu konuşmadaki “base model”; SFT/RLHF onun üstüne gelir.
Bağımsızlık notu: Bu ders, serinin kod-akışının dışında bir kuş bakışıdır (konferans konuşması). Ders 9 (tokenizer) ve Ders 10 (GPT-2) yine koda döner.
İleriye: Dört aşamalı hat, tüm modern LLM ürünlerinin (ChatGPT, Claude, Gemini) production pipeline’ı. Modern hizalama yöntemleri bunun üzerine kurulur: DPO (RLHF’nin basitleştirilmesi), Constitutional AI, RLAIF. Agent framework’leri (ReAct, tool use) bu dersin prompt fikirlerinin gelişmiş hâli.
Tek cümleyle: Ham bir pretrain edilmiş GPT, internet metnini taklit eden bir “token simülatörü”dür; onu yardımcı bir asistana çevirmek insan örnekleri (SFT) + insan tercihleri (ödül modeli + RLHF) ile ek eğitim ve doğru prompt mühendisliği gerektirir.
9.2 Bu Ne Tür Bir Ders? (Kuş Bakışı)
Karpathy iki parçalık bir harita çizer: önce GPT asistanlarının nasıl eğitildiği, sonra nasıl kullanıldığı. Bu, Ders 1-7’nin “sıfırdan kur” yaklaşımından farklı: artık mekanizmayı (transformer, Ders 7) biliyoruz; bu ders o mekanizmanın production’da nasıl ürüne dönüştüğünü anlatır.
İpucuBuilder Notu — Mekanizma + Ürün
İleriye: “Mekanizmayı anla, sonra ürüne dönüştürmeyi anla” — bir builder’ın iki ayrı yetkinliği. Ders 7 birincisini, Ders 8 ikincisini verir. İkisi birlikte, LLM uygulaması geliştirmenin tam resmidir.
9.3 Dört Aşamalı Eğitim Hattı
GPT asistanı dört aşamada, sırayla eğitilir:
“Roughly speaking, we have four major stages: pretraining, supervised finetuning, reward modeling, reinforcement learning — and they follow each other serially.” — Karpathy, 0:59
- Pretraining — devasa internet metninde “bir sonraki token’ı tahmin et” (Ders 2-7’nin yaptığı, dev ölçekte). Hesabın \(\approx\%99\)’u burada; aylar sürer. Çıktı: base model (genel bilgi ama asistan değil).
- SFT (gözetimli ince ayar) — az sayıda, yüksek kaliteli (prompt, ideal yanıt) çiftiyle ince ayar. Çıktı: asistan formatını öğrenmiş model.
- Ödül modeli (reward modeling) — insanların yanıtları sıralamasından, “iyi yanıt” skorlayan bir model öğren.
- RLHF — ödül modeline göre, asistanı pekiştirmeli öğrenmeyle optimize et.
Her aşama daha az veri ama daha yüksek “kalite/hizalama” ekler.
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
NL = chr(10)
fig, ax = plt.subplots(figsize=(11, 4.6))
ax.set_xlim(0, 11.6); ax.set_ylim(0, 5); ax.axis("off")
label_tr = ["Pretraining", "SFT", "Ödül Modeli", "RLHF"]
role_tr = ["bilgi" + NL + "(next-token)", "asistan" + NL + "formatı",
"insan" + NL + "tercihi", "tercihe göre" + NL + "optimize"]
xs = [1.4, 4.0, 6.6, 9.2]
for i, x in enumerate(xs):
ax.add_patch(FancyBboxPatch((x-1.05, 2.3), 2.1, 1.5,
boxstyle="round,pad=0.02,rounding_size=0.12", fc="#eef2ff",
ec=STAGE_COL[i], lw=2.6, zorder=2))
ax.text(x, 3.45, str(i+1) + ". " + label_tr[i], ha="center", va="center",
color=COL_TEXT, fontsize=12, weight="bold")
ax.text(x, 2.75, role_tr[i], ha="center", va="center", color=STAGE_COL[i], fontsize=9.5)
ax.text(x, 1.7, DATA_DESC[i], ha="center", va="center", color=COL_SLATE_400, fontsize=8.5, style="italic")
if i < 3:
ax.add_patch(FancyArrowPatch((x+1.05, 3.05), (xs[i+1]-1.05, 3.05),
arrowstyle="-|>", mutation_scale=18, color=COL_PRIMARY, lw=2.0, zorder=1))
ax.text(0.2, 4.55, "base model →", ha="left", color=COL_SLATE_400, fontsize=10, style="italic")
ax.text(5.8, 4.55, "← — — — asistan model (ChatGPT) — — — →", ha="center", color=COL_INDIGO_600, fontsize=10, weight="bold")
ax.text(5.8, 0.7, "veri ↓ · hizalama/kalite ↑ (her aşamada)", ha="center", color=COL_TEXT, fontsize=10)
ax.text(5.8, 4.95, "4-aşamalı eğitim hattı (sırayla)", ha="center", color=COL_TEXT, fontsize=13, weight="bold")
plt.tight_layout()
plt.show()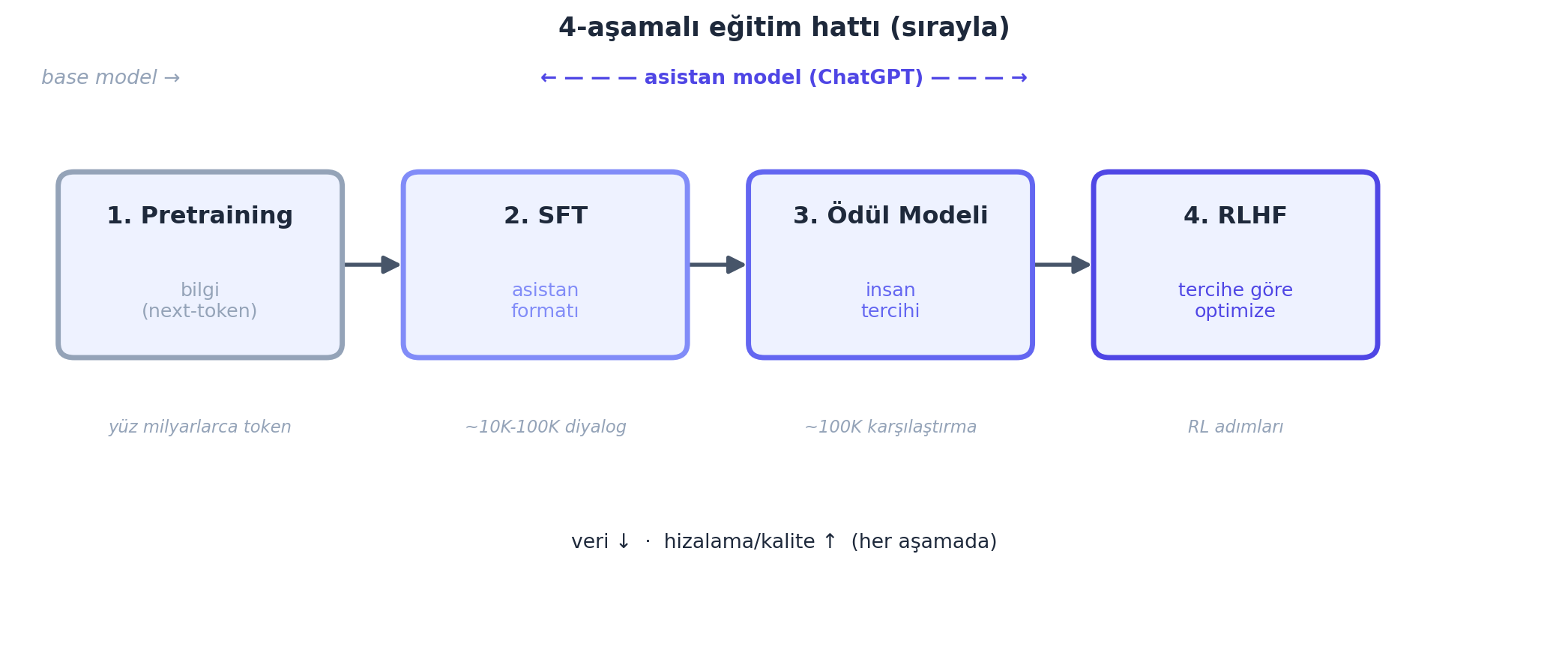
İpucuBuilder Notu — 1. Aşama = Ders 7
Geriye (Ders 7): 1. aşama (pretraining), Ders 7’de kurduğumuz GPT’nin eğitimidir — yalnızca ölçek farklı. Geri kalan 3 aşama, o base model’i asistana çevirir.
