flowchart TD
C["Backprop = ters-mod AD"]
C --> G["backprop = grad f<br/>(SGD nin ihtiyaci)"]
C --> Z["zincir kurali:<br/>dF/dx = (dF3/dF2)(dF2/dF1)(dF1/dx)"]
C --> P["computational graph:<br/>ileri hesapla + geri yay"]
C --> M["mucize: m turev ~4-5x maliyet<br/>(m x DEGIL)"]
C --> S["matris-zinciri: A(BC) vs (AB)C<br/>sira maliyeti belirler"]
V["kolon vektor (q=1):<br/>skalerden geriye hep vektor-Jacobian"]
T["DORT TANIK: Strang = Karpathy micrograd<br/>= fast.ai .g = NYU Jacobian"]
D["Ders 28-29 lab (atlanir) -> Ders 30 sirkulant"]
classDef merkez fill:#1f4e79,stroke:#13243a,stroke-width:2px,color:#ffffff;
classDef dal fill:#2e75b6,stroke:#1f4e79,stroke-width:1.5px,color:#ffffff;
classDef vec fill:#ff8c42,stroke:#c25a16,stroke-width:1.5px,color:#1f2330;
classDef teal fill:#2ca6a4,stroke:#1f6f6e,stroke-width:1.5px,color:#ffffff;
class C merkez;
class G,Z,P,M,S dal;
class V,D vec;
class T teal;
28 Backpropagation — Kısmi Türevleri Bulmak
Ters-mod otomatik türev, matris-zinciri sırası ve dört tanığın buluşması
NotBölüm bilgisi
Bu ders, SGD’nin (Ders 25) her adımda ihtiyaç duyduğu gradyanı verimli hesaplayan algoritmayı kurar: backpropagation = ters-mod otomatik türev (reverse-mode AD); zincir kuralının matris-çarpım hâli. Strang’in Ders 27 videosu (≈52 dk) ve OCW Lecture 27 temel alınmıştır. Okuma süresi ≈34 dk; önkoşul Ders 26 (sinir ağı = kompozisyon \(F = F_3\circ F_2\circ F_1\)). Bu ders optimizasyon ve derin öğrenme bloğunun kapanışıdır.
28.1 Bu Derste Ne Var?
SGD’nin (Ders 25) her adımda ihtiyacı olan gradyanı verimli hesaplama: backpropagation = ters-mod otomatik türev (reverse-mode AD). Bu, sinir ağlarını haritaya koyan hesap.
Beş sonuç:
- Backprop = grad f: tüm kısmi türevler (\(\partial F/\partial x_1, \dots, \partial F/\partial x_m\)); her steepest descent adımı gradyan ister.
- Zincir kuralı: \(F = F_3(F_2(F_1(x)))\) türevi \(dF/dx = (dF_3/dF_2)(dF_2/dF_1)(dF_1/dx)\).
- Computational graph: ileri (\(F\)’yi hesapla) + geri (\(dF/dF=1\)’den başlayıp türevleri geri yay).
- Mucize: ters-mod, \(m\) değişkenin TÜM türevlerini \(m\times\) değil ~4-5× maliyetle hesaplar (zincir parçaları yeniden kullanılır).
- Neden hızlı: matris-zinciri \((AB)C\) vs \(A(BC)\) — sıra önemli; ters-mod doğru sıra (skaler çıktıdan geriye).
“…you could compute n first derivatives with about four or five times the cost, not n times.” — Strang, 30:03
Şekil 28.1 dersin iskeletini gösterir: merkezdeki “backprop = ters-mod AD” fikrinden, SGD’nin ihtiyacı olan grad \(f\)’yi zincir kuralıyla hesaplamaya, ileri hesaplayıp geri yayan computational graph’a, \(m\) türevi \(m\times\) değil ~4-5× maliyetle veren mucizeye ve sıranın maliyeti belirlediği matris-zincirine (\(A(BC)\) vs \((AB)C\)) dallanır; ayrı düğümlerde skalerden geriye hep vektör-Jacobian olan kolon-vektör durumu, DÖRT TANIK (Strang = Karpathy micrograd = fast.ai .g = NYU Jacobian) buluşması ve Ders 28-29 lab (atlanır) → Ders 30 sirkülant köprüsü durur.
İpucuBuilder Notu — Dört Yol Tek Gradyan
Backprop = autograd — PyTorch/TensorFlow/JAX’in .backward()’ı; reverse-mode AD, vektör-Jacobian çarpımları (VJP). Derin öğrenmeyi pratik kılan algoritma (Hinton + öncesi AD). DÖRT TANIK BULUŞUR (Phase 2 sentezi): Strang’ın matris-zinciri = Karpathy micrograd _backward = fast.ai manuel .g = NYU Jacobian zinciri — dört yol, aynı backprop. Matris-zinciri sırası (\((AB)C\) vs \(A(BC)\) maliyet farkı) ters-mod’un neden verimli olduğunun özü; skaler kayıptan geriye çarpmak = vektör×matris (ucuz), matris×matris değil (pahalı). Geriye köprü: Ders 25 (SGD gradyan ister), Ders 26 (\(F\) kompozisyon), Ders 21 (zincir kuralı/Jacobian), Ders 2 (kompozisyon).
Tek cümle: Backpropagation, \(F = F_3\circ F_2\circ F_1\) kompozisyonunun gradyanını zincir kuralını ters sırada (skaler çıktıdan geriye) uygulayarak hesaplar; bu matris-zinciri “doğru sıra” seçimi, tüm türevleri tek değişkeninkinin sadece 4-5 katı maliyetle verir — derin öğrenmeyi mümkün kılan algoritma.
28.2 Backprop = Gradyan Hesaplama
Backpropagation tek bir iş yapar: gradyanı hesaplamak.
“This is all to compute grad f…” — Strang, 8:39
Tüm kısmi türevler \(\partial F/\partial x_1, \dots, \partial F/\partial x_m\). Steepest descent’in (Ders 22) her adımı gradyan ister; hızlı hesaplayamazsan battın. Çözüm:
“…automatic differentiation in reverse mode…” — Strang, 9:45
\[\nabla F = \left(\frac{\partial F}{\partial x_{1}}, \dots, \frac{\partial F}{\partial x_{m}}\right)\]
Backprop = ters-mod otomatik türev (reverse-mode AD). Sinir ağlarını haritaya koyan keşif buydu (Hinton’a büyük pay; ama daha önce “Automatic Differentiation” adıyla çalışılmıştı). Hızlı gradyan = uygulanabilir derin öğrenme.
Şekil 28.2 Strang’ın matris diliyle aynı hesabı verir: ileri geçişte \(x \to [W_1, b_1] \to z_1 \to \text{ReLU} \to h_1 \to [W_2, b_2] \to \text{out} \to L\) akar; geri geçişte \(\delta\)’lar geriye matris-çarpılır (\(\delta_2 = \text{out} - y\), \(\delta_1 = (W_2^{\top}\delta_2)\odot\text{ReLU}'(z_1)\)) ve parametre gradyanı \(dW = \delta\,(\text{girdi})^{\top}\) bir rank-1 dış-çarpım olur — bu tam Ders 1’in \(uv^{\top}\) köprüsü.
