flowchart TD
subgraph CONV["convolution sıfırdan"]
KERNEL["kernel<br/>(kaydırılan pencere)"] --> APPLY["apply_kernel<br/>yama × kernel<br/>= dot product"]
APPLY --> IM2COL["im2col<br/>yamaları aç<br/>(satır = yama)"]
IM2COL --> MATMUL["tek matmul<br/>(Ders 10-12)<br/>conv = matris çarpımı"]
MATMUL --> UNFOLD["F.unfold / F.conv2d<br/>(cuDNN, GPU)"]
UNFOLD --> CONV2D["nn.Conv2d<br/>stride / padding<br/>(n+2p−k)/s + 1"]
end
subgraph AE["autoencoder"]
ENCODER["encoder<br/>conv ile küçült<br/>28 → 14 → 7"] --> BOTTLE["darboğaz<br/>(bottleneck)<br/>sıkıştırılmış kod"]
BOTTLE --> DECODER["decoder<br/>deconv ile büyüt<br/>7 → 14 → 28"]
DECODER --> RECON["reconstruction loss<br/>çıktı vs GİRDİ<br/>(self-supervised)"]
RECON --> VAE["= Stable Diffusion<br/>VAE temeli<br/>(Ders 9 / 25)"]
end
CONV2D --> ENCODER
classDef cyan fill:#cffafe,stroke:#0e7490,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
class KERNEL,APPLY,MATMUL,UNFOLD,CONV2D,ENCODER,BOTTLE,DECODER cyan;
class IM2COL,RECON,VAE rose;
18 Ders 15 — Autoencoder’lar (Autoencoders)
Temeller B’nin ilk dersi iki şey kurar: convolution’ı sıfırdan (Part 1 Ders 8’de kavramsal görmüştük; şimdi koddan) ve onun üstüne bir convolutional autoencoder — görüntüyü sıkıştırıp geri açan ağ. Önce convolution’ın ne olduğunu apply_kernel ile en yalın hâlde kurar, sonra onu im2col ile bir matris çarpımına indirger (F.unfold + matmul = F.conv2d), en sonunda bir autoencoder inşa eder: encoder conv’la küçültür, decoder deconv’la büyütür, kayıp ise çıktı ile girdinin kendisi arasındadır (reconstruction, self-supervised). Tek cümleyle: convolution kaydırılan bir matris çarpımıdır; autoencoder ise conv’la sıkıştırıp deconv’la geri açan, girdisini yeniden kurmayı öğrenen ve Stable Diffusion’ın VAE’sine giden ağdır.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 15: Autoencoders (~97 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 15
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/07_convolutions + 08_autoencoder
- Okuma süresi: ~38 dk
- 🔗 Temeller B başlar (ETAP 5): Ders 14 Temeller A’yı kapadı (matmul → mean shift → backprop → nn.Module). Ders 15 Temeller B’yi açar: convolution’ı sıfırdan kurup üstüne bir convolutional autoencoder inşa eder — Stable Diffusion’ın VAE’sinin (Ders 9 / 25) temeli.
18.1 Bu Derste Ne Var?
Temeller B’nin ilk dersi iki şey kurar: convolution’ı sıfırdan (Part 1 Ders 8’de kavramsal görmüştük; şimdi koddan) ve onun üstüne bir convolutional autoencoder — görüntüyü sıkıştırıp geri açan ağ. Bu, Stable Diffusion’ın VAE’sinin (Ders 9) temelidir.
Üç temel fikir bu dersin omurgasını kurar:
- Convolution = kaydırılan dot product — küçük bir kernel’i görüntü üzerinde gezdirip her konumda dot product; mekânsal yapıyı yakalar, az parametre kullanır (kernel ve sliding window → apply_kernel).
- im2col — convolution’ı bir matris çarpımına çevirme; yamaları “açıp” (unfold) matmul yapma; PyTorch
F.unfold/F.conv2dbunu optimize eder (im2col → F.conv2d). - Autoencoder — encoder (conv ile küçült) + decoder (deconv ile büyüt); girdiyi bir darboğazdan (bottleneck) geçirip yeniden kurmayı öğrenir (autoencoder nedir → VAE köprüsü).
“Today, let’s start by talking, before we can create a convolutional autoencoder, [about] what are convolutions.” — Howard, 0:53
Şekil 28.1 bu yolculuğu tek bir yol haritasında birleştirir: üstte convolution sıfırdan (kaydırılan kernel → dot product → im2col → tek matmul → F.unfold/F.conv2d → nn.Conv2d), altta autoencoder (encoder küçültür → darboğaz → decoder büyütür → reconstruction loss → Stable Diffusion VAE temeli).
İpucuBuilder Notu — Temeller B Başlar: Convolution + Autoencoder
- Geriye (Ders 8/9/10-12): Convolution Ders 8’de (Part 1) kavramsal; burada Ders 10-12’nin matmul’uyla sıfırdan. Autoencoder = Ders 9’un VAE’sinin temeli.
- İleriye (Ders 25 / NYU §4.J): Autoencoder, latent diffusion’ın (Ders 25) VAE’sine; NYU §4.J’de autoencoder enerji-tabanlı model olarak işlenir.
- Tek cümle: Convolution kaydırılan bir matris çarpımıdır; autoencoder ise conv’la sıkıştırıp deconv’la geri açan, VAE’ye giden ağdır.
18.2 1. Hedef: Convolutional Autoencoder
Howard hedefi koyar: bir convolutional autoencoder kurmak. Ama önce convolution’ın ne olduğunu (Part 1’de kavramsal görmüştük) koddan, “from the foundations” ruhuyla yeniden kurar. Hedefi baştan ortaya koymak, her ara adımın (apply_kernel, im2col, F.conv2d) neye hizmet ettiğini netleştirir.
“We will create a convolutional autoencoder. And in the process, we will see why [convolutions matter].” — Howard, 0:53
İpucuBuilder Notu — Hedef Önce: Neden Convolution Kuruyoruz?
- Geriye (Ders 8): Part 1 Ders 8 convolution’ı tanıttı; bu ders onu sıfırdan kodlayıp autoencoder’a bağlar.
- Sezgi: Hedefi (autoencoder) baştan koymak, “neden convolution’ı sıfırdan kuruyoruz” sorusunu yanıtlar — her ara adım bir amaca hizmet eder, “yan iş” değildir.
18.3 2. Convolution Nedir, Ne İşe Yarar?
Convolution, ağa görüntünün mekânsal yapısını söyler: yakın pikseller ilişkilidir, bir desen (kenar, köşe) görüntünün her yerinde aynıdır. Bu, Convolutional Neural Network (CNN)’in doğal olarak yakaladığı şeydir. Yalnızca görüntü değil, 1B convolution dil için de kullanılır.
“Convolutions are something that allows us to tell our neural network a little bit about [the spatial structure].” — Howard, 0:53
İpucuBuilder Notu — Inductive Bias: Mekânsal Yapı + Paylaşım
- Geriye (Ders 8): “Mekânsal yapı + parametre paylaşımı” = convolution’ın doğru inductive bias’ı; görüntü için ideal.
- Sezgi: Tam bağlı katman her pikseli bağımsız sanır; convolution ise “yakın pikseller ilişkilidir, bir kenar her yerde kenardır” bilgisini ağa gömer — bu doğru ön-yargı, daha az veriyle daha iyi genelleme demektir.
18.4 3. Kernel ve Sliding Window
Convolution bir kernel (küçük matris, örn. 3×3) kullanır. Kernel görüntü üzerinde kaydırılan bir pencere gibi gezer; her konumda kernel ile o yamanın elemanları çarpılıp toplanır — yani bir dot product.
“We’re going to slide — it’s like a sliding window — we’re going to slide our kernel over [the image].” — Howard, 5:27
Şekil 18.2 bu kayan pencereyi gösterir: aynı 3×3 kernel görüntünün üç farklı konumunda (sol-üst, orta, sağ-alt) aynı işlemi yapar — her konumda yama × kernel toplamı bir tek çıktı pikseli üretir. Aynı kernel her yerde kaydığı için bu parametre paylaşımıdır: az parametre, mekânsal yapı korunur.
