flowchart TD
C["Sinir agi = affine + ReLU zinciri"]
C --> F["ogrenme fonksiyonu F: F<0 sinif -1, F>0 sinif +1"]
C --> R["ReLU = max(0,x): dogrusal-olmamazlik SART"]
C --> L["katman: y = Ax + b -> x = ReLU(y)"]
C --> K["kompozisyon: F = F3(F2(F1(x)))"]
C --> O["F surekli PARCALI-DOGRUSAL (origami)"]
U["universality: her surekli fonksiyon yaklasilabilir"]
P["parca sayimi: r(N,m) = binom toplami"]
B["kompozisyon -> zincir kurali -> backprop (Ders 27)"]
M["Karpathy micrograd + NYU spiral koprusu"]
27 Derin Öğrenme için Sinir Ağlarının Yapısı
Öğrenme fonksiyonu, ReLU, origami ve universality
NotBölüm bilgisi
Bu ders, SGD’nin minimize ettiği şeyi açıklar: bir sinir ağı = affine katman (ağırlık matrisi \(Ax+b\)) + doğrusal-olmayan aktivasyon (ReLU) zinciri; sonuç öğrenme fonksiyonu \(F(x)\) sürekli parçalı-doğrusaldır. Strang’in Ders 26 videosu (≈53 dk) ve OCW Lecture 26 temel alınmıştır. Okuma süresi ≈34 dk; önkoşul Ders 25 (SGD, finite-sum). Anlatım konuk dersinden Strang’a döner.
27.1 Bu Derste Ne Var?
SGD’nin minimize ettiği fonksiyonu açıyoruz: öğrenme fonksiyonu \(F(x)\). Bir sinir ağı = affine katman (ağırlık matrisi \(Ax+b\)) + doğrusal-olmayan aktivasyon (ReLU) zinciri. \(F\) sürekli parçalı-doğrusal bir fonksiyondur.
Beş sonuç:
- Öğrenme fonksiyonu: \(F(x)\) eğitim verisini öğrenir; sınıflandırmada \(F(x)<0 \Rightarrow\) sınıf \(-1\), \(F(x)>0 \Rightarrow +1\). Her noktayı doğru yapma (aşırı-öğrenme).
- ReLU: \(\text{ReLU}(x) = \max(0, x)\); doğrusal-olmamazlık ŞART (yoksa sadece düzlemle ayırır, spiral çözülemez).
- Katman: \(y = Ax + b\) (affine) \(\rightarrow x = \text{ReLU}(y)\) (bileşen-bileşen); \(F = F_3(F_2(F_1(x)))\) kompozisyon.
- \(F\) = sürekli parçalı-doğrusal: origami gibi katlanmış; universality — yeterli katlamayla her sürekli fonksiyon yaklaşılabilir.
- Parça sayımı: \(N\) katlama, \(m\) boyut \(\rightarrow r(N,m) = \sum \binom{N}{k}\) (binom); derinlik ifade gücünü artırır.
“…constructing this function F which learns the training data…” — Strang, 1:41
Şekil 27.1 dersin iskeletini gösterir: merkezdeki “sinir ağı = affine + ReLU zinciri” fikrinden, sınıf kararını veren öğrenme fonksiyonu \(F\)’den, doğrusal-olmamazlığı sağlayan ReLU’dan, kompoze olan katmanlardan ve sürekli parçalı-doğrusal (origami) çıkan \(F\)’den dallanır; ayrı düğümlerde her sürekli fonksiyonu yaklaşan universality, binom toplamı parça sayımı \(r(N,m)\), kompozisyondan zincir kuralına oradan backprop’a (Ders 27) uzanan köprü ve Karpathy micrograd + NYU spiral paraleli durur.
İpucuBuilder Notu — SGD’nin Minimize Ettiği Şey
- \(F\) = ağırlık matrisleri + ReLU zinciri — her PyTorch
nn.Sequentialtam bu; \(A\)’lar öğrenilen ağırlıklar, SGD (Ders 25) onları ayarlar. - ReLU doğrusal-olmamazlığı = ifade gücü — doğrusal katmanlar üst üste hâlâ doğrusaldır; ReLU olmadan derinlik anlamsız.
- Universality + parça sayımı — derin ağların neden her fonksiyonu öğrenebildiği; derinlik parça sayısını üstel artırır (expressivity).
- Kompozisyon → zincir kuralı → backprop (Ders 27): \(F=F_3\circ F_2\circ F_1\) türevi zincir kuralıyla. Paralel: NYU H1 spiral sınıflandırma, Karpathy micrograd kompozisyon.
27.2 Öğrenme Fonksiyonu F(x)
Tüm sistem tek bir hedefe yöneliktir:
“…constructing this function F which learns the training data…” — Strang, 1:41
Eğitim verisini öğrenen, sonra test verisine uygulanan bir öğrenme fonksiyonu \(F\) kur. İkili sınıflandırmada (kedi/köpek, \(\pm1\)): \(F(x)\) sınıf \(-1\) için negatif, sınıf \(+1\) için pozitif olsun. Her örneği doğru yapmaya çalışmak şart değil — tuhaf bir örneği zorla doğru yapmak aşırı-öğrenme (overfitting) olur. Amaç neredeyse tüm durumları kapsayan kuralı bulmak.
\[F(x) < 0 \Rightarrow -1, \qquad F(x) > 0 \Rightarrow +1\]
İpucuBuilder Notu — Kuralı Öğren Noktayı Değil
“Her noktayı doğru yapma, kuralı öğren” derin öğrenmenin temel gerilimi: eğitim hatasını sıfırlamak ≠ iyi model. ML köprüsü: \(F\)’nin sıfır-kümesi \(\{F(x)=0\}\) sınıfları ayıran karar sınırıdır (decision boundary); SGD (Ders 25) \(A\) ağırlıklarını bu sınır veriyi ayıracak şekilde ayarlar. Mucize: pratikte test verisinde de iyi çalışır.
