flowchart TD
L21["L21<br/>Üç Pratik Araç"]
L21 --> TRACK["1 · Deney Takibi"]
L21 --> QUAL["2 · Kaliteyi Ölçme"]
L21 --> SPEED["3 · Hızlandırma"]
TRACK --> WANDB["W&B → WandBCB<br/>MetricsCB'den türer"]
WANDB --> WLOG["wandb.init / log / finish<br/>→ bulut pano"]
QUAL --> FEAT["pikseller anlamsız<br/>→ Inception özellikleri"]
FEAT --> STAT["ortalama mü + kovaryans C"]
STAT --> FID["FID (Fréchet)"]
STAT --> KID["KID (MMD, polinom kernel)"]
SPEED --> SLOW["DDPM 1000 adım — yavaş"]
SLOW --> DDIM["DDIM: x0_hat tahmini<br/>+ adım atlama 1000 → 50"]
DDIM --> ETA["eta: 1=stokastik, 0=deterministik"]
classDef cyan fill:#cffafe,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
class L21,TRACK,QUAL,SPEED,WANDB,WLOG,FEAT,STAT,KID,SLOW,ETA cyan;
class FID,DDIM rose;
24 Ders 21 — Deney Takibi, FID/KID ve DDIM (Experiment Tracking, FID/KID and DDIM)
ETAP 6’nın (Sıfırdan Diffusion A) üç pratik aracı, tek dersin altında — Howard, Johno ve Tanishq’le. Önce deney takibi: büyük modelleri eğitirken neyin işe yaradığını sistematik izlemek, miniai’ye bir Weights & Biases callback’i (WandBCB) olarak. Sonra FID ve KID: üretilen görüntülerin gerçek görüntülere ne kadar benzediğini gözle değil sayısal ölçmek — bir Inception ağının özellik istatistikleriyle (ortalama ve kovaryans, Fréchet mesafesi; ya da polinom çekirdekli MMD). Son olarak DDIM: DDPM örneklemesini 1000 adımdan elli civarına indiren, eta ile deterministik olabilen hızlandırma. Dersin builder dersi şu: üretkeni ölçmek demek, üretilen dağılımı gerçek dağılımla anlamsal özellik uzayında karşılaştırmak demektir — sınıflandırmadaki doğruluk gibi tek bir doğru cevap yoktur, dağılım yakınlığı vardır. Tek cümleyle: deney takibi neyin işe yaradığını izler, FID ve KID üretilen görüntü kalitesini gerçek dağılıma yakınlıkla ölçer, DDIM ise diffusion örneklemesini adım atlayarak ve eta ile deterministik yaparak hızlandırır.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 21: Experiment tracking, FID & DDIM (~116 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 21
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/21_cifar10_and_wandb + nbs/18_fid + nbs/20_DDIM
- Okuma süresi: ~42 dk
- Hocalar: Howard + Jonathan Whitaker (Johno) + Tanishq Abraham
- 🔗 ETAP 6 (Sıfırdan Diffusion A): Ders 19’da DDPM’i sıfırdan kurduk; diffusion artık kara kutu değil — ama iki açık sorun kaldı. Birincisi: örnekleme yavaş (1000 adım, her biri bir U-Net çağrısı). İkincisi: kaliteyi gözle değerlendirdik (öznel, ölçeklenmez). Ders 21 ikisini de çözer. FID/KID kaliteyi sayısal ölçer, DDIM örneklemeyi hızlandırır; deney takibi ise ağır eğitimlerde neyin işe yaradığını izler.
24.1 Bu Derste Ne Var?
Üretken modelciliğin üç pratik aracı, tek dersin altında. Önce deney takibi (Weights & Biases) — büyük modelleri eğitirken neyin işe yaradığını sistematik izlemek. Sonra FID/KID — üretilen görüntülerin “ne kadar iyi” olduğunu sayısal ölçmek (gözle bakmak yetmez). Son olarak DDIM — DDPM örneklemesini 1000 adımdan ~50 adıma indiren, deterministik olabilen hızlandırma.
Üç temel fikir bu dersin omurgasını kurar:
- Deney takibi (W&B) — eğitim metriklerini, hiperparametreleri ve örnekleri otomatik kaydetmek; bir callback ile (deney takibi → WandBCB).
- FID/KID — üretilen görüntü kümesinin gerçek görüntülere yakınlığını, bir Inception ağının özellik istatistikleriyle (ortalama + kovaryans) ölçmek (FID, KID).
- DDIM — DDPM’in ters sürecini çok daha az adımda çalıştıran,
etaile stokastikliği ayarlanabilen örnekleyici (DDIM, eta).
“we’re now at the point where… the most popular paper for doing it faster is DDIM.” — Howard, 1:19:06
Şekil 28.1 bu üç aracı tek bir kavram haritasında birleştirir: solda deney takibi (W&B → WandBCB → bulut pano), ortada kaliteyi ölçme (pikseller anlamsız → Inception özellikleri → ortalama μ + kovaryans C → FID ya da KID), sağda hızlandırma (DDPM 1000 adım yavaş → DDIM x0_hat tahmini + adım atlama → eta’yla determinizm). FID ve DDIM rose ile işaretlidir: dersin iki ana kazanımı, ölçüm (FID) ve hız (DDIM).
İpucuBuilder Notu — Üç Araç, Bir Çatı: Ölçüm, Hız ve Takip
- Geriye (Ders 19): DDPM’i kurduk ama örnekleme yavaş (1000 adım) ve kalitesini gözle değerlendirdik; bu ders ikisini de çözer — DDIM (hız) + FID/KID (ölçüm).
- Geriye (Ders 18): FID, Ders 18’de gördüğümüz kovaryans matrisini kullanır; KID, Ders 20’nin Gram/kernel fikirlerine yakın.
- İleriye (Ders 22-25): FID, sonraki tüm diffusion iyileştirmelerinin (Karras, latent) “daha iyi mi?” sorusunu yanıtlayan ölçüt.
- Tek cümle: Deney takibi neyin işe yaradığını izler; FID/KID üretilen görüntü kalitesini gerçek dağılıma yakınlıkla ölçer; DDIM diffusion örneklemesini deterministik ve çok daha hızlı yapar.
24.2 1. Deney Takibi: Neden Gerekli?
Modeller büyüyüp eğitimler uzayınca “hangi ayar daha iyiydi?” sorusu kaybolur. Deney takibi her koşunun metriklerini, hiperparametrelerini ve çıktılarını otomatik kaydeder; koşuları karşılaştırılabilir kılar. Howard model boyutunu artırırken (CIFAR-10) bunu devreye sokar — daha büyük model, daha uzun eğitim, daha çok deneme demektir; defter tutmadan ilerlemek imkânsız hale gelir.
“this kind of experiment tracking thing… I’m bumping up the size of the model substantially.” — Howard, 6:17
İpucuBuilder Notu — Deney Takibi: Production ML’in Temeli
- İleriye (MLOps): Deney takibi (W&B, MLflow) production ML’in temelidir; “reproducibility” (tekrarlanabilirlik) ve “ne işe yaradı” sorularının yanıtı. Bir model ne kadar büyürse, takip o kadar vazgeçilmez olur.
- Sezgi: Takip, bir kayıt değil bir karşılaştırma aracıdır — onlarca koşunun loss eğrilerini ve hiperparametrelerini yan yana koyup hangi seçimin neye yol açtığını okumayı sağlar. “İçgüdü” yerine veri.
24.3 2. Weights & Biases Callback
Weights & Biases (W&B), en yaygın deney takip aracıdır. miniai’ye yine bir callback olarak girer: WandBCB, MetricsCB’den türer; before_fit’te koşuyu başlatır (wandb.init), her metriği loglar (wandb.log), sonunda kapatır (wandb.finish).
import wandb
class WandBCB(MetricsCB):
order = 100
def __init__(self, config, *ms, project='ddpm_cifar10', **metrics):
fc.store_attr()
super().__init__(*ms, **metrics)
def before_fit(self, learn): wandb.init(project=self.project, config=self.config)
def after_fit(self, learn): wandb.finish()
def _log(self, d):
if self.train: wandb.log({'train_'+m:float(d[m]) for m in self.all_metrics})“called Weights and Biases (W&B)… I’m running a training with this additional [callback].” — Howard, 8:43
Şekil 24.2 callback’in eğitim döngüsüne nasıl oturduğunu şematik gösterir: solda miniai eğitim döngüsü (Learner.fit() → her epoch → her batch), ortada WandBCB’nin üç kancası (before_fit → wandb.init, _log → wandb.log, after_fit → wandb.finish), sağda W&B bulut panosu (loss eğrileri, hiperparametreler, koşu karşılaştırma, örnek görüntüler). Mesaj net: Ders 16 callback deseni sayesinde deney takibi çekirdek döngüye dokunmadan tek satırla eklenir; MLflow gibi başka araçlar da aynı fikrin farklı bir MetricsCB alt sınıfından ibarettir.
Kod
fig, ax = plt.subplots(figsize=(11.5, 5.0))
ax.set_xlim(0, 11.5)
ax.set_ylim(0, 5.0)
ax.axis("off")
fig.patch.set_facecolor(COL_WHITE)
# ---- SOL: eğitim döngüsü (Learner fit -> epoch -> batch) ----
ax.text(1.55, 4.78, "eğitim döngüsü", ha="center", va="center",
fontsize=9.5, color=COL_CYAN_800, weight="bold")
boxed_node(ax, 1.55, 4.05, 2.05, 0.66, "Learner.fit()",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.5)
boxed_node(ax, 1.55, 3.05, 2.05, 0.66, "her epoch",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.5)
boxed_node(ax, 1.55, 2.05, 2.05, 0.66, "her batch",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.5)
arrow_between(ax, (1.55, 4.05 - 0.33), (1.55, 3.05 + 0.33),
color=COL_CYAN_700, lw=1.8, shrink=4)
arrow_between(ax, (1.55, 3.05 - 0.33), (1.55, 2.05 + 0.33),
color=COL_CYAN_700, lw=1.8, shrink=4)
# ---- ORTA: WandBCB üç kancası (MetricsCB'den türer, order=100) ----
ax.text(5.55, 4.78, "WandBCB (MetricsCB'den türer, order=100)",
ha="center", va="center", fontsize=9.5, color=COL_ACCENT, weight="bold")
boxed_node(ax, 5.55, 4.05, 3.55, 0.66,
"before_fit: wandb.init(project, config)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=8.6, weight="normal")
boxed_node(ax, 5.55, 3.05, 3.55, 0.66,
"_log: wandb.log({train_loss, ...})",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=8.6, weight="normal")
boxed_node(ax, 5.55, 2.05, 3.55, 0.66,
"after_fit: wandb.finish()",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=8.6, weight="normal")
# döngü -> ilgili kanca (callback tetiklenmesi)
arrow_between(ax, (1.55 + 2.05 / 2, 4.05), (5.55 - 3.55 / 2, 4.05),
color=COL_ROSE_500, lw=1.7, shrink=6)
arrow_between(ax, (1.55 + 2.05 / 2, 2.05), (5.55 - 3.55 / 2, 3.05),
color=COL_ROSE_500, lw=1.7, shrink=6,
connectionstyle="arc3,rad=-0.12")
arrow_between(ax, (1.55 + 2.05 / 2, 3.05), (5.55 - 3.55 / 2, 2.05),
color=COL_ROSE_500, lw=1.7, shrink=6,
connectionstyle="arc3,rad=0.12")
# ---- SAĞ: W&B bulut panosu ----
ax.text(9.75, 4.78, "W&B bulut panosu", ha="center", va="center",
fontsize=9.5, color=COL_CYAN_800, weight="bold")
boxed_node(ax, 9.75, 3.05, 2.85, 2.30,
"loss eğrileri\nhiperparametreler\nkoşu karşılaştırma\nörnek görüntüler",
fc=COL_CYAN_50, ec=COL_CYAN_800, tc=COL_CYAN_800,
fontsize=9.0, weight="normal")
# kancalar -> bulut (wandb.log akışı)
arrow_between(ax, (5.55 + 3.55 / 2, 3.05), (9.75 - 2.85 / 2, 3.05),
color=COL_CYAN_700, lw=2.0, shrink=8)
arrow_between(ax, (5.55 + 3.55 / 2, 4.05), (9.75 - 2.85 / 2, 3.05 + 0.55),
color=COL_CYAN_700, lw=1.6, shrink=8,
connectionstyle="arc3,rad=-0.14")
# ---- Alt annotate: callback deseninin gücü ----
ax.text(5.75, 0.95,
"Ders 16 callback deseni: deney takibi çekirdek döngüye DOKUNMADAN "
"tek satırla eklenir",
ha="center", va="center", fontsize=9.2, color=COL_CYAN_800,
weight="bold")
ax.text(5.75, 0.42,
"MLflow vb. aynı fikir — sadece farklı bir MetricsCB alt sınıfı",
ha="center", va="center", fontsize=8.6, color=COL_ACCENT,
style="italic")
plt.tight_layout()
plt.show()
İpucuBuilder Notu — W&B Callback: Metrik Zaten Bir Callback’ti
- Geriye (Ders 16): Metrikler zaten bir callback’ti (L16); W&B sadece o metrikleri bulut panosuna loglayan bir alt sınıf. Callback deseninin gücü tam burada — yeni bir altyapı değil, var olanın bir uzantısı.
