flowchart TD
L12(["L12 — Mean Shift Clustering"])
%% ÜST PARÇA — matmul'u bitir
FIN["matmul'u BİTİR"]
EIN["einsum 'ik,kj->ij'<br/>(tekrarlanan k =<br/>çarpım + toplam)"]
AT["@ operatörü<br/>(BLAS / cuBLAS)"]
CUDA["CUDA kernel<br/>(her hücre = bir<br/>iş parçacığı / thread)"]
L12 --> FIN
FIN --> EIN
EIN --> AT
AT --> CUDA
%% ALT PARÇA — ilk foundations algoritması
MS["ilk foundations algoritması:<br/>mean shift clustering"]
DATA["etiketsiz veri"]
GK["Gaussian kernel<br/>(mesafe → ağırlık)"]
SHIFT["her noktayı ağırlıklı<br/>ortalamaya kaydır"]
REP["tekrarla"]
CLU["kümeler"]
BW["bandwidth →<br/>küme sayısını belirler"]
KM["k-means'ten farkı:<br/>k önceden GEREKMEZ"]
L12 --> MS
MS --> DATA
DATA --> GK
GK --> SHIFT
SHIFT --> REP
REP --> CLU
BW --> CLU
CLU --> KM
classDef cyan fill:#cffafe,stroke:#0e7490,stroke-width:1.5px,color:#155e75;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:1.5px,color:#9f1239;
class L12,FIN,AT,CUDA,DATA,GK,SHIFT,REP,CLU,BW cyan;
class EIN,MS,KM rose;
15 Ders 12 — Mean Shift Kümeleme (Mean shift clustering)
Part 2’nin dördüncü dersi iki şey yapar. Önce matris çarpımını « bitirir »: einsum’la kompakt notasyona, sonra @ operatörüyle (BLAS/cuBLAS) en kısa hâle, ardından GPU CUDA kernel’ına taşır. Sonra ilk tam « from the foundations » algoritmasını sıfırdan kurar: mean shift clustering — etiketsiz veriyi, her noktayı yakın komşularının Gaussian-ağırlıklı ortalamasına çekerek kümeleyen bir yöntem. Anahtar fikir tek cümleyle: matmul’u einsum/@ ile bitirip GPU’ya taşıdık; sonra küme sayısını önceden bilmeden veriyi kümeleyen mean shift’i sıfırdan kurduk.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 12: Mean shift clustering (~110 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 12
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/01_matmul + 02_meanshift
- Okuma süresi: ~38 dk
- 🔁 İki kol: İlk yarı matmul’u bitirir (einsum →
@→ GPU kernel), ikinci yarı ilk foundations algoritması (mean shift). Bu ders ETAP 4 (Temeller A) içindedir.
15.1 Bu Derste Ne Var?
Part 2’nin dördüncü dersi matris çarpımını bitirir (einsum + @ + GPU) ve ilk tam “from foundations” algoritmasını sıfırdan kurar: mean shift clustering. Açılışta eğlenceli bir demo var: CLIP Interrogator (görüntüden prompt üretme).
Üç temel fikir bu dersin omurgasını kurar:
- Einstein toplamı (einsum) —
'ik,kj->ij'gibi kompakt bir notasyonla matris çarpımı; tekrarlanan indeks çarpım+toplamı ifade eder (einsum → matmul). @ve GPU — matmul’un en kısa hâlia @ b; GPU’da bir CUDA kernel ile binlerce işlem paralel (@ ve hız → CUDA kernel).- Mean shift clustering — etiketsiz veriyi, her noktayı yakın noktaların (Gaussian ağırlıklı) ortalamasına doğru kaydırarak kümelere ayırma (mean shift → döngü).
“Einstein summation is a compact representation for representing products and sums.” — Howard, 12:03
Şekil 28.1 bu yapıyı tek bir yol haritasında birleştirir: üstte “matmul’u bitir” kolu (einsum → @/BLAS → CUDA kernel ile hızlandırma), altta “from the foundations”ın ilk algoritması mean shift clustering (etiketsiz veri → Gaussian kernel → ağırlıklı ortalamaya kaydır → tekrarla → kümeler; bandwidth küme sayısını belirler, k-means’ten farkı k’yı önceden gerektirmez).
İpucuBuilder Notu — İki Kol, Tek Ders
- Geriye (Ders 11/18.06): Ders 11 broadcasting matmul’u verdi; burada einsum/
@ile bitiyor. matmul = 18.06’nın kalbi; mean shift = unsupervised learning (6.S191 yelpazesi). - İleriye (Ders 13 / NYU §4.J): Mean shift, gradient-tabanlı olmayan bir foundations algoritması; Ders 13’ten itibaren backprop’a geçilir. Clustering, NYU’nun self-supervised/temsil öğrenme bağlamıyla akraba.
- Tek cümle: matmul’u einsum/
@ile bitirip GPU’ya taşıdık; sonra her noktayı komşularının ağırlıklı ortalamasına çeken mean shift’i sıfırdan kurduk.
15.2 1. CLIP Interrogator: Görüntüden Prompt
Howard eğlenceli bir demoyla açar: CLIP Interrogator — bir görüntü verirsin, sana onu üretebilecek bir prompt tahmini döner. CLIP image encoder görüntüyü bir embedding’e (birkaç float’lık vektör) çevirir; Interrogator bu embedding’e en uyan metin parçalarını (medium, sanatçı, stil) arar.
“The CLIP Interrogator… I upload [an image and it suggests a prompt].” — Howard, 0:52
Howard önemli bir nüans ekler: bu, görüntüyü tam tersine çevirmez — embedding küçük olduğu için bilgi kaybı vardır; yalnızca yaklaşık bir prompt tahminidir. Yani embedding görüntüyü “sıkıştırır”; oradan geri okunan prompt yakındır ama orijinalin kendisi değildir.
İpucuBuilder Notu — CLIP Interrogator: Embedding Eşleştirme
- Geriye (Ders 8/9): CLIP embedding’i (Ders 9) + embedding mesafesi (Ders 8); Interrogator, metin parçalarını görüntü embedding’ine en yakın olanı arayarak bulur.
- Sezgi: Küçük embedding bilgi kaybeder; bu yüzden Interrogator “tam tersine çevirme” değil, “en yakın metni bulma” işidir — yaklaşık bir tahmin, kesin geri-dönüşüm değil.
15.3 2. Einstein Toplamı (einsum)
Howard matmul’u daha da kısaltan bir araç tanıtır: Einstein toplamı. 'ik,kj->ij' notasyonunda girdi matrisleri ik ve kj indeksli; çıktı ij. Tekrarlanan indeks (k) hem çarpımı hem toplamı ifade eder — k çıktıda olmadığı için o eksen üzerinden otomatik toplanır.
“Einstein summation is a compact representation for representing products and sums. The repeated letter [k] means those values will be summed.” — Howard, 12:03
Şekil 15.2 bu kuralı gerçek hesaplama ile gösterir: solda 'ik,kj->ij' şeması (k iki girdide tekrarlanır → eşlenen elemanlar çarpılır; k çıktıda yok → o eksen toplanır), sağda torch.einsum('ik,kj->ij') ile numpy a @ b sonuçlarının np.allclose ile özdeş olduğu karşılaştırma.
Kod
d = E.einsum_matmul_demo()
a, b = d["a"], d["b"]
c_einsum, c_at, correct = d["c_einsum"], d["c_at"], d["correct"]
ar, ac = a.shape
bc = b.shape[1]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5),
gridspec_kw={"width_ratios": [1.15, 1.0]})
# ---- SOL: einsum kuralı şeması ----
axL.set_xlim(0, 10); axL.set_ylim(0, 10); axL.axis("off")
axL.text(5, 9.4, "'ik,kj->ij'", ha="center", va="center",
fontsize=20, weight="bold", color=COL_CYAN_800, family="monospace")
# üç indeks kutusu (i, k, j)
boxed_node(axL, 2.0, 7.4, 1.8, 1.0, "i", fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800)
boxed_node(axL, 5.0, 7.4, 1.8, 1.0, "k", fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT)
boxed_node(axL, 8.0, 7.4, 1.8, 1.0, "j", fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800)
# k'nin iki girdide tekrarı → çarpım okları
arrow_between(axL, (5.0, 6.9), (3.4, 5.6), color=COL_ACCENT, lw=2.2)
arrow_between(axL, (5.0, 6.9), (6.6, 5.6), color=COL_ACCENT, lw=2.2)
axL.text(2.9, 5.9, "a[i,k]", ha="center", fontsize=11.5, color=COL_TEXT,
weight="bold", family="monospace")
axL.text(7.1, 5.9, "b[k,j]", ha="center", fontsize=11.5, color=COL_TEXT,
weight="bold", family="monospace")
# kural metinleri
axL.text(5.0, 4.4,
"k iki girdide TEKRARLANIR\n→ eşlenen elemanlar ÇARPILIR",
ha="center", va="center", fontsize=12, color=COL_ACCENT, weight="bold")
axL.text(5.0, 2.9,
"k çıktıda YOK\n→ o eksen TOPLANIR (Σ)",
ha="center", va="center", fontsize=12, color=COL_CYAN_800, weight="bold")
axL.text(5.0, 1.3, "= matris çarpımı c[i,j] = Σₖ a[i,k]·b[k,j]",
ha="center", va="center", fontsize=12.5, color=COL_TEXT, weight="bold")
axL.set_title("Tekrarlanan indeks = çarpım + toplam",
fontsize=13, color=COL_TEXT, weight="bold", pad=8)
# ---- SAĞ: iki sonucun imshow karşılaştırması ----
vmin = min(c_einsum.min(), c_at.min())
vmax = max(c_einsum.max(), c_at.max())
sub = axR.get_subplotspec().subgridspec(1, 2, wspace=0.35)
ax1 = fig.add_subplot(sub[0]); ax2 = fig.add_subplot(sub[1])
axR.axis("off")
for ax, M, ttl in ((ax1, c_einsum, "einsum('ik,kj->ij')"),
(ax2, c_at, "numpy a @ b")):
im = ax.imshow(M, cmap="cividis", vmin=vmin, vmax=vmax, aspect="equal")
for ii in range(M.shape[0]):
for jj in range(M.shape[1]):
ax.text(jj, ii, f"{M[ii, jj]:.2f}", ha="center", va="center",
fontsize=8.5, color=COL_WHITE, weight="bold")
ax.set_title(ttl, fontsize=11, color=COL_CYAN_800, weight="bold",
family="monospace")
ax.set_xticks(range(M.shape[1])); ax.set_yticks(range(M.shape[0]))
ax.tick_params(length=0, labelsize=8, colors=COL_SLATE_400)
# np.allclose rozeti
badge = f"np.allclose = {correct}"
axR.text(0.5, 1.06, badge, transform=axR.transAxes, ha="center", va="bottom",
fontsize=13, weight="bold", color=COL_WHITE,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_PRIMARY, ec=COL_CYAN_800, lw=1.5))
axR.text(0.5, -0.12,
"tekrarlanan indeks = çarpım+toplam;\n@ ile özdeş, daha okunabilir",
transform=axR.transAxes, ha="center", va="top",
fontsize=10.5, color=COL_TEXT, style="italic")
plt.tight_layout()
plt.show()
İpucuBuilder Notu — einsum: Çarpım-Toplamın Kompakt Notasyonu
- Geriye (Ders 11): einsum, broadcasting matmul’un kompakt notasyonu; aynı işi tek satırda yapar.
