flowchart TD
A["Ders 2: Veri Yapıları ve Dinamik Diziler"] --> B["Arayüz (ne)"]
A --> C["Veri Yapısı (nasıl)"]
C --> D["Dizi (sequence) arayüzü"]
D --> E["Statik Dizi<br/>rastgele erişim O(1)<br/>insert/delete Θ(n)"]
D --> F["Bağlı Liste<br/>uç işlemi O(1)<br/>erişim O(i)"]
D --> G["Dinamik Dizi<br/>ikisinin en iyisi<br/>insert_last amortize O(1)"]
G --> H["İkiye-katlama + geometrik seri"]
H --> I["Amortize analiz<br/>nadiren pahalı, çoğu ucuz"]
classDef root fill:#fef3c7,stroke:#b45309,stroke-width:3px,color:#1f2937
classDef branch fill:#f3f4f6,stroke:#374151,stroke-width:2px,color:#1f2937
classDef leaf fill:#ffffff,stroke:#9ca3af,stroke-width:1px,color:#1f2937
class A root
class B,C,D branch
class E,F,G,H,I leaf
3 Veri Yapıları ve Dinamik Diziler
Arayüz vs veri yapısı, statik dizi / bağlı liste / dinamik dizi, geometrik seri ve amortize analiz
NotBölüm bilgisi
- Demaine’in videosu: YouTube — Lecture 2: Data Structures and Dynamic Arrays (≈50 dk)
- OCW sayfası: MIT 6.006 Lecture 2: Data Structures and Dynamic Arrays
- Seri: MIT 6.006 — Introduction to Algorithms (Spring 2020) — Ders 2
- Hocalar: Erik Demaine (Jason Ku, Justin Solomon)
- Okuma süresi: ≈24 dk
3.1 Bu Derste Ne Var?
Ders 1 problem ile algoritma arasındaki farkı kurdu. Bu ders, aynı ayrımı veri tarafında yapar: arayüz (interface) ile veri yapısı (data structure) arasındaki fark. Erik Demaine, dersin ilk veri yapıları bölümüne enerjik bir girişle başlar.
Üç temel kavram bu derste yan yana gelir:
- Arayüz vs veri yapısı — arayüz ne yapılacağını (desteklenen işlemler), veri yapısı nasıl yapılacağını (gerçekleştirim) söyler.
- Dizi (sequence) arayüzü — \(n\) öğeyi sıralı tutma; statik dizi, bağlı liste ve dinamik dizi ile çözülür.
- Amortize analiz — dinamik dizinin (Python
list) neden sona eklemede amortize \(O(1)\) olduğunun ispatı.
“an interface says what you want to do. A data structure says how you do it.” — Demaine, 1:18
İpucuBuilder Notu — Arayüz/Implementasyon Ayrımı ve PyTorch
Demaine’in arayüz/veri yapısı ayrımı, modern ML kütüphanelerinin temel tasarım desenidir — aynı sözleşme (interface), değişebilir gerçekleştirim (implementation):
- İleriye → PyTorch
nn.Module: Bir katmanınforward()arayüzü ne hesaplanacağını söyler; arkadaki tensör depolaması, bellek düzeni ve çekirdek (kernel) seçimi nasıl yapılacağını. Aynınn.LinearAPI’si CPU, CUDA veya MPS backend’iyle çalışır — arayüz sabit, veri yapısı değişir. - Geriye → Python (Phase 1): Demaine açıkça söyler, bu giriş dersleri “Python’ın nasıl gerçekleştirildiğini” anlatır. Python
list= dinamik dizi; bu ders onun iç mekanizmasını açar. - Geriye → word RAM (Ders 1): statik dizinin \(O(1)\) erişimi doğrudan Ders 1’in word RAM modeline dayanır (ardışık bellek + rastgele erişim).
Tek cümle: Aynı arayüzü farklı veri yapıları çözer; doğru seçim, hangi işlemin ne sıklıkta çağrıldığına bağlıdır.
3.2 Arayüz mü, Veri Yapısı mı?
Demaine, bir programcının API, eski kuşak bir algoritmacının ADT (abstract data type) dediği şeyi arayüz olarak adlandırır. Ayrım nettir:
- Arayüz = ne: hangi veriyi saklayabilirsin, hangi işlemleri destekler, bu işlemler ne anlama gelir. Bu bir spesifikasyondur (problem ifadesinin veri karşılığı).
- Veri yapısı = nasıl: verinin somut gösterimi ve işlemleri destekleyen algoritmalar. Algoritmalar tam da burada devreye girer.
“The same problem can be solved by many different data structures.” — Demaine, 3:23
Veriyi sadece saklamak sıkıcıdır (bir dosyaya atarsın). İşi ilginç kılan, o veri üzerindeki işlemlerdir — ve farklı veri yapıları bazı işlemleri diğerlerinden hızlı destekler. Doğru veri yapısı, ne için kullanacağına bağlıdır.
3.3 İki Temel Arayüz: Küme ve Dizi
6.006 iki ana arayüze odaklanır:
- Küme (set): öğeleri değerlerine (anahtar/key) göre tutar — sıralı tutma, bir değeri arama. “Set” bir matematikçi için başka, bir Python programcısı için başka şey ifade eder.
- Dizi (sequence): öğeleri belirli bir sırada tutar — örneğin 5, 2, 9, 7 sayılarını bu sırayla. Python’da bunu bir
listile saklarsın; sırayı korur.
Bu ders dizi arayüzüne odaklanır (küme arayüzüne sonda değinilir, Ders 3-4’te derinleşir). İki temel araç vardır: diziler (arrays) ve işaretçiler (pointers / bağlı yapılar). Bugün ikisini de göreceğiz.
3.4 Statik Dizi Arayüzü
En basit dizi arayüzü statik dizidir: öğe sayısı \(n\) değişmez (ama öğelerin kendisi değişebilir). Öğeler \(x_0, x_1, \ldots, x_{n-1}\) olarak etiketlenir (Python’daki gibi 0’dan başlar). Desteklenen işlemler:
- build(x): verilen öğelerden \(n\) boyutlu yeni bir dizi kur.
- length(): sabit \(n\) değerini döndür.
- iter(): öğeleri \(x_0\)’dan \(x_{n-1}\)’e sırayla üret (en az lineer zaman).
- get_at(i): \(i\)’inci öğeyi (\(x_i\)) döndür.
- set_at(i, x): \(i\)’inci öğeyi yeni bir değerle değiştir.
build ve iter doğası gereği tüm öğelere dokunur → \(\Theta(n)\). Asıl ilginç olan, dizinin ortasına dinamik erişim: get_at ve set_at.
3.5 Statik Dizi (Static Array)
Bu arayüzün doğal çözümü statik dizidir (Python’da list denir; Demaine “array” demeyi tercih eder). Python’da aslında statik dizi yoktur — yalnızca dinamik diziler vardır — ama kavramı anlamak gerekir.
