flowchart TB
M["Gradient descent: minimuma doğru aşağı"]
M --> A["x+ = x - s grad F<br/>(s = learning rate)"]
M --> B["gradyan = en dik çıkış<br/>-gradyan iniş; seviye kümesine DİK"]
M --> C["Hessian PYT <-> konveks<br/>kuadratikte H = S sabit"]
M --> D["adım boyu: büyük -> salınım<br/>küçük -> yavaş<br/>line search: exact / backtracking"]
M --> E["kritik örnek: f = (1/2)(x^2 + b y^2)<br/>kapalı-form (Boyd-Vandenberghe)"]
E --> R["yakınsama oranı<br/>r = (1-b)/(1+b)"]
R --> K["kötü kondisyon -> uzun-dar vadi -> ZİKZAK"]
K --> N["Ders 23: momentum zikzağı söndürür"]
classDef merkez fill:#1f4e79,stroke:#15375a,stroke-width:2px,color:#ffffff;
classDef dal fill:#2e75b6,stroke:#1f4e79,stroke-width:1.5px,color:#ffffff;
classDef sky fill:#9dc3e6,stroke:#2e75b6,stroke-width:1.5px,color:#1f4e79;
class M merkez;
class A,B,C,D,E dal;
class R,K,N sky;
23 Gradient Descent — Minimuma Doğru Aşağı
Adım boyu, line search ve kondisyon sayısının zikzak dersi
NotBölüm bilgisi
Bu ders derin öğrenmenin merkezi algoritmasını kurar: bir maliyet fonksiyonunu sadece birinci türevle (gradyan) adım adım küçültmek. Strang’in Ders 22 videosu (≈53 dk) ve OCW Lecture 22 temel alınmıştır. Okuma süresi ≈34 dk; önkoşul Ders 21 (Newton, Taylor, konvekslik).
23.1 Bu Derste Ne Var?
Newton’ın pahalı Hessian’ını (Ders 21) bıraktıktan sonra geriye derin öğrenmenin merkezi algoritması kalır: bir maliyet fonksiyonunu sadece birinci türevle (gradyan) iniş yönünde adım atarak küçültmek. İkinci türev (Hessian) milyon parametrede erişilemez olduğundan, her adım yalnızca bir gradyan hesabıdır. Strang her şeyi gören tek bir kuadratik örnek seçer (\(f = \tfrac{1}{2}(x^{2} + by^{2})\)), her adımı kapalı-formda çözer ve kondisyon sayısının yakınsama hızını nasıl kontrol ettiğini gözle görülür kılar.
Beş sonuç:
- Gradient descent: \(x_{+} = x - s\nabla F(x)\); \(s\) = adım boyu (learning rate).
- Gradyan = en dik çıkış yönü; \(-\)gradyan = en dik iniş, seviye kümesine dik.
- Hessian ⊕ konvekslik: \(H\) pozitif yarı-tanımlı ⇔ konveks; pozitif tanımlı ⇔ kesin konveks.
- Adım boyu seçimi: tam çizgi araması (exact line search) veya backtracking; çok büyük → salınım, çok küçük → yavaş.
- Kondisyon sayısı hızı belirler: örnekte yakınsama oranı \((1-b)/(1+b)\); \(b\) küçük (kötü \(\kappa\)) → oran ≈1 → yavaş, zikzak.
“…that central algorithm of neural net deep learning, machine learning…” — Strang, 0:24
Şekil 23.1 dersin iskeletini gösterir: merkezdeki “minimuma doğru aşağı” fikri tek satırlık güncelleme kuralından gradyanın geometrisine, Hessian/konvekslik testine ve adım boyu seçimine dallanır; kritik kuadratik örnek ise yakınsama oranı \(r\) üzerinden kötü kondisyonun yarattığı zikzağa ve Ders 23’ün momentum çözümüne bağlanır.
İpucuBuilder Notu — Tek Satırlık Devrim
Bu dersin tamamı tek bir satıra indirgenir: \(x_{+} = x - s\nabla F\). Derin öğrenmenin her ağırlık güncellemesi bu satırdır — gradyan yönü zaten belli, geriye yalnızca “ne kadar gidelim?” (adım boyu \(s\)) kalır. Newton’ın akıllı ama pahalı Hessian’ını bırakıp sadece eğimle inmek; milyar-parametreli modeller ancak bu ucuz adım sayesinde eğitilebilir. ML köprüsü: PyTorch’ta w -= lr * w.grad tam bu satırdır; SGD, Adam, RMSProp hepsi bu iskeletin üzerine adım-boyu/yön ayarlamaları ekler.
23.2 Gradient Descent ve Kritik Örnek
Çok değişken varsa (ikinci türev/Hessian almak için fazla), birinci türevle (gradyan) yetiniriz. Strang her şeyi gösteren tek bir örnek seçer — saf kuadratik, iki bilinmeyen:
\[F(x, y) = \tfrac{1}{2}(x^{2} + b\,y^{2}), \qquad S = \begin{bmatrix} 1 & 0 \\ 0 & b \end{bmatrix}\]
\(S\) simetrik, köşegen, özdeğerleri \(1\) ve \(b\) (\(b < 1\), küçük olan). Minimum \((0, 0)\)’da. Kritik büyüklük kondisyon sayısı \(= \lambda_{\max}/\lambda_{\min} = 1/b\):
“…the condition number, which we’ll see [is all important in the speed of convergence]…” — Strang, 1:52
\(1/b\) büyükse (\(b\) çok küçük), başımız dertte. Bu küçük örnekte adımları tam yazıp ne kadar hızlı yakınsadığımızı göreceğiz.
İpucuBuilder Notu — Her Şeyi Gören Küçük Örnek
“Her şeyi gören küçük örnek” Strang’ın pedagojik imzası: \(2\times 2\) kuadratikte gradient descent’in tüm davranışı (hız, zikzak, kondisyon bağı) kapalı-formda okunur. ML köprüsü: gerçek kayıp yüzeyleri milyon-boyutlu ama yerel olarak kuadratiktir (Taylor, Ders 21); bu örnekteki kondisyon-sayısı dersi doğrudan gerçek eğitime taşınır.
