---
title: "Kümeler ve Sıralama"
subtitle: "Küme arayüzü, sırasız/sıralı dizi tradeoff'u, permutation/selection/insertion/merge sort ve substitution analizi"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Solomon'un videosu:** [YouTube — Lecture 3: Sets and Sorting](https://www.youtube.com/watch?v=oS9aPzUNG-s) (≈53 dk)
- **OCW sayfası:** [MIT 6.006 Lecture 3: Sets and Sorting](https://ocw.mit.edu/courses/6-006-introduction-to-algorithms-spring-2020/resources/lecture-3-sets-and-sorting/)
- **Seri:** MIT 6.006 — Introduction to Algorithms (Spring 2020) — Ders 4 (L3)
- **Hoca:** Justin Solomon (Jason Ku, Erik Demaine)
- **Okuma süresi:** ≈25 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste-d04}
Ders 2 **dizi (sequence)** arayüzünü çözdü — öğeleri *sıraya* göre tutmak. Bu ders ikinci temel arayüze geçer: **küme (set)** — öğeleri *anahtarına* göre tutmak. Justin Solomon, set'i çözmenin doğal yolunun **sıralama** olduğunu gösterir ve dersin yarısını sıralama algoritmalarına ayırır.
Üç temel kavram bu derste yan yana gelir:
1. **Küme arayüzü** — anahtarla (key) erişilen bir koleksiyon: find, insert, delete, find_min/max.
2. **Sırasız vs sıralı dizi tradeoff'u** — sıralı dizide arama $O(\log n)$ ama sıralamanın kendisi $O(n \log n)$ maliyetlidir.
3. **Sıralama algoritmaları** — permutation, selection, insertion ve merge sort; özyineleme + substitution ile çalışma süresi analizi.
> *"there's an object called an interface, which is just a program specification."* — Justin, 1:42
```{mermaid}
%%| label: fig-concept-map
%%| echo: false
%%| fig-cap: "Ders 4'ün kavram haritası: küme arayüzünden iki dizi gerçekleştirimine (sırasız dizi → find O(n) / sıralı dizi → find O(log n)), oradan sıralama problemine ve dört sıralama algoritmasına (permutation Ω(n!·n), selection Θ(n²), insertion Θ(n²), merge Θ(n log n))."
flowchart TD
A["Ders 4: Kümeler ve Sıralama"] --> B["Küme (set) arayüzü<br/>anahtarla erişim"]
A --> S["Sıralama problemi<br/>girdi A → sıralı B"]
B --> U["Sırasız Dizi<br/>find O(n)<br/>lineer tarama"]
B --> O["Sıralı Dizi<br/>find O(log n) ikili arama<br/>find_min/max O(1)"]
O -->|kurma maliyeti| S
S --> P["Permutation sort<br/>Ω(n!·n) · kaba kuvvet"]
S --> SE["Selection sort<br/>Θ(n²) · en büyüğü sona"]
S --> IN["Insertion sort<br/>Θ(n²) · yerine kaydır"]
S --> ME["Merge sort<br/>Θ(n log n) · böl-yönet"]
ME --> R["T(n)=2T(n/2)+Θ(n)<br/>two-finger merge"]
classDef root fill:#fef3c7,stroke:#b45309,stroke-width:3px,color:#1f2937
classDef branch fill:#f3f4f6,stroke:#374151,stroke-width:2px,color:#1f2937
classDef leaf fill:#ffffff,stroke:#9ca3af,stroke-width:1px,color:#1f2937
class A root
class B,S,O branch
class U,P,SE,IN,ME,R leaf
```
::: {.callout-tip title="Builder Notu — Set Arayüzü ve Python dict/Veritabanı"}
Bu dersin **küme (set)** arayüzü, her veri katmanının altında yatan "anahtarla eriş" desenidir — Python'dan veritabanlarına:
- **Geriye → Python (Phase 1):** Python `set`/`dict` tam da bu set arayüzünün gerçekleştirimidir; Solomon "bu çirkin detayları sizin için hallederler" der. `key in d` ortalama $O(1)$ görünür, ama o sabit zamanın *nasıl* elde edildiği (Ders 4 / Hashing) burada başlayan sorudur.
- **Geriye → Calculus (Phase 1):** $n^2$ ile $n \log n$ büyüme farkı — bir milyar öğede biri saatler, diğeri saniyeler. Asimptotik mertebeleri karşılaştırma disiplini doğrudan fonksiyon büyümesi sezgisidir.
- **İleriye → veritabanı/arama:** sıralı/indeksli veri, ikili aramayla $O(\log n)$ sorgu; her veritabanı indeksinin (B-tree) temeli.
- **İleriye → OMSCS / böl-yönet:** merge sort, "böl ve yönet + substitution" kalıbının ilk örneği; CS 6515'te (Graduate Algorithms) her yerde.
Tek cümle: *Bir kümeyi sıralı tutmak, aramayı $O(\log n)$'e indirir — ama bu hızın bedeli, baştaki $O(n \log n)$'lik sıralamadır.*
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — 6.006 Ders 4 (L3) motoru (_engine.py) + Slate+Amber viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri bu hücrede
# tanımlanan prefix_max / selection_* / merge_* / binary_search* + draw_* + COL_*
# + _cells_row'u IMPORT ETMEDEN kullanır. Notion'daki öğretim içeriği (görünür
# pseudocode / display ```python bloklar) bu motorun tarif seviyesidir; burada
# tam, deterministik, test edilmiş sürüm yaşar.
#
# NOT: matplotlib.use("Agg") ÇAĞRILMAZ — Quarto'nun inline figür-yakalama
# backend'ini ezer (plt.show() 0 figür üretir; brief §2/§11). Standalone testte
# savefig kullanılır; Quarto render'da jupyter inline backend'i ayarlar.
# ============================================================================
import math
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
import networkx as nx
# ---------------------------------------------------------------------------
# _engine.py — Ders 4 algoritma motoru (DETERMİNİSTİK + TEST EDİLEBİLİR)
# Solomon §5/§8-10 anlatımına sadık; sıralamalar Notion'daki özyinelemeli
# pseudocode'a uygun, dış API saf (yeni sıralı liste döndürür).
# ---------------------------------------------------------------------------
def prefix_max(A, i):
"""A[0..i] aralığındaki en büyük öğenin INDEKSİNİ döndürür (Solomon §8).
Solomon'un "derin gözlemi": 0..i aralığındaki en büyük öğe ya tam i'dedir ya da
i'den önceki bir indekstedir → tam tümevarım hipotezi. S(n)=S(n−1)+Θ(1)=Θ(n).
"""
if i == 0:
return 0
j = prefix_max(A, i - 1) # 0..i-1'in en büyüğü (tümevarım hipotezi)
if A[i] > A[j]:
return i
return j
def selection_sort(A):
"""Seçmeli sıralama (Solomon §8): en büyüğü seç → sona koy → solu özyinele. Θ(n²).
i = n−1'den başla; prefix_max(A, i) ile 0..i'nin en büyüğünü bul, indeks i'ye swap
et, sonra 0..i−1'i özyinelemeli sırala. Kopya üstünde çalışır (saf API).
T(n)=T(n−1)+Θ(n) → T(n)=Θ(n²).
"""
B = list(A) # dış girdiyi bozma (saf API)
def _rec(i):
if i > 0:
j = prefix_max(B, i) # 0..i'nin en büyüğü
B[i], B[j] = B[j], B[i] # en büyüğü sona koy
_rec(i - 1) # solu (0..i−1) sırala
if len(B) > 0:
_rec(len(B) - 1)
return B
def selection_trace(A):
"""fig-selection-trace için seçmeli sıralamanın adım-adım izi (prefix_max + swap).
Her dış adımda (i = n−1, ..., 1): swap'tan ÖNCEKİ dizi, prefix_max sonucu (max_idx),
swap çifti ve swap SONRASI dizi. Sıralı "kuyruk" (i+1..n−1) her adımda büyür.
"""
B = list(A)
steps = []
n = len(B)
for i in range(n - 1, 0, -1):
before = list(B)
j = prefix_max(B, i)
B[i], B[j] = B[j], B[i]
steps.append({
"i": i,
"before": before,
"max_idx": j,
"swap": (i, j),
"after": list(B),
"sorted_tail": n - i,
})
return steps
def insertion_sort(A):
"""Eklemeli sıralama (Solomon §9): solu sırala → i'inci öğeyi yerine kaydır. Θ(n²).
Seçmeli sıralamanın "tersi": önce 0..i−1'i özyinelemeli sırala, sonra A[i]'yi sıralı
sol kısma kaydırarak (swap zinciri) yerine yerleştir. T(n)=T(n−1)+O(n) → Θ(n²).
"""
B = list(A)
def _rec(i):
if i > 0:
_rec(i - 1) # önce 0..i−1'i sırala
k = i
while k > 0 and B[k - 1] > B[k]:
B[k - 1], B[k] = B[k], B[k - 1]
k -= 1
if len(B) > 0:
_rec(len(B) - 1)
return B
def merge(left, right):
"""İki sıralı listeyi two-finger tekniğiyle Θ(n)'de birleştirir (Solomon §10).
Her listenin BAŞINA birer parmak (indeks) koy; küçük olanı sonuca al, o parmağı
kaydır. İki liste zaten sıralı olduğundan her öğeye TAM BİR KEZ dokunulur → lineer.
Kararlı (stable): eşitlikte sol öğe önce.
"""
out = []
i, j = 0, 0
nl, nr = len(left), len(right)
while i < nl and j < nr:
if left[i] <= right[j]: # eşitlikte sol önce → kararlı
out.append(left[i])
i += 1
else:
out.append(right[j])
j += 1
if i < nl:
out.extend(left[i:])
if j < nr:
out.extend(right[j:])
return out
def merge_sort(A):
"""Birleştirmeli sıralama (Solomon §10): böl-yönet + two-finger merge. Θ(n log n).
Diziyi ortadan ikiye böl, her yarıyı özyinelemeli sırala, two-finger merge ile
birleştir. T(n)=2T(n/2)+Θ(n) → T(n)=Θ(n log n).
"""
n = len(A)
if n <= 1:
return list(A)
c = n // 2 # orta (center)
left = merge_sort(A[:c]) # solu sırala
right = merge_sort(A[c:]) # sağı sırala
return merge(left, right) # iki sıralı yarıyı birleştir (two-finger)
def merge_sort_tree(A):
"""fig-merge-tree için böl-yönet özyineleme ağacının yapısını döndürür (İMZA figür).
merge_sort'un çağrı ağacını açık veri yapısı olarak üretir: her düğüm bir aralık
([lo,hi)) + o aralığın sıralı sonucu; yapraklar tek öğe, iç düğümler two-finger
merge. Ağaç derinliği = ⌈log₂ n⌉; seviye sayısı = ⌈log₂ n⌉+1.
"""
def _build(lo, hi, depth):
sub = A[lo:hi]
if hi - lo <= 1:
return {
"lo": lo, "hi": hi,
"values": list(sub), "input": list(sub),
"is_leaf": True, "left": None, "right": None, "depth": depth,
}
c = (lo + hi) // 2
left = _build(lo, c, depth + 1)
right = _build(c, hi, depth + 1)
return {
"lo": lo, "hi": hi,
"values": merge(left["values"], right["values"]),
"input": list(sub),
"is_leaf": False, "left": left, "right": right, "depth": depth,
}
if len(A) == 0:
return {
"lo": 0, "hi": 0, "values": [], "input": [],
"is_leaf": True, "left": None, "right": None, "depth": 0,
}
return _build(0, len(A), 0)
def binary_search(A, k):
"""Sıralı dizide ikili arama (Solomon §5): anahtarı k olan öğenin indeksi. O(log n).
A SIRALI varsayılır. Arama aralığı [lo, hi); her adım ortayı (mid) inceler ve aralığı
YARIYA böler. Bulursa mid, yoksa −1.
"""
lo, hi = 0, len(A)
while lo < hi:
mid = (lo + hi) // 2 # aralığın ortası
if A[mid] == k:
return mid
elif A[mid] < k:
lo = mid + 1 # sağ yarıya in
else:
hi = mid # sol yarıya in
return -1
def binary_search_trace(A, k):
"""fig-binary-search için ikili aramanın yarıya-bölme adım izi + adım sayacı.
