flowchart TD
MANUAL["manuel .g gradyanları<br/>(Ders 13)<br/>elle forward + backward"] --> LAYER["katman sınıfları<br/>Relu, Lin<br/>__call__ (forward)<br/>+ backward (.g hesapla)"]
LAYER --> MODEL["Model<br/>forward: katmanlar sırayla<br/>backward: reversed(layers)<br/>chain rule otomatik"]
MODEL --> MODULE["Module taban sınıfı<br/>ortak desen soyutlanır<br/>alt sınıf yalnız<br/>forward + bwd yazar"]
MODULE --> NNMODULE["PyTorch nn.Module<br/>backward OTOMATİK<br/>= autograd<br/>(.g'yi sen yazmazsın)"]
NNMODULE --> REGISTER["super().__init__()<br/>parametre kaydı<br/>self.parameters() izler"]
NNMODULE --> REUSE["yeniden kur sonra kullan:<br/>nn.Module artık hazır<br/>(elle kurduk → güvenle kullan)"]
LAYER --> BRIDGE["Karpathy köprüsü:<br/>Module = micrograd<br/>Neuron / Layer / MLP"]
NNMODULE --> BRIDGE
classDef cyan fill:#cffafe,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
class MANUAL,LAYER,MODEL,MODULE,REGISTER,REUSE cyan;
class NNMODULE,BRIDGE rose;
17 Ders 14 — Geri Yayılım: nn.Module’ü Sıfırdan (Backpropagation)
Part 2’nin altıncı dersi backpropagation’ı tamamlar ve temizler. Önce Ders 13’ün manuel backprop’unu chain rule matematiğine satır satır eşler, sonra kodu adım adım refactor eder: tekrar eden ‘girdiyi sakla, gradyanı hesapla’ desenini önce katman sınıflarına, sonra bir Module taban sınıfına, en sonunda PyTorch’un nn.Module’üne taşır. Bu, ‘kendi PyTorch’unu sıfırdan kur’ yolculuğunun zirvesidir — ve Karpathy köprüsünü tamamlar: bizim Module taban sınıfımız, micrograd’ın Neuron/Layer/MLP Module’üyle aynı yapıdır. Tek cümleyle: manuel backprop’u her katmanı forward/backward bilen sınıflara refactor ederek PyTorch’un nn.Module’ünü yeniden kurduk; tek fark, PyTorch’un backward’ı autograd ile otomatik yapması — ama altında tam olarak Ders 13’ün chain rule’u var.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 14: Backpropagation (~109 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 14
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/03_backprop
- Okuma süresi: ~38 dk
- 🔗 Karpathy köprüsü TAMAMLANIR: Bu ders, Ders 13’te merkeze aldığımız Karpathy köprüsünü zirveye taşır. Karpathy micrograd’ın sonunda bir
Moduletaban sınıfı (Neuron/Layer/MLP) kurar; Howard burada aynıModuledesenini kurup PyTorchnn.Module’üne bağlar. İki “from scratch” yolu nn.Module’de buluşur. Bu ders ETAP 4 (Temeller A) finalidir.
17.1 Bu Derste Ne Var?
Part 2’nin altıncı dersi backpropagation’ı tamamlar ve temizler. Önce Ders 13’ün manuel backprop’unu gözden geçirir (chain rule’u matematikle koda eşler), sonra kodu adım adım refactor eder: tekrar eden deseni sınıflara, oradan bir Module taban sınıfına, en sonunda PyTorch’un nn.Module’üne. Bu, “kendi PyTorch’unu sıfırdan kurma” yolculuğunun zirvesidir.
Üç temel fikir bu dersin omurgasını kurar:
- Chain rule ↔︎ kod — Ders 13’ün manuel
.ggradyanlarının her satırı, zincir kuralının bir parçasıdır; math ile kod birebir eşleşir (chain rule eşlemesi → refactor). - Refactoring = soyutlama — her katmanı
forward+backwardbilen bir sınıfa sarmak; tekrar eden “girdiyi sakla, gradyanı hesapla” deseni birModuletaban sınıfında toplanır (katman sınıfları → Module taban). - nn.Module’e varış — kendi Module’ümüz, PyTorch’un
nn.Module’üyle aynı yapıdadır; “yeniden kur, sonra kullan” kuralıyla artık onu güvenle kullanırız (nn.Module → Karpathy köprüsü).
“We had a lesson last time talking about calculus and how we implement the chain rule.” — Howard, 0:36
Şekil 28.1 bu yolculuğu tek bir yol haritasında birleştirir: manuel .g gradyanlarından (Ders 13) katman sınıflarına, Model’e, Module taban sınıfına ve nihayet PyTorch nn.Module’üne (backward’ı otomatik yapar). Karpathy köprüsü tamamlanır: nn.Module = micrograd Neuron/Layer/MLP.
İpucuBuilder Notu — İki « From Scratch » Yolu nn.Module’de Buluşur
- Geriye (Karpathy / Calculus):
Moduletaban sınıfı = Karpathy micrograd’ınınModule’ü; chain rule = Calculus (3Blue1Brown). İki “from scratch” yolu nn.Module’de buluşur — Ders 13’te açtığımız köprü burada kapanır. - İleriye (Ders 15-18): nn.Module hazır olunca, Learner (Ders 16), init/norm (Ders 17), SGD (Ders 18) bunun üstüne kurulur.
- Tek cümle: Manuel backprop’u her katmanı
forward/backwardbilen sınıflara refactor ederek PyTorch’unnn.Module’ünü sıfırdan yeniden kurduk.
17.2 1. Ders 13’ün Gözden Geçirilmesi
Howard Ders 13’ün manuel backprop kodunu ve matematiğini tekrar eder. Amaç: chain rule’un her parçasının kodda nereye karşılık geldiğini netleştirmek. Ders 13’te kurduğumuz forward_and_backward (lin → relu → lin + geri gradyanlar) burada satır satır matematiğe bağlanır.
“Review of code and math from Lesson 13.” — Howard, 0:36
İpucuBuilder Notu — Geri Dönüş: Manuel Backprop’tan Devam
- Geriye (Ders 13): Ders 13’ün
forward_and_backward’ı (manuel.ggradyanları) bu dersin başlangıç noktası; refactor onun üstüne kurulur. - Sezgi: Bir kodu temizlemeden önce onu tam anlaman gerekir; Howard önce eski kodu tekrar edip her satırın “neden orada” olduğunu netleştirir — temiz refactor’un ön koşulu, mevcut davranışı tam kavramaktır.
17.3 2. Chain Rule ↔︎ Kod Eşlemesi
Howard kritik bağı kurar: kaybın ağırlığa göre türevi, zincir kuralıyla parçaların çarpımıdır.
\[\frac{\partial L}{\partial w} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial w}\]
Burada \(\hat{y}\) ağın çıktısı (tahmin); kaybın bu çıktıya göre türevini, çıktının ağırlığa göre türeviyle çarparız. Kodda out.g “loss’un çıktıya göre türevi”dir (∂L/∂çıktı); lin_grad ise bunu ağırlığa/girdiye taşır — lineer katman için ∂çıktı/∂girdi = ağırlık (transpoze). Yani Ders 13’ün her .g satırı, bu çarpımın bir parçasıdır.
“The derivative of the loss with respect to the weights is going to be equal to the derivative of the loss [w.r.t. output] times — this is the chain rule — the derivative of the outputs [w.r.t. weights].” — Howard, 1:43
İpucuBuilder Notu — Math’ten Koda: Her .g Bir Türev Parçası
- Geriye (Calculus): Howard chain rule için 3Blue1Brown’u önerir; “temel türev ve zincir kuralı bilgisi” backprop’u anlamanın ön koşulu.
- Geriye (18.06): Lineer katmanın girdiye göre türevi = ağırlık matrisinin transpozu; bu yüzden
inp.g = out.g @ w.t()— matris kalkülüsünün temel sonucu (18.06).
17.4 3. Refactoring Neden Gerekli?
Manuel backprop çalışır ama tekrar doludur: her katman için “girdiyi sakla, ileri hesapla; sonra gradyanı hesapla”. Howard bu tekrarı temizler — refactoring, kodu daha sade ve yeniden kullanılabilir yapmaktır.
“So let’s start refactoring it. Refactoring is all about making it simpler.” — Howard, 11:02
Şekil 17.2 bu yolculuğu soldan sağa gösterir (FLAGSHIP): manuel backprop (~15 satır, dağınık) → katman sınıfları (~13 satır, tekrarlı desen) → Module taban (~7 satır, tekrar kalktı) → nn.Module (backward = 0 satır, autograd). Her ok bir sadeleşmeyi işaret eder: “tekrarı kaldır”, “ortak deseni topla”, “PyTorch’a bırak”. Alt şerit Karpathy + fast.ai yollarının nn.Module’de buluştuğunu vurgular.
Kod
fig, ax = plt.subplots(figsize=(12.5, 6.5))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 6.5)
ax.axis("off")