23.3 Gradyanın Anlamı: En Dik İniş
Gradyanı sezgiyle yerleştir. Lineer örnek \(f(x,y) = 3x + 4y\): gradyan sabit \((3, 4)\), Hessian sıfır. Gradyan bir yön gösterir:
“The gradient direction is the way up.” — Strang, 7:14
Gradyan = yüzeyde en dik çıkış yönü; \(-\)gradyan = en dik iniş yönü (steepest descent’teki eksi). Gradyan, seviye kümesine ($f = $ sabit) diktir: seviye kümesinde kalırsan \(f\) değişmez (gradyan oraya teğet sıfır bileşen), gradyan yönünde gidersen en hızlı değişir.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4))
# --- SOL: lineer f = 3x + 4y, seviye dogrulari + gradyan (3,4) ---
g_lin = np.array([3.0, 4.0])
xs = np.linspace(-3, 3, 50)
# 3x + 4y = c -> y = (c - 3x) / 4
for c in [-12, -4, 4, 12]:
ys = (c - 3 * xs) / 4.0
axL.plot(xs, ys, color=COL_ACCENT, lw=1.6, alpha=0.85)
# gradyan oku (1,2) noktasinda, (3,4)/5 olcekli
p0 = np.array([1.0, 2.0])
g_hat = g_lin / np.linalg.norm(g_lin) # (0.6, 0.8)
axL.annotate("", xy=(p0[0] + 1.4 * g_hat[0], p0[1] + 1.4 * g_hat[1]),
xytext=(p0[0], p0[1]),
arrowprops=dict(arrowstyle="-|>", color=COL_VEC3, lw=2.6))
axL.plot(*p0, "o", color=COL_VEC3, ms=7)
axL.text(p0[0] + 1.5 * g_hat[0], p0[1] + 1.5 * g_hat[1], r"$\nabla f=(3,4)$",
color=COL_VEC3, fontsize=10, fontweight="bold", ha="left", va="bottom")
axL.set_xlim(-3, 3); axL.set_ylim(-3, 3.5)
axL.set_aspect("equal", adjustable="box")
axL.set_title("lineer: gradyan sabit (3,4),\nseviye dogrularina dik (Egz2: ic carpim 0)",
fontsize=10, fontweight="bold")
axL.set_xlabel("x"); axL.set_ylabel("y")
apply_style(axL)
# --- SAG: kuadratik F = 0.5(x^2 + 0.3 y^2) konturlari + -gradyan oklari ---
b_r = 0.3
xg = np.linspace(-3, 3, 240); yg = np.linspace(-3.5, 3.5, 240)
X, Y = np.meshgrid(xg, yg)
Z = 0.5 * (X**2 + b_r * Y**2)
axR.contour(X, Y, Z, levels=10, cmap=NAVY_CMAP, linewidths=1.2)
# 5 noktada -gradyan (normalize) — kontura dik, merkezi gostermiyor
pts = [(2.4, 2.8), (-2.2, 2.4), (2.6, -2.2), (-2.4, -2.6), (2.8, 0.6)]
for px, py in pts:
g = grad_quad((px, py), b_r) # (x, 0.3 y)
ng = g / np.linalg.norm(g)
axR.annotate("", xy=(px - 0.9 * ng[0], py - 0.9 * ng[1]),
xytext=(px, py),
arrowprops=dict(arrowstyle="-|>", color=COL_VEC3, lw=2.2))
axR.plot(px, py, "o", color=COL_VEC3, ms=4.5)
axR.plot(0, 0, "x", color=COL_PRIMARY, ms=10, mew=2.5)
axR.set_xlim(-3.4, 3.4); axR.set_ylim(-3.8, 3.8)
axR.set_aspect("equal", adjustable="box")
axR.set_title("kuadratik: -gradyan kontura dik\nama merkezi GOSTERMEZ",
fontsize=10, fontweight="bold")
axR.set_xlabel("x"); axR.set_ylabel("y")
apply_style(axR)
fig.suptitle("Gradyan = en dik cikis, seviye kumesine dik; -gradyan en dik inis "
"- ama en dik yol her zaman en kisa yol degil",
fontsize=11, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()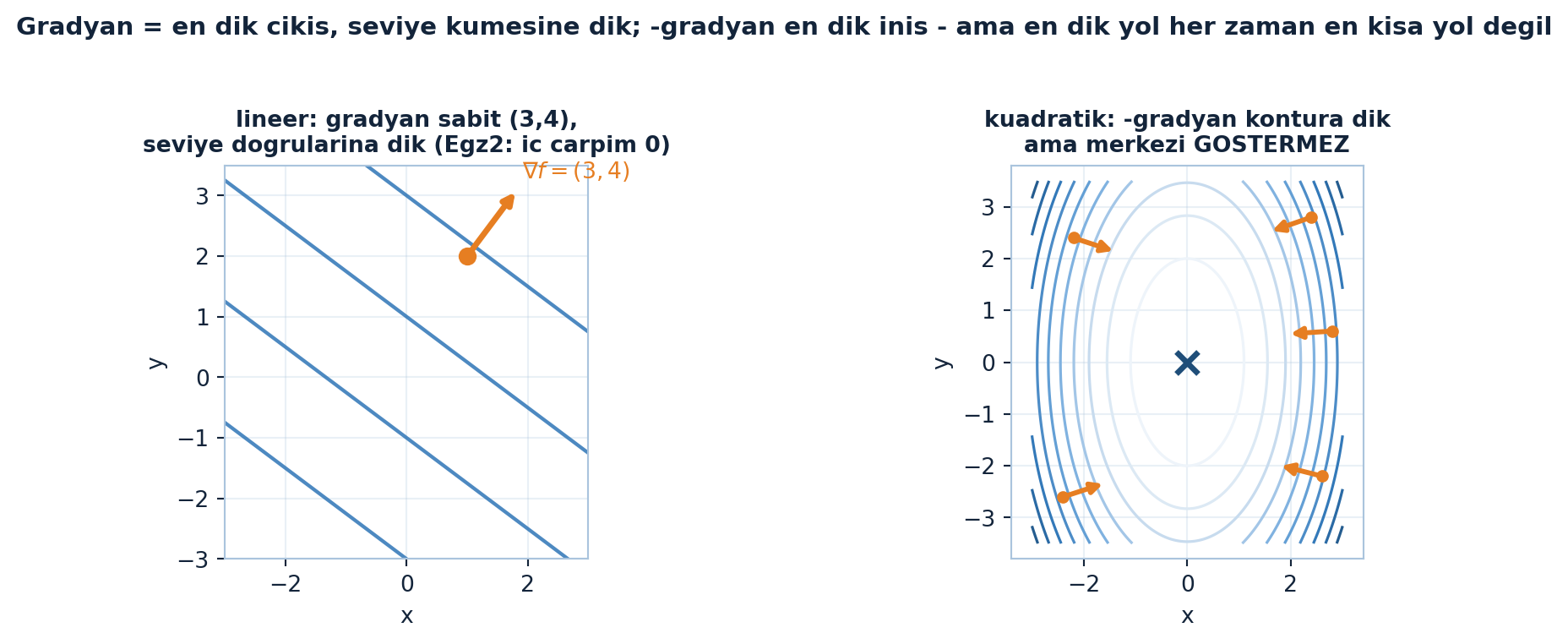
Şekil 23.2 gradyanın iki yüzünü yan yana koyar: solda lineer \(f = 3x + 4y\)’nin sabit gradyanı \((3,4)\) seviye doğrularına dik (iç çarpım 0, Egzersiz 2); sağda kuadratik konturlarda \(-\)gradyan her noktada kontura dik ama merkeze işaret etmez — en dik iniş yönü her zaman en kısa yol değildir.
İpucuBuilder Notu — Yokuş Yukarı Gradyan Aşağı Eksi
“Gradyan seviye kümesine dik, en dik çıkış yönü” geometrisi optimizasyonun temel sezgisidir: tepeye en hızlı tırmanmak = gradyan, vadiye en hızlı inmek = \(-\)gradyan. ML köprüsü: backprop (Ders 27) tam bu gradyanı hesaplar; her ağırlık güncellemesi \(-\)gradyan yönünde küçük bir adımdır. “En dik” yön her zaman en kısa yol değildir (zikzak) — Newton/momentum bunu düzeltir.
23.4 Hessian ve Konvekslik
Hessian (ikinci türev matrisi) yüzeyin eğriliğini söyler — ve konveksliği belirler:
“Positive definite or semi definite.” — Strang, 11:12
Test: \(H\) pozitif yarı-tanımlı ⟺ fonksiyon konveks; \(H\) pozitif tanımlı ⟺ kesin konveks (her yönde gerçekten yukarı büker). Lineer fonksiyon konvekstir ama kesin değil (\(H = 0\)). Saf kuadratik için:
\[F(x) = \tfrac{1}{2}x^{T}Sx - a^{T}x \;\Rightarrow\; \nabla F = Sx - a, \quad H = S\]
Burada Hessian sabittir (\(H = S\), her noktada aynı) — kuadratiğin güzelliği. \(S\) pozitif tanımlıysa \(F\) kesin konvekstir, tek minimumu vardır: \(\nabla F = 0 \Rightarrow Sx = a \Rightarrow x^{*} = S^{-1}a\).
İpucuBuilder Notu — Kuadratiğin Sabit Eğriliği
“Hessian PYT ⟺ konveks” testi (Ders 5 + Ders 21) eğitim peyzajını sınıflar. ML köprüsü: kuadratik yaklaşımda \(H = S\) sabit; gerçek ağlarda \(H\) noktadan noktaya değişir ve çoğu yerde belirsizdir (eyer, Ders 19) — bu yüzden derin öğrenme konveks değildir ama yerel kuadratik analiz (bu örnek) yine de eğitim dinamiğini açıklar.
