---
title: "Ders 9A — Stable Diffusion Derinlemesine (Whitaker)"
subtitle: "Misafir ders: Jonathan Whitaker (fastai), Ders 9'da kavramsal gördüğümüz hazır `pipe()`'ı parça parça açar ve sampling loop'u sıfırdan replike eder. VAE ile latent uzaya inip çıkarız (0.18215 ölçek), CLIP ile metni embedding'e çeviririz, noise schedule (σ) ile gürültü ekleriz, classifier-free guidance'lı bir U-Net her adımda iki tahmin yapar, scheduler gürültüyü kısmen çıkarır. img2img bu mekanizmanın bir uygulamasıdır; en güçlüsü ise özel guidance: istediğin herhangi bir hedefin gradyanını sampling'e enjekte etmek — tam da Ders 9'un 'pixel gradyanı' sezgisi."
---
::: {.callout-note title="Bölüm bilgisi"}
- **Whitaker'ın videosu:** [course.fast.ai — Lesson 9A: Stable Diffusion Deep Dive](https://course.fast.ai/Lessons/part2.html) (~41 dk, misafir: Jonathan Whitaker)
- **Seri:** Practical Deep Learning for Coders — Part 2, Ders 9A (Ders 9'un derinlemesine eki)
- **Misafir hoca:** Jonathan Whitaker (fastai)
- **Playlist:** [Part 2 — Foundations to Stable Diffusion (2022)](https://www.youtube.com/playlist?list=PLfYUBJiXbdtRUvTUYpLdfHHp9a58nWVXP)
- **Notebook:** [diffusion-nbs — Stable Diffusion Deep Dive](https://github.com/fastai/diffusion-nbs/blob/master/Stable%20Diffusion%20Deep%20Dive.ipynb)
- **Okuma süresi:** ~28 dk
:::
```{python}
#| label: setup-l9a
#| include: false
# ============================================================================
# SETUP — fast.ai L9A figür motoru (_engine.py) + Cyan+Rose viz (_viz.py)
# Bu hücre gizlidir (#| include: false). Aşağıdaki figür hücreleri _viz'in
# çizim primitiflerini ve COL_* renk sabitlerini bare-name + viz.* olarak
# kullanır; veri üreticileri _engine (E) üzerinden gelir (latent_roundtrip_demo,
# sigma_schedule_demo, img2img_demo, cfg_twopred_demo, custom_guidance_demo).
# fig-sampling-loop ayrıca FancyBboxPatch'i bare-name kullanır → ayrıca import.
# matplotlib backend'i AYARLANMAZ — Quarto kendi inline backend'ini kurar.
# ============================================================================
import sys
sys.path.insert(0, "_source")
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch
import _engine as E
import _viz as viz
from _viz import (COL_PRIMARY, COL_ACCENT, COL_TEXT, COL_BG, COL_BG_ROSE,
COL_CYAN_700, COL_CYAN_400, COL_ROSE_400, COL_ROSE_500,
COL_SLATE_400, COL_WHITE, COL_CYAN_50)
```
## Bu Derste Ne Var? {#sec-bu-derste-d09a}
Misafir ders. Jonathan Whitaker (fastai), [Ders 9'da](09-stable-diffusion.qmd) kavramsal gördüğümüz hazır `StableDiffusionPipeline`'ı **parça parça açar** ve sampling loop'u **sıfırdan replike eder**. Ders 9 "üç bileşen + pixel gradyanı" sezgisini verdi; Whitaker o sezgiyi çalışan koda çevirir: VAE, tokenizer + CLIP, U-Net, scheduler ve classifier-free guidance birer ayrı bileşen olur, gürültü-giderme döngüsü elle kurulur.
Üç temel fikir bu dersin omurgasını kurar:
1. **Latent uzayda çalışma** — VAE görüntüyü 4×64×64'e sıkıştırır; tüm diffusion bu küçük uzayda olur (`pil_to_latent` / `latents_to_pil`, 0.18215 ölçekleme) ([VAE/latent](#sec-vae-latent) → [encode/decode](#sec-encode-decode)).
2. **Gürültü ekleme + sampling loop** — eğitimde gürültü eklenir, çıkarımda σ çizelgesine göre adım adım çıkarılır; img2img bu mekanizmanın bir uygulamasıdır ([noise schedule](#sec-noise-schedule) → [sampling döngüsü](#sec-sampling-dongusu)).
3. **Classifier-free guidance** — her adımda **iki tahmin** (prompt'lu + prompt'suz) yapılır; fark `guidance_scale` ile çarpılıp prompt yönüne ittirilir ([U-Net + CFG](#sec-cfg)).
> *"We're going to be basically replicating this code, but now we'll be doing it ourselves."* — Whitaker, 0:43
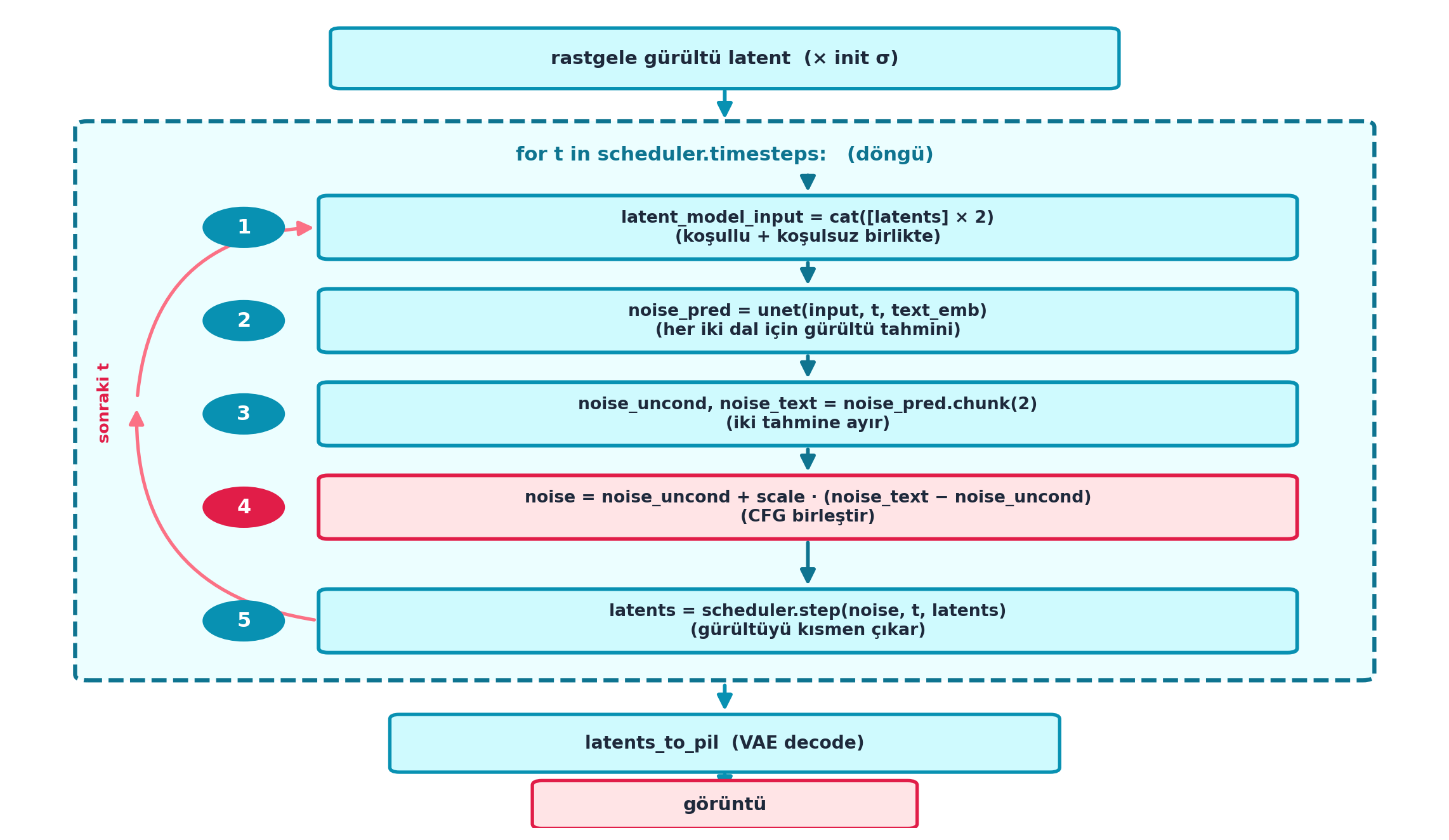
@fig-concept-map bu yapıyı tek bir yol haritasında birleştirir: hazır `pipe()` beş bileşene (VAE, CLIP, U-Net, scheduler, CFG) ayrılır; sampling loop bunları her adımda birleştirir (rastgele gürültü → CFG'li U-Net tahmini → `scheduler.step` → VAE decode); ve özel guidance, istediğin herhangi bir hedefin gradyanını döngüye enjekte eder — rose vurgulu "hazır pipe()" ve "sampling loop" düğümleri dersin doruğudur.
