flowchart TD
Q["QᵀQ = I — ortonormal kolonlar"] --> R["döndürme (det +1)"]
Q --> Y["yansıma (det −1)"]
Q --> H["Householder I − 2uuᵀ"]
Q --> HD["Hadamard ±1"]
Q --> HA["Haar dalgacık"]
Q --> F["Fourier / DFT"]
Q --> N["uzunluk korunur ‖Qx‖ = ‖x‖"]
style Q fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style N fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style R fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style Y fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style H fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style HD fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style HA fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style F fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
4 Ortonormal Kolonlar — QᵀQ = I
Tek bir özdeşlik: uzunluk korunur, ters bedava gelir, bir aile açılır
NotBölüm bilgisi
- Video: Orthonormal Columns in Q Give QᵀQ = I — Gilbert Strang, MIT 18.065
- OCW: Lecture 3 — Orthonormal Columns in Q Give QᵀQ = I
- Okuma süresi: ≈ 35 dk
- Önkoşul: Ders 2 (beş faktorizasyon, \(A = QR\) ve \(S = Q\Lambda Q^{T}\))
4.1 Bu Derste Ne Var?
Ders 2’de beş faktorizasyon arasında QR’a değindik. Ders 3, \(Q\) matrislerinin — ortonormal kolonlu matrislerin — derinine iniyor. Tek bir özdeşlik (\(Q^{T}Q = I\)) her şeyi açar: uzunluk korunur, sayısal kararlılık gelir ve döndürme, yansıma, Householder, Hadamard, dalgacık, Fourier gibi bir ailenin kapısı aralanır.
Üç temel fikir:
- \(Q^{T}Q = I\) — ortonormal kolonların tek satırlık ifadesi; kare \(Q\) için bu ortogonal matristir (\(Q^{T}Q = QQ^{T} = I\)).
- Uzunluk korunur — \(\|Qx\| = \|x\|\); bu yüzden ortogonal matrisler sayısal algoritmaların gözdesidir (taşma yok).
- Ortogonal matris ailesi — döndürme, yansıma, Householder (\(I - 2uu^{T}\)), Hadamard (\(\pm 1\)), Haar dalgacık, Fourier (DFT).
“…every time you see Q transpose Q, you’ve got the identity matrix.” — Strang, 0:47
Dersin tüm dallarını tek bir kavram haritasında topladık: Şekil 4.1 ortadaki \(Q^{T}Q = I\) özdeşliğinden çıkan ortonormal kolon ailelerini ve onların ortak sonucu olan uzunluk korunumunu gösteriyor.
İpucuBuilder Notu — Açı ve Uzunluğu Koru
- Uzunluk korunumu → gradyan kararlılığı: ortonormal ağırlıklar gradyanı ne büyütür ne küçültür; orthogonal initialization ve ortonormal RNN/transformer katmanları gradyan patlama/sönmesini önler.
- \(Q^{T}Q = I\) → ucuz ters: \(Q^{-1} = Q^{T}\); ters almak bedavadır, normalizing flow ve invertible ağlarda kritik.
- Householder ve Givens — QR ve özdeğer algoritmalarının yapı taşları (LAPACK).
- Fourier/DFT — sinyal işleme, evrişim (Ders 32) ve FFT’nin temeli; ortogonal taban değişimi.
Tek cümle: \(Q^{T}Q = I\), “açıyı ve uzunluğu koru” demektir — geometride döndürme ve yansıma, sayısal hesapta kararlılık, ML’de gradyan sağlığı.
4.2 Ortonormal Kolonlar → QᵀQ = I
\(Q\)’nun kolonları ortonormaldir: her biri birim uzunlukta (normalize) ve birbirine dik (ortogonal). Bu iki kelimelik özellik tek bir matris denklemine sıkışır:
\[ Q^{T} Q = I \]
Neden? \(Q^{T}Q\)’nun \((i, j)\) girdisi \(q_i^{T} q_j\)’dir. Köşegende (\(i = j\)) $q_i^{T} q_i = $ uzunluk\(^2 = 1 \to I\)’nın 1’leri. Köşegen dışında (\(i \neq j\)) \(q_i^{T} q_j = 0\) (diklik) \(\to I\)’nın 0’ları.
“…every time you see Q transpose Q, you’ve got the identity matrix.” — Strang, 0:47
İpucuBuilder Notu — İyi Koşullu Taban
\(Q^{T}Q = I\), “kolonlar bağımsız ve dik” demektir — bu, bir tabanı en iyi koşullu (well-conditioned) hâline getirir. ML’de ortonormal taban, koordinatları gürültüye dayanıklı ve birbirinden bağımsız tutar (whitening, PCA sonrası ortonormal eksenler).
4.3 Ortogonal Matris (Kare Q)
\(Q\) kare olduğunda \(Q^{T}Q = I\), \(Q\)’nun soldan tersinin \(Q^{T}\) olduğunu söyler. Kare matrislerde tek taraflı ters iki taraflı terstir, yani \(QQ^{T} = I\) de doğrudur. Böyle bir matrise ortogonal matris denir:
\[ Q^{T} Q = Q Q^{T} = I \quad \Longrightarrow \quad Q^{-1} = Q^{T} \]
“an orthogonal matrix.” — Strang, 3:06
Tersinin transpozdan ibaret olması olağanüstü pratiktir: \(Q\) katsayılı her denklem, ters hesabı olmadan tek bir transpozla çözülür.
İpucuBuilder Notu — Bedava Ters
\(Q^{-1} = Q^{T}\) olması, ortogonal katmanların ileri ve geri geçişini simetrik kılar: backward pass’te \(Q^{T}\) ile çarpmak, forward’ın tam tersidir. Normalizing flow ve invertible ağlar bu özelliği kullanır (Jacobian determinantı \(\pm 1\)).
4.4 Döndürme Matrisi
İlk örnek \(2\times 2\) döndürmedir. İlk kolon birim vektör (\(\cos^2\theta + \sin^2\theta = 1\)), ikinci kolon ona dik:
\[ Q = \begin{pmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{pmatrix} \]
Bu matris tüm düzlemi \(\theta\) açısıyla döndürür: \((1, 0) \to (\cos\theta, \sin\theta)\), \((0, 1) \to (-\sin\theta, \cos\theta)\).
“It’s a rotation of the whole plane by theta.” — Strang, 5:00
Tersi \(Q^{-1} = Q^{T}\), eksi işaretini alt köşeye taşır — yani \(-\theta\) döndürmesi, beklendiği gibi.