27.3 ReLU ve Doğrusal-Olmamazlık
TensorFlow Playground örneği: iç içe sınıflar (mavi içeride, turuncu dışarıda; ya da iki spiral). Doğrusal sınıflandırıcı (düzlem) bunları ayıramaz — doğrusal-olmamazlık şart. Modern aktivasyon fonksiyonu ReLU:
“…ReLU is a function of x is the maximum, the larger of 0 and x.” — Strang, 10:13
\[\text{ReLU}(x) = \max(0, x)\]
Kod
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(9, 3.8))
# Sol: ReLU + sigmoid kıyas
xs = np.linspace(-3, 3, 300)
ax1.plot(xs, relu(xs), color=COL_PRIMARY, lw=2.5, label="ReLU(x) = max(0, x)")
ax1.plot(xs, 1.0 / (1.0 + np.exp(-xs)), color=COL_ACCENT, lw=2.0, ls="--", label="sigmoid (eski)")
ax1.scatter([0], [0], color=COL_VEC3, s=70, zorder=5, label="kink (x = 0)")
ax1.set_title("ReLU vs sigmoid: keskin büküm", color=COL_TEXT, fontsize=11, fontweight="bold")
ax1.set_xlabel("x"); ax1.set_ylabel("çıkış")
apply_style(ax1); ax1.legend(fontsize=8, loc="upper left")
# Sağ: Egz2 bar — giriş vs ReLU çıkış
y_in = np.array([3.0, -2.0, 0.0, 5.0])
y_out = relu(y_in) # (3, 0, 0, 5)
idx = np.arange(4)
ax2.bar(idx - 0.18, y_in, width=0.36, color=COL_ACCENT, label="giriş y = (3, −2, 0, 5)")
ax2.bar(idx + 0.18, y_out, width=0.36, color=COL_PRIMARY, label="ReLU(y) = (3, 0, 0, 5)")
ax2.scatter([1 + 0.18, 2 + 0.18], [0.18, 0.18], color=COL_VEC3, marker="X", s=110, zorder=6, label="2 bileşen öldü")
ax2.axhline(0, color=COL_TEXT, lw=0.8)
ax2.set_xticks(idx); ax2.set_xticklabels(["y₁", "y₂", "y₃", "y₄"])
ax2.set_title("Egz2: ReLU iki bileşeni sıfırlar", color=COL_TEXT, fontsize=11, fontweight="bold")
ax2.set_ylabel("değer")
apply_style(ax2); ax2.legend(fontsize=8, loc="upper center")
fig.suptitle("ReLU(x) = max(0, x): tek bukum dogrusalligi kirar — sigmoid in yerini aldi (Egz2: (3,-2,0,5) -> (3,0,0,5))",
color=COL_PRIMARY, fontsize=11, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.94])
plt.show()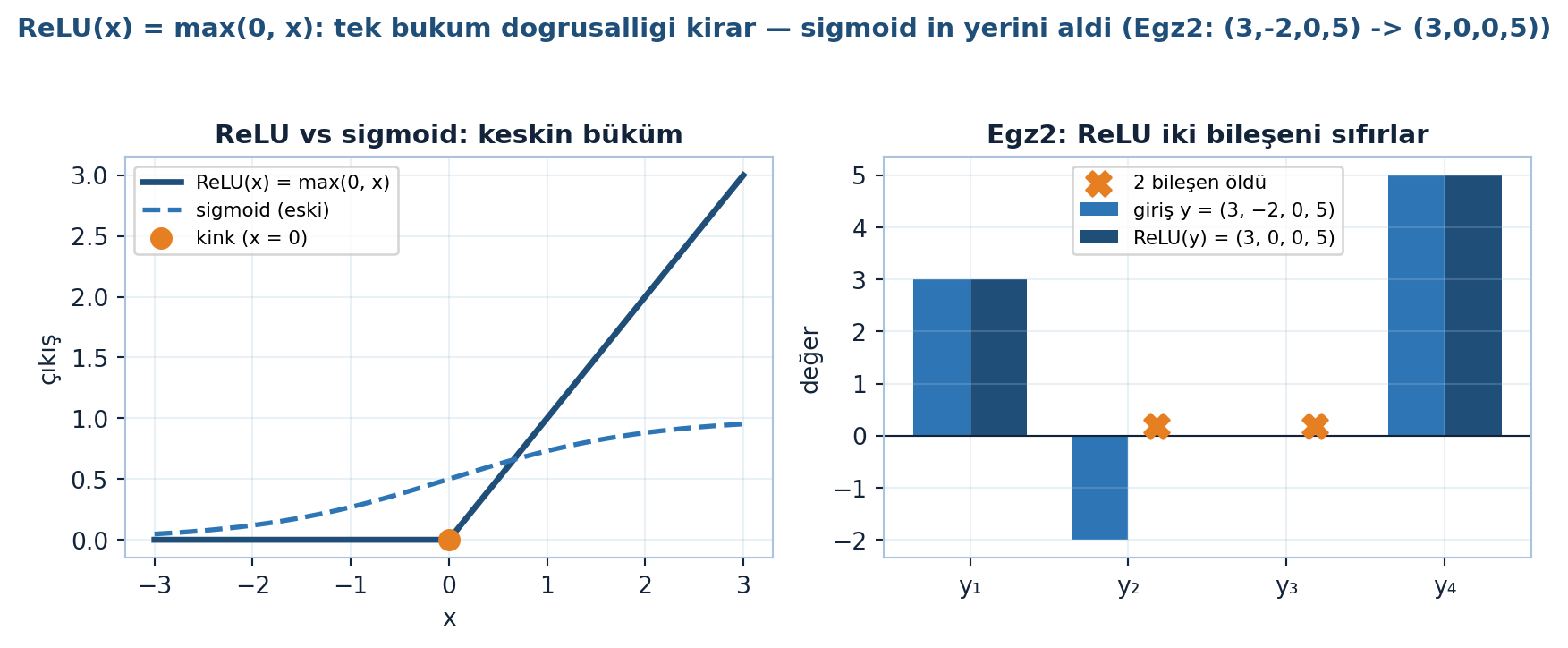
Neden kritik: tüm katmanlar doğrusal olsaydı, bileşkeleri yine doğrusal olurdu (bir düzlem) — spirali ayıramazdık. ReLU her katmana doğrusal-olmamazlık enjekte eder; ancak o zaman ağ doğrusal-olmayan karar sınırları (örn. \(r - 5\) gibi yarıçap fonksiyonları) öğrenebilir. Şekil 27.3 bunu kanıtlar: iç-içe elmas verisini en iyi doğrusal sınıflandırıcı bile ayıramaz (acc \(< 0.75\)), oysa elle kurulan 4-ReLU ağ \(F = c - |x| - |y|\) tam ayırır (acc \(= 1.000\)).
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10.5, 4.6))
P, y = make_diamond_data()
ici = P[y == 1]; disi = P[y == -1]
acc = best_linear_accuracy(P, y)
# Sol: en iyi doğrusal sınır (temsili doğru y = -x + 2.1) — ayıramaz
axL.scatter(ici[:, 0], ici[:, 1], c=COL_PRIMARY, s=12, label="iç (+1)")
axL.scatter(disi[:, 0], disi[:, 1], c=COL_ACCENT, s=12, label="dış (−1)")
xline = np.linspace(-3, 3, 100)
axL.plot(xline, -xline + 2.1, color=COL_VEC3, linestyle="--", linewidth=2.2, label="en iyi doğrusal")
axL.set_xlim(-3.2, 3.2); axL.set_ylim(-3.2, 3.2); axL.set_aspect("equal")
axL.set_title(f"en iyi DOĞRUSAL: acc = {acc:.2f} (ayıramaz)", fontsize=11, fontweight="bold")
axL.legend(loc="upper right", fontsize=8)
apply_style(axL)
# Sağ: 4-ReLU el-yapımı ağ karar bölgeleri
axR.scatter(ici[:, 0], ici[:, 1], c=COL_PRIMARY, s=12)
axR.scatter(disi[:, 0], disi[:, 1], c=COL_ACCENT, s=12)
gx = np.linspace(-3, 3, 300)
GX, GY = np.meshgrid(gx, gx)
Z = f_l1_net(np.stack([GX, GY], axis=-1))
axR.contourf(GX, GY, np.sign(Z), levels=[-1.5, 0, 1.5], colors=["#f5e6d8", "#dbe7f3"], alpha=0.7)
axR.contour(GX, GY, Z, levels=[0], colors=[COL_PRIMARY], linewidths=2.4)