Kod
fig, ax = plt.subplots(figsize=(9.5, 4))
ax.axis("off")
ax.set_xlim(0, 100); ax.set_ylim(0, 100)
top_y = 70
bot_y = 28
box_w, box_h = 11.5, 9.5
def box(ax, cx, cy, label, fc, tc="white", fs=10, w=box_w, h=box_h):
rect = plt.Rectangle((cx - w/2, cy - h/2), w, h, facecolor=fc,
edgecolor=COL_TEXT, linewidth=1.4, zorder=3)
ax.add_patch(rect)
ax.text(cx, cy, label, ha="center", va="center", color=tc,
fontsize=fs, fontweight="bold", zorder=4)
def arrow(ax, x0, y0, x1, y1, color, lw=2.0):
ax.annotate("", xy=(x1, y1), xytext=(x0, y0),
arrowprops=dict(arrowstyle="-|>", color=color, lw=lw,
shrinkA=2, shrinkB=2), zorder=2)
# ÜST SIRA — İLERİ
top_nodes = [
(8, "x"),
(24, "[W1, b1]"),
(40, "z1"),
(54, "ReLU"),
(68, "h1"),
(82, "[W2, b2]"),
(95, "out"),
]
for cx, lab in top_nodes:
box(ax, cx, top_y, lab, COL_PRIMARY)
for k in range(len(top_nodes) - 1):
x0 = top_nodes[k][0] + box_w/2
x1 = top_nodes[k+1][0] - box_w/2
arrow(ax, x0, top_y, x1, top_y, COL_PRIMARY)
box(ax, 95, top_y - 22, "L", COL_PRIMARY)
arrow(ax, 95, top_y - box_h/2, 95, top_y - 22 + box_h/2, COL_PRIMARY)
ax.text(50, 90, "İleri geçiş", ha="center", va="center",
color=COL_PRIMARY, fontsize=12, fontweight="bold")
# ALT SIRA — GERİ
bot_nodes = [
(8, r"$dW_1=\delta_1 x^T$"),
(28, r"$\delta_1=(W_2^T\delta_2)\odot$ReLU$'(z_1)$"),
(62, r"$dW_2=\delta_2 h_1^T$"),
(84, r"$\delta_2=$out$-y$"),
]
for cx, lab in bot_nodes:
w = 17 if cx in (28,) else 13
box(ax, cx, bot_y, lab, COL_VEC3, tc="white", fs=8.5, w=w, h=11)
arrow(ax, 95, top_y - 22 - box_h/2, 84 + 6.5, bot_y, COL_VEC3)
arrow(ax, 84 - 6.5, bot_y, 62 + 6.5, bot_y, COL_VEC3)
arrow(ax, 62 - 6.5, bot_y, 28 + 8.5, bot_y, COL_VEC3)
arrow(ax, 28 - 8.5, bot_y, 8 + 6.5, bot_y, COL_VEC3)
ax.text(50, 8, "Geri geçiş ($\\delta$ akışı)", ha="center", va="center",
color=COL_VEC3, fontsize=12, fontweight="bold")
# VURGU METNİ (teal)
ax.text(50, 47,
r"$dW = \delta\,(\mathrm{girdi})^T = $ RANK-1 DIŞ-ÇARPIM (Ders 1 $uv^T$!)",
ha="center", va="center", color=COL_TEAL, fontsize=11.5,
fontweight="bold",
bbox=dict(boxstyle="round,pad=0.4", facecolor="white",
edgecolor=COL_TEAL, linewidth=1.6))
fig.suptitle("Strang dili: delta lari geriye matris-carp; parametre gradyani dis-carpim — rank-1 (D1 koprusu)",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout()
plt.show()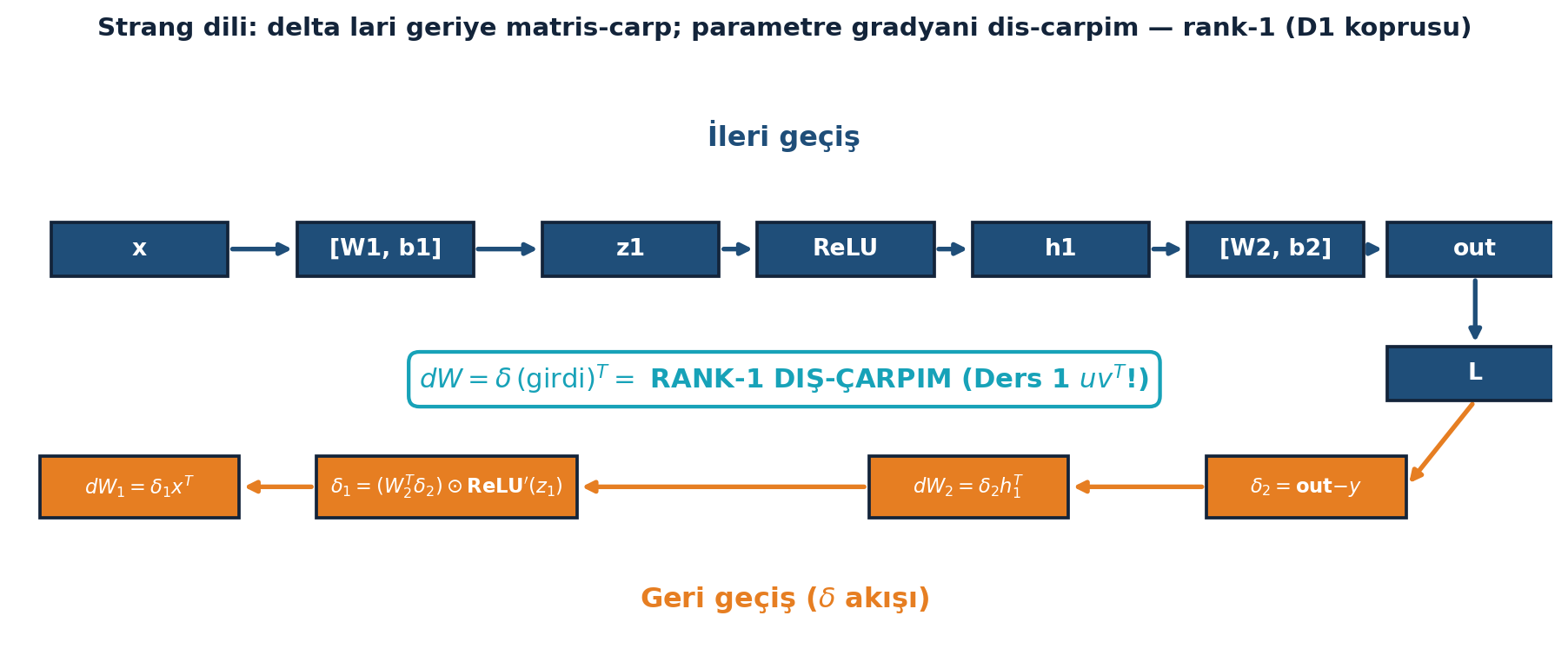
İpucuBuilder Notu — Eğitim Değil Türev Hesabı
“Backprop sadece gradyan hesaplar” — eğitim algoritması SGD’dir (Ders 25), backprop ise SGD’nin ihtiyacı olan gradyanı sağlar. ML köprüsü: bazıları “backprop” deyince tüm eğitimi kasteder, ama backprop yalnızca türev-hesaplama algoritmasıdır; PyTorch’ta loss.backward() tam bu, optimizer.step() ise SGD adımı.
28.3 Zincir Kuralı: F = F₃(F₂(F₁(x)))
Ders 26’dan: \(F\) bir kompozisyon. Türevini zincir kuralı verir. Strang’ın basit örneği (Christopher Olah’ın blogundan ilham):
“…x cubed times x plus 2y.” — Strang, 12:04
\(F = x^3(x + 2y)\), iki fonksiyonun çarpımı (çarpım kuralı + kuvvet kuralı + doğrusal kombinasyon). Kompozisyon \(F = F_3(F_2(F_1(x)))\) için zincir kuralı:
“…of course, the chain rule.” — Strang, 14:58
\[\frac{dF}{dx} = \frac{dF_{3}}{dF_{2}}\Big|_{F_{2}(F_{1}(x))} \cdot \frac{dF_{2}}{dF_{1}}\Big|_{F_{1}(x)} \cdot \frac{dF_{1}}{dx}\Big|_{x}\]
Her çarpan doğru noktada değerlendirilir. Bu, kalkülüsün özü: birkaç temel türevi (\(x^n\), \(\sin\), \(e^x\)) bil, gerisini zincir kuralıyla birleştir. Bu hesabın somut grafik hâlini Şekil 28.3 bir sonraki bölümde gösterir.
İpucuBuilder Notu — Kalkülüsün Tek Numarası
“\(F\) kompozisyon → türev zincir kuralı” backprop’un matematiksel çekirdeği. ML köprüsü: her sinir ağı katmanı bir fonksiyon; gradyan, katman türevlerinin (Jacobian’ların) zincir-çarpımıdır. Karpathy’nin micrograd’ı tam bunu yapar — her işlem bir düğüm, türevi yerel olarak bilinir, zincir kuralı bağlar.