# ----------------------------------------------------------------------------
# 4 AŞAMA — soldan sağa: manuel backprop → nn.Module
# Her aşama: başlık + içerik + kod-yoğunluğu rozeti. Son aşama rose vurgulu.
# ----------------------------------------------------------------------------
y_stage = 4.05
bw, bh = 2.65, 2.05
centers = [1.55, 4.55, 7.55, 10.85]
stages = [
("1 · Manuel",
"forward_and_backward\nfonksiyonu;\nher gradyanı elle .g\nile geriye yay",
"kod: ~15 satır,\ndağınık"),
("2 · Katman sınıfları",
"her katman bir nesne:\n__call__ (forward) +\nbackward bilir\n(girdi/çıktıyı saklar)",
"kod: ~13 satır,\ntekrarlı desen"),
("3 · Module taban",
"ortak desen toplanır:\ngirdiyi sakla → forward\nçağır → bwd çağır;\nalt sınıf yalnız fwd+bwd",
"kod: ~7 satır,\ntekrar kalktı"),
("4 · nn.Module (PyTorch)",
"backward OTOMATİK\n(autograd);\nyalnız forward yaz —\nparametreler kendiliğinden",
"kod: yalnız forward,\nbackward = 0 satır"),
]
# ilk 3 aşama cyan, son aşama rose (PyTorch'a varış)
for i, (cx, (title, body, badge)) in enumerate(zip(centers, stages)):
is_last = (i == len(stages) - 1)
fc = COL_BG_ROSE if is_last else COL_BG
ec = COL_ACCENT if is_last else COL_PRIMARY
title_col = COL_ACCENT if is_last else COL_CYAN_700
lw = 2.6 if is_last else 2.0
# ana kutu (gövde metni)
boxed_node(ax, cx, y_stage, bw, bh, body,
fc=fc, ec=ec, tc=COL_TEXT, fontsize=9.2, lw=lw, weight="normal")
# başlık (kutunun üstünde)
ax.text(cx, y_stage + bh / 2 + 0.34, title, ha="center", va="center",
fontsize=11.5, weight="bold", color=title_col)
# kod-yoğunluğu rozeti (kutunun altında)
badge_col = COL_ROSE_500 if is_last else COL_SLATE_400
ax.text(cx, y_stage - bh / 2 - 0.42, badge, ha="center", va="center",
fontsize=8.8, weight="bold", color=COL_CYAN_800 if not is_last else COL_ACCENT,
bbox=dict(boxstyle="round,pad=0.28", fc=COL_WHITE, ec=badge_col, lw=1.3))
# ----------------------------------------------------------------------------
# Aşamalar arası oklar — üstünde "tekrarı kaldır" (kod sadeleşir)
# ----------------------------------------------------------------------------
arrow_labels = ["tekrarı kaldır", "ortak deseni topla", "PyTorch'a bırak"]
for i in range(3):
x0 = centers[i] + bw / 2
x1 = centers[i + 1] - bw / 2
last_arrow = (i == 2)
acol = COL_ACCENT if last_arrow else COL_PRIMARY
arrow_between(ax, (x0, y_stage), (x1, y_stage),
color=acol, lw=2.4, shrink=4)
xmid = (x0 + x1) / 2
ax.text(xmid, y_stage + 0.52, arrow_labels[i], ha="center", va="center",
fontsize=9.2, weight="bold", color=acol, style="italic")
ax.text(xmid, y_stage - 0.52, "kod ↓", ha="center", va="center",
fontsize=9.0, weight="bold", color=COL_SLATE_400)
# ----------------------------------------------------------------------------
# Üst başlık + Karpathy/fast.ai buluşma notu (alt şerit)
# ----------------------------------------------------------------------------
ax.text(0.12, 6.18, "Refactor yolculuğu — kendi PyTorch'unu kur, sonra bırak",
ha="left", va="center", fontsize=12.5, weight="bold", color=COL_CYAN_800)
ax.text(6.25, 1.30,
"İki 'from scratch' yolu — Karpathy (micrograd) + fast.ai —\n"
"aynı yerde buluşur: nn.Module",
ha="center", va="center", fontsize=10.5, color=COL_ACCENT, weight="bold",
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG_ROSE, ec=COL_ROSE_400, lw=1.6))
# Karpathy yolu (sol) → buluşma; fast.ai yolu (sağ) → buluşma (hafif ima okları)
arrow_between(ax, (1.55, y_stage - bh / 2 - 0.95), (5.05, 1.78),
color=COL_ROSE_400, lw=1.6, shrink=6, style="-|>",
connectionstyle="arc3,rad=0.18")
arrow_between(ax, (10.85, y_stage - bh / 2 - 0.95), (7.45, 1.78),
color=COL_ROSE_400, lw=1.6, shrink=6, style="-|>",
connectionstyle="arc3,rad=-0.18")
plt.tight_layout()
plt.show()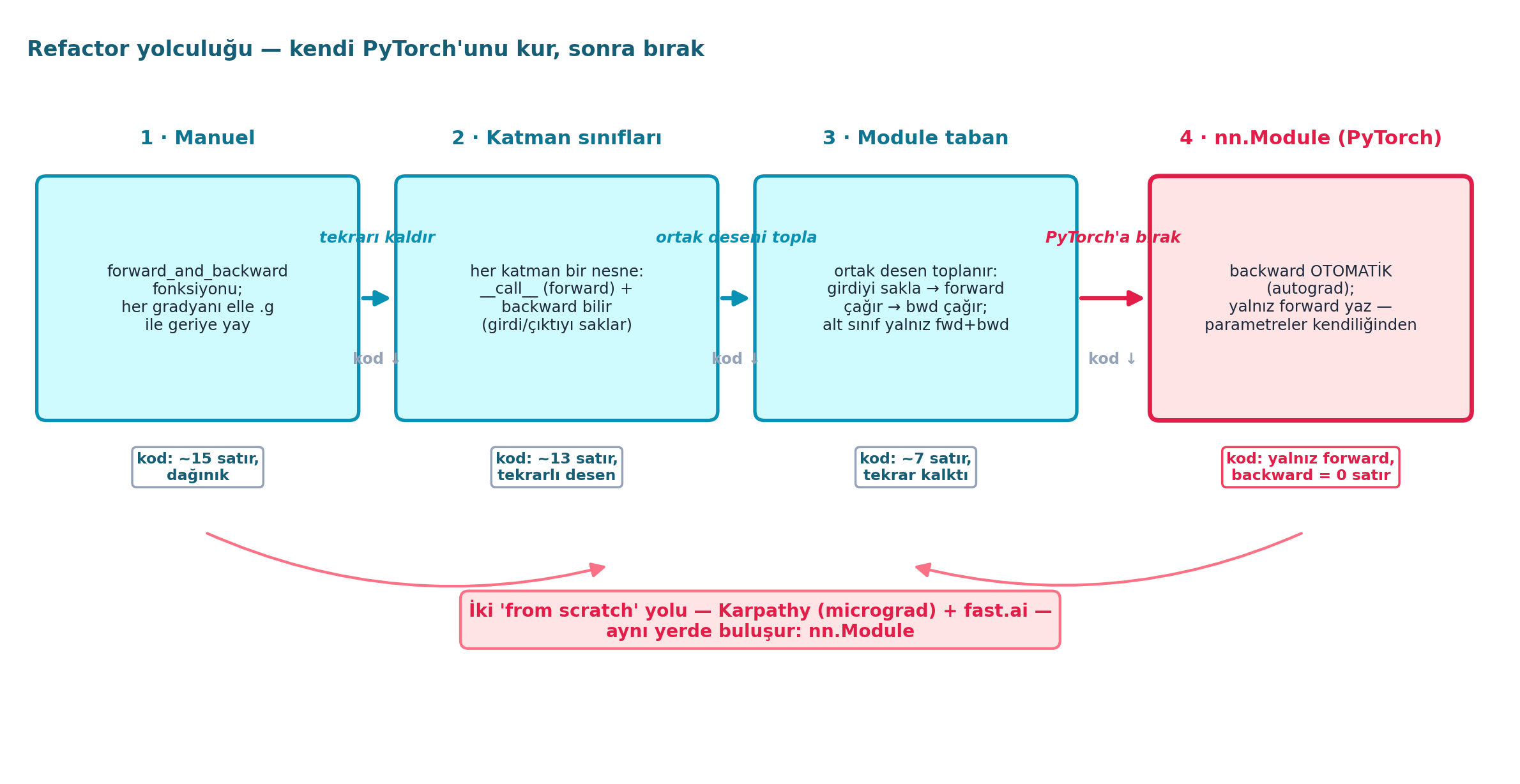
İpucuBuilder Notu — Refactoring: Tekrar Kanıtlandıktan Sonra Soyutla
- İleriye (coding-standards): Refactoring, “üç benzer satırı erken soyutlama” değil; tekrar kanıtlandıktan sonra ortak deseni çıkarmaktır.
- Sezgi: Önce kodu yaz ve çalıştır, sonra tekrarı gör, sonra soyutla — bu sıra, erken soyutlamanın kuracağı yanlış sınırlardan korur. Howard tekrarı önce gözle gösterir, sonra
Moduletabanına taşır.
17.5 4. Katmanları Sınıflara Çevirmek
İlk refactor: her katman bir sınıf olsun, __call__ (forward) ve backward bilsin. __call__ girdiyi saklar ve çıktıyı üretir; backward saklı girdi/çıktıyı kullanıp gradyanı hesaplar.
class Relu():
def __call__(self, inp):
self.inp = inp
self.out = inp.clamp_min(0.)
return self.out
def backward(self): self.inp.g = (self.inp>0).float() * self.out.g
İpucuBuilder Notu — Katman = Nesne: call + backward
- Geriye (Ders 7): PyTorch’ta model = sınıf;
__call__/forward deseni Ders 7’de (collab DotProduct) görülmüştü. - Sezgi: Bir katmanı sınıfa sarmak, “ileri sonucu sakla, geride gradyanı hesapla” mantığını kendi içinde tutar; her katman bağımsız, yeniden kullanılabilir bir nesne olur — Ders 13’ün tek devasa fonksiyonu parçalanır.
17.6 5. Lineer Katman Sınıfı
Aynı desen lineer katman için: __call__ ileri (x@w+b), backward ise girdi/ağırlık/bias gradyanlarını (Ders 13’teki lin_grad) hesaplar.
class Lin():
def __init__(self, w, b): self.w, self.b = w, b
def __call__(self, inp):
self.inp = inp
self.out = lin(inp, self.w, self.b)
return self.out
def backward(self):
self.inp.g = self.out.g @ self.w.t()
self.w.g = self.inp.t() @ self.out.g
self.b.g = self.out.g.sum(0)
İpucuBuilder Notu — Lin Sınıfı: lin_grad Artık Katmanın İçinde
- Geriye (Ders 13):
backwardiçindeki üç satır = Ders 13’ünlin_grad’ı; artık katmanın kendi içinde — girdiye, ağırlığa ve bias’a göre üç gradyan. - Sezgi:
inp.g = out.g @ wᵀgradyanı geriye taşır (chain rule),w.g = inpᵀ @ out.gher ağırlığın katkısını biriktirir,b.g = out.g.sum(0)bias gradyanıdır. Aynı matematik, ama artıkLin’in sorumluluğunda — bu, sorumluluğun katmana yerelleşmesidir.
17.7 6. Model Sınıfı
Katmanları bir listede toplayan Model sınıfı: __call__ katmanları sırayla çalıştırır (forward); backward ise ters sırada her katmanın backward’ını çağırır — chain rule’un “en dıştan içe” yayılımı.
class Model():
def __init__(self, w1, b1, w2, b2):
self.layers = [Lin(w1,b1), Relu(), Lin(w2,b2)]
self.loss = Mse()
def __call__(self, x, targ):
for l in self.layers: x = l(x) # forward: sirayla
return self.loss(x, targ)
def backward(self):
self.loss.backward()
for l in reversed(self.layers): l.backward() # backward: ters sira
İpucuBuilder Notu — reversed(layers): Chain Rule’un Yönü
- Geriye (Karpathy):
reversed(self.layers)= Karpathy’nin topolojik sıralamasının basit hâli; gradyan en dıştan içe akar. - Sezgi: Forward girdiden çıktıya akar, backward ise loss’tan ilk katmana — çünkü bir katmanın gradyanı, kendisinden sonraki katmanın gradyanına (
out.g) bağlıdır.reversed(layers)tam olarak bu bağımlılık sırasını kodlar.
