---
title: "Doğrusal Zamanlı Sıralama"
subtitle: "Karşılaştırma alt sınırı Ω(n log n), direct access array sort, tuple/Excel sort, kararlı sıralama, counting sort ve radix sort O(n)"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Ku'nun videosu:** [YouTube — Lecture 5: Linear Sorting](https://www.youtube.com/watch?v=yndgIDO0zQQ) (≈52 dk)
- **OCW sayfası:** [MIT 6.006 Lecture 5: Linear Sorting](https://ocw.mit.edu/courses/6-006-introduction-to-algorithms-spring-2020/resources/lecture-5-linear-sorting/)
- **Seri:** MIT 6.006 — Introduction to Algorithms (Spring 2020) — Ders 7 (L5)
- **Hoca:** Jason Ku (Erik Demaine, Justin Solomon)
- **Okuma süresi:** ≈25 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste-d07}
Ders 4'te merge sort, bir diziyi $O(n \log n)$'de sıraladı. Bu ders iki soru sorar: (1) **karşılaştırma** modelinde daha hızlı olabilir miyiz — **hayır**, $n \log n$ optimaldir; (2) modeli genişletirsek — **evet**, anahtarlar küçük tam sayıysa **$O(n)$** sıralama mümkündür.
Üç temel kavram bu derste yan yana gelir:
1. **Sıralama alt sınırı** — karşılaştırma modelinde her sıralama $\Omega(n \log n)$'dir ($n!$ yaprak → karar ağacı argümanı).
2. **Direct access array sort → counting sort** — anahtarı doğrudan indeks yap; çakışmaları zincirle, geliş sırasını koru.
3. **Radix sort** — büyük anahtarları base-$n$ basamaklara ayır, kararlı (stable) sıralamayla basamak basamak sırala.
> *"n log n is optimal."* — Ku, 10:19
```{mermaid}
%%| label: fig-concept-map
%%| echo: false
%%| fig-cap: "Ders 7'nin kavram haritası: karşılaştırma modelinin Ω(n log n) alt sınırından (n! yaprak → karar ağacı) modeli değiştirmeye — direct access array sort (benzersiz anahtar) → counting sort (zincir + geliş sırası, kararlı) → radix sort (base-n basamak + kararlı counting sort) → u ≤ n^c koşulunda O(n) doğrusal sıralama."
flowchart TD
A["Ders 7: Doğrusal Zamanlı Sıralama"] --> L["Karşılaştırma alt sınırı<br/>Ω(n log n) · n! yaprak"]
A --> M["Modeli değiştir<br/>karşılaştırma → indeks"]
L --> L1["Karar ağacı<br/>log(n!) = Θ(n log n)"]
M --> D["Direct access array sort<br/>benzersiz anahtar · O(n + u)"]
D --> T["Anahtarı base-n böl<br/>k = a·n + b"]
T --> TS["Tuple / Excel sort<br/>en az → en önemli basamak"]
TS --> ST["Kararlı (stable) sort<br/>eşit anahtar girdi sırasını korur"]
ST --> C["Counting sort<br/>zincir + geliş sırası · O(n + u)"]
C --> R["Radix sort<br/>log_n u basamak · kararlı counting"]
R --> O["u ≤ n^c → O(n)<br/>DOĞRUSAL"]
classDef root fill:#fef3c7,stroke:#b45309,stroke-width:3px,color:#1f2937
classDef branch fill:#f3f4f6,stroke:#374151,stroke-width:2px,color:#1f2937
classDef leaf fill:#ffffff,stroke:#9ca3af,stroke-width:1px,color:#1f2937
class A root
class L,M,D,C,R branch
class L1,T,TS,ST,O leaf
```
::: {.callout-tip title="Builder Notu — Counting Sort = Hash'in Sıra-Koruyan İkizi"}
Bu dersin çekirdeği, Ders 5'teki (Hashing) "anahtar = indeks" fikrinin **arama** yerine **sıra** için yeniden kullanılmasıdır:
- **Geriye → Ders 5 (Hashing):** Counting sort'un "her indekste bir zincir" yapısı, hash tablosunun çakışma çözümüyle (chaining) birebir aynı veri yapısıdır — fark, amacın *arama* değil *sıra korumak* olmasıdır. Hash'te zincir sırası önemsizdi; burada zincire **geldikleri sırada** ekleme, kararlılığın (stability) ta kendisidir.
- **Geriye → PS1 (Stirling):** $\log(n!) = \Theta(n \log n)$ alt sınırı, problem setindeki Stirling yaklaşımının doğrudan uygulamasıdır; $\log(10^9!) \approx$ milyarlarca karşılaştırma mertebesi.
- **İleriye → büyük veri:** radix sort, tam sayı / sabit-uzunluk anahtarlarda (IP adresleri, timestamp, sabit ID) karşılaştırmalı sıralamayı geçer; veritabanı ve GPU sıralamasında standart.
- **İleriye → çok-kolonlu sıralama:** "Excel spreadsheet sort" — kararlı sıralamayı en az önemliden en önemliye uygulamak, SQL `ORDER BY a, b` ve pandas `sort_values` mantığının ta kendisidir.
Tek cümle: *Karşılaştırma seni $n \log n$'de tutar; ama anahtarlar küçük tam sayıysa, onları doğrudan indeks yapıp basamak basamak kararlı sıralayarak $O(n)$'e inebilirsin.*
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — 6.006 Ders 7 (L5) motoru (_engine.py) + Slate+Amber viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri bu hücrede
# tanımlanan counting_sort / base_n_digits / radix_sort_trace / counting_sort_trace
# / log_factorial + draw_* + COL_* + apply_style'ı IMPORT ETMEDEN kullanır.
# Notion'daki öğretim içeriği (görünür pseudocode / display ```python bloklar) bu
# motorun tarif seviyesidir; burada tam, deterministik, test edilmiş sürüm yaşar.
#
# NOT: matplotlib.use("Agg") ÇAĞRILMAZ — Quarto'nun inline figür-yakalama
# backend'ini ezer (plt.show() 0 figür üretir; brief §2/§11). Standalone testte
# savefig kullanılır; Quarto render'da jupyter inline backend'i ayarlar.
# ============================================================================
import math
from collections import defaultdict
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# ---------------------------------------------------------------------------
# _engine.py — Ders 7 (L5) doğrusal sıralama motoru (DETERMİNİSTİK + TEST EDİLEBİLİR)
# ---------------------------------------------------------------------------
def counting_sort(items, key_fn, base):
"""Counting sort (L5 §7): her indekste ZİNCİR + geliş sırası → KARARLI. O(n + u).
Her indekste tek öğe yerine bir ZİNCİR tutar ve öğeleri GELDİKLERİ SIRADA sona
ekler → anahtar tekrarı + kararlılık (eşit anahtarlar girdi sırasını korur).
Okurken zincirleri 0..base−1 gez, içlerini sırayla oku → kararlı sıralı çıktı.
"""
chains = [[] for _ in range(base)]
for x in items:
k = key_fn(x)
if not 0 <= k < base:
raise ValueError(
f"counting_sort: anahtar {k} aralık dışı (0 ≤ k < base={base})")
chains[k].append(x) # geldiği sırada sona ekle → KARARLI
out = []
for chain in chains: # 0..base−1 sırayla gez
out.extend(chain) # zincir içi geliş sırası korunur
return out
def base_n_digits(k, base, num_digits):
"""Anahtar k'yi base-n basamaklara ayır (L5 §4): EN AZ önemli → EN önemli sırada.
d₀ = k mod base (birler), d₁ = (k // base) mod base, ... ve k = Σ dᵢ · baseⁱ.
Döndürülen liste EN AZ önemliden (index 0) EN önemliye sıralıdır — radix sort'un
LSD→MSD geçiş sırasıyla birebir uyumlu.
"""
if base < 2:
raise ValueError("base_n_digits: base ≥ 2 olmalı")
if k < 0:
raise ValueError("base_n_digits: k ≥ 0 olmalı")
digits = []
rem = k
for _ in range(num_digits):
digits.append(rem % base) # mevcut en az önemli basamak
rem //= base
return digits
def num_radix_digits(u, base):
"""Radix sort basamak sayısı: en büyük anahtar evreni u için ⌈log_base u⌉ (L5 §8).
base^d ≥ u olan en küçük d; tam-kuvvet sınır durumlarında kayan-nokta yuvarlama
hatasından kaçınmak için tamsayı aritmetiğiyle hesaplanır.
"""
if base < 2:
raise ValueError("num_radix_digits: base ≥ 2 olmalı")
if u <= 1:
return 1
d = 0
power = 1
while power < u: # base^d < u olduğu sürece basamak ekle
power *= base
d += 1
return d # base^d ≥ u olan en küçük d = ⌈log_base u⌉
def log_factorial(n):
"""log₂(n!) — sıralama alt sınırı eğrisi (L5 §2): Θ(n log n) (Stirling ile uyumlu)."""
if n < 0:
raise ValueError("log_factorial: n ≥ 0 olmalı")
total = 0.0
for i in range(2, n + 1):
total += math.log2(i)
return total
def counting_sort_trace(items, key_fn, base):
"""fig-counting-sort için counting sort izi (zincir/histogram + kararlılık).
Her öğeyi geliş sırasıyla zincire ekler (dağıtım), sonra zincirleri 0..base−1
okuyarak kararlı sıralı çıktı üretir. Öğeler (anahtar, etiket) ikilisi olabilir;
etiket girdi sırasını işaretler → eşit anahtarlarda kararlılık görselleşir.
"""
chains = [[] for _ in range(base)]
keys = []
scatter = []
for step, x in enumerate(items):
k = key_fn(x)
keys.append(k)
chains[k].append(x)
scatter.append({
"step": step,
"item": x,
"key": k,
"chain_pos": len(chains[k]) - 1,
"chains": [list(c) for c in chains], # bağımsız kopya (figür güvenli)
})
histogram = [len(c) for c in chains]
output = []
for c in chains:
output.extend(c)
return {
"base": base,
"keys": keys,
"scatter": scatter,
"chains": [list(c) for c in chains],
"histogram": histogram,
"output": output,
}
def radix_sort_trace(ints, base):
"""fig-radix-sort için radix sort izi (LSD→MSD kararlı counting geçişleri).
Her counting sort geçişinin (i. basamak) girdi/çıktı dizilerini ve her öğenin o
basamağını kaydeder. 17,3,24,22,12 (n=5, base=5) → iki geçiş (LSD→MSD).
