flowchart TD
C["SGD: rastgele tek gradyan"]
C --> F["finite-sum: f = (1/n) toplam f_i (her ML problemi)"]
C --> S["SGD: x+ = x - eta grad f_ik (n kat hizli, Robbins-Monro 1951)"]
C --> M["misnomer: her adimda INMEZ, dalgalanir"]
C --> D["davranis: basta hizli, sonda dalgali (ML icin iyi)"]
C --> R["confusion region: [min b_i/a_i, max b_i/a_i]"]
U["yansizlik E[grad f_i] = grad f + varyans hizi belirler"]
B["mini-batch: varyans/paralelizm; buyuk batch -> overfit"]
K["konuk: Suvrit Sra (MIT EECS)"]
P["tek gradyan = backprop (Ders 27)"]
26 Stochastic Gradient Descent
Konuk ders, Suvrit Sra: finite-sum, confusion region ve mini-batch
NotBölüm bilgisi
Bu bir konuk dersidir: ana içeriği EECS’ten Prof. Suvrit Sra (MIT EECS, 6.036 hocası) anlatır; Strang yalnız konuğu takdim eder. Ders, derin öğrenmenin asıl çalışan algoritmasını işler: stochastic gradient descent (SGD) — 1951’den (Robbins-Monro) beri var, gradient descent’ten tek satır farkı var ama tüm büyük-ölçek ML’i sürüyor. Strang’in Ders 25 videosu (≈53 dk) ve OCW Lecture 25 temel alınmıştır. Okuma süresi ≈35 dk; önkoşul Ders 24 (lineer programlama, dualite). Ana içerik alıntıları Sra’ya atfedilir (“— Sra, X:XX”).
26.1 Bu Derste Ne Var?
Bu konuk dersinde beş sonuç var:
- Finite-sum problem: ML hedefi \(f(x) = \frac{1}{n}\sum_{i} f_{i}(x)\); \(n\) (veri) ve \(d\) (boyut) çok büyük.
- SGD fikri: tüm gradyan yerine rastgele tek veri noktasının gradyanı; bir iterasyon \(n\) kat hızlı.
- Misnomer: SGD her adımda inmez (dalgalanır); adım boyuna çok duyarlı.
- Davranış: başta hızlı ilerler, optimuma yakın dalgalanır (confusion region) — ML için iyi (aşırı-öğrenmeyi önler).
- Unbiased + variance: stokastik gradyan gerçeğin yansız tahmini ama hızı varyans belirler; mini-batch varyansı azaltır + paralelizm.
“Stochastic gradient descent is actually a misnomer. At every step it doesn’t do any descent.” — Sra, 18:48
Şekil 26.1 dersin iskeletini gösterir: merkezdeki “SGD: rastgele tek gradyan” fikri, her ML problemini ortak bir biçime sokan finite-sum yapısından, bir iterasyonu \(n\) kat hızlandıran SGD adımından (Robbins-Monro 1951), her adımda inmeyip dalgalanan misnomer davranışından, başta hızlı sonda dalgalı seyirden ve confusion region’dan dallanır; ayrı düğümlerde yansızlık + varyans, mini-batch (varyans/paralelizm; büyük batch → overfit), konuğun adı Suvrit Sra ve tek gradyanın backprop’la (Ders 27) hesaplandığı köprüsü durur.
İpucuBuilder Notu — Tek Satırlık İkinci Devrim
- SGD = derin öğrenmenin motoru — her PyTorch/TensorFlow eğitimi SGD veya türevi (Adam, Ders 23); tek stokastik gradyan backprop ile hesaplanır (Ders 27).
- Mini-batch = paralelizm — GPU’da her çekirdek bir gradyan; büyük batch hızlı ama aşırı-öğrenme riski (generalization gap).
- Yansızlık + varyans — Ders 20’nin beklenen değer/varyansı burada doğrudan: stokastik gradyan \(E[\nabla f_{i}] = \nabla f\) ama varyans yakınsamayı belirler.
- Geriye köprü: Ders 22 (GD), Ders 23 (momentum/Adam), Ders 20 (beklenen değer/varyans), Ders 9 (least squares). Paralel: NYU H4 (Defazio SGD/momentum pratik bakış).
26.2 Strang’ın Takdimi ve SGD Nedir
Strang konuğu tanıtır: Prof. Suvrit Sra (EECS, 6.036 hocası), SGD anlatacak. Buradan sonra içerik Sra’ya aittir. Sra’nın açılışı: SGD en eski optimizasyon yöntemlerinden biri (Cauchy’ye dayanır), sınıfta gördüğünüz gelişmiş yöntemlerden çok daha basit — ama hâlâ büyük-ölçek ML eğitiminin “the” yöntemi. Gradient descent’ten farkı tek bir satır; o tek satır tüm derin öğrenme araç kutularını sürüyor.
İpucuBuilder Notu — Yetmiş Yıllık Genç Fikir
“En basit yöntem hâlâ en yaygın” SGD’nin paradoksu: 70 yıllık fikir, modern derin öğrenmenin motoru. ML köprüsü: PyTorch’ta optim.SGD bir satır; gelişmiş Adam/RMSProp (Ders 23) bile SGD iskeletinin üzerine kurulu. Basitlik + ölçeklenebilirlik, karmaşıklığı yener.
26.3 Finite-Sum Problem (ML Hedefi)
Tüm ML optimizasyon problemleri aynı biçimde:
\[\min_{x}\ f(x) = \frac{1}{n}\sum_{i=1}^{n} f_{i}(x)\]
“…also called finite sum problems…” — Sra, 4:01
Eğitim verisi: \(a_{1}, \ldots, a_{n}\) (özellikler), \(y_{1}, \ldots, y_{n}\) (etiketler: \(\pm 1\) sınıflandırma veya reel regresyon). Her \(f_{i}\) tek bir veri noktasının kaybı. Büyük-ölçek ML = hem \(n\) (veri sayısı: milyon-milyar) hem \(d\) (boyut: piksel/özellik, milyona-milyara) büyük. Örnekler hep bu finite-sum: least squares, LASSO, SVM, derin sinir ağları (\(f_{i}\) = tüm ağ mimarisi + kayıp), maksimum olabilirlik.