23.5 Gradient Descent Formülü
Algoritma basit: her adımda negatif gradyan yönünde bir adım at:
\[x_{k+1} = x_{k} - s_{k}\,\nabla F(x_{k})\]
\(s_{k}\) = adım boyu (step size / learning rate). Tek karar verilmesi gereken şey budur — gradyan yönü zaten belli, geriye “ne kadar gidelim?” kalır. Kuadratik örnekte \(\nabla F = (x, by)\) (\(S = \mathrm{diag}(1,b)\)), yani:
\[(x_{k+1}, y_{k+1}) = (x_{k}, y_{k}) - s_{k}\,(x_{k},\, b\,y_{k})\]
Her iterasyon mevcut noktadan eğim aşağı küçük bir adım. Milyonlarca parametre için bile her adım sadece bir gradyan hesabı (ucuz) — Newton’ın Hessian-tersi (pahalı) yerine.
İpucuBuilder Notu — PyTorch’un O Satırı
\(x_{k+1} = x_{k} - s\nabla F\) derin öğrenmenin tek satırıdır: her ağırlık güncellemesi budur. ML köprüsü: PyTorch’ta w -= lr * w.grad tam bu satır; SGD (Ders 25), Adam, RMSProp hepsi bu iskeletin üzerine adım-boyu/yön ayarlamaları ekler. Ucuz adım (sadece gradyan) sayesinde milyar-parametreli modeller eğitilebilir.
23.6 Adım Boyu (Learning Rate)
Geriye tek karar kalır: adım boyu.
“…a step size, the learning rate.” — Strang, 34:52
Sabit alınabilir. Çok büyük learning rate → fonksiyon her yere sıçrar, salınır, felaket. Çok küçük → adımlar minik, çok uzun sürer. Sorun “tam doğru”yu bulmak. Pratikte büyük problemlerde: uygun bir \(s\) tahmin et, bir süre kullan, sonra geriye bakıp (salınım var mı?) ayarla.
Kod
b = 0.1
p0 = np.array([0.1, 1.0])
path_a = gd_fixed(b, 0.05, p0, 40)
path_b = gd_fixed(b, 1.0, p0, 40)
path_c = gd_fixed(b, 2.5, p0, 40)
na = np.clip(np.linalg.norm(path_a, axis=1), 1e-17, None)
nb = np.clip(np.linalg.norm(path_b, axis=1), 1e-17, None)
nc = np.clip(np.linalg.norm(path_c, axis=1), 1e-17, None)
fig, ax = plt.subplots(figsize=(7.5, 4.4))
ax.semilogy(na, color=COL_ACCENT, lw=2.2, marker="o", ms=3,
label="s = 0.05: surunur (40 adimda 0.82)")
ax.semilogy(nb, color=COL_PRIMARY, lw=2.2, marker="o", ms=3,
label="s = 1.0: iner (1.5e-2)")
ax.semilogy(nc, color=COL_VEC3, lw=2.2, marker="o", ms=3,
label="s = 2.5 > 2/lambda_max: IRAKSAR (1e+6)")
ax.set_xlabel("adim k")
ax.set_ylabel("uzaklik (log)")
ax.set_title("Adim boyu uclari: cok kucuk surunur, iyi iner, cok buyuk PATLAR\n(stabilite siniri s < 2/lambda_max = 2)",
fontsize=11, fontweight="bold")
ax.legend(loc="center left", framealpha=0.9)
apply_style(ax)
plt.show()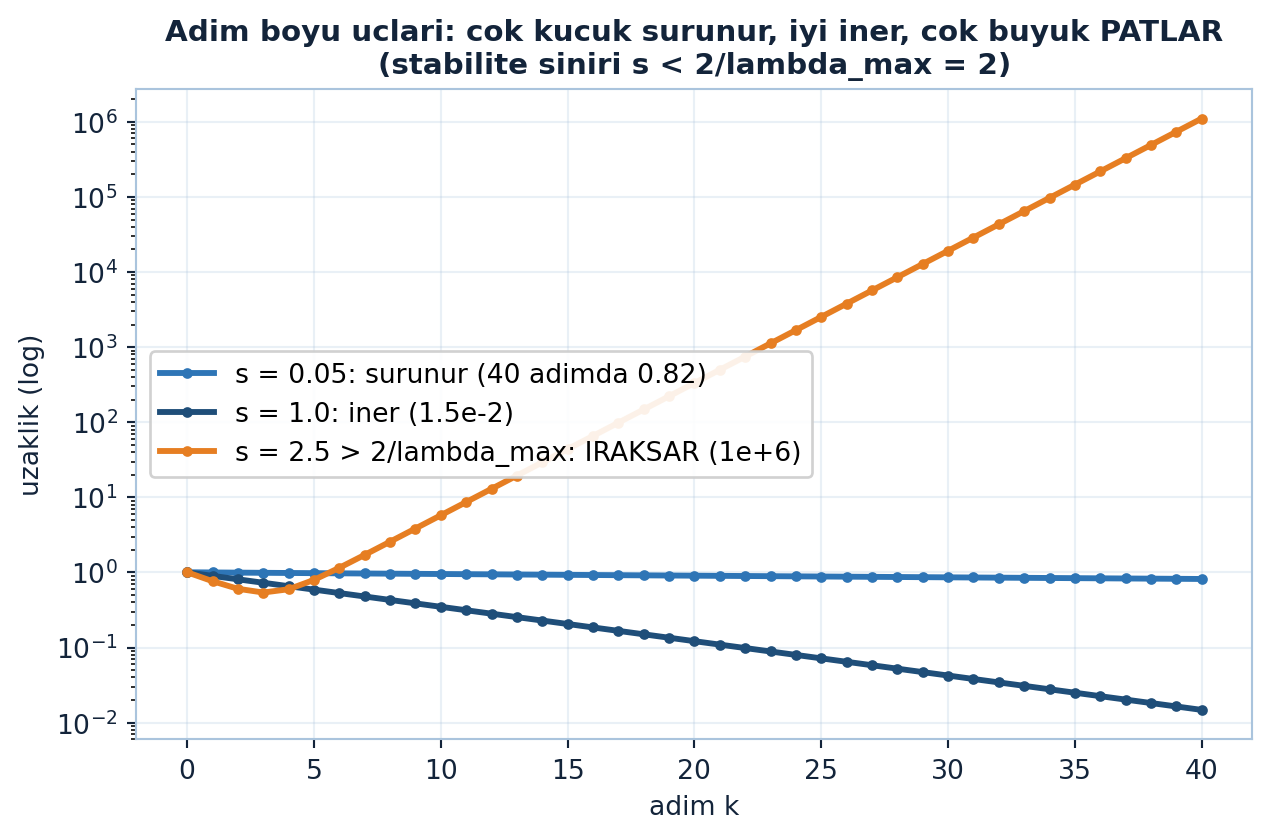
Şekil 23.3 üç adım boyu senaryosunu tek bir semilogy ekranda kıyaslar (\(b = 0.1\), başlangıç \((0.1, 1)\)): \(s = 0.05\) sürünür (40 adımda hâlâ 0.82 uzakta), \(s = 1.0\) düzgün iner (1.5e-2), \(s = 2.5\) ise stabilite sınırını (\(2/\lambda_{\max} = 2\)) aştığı için iraksar (\(\|p_{40}\| \approx 10^{6}\) yukarı fırlar).
İpucuBuilder Notu — En Pahalı Tek Sayı
Learning rate, derin öğrenmenin en kritik hiperparametresidir: çok büyük → kayıp NaN’a patlar; çok küçük → günlerce eğitir. ML köprüsü: learning rate schedule (cosine decay, warmup), adaptif yöntemler (Adam, RMSProp) ve learning-rate-finder araçları bu “tam doğru” arayışını otomatikleştirir. Strang’ın “tahmin et, kullan, geriye bak” reçetesi pratikte hâlâ geçerli.
