flowchart TD
M["model = parametreli fonksiyon<br/>a·x² + b·x + c"] --> L["loss ölç<br/>MAE / MSE"]
L --> D["türev / gradient<br/>iniş yönü"]
D --> G["gradient descent<br/>p ← p − η·grad"]
G --> R["ReLU toplamı<br/>esnek (kıvrımlı) fonksiyon"]
R --> U["universal approximation<br/>her fonksiyon kurulabilir"]
U --> DL["derin öğrenmeyi türettik"]
style M fill:#cffafe,stroke:#0891b2,stroke-width:2px
style G fill:#cffafe,stroke:#0891b2,stroke-width:2px
style R fill:#cffafe,stroke:#0891b2,stroke-width:2px
style DL fill:#ffe4e6,stroke:#e11d48,stroke-width:3px
4 Sinir Ağı Temelleri — Derin Öğrenmeyi Türetmek (Neural net foundations)
Bir model = parametreli bir fonksiyondur: önce quadratic \(a x^2 + b x + c\)’yi gürültülü veriye uydur, loss’u (MAE/MSE) ölç, türev/gradient ile yönü bul, gradient descent (\(p \leftarrow p - \eta\,\nabla L\)) ile parametreleri otomatik ayarla ve yeterince ReLU toplayarak derin öğrenmeyi sıfırdan türet
NotBölüm bilgisi
- Howard’ın videosu: course.fast.ai — Lesson 3: Neural net foundations (~90 dk)
- Seri: Practical Deep Learning for Coders — Part 1, Ders 3
- Hoca: Jeremy Howard
- Playlist: Practical Deep Learning Part 1 (2022)
- Notebook: course22 — 04-how-does-a-neural-net-really-work
- Okuma süresi: ~35 dk
4.1 Bu Derste Ne Var?
Ders 1-2’de vision_learner ve fine_tune’u bir kara kutu olarak kullandık. Ders 3 perdeyi aralar: bir sinir ağı gerçekte nasıl çalışır? Howard önce pratik tarafı (timm ile daha iyi modeller, bulut ortamları) gösterir, sonra en aşağıya iner — bir modelin aslında gradient descent ile parametreleri uydurulmuş bir fonksiyon olduğunu sıfırdan kurar.
Üç temel fikir:
- Model = parametreli fonksiyon — basit bir quadratic \(f(x) = a x^2 + b x + c\) bile bir modeldir; “öğrenmek” doğru \(a, b, c\)’yi bulmaktır (Model = Parametreli Fonksiyon).
- Gradient descent — kayıp (loss) fonksiyonunun eğimini (gradient) hesaplayıp parametreleri eğimin tersine küçük adımlarla, \(p \leftarrow p - \eta\,\nabla L\), güncellemek (Gradient Descent).
- ReLU toplamı = her şey — yeterince rectified linear unit toplanırsa istenen kadar karmaşık herhangi bir fonksiyon kurulabilir; parametreleri gradient descent verir. “İşte derin öğrenmeyi türettik.” (Sonsuz Karmaşık Fonksiyon → “Deep Learning’i Türettik”).
“We have just derived deep learning. Everything from now on is tweaks to make it faster and make it need less data.” — Howard, 47:59
Şekil 28.1 bu üç fikri, parametreli fonksiyondan “derin öğrenmeyi türettik” sonucuna uzanan tek bir zincirde birleştirir.
İpucuBuilder Notu — Bir Kara Kutuyu Türevden Türetmek
- Geriye (Ders 1-2): Ders 1-2’de
vision_learner+fine_tune“büyü” gibiydi; bu ders o büyünün altındaki tek mekanizmayı — gradient descent ile parametre uydurma — elle kurar. - Geriye (Karpathy / Calculus): Bu ders Karpathy’nin micrograd’ının kavramsal özüdür —
loss.backward()+param -= grad·lr. Türev (Calculus) ve zincir kuralı tam burada işler. - İleriye: “ReLU toplamı + gradient descent” universal approximation’dır; tüm modern mimariler bu çekirdeğin üstünde durur — “gerisi hız ve veri verimliliği ayarı”.
- Tek cümle: Bir model, gradient descent ile parametreleri uydurulan esnek bir fonksiyondur — gerisi hız ve verimlilik ayarıdır.
4.2 Bir fast.ai Dersi Nasıl Çalışılır?
Howard “Lesson 0” niteliğinde bir yöntem önerir: önce videoyu izle, sonra notebook’u aç, her hücreyi çalıştırmadan önce çıktısının ne olacağını tahmin et, sonra çalıştır ve doğrula. Kendi kendine çalışmanın (self-study) tuzaklarına da değinir; forum ve Discord topluluğunu önerir.
Howard ayrıca haftanın öğrenci işlerini gösterir (Marvel karakter tanıyıcı, müzik türü sınıflandırıcı, Power App uygulamaları) — Ders 1-2’nin birkaç satırı gerçek ürünlere dönüşüyor.
“Before you run each cell, try to think about what it’s going to show, to test your understanding.” — Howard, 4:01
İpucuBuilder Notu — Çıktıyı Tahmin Et, Sonra Çalıştır
- İleriye (aktif öğrenme): “Çıktıyı tahmin et, sonra çalıştır” aktif öğrenmedir; pasif izlemeye kıyasla kavrayışı kat kat artırır — bu derste birazdan kuracağımız gradient descent döngüsünü adım adım kafanda canlandırmak tam bu disiplindir.
- Geriye (Ders 1): Ders 1’deki “her adımda veriye bak” alışkanlığının kardeşi; orada veriye, burada koda bakarsın.
4.3 Daha İyi Bir Pet Detektörü
Howard kedi/köpek değil, cins (breed) tanıyan daha zor bir model kurar. Doğruluğu artırmanın ilk yolu daha güçlü bir mimaridir: resnet18 yerine resnet34. Kod Ders 1-2 ile birebir aynıdır; yalnızca mimari değişir.
“How do you make your neural network more accurate during the week?” — Howard, 8:15
İpucuBuilder Notu — Aynı Zincir, Tek Değişen Mimari
- Geriye (Ders 1): Aynı
DataBlock→vision_learner→fine_tunezinciri; tek fark mimari adı (resnet18→resnet34). - İleriye (timm karşılaştırması): Mimari seçimi doğruluk/hız dengesidir; bir sonraki bölüm bunu ölçen grafiği gösterir.
4.4 timm ile Model Karşılaştırması
fastai, Ross Wightman’ın timm (PyTorch Image Models) kütüphanesini entegre eder — dünyanın en büyük görü modeli koleksiyonu. Howard, modelleri hız (saniye/örnek) vs doğruluk ekseninde karşılaştıran bir grafik gösterir: sola doğru hızlı, yukarı doğru doğru. resnet’ler iyi bir başlangıç, convnext modelleri ise daha yeni ve güçlü.
import timm
timm.list_models('convnext*') # convnext ailesindeki modelleri listele
learn = vision_learner(dls, 'convnext_tiny', metrics=error_rate)
learn.fine_tune(3)“On the x-axis we’ve got seconds per sample, so how fast is it; to the left is better, it’s faster.” — Howard, 15:08
İpucuBuilder Notu — Hız mı Doğruluk mu?
- İleriye (production): “Hız mı doğruluk mu?” kararı deploy bağlamına bağlıdır — mobil cihaz hız ister, batch işlem doğruluk; bu ayrımı Ders 2’deki CPU çıkarım tartışmasıyla birlikte düşün.
- Pratik: Önce küçük bir modelle (
resnet18) hızlı denersin; mimari değiştirmek tek satırdır.
4.5 Bulut ve JupyterLab
Howard, kalıcı bir ortam isteyenler için Paperspace gibi bulut sağlayıcılarını ve JupyterLab arayüzünü tanıtır: git repo, terminal ve notebook’lar bir arada. Kaggle ücretsiz GPU verir ama kalıcı ortam sunmaz; Paperspace kalıcılık sağlar.
“Paperspace is another amazing platform; here you can see I’ve got my pets repo with a git repository.” — Howard, 9:19
İpucuBuilder Notu — Kalıcı Ortam = Reproducibility
- İleriye (reproducibility): Kalıcı ortam (kütüphaneler, veriler) gerçek projeler için önemlidir; tekrar üretilebilirlik ve hız kazandırır.
- Geriye (Ders 1): Ders 1’deki “notebook’un başına
!pip install -Uqq fastai” disiplini, kalıcı ortamda bir kez kurulup unutulan bir adıma dönüşür.
4.6 model.pkl’in İçinde Ne Var?
Howard kritik soruyu sorar: bu “sihirli” model.pkl aslında nedir? İçine bakınca görülen şey, iç içe katmanlardan (Sequential, timm body) oluşan bir yapı — ve her katmanın parametreleri: büyük sayı yığınları.
“What did we just do, really? What is this magic model.pkl file? It’s an object.” — Howard, 20:49
Yani bir model = bir mimari (sayıların nasıl birleştirileceğinin tarifi) + parametreler (öğrenilen sayılar). Sıradaki bölümler bu “sayıları öğrenme” işinin en yalın hâlini kurar.
