flowchart LR
P["Top-down felsefe<br/>önce çalıştır, sonra anla"] --> A["veri<br/>(kuş + orman fotoğrafları)"]
A --> B["DataBlock<br/>5 soru: blocks · get_items · splitter · get_y · item_tfms"]
B --> C["DataLoaders (dls)<br/>batch · validation set"]
C --> D["Learner<br/>vision_learner + pretrained resnet18"]
D --> E["fine_tune<br/>transfer learning"]
E --> F["predict<br/>kuş / orman"]
style P fill:#cffafe,stroke:#0891b2,stroke-width:2px
style B fill:#cffafe,stroke:#0891b2,stroke-width:2px
style D fill:#cffafe,stroke:#0891b2,stroke-width:2px
style F fill:#ffe4e6,stroke:#e11d48,stroke-width:3px
2 Başlangıç — İlk Modelini Eğit (Is it a bird?)
Önce çalıştır, sonra anla: DuckDuckGo’dan kuş fotoğrafı indir, DataBlock ile veriyi modele sok, pretrained resnet18’i fine_tune et ve iki dakikada bir kuş sınıflandırıcısı kur
NotBölüm bilgisi
- Howard’ın videosu: YouTube — Lesson 1: Getting started (~83 dk)
- Seri: Practical Deep Learning for Coders — Part 1, Ders 1
- Hoca: Jeremy Howard
- Kurs sayfası: course.fast.ai — Lesson 1
- Notebook: course22 — Is it a bird?
- Okuma süresi: ~30 dk
2.1 Bu Derste Ne Var?
fast.ai serisinin ilk dersi, diğer her kurstan farklı bir yerden başlar: önce çalışan bir model eğitiriz, kavramları sonra geriye açarız. Howard 2015’te “bir fotoğraf kuş mu?” sorusunu yanıtlamanın imkânsız sayıldığı bir xkcd şakasını gösterir — sonra tam o sistemi dizüstü bilgisayarında iki dakikada kurar. Ders, derin öğrenmenin artık matematik veya devasa donanım gerektirmeden erişilebilir olduğunu çalıştırarak kanıtlar.
Üç temel fikir:
- Top-down öğrenme — sporu nasıl öğreniyorsak (önce oyna, sonra teoriyi derinleştir) derin öğrenmeyi de öyle öğreniriz.
- fastai / DataBlock / Learner — veriyi modele sokan ve modeli eğiten yüksek-seviye araçlar; “matrix multiplication ve gradient” pratikte nadiren karşımıza çıkar.
- Pretrained model + fine_tune — sıfırdan değil, ImageNet üstünde eğitilmiş bir ağdan başlar, onu kendi verimize uyarlarız (transfer learning).
“We’re now going to build exactly that system for free in about two minutes!” — Howard, 1:06
Şekil 28.1 bu üç fikri, veriden tahmine uzanan tek bir akışta birleştirir.
İpucuBuilder Notu — Top-down ↔︎ Bottom-up
- Geriye (Karpathy): Bu dersin “büyü” gibi görünen
vision_learner/fine_tunesatırlarının altında, Karpathy serisinde sıfırdan kurduğun micrograd → makemore çekirdeği durur. fast.ai top-down, Karpathy bottom-up — aynı madalyonun iki yüzü. Howard bunu kendisi söyler: Tesla’da AI ekibine katılan herkesin bu kursu yapması beklenir (21:59). - Geriye (6.S191): “Görüntü = sayı tensörü” fikri 6.S191 Ders 3’teki (CNN) girdi temsiliyle aynıdır.
- İleriye (production): Ders sonunda model
learn.predict()ile tek satırda çalışır hale gelir; Hugging Face Spaces + Gradio ile web uygulamasına dönüşür (Ders 2). - Tek cümle: Doğru araçlarla, önce çalıştır-sonra-anla yaklaşımı derin öğrenmeyi herkese açar.
2.2 xkcd 2015: İmkânsız Şakadan Trivial’e
Howard derse 2015 sonundan bir xkcd çizgi-romanıyla başlar. Şakanın özü: bir kullanıcı “fotoğrafın bir kuş içerip içermediğini kontrol eden bir uygulama” ister; mühendis “bunun için bir araştırma ekibi ve beş yıl gerekir” der. 2015’te bir fotoğrafın kuş içerip içermediğini anlamak neredeyse imkânsız kabul ediliyordu — o kadar ki bir şakanın temeli olabiliyordu.
Howard’ın iddiası şu: aradan geçen sürede bu, imkânsızdan trivial’e dönüştü. Aynı sistemi birkaç dakikada, ücretsiz, bir dizüstü bilgisayarda kuracak.
“In 2015 the idea of checking whether something is a photo of a bird was considered nearly impossible. So impossible, it was the basic idea of a joke.” — Howard, 0:51
Bu çerçeve dersin tonunu belirler: teoriyle değil, çalışan bir sonuçla başlarız.
İpucuBuilder Notu — İmkânsızdan Trivial’e
- İleriye (bu dersin kanıtı): 2015’te imkânsız sayılan “kuş mu?” problemi, bu dersin sonunda predict bölümünde tek satırlık
learn.predict()ile çözülür — imkânsızdan trivial’e geçişin kanıtı dersin kendisidir. - Geriye (alan tarihi): 2015 öncesi bu problem elle öznitelik mühendisliği gerektiriyordu; trivial’e dönüşmesini sağlayan tam olarak modelin kendi öğrendiği öznitelikler.
- Tek cümle: Bir şakanın temeli olan problem, doğru araçlarla bir dizüstü demosu hâline geldi.
2.3 “Önce Çalıştır” — Kuşu İki Dakikada Eğitelim
Howard hiç beklemeden kodu çalıştırır. Önce DuckDuckGo’dan kuş fotoğrafları aranır ve bir tanesi indirilip gösterilir — her adımda veriye bakmak bir alışkanlıktır:
from duckduckgo_search import DDGS
from fastcore.all import *
def search_images(keywords, max_images=200):
# keyword icin gorsel URL listesi dondur
return L(DDGS().images(keywords, max_results=max_images)).itemgot('image')
# Once tek bir kus fotografi bul ve indir, gozunle dogrula
urls = search_images('bird photos', max_images=1)
from fastdownload import download_url
download_url(urls[0], 'bird.jpg', show_progress=False)
from fastai.vision.all import *
Image.open('bird.jpg').to_thumb(256,256)Sonra iki sınıf için (kuş ve orman) yüzlerce fotoğraf indirilir ve küçültülür. “Kuş olmayan” diye arama yapılamayacağı için Howard zıt sınıf olarak “orman”ı seçer:
searches = 'forest','bird'
path = Path('bird_or_not')
for o in searches:
dest = (path/o)
dest.mkdir(exist_ok=True, parents=True)
download_images(dest, urls=search_images(f'{o} photo'))
# Buyuk gorsel gerekmez; 400px GPU icin yeterli ve hizli
resize_images(path/o, max_size=400, dest=path/o)“You can’t really search Google images or DuckDuckGo images for ‘not a bird’, it just doesn’t work that way. So I just decided to use forest.” — Howard, 3:31
İpucuBuilder Notu — Veri Toplama Döngüsü
- İleriye (veri toplama): Gerçek projelerde veri nadiren hazır gelir. Buradaki “ara-indir-temizle” döngüsü, production ML pipeline’ının minyatürüdür.
- Top-down disiplini: Henüz
DataBlock’un ne olduğunu bilmiyoruz — önemli değil. Önce çalışıyor, kavram DataBlock bölümünde geri açılacak.
2.4 Görüntüler Sayılardan Oluşur
Modelin fotoğrafı “görmesi” için onu sayıya çevirmek gerekir — ve şansa bakın ki görüntüler zaten sayılardan oluşur. Her piksel kırmızı, yeşil ve mavi için 0–255 arası bir parlaklık değeri taşır. Howard örnek bir fotoğrafın gaga bölgesinde kırmızı 251, yeşil 48, mavi 21 olduğunu gösterir.
Böylece tanıdığımız bir resim, aslında bir sayı tensörüdür: örnek görüntü \(256 \times 171 \times 3 \approx 131.000\) sayı. Bu tensör modelin girdisidir; çıktısı “kuş” veya “orman” olasılığıdır.
Girdi → model → çıktı akışı şöyledir: piksel tensörü (256 × 171 × 3) → sinir ağı → olasılık (kuş / orman). Şekil 2.2 bu tensörü R/G/B kanallarına ayırarak somutlaştırır.