28.4 Computational Graph: İleri ve Geri
Örneği bir hesaplama grafına (computational graph) çevir. \(F = x^3(x + 2y)\) için ara değişkenler: \(c = x^3\) ve \(s = x + 2y\), sonra \(F = c\cdot s\). İleri geçiş (forward): \(x, y\)’den \(c, s, F\)’yi sırayla hesapla. Geri geçiş (backward): çıktıdan başla, türevleri geriye yay:
\[\frac{dF}{dF} = 1, \quad \frac{dF}{dc} = s, \quad \frac{dF}{ds} = c\]
(\(F = c\cdot s\) çarpım olduğundan \(\partial F/\partial c = s\), \(\partial F/\partial s = c\).) Sonra yerel türevler \(\partial c/\partial x\), \(\partial c/\partial y\), \(\partial s/\partial x\), \(\partial s/\partial y\) ile çarpıp zinciri tamamla. Kilit: tek bir geri geçiş, hem \(dF/dx\) hem \(dF/dy\)’yi birden verir — her değişken için ayrı zincir değil.
Kod
# ---- Olah örneği: F = x^3 (x + 2y), x=2, y=3 ----
xv, yv = 2, 3
dFdx, dFdy, F, c, s = olah_backward(xv, yv) # 104, 16, 64, 8, 8
fig, (axF, axB) = plt.subplots(1, 2, figsize=(10.5, 4.4))
# düğüm konumları (axes fraction): sol-üst x, sol-alt y, orta-üst c, orta-alt s, sağ F
POS = {
"x": (0.07, 0.78),
"y": (0.07, 0.20),
"c": (0.45, 0.78),
"s": (0.45, 0.20),
"F": (0.83, 0.49),
}
BW, BH = 0.17, 0.16 # kutu yarı-genişlik/yükseklik (axes fraction)
def draw_node(ax, key, label, sub):
cx, cy = POS[key]
ax.add_patch(plt.Rectangle((cx - BW / 2, cy - BH / 2), BW, BH,
fc=COL_BG, ec=COL_PRIMARY, lw=2.0,
transform=ax.transAxes, zorder=3))
ax.text(cx, cy + 0.018, label, ha="center", va="center", fontsize=12.5,
color=COL_TEXT, fontweight="bold", transform=ax.transAxes, zorder=4)
ax.text(cx, cy - 0.045, sub, ha="center", va="center", fontsize=10.5,
color=COL_PRIMARY, fontweight="bold", transform=ax.transAxes, zorder=4)
def arrow(ax, src, dst, color, off=BW / 2):
sx, sy = POS[src]; dx, dy = POS[dst]
# kutu kenarlarından başlat/bitir (yataya yakın bağlantılar için x-ofset)
x0, x1 = sx + off, dx - off
ax.annotate("", xy=(x1, dy), xytext=(x0, sy), xycoords="axes fraction",
arrowprops=dict(arrowstyle="-|>", color=color, lw=2.2,
shrinkA=2, shrinkB=2,
connectionstyle="arc3,rad=0.0"))
def edge_label(ax, src, dst, txt, dyoff=0.05):
sx, sy = POS[src]; dx, dy = POS[dst]
mx, my = (sx + dx) / 2, (sy + dy) / 2 + dyoff
ax.text(mx, my, txt, ha="center", va="center", fontsize=9.5,
color=COL_VEC3, fontweight="bold", transform=ax.transAxes, zorder=5)
# ===== SOL PANEL: İLERİ GEÇİŞ =====
draw_node(axF, "x", "x = 2", "")
draw_node(axF, "y", "y = 3", "")
draw_node(axF, "c", "c = x^3", "= 8")
draw_node(axF, "s", "s = x+2y", "= 8")
draw_node(axF, "F", "F = c*s", "= 64")
# ileri oklar (navy)
arrow(axF, "x", "c", COL_PRIMARY)
arrow(axF, "x", "s", COL_PRIMARY)
arrow(axF, "y", "s", COL_PRIMARY)
arrow(axF, "c", "F", COL_PRIMARY)
arrow(axF, "s", "F", COL_PRIMARY)
# yerel türev kenar etiketleri (turuncu)
edge_label(axF, "x", "c", "dc/dx = 3x^2 = 12", 0.055)
edge_label(axF, "x", "s", "ds/dx = 1", -0.05)
edge_label(axF, "y", "s", "ds/dy = 2", 0.055)
edge_label(axF, "c", "F", "dF/dc = s = 8", 0.055)
edge_label(axF, "s", "F", "dF/ds = c = 8", -0.05)
axF.text(0.5, 1.04, "ILERI: hesapla (F = 64)", ha="center", va="bottom",
fontsize=11.5, color=COL_PRIMARY, fontweight="bold", transform=axF.transAxes)
axF.set_xlim(0, 1); axF.set_ylim(0, 1); axF.axis("off")
# ===== SAĞ PANEL: GERİ GEÇİŞ =====
draw_node(axB, "x", "x", "dF/dx = %d" % int(dFdx)) # 104
draw_node(axB, "y", "y", "dF/dy = %d" % int(dFdy)) # 16
draw_node(axB, "c", "c", "dF/dc = %d" % int(c)) # 8
draw_node(axB, "s", "s", "dF/ds = %d" % int(s)) # 8
draw_node(axB, "F", "F", "dF/dF = 1")
# ters oklar (turuncu) — F'den geriye
arrow(axB, "c", "x", COL_VEC3)
arrow(axB, "s", "x", COL_VEC3)
arrow(axB, "s", "y", COL_VEC3)
arrow(axB, "F", "c", COL_VEC3)
arrow(axB, "F", "s", COL_VEC3)
# birikim katkı etiketleri (turuncu)
edge_label(axB, "c", "x", "*3x^2", 0.055)
edge_label(axB, "s", "x", "*1", -0.05)
edge_label(axB, "s", "y", "*2", 0.055)
edge_label(axB, "F", "c", "*s", 0.055)
edge_label(axB, "F", "s", "*c", -0.05)
axB.text(0.5, 1.04, "GERI: TEK gecis (dF/dx = 104, dF/dy = 16)", ha="center",
va="bottom", fontsize=11.5, color=COL_VEC3, fontweight="bold",
transform=axB.transAxes)
axB.set_xlim(0, 1); axB.set_ylim(0, 1); axB.axis("off")
fig.suptitle("Computational graph (Olah ornegi): ileri F = 64, geri TEK gecis dF/dx = 104 VE dF/dy = 16 birden — sayisal hakem birebir",
fontsize=11.5, color=COL_PRIMARY, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.93])
plt.show()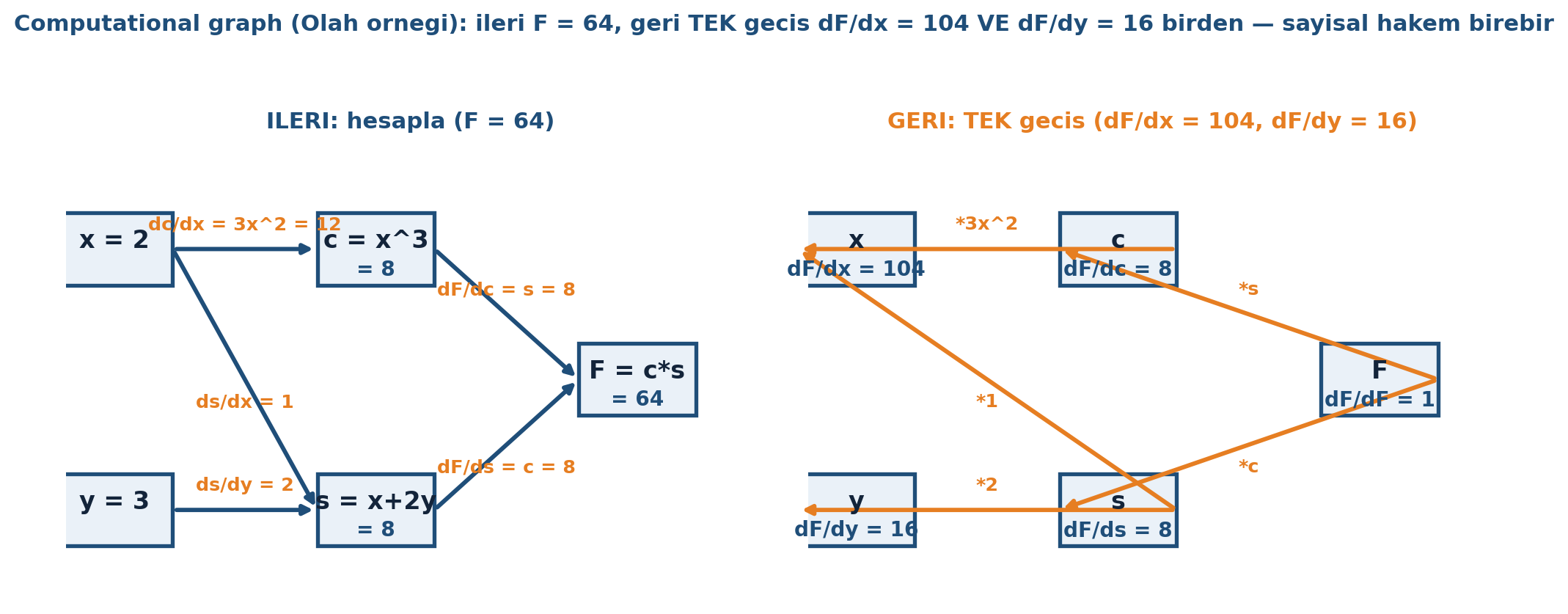
Şekil 28.3 sol panelde ileri geçişi (\(x=2, y=3 \to c=8, s=8, F=64\)) ve sağ panelde geri geçişi gösterir: \(dF/dF=1\)’den başlayıp tek geçişte \(dF/dx = 104\) VE \(dF/dy = 16\) birden çıkar; motor ile merkez-fark sayısal hakem birebir örtüşür (\(dF/dx = s\cdot 3x^2 + c = 8\cdot12 + 8 = 104\), \(dF/dy = 2c = 16\)).