İpucuBuilder Notu — Mimari + Parametreler Ayrımı
- Geriye (Ders 2): Ders 2’de
model.pkl’i deploy artefaktı olarak dondurup taşımıştık; burada içini açıp “ne sakladığını” görüyoruz: mimari + öğrenilen sayılar. - İleriye (Model = Parametreli Fonksiyon): “Mimari sabit, parametreler eğitimle değişir” ayrımı tüm derin öğrenmenin temelidir; bir sonraki bölümde bu fikri 3 parametreli bir quadratic’e indirgiyoruz.
4.7 Bir Model = Parametreli Fonksiyon
Howard sinir ağı yerine çok daha basit bir örnek seçer: bir quadratic fonksiyon, \(f(x) = a x^2 + b x + c\). Buradaki \(a, b, c\) parametrelerdir; onları değiştirerek fonksiyonun şeklini değiştiririz.
def quad(a, b, c, x): return a*x**2 + b*x + c
def mk_quad(a, b, c): return partial(quad, a, b, c)
f = mk_quad(3, 2, 1) # 3x^2 + 2x + 1 fonksiyonunu uretirGerçek veri gürültülüdür; Howard \(f(x)\)’e rastgele gürültü ekleyip “gerçek dünya verisi” taklit eder. Soru şudur: bu gürültülü veriye en iyi uyan \(a, b, c\) nedir? Şekil 4.2 üç farklı \((a, b, c)\) seçiminin aynı gürültülü veriye nasıl uyduğunu gösterir — parametre değişince şekil değişir.
Kod
# GERÇEK hesaplama: noisy_quadratic (gürültülü veri) + quad (aday eğriler)
x, y, y_true, abc = noisy_quadratic()
# Üç aday parametre seti (a, b, c)
adaylar = [
(0.2, 0.0, 0.0), # kötü uyum: neredeyse düz
(1.0, 0.5, -1.0), # orta uyum
QUAD_TRUE, # iyi uyum (gerçek katsayılar)
]
stiller = [
dict(color=COL_SLATE_400, ls="--", lw=2.0, label="kötü uyum: a=0.2, b=0, c=0"),
dict(color=COL_CYAN_400, ls="-", lw=2.2, label="orta uyum: a=1.0, b=0.5, c=-1"),
dict(color=COL_PRIMARY, ls="-", lw=3.2,
label=f"iyi uyum: a={QUAD_TRUE[0]}, b={QUAD_TRUE[1]}, c={QUAD_TRUE[2]}"),
]
xs = np.linspace(x.min(), x.max(), 300)
fig, ax = plt.subplots(figsize=(8.0, 5.0))
fig.patch.set_facecolor(COL_WHITE)
# Gürültülü veri noktaları
ax.scatter(x, y, s=20, color=COL_ACCENT, alpha=0.8, zorder=3,
label="gürültülü veri")
# Üç aday quadratic eğri
for (a, b, c), st in zip(adaylar, stiller):
ax.plot(xs, quad(a, b, c, xs), zorder=2, **st)
apply_style(ax)
ax.set_title("Model = parametreli fonksiyon: $f(x)=a\\,x^2 + b\\,x + c$",
fontsize=12, weight="bold", color=COL_TEXT)
ax.set_xlabel("$x$", fontsize=11)
ax.set_ylabel("$f(x)$", fontsize=11)
ax.legend(loc="upper center", fontsize=8.5, framealpha=0.9)
# Not: a,b,c değişince şekil değişir; en iyi a,b,c?
ax.text(0.02, 0.97,
"a, b, c değişince şekil değişir;\nen iyi a, b, c?",
transform=ax.transAxes, ha="left", va="top", fontsize=9.5,
color=COL_TEXT, style="italic",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_WHITE, ec=COL_SLATE_400,
alpha=0.85))
plt.tight_layout()
plt.show()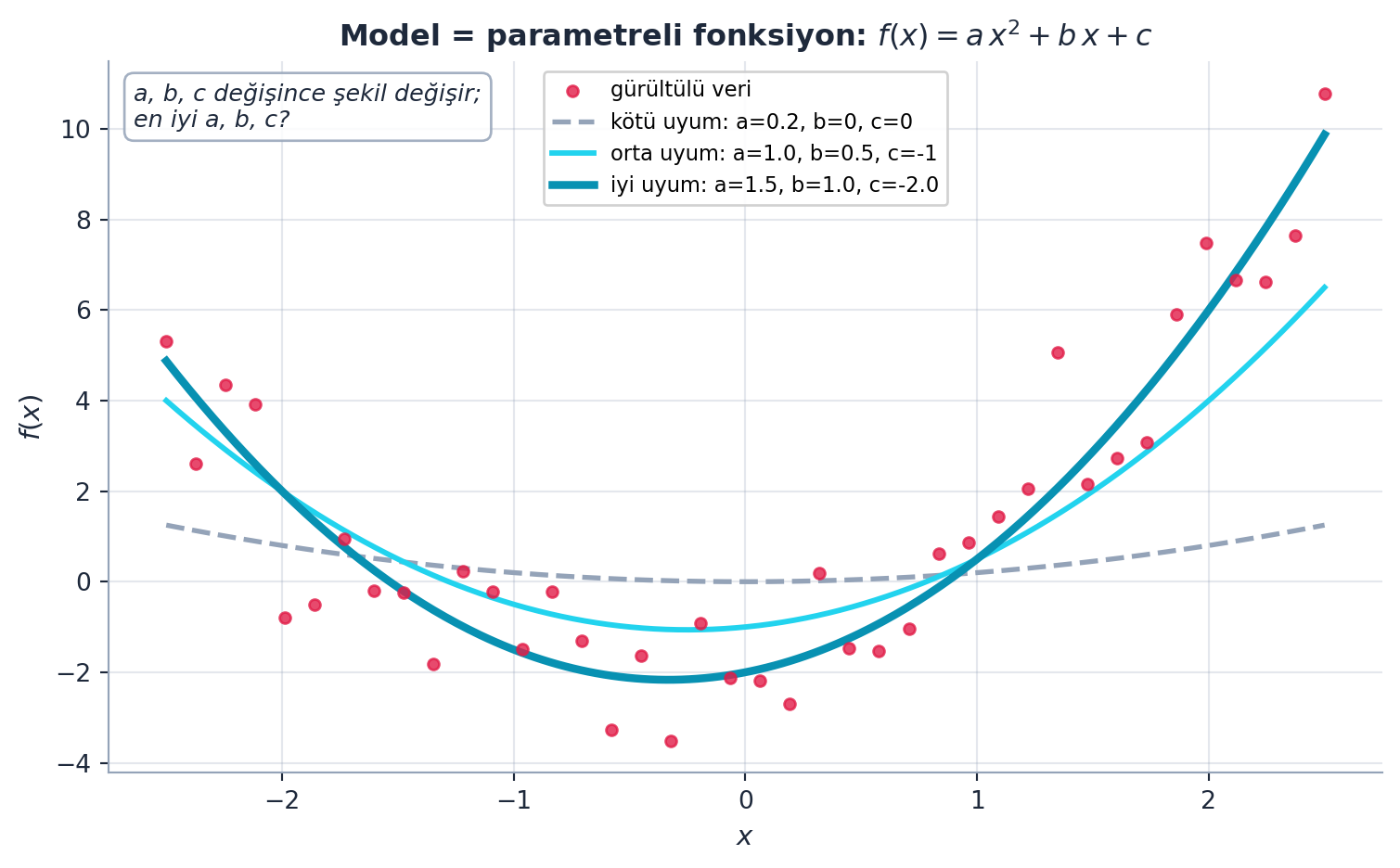
İpucuBuilder Notu — 3 Parametre, Sonra Milyonlar
- Geriye (Stat 110): Gürültü ekleme, normal dağılımdan örnekleme; veri = sinyal + gürültü — Howard’ın “gerçek dünya verisi” taklidi tam budur.
- İleriye (Sonsuz Karmaşık Fonksiyon): Quadratic’in 3 parametresi yerine bir sinir ağının milyonlarca parametresi olur; fikir aynıdır — yalnızca esneklik ve ölçek değişir.
4.8 Fonksiyonu Elle Uydurmak
Howard Jupyter’in @interact kaydırıcılarıyla \(a, b, c\)’yi elle oynatıp veriye uydurmaya çalışır. Bir parametreyi artırıp azaltarak veriye yaklaşır — ama “iyi uyum”u gözle yargılamak özneldir ve yavaştır.
@interact(a=1.1, b=1.1, c=1.1)
def plot_quad(a, b, c):
plt.scatter(x, y)
plot_function(mk_quad(a, b, c), ylim=(-3, 13))
İpucuBuilder Notu — Gözle Ayarlama Ölçeklenemez
- İleriye (Loss → Gradient Descent): “Gözle ayarlama” ölçeklenemez; bize iyiliği sayıyla ölçen bir araç (loss) ve onu otomatik iyileştiren bir yöntem (gradient descent) gerekir — sıradaki iki bölüm tam bunu kurar.
