flowchart TD
M["Ax = λx — özvektör yön değiştirmez"] --> DYN["Aᵏx = λᵏx (dinamik)"]
M --> ZERO["λ = 0 → tersinmez"]
M --> BASE["özvektör bazı"]
M --> SIM["benzer B = M⁻¹AM"]
M --> ABBA["AB & BA aynı λ"]
M --> SYM["simetrik: gerçek λ / anti-simetrik: sanal λ"]
M --> DIAG["A = XΛX⁻¹"]
M --> SPEC["S = QΛQᵀ (spektral)"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style DIAG fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style SPEC fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style DYN fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style BASE fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style SYM fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style ZERO fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style SIM fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style ABBA fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
5 Özdeğerler ve Özvektörler
Ax = λx: bir matrisin doğal eksenleri, köşegenleştirme ve spektral teorem
NotBölüm bilgisi
- Video: Eigenvalues and Eigenvectors — Gilbert Strang, MIT 18.065
- OCW: Lecture 4 — Eigenvalues and Eigenvectors
- Okuma süresi: ≈ 35 dk
- Önkoşul: Ders 3 (ortonormal kolonlar, \(Q^{T}Q = I\), “simetrik → ortogonal özvektörler”)
5.1 Bu Derste Ne Var?
Ders 3’ü “simetrik matrislerin özvektörleri ortogonaldir” gözlemiyle kapatmıştık. Ders 4 doğrudan özdeğer ve özvektörlere giriyor: önce her kare matris \(A\), sonra simetrik \(S\), en sonunda özel olan pozitif tanımlı \(S\) (Ders 5).
Üç temel fikir:
- \(Ax = \lambda x\) — özvektör, \(A\) ile çarpılınca yön değiştirmeyen özel vektör; \(A^{k}\), \(A^{-1}\), \(e^{At}\) hepsi aynı özvektörü taşır, özdeğer \(\lambda^{k}\), \(1/\lambda\), \(e^{\lambda t}\) olur.
- Köşegenleştirme \(A = X\Lambda X^{-1}\) — özvektörler \(X\)’i, özdeğerler \(\Lambda\)’yı oluşturur; benzer matrisler (\(M^{-1}AM\)) aynı özdeğeri paylaşır.
- Spektral teorem \(S = Q\Lambda Q^{T}\) — simetrik matris: gerçek özdeğer, ortonormal özvektör (\(Q\) ortogonal).
“Ax comes out some number times x.” — Strang, 1:51
Bu üç fikrin nasıl tek bir merkezden (\(Ax = \lambda x\)) dallandığını Şekil 5.1 özetliyor: dinamikten köşegenleştirmeye, simetri-anti-simetri ayrımından spektral teoreme kadar dersin bütün hatları.
İpucuBuilder Notu — Doğal Eksenler
- \(A^{k} = X\Lambda^{k}X^{-1}\) → dinamik/kararlılık: bir tekrarlı sistemin (RNN, power iteration, Markov) uzun-vadeli davranışı en büyük \(|\lambda|\) tarafından belirlenir; \(|\lambda| > 1\) patlar, \(|\lambda| < 1\) söner.
- Spektral teorem → PCA: kovaryans simetriktir, özvektörleri (ana bileşenler) ortonormal, özdeğerleri (varyanslar) gerçektir.
- Trace ve determinant — \(\sum\lambda = \text{trace}\), \(\prod\lambda = \det\); modelde hızlı sağlama ve düzenlileştirme terimleri (nuclear/log-det) bu kimliklere dayanır.
- Benzer matrisler — taban değişimi özdeğeri korur; özellik mühendisliğinde ve ağ reparametrizasyonunda kritik.
Tek cümle: özvektörler bir matrisin “doğal eksenleridir” — o eksenlerde matris yalnızca ölçekler (\(\lambda\) ile), ve \(A = X\Lambda X^{-1}\) tüm kuvvet/fonksiyon hesabını önemsizleştirir.
5.2 Özdeğer ve Özvektör: Ax = λx
Bir \(A\) matrisini çoğu vektörle çarpınca yön değişir. Ama bazı özel vektörlerde \(Ax\), \(x\) ile aynı doğrultuda çıkar — yalnızca ölçeklenir:
\[ A x = \lambda x \]
Buradaki \(x\) özvektör, \(\lambda\) ise özdeğer. \(n \times n\) bir matrisin (iyi durumda) \(n\) tane bağımsız özvektörü vardır.
“Ax comes out some number times x.” — Strang, 1:51
Bu “yön korunur, yalnızca ölçek değişir” sezgisi Şekil 5.2’de görülüyor: özvektör doğrultularında \(A\) vektörü kendi doğrusu üzerinde tutar, genel bir vektörde ise yön kayar.
