flowchart TD
DT["karar ağacı<br/>(ardışık ikili bölmeler)"] --> SC["bölme skoru<br/>(Gini saflık)"]
SC --> BAG["bagging<br/>(bağımsız yansız ortalama)"]
BAG --> RF["random forest<br/>(rastgele alt küme × N ağaç)"]
RF --> FI["feature importance"]
RF --> OOB["OOB hatası<br/>(bedava validation)"]
RF --> GBM["gradient boosting<br/>(ardışık · residual)"]
style DT fill:#cffafe,stroke:#0891b2,stroke-width:2px
style SC fill:#cffafe,stroke:#0891b2,stroke-width:2px
style BAG fill:#cffafe,stroke:#0891b2,stroke-width:2px
style RF fill:#ffe4e6,stroke:#e11d48,stroke-width:3px
style GBM fill:#ffe4e6,stroke:#e11d48,stroke-width:3px
7 Rastgele Ormanlar — Karar Ağacından Random Forest’a (Random forests)
Ders 5’te tablo verisinde bir sinir ağını sıfırdan kurduk; Ders 6 tamamen farklı ama tablo verisinde çoğu zaman daha güçlü bir aileyi tanıtır — karar ağaçlarını (ardışık ikili bölmeler) ve onların topluluğu random forest’ı: tek bir bölmeden Gini saflık ölçüsüne, bagging’e (Leo Breiman: çok sayıda bağımsız yansız modelin ortalaması), oradan random forest’a, feature importance’a, OOB hatasına ve gradient boosting’e — tablo verisinde ‘bozması neredeyse imkânsız’, hızlı, sağlam ve yorumlanabilir bir temel
NotBölüm bilgisi
- Howard’ın videosu: course.fast.ai — Lesson 6: Random forests (~103 dk)
- Seri: Practical Deep Learning for Coders — Part 1, Ders 6
- Hoca: Jeremy Howard
- Playlist: Practical Deep Learning Part 1 (2022)
- Notebook: course22 — 07-how-random-forests-really-work
- Okuma süresi: ~35 dk
7.1 Bu Derste Ne Var?
Ders 5’te tablo verisinde sinir ağını sıfırdan kurduk. Ders 6 tamamen farklı ama tablo verisinde çoğu zaman daha güçlü bir aileyi tanıtır: karar ağaçları (decision trees) ve onların topluluğu random forests. Howard adım adım, bir karar ağacından bagging’e, oradan random forest’a ve gradient boosting’e ilerler.
Üç temel fikir:
- Karar ağacı = ardışık ikili bölmeler — veriyi en iyi ayıran sorulara göre dallara böler (örn. “kadın mı?”); derin öğrenme değildir, neredeyse hiç ön işleme istemez (Karar Ağaçları → İlk Bölme → Bölme Skoru → Karar Ağacı Kurma).
- Bagging — çok sayıda bağımsız, yansız (ama kusurlu) modelin ortalaması, tek tek hepsinden iyidir; çünkü hatalar birbirini götürür (Leo Breiman) (Bagging).
- Random forest = bagging + karar ağaçları — verinin rastgele alt kümeleriyle yüzlerce ağaç kur, ortalamasını al; “bozması neredeyse imkânsız” sağlam bir başlangıç (Random Forest Fikri → Random Forest Kurma).
“Leo Breiman came up with this idea called bagging.” — Howard, 16:52
Şekil 28.1 bu üç fikri tek bir haritada birleştirir: tek bir karar ağacından (bölme skoru = Gini) başlayıp bagging’e, oradan random forest’a (feature importance + OOB ile) ve son olarak güçlü akrabası gradient boosting’e (rose vurgulu) ilerler.
İpucuBuilder Notu — Tablo Verisinde Ağaçlar, Sinir Ağına Karşı
- Geriye (Stat 110 / Ders 5): Bagging, “bağımsız yansız tahminlerin ortalaması varyansı düşürür” ilkesidir — istatistiğin örneklem ortalaması fikri; Ders 5’in sıfırdan sinir ağı tablo verisinde tek araçtı, bu ders ona güçlü bir alternatif koyar.
- İleriye (production): Random forest, tablo verisinde hızlı, sağlam ve yorumlanabilir bir temel; çoğu gerçek iş probleminde ilk denenecek model — sinir ağına koşmadan önce.
- Tek cümle: Random forest, çok sayıda kusurlu karar ağacının ortalamasını alarak güçlü, sağlam ve yorumlanabilir bir tablo modeli üretir.
7.2 Karar Ağaçları: Derin Öğrenme Olmayan ML
Howard derin öğrenmeden bir an için ayrılır ve karar ağaçlarını tanıtır: veriyi giderek ayıran bir dizi ikili bölme (örn. “cinsiyet kadın mı?”, “yaş < 6 mı?”). Bu, sinir ağı değil; klasik makine öğrenmesidir.
“Non-deep learning ish machine learning methods like decision trees.” — Howard, 5:09
Şekil 7.2 küçük bir Titanic karar ağacını gösterir: kökten başlayıp “kadın mı?” ve “yaş < 6 mı?” gibi ikili sorularla dallanır; her yaprak bir tahmindir (hayatta kaldı / kalmadı). Aynı ağaç İlk Bölme, Bölme Skoru ve Karar Ağacı Kurma bölümlerinin somut görüntüsüdür.
Kod
# SEMATIK: kucuk Titanic karar agaci (ardisik ikili bolmeler).
# Sahte olcum yok: yalnizca yapi/soru/yaprak etiketleri (Howard'in
# DecisionTreeClassifier(max_leaf_nodes=4) ornegi ruhunda kavramsal).
fig, ax = plt.subplots(figsize=(11.0, 6.6))
fig.patch.set_facecolor(COL_WHITE)
ax.set_xlim(0, 22)
ax.set_ylim(0, 12)
ax.axis("off")
NW, NH = 4.4, 1.25 # karar dugumu kutu boyutu
LW, LH = 3.3, 1.15 # yaprak kutu boyutu
def decision(x, y, text, w=NW, h=NH):
"""Karar (soru) dugumu — cyan."""
return boxed_node(ax, x, y, w, h, text,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=10.5, lw=2.2)
def leaf(x, y, text):
"""Yaprak (tahmin) dugumu — rose vurgulu."""
return boxed_node(ax, x, y, LW, LH, text,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=10.0, lw=2.2)
def edge(p0, p1, label, dx=0.0, color=COL_PRIMARY):
"""Iki dugum arasi dal + evet/hayir etiketi."""
arrow_between(ax, p0, p1, color=color, lw=2.0, shrink=10)
xm = (p0[0] + p1[0]) / 2.0 + dx
ym = (p0[1] + p1[1]) / 2.0
ax.text(xm, ym, label, ha="center", va="center", fontsize=9.5,
color=COL_CYAN_700, weight="bold",
bbox=dict(boxstyle="round,pad=0.18", fc=COL_WHITE,
ec=COL_SLATE_400, lw=0.8))
# KÖK — en iyi ilk bölme: cinsiyet
ROOT = (11.0, 10.6)
decision(*ROOT, "Cinsiyet kadın mı?")
# 2. SEVIYE — sol (kadın) ve sağ (erkek)
L2_L = (5.5, 6.9)
L2_R = (16.5, 6.9)
decision(*L2_L, "Sınıf 1-2 mi?")
decision(*L2_R, "Yaş < 6 mı?")
edge((ROOT[0] - 1.6, ROOT[1] - NH / 2), (L2_L[0] + 1.4, L2_L[1] + NH / 2),
"evet (kadın)", dx=-1.3)
edge((ROOT[0] + 1.6, ROOT[1] - NH / 2), (L2_R[0] - 1.4, L2_R[1] + NH / 2),
"hayır (erkek)", dx=1.3)
# 3. SEVIYE — yapraklar (tahminler)
LF1 = (2.6, 2.7)
LF2 = (8.4, 2.7)
LF3 = (13.6, 2.7)
LF4 = (19.4, 2.7)
leaf(*LF1, "hayatta\nKALDI")
leaf(*LF2, "büyük olasılıkla\nkaldı")
leaf(*LF3, "hayatta\nKALDI")
leaf(*LF4, "hayatta\nKALMADI")
edge((L2_L[0] - 1.4, L2_L[1] - NH / 2), (LF1[0] + 0.9, LF1[1] + LH / 2),
"evet", dx=-1.1)
edge((L2_L[0] + 1.4, L2_L[1] - NH / 2), (LF2[0] - 0.9, LF2[1] + LH / 2),
"hayır", dx=1.1)
edge((L2_R[0] - 1.4, L2_R[1] - NH / 2), (LF3[0] + 0.9, LF3[1] + LH / 2),
"evet", dx=-1.1)
edge((L2_R[0] + 1.4, L2_R[1] - NH / 2), (LF4[0] - 0.9, LF4[1] + LH / 2),
"hayır", dx=1.1)
# kök etiket
ax.text(11.0, 11.7, "kök = en iyi tek bölme (cinsiyet)",
ha="center", va="bottom", fontsize=10.0, color=COL_CYAN_800,
weight="bold", style="italic")
# alt not
ax.text(11.0, 0.5,
"her düğüm bir evet/hayır sorusu; her yaprak bir tahmin — "
"izlenebilir, yorumlanabilir, ön işlemesiz",
ha="center", va="center", fontsize=10.0, color=COL_TEXT,
weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_PRIMARY,
alpha=0.9, lw=1.5))
plt.tight_layout()
plt.show()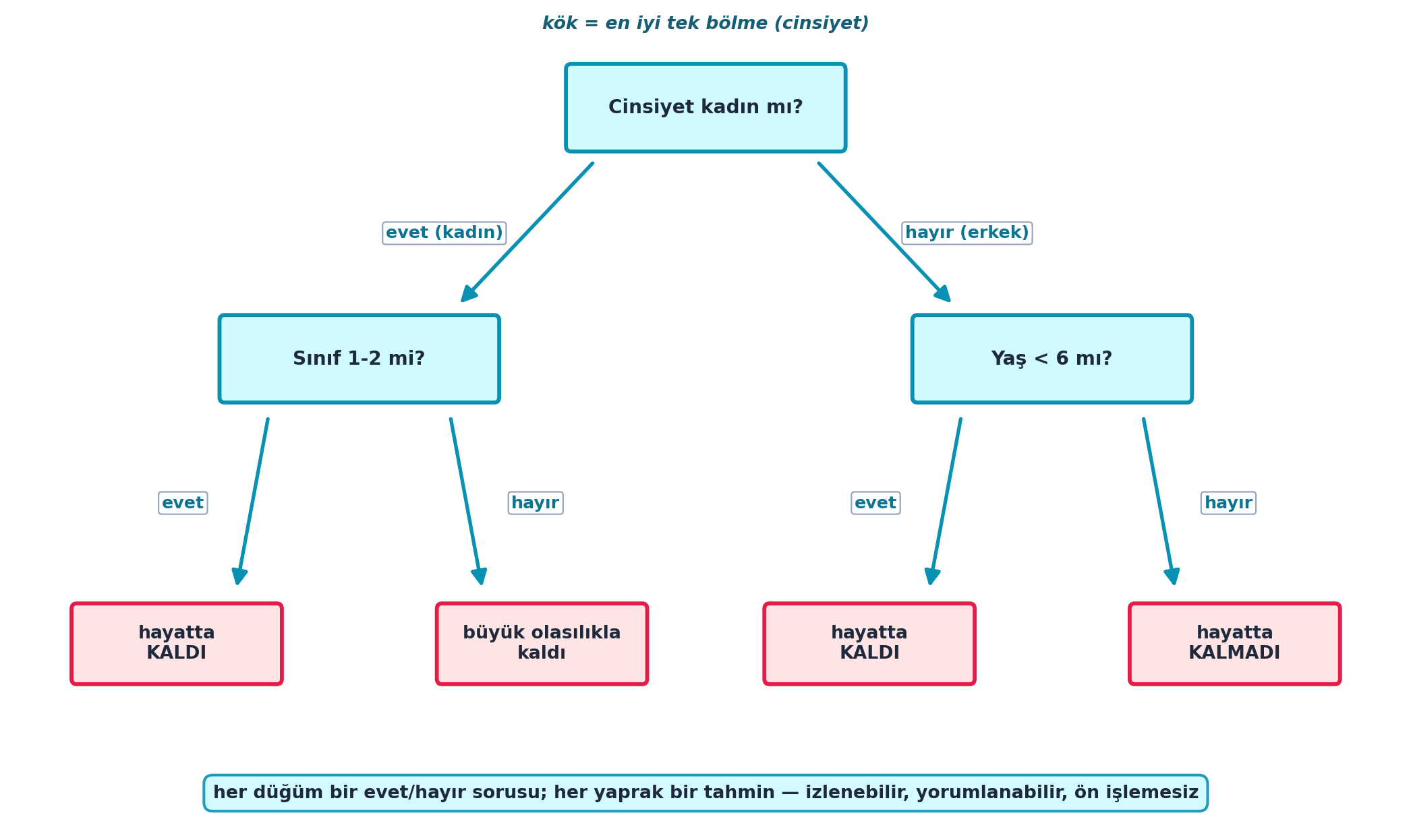
İpucuBuilder Notu — Araç Çantasında İki Yöntem
- İleriye: Tablo verisinde karar ağacı tabanlı yöntemler çoğu zaman sinir ağından daha iyi ve çok daha hızlıdır; builder’ın araç çantasında ikisi de bulunmalı — Şekil 7.2’deki evet/hayır zinciri, Ders 5’in matris çarpımı + ReLU yığınına bambaşka bir alternatiftir.
