flowchart TD
CONV["convolution YEREL<br/>(komşu pikseller)"]
PROB["sorun: uzak ilişki<br/>tek adımda kurulamaz"]
ATTN["attention = ağırlıklı ortalama<br/>(uzaklıktan bağımsız)"]
QKV["Q (ne arıyorum) /<br/>K (ne sunuyorum) /<br/>V (taşıdığım bilgi)"]
DOT["dot product = benzerlik"]
SOFT["softmax + kok-d ölçekleme<br/>(varyans korunumu, Ders 17)"]
SELF["SelfAttention<br/>(+residual, Ders 18)"]
MULTI["multi-head<br/>(einops rearrange)"]
UNET["U-Net'e ekleme<br/>(düşük çözünürlük katmanları)"]
BLOCK["transformer bloğu =<br/>residual + attention"]
KARP["Karpathy nanoGPT ile<br/>BİREBİR buluşma"]
CONV --> PROB
PROB --> ATTN
ATTN --> QKV
QKV --> DOT
DOT --> SOFT
SOFT --> SELF
SELF --> MULTI
MULTI --> UNET
SELF --> BLOCK
BLOCK --> KARP
classDef cyan fill:#ecfeff,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
class CONV,PROB,ATTN,QKV,DOT,SOFT,UNET cyan;
class SELF,MULTI,BLOCK,KARP rose;
27 Ders 24 — Attention ve Transformer Blokları (Attention and Transformer Blocks)
SON ETAP’ın teknik zirvesi — Howard, Jonathan Whitaker (Johno) ve Tanishq Abraham’la. Attention’ı sıfırdan kurmak: convolution yereldir (yalnız komşu pikseller), attention ise görüntünün ya da dizinin uzak bölgelerini uzaklıktan bağımsız biçimde birbiriyle ilişkilendirir. Self-attention (Q/K/V), softmax(QKᵀ/√d)V, multi-head attention ve U-Net’e attention ekleme. Bu ders Phase 2’nin iki ana kursunun tam buluşma noktasıdır: Karpathy nanoGPT’de attention’ı metin için sıfırdan kurdu, Howard burada aynı attention’ı görüntü/diffusion için miniai’da yeniden inşa eder — aynı kod, aynı matematik. √d ölçeklemesi Ders 17’nin varyans korunumudur; residual x+inp Ders 18’in skip’idir; ikisi + attention = transformer bloğu. Dersin tek cümlesi: attention bir ağırlıklı ortalamadır — her konum, diğer tüm konumların value’larını query·key benzerliğinden gelen ağırlıklarla harmanlar, böylece convolution’ın yerelliğini aşar.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 24: Attention & Transformers (~116 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 24
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/27_attention (+ nbs/26_diffusion_unet)
- Okuma süresi: ~42 dk
- Hocalar: Howard + Jonathan Whitaker (Johno) + Tanishq Abraham
- 🔗 Phase 2’nin iki-kurs buluşma dersi: Karpathy nanoGPT’de self-attention’ı (Q/K/V, scaled dot product, multi-head, residual) sıfırdan kurmuştu; bu ders aynı attention’ı fast.ai/miniai’da yeniden inşa eder. İki kurs burada tam buluşur — “yeniden kur, sonra kullan” döngüsünün doruğu.
27.1 Bu Derste Ne Var?
SON ETAP’ın teknik zirvesi: attention’ı sıfırdan kurmak. Convolution (Ders 15-18) yereldir — her çıktı pikseli yalnızca küçük bir komşuluğa (çekirdek boyutu) bakar. Attention ise görüntünün (veya dizinin) uzak bölgelerini birbiriyle ilişkilendirir — uzaklıktan bağımsız. Self-attention (Q/K/V), multi-head attention ve U-Net’e attention ekleme. Bu, Karpathy’nin nanoGPT’sinde sıfırdan kurduğu attention’ın fast.ai/miniai’da yeniden inşasıdır — “yeniden kur, sonra kullan” döngüsünün doruğu.
Üç temel fikir bu dersin omurgasını kurar:
- Attention = ağırlıklı ortalama — her konum, diğer tüm konumların ağırlıklı ortalamasını alır; ağırlık, query·key benzerliğinden gelir (attention fikri, Q/K/V).
- softmax(QKᵀ/√d)V — query ve key’lerin iç çarpımı benzerliği verir, softmax onu ağırlığa çevirir, value’lar bu ağırlıkla harmanlanır (formül).
- Transformer bloğu = residual + attention — L18’in skip connection’ı + L24’ün attention’ı, tam bir transformer bloğu yapar (Karpathy nanoGPT’siyle birebir) (transformer bloğu, Karpathy köprüsü).
“[attention is] one of the two basic building blocks of Transformers. A Transformer layer is attention attached to a [MLP].” — Howard, 48:21
Şekil 28.1 bu fikirleri tek bir kavram haritasında birleştirir: convolution yerel komşuluğu işler, uzak ilişkiyi tek adımda kuramaz → attention = uzaklıktan bağımsız ağırlıklı ortalama (Q/K/V, dot product benzerliği, softmax + √d ölçekleme) → SelfAttention + residual ile derin ağa girer → multi-head ile çoğalır → U-Net’e eklenir → transformer bloğu Karpathy nanoGPT ile birebir buluşur. Rose ile işaretli düğümler (SelfAttention, multi-head, transformer bloğu, Karpathy buluşması) dersin builder mesajını taşır: aynı attention iki kursta da sıfırdan kuruldu.
İpucuBuilder Notu — Giriş: İki Kursun Buluşması, Sıfırdan Attention
- Geriye (Karpathy nanoGPT) — MERKEZÎ: Karpathy nanoGPT’de self-attention’ı sıfırdan kurdu (Q/K/V, scaled dot product, multi-head); bu ders aynı kodu fast.ai/miniai’da yeniden inşa eder. İki kurs burada tam buluşur.
- Geriye (Ders 18): L18’in residual’ı + bu dersin attention’ı = transformer bloğu; L18 olmadan bu blok eğitilemezdi.
- İleriye (Ders 25): Attention, latent diffusion’da metin koşullamasının (cross-attention, text→image) mekanizmasıdır.
- Tek cümle: Attention, her konumun diğer tüm konumların ağırlıklı ortalamasını (softmax(QKᵀ/√d)V) alarak uzak ilişkileri yakalamasıdır; residual ile birleşince transformer bloğunu oluşturur — Karpathy’nin nanoGPT’sinin fast.ai’daki yeniden inşası.
27.2 1. Convolution’ın Sınırı: Yerel Bakış
Convolution (Ders 15-18) güçlüdür ama yereldir: her çıktı pikseli yalnızca küçük bir komşuluğa (çekirdek boyutu) bakar. Görüntünün uzak iki bölgesini (örn. bir yüzün iki gözü, bir desenin simetrisi) doğrudan ilişkilendiremez — bilgi ancak çok katman sonra yayılır. Attention bu sınırı aşar.
Şekil 27.2 bu farkı gerçek bir menzil testiyle gösterir: tek bir δ-impulse (6. konumda) verildiğinde, bir 3×3 convolution (k=3) tek adımda yalnızca 3 konumu etkiler (impulse ve ±1 komşusu); bilgi diziye ancak katman katman yayılır. Aynı impulse’a attention uygulandığında, impulse’un value’su 24/24 konumun hepsinin ağırlıklı ortalamasına girer — yani tek adımda dizinin tamamına ulaşır. Yerel (3) ile küresel (24) arasındaki uçurum, attention’ın uzun-menzilli bağımlılık için neden gerekli olduğunu sayısal olarak ortaya koyar.
Kod
d = E.longrange_demo()
imp = d["impulse"]
conv = d["conv_out"]