Kod
A = np.array([[2.0, 1.0], [1.0, 2.0]]) # özdeğerler 3, 1; özvektörler (1,1), (1,-1)
fig, ax = plt.subplots(figsize=(6.2, 6.2))
style_square_axes(ax, 3)
# Birim çember (gri) ve A ile görüntüsü (elips, accent)
circle = unit_circle()
ax.plot(circle[0], circle[1], color=COL_STEEL_300, lw=1.6, ls="--", label="birim çember")
ellipse = A @ circle
plot_pointset(ax, ellipse, color=COL_ACCENT, label="A·(birim çember)", lw=2.2, fill_alpha=0.10)
# Özvektör doğruları: (1,1) ve (1,-1) yönünde uzun kesik çizgiler
t = np.linspace(-3, 3, 2)
d1 = np.array([1.0, 1.0]) / np.sqrt(2) # λ = 3 yönü
d2 = np.array([1.0, -1.0]) / np.sqrt(2) # λ = 1 yönü
ax.plot(t * d1[0] * 3, t * d1[1] * 3, color=COL_PRIMARY, lw=1.6, ls=":", zorder=1)
ax.plot(t * d2[0] * 3, t * d2[1] * 3, color=COL_VEC2, lw=1.6, ls=":", zorder=1)
# Özvektör yönlerinde: vektör ve A·vektör aynı doğruda (sadece ölçeklenir)
v1 = d1 # özvektör (1,1)/√2
draw_vec2d(ax, v1, color=COL_PRIMARY, label="x₁", lw=2.4)
draw_vec2d(ax, A @ v1, color=COL_PRIMARY, lw=2.0, ls="--") # = 3·x₁, aynı doğru
ax.text((A @ v1)[0], (A @ v1)[1] + 0.2, "A x₁ = 3 x₁", color=COL_PRIMARY,
fontsize=10, fontweight="bold", ha="center")
v2 = d2 # özvektör (1,-1)/√2
draw_vec2d(ax, v2, color=COL_VEC2, label="x₂", lw=2.4)
draw_vec2d(ax, A @ v2, color=COL_VEC2, lw=2.0, ls="--") # = 1·x₂, aynı doğru
ax.text((A @ v2)[0] + 0.1, (A @ v2)[1] - 0.25, "A x₂ = 1 x₂", color=COL_VEC2,
fontsize=10, fontweight="bold", ha="left")
# Genel bir vektör: yön DEĞİŞİR (özvektör değil)
g = np.array([1.0, 0.2])
draw_vec2d(ax, g, color=COL_VEC3, label="genel v", lw=2.4)
Ag = A @ g
draw_vec2d(ax, Ag, color=COL_VEC3, lw=2.2, ls="--")
ax.text(Ag[0], Ag[1] + 0.2, "A v (yön değişir)", color=COL_VEC3,
fontsize=10, fontweight="bold", ha="center")
ax.set_title("Özvektörler doğal eksenler: o yönde A yalnızca λ ile gerer",