axR.set_xlim(-3.2, 3.2); axR.set_ylim(-3.2, 3.2); axR.set_aspect("equal")
axR.set_title("4-ReLU el-yapımı ağ: acc = 1.000", fontsize=11, fontweight="bold")
apply_style(axR)
fig.suptitle("Doğrusal-olmamazlığın kanıtı: iç-içe elmas verisini hiçbir doğru ayıramaz (Egz4: A₂ A₁ = tek matris), 4 ReLU elması çizer", fontsize=11.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()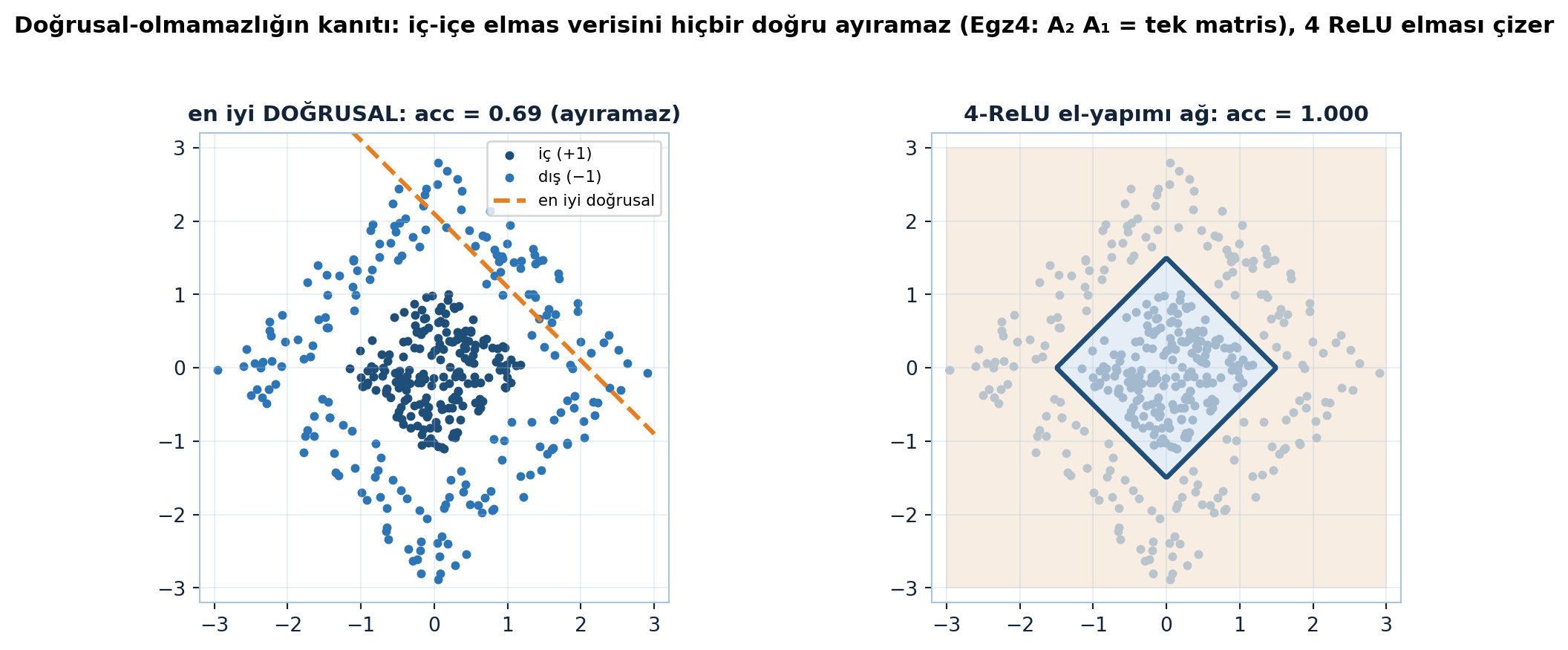
İpucuBuilder Notu — Doğrusalı Kıran Tek Büküm
“Doğrusal × doğrusal = doğrusal, ReLU kırar” derin öğrenmenin neden derinlik gerektirdiğinin özü: ReLU olmadan 100 katman bile tek bir matrise çöker. ML köprüsü: NYU H1’in spiral sınıflandırması (Phase 2 paralel ders) tam bu Playground örneği — doğrusal-olmayan aktivasyon olmadan spiral öğrenilemez; ReLU bugün varsayılan (sigmoid’in yerini aldı).
27.4 Katman Yapısı: Affine + ReLU
Bir katman iki adımdan oluşur. Önce affine dönüşüm (ağırlık matrisi + bias): özellik vektörü \(x_0\) (5 bileşen) bir \(A_1\) matrisiyle (\(6\times5\), yani 30 ağırlık) çarpılıp bir \(b_1\) bias’ı eklenir:
\[y_{1} = A_{1}x_{0} + b_{1} \qquad (A_{1}:\ 6\times5,\ b_{1}:\ 6\times1)\]
\(30 + 6 = 36\) ağırlık (öğrenilecek parametre). Sonra ReLU bileşen-bileşen uygulanır (6 kopya):
\[x_{1} = \text{ReLU}(y_{1}) = \max(0, y_{1})\]
Derin ağ = bu katmanı tekrar tekrar yığmak. Katman 1 verinin temel özelliklerini, katman 2 daha ince detayları, katman 3 daha da incesini öğrenir — derinliğin gücü bu. Şekil 27.4 hem tek katmanın 36 parametresini hem de katmanların kompozisyon zincirini gösterir.
İpucuBuilder Notu — Derin Öğrenmenin Atomu
“Affine (\(Ax+b\)) sonra ReLU” tek bir katman; \(A\) ve \(b\) öğrenilen ağırlıklar. ML köprüsü: PyTorch’ta nn.Linear(5,6) tam \(A_1x_0+b_1\), ardından nn.ReLU(); gerçek ağlarda 36 yerine on binlerce-milyonlarca parametre, onlarca-yüzlerce katman. Affine + nonlinearity ikilisi tüm derin öğrenmenin atomu.
27.5 Kompozisyon: F = F₃(F₂(F₁(x)))
Katmanları zincirle. Her katman bir fonksiyon \(F_k(v) = \text{ReLU}(A_k v + b_k)\); tüm ağ bunların kompozisyonu:
“F of x is going to be F3… of F2 of F1 of x…” — Strang, 25:44
\[F(x) = F_{3}(F_{2}(F_{1}(x))), \qquad F_{k}(v) = \text{ReLU}(A_{k}v + b_{k})\]
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4))
# --- Sol panel: 5 -> 6 katman diyagramı ---
n_in, n_out = 5, 6
ys_in = np.linspace(0.12, 0.88, n_in)
ys_out = np.linspace(0.08, 0.92, n_out)
x_in, x_out = 0.0, 1.0
# bağlantılar (30 ince steel çizgi)
for yi in ys_in:
for yo in ys_out:
axL.plot([x_in, x_out], [yi, yo], color=COL_ACCENT, linewidth=0.45, alpha=0.55, zorder=1)
# nöron noktaları
axL.scatter([x_in] * n_in, ys_in, s=140, color=COL_PRIMARY, edgecolors=COL_WHITE, linewidths=1.4, zorder=3)
axL.scatter([x_out] * n_out, ys_out, s=140, color=COL_VEC3, edgecolors=COL_WHITE, linewidths=1.4, zorder=3)
# üst metin
axL.text(0.5, 1.06, "A1: 6x5 = 30 agirlik + b1: 6 -> 36 parametre",
ha="center", va="bottom", fontsize=10.5, color=COL_TEXT, fontweight="bold")
# ReLU kutusu sağ sütun yanında
axL.text(1.34, 0.5, "ReLU", ha="center", va="center", fontsize=11, color=COL_VEC3,
fontweight="bold", bbox=dict(boxstyle="round,pad=0.35", fc=COL_WHITE, ec=COL_VEC3, lw=1.8))
# katman etiketleri
axL.text(x_in, -0.04, "x (5 giris)", ha="center", va="top", fontsize=9.5, color=COL_PRIMARY)
axL.text(x_out, -0.04, "Ax+b (6)", ha="center", va="top", fontsize=9.5, color=COL_VEC3)
axL.set_xlim(-0.35, 1.7); axL.set_ylim(-0.12, 1.16)
axL.axis("off")