attn = d["attn_out"]
s = d["s"]
pos = int(np.argmax(imp)) # impuls konumu (6)
idx = np.arange(s)
fig, (ax_top, ax_bot) = plt.subplots(2, 1, figsize=(11, 6), sharex=True)
# --- ÜST: convolution (k=3), tek adım ---
# impuls konumu rose stem
ax_top.stem([pos], [imp[pos]], linefmt="-", markerfmt="o", basefmt=" ")
ml, sl, bl = ax_top.stem([pos], [imp[pos]], linefmt="-", markerfmt="o", basefmt=" ")
plt.setp(sl, color=COL_ACCENT, linewidth=2.4)
plt.setp(ml, color=COL_ACCENT, markersize=8)
# conv çıktısı (cyan barlar) — yalnız ±1 komşuda ≠0
ax_top.bar(idx, conv, width=0.6, color=COL_PRIMARY, alpha=0.9,
zorder=3, label="conv çıktısı")
apply_style(ax_top)
ax_top.set_title("convolution (k=3), tek adım", color=COL_TEXT,
fontsize=12, weight="bold", loc="left")
ax_top.set_ylabel("etki", color=COL_TEXT)
ax_top.set_ylim(-0.08, 1.12)
ax_top.text(pos, imp[pos] + 0.05, "δ-impuls", ha="center", va="bottom",
color=COL_ACCENT, fontsize=9.5, weight="bold")
# rozet
ax_top.text(0.985, 0.86, "etki: 3 konum — bilgi katman katman yayılır",
transform=ax_top.transAxes, ha="right", va="center",
fontsize=10, color=COL_CYAN_800, weight="bold",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BG, ec=COL_PRIMARY, lw=1.6))
# --- ALT: attention, tek adım ---
ax_bot.bar(idx, attn, width=0.6, color=COL_PRIMARY, alpha=0.9,
zorder=3, label="attention çıktısı")
apply_style(ax_bot)
ax_bot.set_title("attention, tek adım", color=COL_TEXT,
fontsize=12, weight="bold", loc="left")
ax_bot.set_ylabel("etki", color=COL_TEXT)
ax_bot.set_xlabel("konum (token dizini)", color=COL_TEXT)
ax_bot.set_xticks(idx[::2])
ax_bot.set_ylim(0, max(attn) * 1.25)
# rozet
ax_bot.text(0.985, 0.86, "etki: 24/24 konum — uzaklıktan bağımsız",
transform=ax_bot.transAxes, ha="right", va="center",
fontsize=10, color=COL_ROSE_500, weight="bold",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BG_ROSE, ec=COL_ACCENT, lw=1.6))
# açıklama notu (alt panel altına)
fig.text(0.5, -0.04,
"δ-impuls testi: conv yerel komşuluk; attention'da impulsun value'su HER konumun "
"ağırlıklı ortalamasına\ngirer — uzun-menzil bağımlılığın (büyük görüntü yapısı, "
"uzun metin) tek-adım çözümü",
ha="center", va="top", fontsize=9.2, color=COL_TEXT, style="italic")
plt.tight_layout()
plt.show()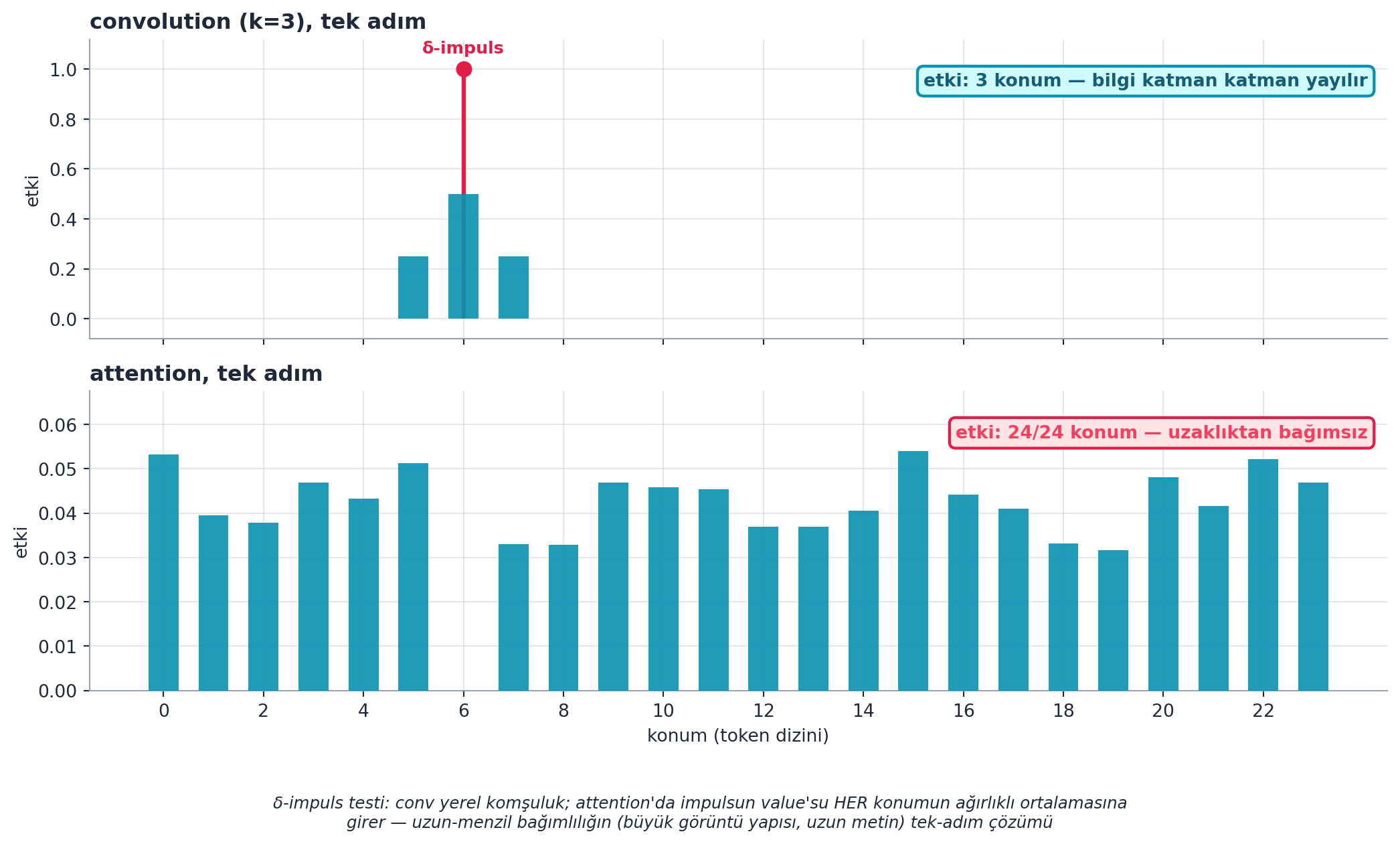
İpucuBuilder Notu — Convolution Yerel, Attention Tamamlayıcı
- Geriye (Ders 8/15): Convolution’ın parametre paylaşımı + yerelliği, görüntü için harika; ama uzak ilişki için yetersiz — attention tamamlayıcısıdır.
- Sayısal kanıt: Aynı δ-impulse, conv’da tek adımda 3 konumu, attention’da 24/24 konumu etkiler; menzil farkı 3 → 24 (8×) tek figürde görünür.
27.3 2. Attention Fikri: Ağırlıklı Ortalama
Attention’ın özü basittir: her konum, diğer tüm konumların ağırlıklı ortalamasını alır — uzaklıktan bağımsız. Ağırlıklar, “bu konum şu konuma ne kadar ilgili” sorusuna göre belirlenir. Böylece bir piksel, görüntünün herhangi bir yerindeki ilgili bilgiyi tek adımda toplayabilir.
“take a weighted average of other pixels around the image regardless of how far away they are.” — Howard, 52:10
İpucuBuilder Notu — Uzaklıktan Bağımsız Ağırlıklı Ortalama
- İleriye: “Uzaklıktan bağımsız ağırlıklı ortalama” — transformer’ların uzun-menzilli bağımlılığı (uzun metin, büyük görüntü) yakalamasının sırrı.
- Sezgi: Şekil 27.2’deki 24/24 erişim, “ağırlıklı ortalama”nın somut hâli; her konum tüm konumlara erişir, ağırlık ilgililiği belirler.
27.4 3. Query, Key, Value
Ağırlıkların nasıl hesaplandığı üç projeksiyona dayanır: her konum bir query (ne arıyorum), bir key (ne sunuyorum) ve bir value (taşıdığım bilgi) üretir. Bir konumun query’si, diğerlerinin key’leriyle karşılaştırılır; benzerlik ağırlık verir; value’lar bu ağırlıkla harmanlanır. Üçü de basit lineer katmanlardır.
“our keys, queries and values, or k q and v. I just think of them as k q and v.” — Howard, 1:06:18
İpucuBuilder Notu — Q/K/V: Aynı Zihinsel Model (Karpathy)
- Geriye (Karpathy): Karpathy de Q/K/V’yi tam böyle anlatır — “query: ne arıyorum, key: ne sunuyorum, value: ne veriyorum”. Aynı zihinsel model, iki kursta da özdeş.
- Sezgi: Q/K/V üç lineer projeksiyondur; “akıllı” olan kısım değil, onları nasıl çarpıp ağırlığa çevirdiğimiz (sonraki bölümler).
27.5 4. Dot Product = Benzerlik
Bir query ile bir key’in iç çarpımı (dot product), ikisinin ne kadar benzer olduğunu söyler — büyükse ilgili, küçükse ilgisiz. Tüm query-key çiftleri için bu hesaplanır (q@kᵀ), bir benzerlik matrisi oluşur. Bu matris, “hangi konum hangisine ne kadar dikkat etmeli”yi kodlar.
“the dot product between those two things… will tell us how similar they are.” — Howard, 57:31
İpucuBuilder Notu — İç Çarpım = Benzerlik (Ders 11-12, Ders 20)
- Geriye (Ders 11-12): İç çarpım = benzerlik; Ders 11-12’nin matmul/einsum’unun anlamsal kullanımı (Ders 20 Gram matrisi de aynı fikir).
- Sezgi:
q@kᵀbir s×s benzerlik matrisidir; satır = bir query’nin tüm key’lerle benzerliği. Henüz ağırlık değil — softmax onu ağırlığa çevirecek.
27.6 5. softmax(QKᵀ/√d)V
Attention’ın tam formülü: benzerlik matrisini (Q·Kᵀ) boyuta (√d) bölerek ölçekle (büyük d’de softmax’ı dengeli tut), softmax ile ağırlığa çevir (her satır toplamı 1), value’larla çarp. Sonuç: her konum için value’ların ağırlıklı ortalaması.
attention(Q, K, V) = softmax(Q·Kᵀ / √d) · V
√d bölmesi kritiktir: d büyükse iç çarpımlar büyür, softmax doygunlaşır (gradyan kaybolur); √d ile ölçekleme varyansı sabit tutar — Ders 17’nin varyans korunumu ilkesinin attention’daki yansıması.
Şekil 27.3 bu formülü tam hesapla (s=6, d=8) gösterir: solda S = QKᵀ/√d (ölçekli benzerlik matrisi), ortada A = softmax(S) — her satır bir olasılık dağılımı; sağda kolonda her satırın toplamı = 1.000 olarak işaretli (ağırlıklı ortalama kanıtı), sağda out = A·V (value’ların ağırlıklı ortalaması). Satır toplamlarının hepsi tam 1.000 olması, “her konum diğerlerinin ağırlıklı ortalamasını alır” iddiasının sayısal ispatıdır. Bu hesap, Karpathy’nin nanoGPT’sindeki ([email protected])/√d → softmax → @v ile birebir aynıdır.