İleriye: Bu hat OpenAI’nin InstructGPT makalesinden gelir ve tüm asistan-LLM’lerin (Claude dahil) standardıdır; modern varyantlar (DPO, RLAIF, Constitutional AI) 3-4. aşamayı değiştirir.
9.4 Pretraining: Veri ve Tokenization
İlk ve en pahalı aşama. Devasa miktarda internet metni toplanır (terabaytlarca), tokenize edilir (Ders 9’un konusu — BPE), ve modele “bir sonraki token’ı tahmin et” hedefiyle verilir. Karpathy ölçekleri verir: yüz milyarlarca token, binlerce GPU, aylar süren eğitim, milyonlarca dolarlık maliyet.
Veri farklı kaynaklardan (web, kitap, kod, …) belirli oranlarda karıştırılır. Token’lar, eğitim için \(B \times T\)’lik batch’lere dizilir (Ders 7’deki \((B, T)\) yapısı) — metin parçaları arasına özel <|endoftext|> ayraç token’ı konur.
İpucuBuilder Notu — Ders 7’nin Dev Ölçeği
Geriye (Ders 7): Bu, Ders 7’deki \((B, T)\) batch yapısının + cross-entropy hedefinin dev ölçekli hâli. Tek fark: karakter yerine BPE token (Ders 9), tiny Shakespeare yerine internet.
İleriye: Veri karışımı (data mixture), modern LLM’lerin gizli sosudur; veri kalitesi (FineWeb-EDU, Ders 10) model kalitesini doğrudan belirler.
9.5 Pretraining: Hiperparametreler ve Next-Token Hedefi
Pretraining’in çekirdeği, tüm seri boyunca gördüğümüz hedeftir: bir sonraki token’ı tahmin et (cross-entropy loss). Karpathy GPT’lerin kabaca büyüklük mertebelerini verir: parametre sayısı (milyarlar), token sayısı (yüz milyarlar), bağlam uzunluğu (binler).
Sonuç: base model — internet metnini taklit eden, devasa genel bilgi barındıran ama henüz “asistan” olmayan bir model. Base model bir soruyu yanıtlamaz; onu sürdürür (örneğin bir soru verirseniz, daha çok soru üretebilir — çünkü internette sorular soru listeleri içinde geçer).
Kod
import matplotlib.pyplot as plt
import numpy as np
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5))
# Sol: compute payi (log olcek, %99 vurgusu)
labels = ["Pretraining", "SFT", "Ödül M.", "RLHF"]
bars = axL.bar(labels, COMPUTE_PCT, color=STAGE_COL, width=0.62, zorder=3)
axL.set_yscale("log")
apply_style(axL)
axL.set_ylabel("compute payı (%) — log ölçek")
axL.set_title("Hesabın ≈%99'u pretraining'de", color=COL_TEXT)
for b, v in zip(bars, COMPUTE_PCT):
axL.text(b.get_x()+b.get_width()/2, v*1.15, ("%" + (str(v) if v < 1 else str(int(v)))),
ha="center", va="bottom", color=COL_TEXT, fontsize=9.5, weight="bold")
# Sag: veri olcegi (azalan) — yatay bar, illustratif
axR.axis("off")
axR.text(0.5, 1.02, "Veri ölçeği (her aşamada azalır)", ha="center", va="top",
transform=axR.transAxes, color=COL_TEXT, fontsize=12, weight="bold")
widths = [0.95, 0.30, 0.22, 0.16]
descs = DATA_DESC
for i, (w, d) in enumerate(zip(widths, descs)):
y = 0.80 - i*0.20
axR.add_patch(plt.Rectangle((0.05, y-0.06), w*0.9, 0.12, transform=axR.transAxes,
fc=STAGE_COL[i], ec="none", alpha=0.85))
axR.text(0.06, y, labels[i], transform=axR.transAxes, ha="left", va="center",
color=COL_WHITE if i >= 2 else COL_TEXT, fontsize=9.5, weight="bold")
axR.text(0.97, y, d, transform=axR.transAxes, ha="right", va="center",
color=COL_TEXT, fontsize=8.5, style="italic")
plt.tight_layout()
plt.show()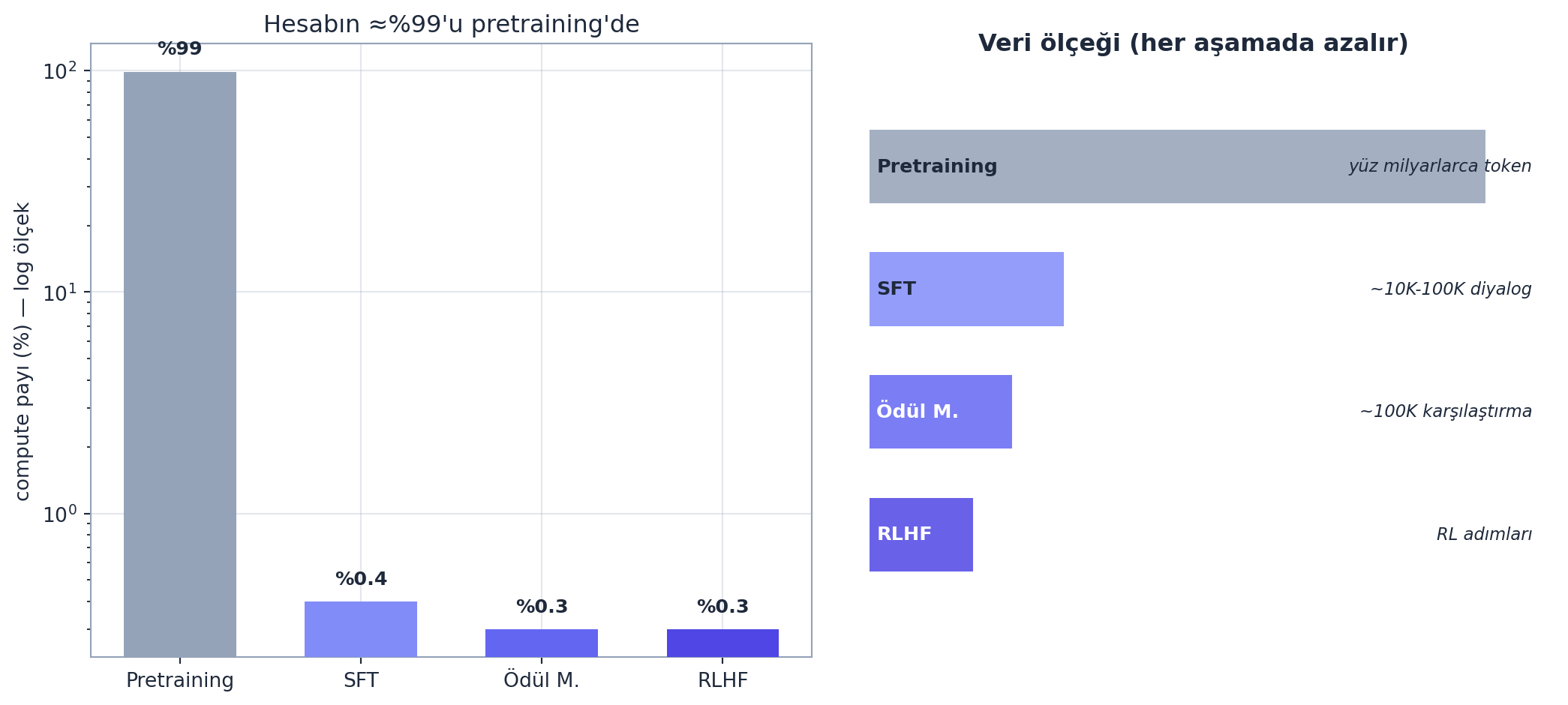
İpucuBuilder Notu — Next-Token = Ders 2’den Ders 7’ye
Geriye (Ders 2-7): “Next-token prediction + cross-entropy” tam olarak Ders 2’den (bigram NLL) Ders 7’ye (GPT) kadar yaptığımız şey. Pretraining = bu hedefin dev ölçeği. Ders 5’te bu cross-entropy’nin gradyanını elle yazmıştık — RLHF (aşama 4) ise farklı bir hedef (ödül maksimizasyonu) kullanır. Ders 4 köprüsü: bu dev ölçekte (milyarlarca parametre, derin transformer) eğitimi kararlı kılan şey normalizasyondur — Ders 4’te küçük ölçekte aktivasyon/gradyan dağılımını ve BatchNorm’u incelemiştik; pretraining aynı stabilizasyonu transformer bloğunda LayerNorm (Ders 7) ile sağlar, yoksa derin ağ bu ölçekte eğitilemezdi.
