flowchart TD
MLP["MLP<br/>(çok katmanlı algılayıcı)"] --> LIN1["lineer katman 1<br/>x·w + b"]
LIN1 --> RELU["ReLU<br/>clamp_min(0)<br/>doğrusal-olmama"]
RELU --> LIN2["lineer katman 2<br/>l2·w + b"]
LIN2 --> OUT["çıktı (tahmin)"]
OUT --> LOSS["MSE kayıp<br/>(ortalama kare hata)"]
LOSS --> GRAD["gradient (eğim)<br/>∂L/∂çıktı"]
GRAD --> BACKPROP["backpropagation<br/>= chain rule<br/>∂L/∂w = ∂L/∂çıktı · ∂çıktı/∂w"]
BACKPROP --> LINGRAD["lin_grad<br/>w.g = girdiᵀ · çıktı.g"]
BACKPROP --> RELUGRAD["ReLU gradyanı<br/>kapı: (l1 > 0) · dl2"]
LINGRAD --> KARPATHY["Karpathy köprüsü:<br/>manuel .g = micrograd _backward"]
RELUGRAD --> KARPATHY
classDef cyan fill:#cffafe,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
class MLP,LIN1,RELU,LIN2,OUT,LOSS,GRAD,LINGRAD,RELUGRAD cyan;
class BACKPROP,KARPATHY rose;
16 Ders 13 — Geri Yayılım ve MLP (Backpropagation & MLP)
Part 2’nin beşinci dersi sinir ağının kalbine iner: bir MLP’yi (çok katmanlı algılayıcı) sıfırdan kurar — lineer katman + ReLU + lineer katman — MSE loss’u tanımlar ve backpropagation’ı elle hesaplar. Anahtar fikir tek cümleyle: bir MLP matris çarpımı + ReLU yığınıdır; onu eğitmek, kaybın her parametreye göre türevini chain rule ile en dıştan içe katman katman geriye yaymaktır. Bu ders Karpathy micrograd’ının fast.ai karşılığıdır — manuel .g gradyanları = micrograd’ın _backward kapanışları; iki « from scratch » yolu burada buluşur.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 13: Backpropagation & MLP (~106 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 13
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/03_backprop
- Okuma süresi: ~38 dk
- 🔗 Karpathy köprüsü MERKEZÎ: Bu ders Karpathy micrograd’ının (Zero to Hero) fast.ai karşılığıdır — Howard’ın elle yazdığı
.ggradyanları = micrograd’ın_backwardkapanışları. İki “from scratch” yolu aynı yerde buluşur. Bu ders ETAP 4 (Temeller A) içindedir.
16.1 Bu Derste Ne Var?
Part 2’nin beşinci dersi sinir ağının kalbine iner: bir MLP’yi (çok katmanlı algılayıcı) sıfırdan kurar (lineer katman + ReLU), MSE loss’u tanımlar ve backpropagation’a başlar. Bu, Karpathy’nin micrograd’ının (Zero to Hero serisi) fast.ai karşılığıdır — iki “from scratch” yolu aynı yerde buluşur.
Üç temel fikir bu dersin omurgasını kurar:
- MLP = lineer + ReLU + lineer — matris çarpımı (Ders 10-12) ile katmanlar, aralarında ReLU; “ReLU toplamı” istenen kadar karmaşık fonksiyonu kurar (Ders 3’ün somut hâli) (ReLU toplamı → MLP mimari).
- Loss ve gradient — MSE ile hatayı ölç; her parametreyi hangi yönde değiştireceğini gradient (eğim) söyler (MSE → gradyanlar).
- Backpropagation = chain rule — kaybın her parametreye göre türevini, zincir kuralıyla katman katman geriye yayarak hesaplama (chain rule → forward_and_backward).
“Welcome to Lesson 13, where we’re gonna start talking about back propagation.” — Howard, 0:00
Şekil 28.1 bu yapıyı tek bir yol haritasında birleştirir: üstte MLP’nin ileri yayılımı (lineer katman 1 → ReLU → lineer katman 2 → çıktı), ardından MSE kaybı ve gradient; altta backpropagation = chain rule kolu (lin_grad + ReLU gradyanı), hepsi Karpathy köprüsünde birleşir — manuel .g = micrograd _backward.
İpucuBuilder Notu — İki « From Scratch » Yolu Aynı Yerde
- Geriye (Karpathy — merkezî köprü): Bu ders Karpathy micrograd’ının ta kendisidir: manuel
.ggradyanları = micrograd’ın_backwardkapanışları. Howard “from scratch”, Karpathy “from scratch” — iki ayrı yol, aynı yer. - Geriye (Ders 3/5/Calculus): Ders 3’ün “ReLU toplamı” + Ders 5’in gradient descent’i; chain rule = Calculus zincir kuralı (3Blue1Brown).
- Tek cümle: Bir MLP, matris çarpımı + ReLU yığınıdır; onu eğitmek, kaybın gradyanını chain rule ile geriye yaymaktır.
16.2 1. Notebook 3 ve ReLU ile Esneklik
Howard 03_backprop notebook’una geçer. Önce Ders 3’ü hatırlatır: tek bir lineer model düz bir çizgidir, karmaşık şekilleri temsil edemez. Çözüm ReLU (rectified line): bir doğrunun negatif kısmını sıfıra kırpmak. Negatifi kırpılmış bir doğru artık bir “bükülme noktası” olan parçalı bir fonksiyondur.
“If we just have a linear model, then it’s gonna look like this [a straight line].” — Howard, 4:28
İpucuBuilder Notu — ReLU: Düz Çizgiyi Bükmek
- Geriye (Ders 3): Ders 3’teki ReLU tanımı (
max(0, x)); burada onu bir MLP’nin yapı taşı olarak kullanacağız. - Sezgi: Tek bir doğru karmaşık şekli kuramaz; ama doğruyu negatifte sıfıra kırpıp bir “köşe” eklersek, bu köşeleri toplayarak istenen kadar karmaşık eğriler kurabiliriz.
16.3 2. Lineer Modeller ve Rectified Lines
Howard bir diyagramla gösterir: tek doğru yetersiz, ama doğruları ReLU’dan geçirip toplarsak inişli-çıkışlı, karmaşık eğriler kurabiliriz. Yeterince rectified line toplamı, istenen kadar karmaşık bir şekil verir — bu, Ders 3’ün “universal approximation” fikrinin somut hâlidir.
“Using this approach, we could add up lots of these rectified lines.” — Howard, 6:03
