---
title: "Hashing"
subtitle: "Karşılaştırma modeli alt sınırı, doğrudan erişim dizisi, hash fonksiyonu, çakışma + zincirleme ve evrensel hashing ile beklenen $O(1)$"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Ku'nun videosu:** [YouTube — Lecture 4: Hashing](https://www.youtube.com/watch?v=Nu8YGneFCWE) (≈53 dk)
- **OCW sayfası:** [MIT 6.006 Lecture 4: Hashing](https://ocw.mit.edu/courses/6-006-introduction-to-algorithms-spring-2020/resources/lecture-4-hashing/)
- **Seri:** MIT 6.006 — Introduction to Algorithms (Spring 2020) — Ders 5 (L4)
- **Hoca:** Jason Ku
- **Okuma süresi:** ≈26 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste-d05}
Ders 3, kümeyi (set) sıralı diziyle gerçekleştirip aramayı $O(\log n)$'e indirdi. Bu ders tek bir soruyla başlar: *daha hızlı olur mu?* Jason Ku önce **olamaz** der — karşılaştırma modelinde $\log n$ bir alt sınırdır — sonra modeli genişletip **olur** der: **hashing** ile find/insert/delete *beklenen* $O(1)$.
Üç temel kavram bu derste yan yana gelir:
1. **Karşılaştırma modeli alt sınırı** — yalnızca anahtarları karşılaştıran her algoritma için arama $\Omega(\log n)$'dir (karar ağacı argümanı).
2. **Direct access array → hash tablosu** — anahtarı doğrudan adres yap; evren çok büyükse bir hash fonksiyonuyla küçült.
3. **Evrensel hashing** — rastgele seçilen bir hash ailesi, beklenen zincir uzunluğunu sabit yapar.
> *"Today we are going to be talking about hashing."* — Ku, 0:20
```{mermaid}
%%| label: fig-concept-map
%%| echo: false
%%| fig-cap: "Ders 5'in (L4) kavram haritası: karşılaştırma modelinin Ω(log n) sınırından, doğrudan erişim dizisine (O(1) ama u kadar yer), oradan hash fonksiyonuna (m ≈ n), çakışmaya ve zincirleme + evrensel hashing yoluyla beklenen O(1)'e."
flowchart TD
A["Ders 5 (L4): Hashing"] --> B["Karşılaştırma modeli<br/>alt sınır Ω(log n)"]
A --> C["Direct access array"]
A --> D["Hash fonksiyonu"]
B --> B1["Karar ağacı<br/>n+1 yaprak → yükseklik log n"]
B --> B2["Daha hızlısı için<br/>rastgele erişim gerek"]
C --> C1["anahtar = indeks<br/>O(1) en kötü durum"]
C --> C2["evren u kadar yer<br/>n ≪ u → israf"]
D --> D1["h: 0..u−1 → 0..m−1<br/>(m ≈ n)"]
D --> D2["çakışma (pigeonhole)<br/>→ chaining"]
D2 --> E["Evrensel hashing<br/>P(çakışma) ≤ 1/m"]
E --> F["Beklenen zincir<br/>1 + (n−1)/m → O(1)"]
classDef root fill:#fef3c7,stroke:#b45309,stroke-width:3px,color:#1f2937
classDef branch fill:#f3f4f6,stroke:#374151,stroke-width:2px,color:#1f2937
classDef leaf fill:#ffffff,stroke:#9ca3af,stroke-width:1px,color:#1f2937
classDef win fill:#fef3c7,stroke:#f59e0b,stroke-width:2px,color:#1f2937
class A root
class B,C,D branch
class B1,B2,C1,C2,D1,D2 leaf
class E,F win
```
::: {.callout-tip title="Builder Notu — Hash Tablosu = Python dict ve Randomized Algoritma"}
Bu ders ML değil, ama ML'in ve her ciddi yazılımın altındaki **erişim mekanizmasını** ve **olasılıksal analizi** kurar:
- **Geriye → Python (Phase 1):** Python `dict`/`set` bir hash tablosudur (open addressing şeması). Bu ders onun iç mantığını ve "neden bazen yavaşladığını" açıklar — bedava görünen `d[key]` çağrısının arkasındaki $O(1)$ buradan gelir.
- **Geriye → Stat 110 (Phase 1):** dersin kalbi olasılıktır — **gösterge rastgele değişkeni** (indicator RV), **beklenen değer**, **beklentinin doğrusallığı** (linearity of expectation). Evrensel hashing, randomized algoritmanın bu kursta gördüğün **ilk ciddi örneğidir**: garanti "her girdide" değil, "beklenen" anlamda verilir.
- **İleriye → ML ve sistem tasarımı:** feature hashing, embedding indeksleme, cache, veritabanı indeksi, dağıtık sistemlerde consistent hashing — hepsi anahtar → kova $O(1)$ erişimine dayanır.
Tek cümle: *Sıralamayı bırakıp anahtarı doğrudan adrese "serpiştirirsek" arama $O(1)$ olur — yeter ki hash fonksiyonunu rastgele seçip çakışmayı beklenen anlamda küçük tutalım.*
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — 6.006 Ders 5 (L4) motoru (_engine.py) + Slate+Amber viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri bu hücrede
# tanımlanan DirectAccessArray / HashTableChaining / universal_hash /
# random_universal_params / expected_chain_empirical / decision_tree_min_height
# + draw_* + COL_* + apply_style'ı IMPORT ETMEDEN kullanır. Notion'daki öğretim
# içeriği (görünür prose + display ```python bloklar) bu motorun tarif seviyesidir;
# burada tam, deterministik, test edilmiş sürüm yaşar.
#
# NOT: matplotlib.use("Agg") ÇAĞRILMAZ — Quarto'nun inline figür-yakalama
# backend'ini ezer (plt.show() 0 figür üretir; brief §2/§11). Standalone testte
# savefig kullanılır; Quarto render'da jupyter inline backend'i ayarlar.
# ============================================================================
import math
import random
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
import networkx as nx
# ---------------------------------------------------------------------------
# _engine.py (D5 kısmı) — Hashing motoru (DETERMİNİSTİK + TEST EDİLEBİLİR)
# ---------------------------------------------------------------------------
class DirectAccessArray:
"""Doğrudan erişim dizisi (L4 §3-4): anahtar = indeks → O(1) en kötü durum.
Anahtarı k olan öğeyi doğrudan k. indekse koyarız (Ku: "direct access array").
word RAM'in rastgele erişimi sayesinde find/insert/delete sabit zaman EN KÖTÜ
durum. Bedeli: anahtar evreni u kadar yer ister; n ≪ u ise çoğu hücre boş kalır.
"""
def __init__(self, u):
self.u = u
self.data = [None] * u
def insert(self, key, value=True):
if not 0 <= key < self.u:
raise IndexError(f"DirectAccessArray.insert: anahtar {key} aralık dışı (u={self.u})")
self.data[key] = value
def find(self, key):
if not 0 <= key < self.u:
raise IndexError(f"DirectAccessArray.find: anahtar {key} aralık dışı (u={self.u})")
return self.data[key]
def delete(self, key):
if not 0 <= key < self.u:
raise IndexError(f"DirectAccessArray.delete: anahtar {key} aralık dışı (u={self.u})")
self.data[key] = None
def occupancy(self):
"""İsraf gösterimi (fig-direct-access): (dolu_hücre, toplam_hücre)."""
filled = sum(1 for x in self.data if x is not None)
return filled, self.u
def universal_hash(a, b, p, m, k):
"""Evrensel hash ailesi (L4 §8): h(k) = ((a·k + b) mod p) mod m.
p, anahtar evreninden büyük sabit bir asal; a, b kurulumda RASTGELE seçilir
(a ≠ 0). Evrensellik: rastgele seçilen bir h için herhangi iki farklı anahtarın
çakışma olasılığı ≤ 1/m.
"""
if a == 0:
raise ValueError("universal_hash: a = 0 yasak (anahtar bilgisi kaybolur; L4 Egzersiz 3)")
return ((a * k + b) % p) % m
def random_universal_params(p, m, seed):
"""Evrensel aileden DETERMİNİSTİK rastgele hash parametreleri seç (L4 §8).
Aynı (p, m, seed) her zaman aynı (a, b)'yi üretir → testler/figürler tekrarlanabilir.
a ∈ [1, p−1] (a ≠ 0 zorunlu), b ∈ [0, p−1].
"""
rng = random.Random(seed)
a = rng.randint(1, p - 1)
b = rng.randint(0, p - 1)
return {"a": a, "b": b, "p": p, "m": m}
class HashTableChaining:
"""Zincirlemeli hash tablosu (L4 §6-9): m kova + her kovada zincir (chain).
İki hash yöntemi: "division" (h(k)=k mod m, deterministik) ve "universal"
(h(k)=((a·k+b) mod p) mod m, rastgele a,b; P(çakışma) ≤ 1/m). Çakışan anahtarlar
aynı kovanın zincirine eklenir; m = Θ(n) ile işlemler beklenen O(1).
"""
def __init__(self, m, method="division", a=None, b=None, p=None, seed=None):
if m <= 0:
raise ValueError("HashTableChaining: m > 0 olmalı")
if method not in ("division", "universal"):
raise ValueError(f"HashTableChaining: bilinmeyen method {method!r}")
self.m = m
self.method = method
self.buckets = [[] for _ in range(m)]
self.n = 0
if method == "universal":
if a is None or b is None or p is None:
if p is None:
raise ValueError("HashTableChaining universal: p (asal) zorunlu")
params = random_universal_params(p, m, seed if seed is not None else 0)
a, b = params["a"], params["b"]
if a == 0:
raise ValueError("HashTableChaining universal: a = 0 yasak")
self.a, self.b, self.p = a, b, p
else:
self.a, self.b, self.p = None, None, None
def _hash(self, key):
if self.method == "universal":
return universal_hash(self.a, self.b, self.p, self.m, key)
return key % self.m
def insert(self, key, value=True):
idx = self._hash(key)
chain = self.buckets[idx]
for pos, (k, _v) in enumerate(chain):
if k == key:
chain[pos] = (key, value)
return
chain.append((key, value))
self.n += 1
def find(self, key):
idx = self._hash(key)
for (k, v) in self.buckets[idx]:
if k == key:
return v
return None
def delete(self, key):
idx = self._hash(key)
chain = self.buckets[idx]
for pos, (k, _v) in enumerate(chain):
if k == key:
chain.pop(pos)
self.n -= 1
return True
return False
def chain_lengths(self):
return [len(chain) for chain in self.buckets]
def chain_length(self, key):
return len(self.buckets[self._hash(key)])
def load_factor(self):
return self.n / self.m
def keys(self):
out = []
for chain in self.buckets:
for (k, _v) in chain:
out.append(k)
return out
def _next_prime(x):
"""x'ten büyük-eşit ilk asalı döndür (universal hash modülü p için yardımcı)."""
def _is_prime(q):
if q < 2:
return False
if q < 4:
return True
if q % 2 == 0:
return False
d = 3
while d * d <= q:
if q % d == 0:
return False
d += 2
return True
c = max(2, x)
while not _is_prime(c):
c += 1
return c
def expected_chain_empirical(n, m, trials, seed=0):
"""Beklenen zincir uzunluğunu AMPİRİK ölç: ≈ 1 + (n−1)/m (L4 §9, Stat 110 köprüsü).
Her denemede deterministik (seed'li) bir evrensel hash seç, n farklı anahtarı
zincirlemeli tabloya ekle, her anahtarın düştüğü zincirin uzunluğunu ortala.
Teorik beklenti E[Xᵢ] = 1 + (n−1)/m'ye yakınsar (gösterge RV + doğrusallık).