- Geriye (Ders 5): Ders 5’te tablo için tek seçenek sıfırdan sinir ağıydı; bu ders aynı Titanic verisine ağaçla yaklaşır — az ön işlemeyle başlamak çok daha hızlıdır.
7.3 İlk Bölme: Bir Kuralla Başlamak
Howard en basit modelle başlar: tek bir bölme. Titanic’te en iyi tek ayırım cinsiyettir — kadınların çoğu hayatta kaldı, erkeklerin çoğu kalmadı. Soru: hangi sütun, hangi eşikte veriyi en iyi ikiye ayırır?
Şekil 7.2’nin kök düğümü (“Cinsiyet kadın mı?”) tam bu tek bölmedir — ağacın geri kalanı bu ilk kuralın üstüne kurulur. Bu “en iyi”yi nesnel kılmak için bir skor gerekir, sıradaki Bölme Skoru bölümünün konusu.
İpucuBuilder Notu — Confusion Matrix Sezgisinin Kök Hâli
- Geriye (Ders 2): Bu, Ders 2’deki confusion matrix sezgisinin kök hâli — hangi özellik sınıfları en iyi ayırır; tek bölme, “en ayırıcı sütun” sorusunun en yalın cevabıdır.
- İleriye (Karar Ağacı Kurma): Tek bölmeyi tüm sütun/eşik kombinasyonları üzerinde aramak elle yorucudur; sklearn bunu otomatikleştirir — ama önce “iyi bölme” sayıya dökülmeli.
7.4 Bölme Skoru
“En iyi bölme”yi nesnel kılmak için bir skor gerekir. Howard her olası bölmeyi, iki tarafın standart sapmasının (ağırlıklı) toplamıyla puanlar: bir bölme iki tarafı ne kadar “saf” (homojen) yaparsa o kadar iyidir.
def _side_score(side, y):
tot = side.sum()
if tot <= 1: return 0
return y[side].std() * tot # bir tarafin standart sapmasi x boyutuHer olası “sütun + eşik” çifti için iki tarafın skorunu toplar, en düşük toplamı (en saf iki taraf) veren bölmeyi seçeriz. Şekil 7.2’deki her düğüm, bu skorla seçilmiş bir bölmedir; Gini bölümünde aynı saflık fikrinin sınıflandırmaya özel hâlini göreceğiz.
İpucuBuilder Notu — Standart Sapma = Homojenlik Ölçüsü
- Geriye (Stat 110): Standart sapma homojenlik ölçüsüdür; düşük std = saf grup. Bölme, toplam saflığı en çok artıranı seçer — istatistiğin “varyansı azalt” sezgisinin ağaç hâli.
- İleriye (Gini): Regresyonda standart sapma; sınıflandırmada onun yerini Gini (1 − Σp²) alır — ikisi de aynı “iki tarafı saflaştır” amacına hizmet eder.
7.5 Karar Ağacı Kurma
Tüm bölmeleri elle aramak yerine scikit-learn’in DecisionTreeClassifier’ı bunu otomatik yapar. max_leaf_nodes ile ağacın büyüklüğünü sınırlarız; ağacı çizerek hangi soruları sorduğunu görebiliriz.
from sklearn.tree import DecisionTreeClassifier
m = DecisionTreeClassifier(max_leaf_nodes=4).fit(trn_xs, trn_y)
draw_tree(m, trn_xs, size=10)“There’s no magic in here, just doing what we’ve just described.” — Howard, 5:09
draw_tree’nin çizdiği ağaç tam Şekil 7.2 gibidir: kökte en iyi bölme, dallarda ardışık eşik soruları, yapraklarda tahminler — hiçbir gizem yok, az önce bölme skoruyla anlattığımızın otomatik hâli.
İpucuBuilder Notu — Yorumlanabilir, İzlenebilir Model
- İleriye (Model Yorumlama): Karar ağacı yorumlanabilir bir modeldir — her tahmin, izlenebilir bir dizi evet/hayır sorusuyla açıklanır; bu yorumlanabilirlik random forest’a da taşınır.
- Geriye (İlk Bölme):
max_leaf_nodes=4, ağacı tek bölmenin birkaç adım ötesine taşır; sınır koymazsak ağaç her satırı ezberler (overfit) — sınırlama saflık ile genelleme arasındaki dengeyi tutar.
7.6 Gini Saflık Ölçüsü
Sınıflandırmada saflık için sık kullanılan ölçü Gini’dir: bir gruptan rastgele iki örnek seçtiğinde farklı sınıfta olma olasılığı. Saf grupta (hepsi aynı) Gini düşük, karışık grupta yüksektir.
def gini(cond):
act = df.loc[cond, dep]
return 1 - act.mean()**2 - (1 - act).mean()**2
gini(df.Sex=='female'), gini(df.Sex=='male')Şekil 7.3 bu ölçünün şeklini gerçek hesaplamayla gösterir: bir sınıftaki oran \(p\) değiştikçe Gini \(= 1 - p^2 - (1-p)^2 = 2p(1-p)\) ters bir parabol çizer — saf grupta (\(p=0\) veya \(p=1\)) sıfır, en karışık grupta (\(p=0.5\)) tepe.