{{< include _source/cells_l9a/fig-concept-map.qmd >}}
::: {.callout-tip title="Builder Notu — pipe()'ın İçi: Sezgiden Çalışan Koda"}
- **Geriye (Ders 9):** Ders 9'un "sihirli API + pixel gradyanı" sezgisi burada gerçek koda dönüşür — U-Net + scheduler + CFG. [Pixel gradyanı](09-stable-diffusion.qmd#sec-pixel-gradyani) fikri hem CFG'de hem [özel guidance'ta](#sec-ozel-guidance) somutlaşacak.
- **İleriye (Part 2 / NYU §4.J):** Bu loop, Part 2 Ders 19-22'de (DDPM/DDIM) sıfırdan kurulacak; CFG ve guidance, enerji-tabanlı modellerle (NYU §4.J) kavramsal akraba.
- **Tek cümle:** Whitaker, `pipe()`'ı VAE + CLIP + U-Net + scheduler + classifier-free guidance parçalarına ayırıp gürültü-giderme döngüsünü elle kurar.
:::
## Sampling Loop'u Replike Etmek {#sec-replike}
Whitaker hedefi koyar: hazır pipeline'ın yaptığını **kendi kodumuzla** yapmak — bir dizi sampling adımında latent'i gürültüden arındırıp görüntü üretmek. Önce parçaları ([VAE](#sec-vae-latent), tokenizer, [text_encoder](#sec-text-encoding), U-Net, [scheduler](#sec-noise-schedule)) ayrı ayrı yükler; sonra [sampling döngüsünde](#sec-sampling-dongusu) hepsini birleştirir. Yani [konsept haritasının](#sec-bu-derste-d09a) "hazır pipe() → beş bileşen → sampling loop" akışını gerçek kodla yürütür.
> *"You'll see that we're going to be basically replicating this code, going through a number of sampling time steps and regenerating an image."* — Whitaker, 0:43
::: {.callout-tip title="Builder Notu — Replikasyon: Düşük Seviye Taslağın Çalışır Hâli"}
- **Geriye (Ders 9):** Ders 9'daki [düşük seviye pipeline taslağı](09-stable-diffusion.qmd#sec-dusuk-seviye) — beş adım — burada satır satır çalışır koda dönüşür.
- **Geriye (Ders 8):** "Framework sihir değil; bizim kuracağımızın temiz hâli" disiplini ([Ders 8](08-evrisimler.qmd)) burada da geçerli — `pipe()`'ı söküp parçalarından yeniden kurarız.
:::
## Auto-Encoder (VAE) ve Latent Uzay {#sec-vae-latent}
İlk bileşen VAE. Whitaker vurgular: Stable Diffusion bir **latent diffusion** modelidir — piksellerle değil, bir autoencoder'ın latent uzayında çalışır. VAE büyük görüntüyü 4×64×64'lük bir latent'e sıkıştırır. Tüm gürültü ekleme/çıkarma bu küçük uzayda olur; piksele yalnızca en sonda, [decode](#sec-encode-decode) ile geri çıkarız.
> *"This is a latent diffusion model, which means it doesn't operate on pixels, it operates in the latent space of an autoencoder. We go from this big image down to this 4 by 64 by 64 latent representation."* — Whitaker, 1:21
::: {.callout-tip title="Builder Notu — Latent Diffusion: 786K → 16K'nın Kod Karşılığı"}
- **Geriye (Ders 9):** Ders 9'daki [VAE sıkıştırması](09-stable-diffusion.qmd#sec-vae-d09) (786K → 16K) burada `pil_to_latent`/`latents_to_pil` koduyla somutlaşır; latent uzay diffusion'ı ~48× ucuzlatır.
- **Geriye (Ders 8):** VAE bir autoencoder'ın ([Ders 8](08-evrisimler.qmd)) olasılıksal (dağılımdan örnekleyen) hâlidir — encode/decode yapısı aynı, çıkışı bir dağılımdan örnekler.
:::
## Latent'i Kodlama ve Çözme {#sec-encode-decode}
Whitaker iki yardımcı yazar: `pil_to_latent` (görüntü → latent, VAE encode) ve `latents_to_pil` (latent → görüntü, VAE decode). Dikkat: latent'ler **0.18215** ile ölçeklenir — modelin yazarlarının seçtiği, latent'leri U-Net'in eğitildiği büyüklüğe getiren bir normalleştirme sabiti; encode'da çarpılır, decode'da bölünür.
```python
def pil_to_latent(input_im):
with torch.no_grad():
latent = vae.encode(tfms.ToTensor()(input_im).unsqueeze(0).to(torch_device)*2-1)
return 0.18215 * latent.latent_dist.sample() # olcekleme sabiti
def latents_to_pil(latents):
latents = (1 / 0.18215) * latents
with torch.no_grad():
image = vae.decode(latents).sample
return image # (normalize + PIL'e cevirme adimlari izler)
```
> *"The decoded version — very impressive compression, this is a factor of [48]; we get nice high-resolution results even though we're only working with these 64 by 64 latents."* — Whitaker, 1:21
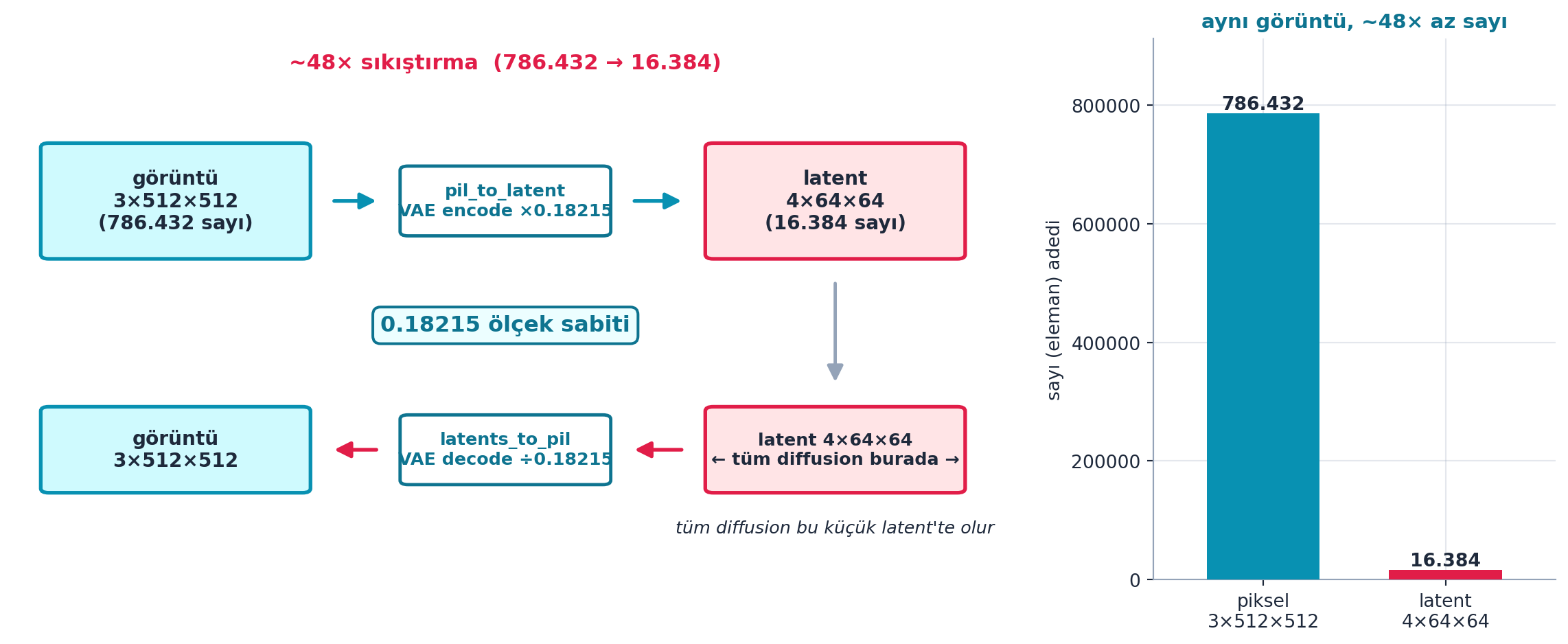
@fig-latent-roundtrip bu gidiş-dönüşü gerçek sayılarla gösterir: sol panel akış şemasıyla `görüntü (3×512×512 = 786.432 sayı) → pil_to_latent (×0.18215) → latent (4×64×64 = 16.384 sayı)` ve geri dönüşte `latents_to_pil (÷0.18215)`; sağ panel iki büyüklüğü bar olarak karşılaştırır — ~48× az sayı. "Tüm diffusion bu küçük latent'te olur" mesajı dikey köprüyle vurgulanır.