Döndürme ve yansıma, aynı \(Q^{T}Q = I\) özdeşliğini paylaşan iki temel ortogonal matristir; aralarındaki farkı determinant ele verir. Şekil 4.2 solda döndürmeyi (det \(+1\), açı/yön korunur) sağda yansımayı (det \(-1\), aynaya göre yön çevrilir) yan yana gösteriyor.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 5))
# --- SOL: Döndürme (det +1) ---
circ = unit_circle(200)
Q = rotation_matrix(np.pi / 4)
Qcirc = Q @ circ
plot_pointset(axL, circ, color=COL_STEEL_300, lw=1.8)
plot_pointset(axL, Qcirc, color=COL_ACCENT, lw=2.2)
e1 = np.array([1.0, 0.0])
Qe1 = Q @ e1
draw_vec2d(axL, e1, color=COL_PRIMARY, label="e₁")
draw_vec2d(axL, Qe1, color=COL_VEC3, label="Qe₁")
style_square_axes(axL, 1.5, title="Döndürme (det +1)")
# --- SAĞ: Yansıma (det −1) ---
R = reflection_matrix(np.pi / 3)
# ayna doğrusu: yansıma açısının yarısı (π/6)
mt = np.pi / 6
mdir = np.array([np.cos(mt), np.sin(mt)])
L = 1.8
axR.plot([-L * mdir[0], L * mdir[0]], [-L * mdir[1], L * mdir[1]],
color=COL_STEEL_300, lw=1.6, ls="--", zorder=1)
v = np.array([1.0, 0.3])
Rv = R @ v
draw_vec2d(axR, v, color=COL_PRIMARY, label="v")
draw_vec2d(axR, Rv, color=COL_VEC3, label="Rv")
style_square_axes(axR, 1.5, title="Yansıma (det −1)")
fig.suptitle("Döndürme vs Yansıma: aynı QᵀQ=I, farklı determinant",
color=COL_TEXT, fontsize=13, fontweight="bold")
plt.show()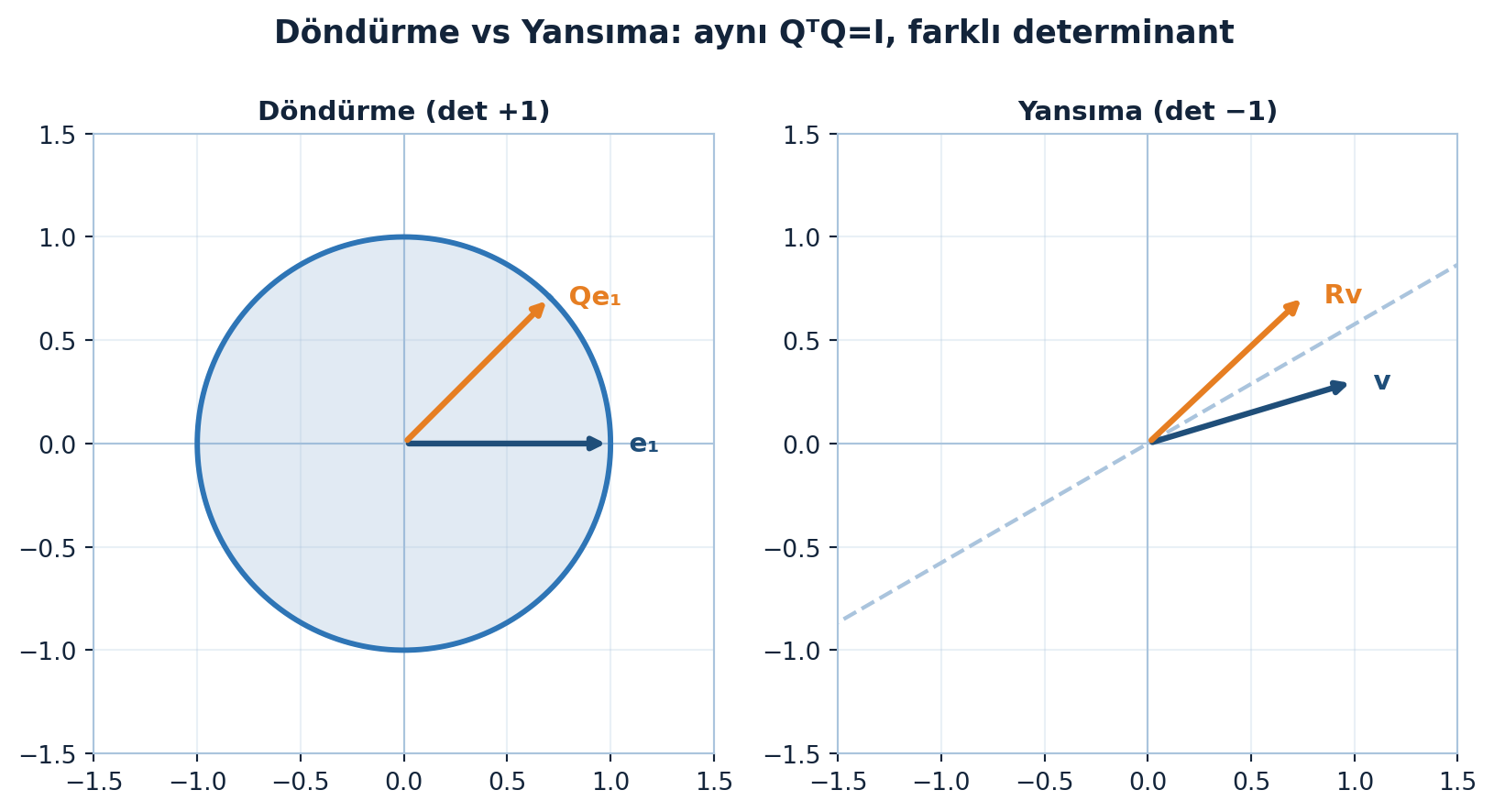
İpucuBuilder Notu — Düzlemi Döndür
Döndürme matrisleri, geometrik derin öğrenmede (rotation-equivariant ağlar), poz tahmininde (3B döndürmeler, SO(3)) ve veri artırmada (görüntü döndürme) doğrudan kullanılır. Determinantı \(+1\) olan ortogonal matrisler “uygun döndürmeler”dir.
4.5 Uzunluk Korunur: ‖Qx‖ = ‖x‖
Ortogonal matrislerin en önemli özelliği: bir vektörün uzunluğunu değiştirmezler.
“It doesn’t change length.” — Strang, 5:43
Kanıt tamamen \(Q^{T}Q = I\)’den çıkar. Kareleri karşılaştırmak kolay:
\[ \|Qx\|^{2} = (Qx)^{T}(Qx) = x^{T} Q^{T} Q x = x^{T} I x = x^{T} x = \|x\|^{2} \]
Parantezleri kaydırınca ortada \(Q^{T}Q = I\) belirir ve düşer. Uzunluk korunduğu için ortogonal matrislerle çarparken taşma (overflow) olmaz:
“…no overflow can happen with orthogonal matrices. The lengths don’t change.” — Strang, 6:20 “Every numerical algorithm is written to use orthogonal matrices wherever it can.” — Strang, 8:26
Bu korunumu somut bir örnekte görmek için Şekil 4.3’na bakın: \(x = (3, 4)\) vektörü ve onun bir döndürme matrisiyle çarpılmış hâli \(Qx\), aynı \(\|x\| = 5\) yarıçaplı çember üzerinde kalır — yön döner, uzunluk değişmez.