"""
A = list(ints)
if base < 2:
raise ValueError("radix_sort_trace: base ≥ 2 olmalı")
if not A:
return {"base": base, "input": [], "u": 0, "num_digits": 0,
"passes": [], "output": []}
if any(v < 0 for v in A):
raise ValueError("radix_sort_trace: negatif olmayan tamsayılar bekler")
u = max(A) + 1
num_digits = num_radix_digits(u, base)
passes = []
cur = A
for i in range(num_digits):
before = list(cur)
digits = [base_n_digits(v, base, num_digits)[i] for v in before]
cur = counting_sort(
before,
key_fn=lambda v, _i=i: base_n_digits(v, base, num_digits)[_i],
base=base,
)
passes.append({
"digit_index": i,
"before": before,
"digits": digits,
"after": list(cur),
})
return {
"base": base,
"input": list(A),
"u": u,
"num_digits": num_digits,
"passes": passes,
"output": list(cur),
}
# ---------------------------------------------------------------------------
# _viz.py — Slate+Amber stil sabitleri + Ders 7 figür çizimleri
# ---------------------------------------------------------------------------
COL_PRIMARY = "#374151" # slate-700 — birincil çizgi/çerçeve
COL_ACCENT = "#f59e0b" # amber-500 — vurgu
COL_TEXT = "#1f2937" # slate-800 — metin
COL_BG = "#f3f4f6" # slate-100 — arka plan / kutu dolgusu
COL_AMBER_700 = "#b45309" # bağlantı/okunur kontrast
COL_AMBER_600 = "#d97706" # koyu amber
COL_AMBER_300 = "#fcd34d" # açık amber
COL_AMBER_100 = "#fef3c7" # en açık amber (dolgu)
COL_SLATE_500 = "#6b7280" # orta slate — ikincil metin
COL_SLATE_400 = "#9ca3af" # soluk slate — pasif kenar / izgara
COL_WHITE = "#ffffff"
def apply_style(ax):
"""Bir eksene tutarlı Slate+Amber görünümü uygular (curve figürleri için)."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_SLATE_400, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_SLATE_400)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_sort_lower_bound(ax_tree, ax_curve, n_tree=3, n_max=20):
"""Sıralama alt sınırı (L5 §2): karar ağacı n! yaprak → log(n!) = Θ(n log n)."""
import math as _m
# --- Sol panel: karar ağacı (n_tree! yaprak) ---
leaves = _m.factorial(n_tree)
height = _m.ceil(_m.log2(leaves)) if leaves > 1 else 0
x_gap, y_gap = 1.0, 1.2
full_leaves = 2 ** height if height > 0 else 1
leaf_xs = [i * x_gap for i in range(full_leaves)]
level_positions = {height: list(leaf_xs)}
for d in range(height - 1, -1, -1):
below = level_positions[d + 1]
xs = []
for i in range(0, len(below), 2):
if i + 1 < len(below):
xs.append((below[i] + below[i + 1]) / 2.0)
else:
xs.append(below[i])
level_positions[d] = xs
for d in range(height):
parents = level_positions[d]
children = level_positions[d + 1]
for i, px in enumerate(parents):
for ci in (2 * i, 2 * i + 1):
if ci < len(children):
cx = children[ci]
ax_tree.plot([px, cx], [-d * y_gap - 0.16, -(d + 1) * y_gap + 0.16],
color=COL_SLATE_400, linewidth=1.3, zorder=1)
leaf_count = 0
for d in range(height + 1):
for x in level_positions[d]:
is_leaf = (d == height)
if is_leaf:
leaf_count += 1
wanted = leaf_count <= leaves # ilk n! yaprak = permütasyon
ax_tree.add_patch(FancyBboxPatch(
(x - 0.30, -d * y_gap - 0.20), 0.60, 0.40,
boxstyle="round,pad=0.02,rounding_size=0.05",
fc=COL_AMBER_100 if wanted else COL_WHITE,
ec=COL_ACCENT if wanted else COL_SLATE_400,
linewidth=2.0 if wanted else 1.0, zorder=3))
else:
ax_tree.add_patch(plt.Circle(
(x, -d * y_gap), 0.24, fc=COL_BG, ec=COL_PRIMARY,
linewidth=1.5, zorder=3))
ax_tree.text(x, -d * y_gap, "<", ha="center", va="center",
fontsize=8.5, color=COL_TEXT, weight="bold", zorder=4)
xs_all = [x for lvl in level_positions.values() for x in lvl]
x_right = max(xs_all) + 0.85
ax_tree.annotate("", xy=(x_right, -height * y_gap), xytext=(x_right, 0.0),
arrowprops=dict(arrowstyle="<|-|>", color=COL_AMBER_700, lw=1.6))
ax_tree.text(x_right + 0.15, -height * y_gap * 0.5,
f"yükseklik\n≥ log₂({n_tree}!)\n= {height}", ha="left", va="center",
fontsize=8.5, color=COL_AMBER_700, weight="bold")
ax_tree.text((min(xs_all) + max(xs_all)) / 2, 0.8,
f"Karar ağacı: n! = {n_tree}! = {leaves} yaprak (permütasyon)",
ha="center", va="center", fontsize=10, color=COL_PRIMARY, weight="bold")
ax_tree.text((min(xs_all) + max(xs_all)) / 2, -height * y_gap - 0.65,
"her yaprak bir permütasyon · yükseklik = en kötü karşılaştırma",
ha="center", va="center", fontsize=8.5, color=COL_SLATE_500, style="italic")
ax_tree.set_xlim(min(xs_all) - 0.7, x_right + 1.9)
ax_tree.set_ylim(-height * y_gap - 1.05, 1.1)
ax_tree.set_aspect("equal")
ax_tree.axis("off")
# --- Sağ panel: log₂(n!) vs (n/2)·log₂(n/2) vs n log n ---
apply_style(ax_curve)
ns = list(range(2, n_max + 1))
log_fact = [sum(_m.log2(i) for i in range(2, n + 1)) for n in ns] # log₂(n!)
lower = [(n / 2) * _m.log2(n / 2) if n >= 2 else 0.0 for n in ns] # (n/2)log(n/2)
nlogn = [n * _m.log2(n) for n in ns] # n log n referans
ax_curve.plot(ns, log_fact, color=COL_PRIMARY, linewidth=2.6, zorder=4,
marker="o", markersize=3, label="log₂(n!) (tam alt sınır)")
ax_curve.plot(ns, lower, color=COL_ACCENT, linewidth=2.2, linestyle="--",
zorder=3, label="(n/2)·log₂(n/2) (kaba alt sınır)")
ax_curve.plot(ns, nlogn, color=COL_SLATE_500, linewidth=1.8, linestyle=":",
zorder=2, label="n·log₂ n (Θ referansı)")
ax_curve.set_xlabel("n (girdi boyutu)")
ax_curve.set_ylabel("karşılaştırma sayısı (log₂)")
ax_curve.set_title("log(n!) = Θ(n log n) → Ω(n log n) duvarı",
color=COL_TEXT, fontsize=10.5)
ax_curve.legend(loc="upper left", fontsize=8.5, framealpha=0.92)
return ax_tree, ax_curve
def draw_tuple_sort(ax, rows=None):
"""Tuple sort = Excel tablo sıralaması (L5 §5): kolonları en az → en önemli sırala."""
if rows is None:
# Ku §5 örneği: 17=(3,2) 3=(0,3) 24=(4,4) 22=(4,2) 12=(2,2) [hi=n'ler, lo=birler]
rows = [(3, 2, "17"), (0, 3, "3"), (4, 4, "24"), (4, 2, "22"), (2, 2, "12")]
rows = list(rows)
# geçiş 1: en az önemli (lo) kolona göre kararlı sırala
pass1 = sorted(rows, key=lambda r: r[1])
# geçiş 2: en önemli (hi) kolona göre kararlı sırala (pass1 üstüne)
pass2 = sorted(pass1, key=lambda r: r[0])
cell_w, cell_h = 0.95, 0.62
row_gap = cell_h + 0.12
col_gap = 3.6
titles = ["1) Orijinal tablo", "2) EN AZ önemli (birler) →\n kararlı sırala",
"3) EN önemli (n'ler) →\n kararlı sırala = SONUÇ"]
tables = [rows, pass1, pass2]
sort_col = [None, 1, 0] # hangi kolon bu geçişte sıralandı (vurgu)
for t, (tbl, title, scol) in enumerate(zip(tables, titles, sort_col)):
x0 = t * col_gap
ax.text(x0 + cell_w, cell_h + 1.05, title, ha="center", va="center",
fontsize=9.5, color=COL_PRIMARY, weight="bold")
# başlık satırı (n'ler | birler)
for c, head in enumerate(["n'ler", "birler"]):
hot = (scol == c)
ax.add_patch(FancyBboxPatch(
(x0 + c * cell_w, cell_h + 0.18), cell_w * 0.92, cell_h * 0.7,
boxstyle="square,pad=0.0",
fc=COL_ACCENT if hot else COL_PRIMARY, ec=COL_PRIMARY,
linewidth=1.4, zorder=2))
ax.text(x0 + c * cell_w + cell_w * 0.46, cell_h + 0.18 + cell_h * 0.35,
head, ha="center", va="center", fontsize=8.5,
color=COL_WHITE, weight="bold", zorder=4)
# veri satırları
for r, (hi, lo, lab) in enumerate(tbl):
y = -r * row_gap
for c, dval in enumerate((hi, lo)):
hot = (scol == c)
ax.add_patch(FancyBboxPatch(
(x0 + c * cell_w, y), cell_w * 0.92, cell_h,
boxstyle="square,pad=0.0",
fc=COL_AMBER_100 if hot else COL_BG,
ec=COL_ACCENT if hot else COL_PRIMARY,
linewidth=2.0 if hot else 1.4, zorder=2))
ax.text(x0 + c * cell_w + cell_w * 0.46, y + cell_h * 0.5, str(dval),
ha="center", va="center", fontsize=10, color=COL_TEXT,
weight="bold", zorder=4)
# değer etiketi (sağda)
ax.text(x0 + 2 * cell_w + 0.12, y + cell_h * 0.5, f"={lab}",
ha="left", va="center", fontsize=8.5, color=COL_SLATE_500, zorder=4)
# geçişler arası ok
if t < len(tables) - 1:
ax.add_patch(FancyArrowPatch(
(x0 + 2 * cell_w + 0.7, -len(tbl) * row_gap * 0.5),
(x0 + col_gap - 0.25, -len(tbl) * row_gap * 0.5),
arrowstyle="-|>", mutation_scale=15, color=COL_AMBER_700,
linewidth=2.0, zorder=5))
ax.text(col_gap * 1.0, -len(rows) * row_gap - 0.35,
"kararlılık şart: 3. geçişte n'ler eşit olan (24,22) ikilileri birler sırasını korur",
ha="center", va="center", fontsize=8.5, color=COL_SLATE_500, style="italic")
ax.set_xlim(-0.4, 2 * col_gap + 2.6)
ax.set_ylim(-len(rows) * row_gap - 0.7, cell_h + 1.5)
ax.set_aspect("equal")
ax.axis("off")
return pass2
def draw_stable_sort(ax, pairs=((3, "a"), (1, "b"), (3, "c"), (2, "d"), (1, "e"), (3, "f"))):
"""Kararlı sıralama (L5 §6): eşit anahtarlar girdi sırasını korur — kararlı vs kararsız."""