Her adımda [lo, hi) aralığını, ortayı (mid) ve kararı (found / go_right / go_left)
kaydeder. Adım sayısı = mid inceleme sayısı ≤ ⌈log₂ n⌉+1.
"""
lo, hi = 0, len(A)
steps = []
while lo < hi:
mid = (lo + hi) // 2
if A[mid] == k:
decision = "found"
elif A[mid] < k:
decision = "go_right"
else:
decision = "go_left"
steps.append({
"lo": lo, "hi": hi, "mid": mid,
"value": A[mid], "decision": decision,
})
if decision == "found":
return {"steps": steps, "found": mid, "count": len(steps)}
elif decision == "go_right":
lo = mid + 1
else:
hi = mid
return {"steps": steps, "found": -1, "count": len(steps)}
def recurrence_levels_selection(n):
"""Selection yineleme ağacının seviye sayısı = n (T(n)=T(n−1)+Θ(n))."""
return n
def recurrence_levels_merge(n):
"""Merge yineleme ağacının seviye sayısı = ⌈log₂ n⌉+1 (T(n)=2T(n/2)+Θ(n))."""
if n <= 1:
return 1
return math.ceil(math.log2(n)) + 1
# ---------------------------------------------------------------------------
# _viz.py — Slate + Amber stil sabitleri (HEX birebir brief §1/§8)
# ---------------------------------------------------------------------------
COL_PRIMARY = "#374151" # slate-700 — birincil çizgi/çerçeve
COL_ACCENT = "#f59e0b" # amber-500 — vurgu (hızlı/kötü büyüme, aktif öğe)
COL_TEXT = "#1f2937" # slate-800 — metin
COL_BG = "#f3f4f6" # slate-100 — arka plan / callout / kutu dolgusu
# Türev amber tonları
COL_AMBER_700 = "#b45309" # bağlantı/okunur kontrast
COL_AMBER_600 = "#d97706" # koyu amber
COL_AMBER_300 = "#fcd34d" # açık amber
COL_AMBER_100 = "#fef3c7" # en açık amber (dolgu)
# Türev slate tonları
COL_SLATE_500 = "#6b7280" # orta slate — ikincil metin
COL_SLATE_400 = "#9ca3af" # soluk slate — pasif kenar / izgara
COL_WHITE = "#ffffff"
def apply_style(ax):
"""Bir eksene tutarlı Slate+Amber görünümü uygular (curve figürleri için)."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_SLATE_400, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_SLATE_400)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
# ----------------------------------------------------------------------------
# Yardımcı: tek satır dizi hücreleri (sıralama figürleri için)
# ----------------------------------------------------------------------------
def _cells_row(ax, values, x0, y, cell_w, cell_h, highlight=None,
dim=None, label_indices=False, fontsize=11):
"""Tek satır dizi hücreleri çizer. highlight=amber (aktif), dim=soluk (işlenmiş)."""
highlight = set(highlight or [])
dim = set(dim or [])
centers = []
for k, v in enumerate(values):
x = x0 + k * cell_w
if k in highlight:
fc, ec, lw = COL_AMBER_100, COL_ACCENT, 2.4
elif k in dim:
fc, ec, lw = COL_WHITE, COL_SLATE_400, 1.2
else:
fc, ec, lw = COL_BG, COL_PRIMARY, 1.6
ax.add_patch(FancyBboxPatch(
(x, y), cell_w * 0.94, cell_h * 0.94, boxstyle="square,pad=0.0",
fc=fc, ec=ec, linewidth=lw, zorder=2))
cx, cy = x + cell_w * 0.47, y + cell_h * 0.47
centers.append((cx, cy))
ax.text(cx, cy, str(v), ha="center", va="center",
fontsize=fontsize, color=COL_TEXT, weight="bold", zorder=4)
if label_indices:
ax.text(cx, y - cell_h * 0.26, str(k), ha="center", va="center",
fontsize=8, color=COL_SLATE_500, zorder=4)
return centers
# ----------------------------------------------------------------------------
# fig-unordered-vs-sorted — sırasız lineer tarama O(n) vs sıralı ikili arama O(log n)
# ----------------------------------------------------------------------------
def draw_sorted_vs_unsorted(ax, values=(5, 2, 8, 1, 9, 3, 7, 4), target=7):
"""Sırasız (lineer tarama O(n)) vs sıralı (ikili arama O(log n)) — fig-unordered-vs-sorted."""
values = list(values)
srt = sorted(values)
n = len(values)
cell_w, cell_h = 0.92, 0.7
y_top, y_bot = 2.0, 0.0
# --- Üst: sırasız dizi, lineer tarama ---
tgt_unsorted = values.index(target) if target in values else None
hi_top = [tgt_unsorted] if tgt_unsorted is not None else []
centers_top = _cells_row(ax, values, 0.0, y_top, cell_w, cell_h,
highlight=hi_top, label_indices=True, fontsize=10)
scan_to = tgt_unsorted if tgt_unsorted is not None else n - 1
for k in range(scan_to):
cx, cy = centers_top[k]
ax.add_patch(FancyArrowPatch(
(cx, cy + cell_h * 0.62), (cx + cell_w, cy + cell_h * 0.62),
arrowstyle="-|>", mutation_scale=10, color=COL_SLATE_400,
linewidth=1.3, zorder=3))
ax.text(n * cell_w * 0.5, y_top + cell_h + 0.55,
"Sırasız dizi — find baştan sona TARAR", ha="center", va="center",
fontsize=10.5, color=COL_PRIMARY, weight="bold")
ax.text(n * cell_w + 0.35, y_top + cell_h * 0.45, "O(n)",
ha="left", va="center", fontsize=12, color=COL_AMBER_700, weight="bold")
# --- Alt: sıralı dizi, ikili arama (sadece ortaları incele) ---
lo, hi = 0, n
probed = []
while lo < hi:
mid = (lo + hi) // 2
probed.append(mid)
if srt[mid] == target:
break
elif srt[mid] < target:
lo = mid + 1
else:
hi = mid
hi_bot = list(probed)
centers_bot = _cells_row(ax, srt, 0.0, y_bot, cell_w, cell_h,
highlight=hi_bot, label_indices=True, fontsize=10)
for order_idx, mid in enumerate(probed, start=1):
cx, cy = centers_bot[mid]
ax.add_patch(FancyArrowPatch(
(cx, cy + cell_h * 0.95), (cx, cy + cell_h * 0.50),
arrowstyle="-|>", mutation_scale=12, color=COL_ACCENT,
linewidth=1.8, zorder=5))
ax.text(cx, cy + cell_h * 1.12, str(order_idx), ha="center", va="center",
fontsize=9, color=COL_AMBER_700, weight="bold", zorder=5)
ax.text(n * cell_w * 0.5, y_bot - 0.42,
"Sıralı dizi — ikili arama yalnız ORTALARI inceler", ha="center",
va="center", fontsize=10.5, color=COL_PRIMARY, weight="bold")
ax.text(n * cell_w + 0.35, y_bot + cell_h * 0.45, "O(log n)",
ha="left", va="center", fontsize=12, color=COL_AMBER_700, weight="bold")
ax.set_xlim(-0.4, n * cell_w + 1.7)
ax.set_ylim(y_bot - 0.8, y_top + cell_h + 0.95)
ax.set_aspect("equal")
ax.axis("off")
return centers_top, centers_bot
# ----------------------------------------------------------------------------
# fig-binary-search — sıralı dizi + yarıya-bölme okları
# ----------------------------------------------------------------------------
def draw_binary_search(ax, values=(1, 3, 4, 7, 9, 11, 14, 18, 21), target=14):
"""Sıralı dizide ikili arama — yarıya-bölme okları (fig-binary-search). O(log n)."""
values = list(values)
n = len(values)
cell_w, cell_h = 0.92, 0.8
y0 = 0.0
lo, hi = 0, n
steps = []
while lo < hi:
mid = (lo + hi) // 2
if values[mid] == target:
steps.append((lo, hi, mid, "found"))
break
elif values[mid] < target:
steps.append((lo, hi, mid, "right"))
lo = mid + 1
else:
steps.append((lo, hi, mid, "left"))
hi = mid
probed = [s[2] for s in steps]
final_lo, final_hi = (steps[-1][0], steps[-1][1]) if steps else (0, n)
if steps and steps[-1][3] == "found":
final_lo, final_hi = steps[-1][2], steps[-1][2] + 1
dim = [k for k in range(n) if not (final_lo <= k < final_hi)]
centers = _cells_row(ax, values, 0.0, y0, cell_w, cell_h,
highlight=probed, dim=dim, label_indices=True, fontsize=10.5)
for order_idx, (lo_s, hi_s, mid, dec) in enumerate(steps, start=1):
cx, cy = centers[mid]
ax.add_patch(FancyArrowPatch(
(cx, cy + cell_h * 1.05), (cx, cy + cell_h * 0.52),
arrowstyle="-|>", mutation_scale=13, color=COL_ACCENT,
linewidth=2.0, zorder=5))
tag = f"{order_idx}"
if dec == "found":
tag += " ✓"
ax.text(cx, cy + cell_h * 1.28, tag, ha="center", va="center",
fontsize=9.5, color=COL_AMBER_700, weight="bold", zorder=5)
ax.text(n * cell_w * 0.5, y0 - 0.55,
f"ikili arama: her adım aralığı YARIYA böler → {len(steps)} adım",
ha="center", va="center", fontsize=10, color=COL_AMBER_700, weight="bold")
ax.text(n * cell_w * 0.5, y0 + cell_h + 0.85,
f"find({target}) sıralı dizide → O(log n)", ha="center", va="center",
fontsize=11.5, color=COL_PRIMARY, weight="bold")
ax.set_xlim(-0.4, n * cell_w + 0.4)
ax.set_ylim(y0 - 0.95, y0 + cell_h + 1.55)
ax.set_aspect("equal")
ax.axis("off")
return centers
# ----------------------------------------------------------------------------
# fig-selection-trace — prefix_max en-büyüğü-bul + sona-swap adımları (Θ(n²))
# ----------------------------------------------------------------------------
def draw_selection_trace(ax, trace, max_rows=5):
"""Seçmeli sıralama izi — prefix_max + sona-swap adımları (fig-selection-trace). Θ(n²)."""
if not trace:
ax.axis("off")
return ax
rows = trace[:max_rows]
n = len(rows[0]["before"])
cell_w, cell_h = 0.8, 0.62
row_gap = 1.15
for r, step in enumerate(rows):
y = -r * row_gap
before = step["before"]
max_idx = step["max_idx"]
i = step["i"]
dim = list(range(i + 1, n))
centers = _cells_row(ax, before, 0.0, y, cell_w, cell_h,
highlight=[max_idx], dim=dim, fontsize=10)
cx0, cy0 = centers[max_idx]
cx1, cy1 = centers[i]
ax.add_patch(FancyArrowPatch(
(cx0, cy0 + cell_h * 0.55), (cx1, cy1 + cell_h * 0.55),
arrowstyle="-|>", mutation_scale=12, color=COL_AMBER_700,
linewidth=1.8, zorder=5, connectionstyle="arc3,rad=-0.35"))
ax.text(-0.55, y + cell_h * 0.45,
f"prefix_max(0..{i})\n= idx {max_idx}", ha="right", va="center",
fontsize=8, color=COL_SLATE_500)
ax.text(n * cell_w + 0.30, y + cell_h * 0.45, "→ sona swap",
ha="left", va="center", fontsize=8.5, color=COL_AMBER_700,
weight="bold")
y_final = -len(rows) * row_gap
final_after = rows[-1]["after"]
_cells_row(ax, final_after, 0.0, y_final, cell_w, cell_h,
dim=list(range(n)), fontsize=10)
ax.text(n * cell_w * 0.5, y_final - cell_h * 0.55,
"her adım en büyüğü sona koyar — n adım × Θ(n) tarama = Θ(n²)",
ha="center", va="center", fontsize=9, color=COL_SLATE_500, style="italic")
ax.set_xlim(-2.6, n * cell_w + 2.2)
ax.set_ylim(y_final - 0.9, cell_h + 0.3)
ax.set_aspect("equal")
ax.axis("off")
return ax
# ----------------------------------------------------------------------------
# fig-merge-tree — böl-yönet ağacı + two-finger merge (İMZA figür)
# ----------------------------------------------------------------------------
def draw_merge_tree(ax, tree):
"""Böl-yönet özyineleme ağacı + two-finger merge (fig-merge-tree, İMZA figür)."""