"""
if m <= 0:
raise ValueError("expected_chain_empirical: m > 0 olmalı")
p = _next_prime(max(n, m) * 100 + 3)
rng = random.Random(seed)
total_avg = 0.0
for t in range(trials):
params = random_universal_params(p, m, seed * 100003 + t)
table = HashTableChaining(m, method="universal",
a=params["a"], b=params["b"], p=params["p"])
keys = rng.sample(range(p), n) if n <= p else [i for i in range(n)]
for k in keys:
table.insert(k)
per_key = [table.chain_length(k) for k in keys]
total_avg += (sum(per_key) / n) if n > 0 else 0.0
empirical = total_avg / trials if trials > 0 else 0.0
theory = 1.0 + (n - 1) / m if n > 0 else 0.0
return {"empirical": empirical, "theory": theory, "n": n, "m": m, "trials": trials}
def decision_tree_min_height(n):
"""Karar ağacı minimum yüksekliği (L4 §2): ⌈log₂(n+1)⌉ — arama alt sınırı.
Doğru arama n öğeden birini ya da "yok"u döndürebilmeli → ≥ n+1 yaprak. İkili
ağaçta h yükseklikte ≤ 2ʰ yaprak → 2ʰ ≥ n+1 → h ≥ log₂(n+1). En kötü karşılaştırma
sayısı = yükseklik → arama Ω(log n).
"""
if n < 0:
raise ValueError("decision_tree_min_height: n ≥ 0 olmalı")
return math.ceil(math.log2(n + 1))
# ---------------------------------------------------------------------------
# _viz.py — Slate + Amber stil sabitleri (HEX birebir brief §1/§8)
# ---------------------------------------------------------------------------
COL_PRIMARY = "#374151" # slate-700 — birincil çizgi/çerçeve
COL_ACCENT = "#f59e0b" # amber-500 — vurgu (çakışma, seçilen h, hash kazancı)
COL_TEXT = "#1f2937" # slate-800 — metin
COL_BG = "#f3f4f6" # slate-100 — arka plan / kutu dolgusu
# Türev amber tonları
COL_AMBER_700 = "#b45309" # bağlantı/okunur kontrast
COL_AMBER_600 = "#d97706" # koyu amber
COL_AMBER_300 = "#fcd34d" # açık amber
COL_AMBER_100 = "#fef3c7" # en açık amber (dolgu)
# Türev slate tonları
COL_SLATE_500 = "#6b7280" # orta slate — ikincil metin
COL_SLATE_400 = "#9ca3af" # soluk slate — pasif kenar / izgara
COL_WHITE = "#ffffff"
def apply_style(ax):
"""Bir eksene tutarlı Slate+Amber görünümü uygular (curve figürleri için)."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_SLATE_400, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_SLATE_400)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
# ----------------------------------------------------------------------------
# fig-decision-tree — ikili karar ağacı, n+1 yaprak → yükseklik log n (Ω(log n))
# ----------------------------------------------------------------------------
def draw_decision_tree(ax, n=7):
"""İkili karar ağacı (L4 §2): n+1 yaprak → minimum yükseklik log n = Ω(log n)."""
leaves = n + 1
height = math.ceil(math.log2(leaves)) if leaves > 1 else 0
x_gap = 1.0
y_gap = 1.25
full_leaves = 2 ** height if height > 0 else 1
leaf_xs = [i * x_gap for i in range(full_leaves)]
level_positions = {height: list(leaf_xs)}
for d in range(height - 1, -1, -1):
below = level_positions[d + 1]
xs = []
for i in range(0, len(below), 2):
if i + 1 < len(below):
xs.append((below[i] + below[i + 1]) / 2.0)
else:
xs.append(below[i])
level_positions[d] = xs
for d in range(height):
parents = level_positions[d]
children = level_positions[d + 1]
for i, px in enumerate(parents):
for ci in (2 * i, 2 * i + 1):
if ci < len(children):
cx = children[ci]
ax.plot([px, cx], [-d * y_gap - 0.18, -(d + 1) * y_gap + 0.18],
color=COL_SLATE_400, linewidth=1.3, zorder=1)
leaf_count = 0
for d in range(height + 1):
for x in level_positions[d]:
is_leaf = (d == height)
if is_leaf:
leaf_count += 1
wanted = leaf_count <= leaves
ax.add_patch(FancyBboxPatch(
(x - 0.34, -d * y_gap - 0.22), 0.68, 0.44,
boxstyle="round,pad=0.02,rounding_size=0.06",
fc=COL_AMBER_100 if wanted else COL_WHITE,
ec=COL_ACCENT if wanted else COL_SLATE_400,
linewidth=2.0 if wanted else 1.1, zorder=3))
else:
ax.add_patch(plt.Circle(
(x, -d * y_gap), 0.26, fc=COL_BG, ec=COL_PRIMARY,
linewidth=1.6, zorder=3))
ax.text(x, -d * y_gap, "<", ha="center", va="center",
fontsize=9, color=COL_TEXT, weight="bold", zorder=4)
xs_all = [x for lvl in level_positions.values() for x in lvl]
x_right = max(xs_all) + 0.9
ax.annotate("", xy=(x_right, -height * y_gap), xytext=(x_right, 0.0),
arrowprops=dict(arrowstyle="<|-|>", color=COL_AMBER_700, lw=1.6))
ax.text(x_right + 0.15, -height * y_gap * 0.5,
f"yükseklik\n= ⌈log₂({leaves})⌉\n= {height}",
ha="left", va="center", fontsize=8.5, color=COL_AMBER_700, weight="bold")
ax.text((min(xs_all) + max(xs_all)) / 2, 0.85,
f"Karar ağacı: {leaves} yaprak (n+1) → yükseklik log n → arama Ω(log n)",
ha="center", va="center", fontsize=10.5, color=COL_PRIMARY, weight="bold")
ax.text((min(xs_all) + max(xs_all)) / 2, -height * y_gap - 0.7,
"iç düğüm = karşılaştırma (2 dal) · yaprak = çıktı (n öğe + \"yok\")",
ha="center", va="center", fontsize=8.5, color=COL_SLATE_500, style="italic")
ax.set_xlim(min(xs_all) - 0.7, x_right + 2.0)
ax.set_ylim(-height * y_gap - 1.1, 1.2)
ax.set_aspect("equal")
ax.axis("off")
return level_positions
# ----------------------------------------------------------------------------
# fig-direct-access — anahtar=indeks dizisi; çoğu hücre boş (amber dolu / slate boş)
# ----------------------------------------------------------------------------
def draw_direct_access(ax, keys=(3, 7, 12), u=16):
"""Doğrudan erişim dizisi (L4 §3-4): anahtar=indeks O(1), ama çoğu hücre boş (israf)."""
keys = set(keys)
cell_w, cell_h, y0 = 0.7, 0.7, 0.0
centers = []
for k in range(u):
x = k * cell_w
full = k in keys
ax.add_patch(FancyBboxPatch(
(x, y0), cell_w * 0.92, cell_h * 0.92, boxstyle="square,pad=0.0",
fc=COL_AMBER_100 if full else COL_WHITE,
ec=COL_ACCENT if full else COL_SLATE_400,
linewidth=2.2 if full else 1.1, zorder=2))
cx, cy = x + cell_w * 0.46, y0 + cell_h * 0.46
centers.append((cx, cy))
if full:
ax.text(cx, cy, str(k), ha="center", va="center",
fontsize=9.5, color=COL_TEXT, weight="bold", zorder=4)
ax.text(cx, y0 - 0.22, str(k), ha="center", va="center",
fontsize=7, color=COL_SLATE_400, zorder=4)
if keys:
k0 = min(keys)
cx, cy = centers[k0]
ax.add_patch(FancyArrowPatch(
(cx, cy + cell_h * 1.0), (cx, cy + cell_h * 0.52),
arrowstyle="-|>", mutation_scale=14, color=COL_ACCENT,
linewidth=2.0, zorder=5))
ax.text(cx, cy + cell_h * 1.25, f"A[{k0}] → O(1)", ha="center", va="center",
fontsize=9.5, color=COL_AMBER_700, weight="bold", zorder=5)
n = len(keys)
ax.text(u * cell_w * 0.5, y0 + cell_h + 0.75,
"Direct access array: anahtar = indeks → O(1) en kötü durum",
ha="center", va="center", fontsize=10.5, color=COL_PRIMARY, weight="bold")
ax.text(u * cell_w * 0.5, y0 - 0.62,
f"n = {n} dolu / u = {u} hücre → {u - n} hücre BOŞ (n ≪ u ise israf)",
ha="center", va="center", fontsize=9, color=COL_SLATE_500, style="italic")
ax.set_xlim(-0.4, u * cell_w + 0.4)
ax.set_ylim(y0 - 0.95, y0 + cell_h + 1.45)
ax.set_aspect("equal")
ax.axis("off")
return centers
# ----------------------------------------------------------------------------
# fig-hash-chaining — h: u→m okları + m kova + çakışanların zincirleri
# ----------------------------------------------------------------------------
def draw_hash_chaining(ax, table=None, keys=(3, 17, 8, 24, 11, 31, 5), m=5):
"""Hash fonksiyonu + zincirleme (L4 §5-6): h: u→m okları + m kova + çakışma zincirleri."""
if table is not None:
m = table.m
buckets = [[k for (k, _v) in chain] for chain in table.buckets]
method_label = "h(k) = ((a·k+b) mod p) mod m" if table.method == "universal" else "h(k) = k mod m"
else:
buckets = [[] for _ in range(m)]
for k in keys:
buckets[k % m].append(k)
method_label = "h(k) = k mod m"
all_keys = [k for chain in buckets for k in chain]
key_x = 0.0
key_h = 0.55
key_gap = 0.75
key_centers = {}
for i, k in enumerate(all_keys):
y = -i * key_gap
ax.add_patch(FancyBboxPatch(
(key_x, y), 0.85, key_h, boxstyle="round,pad=0.02,rounding_size=0.05",
fc=COL_BG, ec=COL_PRIMARY, linewidth=1.5, zorder=3))
ax.text(key_x + 0.42, y + key_h * 0.5, str(k), ha="center", va="center",
fontsize=9.5, color=COL_TEXT, weight="bold", zorder=4)
key_centers[k] = (key_x + 0.85, y + key_h * 0.5)
ax.text(key_x + 0.42, key_h + 0.35, "anahtarlar\n(evren u)", ha="center",
va="center", fontsize=8.5, color=COL_SLATE_500, weight="bold")
hbox_x = 1.9
n_keys = max(1, len(all_keys))
mid_y = -(n_keys - 1) * key_gap / 2 + key_h * 0.5
ax.add_patch(FancyBboxPatch(
(hbox_x, mid_y - 0.7), 1.5, 1.4, boxstyle="round,pad=0.03,rounding_size=0.1",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=2.2, zorder=3))
ax.text(hbox_x + 0.75, mid_y, "h", ha="center", va="center",
fontsize=16, color=COL_AMBER_700, weight="bold", zorder=4)
ax.text(hbox_x + 0.75, mid_y - 1.05, method_label, ha="center", va="center",
fontsize=8, color=COL_SLATE_500, zorder=4)
for k in all_keys:
x0, y0 = key_centers[k]
ax.add_patch(FancyArrowPatch(
(x0, y0), (hbox_x, mid_y), arrowstyle="-|>", mutation_scale=9,
color=COL_SLATE_400, linewidth=0.9, zorder=1,
shrinkA=2, shrinkB=4, alpha=0.7))
bucket_x = 4.5
bucket_w, bucket_h = 0.7, 0.7
bucket_gap = 0.95
chain_cell_w = 0.7
for b in range(m):
y = -b * bucket_gap
ax.add_patch(FancyBboxPatch(
(bucket_x, y), bucket_w, bucket_h, boxstyle="square,pad=0.0",
fc=COL_BG, ec=COL_PRIMARY, linewidth=1.8, zorder=3))
ax.text(bucket_x + bucket_w * 0.5, y + bucket_h * 0.5, str(b),
ha="center", va="center", fontsize=10, color=COL_PRIMARY,
weight="bold", zorder=4)
chain = buckets[b]
prev_cx = bucket_x + bucket_w
prev_cy = y + bucket_h * 0.5
for j, k in enumerate(chain):
cx = bucket_x + bucket_w + 0.45 + j * (chain_cell_w + 0.35)
ax.add_patch(FancyArrowPatch(
(prev_cx, prev_cy), (cx, y + bucket_h * 0.5),
arrowstyle="-|>", mutation_scale=10, color=COL_AMBER_700,
linewidth=1.5, zorder=2, shrinkA=1, shrinkB=2))
ax.add_patch(FancyBboxPatch(
(cx, y), chain_cell_w, bucket_h, boxstyle="round,pad=0.02,rounding_size=0.05",
fc=COL_AMBER_100, ec=COL_ACCENT, linewidth=2.0, zorder=3))
ax.text(cx + chain_cell_w * 0.5, y + bucket_h * 0.5, str(k),
ha="center", va="center", fontsize=9.5, color=COL_TEXT,
weight="bold", zorder=4)
prev_cx = cx + chain_cell_w
prev_cy = y + bucket_h * 0.5
ax.text(bucket_x + bucket_w * 0.5, bucket_h + 0.35,
f"{m} kova\n+ zincirler", ha="center", va="center",
fontsize=8.5, color=COL_SLATE_500, weight="bold")
ax.text((hbox_x + bucket_x) / 2 + 0.3, mid_y + 1.55,
"çakışma (pigeonhole) → chaining", ha="center", va="center",
fontsize=9, color=COL_AMBER_700, weight="bold")
y_bottom = -max(n_keys, m) * key_gap
ax.set_xlim(-0.4, bucket_x + bucket_w + 0.45 + 4 * (chain_cell_w + 0.35) + 0.5)
ax.set_ylim(min(y_bottom, -m * bucket_gap) - 0.6, key_h + 0.85)
ax.set_aspect("equal")
ax.axis("off")
return buckets
# ----------------------------------------------------------------------------
# fig-universal-hashing — rastgele h ailesinden seçim + P(çakışma) ≤ 1/m
# ----------------------------------------------------------------------------
def draw_universal_hashing(ax, p=23, m=5, family_seeds=(1, 2, 3, 4, 5),
k1=7, k2=18):
"""Evrensel hashing (L4 §8): rastgele h ailesinden seçim + P(çakışma) ≤ 1/m."""