Kod
# ‖Qx‖ = ‖x‖ — ortogonal dönüşüm uzunluğu korur
x = np.array([3.0, 4.0])
Q = rotation_matrix(np.pi / 5)
Qx = Q @ x
r = np.linalg.norm(x) # = 5
fig, ax = plt.subplots(figsize=(5.4, 5.4))
style_square_axes(ax, 5.5)
# |x| = 5 yarıçaplı çember (gri kesik)
circ = unit_circle()
ax.plot(r * circ[0], r * circ[1], color=COL_STEEL_300, lw=1.6, ls="--", zorder=1)
# x (navy) ve Qx (teal) — uçları çember üzerinde
draw_vec2d(ax, x, color=COL_PRIMARY, label="x", lw=2.6)
draw_vec2d(ax, Qx, color=COL_TEAL, label="Qx", lw=2.6)
# yarıçap etiketi (çemberin sağ-üst yayına, oklardan uzak)
ax.text(r * np.cos(np.pi / 7), r * np.sin(np.pi / 7) + 0.2,
"r = 5", color=COL_STEEL_300, fontsize=10, fontweight="bold")
ax.set_title("Ortogonal dönüşüm uzunluğu korur: |Qx| = |x| = 5",
color=COL_TEXT, fontsize=11, fontweight="bold")
plt.show()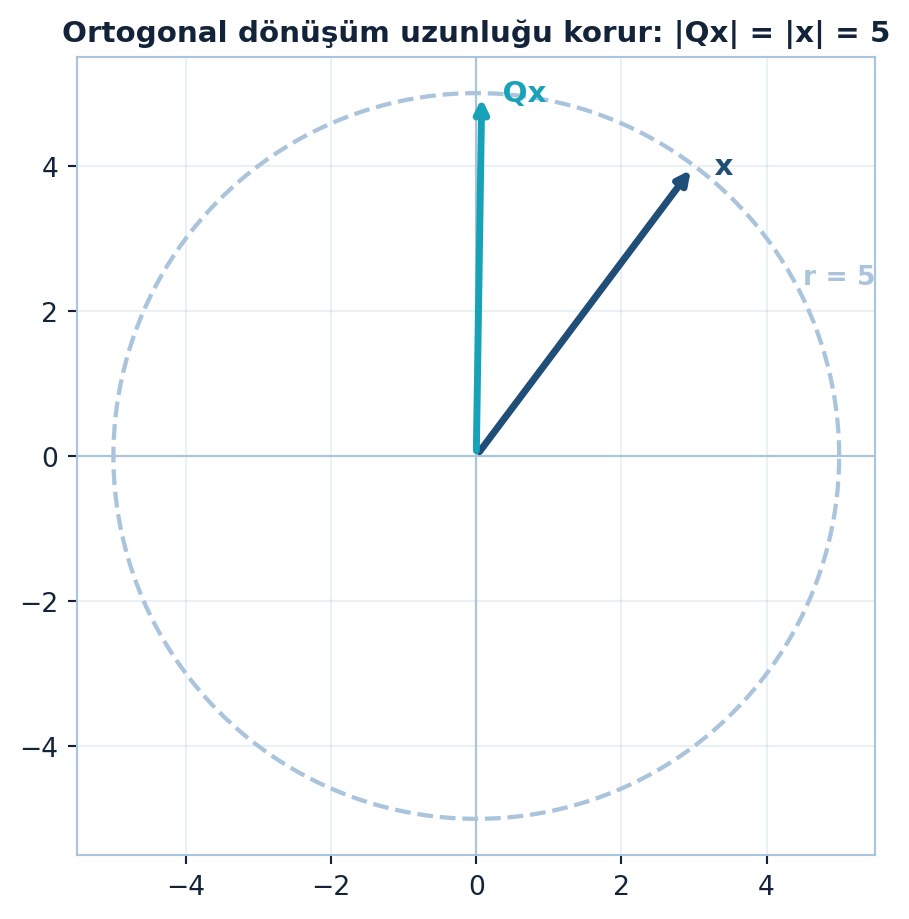
İpucuBuilder Notu — Gradyan Kararlılığı
Uzunluk korunumu = gradyan kararlılığı. Bir katman ortogonalse, ileri geçişte aktivasyon normu, geri geçişte gradyan normu sabit kalır — derin ağlarda patlama/sönme olmaz. Bu, ortogonal başlatma (orthogonal init) ve spektral normalizasyonun matematiksel gerekçesidir.
4.6 Yansıma Matrisi
Döndürmedeki tek bir işaret değişikliği farklı bir ortogonal matris verir. İlk kolon aynı \((\cos\theta, \sin\theta)\), ikinci kolonun işaretini değiştir:
\[ \begin{pmatrix} \cos\theta & \sin\theta \\ \sin\theta & -\cos\theta \end{pmatrix} \]
Bu artık döndürme değil; simetriktir ve determinantı \(-1\)’dir. Düzlemi \(\theta/2\) açısındaki bir aynaya göre yansıtır.
“This is a reflection matrix.” — Strang, 11:29
Determinant \(-1\), yansımaların imzasıdır (döndürmelerde \(+1\)). Özdeğerlerinden biri \(-1\) çıkar — ayna ekseninin tersi.
İpucuBuilder Notu — Ayna Simetrisi
Yansımalar, ileride göreceğimiz Householder dönüşümlerinin \(2\times 2\) hâlidir. Geometrik ML’de parite/yansıma simetrisi (reflection-equivariance) modellenirken bu yapı kullanılır.
4.7 Householder Yansımaları
Strang yansımayı \(n\) boyuta taşıyor. Bir birim vektör \(u\) (\(u^{T}u = 1\)) al ve şu matrisi kur:
\[ H = I - 2uu^{T} \]
İçindeki \(uu^{T}\) bir kolon çarpı satır (rank-1) matristir. \(H\) hem simetriktir hem ortogonaldir.
“So these are Householder reflections.” — Strang, 14:53
Ortogonalliğini kareyle gör — \(H\) simetrik olduğu için \(H^{T}H = H^{2}\):
\[ H^{2} = (I - 2uu^{T})^{2} = I - 4uu^{T} + 4u(u^{T}u)u^{T} = I - 4uu^{T} + 4uu^{T} = I \]
Ortadaki \(u^{T}u = 1\) sayesinde son iki terim birbirini götürür.