leaves = []
def _collect_leaves(node):
if node is None:
return
if node["is_leaf"]:
leaves.append(node)
else:
_collect_leaves(node["left"])
_collect_leaves(node["right"])
_collect_leaves(tree)
def _max_depth(node):
if node is None or node["is_leaf"]:
return node["depth"] if node else 0
return max(_max_depth(node["left"]), _max_depth(node["right"]))
max_depth = _max_depth(tree)
x_gap = 1.7
leaf_x = {id(lf): i * x_gap for i, lf in enumerate(leaves)}
y_gap = 1.5
positions = {}
def _assign(node):
if node is None:
return None
y = -node["depth"] * y_gap
if node["is_leaf"]:
x = leaf_x[id(node)]
else:
lx = _assign(node["left"])
rx = _assign(node["right"])
x = (lx + rx) / 2.0
positions[id(node)] = (x, y)
return x
_assign(tree)
def _draw_edges(node):
if node is None or node["is_leaf"]:
return
px, py = positions[id(node)]
for child in (node["left"], node["right"]):
cx, cy = positions[id(child)]
ax.plot([px, cx], [py - 0.22, cy + 0.22],
color=COL_SLATE_400, linewidth=1.4, zorder=1)
_draw_edges(child)
_draw_edges(tree)
def _draw_nodes(node):
if node is None:
return
x, y = positions[id(node)]
label = "[" + ",".join(str(v) for v in node["values"]) + "]"
is_leaf = node["is_leaf"]
w = max(0.5, 0.30 * len(node["values"]) + 0.45)
h = 0.55
ax.add_patch(FancyBboxPatch(
(x - w / 2, y - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=COL_BG if is_leaf else COL_AMBER_100,
ec=COL_PRIMARY if is_leaf else COL_ACCENT,
linewidth=1.6 if is_leaf else 2.4, zorder=3))
ax.text(x, y, label, ha="center", va="center",
fontsize=8.5, color=COL_TEXT, weight="bold", zorder=4)
_draw_nodes(node["left"])
_draw_nodes(node["right"])
_draw_nodes(tree)
xs = [p[0] for p in positions.values()]
ys = [p[1] for p in positions.values()]
x_right = max(xs) + 1.2
ax.annotate("", xy=(x_right, min(ys)), xytext=(x_right, max(ys)),
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_500, lw=1.6))
ax.text(x_right + 0.18, (max(ys) + min(ys)) / 2, "böl ↓\n(divide)",
ha="left", va="center", fontsize=8.5, color=COL_SLATE_500)
ax.annotate("", xy=(x_right + 0.9, max(ys)), xytext=(x_right + 0.9, min(ys)),
arrowprops=dict(arrowstyle="-|>", color=COL_AMBER_700, lw=1.8))
ax.text(x_right + 1.08, (max(ys) + min(ys)) / 2,
"birleştir ↑\ntwo-finger\nΘ(n)/seviye",
ha="left", va="center", fontsize=8.5, color=COL_AMBER_700, weight="bold")
ax.text((min(xs) + max(xs)) / 2, max(ys) + 0.7,
"Merge sort: böl-yönet · T(n)=2T(n/2)+Θ(n)=Θ(n log n)",
ha="center", va="center", fontsize=11, color=COL_PRIMARY, weight="bold")
ax.set_xlim(min(xs) - 1.1, x_right + 2.6)
ax.set_ylim(min(ys) - 0.7, max(ys) + 1.1)
ax.set_aspect("equal")
ax.axis("off")
return positions
# ----------------------------------------------------------------------------
# fig-recurrence-levels — selection n-seviye vs merge log n-seviye (n² vs n log n)
# ----------------------------------------------------------------------------
def draw_recurrence_levels(ax_sel, ax_mrg, n=8):
"""Selection n-seviye vs merge log n-seviye — neden n² vs n log n (fig-recurrence-levels)."""
bar_h = 0.5
y = 0.0
sel_levels = 0
cur = n
while cur >= 1:
width = cur
ax_sel.add_patch(FancyBboxPatch(
(0, y), width, bar_h, boxstyle="square,pad=0.0",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=1.6, zorder=2))
ax_sel.text(-0.25, y + bar_h * 0.5, f"T({cur})", ha="right", va="center",
fontsize=8, color=COL_SLATE_500)
sel_levels += 1
cur -= 1
y -= bar_h + 0.18
ax_sel.set_title("Selection: T(n)=T(n−1)+Θ(n)", color=COL_TEXT, fontsize=10.5)
ax_sel.text(n * 0.5, bar_h + 0.45,
f"{sel_levels} seviye → Θ(n²)", ha="center", va="center",
fontsize=10, color=COL_AMBER_700, weight="bold")
ax_sel.text(n * 0.5, y + 0.05, "her adım problemi BİR azaltır (n seviye)",
ha="center", va="center", fontsize=8.5, color=COL_SLATE_500, style="italic")
ax_sel.set_xlim(-n * 0.5, n + 0.5)
ax_sel.set_ylim(y - 0.3, bar_h + 0.85)
ax_sel.set_aspect("equal")
ax_sel.axis("off")
y = 0.0
mrg_levels = 0
num_nodes = 1
size = n
while size >= 1:
node_w = n / num_nodes
for j in range(num_nodes):
x = j * node_w
ax_mrg.add_patch(FancyBboxPatch(
(x + 0.03, y), node_w - 0.06, bar_h, boxstyle="square,pad=0.0",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=1.4, zorder=2))
ax_mrg.text(-0.25, y + bar_h * 0.5,
f"{num_nodes}×{size}", ha="right", va="center",
fontsize=8, color=COL_SLATE_500)
mrg_levels += 1
if size == 1:
break
num_nodes *= 2
size = (size + 1) // 2
y -= bar_h + 0.18
ax_mrg.set_title("Merge: T(n)=2T(n/2)+Θ(n)", color=COL_TEXT, fontsize=10.5)
ax_mrg.text(n * 0.5, bar_h + 0.45,
f"{mrg_levels} seviye → Θ(n log n)", ha="center", va="center",
fontsize=10, color=COL_AMBER_700, weight="bold")
ax_mrg.text(n * 0.5, y - 0.12,
"her seviye toplam Θ(n) iş · log n seviye",
ha="center", va="center", fontsize=8.5, color=COL_SLATE_500, style="italic")
ax_mrg.set_xlim(-n * 0.5, n + 0.5)
ax_mrg.set_ylim(y - 0.4, bar_h + 0.85)
ax_mrg.set_aspect("equal")
ax_mrg.axis("off")
return ax_sel, ax_mrg
# ----------------------------------------------------------------------------
# fig-sort-comparison — §11 4 algoritma × (süre / yerinde / yöntem) renkli tablo
# ----------------------------------------------------------------------------
def draw_sort_comparison(ax):
"""§11 sıralama karşılaştırma tablosu: 4 algoritma × (süre / yerinde / yöntem)."""
rows = [
("Permutation", "Ω(n!·n)", "Hayır", "Tüm permütasyonlar (kaba kuvvet)", 0),
("Selection", "Θ(n²)", "Evet", "En büyüğü seç, sona koy, özyinele", 1),
("Insertion", "Θ(n²)", "Evet", "Solu sırala, yeni öğeyi kaydır", 1),
("Merge", "Θ(n log n)", "Hayır", "Böl-yönet, two-finger merge", 3),
]
headers = ["Algoritma", "Çalışma süresi", "Yerinde?", "Yöntem"]
col_w = [2.6, 2.4, 1.6, 5.4]
col_x = [0.0]
for w in col_w[:-1]:
col_x.append(col_x[-1] + w)
total_w = sum(col_w)
row_h = 1.0
COL_GOOD = "#cfe8da"
COL_GOOD_EC = "#3f7d5e"
time_palette = {
0: (COL_AMBER_300, COL_AMBER_700),
1: (COL_AMBER_100, COL_ACCENT),
3: (COL_GOOD, COL_GOOD_EC),
}
y_head = 0.0
for c, head in enumerate(headers):
ax.add_patch(FancyBboxPatch(
(col_x[c], y_head), col_w[c] * 0.98, row_h * 0.92,
boxstyle="square,pad=0.0", fc=COL_PRIMARY, ec=COL_PRIMARY,
linewidth=1.4, zorder=2))
ax.text(col_x[c] + col_w[c] * 0.5, y_head + row_h * 0.46, head,
ha="center", va="center", fontsize=10, color=COL_WHITE,
weight="bold", zorder=4)
for r, (alg, t, inplace, method, grade) in enumerate(rows):
y = -(r + 1) * row_h
ax.add_patch(FancyBboxPatch(
(col_x[0], y), col_w[0] * 0.98, row_h * 0.92, boxstyle="square,pad=0.0",
fc=COL_BG, ec=COL_PRIMARY, linewidth=1.4, zorder=2))
ax.text(col_x[0] + col_w[0] * 0.5, y + row_h * 0.46, alg,
ha="center", va="center", fontsize=10, color=COL_TEXT,
weight="bold", zorder=4)
fc, ec = time_palette[grade]
ax.add_patch(FancyBboxPatch(
(col_x[1], y), col_w[1] * 0.98, row_h * 0.92, boxstyle="square,pad=0.0",
fc=fc, ec=ec, linewidth=2.0, zorder=2))
ax.text(col_x[1] + col_w[1] * 0.5, y + row_h * 0.46, t,
ha="center", va="center", fontsize=10.5, color=COL_TEXT,
weight="bold", zorder=4)
in_fc, in_ec = (COL_GOOD, COL_GOOD_EC) if inplace == "Evet" else (COL_AMBER_100, COL_ACCENT)
ax.add_patch(FancyBboxPatch(
(col_x[2], y), col_w[2] * 0.98, row_h * 0.92, boxstyle="square,pad=0.0",
fc=in_fc, ec=in_ec, linewidth=1.6, zorder=2))
ax.text(col_x[2] + col_w[2] * 0.5, y + row_h * 0.46, inplace,
ha="center", va="center", fontsize=10, color=COL_TEXT,
weight="bold", zorder=4)
ax.add_patch(FancyBboxPatch(
(col_x[3], y), col_w[3] * 0.98, row_h * 0.92, boxstyle="square,pad=0.0",
fc=COL_WHITE, ec=COL_SLATE_400, linewidth=1.2, zorder=2))
ax.text(col_x[3] + 0.18, y + row_h * 0.46, method,
ha="left", va="center", fontsize=9, color=COL_TEXT, zorder=4)
ax.set_xlim(-0.3, total_w + 0.3)
ax.set_ylim(-(len(rows) + 1) * row_h - 0.2, row_h + 0.2)
ax.set_aspect("equal")
ax.axis("off")
return ax
```
## Arayüz Tekrarı: Küme Nedir? {#sec-arayuz-tekrari}
Ders 1'de tanıtılan ayrım burada da merkezdedir: **arayüz** bir *program spesifikasyonudur* (hangi işlemler destekleniyor); **veri yapısı** o arayüzü perde arkasında *gerçekleştiren* somut yapıdır.
> *"there's an object called an interface, which is just a program specification... a data structure, which is a way to actually implement an interface."* — Justin, 1:42
Bir **küme (set)** "bir yığın şey"dir: içine öğe eklersin ve "bu öğe var mı?" diye sorarsın. Her öğe bir **anahtarla (key)** ilişkilidir — örneğin sınıftaki öğrencilerin ID numarası. Aramayı anahtarla yaparsın; bulunca öğenin geri kalan bilgisine (isim, vb.) erişirsin.
## Küme (Set) Arayüzü {#sec-kume-arayuzu}
Set arayüzü şu işlemleri destekler:
- **build(A):** bir iterable `A`'dan küme kur.
- **len():** içindeki öğe sayısı.
- **find(k):** anahtarı `k` olan öğeyi döndür (yoksa null).
- **insert(x) / delete(k):** dinamik işlemler — kümeyi değiştirir.
- **find_min() / find_max():** en küçük / en büyük anahtarlı öğe.
- **find_prev(k) / find_next(k):** sıralı komşular.
Burada **x** tüm nesneyi (ID + isim + ...), **k** ise aramada kullanılan anahtarı temsil eder. Bu bir *arayüzdür* — nasıl gerçekleştirildiği henüz söylenmedi.
## Küme mi, Dizi mi? {#sec-kume-mi-dizi-mi}
İki temel arayüzün farkı, öğeleri *neye göre* tuttuğudur:
- **Dizi (sequence):** öğeler **dışsal (extrinsic)** bir sıraya göre — ilk, onuncu, son. Pozisyonla erişim.