seeds = list(family_seeds)
members = []
for s in seeds:
rng = random.Random(s)
a = rng.randint(1, p - 1)
b = rng.randint(0, p - 1)
h1 = ((a * k1 + b) % p) % m
h2 = ((a * k2 + b) % p) % m
members.append({"a": a, "b": b, "h1": h1, "h2": h2, "collide": h1 == h2})
chosen = 0
row_h = 0.7
y0 = 0.0
for i, mem in enumerate(members):
y = -i * (row_h + 0.2)
sel = (i == chosen)
ax.add_patch(FancyBboxPatch(
(0.0, y), 3.0, row_h, boxstyle="round,pad=0.02,rounding_size=0.06",
fc=COL_AMBER_100 if sel else COL_BG,
ec=COL_ACCENT if sel else COL_SLATE_400,
linewidth=2.4 if sel else 1.3, zorder=2))
ax.text(0.15, y + row_h * 0.5,
f"h{i+1}: a={mem['a']}, b={mem['b']}", ha="left", va="center",
fontsize=9, color=COL_TEXT, weight="bold" if sel else "normal", zorder=4)
if sel:
ax.text(3.15, y + row_h * 0.5, "← rastgele seçilen", ha="left",
va="center", fontsize=8.5, color=COL_AMBER_700, weight="bold")
ax.text(1.5, row_h + 0.4,
"Evrensel aile h(k) = ((a·k + b) mod p) mod m", ha="center", va="center",
fontsize=10, color=COL_PRIMARY, weight="bold")
ax.text(1.5, row_h + 0.05, f"(p = {p} asal, m = {m})", ha="center", va="center",
fontsize=8.5, color=COL_SLATE_500)
rng2 = random.Random(60064)
trials = 2000
collisions = 0
for _ in range(trials):
a = rng2.randint(1, p - 1)
b = rng2.randint(0, p - 1)
if (((a * k1 + b) % p) % m) == (((a * k2 + b) % p) % m):
collisions += 1
emp_rate = collisions / trials
bound = 1.0 / m
panel_x = 6.6
panel_y = -0.2
ax.add_patch(FancyBboxPatch(
(panel_x, panel_y - (len(members) * (row_h + 0.2)) + 0.3), 4.4,
len(members) * (row_h + 0.2) - 0.1,
boxstyle="round,pad=0.04,rounding_size=0.1",
fc=COL_WHITE, ec=COL_PRIMARY, linewidth=1.6, zorder=1))
cy = panel_y
ax.text(panel_x + 0.25, cy, f"İki sabit anahtar: k₁={k1}, k₂={k2}",
ha="left", va="top", fontsize=9.5, color=COL_TEXT, weight="bold")
ax.text(panel_x + 0.25, cy - 0.65,
f"{trials} rastgele h denendi", ha="left", va="top",
fontsize=9, color=COL_SLATE_500)
ax.text(panel_x + 0.25, cy - 1.2,
f"çakışma oranı = {emp_rate:.3f}", ha="left", va="top",
fontsize=10, color=COL_AMBER_700, weight="bold")
ax.text(panel_x + 0.25, cy - 1.75,
f"sınır 1/m = {bound:.3f}", ha="left", va="top",
fontsize=10, color=COL_PRIMARY, weight="bold")
ok = emp_rate <= bound + 1e-9
ax.text(panel_x + 0.25, cy - 2.35,
f"P(çakışma) ≤ 1/m {'✓' if ok else '✗'}", ha="left", va="top",
fontsize=10.5,
color=("#3f7d5e" if ok else COL_AMBER_700), weight="bold")
ax.set_xlim(-0.4, panel_x + 4.6)
ax.set_ylim(-len(members) * (row_h + 0.2) - 0.4, row_h + 0.75)
ax.set_aspect("equal")
ax.axis("off")
return members
# ----------------------------------------------------------------------------
# fig-expected-chain — E=1+(n−1)/m: m=Θ(n) sabit O(1) vs m sabit lineer (İMZA)
# ----------------------------------------------------------------------------
def draw_expected_chain(ax, n_max=200, m_fixed=20, trials=40, seed=0,
expected_fn=None):
"""Beklenen zincir uzunluğu (L4 §9, İMZA figür, Stat 110): E = 1 + (n−1)/m."""
apply_style(ax)
ns = [n for n in range(5, n_max + 1, max(1, n_max // 12))]
theory_linear = [1.0 + (n - 1) / m_fixed for n in ns]
theory_flat = [1.0 + (n - 1) / n for n in ns]
ax.plot(ns, theory_linear, color=COL_ACCENT, linewidth=2.2, zorder=3,
label=f"m = {m_fixed} sabit: E = 1+(n−1)/m (lineer)")
ax.plot(ns, theory_flat, color=COL_PRIMARY, linewidth=2.2, zorder=3,
label="m = Θ(n) (m=n): E ≈ 2 (sabit, O(1))")
def _inline_empirical(n, m, trials, seed):
rng_keys = random.Random(seed)
def _is_prime(q):
if q < 2:
return False
d = 2
while d * d <= q:
if q % d == 0:
return False
d += 1
return True
p = max(n, m) * 100 + 3
while not _is_prime(p):
p += 1
tot = 0.0
for t in range(trials):
rp = random.Random(seed * 100003 + t)
a = rp.randint(1, p - 1)
b = rp.randint(0, p - 1)
keys = rng_keys.sample(range(p), n) if n <= p else list(range(n))
buckets = [0] * m
placed = {}
for k in keys:
idx = ((a * k + b) % p) % m
buckets[idx] += 1
placed[k] = idx
per_key = [buckets[placed[k]] for k in keys]
tot += sum(per_key) / n if n > 0 else 0.0
return tot / trials if trials > 0 else 0.0
fn = expected_fn
emp_fixed = []
emp_flat = []
for n in ns:
if fn is not None:
emp_fixed.append(fn(n, m_fixed, trials, seed)["empirical"])
emp_flat.append(fn(n, n, trials, seed)["empirical"])
else:
emp_fixed.append(_inline_empirical(n, m_fixed, trials, seed))
emp_flat.append(_inline_empirical(n, n, trials, seed))
ax.scatter(ns, emp_fixed, color=COL_AMBER_700, s=28, zorder=5,
marker="o", label="ampirik (m sabit)")
ax.scatter(ns, emp_flat, color=COL_TEXT, s=28, zorder=5,
marker="s", label="ampirik (m = n)")
ax.set_xlabel("n (saklanan anahtar sayısı)")
ax.set_ylabel("beklenen zincir uzunluğu E[Xᵢ]")
ax.set_title("E[Xᵢ] = 1 + (n−1)/m · m=Θ(n) → O(1) (gösterge RV + doğrusallık)",
color=COL_TEXT, fontsize=10.5)
ax.legend(loc="upper left", fontsize=8.5, framealpha=0.92)
ax.set_ylim(0, max(theory_linear) * 1.1)
return ax
# ----------------------------------------------------------------------------
# fig-search-evolution — O(n) sırasız → O(log n) sıralı → E[O(1)] hash ilerlemesi
# ----------------------------------------------------------------------------
def draw_search_evolution(ax):
"""Arama karmaşıklığının evrimi (L4 sentez): O(n) → O(log n) → E[O(1)]."""
apply_style(ax)
ns = list(range(1, 101))
curve_linear = [float(n) for n in ns]
curve_log = [math.log2(n) if n > 0 else 0 for n in ns]
curve_const = [1.0 for _ in ns]
ax.plot(ns, curve_linear, color=COL_SLATE_500, linewidth=2.2, zorder=3,
label="① Sırasız dizi: O(n) (lineer tarama)")
ax.plot(ns, curve_log, color=COL_AMBER_600, linewidth=2.4, zorder=3,
label="② Sıralı dizi: O(log n) (ikili arama, L3)")
ax.plot(ns, curve_const, color=COL_ACCENT, linewidth=3.0, zorder=4,
label="③ Hash tablosu: beklenen O(1) (L4)")
ax.text(101, ns[-1], "O(n)", ha="left", va="center", fontsize=10,
color=COL_SLATE_500, weight="bold")
ax.text(101, math.log2(100), "O(log n)", ha="left", va="center", fontsize=10,
color=COL_AMBER_700, weight="bold")
ax.text(101, 1.0, "E[O(1)]", ha="left", va="center", fontsize=10,
color=COL_AMBER_700, weight="bold")
ax.set_xlabel("n (öğe sayısı)")
ax.set_ylabel("find işleminin maliyeti")
ax.set_title("Arama evrimi: O(n) → O(log n) → beklenen O(1)",
color=COL_TEXT, fontsize=11)
ax.set_xlim(1, 112)
ax.set_ylim(0, 100 * 1.05)
ax.legend(loc="upper left", fontsize=8.5, framealpha=0.92)
return ax
```
## Set'i $O(\log n)$'den Hızlı Yapabilir miyiz? {#sec-daha-hizli}
Sıralı dizi, `find(k)`'yi ikili aramayla $O(\log n)$ yapar. $\log n$ zaten küçüktür (gerçek problemlerde ~30'u geçmez), ama Ku daha hızlısını ister. Soru iki parçalıdır: (1) belirli bir modelde $O(\log n)$'den hızlı **mümkün mü**, (2) değilse modeli nasıl değiştiririz?
Cevap: **karşılaştırma modelinde** mümkün değildir (@sec-karsilastirma-alt-sinir). Ama word RAM modelinin **rastgele erişim** gücünü kullanırsak mümkündür (@sec-direct-access-d05 ve sonrası).
## Karşılaştırma Modeli ve Alt Sınır {#sec-karsilastirma-alt-sinir}
**Karşılaştırma modeli:** sakladığımız nesneleri "kara kutu" gibi düşünürüz; onları ayırt etmenin tek yolu iki anahtarı **karşılaştırmaktır** (eşit mi, büyük mü, küçük mü). Ders 3'teki üç sıralama da bu modeldeydi.