- Sezgi: Tek kuralı hatırla — tekrarlanan harf “bu eksen üzerinden çarp ve topla”, çıktıda olmayan harf “topla” demektir; gerisi indekslerin yeniden düzenlenmesidir.
15.4 3. einsum ile Matmul
Tüm matris çarpımı tek satıra iner. Tekrarlanan k indeksi çarpım+toplamı, ij ise sonucun şeklini verir:
def matmul(a, b): return torch.einsum('ik,kj->ij', a, b)“We can now define our matmul as simply this torch.einsum.” — Howard, 12:03
Howard bunun broadcasting versiyonuyla aynı hızda olduğunu ölçer — ama çok daha okunabilir. Tek satır, tüm iç döngülerin yerini tutar.
İpucuBuilder Notu — einsum matmul: Tek Satır, Tüm İş
- İleriye (Ders 24): einsum, attention (Ders 24) gibi karmaşık tensör işlemlerini tek satırda ifade etmenin güçlü yolu; “biraz pratik ister” ama kodu sadeleştirir.
- Sezgi:
'ik,kj->ij'matris çarpımının matematiksel tanımının kelime kelimesi yazılışıdır — kod ile formül burada birebir örtüşür.
15.5 4. PyTorch @ ve Hız
En kısa hâl: PyTorch’un @ operatörü. a @ b doğrudan optimize matris çarpımını çağırır — CPU’da BLAS, GPU’da cuBLAS. einsum ve broadcasting’den de hızlıdır, çünkü onlarca yıllık optimize lineer cebir kütüphanelerini kullanır:
a @ b # PyTorch'un optimize matris carpimi (CPU BLAS / GPU cuBLAS)
İpucuBuilder Notu —
@: Yeniden Kur, Sonra Kullan
- Geriye (Ders 5): Ders 5’teki
@’in içini (Ders 10-12 boyunca) sıfırdan kurduk; artık onu güvenle kullanabiliriz — “yeniden kur, sonra kullan” kuralı. - Sezgi:
@bir “kara kutu” değil artık, “anlaşılmış kutu” — mekanizmayı kurduktan sonra optimize aracı kullanmak hem doğru hem verimlidir.
15.6 5. CUDA Kernel: GPU’da Matmul
Howard GPU’da nasıl çalışıldığını gösterir: bir kernel (GPU’da paralel çalışan fonksiyon) yazılır; her çıktı hücresi ayrı bir GPU iş parçacığında (thread) hesaplanır. @cuda.jit ile işaretlenen matmul, binlerce hücreyi aynı anda hesaplar.
“A [function we run on] a GPU is called a kernel.” — Howard, ~1:00:00
Şekil 15.3 bu fikri şematik gösterir: solda çıktı matrisi C’nin her hücresi bağımsız, ortada her hücre ayrı bir GPU iş parçacığına eşlenir, sağda GPU’nun binlerce thread’i @cuda.jit kernel’ı ile aynı anda çalıştırışı — CPU hücreleri sırayla, GPU hepsini paralel işler.
Kod
fig, ax = plt.subplots(figsize=(11, 5))
ax.set_xlim(0, 11)
ax.set_ylim(0, 5)
ax.axis("off")
# --- SOL: çıktı matrisi C (3x3 ızgara, birkaç hücre vurgulu) ---
ax.text(1.55, 4.62, "çıktı matrisi C", ha="center", va="center",
fontsize=11.5, color=COL_CYAN_800, weight="bold")
ax.text(1.55, 4.22, "(her hücre bağımsız)", ha="center", va="center",
fontsize=9, color=COL_TEXT, style="italic")
grid_n = 3
cell = 0.62
gx0, gy0 = 0.62, 1.55 # ızgara sol-alt köşe
highlight = {(0, 2), (1, 0), (2, 1)} # vurgulu hücreler (col, row)
for r in range(grid_n):
for c in range(grid_n):
cx = gx0 + c * cell + cell / 2
cy = gy0 + r * cell + cell / 2
if (c, r) in highlight:
fc, ec, tc = COL_BG_ROSE, COL_ACCENT, COL_ACCENT
else:
fc, ec, tc = COL_WHITE, COL_SLATE_400, COL_TEXT
boxed_node(ax, cx, cy, cell * 0.92, cell * 0.92,
f"c{r}{c}", fc=fc, ec=ec, tc=tc,
fontsize=8.5, lw=1.6)
# --- ORTA: "her hücre → ayrı GPU thread" eşleme okları ---
mid_x = 5.5
# vurgulu hücrelerden ortadaki thread bloğuna oklar
src_pts = [(gx0 + 2 * cell + cell / 2, gy0 + 0 * cell + cell / 2),
(gx0 + 0 * cell + cell / 2, gy0 + 1 * cell + cell / 2),
(gx0 + 1 * cell + cell / 2, gy0 + 2 * cell + cell / 2)]
thread_y = [1.05, 2.5, 3.95]
for (sx, sy), ty in zip(src_pts, thread_y):
arrow_between(ax, (sx + cell / 2, sy), (mid_x - 0.95, ty),
color=COL_ACCENT, lw=1.8, mutation_scale=15, shrink=6)
ax.text(mid_x, 4.62, "her hücre →", ha="center", va="center",
fontsize=9.5, color=COL_TEXT, weight="bold")
ax.text(mid_x, 4.28, "ayrı GPU iş parçacığı (thread)", ha="center", va="center",
fontsize=8.8, color=COL_CYAN_700, style="italic")
# --- SAĞ: GPU binlerce thread AYNI ANDA (paralel thread şeması) ---
ax.text(8.85, 4.62, "GPU: binlerce thread", ha="center", va="center",
fontsize=11.5, color=COL_CYAN_800, weight="bold")
ax.text(8.85, 4.22, "AYNI ANDA", ha="center", va="center",
fontsize=10, color=COL_ACCENT, weight="bold")
# kernel fonksiyonu kutusu (çatı)
boxed_node(ax, 8.85, 3.55, 4.0, 0.5,
"kernel fonksiyonu @cuda.jit", fc=COL_CYAN_50, ec=COL_PRIMARY,
tc=COL_CYAN_800, fontsize=9.5, lw=2.0)
# paralel thread şeridi (12 ince dikey çubuk = aynı anda çalışan thread'ler)
n_thr = 12
tw = 0.26
tx0 = 7.05
ty_lo, ty_hi = 1.35, 3.05
for i in range(n_thr):
tx = tx0 + i * (tw + 0.045)
