---
title: "Algoritmalar ve Hesaplama"
subtitle: "Problem vs algoritma, tümevarımla doğruluk, asimptotik verimlilik ve word RAM modeli"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Ku'nun videosu:** [YouTube — Lecture 1: Algorithms and Computation](https://www.youtube.com/watch?v=ZA-tUyM_y7s) (≈46 dk)
- **OCW sayfası:** [MIT 6.006 Lecture 1: Algorithms and Computation](https://ocw.mit.edu/courses/6-006-introduction-to-algorithms-spring-2020/resources/lecture-1-algorithms-and-computation/)
- **Seri:** MIT 6.006 — Introduction to Algorithms (Spring 2020) — Ders 1
- **Hocalar:** Jason Ku, Erik Demaine, Justin Solomon
- **Okuma süresi:** ≈22 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste-d01}
6.006'nın ilk dersi, kursun *neyi* öğrettiğini tanımlar: hesaplamalı problemleri çözmeyi, çözümün **doğru** olduğunu ispatlamayı ve **verimli** olduğunu savunmayı. Jason Ku, kodlamadan çok düşünmeye ve iletişime odaklandığımızı vurgular — bu derste yazacağınız ispat, çoğu zaman yazacağınız koddan fazladır.
Üç temel kavram bu derste yan yana gelir:
1. **Problem vs Algoritma** — bir problem girdi-çıktı ilişkisidir; bir algoritma o ilişkiyi hesaplayan bir prosedürdür.
2. **Tümevarımla doğruluk** — bir algoritmanın *her* girdi için doğru çalıştığını sonlu bir argümanla ispatlama.
3. **Asimptotik verimlilik + hesaplama modeli** — zamanı saniyeyle değil, temel işlem sayısıyla ölçme; word RAM modeli.
> *"Really what the course is about is teaching you to solve computational problems."* — Ku, 1:00
```{mermaid}
%%| label: fig-concept-map
%%| echo: false
%%| fig-cap: "Ders 1'in kavram haritası: problem vs algoritma ikili ilişkisinden, tümevarımla doğruluğa, oradan asimptotik verimlilik + word RAM hesaplama modeline."
flowchart TD
A["Ders 1: Algoritmalar ve Hesaplama"] --> B["Problem vs Algoritma"]
A --> C["Doğruluk → Tümevarım"]
A --> D["Verimlilik → Asimptotik"]
B --> B1["Problem = ikili ilişki<br/>(girdi → çıktı)"]
B --> B2["Algoritma = prosedür<br/>(fonksiyon, sabit boyutlu)"]
C --> C1["Hipotez P(K)"]
C --> C2["Temel durum K = 0<br/>(boş-doğru)"]
C --> C3["Tümevarım adımı<br/>P(K′) → P(K′+1)"]
D --> D1["O · Θ · Ω sınırları"]
D --> D2["1 ≪ log n ≪ n ≪ n log n ≪ n² ≪ 2ⁿ"]
D --> D3["word RAM modeli<br/>(sabit-zaman erişim, word)"]
classDef root fill:#fef3c7,stroke:#b45309,stroke-width:3px,color:#1f2937
classDef branch fill:#f3f4f6,stroke:#374151,stroke-width:2px,color:#1f2937
classDef leaf fill:#ffffff,stroke:#9ca3af,stroke-width:1px,color:#1f2937
class A root
class B,C,D branch
class B1,B2,C1,C2,C3,D1,D2,D3 leaf
```
::: {.callout-tip title="Builder Notu — ML ve OMSCS Köprüleri"}
Bu ders ML değil, **mühendislik temeli** kurar. Phase 1 ve ileri hedeflerle köprüler:
- **Geriye → Python (Phase 1):** Ku, Python'ın `list`, `set`, `dict` yapılarının "bu modelde olmadığını" söyler (42:28). Python'da bedava görünen işlemlerin gerçek bir zaman maliyeti var — bu kurs o maliyeti görünür kılar.
- **Geriye → Calculus (Phase 1):** asimptotik mertebeler ($\log$, lineer, polinom, üstel büyüme) — fonksiyonların büyüme hızını karşılaştırma.
- **İleriye → OMSCS CS 6515 (Graduate Algorithms):** bu dersin formal devamı; aynı dil ($O/\Theta/\Omega$, DP, çizge).
- **İleriye → kompetitif programlama ve sistem tasarımı:** "büyük N'de hangi karmaşıklık geçer" sezgisi; routing, cache, scheduler tasarımı.
Tek cümle: *Bu ders, "hızlı kod" ile "hızlı algoritma" arasındaki farkı ve bunu nasıl ispatlayacağını öğretir.*
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — 6.006 Ders 1 motoru (_engine.py) + Slate+Amber viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri bu hücrede
# tanımlanan birthday_algorithm / birthday_trace / growth_funcs + draw_* + COL_*
# + apply_style'ı IMPORT ETMEDEN kullanır. Notion'daki öğretim içeriği (görünür
# pseudocode / display ```python bloklar) bu motorun tarif seviyesidir; burada
# tam, deterministik, test edilmiş sürüm yaşar.
#
# NOT: matplotlib.use("Agg") ÇAĞRILMAZ — Quarto'nun inline figür-yakalama
# backend'ini ezer (plt.show() 0 figür üretir; brief §2/§11). Standalone testte
# savefig kullanılır; Quarto render'da jupyter inline backend'i ayarlar.
# ============================================================================
import math
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
import networkx as nx
# ---------------------------------------------------------------------------
# _engine.py — algoritma motoru (DETERMİNİSTİK + TEST EDİLEBİLİR)
# ---------------------------------------------------------------------------
def birthday_algorithm(birthdays):
"""İlk eşleşen doğum günü çiftini bulur (Ku L1, doğum günü problemi).
Sınıftaki öğrenciler sırayla "görüşülür". Her öğrencinin doğum gününü daha önce
görülen doğum günlerini tutan bir `record` sözlüğünde ararız. Aynı doğum günü
daha önce görülmüşse, ilk eşleşen çifti döndürürüz. Her öğrenci için sabit-zamanlı
sözlük (hash-set) işlemi → toplam O(n).
"""
record = {} # doğum günü -> ilk gören öğrencinin index'i
for j, b in enumerate(birthdays):
if b in record:
return (record[b], j)
record[b] = j
return None
def birthday_trace(birthdays):
"""Doğum günü algoritmasının adım-adım izini üretir (fig-birthday-trace için).
Her görüşme adımında bir kayıt döndürür: o adımda görüşülen öğrencinin index'i,
o ANKİ record sözlüğünün bir KOPYASI ve o adımda eşleşme bulunup bulunmadığı.
Algoritma eşleşme bulduğu adımda DURUR: iz uzunluğu = eşleşmeye kadar görüşülen
öğrenci sayısı; eşleşme yoksa tüm n öğrenci görüşülür.
"""
record = {}
steps = []
for j, b in enumerate(birthdays):
if b in record:
# Eşleşme bulundu: record'a EKLEMEYİZ (algoritma durur), durumu kopyala.
steps.append({
"student": j,
"birthday": b,
"record": dict(record),
"match": True,
"match_with": record[b],
})
break
record[b] = j
steps.append({
"student": j,
"birthday": b,
"record": dict(record),
"match": False,
"match_with": None,
})
return steps
def growth_funcs():
"""fig-growth-hierarchy için büyüme fonksiyonları (asimptotik hiyerarşi).
Ku'nun tahtada çizdiği sıralama: 1 ≪ log n ≪ n ≪ n log n ≪ n² ≪ 2ⁿ.
log n: 2 tabanında (algoritma analizinde standart; taban sıralamayı değiştirmez).
"""
return {
"1": lambda n: 1.0,
"log n": lambda n: math.log2(n) if n > 0 else 0.0,
"n": lambda n: float(n),
"n log n": lambda n: n * math.log2(n) if n > 0 else 0.0,
"n²": lambda n: float(n) ** 2,
"2ⁿ": lambda n: float(2) ** n,
}
# ---------------------------------------------------------------------------
# _viz.py — Slate + Amber stil sabitleri (HEX birebir brief §1/§8)
# ---------------------------------------------------------------------------
COL_PRIMARY = "#374151" # slate-700 — birincil çizgi/çerçeve
COL_ACCENT = "#f59e0b" # amber-500 — vurgu (hızlı/kötü büyüme, aktif eşleşme)
COL_TEXT = "#1f2937" # slate-800 — metin
COL_BG = "#f3f4f6" # slate-100 — arka plan / callout / kutu dolgusu
# Türev amber tonları
COL_AMBER_700 = "#b45309" # bağlantı/okunur kontrast
COL_AMBER_600 = "#d97706" # koyu amber
COL_AMBER_300 = "#fcd34d" # açık amber
COL_AMBER_100 = "#fef3c7" # en açık amber (dolgu)
# Türev slate tonları
COL_SLATE_500 = "#6b7280" # orta slate — ikincil metin
COL_SLATE_400 = "#9ca3af" # soluk slate — pasif kenar / izgara
COL_WHITE = "#ffffff"
# Çizgi-grafik (curve) figürleri için tutarlı renk seti
LINE_PRIMARY = COL_PRIMARY
LINE_ACCENT = COL_ACCENT
LINE_SECONDARY = COL_AMBER_600
# Büyüme eğrilerine atanan renk şeması (yavaş=slate, hızlı=amber tonlama)
_GROWTH_COLORS = {
"1": COL_SLATE_400,
"log n": COL_SLATE_500,
"n": COL_PRIMARY,
"n log n": COL_AMBER_700,
"n²": COL_AMBER_600,
"2ⁿ": COL_ACCENT,
}
def apply_style(ax):
"""Bir eksene tutarlı Slate+Amber görünümü uygular (curve figürleri için)."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_SLATE_400, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_SLATE_400)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
# ----------------------------------------------------------------------------
# fig-growth-hierarchy — büyüme hiyerarşisi iki-panel (lineer + semilogy)
# ----------------------------------------------------------------------------
def draw_growth(ax_linear, ax_log, nmax=40):
"""Asimptotik büyüme hiyerarşisini iki panelde çizer: 1, log n, n, n log n, n², 2ⁿ.
Sol panel (lineer eksen): küçük n'de (≤ nmax) 2ⁿ patlamasını gösterir.
Sağ panel (semilogy): polinom/üstel sıralamayı log-y'de ayırır. DETERMİNİSTİK.
"""
ns = list(range(1, nmax + 1))
funcs = {
"1": lambda n: 1.0,
"log n": lambda n: math.log2(n),
"n": lambda n: float(n),
"n log n": lambda n: n * math.log2(n),
"n²": lambda n: float(n) ** 2,
"2ⁿ": lambda n: float(2) ** n,
}
order = ["1", "log n", "n", "n log n", "n²", "2ⁿ"]
for ax in (ax_linear, ax_log):
apply_style(ax)
ax.set_xlabel("n (girdi boyutu)")
# Sol panel: lineer — küçük n'de 2ⁿ patlaması
for name in order:
ys = [funcs[name](n) for n in ns]
ax_linear.plot(ns, ys, label=name, color=_GROWTH_COLORS[name],
linewidth=2.4 if name == "2ⁿ" else 1.8)
# 2ⁿ devasa; lineer panelde okunabilir bir tavanla sınırla
ax_linear.set_ylim(0, funcs["n²"](nmax) * 1.15)
ax_linear.set_ylabel("işlem sayısı (lineer)")
ax_linear.set_title("Lineer eksen — küçük n", color=COL_TEXT, fontsize=12)
ax_linear.legend(loc="upper left", fontsize=8.5, framealpha=0.9)
# Sağ panel: semilogy — tüm sıralama log-y'de ayrışır
for name in order:
ys = [funcs[name](n) for n in ns]
ax_log.semilogy(ns, ys, label=name, color=_GROWTH_COLORS[name],
linewidth=2.4 if name == "2ⁿ" else 1.8)
ax_log.set_ylabel("işlem sayısı (log ölçek)")
ax_log.set_title("Logaritmik eksen — sıralama netleşir", color=COL_TEXT, fontsize=12)
ax_log.legend(loc="upper left", fontsize=8.5, framealpha=0.9)
return ax_linear, ax_log
# ----------------------------------------------------------------------------
# fig-problem-relation — bipartite ikili ilişki (networkx)
# ----------------------------------------------------------------------------
def draw_relation(ax, inputs, outputs, edges, highlight_edges=None,
input_title="Girdiler", output_title="Çıktılar"):
"""Bir problemi ikili ilişki olarak çizer: sol sütun girdiler, sağ sütun çıktılar,
kenarlar (girdi → geçerli çıktı) çiftleri. BİR girdinin BİRDEN ÇOK doğru çıktısı
olabilir (highlight_edges ile amber vurgu)."""