pairs = list(pairs)
n = len(pairs)
cell_w, cell_h = 1.05, 0.78
y_in, y_stable, y_unstable = 4.0, 2.0, 0.0
# kararlı sıralama: anahtar artan, eşitlikte girdi sırası (Python sort stabildir)
stable = sorted(pairs, key=lambda p: p[0])
# kararsız sıralama: eşit anahtar gruplarını TERS çevirerek sırayı boz (gösterim)
groups = defaultdict(list)
for p in pairs:
groups[p[0]].append(p)
unstable = []
for k in sorted(groups):
unstable.extend(reversed(groups[k])) # eşitlerin sırası tersine → kararsız
# eşit-anahtar grupları için renk paleti (anahtar → dolgu/çerçeve)
uniq_keys = sorted(set(k for k, _ in pairs))
palette = [
(COL_AMBER_100, COL_ACCENT),
(COL_BG, COL_PRIMARY),
("#dbeafe", "#2563eb"),
("#dcfce7", "#16a34a"),
]
key_color = {k: palette[i % len(palette)] for i, k in enumerate(uniq_keys)}
def _strip(row, y):
for j, (k, lab) in enumerate(row):
x = j * cell_w
fc, ec = key_color[k]
ax.add_patch(FancyBboxPatch(
(x, y), cell_w * 0.92, cell_h, boxstyle="round,pad=0.02,rounding_size=0.06",
fc=fc, ec=ec, linewidth=2.0, zorder=3))
ax.text(x + cell_w * 0.46, y + cell_h * 0.62, str(k),
ha="center", va="center", fontsize=12, color=COL_TEXT,
weight="bold", zorder=4)
ax.text(x + cell_w * 0.46, y + cell_h * 0.24, lab,
ha="center", va="center", fontsize=8.5, color=COL_SLATE_500,
style="italic", zorder=4)
_strip(pairs, y_in)
_strip(stable, y_stable)
_strip(unstable, y_unstable)
ax.text(-0.35, y_in + cell_h * 0.5, "Girdi", ha="right", va="center",
fontsize=10.5, color=COL_PRIMARY, weight="bold")
ax.text(-0.35, y_stable + cell_h * 0.5, "Kararlı ✓", ha="right", va="center",
fontsize=10.5, color=COL_AMBER_700, weight="bold")
ax.text(-0.35, y_unstable + cell_h * 0.5, "Kararsız ✗", ha="right", va="center",
fontsize=10.5, color=COL_SLATE_500, weight="bold")
ax.text(n * cell_w * 0.5, y_in + cell_h + 0.45,
"Eşit anahtarlar (etiketler girdi sırasını işaretler)",
ha="center", va="center", fontsize=9.5, color=COL_SLATE_500, style="italic")
ax.text(n * cell_w * 0.5, y_stable - 0.38,
"kararlı: anahtar=3 grubu a → c → f (girdi sırası KORUNUR)",
ha="center", va="center", fontsize=9, color=COL_AMBER_700, weight="bold")
ax.text(n * cell_w * 0.5, y_unstable - 0.42,
"kararsız: anahtar=3 grubu f → c → a (girdi sırası BOZULUR)",
ha="center", va="center", fontsize=9, color=COL_SLATE_500, style="italic")
ax.set_xlim(-2.0, n * cell_w + 0.4)
ax.set_ylim(y_unstable - 0.85, y_in + cell_h + 0.85)
ax.set_aspect("equal")
ax.axis("off")
return stable, unstable
def draw_counting_sort(ax, trace, base=None):
"""Counting sort (L5 §7, İMZA figür): her indekste zincir/histogram + geliş sırası → kararlı."""
chains = trace["chains"]
output = trace["output"]
histogram = trace["histogram"]
base = base if base is not None else trace["base"]
def _label(item):
# öğe (key, tag) ikilisi olabilir; değilse kendisi
if isinstance(item, tuple) and len(item) == 2:
return f"{item[0]}{item[1]}"
return str(item)
cell_w, cell_h = 0.8, 0.62
# --- Orta: base kova + dikey zincirler (histogram) ---
bucket_x0 = 0.0
bucket_gap = 1.05
max_chain = max((len(c) for c in chains), default=1)
for b in range(base):
x = bucket_x0 + b * bucket_gap
# kova tabanı (indeks)
ax.add_patch(FancyBboxPatch(
(x, 0.0), cell_w, cell_h, boxstyle="square,pad=0.0",
fc=COL_BG, ec=COL_PRIMARY, linewidth=1.8, zorder=3))
ax.text(x + cell_w * 0.5, cell_h * 0.5, str(b), ha="center", va="center",
fontsize=10, color=COL_PRIMARY, weight="bold", zorder=4)
# zincir: öğeler geliş sırasıyla YUKARI yığılır (alt = ilk gelen)
for pos, item in enumerate(chains[b]):
cy = cell_h + 0.12 + pos * (cell_h + 0.1)
ax.add_patch(FancyBboxPatch(
(x, cy), cell_w, cell_h, boxstyle="round,pad=0.02,rounding_size=0.05",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=2.0, zorder=3))
ax.text(x + cell_w * 0.5, cy + cell_h * 0.5, _label(item),
ha="center", va="center", fontsize=9.5, color=COL_TEXT,
weight="bold", zorder=4)
if pos > 0: # geliş sırası oku (alttan üste ekleme)
ax.add_patch(FancyArrowPatch(
(x + cell_w * 0.5, cy - 0.10), (x + cell_w * 0.5, cy + 0.02),
arrowstyle="-|>", mutation_scale=8, color=COL_AMBER_700,
linewidth=1.2, zorder=4))
# histogram sayım etiketi (kova altı)
ax.text(x + cell_w * 0.5, -0.30, f"#{histogram[b]}", ha="center", va="center",
fontsize=8, color=COL_SLATE_500, zorder=4)
top_y = cell_h + 0.12 + max_chain * (cell_h + 0.1) + 0.2
ax.text(bucket_x0 + (base - 1) * bucket_gap * 0.5 + cell_w * 0.5, top_y + 0.25,
"her indekste ZİNCİR — öğeler geliş sırasıyla yığılır (sayma histogramı)",
ha="center", va="center", fontsize=9.5, color=COL_PRIMARY, weight="bold")
# --- Alt: zincirleri sırayla oku → kararlı sıralı çıktı ---
out_y = -1.7
for j, item in enumerate(output):
x = bucket_x0 + j * (cell_w + 0.06)
ax.add_patch(FancyBboxPatch(
(x, out_y), cell_w, cell_h, boxstyle="square,pad=0.0",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=1.8, zorder=3))
ax.text(x + cell_w * 0.5, out_y + cell_h * 0.5, _label(item),
ha="center", va="center", fontsize=9.5, color=COL_TEXT,
weight="bold", zorder=4)
ax.text(bucket_x0, out_y - 0.32,
"0..u−1 zincirlerini sırayla oku → KARARLI sıralı çıktı · O(n + u)",
ha="left", va="center", fontsize=9.5, color=COL_AMBER_700, weight="bold")
width = max(base * bucket_gap, len(output) * (cell_w + 0.06))
ax.set_xlim(-0.5, width + 0.4)
ax.set_ylim(out_y - 0.7, top_y + 0.55)
ax.set_aspect("equal")
ax.axis("off")
return chains, output
def draw_radix_sort(ax, trace):
"""Radix sort (L5 §8, İMZA figür): base-n basamak, LSD→MSD counting geçişleri."""
passes = trace["passes"]
base = trace["base"]
num_digits = trace["num_digits"]
cell_w, cell_h = 0.85, 0.66
row_gap = 1.7
def _row(values, digits, x0, y, highlight_digit=True):
for j, v in enumerate(values):
x = x0 + j * cell_w
ax.add_patch(FancyBboxPatch(
(x, y), cell_w * 0.92, cell_h, boxstyle="square,pad=0.0",
fc=COL_BG, ec=COL_PRIMARY, linewidth=1.6, zorder=3))
ax.text(x + cell_w * 0.46, y + cell_h * 0.5, str(v),
ha="center", va="center", fontsize=10.5, color=COL_TEXT,
weight="bold", zorder=4)
if digits is not None and highlight_digit:
# bu sayının aktif basamağı (amber rozet, sayının altında)
ax.text(x + cell_w * 0.46, y - 0.22, f"[{digits[j]}]",
ha="center", va="center", fontsize=8.5, color=COL_AMBER_700,
weight="bold", zorder=4)
y = 0.0
n = len(trace["input"])
# başlık: girdi
_row(trace["input"], None, 0.0, y, highlight_digit=False)
ax.text(-0.4, y + cell_h * 0.5, "girdi", ha="right", va="center",
fontsize=9.5, color=COL_PRIMARY, weight="bold")
for idx, p in enumerate(passes):
y_before = y
y -= row_gap
# bu geçişin sonucu (after) yeni satır; basamak etiketi before'un basamağı
place = ["birler", "n'ler", "n²'ler", "n³'ler"]
place_label = place[p["digit_index"]] if p["digit_index"] < len(place) else f"basamak {p['digit_index']}"
# before satırının basamak rozetlerini ekle (önceki satıra)
_row(p["before"], p["digits"], 0.0, y_before, highlight_digit=True)
# ok: before → after (kararlı counting sort)
ax.add_patch(FancyArrowPatch(
(n * cell_w * 0.5, y_before - 0.36), (n * cell_w * 0.5, y + cell_h + 0.04),
arrowstyle="-|>", mutation_scale=14, color=COL_ACCENT,
linewidth=2.2, zorder=5))
ax.text(n * cell_w + 0.25, (y_before + y + cell_h) * 0.5,
f"counting sort\n{place_label} basamağı\n(kararlı)", ha="left", va="center",
fontsize=8.5, color=COL_AMBER_700, weight="bold")
# after satırı
is_last = (idx == len(passes) - 1)
_row(p["after"], None, 0.0, y, highlight_digit=False)
if is_last:
for j in range(len(p["after"])):
x = j * cell_w
ax.add_patch(FancyBboxPatch(
(x, y), cell_w * 0.92, cell_h, boxstyle="square,pad=0.0",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=2.0, zorder=2))
ax.text(x + cell_w * 0.46, y + cell_h * 0.5, str(p["after"][j]),
ha="center", va="center", fontsize=10.5, color=COL_TEXT,
weight="bold", zorder=4)
ax.text(-0.4, y + cell_h * 0.5, "sıralı ✓", ha="right", va="center",
fontsize=9.5, color=COL_AMBER_700, weight="bold")
ax.text(n * cell_w * 0.5, cell_h + 0.55,
f"Radix sort: base={base}, {num_digits} basamak · LSD → MSD kararlı counting sort",
ha="center", va="center", fontsize=10, color=COL_PRIMARY, weight="bold")
ax.text(n * cell_w * 0.5, y - 0.55,
f"u ≤ n^c → {num_digits} basamak (sabit) → O(n) (lineer)",
ha="center", va="center", fontsize=9.5, color=COL_AMBER_700, weight="bold")
ax.set_xlim(-1.9, n * cell_w + 3.2)
ax.set_ylim(y - 0.95, cell_h + 0.9)
ax.set_aspect("equal")
ax.axis("off")
return passes
def draw_sort_evolution(ax):
"""Sıralamanın evrimi (L5 sentez): n log n (merge, L3) → O(n) (radix, küçük int anahtar)."""
apply_style(ax)
ns = list(range(2, 201))
merge_curve = [n * math.log2(n) for n in ns] # n log n (karşılaştırma)
radix_c = 3 # sabit basamak (u ≤ n³ örneği)
radix_curve = [radix_c * n for n in ns] # O(n) radix (küçük int anahtar)
ax.plot(ns, merge_curve, color=COL_SLATE_500, linewidth=2.4, zorder=3,
label="merge sort: n·log₂ n (karşılaştırma, L3)")
ax.plot(ns, radix_curve, color=COL_ACCENT, linewidth=3.0, zorder=4,
label=f"radix sort: {radix_c}·n = O(n) (küçük int anahtar, u≤n³)")
# kesişimden sonra radix bölgesini işaretle (radix kazanır)
cross = None
for i, n in enumerate(ns):
if radix_curve[i] < merge_curve[i]:
cross = n
break
if cross is not None:
ax.axvline(cross, color=COL_AMBER_700, linewidth=1.2, linestyle=":", zorder=2)
ax.text(cross + 3, max(merge_curve) * 0.25,
f"n ≳ {cross}: radix < merge\n(lineer kazanır)", ha="left", va="center",
fontsize=8.5, color=COL_AMBER_700, weight="bold")
ax.set_xlabel("n (öğe sayısı)")
ax.set_ylabel("işlem sayısı")
ax.set_title("Sıralamanın evrimi: Ω(n log n) duvarı → O(n) (anahtar = küçük int)",
color=COL_TEXT, fontsize=10.5)
ax.text(ns[-1] * 0.5, max(merge_curve) * 0.92,
"model değişimi: karşılaştırma → rastgele erişim (indeks)",
ha="center", va="center", fontsize=9, color=COL_SLATE_500, style="italic")
ax.set_xlim(2, 215)
ax.set_ylim(0, max(merge_curve) * 1.05)
ax.legend(loc="upper left", fontsize=8.5, framealpha=0.92)
return ax
```
## Önceki Ders: Hash Tablosunun Sınırı {#sec-hash-siniri}
Hash tablosu find/insert/delete'i *beklenen* $O(1)$ yapar — ama **en kötü durumda $O(n)$**'dir (kötü hash → tüm anahtarlar tek zincirde). Bu yüzden en-kötü-durum garantisi gerektiğinde (örneğin worst-case isteyen problem setlerinde) hash tablosu uygun değildir; sıralı dizi ($O(\log n)$ garantili) tercih edilir. (Java, zincirleri ağaçla tutarak worst-case $O(\log n)$ elde eder.) Bu ders aramayı değil, **sıralamayı** ele alır.