Statik dizi, belleğin ardışık (consecutive) bir parçasıdır. Ders 1’in word RAM modeline dayanır: bellek, \(w\)-bitlik word’lerden oluşan bir dizidir ve herhangi bir word’e sabit zamanda rastgele erişilebilir. Bir diziye \(i\) indeksinden erişmek, basit bir ofset aritmetiğidir (Şekil 3.2): dizinin başlangıç adresi (Python’da id(array)) artı \(i\).
“as long as I store my array consecutively in memory, I can access the array in constant time.” — Demaine, 11:26
Bu yüzden statik dizi, get_at ve set_at işlemlerini \(O(1)\) zamanda çözer. length de \(O(1)\)’dir (\(n\)’i adresle birlikte saklarız). build ve iter \(\Theta(n)\)’dir. Bu çalışma süreleri optimaldir — basit ama bu modele giderek daha çok ihtiyaç duyacağız.
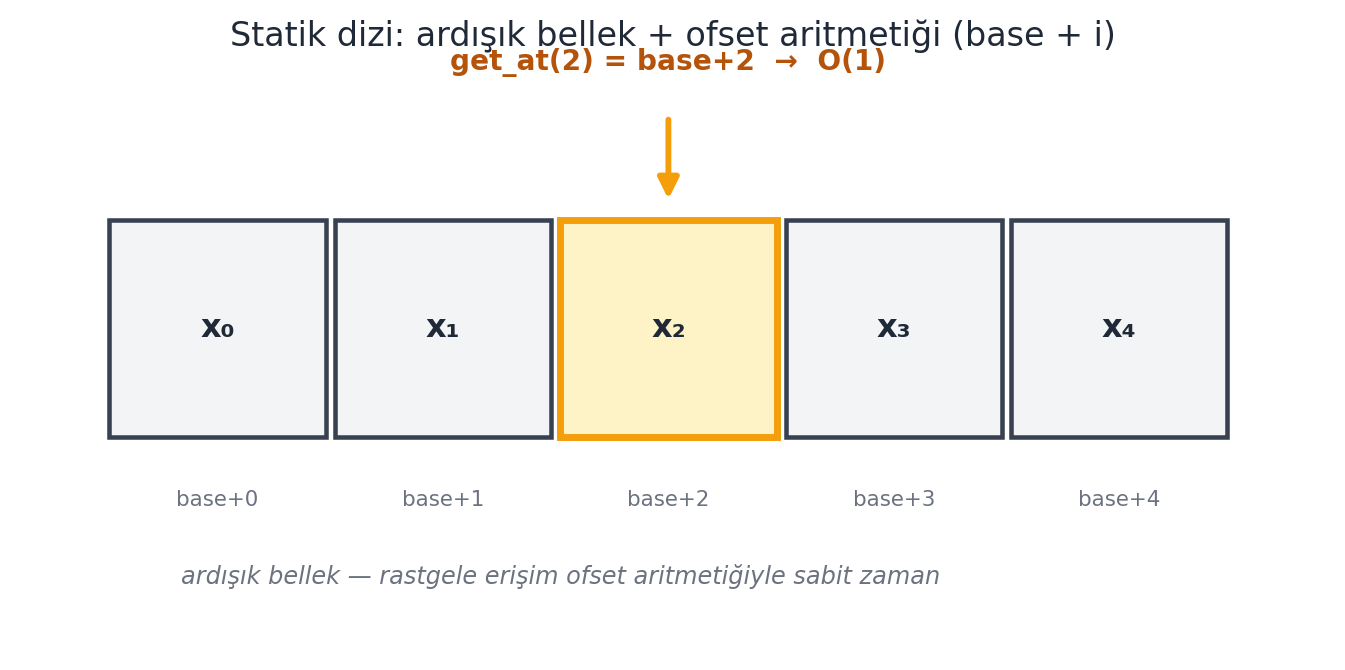
base + i. Bu yüzden get_at(i) herhangi bir indekse tek hamlede ulaşır — \(O(1)\) rastgele erişim (amber vurgulu \(x_2\)). Bu, Ders 1’in word-RAM modeline dayanır: bir adres tek word’e sığar ve bellek hücresine sabit zamanda erişilir. Bedeli, dizinin boyutunun sabit olmasıdır.
3.6 Bellek Ayırma Modeli ve Word Boyutu
build’in nasıl çalıştığını tanımlamak için bellek ayırma modeli gerekir. En temiz varsayım: \(n\) boyutlu bir diziyi \(\Theta(n)\) zamanda ayırabiliriz.
“the cleanest one is just to assume that you can allocate an array of size n in theta n time.” — Demaine, 13:09
Neden sabit değil de lineer? Çünkü ayrılan bellek başlangıçta belirsizdir; onu 0’larla başlatmak lineer maliyet ister. Bu modelin güzel bir yan etkisi: kullandığın yer (space), kullandığın zamandan (time) fazla olamaz. Sonsuz boyutlu bir dizi ayırıp birkaç öğe kullanmak gerçekçi değildir — bellek ayırmanın bir bedeli olmalıdır.
Word boyutu (\(w \geq \log n\)): Dizi erişiminin sabit zaman olması için, word boyutu \(w\) en az \(\log n\) kadar olmalıdır. Sebep: \(n\) öğeyle çalışıyorsak, en azından onları adresleyebilmeliyiz — “\(i\)’inciyi ver” diyebilmek için \(i\) sayısını bir word’e sığdırmalıyız. Bu yüzden \(w \geq \log n\).
“the word size has to grow with n… at least as fast as log n.” — Demaine, 15:13
Bu, gerçek makineler (sabit boyut) ile teori (ölçeklenebilirlik) arasında köprü kurar: gerçekte daha büyük girdi için daha çok RAM alırsın; teoride de \(w\), \(n\) ile birlikte asimptotik olarak büyür.
3.7 Dinamik Dizi Arayüzü
Statik arayüze iki dinamik işlem ekleriz: dizinin ortasına insert_at ve ortasından delete_at. insert_at, set_at’ten farklıdır: hiçbir bilgiyi silmez; eklenen konumdan sonraki tüm öğeler indekslerini bir kaydırır (\(n' = n+1\)).
İndeksleme inceliği önemlidir: insert_at(2, x)’ten sonra get_at(2) yeni öğeyi, get_at(3) eski \(x_2\)’yi döndürür. Bu izlemesi zordur ama uçlarda (baş/son) ekleme/silme yaparken çok kullanışlıdır. Bu yüzden özel durumları tanımlarız: insert/delete first ve last, get/set first ve last.
“insert_last doesn’t change the indices of any of the old items.” — Demaine, 19:59
Kritik gözlem: insert_last eski öğelerin indekslerini değiştirmez (güzel özellik); insert_first hepsini \(+1\) kaydırır. Tüm dinamik dizi arayüzünü sabit zamanda çözmek imkânsızdır (ispatlanabilir), ama özel durumları — yalnızca uçlardan ekleme/silme — verimli çözebiliriz. İşte bu yüzden özel durumlar ilginçtir.
3.8 Bağlı Liste (Linked List)
Dinamik diziyi çözen ilk veri yapısı bağlı listedir. Öğeleri düğümlerde (node) saklarız; her düğümde bir item alanı ve bir next (sonraki) işaretçisi vardır — iki sınıf değişkenli bir nesne gibi. Düğümler next işaretçileriyle birbirine bağlanır; sıra, bu işaretçilerle örtük olarak temsil edilir (Şekil 3.3). Veri yapısı bir head (baş) işaretçisiyle temsil edilir.