highlight_edges = set(highlight_edges or [])
G = nx.Graph()
pos = {}
n_in = len(inputs)
n_out = len(outputs)
in_nodes = [f"in{i}" for i in range(n_in)]
out_nodes = [f"out{j}" for j in range(n_out)]
# Dikeyde ortalanmış konumlar (deterministik manuel layout)
for i, name in enumerate(in_nodes):
y = (n_in - 1) / 2.0 - i
pos[name] = (0.0, y)
G.add_node(name)
for j, name in enumerate(out_nodes):
y = (n_out - 1) / 2.0 - j
pos[name] = (2.4, y)
G.add_node(name)
# Kenarları çiz (amber vurgulu olanlar üstte, kalın)
for (i, j) in edges:
x0, y0 = pos[in_nodes[i]]
x1, y1 = pos[out_nodes[j]]
hot = (i, j) in highlight_edges
ax.plot([x0, x1], [y0, y1],
color=COL_ACCENT if hot else COL_SLATE_400,
linewidth=2.6 if hot else 1.3,
zorder=3 if hot else 1, alpha=0.95 if hot else 0.8)
# Düğüm kutuları
box_w, box_h = 1.55, 0.62
for i, label in enumerate(inputs):
x, y = pos[in_nodes[i]]
_node_box(ax, x, y, box_w, box_h, label, ec=COL_PRIMARY, fc=COL_BG)
for j, label in enumerate(outputs):
x, y = pos[out_nodes[j]]
hot = any(e[1] == j for e in highlight_edges)
_node_box(ax, x, y, box_w, box_h, label,
ec=COL_ACCENT if hot else COL_PRIMARY,
fc=COL_AMBER_100 if hot else COL_BG)
# Sütun başlıkları
top = max((n_in - 1) / 2.0, (n_out - 1) / 2.0) + 0.95
ax.text(0.0, top, input_title, ha="center", va="center",
fontsize=11.5, color=COL_TEXT, weight="bold")
ax.text(2.4, top, output_title, ha="center", va="center",
fontsize=11.5, color=COL_TEXT, weight="bold")
ax.set_xlim(-box_w, 2.4 + box_w)
ax.set_ylim(-top - 0.3, top + 0.5)
ax.set_aspect("equal")
ax.axis("off")
return ax
# ----------------------------------------------------------------------------
# fig-cost-shift / dizi görselleri — dizi hücreleri + opsiyonel kaydırma okları
# ----------------------------------------------------------------------------
def draw_array(ax, cells, highlight=None, shift=None, y=0.0, x0=0.0,
cell_w=1.0, cell_h=1.0, label_indices=True, title=None):
"""Bir diziyi (adresli hücreler) çizer; opsiyonel kaydırma oklarıyla.
fig-cost-shift için: list.insert(0,x) → tüm elemanların bir sağa kayması
(amber oklar) vs append → tek hücre."""
highlight = set(highlight or [])
centers = []
for k, content in enumerate(cells):
x = x0 + k * cell_w
hot = k in highlight
box = FancyBboxPatch(
(x, y), cell_w * 0.94, cell_h * 0.94,
boxstyle="square,pad=0.0",
fc=COL_AMBER_100 if hot else COL_BG,
ec=COL_ACCENT if hot else COL_PRIMARY,
linewidth=2.4 if hot else 1.6, zorder=2,
)
ax.add_patch(box)
cx, cy = x + cell_w * 0.47, y + cell_h * 0.47
centers.append((cx, cy))
if content != "":
ax.text(cx, cy, str(content), ha="center", va="center",
fontsize=11, color=COL_TEXT, weight="bold", zorder=4)
if label_indices:
ax.text(cx, y - cell_h * 0.22, str(k), ha="center", va="center",
fontsize=8.5, color=COL_SLATE_500, zorder=4)
# Kaydırma okları (her hücre bir sağ komşuya kayar)
if shift == "right":
for k in range(len(cells)):
cx, cy = centers[k]
arrow = FancyArrowPatch(
(cx, cy + cell_h * 0.55), (cx + cell_w, cy + cell_h * 0.55),
arrowstyle="-|>", mutation_scale=14,
color=COL_ACCENT, linewidth=1.8, zorder=5,
)
ax.add_patch(arrow)
if title is not None:
ax.set_title(title, color=COL_TEXT, fontsize=12)
ax.set_xlim(x0 - 0.4, x0 + len(cells) * cell_w + 0.4)
ax.set_ylim(y - cell_h * 0.6, y + cell_h * 1.3)
ax.set_aspect("equal")
ax.axis("off")
return centers
# ----------------------------------------------------------------------------
# Yardımcı: tek düğüm kutusu
# ----------------------------------------------------------------------------
def _node_box(ax, x, y, w, h, label, ec=COL_PRIMARY, fc=COL_BG, fontsize=10):
"""Ortalanmış yuvarlatılmış bir kutu + etiket çizer (relation/graph düğümü)."""
box = FancyBboxPatch(
(x - w / 2, y - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, linewidth=2.0, zorder=2,
)
ax.add_patch(box)
ax.text(x, y, label, ha="center", va="center",
fontsize=fontsize, color=COL_TEXT, weight="bold", zorder=4)
return box
```
## Hesaplamalı Problem Nedir? {#sec-hesaplamali-problem}
Ku derse bir soruyla başlar: *"What is a problem? What is an algorithm?"* — ve cevabı söylemek yerine sınıfı oraya taşır (Sokratik üslup). Kursun dört hedefi vardır:
1. Hesaplamalı problemi **çöz**.
2. Çözümün **doğru** olduğunu ispatla.
3. Çözümün **verimli** olduğunu savun.
4. Bunların hepsini başkalarına **iletişimle** aktar.
Ku'ya göre bu sınıfı diğer kodlama derslerinden ayıran şey budur: sadece bilgisayara değil, *insanlara* doğruluğu kanıtlamak. Bu yüzden derste bol bol yazı yazılır.
> *"we really concentrate on being able to prove that the things you're doing are correct and better than other things, and being able to communicate those ideas to others, and not just to a computer"* — Ku, 2:40
## Problem = Girdi-Çıktı İlişkisi {#sec-problem-iliski}
Soyut tanım: bir **problem**, girdiler kümesi ile çıktılar kümesi arasında bir **ikili ilişkidir** (binary relation). Her girdi için hangi çıktıların *doğru* olduğunu belirtir — bu, girdiler ile çıktılar arasında iki-parçalı (bipartite) bir çizge gibidir (@fig-problem-relation). Bir girdinin birden çok doğru çıktısı olabilir: örneğin "dizide 5 değerini içeren bir indeks ver" probleminde birden çok 5 varsa, o indekslerin herhangi biri doğrudur.
Pratikte bir problemi tek tek girdi-çıktı çiftleriyle değil, bir **yüklem (predicate)** ile tanımlarız: bir girdi-çıktı çifti verildiğinde, çıktının doğru olup olmadığını *kontrol edebiliriz*. Bu, sonsuz sayıda girdiyi sonlu bir kuralla ifade etmenin yoludur.
> *"what a problem is is a binary relation between these inputs and outputs."* — Ku, 3:48
**Çalışılan Örnek — Doğum Günü Problemi (kurulum):** Bir sınıftaki öğrenciler arasında, *herhangi iki* öğrencinin aynı doğum anına (gün + yıl + saat) sahip olup olmadığını soralım. Ku, algoritmanın yalnızca bu sınıf için değil, **keyfi boyutta** herhangi bir girdi için çalışmasını ister — 300 öğrenci de olabilir, bir milyar öğrenci de. İşte bu yüzden "sabit boyutlu" bir makine ile "keyfi boyutlu" girdiyi işlemek zorundayız.
```{python}
#| label: fig-problem-relation
#| fig-cap: "Problem bir **ikili ilişkidir**: sol sütun girdiler (örnek diziler), sağ sütun olası çıktılar (5'in indeksi). Kenarlar geçerli (girdi → çıktı) çiftleridir. `[7, 5, 2]` için tek doğru çıktı (indeks 1), `[3, 8, 4]` için \"5 yok\"; ama `[5, 9, 5, 1]` için **iki** geçerli çıktı vardır (indeks 0 ve indeks 2, amber vurgulu) — bir girdinin birden çok doğru cevabı olabilir, yani problem fonksiyon olmak zorunda değildir."
#| fig-width: 8.5
#| fig-height: 5
# --- Deterministik problem örneği: "dizide 5'in indeksi" ---
# Girdiler (sol): üç farklı dizi. Çıktılar (sağ): olası indeks değerleri + "5 yok".
inputs = [
"[7, 5, 2]", # 5 yalnız indeks 1'de → tek doğru çıktı
"[5, 9, 5, 1]", # 5 hem indeks 0 hem indeks 2'de → İKİ doğru çıktı (amber)
"[3, 8, 4]", # 5 hiç yok → "5 yok" çıktısı
]
outputs = ["indeks 0", "indeks 1", "indeks 2", "5 yok"]
# Geçerli (girdi_idx, çıktı_idx) çiftleri:
# [7,5,2] → indeks 1
# [5,9,5,1] → indeks 0 VE indeks 2 (çoklu doğru cevap)
# [3,8,4] → "5 yok"
edges = [
(0, 1),
(1, 0),
(1, 2),
(2, 3),
]
# Çoklu-çıktı vurgusu: ikinci girdinin İKİ geçerli çıktısı amber
highlight_edges = [(1, 0), (1, 2)]
fig, ax = plt.subplots(figsize=(8.5, 5))
draw_relation(
ax,
inputs=inputs,
outputs=outputs,
edges=edges,
highlight_edges=highlight_edges,
input_title="Girdiler (dizi)",
output_title="Çıktı(lar): 5'in indeksi",
)
ax.set_title(
"Problem = ikili ilişki: bir girdinin birden çok doğru çıktısı olabilir",
color=COL_TEXT, fontsize=12.5, pad=14,
)
# Açıklayıcı dipnot (çoklu-cevap sezgisi)
ax.text(
0.5, -0.04,
"Amber: tek girdi → iki geçerli çıktı (5 dizide iki kez geçiyor)",
transform=ax.transAxes, ha="center", va="top",
fontsize=10, color=COL_AMBER_700,
)
plt.tight_layout()
plt.show()
```
## Algoritma Nedir? {#sec-algoritma-nedir}
Bir **algoritma**, problemin tersine, çıktıları önceden bilmez — o bir **prosedürdür**: sabit boyutlu bir makine ya da tarif ki, kendisine bir girdi verildiğinde bir çıktı *üretir*. Matematiksel olarak algoritma bir **fonksiyondur**: her girdiyi tek bir çıktıya eşler ve o çıktı, problemin tanımına göre doğru olmalıdır.
Kritik gerilim şudur: girdi keyfi büyüklükte olabilir (bir milyar öğrenci), ama algoritmamız **sabit boyutludur**. Sabit boyutlu bir kod, keyfi büyük girdiyi işleyebilmek için **döngü kurmalı veya özyineleme (recursion) yapmalıdır** — aynı kod satırlarını tekrar tekrar çalıştırarak. Bu gözlem, neden bir sonraki adımda tümevarıma ihtiyaç duyacağımızın da habercisidir.