“…this is a family of symmetric orthogonal matrices.” — Strang, 16:57
Householder dönüşümünün geometrisi Şekil 4.4’da görülüyor: birim normal \(u\) bir aynayı (ona dik doğruyu) tanımlar, bir \(v\) vektörü bu aynaya göre \(Hv\)’ye yansır — uzunluk korunur, \(H^{T}H = I\).
Kod
# Householder yansıması: H = I - 2uuᵀ, u'ya dik düzleme (ayna) yansıtır.
u = np.array([1.0, 1.0]) / np.sqrt(2.0) # birim normal vektör
H = householder(u) # H = I - 2uuᵀ
v = np.array([1.6, 0.4]) # yansıtılacak vektör
Hv = H @ v # aynaya göre yansıması
# Ayna = u'ya DİK doğru, yön (-1,1)/√2 — orijinden geçen uzun kesik gri çizgi
mdir = np.array([-1.0, 1.0]) / np.sqrt(2.0)
t = 2.6
mline = np.array([-t * mdir, t * mdir])
fig, ax = plt.subplots(figsize=(6.6, 6.4))
fig.patch.set_facecolor(COL_WHITE)
style_square_axes(ax, 2)
# --- ayna doğrusu (u'ya dik), uzun kesik gri çizgi ---
ax.plot(mline[:, 0], mline[:, 1], color=COL_STEEL_300, lw=1.8, ls="--", zorder=1)
ax.text(1.30, -1.55, "ayna ($u^{T}x = 0$)",
color=COL_TEXT, fontsize=10, fontweight="bold", ha="center")
# --- v'den Hv'ye yansıma bağıntısı (ince yardımcı kesik çizgi) ---
ax.plot([v[0], Hv[0]], [v[1], Hv[1]], color=COL_VEC3, lw=1.1, ls=":", zorder=2)
# --- vektörler: u çelik (kısa, normal), v navy, Hv orange ---
draw_vec2d(ax, u, color=COL_VEC2, label="$u$", lw=2.2)
draw_vec2d(ax, v, color=COL_PRIMARY, label="$v$", lw=2.6)
draw_vec2d(ax, Hv, color=COL_VEC3, label="$Hv$", lw=2.6)
ax.set_title("Householder: u'ya dik düzleme yansıma (H = I - 2uuᵀ)",
color=COL_PRIMARY, fontsize=12.5, fontweight="bold", pad=12)
plt.show()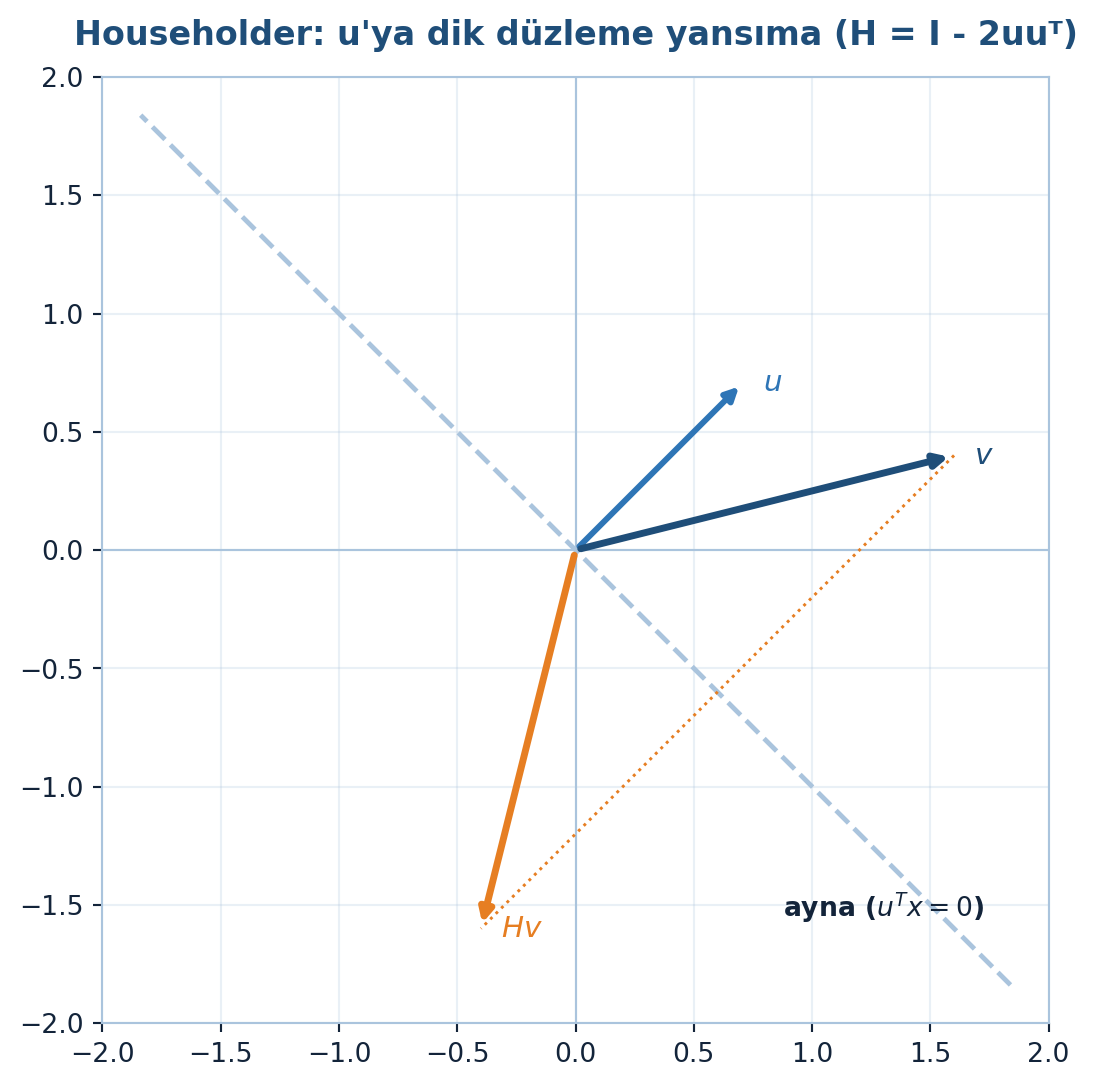
İpucuBuilder Notu — QR’ın Çekirdeği
Householder yansımaları, QR faktorizasyonunun ve özdeğer algoritmalarının (LAPACK’in geqrf) çekirdeğidir — Gram-Schmidt’ten sayısal olarak daha kararlıdır. Bir vektörü tek adımda eksen yönüne yansıtarak kolonları sıfırlar.