- Sezgi:
WandBCB’ninMetricsCB’den türemesi tesadüf değil: metrikleri hesaplama işi zaten orada; tek eklenen, hesaplanan sayıları yerel ekran yerine buluta yollamak. Üç satır (init/log/finish) tüm deney takibini sağlar.
24.4 3. Üretilen Görüntü Kalitesini Ölçme Sorunu
DDPM örnekleri ürettik — ama “iyi mi”? Gözle bakmak öznel ve ölçeklenmez. Gerekli olan, üretilen görüntü kümesinin gerçek görüntülere ne kadar benzediğini veren tek bir sayı. Sorun: pikselleri doğrudan karşılaştırmak anlamsız (iki gerçekçi görüntü piksel olarak çok farklı olabilir).
“how close are they to real images… we’re going to actually look specifically at [features].” — Howard, 25:09
İpucuBuilder Notu — Kalite: Karşılaştırma Özellik Uzayında Yapılmalı
- Geriye (Ders 20): Ders 20’de öğrendik ki anlamlı karşılaştırma piksellerde değil, bir ağın özellik uzayında yapılır; FID tam bunu kullanır. Style transfer’da içerik ve stili özellik/Gram uzayında ölçtük; aynı sezgi.
- Sezgi: Piksel MSE’si iki kedinin iki farklı fotoğrafını “çok farklı” sayar — oysa anlamca aynıdırlar. “Kalite” piksel değil, içerik sorusudur; bu yüzden anlamsal bir temsile (özellik uzayı) ihtiyaç var.
24.5 4. Inception Özellikleri
Çözüm: üretilen ve gerçek görüntüleri önceden eğitilmiş bir Inception sınıflandırıcısından geçir, ara katman özelliklerini al. Bu özellikler görüntünün anlamsal içeriğini kodlar. Artık “kalite”, iki özellik kümesinin (gerçek vs üretilen) dağılımlarının ne kadar örtüştüğüdür.
İpucuBuilder Notu — Inception Özellikleri: Ön-Eğitimli Ağ = Özellik Çıkarıcı
- Geriye (Ders 20): VGG16 özellikleri (style transfer) ile aynı fikir — ön-eğitimli ağ özellik çıkarıcı olarak kullanılır. Style transfer’da VGG16, burada Inception; her ikisi de görüntünün anlamsal içeriğini ara katman aktivasyonlarına çıkarır.
- Sezgi: Inception sınıflandırma için eğitilmişti, görüntü değerlendirmeyi hiç bilmez. Ama öğrendiği temsiller o kadar genel ki, “iki görüntü kümesi ne kadar benzer” sorusunu yanıtlamak için doğrudan kullanılabilir — iyi temsiller görevden bağımsız zengindir.
24.6 5. FID: Fréchet Inception Distance
FID, iki özellik dağılımını Gaussian varsayıp aralarındaki Fréchet mesafesini ölçer. Her küme için ortalama (μ) ve kovaryans (C) hesaplanır; FID şudur:
\[\text{FID} = \lVert \mu_1 - \mu_2 \rVert^2 + \text{Tr}\!\left(C_1 + C_2 - 2\sqrt{C_1 C_2}\right)\]
Düşük FID = üretilen dağılım gerçeğe yakın = iyi. Ortalama farkı “merkez kayması”nı (üretilen görüntülerin ortalama içeriği gerçeğinkinden ne kadar uzakta), kovaryans terimi ise “yayılım/şekil farkını” (çeşitlilik ve korelasyon yapısının benzerliği) ölçer.
def _calc_stats(feats):
feats = feats.squeeze()
return feats.mean(0), feats.T.cov()
def _calc_fid(m1,c1,m2,c2):
csr = tensor(linalg.sqrtm(c1@c2, 256).real)
return (((m1-m2)**2).sum() + c1.trace() + c2.trace() - 2*csr.trace()).item()“what the Fréchet Inception Distance does.” — Howard, 40:41
Şekil 24.3 bu metriği gerçek hesaplamayla kanıtlar (FLAGSHIP): solda özellik uzayında üç bulut (gerçek, üretilen-yakın, üretilen-uzak) ve her birinin ortalaması μ; sağda üç FID değeri log eksende. Aynı dağılım (gerçek↔︎gerçek) FID = 0.0135 ≈ 0 verir — beklendiği gibi sıfıra yakın; yakın üretilen dağılım FID = 0.2037, uzak dağılım ise FID = 19.63. Sayı büyüdükçe dağılımlar ayrışır; metrik “ne kadar uzak”ı ölçtüğünü gerçek verilerle doğrular: düşük FID = dağılım yakın = iyi.
Kod
d = E.fid_demo()
st = d["stats"]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12, 5.5))
# --- SOL: 2B özellik bulutları (gerçek vs üretilen-yakın vs üretilen-uzak) ---
axL.scatter(d["real"][:, 0], d["real"][:, 1], s=14, c=COL_PRIMARY,
alpha=0.30, edgecolors="none", zorder=2, label="gerçek")
axL.scatter(d["close"][:, 0], d["close"][:, 1], s=14, c=COL_CYAN_400,
alpha=0.45, edgecolors="none", zorder=2, label="üretilen — yakın")
axL.scatter(d["far"][:, 0], d["far"][:, 1], s=14, c=COL_ACCENT,
alpha=0.30, edgecolors="none", zorder=2, label="üretilen — uzak")
# Her bulutun ortalaması (μ) — büyük marker
for mu, col, ring in ((st["mu_real"], COL_CYAN_800, COL_WHITE),
(st["mu_close"], COL_CYAN_700, COL_WHITE),
(st["mu_far"], COL_ROSE_500, COL_WHITE)):
axL.scatter(mu[0], mu[1], s=240, marker="X", c=col,
edgecolors=ring, linewidths=2.0, zorder=5)
axL.annotate("μ", (st["mu_real"][0], st["mu_real"][1]),
textcoords="offset points", xytext=(10, 8),
fontsize=13, weight="bold", color=COL_CYAN_800, zorder=6)
axL.annotate("μ", (st["mu_far"][0], st["mu_far"][1]),
textcoords="offset points", xytext=(10, 8),
fontsize=13, weight="bold", color=COL_ROSE_500, zorder=6)
apply_style(axL)
axL.set_title("Özellik uzayı: 'gerçek' vs 'üretilen' bulutları",
fontsize=12, weight="bold", color=COL_TEXT)
axL.set_xlabel("özellik 1")
axL.set_ylabel("özellik 2")
axL.legend(loc="lower right", fontsize=9, framealpha=0.9)
axL.text(0.02, 0.97,
"FID = ‖μ₁−μ₂‖² + Tr(C₁+C₂−2√(C₁C₂))\n"
"ortalama farkı (merkez kayması) + kovaryans farkı (yayılım/şekil)",
transform=axL.transAxes, ha="left", va="top", fontsize=8.6,
color=COL_CYAN_800, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_50,
ec=COL_PRIMARY, lw=1.2))
# --- SAĞ: üç FID değeri yatay bar ---
labels = ["aynı dağılım\n(gerçek↔gerçek)", "yakın\n(gerçek↔üretilen)",
"uzak\n(gerçek↔üretilen)"]
vals = [d["fid_self"], d["fid_close"], d["fid_far"]]
cols = [COL_PRIMARY, COL_CYAN_400, COL_ACCENT]
ypos = range(len(labels))
axR.barh(list(ypos), vals, color=cols, height=0.55, zorder=3)
axR.set_yticks(list(ypos))
axR.set_yticklabels(labels, color=COL_TEXT, fontsize=10)
axR.invert_yaxis()
axR.set_xscale("log")
axR.set_xlim(0.008, 60)
for i, v in enumerate(vals):
axR.text(v * 1.25, i, f"FID = {v:.4f}", va="center", ha="left",
color=COL_TEXT, fontsize=10, weight="bold", zorder=4)
apply_style(axR)
axR.grid(True, axis="x", alpha=0.2, color=COL_SLATE_400)
axR.grid(False, axis="y")
axR.set_title("Üç FID değeri (log eksen): düşük FID = dağılım yakın = iyi",
fontsize=12, weight="bold", color=COL_TEXT)
axR.set_xlabel("FID (logaritmik)")
plt.tight_layout()
plt.show()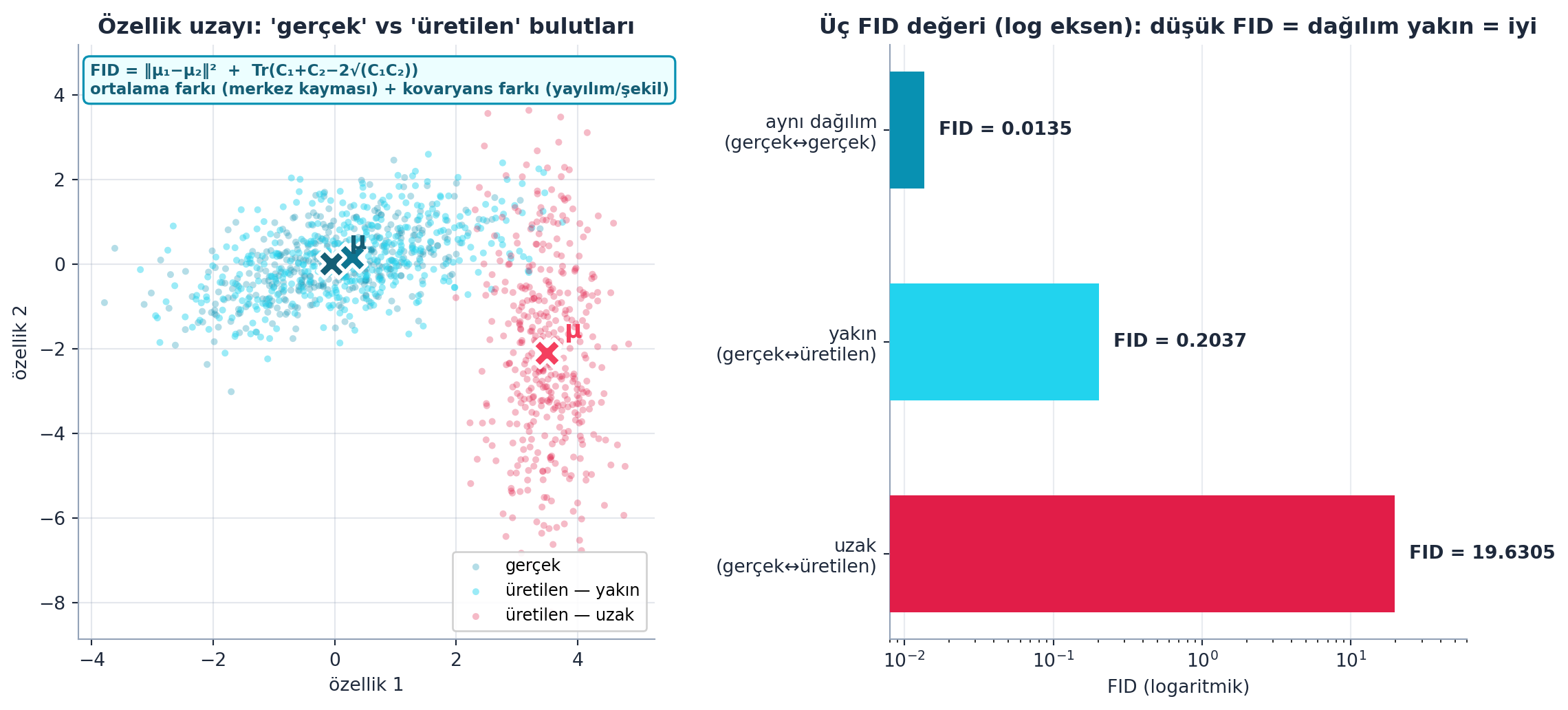
İpucuBuilder Notu — FID: Ders 18 Kovaryansının Üretken Modellemeye Uygulanması
- Geriye (Ders 18): Kovaryans matrisi (
C = feats.T.cov()) Ders 18’de gördüğümüz kavram; FID iki dağılımın ortalama+kovaryansını karşılaştırır. Ders 18’de kovaryansı bir veri yapısı olarak öğrendik; burada iki üretken dağılımı kıyaslamanın aracı. - Sezgi: FID’in iki terimi iki farklı “yanlışlığı” yakalar: ortalama farkı (
‖μ₁−μ₂‖²) merkez kaymasını, kovaryans terimi yayılım ve şekil farkını. Bir model doğru ortalamayı ama yanlış çeşitliliği üretirse (mode collapse), ortalama terimi düşük kalır ama kovaryans terimi fırlar — FID ikisini birden cezalandırır.