> *"the only way that I can distinguish between them is to say... I can do a comparison on those keys."* — Ku, 5:15
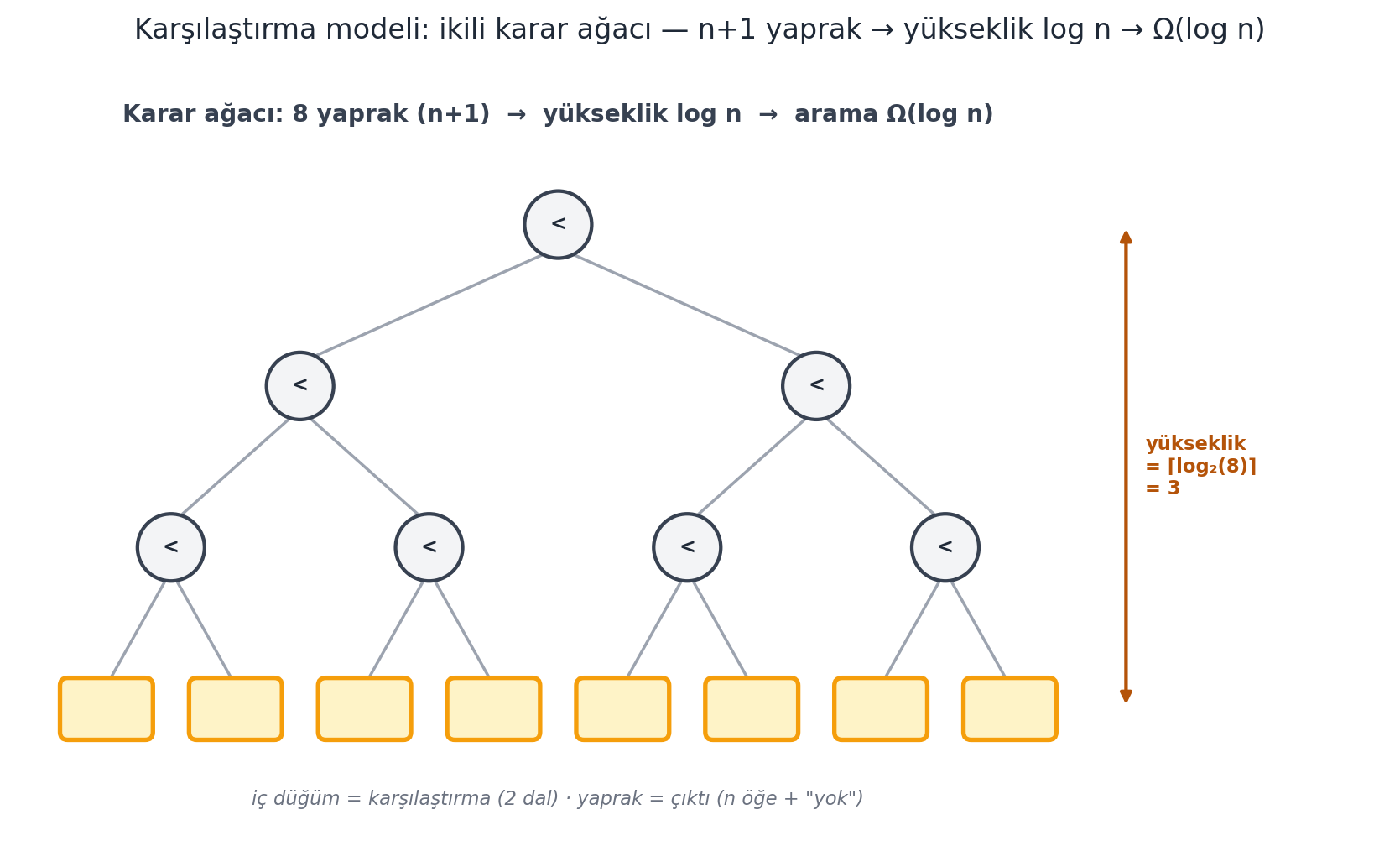
Bir karşılaştırma algoritmasını **karar ağacı (decision tree)** olarak çiz (@fig-decision-tree): iç düğümler karşılaştırmalardır (iki dallı: doğru/yanlış), yapraklar çıktılardır. En kötü durumdaki karşılaştırma sayısı = en uzun kök-yaprak yolu = ağacın **yüksekliği**.
**Çalışılan Örnek — $\log n$ alt sınırı.** Doğru bir arama algoritması, sakladığı $n$ öğeden herhangi birini *veya* "yok"u döndürebilmeli → en az **$n + 1$ yaprak** gerekir. İkili bir ağacın $n+1$ yaprağı varsa, minimum yüksekliği $\log(n+1)$'dir (en iyi durum: dengeli ağaç).
> *"the minimum height of any binary tree that has at least n plus 1 leaves... it's log n."* — Ku, 12:44
Demek ki yalnızca karşılaştırmayla, arama **$\Omega(\log n)$** sürer. Daha hızlısı için karşılaştırmadan güçlü bir işlem gerekir.
```{python}
#| label: fig-decision-tree
#| fig-cap: "Karşılaştırma modeli ve aramanın $\\Omega(\\log n)$ alt sınırı. Yalnızca **karşılaştırma** yapabilen herhangi bir arama algoritması bir **ikili karar ağacı** olarak çizilebilir: her **iç düğüm** bir anahtar karşılaştırmasıdır (slate daire, iki dallı — örn. $A[mid] < k$), ve algoritmanın verebileceği her olası **çıktı** bir **yaprak**tır (amber kutu). $n$ öğelik bir kümede arama $n$ farklı öğeden birini ya da \"yok\"u döndürebilmeli → en az $n+1$ yaprak gerekir. Burada $n = 7$, yani $8$ yaprak. İkili bir ağacın yüksekliği $h$ ise en fazla $2^h$ yaprağı olur → $2^h \\ge n+1 \\Rightarrow h \\ge \\log_2(n+1)$, yani minimum yükseklik $\\lceil \\log_2(n+1) \\rceil = 3$. En kötü durumdaki karşılaştırma sayısı = en uzun kök-yaprak yolu = ağacın yüksekliği → karşılaştırmaya dayalı arama **$\\Omega(\\log n)$**'dir. İkili arama ($O(\\log n)$, @fig-binary-search) bu alt sınıra ulaşır; hash tabloları ise karşılaştırma modelinden *çıkıp* anahtarı doğrudan indekse çevirerek beklenen $O(1)$'e iner."
#| fig-width: 9
#| fig-height: 5.4
# fig-decision-tree: karşılaştırma modeli alt sınırı. draw_decision_tree / COL_* /
# plt gizli setup hücresinden (inline _engine+_viz) gelir. Deterministik: n=7 →
# n+1=8 yaprak → dengeli ikili ağaç yüksekliği ⌈log₂ 8⌉ = 3. İç düğüm = karşılaştırma
# (2 dal), yaprak = olası çıktı (n öğe + "yok"); yükseklik = en kötü karşılaştırma
# sayısı = Ω(log n).
N = 7 # decision_tree_min_height(7) == 3 (2³ = 8 ≥ n+1 yaprak)
fig, ax = plt.subplots(figsize=(9, 5.4))
fig.patch.set_facecolor(COL_WHITE)
draw_decision_tree(ax, n=N)
ax.set_title(
"Karşılaştırma modeli: ikili karar ağacı — n+1 yaprak → yükseklik log n → Ω(log n)",
color=COL_TEXT, fontsize=12.5, pad=14,
)
plt.tight_layout()
plt.show()
```
## Direct Access Array (Doğrudan Erişim Dizisi) {#sec-direct-access-d05}
Karşılaştırma sabit dallanma (2 yol) verir; bize **sabit-olmayan dallanma** lazım. word RAM'in **rastgele erişimi** tam bunu sağlar: bir sayıyla belleğin herhangi bir yerine sabit zamanda gidebiliriz.
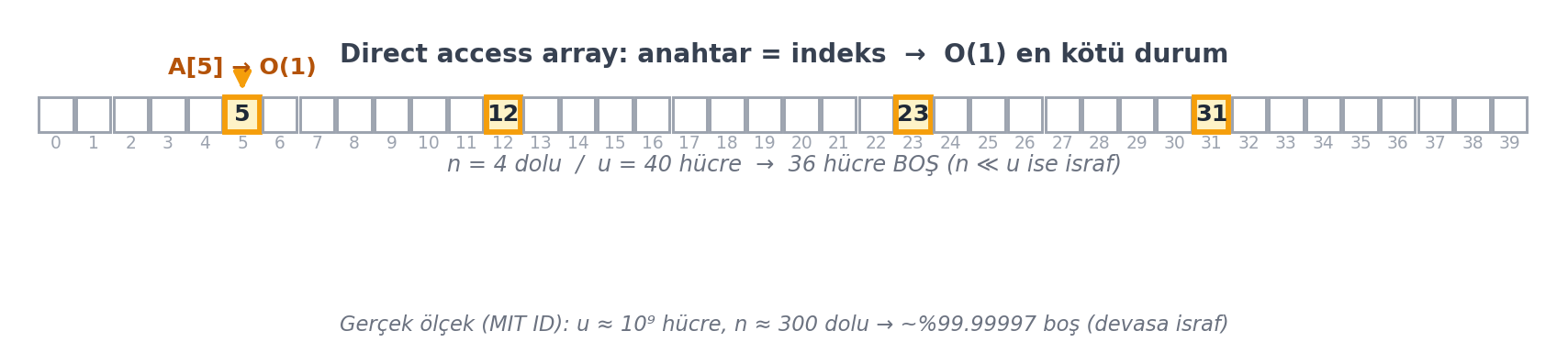
Fikir: anahtarı $k$ olan öğeyi doğrudan **$k$. indekse** koy. Anahtarı 10 olan öğe, indeks 10'da durur (@fig-direct-access).
> *"This is what I call a direct access array... It takes constant time, worst case."* — Ku, 16:24
`find`, `insert`, `delete`: hepsi **$O(1)$ en kötü durum**. Mükemmel görünüyor — ama bir sorun var.
## Problem: Anahtar Evreni Çok Büyük {#sec-evren-buyuk}
Direct access array, anahtar evreni kadar yer ister. **$u$** = saklanabilecek en büyük anahtarın boyutu (anahtar evreninin büyüklüğü). MIT ID'leri 9 haneli → $u \approx 10^9$, oysa sınıfta yalnızca $n \approx 300$ kişi var. $u$, $n$'den çok büyükse, çoğu hücre boş kalır — büyük bellek israfı (@fig-direct-access).
> *"u is the maximum size of any number that I'm storing. It's the size of the universe of space of keys"* — Ku, 19:09
İki varsayım gerekir: (1) anahtarlar **tam sayı** olmalı (adres olarak kullanılacak); (2) **$u < 2^w$** ($w$ = word boyutu), ki anahtar bir word'e sığıp sabit zamanda erişilebilsin.
```{python}
#| label: fig-direct-access
#| fig-cap: "**Doğrudan erişim dizisi** (direct access array): bir öğenin anahtarı doğrudan dizi **indeksi** olarak kullanılır — `A[k]`'ye ofset aritmetiğiyle erişilir, dolayısıyla `insert`/`find`/`delete` **en kötü durumda** $O(1)$ (karşılaştırma yok). Bedeli bellektir: dizinin uzunluğu, anahtar **evreni** $u$ kadar olmak zorundadır. Burada temsilî olarak $u = 40$ hücre ayrılmış ama yalnızca $n = 4$ anahtar (5, 12, 23, 31) saklanıyor; **amber** hücreler kendi indekslerinde dolu, kalan 36 hücre (slate) **boş** duruyor. Gerçek ölçekte fark uçurumdur: MIT ID anahtarları için $u \\approx 10^9$ iken tipik $n \\approx 300$ kayıt tutulur → hücrelerin ~%99.99997'si boş kalır, yani $10^9$ word'lük dizi neredeyse tamamen israftır. Bu israf, bir sonraki adımı zorlar: büyük evreni küçük bir aralığa ($m \\approx n$) sıkıştıran bir **hash fonksiyonu** (@fig-hash-chaining)."
