flowchart LR
J["Jupyter<br/>eğit + fine_tune"] --> E["learn.export<br/>model.pkl (GPU)"]
E --> L["load_learner<br/>(CPU)"]
L --> G["Gradio app.py<br/>classify_image"]
G --> H["HF Spaces<br/>canlı web uygulaması"]
style J fill:#ffe4e6,stroke:#e11d48,stroke-width:2px
style E fill:#ffe4e6,stroke:#e11d48,stroke-width:2px
style L fill:#cffafe,stroke:#0891b2,stroke-width:2px
style G fill:#cffafe,stroke:#0891b2,stroke-width:2px
style H fill:#ffe4e6,stroke:#e11d48,stroke-width:3px
3 Dağıtım — Modeli Dünyaya Aç (Deployment)
Önce eğit-sonra temizle, modeli learn.export ile dondur, load_learner + predict ile her yerde çalıştır ve Gradio + Hugging Face Spaces ile ücretsiz bir canlı web uygulaması yayınla
NotBölüm bilgisi
- Howard’ın videosu: course.fast.ai — Lesson 2: Deployment (~77 dk)
- Seri: Practical Deep Learning for Coders — Part 1, Ders 2
- Hoca: Jeremy Howard
- Playlist: Practical Deep Learning Part 1 (2022)
- Notebook: course22 — 02-saving-a-basic-fastai-model
- Okuma süresi: ~30 dk
3.1 Bu Derste Ne Var?
Ders 1’de bir model eğittik. Ders 2 onu gerçek dünyaya çıkarır — çünkü eğitim değil, deploy üretimin asıl zorluğudur. Howard yolu baştan sona yürür: veri toplama, modeli eğiterek veriyi temizleme (ters sezgi), modeli learn.export ile dondurma ve Hugging Face Spaces + Gradio ile ücretsiz bir web uygulaması yayınlama.
Üç temel fikir:
- Önce eğit, sonra temizle — “önce veri hazırla, sonra eğit” sezgisinin tersi; eğitilmiş model en kötü verileri (yanlış etiket, bozuk görsel) senin yerine bulur (Ters Sezgi bölümü).
- Veri artırımı (data augmentation) — aynı görüntüden her epoch’ta biraz farklı bir kopya üretip modeli sağlamlaştırma (Veri Artırımı bölümü).
- export → load → predict — eğitilen model bir
pkldosyasına dondurulur, GPU’suz herhangi bir yerde yüklenip milisaniyelerde tahmin yapar (export → load + predict).
“It feels like I’m really really pumped about this lesson.” — Howard, 0:31
Şekil 3.1 bu üç fikri, Jupyter’da eğitimden Hugging Face Spaces’te canlı web uygulamasına uzanan tek bir deploy hattında birleştirir.
İpucuBuilder Notu — Deploy = Üretimin Asıl İşi
- İleriye (production): Bu ders tamamen MLOps’un giriş kapısıdır — model bir notebook’ta kalmaz, internette çalışan bir servise dönüşür. “Deploy = asıl zor kısım” tezi tüm production ML’in gerçeğidir.
- Geriye (Ders 1):
vision_learner+fine_tuneaynı; yeni olan tek şeyexport/load_learner/predictzinciri ve veri temizleme araçları. - Tek cümle: Bir model ancak başkalarının kullanabildiği anda değer üretir; bu ders modeli notebook’tan çıkarıp dünyaya verir.
3.2 Geri Dönüş: Öğrenciler Neler Yaptı?
Howard derse, geçen haftanın ödevinden (“yaptığını paylaş”) gelen öğrenci projeleriyle başlar — bir hasarlı araç sınıflandırıcısı dahil. Mesaj açık: Ders 1’in birkaç satırıyla bile insanlar gerçek, çalışan uygulamalar kurabiliyor.
Howard ayrıca kitabı (Deep Learning for Coders) ve forumları (forums.fast.ai) hatırlatır: aynı bilgiyi farklı yollardan duymak öğrenmeyi pekiştirir.
“As promised, I put up the ‘show us what you’ve made’ post, and already a lot of people have posted.” — Howard, 4:16
İpucuBuilder Notu — Önce Üret, Sonra Paylaş
- Geriye (Ders 1): Bu, Ders 1 sonundaki “yaptığını paylaş” ödevinin karşılığıdır — derste gösterilen öğrenci projeleri (hasarlı araç sınıflandırıcısı dahil) tam o ödevden geldi.
- İleriye: “Önce bir şey üret, paylaş” — fast.ai felsefesinin merkezi; portfolyo, ilk işi bulmanın en hızlı yoludur.
3.3 Hedef: Modeli Production’a Almak
Dersin omurgası net bir hedeftir: eğittiğimiz modeli production’a (kullanıma) almak. Howard adımları sayar — veriyi bul, modeli eğit, temizle, dışa aktar, bir web uygulaması olarak yayınla.
“Step one is, well, you’ve kind of done it: you train a model. Now we have to figure out how to put it into production.” — Howard, 6:49
Ders 1’in top-down ruhu burada da geçerli: önce çalışan bir deploy görürüz, ayrıntılar yolda açılır.
İpucuBuilder Notu — Eğitim Bir Kez, Deploy Sürekli
- Geriye (Ders 1): Ders 1’de modeli
fine_tuneile bir kez eğitip orada bırakmıştık; o “bir kez”lik eğitim adımı bu dersin başlangıç noktası, asıl iş ise sonrasıdır. - İleriye (MLOps): Eğitim bir kez olur; deploy sürekli çalışmalıdır. Üretimde zamanın çoğu modeli değil, modelin çevresini (servis, izleme, güncelleme) kurmaya gider.
3.4 Veriyi Toplamak
Howard bir ayı sınıflandırıcısı (grizzly / black / teddy) kurar. Veri yine arama motorundan (Bing/DuckDuckGo) toplanır ve Ders 1’deki DataBlock ile yüklenir. Yardım bulmanın yollarını da gösterir: bir fonksiyon adının yanına tek ? kısa bilgi, çift ?? tüm kaynak kodu verir.
“If you put a double question mark next to any function name, you’ll actually get the whole source code for it.” — Howard, 11:26
İpucuBuilder Notu —
?? ile Kaynağa İnmek
- Geriye (Ders 1):
DataBlock’un beş parçası (blocks, get_items, splitter, get_y, item_tfms) burada aynen kullanılır. - İleriye:
??ile kaynağa inme alışkanlığı, kütüphane içini okuyup öğrenmenin en hızlı yoludur — Karpathy’nin “from scratch” ruhunun pratik versiyonu.
3.5 Ters Sezgi: Önce Eğit, Sonra Temizle
Howard kasıtlı olarak şaşırtıcı bir şey söyler: veriyi temizlemeden önce bir model eğitiriz. “Önce veriyi hazırla, sonra eğit” sezgisinin tam tersidir.