Kod
from matplotlib.patches import Rectangle
# Sentetik 8×8 görüntü ızgarası (imshow zemini — şematik gösterim)
demo = E.conv_im2col_demo(n=8, k=3)
img = demo["img"]
H, W = img.shape # 8×8
k = 3 # 3×3 kernel penceresi
fig, ax = plt.subplots(figsize=(10, 5))
# ----------------------------------------------------------------------------
# Görüntü ızgarası — açık cyan tonlu imshow + hücre çizgileri
# ----------------------------------------------------------------------------
ax.imshow(img, cmap="Blues", alpha=0.55, extent=(0, W, H, 0), zorder=0)
for gx in range(W + 1):
ax.plot([gx, gx], [0, H], color=COL_SLATE_300, lw=0.8, zorder=1)
for gy in range(H + 1):
ax.plot([0, W], [gy, gy], color=COL_SLATE_300, lw=0.8, zorder=1)
ax.set_xlim(-0.3, W + 4.7)
ax.set_ylim(H + 0.8, -1.2)
ax.axis("off")
ax.set_aspect("equal")
# ----------------------------------------------------------------------------
# 3×3 kernel penceresinin üç konumu (sol-üst, orta, sağ-alt) — renkli çerçeve
# her konumda "yama × kernel topla = 1 çıktı pikseli (dot product)"
# ----------------------------------------------------------------------------
positions = [
(0, 0, COL_PRIMARY, "sol-üst"), # (satır, sütun) sol köşesi
(2, 2, COL_ROSE_500, "orta"),
(5, 5, COL_CYAN_700, "sağ-alt"),
]
for (r0, c0, col, name) in positions:
rect = Rectangle((c0, r0), k, k, fill=False, edgecolor=col,
linewidth=3.2, zorder=4)
ax.add_patch(rect)
cx, cy = c0 + k / 2.0, r0 + k / 2.0
ax.text(cx, cy, "3×3\npencere", ha="center", va="center",
fontsize=8.5, color=col, weight="bold", zorder=5)
# her pencere → tek çıktı pikseli (dot product) oku
out_x = W + 2.6
out_y = cy
arrow_between(ax, (c0 + k, cy), (out_x - 0.45, out_y),
color=col, lw=2.2, shrink=3, mutation_scale=15)
out = boxed_node(ax, out_x, out_y, 0.95, 0.95, "1 px",
fc=COL_WHITE, ec=col, tc=COL_TEXT, fontsize=8.5, lw=2.2)
ax.text(out_x + 0.75, out_y, f"({name})", ha="left", va="center",
fontsize=8.5, color=col, weight="bold", zorder=5)
# Çıktı sütunu başlığı — "öznitelik haritası (çıktı)"
ax.text(W + 2.6, -0.6, "öznitelik haritası\n(çıktı pikselleri)",
ha="center", va="center", fontsize=9, color=COL_CYAN_800, weight="bold")
# ----------------------------------------------------------------------------
# "yama × kernel topla = dot product" açıklaması (alt orta)
# ----------------------------------------------------------------------------
ax.annotate(
"her konumda: yama (3×3) × kernel (3×3) topla = 1 çıktı pikseli (dot product)",
xy=(W / 2.0, H + 0.55), xytext=(W / 2.0, H + 0.55),
ha="center", va="center", fontsize=10, color=COL_ACCENT,
weight="bold", style="italic",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_WHITE,
ec=COL_ROSE_400, lw=1.4), zorder=6)
# ----------------------------------------------------------------------------
# Parametre paylaşımı notu — aynı kernel her yerde
# ----------------------------------------------------------------------------
ax.text(W / 2.0, -1.05,
"kernel = öğrenilen öznitelik dedektörü; AYNI kernel her konumda kayar\n"
"(parametre paylaşımı → az parametre + mekânsal yapı korunur)",
ha="center", va="center", fontsize=9.5, color=COL_CYAN_700,
weight="bold", zorder=6)
plt.tight_layout()
plt.show()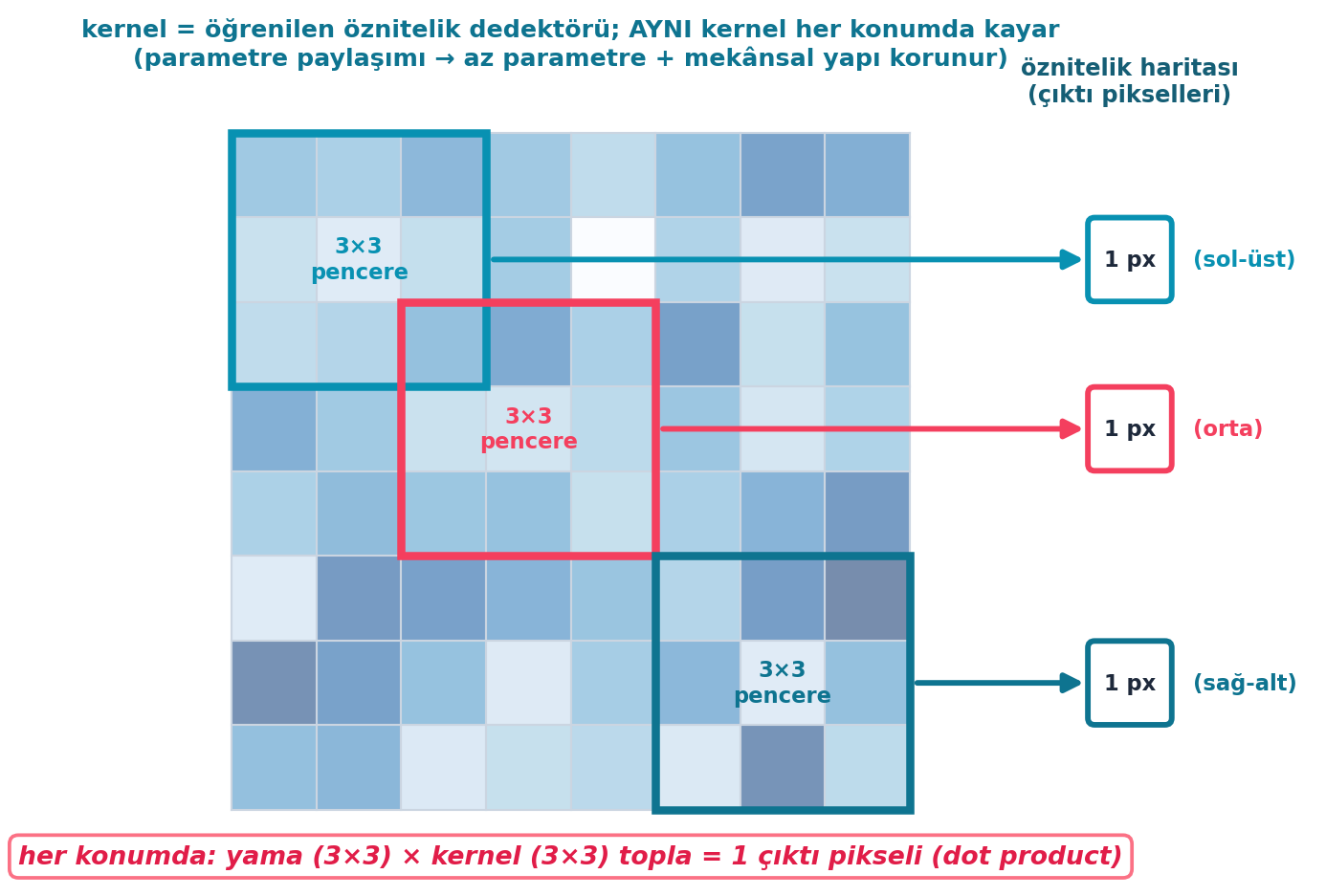
İpucuBuilder Notu — Kernel = Öğrenilen Öznitelik Dedektörü
- Geriye (Ders 8/11): Ders 8’deki “kaydırılan mini dot product” + Ders 11’in dot product’ı; kernel = öğrenilen öznitelik dedektörü.
- Sezgi: Bir kenar-kernel’i (örn. dikey kenar dedektörü) görüntünün her yerinde aynı deseni arar; öğrenme sırasında bu kernel’in 9 sayısı, ağın hangi öznitelikleri arayacağına karar verir — ve aynı 9 sayı tüm görüntüyü tarar.
18.5 4. apply_kernel: Sıfırdan Convolution
Howard convolution’ı en yalın hâlde kurar: bir apply_kernel fonksiyonu, görüntünün (row, col) merkezli 3×3 yamasını kernel ile çarpıp toplar. Bunu tüm konumlara uygulayınca öznitelik haritası (feature map) çıkar.
def apply_kernel(row, col, kernel):
return (im3[row-1:row+2, col-1:col+2] * kernel).sum() # 3x3 yama . kernel
rng = range(1, 27)
top_edge3 = tensor([[apply_kernel(i, j, top_edge) for j in rng] for i in rng])
İpucuBuilder Notu — apply_kernel: Ders 8’in Aynısı, Koddan
- Geriye (Ders 8): Bu, Ders 8’deki
apply_kernel’in aynısı; her konumda yama × kernel toplamı. - Sezgi: İç içe iki list comprehension, kernel’i tüm (i, j) konumlarına kaydırır — yani saf Python’da kayan pencere döngüsüdür. Çalışır ama yavaştır; bu yavaşlık sonraki adımın (im2col + matmul) motivasyonudur.
18.6 5. Convolution = Dot Product
Howard kritik bağı kurar: her konumdaki “yama × kernel topla” işlemi, yamayı ve kernel’i vektöre açıp dot product almakla aynıdır. Bu içgörü, convolution’ı matris çarpımına çevirmenin (im2col) yolunu açar.
“Flattening rank 1 tensors into vectors and then doing a dot product would be one way of thinking [about it].” — Howard, 13:24
İpucuBuilder Notu — Dot Product: matmul’a Açılan Kapı
- Geriye (Ders 11): Dot product (Ders 11); convolution = mekânsal olarak tekrarlanan dot product.
- Sezgi: “Yama × kernel topla” = iki 9’luk vektörün dot product’ı. Bu eşitlik fark edilince, convolution’ı bir matris çarpımına dönüştürmek (her yama bir satır, kernel bir vektör) doğal bir adım olur — bu, im2col’un tohumudur.
18.7 6. im2col: Convolution’ı Matmul’a Çevirme
Büyük içgörü: convolution bir matris çarpımı olarak yazılabilir. im2col tekniği, her yamayı bir sütuna “açar” (unroll); kernel’i de vektöre açar. Sonra tek bir matmul tüm konumları hesaplar — Ders 10-12’de kurduğumuz hızlı matmul’u kullanır.
“im2col is a way of converting a convolution into a matrix multiply.” — Howard, 19:30
Şekil 18.3 bu dönüşümü gerçek hesaplamayla kanıtlar (FLAGSHIP): solda kaydırılan dot product (3×3 pencereyi görüntü üzerinde gezdir), ortada im2col matrisi (her 3×3 yama → bir satır, sonra × kernel vektörü), sağda sonuç. np.allclose(kaydırılan, im2col) = True — yani iki yöntem birebir aynı çıktıyı verir; convolution sıradan bir matris çarpımıdır ve Ders 10-12’nin hızlı matmul’unu doğrudan kullanır.