> *"An algorithm is some kind of function that takes these inputs, maps it to a single output, and that output better be correct based on our problem."* — Ku, 10:19
> *"So it's just a procedure. You can think of it as like a recipe."* — Ku, 14:56
## Doğum Günü Algoritması {#sec-dogum-gunu-algoritmasi}
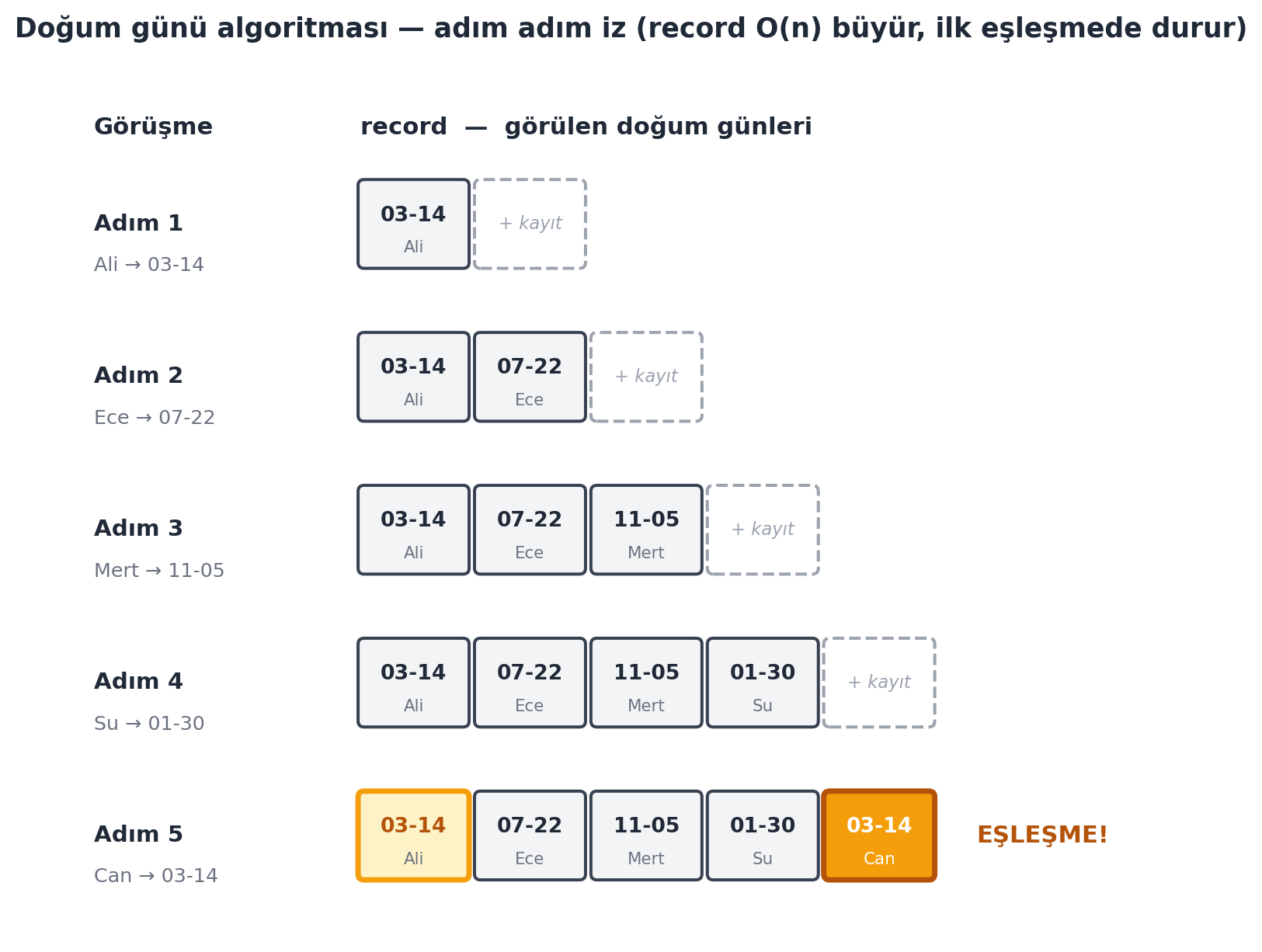
Ku, bir öğrenciden algoritma önerisi alır ve onu formalize eder. Algoritma dört adımdan oluşur (somut bir izi için @fig-birthday-trace):
1. Bir **kayıt (record)** tut.
2. Öğrencileri bir sırayla **görüşmeye al** (interview).
3. Her görüşmede: doğum günü kayıtta var mı **kontrol et** → varsa bir **çift döndür**; yoksa öğrenciyi kayda **ekle**.
4. Herkes bittiğinde eşleşme bulunamadıysa "eşleşme yok" döndür.
> *"Maintain a record. Interview students in some order... check if birthday in record... return pair... Otherwise, add a new student to record."* — Ku, 12:11
Bu, problem setlerinde beklenen **tarif seviyesinde** açıklamadır: bir bilgisayara değil, sınıftaki bir arkadaşına anlatabileceğin netlikte sözel bir tanım.
> *"if you said this algorithm to any of your friends in this class... they would at least understand what it is that you're doing."* — Ku, 13:46
Şimdi elimizde bir algoritma var. Ama bu yeterli değil: Ku'nun dört hedefinden ikisi henüz eksik — bu algoritmanın **doğru** ve **verimli** olduğunu göstermek. Sonraki iki bölüm tam olarak bunu yapar.
```{python}
#| label: fig-birthday-trace
#| fig-cap: "Doğum günü algoritmasının adım-adım izi. Öğrenciler sırayla görüşülür; her satır bir görüşme adımıdır ve o ana kadar **record** sözlüğünde biriken doğum günlerini kutucuklarla gösterir (kutuda gün + ilk gören öğrenci). Eşleşme bulunana kadar her adımda kayıt bir hücre **büyür** (slate kutular, kesik çizgili '+ kayıt' = yeni eklenen). Adım 5'te Can'ın doğum günü (03-14) daha önce Ali'de görüldüğü için **çarpışma** olur: çakışan önceki kayıt amber çerçeveyle, aktif sorgu dolu amber kutuyla vurgulanır ('EŞLEŞME!') ve algoritma orada **durur** — bu yüzden iz yalnızca 5 adım. record sabit-zamanlı sözlük araması sayesinde toplam maliyet $O(n)$."
#| fig-width: 11
#| fig-height: 6.4
# --- DETERMİNİSTİK girdi: sırayla görüşülen öğrencilerin doğum günleri ---
# Çarpışma kısmen ortada olur: 5. öğrenci (index 4, "03-14"), 1. öğrenciyle
# (index 0, "03-14") eşleşir. Algoritma o adımda DURUR → iz 5 adım uzunluğunda.
birthdays = ["03-14", "07-22", "11-05", "01-30", "03-14", "09-09"]
isimler = ["Ali", "Ece", "Mert", "Su", "Can", "Lara"] # öğrenci index → isim
steps = birthday_trace(birthdays)
n_steps = len(steps)
# --- yerleşim sabitleri ---
cell_w, cell_h = 1.18, 0.86 # bir record-kutucuğunun boyutu
row_gap = 1.55 # adım satırları arası dikey boşluk
left_label_x = -2.7 # sol etiket sütununun x'i
max_record_size = max(len(s["record"]) for s in steps) + 1 # +1 = aktif eşleşme kutusu
fig, ax = plt.subplots(figsize=(11, 6.4))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
# Adımları yukarıdan aşağıya çiz (1. adım en üstte)
for row, step in enumerate(steps):
y = (n_steps - 1 - row) * row_gap
student = step["student"]
bday = step["birthday"]
is_match = step["match"]
record = step["record"] # bu adımdan SONRAKİ record (eşleşmede eklenmemiş hali)
# --- sol etiket: adım no + görüşülen öğrenci ---
ax.text(left_label_x, y + cell_h * 0.5,
f"Adım {row + 1}", ha="left", va="center",
fontsize=11, color=COL_TEXT, weight="bold")
ax.text(left_label_x, y + cell_h * 0.5 - 0.42,
f"{isimler[student]} → {bday}", ha="left", va="center",
fontsize=9.5, color=COL_SLATE_500)
# --- record içeriğini kutucuklarla çiz (görülen doğum günleri) ---
# record: {doğum_günü: ilk_gören_index}. Ekleniş sırasını korumak için index'e göre sırala.
record_items = sorted(record.items(), key=lambda kv: kv[1])
x = 0.0
for (rb, ridx) in record_items:
# Eşleşme adımında, çarpışan ÖNCEKİ kayıt amber vurgulanır.
hot = is_match and (ridx == step["match_with"])
box = FancyBboxPatch(
(x, y), cell_w * 0.92, cell_h,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=COL_AMBER_100 if hot else COL_BG,
ec=COL_ACCENT if hot else COL_PRIMARY,
linewidth=2.6 if hot else 1.5, zorder=2,
)
ax.add_patch(box)
cx = x + cell_w * 0.46
ax.text(cx, y + cell_h * 0.60, rb, ha="center", va="center",
fontsize=10, color=COL_AMBER_700 if hot else COL_TEXT,
weight="bold", zorder=4)
ax.text(cx, y + cell_h * 0.22, isimler[ridx], ha="center", va="center",
fontsize=8, color=COL_SLATE_500, zorder=4)
x += cell_w
# --- aktif öğrencinin sorgu kutusu (record'un sağında) ---
if is_match:
# Eşleşme: aktif öğrenci dolu amber kutu, "EŞLEŞME!" vurgusu
qbox = FancyBboxPatch(
(x, y), cell_w * 0.92, cell_h,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=COL_ACCENT, ec=COL_AMBER_700, linewidth=2.6, zorder=3,
)
ax.add_patch(qbox)
cx = x + cell_w * 0.46
ax.text(cx, y + cell_h * 0.60, bday, ha="center", va="center",
fontsize=10, color=COL_WHITE, weight="bold", zorder=5)
ax.text(cx, y + cell_h * 0.22, isimler[student], ha="center", va="center",
fontsize=8, color=COL_WHITE, zorder=5)
ax.text(x + cell_w + 0.35, y + cell_h * 0.5, "EŞLEŞME!",
ha="left", va="center", fontsize=11.5,
color=COL_AMBER_700, weight="bold", zorder=5)
else:
# Eşleşme yok: aktif öğrenci kayda EKLENDİ → kesik çizgili "yeni" kutu
qbox = FancyBboxPatch(
(x, y), cell_w * 0.92, cell_h,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=COL_WHITE, ec=COL_SLATE_400, linewidth=1.5,
linestyle="--", zorder=2,
)
ax.add_patch(qbox)
cx = x + cell_w * 0.46
ax.text(cx, y + cell_h * 0.5, "+ kayıt", ha="center", va="center",
fontsize=8.5, color=COL_SLATE_400, style="italic", zorder=4)
# --- başlık satırı: "record (görülen doğum günleri)" ---
top_y = (n_steps - 1) * row_gap + cell_h + 0.55
ax.text(0.0, top_y, "record — görülen doğum günleri",
ha="left", va="center", fontsize=11.5, color=COL_TEXT, weight="bold")
ax.text(left_label_x, top_y, "Görüşme",
ha="left", va="center", fontsize=11.5, color=COL_TEXT, weight="bold")
# --- eksen sınırları + temizlik ---
ax.set_xlim(left_label_x - 0.3, max_record_size * cell_w + 2.6)
ax.set_ylim(-0.6, top_y + 0.5)
ax.set_aspect("equal")
ax.axis("off")
fig.suptitle("Doğum günü algoritması — adım adım iz (record O(n) büyür, ilk eşleşmede durur)",
color=COL_TEXT, fontsize=13, weight="bold", y=0.99)
fig.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Çarpışma Tespiti ve Hash Fonksiyonları"}
Doğum günü algoritmasının "kayıt"ı aslında bir **hash kümesidir** (Python `dict`/`set`). "Doğum günü kayıtta var mı?" kontrolünün $O(1)$ olması, hash fonksiyonunun anahtarı sabit zamanda bir kovaya eşlemesinden gelir — bu, Ders 4'ün (Hashing) konusu.
- **Geriye → çarpışma matematiği:** Doğum günü *paradoksu* (sürpriz biçimde az sayıda öğrencide eşleşme olasılığının yükselmesi), hash tablolarındaki çarpışma analizinin (yük faktörü, beklenen çarpışma sayısı) ta kendisidir. Phase 1 Stat 110 olasılık dersiyle doğrudan köprü.
- **İleriye → feature hashing (ML):** Yüksek-kardinaliteli kategorik öznitelikleri sabit boyutlu bir vektöre indirgeyen "hashing trick", çarpışmaları *bilerek tolere eder* — kabul edilebilir çarpışma oranını yine bu doğum günü matematiği sınırlar.
- **İleriye → embedding lookup:** Bir token → indeks → embedding satırı erişimi, bu kayıt sözlüğünün ölçeklenmiş hâlidir: anahtar→değer $O(1)$ erişim. Karpathy'nin makemore serisinde embedding tablosu tam olarak budur.
:::
## Tümevarımla Doğruluk İspatı {#sec-tumevarim-dogruluk}
Dört öğrenci için algoritmanın doğruluğunu elle deneyerek gösterebilirdik. Ama 300 (ya da bir milyar) öğrenci için tek tek denemek imkânsız. Sabit boyutlu bir kodun *keyfi büyük* bir girdide doğru çalıştığını göstermenin yolu **tümevarımdır (induction)** — bu yüzden 6.006 öncesi bir ispat/ayrık matematik dersi şarttır.