17.8 7. Module Taban Sınıfı
Hâlâ tekrar var: her katman “girdiyi sakla, forward çağır, backward’da gradyanı hesapla” yapıyor. Howard ortak deseni bir Module taban sınıfında toplar: __call__ girdiyi saklayıp forward’ı çağırır; backward ise bwd’yi çağırır. Alt sınıflar yalnızca forward ve bwd yazar.
class Module():
def __call__(self, *args):
self.args = args
self.out = self.forward(*args)
return self.out
def forward(self): raise Exception('not implemented')
def backward(self): self.bwd(self.out, *self.args)
def bwd(self): raise Exception('not implemented')Şekil 17.3 bu deseni şematik gösterir: üstte Module taban sınıfı (cyan) ortak mekaniği — __call__ args’ı saklar → forward çağırır → out döndürür; backward ise bwd’yi çağırır. Altta iki alt sınıf (rose) yalnızca forward + bwd yazar. Taban “sakla/çağır” mekaniğini sağlar; alt sınıflar onu tekrar yazmaz — bu tam olarak PyTorch nn.Module arayüzüdür.
Kod
fig, ax = plt.subplots(figsize=(11.5, 5.5))
ax.set_xlim(0, 11.5)
ax.set_ylim(0, 5.5)
ax.axis("off")
# ----------------------------------------------------------------------------
# ÜST KUTU — Module taban sınıfı (cyan): ortak mekanik (sakla/çağır)
# __call__ args'ı saklar → forward'ı çağırır → out döndürür; backward bwd'yi çağırır
# ----------------------------------------------------------------------------
y_base = 4.30
base_txt = (
"Module taban\n"
"__call__(*args): args'ı sakla → forward(*args) çağır → out döndür\n"
"backward(): bwd(out, *args) çağır"
)
boxed_node(ax, 5.75, y_base, 9.4, 1.45, base_txt,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=10.5, lw=2.4)
ax.text(0.95, 5.20, "ortak mekanik — bir kez yaz", color=COL_CYAN_700,
fontsize=11, weight="bold", ha="left")
# ----------------------------------------------------------------------------
# ALT İKİ KUTU — alt sınıflar (rose): YALNIZCA forward + bwd
# ----------------------------------------------------------------------------
y_sub = 1.55
relu_txt = (
"Relu(Module)\n"
"yalnız forward(inp) = inp.clamp_min(0)\n"
"+ bwd"
)
lin_txt = (
"Lin(Module)\n"
"yalnız forward(inp) = inp@w + b\n"
"+ bwd"
)
boxed_node(ax, 3.05, y_sub, 4.7, 1.35, relu_txt,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10, lw=2.2)
boxed_node(ax, 8.45, y_sub, 4.7, 1.35, lin_txt,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10, lw=2.2)
# ----------------------------------------------------------------------------
# Oklar — taban sınıf saklama/çağırma mekaniğini alt sınıflara SAĞLAR
# ----------------------------------------------------------------------------
arrow_between(ax, (4.55, y_base - 0.725), (3.05, y_sub + 0.675),
color=COL_PRIMARY, lw=2.2, shrink=4)
arrow_between(ax, (6.95, y_base - 0.725), (8.45, y_sub + 0.675),
color=COL_PRIMARY, lw=2.2, shrink=4)
ax.text(5.75, 2.95,
"taban: sakla / çağır mekaniğini sağlar\n(alt sınıflar tekrar yazmaz)",
ha="center", va="center", fontsize=9.5, color=COL_CYAN_800,
weight="bold")
# ----------------------------------------------------------------------------
# Açıklama notu — özel hesap alt sınıfa = PyTorch nn.Module arayüzü
# ----------------------------------------------------------------------------
ax.annotate(
"ortak mekanik tabana, özel hesap alt sınıfa = PyTorch nn.Module arayüzü",
xy=(5.75, 0.55), xytext=(5.75, 0.40),
ha="center", va="center", fontsize=10.5, color=COL_ACCENT,
weight="bold", style="italic",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_WHITE,
ec=COL_ROSE_400, lw=1.4))
plt.tight_layout()
plt.show()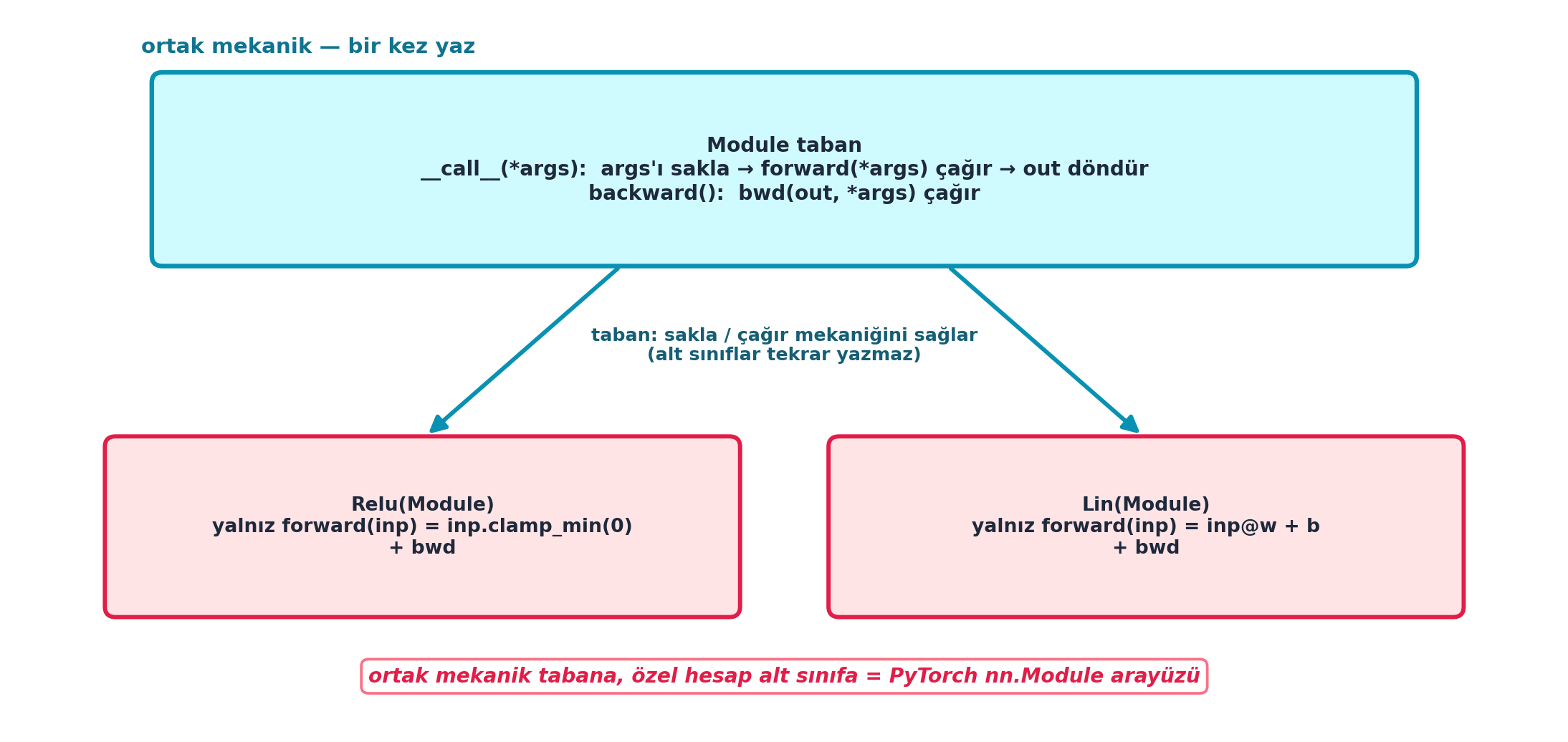
İpucuBuilder Notu — Module Taban: Karpathy micrograd Module’ü
- Geriye (Karpathy): Bu, Karpathy micrograd’ının
Module’üyle aynı fikir; ortak mekaniği taban sınıfa koyup tekrarı kaldırmak. İki “from scratch” yolu burada somut olarak buluşur. - Sezgi: Ortak mekanik (sakla/çağır) tabana, özel hesap (her katmanın
forward/bwd’si) alt sınıfa — bu ayrım, hem tekrarı kaldırır hem de yeni katman eklemeyi (yalnızforward+bwdyaz) kolaylaştırır.
17.9 8. Temiz Alt Sınıflar
Taban sınıf sayesinde katmanlar çok kısalır: yalnızca forward ve bwd.
class Relu(Module):
def forward(self, inp): return inp.clamp_min(0.)
def bwd(self, out, inp): inp.g = (inp>0).float() * out.g
class Lin(Module):
def __init__(self, w, b): self.w, self.b = w, b
def forward(self, inp): return inp@self.w + self.b
def bwd(self, out, inp):
inp.g = out.g @ self.w.t()
self.w.g = inp.t() @ out.g
self.b.g = out.g.sum(0)Şekil 17.4 bu sadeleşmeyi sayıyla gösterir: refactor aşamaları boyunca alt-sınıf kod satırı azalır — Module taban ortak deseni soyutlayınca Relu ve Lin sınıfları kısalır. Tekrar (saklama/çağırma mantığı) tabana çıktığı için alt sınıflar yalnızca kendi işlerini (forward + bwd) yazar.