24.7 6. Matris Karekökü
FID formülündeki √(C₁·C₂) bir matris kareköküdür (skaler değil). İki yol: SciPy’nin linalg.sqrtm’i veya iteratif Newton-Schulz algoritması (GPU’da çalışan, türevlenebilir). Bu, FID’in tek matematiksel inceliğidir.
def _sqrtm_newton_schulz(mat, num_iters=100):
mat_nrm = mat.norm()
Y = mat/mat_nrm
I = torch.eye(len(mat)).to(mat); Z = torch.eye(len(mat)).to(mat)
for i in range(num_iters):
T = (3*I - Z@Y)/2
Y, Z = Y@T, T@Z
res = Y*mat_nrm.sqrt()
return resŞekil 24.4 bu iterasyonu gerçek hesaplamayla gösterir: solda yakınsama eğrisi (log ölçek) — başlangıç hatası ≈ 5.26’dan 24 iterasyonda 1.9e-14’e (makine hassasiyeti) düşer; bağımsız bir yöntemle (eigh özdeşliği) çapraz kontrol farkı yalnızca 5.9e-15. Sağda kovaryans matrisi C ve karekökü √C yan yana; özdeşlik √C·√C = C sağlanır. Newton-Schulz’un erdemi: GPU-dostu ve türevlenebilir olması — SciPy sqrtm CPU’da çalışırken bu iterasyon gradyan akışına izin verir.
Kod
ns = E.newton_schulz_demo()
errors = ns["errors"]
C = ns["C"]
sqrt_C = ns["sqrt_C"]
final_err = ns["final_err"]
eigh_err = ns["eigh_err"]
iters = np.arange(1, len(errors) + 1)
fig = plt.figure(figsize=(11.5, 5))
gs = fig.add_gridspec(1, 2, width_ratios=[1.55, 1.0], wspace=0.32)
# --- SOL: yakınsama eğrisi (log ölçek) ----------------------------------
axL = fig.add_subplot(gs[0, 0])
axL.semilogy(iters, errors, "-o", color=COL_PRIMARY, lw=2.2, ms=5.5,
markerfacecolor=COL_WHITE, markeredgecolor=COL_PRIMARY,
markeredgewidth=1.6, zorder=3, label="‖√C·√C − C‖")
axL.semilogy([iters[-1]], [max(errors[-1], 1e-16)], "o", color=COL_ACCENT,
ms=10, zorder=4, label="son iterasyon")
apply_style(axL)
axL.set_xlabel("Newton-Schulz iterasyonu")
axL.set_ylabel("‖√C·√C − C‖ (log ölçek)")
axL.set_title("Matris karekökü yakınsaması", color=COL_CYAN_700,
fontsize=12.5, weight="bold")
axL.set_xlim(0.3, len(errors) + 0.7)
# başlangıç + bitiş annotate
axL.annotate(f"başlangıç hatası ≈ {errors[0]:.2f}",
xy=(iters[0], errors[0]), xytext=(3.2, errors[0] * 0.9),
fontsize=9.5, color=COL_CYAN_800, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=1.5))
axL.annotate("24 iterasyonda\nmakine hassasiyetine\n(≈ 1.9e-14)",
xy=(iters[-1], max(errors[-1], 1e-15)),
xytext=(len(errors) - 8.5, errors[0] * 1e-5),
fontsize=9.5, color=COL_ACCENT, weight="bold", ha="center",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.6))
# çapraz kontrol rozeti
axL.text(0.97, 0.97,
f"bağımsız yöntem (eigh özdeşliği)\nile fark {eigh_err:.1e}",
transform=axL.transAxes, ha="right", va="top", fontsize=9,
color=COL_CYAN_800, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_50,
ec=COL_PRIMARY, lw=1.4))
axL.legend(loc="lower left", fontsize=9, framealpha=0.92,
edgecolor=COL_SLATE_300)
# alt annotate: neden önemli
axL.text(0.5, -0.20,
"FID'in tek matematiksel inceliği: √(C₁·C₂) — Newton-Schulz GPU-dostu + türevlenebilir",
transform=axL.transAxes, ha="center", va="top", fontsize=9.5,
color=COL_TEXT, style="italic")
# --- SAĞ: C ve √C imshow yan yana ---------------------------------------
gsR = gs[0, 1].subgridspec(1, 2, wspace=0.18)
axC = fig.add_subplot(gsR[0, 0])
axS = fig.add_subplot(gsR[0, 1])
vmax = max(abs(C).max(), abs(sqrt_C).max())
imC = axC.imshow(C, cmap="cividis", vmin=-vmax, vmax=vmax)
axC.set_title("C (6×6 PSD)", color=COL_CYAN_700, fontsize=10.5, weight="bold")
imS = axS.imshow(sqrt_C, cmap="cividis", vmin=-vmax, vmax=vmax)
axS.set_title("√C", color=COL_ACCENT, fontsize=10.5, weight="bold")
for ax in (axC, axS):
ax.set_xticks([])
ax.set_yticks([])
for sp in ax.spines.values():
sp.set_edgecolor(COL_SLATE_400)
axS.text(1.18, 0.5, "matris karekökü:\n√C·√C = C\n(skaler değil)",
transform=axS.transAxes, ha="left", va="center", fontsize=9,
color=COL_TEXT, weight="bold")
fig.suptitle("Fréchet mesafesinin matematiksel inceliği: matris karekökü",
fontsize=13.5, color=COL_TEXT, weight="bold", y=1.02)
plt.tight_layout()
plt.show()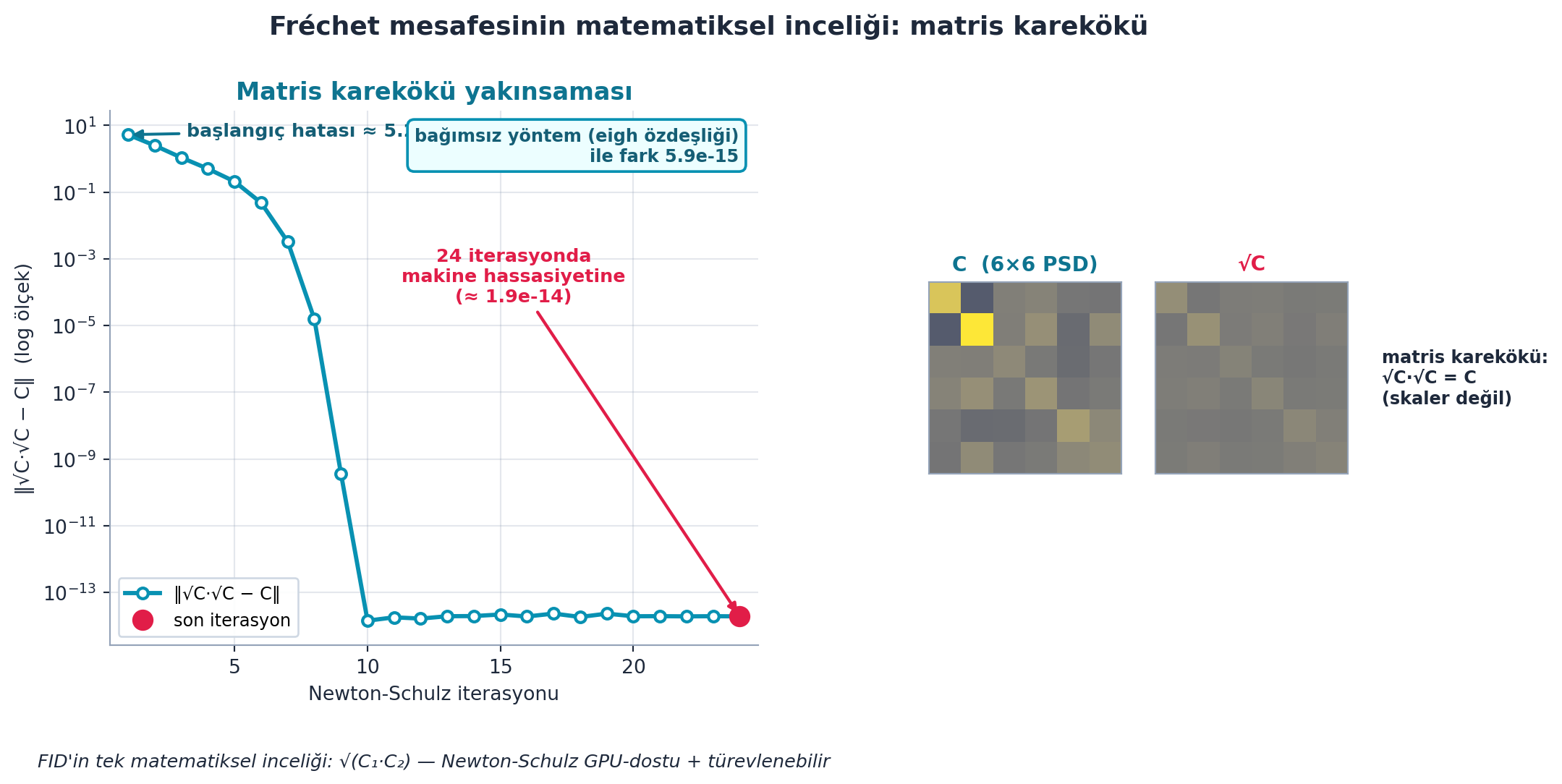
İpucuBuilder Notu — Matris Karekökü: 18.065 İteratif Yöntemlerinin Güzel Örneği
- Geriye (Ders 11-12 / 18.065): Matris fonksiyonları (karekök) lineer cebirin ileri konusu; Newton-Schulz, iteratif sayısal yöntemlerin (18.065) güzel bir örneği. Skaler karekökü Newton iterasyonuyla bulmanın matris karşılığı.