- **Küme (set):** öğeler **içsel (intrinsic)** anahtarlarına göre. Değerle (key) erişim.
Aynı veri her iki arayüzle de tutulabilir, ama sorular farklıdır: dizi "5. öğe ne?" diye sorar, küme "anahtarı 42 olan öğe var mı?" diye sorar.
## Sırasız Dizi ile Küme {#sec-sirasiz-dizi}
En basit gerçekleştirim: öğeleri **sırasız bir dizide** (unordered array), gelişigüzel sıralamayla sakla. Kurması kolaydır — büyük bir dizi al, her şeyi içine at.
> *"an unordered array is a perfectly reasonable way to implement this set interface. And then searching that array it will take linear time"* — Justin, 12:00
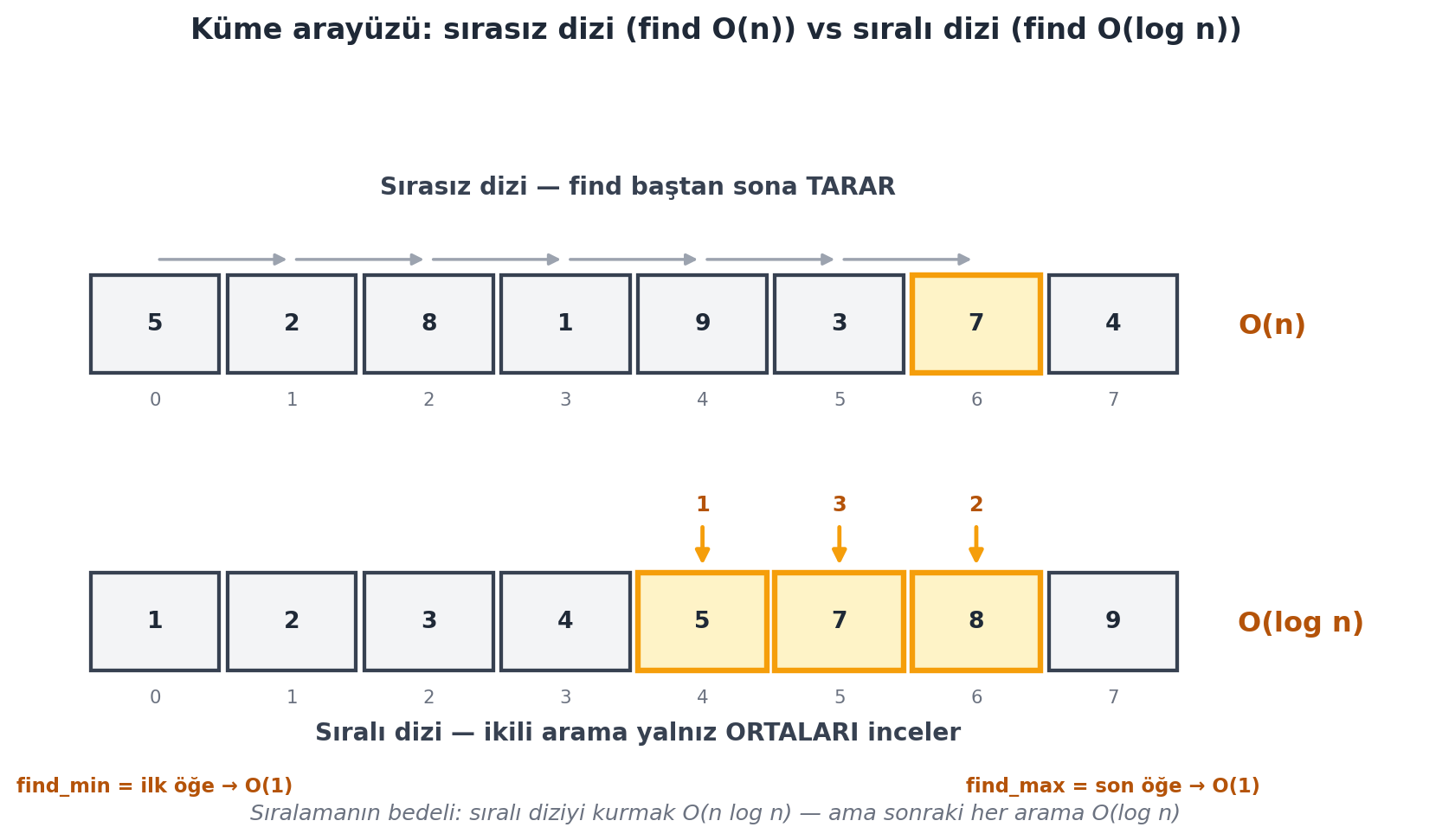
Ama her arama, diziyi baştan sona taramayı gerektirir: `find(k)` en kötü durumda $O(n)$. Aslında tüm işlemler (build, insert, delete, find_min) lineer zamandır. Basit ama yavaş. @fig-unordered-vs-sorted bu sırasız gerçekleştirimi, hemen ardından gelen sıralı alternatifle yan yana gösterir.
## Sıralı Dizi ile Küme {#sec-sirali-dizi}
Daha iyisi: öğeleri **anahtara göre sıralı** bir dizide tut. Artık:
- **find_min() / find_max():** ilk / son öğe → $O(1)$.
- **find(k):** **ikili arama (binary search)** ile diziyi her adımda yarıya böl → $O(\log n)$.
> *"if my array is sorted, how long does it take for me to search for any given element? ... Log n time."* — Justin, 16:24
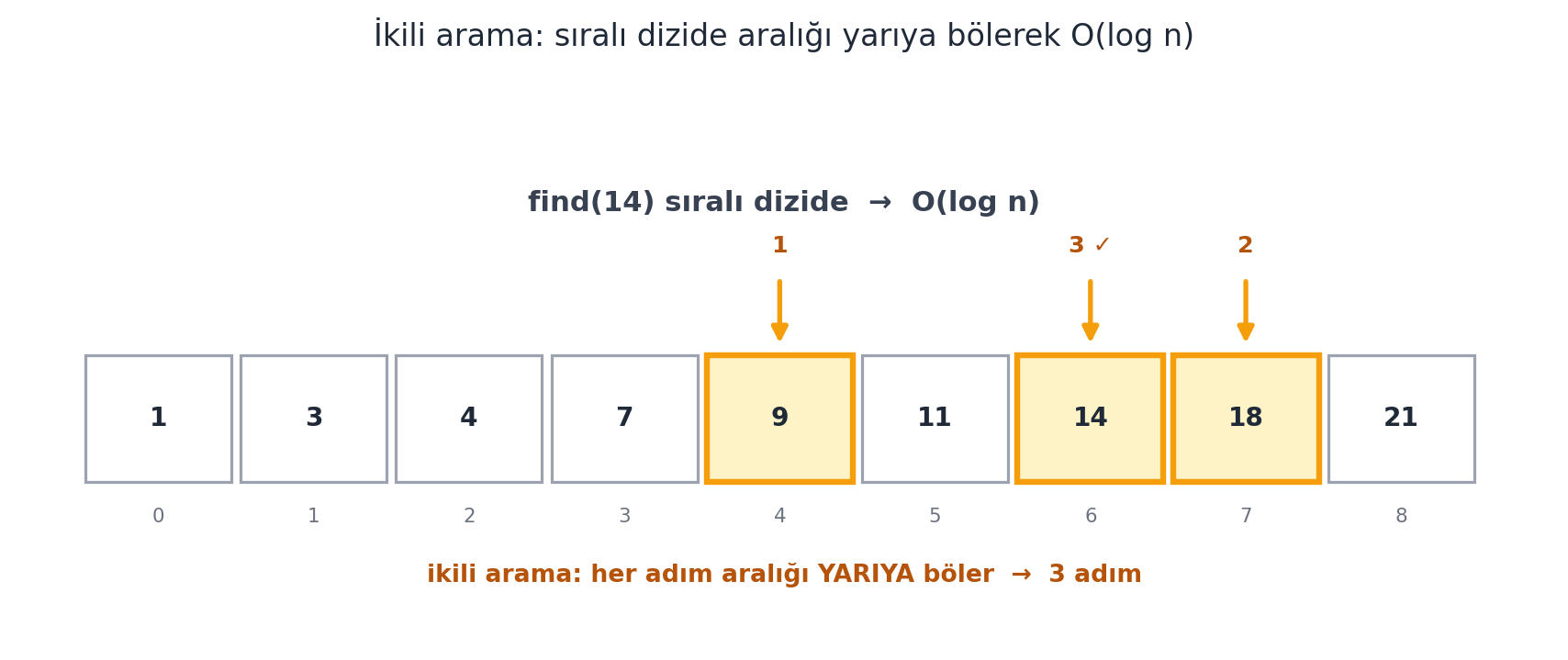
Bir milyar öğede sırasız dizi ~bir milyar işlem, sıralı dizi yalnızca ~30 işlem ($\log_2 10^9 \approx 30$) ister. Ama bir bedel var: sıralı diziyi **elde etmek** = sıralama, ve sıralama $O(n \log n)$ zaman alır. Dersin geri kalanı bu sıralamayı çözer. @fig-unordered-vs-sorted iki gerçekleştirimi karşılaştırır; @fig-binary-search ise ikili aramanın yarıya-bölme mekaniğini tek tek izler.
```{python}
#| label: fig-unordered-vs-sorted
#| fig-cap: "Küme arayüzünü diziyle gerçekleştirmenin iki yolu ve **arama** maliyetinin ayrışması. Üstte **sırasız dizi**: `find(7)` öğeyi bulana dek baştan sona tarar (soluk slate okları), öğe nerede olursa olsun en kötü durumda her hücreye bakılır → $O(n)$; `find_min/max` de aynı şekilde tüm diziyi tarar. Altta **aynı veri sıralı**: `find(7)` **ikili aramayla** yalnızca ortaları inceler (amber, 1-2-3 sırasıyla: index 4 → 6 → 5), her adım aralığı yarıya böler → $O(\\log n)$; üstelik `find_min` = ilk öğe ve `find_max` = son öğe **uçlardan** doğrudan okunur → $O(1)$. Bedel: sıralı diziyi *kurmak* bir kez $O(n \\log n)$ sıralama gerektirir — ama sonraki her arama logaritmik kalır (@fig-binary-search bunu ayrıntılandırır)."
#| fig-width: 9
#| fig-height: 5.2
# DETERMİNİSTİK: sabit sırasız dizi + hedef (seed yok). draw_sorted_vs_unsorted /
# COL_* / plt gizli setup hücresinden (inline _engine+_viz) gelir. Sıralı şerit
# fonksiyon içinde sorted(values) ile üretilir; ikili arama izi birebir aynıdır.
fig, ax = plt.subplots(figsize=(9, 5.2))
fig.patch.set_facecolor(COL_WHITE)
VALUES = (5, 2, 8, 1, 9, 3, 7, 4)
TARGET = 7
draw_sorted_vs_unsorted(ax, values=VALUES, target=TARGET)
# Sıralı şeridin uçlarına find_min/max O(1) notu (ilk/son öğe doğrudan okunur).
n = len(VALUES)
cell_w, y_bot = 0.92, 0.0
ax.text(cell_w * 0.47, y_bot - 0.78, "find_min = ilk öğe → O(1)",
ha="center", va="center", fontsize=8.5, color=COL_AMBER_700, weight="bold")
ax.text((n - 1) * cell_w + cell_w * 0.47, y_bot - 0.78, "find_max = son öğe → O(1)",
ha="center", va="center", fontsize=8.5, color=COL_AMBER_700, weight="bold")
fig.suptitle(
"Küme arayüzü: sırasız dizi (find O(n)) vs sıralı dizi (find O(log n))",
color=COL_TEXT, fontsize=12.5, weight="bold", y=0.98,
)
fig.text(
0.5, 0.045,
"Sıralamanın bedeli: sıralı diziyi kurmak O(n log n) — ama sonraki her arama O(log n)",
ha="center", va="bottom", fontsize=9.5, color=COL_SLATE_500, style="italic",
)
plt.tight_layout(rect=(0, 0.05, 1, 0.95))
plt.show()
```
```{python}
#| label: fig-binary-search
#| fig-cap: "Sıralı dizide **ikili arama** (binary search): aralık $[lo, hi)$ her adımda **ortadan** ikiye bölünür. Ortadaki öğe ($A[mid]$) hedefle karşılaştırılır; küçükse sağ yarıya, büyükse sol yarıya inilir, eşitse bulunur. Burada `find(14)` üç adımda çözülür: 1. adım indeks $4$ (değer $9 < 14$ → sağa), 2. adım indeks $7$ (değer $18 > 14$ → sola), 3. adım indeks $6$ (değer $14$ ✓, bulundu). İncelenen ortalar **amber** vurgulu ve sıra-numaralı; elenen yarılar soluklaşır. Her adım arama uzayını yarıladığından maliyet $O(\\log n)$'dir — $n = 10^9$ için bile yalnızca $\\log_2 10^9 \\approx 30$ adım yeter (sırasız dizide aynı arama $O(n)$, yani milyarlarca işlem olurdu)."