23.7 Line Search: Exact ve Backtracking
Adım boyunu sistematik seçmenin iki yolu. Exact line search (tam çizgi araması): \(s_{k}\)’yi, \(F\)’yi arama yönü (\(-\)gradyan) boyunca minimum yapacak şekilde seç.
“…an exact line search…” — Strang, 36:09
Konveks fonksiyonda arama çizgisi boyunca ilerledikçe \(F\) önce düşer, bir noktada yükselmeye başlar; exact search tam o dönüm noktasını bulur. Pahalıdır (her adımda bir alt-optimizasyon). Backtracking line search: sabit bir \(s_{0}\) ile başla; çok ileri gittiyse yarıya kes (\(s_{0} \to \tfrac{1}{2}s_{0} \to \tfrac{1}{4}s_{0} \to \dots\)), tatmin olana dek geri çekil:
\[s_{0},\ \tfrac{1}{2}s_{0},\ \tfrac{1}{4}s_{0},\ \dots \quad (\text{veya } a\, s_{0},\ a^{2}s_{0}, \dots)\]
Backtracking ucuz ve pratiktir; exact search optimal ama yavaş.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4))
# --- Sol: exact line search ---
p = np.array([0.3, 0.8])
ss = np.linspace(0, 3, 300)
prof = line_profile(p, 0.1, ss)
axL.plot(ss, prof, color=COL_PRIMARY, lw=2, label="F(p - s·∇F)")
s_e = exact_step_quad(p, 0.1) # = 1.0635
F_e = F_quad(p - s_e * grad_quad(p, 0.1), 0.1)
axL.axvline(s_e, color=COL_VEC3, lw=1.8, ls="-")
axL.plot([s_e], [F_e], "o", color=COL_VEC3, ms=9, zorder=5)
axL.annotate("exact: 1.0635 (dönüm noktası)", xy=(s_e, F_e),
xytext=(s_e + 0.25, F_e + 0.04), color=COL_VEC3, fontsize=10, fontweight="bold",
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.4))
axL.set_xlabel("adım boyu s"); axL.set_ylabel("F arama doğrusu boyunca")
axL.set_title("exact line search: F önce düşer sonra çıkar", fontsize=11, fontweight="bold")
apply_style(axL)
# --- Sağ: backtracking (Armijo) ---
p2 = np.array([0.1, 1.0])
ss2 = np.linspace(0, 8.5, 400)
prof2 = line_profile(p2, 0.1, ss2)
axR.plot(ss2, prof2, color=COL_PRIMARY, lw=2, label="F(p - s·∇F)")
g2 = grad_quad(p2, 0.1); gnorm2 = float(g2 @ g2)
F_p2 = F_quad(p2, 0.1)
# Armijo koşul çizgisi: F(p2) - 0.5*s*||g||^2
armijo = F_p2 - 0.5 * ss2 * gnorm2
axR.plot(ss2, armijo, color="#888888", lw=1.6, ls="--", label="Armijo koşul çizgisi")
# denenenler [8,4,2] reddedildi, s=1 kabul
for s_try in [8, 4, 2]:
Fs = F_quad(p2 - s_try * g2, 0.1)
axR.plot([s_try], [Fs], "X", color="#d6541f", ms=11, zorder=5)
s_acc, tried = backtracking_step(p2, 0.1, s0=8, alpha=0.5, c=0.5) # accept 1.0
F_acc = F_quad(p2 - s_acc * g2, 0.1)
axR.plot([s_acc], [F_acc], "*", color=COL_TEAL, ms=18, zorder=6, label="kabul s = 1")
axR.annotate("8 → 4 → 2 → 1 KABUL", xy=(s_acc, F_acc),
xytext=(2.6, F_p2 + 0.08), color=COL_TEAL, fontsize=10, fontweight="bold",
arrowprops=dict(arrowstyle="->", color=COL_TEAL, lw=1.4))
axR.set_xlabel("adım boyu s"); axR.set_ylabel("F arama doğrusu boyunca")
axR.set_title("backtracking: yarıla-yarıla kabul (ucuz)", fontsize=11, fontweight="bold")
axR.legend(loc="upper right", fontsize=8.5, framealpha=0.92)
apply_style(axR)
fig.suptitle("Adım boyu seçimi: exact (optimal, pahalı) vs backtracking (Armijo — pratik)",
color=COL_TEXT, fontsize=12.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()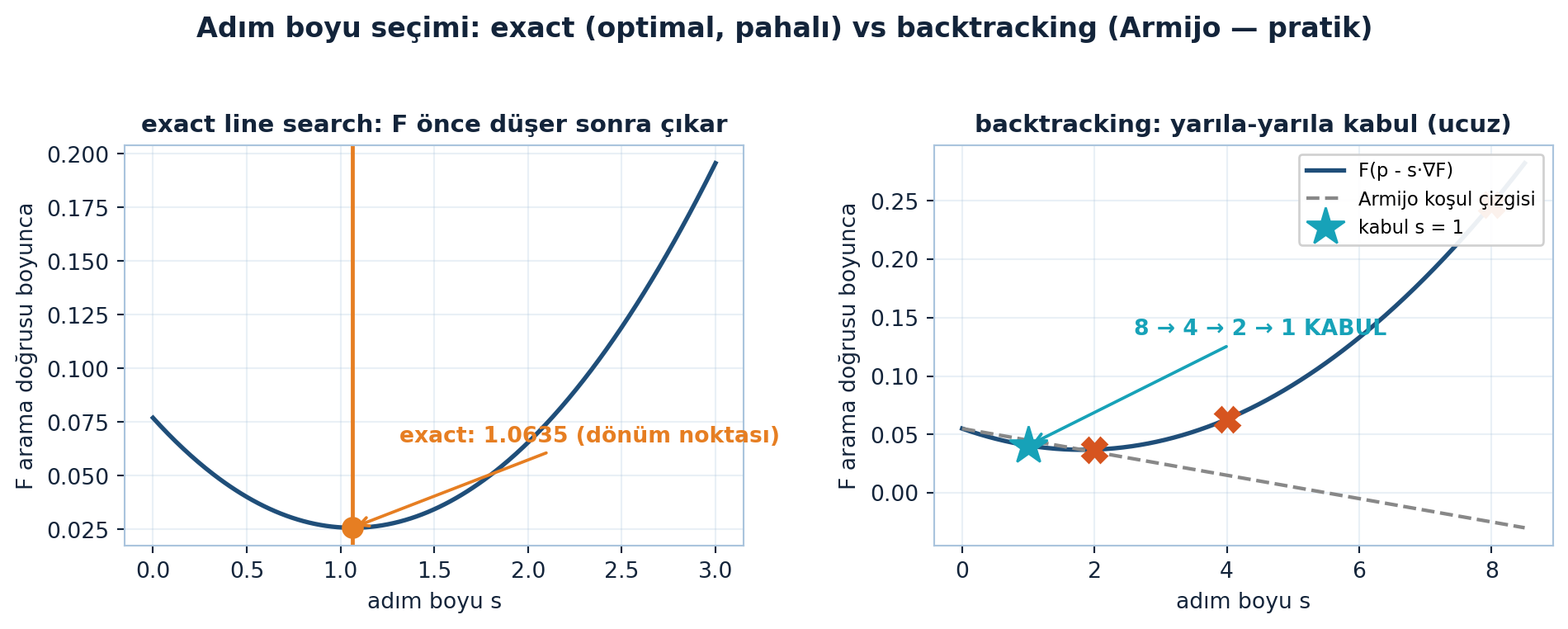
Şekil 23.4 iki stratejiyi yan yana koyar: solda exact line search arama doğrusu boyunca \(F\)’nin tam dönüm noktasını (\(s = 1.0635\)) bulur (optimal ama pahalı); sağda backtracking \(s_{0} = 8\)’den başlayıp \(8 \to 4 \to 2 \to 1\) yarılayarak Armijo koşulunu sağlayan \(s = 1\)’i kabul eder (ucuz ve pratik).