{{< include _source/cells_l9a/fig-latent-roundtrip.qmd >}}
::: {.callout-tip title="Builder Notu — encode/decode: Arama Tablosu Değil, Öğrenilmiş Sıkıştırma"}
- **Geriye (Ders 8):** Autoencoder encode/decode ([Ders 8](08-evrisimler.qmd)); VAE bunun olasılıksal (dağılımdan örnekleyen) hâli — `latent_dist.sample()` tam bu örneklemedir.
- **Builder ipucu:** 0.18215 unutulursa latent'lerin büyüklüğü U-Net'in beklediğiyle uyuşmaz; encode'da çarp, decode'da böl — ölçeği [roundtrip](#sec-encode-decode) boyunca tutarlı tut.
:::
## Gürültü Ekleme ve Noise Schedule {#sec-noise-schedule}
Eğitimde görüntüye gürültü eklenir; model bu gürültüyü tahmin etmeyi öğrenir. Ne kadar gürültü eklendiğini **noise schedule** belirler. `scheduler.sigmas` her adımdaki gürültü miktarını verir: başta çok yüksek, sona doğru sıfıra iner. Çıkarımda 1000 değil, az adım (örn. 15-50) kullanılır — bu, [konsept haritasındaki](#sec-bu-derste-d09a) σ-çizelgesinin alt-örneklenmesidir.
```python
scheduler.set_timesteps(15)
print(scheduler.sigmas) # her adimdaki gurultu miktari (yuksek -> dusuk)
# gurultu ekleme: noisy = latent + noise * sigma
noisy = scheduler.add_noise(encoded, noise, timesteps)
```
> *"This sigma is the amount of noise added; we're going to slowly slowly try and reduce this down until ideally we get a clean image."* — Whitaker, 8:44
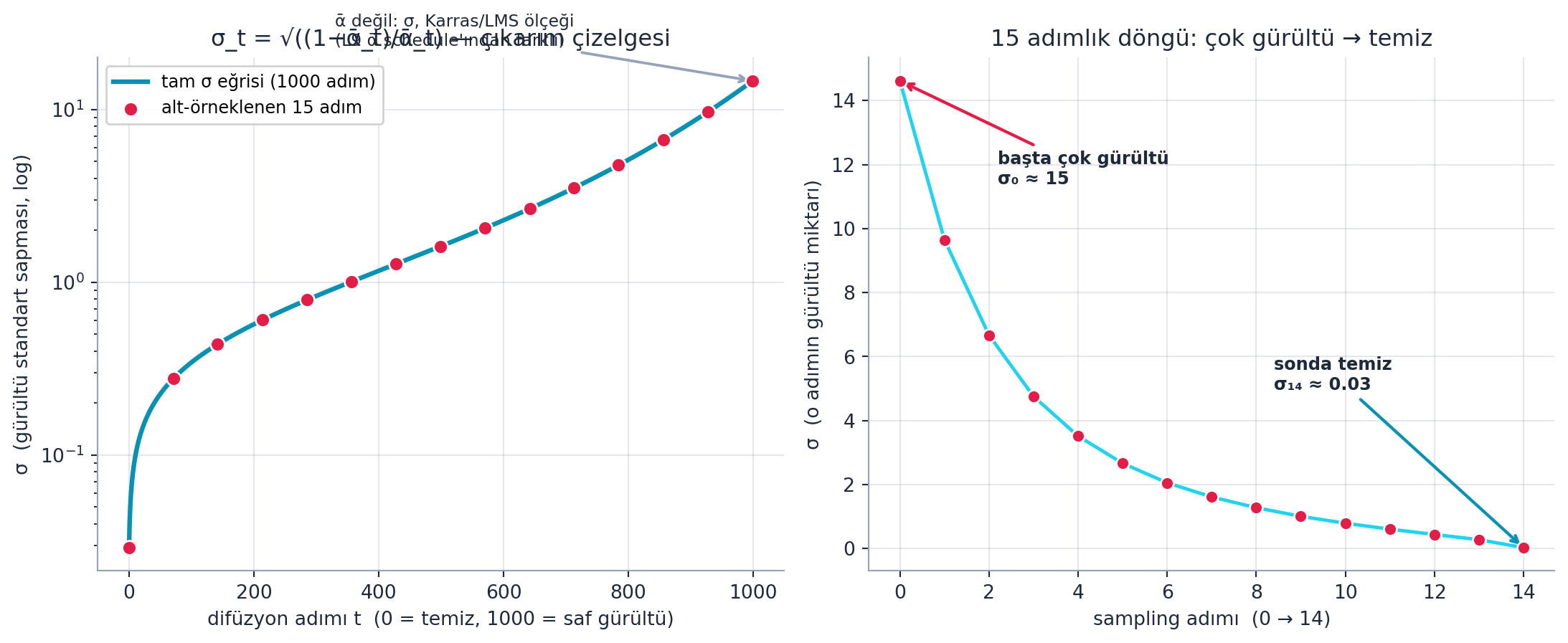
@fig-sigma-schedule çizelgeyi gerçek hesaplamayla gösterir (SD v1 scaled_linear β: β_start=0.00085, β_end=0.012): sol panel tam σ eğrisini (1000 adım, $\sigma_t = \sqrt{(1-\bar{\alpha}_t)/\bar{\alpha}_t}$, log eksen) ve ondan alt-örneklenen 15 adımı; sağ panel bu 15 sampling adımının σ değerlerinin $\sigma_0 \approx 14.6$'dan $\sigma_{14} \approx 0$'a inişini. Bu tepe değer `scheduler.sigmas`'ın tepesiyle (init_noise_sigma) eşleşir. Whitaker'ın "yavaş yavaş σ'yı sıfıra indir" dediği eğri tam budur — Ders 9'un $\bar{\alpha}$ çizelgesinden farklı bir ölçek (σ, Karras/LMS).
{{< include _source/cells_l9a/fig-sigma-schedule.qmd >}}
::: {.callout-tip title="Builder Notu — σ Çizelgesi: DDPM/Karras'ın Çekirdeği"}
- **İleriye (Ders 19-22):** β/σ noise schedule, DDPM (Ders 19) ve Karras (Ders 22) ile Part 2'de sıfırdan kurulur (§4.I); @fig-sigma-schedule'ın σ ölçeği orada $\bar{\alpha}$ çizelgesiyle karşılaştırılır.
- **Geriye (Ders 9):** Bu σ, Ders 9'un [forward diffusion](09-stable-diffusion.qmd#sec-scheduler) formülü $x_t = \sqrt{\bar{\alpha}_t}\,x_0 + \sqrt{1-\bar{\alpha}_t}\,\varepsilon$'nun çıkarım-zamanı yeniden parametrizasyonudur.