Kod
d = E.conv_im2col_demo()
img, kernel = d["img"], d["kernel"]
out_slide, out_im2col = d["out_slide"], d["out_im2col"]
correct, n_patches, patch_len = d["correct"], d["n_patches"], d["patch_len"]
fig, (axL, axM, axR) = plt.subplots(1, 3, figsize=(12, 5))
# --- SOL: kaydırılan dot product (img + 3×3 pencere + out_slide) ---
axL.imshow(img, cmap="gray", aspect="equal")
# 3×3 kaydırma penceresi şeması (sol üst köşe konumu)
win = plt.Rectangle((-0.5, -0.5), 3, 3, fill=False, ec=COL_ACCENT, lw=2.6, zorder=5)
axL.add_patch(win)
# bir adım kaymış ikinci pencere (kaydırma fikri)
win2 = plt.Rectangle((0.5, -0.5), 3, 3, fill=False, ec=COL_ROSE_400,
lw=1.6, ls="--", zorder=4)
axL.add_patch(win2)
axL.annotate("", xy=(1.4, -0.5), xytext=(0.4, -0.5),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0))
axL.text(3.5, -1.1, "3×3 pencereyi kaydır →", color=COL_ACCENT,
fontsize=9.5, weight="bold")
axL.set_title("(a) kaydırılan dot product\nimg (8×8) üstünde 3×3 pencere",
color=COL_TEXT, fontsize=11, weight="bold")
axL.set_xticks([]); axL.set_yticks([])
for sp in axL.spines.values():
sp.set_color(COL_SLATE_400)
# küçük gömülü out_slide önizlemesi (sağ alt köşe)
axins = axL.inset_axes([0.60, 0.04, 0.36, 0.36])
axins.imshow(out_slide, cmap="cividis", aspect="equal")
axins.set_xticks([]); axins.set_yticks([])
axins.set_title("out_slide", color=COL_CYAN_700, fontsize=8, weight="bold")
for sp in axins.spines.values():
sp.set_color(COL_PRIMARY); sp.set_linewidth(1.6)
# --- ORTA: im2col matris (her 3×3 yamayı bir satıra aç) ---
axM.set_xlim(0, 10); axM.set_ylim(0, 10); axM.axis("off")
# (n_patches × patch_len) matris kutusu
mat = FancyBboxPatch((1.2, 1.6), 3.4, 7.0,
boxstyle="round,pad=0.04,rounding_size=0.15",
fc=COL_BG, ec=COL_PRIMARY, lw=2.4, zorder=2)
axM.add_patch(mat)
# satır çizgileri (yamalar)
for yy in np.linspace(2.0, 8.2, 8):
axM.plot([1.4, 4.4], [yy, yy], color=COL_PRIMARY, lw=0.7, alpha=0.45, zorder=3)
axM.text(2.9, 9.1, f"im2col matrisi\n({n_patches} × {patch_len})",
ha="center", color=COL_CYAN_800, fontsize=10.5, weight="bold")
axM.text(2.9, 0.95, "her 3×3 yama → bir satır", ha="center",
color=COL_TEXT, fontsize=9)
# × kernel(9) vektörü
kvec = FancyBboxPatch((5.6, 4.2), 0.95, 2.0,
boxstyle="round,pad=0.03,rounding_size=0.1",
fc=COL_BG_ROSE, ec=COL_ACCENT, lw=2.2, zorder=2)
axM.add_patch(kvec)
axM.text(6.07, 5.2, "kernel\n(9,)", ha="center", va="center",
color=COL_ACCENT, fontsize=9.5, weight="bold")
axM.text(5.05, 5.2, "×", ha="center", va="center",
color=COL_TEXT, fontsize=20, weight="bold")
# = matmul oku → sonuç
arrow_between(axM, (6.75, 5.2), (8.6, 5.2), color=COL_PRIMARY, lw=2.4, shrink=4)
axM.text(7.65, 5.9, "tek matmul", ha="center", color=COL_CYAN_700,
fontsize=9.5, weight="bold")
axM.text(9.1, 5.2, "= out", ha="center", va="center",
color=COL_TEXT, fontsize=11, weight="bold")
axM.set_title("(b) im2col: yamaları aç → matris × kernel",
color=COL_TEXT, fontsize=11, weight="bold")
# --- SAĞ: out_im2col + allclose rozeti ---
im = axR.imshow(out_im2col, cmap="cividis", aspect="equal")
axR.set_title("(c) im2col + matmul sonucu\nout_im2col (6×6)",
color=COL_TEXT, fontsize=11, weight="bold")
axR.set_xticks([]); axR.set_yticks([])
for sp in axR.spines.values():
sp.set_color(COL_PRIMARY); sp.set_linewidth(1.6)
# allclose rozeti
badge = FancyBboxPatch((0.02, 1.02), 0.96, 0.16,
boxstyle="round,pad=0.01,rounding_size=0.04",
fc=COL_BG, ec=COL_PRIMARY, lw=2.0,
transform=axR.transAxes, zorder=6, clip_on=False)
axR.add_patch(badge)
axR.text(0.5, 1.10, f"np.allclose(kaydırılan, im2col) = {correct}",
transform=axR.transAxes, ha="center", va="center",
color=COL_CYAN_800, fontsize=10, weight="bold", zorder=7)
# alt ortak mesaj: convolution = sıradan matmul → Ders 10-12 hızlı matmul
fig.text(0.5, 0.005,
"convolution sıradan bir matris çarpımıdır → Ders 10-12 hızlı matmul'unu "
"doğrudan kullanır",
ha="center", color=COL_ACCENT, fontsize=10.5, weight="bold")
plt.tight_layout(rect=(0, 0.04, 1, 1))
plt.show()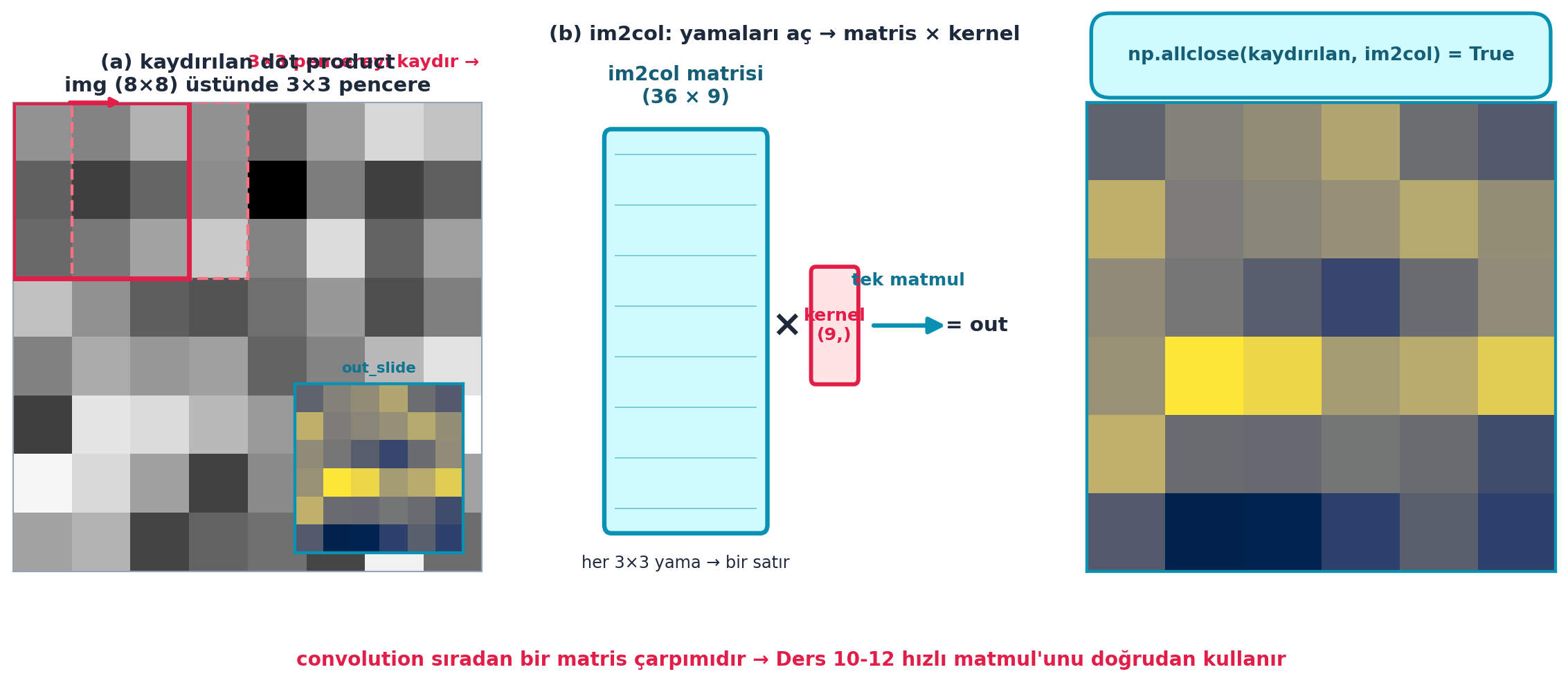
İpucuBuilder Notu — im2col: « Her Şeyi matmul’a Çevir » Deseni
- Geriye (Ders 10-12): Convolution’ı matmul’a indirgemek, onu optimize C/GPU koduyla (matmul) hızlandırır; “her şeyi matmul’a çevir” deseni.
- Sezgi: im2col bellek harcar (yamalar tekrar tekrar kopyalanır) ama hesabı tek bir matmul’a indirger — ve matmul, on yıllardır optimize edilmiş en hızlı işlemdir. “Bellek karşılığı hız” takası, GPU çağında neredeyse her zaman kazançlıdır.
18.8 7. F.unfold + Matris Çarpımı
PyTorch’un F.unfold’u im2col’u yapar: girdiyi yamalara “açar”. Sonra açılmış yamaları kernel ile çarparız (matmul). Sonuç, convolution ile birebir aynıdır.
inp_unf = F.unfold(inp, (3,3))[0] # yamalari ac (im2col)
w = left_edge.view(-1) # kernel'i vektore ac
out = (w @ inp_unf).view(26, 26) # matmul = convolution
İpucuBuilder Notu — F.unfold: Ders 12’nin @ İşareti
- Geriye (Ders 12):
w @ inp_unf= Ders 12’nin@’i; convolution artık tek bir matris çarpımı. - Sezgi:
F.unfoldel yazımı im2col döngüsünün yerini alır (yamaları C hızında açar);w @ inp_unfise Ders 12’de sıfırdan kurduğumuz matmul’dur. İkisi birleşince convolution = tek satır matris çarpımı olur — kavramsal olarakapply_kernel’le aynı, ama vektörize.
18.9 8. F.conv2d ve Hız
Elle unfold + matmul yerine PyTorch’un F.conv2d’si bunu optimize biçimde, tek çağrıda yapar. Howard %timeit ile kıyaslar: elle döngü ~9 ms, unfold+matmul çok daha hızlı, F.conv2d en hızlı (cuDNN).
F.conv2d(inp, left_edge[None,None]) # optimize convolution (cuDNN)
batch_features = F.conv2d(xb, edge_kernels) # tum batch + tum kernellerŞekil 18.4 bu hız farkını gerçek canlı zamanlamayla ölçer: kaydırılan döngü (saf Python) vs im2col + matmul (vektörize); log-skalada iki büyüklük mertebesi fark görünür. np.allclose = True (aynı sonuç) ama im2col çok daha hızlı — convolution’ı matmul’a indirgemenin kazancı budur (F.conv2d cuDNN ile daha da hızlı).