Bu, işaretçi tabanlı bir veri yapısıdır (statik dizi ise dizi tabanlıydı). İşaretçiler tek bir word’e sığar, bu yüzden word RAM modelinde sabit zamanda dereference edilebilir (işaret edilen düğüme bakılabilir). Düğümler bellekte rastgele sırada durur — işaretçiler aslında dev bellek dizisindeki indekslerdir.
“linked list, insert- and delete_first are constant time.” — Demaine, 30:41
Bağlı listenin uçlarda dinamik olması güçlüdür: yeni bir baş öğe eklemek (insert_first) sabit zamandır — yeni düğüm ayır, next’ini eski başa bağla, head’i güncelle. Ancak rastgele erişim zayıftır: \(i\)’inci öğeye ulaşmak için \(i\) kez next takip etmek gerekir → get_at/set_at \(O(i)\), en kötü durumda \(\Theta(n)\). Statik dizinin tam tersi: dizi rastgele erişimde iyi, bağlı liste uçlarda dinamiklikte iyidir.
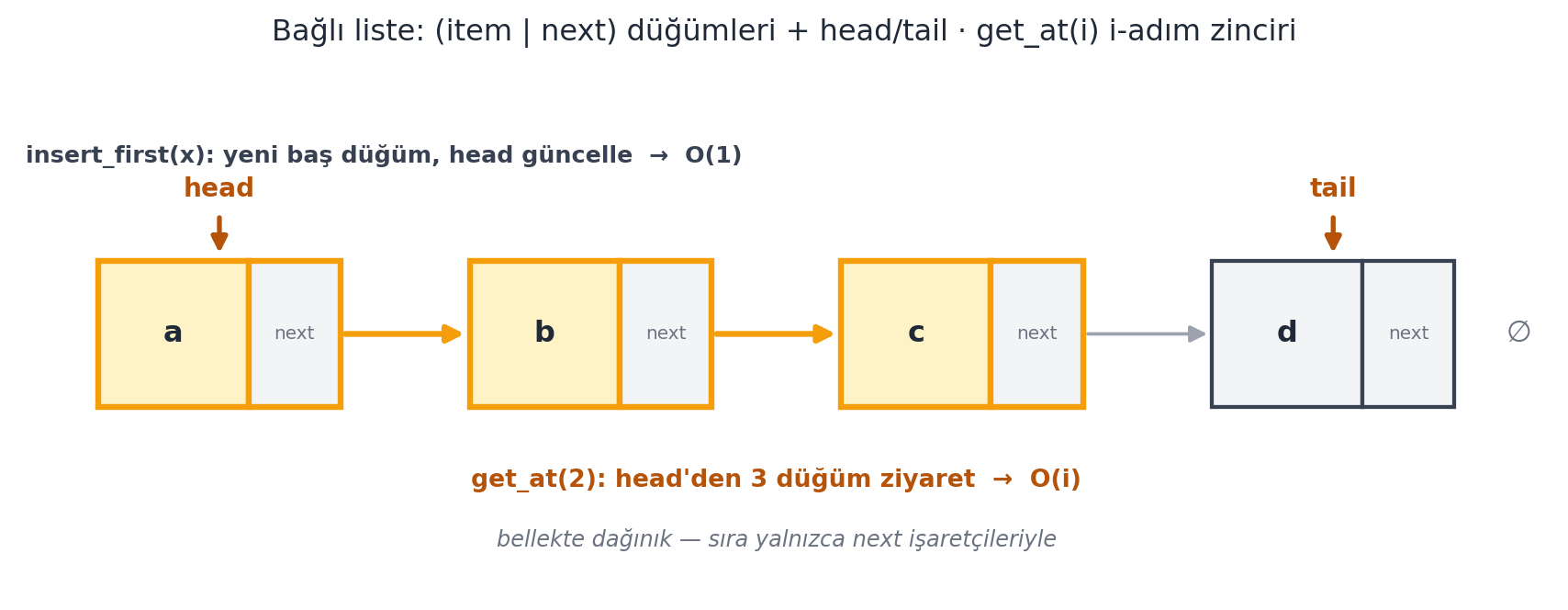
next işaretçileriyle örtük tutulur (bellekte düğümler dağınık olabilir). head ilk, tail son düğüme işaret eder (\(\S 8\) augmentation) → insert_first ve insert_last \(O(1)\). Rastgele erişim zayıftır: get_at(2) head’den next zincirini \(i\) kez takip eder — burada \(3\) düğüm ziyareti (amber zincir) → \(O(i)\). Son düğümün next’i \(\varnothing\) (None).
3.9 Veri Yapısı Zenginleştirme (Augmentation)
Küçük bir bulmaca: bağlı listede get_last’ı sabit zamanda nasıl çözeriz? Cevap: son öğeye bir işaretçi sakla (genelde tail denir). Bu, veri yapısı zenginleştirmedir (augmentation): yapıya ekstra bilgi ekleyip onu her zaman güncel tutmak.
“data structure augmentation, where we add some extra information to the data structure” — Demaine, 33:09
tail işaretçisiyle get_last ve insert_last \(O(1)\) olur. delete_last ise daha zordur — onun için çift bağlı liste (doubly linked list, her düğümde bir de prev işaretçisi) gerekir. Zenginleştirmenin bedeli: yapıyı değiştiren her işlemde ekstra bilgiyi (örneğin tail) güncel tutmak zorundasın.
İpucuBuilder Notu — Augmentation ve Veritabanı İndeksleri
Augmentation — “yapıya ekstra bilgi ekle, onu güncel tut, bir sorguyu hızlandır” — sistem mühendisliğinin en yaygın takasıdır:
- İleriye → veritabanı indeksleri: Bir tabloya B-ağacı veya hash indeksi eklemek tam olarak augmentation’dır: aramayı \(O(n)\) tam-taramadan \(O(\log n)\)’e (veya \(O(1)\)’e) indirir. Bedeli, tail’i güncel tutmak gibi — her
INSERT/UPDATE/DELETEindeksi de güncellemek zorundadır (yazma daha pahalı, okuma çok daha ucuz). - Sezgi → skip-list / B-tree: tail ve prev işaretçileri, daha zengin augmentation’ların (skip-list’in atlama katmanları, B-ağacının iç düğüm anahtarları) ilk basamağıdır; hepsi “ekstra yapısal bilgi sakla, navigasyonu hızlandır” fikrinin türevidir.
- İleriye → ML feature store: Önceden hesaplanmış (materialized) öznitelik tabloları, çıkarım anında yeniden hesaplamayı önlemek için tutulan augmentation’lardır — güncel tutma maliyeti (cache invalidation), tail güncellemesiyle aynı disiplini ister.
3.10 Statik Dizi mi, Bağlı Liste mi?
İki veri yapısı birbirini tamamlar:
- Statik dizi: get_at/set_at sabit zaman \(O(1)\) (rastgele erişimde mükemmel), ama insert/delete her yerde \(\Theta(n)\) (kaydırma veya yeniden ayırma + kopyalama gerekir). Sona ekleme bile zordur, çünkü ayrılan dizi büyütülemez — yeni bir dizi ayırıp her şeyi kopyalamak \(\Theta(n)\)’dir.