> *"Induction, right? ... we write a constant sized piece of code that can take on any arbitrarily large size input."* — Ku, 16:23
**Çalışılan Örnek — Doğum Günü Algoritmasının Doğruluğu**
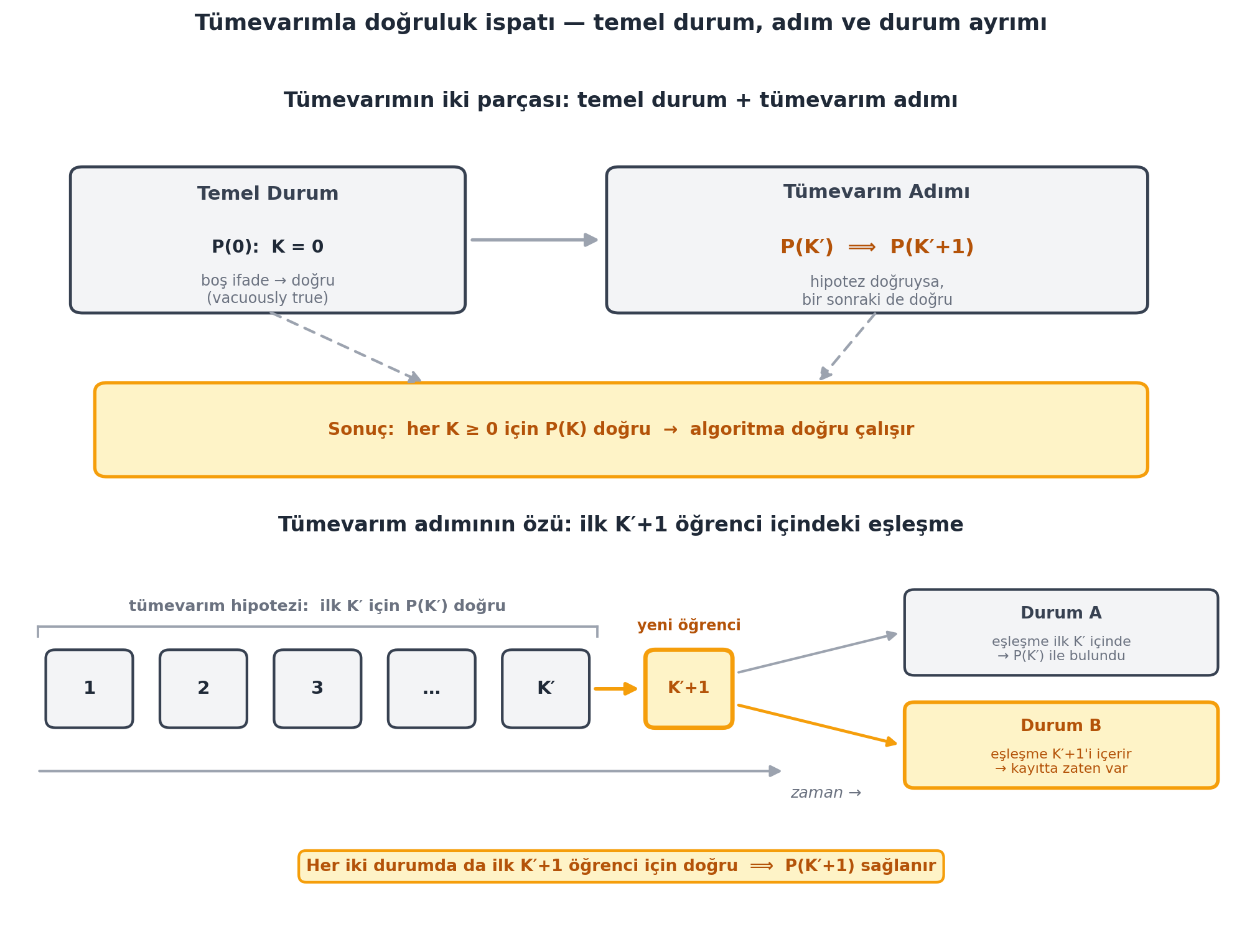
Tümevarımı kurmak için üç parça gerekir: hipotez, temel durum, tümevarım adımı. Bu üç parça @fig-induction içinde bir arada görülür.
**1) Tümevarım hipotezi (P(K)):** İlk K öğrenci bir eşleşme içeriyorsa, algoritma K+1'inci öğrenciyi görüşmeden *önce* bir çift döndürmüştür.
> *"If first K students contain a match, algorithm returns a match before interviewing student K plus 1."* — Ku, 19:29
**2) Temel durum (K = 0):** Hiç öğrenci görüşülmeden önce hiçbir iş yapılmamıştır. İlk 0 öğrenci bir eşleşme *içeremez*, dolayısıyla hipotez boş-doğru (vacuously true) olarak sağlanır. Ku, en kolay temel durumun 2 veya 1 değil, 0 olduğunu vurgular.
> *"After interviewing 0 students, I haven't done any work... the first 0 can't have a match."* — Ku, 21:21
**3) Tümevarım adımı:** P(K′) doğru varsayılır, P(K′+1) gösterilir. İki durum vardır:
- **Durum A:** İlk K′ öğrenci zaten bir eşleşme içeriyorsa → tümevarım hipotezi gereği algoritma çoktan doğru çıktıyı döndürmüştür.
- **Durum B:** İlk K′ öğrenci eşleşme içermiyorsa ve K′+1'inci öğrenci görüşülür → eğer ilk K′+1 öğrenci içinde bir eşleşme varsa, bu eşleşme *zorunlu olarak* K′+1'inci öğrenciyi içerir (aksi halde daha önce eşleşme olurdu). Algoritma yeni öğrencinin doğum gününü kayıtta arar; varsa çifti döndürür, yoksa öğrenciyi kayda ekler ve hipotez K′+1 için yeniden kurulur.
**Sonuç:** K = n alındığında, n öğrencinin tümü görüşüldükten sonra bir eşleşme varsa döndürülmüş olur; yoksa algoritma "eşleşme yok" döndürür. İkisi de doğrudur.
> *"OK, so that's how we prove correctness."* — Ku, 24:52
Ku, bu seviyede bir formalliğin her zaman gerekmediğini, ama kalibrasyon için yeterli olduğunu belirtir:
> *"This is a little bit more formal than we would ask you to do... but it's definitely sufficient."* — Ku, 24:57
Hedef çıta: bir başkası senin algoritmanı okuyup kodlayabilmeli.
> *"if you communicated to someone else taking this class what your algorithm was, they would be able to code it up and tell a stupid computer how to do that thing."* — Ku, 25:10
```{python}
#| label: fig-induction
#| fig-cap: "Tümevarımla doğruluk ispatının iskeleti. **Üst panel:** ispat iki parçadan oluşur — temel durum P(0) (K = 0 için ifade boş, dolayısıyla doğru / *vacuously true*) ve tümevarım adımı P(K′) ⟹ P(K′+1) (hipotez doğruysa bir sonraki de doğru); ikisi birleşince her K ≥ 0 için P(K) doğru → algoritma doğru çalışır. **Alt panel:** adımın özü — ilk K′ öğrenci için P(K′) doğru kabul edilir (slate hipotez şeridi), sıraya yeni öğrenci K′+1 eklenir (amber vurgu). İlk K′+1 öğrenci içindeki eşleşme iki durumdan biridir: **Durum A** eşleşme ilk K′ içindedir (P(K′) ile zaten bulunmuştur), **Durum B** eşleşme K′+1'inci öğrenciyi içerir (o öğrencinin doğum günü kayıtta zaten vardır). Her iki durumda da ilk K′+1 öğrenci için doğru ⟹ P(K′+1) sağlanır."
#| fig-width: 10.5
#| fig-height: 8
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# Tümevarım yapısı görseli: temel durum + tümevarım adımı (üst panel) ve
# ilk K′+1 öğrenci içindeki eşleşmenin Durum A / Durum B ayrımı (alt panel).
# DETERMİNİSTİK — sabit yerleşim; Slate birincil, Amber vurgu (yeni öğrenci / Durum B).
fig, (ax_t, ax_b) = plt.subplots(
2, 1, figsize=(10.5, 8.0), gridspec_kw={"height_ratios": [1.0, 1.05]}
)
def _box(ax, x, y, w, h, text, fc, ec, lw=1.8, fontsize=10.5,
weight="bold", tc=None, rounding=0.10, va="center"):
"""Ortalanmış yuvarlatılmış bir kutu + metin çizer."""
box = FancyBboxPatch(
(x - w / 2, y - h / 2), w, h,
boxstyle=f"round,pad=0.02,rounding_size={rounding}",
fc=fc, ec=ec, linewidth=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x, y, text, ha="center", va=va, fontsize=fontsize,
color=tc if tc is not None else COL_TEXT, weight=weight, zorder=4)
return box
def _arrow(ax, p0, p1, color=COL_PRIMARY, lw=2.0, ls="-", scale=16, zorder=3):
ax.add_patch(FancyArrowPatch(
p0, p1, arrowstyle="-|>", mutation_scale=scale,
color=color, linewidth=lw, linestyle=ls, zorder=zorder,
))
# ========================================================================
# ÜST PANEL: Tümevarım iskeleti — Temel durum + Tümevarım adımı
# ========================================================================
ax_t.set_xlim(0, 10)
ax_t.set_ylim(0, 4)
ax_t.axis("off")
ax_t.set_title("Tümevarımın iki parçası: temel durum + tümevarım adımı",
fontsize=12.5, color=COL_TEXT, weight="bold", pad=6)
# --- Temel durum kutusu (K=0, boş-doğru) ---
_box(ax_t, 2.1, 2.7, 3.2, 1.5, "", COL_BG, COL_PRIMARY, lw=1.8)
ax_t.text(2.1, 3.18, "Temel Durum", ha="center", va="center",
fontsize=11.5, color=COL_PRIMARY, weight="bold")
ax_t.text(2.1, 2.62, "P(0): K = 0", ha="center", va="center",
fontsize=10.5, color=COL_TEXT, weight="bold")
ax_t.text(2.1, 2.18, "boş ifade → doğru\n(vacuously true)", ha="center",
va="center", fontsize=9.0, color=COL_SLATE_500)
# --- Tümevarım adımı kutusu P(K′) → P(K′+1) ---
_box(ax_t, 7.1, 2.7, 4.4, 1.5, "", COL_BG, COL_PRIMARY, lw=1.8)
ax_t.text(7.1, 3.20, "Tümevarım Adımı", ha="center", va="center",
fontsize=11.5, color=COL_PRIMARY, weight="bold")
ax_t.text(7.1, 2.62, "P(K′) ⟹ P(K′+1)", ha="center", va="center",
fontsize=12.0, color=COL_AMBER_700, weight="bold")
ax_t.text(7.1, 2.16, "hipotez doğruysa,\nbir sonraki de doğru",
ha="center", va="center", fontsize=9.0, color=COL_SLATE_500)
# --- Temel durum → Adım oku (zincir) ---
_arrow(ax_t, (3.75, 2.7), (4.85, 2.7), color=COL_SLATE_400, lw=2.0)
# --- Sonuç şeridi: tüm K için doğru ---
_box(ax_t, 5.0, 0.7, 8.6, 0.95, "", COL_AMBER_100, COL_ACCENT, lw=2.0,
rounding=0.10)
ax_t.text(5.0, 0.7, "Sonuç: her K ≥ 0 için P(K) doğru → algoritma doğru çalışır",
ha="center", va="center", fontsize=10.5, color=COL_AMBER_700,
weight="bold")
_arrow(ax_t, (2.1, 1.95), (3.4, 1.18), color=COL_SLATE_400, lw=1.6, ls=(0, (4, 3)))
_arrow(ax_t, (7.1, 1.95), (6.6, 1.18), color=COL_SLATE_400, lw=1.6, ls=(0, (4, 3)))
# ========================================================================
# ALT PANEL: Merdiven / zaman-ekseni — ilk K′+1 öğrenci, Durum A vs Durum B
# ========================================================================
ax_b.set_xlim(0, 12.6)
ax_b.set_ylim(0, 4.6)
ax_b.axis("off")
ax_b.set_title("Tümevarım adımının özü: ilk K′+1 öğrenci içindeki eşleşme",
fontsize=12.5, color=COL_TEXT, weight="bold", pad=6)
# Zaman ekseni (öğrenciler sırayla görüşülür) — soldan sağa
n_prev = 5 # ilk K′ öğrenci (1..K′)
x0 = 0.8
dx = 1.18
cw = 0.86 # öğrenci kutusu genişliği
cy = 2.9 # öğrenci sırası y
labels = ["1", "2", "3", "…", "K′"]
# zaman ekseni oku (altta)
_arrow(ax_b, (0.25, 1.95), (8.0, 1.95), color=COL_SLATE_400, lw=1.6, scale=14)
ax_b.text(8.05, 1.78, "zaman →", ha="left", va="top",
fontsize=9.5, color=COL_SLATE_500, style="italic")
# ilk K′ öğrenci kutuları (slate — tümevarım hipotezi P(K′) bölgesi)
prev_centers = []
for i, lab in enumerate(labels):
cx = x0 + i * dx
prev_centers.append(cx)
_box(ax_b, cx, cy, cw, cw, lab, COL_BG, COL_PRIMARY, lw=1.6, fontsize=11)
# hipotez şeridi (ilk K′ öğrenciyi kapsayan kavis altı)
hyp_x0 = x0 - cw / 2 - 0.1
hyp_x1 = prev_centers[-1] + cw / 2 + 0.1
ax_b.plot([hyp_x0, hyp_x1], [3.62, 3.62], color=COL_SLATE_400, lw=1.4)
ax_b.plot([hyp_x0, hyp_x0], [3.5, 3.62], color=COL_SLATE_400, lw=1.4)
ax_b.plot([hyp_x1, hyp_x1], [3.5, 3.62], color=COL_SLATE_400, lw=1.4)
ax_b.text((hyp_x0 + hyp_x1) / 2, 3.85,
"tümevarım hipotezi: ilk K′ için P(K′) doğru",
ha="center", va="center", fontsize=9.5, color=COL_SLATE_500,
weight="bold")
# YENİ öğrenci K′+1 (amber vurgu)
new_cx = x0 + n_prev * dx + 0.30
_box(ax_b, new_cx, cy, cw, cw, "K′+1", COL_AMBER_100, COL_ACCENT, lw=2.6,
fontsize=10.0, tc=COL_AMBER_700)
ax_b.text(new_cx, cy + cw / 2 + 0.30, "yeni öğrenci",
ha="center", va="center", fontsize=9.0, color=COL_AMBER_700,
weight="bold")
# "ekle" oku K′ → K′+1
_arrow(ax_b, (prev_centers[-1] + cw / 2 + 0.05, cy),
(new_cx - cw / 2 - 0.05, cy), color=COL_ACCENT, lw=2.2, scale=15)
# --- Durum A / Durum B ayrımı (sağ blok) ---
case_cx = 10.85 # durum kutularının merkez x'i
case_w = 3.2
_box(ax_b, case_cx, 3.55, case_w, 0.95, "", COL_BG, COL_PRIMARY, lw=1.6)
ax_b.text(case_cx, 3.76, "Durum A", ha="center", va="center",
fontsize=10.0, color=COL_PRIMARY, weight="bold")
ax_b.text(case_cx, 3.36,
"eşleşme ilk K′ içinde\n→ P(K′) ile bulundu",
ha="center", va="center", fontsize=8.3, color=COL_SLATE_500)
_box(ax_b, case_cx, 2.25, case_w, 0.95, "", COL_AMBER_100, COL_ACCENT,
lw=2.2)
ax_b.text(case_cx, 2.46, "Durum B", ha="center", va="center",
fontsize=10.0, color=COL_AMBER_700, weight="bold")
ax_b.text(case_cx, 2.06,
"eşleşme K′+1'i içerir\n→ kayıtta zaten var",
ha="center", va="center", fontsize=8.3, color=COL_AMBER_700)
# durum kutularına ok (K′+1 öğrenciden)
_arrow(ax_b, (new_cx + cw / 2 + 0.05, cy + 0.18), (case_cx - case_w / 2 - 0.05, 3.55),
color=COL_SLATE_400, lw=1.5, scale=12)
_arrow(ax_b, (new_cx + cw / 2 + 0.05, cy - 0.18), (case_cx - case_w / 2 - 0.05, 2.25),
color=COL_ACCENT, lw=1.8, scale=12)
# alt çıkarım şeridi
ax_b.text(6.3, 0.85,
"Her iki durumda da ilk K′+1 öğrenci için doğru ⟹ P(K′+1) sağlanır",
ha="center", va="center", fontsize=10.0, color=COL_AMBER_700,
weight="bold",
bbox=dict(boxstyle="round,pad=0.45", fc=COL_AMBER_100,
ec=COL_ACCENT, lw=1.6))
fig.suptitle("Tümevarımla doğruluk ispatı — temel durum, adım ve durum ayrımı",
fontsize=13.5, color=COL_TEXT, weight="bold", y=0.99)
plt.tight_layout(rect=(0, 0, 1, 0.97))
plt.show()
```
## Verimlilik: Zamanı Değil, İşlemi Say {#sec-verimlilik}
Algoritma doğru; şimdi **verimli** olduğunu savunmalıyız. Verimlilik yalnızca "ne kadar hızlı çalışıyor" değil, "diğer olası yaklaşımlara *kıyasla* ne kadar hızlı" demektir.