“I’m going to tell you something that you might find really surprising. You clean the data, you train a model. I know that’s going to sound really backwards. First we’re going to train a model and you’ll see why in a moment.” — Howard, 12:47
Sebebi sonraki bölümlerde açılacak: eğitilmiş model, hangi örneklerin yanlış etiketli veya bozuk olduğunu (en yüksek kayıplı örnekler) bizim için işaret eder — somut araç ImageClassifierCleaner bölümünde. Şekil 3.2 bu ters sezgili döngüyü — eğit → temizle → yeniden eğit — bir bütün olarak gösterir. Önce hızlıca eğitiriz:
bears = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=RandomResizedCrop(224, min_scale=0.5),
batch_tfms=aug_transforms())
dls = bears.dataloaders(path)
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(4)Kod
fig = plt.figure(figsize=(9.4, 6.4))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.axis("off")
# 4 kutu dörtgen/dairesel yerleşim (saat yönünde döngü)
# üst-sol: veri topla üst-sağ: hızlı eğit (fine_tune)
# alt-sol: temizle/etiketle alt-sağ: ImageClassifierCleaner
bw, bh = 3.1, 1.5
pos_collect = (2.6, 7.7) # üst-sol
pos_train = (7.4, 7.7) # üst-sağ
pos_cleaner = (7.4, 2.3) # alt-sağ (rose vurgulu)
pos_clean = (2.6, 2.3) # alt-sol
boxed_node(ax, *pos_collect, bw, bh,
"veri topla",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11.5, lw=2.2)
boxed_node(ax, *pos_train, bw, bh,
"hızlı eğit\n(fine_tune)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11.5, lw=2.2)
boxed_node(ax, *pos_cleaner, bw, bh,
"ImageClassifierCleaner\nkayba göre sıralı",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10.5, lw=2.6)
boxed_node(ax, *pos_clean, bw, bh,
"temizle /\nyeniden etiketle",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11.5, lw=2.2)
# Döngü okları (saat yönünde): topla -> eğit -> cleaner -> temizle -> (geri) eğit
# 1) veri topla -> hızlı eğit (üst kenar, yatay)
arrow_between(ax, (pos_collect[0] + bw / 2, pos_collect[1]),
(pos_train[0] - bw / 2, pos_train[1]),
color=COL_PRIMARY, lw=2.4)
# 2) hızlı eğit -> cleaner (sağ kenar, dikey aşağı)
arrow_between(ax, (pos_train[0], pos_train[1] - bh / 2),
(pos_cleaner[0], pos_cleaner[1] + bh / 2),
color=COL_PRIMARY, lw=2.4)
# 3) cleaner -> temizle/etiketle (alt kenar, yatay sola)
arrow_between(ax, (pos_cleaner[0] - bw / 2, pos_cleaner[1]),
(pos_clean[0] + bw / 2, pos_clean[1]),
color=COL_ACCENT, lw=2.4)
# 4) temizle -> hızlı eğit (GERİYE dönen ok: döngü kapanır, çapraz eğimli)
arrow_between(ax, (pos_clean[0] + bw / 2 - 0.15, pos_clean[1] + bh / 2),
(pos_train[0] - bw / 2 + 0.15, pos_train[1] - bh / 2),
color=COL_ACCENT, lw=2.6,
connectionstyle="arc3,rad=-0.18", style="-|>")
# "yeniden eğit" etiketi geri-ok yanında
ax.text(5.0, 5.45, "yeniden eğit ↺", ha="center", va="center",
fontsize=10, color=COL_ACCENT, weight="bold", style="italic", zorder=5)
# Orta metin: "önce eğit, sonra temizle" (accent)
ax.text(5.0, 4.65, "önce eğit,\nsonra temizle", ha="center", va="center",
fontsize=15, color=COL_ACCENT, weight="bold", zorder=5)
# Alt not: model = veri kalitesinin denetçisi
ax.text(5.0, 0.55, "model, veri kalitesinin denetçisi", ha="center", va="center",
fontsize=9.5, color=COL_SLATE_400, weight="bold", style="italic")
plt.show()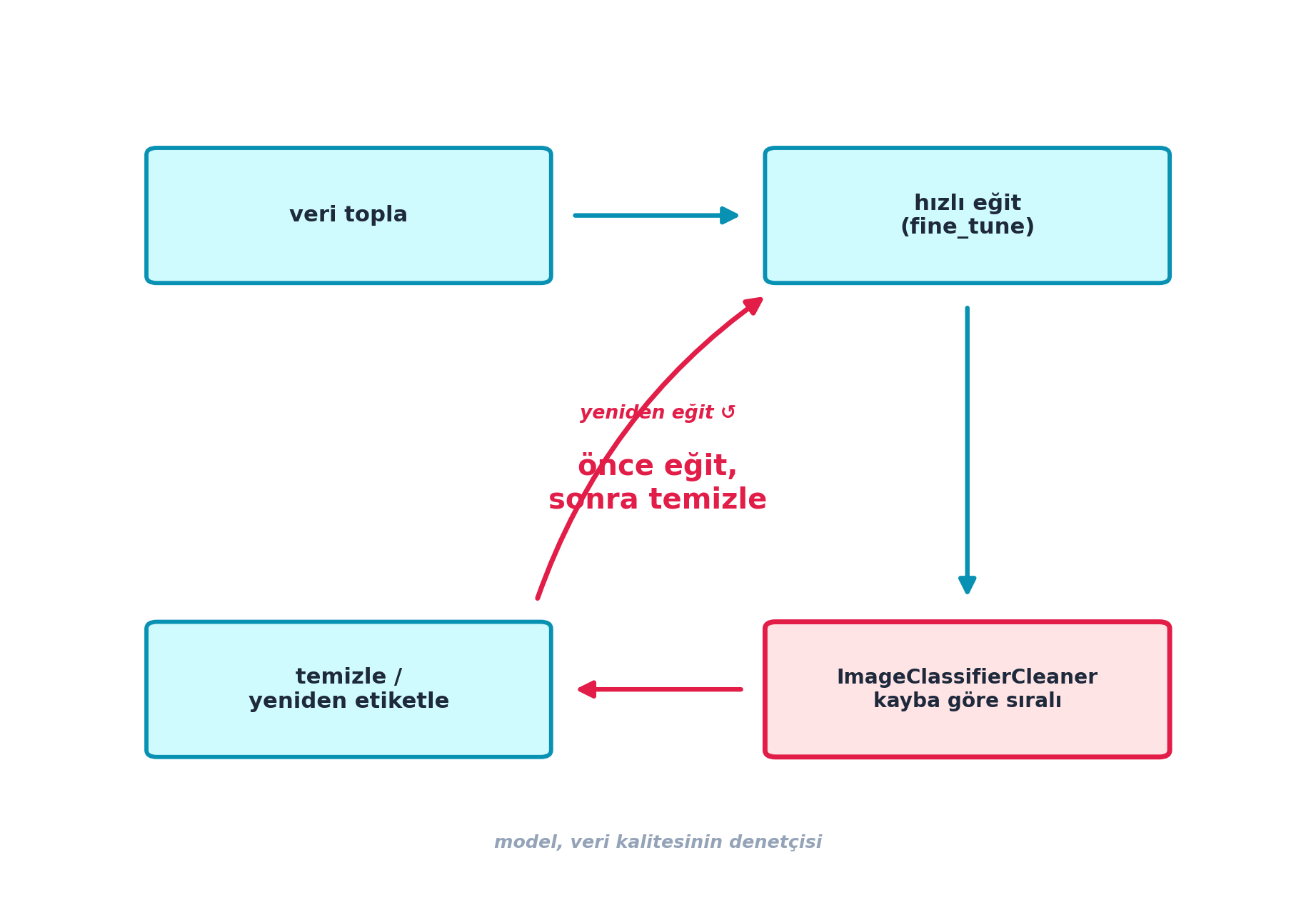
İpucuBuilder Notu — Veri-Merkezli ML’in Çekirdeği
- Geriye (Ders 1): Döngüdeki “hızlı eğit” adımı, Ders 1’in
vision_learner+fine_tunezincirinin aynısıdır; yeni olan, o modeli veri kalitesini ölçmek için kullanmaktır. - İleriye (veri-merkezli ML): “Model, veri kalitesini denetler” fikri modern veri-merkezli (data-centric) ML’in temelidir; etiket gürültüsünü modelle bulmak yaygın bir production tekniğidir.
3.6 Yeniden Boyutlandırma Yöntemleri
Çoğu görü modeli tüm girdilerin aynı boyutta olmasını ister. fastai üç yol sunar: squish (sıkıştır — en-boy oranı bozulur, bütün görünür), crop (ortadan kırp — oran korunur, kenarlar kaybolur), pad (kenarlara siyah ekle — hem oran hem bütünlük korunur).
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Squish)) # sikistir
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Pad, pad_mode='zeros')) # doldur
bears = bears.new(item_tfms=RandomResizedCrop(128, min_scale=0.3)) # rastgele kirpŞekil 3.3 bu üç yöntemi aynı sentetik foto üstünde yan yana gösterir — squish ezer, crop kenarı atar, pad siyah kenar ekler.