“Computers need numbers to work with, but luckily images are made of numbers.” — Howard, 2:04
Kod
# Sentetik 16x24x3 sahne + Howard gaga pikseli (R=251, G=48, B=21)
img, beak_rc = synthetic_rgb_patch()
br, bc = beak_rc
H, W = img.shape[:2]
fig, axes = plt.subplots(1, 4, figsize=(13.5, 4.0))
fig.patch.set_facecolor(COL_WHITE)
# Piksel ızgarasını gösteren ortak çizici
def show_panel(ax, data, title, cmap, title_color):
if cmap is None:
ax.imshow(data, interpolation="nearest")
else:
ax.imshow(data, cmap=cmap, interpolation="nearest", vmin=0, vmax=255)
ax.set_title(title, color=title_color, fontsize=11, weight="bold", pad=8)
# küçük görüntü -> ince piksel ızgarası
ax.set_xticks(np.arange(-0.5, W, 1), minor=True)
ax.set_yticks(np.arange(-0.5, H, 1), minor=True)
ax.grid(which="minor", color=COL_SLATE_400, linewidth=0.4, alpha=0.45)
ax.tick_params(which="both", length=0, labelleft=False, labelbottom=False)
for spine in ax.spines.values():
spine.set_color(COL_SLATE_400)
spine.set_linewidth(0.8)
# (a) Tam RGB görüntü — başlık cyan
show_panel(axes[0], img, "görüntü (H×W×3)", None, COL_CYAN_800)
# (b) R kanalı — başlık rose (accent)
show_panel(axes[1], img[:, :, 0], "R kanalı", "Reds", COL_ACCENT)
# (c) G kanalı — başlık cyan
show_panel(axes[2], img[:, :, 1], "G kanalı", "Greens", COL_CYAN_700)
# (d) B kanalı — başlık cyan
show_panel(axes[3], img[:, :, 2], "B kanalı", "Blues", COL_PRIMARY)
# Gaga pikseline anotasyon oku (tam RGB panelinde)
ax0 = axes[0]
ax0.annotate(
"R=251, G=48, B=21",
xy=(bc, br), xytext=(bc - 11, br - 6.5),
fontsize=9.5, color=COL_TEXT, weight="bold",
ha="left", va="center",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_PRIMARY, lw=1.4),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.8,
shrinkA=2, shrinkB=2),
zorder=10,
)
# Alt-not: Howard'ın gerçek örneği
fig.text(0.5, -0.02,
"Howard örneği: 256×171×3 ≈ 131.000 sayı",
ha="center", va="top", fontsize=10, color=COL_CYAN_700, weight="bold")
fig.tight_layout(rect=[0, 0.02, 1, 1])
plt.show()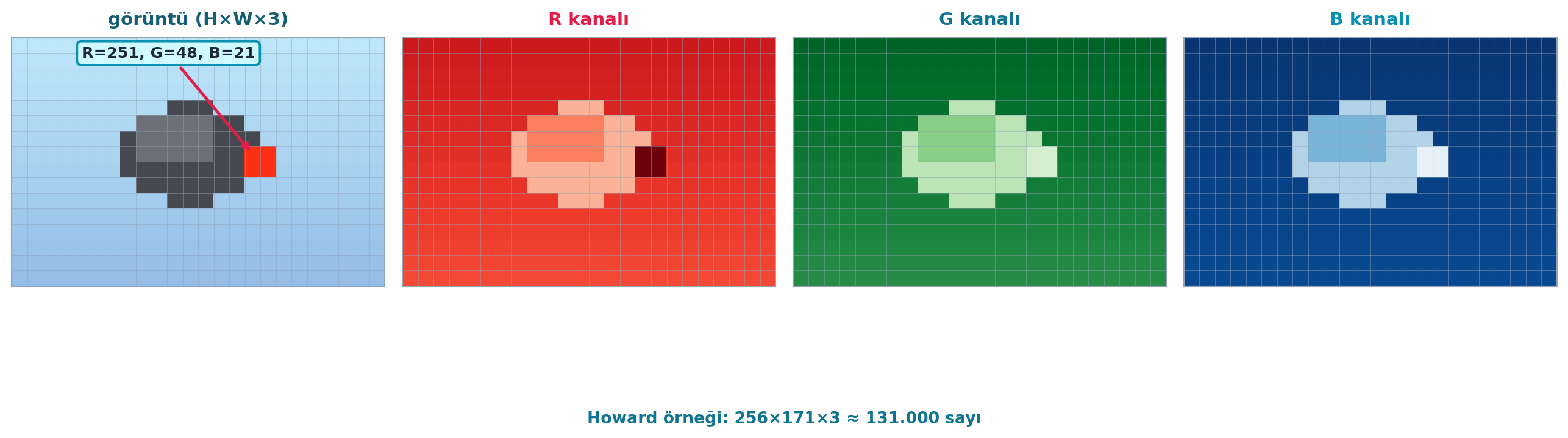
İpucuBuilder Notu — Her Şey Tensör
- Geriye (6.S191 / 18.06): Bu çok boyutlu sayı dizisi bir tensördür. CNN’in girdi temsili (6.S191 Ders 3) ve matris-vektör yapısı (18.06) tam buradan başlar.
- İleriye: “Her şey sayıdır” ilkesi ses (spektrogram), zaman serisi ve metin (token) için de geçerlidir — Ses bölümünde göreceğiz.
2.5 Sonuç: Bu Bir Kuş
Model birkaç saniyede eğitilir. Başta indirdiğimiz kuş fotoğrafını ona sorduğumuzda cevap nettir:
is_bird,_,probs = learn.predict(PILImage.create('bird.jpg'))
print(f"This is a: {is_bird}.")
print(f"Probability it's a bird: {probs[0]:.4f}")
# This is a: bird.
# Probability it's a bird: 1.0000Howard’ın vurgusu: bütün bu süreç 30 saniyenin altında sürdü ve 2015’te imkânsız sayılan şeyi tamamladı.
“Something that has gone from so impossible it’s a joke to so easy that I can run it on my laptop computer in about two minutes. It didn’t take any math, didn’t take more than my laptop computer. It’s pretty accessible in fact.” — Howard, 6:23
Şekil 2.3 baştan sona bu akışı özetler: piksel tensöründen pretrained resnet18’e, oradan kuş/orman olasılığına.
Kod
fig = plt.figure(figsize=(11.0, 3.6))
fig.patch.set_facecolor(COL_WHITE)
# --- Sol bölge: uçtan uca akış kutuları (tek ax, axis off) ---
ax = fig.add_axes([0.0, 0.0, 0.74, 1.0])
ax.set_xlim(0, 10)
ax.set_ylim(0, 4)
ax.axis("off")
yc = 2.0
# Kutu 1: piksel tensörü (cyan, bilgi kutusu)
boxed_node(ax, 1.55, yc, 2.7, 1.7,
"piksel tensörü\n256 × 171 × 3",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11, lw=2.2)
# Kutu 2: sinir ağı / resnet18 (cyan, bilgi kutusu)
boxed_node(ax, 5.0, yc, 3.0, 1.7,
"sinir ağı\nresnet18\n(pretrained)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11, lw=2.2)
# Oklar
arrow_between(ax, (3.0, yc), (3.45, yc), color=COL_PRIMARY, lw=2.4)
arrow_between(ax, (6.55, yc), (7.35, yc), color=COL_ACCENT, lw=2.4)
# "predict" / "softmax" etiketleri sağ ok çevresinde
ax.text(6.95, yc + 0.45, "predict", ha="center", va="bottom",
fontsize=9.5, color=COL_CYAN_700, weight="bold", style="italic")
ax.text(6.95, yc - 0.45, "softmax", ha="center", va="top",
fontsize=8.5, color=COL_SLATE_400, weight="bold")
# --- Sağ bölge: olasılık çubukları (inset ax) ---
axp = fig.add_axes([0.78, 0.24, 0.20, 0.52])
prob_bars(axp, ["kuş", "orman"], [1.0, 0.0], fmt="{:.4f}")
axp.set_title("olasılık", fontsize=10, color=COL_TEXT, weight="bold", pad=6)
plt.show()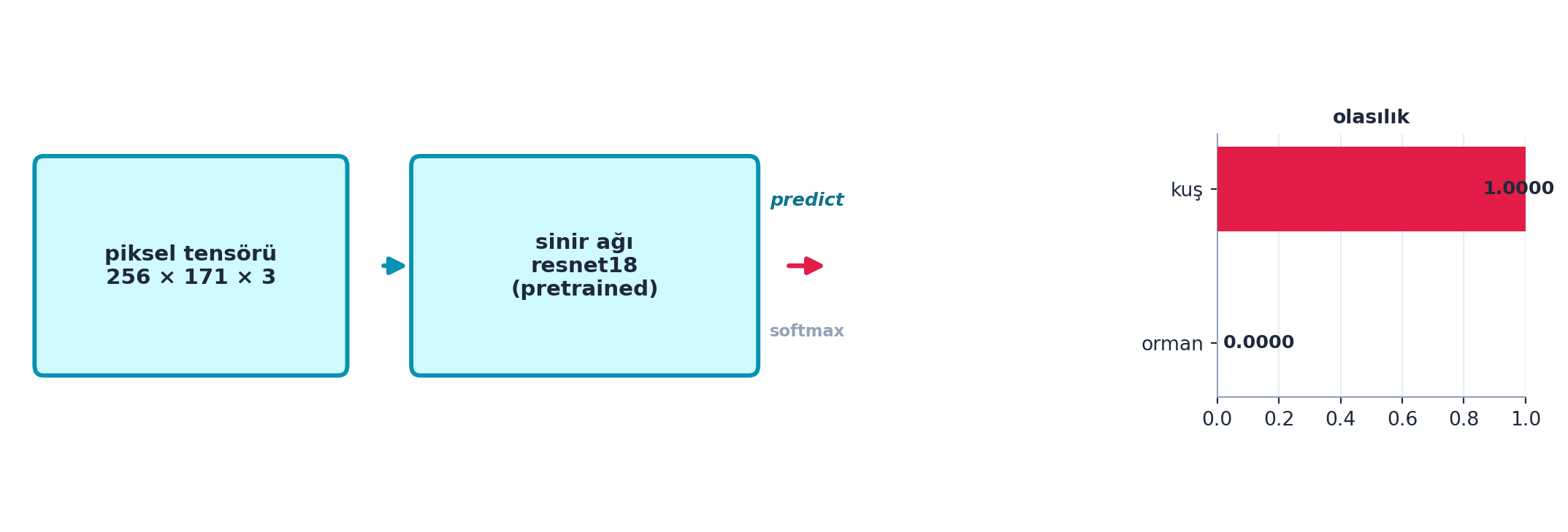
predict çıktısı softmax üzerinden okunur; burada kuş 1.0000.