Kod
fig, ax = plt.subplots(figsize=(6.5, 4))
labels = ["GD (tam)", "mini-batch |B|=100", "SGD (tek)"]
costs = [1e6, 100, 1] # ms
val_labels = ["1000 s", "100 ms", "1 ms"]
colors = [COL_PRIMARY, COL_ACCENT, COL_VEC3]
bars = ax.bar(range(3), costs, color=colors, edgecolor=COL_TEXT, linewidth=1.0, width=0.62)
ax.set_yscale("log")
ax.set_xticks(range(3)); ax.set_xticklabels(labels)
ax.set_ylabel("bir iterasyon (ms, log)")
ax.set_ylim(0.4, 5e6)
for b, vl in zip(bars, val_labels):
ax.text(b.get_x() + b.get_width()/2, b.get_height()*1.4, vl,
ha="center", va="bottom", color=COL_TEXT, fontsize=11, fontweight="bold")
apply_style(ax)
ax.set_title("n = 10^6 veride bir iterasyon: 1000 saniye vs 100 ms vs 1 ms — n kat hizlanma somut (Egz1)",
fontsize=10.5, fontweight="bold")
fig.tight_layout()
plt.show()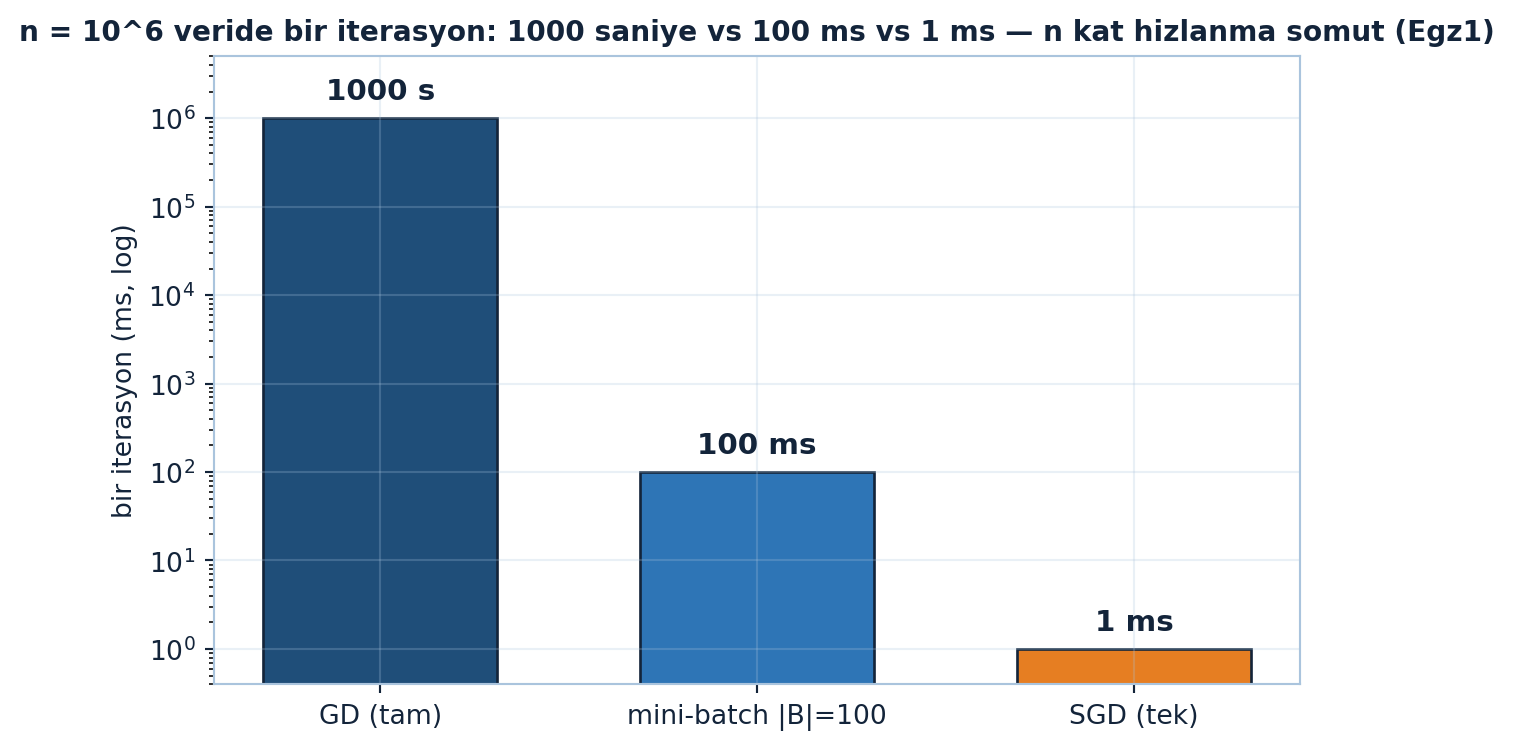
Şekil 26.2 finite-sum’ın hesaplama bedelini somutlaştırır: \(n = 10^6\) veri noktasında bir gradyan 1 ms sürüyorsa, tam gradient descent bir iterasyonu \(10^6\) ms = 1000 saniye, mini-batch (\(|B|=100\)) 100 ms, saf SGD (tek nokta) yalnız 1 ms alır — log-ölçekli çubuklar tam \(n\) kat hızlanmayı gösterir. Bu sayı, neden tam gradyanın (\(n\) terim) milyar-örnekli bir veride imkânsız olduğunu açıklar.
İpucuBuilder Notu — Her Şey Bir Finite-Sum
“Her ML problemi bir finite-sum” birleştirici görüş: least squares’ten derin ağlara kadar hepsi \(\frac{1}{n}\sum f_{i}\). ML köprüsü: bu yapı SGD’yi evrensel kılar — \(f_{i}\) ister kuadratik (regresyon) ister milyar-parametreli transformer kaybı olsun, aynı algoritma çalışır. \(n\) ve \(d\)’nin ikisinin de büyük olması, tam gradyanı (\(n\) terim) hesaplamayı imkânsız kılar — SGD’nin doğuş sebebi.
26.4 SGD Fikri: Rastgele Tek Nokta
Tam gradient descent her adımda tüm \(n\) terimin gradyanını toplar — büyük \(n\)’de bir adım saatler/günler sürebilir. Fikir (sınıftan çıktı):
“One example at a time.” — Sra, 14:38
Her iterasyonda rastgele bir \(i_{k}\) seç, sadece o tek veri noktasının gradyanını kullan:
\[\text{GD:}\quad x_{k+1} = x_{k} - \eta\,\frac{1}{n}\sum_{i=1}^{n}\nabla f_{i}(x_{k}) \qquad \text{SGD:}\quad x_{k+1} = x_{k} - \eta_{k}\,\nabla f_{i_{k}}(x_{k})\]
Bir iterasyon artık \(n\) kat hızlı (\(n\) bir milyarsa, muazzam). Bu fikir Robbins ve Monro’dan (1951) — ve hâlâ kullandığımız en gelişmiş yöntem.
Şekil 26.3 bu tek-satır farkın izini aynı 2D least squares probleminde çizer: GD düz iner, SGD ise \(x^{*}\) çevresinde zikzaklayan ucuz adımlar atar (figürün ayrıntısı bir sonraki “Misnomer” bölümünde).
İpucuBuilder Notu — Milyarda Bir Yeter
“Tüm gradyan yerine rastgele bir tane” SGD’nin tek-satır devrimi. ML köprüsü: bir milyar örnekli veri kümesinde tam gradyan bir adım = bir milyar gradyan; SGD bir adım = bir gradyan. Eğitim, veriyi tek tek (veya mini-batch) tarayarak ilerler — “epoch” = veri kümesinin bir tam geçişi.
26.5 “Misnomer”: Her Adımda İnmez
SGD aslında yanlış-adlandırılmış: gradient descent her adımda iner (maliyeti düşürür); SGD bunu yapmaz.
