flowchart TD
GA["gradient accumulation<br/>+ ensembling<br/>(yarışma araçları)"] --> SM["softmax<br/>(logit → olasılık)"]
SM --> CE["cross-entropy<br/>(çok-sınıflı kayıp)"]
CE --> CF["collaborative filtering<br/>(matris tamamlama)"]
CF --> LF["latent faktör<br/>+ dot product"]
LF --> EMB["embedding = arama<br/>(diziden satır oku)"]
style GA fill:#cffafe,stroke:#0891b2,stroke-width:2px
style SM fill:#cffafe,stroke:#0891b2,stroke-width:2px
style CE fill:#cffafe,stroke:#0891b2,stroke-width:2px
style CF fill:#cffafe,stroke:#0891b2,stroke-width:2px
style LF fill:#cffafe,stroke:#0891b2,stroke-width:2px
style EMB fill:#ffe4e6,stroke:#e11d48,stroke-width:3px
8 Ortak Filtreleme — Embedding, Latent Faktör ve Dot Product (Collaborative filtering)
Serinin sondan bir önceki dersi iki büyük yarıyı birleştirir: önce yarışma araçları — gradient accumulation (küçük GPU’da büyük model), ensembling, multi-target ve çok-sınıflı kaybın altındaki softmax + cross-entropy — sonra dersin asıl başlığı collaborative filtering: kullanıcı × ürün matrisindeki boşlukları, her ikisi için öğrenilen latent faktör vektörlerinin dot product’ıyla doldurma; ve perdenin arkası — ‘embedding’ gizemli bir kavram değil, yalnızca bir diziden satır aramaktır (one-hot çarpımının hızlı kısayolu)
NotBölüm bilgisi
- Howard’ın videosu: course.fast.ai — Lesson 7: Collaborative filtering (~106 dk)
- Seri: Practical Deep Learning for Coders — Part 1, Ders 7
- Hoca: Jeremy Howard
- Playlist: Practical Deep Learning Part 1 (2022)
- Notebook: fastbook — 08_collab
- Okuma süresi: ~38 dk
8.1 Bu Derste Ne Var?
Serinin sondan bir önceki dersi iki büyük konuyu kapsar. İlk yarı, yarışma performansını zorlamanın araçlarını verir: büyük modelleri sığdırmak için gradient accumulation, doğruluğu artırmak için ensembling, ve multi-target modeller ile cross-entropy/softmax derinlemesine. İkinci yarı dersin başlığıdır: collaborative filtering (öneri sistemleri) — latent faktörler ve embedding’lerle.
Üç temel fikir:
- Gradient accumulation + ensembling — küçük GPU’da büyük model eğitmenin ve birden çok modeli birleştirip doğruluğu artırmanın pratik yolları (Gradient Accumulation → Ensembling).
- Cross-entropy = softmax + log likelihood — çok-sınıflı sınıflandırmanın standart kaybı; her modelin altında bu yatar (Softmax → Cross-Entropy).
- Collaborative filtering = matris tamamlama — kullanıcı ve ürün için latent faktörler öğren, dot product’larını al; embedding ise “bir diziden arama yapmak”tan başka bir şey değildir (Collaborative Filtering → Latent Faktörler → Dot Product → Embedding = Arama).
“An embedding actually means: look something up in an array.” — Howard, 1:19:29
Şekil 28.1 bu üç fikri tek bir haritada birleştirir: yarışma araçlarından (gradient accumulation / ensembling) çok-sınıflı kaybın çekirdeğine (softmax → cross-entropy), oradan dersin kalbine — collaborative filtering’e (latent faktör + dot product) ve hepsinin altındaki “embedding = arama” fikrine (rose vurgulu) ilerler.
İpucuBuilder Notu — İki Yarı, Tek Zincir: Yarışma Araçları ve Öneri Çekirdeği
- Geriye (Ders 4-6): Cross-entropy Ders 4’ün loss’unu, embedding Ders 6’nın dummy variable’ını genelleştirir; dot product ise 18.06’nın kalbidir.
- İleriye (Part 2 / Karpathy): Embedding ve cross-entropy, Karpathy makemore ve GPT’nin temel taşları; collaborative filtering modern öneri sistemlerinin çekirdeği.
- Tek cümle: Embedding bir arama tablosudur; collaborative filtering bu tablolardaki latent faktörlerin dot product’ıyla boş hücreleri tahmin eder.
8.2 Daha Büyük Modeller ve GPU Belleği
Howard daha büyük (daha doğru) modeller kullanmak ister ama bunlar GPU belleğini (VRAM) aşar — “out of memory” hatası. Sorun: bellek, batch’teki görüntü sayısıyla ve model boyutuyla artar.
“Out of memory error. What do we do? We can use a cool little trick called gradient accumulation.” — Howard, 5:58
Çözüm hemen Gradient Accumulation bölümünde geliyor: batch’i belleğe sığacak küçük parçalara böl, gradyanları biriktir.
İpucuBuilder Notu — ‘GPU Swap Yapamaz’ Notunun Çözümü
- Geriye (Ders 2): Ders 2’deki “GPU swap yapamaz” notunun çözümü tam burada geliyor — CPU RAM’ine taşamayan VRAM, batch’i bölmekle idare edilir.
- İleriye (Gradient Accumulation): “Out of memory” hatası modelin yanlış olduğunu değil, batch’in büyük olduğunu söyler; çözüm modeli küçültmek değil, batch’i bölmektir.
8.3 Gradient Accumulation
Gradient accumulation: büyük bir batch yerine birkaç küçük batch’in gradyanlarını biriktir, sonra tek adım at. Matematiksel olarak büyük batch’le neredeyse aynıdır ama belleğe sığar.
# Kavram: kucuk batch'lerin gradyanlarini biriktir, n_acc batch'te bir adim at
for i, (xb, yb) in enumerate(dl):
loss = loss_func(model(xb), yb)
loss.backward() # gradyanlar birikir (henuz sifirlama)
if (i+1) % n_acc == 0:
opt.step(); opt.zero_grad() # adim at, sonra sifirla
# fastai'de: cbs=GradientAccumulation(n_acc) callback'i bunu otomatik yapar“Gradient accumulation in fastai is very straightforward, you just [add a parameter] and it updates the weights once it’s got 64 images.” — Howard, 18:10
Şekil 8.2 bu mekanizmayı şematik olarak gösterir: ilk birkaç küçük batch yalnızca gradyanı biriktirir (loss.backward(), sıfırlama yok), son batch’te tek adım atılır ve gradyan sıfırlanır — biriken gradyan büyük bir batch’in gradyanına yaklaşır.
Kod
# SEMATIK: gradient accumulation akisi — biriktir x3 -> ADIM AT.
# Sahte olcum yok; yalnizca yapi/akis/etiketler (Howard'in dongusu ruhunda).
fig = plt.figure(figsize=(11.0, 4.4))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 12)
ax.set_ylim(0, 5)
ax.axis("off")
ax.text(6.0, 4.62,
"Gradient accumulation (şematik): biriktir → biriktir → biriktir → ADIM AT",
ha="center", va="center", fontsize=12.5, color=COL_CYAN_700, weight="bold")
yc = 2.75
xs = [1.45, 4.0, 6.55, 9.55]
# 3 kucuk batch (cyan): gradyani biriktir, henuz sifirlama
for i, x in enumerate(xs[:3]):
boxed_node(ax, x, yc, 2.05, 1.55,
f"batch {i+1}\n→ grad biriktir",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=10.5, lw=2.2)
ax.text(x, yc - 1.18, "loss.backward()", ha="center", va="center",
fontsize=7.8, color=COL_CYAN_700, style="italic")
# 4. kutu (rose vurgulu): ADIM AT + sifirla
boxed_node(ax, xs[3], yc, 2.35, 1.7,
"batch 4\nADIM AT\n+ sıfırla",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10.5, lw=2.8)
ax.text(xs[3], yc - 1.28, "opt.step(); opt.zero_grad()", ha="center", va="center",
fontsize=7.8, color=COL_ACCENT, weight="bold", style="italic")
# Oklar: batch1 -> batch2 -> batch3 -> batch4
arrow_between(ax, (xs[0] + 1.03, yc), (xs[1] - 1.03, yc), color=COL_PRIMARY, lw=2.4)
arrow_between(ax, (xs[1] + 1.03, yc), (xs[2] - 1.03, yc), color=COL_PRIMARY, lw=2.4)
arrow_between(ax, (xs[2] + 1.03, yc), (xs[3] - 1.20, yc), color=COL_ACCENT, lw=2.6)
# Biriken gradyan ~ buyuk batch (ust kopru etiketi 3 cyan kutu ustunde)
bx0, bx1 = xs[0] - 0.6, xs[2] + 0.6
by = yc + 1.18
ax.plot([bx0, bx0, bx1, bx1], [by - 0.16, by, by, by - 0.16],
color=COL_CYAN_800, linewidth=1.6, zorder=1)
ax.text((bx0 + bx1) / 2, by + 0.22,
"biriken gradyan ≈ büyük batch",
ha="center", va="center", fontsize=10.0, color=COL_CYAN_800, weight="bold")
# Alt vurgu satiri
ax.text(6.0, 0.74,
"küçük GPU'da büyük efektif batch | grad.zero_() geciktir",
ha="center", va="center", fontsize=10.5, color=COL_TEXT, weight="bold")
ax.text(6.0, 0.30, "Howard 8:04 / 18:10", ha="center", va="center",
fontsize=8.0, color=COL_SLATE_400, style="italic")
plt.show()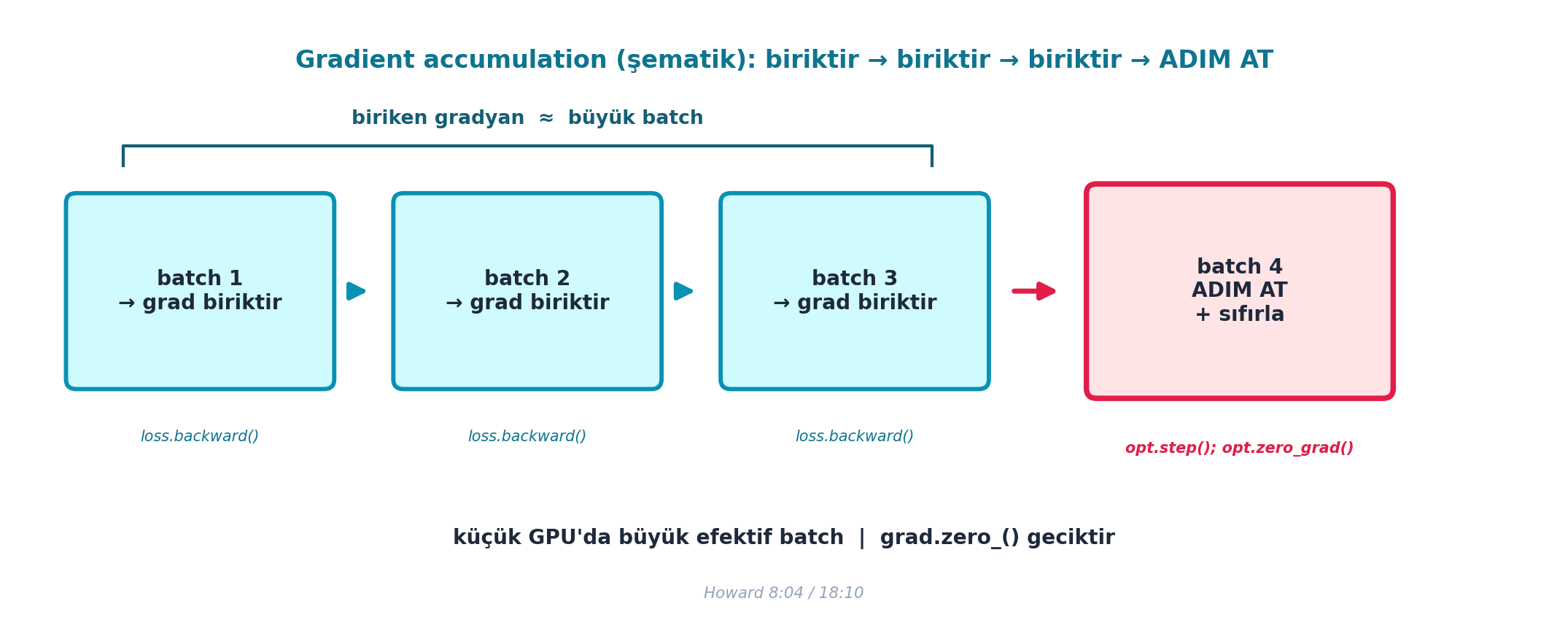
İpucuBuilder Notu — grad.zero_()’ı Geciktirmek = Biriktirmek
- Geriye (Ders 5): Ders 5’teki
grad.zero_()’ı geciktirmek = gradyan biriktirmek; Şekil 8.2’in “henüz sıfırlama yok” adımı, aynı mekanizmanın bilinçli kullanımıdır. - İleriye (Karpathy Ders 10): Gradient accumulation, GPT-2 eğitiminde büyük efektif batch için standart tekniktir — sınırlı VRAM’de devasa modelleri eğitmenin yolu.