Kod
d = E.refactor_codesize_demo()
stages = d["stages"]
isimler = [s[0] for s in stages]
relu_lines = [s[1] for s in stages]
lin_lines = [s[2] for s in stages]
fig, ax = plt.subplots(figsize=(9, 5))
x = np.arange(len(stages))
w = 0.36
b1 = ax.bar(x - w / 2, relu_lines, width=w, color=COL_PRIMARY,
edgecolor=COL_CYAN_800, linewidth=1.2, label="Relu sınıfı", zorder=3)
b2 = ax.bar(x + w / 2, lin_lines, width=w, color=COL_ACCENT,
edgecolor=COL_ROSE_500, linewidth=1.2, label="Lin sınıfı", zorder=3)
for bars in (b1, b2):
for r in bars:
h = r.get_height()
ax.text(r.get_x() + r.get_width() / 2, h + 0.18, f"{int(h)}",
ha="center", va="bottom", fontsize=10.5, weight="bold",
color=COL_TEXT, zorder=4)
ax.set_xticks(x)
ax.set_xticklabels(isimler, fontsize=9.5, color=COL_TEXT)
ax.set_ylabel("alt-sınıf kod satırı (~)", fontsize=11)
ax.set_title("Refactor yolculuğu: Module taban'a doğru alt sınıflar kısalır",
fontsize=12.5, color=COL_CYAN_800, weight="bold", pad=12)
ax.set_ylim(0, max(lin_lines) + 2.4)
ax.legend(loc="upper right", frameon=True, fontsize=10)
apply_style(ax)
ax.grid(True, axis="y", alpha=0.22, color=COL_SLATE_400)
ax.grid(False, axis="x")
# azalma yönü oku (ilk aşama Lin tepesi → son aşama Lin tepesi)
arrow_between(ax,
(x[0] + w / 2, lin_lines[0] + 1.3),
(x[2] + w / 2, lin_lines[2] + 1.3),
color=COL_CYAN_700, lw=2.0, mutation_scale=16,
shrink=6, connectionstyle="arc3,rad=-0.18", zorder=2)
ax.annotate(
"Module taban'a doğru alt sınıflar kısalır\n(ortak mekanik soyutlandı)",
xy=(x[2] + w / 2, lin_lines[2] + 1.3),
xytext=(x[1] - 0.10, max(lin_lines) + 1.4),
ha="center", va="bottom", fontsize=9.8, color=COL_CYAN_800, weight="bold",
zorder=5)
plt.tight_layout()
plt.show()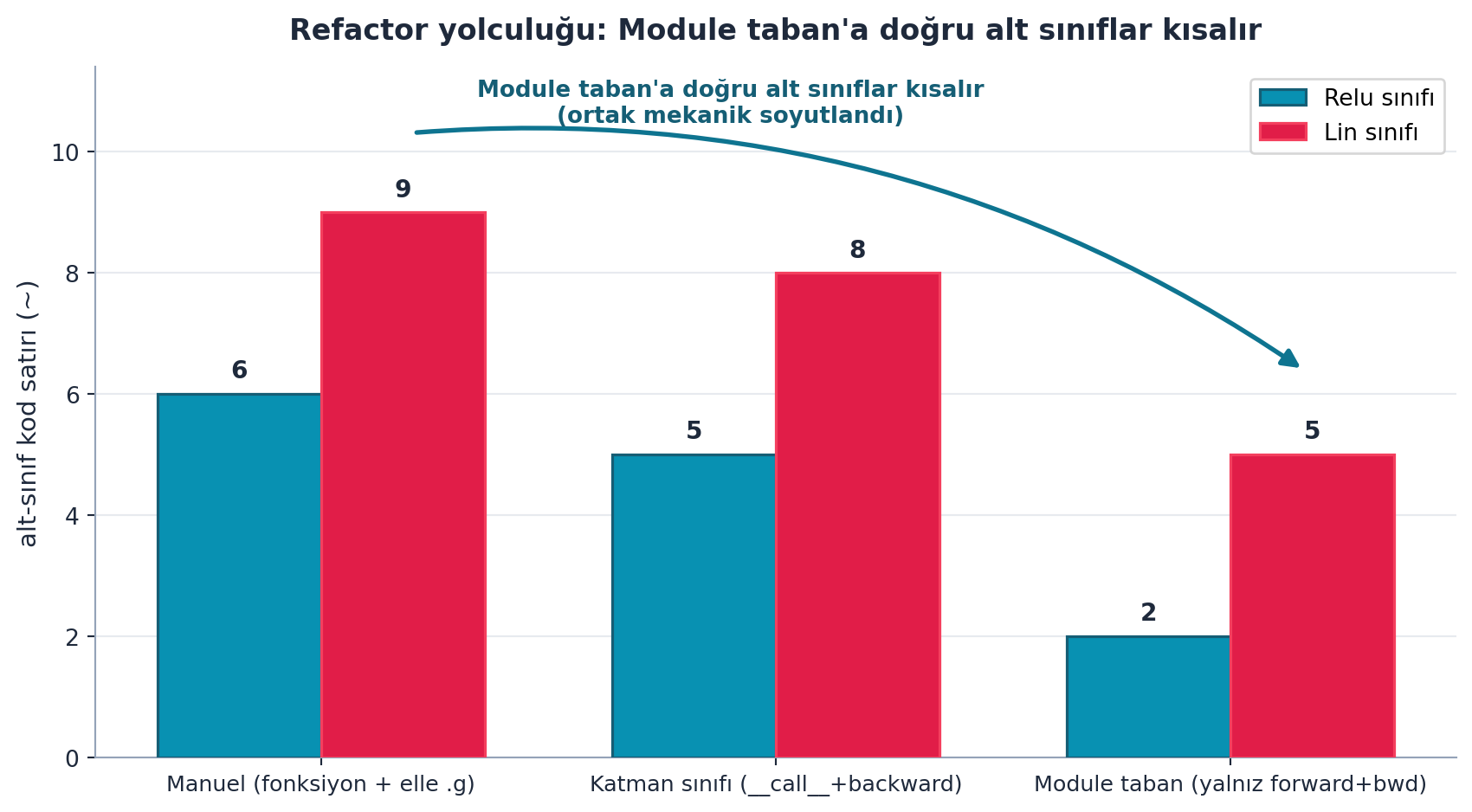
İpucuBuilder Notu — Alt Sınıflar: forward + bwd = nn.Module Arayüzü
- İleriye: Her katman =
forward+bwd; bu tam olarak PyTorch’unnn.Modulearayüzü (forward + autograd backward). - Sezgi: Kodun kısalması yan ürün değil amaç: her katman artık yalnızca “ne hesaplar” (forward) ve “gradyanı nasıl geçirir” (bwd) sorularını yanıtlar; mekanik altyapı görünmez olur — okunabilirlik ve bakım kolaylaşır.
17.10 9. PyTorch nn.Module
Howard son adımı atar: kendi Module’ümüz zaten PyTorch’un nn.Module’üyle aynı yapıda. Tek fark: PyTorch backward’ı otomatik yapar (autograd) — bwd yazmamıza gerek yok, sadece forward yeter.
“If we create a model in PyTorch, you have to make Module your super class. This is actually fastai’s version of Module, but it’s nearly the same as PyTorch’s.” — Howard, 11:02
Şekil 17.5 bu “tek farkı” görselleştirir: üstte bizim Module (cyan) — forward yaz + bwd’yi elle yaz; altta PyTorch nn.Module (rose) — yalnız forward yaz, requires_grad_() işaretle, loss.backward() otomatik. İki “backward” kutusu dikey bağlanır: tek fark backward’ın otomatik olması. Ama altında Ders 13’ün manuel chain rule’u var (∂L/∂w = yerel türevlerin çarpımı, aynı matematik).
Kod
fig, ax = plt.subplots(figsize=(11.5, 5.5))
bw, bh = 2.7, 1.0 # adım kutusu boyutu
# === ÜST PANEL: "Bizim Module" (cyan) — backward'ı ELLE yazarız ============
yt = 4.35
boxed_node(ax, 1.95, yt, 2.5, 0.85, "Bizim\nModule",
fc=COL_CYAN_700, ec=COL_CYAN_800, tc=COL_WHITE, fontsize=12, lw=2.2)
boxed_node(ax, 5.55, yt, bw, bh, "forward yaz\n(ileri geçiş)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=10)
boxed_node(ax, 9.15, yt, bw + 0.35, bh,
"bwd ELLE yaz\ngradyanı kendin hesapla",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.8)
arrow_between(ax, (1.95, yt), (5.55, yt), color=COL_CYAN_700, lw=2.2)
arrow_between(ax, (5.55, yt), (9.15, yt), color=COL_CYAN_700, lw=2.2)
# === ALT PANEL: "PyTorch nn.Module" (rose) — backward OTOMATİK =============
yb = 1.65
boxed_node(ax, 1.95, yb, 2.5, 0.85, "PyTorch\nnn.Module",
fc=COL_ACCENT, ec=COL_ROSE_500, tc=COL_WHITE, fontsize=11.5, lw=2.2)
boxed_node(ax, 5.55, yb, bw, bh, "yalnız\nforward yaz",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ROSE_500, fontsize=10)
boxed_node(ax, 9.15, yb, bw + 0.35, bh,
"requires_grad_() işaretle\nloss.backward() OTOMATİK",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ROSE_500, fontsize=9.4)
arrow_between(ax, (1.95, yb), (5.55, yb), color=COL_ACCENT, lw=2.2)
arrow_between(ax, (5.55, yb), (9.15, yb), color=COL_ACCENT, lw=2.2)
# autograd etiketi (alt panel son okun yanında)
ax.text(9.15, yb - 0.78, "autograd: chain rule'u senin yerine uygular",
ha="center", va="top", fontsize=9.5, color=COL_ROSE_500, weight="bold")
# === TEK FARK vurgusu: iki "backward" kutusunu dikey bağla ================
arrow_between(ax, (9.15, yt - bh / 2), (9.15, yb + bh / 2),
color=COL_SLATE_400, lw=2.0, style="<|-|>",
connectionstyle="arc3,rad=0.0", shrink=4)
ax.text(10.95, (yt + yb) / 2,
"tek fark:\nbackward\nOTOMATİK",
ha="center", va="center", fontsize=10, color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_WHITE, ec=COL_SLATE_300, lw=1.3))
# === ALTTAKİ ORTAK KATMAN: aynı chain rule (Ders 13) ======================
ax.text(5.55, 0.35,
"ama ALTINDA Ders 13'ün manuel chain rule'u var — "
"∂L/∂w = yerel türevlerin çarpımı (aynı matematik)",
