flowchart TD
PIVOT["L10 DÖNÜM NOKTASI<br/>Daha Derine"]
subgraph FINISH["Stable Diffusion'ı BİTİR"]
REC["tam pipeline recap<br/>VAE + U-Net + CLIP"]
DIST["distillation<br/>öğretmen → öğrenci"]
PROG["progressive distillation<br/>her tur adım yarıya<br/>1000 → 500 → 250"]
REC --> DIST --> PROG
end
subgraph FOUND["FROM THE FOUNDATIONS başlat"]
RULE["kural: yalnız Python +<br/>stdlib + tensör"]
REBUILD["yeniden kur,<br/>sonra kullan"]
MNIST["MNIST 28×28 = 784 sayı"]
MATMUL["matris çarpımı:<br/>3 iç içe döngü"]
SPEED["→ numba → broadcasting<br/>(ileriye)"]
RULE --> REBUILD
RULE --> MNIST
MNIST --> MATMUL --> SPEED
end
FINISH --> PIVOT
PIVOT --> FOUND
classDef cyan fill:#cffafe,stroke:#0e7490,stroke-width:1px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
class REC,DIST,PROG,REBUILD,MNIST,MATMUL,SPEED cyan;
class PIVOT,RULE rose;
13 Ders 10 — Daha Derine (Diving Deeper)
Part 2’nin dönüm noktası: Howard önce Stable Diffusion’ı bitirir (distillation ile hızlandırma + tam pipeline kod yürüyüşü), sonra Part 2’nin asıl omurgasını başlatır — « from the foundations »: yalnızca Python + standart kütüphane + tensör izinli; matmul’dan U-Net’e kadar her şey sıfırdan kurulur. İlk foundation matris çarpımıdır: üç iç içe döngüden numba’ya, oradan (Ders 11’de) broadcasting’e. Kural net: bir şeyi bir kez sıfırdan kur, gerçekten anla, sonra hazır versiyonunu güvenle kullan.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 10: Diving Deeper (~109 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 10
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/01_matmul
- Okuma süresi: ~38 dk
- 🔁 Dönüm noktası: Part 2’nin ilk yarısı Stable Diffusion’ı bitirir, ikinci yarısı « from the foundations » omurgasını başlatır. Bu ders ikisini birbirine bağlar.
13.1 Bu Derste Ne Var?
Part 2’nin ikinci dersi bir dönüm noktasıdır. İlk yarı Stable Diffusion’ı bitirir: hızlandırma (distillation), tam pipeline kod yürüyüşü (pipeline). İkinci yarı Part 2’nin asıl omurgasını başlatır: « from the foundations » — Stable Diffusion’a giden her şeyi (matris çarpımından itibaren) sıfırdan yeniden kurmak (felsefe).
Üç temel fikir bu dersin omurgasını kurar:
- Distillation ile hızlandırma — bir “öğretmen” modelin birkaç adımını, bir “öğrenci” modelin tek adımına sıkıştırma; diffusion’ı az adımda çalıştırma (distillation → progressive).
- « From the foundations » kuralı — yalnızca Python + standart kütüphane + tensör oluşturma izinli; geri kalan her şey (matmul, autograd, Learner, U-Net) sıfırdan kurulacak. Bir şeyi yeniden kurunca, hazır versiyonunu kullanmaya hak kazanırız (felsefe → incelik).
- Matris çarpımından başlamak — ilk foundation matmul: önce üç iç içe Python döngüsüyle (çok yavaş), sonra adım adım hızlandırma (matmul → üç döngü → numba).
“The goal is to get to Stable Diffusion from the foundations… we’re going to rebuild everything starting from this foundation.” — Howard, 53:47
Şekil 28.1 bu yapıyı tek bir yol haritasında birleştirir: solda Stable Diffusion’ı bitir (recap + distillation + progressive distillation), sağda « from the foundations »ı başlat (kural → MNIST → matmul → numba/broadcasting). Ortadaki dönüm noktası ikisini birbirine bağlar.
İpucuBuilder Notu — Dönüm Noktası: Kullanmaktan Kurmaya
- Geriye (Ders 5 + Karpathy): “Sıfırdan kur” felsefesi Ders 5’in (Titanic from-scratch) ve tüm Karpathy serisinin ruhu; Part 2 bunu Stable Diffusion ölçeğine taşır.
- İleriye (Ders 11-25): Bu lesson, foundations yolculuğunu açar — matmul (11) → backprop (13) → Learner (16) → DDPM (19) → diffusion (25).
- Tek cümle: Stable Diffusion’a “yalnızca Python’la başlayıp” her parçayı sıfırdan kurarak varacağız; ilk parça matris çarpımı.
13.2 1. Ders 9 Özeti ve Öğrenci İşleri
Howard derse haftanın öğrenci projeleriyle ve Ders 9’un özetiyle başlar. Stable Diffusion’ın üç bileşenini (VAE, CLIP, U-Net) ve gürültü-giderme döngüsünü hatırlatır. Bu özet bir köprüdür: önceki üç ders (Ders 9 sezgi, Ders 9A kod, Ders 9B matematik) tek bir omurgada birleşir ve Ders 10 bunu ileriye taşır.
“It’s the second lesson in Part 2, which is where we’re going from Deep Learning Foundations [to Stable Diffusion].” — Howard, 0:00
İpucuBuilder Notu — Üç Dersin Sentezi
- Geriye (Ders 9/9A/9B): Bu ders öncekilerin üçünü (sezgi + kod + matematik) tek bir omurgada birleştirip ileriye taşır.
- Sezgi: Stable Diffusion’ı artık “kullanabiliyoruz”; şimdi onu altından nasıl çalıştığını bilerek “kurmaya” geçiyoruz.
13.3 2. Stable Diffusion’ı Hızlandırma: Distillation
Howard bir hızlandırma yöntemini anlatır: distillation (damıtma). Fikir: iyi ama yavaş bir öğretmen (teacher) modeli, daha hızlı bir öğrenci (student) modele “öğretmek”. Öğrenci, öğretmenin yaptığını daha az adımda taklit etmeyi öğrenir. Diffusion’ın temel sorunu hızdır: üretim çok sayıda (örn. 1000) sampling adımı gerektirir; distillation bu adım sayısını dramatik biçimde azaltmanın bir yoludur.
“Distillation is that you take something called a Teacher Network, which is some neural net [that works well].” — Howard, 16:56
Şekil 13.2 bu süreci şematik gösterir: üstte ÖĞRETMEN (N adımda gürültü → görüntü, yavaş ama kaliteli), distillation oku ile aşağıda ÖĞRENCİ (N/2 adımda aynı kalite); yan panelde adım sayısının her turda yarıya inişi (1000 → 500 → 250 → …) ve öğrencinin yeni öğretmen olarak döngüye geri besleneceği işaret edilir.
Kod
# Adım-yarılama dizisi GERÇEK aritmetikle gelir (1000→500→...); şema ŞEMATİK.
dist = E.progressive_distillation_demo(start=1000, rounds=7)
steps = dist["steps"]
fig, ax = plt.subplots(figsize=(11.5, 6.5))
ax.set_xlim(0, 11.5)
ax.set_ylim(0, 6.5)
ax.axis("off")
# --- (ÜST) ÖĞRETMEN: N adımda gürültü → görüntü (cyan) ---
viz.boxed_node(ax, 3.1, 5.6, 4.6, 1.05,
"ÖĞRETMEN\nN adımda gürültü → görüntü",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=11.0, lw=2.4)
ax.text(3.1, 6.32, "yavaş ama kaliteli üretim", ha="center", va="center",
fontsize=8.4, color=COL_CYAN_700, style="italic", weight="bold")
# --- distillation oku (aşağı, rose vurgulu) ---
viz.arrow_between(ax, (3.1, 5.0), (3.1, 3.62), color=COL_ACCENT, lw=2.6,