## Sıralama Alt Sınırı: n log n {#sec-alt-sinir}
Ders 5'teki karar ağacı argümanını sıralamaya uygularız. Bir sıralama algoritmasının çıktısı, girdinin bir **permütasyonudur**: ilk öğe nereye, ikinci nereye, ... Her öğe için bağımsız seçim → toplam **$n!$** olası çıktı.
> *"I need at least n factorial leaves."* — Ku, 13:55
**Çalışılan Örnek — $n \log n$ alt sınırı.** Doğru bir sıralama, $n!$ permütasyonun her birini üretebilmeli → karar ağacında en az **$n!$ yaprak**. İkili ağacın minimum yüksekliği $\log(n!)$. Bunu alttan sınırla: $n!$ çarpımındaki $n$ terimden yarısı ($n/2$ terim) en az $n/2$'dir, dolayısıyla $n! \ge (n/2)^{n/2}$. Logaritması:
$$\log(n!) \ge \frac{n}{2} \cdot \log\frac{n}{2} = \Theta(n \log n)$$
> *"any sorting algorithm here takes at least n log n comparisons, and so a merge sort's the best we can do."* — Ku, 16:17
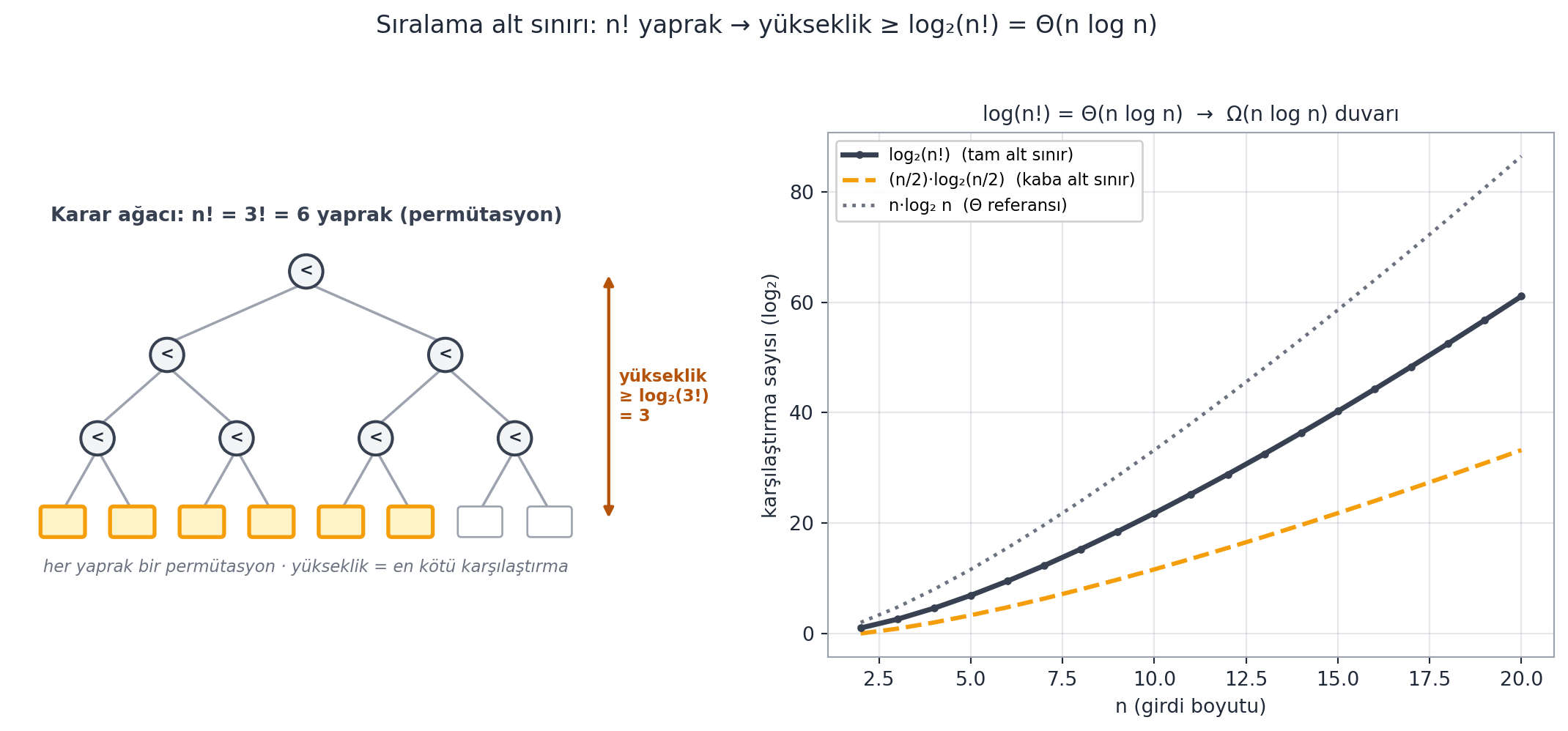
Demek ki karşılaştırma modelinde **$\Omega(n \log n)$** alt sınırı vardır; merge sort optimaldir. (PS1'deki Stirling yaklaşımı da aynı sonucu verir.) Daha hızlısı için karşılaştırmadan çıkıp **rastgele erişim** kullanmak gerekir. @fig-sort-lower-bound bu argümanı küçük bir karar ağacı ve $\log(n!)$ büyüme eğrisiyle birlikte gösterir.
```{python}
#| label: fig-sort-lower-bound
#| fig-cap: "Karşılaştırma modelinde sıralamanın alt sınırı: doğru bir sıralama, girdideki $n$ öğenin **herhangi** bir sıralanışını düzeltebilmeli — yani $n!$ olası permütasyonun her birini üretebilmelidir. Algoritmayı bir **karar ağacı** olarak düşünün: her iç düğüm bir karşılaştırma ($<$), her yaprak nihai bir permütasyon. **Sol:** $n=3$ için ağaç — $3! = 6$ yaprak (amber) gerekir; ikili bir ağacın $h$ yükseklikte en fazla $2^h$ yaprağı olduğundan $2^h \\ge n!$, yani yükseklik $\\ge \\lceil\\log_2(3!)\\rceil = 3$. Bu yükseklik en kötü durumdaki karşılaştırma sayısıdır. **Sağ:** $\\log_2(n!)$ (tam alt sınır, $\\sum_{i=1}^{n}\\log_2 i$) ile kaba alt sınır $(n/2)\\log_2(n/2)$ ve $n\\log_2 n$ referansı aynı büyüme bandında ilerler — Stirling ile $\\log_2(n!) = n\\log_2 n - n\\log_2 e + \\tfrac{1}{2}\\log_2(2\\pi n) = \\Theta(n\\log n)$. Sonuç: yalnız karşılaştırmaya dayanan **hiçbir** sıralama $\\Omega(n\\log n)$'den hızlı olamaz — bu, doğrusal zamanın önündeki **$n\\log n$ duvarıdır**. Duvarı yıkmanın tek yolu karşılaştırmayı bırakıp anahtarı doğrudan adres olarak kullanmaktır (counting / radix sort)."
#| fig-width: 11.5
#| fig-height: 5.2
# --- Sıralama alt sınırı: küçük karar ağacı (n!=3!=6 yaprak) + log(n!) eğrisi ---
# n_tree=3 → 6 permütasyon yaprağı, yükseklik ⌈log₂ 6⌉ = 3 (deterministik).
N_TREE = 3
N_MAX = 20
fig, (ax_tree, ax_curve) = plt.subplots(1, 2, figsize=(11.5, 5.2))
draw_sort_lower_bound(ax_tree, ax_curve, n_tree=N_TREE, n_max=N_MAX)
fig.suptitle(
"Sıralama alt sınırı: n! yaprak → yükseklik ≥ log₂(n!) = Θ(n log n)",
color=COL_TEXT, fontsize=12.5, y=0.99,
)
plt.tight_layout(rect=(0, 0, 1, 0.96))
plt.show()
```
::: {.callout-tip title="Builder Notu — n log n Duvarı ve Model Değiştirme"}
$\Omega(n \log n)$ bir **algoritma** sınırı değil, bir **model** sınırıdır — ve bu ayrım bir builder için kritiktir:
- **Sınır neye bağlı:** Alt sınır "yalnız karşılaştırma yapan" algoritmalar için geçerlidir. İki öğeyi karşılaştırmak en çok 1 bit bilgi verir; $n!$ olası çıktıyı ayırt etmek için en az $\log_2(n!) = \Theta(n \log n)$ bit, yani o kadar karşılaştırma gerekir. Merge sort bu sınıra ulaştığı için karşılaştırma dünyasında **optimaldir**.
- **Tek çıkış = modeli değiştirmek:** Daha hızlı olmak istiyorsan karşılaştırmayı bırakıp anahtarı **doğrudan adres** olarak kullanmalısın (rastgele erişim). Counting/radix sort tam da bunu yapar — bu yüzden alt sınırı ihlal etmezler, *dışına çıkarlar*.
- **Genel ders:** Bir alt sınıra çarptığında soru "daha akıllı bir algoritma var mı?" değil, "varsayımlardan hangisini gevşetebilirim?" olur. Burada gevşetilen varsayım "anahtarlar yalnız karşılaştırılabilir"; yerine "anahtarlar küçük tam sayı" konur.
:::
## Karşılaştırmanın Ötesi: Direct Access Array Sort {#sec-direct-access-d07}
Anahtarlar **benzersiz (unique)** ve **küçük aralıkta** ise: büyük bir direct access array kur, her öğeyi `x.key` indeksine koy ($O(1)$), sonra diziyi baştan sona gez ve dolu hücreleri sırayla topla.
> *"if u is on the order of n, then we now have linear time sorting algorithm."* — Ku, 21:56
```python
def daa_sort(A, u):
D = [None] * u
for x in A:
D[x.key] = x # benzersiz anahtar -> cakisma yok
out = []
for slot in D: # 0..u-1 sirayla gez
if slot is not None:
out.append(slot)
return out
```
**Karmaşıklık:** diziyi kurmak + gezmek $O(u)$, $n$ öğe eklemek $O(n)$ → toplam **$O(n + u)$**. $u = \Theta(n)$ ise **lineer**. Ama iki kısıt var: anahtarlar benzersiz ve aralık küçük olmalı.
## Daha Büyük Aralık: Anahtarı Basamaklara Ayır {#sec-base-n}
$u \le n^2$ olsun. $n^2$-boyutlu bir dizi quadratik olur — işe yaramaz. Çözüm: her anahtarı **base-$n$** iki basamağa ayır. $k$ için:
$$a = k // n, \quad b = k \bmod n, \quad k = a \cdot n + b$$
Burada $a$ **n'ler basamağı**, $b$ **birler basamağı**dır. Her basamak $0..n-1$ aralığındadır. Örneğin $n = 5$ için $17 = (3, 2)$ çünkü $3 \cdot 5 + 2 = 17$. Artık tam sayıları değil, bu **ikililer (tuple)** üzerinden sıralayacağız.