İpucuBuilder Notu — Optimal mi Ucuz mu
Exact vs backtracking, “optimal ama pahalı” vs “yaklaşık ama ucuz” klasik ödünleşmesidir. ML köprüsü: derin öğrenmede line search neredeyse hiç kullanılmaz (her adım çok pahalı) — bunun yerine sabit/programlı learning rate tercih edilir. Backtracking (Armijo koşulu) klasik optimizasyonda ve L-BFGS’te standarttır; “geri çekil, kontrol et” mantığı trust-region yöntemlerinin de temeli.
23.8 Kritik Örnek: Tam Çözüm
Kuadratik örnekte (\(f = \tfrac{1}{2}(x^{2} + by^{2})\)) exact line search’le başla, başlangıç \((x_{0}, y_{0}) = (b, 1)\) — formülleri sadeleştiren akıllı seçim. Strang sonucu Boyd & Vandenberghe’nin Convex Optimization kitabından alır:
“…the book by Steven Boyd and Vandenberghe called Convex Optimization.” — Strang, 42:56
İterasyonlar kapalı-formda çıkar (\(q = (b-1)/(b+1)\) ve \(r = (1-b)/(1+b)\) kilit oranlar):
\[x_{k} = b\,q^{k} \quad (q < 0), \qquad y_{k} = r^{k}, \qquad F_{k} = r^{2k}\,F_{0}\]
[motor notu]: Notion/Boyd-Vandenberghe özeti \(y_{k}\)’yi \(q^{k}\) yazar; sayısal iz (maxdiff 1e-16) \(y_{k}\)’nin pozitif-monoton \(r^{k}\) olduğunu gösterir — zikzak dar (x) eksendedir; \(F_{k} = r^{2k}F_{0}\) işaretten bağımsız birebir.
Her adımda \(x\) işaret değiştirir (\(q < 0\), dar eksende zikzak), \(y\) pozitif-monoton sürünür, \(F\) sabit \(r^{2}\) oranıyla çarpılır. İşte gradient descent’in hızı tek bir sayıda: \(r = (1-b)/(1+b)\).
“…this ratio 1 minus b over 1 plus b is crucial.” — Strang, 45:11
Kod
b = 0.1
path = gd_exact(0.1, n_iter=20)
xk, yk, Fk, r = closed_form(0.1, 20)
k = np.arange(21)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4.2))
# Sol: x_k ve y_k — sayısal vs formül üst üste
ax1.semilogy(k, np.abs(path[:, 0]), "o", color=COL_PRIMARY, ms=5, label="sayısal |x_k|")
ax1.semilogy(k, np.abs(xk), "--", color=COL_PRIMARY, label="formül b|q|^k")
ax1.semilogy(k, path[:, 1], "s", color=COL_ACCENT, ms=5, label="sayısal y_k")
ax1.semilogy(k, yk, "--", color=COL_ACCENT, label="formül r^k")
ax1.set_xlabel("adım k"); ax1.set_ylabel("bileşen (log)")
ax1.set_title("bileşenler: sayısal noktalar = formül kesik (üst üste)", color=COL_TEXT, fontsize=11, fontweight="bold")
ax1.legend(fontsize=8)
apply_style(ax1)
# Sağ: F_k — sayısal vs formül üst üste
Fs = np.array([F_quad(p, 0.1) for p in path])
ax2.semilogy(k, Fs, "o", color=COL_VEC3, ms=5, label="sayısal F_k")
ax2.semilogy(k, Fk, "--", color=COL_VEC3, label="formül r^2k F_0")
ax2.annotate("her adım × 0.6694 = r^2", xy=(10, Fk[10]), xytext=(6, Fk[2]),
fontsize=9, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_PRIMARY, lw=1.2))
ax2.set_xlabel("adım k"); ax2.set_ylabel("F (log)")
ax2.set_title("değer F_k: sayısal = formül r^2k F_0", color=COL_TEXT, fontsize=11, fontweight="bold")
ax2.legend(fontsize=8)
apply_style(ax2)
fig.suptitle("Boyd-Vandenberghe kapalı-formu SAYISALLA BİREBİR (maxdiff ~ 1e-16): r = 9/11 = 0.8182 (b = 0.1)",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()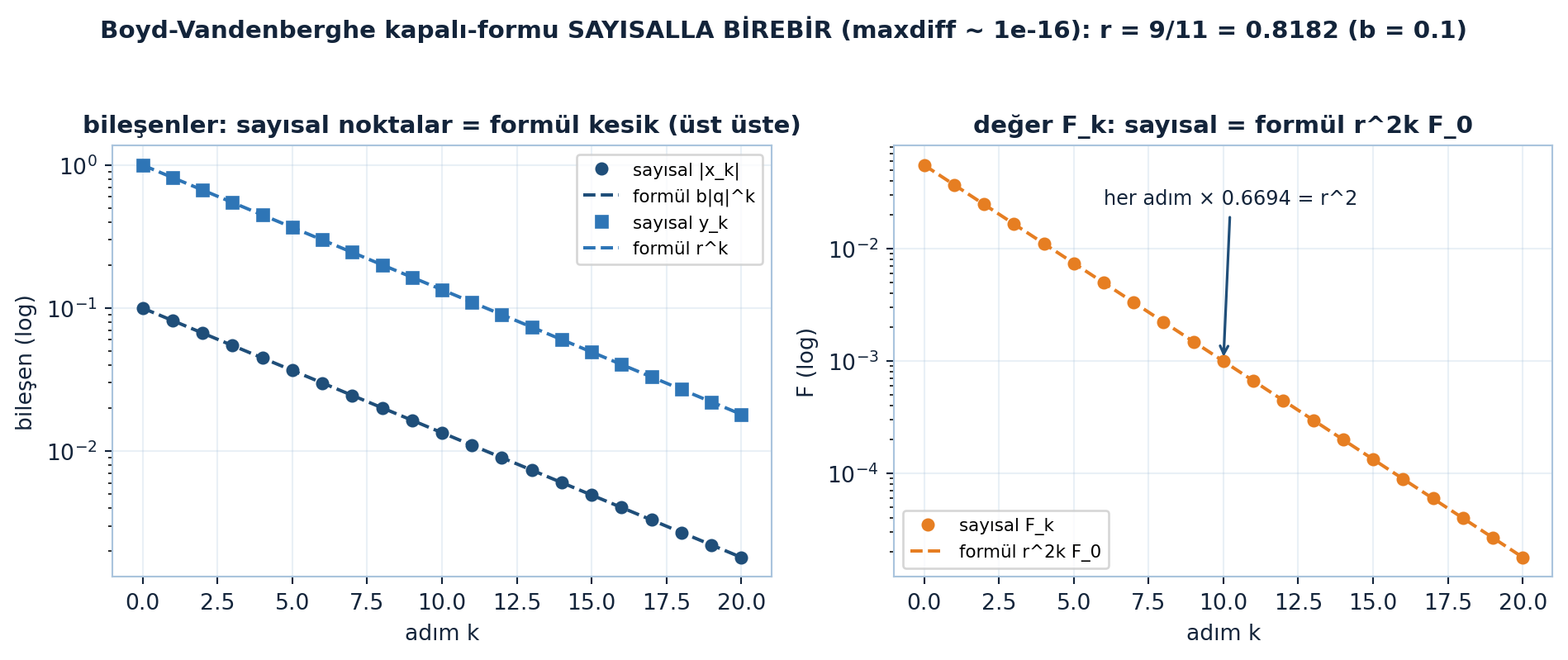
Şekil 23.5 Boyd-Vandenberghe kapalı-formunun sayısal exact-GD ile birebir çakıştığını gösterir (\(b = 0.1\), \(r = 9/11 = 0.8182\), maxdiff \(\sim 10^{-16}\)): solda sayısal \(|x_{k}|\) ve \(y_{k}\) formül eğrilerinin üstüne oturur, sağda sayısal \(F_{k}\) formül \(r^{2k}F_{0}\) ile çakışır — her adımda \(F\) değeri \(\times 0.6694 = r^{2}\).