> *"Efficiency just means not only how fast does this algorithm run, but how fast does it compare to other possible ways of approaching this problem?"* — Ku, 26:05
Akla ilk gelen ölçüm — kronometreyle süreyi ölçmek — işe yaramaz, çünkü süre **donanıma bağlıdır**: bir kol saati hesaplayıcısı ile IBM araştırma bilgisayarı aynı kodu çok farklı sürelerde çalıştırır. Makineyi denklemden çıkarmak için, her **temel işlemin** sabit zaman aldığını varsayar ve algoritmanın kaç temel işlem yaptığını sayarız.
> *"Instead, count fundamental operations."* — Ku, 27:57
**Önemli nüans — girdi boyutu (n):** Performans, girdinin *boyutuna* göre ölçülür. Ama $n$ her zaman "eleman sayısı" değildir: $n \times n$ bir dizi için girdi boyutu $n^2$'dir; bir çizge için genellikle düğüm sayısı artı kenar sayısıdır ($V + E$). Doğru $n$'i seçmek analizin ilk adımıdır.
## Asimptotik Gösterim: O, Ω, Θ {#sec-asimptotik}
İşlem sayısını bir fonksiyonla ifade ettikten sonra, onu **asimptotik gösterimle** sadeleştiririz — sabitleri ve düşük dereceli terimleri atıp, girdi büyüdükçe baskın olan büyüme mertebesine bakarız. Üç temel sınır vardır:
- **$O$ (Big-O)** — *üst sınır*: "çalışma süresi en fazla bu mertebede büyür."
- **$\Omega$ (Omega)** — *alt sınır*: "çalışma süresi en az bu mertebede büyür."
- **$\Theta$ (Theta)** — *sıkı sınır*: hem üstten hem alttan aynı mertebeyle sınırlı ($O$ ve $\Omega$ birlikte).
> *"We have big O notation, which corresponds to upper bounds. We will have omega, which corresponds to lower bounds. And we have theta, which corresponds to both."* — Ku, 30:54
Ku, asimptotik gösterimin formal tanımının ertesi gün **recitation'da** (problem oturumu) işleneceğini söyler — bu kurs, ders ile problem oturumunu bilinçli olarak ayırır. Bizim için pratik sezgi şudur: $\Theta$ "tam olarak bu hızda", $O$ "en kötü ihtimalle bu hızda" demektir.
## Yaygın Çalışma Süresi Fonksiyonları {#sec-buyume-fonksiyonlari}
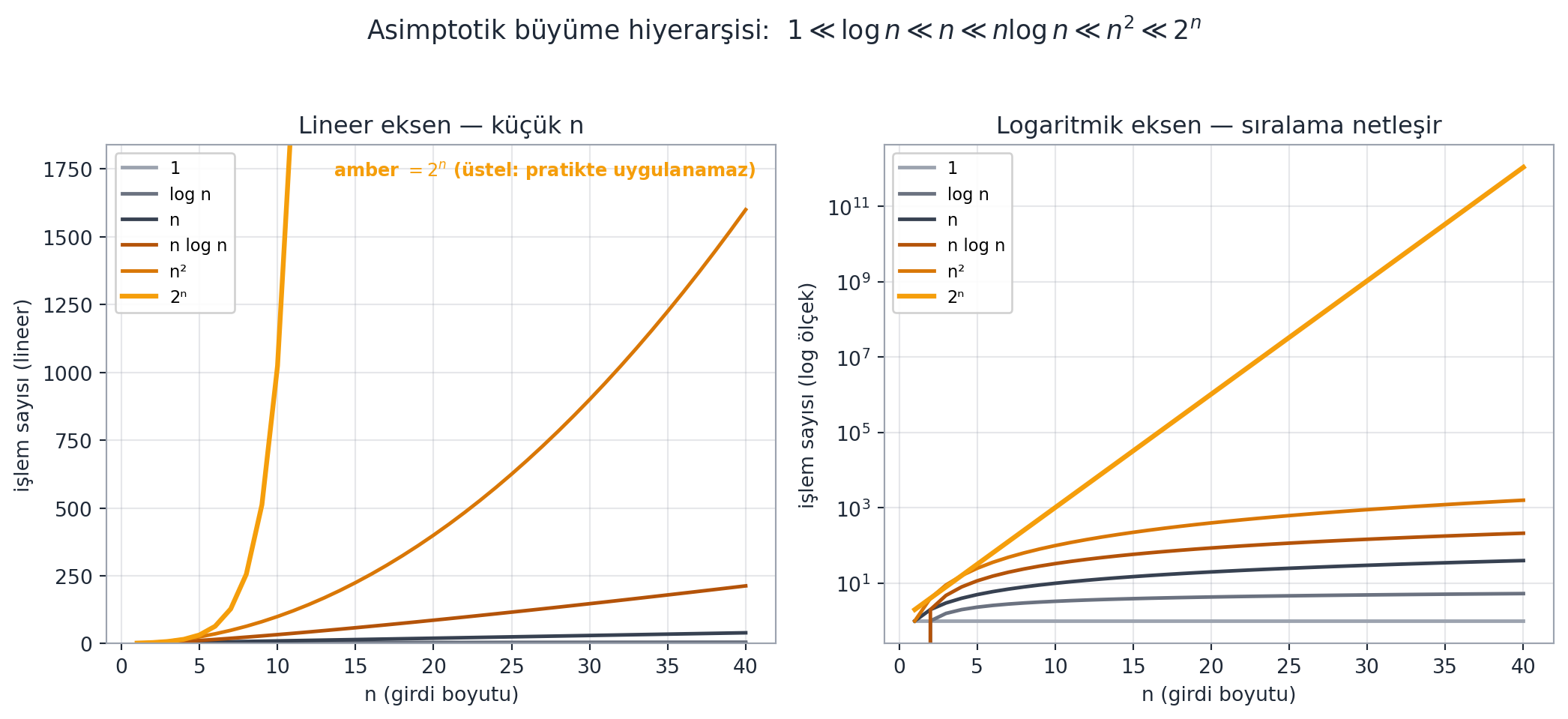
Ku, sık karşılaşılan büyüme mertebelerini tahtada en yavaştan en hızlıya sıralar:
$$1 \ll \log n \ll n \ll n \log n \ll n^2 \ll n^c \ll 2^n$$
Bu sıralamada **polinom** zamana kadar olan her şey ($n^c$, $c$ sabit) bu derste "verimli" sayılır. Üstel ($2^n$) ise pratikte kullanılamaz.
> *"this right here is what we mean by efficient, in this class, usually... generally what we mean is polynomial."* — Ku, 33:45
Ku, fonksiyonları $n = 1000$'e kadar çizdiğinde önemli bir sezgi verir: $\log$ eğrisi o kadar yavaş büyür ki neredeyse sabit gibi görünür; üstel ise neredeyse dik bir çizgi gibi yukarı fırlar.
> *"So log is almost just as good as constant."* — Ku, 35:52
> *"So this is crap. This is really good."* — Ku, 36:07
Burada "crap" (berbat) üstel için, "really good" (çok iyi) ise polinom/altı içindir. Builder sezgisi: bir algoritmanın $2^n$ mi yoksa $n^c$ mi olduğu, $n = 50$'de bile dünyaları ayırır — biri evrenin yaşından uzun sürer, diğeri milisaniyeler.
```{python}
#| label: fig-growth-hierarchy
#| fig-cap: "Asimptotik büyüme hiyerarşisi $1 \\ll \\log n \\ll n \\ll n\\log n \\ll n^2 \\ll 2^n$ iki panelde. **Sol (lineer eksen, $n \\le 40$):** $2^n$ daha $n\\approx 11$'de görünür tavanı aşıp patlar; polinomlar ($n$, $n\\log n$, $n^2$) tabanda okunur kalır. **Sağ (logaritmik y):** log ölçek tüm eğrileri birbirinden ayırır ve sıralamayı netleştirir — düz çizgiler farklı eğimlerle dizilir. Amber $= 2^n$ (üstel, pratikte uygulanamaz); slate→amber tonlaması yavaştan hızlıya iyi büyümeyi gösterir."
#| fig-width: 11
#| fig-height: 5
fig, (ax_linear, ax_log) = plt.subplots(1, 2, figsize=(11, 5))
draw_growth(ax_linear, ax_log, nmax=40)
# Üstel uyarısı: amber=2ⁿ (hızlı/kötü), slate tonları=iyi büyüme
fig.suptitle(
r"Asimptotik büyüme hiyerarşisi: $1 \ll \log n \ll n \ll n\log n \ll n^2 \ll 2^n$",
color=COL_TEXT, fontsize=13, y=0.99,
)
ax_linear.text(
0.97, 0.97,
"amber $= 2^n$ (üstel: pratikte uygulanamaz)",
transform=ax_linear.transAxes, ha="right", va="top",
fontsize=9, color=COL_ACCENT, weight="bold",
)
plt.tight_layout(rect=(0, 0, 1, 0.96))
plt.show()
```
::: {.callout-tip title="Builder Notu — Big-O ve Model Karmaşıklığı"}
Bu büyüme hiyerarşisi (@fig-growth-hierarchy) ML'de doğrudan karar verir:
- **İleriye → transformer dikkati (attention):** Self-attention, dizinin uzunluğu $n$'de $O(n^2)$'dir — her token her tokenla eşleşir. $n^2$ ile $n \log n$ arasındaki uçurum, uzun-bağlam modellerinin neden alt-karesel dikkat aradığını (linear attention; FlashAttention'ın bellek tasarrufu) açıklar.