mutation_scale=22, shrink=10)
ax.text(3.4, 4.32, "distillation:\nöğrenci, öğretmenin 2 adımını\n1 adımda yapmayı öğrenir",
ha="left", va="center", fontsize=8.6, color=COL_ACCENT, weight="bold")
# --- (ORTA) ÖĞRENCİ: N/2 adım (rose) ---
viz.boxed_node(ax, 3.1, 3.0, 4.6, 1.05,
"ÖĞRENCİ\nN/2 adımda gürültü → görüntü",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=11.0, lw=2.4)
ax.text(3.1, 2.28, "yarı adımda ≈ aynı kalite", ha="center", va="center",
fontsize=8.4, color=COL_ACCENT, style="italic", weight="bold")
# --- döngü oku: öğrenci → yeni öğretmen olur (her turda adım yarıya) ---
# soldan yukarı kıvrılan geri-besleme oku (öğrenci → öğretmen rolü)
viz.arrow_between(ax, (0.85, 3.0), (0.85, 5.6), color=COL_CYAN_700, lw=2.2,
mutation_scale=18, shrink=12,
connectionstyle="arc3,rad=-0.42")
ax.text(0.18, 4.3, "öğrenci →\nyeni öğretmen\nolur (tekrar)",
ha="left", va="center", fontsize=8.2, color=COL_CYAN_700,
weight="bold", rotation=90)
# --- (YAN) küçük şema: 1000→500→250→...→8 adım azalışı ---
panel_x = 6.55
ax.add_patch(plt.Rectangle((panel_x, 1.45), 4.55, 4.55, facecolor=COL_CYAN_50,
edgecolor=COL_CYAN_400, linewidth=1.4,
linestyle="--", zorder=0))
ax.text(panel_x + 2.27, 5.66, "her turda sampling adımı yarıya iner",
ha="center", va="center", fontsize=8.8, color=COL_CYAN_700, weight="bold")
# basamaklı adım dizisi (1000 → 500 → 250 → ... → 8)
ys = np.linspace(5.05, 1.95, len(steps))
for ti, (yv, s) in enumerate(zip(ys, steps)):
# tur ilerledikçe kutu rengi cyan'dan rose'a doğru kayar (öğretmen→öğrenci zinciri)
frac = ti / (len(steps) - 1)
ec = COL_PRIMARY if frac < 0.5 else COL_ACCENT
fc = COL_BG if frac < 0.5 else COL_BG_ROSE
viz.boxed_node(ax, panel_x + 0.95, yv, 1.5, 0.40,
f"{s} adım", fc=fc, ec=ec, tc=COL_TEXT,
fontsize=9.0, lw=1.6)
if ti < len(steps) - 1:
viz.arrow_between(ax, (panel_x + 0.95, yv - 0.20),
(panel_x + 0.95, ys[ti + 1] + 0.20),
color=COL_SLATE_400, lw=1.4, mutation_scale=12, shrink=4)
ax.text(panel_x + 1.95, (yv + ys[ti + 1]) / 2, "÷2",
ha="left", va="center", fontsize=8.0, color=COL_ACCENT, weight="bold")
# alt not: az adımda kaliteli üretim (DDIM Ders 21 hedefi)
ax.text(panel_x + 2.27, 1.66, "az adımda kaliteli üretim\n(DDIM — Ders 21 hedefi)",
ha="center", va="center", fontsize=8.2, color=COL_TEXT, style="italic")
plt.tight_layout()
plt.show()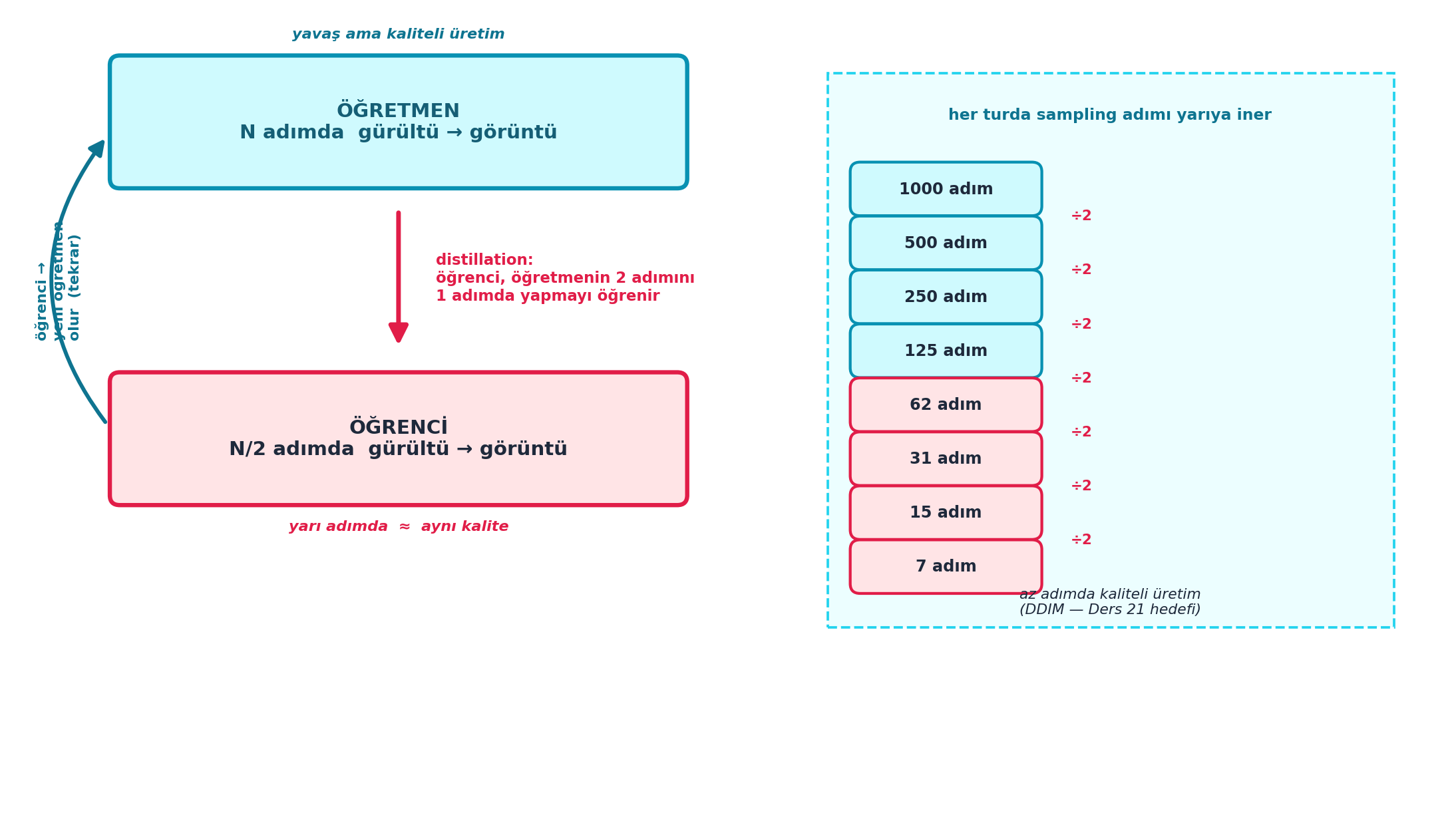
İpucuBuilder Notu — Distillation: Bilgiyi Sıkıştırma
- Mekanizma: Öğrenci, kendi ham verisinden değil öğretmenin çıktısından öğrenir; öğretmenin yumuşak hedeflerini taklit ederek bilgisini daha az adıma sıkıştırır.
- İleriye: Distillation diffusion’a özgü değil — LLM’lerde de büyük/yavaş modeli küçük/hızlıya sıkıştırmanın production standardıdır; kalite/hız dengesini optimize eder.
13.4 3. Progressive Distillation: Adımları Yarıya İndirme
“Progressive Distillation” makalesi şunu yapar: öğrenci, öğretmenin iki adımını tek adımda yapmayı öğrenir. Sonra bu öğrenci yeni öğretmen olur ve süreç tekrarlanır — her turda gereken adım sayısı yarıya iner. Böylece 1000 adımlık diffusion, çok daha azına sıkışır.
“They take that student model… it learns to go directly from the noise to two goes of the student model, and then they copy that to become the next student model.” — Howard, 19:36
Şekil 13.3 bu yarılamayı gerçek aritmetikle gösterir: 1000 → 500 → 250 → 125 → 62 → 31 → 15 → 7 — yedi turda 1000 adım, yalnızca ~7 adıma iner (≈140× azalma, kalite korunur). Log-skalada her ardışık bar bir öncekinin yarısıdır; son tur (7 adım) rose ile vurgulanır.
Kod
d = E.progressive_distillation_demo()
rounds = d["rounds"] # [0, 1, 2, ..., 7]
steps = d["steps"] # [1000, 500, 250, 125, 62, 31, 15, 7]
fig, ax = plt.subplots(figsize=(9, 5))
# Son tur (7 adım) rose ile vurgulu, diğerleri cyan
colors = [COL_PRIMARY] * (len(steps) - 1) + [COL_ACCENT]
bars = ax.bar(rounds, steps, color=colors, width=0.62,
edgecolor=COL_WHITE, linewidth=1.2, zorder=3)
ax.set_yscale("log")
ax.set_ylim(4, 2000)
# Barların üstüne değer yaz
for x, v, col in zip(rounds, steps, colors):
ax.text(x, v * 1.12, f"{v}", ha="center", va="bottom",
fontsize=11, weight="bold", color=col, zorder=4)
# Her turun bir öncekinin yarısı olduğunu annotate et: ardışık barlar arası "÷2"
for i in range(1, len(steps)):
xm = (rounds[i - 1] + rounds[i]) / 2.0
ym = (steps[i - 1] * steps[i]) ** 0.5 # log-skalada geometrik orta
ax.annotate("÷2", xy=(xm, ym), ha="center", va="center",
fontsize=8.5, weight="bold", color=COL_SLATE_400,
bbox=dict(boxstyle="round,pad=0.18", fc=COL_WHITE,
ec=COL_SLATE_400, lw=0.8), zorder=5)
# "Her tur ÷2" genel etiketi (sol üst)
ax.text(0.03, 0.94, "her tur ÷2", transform=ax.transAxes,
ha="left", va="top", fontsize=11, weight="bold",
color=COL_CYAN_700,
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG,
ec=COL_PRIMARY, lw=1.5))
# 1000 → 7 sıkışma vurgusu: ilk ve son bar arası ok + "≈140× az adım"
ax.annotate("", xy=(rounds[-1], steps[-1] * 1.9),
xytext=(rounds[0], steps[0] * 0.78),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT,
lw=2.2, connectionstyle="arc3,rad=-0.18"),
zorder=4)
oran = steps[0] / steps[-1] # gerçek oran: 1000/7 ≈ 142.9
ax.text(rounds[-1] - 0.1, steps[-1] * 3.6,
f"1000 → 7 adım\n(≈{oran:.0f}× az, kalite korunur)",
ha="right", va="bottom", fontsize=10.5, weight="bold",
color=COL_ACCENT,
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG_ROSE,
ec=COL_ACCENT, lw=1.5), zorder=5)
ax.set_xticks(rounds)
ax.set_xlabel("distillation turu", fontsize=11)
ax.set_ylabel("sampling adım sayısı (log)", fontsize=11)
ax.set_title("Progressive distillation: her turda örnekleme adımı yarıya iner",
fontsize=12.5, weight="bold", color=COL_CYAN_700, pad=12)
viz.apply_style(ax)
ax.grid(True, axis="y", alpha=0.22, color=COL_SLATE_400)
ax.grid(False, axis="x")
plt.tight_layout()
plt.show()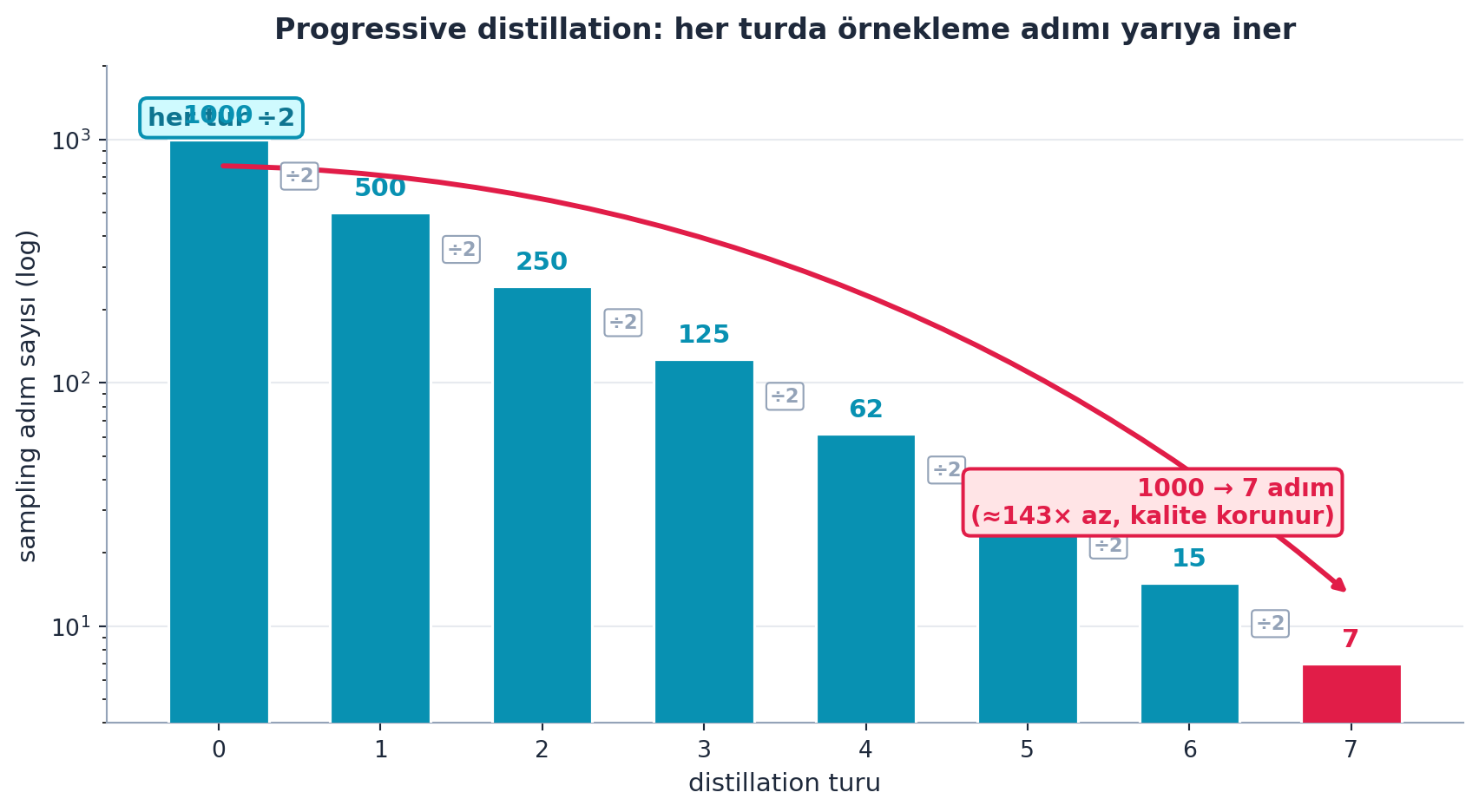
İpucuBuilder Notu — Az Adımda Üretim: Geometrik Sıkışma
- İleriye (Ders 21): Az adımda kaliteli üretim, DDIM (Ders 21) ve consistency modellerinin de hedefi; distillation bunun bir yolu.