Kod
# GERÇEK hesaplama — Gini saflık: 1 − p² − (1−p)² = 2p(1−p) (bkz. gini_curve)
p, gini = gini_curve()
fig, ax = plt.subplots(figsize=(7.4, 4.7))
# referans çizgiler: tepe (0.5) ve dikey orta (p=0.5)
ax.axhline(0.5, lw=1.0, color=COL_SLATE_400, ls="--", zorder=1)
ax.axvline(0.5, lw=0.9, color=COL_SLATE_400, ls=":", zorder=1)
# eğri altını hafif cyan ile gölgele (saflık havuzu)
ax.fill_between(p, 0.0, gini, color=COL_BG, alpha=0.45, zorder=0)
# Gini eğrisi — ters parabol, birincil cyan, kalın
ax.plot(p, gini, lw=2.6, color=COL_PRIMARY, zorder=3)
# tepe p=0.5, gini=0.5 — en karışık (rose nokta)
ax.scatter([0.5], [0.5], s=52, color=COL_ACCENT, zorder=5)
ax.annotate(
"en karışık\n(p=0.5 → Gini 0.5)",
xy=(0.5, 0.5),
xytext=(0.5, 0.30),
fontsize=10.5, weight="bold", color=COL_ACCENT, ha="center",
arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.6),
)
# uçlar p=0 ve p=1, gini=0 — saf grup (cyan noktalar)
ax.scatter([0.0, 1.0], [0.0, 0.0], s=52, color=COL_CYAN_700, zorder=5)
ax.annotate(
"saf grup\n(p=0 → Gini 0)",
xy=(0.0, 0.0),
xytext=(0.16, 0.20),
fontsize=10, weight="bold", color=COL_CYAN_700, ha="center",
arrowprops=dict(arrowstyle="->", color=COL_CYAN_700, lw=1.5),
)
ax.annotate(
"saf grup\n(p=1 → Gini 0)",
xy=(1.0, 0.0),
xytext=(0.84, 0.20),
fontsize=10, weight="bold", color=COL_CYAN_700, ha="center",
arrowprops=dict(arrowstyle="->", color=COL_CYAN_700, lw=1.5),
)
apply_style(ax)
ax.set_xlim(-0.04, 1.04)
ax.set_ylim(-0.06, 0.60)
ax.set_title("Gini: saf grupta 0, en karışık grupta tepe",
fontsize=13, weight="bold", color=COL_CYAN_700)
ax.set_xlabel("bir sınıftaki oran p")
ax.set_ylabel("Gini saflık (1 − Σp²)")
# açıklama notu
ax.text(0.5, -0.30,
"bölme, toplam Gini'yi en çok düşüreni seçer",
transform=ax.transAxes, ha="center", va="top",
fontsize=9.5, color=COL_TEXT, style="italic")
fig.tight_layout()
plt.show()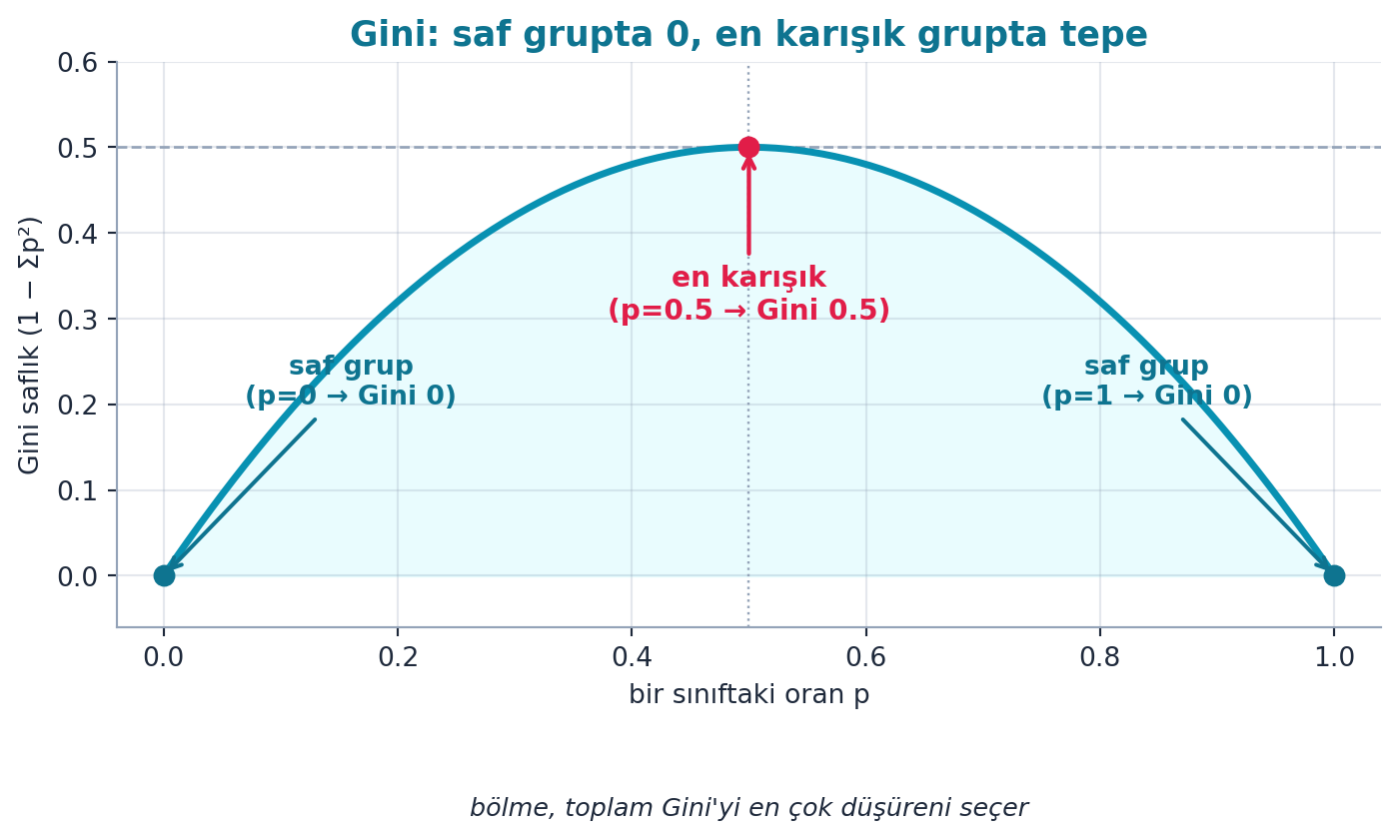
İpucuBuilder Notu — Gini = 1 − Σp²
- Geriye (Stat 110): Gini \(= 1 - \sum p^2\); saf grupta olasılıkların karelerinin toplamı 1’e yaklaşır, Gini 0’a iner — Şekil 7.3’nin uç noktaları (\(p=0,1\)) tam bu sıfır saflığı gösterir.
- İleriye (Feature Importance): Bir sütunun “Gini’yi ne kadar düşürdüğü” birazdan feature importance’ın temel ölçütü olacak; Şekil 7.3’nin eğrisi o katkının nereden geldiğini anlatır.
7.7 Az Ön İşleme: Karar Ağacının Avantajı
Howard kritik bir avantajı vurgular: karar ağaçları çok az ön işleme ister. Dummy variable oluşturabilirsin ama çoğu zaman gerekmez; normalizasyon gerekmez. Ağacın tek umursadığı, verinin sıralamasıdır (değerlerin büyüklüğü değil). Bu yüzden Howard tablo verisine her zaman bir karar ağacıyla başlar.
“All that a decision tree cares about is the ordering of the data. For tabular data I would always start by using a decision tree based approach.” — Howard, 17:53
İpucuBuilder Notu — Normalizasyon/Dummy Yükünü Kaldırır
- Geriye (Ders 5): Ders 5’te dummy + normalizasyon zorunluydu (lineer model için); karar ağacı bu yükü kaldırır — “Age < 24” eşiği, Age normalize edilse de edilmese de aynı bölmeyi verir, çünkü sadece sıralama önemlidir.
- Geriye (Ders 5): Lineer model/sinir ağı değerleri katsayılarla çarptığı için ölçek ve kodlamaya duyarlıdır; ağaç değeri eşiklerle böldüğü için duyarsızdır — başlamak çok hızlıdır.
7.8 Bagging
Tek bir karar ağacı ne kadar iyi olabilir ki? Howard, Leo Breiman’ın dâhiyane fikrini anlatır: bagging. Kusurlu ama yansız (sistematik olarak yüksek/düşük tahmin etmeyen) bir modelin hataları rastgeledir. Böyle çok sayıda bağımsız model üretip ortalamalarını alırsan, hatalar birbirini götürür ve ortalama, tek tek hepsinden iyi olur.
“The predictions of these multiple uncorrelated models — each of which is unbiased — will be better, because the average of the error will tend to zero.” — Howard, 16:52
Şekil 7.4 bu yakınsamayı gerçek bir Monte Carlo simülasyonuyla gösterir: tek tek (gri) tahminler gerçek değer etrafında dağınıkken, \(k\) modelin ortalaması (cyan) gerçeğe yakınsar — varyans \(1/k\) ile düşer.
Kod
bg = bagging_demo()
true_val = bg["true_val"]
estimates = bg["estimates"]
running_mean = bg["running_mean"]
k = bg["k"]
fig, ax = plt.subplots(figsize=(7.4, 4.6))
# Bireysel agac tahminleri — gri, dagink, true_val etrafinda
ax.scatter(k, estimates, s=26, color=COL_SLATE_400, alpha=0.75, zorder=2,
edgecolors="none", label="bireysel ağaç tahmini")
# Calisan ortalama — cyan, kalin: k agacin ortalamasi gercege yakinsar
ax.plot(k, running_mean, color=COL_PRIMARY, linewidth=2.4, zorder=4,
label="k ağacın ortalaması")
# Gercek deger — rose kesik cizgi
ax.axhline(true_val, color=COL_ACCENT, linestyle="--", linewidth=2.0,
zorder=3, label="gerçek değer")
apply_style(ax)
ax.set_xlabel("ağaç sayısı (k)")
ax.set_ylabel("tahmin")
ax.set_title("Bagging: ortalama gerçeğe yakınsar (varyans 1/k düşer)",
fontsize=12, weight="bold")
ax.legend(loc="upper right", frameon=True, framealpha=0.95,
edgecolor=COL_PRIMARY, fontsize=9)
# Breiman notu — alt
ax.text(0.5, -0.205,
"kusurlu ama yansız tahminler; hataları birbirini götürür (Leo Breiman)",
transform=ax.transAxes, ha="center", va="top",
fontsize=9, color=COL_TEXT, style="italic")
plt.show()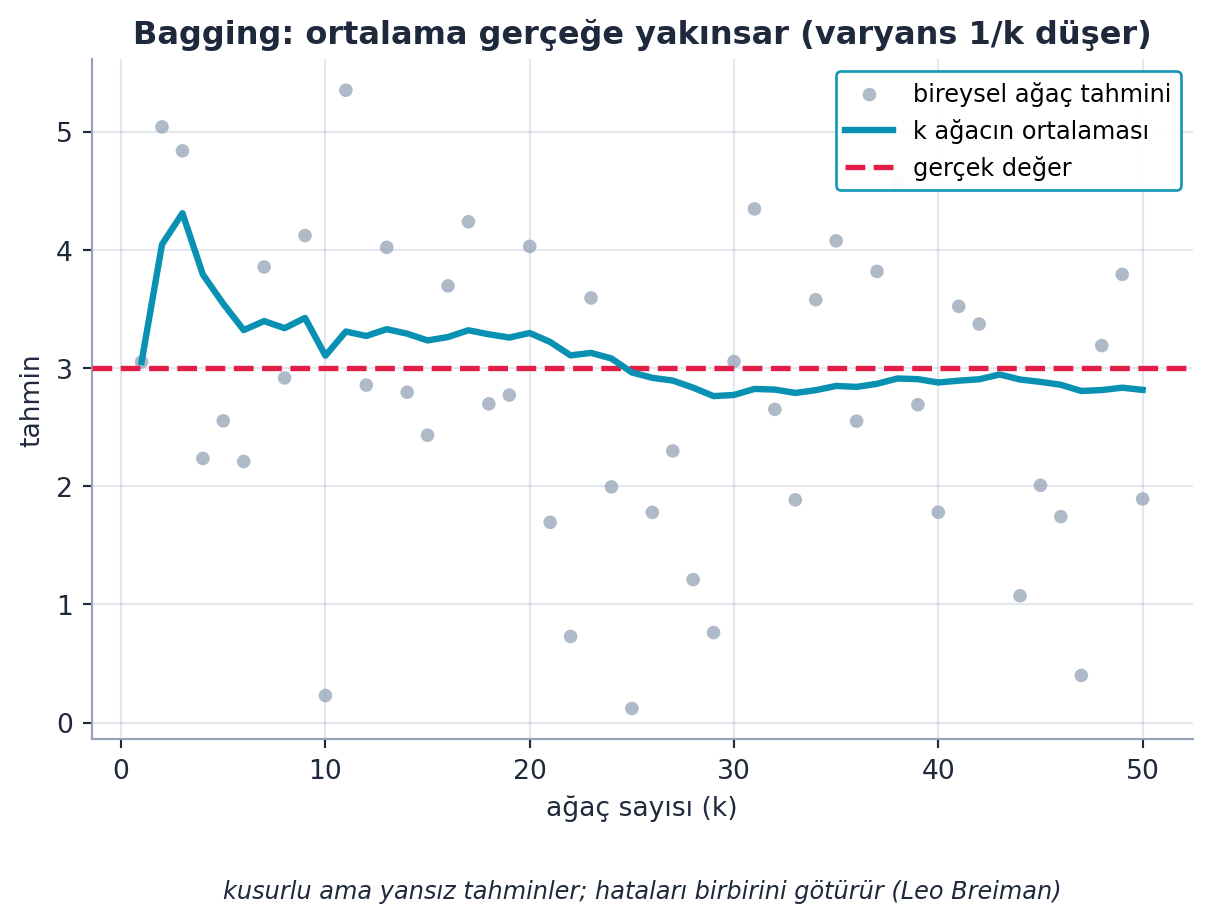
İpucuBuilder Notu — Bagging = Büyük Sayılar Yasası
- Geriye (Stat 110): Bağımsız yansız tahminlerin ortalaması, varyansı örneklem sayısıyla düşürür (büyük sayılar yasası); bagging’in matematiksel temeli budur — Şekil 7.4’in \(1/k\) daralması bu yasanın görsel kanıtıdır.