8.4 Ensembling
Doğruluğu artırmanın bir başka yolu: birden çok modeli eğitip tahminlerini birleştirmek (ensembling). Howard farklı mimarileri (convnext, vit) ve farklı validation set’leri (k-folds) birleştirir; her ekleme skoru biraz daha iyileştirir.
“These are my four submissions, and you can see each one got better.” — Howard, 23:01
İpucuBuilder Notu — Bagging’in Mimariye Uygulanmış Hâli
- Geriye (Ders 6): Ensembling, random forest’ın bagging fikrinin (bağımsız modellerin ortalaması) farklı mimarilere uygulanmış hâli — orada rastgele alt kümeler, burada farklı mimari/validation.
- İleriye (production): Yarışma kazanan çözümlerin neredeyse hepsi ensemble’dır; production’da maliyet/doğruluk dengesi gerektirir — her ek model çıkarım maliyetini de artırır.
8.5 Multi-Target Modeller
Howard tek değil iki şey tahmin eden bir model kurar (paddy yarışmasında: hem hastalık hem pirinç çeşidi). Model son katmanında iki çıktı grubu üretir ve kayıp ikisinin toplamıdır. Tek bir modelin birden çok hedefi öğrenmesi çoğu zaman her birini ayrı öğrenmekten iyidir.
“So now we need a model that predicts two things.” — Howard, 37:51
Bu “iki çıktı grubu” fikri doğrudan Softmax bölümüne bağlanır: her grup kendi içinde softmax + cross-entropy ile puanlanır, kayıplar toplanır.
İpucuBuilder Notu — Paylaşılan Temsil, İki Hedef
- İleriye: Multi-task learning, paylaşılan temsillerden yararlanır; bir görevdeki bilgi diğerine yardım eder (transfer’in içsel hâli) — model gövdesi ortak, yalnızca son katman ikiye ayrılır.
- İleriye (Cross-Entropy): İki hedefin her biri kendi cross-entropy’sini üretir; toplam kayıp ikisinin toplamıdır — aynı kayıp tek modelde iki kez kullanılır.
8.6 Softmax
Çok-sınıflı sınıflandırmada modelin ham çıktıları (logit’ler) bir olasılık dağılımına çevrilmelidir. Softmax bunu yapar: her çıktının üstelini alıp toplama böler — sonuçlar pozitif ve toplamı 1 olur, en büyük logit baskınlaşır.
\[ \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}} \]
“We’re trying to predict which one is it, and so this is called softmax.” — Howard, 45:45
Şekil 8.3 bu dönüşümü gerçek hesaplamayla gösterir: solda ham logit’ler (negatif olabilir), sağda softmax’tan geçince toplamı 1 olan olasılıklar — en büyük logit (rose) baskın olasılığı alır.
Kod
# GERCEK hesaplama: softmax(z) = e^z / Σ e^z (bkz. softmax_demo).
sm = softmax_demo()
classes = sm["classes"]
logits = sm["logits"]
probs = sm["probs"]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(9.2, 4.0))
# SOL: ham logit'ler (negatif olabilir)
axL.bar(classes, logits, color=COL_SLATE_400, edgecolor=COL_TEXT, linewidth=0.8,
width=0.62, zorder=3)
axL.axhline(0, color=COL_TEXT, linewidth=0.9, zorder=2)
axL.set_title("Ham logit'ler (zᵢ)", fontsize=11, color=COL_TEXT, weight="bold")
axL.set_ylabel("logit değeri", fontsize=10)
for i, v in enumerate(logits):
off = 0.12 if v >= 0 else -0.12
va = "bottom" if v >= 0 else "top"
axL.text(i, v + off, f"{v:.1f}", ha="center", va=va, fontsize=9,
color=COL_TEXT, weight="bold")
axL.set_ylim(logits.min() - 0.9, logits.max() + 0.9)
apply_style(axL)
# SAG: softmax olasiliklari (en buyuk accent)
top = int(np.argmax(probs))
bar_colors = [COL_ACCENT if i == top else COL_PRIMARY for i in range(len(probs))]
axR.bar(classes, probs, color=bar_colors, edgecolor=COL_TEXT, linewidth=0.8,
width=0.62, zorder=3)
axR.set_title("Softmax olasılıkları (pᵢ)", fontsize=11, color=COL_TEXT, weight="bold")
axR.set_ylabel("olasılık", fontsize=10)
for i, v in enumerate(probs):
axR.text(i, v + 0.015, f"{v:.2f}", ha="center", va="bottom", fontsize=9,
color=COL_TEXT, weight="bold")
axR.set_ylim(0, max(probs) + 0.16)
apply_style(axR)
axR.text(0.97, 0.95, f"Σ pᵢ = {probs.sum():.2f}", transform=axR.transAxes,
ha="right", va="top", fontsize=9.5, color=COL_CYAN_700, weight="bold",
bbox=dict(boxstyle="round,pad=0.3", fc="white", ec=COL_PRIMARY, lw=1.2))
# Ortada ok + formul
fig.text(0.505, 0.52, "→ softmax →", ha="center", va="center", fontsize=12,
color=COL_ACCENT, weight="bold")
fig.text(0.505, 0.40, r"$\dfrac{e^{z_i}}{\sum_j e^{z_j}}$", ha="center",
va="center", fontsize=15, color=COL_TEXT)
fig.suptitle("Softmax: logit'leri toplamı 1 olasılığa çevirir",
fontsize=13, color=COL_TEXT, weight="bold", y=1.0)
fig.text(0.5, -0.04,
r"$e^{z_i}/\sum_j e^{z_j}$; en büyük logit baskınlaşır",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, style="italic")
fig.subplots_adjust(wspace=0.45)
fig.tight_layout(rect=[0, 0, 1, 0.97])
plt.show()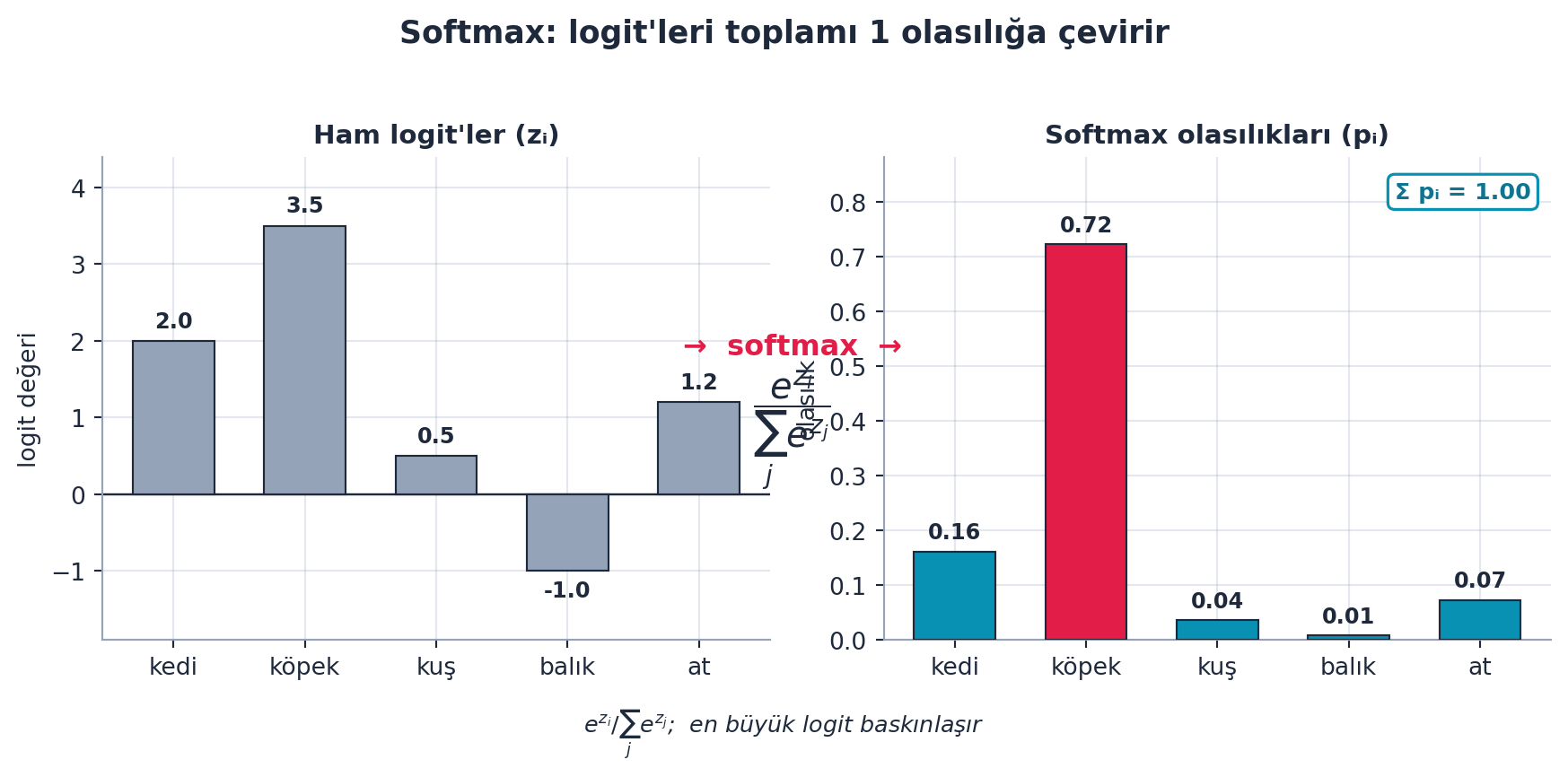
İpucuBuilder Notu — Sigmoid’in Çok-Sınıflı Genellemesi
- Geriye (Ders 5 / Calculus): Softmax, Ders 5’teki sigmoid’in çok-sınıflı genellemesidir; \(e^x\) tabanlı (Calculus), “tek doğru sınıf” varsayımı için — Şekil 8.3’in toplamı-1 kısıtı tam bu “tek doğru” varsayımının matematik karşılığıdır.