“Different situations result in different quality models; you can try them all, it doesn’t normally make too big a difference, so I wouldn’t worry about it too much.” — Howard, 14:37
Kod
# Gerçek numpy dönüşüm — sentetik foto üstünde squish/crop/pad
orig, squish, crop, pad = resize_demo(96)
panels = [
(orig, "orijinal (90x140)", COL_CYAN_700),
(squish, "squish — oran bozulur", COL_ACCENT),
(crop, "crop — kenar kaybolur", COL_CYAN_700),
(pad, "pad — siyah kenar", COL_ACCENT),
]
fig, axes = plt.subplots(1, 4, figsize=(11, 3.1))
for ax, (img, title, tc) in zip(axes, panels):
ax.imshow(img, interpolation="nearest")
ax.set_title(title, color=tc, fontsize=10.5, weight="bold", pad=8)
ax.axis("off")
fig.text(0.5, 0.015, "fastai Resize: squish / crop / pad",
ha="center", va="bottom", color=COL_TEXT, fontsize=9.5, style="italic")
fig.tight_layout(rect=(0, 0.05, 1, 1))
plt.show()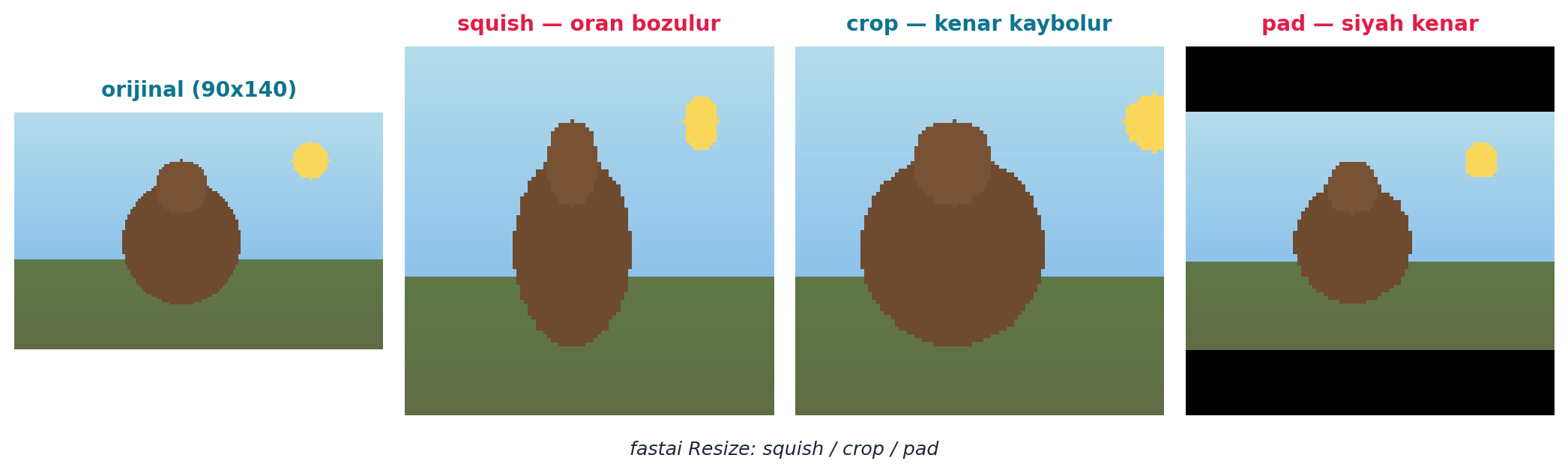
İpucuBuilder Notu — Squish/Crop/Pad Tercihi
- Geriye (Ders 1): Ders 1’de
Resize(192, method='squish')kullanmıştık; burada üç seçeneğin sonuçlara etkisini görüyoruz. - İleriye: Howard’a göre fark çoğu zaman küçüktür (14:37); pratikte üçünü de deneyip confusion matrix ile karşılaştırmak en sağlam yoldur.
3.7 Veri Artırımı (Data Augmentation)
En ilginç yöntem RandomResizedCrop’tur: her epoch’ta görüntünün farklı bir parçası seçilir. Bu, aynı görüntüden her seferinde biraz farklı bir kopya üretme fikrine, yani veri artırımına (data augmentation) açılır — döndürme, eğme, renk kaydırma. aug_transforms() bunları otomatik uygular.
“This idea of getting different pictures each time from the same image is called data augmentation.” — Howard, 15:53
Önemli nüans: kopyalar diske kaydedilmez; her epoch’ta görüntü bellekte gerçek zamanlı dönüştürülür. Şekil 3.4 aynı fotodan üretilen altı farklı kopyayı gösterir.
“There’s no copies being stored on your computer, but effectively it’s almost like there’s infinitely slightly different copies, because that’s what the model ends up sees.” — Howard, 17:38
bears = bears.new(
item_tfms=RandomResizedCrop(224, min_scale=0.5),
batch_tfms=aug_transforms())
dls = bears.dataloaders(path)Kod
# GERÇEK dönüşüm — RandomResizedCrop + flip + brightness (bkz. augmentation_demo)
augs = augmentation_demo(6, seed=2)
fig, axes = plt.subplots(2, 3, figsize=(8.4, 5.6))
for i, ax in enumerate(axes.flat):
ax.imshow(augs[i], interpolation="nearest")
ax.axis("off")
fig.suptitle("Aynı fotodan 6 farklı kopya — data augmentation",
fontsize=13, weight="bold", color=COL_CYAN_700, y=0.99)
# Alt-not: bellekte üretim, diske yazılmaz
fig.text(0.5, 0.015, "her epoch'ta bellekte üretilir, diske yazılmaz",
ha="center", va="bottom", fontsize=10.5, weight="bold", color=COL_TEXT)
fig.tight_layout(rect=(0, 0.04, 1, 0.96))
plt.show()
İpucuBuilder Notu — Bellekte Çoğalan Veri
- Geriye (Stat 110): Augmentation, modelin gördüğü dağılımı genişletip aşırı öğrenmeyi azaltır — örneklem çeşitliliği fikri.
- İleriye: Beş-on epoch’tan fazla eğiteceksen RandomResizedCrop + aug_transforms neredeyse her zaman işe yarar; production görü modellerinin standart parçasıdır.
3.8 Confusion Matrix (Karışıklık Matrisi)
Model eğitildikten sonra ClassificationInterpretation ile hatalarını inceleriz. Confusion matrix, hangi kategorinin hangisiyle karıştırıldığını gösterir — yalnızca kategorik etiketlerde anlamlıdır.
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()Howard’ın ayı örneğinde model grizzly ile black bear’ı birbirine karıştırır ama teddy’yi hiç şaşırmaz — mantıklı, çünkü teddy ikisinden de çok farklı görünür. Şekil 3.5 bu örüntüyü gösterir: çapraz hücreler dolu, teddy köşegeni temiz.
“What it says is, what category errors are you making? There were two times when it was actually a grizzly bear and it thought it was a black bear.” — Howard, 19:04
Kod
from matplotlib.colors import LinearSegmentedColormap
mat, labels = bear_confusion()
n = len(labels)
cmap = LinearSegmentedColormap.from_list("cy", ["#ffffff", COL_PRIMARY])
fig, ax = plt.subplots(figsize=(5.2, 4.6))
im = ax.imshow(mat, cmap=cmap, vmin=0, vmax=mat.max())
# her hücreye sayı yaz (>10 ise beyaz, değilse koyu metin)
for i in range(n):
for j in range(n):
v = int(mat[i, j])
ax.text(j, i, str(v), ha="center", va="center",
fontsize=15, weight="bold",
color=(COL_WHITE if v > 10 else COL_TEXT))
ax.set_xticks(range(n))
ax.set_yticks(range(n))
ax.set_xticklabels(labels, color=COL_TEXT, fontsize=11)
ax.set_yticklabels(labels, color=COL_TEXT, fontsize=11)
ax.set_xlabel("tahmin", color=COL_TEXT, fontsize=12, weight="bold")
ax.set_ylabel("gerçek", color=COL_TEXT, fontsize=12, weight="bold")
ax.set_title("Ayı sınıflandırıcı — confusion matrix",
color=COL_TEXT, fontsize=13, weight="bold", pad=12)
# hücre ayrım ızgarası (okunabilirlik)
ax.set_xticks(np.arange(-0.5, n, 1), minor=True)
ax.set_yticks(np.arange(-0.5, n, 1), minor=True)
ax.grid(which="minor", color=COL_WHITE, linewidth=2.0)
ax.tick_params(which="minor", length=0)
for spine in ax.spines.values():
spine.set_visible(False)
fig.tight_layout()
plt.show()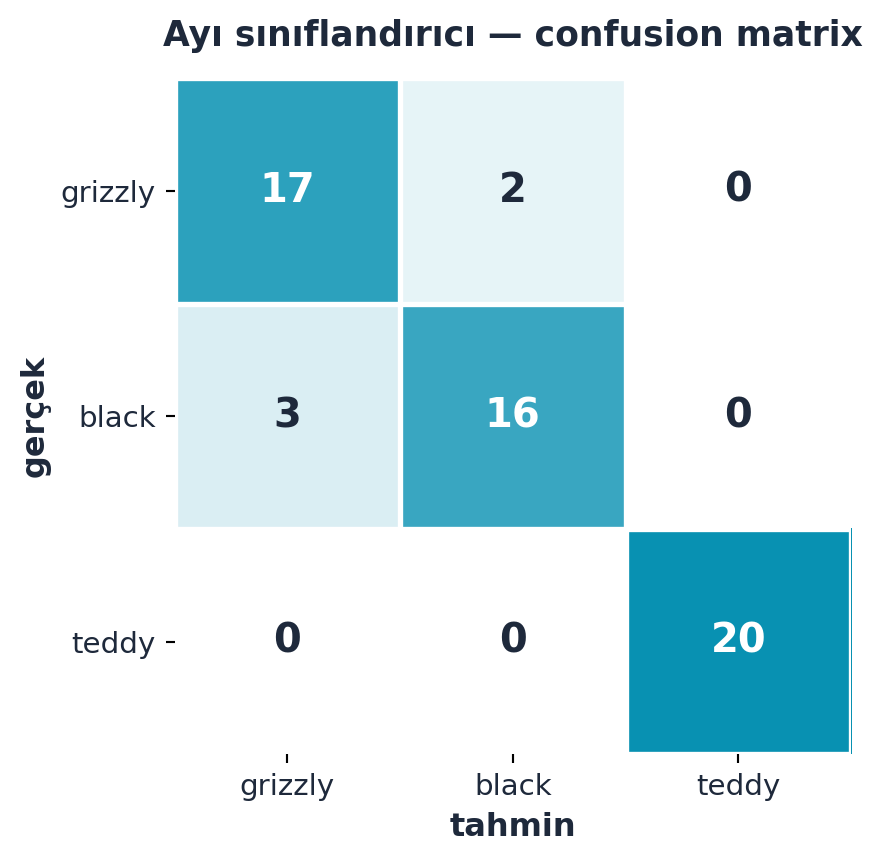
İpucuBuilder Notu — Hata Analizinin İlk Adımı
- Geriye (Stat 110): Confusion matrix, sınıflandırma değerlendirmesinin temelidir; precision/recall buradan türer.