İpucuBuilder Notu — predict ve Olasılık Dağılımı
- İleriye (production):
learn.predict()modelin deploy yüzüdür — üç şey döndürür: tahmin (string), tahmin indeksi (integer) ve olasılıklar. Bunu predict ve Deploy bölümünde deploy bağlamında tekrar göreceğiz. - Geriye (Stat 110): Çıktı bir olasılık dağılımıdır (kuş vs orman); softmax’ın ürettiği bu olasılıklar Stat 110’daki kategorik dağılımla aynı şeydir.
2.6 Derin Öğrenme Bugün Ne Yapabiliyor?
Howard alanın ne kadar hızlı ilerlediğini birkaç örnekle gösterir. DALL·E 2 ve MidJourney metin girdisinden yeni görüntüler üretir; bir kullanıcı arkadaşlarının Twitter biyografilerini girip portreler oluşturmuştur. Google’ın PaLM dil modeli ise bir soruyu yanıtlamakla kalmaz, akıl yürütmesini açıklar — hatta bir esprinin neden komik olduğunu anlatabilir.
“When I look at these I still get pretty blown away that this is a computer algorithm using nothing but this text input to generate these arbitrary pictures.” — Howard, 8:22
Howard bunun etik ve pratik sonuçları olduğunu da ekler ve Rachel Thomas’ın veri etiği dersine (ethics.fast.ai) yönlendirir.
İpucuBuilder Notu — Diffusion’a Giden Yol
- İleriye (bu kursun varış noktası): DALL·E ve MidJourney’in arkasındaki teknoloji diffusion’dır. Bu serinin Part 2’si (Ders 9–25) tam olarak Stable Diffusion’ı sıfırdan kurar. Bugün “büyü” gibi görünen şey, dersin sonunda anlayacağın bir mekanizmaya dönüşecek.
- Geriye (6.S191): Üretken modeller (VAE, GAN, diffusion) 6.S191 Ders 4’te kavramsal olarak işlendi; fast.ai bunları kodla kuracak.
2.7 Kurs Nasıl İşlenecek — Top-Down Öğrenme
Howard’ın pedagojisi kasıtlı olarak terstir: derse lineer cebir ve calculus’un derinlemesine gözden geçirilmesiyle değil, doğrudan bir model eğiterek başladık. Gerekçesi eğitim araştırmalarına dayanır — insanlar bir bağlam içinde çok daha iyi öğrenir.
“We started by training a model. We didn’t start by doing an in-depth review of linear algebra and calculus.” — Howard, 15:39
Analojisi spordur: kimseye önce yıllarca fizik ve fizyoloji öğretmeyiz; önce oyunun tamamını gösterir, basit versiyonlarını oynatır, sonra giderek daha fazla parçayı bir araya getiririz.
“The way most people learn effectively is from the way we teach sports, where we show you a whole game of sports. We show you how much fun it is. You go and start playing sports, simple versions of them, and then you gradually put more and more pieces together.” — Howard, 16:24
Derinlik gelecek — ama ihtiyaç duydukça. Önce model kurup deploy etmekte çok iyi olacak, “neden” ve “nasıl”ı gerektikçe öğreneceğiz.
“First you’ll learn to be very very good at actually building and deploying models. And you will learn why and how things work as you need, to get to the next level.” — Howard, 17:01
İpucuBuilder Notu — fast.ai ↔︎ Karpathy Yön Zıtlığı
- Geriye (Karpathy — yön zıtlığı): Karpathy serisi tam tersini yapar: önce sıfırdan kurar (bottom-up), soyutlamaya en son varır. İki yaklaşım çelişmez, tamamlar — fast.ai sana “ne mümkün”ü hızla gösterir, Karpathy “altında ne var”ı kazır. İkisini birlikte yapan, hem hızlı üretir hem derinlemesine anlar.
- PhD uyarısı: Howard, teknik eğitim almış kişilerin “her şeyi baştan anlamak” isteyeceğini, bunun bu yöntemde rahatsız edici olacağını söyler — “just do your best to go along with it” (17:10).
2.8 Neden Artık Yapabiliyoruz? 2012 vs Sinir Ağları
Howard 2015 öncesine bakar. 2012’de görüntü tanıma şöyle yapılıyordu: Stanford’daki “computational pathologist” projesi, meme kanseri sağkalımını tahmin etmek için matematikçi, bilgisayar bilimci ve patologlardan oluşan büyük bir ekibin elle binlerce öznitelik (epitel çekirdek komşulukları gibi) tasarlamasını gerektirdi. Sonra bu öznitelikler bir lojistik regresyona beslendi.
“This project took years, and a lot of people, and a lot of code, and a lot of math.” — Howard, 23:48
Sinir ağlarının farkı tam buradadır: öznitelikleri bizim kurmamızı gerektirmezler, kendileri öğrenirler.
“Neural networks don’t require us to build these features. They build them for us! We don’t give it features, we ask it to learn features.” — Howard, 24:06
Şekil 2.4 bu iki yaklaşımı yan yana koyar.
Kod
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11, 5.4))
# --- SOL PANEL: 2012 elle öznitelik mühendisliği (nötr/gri tonlar) ---
ax_l.set_title("2012: elle öznitelik mühendisliği",
fontsize=12.5, color=COL_TEXT, weight="bold", pad=12)
ax_l.set_xlim(0, 10); ax_l.set_ylim(0, 10); ax_l.axis("off")
gx = 5.0
y_steps = [8.6, 6.4, 4.2, 2.0]
labels_l = [
"ham görüntü",
"elle tasarlanan öznitelikler\n(yıllar, ekip)",
"lojistik regresyon",
"tahmin",
]
bw, bh = 5.4, 1.5
for y, txt in zip(y_steps, labels_l):
boxed_node(ax_l, gx, y, bw, bh, txt,
fc=COL_SLATE_300, ec=COL_SLATE_400, tc=COL_TEXT,
fontsize=10.5, lw=2.0)
for y0, y1 in zip(y_steps[:-1], y_steps[1:]):
arrow_between(ax_l, (gx, y0), (gx, y1), color=COL_SLATE_400, lw=2.0)
ax_l.text(gx, 0.55, "yavaş, çok emek", ha="center", va="center",
fontsize=11, color=COL_SLATE_400, style="italic", weight="bold")
# --- SAĞ PANEL: Sinir ağı öğrenilen öznitelikler (canlı cyan + rose) ---
ax_r.set_title("Sinir ağı: öğrenilen öznitelikler",
fontsize=12.5, color=COL_CYAN_700, weight="bold", pad=12)
ax_r.set_xlim(0, 10); ax_r.set_ylim(0, 10); ax_r.axis("off")
rx = 5.0
y_steps_r = [8.6, 5.4, 2.2]
labels_r = [
"ham görüntü",
"öğrenilen öznitelikler\n(ağ kendi bulur)",
"tahmin",
]
fcs_r = [COL_BG, COL_BG_ROSE, COL_BG]
ecs_r = [COL_PRIMARY, COL_ACCENT, COL_PRIMARY]
for y, txt, fc, ec in zip(y_steps_r, labels_r, fcs_r, ecs_r):
boxed_node(ax_r, rx, y, bw, bh, txt,
fc=fc, ec=ec, tc=COL_TEXT,
fontsize=10.5, lw=2.2)
for y0, y1 in zip(y_steps_r[:-1], y_steps_r[1:]):
arrow_between(ax_r, (rx, y0), (rx, y1), color=COL_PRIMARY, lw=2.2)
ax_r.text(rx, 0.55, "öznitelikleri model öğrenir", ha="center", va="center",
fontsize=11, color=COL_ACCENT, style="italic", weight="bold")
fig.tight_layout()
plt.show()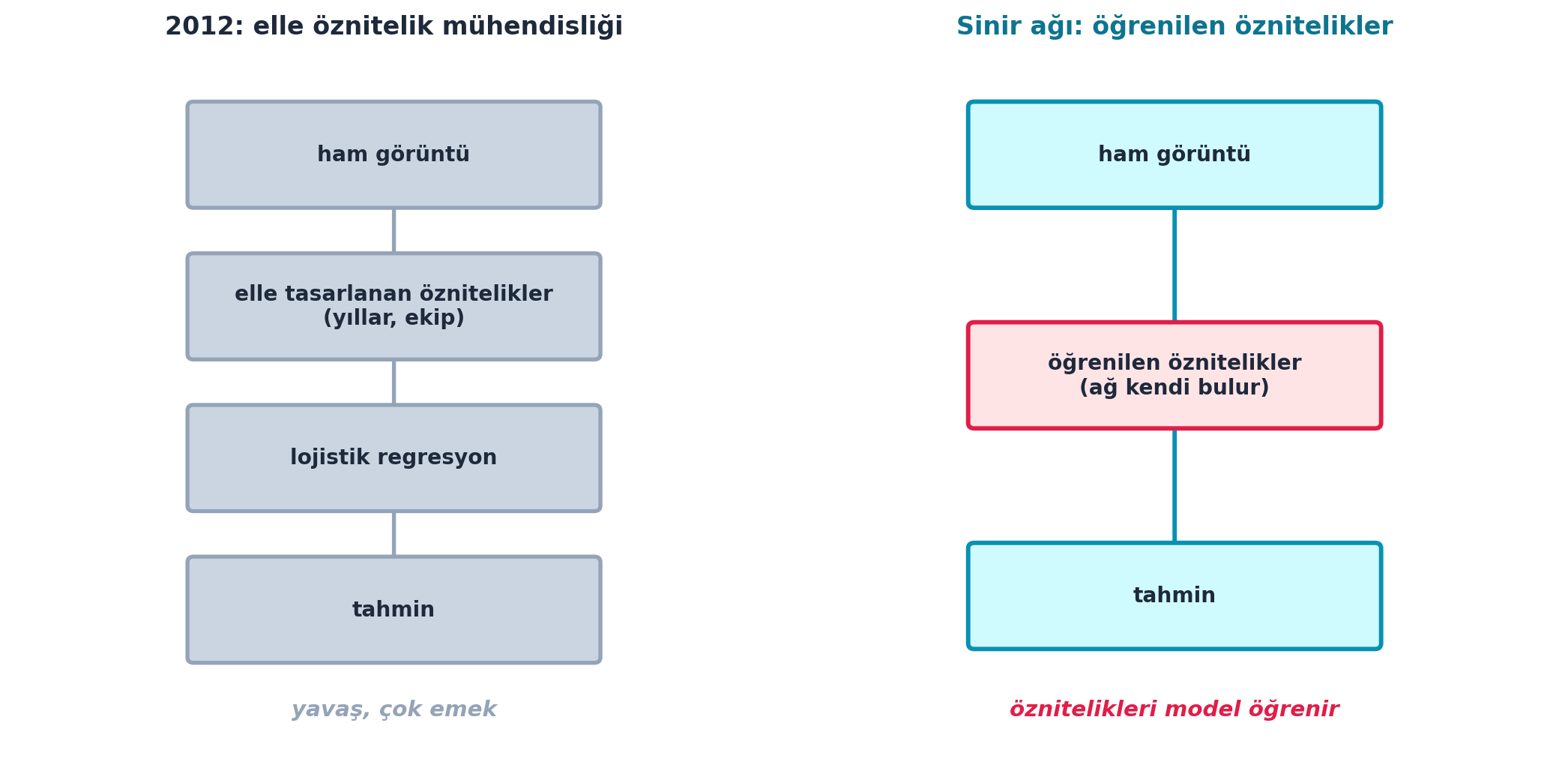
İpucuBuilder Notu — Elle vs Öğrenilen Öznitelik
- Geriye (klasik ML): 2012 yaklaşımı = elle öznitelik mühendisliği + sığ model. Bu serinin Part 1 Ders 6’sında (random forest) hâlâ güçlü olan bu klasik yolu göreceğiz — ama farkı anlamak için.