- Pratik: Birden çok şey aynı anda doğru olabiliyorsa softmax DEĞİL, her çıktıya ayrı sigmoid kullanılır; softmax sınıfları birbiriyle yarıştırır (biri kazanırsa diğerleri kaybeder).
8.7 Cross-Entropy Loss
Cross-entropy, softmax + negatif log likelihood’dur. Modelin doğru sınıfa verdiği olasılığın logaritmasını cezalandırır: doğru sınıfa yüksek olasılık → düşük kayıp; düşük olasılık → yüksek kayıp.
\[ \text{cross-entropy} = -\sum_i y_i \cdot \log(p_i) \]
PyTorch F.cross_entropy softmax’ı (aslında log-softmax’ı) ve negatif log likelihood’u tek adımda, sayısal olarak kararlı biçimde hesaplar.
“The first part of what cross-entropy loss in PyTorch does is to calculate the softmax. It’s actually the log of the softmax.” — Howard, 46:24
Şekil 8.4 bu kaybı gerçek hesaplamayla gösterir: doğru sınıfa verilen olasılık \(p\) 1’e yaklaşınca kayıp ~0; \(p\) 0’a yaklaşınca kayıp asimptotik olarak sonsuza gider — “yanlış ve emin” en sert cezayı alır.
Kod
# GERÇEK hesaplama: loss = -log p (doğru sınıfa verilen olasılık p)
p, loss = cross_entropy_curve()
fig, ax = plt.subplots(figsize=(7.4, 4.6))
# Ana eğri: cross-entropy kaybı
ax.plot(p, loss, color=COL_PRIMARY, lw=2.6, zorder=3,
label=r"$-\log p$")
# Doğru sınıfa yüksek olasılık (p→1) → loss→0 : cyan nokta + anotasyon
p_hi = p[-1]
loss_hi = loss[-1]
ax.scatter([p_hi], [loss_hi], s=70, color=COL_CYAN_700, zorder=5,
edgecolor="white", linewidth=1.2)
ax.annotate("p→1 → kayıp ~0\n(doğru + emin)",
xy=(p_hi, loss_hi), xytext=(0.55, 0.55),
fontsize=10, color=COL_CYAN_700, weight="bold",
ha="left", va="center",
arrowprops=dict(arrowstyle="->", color=COL_CYAN_700, lw=1.6))
# Düşük olasılık (p→0) → loss→∞ : rose anotasyon
p_lo = p[0]
loss_lo = loss[0]
ax.scatter([p_lo], [loss_lo], s=70, color=COL_ROSE_500, zorder=5,
edgecolor="white", linewidth=1.2)
ax.annotate("p→0 → kayıp → ∞\nyanlış + emin = büyük ceza",
xy=(p_lo, loss_lo), xytext=(0.18, 3.05),
fontsize=10, color=COL_ACCENT, weight="bold",
ha="left", va="center",
arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.6))
apply_style(ax)
ax.set_xlim(0, 1.02)
ax.set_ylim(0, max(loss) * 1.05)
ax.set_xlabel("doğru sınıfa verilen olasılık p", fontsize=11)
ax.set_ylabel("cross-entropy kaybı (-log p)", fontsize=11)
ax.set_title("Cross-entropy: doğru sınıfa düşük olasılık = büyük ceza",
fontsize=12.5, color=COL_TEXT, weight="bold", pad=10)
# Alt not: softmax + negatif log likelihood
ax.text(0.99, 0.93, "softmax + negatif log likelihood",
transform=ax.transAxes, ha="right", va="top",
fontsize=9.5, color=COL_CYAN_700, style="italic")
fig.tight_layout()
plt.show()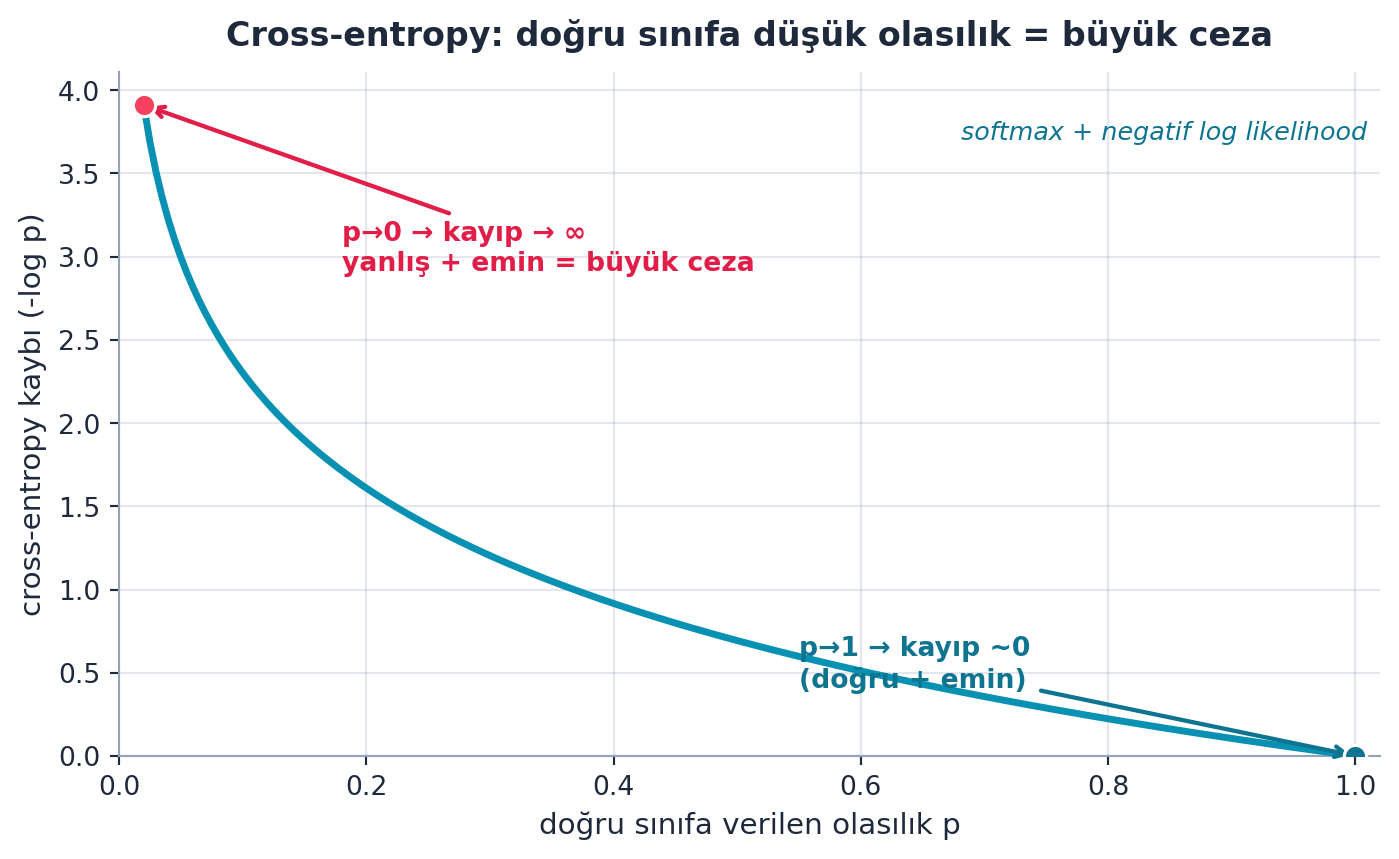
İpucuBuilder Notu — Maximum Likelihood’dan Türeyen Kayıp
- Geriye (Stat 110 / 6.S191): Cross-entropy, iki dağılım arasındaki farkın ölçüsü; maximum likelihood’dan türer. 6.S191 Ders 1’in ana kaybı — Şekil 8.4’nin \(-\log p\) eğrisi, “doğru sınıfa atanan olasılığı en büyük yap” hedefinin matematik karşılığıdır.
- İleriye (Karpathy): Dil modellerinin (makemore, GPT) kaybı tam budur — sonraki token’ın cross-entropy’si; softmax + bu eğri, her dil modelinin çıkış katmanında çalışır.
8.8 Collaborative Filtering: Öneri Problemi
İkinci yarı dersin başlığıdır. Collaborative filtering: bir kullanıcının daha önce puanlamadığı bir filmi/ürünü ne kadar seveceğini, benzer kullanıcıların davranışından tahmin etme. Veri, kullanıcı × ürün matrisidir; çoğu hücre boştur. Amaç bu boşlukları doldurmaktır.
“The core of collaborative filtering is a matrix completion exercise.” — Howard, 1:14:00
Şekil 8.5 bu problemi şematik bir kullanıcı × film matrisiyle gösterir: birkaç hücrede puan (1-5) var, çoğu hücre boş (“?”); collaborative filtering’in işi bu boşlukları, benzer kullanıcıların davranışından tahmin ederek doldurmaktır.