- **İleriye → neden gradient descent:** Tüm parametre kombinasyonlarını denemek üstel ($2^n$) — imkânsız. Gradient descent her adımda yalnızca polinom iş yapar; "polinom = verimli" disiplini, kaba-kuvvet aramayı optimizasyonla değiştirmeyi zorunlu kılar.
- **Geriye → SVD rank kesimi (Phase 1 / 18.065):** Bir $m \times n$ matrisi rank-$k$'ya kesmek, çarpımı $O(mn \cdot \min(m,n))$'den $O(mnk)$'ya indirir. $k$'yı seçmek, "karşılayabildiğin büyüme mertebesi" için doğruluğu takas etmektir — bu dersin asimptotik disiplininin lineer cebire taşınmış hâli.
:::
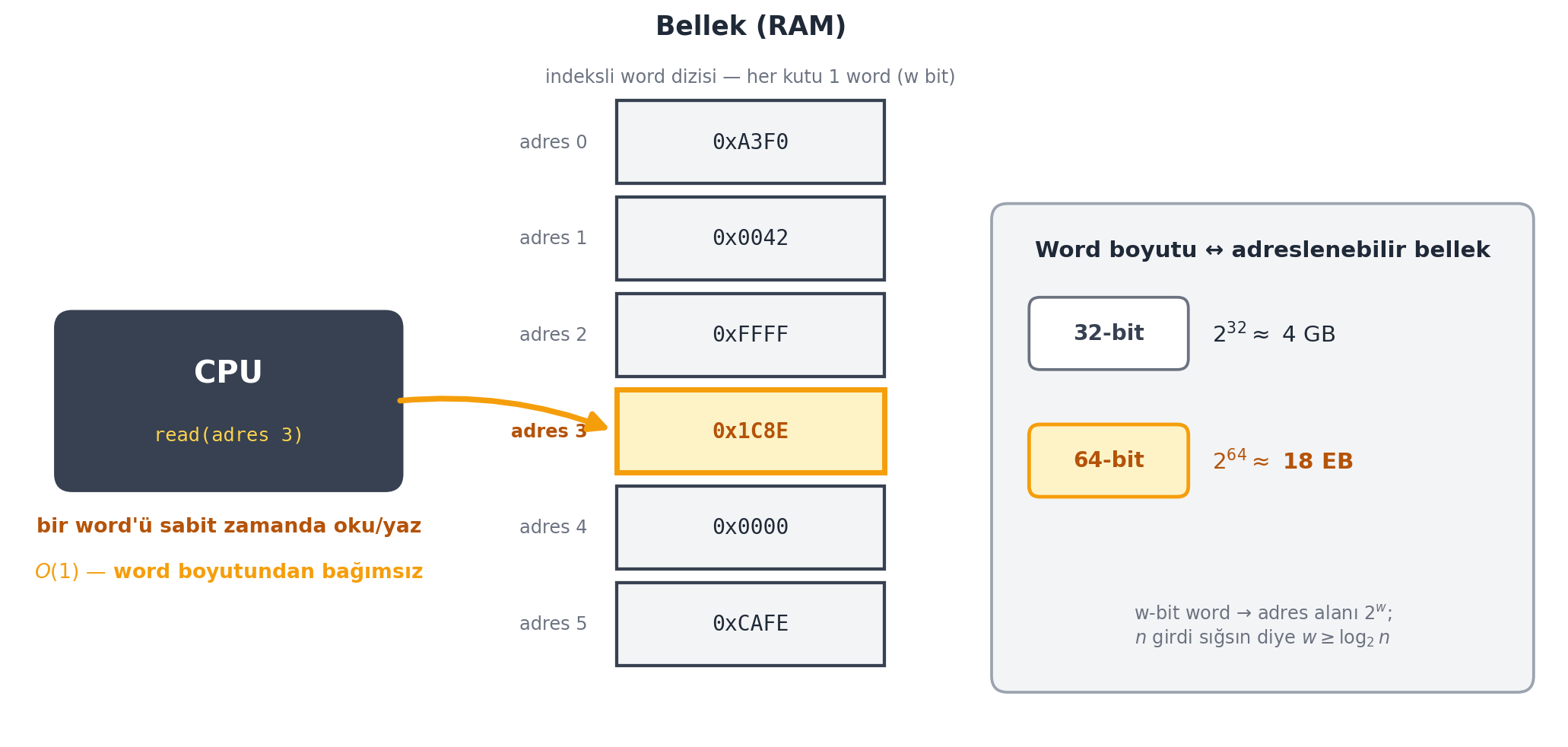
## Hesaplama Modeli: word RAM {#sec-word-ram}
Temel işlemleri "saymak" için, bilgisayarın *neyi* sabit zamanda yapabildiğini tanımlayan bir **hesaplama modeli** gerekir. 6.006'nın kullandığı model **word RAM**'dir (word = kelime, RAM = random access memory).
> *"a machine called a word RAM, which we use for its theoretical brevity."* — Ku, 37:21
İki kavram:
- **Random access memory (RAM):** Bellekteki herhangi bir konuma **sabit zamanda** rastgele erişebiliriz. Bellek, devasa bir bit dizisidir (1'ler ve 0'lar); CPU küçük bir miktar bilgiyi tutup işleyebilir ve bellekten istediği adresi getirip geri yazabilir.
> *"Random access memory-- it means that I can randomly access different places in memory in constant time."* — Ku, 37:44
- **Word (kelime):** CPU'nun bellekten bir seferde alıp üzerinde işlem yapabildiği sabit boyutlu bit öbeği. Bu, modelin "sabit zaman" varsayımının temel birimidir — bir sonraki bölümün konusu.
## Bellek ve Word Boyutu {#sec-bellek-word-d01}
Modern bilgisayarlar belleği **byte** (8 bitlik öbekler) düzeyinde adresler — her 8 bit için bir adres vardır. CPU bir adres verip o adresteki **word**'ü (kelimeyi) içeri alır, işler ve geri yazar.
> *"A word is how big of a chunk that the CPU can take in from memory at a time and operate on."* — Ku, 39:40
Word boyutu neden önemli? Çünkü bir adresi CPU'da saklayabilmek için adresin bir word'e sığması gerekir. Ku kendi gençliğindeki **32-bit** word'lerle bugünkü **64-bit** word'leri karşılaştırır:
- **32 bit** → $2^{32}$ farklı adres → yaklaşık 4 GB bellek sınırı (eski disklerin neden bölümlere ayrıldığının sebebi).
- **64 bit** → $2^{64}$ adres → yaklaşık 18 exabyte; pratikte sınırsız (Google'ın tüm sunucularındaki veri ≈ 10 exabyte mertebesinde).
```{python}
#| label: fig-word-ram
#| fig-cap: "Word RAM modeli şeması: bellek, indeksli bir **word** dizisidir (her kutu w bitlik bir word). CPU, herhangi bir adresteki bir word'ü **sabit zamanda** ($O(1)$, word boyutundan bağımsız) okur/yazar — amber okla vurgulanan `read(adres 3)` işlemi. Sağdaki yan not word boyutunu adreslenebilir bellekle bağlar: 32-bit word $2^{32} \\approx$ 4 GB, 64-bit word $2^{64} \\approx$ 18 EB adres alanı sunar. $n$ girdinin sığması için word $w \\geq \\log_2 n$ bit olmalıdır."
#| fig-width: 11
#| fig-height: 5.2
# ---- Word RAM şeması: bellek (adresli word kutuları) + CPU + sabit-zaman okuma ----
# DETERMİNİSTİK: tamamen statik girdi (seed yok). COL_*/FancyBboxPatch/FancyArrowPatch/plt
# gizli setup hücresinden (inline _viz) gelir.
fig, ax = plt.subplots(figsize=(11, 5.2))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
# Bellek = dikey word kutuları dizisi (yukarıdan aşağıya artan adres).
n_words = 6
cell_w, cell_h = 2.0, 0.62
mem_x = 4.7 # bellek sütununun sol-x'i
top_y = 4.30 # en üst word'ün alt kenarı
read_addr = 3 # CPU'nun sabit-zamanda okuduğu word adresi (0-tabanlı)
# Word içerikleri (örnek bit kalıpları — statik; "word = sabit bit" sezgisi).
word_contents = ["0xA3F0", "0x0042", "0xFFFF", "0x1C8E", "0x0000", "0xCAFE"]
# "Bellek" başlığı
ax.text(mem_x + cell_w / 2, top_y + cell_h + 0.55, "Bellek (RAM)",
ha="center", va="center", fontsize=13, weight="bold", color=COL_TEXT)
ax.text(mem_x + cell_w / 2, top_y + cell_h + 0.18,
"indeksli word dizisi — her kutu 1 word (w bit)",
ha="center", va="center", fontsize=9, color=COL_SLATE_500)
word_centers = []
for k in range(n_words):
y = top_y - k * (cell_h + 0.10)
hot = (k == read_addr)
box = FancyBboxPatch(
(mem_x, y), cell_w, cell_h,
boxstyle="square,pad=0.0",
fc=COL_AMBER_100 if hot else COL_BG,
ec=COL_ACCENT if hot else COL_PRIMARY,
linewidth=2.6 if hot else 1.6, zorder=2,
)
ax.add_patch(box)
cx, cy = mem_x + cell_w / 2, y + cell_h / 2
word_centers.append((cx, cy))
ax.text(cx, cy, word_contents[k], ha="center", va="center",
fontsize=10.5, family="monospace",
color=COL_AMBER_700 if hot else COL_TEXT,
weight="bold" if hot else "normal", zorder=4)
ax.text(mem_x - 0.22, cy, f"adres {k}", ha="right", va="center",
fontsize=9, color=COL_AMBER_700 if hot else COL_SLATE_500,
weight="bold" if hot else "normal", zorder=4)
# ---- CPU kutusu (solda) ----
cpu_x, cpu_y, cpu_w, cpu_h = 0.55, 2.05, 2.5, 1.25
cpu = FancyBboxPatch(
(cpu_x, cpu_y), cpu_w, cpu_h,
boxstyle="round,pad=0.04,rounding_size=0.12",
fc=COL_PRIMARY, ec=COL_PRIMARY, linewidth=2.0, zorder=3,
)
ax.add_patch(cpu)
ax.text(cpu_x + cpu_w / 2, cpu_y + cpu_h * 0.66, "CPU",
ha="center", va="center", fontsize=15, weight="bold",
color=COL_WHITE, zorder=4)
ax.text(cpu_x + cpu_w / 2, cpu_y + cpu_h * 0.30, "read(adres 3)",
ha="center", va="center", fontsize=9.5, family="monospace",
color="#fcd34d", zorder=4)
# ---- Sabit-zaman okuma oku: CPU → okunan word (amber) ----
cpu_right = (cpu_x + cpu_w, cpu_y + cpu_h / 2)
target = (mem_x - 0.02, word_centers[read_addr][1])
arrow = FancyArrowPatch(
cpu_right, target,
arrowstyle="-|>", mutation_scale=20,
color=COL_ACCENT, linewidth=2.8,
connectionstyle="arc3,rad=-0.12", zorder=5,
)
ax.add_patch(arrow)
# Ok etiketi: O(1) sabit-zaman (CPU'nun altındaki boşlukta)
lbl_x = cpu_x + cpu_w / 2
lbl_y = cpu_y - 0.55
ax.text(lbl_x, lbl_y + 0.24, "bir word'ü sabit zamanda oku/yaz",
ha="center", va="center", fontsize=10, weight="bold", color=COL_AMBER_700)
ax.text(lbl_x, lbl_y - 0.10, r"$O(1)$ — word boyutundan bağımsız",
ha="center", va="center", fontsize=10, weight="bold", color=COL_ACCENT)
# ---- Yan not: 32-bit vs 64-bit adres alanı ----
panel_x, panel_y, panel_w, panel_h = 7.55, 0.55, 3.95, 3.55
panel = FancyBboxPatch(
(panel_x, panel_y), panel_w, panel_h,
boxstyle="round,pad=0.05,rounding_size=0.12",
fc=COL_BG, ec=COL_SLATE_400, linewidth=1.4, zorder=1,
)
ax.add_patch(panel)
px = panel_x + 0.25
ax.text(panel_x + panel_w / 2, panel_y + panel_h - 0.30,
"Word boyutu ↔ adreslenebilir bellek",
ha="center", va="center", fontsize=11, weight="bold", color=COL_TEXT)
# 32-bit satırı
y32 = panel_y + panel_h - 0.95
chip32 = FancyBboxPatch(
(px, y32 - 0.22), 1.15, 0.50,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=COL_WHITE, ec=COL_SLATE_500, linewidth=1.4, zorder=2,
)
ax.add_patch(chip32)
ax.text(px + 0.575, y32 + 0.03, "32-bit", ha="center", va="center",
fontsize=10.5, weight="bold", color=COL_PRIMARY, zorder=3)
ax.text(px + 1.35, y32 + 0.03, r"$2^{32} \approx$ 4 GB",
ha="left", va="center", fontsize=11, color=COL_TEXT, zorder=3)
# 64-bit satırı (amber vurgulu — bugünkü standart)
y64 = y32 - 0.95
chip64 = FancyBboxPatch(
(px, y64 - 0.22), 1.15, 0.50,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=1.8, zorder=2,
)
ax.add_patch(chip64)
ax.text(px + 0.575, y64 + 0.03, "64-bit", ha="center", va="center",
fontsize=10.5, weight="bold", color=COL_AMBER_700, zorder=3)
ax.text(px + 1.35, y64 + 0.03, r"$2^{64} \approx$ 18 EB",
ha="left", va="center", fontsize=11, weight="bold", color=COL_AMBER_700, zorder=3)
# Alt not
ax.text(panel_x + panel_w / 2, panel_y + 0.45,
"w-bit word → adres alanı $2^w$;\n$n$ girdi sığsın diye $w \\geq \\log_2 n$",
ha="center", va="center", fontsize=9, color=COL_SLATE_500, zorder=3)
# Sınırlar
ax.set_xlim(0.2, 11.7)
ax.set_ylim(0.2, 5.3)
ax.set_aspect("equal")
ax.axis("off")
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — GPU'da O(1) Erişim ve Bellek Bandwidth"}
word RAM'in "her adrese sabit zamanda eriş" varsayımı, gerçek donanımda **kırılır** — ve bu kırılma ML performansının kalbidir:
- **İleriye → cache ve coalesced erişim:** Önbellek hiyerarşisi yüzünden *sıralı* (bitişik) erişim, *rastgele* erişimden kat kat hızlıdır. GPU'da iş parçacıkları bitişik adresleri okuduğunda erişim "coalesced" olur ve tam bant genişliği kullanılır; saçılmış (scatter/gather) erişim bant-genişliği darboğazına takılır.