İpucuBuilder Notu — Gözle Görülür Teori
Kapalı-form çözüm gradient descent teorisini “gözle görülür” kılar: yakınsama geometrik (her adım \(\times r\)), hız tek orana bağlı. ML köprüsü: gerçek eğitimde de kayıp geometrik düşer (log-lineer eğri); düşüş hızı yerel Hessian’ın kondisyon sayısına bağlıdır — bu örnek o bağı ispatlar.
23.9 Kondisyon Sayısı ve Zikzak
Kilit ders: yakınsama oranı \(r = (1-b)/(1+b)\), kondisyon sayısına (\(1/b\)) bağlı. \(b \approx 1\) (iyi kondisyon): $r /2 = $ küçük → hızlı yakınsama, sorun yok. \(b \approx 0\) (kötü kondisyon, \(1/b\) büyük): \(r \approx 1\) → çok yavaş. Yakınsar (\(r < 1\)) ama her adımda az ilerler:
\[b \to 1: r \to 0\ (\text{hizli}), \qquad b \to 0: r \to 1\ (\text{cok yavas, zikzak})\]
Kötü-koşullu durumda seviye kümeleri uzun-dar bir vadidir; gradient descent vadiyi geçerek zikzak çizer — biraz iner, karşı duvara tırmanır, geri döner. İlerleme vadinin uzun ekseni boyunca çok yavaştır.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10.5, 4.2))
# --- Sol: b = 0.05 uzun-dar vadi -> ZIKZAK ---
xg = np.linspace(-0.15, 0.15, 150)
yg = np.linspace(-0.15, 1.1, 150)
XG, YG = np.meshgrid(xg, yg)
axL.contour(XG, YG, 0.5 * (XG**2 + 0.05 * YG**2), levels=18, cmap=NAVY_CMAP)
pb = gd_exact(0.05, n_iter=12)
axL.plot(pb[:, 0], pb[:, 1], "o-", color=COL_VEC3, ms=4, lw=1.6)
axL.set_title("b = 0.05: ZIKZAK — x işaret değiştirir (+0.05, -0.045, +0.041), y sürünür (12 adımda F/F0 = 0.09)",
color=COL_TEXT, fontsize=9.5, fontweight="bold")
axL.tick_params(colors=COL_TEXT)
for sp in axL.spines.values(): sp.set_color(COL_STEEL_300)
# --- Sağ: b = 0.9 neredeyse daire -> doğrudan iniş ---
xg2 = np.linspace(-1, 1, 150)
yg2 = np.linspace(-0.15, 1.1, 150)
XG2, YG2 = np.meshgrid(xg2, yg2)
axR.contour(XG2, YG2, 0.5 * (XG2**2 + 0.9 * YG2**2), levels=18, cmap=NAVY_CMAP)
pg = gd_exact(0.9, n_iter=12)
axR.plot(pg[:, 0], pg[:, 1], "o-", color=COL_PRIMARY, ms=4, lw=1.6)
axR.set_title("b = 0.9: neredeyse daire — hızlı (F_12 ~ 1e-31)",
color=COL_TEXT, fontsize=9.5, fontweight="bold")
axR.tick_params(colors=COL_TEXT)
for sp in axR.spines.values(): sp.set_color(COL_STEEL_300)
fig.suptitle("Kondisyon geometrisi: kötü b -> uzun-dar vadi -> vadiyi geçen zikzak; iyi b -> daire -> doğrudan iniş",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout()
plt.show()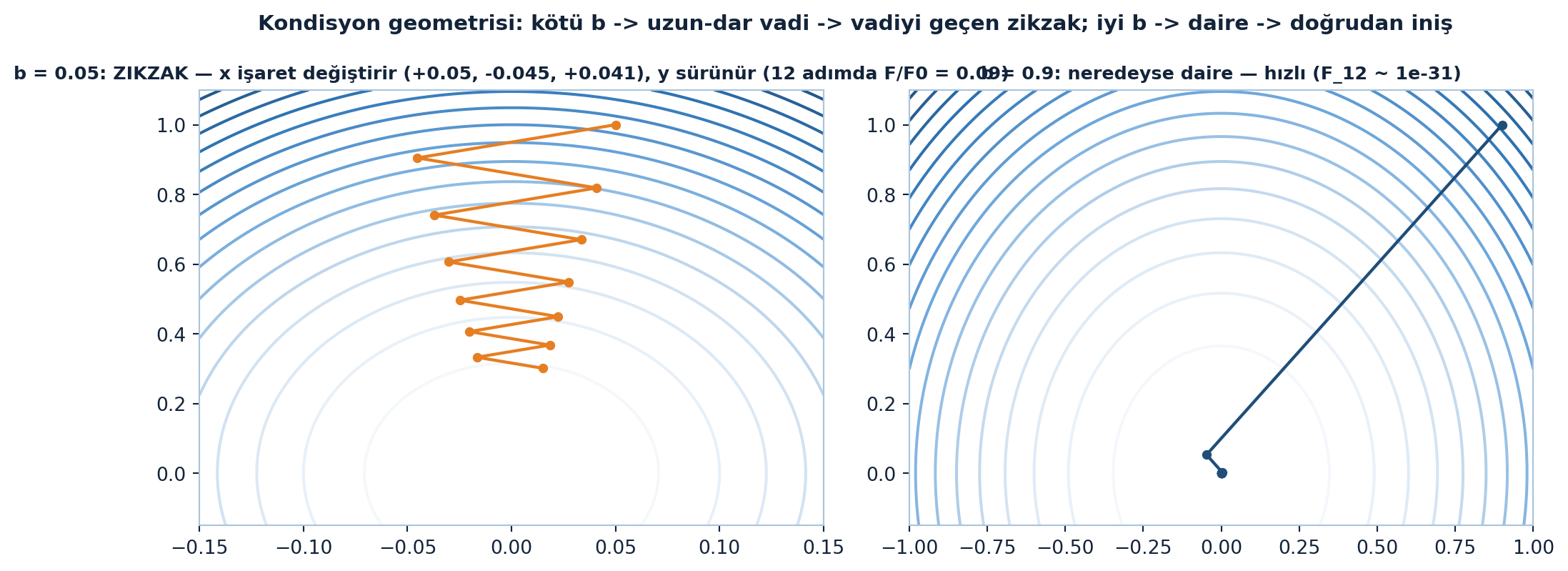
Şekil 23.6 kondisyon sayısını geometriye çevirir: solda \(b = 0.05\) uzun-dar vadisinde exact line search yörüngesi vadiyi geçen zikzak çizer (\(x\) her adımda işaret değiştirir: \(+0.05, -0.045, +0.041, \dots\); \(y\) sürünür, 12 adımda \(F/F_{0} = 0.09\)); sağda \(b = 0.9\) neredeyse daire olduğundan yörünge 2-3 adımda merkeze iner (\(F_{12} \approx 10^{-31}\)).