“Stochastic gradient descent is actually a misnomer. At every step it doesn’t do any descent.” — Sra, 18:48
Tek bir rastgele noktanın gradyanı tüm fonksiyonu temsil etmediğinden, bazı adımlar maliyeti yükseltir, bazıları düşürür — dalgalanır (fluctuate), ama stokastik olarak yine de optimuma doğru ilerler. Gradient descent’ten çok daha adım-boyu duyarlı: çok küçük \(\eta\) → neredeyse hareketsiz, kararlı görünür; çok büyük \(\eta\) → optimum çevresinde çılgın salınım.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10.5, 4.4))
# --- Sol: kontur + GD düz yol vs SGD gürültülü ---
A, b = make_ls_data()
xs = np.linalg.lstsq(A, b, rcond=None)[0]
xg = np.linspace(xs[0] - 7, xs[0] + 6, 120)
yg = np.linspace(xs[1] - 5, xs[1] + 8, 120)
XX, YY = np.meshgrid(xg, yg)
Z = np.array([[full_loss([XX[i, j], YY[i, j]], A, b) for j in range(XX.shape[1])] for i in range(XX.shape[0])])
axL.contour(XX, YY, Z, levels=20, cmap=NAVY_CMAP, linewidths=0.8)
gd = gd_full(A, b, [6., 5.], 0.05, 60)
sg = sgd(A, b, [6., 5.], 0.05, 200, batch=1)
axL.plot(gd[:, 0], gd[:, 1], "s-", color=COL_PRIMARY, ms=3, lw=1.4, label="GD (düz yol)")
axL.plot(sg[:, 0], sg[:, 1], "o-", color=COL_VEC3, ms=2, lw=0.8, alpha=0.7, label="SGD (gürültülü)")
axL.plot(xs[0], xs[1], "*", color=COL_TEAL, ms=18, markeredgecolor=COL_TEXT, markeredgewidth=0.6, label="x* (çözüm)", zorder=5)
axL.set_xlabel("x₁"); axL.set_ylabel("x₂")
axL.set_title("Yörünge: GD düz iner, SGD zikzaklar", color=COL_TEXT, fontsize=11, fontweight="bold")
axL.legend(loc="upper right", fontsize=8)
apply_style(axL)
# --- Sağ: f-eğrileri semilogy GD monoton vs SGD dişli ---
n_up, fs_sgd = count_increases(sg, A, b)
_, fs_gd = count_increases(gd, A, b)
axR.semilogy(fs_gd, color=COL_PRIMARY, lw=1.8, label="GD: monoton")
axR.semilogy(fs_sgd, color=COL_VEC3, lw=1.0, alpha=0.85, label="SGD: dişli")
axR.set_xlabel("adım"); axR.set_ylabel("f(x) (log)")
axR.set_title("Kayıp eğrisi: GD hep iner, SGD dalgalanır", color=COL_TEXT, fontsize=11, fontweight="bold")
axR.annotate("SGD %d/200 adımda f YÜKSELİR (misnomer); GD 0" % n_up,
xy=(0.5, 0.92), xycoords="axes fraction", ha="center", fontsize=8.5,
color=COL_VEC3, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_VEC3, lw=0.8))
axR.legend(loc="lower left", fontsize=8)
apply_style(axR)
fig.suptitle("SGD vs GD aynı problemde: SGD gürültülü ama çoook ucuz adım — her adımda inmez (misnomer), ortalamada ilerler",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout()
plt.show()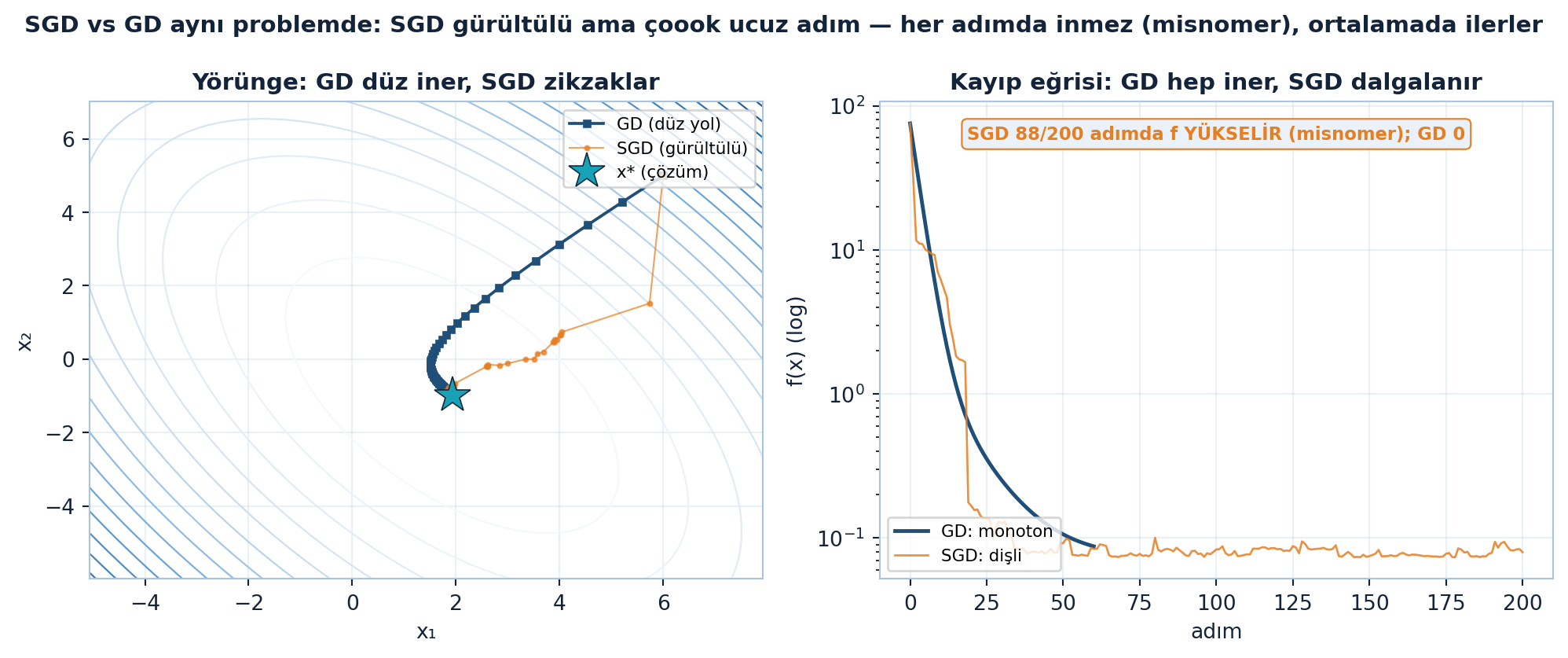
Şekil 26.3 misnomer’i sayıyla kanıtlar: solda aynı LS kontur haritasında GD düz iner (navy kare), SGD ise \(x^{*}\) (teal yıldız) çevresinde zikzaklayan gürültülü bir bulut bırakır (turuncu); sağda kayıp eğrileri log-ölçekte — GD monoton düşerken SGD dişlidir ve 200 adımın 88’inde \(f\)’yi gerçekten YÜKSELTİR (GD’de 0 yükselme). Her adımda inmez ama ortalamada optimuma ilerler — “descent” adı tam da bu yüzden yanlıştır.
İpucuBuilder Notu — İnmeyen İniş
“Her adımda inmez ama ortalamada ilerler” SGD’nin doğası: gürültülü ama doğru yöne. ML köprüsü: eğitim kayıp eğrisi (loss curve) bu yüzden pürüzsüz değil, dişlidir (gürültülü iner); learning rate çok büyükse kayıp patlar/salınır, çok küçükse öğrenme durur. Learning rate seçimi SGD’nin en kritik ve hâlâ açık problemi.
26.6 SGD Davranışı: Hızlı Başlangıç, Sonda Dalgalanma
SGD’nin karakteristik deseni:
“…in the beginning, it makes rapid strides.” — Sra, 23:30
Başlangıçta hızlı ilerler (eğitim kaybı süper hızlı düşer), sonra optimuma yaklaşınca dalgalanır — takılır, kaosa girer ya da çılgınca davranır. İlginç olan: bu ML için iyi.
“…you actually care about finding solutions that work well on unseen data.” — Sra, 24:04
ML’de amaç optimizasyon problemini mükemmel çözmek değil, görülmemiş veride iyi çalışan çözüm bulmaktır. Optimizasyonu aşırı iyi çözmek = aşırı-öğrenme (overfitting). Hızlı kaba ilerleme + sonda durulma tam istenen.