- **İleriye → bellek-bağlı çekirdekler:** matmul ve attention gibi birçok ML çekirdeği işlem değil **bellek-bandwidth bağlıdır** (roofline modeli, aritmetik yoğunluk). "İşlem say" modeli bu trafiği eksik sayar — gerçek hız çoğu zaman taşınan byte miktarına bağlıdır.
- **Geriye → word = pointer boyutu:** 64-bit word, dev tensörleri adresleyebilmenin nedenidir; darboğaz adresleme değil, o adreslere veriyi *taşıma* hızıdır.
:::
## Temel İşlemler {#sec-temel-islemler}
word RAM modelinde CPU'nun **sabit zamanda** yapabildiği işlemler şunlardır:
- İki word'ü **karşılaştırma**.
- **Tam sayı aritmetiği**, **mantıksal işlemler**, **bit düzeyi işlemler** (sonuncusunu bu derste pek kullanmayız).
- Bir bellek adresinden bir word **okuma** ve **yazma**.
> *"I can either do integer arithmetic, logical operations, bitwise operations... And I can read and write from an address in memory, a word in constant time."* — Ku, 41:53
Kritik kısıt: CPU her seferinde yalnızca **sabit miktarda** bilgi (genelde iki word) üzerinde işlem yapar. Lineer miktarda veriyi ($n$ öğe) işlemek istiyorsak — örneğin hepsini okumak — bu **lineer zaman** $O(n)$ alır, çünkü her parçayı ayrı ayrı okumak zorundayız. Sabit zaman ile lineer zaman arasındaki bu ayrım, tüm algoritma analizinin tohumudur.
## Veri Yapıları: İlk Bakış {#sec-veri-yapilari}
Dersin ilk yarısı (ilk sekiz ders) **veri yapıları** üzerinedir: CPU gibi sabit miktarda değil, *büyük* miktarda veriyi saklayıp üzerinde verimli işlemler desteklemek. İlk örnek **statik dizidir** (static array).
> *"Python has a lot of really interesting data structures, like a list, and a set, and a dictionary... that are actually not in this model."* — Ku, 44:07
Bu cümle bu kursun en önemli uyarısıdır. Python'da `list`, `set`, `dict` bedava ve sihirli görünür — ama word RAM modelinde *yokturlar*. Aralarında çok sayıda kod katmanı vardır ve o arayüzün ne kadar zaman aldığı her zaman belli değildir.
::: {.callout-tip title="Builder Notu — Gizli Maliyet ve Sistem Tasarımı"}
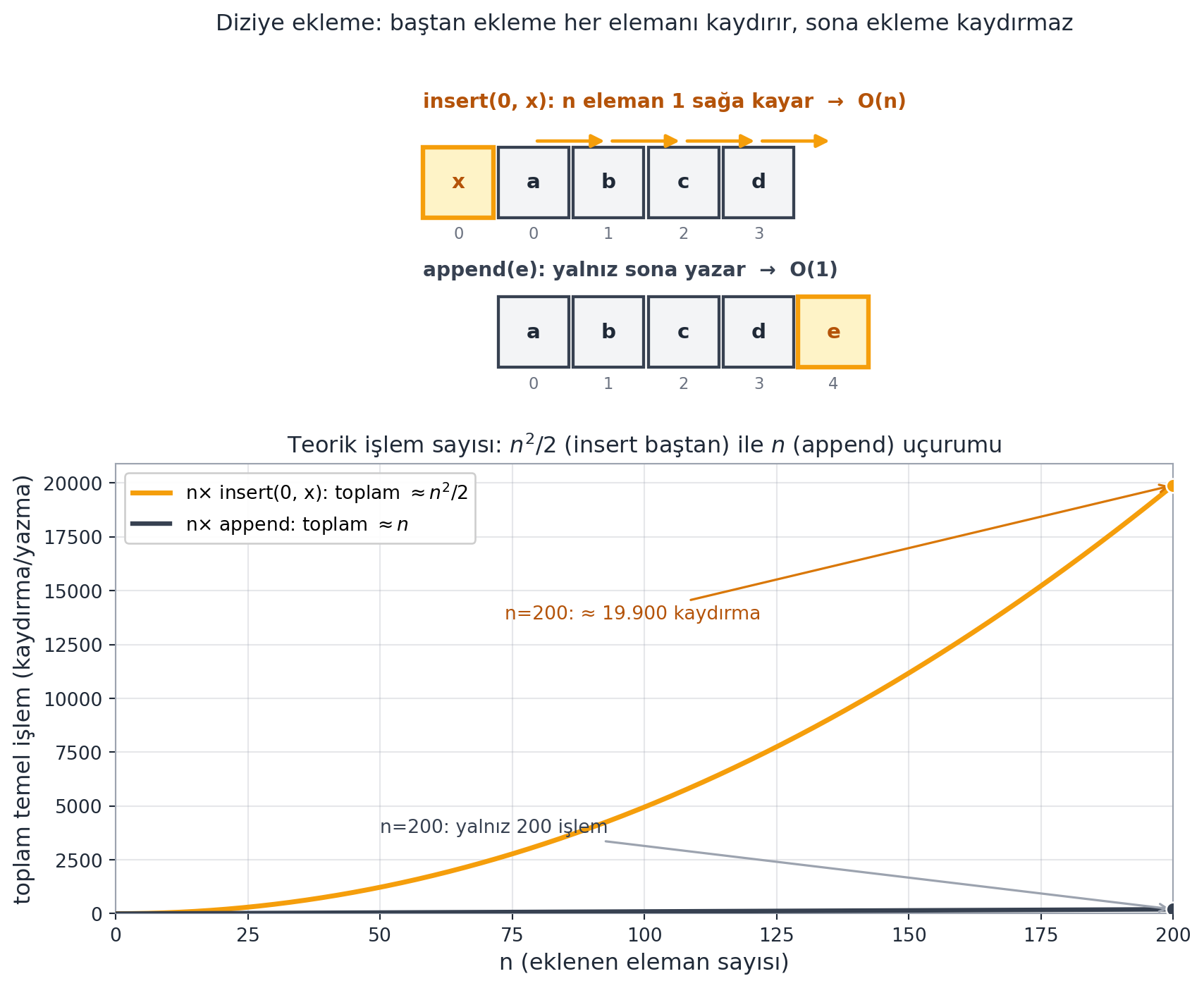
- **Geriye → Python (Phase 1):** `lst.insert(0, x)` bir satır görünür ama $O(n)$'dir (her elemanı kaydırır); `dict[key]` ortalama $O(1)$'dir ama bunun arkasında hashing vardır (Ders 4). Bu kurs o gizli maliyeti açar.
- **Ampirik doğrulama:** `time.perf_counter` ile farklı $n$ değerlerinde süre ölçüp asimptotik tahmini test edebilirsin — teori ile ölçümü buluşturmak builder disiplinidir.
- **İleriye → sistem tasarımı:** "hangi işlem sabit, hangisi lineer" ayrımı, bir veri yapısını (hash map mı, dizi mi, ağaç mı) seçerken verdiğin her kararın temelidir.
:::
```{python}
#| label: fig-cost-shift
#| fig-cap: "Python `list` gizli maliyeti: `insert(0, x)` baştan ekleme, mevcut tüm $n$ elemanı bir konum sağa kaydırır (amber oklar) → $O(n)$; `append` yalnız sona tek hücre yazar → $O(1)$. Alttaki teorik işlem-sayısı eğrisi DETERMİNİSTİKtir (zaman ölçümü değil): $n$ kez baştan ekleme toplam $\\approx n^2/2$ kaydırma yaparken, $n$ kez `append` toplam $\\approx n$ işlemde kalır. $n=200$'de uçurum ≈ 19.900'e karşı 200."
#| fig-width: 9
#| fig-height: 7.4
fig, (ax_top, ax_curve) = plt.subplots(
2, 1, figsize=(9, 7.4), gridspec_kw={"height_ratios": [1.0, 1.25]}
)
# === ÜST PANEL: dizi kaydırma şeması (insert(0,x) vs append) =================
ax_top.axis("off")
# Deterministik küçük dizi
base = ["a", "b", "c", "d"]
# Diziyi x0=1.5'ten başlat → sol konum yeni 'x' hücresine açık kalsın (overlap yok).
X0 = 1.5
# (1) insert(0,'x'): tüm n eleman bir sağa kayar (amber oklar)
draw_array(
ax_top, base, shift="right",
y=2.35, x0=X0, label_indices=True,
)