#| fig-width: 9
#| fig-height: 3.8
# fig-binary-search: sıralı dizide ikili arama, yarıya-bölme, O(log n).
# Deterministik: VALUES artan sıralı (n=9), TARGET=14 → binary_search_trace 3 adımda
# indeks 6'yı bulur (mid sırası 4 → 7 → 6). draw_binary_search aynı izi sıralı dizi
# üstünde yarıya-bölme oklarıyla çizer (incelenen ortalar amber + sıra numarası).
VALUES = (1, 3, 4, 7, 9, 11, 14, 18, 21)
TARGET = 14
idx = binary_search(list(VALUES), TARGET) # 6
trace = binary_search_trace(list(VALUES), TARGET) # count == 3, found == 6
fig, ax = plt.subplots(figsize=(9, 3.8))
# sıralı dizi + yarıya-bölme okları + adım sayacı (O(log n) görseli)
draw_binary_search(ax, values=VALUES, target=TARGET)
ax.set_title(
"İkili arama: sıralı dizide aralığı yarıya bölerek O(log n)",
color=COL_TEXT, fontsize=12.5, pad=16,
)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — O(log n) ve Veritabanı İndeksleri (B-tree)"}
"Sıralı dizi + ikili arama = $O(\log n)$ arama" sezgisi, her ölçeklenebilir veri sisteminin kalbindedir:
- **İleriye → veritabanı indeksleri:** Bir tabloya indeks eklemek, anahtarları **sıralı** bir yapıda (B-tree, sıralı dizinin disk-dostu çok-yollu genellemesi) tutmak demektir; `WHERE id = 42` sorgusu tam tamına ikili aramadır → milyarlarca satırda ~30 disk erişimi. İndekssiz sorgu ise sırasız diziye eşdeğer: tam tablo taraması, $O(n)$.
- **İleriye → arama motoru posting list'leri:** Ters indekslerdeki belge ID listeleri sıralı tutulur; iki listenin kesişimi (AND sorgusu) tam da two-finger merge mantığıyla, sıralılıktan faydalanarak yapılır.
- **Bedel-fayda dengesi:** İndeks "ücretsiz" değildir — onu *kurmak* ve *güncel tutmak* (her insert'te sıralı yapıyı koruma) maliyettir, tıpkı sıralı diziyi kurmanın $O(n \log n)$ bedeli gibi. "Çok okunan, az yazılan" veride indeks kazandırır.
:::
## Sıralama Problemi ve Sözlük {#sec-siralama-problemi}
**Sıralama problemi:** girdi, $n$ anahtardan oluşan bir dizi `A`; çıktı, aynı öğelerin sıralı bir dizisi `B`. İki terim algoritmaları ayırır:
- **Yıkıcı (destructive):** yeni bir `B` dizisi ayırmak yerine, `A`'nın üzerine sıralı hâlini yazar (C++ ve Python sort'u böyledir).
- **Yerinde (in-place):** yıkıcı *ve* ek bellek kullanmaz (sabit $O(1)$ fazlası dışında — döngü sayaçları gibi).
> *"a destructive algorithm is one that just overwrites A with a sorted version of A... in place, meaning that they also don't use extra memory"* — Justin, 20:13
## Permütasyon Sıralaması {#sec-permutasyon-siralama}
En basit (ve en kötü) sıralama: bir listenin sıralı hâli, onun bir permütasyonudur. O hâlde **tüm permütasyonları listele**, her birinin sıralı olup olmadığını kontrol et.
> *"list every possible permutation, and then just double check which one's in the right order."* — Justin, 22:04
$n$ öğenin $n!$ permütasyonu vardır; her birinin sıralılığını kontrol etmek $\Theta(n)$'dir. Toplam $\Omega(n! \cdot n)$ — $n!$'den bile kötü. (Burada $\Omega$ kullanılır çünkü permütasyonları üretmenin maliyeti *en az* bu kadardır — bir alt sınır.) Pratikte tamamen kullanılamaz; ama doğruluğu ispatlaması çok kolaydır.
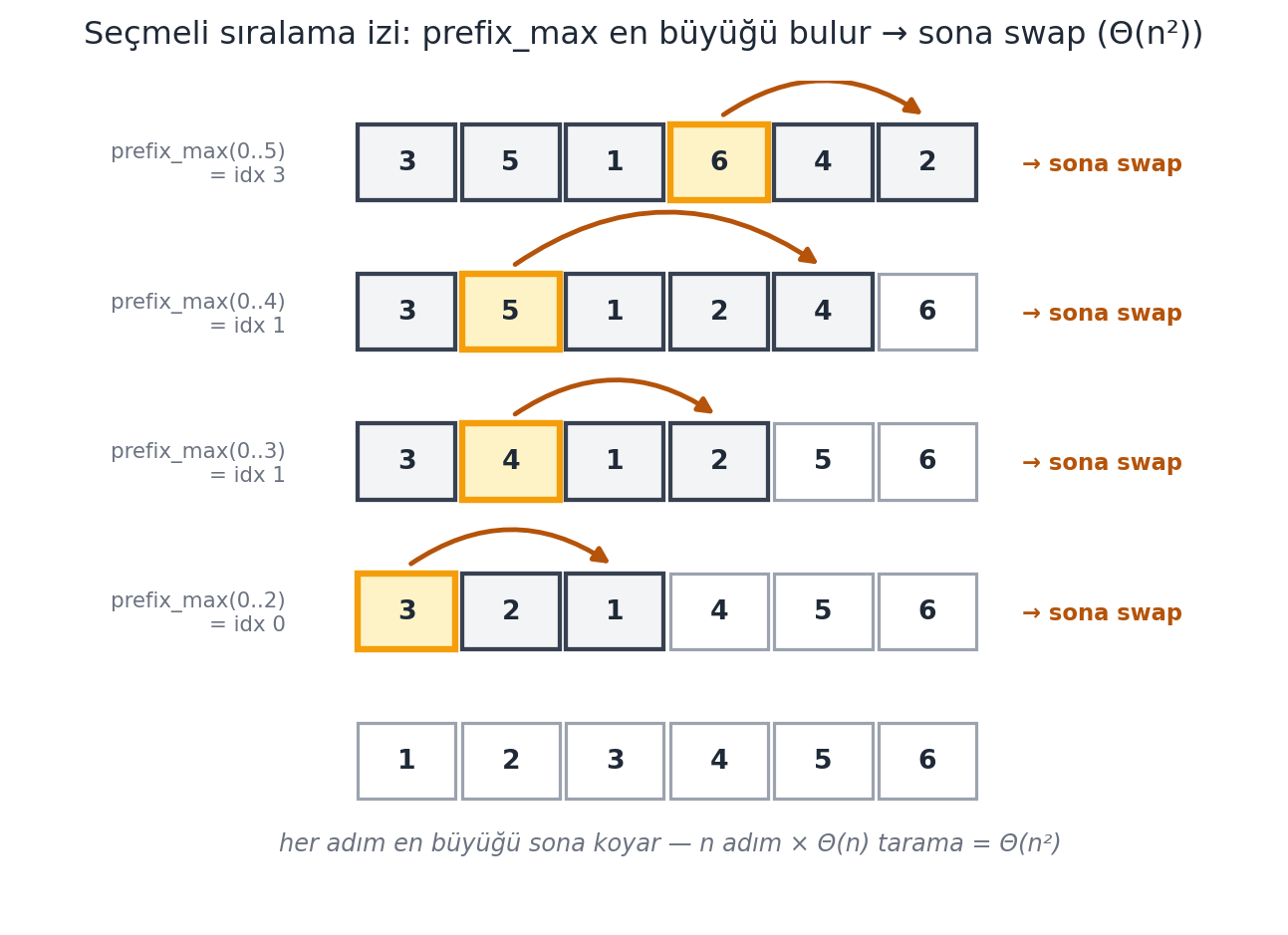
## Seçmeli Sıralama (Selection Sort) {#sec-secmeli-siralama}
Daha akıllı bir algoritma. 6.006'da onu — alışılmadık biçimde — **özyinelemeli** yazarız (doğruluk ve süre analizini kolaylaştırmak için; pratikte iki döngüyle yazılır).
Önce bir yardımcı: `prefix_max(A, i)` — `A`'nın 0'dan `i`'ye kadarki en büyük öğesinin indeksini bulur. Solomon'un "derin gözlemi": 0..i aralığındaki en büyük öğe ya **tam i'dedir** ya da **i'den önceki** bir indekstedir.
> *"the biggest element from 0 to i... Either it's at index i... or it has index less than i. ... Another term for this is induction."* — Justin, 31:15
```python
def prefix_max(A, i):
if i == 0:
return 0
j = prefix_max(A, i - 1) # 0..i-1'in en buyugu (tumevarim hipotezi)
if A[i] > A[j]:
return i
return j
```
**Seçmeli sıralama:** `i = n−1`'den başla; 0..i'nin en büyüğünü `prefix_max` ile bul, indeks `i`'ye **swap** et, sonra 0..i−1'i özyinelemeli sırala (somut bir iz için @fig-selection-trace).
```python
def selection_sort(A, i):
if i > 0:
j = prefix_max(A, i)
A[i], A[j] = A[j], A[i] # en buyugu sona koy
selection_sort(A, i - 1) # solu sirala
```
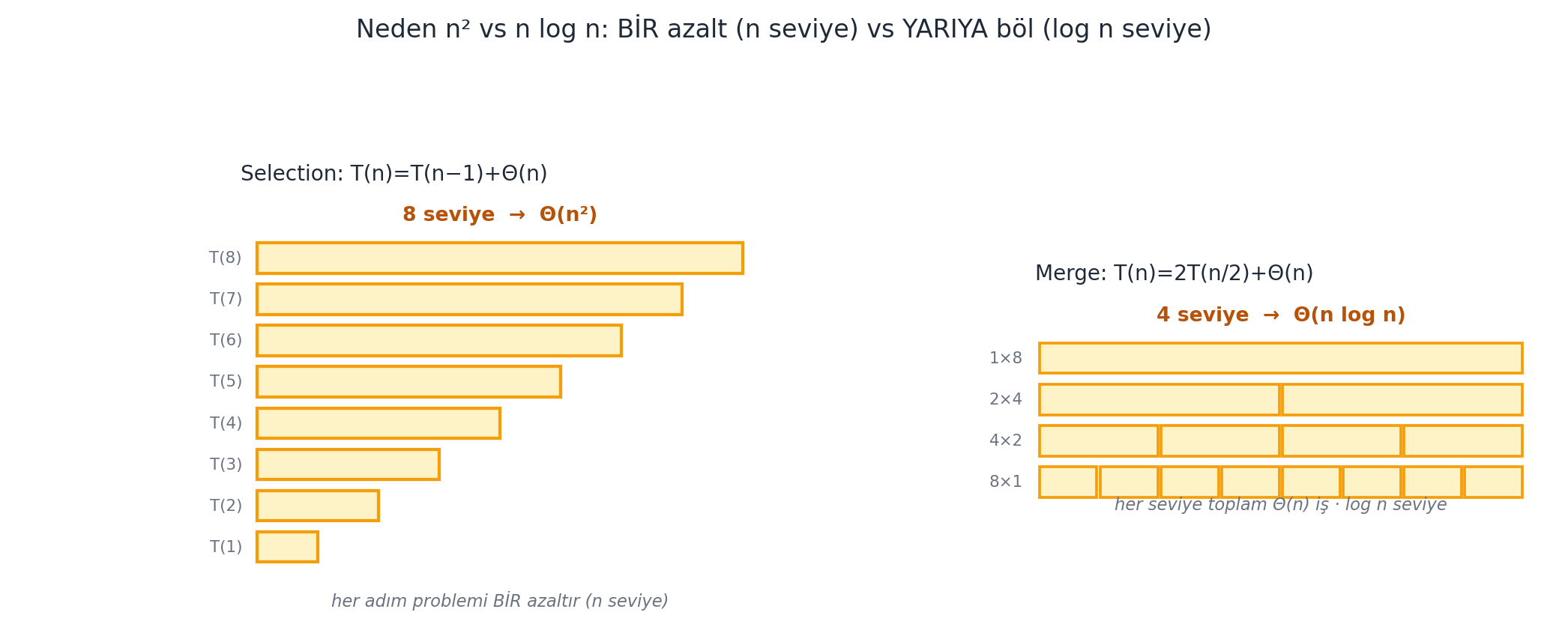
**Çalışılan Örnek — substitution ile çalışma süresi.** `prefix_max` için: $S(n) = S(n-1) + \Theta(1)$. $S(n) = cn$ tahmin et, yerine koy: $cn = c(n-1) + \Theta(1) \to \Theta(1) = c$, sabit. Yani $S(n) = \Theta(n)$. Seçmeli sıralama için: $T(n) = T(n-1) + \Theta(n)$ (her çağrı bir `prefix_max` = $\Theta(n)$). $T(n) = cn^2$ tahmin et: $cn^2 = c(n-1)^2 + \Theta(n) = cn^2 - 2cn + c + \Theta(n) \to \Theta(n) = 2cn - c$, tutarlı. Yani $T(n) = \Theta(n^2)$. @fig-recurrence-levels bu $n$ seviyeli yineleme ağacını, merge sort'un $\log n$ seviyesiyle yan yana koyar.