Kod
A, b = make_ls_data()
xs = np.linalg.lstsq(A, b, rcond=None)[0]
gd = gd_full(A, b, [6., 5.], 0.05, 400)
sg = sgd(A, b, [6., 5.], 0.05, 400, batch=1)
sgdec = sgd(A, b, [6., 5.], 0.05, 400, batch=1, decay=True)
d_gd = np.linalg.norm(gd - xs, axis=1)
d_sg = np.linalg.norm(sg - xs, axis=1)
d_dec = np.linalg.norm(sgdec - xs, axis=1)
fig, ax = plt.subplots(figsize=(7.5, 4.4))
ax.semilogy(d_gd, color=COL_PRIMARY, lw=2.2, label="GD (tam gradyan)")
ax.semilogy(d_sg, color=COL_VEC3, lw=1.4, alpha=0.85, label="SGD sabit $\eta$")
ax.semilogy(d_dec, color=COL_TEAL, lw=1.8, label="SGD azalan $\eta_k$")
ax.annotate("rapid strides: 7.24 -> 0.24 (30 adim)", xy=(30, d_sg[30]),
xytext=(70, 3.0), fontsize=9, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_TEXT, lw=0.9))
ax.annotate("sabit eta kuyrugu ~0.073 e OTURMAZ", xy=(300, np.mean(d_sg[100:])),
xytext=(150, 0.4), fontsize=9, color=COL_VEC3,
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=0.9))
apply_style(ax)
ax.set_xlabel("adim")
ax.set_ylabel("uzaklik $\|x_k - x^*\|$ (log)")
ax.set_title("Basta hizli sonda dalgali: sabit eta kuyrukta dalgalanir (ort 0.073),\nazalan eta_k yaklasir (0.033) — dalga ML icin IYI",
fontsize=10, fontweight="bold")
ax.legend(loc="upper right", fontsize=9)
fig.tight_layout()
plt.show()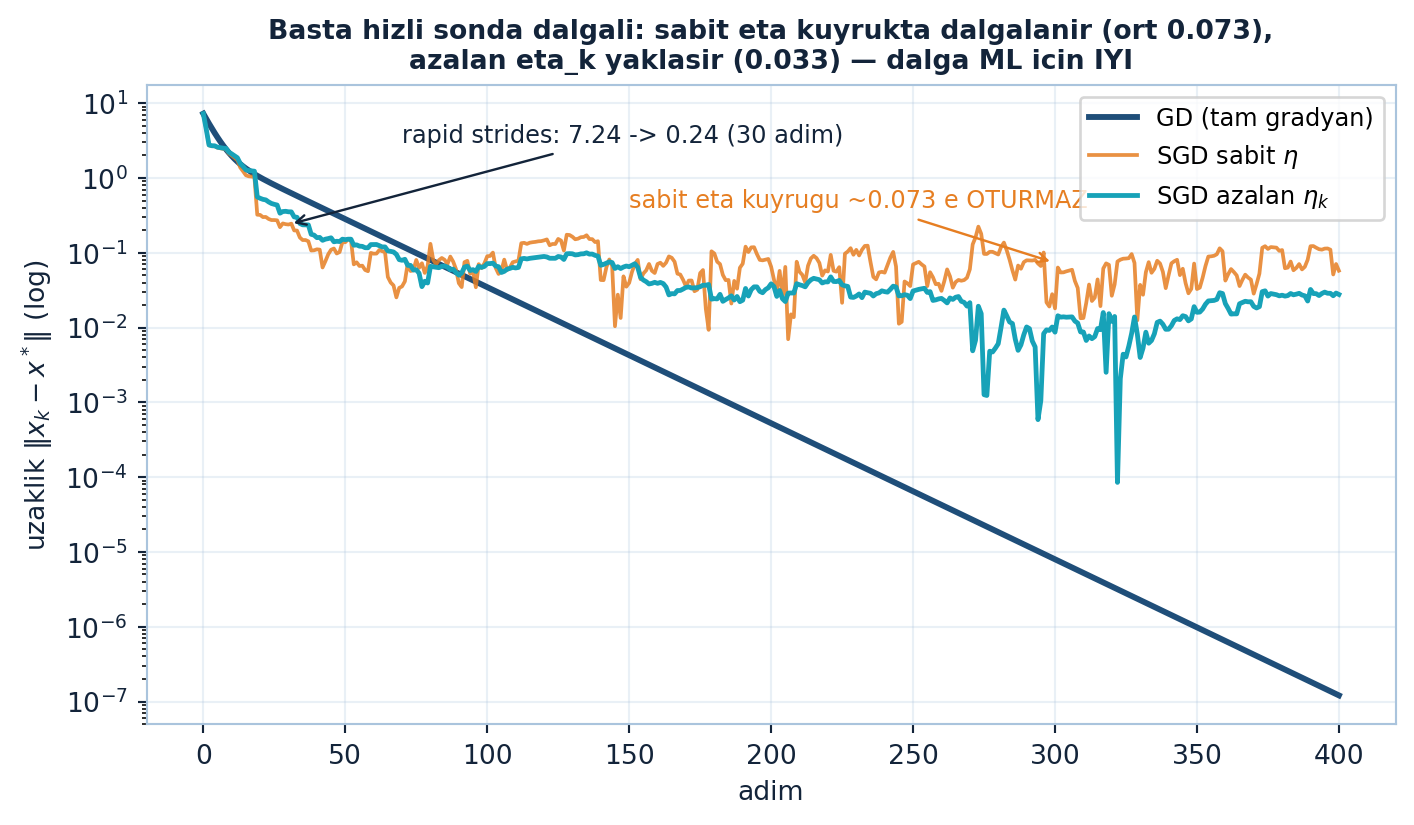
Şekil 26.4 bu deseni uzaklık eğrileriyle gösterir: \(\|x_{k} - x^{*}\|\) üç iz halinde log-ölçekte — GD (navy) pürüzsüz iner, SGD sabit-\(\eta\) (turuncu) başta rapid strides yapar (\(d_{0}=7.24 \to d_{30}=0.24\), %97 düşüş 30 adımda) ama kuyrukta ortalama 0.073’e oturup 0’a inMEZ, azalan-\(\eta_{k}\) (teal) ise platoyu 0.033’e indirir. Sabit adım optimuma yapışmaz; azalan adım yaklaştırır — ama ML için bu dalga bir kusur değil, erdemdir.
İpucuBuilder Notu — Mükemmel Çözme Genelle
“Optimumu mükemmel çözme, genelle” SGD’nin gizli erdemi: dalgalanma bir kusur değil, düzenleyici (regularizer). ML köprüsü: SGD gürültüsü düz minimumlara (flat minima) yönelir — bunlar genelde daha iyi genelleşir; tam gradient descent keskin minimumlara saplanıp aşırı-öğrenebilir. “Erken durdurma” (early stopping) da aynı mantık: optimuma varmadan dur.
26.7 Confusion Region (Karışıklık Bölgesi)
Neden başta hızlı, sonda dalgalı? 1B least squares sezgisi: \(f_{i} = (a_{i}x - b_{i})^{2}\), her bir bileşen kendi minimumuna \(x = b_{i}/a_{i}\)’da ulaşır. Gerçek çözüm \(x^{*}\) bu tekil minimumların aralığındadır:
\[x^{*} \in \left[\min_{i}\frac{b_{i}}{a_{i}},\ \max_{i}\frac{b_{i}}{a_{i}}\right]\]
“…within this range of the individual mins and max is where [the solution lies].” — Sra, 29:22
Dışarıda (bu aralığın dışında): tüm \(f_{i}\)’lerin gradyanları aynı yönü gösterir — hangi noktayı seçersen seç, doğru yöne inersin (hızlı, güvenli ilerleme). İçeride (confusion region): farklı \(f_{i}\)’ler farklı yönler söyler — rastgele seçtiğin nokta seni bazen ileri bazen geri iter (dalgalanma). SGD bu yüzden uzaktan hızlı yaklaşır, yakında kararsızlaşır.