Kod
r = E.attention_demo() # s=6, d=8
S, A, V, out = r["S"], r["A"], r["V"], r["out"]
row_sums = r["row_sums"]
s = A.shape[0]
fig, (axS, axA, axO) = plt.subplots(
1, 3, figsize=(12.5, 5),
gridspec_kw={"width_ratios": [1.0, 1.35, 0.85], "wspace": 0.42},
)
fig.patch.set_facecolor(COL_WHITE)
# --- SOL: S = QKᵀ/√d (benzerlik, ölçekli) — Greys imshow + değer etiketleri ---
imS = axS.imshow(S, cmap="Greys", aspect="equal")
axS.set_title("S = QKᵀ/√d\n(benzerlik, ölçekli)", fontsize=11,
color=COL_CYAN_800, weight="bold", pad=8)
for i in range(s):
for j in range(s):
axS.text(j, i, f"{S[i, j]:.1f}", ha="center", va="center",
fontsize=7.5, color=COL_TEXT)
axS.set_xticks(range(s)); axS.set_yticks(range(s))
axS.set_xticklabels(range(1, s + 1), fontsize=8, color=COL_TEXT)
axS.set_yticklabels(range(1, s + 1), fontsize=8, color=COL_TEXT)
axS.set_xlabel("anahtar (key) konumu", fontsize=8.5, color=COL_TEXT)
axS.set_ylabel("sorgu (query) konumu", fontsize=8.5, color=COL_TEXT)
for sp in axS.spines.values():
sp.set_color(COL_SLATE_400)
# --- ORTA: A = softmax(S) (her satır olasılık) + satır toplamı "=1.000" kolonu ---
imA = axA.imshow(A, cmap="Greys", aspect="equal", vmin=0, vmax=1)
axA.set_title("A = softmax(S)\n(her satır olasılık)", fontsize=11,
color=COL_CYAN_800, weight="bold", pad=8)
for i in range(s):
for j in range(s):
v = A[i, j]
axA.text(j, i, f"{v:.2f}", ha="center", va="center",
fontsize=7.5,
color=(COL_WHITE if v > 0.45 else COL_TEXT),
weight=("bold" if v > 0.30 else "normal"))
# sağda satır toplamı kolonu: hepsi =1.000 (ağırlıklı ortalama kanıtı)
axA.text(s + 0.15, i, f"= {row_sums[i]:.3f}", ha="left", va="center",
fontsize=9, color=COL_ACCENT, weight="bold")
axA.text(s + 0.15, -0.85, "satır\ntoplamı", ha="left", va="center",
fontsize=8, color=COL_ACCENT, weight="bold")
axA.set_xlim(-0.5, s + 1.9)
axA.set_xticks(range(s)); axA.set_yticks(range(s))
axA.set_xticklabels(range(1, s + 1), fontsize=8, color=COL_TEXT)
axA.set_yticklabels(range(1, s + 1), fontsize=8, color=COL_TEXT)
axA.set_xlabel("ağırlık verilen konum", fontsize=8.5, color=COL_TEXT)
for sp in axA.spines.values():
sp.set_color(COL_SLATE_400)
# --- SAĞ: out = A·V (value'ların ağırlıklı ortalaması) küçük imshow ---
imO = axO.imshow(out, cmap="Greys", aspect="auto")
axO.set_title("out = A·V\n(ağırlıklı ortalama)", fontsize=11,
color=COL_CYAN_800, weight="bold", pad=8)
axO.set_xticks(range(0, out.shape[1], 2))
axO.set_xticklabels(range(1, out.shape[1] + 1, 2), fontsize=8, color=COL_TEXT)
axO.set_yticks(range(s))
axO.set_yticklabels(range(1, s + 1), fontsize=8, color=COL_TEXT)
axO.set_xlabel("value boyutu (d=8)", fontsize=8.5, color=COL_TEXT)
axO.set_ylabel("çıktı konumu", fontsize=8.5, color=COL_TEXT)
for sp in axO.spines.values():
sp.set_color(COL_SLATE_400)
# --- Paneller arası oklar: S → A "softmax" / A → out "·V" ---
arS = FancyArrowPatch(
(1.02, 0.5), (1.20, 0.5), transform=axS.transAxes,
arrowstyle="-|>", mutation_scale=18, color=COL_PRIMARY,
linewidth=2.0, clip_on=False, zorder=5,
)
fig.add_artist(arS)
axS.text(1.11, 0.58, "softmax", transform=axS.transAxes, ha="center",
va="bottom", fontsize=9, color=COL_CYAN_700, weight="bold")
arO = FancyArrowPatch(
(1.30, 0.5), (1.52, 0.5), transform=axA.transAxes,
arrowstyle="-|>", mutation_scale=18, color=COL_ACCENT,
linewidth=2.0, clip_on=False, zorder=5,
)
fig.add_artist(arO)
axA.text(1.41, 0.58, "· V", transform=axA.transAxes, ha="center",
va="bottom", fontsize=10, color=COL_ROSE_500, weight="bold")
# --- Açıklama notu (altta) ---
fig.text(
0.5, 0.015,
"Her konum (satır), diğer konumların value'larını A ağırlıklarıyla harmanlar "
"= ağırlıklı ortalama; satır toplamı 1 bunun kanıtı.\n"
"Karpathy notu: nanoGPT'deki ([email protected])/√d → softmax → @v ile BİREBİR aynı hesap.",
ha="center", va="bottom", fontsize=8.8, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE, ec=COL_ROSE_400, lw=1.0),
)
plt.tight_layout(rect=(0, 0.10, 1, 1))
plt.show()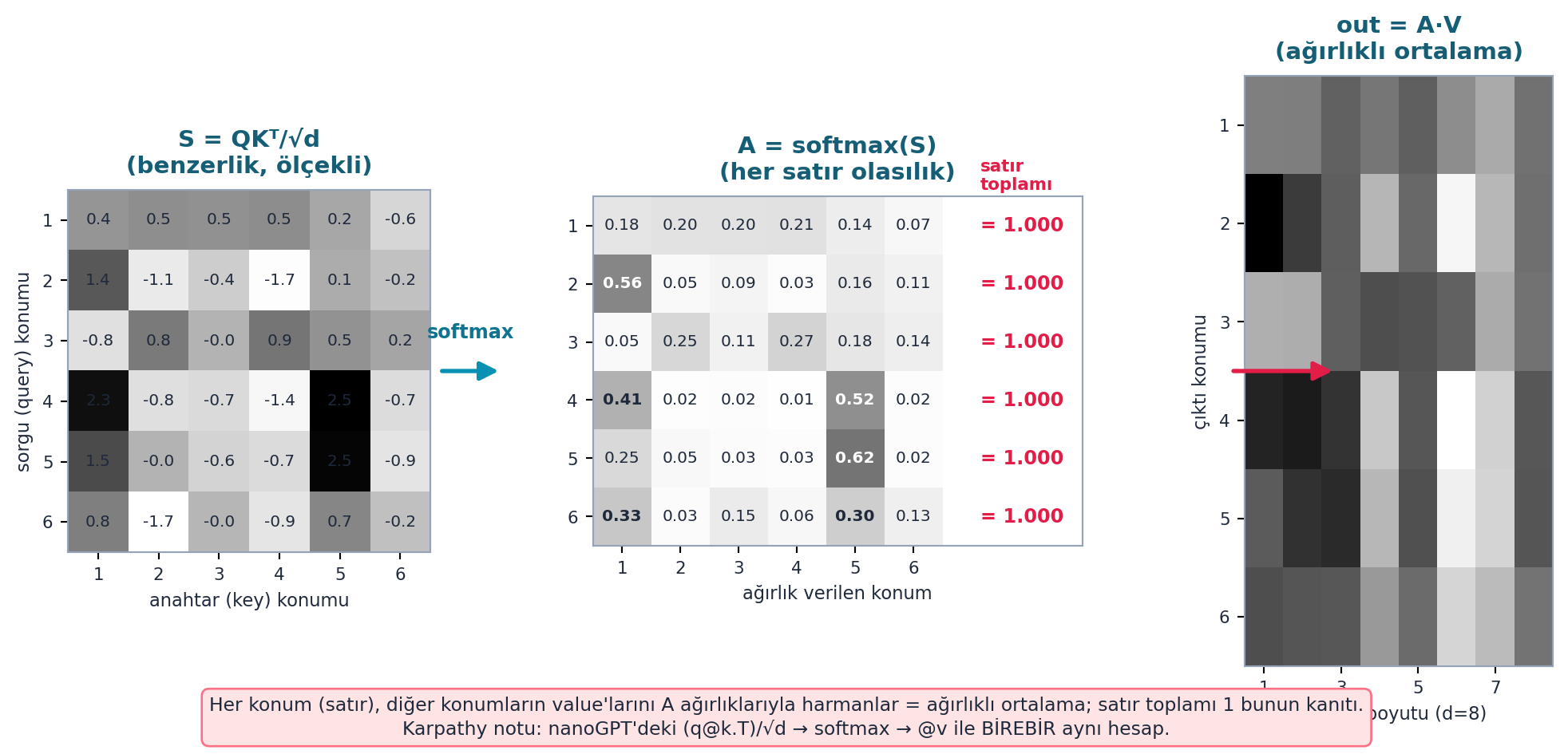
Şekil 27.4 √d ölçeklemesinin neden zorunlu olduğunu gerçek hesapla kanıtlar. Boyut büyüdükçe (d = 8, 64, 512), ölçeklenmemiş logit’lerin standart sapması 2.81 → 7.99 → 22.59 olur — bu değerler tam √d’ye (2.83, 8.0, 22.63) yakındır. Ölçeklenmemiş hâlde softmax’ın ortalama max-prob’u 0.484’ten 0.934’e tırmanır (one-hot’a doğru doygunlaşır, gradyan ölür); /√d ile ölçeklenince max-prob üç boyutta da ~0.16 sabit kalır. Yani √d ölçeklemesi, varyansı sabit tutarak softmax’ı dengeli tutar — Ders 17’nin varyans korunumu ilkesinin attention’daki tam karşılığı.
Kod
d = E.scale_saturation_demo()
dims = np.asarray(d["dims"], dtype=float)
std_raw = np.asarray(d["logit_std_raw"], dtype=float)
std_sc = np.asarray(d["logit_std_scaled"], dtype=float)
mp_raw = np.asarray(d["maxprob_raw"], dtype=float)
mp_sc = np.asarray(d["maxprob_scaled"], dtype=float)
sqrt_d = np.sqrt(dims)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12, 5))
# --- SOL: logit standart sapması (log-x) ---
axL.plot(dims, std_raw, "o-", color=COL_ACCENT, lw=2.4, ms=9,
label="ölçeksiz (QKᵀ)", zorder=4)
axL.plot(dims, sqrt_d, "--", color=COL_ROSE_400, lw=2.0,
label="√d referans", zorder=3)
axL.plot(dims, std_sc, "s-", color=COL_PRIMARY, lw=2.4, ms=8,
label="/√d ölçekli", zorder=4)
axL.set_xscale("log", base=2)
axL.set_xticks(dims)
axL.set_xticklabels([f"{int(v)}" for v in dims])
axL.set_xlabel("boyut d (log ölçek)")
axL.set_ylabel("logit standart sapması")
axL.set_title("Logit std: ölçeksiz ≈ √d büyür, /√d ≈ 1 sabit",
fontsize=11.5, weight="bold")
apply_style(axL)
axL.legend(frameon=False, fontsize=9.5, loc="upper left")
for xv, yv in zip(dims, std_raw):
axL.annotate(f"{yv:.2f}", (xv, yv), textcoords="offset points",
xytext=(6, 8), fontsize=9, color=COL_ACCENT, weight="bold")
axL.annotate("≈ 1.00", (dims[-1], std_sc[-1]), textcoords="offset points",
xytext=(6, -16), fontsize=9, color=COL_CYAN_700, weight="bold")