# --- Sağ panel: F = F3(F2(F1(x))) kompozisyon kutuları ---
labels = ["F1 = ReLU(A1 x + b1)", "F2 = ReLU(A2 F1 + b2)", "F3 = ReLU(A3 F2 + b3)"]
box_y = [0.78, 0.5, 0.22]
for lbl, by in zip(labels, box_y):
axR.add_patch(plt.Rectangle((0.08, by - 0.06), 0.84, 0.12, fc=COL_BG, ec=COL_PRIMARY, lw=1.8,
transform=axR.transAxes, zorder=2))
axR.text(0.5, by, lbl, ha="center", va="center", fontsize=10.5, color=COL_TEXT,
fontweight="bold", transform=axR.transAxes, zorder=3)
# oklar arası
for by_top, by_bot in [(box_y[0], box_y[1]), (box_y[1], box_y[2])]:
axR.annotate("", xy=(0.5, by_bot + 0.06), xytext=(0.5, by_top - 0.06),
xycoords="axes fraction",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0))
# alt navy metin
axR.text(0.5, 0.04, "F = F3(F2(F1(x))) — zincir -> zincir kurali -> backprop (Ders 27)",
ha="center", va="center", fontsize=9.8, color=COL_PRIMARY, fontweight="bold",
transform=axR.transAxes)
axR.set_xlim(0, 1); axR.set_ylim(0, 1)
axR.axis("off")
fig.suptitle("Derin ogrenmenin atomu: affine (Ax+b) + ReLU; agi kur = atomlari zincirle",
fontsize=12.5, color=COL_PRIMARY, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()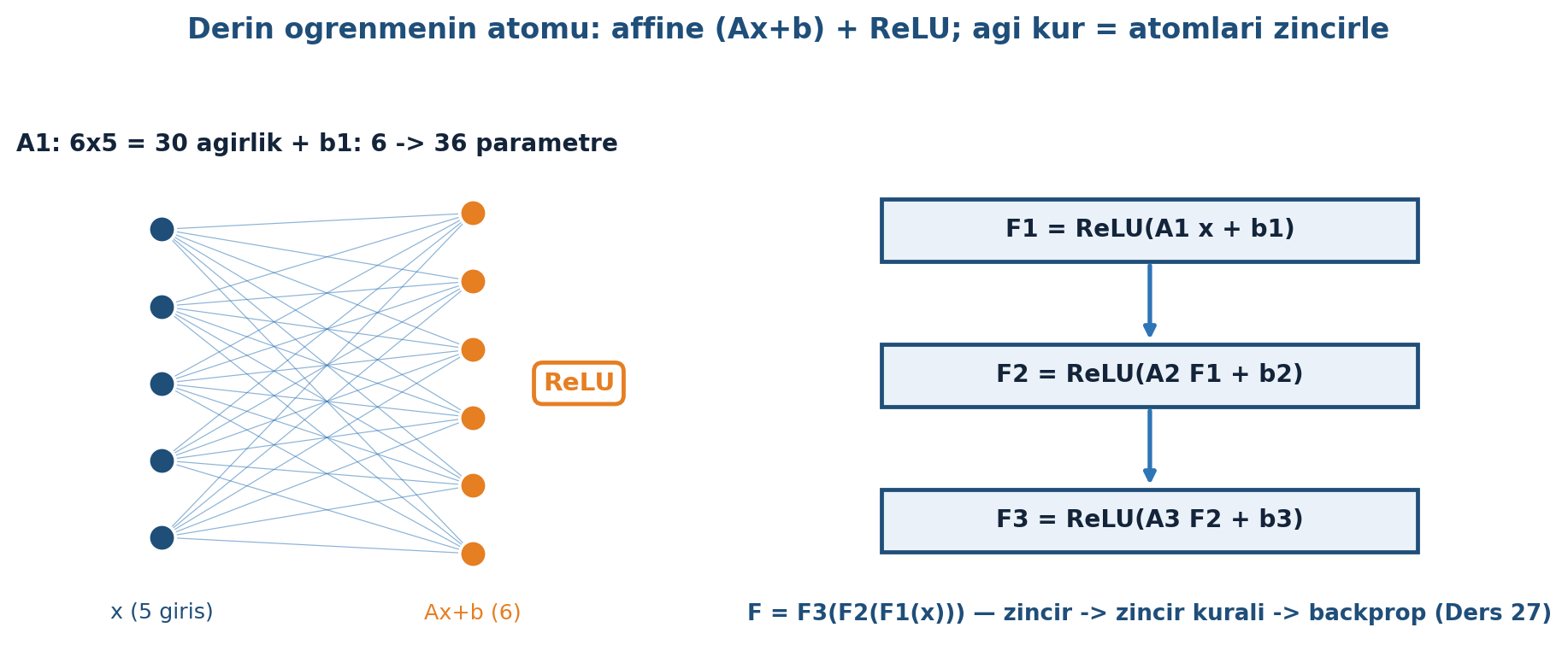
“Zincir” kelimesi kasıtlı: bir fonksiyonun fonksiyonunun fonksiyonu = kompozisyon, ve türevini zincir kuralı verir (Ders 27 backprop). Tarihsel not: eskiden aktivasyon sigmoid (S-eğrisi) idi:
“…the original functions were sigmoids, like S curves…” — Strang, 27:33
ama deneyler ReLU’nun daha iyi çalıştığını gösterdi.
İpucuBuilder Notu — Zincirin Kendisi
\(F = F_3\circ F_2\circ F_1\) kompozisyonu derin öğrenmenin iskeleti; “deep” = çok katmanlı kompozisyon. ML köprüsü: kompozisyon → zincir kuralı → backprop (Ders 27); bu tam Karpathy’nin micrograd’ı (fonksiyon kompozisyonu + geri-türev) ve fast.ai’nin manuel backprop’u (Phase 2 paralel dersler). Sigmoid→ReLU geçişi derin öğrenme devrimini (2010’lar) tetikleyen pratik buluşlardan.
27.6 F Sürekli Parçalı-Doğrusaldır
\(F\) matematiksel olarak ne tür bir fonksiyon? Affine (sürekli) ve ReLU (sürekli, parçalı-doğrusal) kompozisyonu olduğundan:
“…a continuous piecewise linear function.” — Strang, 29:04
\(F\) bir sürekli parçalı-doğrusal fonksiyondur.
Her parça düz (doğrusal), parçalar kenarlarda birleşir (sürekli). Görsel benzetme: origami.
“This is the theory of origami almost.” — Strang, 32:20
Düz bir kâğıdı düz çizgiler boyunca katlamak gibi. ReLU her katmanda “katlama” (fold) çizgileri yaratır; \(F\) bu katlamalarla parçalanmış düz yüzeylerden oluşur. 1B’de “kırık çizgi” (broken line), 2B’de katlanmış düzlem. Şekil 27.5 hem 1B’de derinlikle artan kink sayısını hem de 2B’de 4 katlamanın 11 bölge yaratışını gösterir.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10.5, 4.4))
# Sol: 1B origami — derinlik kırık-çizgiyi katlar
xs = np.linspace(-3, 3, 6000)
n1 = make_random_1d_net([8], seed=26)
n2 = make_random_1d_net([8, 8], seed=26)
n3 = make_random_1d_net([8, 8, 8], seed=26)
y1 = deep_relu_1d(xs, n1)
y2 = deep_relu_1d(xs, n2)
y3 = deep_relu_1d(xs, n3)
k1 = count_kinks(xs, y1, tol=1e-4)
k2 = count_kinks(xs, y2, tol=1e-4)
k3 = count_kinks(xs, y3, tol=1e-4)
axL.plot(xs, y1, color="#2e75b6", lw=1.5, label=f"1 katman ({k1} kink)")
axL.plot(xs, y2, color="#3aa6a0", lw=1.8, label=f"2 katman ({k2} kink)")
axL.plot(xs, y3, color="#1f4e79", lw=2.2, label=f"3 katman ({k3} kink)")
axL.set_title("1B origami: derinlik kırık-çizgiyi katlar")
axL.legend(loc="best", fontsize=8)
axL.set_xlabel("x")
axL.set_ylabel("F(x)")
apply_style(axL)
# Sağ: 2B — 4 katlama → 11 bölge
cnt, (th, off) = regions_numeric(4, seed=5, grid=400)