color=COL_TEXT, fontsize=11, fontweight="bold")
ax.legend(loc="lower right", fontsize=9, framealpha=0.9)
plt.show()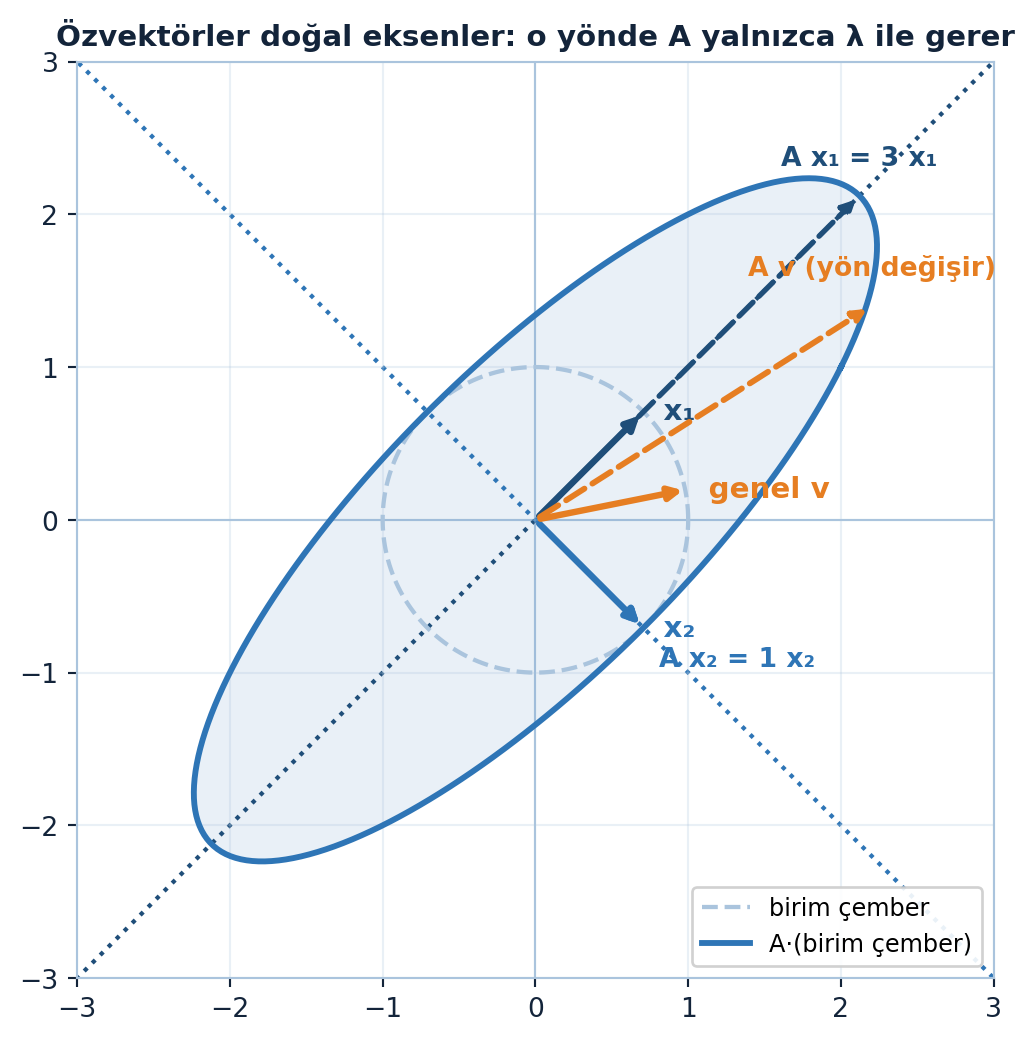
İpucuBuilder Notu — PCA’nın Sezgisi
Özvektörler matrisin “doğal eksenleri”dir: o eksenlerde matris döndürmez, sadece gerer/sıkıştırır. PCA tam da veri kovaryansının bu doğal eksenlerini bulur; ana bileşenler en büyük özdeğerli özvektörlerdir.
5.3 Neden Yararlı: Aᵏx = λᵏx
Özvektörlerin gücü, \(A\)’nın kuvvetlerinde ortaya çıkar. \(A^{2}x\)’i hesapla: \(A(Ax) = A(\lambda x) = \lambda(Ax) = \lambda^{2}x\). Devam ederek:
\[ A^{2} x = \lambda^{2} x, \quad A^{k} x = \lambda^{k} x, \quad A^{-1} x = \frac{1}{\lambda} x, \quad e^{At} x = e^{\lambda t} x \]
Özvektör değişmez; yalnızca özdeğer kuvvet alır. Matrisin herhangi bir kuvveti veya fonksiyonu (üstel dâhil) özvektör tabanında önemsizleşir.
“…and the eigenvalue is lambda squared.” — Strang, 4:28
Kuvvet aldıkça en büyük \(|\lambda|\)’nın yönünün baskın hâle gelişi Şekil 5.3’da somutlaşıyor: \(v_k = A^{k}v_0\) yön dizisi baskın özvektöre yelpaze gibi yakınsar.
Kod
A = np.array([[2.0, 1.0], [1.0, 2.0]])
v0 = np.array([1.0, 0.0])
dirs = power_dir_sequence(A, v0, 8)
fig, ax = plt.subplots(figsize=(6.2, 6.2))
style_square_axes(ax, 1.3, title="Power iteration: vₖ baskın özvektöre yakınsar (en büyük |λ|)")
# Baskın özvektör doğrultusu (1,1)/sqrt2 (orange kesik çizgi)
d = np.array([1.0, 1.0]) / np.sqrt(2)
L = 1.3
ax.plot([-d[0]*L, d[0]*L], [-d[1]*L, d[1]*L], color=COL_VEC3, lw=2.0, ls="--", zorder=2,
label="baskın özvektör (1,1)/√2")
# Ardışık yön okları: açık -> koyu (Blues cmap), k+1 ok
n = len(dirs)
cmap = plt.get_cmap("Blues")
for i, dvec in enumerate(dirs):
c = cmap(0.30 + 0.65 * (i / (n - 1)))
draw_vec2d(ax, dvec, color=c, lw=2.2)
if i == 0:
ax.text(dvec[0] + 0.03, dvec[1] - 0.10, "v₀", color=cmap(0.30),
fontsize=11, fontweight="bold")