# --- SAĞ: softmax ortalama max-prob ---
axR.axhline(1.0, ls="--", color=COL_SLATE_400, lw=1.6, zorder=2)
axR.text(dims[0], 1.005, "1.0 = one-hot (doygun, gradyan ölür)",
fontsize=8.5, color=COL_SLATE_400, va="bottom")
axR.plot(dims, mp_raw, "o-", color=COL_ACCENT, lw=2.4, ms=9,
label="ölçeksiz", zorder=4)
axR.plot(dims, mp_sc, "s-", color=COL_PRIMARY, lw=2.4, ms=8,
label="/√d ölçekli", zorder=4)
axR.set_xscale("log", base=2)
axR.set_xticks(dims)
axR.set_xticklabels([f"{int(v)}" for v in dims])
axR.set_ylim(0, 1.08)
axR.set_xlabel("boyut d (log ölçek)")
axR.set_ylabel("softmax ortalama max-prob")
axR.set_title("Max-prob: ölçeksiz 0.48→0.93 doygunlaşır, /√d ~0.16 sabit",
fontsize=11.5, weight="bold")
apply_style(axR)
axR.legend(frameon=False, fontsize=9.5, loc="center right")
for xv, yv in zip(dims, mp_raw):
axR.annotate(f"{yv:.3f}", (xv, yv), textcoords="offset points",
xytext=(6, -16), fontsize=9, color=COL_ACCENT, weight="bold")
for xv, yv in zip(dims, mp_sc):
axR.annotate(f"{yv:.3f}", (xv, yv), textcoords="offset points",
xytext=(6, 8), fontsize=8.5, color=COL_CYAN_700, weight="bold")
fig.text(0.5, -0.02,
"ölçeksiz: büyük d'de logitler büyür → softmax doygun → gradyan ölür "
"(eğitilemez); /√d varyansı sabitler → Ders 17 varyans korunumu "
"ilkesinin attention'daki hâli",
ha="center", va="top", fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE, ec=COL_ROSE_400, lw=1.0))
plt.tight_layout()
plt.show()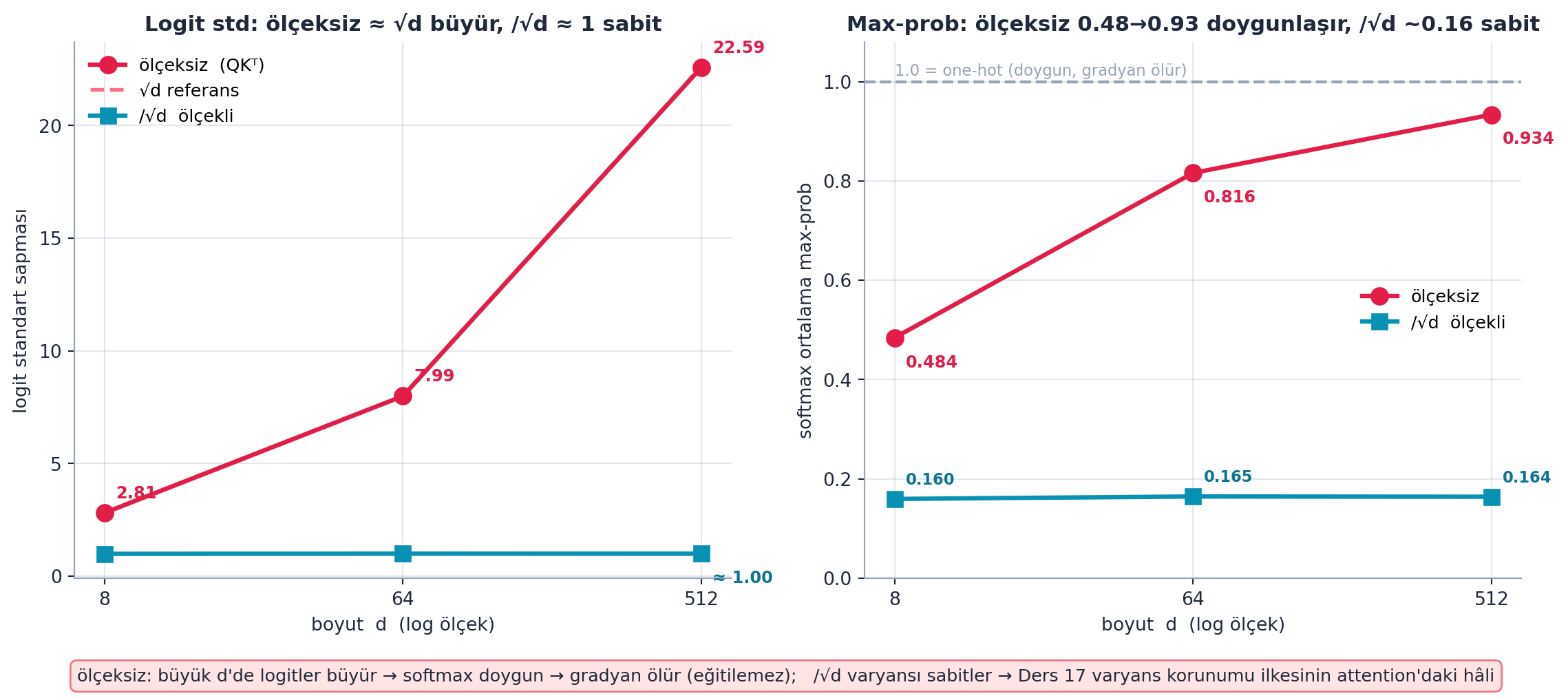
İpucuBuilder Notu — √d Ölçekleme = Ders 17 Varyans Korunumu
- Geriye (Ders 17): √d ölçeklemesi = varyans korunumu (L17); ölçeklenmemiş attention eğitilemez. Aynı ilke, yeni yer.
- Sayısal kanıt: Logit std 2.81/7.99/22.59 ≈ √d; ölçeksiz max-prob 0.484→0.934 doygunlaşır, /√d ile ~0.16 sabit. Satır toplamı 1.000 ağırlıklı ortalamayı kanıtlar.
27.7 6. SelfAttention Sıfırdan
Self-attention (query, key, value aynı girdiden gelir) tek bir küçük modüldür: q/k/v lineer katmanları, ölçeklenmiş iç çarpım, softmax, value harmanı, çıkış projeksiyonu — ve bir residual bağlantı (x+inp).
class SelfAttention(nn.Module):
def __init__(self, ni):
super().__init__()
self.scale = math.sqrt(ni)
self.norm = nn.BatchNorm2d(ni)
self.qkv = nn.Linear(ni, ni*3)
self.proj = nn.Linear(ni, ni)
def forward(self, inp):
n,c,h,w = inp.shape
x = self.norm(inp).view(n, c, -1).transpose(1, 2)
q,k,v = torch.chunk(self.qkv(x), 3, dim=-1)
s = (q@k.transpose(1,2))/self.scale
x = s.softmax(dim=-1)@v
x = self.proj(x).transpose(1,2).reshape(n,c,h,w)
return x+inpŞekil 27.5 bu forward’ın adım adım kod zincirini şematize eder: inp (n,c,h,w) → norm (BatchNorm2d) → view + transpose ile uzamsal diziye (n, s=h·w, c) → qkv = Linear(ni, 3·ni) → chunk ile Q/K/V → S = (Q@Kᵀ)/√ni → A = softmax(S) → x = A@V → proj → reshape geri (n,c,h,w) → return x + inp (residual, Ders 18). Sağdaki not anahtar köprüyü vurgular: görüntü pikselleri bir token dizisi gibi işlenir (s = h·w konum); Karpathy metinde aynı zinciri token dizisine uygular — matematik özdeş (nanoGPT self-attention).
Kod
fig, ax = plt.subplots(figsize=(12.0, 5.5))
ax.set_xlim(0, 12.0)
ax.set_ylim(0, 5.5)
ax.axis("off")
ax.text(4.0, 5.22, "SelfAttention.forward — adım adım kod zinciri",
ha="center", va="center", fontsize=12.5, weight="bold",
color=COL_CYAN_800)
# ----------------------------------------------------------------------------
# SOL SÜTUN — forward akış kutu zinciri (yukarıdan aşağıya)
# ----------------------------------------------------------------------------
col_x = 4.0
steps = [
(4.60, "inp (n, c, h, w)", COL_BG, COL_PRIMARY),
(4.05, "norm (BatchNorm2d)", COL_BG, COL_PRIMARY),
(3.50, "view + transpose → (n, s=h·w, c) DİZİ", COL_CYAN_50, COL_CYAN_700),
(2.95, "qkv = Linear(ni, 3·ni) → chunk → Q, K, V", COL_BG, COL_PRIMARY),
(2.40, "S = (Q @ Kᵀ) / √ni", COL_BG, COL_PRIMARY),
(1.85, "A = softmax(S)", COL_BG, COL_PRIMARY),
(1.30, "x = A @ V", COL_BG, COL_PRIMARY),
(0.75, "proj (Linear)", COL_BG, COL_PRIMARY),
(0.20, "reshape geri → (n, c, h, w)", COL_CYAN_50, COL_CYAN_700),
]
box_w, box_h = 5.7, 0.42
for y, txt, fc, ec in steps:
boxed_node(ax, col_x, y, box_w, box_h, txt, fc=fc, ec=ec,
fontsize=9.2, lw=1.8)
# zincir okları (aşağı doğru)
for i in range(len(steps) - 1):
y0 = steps[i][0]
y1 = steps[i + 1][0]
arrow_between(ax, (col_x, y0 - 0.21), (col_x, y1 + 0.21),
color=COL_PRIMARY, shrink=1, mutation_scale=14, lw=1.6)
# ----------------------------------------------------------------------------
# RESIDUAL kutusu — rose vurgu, ayrı (return x + inp)
# ----------------------------------------------------------------------------
res_y = 0.20
boxed_node(ax, 9.7, res_y, 3.6, 0.52,
"return x + inp\n(RESIDUAL, Ders 18)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=9.5, lw=2.2)
# son adımdan residual'a yatay rose ok
ax.annotate("", xy=(9.7 - 1.8 - 0.05, res_y), xytext=(col_x + box_w / 2 + 0.05, res_y),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0,
mutation_scale=15, shrinkA=2, shrinkB=2),
zorder=1)
# inp'ten residual'a giden uzun atlama (skip) — kesikli rose
ax.annotate("", xy=(9.7, res_y + 0.28), xytext=(col_x + box_w / 2 + 0.05, 4.60),
arrowprops=dict(arrowstyle="-|>", color=COL_ROSE_400, lw=1.8,
linestyle=(0, (5, 3)), mutation_scale=13,
connectionstyle="arc3,rad=-0.25",
shrinkA=2, shrinkB=4),
zorder=1)
ax.text(8.55, 2.75, "inp atlanır\n(skip)", ha="center", va="center",
fontsize=8.4, style="italic", color=COL_ACCENT)
# ----------------------------------------------------------------------------
# SAĞ — yan not: görüntü → uzamsal dizi (her piksel bir 'token')
# ----------------------------------------------------------------------------
note = ("görüntü → uzamsal dizi:\n"
"her piksel bir 'token'\n"
"(s = h·w konum).\n\n"
"Karpathy metinde AYNI\n"
"zinciri token dizisine\n"
"uygular — matematik özdeş\n"
"(nanoGPT self-attention).")