```{python}
#| label: fig-selection-trace
#| fig-cap: "Seçmeli sıralama izi (Solomon $\\S 8$): dizi **sağdan sola** sıralanır. Her dış adımda `prefix_max(0..i)` aralığın **en büyük** öğesini bulur (amber vurgulu) ve onu pozisyon $i$'ye **swap** eder (amber yay) — böylece sağ uçta giderek büyüyen bir **sıralı kuyruk** (soluk hücreler) oluşur. Burada $[3,5,1,6,4,2]$ dört geçişte tamamen sıralanır: $6 \\to 5 \\to 4 \\to 3$ sırayla sona yerleşir, en altta sonuç $[1,2,3,4,5,6]$. $n$ adımın her biri $\\Theta(n)$'lik bir `prefix_max` taraması içerir → $T(n)=T(n-1)+\\Theta(n)=\\Theta(n^2)$."
#| fig-width: 8.5
#| fig-height: 5.0
# fig-selection-trace: seçmeli sıralama izi (prefix_max + sona-swap), Θ(n²).
# Deterministik 6-eleman dizi; 4 pass içinde tamamen sıralanır (her pass'ta gerçek swap).
A = [3, 5, 1, 6, 4, 2]
trace = selection_trace(A) # 5 dış adım (i = 5..1); ilk 4 pass tam sıralar
fig, ax = plt.subplots(figsize=(8.5, 5.0))
# Her satır bir dış adım: en büyük öğe amber, max_idx → i swap oku, sıralı kuyruk soluk.
draw_selection_trace(ax, trace, max_rows=4)
ax.set_title(
"Seçmeli sıralama izi: prefix_max en büyüğü bulur → sona swap (Θ(n²))",
color=COL_TEXT, fontsize=12, pad=14,
)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Yineleme Analizi Disiplini"}
`prefix_max` ve `selection_sort`'taki "form tahmin et → yerine koy → doğrula" (substitution) hareketi, her özyinelemeli maliyeti kapalı bir formüle bağlamanın temel disiplinidir:
- **İleriye → ML kernel maliyetleri:** Bir transformer'da self-attention'ın $O(n^2)$ maliyeti (her token diğer her token'a bakar) tam bu tür bir sayımla türetilir — ve neden uzun bağlamın pahalı olduğunun, FlashAttention/lineer-attention gibi optimizasyonların *neden* gerektiğinin cevabıdır.
- **İleriye → OMSCS CS 6515:** Graduate algoritma derslerinde her dinamik programlama / böl-yönet çözümünün ardından bir yineleme bağıntısı yazılır ve substitution (veya master teoremi) ile çözülür; bu dersin alıştırması oraya doğrudan taşınır.
- **Sezgi:** Selection sort'un $T(n)=T(n-1)+\Theta(n)$'i, "her adım problemi yalnız bir azaltır" demektir; bu yüzden $n + (n-1) + \dots + 1 = \Theta(n^2)$. Yineleme bağıntısı, performansın *neden*ini koddan önce gösterir.
:::
## Eklemeli Sıralama (Insertion Sort) {#sec-eklemeli-siralama}
Seçmeli sıralamanın "tersi": önce 0..i−1'i sırala, sonra `i`'inci öğeyi sıralı kısma doğru yerine **kaydır**. O da özyinelemeli yazılır ve yine $\Theta(n^2)$'dir (her ekleme en kötü durumda lineer kaydırma). Solomon zaman darlığından detayını atlar; argüman seçmeli sıralamayla aynıdır.
## Birleştirmeli Sıralama (Merge Sort) {#sec-birlestirmeli-siralama}
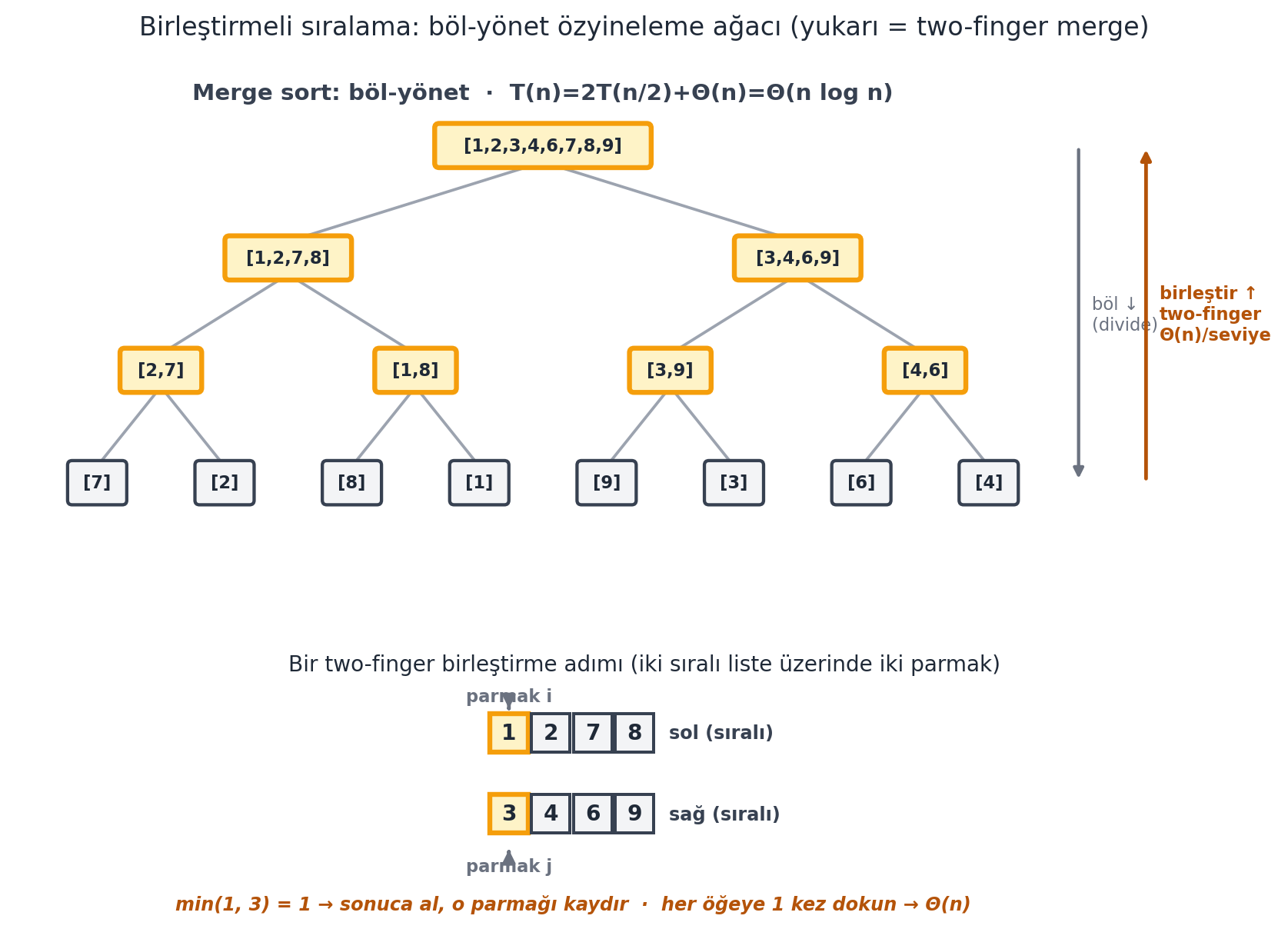
İlk *gerçekten verimli* sıralama: **böl ve yönet**. Diziyi ortadan ikiye böl, her yarıyı özyinelemeli sırala, sonra iki sıralı yarıyı **birleştir (merge)**.
Birleştirmenin püf noktası **iki parmak (two-finger)** tekniğidir: her sıralı listenin sonuna birer parmak koy, büyük olanı sonuca al, o parmağı sola kaydır. İki yarı zaten sıralı olduğundan, parmağın soluna hiç bakmana gerek kalmaz → birleştirme $\Theta(n)$ (lineer).
> *"I'm going to take two sorted lists. And I'm going to make a new sorted list, which is twice as long, by using two fingers... it takes linear time to merge."* — Justin, 44:40
```python
def merge_sort(A, a, b): # A[a:b] araligini sirala
if b - a > 1:
c = (a + b) // 2 # orta (center)
merge_sort(A, a, c) # solu sirala
merge_sort(A, c, b) # sagi sirala
merge(A, a, c, b) # iki sirali yariyi birlestir (two-finger)
```
**Çalışılan Örnek — substitution ile çalışma süresi.** Merge sort iki kez yarı boyutta çağrılır + $\Theta(n)$ birleştirme: $T(n) = 2 \cdot T(n/2) + \Theta(n)$. $T(n) = cn \log n$ tahmin et, yerine koy: $cn \log n = 2 \cdot c(n/2) \cdot \log(n/2) + \Theta(n) = cn(\log n - \log 2) + \Theta(n) = cn \log n - cn \log 2 + \Theta(n)$. İki taraftan $cn \log n$ gider; $\Theta(n) = cn \log 2$, tutarlı ($\log 2$ sabit). Yani $T(n) = \Theta(n \log n)$ — sıralı diziyi vaat edilen sürede elde ettik. @fig-merge-tree bu böl-yönet akışını ve tek bir two-finger merge adımını birlikte gösterir.
```{python}
#| label: fig-merge-tree
#| fig-cap: "Birleştirmeli sıralama = **böl-yönet**. Üstte özyineleme ağacı: dizi her seviyede tam ortadan **ikiye bölünür** (aşağı, böl), $\\lceil \\log_2 n \\rceil + 1$ seviye sonra yapraklara (tek öğe, zaten sıralı; slate) iner. Sonra **aşağıdan yukarı** her düğüm iki sıralı çocuğunu **two-finger merge** ile birleştirir (amber, yukarı ok). Altta tek bir two-finger adımı: iki sıralı liste $[1,2,7,8]$ ve $[3,4,6,9]$ üstündeki iki parmak ($i$, $j$) karşılaştırılır, küçük olan ($\\min(1,3)=1$) sonuca alınır ve o parmak kaydırılır — her öğeye tam bir kez dokunulur, bu yüzden birleştirme bir seviyede $\\Theta(n)$. $\\log n$ seviye $\\times$ seviye-başına $\\Theta(n)$ iş: $T(n) = 2T(n/2) + \\Theta(n) = \\Theta(n \\log n)$."