::: {.callout-tip title="Builder Notu — Böl ve Eşle (radix/bucket/hash ortak kök)"}
Anahtarı base-$n$ basamaklara ayırmak, yalıtık bir hile değil — bilgisayar biliminin tekrar tekrar gördüğü bir kalıptır: **büyük bir problemi sabit sayıda küçük parçaya böl, her parçayı bir kovaya eşle.**
- **Radix:** anahtarı basamaklara böl, her basamağı $0..n-1$ kovasına eşle (bu ders).
- **Bucket sort:** anahtar aralığını eşit kovalara böl, her öğeyi kovasına at, kova içini sırala — aynı "böl ve eşle" sezgisi, farklı bölme kuralı.
- **Hash bölmeleri (partitioning):** dağıtık sistemlerde (Spark, veritabanı sharding) anahtarı `hash(k) mod p` ile $p$ parçaya böl — her parça bağımsız işlenir.
Üçü de $k = a \cdot n + b$ türünden bir ayrıştırmayla "tek büyük indeks" yerine "sabit sayıda küçük indeks" kullanır. Bir builder bu kalıbı tanırsa, "anahtar evreni çok büyük" probleminde refleks olarak basamaklara/kovaları bölmeyi dener.
:::
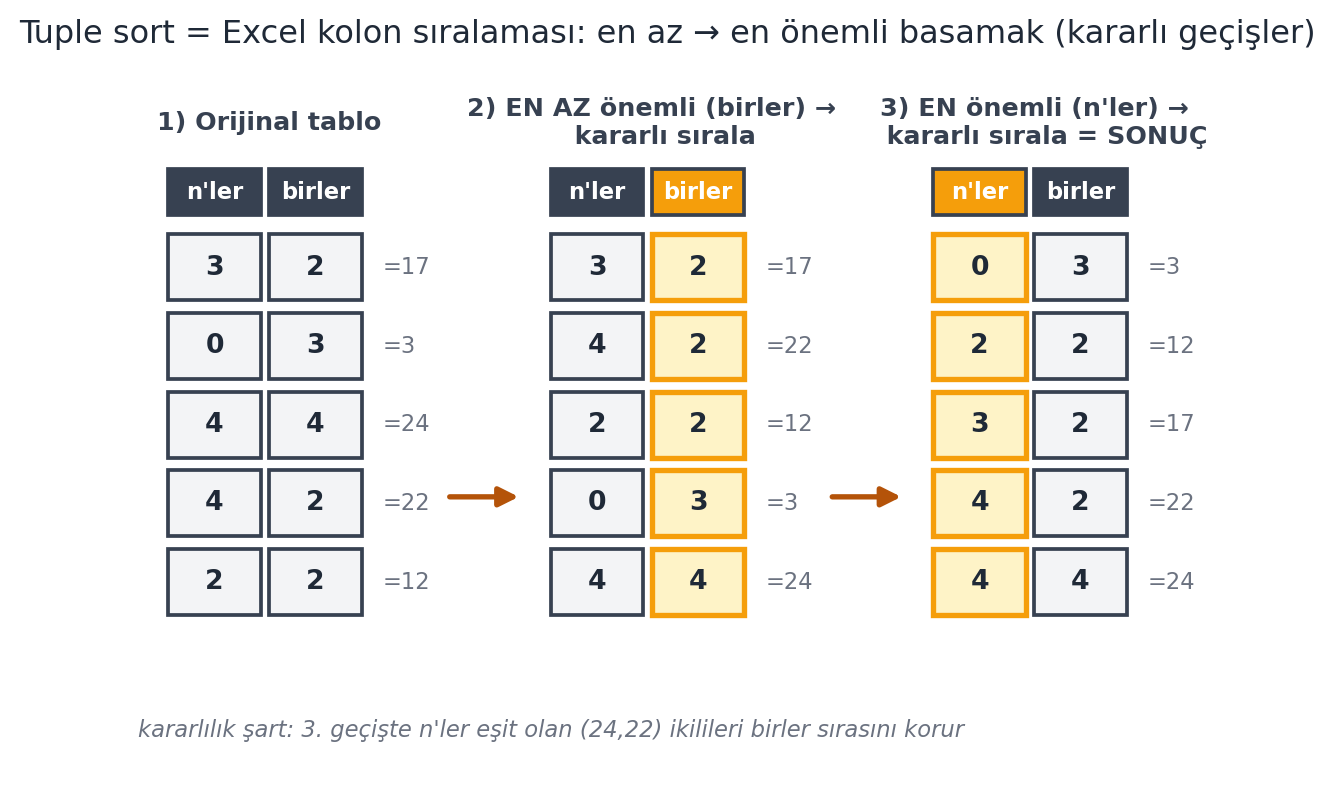
## Tuple Sort (Excel Tablo Sıralaması) {#sec-tuple-sort}
İkilileri sıralamak, bir **Excel tablosunu kolonlara göre** sıralamaya benzer: her kolonun bir öncelik sırası var. En önemli basamak ($a$), en az önemliden ($b$) daha belirleyicidir — $a$'yı 1 artırmak, $b$ ne olursa olsun sayıyı büyütür.
> *"tuple sort, but you can also think of it as Excel spreadsheets sort."* — Ku, 29:14
Strateji: basamakları **en az önemliden en önemliye** doğru, art arda sırala. Ama bu yalnızca her geçişte **kararlı (stable)** bir sıralama kullanılırsa işe yarar — sonraki bölümün konusu. @fig-tuple-sort, $17, 3, 24, 22, 12$ örneğinde iki kararlı geçişi yan yana gösterir.
```{python}
#| label: fig-tuple-sort
#| fig-cap: "Tuple sort = Excel kolon sıralaması (Ku $\\S 5$): bir sayıyı base-$n$ basamaklarından oluşan bir **ikili** $(a, b)$ gibi düşün ($a$ = $n$'ler, $b$ = birler). $17,3,24,22,12$ ($n=5$, base-$5$) örneği iki **kararlı** geçişle sıralanır: önce **EN AZ önemli** basamağa (birler, amber kolon) göre kararlı sırala, sonra **EN önemli** basamağa ($n$'ler, amber kolon) göre kararlı sırala. Sonuç $3,12,17,22,24$. Kararlılık şart: 3. geçişte $n$'ler basamağı eşit olan $24=(4,4)$ ve $22=(4,2)$ ikilileri, 1. geçişte kurulan birler sırasını korur ($22$ önce, $24$ sonra). Bu, radix sort'un counting sort'u neden **kararlı** yardımcı olarak kullandığının çekirdeğidir."
#| fig-width: 11.0
#| fig-height: 4.2
# fig-tuple-sort: Excel/tuple sort — base-n tuple (a,b), en az → en önemli basamak.
# rows=None → Ku §5 örneği 17=(3,2) 3=(0,3) 24=(4,4) 22=(4,2) 12=(2,2); iki kararlı geçiş.
fig, ax = plt.subplots(figsize=(11.0, 4.2))
# Üç durum: orijinal tablo → birler (lo, amber) kararlı sırala → n'ler (hi, amber) kararlı sırala.
draw_tuple_sort(ax)
ax.set_title(
"Tuple sort = Excel kolon sıralaması: en az → en önemli basamak (kararlı geçişler)",
color=COL_TEXT, fontsize=12, pad=12,
)
plt.tight_layout()
plt.show()
```
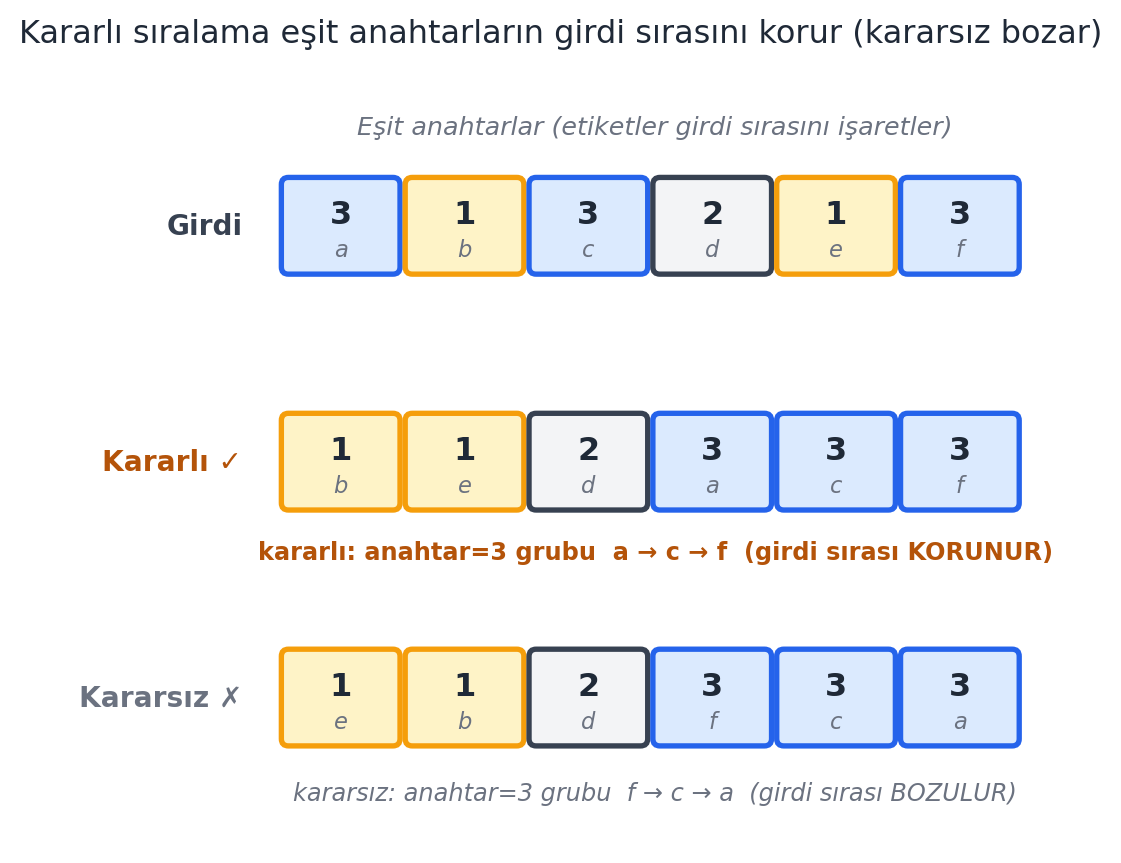
## Kararlı Sıralama (Stable Sort) {#sec-stable-sort}
Bir sıralama **kararlıdır** eğer eşit anahtarlı öğeler, çıktıda girdideki **göreli sıralarını korur**.
> *"if they are the same thing, then the output maintains their order from the input... that's what we call a stable sorting algorithm."* — Ku, 36:18
Neden kritik? Tuple sort'ta önce en az önemli basamağı sıralarız; sonra en önemliyi. En önemli basamak eşit olan öğeler için, *önceki* (az önemli) sıralamanın korunması gerekir — bu yalnızca kararlı sıralamayla olur. @fig-stable-sort, aynı girdiyi kararlı ve kararsız sıralayarak farkı görselleştirir.