Kod
d = E.conv_speed_demo()
loop_ms = d["loop_ms"]
im2col_ms = d["im2col_ms"]
speedup = d["speedup"]
correct = d["correct"]
isimler = ["kaydırılan döngü\n(saf Python)", "im2col + matmul\n(vektörize)"]
degerler = [loop_ms, im2col_ms]
renkler = [COL_ACCENT, COL_PRIMARY]
kenarlar = [COL_ROSE_500, COL_CYAN_800]
fig, ax = plt.subplots(figsize=(10, 5))
x = np.arange(2)
bars = ax.bar(x, degerler, width=0.52, color=renkler, edgecolor=kenarlar,
linewidth=1.4, zorder=3)
# LOG-skala: iki büyüklük mertebesi farkı görünür olsun
ax.set_yscale("log")
# barların üstüne ms değeri
for r, v in zip(bars, degerler):
ax.text(r.get_x() + r.get_width() / 2, v * 1.25, f"{v:.2f} ms",
ha="center", va="bottom", fontsize=11.5, weight="bold",
color=COL_TEXT, zorder=4)
ax.set_xticks(x)
ax.set_xticklabels(isimler, fontsize=10.5, color=COL_TEXT)
ax.set_ylabel("süre (ms, log-skala)", fontsize=11)
ax.set_title("Convolution hızı: kaydırılan döngü vs im2col + matmul",
fontsize=12.5, color=COL_CYAN_800, weight="bold", pad=12)
ax.set_ylim(im2col_ms * 0.5, loop_ms * 4.0)
apply_style(ax)
ax.grid(True, axis="y", alpha=0.22, color=COL_SLATE_400, which="both")
ax.grid(False, axis="x")
# hızlanma + doğruluk rozeti
rozet = f"im2col {speedup:.0f}× hızlanma\nnp.allclose = {correct} (aynı sonuç)"
ax.text(0.97, 0.95, rozet, transform=ax.transAxes, ha="right", va="top",
fontsize=10.5, weight="bold", color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_PRIMARY, lw=1.6),
zorder=5)
# im2col açıklama annotate
ax.annotate(
"im2col yamaları tek seferde açıp matmul'a devreder\n"
"→ optimize koda düşer (F.conv2d cuDNN daha da hızlı)",
xy=(1, im2col_ms), xytext=(1.0, loop_ms * 0.32),
ha="center", va="center", fontsize=9.6, color=COL_ROSE_500, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_ROSE_400, lw=1.8,
shrinkA=4, shrinkB=8, connectionstyle="arc3,rad=-0.2"),
zorder=5)
plt.tight_layout()
plt.show()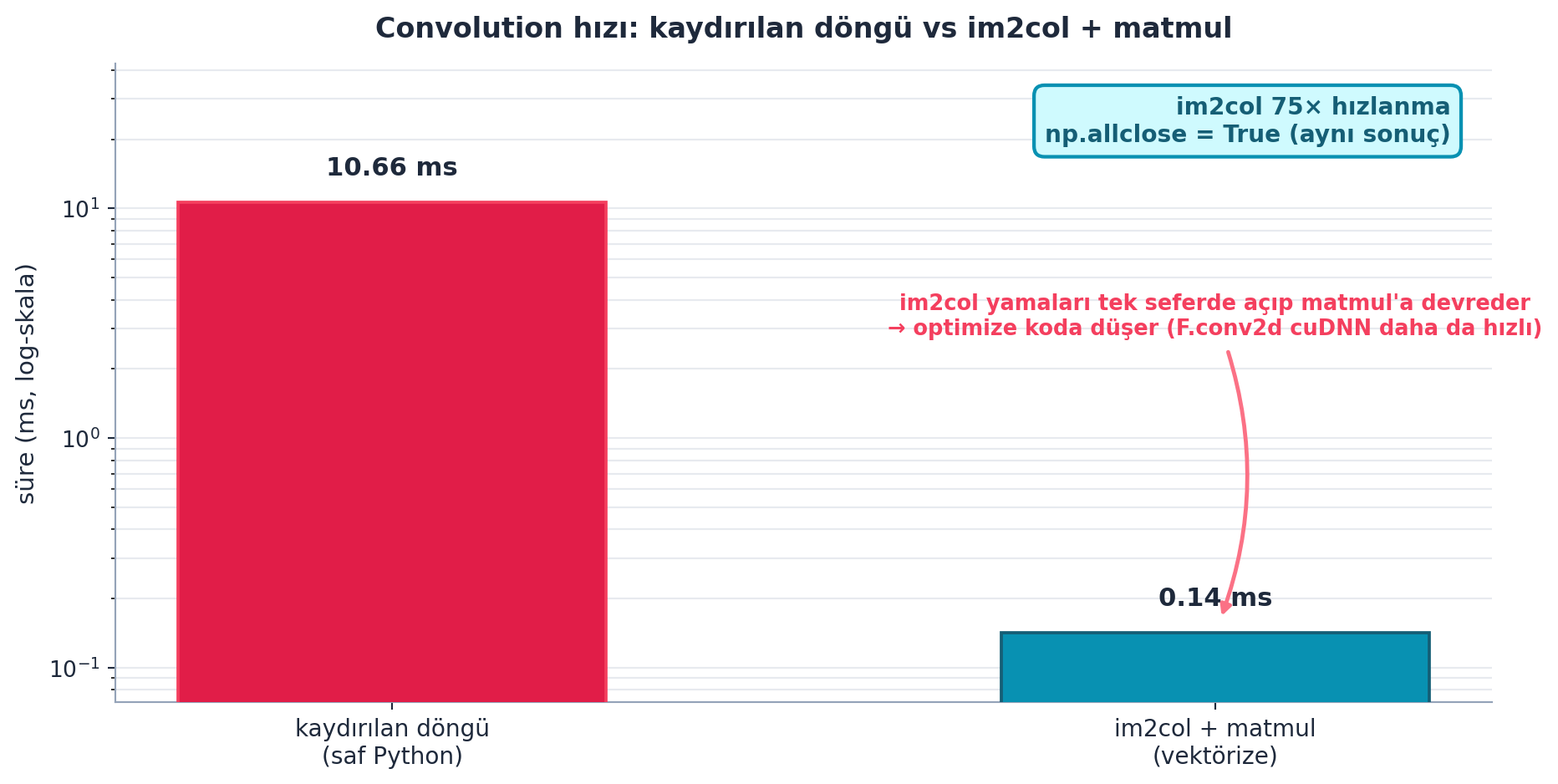
İpucuBuilder Notu — F.conv2d: Kurduktan Sonra Kullanma Hakkı
- Geriye (Ders 10 kuralı): Convolution’ı sıfırdan kurduk (apply_kernel → im2col → unfold); artık
F.conv2d’yi güvenle kullanırız. - Sezgi: “Yeniden kur, sonra kullan” kuralı:
F.conv2d’nin içinde ne olduğunu (im2col + matmul) bildiğimiz için onu kara kutu olarak değil, okuyabildiğimiz optimize bir araç olarak kullanırız — beklenmedik davranışta nereye bakacağımızı biliriz.
18.10 9. nn.Conv2d ile CNN
Hazır parça: nn.Conv2d. Howard bir conv yardımcısı yazar (conv + ReLU, stride ile küçültme) ve bir CNN kurar. stride=2 görüntüyü yarıya indirir, padding=ks//2 kenarları korur.
def conv(ni, nf, ks=3, stride=2, act=True):
res = nn.Conv2d(ni, nf, stride=stride, kernel_size=ks, padding=ks//2)
if act: res = nn.Sequential(res, nn.ReLU())
return resŞekil 18.5 çıktı boyutunu gerçek hesaplamayla gösterir: formül \((n + 2p - k)/s + 1\). stride=2 boyutu yarılar (encoder küçültme, rose), stride=1 + padding=1 boyutu sabit tutar (kenarı korur, cyan). Sağ panel girdi karesi (28×28) ile yarılanan çıktı karesini (14×14) yan yana çizer — stride’ın “küçültme” rolü görselleşir.