4.8 Hadamard Matrisleri
Yalnızca \(+1\) ve \(-1\) girdili ortogonal matrisler. En küçüğü \(2\times 2\); büyükleri ikiye katlayarak kurulur:
\[ H_2 = \begin{pmatrix} 1 & 1 \\ 1 & -1 \end{pmatrix}, \quad H_4 = \begin{pmatrix} H_2 & H_2 \\ H_2 & -H_2 \end{pmatrix} \]
Kolonlar diktir; ortonormal yapmak için \(1/\sqrt{n}\) ile ölçeklenir (\(4\times 4\) için \(1/2\)). Doğal soru: her boyutta var mı? Doubling yalnızca 2’nin katlarını verir, ama Strang daha cüretkar bir tahmin atıyor:
“…orthogonal matrix with orthogonal columns of every size n.” — Strang, 25:09
Tahmin: \(\pm 1\)’li ortogonal bir matris, \(n\)’in 4’ün katı olduğu her boyutta vardır. Bazı boyutlar (örneğin 668) hâlâ tek tek aranır — sistematik bir üretim yöntemi yok.
\(H_4\)’ün \(\pm 1\) yapısı ve dik kolonları Şekil 4.5’da görülüyor: navy \(+1\), turuncu \(-1\); \(H^{T}H = 4I\) olduğundan \(1/2\) ile ölçeklenince ortonormal taban olur.
Kod
H4 = hadamard(4)
fig, ax = plt.subplots(figsize=(4.8, 4.8))
heatmap(ax, H4, cmap=PM1_CMAP, vmin=-1, vmax=1,
title="Hadamard H₄ (±1)", fmt="{:.0f}", fontsize=13)
fig.text(0.5, -0.02,
"Kolonlar dik: HᵀH = 4I → ½ ile ölçeklenince ortonormal",
ha="center", va="top", color=COL_TEXT, fontsize=10, style="italic")
plt.show()
İpucuBuilder Notu — Ucuz Ortogonal Dönüşüm
Hadamard matrisleri kodlama teorisi, hata düzeltme ve hızlı dönüşümlerde (fast Hadamard transform) kullanılır. ML’de rastgele projeksiyon ve boyut indirgemede (örneğin structured random features, Fastfood) ucuz ortogonal dönüşüm olarak iş görür.
4.9 Dalgacıklar (Haar)
Hadamard’a benzer ama bir farkla: dalgacıklar kendini ölçekler (self-scaling). Haar dalgacık matrisi \(W_4\)’ün kolonları farklı ölçeklerde \(\pm 1\) ve 0 içerir:
\[ W_4 = \begin{pmatrix} 1 & 1 & 1 & 0 \\ 1 & 1 & -1 & 0 \\ 1 & -1 & 0 & 1 \\ 1 & -1 & 0 & -1 \end{pmatrix} \]
İlk kolon ortalama (hepsi 1), ikincisi büyük ölçekli fark, son ikisi küçük ölçekli farklar. Hadamard’dan farkı: sıfırlar sayesinde seyrek (sparse) ve çok-ölçeklidir.
“This is the Haar wavelet…” — Strang, 30:17
Haar bunu 1910’da buldu; çok sonra (1988) Ingrid Daubechies daha pürüzsüz dalgacık ailelerini keşfetti.
\(W_4\)’ün çok-ölçekli ve seyrek yapısı Şekil 4.6’da görülüyor: kolonlar ortalama, büyük ölçek ve küçük ölçek rollerine ayrılır; küçük ölçek kolonları seyrektir (yarısı 0) ve \(W^{T}W\) köşegendir (kolonlar dik).
Kod
# Haar dalgacık W4: çok-ölçekli, seyrek ortogonal kolonlar
W = haar_w4()
fig, ax = plt.subplots(figsize=(5.6, 5.4))
heatmap(ax, W, cmap=PM1_CMAP, vmin=-1, vmax=1, fmt="{:.0f}", fontsize=15)
# Kolon rolleri: kol1 = ortalama, kol2 = büyük ölçek, kol3-4 = küçük ölçek (seyrek)
roles = ["ortalama", "büyük\nölçek", "küçük\nölçek", "küçük\nölçek"]
for j, r in enumerate(roles):
ax.text(j, -0.85, r, ha="center", va="bottom",
color=COL_PRIMARY, fontsize=10, fontweight="bold")
ax.text(1.5, 3.95,
"çok-ölçekli · küçük ölçekte seyrek 0'lar · WᵀW köşegen (ortogonal)",
ha="center", va="top", color=COL_TEXT, fontsize=9.5)
fig.suptitle("Haar dalgacık W₄: çok-ölçekli, seyrek ortogonal",
color=COL_PRIMARY, fontsize=14, fontweight="bold", y=0.97)
fig.tight_layout()
plt.show()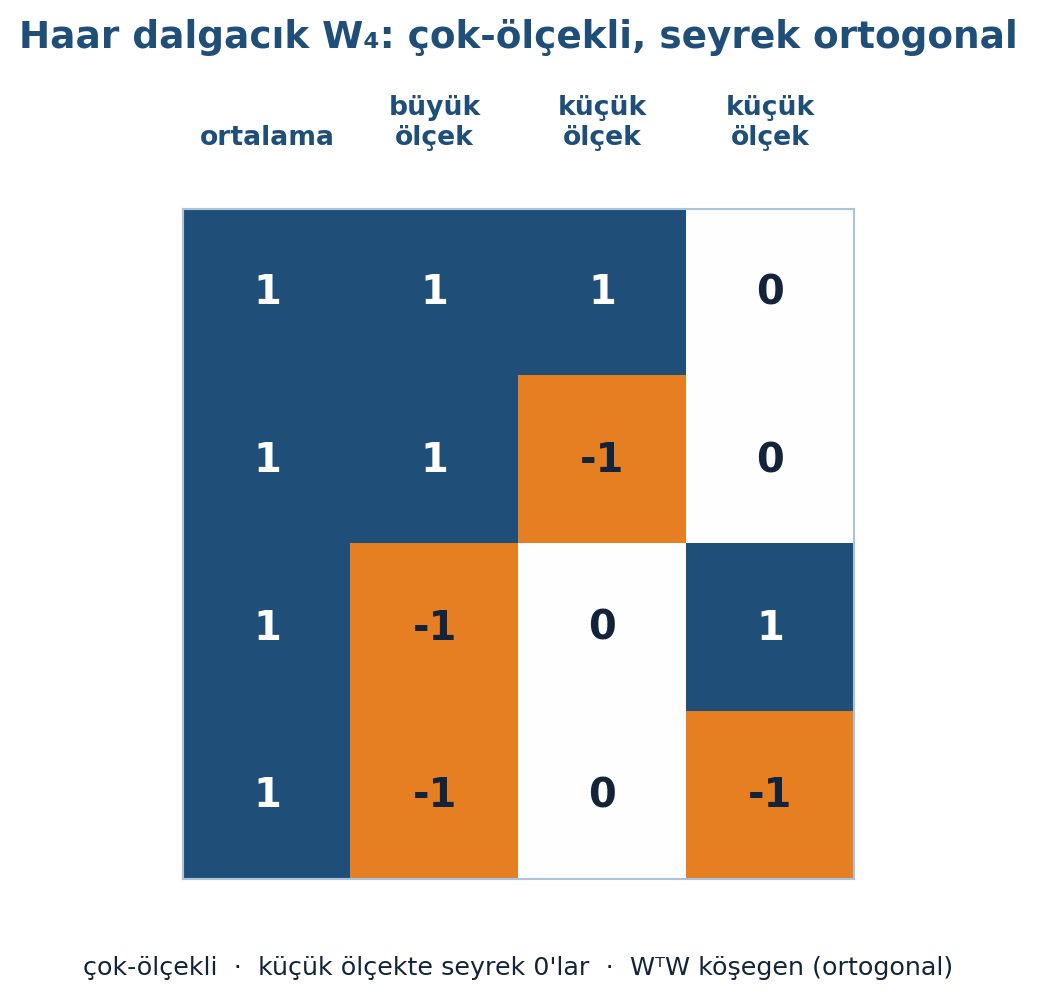
İpucuBuilder Notu — Çok-Ölçekli Görüş
Dalgacıklar JPEG2000 sıkıştırma, çok-ölçekli analiz ve gürültü gidermede kullanılır. Çok-ölçekli yapı, evrişimli ağların (CNN) havuzlama (pooling) piramidiyle aynı sezgiyi paylaşır: kaba ölçekten ince ölçeğe bilgi ayrıştırma.