col = COL_ACCENT if i in (2, 5, 8) else COL_PRIMARY
boxed_node(ax, tx + tw / 2, (ty_lo + ty_hi) / 2, tw, ty_hi - ty_lo,
"", fc=col, ec=col, lw=0.6)
ax.text(8.85, 1.05, "thread 0 thread 1 … thread N",
ha="center", va="center", fontsize=8.2, color=COL_TEXT, style="italic")
# kernel kutusundan thread şeridine "hepsi paralel başlatılır" oku
arrow_between(ax, (8.85, 3.30), (8.85, 3.10),
color=COL_PRIMARY, lw=2.0, mutation_scale=14, shrink=2)
# --- ALT: CPU sıralı vs GPU paralel karşıtlık ---
ax.text(5.5, 0.42,
"CPU: hücreleri sırayla · GPU: hepsi paralel",
ha="center", va="center", fontsize=10, color=COL_CYAN_800, weight="bold")
# --- Karpathy köprü notu ---
ax.text(5.5, 0.05,
"Karpathy nanoGPT hız dersi (§4.F): her hücre bir thread",
ha="center", va="center", fontsize=8.3, color=COL_SLATE_400, style="italic")
plt.tight_layout()
plt.show()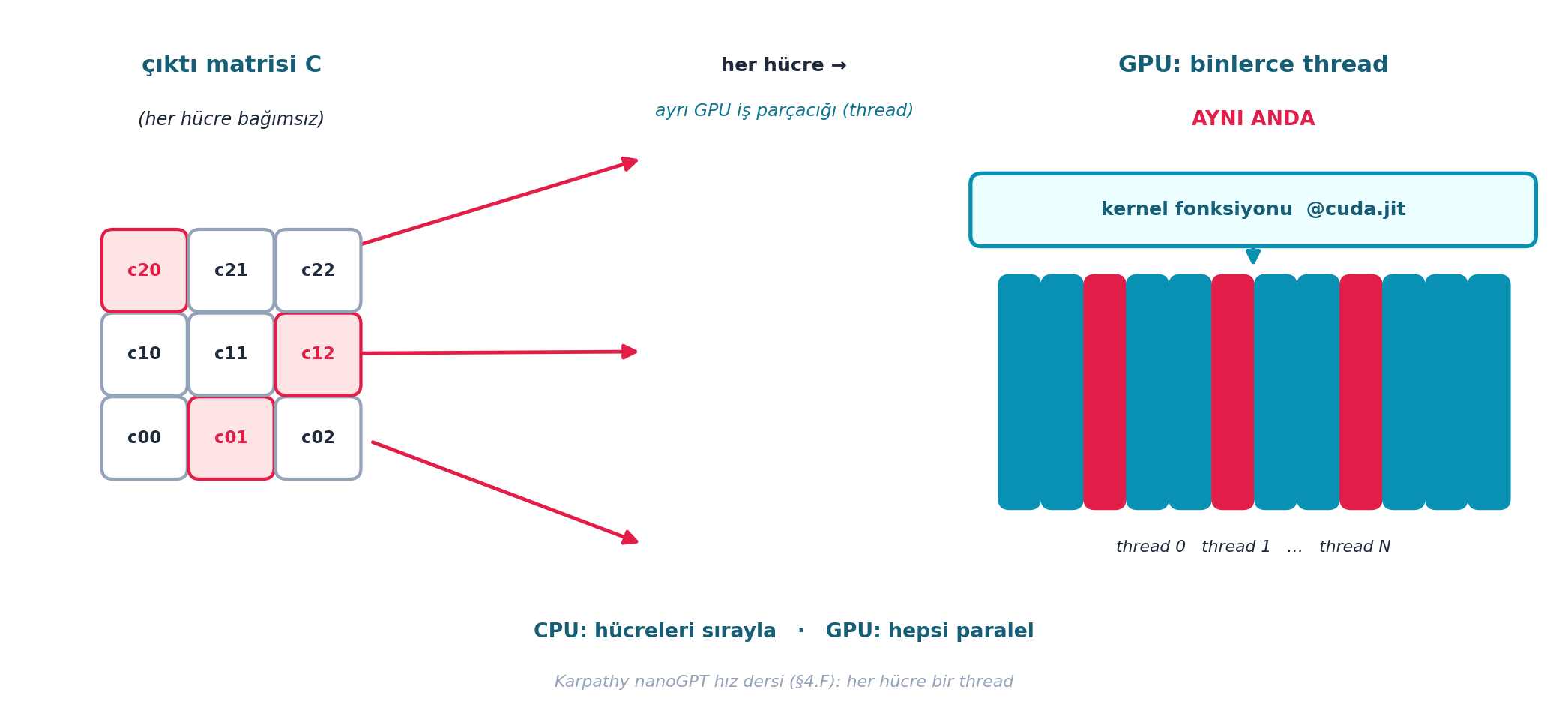
İpucuBuilder Notu — Kernel: Her Hücre Bir Thread
- İleriye (Karpathy Ders 10 / §4.F): GPU kernel programlama (Triton/CUDA), Karpathy’nin nanoGPT hız dersinin (§4.F) konusu; “her hücre bir iş parçacığı” temel fikir.
- Sezgi: GPU’nun gücü çiplerin tek tek hızında değil, paralellikte: az Python çağrısı, binlerce eşzamanlı hesap.
15.7 6. Kümeleme (Clustering) Nedir?
Şimdi ilk tam foundations algoritması. Clustering (kümeleme), etiketsiz veriyi benzer gruplara (kümelere) ayırır — şimdiye kadarki her şeyden farklı, çünkü etiket yok (unsupervised). Howard kümelemenin bazen kötüye kullanıldığını da dürüstçe ekler.
“Cluster analysis is very different to anything that we’ve [seen]… we group data and those groups we call clusters.” — Howard, 8:46
İpucuBuilder Notu — Clustering: Etiketsiz Yapı Keşfi
- Geriye (Ders 4): Şimdiye kadar supervised (etiketli) çalıştık; clustering etiketsizdir — model yapıyı kendisi bulur.
- Sezgi: Supervised’da “doğru cevap” (etiket) verilir; clustering’de model yalnız verinin yoğunluk yapısına bakarak grupları kendisi keşfeder.
15.8 7. Sentetik Veri: Centroid’ler
Algoritmayı test etmek için Howard “nasıl davranacağını bildiği” sentetik veri üretir: önce 6 rastgele centroid (küme merkezi, X-Y koordinatı), sonra her birinin etrafında rastgele noktalar. Amaç: algoritmanın bu 6 kümeyi yeniden bulup bulamayacağını görmek.
n_clusters = 6
centroids = torch.rand(n_clusters, 2) * 70 - 35 # 6 kume merkezi
# her merkez etrafinda rastgele noktalar uretilir -> data
İpucuBuilder Notu — Sentetik Veri: Cevabı Bildiğin Test
- İleriye (builder): “Cevabını bildiğin sentetik veriyle algoritmayı doğrula” — sağlam bir test stratejisi; sonuç gerçek centroid’lere oturuyorsa algoritma çalışıyor demektir.
- Sezgi: Önce kontrollü, bilinen-cevaplı bir oyuncak veri; karmaşık gerçek veriye geçmeden önce mekanizmayı burada doğrula.
15.9 8. Mean Shift: Temel Fikir
Mean shift’in fikri zarif: her noktayı, yakınındaki noktaların ağırlıklı ortalamasına doğru kaydır; yakın noktalar daha ağır sayılır. Bunu birkaç kez tekrarlarsan, noktalar yoğun bölgelerin (kümelerin) merkezine doğru toplanır.
“Mean shift clustering, which hopefully you’ve never heard of before [so we can build it cleanly].” — Howard, clustering bölümü
İpucuBuilder Notu — Mean Shift: Yoğun Bölgeye Tırman
- Geriye (Stat 110): Mean shift, yoğunluk tahmini (kernel density) üstüne kurulu; “yoğun bölgeye tırman” sezgisi.
- Sezgi: Her nokta, kendi mahallesindeki kütle merkezine doğru ufak bir adım atar; bu adımlar tekrarlanınca tüm noktalar yoğunluk tepelerine “tırmanır”.
15.10 9. Mesafe ve Gaussian Kernel
“Yakınlık” nasıl ağırlığa çevrilir? Her noktanın diğerlerine mesafesi hesaplanır, sonra bir Gaussian kernel ile ağırlığa dönüştürülür: yakın = yüksek ağırlık, uzak = sıfıra yakın. bandwidth (bant genişliği) “yakın” sayılan yarıçapı belirler.
import math
def gaussian(d, bw):
return torch.exp(-0.5 * (d/bw)**2) / (bw * math.sqrt(2*math.pi))
# d = mesafe, bw = bandwidth; yakin -> buyuk agirlikŞekil 15.4 bunu gerçek hesaplama ile gösterir (yukarıdaki normalize formülle birebir): mesafe (d) arttıkça ağırlık (\(w = \exp(-\tfrac{1}{2}(d/\mathrm{bw})^2)/(\mathrm{bw}\sqrt{2\pi})\)) azalır; d=0’da tepe değeri \(1/(\mathrm{bw}\sqrt{2\pi})\)’dir — yani her bandwidth için farklıdır (büyük bandwidth daha alçak ama daha geniş bir tepe verir, böylece daha geniş bir komşuluğu “yakın” sayar). Not: bu normalizasyon sabiti ağırlıklı ortalamada \((\Sigma w_i x_i)/(\Sigma w_i)\) sadeleştiği için mean shift sonucunu etkilemez.