İleriye: Bu büyüklük mertebeleri (parametre/token/compute), scaling laws’ın (Chinchilla) konusu — optimal eğitim için bu üçünün dengesi (Ders 10’da pratiği).
9.6 Base Model: Güçlü Genel Temsiller
Base model, “asistan” değil ama inanılmaz güçlü bir genel temsil taşır. 2020’de GPT-3 (base model) bir şey gösterdi: model, birkaç örnek (few-shot) verilince, ince ayar olmadan yeni görevleri prompt içinden öğrenebiliyor.
“This kicked off the era of prompting over finetuning, and seeing that this [works].” — Karpathy, 9:45
Yani base model’i doğrudan kullanmanın iki yolu: few-shot prompting (prompt içine birkaç örnek koy) veya finetuning (ek eğitim). Karpathy örnek olarak GPT-3 base’i (API’de “Davinci”) ve açık base modelleri (Meta’nın LLaMA serisi) anar. Base model güçlü ama “ham” — kullanışlı asistan için sonraki aşamalar gerek.
Kod
import matplotlib.pyplot as plt
NL = chr(10)
prompt = "Türkiye'nin başkenti nedir?"
base_txt = ("Türkiye'nin başkenti nedir?" + NL +
"Türkiye'nin en kalabalık şehri nedir?" + NL +
"Türkiye'nin yüzölçümü kaçtır?" + NL +
"Türkiye hangi kıtadadır?" + NL + NL +
"(soruyu yanıtlamaz — SÜRDÜRÜR;" + NL +
" internetteki soru-listelerini taklit eder)")
asst_txt = ("Türkiye'nin başkenti Ankara'dır." + NL + NL +
"(talimatı İZLER, doğrudan yanıtlar;" + NL +
" SFT + RLHF asistan formatını kazandırdı)")
fig, axes = plt.subplots(1, 2, figsize=(11, 5))
for ax, title, txt, ec in [
(axes[0], "BASE MODEL (yalnız pretraining)", base_txt, COL_SLATE_400),
(axes[1], "ASİSTAN MODEL (SFT + RLHF)", asst_txt, COL_INDIGO_600),
]:
ax.axis("off")
ax.add_patch(plt.Rectangle((0.04, 0.04), 0.92, 0.86, transform=ax.transAxes, fc="#ffffff", ec=ec, lw=2.0))
ax.text(0.5, 0.96, title, transform=ax.transAxes, ha="center", va="top", color=ec, fontsize=11.5, weight="bold")
ax.text(0.08, 0.80, "İstem: " + prompt, transform=ax.transAxes, ha="left", va="top",
color=COL_TEXT, fontsize=9.5, weight="bold")
ax.text(0.08, 0.66, txt, transform=ax.transAxes, ha="left", va="top",
color=COL_TEXT, fontsize=9.5, family="monospace")
fig.suptitle("Aynı istem, iki model: \"sürdürmek\" vs \"yanıtlamak\"", color=COL_TEXT, fontsize=13)
plt.tight_layout()
plt.show()
İpucuBuilder Notu — Prompting over Finetuning
İleriye: “Prompting over finetuning” (few-shot, in-context learning), modern LLM kullanımının temelidir — modeli yeniden eğitmeden, prompt ile yönlendirmek. Base modeller (LLaMA, Mistral) açık kaynak ekosisteminin temeli; üstüne kendi SFT/LoRA’nı eklersin.
9.7 SFT (Gözetimli İnce Ayar)
İkinci aşama: base model’i asistan formatına sokmak. İnsan etiketleyiciler, az sayıda ama yüksek kaliteli (prompt, ideal yanıt) çifti yazar (binlerce, on binlerce). Base model bu veride ince ayarlanır (aynı next-token hedefi, ama artık asistan-vari yanıtlar üzerinde).
Sonuç: SFT modeli — soruları yanıtlayan, talimat izleyen bir model. Veri az ama kalite yüksek; model “böyle davran” formatını öğrenir. Pek çok pratik uygulama için SFT modeli yeterlidir.
İpucuBuilder Notu — Mekanizma Aynı, Veri Değişti
Geriye (Ders 7): SFT, Ders 7’deki aynı eğitim (next-token + cross-entropy), yalnızca veri = elle yazılmış asistan diyalogları. Mekanizma değişmedi, veri değişti.
İleriye: SFT, kendi asistanını kurmanın en erişilebilir adımı; LoRA/QLoRA (parametre-verimli ince ayar) ile küçük donanımda bile yapılabilir. Veri kalitesi (çeşitlilik + doğruluk) SFT’nin her şeyi.
9.8 Ödül Modeli (Reward Modeling)
Üçüncü aşama, RLHF’nin ilk yarısı. Fikir: bir prompt için modelin ürettiği birden çok yanıtı insanlara sıralat (hangisi daha iyi?). Bu sıralamalardan, bir yanıta “ne kadar iyi” skoru veren bir ödül modeli eğit.
Neden sıralama? Çünkü insanların “iyi yanıtı sıfırdan yazması” zor ama “iki yanıttan iyisini seçmesi” kolay — bu asimetri, ölçeklenebilir veri toplamayı sağlar. Ödül modeli, prompt + yanıt çiftlerini alıp tek bir skor (özel bir “ödül” token’ından okunan) üretir; insan tercih sıralamasıyla eğitilir.
İpucuBuilder Notu — Sıralamadan Skor (Stat 110)
Geriye (Stat 110): Sıralamadan skor öğrenmek, Stat 110’daki Bradley-Terry tercih modeli (hangi öğenin tercih edileceğinin olasılığı). Ödül modeli = “insan tercihini taklit eden” bir sınıflandırıcı.
İleriye: Ödül modeli, RLHF’nin kalbi; modern alternatifler (DPO) ödül modelini atlayıp tercihleri doğrudan optimize eder; RLAIF ise insan yerine AI tercihi kullanır (Constitutional AI).
9.9 RLHF (Pekiştirmeli Öğrenme) ve Mode Collapse
RLHF’nin ikinci yarısı: SFT modelini, ödül modeline göre pekiştirmeli öğrenmeyle (PPO) optimize et. Model yanıtlar üretir, ödül modeli skorlar, model yüksek-skorlu yanıtlar üretmeye yönlendirilir.
Neden işe yarar? Yine asimetri: bir şeyi yargılamak, üretmekten kolaydır. Ödül modeli (yargıç) iyi yanıtı tanıyabildiği için, üreticiyi o yöne itebilir. Sonuç: ChatGPT gibi PPO modelleri.
Bir yan etki var: mode collapse.