if i == n - 1:
ax.text(dvec[0] + 0.03, dvec[1] + 0.03, "vₘ", color=cmap(0.95),
fontsize=11, fontweight="bold")
ax.legend(loc="lower right", fontsize=9, framealpha=0.9)
plt.show()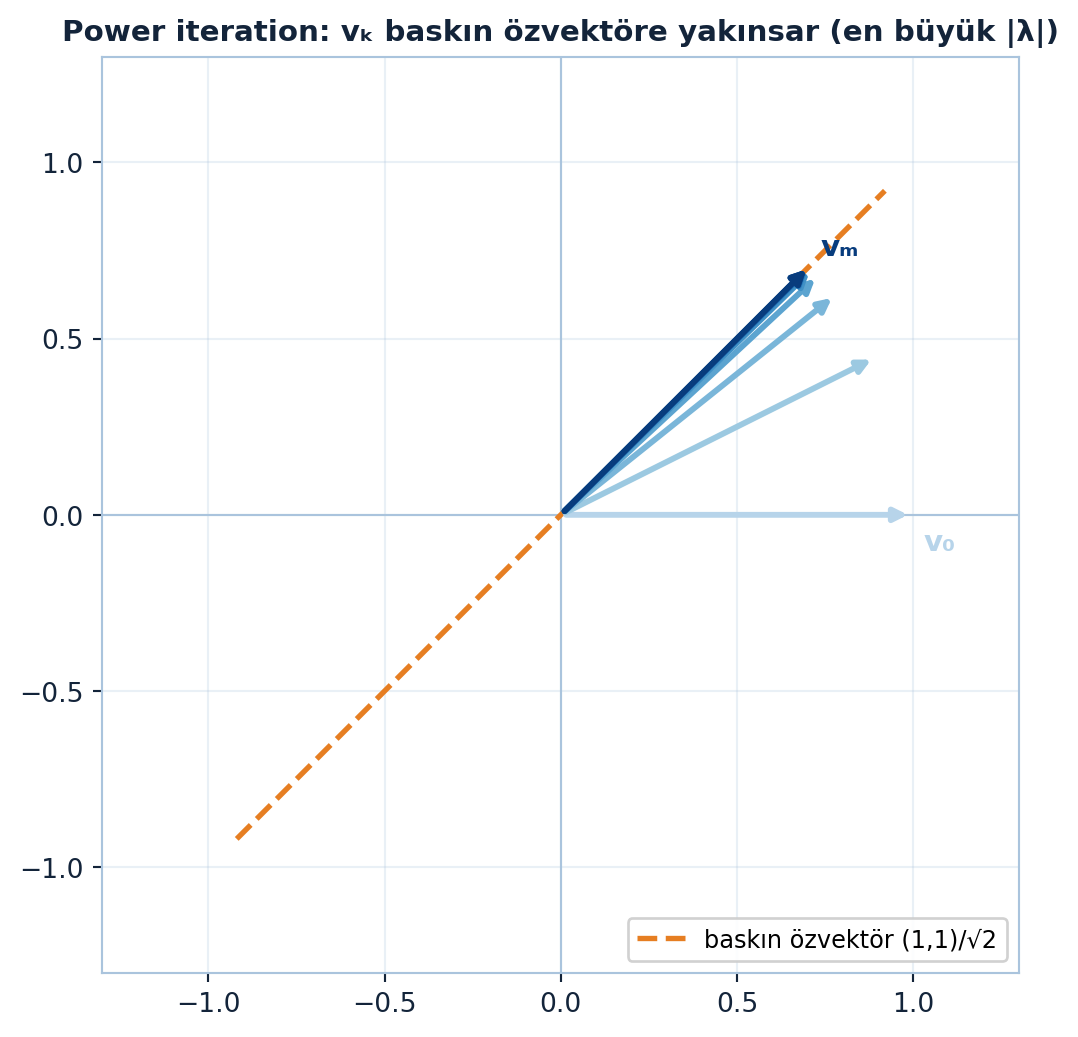
İpucuBuilder Notu — Tekrarın Kaderi
\(A^{k}\) davranışı, tekrarlı sistemlerin (RNN, power iteration, Markov zinciri, difüzyon) kaderini belirler: en büyük \(|\lambda|\) baskındır. \(|\lambda| > 1\) ise tekrarda patlar, \(|\lambda| < 1\) ise söner — gradyan patlama/sönmesinin özdeğer dilindeki ifadesi.
5.4 λ = 0 ve Tersinirlik
Özel durum: \(\lambda = 0\) olabilir. O zaman \(Ax = 0 \cdot x = 0\), yani özvektör \(A\)’nın null uzayındadır ve \(A\) tersinir değildir.
“A doesn’t even have an inverse.” — Strang, 5:22
\(A^{-1}x = (1/\lambda)x\) formülü tam da bu yüzden \(\lambda = 0\)’da çöker: \(1/0\) tanımsızdır, çünkü tersi olmayan bir matrisin o yöndeki “tersi” yoktur. Özdeğerlerden biri \(0\) ise matris tekildir (singular).
İpucuBuilder Notu — Sıfır Özdeğer = Tehlike
\(\lambda = 0\) (veya çok küçük \(\lambda\)) = kötü koşullanma. Kovaryans veya Hessian matrisinde sıfıra yakın özdeğer, o yönde bilginin/eğriliğin yok olduğunu söyler — düzenlileştirme (\(\lambda I\) ekleme, ridge) tam da bu sıfır özdeğerleri kaldırıp matrisi tersinir kılmak içindir.
5.5 Özvektör Bazı ve Fark Denklemleri
\(n\) bağımsız özvektör bir baz oluşturur. Herhangi bir \(v\) vektörünü bu bazda yaz:
\[ v = c_1 x_1 + c_2 x_2 + \cdots + c_n x_n \]
\(A\)’nın \(k\). kuvvetini uygulamak artık önemsiz — her parça kendi \(\lambda\)’sının kuvvetini alır:
\[ A^{k} v = c_1 \lambda_1^{k} x_1 + c_2 \lambda_2^{k} x_2 + \cdots + c_n \lambda_n^{k} x_n \]
Bu, özvektörlerin icat ediliş amacıdır: fark denklemlerini (\(v_{k+1} = Av_k\)) ve sürekli zamanlı denklemleri (\(dv/dt = Av \to v(t) = \sum_i c_i e^{\lambda_i t} x_i\)) anında çözmek.