- İleriye (Random Forest Fikri): Bagging bir “meta yöntem”dir; onu karar ağaçlarına uygulayınca random forest çıkar — ama önce “bağımsız modeller nasıl üretilir?” sorusu yanıtlanmalı.
7.9 Random Forest Fikri
Çok sayıda bağımsız model nasıl üretilir? Basit: verinin her seferinde farklı bir rastgele alt kümesiyle (örn. %75) ayrı bir karar ağacı eğit. Her ağaç biraz farklı, hiçbiri mükemmel değil ama hepsi yansız. Bunların ortalaması bir random foresttir.
“Each of those decision trees is going to be not very good, but it will be unbiased. When you do this you create something called a Random Forest.” — Howard, 19:07
Şekil 7.5 bu mimariyi şematik olarak gösterir: tek bir eğitim verisinden rastgele alt kümeler çekilir, her birine bir ağaç eğitilir, sonra tüm ağaçların ortalaması (rose) alınır — bu ortalama random forest’ın tahminidir.
Kod
fig = plt.figure(figsize=(10.5, 6.4))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 12)
ax.set_ylim(0, 12)
ax.axis("off")
# ----- ÜST: eğitim verisi -----
x_data = 6.0
y_data = 11.0
boxed_node(ax, x_data, y_data, 4.4, 1.2,
"Eğitim verisi\n(tüm satırlar)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11.5, lw=2.4)
# ----- ORTA: 3 rastgele alt küme + ağaç -----
# Üç dal: sol, orta, sağ
x_trees = [2.6, 6.0, 9.4]
y_subset = 8.0 # "rastgele alt küme" kutuları
y_tree = 5.2 # "Ağaç k" kutuları
labels = ["Ağaç 1", "Ağaç 2", "Ağaç 3"]
for xt, lbl in zip(x_trees, labels):
# rastgele alt küme kutusu (küçük, açık cyan)
boxed_node(ax, xt, y_subset, 2.7, 0.95,
"rastgele alt küme\n~%75",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=9.5, lw=1.8)
# ağaç kutusu (cyan, biraz koyu kenar)
boxed_node(ax, xt, y_tree, 2.2, 1.05,
lbl,
fc=COL_BG, ec=COL_CYAN_700, tc=COL_TEXT,
fontsize=11, lw=2.2)
# veri -> alt küme (farklı alt küme okları)
arrow_between(ax, (x_data, y_data - 0.6), (xt, y_subset + 0.55),
color=COL_PRIMARY, lw=2.0)
# alt küme -> ağaç
arrow_between(ax, (xt, y_subset - 0.55), (xt, y_tree + 0.6),
color=COL_PRIMARY, lw=2.0)
# "... yüzlerce ağaç" işareti sağda
ax.text(11.4, y_tree, "···\nyüzlerce\nağaç",
ha="center", va="center", fontsize=9.5,
color=COL_SLATE_400, weight="bold", style="italic")
# ----- ALT: ORTALAMA (rose vurgulu) -----
x_avg = 6.0
y_avg = 2.7
boxed_node(ax, x_avg, y_avg, 3.2, 1.1,
"ORTALAMA",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT,
fontsize=12.5, lw=2.6)
# her ağaç -> ORTALAMA
for xt in x_trees:
arrow_between(ax, (xt, y_tree - 0.6), (x_avg, y_avg + 0.6),
color=COL_ROSE_500, lw=2.0)
# ----- EN ALT: Random Forest tahmini -----
y_pred = 0.85
boxed_node(ax, x_avg, y_pred, 4.6, 1.0,
"Random Forest tahmini",
fc=COL_BG, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=11.5, lw=2.4)
arrow_between(ax, (x_avg, y_avg - 0.6), (x_avg, y_pred + 0.55),
color=COL_ACCENT, lw=2.4)
# Not (alt sol)
ax.text(0.15, 0.35,
"verinin rastgele alt kümeleriyle yüzlerce ağaç;\n"
"ortalaması = random forest",
ha="left", va="bottom", fontsize=9.5,
color=COL_CYAN_800, weight="bold", style="italic")
plt.show()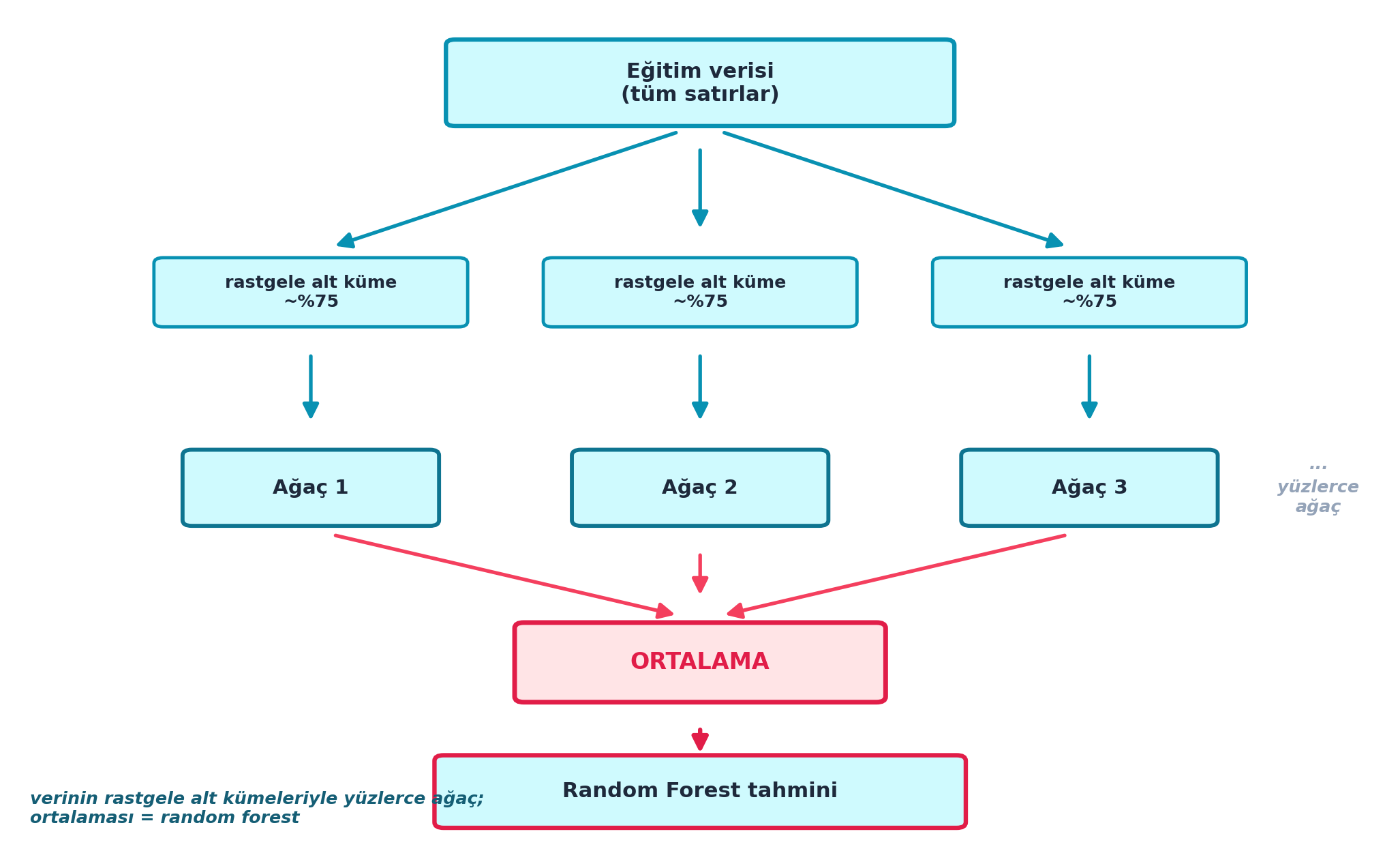
İpucuBuilder Notu — Bagging’in Karar Ağacına Uygulanmış Hâli
- İleriye: Bagging bir “meta yöntem”dir — modelleme değil, modelleri birleştirme yöntemi. Random forest, karar ağaçlarına uygulanmış bagging’dir; Şekil 7.5’in alt-küme → ağaç → ortalama akışı, Şekil 7.4’in yakınsamasının somut mimarisidir.
- Geriye (Bagging): Her ağacın farklı bir rastgele alt kümeyle eğitilmesi, ağaçları “bağımsız” kılan şeydir; bağımsızlık olmadan ortalamanın varyans-düşürme gücü çalışmaz.
7.10 Random Forest Kurma
Tüm bu fikir scikit-learn’de dört satırdır: kaç ağaç, yaprak başına kaç örnek, sonra fit.
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(100, min_samples_leaf=5)
rf.fit(trn_xs, trn_y)
mean_absolute_error(val_y, rf.predict(val_xs))“So let’s create one in four lines of code.” — Howard, 20:18
Gerçek dünyada, makul boyuttaki veri setlerinde random forest neredeyse her zaman tek bir karar ağacından çok daha iyidir.