Kod
gk = E.gaussian_kernel_demo()
d = gk["d"]
curves = gk["curves"]
fig, ax = plt.subplots(figsize=(9, 5.5))
# Üç bandwidth eğrisi: yakını (büyük) → uzağı (küçük) ağırlığa çevirir
curve_colors = [COL_PRIMARY, COL_ROSE_500, COL_CYAN_400]
for (bw, w), col in zip(curves, curve_colors):
ax.plot(d, w, color=col, linewidth=2.6, zorder=3,
label=f"bandwidth = {bw:g}")
# Eğri sonuna etiket
ax.text(d[-1] + 0.15, w[-1], f"bw={bw:g}", color=col,
fontsize=10, va="center", weight="bold")
# d=0'da tepe = 1/(bw·√(2π)): her bandwidth farklı (büyük bw → alçak tepe)
peak_small = 1.0 / (curves[0][0] * np.sqrt(2 * np.pi))
ax.scatter([0], [peak_small], color=COL_TEXT, s=40, zorder=5)
ax.annotate("d=0 → tepe = 1/(bw·√2π)\n(büyük bw → daha alçak tepe)", xy=(0, peak_small),
xytext=(2.4, peak_small * 0.78), fontsize=9.5, color=COL_TEXT,
ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=1.6))
# Kavramsal not: bandwidth = "yakın" yarıçapı
ax.annotate(
"bandwidth = 'yakın' sayılan yarıçap;\nküme sayısını dolaylı belirler",
xy=(2.5, np.exp(-0.5 * (2.5 / 2.5) ** 2) / (2.5 * np.sqrt(2 * np.pi))),
xytext=(6.0, 0.30),
fontsize=9.5, color=COL_CYAN_800, ha="left", va="center",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_50,
ec=COL_PRIMARY, lw=1.4),
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.6,
connectionstyle="arc3,rad=-0.2"))
ax.set_xlabel("mesafe d (komşuya uzaklık)")
ax.set_ylabel("ağırlık w = exp(−½(d/bw)²)/(bw·√2π)")
ax.set_title("Gaussian çekirdeği: mesafeyi ağırlığa çevirir", color=COL_TEXT)
ax.set_xlim(-0.3, d[-1] + 1.4)
ax.set_ylim(-0.02, peak_small * 1.12)
ax.legend(loc="upper right", frameon=True, framealpha=0.95)
apply_style(ax)
plt.tight_layout()
plt.show()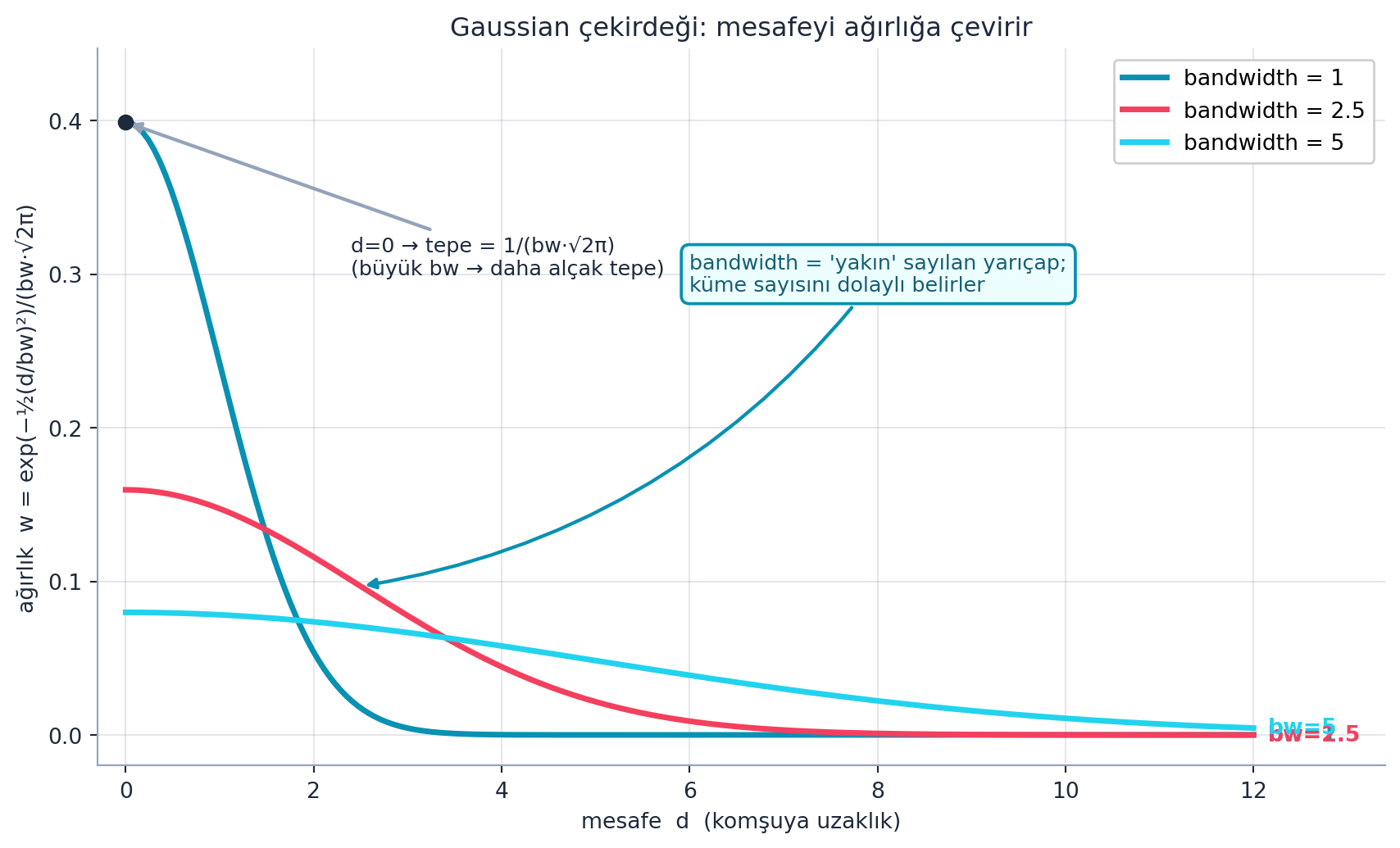
İpucuBuilder Notu — Gaussian Kernel: Mesafeyi Ağırlığa Çevir
- Geriye (Ders 9B / Stat 110): Gaussian, 9B’deki normal dağılımın ta kendisi; burada “mesafeyi ağırlığa çeviren” kernel olarak kullanılır.
- Sezgi: Eğri yumuşak bir “yakınlık” tartısıdır — yakın komşu neredeyse tam sayılır, uzak nokta sessizce sıfıra iner; bandwidth bu yumuşaklığın genişliğini ayarlar.
15.11 10. Tek Güncelleme Adımı
Çekirdek işlem: her nokta için, tüm noktalara mesafeyi bul, Gaussian ile ağırlıkla, sonra noktayı bu ağırlıklı ortalamaya taşı. Broadcasting (Ders 11) burada işi döngüsüz yapar.
def one_update(X):
for i, x in enumerate(X):
dist = torch.sqrt(((x - X)**2).sum(1)) # x'in tum noktalara mesafesi
weight = gaussian(dist, 2.5) # mesafeyi agirliga cevir
X[i] = (weight[:,None] * X).sum(0) / weight.sum() # agirlikli ortalamaŞekil 15.5 bu tek adımı gerçek hesaplama ile gösterir: seçilen bir x noktası (rose ✕), tüm noktalar Gaussian ağırlığına göre renklenmiş, ve x’in yeni konumu ağırlıklı ortalama \((\Sigma w_i x_i)/(\Sigma w_i)\) (yıldız) — ok, x’in komşularının kütle merkezine kayışını gösterir.