“…to be able to solve difference equations.” — Strang, 10:38
İpucuBuilder Notu — Dinamiği Çözmek
Bu ayrışım, lineer dinamik sistemlerin (kontrol, difüzyon modelleri, lineerleştirilmiş RNN) çözümüdür. Bir başlangıç durumunu özvektör tabanına yansıt, her bileşeni \(\lambda^{k}\) ile evrimleştir, geri topla — eğitim dinamiğini ve kararlılığı analiz etmenin standart yolu.
5.6 Benzer Matrisler: B = M⁻¹AM
İki matris, tersinir bir \(M\) ile şöyle bağlıysa benzer (similar) denir:
\[ B = M^{-1} A M \]
Benzer matrislerin anahtar özelliği: aynı özdeğerlere sahiptirler.
“They have the same eigenvalues.” — Strang, 13:56
Kanıt kısa: \(M^{-1}AM\)’in özvektörü \(y\), özdeğeri \(\lambda\) olsun (\(M^{-1}AM\, y = \lambda y\)). Her iki tarafı \(M\) ile çarp → \(A(My) = \lambda(My)\). Yani \(\lambda\), \(A\)’nın da özdeğeridir; özvektör \(y\)’den \(My\)’ye değişti ama özdeğer aynı kaldı.
İpucuBuilder Notu — Taban Değiştir, Özü Koru
Benzerlik = taban değişimi. \(M\) ile koordinat değiştirmek matrisin “özünü” (özdeğerlerini) korur, yalnızca temsili değişir. ML’de ağ reparametrizasyonu, beyazlatma (whitening) ve özellik dönüşümleri bu çerçevededir — doğru \(M\), problemi köşegen (bağımsız) hâle getirir.
5.7 eig(A) Nasıl Hesaplanır
Özdeğerler pratikte eig(A) ile bulunur. Arka planda ne olur? Algoritma, ardışık iyi \(M\)’ler seçerek \(A\)’yı benzer matrislere taşır ve giderek üçgensel (simetrikte köşegen) hâle getirir; özdeğerler köşegende belirir.
“It brings the matrix to a triangular matrix.” — Strang, 16:13
Her \(M\) benzerliği koruduğundan özdeğerler boyunca değişmez; köşegen-dışı terimler küçülürken köşegende gerçek özdeğerler ortaya çıkar. Simetrik matrislerde bu süreç temizdir (köşegene yakınsar).
İpucuBuilder Notu — QR İterasyonu
Bu, QR iterasyonunun (Ders 12) sezgisidir: ortogonal benzerlik dönüşümleriyle (\(Q\)’lar, Ders 3) köşegene yakınsama. Büyük matrislerde tam eig yerine Lanczos/güç iterasyonu gibi yalnızca baskın özdeğerleri bulan yöntemler kullanılır — PCA ve spektral kümelemenin pratiği.
5.8 AB ve BA Aynı Özdeğerlere Sahiptir
Hoş bir gerçek: herhangi iki \(A\), \(B\) matrisi için \(AB\) ile \(BA\) aynı (sıfırdan farklı) özdeğerlere sahiptir.
“…the same non-zero ones… as BA.” — Strang, 19:58
Kanıt benzerlikten gelir: \(M = B\) seç, o zaman \(BA = B(AB)B^{-1}\), yani \(BA\), \(AB\)’ye benzerdir → aynı özdeğerler:
\[ BA = B(AB)B^{-1} \]
Dikkat: bu, özdeğerlerin çarpılabileceği anlamına gelmez. \(A\)’nın ve \(B\)’nin özdeğerlerini bilmek, \(AB\)’nin veya \(A + B\)’nin özdeğerlerini vermez — çünkü özvektörler farklıdır.
İpucuBuilder Notu — Gram Matrisi Numarası
\(AB\) ile \(BA\)’nın özdeşliği, derin öğrenmede Gram matrisi numarasıdır: \(m \times n\) veride \(XX^{T}\) (\(m \times m\)) ile \(X^{T}X\) (\(n \times n\)) aynı sıfırdan-farklı özdeğerlere sahiptir. Hangisi küçükse onu hesaplarsın (kernel trick, SVD’nin iki tarafı) — büyük boyutta muazzam tasarruf.
5.9 Simetrik vs Anti-simetrik
Şimdi simetrik matrise (\(S = S^{T}\)) özelleşelim. İki garanti: özdeğerler gerçek, özvektörler ortogonal. Karşıtını görmek için anti-simetrik matrise (\(A^{T} = -A\)) bak — onun özdeğerleri tamamen sanaldır. Klasik örnek 90° döndürme:
\[ A = \begin{pmatrix} 0 & -1 \\ 1 & 0 \end{pmatrix}, \quad \det(A - \lambda I) = \lambda^{2} + 1 = 0 \;\Rightarrow\; \lambda = \pm i \]
“…have imaginary eigenvalues.” — Strang, 25:51
90° döndürme hiçbir gerçek vektörü kendi doğrultusunda bırakmaz, o yüzden gerçek özvektörü yoktur. Simetrik matrisin gerçek özdeğer garantisi, tam da bunun olamayacağını söyler.