“Mode collapse.” — Karpathy, 18:46
RLHF modelleri, base modellere göre daha az çeşitli çıktı üretir — ödülü maksimize ederken belli kalıplara yapışırlar (entropi düşer). Bu yüzden çeşitlilik gereken görevlerde (örn. çok sayıda farklı fikir üretmek) base model bazen daha iyidir.
İpucuBuilder Notu — Hizalama-Yetenek Dengesi
İleriye: RLHF (PPO), ChatGPT’yi mümkün kıldı ama karmaşık ve kararsız; bu yüzden DPO (Direct Preference Optimization) gibi basitleştirmeler popülerleşti. Mode collapse / çeşitlilik kaybı, hizalama-yetenek dengesinin (alignment tax) bir yüzü — aktif araştırma konusu.
Üç model tipinin davranış farkı:
| Model | Nasıl eğitildi | Davranış | Ne zaman kullan |
|---|---|---|---|
| Base | yalnız pretraining | metni sürdürür, yanıtlamaz; en çeşitli | few-shot, ham tamamlama, kendi finetuning temelin |
| SFT | + asistan diyalogları | talimat izler, yanıtlar | çoğu pratik asistan uygulaması |
| RLHF | + ödül modeli + PPO | en hizalı/kibar; çeşitlilik düşük (mode collapse) | ChatGPT-vari ürün; çeşitlilik gerekmeyen işler |
9.10 Token Simülatörü Zihniyeti
İkinci bölüm: bu asistanları nasıl etkili kullanırız? Karpathy kritik bir zihinsel model verir. İnsan bir metin yazarken zengin bir iç monolog çalıştırır (planlar, geri döner, düzeltir). LLM ise öyle değil:
“Basically these transformers are just like token simulators — they don’t know what they don’t know.” — Karpathy, 23:13
LLM her token için sabit miktarda hesap yapar; arada “durup düşünmez”. O hâlde düşünmesini istiyorsak, ona düşünmek için token vermeliyiz:
“These transformers need tokens to think, I like to say sometimes.” — Karpathy, 24:57
Ve en pratik kural — LLM taklit eder, başarmayı hedeflemez:
“LLMs don’t want to succeed, they want to imitate. You want to succeed, and you should ask for it.” — Karpathy, 30:16
Yani “uzman gibi, adım adım, dikkatli düşün” demek, modeli internetteki iyi örnekleri taklit etmeye yöneltir. İstediğin davranışı açıkça iste.
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
fig, ax = plt.subplots(figsize=(11, 5))
ax.set_xlim(0, 12); ax.set_ylim(0, 5); ax.axis("off")
def tok(x, y, t, fc, ec, w=1.05, tc=None):
ax.add_patch(FancyBboxPatch((x-w/2, y-0.32), w, 0.64,
boxstyle="round,pad=0.02,rounding_size=0.10", fc=fc, ec=ec, lw=1.8, zorder=2))
ax.text(x, y, t, ha="center", va="center", color=tc or COL_TEXT, fontsize=9, weight="bold")
def arr(x0, y, x1):
ax.add_patch(FancyArrowPatch((x0, y), (x1, y), arrowstyle="-|>", mutation_scale=13, color=COL_SLATE_400, lw=1.6, zorder=1))
# Ust: dogrudan cevap
ax.text(0.2, 4.5, "Doğrudan cevap (tek adım — sabit hesap):", ha="left", color=COL_TEXT, fontsize=11, weight="bold")
tok(1.3, 3.7, "Soru", "#ffffff", COL_SLATE_400)
arr(1.95, 3.7, 2.85)
tok(3.4, 3.7, "Cevap", "#fee2e2", "#b91c1c", tc="#b91c1c")
ax.text(5.0, 3.7, "← ara hesap YOK, sık sık hatalı", ha="left", color="#b91c1c", fontsize=9.5, style="italic")
# Alt: chain-of-thought
ax.text(0.2, 2.6, "Chain-of-thought (\"adım adım düşünelim\" — diziyi uzat):", ha="left", color=COL_TEXT, fontsize=11, weight="bold")
labels = ["Soru", "adım 1", "adım 2", "adım 3", "Cevap"]
xs = [1.3, 3.0, 4.7, 6.4, 8.3]
for i, (x, lb) in enumerate(zip(xs, labels)):
if i == 0:
tok(x, 1.7, lb, "#ffffff", COL_SLATE_400)
elif i == len(labels)-1:
tok(x, 1.7, lb, "#dcfce7", "#15803d", tc="#15803d")
else:
tok(x, 1.7, lb, "#eef2ff", COL_INDIGO_600, tc=COL_INDIGO_600)
if i < len(labels)-1:
arr(x+0.55, 1.7, xs[i+1]-0.55)
ax.text(9.3, 1.7, "← ara token = ara hesap", ha="left", color="#15803d", fontsize=9.5, style="italic")
ax.text(6.0, 0.6, "Her token sabit hesap → düşünmek için TOKEN gerekir (test-time compute)", ha="center", color=COL_TEXT, fontsize=10)
plt.tight_layout()
plt.show()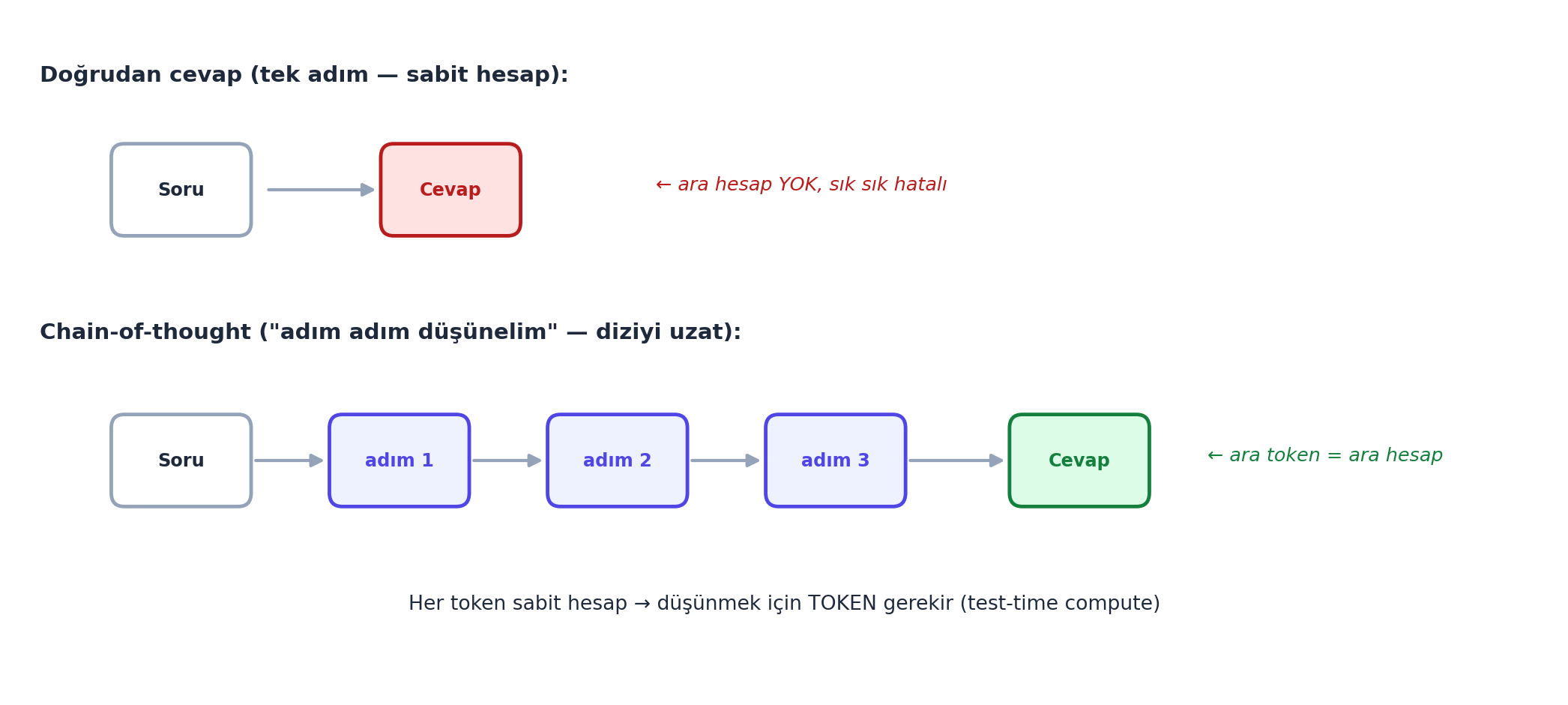
İpucuBuilder Notu — Sabit Hesap, Ders 7 Köprüsü
Geriye (Ders 7): Ders 7’de gördük: transformer her token için sabit miktarda hesap yapar (sabit derinlik). “Düşünmek için token” = bu sabit-derinlik kısıtını, diziyi uzatarak (kendi ürettiğine self-attention) aşmak.