ax.text(9.7, 3.55, note, ha="center", va="center", fontsize=9.0,
weight="bold", color=COL_TEXT, linespacing=1.45,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_CYAN_50, ec=COL_CYAN_700,
lw=1.6))
plt.tight_layout()
plt.show()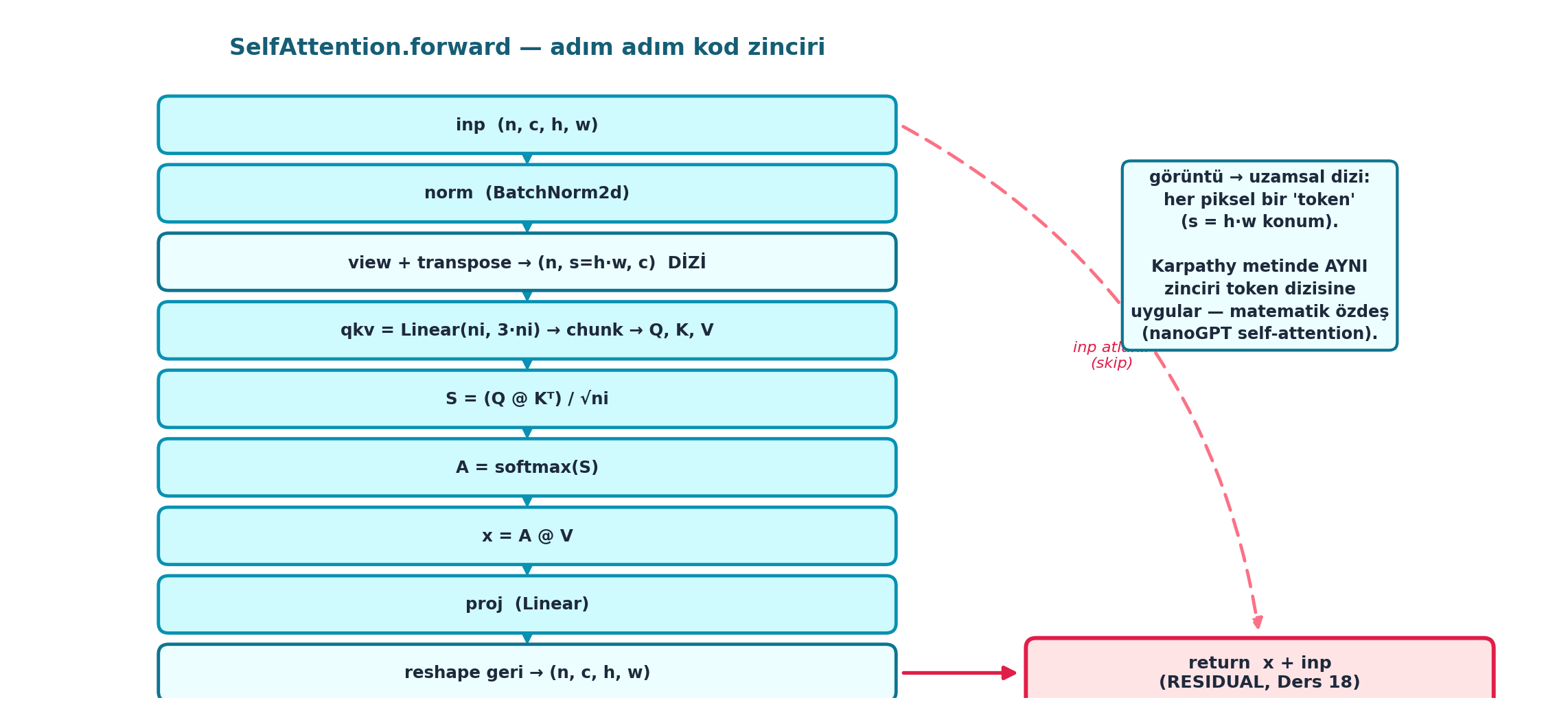
İpucuBuilder Notu — SelfAttention = nanoGPT self-attention (MERKEZÎ)
- Geriye (Karpathy nanoGPT) — MERKEZÎ: Bu kod, Karpathy’nin nanoGPT’sindeki self-attention’la birebir aynı: q/k/v projeksiyon,
([email protected])/√d, softmax,@v, proj. fast.ai görüntüye (n,c,h,w → diziye), Karpathy metne uyguladı; matematik özdeş. - Sezgi: Görüntüyü uzamsal diziye çevirmek (view+transpose), “her piksel bir token” demektir; attention için görüntü ile metin arasında yapısal fark kalmaz.
27.8 7. Residual: Attention + Skip
SelfAttention’ın son satırı return x+inp — bir residual (skip) bağlantı (Ders 18). Bu kritiktir: attention ham çıktısını değil, girdiye eklenen bir katkı üretir. Böylece bilgi blok boyunca korunur ve gradyan doğrudan akar — derin transformer’ları eğitilebilir kılan tam budur.
İpucuBuilder Notu — x+inp = Ders 18 Skip (Residual Stream)
- Geriye (Ders 18):
x+inp= L18 skip connection; attention bir “artık” (residual) katkıdır. Residual stream, ResNet’ten transformer’a taşınan fikir. - Sezgi: Şekil 27.5’daki rose “inp atlanır (skip)” oku tam budur; attention katkıyı üretir, residual ham girdiyi korur.
27.9 8. Multi-Head Attention
Tek attention bir tür ilişki yakalar; multi-head attention birden fazla yakalar. Girdiyi nheads parçaya böl (rearrange), her parçada ayrı attention yap (farklı ilişki türleri öğrenir), sonra birleştir. Ölçek √(d/nheads) olur. “Aslında çok basit ve özlü.”
class SelfAttentionMultiHead(nn.Module):
def __init__(self, ni, nheads):
super().__init__()
self.nheads = nheads
self.scale = math.sqrt(ni/nheads)
self.norm = nn.BatchNorm2d(ni)
self.qkv = nn.Linear(ni, ni*3)
self.proj = nn.Linear(ni, ni)
def forward(self, inp):
n,c,h,w = inp.shape
x = self.norm(inp).view(n, c, -1).transpose(1, 2)
x = self.qkv(x)
x = rearrange(x, 'n s (h d) -> (n h) s d', h=self.nheads)
q,k,v = torch.chunk(x, 3, dim=-1)
s = (q@k.transpose(1,2))/self.scale
x = s.softmax(dim=-1)@v
x = rearrange(x, '(n h) s d -> n s (h d)', h=self.nheads)
x = self.proj(x).transpose(1,2).reshape(n,c,h,w)
return x+inp“this is with multi-headed attention, and multi-headed attention actually turns out to be really simple and concise.” — Howard, 1:13:58
Şekil 27.6 4 head’in attention haritalarının belirgin biçimde farklı olduğunu gerçek hesapla gösterir: head’ler arası ortalama |korelasyon| yalnızca 0.181 (düşük) — yani her head ayrı bir ilişki desenini yakalar, hepsi aynı şeyi öğrenmez. Bu, multi-head’in neden işe yaradığının sayısal kanıtıdır: paralel başlıklar çeşitli ilişki türlerini (yakınlık, simetri, doku) aynı anda öğrenir.
Kod
mh = E.multihead_demo()
heads = mh["heads"] # (4, 8, 8)
mac = mh["mean_abs_corr"] # 0.181
nh = mh["nheads"] # 4
dh = mh["dh"] # 4
fig, axes = plt.subplots(1, nh, figsize=(12, 4))
for h, ax in enumerate(axes):
im = ax.imshow(heads[h], cmap="Greys", vmin=0.0, vmax=heads[h].max(),
aspect="equal")
ax.set_title(f"head {h + 1}", color=COL_CYAN_700, fontsize=12, weight="bold",
pad=8)
ax.set_xticks(range(0, heads.shape[2], 2))
ax.set_yticks(range(0, heads.shape[1], 2))
ax.tick_params(colors=COL_SLATE_400, labelsize=8, length=2)
for spine in ax.spines.values():
spine.set_edgecolor(COL_SLATE_300)
spine.set_linewidth(1.0)
# Rozet — head'ler arası düşük korelasyon (üst orta, accent çerçeve)
fig.text(
0.5, 1.015,
f"head'ler arası ortalama |korelasyon| = {mac:.3f} (düşük) — her head FARKLI ilişki deseni yakalar",
ha="center", va="bottom", fontsize=11, color=COL_ROSE_500, weight="bold",
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG_ROSE, ec=COL_ACCENT, lw=1.6),
)
# Alt annotate — reshape/rearrange mantığı
fig.text(
0.5, -0.06,
"reshape (s, h·dh) → (h, s, dh) = einops rearrange 'n s (h d) -> (n h) s d' mantığı; ölçek √(d/nheads)",
ha="center", va="top", fontsize=9.5, color=COL_TEXT, style="italic",
)
plt.tight_layout()
plt.show()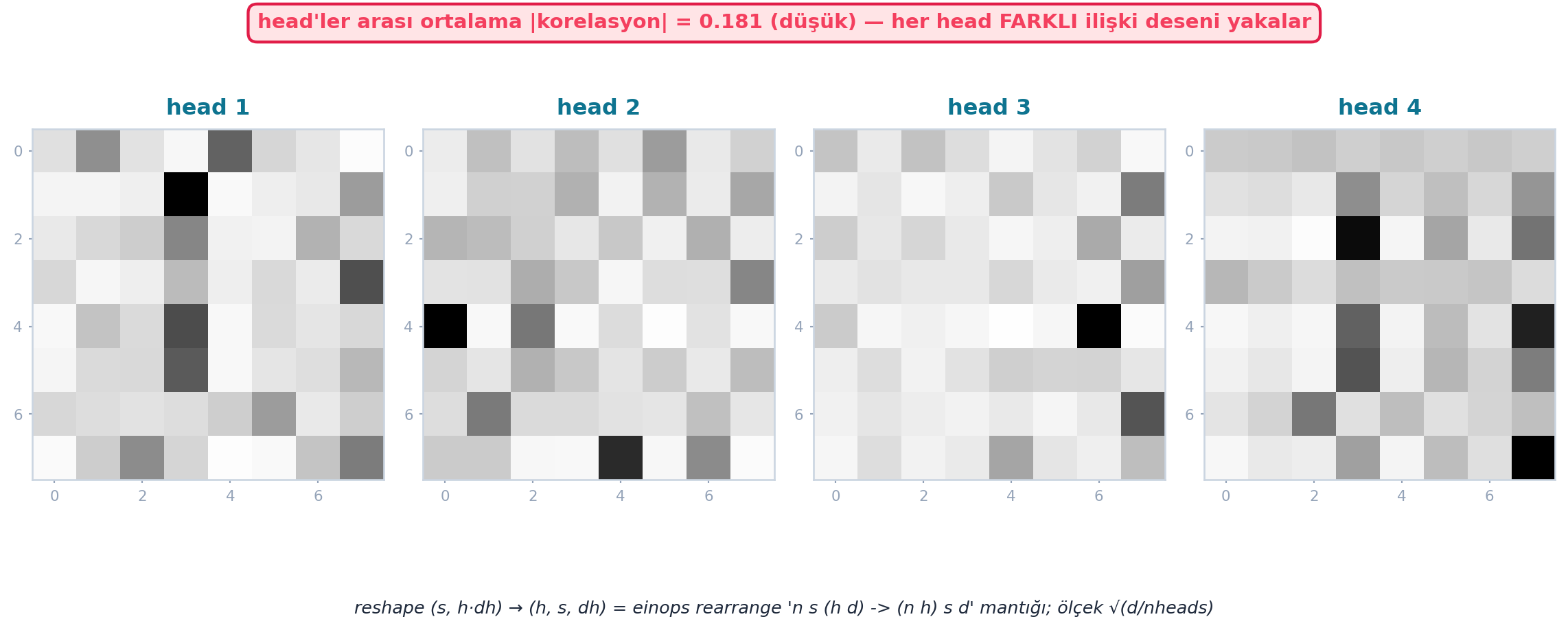
İpucuBuilder Notu — Multi-Head: Paralel Farklı İlişkiler (Karpathy)
- Geriye (Karpathy): Karpathy de multi-head’i “birden fazla bağımsız attention paralel” diye kurar; einops
rearrangeile head’leri bölmek fast.ai’nin zarif yolu. - Sayısal kanıt: 4 head arası |korelasyon| 0.181 (düşük); head’ler farklı desen yakalar. Ölçek √(d/nheads), tek-head’in √d’sinin head başına hâli.