Bu karşıtlık Şekil 5.4’de yan yana: solda simetrik \(S\) dik özvektör eksenleriyle bir elips gerer, sağda anti-simetrik \(R\) her vektörü döndürür ve hiçbir gerçek yönü sabit bırakmaz.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5.4))
# --- SOL: Simetrik S (gerçek λ, dik özvektör) ---
S = np.array([[2.0, 1.0], [1.0, 2.0]])
valsS, Q = eig_symmetric(S)
style_square_axes(axL, 3.2, title="Simetrik S (gerçek λ, dik özvektör)")
circle = unit_circle()
plot_pointset(axL, circle, color=COL_STEEL_300, lw=1.4, fill_alpha=0.0)
ellipse = S @ circle
plot_pointset(axL, ellipse, color=COL_ACCENT, label="S·(birim çember)", lw=2.4, fill_alpha=0.12)
# 2 ortonormal özvektör ekseni (dik), λ ile ölçekli
for i, (col, name) in enumerate([(COL_PRIMARY, "q₁"), (COL_VEC2, "q₂")]):
q = Q[:, i] * valsS[i]
draw_vec2d(axL, q, color=col, label=f"{name} (λ={valsS[i]:.0f})", lw=2.8)
draw_vec2d(axL, -q, color=col, lw=2.8)
axL.legend(loc="upper left", fontsize=8, framealpha=0.9)
# --- SAĞ: Anti-simetrik R (sanal λ=±i) ---
R = np.array([[0.0, -1.0], [1.0, 0.0]])
style_square_axes(axR, 1.6, title="Anti-simetrik R (sanal λ=±i)")
plot_pointset(axR, circle, color=COL_STEEL_300, label="birim çember", lw=1.4, fill_alpha=0.0)
Rcircle = R @ circle
plot_pointset(axR, Rcircle, color=COL_ACCENT, lw=2.0, fill_alpha=0.0)
# 4 vektör -> R@vektör (döndürme: hiçbir gerçek yön sabit değil)
base = [np.array([1.0, 0.0]), np.array([0.0, 1.0]),
np.array([0.9, 0.5]) / np.linalg.norm([0.9, 0.5]),
np.array([-0.6, 0.7]) / np.linalg.norm([-0.6, 0.7])]
for v in base:
draw_vec2d(axR, v, color=COL_STEEL_300, lw=2.0, ls="--")
draw_vec2d(axR, R @ v, color=COL_VEC3, lw=2.6)
axR.text(0, -1.42, "R: 90° döndürme — sabit gerçek yön yok",
ha="center", color=COL_VEC3, fontsize=9, fontweight="bold")