Bu doğruluk yalnızca düzgün noktalarda değil, ReLU’nun kink (kırılım) noktalarında da geçerli: ölü nöronlarda gradyan akmaz, ve dört tanık bu istisnai durumda bile hemfikirdir.
Kod
W1, b1, W2, b2, x, y = make_net(27)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(9, 3.8))
heatmap(ax1, grad_strang(W1, b1, W2, b2, x, y)["W1"],
"normal ağ: dW1 (Strang)", fmt="{:.3f}")
heatmap(ax2, grad_strang(W1, b1 - 5.0, W2, b2, x, y)["W1"],
"ölü ağ (b1 - 5): dW1 = TAM SIFIR", fmt="{:.0f}")
ax2.text(0.5, -0.18, "dört tanık yine hemfikir (maxdiff < 1e-12)",
transform=ax2.transAxes, ha="center", va="top",
fontsize=9, color=COL_TEXT, style="italic")
fig.suptitle("ReLU kink doğruluğu: ölü nöronlarda gradyan akmaz — kink istisna değil, kural (tüm tanıklar aynı)",
color=COL_TEXT, fontsize=11, fontweight="bold")
plt.show()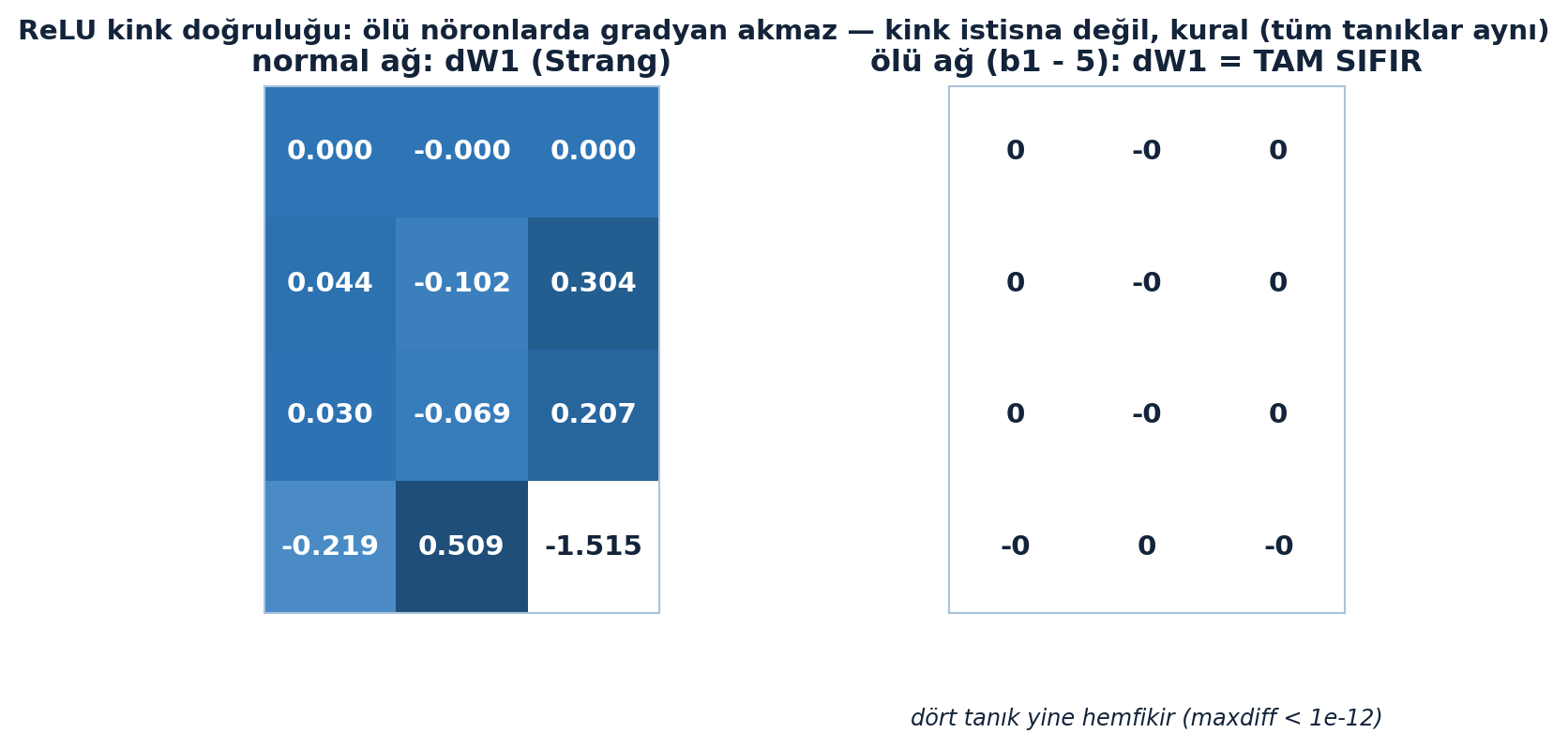
Şekil 28.4 solda normal ağın \(dW_1\) gradyanını (Strang \(\delta\) dış-çarpımı), sağda \(b_1 - 5\) ile tüm ReLU’lar öldürülünce \(dW_1 = \text{TAM SIFIR}\) olduğunu gösterir — dört tanık yine hemfikir (maxdiff \(< 10^{-12}\)). Kink istisna değil, kuraldır.
İpucuBuilder Notu — Bir Geri Geçiş Hepsi
“İleri hesapla, geri türev yay” computational graph backprop’un iskeleti. ML köprüsü: PyTorch dinamik graf kurar (her işlem bir düğüm), .backward() grafı ters topolojik sırada gezip her düğümde yerel türevi zincirler. Karpathy micrograd’da _backward() tam bu — her düğüm kendi katkısını geriye ekler.
28.5 Ters-Mod Mucizesi
Asıl şaşırtıcı sonuç maliyet hakkında:
“…you could compute n first derivatives with about four or five times the cost, not n times.” — Strang, 30:03
\(m\) değişkenli bir fonksiyonun TÜM kısmi türevlerini, tek değişkeninkinin sadece 4-5 katı maliyetle hesaplarsın — \(m\) katı değil. 100 değişken için 100 zincir kuralı beklerken, ters-mod bunu ~5 kat maliyetle verir. Neden? Çünkü geriye giderken zincirin parçalarını yeniden kullanıyoruz: zincir “daha geniş” ama “daha uzun değil”, tekrarlanmıyor. İleri-mod (her girdiye ayrı zincir) \(m\) kat maliyetli olurdu; ters-mod (skaler çıktıdan geriye) hepsini tek seferde toplar.