- İleriye: Hangi sınıfların karıştığını bilmek, veri toplama önceliğini belirler (production’da hata analizinin ilk adımı).
3.9 plot_top_losses
plot_top_losses, kaybın (loss) en yüksek olduğu örnekleri gösterir. Howard kritik bir ayrım yapar: kötü kayıp iki şekilde olur — ya yanlış ve emin, ya doğru ama emin değil.
“You can have a bad loss either by being wrong and confident, or being right and unconfident.” — Howard, 22:02
interp.plot_top_losses(5, nrows=1)Bu, hangi örneklerin “zor” veya “şüpheli” olduğunu hızla ortaya çıkarır. Şekil 3.6 bu iki yüksek-kayıp durumunu güven ekseninde konumlandırır.
Kod
pts = loss_quadrant_points()
fig, ax = plt.subplots(figsize=(7.4, 4.6))
# Arka plan bölge gölgeleri: yüksek-kayıp köşeler hafif rose, düşük-kayıp köşe hafif cyan
# sağ-alt (yanlış + emin) -> yüksek kayıp
ax.add_patch(plt.Rectangle((0.78, -0.35), 0.30, 0.55, fc=COL_BG_ROSE, ec="none",
alpha=0.55, zorder=0))
# sol-üst civarı (doğru + emin değil = düşük güven) -> yüksek kayıp
ax.add_patch(plt.Rectangle((0.40, 0.80), 0.32, 0.55, fc=COL_BG_ROSE, ec="none",
alpha=0.55, zorder=0))
# sağ-üst (doğru + emin) -> düşük kayıp
ax.add_patch(plt.Rectangle((0.78, 0.80), 0.30, 0.55, fc=COL_BG, ec="none",
alpha=0.45, zorder=0))
# Noktaları yerleştir (deterministik jitter ile üst üste binmesin)
rng = np.random.default_rng(7)
for p in pts:
x = p["x"]
y = 1 if p["correct"] else 0
# küçük dikey jitter (kategorik seviyeyi koru, ±0.10 içinde)
yj = y + rng.uniform(-0.10, 0.10)
if p["high_loss"]:
ax.scatter(x, yj, s=320, color=COL_ACCENT, edgecolors=COL_WHITE,
linewidths=1.6, zorder=4)
else:
ax.scatter(x, yj, s=150, color=COL_PRIMARY, edgecolors=COL_WHITE,
linewidths=1.2, zorder=3)
# Üç bölge açıklaması
ax.annotate("yanlış + EMİN\n= yüksek kayıp", xy=(0.94, 0.0), xytext=(0.80, -0.27),
ha="center", va="center", fontsize=9.5, color=COL_ACCENT, weight="bold")
ax.annotate("doğru + emin DEĞİL\n= yüksek kayıp", xy=(0.55, 1.0), xytext=(0.555, 1.27),
ha="center", va="center", fontsize=9.5, color=COL_ACCENT, weight="bold")
ax.annotate("doğru + emin\n= düşük kayıp", xy=(0.93, 1.0), xytext=(0.93, 1.27),
ha="center", va="center", fontsize=9.5, color=COL_CYAN_700, weight="bold")
apply_style(ax)
ax.set_xlim(0.40, 1.04)
ax.set_ylim(-0.45, 1.55)
ax.set_xticks([0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
ax.set_yticks([0, 1])
ax.set_yticklabels(["yanlış", "doğru"])
ax.set_xlabel("güven (tahmin olasılığı)")
ax.set_ylabel("tahmin")
ax.set_title("Kayıp iki şekilde yüksek olur", color=COL_TEXT, weight="bold", fontsize=13)
ax.grid(True, axis="y", alpha=0.0)
plt.show()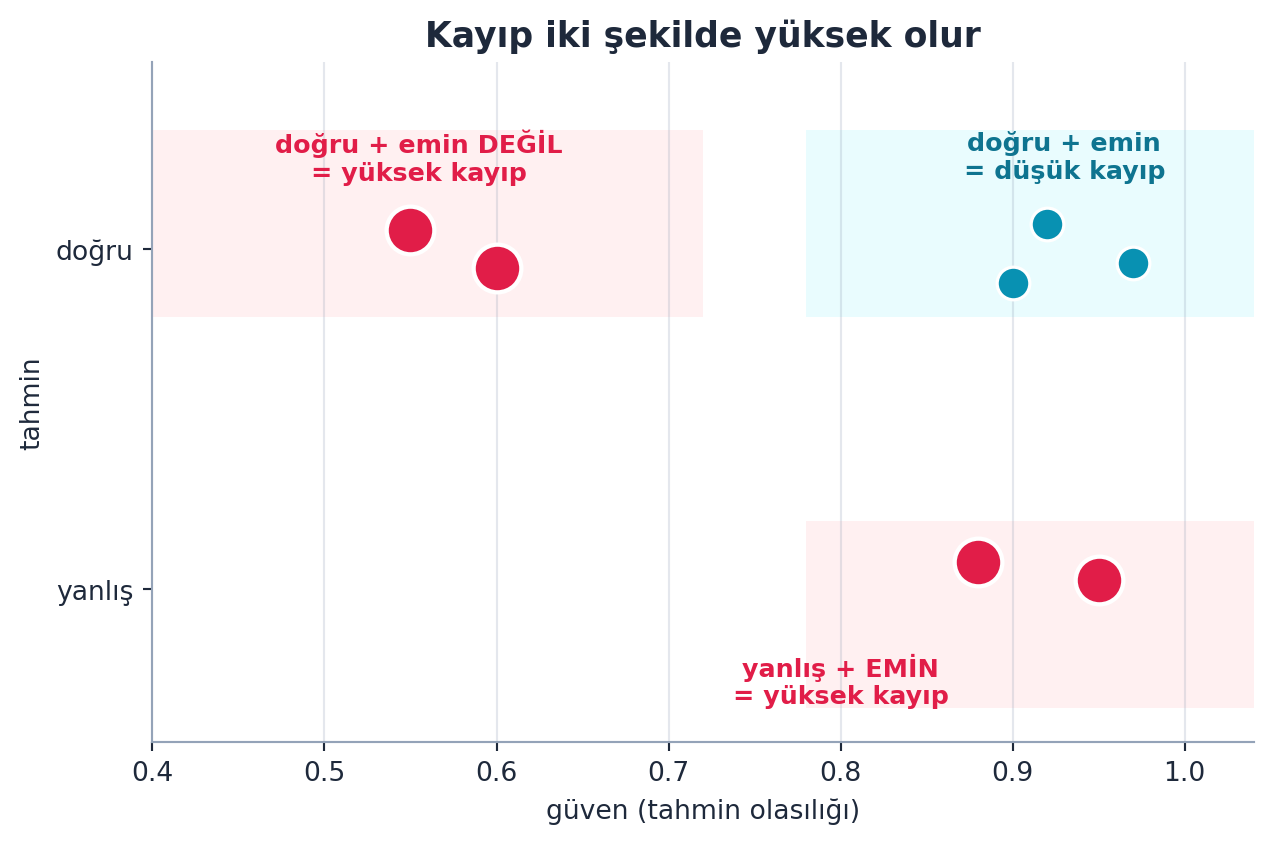
İpucuBuilder Notu — Emin ve Yanlış = Kalibrasyon Sorunu
- Geriye (Ders 1): Loss, Ders 1’deki “modelin ne kadar iyi olduğunun ölçüsü”dür; yüksek loss = ya hata ya düşük güven.