Kod
# Mean shift TEK güncelleme adımı (gerçek hesaplama).
# E.meanshift_demo() verisini al; bir x noktası seç; tüm noktalara Gaussian
# ağırlık hesapla (w = exp(-0.5·(mesafe/bw)²)); x'in yeni konumu = (Σwᵢxᵢ)/(Σwᵢ).
d = E.meanshift_demo()
data = d["data0"]
bw = d["bandwidth"]
# Bir küme kenarındaki tek nokta seç (kayma görünür olsun) — merkezden uzakça biri
center0 = d["centroids"][0]
order = np.argsort(((data - center0) ** 2).sum(1))
xi = order[len(order) // 3] # merkeze yakın kümeden, biraz kenarda bir nokta
x = data[xi]
# GERÇEK tek adım (E._meanshift_run ile birebir aynı formül)
dist = np.sqrt(((x - data) ** 2).sum(1)) # x'in tüm noktalara mesafesi
w = np.exp(-0.5 * (dist / bw) ** 2) # Gaussian kernel ağırlık
x_new = (w[:, None] * data).sum(0) / w.sum() # ağırlıklı ortalama (Σwᵢxᵢ)/(Σwᵢ)
fig, ax = plt.subplots(figsize=(9, 7))
apply_style(ax)
# Tüm noktalar: Gaussian ağırlığa göre renk/boyut (yakın = büyük + koyu)
wn = w / w.max()
sizes = 18 + 230 * wn ** 1.4
sc = ax.scatter(data[:, 0], data[:, 1], c=wn, cmap="cool",
s=sizes, edgecolors=COL_WHITE, linewidths=0.5,
alpha=0.9, zorder=3)
cb = fig.colorbar(sc, ax=ax, fraction=0.045, pad=0.02)
cb.set_label("Gaussian ağırlık w = exp(−½·(mesafe/bw)²)", color=COL_TEXT, fontsize=10)
cb.ax.tick_params(colors=COL_TEXT)
# Seçilen x noktası: rose ✕
ax.scatter([x[0]], [x[1]], marker="x", s=320, c=COL_ACCENT,
linewidths=4.0, zorder=6, label="seçilen nokta x")
# Yeni konum: ağırlıklı ortalama
ax.scatter([x_new[0]], [x_new[1]], marker="*", s=600, c=COL_CYAN_800,
edgecolors=COL_WHITE, linewidths=1.5, zorder=7,
label="yeni konum (Σwᵢxᵢ)/(Σwᵢ)")
# Kayma oku: x → x_new
arrow_between(ax, (x[0], x[1]), (x_new[0], x_new[1]),
color=COL_ACCENT, lw=3.0, mutation_scale=26, shrink=10,
style="-|>", zorder=5)
# Annotate: tek adımın mantığı
ax.annotate(
"tek adım:\nmesafe → Gaussian ağırlık →\nağırlıklı ortalama (Σwᵢxᵢ)/(Σwᵢ)\nx oraya kayar",
xy=(x_new[0], x_new[1]),
xytext=(0.03, 0.97), textcoords="axes fraction",
ha="left", va="top", fontsize=10.5, color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG_ROSE, ec=COL_ACCENT, lw=1.6),
zorder=8,
)
ax.set_xlabel("özellik 1", fontsize=11)
ax.set_ylabel("özellik 2", fontsize=11)
ax.set_title("Mean shift — tek güncelleme adımı", color=COL_TEXT,
fontsize=13, weight="bold")
ax.legend(loc="lower right", fontsize=9.5, framealpha=0.95)
plt.tight_layout()
plt.show()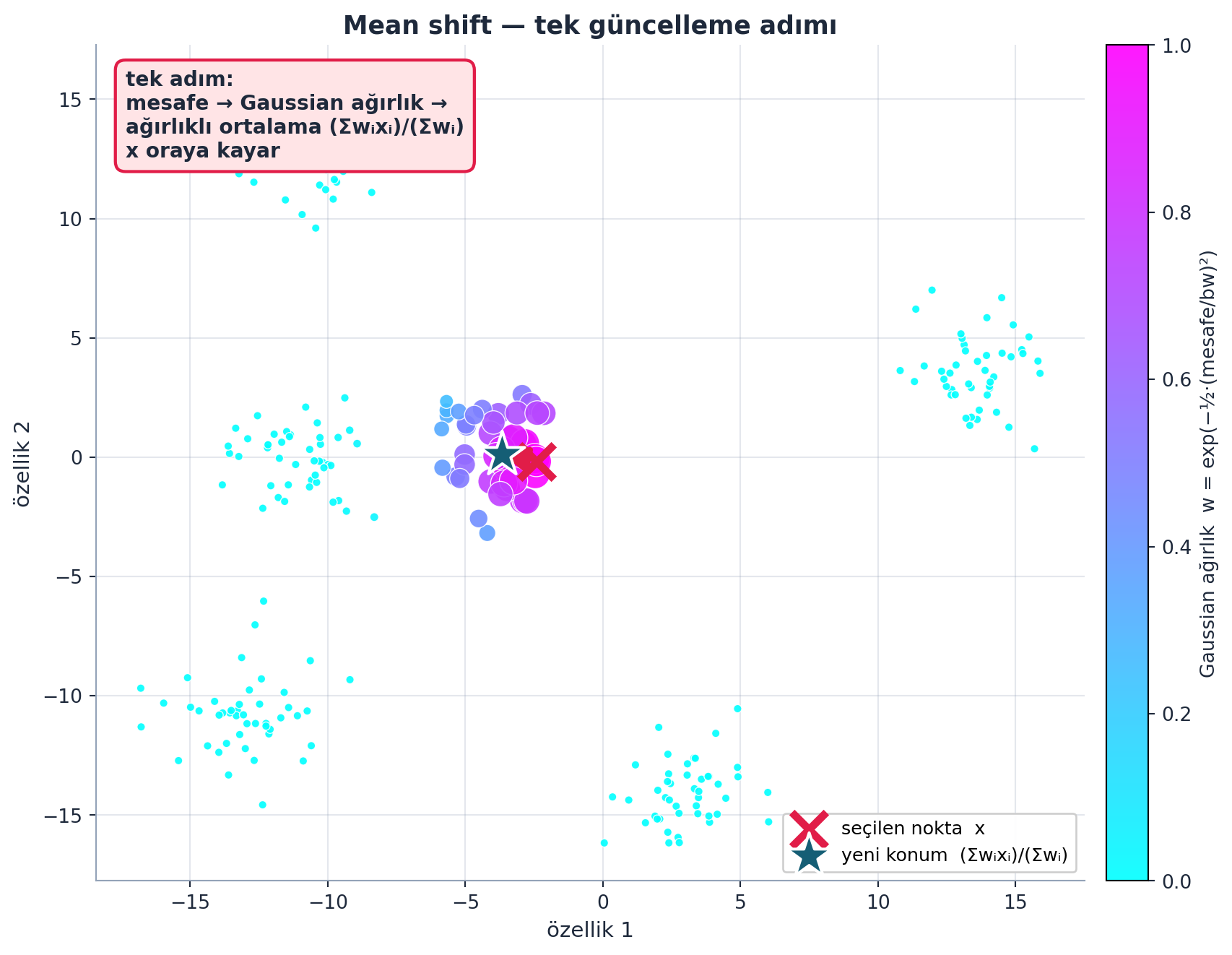
İpucuBuilder Notu — Tek Adım: Ağırlıklı Ortalama
- Geriye (Ders 11):
weight[:,None] * Xbroadcasting’dir; ağırlıklı ortalama = (Σ wᵢ·xᵢ) / (Σ wᵢ). - Sezgi: Bir adım sadece “komşularının ağırlıklı kütle merkezine git”tir; Gaussian sayesinde yakın komşular bu merkezi belirler, uzaklar neredeyse hiç söz sahibi değildir.
15.12 11. Mean Shift Döngüsü
Tek güncelleme bir adımdır; algoritma bunu birkaç kez (örn. 5) tekrarlar. Her turda noktalar küme merkezlerine biraz daha yaklaşır; sonunda her küme tek bir noktada toplanır.
def meanshift(data):
X = data.clone()
for it in range(5): one_update(X)
return XŞekil 15.6 bu yakınsamayı gerçek hesaplama ile gösterir (FLAGSHIP): 270 nokta, iterasyon 0’da (dağınık ham veri) başlar ve birkaç turda gerçek centroid’lere (rose ✕) doğru toplanarak ~6 küme merkezinde yakınsar — her panel bir iterasyon, aynı pencerede kayış görünür.
Kod
d = E.meanshift_demo()
centroids = d["centroids"] # (6, 2) gerçek küme merkezleri
snaps = d["snapshots"] # {0,1,2,3,4,5: X}
bw = d["bandwidth"]
# Çizilecek iterasyonlar (0=dağınık ham veri ... 5=toplanmış)
its = [0, 1, 2, 3, 5]
panels = its[:6] if len(its) <= 6 else its
# 2×3 yerleşim: 6 panel (0,1,2,3,5 + son boş değil → 5 doldurulur)
show = [0, 1, 2, 3, 4, 5]
fig, axes = plt.subplots(2, 3, figsize=(12, 9))
fig.patch.set_facecolor(COL_WHITE)
# Sabit eksen sınırları (tüm panellerde aynı pencere → kayışı görmek için)
all_xy = snaps[0]
pad = 2.5
xlo, xhi = all_xy[:, 0].min() - pad, all_xy[:, 0].max() + pad
ylo, yhi = all_xy[:, 1].min() - pad, all_xy[:, 1].max() + pad
for ax, it in zip(axes.ravel(), show):
X = snaps[it]
apply_style(ax)
# noktalar: cyan, düşük alpha (yoğunluk birikimi görünür)
ax.scatter(X[:, 0], X[:, 1], s=20, color=COL_PRIMARY,
alpha=0.30, edgecolors="none", zorder=2)
# gerçek centroid'ler: rose ✕
ax.scatter(centroids[:, 0], centroids[:, 1], marker="x",
s=130, color=COL_ACCENT, linewidths=2.6, zorder=4)
ax.set_title(f"iterasyon {it}", color=COL_TEXT, fontsize=12, weight="bold")
ax.set_xlim(xlo, xhi)
ax.set_ylim(ylo, yhi)
ax.set_xticks([])
ax.set_yticks([])
ax.set_aspect("equal", adjustable="box")
# İlk panele algoritma açıklaması, son panele "toplandı" notu
axes.ravel()[0].annotate(
f"her nokta komşularının\nGaussian-ağırlıklı ortalamasına kayar; bw={bw}",
xy=(0.5, -0.10), xycoords="axes fraction", ha="center", va="top",
fontsize=10.5, color=COL_CYAN_800, weight="bold")
axes.ravel()[-1].annotate(
"~6 küme merkezinde toplandı",
xy=(0.5, -0.10), xycoords="axes fraction", ha="center", va="top",
fontsize=10.5, color=COL_ACCENT, weight="bold")
fig.suptitle("Mean shift yakınsaması: dağınık veri → küme merkezleri",
color=COL_CYAN_700, fontsize=14, weight="bold", y=0.98)
plt.tight_layout(rect=(0, 0.02, 1, 0.96))
plt.show()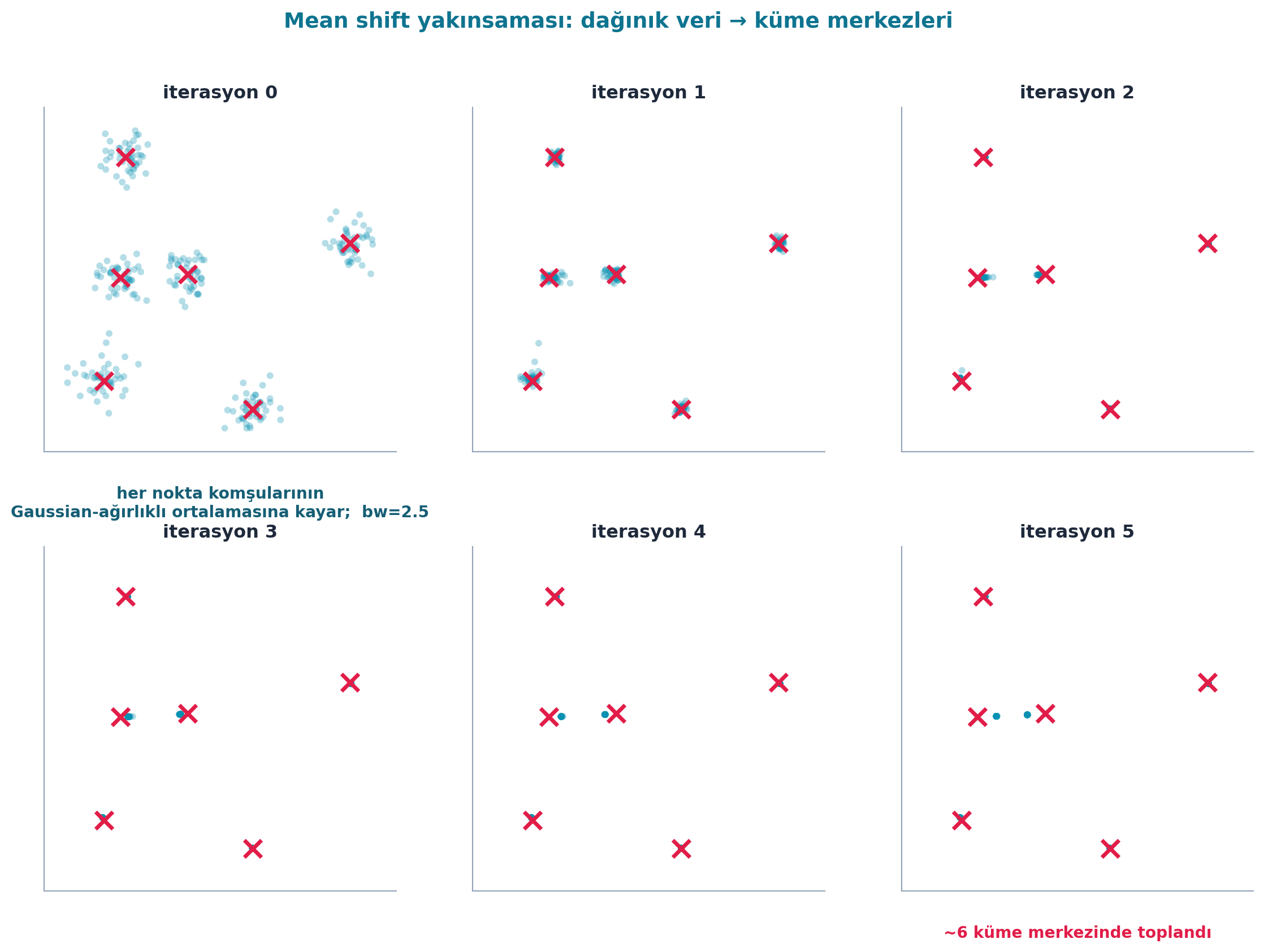
İpucuBuilder Notu — Döngü: k Önceden Gerekmez
- İleriye: Mean shift, k-means’in aksine küme sayısını önceden bilmeyi gerektirmez; bandwidth küme sayısını dolaylı belirler.