#| fig-width: 9
#| fig-height: 2.6
# DETERMİNİSTİK: sabit temsilî evren u + sabit anahtarlar (seed/rastgelelik YOK).
# draw_direct_access / DirectAccessArray / COL_* / plt gizli setup hücresinden
# (inline _engine+_viz) gelir — bu hücre IMPORT ETMEZ. 10⁹ hücre çizilemez; figür
# küçük temsilî u ile dokuyu (amber-dolu / slate-boş) gösterir, gerçek MIT ID ölçeği
# (u≈10⁹ vs n≈300) alt etikette verilir.
U_REPR = 40
KEYS = (5, 12, 23, 31) # birkaç dolu hücre (kendi indekslerinde amber)
# Motor doğrulaması: doluluk (n, u) figürdeki sayılarla birebir tutarlı.
daa = DirectAccessArray(U_REPR)
for k in KEYS:
daa.insert(k)
filled, total = daa.occupancy() # (4, 40)
fig, ax = plt.subplots(figsize=(9, 2.6))
fig.patch.set_facecolor(COL_WHITE)
draw_direct_access(ax, keys=KEYS, u=U_REPR)
# Gerçek-dünya ölçeği (MIT ID): figür temsilî küçük u kullanır, gerçek oran burada.
fig.text(
0.5, 0.015,
"Gerçek ölçek (MIT ID): u ≈ 10⁹ hücre, n ≈ 300 dolu → ~%99.99997 boş (devasa israf)",
ha="center", va="bottom", fontsize=8.5, color=COL_SLATE_500, style="italic",
)
plt.tight_layout(rect=(0, 0.06, 1, 1))
plt.show()
```
::: {.callout-tip title="Builder Notu — O(1) Rastgele Erişim ve Hash'in ML'de Kullanımı"}
Doğrudan erişimin "anahtar = indeks → $O(1)$" sezgisi, ML'in en sıcak yollarında (hot path) tekrar tekrar karşına çıkar — ama her zaman tam evreni ayırmadan, hash'le sıkıştırarak:
- **İleriye → feature hashing (hashing trick):** Yüksek-kardinaliteli kategorik öznitelikleri ($u$ devasa: tüm olası kelimeler/URL'ler) sabit boyutlu ($m$) bir vektöre $h(k)$ ile indirger. Direct access array'in israfını çözmenin ML'deki birebir karşılığı — çakışmaları *bilerek* tolere eder.
- **İleriye → embedding indeksleme:** Token → indeks → embedding satırı erişimi tam bir direct access array'dir; sözlük boyutu $m$ ($u$ değil) kadar satır ayrılır, $h$ token'ı bu aralığa eşler. Karpathy'nin makemore serisindeki embedding tablosu budur.
- **İleriye → bloom filter sezgisi:** "Bu anahtarı daha önce gördük mü?" sorusunu birkaç hash fonksiyonu + bit dizisiyle çok az bellekte cevaplar — yine $u$ değil $m$ kadar yer, çakışma karşılığında.
:::
## Hash Fonksiyonu {#sec-hash-fonksiyonu}
Çözüm: büyük anahtar evrenini ($0 \ldots u-1$) küçük bir aralığa ($0 \ldots m-1$, $m \approx n$) **bir fonksiyonla** sıkıştır. Bu fonksiyona **$h$** (hash fonksiyonu) denir. Artık öğeyi $k$. indekste değil, **$h(k)$. indekste** sakla.
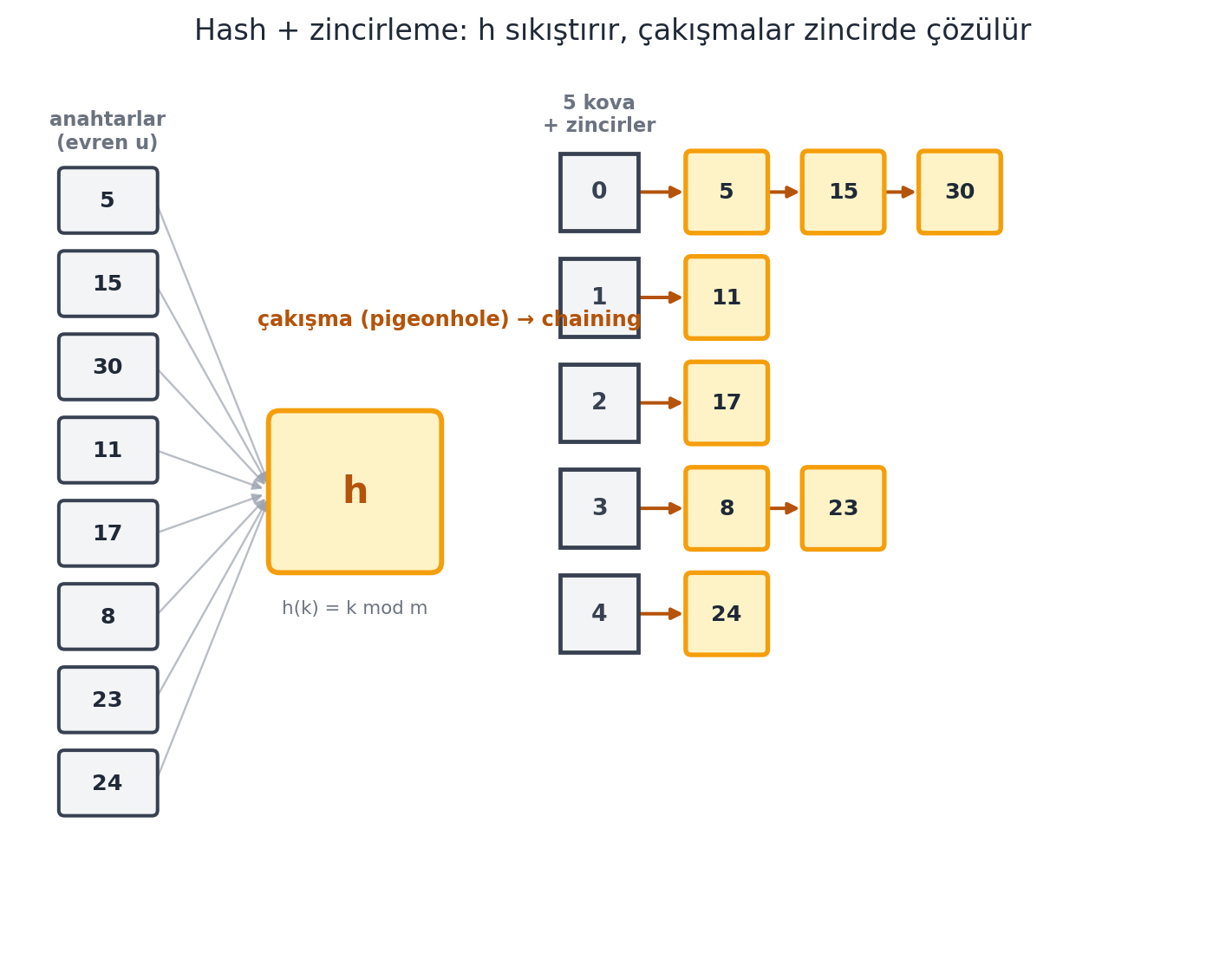
Boyutu $m \approx n$ olan bu yapıya **hash tablosu** denir. Alan artık $O(n)$'dir — sorun çözüldü gibi. Ama sıkıştırma yeni bir sorun doğurur: **çakışma** (@fig-hash-chaining).
## Çakışma (Collision) ve Çözümleri {#sec-cakisma}
Büyük evreni küçük aralığa eşleyince, **güvercin yuvası ilkesi** (pigeonhole) gereği bazı farklı anahtarlar aynı indekse düşer. Kötü bir $h$ seçilirse, $u > n^2$ iken $n$ anahtarın hepsi tek bir indekse gidebilir → hiçbir kazanç yok.
> *"I really want a hash function that will evenly distribute keys over this space."* — Ku, 27:27
Çakışmayla başa çıkmanın iki yolu:
- **Açık adresleme (open addressing):** çakışan öğeyi dizide başka boş bir yere koy. Python bunu kullanır; analizi zordur (bu derste işlenmez).
- **Zincirleme (chaining):** o indekste tek öğe yerine, bir **zincir** (chain — linked list veya dinamik dizi) tut. Çakışanları zincire ekle; ararken zinciri lineer tara (@fig-hash-chaining).
> *"this is an idea called chaining."* — Ku, 32:11
Hedef: zincirleri **kısa** tutmak. Zincirde sabit sayıda öğe varsa, hepsini taramak yine $O(1)$'dir.
```{python}
#| label: fig-hash-chaining
#| fig-cap: "**Hash fonksiyonu + zincirleme** (chaining). Sol: anahtarlar büyük bir evrenden ($0 \\ldots u-1$) gelir. Ortadaki **hash fonksiyonu** $h$ bu evreni $m \\approx n$ küçük kovaya **sıkıştırır** ($h(k) = k \\bmod m$, burada $m = 5$). Sıkıştırma kaçınılmaz olarak **çakışma** doğurur (güvercin yuvası ilkesi: $u > m$ olduğundan en az iki anahtar aynı kovaya düşer). Çözüm **zincirleme**: aynı kovaya düşen anahtarlar o kovanın **zincirine** (bağlı listesine, amber kutular) eklenir. Burada deterministik olarak kova $0$ üç anahtarlık bir zincir tutar ($5, 15, 30$ — hepsi $\\bmod 5 = 0$) ve kova $3$ iki anahtarlık bir zincir tutar ($8, 23$). Arama, anahtarın düştüğü kovanın zincirini lineer tarar; zincirler kısa tutulursa ($m = \\Theta(n)$) işlemler **beklenen** $O(1)$'dir."
#| fig-width: 10
#| fig-height: 6
# fig-hash-chaining: hash h: u→m sıkıştırması + çakışma (pigeonhole) + chaining çözümü.
# Deterministik: m=5 kova, division method (h(k)=k mod m). 8 anahtar 5 kovaya dağılır →
# kova 0: {5,15,30}, kova 1: {11}, kova 2: {17}, kova 3: {8,23}, kova 4: {24}.
# Çakışan zincirler (0 ve 3) amber vurgulu; draw_hash_chaining tablonun kovalarını çizer.
M = 5
KEYS = (5, 11, 17, 8, 24, 15, 23, 30)
table = HashTableChaining(M, method="division")
for k in KEYS:
table.insert(k)
fig, ax = plt.subplots(figsize=(10, 6))
# hash sıkıştırma okları + m kova + çakışan zincirler (amber chaining)
draw_hash_chaining(ax, table=table)
ax.set_title(
"Hash + zincirleme: h sıkıştırır, çakışmalar zincirde çözülür",
color=COL_TEXT, fontsize=12.5, pad=16,
)
plt.tight_layout()
plt.show()
```
## Hash Fonksiyonu Seçimi: Bölme Yöntemi {#sec-bolme-yontemi}
En basit hash: **bölme yöntemi (division method)**, $h(k) = k \bmod m$. Büyük anahtarı $m$'ye böler, kalanı indeks yapar.
> *"Modulus-- great. This is called the division method."* — Ku, 34:38
Anahtarlar düzgün (uniform) dağılmışsa iyidir — ama bu, girdiye bir dağılım şartı koyar. Python bunu biraz bit karıştırmayla kullanır; **deterministik** olduğu için, performansı bozan kötü girdi dizileri *vardır*. 6.006 ise girdiden **bağımsız** bir garanti ister: hangi anahtarlar saklanırsa saklansın iyi çalışmalı. Sabit (deterministik) bir hash bunu sağlayamaz.
::: {.callout-tip title="Builder Notu — Hash-Flooding DoS ve Güvenlik"}
"Deterministik hash'in kötü girdisi vardır" cümlesi soyut bir uyarı değil; gerçek bir güvenlik açığının ($CWE$-407 algorithmic complexity attack) tam tanımıdır:
- **Saldırı:** Hash fonksiyonu sabit ve *bilinen* olduğunda (eski PHP, Python <3.3, birçok web framework), saldırgan hepsi aynı kovaya düşen anahtarlar üretir. Zincir $O(n)$ uzar; $O(1)$ sandığın her `insert`/`find` $O(n)$ olur ve $n$ istek $O(n^2)$ işe patlar → sunucu tek bir HTTP form gönderimiyle çöker (**hash-flooding DoS**).