Kod
# SEMATIK: 5 kullanici x 6 film puan matrisi. Cogu hucre BOS (?); birkac
# hucrede 1-5 puan (elle secilmis kavramsal ornek, sahte istatistik degil).
# np.nan = bilinmeyen (doldurulacak bosluk).
users = ["Ali", "Ayşe", "Mehmet", "Zeynep", "Can"]
movies = ["Matrix", "Titanic", "Toy Story", "Inception", "Notebook", "Shrek"]
NA = np.nan
ratings = np.array([
[5, NA, 4, NA, NA, 3 ], # Ali
[NA, 5, NA, NA, 4, NA], # Ayşe
[4, NA, NA, 5, NA, NA], # Mehmet
[NA, 4, NA, NA, 5, 2 ], # Zeynep
[NA, NA, 3, 4, NA, NA], # Can
], dtype=float)
n_users, n_movies = ratings.shape
# Puan -> renk: dusuk puan (1) cyan, yuksek puan (5) rose.
rate_cmap = LinearSegmentedColormap.from_list("cyan_rose", [COL_PRIMARY, COL_ACCENT])
fig, ax = plt.subplots(figsize=(7.0, 4.8))
# Bos hucreler acik gri, dolu hucreler acik cyan (arka plan tonu)
bg = np.where(np.isnan(ratings), 0.0, 1.0)
ax.imshow(bg, cmap=LinearSegmentedColormap.from_list(
"bg", [COL_SLATE_300, COL_CYAN_50]), vmin=0, vmax=1, aspect="auto")
for i in range(n_users):
for j in range(n_movies):
v = ratings[i, j]
if np.isnan(v):
ax.text(j, i, "?", ha="center", va="center",
fontsize=18, weight="bold", color=COL_SLATE_400)
else:
frac = (v - 1) / 4.0 # 1->0 (cyan), 5->1 (rose)
ax.scatter(j, i, s=900, color=rate_cmap(frac), zorder=2,
edgecolors=COL_WHITE, linewidths=1.5)
ax.text(j, i, str(int(v)), ha="center", va="center",
fontsize=14, weight="bold", color=COL_WHITE, zorder=3)
ax.set_xticks(range(n_movies))
ax.set_yticks(range(n_users))
ax.set_xticklabels(movies, color=COL_TEXT, fontsize=10.5, rotation=20, ha="right")
ax.set_yticklabels(users, color=COL_TEXT, fontsize=11)
ax.set_xlabel("film", color=COL_TEXT, fontsize=12, weight="bold")
ax.set_ylabel("kullanıcı", color=COL_TEXT, fontsize=12, weight="bold")
ax.set_title("Collaborative filtering = matris tamamlama",
color=COL_TEXT, fontsize=13.5, weight="bold", pad=14)
ax.set_xticks(np.arange(-0.5, n_movies, 1), minor=True)
ax.set_yticks(np.arange(-0.5, n_users, 1), minor=True)
ax.grid(which="minor", color=COL_WHITE, linewidth=2.5)
ax.tick_params(which="minor", length=0)
ax.tick_params(which="major", length=0)
for spine in ax.spines.values():
spine.set_visible(False)
ax.annotate(
"“?” hücreleri latent faktörlerle doldurulur\n(benzer kullanıcıların davranışından)",
xy=(0.5, -0.30), xycoords="axes fraction",
ha="center", va="top", fontsize=10, color=COL_PRIMARY, weight="bold",
)
fig.tight_layout()
plt.show()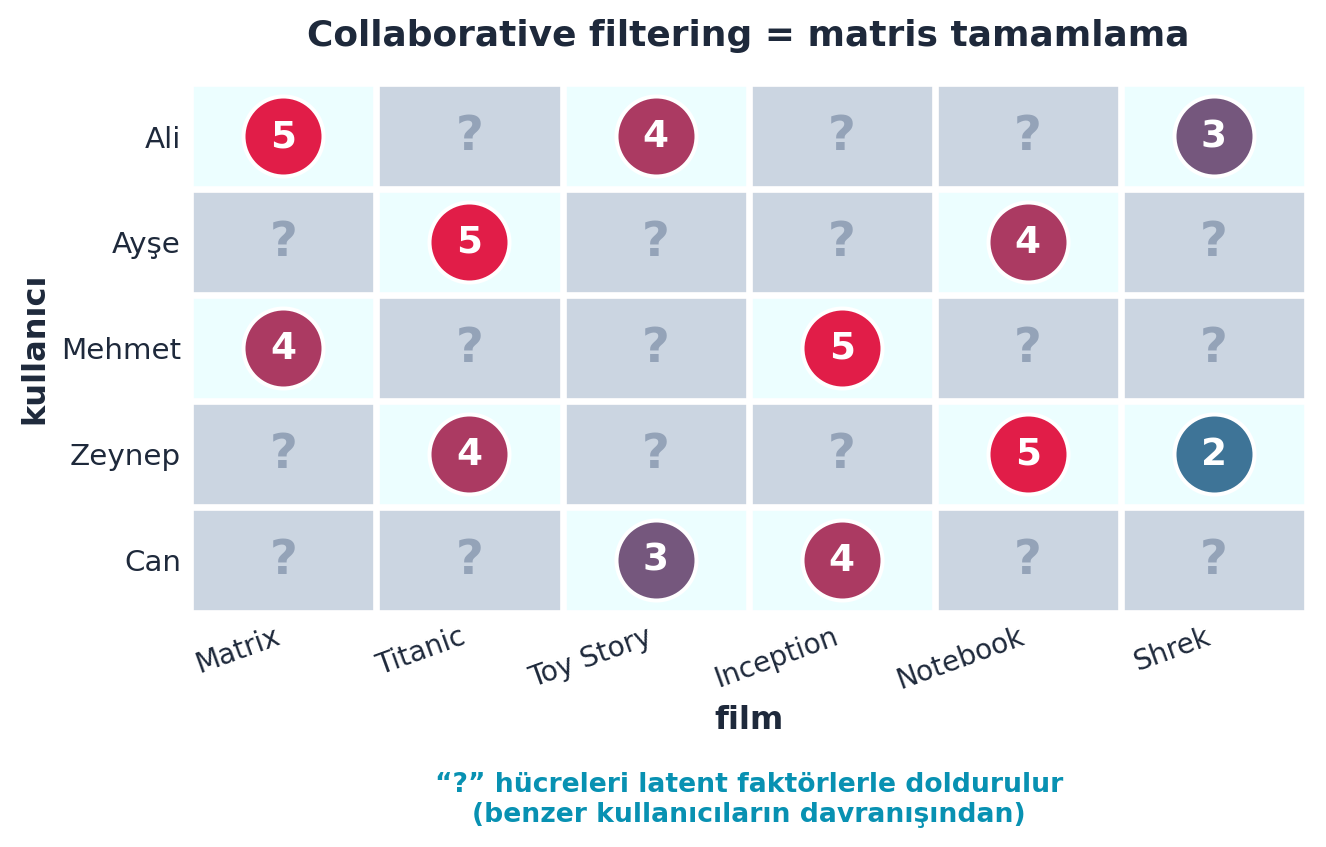
İpucuBuilder Notu — Netflix/Spotify’ın Ölçeklenmiş Hâli
- İleriye (production): Netflix, Spotify, Amazon önerileri bu fikrin ölçeklenmiş hâli; “bunu sevenler şunu da sevdi.” Şekil 8.5’in 5×6 oyuncak matrisi, gerçekte milyonlarca kullanıcı × milyon ürün boyutunda çalışır.
- İleriye (Latent Faktörler): Boşlukları doldurmanın yolu, sıradaki bölümde gelen latent faktörlerdir — her kullanıcı ve ürün için öğrenilen gizli sayılar.
8.9 Latent Faktörler
Boş hücreleri nasıl doldururuz? Latent faktörler ile: her kullanıcı için (örn. 5) gizli sayı, her film için (örn. 5) gizli sayı icat ederiz. Bu faktörlerin ne anlama geldiğini önceden bilmeyiz — model onları öğrenir. Belki biri “aksiyon sevme derecesi”, biri “eskilik” olur; ama biz tanımlamayız.
“We can create things called latent factors. There are five latent factors — I don’t know what they’re for — they’re just five latent factors.” — Howard, 1:21:00
Bu faktörler nasıl puana dönüşür? Sıradaki Dot Product bölümünün konusu: kullanıcı ve film faktör vektörlerinin eleman-eleman çarpımının toplamı.
İpucuBuilder Notu — Matris Faktörizasyonu / SVD Ruhu
- Geriye (18.06): Latent faktörler, kullanıcı-film matrisinin düşük-ranklı çarpanlara ayrılmasıdır (matris faktörizasyonu / SVD ruhu); collaborative filtering matrisinin boşlukları, bu iki küçük faktör matrisinin çarpımıyla doldurulur.
- İleriye (Latent Uzay): Anlamı önceden bilinmeyen bu faktörler, eğitimden sonra yorumlanabilir bir latent uzay oluşturur — benzer filmler yakın düşer.
8.10 Dot Product
Bir kullanıcının bir filmi ne kadar seveceği = kullanıcının latent faktörleri ile filmin latent faktörlerinin dot product’ı (eleman eleman çarp, topla). Kullanıcının “aksiyon sevgisi” yüksek + filmin “aksiyonluğu” yüksek → yüksek skor.
n_factors = 5
user_factors = torch.randn(n_users, n_factors) # her kullanici icin 5 gizli sayi
movie_factors = torch.randn(n_movies, n_factors) # her film icin 5 gizli sayi
# tahmin = ilgili kullanici ve film faktorlerinin dot product'i“This is the dot product of the user’s preferences and the movie’s… the matrix product of a row with a column is the same thing as a dot product.” — Howard, 1:08:00
Şekil 8.6 bu işlemi gerçek hesaplamayla gösterir: kullanıcı faktör vektörü (zevk) ile film faktör vektörü (nitelik) eleman-eleman çarpılır; çarpımların toplamı (Σ, rose) tahmin edilen puandır — uyumlu faktörler (aynı işaret) pozitif katkı verir.