Şekil 16.2 bunu gerçek hesaplama ile gösterir: tek tek soluk rectified line (ReLU) bileşenleri toplandığında, kalın rose eğri (ReLU toplamı / fit) ince cyan hedef eğriye oturur — lstsq ile fit edilen MSE çok küçüktür. Yani yeterli sayıda ReLU toplamı istenen karmaşıklığı kurar (universal approximation, Ders 3); MLP bunu matrislerle yapar.
Kod
d = E.relu_sum_demo()
x, target, fit, lines = d["x"], d["target"], d["fit"], d["lines"]
k, mse = d["k"] if "k" in d else len(lines), d["mse"]
fig, ax = plt.subplots(figsize=(9.5, 5.5))
# tek tek rectified line (ReLU) bileşenleri — soluk, ince
for i, ln in enumerate(lines):
ax.plot(x, ln, color=COL_SLATE_300, lw=1.0, alpha=0.85, zorder=1,
label="tek tek rectified line (ReLU)" if i == 0 else None)
# hedef eğri — ince cyan
ax.plot(x, target, color=COL_PRIMARY, lw=1.6, zorder=3,
label="hedef eğri (karmaşık)")
# ReLU toplamı (fit) — kalın rose, üstte
ax.plot(x, fit, color=COL_ACCENT, lw=3.0, zorder=4,
label=f"{k} ReLU toplamı (fit)")
# fit ≈ target, MSE rozeti
ax.text(0.04, 0.93, f"fit ≈ target, MSE = {mse:.4f}",
transform=ax.transAxes, ha="left", va="top", fontsize=11.5,
weight="bold", color=COL_ROSE_500,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE,
ec=COL_ROSE_400, lw=1.4))
# universal approximation annotate (Ders 3 köprüsü)
ax.annotate(
"yeterli ReLU toplamı = istenen karmaşıklık\n"
"(universal approximation, Ders 3);\nMLP bunu matrislerle kurar",
xy=(x[int(0.74 * len(x))], fit[int(0.74 * len(x))]),
xytext=(0.40, 0.16), textcoords=ax.transAxes,
ha="left", va="bottom", fontsize=10, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_CYAN_50,
ec=COL_CYAN_400, lw=1.3),
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=1.8,
connectionstyle="arc3,rad=-0.25"))
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_title(f"{k} doğrultulmuş doğru (ReLU) toplamı → karmaşık eğri", color=COL_TEXT)
apply_style(ax)
ax.legend(loc="lower right", framealpha=0.95, fontsize=9.5)
plt.tight_layout()
plt.show()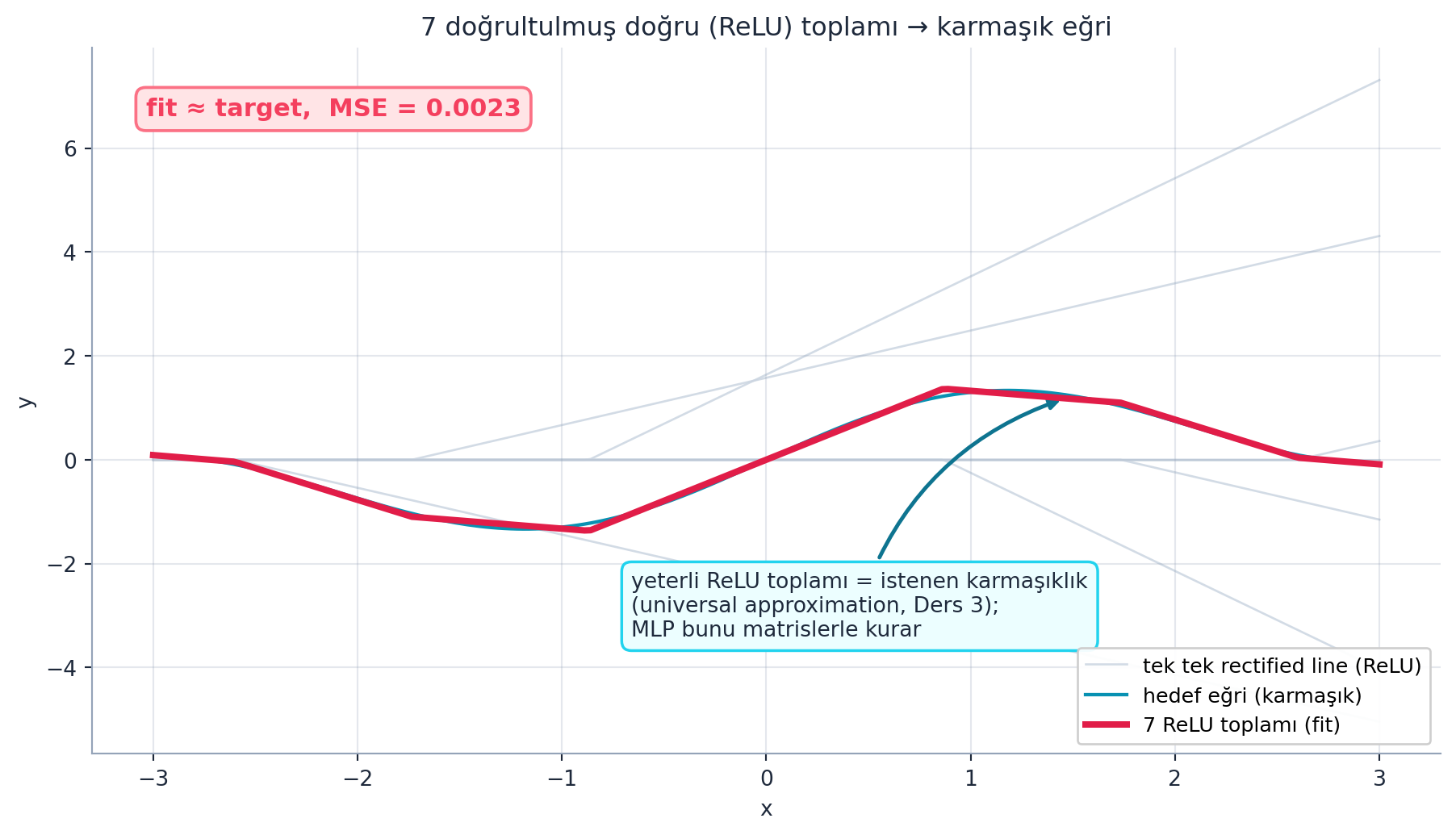
İpucuBuilder Notu — ReLU Toplamı: Universal Approximation
- Geriye (Ders 3): Bu, Ders 3’ün “ReLU toplamı = universal approximation” fikrinin görsel tekrarı; şimdi matrislerle kuracağız.
- Sezgi: Her ReLU bir “köşe” katar; köşeleri uygun ağırlıklarla toplayınca herhangi bir sürekli eğriyi istenen hassasiyetle yaklaşıklayabilirsin — sinir ağının gücü buradan gelir.
16.4 3. ReLU Toplamı ile Yüzeyler
Tek girdide rectified lines topluyorduk; çok girdide aynı fikir rectified planes (düzlemler) toplamına genişler. Böylece çok boyutlu girdiler için karmaşık karar yüzeyleri kurulur — bu bir sinir ağının yaptığı şeydir. Fikir birebir aynı; sadece doğrular düzlemlere dönüşür.
“But now they’re going to be kind of rectified planes. It’s going to be exactly the same [idea].” — Howard, 9:35
İpucuBuilder Notu — Rectified Planes: Aynı Fikir, Çok Boyut
- Geriye (Ders 8): Çok boyutlu girdi = matris; her ReLU bir doğrusal dönüşüm + kırpma (Ders 8 convolution’la akraba).
- Sezgi: Tek girdide “kırpılmış doğru”, çok girdide “kırpılmış düzlem” olur; düzlemleri toplayınca karmaşık karar yüzeyleri (sinir ağının öğrendiği şey) çıkar. Şekil 16.2’daki tek-girdi sezgisi doğrudan çok boyuta genişler.
16.5 4. MLP from Scratch: Mimari
Howard MNIST için bir MLP kurar. Girdi: 50.000 satır × 784 sütun (28×28 piksel). Mimari: 784 girdi → nh gizli birim → 1 çıktı (şimdilik tek çıktı; MSE basitliği için — gerçek 10-sınıf cross-entropy’ye Part 2’de geçilecek). Ağırlıklar rastgele başlar; eğitim onları gradyanlarla düzeltecek.
n, m = x_train.shape # 50000, 784
nh = 50 # gizli birim sayisi
w1 = torch.randn(m, nh); b1 = torch.zeros(nh) # 784 -> 50
w2 = torch.randn(nh, 1); b2 = torch.zeros(1) # 50 -> 1
İpucuBuilder Notu — MLP Mimarisi: İki Katman, Bir Gizli Kat
- Geriye (Ders 5): Ders 5’teki Titanic MLP’siyle aynı yapı (layer1, layer2); burada MNIST’te, daha sistematik.
- Sezgi:
w1girdiyi gizli kata (784→50) taşır,w2gizli katı çıktıya (50→1); aradaki ReLU olmadan bu iki çarpım tek bir çarpıma çökerdi. Ağırlıklarınrandnile rastgele başlaması, eğitimin onları kademeli düzeltmesi içindir.
16.6 5. Lineer Katman
İlk yapı taşı: lineer katman = girdi × ağırlık + bias. Tek satır, ama her sinir ağının temeli (Ders 10-12’de kurduğumuz matmul burada işler).
def lin(x, w, b): return x@w + b # matris carpimi + bias
İpucuBuilder Notu — Lineer Katman: x@w + b
- Geriye (Ders 5/10):
x@w + b= Ders 5’teki lineer model;@artık güvenle kullanılıyor (Ders 10-12’de sıfırdan kuruldu). - Sezgi: Lineer katman her girdiyi ağırlıklı toplamına çevirir; “yeniden kur, sonra kullan” disiplini sayesinde
@’in altını bildiğimiz için onu burada gönül rahatlığıyla kullanırız (Ders 12).
16.7 6. ReLU Katmanı
İkinci yapı taşı: ReLU = negatifleri sıfıra kırp. Bu, katmanlar arası doğrusal-olmamayı sağlar; olmazsa iki lineer katman tek lineer katmana çöker.
def relu(x): return x.clamp_min(0.) # negatifleri sifira cekŞekil 16.3 ReLU’yu ve gradyanını gerçek hesaplama ile gösterir: solda ReLU(x) = max(0, x) (x<0’da düz 0, x>0’da y=x), sağda gradyanı — pozitif girdide 1, negatif girdide 0. Bu adım-fonksiyonu gradyanı ReLU’nun “kapı” davranışıdır; backprop’ta (l1>0) maskesi olarak görünecek (§12).