- Bağlı liste: insert/delete_first sabit zaman \(O(1)\) (uçlarda dinamiklikte iyi), ama get_at/set_at \(O(i)\), en kötü \(\Theta(n)\) (rastgele erişimde kötü).
Demaine’in deyişiyle: diziler statik rastgele erişim için, bağlı listeler dinamik uç işlemleri için iyidir. Hiçbiri her ikisini birden iyi yapmaz. Hedefimiz, ikisinin de güçlü yanlarını birleştiren bir yapı. Bu tercihin gerçek donanımdaki bir başka boyutu da bellek yerelliğidir (Şekil 3.4): aynı asimptotik tarama, ardışık dizide bağlı listeden çok daha hızlı koşar.
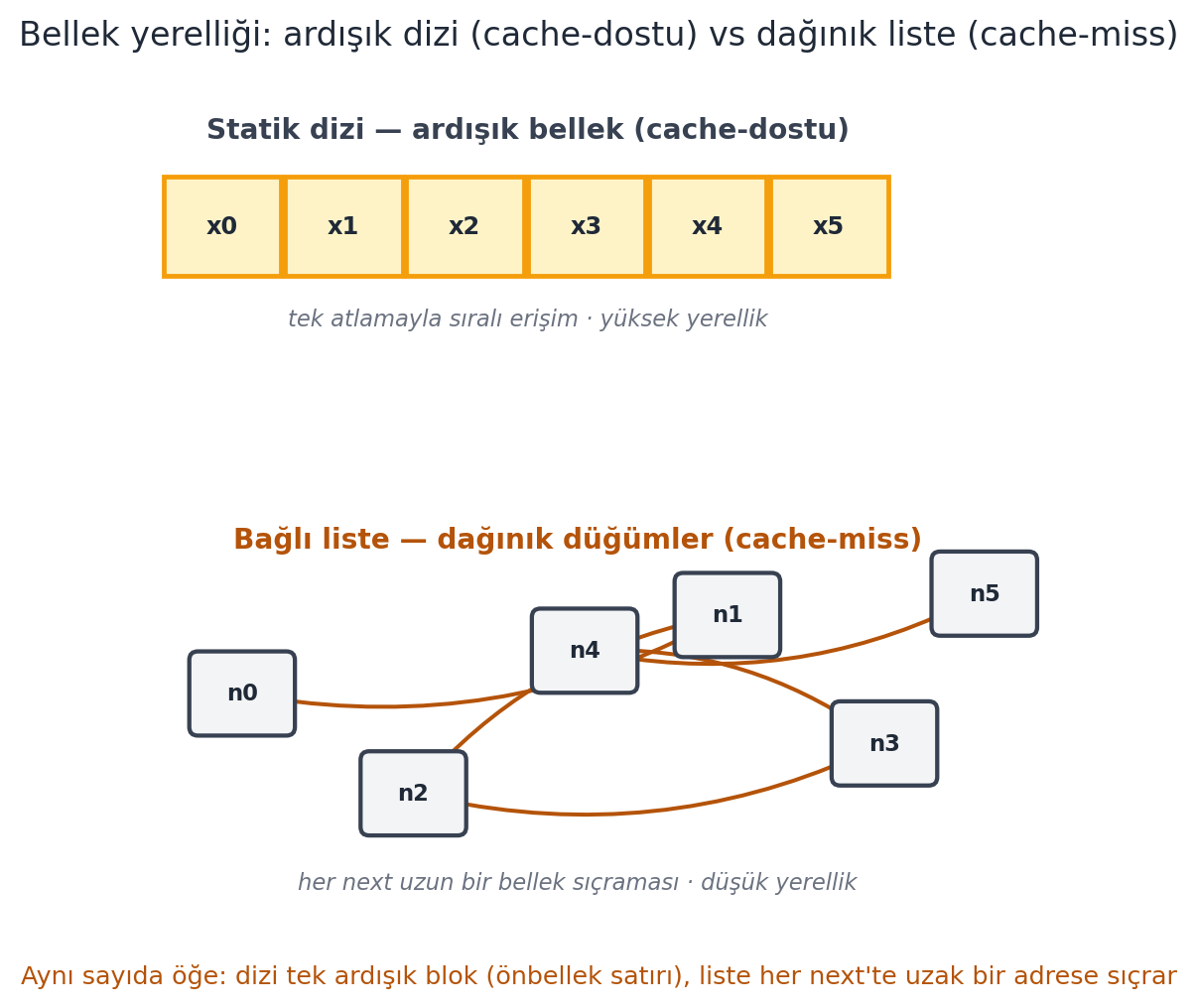
next işaretçisi uzak bir adrese sıçrar (amber oklar), her erişim önbellek-ıskası (cache-miss) riski taşır. Aynı asimptotik \(\Theta(n)\) tarama, gerçek donanımda dizide çok daha hızlıdır — düşük yerellik bağlı listeyi cezalandırır.
3.11 Dinamik Dizi (Dynamic Array)
Çözüm dinamik dizidir — ve bu tam olarak Python’ın list dediği şeydir.
“another way to describe what these introductory lectures are about is telling you about how Python is implemented.” — Demaine, 34:19
Fikir, statik dizinin katı kuralını gevşetmektir: ayrılan dizinin boyutu tam \(n\) olmak zorunda değil; kabaca \(n\) olsun. Algoritma dilinde “kabaca” = sabit çarpanları at. Diziyi boyutu \(\Theta(n)\) ve \(n\)’den büyük-eşit tutarız (örneğin \(2n\)).
“the size of the array is theta n– probably also greater than or equal to n.” — Demaine, 36:11
Yapı, bir dizi artı bir length (gerçek öğe sayısı) tutar. length, dizinin gerçek boyutu size’dan küçük-eşittir; ilk length konum veriyi, kalanı boş yeri temsil eder. insert_last basittir: a[length] = x, sonra length’i artır → \(O(1)\). Ama bir sorun var: length = size olduğunda boş yer kalmaz. İşte o zaman diziyi büyütmek gerekir — sonraki bölümün konusu.
3.12 Dizi Büyütme ve Geometrik Seri
length = size olduğunda diziyi büyütmek gerekir. Ne kadar? İki doğal seçenek:
- Sabit ekleme (size + 5): Kötü. Her 5 adımda bir lineer yeniden ayırma → işlem başına hâlâ lineer zaman. Statik dizinin “her seferinde yeniden ayır” sorununu sadece sabit çarpanla iyileştirir.
- Sabit çarpan (2 × size): İyi. Diziyi her dolduğunda iki katına çıkar.