- Sezgi: Her tur adımı ÷2 yaptığı için sıkışma geometriktir — yalnızca 7 turda ≈140× hızlanma; üretim maliyeti doğrudan adım sayısıyla orantılı olduğundan bu pratikte büyük fark demektir.
13.5 4. CFG ve Empty Prompt (Recap)
Howard classifier-free guidance’ı (CFG) hatırlatır: her adımda prompt’lu ve boş prompt’lu iki tahmin yapılır; boş prompt da CLIP text encoder’dan geçer. İkisinin farkı guidance ile abartılır — bu fark, modeli “istenen yöne” daha güçlü iter (Ders 9A).
“We also put the empty prompt into our CLIP text encoder.” — Howard, 22:42
İpucuBuilder Notu — Boş Prompt = Koşulsuz Tahmin
- Geriye (Ders 9A): CFG mekaniği; boş prompt = koşulsuz tahmin. Koşullu (prompt’lu) ile koşulsuz (boş) arasındaki fark guidance ile ölçeklenir.
- Sezgi: Boş prompt’un da text encoder’dan geçmesi, “hiçbir şey istemiyorum” durumunu modele anlatmanın yoludur — fark bu referansa göre ölçülür.
13.6 5. Tam SD Pipeline Kod Yürüyüşü
Howard Ders 9’un düşük-seviye pipeline’ını koddan tekrar gezer: CLIP ile prompt’u embedding’e çevir, latent’i rastgele gürültüyle başlat, döngüde U-Net + CFG ile gürültüyü tahmin et, scheduler ile çıkar, VAE ile decode et. Önemli bir verimlilik vurgusu: koşullu ve koşulsuz tahminler tek bir batch’te birleştirilir — GPU aynı anda mümkün olduğunca çok iş yapsın diye.
“So we do exactly the same thing… because we like the GPU to do as many things at once as possible.” — Howard, 39:36
Pipeline’ın iskeleti, diffusers kütüphanesinin StableDiffusionPipeline parçalarıyla tam olarak şöyle görünür (kavramsal kesit):
# prompt -> CLIP text embedding (koşullu + koşulsuz/boş prompt birlikte)
text_input = tokenizer(prompt, padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True, return_tensors="pt")
text_embeddings = text_encoder(text_input.input_ids.to("cuda"))[0]
uncond_input = tokenizer([""], padding="max_length",
max_length=text_input.input_ids.shape[-1],
return_tensors="pt")
uncond_embeddings = text_encoder(uncond_input.input_ids.to("cuda"))[0]
# GPU tek batch'te ikisini birden işlesin diye birleştir
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# latent'i rastgele gürültüyle başlat, scheduler varyansına ölçekle
latents = torch.randn((1, unet.in_channels, height // 8, width // 8))
latents = latents.to("cuda") * scheduler.init_noise_sigma
# sampling döngüsü: U-Net gürültüyü tahmin et -> CFG -> scheduler çıkar
for t in scheduler.timesteps:
latent_model_input = torch.cat([latents] * 2) # koşullu+koşulsuz
noise_pred = unet(latent_model_input, t,
encoder_hidden_states=text_embeddings).sample
noise_uncond, noise_text = noise_pred.chunk(2)
noise_pred = noise_uncond + guidance_scale * (noise_text - noise_uncond) # CFG
latents = scheduler.step(noise_pred, t, latents).prev_sample
# tüm adımlar bitince VAE decode latent -> görüntü
image = vae.decode(latents / 0.18215).sample
İpucuBuilder Notu — GPU Verimliliği: Batch’te Birleştir
- Geriye (Ders 9/9A): Aynı pipeline; burada GPU verimliliği (batch’te koşullu+koşulsuz birlikte) vurgulanır.
torch.cat([latents] * 2)ile iki tahmin tek geçişte yapılır. - İleriye (Ders 19): Bu döngünün her parçası (scheduler, noise tahmini, decode) Part 2’nin geri kalanında sıfırdan kurulacak; şimdi hazır kütüphane sürümüyle tanışıyoruz.
13.7 6. Rastgele Gürültüyü Ölçekleme
İnce bir nokta: başlangıç latent’i torch.randn ile üretilir ama scheduler’ın beklediği varyansa ölçeklenmelidir (init_noise_sigma ile çarpılır). Bu olmadan üretim bozulur — başlangıç gürültüsü yanlış ölçekteyse, döngünün matematiği tutmaz.
“Scaling random noise to ensure variance.” — Howard, 41:29
İpucuBuilder Notu — init_noise_sigma: Doğru Ölçek
- Geriye (Ders 9B): Reparameterization (μ + σ·ε) mantığı; başlangıç gürültüsü doğru ölçekte olmalı — yanlış varyans, scheduler’ın beklediği dağılımı bozar.
- Builder ipucu:
latents = torch.randn(...) * scheduler.init_noise_sigmatek satır gibi görünür ama atlanırsa üretim çöker; “küçük detay, büyük etki”.
13.8 7. Sampling Loop ve VAE Decode
Döngünün özü: her adımda gürültüyü tahmin et, latent’ten çıkar, yeni latent elde et. Tüm adımlar bitince VAE decoder latent’i görüntüye çevirir. Bu, §5’teki pipeline kodunun kavramsal özetidir: tahmin → çıkar → tekrarla → decode.
“And remove it to give us our new latents. So that’s the loop. And at the end of all that, we decode it in the VAE.” — Howard, 44:31
İpucuBuilder Notu — Loop = Reverse Process
- İleriye (Ders 19): Bu loop, Part 2 Ders 19-22’de sıfırdan (DDPM/DDIM) kurulacak. Her adım Ders 9B’nin reverse process’inin bir basamağıdır.
- Sezgi: “Tahmin et, çıkar, tekrarla” üç kelimelik özet; bütün üretim bundan ibaret — ve sonunda VAE latent’i piksele döker.
13.9 8. « From the Foundations » Felsefesi
Dönüm noktası. Howard hedefi koyar: Stable Diffusion’a sıfırdan varmak. Ama “sıfırdan” ne demek? Tanımlar: yalnızca Python, Python standart kütüphanesi, Jupyter/nbdev ve tensör oluşturma izinli. Geri kalan her şey (matmul, gradyan, optimizer, katmanlar, U-Net) elle kurulacak.
“The goal is to get to Stable Diffusion from the foundations, which means we have to define what are the foundations. We’re allowed to use Python, the Python standard library, Jupyter notebooks and nbdev. We’re going to rebuild everything starting from this foundation.” — Howard, 53:47
Şekil 13.4 bu kuralı şematize eder: solda İZİNLİ (yalnız Python + stdlib + Jupyter/nbdev + tensör oluşturma), sağda SIFIRDAN KURULACAK (matmul, gradyan/backprop, optimizer, katmanlar/U-Net); altta kural bandı: bir şeyi bir kez kur (anla) → sonra hazır kütüphane versiyonunu kullanmaya hak kazan.