- İleriye: “Öznitelikleri model öğrensin” fikri, modern temel modellerin (foundation models) tüm temelidir.
2.9 Bir Sinir Ağı Ne Öğrenir?
Peki ağ neyi öğrenir? 2013’te Matt Zeiler ve Rob Fergus eğitilmiş bir ağın içine bakıp ağırlıkların resmini çizdiler (Visualizing and Understanding Convolutional Networks; arXiv 1311.2901, ECCV 2014). İlk katmanda dokuz öznitelik dedektörü buldular: biri çapraz kenarları, biri sarı-mavi geçişleri, biri kırmızı-yeşil geçişleri buluyordu. Bunların hiçbiri elle kodlanmadı — ağ rastgele başlayıp örneklerden kendi öğrendi.
“When Zeiler and Fergus looked inside a neural network, they looked at the actual weights in the model and they drew a picture of them. We don’t have to hand code any of these.” — Howard, 24:40
“Derin” sıfatı buradan gelir: ağ basit öznitelikleri birleştirip daha karmaşık olanları kurar. İkinci katmanda köşe, eğri ve daire bulan dedektörler; daha derinde geometrik desenler, çiçek kenarları, hatta metin bulan dedektörler oluşur.
“Deep learning is deep because we can then take these features and combine them to create more advanced features.” — Howard, 25:13
Şekil 2.5 bu hiyerarşiyi gösterir: ilk katmanda gerçek kenar dedektörleri, üstte giderek karmaşıklaşan kavramlar.
Kod
# Deterministik (engine analitik; yine de sabitle)
np.random.seed(0)
# --- Veri: Katman 1 GERCEK Gabor cekirdekleri (hesaplanmis) ---
kernels = gabor_bank(n=9, k=15) # (9, 15, 15) [-1, 1]
# --- Figur iskeleti ---
fig = plt.figure(figsize=(12.5, 5.2))
fig.patch.set_facecolor(COL_WHITE)
# 3 bolge: SOL (gercek gabor grid) | ORTA (kavramsal kutular) | SAG (kavramsal kutular)
gs = fig.add_gridspec(
3, 3,
width_ratios=[1.05, 1.0, 1.0],
left=0.04, right=0.985, top=0.86, bottom=0.10,
wspace=0.30, hspace=0.18,
)
# --- SOL BOLGE — Katman 1: 3x3 izgara GERCEK Gabor filtreleri ---
gs_left = gs[:, 0].subgridspec(3, 3, wspace=0.12, hspace=0.12)
for idx in range(9):
r, c = divmod(idx, 3)
axk = fig.add_subplot(gs_left[r, c])
axk.imshow(kernels[idx], cmap="RdBu_r", vmin=-1, vmax=1)
axk.set_xticks([])
axk.set_yticks([])
for spine in axk.spines.values():
spine.set_color(COL_SLATE_300)
spine.set_linewidth(0.8)
fig.text(0.155, 0.905, "Katman 1", ha="center", va="bottom",
fontsize=14, weight="bold", color=COL_CYAN_800)
fig.text(0.155, 0.045, "gerçek yönelimli kenar / Gabor dedektörleri",
ha="center", va="bottom", fontsize=9.5, color=COL_TEXT, style="italic")
# --- ORTA + SAG BOLGE — kavramsal kutular tek bir eksende ---
axc = fig.add_subplot(gs[:, 1:])
axc.set_xlim(0, 10)
axc.set_ylim(0, 10)
axc.axis("off")
# Katman 2 (ORTA) — kose, egri, daire
fig.text(0.475, 0.905, "Katman 2", ha="center", va="bottom",
fontsize=14, weight="bold", color=COL_CYAN_700)
l2_x = 2.0
l2_labels = ["köşe", "eğri", "daire"]
l2_y = [7.7, 5.0, 2.3]
for lbl, yy in zip(l2_labels, l2_y):
boxed_node(axc, l2_x, yy, 2.7, 1.7, lbl,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=12)
# Derin katmanlar (SAG) — geometrik desen, doku, nesne parcalari
fig.text(0.80, 0.905, "Derin katmanlar", ha="center", va="bottom",
fontsize=14, weight="bold", color=COL_ACCENT)
l3_x = 7.0
l3_labels = ["geometrik\ndesen", "doku", "nesne\nparçaları"]
l3_y = [7.7, 5.0, 2.3]
for lbl, yy in zip(l3_labels, l3_y):
boxed_node(axc, l3_x, yy, 2.9, 1.8, lbl,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ROSE_500, fontsize=11.5)
# Bolgeler arasi derinlesme oklari
for yy in l2_y:
arrow_between(axc, (-0.5, 5.0), (l2_x - 1.45, yy),