gx = np.linspace(-3, 3, 400)
GX, GY = np.meshgrid(gx, gx)
code = sum((2 ** i) * ((np.cos(th[i]) * GX + np.sin(th[i]) * GY - off[i]) > 0) for i in range(4))
axR.imshow(code, cmap=NAVY_CMAP, extent=[-3, 3, -3, 3], origin="lower")
for i in range(4):
if abs(np.sin(th[i])) > 1e-6:
yy = (off[i] - np.cos(th[i]) * gx) / np.sin(th[i])
axR.plot(gx, yy, color="white", lw=1.0)
else:
axR.axvline(off[i] / np.cos(th[i]), color="white", lw=1.0)
axR.set_xlim(-3, 3)
axR.set_ylim(-3, 3)
axR.set_title("2B: 4 katlama -> 11 bölge (r(4,2) = 1+4+6)")
axR.axis("off")
fig.suptitle("F sürekli parçalı-doğrusal: ReLU katlama çizgileri origami gibi — 1B kırık çizgi, 2B katlanmış düzlem")
plt.show()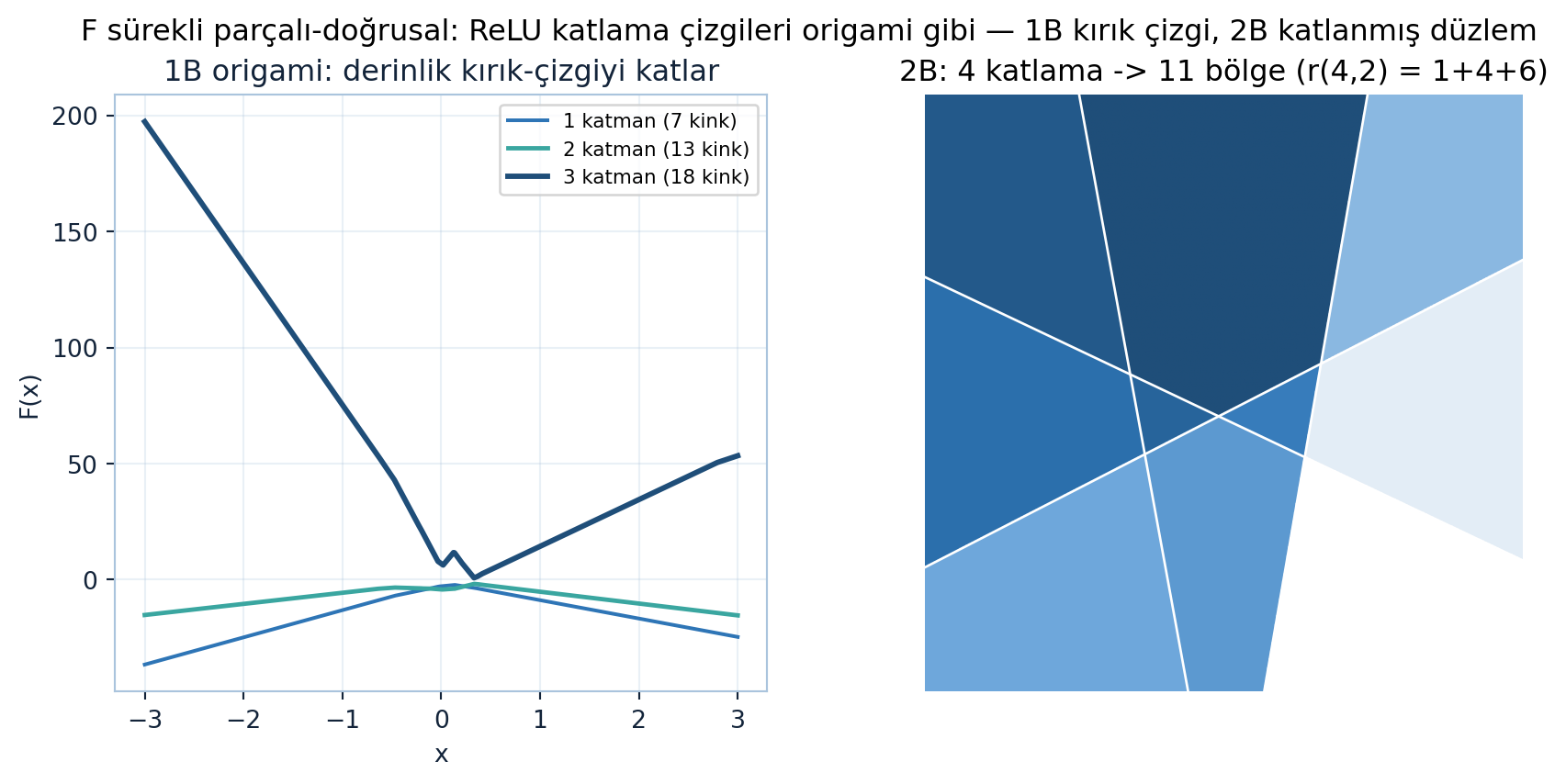
İpucuBuilder Notu — Origami Matematiği
“\(F\) = sürekli parçalı-doğrusal” ReLU ağlarının kesin matematiksel karakterizasyonu: eğri değil, düz parçaların birleşimi. ML köprüsü: bu yüzden ReLU ağları girdi uzayını çokyüzlü (polytope) bölgelere böler, her bölgede doğrusaldır; ağın “karar sınırı” bu parçaların kenarlarıdır. Modern yorumlanabilirlik (interpretability) araştırması bu bölge yapısını inceler.
27.7 Universality Teoremi
Bu fonksiyon sınıfı ne kadar güçlü? Her fonksiyonu üretebilir mi? Tam olarak değil — sadece sürekli parçalı-doğrusal olanları. Ama:
“…the universality theorem would be to say that any function [can be approximated]…” — Strang, 39:41
Universality (evrensellik): herhangi bir sürekli fonksiyon (\(\sin x\), ne olursa olsun), yeterli katlamayla (yeterli nöron/katman) istenildiği kadar yakından yaklaşıklanabilir. Düz parçalarla bir eğriyi istediğin hassasiyette örtebilirsin — yeterince çok küçük düz parça kullan. Şekil 27.6 bunu sayısal olarak doğrular: parça sayısı \(N\) büyüdükçe hata \(1/N^2\) ile sıfıra iner (N=64’te 0.0012).
Kod
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4.2))
# Sol: sin(x) + N=4 ve N=16 parçalı-doğrusal interpolantlar
xs = np.linspace(0, 2 * np.pi, 500)
ax1.plot(xs, np.sin(xs), color=COL_PRIMARY, linewidth=2.5, label="sin(x)")
knots4 = np.linspace(0, 2 * np.pi, 5)
ax1.plot(xs, np.interp(xs, knots4, np.sin(knots4)), color=COL_VEC3, linewidth=1.8, label="N=4 parçalı-doğrusal")
knots16 = np.linspace(0, 2 * np.pi, 17)
ax1.plot(xs, np.interp(xs, knots16, np.sin(knots16)), color=COL_TEAL, linewidth=1.6, label="N=16 parçalı-doğrusal")
ax1.set_xlabel("x"); ax1.set_ylabel("y")
ax1.set_title("sin(x) düz parçalarla yaklaşım", color=COL_TEXT, fontsize=12, fontweight="bold")
ax1.legend(loc="upper right", fontsize=9)
apply_style(ax1)
# Sağ: loglog hata-N + 1/N^2 referans
Ns = [4, 8, 16, 32, 64]
errs = [pwl_approx_error(np.sin, 0, 2 * np.pi, N) for N in Ns]
ax2.loglog(Ns, errs, "o-", color=COL_PRIMARY, markersize=8, linewidth=2, label="parçalı-doğrusal hata")
# 1/N^2 referans (gri kesik, ilk noktadan normalize)
Ns_arr = np.array(Ns, dtype=float)
ref = errs[0] * (Ns_arr[0] ** 2) / (Ns_arr ** 2)
ax2.loglog(Ns_arr, ref, "--", color="#8a96a3", linewidth=1.6, label="1/N² referans")
# değer etiketleri
for N, e in zip(Ns, errs):
ax2.annotate("{:.4f}".format(e), (N, e), textcoords="offset points", xytext=(6, 8),
fontsize=8, color=COL_TEXT)
ax2.annotate("N 4 kat → hata ~15 kat (1/N²)", xy=(16, errs[2]), xytext=(8, errs[0] * 0.5),
fontsize=9, color=COL_VEC3, fontweight="bold",
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.3))
ax2.set_xlabel("N (parça sayısı)"); ax2.set_ylabel("max |hata|")
ax2.set_title("Hata 1/N² ile sıfıra iner", color=COL_TEXT, fontsize=12, fontweight="bold")