Kod
# GERCEK hesaplama: score = Σ (user * movie) (bkz. dot_product_demo).
dp = dot_product_demo()
factors = dp["factors"] # 5 latent faktör adı
user = dp["user"] # (5,) kullanıcının zevki
movie = dp["movie"] # (5,) filmin nitelikleri
products = dp["products"] # (5,) eleman-eleman çarpım
score = dp["score"] # skalar: tahmin edilen puan
n = len(factors)
vmax = float(max(np.abs(user).max(), np.abs(movie).max(),
np.abs(products).max()))
def _bar_color(v):
return COL_PRIMARY if v >= 0 else COL_ACCENT
fig = plt.figure(figsize=(10.6, 6.2))
gs = fig.add_gridspec(3, 1, hspace=0.55)
ax_u = fig.add_subplot(gs[0, 0])
ax_m = fig.add_subplot(gs[1, 0])
ax_p = fig.add_subplot(gs[2, 0])
x = np.arange(n)
bar_w = 0.62
def _draw_vec(ax, vals, title, title_col):
colors = [_bar_color(v) for v in vals]
ax.bar(x, vals, width=bar_w, color=colors, zorder=3)
ax.axhline(0.0, color=COL_SLATE_400, linewidth=1.0, zorder=2)
ax.set_xticks(x)
ax.set_xticklabels(factors, color=COL_TEXT, fontsize=10)
ax.set_title(title, color=title_col, fontsize=11.5, weight="bold",
loc="left", pad=6)
ax.set_ylim(-vmax - 0.28, vmax + 0.28)
for i, v in enumerate(vals):
off = 0.07 if v >= 0 else -0.07
va = "bottom" if v >= 0 else "top"
ax.text(i, v + off, f"{v:+.2f}", ha="center", va=va,
fontsize=9, color=COL_TEXT, weight="bold")
apply_style(ax)
ax.grid(True, axis="y", alpha=0.2, color=COL_SLATE_400)
ax.grid(False, axis="x")
_draw_vec(ax_u, user, "kullanıcı latent faktörleri (zevk)", COL_CYAN_800)
_draw_vec(ax_m, movie, "film latent faktörleri (nitelik)", COL_CYAN_700)
_draw_vec(ax_p, products, "eleman-eleman çarpım (kullanıcı × film)", COL_ACCENT)
# '×' ve '↓ topla' isaretleri (figur koordinatinda, sol)
fig.text(0.045, 0.515, "×", ha="center", va="center",
fontsize=26, color=COL_ACCENT, weight="bold")
fig.text(0.045, 0.255, "↓", ha="center", va="center",
fontsize=22, color=COL_CYAN_700, weight="bold")
# SAG — buyuk skor kutusu (rose): Σ products = score
score_str = f"{score:+.3f}"
fig.text(0.875, 0.30, "Σ =", ha="center", va="center",
fontsize=15, color=COL_CYAN_800, weight="bold")
fig.text(0.875, 0.18, score_str, ha="center", va="center",
fontsize=30, color=COL_ACCENT, weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc="#ffe4e6",
ec=COL_ACCENT, lw=2.2))
fig.text(0.875, 0.075, "tahmin edilen puan", ha="center", va="center",
fontsize=9.5, color=COL_TEXT, style="italic")
fig.suptitle("Dot product: latent faktörlerin uyumu = puan",
color=COL_CYAN_800, fontsize=14, weight="bold", y=0.99)
fig.text(0.5, 0.005,
"aksiyon-sevgisi yüksek + aksiyon-filmi → yüksek skor; "
"uyumlu faktörler (aynı işaret) çarpımı pozitif katkı verir",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, style="italic")
plt.show()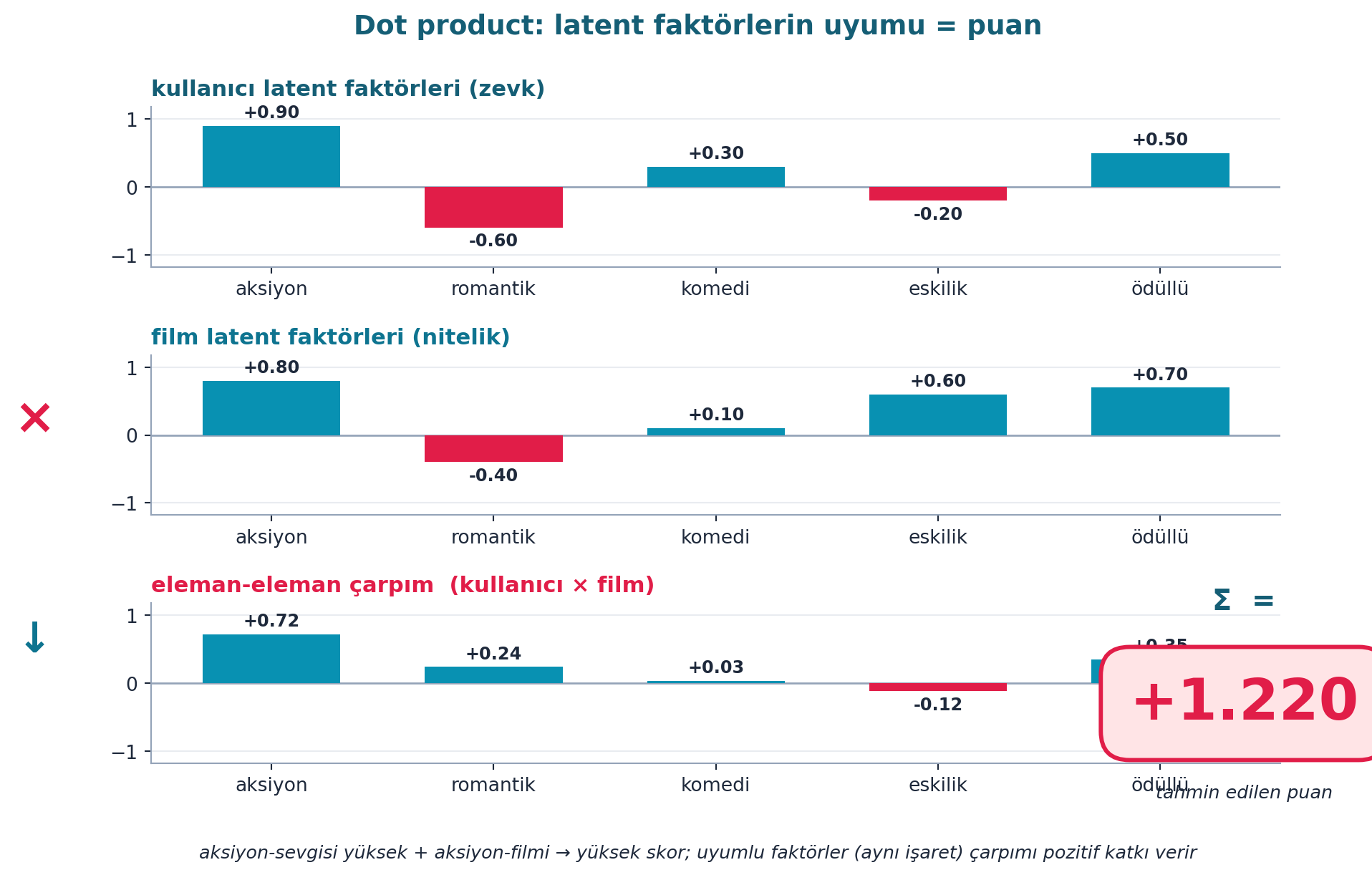
İpucuBuilder Notu — Dot Product = SUMPRODUCT, 18.06’nın Kalbi
- Geriye (18.06 / Ders 5): Dot product = SUMPRODUCT (Excel); 18.06’nın temel işlemi, Ders 5’teki lineer modelin çekirdeği — Şekil 8.6’in eleman-eleman çarp-topla akışı, “bir satır × bir sütun = skaler” matris çarpımının ta kendisidir.
- İleriye (Sıfırdan Dot Product Modeli): Bu skaler, sıfırdan kurulacak modelin
forward’ında satır başına bir kez hesaplanır; tüm model bu tek işlemin etrafında döner.
8.11 Embedding = Arama Tablosu
“Embedding” kulağa gizemli gelir ama Howard perdesini kaldırır: embedding, bir diziden (matristen) satır aramaktan ibarettir. Kullanıcı 14’ün faktörlerini istiyorsak, faktör matrisinin 14. satırını alırız. Bu, bir one-hot vektörle matris çarpımıyla matematiksel olarak aynıdır — embedding sadece bunun hızlı kısayoludur (dummy variable hiç oluşturulmaz).
“An embedding actually means: look something up in an array. You can think of an embedding as a computational shortcut for multiplying something by a one-hot-encoded vector — we never even have to create the dummy variables.” — Howard, 1:19:29
Şekil 8.7 bu eşitliği şematik olarak gösterir: bir one-hot vektörle faktör matrisini çarpmak = o satırı seçmek; embedding bu çarpımı atlayıp doğrudan ilgili satırı okur (alt rose ok = kısayol).