:::
## img2img: Gürültüleyip Yeniden Çizme {#sec-img2img-d09a}
img2img basit bir uygulamadır: bir görüntüyü [latent'e çevir](#sec-encode-decode), **belirli bir adıma kadar** gürültüle (sıfıra değil), sonra oradan [sampling'e](#sec-sampling-dongusu) devam et. Ne kadar gürültülersen o kadar değişir — bunu `strength` belirler. Yani [σ çizelgesine](#sec-noise-schedule) baştan değil, ortadan gireriz.
> *"I'm now going to start with this noisy version of my input image and I'm going to [continue sampling from there]."* — Whitaker, 3:55
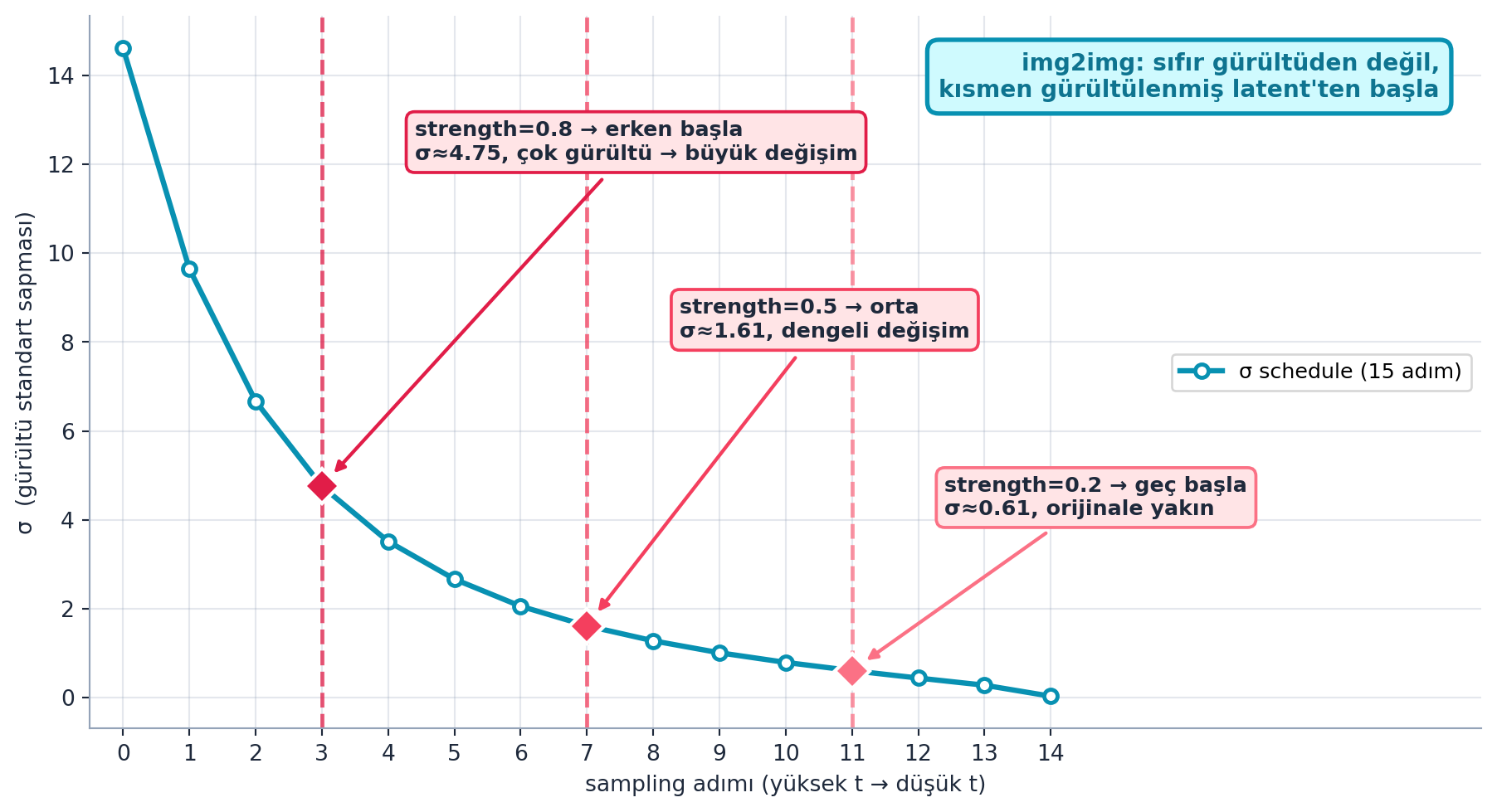
@fig-img2img bu girişi σ çizelgesi üstünde gösterir: cyan eğri 15 adımlık σ inişi; her `strength` için rose dikey çizgi + işaretçi başlangıç noktasını işaretler — `strength=0.8` erken başlar (σ≈4.75, çok gürültü → büyük değişim), `strength=0.5` ortadan (σ≈1.61, dengeli), `strength=0.2` geç (σ≈0.61, orijinale yakın). Çekirdek sezgi: sıfır gürültüden değil, kısmen gürültülenmiş latent'ten başla.
{{< include _source/cells_l9a/fig-img2img.qmd >}}
::: {.callout-tip title="Builder Notu — strength: Yörüngeye Hangi σ'dan Girersin"}
- **Geriye (Ders 9):** Ders 9'daki [img2img `strength`'inin](09-stable-diffusion.qmd#sec-img2img-d09) iç mekanizması budur: "ne kadar adımdan / hangi σ'dan başlanacağı".
- **Builder ipucu:** strength orijinalin ne kadarının korunacağını ayarlar — düşük strength stil aktarımı/ince düzenleme, yüksek strength neredeyse sıfırdan üretim; aynı mekanizma inpainting ve DiffEdit'in temelidir.
:::
## Text Encoding: Tokenizer → CLIP {#sec-text-encoding}
Prompt önce token'lara bölünür (`tokenizer`), sonra CLIP text encoder bunları embedding dizisine çevirir. Whitaker hazır `pipe`'ın atladığı bu adımları açıkça gösterir; bu embedding dizisi, [sampling döngüsünde](#sec-sampling-dongusu) U-Net'i koşullar.
```python
text_input = tokenizer(prompt, padding="max_length",
max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
output_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
```
> *"How do we get from this sequence of tokens to [embeddings]? We look at the text_encoder embeddings."* — Whitaker, 8:44
::: {.callout-tip title="Builder Notu — CLIP Koşullama: Tokenize + Embedding'in Çok-Modal Hâli"}
- **Geriye (Ders 4/7):** Tokenization ([Ders 4](04-dogal-dil-isleme.qmd)) + embedding ([Ders 7](07-ortak-filtreleme.qmd#sec-embedding-arama)); CLIP, metin embedding'lerini U-Net'e koşullama olarak verir.
- **İleriye:** Bu embedding dizisinin tek tek satırlarına müdahale [token oynama](#sec-token-oynama) ve [textual inversion'ın](#sec-textual-inversion-d09a) kapısını açar.
:::
## Token Embeddings ile Oynama {#sec-token-oynama}
Whitaker embedding'lere **token düzeyinde** müdahale edebileceğimizi gösterir: bir token'ın embedding'ini alıp değiştirebilir veya yenisini ekleyebiliriz. Bu, [CLIP'in](#sec-text-encoding) ürettiği dizinin tek bir satırını okuyup yazmaktır — [textual inversion'ın](#sec-textual-inversion-d09a) temelidir.
```python
prompt = 'skunk'
print(tokenizer(prompt)) # kelime -> token id'leri
token_emb_layer(torch.tensor([8797])) # token id -> embedding vektoru
```
::: {.callout-tip title="Builder Notu — Embedding = Arama Tablosu Satırı"}
- **Geriye (Ders 7/8):** Embedding bir arama tablosudur ([Ders 7](07-ortak-filtreleme.qmd#sec-embedding-arama)); burada o tablonun tek bir satırını (`token_emb_layer[8797]`) okuyup değiştiriyoruz.
- **Builder ipucu:** Token id → embedding eşlemesi türevlenebilir olduğundan, bu tek satır eğitilebilir bir parametredir — [textual inversion](#sec-textual-inversion-d09a) tam bu satırı öğretir.