Kod
d = E.relu_gradient_demo()
x, r, g = d["x"], d["relu"], d["grad"]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.5))
# --- SOL: ReLU(x) = max(0, x) ---
axL.plot(x, r, color=COL_PRIMARY, linewidth=2.6, zorder=3)
axL.axhline(0, color=COL_SLATE_400, linewidth=1.0, zorder=1)
axL.axvline(0, color=COL_SLATE_400, linewidth=1.0, zorder=1)
axL.fill_between(x, 0, r, color=COL_BG, alpha=0.6, zorder=2)
axL.set_title("ReLU(x) = max(0, x)", color=COL_CYAN_700, fontsize=12, weight="bold")
axL.set_xlabel("x")
axL.set_ylabel("ReLU(x)")
axL.annotate("x < 0 → düz 0", xy=(-2.0, 0.0), xytext=(-3.7, 1.6),
color=COL_CYAN_800, fontsize=9.5, weight="bold",
arrowprops=dict(arrowstyle="->", color=COL_CYAN_700, lw=1.4))
axL.annotate("x > 0 → y = x", xy=(2.6, 2.6), xytext=(0.5, 3.4),
color=COL_CYAN_800, fontsize=9.5, weight="bold",
arrowprops=dict(arrowstyle="->", color=COL_CYAN_700, lw=1.4))
apply_style(axL)
# --- SAĞ: ReLU gradyanı (adım fonksiyonu = 'kapı') ---
axR.plot(x, g, color=COL_ACCENT, linewidth=2.6, zorder=3,
drawstyle="steps-mid")
axR.axhline(0, color=COL_SLATE_400, linewidth=1.0, zorder=1)
axR.axvline(0, color=COL_SLATE_400, linewidth=1.0, zorder=1)
axR.fill_between(x, 0, g, step="mid", color=COL_BG_ROSE, alpha=0.6, zorder=2)
axR.set_title("∂ ReLU / ∂x (gradyan = 'kapı')", color=COL_ROSE_500,
fontsize=12, weight="bold")
axR.set_xlabel("x")
axR.set_ylabel("gradyan")
axR.set_ylim(-0.15, 1.25)
axR.set_yticks([0, 1])
axR.annotate("pozitif girdi: gradyan 1\n(gradyan GEÇER)", xy=(2.0, 1.0),
xytext=(0.2, 0.45), color=COL_ROSE_500, fontsize=9.5, weight="bold",
ha="left", arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.4))
axR.annotate("negatif girdi: gradyan 0\n(gradyan GEÇMEZ)", xy=(-2.0, 0.0),
xytext=(-3.9, 0.55), color=COL_ROSE_500, fontsize=9.5, weight="bold",
ha="left", arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.4))
apply_style(axR)
plt.tight_layout()
plt.show()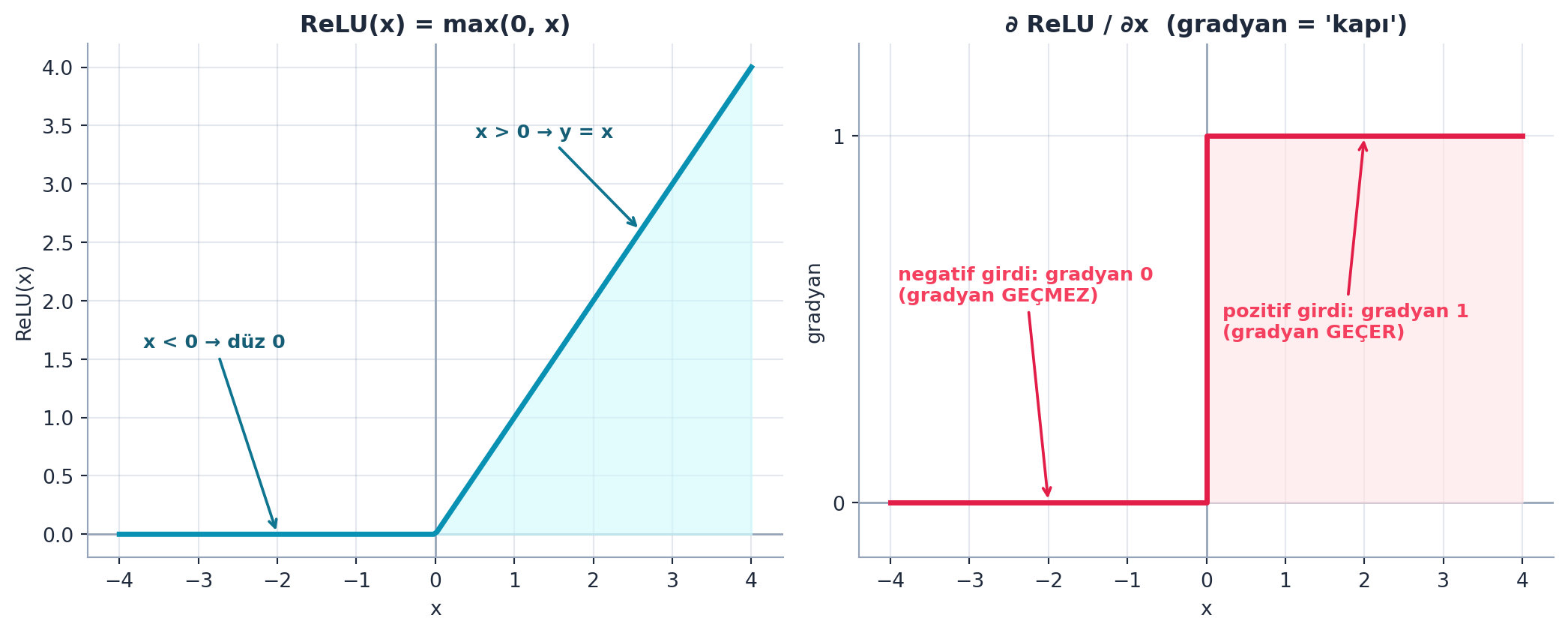
İpucuBuilder Notu — ReLU: Doğrusal-Olmamanın Anahtarı
- Geriye (Ders 3): ReLU olmadan ağ “derin” olamaz — iki matris çarpımı tek bir matris çarpımına indirgenir (doğrusallık).
- İleriye (§12): ReLU’nun gradyanı (pozitifte 1, negatifte 0) backprop’un kritik parçasıdır:
l1.g = (l1>0).float() * l2.g. Negatif girdili nöronlardan gradyan geçmez — “kapı” kapalıdır.
16.8 7. MLP Forward Pass
İki yapı taşını birleştir: lineer → ReLU → lineer. Bu, ileri geçiştir (forward pass) — girdiden tahmine.
def model(xb):
l1 = lin(xb, w1, b1) # 1. lineer katman
l2 = relu(l1) # ReLU (dogrusal-olmama)
return lin(l2, w2, b2) # 2. lineer katman -> ciktiŞekil 16.4 bu ileri geçişi gerçek hesaplama ile gösterir: x → l1 → l2 → out şekil akışı ve her aşamanın aktivasyon dağılımı. Kritik gözlem orta panelde: ReLU sonrası l2 dağılımında sol yığılma vardır — negatif aktivasyonlar 0’a kırpılmıştır; işte doğrusal-olmama tam burada devreye girer.
Kod
d = E.mlp_forward_demo()
l1, l2, out = d["l1"].ravel(), d["l2"].ravel(), d["out"].ravel()
sh = d["shapes"]
def _shape(t):
return "×".join(str(v) for v in t)
fig, axes = plt.subplots(1, 3, figsize=(12, 4.5))
panels = [
(axes[0], l1, COL_PRIMARY, "lin1 çıktısı (l1)", sh["l1"]),
(axes[1], l2, COL_ACCENT, "ReLU sonrası (l2)", sh["l2"]),
(axes[2], out, COL_CYAN_700, "çıktı (out)", sh["out"]),
]
for ax, data, col, title, shp in panels:
ax.hist(data, bins=28, color=col, edgecolor=COL_WHITE, linewidth=0.6, zorder=3)
ax.axvline(0.0, color=COL_SLATE_400, lw=1.2, ls="--", zorder=2)
ax.set_title(f"{title}\nshape: {_shape(shp)}", color=COL_TEXT,
fontsize=11, weight="bold")
ax.set_xlabel("aktivasyon değeri", color=COL_TEXT, fontsize=9.5)
ax.set_ylabel("frekans", color=COL_TEXT, fontsize=9.5)
apply_style(ax)
# l2 panelinde ReLU sol-yığılma vurgusu (negatifler 0'a çekilmiş)
ax_relu = axes[1]
ymax = ax_relu.get_ylim()[1]
ax_relu.annotate("ReLU negatifleri\nsıfıra çeker → doğrusal-olmama",
xy=(0.0, ymax * 0.62), xytext=(0.18, 0.78),
textcoords="axes fraction",
ha="left", va="center", fontsize=9, color=COL_TEXT, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.8,
shrinkA=2, shrinkB=4))
# shapes akış başlığı: x → l1 → l2 → out
flow = (f"x ({_shape(sh['x'])}) → l1 ({_shape(sh['l1'])}) → "
f"l2 ({_shape(sh['l2'])}) → out ({_shape(sh['out'])})")
fig.suptitle(flow, color=COL_CYAN_800, fontsize=10.5, weight="bold", y=1.02)
plt.tight_layout()
plt.show()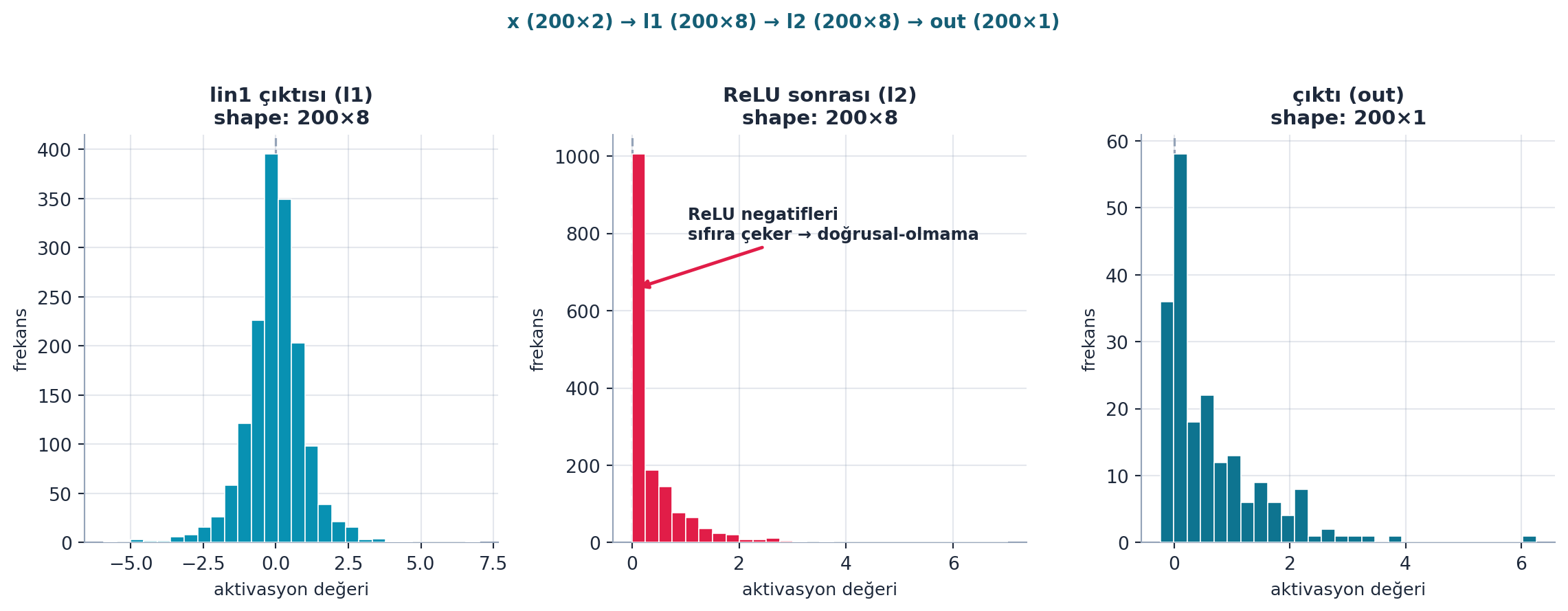
İpucuBuilder Notu — Forward Pass: lin → relu → lin
- Geriye (Ders 5): Ders 5’teki
calc_preds’in aynısı; “matris çarpımı + ReLU + matris çarpımı” deseni. - Sezgi: Forward pass sadece üç satır — girdiyi gizli kata taşı, doğrusal-olmama ekle, çıktıya taşı; ReLU’nun negatifleri kırpması (orta paneldeki sol yığılma) ağın “derinliğini” anlamlı kılan tek adımdır.