```{python}
#| label: fig-stable-sort
#| fig-cap: "**Kararlı (stable) sıralama**: eşit anahtarlı ama farklı yüklü (payload) öğeler için, kararlı bir sıralama bunların **girdideki göreli sırasını korur**; kararsız bir sıralama onları yeniden dizebilir. Üstte **girdi**: anahtarlar $3, 1, 3, 2, 1, 3$ (altlarındaki $a..f$ etiketleri girdi sırasını işaretler — eşit anahtarlı öğeleri birbirinden ayıran yük). Ortada **kararlı** çıktı (**amber** ✓): anahtar $= 3$ grubu $a \\to c \\to f$ sırasını AYNEN korur, anahtar $= 1$ grubu $b \\to e$ kalır. Altta **kararsız** çıktı (✗): anahtarlar yine artan ($1,1,2,3,3,3$) ama eşit anahtar içinde sıra bozulur ($3$ grubu $f \\to c \\to a$). Anahtarlar sıralı olsa bile kararsız sonuç farklıdır — bu yüzden çok-kolonlu sıralama (önce ikincil, sonra birincil anahtar) ve radix sort yalnız **kararlı** bir alt-sıralama ile doğru çalışır."
#| fig-width: 8.5
#| fig-height: 4.6
# fig-stable-sort: kararlı vs kararsız sıralama, eşit anahtar + farklı yük (payload).
# DETERMİNİSTİK: sabit (anahtar, etiket) ikilileri (seed yok). draw_stable_sort /
# COL_* / plt gizli setup hücresinden (inline _engine + _viz) gelir. Kararlı sıra
# Python'un stable sorted'ı; kararsız sıra eşit-anahtar gruplarını ters çevirir.
# anahtar=3 grubu: girdi a,c,f → kararlı a→c→f (KORUNUR), kararsız f→c→a (BOZULUR).
PAIRS = ((3, "a"), (1, "b"), (3, "c"), (2, "d"), (1, "e"), (3, "f"))
fig, ax = plt.subplots(figsize=(8.5, 4.6))
fig.patch.set_facecolor(COL_WHITE)
# üç şerit: Girdi / Kararlı ✓ (amber, sıra korunur) / Kararsız ✗ (sıra bozulur)
draw_stable_sort(ax, pairs=PAIRS)
ax.set_title(
"Kararlı sıralama eşit anahtarların girdi sırasını korur (kararsız bozar)",
color=COL_TEXT, fontsize=12, pad=14,
)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Kararlılık ve Çok-Kolonlu Sıralama (SQL ORDER BY)"}
Kararlılık akademik bir incelik değil, her gün kullandığın çok-kolonlu sıralamanın temelidir:
- **SQL `ORDER BY a, b`:** Bunu doğru gerçekleştirmenin bir yolu, önce **ikincil** anahtar `b`'ye göre kararlı sırala, sonra **birincil** anahtar `a`'ya göre kararlı sırala. `a` eşit olan satırlar `b` sırasını korur — tuple sort'un birebir aynısı. Anahtar her zaman *az önemliden çok önemliye* uygulanır.
- **pandas `df.sort_values([...])` ve Excel'in çok-seviyeli sıralaması** aynı mantığı kullanır; altta yatan sıralama kararlı olmasaydı ikincil sıra rastgele bozulurdu.
- **Programlama dili garantisi:** Python'un `sorted`/`list.sort` ve Java'nın nesne sıralaması **kararlı** olmayı garanti eder (Timsort); C++ `std::sort` etmez (kararlı isterse `std::stable_sort`). Bir builder bu garantiyi bilmeden çok-kolonlu sıralama yazarsa, dilden dile sessizce farklı sonuçlar alır.
Tek cümle: *Kararlılık, "önce ikincil sonra birincil anahtar" hilesiyle çok-kolonlu sıralamayı tek-kolonlu sıralamalardan kurmanı sağlar.*
:::
## Counting Sort {#sec-counting-sort}
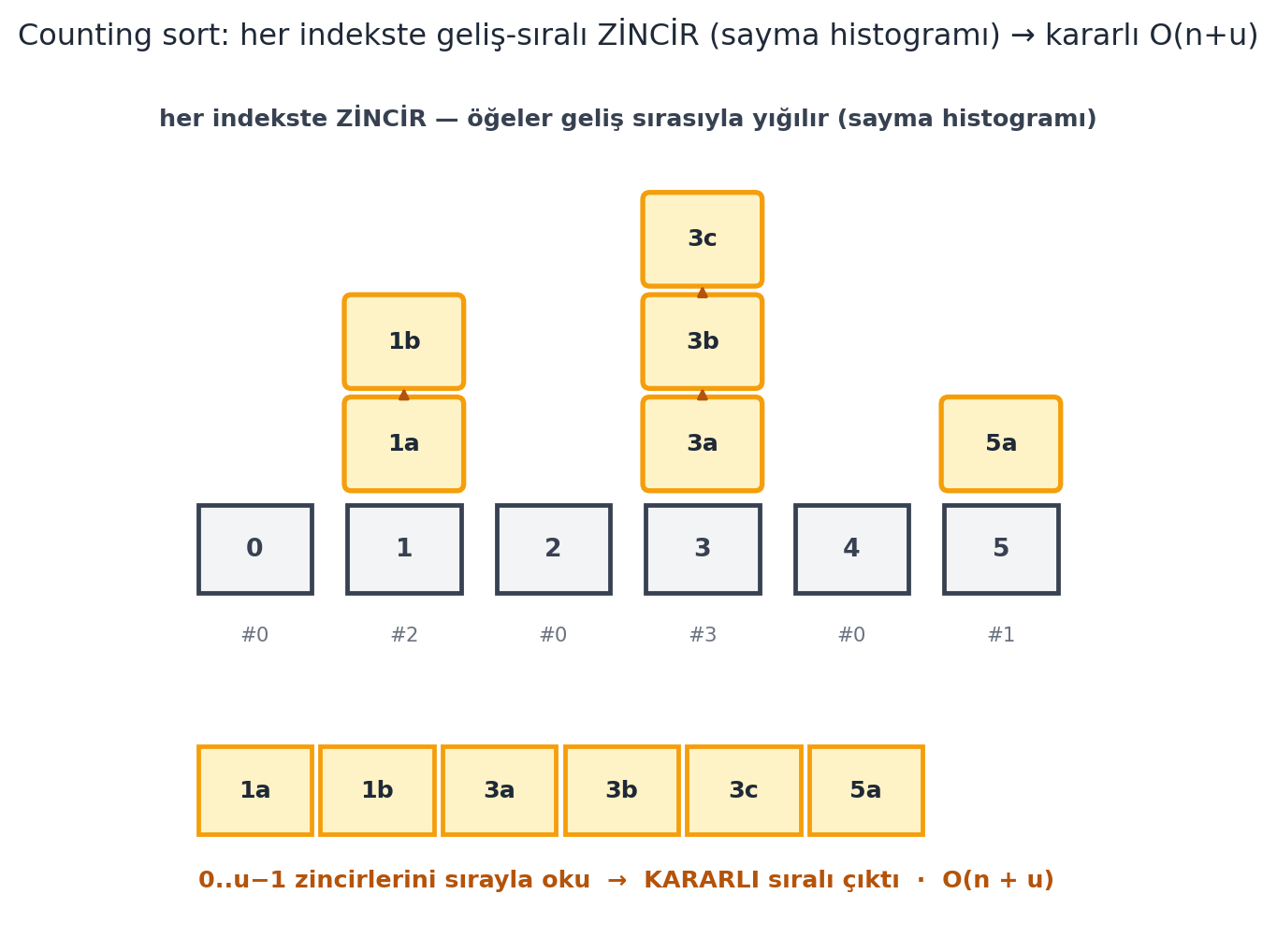
Direct access array sort benzersiz anahtar isterdi; ama tuple sort'ta basamaklar **tekrar eder**. Çözüm: her indekste tek öğe yerine bir **zincir** (sequence veri yapısı — dinamik dizi/bağlı liste) tut ve öğeleri **geldikleri sırada** sona ekle. Bu **counting sort**'tur — hashing'e benzer ama amaç sıra korumak.
> *"This is called counting sort."* — Ku, 39:41
Okurken, dolu zincirleri $0$'dan $u-1$'e gez ve içlerini sırayla oku. Geliş sırası korunduğu için counting sort **kararlıdır**. Zincirlerin toplam uzunluğu $n$, dizi boyutu $u$ → **$O(n + u)$**. @fig-counting-sort bu zincir/histogram yapısını ve kararlılığı adım adım gösterir.
```{python}
#| label: fig-counting-sort
#| fig-cap: "Counting sort (Ku $\\S 7$, **İMZA** figür): doğrudan erişim dizisinin sıra-koruyan ikizi. $u$ kova (burada $u = 6$, indeks $0..5$); her öğenin anahtarı $k$, onu $k$. kovaya yollar. Doğrudan erişim sortundan farkı: her kovada tek öğe değil bir **ZİNCİR** (chain) tutulur ve öğeler **geliş sırasıyla** sona eklenir (amber yukarı-oklar geliş yönünü gösterir). Girdi $(3a, 1a, 3b, 5a, 1b, 3c)$ — harfler eşit anahtarların girdi sırasını işaretler. Dağıtımdan sonra zincirler sayma histogramıdır: kova $1 = [1a, 1b]$ (#2), kova $3 = [3a, 3b, 3c]$ (#3), kova $5 = [5a]$ (#1), gerisi boş. Çıktıyı üretmek için zincirleri $0$'dan $u-1$'e **sırayla oku**: $[1a, 1b, 3a, 3b, 3c, 5a]$ — eşit anahtarlı öğeler girdi sırasını korur, yani sıralama **kararlıdır** (stable). Toplam iş = zincirlere $n$ öğe ekle + $u$ kovayı gez $= O(n + u)$; $u = \\Theta(n)$ ise **lineer**. Bu kararlılık, radix sort'un (@fig-radix-sort) basamak-basamak doğru çalışmasının temelidir."
#| fig-width: 9
#| fig-height: 5.4
# --- Counting sort: zincir/histogram + geliş sırası → kararlılık (deterministik) ---
# Öğe = (anahtar, etiket); etiket girdi sırasını işaretler → eşit anahtarlarda
# kararlılık (a < b < c geliş sırası) çıktıda korunur. n = 6, u = base = 6.
items = [(3, "a"), (1, "a"), (3, "b"), (5, "a"), (1, "b"), (3, "c")]
base = 6 # u = 6 kova (0..5)
trace = counting_sort_trace(items, key_fn=lambda x: x[0], base=base)
fig, ax = plt.subplots(figsize=(9, 5.4))
draw_counting_sort(ax, trace, base=base)
ax.set_title(
"Counting sort: her indekste geliş-sıralı ZİNCİR (sayma histogramı) → kararlı O(n+u)",
color=COL_TEXT, fontsize=12, pad=12,
)
plt.tight_layout()
plt.show()
```
## Radix Sort {#sec-radix-sort}
Counting sort'u tuple sort'un yardımcı (kararlı) sıralaması olarak kullanırsak, büyük anahtarları sıralayabiliriz. **Radix sort**: en büyük anahtar $u$ olan tam sayıları base-$n$ basamaklara ayır ($\log_n u$ basamak), sonra counting sort ile en az önemliden en önemliye tuple sort yap.