- Sezgi: Her tur tüm noktaları biraz daha yoğunluk tepelerine iter; birkaç tur sonra noktalar birkaç ayrı tepede yığılır ve bu tepelerin sayısı küme sayısını kendiliğinden verir.
15.13 12. Triangular Kernel (Alternatif)
Howard Gaussian yerine başka kernel’lar da denenebileceğini gösterir, örneğin triangular (üçgen) kernel: mesafe arttıkça ağırlık doğrusal azalır, belli bir noktadan sonra sıfır olur.
def tri(d, i): return (-d + i).clamp_min(0) / i # ucgen kernel
İpucuBuilder Notu — Kernel Seçimi: Deneysel Ayar
- İleriye: Kernel seçimi sonucu etkiler; farklı kernel’lar farklı yoğunluk tahminleri verir (deneysel ayar).
- Sezgi: Gaussian “yumuşak ve sonsuz kuyruklu”, triangular “sert kesimli” bir yakınlık tartısıdır; ağırlık fonksiyonunu değiştirmek kümelenmenin şeklini değiştirir.
15.14 13. Kaç Küme?
Mean shift’in güzelliği: küme sayısını otomatik bulur. Noktalar yoğun bölgelere toplandığında, kaç ayrı toplanma noktası oluştuğu küme sayısını verir — k-means gibi “k’yı önceden ver” gerekmez. Küme sayısını dolaylı olarak bandwidth belirler.
Şekil 15.7 bunu gerçek hesaplama ile gösterir: aynı veride üç bandwidth (1.0 / 2.5 / 6.0) için mean shift çalıştırılır — küçük bandwidth çok sayıda küçük küme, büyük bandwidth az sayıda büyük küme verir; bandwidth, k-means’in k’sı gibi ama dolaylı çalışır.
Kod
d = E.bandwidth_effect_demo() # GERÇEK mean shift, bw = 1.0 / 2.5 / 6.0
data0 = d["data0"]
results = d["results"]
fig, axes = plt.subplots(1, 3, figsize=(12, 4.5))
for ax, (bw, final_X, n_clusters) in zip(axes, results):
apply_style(ax)
# ham veri (sönük arka plan referansı)
ax.scatter(data0[:, 0], data0[:, 1], s=10, color=COL_SLATE_300,
alpha=0.45, zorder=1, label="ham veri")
# yakınsanan noktalar (mean shift sonrası → küme merkezlerinde toplanır)
ax.scatter(final_X[:, 0], final_X[:, 1], s=26, color=COL_PRIMARY,
edgecolor=COL_CYAN_800, linewidth=0.5, alpha=0.85, zorder=3,
label="yakınsanan noktalar")
ax.set_title(f"bw={bw:g}: {n_clusters} küme",
fontsize=12, color=COL_CYAN_700, weight="bold")
ax.set_xlabel("özellik 1", fontsize=9.5)
ax.set_ylabel("özellik 2", fontsize=9.5)
ax.tick_params(labelsize=8)
# küçük bw → çok küme, büyük bw → az küme: ortak okuma
axes[0].annotate("küçük bw → çok küme", xy=(0.5, 1.0), xytext=(0.5, 1.14),
xycoords="axes fraction", ha="center", fontsize=9.5,
color=COL_ACCENT, weight="bold")
axes[2].annotate("büyük bw → az küme", xy=(0.5, 1.0), xytext=(0.5, 1.14),
xycoords="axes fraction", ha="center", fontsize=9.5,
color=COL_ACCENT, weight="bold")
axes[1].annotate("bandwidth küme sayısını belirler\n(k-means'in k'sı gibi ama dolaylı)",
xy=(0.5, 1.0), xytext=(0.5, 1.13), xycoords="axes fraction",
ha="center", fontsize=9.5, color=COL_TEXT, weight="bold")
axes[0].legend(loc="lower left", fontsize=7.5, framealpha=0.85)
plt.tight_layout()
plt.show()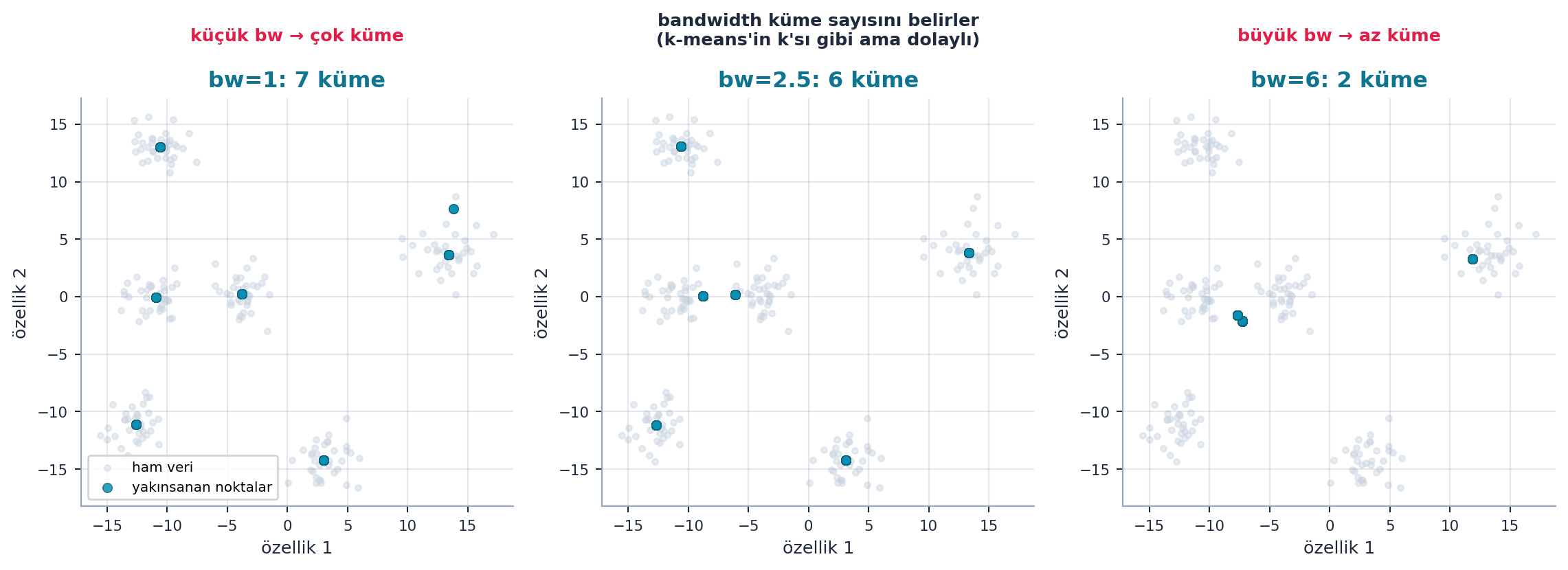
İpucuBuilder Notu — Kaç Küme: Veriden Keşfet
- Geriye (Ders 6): Random forest gibi mean shift de az varsayım ister; “veriden yapıyı keşfet” yaklaşımı.