:::
## Textual Inversion {#sec-textual-inversion-d09a}
**Textual inversion**: yeni bir kavram için (örn. özel bir stil) yeni bir embedding eğitilir ve token sözlüğüne eklenir. Whitaker, eğitilmiş bir embedding'i prompt'un token embedding'leri arasına ekleyerek o kavramı çağırır — yani [token oynama](#sec-token-oynama) fikrini öğrenilmiş bir satırla yapar.
> *"I'm inserting them into my set of token embeddings for my prompt."* — Whitaker, 15:03
::: {.callout-tip title="Builder Notu — Tek Satır Eğit, Kavramı Çağır"}
- **Geriye (Ders 9):** Ders 9'da [textual inversion/DreamBooth](09-stable-diffusion.qmd#sec-textual-inversion-d09) kavramsal verildi; burada eğitilmiş embedding'i [prompt dizisine](#sec-text-encoding) elle enjekte ederek mekanizmasını görüyoruz.
- **İleriye (production):** Textual inversion (tek embedding) + DreamBooth (model ağırlıkları), kişiselleştirilmiş üretimin (özel stil/nesne) standart yöntemleridir.
:::
## U-Net ve Classifier-Free Guidance {#sec-cfg}
En kritik teknik: **classifier-free guidance (CFG)**. Her sampling adımında U-Net **iki tahmin** yapar — biri prompt'la (koşullu), biri boş prompt'la (koşulsuz). Sonuç:
$$\text{noise} = \text{uncond} + s \cdot (\text{text} - \text{uncond})$$
Yani "prompt'un yönüne" ittiririz; $s$ (guidance_scale) 1'den büyükse prompt etkisini abartırız. Bu yön farkını [sampling döngüsünde](#sec-sampling-dongusu) her adımda hesaplarız.
> *"We get out two predictions for the noise... guidance_scale times the difference. If I predict without the prompt [and with], I'd like to move more in that direction, push it even further."* — Whitaker, 18:38
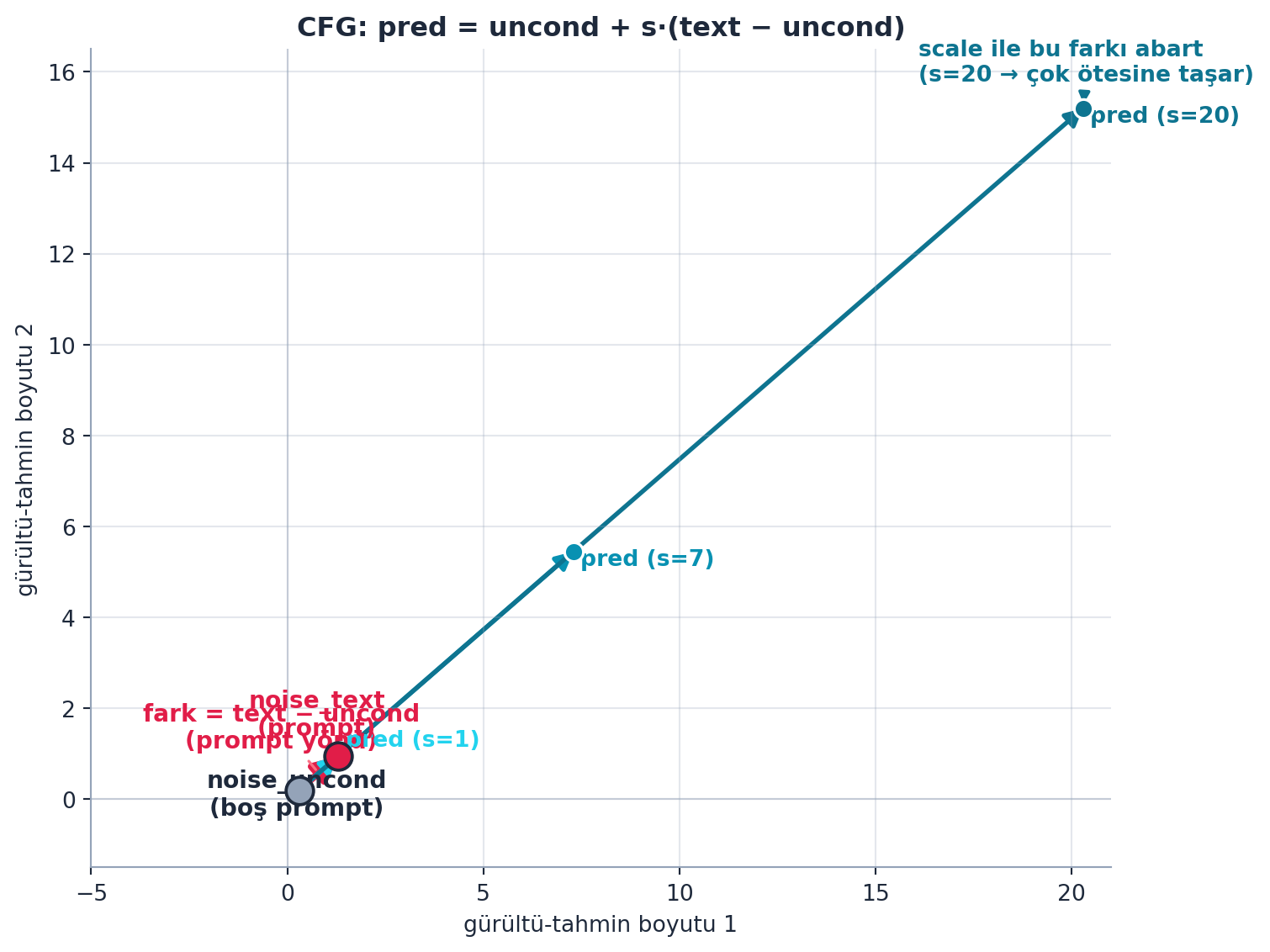
@fig-cfg-twopred bu iki-tahmin yapısını vektör aritmetiğiyle gösterir: `noise_uncond` (boş prompt) ile `noise_text` (prompt) iki nokta; aralarındaki rose ok `fark = text − uncond` (prompt yönü). Her scale için ($s = 1, 7, 20$) cyan oklar `pred = uncond + s·(text − uncond)`'u çizer — $s$ büyüdükçe tahmin koşullu noktanın ötesine taşar. Whitaker'ın "farkı daha da abart" dediği şey tam bu uzayan oktur.
{{< include _source/cells_l9a/fig-cfg-twopred.qmd >}}
::: {.callout-tip title="Builder Notu — CFG: İki Tahminin Farkını Abartmak"}
- **Geriye (Ders 9):** Ders 9'daki [`guidance_scale`'in](09-stable-diffusion.qmd#sec-guidance) iç mekanizması; "iki tahminin farkını ($s$ ile) abartmak" — sınıflandırıcı eğitmeden (classifier-free) prompt etkisini güçlendirmek. Maliyeti: adım başına iki U-Net geçişi.
- **Geriye (NYU §4.J):** CFG, koşullu/koşulsuz enerji farkını kullanır — enerji-tabanlı modellerle (NYU §4.J) kavramsal akraba; "fark = yön" sezgisi ortak.
:::
## Sampling Döngüsü {#sec-sampling-dongusu}
Her şey burada birleşir: rastgele gürültüden başla, her timestep'te [CFG](#sec-cfg) ile gürültüyü tahmin et, [scheduler](#sec-noise-schedule) ile kısmen çıkar, tekrarla. [Konsept haritasının](#sec-bu-derste-d09a) sampling-loop kolu, satır satır budur.