Kod
fig, ax = plt.subplots(figsize=(11.5, 5.5))
ax.set_xlim(0, 11.5)
ax.set_ylim(0, 5.5)
ax.axis("off")
ax.text(5.75, 5.22, "« From the Foundations » — Temellerden başla",
ha="center", va="center", fontsize=13.5,
color=COL_CYAN_800, weight="bold")
# --- (SOL) İZİNLİ (yalnız bunlar) — cyan, yeşilimsi onay ---
ax.add_patch(FancyBboxPatch((0.35, 1.95), 4.85, 2.7,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_CYAN_50, ec=COL_PRIMARY, linewidth=2.4, zorder=1))
ax.text(2.775, 4.35, "✓ İZİNLİ (yalnız bunlar)", ha="center", va="center",
fontsize=11.0, color=COL_CYAN_800, weight="bold", zorder=3)
_allowed = [
"Python dili",
"Python standart kütüphanesi",
"Jupyter / nbdev",
"tensör oluşturma (PyTorch)",
]
for i, t in enumerate(_allowed):
yy = 3.75 - i * 0.56
viz.boxed_node(ax, 2.775, yy, 4.1, 0.46, t,
fc=COL_WHITE, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=9.5, lw=1.6, weight="bold")
# --- (SAĞ) SIFIRDAN KURULACAK — rose ---
ax.add_patch(FancyBboxPatch((6.30, 1.95), 4.85, 2.7,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_BG_ROSE, ec=COL_ACCENT, linewidth=2.4, zorder=1))
ax.text(8.725, 4.35, "⚙ SIFIRDAN KURULACAK", ha="center", va="center",
fontsize=11.0, color=COL_ACCENT, weight="bold", zorder=3)
_build = [
"matmul (matris çarpımı)",
"gradyan / backprop",
"optimizer (SGD, Adam)",
"katmanlar, U-Net, …",
]
for i, t in enumerate(_build):
yy = 3.75 - i * 0.56
viz.boxed_node(ax, 8.725, yy, 4.1, 0.46, t,
fc=COL_WHITE, ec=COL_ROSE_400, tc=COL_TEXT,
fontsize=9.5, lw=1.6, weight="bold")
# --- iki kutu arasında "→ kur" oku ---
viz.arrow_between(ax, (5.25, 3.3), (6.28, 3.3), color=COL_SLATE_400,
lw=2.0, mutation_scale=18, shrink=4)
# --- (ALT) KURAL bandı: bir kez kur (anla) → sonra hazırı kullan ---
ax.add_patch(FancyBboxPatch((0.35, 0.35), 10.8, 1.25,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=COL_BG, ec=COL_CYAN_700, linewidth=2.2, zorder=1))
ax.text(5.75, 1.22, "KURAL: bir şeyi BİR KEZ sıfırdan kur (anla) "
"→ sonra hazır kütüphane versiyonunu kullanmaya hak kazan",
ha="center", va="center", fontsize=10.2,
color=COL_CYAN_800, weight="bold", zorder=3)
ax.text(5.75, 0.66, "« yeniden kur, sonra kullan » — anlamak + verimlilik",
ha="center", va="center", fontsize=9.4,
color=COL_TEXT, style="italic", zorder=3)
plt.tight_layout()
plt.show()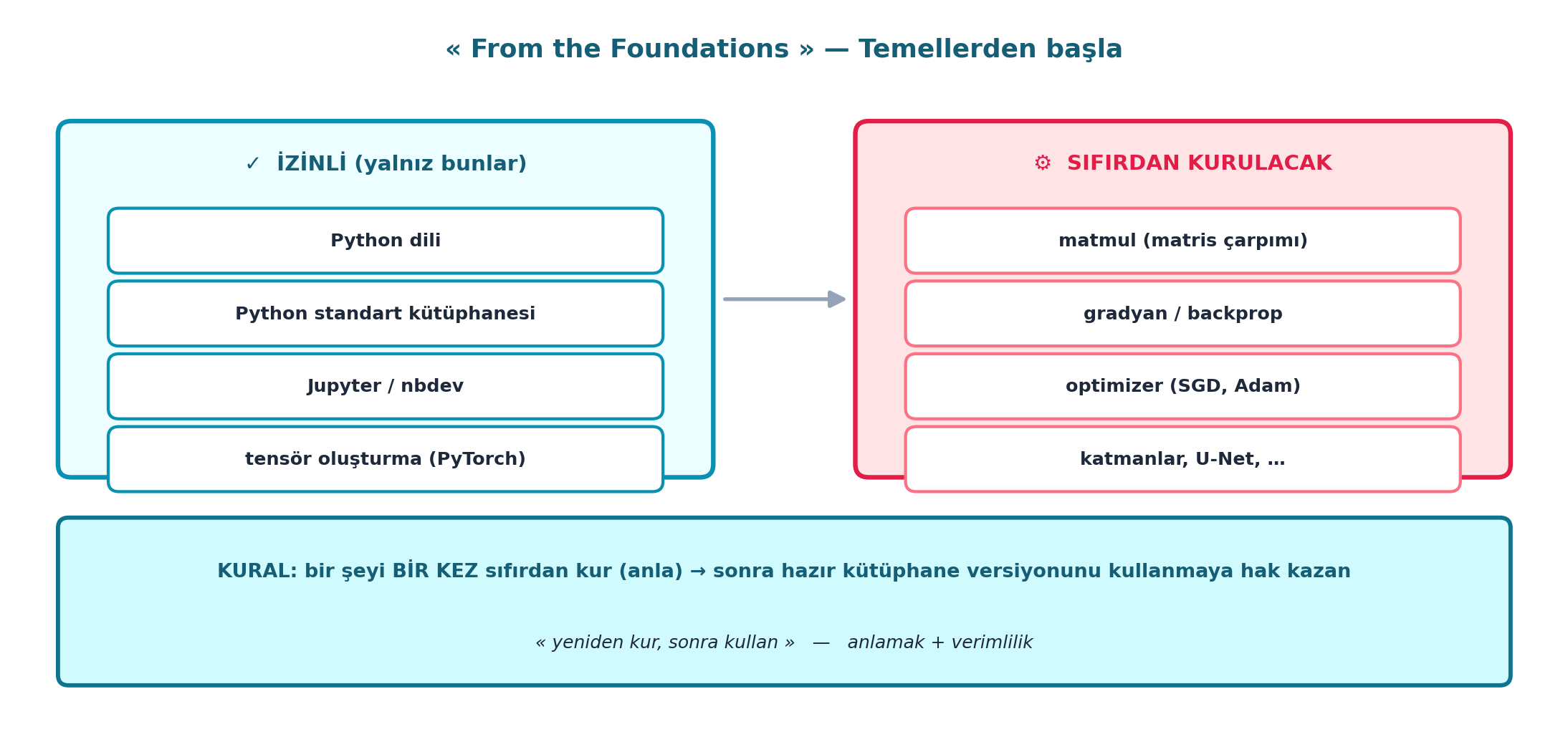
İpucuBuilder Notu — Top-Down Kursun En Bottom-Up Anı
- Geriye (Karpathy): Bu, Karpathy’nin “from scratch” kuralının ta kendisi; fast.ai top-down kursunun en bottom-up bölümü.
- Sezgi: “İzin verilenler” listesi kasıtlı olarak minimaldir — amaç, üst katmanların altında ne olduğunu görmezden gelmemek; her soyutlamayı bir kez elimizle kurmak.
13.10 9. Kuralın İncelikleri: Yeniden Kur, Sonra Kullan
Howard kuralı netleştirir: bir şeyi bir kez sıfırdan kurunca, sonrasında hazır (kütüphane) versiyonunu kullanmaya hak kazanırız. Yani amaç her şeyi sürekli elle yazmak değil; her parçanın altında ne olduğunu bir kez anlamak.
“Once we’ve reimplemented something, we’ll then be allowed to use the big pretrained versions.” — Howard, 53:47
İpucuBuilder Notu — Anlamak + Verimlilik
- İleriye: “Bir kez sıfırdan kur, sonra kütüphaneyi güvenle kullan” — fast.ai’nin tüm pedagojisinin özeti; anlamak + verimlilik.
- Sezgi: Matmul’u bir kez elle yazıp anladıktan sonra PyTorch’un
@’ini güvenle kullanırsın — çünkü artık altında ne olduğunu biliyorsun, “kara kutu” değil.
13.11 10. MNIST Veri Seti
İlk foundation çalışması için klasik veri: MNIST — 28×28 piksel, gri tonlamalı el yazısı rakamlar. Howard veriyi yükler ve tensöre çevirir (izin verilen tek şey: Python + tensor). Her görüntü 28×28 = 784 sayıdır — sıfırdan matmul/model kurmaya tam ölçek: gerçek ama yeterince küçük.
“It’s a classic dataset. They’re 28 by 28 pixel, grayscale images.” — Howard, 57:09
Şekil 13.5 bu veriyi gösterir: solda 28×28 gri ızgara (bir “el yazısı” rakam, bir piksel değeri işaretli), sağda büyük “28 × 28 = 784” hesabı ve foundation notu — Ders 9’un “el yazısı rakam” sezgisinin gerçek verisi.