- Sezgi: k’yı önceden vermek yerine “yakın ne demek?” sorusunu (bandwidth) yanıtlarsın; küme sayısı bu yarıçaptan kendiliğinden doğar.
15.15 14. Batched Mean Shift (GPU)
Tek tek nokta döngüsü yavaştır. Howard işi batch’lerde yapar: bir grup noktanın tüm mesafelerini tek tensör işleminde (broadcasting ile) hesaplar. Bu, GPU’da binlerce noktayı paralel işlemeyi sağlar.
def dist_b(a, b): return (((a[None] - b[:,None])**2).sum(2)).sqrt() # batch mesafe matrisi
İpucuBuilder Notu — Batched: Broadcasting’in Gücü
- Geriye (Ders 11): Batched mesafe = broadcasting’in
(a[None] − b[:,None])gücü; döngüsüz, GPU-dostu. - Sezgi: Nokta-nokta döngüsü yerine tüm ikili mesafeleri tek tensör çağrısıyla üretirsin; Ders 11’in broadcasting deseni burada doğrudan hesabı GPU’ya devreder.
15.16 15. İleriye: Foundations Devam
Mean shift, gradient kullanmayan bir foundations algoritmasıydı. Howard sonraki adımı işaret eder: sinir ağlarına dönüp backpropagation’ı sıfırdan kurmak (Ders 13). Buraya kadarki araçlar (matmul, broadcasting) orada kullanılacak.
İpucuBuilder Notu — Foundations Zinciri İlerliyor
- İleriye (Ders 13): matmul + broadcasting artık hazır; Ders 13 bunlarla bir MLP’yi forward+backward sıfırdan kurar.
- Sezgi: Aynı “sıfırdan kur, sonra kullan” disiplini devam eder; mean shift gradyansız bir aradı, sıradaki parça (backprop) bütün derin öğrenmenin motorudur.
15.17 16. Kapanış
Ders 12 matris çarpımını bitirdi (einsum → @ → GPU kernel) ve ilk tam foundations algoritmasını kurdu: mean shift clustering. Etiketsiz veriyi, her noktayı komşularının Gaussian-ağırlıklı ortalamasına çekerek kümeledik — broadcasting sayesinde döngüsüz ve GPU’da.
Şekil 15.8 dersin sentezidir: solda L12’nin parçaları (einsum/@/GPU kernel, clustering, Gaussian kernel, mean shift, batched broadcasting), sağda her birinin nereden/nereye köprüsü — Ders 10-11 matmul yolculuğu biter + Karpathy nanoGPT GPU, Ders 4 supervised’ın karşıtı, Ders 9B normal dağılım, Ders 6 random forest gibi az varsayım, Ders 11 broadcasting.
Kod
fig, ax = plt.subplots(figsize=(12, 6.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.5)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# Başlıklar (sütun etiketleri)
ax.text(2.55, 6.18, "L12'de", ha="center", va="center",
fontsize=14, weight="bold", color=COL_ROSE_500)
ax.text(9.15, 6.18, "nereden / nereye", ha="center", va="center",
fontsize=14, weight="bold", color=COL_CYAN_700)
# SOL sütun (L12-parçaları, rose) — 5 satır
left_x, lw_box, lh_box = 2.55, 4.0, 0.86
right_x, rw_box, rh_box = 9.15, 4.7, 0.92
ys = [5.30, 4.20, 3.10, 2.00, 0.90]
left_labels = [
"einsum / @ / GPU kernel",
"clustering (unsupervised)",
"Gaussian kernel",
"mean shift (k otomatik)",
"batched broadcasting",
]
right_labels = [
"Ders 10-11 matmul yolculuğu BİTER\nKarpathy nanoGPT GPU (§4.F)",
"Ders 4 supervised'ın KARŞITI\netiketsiz yapı keşfi (6.S191)",
"Ders 9B normal dağılım\nmesafeyi ağırlığa çevir",
"Ders 6 random forest gibi az varsayım\nkernel density",
"Ders 11 (a[None]−b[:,None])\nGPU-dostu",
]
for y, lt, rt in zip(ys, left_labels, right_labels):
# L12-parçası (rose dolgu/çerçeve)
boxed_node(ax, left_x, y, lw_box, lh_box, lt,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=10.5, lw=2.0)
# kaynak/hedef (cyan dolgu/çerçeve)
boxed_node(ax, right_x, y, rw_box, rh_box, rt,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=9.5, lw=2.0)
# ok: L12-parçası → kaynak/hedef (cyan)
arrow_between(ax, (left_x + lw_box / 2, y), (right_x - rw_box / 2, y),
color=COL_CYAN_700, lw=2.0, mutation_scale=16, shrink=4)
plt.tight_layout()
plt.show()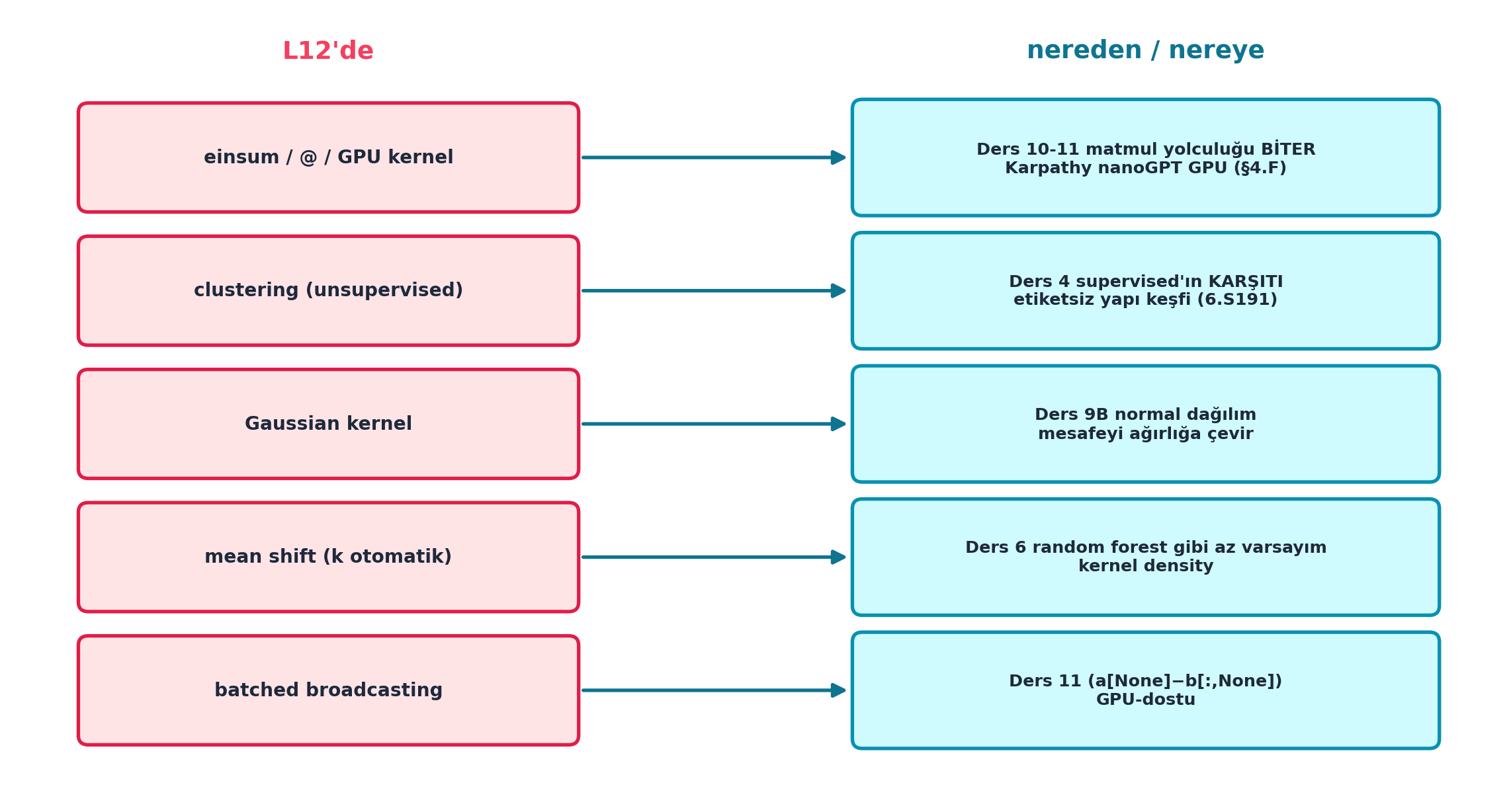
İpucuBuilder Notu — L12 Sentezi: İki Kol Birleşti
- İleriye (Ders 13-14): Sıradaki iki ders backpropagation’ı sıfırdan kurar — Karpathy micrograd’ının fast.ai karşılığı; matmul/broadcasting temeli hazır.
- Tek cümle: matmul yolculuğu einsum/
@/GPU ile bitti; mean shift ilk unsupervised foundations algoritmasıydı, sıradaki parçalar (backprop, Learner, diffusion) aynı zincirde elle kurulacak.
15.18 Bu Dersin Özeti
- CLIP Interrogator bir görüntüden yaklaşık prompt üretir (embedding’e en yakın metin parçaları); tam tersine çeviremez (bilgi kaybı) (CLIP).
- Einstein toplamı (einsum) matmul’u
'ik,kj->ij'ile kompakt ifade eder; tekrarlanan indeks (k) çarpım+toplamı (einsum). @en kısa ve hızlı matmul’dur (BLAS/cuBLAS); GPU’da bir kernel her hücreyi paralel hesaplar (@ ve hız → CUDA kernel).- Clustering etiketsiz (unsupervised) veriyi benzer gruplara ayırır (clustering).