ax2.legend(loc="lower left", fontsize=9)
apply_style(ax2)
fig.suptitle("Universality: düz parçalarla her sürekli fonksiyon — hata 1/N² ile sıfıra (N=64'te 0.0012)",
color=COL_TEXT, fontsize=12.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()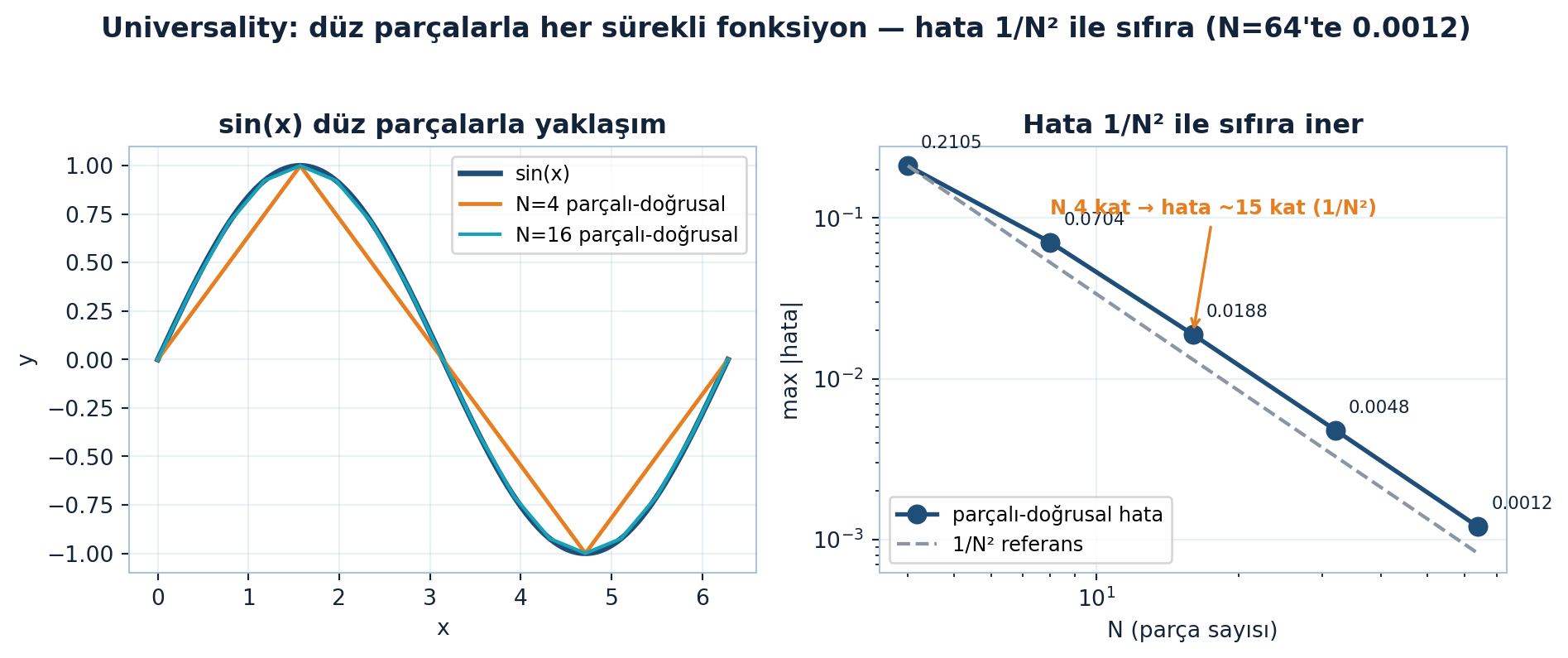
İpucuBuilder Notu — Her Eğriye Yetecek Katlama
Universal approximation teoremi derin öğrenmenin teorik güvencesi: yeterli kapasiteyle ağ her sürekli fonksiyonu öğrenebilir. ML köprüsü: bu “öğrenebilir mi?” sorusunu çözer (evet); ama “verimli öğrenir mi, genelleşir mi?” ayrı sorular (SGD, Ders 25; genelleme). Universality gerek-koşul, yeterli-koşul değil — pratikte derinlik + SGD + veri birlikte çalışır.
27.8 Parça Sayımı: Binom Formülü
\(F\) ne kadar “kıvrımlı” olabilir? Düz parça (flat piece) sayısını say. \(m\)-boyutlu uzayı \(N\) kez katla (\(N\) fold). 2B’de bir düzlemi katla: 1 katlama → 2 parça, 2 katlama → 4, 3 katlama → 7, 4 katlama → 11. Bir özyineleme (her yeni katlama mevcut çizgileri keserek yeni parçalar ekler) ve sonuç binom sayıları:
“…it turns out it’s binomial numbers — N 0, N 1, up to N m.” — Strang, 47:00
\[r(N, m) = \binom{N}{0} + \binom{N}{1} + \cdots + \binom{N}{m}\]
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4.2))
# --- Sol: formul bar + sayisal izgara noktalari (BIREBIR ustune) ---
Ns = list(range(1, 7))
formul = [r_pieces(N, 2) for N in Ns] # [2,4,7,11,16,22]
numeric = [regions_numeric(N, seed=5, grid=700 + 200 * N)[0] for N in Ns]
axL.bar(Ns, formul, color=COL_PRIMARY, width=0.6, label="formül r(N,2)", zorder=2)
axL.scatter(Ns, numeric, color=COL_VEC3, s=80, zorder=5, edgecolor="white",
linewidth=1.2, label="ızgara sayımı")
for N, f in zip(Ns, formul):
axL.text(N, f + 0.5, str(f), ha="center", va="bottom",
color=COL_TEXT, fontsize=10, fontweight="bold")
axL.set_xlabel("N (katlama)"); axL.set_ylabel("parça sayısı")
axL.set_title("izgara sayımı = formül (6/6 birebir)", color=COL_TEXT,
fontsize=11, fontweight="bold")
axL.set_xticks(Ns); axL.legend(loc="upper left", fontsize=9)
apply_style(axL)
# --- Sag: r(N,m) m=1/2/3 uc egri ---
Ns2 = list(range(1, 11))
r1 = [r_pieces(N, 1) for N in Ns2]
r2 = [r_pieces(N, 2) for N in Ns2]
r3 = [r_pieces(N, 3) for N in Ns2]
axR.plot(Ns2, r1, "-o", color=COL_ACCENT, label="m=1", linewidth=2, markersize=5)
axR.plot(Ns2, r2, "-s", color=COL_PRIMARY, label="m=2", linewidth=2, markersize=5)
axR.plot(Ns2, r3, "-^", color=COL_TEAL, label="m=3", linewidth=2, markersize=5)
axR.set_xlabel("N (katlama)"); axR.set_ylabel("parça sayısı r(N,m)")
axR.set_xticks(Ns2); axR.legend(loc="upper left", fontsize=9, title="boyut m")
axR.annotate("tek katman: N de polinom —\nderinlik (kompozisyon) üstel büyütür",
xy=(6, r3[5]), xytext=(2.6, max(r3) * 0.78),
color=COL_TEXT, fontsize=9,
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_ACCENT, alpha=0.9))
apply_style(axR)
fig.suptitle("Parça sayımı r(N,m) = binom toplamı: formül sayısal bölge sayımıyla BİREBİR (2,4,7,11,16,22)",
color=COL_TEXT, fontsize=12, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()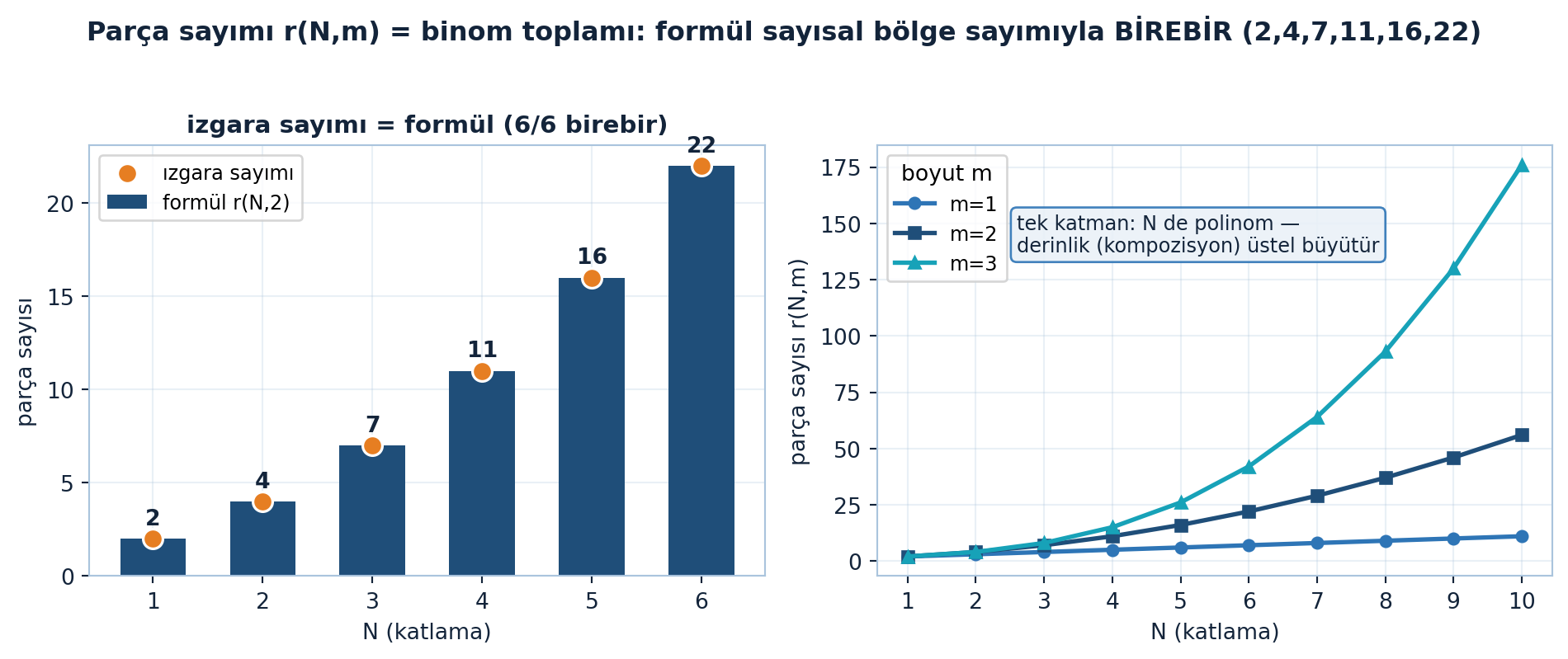
\(m = 2\) (düzlem) için: \(r = \binom{N}{0} + \binom{N}{1} + \binom{N}{2} = 1 + N + N(N-1)/2\). (\(N=4 \rightarrow 1+4+6 = 11\) ✓.) Şekil 27.7 formülün sayısal bölge sayımıyla birebir (\(2,4,7,11,16,22\)) örtüştüğünü ve derinliğin parça sayısını üstel büyüttüğünü gösterir. Parça sayısı boyut \(m\)’de \(N\) ile polinom, ama katman sayısıyla (derinlikle) bileşke alındığında üstel büyür — derin ağların ifade gücü (expressivity) buradan.