Kod
# §4: ters-mod maliyetinin girdi-bağımsızlığı — d0 taraması, zincir [d0, 64, 64, 1]
dims0 = [10, 100, 1000, 10000]
rev_costs, fwd_costs = [], []
for d0 in dims0:
rev, fwd = reverse_vs_forward_cost([d0, 64, 64, 1])
rev_costs.append(rev); fwd_costs.append(fwd)
rev_costs = np.array(rev_costs, dtype=float)
fwd_costs = np.array(fwd_costs, dtype=float)
ratios = fwd_costs / rev_costs # = d0 birebir
fig, ax = plt.subplots(figsize=(7.5, 4.2))
apply_style(ax)
# Ters-mod: tek geri-geçiş (navy, daire)
ax.loglog(dims0, rev_costs, color=COL_PRIMARY, lw=2, marker="o", ms=9,
markeredgecolor=COL_TEXT, label="ters-mod (tek geri-geçiş)", zorder=4)
# İleri-mod: girdiyle KATLANIR (turuncu, kare)
ax.loglog(dims0, fwd_costs, color=COL_VEC3, lw=2, marker="s", ms=9,
markeredgecolor=COL_TEXT, label="ileri-mod (her girdi-yönü ayrı)", zorder=4)
# Her noktada oran etiketi (10x / 100x / 1000x / 10000x)
for d0, rc, fc, r in zip(dims0, rev_costs, fwd_costs, ratios):
ymid = np.sqrt(rc * fc) # log-orta nokta
ax.annotate(f"{int(round(r))}x", (d0, ymid), textcoords="offset points",
xytext=(8, 0), color=COL_TEXT, fontsize=10, fontweight="bold", va="center")
ax.set_xlabel("girdi boyutu d0 (log)")
ax.set_ylabel("carpma maliyeti (log)")
ax.set_title("Ileri-mod girdiyle KATLANIR, ters-mod tek geri-gecis — derin\n"
"ogrenme (milyon girdi, 1 kayip) icin ters-mod tek secenek (mucize ~4-5x)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
ax.legend(loc="upper left", fontsize=9, framealpha=0.92)
plt.show()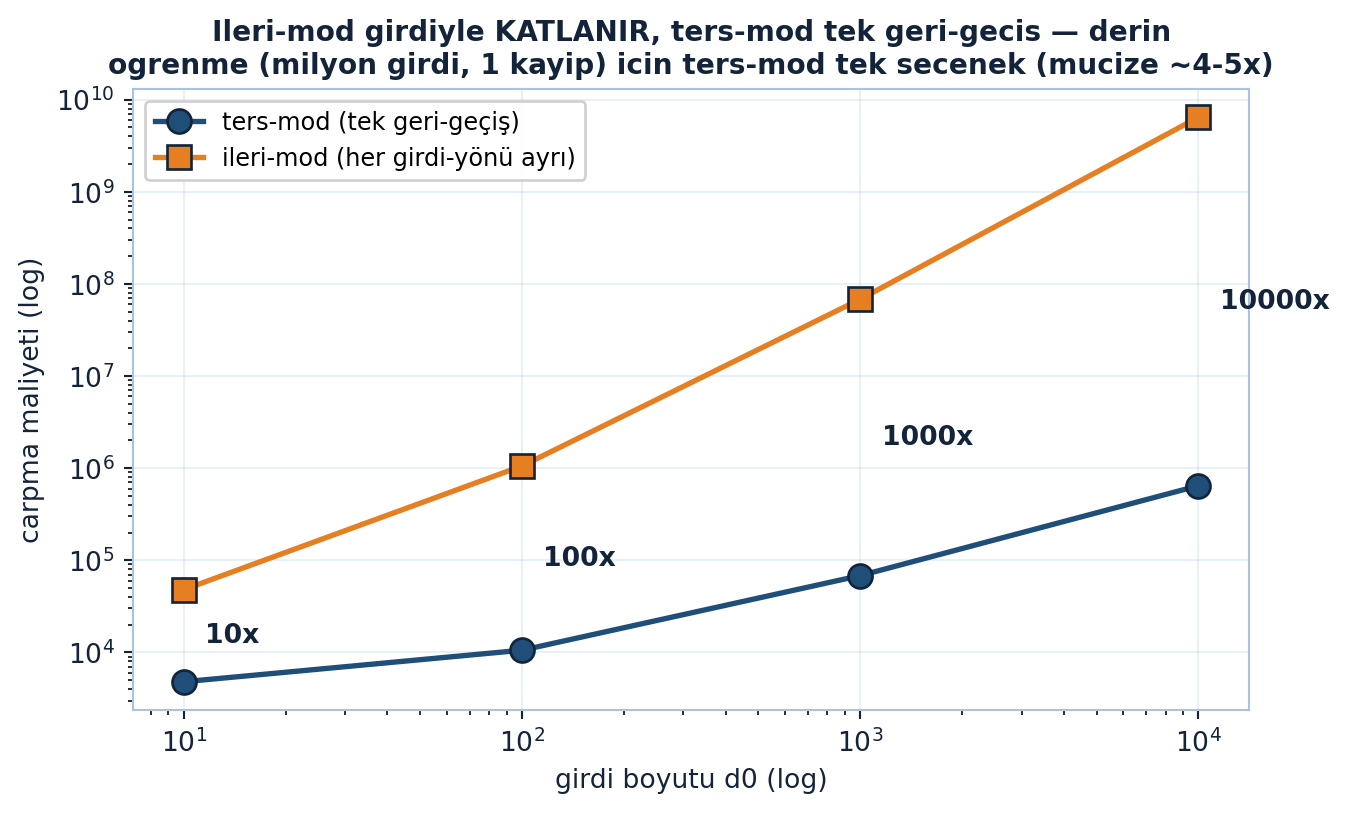
Şekil 28.5 bunu ölçek taramasıyla kanıtlar: zincir \([d_0, 64, 64, 1]\) için girdi boyutu \(d_0\) büyüdükçe ters-mod (navy) tek geri-geçiş kalır, ileri-mod (turuncu) ise her girdi-yönü için zinciri yeniden koşar ve \(d_0\) katına katlanır; oran her noktada tam girdi sayısına eşittir (\(d_0 = 1000 \to 1000\times\)). Derin öğrenmede girdi milyonlarca parametre, çıktı tek kayıptır — ters-mod tek seçenektir.
İpucuBuilder Notu — Dört-Beş Kat Mucizesi
“Tüm gradyan, tek türevin 4-5 katı maliyeti” backprop’un neden devrim olduğunu açıklar: milyon-parametreli ağda gradyanı bir ileri+bir geri geçişle alırsın (milyon ayrı türev değil). ML köprüsü: bu yüzden büyük modeller eğitilebilir; ileri-mod AD (girdi sayısıyla ölçeklenir) küçük-girdi/çok-çıktı için, ters-mod (çıktı sayısıyla ölçeklenir) çok-girdi/skaler-çıktı (kayıp) için — derin öğrenme tam ikinci durum.
28.6 Neden Hızlı: Matris-Zinciri Sırası
Ters-mod’un neden hızlı olduğunu daha basit bir örnek gösterir: üç matrisi çarpmak.
“…one way could be way faster than another way is when I’m multiplying three matrices.” — Strang, 34:53
\(ABC\) çarpımı (\(A\): \(m\times n\), \(B\): \(n\times p\), \(C\): \(p\times q\)). İki sıra, aynı sonuç, çok farklı maliyet:
\[A(BC):\ npq + mnq \qquad (AB)C:\ mnp + mpq\]
Matris çarpımı birleşmelidir (associative) — sonuç aynı — ama işlem sayısı sıraya göre 1000 kat değişebilir. Hangi sıra ucuz? Boyutlara bağlı. Zincir kuralı da bir matris (Jacobian) çarpımı zinciridir; doğru sırada çarpmak backprop’un sırrı. Sonraki bölümde bu farkı kolon-vektör durumunda Şekil 28.6 sayılarla gösterir.