Kod
# Embedding = bir diziden satır arama = one-hot çarpımının kısayolu (ŞEMATİK).
# Tek eksen + elle koordinat. Latent faktörler illüstratif (öğrenilir).
n_users = 5
n_fac = 4
sel = 2 # kullanıcı 3 -> satır indeksi 2 (0-tabanlı)
onehot = np.array([0, 0, 1, 0, 0])
factors = np.array([
[0.7, -0.3, 0.2, 0.5],
[-0.4, 0.6, 0.1, -0.2],
[0.9, -0.6, 0.3, 0.5], # <- kullanıcı 3 satırı (vurgulanan embedding)
[0.1, 0.4, -0.5, 0.2],
[-0.2, -0.1, 0.8, -0.6],
])
fac_labels = ["f₁", "f₂", "f₃", "f₄"]
user_labels = [f"k{u+1}" for u in range(n_users)]
CELL = 1.0
y_of = lambda i: (n_users - 1 - i) * CELL
cy = lambda i: y_of(i) + CELL / 2
OH_X = 0.0
MAT_X0 = 3.2
EMB_X0 = 11.0
fig, ax = plt.subplots(figsize=(12.0, 5.8))
ax.set_xlim(-1.6, EMB_X0 + n_fac - 0.2)
ax.set_ylim(-1.7, n_users + 1.7)
ax.axis("off")
ax.set_aspect("equal")
def cell(x, y, w, h, fc, ec, lw, text, tc, fs=9.5, weight="bold", z=2):
ax.add_patch(Rectangle((x - w / 2, y - h / 2), w, h, facecolor=fc,
edgecolor=ec, linewidth=lw, zorder=z))
ax.text(x, y, text, ha="center", va="center", fontsize=fs,
color=tc, weight=weight, zorder=z + 1)
# SOL — one-hot vektör (5×1): seçili hücre cyan dolu
for i in range(n_users):
on = onehot[i] == 1
cell(OH_X, cy(i), 0.9, 0.9,
fc=COL_PRIMARY if on else COL_WHITE,
ec=COL_CYAN_700, lw=1.8,
text=str(onehot[i]),
tc=COL_WHITE if on else COL_SLATE_400, fs=13)
ax.text(OH_X - 0.75, cy(i), user_labels[i], ha="right", va="center",
fontsize=9.5, color=COL_TEXT)
ax.text(OH_X, n_users + 0.30, "one-hot\n(kullanıcı 3)\n[0,0,1,0,0]",
ha="center", va="bottom", fontsize=10.5, color=COL_CYAN_800,
weight="bold")
# '×' işareti
ax.text((OH_X + 0.45 + MAT_X0 - 0.5) / 2, cy(sel), "×", ha="center",
va="center", fontsize=30, color=COL_CYAN_700, weight="bold")
# ORTA — faktör matrisi (5×4): 3. satır rose vurgulu
for i in range(n_users):
is_sel = i == sel
for j in range(n_fac):
cell(MAT_X0 + j, cy(i), 0.96, 0.96,
fc=COL_BG_ROSE if is_sel else COL_WHITE,
ec=COL_ACCENT if is_sel else COL_SLATE_300,
lw=2.0 if is_sel else 1.0,
text=f"{factors[i, j]:+.1f}",
tc=COL_ACCENT if is_sel else COL_TEXT,
fs=9.5, weight="bold" if is_sel else "normal",
z=3 if is_sel else 2)
ax.text(MAT_X0 - 0.75, cy(i), user_labels[i], ha="right", va="center",
fontsize=9.5, color=COL_ACCENT if is_sel else COL_TEXT,
weight="bold" if is_sel else "normal")
for j in range(n_fac):
ax.text(MAT_X0 + j, -0.75, fac_labels[j], ha="center", va="center",
fontsize=10, color=COL_TEXT)
ax.text(MAT_X0 + (n_fac - 1) / 2, n_users + 0.30,
"faktör matrisi (5 kullanıcı × 4 latent faktör)", ha="center",
va="bottom", fontsize=11, color=COL_CYAN_800, weight="bold")
# '=' işareti
ax.text((MAT_X0 + n_fac - 0.5 + EMB_X0 - 0.5) / 2, cy(sel), "=", ha="center",
va="center", fontsize=30, color=COL_ACCENT, weight="bold")
# SAĞ — seçilen 3. satır = embedding (1×4)
emb = factors[sel]
for j in range(n_fac):
cell(EMB_X0 + j, cy(sel), 0.96, 0.96,
fc=COL_BG_ROSE, ec=COL_ACCENT, lw=2.0,
text=f"{emb[j]:+.1f}", tc=COL_ACCENT, fs=10.5)
ax.text(EMB_X0 + j, cy(sel) - 0.78, fac_labels[j], ha="center",
va="center", fontsize=10, color=COL_TEXT)
ax.text(EMB_X0 - 0.75, cy(sel), "k3", ha="right", va="center", fontsize=9.5,
color=COL_ACCENT, weight="bold")
ax.text(EMB_X0 + (n_fac - 1) / 2, n_users + 0.30,
"embedding\n(kullanıcı 3'ün faktörleri)", ha="center", va="bottom",
fontsize=10.5, color=COL_ACCENT, weight="bold")
# ÜST OK — one-hot × matris = 3. satırın seçimi
arrow_between(ax, (OH_X, n_users + 1.05), (EMB_X0 + n_fac - 1, n_users + 1.05),
color=COL_CYAN_700, lw=2.0,
connectionstyle="arc3,rad=-0.12", shrink=2)
ax.text((OH_X + EMB_X0 + n_fac - 1) / 2, n_users + 1.55,
"one-hot × matris = 3. satırın seçimi", ha="center", va="center",
fontsize=10.5, color=COL_CYAN_800, weight="bold")
# ALT OK — KISAYOL: embedding = doğrudan 3. satırı OKU
arrow_between(ax, (OH_X, -1.05), (EMB_X0 + n_fac - 1, -1.05),
color=COL_ACCENT, lw=2.2, connectionstyle="arc3,rad=0.12",
shrink=2)
ax.text((OH_X + EMB_X0 + n_fac - 1) / 2, -1.55,
"KISAYOL: embedding = doğrudan 3. satırı OKU "
"(dummy variable hiç oluşturulmaz)", ha="center", va="center",
fontsize=10.5, color=COL_ACCENT, weight="bold")
fig.suptitle("Embedding = diziden satır arama (one-hot çarpımının kısayolu)",
color=COL_CYAN_800, fontsize=14, weight="bold", y=1.0)
plt.show()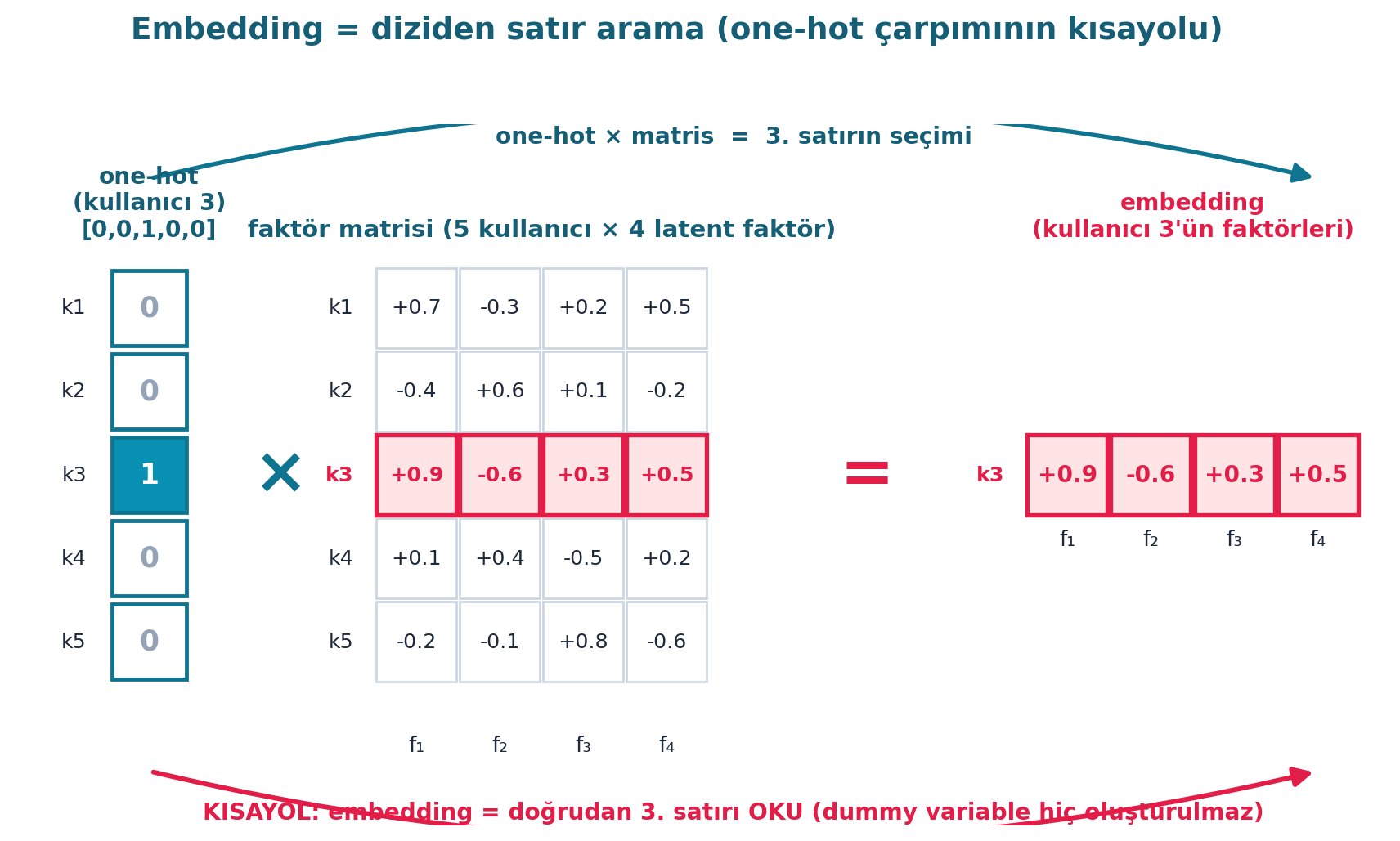
İpucuBuilder Notu — Dummy Variable’ın Hızlı Hâli
- Geriye (Ders 6): Embedding = dummy variable + matris çarpımının hızlı hâli; “her kategori bir 0/1 sütunu” fikrinin verimli versiyonu — Şekil 8.7’in alt rose oku, dummy variable’ları hiç oluşturmadan satırı okur.
- İleriye (NLP/Karpathy): Token embedding’leri (Ders 4, Karpathy makemore) tam budur — kelime id’sini bir vektöre çeviren arama tablosu; aynı one-hot kısayolu dil modellerinin girişinde çalışır.
8.12 Sıfırdan Dot Product Modeli
Howard collaborative filtering modelini PyTorch’ta bir sınıf olarak kurar. Embedding katmanları faktörleri tutar; forward metodu (PyTorch modeli çağırınca otomatik çalışır) kullanıcı ve film faktörlerini arar, dot product’larını alır. sigmoid_range çıktıyı puan aralığına (0-5) sıkıştırır.
class DotProduct(Module):
def __init__(self, n_users, n_movies, n_factors, y_range=(0, 5.5)):
self.user_factors = Embedding(n_users, n_factors)
self.movie_factors = Embedding(n_movies, n_factors)
self.y_range = y_range
def forward(self, x):
users = self.user_factors(x[:, 0])
movies = self.movie_factors(x[:, 1])
return sigmoid_range((users * movies).sum(dim=1), *self.y_range)
model = DotProduct(n_users, n_movies, 50)
learn = Learner(dls, model, loss_func=MSELossFlat())
learn.fit_one_cycle(5, 5e-3)“PyTorch is going to call a method called forward in your class. This is where you put your calculation of your model.” — Howard, 1:29:58
forward içindeki (users * movies).sum(dim=1) tam dot product’tır (Şekil 8.6); user_factors(x[:, 0]) ise embedding araması’dır (Şekil 8.7) — model bu iki işlemden ibarettir.
İpucuBuilder Notu — Module + forward = calc_preds’in Nesne Hâli
- Geriye (Ders 5):
Module+forward= Ders 5’tekicalc_preds’in nesne hâli; PyTorch’un model API’si — sıfırdan yazdığımız tahmin fonksiyonu, artık bir sınıfınforward’ı. - İleriye (Ders 5):
sigmoid_range, Ders 5’teki sigmoid’in aralık genelleştirilmiş hâli; çıktıyı 0-5.5 puan aralığına sıkıştırır, böylece model “aralık dışı” tahmin etmez.
8.13 Bias Terimleri
Sadece dot product yetmez: bazı kullanıcılar her şeye yüksek puan verir, bazı filmler herkesçe sevilir. Bunu yakalamak için her kullanıcıya ve her filme bir bias (sabit terim) eklenir. Model artık “bu kullanıcı genelde cömert + bu film genelde sevilir + ikisinin uyumu” der.
class DotProductBias(Module):
def __init__(self, n_users, n_movies, n_factors, y_range=(0, 5.5)):
self.user_factors = Embedding(n_users, n_factors)
self.user_bias = Embedding(n_users, 1)
self.movie_factors = Embedding(n_movies, n_factors)
self.movie_bias = Embedding(n_movies, 1)
self.y_range = y_range
def forward(self, x):
users = self.user_factors(x[:, 0]); movies = self.movie_factors(x[:, 1])
res = (users * movies).sum(dim=1, keepdim=True)
res += self.user_bias(x[:, 0]) + self.movie_bias(x[:, 1])
return sigmoid_range(res, *self.y_range)Tahmin artık “uyum (dot product) + kullanıcı cömertliği + film popülerliği” toplamıdır; bias terimleri de birer embedding’dir (yalnızca tek sütunlu).