Çalışılan Örnek — Doubling’in Toplam Maliyeti
Boş bir diziden başlayıp \(n\) kez insert_last yapalım (size = 1 başlasın). Yeniden boyutlandırmalar \(n = 1, 2, 4, 8, 16, \ldots\) değerlerinde, yani 2’nin kuvvetlerinde olur (çünkü ikiye katlıyoruz; Şekil 3.5). Her resize, ayırma + kopyalama nedeniyle lineerdir. Toplam resize maliyeti:
\[1 + 2 + 4 + 8 + \cdots + (\approx n) = \sum_i 2^i \quad (i = 0 \text{'dan} \approx \log_2 n \text{'e})\]
Bu bir geometrik seridir. Kimliği: \(1 + 2 + 4 + \cdots + 2^k = 2^{k+1} - 1\). Geometrik seriler son terim tarafından domine edilir:
“Geometric series are dominated by the last term” — Demaine, 45:46
Son terim \(2^{\log_2 n} = n\) olduğundan, toplam \(\Theta(n)\)’dir. Yani \(n\) işlem için toplam yeniden boyutlandırma maliyeti yalnızca \(\Theta(n)\) — işlem başına “kabaca sabit”.
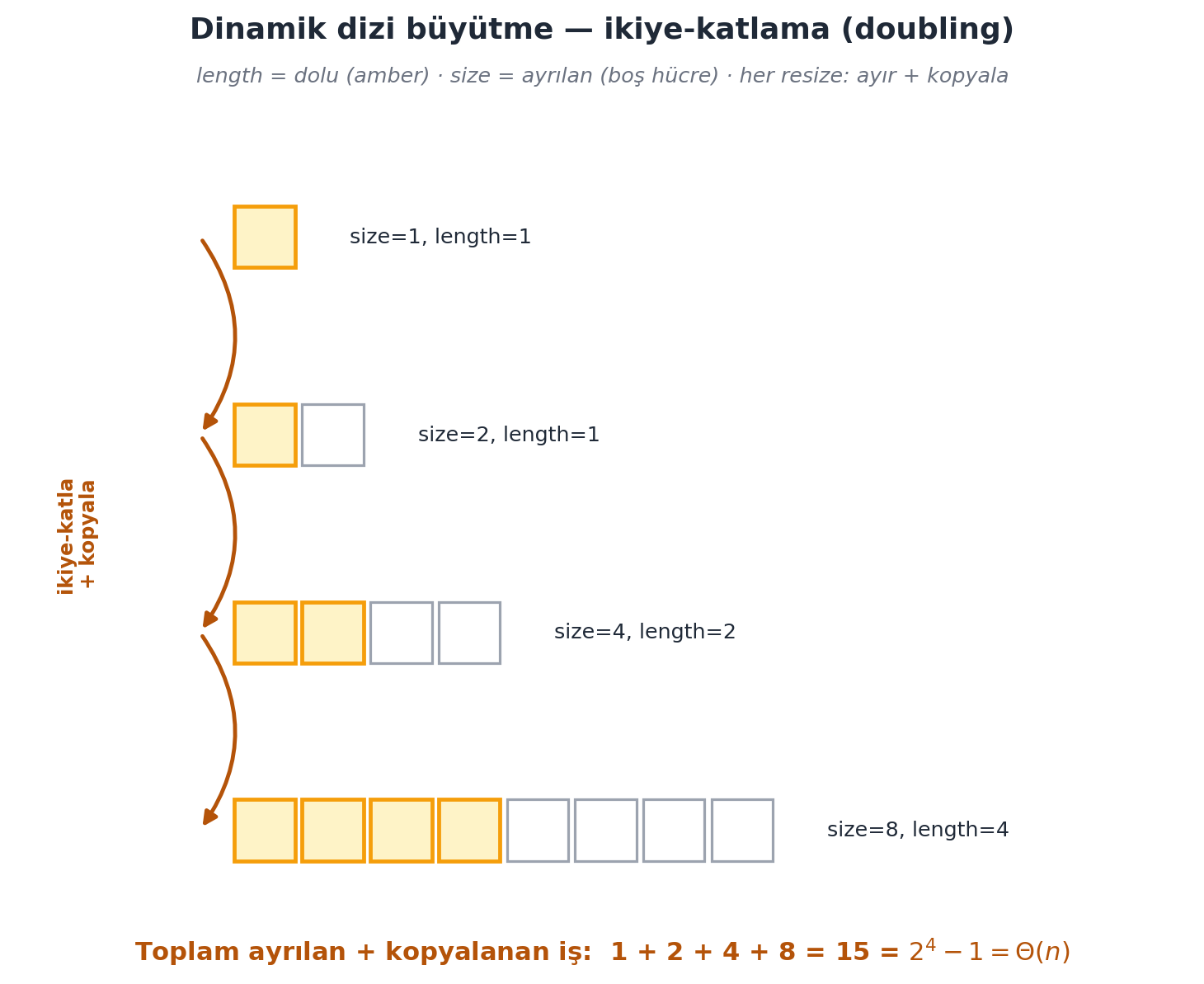
length == size olunca yeni (iki kat) dizi ayrılır ve eski öğeler taşınır (\(\Theta(\text{length})\)). Toplam ayrılan + kopyalanan iş bir geometrik seridir: \(1 + 2 + 4 + 8 = 15 = 2^{4} - 1\) — son terim toplamı domine eder, bu yüzden \(n\) append toplam \(\Theta(n)\)’dir ve insert_last amortize \(O(1)\) olur.
İpucuBuilder Notu — İkiye-Katlama Her Yerde
Demaine’in “dolunca iki katına çık” stratejisi, tek bir veri yapısının özelliği değil — ölçeklenen sistemlerin tekrar eden bir motifidir:
- İleriye → PyTorch
DataLoadervetorch.cat: Boyutu önceden bilinmeyen bir tampona (buffer) tensör biriktirirken, kapasitenin geometrik büyütülmesi (hertorch.catrealloc’unda sabit çarpan) toplam kopya işini \(\Theta(n)\)’de tutar; sabit ekleme olsa \(\Theta(n^2)\)’ye patlardı. - İleriye → exponential backoff: Başarısız bir isteği yeniden denerken bekleme süresini ikiye katlamak (1s, 2s, 4s, 8s), aynı geometrik seri sezgisidir — toplam bekleme son terimle domine olur, sistem yükü sınırlı kalır.
- İleriye → batch-size / LR taraması: Hiperparametre ararken batch boyutunu veya öğrenme oranını ikiye katlayarak (32, 64, 128, …) geometrik bir ızgara taramak, lineer ızgaraya göre çok daha geniş bir aralığı logaritmik sayıda denemeyle kapsar — “son terim toplamı domine eder” disiplini.
3.13 Amortize Analiz (Amortized Analysis)
Bu “kabaca sabit” kavramı amortizasyondur. Tanım: bir işlem \(T(n)\) amortize zaman alır, eğer herhangi \(k\) işlem en fazla \(k \cdot T(n)\) toplam zaman alıyorsa.
“Amortized means a particular kind of averaging– averaging over the sequence of operations.” — Demaine, 47:42
Doubling’de \(n\) işlem toplam \(\Theta(n)\) zaman aldığından, insert_last sabit amortize (constant amortized) zamandır. Sezgi: tek tek işlemler bazen pahalıdır (resize anında lineer), ama çoğu ucuzdur (sabit). Pahalı işlemin maliyetini, onu mümkün kılan tüm ucuz işlemlere “dağıtırız” — bu, işlem dizisi üzerinde ortalamadır (Şekil 3.6). delete_last için resize gerekmez (length’i azalt, biter), o da sabit amortizedir.