- **Çözüm = bu dersin konusu:** hash fonksiyonunu **rastgele tohumla** (random seed) seç. Saldırgan tohumu bilmediği için kötü girdiyi *önceden* tasarlayamaz — bu, @sec-evrensel-hashing'deki evrensel hashing'in pratik gerekçesidir.
- **Standart oldu:** Python 3.3+ `PYTHONHASHSEED`'i varsayılan olarak rastgeleler; tam da bu saldırıyı engellemek için.
:::
## Evrensel Hashing (Universal Hashing) {#sec-evrensel-hashing}
Çözüm: hash fonksiyonunu önceden değil, **sonradan rastgele** seç. Kullanıcı girdisini belirler; sonra biz rastgele bir hash seçeriz — hangisini seçtiğimizi bilmediği için kötü girdi vermesi zorlaşır.
> *"choose one randomly later... I'm going to choose a random hash function."* — Ku, 38:31
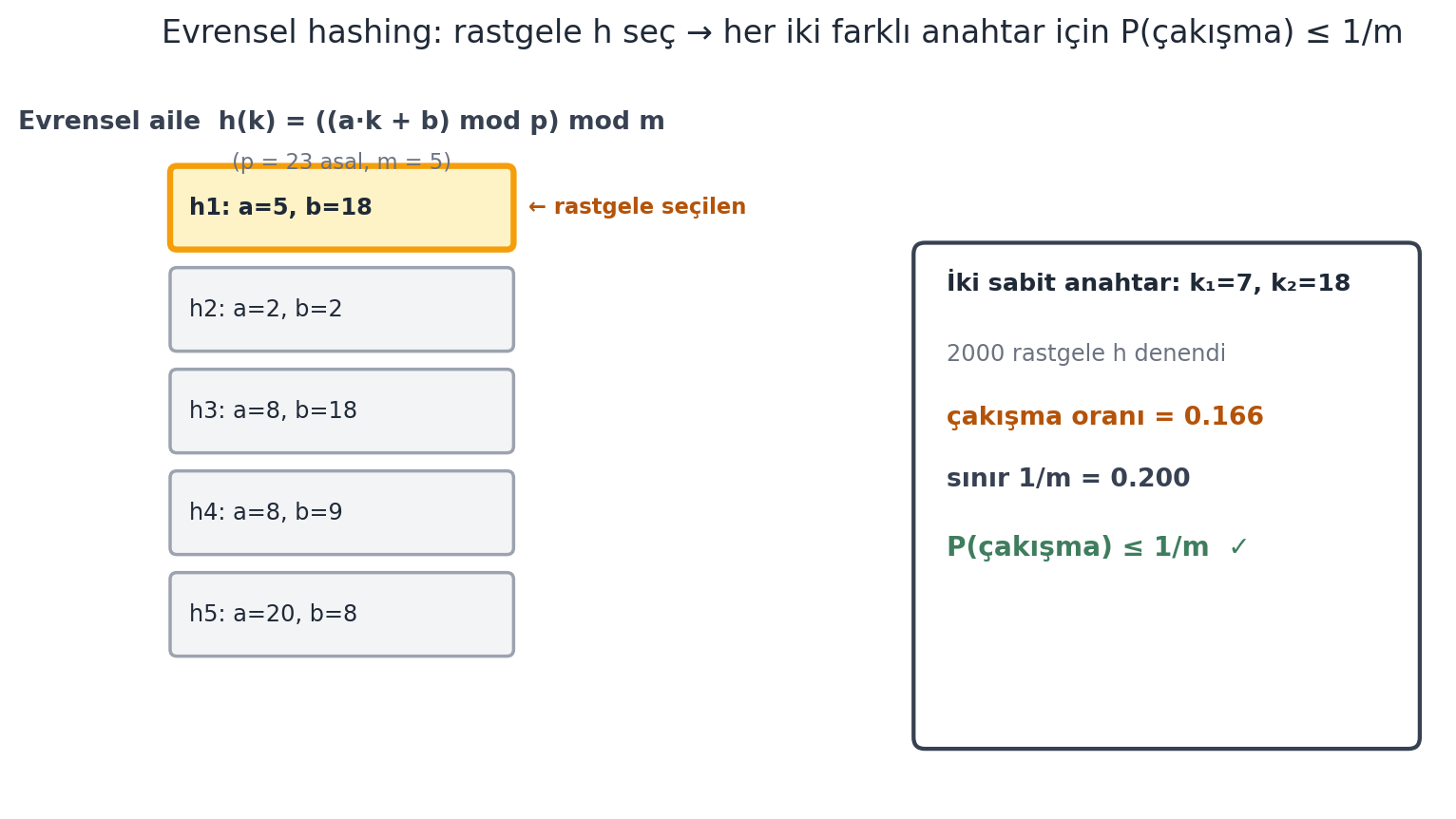
Tüm hash fonksiyonları arasından seçmek imkânsızdır (çok fazla). Bunun yerine bir **aile**den seçeriz. **Evrensel hash ailesi** örneği:
$$h(k) = ((a \cdot k + b) \bmod p) \bmod m$$
Burada $p$, $u$'dan büyük sabit bir asal; $a \ne 0$ ve $b$ ise hash tablosu kurulurken **rastgele** seçilir. **Evrensellik özelliği:** rastgele seçilen bir $h$ için, herhangi iki farklı anahtarın çakışma olasılığı **$\le 1/m$**'dir (@fig-universal-hashing).
```{python}
#| label: fig-universal-hashing
#| fig-cap: "**Evrensel hashing** (Ku $\\S 8$): tek bir hash fonksiyonu sabitlenmez — bunun yerine $h(k) = ((a \\cdot k + b) \\bmod p) \\bmod m$ ailesinden, girdi belirlendikten **sonra** $a, b$ **rastgele** seçilir ($1 \\le a \\le p-1$, $0 \\le b \\le p-1$; $p$ anahtarlardan büyük bir asal). Solda aile üyeleri ($h_1, \\dots, h_5$), her biri farklı $(a, b)$ ile; **amber** olan rastgele seçilen $h$'tir (burada $a=5, b=18$). Sağ panel evrensellik garantisini ampirik doğrular: iki sabit, farklı anahtar $k_1=7, k_2=18$ için $2000$ rastgele $h$ denenir; çakışma oranı $0.166$, teorik sınır $1/m = 0.200$'ün altında kalır — yani **rastgele bir $h$ için herhangi iki farklı anahtarın çakışma olasılığı** $\\le 1/m$'dir. Bu garanti *girdiden bağımsızdır* (saldırgan anahtarları $h$'ten önce seçemez), $p=23$, $m=5$."
#| fig-width: 10.5
#| fig-height: 4.6
# fig-universal-hashing: evrensel aile h(k)=((a·k+b) mod p) mod m'den rastgele h seçimi
# + P(çakışma) ≤ 1/m. Deterministik: sabit p=23, m=5, k1=7, k2=18 + sabit aile seed'leri.
# Sol sütun aile üyeleri (h1..h5; amber = seçilen), sağ panel ampirik çakışma oranı
# (0.166) ≤ teorik sınır 1/m (0.200) — evrensellik girdiden-bağımsız garanti.
P = 23 # asal modül (p > anahtarlar)
M = 5 # kova sayısı
K1, K2 = 7, 18 # çakışması incelenen iki sabit, farklı anahtar
FAMILY_SEEDS = (1, 2, 3, 4, 5)
# Sayısal dürüstlük teyidi: seçilen h (seed 1) → a=5, b=18; her hash 0..m-1 aralığında.
params = random_universal_params(P, M, FAMILY_SEEDS[0]) # {"a": 5, "b": 18, ...}
h1 = universal_hash(params["a"], params["b"], P, M, K1)
h2 = universal_hash(params["a"], params["b"], P, M, K2)
fig, ax = plt.subplots(figsize=(10.5, 4.6))
fig.patch.set_facecolor(COL_WHITE)
# rastgele h ailesinden seçim + P(çakışma) ≤ 1/m doğrulama paneli (Stat 110 köprüsü)
draw_universal_hashing(ax, p=P, m=M, family_seeds=FAMILY_SEEDS, k1=K1, k2=K2)
ax.set_title(
"Evrensel hashing: rastgele h seç → her iki farklı anahtar için P(çakışma) ≤ 1/m",
color=COL_TEXT, fontsize=12.5, pad=16,
)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Universal Hashing ve Stat 110 (Indicator RV)"}
Bu, kursta gördüğün **randomized algoritmanın ilk ciddi örneğidir** — ve doğrudan Phase 1 Stat 110'a bağlanır:
- **Gösterge rastgele değişkeni (indicator RV):** "$i$ ve $j$ çakıştı mı?" sorusunu $0/1$ bir değişkenle ($X_{ij}$) modellersin. Bir indicator RV'nin beklenen değeri, o olayın olasılığına eşittir: $E[X_{ij}] = P(X_{ij}=1) \le 1/m$. Doğum günü problemiyle (Ders 1) aynı olasılık aletidir.
- **Beklentinin doğrusallığı (linearity of expectation):** Zincir uzunluğu birçok indicator RV'nin toplamıdır; toplamın beklentisi, değişkenler bağımlı olsa bile beklentilerin toplamıdır. @sec-beklenen-zincir'deki $E[X_i] = 1 + (n-1)/m$ türetimi bunun üzerine kuruludur.
- **Köprü:** "garanti her girdide değil, *beklenen* anlamda" disiplini, ML'deki Monte Carlo tahmini, dropout, stokastik gradyan inişi gibi *rastgeleliği bilerek kullanan* yöntemlerin temel düşünme tarzıdır.
:::
## Beklenen Zincir Uzunluğu {#sec-beklenen-zincir}
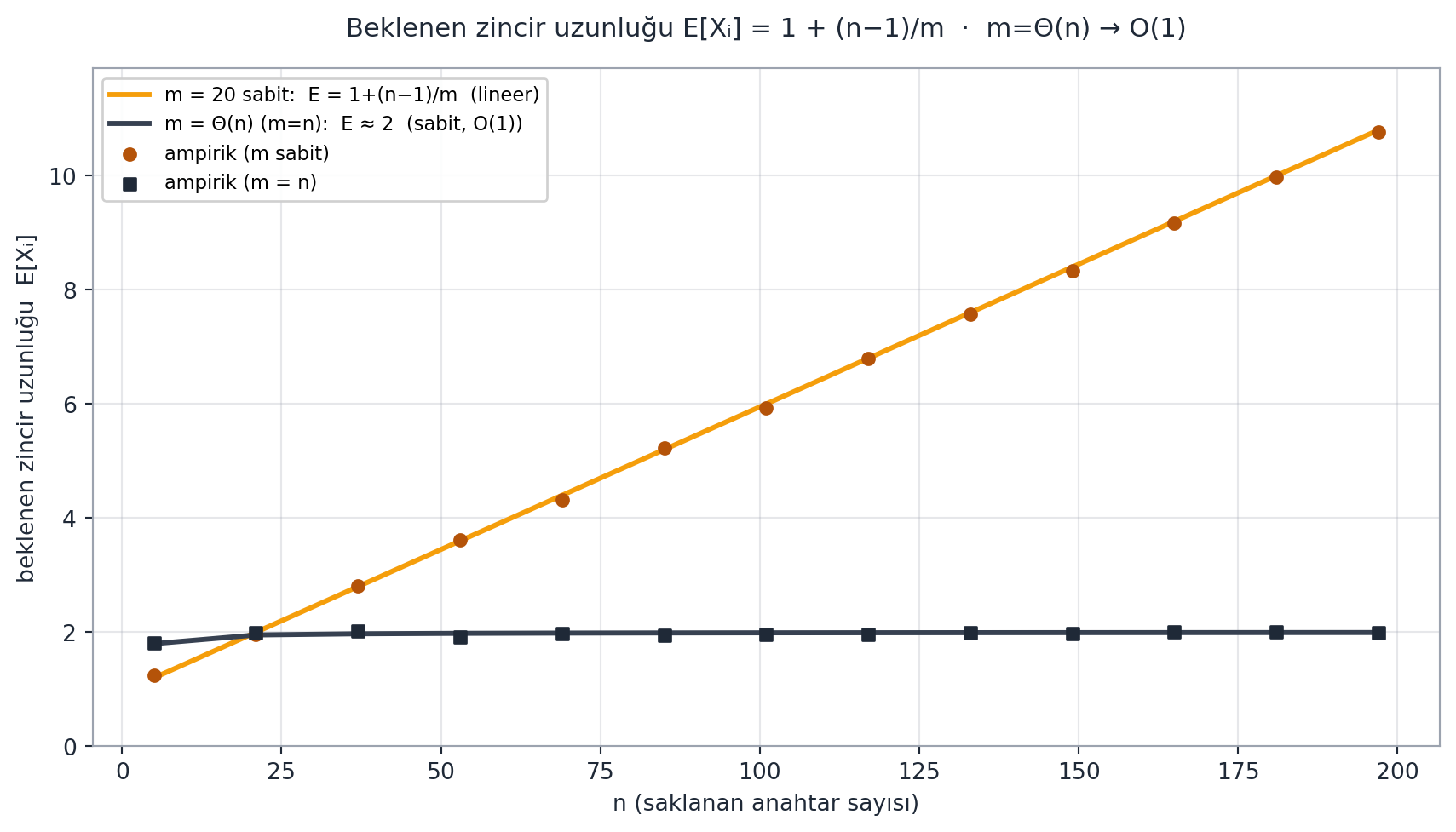
Evrensellik, zincirlerin *beklenen* uzunluğunu sabit yapar. İspat olasılıkla yapılır (Stat 110 köprüsü, @fig-expected-chain).