- Sezgi: “Matris karekökü” skaler kareköke benzemez —
√(C₁C₂), çarpanların eleman-eleman karekökü değil, kareye alındığındaC₁C₂veren matristir. Newton-Schulz bunu yalnızca matris çarpımlarıyla (özdeğer ayrışması olmadan) yaklaşık hesaplar; bu yüzden GPU’da hızlı ve türevlenebilir.
24.8 7. KID: Kernel Inception Distance
KID, FID’e bir alternatiftir: Gaussian varsaymaz, iki dağılım arasındaki MMD’yi (Maximum Mean Discrepancy) polinom çekirdekle hesaplar. Daha az örnekte FID’den daha güvenilir ve yansızdır (unbiased). FID gibi: düşük = iyi.
def _squared_mmd(x, y):
def k(a,b): return (a@b.transpose(-2,-1)/a.shape[-1]+1)**3 # polinom kernel
m,n = x.shape[-2], y.shape[-2]
kxx,kyy,kxy = k(x,x), k(y,y), k(x,y)
kxx_sum = kxx.sum([-1,-2]) - kxx.diagonal(0,-1,-2).sum(-1)
kyy_sum = kyy.sum([-1,-2]) - kyy.diagonal(0,-1,-2).sum(-1)
kxy_sum = kxy.sum([-1,-2])
return kxx_sum/m/(m-1) + kyy_sum/n/(n-1) - kxy_sum*2/m/nŞekil 24.5 KID’i gerçek hesaplamayla gösterir: solda iki MMD² değeri (log eksen) — aynı dağılım (real↔︎real) MMD² = 0.016 ≈ 0, +1.5 kaymış dağılım ise MMD² = 36.91 (üç büyüklük mertebesi fırlar); sağda KID’in FID’den üç farkı: polinom çekirdek k(a,b) = (a·bᵀ / d + 1)³, unbiased MMD² (köşegen çıkarılır), ve Gaussian VARSAYMAması — bu yüzden az örnekte daha güvenilir ve yansız. Aynı dağılımın MMD²’sinin sıfıra çökmesi, kaymış dağılımın fırlaması: metriğin dağılım farkını sadakatle ölçtüğünün kanıtı.
Kod
r = E.kid_mmd_demo()
mmd_same = r["mmd_same"] # 0.0161
mmd_shifted = r["mmd_shifted"] # 36.91
shift = r["shift"] # 1.5
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.8),
gridspec_kw={"width_ratios": [1.0, 1.15]})
# ---- SOL: iki bar, log eksen (0.016 vs 36.9 ölçek farkını taşımak için) ----
labels = ["aynı dağılım\n(real ↔ real)", "kaymış dağılım\n(+1.5)"]
vals = [mmd_same, mmd_shifted]
cols = [COL_PRIMARY, COL_ACCENT]
xpos = [0, 1]
bars = axL.bar(xpos, vals, width=0.58, color=cols, zorder=3,
edgecolor=COL_WHITE, linewidth=1.5)
axL.set_yscale("log")
axL.set_ylim(0.005, 80)
axL.set_xticks(xpos)
axL.set_xticklabels(labels, fontsize=10, color=COL_TEXT)
axL.set_ylabel("unbiased MMD² (log ölçek)", fontsize=10.5)
axL.set_title("KID skoru: dağılımlar ayrıştıkça MMD² fırlar",
fontsize=11.5, color=COL_CYAN_700, weight="bold", pad=10)
apply_style(axL)
axL.grid(True, axis="y", alpha=0.25, color=COL_SLATE_400)
axL.grid(False, axis="x")
# değer etiketleri (gerçek sayılar)
axL.text(0, mmd_same * 1.45, f"MMD² = {mmd_same:.3f}\n≈ 0",
ha="center", va="bottom", fontsize=10, color=COL_CYAN_800, weight="bold")
axL.text(1, mmd_shifted * 1.12, f"MMD² = {mmd_shifted:.1f}",
ha="center", va="bottom", fontsize=10.5, color=COL_ACCENT, weight="bold")
# ---- SAĞ: açıklama kutuları (kavramsal) ----
axR.set_xlim(0, 1)
axR.set_ylim(0, 1)
axR.axis("off")
axR.set_title("KID neden FID'den farklı?", fontsize=11.5,
color=COL_CYAN_700, weight="bold", pad=10)
box_texts = [
("Polinom çekirdek\n"
"$k(a,b) = (a·bᵀ / d + 1)^3$",
COL_BG, COL_PRIMARY, COL_CYAN_800),
("Unbiased MMD²\n"
"köşegen çıkarılır: kxx.sum() − trace(kxx)",
COL_CYAN_50, COL_CYAN_400, COL_TEXT),
("FID'den farkı\n"
"Gaussian VARSAYMAZ → az örnekte\n"
"daha güvenilir ve yansız",
COL_BG_ROSE, COL_ACCENT, COL_TEXT),
]
ys = [0.80, 0.50, 0.18]
for (txt, fc, ec, tc), yc in zip(box_texts, ys):
boxed_node(axR, 0.5, yc, 0.92, 0.24, txt,
fc=fc, ec=ec, tc=tc, fontsize=10.0, lw=2.0, weight="normal")
plt.tight_layout()
plt.show()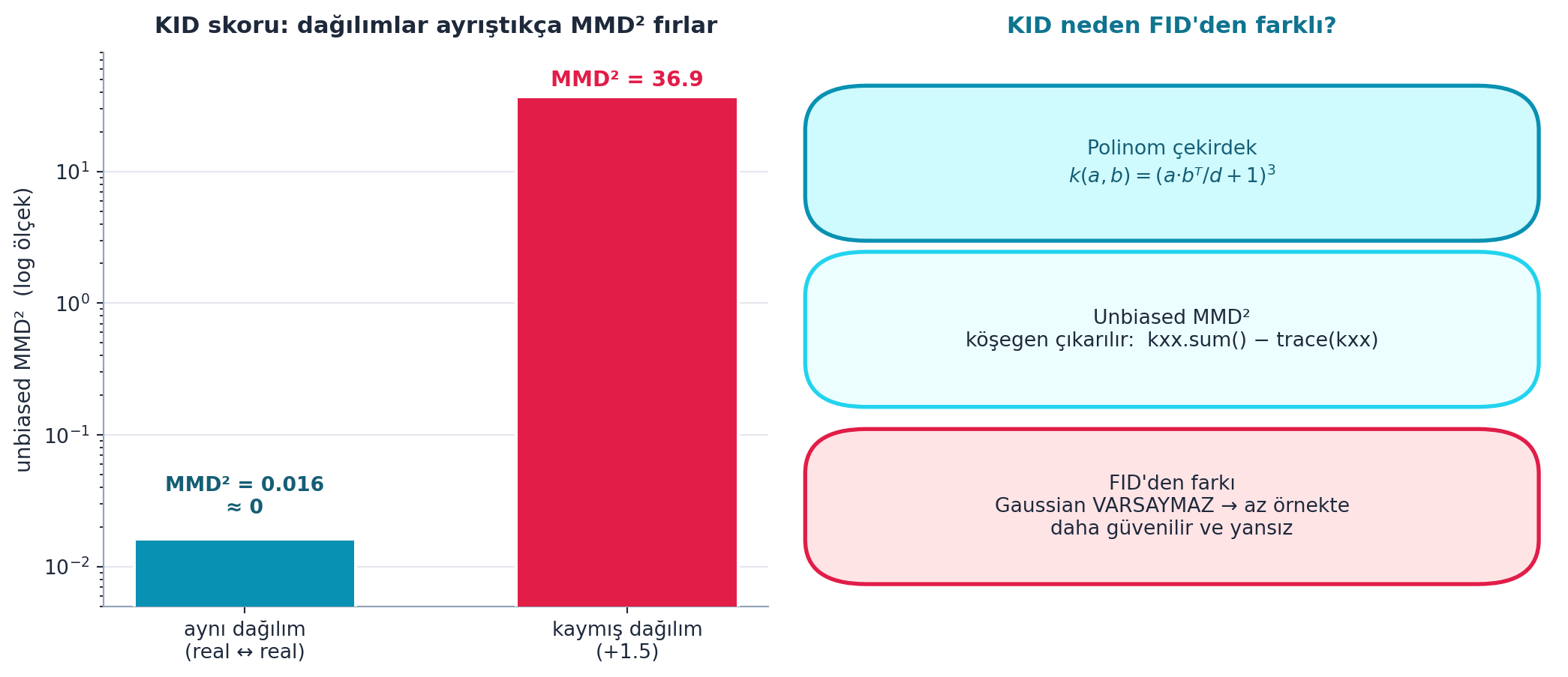
_squared_mmd birebir).
İpucuBuilder Notu — KID: Ders 20 Gram/Kernel Fikrinin Akrabası
- Geriye (Ders 20): Kernel (iç çarpım tabanlı benzerlik) fikri, style transfer’ın Gram matrisiyle akraba; ikisi de “özellikler nasıl ilişkili” sorusunu sorar. Gram matrisi kanal korelasyonlarını, MMD ise iki örnek kümesinin çekirdek-uzayı benzerliğini hesaplar.
- Sezgi: KID’in FID’e üstünlüğü “varsayımsız” olmasından gelir: FID iki dağılımı Gaussian kabul eder (sadece ortalama+kovaryans), KID ise polinom çekirdekle daha yüksek mertebeli istatistikleri de yakalar. Az örnekte FID’in kovaryans tahmini gürültülüdür; KID yansız (unbiased) olduğu için daha güvenilirdir.
24.9 8. FID/KID Uyarıları
FID güçlüdür ama mükemmel değil: örnek sayısına duyarlıdır (az örnekte yanıltıcı), Inception ağının önyargılarını taşır, ve “güzellik”i değil “dağılım yakınlığını” ölçer. KID daha küçük kümelerde daha güvenilirdir. Howard’ın uyarısı: metrik bir araçtır, mutlak gerçek değil.