İpucuBuilder Notu — Birleşmeli Ama Eşit-Maliyetli Değil
“Matris çarpımı birleşmeli ama maliyet sıraya bağlı” backprop’un derin sebebi. ML köprüsü: backprop = Jacobian’ların zinciri \(J_3 J_2 J_1\); ters-mod bunları sağdan-sola değil, çıktıdan (skaler kayıp) başlayıp sola doğru vektör-Jacobian çarpımlarıyla hesaplar — her adım vektör×matris (ucuz). Matris-zinciri optimizasyonu (matrix chain order) klasik dinamik programlama problemidir (6.006 paralel).
28.7 Kolon Vektör ve Ters-Mod
En önemli özel durum: \(C\) bir kolon vektör (\(q = 1\)). O zaman iki sıra dramatik ayrışır:
\[A(BC):\ n(m + p) \quad (\mathrm{ucuz}) \qquad\qquad (AB)C:\ mp(n + 1) \quad (\mathrm{felaket})\]
\(A(BC)\): önce \(BC\) (matris × vektör → vektör), sonra \(A \times\) vektör → vektör. Hep matris-vektör, ucuz. \((AB)C\): önce \(AB\) (matris × matris → büyük \(m\times p\) matris!), sonra × vektör. Büyük matris çarpımı boşuna — felaket.
“…back propagation is the right order…” — Strang, 52:16
Backprop tam \(A(BC)\) sırasını seçer: skaler çıktıdan (kayıp) başla, geriye doğru her katmanın Jacobian’ıyla vektör çarp — asla büyük Jacobian matrislerini açıkça oluşturma. İşte ters-mod’un “doğru sıra”sı.
Kod
# FLAGSHIP-2 — §5-6: matris-zinciri sırası + ters-mod mucizesi
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4.2))
# ---- SOL: Egz3 — A(BC) vs (AB)C maliyeti ----
a_bc, ab_c = chain_cost(100, 1, 100, 1) # -> (200, 20000)
labels = ["A(BC)", "(AB)C"]
vals = [a_bc, ab_c]
cols = [COL_PRIMARY, COL_VEC3]
bars = axL.bar(labels, vals, color=cols, edgecolor=COL_TEXT, linewidth=0.8, width=0.55)
axL.set_yscale("log")
apply_style(axL)
axL.set_ylabel("çarpma sayısı (log)")
for b, v in zip(bars, vals):
axL.text(b.get_x() + b.get_width() / 2, v * 1.15, f"{v:,}".replace(",", "."),
ha="center", va="bottom", color=COL_TEXT, fontsize=11, fontweight="bold")
axL.annotate("100x", xy=(1, ab_c), xytext=(0.5, ab_c * 2.2),
ha="center", color=COL_VEC3, fontsize=20, fontweight="bold")
axL.set_ylim(top=ab_c * 6)
axL.set_title("Egz3: sıra maliyeti belirler", color=COL_TEXT, fontsize=12, fontweight="bold")
axL.text(0.5, -0.30,
"A(BC): BC=skaler ilk (ucuz) vs (AB)C: 100x100 dev matris ilk (felaket)",
transform=axL.transAxes, ha="center", va="top", color=COL_TEXT, fontsize=8.5)
# ---- SAĞ: ters-mod vs ileri-mod ----
rev, fwd = reverse_vs_forward_cost([1000, 64, 64, 1]) # -> (68160, 68160000)
labels2 = ["ters-mod\n(backprop)", "ileri-mod"]
vals2 = [rev, fwd]
bars2 = axR.bar(labels2, vals2, color=[COL_PRIMARY, COL_VEC3], edgecolor=COL_TEXT, linewidth=0.8, width=0.55)
axR.set_yscale("log")
apply_style(axR)
axR.set_ylabel("çarpma sayısı (log)")
for b, v in zip(bars2, vals2):
axR.text(b.get_x() + b.get_width() / 2, v * 1.15, f"{v:,}".replace(",", "."),
ha="center", va="bottom", color=COL_TEXT, fontsize=10.5, fontweight="bold")
axR.annotate("oran TAM 1000x = girdi sayısı", xy=(1, fwd), xytext=(0.5, fwd * 3.0),
ha="center", color=COL_VEC3, fontsize=10.5, fontweight="bold")
axR.set_ylim(top=fwd * 12)
axR.set_title("ters-mod: zincir GENİŞLER ama UZAMAZ", color=COL_TEXT, fontsize=11, fontweight="bold")
fig.suptitle("Sıra her şeydir: kolon vektörle A(BC) 100x ucuz; ters-mod tüm gradyanı girdi-sayısından\n"
"BAĞIMSIZ maliyetle verir (mucize ~4-5x)", fontsize=11.5, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0.02, 1, 0.93])
plt.show()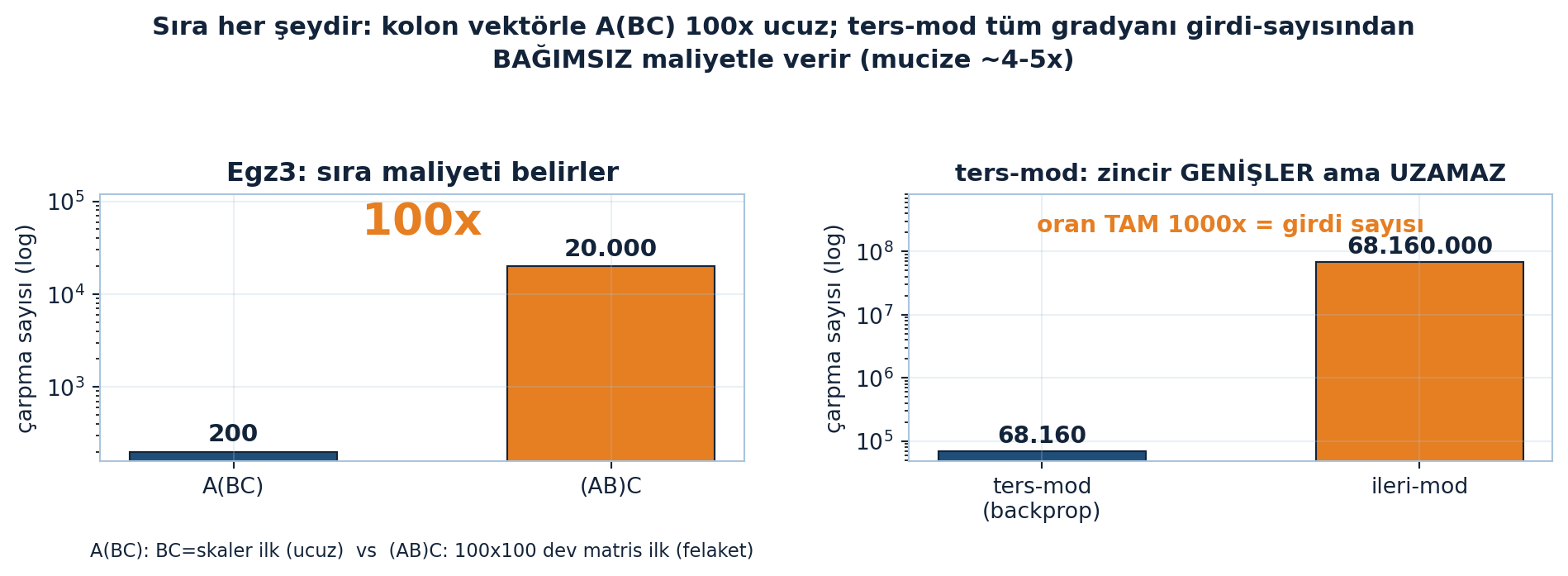
Şekil 28.6 solda Egzersiz 3’ün maliyetini gösterir: \(A\) (\(100\times1\)), \(B\) (\(1\times100\)), \(C\) (\(100\times1\)) için \(A(BC) = 200\) çarpma vs \((AB)C = 20.000\) — \(BC\) önce hesaplanırsa skaler (ucuz), \(AB\) önce hesaplanırsa \(100\times100\) dev matris (felaket); tam 100× fark. Sağda zincir \([1000, 64, 64, 1]\) için ters-mod \(68.160\) vs ileri-mod \(68.160.000\), oran tam 1000× = girdi sayısı; ters-mod zincir genişler ama uzamaz.