İpucuBuilder Notu — Bias = Wx+b’deki b
- Geriye (Ders 3): Bias, Ders 3’teki \(Wx+b\)’deki \(b\) ile aynı fikir — sabit kaydırma terimi (§4.D “bias tuzağı”: istatistiksel yanlılık değil, modelin sabit ofseti).
- İleriye (Weight Decay): Bias eklemek modeli daha esnek (ve overfit’e yatkın) kılar; sıradaki weight decay tam bu esnekliği frenler.
8.14 Weight Decay (Regularization)
Bias eklenince model overfit etmeye başlayabilir. Çözüm weight decay (L2 regularization): kayba, katsayıların karelerinin toplamını ekleyerek modeli küçük ağırlıklar tutmaya zorlar. fastai’de wd parametresiyle verilir.
learn.fit_one_cycle(5, 5e-3, wd=0.1) # weight decay ile overfit'i azalt“It’s a mathematical function that fits my intuition about what works well.” — Howard, 1:22:24
İpucuBuilder Notu — Occam’ın Usturası, Sayıya Dökülmüş
- Geriye (Ders 4 / Stat 110): Weight decay, Ders 4’teki overfitting’in panzehirlerinden biri; büyük ağırlıkları cezalandırarak modeli basit tutar (Occam’ın usturası) — bias terimlerini ekleyince doğan esneklik, weight decay ile dengelenir.
- İleriye (collab_learner):
wd=0.1tek bir parametredir ama overfit/underfit dengesini kurar; collab_learner çağrısında doğrudan verilir.
8.15 collab_learner ve Embedding Boyutu
Tüm bu sıfırdan kodu fastai tek satırda sarar: collab_learner. Latent faktör sayısını ve puan aralığını verir. Howard, embedding boyutu için kendi “rule of thumb” formülünü kullandığını söyler — kâğıt üstünde sezgisini bir tabloya yazıp ona fonksiyon uydurmuş; şimdi birçok makalede kullanılıyor.
learn = collab_learner(dls, n_factors=50, y_range=(0, 5.5))
learn.fit_one_cycle(5, 5e-3, wd=0.1)“It’s a mathematical function that fits my intuition about what works well. Lots of papers now say: using fastai’s rule of thumb for embedding sizes.” — Howard, 1:22:24
Bu tek satır, sıfırdan kurduğumuz DotProductBias’ı ve weight decay’i birlikte sarar — framework, “fiddly” parçaları gizler.
İpucuBuilder Notu — vision_learner Ailesinin Collab Üyesi
- Geriye (Ders 1):
collab_learner,vision_learner/text_learnerailesinin collaborative filtering üyesi (§4.I) — aynılearn.fit_one_cycleAPI’si, farklı veri türü. - İleriye (Latent Uzay):
n_factors=50embedding boyutudur; bu 50 boyutlu uzay, eğitimden sonra yorumlanabilir bir latent uzaya dönüşür.
8.16 Derin Öğrenme ile Collab ve Latent Uzay
Dot product yerine embedding’leri birleştirip bir sinir ağına besleyebiliriz (use_nn=True). Daha da önemlisi: embedding fikri her yere taşınır — kategorik tablo sütunları, NLP token’ları, hatta öneri dışı problemler. Öğrenilen embedding’ler yorumlanabilir bir latent uzay oluşturur (benzer filmler yakın olur).
learn = collab_learner(dls, use_nn=True, y_range=(0, 5.5), layers=[100, 50])
learn.fit_one_cycle(5, 5e-3, wd=0.1)Şekil 8.8 bu yorumlanabilirliği gerçek (kümeli sentetik) 2B noktalarla gösterir: öğrenilen film embedding’leri latent uzayda türlerine göre kümelenir — aksiyon, romantik ve animasyon filmleri ayrı bölgelere düşer; benzer filmler yakın olur.
Kod
# GERCEK hesaplama: kumeli sentetik 2B embedding noktalari (bkz. embedding_space_demo).
es = embedding_space_demo()
points = es["points"] # (18, 2)
labels = es["labels"] # tür indeksi 0/1/2
genres = es["genres"] # ["aksiyon", "romantik", "animasyon"]
names = es["names"]
# Tur basina renk + marker (3 tur)
genre_colors = [COL_PRIMARY, COL_ACCENT, COL_CYAN_700] # aksiyon / romantik / animasyon
genre_markers = ["o", "s", "^"]
fig, ax = plt.subplots(figsize=(7.2, 5.4))
for gi, genre in enumerate(genres):
mask = labels == gi
ax.scatter(points[mask, 0], points[mask, 1],
s=120, c=genre_colors[gi], marker=genre_markers[gi],
edgecolors="white", linewidths=1.2, alpha=0.92,
label=genre, zorder=3)
# Secili kume orneklerine film adi anotasyonu (okunabilirlik icin)
ann_idx = [0, 3, 6, 9, 12, 15]
for i in ann_idx:
ax.annotate(names[i], (points[i, 0], points[i, 1]),
textcoords="offset points", xytext=(7, 6),
fontsize=8.5, color=COL_TEXT, weight="bold", zorder=4)
apply_style(ax)
ax.set_xlabel("latent boyut 1", fontsize=11)
ax.set_ylabel("latent boyut 2", fontsize=11)
ax.set_title("Öğrenilen embedding'ler: benzer filmler latent uzayda yakın",
fontsize=12.5, weight="bold", pad=12)
ax.legend(title="tür", loc="upper right", framealpha=0.92, fontsize=9.5)
ax.text(0.5, -0.16,
"embedding yorumlanabilir bir latent uzay oluşturur",
transform=ax.transAxes, ha="center", va="top",
fontsize=9.5, color=COL_SLATE_400, style="italic")
fig.tight_layout()
plt.show()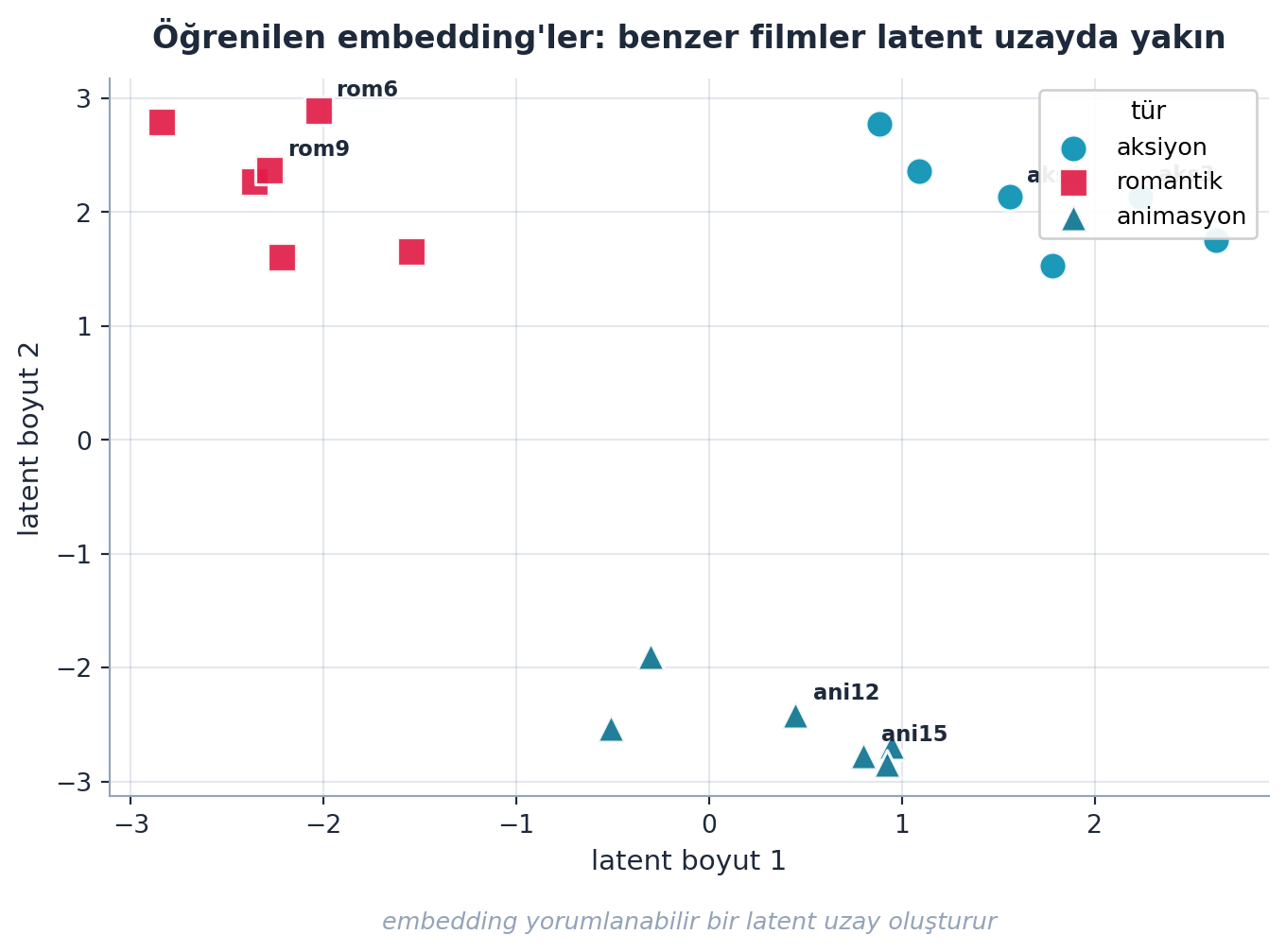
İpucuBuilder Notu — Embedding Her Yerde: Tablo, NLP, Öneri
- İleriye: Tablo modellerinde kategorik değişkenler için embedding (EmbeddingNN), NLP’de kelime embedding’leri, öneri sistemlerinde kullanıcı/ürün embedding’leri — hepsi aynı “arama tablosu” fikri; Şekil 8.8’in kümeleri, modelin yapıyı kendiliğinden bulduğunu gösterir.
- Geriye (Latent Faktörler): Anlamı önceden bilinmeyen latent faktörler, eğitimden sonra bu kümeleri oluşturur — “aksiyon-sevgisi” ekseni biz tanımlamadan ortaya çıkar.