UyarıBuilder Notu — Goodhart Yasası: Metriğe Değil, Ölçtüğüne Odaklan
- İleriye: “Metriğe değil, metriğin ölçtüğü şeye odaklan” — FID’i optimize etmek her zaman daha iyi görüntü demek değildir (Goodhart yasası: bir ölçüt hedef haline gelince ölçüt olmaktan çıkar).
- Sezgi: FID düşük çıkabilir ama görüntüler hâlâ “kötü” görünebilir — çünkü FID Inception’ın gördüğü istatistiklere bakar, insan algısına değil. Metrik, modeli yönlendirmek için faydalı bir pusula; ama tek karar verici değil. Sayıya körü körüne güvenmek, ölçmediği şeyi (algısal kalite, çeşitlilik dengeleri) kaybetmek demektir.
24.10 9. DDPM Yavaş: 1000 Adım Sorunu
Ders 19’un DDPM örneklemesi, n_steps (örn. 1000) ters adım gerektirir — her biri bir U-Net çağrısı. Tek görüntü için 1000 ileri geçiş, çok yavaş. Pratikte kullanılabilmesi için bunu kısaltmak şart.
“the most popular paper for doing it faster is DDIM.” — Howard, 1:19:06
İpucuBuilder Notu — 1000 Adım: Darboğaz Tam Burada
- Geriye (Ders 19): DDPM sampling döngüsü (
reversed(range(n_steps))) tam burada darboğaz; DDIM onu yeniden tasarlar. Eğitim bir kez yapılır ama örnekleme her görüntü için tekrarlanır — 1000× U-Net çağrısı, üretimi pratikte ağırlaştırır. - Sezgi: DDPM’in 1000 adımı, ters difüzyonu çok küçük gürültü-giderme basamaklarına bölmesinden gelir. DDIM’in içgörüsü: bu basamakların çoğu atlanabilir — her adımda zaten “temiz görüntü tahmini” hesaplanıyorsa, daha büyük sıçramalarla aynı sonuca varılabilir.
24.11 10. DDIM: Daha Hızlı, Deterministik Örnekleme
DDIM (Denoising Diffusion Implicit Models), aynı eğitilmiş modelle ama daha akıllı bir ters adımla çalışır. Her adımda gürültüden temiz görüntü tahminini (x_0_hat) çıkarır, sonra bir sonraki (daha az gürültülü) duruma deterministik (veya kısmen stokastik) geçer. eta parametresi rastgeleliği kontrol eder: eta=0 tamamen deterministik, eta=1 DDPM gibi.
def ddim_step(x_t, t, noise, abar_t, abar_t1, bbar_t, bbar_t1, eta):
sig = (((bbar_t1/bbar_t) * (1-abar_t/abar_t1)).sqrt()) * eta
x_0_hat = (x_t - bbar_t.sqrt()*noise) / abar_t.sqrt()
x_t = abar_t1.sqrt()*x_0_hat + (bbar_t1-sig**2).sqrt()*noise
if t>0: x_t += sig * torch.randn(x_t.shape).to(x_t)
return x_t“this could be completely deterministic. So that’s one aspect of it.” — Howard, 1:43:38
İpucuBuilder Notu — DDIM: Ders 19 Temiz-Görüntü Tahmininin Üzerine Kurulur
- Geriye (Ders 19):
x_0_hat = (x_t − √bbar·noise)/√abarsatırı, Ders 19 sampling’deki temiz-görüntü tahmininin aynısı; DDIM farkı, sonraki adıma nasıl geçildiğinde. DDPM her adımda küçük bir gürültü-giderme yaparken, DDIM doğrudanx_0_hat’i hesaplayıp seçilen bir sonraki zaman adımına sıçrar. - Sezgi:
sigterimi (eta ile çarpılan) tüm stokastikliği taşır: eta=0 ikensig=0, eklenen gürültü yok, geçiş tamamen belirlenimci. Üç satırlık fonksiyon hem DDPM’i (eta=1) hem deterministik DDIM’i (eta=0) tek formülde birleştirir.
24.12 11. Adım Atlama: 1000 → 50
DDIM’in pratik gücü: ters süreci her adımda değil, adım atlayarak (skips) çalıştırabilmesi. 1000 adımlık çizelgeyi 50 adımda gezerek ~20 kat hızlanma, kalitede çok az kayıpla. Bu, DDPM’in saf adım-atlamasından (her üçüncü adım) daha akıllıdır.
@torch.no_grad()
def sample(f, model, sz, n_steps, skips=1, eta=1.):
tsteps = list(reversed(range(0, n_steps, skips))) # adım atla
x_t = torch.randn(sz).to(model.device)
for i,t in enumerate(tsteps):
abar_t1 = abar[tsteps[i+1]] if t > 0 else torch.tensor(1)
noise = model(x_t, t).sample
x_t = f(x_t, t, noise, abar[t], abar_t1, 1-abar[t], 1-abar_t1, eta)
return x_t“DDIM as we’ll see, does it in a smarter way.” — Howard, 1:24:38
Şekil 24.6 adım atlamayı gerçek hesaplamayla gösterir: 1000 adımlık ᾱ (kümülatif sinyal-koruma) çizelgesi ince bir eğri olarak (DDPM: her adım bir U-Net çağrısı), DDIM ise yalnızca alt-örneklenen ~50 noktada (skips=20) gezer — tsteps = reversed(range(0, 1000, 20)). Çizelge aynıdır, sadece gezilen durak sayısı azalır; sonuç 20× hızlanma. Anahtar: DDIM, DDPM’in saf “her n’inci adım” atlamasından farklı olarak her sıçramada x_0_hat’i yeniden hesaplayarak hatayı düzeltir, bu yüzden kalite çok az kayıpla korunur.
Kod
d = E.ddim_skip_demo()
t_full, abar_full = d["t_full"], d["abar_full"]
t_sub, abar_sub = d["t_sub"], d["abar_sub"]
speedup = d["speedup"]
fig, ax = plt.subplots(figsize=(10.5, 5))
apply_style(ax)
# DDPM: tam çizelge — her adım bir U-Net çağrısı (ince cyan eğri)
ax.plot(t_full, abar_full, color=COL_PRIMARY, lw=1.4, alpha=0.9,
label=f"DDPM: her adım — {d['n_full']} U-Net çağrısı", zorder=2)
# DDIM: yalnız alt-örneklenen noktalar gezilir (rose markerlar)
ax.scatter(t_sub, abar_sub, s=46, color=COL_ACCENT, edgecolor=COL_WHITE,
linewidth=0.8, zorder=4,
label=f"DDIM skips=20: yalnız bu noktalar — {d['n_sub']} çağrı")
ax.set_xlabel("zaman adımı t (0 = temiz, 999 = saf gürültü)", fontsize=11)
ax.set_ylabel(r"$\bar{\alpha}_t$ (kümülatif sinyal-koruma)", fontsize=11)
ax.set_title("DDIM adım atlama: aynı çizelge, daha az durak",
fontsize=12.5, weight="bold", color=COL_CYAN_800)
ax.set_xlim(-15, 1014)
ax.set_ylim(-0.04, 1.05)
ax.legend(loc="upper right", framealpha=0.95, fontsize=10)
# Açıklama oku: kod satırı + hızlanma
ax.annotate(
"tsteps = reversed(range(0, 1000, 20))\n"
f"→ {speedup:.0f}× hızlanma\nçizelge AYNI, gezilen nokta az",
xy=(620, abar_full[620]), xytext=(430, 0.62),
fontsize=10.5, color=COL_TEXT, weight="bold", ha="left",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE, ec=COL_ACCENT, lw=1.6),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0,
connectionstyle="arc3,rad=-0.2"),
zorder=6)
plt.tight_layout()
plt.show()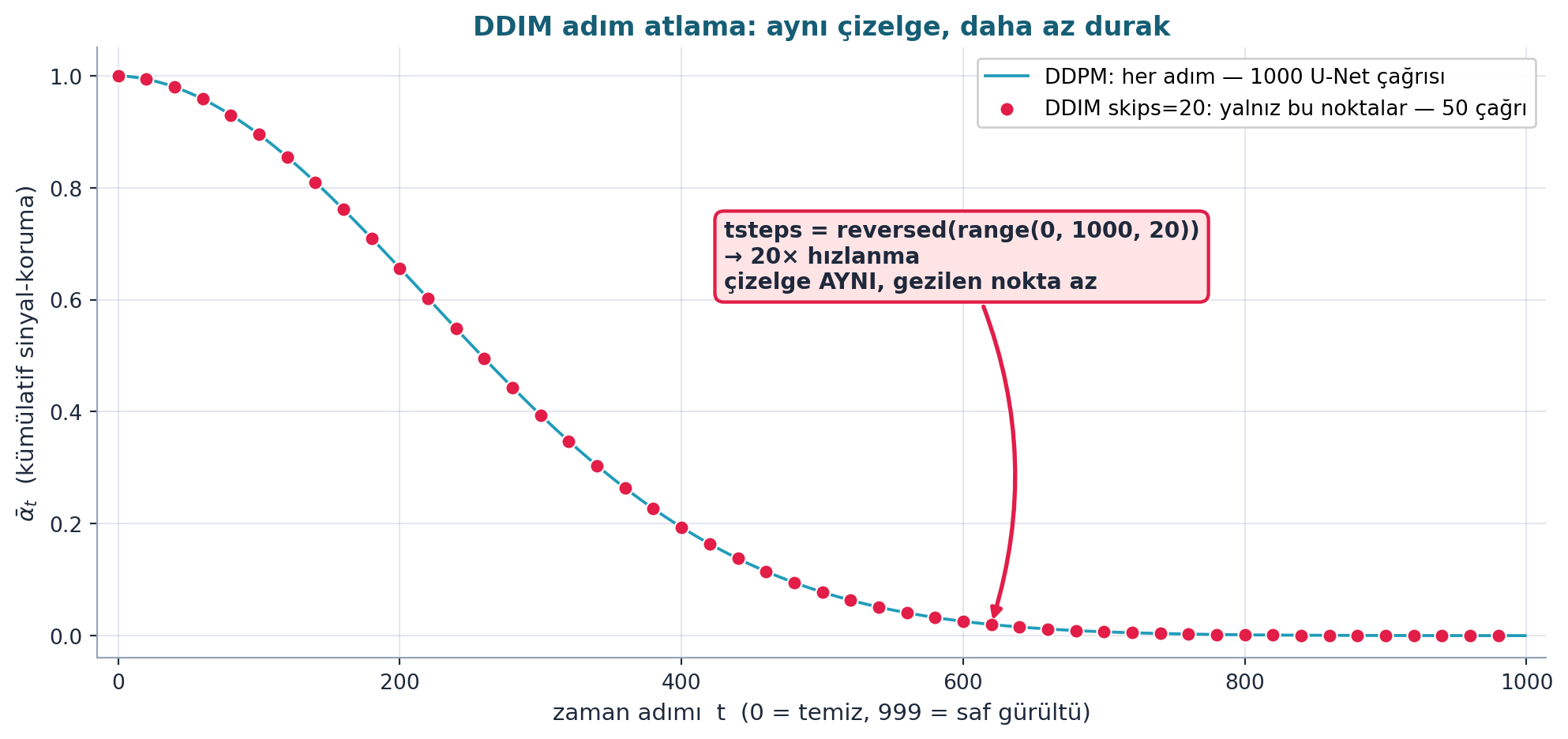
İpucuBuilder Notu — Adım Atlama: Hâlâ Adım Sayısına Bağımlı
- İleriye (Ders 22): DDIM hâlâ adım sayısına bağımlı; Ders 22 (Karras) örnekleyiciyi (Heun, LMS) daha da iyileştirir — gürültü çizelgesini ve adım yerleşimini yeniden tasarlayarak daha az adımda daha yüksek kalite.