> *"this is what we call radix sort."* — Ku, 47:39
Her basamağı sıralamak $O(n)$ (counting sort, $u = n$). Basamak sayısı $\log_n u$. Ayrıca her sayıyı ayırmak da $O(n \cdot \log_n u)$. Toplam:
$$T(n) = O(n + n \cdot \log_n u)$$
**Kritik sonuç:** $u \le n^c$ (sabit $c$) ise, $\log_n u = \log_n n^c = c$ (sabit) → $T(n) = $ **$O(n)$**.
> *"if u is less than n to the c for some constant c... we get a linear time algorithm."* — Ku, 50:35
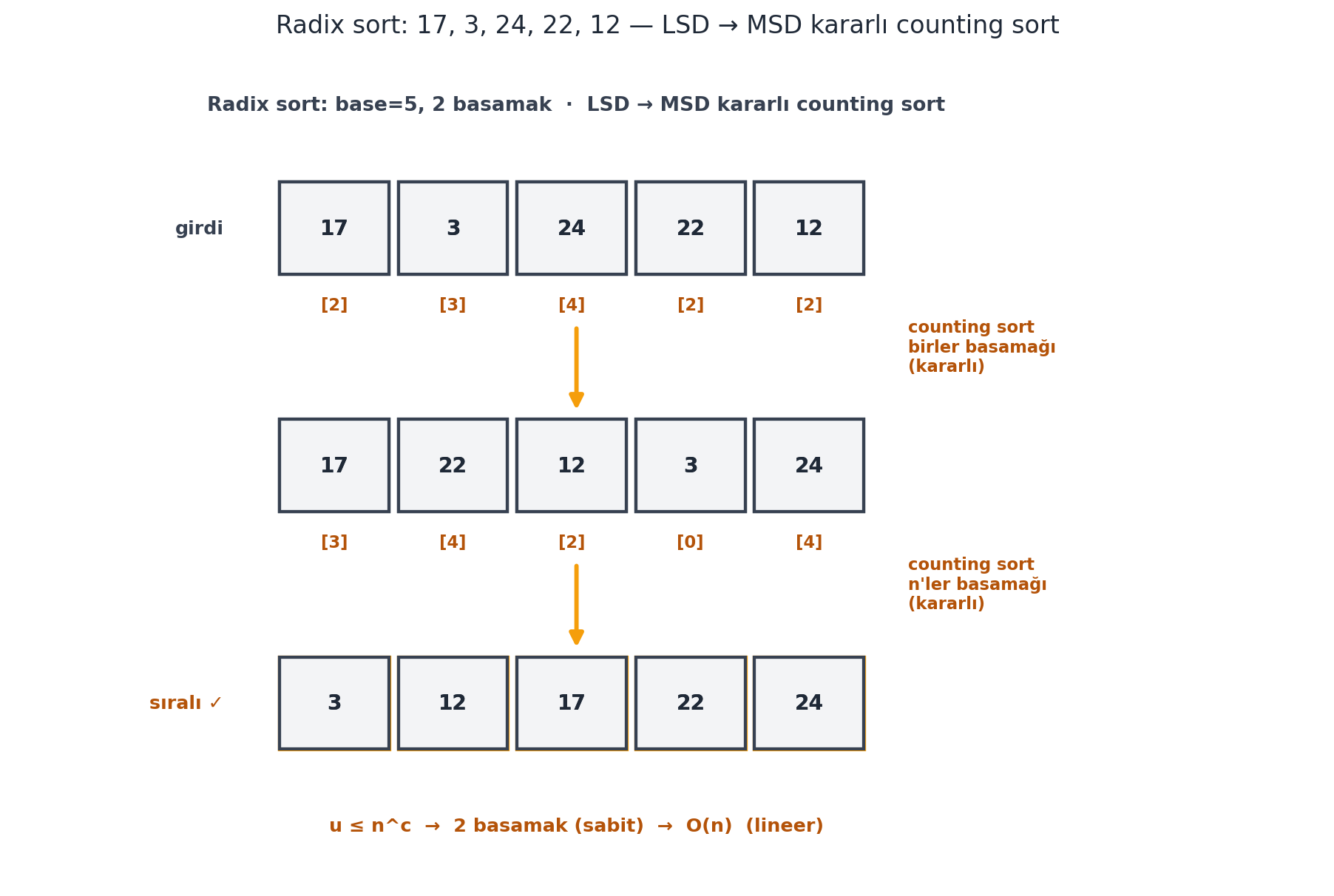
Yani anahtarlar $n$'in bir polinomuyla sınırlıysa, radix sort **lineer** zamanda sıralar. @fig-radix-sort, $17, 3, 24, 22, 12$ üzerinde iki kararlı counting sort geçişini (LSD → MSD) gösterir.
```{python}
#| label: fig-radix-sort
#| fig-cap: "Radix sort = **counting sort + base-$n$ basamaklar** (Ku §8, İMZA örneği $17, 3, 24, 22, 12$; $n=5$, taban $5$ → her sayı iki basamak). $u = \\max + 1 = 25 \\le n^2$ olduğu için $\\lceil \\log_5 25 \\rceil = 2$ basamak yeter. **1. geçiş (LSD, birler basamağı):** girdideki her sayının **en az** önemli basamağı (amber rozet $[d_0]$: $17{=}[2]$, $3{=}[3]$, $24{=}[4]$, $22{=}[2]$, $12{=}[2]$) ile **kararlı** counting sort → $[17, 22, 12, 3, 24]$. **2. geçiş (MSD, n'ler basamağı):** bu kez **en** önemli basamak ($[d_1]$: $17{=}[3]$, $22{=}[4]$, $12{=}[2]$, $3{=}[0]$, $24{=}[4]$) ile yine kararlı counting sort → $[3, 12, 17, 22, 24]$ (amber, **sıralı ✓**). Kararlılık şarttır: 2. geçişte n'ler basamağı eşit olan ($22$ ve $24$, ikisi de $4$) öğeler 1. geçişten gelen birler sırasını korur → tuple sort doğru çalışır. Her geçiş $O(n + \\text{base})$; sabit sayıda geçiş ($u \\le n^c$ → $c$ basamak), $\\text{base} = n$ alınırsa toplam $O(n)$ — **doğrusal zaman**, karşılaştırma sınırı $\\Omega(n \\log n)$ aşılır."
#| fig-width: 9.5
#| fig-height: 7.2
# --- Radix sort izi: 17,3,24,22,12 (n=5), base-5, iki basamak (LSD→MSD) ---
# u = max+1 = 25 ≤ n² → ⌈log₅ 25⌉ = 2 basamak → sabit geçiş → O(n) (deterministik).
INTS = [17, 3, 24, 22, 12]
BASE = 5
trace = radix_sort_trace(INTS, BASE)
fig = plt.figure(figsize=(9.5, 7.2))
ax = fig.add_subplot(1, 1, 1)
draw_radix_sort(ax, trace)
ax.set_title(
"Radix sort: 17, 3, 24, 22, 12 — LSD → MSD kararlı counting sort",
color=COL_TEXT, fontsize=12.5, pad=12,
)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Radix Sort, GPU ve Büyük Veri"}
Radix sort akademik bir oyuncak değil; **sabit-uzunluk tam sayı anahtarlar** söz konusu olduğunda gerçek dünyada karşılaştırmalı sıralamayı geçer:
- **Sabit-uzunluk anahtarlar her yerde:** 32-bit IP adresleri, 64-bit timestamp'ler, sabit ID'ler — hepsi $u \le n^c$ koşulunu pratikte sağlar (örn. $u = 2^{32}$, $n = 10^6$ için $\log_n u \approx \log_{10^6} 2^{32} \approx 1.6$, yani 2 basamak yeter). Bu yüzden ağ/log işleme boru hatlarında radix sort doğal tercihtir.
- **GPU sıralama:** Radix sort, karşılaştırma yerine basamak sayımına (histogram) dayandığından **paralelleştirmesi kolaydır** — her thread bir öğenin basamağını sayar, prefix-sum ile yerini bulur. CUDA Thrust ve cuDF gibi kütüphanelerin varsayılan tam sayı sıralaması radix tabanlıdır; merge sort'un dallanması GPU'da pahalıdır, radix'in düz histogramı değildir.
- **Veritabanı / büyük veri:** Spark, ClickHouse gibi sistemler tam sayı/sabit anahtar kolonlarında radix veya hibrit (radix + merge) sıralama kullanır; "anahtar küçük tam sayı mı?" sorusu sıralama planlayıcısının ilk kontrolüdür.
Tek cümle: *Anahtarların küçük tam sayı olduğunu bildiğin an, radix sort hem asimptotik ($O(n)$) hem donanım (GPU paralelliği) açısından merge sort'u geçer.*
:::
## Bu Dersin Özeti {#sec-ozet-d07}
1. **Karşılaştırma modelinde** sıralama $\Omega(n \log n)$'dir: $n!$ permütasyon → $n!$ yaprak → $\log(n!) = \Theta(n \log n)$.
2. **Direct access array sort**: benzersiz anahtar + küçük aralık → $O(n + u)$; $u = \Theta(n)$ ile lineer.
3. **Anahtarı base-$n$ basamaklara ayır** ($a = k // n$, $b = k \bmod n$) → $u \le n^2$ için ikililer.
4. **Tuple sort**: basamakları en az önemliden en önemliye, kararlı sıralamayla sırala.
5. **Kararlı (stable) sıralama**: eşit anahtarlar girdi sırasını korur — tuple sort için şart.
6. **Counting sort**: direct access + zincir (sıra korur); kararlı; $O(n + u)$.
7. **Radix sort**: $\log_n u$ basamak, counting sort ile; $u \le n^c$ ise **$O(n)$**.
::: {.callout-important title="Tek Bir Cümle"}
Karşılaştırma $n \log n$'de tıkanır; ama anahtarlar küçük tam sayıysa, onları indeks yapıp (counting sort) basamak basamak kararlı sıralayarak (radix sort) $O(n)$'e inilir.
:::
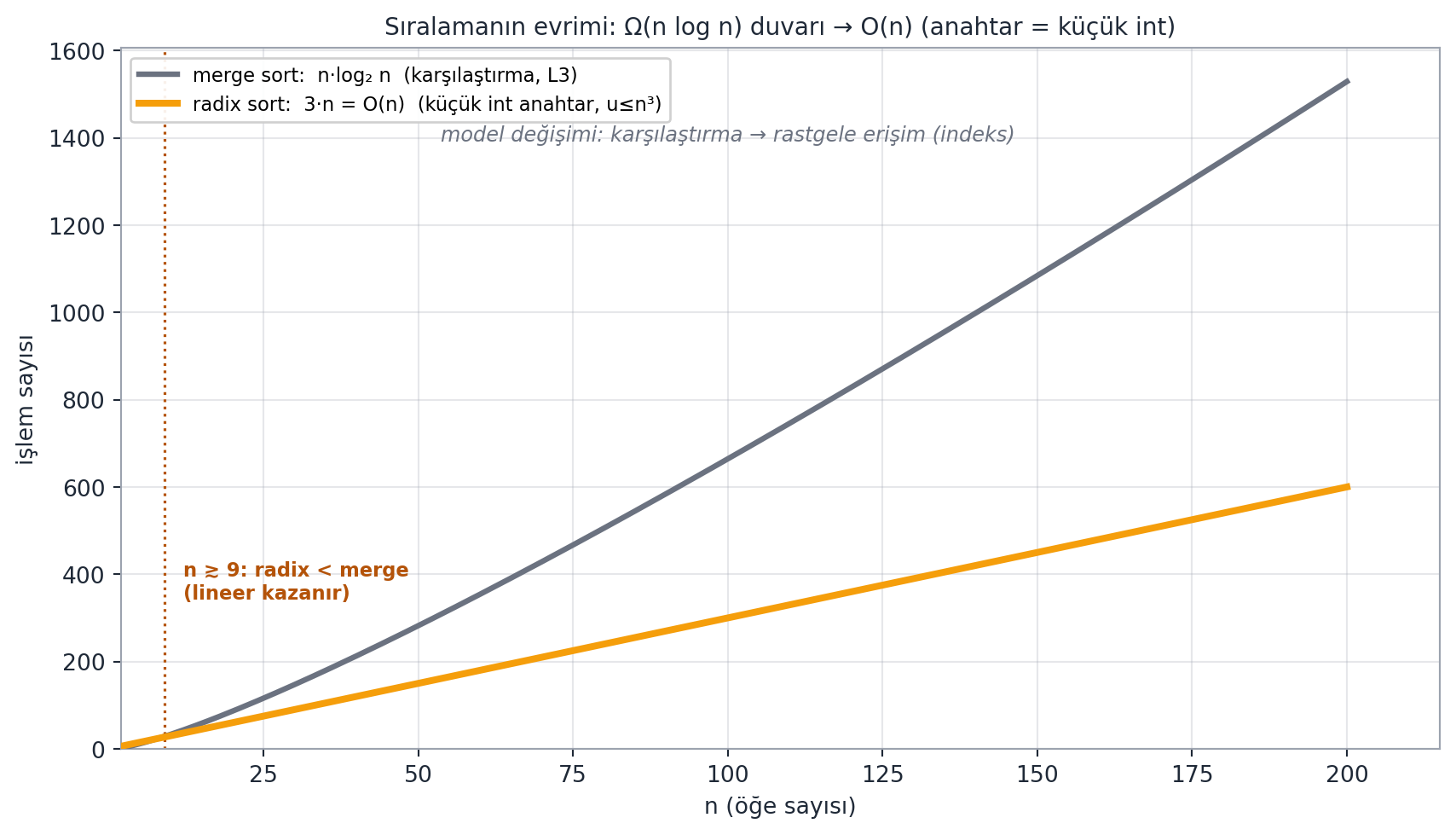
@fig-sort-evolution bu sıçramayı tek grafikte özetler: Ders 4'ün $n \log n$ merge sort'undan, bu dersin $O(n)$ radix sort'una.