İpucuBuilder Notu — Classifier ve Regressor, Aynı Mantık
- İleriye:
RandomForestClassifier(sınıflandırma) veRandomForestRegressor(regresyon) — ikisi de aynı mantık;min_samples_leafaşırı öğrenmeyi sınırlar (her yaprakta en az 5 örnek = ezber engeli). - Geriye (Ders 5): Ders 5’te sıfırdan yazdığımız onlarca satır burada dört satıra iner; framework (sklearn) “fiddly” parçaları gizler — Howard’ın Ders 5 kapanışındaki “framework neden gerekli” sorusunun tablo-ağaç cevabı.
7.11 Feature Importance
Howard’ın en sevdiği özellik: feature importance. Her ağaçta, her sütunun Gini’yi ne kadar iyileştirdiğini (ve kaç kez seçildiğini) toplar, tüm ağaçlar üzerinde birleştirir. Sonuç: hangi özelliklerin önemli olduğunu gösteren bir grafik. Titanic’te cinsiyet ve sınıf açık ara önde çıkar.
import pandas as pd
pd.DataFrame(dict(cols=trn_xs.columns, imp=rf.feature_importances_)).plot('cols', 'imp', 'barh')“A feature importance plot tells you how important is each feature, how often did the trees pick it and how much did it improve the Gini when it did.” — Howard, 24:16
Şekil 7.6 bu grafiği Titanic için (Howard’ın örnek değerleriyle) gösterir: cinsiyet (Sex) ve sınıf (Pclass) açık ara önde — yüzlerce sütunlu bir veride bile en önemli olanları saniyelerde bulur.
Kod
# Feature importance: random forest her ozelligin (sutun) tum agaclar uzerinde
# Gini'yi ne kadar iyilestirdigini toplar. Titanic'te cinsiyet (Sex) + sinif
# (Pclass) acik ara onde — yuzlerce sutunlu veride en onemliyi saniyelerde bulur.
# (illustratif — Howard ornegi degerleri)
fi = feature_importance_demo()
features = fi["features"] # buyukten kucuge sirali (Sex, Pclass, ...)
importances = fi["importances"]
# Engine zaten buyukten kucuge sirali doner; barh icin ters cevir ki
# en buyuk EN USTTE gozuksun (invert_yaxis yerine acik siralama).
order = np.argsort(importances) # kucukten buyuge -> barh alttan ust
feats_sorted = [features[i] for i in order]
imps_sorted = importances[order]
# En onemli 1-2 cubuk rose (accent) vurgulu; digerleri cyan (primary).
# imps_sorted artan; son iki eleman en buyuk ikisi (Sex + Pclass).
n = len(imps_sorted)
colors = [COL_ACCENT if i >= n - 2 else COL_PRIMARY for i in range(n)]
fig, ax = plt.subplots(figsize=(8.6, 4.8))
y_pos = np.arange(n)
ax.barh(y_pos, imps_sorted, color=colors, height=0.62, zorder=3,
edgecolor=COL_WHITE, linewidth=0.8)
ax.set_yticks(y_pos)
ax.set_yticklabels(feats_sorted, color=COL_TEXT, fontsize=10.5, weight="bold")
ax.set_xlabel("önem (Gini iyileştirme katkısı)", color=COL_TEXT, fontsize=10.5)
ax.set_xlim(0, max(imps_sorted) * 1.18)
# Deger etiketleri (cubuk ucunda)
for i, v in enumerate(imps_sorted):
ax.text(v + max(imps_sorted) * 0.012, i, f"{v:.2f}", va="center",
ha="left", color=COL_TEXT, fontsize=9.5, weight="bold")
ax.set_title("Feature importance: hangi özellik önemli (Titanic)",
fontsize=12.5, weight="bold", color=COL_TEXT, pad=10)
apply_style(ax)
ax.grid(True, axis="x", alpha=0.2, color=COL_SLATE_400)
ax.grid(False, axis="y")
# Not: cinsiyet + sinif acik ara onde
fig.text(0.5, -0.04,
"cinsiyet + sınıf açık ara önde; saniyelerde 100'lerce sütunda "
"en önemliyi bul",
ha="center", va="top", fontsize=9, color=COL_TEXT, style="italic")
fig.tight_layout()
plt.show()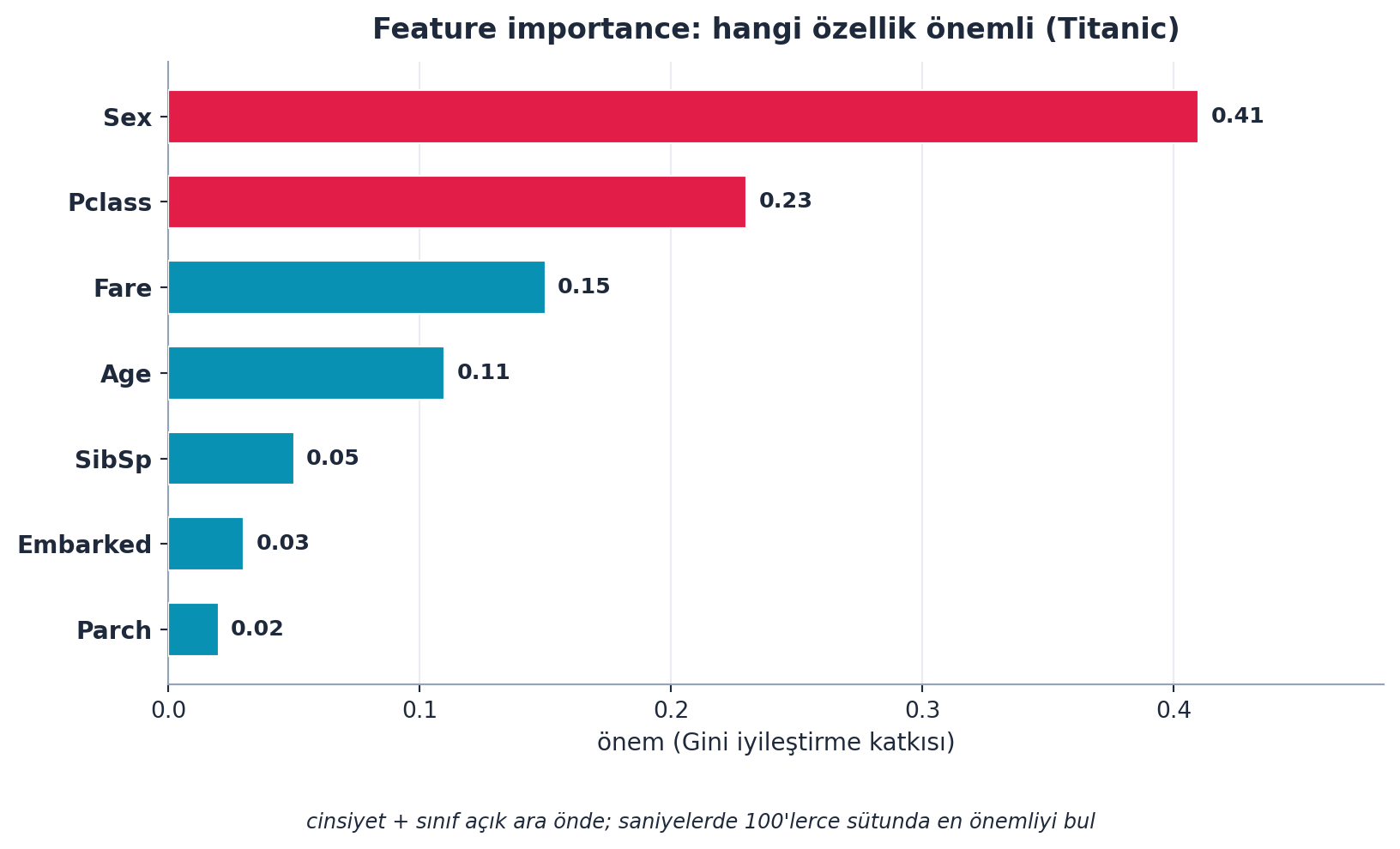
Howard bir hikâye anlatır: kredi skorlamada 7000 sütunluk bir veriyi random forest’a verip iki saatte ~30 önemli sütun bulmuş — bir danışmanlık firmasının iki yılda, milyonlarca dolara bulduğuyla aynı.
İpucuBuilder Notu — Önce Feature Importance Çiz
- İleriye (production): Yüzlerce sütunlu bir veride önce feature importance çiz, önemli ~30 sütunu bul — devasa zaman kazandıran ilk adım; Şekil 7.6’ın Howard’ın kredi-skorlama hikâyesiyle birleşimi (7000 sütun → 2 saat) bunun pratik gücünü gösterir.
- Geriye (Gini): Önem ölçüsü doğrudan Gini iyileştirmesidir — Şekil 7.3’deki eğrinin “bir sütun bölmeyi ne kadar saflaştırdı” katkısı, tüm ağaçlar üzerinde toplanır.
7.12 Kaç Ağaç?
Daha fazla ağaç her zaman hatayı düşürür (azalan getiriyle) — çünkü daha çok şey ortalanır. Ama her ağaç çıkarım (inference) zamanında maliyet getirir. Howard pratik kuralını verir.
“I don’t often use more than 100 trees, this is a rule of thumb.” — Howard, 29:26
Şekil 7.7 bu davranışı gerçek bir bagging simülasyonuyla gösterir: ağaç sayısı arttıkça hata azalan getiriyle düşer ve bir platoya oturur — daha fazla ağaç eklemek artık pek bir şey kazandırmaz (ama overfit de ettirmez).