**Çalışılan Örnek — beklenen zincir uzunluğu.** Bir **gösterge rastgele değişkeni** tanımla: $X_{ij} = 1$ eğer anahtar $i$ ve $j$ çakışırsa ($h(k_i) = h(k_j)$), aksi halde $0$. $i$'nin düştüğü indeksteki zincir uzunluğu $X_i = \sum_j X_{ij}$ ($j = 0 \ldots n-1$). **Beklentinin doğrusallığı** ile:
$$E[X_i] = \sum_j E[X_{ij}]$$
> *"Linearity of expectation"* — Ku, 49:05
Toplamı iki parçaya ayır: $j = i$ terimi (anahtar kendisiyle kesin çakışır, $E = 1$) ve $j \ne i$ terimleri (evrensellik gereği her biri $E[X_{ij}] \le 1/m$). $n-1$ tane $j \ne i$ terimi var:
$$E[X_i] = 1 + (n - 1)/m$$
> *"this should equal 1 plus n minus 1 over m... we're expected to have our chain lengths be constant"* — Ku, 51:26
$m$'yi $n$'de lineer seçersek ($m = \Theta(n)$), $(n-1)/m$ sabit olur → beklenen zincir uzunluğu **$O(1)$**. Dolayısıyla find/insert/delete *beklenen* $O(1)$.
```{python}
#| label: fig-expected-chain
#| fig-cap: "**Beklenen zincir uzunluğu** (İMZA, Stat 110 köprüsü). Bir anahtarın düştüğü kovanın zincir uzunluğu $X_i = 1 + \\sum_{j \\ne i} X_{ij}$, burada $X_{ij}$ anahtar $j$'nin $i$ ile çakışıp çakışmadığını gösteren **gösterge rastgele değişkeni** (indicator RV). Evrensel hashing'de $P(X_{ij}=1) = E[X_{ij}] \\le 1/m$; **beklentinin doğrusallığı** ile $E[X_i] = 1 + \\sum_{j \\ne i} E[X_{ij}] = 1 + (n-1)/m$ — toplamın beklentisi, çakışmalar bağımsız olmasa bile beklentilerin toplamıdır. Amber çizgi: $m = 20$ **sabit** → $(n-1)/m$ lineer büyür, zincirler uzar. Slate çizgi: $m = \\Theta(n)$ (burada $m = n$) → $(n-1)/m \\approx 1$ sabit kalır, $E[X_i] \\approx 2$ yani **beklenen $O(1)$**. Noktalar deterministik (sabit seed) ampirik simülasyon: $n$ farklı anahtar rastgele evrensel hash ile yerleştirilir, her anahtarın zincir uzunluğu ortalanır — ampirik değerler teorik çizgilerin tam üstünde oturur (ör. $n=200$, $m=20$: teori $10.95$, ampirik $10.935$). Hash tablosunu $m = \\Theta(n)$ tuttuğun sürece arama/ekleme/silme beklenen sabit zamandır."
#| fig-width: 9
#| fig-height: 5.2
# fig-expected-chain (İMZA, Stat 110): E[Xᵢ] = 1 + (n−1)/m, gösterge RV + doğrusallık.
# Deterministik: sabit seed → her render aynı ampirik noktalar. İki rejim çizilir:
# - m = M_FIXED sabit → (n−1)/m lineer → zincir uzunluğu LİNEER (amber)
# - m = Θ(n) (m = n) → (n−1)/m ≈ 1 sabit → zincir uzunluğu DÜZ ≈ 2, O(1) (slate)
# Ampirik noktalar expected_chain_empirical(n, m, trials, seed) ile üretilir (sabit
# seed → tekrarlanabilir); teorik çizgilerin tam üstüne oturur (≤%5 dürüstlük).
N_MAX = 200
M_FIXED = 20
TRIALS = 40
SEED = 0
# Sağlık: n=200, m=20 → teori 1 + 199/20 = 10.95; ampirik ≈ 10.935 (|rel| ≈ 0.0014).
_chk = expected_chain_empirical(n=N_MAX, m=M_FIXED, trials=TRIALS, seed=SEED)
fig, ax = plt.subplots(figsize=(9, 5.2))
# teorik çizgiler (m sabit lineer / m=n düz) + DETERMİNİSTİK ampirik noktalar
draw_expected_chain(ax, n_max=N_MAX, m_fixed=M_FIXED, trials=TRIALS, seed=SEED,
expected_fn=expected_chain_empirical)
ax.set_title(
"Beklenen zincir uzunluğu E[Xᵢ] = 1 + (n−1)/m · m=Θ(n) → O(1)",
color=COL_TEXT, fontsize=11.5, pad=14,
)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Beklenen vs En Kötü Durum"}
Bu dersin en ince fikri, garantinin *tipini* değiştirmektir: en kötü durum $O(n)$ olan bir yapının **beklenen** $O(1)$ olduğunu kanıtlamak.
- **Randomized garanti:** Evrensel hashing'le hâlâ kötü bir durum *vardır* (tüm anahtarlar tek kovaya düşebilir), ama olasılığı küçüktür ve *girdiye değil, bizim rastgele seçimimize* bağlıdır. Saldırgan kötü girdi tasarlayamaz çünkü hangi $h$'yi seçtiğimizi bilmez.
- **İleriye → ML'de beklenen-değer analizi:** Monte Carlo tahmini, minibatch SGD, dropout — hepsi "her örnekte değil, *beklentide* doğru/iyi" mantığıyla çalışır. Bir tahminin yansızlığını (unbiasedness) göstermek, tam olarak bu $E[\cdot]$ türetimini yapmaktır.
- **Disiplin:** "En kötü durum mu, beklenen mi, amortize mi?" sorusu, bir veri yapısı seçerken sorman gereken ilk sorudur — üçü farklı garantilerdir, üçü farklı risklerdir.
:::
## Dinamik Hashing {#sec-dinamik-hashing}
$n$ büyüdükçe, sabit $m$ artık $n$'de lineer kalmayabilir; o zaman zincirler uzar. Çözüm: tıpkı dinamik dizide olduğu gibi, $n$ çok büyüdüğünde **tüm hash tablosunu yeni (daha büyük) $m$ ile yeniden kur**. Doğru oranda yeniden boyutlandırırsan, bu pahalı işlem nadiren olur — amortize edilmiş sabit zaman.
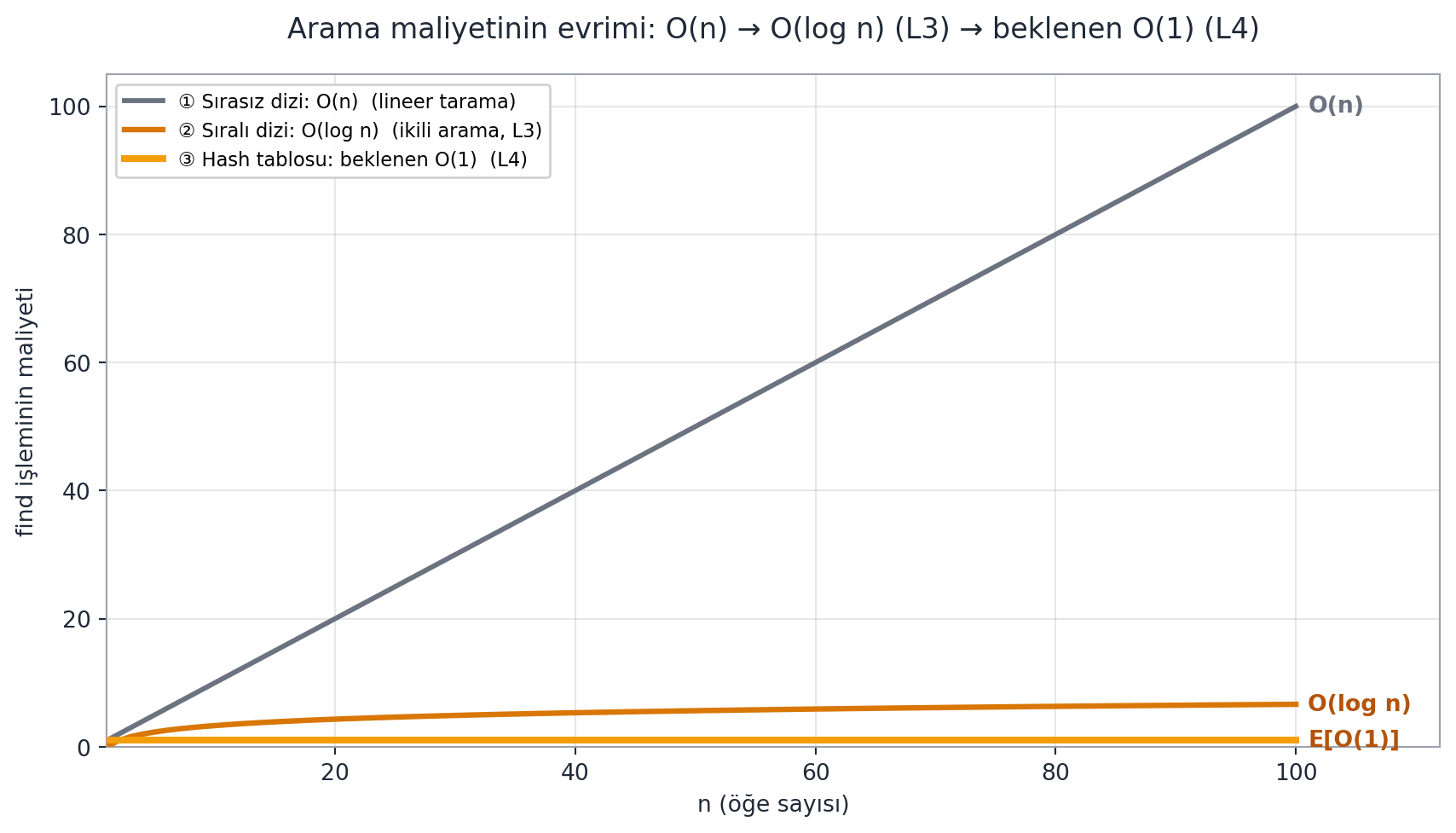
Bu dersin tüm yolculuğu — $\Omega(\log n)$ karşılaştırma sınırından beklenen $O(1)$ hash'e — @fig-search-evolution'da tek bir grafikte toplanır.