İleriye: “Token simülatörü” + “düşünmek için token” zihniyeti, tüm prompt mühendisliğinin temeli. Modern reasoning modelleri (o1, vb.) bu fikri içselleştirir: cevaptan önce uzun bir “düşünme” zinciri üretirler (test-time compute).
9.11 Prompt Mühendisliği: Sistem 2’yi Dışarıdan Kurmak
Karpathy bu tekniklerin ortak temasını verir: modelin eksik olan Sistem 2’sini (yavaş, kasıtlı düşünme) dışarıdan kurmak.
“A lot of these techniques fall into the bucket of recreating our System 2.” — Karpathy, 27:34
- Chain-of-thought (CoT): “Adım adım düşünelim” de — model ara adımları token olarak üretir, böylece “düşünme” için hesap kazanır.
- Self-consistency: Aynı soruyu birkaç kez çözdür, en sık çıkan cevabı al (çoğunluk oyu).
- Yansıma (reflection): Modele kendi cevabını eleştirmesini/düzeltmesini iste.
- Düşünce Ağacı (Tree of Thought): Birden çok düşünme yolunu dallandırıp en iyisini ara (AlphaGo’nun Monte Carlo ağaç aramasına koşut).
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyArrowPatch
fig, axes = plt.subplots(2, 2, figsize=(11, 6))
for ax in axes.flat:
ax.set_xlim(0, 10); ax.set_ylim(0, 10); ax.axis("off")
def node(ax, x, y, fc=COL_BG, ec=COL_INDIGO_600, r=0.9):
ax.add_patch(plt.Circle((x, y), r, fc=fc, ec=ec, lw=2.0, zorder=2))
def edge(ax, x0, y0, x1, y1, c=COL_SLATE_400):
ax.add_patch(FancyArrowPatch((x0, y0), (x1, y1), arrowstyle="-|>", mutation_scale=13, color=c, lw=1.8, zorder=1))
# 1 CoT: zincir
ax = axes[0, 0]; ax.set_title("Chain-of-thought", color=COL_TEXT, fontsize=12, weight="bold")
xs = [1.6, 4.0, 6.4, 8.6]
for i, x in enumerate(xs):
node(ax, x, 5, ec=COL_INDIGO_600 if 0 < i < 3 else COL_SLATE_400, r=0.85)
if i < 3: edge(ax, x+0.85, 5, xs[i+1]-0.85, 5)
ax.text(5, 1.8, "ara adımlar = ara hesap", ha="center", color=COL_TEXT, fontsize=9, style="italic")
# 2 Self-consistency: 3 yol -> oy
ax = axes[0, 1]; ax.set_title("Self-consistency", color=COL_TEXT, fontsize=12, weight="bold")
node(ax, 1.6, 5, ec=COL_SLATE_400, r=0.8)
for k, y in enumerate([8.2, 5, 1.8]):
node(ax, 5, y, ec=COL_INDIGO_400, r=0.7); edge(ax, 2.4, 5, 4.3, y)
edge(ax, 5.7, y, 7.6, 5.2)
node(ax, 8.4, 5, ec=COL_INDIGO_600, r=0.85)
ax.text(8.4, 3.4, "çoğunluk", ha="center", color=COL_TEXT, fontsize=8.5)
# 3 Reflection: cevap -> elestir -> duzelt
ax = axes[1, 0]; ax.set_title("Yansıma (reflection)", color=COL_TEXT, fontsize=12, weight="bold")
node(ax, 2.0, 6.5, ec=COL_INDIGO_400, r=0.85); ax.text(2.0, 6.5, "cevap", ha="center", va="center", fontsize=8, color=COL_TEXT)
node(ax, 7.5, 6.5, ec=COL_ACCENT, r=0.85); ax.text(7.5, 6.5, "eleştir", ha="center", va="center", fontsize=8, color=COL_TEXT)
node(ax, 4.7, 2.5, ec=COL_INDIGO_600, r=0.9); ax.text(4.7, 2.5, "düzelt", ha="center", va="center", fontsize=8, color=COL_TEXT)
edge(ax, 2.85, 6.5, 6.65, 6.5); edge(ax, 7.2, 5.7, 5.3, 3.3); edge(ax, 4.0, 3.1, 2.4, 5.7)
# 4 Tree of Thought: dallanma
ax = axes[1, 1]; ax.set_title("Düşünce Ağacı (ToT)", color=COL_TEXT, fontsize=12, weight="bold")
node(ax, 5, 8.4, ec=COL_SLATE_400, r=0.7)
mid = [(2.6, 5), (5, 5), (7.4, 5)]
for (mx, my) in mid:
node(ax, mx, my, ec=COL_INDIGO_400, r=0.65); edge(ax, 5, 7.7, mx, my+0.65)
leaves = [(1.6, 1.8), (3.6, 1.8), (6.4, 1.8), (8.4, 1.8)]
best = (6.4, 1.8)
for (lx, ly) in leaves:
node(ax, lx, ly, ec=COL_INDIGO_600 if (lx, ly) == best else COL_SLATE_400, r=0.6)
edge(ax, 2.6, 4.4, 1.7, 2.4); edge(ax, 2.6, 4.4, 3.5, 2.4)
edge(ax, 7.4, 4.4, 6.4, 2.4); edge(ax, 7.4, 4.4, 8.3, 2.4)
ax.text(6.4, 0.7, "en iyi yol", ha="center", color=COL_INDIGO_600, fontsize=8.5, weight="bold")
fig.suptitle("Sistem 2'yi dışarıdan kurmak — prompt mühendisliği", color=COL_TEXT, fontsize=13)