Kod
d = E.mnist_digit_demo()
img = d["img"]
n_pixels = d["n_pixels"]
fig, (ax_img, ax_txt) = plt.subplots(1, 2, figsize=(10.5, 5))
# SOL — 28×28 sentetik '7' deseni, gri colormap + ızgara çizgileri
ax_img.imshow(img, cmap="gray_r", vmin=0.0, vmax=1.0, interpolation="nearest")
ax_img.set_xticks(np.arange(-0.5, 28, 1), minor=True)
ax_img.set_yticks(np.arange(-0.5, 28, 1), minor=True)
ax_img.grid(which="minor", color=COL_SLATE_400, linewidth=0.4, alpha=0.55)
ax_img.tick_params(which="both", length=0)
ax_img.set_xticks([0, 7, 14, 21, 27])
ax_img.set_yticks([0, 7, 14, 21, 27])
ax_img.tick_params(colors=COL_TEXT, labelsize=8)
ax_img.set_title("28 × 28 gri ızgara — bir 'el yazısı' rakam",
color=COL_CYAN_700, fontsize=12, weight="bold", pad=10)
for spine in ax_img.spines.values():
spine.set_color(COL_SLATE_400)
# bir piksel-değer örneği (0-1 gri) — gövdeden bir hücre işaretle
pr, pc = 5, 12 # üst çubuk içinde (değer = 1.0)
ax_img.add_patch(plt.Rectangle((pc - 0.5, pr - 0.5), 1, 1,
fill=False, edgecolor=COL_ACCENT, linewidth=2.2, zorder=5))
ax_img.annotate(f"piksel ({pr},{pc}) = {img[pr, pc]:.1f}",
xy=(pc, pr), xytext=(pc + 4.5, pr - 3.2),
color=COL_ACCENT, fontsize=9.5, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.8))
# SAĞ — "28 × 28 = 784 sayı" hesabı büyük + foundation notu
ax_txt.axis("off")
ax_txt.set_xlim(0, 1)
ax_txt.set_ylim(0, 1)
ax_txt.text(0.5, 0.80, "28 × 28 = 784", ha="center", va="center",
color=COL_CYAN_700, fontsize=34, weight="bold")
ax_txt.text(0.5, 0.65, "sayı (piksel)", ha="center", va="center",
color=COL_TEXT, fontsize=15)
assert n_pixels == 784 # gerçek değer teyidi
ax_txt.text(0.5, 0.52, "her piksel 0–1 arası bir gri yoğunluk",
ha="center", va="center", color=COL_SLATE_400, fontsize=11)
# alt bilgi kutusu — foundation notu
ax_txt.add_patch(plt.Rectangle((0.05, 0.10), 0.90, 0.28,
facecolor=COL_BG, edgecolor=COL_PRIMARY,
linewidth=2.0, zorder=2))
ax_txt.text(0.5, 0.30,
"foundation hesapları için yeterince küçük",
ha="center", va="center", color=COL_CYAN_700,
fontsize=12.5, weight="bold", zorder=3)
ax_txt.text(0.5, 0.18,
"(Ders 9'un 'el yazısı rakam' verisi — sıfırdan\nmatmul/model kurmaya tam ölçek)",
ha="center", va="center", color=COL_TEXT, fontsize=10.5, zorder=3)
plt.tight_layout()
plt.show()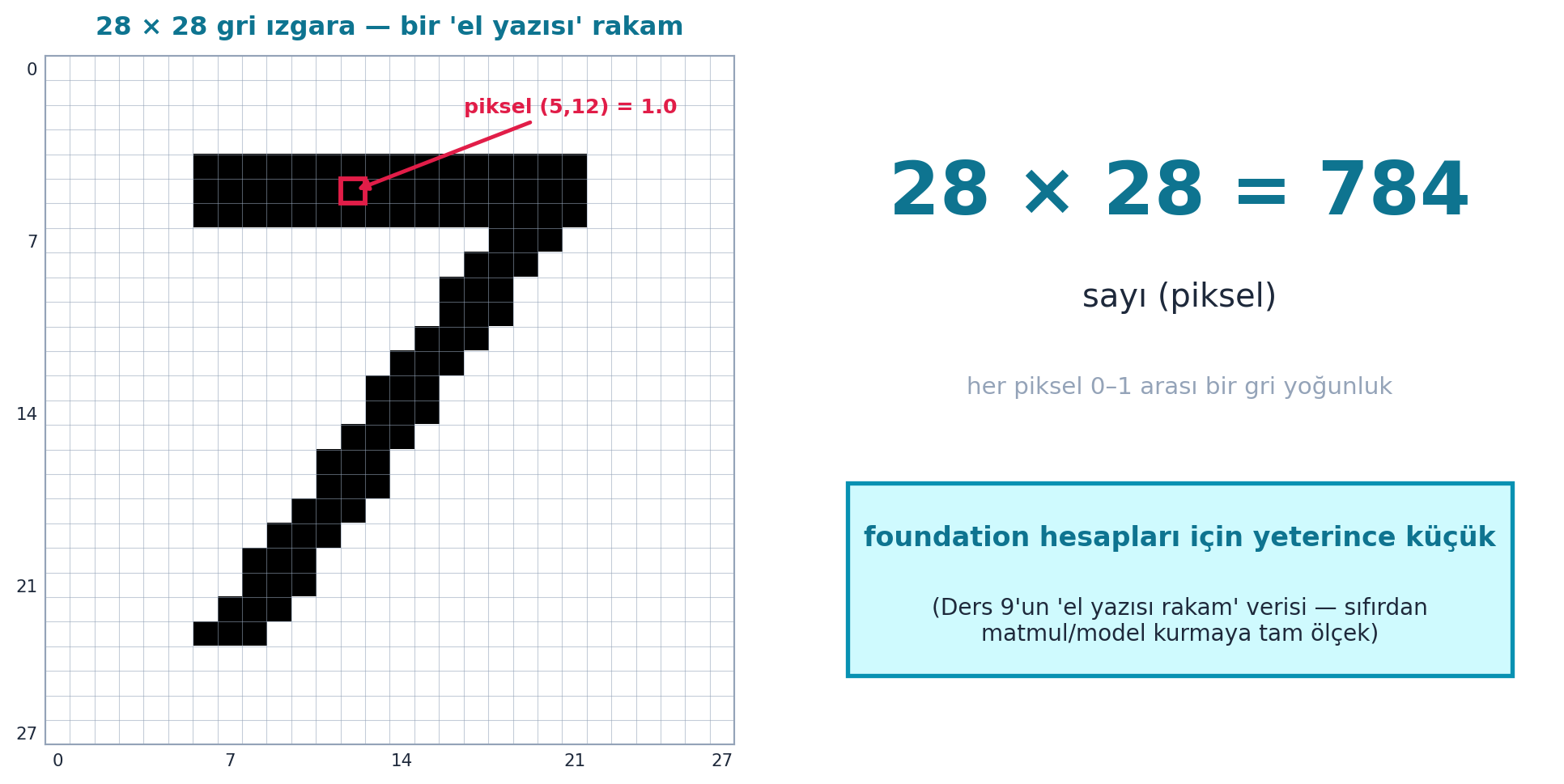
İpucuBuilder Notu — 784 Sayı: Tam Ölçek
- Geriye (Ders 9/9B): Ders 9’un “el yazısı rakam” örneği gerçek veriye dönüşüyor; 28×28 = 784 sayı (foundation hesapları için yeterince küçük).
- Sezgi: MNIST yeterince küçük olduğu için matmul’u Python döngüsüyle bile çalıştırıp ölçebiliriz — yavaşlığı gözle görmenin de ideal boyutu.
13.12 11. Matris Çarpımı: İlk Foundation
İlk yeniden kurulacak şey matris çarpımı (matmul) — sinir ağının kalbi. Bir görüntü batch’ini (m1) ağırlıklarla (m2) çarpmak gerekir. Howard çarpımın tanımıyla başlar: sonuç matrisinin her (i,j) hücresi, m1’in i. satırı ile m2’nin j. sütununun dot product’ıdır.
“We’re going to take a deep dive into matrix multiplication today.” — Howard, 53:40
İpucuBuilder Notu — matmul = @ Operatörünün İçi
- Geriye (Ders 5/18.06): matmul, Ders 5’teki
@operatörünün içi; 18.06’nın temel işlemi. Şimdi onu sıfırdan kuruyoruz. - Sezgi: “Her hücre = bir satır × bir sütun dot product” tek cümlelik tanımdır; bütün matris çarpımı bu tanımın her (i,j) için tekrarıdır.
13.13 12. Üç İç İçe Döngüyle Matmul
En yalın hâl: üç iç içe döngü. Dış iki döngü çıktı hücrelerini (i, j), iç döngü dot product’ı (k) gezer.
def matmul(a, b):
(ar, ac), (br, bc) = a.shape, b.shape # satir/sutun sayilari
c = torch.zeros(ar, bc)
for i in range(ar):
for j in range(bc):
for k in range(ac):
c[i,j] += a[i,k] * b[k,j] # dot product birikimi
return cŞekil 13.6 bu üç döngüyü görselleştirir: solda iç içe kutular (i sarar j, j sarar k; en içteki c[i,j] += a[i,k] · b[k,j]), sağda küçük bir matris çarpımı şeması — a’nın i. satırı ile b’nin j. sütununun c’nin (i,j) hücresine nasıl aktığı.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5),
gridspec_kw={"width_ratios": [1.35, 1.0]})
# ---------------------------------------------------------------------------
# SOL panel — üç iç içe döngü (i sarar j, j sarar k)
# ---------------------------------------------------------------------------
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.axis("off")
axL.set_title("Üç iç içe döngü", color=COL_TEXT, fontsize=12.5, weight="bold")
# Dış kutu: for i (çıktı satırı) — en geniş, cyan
viz.boxed_node(axL, 5.0, 8.55, 8.6, 2.4,
"for i (çıktı satırı 0…ar−1)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_700,
fontsize=11.5, lw=2.4)
# Orta kutu: for j (çıktı sütunu) — i'nin içinde
viz.boxed_node(axL, 5.0, 6.4, 7.2, 1.55,
"for j (çıktı sütunu 0…bc−1)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_700,
fontsize=11, lw=2.2)
# İç kutu: for k (dot product) — j'nin içinde, ROSE vurgu
viz.boxed_node(axL, 5.0, 4.25, 6.0, 2.05,
"for k (dot product)\nc[i,j] += a[i,k] · b[k,j]",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT,
fontsize=10.5, lw=2.4)
# "iç döngü = Ders 5 (girdi × ağırlık) topla" notu — alta, rose ok
axL.annotate(
"iç döngü (k) = Ders 5'in\n(girdi × ağırlık) toplamı",
xy=(5.0, 3.25), xytext=(5.0, 1.35),
ha="center", va="center", fontsize=10, color=COL_ACCENT, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0,