Kod
fig, ax = plt.subplots(figsize=(8.5, 4.6))
xs_p = np.linspace(-1, 8, 400)
# 5 bileşen parabol f_i = 0.5*(a_i*x - b_i)^2 (steel ince eğriler)
for i in range(len(CR_A)):
fi = 0.5 * (CR_A[i] * xs_p - CR_B[i]) ** 2
ax.plot(xs_p, fi, color=COL_VEC2, lw=1.0, alpha=0.55,
label="bileşenler $f_i$" if i == 0 else None)
# ortalama f (navy kalın)
f_avg = np.mean([0.5 * (CR_A[i] * xs_p - CR_B[i]) ** 2 for i in range(len(CR_A))], axis=0)
ax.plot(xs_p, f_avg, color=COL_VEC1, lw=2.5, label="f = ortalama")
# confusion aralığı + x*
lo, hi, xstar, mins = confusion_interval()
# axvspan confusion region
ax.axvspan(lo, hi, color=COL_VEC3, alpha=0.13)
ax.text((lo + hi) / 2.0, 36.0, "confusion region [1, 6]",
ha="center", va="center", color=COL_VEC3, fontsize=10, fontweight="bold")
# tekil minimumlar b_i/a_i (turuncu marker), değerler 2/6/1/3/1.5
y_min = np.zeros_like(mins)
ax.scatter(mins, y_min, color=COL_VEC3, s=60, zorder=5, edgecolor="white",
linewidth=0.8, label="bileşen minimumları $b_i/a_i$")
# x* teal yıldız
ax.scatter([xstar], [0.0], marker="*", s=140, color=COL_TEAL, zorder=6,
edgecolor="white", linewidth=0.8, label=f"$x^* = {xstar:.2f}$")
# x=7.5: 5 küçük sola-ok (hemfikir)
x_out = 7.5
for j, yo in enumerate(np.linspace(8, 16, 5)):
ax.annotate("", xy=(x_out - 0.6, yo), xytext=(x_out, yo),
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.4))
ax.text(x_out, 17.5, "hemfikir\n(hepsi sola)", ha="center", va="bottom",
color=COL_VEC3, fontsize=8.5)
# xstar civarı karışık yönlü küçük oklar
g_in = grads_at(xstar)
for j in range(len(CR_A)):
yc = 3.0 + j * 1.4
dx = -0.45 if g_in[j] > 0 else 0.45
ax.annotate("", xy=(xstar + dx, yc), xytext=(xstar, yc),
arrowprops=dict(arrowstyle="->", color=COL_VEC1, lw=1.2, alpha=0.8))
ax.text(xstar, 11.0, "çelişir\n(karışık yön)", ha="center", va="bottom",
color=COL_VEC1, fontsize=8.5)
apply_style(ax)
ax.set_xlim(-1, 8)
ax.set_ylim(0, 40)
ax.set_xlabel("x")
ax.set_ylabel("f(x)")
ax.set_title("Confusion region [1, 6]: dışarıda TÜM gradyanlar hemfikir, içeride çelişir — x* = 2.22 içeride\n(motor: dış işaretler [6, 2, 28, 11.2, 4.2] hep +)",
fontsize=10, fontweight="bold")
ax.legend(loc="upper left", fontsize=8.5, framealpha=0.92)
plt.show()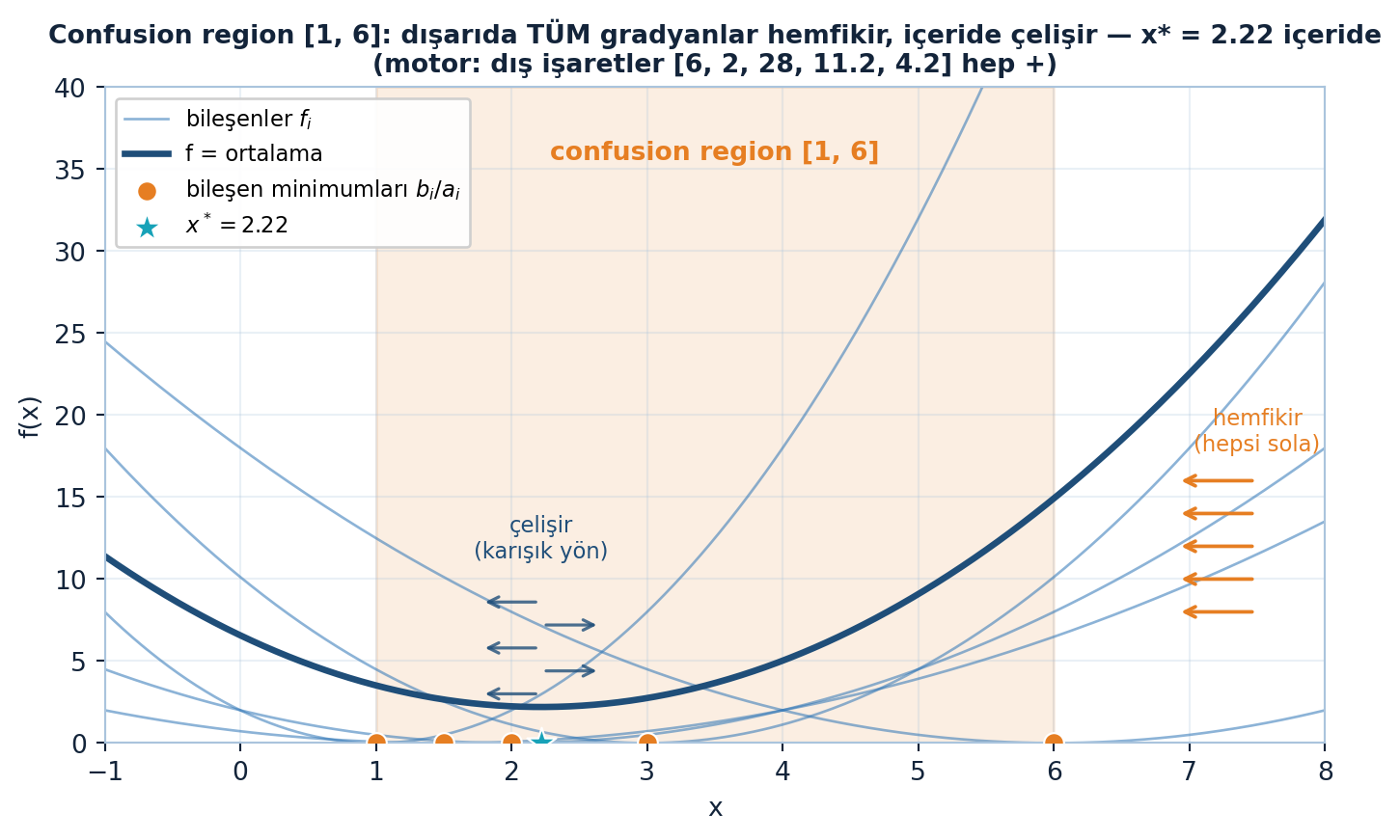
Şekil 26.5 sezgiyi 1B paraboller üzerinde gösterir: beş bileşen \(f_{i} = \tfrac12(a_{i}x - b_{i})^{2}\) (steel ince eğriler) ve ortalama \(f\) (navy kalın); bileşen minimumları \(b_{i}/a_{i}\) (turuncu markerlar, değerler 2/6/1/3/1.5) ve confusion aralığı \([1, 6]\) (turuncu gölge) içinde \(x^{*} = 2.22\) (teal yıldız) durur. Dışarıda (\(x=8\)): motor beş gradyanı \([6,\ 2,\ 28,\ 11.2,\ 4.2]\) verir — hepsi pozitif, yani hepsi sola (hemfikir, hızlı iniş). İçeride (\(x^{*}\)): işaretler \([0.22,\ -3.78,\ 4.87,\ -1.76,\ 0.46]\) — karışık yönlü (çelişir, dalgalanma). SGD bu yüzden uzaktan hızlı, yakında kararsızdır.
İpucuBuilder Notu — Hemfikir Dışarısı Kavgalı İçerisi
“Dışarıda gradyanlar hemfikir, içeride çelişir” confusion region SGD davranışının zarif açıklaması. ML köprüsü: bu, mini-batch boyutunun neden önemli olduğunu açıklar — daha büyük batch confusion region’ı küçültür (gradyanlar ortalanır, daha az çelişki) ama birazdan göreceğimiz gibi bu her zaman iyi değil.
26.8 Yansızlık ve Varyans
SGD neden çalışır? İki istatistiksel sebep (Ders 20). Birincisi yansızlık (unbiased): rastgele seçilen tek gradyanın beklenen değeri tam gerçek gradyandır:
\[E[\nabla f_{i_{k}}(x)] = \frac{1}{n}\sum_{i=1}^{n}\nabla f_{i}(x) = \nabla f(x)\]
Yani ortalamada doğru yöne gidiyoruz. Ama bu yetmez:
“…beyond this unbiasedness [the amount of noise is controlled]…” — Sra, 38:03
İkincisi varyans: yansız ama varyans devasaysa (bir adım \(+\infty\), diğeri \(-\infty\), ortalama 0) işe yaramaz. SGD’nin hızını, stokastik gradyanların varyansı belirler. Son yılların araştırma cephesi: yansızlığı koruyup varyansı düşüren yöntemler (variance reduction: SVRG, SAGA).
Kod
A, b = make_ls_data()
x_t = np.array([3., -2.])