4.10 Ortogonal Özvektörler
Ortogonal matrisler nereden bol bol üretilir? En büyük kaynak, simetrik (ve ortogonal) matrislerin özvektörleridir.
“So the eigenvectors of a symmetric matrix [are orthogonal].” — Strang, 35:09
Bir simetrik matris yaz, özvektörleri otomatik olarak ortogonal çıkar — uğraşmadan ortonormal bir taban elde edersin. Bu, Ders 4-5’in (özdeğerler, simetrik matrisler) habercisidir ve spektral teoremin (Ders 2) temelidir.
İpucuBuilder Notu — PCA Neden Çalışır
“Simetrik matris → ortonormal özvektörler” garantisi, PCA’nın neden her zaman çalıştığını açıklar: kovaryans matrisi simetriktir, ana bileşenler (özvektörler) otomatik diktir. Aynı şey kernel matrisleri ve graf Laplacian’ları için de geçerli (Ders 35).
4.11 Fourier Matrisi ve DFT
En önemli ortogonal taban Fourier’dir. Strang şaşırtıcı bir kaynaktan türetiyor: bir permütasyon matrisinin özvektörleri. Permütasyon matrisi birim matrisin satırları karıştırılmış hâlidir — kolonları açıkça ortogonaldir, yani bir \(Q\)’dur, dolayısıyla özvektörleri ortogonaldir. Bu özvektörler Fourier matrisi \(F\)’i oluşturur:
\[ F = \begin{pmatrix} 1 & 1 & 1 & 1 \\ 1 & i & i^{2} & i^{3} \\ 1 & i^{2} & i^{4} & i^{6} \\ 1 & i^{3} & i^{6} & i^{9} \end{pmatrix} \]
“…they’re tremendously useful. They’re the heart of signal processing.” — Strang, 37:37
İlk kolon sabit (sıfır frekans), diğerleri \(i\)’nin (sanal birim) kuvvetleriyle artan frekanslar. Önemli uyarı: \(F\) kompleks olduğundan ortogonalliği test ederken kompleks eşlenik (conjugate) almak gerekir — her \(i\)’yi \(-i\) ile değiştir, yoksa dik çıkmaz.
“…the complex conjugate of one is one.” — Strang, 46:15
Fourier matrisinin kompleks yapısı Şekil 4.7’da görülüyor: sol panel reel kısım \(\text{Re}(F_4)\), sağ panel sanal kısım \(\text{Im}(F_4)\). Kolonlar kompleks eşlenikle diktir: \(F^{H}F = 4I\), yani \(F/\sqrt{4}\) üniterdir.
Kod
F = fourier_matrix(4)
fig, axs = plt.subplots(1, 2, figsize=(9, 4.4))
heatmap(axs[0], np.real(F) + 0.0, cmap=PM1_CMAP, vmin=-1, vmax=1, title="Re(F4)")
heatmap(axs[1], np.imag(F) + 0.0, cmap=PM1_CMAP, vmin=-1, vmax=1, title="Im(F4)")
fig.suptitle("Fourier matrisi F4: kompleks, eşlenikle ortogonal (FH F = 4I)",
color=COL_TEXT, fontsize=12, fontweight="bold")
fig.tight_layout()
plt.show()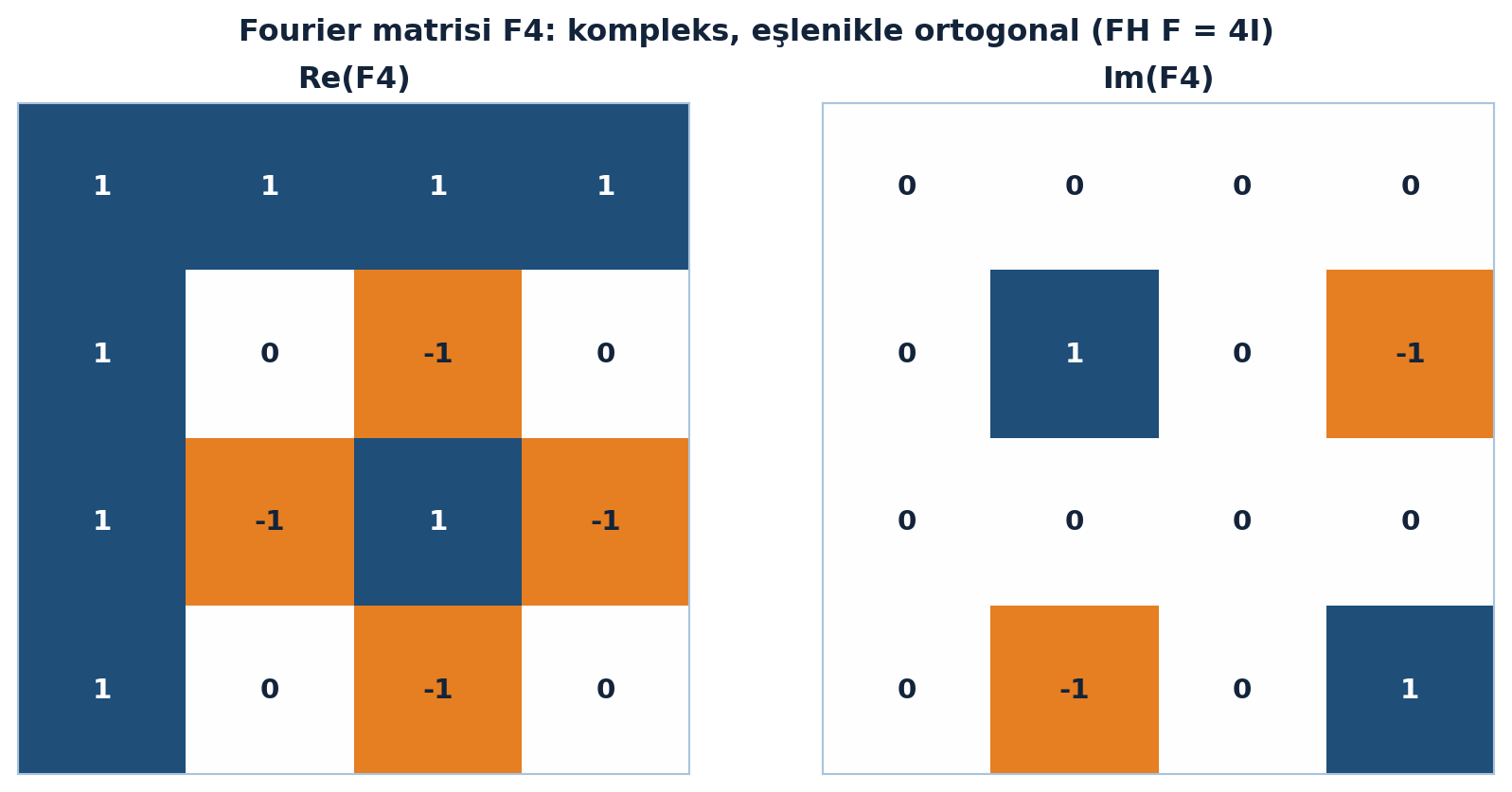
İpucuBuilder Notu — Sinyal İşlemenin Kalbi
Ayrık Fourier dönüşümü (DFT) ve onun hızlı hâli FFT, sinyal işlemenin ve evrişimin (Ders 32) temelidir: evrişim, Fourier uzayında çarpmaya dönüşür. ML’de spektral yöntemler, ses/görüntü ön-işleme ve bazı dikkat (attention) hızlandırmaları DFT üzerine kuruludur.
4.12 Bu Dersin Özeti
- \(Q^{T}Q = I\) — ortonormal kolonların (birim + dik) tek satırlık ifadesi.