27.10 9. einops rearrange
Multi-head’in inceliği, tensörü head’lere bölmektir: rearrange(x, 'n s (h d) -> (n h) s d'). einops kütüphanesi, tensör yeniden şekillendirmeyi okunabilir bir notasyonla yapar — boyutları isimlendirerek “kanalı head × derinlik olarak böl, head’i batch’e taşı” der. Hata yapması zor, anlaması kolay.
İpucuBuilder Notu — einops: Modern DL Standardı
- İleriye: einops, modern DL kodunun standart aracı; karmaşık reshape/transpose’ları okunabilir kılar (transformer kodunun her yerinde).
- Sezgi:
'n s (h d) -> (n h) s d'notasyonu, “kanalı (h d) çarpanına ayır, h’yi batch’e taşı” demektir; head’leri bağımsız batch örnekleri gibi işleyip tek matmul’da çözer.
27.11 10. nn.MultiheadAttention (PyTorch)
Sıfırdan kurduktan sonra PyTorch’un hazır nn.MultiheadAttention’ını kullanırız — artık içinde ne olduğunu biliyoruz. Self-attention için query=key=value=girdi verilir; residual elle eklenir. “Yeniden kur, sonra kullan” kuralı.
nm = nn.MultiheadAttention(32, num_heads=8, batch_first=True)
nmx, nmw = nm(t, t, t) # self-attention: q=k=v=t
nmx = nmx + t # residual
İpucuBuilder Notu — Yeniden Kur, Sonra Kullan (Ders 10/16)
- Geriye (Ders 10/16): Sıfırdan kur → kütüphaneyi kullan döngüsü;
nn.MultiheadAttentionartık kara kutu değil. - Sezgi: Self-attention’da query=key=value=aynı girdi (
nm(t, t, t)); residual PyTorch’un içinde yok, elle eklenir (nmx + t).
27.12 11. Attention’ı U-Net’e Ekleme
Attention, diffusion U-Net’ine (Ders 19/23) eklenir — genellikle düşük çözünürlüklü ara katmanlarda (yüksek çözünürlükte attention pahalıdır). Böylece U-Net hem yerel (convolution) hem küresel (attention) ilişkileri yakalar. Bu, modern diffusion U-Net’lerinin (Stable Diffusion dahil) standart yapısıdır.
İpucuBuilder Notu — U-Net + Attention = SD’nin Gürültü Tahmincisi
- Geriye (Ders 19/23): Diffusion U-Net (ResBlock’lar) + attention blokları = SD’nin gürültü tahmincisi; convolution + attention birlikte.
- Sezgi: Attention düşük çözünürlük katmanlarına eklenir çünkü hesap maliyeti s² (konum sayısının karesi); küçük uzamsal boyutta küresel ilişki ucuz, yüksek çözünürlükte pahalı.
27.13 12. Transformer Bloğu = Residual + Attention
Bir transformer bloğu, iki residual alt-bloktan oluşur: x = x + attention(x) ve x = x + mlp(x). İlki konumları ilişkilendirir (attention), ikincisi her konumu ayrı işler (MLP). L18’in residual’ı + bu dersin attention’ı = transformer bloğunun kalbi. Bunu artık tamamen sıfırdan kurduk.
“a Transformer layer is attention attached to a [MLP].” — Howard, 48:21
Şekil 27.7 bloğu iki residual alt-blok olarak gösterir (solda dikey akış): x → + attention(x) (konumları İLİŞKİLENDİRİR) → + mlp(x) (her konumu AYRI işler) → çıktı; her “+” bir residual toplamasıdır (Ders 18). Sağda miras zinciri: ResNet 2015 (L18: out = F(x) + x) → Transformer 2017 (L24: x = x + attn(x)) → GPT (Karpathy nanoGPT: aynı blok × N katman). Çekirdek sezgi: attention bilgiyi toplar, residual onu korur — bu yüzden 96+ katmanlı transformer’lar eğitilebilir. Howard görüntüde (diffusion U-Net), Karpathy metinde (nanoGPT) aynı bloğu kurdu.
Kod
fig, ax = plt.subplots(figsize=(12, 5.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 5.5)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# ============================================================================
# SOL AKIŞ — transformer bloğu = iki residual alt-blok (dikey, aşağıdan yukarı)
# x → + attention(x) (konumları İLİŞKİLENDİRİR) → + mlp(x) (her konumu AYRI)
# ============================================================================
xL = 2.6 # sol akış sütun ekseni
# x (girdi, altta)
boxed_node(ax, xL, 0.7, 2.7, 0.7, "x (girdi)",
fc=COL_BG, ec=COL_PRIMARY, fontsize=10.5)
# 1. residual alt-blok: + attention(x) — konumları ilişkilendirir
boxed_node(ax, xL, 2.25, 3.7, 1.0,
"+ attention(x)\n(konumları İLİŞKİLENDİRİR)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=10, lw=2.2)
# 2. residual alt-blok: + mlp(x) — her konumu ayrı işler
boxed_node(ax, xL, 3.8, 3.7, 1.0,
"+ mlp(x)\n(her konumu AYRI işler)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=10, lw=2.2)
# çıktı (en üst)
boxed_node(ax, xL, 5.05, 2.7, 0.6, "çıktı",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10.5)
# --- residual okları (rose, her '+' bir residual toplaması — Ders 18) ---
arrow_between(ax, (xL, 1.05), (xL, 1.75),
color=COL_ACCENT, lw=2.6) # x → + attention
arrow_between(ax, (xL, 2.75), (xL, 3.30),
color=COL_ACCENT, lw=2.6) # → + mlp
arrow_between(ax, (xL, 4.30), (xL, 4.75),
color=COL_ACCENT, lw=2.6) # → çıktı
# residual etiketi (sol kenar, dikey okların yanında)
ax.text(0.55, 2.25, "residual\noku\n(Ders 18)", ha="center", va="center",
fontsize=8.5, weight="bold", color=COL_ACCENT, style="italic")
# ============================================================================
# SAĞ — miras zinciri (dikey, cyan): ResNet → Transformer → GPT
# ============================================================================
xR = 8.7 # sağ zincir sütun ekseni
boxed_node(ax, xR, 1.0, 4.4, 0.95,
"ResNet 2015\n(L18: out = F(x) + x)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.5, lw=2.0)
boxed_node(ax, xR, 2.6, 4.4, 0.95,
"Transformer 2017\n(L24: x = x + attn(x))",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.5, lw=2.2)
boxed_node(ax, xR, 4.2, 4.4, 0.95,
"GPT (Karpathy nanoGPT:\naynı blok × N katman)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=9.5, lw=2.2)
# zincir okları (cyan, yukarı doğru miras)
arrow_between(ax, (xR, 1.50), (xR, 2.10), color=COL_PRIMARY, lw=2.2)
arrow_between(ax, (xR, 3.10), (xR, 3.70), color=COL_PRIMARY, lw=2.2)
ax.text(xR, 5.05, "miras zinciri", ha="center", va="center",
fontsize=9.5, weight="bold", color=COL_CYAN_700)
# ============================================================================
# Annotate (alt orta) — çekirdek sezgi kutusu
# ============================================================================
ax.text(
5.65, 0.35,
"attention bilgiyi toplar, residual korur → 96+ katman eğitilebilir; "
"L18 + L24 = transformer bloğunun kalbi;\n"
"Howard görüntüde (diffusion U-Net), Karpathy metinde (nanoGPT) — AYNI blok",
ha="center", va="center", fontsize=9.0, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_CYAN_50,
ec=COL_SLATE_300, lw=1.2),
)
plt.tight_layout()
plt.show()
İpucuBuilder Notu — L18 + L24 = Transformer Bloğu (MERKEZÎ)
- Geriye (Ders 18 + Karpathy) — MERKEZÎ: L18 (residual
out=F(x)+x) + L24 (attention) =x = x + attn(x); Karpathy nanoGPT’deki transformer bloğunun tam karşılığı. ResNet→Transformer→GPT zinciri kapanır. - Sezgi: Blok iki işlevi ayırır: attention konumlar arası (uzamsal/diziye yayılan), MLP konum içi (her token’ı bağımsız dönüştüren) — bu ayrım transformer’ın gücünün kaynağı.
27.14 13. Karpathy nanoGPT Köprüsü
Bu ders, Phase 2’nin iki ana kursunun (fast.ai + Karpathy) tam buluşma noktasıdır. Karpathy nanoGPT’de (bottom-up): self-attention’ı sıfırdan kurdu — Q/K/V, scaled dot product, masked softmax, multi-head, residual. Howard L24’te (top-down): aynı attention’ı miniai’da yeniden inşa etti — aynı matematik (softmax(QKᵀ/√d)V), aynı kod. Tek fark uygulama alanı: Karpathy metin (GPT), Howard görüntü (diffusion U-Net). “Kütüphane altındaki büyü = Karpathy’nin elle kurduğu şey” tezi, attention’da en net hâlini alır.
Şekil 27.8 bu buluşmayı dersin sentezi olarak çerçeveler: merkezde ana mesaj — iki kurs (Karpathy bottom-up/METİN, fast.ai top-down/GÖRÜNTÜ) aynı softmax(QKᵀ/√d)·V’yi sıfırdan kurdu, aynı kod aynı matematik. Solda geriye köprüler: √d ölçekleme = Ders 17 varyans korunumu (d=8/64/512 logit std 2.81/7.99/22.59 ≈ √d), residual x+inp = Ders 18 skip, nokta-çarpım=benzerlik = Ders 11-12 matmul + Ders 20 Gram, U-Net’e attention = Ders 19/23. Sağda ileriye: cross-attention (query=görüntü, key/value=metin) → text→image (L25), einops rearrange = modern DL standardı, nn.MultiheadAttention artık kara kutu değil. Altta tez: “büyü = elle kurulan şey”, “yeniden kur, sonra kullan” iki yönden (METİN + GÖRÜNTÜ tabanı) tamamlandı.