16.9 8. MSE Loss from Scratch
Tahminin ne kadar iyi olduğunu ölçmek için MSE (ortalama karesel hata). Şimdilik (sınıflandırma için ideal olmasa da, basitlik için) çıktı ile hedefin farkının karesinin ortalaması.
def mse(output, targ): return (output[:,0] - targ).pow(2).mean()“Loss function from scratch — Mean Squared Error.” — Howard, 18:26
İpucuBuilder Notu — MSE: Basitlik İçin Şimdilik
- Geriye (Ders 3/4): MSE Ders 3’te tanımlandı; Ders 4’te cross-entropy’nin sınıflandırma için daha uygun olduğunu görmüştük (Part 2’de ona geçilecek).
- Sezgi: MSE rakam sınıflandırması için ideal değil (ona Part 2’de geçeceğiz), ama backprop mekanizmasını öğrenmek için en sade loss; önce mekanizmayı kur, doğru loss’a sonra geç.
16.10 9. Gradyanlar ve Backpropagation
Modeli eğitmek için her parametreyi hangi yönde değiştireceğimizi bilmeliyiz — gradient (eğim). Howard hatırlatır: gradyan, bir parametreyi azıcık değiştirince kaybın ne kadar değiştiğidir. Eğer bir ağırlığı artırınca kayıp artıyorsa, onu azaltırız.
“Gradients are slopes. If we can get the derivative of the loss with respect to one particular weight… if it makes the loss go up, then I want to do the opposite.” — Howard, 18:26
İpucuBuilder Notu — Gradient: Hangi Yöne Adım?
- Geriye (Ders 3/5): Gradient descent (Ders 3/5); fark: burada gradyanı elle, katman katman hesaplayacağız (PyTorch autograd yerine).
- Sezgi: Gradyan bir pusuladır: işareti hangi yöne adım atacağını söyler — kaybı artıran ağırlığı azalt, azaltanı artır. Backprop’un tüm derdi, bu pusulayı her parametre için verimli üretmektir.
16.11 10. Chain Rule: Zincir Kuralı
Bir ağ, fonksiyonların bileşkesidir (lin → relu → lin → loss). Kaybın bir ağırlığa göre türevini bulmak için zincir kuralı gerekir: bileşke fonksiyonun türevi, parçaların türevlerinin çarpımıdır.
\[\frac{\partial L}{\partial w} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial w}\]
Burada \(\hat{y}\) ağın çıktısı (tahmin); kaybın türevini, en dıştan (loss) en içe (ağırlık) doğru, her katmanın yerel türeviyle çarparak geriye yayarız. ∂L/∂w değerini doğrudan değil, parçaların çarpımı olarak biriktiririz (prose’da ∂L/∂çıktı · ∂çıktı/∂w olarak da okunur).
Şekil 16.5 bu fikri şematik gösterir: üstte ileri akış (w → z = lin(w) → a = relu(z) → ŷ = lin(a) → L), altta her bağlantının yerel türevi (∂L/∂ŷ, ∂ŷ/∂a, ∂a/∂z, ∂z/∂w) ve bunların çarpımı. Bileşke fonksiyonun türevi = parçaların türevlerinin çarpımı; backprop bunu en dıştan (kayıp) içe (ağırlık) doğru biriktirir.
Kod
fig, ax = plt.subplots(figsize=(11.5, 4.5))
# --- İleri yön (üst sıra): ağ = fonksiyonlar bileşkesi -------------------
yf = 3.05
nodes = [
(1.1, "w\n(ağırlık)"),
(3.4, "z = lin(w)\nara değer"),
(5.7, "a = relu(z)\naktivasyon"),
(8.0, "ŷ = lin(a)\nçıktı"),
(10.4, "L\n(kayıp)"),
]
node_w, node_h = 1.75, 0.95
for x, txt in nodes:
boxed_node(ax, x, yf, node_w, node_h, txt, fontsize=9.5)
# ileri oklar (cyan) — bileşke fonksiyonun ileri akışı
fwd_x = [n[0] for n in nodes]
for x0, x1 in zip(fwd_x[:-1], fwd_x[1:]):
arrow_between(ax, (x0, yf), (x1, yf), color=COL_CYAN_700, lw=2.2)
ax.text(5.7, yf + 0.92, "ileri: lin → relu → lin → kayıp (fonksiyonlar bileşkesi)",
ha="center", va="bottom", fontsize=10.5, color=COL_CYAN_800, weight="bold")
# --- Geri yön (alt sıra): yerel türevler ve ÇARPIM ------------------------
yb = 1.05
locals_lbl = [
(9.2, "∂L/∂ŷ"),
(6.85, "∂ŷ/∂a"),
(4.55, "∂a/∂z"),
(2.25, "∂z/∂w"),
]
for x, txt in locals_lbl:
boxed_node(ax, x, yb, 1.55, 0.7, txt, fc=COL_BG_ROSE, ec=COL_ACCENT,
tc=COL_ROSE_500, fontsize=11, lw=2.0)
# geri oklar (rose) — kaybın türevini en dıştan içe biriktir
back_x = [10.4] + [l[0] for l in locals_lbl] + [1.1]
for i in range(len(back_x) - 1):
y0 = yf - node_h / 2 if i == 0 else yb
y1 = yf - node_h / 2 if i == len(back_x) - 2 else yb
arrow_between(ax, (back_x[i], y0), (back_x[i + 1], y1),
color=COL_ACCENT, lw=2.2,
connectionstyle="arc3,rad=-0.12")
# her ok arası çarpım işareti
mult_x = [8.0, 5.7, 3.4]
for x in mult_x:
ax.text(x, yb, "×", ha="center", va="center", fontsize=15,
color=COL_ROSE_500, weight="bold", zorder=5)
ax.text(5.7, yb - 0.85,
"∂L/∂w = ∂L/∂ŷ · ∂ŷ/∂a · ∂a/∂z · ∂z/∂w "
"(yerel türevlerin çarpımı)",
ha="center", va="top", fontsize=11.5, color=COL_ACCENT, weight="bold")
# köprü açıklaması
ax.annotate(
"bileşke fonksiyonun türevi = parçaların türevlerinin çarpımı;\n"
"backprop bunu en dıştan (kayıp) içe (ağırlık) doğru biriktirir",
xy=(10.4, yf - node_h / 2), xytext=(6.0, 2.18),
ha="center", va="center", fontsize=9.8, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_WHITE, ec=COL_SLATE_300, lw=1.2),
zorder=6)
ax.set_xlim(-0.1, 11.7)
ax.set_ylim(0.0, 4.3)
ax.axis("off")
plt.tight_layout()
plt.show()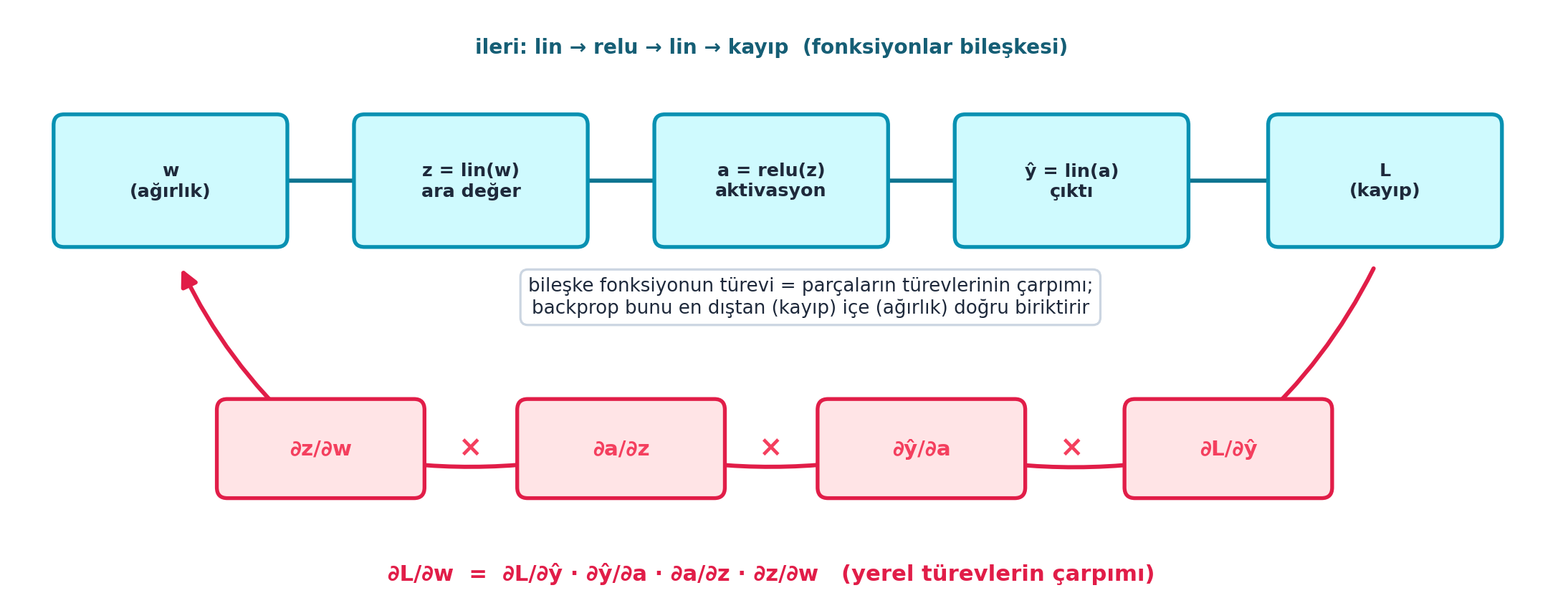
İpucuBuilder Notu — Chain Rule: Backprop’un Kalbi
- Geriye (Calculus / Karpathy): Chain rule, Calculus’un (3Blue1Brown) kalbi; Karpathy micrograd’ı bunu her düğümde
_backwardile uygular. Howard 3Blue1Brown’u izlemeyi önerir. - Sezgi: “Bileşke fonksiyonun türevi = parçaların türevlerinin çarpımı.” Backprop bu çarpımı sağdan (loss) sola (ilk ağırlık) doğru biriktirir; her katman kendi yerel türevini bilir, gerisi çarpmadır.