ha="center", va="center", fontsize=10.5, color=COL_CYAN_800, weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_CYAN_50,
ec=COL_PRIMARY, lw=1.6))
# Başlık + köprü notu
ax.set_title("autograd 'sihri' = otomatikleştirilmiş chain rule",
fontsize=15, weight="bold", color=COL_CYAN_800, pad=14)
ax.text(5.55, 5.18,
"elle kurduk (Ders 13) → artık loss.backward() güvenle çağrılır",
ha="center", va="center", fontsize=10.5, color=COL_TEXT)
ax.set_xlim(0.2, 12.2)
ax.set_ylim(-0.1, 5.5)
ax.axis("off")
plt.tight_layout()
plt.show()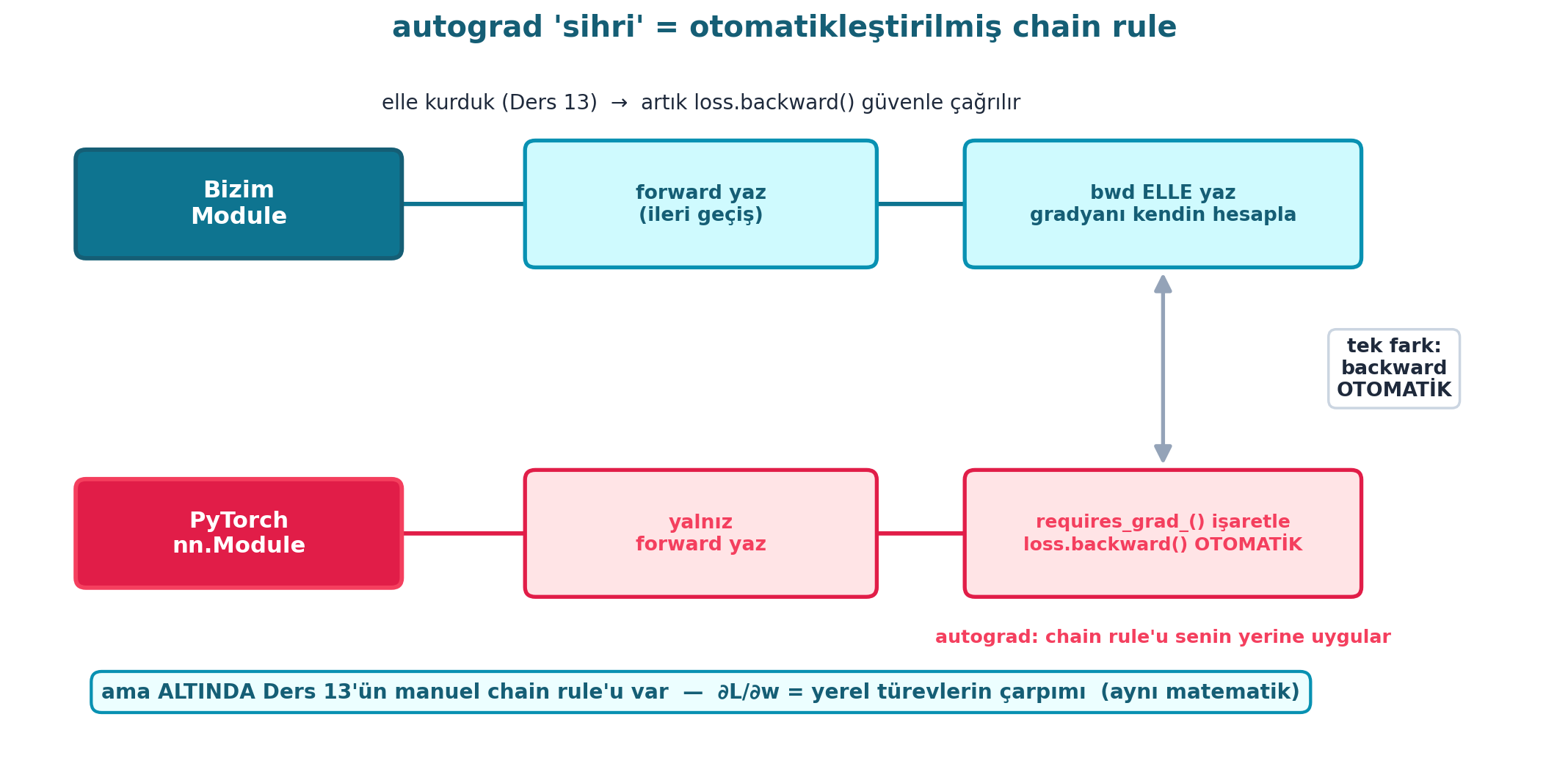
İpucuBuilder Notu — nn.Module: Yeniden Kur, Sonra Kullan (Zirve)
- Geriye (Ders 10): “Yeniden kur, sonra kullan” kuralı zirvede: nn.Module’ü sıfırdan kurduk, artık güvenle kullanabiliriz.
- Sezgi: PyTorch nn.Module’ünü “büyü” gibi kullanmak yerine onu sıfırdan kurmak, tek fark olan autograd’ı (otomatik backward) bir kara kutu olmaktan çıkarır — altında ne olduğunu (Ders 13 chain rule) tam bilirsin.
17.11 10. nn.Module ile Linear ve Model
PyTorch nn.Module versiyonu: super().__init__() çağrılır, ağırlıklar requires_grad_() ile işaretlenir (autograd izlesin), yalnızca forward yazılır. backward PyTorch’a bırakılır.
class Linear(nn.Module):
def __init__(self, n_in, n_out):
super().__init__()
self.w = torch.randn(n_in, n_out).requires_grad_()
self.b = torch.zeros(n_out).requires_grad_()
def forward(self, inp): return inp@self.w + self.b
class Model(nn.Module):
def __init__(self, n_in, nh, n_out):
super().__init__()
self.layers = [Linear(n_in,nh), nn.ReLU(), Linear(nh,n_out)]
def __call__(self, x, targ):
for l in self.layers: x = l(x)
return F.mse_loss(x, targ[:,None])
İpucuBuilder Notu — nn.Module: Manuel bwd Artık Yok
- Geriye (Ders 13): Manuel
bwdartık yok;requires_grad_()+loss.backward()(autograd) onu otomatik yapar — ama altında Ders 13’ün chain rule’u var. - Sezgi: Yalnızca
forwardyazarsın;requires_grad_()ile işaretlenen ağırlıklar için PyTorch grafı izler veloss.backward()’ta tüm zincir kuralını uygular. “Gradyanlar bedava gelir” — ama bedavalığın bedeli bir kez elle kurmuş olmaktır.
17.12 11. super().__init__() {#sec-super}
Howard PyTorch nesne-yönelimli detayına değinir: nn.Module’den miras alan bir sınıf, __init__’inde mutlaka super().__init__() çağırmalıdır — bu, PyTorch’un parametreleri izlemesini sağlayan altyapıyı kurar. Atlanırsa parametreler kaydedilmez.
Şekil 17.6 bunu gerçek hesaplama ile kanıtlar: super().__init__() VAR ise 39.760 parametre kayıtlı (Linear(784,50) = 39.250 + Linear(50,10) = 510); YOK ise model.parameters() boş (0) — registry hiç kurulmaz. Yani bu çağrı, parametre kayıt altyapısını kuran zorunlu satırdır; atlanırsa parametreler izlenmez ve eğitilmez.
Kod
d = E.param_registration_demo()
with_super = d["with_super"] # 39760 — hepsi kayıtlı
without_super = d["without_super"] # 0 — registry kurulmaz
layers = d["layers"] # [("Linear(784,50)", 39250), ("Linear(50,10)", 510)]
fig, (ax_l, ax_r) = plt.subplots(
1, 2, figsize=(10.5, 5), gridspec_kw={"width_ratios": [1.35, 1.0]}
)
# --- Sol panel: iki durum karşılaştırması (VAR vs YOK) -----------------------
cases = [
"super().__init__()\nVAR",
"super().__init__()\nYOK",
]
values = [with_super, without_super]
colors = [COL_PRIMARY, COL_ACCENT]
xpos = [0, 1]
bars = ax_l.bar(xpos, values, width=0.56, color=colors,
edgecolor=COL_TEXT, linewidth=1.2, zorder=3)
ax_l.set_xticks(xpos)
ax_l.set_xticklabels(cases, fontsize=10.5, color=COL_TEXT, weight="bold")
ax_l.set_ylabel("model.parameters() — kayıtlı parametre sayısı",
fontsize=10, color=COL_TEXT)
ax_l.set_ylim(0, with_super * 1.22)
apply_style(ax_l)
ax_l.grid(True, axis="y", alpha=0.2, color=COL_SLATE_400)
ax_l.grid(False, axis="x")
# VAR çubuğu etiketi
ax_l.text(0, with_super + with_super * 0.03,
f"{with_super:,} param".replace(",", "."),
ha="center", va="bottom", fontsize=11, weight="bold", color=COL_CYAN_800)
ax_l.text(0, with_super * 0.5, "parametreler\nKAYITLI\n(izlenir, eğitilir)",
ha="center", va="center", fontsize=9.5, weight="bold", color=COL_WHITE)
# YOK çubuğu (sıfır) — boş registry vurgusu
ax_l.text(1, with_super * 0.06, "0",
ha="center", va="bottom", fontsize=13, weight="bold", color=COL_ACCENT)
ax_l.text(1, with_super * 0.30,
"registry kurulmaz\nmodel.parameters()\nBOŞ",
ha="center", va="center", fontsize=9.5, weight="bold", color=COL_ACCENT,
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BG_ROSE,
ec=COL_ROSE_500, lw=1.4))
ax_l.set_title("Parametre kaydı: super().__init__() VAR mı YOK mu?",
fontsize=11, weight="bold", color=COL_TEXT, pad=10)
# --- Sağ panel: katman dökümü (VAR durumu toplamı nasıl çıkıyor) -------------
lab = [name for name, _ in layers] + ["Toplam"]
cnt = [p for _, p in layers] + [with_super]
ypos = list(range(len(lab)))[::-1]
bar_cols = [COL_CYAN_400, COL_CYAN_400, COL_PRIMARY]
ax_r.barh(ypos, cnt, height=0.52, color=bar_cols,
edgecolor=COL_TEXT, linewidth=1.0, zorder=3)
ax_r.set_yticks(ypos)
ax_r.set_yticklabels(lab, fontsize=10, color=COL_TEXT, weight="bold")
ax_r.set_xlim(0, with_super * 1.30)
ax_r.set_xlabel("parametre sayısı (ağırlık + bias)", fontsize=10, color=COL_TEXT)
apply_style(ax_r)
ax_r.grid(True, axis="x", alpha=0.2, color=COL_SLATE_400)