- Sezgi: 20× hızlanma “bedava” değil: her atlanan adım,
x_0_hattahminine güvenmeyi gerektirir. Model tahmini ne kadar iyiyse o kadar atlayabilirsin; bu yüzden DDIM’in pratik adım sayısı (örn. 50) modelin kalitesine bağlıdır — Karras bu dengeyi daha da zorlar.
24.13 12. eta: Stokastiklikten Determinizme
eta DDIM’in kalbidir. eta=1 iken DDIM, DDPM’le aynı (her adımda gürültü eklenir, stokastik). eta=0 iken süreç tamamen deterministik olur — aynı başlangıç gürültüsü her zaman aynı görüntüyü verir. Determinizm, latent uzayda gezinme (interpolation) ve tekrarlanabilirlik için değerlidir.
Şekil 24.7 bu farkı gerçek hesaplamayla kanıtlar: gerçek ddim_step ve kusurlu-oracle bir model (ε̂ = 0.9·ε, gerçek ağın tahmin hatasını temsil eder) ile iki bağımsız koşu (farklı seed) çalıştırılır. Solda eta=0: iki koşu bit-özdeş, maxdiff = 0 (tek çizgi görünür, A ve B üst üste) — determinizm. Sağda eta=1: koşular ayrışır, final maxdiff = 0.0118 (DDPM gibi stokastik). Fark yalnızca sig·randn teriminden gelir; eta onu açıp kapar. Not: kusursuz oracle’da her koşu x₀’a çöker ve fark görünmez olurdu — kusurlu-oracle etiketi bunun için.
Kod
d = E.ddim_eta_demo()
res = d["results"]
scale = d["model_scale"]
r0, r1 = res[0.0], res[1.0]
steps = range(len(r0["traj_a"])) # DDIM yörünge adımı (skips=50 → 20 durak)
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# ---- SOL: eta=0 — deterministik, iki koşu BİT-ÖZDEŞ ----
ax = axes[0]
apply_style(ax)
ax.plot(steps, r0["traj_a"], color=COL_PRIMARY, lw=4.0, alpha=0.95,
label="koşu A (seed=1)", zorder=3)
ax.plot(steps, r0["traj_b"], color=COL_ACCENT, lw=2.0, ls="--", dashes=(4, 3),
label="koşu B (seed=2)", zorder=4)
ax.set_xlabel("DDIM adımı (skips=50 → 20 durak)", fontsize=11)
ax.set_ylabel(r"$x_t$'nin $x_0$'a RMS uzaklığı", fontsize=11)
ax.set_title("eta = 0 (deterministik)", fontsize=12.5, weight="bold",
color=COL_CYAN_800)
ax.legend(loc="upper right", framealpha=0.95, fontsize=9.5)
ax.text(0.5, 0.06,
f"iki koşu BİT-ÖZDEŞ: maxdiff = {r0['maxdiff']:.0f}\n(tek çizgi görünür — A ve B üst üste)",
transform=ax.transAxes, ha="center", va="bottom",
fontsize=10.5, color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_PRIMARY, lw=1.8))
# ---- SAĞ: eta=1 — stokastik (DDPM gibi), koşular AYRIŞIR ----
ax = axes[1]
apply_style(ax)
traj_div = float(np.abs(r1["traj_a"] - r1["traj_b"]).max())
ax.plot(steps, r1["traj_a"], color=COL_PRIMARY, lw=3.0, alpha=0.95,
label="koşu A (seed=1)", zorder=3)
ax.plot(steps, r1["traj_b"], color=COL_ACCENT, lw=3.0, alpha=0.95,
label="koşu B (seed=2)", zorder=3)
ax.set_xlabel("DDIM adımı (skips=50 → 20 durak)", fontsize=11)
ax.set_ylabel(r"$x_t$'nin $x_0$'a RMS uzaklığı", fontsize=11)
ax.set_title("eta = 1 (stokastik, DDPM gibi)", fontsize=12.5, weight="bold",
color=COL_CYAN_800)
ax.legend(loc="upper right", framealpha=0.95, fontsize=9.5)
ax.text(0.5, 0.06,
f"final maxdiff = {r1['maxdiff']:.4f}\nyörünge ayrışması = {traj_div:.3f}",
transform=ax.transAxes, ha="center", va="bottom",
fontsize=10.5, color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE, ec=COL_ACCENT, lw=1.8))
# Alt açıklama şeridi — determinizmin nereden geldiği + dürüst model notu
fig.text(0.5, -0.02,
"Determinizm farkı YALNIZ sig·randn teriminden gelir — eta onu açıp kapar.\n"
f"Model: kusurlu-oracle (ε̂ = {scale}·ε), gerçek ağın tahmin hatasını temsil eder; "
"kusursuz oracle'da her koşu $x_0$'a çöker, fark görünmez.",
ha="center", va="top", fontsize=9.8, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_CYAN_50, ec=COL_SLATE_400, lw=1.2))
plt.tight_layout()
plt.show()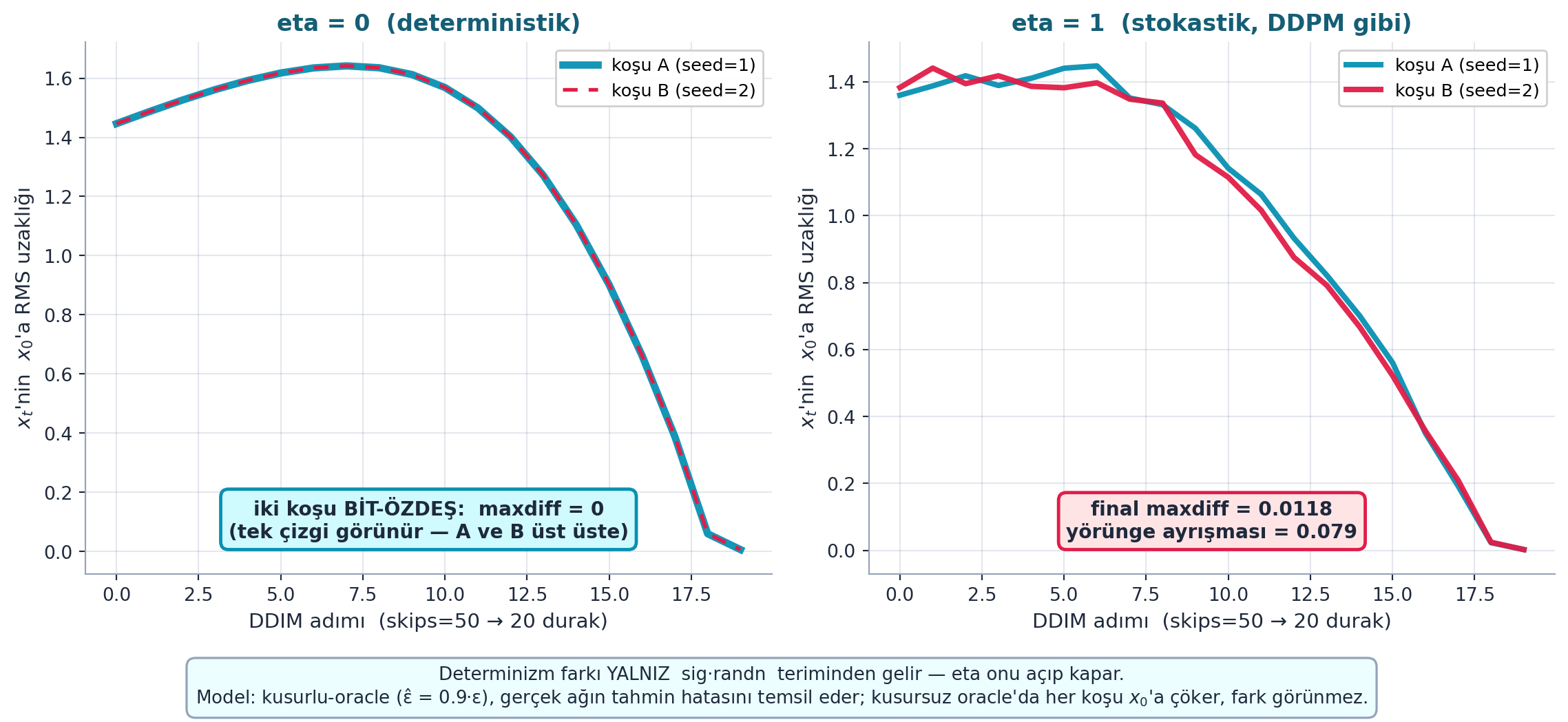
İpucuBuilder Notu — eta=0 Determinizm: Latent Gezinmenin Temeli
- İleriye (Ders 25): Deterministik örnekleme, latent diffusion’da görüntüler arası yumuşak geçiş (interpolation) ve düzenleme için temel; DDIM bunu mümkün kılar. eta=0 sayesinde “başlangıç gürültüsü → görüntü” eşlemesi tersine çevrilebilir bir fonksiyon olur.
- Sezgi: Determinizm neden işe yarar? eta=0 iken her görüntü tek bir başlangıç gürültüsüne karşılık gelir. İki gürültü arasında düz çizgi çizip ara noktaları örneklersen, iki görüntü arasında pürüzsüz bir geçiş elde edersin — stokastik DDPM’de bu mümkün değildir, çünkü her adımda eklenen rastgelelik eşlemeyi belirsizleştirir.
24.14 13. miniai Köprüsü
Üç konu da miniai üstünde: W&B bir callback (WandBCB), FID/KID ImageEval (bir TrainLearner ile özellik toplar), DDIM örnekleme fonksiyonu eğitilmiş modeli kullanır. Foundations’ın esnek altyapısı, eğitim + ölçüm + hızlı örnekleme zincirini bir arada tutuyor.
İpucuBuilder Notu — miniai: Üç Bağımsız Yetenek, Tek Çekirdek
- Geriye (Ders 16): Yine callback deseni — deney takibi çekirdek döngüye dokunmadan eklenir; ölçüm ayrı, örnekleme ayrı, hepsi bağımsız. Üç tamamen farklı problem (takip, değerlendirme, hızlı üretim) aynı sade çekirdeğe takılır.
- Sezgi: Bu üç aracın birbirinden bağımsız olması, miniai’nin gevşek bağlılığının (loose coupling) meyvesidir: W&B’yi eklemek FID’i etkilemez, DDIM örneklemesi takip ya da ölçümden habersiz çalışır. Her biri tek sorumluluk taşır; bu, büyük sistemleri yönetilebilir kılan mühendislik disiplinidir.
24.15 14. Builder İçgörüsü: Üretkeni Nasıl Ölçeriz?
Sınıflandırmada doğruluk (accuracy) açıktır; üretimde “doğru cevap” yoktur. Bu dersin builder dersi: üretkeni ölçmek, üretilen dağılımı gerçek dağılımla karşılaştırmaktır — anlamsal özellik uzayında (Inception), istatistiklerle (ortalama μ + kovaryans C). Bu, üretken modellemenin değerlendirme felsefesidir; “iyi” tanımı dağılım yakınlığıdır.