color=COL_PRIMARY, lw=1.8, mutation_scale=15, shrink=6)
for y2 in l2_y:
arrow_between(axc, (l2_x + 1.45, y2), (l3_x - 1.55, 5.0),
color=COL_ROSE_400, lw=1.6, mutation_scale=14, shrink=6)
# Genel soldan-saga derinlesme oku (alt serit)
arrow_between(axc, (-0.7, 0.55), (9.2, 0.55),
color=COL_CYAN_400, lw=2.6, mutation_scale=22, shrink=2,
connectionstyle="arc3,rad=0.0")
axc.text(4.2, 0.95, "derinleşme → basit öznitelikler birleşip karmaşıklaşır",
ha="center", va="bottom", fontsize=10.5, color=COL_CYAN_700, weight="bold")
# Baslik + alt-not
fig.suptitle("Bir Sinir Ağı Ne Öğrenir? — Zeiler-Fergus Öznitelik Hiyerarşisi",
fontsize=14.5, weight="bold", color=COL_TEXT, y=0.975)
fig.text(0.5, 0.005,
"Katman 1 gerçek Gabor filtreleri (hesaplanmış); üst katmanlar kavramsal.",
ha="center", va="bottom", fontsize=9, color=COL_SLATE_400, style="italic")
plt.show()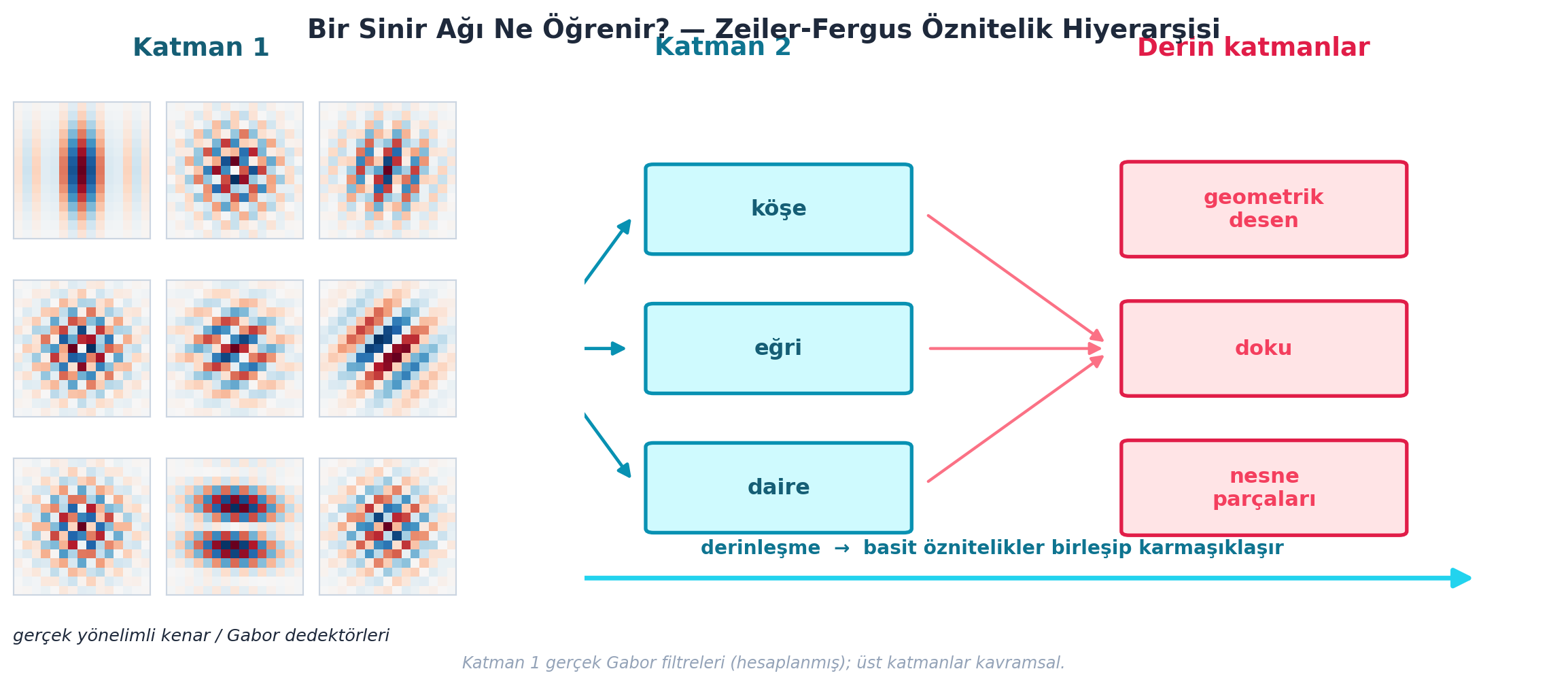
İpucuBuilder Notu — Hiyerarşi = Fonksiyon Bileşkesi
- Geriye (Calculus / 18.06): Bu hiyerarşik birleştirme, fonksiyon bileşkesidir — Calculus zincir kuralının (geri yayılım) ve katmanlı doğrusal dönüşümlerin (18.06) çalışma biçimi. Karpathy serisinde bunu satır satır kuracaksın.
- İleriye: Katman görselleştirmesi, yorumlanabilirlik (interpretability) araştırmasının başlangıç noktasıdır.
2.10 Görü Dışında: Ses, Zaman Serisi, Tablo
Howard kritik bir genelleme yapar: görüntü tabanlı algoritmalar yalnızca görüntü için değildir. Bir öğrenci, sesleri dalga formlarından görüntüye (spektrograma) çevirip aynı görüntü sınıflandırıcısıyla sınıflandırmıştır. Aynı teknik zaman serisi ve dolandırıcılık tespiti gibi problemlere de uygulanır.
“An image recognizer can also be used to classify sounds. They basically took sounds and created pictures from their waveforms.” — Howard, 27:29
Yaratıcılıkla, az sayıda temel teknik çok geniş bir alana yayılır — bu kursun ana temalarından biri budur. Şekil 2.6 bunu somutlaştırır: bir ses dalga formu spektrograma (görüntüye) dönüşür ve aynı sınıflandırıcıya girer.
Kod
# GERÇEK hesaplama — scipy.signal.spectrogram (bkz. make_spectrogram)
t, sig, f, t_spec, Sxx_dB = make_spectrogram()
fig, (ax_wave, ax_spec) = plt.subplots(1, 2, figsize=(10.0, 3.8))
# SOL panel: ses dalga formu
ax_wave.plot(t, sig, color=COL_PRIMARY, lw=0.6)
apply_style(ax_wave)
ax_wave.set_title("ses dalga formu", fontsize=11.5, weight="bold")
ax_wave.set_xlabel("zaman (s)")
ax_wave.set_ylabel("genlik")
# SAĞ panel: spektrogram (= görüntü)
pcm = ax_spec.pcolormesh(t_spec, f, Sxx_dB, shading="gouraud", cmap="magma")
ax_spec.set_title("spektrogram (= görüntü)", fontsize=11.5, weight="bold")
ax_spec.set_xlabel("zaman (s)")
ax_spec.set_ylabel("frekans (Hz)")
ax_spec.tick_params(colors=COL_TEXT)
ax_spec.title.set_color(COL_TEXT)
ax_spec.xaxis.label.set_color(COL_TEXT)
ax_spec.yaxis.label.set_color(COL_TEXT)
cbar = fig.colorbar(pcm, ax=ax_spec, fraction=0.046, pad=0.04)
cbar.set_label("güç (dB)", color=COL_TEXT, fontsize=9)
cbar.ax.tick_params(colors=COL_TEXT)
# Altta not: "aynı görüntü sınıflandırıcı"
fig.text(0.5, -0.02, "ses → spektrogram (görüntü) → aynı görüntü sınıflandırıcı",
ha="center", va="top", fontsize=10.5, weight="bold", color=COL_CYAN_700)
fig.tight_layout()
plt.show()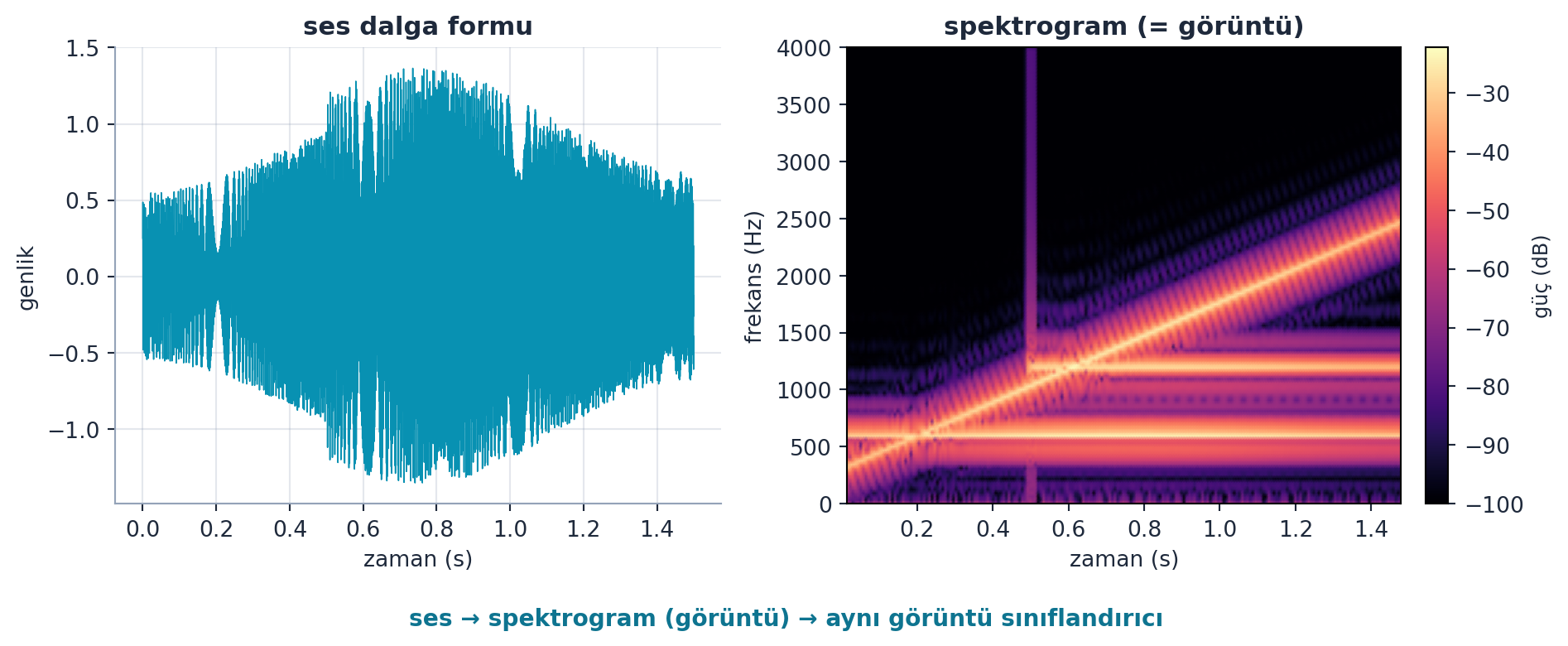
İpucuBuilder Notu — Modaliteler Arası Transfer
- Geriye (“her şey sayıdır”): Görüntü = tensör bölümündeki fikir burada meyvesini verir — ses, metin, tablo hepsi sayıya çevrilince aynı makineye girer.