shrinkA=4, shrinkB=4),
)
# ---------------------------------------------------------------------------
# SAĞ panel — küçük matris çarpımı: a (ar×ac) @ b (ac×bc) = c (ar×bc)
# ---------------------------------------------------------------------------
axR.set_xlim(0, 10)
axR.set_ylim(0, 10)
axR.axis("off")
axR.set_title("a @ b = c", color=COL_TEXT, fontsize=12.5, weight="bold")
# matris a (ar×ac) — sol, vurgulu satır i
viz.boxed_node(axR, 1.7, 6.0, 2.4, 3.4, "a\n(ar×ac)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_700,
fontsize=11, lw=2.2)
axR.plot([0.75, 2.65], [6.85, 6.85], color=COL_ACCENT, lw=3.2,
solid_capstyle="round", zorder=4) # satır i
# matris b (ac×bc) — orta üst, vurgulu sütun j
viz.boxed_node(axR, 4.9, 8.05, 2.4, 2.6, "b\n(ac×bc)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_700,
fontsize=11, lw=2.2)
axR.plot([4.9, 4.9], [6.95, 9.15], color=COL_ACCENT, lw=3.2,
solid_capstyle="round", zorder=4) # sütun j
# matris c (ar×bc) — sağ alt, vurgulu hücre (i,j)
viz.boxed_node(axR, 7.9, 4.1, 2.4, 3.4, "c\n(ar×bc)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT,
fontsize=11, lw=2.4)
viz.boxed_node(axR, 7.9, 5.15, 0.7, 0.7, "",
fc=COL_ROSE_400, ec=COL_ACCENT, tc=COL_WHITE,
fontsize=8, lw=1.8) # hücre (i,j)
axR.text(8.55, 5.15, "(i,j)", ha="left", va="center",
fontsize=9, color=COL_ACCENT, weight="bold")
# satır i ve sütun j → hücre (i,j) oklar
viz.arrow_between(axR, (2.9, 6.85), (7.3, 5.45),
color=COL_ACCENT, lw=1.8, shrink=6,
connectionstyle="arc3,rad=-0.18")
viz.arrow_between(axR, (4.9, 6.75), (7.55, 5.45),
color=COL_ACCENT, lw=1.8, shrink=6,
connectionstyle="arc3,rad=0.18")
# açıklama: her hücre = satır × sütun dot product
axR.text(5.0, 1.35,
"her hücre = satır × sütun\ndot product (k üzerinden çarpım-toplam)",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, weight="bold")
plt.tight_layout()
plt.show()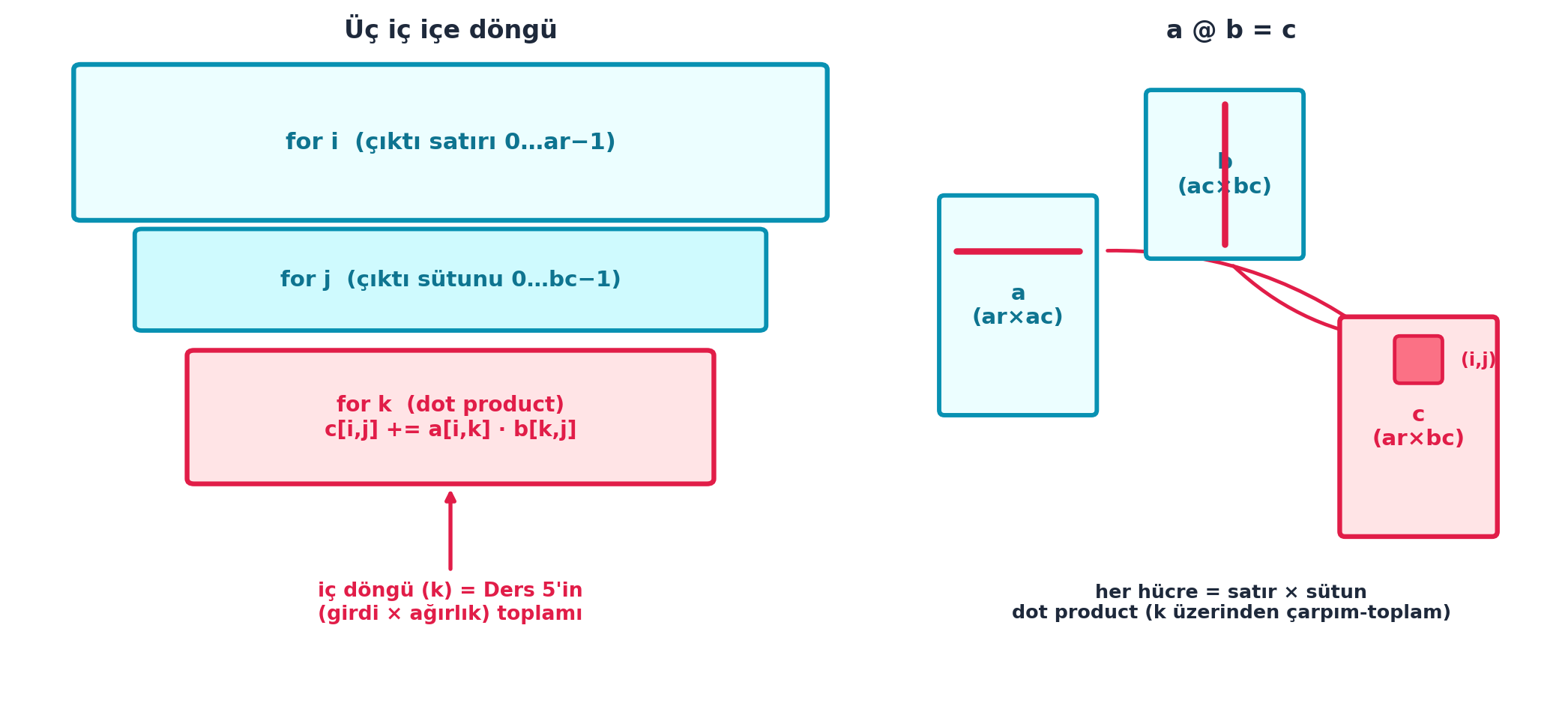
İpucuBuilder Notu — İç Döngü = Ders 5’in Toplamı
- Geriye (Ders 5): İç döngü (k) tam Ders 5’teki “(girdi × ağırlık) topla” işlemi; burada her hücre için tekrarlanıyor.
- Sezgi: Dış iki döngü “hangi çıktı hücresi”, iç döngü “o hücrenin değeri (satır×sütun çarpım-toplamı)” — matematiksel tanımın birebir koda dökülmüş hâli.
13.14 13. Python Döngüsü Çok Yavaş
Bu çalışır ama korkunç yavaştır: MNIST boyutunda matmul Python döngüsüyle saniyeler sürer (5×784 × 784×10 = milyonlarca işlem, her biri yorumlanan Python). Howard %timeit ile ölçer — bir sinir ağı için kabul edilemez. Yavaşlığın tek sebebi Python’un yorumlanan bir dil olması: her c[i,j] += a[i,k] * b[k,j] işlemi tek tek, yavaş yorumlayıcı üzerinden çalışır.
“[This is] really slow.” — Howard, ~58:00 (matmul timing)
Şekil 13.7 bu yavaşlığı gerçek bir benchmark ile gösterir: aynı çarpımı bir kez üç iç içe Python döngüsüyle, bir kez de optimize (C/BLAS) @ ile ölçer; ikisinin sonucu np.allclose ile aynıdır ama süreler arasında yüzlerce kat fark vardır.
Kod
b = E.matmul_benchmark_demo() # 3-döngü vs numpy @ GERÇEK zamanlama
loop_ms, numpy_ms = b["loop_ms"], b["numpy_ms"]
speedup = b["speedup"]
(ar, ac), (_, bc) = b["shapes"]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5),
gridspec_kw={"width_ratios": [1.15, 1.0]})
# SOL — süre çubukları (log skala), Python döngüsü vs optimize @
labels = ["3 iç içe\nPython döngüsü", "optimize\nC/BLAS @"]
vals = [loop_ms, numpy_ms]
cols = [COL_ACCENT, COL_PRIMARY]
bars = axL.bar(labels, vals, color=cols, width=0.6,
edgecolor=COL_WHITE, linewidth=1.4, zorder=3)
axL.set_yscale("log")
for x, v, col in zip(range(2), vals, cols):
axL.text(x, v * 1.18, f"{v:.2f} ms", ha="center", va="bottom",
fontsize=11.5, weight="bold", color=col, zorder=4)
axL.set_ylabel("süre (ms, log)", fontsize=11)
axL.set_title("Aynı çarpım — iki yol", fontsize=12.5,
weight="bold", color=COL_CYAN_700, pad=10)
viz.apply_style(axL)
axL.grid(True, axis="y", alpha=0.22, color=COL_SLATE_400)
axL.grid(False, axis="x")
# SAĞ — hızlanma + doğruluk teyidi
axR.axis("off")
axR.set_xlim(0, 1)
axR.set_ylim(0, 1)
axR.text(0.5, 0.82, f"≈ {speedup:,.0f}×", ha="center", va="center",
color=COL_ACCENT, fontsize=40, weight="bold")
axR.text(0.5, 0.66, "optimize @ daha hızlı", ha="center", va="center",
color=COL_TEXT, fontsize=13)
axR.text(0.5, 0.52,
f"matris: {ar}×{ac} @ {ac}×{bc}\n"
f"iç döngü işlemi: {b['inner_ops']:,}",
ha="center", va="center", color=COL_SLATE_400, fontsize=10.5)
# doğruluk kutusu — iki yol AYNI sonucu verir
axR.add_patch(plt.Rectangle((0.08, 0.12), 0.84, 0.26,
facecolor=COL_BG, edgecolor=COL_PRIMARY,
linewidth=2.0, zorder=2))
ok = "✓" if b["correct"] else "✗"
axR.text(0.5, 0.31, f"{ok} np.allclose(3-döngü, @) = {b['correct']}",
ha="center", va="center", color=COL_CYAN_700,
fontsize=12, weight="bold", zorder=3)
axR.text(0.5, 0.19, "aynı matematik, sadece hız farkı\n(yavaşlık = Python yorumlayıcısı)",
ha="center", va="center", color=COL_TEXT, fontsize=10, zorder=3)
plt.tight_layout()
plt.show()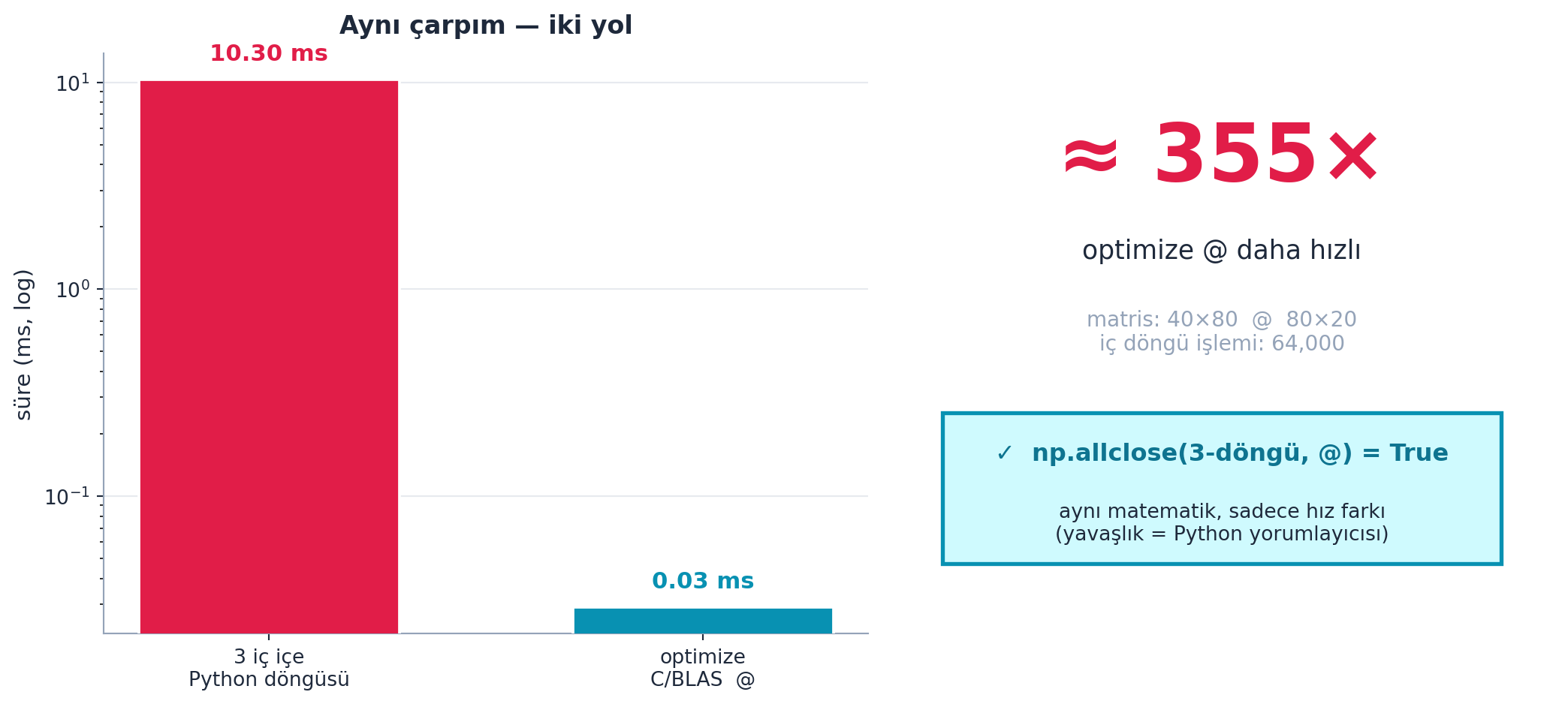
İpucuBuilder Notu — Yavaşlığın Kaynağı: Yorumlayıcı
- İleriye: Yavaşlığın sebebi Python yorumlayıcısının her işlemi tek tek yapması; çözüm, işi optimize edilmiş (C/GPU) koda devretmek — sonraki adımlar (numba, broadcasting).