16.12 11. Lineer Katmanın Gradyanı
Backprop’un parçası: bir lineer katmanın gradyanı. Çıktının gradyanı (out.g) verildiğinde, girdiye, ağırlığa ve bias’a göre gradyanlar zincir kuralıyla hesaplanır. Howard her birini elle yazar.
def lin_grad(inp, out, w, b):
inp.g = out.g @ w.t() # girdiye gore (zincir kurali)
w.g = (inp.unsqueeze(-1) * out.g.unsqueeze(1)).sum(0) # agirliga gore
b.g = out.g.sum(0) # bias'a gore
İpucuBuilder Notu — lin_grad: Transpoze Gradyanı
- Geriye (18.06): Lineer katmanın girdiye göre türevi = ağırlık matrisinin transpozu (
w.t()); bu, matris kalkülüsünün temel sonucu (18.06). - Sezgi: Üç satır, üç gradyan: girdiye göre =
out.g @ wᵀ(gradyanı geri taşı), ağırlığa göre = girdi ⊗ çıktı.g (her ağırlığın katkısı), bias’a göre = çıktı.g’nin toplamı.out.g’yi alır, üç yöne dağıtır — micrograd’ın çarpma/toplama düğümünün matris hâli.
16.13 12. forward_and_backward: Tam Manuel Backprop
Howard tüm ileri ve geri geçişi tek fonksiyonda birleştirir. İleri: lin → relu → lin → loss. Geri: en dıştan (loss’un gradyanı) başlayıp her katmanın gradyanını zincir kuralıyla geriye yayar. ReLU’nun gradyanı: girdi pozitifse 1, değilse 0.
def forward_and_backward(inp, targ):
# forward:
l1 = lin(inp, w1, b1); l2 = relu(l1); out = lin(l2, w2, b2)
diff = out[:,0] - targ; loss = diff.pow(2).mean()
# backward (zincir kurali, en distan ice):
out.g = 2.*diff[:,None] / inp.shape[0] # loss'un ciktiya gore turevi
lin_grad(l2, out, w2, b2) # 2. katman geri
l1.g = (l1>0).float() * l2.g # ReLU gradyani
lin_grad(inp, l1, w1, b1) # 1. katman geriŞekil 16.6 bu tam akışı şematik gösterir (FLAGSHIP): üstte forward geçiş (girdi → lin1 → ReLU → lin2 → çıktı → MSE loss, cyan soldan sağa), altta manuel backward (loss → girdi, rose sağdan sola) — her backward kutusu yukarıdaki forward kutusunun altında hizalı. out.g’den başlar, lin2 backward → ReLU gradyanı (× (l1>0)) → lin1 backward ile geriye yayar. Ortadaki not Karpathy köprüsünü işaret eder: her .g = micrograd _backward().
Kod
fig, ax = plt.subplots(figsize=(12.5, 6))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 6)
ax.axis("off")
# ----------------------------------------------------------------------------
# ÜST SIRA — forward geçiş (cyan, soldan sağa): girdi → loss
# ----------------------------------------------------------------------------
y_fwd = 4.55
fwd_nodes = [
(1.15, "girdi x"),
(3.30, "lin1\n(x@w1+b1)"),
(5.30, "ReLU"),
(7.30, "lin2\n(@w2+b2)"),
(9.20, "çıktı"),
(11.20, "MSE loss"),
]
bw, bh = 1.55, 0.95
for x, txt in fwd_nodes:
boxed_node(ax, x, y_fwd, bw, bh, txt,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=10)
# forward okları (cyan, soldan sağa)
for (x0, _), (x1, _) in zip(fwd_nodes[:-1], fwd_nodes[1:]):
arrow_between(ax, (x0 + bw / 2, y_fwd), (x1 - bw / 2, y_fwd),
color=COL_PRIMARY, lw=2.2, shrink=2)
ax.text(0.15, 5.55, "forward — girdi → loss", color=COL_CYAN_700,
fontsize=11.5, weight="bold", ha="left")
# ----------------------------------------------------------------------------
# ALT SIRA — backward geçiş (rose, SAĞDAN SOLA): loss → girdi
# Her backward kutusu yukarıdaki forward kutusunun ALTINDA hizalı.
# ----------------------------------------------------------------------------
y_bwd = 1.85
bwd_nodes = [
(11.20, "out.g\n= ∂L/∂out"),
(7.30, "lin2 backward\n(w2.g, ∂l2)"),
(5.30, "ReLU gradyanı\n(× (l1>0))"),
(3.30, "lin1 backward\n(w1.g)"),
]
for x, txt in bwd_nodes:
boxed_node(ax, x, y_bwd, bw, bh, txt,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=9.5)
# backward okları (rose, sağdan sola)
for (x0, _), (x1, _) in zip(bwd_nodes[:-1], bwd_nodes[1:]):
arrow_between(ax, (x0 - bw / 2, y_bwd), (x1 + bw / 2, y_bwd),
color=COL_ACCENT, lw=2.2, shrink=2)
# loss kutusundan backward zincirine geçiş (dikey, rose kesikli his)
arrow_between(ax, (11.20, y_fwd - bh / 2), (11.20, y_bwd + bh / 2),
color=COL_ACCENT, lw=2.0, shrink=2, style="-|>")
ax.text(12.35, 2.85, "backward — loss → girdi", color=COL_ACCENT,
fontsize=11.5, weight="bold", ha="right")
# ----------------------------------------------------------------------------
# Açıklama notları
# ----------------------------------------------------------------------------
ax.annotate(
"chain rule: en dıştan içe, her katman yerel türeviyle çarpar",
xy=(6.25, 0.95), xytext=(6.25, 0.55),
ha="center", va="center", fontsize=10.5, color=COL_CYAN_800,
weight="bold",
)
ax.text(6.25, 3.20,
"Karpathy: her .g = micrograd _backward()",
ha="center", va="center", fontsize=10, color=COL_ACCENT,
style="italic",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_WHITE,
ec=COL_ROSE_400, lw=1.4))
plt.tight_layout()
plt.show()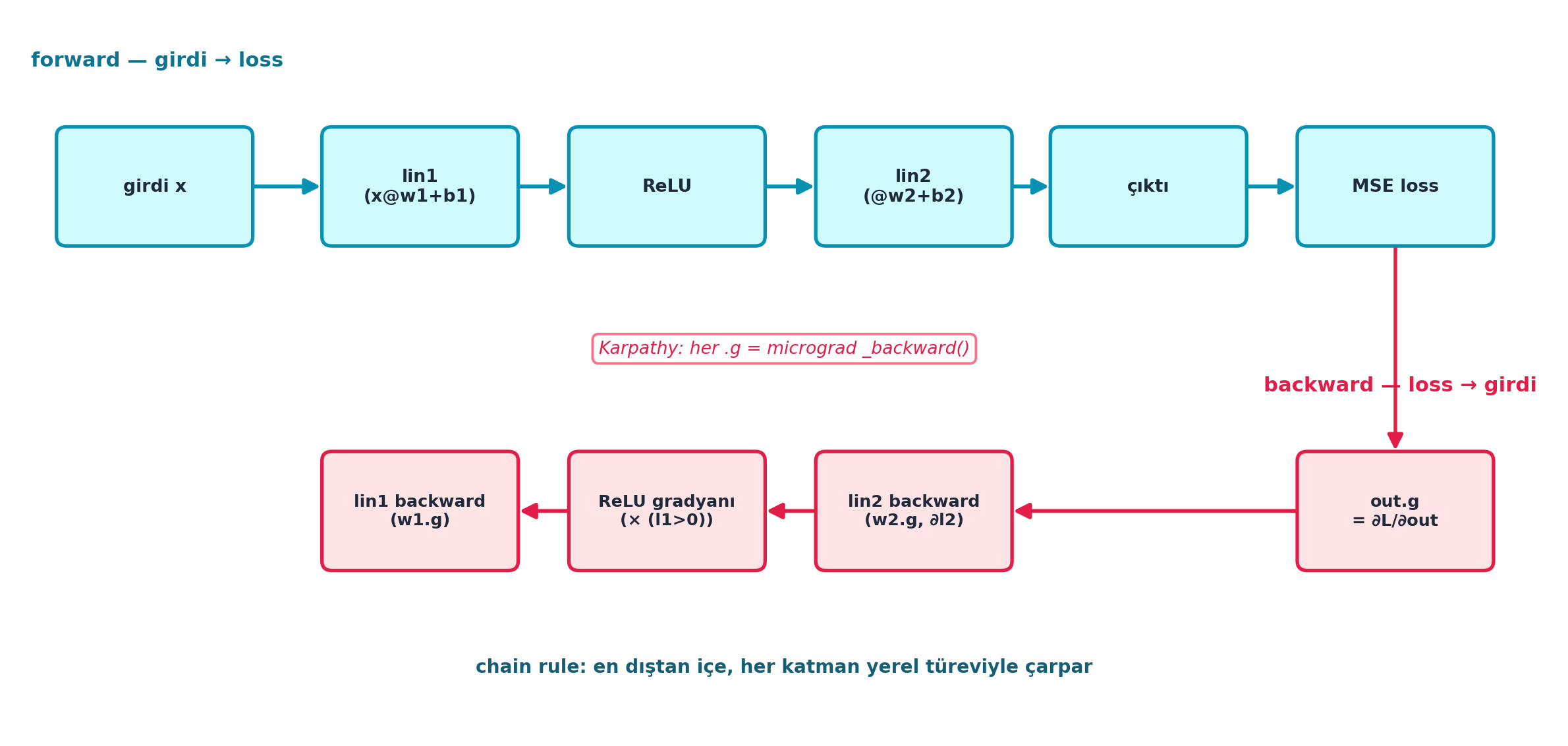
İpucuBuilder Notu — forward_and_backward: Her Satır Bir _backward
- Geriye (Karpathy): Bu, micrograd’ın
backward()’ının tam karşılığı; her satır bir_backwardadımı.out.g,l1.g= her düğümün gradyanı. - Sezgi:
out.g = 2.*diff/nMSE’nin türevidir (en dış katman); sonralin_gradile katman 2’yi,(l1>0)maskesiyle ReLU’yu, tekrarlin_gradile katman 1’i geriye yayar. Backward kodu forward kodunun tersten okunuşudur — her ileri işlemin bir geri eşi vardır.