Kod
fig, ax = plt.subplots(figsize=(12.5, 6.5))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 6.5)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# --- MERKEZ: ana mesaj — iki kursun TAM buluşması ---
boxed_node(
ax, 6.25, 4.5, 5.9, 1.7,
"İKİ KURS, AYNI ATTENTION, SIFIRDAN\n"
"Karpathy nanoGPT (bottom-up, METİN) ve\n"
"fast.ai L24 (top-down, GÖRÜNTÜ) AYNI şeyi kurdu\n"
"softmax(QKᵀ/√d)·V — aynı kod, aynı matematik",
fc=COL_BG, ec=COL_CYAN_800, tc=COL_CYAN_800,
fontsize=11.5, lw=2.6,
)
# --- SOL KÖPRÜLER (cyan): geriye doğru kurs-içi/kurslar-arası bağ ---
left_x, left_w, left_h = 2.35, 4.3, 0.66
left_ys = [5.85, 5.0, 4.15, 3.3]
left_texts = [
"√d ölçekleme = Ders 17 varyans korunumu\n(d=8/64/512 logit std 2,81/7,99/22,59 ≈ √d)",
"residual x+inp = Ders 18 skip-bağlantısı",
"nokta-çarpım=benzerlik = Ders 11-12 matmul\n+ Ders 20 Gram matrisi",
"U-Net'e attention → Ders 19/23",
]
for y, t in zip(left_ys, left_texts):
boxed_node(ax, left_x, y, left_w, left_h, t,
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=8.4, lw=1.8)
arrow_between(ax, (left_x + left_w / 2, y), (3.55, 4.6),
color=COL_PRIMARY, lw=1.6, mutation_scale=13)
# --- SAĞ İLERİ (rose): ileriye doğru / modern DL ---
right_x, right_w, right_h = 10.15, 4.0, 0.74
right_ys = [5.75, 4.85, 3.95]
right_texts = [
"cross-attention: query=GÖRÜNTÜ,\nkey/value=METİN → text-to-image (L25)",
"einops rearrange = modern DL standardı",
"nn.MultiheadAttention artık kara kutu değil",
]
for y, t in zip(right_ys, right_texts):
boxed_node(ax, right_x, y, right_w, right_h, t,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT,
fontsize=8.8, lw=1.8)
arrow_between(ax, (8.95, 4.6), (right_x - right_w / 2, y),
color=COL_ACCENT, lw=1.7, mutation_scale=14)
# --- ALT: tez vurgusu — büyü = elle kurulan şey ---
boxed_node(
ax, 6.25, 1.3, 9.6, 1.0,
"«kütüphane altındaki büyü = Karpathy'nin elle kurduğu şey» tezi en net BURADA\n"
"«yeniden kur, sonra kullan» iki yönden tamamlandı (METİN tabanı + GÖRÜNTÜ tabanı)",
fc=COL_WHITE, ec=COL_SLATE_400, tc=COL_TEXT,
fontsize=9.6, lw=1.6,
)
arrow_between(ax, (6.25, 3.65), (6.25, 1.8),
color=COL_SLATE_400, lw=1.6, mutation_scale=14)
# --- başlık şeritleri ---
ax.text(2.35, 6.3, "← GERİYE: kurs köprüleri", ha="center", va="center",
fontsize=10, color=COL_PRIMARY, weight="bold")
ax.text(10.15, 6.3, "İLERİYE: modern attention →", ha="center", va="center",
fontsize=10, color=COL_ACCENT, weight="bold")
plt.tight_layout()
plt.show()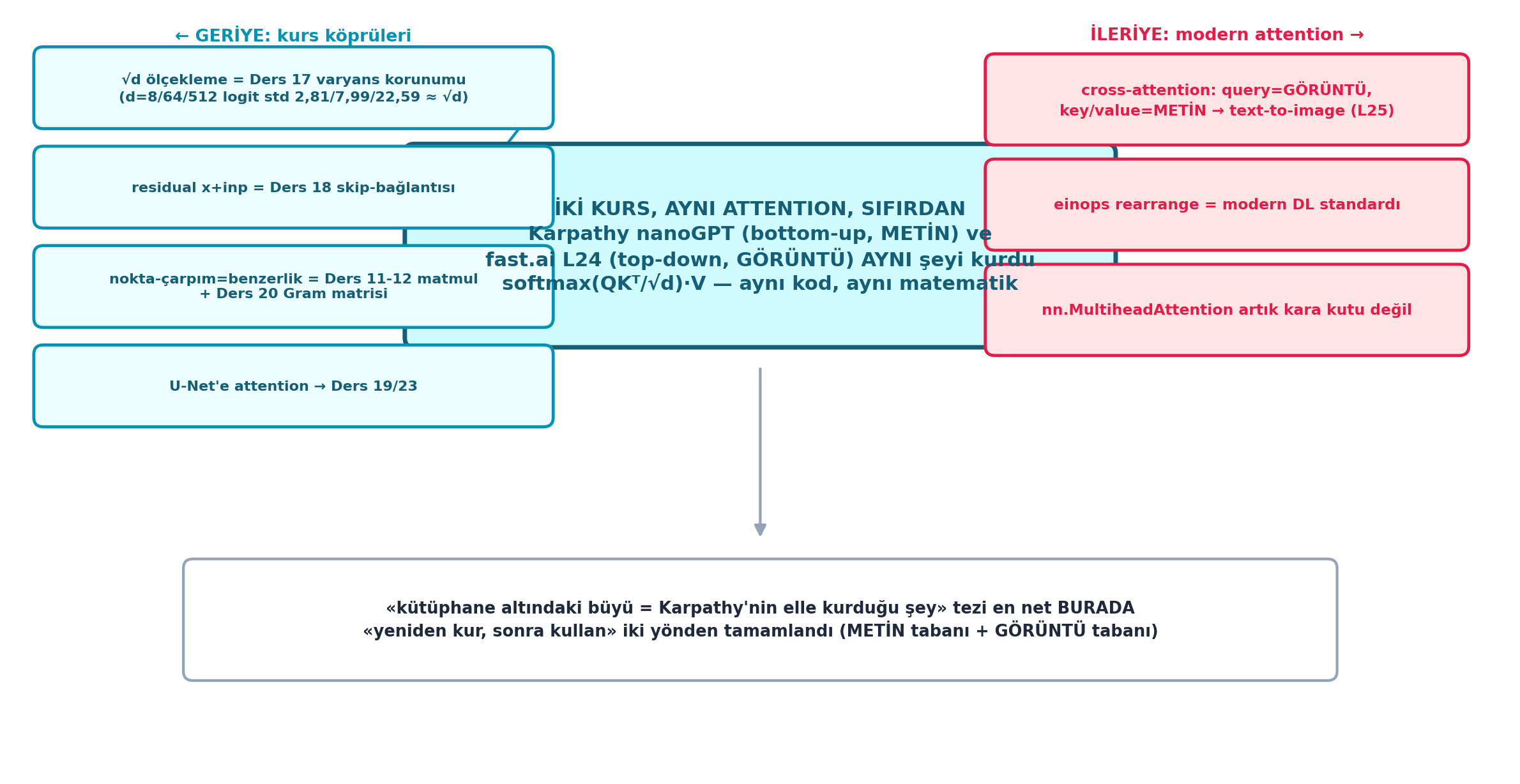
İpucuBuilder Notu — §4.F: Yeniden Kur, Sonra Kullan’ın Doruğu
- Geriye (§4.F): “Yeniden kur, sonra kullan” döngüsü için yeni doruk örnek; attention iki kursta da sıfırdan kuruldu, builder her iki yönden de tam anlıyor.
- Sentez: Sayısal köprü kanıtları (logit std ≈ √d, satır toplamı 1.000, max-prob doygunluğu) Karpathy nanoGPT’siyle aynı matematiğin fast.ai’da çalıştığını gösterir.
27.15 14. miniai/Builder: Yeniden Kur, Sonra Kullan
Attention da miniai felsefesine uyar: önce sıfırdan kur (SelfAttention, multi-head), anla, sonra PyTorch’un hazırını (nn.MultiheadAttention) güvenle kullan. Bu döngü, Part 2’nin omurgasıdır — matmul’dan (L11) attention’a (L24) her şey önce elle kuruldu.
İpucuBuilder Notu — miniai: matmul’dan (L11) attention’a (L24)
- İleriye (Ders 25): Attention hazır; latent diffusion’da metin koşullaması (cross-attention) için kullanılacak — text→image’ın mekanizması.
- Sezgi: L11 matmul → L17 init → L18 residual → L24 attention; her parça elle kuruldu, transformer bloğu bu parçaların birleşimi.
27.16 15. Kapanış
Ders 24 attention’ı sıfırdan kurdu: ağırlıklı ortalama fikri → Q/K/V → dot product benzerlik → softmax(QKᵀ/√d)V → SelfAttention (residual ile) → multi-head (einops) → U-Net’e ekleme → transformer bloğu. Bu, convolution’ın yerelliğini aşan küresel ilişkilendirme mekanizmasıdır ve Karpathy nanoGPT’sinin fast.ai’daki yeniden inşasıdır. L18 residual + L24 attention = transformer.
ÖnemliBuilder Notu — Kapanış: SON DERS’e Hazırız
- İleriye (Ders 25, SON DERS): Tüm parçalar hazır — DDPM (L19), Karras (L22), U-Net (L23), attention (L24); Ders 25 bunları VAE + latent uzayla birleştirip gerçek Stable Diffusion’ı sıfırdan kurar.
- Çekirdek ders: Attention bir ağırlıklı ortalamadır (satır toplamı 1.000); √d = Ders 17 varyans, residual = Ders 18 skip; ikisi + attention = transformer. Karpathy nanoGPT’siyle birebir buluşma — Phase 2’nin iki kursunun tam kesişimi.
27.17 Bu Dersin Özeti
- Convolution yereldir: Sadece komşu pikseller; uzak ilişkiyi yakalayamaz (menzil 3 vs attention 24) (convolution sınırı).
- Attention = ağırlıklı ortalama: Her konum, diğer tüm konumların ağırlıklı ortalamasını alır (uzaklıktan bağımsız) (attention fikri).
- Q/K/V: Query (ne arıyorum), key (ne sunuyorum), value (taşıdığım bilgi); üç lineer projeksiyon (Q/K/V).
- Dot product = benzerlik: Query·key iç çarpımı ilgililik ağırlığını verir (dot product).
- softmax(QKᵀ/√d)V: Benzerliği √d ile ölçekle (varyans korunumu, L17; logit std 2.81/7.99/22.59 ≈ √d), softmax ile ağırlığa çevir (satır toplamı 1.000), value harmanla (formül).
- Residual: Attention
x+inpdöner (L18 skip); bilgi korunur, gradyan akar (residual). - Multi-head: Girdiyi head’lere böl (einops rearrange), her birinde ayrı attention (|korelasyon| 0.181), birleştir; farklı ilişkiler (multi-head).
- Transformer bloğu: residual + attention (L18+L24); Karpathy nanoGPT’siyle birebir (transformer bloğu).
ÖnemliTek Bir Cümle
Attention, her konumun diğer tüm konumların ağırlıklı ortalamasını (softmax(Q·Kᵀ/√d)·V — query·key benzerliğini √d ile ölçekleyip softmax ile ağırlığa çevirip value’ları harmanlayarak; satır toplamı 1.000) alarak convolution’ın yerelliğini aşan küresel ilişkilendirme mekanizmasıdır; residual ile birleşince (L18) transformer bloğunu oluşturur — Karpathy’nin nanoGPT’sinde sıfırdan kurduğu attention’ın fast.ai/miniai’daki birebir yeniden inşası.