plt.tight_layout()
plt.show()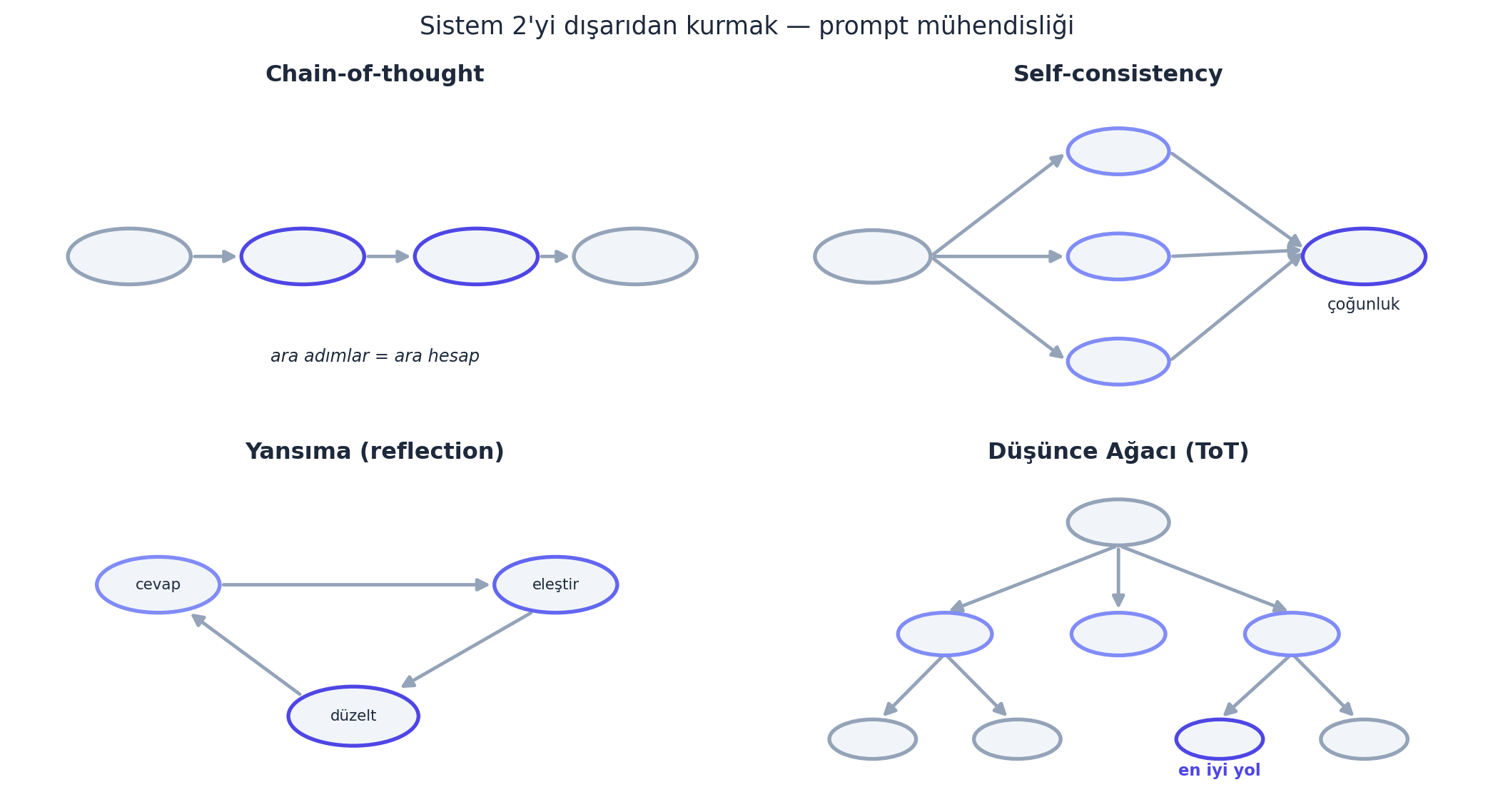
İpucuBuilder Notu — CoT = Ara Token = Ara Hesap
Geriye (Ders 5/7): CoT, “ara token’lar = ara hesap” — Ders 7’deki autoregressive üretimin, modele alan açacak biçimde kullanılması. Düşünce Ağacı, arama (search) + LLM birleşimi.
İleriye: CoT/self-consistency/ToT, modern reasoning’in (test-time compute, o1/o3) temeli; ReAct ve agent framework’leri bunları tool use ile birleştirir.
9.12 Tool Use, RAG ve Limitler
Karpathy birkaç pratik araç daha sıralar:
- Tool use: Modele hesap makinesi, kod yürütücü, arama gibi araçları kullanmayı öğret (Python “glue code” ile) — kendi yapamadığını araca yaptırır.
- Retrieval-augmented generation (RAG): İlgili belgeleri getirip prompt’a koy — model “ezberden” değil, getirilen bilgiden yanıtlar (LlamaIndex gibi araçlar). “Yalnızca-ezber”den “yalnızca-getirme”ye bir yelpaze; ortası en güçlü.
- Kısıtlı istem (constraint prompting): Çıktıyı belli bir formata (örn. JSON) zorla (Microsoft Guidance gibi).
- Finetuning: Gerekirse modeli kendi verinle ince ayarla (LoRA/QLoRA — parametre-verimli).
Limitler: Karpathy modellerin sınırlarını da hatırlatır — hallüsinasyon, prompt injection / jailbreak / veri zehirleme gibi güvenlik açıkları, “ne bilmediğini bilmeme”. Bu yüzden kritik uygulamalarda insan denetimi şart.
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
NL = chr(10)
fig, ax = plt.subplots(figsize=(11, 5))
ax.set_xlim(0, 12); ax.set_ylim(0, 6); ax.axis("off")
def box(x, y, w, h, t, fc, ec, tc=None, fs=10):
ax.add_patch(FancyBboxPatch((x-w/2, y-h/2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.12", fc=fc, ec=ec, lw=2.2, zorder=2))
ax.text(x, y, t, ha="center", va="center", color=tc or COL_TEXT, fontsize=fs, weight="bold")
def biarrow(x0, y0, x1, y1, c=COL_INDIGO_600):
ax.add_patch(FancyArrowPatch((x0, y0), (x1, y1), arrowstyle="<|-|>", mutation_scale=15, color=c, lw=2.0, zorder=1))
# Merkez: LLM
box(6, 3, 3.0, 1.4, "LLM" + NL + "(transformer)", "#eef2ff", COL_INDIGO_600, fs=12)
# Sol ust: tool use
box(2.0, 4.8, 3.0, 1.0, "Araç: hesap makinesi /" + NL + "kod yürütücü / arama", "#ffffff", COL_ACCENT, tc=COL_ACCENT, fs=9)
biarrow(3.5, 4.5, 4.7, 3.5)
ax.text(2.6, 3.7, "tool use", ha="center", color=COL_ACCENT, fontsize=9, style="italic")
# Sol alt: RAG
box(2.0, 1.4, 3.0, 1.0, "Getirilen belgeler" + NL + "(RAG / retrieval)", "#ffffff", COL_INDIGO_400, tc=COL_PRIMARY, fs=9)
biarrow(3.5, 1.7, 4.7, 2.6)
ax.text(2.6, 2.4, "getirilen bilgi", ha="center", color=COL_PRIMARY, fontsize=9, style="italic")
# Sag: cikti
box(10.0, 3, 2.6, 1.0, "Yanıt" + NL + "(daha doğru, daha az hallüsinasyon)", "#dcfce7", "#15803d", tc="#15803d", fs=8.5)
ax.add_patch(FancyArrowPatch((7.5, 3), (8.7, 3), arrowstyle="-|>", mutation_scale=16, color=COL_PRIMARY, lw=2.0, zorder=1))
ax.text(6, 5.6, "Tool use + RAG: modelin eksiğini araç ve getirilen bilgiyle tamamla", ha="center", color=COL_TEXT, fontsize=12, weight="bold")
ax.text(6, 0.5, "Limitler: hallüsinasyon · jailbreak/injection · \"ne bilmediğini bilmeme\" → kritik işte insan denetimi", ha="center", color=COL_SLATE_400, fontsize=8.5, style="italic")
plt.tight_layout()
plt.show()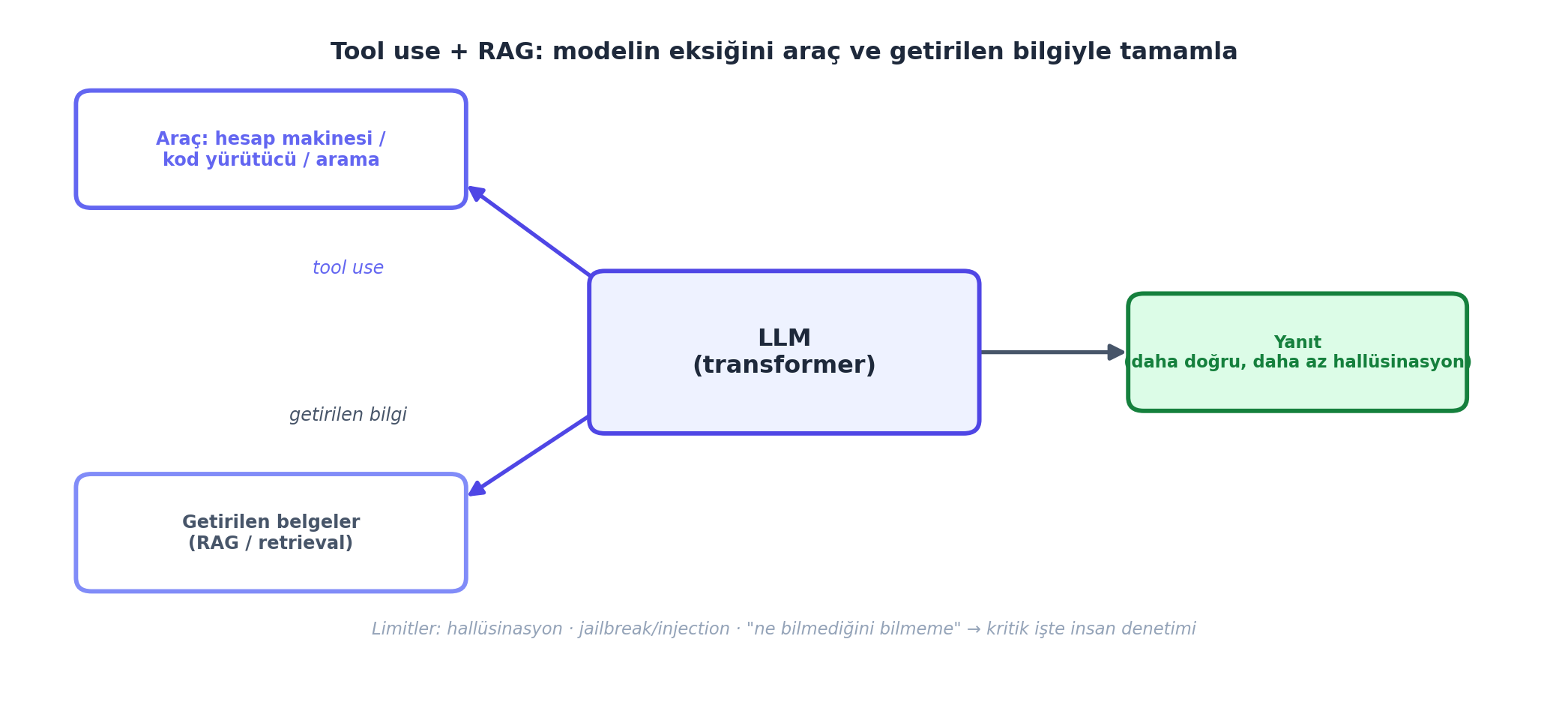
İpucuBuilder Notu — Modern LLM Uygulama Mimarisi
İleriye: Tool use + RAG + constraint prompting, modern LLM uygulama geliştirmenin (Claude/GPT uygulamaları) çekirdeği; MCP, LangChain, agent framework’leri bunları standartlaştırır. Güvenlik açıkları (jailbreak, injection) production’da ciddi bir konu — OWASP Top 10 for LLMs.
9.13 Bu Dersin Özeti