Bunun neden bu kadar merkezî olduğunu görmek için sınıflandırmayla karşıtlığı düşün. Sınıflandırmada her örneğin tek bir doğru etiketi vardır; tahmini etiketle karşılaştırır, doğruluğu sayarsın. Üretimde ise geçerli çıktı sonsuzdur — bir “kedi görüntüsü” üretmenin milyonlarca doğru yolu vardır. O halde tek bir örneği “doğru/yanlış” diye yargılayamazsın; modelden beklenen, üretilen örneklerin bütününün gerçek veri dağılımına benzemesidir. FID ve KID tam bunu yapar: tek görüntüyü değil, üretilen küme ile gerçek kümenin istatistiklerini (ortalama, kovaryans; ya da çekirdek-uzayı benzerliği) karşılaştırır. “Üretkeni nasıl ölçeriz” sorusunun cevabı budur — dağılım karşılaştırması.
Şekil 24.8 bu içgörüyü dersin sentezi olarak çerçeveler: merkezde çekirdek fikir — üretkeni ölçmek = üretilen dağılımı gerçek dağılımla anlamsal özellik uzayında karşılaştırmak (tek görüntü değil, bütün küme); üstte iki metrik ailesi (FID: μ+C Gaussian varsayımı; KID: MMD+polinom kernel, varsayımsız) ve Goodhart uyarısı (metrik bir araçtır); solda önceki ders köprüleri (Inception→L20 VGG16, kovaryans→L18, W&B→L16, DDIM x0_hat→L19); sağda ileriye ölçüt (L22 Karras “daha iyi mi?”, eta=0→L25 latent interpolation, aynı felsefe LLM/ses/video). Sentez: L21, üretken modelciliğin ölçüm ve hız altyapısıdır.
Kod
fig, ax = plt.subplots(figsize=(12.5, 6.5))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 6.5)
ax.axis("off")
# --- MERKEZ: çekirdek fikir (büyük vurgu) ---
cx, cy = 6.25, 3.45
boxed_node(
ax, cx, cy, 4.7, 1.75,
"L21: üretkeni ölçmek =\n"
"üretilen DAĞILIMI gerçek\n"
"dağılımla karşılaştırmak\n"
"(anlamsal özellik uzayında —\n"
"tek görüntü değil, bütün küme)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=11.5, lw=2.6,
)
# --- ÜST: iki metrik ailesi + Goodhart uyarısı (rose) ---
metrics = [
("FID\nμ + C, Gaussian varsayımı,\nmatris karekökü √(C₁C₂)", 3.05, 5.85),
("KID\nMMD + polinom kernel,\nVARSAYIMSIZ", 6.25, 5.95),
("Goodhart uyarısı:\nmetrik bir ARAÇtır,\nmutlak gerçek değil", 9.55, 5.85),
]
for txt, mx, my in metrics:
boxed_node(ax, mx, my, 3.0, 1.15, txt,
fc=COL_BG_ROSE, ec=COL_ROSE_500, tc=COL_TEXT,
fontsize=8.6, lw=1.9)
arrow_between(ax, (mx, my - 0.62), (cx + 0.7 * (mx - cx) / 3.3, cy + 0.95),
color=COL_ROSE_400, lw=2.0)
# --- SOL: köprüler (cyan) — hangi önceki ders bileşeni ---
bridges = [
("Inception özellikleri\n→ Ders 20 VGG16", 1.55, 4.45),
("kovaryans C\n→ Ders 18", 1.55, 3.15),
("W&B deney takibi\n→ Ders 16 callback", 1.55, 1.85),
("DDIM x0_hat\n→ Ders 19 sampling", 1.55, 0.60),
]
for txt, bx, by in bridges:
boxed_node(ax, bx, by, 2.7, 1.0, txt,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=8.6, lw=1.8)
arrow_between(ax, (bx + 1.35, by), (cx - 2.35, cy + 0.30 * (by - cy)),
color=COL_CYAN_400, lw=1.9)
# --- SAĞ: ileriye ölçüt (rose vurgu) ---
forwards = [
("Ders 22 Karras:\n'daha iyi mi?' sorusunu\nFID yanıtlar", 11.0, 3.95),
("eta=0 determinizm\n→ Ders 25 latent\ninterpolation", 11.0, 2.55),
("aynı felsefe:\nLLM / ses / video\nüretimi", 11.0, 1.20),
]
for txt, fx, fy in forwards:
boxed_node(ax, fx, fy, 2.75, 1.05, txt,
fc=COL_BG_ROSE, ec=COL_ROSE_400, tc=COL_TEXT,
fontsize=8.4, lw=1.8)
arrow_between(ax, (cx + 2.35, cy + 0.30 * (fy - cy)), (fx - 1.4, fy),
color=COL_ROSE_400, lw=1.9)
# --- başlık şeritleri ---
ax.text(1.55, 5.35, "önceki ders köprüleri", ha="center", va="center",
fontsize=10.5, color=COL_CYAN_700, weight="bold")
ax.text(11.0, 5.10, "ileriye: ölçüt", ha="center", va="center",
fontsize=10.5, color=COL_ACCENT, weight="bold")
plt.tight_layout()
plt.show()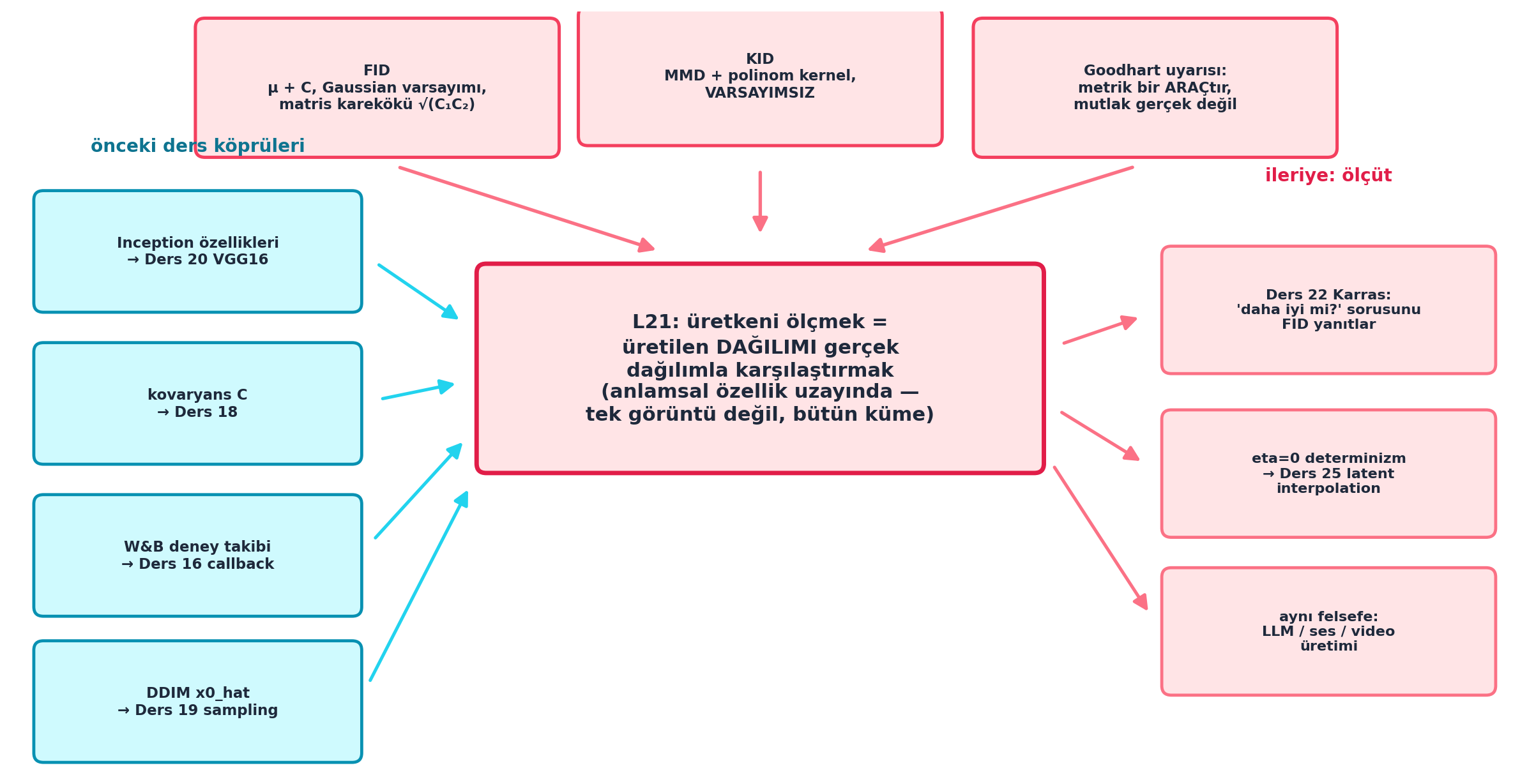
ÖnemliBuilder Notu — Üretkeni Ölçme: Her Üretken Alanın Temel Sorusu (MERKEZÎ)
- İleriye: Aynı felsefe LLM’lerde (perplexity, benzerlik), ses/video üretiminde de geçerli; “üretkeni nasıl ölçersin” her üretken alanın temel sorusu. Bir üretken sistem kurarken “başarıyı nasıl ölçeceğim” sorusu, hedefi tanımlamak kadar kritiktir (CLAUDE.md: “test yazılabilir bir hedef tanımı yoksa, iş tanımı yetersizdir”).
- Çekirdek ders: Sınıflandırma “doğru cevap” üzerine kuruludur; üretim “dağılım yakınlığı” üzerine. Bu kaymayı anlamak, üretken bir projeyi nasıl değerlendireceğini baştan belirler — gözle bakmak yerine, üretilen küme ile gerçek küme arasındaki ölçülebilir bir mesafeyi tanımlarsın.
- Sezgi: Bu çerçeveyi bir kez gördüğünde, herhangi bir üretken sistemi “ne ürettiğini değil, ürettiklerinin dağılımının hedefe ne kadar yakın olduğunu” sorarak değerlendirebilirsin. FID/KID görüntüler için; aynı mantık metin, ses ve video için de uyarlanır.
24.16 15. Kapanış
Ders 21 üretken modelciliğin üç pratik aracını verdi: deney takibi (W&B callback), FID/KID (üretilen görüntü kalitesini Inception özellik istatistikleriyle ölçme) ve DDIM (1000 adımı ~50’ye indiren, deterministik olabilen örnekleyici). Artık DDPM’i hem hızlı örnekleyebilir hem nesnel ölçebiliriz.
İpucuBuilder Notu — Kapanış: Ölçüm + Hız, Sonraki Adımın Zemini
- İleriye (Ders 22): DDIM örneklemeyi hızlandırdı; Ders 22 (Karras) gürültü çizelgesini ve örnekleyiciyi (Heun, LMS) yeniden tasarlayarak kaliteyi daha da artırır. FID artık elimizde olduğu için, Karras’ın “daha iyi mi?” iddiası nesnel olarak sınanabilir.
- Sezgi: Bu dersin asıl kazanımı bir araç seti değil, bir döngü kurmasıdır: hızlı üret (DDIM) → nesnel ölç (FID/KID) → neyin işe yaradığını izle (W&B). Bu üçlü, sonraki tüm diffusion iyileştirmelerinin üzerinde yürüyeceği zemindir.
24.17 Bu Dersin Özeti
- Deney takibi: Eğitim metriklerini/hiperparametreleri otomatik kaydetme; “ne işe yaradı” sorusunun yanıtı (deney takibi).