- İleriye (calibration): “Emin ve yanlış” örnekler, modelin kalibrasyon sorunlarını ve etiket hatalarını işaret eder.
3.10 ImageClassifierCleaner
Şimdi önce eğit, sonra temizle mantığı meyvesini verir. ImageClassifierCleaner modeli çalıştırır (bu yüzden ona learn veririz) ve her sınıfın örneklerini kayba göre sıralı (plot_top_losses mantığıyla) gösterir — en şüpheliler en üstte. Yanlış etiketlileri yeniden etiketler veya sileriz. Bu, Şekil 3.2 döngüsündeki “temizle” adımının somut aracıdır.
“Now we can use the fastai ImageClassifierCleaner to clean up the ones that are wrongly labeled. It actually runs our model, that’s why we pass it learn. And here’s what’s really important: they’re ordered by loss.” — Howard, 22:13
cleaner = ImageClassifierCleaner(learn)
cleaner
İpucuBuilder Notu — Veri Denetçisi Olarak Model
- İleriye (veri-merkezli ML): Modeli “etiket denetçisi” olarak kullanmak, büyük veri setlerini elle taramaya kıyasla devasa zaman kazandırır.
- Pratik: Temizledikten sonra modeli yeniden eğitirsin; döngü (eğit → temizle → eğit) doğruluğu artırır.
3.11 CPU RAM vs GPU RAM (VRAM)
Howard pratik bir uyarı yapar: GPU belleği (VRAM) CPU belleğinden farklı çalışır. CPU RAM dolduğunda işletim sistemi fazlasını diske yazabilir (swap); GPU bunu yapamaz. VRAM dolarsa “out of memory” hatası alırsın — çözüm genellikle Jupyter kernel’ini yeniden başlatmaktır.
“If you use up your GPU RAM, GPUs can’t swap that RAM onto the hard disk to use it later.” — Howard, 26:00
İpucuBuilder Notu — VRAM Gerçeği
- Geriye (Ders 1): Ders 1’de veriyi GPU’ya batch (mini-batch) hâlinde besliyorduk; işte o batch’ler VRAM’de tutulur — bu not, oradaki batch kavramının donanım tarafıdır.
- İleriye (production): Batch boyutu doğrudan VRAM tüketimini belirler; OOM hatası, batch boyutunu küçültmenin veya gradient accumulation’ın (Part 2 Ders 9 / Karpathy) gerekçesidir.
3.12 Production’a Alma: Hugging Face Spaces + Gradio
Modeli internette yayınlamak için Howard Hugging Face Spaces (ücretsiz barındırma) + Gradio (ücretsiz arayüz kütüphanesi) kullanır. Bir Space oluşturulur, Gradio uygulaması yazılır ve git ile yüklenir. Howard önce minimal bir “hello name” Gradio arayüzüyle mekaniği gösterir.
“Let’s go create a new space. We’re going to use Gradio, also free.” — Howard, 29:33
Süreç git tabanlıdır (GitHub Desktop veya terminal); Windows kullanıcıları için WSL/PowerShell notları da verilir.
İpucuBuilder Notu — En Hızlı Deploy Yolu
- İleriye (deploy seçenekleri): HF Spaces + Gradio, bir ML demosunu dünyaya açmanın en hızlı yoludur; alternatifler Streamlit, FastAPI, AWS/GCP container’larıdır.
- Geriye: Git, üretim akışının zorunlu aracı — coding-standards’taki branch/commit disiplini buraya da uygulanır.
3.13 learn.export — Modeli Dondurmak
Asıl köprü learn.exporttır: eğitilmiş Learner’ı tek bir dosyaya (model.pkl) yazar. Bu, GPU gerektiren tek adımdır; geri kalan her şey (tahmin) CPU’da çalışır (load_learner + predict bölümü). Şekil 3.7 bu ayrımı gösterir — model.pkl GPU bölgesiyle CPU bölgesini köprüleyen tek artefakttır.
# Egitim (Kaggle/Colab, GPU): deploy edilebilir bir model uret
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func('.',
get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(192))
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(3)
learn.export('model.pkl') # modeli tek dosyaya dondur“I go learn.export and I give it a name. That’s going to create a file containing our trained model. And that’s the only thing you need a GPU for.” — Howard, 38:56
Kod
fig = plt.figure(figsize=(11.0, 4.2))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 12)
ax.set_ylim(0, 5)
ax.axis("off")
# ----- Ortadaki dikey kesikli ayraç -----
ax.axvline(6.0, ymin=0.06, ymax=0.94, color=COL_SLATE_400,
linewidth=1.8, linestyle=(0, (5, 4)), zorder=0)
# ----- Bölge başlıkları -----
ax.text(2.9, 4.62, "GPU — bir kez", ha="center", va="center",
fontsize=13, color=COL_ACCENT, weight="bold")
ax.text(9.1, 4.62, "CPU — her yerde", ha="center", va="center",
fontsize=13, color=COL_CYAN_700, weight="bold")
# =========================================================
# SOL (rose): egit + fine_tune -> learn.export -> model.pkl
# =========================================================
yc = 2.55
boxed_node(ax, 1.25, yc, 2.1, 1.5,
"eğit +\nfine_tune",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10.5, lw=2.2)
boxed_node(ax, 3.75, yc, 2.1, 1.5,
"learn.export",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10.5, lw=2.2)
arrow_between(ax, (2.3, yc), (2.7, yc), color=COL_ACCENT, lw=2.4)