27.18 Kontrol Soruları
NotSoru 1: Attention ne yapar ve convolution’dan farkı nedir?
Cevap:
Attention, her konumun (piksel/token) diğer tüm konumların ağırlıklı ortalamasını almasını sağlar — ağırlıklar, o konumun diğerlerine ne kadar “ilgili” olduğuna göre belirlenir. Convolution yereldir: her çıktı yalnızca küçük bir komşuluğa (çekirdek boyutu, örn. 3×3) bakar; uzak iki bölgeyi ilişkilendirmek için bilginin birçok katman boyunca yavaşça yayılması gerekir (Şekil 27.2: conv tek adımda 3 konum). Attention ise uzaklıktan bağımsızdır: bir konum, görüntünün/dizinin herhangi bir yerindeki ilgili bilgiyi tek adımda toplayabilir (figürde attention 24/24 konum; örn. bir yüzün iki gözünün simetrisi, bir cümlenin başı ile sonu arasındaki bağ). Bu yüzden uzun-menzilli bağımlılıklarda (uzun metin, büyük görüntü yapısı) attention çok güçlüdür. İkisi tamamlayıcıdır: modern diffusion U-Net’leri hem convolution (yerel doku) hem attention (küresel yapı) kullanır.
NotSoru 2: Q, K, V nedir ve softmax(QKᵀ/√d)V formülü ne yapar?
Cevap:
Her konum üç lineer projeksiyon üretir: Query (ne arıyorum), Key (ne sunuyorum), Value (taşıdığım bilgi). Formül adım adım: (1) Q·Kᵀ — her query’yi her key ile iç çarp; bu, “hangi konum hangisine ne kadar benzer/ilgili” benzerlik matrisidir (dot product = benzerlik). (2) /√d — boyuta böl; d (özellik boyutu) büyükse iç çarpımlar büyür (Şekil 27.4: logit std 2.81→7.99→22.59 ≈ √d), softmax doygunlaşıp gradyan kaybolur (max-prob 0.484→0.934), √d ile ölçekleme varyansı sabit tutar (~0.16, Ders 17 varyans korunumu). (3) softmax(…) — her satırı olasılığa çevir (toplam 1; Şekil 27.3: satır toplamı 1.000); artık her konum için “diğerlerine ne kadar dikkat etmeli” ağırlıkları. (4) ·V — bu ağırlıklarla value’ları harmanla; her konum, ilgili olduğu konumların value’larının ağırlıklı ortalamasını alır. Sonuç: bağlama duyarlı yeni bir temsil.
NotSoru 3: Transformer bloğu nedir ve hangi iki önceki dersi birleştirir?
Cevap:
Bir transformer bloğu iki residual alt-bloktan oluşur: x = x + attention(x) (konumları birbiriyle ilişkilendirir) ve x = x + mlp(x) (her konumu ayrı işler/dönüştürür). İki dersi birleştirir: Ders 18 residual/skip connection (out = F(x) + x) — bilginin korunması ve gradyanın akması; Ders 24 attention — konumlar arası ilişkilendirme. İkisi birleşince: x = x + attn(x) tam transformer bloğunun kalbidir (Şekil 27.7). Bu yapı sayesinde çok derin transformer’lar (96+ katman GPT) eğitilebilir: attention bilgiyi toplar, residual onu korur. fast.ai bunu görüntü için (diffusion U-Net’inde), Karpathy metin için (nanoGPT’de) kurdu — aynı blok, farklı alan. ResNet (2015, L18) → Transformer (2017, L24) → GPT doğrudan miras zinciridir.
NotSoru 4: Bu ders Karpathy’nin nanoGPT’siyle nasıl tam buluşur? (builder bağlantısı)
Cevap:
Phase 2’nin iki ana kursu (fast.ai top-down + Karpathy bottom-up) attention’da birebir buluşur (Şekil 27.8). Karpathy nanoGPT (bottom-up): self-attention’ı metin için sıfırdan kurdu — Q/K/V projeksiyonları, scaled dot product ([email protected])/√d, (causal) softmax, multi-head paralel attention, residual bağlantı. Howard L24 (top-down): aynı attention’ı görüntü/diffusion için miniai’da yeniden inşa etti — aynı SelfAttention kodu, aynı softmax(QKᵀ/√d)V matematiği (satır toplamı 1.000), aynı multi-head (|korelasyon| 0.181), aynı residual. Tek fark: Karpathy metne (token dizisi), Howard görüntüye (n,c,h,w → uzamsal dizi) uyguladı; matematik özdeştir. Builder içgörüsü: “kütüphane altındaki büyü = Karpathy’nin elle kurduğu şey” tezi en net burada — nn.MultiheadAttention’ın içi, iki kursta da sıfırdan kurduğumuz tam o koddur. “Yeniden kur, sonra kullan” döngüsü, attention’da iki yönden de tamamlanır.
27.19 Egzersizler
Egzersiz 1 (Direkt uygulama). SelfAttention’ı yaz; küçük bir girdiye uygula, benzerlik matrisinin (softmax sonrası) satır toplamlarının 1 olduğunu doğrula (§5, §6).
Egzersiz 2 (İki-aşamalı). Multi-head attention’ı rearrange ile kur; tek-head ve çok-head çıktılarını karşılaştır (head’ler arası |korelasyon|’a bak, §8’deki 0.181 ile kıyasla) (§8, §9).
Egzersiz 3 (Edge case). √d ölçeklemesini kaldır (/self.scale çıkar); büyük d’de softmax’ın nasıl doygunlaştığını (max-prob → 1) ve eğitimin nasıl bozulduğunu gözle (§5’teki 0.484→0.934 ile karşılaştır; Ders 17 varyans bağlantısı) (§5).
Egzersiz 4 (Kavramsal). nn.MultiheadAttention ile kendi SelfAttention’ın aynı sonucu mu verir? Q=K=V verince ne olur (self-attention)? (§10)
Egzersiz 5 (Sonraki dersin habercisi — Ders 25). Attention ile çıktıyı bir metne koşullamak (text→image) nasıl mümkün olur? Query görüntüden, key/value metinden gelirse ne olur, düşün (cross-attention) (§13).
27.20 Sonraki: Ders 25 İçin Hazırlık
Ders 25: Latent Diffusion (SON DERS — Stable Diffusion’ı Sıfırdan Kur)
Ders 24 attention’ı kurdu. Ders 25, kursun SON dersi: tüm parçaları (DDPM, Karras, U-Net, attention) VAE + latent uzayla birleştirip gerçek Stable Diffusion’ı sıfırdan kurar. Diffusion’ı piksel yerine sıkıştırılmış latent uzayda yapmak (hız + çözünürlük) ve metin koşullaması. Ders 9’da kullandığımız SD’yi şimdi kendimiz kuruyoruz — “yeniden kur, sonra kullan” döngüsü tam kapanıyor.
Ana konular (Ders 25):
- VAE (encoder/decoder; piksel → latent → piksel)
- Latent diffusion (diffusion latent uzayda)
- Text conditioning (CLIP — kısmen sonraki kursa)
- Stable Diffusion’ın tam mimarisi (sıfırdan)
UyarıDers 25 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 3 — SelfAttention + √d ölçekleme).
- Ders 15’in autoencoder/VAE sezgisini tekrar oku (latent uzay).
- Ders 9’u (Stable Diffusion’ı kullandık) tekrar gözden geçir — son ders onu sıfırdan kuracak.
27.21 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Attention | Konumların ağırlıklı ortalaması (uzaklıktan bağımsız) | 52:10 |
| Query / Key / Value | Ne arıyorum / ne sunuyorum / taşıdığım bilgi | 1:06:18 |
| Dot product | Q·K iç çarpımı = benzerlik/ilgililik | 57:31 |
| softmax(QKᵀ/√d)V | Ölçekli benzerlik → softmax ağırlık → value harmanı | 1:01:23 |
| √d ölçeklemesi | Varyansı sabit tutar (L17); doygunluğu önler (logit std ≈ √d) | — |
SelfAttention |
q/k/v aynı girdiden; residual ile (x+inp) | 1:01:23 |
| Multi-head | Paralel birden çok attention; farklı ilişkiler (|corr| 0.181) | 1:13:58 |
einops rearrange |
Okunabilir tensör yeniden şekillendirme (head split) | 1:19:31 |
nn.MultiheadAttention |
PyTorch hazır attention (içini biliyoruz) | — |
| Transformer bloğu | residual + attention (L18+L24); nanoGPT’yle birebir | 48:21 |
27.22 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: Attention, Transformer ve İki Kursun Buluşması
Bu ders attention’ı önceki derslerin altyapısına bağlar ve Phase 2’nin iki ana kursunu (fast.ai + Karpathy) tam buluşturur; köprülerin özeti:
- Attention → Karpathy nanoGPT self-attention (MERKEZÎ); aynı kod, aynı matematik (metin↔︎görüntü) (Karpathy köprüsü).
- Transformer bloğu → Ders 18 residual + L24 attention; ResNet→Transformer→GPT zinciri (transformer bloğu).
- √d ölçeklemesi → Ders 17 varyans korunumu; ölçeklenmemiş attention eğitilemez (logit std 2.81/7.99/22.59 ≈ √d) (formül).
- Dot product benzerlik → Ders 11-12 matmul/einsum + Ders 20 Gram; iç çarpım = ilişki (dot product).
- Attention U-Net’te → Ders 19/23 diffusion U-Net; convolution (yerel) + attention (küresel) (U-Net’e ekleme).
- Cross-attention → Ders 25 text→image; query görüntü, key/value metin (Karpathy köprüsü).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten tek bir şey alıp gideceksen: attention bir ağırlıklı ortalamadır. Her konum, diğer tüm konumların value’larını, query·key benzerliğinden gelen ağırlıklarla (softmax(QKᵀ/√d)V; satır toplamı 1.000) harmanlar — convolution’ın yerelliğini (tek adımda 3 konum) aşıp uzak ilişkileri tek adımda yakalar (24/24 konum). √d ölçeklemesi Ders 17’nin varyans korunumudur (logit std 2.81/7.99/22.59 ≈ √d; ölçeksiz max-prob 0.484→0.934 doygunlaşır, /√d ile ~0.16 sabit); residual x+inp Ders 18’in skip’idir; ikisi + attention = transformer bloğu (|head korelasyon| 0.181 ile multi-head farklı ilişkiler yakalar). Ve bu, Karpathy’nin nanoGPT’sinde metin için sıfırdan kurduğu attention’ın, fast.ai’da görüntü için birebir yeniden inşasıdır — Phase 2’nin iki kursunun tam buluştuğu nokta. SON DERS, bunu VAE + latent uzayla birleştirip gerçek Stable Diffusion’ı kuracak.