İpucuBuilder Notu — Skalerden Geriye Hep Vektör
“Kolon vektörle başla, geriye matris-vektör çarp” ters-mod AD’nin tüm verimliliği buradan. ML köprüsü: derin öğrenmede çıktı bir skaler kayıptır (\(q=1\)); ters-mod (backprop) bu yüzden ideal — gradyanı bir geri geçişte, hiç büyük Jacobian oluşturmadan toplar. İleri-mod büyük ara matrisleri oluştururdu (felaket). Bu, JAX/PyTorch’un grad/.backward() tasarımının matematiksel gerekçesi.
28.8 Dört Tanık Buluşur (Phase 2 Sentezi)
Backpropagation, Phase 2’nin “farklı yollar aynı yere varır” tezinin doruğudur. Dört ayrı ders, dört ayrı dil, tek bir backprop:
| Tanık | Dil | Backprop nasıl görünür |
|---|---|---|
| Strang (Ders 27) | Matris/lineer cebir | Zincir kuralı = Jacobian-matris çarpımı; ters-mod = doğru matris-zinciri sırası |
| Karpathy micrograd | Kod (Python) | Her Value düğümünde _backward(); ters topolojik geçiş |
| fast.ai (L13-14) | Elle “from scratch” | Her tensörde .g gradyanı; geriye elle hesap |
| NYU (H2, LeCun) | Teori/Jacobian | Her katman bir Jacobian; backprop = Jacobian zincir-çarpımı |
Dördü de aynı şeyi söyler: \(F = F_3\circ F_2\circ F_1\) kompozisyonunun gradyanı, katman türevlerinin (Jacobian’ların) ters sırada çarpımıdır. Strang’ın matris-çarpım dili, Karpathy’nin _backward’ı, Howard’ın elle .g’si ve LeCun’un Jacobian zinciri — aynı matematik, dört pencere.
Kod
# ===== FLAGSHIP §7: DÖRT TANIK AYNI GRADYAN (dW1 heatmap, 1x4) =====
gs, pair, dnum = four_witness_maxdiff()
W1_strang = gs["strang"]["W1"]
W1_karpathy = gs["karpathy"]["W1"]
W1_fastai = gs["fastai"]["W1"]
W1_nyu = gs["nyu"]["W1"]
all_vals = np.concatenate([
W1_strang.ravel(), W1_karpathy.ravel(), W1_fastai.ravel(), W1_nyu.ravel()
])
vmin = float(np.min(all_vals)); vmax = float(np.max(all_vals))
fig, axs = plt.subplots(1, 4, figsize=(12.5, 3.8))
panels = [
(W1_strang, "Strang: delta dis-carpim"),
(W1_karpathy, "Karpathy: Value._backward"),
(W1_fastai, "fast.ai: elle .g"),
(W1_nyu, "NYU: Jacobian vJp"),
]
for ax, (G, baslik) in zip(axs, panels):
heatmap(ax, G, baslik, fmt="{:.3f}", vmin=vmin, vmax=vmax)
fig.suptitle(
"DORT TANIK AYNI GRADYAN (dW1, ayni ag seed 27): 6/6 cift maxdiff <= 4.4e-16 "
"(cogu TAM 0.0) + merkez-fark hakem 1.2e-10 — dort pedagoji ayni matematige iner",
color=COL_TEXT, fontsize=11.5, fontweight="bold", y=1.04,
)
fig.tight_layout()
plt.show()
Value._backward’ı, fast.ai’nin elle .g gradyanı, NYU’nun Jacobian vJp’si. Dört panel ortak ölçekte (vmin/vmax) BİREBİR aynı: 6/6 çift maxdiff \(\le 4.4 \times 10^{-16}\) (çoğu TAM 0.0) + merkez-fark hakem \(1.2 \times 10^{-10}\). Phase 2 tezinin sayısal ispatı — dört yol aynı matematiğe iner.
Şekil 28.7 bu tezin sayısal ispatıdır: aynı ağ (seed 27) için \(dW_1\) gradyanı dört farklı pedagojiyle hesaplanır — Strang’ın delta dış-çarpımı, Karpathy’nin Value._backward’ı, fast.ai’nin elle .g’si, NYU’nun Jacobian vJp’si. Dört panel ortak ölçekte birebir aynıdır: 6/6 çift maxdiff \(\le 4.4\times10^{-16}\) (çoğu TAM \(0.0\)) + merkez-fark hakem \(1.2\times10^{-10}\). Dört pedagoji aynı matematiğe iner.
İpucuBuilder Notu — Aynı Matematiğin Dört Penceresi
Bu dörtlü buluşma Phase 2’nin felsefesidir: aynı kavramı (backprop) matris cebiri, kod, elle hesap ve teori dillerinden görmek anlayışı sağlamlaştırır. ML köprüsü: bir kavramı dört yoldan tanımak, onu gerçekten “bilmek”tir — micrograd’ı yazabilmek (Karpathy), elle türetebilmek (fast.ai), matris diliyle ifade etmek (Strang) ve Jacobian olarak görmek (NYU) aynı backprop’un dört yüzü. Bir sonraki gördüğün autograd kütüphanesi bu dördünün de uygulaması.
28.9 Bu Dersin Özeti
- Backprop = grad f: tüm kısmi türevler (\(\partial F/\partial x_i\)); ters-mod otomatik türev (reverse-mode AD); SGD’nin gradyanını sağlar.
- Zincir kuralı: \(F = F_3(F_2(F_1(x)))\) → \(dF/dx = (dF_3/dF_2)(dF_2/dF_1)(dF_1/dx)\), her çarpan doğru noktada.
- Computational graph: ileri (\(F\)’yi hesapla) + geri (\(dF/dF=1\)’den türevleri yay); tek geri geçiş tüm türevleri verir.
- Mucize: \(m\) değişkenin tüm türevleri \(m\times\) değil ~4-5× maliyetle (zincir parçaları yeniden kullanılır).
- Matris-zinciri: \(ABC\) sırası maliyeti değiştirir; \(A(BC)\) vs \((AB)C\). Kolon vektörle (\(q=1\)) \(A(BC)\) ucuz, \((AB)C\) felaket.
- Ters-mod = doğru sıra: skaler kayıptan geriye, vektör-Jacobian çarpımları (büyük Jacobian oluşturma).
- Dört tanık: Strang matris-zinciri = Karpathy micrograd
_backward= fast.ai manuel.g= NYU Jacobian zinciri.
ÖnemliTek Bir Cümle
Backpropagation, \(F = F_3\circ F_2\circ F_1\) kompozisyonunun gradyanını zincir kuralını ters sırada (skaler çıktıdan geriye, vektör-Jacobian çarpımlarıyla) uygulayarak hesaplar; bu “doğru matris-zinciri sırası” tüm türevleri tek değişkeninkinin sadece 4-5 katı maliyetle verir — derin öğrenmeyi mümkün kılan algoritma.
28.10 Kontrol Soruları
NotSoru 1 — Backprop ne hesaplar ve eğitimdeki rolü
Soru: Backpropagation tam olarak ne hesaplar ve eğitimdeki rolü nedir?
Cevap: Backprop gradyanı hesaplar: tüm kısmi türevler \(\nabla F = (\partial F/\partial x_1, \dots, \partial F/\partial x_m)\), ters-mod otomatik türevle. Eğitim algoritması SGD’dir (Ders 25); backprop ise SGD’nin her adımda ihtiyaç duyduğu gradyanı sağlar. PyTorch’ta loss.backward() = backprop, optimizer.step() = SGD adımı. İkisi ayrı işlerdir.
NotSoru 2 — İleri ve geri geçiş ne yapar
Soru: Computational graph’ta ileri ve geri geçiş ne yapar?
Cevap: İleri geçiş girdiden ara değişkenleri (\(c=x^3\), \(s=x+2y\)) ve çıktıyı (\(F=c\cdot s\)) hesaplar. Geri geçiş çıktıdan başlar (\(dF/dF=1\)), türevleri ters topolojik sırada yayar (\(dF/dc=s\), \(dF/ds=c\), sonra yerel türevlerle çarp). Kilit: tek bir geri geçiş hem \(dF/dx\) hem \(dF/dy\)’yi (tüm gradyanı) birden verir — her değişken için ayrı zincir değil.