16.14 13. Karpathy Köprüsü
Bu ders, fast.ai ile Karpathy serisinin en net buluştuğu yerdir. Karpathy micrograd’da her işlem için bir _backward kapanışı yazar ve topolojik sırayla çağırır; Howard burada her katman için elle .g gradyanı hesaplar. İki yöntem aynı şeyin iki ifadesidir: chain rule’u katman katman geriye uygulamak.
“That’s how what’s happening in our code is mapping to the math.” — Howard, 6:28
Şekil 16.7 bunu gerçek hesaplama ile kanıtlar (FLAGSHIP): elle yazılan backprop gradyanları, sayısal türevle (finite-difference) ~1e-11 hassasiyetle EŞLEŞİR — yani her .g doğru. Log-skala barlar tüm parametreler için maksimum mutlak farkı 1e-4 tolerans çizgisinin çok solunda gösterir. Bu, Karpathy’nin backprop-ninja dersindeki cmp emsalidir: elle yazdığın gradyanı referans gradyanla karşılaştır, eşleşiyorsa backprop doğru.
Kod
d = E.manual_backprop_demo()
checks = d["checks"] # [(ad, maxdiff, match), ...]
names = [c[0] for c in checks]
diffs = [c[1] for c in checks] # maxdiff ~1e-11 (gerçek)
matches = [c[2] for c in checks]
fig, ax = plt.subplots(figsize=(10, 5.5))
# Log-skala yatay bar: elle hesap vs sayısal (finite-diff) maksimum farkı
y = np.arange(len(names))
ax.barh(y, diffs, height=0.46, color=COL_PRIMARY, zorder=3,
edgecolor=COL_CYAN_800, linewidth=1.4)
ax.set_xscale("log")
ax.set_yticks(y)
ax.set_yticklabels(names, fontsize=12.5, color=COL_TEXT)
ax.invert_yaxis()
ax.set_xlabel("elle hesap vs sayısal türev — maksimum mutlak fark (log)",
fontsize=11, color=COL_TEXT)
ax.set_xlim(1e-13, 1e-3)
# Tolerans çizgisi (1e-4): farklar bunun SOLUNDA → backprop doğru
ax.axvline(1e-4, color=COL_ACCENT, lw=1.8, ls="--", zorder=2)
ax.text(1e-4, -0.62, "tolerans 1e-4", color=COL_ACCENT, fontsize=9.5,
weight="bold", ha="center", va="bottom")
# Her bar için değer + "EŞLEŞTİ ✓" rozeti
for yi, (val, ok) in enumerate(zip(diffs, matches)):
ax.text(val * 1.6, yi, f"{val:.1e}", va="center", ha="left",
fontsize=11, color=COL_CYAN_800, weight="bold")
ax.annotate(" EŞLEŞTİ ✓ ", xy=(1, yi), xycoords=("axes fraction", "data"),
xytext=(-10, 0), textcoords="offset points",
va="center", ha="right", fontsize=11.5, weight="bold",
color=COL_WHITE,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_PRIMARY,
ec=COL_CYAN_800, lw=1.4))
apply_style(ax)
ax.grid(True, axis="x", which="both", alpha=0.18, color=COL_SLATE_400)
ax.grid(False, axis="y")
# Büyük başlık + Karpathy köprüsü notu
ax.set_title("manuel backprop = sayısal gradyan",
fontsize=16, weight="bold", color=COL_CYAN_800, pad=26)
ax.text(0.5, 1.045,
"elle yazılan ∂L/∂w (chain rule) ≈ finite-diff türev → backprop DOĞRU",
transform=ax.transAxes, ha="center", va="bottom",
fontsize=10.5, color=COL_TEXT)
ax.text(0.5, -0.20,
f"Karpathy backprop-ninja cmp emsali · MSE loss = {d['loss']:.3f} · "
f"tüm parametreler EŞLEŞTİ: {d['all_match']}",
transform=ax.transAxes, ha="center", va="top",
fontsize=10, color=COL_ACCENT, weight="bold")
plt.tight_layout()
plt.show()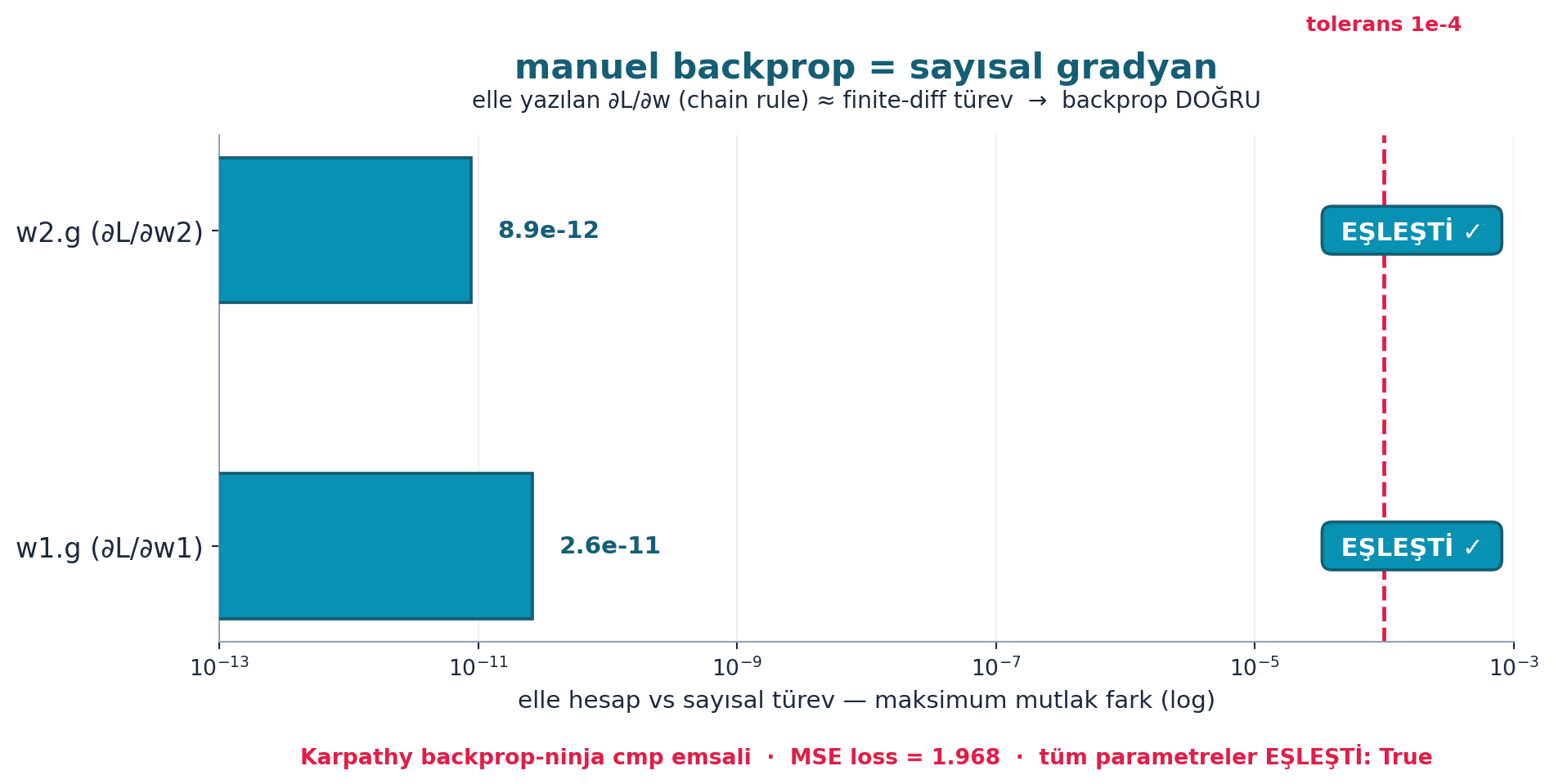
İpucuBuilder Notu — Karpathy Köprüsü: İki Yol, Aynı Matematik
- Geriye (Karpathy 1-5): Karpathy Ders 1 (micrograd) + Ders 5 (backprop ninja, elle gradyan) = bu dersin birebir akrabası; ikisini birlikte yapan backprop’u asla unutmaz. Howard’ın manuel
.g’si = Karpathy’nin_backwardkapanışı; aynı chain rule, farklı kod stili. - İleriye: Bir kez elle kurduktan sonra
loss.backward()(PyTorch autograd) güvenle kullanılır — altında bu var. Şekil 16.7 elle hesabın sayısal türevle eşleştiğini gösterdiği an, autograd artık “büyü” değil, anladığın bir araçtır.