#| fig-width: 11
#| fig-height: 8.2
# --- Merge sort: böl-yönet özyineleme ağacı + tek two-finger merge adımı (deterministik) ---
# 8 öğelik dizi (2'nin kuvveti → dengeli ağaç, ⌈log₂ 8⌉+1 = 4 seviye).
A = [7, 2, 8, 1, 9, 3, 6, 4]
tree = merge_sort_tree(A)
def _draw_two_finger_step(ax, left, right, i, j):
"""Tek bir two-finger merge adımı: iki sıralı liste + iki parmak (i, j).
left[i] ile right[j] karşılaştırılır; küçük olan (amber) sonuca alınır,
o parmak kaydırılır. Solomon §10 two-finger sezgisi; her öğeye 1 kez → Θ(n).
"""
cw, ch = 0.62, 0.62
y_left, y_right = 1.2, 0.0
x0 = 0.0
def _row(values, y, finger):
for k, v in enumerate(values):
x = x0 + k * cw
on = (k == finger)
ax.add_patch(FancyBboxPatch(
(x, y), cw * 0.92, ch * 0.92, boxstyle="square,pad=0.0",
fc=COL_AMBER_100 if on else COL_BG,
ec=COL_ACCENT if on else COL_PRIMARY,
linewidth=2.4 if on else 1.5, zorder=2))
ax.text(x + cw * 0.46, y + ch * 0.46, str(v), ha="center", va="center",
fontsize=10.5, color=COL_TEXT, weight="bold", zorder=4)
return x0 + finger * cw + cw * 0.46
fx_l = _row(left, y_left, i)
fx_r = _row(right, y_right, j)
# parmak okları (her listenin aktif öğesine)
ax.add_patch(FancyArrowPatch(
(fx_l, y_left + ch * 1.15), (fx_l, y_left + ch * 0.95),
arrowstyle="-|>", mutation_scale=12, color=COL_SLATE_500, linewidth=1.8, zorder=5))
ax.text(fx_l, y_left + ch * 1.34, "parmak i", ha="center", va="center",
fontsize=8.5, color=COL_SLATE_500, weight="bold")
ax.add_patch(FancyArrowPatch(
(fx_r, y_right - ch * 0.55), (fx_r, y_right - ch * 0.30),
arrowstyle="-|>", mutation_scale=12, color=COL_SLATE_500, linewidth=1.8, zorder=5))
ax.text(fx_r, y_right - ch * 0.80, "parmak j", ha="center", va="center",
fontsize=8.5, color=COL_SLATE_500, weight="bold")
nl, nr = len(left), len(right)
ax.text(x0 + nl * cw + 0.18, y_left + ch * 0.46, "sol (sıralı)",
ha="left", va="center", fontsize=9, color=COL_PRIMARY, weight="bold")
ax.text(x0 + nr * cw + 0.18, y_right + ch * 0.46, "sağ (sıralı)",
ha="left", va="center", fontsize=9, color=COL_PRIMARY, weight="bold")
small = left[i] if left[i] <= right[j] else right[j]
ax.text((x0 + max(nl, nr) * cw) * 0.5, y_right - 1.05,
f"min({left[i]}, {right[j]}) = {small} → sonuca al, o parmağı kaydır · her öğeye 1 kez dokun → Θ(n)",
ha="center", va="center", fontsize=9, color=COL_AMBER_700,
weight="bold", style="italic")
ax.set_xlim(-0.4, x0 + max(nl, nr) * cw + 2.5)
ax.set_ylim(y_right - 1.35, y_left + ch * 1.65)
ax.set_aspect("equal")
ax.axis("off")
ax.set_title("Bir two-finger birleştirme adımı (iki sıralı liste üzerinde iki parmak)",
color=COL_TEXT, fontsize=10.5, pad=6)
fig = plt.figure(figsize=(11, 8.2))
gs = fig.add_gridspec(2, 1, height_ratios=[2.55, 1.0], hspace=0.18)
ax_tree = fig.add_subplot(gs[0])
ax_step = fig.add_subplot(gs[1])
# Üst panel: böl-yönet özyineleme ağacı (yapraklar slate, iç düğümler amber merge sonucu)
draw_merge_tree(ax_tree, tree)
ax_tree.set_title(
"Birleştirmeli sıralama: böl-yönet özyineleme ağacı (yukarı = two-finger merge)",
color=COL_TEXT, fontsize=12.5, pad=14,
)
# Alt panel: iki sıralı yarının ([1,2,7,8] ve [3,4,6,9]) ilk two-finger merge adımı
_draw_two_finger_step(ax_step, tree["left"]["values"], tree["right"]["values"], i=0, j=0)
plt.tight_layout()
plt.show()
```
```{python}
#| label: fig-recurrence-levels
#| fig-cap: "Neden seçmeli sıralama $\\Theta(n^2)$ ama birleştirmeli sıralama $\\Theta(n\\log n)$ — fark yineleme ağacının **seviye sayısındadır** ($n=8$). **Sol (selection):** $T(n)=T(n-1)+\\Theta(n)$ — her adım problemi yalnız **BİR** azaltır, alt-problem boyutu $8, 7, 6, \\dots, 1$ olur; bu yüzden $8$ seviye (genel: $n$ seviye). Çubuk genişlikleri o seviyedeki alt-problem boyutudur ($T(8)$ en uzun, $T(1)$ en kısa). $n$ seviye $\\times$ ortalama $\\Theta(n)$ iş $\\Rightarrow \\Theta(n^2)$. **Sağ (merge):** $T(n)=2T(n/2)+\\Theta(n)$ — her seviye problemi **YARIYA** böler, alt-problem sayısı $1, 2, 4, 8$ ve boyutları $8, 4, 2, 1$ olur; bu yüzden yalnız $\\lceil\\log_2 8\\rceil+1 = 4$ seviye (genel: $\\log n$ seviye). Her seviyede toplam genişlik (toplam iş) sabit $\\Theta(n)$ kalır — alt-problemler küçülürken sayıları artar. $\\log n$ seviye $\\times \\Theta(n)$/seviye $\\Rightarrow \\Theta(n\\log n)$. İki algoritma da seviye başına $\\Theta(n)$ iş yapar; tek fark seviye sayısı: $n$'e karşı $\\log n$ — $n=10^6$'da bu, bir milyon kata karşı $\\approx 20$ kat demektir."
#| fig-width: 11
#| fig-height: 5.0
N = 8
fig, (ax_sel, ax_mrg) = plt.subplots(1, 2, figsize=(11, 5.0))
draw_recurrence_levels(ax_sel, ax_mrg, n=N)
fig.suptitle(
"Neden n² vs n log n: BİR azalt (n seviye) vs YARIYA böl (log n seviye)",
color=COL_TEXT, fontsize=12.5, y=0.99,
)
plt.tight_layout(rect=(0, 0, 1, 0.96))
plt.show()
```
::: {.callout-tip title="Builder Notu — Böl-Yönet ve OMSCS / quicksort-FFT"}
Merge sort'un $T(n) = 2T(n/2) + \Theta(n) = \Theta(n \log n)$ yinelemesi, *tüm* verimli özyinelemeli algoritmaların habercisidir:
- **İleriye → OMSCS CS 6515 çekirdek paradigması:** Graduate algoritmada **böl-ve-yönet** ayrı bir ünitedir; quicksort, ikili arama, en yakın nokta çifti ve hepsi aynı "böl → özyinele → birleştir" kalıbını ve master teoremini paylaşır.
- **İleriye → FFT ($\Theta(n \log n)$):** Hızlı Fourier Dönüşümü, polinomu çift/tek katsayılara böler, her yarıyı özyinelemeli dönüştürür, sonra birleştirir — merge sort'un birebir aynı yineleme ağacı. ML'de hızlı evrişim (convolution) ve sinyal işleme buna dayanır.
- **Pratik nüans:** Merge sort kararlıdır ama $\Theta(n)$ ek alan ister; quicksort yerinde ve genelde daha hızlıdır ama en kötü durumda $\Theta(n^2)$. "Hangi $\Theta(n \log n)$ sıralama" kararı bu uzay/kararlılık/en-kötü-durum dengeleriyle verilir.
:::
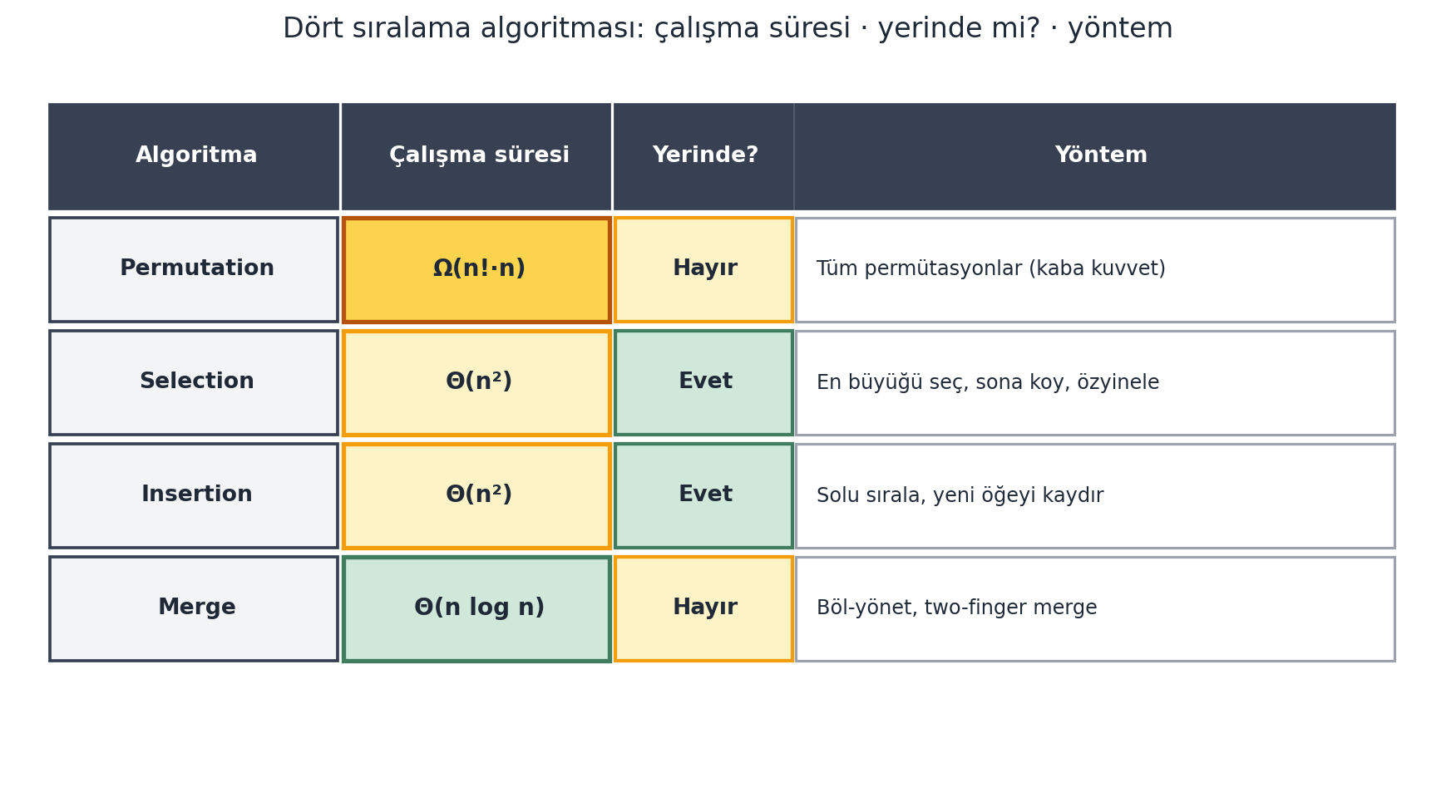
## Sıralama Algoritmaları — Karşılaştırma {#sec-karsilastirma-d04}
| Algoritma | Çalışma süresi | Yerinde mi? | Yöntem |
|---|---|---|---|
| Permutation sort | $\Omega(n! \cdot n)$ | Hayır | Kaba kuvvet (tüm permütasyonlar) |
| Selection sort | $\Theta(n^2)$ | Evet | En büyüğü seç, sona koy, özyinele |
| Insertion sort | $\Theta(n^2)$ | Evet | Solu sırala, yeni öğeyi yerine kaydır |
| Merge sort | $\Theta(n \log n)$ | Hayır ($\Theta(n)$ ek alan) | Böl ve yönet, two-finger merge |
@fig-sort-comparison aynı dört satırı, çalışma süresini büyümeye göre renklendirerek görselleştirir.