- Ortogonal matris — kare \(Q\) için \(Q^{T}Q = QQ^{T} = I\); \(Q^{-1} = Q^{T}\).
- Döndürme — \(2\times 2\), determinant \(+1\), düzlemi \(\theta\) döndürür.
- Uzunluk korunur — \(\|Qx\| = \|x\|\); taşma yok, sayısal algoritmaların gözdesi.
- Yansıma — \(2\times 2\), determinant \(-1\), aynaya göre yansıtır.
- Householder — \(H = I - 2uu^{T}\); simetrik + ortogonal, \(H^{2} = I\).
- Hadamard — \(\pm 1\) girdili ortogonal matrisler; 4’ün katı boyut tahmini.
- Dalgacıklar (Haar) — kendini ölçekleyen, seyrek \(\pm 1/0\) matrisler.
- Ortogonal özvektörler — simetrik/ortogonal matrislerden bedava gelir.
- Fourier (DFT) — permütasyonun özvektörleri; kompleks, eşlenikle dik.
ÖnemliTek Bir Cümle
\(Q^{T}Q = I\) tek bir denklemdir ama “açıyı ve uzunluğu koru” demektir: geometride döndürme ve yansıma, sayısal hesapta taşmasız kararlılık, ML’de gradyan sağlığı — ve döndürme, Householder, Hadamard, dalgacık, Fourier hep bu tek özelliğin aileleridir.
4.13 Kontrol Soruları
NotSoru 1: Aşağıdaki Q için QᵀQ = I olduğunu doğrula ve x = (3, 4) vektörünün uzunluğunu koruduğunu göster.
\[ Q = \frac{1}{\sqrt{2}}\begin{pmatrix} 1 & -1 \\ 1 & 1 \end{pmatrix} \]
Cevap:
\[ Q^{T}Q = \frac{1}{2}\begin{pmatrix} 1 & 1 \\ -1 & 1 \end{pmatrix}\begin{pmatrix} 1 & -1 \\ 1 & 1 \end{pmatrix} = \frac{1}{2}\begin{pmatrix} 2 & 0 \\ 0 & 2 \end{pmatrix} = I \]
Uzunluk: \(\|x\| = \sqrt{9 + 16} = 5\). \(Qx = (1/\sqrt{2})(3 - 4, 3 + 4) = (1/\sqrt{2})(-1, 7)\), \(\|Qx\|^{2} = (1 + 49)/2 = 25\), \(\|Qx\| = 5 = \|x\|\) ✓. (Bu \(Q\), 45° döndürmedir.)
NotSoru 2: u = (1/√2)(1, 1) için Householder matrisi H = I − 2uuᵀ’yi hesapla. Simetrik ve ortogonal olduğunu doğrula.
Cevap:
\[ uu^{T} = \frac{1}{2}\begin{pmatrix} 1 & 1 \\ 1 & 1 \end{pmatrix}, \quad H = I - 2uu^{T} = \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix} - \begin{pmatrix} 1 & 1 \\ 1 & 1 \end{pmatrix} = \begin{pmatrix} 0 & -1 \\ -1 & 0 \end{pmatrix} \]
Simetrik ✓ (\(H^{T} = H\)). Ortogonal: \(H \cdot H = I\) (çünkü \(u^{T}u = 1\)). Bu \(H\), koordinatları takas edip işaret değiştirir — \(u\)’ya dik doğruya göre yansıma.
NotSoru 3: 90° döndürme matrisi tamamen gerçek olduğu hâlde özvektörleri neden kompleks çıkar?
\[ Q = \begin{pmatrix} 0 & -1 \\ 1 & 0 \end{pmatrix} \]
Cevap:
Özdeğerler \(\det(Q - \lambda I) = \lambda^{2} + 1 = 0 \to \lambda = \pm i\) (kompleks). 90° döndürme, düzlemde hiçbir gerçek yönü sabit bırakmaz (her vektör döner), o yüzden gerçek özvektör yoktur. Özvektörler \((1, \mp i)\) gibi kompleks vektörlerdir. Bu, ortogonal matrislerin (\(S\) simetrikten farklı olarak) kompleks özvektörlü olabilmesinin nedenidir — Fourier matrisindeki \(i\)’nin kaynağı.
NotSoru 4: Ortogonal başlatma (orthogonal init) derin ağlarda gradyan kararlılığına nasıl yardım eder? ‖Qx‖ = ‖x‖ ile bağ kur.