16.15 14. Refactoring’e Doğru
Howard manuel backprop’u temizlemeye hazırlanır: tekrar eden “ileri sonucu sakla, geri gradyanı hesapla” desenini sınıflara sarmak (Ders 14). Her katman kendi forward ve backward’ını bilen bir nesne olacak — PyTorch’un nn.Module’üne giden yol.
İpucuBuilder Notu — Refactoring: Her Katman Bir Sınıf
- İleriye (Ders 14): “Her katman = forward + backward bilen sınıf” deseni; nn.Module’ün özü.
- Sezgi: Şu an
forward_and_backwardtek devasa fonksiyon; aynı desen (“ileriyi sakla, geriyi hesapla”) her katmanda tekrarlanıyor. Onu sınıflara sarınca her katman bağımsız, yeniden kullanılabilir bir nesne olur — bu,nn.Module’ün doğuşudur (Ders 14).
16.16 15. Neden Elle Kurmak?
Howard’ın “from the foundations” felsefesi burada zirve yapar: backprop’u elle kurmak, sonra PyTorch’un otomatik türevini (autograd) güvenle kullanmamızı sağlar. Mekanizmayı anlamadan kütüphaneye güvenmek, hata ayıklamayı imkânsız kılar.
İpucuBuilder Notu — Neden Elle: Kara Kutu Olmasın
- Geriye (Ders 10): “Bir kez sıfırdan kur, sonra kullan” kuralı; backprop bunun en kritik örneği.
- Sezgi:
loss.backward()bir kara kutu olarak kalırsa, gradyan patlaması/sönmesi gibi sorunları teşhis edemezsin. Bir kez elle kurarsan, altında tam olarak ne olduğunu bilirsin — hata ayıklayabilir, özel katmanlar yazabilirsin.
16.17 16. Kapanış
Ders 13, sinir ağının kalbini sıfırdan kurdu: MLP (lin + ReLU + lin), MSE loss ve manuel backpropagation (chain rule ile katman katman geriye gradyan). Bu, Karpathy micrograd’ının fast.ai karşılığı — iki “from scratch” yolu burada buluşur. Ders 14 bunu nn.Module’e refactor edecek.
Şekil 16.8 dersin sentezidir (Karpathy köprüsü merkezde): solda L13’ün parçaları (manuel .g gradyanları, MLP, chain rule, lin_grad, “elle kur → loss.backward()”), sağda her birinin kaynağı/karşılığı — manuel .g = Karpathy micrograd _backward kapanışları (Ders 1 + 5 backprop-ninja, BİREBİR aynı), MLP = Ders 3 + Ders 5, chain rule = Calculus, lin_grad = 18.06 matris kalkülüsü, “elle kur → kullan” = Ders 10. Ortada vurgu: iki “from scratch” yolu burada buluşur.
Kod
fig, ax = plt.subplots(figsize=(12, 6.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.5)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# Başlıklar (sütun etiketleri)
ax.text(2.55, 6.30, "L13'te (fast.ai)", ha="center", va="center",
fontsize=14, weight="bold", color=COL_ROSE_500)
ax.text(9.15, 6.30, "karşılığı / kaynak", ha="center", va="center",
fontsize=14, weight="bold", color=COL_CYAN_700)
# SOL sütun (L13-parçaları, rose) — 5 satır
left_x, lw_box, lh_box = 2.55, 4.1, 0.84
right_x, rw_box, rh_box = 9.15, 4.7, 0.92
ys = [5.30, 4.25, 3.20, 2.15, 1.10]
left_labels = [
"manuel .g gradyanları",
"MLP (lin + ReLU)",
"chain rule (zincir kuralı)",
"lin_grad: out.g @ wᵀ",
"elle kur → loss.backward()",
]
right_labels = [
"Karpathy micrograd _backward kapanışları\n(Ders 1 + 5 backprop-ninja) — BİREBİR aynı",
"Ders 3 'ReLU toplamı' + Ders 5 gradient descent\nmatrislerle somut",
"Calculus zincir kuralı\n(3Blue1Brown)",
"18.06 matris kalkülüsü\n(transpoze gradyan: ∂L/∂x = ∂L/∂out · wᵀ)",
"Ders 10 'yeniden kur sonra kullan'\nartık güvenle .backward()",
]
for y, lt, rt in zip(ys, left_labels, right_labels):
# L13-parçası (rose dolgu/çerçeve)
boxed_node(ax, left_x, y, lw_box, lh_box, lt,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=10.5, lw=2.0)
# kaynak/hedef (cyan dolgu/çerçeve)
boxed_node(ax, right_x, y, rw_box, rh_box, rt,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=9.0, lw=2.0)
# ok: L13-parçası → kaynak (cyan)
arrow_between(ax, (left_x + lw_box / 2, y), (right_x - rw_box / 2, y),
color=COL_CYAN_700, lw=2.0, mutation_scale=16, shrink=4)
# ORTADA vurgu: iki 'from scratch' yolu burada buluşur
ax.text(6.0, 0.18, "iki 'from scratch' yolu burada buluşur",
ha="center", va="center", fontsize=12.5, weight="bold",
color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_50,
ec=COL_ACCENT, lw=2.0))
plt.tight_layout()
plt.show()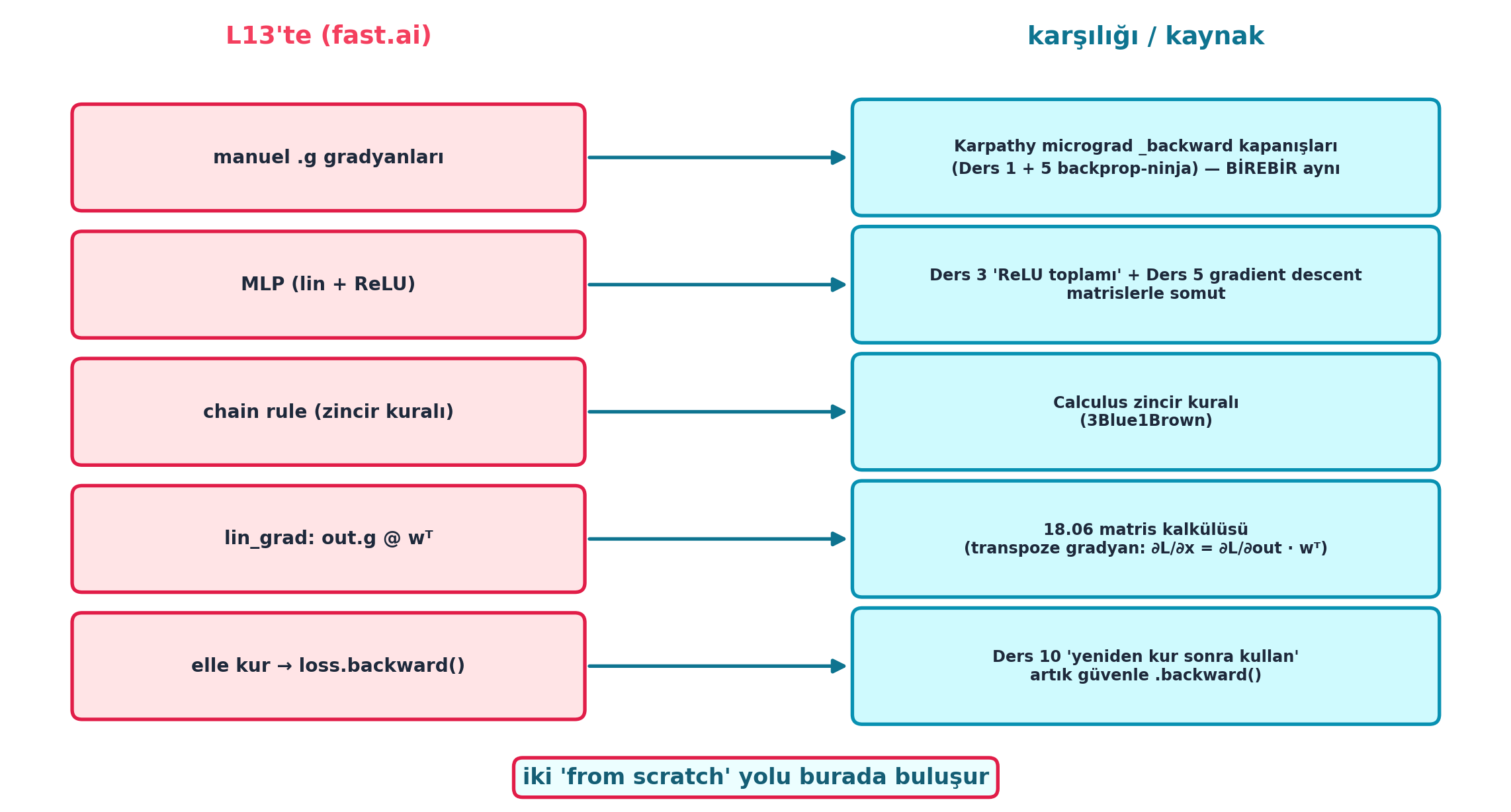
İpucuBuilder Notu — L13 Sentezi: Backprop’un Doğuşu
- İleriye (Ders 14): Manuel
.ggradyanları →forward/backwardsınıfları → nn.Module; aynı backprop, daha temiz kod. - Tek cümle: Bir MLP, matris çarpımı + ReLU yığınıdır; onu eğitmek, kaybın gradyanını chain rule ile en dıştan içe geriye yaymaktır — ve bunu bir kez elle kurmak, Karpathy’nin micrograd’ıyla aynı şeyi öğretir.
16.18 Bu Dersin Özeti
- Tek lineer model düz çizgidir; ReLU toplamı karmaşık şekiller (ve çok boyutta yüzeyler) kurar (Ders 3’ün somut hâli) (ReLU toplamı).
- MLP = lineer katman (
x@w+b) → ReLU (clamp_min(0)) → lineer katman; ReLU olmadan ağ tek lineer katmana çöker (MLP → forward). - MSE loss tahmin-hedef farkının karesinin ortalaması; modelin iyiliğini ölçer (MSE).