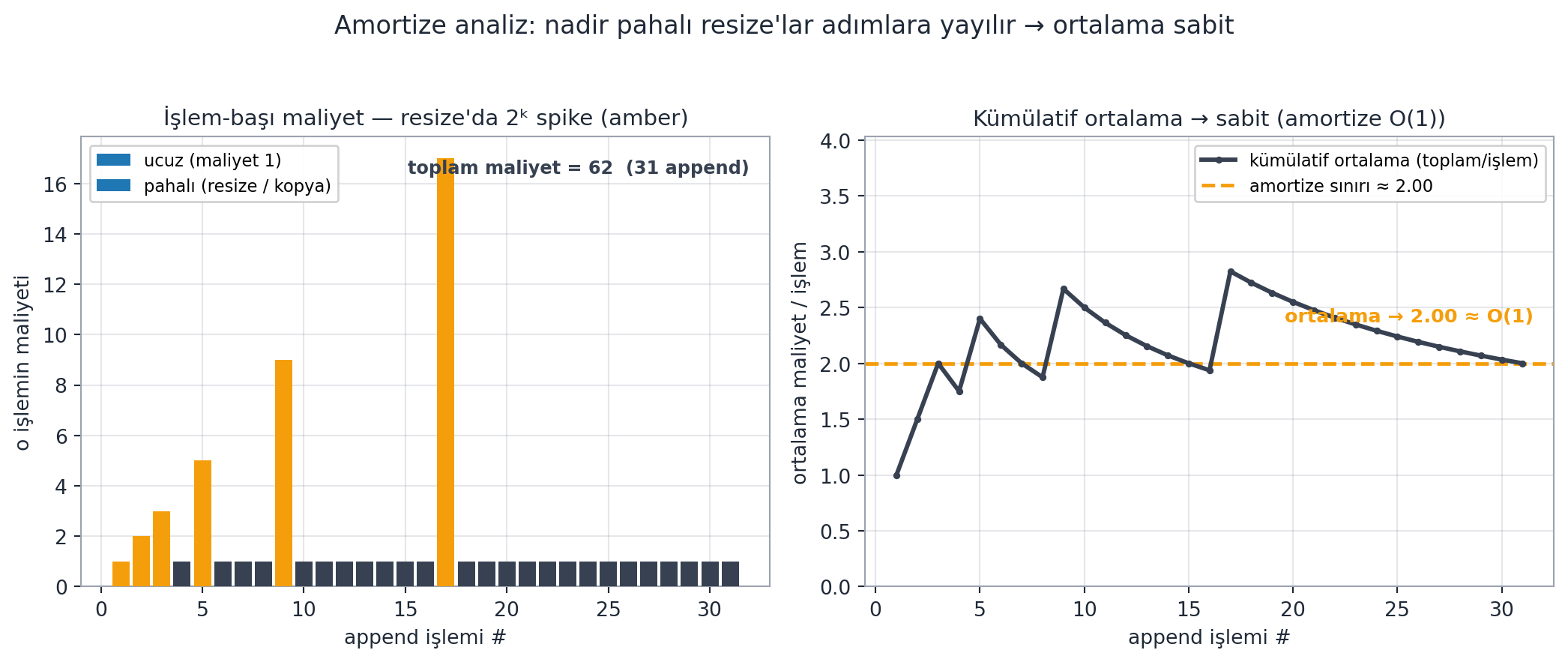
append. Sol: her işlemin maliyeti — çoğu yalnız 1 (tek slot yazımı, slate çubuklar); length == size olduğunda ikiye-katlama tetiklenir ve o işlemin maliyeti o anki boyut kadar sıçrar (amber çubuklar, append #1, 2, 3, 5, 9, 17’de değerler \(1, 2, 3, 5, 9, 17\) — yani o anki boyutu kopyalama + 1 slot yazımı; resize boyutları \(1, 2, 4, 8, 16\) (\(2^k\)) olduğundan ilk hariç maliyet \(2^k+1\)’e sıçrar). Sağ: kümülatif ortalama (toplam maliyet / işlem sayısı, slate çizgi) her resize’da yukarı sıçrayıp ardından düşer ve sabit bir değere — tam olarak \(62/31 = 2{,}00\) (amber kesik çizgi) — düzleşir. Nadiren pahalı resize’ların maliyeti tüm adımlara yayıldığı için insert_last amortize \(O(1)\)’dir; geometrik seri toplamı \(\sum_{i} 2^i = 2^{k+1}-1 \approx 2n\) bu sabiti garanti eder.
İpucuBuilder Notu — Amortize Düşünme ve Mini-batch/Checkpoint
“Nadiren pahalı, çoğu zaman ucuz; maliyeti diziye yay” analizi, eğitim ve altyapı kodunun her yerinde aynı biçimde karşına çıkar:
- İleriye → checkpoint kaydetme: Bir modeli her \(N\) adımda bir diske yazmak pahalıdır (tüm ağırlıkları serialize et), ama bu maliyet aradaki \(N\) ucuz eğitim adımına yayıldığında adım başına amortize maliyet ihmal edilebilir kalır — tam olarak resize’ın append’lere yayılması gibi.
- İleriye → gradient accumulation: Birkaç mini-batch’in gradyanını biriktirip seyrek aralıklarla bir optimizer adımı atmak, pahalı
step()çağrısının maliyetini birikim adımlarına amortize eder. - İleriye → rehash ve GC: Hash tablosu yük faktörü eşiği aşınca yeniden hash’leme (\(\Theta(n)\)) ve çöp toplama (garbage collection) duraklamaları, doubling resize’la birebir aynı amortize argümanına dayanır: nadir, pahalı, ama dizi boyunca sabit ortalama.
3.14 Üç Veri Yapısı — Karşılaştırma
Demaine dersi bu özet tabloyla kapatır (\(\Theta\)’lar atılmış, çalışma süreleri; Şekil 3.7):
| İşlem | Statik Dizi | Bağlı Liste | Dinamik Dizi |
|---|---|---|---|
| get_at / set_at | \(O(1)\) | \(O(n)\) | \(O(1)\) |
| insert / delete_first | \(O(n)\) | \(O(1)\) | \(O(n)\) |
| insert / delete_last | \(O(n)\) | \(O(n)\) | \(O(1)\) amortize |
| insert / delete_at | \(O(n)\) | \(O(n)\) | \(O(n)\) |
Dinamik dizi, rastgele erişimde statik dizinin hızını (\(O(1)\) get_at) ve sona eklemede neredeyse bağlı listenin esnekliğini (\(O(1)\) amortize insert_last) birleştirir — ikisinin en iyisi.