- İleriye: “Bir modaliteyi başkasına çevirip mevcut güçlü modeli kullanma” stratejisi, çok-modal (multi-modal) öğrenmenin ve CLIP’in (Ders 9A) habercisidir.
2.11 Araçlar: PyTorch + fastai
Bu kurs PyTorch kullanır. Howard, TensorFlow’un araştırma dünyasında hızla gerilediğini, PyTorch’un ise büyüdüğünü belirtir — ve araştırmada kullanılan şeyin endüstrinin geleceğinin güçlü bir göstergesi olduğunu ekler.
“What people use in research is a very strong leading indicator of what’s going to happen in industry.” — Howard, 31:06
Ama PyTorch basit şeyler için bile çok kod gerektirir. Howard, AdamW optimizer’ını saf PyTorch’ta uygulayan uzun kodu, fast.ai’deki tek satırlık karşılığıyla yan yana gösterir. Fark PyTorch kötü olduğundan değil — PyTorch üstüne inşa edilecek sağlam bir temel olsun diye tasarlandığından.
“PyTorch is designed to be a strong foundation to build things on top of, like fast.ai. Particularly with deep learning: less code is better.” — Howard, 32:06
Az kod = daha az hata, daha az bakım, gömülü en iyi pratikler. Kurs derinleştikçe perdenin arkasındaki saf PyTorch giderek daha çok görünecek.
İpucuBuilder Notu — fast.ai’nin Altındaki PyTorch
- Geriye (Karpathy): Karpathy serisi tam o “saf PyTorch / sıfırdan” katmanıdır. fast.ai’nin gizlediği AdamW, autograd, nn.Module — Karpathy’de elle kurulur. fast.ai’nin
fine_tune’u altında onun kodu yatar. - İleriye: transfer learning (Learner bölümü) Howard’a göre “çok az kişinin değerinin farkında olduğu” şeydir (29:50) ve sıfırdan eğitim gereğini büyük ölçüde ortadan kaldırır.
2.12 Jupyter ve Bulut
Howard’ın slaytları aslında PowerPoint değil, Jupyter notebook’tur — kod ve prose’u birlikte tutan, endüstride ve akademide yaygın bir ortam. Çoğu öğrenci notebook’ları kendi bilgisayarında değil, bir bulut sunucusunda çalıştırır.
“Most people, at least most students, run Jupyter notebooks not on their own computers, but on a cloud server.” — Howard, 34:30
Howard örnek olarak Kaggle’ı kullanır: ücretsiz bulut notebook sunucusu + GPU. Bir hücrede ! ile başlayan satırlar Python değil, bash kabuk komutudur (örneğin !pip install -Uqq fastai en güncel sürümü kurar).
“Sometimes you’ll see me use cells with an exclamation mark at the start. That’s not Python, that’s a bash shell command.” — Howard, 37:46
İpucuBuilder Notu — Reproducibility Disiplini
- İleriye (reproducibility): Notebook’un başına daima
!pip install -Uqq fastaikoymak, “neden çalışmıyor?” forum mesajlarının çoğunu önler — sürüm sabitleme, production ML’in temel disiplinidir. - Pratik: Kaggle, internet ve GPU için telefon doğrulaması ister; notebook’un ilk hücresi bunu kontrol eder.
2.13 DataBlock — Veriyi Modele Sokmak
Howard’a göre yolculuğun başında öğrenilecek en kritik şey, mimari değil, veriyi modele nasıl soktuğundur. Bu şaşırtıcı gelebilir:
“You might be thinking we should be spending all of our time talking about neural network architectures, and matrix multiplication and gradients. The truth is very little of that comes up in practice.” — Howard, 42:04
Sebebi: derin öğrenme topluluğu, neredeyse tüm uygulamalar için işe yarayan az sayıda model tipi bulmuştur ve fast.ai çoğu zaman doğru modeli senin için seçer. Bu yüzden kursun adı Practical Deep Learning’dir — pratikte önemli olana odaklanır.
İşte önce-çalıştır bölümünde “büyü” gibi geçen DataBlock artık açılıyor. Yüzlerce projeden damıtılan beş soruyu yanıtlar:
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock), # girdi = goruntu, cikti = kategori
get_items=get_image_files, # ogeleri nasil bul
splitter=RandomSplitter(valid_pct=0.2, seed=42), # %20 dogrulama ayir
get_y=parent_label, # etiket = ust klasor adi (bird/forest)
item_tfms=[Resize(192, method='squish')] # her goruntuyu 192x192'ye getir
).dataloaders(path)
dls.show_batch(max_n=6)“This course is called practical deep learning, and so we’re going to focus on the stuff that is practically important.” — Howard, 43:14
İpucuBuilder Notu — Veri Pipeline Önceliği
- İleriye (production gerçeği): “Veri hazırlama, mimariden daha çok zaman alır” — bu, her ML mühendisinin tecrübeyle öğrendiği gerçektir. fast.ai bunu en başa koyar.
- Geriye (Karpathy / 18.06): Howard “matrix multiplication ve gradient nadiren gelir” derken pratiği kasteder; ama altında onlar vardır. Karpathy serisi ve 18.06 tam o gizli katmanı açar.
2.14 DataLoaders, Batch ve Validation Set
DataBlock’tan DataLoaders (kısaca dls) üretilir. PyTorch bunların üzerinden veriyi parça parça çeker. GPU aynı anda binlerce işlem yapabildiği için, ona aynı anda binlerce iş vermek gerekir — bu yüzden veri tek tek değil, batch (veya mini-batch) hâlinde beslenir.
“A data loader will feed the training algorithm with a batch of your images at once; in fact we don’t call it a bunch, we call it a batch or a mini batch.” — Howard, 47:24
DataBlock’taki en kritik parçalardan biri validation set’tir: modelin doğruluğunu ölçmek için ayrılan, eğitimde görülmeyen veri. fast.ai bunu o kadar önemser ki, validation set olmadan model eğitmene izin vermez.
“It’s critical that you put aside some data for testing the accuracy of your model — that’s called a validation set. It’s so critical that fast.ai won’t let you train a model without one.” — Howard, 45:26
show_batch() ile bir batch’i (görüntü + etiket) gözle doğrulayabiliriz — Howard her adımda veriye bakmayı bir alışkanlık olarak öğütler. Şekil 2.7 train/validation ayrımını ve overfitting’i şematik olarak gösterir.
Kod
# (a) Train/validation ayrımı + (b) overfitting eğrisi
fig, (ax_a, ax_b) = plt.subplots(1, 2, figsize=(10.5, 4.0),
gridspec_kw={"width_ratios": [1.0, 1.8]})
# (a) %80 train / %20 validation — yatay yığılı bar
valid_pct = 0.2
train_pct = 1.0 - valid_pct
ax_a.barh([0], [train_pct], color=COL_PRIMARY, height=0.5, zorder=3,
label="training (%80)")
ax_a.barh([0], [valid_pct], left=[train_pct], color=COL_ACCENT, height=0.5,
zorder=3, label="validation (%20)")
ax_a.text(train_pct / 2, 0, "%80", ha="center", va="center",
color=COL_WHITE, fontsize=12, weight="bold", zorder=4)
ax_a.text(train_pct + valid_pct / 2, 0, "%20", ha="center", va="center",
color=COL_WHITE, fontsize=12, weight="bold", zorder=4)
ax_a.text(train_pct, 0.42, "valid_pct=0.2", ha="center", va="bottom",
color=COL_TEXT, fontsize=10, weight="bold", zorder=4)
ax_a.set_xlim(0, 1.0)
ax_a.set_ylim(-0.6, 0.7)
ax_a.set_yticks([])
ax_a.set_xticks([0, 0.5, 1.0])
ax_a.set_xticklabels(["0", "%50", "%100"])
ax_a.set_title("Veri ayrımı: train / validation", fontsize=11)
apply_style(ax_a)
ax_a.grid(False, axis="y")
ax_a.legend(loc="lower center", frameon=False, fontsize=8.5, ncol=2,
bbox_to_anchor=(0.5, -0.28))