- Geriye (Daha İyi Pet Detektörü): Mimariyi tek satırla değiştirmek kolaydı; ama milyonlarca parametreyi elle oynatmak imkânsız — otomasyon şart.
4.9 Loss: Modelin İyiliğini Ölçmek
“İyi uyum”u nesnel kılmak için bir loss fonksiyonu gerekir: tahminlerle gerçek değerler arasındaki farkın bir özeti. Howard ortalama mutlak hatayı (MAE, \(\text{mean absolute error}\)) kullanır; karesel varyantı MSE’dir (\(\text{mean squared error}\)). Loss ne kadar küçükse model o kadar iyi.
def mae(preds, acts): return (torch.abs(preds - acts)).mean()
# MSE varyanti: ((preds - acts)**2).mean()“That’s mean squared error.” — Howard, 32:07
Artık \(a, b, c\)’yi öyle ayarlamak istiyoruz ki loss en küçük olsun. Bu loss değerinin tek bir parametreye göre nasıl bir “kâse” çizdiğini Şekil 4.3 gösterir.
İpucuBuilder Notu — Loss = Optimize Edilecek Hedef
- Geriye (Ders 1): Loss, Ders 1’deki “modelin ne kadar iyi olduğunun ölçüsü”nün somut hâli; orada
error_rateraporlanıyordu, burada optimize edilen sayı budur. - Geriye (Stat 110): MSE/MAE, tahmin hatasının istatistiksel ölçütleri; MSE büyük hataları daha çok cezalandırır — Egzersiz 5 tam bu farkı deneyletir.
4.10 Türev ve Gradient
Loss’u küçültmek için her parametreyi hangi yönde değiştireceğimizi bilmeliyiz. Cevap türevdir: bir parametreyi azıcık artırınca loss artar mı azalır mı, ne kadar? Howard türevi hatırlatır — korkmaya gerek yok, fikir basittir: eğim.
“The derivative is, if I increase a, the loss will go down.” — Howard, 38:42
Tüm parametreler için türevlerin tamamına gradient (\(\nabla L\)) denir. Gradient bize en dik iniş yönünü verir. Şekil 4.3’teki rose teğet çizgisi tam bu eğimi — loss kâsesinin bir noktasındaki türevi — görselleştirir.
Kod
# Loss manzarasi: 'a' parametresine gore MSE kasesi + gradient descent inisi
# loss_landscape_a() GERCEK hesaplama (noisy_quadratic verisi, analitik MSE).
ll = loss_landscape_a()
a_vals = ll["a_vals"]
losses = ll["losses"]
a_opt = ll["a_opt"]
a_traj = ll["a_traj"]
loss_traj = ll["loss_traj"]
fig, ax = plt.subplots(figsize=(9.5, 5.2))
# Loss kasesi (egri)
ax.plot(a_vals, losses, color=COL_SLATE_400, lw=1.8, zorder=2,
label="loss eğrisi $L(a)$")
# Minimum: dikey kesik cizgi + isaret
loss_opt = float(np.min(losses))
ax.axvline(a_opt, color=COL_TEXT, ls=":", lw=1.6, alpha=0.7, zorder=2)
ax.scatter([a_opt], [loss_opt], color=COL_TEXT, s=55, zorder=6,
edgecolor=COL_WHITE, linewidth=1.2)
ax.annotate("en düşük loss\n($a \\approx %.2f$)" % a_opt,
xy=(a_opt, loss_opt),
xytext=(a_opt + 0.55, loss_opt + 0.18 * (losses.max() - loss_opt)),
fontsize=9.5, color=COL_TEXT, weight="bold",
ha="left", va="bottom")
# GD adimlari: kase boyunca minimuma inen 'o-' yol
ax.plot(a_traj, loss_traj, "o-", color=COL_PRIMARY, lw=2.0, ms=6,
zorder=5, markeredgecolor=COL_WHITE, markeredgewidth=0.8,
label="gradient descent adımları")
# Kasenin egimli (azalan) bir noktasinda turev/teget cizgisi.
# Teget GERCEK loss egrisi uzerine kurulur; egim = dL/da sayisal turev (np.gradient).
a0 = 0.3 # minimumun solunda, egimin belirgin oldugu nokta
j = int(np.argmin(np.abs(a_vals - a0)))
a0 = float(a_vals[j])
L0 = float(losses[j])
slope = float(np.gradient(losses, a_vals)[j])
da = 0.85
a_line = np.array([a0 - da, a0 + da])
L_line = L0 + slope * (a_line - a0)
ax.plot(a_line, L_line, color=COL_ACCENT, lw=2.6, zorder=4,
solid_capstyle="round")
ax.scatter([a0], [L0], color=COL_ACCENT, s=46, zorder=6,
edgecolor=COL_WHITE, linewidth=1.0)
ax.annotate("türev = eğim → iniş yönü",
xy=(a0, L0),
xytext=(a0 - 0.05, L0 + 0.30 * (losses.max() - loss_opt)),
fontsize=10, color=COL_ACCENT, weight="bold",
ha="center", va="bottom",
arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.6))
ax.set_xlabel("a parametresi")
ax.set_ylabel("loss (MSE)")
ax.set_title("Loss manzarası: gradient descent minimuma iner",
fontsize=12.5, weight="bold")
apply_style(ax)
ax.legend(loc="upper center", frameon=False, fontsize=9.5)
fig.tight_layout()
plt.show()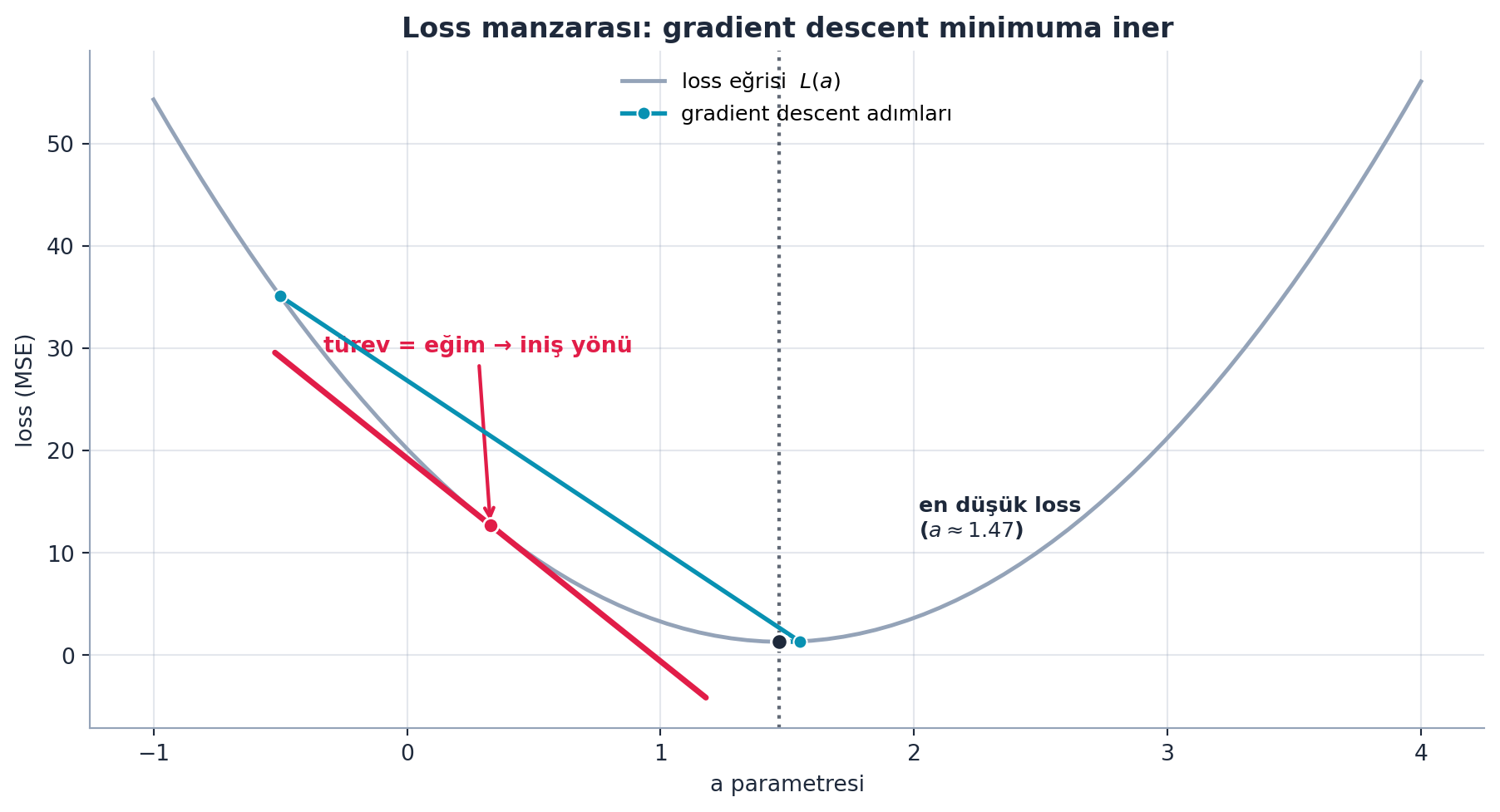
İpucuBuilder Notu — Türev = Eğim = İniş Yönü
- Geriye (Calculus): Türev = anlık değişim oranı; gradient = çok değişkenli türev vektörü \(\nabla L\). Calculus’un derin öğrenmedeki tek ama temel rolü budur — eğimi bilmek, nereye adım atacağımızı söyler.