# Açılan 0. konuma yeni eleman 'x' (amber vurgulu hücre); diziden bir hücre solda.
xnew = X0 - 1.0
ax_top.add_patch(
FancyBboxPatch(
(xnew, 2.35), 0.94, 0.94, boxstyle="square,pad=0.0",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=2.4, zorder=3,
)
)
ax_top.text(xnew + 0.47, 2.35 + 0.47, "x", ha="center", va="center",
fontsize=11, color=COL_AMBER_700, weight="bold", zorder=4)
ax_top.text(xnew + 0.47, 2.35 - 0.22, "0", ha="center", va="center",
fontsize=8.5, color=COL_SLATE_500, zorder=4)
# açıklama: dizinin ÜSTÜNE (oklarla çakışmasın diye sola dayalı)
ax_top.text(
xnew, 2.35 + 1.55,
"insert(0, x): n eleman 1 sağa kayar → O(n)",
ha="left", va="center", fontsize=10.5, color=COL_AMBER_700, weight="bold",
)
# (2) append('e'): mevcut hücreler yerinde, sona TEK yeni hücre (amber vurgu)
draw_array(
ax_top, base, highlight=None,
y=0.35, x0=X0, label_indices=True,
)
# Sona tek yeni hücre 'e' (amber vurgulu)
xapp = X0 + len(base) * 1.0
ax_top.add_patch(
FancyBboxPatch(
(xapp, 0.35), 0.94, 0.94, boxstyle="square,pad=0.0",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=2.4, zorder=3,
)
)
ax_top.text(xapp + 0.47, 0.35 + 0.47, "e", ha="center", va="center",
fontsize=11, color=COL_AMBER_700, weight="bold", zorder=4)
ax_top.text(xapp + 0.47, 0.35 - 0.22, "4", ha="center", va="center",
fontsize=8.5, color=COL_SLATE_500, zorder=4)
ax_top.text(
xnew, 0.35 + 1.30,
"append(e): yalnız sona yazar → O(1)",
ha="left", va="center", fontsize=10.5, color=COL_PRIMARY, weight="bold",
)
ax_top.set_xlim(0.0, X0 + len(base) * 1.0 + 1.4)
ax_top.set_ylim(-0.2, 4.6)
ax_top.set_aspect("equal")
ax_top.set_title(
"Diziye ekleme: baştan ekleme her elemanı kaydırır, sona ekleme kaydırmaz",
color=COL_TEXT, fontsize=12, pad=10,
)
# === ALT PANEL: teorik işlem-sayısı eğrisi (DETERMİNİSTİK, timing DEĞİL) ======
apply_style(ax_curve)
ns = list(range(0, 201))
# n kez insert(0,x): k. ekleme k eleman kaydırır → toplam ≈ n(n-1)/2 ≈ n²/2
insert_ops = [k * (k - 1) / 2.0 for k in ns]
# n kez append: her biri amortize O(1) → toplam ≈ n
append_ops = [float(k) for k in ns]
ax_curve.plot(ns, insert_ops, color=COL_ACCENT, linewidth=2.6,
label=r"n× insert(0, x): toplam $\approx n^2/2$", zorder=3)
ax_curve.plot(ns, append_ops, color=COL_PRIMARY, linewidth=2.4,
label=r"n× append: toplam $\approx n$", zorder=3)
# n=200'de ayrımı anotla
n_end = 200
ax_curve.scatter([n_end], [insert_ops[-1]], s=55, color=COL_ACCENT,
edgecolor=COL_WHITE, linewidth=1.0, zorder=4)
ax_curve.scatter([n_end], [append_ops[-1]], s=55, color=COL_PRIMARY,
edgecolor=COL_WHITE, linewidth=1.0, zorder=4)
ax_curve.annotate(
f"n={n_end}: ≈ {int(insert_ops[-1]):,} kaydırma".replace(",", "."),
xy=(n_end, insert_ops[-1]), xytext=(n_end - 78, insert_ops[-1] * 0.70),
color=COL_AMBER_700, fontsize=10, va="center", ha="right",
arrowprops=dict(arrowstyle="->", color=COL_AMBER_600, lw=1.2),
)
ax_curve.annotate(
f"n={n_end}: yalnız {n_end} işlem",
xy=(n_end, append_ops[-1]), xytext=(n_end - 150, insert_ops[-1] * 0.20),
color=COL_PRIMARY, fontsize=10, va="center",
arrowprops=dict(arrowstyle="->", color=COL_SLATE_400, lw=1.2),
)
ax_curve.set_xlabel("n (eklenen eleman sayısı)", fontsize=12)
ax_curve.set_ylabel("toplam temel işlem (kaydırma/yazma)", fontsize=12)
ax_curve.set_title(
"Teorik işlem sayısı: $n^2/2$ (insert baştan) ile $n$ (append) uçurumu",
color=COL_TEXT, fontsize=12,
)
ax_curve.set_xlim(0, n_end)
ax_curve.set_ylim(bottom=0)
ax_curve.legend(loc="upper left", fontsize=10, framealpha=0.95)
plt.tight_layout()
plt.show()
```
Egzersiz 4'teki ölçüm deneyi bu uçurumu *ampirik olarak* doğrular — aşağıdaki Egzersizler bölümünde kodu var.
## Bu Dersin Özeti {#sec-ozet-d01}
1. **Problem**, girdiler ile çıktılar arasında bir ikili ilişkidir; **algoritma**, o ilişkiyi hesaplayan bir fonksiyon/prosedürdür.
2. Bir algoritmanın doğruluğu, keyfi büyük girdiler için **tümevarımla** ispatlanır (hipotez + temel durum + tümevarım adımı).
3. Verimlilik, saniyeyle değil, **temel işlem sayısıyla** ölçülür — donanımdan bağımsız olmak için.
4. **Asimptotik gösterim**: $O$ (üst sınır), $\Omega$ (alt sınır), $\Theta$ (sıkı sınır).
5. Büyüme hiyerarşisi: $1 \ll \log n \ll n \ll n \log n \ll n^2 \ll 2^n$. Polinom ve altı "verimli", üstel kullanılamaz.
6. **word RAM** modeli: belleğe sabit-zaman rastgele erişim; bir word, CPU'nun bir kerede işlediği bit öbeği.
7. Python'ın `list`/`dict`/`set` yapıları word RAM modelinde doğrudan yoktur — bedava görünen işlemlerin gizli zaman maliyeti vardır.
::: {.callout-important title="Tek Bir Cümle"}
Bir algoritmayı anlamak, onun *ne* yaptığını değil; **neden doğru** ve **ne kadar hızlı** olduğunu — ve bunu başkasına nasıl kanıtlayacağını bilmektir.
:::
## Kontrol Soruları {#sec-sorular-d01}
::: {.callout-note collapse="true" title="Soru 1: Problem ile algoritma arasındaki fark nedir?"}
**Cevap:**
Bir **problem**, girdiler ile çıktılar arasında bir ikili ilişkidir — *ne* hesaplanacağını söyler (hangi girdiye hangi çıktı doğru). Bir **algoritma** ise o ilişkiyi gerçekleştiren bir prosedürdür — *nasıl* hesaplanacağını söyler. Problem çıktıları bilir (ilişkiyi tanımlar); algoritma çıktıları üretir. Matematiksel olarak algoritma, her girdiyi tek bir (doğru) çıktıya eşleyen bir fonksiyondur.
:::
::: {.callout-note collapse="true" title="Soru 2: n = 1.000.000 girdi için O(n) bir algoritma mı yoksa O(n²) bir algoritma mı tercih edilir? Neden?"}
**Cevap:**
$O(n)$ tercih edilir. $n = 10^6$ için $O(n) \approx 10^6$ işlem (milisaniyeler), $O(n^2) \approx 10^{12}$ işlem (mertebe olarak dakikalar–saatler) demektir. Asimptotik fark, $n$ büyüdükçe pratik bir uçuruma dönüşür. Ku'nun deyişiyle: polinom "verimli", ama düşük dereceli polinom her zaman daha iyidir.
:::
::: {.callout-note collapse="true" title="Soru 3: Doğum günü algoritmasının tümevarım ispatında temel durum neden K = 1 değil de K = 0 seçilir?"}
**Cevap:**
$K = 0$, ispatın *en kolay* ve *en sağlam* tabanıdır: hiç öğrenci görüşülmediğinde hiçbir iş yapılmamıştır ve ilk 0 öğrenci bir eşleşme içeremez, dolayısıyla hipotez **boş-doğru** (vacuously true) olarak sağlanır. $K = 1$ veya $K = 2$ de işe yarar ama gereksiz yere durum kontrolü gerektirir. Daha zayıf (daha kolay) temel durum, daha temiz bir ispattır.
:::
::: {.callout-note collapse="true" title="Soru 4: Python'da lst.insert(0, x) neden sabit zaman O(1) değildir? Bu, word RAM modeliyle nasıl ilişkilidir?"}
**Cevap:**
`lst.insert(0, x)`, listenin başına ekleme yapar; bunun için mevcut tüm $n$ elemanı bir konum sağa kaydırmak gerekir → $O(n)$. Tek satırlık "bedava" görünen bu işlem, word RAM modelinde lineer sayıda word okuma/yazma anlamına gelir. Ku'nun uyarısı tam buna işaret eder: Python yapıları modelde doğrudan yoktur; gerçek maliyeti görmek için arayüzün altına bakmak gerekir.
:::
## Egzersizler {#sec-egzersizler-d01}
**Egzersiz 1.** Şu problemi girdi-çıktı ilişkisi olarak tanımla: "bir tam sayı dizisinde en büyük elemanı bul." Girdi kümesi, çıktı kümesi ve doğruluğu kontrol eden yüklemi (predicate) yaz.
**Egzersiz 2.** Doğum günü algoritmasının çalışma süresini analiz et. "Kayıtta var mı?" kontrolü her seferinde tüm kaydı lineer taramayla yapılırsa toplam süre ne olur? Bu kontrol $O(1)$ olsaydı (örneğin hash ile) toplam süre ne olurdu?
**Egzersiz 3.** Tümevarım adımındaki "Durum B"yi kendi cümlelerinle yeniden ifade et: ilk K′+1 öğrenci içinde bir eşleşme varsa, bu eşleşme neden *zorunlu olarak* K′+1'inci öğrenciyi içerir?
**Egzersiz 4.** Python'da aşağıdaki deneyi çalıştır; baştan ekleme (`insert(0, x)`) ile sona ekleme (`append`) sürelerini farklı $n$ değerlerinde karşılaştır ve asimptotik farkı gözlemle:
```python
import time
def measure(n):
a, b = [], []
t0 = time.perf_counter()
for i in range(n):
a.insert(0, i) # bas: her ekleme O(n) -> toplam O(n^2)
t1 = time.perf_counter()
for i in range(n):
b.append(i) # son: amortize O(1) -> toplam O(n)
t2 = time.perf_counter()
print(n, "insert(0):", t1 - t0, "append:", t2 - t1)
for n in (1000, 2000, 4000, 8000):
measure(n)
```
**Egzersiz 5.** Statik bir dizide "i'inci elemana eriş" işlemi neden $O(1)$'dir (word RAM modelinde)? Bu, bir bağlı listede (linked list) neden $O(1)$ *değildir*? Ders 2'nin dinamik dizi konusuna bir köprü kur.
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d01}
**Ders 2 (L2): Veri Yapıları ve Dinamik Diziler**
Erik Demaine ile dersin ilk veri yapısı bölümüne giriyoruz. Statik dizinin sınırını (sabit boyut) aşan **dinamik dizi** (Python `list`'in altında yatan yapı) ve **bağlı liste** ele alınır; sona eklemenin neden **amortize $O(1)$** olduğunu göreceğiz — bu dersteki "gizli maliyet" sorusunun ilk cevabı.
::: {.callout-warning title="Ders 2 Öncesi Yapılacak"}
- Bu dersin egzersizlerini, özellikle Egzersiz 4'ü (Python ölçümü) çöz.
- `dizi (sequence)` arayüzünü düşün: hangi işlemler $O(1)$, hangileri $O(n)$ olmalı?
- Ana cümleyi tekrar oku: *"Bir algoritmayı anlamak, onun ne yaptığını değil; neden doğru ve ne kadar hızlı olduğunu bilmektir."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet-d01}
| Kavram | Tanım | Sayfada |
|--------|-------|---------|
| **Problem** | Girdi-çıktı ikili ilişkisi (binary relation) | Böl. 2 |
| **Algoritma** | İlişkiyi hesaplayan prosedür/fonksiyon | Böl. 3 |
| **Tümevarımla doğruluk** | Hipotez + temel durum ($K=0$) + tümevarım adımı | Böl. 5 |
| **Verimlilik** | Temel işlem sayısı (saniye değil) | Böl. 6 |
| **$O$ / $\Omega$ / $\Theta$** | Üst / alt / sıkı asimptotik sınır | Böl. 7 |
| **Büyüme hiyerarşisi** | $1 \ll \log n \ll n \ll n \log n \ll n^2 \ll 2^n$ | Böl. 8 |
| **Polinom = verimli** | $n^c$ sınırı; üstel ($2^n$) kullanılamaz | Böl. 8 |
| **word RAM** | Sabit-zaman rastgele erişimli hesaplama modeli | Böl. 9 |
| **Word** | CPU'nun bir kerede işlediği bit öbeği | Böl. 10 |
| **Temel işlemler** | Aritmetik, mantık, oku/yaz; her biri $O(1)$ | Böl. 11 |
| **Statik dizi** | İlk veri yapısı; Python list/dict modelde yok | Böl. 12 |
## Builder ve OMSCS Bağlantıları {#sec-ml-baglantilar-d01}
::: {.callout-tip title="6 köprü"}
Bu ders, ileri algoritma ve sistem mühendisliğinin temel dilini kurar — köprülerin özeti:
1. **Asimptotik sezgi** → kompetitif programlama: "$n = 10^5$ için $O(n^2)$ geçer mi?" sorusunun cevabı bu derste oturur.
2. **word RAM modeli** → sistem tasarımı: hangi işlemin gerçekten sabit zaman olduğunu bilmek, veri yapısı seçiminin temelidir (hash map, dizi, ağaç).
3. **Tümevarımla doğruluk** → OMSCS CS 6515: graduate algoritma derslerinde her algoritma ispatla sunulur; bu dersin disiplini oraya taşınır.
4. **İndirgeme (reduction) sezgisi** → "bilinen bir probleme indirge" yaklaşımı, hem 6.006'nın hem de ileri derslerin çekirdek stratejisidir.
5. **Python gizli maliyet** → üretim kodu: `list.insert(0, x)` veya `x in list` gibi "masum" çağrıların asimptotik bedelini görmek, ölçeklenen sistemlerde performans hatalarını önler.
6. **`time.perf_counter` ile ampirik doğrulama** → teori ile ölçümü buluşturmak; bir builder, asimptotik tahmini deneyle test eder.
:::
---
::: {.callout-important title="Tek bir şey alıp gideceksen"}
Bir algoritma yazmak yarısıdır; diğer yarısı onun *doğru* ve *verimli* olduğunu — başkasını ikna edecek netlikte — kanıtlamaktır. 6.006 boyunca her ders bu iki yarıyı birlikte öğretir.
:::