# (b) Overfitting eğrisi — training düşer, validation bir noktadan sonra yükselir
epochs, train_loss, valid_loss, best = overfit_curves()
ax_b.plot(epochs, train_loss, color=COL_PRIMARY, lw=2.4, label="training loss")
ax_b.plot(epochs, valid_loss, color=COL_ACCENT, lw=2.4, label="validation loss")
ax_b.axvline(best, color=COL_SLATE_400, ls=":", lw=2.0, label="en iyi nokta")
ax_b.scatter([best], [valid_loss[best]], color=COL_ACCENT, s=45, zorder=5,
edgecolor=COL_WHITE, linewidth=1.0)
ax_b.annotate("overfitting →", xy=(epochs[-1], valid_loss[-1]),
xytext=(epochs[-1] - 9, valid_loss[-1] + 0.06),
color=COL_ACCENT, fontsize=9.5, weight="bold")
ax_b.set_xlabel("epoch")
ax_b.set_ylabel("loss")
ax_b.set_title("Eğitim ilerledikçe loss", fontsize=11)
apply_style(ax_b)
ax_b.legend(loc="upper right", frameon=False, fontsize=9)
fig.suptitle("Validation ile overfitting'i yakala", fontsize=12.5,
weight="bold", color=COL_TEXT, y=1.02)
fig.tight_layout()
plt.show()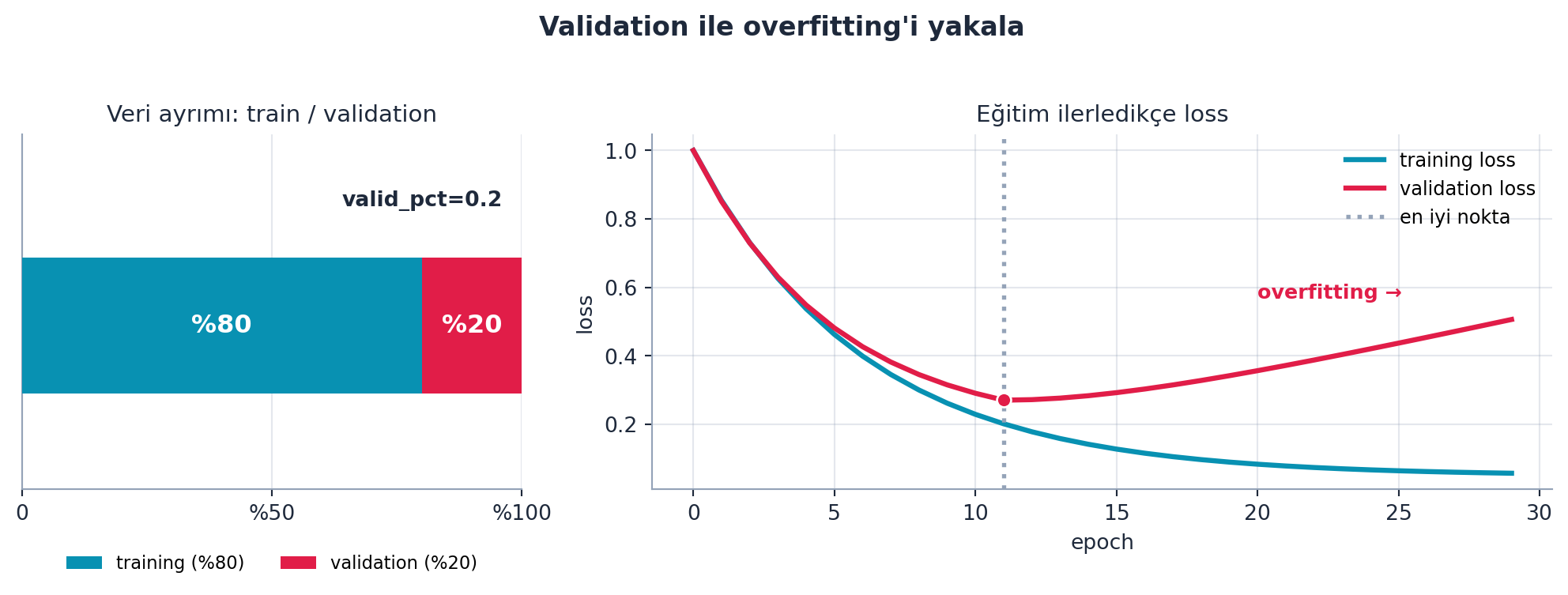
İpucuBuilder Notu — Validation ve Overfitting
- Geriye (Stat 110): validation set, aşırı öğrenmeyi (overfitting) ölçmenin yoludur; istatistikteki train/test ayrımının ML karşılığı.
valid_pct=0.2rastgele %20 örneklemdir. - İleriye: batch boyutu, GPU bellek/throughput dengesini belirler — Part 2’de (Ders 20, mixed precision) bunu derinleştireceğiz.
2.15 Learner + Pretrained Model
Şimdi modele ihtiyaç var. fast.ai’nin merkez kavramı Learner’dır: modeli (sinir ağı fonksiyonu) ve onu eğiteceğimiz veriyi tek nesnede birleştirir. Bu yüzden iki şey verilir — dls ve bir model mimarisi:
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(3)“The critical concept here in fastai is called a learner. A learner is something which combines a model and the data we use to train it with.” — Howard, 49:39
Burada asıl sihir resnet18’in pretrained (önceden eğitilmiş) olmasıdır. vision_learner çağrıldığında fast.ai resnet18.pth ağırlıklarını indirir — bu ağ daha önce ImageNet üstünde, 1000’den fazla kategoride, 1 milyondan fazla görüntüyle eğitilmiştir.
“You don’t start with a random network that can’t do anything. You actually start with a network that can do an awful lot.” — Howard, 52:26
fine_tune ise bu hazır ağırlıkları alıp, dikkatlice kontrol edilmiş bir biçimde yalnızca bizim veri setimizle ImageNet arasındaki farkı öğretir. Adı buradan gelir: ince ayar (transfer learning).
“fine_tune takes those pre-trained weights and adjusts them in a really carefully controlled way to just teach the model the differences between your data set and what it was originally trained for. That’s called fine tuning.” — Howard, 52:38
(fast.ai, Ross Wightman’ın timm kütüphanesini entegre eder — dünyanın en büyük görü modeli koleksiyonu; ama resnet ailesi çoğu iş için yeterlidir.)
Şekil 2.8, pretrained bir ağın neden sıfırdan eğitime kıyasla çok daha hızlı yüksek doğruluğa ulaştığını gösterir.
Kod
epochs, pre, scr = transfer_curves()
fig, ax = plt.subplots(figsize=(7.2, 4.4))
ax.plot(epochs, pre, "o-", color=COL_PRIMARY, linewidth=2.4, markersize=6,
label="pretrained + fine_tune")
ax.plot(epochs, scr, "s--", color=COL_ACCENT, linewidth=2.2, markersize=5,
label="sıfırdan (random)")
apply_style(ax)
ax.set_xlabel("epoch")
ax.set_ylabel("error_rate")
ax.set_ylim(0.0, 1.0)
ax.set_xlim(epochs.min() - 0.3, epochs.max() + 0.3)
ax.legend(loc="upper right", frameon=True, framealpha=0.95, edgecolor=COL_PRIMARY)
# Anotasyon: ImageNet on-egitimi -> fine_tune -> kus/orman
ax.annotate(
"ImageNet: 1M+ görüntü, 1000 sınıf\n-> fine_tune -> kuş/orman",
xy=(epochs[1], pre[1]), xytext=(2.9, 0.52),
fontsize=9.5, color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_PRIMARY, lw=1.8),
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=1.8,
connectionstyle="arc3,rad=-0.25"),
)
plt.show()
İpucuBuilder Notu — Transfer Learning’in Gücü
- Geriye (Karpathy / 6.S191):
resnet18bir CNN’dir (6.S191 Ders 3); pretrained ağırlıklar, Bir Sinir Ağı Ne Öğrenir bölümündeki öğrenilmiş öznitelik dedektörleridir. fine_tune’un altındaki gradient/backprop, Karpathy serisinde elle kurulur. - İleriye (production): Transfer learning, modern ML’in kalbidir — sıfırdan eğitim nadirdir. Aynı mantık LLM’lerde “base model + fine-tune” (Ders 4 ULMFiT, Part 2) olarak devam eder.
2.16 predict ve Deploy
Artık elimizde, kuşları ormanlardan ayırmak için ince ayar yapılmış bir Learner var. Sonuç bölümünde gördüğümüz learn.predict() tam da modelin deploy (kullanıma alma) yüzüdür. Üç şey döndürür: tahmin (string, örn. “bird”), tahmin indeksi (integer) ve her sınıfın olasılığı.
“learn.predict() is going to return whether it’s a bird or not as a string, whether it’s a bird or not as an integer, and the probability that it’s a non-bird or a bird.” — Howard, 54:14
Gerçek bir uygulamada (örneğin bir milli parkta kuş fotoğrafı doğrulayan bir app), gereken tek şey bu tek satırdır.
İpucuBuilder Notu — Deploy: Üretimin Asıl Zorluğu
- İleriye (Ders 2): Bir sonraki ders bu modeli Hugging Face Spaces + Gradio ile gerçek bir web uygulamasına dönüştürür. Eğitim değil, deploy üretimin asıl zorluğudur.
- Geriye (Stat 110): Olasılık çıktısı softmax’tan gelir; modelin güveni (calibration) Stat 110 kavramıdır.
2.17 Diğer Uygulamalar ve Kapanış
Howard, aynı birkaç satırın bilgisayarlı görünün ötesine nasıl yayıldığını gösterir. Segmentation’da her piksel, ait olduğu nesneye göre renklendirilir (yol sahnelerinde araba, bina, çit). Model yaklaşık 20 saniyede, çok az veriyle eğitilir ve adımlar tanıdıktır.
“Segmentation is where we take photos and we color in every pixel according to what it is. The steps are actually going to look quite familiar.” — Howard, 55:03
Tabular analiz (tablolardan, veritabanlarından sütun tahmini) endüstride en yaygın model türüdür ve o da daha önce gördüğümüze çok benzer: yine dataloaders, yine show_batch, sadece “hangi sütunlar kategorik, hangileri sürekli” bilgisi eklenir.
“Perhaps the most widely used kind of model used in industry is tabular analysis. It really looks very similar to what we’ve seen already.” — Howard, 58:19
Howard dersi bir çağrıyla kapatır: bir şeye başla, ilginç veya eğlenceli bulduğun bir şey yap, forumda paylaş — ve kitabın sonundaki quiz sorularını cevapla.
“Have a go at starting something. Create something you think would be fun or interesting and share it in the forum. And don’t forget to look at the quiz questions at the end of the book.” — Howard, 1:22:11
İpucuBuilder Notu — Aynı Omurga, Farklı Baş
- İleriye: Segmentation’da kullanılan U-Net, Part 2’de diffusion’ın gürültü tahmincisi olarak geri dönecek (Ders 19, 23). Aynı omurga, farklı baş.