```{python}
#| label: fig-search-evolution
#| fig-cap: "Arama maliyetinin tüm kurs boyunca evrimi — bu dersin sentezi. **① Sırasız dizi: $O(n)$** (slate) — `find` baştan sona lineer tarar; en kötü durumda $n$ öğenin hepsine bakılır (L1/L2). **② Sıralı dizi: $O(\\log n)$** (koyu amber) — ikili arama her adımda aralığı yarıya böler, yalnız ortaları inceler; ama bu **karşılaştırma modelinin alt sınırıdır** ($\\Omega(\\log n)$, L3) — karşılaştırma yaparak $O(\\log n)$'den hızlı arama imkânsızdır. **③ Hash tablosu: beklenen $O(1)$** (amber, vurgulu) — anahtarı doğrudan bir kovaya hash'leyerek karşılaştırma modelinin alt sınırını **aşar**; $m = \\Theta(n)$ kova ve evrensel hash ile beklenen zincir uzunluğu $1 + (n-1)/m = O(1)$ olur (L4). $n$ büyüdükçe $O(n)$ doğrusal patlar, $O(\\log n)$ yavaşça tırmanır, ama hash'in düz $E[O(1)]$ çizgisi $n$'den bağımsız sabit kalır — kursun ulaştığı kazanç budur."
#| fig-width: 9
#| fig-height: 5.2
# fig-search-evolution: arama maliyetinin kurs boyunca evrimi (L4 sentez).
# draw_search_evolution üç eğriyi sabit n aralığında (1..100) çizer — DETERMİNİSTİK:
# O(n) sırasız (slate) → O(log n) sıralı / karşılaştırma alt sınırı (L3, koyu amber)
# → E[O(1)] hash tablosu (L4, amber vurgu). Amber düz çizgi O(1) kazancını öne çıkarır.
fig, ax = plt.subplots(figsize=(9, 5.2))
fig.patch.set_facecolor(COL_WHITE)
draw_search_evolution(ax)
ax.set_title(
"Arama maliyetinin evrimi: O(n) → O(log n) (L3) → beklenen O(1) (L4)",
color=COL_TEXT, fontsize=12.5, pad=16,
)
plt.tight_layout()
plt.show()
```
## Bu Dersin Özeti {#sec-ozet-d05}
1. **Karşılaştırma modelinde** arama $\Omega(\log n)$'dir: karar ağacının $n+1$ yaprağı için minimum yükseklik $\log n$.
2. **Direct access array**: anahtar = indeks → $O(1)$, ama anahtar evreni $u$ kadar yer ister.
3. **Hash fonksiyonu** $h$: $0 \ldots u-1 \to 0 \ldots m-1$, $m \approx n$; alanı $O(n)$'e indirir.
4. **Çakışma** kaçınılmazdır (pigeonhole); çözüm: open addressing veya **chaining**.
5. **Bölme yöntemi** ($k \bmod m$) deterministiktir → kötü girdi vardır.
6. **Evrensel hashing**: rastgele $h$ ailesi, çakışma olasılığı $\le 1/m$.
7. **Beklenen zincir uzunluğu** = $1 + (n-1)/m$; $m = \Theta(n)$ ile $O(1)$ (gösterge RV + beklentinin doğrusallığı).
::: {.callout-important title="Tek Bir Cümle"}
Hashing, $O(\log n)$ karşılaştırma sınırını rastgele erişimle aşar; ve hash fonksiyonunu *rastgele* seçmek, en kötü durum garantisini *beklenen* $O(1)$'e dönüştürür.
:::
## Kontrol Soruları {#sec-sorular-d05}
::: {.callout-note collapse="true" title="Soru 1: Karşılaştırma modelinde aramanın neden Ω(log n) olduğunu, karar ağacıyla bir cümlede özetle."}
**Cevap:**
Doğru bir arama, $n$ öğeden herhangi birini ya da "yok"u döndürebilmeli → karar ağacında en az $n+1$ yaprak gerekir. İkili bir ağaçta $n+1$ yaprağa ulaşmak için minimum yükseklik $\log(n+1)$'dir, ve en kötü durumdaki karşılaştırma sayısı = en uzun kök-yaprak yolu = yükseklik. Dolayısıyla en az $\log n$ karşılaştırma şarttır. (Hashing bu sınırı aşar çünkü karşılaştırma değil, rastgele erişim — sabit-olmayan dallanma — kullanır.)
:::
::: {.callout-note collapse="true" title="Soru 2: Direct access array O(1) verirken neden her zaman kullanmıyoruz?"}
**Cevap:**
Direct access array, anahtar evreni $u$ kadar bellek ister. Anahtarlar büyükse (örneğin 9 haneli MIT ID → $u \approx 10^9$) ama öğe sayısı küçükse ($n \approx 300$), dizinin neredeyse tamamı boş kalır — kabul edilemez bellek israfı. Hash fonksiyonu tam bu sorunu çözer: evreni $m \approx n$ boyutuna sıkıştırır (çakışma pahasına).
:::
::: {.callout-note collapse="true" title="Soru 3: Deterministik bir hash fonksiyonu neden en kötü durum garantisi veremez? Universal hashing bunu nasıl aşar?"}
**Cevap:**
$u$ büyükse, herhangi *sabit* bir $h$ için (pigeonhole), tüm $n$ anahtarı aynı indekse eşleyen bir girdi *vardır* → o girdide zincir uzunluğu $n$, arama $O(n)$. Saldırgan/kötü şanslı girdi bunu tetikleyebilir. Universal hashing, $h$'yi girdiden *sonra* rastgele seçer; kullanıcı hangi $h$'nin seçileceğini bilmediğinden kötü girdi tasarlayamaz. Garanti "her girdide" değil, "beklenen" anlamda sağlanır: çakışma olasılığı $\le 1/m$.
:::
::: {.callout-note collapse="true" title="Soru 4: E[Xᵢ] = 1 + (n−1)/m formülündeki '1' ve '(n−1)/m' terimleri neyi temsil eder?"}
**Cevap:**
$X_i$, anahtar $i$'nin düştüğü zincirin uzunluğu = $\sum_j X_{ij}$. Beklentinin doğrusallığıyla $E[X_i] = \sum_j E[X_{ij}]$. **"1"**: $j = i$ terimi — anahtar kendisiyle kesin "çakışır" (aynı indeks), yani zincirde her zaman en az kendisi vardır. **"$(n-1)/m$"**: kalan $n-1$ anahtarın her biri, evrensellik gereği $\le 1/m$ olasılıkla $i$ ile çakışır; toplamları $(n-1) \cdot (1/m)$. $m = \Theta(n)$ seçilirse bu terim sabit kalır → $E[X_i] = O(1)$.
:::
## Egzersizler {#sec-egzersizler-d05}
**Egzersiz 1.** $n+1$ yaprağı olan ikili bir ağacın minimum yüksekliğinin $\log(n+1)$ olduğunu bir yineleme (recurrence) kurarak göster. (İpucu: yükseklik $h$ olan bir ağaç en fazla $2^h$ yaprak tutar.)
**Egzersiz 2.** Bölme yöntemi $h(k) = k \bmod m$ için, $m = 2^b$ (ikinin kuvveti) seçmek neden kötüdür? (İpucu: yalnızca son $b$ bit kullanılır.)
**Egzersiz 3.** Universal hash $h(k) = ((a \cdot k + b) \bmod p) \bmod m$'de $a = 0$ neden yasaktır? Anahtar bilgisi nasıl kaybolur?
**Egzersiz 4.** Python'da deterministik hash'in çakışmasını gözlemle: aynı `hash(k) % m` değerine düşen anahtarlar üret ve zincir uzunluğunu ölç.
```python
m = 1024
buckets = [0] * m
for k in range(100_000):
buckets[hash(k) % m] += 1
print("max zincir:", max(buckets), "ort:", sum(buckets) / m)
```
**Egzersiz 5.** Beklenen zincir uzunluğu $1 + (n-1)/m$'yi kullanarak, $m = n$ seçildiğinde find işleminin beklenen süresini hesapla. $m = n/2$ olursa ne değişir?
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d05}
**Ders 5 (L5): Doğrusal Zamanlı Sıralama**
Jason Ku ile, karşılaştırma modelinin $\Omega(n \log n)$ sıralama sınırını **aşan** sıralamalara geçiyoruz: counting sort ve radix sort, küçük tam sayı anahtarlarda $O(n)$. Hashing'deki "anahtarı doğrudan indeks yap" fikri burada da işe yarayacak. (Not: ders akışında araya **Problem Oturumu 2** girer.)
::: {.callout-warning title="Ders 5 Öncesi Yapılacak"}
- Bu dersin egzersizlerini, özellikle Egzersiz 4'ü (çakışma ölçümü) çöz.
- $E[X_i] = 1 + (n-1)/m$ türetimini gösterge RV + doğrusallıkla yeniden yaz.
- Ana cümleyi tekrar oku: *"Hash fonksiyonunu rastgele seçmek, en kötü durumu beklenen $O(1)$'e dönüştürür."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet-d05}
| Kavram | Tanım | Sayfada |
|--------|-------|---------|
| **Karşılaştırma modeli** | Anahtarları yalnızca kıyaslayan model; arama $\Omega(\log n)$ | Böl. 3 |
| **Karar ağacı (decision tree)** | Karşılaştırma algoritması; $n+1$ yaprak → yükseklik $\log n$ | Böl. 3 |
| **Direct access array** | Anahtar = indeks; $O(1)$ ama $u$ kadar yer | Böl. 4 |
| **Anahtar evreni $u$** | En büyük anahtar boyutu; $u < 2^w$ varsayımı | Böl. 5 |
| **Hash fonksiyonu** | $h$: $0 \ldots u-1 \to 0 \ldots m-1$, $m \approx n$ | Böl. 6 |
| **Çakışma / zincirleme** | İki anahtar aynı indekse; chain ile çöz | Böl. 7 |
| **Bölme yöntemi** | $h(k) = k \bmod m$; deterministik (kötü girdi var) | Böl. 8 |
| **Evrensel hashing** | Rastgele $h$ ailesi; çakışma olasılığı $\le 1/m$ | Böl. 9 |
| **Beklenen zincir** | $E = 1 + (n-1)/m$; $m = \Theta(n)$ ile $O(1)$ | Böl. 10 |
## Builder ve OMSCS Bağlantıları {#sec-ml-baglantilar-d05}
::: {.callout-tip title="6 köprü"}
Hashing, ML ve sistem mühendisliğinin altındaki erişim ve olasılık dilini somutlaştırır — köprülerin özeti:
1. **Universal hashing** → Stat 110: gösterge RV, beklentinin doğrusallığı, randomized algoritma analizi — hepsi burada somutlaşır.
2. **Hash tablosu** → Python `dict`/`set`, her dilin map/HashMap'i: $O(1)$ erişimin iç mekanizması.
3. **Consistent hashing** → dağıtık sistemler (cache, sharding, yük dengeleme): anahtarları sunuculara dağıtma.
4. **Hash-flooding (DoS)** → güvenlik: deterministik hash saldırıya açık; rastgele seed bu yüzden standart oldu.
5. **Beklenen vs en kötü durum** → randomized algoritma disiplini: garantiyi "her girdi" yerine "ortalama girdi" üzerinden vermek (ML'de Monte Carlo / beklenen-değer analizi).
6. **$u < 2^w$ varsayımı** → düşük seviye: anahtarın bir word'e sığması, gerçek donanımda sabit-zaman erişimin koşulu.
:::
---
::: {.callout-important title="Tek bir şey alıp gideceksen"}
Karşılaştırma seni $O(\log n)$'de tutar; rastgele erişim + hash bunu $O(1)$'e indirir. Ama bedava değildir — hash fonksiyonunu *rastgele* seçmezsen, en kötü durum seni $O(n)$ zincire mahkûm eder. Universal hashing, olasılığı senin lehine çevirir.
:::