- İleriye (Gradient Descent): Şekil 4.3’teki cyan adımlar bu eğimi kullanarak minimuma iner; bir sonraki bölüm bu inişi PyTorch’la otomatikleştirir.
4.11 Gradient Descent
Şimdi sihir: PyTorch türevleri otomatik hesaplar. Parametrelere requires_grad_() deriz, loss’u hesaplayıp loss.backward() çağırırız — PyTorch her parametrenin gradyanını .grad’a yazar. Sonra parametreleri gradyanın tersine küçük bir adım kaydırırız, \(p \leftarrow p - \eta\,\nabla L\). Bu döngü gradient descenttir.
abc = torch.tensor([1.1, 1.1, 1.1])
abc.requires_grad_()
for i in range(10):
loss = quad_mae(abc) # tahmin et, kaybi olc
loss.backward() # her parametrenin gradyanini hesapla
with torch.no_grad():
abc -= abc.grad * 0.01 # gradyanin tersine kucuk adim (lr=0.01)
print(f'step={i}; loss={loss:.2f}')“Call backward to calculate the gradients, and then with no grad, subtract the gradients times a small number. And there we go: the loss keeps improving.” — Howard, 41:42
Şekil 4.4 bu döngünün gerçek bir çalıştırmasını gösterir: solda başlangıçtaki düz çizgi adım adım verinin parabolüne yaklaşır, sağda loss her adımda düşer.
Kod
gd = gd_quadratic()
fig, (axL, axR) = plt.subplots(1, 2, figsize=(9.6, 4.3))
# SOL: veri + baslangic fit + GD sonrasi fit
axL.scatter(gd["x"], gd["y"], s=18, color=COL_ACCENT, zorder=3,
label="gürültülü veri")
axL.plot(gd["x"], gd["y_init"], "--", color=COL_SLATE_400, linewidth=2.0,
label="başlangıç (a=b=c=0)")
axL.plot(gd["x"], gd["y_final"], color=COL_PRIMARY, linewidth=2.4,
label="GD sonrası")
apply_style(axL)
axL.set_title("quadratic veriye uyduruluyor", fontsize=11, weight="bold")
axL.set_xlabel("x")
axL.set_ylabel("y")
axL.legend(loc="upper center", frameon=True, framealpha=0.95,
edgecolor=COL_PRIMARY, fontsize=8.5)
# SAG: loss dususu
axR.plot(gd["loss_hist"], "o-", color=COL_PRIMARY, linewidth=2.2, markersize=5)
apply_style(axR)
axR.set_title("loss her adımda düşer", fontsize=11, weight="bold")
axR.set_xlabel("adım")
axR.set_ylabel("MSE")
axR.annotate(
f"L: {gd['loss_hist'][0]:.1f} → {gd['loss_hist'][-1]:.2f}",
xy=(len(gd["loss_hist"]) - 1, gd["loss_hist"][-1]),
xytext=(0.40, 0.55), textcoords="axes fraction",
fontsize=9.0, color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.35", fc="#ecfeff", ec=COL_PRIMARY, lw=1.6),
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=1.6,
connectionstyle="arc3,rad=0.2"),
)
fig.text(0.5, -0.02, r"loss.backward() + p $\leftarrow$ p $-$ $\eta\,\nabla L$",
ha="center", va="top", fontsize=10.5, color=COL_CYAN_700, weight="bold")
fig.tight_layout()
plt.show()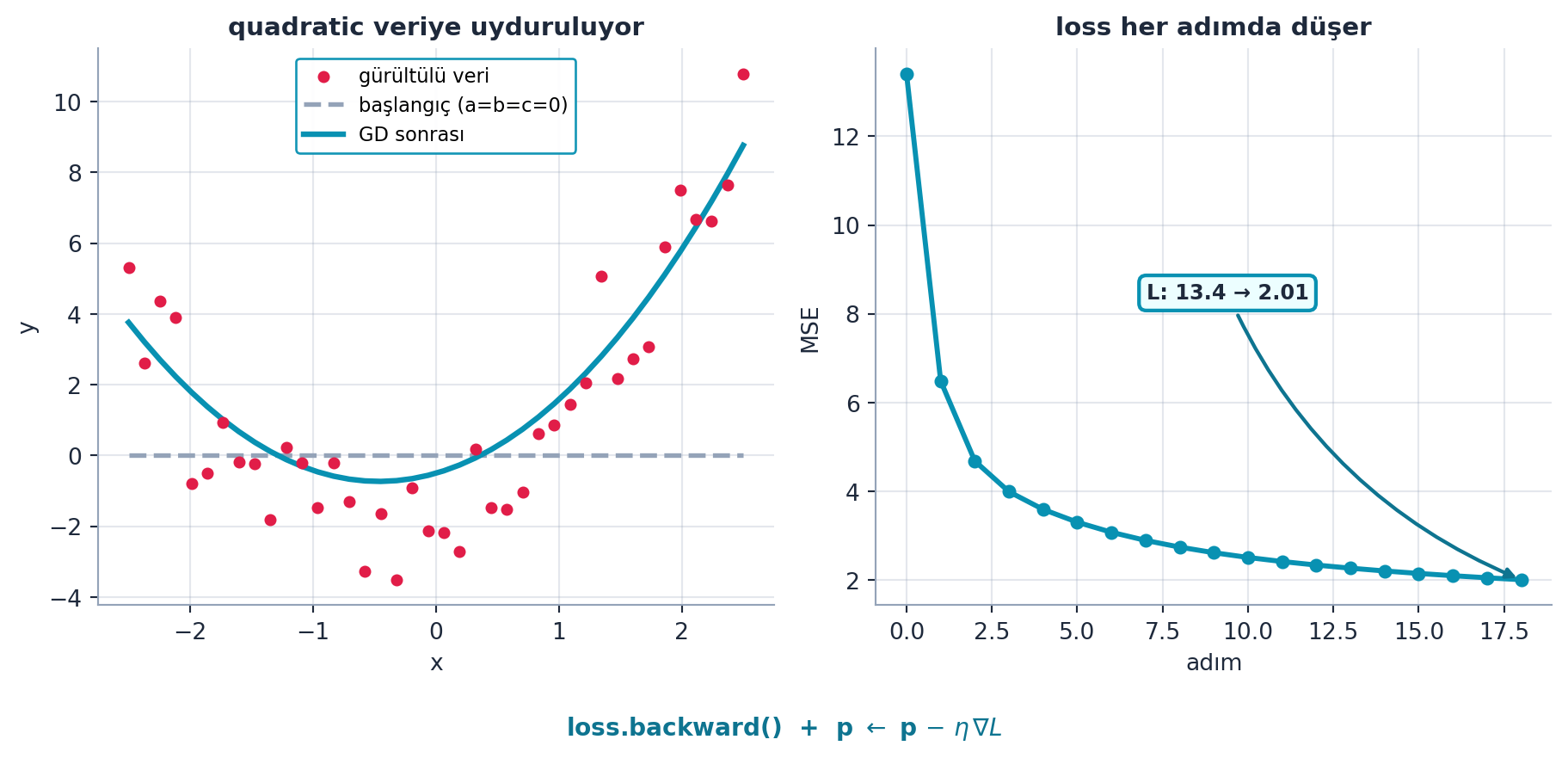
İpucuBuilder Notu — micrograd’ın Tam Çekirdeği
- Geriye (Karpathy):
loss.backward()+param -= grad·lr= Karpathy micrograd’ının tam çekirdeği; orada bu elle (her düğümün türevi zincir kuralıyla), burada PyTorch’la otomatik kurulur. - İleriye:
with torch.no_grad()bloğu, güncelleme adımının gradyan grafiğine girmemesini sağlar — production eğitim döngülerinin standart desenidir; learning rate ise bu adımın çarpanıdır.
4.12 ReLU: Rectified Linear Unit
Quadratic basit kaldı; gerçek dünya çok daha karmaşık fonksiyonlar ister. Howard en küçük esnek yapı taşını tanıtır: bir doğru (\(m x + b\)) alıp negatif kısmını sıfıra kırpmak. Buna rectified linear unit (ReLU) denir — kısaca \(\max(0,\, m x + b)\).
def rectified_linear(m, b, x):
y = m*x + b
return torch.clip(y, 0.) # negatifleri sifira cek
# Esdegeri: F.relu(m*x + b)“If it’s bigger than zero, leave it; if it’s smaller than zero, it’ll make it zero. So that’s rectified linear.” — Howard, 44:10
Şekil 4.5 bu tek kırılma noktasını (köşeyi) gösterir: ham doğru negatif bölgede sıfıra kırpılır ve doğrusal-olmamayı verir.