İpucuBuilder Notu — Binomun İfade Gücü
“Parça sayısı = binom toplamı” ağın geometrik kapasitesini ölçer. ML köprüsü: derin (çok katmanlı) ağların sığ (tek katman, çok nöron) ağlardan daha verimli olmasının sebebi — derinlik parça sayısını üstel artırır (her katman önceki katlamaları çarpar), sığlık sadece polinom. “Neden derin?” sorusunun matematiksel cevabı.
27.9 Derinlik ve Epoch
Neden çok katman? Katmanlar bilgiyi ayrıştırır:
“…you can separate what layer one learns about the data and from what layer two learns…” — Strang, 22:29
Katman 1 temel özellikleri (kenarlar), katman 2 daha karmaşık desenleri (şekiller), katman 3 daha soyut kavramları öğrenir — hiyerarşik temsil. Eğitim epoch’larla ölçülür:
“…one epoch is the number of steps that matches [the training data size]…” — Strang, 12:58
Bir epoch = SGD adımlarının (mini-batch’lerin) tüm eğitim verisini bir kez taraması. Spiral gibi zor problemler binlerce epoch ister.
İpucuBuilder Notu — Kenardan Kavrama
“Katman 1 kenar, katman 2 şekil, katman 3 kavram” hiyerarşik özellik öğrenme derin öğrenmenin sezgisel gücü. ML köprüsü: CNN’lerde (Ders 32) bu somut — ilk katmanlar kenar/doku, son katmanlar nesne dedektörleri; transfer öğrenme bu hiyerarşiyi yeniden kullanır. Epoch, learning rate schedule ve early stopping eğitim döngüsünün pratik parametreleri.
27.10 Bu Dersin Özeti
- Öğrenme fonksiyonu \(F(x)\): eğitim verisini öğrenir; sınıflandırmada \(F<0 \rightarrow -1\), \(F>0 \rightarrow +1\). Her noktayı doğru yapma (aşırı-öğrenme).
- ReLU: \(\text{ReLU}(x) = \max(0,x)\); doğrusal-olmamazlık şart (yoksa derinlik tek matrise çöker).
- Katman: \(y = Ax + b\) (affine, ağırlık matrisi + bias) \(\rightarrow x = \text{ReLU}(y)\) (bileşen-bileşen).
- Kompozisyon: \(F = F_3(F_2(F_1(x)))\), \(F_k(v) = \text{ReLU}(A_k v + b_k)\); zincir → zincir kuralı → backprop (Ders 27).
- \(F\) sürekli parçalı-doğrusal: origami; ReLU katlama çizgileri yaratır.
- Universality: yeterli katlamayla her sürekli fonksiyon yaklaşıklanabilir.
- Parça sayımı: \(r(N,m) = \sum \binom{N}{k}\); \(m=2 \rightarrow 1+N+N(N-1)/2\); derinlik ifade gücünü üstel artırır (motor: \(r(N,2) = 2,4,7,11,16,22\) ızgara sign-pattern sayımıyla birebir).
ÖnemliTek Bir Cümle
Bir sinir ağı, affine katmanların (\(Ax+b\)) ve doğrusal-olmayan ReLU’nun zincirlenmiş kompozisyonudur (\(F = F_3\circ F_2\circ F_1\)); sonuç \(F\) sürekli parçalı-doğrusal bir öğrenme fonksiyonudur, yeterli katmanla her sürekli fonksiyonu yaklaşıklayabilir (universality) ve derinlik parça sayısını üstel artırarak ifade gücünü büyütür.
27.11 Kontrol Soruları
NotSoru 1 — Katmanın iki adımı ve ReLU neden zorunlu
Soru: Bir sinir ağı katmanı hangi iki adımdan oluşur, ve ReLU neden zorunludur?
Cevap: (1) Affine dönüşüm: \(y = Ax + b\) (ağırlık matrisi \(A \times\) girdi \(+\) bias \(b\)). (2) ReLU aktivasyonu: \(x = \text{ReLU}(y) = \max(0,y)\), bileşen-bileşen. ReLU zorunlu çünkü doğrusal-olmamazlık sağlar — onsuz tüm katmanlar doğrusal olurdu ve bileşkeleri tek bir matrise (tek düzleme) çökerdi; spiral gibi doğrusal-ayrılamaz verileri ayıramazdık.
NotSoru 2 — F ne tür bir fonksiyon ve neden
Soru: \(F(x) = F_3(F_2(F_1(x)))\) ne tür bir matematiksel fonksiyondur ve neden?
Cevap: \(F\) sürekli parçalı-doğrusaldır. Her katman affine (sürekli, doğrusal) \(+\) ReLU (sürekli, parçalı-doğrusal) bileşimidir; süreklilerin kompozisyonu sürekli, doğrusal/parçalı-doğrusalların kompozisyonu parçalı-doğrusaldır. Görsel: origami — düz parçalar kenarlarda (ReLU katlama çizgileri) birleşir.