ax_r.grid(False, axis="y")
for y, v in zip(ypos, cnt):
ax_r.text(v + with_super * 0.02, y, f"{v:,}".replace(",", "."),
va="center", ha="left", fontsize=10, weight="bold", color=COL_TEXT)
ax_r.set_title("Katman dökümü (kayıtlı parametreler)",
fontsize=11, weight="bold", color=COL_TEXT, pad=10)
# --- Alt açıklama (annotate): mekanizmanın özeti -----------------------------
fig.text(
0.5, -0.02,
"nn.Module super().__init__() parametre kayıt altyapısını kurar; "
"atlanırsa parametreler izlenmez/eğitilmez.",
ha="center", va="top", fontsize=9.8, style="italic", color=COL_CYAN_800,
wrap=True,
)
plt.tight_layout()
plt.show()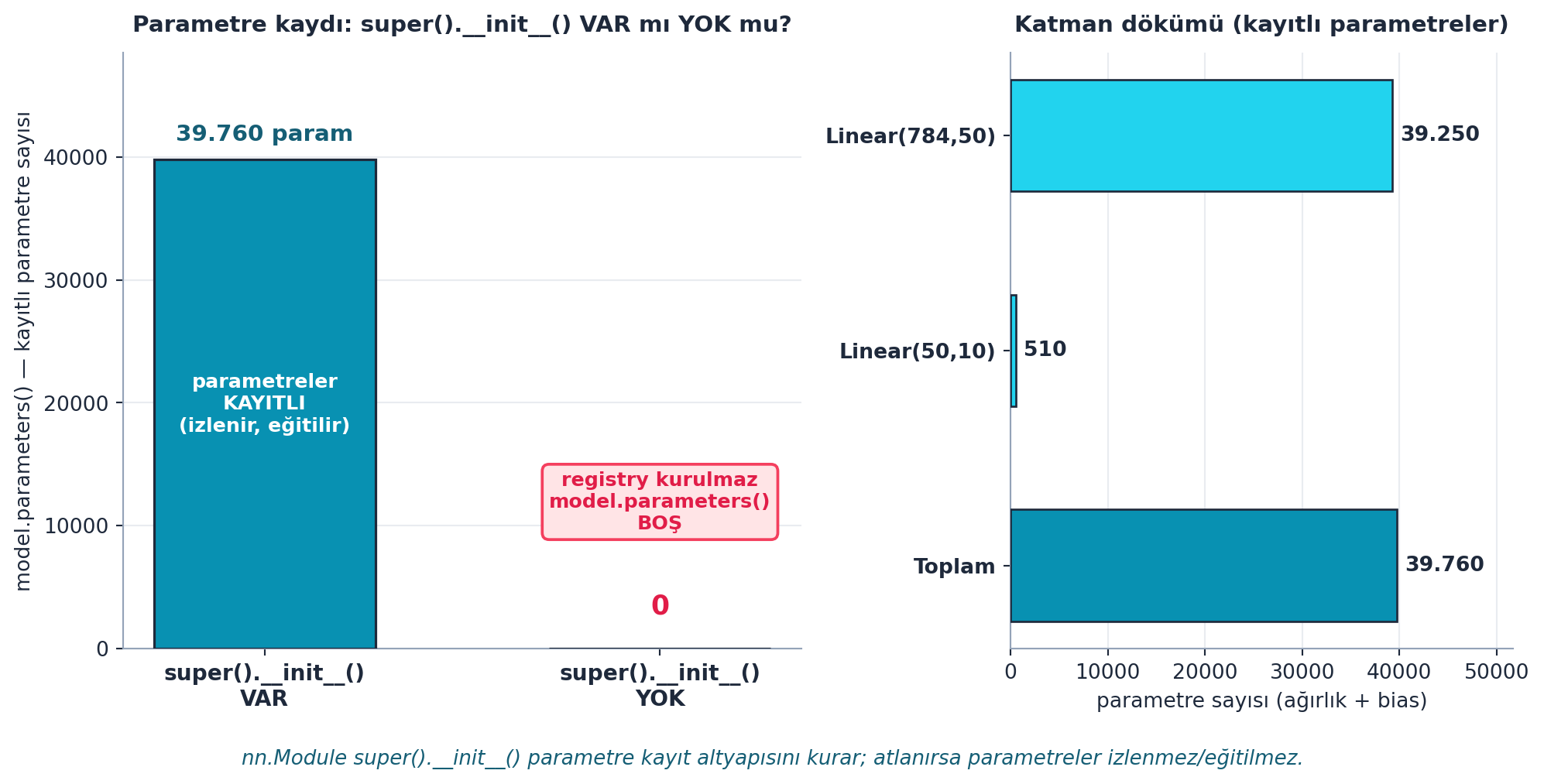
İpucuBuilder Notu — super().__init__(): Parametre Kaydının Anahtarı
- Geriye (Python): super() = üst sınıfın kurucusu; nn.Module’ün parametre kayıt mekanizması için zorunlu.
- Sezgi:
nn.Module.__init__bir parametre registry’si (_parameterssözlüğü) kurar;super().__init__()atlanırsa bu registry hiç oluşmaz,self.w = ...ataması hiçbir yere “kaydedilmez” —model.parameters()boş döner, optimizer hiçbir şeyi eğitemez. Şekil 17.6 bu sessiz başarısızlığı sayıyla gösterir.
17.13 12. requires_grad_ ve Autograd
requires_grad_(), bir tensöre “senin gradyanını izle” der. Sonra loss.backward() çağrıldığında PyTorch, Ders 13’te elle yaptığımız tüm chain rule adımlarını otomatik yapar ve gradyanları .grad’a yazar.
“Just call .backward() [and PyTorch does the chain rule for us].” — Howard
Şekil 17.7 refactor’un doğruluğu bozmadığını gerçek hesaplama ile kanıtlar: Module yapısına geçtikten sonra da backprop gradyanları sayısal türevle ~1e-11 hassasiyetle EŞLEŞİR — yani yapı değişti, chain rule aynı kaldı. Log-skala barlar tüm parametreler için maksimum farkı 1e-4 tolerans çizgisinin çok solunda gösterir. Bu, Ders 13’ün cmp emsalinin devamıdır: refactor kodu sadeleştirir ama gradyan matematiğini değiştirmez.
Kod
d = E.manual_backprop_demo()
checks = d["checks"] # [(ad, maxdiff, match), ...]
names = [c[0] for c in checks]
diffs = [c[1] for c in checks] # ~1e-11
tol = 1e-4 # cmp tolerans çizgisi
fig, ax = plt.subplots(figsize=(10, 5))
apply_style(ax)
y = np.arange(len(names))
bar_colors = [COL_PRIMARY, COL_CYAN_400]
ax.barh(y, diffs, height=0.52, color=bar_colors, edgecolor=COL_CYAN_800,
linewidth=1.4, zorder=3, log=True)
# tolerans çizgisi (1e-4): bunun ALTINDA kalmak = EŞLEŞTİ
ax.axvline(tol, color=COL_ACCENT, lw=2.4, ls="--", zorder=4)
ax.text(tol, len(names) - 0.40, "tolerans 1e-4", color=COL_ACCENT,
fontsize=10.5, weight="bold", ha="right", va="center", rotation=0)
# her çubuğun ucuna maxdiff değeri + EŞLEŞTİ rozeti
for i, (nm, md, match) in enumerate(checks):
ax.text(md * 1.6, i, f"{md:.2e}", va="center", ha="left",
fontsize=10, weight="bold", color=COL_TEXT, zorder=5)
badge = "EŞLEŞTİ ✓" if match else "FARK ✗"
bcol = COL_PRIMARY if match else COL_ACCENT
ax.text(0.985, i, badge, transform=ax.get_yaxis_transform(),
va="center", ha="right", fontsize=10.5, weight="bold",
color=COL_WHITE, zorder=6,
bbox=dict(boxstyle="round,pad=0.34", fc=bcol, ec=bcol))
ax.set_yticks(y)
ax.set_yticklabels(names, fontsize=11, color=COL_TEXT)
ax.invert_yaxis()
ax.set_xscale("log")
ax.set_xlim(1e-12, 1e-2)
ax.set_xlabel("manuel (Module) gradyan ↔ sayısal türev maksimum farkı (LOG ölçek)",
fontsize=10.5)
ax.set_title("Refactor sonrası backprop HÂLÂ doğru — Module yapısı chain rule'u bozmaz",
fontsize=12, weight="bold", color=COL_CYAN_800, pad=12)
ax.grid(True, axis="x", which="both", alpha=0.20, color=COL_SLATE_400)
ax.grid(False, axis="y")
ax.annotate(
"refactor kodu sadeleştirir ama chain rule AYNI;\n"
"backprop doğruluğu korunur (Ders 13 cmp'sinin devamı)",
xy=(diffs[1] * 1.6, 1), xycoords="data",
xytext=(0.05, 0.16), textcoords="axes fraction",
fontsize=10, color=COL_CYAN_800, weight="bold",
ha="left", va="center",
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_PRIMARY, lw=1.5),
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.8,
connectionstyle="arc3,rad=-0.25"))
plt.tight_layout()
plt.show()
İpucuBuilder Notu — Autograd: Otomatikleşmiş Chain Rule
- Geriye (Ders 5/13): Ders 5’te
requires_grad_()+backward()’ı kullanmıştık; şimdi altında ne olduğunu (Ders 13 manuel backprop) biliyoruz. - Sezgi: Autograd “sihir” değil, otomatikleştirilmiş chain rule; Şekil 17.7 elle hesabın refactor sonrası bile sayısal türevle eşleştiğini gösterdiği an,
loss.backward()artık anladığın bir araçtır — kara kutu değil.
17.14 13. Hazır Parçalar: F.mse_loss, nn.ReLU
nn.Module’e geçince hazır parçaları da kullanabiliriz: nn.ReLU() (ReLU katmanı), F.mse_loss (MSE kaybı). Hepsini sıfırdan kurduğumuz için artık güvenle kullanırız.
İpucuBuilder Notu — Hazır Parçalar: Kurduktan Sonra Kullanma Hakkı
- Geriye (Ders 10 kuralı): Relu, MSE, Linear, backward — hepsini elle kurduk; şimdi PyTorch’un optimize versiyonlarını kullanmaya hak kazandık.
- Sezgi:
nn.ReLU()veF.mse_loss’u sıfırdan kurduğumuz için içlerinde ne olduğunu biliriz; bir gün beklenmedik davranış görürsek (sayısal kararlılık, kenar durumlar) nereye bakacağımızı biliriz — kütüphane bizim için artık “okuyabildiğimiz kod”.