Kod
d = E.output_size_demo()
n = d["n"]
cases = d["cases"]
fig, (ax_bar, ax_sq) = plt.subplots(1, 2, figsize=(9.5, 5),
gridspec_kw={"width_ratios": [1.25, 1.0]})
# --- Sol panel: girdi (28) -> çıktı boyutu, durum başına çubuk ----------------
labels = [f"k{k} s{s} p{p}" for (k, s, p, desc, out) in cases]
outs = [out for (k, s, p, desc, out) in cases]
strides = [s for (k, s, p, desc, out) in cases]
# stride=2 (boyut yarılayan = encoder küçültme) rose, stride=1 cyan
bar_cols = [COL_ACCENT if s == 2 else COL_PRIMARY for s in strides]
ypos = range(len(labels))
ax_bar.barh(list(ypos), outs, color=bar_cols, height=0.6, zorder=3)
ax_bar.axvline(n, color=COL_SLATE_400, ls="--", lw=1.5, zorder=2)
ax_bar.text(n, len(labels) - 0.35, f"girdi n={n}", color=COL_TEXT,
fontsize=9.5, ha="center", va="bottom", weight="bold")
ax_bar.set_yticks(list(ypos))
ax_bar.set_yticklabels(labels, fontsize=10)
ax_bar.invert_yaxis()
ax_bar.set_xlim(0, n + 4)
ax_bar.set_xlabel("çıktı boyutu (kenar)")
ax_bar.set_title("(n + 2p − k) / s + 1", color=COL_CYAN_700, fontsize=11, weight="bold")
for i, (k, s, p, desc, out) in enumerate(cases):
ax_bar.text(out + 0.4, i, f"{out}", va="center", ha="left",
color=COL_TEXT, fontsize=10, weight="bold")
apply_style(ax_bar)
ax_bar.grid(True, axis="x", alpha=0.2, color=COL_SLATE_400)
ax_bar.grid(False, axis="y")
# --- Sağ panel: girdi vs çıktı kareleri (boyut görselleştirme) ----------------
ax_sq.set_xlim(0, n + 6)
ax_sq.set_ylim(0, n + 6)
ax_sq.set_aspect("equal")
ax_sq.axis("off")
ax_sq.set_title("girdi karesi → çıktı karesi", color=COL_TEXT, fontsize=10.5, weight="bold")
# girdi karesi (28x28) — soluk cyan çerçeve
from matplotlib.patches import Rectangle
ax_sq.add_patch(Rectangle((2, 2), n, n, fill=False, ec=COL_PRIMARY, lw=2.2, zorder=2))
ax_sq.text(2 + n / 2, 2 + n + 1.0, f"girdi {n}×{n}", ha="center", va="bottom",
color=COL_CYAN_700, fontsize=9.5, weight="bold")
# iki temsilî çıktı: korunan (28) ve yarılanan (14)
out_keep = cases[0][4] # k3 s1 p1 -> 28
out_half = cases[1][4] # k3 s2 p1 -> 14
ax_sq.add_patch(Rectangle((2, 2), out_keep, out_keep, fill=True,
fc=COL_BG, ec=COL_PRIMARY, lw=1.4, alpha=0.45, zorder=1))
ax_sq.add_patch(Rectangle((2, 2), out_half, out_half, fill=True,
fc=COL_BG_ROSE, ec=COL_ACCENT, lw=2.0, alpha=0.85, zorder=3))
ax_sq.text(2 + out_half / 2, 2 + out_half / 2, f"{out_half}×{out_half}",
ha="center", va="center", color=COL_ACCENT, fontsize=10, weight="bold")
ax_sq.annotate("stride=2 →\nyarı boyut\n(encoder küçültme)",
xy=(2 + out_half, 2 + out_half), xytext=(2 + n + 0.5, 2 + n * 0.62),
color=COL_ACCENT, fontsize=8.5, weight="bold", ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.6))
ax_sq.annotate("padding kenarı korur\n(p=1 → boyut sabit)",
xy=(2 + 1.0, 2 + n - 1.0), xytext=(2 + n + 0.5, 2 + n * 0.18),
color=COL_CYAN_700, fontsize=8.5, weight="bold", ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=1.6))
plt.tight_layout()
plt.show()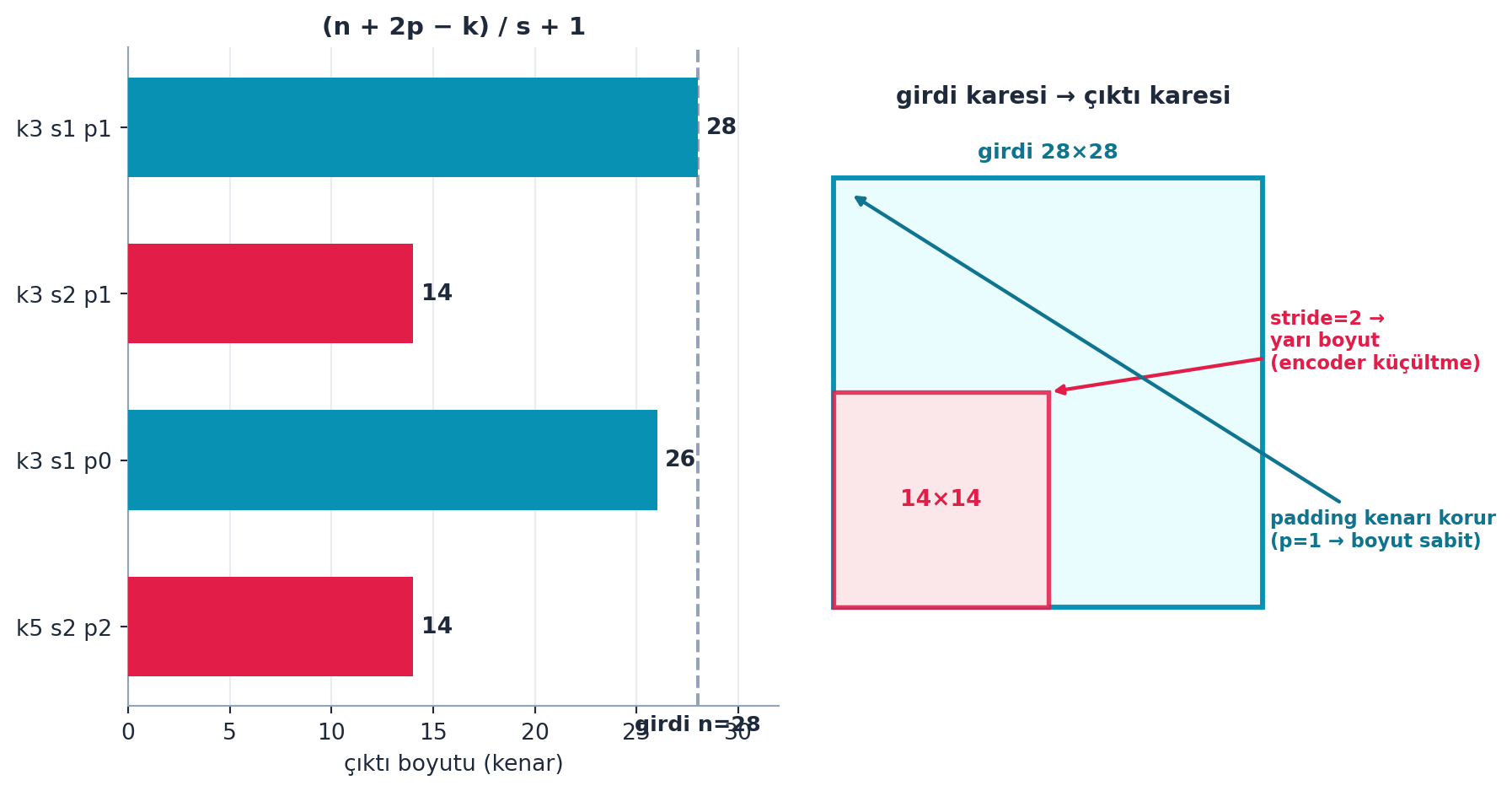
İpucuBuilder Notu — stride/padding: Boyut Kontrolü
- Geriye (Ders 8): Ders 8’deki
simple_cnndeseni; stride boyutu küçültür, kanal sayısı artar. - Sezgi:
stride=2her adımda iki piksel atlar → çıktı yarı boyut (encoder’ın “sıkıştırma” mekaniği);padding=ks//2kenarda kaybolan pikselleri telafi eder → boyut sabit kalır. Bu iki düğme, bir autoencoder’da encoder’ın daraltma profilini belirler.
18.11 10. Eğitim Döngüsü ve Dataset
Modeli eğitmek için bir Dataset (x, y çiftleri) ve minibatch döngüsü gerekir. Howard görüntüleri (1,28,28) şekline getirir ve Dataset’e sarar — Ders 14’ün nn.Module’ü üstüne eğitim altyapısı.
x_imgs = x_train.view(-1, 1, 28, 28) # (batch, kanal, yukseklik, genislik)
train_ds = Dataset(x_imgs, y_train)
İpucuBuilder Notu — Dataset: nn.Module Üstündeki Katman
- İleriye (Ders 16): Bu eğitim döngüsü Ders 16’da callback’lerle Learner’a dönüşecek.
- Sezgi:
(batch, kanal, yükseklik, genişlik)= PyTorch’un standart görüntü tensör düzeni (NCHW); MNIST tek kanallı (gri) olduğu için kanal=1. Bu şekillendirme,nn.Conv2d’nin beklediği girdi formatıdır — model ile veri arasındaki arayüz.
18.12 11. Autoencoder Nedir?
İkinci yarı: autoencoder. Fikir: girdiyi (görüntüyü) bir darboğazdan (bottleneck — küçük bir temsil) geçirip sonra geri kurmak. Ağ, girdiyi az sayıda sayıya sıkıştırıp (encoder) tekrar açmayı (decoder) öğrenir — çıktının girdiye benzemesi hedeflenir.
“To remind you about what an autoencoder is… [it compresses and reconstructs].” — Howard, 15:50
İpucuBuilder Notu — Autoencoder: VAE’nin Olasılıksal-Olmayan Atası
- Geriye (Ders 8/9): Embedding/sıkıştırma (Ders 8) + Ders 9’un VAE’si; autoencoder VAE’nin olasılıksal-olmayan atasıdır.
- Sezgi: Bir autoencoder’ın “anlamı keşfetmek zorunda kalması”, darboğazdan gelir: ağ tüm pikselleri küçük bir temsile sığdırmak zorunda olduğu için, gürültüyü atıp yapıyı (kenarlar, şekiller) öğrenir — sıkıştırma, öğrenmeyi zorlar.
18.13 12. Encoder: Conv ile Küçültme
Encoder, stride’lı conv katmanlarıyla görüntüyü adım adım küçültür (28→14→7→…) ve kanal sayısını artırır — bilgiyi küçük bir temsile sıkıştırır.
cnn = nn.Sequential(
conv(1, 4), # 14x14
conv(4, 8), # 7x7
conv(8, 16), # 4x4
conv(16, 16), # 2x2
conv(16, 10, act=False), nn.Flatten())Şekil 18.6 tüm autoencoder mimarisini bir kum saati olarak gösterir (FLAGSHIP): solda encoder conv ile boyutu küçültür (28×28 → 14×14×4 → 7×7×8 → 4×4×16 → latent), ortada darboğaz (en dar temsil), sağda decoder deconv ile geri büyütür (7×7 → 14×14 → 28×28). Boyut önce küçülür sonra büyür; kayıp ise çıktı ile girdinin kendisi arasındadır (self-supervised). Bu yapı = Stable Diffusion VAE’si (pil_to_latent / latents_to_pil).
Kod
fig, ax = plt.subplots(figsize=(12.5, 5.5))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 5.5)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# Kum saati: encoder boyut küçülür → darboğaz → decoder boyut büyür.