- W&B callback:
WandBCB(MetricsCB’den türer);wandb.init/log/finishile bulut panosuna loglar (WandBCB). - Kalite ölçme sorunu: Pikseller anlamsız; karşılaştırma anlamsal özellik uzayında yapılmalı (kalite sorunu).
- Inception özellikleri: Ön-eğitimli sınıflandırıcının ara katman çıktıları; üretilen vs gerçek dağılımı karşılaştırma temeli (Inception).
- FID: ‖μ₁−μ₂‖² + Tr(C₁ + C₂ − 2√(C₁C₂)); Fréchet mesafesi (ortalama + kovaryans). Düşük = iyi (FID).
- KID: MMD + polinom kernel; Gaussian varsaymaz, az örnekte daha güvenilir (KID).
- DDIM: Aynı modelle daha az adımda (skips) örnekleme;
etastokastikliği ayarlar (0=deterministik) (DDIM, eta). - Builder dersi: Üretkeni ölçmek = üretilen dağılımı gerçek dağılımla anlamsal özellik uzayında karşılaştırmak (builder içgörüsü).
ÖnemliTek Bir Cümle
Deney takibi (W&B callback) neyin işe yaradığını sistematik izler; FID/KID üretilen görüntülerin gerçek dağılıma yakınlığını Inception özelliklerinin ortalama+kovaryansıyla (FID = ‖μ₁−μ₂‖² + Tr(C₁+C₂−2√(C₁C₂))) ölçer; DDIM ise diffusion örneklemesini adım atlayarak (1000→~50) ve eta ile deterministik yaparak hızlandırır.
24.18 Kontrol Soruları
NotSoru 1: Üretilen görüntü kalitesi neden piksellerle değil de Inception özellikleriyle ölçülür?
Cevap:
Pikseller anlamsal anlam taşımaz: iki tamamen gerçekçi görüntü (örn. aynı kedinin iki fotoğrafı) piksel düzeyinde çok farklı olabilir, oysa anlamca çok benzerdir. Bu yüzden piksel karşılaştırması “kalite” hakkında bir şey söylemez. Çözüm: görüntüleri önceden eğitilmiş bir Inception sınıflandırıcısından geçirip ara katman özelliklerini almak. Bu özellikler görüntünün anlamsal içeriğini (ne olduğunu, dokusunu, yapısını) kodlar. Artık “kalite” sorusu, üretilen görüntülerin özellik dağılımının, gerçek görüntülerin özellik dağılımına ne kadar yakın olduğuna dönüşür — bu ölçülebilir ve anlamlıdır. (Ders 20’deki VGG16 özellik fikriyle aynı: anlamlı karşılaştırma özellik uzayında yapılır.)
NotSoru 2: FID neyi ölçer? Formülündeki iki terim ne anlama gelir?
Cevap:
FID (Fréchet Inception Distance), üretilen ve gerçek görüntülerin Inception özellik dağılımlarını Gaussian varsayıp aralarındaki Fréchet (Wasserstein-2) mesafesini ölçer: FID = ‖μ₁ − μ₂‖² + Tr(C₁ + C₂ − 2√(C₁·C₂)). İlk terim (‖μ₁ − μ₂‖²) iki dağılımın ortalamaları arasındaki farktır — “merkez kayması” (üretilen görüntülerin ortalama içeriği gerçeğinkinden ne kadar uzakta). İkinci terim (kovaryans terimi) iki dağılımın yayılımı ve şekli arasındaki farktır — çeşitlilik ve korelasyon yapısı ne kadar benzer. √(C₁·C₂) bir matris kareköküdür (skaler değil), Newton-Schulz veya SciPy sqrtm ile hesaplanır. Düşük FID = üretilen dağılım gerçeğe yakın = iyi model. (Şekil 24.3’de aynı dağılım FID ≈ 0.0135, uzak dağılım FID ≈ 19.63 verir.)
NotSoru 3: DDIM, DDPM’i nasıl hızlandırır? eta parametresinin rolü nedir?
Cevap:
DDPM örneklemesi tüm n_steps (örn. 1000) ters adımı tek tek gezer — her biri bir U-Net çağrısı, çok yavaş. DDIM, aynı eğitilmiş modelle ama daha akıllı bir ters adım formülüyle çalışır ve en önemlisi adım atlayabilir (skips): 1000 adımlık çizelgeyi örn. 50 adımda gezerek ~20 kat hızlanma sağlar, kalitede çok az kayıpla. Her adımda önce temiz görüntü tahminini (x_0_hat) çıkarır, sonra bir sonraki duruma geçer. eta parametresi bu geçişin rastgeleliğini kontrol eder: eta=1 iken DDIM, DDPM gibi davranır (her adımda gürültü eklenir, stokastik); eta=0 iken süreç tamamen deterministik olur — aynı başlangıç gürültüsü her zaman aynı görüntüyü üretir. Determinizm, tekrarlanabilirlik ve latent uzayda yumuşak gezinme (interpolation) için değerlidir. (Şekil 24.7’de eta=0 iki koşu bit-özdeş — maxdiff = 0; eta=1 ayrışır — maxdiff ≈ 0.0118.)
NotSoru 4: Üretken bir modeli ölçmek neden sınıflandırmadan farklıdır? (builder bağlantısı)
Cevap:
Sınıflandırmada her örneğin doğru bir cevabı vardır (etiket), dolayısıyla doğruluk (accuracy) doğrudan ölçülür. Üretimde ise “doğru çıktı” yoktur — sonsuz geçerli görüntü vardır; modelden beklenen, gerçek veri dağılımına benzer örnekler üretmesidir. Bu yüzden değerlendirme tekil örnek doğruluğu değil, dağılım karşılaştırmasıdır: üretilen örneklerin (anlamsal özellik uzayındaki) istatistikleri — ortalama ve kovaryans — gerçek verininkine ne kadar yakın (FID), ya da kernel tabanlı dağılım farkı ne kadar küçük (KID/MMD). Builder içgörüsü: “üretkeni ölçmek = üretilen dağılımı gerçek dağılımla karşılaştırmak”. Aynı felsefe LLM, ses ve video üretiminde de geçerlidir; bir üretken sistem kurarken “başarıyı nasıl ölçeceğim” sorusu, hedefi tanımlamak kadar kritiktir (CLAUDE.md: “test yazılabilir bir hedef tanımı”).
24.19 Egzersizler
Egzersiz 1 (Direkt uygulama). Bir eğitime WandBCB ekle; W&B panosunda kayıp eğrisini ve hiperparametreleri izle (§2).
Egzersiz 2 (İki-aşamalı). Bir DDPM modelinin örneklerinden FID hesapla; daha çok / daha az eğitilmiş modellerin FID’lerini karşılaştır (§5, §6).
Egzersiz 3 (Edge case). DDIM sample’ı eta=0 ve eta=1 ile çalıştır; aynı başlangıç gürültüsünün eta=0’da deterministik, eta=1’de değişken sonuç verdiğini gözle (§12).
Egzersiz 4 (Kavramsal). FID neden matris karekökü gerektirir? Newton-Schulz iterasyonu skaler karekök yöntemlerinden nasıl farklıdır? (§6)
Egzersiz 5 (Sonraki dersin habercisi — Ders 22). DDIM adım sayısına hâlâ bağımlı. Gürültü çizelgesini (β) yeniden tasarlamak ve daha akıllı örnekleyiciler (Heun) kullanmak kaliteyi nasıl artırabilir, düşün (Karras) (§11).
24.20 Sonraki: Ders 22 İçin Hazırlık
Ders 22: Cosine Schedule, Noise Prediction ve Karras
Ders 21 ölçüm (FID/KID) ve hızlandırma (DDIM) verdi. Ders 22 örneklemeyi daha da iyileştirir: cosine schedule (lineer β yerine daha iyi gürültü çizelgesi), gürültü seviyesini tahmin etme, ve Karras (“Elucidating the Design Space of Diffusion Models”) — sigma tabanlı çizelge, ρ (rho) örnekleme, Heun ve LMS örnekleyiciler.
Ana konular (Ders 22):
- Cosine noise schedule (lineerden daha iyi)
- Gürültü seviyesini tahmin etme (timestep’siz eğitim)
- Karras: sigma çizelgesi, ρ, ölçekleme
- Heun’s method, LMS örnekleyiciler
UyarıDers 22 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 2 ve 3 — FID + DDIM eta).
- DDPM’i DDIM ile 50 adımda örnekle, 1000-adım DDPM ile FID karşılaştır.
- Ders 19’un β çizelgesini tekrar oku (Karras onu yeniden tasarlayacak).
24.21 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Deney takibi | Metrik/hiperparametre/çıktı otomatik kaydı | 6:17 |
WandBCB |
Weights & Biases callback (MetricsCB’den) | 8:43 |
| Inception features | Ön-eğitimli sınıflandırıcının ara katman özellikleri | 25:09 |
| FID | ‖μ₁−μ₂‖² + Tr(C₁+C₂−2√(C₁C₂)); Fréchet mesafesi | 40:41 |
| Kovaryans matrisi | Özelliklerin yayılım/korelasyon yapısı (C) | 37:22 |
| Matris karekökü | √(C₁C₂); Newton-Schulz veya sqrtm | 42:23 |
| KID | MMD + polinom kernel; Gaussian varsaymaz | 50:17 |
| DDIM | Daha az adımda, deterministik olabilen örnekleyici | 1:19:06 |
ddim_step |
x_0_hat tahmini + bir sonraki duruma geçiş | 1:24:38 |
| skips | Adım atlama; 1000 → ~50 (hızlanma) | 1:24:38 |
| eta | Stokastiklik (1=DDPM, 0=deterministik) | 1:43:38 |
ImageEval |
FID/KID hesaplayan değerlendirici (özellik toplar) | 31:13 |
24.22 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: Ölçüm, Hız ve Takip Altyapısı
Bu ders üç pratik aracı (deney takibi, FID/KID, DDIM) önceki derslerin altyapısına bağlar ve “üretkeni ölçme” felsefesini ortaya koyar; köprülerin özeti:
- W&B callback → Ders 16 MetricsCB; deney takibi callback deseninin uzantısı (WandBCB).
- Inception features → Ders 20 VGG16; ön-eğitimli ağ özellik çıkarıcı olarak (Inception).
- FID kovaryans → Ders 18 kovaryans + 18.065 matris fonksiyonları (matris karekökü) (FID, matris karekökü).
- KID kernel → Ders 20 Gram/kernel; dağılım farkı (MMD) (KID).
- DDIM → Ders 19 DDPM sampling; aynı
x_0_hattahmini, daha hızlı geçiş (DDIM). - Üretkeni ölçme → genel üretken modelleme felsefesi (LLM/ses/video); “dağılım yakınlığı” (builder içgörüsü).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten üç araç alıp gideceksin. Deney takibi (W&B) büyük modelleri eğitirken neyin işe yaradığını izlemeni sağlar. FID/KID üretilen görüntülerin kalitesini nesnel ölçer — pikselleri değil, Inception özelliklerinin dağılımını (ortalama + kovaryans) karşılaştırarak; üretkeni ölçmenin yolu “üretilen dağılım gerçeğe ne kadar yakın”. DDIM ise diffusion örneklemesini 1000 adımdan ~50’ye indirir ve eta=0 ile deterministik yapar. Artık DDPM’i hızlı üretip nesnel değerlendirebiliyoruz — sıradaki ders (Karras) kaliteyi bir adım daha ileri taşıyacak.