axR.legend(loc="upper left", fontsize=8, framealpha=0.9)
fig.suptitle("Simetrik vs Anti-simetrik: gerçek vs sanal özdeğer",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout(rect=(0, 0, 1, 0.96))
plt.show()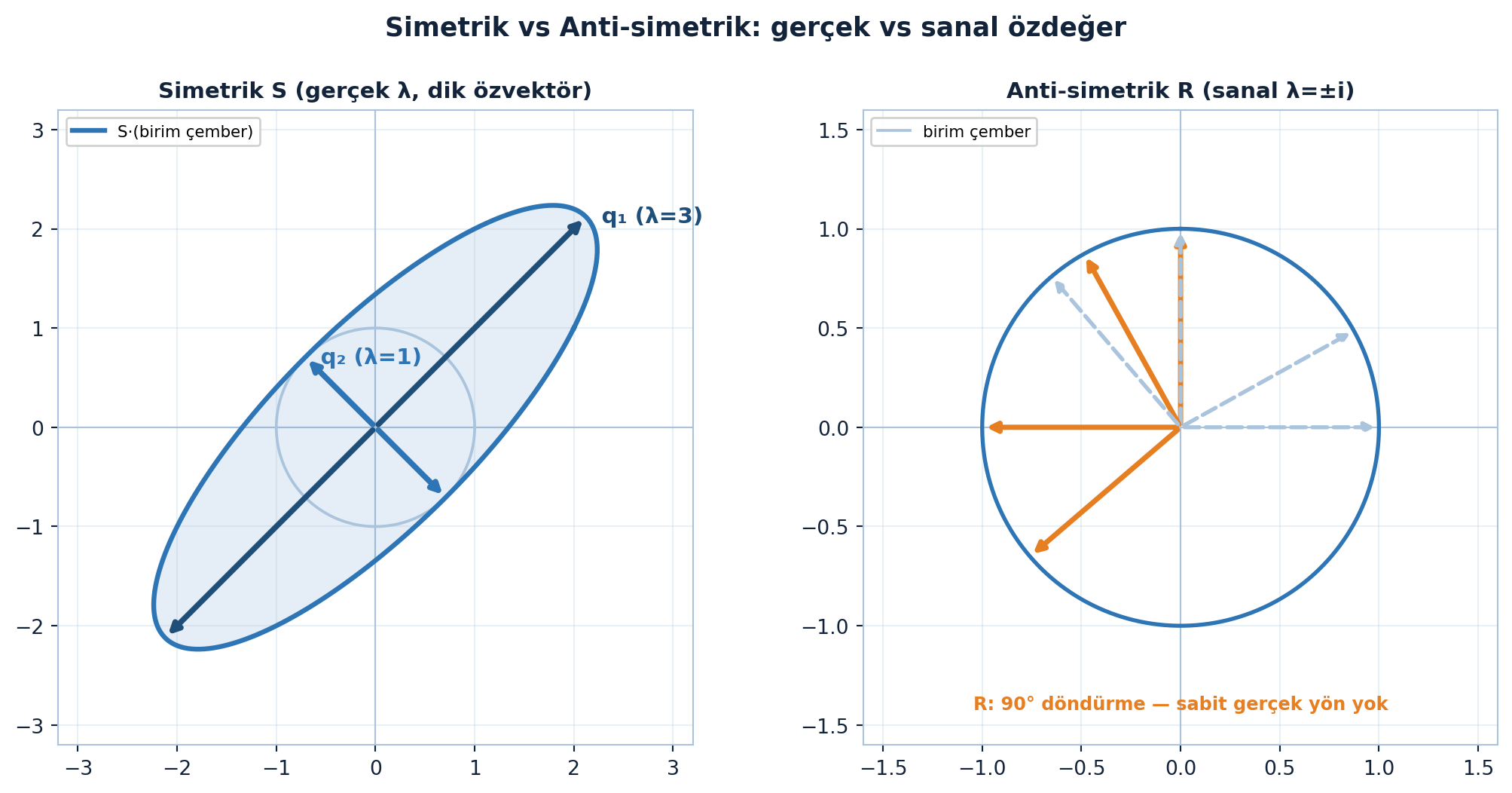
İpucuBuilder Notu — Güvenli Matrisler
Simetrik → gerçek özdeğer + ortonormal özvektör garantisi, ML’nin temel matrislerini (kovaryans, Gram, Hessian, graf Laplacian) güvenli kılar: özdeğerler yorumlanabilir gerçek sayılardır, özvektörler dik bir taban verir. Anti-simetrik kısım ise döndürmeyi (faz) kodlar.
5.10 2×2 Kontrolleri: Trace ve Determinant
Elle özdeğer hesabında iki hızlı sağlama var. Özdeğerlerin toplamı, köşegenin toplamına (trace) eşittir; çarpımları determinanta eşittir:
\[ \text{trace}(A) = \sum_i \lambda_i, \qquad \det(A) = \prod_i \lambda_i \]
Anti-simetrik örnekte: trace \(= 0 + 0 = 0 = i + (-i)\) ✓; det \(= 1 = i \cdot (-i)\) ✓.
“…this number adding the diagonal is called the trace.” — Strang, 31:03
Bu iki kontrol her boyutta toplam/çarpım için geçerli; \(2\times 2\)’de özdeğerleri tamamen belirler (iki denklem, iki bilinmeyen).
İki sağlamanın somut bir örnekte nasıl tuttuğu Şekil 5.5’te görülüyor: \(A = \begin{pmatrix} 4 & 1 \\ 2 & 3 \end{pmatrix}\) için özdeğerler \(5\) ve \(2\), iz \(7\), determinant \(10\).
Kod
A = np.array([[4.0, 1.0], [2.0, 3.0]])
tr, det, sum_lam, prod_lam = trace_det(A)
fig, ax = plt.subplots(figsize=(6.2, 4.6))
bar_values(ax, [5, 2], [r"$\lambda_1$", r"$\lambda_2$"], title="Özdeğerler", highlight=[0])
ax.set_ylim(0, 7.4)
ax.text(0.5, 6.85, "trace = 4 + 3 = 7 = Σλ (5 + 2 = 7)",
ha="center", va="center", fontsize=11, fontweight="bold", color=COL_PRIMARY,
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BG, ec=COL_ACCENT, lw=1.2))