# (x_merkez, yarı-yükseklik, etiket, dolgu, kenar, metin-rengi)
stages = [
(1.05, 1.55, "girdi\n28×28", COL_BG, COL_PRIMARY, COL_TEXT),
(3.05, 1.15, "conv\n14×14×4", COL_CYAN_50, COL_CYAN_700, COL_TEXT),
(4.75, 0.80, "7×7×8", COL_CYAN_50, COL_CYAN_700, COL_TEXT),
(6.05, 0.52, "4×4×16", COL_CYAN_50, COL_CYAN_700, COL_TEXT),
(7.25, 0.42, "latent\n(küçük temsil)", COL_ACCENT, COL_ROSE_500, COL_WHITE), # darboğaz
(8.55, 0.80, "deconv\n7×7", COL_BG_ROSE, COL_ROSE_400, COL_TEXT),
(10.0, 1.15, "14×14", COL_BG_ROSE, COL_ROSE_400, COL_TEXT),
(11.6, 1.55, "çıktı\n28×28", COL_BG, COL_PRIMARY, COL_TEXT),
]
w = 0.92
centers_y = 3.15
for i, (cx, hh, label, fc, ec, tc) in enumerate(stages):
is_latent = (i == 4)
boxed_node(ax, cx, centers_y, w, 2 * hh, label,
fc=fc, ec=ec, tc=tc,
fontsize=9.0 if not is_latent else 9.5,
lw=2.6 if is_latent else 2.0, zorder=3)
# Aşamalar arası oklar (encoder cyan, decoder rose)
for i in range(len(stages) - 1):
cx0, hh0 = stages[i][0], stages[i][1]
cx1 = stages[i + 1][0]
col = COL_PRIMARY if i < 4 else COL_ACCENT
arrow_between(ax, (cx0 + w / 2, centers_y), (cx1 - w / 2, centers_y),
color=col, lw=2.2, mutation_scale=15, shrink=2, zorder=2)
# ENCODER / DECODER bölge etiketleri
ax.text(3.95, 5.05, "ENCODER (conv, stride ile küçült)", ha="center", va="center",
fontsize=10.5, weight="bold", color=COL_CYAN_700)
ax.text(9.45, 5.05, "DECODER (deconv / upsample ile büyüt)", ha="center", va="center",
fontsize=10.5, weight="bold", color=COL_ACCENT)
ax.annotate("", xy=(6.55, 4.85), xytext=(1.35, 4.85),
arrowprops=dict(arrowstyle="-", color=COL_CYAN_700, lw=1.4, alpha=0.7))
ax.annotate("", xy=(11.3, 4.85), xytext=(7.55, 4.85),
arrowprops=dict(arrowstyle="-", color=COL_ROSE_400, lw=1.4, alpha=0.7))
# Darboğaz vurgusu
ax.annotate("darboğaz: en dar temsil", xy=(7.25, centers_y - 0.55),
xytext=(7.25, 1.35), ha="center", va="center",
fontsize=8.8, weight="bold", color=COL_ACCENT,
arrowprops=dict(arrowstyle="-|>", color=COL_ROSE_500, lw=1.6,
shrinkA=2, shrinkB=4))
# Reconstruction loss köprüsü: çıktı vs girdi
ax.annotate("", xy=(11.6, 1.45), xytext=(1.05, 1.45),
arrowprops=dict(arrowstyle="<|-|>", color=COL_SLATE_400, lw=1.6,
connectionstyle="arc3,rad=-0.18", alpha=0.9))
ax.text(6.32, 0.62,
"kayıp = çıktı vs GİRDİ (reconstruction, self-supervised — etiket gerekmez)",
ha="center", va="center", fontsize=9.2, weight="bold", color=COL_TEXT)
# Akış özeti
ax.text(6.32, 4.35,
"encoder sıkıştırır, decoder geri açar — boyut küçülür sonra büyür (kum saati)",
ha="center", va="center", fontsize=9.4, color=COL_CYAN_800)
# Stable Diffusion VAE köprüsü
ax.text(6.32, 0.16,
"= Stable Diffusion VAE: pil_to_latent (encoder) / latents_to_pil (decoder)",
ha="center", va="center", fontsize=9.0, style="italic", color=COL_ROSE_500)
plt.tight_layout()
plt.show()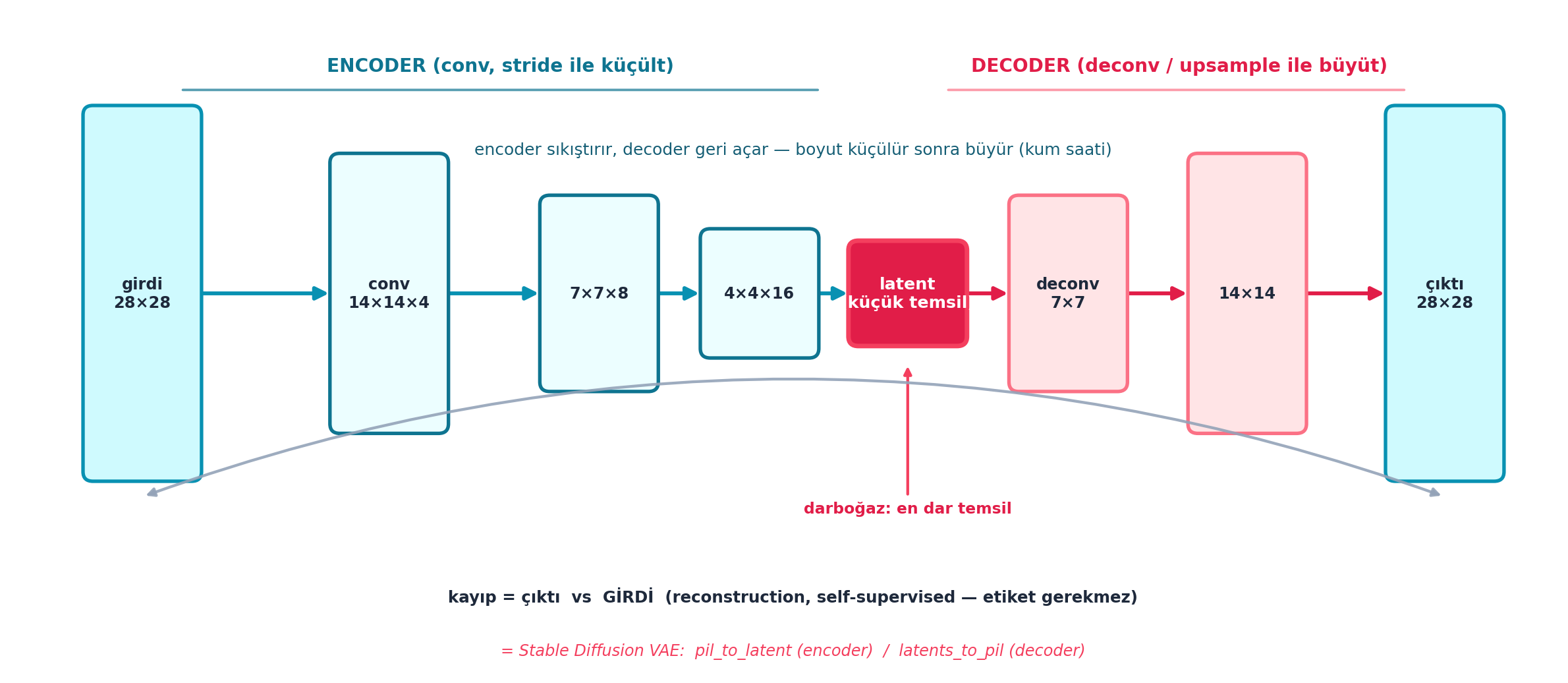
İpucuBuilder Notu — Encoder: Ders 9 VAE’sinin Basit Hâli
- Geriye (Ders 9): Encoder = Ders 9’daki VAE’nin “786K → 16K sıkıştırma”sının basit hâli.
- Sezgi: Her
conv(ni, nf)boyutu yarılarken (stride=2) kanalı artırır — mekânsal çözünürlük azalır, ama her konumdaki “anlam zenginliği” (kanal) artar. Encoder bilgiyi “geniş ve sığ”dan “dar ve derin”e taşır; latent, görüntünün özüdür.
18.14 13. Decoder: Deconv ile Büyütme
Decoder, encoder’ı tersine çevirir: küçük temsili adım adım büyütür. Howard bunu UpsamplingNearest2d (boyutu 2× büyüt) + conv ile yapar — “deconv”.
def deconv(ni, nf, ks=3, act=True):
layers = [nn.UpsamplingNearest2d(scale_factor=2), # 2x buyut
nn.Conv2d(ni, nf, stride=1, kernel_size=ks, padding=ks//2)]
if act: layers.append(nn.ReLU())
return nn.Sequential(*layers)
İpucuBuilder Notu — Decoder: Upsample + Conv = « deconv »
- Geriye (Ders 9): Decoder = VAE’nin “latent → görüntü” decode’unun temeli; upsampling + conv.
- Sezgi:
UpsamplingNearest2dboyutu kabaca 2× büyütür (en yakın komşu — bloklu), ardından conv bu büyütülmüş haritayı yumuşatıp detay ekler. “deconv” = “boyutu büyüten conv”; encoder’ın stride’lı küçültmesinin tersidir. İkisi birlikte simetrik kum saati kurar.
18.15 14. Autoencoder’ı Eğitmek
Encoder + decoder birleşince autoencoder olur. Kayıp: çıktı ile girdinin farkı (reconstruction loss) — etiket değil, girdinin kendisi hedeftir (self-supervised). Howard basit bir autoencoder’ı (conv + deconv) MNIST’te eğitir.
ae = nn.Sequential(
nn.ZeroPad2d(2), conv(1,2), conv(2,4), # encoder
deconv(4,2), deconv(2,1, act=False), nn.ZeroPad2d(-2)) # decoder
# loss: cikti ile GIRDI arasinda (reconstruction)Şekil 18.7 reconstruction’ı gerçek hesaplamayla gösterir: lineer autoencoder (= PCA) için darboğaz \(k\) büyüdükçe (2 → 8 → 32) reconstruction iyileşir (MSE 2.4 → 0.07 → 0.03). Darboğaz ne kadar darsa o kadar çok bilgi atılır; ne kadar genişse o kadar sadık geri kurma — bu, sıkıştırma/kalite dengesidir. Lineer AE, SD VAE’sinin olasılıksal-olmayan atasıdır.