# =========================================================
# KÖPRÜ: model.pkl (iki bölgeyi birleştiren ortak kutu, ayraç üstünde)
# =========================================================
boxed_node(ax, 6.0, yc, 1.7, 1.2,
"model.pkl",
fc=COL_BG, ec=COL_CYAN_800, tc=COL_CYAN_800, fontsize=11, lw=2.6)
# learn.export -> model.pkl (rose ok, GPU adimini noktalar)
arrow_between(ax, (4.8, yc), (5.15, yc), color=COL_ACCENT, lw=2.4)
# model.pkl -> load_learner (cyan ok, CPU tarafina gecer)
arrow_between(ax, (6.85, yc), (7.35, yc), color=COL_PRIMARY, lw=2.4)
# =========================================================
# SAG (cyan): load_learner -> predict ~50ms -> tahmin+olasilik
# =========================================================
boxed_node(ax, 8.45, yc, 2.0, 1.5,
"load_learner",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=10.5, lw=2.2)
boxed_node(ax, 10.85, yc, 2.0, 1.5,
"predict\n~50 ms",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=10.5, lw=2.2)
arrow_between(ax, (9.45, yc), (9.85, yc), color=COL_PRIMARY, lw=2.4)
# tahmin + olasilik (predict ciktisi, alt etiket)
ax.text(10.85, yc - 1.42, "tahmin + olasılık", ha="center", va="center",
fontsize=9.0, color=COL_CYAN_700, weight="bold", style="italic")
arrow_between(ax, (10.85, yc - 0.76), (10.85, yc - 1.12),
color=COL_PRIMARY, lw=2.0, shrink=4)
# ----- Alt vurgu satiri (Howard 38:56) -----
ax.text(6.0, 0.62,
"GPU gereken TEK adım | gerisi CPU",
ha="center", va="center", fontsize=10.5, color=COL_TEXT,
weight="bold")
ax.text(6.0, 0.18, "Howard 38:56", ha="center", va="center",
fontsize=8.0, color=COL_SLATE_400, style="italic")
plt.show()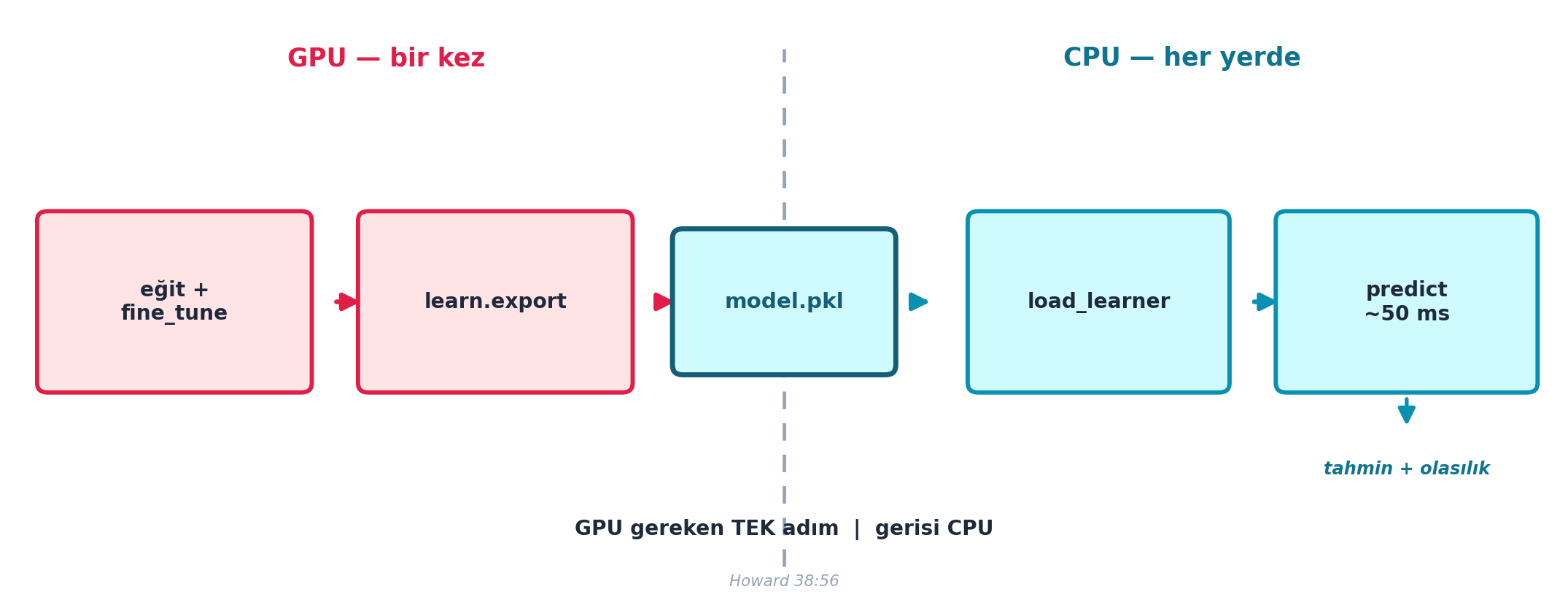
learn.export GPU gereken TEK adımdır (model.pkl üretimi); load_learner + predict CPU’da ~50 ms çalışır. Pahalı GPU yalnızca eğitim için — model.pkl iki bölgeyi köprüler (Howard 38:56).
İpucuBuilder Notu — pickle = Taşınabilir Model Artefaktı
- Geriye (Ders 1):
ImageDataLoaders.from_name_func,DataBlock’un kısa yoludur; etiket buradakiis_catfonksiyonundan gelir. - İleriye:
model.pklbir pickle dosyasıdır — eğitim ortamından bağımsız, taşınabilir bir model artefaktı; production’da versiyonlanır.
3.14 load_learner + predict
Dondurulmuş modeli kullanmak için onu eğitmeyiz, yükleriz: load_learner kaydedilen dosyayı açar ve eğitimin sonundakiyle birebir aynı Learner’ı geri verir.
“Instead of training a learner, we use load_learner, we pass in the file name that we saved, and that returns a learner. This learner is exactly the same as the learner you get when you finish training.” — Howard, 42:45
Howard bunu “zamanda dondurma” diye anlatır: pkl bir pickle (donmuş Python nesnesi) dosyasıdır. Tahmin, CPU’da bile anlıktır — Şekil 3.7 sağ tarafındaki CPU bölgesi (load_learner → predict ~50 ms) tam bu adımı betimler.
“We kind of froze it in time, something called a pickle file. It’s like a frozen object. We saved it to disk, transferred it to our computer, and we’ve now loaded it.” — Howard, 43:07
import gradio as gr
from fastai.vision.all import *
learn = load_learner('model.pkl')
# Etiketleyici fonksiyon (is_cat) tanimi burada da bulunmali:
def is_cat(x): return x[0].isupper()
im = PILImage.create('dog.jpg')
pred, idx, probs = learn.predict(im) # ~54 ms, CPU'da bile anlik
# Cikti yapisi (ornek/illustratif degerler — is_cat vocab [False, True] sirali):
# pred = 'False' (string), idx = tensor(0), probs = tensor([P(dog), P(cat)])
# dog.jpg icin P(dog) yuksek cikar (or. ~0.9998 / ~0.0002)“It took 54 milliseconds to figure out that this is not a cat. It’s returning: is it a cat as a string, is it a cat as a zero or one, and the probability that it’s a dog and a cat.” — Howard, 44:02
İpucuBuilder Notu — Donmuş Model Tuzağı (is_cat)
- Önemli tuzak:
model.pkletiketleyici fonksiyona (is_cat) referans verir ama kaynak kodunu içermez — bu yüzdenis_cattanımı tahmin ortamında da bulunmalıdır; aynı kural Gradio arayüzününclassify_image’ı için de geçerlidir. - İleriye: ~50 ms çıkarım, gerçek zamanlı bir web servisi için fazlasıyla hızlı; CPU yeterli (deploy maliyetini düşürür).
3.15 Gradio Arayüzü (app.py)
Gradio, tahmin fonksiyonunu bir web arayüzüne sarar. Sınıf adları tanımlanır, predict çıktısı bir olasılık sözlüğüne çevrilir ve gr.Interface görüntü girişi + etiket çıkışı kurar.
categories = ('Dog', 'Cat')
def classify_image(img):
pred, idx, probs = learn.predict(img)
return dict(zip(categories, map(float, probs)))
intf = gr.Interface(fn=classify_image, inputs=gr.Image(), outputs=gr.Label())
intf.launch()gr.Label, olasılık sözlüğünü çubuk grafiği olarak gösterir. Şekil 3.8 bu arayüzü somutlaştırır: gr.Image girdisi → classify_image → gr.Label olasılık çubukları. Bu dosya Hugging Face Space’e yüklendiğinde model canlı bir web uygulaması olur.