```{python}
#| label: fig-sort-evolution
#| fig-cap: "Sıralamanın evrimi — maliyet duvarının yıkılışı. **Slate eğri:** merge sort, $n \\cdot \\log_2 n$ (böl-yönet + two-finger merge, Ders 4/L3) — karşılaştırma modelindeki **$\\Omega(n \\log n)$ duvarı**, selection sort'un $\\Theta(n^2)$'sinden çok daha iyi olsa da bu duvarı aşamaz. **Amber çizgi:** radix sort, $3 \\cdot n = O(n)$ — anahtarlar **küçük tamsayı** olduğunda ($u \\le n^3$, yani $c = 3$ sabit basamak) sıralama **doğrusal**. İki eğri $n \\approx 9$'da kesişir (noktalı amber dikey çizgi); ötesinde radix sort merge sort'un altında kalır, yani **doğrusal kazanır**. Sıçramanın sebebi modeli değiştirmektir: karşılaştırma yerine anahtarı doğrudan **indeks** olarak kullanmak (counting/radix sort), karşılaştırma alt sınırının dışına çıkmanın tek yoludur. Bu figür Ders 4'ün $n \\log n$ merge sort'unu (bkz. @fig-merge-tree) Ders 7'nin $O(n)$ radix sort'una (bkz. @fig-radix-sort) bağlar."
#| fig-width: 9
#| fig-height: 5.2
# fig-sort-evolution: L3 (merge, n log n) → L5 (radix, O(n)) sentezi.
# DETERMİNİSTİK: draw_sort_evolution sabit n aralığı (2..200) + sabit katsayılar
# (merge = n·log₂ n, radix = 3·n) çizer; seed yok. Kesişim n ≈ 9'da (3n < n·log₂n
# ilk olarak n=9'da: 27 < 28.5). COL_* / plt / draw_sort_evolution gizli setup
# hücresinden (inline _engine + _viz) gelir.
fig, ax = plt.subplots(figsize=(9, 5.2))
fig.patch.set_facecolor(COL_WHITE)
# merge n·log₂ n (slate, karşılaştırma duvarı L3) vs radix 3·n (amber, O(n) L5);
# kesişimden sonra radix bölgesi + Ω(n log n) duvarı / model-değişimi notları içeride.
draw_sort_evolution(ax)
plt.tight_layout()
plt.show()
```
## Kontrol Soruları {#sec-sorular-d07}
::: {.callout-note collapse="true" title="Soru 1: Sıralama alt sınırının neden Ω(n log n) olduğunu, karar ağacı + n! ile özetle."}
**Cevap:**
Bir sıralama, girdinin $n!$ olası permütasyonundan herhangi birini üretebilmeli → karar ağacında en az $n!$ yaprak. İkili ağacın minimum yüksekliği $\log(n!)$, ve en kötü durum karşılaştırma sayısı = yükseklik. $\log(n!) \ge \log((n/2)^{n/2}) = (n/2)\log(n/2) = \Theta(n \log n)$. Dolayısıyla her karşılaştırmalı sıralama $\Omega(n \log n)$'dir; merge sort bu sınıra ulaştığı için optimaldir.
:::
::: {.callout-note collapse="true" title="Soru 2: Counting sort neden direct access array sort'tan daha geneldir?"}
**Cevap:**
Direct access array sort, her indekste tek öğe sakladığı için **benzersiz anahtar** ister. Counting sort, her indekste bir **zincir** (sıra koruyan sequence yapısı) tutar; böylece tekrar eden anahtarları geldikleri sırada saklar. Bu hem tekrarlı anahtarları destekler hem de **kararlılık** sağlar — ki radix sort'un çalışması için bu şarttır.
:::
::: {.callout-note collapse="true" title="Soru 3: Tuple sort'ta basamakları neden en az önemliden en önemliye sıralarız, tersi değil?"}
**Cevap:**
En önemli basamak, son geçişte sıralanmalı ki nihai sırada baskın olsun. Eğer önce en önemliyi sıralarsak, sonra en az önemliyi sıralamak önceki işi **bozar** (eşitlikler yeniden dağılır). En az önemliden başlayıp en önemliyle bitirince, kararlı sıralama sayesinde en önemli basamakta eşit olanlar önceki (az önemli) sıralamayı korur. Bu yüzden hem sıra (en az → en önemli) hem de **kararlılık** zorunludur.
:::
::: {.callout-note collapse="true" title="Soru 4: Radix sort hangi koşulda O(n) olur? n³'e kadar anahtarlar için kaç basamak gerekir?"}
**Cevap:**
Radix sort $O(n + n \cdot \log_n u)$'dur. $u \le n^c$ (sabit $c$) ise $\log_n u = c$ sabittir → $O(n)$ lineer. $n^3$'e kadar anahtarlar için ($u = n^3$): her anahtarı base-$n$ üç basamağa ayırırız ($\log_n n^3 = 3$, sabit). Üç kararlı counting sort geçişi, her biri $O(n)$ → toplam $O(3n) = O(n)$. Anahtarlar $n$'in bir polinomuyla sınırlı kaldıkça radix sort lineerdir.
:::
## Egzersizler {#sec-egzersizler-d07}
**Egzersiz 1.** Stirling yaklaşımını ($n! \approx \sqrt{2\pi n}(n/e)^n$) kullanarak $\log(n!) = \Theta(n \log n)$'i göster ve Bölüm 2'deki $(n/2)^{n/2}$ alt sınırıyla karşılaştır.
**Egzersiz 2.** $u = n^2$ için, radix sort'un iki basamaklı (base-$n$) çalışmasını $17, 3, 24, 22, 12$ üzerinde elle yürüt; her counting sort geçişinin çıktısını yaz.
**Egzersiz 3.** Bir sıralamanın kararlı olup olmadığını test eden bir örnek tasarla: aynı anahtarlı ama farklı "yük" taşıyan öğelerle. Selection sort kararlı mıdır?
**Egzersiz 4.** Python'da counting sort'u tek basamak için yaz ve `sorted(..., key=...)`'in kararlılığıyla karşılaştır:
```python
def counting_sort(A, key, base):
chains = [[] for _ in range(base)]
for x in A:
chains[key(x)].append(x) # geldigi sirada ekle -> kararli
out = []
for chain in chains:
out.extend(chain)
return out
```
**Egzersiz 5.** Radix sort'un çalışma süresi $O(n \cdot \log_n u)$ için, $u = 2^{32}$ (32-bit tam sayılar) ve $n = 1000$ olduğunda kaç basamak gerekir? Bu $n \log n$'den iyi mi?
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d07}
**Ders 6 (L6): İkili Ağaçlar — Bölüm 1**
Erik Demaine ile, sıralı diziyi ($O(n)$ ekleme) ve hash tablosunu (worst-case $O(n)$) aşan dengeli bir yapıya — **ikili ağaçlara** — geçiyoruz: tüm işlemler worst-case $O(\log n)$. (Not: ders akışında araya **Problem Oturumu 3** girer.)
::: {.callout-warning title="Ders 6 Öncesi Yapılacak"}
- Bu dersin egzersizlerini, özellikle Egzersiz 4'ü (counting sort) çöz.
- Üç sıralama yöntemi (direct access → counting → radix) arasındaki ilişkiyi ezberden anlat.
- Ana cümleyi tekrar oku: *"Anahtarlar küçük tam sayıysa, basamak basamak kararlı sıralayarak $O(n)$'e inilir."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet-d07}
| Kavram | Tanım | Sayfada |
|---|---|---|
| **Sıralama alt sınırı** | Karşılaştırma modelinde $\Omega(n \log n)$; $n!$ yaprak | Böl. 2 |
| **Direct access array sort** | Benzersiz anahtar, küçük aralık; $O(n + u)$ | Böl. 3 |
| **Base-$n$ ayırma** | $k = a \cdot n + b$; $a = k // n$, $b = k \bmod n$ | Böl. 4 |
| **Tuple sort** | Basamakları en az → en önemli, kararlı sırala | Böl. 5 |
| **Kararlı (stable) sıralama** | Eşit anahtarlar girdi sırasını korur | Böl. 6 |
| **Counting sort** | Direct access + zincir; kararlı; $O(n + u)$ | Böl. 7 |
| **Radix sort** | $\log_n u$ basamak + counting sort; $u \le n^c \to O(n)$ | Böl. 8 |
## Builder ve OMSCS Bağlantıları {#sec-ml-baglantilar-d07}
::: {.callout-tip title="6 köprü"}
Bu ders, "ne zaman karşılaştırmadan vazgeçilir" sezgisini kurar — köprülerin özeti:
1. **$n \log n$ alt sınırı** → teorik temel: hiçbir karşılaştırmalı sıralama bunu geçemez; modeli değiştirmek (rastgele erişim) tek çıkış.
2. **Counting/radix sort** → büyük veri: sabit-uzunluk tam sayı/string anahtarlarda (IP, timestamp, sabit ID) karşılaştırmalı sıralamayı geçer; GPU ve veritabanı sıralaması.
3. **Kararlı sıralama** → çok-kolonlu sıralama: SQL `ORDER BY a, b`, pandas `sort_values` — hep kararlı, en az önemliden uygulama mantığı.
4. **Base-$n$ ayırma** → genel teknik: büyük problemi sabit sayıda küçük parçaya bölmek (radix, bucket, hash bölmeleri).
5. **Direct access fikri** → counting sort ve hashing ortak kökü: "anahtar = indeks" — arama ve sıralamanın aynı sezgisi.
6. **Polinom-sınırlı anahtar** → pratik kural: anahtarlar $n^c$ ile sınırlıysa lineer sırala; değilse merge sort'a dön.
:::
---
::: {.callout-important title="Tek bir şey alıp gideceksen"}
Karşılaştırma modelinde $n \log n$ bir duvardır — $n!$ permütasyon onu zorunlu kılar. Ama anahtarların küçük tam sayı olduğunu *bilirsen*, onları doğrudan indekse çevirip (counting sort) basamak basamak kararlı sıralayarak (radix sort) duvarı aşar, $O(n)$'e inersin.
:::