- Builder ipucu: Önemli olan benchmark’ın iki yanının aynı sonucu vermesi (
np.allclose✓); hız kazanırken doğruluğu kaybetmediğimizi her zaman doğrula.
13.15 14. Numba ile Hızlandırma
İlk hızlandırma: Numba. @njit dekoratörü bir Python fonksiyonunu (örn. dot product) makine koduna derler; iç döngü artık C hızında çalışır. Numba’nın güzelliği şudur: Python’u Python gibi yazmaya devam edersin, ama dekoratör fonksiyonu çalışma anında (JIT) derler.
from numba import njit
@njit
def dot(a, b):
res = 0.
for i in range(len(a)): res += a[i] * b[i]
return res
# matmul artik en ic dongu yerine derlenmis dot() kullanir -> cok daha hizli
İpucuBuilder Notu — (njit?): JIT ile C Hızı
- İleriye (Ders 11): Numba bir ara adım; asıl hız broadcasting ve
@(PyTorch’un GPU GEMM’i) ile gelir — Ders 11’in konusu. - Sezgi:
@njitilk çağrıda derler (küçük gecikme), sonraki çağrılarda C hızında çalışır; iç döngünün yorumlama yükünü tamamen kaldırır.
13.16 15. İleriye: Broadcasting
Howard sonraki adımı işaret eder: döngüleri tamamen kaldırıp broadcasting ve tensör işlemleriyle matmul yapmak (Ders 5’te gördüğümüz broadcasting’in derinleşmesi). Bu, hem çok daha kısa hem optimize C/GPU koduna düşen versiyondur — döngü yazmadan, tek bir tensör ifadesiyle tüm satırı işlemek.
İpucuBuilder Notu — Broadcasting: Döngüsüz Tensör
- Geriye (Ders 5/6): Broadcasting (Ders 5) burada matmul’u hızlandırmak için tam gücüyle kullanılacak (Ders 11).
- İleriye (Ders 11):
a[i,:] * bgibi bir ifade tüm satırı tek seferde çarpar; döngüleri kaldırmak hem hızı hem okunabilirliği artırır.
13.17 16. Kapanış
Ders 10, Part 2’nin dönüm noktasıydı: Stable Diffusion’ı (distillation + tam pipeline) bitirdik ve « from the foundations » yolculuğunu başlattık. Kural net: yalnızca Python + standart kütüphane + tensör; her şeyi sıfırdan kur, bir kez kurunca hazırı kullan. İlk foundation matris çarpımıydı — üç döngüden numba’ya, oradan (Ders 11’de) broadcasting’e.
“We’ll be building our own kind of framework from scratch.” — Howard, 50:33
Şekil 13.8 dersin sentezidir: solda L10’un parçaları (distillation, from-the-foundations kuralı, matris çarpımı sıfırdan, MNIST 28×28, yeniden kur sonra kullan), sağda her birinin nereden/nereye köprüsü — DDIM Ders 21 az-adım hedefi, Karpathy from-scratch (§4.F), Ders 5 @ + 18.06 → Ders 11 broadcasting, Ders 9 sezgisi, Ders 11-25 omurgası.
Kod
fig, ax = plt.subplots(figsize=(12, 6.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.5)
ax.axis("off")
fig.patch.set_facecolor(COL_WHITE)
# Başlıklar
ax.text(2.4, 6.25, "L10'da", ha="center", va="center",
fontsize=14, weight="bold", color=COL_CYAN_700)
ax.text(9.2, 6.25, "nereden / nereye", ha="center", va="center",
fontsize=14, weight="bold", color=COL_ACCENT)
# Merkez düğüm: L10 dönüm noktası
boxed_node(ax, 2.4, 3.25, 3.4, 0.95,
"L10 — Daha Derine\n(Part 2 dönüm noktası)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=11.5, lw=2.6)
# SOL: L10 parçaları (rose) — 5 satır
left_x = 2.4
ys = [5.55, 4.45, 3.25, 2.05, 0.85]
left_labels = [
"distillation",
"from the foundations kuralı",
"matris çarpımı sıfırdan",
"MNIST 28×28",
"yeniden kur, sonra kullan",
]
# SAĞ: kaynaklar / köprüler (cyan)
right_x = 9.2
right_labels = [
"öğretmen→öğrenci sıkıştırma\n+ DDIM Ders 21 az-adım hedefi",
"Karpathy 'from scratch' (§4.F)\nfast.ai'nin en bottom-up bölümü",
"Ders 5 @ operatörü + 18.06\n→ ileriye Ders 11 broadcasting",
"Ders 9 'el yazısı rakam' sezgisi\n→ gerçek veri",
"anlamak + verimlilik\nDers 11-25 omurgası",
]
for y, ll, rl in zip(ys, left_labels, right_labels):
# sol parça (rose)
boxed_node(ax, left_x, y, 3.2, 0.78, ll,
fc=COL_BG_ROSE, ec=COL_ROSE_400, tc=COL_TEXT,
fontsize=10.0, lw=1.8)
# sağ köprü (cyan)
boxed_node(ax, right_x, y, 4.0, 0.86, rl,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=9.3, lw=1.8)
# ok: sol parça → sağ köprü
arrow_between(ax, (left_x + 1.6, y), (right_x - 2.0, y),
color=COL_CYAN_400, lw=1.8, mutation_scale=15, shrink=4)
# Merkez düğümden sol parçalara ince bağ çizgileri (L10 = bu parçaların toplamı)
for y in ys:
if abs(y - 3.25) > 0.05:
ax.plot([left_x, left_x], [3.25, y], color=COL_SLATE_400,
lw=0.8, alpha=0.35, zorder=0)
plt.tight_layout()
plt.show()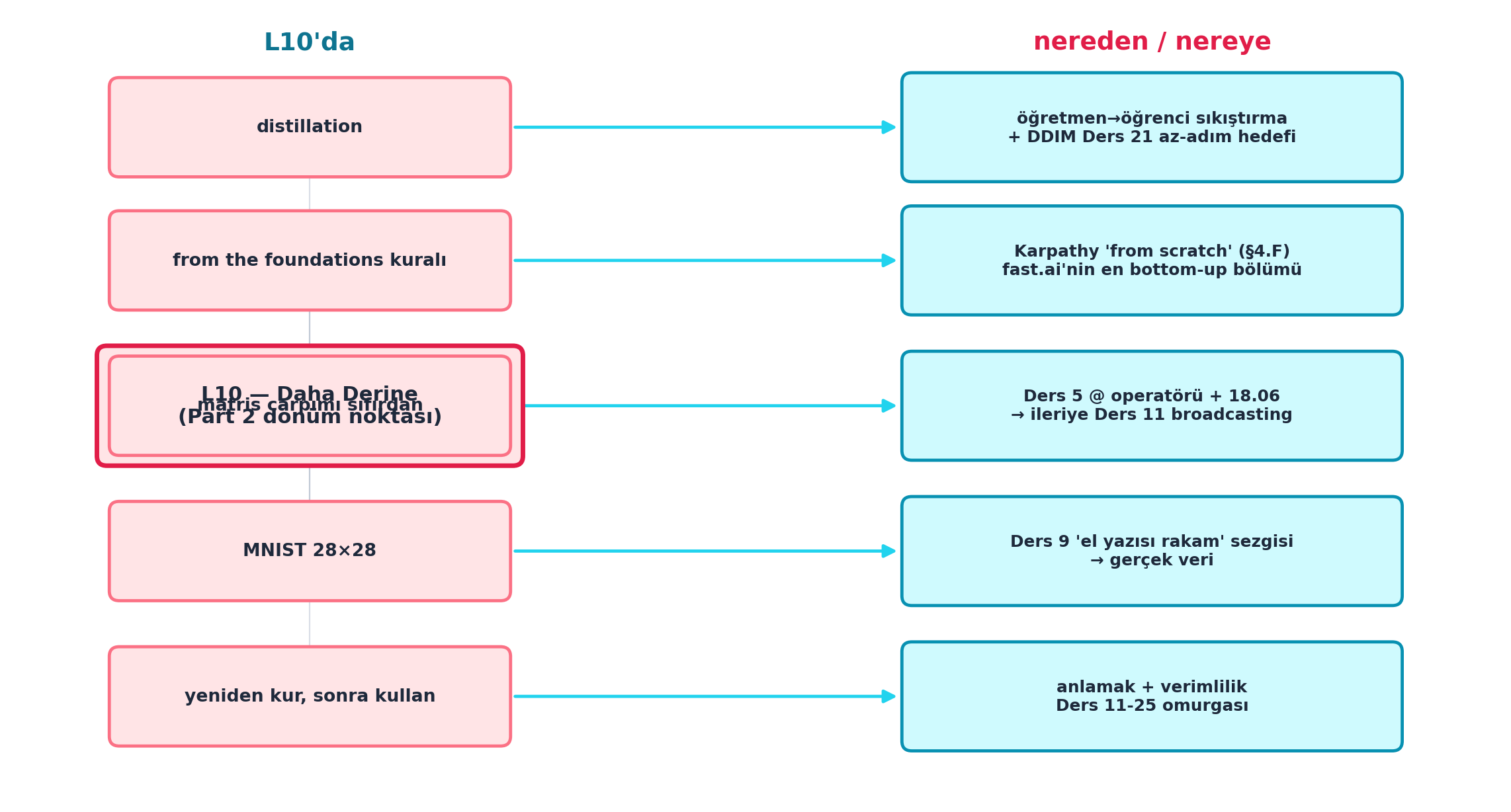
İpucuBuilder Notu — Foundations Zinciri Açılıyor
- İleriye (Ders 11+): Sıradaki dersler matmul’u tamamlar (broadcasting/Einstein toplamı), sonra backprop, Learner ve nihayet diffusion’ı sıfırdan kurar — Karpathy ruhunun fast.ai’deki en yoğun hâli.