Kod
# GERÇEK hesaplama — tek ReLU: max(0, m·x + b) (bkz. relu)
m, b = 1.0, 0.5
x = np.linspace(-3, 3, 200)
line = m * x + b # ham doğru
y = relu(m, b, x) # ReLU çıktısı (negatif kısım sıfıra kırpılır)
fig, ax = plt.subplots(figsize=(7.2, 4.6))
# ham doğru (kesik) — kırpılmadan önceki m·x + b
ax.plot(x, line, ls="--", lw=1.8, color=COL_SLATE_400, label="m·x + b")
# ReLU çıktısı — birincil cyan, kalın
ax.plot(x, y, lw=2.6, color=COL_PRIMARY, label="max(0, m·x + b)")
# kırılma köşesi: m·x + b = 0 → x = -b/m = -0.5
x_kink = -b / m
ax.axhline(0, lw=0.9, color=COL_SLATE_400, zorder=1)
ax.scatter([x_kink], [0.0], s=42, color=COL_ACCENT, zorder=5)
# köşe anotasyonu: negatif kısım sıfıra kırpılır
ax.annotate(
"negatif → 0",
xy=(x_kink, 0.0),
xytext=(x_kink - 1.55, 0.95),
fontsize=10.5, weight="bold", color=COL_ACCENT,
arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.6),
)
apply_style(ax)
ax.set_title("ReLU: rectified linear unit",
fontsize=13, weight="bold", color=COL_CYAN_700)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.legend(loc="upper left", frameon=False, fontsize=10.5)
fig.tight_layout()
plt.show()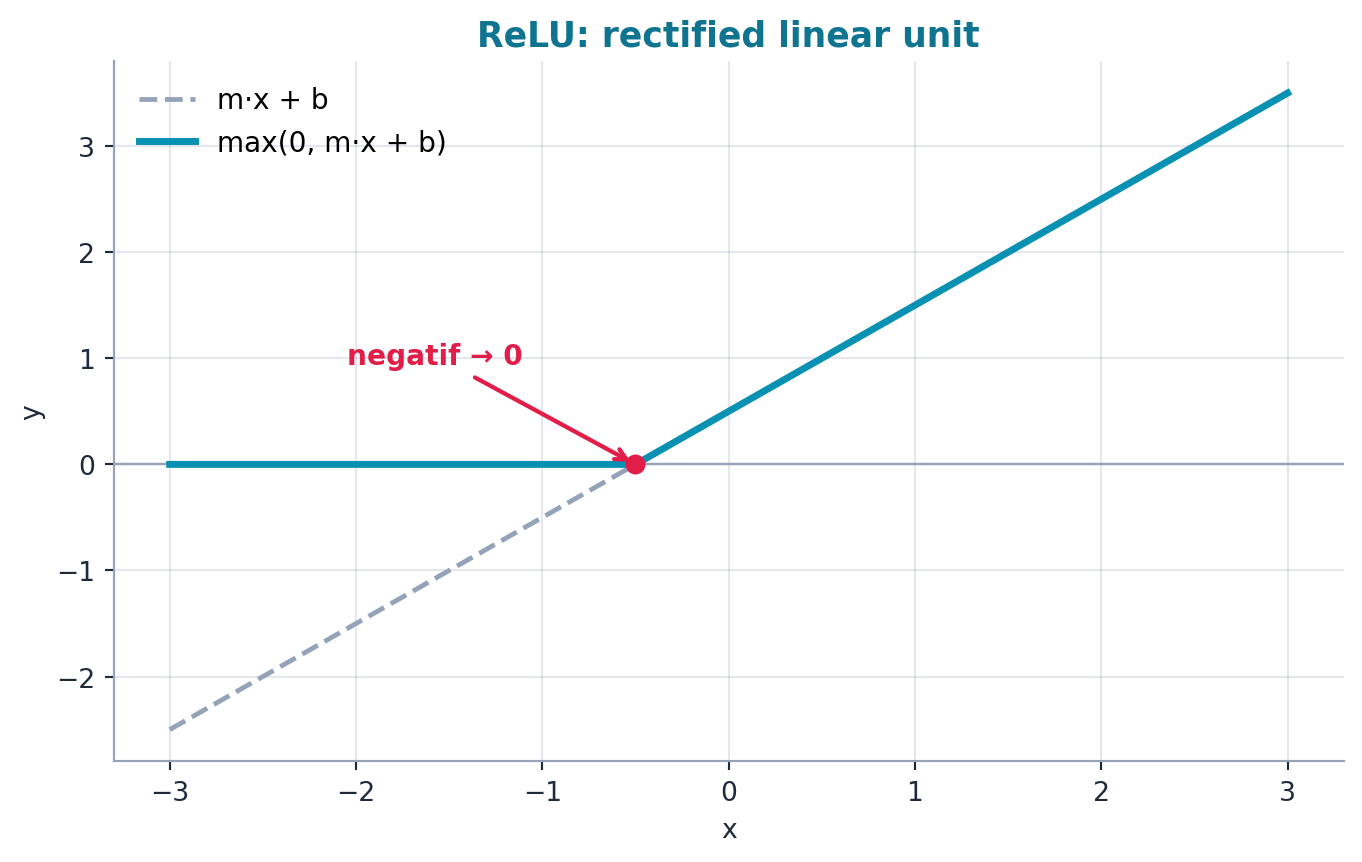
İpucuBuilder Notu — En Küçük Esnek Yapı Taşı
- Geriye (6.S191): ReLU, 6.S191 Ders 1’deki aktivasyon fonksiyonudur; doğrusal-olmamayı sağlayan en yaygın seçim — onsuz katmanlar üst üste binse de tek bir doğrusal dönüşüme çökerdi.
- İleriye (Sonsuz Karmaşık Fonksiyon): Tek ReLU bir “kırık doğru”dur; ama Şekil 16.2’da göreceğin gibi yeterince toplanınca her şeyi kurar.
4.13 Sonsuz Karmaşık Fonksiyon
İşte anahtar fikir: iki ReLU’yu toplarsak inişli-çıkışlı bir şekil elde ederiz. İstediğimiz kadar ReLU toplarsak, istediğimiz kadar “kıvrımlı” herhangi bir fonksiyonu istediğimiz hassasiyette kurabiliriz.
def double_relu(m1, b1, m2, b2, x):
return rectified_linear(m1, b1, x) + rectified_linear(m2, b2, x)“We could add as many values together as we want, and with enough values we can match it as close as we want.” — Howard, 46:31
Howard ses dalgası örneği verir: 100 milyon ReLU verirsen, konuşmamın dalga formunu neredeyse birebir eşleyebilirsin. Aynı fikir 2B, 3B, n-boyutlu girdiler için de geçerlidir. Şekil 16.2 bunu somutlaştırır: 8 ağırlıklı ReLU toplanarak kıvrımlı bir hedef fonksiyon yeniden kurulur.