NotSoru 3 — Universality teoremi ve sınırı
Soru: Universality teoremi ne der, sınırı nedir?
Cevap: Yeterli nöron/katman (yeterli katlama) ile herhangi bir sürekli fonksiyon istenildiği kadar yakından yaklaşıklanabilir — düz parçalarla eğriyi istediğin hassasiyette örtersin. Sınır: bu “öğrenilebilir mi?” sorusunu (evet) çözer ama “verimli öğrenir mi, genelleşir mi?” ayrı sorulardır (gerek-koşul, yeterli-koşul değil).
NotSoru 4 — Parça sayısı ve derinlikle büyüme
Soru: ReLU ağında düz parça sayısı nasıl hesaplanır, derinlikle nasıl büyür?
Cevap: \(m\) boyutta \(N\) katlama için \(r(N,m) = \binom{N}{0}+\binom{N}{1}+\cdots+\binom{N}{m}\) (binom toplamı); \(m=2\)’de \(r = 1+N+N(N-1)/2\) (\(N=4 \rightarrow 11\) parça). Tek katmanda parça sayısı \(N\) ile polinom; ama katmanlar bileşke alındığında (derinlik) üstel büyür — her katman önceki katlamaları çarpar. Bu, derin ağların sığ ağlardan neden daha ifade-güçlü olduğunu açıklar.
27.12 Egzersizler
Parametre sayımı. Girdi 5 boyut, gizli katman 8 nöron, çıktı 1. \(A_1\) (\(8\times5\)) \(+ b_1\) (\(8\)) ve \(A_2\) (\(1\times8\)) \(+ b_2\) (\(1\)) kaç ağırlık eder? Toplam parametre? (Motor tanığı: \(A_1\) \(40+8=48\), \(A_2\) \(8+1=9\), toplam \(48+9=57\); bkz.
param_count([5,8,1]).)ReLU hesabı. \(y = (3, -2, 0, 5)^{\top}\). \(\text{ReLU}(y)\) nedir? Kaç bileşen “öldü” (sıfırlandı)? (Motor tanığı: \(\text{ReLU}(y) = (3, 0, 0, 5)\); 2 bileşen (\(-2\) ve \(0\)) sıfırlandı; bkz. Şekil 27.2 sağ panel.)
Parça sayımı. \(m = 2\) düzlem için \(N = 5\) katlama kaç parça verir? \(r(5,2) = \binom{5}{0}+\binom{5}{1}+\binom{5}{2}\)’yi hesapla. (Motor tanığı: \(1 + 5 + 10 = 16\); ders dizisi \(r(N,2) = 2,4,7,11,16,\dots\) ile uyumlu; \(r(N,1) = N+1\).)
Doğrusal-olmamazlık. İki katmanı ReLU olmadan birleştir: \(A_2(A_1x) = (A_2A_1)x\). Bunun neden tek bir doğrusal katmana eşdeğer olduğunu ve spirali ayıramayacağını açıkla. (Motor tanığı: \(A_2(A_1x) = (A_2A_1)x\) maxdiff \(\approx 10^{-12}\); iç-içe elmas verisinde en iyi doğrusal acc \(< 0.75\), 4-ReLU ağ acc \(= 1.000\); bkz. Şekil 27.3.)
(Ders 27 habercisi) \(F = F_3(F_2(F_1(x)))\) bir kompozisyon; SGD bunu eğitmek için \(\nabla F\) (ağırlıklara göre gradyan) gerektirir. Kompozisyonun türevi hangi kuralla hesaplanır? Bu hesabı verimli organize eden algoritma ne? Bir tahmin yaz — Ders 27 “backpropagation: kısmi türevleri bulmak” ile zincir kuralının matris organizasyonunu işliyor.
27.13 Sonraki Ders İçin Hazırlık
Ders 27: Backpropagation — Kısmi Türevleri Bulmak. SGD’nin ihtiyaç duyduğu gradyanı (\(\nabla F\), ağırlıklara göre) verimli hesaplama: zincir kuralının organize edilmiş hâli. \(F = F_3\circ F_2\circ F_1\) kompozisyonunun türevi, katman Jacobian’larının çarpımıdır. Phase 2’nin dört tanığı buluşur: Strang’ın matris-çarpım dili = Karpathy micrograd _backward = fast.ai manuel .g = NYU Jacobian zinciri — dört yol, aynı backprop.
UyarıHazırlık
Bu dersteki Egzersiz 5’in sorduğu soruyu zihninde tut: \(F = F_3\circ F_2\circ F_1\) kompozisyonunun ağırlıklara göre türevi hangi kuralla, hangi algoritmayla verimli hesaplanır? Ders 27 cevabı veriyor — zincir kuralının matris-çarpım hâli backpropagation. Bu, Phase 2 boyunca dört ayrı kursta (\(18.065\), Karpathy, fast.ai, NYU) gördüğümüz aynı fikrin tek noktada buluştuğu yerdir; backprop’un “neden çarpım” olduğunu Ders 26’nın kompozisyon zinciri (\(F = F_3\circ F_2\circ F_1\)) önceden açıklar.
27.14 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Strang (dk) |
|---|---|---|
| Öğrenme fonksiyonu F | \(F<0 \rightarrow\) sınıf \(-1\), \(F>0 \rightarrow +1\) | 1m41 |
| ReLU | \(\max(0, x)\); doğrusal-olmamazlık şart | 10m13 |
| Katman | \(y = Ax + b\) (affine) \(\rightarrow x = \text{ReLU}(y)\) | 20m23 |
| Kompozisyon | \(F = F_3(F_2(F_1(x)))\); \(F_k = \text{ReLU}(A_k v + b_k)\) | 25m44 |
| Sürekli parçalı-doğrusal | origami; ReLU katlama çizgileri | 29m04 |
| Universality | her sürekli fonksiyon yaklaşıklanabilir | 39m41 |
| Parça sayımı | \(r(N,m) = \binom{N}{0}+\cdots+\binom{N}{m}\) | 47m00 |
| Derinlik | katman 1 kenar, 2 şekil, 3 kavram | 22m29 |
| Epoch | veri kümesinin bir tam geçişi | 12m58 |
27.15 ML Bağlantıları Özeti
- \(F\) = ağırlık matrisleri + ReLU zinciri: PyTorch
nn.Sequential(nn.Linear, nn.ReLU, …); SGD (Ders 25) \(A\)’ları ayarlar. - ReLU = ifade gücü: doğrusal-olmamazlık olmadan derinlik anlamsız; sigmoid→ReLU geçişi derin öğrenme devrimini tetikledi.
- Universality + parça sayımı: derin ağlar her fonksiyonu öğrenebilir; derinlik parça sayısını üstel artırır (sığ ağlardan verimli).
- Hiyerarşik özellik: katman 1 kenar, katman 2 şekil, katman 3 kavram (CNN’lerde somut, Ders 32); transfer öğrenme bu hiyerarşiyi yeniden kullanır.
- Kompozisyon → backprop: \(F = F_3\circ F_2\circ F_1\) türevi zincir kuralıyla (Ders 27); Karpathy micrograd + fast.ai manuel backprop + NYU Jacobian zinciri ile aynı.
- Parçalı-doğrusal geometri: ReLU ağı girdi uzayını polytope bölgelere böler; yorumlanabilirlik araştırmasının konusu.
- Geriye köprü: Ders 25 (SGD, \(f_i\) = NN kaybı), Ders 21 (zincir kuralı → backprop), Ders 2 (kompozisyon/çarpanlama). Paralel: NYU H1 (spiral sınıflandırma), Karpathy micrograd (fonksiyon kompozisyonu).
ÖnemliKapanış
“…constructing this function F which learns the training data…” — Strang, 1:41
Bir sinir ağı, affine katmanlar ve ReLU’nun kompozisyonundan ibarettir; bu basit yapı (\(Ax+b\), sonra \(\max(0,\cdot)\)) yeterince derinleştiğinde her fonksiyonu öğrenebilen evrensel bir makine olur.