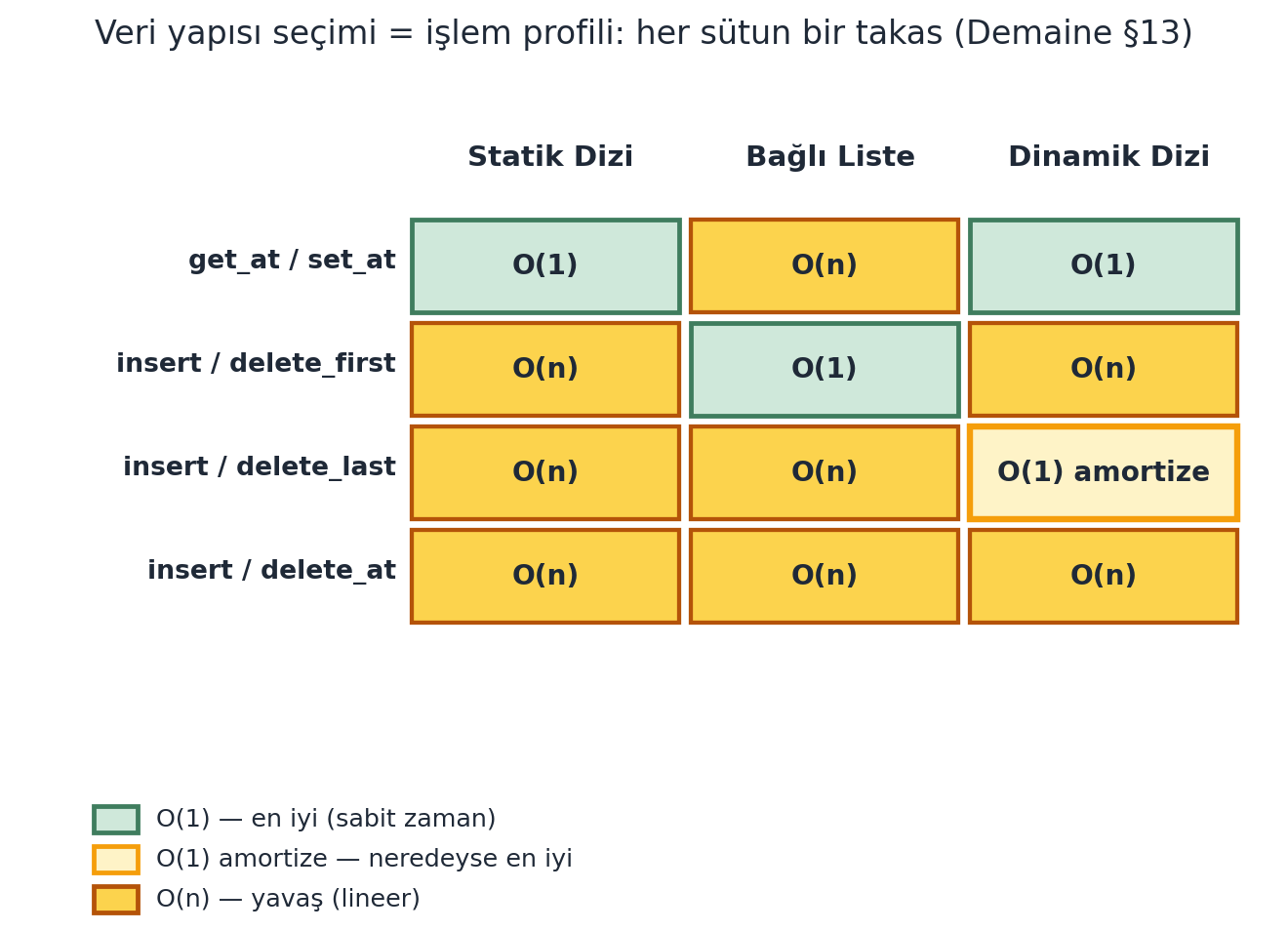
list’in temelidir. Veri yapısı seçimi, hangi işlemlerin sıcak yolda olduğuna bağlı bir takastır.
İpucuBuilder Notu — Veri Yapısı Seçimi = Tensor Layout
Maliyet matrisinin verdiği ders — “her yapı bir takas; sıcak yoldaki işleme göre seç” — derin öğrenmede tensör bellek düzeni seçiminde birebir tekrar eder:
- İleriye → contiguous tensor vs Python list: Bir batch’i Python
list’inde tutmak (dağınık nesneler, bağlı liste sezgisi) ile tek bir contiguous tensörde tutmak (ardışık dizi sezgisi) arasındaki fark, tam olarak bu matristeki rastgele erişim/tarama takasıdır — vektörize işlemler ardışık belleği ister. - İleriye →
.contiguous()çağrısı:transpose/permutesonrası bir tensör mantıksal olarak doğru ama bellekte dağınıktır;.contiguous()onu yeniden ardışık düzene kopyalar (\(\Theta(n)\), tıpkı resize kopyası gibi) — çünkü birçok CUDA çekirdeği ardışık düzen olmadan çalışmaz veya yavaşlar. - İleriye → GPU bellek yerelliği: Şekil 3.4’nin cache argümanı GPU’da daha da keskindir; coalesced (bitişik) erişim tam bant genişliği kullanır, dağınık erişim çekirdeği bellek-bağlı yapar. “Hangi işlem sıcak yolda?” sorusu, layout kararıyla doğrudan performansa çevrilir.
3.15 Bu Dersin Özeti
- Arayüz ne yapılacağını (işlemler), veri yapısı nasıl yapılacağını (gerçekleştirim) söyler.
- İki temel arayüz: küme (değere/anahtara göre) ve dizi (sıraya göre).
- Statik dizi: ardışık bellek; get_at/set_at \(O(1)\), build/iter \(\Theta(n)\).
- Bağlı liste: düğüm + next işaretçisi; insert/delete_first \(O(1)\), erişim \(O(i)\).
- Dinamik dizi (Python
list): boyut \(\Theta(n)\); ikiye-katlama ile insert_last amortize \(O(1)\). - Geometrik seri son terimle domine olur: \(1 + 2 + \cdots + 2^k = \Theta(2^k) = \Theta(n)\).
- Amortize analiz: \(k\) işlem en fazla \(k \cdot T(n)\) zaman alır; nadiren pahalı, ortalama ucuz.
ÖnemliTek Bir Cümle
Python list’in her “ucuz” append’i, arada bir yapılan pahalı ikiye-katlamanın işlem dizisine amortize edilmiş hâlidir — sihir değil, geometrik seri.
3.16 Kontrol Soruları
NotSoru 1: Arayüz (interface) ile veri yapısı (data structure) arasındaki fark nedir?
Cevap: Arayüz, ne yapılacağını söyler: hangi veriyi saklayabilirsin, hangi işlemler desteklenir ve bu işlemler ne anlama gelir (bir spesifikasyon). Veri yapısı, nasıl yapılacağını söyler: verinin somut gösterimi ve işlemleri destekleyen algoritmalar. Aynı arayüz (örneğin “dizi”) birden çok veri yapısıyla (statik dizi, bağlı liste, dinamik dizi) çözülebilir; her birinin farklı çalışma süreleri vardır.
NotSoru 2: Çok sık get_at ama nadiren ekleme gereken bir uygulamada hangi veri yapısı uygundur? Tersine, sürekli baştan ekleme gerekiyorsa?