Kod
rs = relu_sum_fit(k=8)
fig, ax = plt.subplots(figsize=(7.6, 4.6))
# Bireysel ağırlıklı ReLU bileşenleri (ince gri, legend'siz)
for i in range(rs["k"]):
ax.plot(rs["x"], rs["components"][i], color=COL_SLATE_400,
linewidth=0.8, alpha=0.6, zorder=1)
# Hedef fonksiyon (rose) + 8 ReLU toplamı (cyan kesik)
ax.plot(rs["x"], rs["target"], color=COL_ACCENT, linewidth=2.4,
label="hedef fonksiyon", zorder=3)
ax.plot(rs["x"], rs["approx"], color=COL_PRIMARY, linewidth=2.2,
linestyle="--", label=f"{rs['k']} ReLU toplamı", zorder=4)
apply_style(ax)
ax.set_xlabel("x")
ax.set_ylabel("f(x)")
ax.set_title("Universal approximation: yeterli ReLU toplamı → herhangi bir fonksiyon",
fontsize=11.5, weight="bold", color=COL_TEXT)
ax.legend(loc="upper left", frameon=True, framealpha=0.95, edgecolor=COL_PRIMARY)
# Not: daha çok ReLU = daha yüksek hassasiyet
ax.annotate(
"daha çok ReLU = daha yüksek hassasiyet",
xy=(0.98, 0.02), xycoords="axes fraction",
ha="right", va="bottom", fontsize=9.5, color=COL_CYAN_700, weight="bold",
)
plt.show()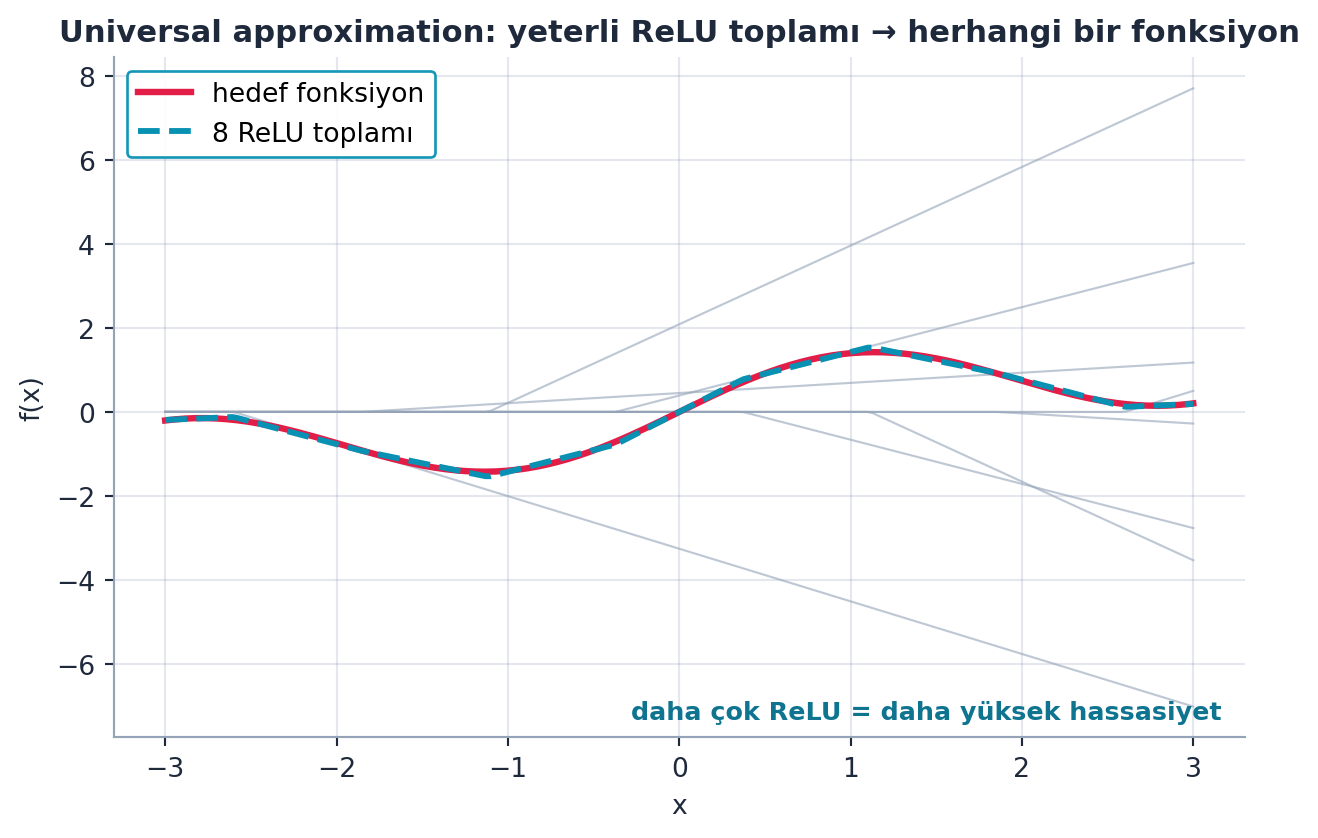
İpucuBuilder Notu — Universal Approximation’ın Resmi
- Geriye (18.06): Çok boyutlu girdi = matris-vektör çarpımı; her ReLU bir doğrusal dönüşüm + kırpmadır. Şekil 16.2’daki ince gri bileşenler tam bu tekil ReLU’lardır.
- İleriye (“Deep Learning’i Türettik”): Bu, universal approximation teoremidir; modern devasa ağlar bu basit fikrin ölçeklenmiş hâlidir — bir sonraki bölüm iki parçayı birleştirip sonucu ilan eder.
4.14 “Deep Learning’i Türettik”
İki parça birleşince her şey tamamlanır: (1) yeterince ReLU toplayarak istenen kadar esnek bir fonksiyon kurarız (ReLU toplamı); (2) onun parametrelerini gradient descent ile uydururuz (Gradient Descent). Howard’ın ünlü cümlesi:
“We have just derived deep learning. Everything from now on is tweaks to make it faster and make it need less data. This is it.” — Howard, 47:59
Howard “draw the rest of the owl” şakasına gönderme yapar: aslında iki adım arasında gizli bir sihir yoktur — değerleri topla, gradient descent ile parametreleri optimize et, istediğin girdi-çıktı örneklerini ver; bilgisayar gerisini çizer. Şekil 4.7 bu sentezi tek bir şemada toplar.
“It’s using gradient descent to set some parameters to make a wiggly function, which is basically the addition of lots of rectified linear units, to match your data.” — Howard, 49:12
Kod
fig = plt.figure(figsize=(10.0, 5.6))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.axis("off")
# --- Üstte küçük not (Howard zaman damgası) ---
ax.text(5.0, 9.5,
"Howard 47:59: gerisi hız ve veri verimliliği ayarı",
ha="center", va="center", fontsize=10, style="italic",
color=COL_CYAN_800, weight="bold")
# --- İki büyük kutu üstte yan yana (cyan, bilgi kutuları) ---
y_top = 7.2
boxed_node(ax, 2.7, y_top, 4.0, 2.0,
"Yeterince ReLU topla\n→ esnek (kıvrımlı) fonksiyon",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11.5, lw=2.4)
boxed_node(ax, 7.3, y_top, 4.0, 2.0,
"Gradient descent\n→ parametreleri uydur",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11.5, lw=2.4)
# --- Altta büyük sonuç kutusu (rose, accent) ---
y_bot = 2.4
boxed_node(ax, 5.0, y_bot, 5.2, 1.9,
"= DERİN ÖĞRENME",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=15, lw=3.0)
# --- İki kutudan alta-ortaya birleşen iki ok ---
arrow_between(ax, (2.7, y_top - 1.0), (4.4, y_bot + 0.95),
color=COL_ACCENT, lw=2.6)
arrow_between(ax, (7.3, y_top - 1.0), (5.6, y_bot + 0.95),
color=COL_ACCENT, lw=2.6)
plt.show()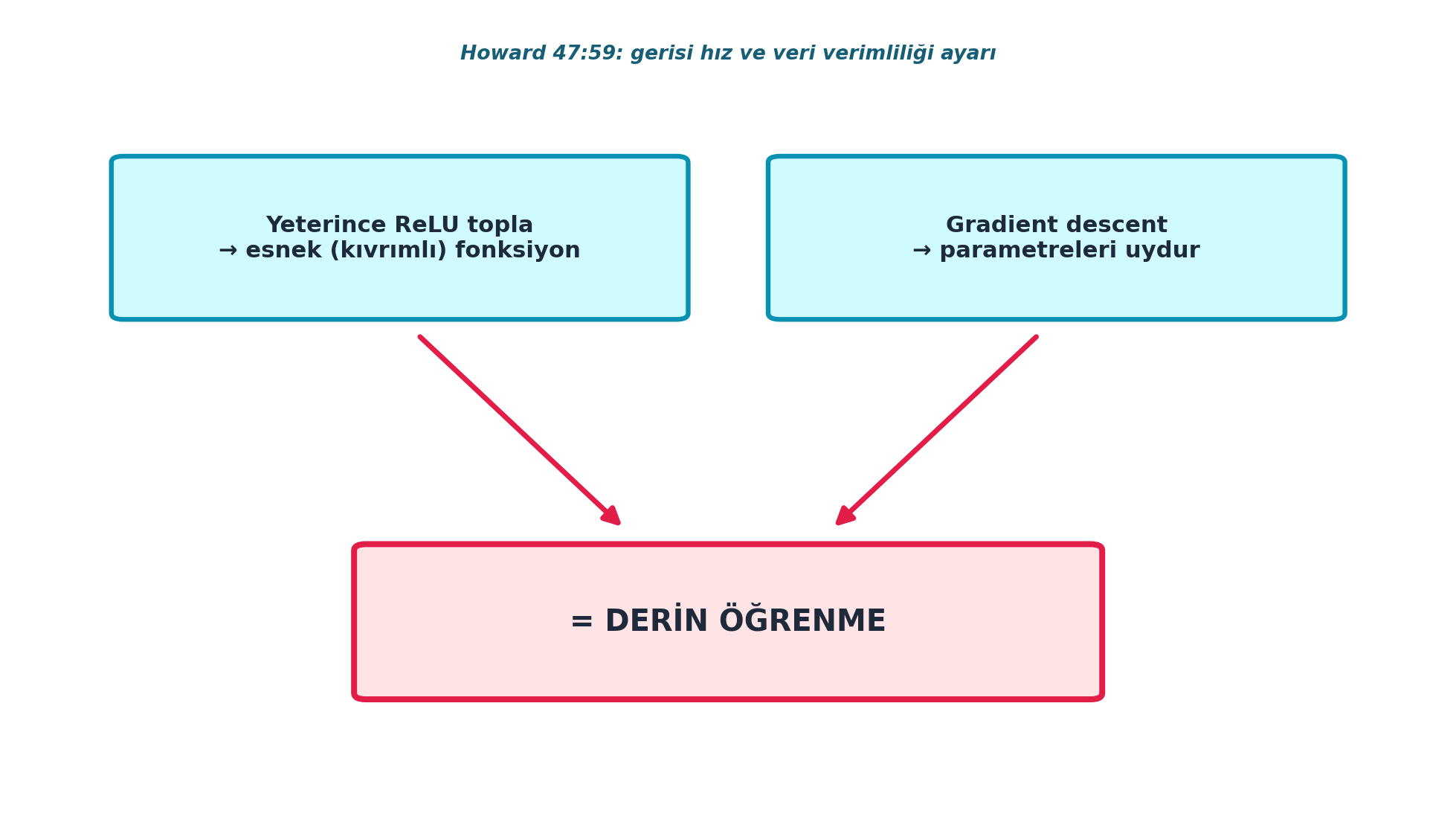
İpucuBuilder Notu — Top-down ile Bottom-up Aynı Yerde Buluşur
- Geriye (tüm seri): Bu cümle Karpathy serisinin de tezidir; fast.ai top-down bu sonuca varır, Karpathy bottom-up aynı yere ulaşır — iki yol, aynı çekirdek.