NotSoru 3 — Neden m× değil ~4-5× maliyet
Soru: Ters-mod neden tüm türevleri \(m\times\) değil ~4-5× maliyetle hesaplar?
Cevap: Geriye giderken zincirin parçaları yeniden kullanılır — zincir “daha geniş ama daha uzun değil”, tekrarlanmaz. İleri-mod her girdiye ayrı zincir kurardı (\(m\) kat). Ters-mod skaler çıktıdan geriye tek geçişte tüm girdilere göre türevleri toplar; ortak ara hesaplar bir kez yapılır. Bu yüzden \(m\) değişkenin gradyanı tek türevin 4-5 katı maliyetinde.
NotSoru 4 — A(BC) vs (AB)C kolon vektörde neden farklı
Soru: Matris-zinciri \(A(BC)\) vs \((AB)C\), \(C\) kolon vektörken neden bu kadar farklıdır?
Cevap: \(A(BC)\): önce \(BC\) (matris × vektör → vektör), sonra \(A \times\) vektör → vektör — hep matris-vektör, ucuz (maliyet \(n(m+p)\)). \((AB)C\): önce \(AB\) (matris × matris → büyük \(m\times p\) matris!), sonra × vektör — büyük matris çarpımı boşuna, felaket (\(mp(n+1)\)). Backprop tam \(A(BC)\) sırasını seçer: skaler kayıptan geriye, hiç büyük Jacobian oluşturmadan vektör-Jacobian çarpımları. Ters-mod’un “doğru sıra”sı budur.
28.11 Egzersizler
Zincir kuralı. \(F(x) = \sin(x^2)\). Bunu \(F_2(F_1(x))\) yaz (\(F_1 = x^2\), \(F_2 = \sin\)). \(dF/dx\)’i zincir kuralıyla hesapla (\(dF_2/dF_1 \cdot dF_1/dx\)). (Motor tanığı: \(dF/dx = 2x\cos(x^2)\); merkez-fark sayısal türevle birebir, fark \(< 10^{-6}\).)
Computational graph. \(F = x^3(x + 2y)\). \(c = x^3\), \(s = x + 2y\). \(\partial F/\partial c\), \(\partial F/\partial s\)’yi yaz. Sonra \(\partial c/\partial x\), \(\partial s/\partial x\), \(\partial s/\partial y\)’yi yaz. Geri geçişle \(\partial F/\partial x\) ve \(\partial F/\partial y\)’yi birleştir. (Motor tanığı: \(x=2, y=3\) için \(c=8\), \(s=8\), \(F=64\); \(\partial F/\partial x = s\cdot 3x^2 + c = 104\), \(\partial F/\partial y = 2c = 16\); bkz. Şekil 28.3.)
Matris-zinciri. \(A\) (\(100\times1\)), \(B\) (\(1\times100\)), \(C\) (\(100\times1\)). \(A(BC)\) ve \((AB)C\) maliyetlerini (çarpma sayısı) hesapla. Hangisi kaç kat ucuz? (\(BC\) bir skaler mi?) (Motor tanığı: \(A(BC) = n(m+p) = 200\) vs \((AB)C = mp(n+1) = 20.000\); \(BC\) önce skaler olduğundan \(A(BC)\) tam 100× ucuz; bkz. Şekil 28.6 sol panel.)
İleri vs ters mod. Bir fonksiyon 1000 girdi, 1 çıktı (skaler kayıp). Gradyanı (1000 türev) ileri-mod ve ters-mod ile hesaplamanın maliyetini karşılaştır. Hangisi derin öğrenme için doğru? (Motor tanığı: zincir \([1000, 64, 64, 1]\) için ters-mod \(68.160\) çarpma vs ileri-mod \(68.160.000\); oran tam 1000× = girdi sayısı; ters-mod maliyeti girdi sayısından bağımsız, derin öğrenme için doğru seçim; bkz. Şekil 28.6 sağ panel.)
(Sonraki — Ders 30) Optimizasyon + DL bloğu kapandı. Ders 28-29 kayıtsız lab oturumlarıdır (atlanır). Ders 30 yeni bir konuya geçer: rank-1 matris tamamlama ve sirkülant matrisler. Bir sirkülant matrisin (her satır bir öncekinin kaydırılmışı) özvektörleri ne olabilir? Bir tahmin yaz.
28.12 Sonraki Ders İçin Hazırlık
Ders 30: Rank-Bir Matris Tamamlama, Sirkülantlar! (Ders 28-29 kayıt edilmemiş lab oturumlarıdır.) Optimizasyon/DL bloğu kapandı; Strang sinyal-işleme blokuna geçer: sirkülant matrisler (kaydırma yapısı), özvektörleri Fourier matrisidir (Ders 31), ve evrişimin (Ders 32 CNN) matris temeli.
UyarıHazırlık
Bu dersin Egzersiz 5’inin sorduğu soruyu zihninde tut: her satırı bir öncekinin kaydırılmışı olan bir sirkülant matrisin özvektörleri ne olabilir? Ders 30, optimizasyon/DL bloğundan sinyal-işleme bloğuna geçişi başlatır; sirkülantların özvektörleri Fourier matrisi (Ders 31) ve bu yapı evrişimin (Ders 32 CNN) lineer-cebir temelidir. Backprop’un zincir kuralını bitirdik; sıradaki blok kaydırma simetrisini işliyor.
28.13 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Strang (dk) |
|---|---|---|
| Backprop = grad f | ters-mod otomatik türev (reverse-mode AD) | 9m45 |
| Zincir kuralı | \(dF/dx = (dF_3/dF_2)(dF_2/dF_1)(dF_1/dx)\) | 14m58 |
| Örnek | \(F = x^3(x+2y)\); \(c=x^3\), \(s=x+2y\), \(F=cs\) | 12m04 |
| Mucize | \(m\) türev \(m\times\) değil ~4-5× maliyet | 30m03 |
| Matris-zinciri | \(A(BC)\) vs \((AB)C\); sıra maliyeti değiştirir | 34m53 |
| Kolon vektör (q=1) | \(A(BC)\) ucuz, \((AB)C\) felaket; ters-mod doğru sıra | 52m16 |
| Kaynak | Christopher Olah blog (computational graph) | 42m17 |
| Dört tanık | Strang = Karpathy = fast.ai = NYU (aynı backprop) | — |
28.14 ML Bağlantıları Özeti
- Backprop = autograd: PyTorch/TensorFlow/JAX
.backward()/grad; reverse-mode AD, vektör-Jacobian çarpımları (VJP). - Ters-mod = çok-girdi/skaler-çıktı: derin öğrenme tam bu (milyon parametre, 1 kayıp); ileri-mod küçük-girdi/çok-çıktı için. Maliyet çıktı sayısıyla ölçeklenir → kayıp skaler olduğundan ucuz.
- Matris-zinciri sırası: backprop = Jacobian’ları doğru sırada (skalerden geriye) çarpmak; büyük ara Jacobian’ları asla oluşturma.
- Computational graph: PyTorch dinamik graf; her işlem düğüm,
_backwardyerel türev (Karpathy micrograd birebir bu). - DÖRT TANIK (Phase 2 tezi): Strang matris-zinciri = Karpathy
_backward= fast.ai manuel.g= NYU Jacobian — aynı backprop, dört dil. - Hinton + AD: backprop’un yeniden keşfi derin öğrenmeyi başlattı; “Automatic Differentiation” olarak önceden de vardı.
- Geriye köprü: Ders 25 (SGD gradyan ister), Ders 26 (\(F\) kompozisyon), Ders 21 (zincir kuralı/Jacobian), Ders 2 (kompozisyon). Paralel: Karpathy micrograd, fast.ai L13-14, NYU H2.
ÖnemliKapanış
“…back propagation is the right order…” — Strang, 52:16
Backprop, zincir kuralını doğru matris sırasında (skaler çıktıdan geriye) uygulamaktan ibarettir; bu basit “sıra” seçimi tüm gradyanı tek geçişte verir ve derin öğrenmeyi mümkün kılan algoritmadır — optimizasyon ve DL bloğunun kapanışı.