```{python}
#| label: fig-sort-comparison
#| fig-cap: "Dört sıralama algoritmasının karşılaştırması (§11): her satır bir algoritma, sütunlar **çalışma süresi**, **yerinde mi?** ve **yöntem**. Çalışma süresi büyümeye göre renklenir — permütasyon sıralama $\\Omega(n! \\cdot n)$ (tüm permütasyonları deneyen kaba kuvvet, en kötü; koyu amber); seçmeli ve eklemeli sıralama $\\Theta(n^2)$ (amber); birleştirmeli sıralama $\\Theta(n\\log n)$ (yeşilimsi-slate = en iyi). \"Yerinde mi?\" sütunu ek alan kullanımını gösterir: seçmeli/eklemeli **Evet** (kopya üstünde $O(1)$ ek alanla swap), permütasyon ve birleştirmeli **Hayır** (merge $\\Theta(n)$ ek alan ister). $n = 10^6$ ölçeğinde $n^2$ ile $n\\log n$ arasındaki fark yaklaşık bir milyon kattır — bu yüzden büyük veride birleştirmeli sıralama seçilir."
#| fig-width: 11
#| fig-height: 5.2
# fig-sort-comparison: §11 4 algoritma × (süre / yerinde / yöntem) renkli tablo.
# draw_sort_comparison deterministik sabit satırları içerir (Notion §11 birebir):
# Permutation Ω(n!·n) Hayır · Selection Θ(n²) Evet · Insertion Θ(n²) Evet ·
# Merge Θ(n log n) Hayır. Süre rengi büyüme kalitesine göre (amber yavaş, yeşilimsi iyi).
fig, ax = plt.subplots(figsize=(11, 5.2))
fig.patch.set_facecolor(COL_WHITE)
draw_sort_comparison(ax)
ax.set_title(
"Dört sıralama algoritması: çalışma süresi · yerinde mi? · yöntem",
color=COL_TEXT, fontsize=12.5, pad=16,
)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — n² vs n log n Ölçek Sezgisi"}
Tablodaki $\Theta(n^2)$ ile $\Theta(n \log n)$ arasındaki fark, soyut değil — pratik bir uçurumdur:
- **Ölçek hesabı:** $n = 10^6$'da $n^2 = 10^{12}$, ama $n \log n \approx 10^6 \times 20 = 2 \times 10^7$. Oran $\approx 50.000$ kat; saniyeler ile günler arasındaki fark. $n = 10^9$'da uçurum bir milyon kata yaklaşır.
- **İleriye → ML veri ön-işleme:** Milyonlarca örneği sıralamak (deduplication, tokenizasyon istatistikleri, nearest-neighbor için ön-sıralama) gerçek bir maliyettir; "hangi sıralama / hangi veri yapısı" kararı eğitim pipeline'ının darboğazını belirler.
- **Disiplin:** Bir builder, $n$'in büyüklük mertebesini görür görmez hangi karmaşıklığın "geçeceğini" tahmin eder: $n \le 10^4$ ise $n^2$ tolere edilebilir; $n \ge 10^6$ ise $n \log n$ (veya daha iyisi) zorunludur. Bu tablo o sezginin temelidir.
:::
## Bu Dersin Özeti {#sec-ozet-d04}
1. **Küme (set)** arayüzü öğeleri **anahtara** göre tutar: find, insert, delete, find_min/max.
2. **Sırasız dizi** ile küme: tüm işlemler $O(n)$ (find = lineer tarama).
3. **Sıralı dizi** ile küme: find_min/max $O(1)$, find $O(\log n)$ (ikili arama) — ama kurma maliyeti $O(n \log n)$.
4. **Sıralama sözlüğü:** yıkıcı (destructive), yerinde (in-place).
5. **Permutation sort** $\Omega(n! \cdot n)$ — kullanılamaz kötü örnek.
6. **Selection/Insertion sort** $\Theta(n^2)$; özyineleme + substitution ile analiz.
7. **Merge sort** $\Theta(n \log n)$: böl-yönet + lineer two-finger birleştirme; $T(n) = 2T(n/2) + \Theta(n)$.
::: {.callout-important title="Tek Bir Cümle"}
Sıralama, bir kümeyi "anahtarla aranabilir" kılmanın bedelidir; merge sort bu bedeli böl-yönet ile $O(n \log n)$'e indirir.
:::
## Kontrol Soruları {#sec-sorular-d04}
::: {.callout-note collapse="true" title="Soru 1: Sırasız dizi ile sıralı dizi, küme arayüzünü gerçekleştirirken hangi işlemlerde ayrışır?"}
**Cevap:**
İkisinde de insert/delete temelde $O(n)$'dir. Ayrışma **aramada** olur: sırasız dizide `find(k)` ve find_min/max her zaman $O(n)$ (lineer tarama); sıralı dizide `find(k)` ikili aramayla $O(\log n)$, find_min/max ise $O(1)$ (ilk/son öğe). Karşılığında sıralı diziyi *kurmak* $O(n \log n)$ sıralama gerektirir — tek seferlik bir ön maliyet.
:::
::: {.callout-note collapse="true" title="Soru 2: Permutation sort neden Ω(n!·n) ile ifade edilir, O(...) ile değil?"}
**Cevap:**
Solomon permütasyonları üreten algoritmayı tanımlamaz, "sihirli" bir fonksiyon varsayar. Ama emin olduğu şey: $n$ öğenin $n!$ permütasyonu vardır ve her birinin sıralılığını kontrol etmek $\Theta(n)$'dir, dolayısıyla iş *en az* $n! \cdot n$ kadardır. "En az" bir **alt sınırdır** → $\Omega$. Kesin çalışma süresi verilmediği için $O$ (üst sınır) iddia edilmez.
:::
::: {.callout-note collapse="true" title="Soru 3: Selection sort için T(n) = T(n−1) + Θ(n) yinelemesi neden Θ(n²) verir? Substitution ile göster."}
**Cevap:**
$T(n) = cn^2$ tahmin et ve yerine koy: $cn^2 \stackrel{?}{=} c(n-1)^2 + \Theta(n)$. Sağ taraf $= c(n^2 - 2n + 1) + \Theta(n) = cn^2 - 2cn + c + \Theta(n)$. İki taraftan $cn^2$ çıkar: $0 \stackrel{?}{=} -2cn + c + \Theta(n)$. Bu, $\Theta(n) = 2cn - c$ demektir; sol ve sağ aynı mertebede (lineer), dolayısıyla tutarlı. Tahmin doğrulandı: $T(n) = \Theta(n^2)$. Sezgi: $n + (n-1) + \dots + 1 = n(n+1)/2 = \Theta(n^2)$.
:::
::: {.callout-note collapse="true" title="Soru 4: Merge sort neden selection sort'tan asimptotik olarak hızlıdır? Yinelemeleri karşılaştır."}
**Cevap:**
Selection sort: $T(n) = T(n-1) + \Theta(n)$ → her adımda problemi *bir* azaltır, $n$ seviye $\times \Theta(n) = \Theta(n^2)$. Merge sort: $T(n) = 2T(n/2) + \Theta(n)$ → her adımda problemi *yarıya* böler, yalnızca $\log n$ seviye $\times$ her seviyede toplam $\Theta(n)$ iş $= \Theta(n \log n)$. Farkın kaynağı: lineer azaltma ($n$ seviye) yerine logaritmik bölme ($\log n$ seviye).
:::
## Egzersizler {#sec-egzersizler-d04}
**Egzersiz 1.** Sıralı bir dizide `find_prev(k)` ve `find_next(k)` işlemlerini tasarla. İkili aramayla $O(\log n)$'de nasıl yapılır?
**Egzersiz 2.** `prefix_max` için tümevarımla doğruluğu tam yaz: taban durum ($i = 0$) ve tümevarım adımı ($i$'deki öğe ile 0..i−1'in en büyüğünün maksimumu).
**Egzersiz 3.** Insertion sort'u özyinelemeli yaz ve $T(n) = T(n-1) + O(n)$ yinelemesini substitution ile $\Theta(n^2)$'ye bağla. En iyi durum (zaten sıralı girdi) ne olur?
**Egzersiz 4.** Python'da merge sort ile yerleşik `sorted`'ı farklı $n$'lerde `time.perf_counter` ile karşılaştır; $n \log n$ eğrisini gözlemle:
```python
import time, random
def measure(n):
A = [random.random() for _ in range(n)]
t0 = time.perf_counter()
sorted(A)
print(n, time.perf_counter() - t0)
for n in (10_000, 100_000, 1_000_000):
measure(n)
```
**Egzersiz 5.** İki sıralı listeyi birleştiren two-finger `merge` fonksiyonunu yaz ve neden $\Theta(n)$ olduğunu (her öğeye bir kez dokunulduğunu) açıkla.
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d04}
**Ders 4 (L4): Hashing**
Jason Ku ile, sıralı dizinin $O(\log n)$ aramasını bile geçen bir yapıya — **hash tablosuna** — geçiyoruz: find/insert/delete *beklenen* $O(1)$. Sıralamadan vazgeçip anahtarları doğrudan adreslere "serpiştirmenin" maliyeti ve riski (çakışma) ele alınır. (Not: ders akışında araya **Problem Oturumu 2** girer.)
::: {.callout-warning title="Ders 4 Öncesi Yapılacak"}
- Bu dersin egzersizlerini, özellikle Egzersiz 4'ü (merge sort ölçümü) çöz.
- Sıralama tablosunu (Bölüm 11) ezberden çizebil.
- Ana cümleyi tekrar oku: *"Sıralama, bir kümeyi anahtarla aranabilir kılmanın bedelidir."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet-d04}
| Kavram | Tanım | Sayfada |
|---|---|---|
| **Küme (set) arayüzü** | Anahtarla erişilen koleksiyon (find, insert, find_min) | Böl. 2 |
| **Sırasız dizi** | Küme gerçekleştirimi; tüm işlemler $O(n)$ | Böl. 4 |
| **Sıralı dizi + ikili arama** | find $O(\log n)$, find_min/max $O(1)$; kurma $O(n \log n)$ | Böl. 5 |
| **Yıkıcı / yerinde** | Destructive: `A`'yı ezer; in-place: ek $O(1)$ alan | Böl. 6 |
| **Permutation sort** | Tüm permütasyonlar; $\Omega(n! \cdot n)$ | Böl. 7 |
| **Selection sort** | En büyüğü seç-sona-koy; $\Theta(n^2)$ | Böl. 8 |
| **Merge sort** | Böl-yönet + two-finger merge; $\Theta(n \log n)$ | Böl. 10 |
| **Substitution yöntemi** | Yineleme için form tahmin et, yerine koy, doğrula | Böl. 8, 10 |
| **Two-finger merge** | İki sıralı listeyi $\Theta(n)$'de birleştirme | Böl. 10 |
## Builder ve OMSCS Bağlantıları {#sec-ml-baglantilar-d04}
::: {.callout-tip title="6 köprü"}
Bu ders, ileri algoritma ve veri mühendisliğinin temel dilini kurar — köprülerin özeti:
1. **Set arayüzü** → Python `dict`/`set`, veritabanı tabloları: anahtarla erişim her veri katmanının temeli.
2. **Sıralı dizi + ikili arama** → veritabanı indeksleri (B-tree), arama motoru sıralı gönderim listeleri: $O(\log n)$ sorgu.
3. **Böl ve yönet (merge sort)** → OMSCS CS 6515'in çekirdek paradigması; quicksort, FFT, en yakın çift hep aynı kalıp.
4. **Substitution / yineleme analizi** → her özyinelemeli algoritmanın çalışma süresini kapalı forma bağlama disiplini.
5. **Destructive / in-place** → bellek-kısıtlı sistemler: yerinde sıralama, ek tampon ayıramayan gömülü ortamlarda kritik.
6. **$n^2$ vs $n \log n$** → ölçek sezgisi: $n = 10^6$'da $n^2$ bir milyon kat daha yavaş; "hangi sıralama" kararının pratik bedeli.
:::
---
::: {.callout-important title="Tek bir şey alıp gideceksen"}
Bir kümeyi sıralı tutmak aramayı $O(\log n)$'e indirir, ama sıralamanın kendisi $O(n \log n)$'dir. Merge sort bu bedeli "böl ve yönet" ile öder; ve $T(n) = 2T(n/2) + \Theta(n)$ yinelemesi, tüm verimli özyinelemeli algoritmaların habercisidir.
:::