- İleriye: “Gerisi tweak” — Part 2’deki tüm teknikler (init, normalization, mimari) bu çekirdeği hızlandırma/iyileştirmedir; foundation burada kapanır.
4.15 Learning Rate
Gradient descent’teki “küçük adım” çarpanı (abc.grad * 0.01) kritik bir hiperparametredir: learning rate (\(\eta\)). Çok büyük seçilirse adımlar hedefi aşar, loss kötüleşir; çok küçük seçilirse ilerleme can sıkıcı derecede yavaş olur.
“If you pick a learning rate that’s too big, you’ll jump too far. Finding the right learning rate is a compromise.” — Howard, 57:24
Şekil 4.8 üç rejimi yan yana koyar: çok küçük adım minimuma sürünür, iyi adım hızlı iner, çok büyük adım hedefi aşıp ıraksar.
Kod
lr = lr_trajectories()
w_grid = lr["w_grid"]
loss_curve = lr["loss_curve"]
w_star = lr["w_star"]
traj = lr["traj"]
fig, ax = plt.subplots(figsize=(7.4, 4.6))
# Loss kasesi L(w) = (w - w*)^2
ax.plot(w_grid, loss_curve, color=COL_SLATE_400, linewidth=1.6, zorder=1)
# 3 learning rate trajektorisi: loss = (w_t - w*)^2 her adimda
for key, color, label in [
("küçük", COL_CYAN_400, "çok küçük — yavaş"),
("iyi", COL_PRIMARY, "iyi — hızlı"),
("büyük", COL_ACCENT, "çok büyük — ıraksar"),
]:
t = traj[key]
ax.plot(t, (t - w_star) ** 2, "o-", color=color, markersize=4,
linewidth=2.0, label=label, zorder=3)
apply_style(ax)
ax.set_ylim(-1, 20)
ax.set_xlabel("parametre w")
ax.set_ylabel("loss")
ax.set_title("Learning rate: adım çok küçük / iyi / çok büyük",
fontsize=12, weight="bold")
ax.legend(loc="upper center", frameon=True, framealpha=0.95,
edgecolor=COL_PRIMARY, fontsize=9)
plt.show()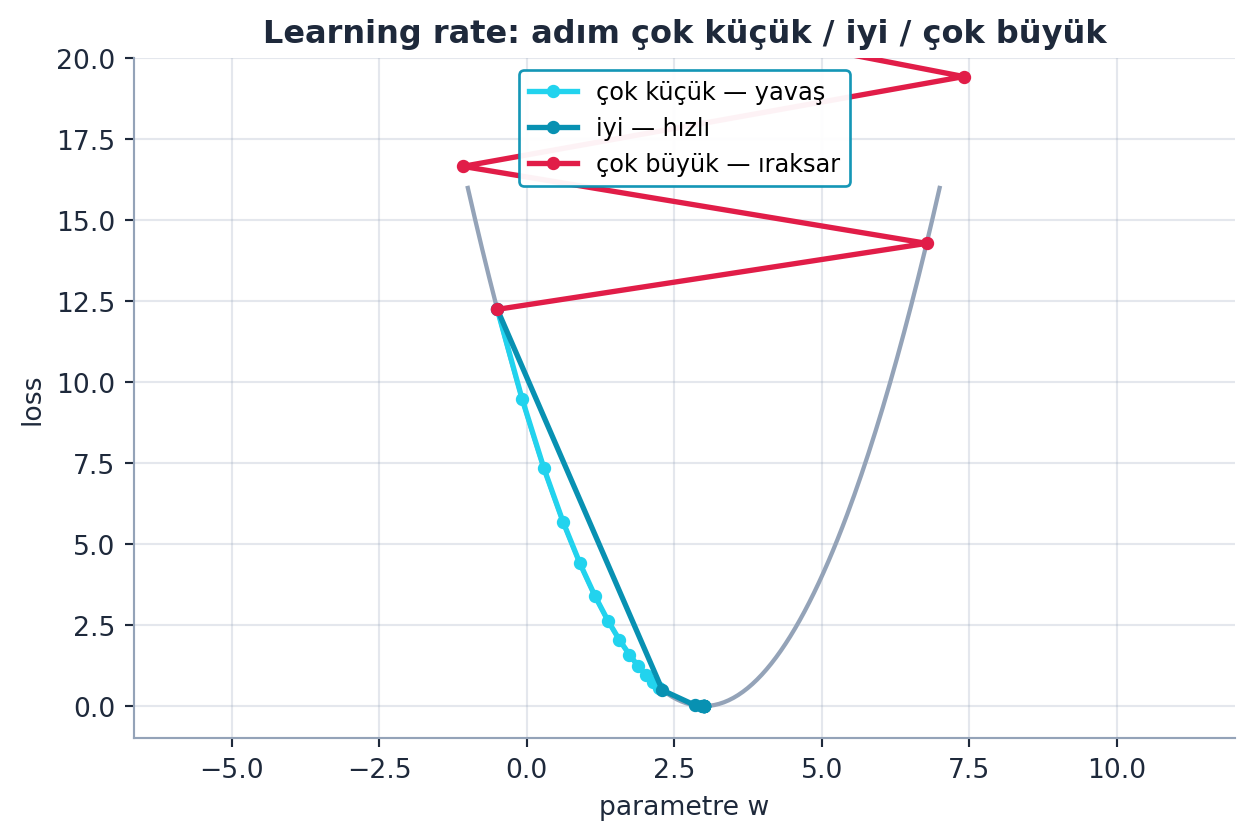
İpucuBuilder Notu — η: Adım Uzunluğu Uzlaşması
- İleriye (Ders 5-6, 18):
lr_find(öğrenme oranı bulucu) ve OneCycle politikası bu sorunu otomatikleştirir; Part 1 Ders 5-6 ve Part 2 Ders 18’de göreceğiz — Şekil 4.8’teki “ıraksar” eğrisi tam onların önlediği felakettir. - Geriye (Calculus): Learning rate, gradyan yönündeki adım uzunluğu \(\eta\)’dır; optimizasyonun yakınsamasını belirler — yön türevden, uzunluk \(\eta\)’dan gelir.
4.16 Pratik Kararlar: Yeterli Veri ve Model Seçimi
Howard foundation’dan pratiğe döner. “Hangi modeli kullanmalıyım?” sorusuna pratik cevap: deney yapana kadar başlangıçta resnet18 ile hızlı çalış, sonra daha güçlü mimariler dene. “Yeterli verim var mı?” sorusu ise baştan sorulmalıdır, sondan değil — yetersizse daha fazla veri toplamak ya da augmentation kullanmak gerekir.
“These are things you want to know at the start, not at the end.” — Howard, 53:39
İpucuBuilder Notu — Başarı Kriterini Baştan Tanımla
- İleriye (goal-driven): “Doğruluk yeterli mi?” sorusu probleme bağlıdır; başarı kriterini önceden tanımlamak projeyi yönlendirir — sonradan değil, baştan ölçülebilir bir hedef koymak işin kendisidir.
- Geriye (timm karşılaştırması): “Önce
resnet18, sonra güçlü mimari” tavsiyesi, hız-doğruluk grafiğinin pratik özetidir; veri yetmiyorsa Ders 2’deki data augmentation devreye girer.
4.17 Kapanış
Ders 3, Ders 1-2’nin kara kutusunu açtı: bir model, gradient descent ile parametreleri uydurulan esnek bir fonksiyondur. Quadratic’ten ReLU toplamına, oradan otomatik gradyan inişine kadar her parça elle kuruldu. Bundan sonraki her şey — daha iyi mimariler, normalizasyon, hız — bu çekirdeğin üstüne eklenen ayarlardır.
İpucuBuilder Notu — Foundation Sağlamsa Gerisi Anlaşılır
- İleriye: Bu temel, Part 2’de (ve Karpathy serisinde) satır satır yeniden kurulacak; foundation sağlamsa gerisi anlaşılır.
- Geriye (Bu Derste Ne Var?): Dersin başında verilen üç fikir — parametreli fonksiyon, gradient descent, ReLU toplamı — burada tek bir cümlede kapanır.
4.18 Bu Dersin Özeti
- Bir model = bir mimari (sayıların nasıl birleşeceği) + parametreler (öğrenilen sayılar);
model.pkltam olarak budur (model.pkl). - En basit model bile parametreli bir fonksiyondur (quadratic: \(a x^2 + b x + c\)) (Model = Parametreli Fonksiyon).