Kod
# Random forest hatasi agac sayisiyla duser (azalan getiri) ve PLATOYA oturur.
# Agac eklemek OVERFIT ETTIRMEZ (sinir agindan temel fark). ~100 agac iyi kural.
te = trees_vs_error()
n_trees = te["n_trees"]
error = te["error"]
fig, ax = plt.subplots(figsize=(8.5, 4.6))
ax.plot(n_trees, error, "-", color=COL_PRIMARY, lw=2.4, label="hata (MAE)")
# Plato bolgesini golgele (egrinin son ~yarisi duzlestigi yer)
plateau_start = int(len(n_trees) * 0.5)
ax.axvspan(n_trees[plateau_start], n_trees[-1], color=COL_BG_ROSE, alpha=0.45,
zorder=0)
plateau_level = float(error[plateau_start:].mean())
ax.axhline(plateau_level, color=COL_ROSE_500, ls=":", lw=1.6, zorder=1)
# Plato anotasyonu (rose, sag tarafta)
ax.annotate("plato — overfit ETMEZ",
xy=(n_trees[-1], error[-1]),
xytext=(n_trees[plateau_start] + 2, plateau_level + 0.10),
color=COL_ACCENT, fontsize=10, weight="bold", ha="left", va="bottom")
# ~100 agac iyi kural referansi (egri 80'de bitiyor; oka kadar uzanan dikey ipucu
# yerine basit metin: plato zaten 100'den once oturuyor)
ax.axvline(n_trees[plateau_start], color=COL_SLATE_400, ls="--", lw=1.4,
zorder=1)
ax.annotate("azalan getiri", xy=(n_trees[5], error[5]),
xytext=(n_trees[8], error[5] + 0.18), color=COL_TEXT,
fontsize=9, weight="bold", ha="left", va="bottom",
arrowprops=dict(arrowstyle="->", color=COL_SLATE_400, lw=1.4))
ax.set_xlabel("ağaç sayısı")
ax.set_ylabel("hata (MAE)")
ax.set_ylim(0, float(error.max()) * 1.15)
ax.set_title("Daha çok ağaç → daha az hata, sonra plato (overfit yok)",
fontsize=12, weight="bold", color=COL_TEXT)
apply_style(ax)
ax.legend(loc="upper right", frameon=False, fontsize=9.5)
# Not: ~100 agac iyi kural; sinir agindan FARKLI — eklemek overfit ettirmez
fig.text(0.5, -0.04,
"~100 ağaç iyi bir kural; sinir ağından FARKLI — ağaç eklemek overfit ettirmez",
ha="center", va="top", fontsize=9, color=COL_TEXT, style="italic")
fig.tight_layout()
plt.show()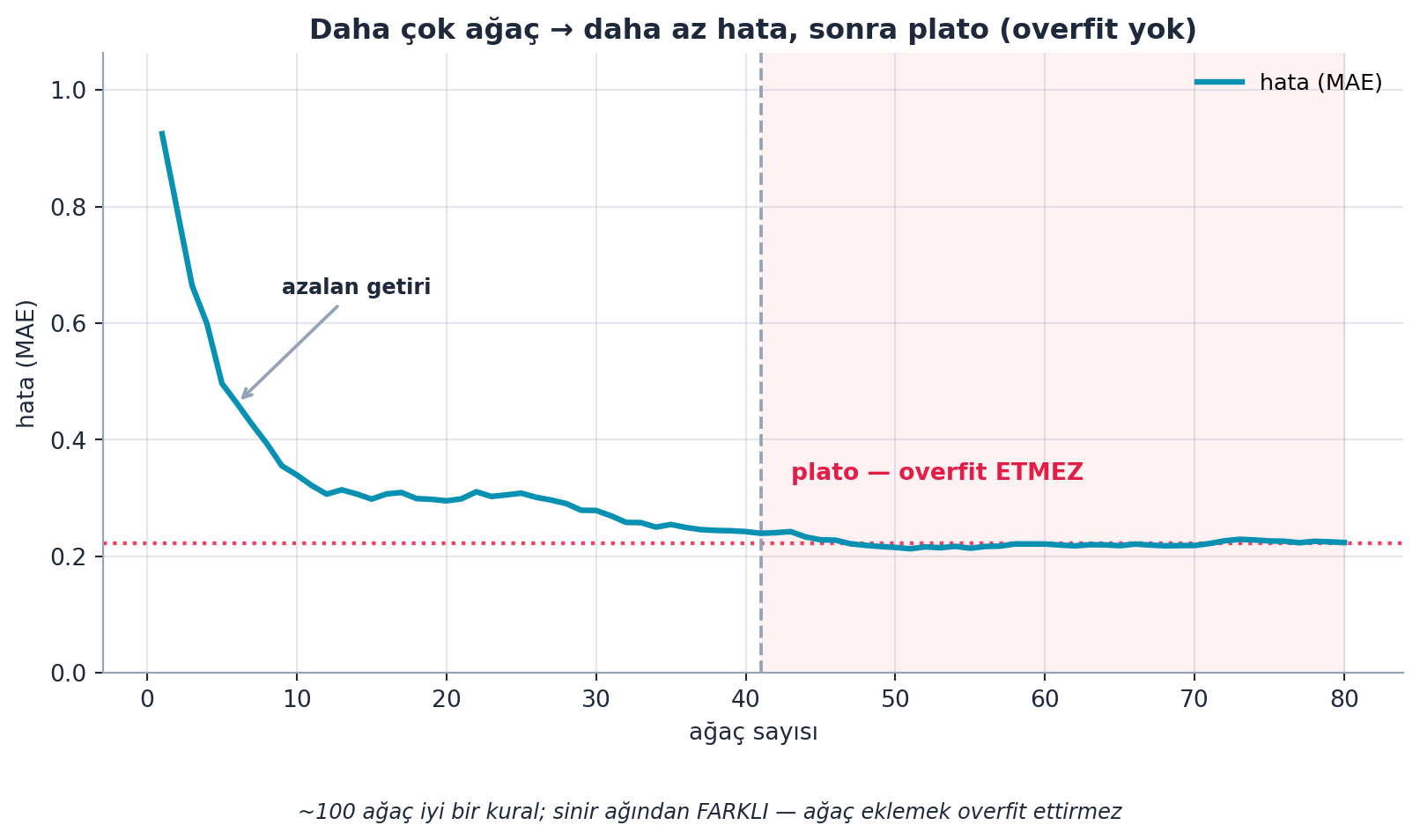
İpucuBuilder Notu — Ağaç Sayısı = Doğruluk/Hız Dengesi
- İleriye: Ağaç sayısı doğruluk/hız dengesidir; ~100 iyi bir varsayılan. Karar ağaçları çıkarımda çok hızlıdır (hatta C++ if’lerine derlenebilir) — Şekil 7.7’in platosu, “daha fazla ağacın maliyeti faydasını geçtiği” noktayı işaret eder.
- İleriye (Random Forest Overfit Eder mi?): Platonun yükselmemesi (sadece düzleşmesi) random forest’ın “güvenli” olmasının ta kendisi; aynı eğri overfit bölümünde sinir ağıyla zıtlık için tekrar okunur.
7.13 OOB: Out-of-Bag Hatası
Her ağaç verinin yalnızca bir alt kümesiyle (örn. %75) eğitildiğinden, her ağacın görmediği bir %25 vardır. Bu görülmeyen kısımda her ağacın doğruluğunu ölçüp ortalayabiliriz: out-of-bag (OOB) hatası. Bu, az veride ayrı bir validation set olmadan da genelleme tahmini verir.
“For each tree there was 25% of the data we didn’t train on… that is called the Out-of-Bag Error. You can get away with not having a validation set.” — Howard, 29:33
Random Forest Fikri bölümündeki “her ağaç ~%75 alt küme” yapısı (Şekil 7.5), OOB’yi bedava kılan şeydir: kalan %25, o ağaç için doğal bir test setidir.
İpucuBuilder Notu — Validation Set’in Bedava Versiyonu
- Geriye (Ders 4): OOB, validation set’in random forest’a özgü “bedava” versiyonudur; yine de büyük/zaman serisi verilerde gerçek validation set tercih edilir.
- Geriye (Random Forest Fikri): OOB doğrudan rastgele alt küme yapısından doğar — her ağacın görmediği %25 zaten elimizde, ekstra veri ayırmaya gerek yok.
7.14 Model Yorumlama
Random forest yorumlamada çok güçlüdür. Feature importance’a ek olarak: partial dependence (bir özelliği değiştirince tahminin nasıl değiştiği), tek bir tahminin neden öyle yapıldığının açıklaması, ve gereksiz (redundant) özelliklerin tespiti. Bu yüzden Howard tablo projelerine random forest’la başlar.
“I would probably always start a tabular project with a Random Forest because they’re nearly impossible to mess up, and they give good insight, and they give a good base case.” — Howard, 31:31
İpucuBuilder Notu — Üç Süper Güç: Bozulmaz + Yorumlanabilir + Hızlı
- İleriye (production): “Bozması imkânsız + yorumlanabilir + hızlı temel” = random forest’ın üç süper gücü; ML projesinin keşif aşamasının standart aracı.
- Geriye (Feature Importance / Karar Ağacı Kurma): Yorumlanabilirlik tek ağacın izlenebilirliğinden ve feature importance’tan gelir; orman bunları yüzlerce ağaç üzerinden istatistiksel olarak sağlamlaştırır.
7.15 Random Forest Overfit Eder mi?
Pratik bir güvence: ağaç eklemek random forest’ı overfit ettirmez — yalnızca platoya oturur. Çünkü her ağaç bağımsız ve yansızdır; ortalama almak varyansı düşürür, bias eklemez. Bu, random forest’ı bu kadar “güvenli” yapan şeydir.
Şekil 7.7’in platoya oturan (ama yükselmeyen) eğrisi tam bu güvenceyi gösterir: Ders 4’teki overfitting eğrisinin aksine, burada validation hatası bir noktadan sonra geri tırmanmaz.
İpucuBuilder Notu — Sinir Ağıyla Temel Fark
- Geriye (Ders 4): Sinir ağında daha fazla eğitim overfit edebilir; random forest’ta daha fazla ağaç etmez — temel bir fark. Şekil 7.7’in düz platosu, Ders 4’ün yükselen validation eğrisinin tam zıttıdır.
- İleriye (Gradient Boosting): “Ağaç eklemek overfit ettirmez” güvencesi yalnızca bagging (bağımsız ağaç) için geçerli; ardışık ağaç kuran gradient boosting bu güvenceyi kaybeder — daha güçlü ama daha dikkatli ayar ister.
7.16 Gradient Boosting
Howard güçlü bir akrabaya değinir: gradient boosting. Random forest bağımsız ağaçların ortalamasıyken, gradient boosting ağaçları ardışık kurar — her yeni ağaç, öncekilerin hatalarını (residual) düzeltmeye çalışır. Genellikle random forest’tan daha doğrudur ama overfit’e daha yatkındır, daha dikkatli ayar ister.
Şekil 7.8 bu iki paradigmayı yan yana koyar: üstte random forest (bağımsız ağaçlar paralel, ortalama), altta gradient boosting (ağaçlar ardışık, her biri öncekinin kalan hatasını düzeltir).