- Geriye (Part 1 yol haritası): Tabular ve collaborative filtering Ders 5–7’de, CNN Ders 8’de derinleşir; “aynı adımlar” sözü tüm Part 1’in iskeletidir.
2.18 Bu Dersin Özeti
- Derin öğrenme, 2015’te imkânsız sayılan görüntü tanımayı bugün dakikalar içinde, matematik veya pahalı donanım olmadan erişilebilir kılar.
- fast.ai top-down öğretir: önce çalışan model, sonra “neden/nasıl” — sporu öğrenir gibi.
- Görüntüler sayı tensörleridir (H × W × 3); “her şey sayıdır” ilkesi ses, zaman serisi ve tabloyu da kapsar.
- Sinir ağları öznitelikleri kendileri öğrenir (Zeiler-Fergus); “derin”, basit özniteliklerin birleşerek karmaşıklaşmasıdır.
DataBlock→DataLoadersveriyi modele sokar; en kritik pratik beceri budur, mimari değil.- Learner model + veriyi birleştirir;
vision_learnerpretrained bir ağ (ImageNet) yükler,fine_tuneonu transfer learning ile kendi verimize uyarlar. learn.predict()modelin deploy yüzüdür; tahmin + indeks + olasılık döndürür.- Aynı birkaç satır segmentation ve tabular gibi çok farklı problemlere genişler.
ÖnemliTek Bir Cümle
Derin öğrenmenin gücü artık özel matematik veya donanımda değil, veriyi doğru biçimde modele sokup hazır bir ağı kendi problemine ince ayarlamakta yatar — ve bunu önce çalıştırıp sonra anlayarak öğrenirsin.
2.19 Kontrol Soruları
NotSoru 1: DataBlock, veriyi modele sokmak için hangi beş soruyu yanıtlar?
Cevap:
- blocks — girdi ve çıktı tipi nedir? (örn.
ImageBlock,CategoryBlock) - get_items — öğeleri nasıl buluruz? (örn.
get_image_files) - splitter — validation set’i nasıl ayırırız? (örn.
RandomSplitter(valid_pct=0.2)) - get_y — etiket nereden gelir? (örn.
parent_label= üst klasör adı) - item_tfms — her öğeye hangi dönüşüm uygulanır? (örn.
Resize(192))
Bu beş parça, yüzlerce projeden damıtılmış “veriyi doğru şekle sokma” reçetesidir.
NotSoru 2: Pretrained bir modelle başlamak, sıfırdan (rastgele) başlamaktan neden çok daha iyidir? fine_tune tam olarak ne yapar?
Cevap: Sıfırdan rastgele bir ağ hiçbir şey bilmez. Pretrained resnet18 ise ImageNet’te 1000+ kategoride, 1M+ görüntüyle eğitilmiştir — kenar, doku, şekil bulan öznitelik dedektörlerini zaten öğrenmiştir (Bir Sinir Ağı Ne Öğrenir). fine_tune bu hazır ağırlıkları alır ve dikkatlice kontrol edilmiş biçimde yalnızca kendi veri setimizle ImageNet arasındaki farkı öğretir. Sonuç: birkaç saniyede yüksek doğruluk. Bu transfer learning’dir ve Howard’a göre “çok az kişinin değerinin farkında olduğu” şeydir.
NotSoru 3: “Kuş olmayan” diye arama yapılamayınca Howard ne yaptı? Ayrıca fast.ai neden validation set olmadan eğitime izin vermez?
Cevap: Howard zıt sınıf olarak “orman” (forest) fotoğraflarını seçti — “not a bird” araması işe yaramaz, ama “bird vs forest” iki net sınıf verir. Validation set zorunluluğu ise aşırı öğrenmeyi (overfitting) yakalamak içindir: model eğitim verisini ezberleyip yeni veride başarısız olabilir. Doğruluğu yalnızca eğitimde görülmeyen veride ölçmek dürüst tek yoldur; fast.ai bunu o kadar kritik görür ki validation set olmadan eğitime izin vermez.
NotSoru 4: fast.ai’nin top-down yaklaşımı ile Karpathy’nin bottom-up yaklaşımı nasıl farklıdır? Hangisi ne zaman işe yarar?
Cevap: fast.ai top-down: önce çalışan model (vision_learner + fine_tune), kavram sonra geriye açılır — “ne mümkün”ü hızla gösterir, hızlı üretim sağlar. Karpathy bottom-up: micrograd → makemore → GPT’yi sıfırdan kurar — “altında ne var”ı kazır, derin anlama verir. İkisi çelişmez, tamamlar: fast.ai’nin fine_tune’unun altında Karpathy’nin elle kurduğu autograd/backprop yatar. Önce fast.ai ile üretmeyi öğren, sonra Karpathy ile büyüyü çöz — tam builder böyle oluşur.
2.20 Egzersizler
Egzersiz 1 (Direkt uygulama). Kendi iki sınıfını seç (örn. “kedi” vs “köpek” veya “elma” vs “armut”), notebook’u baştan çalıştır ve error_rate’i gözle.
Egzersiz 2 (İki-aşamalı). Üçüncü bir sınıf ekle (örn. üç farklı kuş türü). DataBlock ve searches’i güncelle, modelin üç sınıfta doğruluğunu kıyasla.
Egzersiz 3 (Edge case). item_tfms’de Resize(192, method='squish') yerine method='crop' ve method='pad' dene. show_batch ile görsel farkı ve error_rate etkisini karşılaştır.
Egzersiz 4 (Python ile doğrulama). learn.predict()’in döndürdüğü probs’u ve dls.vocab’ı yazdır. Hangi sınıfın hangi indekste olduğunu ve olasılıkların toplamının neden 1 olduğunu açıkla.
Egzersiz 5 (Sonraki dersin habercisi). Eğittiğin modeli nasıl bir web uygulamasına çevirebileceğini araştır (Hugging Face Spaces + Gradio). Ders 2’de bunu yapacağız.
2.21 Sonraki Ders İçin Hazırlık
Ders 2: Dağıtım (Deployment)
Ders 1’de bir model eğittik; Ders 2’de onu gerçek dünyaya çıkarıyoruz. Eğitim değil, deploy üretimin asıl zorluğudur. Veri temizleme, model export ve bir web uygulaması olarak yayınlamayı göreceğiz.
Ana konular:
- Veri temizleme ve modelin iyileştirilmesi
- Modeli dışa aktarma (
learn.export) ve yükleme - Hugging Face Spaces + Gradio ile ücretsiz web uygulaması
- GitHub Pages / JavaScript ile bağlama
UyarıDers 2 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 5).
- Kendi modelini Kaggle veya Colab’da en az bir kez baştan sona çalıştır.
- Ana cümleyi tekrar oku: “Önce çalıştır, sonra anla.”
2.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Top-down öğrenme | Önce çalışan model, teori sonra (spor analojisi) | 15:45 |
| Görüntü = tensör | H × W × 3 boyutlu, 0-255 arası sayı dizisi | 2:04 |
| DataBlock | Veriyi modele sokan 5-parçalı API | 42:04 |
| DataLoaders (dls) | Batch’leri modele besleyen iterator | 47:24 |
| Validation set | Doğruluk ölçen, eğitimde görülmeyen ayrılmış veri (zorunlu) | 45:26 |
| batch / mini-batch | GPU’ya aynı anda verilen veri grubu | 47:24 |
| Learner | Model + veriyi tek nesnede birleştiren çekirdek | 49:39 |
| vision_learner | Görü için hazır Learner üreticisi (resnet18) | 49:58 |
| Pretrained model | ImageNet’te (1M+ görüntü) eğitilmiş başlangıç ağı | 52:04 |
| fine_tune | Hazır ağırlıkları kendi veriye uyarlama (transfer learning) | 52:38 |
| predict | Tahmin + indeks + olasılık döndürür (deploy yüzü) | 54:14 |
| Segmentation | Her pikseli ait olduğu sınıfa göre etiketleme | 55:17 |
2.23 ML Builder Bağlantıları
İpucuBuilder Notu — 6 ML Köprüsü
Bu ders, modern derin öğrenme pratiğinin top-down giriş kapısıdır — köprülerin özeti:
- Tensör → görüntü, ses, metin hepsi sayı dizisidir; tüm derin öğrenmenin ortak girdi temsili (6.S191, 18.06).
- Transfer learning → LLM’lerde “base model + fine-tune” olarak devam eder; modern ML’in standart reçetesi (Ders 4 ULMFiT, Part 2).
- DataBlock disiplini → production ML’de veri pipeline’ı mimariden çok daha fazla zaman alır; en kritik pratik beceri.
- Pretrained CNN → foundation models’ın atasıdır: bir kez pahalı eğit, sayısız yerde ucuza kullan.
- Top-down + bottom-up → fast.ai (üretmeyi öğret) + Karpathy (anlamayı öğret) birlikte tam builder yapar.
- U-Net → segmentation’dan diffusion’a (Part 2 Ders 19, 23) taşınan omurga; aynı yapı, farklı baş.
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten tek bir şey alıp gideceksen: derin öğrenme artık bir büyü değil, erişilebilir bir araçtır. Onu önce çalıştır, sonra altındaki mekanizmayı kazı. fast.ai sana “ne mümkün”ü gösterir; Karpathy serisi ve Part 2 “altında ne var”ı öğretir — ikisi birlikte seni hem üreten hem anlayan bir builder yapar.