Kod
fig = plt.figure(figsize=(11.5, 4.6))
fig.patch.set_facecolor(COL_WHITE)
# --- Tarayıcı penceresi çerçevesi (tek ax, axis off) ---
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 100)
ax.set_ylim(0, 40)
ax.axis("off")
# Dış tarayıcı penceresi (beyaz, soluk slate kenar)
boxed_node(ax, 50, 20, 96, 36, "",
fc=COL_WHITE, ec=COL_SLATE_400, lw=2.2)
# Üst başlık şeridi (cyan dolgu) — pencere başlığı
boxed_node(ax, 50, 35.6, 96, 5.0,
"Gradio: gr.Interface(fn, gr.Image, gr.Label)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=11.5, lw=1.8)
# Tarayıcı "trafik ışığı" noktaları (sol üst, dekoratif)
for i, c in enumerate([COL_ACCENT, "#fbbf24", "#34d399"]):
ax.scatter(5.5 + i * 2.6, 35.6, s=70, color=c, zorder=5,
edgecolors=COL_WHITE, linewidths=0.6)
# --- SOL bölge: gr.Image() girdi kutusu ---
boxed_node(ax, 19, 19.5, 26, 19, "",
fc=COL_WHITE, ec=COL_PRIMARY, lw=2.0)
ax.text(19, 30.5, "gr.Image()", ha="center", va="center",
fontsize=11, color=COL_CYAN_700, weight="bold")
# İçine küçük gerçek-foto placeholder (synthetic_photo inset)
photo = synthetic_photo()
ax_img = fig.add_axes([0.105, 0.345, 0.155, 0.27])
ax_img.imshow(photo)
ax_img.set_xticks([]); ax_img.set_yticks([])
for s in ax_img.spines.values():
s.set_color(COL_SLATE_400); s.set_linewidth(1.2)
ax.text(19, 11.6, "resim yükle ↑", ha="center", va="center",
fontsize=9, color=COL_SLATE_400, weight="bold", style="italic")
# --- ORTA: classify_image oku ---
arrow_between(ax, (33.0, 19.5), (48.5, 19.5), color=COL_PRIMARY, lw=2.6,
mutation_scale=22)
ax.text(40.7, 22.9, "classify_image", ha="center", va="bottom",
fontsize=10.5, color=COL_CYAN_700, weight="bold", style="italic")
ax.text(40.7, 16.1, "predict ~50 ms\n(CPU)", ha="center", va="top",
fontsize=8.5, color=COL_SLATE_400, weight="bold")
# --- SAĞ bölge: gr.Label() = olasılık çubukları ---
boxed_node(ax, 75, 19.5, 30, 19, "",
fc=COL_WHITE, ec=COL_ACCENT, lw=2.0)
ax.text(75, 30.5, "gr.Label()", ha="center", va="center",
fontsize=11, color=COL_ACCENT, weight="bold")
axp = fig.add_axes([0.655, 0.315, 0.235, 0.265])
prob_bars(axp, ["Dog", "Cat"], [0.98, 0.02], fmt="{:.2f}")
# --- Alt-not (çerçeve içinde, alt şerit) ---
boxed_node(ax, 50, 4.0, 96, 4.4, "",
fc=COL_BG_ROSE, ec=COL_SLATE_300, lw=1.2)
ax.text(50, 4.0,
"app.py + model.pkl → Hugging Face Spaces'te canlı web uygulaması",
ha="center", va="center", fontsize=10, color=COL_TEXT, weight="bold")
plt.show()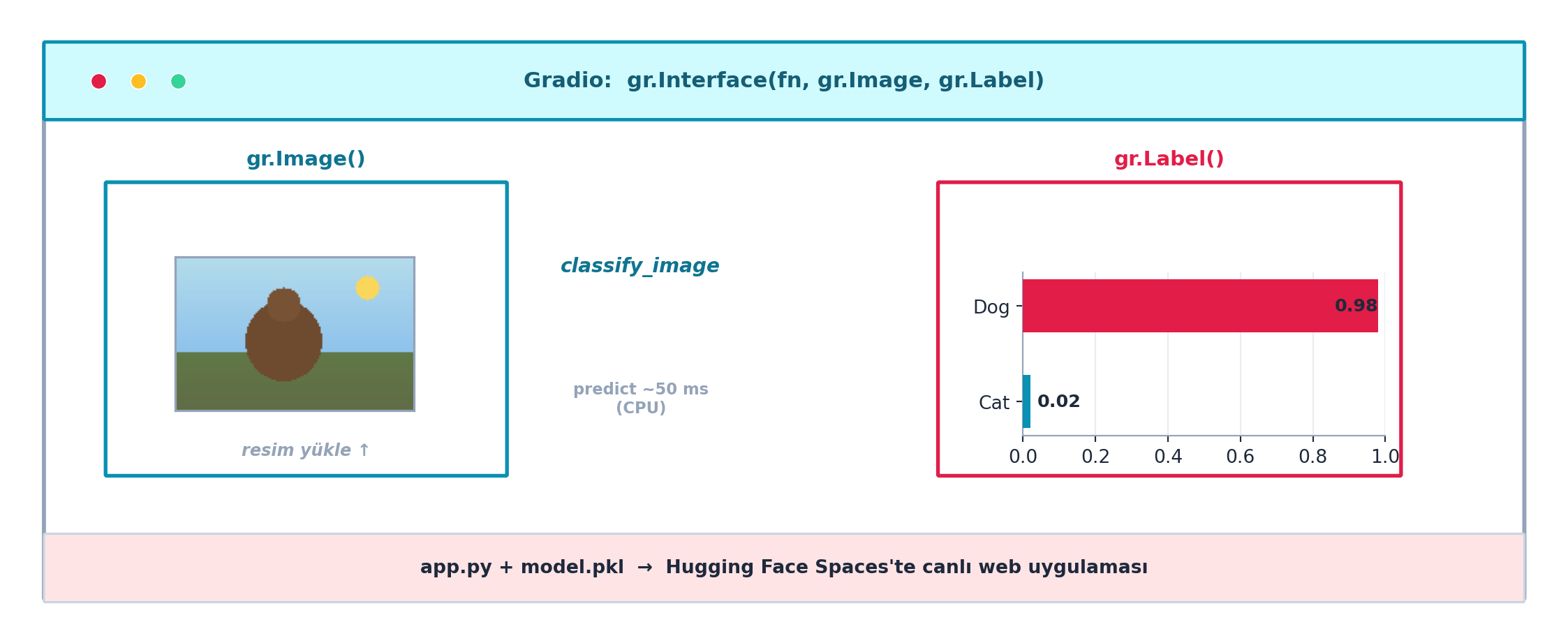
gr.Interface tahmin fonksiyonunu web arayüzüne sarar — gr.Image girdisi, classify_image, gr.Label olasılık çubukları. app.py + model.pkl Hugging Face Spaces’e yüklenince canlı uygulama olur.
İpucuBuilder Notu — Gradio = REST API’nin İnce Katmanı
- Geriye:
classify_image, load_learner + predict bölümündekilearn.predictçağrısını saran ince bir kabuktur — Gradio yeni bir tahmin mantığı eklemez, var olanı sarar. - İleriye: Aynı
classify_imagefonksiyonu bir REST API’nin de çekirdeğidir; Gradio yalnızca onu görselleştiren ince bir katmandır.
3.16 #|export ile Notebook’tan Script
Howard pratik bir numara gösterir: deney yaptığı notebook’tan otomatik olarak app.py üretmek. nbdev’in #|export işareti, hangi hücrelerin script’e gireceğini belirler; bir export komutu bu hücreleri toplayıp app.py yazar.
“That creates a file for me called app.py containing that script. So this is a nice easy way.” — Howard, 48:25
#|export
categories = ('Dog', 'Cat')
def classify_image(img):
pred, idx, probs = learn.predict(img)
return dict(zip(categories, map(float, probs)))
# Son hucre: isaretli hucreleri app.py'ye yaz
from nbdev.export import nb_export
nb_export('app.ipynb', '.')
İpucuBuilder Notu — Notebook = Hem Deney Hem Kaynak
- Geriye (Ders 1): Ders 1’de notebook’u (Jupyter/Kaggle) deney ortamı olarak kullanmıştık;
#|exportaynı notebook’uapp.pykaynağına dönüştürerek deney ile production’ı tek dosyada birleştirir. - İleriye (reproducibility): “Notebook = hem deney hem kaynak” yaklaşımı, deneyle production kodunu senkron tutar; nbdev fast.ai ekosisteminin kendi geliştirme aracıdır.
3.17 Kaç Epoch Eğitmeli? + Kapanış
Topluluktan gelen yaygın bir soru: kaç epoch? Howard’ın pratik cevabı: ya zamanın/sabrın bitene kadar, ya da doğrulama hatası (error rate) artmaya başlayana kadar. Sabit bir sayı yoktur; küçük problemler için birkaç epoch, zor problemler için daha fazla.
“You train until the error rate starts getting worse, or until you run out of time.” — Howard, 53:14
Howard dersi, modeli Colab’da export edip indirme ve yerel ortam kurulumu (mamba/conda) notlarıyla kapatır. Asıl mesaj sabit: artık tam bir uçtan uca hattın var — eğit, temizle, export, deploy.
İpucuBuilder Notu — Erken Durdurma Sezgisi
- Geriye (Ders 1): “Doğrulama hatası artmaya başlayınca dur” kuralı, Ders 1’deki validation set + overfitting fikrinin doğrudan uygulamasıdır — train düşerken validation yükselmeye başladığı an, durulacak noktadır.
- İleriye: “Error rate kötüleşene kadar eğit” = erken durdurma (early stopping) sezgisi; Part 2’de (ve Stat 110 overfitting) bunu derinleştireceğiz.
3.18 Bu Dersin Özeti
- Bir model ancak deploy edildiğinde değer üretir; deploy üretimin asıl zor kısmıdır.
- fast.ai’de ters sezgi: önce modeli eğit, sonra veriyi temizle — model şüpheli örnekleri senin için bulur (Ters Sezgi).