G = np.array([single_grad(x_t, A, b, i) for i in range(40)])
g0 = G[:, 0]
gfull0 = full_grad(x_t, A, b)[0]
sd = g0.std()
fig, ax = plt.subplots(figsize=(7, 4.2))
ax.axvspan(gfull0 - sd, gfull0 + sd, color=COL_TEAL, alpha=0.1, zorder=0)
ax.hist(g0, bins=12, color=COL_STEEL_300, edgecolor=COL_ACCENT, zorder=2)
ax.axvline(gfull0, color=COL_PRIMARY, linewidth=2.8, zorder=3,
label="E[grad f_i] = grad f (yansiz, 4e-16)")
ax.annotate("dagilim GENIS: varyans\nSGD nin hizini belirler",
xy=(gfull0 + sd, ax.get_ylim()[1] * 0.55),
xytext=(gfull0 + 0.7 * sd, ax.get_ylim()[1] * 0.7),
fontsize=9.5, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.4))
apply_style(ax)
ax.set_xlabel("tek-nokta gradyani (1. koordinat)")
ax.set_ylabel("frekans (n=40)")
ax.set_title("Yansizlik: 40 stokastik gradyanin ortalamasi TAM gercek gradyan;\ngenislik (varyans) hizi belirler",
fontsize=11, fontweight="bold")
ax.legend(loc="upper left", fontsize=9)
fig.tight_layout()
plt.show()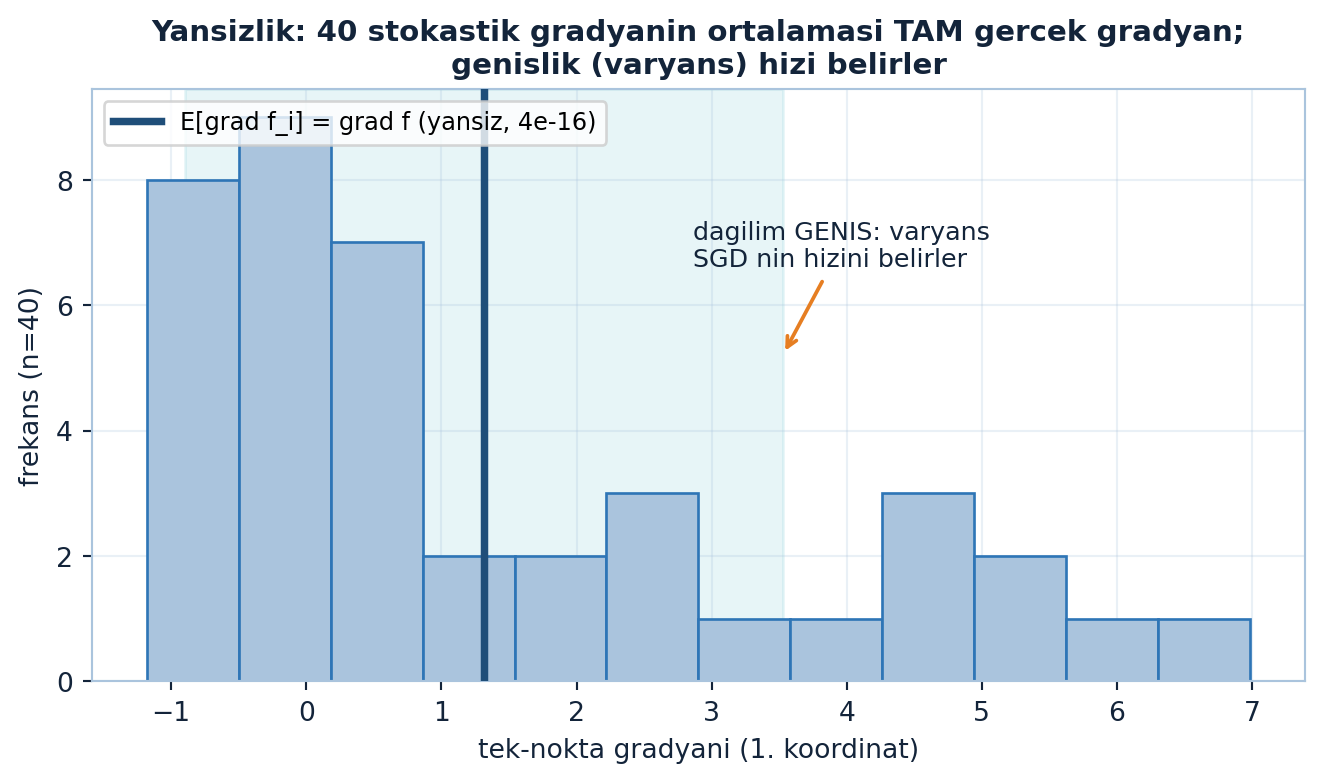
Şekil 26.6 yansızlığı ve varyansı tek bir histogramla gösterir: \(x = (3, -2)\) noktasında 40 tek-nokta gradyanının 1. koordinatı (steel çubuklar) geniş bir dağılım çizer; navy dikey çizgi onların ortalamasıdır ve tam gerçek gradyana eşittir — motor maxdiff \(4 \times 10^{-16}\) ile yansızlığı birebir doğrular. Ama dağılımın genişliği (teal \(\pm\)std bandı) büyüktür: ortalama doğru olsa da tek bir örnek çok gürültülüdür, ve işte bu varyans SGD’nin hızını belirler.
İpucuBuilder Notu — Yansız Ama Gürültülü
“Yansız ama varyans önemli” Ders 20’nin beklenen değer/varyansının doğrudan uygulaması: \(E[\text{tahmin}]\) = doğru (yansız), ama \(\text{Var}[\text{tahmin}]\) yakınsama hızını belirler. ML köprüsü: variance reduction yöntemleri (SVRG) ve momentum (Ders 23) ikisi de gradyan gürültüsünü azaltır; Adam’ın ikinci momenti (gradyan-kare ortalaması) de bir varyans-uyarlaması.
26.9 Mini-Batch ve Paralelizm
Tek nokta yerine küçük bir grup (mini-batch \(B\)) kullan; gradyanları ortala:
\[x_{k+1} = x_{k} - \eta_{k}\,\frac{1}{|B|}\sum_{i \in B}\nabla f_{i}(x_{k})\]
“Averaging things reduces the variance.” — Sra, 44:51
Ortalama almak varyansı azaltır. \(|B| = 1\) saf SGD, \(|B| = n\) tam gradient descent, arası pratikte kullanılan. İki rastgelelik: with replacement (yerine koyarak, IID — teori bunu analiz eder) vs without replacement (pre-shuffle + stream — tüm araç kutuları bunu kullanır, ama IID-olmadığından analizi açık problem). Mini-batch’in asıl değeri paralelizm: GPU’da her çekirdek bir gradyan hesaplar. Ama tehlike:
“…your method starts resembling gradient descent.” — Sra, 47:56
Çok büyük mini-batch → tam gradient descent’e benzer → confusion region aşırı küçülür → aşırı-öğrenme, test hatası kötüleşir (large-batch generalization gap). Optimal mini-batch boyutu hâlâ açık soru.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4.2))
# --- Sol: MC varyans vs teorik sigma^2/|B| (loglog) ---
A, b = make_ls_data()
x_t = np.array([3., -2.])