- Gradient her parametreyi hangi yönde değiştireceğini söyler (eğim); artıran ağırlığı azaltırız (gradyanlar).
- Backpropagation = chain rule: ∂L/∂w = (∂L/∂çıktı)·(∂çıktı/∂w); kaybın türevini en dıştan içe katman katman yayma (chain rule).
- lin_grad lineer katmanın girdi/ağırlık/bias gradyanlarını zincir kuralıyla verir (girdi gradyanı =
out.g @ wᵀ) (lin_grad). - forward_and_backward tüm ileri+geri geçişi elle kurar; ReLU gradyanı: pozitifse 1, değilse 0 (forward_and_backward).
- Bu, Karpathy micrograd’ının
_backwardkapanışlarının fast.ai karşılığıdır; elle kuruncaloss.backward()güvenle kullanılır (Karpathy köprüsü).
ÖnemliTek Bir Cümle
Bir MLP, matris çarpımı + ReLU katmanlarının yığınıdır; onu eğitmek, kaybın her parametreye göre türevini chain rule ile en dıştan içe katman katman geriye yaymaktır (backpropagation) — ve bunu bir kez elle kurmak, Karpathy’nin micrograd’ıyla aynı şeyi öğretir.
16.19 Kontrol Soruları
NotSoru 1: Bir MLP’nin forward pass’i hangi adımlardan oluşur? ReLU neden zorunludur?
Cevap:
Forward pass: girdi → lineer katman (x@w1+b1) → ReLU (clamp_min(0)) → lineer katman (@w2+b2) → çıktı. ReLU zorunludur çünkü doğrusal-olmamayı sağlar: iki lineer katmanı arka arkaya koyarsan (ReLU olmadan), matematiksel olarak tek bir lineer katmana indirgenir (iki matris çarpımı = bir matris çarpımı). ReLU araya girince ağ gerçekten “derin” olur ve karmaşık (doğrusal-olmayan) fonksiyonları temsil edebilir — Ders 3’teki “ReLU toplamı” fikri. (Şekil 16.4 ileri geçişi, Şekil 16.2 ReLU toplamının karmaşık eğri kurmasını gösterir.)
NotSoru 2: Backpropagation chain rule’u nasıl kullanır? ∂L/∂w neyin çarpımıdır?
Cevap:
Bir ağ fonksiyonların bileşkesidir (lin → relu → lin → loss). Bir ağırlığın kayba etkisini bulmak için zincir kuralı gerekir: ∂L/∂w = (∂L/∂çıktı) · (∂çıktı/∂w). Yani kaybın o ağırlığa göre türevi = “kaybın katman çıktısına göre türevi” çarpı “katman çıktısının ağırlığa göre türevi”. Backprop bunu en dıştan (loss) en içe (ilk katman ağırlığı) doğru yapar: önce loss’un gradyanı (out.g), sonra her katmanın yerel türeviyle çarpılarak geriye yayılır (lin_grad, ReLU gradyanı). Her adım bir çarpım; zincir boyunca biriktirilir. (Şekil 16.5 yerel türevlerin çarpımını, Şekil 16.6 tam geri akışı gösterir.)
NotSoru 3: ReLU’nun gradyanı nedir ve kodda nasıl ifade edilir?
Cevap:
ReLU(x) = max(0, x). Türevi basittir: girdi pozitifse 1, negatifse 0 (sıfırda tanımsız ama pratikte 0 alınır). Backprop’ta, ReLU’dan gelen gradyanı bir önceki katmana geçirirken bu türevle çarparız: l1.g = (l1>0).float() * l2.g. Yani (l1>0).float() pozitif girdiler için 1, negatifler için 0 maskesi üretir; bu maske, sonraki katmanın gradyanını (l2.g) süzer — negatif girdili nöronlardan gradyan geçmez. Bu, ReLU’nun “kapı” davranışıdır. (Şekil 16.3 gradyanın adım-fonksiyonu/kapı şeklini gösterir.)
NotSoru 4: Bu ders Karpathy’nin micrograd’ıyla nasıl bağlanır? Neden backprop’u elle kuruyoruz? (builder bağlantısı)
Cevap:
Karpathy micrograd’da her işlem için bir _backward kapanışı yazar ve topolojik sırayla çağırarak gradyanları geriye yayar; Howard burada her katman için elle .g gradyanı hesaplar (lin_grad, ReLU gradyanı). İkisi de chain rule’u katman katman geriye uygulamanın farklı ifadeleridir — aynı matematik, farklı kod stili. Backprop’u elle kurarız çünkü: (1) “from the foundations” kuralı (mekanizmayı bir kez anla); (2) loss.backward() (PyTorch autograd) bir kara kutu olmasın — altında tam olarak bunun olduğunu bilirsek hata ayıklayabilir, özel katmanlar yazabiliriz. Builder açısından: backprop’u bir kez elle kuran, onu asla “büyü” olarak görmez. (Şekil 16.7 elle hesabın sayısal türevle ~1e-11 eşleştiğini, Şekil 16.8 iki “from scratch” yolunun buluşmasını gösterir.)
16.20 Egzersizler
Egzersiz 1 (Direkt uygulama). MNIST için lin, relu, model ve mse’yi yaz; rastgele ağırlıklarla bir forward pass yapıp çıktı şeklini ve loss’u gözle. (Şekil 16.4’ı kendi sayınla yeniden üret — §5-8)
Egzersiz 2 (İki-aşamalı). forward_and_backward’ı kur; elle hesapladığın gradyanları PyTorch’un requires_grad_() + backward() sonucuyla karşılaştır (aynı çıkmalı). (Şekil 16.7’ı kendi modelinde yeniden üret — §12, §13)
Egzersiz 3 (Edge case). ReLU’yu çıkar (sadece lin → lin); modelin neden tek lineer katmana çöktüğünü ve karmaşık şekilleri öğrenemediğini açıkla. (§6)
Egzersiz 4 (Kavramsal). Bir lineer katmanın girdiye göre gradyanının neden out.g @ w.t() olduğunu (matris kalkülüsü) elle bir örnekle türet. (§11)
Egzersiz 5 (Sonraki dersin habercisi — Ders 14). Her katmanı forward ve backward metodu olan bir sınıfa nasıl dönüştürebileceğini düşün (nn.Module’e giden yol). (§14)
16.21 Sonraki: Ders 14 İçin Hazırlık
Ders 14: Geri Yayılım (Backpropagation devamı)
Ders 13 manuel backprop’u kurdu. Ders 14 önce backprop matematiğini ve kodunu gözden geçirir (chain rule’u math ile koda eşler), sonra kodu refactor eder: her katmanı forward/backward bilen bir sınıfa, oradan PyTorch’un nn.Module’üne.
Ana konular (Ders 14):
- Backprop math ve kod eşlemesi (chain rule)
- Katmanları sınıflara refactor etme
- Kendi nn.Module’ümüzü kurma
- PyTorch nn.Module’e geçiş
UyarıDers 14 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 2 ve 4 — manuel backprop + matris kalkülüsü).
- 3Blue1Brown’ın zincir kuralı / backprop videolarını izle (Howard’ın önerisi).
- Ana cümleyi tekrar oku: “Backprop = chain rule’u katman katman geriye yaymak.”
16.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| ReLU toplamı | Rectified line/plane toplamı; karmaşık şekiller | 6:03 |
| MLP | lin → ReLU → lin; çok katmanlı algılayıcı | 10:20 |
| Lineer katman (lin) | x@w + b; matris çarpımı + bias |
10:20 |
| ReLU | clamp_min(0); doğrusal-olmama |
2:54 |
| Forward pass | Girdiden tahmine: lin→relu→lin | 10:20 |
| MSE loss | (çıktı−hedef)² ortalaması | 18:26 |
| Gradient | Eğim; parametreyi hangi yönde değiştirmeli | 18:26 |
| Chain rule | ∂L/∂w = (∂L/∂çıktı)·(∂çıktı/∂w) | 9:35 |
| Backpropagation | Chain rule’u en dıştan içe katman katman yayma | 18:26 |
| lin_grad | Lineer katman gradyanı (girdi = out.g @ wᵀ) |
18:26 |
| ReLU gradyanı | Pozitifse 1, değilse 0 ((l1>0).float()) |
18:26 |
| Karpathy köprüsü | Manuel .g = micrograd _backward kapanışı |
— |
16.23 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: L13’ün Tanıdık Kökleri
Bu ders sinir ağının kalbini sıfırdan kurar ve Karpathy serisiyle en net buluştuğu yerdir; köprülerin özeti:
- MLP (lin+ReLU) → Ders 3’ün “ReLU toplamı”nın matrislerle somut hâli; her ağın temeli (MLP).
- Backprop = chain rule → Calculus zincir kuralı (3Blue1Brown); Karpathy micrograd’ının özü (chain rule).
- Manuel gradyan →
loss.backward()’ın altında ne olduğu; bir kez kur, sonra autograd’ı güvenle kullan (neden elle). - lin_grad (out.g @ wᵀ) → matris kalkülüsü (18.06); lineer katmanın transpoze gradyanı (lin_grad).
- ReLU gradyanı (kapı) → pozitif girdiden gradyan geçer, negatiften geçmez (ReLU katmanı).
- Karpathy köprüsü → fast.ai “from scratch” + Karpathy “from scratch” aynı yerde; backprop’u unutmaman için ikisi (Karpathy köprüsü).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bir sinir ağı, matris çarpımı + ReLU katmanlarından ibarettir ve “öğrenmesi”, kaybın gradyanını chain rule ile en dıştan içe katman katman geriye yaymaktır (backpropagation). Howard bunu fast.ai’de, Karpathy micrograd’da elle kurar — iki yol aynı yere çıkar. Bir kez elle kurarsan, loss.backward() artık büyü değil, anladığın bir araçtır.