Kod
bs = np.linspace(0.005, 1.0, 300)
rs = [rate_r(b) for b in bs]
fig, ax = plt.subplots(figsize=(7.5, 4.2))
ax.plot(bs, rs, color=COL_PRIMARY, lw=2.5)
pts = [
(0.01, 0.9802, "Egz4: yüzde 1'e ~115 adım", (0.18, 0.86)),
(0.1, 0.818, None, None),
(0.5, 0.333, "~2 adım", (0.60, 0.42)),
(0.9, 0.053, None, None),
]
for b, r, txt, xytext in pts:
ax.plot(b, r, marker="o", color=COL_VEC3, markersize=8, zorder=5)
if txt is not None:
ax.annotate(txt, xy=(b, r), xytext=xytext,
color=COL_TEXT, fontsize=9,
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.2))
ax.axhline(1.0, color=COL_STEEL_300, linestyle="--", lw=1.5)
ax.text(0.62, 1.015, "r = 1: yakınsama durur", color=COL_TEXT, fontsize=9, va="bottom")
apply_style(ax)
ax.set_xlabel("b (= 1/kondisyon sayısı)")
ax.set_ylabel("yakınsama oranı r")
ax.set_title("Hızın tek sayısı: r = (1−b)/(1+b) — kondisyon büyüdükçe r 1'e yapışır,\nGD sürünür (115 adım vs 2 adım)", fontsize=11)
plt.show()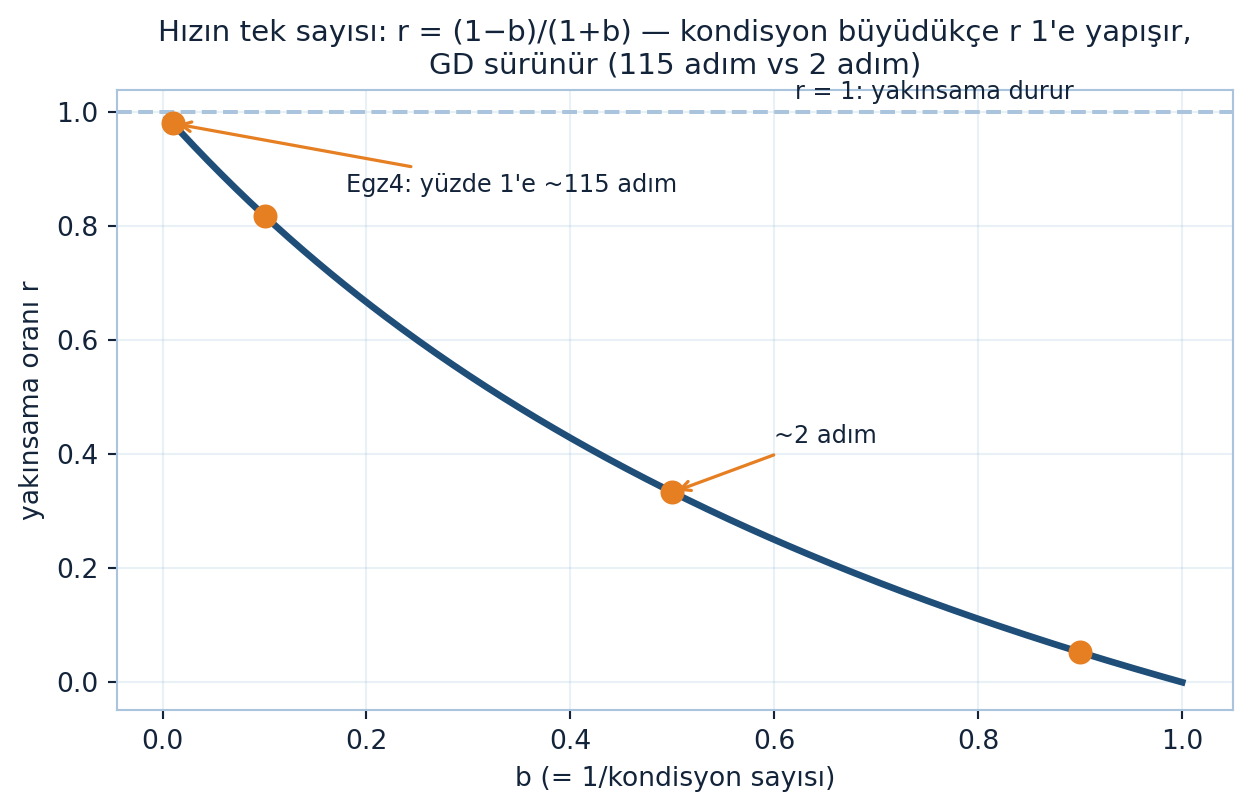
Şekil 23.7 yakınsama oranını tek bir eğride özetler: \(b = 1/\kappa\) küçüldükçe (kondisyon büyüdükçe) \(r = (1-b)/(1+b)\) değeri 1’e yapışır ve GD sürünür — \(b = 0.01 \to r = 0.9802\) (%1’e ~115 adım, Egzersiz 4), \(b = 0.1 \to r = 0.818\), \(b = 0.5 \to r = 0.333\) (~2 adım), \(b = 0.9 \to r = 0.053\).
İpucuBuilder Notu — Vadinin Duvarları
“Kötü kondisyon → uzun-dar vadi → zikzak” gradient descent’in temel zaafıdır. ML köprüsü: derin ağ kayıp yüzeyleri aşırı kötü-koşulludur (kondisyon sayısı milyonlar); saf gradient descent zikzak yapar. Çözümler: momentum (Ders 23) zikzağı söndürür, batch normalization peyzajı yeniden ölçekleyip kondisyonu iyileştirir, Adam her koordinata ayrı adım boyu verir. Kondisyon sayısı (Ders 10) burada eğitim hızının doğrudan belirleyicisidir.
23.10 Bu Dersin Özeti
- Gradient descent: \(x_{k+1} = x_{k} - s_{k}\nabla F(x_{k})\); \(s_{k}\) = adım boyu (learning rate).
- Gradyan: en dik çıkış yönü, seviye kümesine dik; \(-\)gradyan = en dik iniş.
- Hessian ⊕ konvekslik: \(H\) PYT ⟺ konveks; \(H\) pozitif tanımlı ⟺ kesin konveks. Kuadratik: \(H = S\) sabit, \(x^{*} = S^{-1}a\).
- Adım boyu: çok büyük → salınım, çok küçük → yavaş; exact line search (optimal, pahalı) veya backtracking (\(\tfrac{1}{2}s_{0}, \tfrac{1}{4}s_{0}\dots\)).
- Kritik örnek: \(f = \tfrac{1}{2}(x^{2} + by^{2})\), başlangıç \((b,1)\); \(F_{k} = \left(\tfrac{1-b}{1+b}\right)^{2k} F_{0}\).
- Kondisyon sayısı (\(1/b\)) hızı belirler: \(r = (1-b)/(1+b)\); \(b\approx 1\) hızlı, \(b\approx 0\) (kötü \(\kappa\)) yavaş + zikzak (uzun-dar vadi).
ÖnemliTek Bir Cümle
Gradient descent her adımda negatif gradyan yönünde bir adım boyu (learning rate) kadar iner; saf kuadratik örnekte yakınsama oranı tam \(r = (1-b)/(1+b)\)’dir ve kondisyon sayısı kötüleştikçe (\(b\to 0\)) bu oran 1’e yaklaşıp algoritmayı uzun-dar vadide zikzak çizerek yavaşlatır.
23.11 Kontrol Soruları
NotSoru 1 — Gradyan, −gradyan ve seviye kümesi
Soru: Gradyan ve \(-\)gradyan bir yüzeyde hangi yönleri gösterir, seviye kümesiyle ilişkisi nedir?
Cevap: Gradyan \(\nabla F\) en dik çıkış yönünü, \(-\nabla F\) en dik iniş yönünü gösterir (steepest descent’teki eksi işaret). Gradyan, seviye kümesine ($F = $ sabit) diktir: seviye kümesinde hareket edersen \(F\) değişmez, gradyan yönünde gidersen \(F\) en hızlı değişir. Gradient descent bu yüzden \(-\)gradyan yönünde adım atar.
NotSoru 2 — Hessian ile konvekslik
Soru: Bir fonksiyonun konveks olduğunu Hessian’dan nasıl anlarsın, ve kuadratik \(\tfrac{1}{2}x^{T}Sx\) için Hessian nedir?
Cevap: \(H\) pozitif yarı-tanımlı ⟺ konveks; \(H\) pozitif tanımlı ⟺ kesin konveks (her yönde yukarı büker). Saf kuadratik \(F = \tfrac{1}{2}x^{T}Sx - a^{T}x\) için Hessian sabittir: \(H = S\) (her noktada aynı). \(S\) pozitif tanımlıysa \(F\) kesin konveks, tek minimum \(\nabla F = Sx - a = 0 \Rightarrow x^{*} = S^{-1}a\).