```python
for i, t in enumerate(scheduler.timesteps):
latent_model_input = torch.cat([latents] * 2) # kosullu + kosulsuz
noise_pred = unet(latent_model_input, t, text_embeddings).sample
noise_uncond, noise_text = noise_pred.chunk(2)
noise_pred = noise_uncond + guidance_scale * (noise_text - noise_uncond) # CFG
latents = scheduler.step(noise_pred, t, latents).prev_sample # gurultuyu kismen cikar
```
> *"Current noisy latents minus sigma times the model prediction."* — Whitaker, 19:38
@fig-sampling-loop bu döngüyü uçtan uca şematize eder — bu dersin **flagship** diyagramıdır. Üstte rastgele gürültü latent (× init σ); büyük kesikli çerçeve içinde beş sıralı adım: (1) `cat([latents]×2)` (koşullu + koşulsuz birlikte), (2) `unet(input, t, text_emb)` (her iki dal için gürültü tahmini), (3) `chunk(2)` (iki tahmine ayır), (4) rose vurgulu CFG birleştirme `uncond + s·(text − uncond)`, (5) `scheduler.step` (gürültüyü kısmen çıkar); rose geri-besleme oku "sonraki t"ye döner. Döngü bitince `latents_to_pil` (VAE decode) → görüntü.
{{< include _source/cells_l9a/fig-sampling-loop.qmd >}}
::: {.callout-tip title="Builder Notu — scheduler.step = Diffusion'ın Gradient Adımı"}
- **Geriye (Ders 5):** `scheduler.step` = [Ders 5'teki](05-sifirdan-model.qmd#sec-egitim-dongusu) "gradient adımı"nın diffusion karşılığı — latent'i biraz daha temize çeker; Whitaker'ın "current latents − σ × prediction" cümlesi tam bu adımdır.
- **Geriye (Ders 9):** Bu döngü, Ders 9'un [düşük seviye pipeline](09-stable-diffusion.qmd#sec-dusuk-seviye) beş adımının (CLIP → uncond emb → latent → U-Net+scheduler döngüsü → VAE decode) çalışan hâlidir.
:::
## Özel Guidance: Kendi Guidance Fonksiyonun {#sec-ozel-guidance}
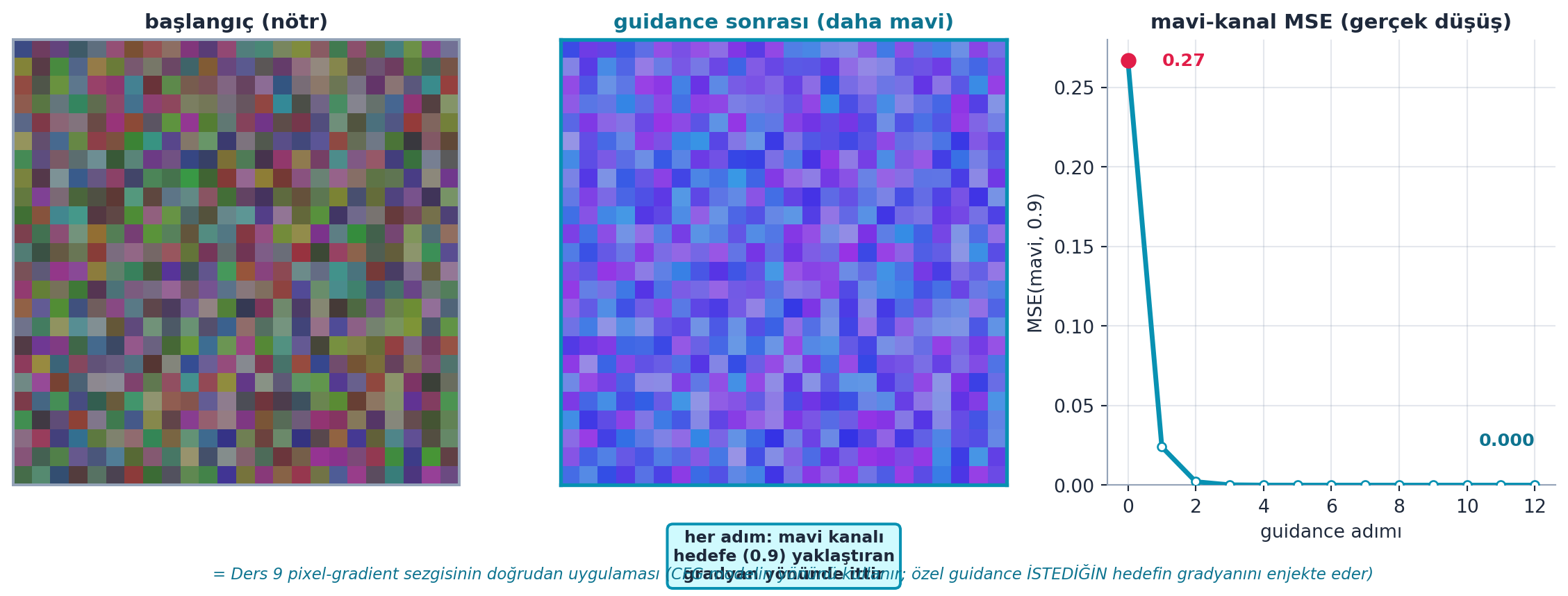
Whitaker'ın güçlü gösterisi: sampling'e **kendi** guidance fonksiyonunu ekleyebilirsin. Örnek olarak "görüntü daha mavi olsun" hedefi koyar — her adımda latent'i, mavi kanal hatasının gradyanı yönünde de ittirir. Bu, [Ders 9'daki](09-stable-diffusion.qmd#sec-pixel-gradyani) "pixel gradyanı" sezgisinin doğrudan uygulamasıdır: [CFG](#sec-cfg) modelin öğrendiği yönü kullanırken, özel guidance **istediğin herhangi bir** türevlenebilir hedefi enjekte eder.
> *"My error is going to be the difference between the blue channel [and target], and [I push the latents by its gradient]."* — Whitaker, 36:32
@fig-custom-guidance bunu gerçek hesaplamayla gösterir: sol panel başlangıç (nötr) görüntüsü, orta panel guidance sonrası (gözle görülür daha mavi), sağ panel mavi-kanal MSE kayıp eğrisinin gerçek düşüşü (~0.27 → ~0). Her adımda mavi kanalı hedefe (0.9) yaklaştıran gradyan yönünde itme; alt not bunun Ders 9'un pixel-gradient sezgisinin doğrudan uygulaması olduğunu vurgular.
{{< include _source/cells_l9a/fig-custom-guidance.qmd >}}
::: {.callout-tip title="Builder Notu — Özel Guidance: Herhangi Bir Loss'un Gradyanıyla Yönlendir"}
- **Geriye (Ders 3/9):** Bu tam Ders 9'un ["sihirli fonksiyon gradyanı"](09-stable-diffusion.qmd#sec-pixel-gradyani) fikri — istediğin herhangi bir hedef fonksiyonun (renk, CLIP benzerliği, kenar haritası) gradyanıyla üretimi yönlendirme; `f.backward()` aynı autograd ([Ders 3](03-sinir-agi-temelleri.qmd)).
- **İleriye:** Özel guidance, CLIP-guided diffusion ve ControlNet gibi yönlendirme tekniklerinin temel mekanizmasıdır — üretimi bir loss'un gradyanıyla itmek.
:::
## Kapanış {#sec-kapanis-d09a}
Whitaker, hazır `pipe()`'ı tamamen açtı: [VAE](#sec-vae-latent) ile latent'e gir/çık, [noise schedule](#sec-noise-schedule) ile gürültü ekle, [CLIP](#sec-text-encoding) ile metni kodla, [U-Net + classifier-free guidance](#sec-cfg) ile her adımda gürültüyü tahmin et, [scheduler](#sec-sampling-dongusu) ile çıkar. Ders 9'un sezgisi (pixel gradyanı) burada hem CFG'de hem [özel guidance'ta](#sec-ozel-guidance) somutlaştı.