Cevap:
Bir katmanın ağırlığı ortogonalse, ileri geçişte aktivasyon normu korunur (\(\|Qx\| = \|x\|\)), geri geçişte de gradyan normu korunur (\(Q^{T}\) ile çarpım da uzunluk korur). Çok katmanlı bir ağda normlar ne katlanarak büyür (patlama) ne de katlanarak küçülür (sönme).
Genel bir ağırlık matrisinde her katman normu \(\sigma_{\max}\) veya \(\sigma_{\min}\) ile çarpar; \(L\) katman sonra \(\sigma^{L}\) patlar/söner. Ortogonalde tüm tekil değerler 1 olduğundan bu sorun ortadan kalkar. Pratikte torch.nn.init.orthogonal_ bunu sağlar; RNN’lerde ve çok derin ağlarda kritiktir.
4.14 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. 60° döndürme matrisini yaz. \(Q^{T}Q = I\) olduğunu ve determinantının \(+1\) olduğunu doğrula.
\[ Q = \begin{pmatrix} \cos 60° & -\sin 60° \\ \sin 60° & \cos 60° \end{pmatrix} \]
Egzersiz 2. \(u = (1/\sqrt{3})(1, 1, 1)\) için \(3\times 3\) Householder matrisi \(H = I - 2uu^{T}\)’yi kur. Simetrik olduğunu ve \(H^{2} = I\) sağladığını göster. \(H\)’nin \(u\)’yu \(-u\)’ya gönderdiğini doğrula (\(Hu = -u\)).
Egzersiz 3. \(4\times 4\) Hadamard matrisi \(H_4\)’ün kolonlarının birbirine dik olduğunu (iç çarpımları 0) göster. Ortonormal yapmak için hangi sabitle ölçeklersin?
\[ H_4 = \begin{pmatrix} 1 & 1 & 1 & 1 \\ 1 & -1 & 1 & -1 \\ 1 & 1 & -1 & -1 \\ 1 & -1 & -1 & 1 \end{pmatrix} \]
Egzersiz 4. Python ile ortogonalliği ve uzunluk korunumunu test et:
import numpy as np
theta = np.pi / 5
Q = np.array([[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)]])
print("Q^T Q = I ?", np.allclose(Q.T @ Q, np.eye(2)))
print("det(Q) =", np.linalg.det(Q)) # +1 (döndürme)
x = np.array([3.0, 4.0])
print("|x| =", np.linalg.norm(x), " |Qx| =", np.linalg.norm(Q @ x)) # eşit
# Householder
u = np.array([1.0, 1.0, 1.0]); u = u / np.linalg.norm(u)
H = np.eye(3) - 2 * np.outer(u, u)
print("H simetrik ?", np.allclose(H, H.T))
print("H^2 = I ?", np.allclose(H @ H, np.eye(3)))Egzersiz 5. (Ders 4 habercisi.) Ders 4 özdeğer ve özvektörlere geçer. Aşağıdaki simetrik matrisin özdeğerlerini bul; özvektörlerinin birbirine dik çıktığını doğrula (bu derste gördüğümüz “simetrik → ortogonal özvektörler” gerçeği).
\[ S = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \]
4.15 Sonraki Ders İçin Hazırlık
Ders 4: Özdeğerler ve Özvektörler
Ders 3’ü “simetrik/ortogonal matrislerin özvektörleri ortogonaldir” gözlemiyle kapattık. Ders 4 doğrudan özdeğer ve özvektörlere giriyor — kursun özüne.
- Özdeğer/özvektör tanımı ve \(Ax = \lambda x\)
- Simetrik matrisler: gerçek özdeğerler, ortonormal özvektörler (spektral teoremin temeli)
- Pozitif tanımlılığa giriş (Ders 5’in hazırlığı)
- Neden özdeğerler ML’de her yerde: PCA, kararlılık, Hessian
UyarıDers 4 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (simetrik matrisin özvektörleri).
- Python’da
np.linalg.eighile birkaç simetrik matrisin özvektörlerini bul,V.T @ Vile ortonormalliklerini kontrol et. - Ana cümleyi tekrar oku: “\(Q^{T}Q = I\) — açıyı ve uzunluğu koru.”
4.16 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| \(Q^{T}Q = I\) | Ortonormal kolonların (birim + dik) ifadesi | 0m47 |
| Ortogonal matris | Kare \(Q\); \(Q^{T}Q = QQ^{T} = I\), \(Q^{-1} = Q^{T}\) | 3m06 |
| Döndürme | \(2\times 2\), determinant \(+1\), düzlemi \(\theta\) döndürür | 5m00 |
| Uzunluk korunur | \(\|Qx\| = \|x\|\); \(Q^{T}Q = I\)’den çıkar | 5m43 |
| Taşma yok | Ortogonal matrisler sayısal algoritmaların gözdesi | 6m20 |
| Yansıma | \(2\times 2\), determinant \(-1\), aynaya yansıtır | 11m29 |
| Householder | \(H = I - 2uu^{T}\); simetrik + ortogonal, \(H^{2} = I\) | 14m53 |
| Hadamard | \(\pm 1\) girdili ortogonal; 4’ün katı boyut tahmini | 25m09 |
| Haar dalgacık | Kendini ölçekleyen, seyrek \(\pm 1/0\) matrisler | 30m17 |
| Ortogonal özvektörler | Simetrik/ortogonal matristen bedava gelir | 35m09 |
| Fourier / DFT | Permütasyonun özvektörleri; kompleks, eşlenikle dik | 37m37 |
4.17 ML Bağlantıları Özeti
- \(Q^{T}Q = I\) → whitening ve ortonormal taban; koordinatlar bağımsız ve iyi koşullu.
- Uzunluk korunumu → orthogonal init, spektral normalizasyon; derin ağda gradyan patlama/sönmesini önler.
- \(Q^{-1} = Q^{T}\) → normalizing flow ve invertible ağlar; ucuz ters, Jacobian determinantı \(\pm 1\).
- Householder/Givens → QR ve özdeğer algoritmalarının çekirdeği (LAPACK).
- Hadamard → hızlı rastgele projeksiyon, structured random features, boyut indirgeme.
- Dalgacıklar → çok-ölçekli analiz, sıkıştırma; CNN havuzlama piramidiyle aynı sezgi.
- Fourier/DFT → sinyal/ses/görüntü ön-işleme, evrişim (Ders 32), spektral yöntemler.
ÖnemliTek bir şey alıp gideceksen
\(Q^{T}Q = I\) tek bir denklemdir ama “açıyı ve uzunluğu koru” demektir. Bu yüzden ortogonal matrisler uzunluğu değiştirmez (\(\|Qx\| = \|x\|\)), tersi transpozdur (\(Q^{-1} = Q^{T}\)) ve sayısal hesabın gözdesidir. Döndürme, yansıma, Householder, Hadamard, dalgacık ve Fourier — hepsi bu tek özelliğin aileleridir; ML’de gradyan kararlılığından evrişime kadar uzanır.