- Ders 8, serinin kavramsal kuş bakışı: kod yok, GPT asistanlarının nasıl eğitildiği + nasıl kullanıldığı.
- Dört aşamalı hat (sırayla): pretraining (bilgi, \(\approx\%99\) compute) → SFT (asistan formatı) → ödül modeli (insan tercihi) → RLHF (tercihe göre optimize).
- Base model (Ders 7 GPT’nin dev hâli) güçlü ama ham; soruyu yanıtlamaz, sürdürür. few-shot prompting veya finetuning ile kullanılır.
- SFT: az ama kaliteli (prompt, yanıt) çiftiyle ince ayar → asistan formatı.
- Ödül modeli + RLHF: insan sıralamasından skor öğren, PPO ile optimize; “yargılamak üretmekten kolay” asimetrisi. Yan etki: mode collapse (çeşitlilik kaybı).
- Token simülatörü zihniyeti: LLM iç monolog çalıştırmaz, “düşünmek için token” gerekir; “başarmayı değil taklit etmeyi ister — istediğini açıkça iste”.
- Prompt mühendisliği (Sistem 2’yi dışarıdan kur): chain-of-thought, self-consistency, yansıma, Düşünce Ağacı.
- Tool use, RAG, kısıtlı istem: modelin yapamadığını araçla/getirilen bilgiyle/formatla tamamla.
- Limitler: hallüsinasyon, jailbreak/injection, “ne bilmediğini bilmeme” → kritik işte insan denetimi.
ÖnemliTek Bir Cümle
Ham bir pretrain edilmiş GPT (Ders 7), internet metnini taklit eden bir “token simülatörü”dür; onu yardımcı bir asistana çevirmek insan örnekleri (SFT) + insan tercihleri (ödül modeli + RLHF) ile ek eğitim gerektirir — ve onu etkili kullanmak, modele “düşünmek için token” verip istediğin davranışı açıkça istemekten (prompt mühendisliği) geçer.
9.14 Kontrol Soruları
NotSoru 1: GPT asistanı eğitiminin 4 aşamasını sırayla say. Her aşama ne ekler ve hangisi en çok compute harcar?
Cevap: (1) Pretraining — devasa internet metninde “bir sonraki token’ı tahmin et”; genel bilgi ekler; compute’un \(\approx\%99\)’u burada (aylar, milyonlarca dolar). Çıktı: base model. (2) SFT (gözetimli ince ayar) — az ama kaliteli (prompt, ideal yanıt) çiftiyle ince ayar; asistan formatını ekler. (3) Ödül modeli — insan sıralamalarından “iyi yanıt” skoru öğrenir; insan tercihini ekler. (4) RLHF — ödül modeline göre PPO ile optimize; tercihe-hizalanmış davranışı ekler. Her aşama daha az veri ama daha yüksek hizalama katar; ilki bilgiyi, sonraki üçü “yardımcı asistan” davranışını verir.
NotSoru 2: Base model ile SFT/RLHF modeli arasındaki fark nedir? Hangi durumda hangisini kullanırsın?
Cevap: Base model internet metnini taklit eder — soruyu yanıtlamaz, sürdürür (bir soru verirsen daha çok soru üretebilir). Devasa genel bilgi taşır ama “asistan” değil. SFT/RLHF modeli (ChatGPT gibi) talimat izler, yardımcı yanıt verir. Kullanım: asistan davranışı, talimat-izleme, sohbet için SFT/RLHF modeli; çeşitlilik gereken (çok sayıda farklı/yaratıcı çıktı), ham tamamlama, veya kendi finetuning’inin temeli için base model (RLHF mode collapse nedeniyle çeşitliliği düşürür). Çoğu uygulama asistan modeli ister; araştırma/özel-eğitim base model ister.
NotSoru 3: RLHF modelleri neden base modellerden daha az çeşitli çıktı üretir (mode collapse)?
Cevap: RLHF, modeli ödülü maksimize etmeye iter. Ödül modeli belli yanıt türlerini (kibar, yapılandırılmış, “güvenli”) yüksek skorlar; model bu kalıplara yapışır ve çıktı dağılımının entropisi düşer (mode collapse) — aynı soruya hep benzer yanıtlar. Base model ise yalnızca internet metnini taklit ettiği için çok daha çeşitli (internetteki tüm üslupları kapsar). Sonuç bir denge (alignment tax): RLHF hizalama/yardımcılık kazandırır ama çeşitlilik kaybettirir. Bu yüzden “bana 30 farklı isim öner” gibi çeşitlilik görevlerinde base model bazen daha iyidir.
NotSoru 4: (Builder) ‘Adım adım düşünelim’ (chain-of-thought) demek neden modelin performansını artırır? Ders 7 (token başına sabit hesap) ile bağla.