17.15 14. Minibatch Eğitime Doğru
Howard sonraki adımı işaret eder: model nn.Module olunca, bir eğitim döngüsü (minibatch, optimizer, dataloader) kurmak gerekir. Şu anki kod tüm veriyi tek batch’te işliyor; sonraki notebook (04) minibatch eğitimi kurar.
İpucuBuilder Notu — Minibatch: nn.Module’ün Üstündeki Katman
- İleriye (Ders 16): Eğitim döngüsü → callback’ler → Learner (Ders 16); nn.Module bunların temeli.
- Sezgi: nn.Module bir modeli temsil eder ama henüz “eğitmez”; eğitim döngüsü (veriyi minibatch’lere böl, ileri geçiş,
loss.backward(), optimizer adımı) bir sonraki soyutlama katmanıdır — ve hepsi nn.Module’ün üstüne kurulur.
17.16 15. Karpathy Köprüsü: nn.Module
Bu ders, Karpathy köprüsünü tamamlar. Karpathy micrograd’da bir Module taban sınıfı (Neuron/Layer/MLP) kurar; Howard burada aynı Module desenini kurup PyTorch nn.Module’üne bağlar. İki seri de “katman = forward + backward bilen nesne” fikrine varır.
Ders 13’te köprüyü açmıştık: Howard’ın manuel .g gradyanları = Karpathy’nin _backward kapanışları. Bu derste köprü kapanır: Howard’ın Module taban sınıfı = Karpathy’nin Module’ü (Neuron/Layer/MLP). İki “from scratch” yolu, nn.Module ortak noktasında buluşur — ikisi de aynı yapıya, farklı bir API’den varır.
İpucuBuilder Notu — Karpathy Köprüsü: İki Yol, Aynı Module
- Geriye (Karpathy 1): Karpathy Ders 1’in son bölümü (Neuron/Layer/MLP + PyTorch karşılaştırması) = bu dersin birebir akrabası; nn.Module ikisinin buluşma noktası.
- Sezgi: Karpathy “tek skaler değerden” (Value), Howard “tensörden” (matris) yola çıkar; ama ikisi de aynı
Moduledesenine (forward + backward bilen, çağrılabilir katman) ulaşır. Farklı ölçek, aynı soyutlama — bu, deseni gerçekten anladığının kanıtıdır.
17.17 16. Kapanış
Ders 14 backprop’u tamamladı ve “kendi PyTorch’unu kurma” yolculuğunu zirveye taşıdı: manuel .g gradyanları → forward/backward sınıfları → Module taban sınıfı → PyTorch nn.Module. Artık nn.Module’ü, autograd’ı ve loss.backward()’ı güvenle kullanabiliriz çünkü altında tam olarak ne olduğunu sıfırdan kurduk.
Şekil 17.8 dersin sentezidir (Karpathy köprüsü merkezde, Temeller A kapanır): solda L14’ün parçaları (Module taban sınıfı, forward sıralı/backward reversed, nn.Module + autograd, lin_grad, “elle kur → kullan”), sağda her birinin kaynağı/karşılığı — Module taban = Karpathy micrograd Module (Neuron/Layer/MLP, BİREBİR aynı, iki “from scratch” burada buluşur), reversed = Karpathy topolojik sıralama, nn.Module+autograd = Ders 13 manuel chain rule (kütüphanede otomatik), lin_grad = 18.06 matris kalkülüsü, “elle kur → kullan” = Ders 10 zirvesi. Ortada vurgu: Temeller A biter (matmul → mean shift → backprop → nn.Module).
Kod
fig, ax = plt.subplots(figsize=(12, 6.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.5)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# Başlıklar (sütun etiketleri)
ax.text(2.45, 6.32, "L14'te (fast.ai)", ha="center", va="center",
fontsize=14, weight="bold", color=COL_ROSE_500)
ax.text(9.15, 6.32, "karşılığı / kaynak", ha="center", va="center",
fontsize=14, weight="bold", color=COL_CYAN_700)
# Sütun konumları ve kutu boyutları
left_x, lw_box, lh_box = 2.45, 4.0, 0.82
right_x, rw_box, rh_box = 9.15, 4.9, 0.94
ys = [5.45, 4.42, 3.39, 2.36, 1.33]
# SOL sütun (L14-parçaları, rose)
left_labels = [
"Module taban sınıfı",
"forward sıralı / backward reversed",
"nn.Module + autograd",
"lin_grad (out.g @ wᵀ)",
"elle kur → kullan",
]
# SAĞ sütun (kaynak / karşılık, cyan)
right_labels = [
"Karpathy micrograd Module (Neuron/Layer/MLP)\nBİREBİR aynı desen — iki 'from scratch' BURADA buluşur",
"Karpathy topolojik sıralama\n(gradyan en dıştan içe)",
"Ders 13 manuel chain rule\nkütüphanede otomatik",
"18.06 matris kalkülüsü\n(transpoze gradyan)",
"Ders 10 'yeniden kur sonra kullan' ZİRVESİ\n(matmul → backprop → nn.Module)",
]
for y, lt, rt in zip(ys, left_labels, right_labels):
# L14-parçası (rose dolgu/çerçeve)
boxed_node(ax, left_x, y, lw_box, lh_box, lt,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=10.5, lw=2.0)
# kaynak/hedef (cyan dolgu/çerçeve)
boxed_node(ax, right_x, y, rw_box, rh_box, rt,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=8.8, lw=2.0)
# ok: L14-parçası → kaynak (cyan)
arrow_between(ax, (left_x + lw_box / 2, y), (right_x - rw_box / 2, y),
color=COL_CYAN_700, lw=2.0, mutation_scale=16, shrink=4)
# ORTADA vurgu: Temeller A kapanır
ax.text(6.0, 0.40, "Temeller A biter: matmul → mean shift → backprop → nn.Module",
ha="center", va="center", fontsize=12.0, weight="bold",
color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_50,
ec=COL_ACCENT, lw=2.0))
plt.tight_layout()
plt.show()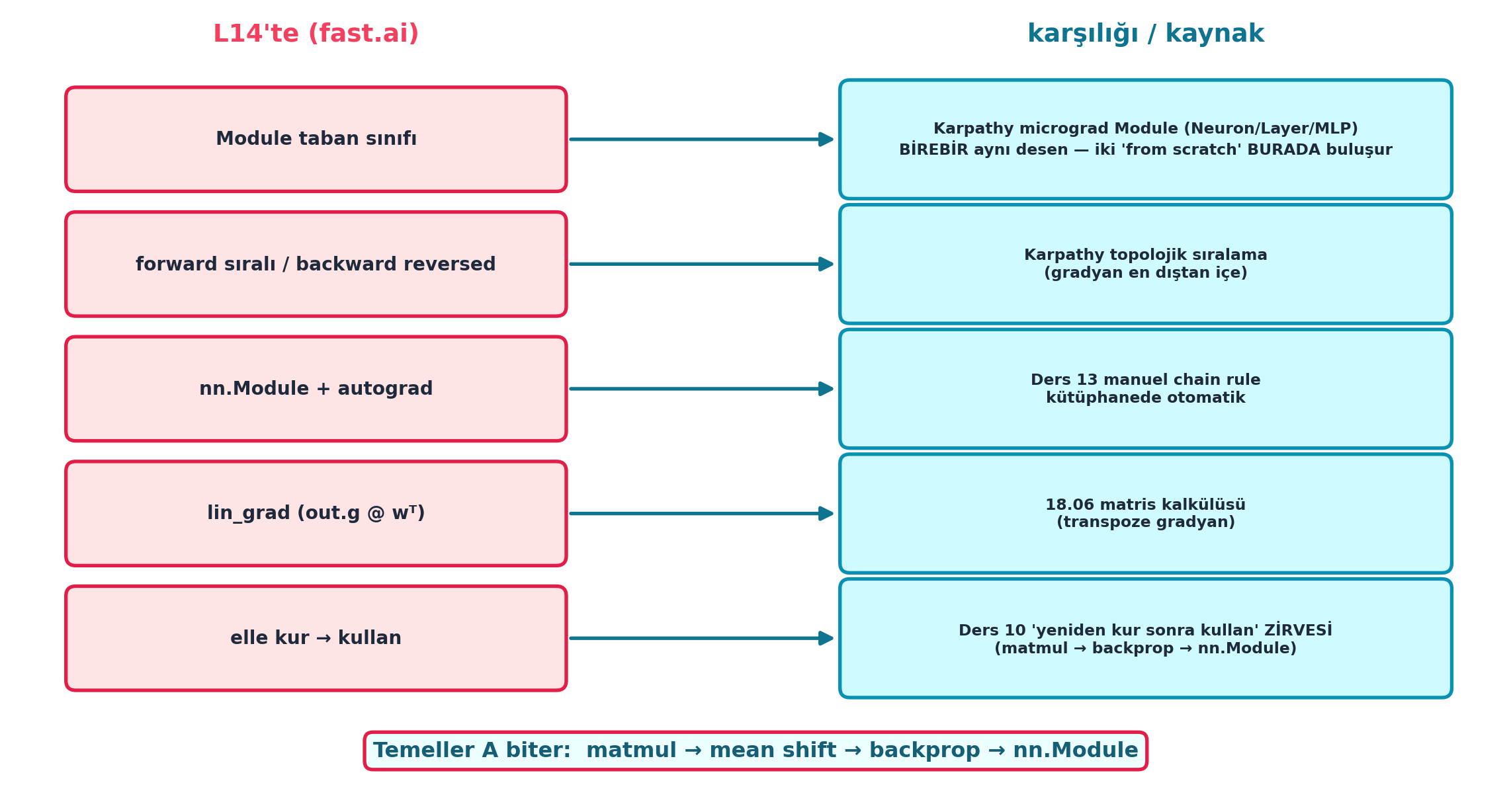
İpucuBuilder Notu — L14 Sentezi: Temeller A Zirvesi
- İleriye (Ders 15-18): Temeller A bitti (matmul → mean shift → backprop → nn.Module). Temeller B (Ders 15-18): autoencoder, Learner, init/norm, hızlandırılmış SGD — hepsi nn.Module üstüne.
- Tek cümle: Manuel backprop’u
forward/backwardsınıflarına, ortak deseni birModuletaban sınıfına refactor ederek PyTorch’un nn.Module’ünü sıfırdan yeniden kurduk — ve Karpathy köprüsü burada kapandı.