Cevap: Sık rastgele erişim için statik dizi veya dinamik dizi uygundur (get_at \(O(1)\)). Sürekli baştan ekleme için bağlı liste uygundur (insert_first \(O(1)\); dizilerde \(O(n)\) çünkü kaydırma gerekir). Eğer hem sık get_at hem sık insert_first gerekiyorsa, tek bir basit yapı ikisini birden \(O(1)\) yapamaz — bu ileri veri yapılarının (örneğin dengeli ağaçlar, Ders 6-7) motivasyonudur.
NotSoru 3: Dinamik dizi dolduğunda neden boyutu size + 1 değil de 2 × size yapılır?
Cevap: size + 1 (ya da sabit ekleme, örn. +5), her birkaç eklemede bir lineer yeniden-ayırma gerektirir → işlem başına hâlâ lineer zaman. 2 × size ise yeniden boyutlandırmaları 2’nin kuvvetlerinde seyrekleştirir; \(n\) eklemenin toplam resize maliyeti geometrik seri olduğu için \(\Theta(n)\)’dir → işlem başına sabit amortize. Sabit çarpanla büyütme, amortize sabit zamanın anahtarıdır.
NotSoru 4: Python’da list.append() amortize O(1) ne demektir? Tek bir append neden bazen yavaş olabilir?
Cevap: “Amortize \(O(1)\)”, herhangi \(k\) append’in toplamda en fazla \(k \cdot O(1) = O(k)\) zaman aldığı anlamına gelir — işlem başına ortalama sabit. Ama tek bir append, dizi tam dolduğu anda denk gelirse, yeni (iki kat) dizi ayırıp tüm öğeleri kopyalar → o tek işlem \(O(n)\). Bu nadir pahalı işlemin maliyeti, onu izleyen birçok ucuz append’e dağıtılır; dolayısıyla ortalama sabit kalır.
3.17 Egzersizler
Egzersiz 1. Statik dizi arayüzünün beş işlemini (build, length, iter, get_at, set_at) listele ve her birinin statik dizi gerçekleştiriminde çalışma süresini yaz. Hangileri \(\Theta(n)\), hangileri \(O(1)\)?
Egzersiz 2. Bağlı listede insert_last’ı \(O(1)\) yapmak için hangi zenginleştirme (augmentation) gerekir? Aynı zenginleştirmeyle delete_last neden hâlâ zordur ve bunu çözmek için ne gerekir?
Egzersiz 3. Dinamik dizide \(n\) öğe ekleyip sonra hepsini delete_last ile silersen, dizi boyutu hâlâ \(\Theta(n)\) kalır (oysa \(n = 0\)). Bu bellek israfını önlemek için “küçültme” (shrinking) kuralını tasarla. (İpucu: dizi ¼ dolduğunda yarıya indir — neden ⅓ veya ½ değil?)
Egzersiz 4. Python’da bir listeye \(n\) kez append yaparken iç kapasitenin ne zaman büyüdüğünü gözlemle:
import sys
lst = []
prev = -1
for i in range(64):
cap = sys.getsizeof(lst)
if cap != prev:
print("uzunluk", len(lst), "-> kapasite baytlari", cap)
prev = cap
lst.append(i)Kapasite hangi uzunluklarda zıplıyor? Bu, ikiye-katlama (doubling) sezgisini doğruluyor mu?
Egzersiz 5. Küme (set) arayüzü, dizi (sequence) arayüzünden nasıl ayrılır? Öğeleri değerine/anahtarına göre aramak (sıraya göre değil), neden farklı bir veri yapısı gerektirir? Ders 3-4’e (sıralama ve hashing) bir köprü kur.
3.18 Sonraki Ders İçin Hazırlık
Ders 3 (L3): Kümeler ve Sıralama
Justin Solomon ile küme (set) arayüzüne ve onu çözmenin ilk adımı olan sıralamaya (insertion, selection, merge sort) geçiyoruz. Bu derste değindiğimiz “değere göre arama” sorusu orada merkeze oturur. (Not: ders akışında araya Problem Oturumu 1 girer — bu dersin kavramlarını pekiştiren problemler.)
UyarıDers 3 Öncesi Yapılacak
- Bu dersin egzersizlerini, özellikle Egzersiz 4’ü (Python kapasite gözlemi) çöz.
- Üç veri yapısı tablosunu (Şekil 3.7) ezberden çizebilecek hâle gel.
- Ana cümleyi tekrar oku: “Aynı işi farklı veri yapıları farklı maliyetlerle yapar.”
3.19 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Sayfada |
|---|---|---|
| Arayüz vs veri yapısı | Ne (spesifikasyon) vs nasıl (gerçekleştirim) | Böl. 1 |
| Dizi (sequence) | Öğeleri belirli bir sırada tutan arayüz | Böl. 2-3 |
| Statik dizi | Ardışık bellek; get_at/set_at \(O(1)\) | Böl. 4 |
| Bellek ayırma modeli | \(n\) boyutlu dizi \(\Theta(n)\) zamanda ayrılır | Böl. 5 |
| Word boyutu | \(w \geq \log n\) (\(n\) öğeyi adresleyebilmek için) | Böl. 5 |
| Bağlı liste | Düğüm + next; insert/delete_first \(O(1)\) | Böl. 7 |
| Augmentation | Ekstra bilgi (tail) ile \(O(1)\) get_last | Böl. 8 |
| Dinamik dizi | Python list; boyut \(\Theta(n)\), ikiye-katlama | Böl. 10 |
| Geometrik seri | \(1+2+\cdots+2^k = \Theta(2^k) = \Theta(n)\) | Böl. 11 |
| Amortize analiz | \(k\) işlem en fazla \(k \cdot T(n)\) zaman | Böl. 12 |
3.20 Builder ve OMSCS Bağlantıları
İpucu6 köprü
Bu ders, ileri algoritma ve sistem mühendisliğinin temel dilini kurar — köprülerin özeti:
- Amortize analiz → altyapı: log-structured storage, hash tablosu rehashing, garbage collection — “nadiren pahalı, çoğu zaman ucuz” her yerde aynı analiz.
- Dinamik dizi → Python
list, C++vector, JavaArrayList’in iç mekanizması; kapasite büyütme stratejisi. - Arayüz / veri yapısı ayrımı → API tasarımı: aynı sözleşme (interface), değişebilir backend (implementation).
- word RAM + işaretçiler → bellek modeli ve cache yerelliği; dizi (ardışık) ile bağlı liste (dağınık) arasındaki gerçek performans farkı.
- Augmentation → veritabanı indeksleri: ekstra bir yapı (B-ağacı, hash) ekleyip sorguyu hızlandırma — aynı augmentation fikri.
- Geometrik seri sezgisi → ikiye-katlama/yarıya-indirme stratejileri: connection pool, buffer büyütme, exponential backoff.
ÖnemliTek bir şey alıp gideceksen
Aynı işi farklı veri yapıları farklı maliyetlerle yapar; mühendislik, “hangi işlem ne sıklıkta çağrılıyor?” sorusuna göre doğru yapıyı seçmektir. Python list’in zarafeti, bu seçimi amortize analizle senin için çoktan çözmüş olmasıdır.