- Veri artırımı (RandomResizedCrop + aug_transforms) aynı görüntüden her epoch’ta farklı kopya üretip aşırı öğrenmeyi azaltır; kopyalar diske yazılmaz, bellekte üretilir (Veri Artırımı).
- Confusion matrix hangi sınıfların karıştığını, plot_top_losses en şüpheli örnekleri (yanlış+emin veya doğru+emin değil) gösterir (Confusion matrix, plot_top_losses).
- ImageClassifierCleaner modeli kullanarak yanlış etiketli/bozuk örnekleri kayba göre sıralı temizler (Cleaner).
- GPU RAM (VRAM) swap yapamaz; dolarsa kernel yeniden başlatılır.
- learn.export modeli tek
pkldosyasına dondurur (GPU gereken tek adım); load_learner onu herhangi bir yerde geri yükler. - predict CPU’da bile ~50 ms’de tahmin döndürür (string + indeks + olasılıklar); Gradio + Hugging Face Spaces ile canlı web uygulamasına dönüşür.
ÖnemliTek Bir Cümle
Eğitmek işin yarısıdır; bir modeli dondurup (export), her yerde yükleyip (load_learner) milisaniyelerde tahmin ettiren ve Gradio + HF Spaces ile dünyaya açan deploy zinciri, derin öğrenmeyi gerçek bir ürüne dönüştürür.
3.19 Kontrol Soruları
NotSoru 1: learn.export ne yapar ve neden “GPU gerektiren tek adım” odur?
Cevap:
learn.export('model.pkl') eğitilmiş Learner’ı (mimari + ağırlıklar + ön işleme) tek bir pickle dosyasına yazar. Eğitim (gradient hesabı, fine_tune) GPU ister; ama dosya oluşturma ve sonraki tahmin (predict) yalnızca ileri geçiştir ve CPU’da hızlıca çalışır. Yani GPU’yu sadece modeli üretmek için kiralarsın; deploy edilen servis ucuz CPU’da koşar.
NotSoru 2: “Önce eğit, sonra temizle” neden mantıklıdır? ImageClassifierCleaner bunu nasıl mümkün kılar?
Cevap:
Eğitilmiş model, hangi örneklerin “zor” olduğunu kayıpla ölçer. Yanlış etiketli veya bozuk görseller genellikle en yüksek kayba sahiptir. ImageClassifierCleaner(learn) modeli çalıştırıp her sınıfın örneklerini kayba göre sıralar — en şüpheliler en üstte. Böylece binlerce görseli elle taramak yerine, yalnızca üstteki birkaç şüpheliyi yeniden etiketler veya silersin. Model, veri kalitesinin denetçisi olur.
NotSoru 3: plot_top_losses’ta bir örnek “doğru tahmin edilmiş” olduğu hâlde neden yüksek kayba sahip olabilir? Ayrıca load_learner sonrası is_cat tanımı neden gerekir?
Cevap:
Kayıp iki şekilde yüksek olur: (a) yanlış ve emin, (b) doğru ama emin değil. Model bir teddy’yi %66 güvenle doğru tahmin etse bile, düşük güven yüksek kayıp demektir — bu yüzden “doğru” örnek listede çıkar. is_cat’e gelince: model.pkl etiketleme fonksiyonuna referans tutar ama kaynak kodunu saklamaz; bu yüzden modeli yüklediğin ortamda is_cat tanımı yeniden bulunmalıdır, yoksa yükleme başarısız olur.
NotSoru 4: Howard neden “deploy, eğitimden daha zor” der? CPU çıkarımın ~50 ms olması ne anlama gelir?
Cevap:
Eğitim bir kez olur ve net bir bitişi vardır; deploy ise sürekli çalışmalı, hataları kaldırmalı, güncellenmeli ve gerçek kullanıcılara hizmet vermelidir (servis, arayüz, izleme, sürüm). Asıl mühendislik buradadır. ~50 ms CPU çıkarımı ise pahalı GPU’ya gerek olmadığını gösterir: bir web servisi saniyede onlarca isteği ucuz donanımda karşılayabilir — deploy maliyetini ve karmaşıklığını ciddi biçimde düşürür.
3.20 Egzersizler
Egzersiz 1 (Direkt uygulama). Kendi iki sınıflı modelini (Ders 1’den) eğit ve learn.export('model.pkl') ile kaydet. Dosya boyutuna bak.
Egzersiz 2 (Temizleme döngüsü). ImageClassifierCleaner ile veri setini temizle, modeli yeniden eğit ve error_rate’i önce/sonra karşılaştır.
Egzersiz 3 (Resizing kıyası). Aynı veride Resize(squish), Resize(pad) ve RandomResizedCrop ile üç model eğit; plot_confusion_matrix ile sonuçları kıyasla.
Egzersiz 4 (Gradio). load_learner + classify_image + gr.Interface ile yerel bir Gradio uygulaması yaz ve launch() ile çalıştır.
Egzersiz 5 (Deploy — dersin ana hedefi). Bir Hugging Face Space oluştur, model.pkl + app.py yükle ve modelini canlı web uygulaması olarak yayınla.
3.21 Sonraki Ders İçin Hazırlık
Ders 3: Sinir Ağı Temelleri (Neural net foundations)
Ders 1-2’de vision_learner/fine_tune’u kara kutu olarak kullandık. Ders 3 perdeyi aralar: bir sinir ağı gerçekte nasıl çalışır? Gradient descent, parametre uydurma, ReLU ve sıfırdan MNIST.
Ana konular:
- Bir fonksiyonu veriye uydurma (gradient descent)
- Türev ve
gradient’in rolü - ReLU ile esnek fonksiyonlar kurma
- Matrix multiplication ve MNIST
UyarıDers 3 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 5 — bir model deploy et).
- Kendi modelini Hugging Face Spaces’te canlıya al.
- Ana cümleyi tekrar oku: “Önce eğit, sonra temizle; sonra dondur ve deploy et.”
3.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Deploy | Modeli kullanılabilir bir servise dönüştürme; asıl zor kısım | 6:49 |
| Önce eğit, sonra temizle | Eğitilmiş modelle şüpheli veriyi bulma (ters sezgi) | 12:47 |
| Data augmentation | Aynı görüntüden her epoch’ta farklı kopya üretme | 15:53 |
| RandomResizedCrop | Her seferinde görüntünün farklı parçasını kırpma | 14:55 |
| aug_transforms | Döndürme/eğme/renk dönüşümleri paketi | 15:53 |
| Confusion matrix | Hangi sınıfların birbirine karıştığını gösterir | 19:04 |
| plot_top_losses | En yüksek kayıplı (şüpheli) örnekler | 22:02 |
| ImageClassifierCleaner | Modelle veri temizleme aracı (kayba göre sıralı) | 22:13 |
| learn.export | Modeli tek pkl dosyasına dondurma (GPU’lu tek adım) | 38:56 |
| load_learner | Dondurulmuş modeli geri yükleme | 42:45 |
| predict | CPU’da ~50 ms tahmin (string + indeks + olasılık) | 43:30 |
| Gradio + HF Spaces | Ücretsiz arayüz + barındırma ile canlı web uygulaması | 27:20 |
3.23 ML Builder Bağlantıları
İpucuBuilder Notu — 6 ML Köprüsü
Bu ders, derin öğrenmeyi notebook’tan gerçek bir ürüne taşıyan deploy hattıdır — köprülerin özeti:
- Deploy = MLOps girişi → model notebook’tan çıkıp servise dönüşür; production’da asıl iş budur.
- Veri-merkezli ML → modeli etiket denetçisi olarak kullanmak (ImageClassifierCleaner), büyük veri setlerinde standart tekniktir.
- Data augmentation → aşırı öğrenmeyi azaltır (Stat 110 örneklem çeşitliliği); tüm görü pipeline’larının parçası.
- pickle artefaktı → taşınabilir, versiyonlanabilir model dosyası; üretimde model registry’nin temeli.
- CPU çıkarım → ~50 ms; pahalı GPU olmadan ölçeklenebilir servis (deploy maliyeti düşer).
- Gradio/HF Spaces → demo-to-production en hızlı yol; Part 2’de Stable Diffusion demoları da aynı altyapıyı kullanır.
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten tek bir şey alıp gideceksen: bir model ancak başkalarının kullanabildiği an gerçek olur. Önce eğit-sonra-temizle ile veriyi sağlamlaştır, export ile dondur, load_learner + predict ile her yerde çalıştır, Gradio + Hugging Face Spaces ile dünyaya aç. Eğitim laboratuvardır; deploy üretimdir.