- Mean shift: her noktayı yakın noktaların Gaussian-ağırlıklı ortalamasına doğru kaydır; tekrarla (mean shift → döngü).
- Gaussian kernel mesafeyi ağırlığa çevirir; bandwidth “yakın” yarıçapını belirler (Gaussian).
- Mean shift küme sayısını otomatik bulur (k-means’in aksine k gerekmez) (kaç küme).
- Batched + broadcasting ile mesafeler döngüsüz, GPU’da paralel hesaplanır (batched).
ÖnemliTek Bir Cümle
Matris çarpımını einsum ve @ ile bitirip GPU’ya taşıdıktan sonra, etiketsiz veriyi her noktayı komşularının Gaussian-ağırlıklı ortalamasına çekerek kümeleyen mean shift’i sıfırdan kurduk — küme sayısını önceden bilmeden, broadcasting sayesinde döngüsüz.
15.19 Kontrol Soruları
NotSoru 1: Einstein toplamında (‘ik,kj->ij’) tekrarlanan indeks (k) ne anlama gelir?
Cevap:
einsum notasyonunda her harf bir eksendir. Girdi matrisleri ik (5×784) ve kj (784×10), çıktı ij (5×10). k harfi iki girdide tekrarlanıyor ama çıktıda yok — bu iki şey demek: (1) ortak eksen (k) boyunca elemanlar çarpılır; (2) k çıktıda olmadığı için o eksen üzerinden toplanır. Yani 'ik,kj->ij' tam olarak matris çarpımıdır: her ij hücresi, k boyunca a[i,k]·b[k,j] çarpımlarının toplamıdır. einsum, çarpım-ve-topla işlemlerini tek bir kompakt string’le ifade eder. (Şekil 15.2 bu kuralı ve @ ile özdeşliğini gösterir.)
NotSoru 2: Mean shift clustering nasıl çalışır? Tek bir güncelleme adımı ne yapar?
Cevap:
Mean shift, her veri noktasını yakınındaki noktaların ağırlıklı ortalamasına doğru kaydırır ve bunu birkaç kez tekrarlar; noktalar yoğun bölgelerin (kümelerin) merkezine toplanır. Bir güncelleme adımı: her nokta x için (1) tüm noktalara mesafe hesapla, (2) mesafeyi bir Gaussian kernel ile ağırlığa çevir (yakın=yüksek, uzak≈0), (3) x’i bu ağırlıklı ortalamaya taşı: (Σ wᵢ·xᵢ)/(Σ wᵢ). Broadcasting sayesinde weight[:,None]*X ile bu döngüsüz yapılır. Birkaç tur sonra her küme tek noktada toplanır. (Şekil 15.5 tek adımı, Şekil 15.6 tüm döngüyü gösterir.)
NotSoru 3: Mean shift’in k-means’e göre avantajı nedir? bandwidth ne işe yarar?
Cevap:
k-means küme sayısını (k) önceden vermeyi gerektirir; mean shift ise küme sayısını otomatik bulur — noktalar yoğun bölgelere toplandığında kaç ayrı toplanma noktası oluştuğu küme sayısını verir. bandwidth (bant genişliği), Gaussian kernel’ın “yakın” saydığı yarıçapı belirler: küçük bandwidth → çok sayıda küçük küme, büyük bandwidth → az sayıda büyük küme. Yani küme sayısını dolaylı olarak bandwidth kontrol eder (k yerine). Bu, veriyi keşfetmek için (kaç küme olduğunu bilmediğinde) avantajlıdır. (Şekil 15.7 üç bandwidth’in küme sayısını nasıl değiştirdiğini gösterir.)
NotSoru 4: ‘@’ operatörünü artık neden güvenle kullanabiliyoruz? (builder bağlantısı)
Cevap:
Çünkü “from the foundations” kuralı gereği matris çarpımını sıfırdan kurduk ve nasıl çalıştığını anladık: Ders 10’da üç döngü + numba, Ders 11’de broadcasting, Ders 12’de einsum. @’in altında ne olduğunu artık biliyoruz. Howard’ın kuralı: “bir şeyi bir kez sıfırdan kur, sonra hazır versiyonunu kullan.” a @ b PyTorch’un onlarca yıllık optimize lineer cebir kütüphanelerini (BLAS/cuBLAS) çağırır — bizim kodumuzdan çok daha hızlı. Builder açısından: mekanizmayı anladıktan sonra optimize aracı kullanmak hem doğru hem verimli; “kara kutu” değil, “anlaşılmış kutu”. (Şekil 15.3 @’in GPU’da nasıl paralelleştiğini gösterir.)
15.20 Egzersizler
Egzersiz 1 (Direkt uygulama). torch.einsum('ik,kj->ij', a, b) ile matmul yap; a @ b ve broadcasting versiyonuyla sonuçların aynı, hızların farklı olduğunu %timeit ile gör. (Şekil 15.2’i kendi sayınla yeniden üret — §2-3)
Egzersiz 2 (İki-aşamalı). 6 centroid’li sentetik veri üret, meanshift ile kümele; sonucu orijinal centroid’lerle karşılaştır. (Şekil 15.6’ı kendi verinde yeniden üret — §7, §11)
Egzersiz 3 (Edge case). bandwidth’i çok küçük (örn. 0.5) ve çok büyük (örn. 20) yap; küme sayısının nasıl değiştiğini gözlemle. (§13)
Egzersiz 4 (Kavramsal). Gaussian yerine tri (üçgen) kernel kullan; kümeleme sonucundaki farkı açıkla. (§12)
Egzersiz 5 (Sonraki dersin habercisi — Ders 13). Bir MLP’nin ileri geçişini (lin → ReLU → lin) matmul ile kur; çıktının şeklini ve neden ReLU gerektiğini düşün. (§15)
15.21 Sonraki: Ders 13 İçin Hazırlık
Ders 13: Geri Yayılım ve MLP (Backpropagation & MLP)
Ders 12 matmul’u bitirdi ve gradient’siz bir algoritma (mean shift) kurdu. Ders 13 sinir ağına döner: bir MLP’yi sıfırdan kurar (lin + ReLU), MSE loss’u tanımlar ve backpropagation’a başlar — Karpathy micrograd’ının fast.ai karşılığı.
Ana konular (Ders 13):
- Lineer katman + ReLU (matmul ile)
- MLP forward pass from scratch
- MSE loss from scratch
- Backpropagation’a giriş (chain rule)
UyarıDers 13 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 5 — einsum + MLP forward).
- Mean shift’i kendi sentetik verinde çalıştır.
- Ana cümleyi tekrar oku: “matmul bitti; sıradaki backprop’u sıfırdan kuracağız.”
15.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| CLIP Interrogator | Görüntüden yaklaşık prompt üretme (embedding eşleştirme) | 0:17 |
| Einstein toplamı (einsum) | 'ik,kj->ij'; tekrarlanan indeks çarpım+toplam |
12:03 |
| @ (matmul) | En kısa/hızlı matris çarpımı (BLAS/cuBLAS) | 12:03 |
| CUDA kernel | GPU’da paralel çalışan fonksiyon (her hücre bir iş parçacığı) | 1:00:00 |
| Clustering | Etiketsiz veriyi benzer gruplara ayırma (unsupervised) | 8:46 |
| Centroid | Küme merkezi (sentetik veri üretiminde) | 9:21 |
| Mean shift | Her noktayı komşuların ağırlıklı ortalamasına kaydırma | 8:46 |
| Gaussian kernel | Mesafeyi ağırlığa çevirir (yakın=yüksek) | 9:21 |
| Bandwidth | “Yakın” yarıçapı; küme sayısını dolaylı belirler | 9:21 |
| Ağırlıklı ortalama | (Σ wᵢ·xᵢ)/(Σ wᵢ); güncelleme adımı | 9:21 |
| Triangular kernel | Doğrusal azalan ağırlık (Gaussian alternatifi) | 9:21 |
| Batched mesafe | Broadcasting ile döngüsüz mesafe matrisi (GPU) | 9:21 |
15.23 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: L12’nin Tanıdık Kökleri
Bu ders matmul yolculuğunu bitirir ve ilk unsupervised algoritmayı tanıdık kavramlara bağlar; köprülerin özeti:
- einsum → çarpım-toplam işlemlerinin kompakt notasyonu; attention (Ders 24) gibi karmaşık işlemlerde güçlü (einsum).
- @ / GPU kernel → matmul’un production hâli; Karpathy nanoGPT hız dersi (§4.F) GPU kernel’ı derinleştirir (CUDA kernel).
- Clustering (unsupervised) → etiketsiz yapı keşfi; supervised öğrenmenin (Ders 4) karşıtı (clustering).
- Mean shift → kernel density’ye dayalı; küme sayısını otomatik bulur (k-means’ten farkı) (mean shift).
- Gaussian kernel → 9B normal dağılımı; mesafeyi ağırlığa çeviren temel araç (Gaussian).
- Batched broadcasting → GPU-dostu paralel hesap; Ders 11’in doğrudan uygulaması (batched).
ÖnemliBu dersten tek bir şey alıp gideceksen
Matris çarpımı yolculuğunu bitirdik (einsum → @ → GPU) ve artık @’i güvenle kullanabiliriz çünkü altını biliyoruz. Sonra ilk tam foundations algoritmasını kurduk: mean shift, her noktayı komşularının Gaussian-ağırlıklı ortalamasına çekerek — küme sayısını önceden bilmeden, broadcasting sayesinde döngüsüz veriyi kümeledik.