Kod
d = E.pca_autoencoder_demo()
orig = d["orig"]
recons = d["recons"]
errors = d["errors"]
ks = sorted(recons.keys()) # [2, 8, 32]
fig, axes = plt.subplots(1, len(ks) + 1, figsize=(12, 4))
# Panel 0: orijinal görüntü
vmin, vmax = orig.min(), orig.max()
ax0 = axes[0]
ax0.imshow(orig, cmap="gray", vmin=vmin, vmax=vmax, interpolation="nearest")
ax0.set_title("orijinal", color=COL_CYAN_800, fontsize=12, weight="bold", pad=8)
ax0.set_xticks([]); ax0.set_yticks([])
for sp in ax0.spines.values():
sp.set_edgecolor(COL_PRIMARY); sp.set_linewidth(2.4)
# Panel 1..: her darboğaz k için reconstruction (artan kalite)
for ax, k in zip(axes[1:], ks):
ax.imshow(recons[k], cmap="gray", vmin=vmin, vmax=vmax, interpolation="nearest")
ax.set_title(f"k={k}, MSE={errors[k]:.3f}", color=COL_TEXT,
fontsize=12, weight="bold", pad=8)
ax.set_xticks([]); ax.set_yticks([])
for sp in ax.spines.values():
sp.set_edgecolor(COL_SLATE_400); sp.set_linewidth(1.4)
# en keskin (en yüksek k) panelini rose ile vurgula
for sp in axes[-1].spines.values():
sp.set_edgecolor(COL_ACCENT); sp.set_linewidth(2.4)
# açıklayıcı annotate (figür altına ortalı)
fig.text(
0.5, -0.02,
"darboğaz büyüdükçe reconstruction iyileşir (sıkıştırma/kalite dengesi) — "
"lineer AE = PCA, SD VAE'sinin olasılıksal-olmayan atası",
ha="center", va="top", fontsize=10.5, color=COL_CYAN_700, style="italic",
)
plt.tight_layout()
plt.show()
İpucuBuilder Notu — Reconstruction: Hedef = Girdinin Kendisi
- Geriye (Ders 9 / NYU §4.J): “Hedef = girdinin kendisi” self-supervised öğrenmedir (etiket gerekmez); Ders 9’un enerji-tabanlı model (EBM) + self-supervised akrabalığıyla aynı fikir, NYU §4.J’nin merkez teması.
- Sezgi: Reconstruction loss
(çıktı − girdi)²etiket istemez — verinin kendisi denetim sinyalidir. Bu, milyonlarca etiketsiz görüntüden öğrenmeyi mümkün kılar (etiketleme pahalıdır); autoencoder, self-supervised öğrenmenin en saf örneğidir.
18.16 15. VAE ve Stable Diffusion’a Köprü
Howard autoencoder’ın neden önemli olduğunu vurgular: Stable Diffusion’ın VAE’si tam olarak budur — görüntüyü latent uzaya sıkıştıran encoder + geri açan decoder. Ders 9’daki “latent diffusion” bu autoencoder üstüne kurulur.
Şekil 18.8 dersin sentezidir (VAE köprüsü merkezde): solda L15’in parçaları (convolution = im2col + matmul, autoencoder encoder/decoder, reconstruction self-supervised, F.conv2d/nn.Conv2d, latent sıkıştırma), sağda her birinin kaynağı/hedefi — convolution = Ders 8 (kavramsal) + Ders 10-12 (matmul → cuDNN), autoencoder = Ders 8 embedding → Ders 9/25 Stable Diffusion VAE, reconstruction = Ders 9 etiketsiz (EBM/self-supervised) + NYU §4.J, latent sıkıştırma = Ders 9 (786K → 16K). Alt şerit: L15 = görü (convolution) + sıkıştırma temeli (autoencoder → VAE).
Kod
fig, ax = plt.subplots(figsize=(12, 6.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.5)
ax.axis("off")
# Başlık şeritleri
ax.text(2.7, 6.25, "L15'te", ha="center", va="center",
fontsize=13, weight="bold", color=COL_ACCENT)
ax.text(9.3, 6.25, "nereden / nereye", ha="center", va="center",
fontsize=13, weight="bold", color=COL_CYAN_700)
# (L15 parçası rose-sol, kaynak cyan-sağ, oklarla bağlı) satırlar
rows = [
(
"convolution =\nim2col + matmul",
"Ders 8 (kavramsal) + Ders 10-12\nmatmul → cuDNN GPU-paralel",
),
(
"autoencoder\n(encoder / decoder)",
"Ders 8 embedding/sıkıştırma →\nDers 9/25 Stable Diffusion VAE",
),
(
"reconstruction\n(self-supervised)",
"Ders 9 etiketsiz (EBM);\nNYU §4.J merkez teması",
),
(
"F.conv2d / nn.Conv2d",
"Ders 10 'yeniden kur sonra kullan'\n(apply_kernel→im2col→F.conv2d)",
),
(
"latent sıkıştırma",
"Ders 9 latent diffusion verimliliği\n(786K→16K)",
),
]
ys = [5.45, 4.40, 3.35, 2.30, 1.25]
lw_, rw_, bh = 3.7, 4.5, 0.84
lx, rx = 2.7, 9.3
for y, (left, right) in zip(ys, rows):
# SOL: L15 parçası (rose)
boxed_node(ax, lx, y, lw_, bh, left,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10, lw=2.0)
# SAĞ: kaynak/hedef köprü (cyan)
boxed_node(ax, rx, y, rw_, bh, right,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.5, lw=2.0)
# ok: L15 parçası → köprü
arrow_between(ax, (lx + lw_ / 2, y), (rx - rw_ / 2, y),
color=COL_CYAN_700, lw=2.2, mutation_scale=18, shrink=4)
# Alt sentez şeridi: L15 = görü + sıkıştırma temeli
ax.text(6.0, 0.42, "L15 = görü (convolution) + sıkıştırma temeli (autoencoder → VAE)",
ha="center", va="center", fontsize=11, weight="bold", color=COL_CYAN_800)
plt.tight_layout()
plt.show()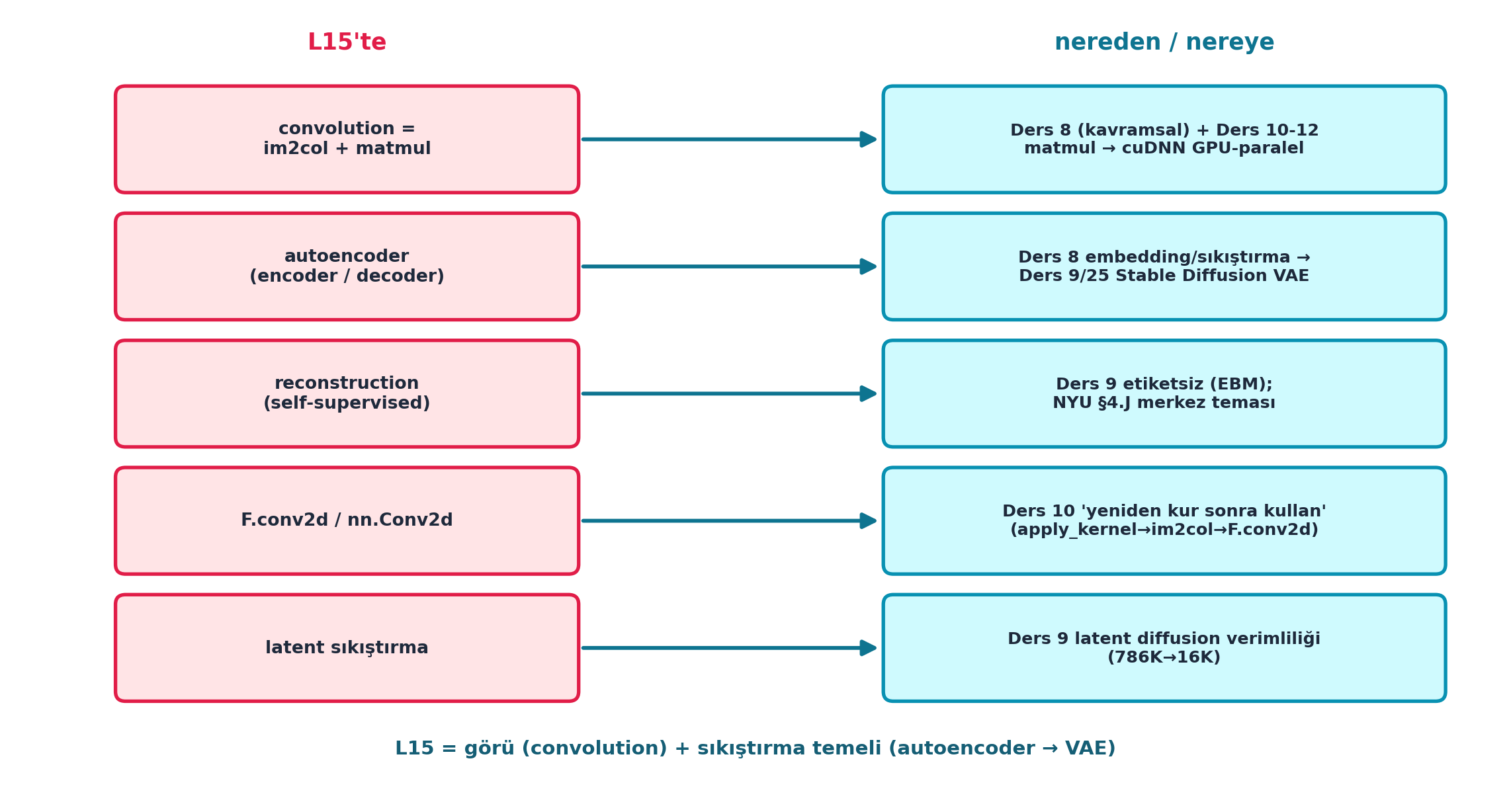
İpucuBuilder Notu — VAE Köprüsü: Autoencoder = SD’nin Kalbi
- İleriye (Ders 25): Bu basit autoencoder, Ders 25’te (latent diffusion) gerçek VAE’ye dönüşür; SD’nin
pil_to_latent/latents_to_pil’i (Ders 9A) bunun ürünü. - Sezgi: Stable Diffusion pahalı işlemi (diffusion) tüm pikseller üzerinde değil, VAE’nin sıkıştırdığı küçük latent uzayda yapar — bu yüzden “latent diffusion”. Bu derste kurduğumuz encoder/decoder, tam olarak o sıkıştırmayı sağlayan parçadır; SD’nin verimliliği bu autoencoder sayesindedir.
18.17 16. Kapanış
Ders 15, convolution’ı sıfırdan kurdu (apply_kernel → im2col/unfold → F.conv2d → nn.Conv2d) ve üstüne bir convolutional autoencoder inşa etti (encoder conv ile sıkıştırır, decoder deconv ile açar). Bu, Stable Diffusion’ın VAE’sinin temelidir — Temeller B’nin görü/sıkıştırma ayağı.
İpucuBuilder Notu — Kapanış: Sırada Eğitim Altyapısı
- İleriye (Ders 16-18): Sıradaki dersler eğitim altyapısını kurar: Learner (16), init/norm (17), accelerated SGD (18) — autoencoder ve sonraki diffusion modelleri bunların üstünde eğitilecek.