- Loss (MAE/MSE) modelin iyiliğini sayıyla ölçer; amaç onu en küçük yapmaktır (Loss).
- Türev/gradient her parametreyi hangi yönde değiştireceğimizi söyler; PyTorch bunu
loss.backward()ile otomatik hesaplar (Türev ve Gradient). - Gradient descent: parametreleri gradyanın tersine küçük adımlarla (learning rate) güncelleyen döngü, \(p \leftarrow p - \eta\,\nabla L\) (Gradient Descent).
- ReLU en küçük esnek yapı taşıdır; yeterince ReLU toplanırsa herhangi bir fonksiyon istenen hassasiyette kurulabilir (universal approximation) (ReLU, Sonsuz Karmaşık Fonksiyon).
- ReLU toplamı + gradient descent = derin öğrenmenin türetilmesi; gerisi hız ve veri verimliliği ayarıdır (“Deep Learning’i Türettik”).
- Learning rate kritik hiperparametredir: çok büyük aşar, çok küçük yavaşlatır (Learning Rate).
ÖnemliTek Bir Cümle
Bir sinir ağı, çok sayıda basit doğrusal-kırpma biriminin (ReLU) toplamıyla kurulan esnek bir fonksiyondur ve “öğrenmesi”, gradient descent’in kayıp fonksiyonunu küçültecek parametreleri bulmasından ibarettir.
4.19 Kontrol Soruları
NotSoru 1: Gradient descent döngüsünün üç adımı nedir ve loss.backward() ne yapar?
Cevap:
Üç adım: (1) tahmin et ve kaybı hesapla (loss = quad_mae(abc)), (2) gradyanları hesapla (loss.backward()), (3) parametreleri gradyanın tersine küçük bir adım kaydır (abc -= abc.grad * lr). loss.backward(), PyTorch’un otomatik türev (autograd) motorunu çalıştırır: her parametrenin kayba olan katkısının türevini hesaplayıp .grad özniteliğine yazar. Güncelleme with torch.no_grad() içinde yapılır ki bu işlem gradyan grafiğine girmesin.
NotSoru 2: Howard “deep learning’i türettik” derken hangi iki parçayı kastediyor? Quadratic ile sinir ağı arasındaki fark nedir?
Cevap:
İki parça: (1) yeterince ReLU (rectified linear unit) toplayarak istenen hassasiyette herhangi bir esnek fonksiyon kurmak (universal approximation), (2) bu fonksiyonun parametrelerini gradient descent ile uydurmak. Quadratic ile sinir ağı arasında kavramsal fark yoktur — ikisi de parametreli fonksiyondur ve aynı gradient descent ile eğitilir. Fark ölçektir: quadratic 3 parametre, sinir ağı milyonlarca; ve sinir ağı ReLU toplamı sayesinde çok daha karmaşık şekilleri temsil edebilir.
NotSoru 3: Learning rate çok büyük seçilirse ne olur, çok küçük seçilirse ne olur?
Cevap:
Çok büyük: her adım hedefi aşar (overshoot), parametreler minimumun etrafında zıplar veya tamamen ışınlanıp uzaklaşır — loss kötüleşir, eğitim ıraksar. Çok küçük: her adım minicik olur, minimuma ulaşmak çok uzun sürer (sıkıcı ve pahalı). Doğru learning rate bir uzlaşmadır; Part 1 Ders 5-6’daki lr_find ve Part 2 Ders 18’deki OneCycle bunu otomatikleştirir.
NotSoru 4: Bir tek ReLU neden tek başına yetersizdir ama toplamları neden her şeyi yapabilir? (builder bağlantısı)
Cevap:
Tek ReLU yalnızca bir “kırık doğru”dur (bir eğim + bir köşe); tek başına karmaşık bir eğriyi temsil edemez. Ama iki ReLU toplanınca inişli-çıkışlı bir şekil oluşur; n tane ReLU toplanınca istenen kadar kıvrımlı herhangi bir fonksiyon istenen hassasiyette kurulabilir. Bu, universal approximation teoremidir. Builder açısından: modern devasa ağlar (transformer, CNN) bu basit “ReLU toplamı + gradient descent” fikrinin ölçeklenmiş ve düzenlenmiş hâlidir — Karpathy serisi ve Part 2 bunu satır satır kurar.
4.20 Egzersizler
Egzersiz 1 (Direkt uygulama). mk_quad, mae ve gradient descent döngüsünü kendin kur; farklı başlangıç \(a, b, c\) ve learning rate’lerle loss’un nasıl düştüğünü gözle.
Egzersiz 2 (İki-aşamalı). double_relu’yu üç-dört ReLU toplamına genişlet; @interact ile parametreleri oynatıp ne kadar karmaşık şekiller kurabildiğini gör.
Egzersiz 3 (Edge case). Learning rate’i kasıtlı olarak çok büyük (örn. 1.0) ve çok küçük (örn. 0.0001) seç; loss’un sırasıyla ıraksamasını ve aşırı yavaşlamasını gözlemle.
Egzersiz 4 (Python ile doğrulama). Bir tensöre requires_grad_() uygula, basit bir fonksiyonun loss’unu hesapla, backward() çağır ve .grad’ı yazdır; gradyanın işaretinin loss’u nasıl etkilediğini açıkla.
Egzersiz 5 (Sonraki dersin habercisi). MAE yerine MSE (karesel hata) kullanıp sonuçları kıyasla; büyük hataların neden daha çok cezalandırıldığını ve bunun gradyanı nasıl etkilediğini düşün.
4.21 Sonraki Ders İçin Hazırlık
Ders 4: Doğal Dil İşleme (NLP)
Şimdiye kadar görüntülerle çalıştık. Ders 4 metne geçer: bir cümlenin olumlu mu olumsuz mu olduğunu, iki sorunun aynı anlama gelip gelmediğini sınıflandırma. Hugging Face Transformers, tokenization ve ULMFiT.
Ana konular:
- Metni sayıya çevirme (tokenization, sayısallaştırma)
- Pretrained dil modelleri ve ince ayar (ULMFiT, Transformers)
- Validation vs test set ve overfitting tuzakları
- Pearson korelasyonu ile metrik
UyarıDers 4 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 4 — gradient descent’i elle kur).
- Quadratic örneğini kendi notebook’unda baştan çalıştır.
- Ana cümleyi tekrar oku: “Model = gradient descent ile uydurulan esnek bir fonksiyon.”
4.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Model = fonksiyon | Mimari + parametreler; en basiti parametreli bir denklem | 20:49 |
| Parametre | Modelin öğrendiği sayılar (quadratic’te a, b, c) | 23:43 |
| Loss (MAE/MSE) | Tahmin-gerçek farkının ölçüsü; küçük = iyi | 31:02 |
| Türev / gradient | Parametreyi hangi yönde değiştirince loss düşer | 38:42 |
requires_grad_ |
PyTorch’a bu tensörün gradyanını izlemesini söyler | 35:59 |
| loss.backward() | Otomatik türev; gradyanları .grad’a yazar | 38:19 |
| Gradient descent | Parametreleri gradyanın tersine küçük adımlarla güncelleme | 39:23 |
| ReLU | max(0, m·x + b); en küçük esnek yapı taşı | 43:23 |
| Universal approximation | Yeterli ReLU toplamı her fonksiyonu kurar | 46:31 |
| Learning rate | Gradient descent adım çarpanı; büyük aşar, küçük yavaşlatır | 56:28 |
| timm | En büyük görü modeli koleksiyonu (resnet, convnext) | 16:35 |
| Mimari seçimi | Hız vs doğruluk dengesi (resnet18 -> convnext) | 13:47 |
4.23 ML Builder Bağlantıları
İpucuBuilder Notu — 6 ML Köprüsü
Bu ders, derin öğrenmeyi en yalın çekirdeğinden — parametreli fonksiyon + gradient descent — türetir; köprülerin özeti:
- Model = parametreli fonksiyon → tüm derin öğrenmenin tek cümlelik özü; mimari değişse de fikir sabit (Model = Parametreli Fonksiyon).
- Gradient descent →
loss.backward()+param -= grad·lr; Karpathy micrograd’ının çekirdeği, Calculus türevinin uygulaması (Gradient Descent). - ReLU + universal approximation → modern devasa ağların matematiksel gerekçesi (Sonsuz Karmaşık Fonksiyon).
- Learning rate → optimizasyonun en kritik hiperparametresi;
lr_find/OneCycle ile otomatikleşir (Learning Rate). - timm / mimari seçimi → production’da hız-doğruluk dengesi; tek satırla model değiştirme (timm).
- PyTorch autograd → otomatik türev; Karpathy bunu sıfırdan, fast.ai hazır kullanır (Gradient Descent).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten tek bir şey alıp gideceksen: derin öğrenmede iki adım arasında gizli sihir yoktur. Çok sayıda ReLU’yu topla, gradient descent ile parametrelerini ayarla, istediğin girdi-çıktı örneklerini ver — bilgisayar gerisini çizer. “İşte derin öğrenmeyi türettik; gerisi hız ve veri verimliliği ayarıdır.”