s2 = grad_variance(x_t, A, b)
Bs = [1, 4, 16, 64]
mc = minibatch_variance_mc(x_t, A, b, Bs)
axL.loglog(Bs, mc, "o", color=COL_PRIMARY, ms=9, label="MC varyans (4000 tekrar)")
axL.loglog(Bs, s2 / np.array(Bs), "--", color=COL_VEC3, lw=2, label="teorik sigma^2/|B|")
axL.set_xlabel("|B| (log)"); axL.set_ylabel("gradyan varyansi (log)")
axL.legend()
apply_style(axL)
# --- Sag: uc f-egrisi semilogy, 200 adim ---
p1 = sgd(A, b, [6, 5], 0.05, 200, batch=1)
p8 = sgd(A, b, [6, 5], 0.05, 200, batch=8)
p32 = sgd(A, b, [6, 5], 0.05, 200, batch=32)
inc1, fs1 = count_increases(p1, A, b)
inc8, fs8 = count_increases(p8, A, b)
inc32, fs32 = count_increases(p32, A, b)
axR.semilogy(fs1, color=COL_VEC3, lw=1.0, alpha=0.85, label="batch=1 (disli)")
axR.semilogy(fs8, color=COL_ACCENT, lw=1.4, label="batch=8")
axR.semilogy(fs32, color=COL_PRIMARY, lw=2.0, label="batch=32 (GD-vari)")
axR.annotate("yukselme %d vs %d" % (inc32, inc1), xy=(120, fs32[120]),
xytext=(60, fs1[5]*0.6), color=COL_TEXT, fontsize=9,
arrowprops=dict(arrowstyle="->", color=COL_PRIMARY, lw=1.2))
axR.set_xlabel("adim"); axR.set_ylabel("kayip f (log)")
axR.legend()
apply_style(axR)
fig.suptitle("Mini-batch: varyans sigma^2/|B| (MC oranlar 0.97-1.00) — buyuk batch GD ye benzer, confusion kuculur (generalization gap riski)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
fig.tight_layout()
plt.show()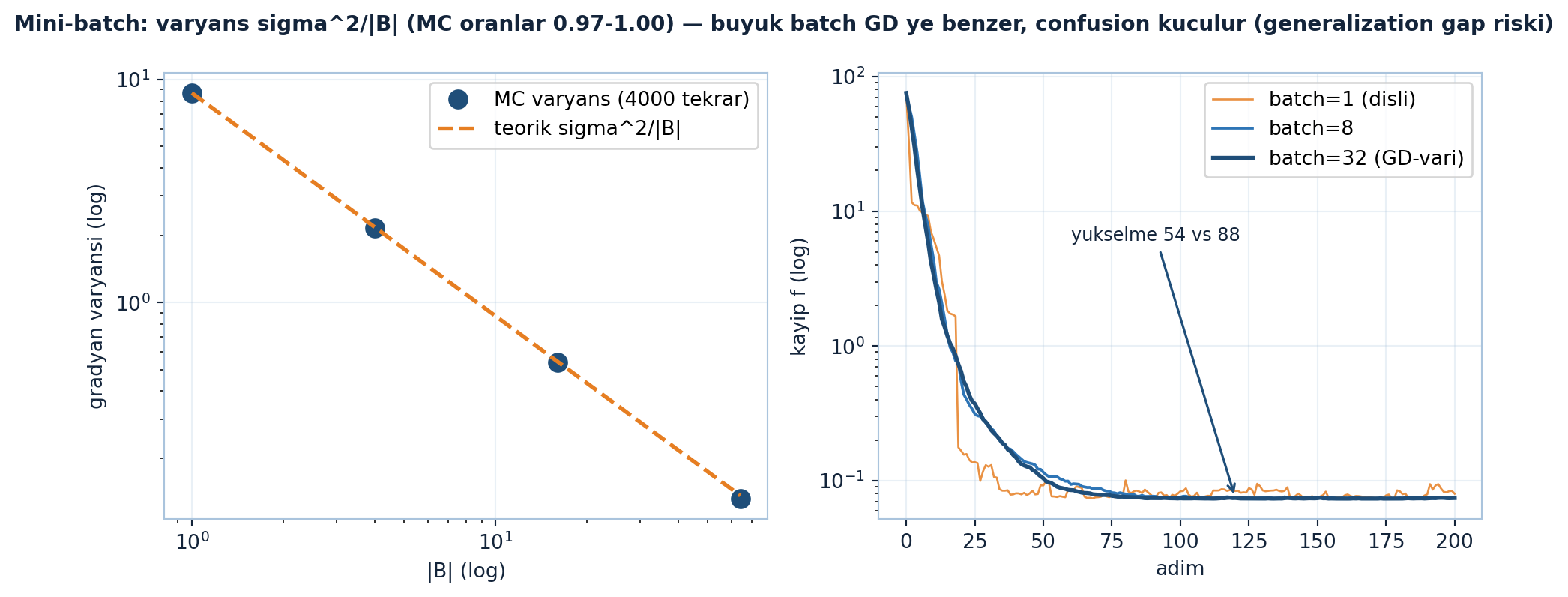
Şekil 26.7 ortalamanın bedelini ve faydasını iki panelde gösterir: solda Monte Carlo varyansı (4000 tekrar, navy markerlar) ile teorik \(\sigma^{2}/|B|\) doğrusu (turuncu kesik) \(|B| = 1, 4, 16, 64\) için neredeyse tam örtüşür — oranlar \([0.997,\ 0.990,\ 0.989,\ 0.969]\), yani ortalama varyansı tam \(|B|\) kat düşürür. Sağda üç SGD izi: \(|B|=1\) (turuncu, dişli, 88 yükselme), \(|B|=8\) (steel), \(|B|=32\) (navy, GD-vari, yalnız 54 yükselme — confusion küçülür). Büyük batch daha düzgün iner ama GD’ye benzedikçe genelleme açığı (generalization gap) doğar.
İpucuBuilder Notu — Ortalamanın Bedeli
“Büyük batch hızlı ama genelleme kötü” derin öğrenmenin meşhur ikilemi: paralelizm için büyük batch isteriz, ama confusion region’ı yok edince düz-minimum arayışı (genelleme) bozulur. ML köprüsü: pratikte batch boyutu 32–8192 arası ayarlanır; büyük-batch eğitimi (warmup, LARS/LAMB optimizer’ları) bu açığı kapatmaya çalışır. Tek stokastik gradyanın nasıl hesaplandığı? Backprop (Ders 27).
26.10 Bu Dersin Özeti
- Finite-sum: ML hedefi \(f(x) = \frac{1}{n}\sum f_{i}(x)\); \(n\) (veri) ve \(d\) (boyut) çok büyük. Least squares/LASSO/SVM/DNN hepsi bu.
- SGD: \(x_{k+1} = x_{k} - \eta_{k}\nabla f_{i_{k}}(x_{k})\), \(i_{k}\) rastgele; bir adım \(n\) kat hızlı (Robbins-Monro 1951).
- Misnomer: her adımda inmez, dalgalanır; adım boyuna çok duyarlı (motor: 88/200 adım yükselir).
- Davranış: başta hızlı, optimuma yakın dalgalı; ML için iyi (genelleme, aşırı-öğrenme önler).
- Confusion region: \(x^{*} \in [\min b_{i}/a_{i}, \max b_{i}/a_{i}] = [1, 6]\); dışarıda gradyanlar hemfikir (hızlı), içeride çelişir (dalgalı).
- Yansızlık + varyans: \(E[\nabla f_{i_{k}}] = \nabla f\) (maxdiff 4e-16); hızı varyans belirler (variance reduction: SVRG).
- Mini-batch: ortalama varyansı \(\sigma^{2}/|B|\) azaltır; \(|B|=1\) SGD, \(|B|=n\) GD; paralelizm (GPU); büyük batch → overfit (generalization gap). Tek gradyan = backprop (Ders 27).
ÖnemliTek Bir Cümle
Stochastic gradient descent, finite-sum hedefin tüm gradyanı yerine rastgele bir veri noktasının (veya mini-batch’in) yansız ama gürültülü gradyanını kullanır — \(n\) kat ucuz, başta hızlı, optimuma yakın dalgalı; yakınsamayı ve genellemeyi varyans ile mini-batch boyutu belirler.
26.11 Kontrol Soruları
NotSoru 1 — Tek satır farkı ve n kat hız
Soru: SGD, gradient descent’ten hangi tek değişiklikle elde edilir ve neden \(n\) kat hızlıdır?
Cevap: GD tüm \(n\) terimin gradyanını toplar: \(x_{k+1} = x_{k} - \eta\frac{1}{n}\sum\nabla f_{i}\). SGD bunun yerine rastgele tek bir \(i_{k}\) seçip yalnız onun gradyanını kullanır: \(x_{k+1} = x_{k} - \eta_{k}\nabla f_{i_{k}}\). Bir iterasyon \(n\) gradyan yerine 1 gradyan hesapladığından \(n\) kat hızlıdır (\(n\) milyarsa devasa kazanç). Robbins-Monro (1951).
NotSoru 2 — Misnomer ve GD’den fark
Soru: SGD neden “misnomer” (yanlış-adlandırma), ve davranışı GD’den nasıl farklıdır?
Cevap: Gradient descent her adımda maliyeti düşürür (descends); SGD bunu yapmaz — tek rastgele gradyan tüm fonksiyonu temsil etmediğinden bazı adımlar maliyeti yükseltir, dalgalanır (motor: 200 adımın 88’i yükselir). Ortalamada doğru yöne gider ama her adımda değil. Ayrıca adım boyuna çok daha duyarlıdır: başta hızlı ilerler, optimuma yakın dalgalanır.
NotSoru 3 — Confusion region
Soru: Confusion region nedir, SGD’nin başta hızlı/sonda dalgalı davranışını nasıl açıklar?