> *"In Part 2 we're going to build our own everything from scratch."* — Howard, 0:45 (Ders 9)
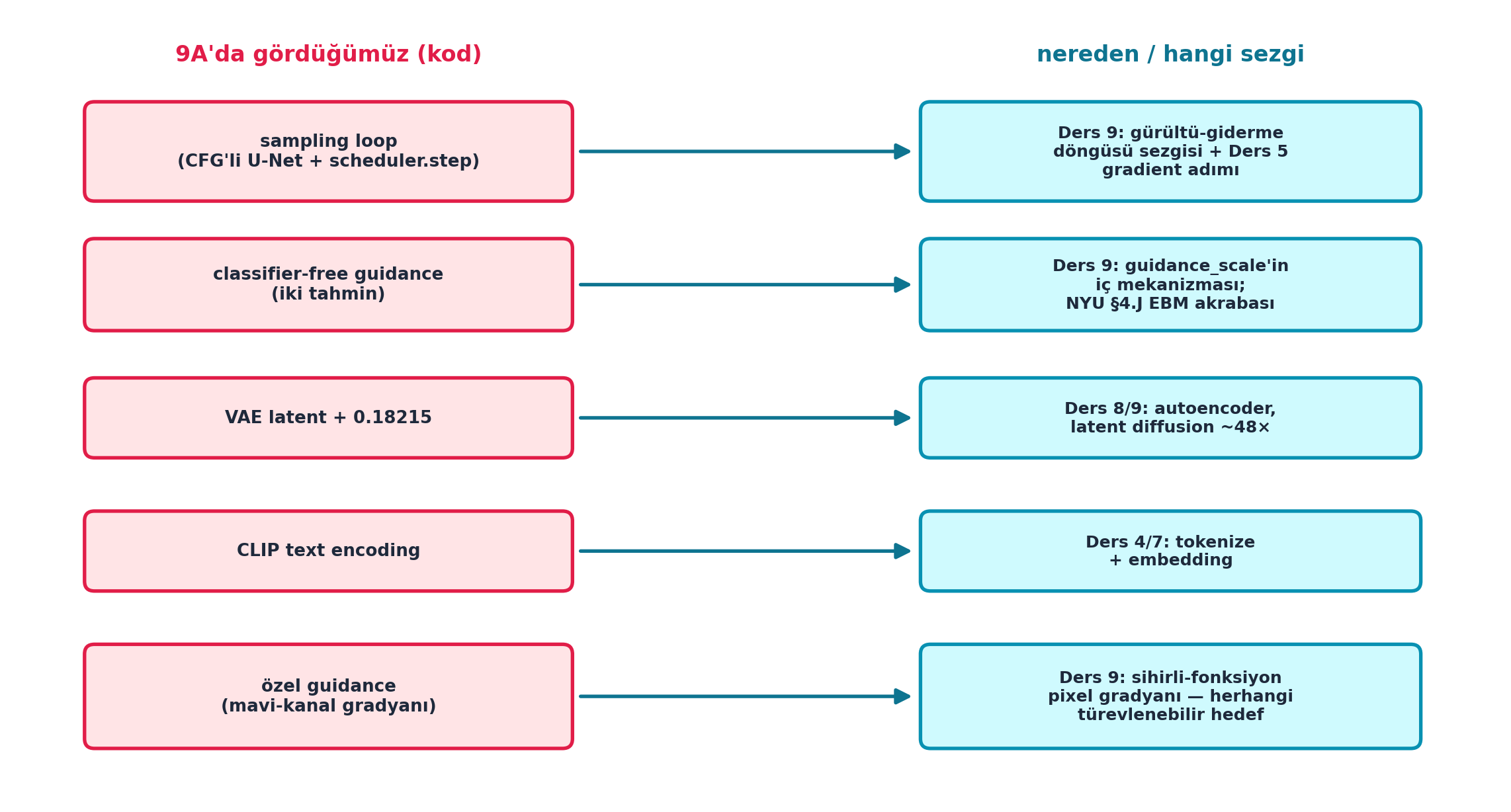
@fig-9a-derived dersin sentezidir: solda 9A'da yazdığımız kod parçaları (rose), sağda her parçanın hangi dersin / hangi sezginin uygulaması olduğu (cyan). Sampling loop ↔ Ders 9 döngü sezgisi + Ders 5 gradient adımı; CFG ↔ Ders 9 guidance_scale + NYU §4.J EBM; VAE latent + 0.18215 ↔ Ders 8/9 autoencoder; CLIP encoding ↔ Ders 4/7 tokenize + embedding; özel guidance ↔ Ders 9 pixel gradyanı. Yeni olan parçalar değil, **çalışan koda dönüşleridir**.
{{< include _source/cells_l9a/fig-9a-derived.qmd >}}
::: {.callout-tip title="Builder Notu — 9A → 9B/10: Sezgiden Matematiğe ve Temellere"}
- **İleriye (Ders 9B):** Ders 9B (Waseem + Tanishq, Stability AI) bu sürecin **matematiğini** açar — forward/reverse process, noise schedule'ın türetimi, score ve olasılıksal çerçeve.
- **İleriye (Ders 10):** Ders 10 "from the foundations"ı başlatır — matmul'dan backprop'a, her şeyi sıfırdan.
:::
## Bu Dersin Özeti {#sec-ozet-d09a}
1. Stable Diffusion **latent diffusion**'dır: VAE görüntüyü 4×64×64 latent'e sıkıştırır, tüm iş orada olur (0.18215 ölçekleme) ([VAE/latent](#sec-vae-latent)).
2. `pil_to_latent`/`latents_to_pil` ile latent'e gir/çık; ~48× sıkıştırmaya rağmen yüksek kalite ([encode/decode](#sec-encode-decode)).
3. **Noise schedule** (σ) her adımda eklenen/çıkarılan gürültüyü belirler; img2img bunun bir uygulamasıdır ([noise schedule](#sec-noise-schedule), [img2img](#sec-img2img-d09a)).
4. Prompt **tokenizer → CLIP** ile embedding'e çevrilir; token embedding'lerine müdahale textual inversion'ı sağlar ([text encoding](#sec-text-encoding), [textual inversion](#sec-textual-inversion-d09a)).
5. **Classifier-free guidance**: her adımda iki tahmin (koşullu + koşulsuz); sonuç = koşulsuz + $s$ × (koşullu − koşulsuz) ([CFG](#sec-cfg)).
6. **Sampling loop**: rastgele gürültü → her adımda CFG ile gürültü tahmini → `scheduler.step` ile çıkar → tekrarla ([sampling döngüsü](#sec-sampling-dongusu)).
7. **Özel guidance** ile herhangi bir hedef fonksiyonun gradyanı sampling'e eklenebilir (örn. "daha mavi") ([özel guidance](#sec-ozel-guidance)).
8. Bu loop, Ders 9'un "pixel gradyanı" sezgisinin tam kod karşılığıdır ([kapanış](#sec-kapanis-d09a)).
::: {.callout-important title="Tek Bir Cümle"}
Stable Diffusion'ın hazır pipeline'ı; VAE ile latent uzaya inip, CLIP ile metni kodlayıp, her adımda classifier-free guidance'lı bir U-Net tahminiyle gürültüyü scheduler üzerinden adım adım gideren bir döngüden ibarettir — ve istediğin herhangi bir hedefin gradyanıyla yönlendirilebilir.
:::
## Kontrol Soruları {#sec-sorular-d09a}
::: {.callout-note collapse="true" title="Soru 1: Classifier-free guidance her adımda neden iki tahmin yapar ve sonucu nasıl birleştirir?"}
**Cevap:**
U-Net her adımda iki gürültü tahmini üretir: biri **prompt'la koşullu**, biri **boş prompt'la (koşulsuz)**. Bu ikisinin farkı, "prompt'un üretimi hangi yöne ittiği"ni gösterir. Sonuç = koşulsuz_tahmin + guidance_scale × (koşullu − koşulsuz). guidance_scale = 1 ise sade koşullu tahmin; 1'den büyükse prompt'un yönü **abartılır** (daha sadık ama bazen aşırı). Böylece ayrı bir sınıflandırıcı eğitmeden (classifier-free) prompt etkisi güçlendirilir — hesaplama maliyeti adım başına iki U-Net geçişidir. (@fig-cfg-twopred iki-tahmin vektör aritmetiğini, @fig-sampling-loop adım-4 birleştirmesini gösterir.)
:::
::: {.callout-note collapse="true" title="Soru 2: Stable Diffusion neden 'latent diffusion'dır ve 0.18215 ne işe yarar?"}
**Cevap:**
"Latent diffusion" demek, diffusion'ın piksel uzayında değil, VAE'nin sıkıştırdığı **latent uzayda** (4×64×64) yapılması demektir — bu ~48× daha az veri, dolayısıyla çok daha ucuz/hızlı. `pil_to_latent` VAE ile görüntüyü latent'e çevirir, `latents_to_pil` geri açar. 0.18215, latent'leri U-Net'in eğitildiği ölçeğe getiren bir **normalleştirme sabitidir** (modelin yazarlarının seçtiği); encode'da çarpılır, decode'da bölünür. Olmazsa latent'lerin büyüklüğü U-Net'in beklediğiyle uyuşmaz. (@fig-latent-roundtrip 786.432 → 16.384 roundtrip'ini gösterir.)