Cevap: Ders 7’de gördük: transformer her token için sabit miktarda hesap yapar (sabit derinlik). Model arada “durup uzun uzun düşünemez” — tek bir token’da karmaşık bir akıl yürütmeyi sıkıştıramaz. Çözüm: modele düşünmek için token ver. “Adım adım düşünelim” deyince, model ara adımları (token olarak) üretir; her ara token, sonraki adım için ek hesap + bağlam sağlar (kendi ürettiğine geri bakar, Ders 7 self-attention). Yani CoT, sabit-derinlik kısıtını, diziyi uzatarak (test-time compute) aşar. Ayrıca “iyi düşünen” örnekleri taklit etmeye yöneltir (“imitate, ask for it”). Karpathy’nin deyişiyle: “transformers need tokens to think”.
9.15 Egzersizler
Bu ders kavramsal olduğundan, egzersizler de düşünme/deney egzersizleridir (canlı kodlama yerine). Bir API (veya açık model) varsa pratikte deneyebilirsin.
Egzersiz 1 (Base vs asistan). Bir base model (tamamlama) ile bir asistan modele (ChatGPT) aynı soruyu sor: “Türkiye’nin başkenti nedir?”. Base model’in soruyu sürdürdüğünü (belki başka sorular ürettiğini), asistanın yanıtladığını gözlemle. Aradaki farkı 4-aşamalı hatla açıkla.
Egzersiz 2 (Chain-of-thought). Zor bir aritmetik/mantık problemi seç. (a) Doğrudan sor. (b) “Adım adım düşünelim” ekleyerek sor. Ara adımların (token’ların) doğruluğu nasıl etkilediğini gözlemle — “düşünmek için token” sezgisini doğrula.
Egzersiz 3 (Self-consistency). Aynı zor soruyu 5 kez çözdür (sıcaklık \(> 0\)), cevapları topla, çoğunluk oyunu al. Tek seferlik cevaba göre güvenilirliğin arttığı durumları gözlemle. Ne zaman yardımcı olur, ne zaman olmaz?
Egzersiz 4 (Tool use / RAG). Modelin tek başına yapamayacağı bir soru kur (örn. büyük bir çarpım, veya güncel bir olay). (a) Bir araç (hesap makinesi / kod yürütücü) kullanan bir prompt tasarla. (b) İlgili bir belgeyi prompt’a koyup (RAG) modelin “getirilen bilgiden” yanıtlamasını sağla. Hallüsinasyonun azaldığını gözlemle.
Egzersiz 5 (Sonraki dersin habercisi). Tüm seri boyunca “token” kelimesini kullandık ama Ders 7’de naif bir karakter tokenizer kurmuştuk. Gerçek GPT’ler farklı tokenize eder. (a) “strawberry” kelimesinde kaç tane ‘r’ var? Bir LLM’e sor — neden bazen yanlış sayar? (İpucu: model karakterleri değil, token’ları görür; “strawberry” birkaç token’a bölünür, tek tek harfleri göremez.) (b) Metni token’lara bölmenin daha iyi bir yolu ne olabilir (karakter de değil, kelime de değil)? Bu sorular, Ders 9’da (GPT Tokenizer / BPE) gerçek tokenizer’ı sıfırdan kurmayı motive eder.
9.16 Sonraki Ders İçin Hazırlık
Ders 9: GPT Tokenizer’ı İnşa Etmek (BPE) — Andrej Karpathy
Ders 8 kavramsaldı; Ders 9 koda döner. Tüm seride “token” dedik ama Ders 7’de en naif (karakter) tokenizer’ı kurmuştuk. Ders 9’da gerçek GPT’lerin kullandığı tokenizer’ı — byte-pair encoding (BPE) — sıfırdan kuracağız: Unicode/UTF-8 byte’larından başlayıp en sık çiftleri birleştirerek bir sözlük inşa etmek. Ayrıca tiktoken, sentencepiece gibi production tokenizer’larını ve LLM’lerin tuhaf davranışlarının (neden “strawberry”deki r’leri sayamaz) kökenini göreceğiz.
Ana konular:
- Unicode kod noktaları, UTF-8 byte kodlaması.
- BPE algoritması: en sık byte/token çiftini birleştir (train/encode/decode).
- GPT-2/GPT-4 regex split, tiktoken, sentencepiece, özel token’lar, tokenizer tuhaflıkları.
UyarıDers 9 Öncesi Yapılacak
- Egzersizleri çöz — özellikle 5 (“strawberry” tuhaflığı).
- “GPT mimariyi Ders 7’de, asistan hattını Ders 8’de gördük; şimdi girdi-tokenizasyonu” çerçevesini hatırla.
- Not: Ders 9 tekrar canlı-kodlama; tokenizer ağ-dışı bir adım (autograd yok).
9.17 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| Dört aşamalı hat | pretraining → SFT → ödül modeli → RLHF (sırayla, her biri hizalama ekler) | 0m53 |
| Pretraining | Devasa metinde next-token; compute’un \(\approx\%99\)’u; çıktı = base model | 1m59 |
| Base model | Güçlü genel bilgi ama asistan değil; soruyu sürdürür, yanıtlamaz | 8m06 |
| SFT | Az ama kaliteli (prompt, yanıt) çiftiyle ince ayar; asistan formatı | 11m32 |
| Ödül modeli | İnsan sıralamalarından “iyi yanıt” skoru öğrenir (yargılamak kolay) | 12m59 |
| RLHF (PPO) | Ödül modeline göre optimize; ChatGPT böyle. Yan etki: mode collapse | 15m22 |
| Mode collapse | RLHF modelleri çeşitliliği kaybeder (entropi düşer); base daha çeşitli | 18m46 |
| Token simülatörü | LLM iç monolog çalıştırmaz; “düşünmek için token” gerekir | 23m13 |
| Chain-of-thought | “Adım adım düşün” → ara token = ara hesap; Sistem 2’yi dışarıdan kur | 24m57 |
| Tool use / RAG | Araç (hesap/kod) + getirilen belge ile modelin eksiğini tamamla | ≈31m |
| Limitler | Hallüsinasyon, jailbreak/injection, “ne bilmediğini bilmeme” | 35m15 |
9.18 ML Builder Bağlantıları
İpucu8 köprü — State of GPT
- Pretraining (next-token) → Ders 2-7’nin tam yaptığı (cross-entropy), dev ölçekte. İleriye: scaling laws (Ders 10).
- Base model → Ders 7 GPT’nin dev hâli. İleriye: LLaMA/Mistral açık base modelleri, kendi SFT/LoRA temelin.
- SFT → Ders 7 eğitiminin asistan-veri hâli. İleriye: LoRA/QLoRA ile erişilebilir ince ayar.
- Ödül modeli → Stat 110 Bradley-Terry tercih. İleriye: DPO (ödül modelini atlar), RLAIF.
- RLHF (PPO) → pekiştirmeli öğrenme + yargı-üretim asimetrisi. İleriye: Constitutional AI, modern hizalama.
- Token simülatörü / tokens-to-think → Ders 7 sabit-derinlik hesap. İleriye: reasoning modelleri, test-time compute.
- CoT / self-consistency / ToT → Ders 7 autoregressive + arama. İleriye: o1/o3 reasoning, ReAct ajanları.
- Tool use / RAG / constraint → LLM uygulama mimarisi. İleriye: MCP, LangChain, agent framework’leri, OWASP Top 10 for LLMs.
9.19 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders/konuşma için referans verdiği kaynaklar:
- ChatGPT: openai.com/chatgpt — konuşmanın merkezindeki asistan.
- Lambda (hesaplama): lambda.ai — GPU bulut sağlayıcı (eğitim altyapısı bağlamında).
- (Kavramsal temel: OpenAI InstructGPT makalesi — dört aşamalı hat bu çalışmadan gelir.)
ÖnemliBu dersten tek bir şey alıp gideceksen
Ham bir pretrain edilmiş GPT (Ders 7), internet metnini taklit eden bir “token simülatörü”dür — başarmayı değil taklit etmeyi ister. Onu yardımcı bir asistana çevirmek insan örnekleri (SFT) + insan tercihleri (ödül modeli + RLHF) ile ek eğitim gerektirir; etkili kullanmak ise modele “düşünmek için token” verip (chain-of-thought) istediğin davranışı açıkça istemekten geçer.