- Sezgi: Bu derste model (convolution + autoencoder) hazır, ama eğitimi hâlâ elle döngüyle yapıyoruz; sonraki dersler bu döngüyü esnek bir Learner’a (callback’lerle) dönüştürür — model ve eğitim altyapısı ayrı soyutlama katmanları olarak olgunlaşır.
18.18 Bu Dersin Özeti
- Convolution mekânsal yapıyı yakalar: bir kernel’i kaydırılan pencere gibi gezdirip her konumda dot product alır (CNN’in temeli) (kernel).
- apply_kernel convolution’ı sıfırdan kurar; her 3×3 yama × kernel toplamı (apply_kernel).
- Her konumdaki işlem bir dot product’tır; bu, convolution’ı matris çarpımına çevirmenin (im2col) yolunu açar (dot product).
- im2col / F.unfold yamaları açıp matmul yapar; F.conv2d bunu optimize (cuDNN) ile en hızlı yapar (im2col, F.conv2d).
- nn.Conv2d + stride/padding ile CNN kurulur (stride küçültür, kanal artar) (CNN).
- Autoencoder girdiyi bir darboğazdan geçirip yeniden kurar: encoder (conv ile sıkıştır) + decoder (deconv ile aç) (encoder, decoder).
- Decoder = UpsamplingNearest + conv; encoder’ı tersine çevirir (decoder).
- Kayıp reconstruction (çıktı vs girdi, self-supervised); bu, Stable Diffusion’ın VAE’sinin temelidir (VAE köprüsü).
ÖnemliTek Bir Cümle
Convolution, kaydırılan bir kernel’in her konumdaki dot product’ıdır ve im2col ile bir matris çarpımına indirgenir; autoencoder ise conv’la sıkıştırıp deconv’la geri açan, girdisini yeniden kurmayı öğrenen ve Stable Diffusion’ın VAE’sine giden bir ağdır.
18.19 Kontrol Soruları
NotSoru 1: im2col nedir ve convolution’ı neden matris çarpımına çevirmek isteriz?
Cevap:
Bir convolution, her konumda “yama × kernel toplamı” yani bir dot product hesaplar. im2col, her yamayı bir sütuna “açar” (unroll) ve kernel’i bir vektöre açar; böylece tüm konumlar tek bir matris çarpımıyla hesaplanır (PyTorch’ta F.unfold + matmul). Bunu isteriz çünkü matris çarpımını Ders 10-12’de sıfırdan kurup optimize ettik (broadcasting, @, cuDNN); convolution’ı matmul’a indirgemek, onu bu yüksek optimize edilmiş, GPU-paralel koda devreder. Yani “her şeyi matmul’a çevir” deseni convolution’ı da hızlandırır. (Şekil 18.3 allclose=True ile, Şekil 18.4 hız kazancını gösterir.)
NotSoru 2: Bir autoencoder’ın encoder ve decoder’ı ne yapar? Kayıp neye göre hesaplanır?
Cevap:
Encoder, girdiyi (görüntüyü) stride’lı conv katmanlarıyla adım adım küçültüp az sayıda sayıya (darboğaz/bottleneck) sıkıştırır. Decoder, bu küçük temsili UpsamplingNearest + conv (deconv) ile adım adım büyütüp orijinal boyuta geri açar. Kayıp reconstruction loss’tur: çıktı ile girdinin kendisi arasındaki fark (etiket değil, girdi hedeftir — self-supervised). Ağ böylece “bilgiyi küçük bir temsile sıkıştırıp geri kurmayı” öğrenir; bu, Stable Diffusion’ın VAE’sinin (görüntü ↔︎ latent) temelidir. (Şekil 18.6 kum saati mimarisini, Şekil 18.7 darboğaz/kalite dengesini gösterir.)
NotSoru 3: Convolution neden tam bağlı katmandan daha uygun bir görüntü işlemcisidir?
Cevap:
İki sebep: (1) Parametre paylaşımı — aynı kernel görüntünün her yerinde kullanılır, az parametre (Ders 8: 784 yerine 9); (2) mekânsal yapı — convolution yakın pikselleri birlikte işler ve “bir kenar her yerde kenardır” (öteleme-değişmezlik) bilgisini gömer. Tam bağlı katman her pikseli bağımsız ele alır, mekânsal komşuluğu yok sayar ve devasa parametre ister. Convolution’ın bu “doğru inductive bias”ı, onu görüntü için tam bağlı katmandan çok daha verimli ve genelleyici yapar. (Şekil 18.2 aynı kernel’in her konumda kaymasını gösterir.)
NotSoru 4: Bu dersteki autoencoder Stable Diffusion’a nasıl bağlanır? (builder bağlantısı)
Cevap:
Stable Diffusion bir latent diffusion modelidir (Ders 9): diffusion’ı piksel uzayında değil, bir VAE’nin sıkıştırdığı latent uzayda yapar. Bu VAE tam olarak bu dersteki autoencoder’dır — encoder görüntüyü küçük bir latent’e sıkıştırır (Ders 9A’daki pil_to_latent), decoder geri açar (latents_to_pil). Bu derste basit bir convolutional autoencoder kurduk; Ders 25’te (latent diffusion) bu gerçek VAE’ye dönüşür. Builder açısından: pahalı işlemi (diffusion) küçük, anlamlı bir temsilde yapmak — autoencoder bu sıkıştırmayı sağlayan parçadır. (Şekil 18.8 VAE köprüsünü merkeze alır.)
18.20 Egzersizler
Egzersiz 1 (Direkt uygulama). apply_kernel ile bir kenar kernel’ini MNIST görüntüsüne uygula; öznitelik haritasını görselleştir. (§4)
Egzersiz 2 (İki-aşamalı). Aynı convolution’ı F.unfold + matmul ve F.conv2d ile yap; üçünün sonucunun aynı, hızlarının farklı olduğunu %timeit ile gör (Şekil 18.4’i kendi zamanlamanla yeniden üret — §7-8).
Egzersiz 3 (Edge case). stride ve padding değerlerini değiştir; çıktı boyutunun nasıl değiştiğini (formül: \((n + 2p - k)/s + 1\)) gözlemle (Şekil 18.5’ı kendi değerlerinle doğrula — §9).
Egzersiz 4 (Kavramsal). Bir convolution’ın neden bir matris çarpımı olduğunu im2col ile bir 3×3 örnek üzerinde elle göster (Şekil 18.3’un mantığını kâğıt üzerinde izle — §6).
Egzersiz 5 (Sonraki dersin habercisi — Ders 16). Eğitim döngüsündeki tekrar eden parçaları (before/after batch, epoch) bir callback sistemine nasıl ayırabileceğini düşün (Learner’a giden yol — §10).
18.21 Sonraki: Ders 16 İçin Hazırlık
Ders 16: Learner Çerçevesi (The Learner framework)
Ders 15 convolution + autoencoder kurdu ve bir eğitim döngüsü kullandı. Ders 16, bu döngüyü esnek bir Learner çerçevesine dönüştürür: callback’ler ile eğitimin her adımına müdahale. Burada fast.ai’nin (ve “miniai”nin) çekirdeği sıfırdan doğar.
Ana konular (Ders 16):
- Esnek eğitim döngüsü (Learner)
- Callback sistemi (before/after fit/epoch/batch)
- CancelFit/Epoch/Batch exceptions
- miniai’nin doğuşu
UyarıDers 16 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 2 ve 5 — conv yöntemleri + callback fikri).
- Kendi autoencoder’ını MNIST’te eğit; reconstruction’ı gözle.
- Ana cümleyi tekrar oku: “Convolution = kaydırılan matmul; autoencoder = sıkıştır + geri aç.”
18.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Convolution | Kaydırılan kernel’in her konumda dot product’ı | 0:53 |
| Kernel | Küçük filtre matrisi (örn. 3×3); öznitelik dedektörü | 5:27 |
| apply_kernel | Bir yama × kernel toplamı (sıfırdan conv) | 13:24 |
| im2col | Convolution’ı matris çarpımına çevirme (yamaları açma) | 19:30 |
| F.unfold | PyTorch’un im2col’u; girdiyi yamalara açar | 22:27 |
| F.conv2d | Optimize convolution (cuDNN); en hızlı | 22:27 |
| stride / padding | Adım büyüklüğü / kenar koruma; çıktı boyutunu belirler | 27:26 |
| Autoencoder | Girdiyi darboğazdan geçirip yeniden kurma | 15:50 |
| Encoder | Conv ile küçültme (sıkıştırma) | 15:50 |
| Decoder (deconv) | UpsamplingNearest + conv ile büyütme | 15:50 |
| Reconstruction loss | Çıktı vs girdi farkı (self-supervised) | 15:50 |
| VAE köprüsü | Autoencoder = SD’nin latent encoder/decoder’ı | — |
18.23 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: Convolution + VAE
Bu ders convolution’ı sıfırdan kurar ve autoencoder ile Stable Diffusion’ın VAE’sine köprü atar; köprülerin özeti:
- Convolution = matmul (im2col) → “her şeyi matmul’a çevir” (Ders 10-12); cuDNN ile GPU-paralel (im2col).
- Parametre paylaşımı → görüntü için doğru inductive bias (Ders 8); az parametre, genelleme (kernel).
- Autoencoder → encoder/decoder; Stable Diffusion VAE’sinin (Ders 9/25) temeli (VAE köprüsü).
- Reconstruction (self-supervised) → etiketsiz öğrenme; Ders 9 (EBM + self-supervised) ile akraba, NYU §4.J’nin merkez teması (reconstruction).
- F.conv2d → sıfırdan kurduktan sonra optimize aracı kullan (Ders 10 kuralı) (F.conv2d).
- Latent sıkıştırma → pahalı işlemi küçük temsilde yapma; latent diffusion verimliliği (VAE köprüsü).
ÖnemliBu dersten tek bir şey alıp gideceksen
Convolution gizemli değildir — kaydırılan bir kernel’in dot product’ı, im2col ile sıradan bir matris çarpımına indirgenir (ve böylece Ders 10-12’nin hızlı matmul’unu kullanır). Üstüne kurduğumuz autoencoder, görüntüyü conv’la sıkıştırıp deconv’la geri açar; bu, Stable Diffusion’ın VAE’sinin ta kendisidir. Temeller B’nin görü/sıkıştırma ayağını kurduk.