- Tek cümle: Bu ders bir kapı; arkasında Stable Diffusion’a kadar uzanan, her parçası elle kurulan bir foundations yolculuğu var.
13.18 Bu Dersin Özeti
- Part 2 Ders 10 bir dönüm noktasıdır: Stable Diffusion’ı bitirir, « from the foundations » omurgasını başlatır (dönüm).
- Distillation ile bir öğretmen modelin adımları, öğrenci modelin daha az adımına sıkıştırılır; progressive distillation’da her turda adım yarıya iner (distillation, progressive).
- SD pipeline kod olarak tekrar gezilir: CLIP → latent gürültü → U-Net+CFG döngüsü → scheduler → VAE decode; başlangıç gürültüsü doğru varyansa (
init_noise_sigma) ölçeklenir (pipeline, ölçekleme). - « From the foundations » kuralı: yalnızca Python + standart kütüphane + tensör izinli; geri kalan sıfırdan kurulur (felsefe).
- Kural inceliği: bir şeyi bir kez sıfırdan kurunca, hazır versiyonunu kullanmaya hak kazanırsın (incelik).
- İlk foundation matris çarpımı; sonucun her hücresi bir satır × sütun dot product’ıdır (matmul).
- En yalın matmul üç iç içe döngüdür ama Python’da korkunç yavaştır (milyonlarca yorumlanan işlem) (üç döngü, yavaşlık).
- Numba ((njit?)) iç döngüyü makine koduna derleyerek hızlandırır; asıl hız (broadcasting/GPU) Ders 11’de gelir (numba, broadcasting).
ÖnemliTek Bir Cümle
Ders 10, Stable Diffusion’ı kullanmayı bitirip onu sıfırdan kurmaya başladığımız andır: yalnızca Python ve tensörle başlayıp, ilk foundation olan matris çarpımını üç döngüyle kurar, sonra adım adım hızlandırırız — çünkü bir şeyi bir kez sıfırdan kurmak, onu gerçekten anlamaktır.
13.19 Kontrol Soruları
NotSoru 1: « From the foundations » kuralı tam olarak nedir? Neden bir kez kurduktan sonra hazır versiyonu kullanmaya izin var?
Cevap:
Kural: yalnızca Python, Python standart kütüphanesi, Jupyter/nbdev ve tensör oluşturma kullanılabilir; matmul, gradyan, optimizer, katmanlar, U-Net dahil her şey sıfırdan kurulur. Amaç her parçanın altında ne olduğunu anlamaktır. “Bir kez kurduktan sonra hazırı kullan” izni şunun içindir: hedef sürekli elle kod yazmak değil, mekanizmayı bir kez kavramaktır. Matmul’u bir kez sıfırdan yazıp anladıktan sonra, sonraki derslerde PyTorch’un @’ini güvenle kullanırsın — çünkü artık altında ne olduğunu biliyorsun. Bu, anlamak ile verimliliği birleştirir. (Şekil 13.4 bu kuralı şematize eder.)
NotSoru 2: Üç iç içe döngülü matmul ne yapar? Hangi döngü neyi gezer?
Cevap:
Sonuç matrisinin her hücresini (i,j), m1’in i. satırı ile m2’nin j. sütununun dot product’ı olarak hesaplar. Dış döngü (i) çıktının satırlarını, ortadaki döngü (j) çıktının sütunlarını gezer; en içteki döngü (k) ise o hücre için dot product’ı biriktirir: c[i,j] += a[i,k] * b[k,j]. Yani dış iki döngü “hangi çıktı hücresi”, iç döngü “o hücrenin değeri (satır×sütun çarpım toplamı)”. Bu, matris çarpımının matematiksel tanımının birebir koda dökülmüş hâlidir. (Şekil 13.6 bu üç döngüyü görselleştirir.)
NotSoru 3: Python döngülü matmul neden bu kadar yavaştır? Numba bunu nasıl hızlandırır?
Cevap:
Python yorumlanan bir dildir: her c[i,j] += a[i,k] * b[k,j] işlemi tek tek, yavaş yorumlayıcı üzerinden çalışır. MNIST boyutunda (5×784 ile 784×10) bu milyonlarca işlem demektir ve saniyeler sürer — bir sinir ağı için kabul edilemez. Numba’nın @njit dekoratörü, işaretlenen fonksiyonu (örn. dot product) çalışma anında makine koduna derler (JIT); böylece iç döngü artık Python yorumlayıcısı yerine C hızında çalışır. Numba bir ara adımdır; asıl hız broadcasting ve GPU matris çarpımıyla (Ders 11) gelir. (Şekil 13.7 döngü vs optimize @ farkını gerçek benchmark’la gösterir.)
NotSoru 4: Distillation diffusion’ı nasıl hızlandırır? (builder bağlantısı)
Cevap:
Diffusion yavaştır çünkü üretim çok sayıda (örn. 1000) sampling adımı gerektirir. Distillation, iyi ama yavaş bir öğretmen modeli, daha az adımda aynı sonucu veren bir öğrenci modele “öğretir”. Progressive distillation’da öğrenci, öğretmenin iki adımını tek adımda yapmayı öğrenir; sonra bu öğrenci yeni öğretmen olur ve süreç tekrarlanır — her turda gereken adım sayısı yarıya iner. Builder açısından: distillation, büyük/yavaş bir modelin bilgisini küçük/hızlı bir modele aktarmanın genel bir yöntemidir (sadece diffusion değil; LLM’lerde de yaygın) — kalite/hız dengesini production için optimize eder. (Şekil 13.3 1000 → 7 sıkışmasını gerçek aritmetikle gösterir.)
13.20 Egzersizler
Egzersiz 1 (Direkt uygulama). MNIST’i yükle (28×28, tensöre çevir) ve üç iç içe döngülü matmul’u kendin yaz; bir batch ile ağırlık matrisini çarp. (§12)
Egzersiz 2 (İki-aşamalı). %timeit ile döngülü matmul’un süresini ölç; sonra Numba @njit’li dot product ile hızlandır ve süreyi kıyasla. (Şekil 13.7’i kendi sayınla yeniden üret — §13-14)
Egzersiz 3 (Edge case). matmul’da boyut uyuşmazlığı (m1’in sütunu ≠ m2’nin satırı) durumunda ne olduğunu gözle; neden ac = br olmak zorunda açıkla.
Egzersiz 4 (Kavramsal). « From the foundations » kuralına göre hangi araçlar izinli, hangileri değil? Bir matmul’u neden NumPy ile değil elle yazıyoruz? (§8)
Egzersiz 5 (Sonraki dersin habercisi — Ders 11). Üç döngüyü broadcasting ile nasıl kaldırabileceğini araştır; a[i,:] * b gibi bir ifadenin tüm satırı tek seferde nasıl çarptığını düşün. (§15)
13.21 Sonraki: Ders 11 İçin Hazırlık
Ders 11: Matris Çarpımı (Matrix multiplication)
Ders 10 matmul’u üç döngüyle kurup numba ile hızlandırdı. Ders 11 işi tamamlar: broadcasting ve Einstein toplamı ile döngüleri tamamen kaldırıp matmul’u optimize (ve sonunda GPU) hıza çıkarmak. Foundations yolculuğunun ilk tam adımı.
Ana konular (Ders 11):
- Broadcasting ile matmul (döngüsüz)
- Broadcasting kuralları (derinlemesine)
- Einstein toplamı (einsum)
@ve GPU hızı
UyarıDers 11 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 2 — matmul’u kur ve numba ile hızlandır).
- « From the foundations » kuralını kendi cümlelerinle yaz.
- Ana cümleyi tekrar oku: “Bir şeyi bir kez sıfırdan kurmak, onu gerçekten anlamaktır.”
13.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| From the foundations | Yalnızca Python + standart kütüphane + tensör; gerisi sıfırdan | 53:47 |
| Distillation | Öğretmen modelin bilgisini hızlı öğrenci modele aktarma | 16:56 |
| Progressive distillation | Her turda adım sayısını yarıya indirme (1000 → 7) | 19:36 |
init_noise_sigma |
Başlangıç gürültüsünü doğru varyansa ölçekleme | 41:29 |
| SD pipeline | CLIP → latent → U-Net+CFG döngüsü → scheduler → VAE | 39:36 |
| MNIST | 28×28 gri el yazısı rakam (784 sayı); klasik veri | 57:09 |
| Matris çarpımı (matmul) | Her hücre = satır × sütun dot product | 53:40 |
| Üç iç içe döngü | i (satır), j (sütun), k (dot product) gezen yalın matmul | 53:40 |
| Python yavaşlığı | Yorumlanan döngü; milyonlarca işlem yavaş | 58:00 |
| Numba ((njit?)) | Python fonksiyonunu makine koduna derleme (JIT) | 58:00 |
| Yeniden kur, sonra kullan | Bir kez sıfırdan kur, sonra hazır versiyon serbest | 53:47 |
| Broadcasting (ileriye) | Döngüsüz tensör işlemi; Ders 11’de matmul hızı | 50:33 |
13.23 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: L10’un Tanıdık Kökleri
Bu ders, Stable Diffusion’ı bitirip foundations’a inerken her parçayı tanıdık kavramlara bağlar; köprülerin özeti:
- From the foundations → Karpathy “from scratch” felsefesi; anlamak için bir kez elle kur (felsefe).
- Distillation → büyük/yavaş modeli küçük/hızlıya sıkıştırma; diffusion ve LLM’lerde production standardı (distillation).
- Matris çarpımı → sinir ağının kalbi (Ders 5
@, 18.06); her katman bir matmul (matmul). - Python yavaşlığı → Numba/GPU → sayısal hesabın optimize koda devri; broadcasting (Ders 11) (yavaşlık, numba).
- init_noise_sigma → reparameterization (Ders 9B); doğru ölçek üretimi belirler (ölçekleme).
- MNIST 28×28 → foundation hesapları için yeterince küçük; Ders 9’un “el yazısı rakam” sezgisinin verisi (MNIST).
ÖnemliBu dersten tek bir şey alıp gideceksen
Part 2’nin asıl yolculuğu burada başlar. Stable Diffusion’ı kullanmayı öğrendik; şimdi onu yalnızca Python ve tensörle, parça parça, sıfırdan kuracağız. İlk parça matris çarpımı — üç basit döngü, sonra hızlandırma. Howard’ın kuralı net: bir şeyi bir kez sıfırdan kur, gerçekten anla, sonra kütüphaneyi güvenle kullan. Karpathy’nin ruhu, fast.ai’nin omurgasında.