8.17 Kapanış
Ders 7 iki güçlü konuyu birleştirdi. İlk yarı yarışma araçlarını verdi: gradient accumulation (bellek), ensembling (doğruluk), multi-target + cross-entropy/softmax (çok-sınıflı kayıp). İkinci yarı collaborative filtering’i kurdu: latent faktörler + dot product + bias + weight decay, hepsi embedding üstünde — ki embedding sadece “bir diziden arama yapmak”tır.
İpucuBuilder Notu — Son Derse ve Part 2’ye Köprü
- İleriye (Ders 8): Son ders evrişimlere (CNN) döner; embedding + cross-entropy + dot product burada öğrenilen temeller Part 2 ve Karpathy boyunca tekrar tekrar karşımıza çıkacak.
- Geriye (tüm seri): Şekil 28.1’in yarışma-araçları → softmax/cross-entropy → collaborative-filtering → embedding zinciri, bu dersin iki yarısını tek bir hikâyede toplar — kayıp fonksiyonundan öneri çekirdeğine.
8.18 Bu Dersin Özeti
- Gradient accumulation: küçük batch’lerin gradyanlarını biriktirip tek adım atarak küçük GPU’da büyük model eğitme (Gradient Accumulation).
- Ensembling: birden çok modelin tahminlerini birleştirip doğruluğu artırma (bagging’in mimari versiyonu) (Ensembling).
- Multi-target modeller birden çok şeyi aynı anda tahmin eder; kayıp hedeflerin toplamıdır (Multi-Target).
- Softmax logit’leri toplamı 1 olan olasılıklara çevirir; cross-entropy = softmax + negatif log likelihood (Softmax, Cross-Entropy).
- Collaborative filtering bir matris tamamlama problemidir: kullanıcı × ürün matrisindeki boşlukları doldurma (Collaborative Filtering).
- Latent faktörler her kullanıcı/ürün için öğrenilen gizli sayılardır; anlamlarını model belirler (Latent Faktörler, Latent Uzay).
- Tahmin = kullanıcı ve ürün latent faktörlerinin dot product’ı (+ bias terimleri); weight decay overfit’i azaltır (Dot Product, Bias, Weight Decay).
- Embedding, bir diziden satır aramaktır — one-hot çarpımının hızlı kısayolu; her yerde (öneri, NLP, tablo) kullanılır (Embedding = Arama).
ÖnemliTek Bir Cümle
Collaborative filtering, kullanıcılar ve ürünler için öğrenilen latent faktör vektörlerinin (embedding’lerin) dot product’ıyla puanları tahmin eden bir matris tamamlama yöntemidir; ve embedding, gizemli görünse de yalnızca bir diziden hızlıca satır aramaktan ibarettir.
8.19 Kontrol Soruları
NotSoru 1: Embedding nedir ve neden one-hot çarpımıyla aynı şeydir?
Cevap:
Embedding, bir matristen (faktör tablosundan) belirli bir satırı aramaktır — örneğin kullanıcı 14’ün faktör vektörünü almak için matrisin 14. satırını çekmek. Bu, “14. eleman 1, gerisi 0” olan bir one-hot vektörle matrisi çarpmakla matematiksel olarak birebir aynıdır: one-hot çarpımı yalnızca o satırı seçer. Embedding bu işlemin hızlı kısayoludur — one-hot vektörü ve dummy variable’ları hiç oluşturmadan doğrudan satırı okur. Yani gizemli bir kavram değil, verimli bir arama işlemidir. (Şekil 8.7 bu eşitliği gösterir.)
NotSoru 2: Collaborative filtering’de latent faktörler ve dot product nasıl çalışır? Bias neden eklenir?
Cevap:
Her kullanıcı ve her ürün için (örn. 5) latent faktör (gizli sayı) öğrenilir; anlamlarını model kendisi belirler (belki “aksiyon sevgisi”, “eskilik”). Bir kullanıcının bir ürünü ne kadar seveceği, ikisinin faktör vektörlerinin dot product’ıdır (eleman eleman çarp, topla) — uyumlu faktörler yüksek skor verir. Bias eklenir çünkü dot product yalnızca “uyum”u yakalar; ama bazı kullanıcılar her şeye yüksek puan verir, bazı ürünler herkesçe sevilir. Kullanıcı ve ürün bias’ları bu genel eğilimleri ayrıca modeller, böylece tahmin “uyum + kullanıcı cömertliği + ürün popülerliği” olur. (Şekil 8.6 dot product’ı, Şekil 8.5 doldurulacak boşlukları gösterir.)
NotSoru 3: Cross-entropy loss ne yapar ve softmax ile ilişkisi nedir?
Cevap:
Cross-entropy iki adımdır: önce softmax modelin ham çıktılarını (logit) toplamı 1 olan bir olasılık dağılımına çevirir (\(e^{z_i}/\sum e^z\)); sonra negatif log likelihood doğru sınıfa verilen olasılığın logaritmasını cezalandırır (\(-\log p\)). Doğru sınıfa yüksek olasılık → küçük kayıp; düşük olasılık → büyük kayıp. PyTorch F.cross_entropy bunu tek adımda ve log-softmax kullanarak sayısal olarak kararlı biçimde yapar. Birden çok şey aynı anda doğru olabiliyorsa softmax yerine her çıktıya ayrı sigmoid + binary cross-entropy kullanılır. (Şekil 8.3 softmax’ı, Şekil 8.4 kaybı gösterir.)
NotSoru 4: Gradient accumulation neden daha büyük batch ile (neredeyse) aynıdır? (builder bağlantısı)
Cevap:
Bir batch’in gradyanı, o batch’teki örneklerin gradyanlarının ortalamasıdır. Gradient accumulation, büyük bir batch’i belleğe sığmadığı için birkaç küçük parçaya böler; her parçanın gradyanını hesaplar ama optimizer adımını atmadan biriktirir (backward() gradyanları toplar). n_acc parça birikince tek adım atılır. Toplanan gradyan, büyük batch’in gradyanıyla matematiksel olarak (neredeyse) aynıdır — fark yalnızca BatchNorm gibi batch-istatistiği kullanan katmanlarda küçük sapmalar olur. Builder açısından: bu, sınırlı VRAM’de büyük efektif batch elde etmenin standart yoludur (Karpathy GPT-2 eğitiminde de kullanır). (Şekil 8.2 akışı gösterir.)
8.20 Egzersizler
Egzersiz 1 (Direkt uygulama). MovieLens verisinde CollabDataLoaders.from_df ile veri yükle ve collab_learner(n_factors=50, y_range=(0,5.5)) ile bir model eğit.
Egzersiz 2 (İki-aşamalı). Sıfırdan DotProduct ve DotProductBias sınıflarını kur; bias eklemenin doğruluğu nasıl değiştirdiğini kıyasla.
Egzersiz 3 (Edge case). wd (weight decay) değerini 0, 0.1, 1.0 yapıp validation kaybını izle; overfit ile underfit arasındaki dengeyi gözlemle.
Egzersiz 4 (Python ile doğrulama). Bir one-hot vektör oluştur ve onehot @ user_factors ile user_factors[index] sonuçlarının aynı olduğunu doğrula (embedding = arama).
Egzersiz 5 (Sonraki dersin habercisi). Öğrenilen film embedding’lerini PCA ile 2 boyuta indir ve benzer filmlerin latent uzayda yakın olduğunu gözlemle.
8.21 Sonraki Ders İçin Hazırlık
Ders 8: Evrişimler / CNN (Convolutions)
Son ders görüntülerin nasıl verimli işlendiğine iner: convolution. Bir filtreyi görüntü üzerinde kaydırarak yerel desenleri (kenar, köşe) yakalama — CNN’lerin temel işlemi. Ayrıca collaborative filtering ve embedding’i tablo modellerine bağlar.
Ana konular:
- Convolution (evrişim) ve filtreler
- CNN mimarisi
- Embedding’in tabloda kullanımı
- Serinin kapanışı
UyarıDers 8 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 4 — collab_learner + embedding=arama).
- Bir öneri veri setinde latent faktörleri eğit ve yorumla.
- Ana cümleyi tekrar oku: “Embedding = bir diziden arama; collab = latent faktörlerin dot product’ı.”
8.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Gradient accumulation | Küçük batch gradyanlarını biriktirip tek adım at | 8:04 |
| Ensembling | Birden çok modelin tahminlerini birleştirme | 23:01 |
| Multi-target | Tek modelle birden çok şeyi tahmin etme | 37:51 |
| Softmax | Logit’leri toplamı 1 olan olasılıklara çevirme | 45:45 |
| Cross-entropy | Softmax + negatif log likelihood; çok-sınıflı kayıp | 46:24 |
| Collaborative filtering | Kullanıcı × ürün matris tamamlama (öneri) | 1:14:00 |
| Latent faktör | Kullanıcı/ürün için öğrenilen gizli sayılar | 1:21:00 |
| Dot product | İki faktör vektörünün eleman çarpımı toplamı | 1:08:00 |
| Embedding | Bir diziden satır arama (one-hot çarpımının kısayolu) | 1:19:29 |
| Bias | Kullanıcı/ürün genel eğilimini yakalayan sabit terim | 1:29:58 |
| Weight decay (wd) | L2 regularization; büyük ağırlıkları cezalandırır | 1:22:24 |
| collab_learner | fastai’nin collaborative filtering Learner’ı | 1:22:24 |
8.23 ML Builder Bağlantıları
İpucuBuilder Notu — 6 ML Köprüsü
Bu ders, yarışma araçlarından öneri sistemlerinin çekirdeğine uzanır; köprülerin özeti:
- Embedding → kategorik veri, NLP token’ları ve öneri için ortak “arama tablosu” fikri; her yerde (Embedding = Arama, Latent Uzay).
- Cross-entropy/softmax → çok-sınıflı sınıflandırmanın standart kaybı; Karpathy makemore/GPT’nin temeli (Softmax, Cross-Entropy).
- Collaborative filtering → matris tamamlama; Netflix/Spotify önerilerinin çekirdeği (Collaborative Filtering).
- Gradient accumulation → sınırlı VRAM’de büyük efektif batch; Karpathy GPT-2 eğitiminde standart (Gradient Accumulation).
- Ensembling → bagging’in mimari versiyonu; yarışma kazanan çözümlerin standardı (Ensembling).
- Weight decay → overfit panzehiri (Ders 4); büyük ağırlıkları cezalandırır (Weight Decay).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten tek bir şey alıp gideceksen: derin öğrenme jargonu seni korkutmak için tasarlanmış gibidir ama altı basittir. “Embedding” sadece bir diziden satır aramaktır; “collaborative filtering” kullanıcı ve ürün için öğrenilen gizli sayıların dot product’ıyla boş hücreleri doldurmaktır. Basitliği keşfettiğinde, kendi başına yapabileceğini fark edersin — ve yapabilirsin.