Kod
# ----------------------------------------------------------------------------
# Random forest vs gradient boosting kontrasti (SEMATIK, kavramsal)
# UST — Random Forest: 3 BAGIMSIZ agac PARALEL (cyan) -> hepsi ORTALAMA'ya
# ALT — Gradient Boosting: 3 agac ARDISIK zincir; her biri oncekinin
# hatasini (residual, rose ok) duzeltir.
# Sahte sayi yok: yalnizca yapi/akis etiketleri.
# ----------------------------------------------------------------------------
fig, ax = plt.subplots(figsize=(11.0, 7.8))
fig.patch.set_facecolor(COL_WHITE)
ax.set_xlim(0, 22)
ax.set_ylim(0, 15)
ax.axis("off")
# satir merkez yukseklikleri
Y_TOP = 11.1 # Random Forest satiri (3 agac bu merkez etrafinda dikey)
Y_BOT = 2.9 # Gradient Boosting satiri
H = 1.2 # agac kutusu yuksekligi (RF dikey istif icin alcak)
TW = 5.2 # RF agac kutusu genisligi (tek satir etiket)
TW_G = 3.4 # GBM agac kutusu genisligi
def lab(y, num, text, sub):
"""Satir basligi (solda, koyu cyan) + alt etiket (rose)."""
ax.text(0.2, y, f"{num} · {text}", ha="left", va="bottom",
fontsize=13.0, color=COL_CYAN_700, weight="bold")
ax.text(0.2, y - 0.6, sub, ha="left", va="bottom",
fontsize=9.5, color=COL_ACCENT, weight="bold", style="italic")
def treebox(x, y, text, ec=COL_PRIMARY, fc=COL_BG, w=TW):
"""Karar agaci kutusu — cyan (bagimsiz) varsayilan."""
return boxed_node(ax, x, y, w, H, text,
fc=fc, ec=ec, tc=COL_TEXT, fontsize=10.5, lw=2.2)
# ============================================================================
# UST SATIR — Random Forest: PARALEL bagimsiz agaclar -> ORTALAMA
# ============================================================================
lab(Y_TOP + 3.15, "1", "Random Forest — PARALEL",
"bağımsız, yansız; overfit etmez")
# 3 BAGIMSIZ agac DIKEY istiflenir (yan yana degil) — ardisik zincir
# yanilsamasini onler; hepsi tek ORTALAMA kutusuna birlesir.
TY = [Y_TOP + 1.7, Y_TOP, Y_TOP - 1.7]
tree_lbls = ["Ağaç 1 (rastgele alt-küme)",
"Ağaç 2 (rastgele alt-küme)",
"Ağaç 3 (rastgele alt-küme)"]
TX = 4.8
for ty, tl in zip(TY, tree_lbls):
treebox(TX, ty, tl)
# ORTALAMA kutusu (sagda, dikey ortada, rose vurgulu — son cikti)
AVG_X = 17.0
boxed_node(ax, AVG_X, Y_TOP, 4.0, H + 0.5, "ORTALAMA\n(oy / mean)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=11.5, lw=2.4)
# her bagimsiz agac -> ORTALAMA (cyan oklar; egri toplama hatti, birbirine
# degmeden tek kutuda birlesir -> bagimsizlik net)
for ty in TY:
rad = (Y_TOP - ty) / 14.0 # ust/alt agaclar hafif egri, orta duz
arrow_between(ax, (TX + TW / 2, ty), (AVG_X - 2.0, Y_TOP),
color=COL_PRIMARY, lw=2.0,
connectionstyle=f"arc3,rad={rad}")
# "bağımsız — paralel" notu agaclarin altinda
ax.text(TX, Y_TOP - 2.85,
"ağaçlar birbirini GÖRMEZ — tam paralel kurulur",
ha="center", va="top", fontsize=9.0, color=COL_SLATE_400,
weight="bold", style="italic")
# ============================================================================
# Ayraç çizgi (iki paradigma arasi)
# ============================================================================
ax.plot([0.4, 21.6], [7.55, 7.55], color=COL_SLATE_400, lw=1.0,
ls=(0, (4, 4)), zorder=0)
# ============================================================================
# ALT SATIR — Gradient Boosting: ARDISIK zincir (residual duzeltme)
# ============================================================================
lab(Y_BOT + 2.55, "2", "Gradient Boosting — ARDIŞIK",
"her ağaç öncekinin hatasını düzeltir; daha güçlü ama overfit'e yatkın")
g_xs = [3.0, 9.4, 15.8]
g_lbls = ["Ağaç 1\n(ilk tahmin)",
"Ağaç 2\nhatayı düzelt",
"Ağaç 3\nhatayı düzelt"]
# Ardisik agaclar — ilki cyan, sonrakiler rose vurgulu (duzeltici)
treebox(g_xs[0], Y_BOT, g_lbls[0], ec=COL_PRIMARY, fc=COL_BG, w=TW_G)
treebox(g_xs[1], Y_BOT, g_lbls[1], ec=COL_ACCENT, fc=COL_BG_ROSE, w=TW_G)
treebox(g_xs[2], Y_BOT, g_lbls[2], ec=COL_ACCENT, fc=COL_BG_ROSE, w=TW_G)
# residual oklar (rose) — agaclar arasi ardisik zincir
for x0, x1 in zip(g_xs[:-1], g_xs[1:]):
arrow_between(ax, (x0 + TW_G / 2, Y_BOT), (x1 - TW_G / 2, Y_BOT),
color=COL_ACCENT, lw=2.4)
# ok etiketleri: "residual"
for x0, x1 in zip(g_xs[:-1], g_xs[1:]):
xm = (x0 + x1) / 2.0
ax.text(xm, Y_BOT + 0.55, "residual\n(kalan hata)", ha="center", va="bottom",
fontsize=9.0, color=COL_ACCENT, weight="bold", style="italic")
# son cikti: agirlikli toplam
ax.text(g_xs[2] + TW_G / 2 + 0.4, Y_BOT, "→ Σ ağaçlar\n(ağırlıklı toplam)",
ha="left", va="center", fontsize=9.5, color=COL_CYAN_700,
weight="bold")
# "ardışık — her biri kalan hataya odaklanir" notu
ax.text(9.4, Y_BOT - 1.25,
"ağaçlar SIRAYLA kurulur — her biri kalan hataya odaklanır",
ha="center", va="top", fontsize=9.0, color=COL_SLATE_400,
weight="bold", style="italic")
# ============================================================================
# Alt not — ana fikir
# ============================================================================
ax.text(11.0, 0.35,
"RF = bağımsız ağaçları ortalar (overfit etmez); "
"GBM = ardışık ağaçlarla hatayı kovalar (XGBoost/LightGBM tablo yarışmalarını kazanır)",
ha="center", va="bottom", fontsize=10.0, color=COL_TEXT,
weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_PRIMARY,
alpha=0.9, lw=1.5))
plt.tight_layout()
plt.show()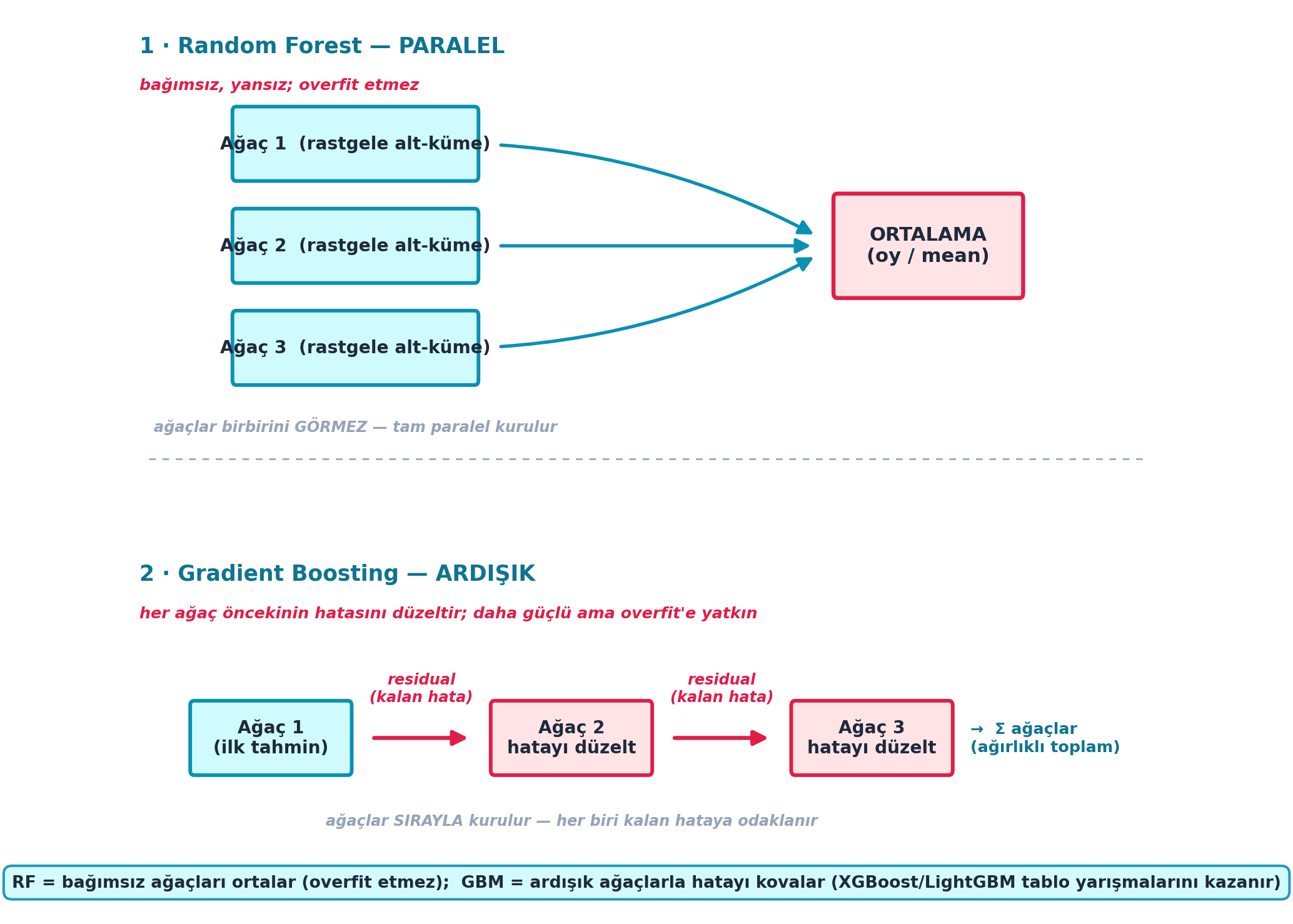
İpucuBuilder Notu — RF Başlangıç, Boosting Son Performans
- İleriye (production): XGBoost, LightGBM, CatBoost gibi gradient boosting kütüphaneleri, tablo verisi yarışmalarının (Kaggle) çoğunu kazanır; random forest sağlam başlangıç, boosting ise son performans — Şekil 7.8’in iki satırı tam bu iş bölümünü gösterir.
- Geriye (Random Forest Overfit Eder mi?): GBM’in ardışıklığı, RF’nin “overfit etmez” güvencesini bozar; her yeni ağaç öncekinin hatasına bakıp eğitim verisine daha çok yapışır — bu yüzden learning rate / ağaç derinliği / erken durdurma dikkatli ayarlanır.