17.18 Bu Dersin Özeti
- Ders 13’ün manuel backprop’u chain rule’a eşlenir:
out.g= ∂L/∂çıktı,lin_grad= ∂çıktı/∂(girdi,ağırlık) (chain rule eşlemesi). - Refactoring ile her katman
__call__(forward) +backwardbilen bir sınıf olur (katman sınıfları). - Model sınıfı katmanları listede tutar; forward sırayla, backward ters sırada (chain rule) (Model).
- Module taban sınıfı ortak deseni (girdiyi sakla, forward çağır, bwd çağır) toplar; alt sınıflar yalnızca
forward+bwdyazar (Module taban). - Bu yapı PyTorch’un nn.Module’üyle aynıdır; tek fark backward’ın otomatik (autograd) olması (nn.Module).
- nn.Module’de
super().__init__()zorunlu (parametre kaydı); ağırlıklarrequires_grad_()ile işaretlenir (super().__init__()). loss.backward()+ autograd, Ders 13’te elle yaptığımız chain rule’u otomatik yapar; refactor doğruluğu bozmaz (~1e-11 eşleşme) (autograd).- Sıfırdan kurduğumuz için artık
nn.Module,nn.ReLU,F.mse_lossgibi hazır parçaları güvenle kullanırız (hazır parçalar).
ÖnemliTek Bir Cümle
Manuel backprop’u, her katmanı forward/backward bilen bir sınıfa ve ortak deseni bir Module taban sınıfına refactor ederek PyTorch’un nn.Module’ünü sıfırdan yeniden kurduk — ve artık autograd’ı, altında tam olarak Ders 13’ün chain rule’u olduğunu bilerek, güvenle kullanabiliriz. Karpathy köprüsü burada kapanır: bizim Module = micrograd Module.
17.19 Kontrol Soruları
NotSoru 1: Bir Model sınıfında forward sırayla, backward neden ters sırada çalışır?
Cevap:
Forward pass girdiden çıktıya doğru akar: katmanlar sırayla çalışır (lin → relu → lin → loss). Backward pass ise chain rule gereği en dıştan (loss) en içe (ilk katman) doğru akar — çünkü bir katmanın gradyanı, kendisinden sonraki katmanın gradyanına (out.g) bağlıdır. Bu yüzden for l in reversed(self.layers): l.backward(): önce loss’un gradyanı, sonra son katman, sonra ReLU, en son ilk katman. Her katman, bir sonrakinden gelen gradyanı alıp kendi yerel türeviyle çarpar (chain rule) ve bir öncekine geçirir. (Şekil 28.1 yolculuğu, Şekil 17.2 sadeleşmeyi gösterir.)
NotSoru 2: Module taban sınıfı hangi tekrarı kaldırır? Alt sınıflar ne yazar?
Cevap:
Refactor öncesi her katman aynı deseni tekrarlıyordu: __call__’da girdiyi sakla + ileri hesapla, backward’da saklı değerlerle gradyanı hesapla. Module taban sınıfı bu ortak mekaniği toplar: __call__ argümanları saklar ve forward’ı çağırır; backward ise bwd’yi saklı argümanlarla çağırır. Böylece alt sınıflar (Relu, Lin) yalnızca forward (ileri hesap) ve bwd (gradyan hesabı) yazar — saklama/çağırma mantığını tekrarlamazlar. Bu, kodu hem kısaltır hem de PyTorch nn.Module arayüzüne yaklaştırır. (Şekil 17.3 deseni, Şekil 17.4 kod azalmasını gösterir.)
NotSoru 3: Kendi Module’ümüz ile PyTorch nn.Module arasındaki temel fark nedir?
Cevap:
Yapı aynıdır: ikisi de bir forward metodu olan, çağrılabilir (__call__) katman nesneleridir. Temel fark backward’tadır: bizim Module’ümüzde her katmanın bwd’sini elle yazıp gradyanları kendimiz hesaplıyoruz; PyTorch nn.Module’de ise backward otomatiktir (autograd) — ağırlıkları requires_grad_() ile işaretler, loss.backward() çağırırsın, PyTorch chain rule’u tüm graf üzerinde otomatik uygular. Yani nn.Module’de yalnızca forward yazarsın; gradyanlar bedava gelir. Ayrıca nn.Module super().__init__() ile parametre kaydı, GPU taşıma gibi altyapı sağlar. (Şekil 17.5 tek farkı, Şekil 17.6 parametre kaydını gösterir.)
NotSoru 4: Bu ders Karpathy serisiyle ve « from the foundations » kuralıyla nasıl bağlanır? (builder bağlantısı)
Cevap:
Karpathy micrograd’ın sonunda bir Module taban sınıfı (Neuron/Layer/MLP) kurar ve PyTorch ile karşılaştırır; Howard burada aynı Module desenini kurup PyTorch nn.Module’üne bağlar. İki “from scratch” yolu nn.Module’de buluşur. “From the foundations” kuralı da burada zirve yapar: matmul (Ders 10-12), backprop (Ders 13), nn.Module (Ders 14) — hepsini sıfırdan kurduk. Artık loss.backward(), nn.Module, nn.ReLU bizim için kara kutu değil; altında tam olarak ne olduğunu bildiğimiz, güvenle kullandığımız araçlar. Builder açısından: bir framework’ü sıfırdan kurmak, onu ustaca (ve gerektiğinde özelleştirerek) kullanmanın ön koşuludur. (Şekil 17.8 iki yolun buluşmasını ve Temeller A’nın kapanışını gösterir.)
17.20 Egzersizler
Egzersiz 1 (Direkt uygulama). Relu ve Lin katmanlarını sınıf olarak (__call__ forward + backward) yaz; bir Model ile forward+backward yapıp gradyanları gözle. (§4-6)
Egzersiz 2 (İki-aşamalı). Ortak deseni bir Module taban sınıfına çıkar; Relu/Lin’i ondan türetip kodun ne kadar kısaldığını gör (Şekil 17.4’ı kendi satır sayınla yeniden üret — §7-8).
Egzersiz 3 (Edge case). PyTorch nn.Module’de super().__init__()’i kasıtlı olarak sil; model.parameters()’ın neden boş döndüğünü açıkla (Şekil 17.6’ı kendi modelinde doğrula — §11).
Egzersiz 4 (Kavramsal). Kendi bwd’lerinle hesapladığın gradyanları, PyTorch autograd (requires_grad_ + backward()) sonucuyla karşılaştır; aynı çıktığını doğrula (Şekil 17.7’i kendi modelinde yeniden üret — §12).
Egzersiz 5 (Sonraki dersin habercisi — Ders 15). Bir eğitim döngüsünün (minibatch + optimizer adımı) nn.Module üstüne nasıl kurulacağını düşün (Learner’a giden yol — §14).
17.21 Sonraki: Ders 15 İçin Hazırlık
Ders 15: Autoencoder’lar (Autoencoders)
Temeller A bitti (matmul → mean shift → backprop → nn.Module). Ders 15, Temeller B’yi başlatır: convolution’larla bir autoencoder kurmak — görüntüyü sıkıştırıp geri açan ağ (Stable Diffusion’ın VAE’sinin temeli).
Ana konular (Ders 15):
- Eğitim döngüsü ve minibatch (nn.Module üstüne)
- Convolution’lar (sıfırdan)
- Autoencoder mimarisi
- VAE’ye köprü
UyarıDers 15 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 2 ve 4 — Module refactor + autograd karşılaştırma).
- Kendi nn.Module modelini kurup
loss.backward()ile eğit. - Ana cümleyi tekrar oku: “nn.Module’ü sıfırdan kurduk; artık güvenle kullanırız.”
17.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Chain rule ↔︎ kod | out.g = ∂L/∂çıktı; lin_grad = ∂çıktı/∂(girdi,ağırlık) | 1:43 |
| Refactoring | Kodu sadeleştirme; tekrarı kaldırma | 11:02 |
| Katman sınıfı | __call__ (forward) + backward bilen nesne |
11:02 |
| Model sınıfı | Katman listesi; forward sıralı, backward ters | 13:26 |
| reversed(layers) | Backward’ın en dıştan içe yayılımı (chain rule) | 13:26 |
| Module taban sınıfı | Ortak deseni toplar; alt sınıf forward+bwd yazar | 17:59 |
| nn.Module | PyTorch katman temeli; backward otomatik (autograd) | 11:02 |
super().__init__() |
nn.Module parametre kaydı için zorunlu | 13:26 |
requires_grad_ |
Tensörün gradyanını izle (autograd) | — |
| F.mse_loss / nn.ReLU | Hazır parçalar; sıfırdan kurduktan sonra güvenli | 21:42 |
| autograd | loss.backward() ile chain rule’u otomatik yapma | — |
| Karpathy köprüsü | Module deseni = micrograd Neuron/Layer/MLP | — |
17.23 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: nn.Module Zirvesi
Bu ders backprop’u tamamlar ve Karpathy köprüsünü kapatır; köprülerin özeti:
- Chain rule ↔︎ kod → backprop’un her satırı bir türev parçası (Calculus/3B1B) (chain rule eşlemesi).
- Module deseni → forward+backward bilen katman; Karpathy micrograd Module’ü (Neuron/Layer/MLP) (Module taban).
- nn.Module + autograd → backward otomatik; Ders 13’ün manuel chain rule’u kütüphanede (autograd).
- Refactoring → tekrar kanıtlanınca soyutla (coding-standards); erken soyutlama değil (refactoring).
- requires_grad_/backward → Ders 5’te kullanmıştık, şimdi altını biliyoruz (Ders 13) (super().__init__()).
- “Yeniden kur, sonra kullan” → nn.Module zirvesi; framework’ü sıfırdan kurmak ustaca kullanmanın koşulu (Karpathy köprüsü).
ÖnemliBu dersten tek bir şey alıp gideceksen
PyTorch’un nn.Module’ü sihir değildir — onu sıfırdan kurduk. Manuel .g gradyanlarından başlayıp, her katmanı forward/backward sınıfına, ortak deseni bir Module taban sınıfına refactor ederek tam olarak nn.Module’e vardık. Tek fark, PyTorch’un backward’ı autograd ile otomatik yapması — ama altında Ders 13’ün chain rule’u var. Artık loss.backward() anladığın bir araç; Karpathy köprüsü kapandı ve Temeller B (Ders 15-18) bunun üstüne kurulacak.