Cevap: 1B least squares’te her bileşen \(f_{i}=(a_{i}x-b_{i})^{2}\) minimumuna \(b_{i}/a_{i}\)’da ulaşır; gerçek \(x^{*}\) bu değerlerin \([\min, \max]\) aralığındadır (confusion region). Dışarıda tüm gradyanlar aynı yönü gösterir → hangi noktayı seçersen seç doğru yöne hızlı inersin. İçeride gradyanlar çelişir → rastgele seçim seni bazen ileri bazen geri iter → dalgalanma. Uzaktan hızlı, yakında kararsız.
NotSoru 4 — Yansızlık, varyans ve mini-batch
Soru: Stokastik gradyanın yansızlığı ne demek, varyans ve mini-batch nasıl devreye girer?
Cevap: Yansızlık: \(E[\nabla f_{i_{k}}] = \frac{1}{n}\sum\nabla f_{i} = \nabla f\), yani rastgele gradyan ortalamada gerçek gradyana eşit (Ders 20; motor maxdiff 4e-16). Ama yansızlık yetmez — varyans büyükse yakınsama yavaş/kaotik. SGD’nin hızı varyansa bağlıdır. Mini-batch birkaç gradyanı ortalayarak varyansı \(\sigma^{2}/|B|\)’ye azaltır (+GPU paralelizmi); ama çok büyük batch confusion region’ı yok edip aşırı-öğrenmeye yol açar (generalization gap).
26.12 Egzersizler
Hız karşılaştırması. \(n = 10^6\) veri noktası, her gradyan 1 ms sürüyor. Tam gradient descent bir iterasyonu kaç saniye? SGD (tek nokta) bir iterasyonu kaç ms? Mini-batch (\(|B|=100\)) kaç ms? (Motor tanığı: GD \(10^6\) ms = 1000 s; SGD 1 ms; \(|B|=100\) → 100 ms; bkz. Şekil 26.2.)
Yansızlık. \(f = \frac{1}{3}(f_{1} + f_{2} + f_{3})\), gradyanları \(\nabla f_{1}=2\), \(\nabla f_{2}=-4\), \(\nabla f_{3}=8\) (1B, bir noktada). Tam gradyan \(\nabla f\) nedir? Rastgele tek-nokta gradyanının beklenen değeri buna eşit mi (yansızlık)? (Motor tanığı: \(\nabla f = (2-4+8)/3 = 2\); tek-nokta beklentisi \(\frac{1}{3}(2) + \frac{1}{3}(-4) + \frac{1}{3}(8) = 2\) — yansız.)
Confusion region. 1B least squares \(f_{i}=(a_{i}x-b_{i})^{2}\), \((a,b)\) çiftleri: \((1,2)\), \((1,6)\), \((2,2)\). Her bileşenin minimumu \(b_{i}/a_{i}\)’yı bul. \(x^{*}\) hangi \([\min, \max]\) aralığında olmalı? (Motor tanığı: minimumlar \(2, 6, 1\) → aralık \([1, 6]\); \(x^{*} = \Sigma ab / \Sigma a^{2} = 12/6 = 2.0\), aralık içinde.)
Mini-batch varyansı. Bağımsız stokastik gradyanların varyansı \(\sigma^{2}\). \(|B|\) büyüklüğünde mini-batch ortalamasının varyansı kaça düşer? (İpucu: bağımsız ortalamanın varyansı \(\sigma^{2}/|B|\).) (Motor tanığı: \(|B|=100\) → \(\sigma^{2}/100\); MC oranları 0.97–1.00 ile birebir; bkz. Şekil 26.7 sol panel.)
(Ders 26 habercisi) SGD’nin minimize ettiği \(f_{i}\), derin sinir ağının kaybıydı (\(f_{i} = \text{DNN}(a_{i}, x)\) kaybı). Peki bir sinir ağı tam olarak nasıl bir fonksiyon? Katmanlar, ağırlıklar, doğrusal-olmayan aktivasyon nasıl birleşir? Bir tahmin yaz — Ders 26 “derin öğrenme için sinir ağlarının yapısı” ile öğrenme fonksiyonunu inşa ediyor.
26.13 Sonraki Ders İçin Hazırlık
Ders 26: Derin Öğrenme için Sinir Ağlarının Yapısı. SGD’nin minimize ettiği fonksiyonu açıyoruz: bir sinir ağı = doğrusal katmanlar (ağırlık matrisleri) + doğrusal-olmayan aktivasyon (ReLU) zinciri. Strang öğrenme fonksiyonu \(F(x, v)\)’yi, katmanların geometrisini ve neden derinliğin işe yaradığını inşa eder.
UyarıHazırlık
Ders 26 ile konuk dersi biter, anlatım Strang’a döner. Bu dersteki Egzersiz 5’in sorduğu soruyu zihninde tut: SGD’nin minimize ettiği \(f_{i}\) bir sinir ağının kaybıysa, o ağ tam olarak nasıl bir fonksiyondur? Strang, doğrusal katmanlar (ağırlık matrisleri) ile doğrusal-olmayan aktivasyonun (ReLU) zincirini, öğrenme fonksiyonu \(F(x, v)\)’yi ve derinliğin neden işe yaradığını inşa edecek — SGD’nin “ne”yi optimize ettiğinin cevabı.
26.14 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Konuşmacı (dk) |
|---|---|---|
| Finite-sum problem | \(f(x) = \frac{1}{n}\sum f_{i}(x)\); \(n\), \(d\) büyük | Sra 4m01 |
| SGD fikri | \(x_{+} = x - \eta\nabla f_{i_{k}}\); rastgele tek nokta, \(n\times\) hızlı | Sra 14m38 |
| Misnomer | her adımda inmez, dalgalanır | Sra 18m48 |
| Hızlı başlangıç | başta rapid strides, sonda dalgalı | Sra 23m30 |
| Confusion region | \(x^{*} \in [\min b_{i}/a_{i}, \max b_{i}/a_{i}]\) | Sra 29m22 |
| Yansızlık + varyans | \(E[\nabla f_{i_{k}}] = \nabla f\); hızı varyans belirler | Sra 38m03 |
| Mini-batch | ortalama varyansı azaltır + paralelizm | Sra 44m51 |
| Büyük batch → overfit | GD’ye benzer; generalization gap | Sra 47m56 |
| Backprop | tek stokastik gradyanı hesaplar (Ders 27) | Sra 50m25 |
26.15 ML Bağlantıları Özeti
- SGD = derin öğrenmenin motoru: her PyTorch/TensorFlow eğitimi SGD/türevi; epoch = veri kümesinin bir tam geçişi.
- Variance reduction: SVRG/SAGA yansızlığı koruyup varyansı düşürür; momentum (Ders 23) ve Adam’ın 2. momenti de gürültü azaltır.
- Mini-batch paralelizmi: GPU’da her çekirdek bir gradyan; batch boyutu 32–8192; büyük-batch eğitimi (warmup, LARS/LAMB) generalization gap’i kapatmaya çalışır.
- SGD gürültüsü = düzenleyici: düz minimumlara (flat minima) yönelir → daha iyi genelleme; erken durdurma da aynı mantık.
- Yansız tahmin / varyans: Ders 20’nin beklenen değer/varyansının doğrudan uygulaması (mini-batch örneklem ortalaması).
- Backprop köprüsü: tek stokastik gradyan backprop ile hesaplanır (Ders 27) — bazıları “backprop” deyince SGD’yi kasteder ama backprop sadece gradyan hesaplama algoritmasıdır.
- Geriye köprü: Ders 22 (GD), Ders 23 (momentum/Adam), Ders 20 (beklenen değer/varyans/Markov), Ders 9 (least squares). Paralel: NYU H4 (Defazio’nun SGD/momentum pratik bakışı).
ÖnemliKapanış
“Stochastic gradient descent is actually a misnomer. At every step it doesn’t do any descent.” — Sra, 18:48
SGD her adımda inmez ama ortalamada doğru yöne gider; bu gürültü hem ölçeklenebilirliğin hem de iyi genellemenin sırrıdır — derin öğrenmeyi mümkün kılan tek-satırlık devrim.