:::
::: {.callout-note collapse="true" title="Soru 3: img2img mekanizması nasıl çalışır? 'strength' neyi kontrol eder?"}
**Cevap:**
img2img, sıfır gürültüden değil, bir **başlangıç görüntüsünden** başlar: görüntü VAE ile latent'e çevrilir, sonra noise schedule'da **belirli bir adıma kadar** gürültülenir (tamamen değil), ve sampling oradan devam eder. `strength` bu "ne kadar gürültüleneceğini" (hangi σ'dan başlanacağını) belirler: düşük strength → az gürültü → çıktı orijinale yakın; yüksek strength → çok gürültü → prompt'a göre büyük değişim. Yani strength, orijinal görüntünün ne kadarının korunacağını ayarlar. (@fig-img2img her strength'in σ çizelgesindeki başlangıç noktasını gösterir.)
:::
::: {.callout-note collapse="true" title="Soru 4: Whitaker'ın 'özel guidance' gösterisi Ders 9'un hangi fikrini somutlaştırır? (builder bağlantısı)"}
**Cevap:**
Ders 9'daki "sihirli fonksiyonun pixel gradyanı yönünde ittir" fikrini. Whitaker, sampling'e kendi hedef fonksiyonunu ekler (örn. "görüntü daha mavi olsun"): her adımda bu hedefin hatasının latent'lere göre **gradyanını** hesaplar ve latent'leri o yönde de ittirir. Yani CFG modelin öğrendiği yönü kullanırken, özel guidance **istediğin herhangi bir** türevlenebilir hedefi (renk, CLIP benzerliği, kenar haritası) sampling'e enjekte eder. Builder açısından: bu, CLIP-guided diffusion ve ControlNet gibi tüm yönlendirme tekniklerinin temel mekanizmasıdır — üretimi bir loss'un gradyanıyla yönlendirmek. (@fig-custom-guidance mavi-kanal MSE'sinin gerçek düşüşünü gösterir.)
:::
## Egzersizler {#sec-egzersizler-d09a}
**Egzersiz 1 (Direkt uygulama).** `pil_to_latent` ve `latents_to_pil` ile bir görüntüyü latent'e çevirip geri aç; sıkıştırma kaybını gözle (0.18215 ölçeği doğru uygula).
**Egzersiz 2 (İki-aşamalı).** `scheduler.sigmas`'ı çiz; bir görüntüye farklı timestep'lerde `add_noise` uygulayıp gürültü seviyelerini karşılaştır (@fig-sigma-schedule'ı kendi adım sayınla yeniden üret).
**Egzersiz 3 (Edge case).** Sampling loop'unda `guidance_scale`'i 1, 7, 20 yap; çıktının prompt'a sadakatini ve "aşırı doygunluk" eşiğini gözlemle.
**Egzersiz 4 (Kavramsal).** CFG formülünü (koşulsuz + $s$ × (koşullu − koşulsuz)) bir adım için elle yaz; $s = 0, 1, 10$ için sonucu açıkla.
**Egzersiz 5 (Sonraki dersin habercisi — 9B).** Noise schedule'ın ($\beta$, $\bar{\alpha}$) nereden geldiğini ve "forward process"in matematiğini araştır (Ders 9B).
## Sonraki: Ders 9B İçin Hazırlık {#sec-sonraki-d09a}
**Ders 9B: Diffusion'ın Matematiği (Waseem + Tanishq)**
Ders 9 ve 9A diffusion'ı sezgi ve kodla verdi. Ders 9B (misafirler: Waseem + Tanishq, Stability AI) altındaki **matematiği** açar: forward/reverse process, noise schedule'ın türetilmesi, score ve olasılıksal çerçeve.
Ana konular (Ders 9B):
- Forward process (gürültü ekleme) ve Markov zinciri
- Reverse process (gürültü giderme) matematiği
- Noise schedule ($\beta$, $\bar{\alpha}$) türetimi
- Olasılıksal/score çerçevesi
::: {.callout-warning title="Ders 9B Öncesi Yapılacak"}
- Bu dersin egzersizlerini çöz (özellikle 1 ve 4 — latent + CFG).
- Sampling loop'unu kendi notebook'unda çalıştır.
- Ana cümleyi tekrar oku: "Sampling = CFG'li U-Net tahmini + scheduler ile adım adım gürültü giderme."
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet-d09a}
| Kavram | Tanım | Whitaker'da |
|---|---|---|
| Latent diffusion | Diffusion'ı piksel değil latent uzayda yapma | 1:21 |
| `pil_to_latent` | VAE encode: görüntü → latent (×0.18215) | 1:21 |
| `latents_to_pil` | VAE decode: latent → görüntü (÷0.18215) | 1:21 |
| Noise schedule (σ) | Her adımdaki gürültü miktarı (yüksek → sıfır) | 8:44 |
| `add_noise` | latent + noise × σ (belirli timestep'te) | 8:44 |
| img2img | Görüntüyü kısmen gürültüleyip sampling'e devam | 3:55 |
| Text encoder (CLIP) | tokenizer → embedding dizisi | 8:44 |
| Textual inversion | Yeni embedding'i token sözlüğüne ekleme | 15:03 |
| Classifier-free guidance | uncond + $s$ × (cond − uncond) | 18:38 |
| Sampling loop | CFG tahmini + `scheduler.step` ile gürültü giderme | 19:38 |
| Özel guidance | Herhangi bir hedefin gradyanını sampling'e ekleme | 36:32 |
| `scheduler.step` | Tahmin edilen gürültüyü latent'ten kısmen çıkarma | 19:38 |
## ML Bağlantıları Özeti {#sec-ml-baglantilar-d09a}
::: {.callout-tip title="Builder Notu — 6 ML Köprüsü: 9A'nın Sezgiden Koda Dönüşü"}
Bu ders, Ders 9'un sezgisini çalışan koda çevirir; köprülerin özeti:
1. **Latent diffusion** → VAE sıkıştırması ([Ders 8/9](09-stable-diffusion.qmd#sec-vae-d09)); pahalı işlemi küçük uzayda yapma ([VAE/latent](#sec-vae-latent)).
2. **Classifier-free guidance** → koşullu/koşulsuz fark; üretimi prompt yönüne abartma; NYU EBM (§4.J) akrabası ([CFG](#sec-cfg)).
3. **Sampling loop** → `scheduler.step` = gradient adımı ([Ders 5](05-sifirdan-model.qmd#sec-egitim-dongusu)) diffusion karşılığı ([sampling döngüsü](#sec-sampling-dongusu)).
4. **Özel guidance** → Ders 9'un [pixel-gradient sezgisi](09-stable-diffusion.qmd#sec-pixel-gradyani); CLIP-guided/ControlNet temeli ([özel guidance](#sec-ozel-guidance)).
5. **CLIP text encoder** → tokenize ([Ders 4](04-dogal-dil-isleme.qmd)) + embedding ([Ders 7](07-ortak-filtreleme.qmd#sec-embedding-arama)) çok-modal koşullama ([text encoding](#sec-text-encoding)).
6. **Noise schedule** → DDPM/DDIM/Karras (Ders 19-22) ile Part 2'de sıfırdan kurulur ([noise schedule](#sec-noise-schedule)).
:::
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Stable Diffusion'ın "büyülü" pipeline'ı, ayrı ayrı anlaşılabilir parçaların bir döngüsüdür — VAE latent'e indirir, CLIP yön verir, U-Net + classifier-free guidance her adımda gürültüyü tahmin eder, scheduler çıkarır. Ve en güçlüsü: istediğin herhangi bir hedefin gradyanını bu döngüye ekleyerek üretimi yönlendirebilirsin — tıpkı [Ders 9'daki](09-stable-diffusion.qmd#sec-pixel-gradyani) "geçerlilik gradyanı" sezgisi gibi.
:::