NotSoru 3 — Adım boyu uçları ve line search
Soru: Adım boyu (learning rate) çok büyük veya çok küçük seçilirse ne olur, line search ne yapar?
Cevap: Çok büyük → fonksiyon salınır/patlar (minimumu aşar). Çok küçük → adımlar minik, yakınsama çok yavaş. Exact line search \(s_{k}\)’yi arama yönünde \(F\)’yi minimize edecek şekilde seçer (optimal ama pahalı); backtracking sabit \(s_{0}\)’dan başlayıp yarıya kese kese (\(\tfrac{1}{2}s_{0}, \tfrac{1}{4}s_{0}\dots\)) tatmin olana dek geri çekilir (ucuz, pratik).
NotSoru 4 — Kondisyon sayısı ve hız
Soru: \(f = \tfrac{1}{2}(x^{2} + by^{2})\) örneğinde kondisyon sayısı yakınsama hızını nasıl etkiler?
Cevap: Yakınsama oranı \(r = (1-b)/(1+b)\); kondisyon sayısı \(= 1/b\). \(b \approx 1\) (iyi kondisyon) → \(r \approx 0\) → çok hızlı. \(b \approx 0\) (kötü kondisyon, \(1/b\) büyük) → \(r \approx 1\) → çok yavaş. Kötü durumda seviye kümeleri uzun-dar bir vadidir; gradient descent vadiyi geçerek zikzak çizer, uzun eksende çok yavaş ilerler. Momentum/batch norm bunu düzeltir.
23.12 Egzersizler
Gradyan ve minimum. \(F(x, y) = \tfrac{1}{2}(x^{2} + 4y^{2})\). Gradyanı \(\nabla F\) ve Hessian \(H\)’yi yaz. Kondisyon sayısı (\(b = 4\) ise) kaç? Minimum nerede? (Motor tanığı: \(\nabla F = (x, 4y)\), \(H = \mathrm{diag}(1,4)\), \(\kappa = 4\), minimum \((0,0)\).)
Yön ve dik. \(f(x, y) = 3x + 4y\) için gradyanı yaz. Seviye kümesi \(3x + 4y = 12\) doğrusuna gradyanın dik olduğunu (iç çarpım) doğrula. (Motor tanığı: \(\nabla f = (3,4) \perp (4,-3)\), iç çarpım \(0\).)
Tek adım kuadratik. \(F = \tfrac{1}{2}x^{2}\) (tek değişken, \(b\) yok). \(\nabla F = x\). \(x_{0} = 5\)’ten \(s = 1\) adım boyuyla bir gradient descent adımı at; minimuma (\(0\)) tek adımda ulaştın mı? (\(s = 1\) neden burada optimal? — \(s = 1/\lambda = 1\) olduğundan tek adım yeter.)
Yakınsama oranı. \(f = \tfrac{1}{2}(x^{2} + by^{2})\) için \(b = 0.01\) (kötü kondisyon). \(r = (1-b)/(1+b)\)’yi hesapla; fonksiyonun her adımda kaçta kaçı kaldığını (\(r^{2}\)) bul. ~%1’e inmek için kaç adım gerekir (kabaca)? (Motor tanığı: \(r = 0.9802\), \(\sim 115\) adım — bkz. Şekil 23.7; karşılaştırma \(b = 0.5 \to r = 1/3\), %1’e \(\sim 2.1\) adım.)
(Ders 23 habercisi) Bu derste kötü kondisyonun zikzak yaptırdığını gördük. Peki zikzağı söndürmek için adıma “momentum” (önceki adımın hafızası) eklersek ne olur? Yakınsama oranı \((1-b)/(1+b)\)’den nasıl iyileşir? Bir tahmin yaz — Ders 23 “gradient descent’i hızlandırmak” (momentum, Nesterov) ile zikzak sorununu çözüyor.
23.13 Sonraki Ders İçin Hazırlık
Ders 23: Gradient Descent’i Hızlandırmak (Momentum, Nesterov). Bu dersin zikzak sorununu çözüyoruz: adıma momentum (önceki yönün hafızası) eklemek vadiyi geçen salınımları söndürür ve yakınsama oranını \((1-b)/(1+b)\)’den \((1-\sqrt{b})/(1+\sqrt{b})\)’ye iyileştirir — kondisyon sayısının karekökü kadar hızlanma. Nesterov ivmelendirmesi optimal birinci-derece yöntem.
UyarıHazırlık
Bu dersteki Şekil 23.6 sol panelindeki uzun-dar vadi yörüngesini zihninde tut: \(b = 0.05\)’te yakınsama oranı \(r = (1-b)/(1+b) = 0.905\)’ti ve GD vadiyi geçerek zikzak çizdi. Ders 23 momentumun bu oranı nasıl \((1-\sqrt{b})/(1+\sqrt{b})\)’ye düşürdüğünü (\(\sqrt{\kappa}\) kadar hızlanma) açacak. Kondisyon sayısının (\(1/b\), Ders 10) neden eğitim hızının düşmanı olduğunu hatırla.
23.14 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Strang (dk) |
|---|---|---|
| Gradient descent | derin öğrenmenin merkezi algoritması | 0m24 |
| Kondisyon sayısı | \(\kappa = \lambda_{\max}/\lambda_{\min} = 1/b\); hızı belirler | 1m52 |
| Gradyan = en dik çıkış | \(-\)gradyan iniş; seviye kümesine dik | 7m14 |
| Hessian ⊕ konvekslik | \(H\) PYT ⟺ konveks; pozitif tanımlı ⟺ kesin | 11m12 |
| Adım boyu / learning rate | \(x_{+} = x - s\nabla F\); büyük → salınım, küçük → yavaş | 34m52 |
| Line search | exact (optimal, pahalı) / backtracking (\(\tfrac{1}{2}s_{0}\)) | 36m09 |
| Kritik örnek | \(f = \tfrac{1}{2}(x^{2}+by^{2})\), start \((b,1)\) (Boyd & Vandenberghe) | 42m56 |
| Yakınsama oranı | \(r = (1-b)/(1+b)\); \(b\to 0\) → zikzak (uzun-dar vadi) | 45m11 |
23.15 ML Bağlantıları Özeti
- Learning rate = en kritik hiperparametre: çok büyük → NaN patlama, çok küçük → yavaş; schedule/warmup/Adam otomatikleştirir.
- Kondisyon = eğitim hızının düşmanı: kötü-koşullu kayıp yüzeyi zikzak; momentum (Ders 23), batch norm (peyzajı yeniden ölçekler) ve Adam (koordinat-başı adım) düzeltir.
- \(x_{+} = x - s\nabla F\): PyTorch’ta
w -= lr * w.grad; tüm SGD/Adam/RMSProp bu iskeletin türevi. - Birinci-derece zaferi: ucuz adım (sadece gradyan) → milyar parametre eğitilebilir (Newton’ın Hessian’ı imkânsız, Ders 21).
- Line search kullanılmaz: derin öğrenmede her adım çok pahalı → sabit/programlı learning rate; backtracking klasik optimizasyonda/L-BFGS’te standart.
- Yerel kuadratik: gerçek kayıp yüzeyi yerel olarak \(\tfrac{1}{2}x^{T}Hx\) (Taylor); bu örneğin kondisyon dersi gerçek eğitime doğrudan taşınır.
- Geriye köprü: Ders 21 (Newton, steepest descent, konvekslik), Ders 10 (kondisyon sayısı \(\kappa\)), Ders 5 (pozitif tanımlı), Ders 18-19 (Hessian, Rayleigh/eyer).
ÖnemliKapanış
“…this ratio 1 minus b over 1 plus b is crucial.” — Strang, 45:11
Gradient descent’in tüm hikayesi tek oranda: kondisyon sayısı iyiyse hızlı, kötüyse zikzak; bir sonraki ders momentum ile bu oranı kökten iyileştirir.