7.17 Kapanış
Ders 6, tablo verisi için sinir ağına güçlü bir alternatif gösterdi: tek karar ağacı → bagging → random forest → gradient boosting. Random forest hızlı, sağlam, yorumlanabilir bir temeldir ve “bozması neredeyse imkânsız”dır. Sinir ağları görüntü/metin/ses gibi yapısız veride; ağaç tabanlı modeller tablo verisinde parlar.
İpucuBuilder Notu — İki Aile, İki Veri Türü
- İleriye (Ders 7-8): Sonraki dersler ortak filtreleme (collaborative filtering) ve evrişimlere (CNN) döner; tablo için ağaçlar, yapısız veri için sinir ağları — builder ikisini de bilir.
- Geriye (tüm seri): Bu ders, Ders 5’in sıfırdan sinir ağına tablo verisinde bir rakip koydu; Şekil 28.1’in karar-ağacı → random-forest → gradient-boosting zinciri, bu rakibin tüm hikâyesidir.
7.18 Bu Dersin Özeti
- Karar ağacı veriyi ardışık ikili bölmelerle ayırır; derin öğrenme değildir, neredeyse hiç ön işleme istemez (yalnızca sıralama önemli) (Karar Ağaçları, Az Ön İşleme).
- Bir bölmenin iyiliği saflıkla ölçülür: standart sapma veya Gini (rastgele iki örneğin farklı sınıfta olma olasılığı) (Bölme Skoru, Gini).
- Bagging (Leo Breiman): çok sayıda bağımsız, yansız ama kusurlu modelin ortalaması, hataları götürdüğü için tek tek hepsinden iyidir (Bagging).
- Random forest = verinin rastgele alt kümeleriyle kurulan yüzlerce karar ağacının ortalaması; dört satır kod, “bozması imkânsız” (Random Forest Fikri, Random Forest Kurma).
- Feature importance hangi özelliklerin önemli olduğunu saniyeler içinde gösterir — yüzlerce sütunlu veride paha biçilmez (Feature Importance).
- Daha çok ağaç hatayı azaltır (azalan getiriyle) ve overfit etmez; ~100 ağaç iyi bir kural (Kaç Ağaç?, Overfit Eder mi?).
- OOB hatası, her ağacın görmediği %25 üzerinden ölçülür; az veride validation set yerine geçebilir (OOB).
- Gradient boosting ağaçları ardışık kurar (her biri öncekinin hatasını düzeltir); daha güçlü ama overfit’e yatkın (Gradient Boosting).
ÖnemliTek Bir Cümle
Random forest, verinin rastgele parçalarıyla kurulan çok sayıda kusurlu karar ağacının ortalamasını alarak, tablo verisinde hızlı, sağlam, yorumlanabilir ve “bozması neredeyse imkânsız” bir model üretir.
7.19 Kontrol Soruları
NotSoru 1: Bagging neden işe yarar? Random forest, bagging’i nasıl uygular?
Cevap:
Bagging, çok sayıda bağımsız (uncorrelated) ve yansız (unbiased) ama kusurlu modelin ortalamasını almaya dayanır. Yansız modellerin hataları rastgeledir (kimi yüksek, kimi düşük); ortalama alınca bu hatalar birbirini götürür ve ortalama tahmin tek tek hepsinden daha doğru olur (varyans düşer, bias eklenmez). Random forest bunu karar ağaçlarına uygular: verinin her seferinde farklı bir rastgele alt kümesiyle yüzlerce ağaç eğitir; her ağaç biraz farklı ve kusurludur ama yansızdır, ortalamaları güçlüdür. (Şekil 7.4 bu yakınsamayı, Şekil 7.5 mimariyi gösterir.)
NotSoru 2: Karar ağaçları neden lineer modele/sinir ağına göre çok az ön işleme ister?
Cevap:
Çünkü karar ağacının tek umursadığı, verinin sıralamasıdır, değerlerin büyüklüğü değil. Bir bölme “Age < 24” gibi bir eşik sorusudur; Age’i normalize etsen de etmesen de aynı sıralama, aynı bölme çıkar. Bu yüzden normalizasyon gerekmez. Kategorik değişkenler de çoğu zaman sayısal kodla (dummy variable olmadan) çalışır, çünkü ağaç değeri eşiklerle böler. Lineer model/sinir ağı ise değerleri katsayılarla çarpıp topladığı için ölçek ve kodlamaya duyarlıdır.
NotSoru 3: Feature importance nasıl hesaplanır ve neden bu kadar kullanışlıdır?
Cevap:
Her karar ağacında, her sütunun bir bölmede Gini’yi (örnek sayısıyla ağırlıklı) ne kadar iyileştirdiği toplanır; bu, tüm ağaçlar üzerinde her sütun için birleştirilir. Sonuç, her özelliğin “ne sıklıkla seçildiği ve seçildiğinde ne kadar fark yarattığı”nı gösteren bir önem sırasıdır. Kullanışlıdır çünkü random forest saniyeler içinde eğitilir ve veri dağılımına/ölçeğine duyarsızdır — yüzlerce (hatta binlerce) sütunlu bir veriyi doğrudan verip en önemli ~30 sütunu hemen bulabilirsin. Howard’ın kredi skorlama örneğinde bu, milyonlarca dolarlık iki yıllık danışmanlığa eşdeğer içgörüyü iki saatte verdi.
NotSoru 4: Random forest ile sinir ağı arasında ne zaman hangisini seçersin? (builder bağlantısı)
Cevap:
Tablo verisinde (spreadsheet, veritabanı) önce random forest (veya gradient boosting): hızlı, sağlam, yorumlanabilir, bozması zor, az ön işleme. Yapısız veride (görüntü, metin, ses) sinir ağı: çünkü öznitelikleri kendisi öğrenir ve mekânsal/dizisel yapıyı yakalar. Pratikte builder, bir tablo projesine random forest ile başlar (temel + feature importance), gerekirse gradient boosting ile performansı zorlar; görüntü/metin için doğrudan derin öğrenmeye gider. İkisi rakip değil, farklı işler için araçtır.
7.20 Egzersizler
Egzersiz 1 (Direkt uygulama). Titanic verisinde bir DecisionTreeClassifier(max_leaf_nodes=4) eğit ve draw_tree ile hangi soruları sorduğunu incele.
Egzersiz 2 (İki-aşamalı). Bir RandomForestClassifier(100, min_samples_leaf=5) kur, doğruluğunu tek ağaçla kıyasla; ağaç sayısını 10, 40, 100 yapıp hatayı izle.
Egzersiz 3 (Edge case). Ağaç sayısını 500’e çıkar; hatanın overfit etmeyip platoya oturduğunu gözlemle (sinir ağıyla zıtlık).
Egzersiz 4 (Python ile doğrulama). feature_importances_’ı çiz; en önemli iki-üç sütunu çıkarıp modeli yeniden eğit ve doğruluk kaybını ölç.
Egzersiz 5 (Sonraki dersin habercisi). Aynı veride bir gradient boosting modeli (örn. GradientBoostingClassifier veya XGBoost) dene; random forest’la doğruluk ve overfit eğilimini kıyasla.
7.21 Sonraki Ders İçin Hazırlık
Ders 7: Ortak Filtreleme (Collaborative filtering)
Ders 6 tablo verisi için ağaçları gösterdi. Ders 7 öneri sistemlerinin kalbine iner: bir kullanıcının bir ürünü/filmi ne kadar seveceğini, embedding’ler ve latent faktörlerle tahmin etme.
Ana konular:
- Collaborative filtering ve latent faktörler
- Embedding’ler (gömme tabloları)
- Bias terimleri
- Derin öğrenme ile öneri
UyarıDers 7 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 2 ve 4 — random forest + feature importance).
- Bir tablo veri setinde feature importance çiz ve sonuçları yorumla.
- Ana cümleyi tekrar oku: “Random forest = çok kusurlu ağacın ortalaması.”
7.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Karar ağacı | Ardışık ikili bölmelerle veriyi ayırma | 4:43 |
| Bölme skoru | İki tarafı en saf yapan bölme (std/Gini) | 7:05 |
| Gini | 1 − Σp²; rastgele iki örneğin farklı sınıfta olma olasılığı | 7:05 |
| Az ön işleme | Ağaç yalnızca sıralamayı umursar; normalize gerekmez | 17:53 |
| Bagging | Bağımsız yansız modellerin ortalaması (Leo Breiman) | 16:52 |
| Random forest | Rastgele alt kümelerle çok ağacın ortalaması | 19:07 |
| Feature importance | Her sütunun Gini’yi iyileştirme katkısı | 24:16 |
| Ağaç sayısı | Daha çok ağaç = daha az hata (azalan getiri); ~100 | 29:26 |
| OOB hatası | Her ağacın görmediği %25 üzerinden genelleme tahmini | 29:33 |
| Yorumlanabilirlik | Partial dependence, tahmin açıklama, redundant tespit | 32:08 |
| Gradient boosting | Ardışık ağaçlar; her biri öncekinin hatasını düzeltir | 49:08 |
| RF vs sinir ağı | Tablo → ağaç; yapısız veri → sinir ağı | 31:31 |
7.23 ML Builder Bağlantıları
İpucuBuilder Notu — 6 ML Köprüsü
Bu ders, derin öğrenmeden bir an için ayrılıp tablo verisinin en güçlü klasik ailesini — karar ağaçları ve random forest’ı — kurar. Köprülerin özeti:
- Bagging → bağımsız yansız tahminlerin ortalaması varyansı düşürür (Stat 110 büyük sayılar yasası) (Bagging).
- Random forest → tablo verisinde hızlı, sağlam, yorumlanabilir temel; production keşif aşamasının standardı (Random Forest Fikri, Model Yorumlama).
- Feature importance → yüzlerce sütunda önemli olanları saniyelerde bulma; veri keşfinin ilk adımı (Feature Importance).
- OOB hatası → random forest’a özgü “bedava” validation; az veride pratik (OOB).
- Gradient boosting → XGBoost/LightGBM; tablo yarışmalarının çoğunu kazanır (Gradient Boosting).
- Ağaç vs sinir ağı → tablo için ağaç, görüntü/metin/ses için sinir ağı; builder ikisini de kullanır (Karar Ağaçları, Kapanış).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten tek bir şey alıp gideceksen: tablo verisinde sinir ağına koşma — önce bir random forest kur. Bozması neredeyse imkânsızdır, saniyelerde eğitilir, feature importance ile sana veriyi anlatır ve sağlam bir temel verir. “Çok sayıda kusurlu ağacın ortalaması” basit ama şaşırtıcı derecede güçlü bir fikirdir.