ax.text(0.5, 6.1, "det = 10 = Πλ (5 × 2 = 10)",
ha="center", va="center", fontsize=11, fontweight="bold", color=COL_VEC3,
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BG, ec=COL_VEC3, lw=1.2))
ax.set_ylabel("özdeğer değeri", color=COL_TEXT)
fig.suptitle("Trace = toplam λ, det = çarpım λ (hızlı sağlama)",
color=COL_TEXT, fontsize=12.5, fontweight="bold")
fig.tight_layout()
plt.show()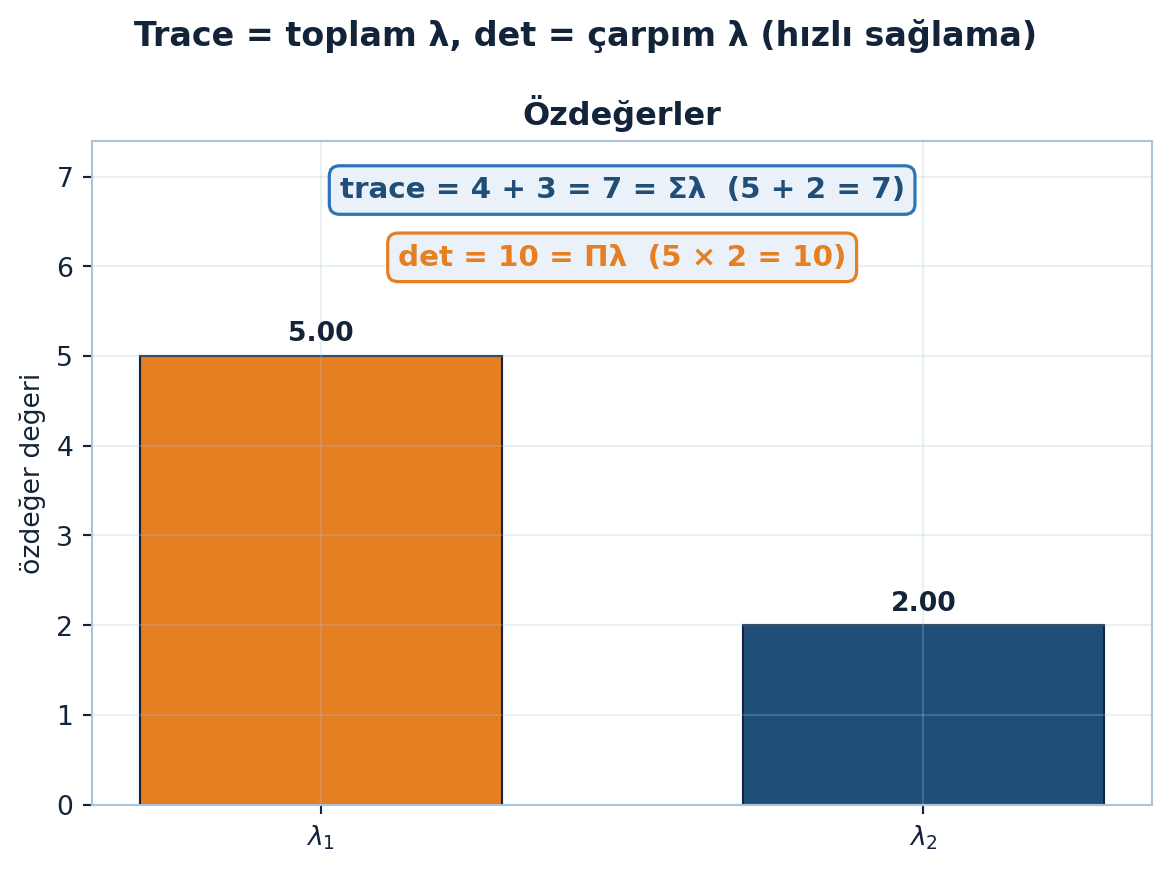
İpucuBuilder Notu — Toplu Sağlama
Trace ve determinant ML düzenlileştirmesinde doğrudan görünür: nuclear norm (tekil değerler toplamı), log-det terimi (Gauss olabilirliği, determinantal point process), ve $(A^{T}A) = $ Frobenius norm². Bu kimlikler özdeğerleri tek tek hesaplamadan toplu bilgi verir.
5.11 Köşegenleştirme: A = XΛX⁻¹
Tüm özvektörleri \(X\) matrisinin kolonlarına, özdeğerleri köşegen \(\Lambda\)’ya koy. \(AX = X\Lambda\) ilişkisi şu kompakt forma dönüşür:
\[ A X = X \Lambda \quad \Longrightarrow \quad A = X \Lambda X^{-1} \]
“…A equal x lambda x inverse.” — Strang, 45:39
Bu, \(A\)’nın \(\Lambda\)’ya benzer olduğunu (\(M = X\)) söyler. Kuvvet almak artık çok kolay — ortadaki \(X^{-1}X = I\) düşer:
\[ A^{2} = X \Lambda X^{-1} \cdot X \Lambda X^{-1} = X \Lambda^{2} X^{-1}, \quad A^{k} = X \Lambda^{k} X^{-1} \]
“…diagonalizing a matrix.” — Strang, 39:57
\(A = X\Lambda X^{-1}\) ayrışmasının üçlü yapısı (özvektör \(X\), köşegen \(\Lambda\), ters \(X^{-1}\)) Şekil 5.6’da görülüyor: köşegen \(\Lambda\) vurgulanmış, ve kuvvet almanın neden \(\Lambda^{k}\)’ya indirgendiği netleşiyor.
Kod
A = np.array([[2.0, 1.0], [1.0, 2.0]])
X, Lam, Xinv, vals = diagonalize(A)
X = np.real(X); Lam = np.real(Lam); Xinv = np.real(Xinv)
fig = plt.figure(figsize=(11.0, 4.4))
gs = fig.add_gridspec(1, 3, wspace=0.42)
ax0 = fig.add_subplot(gs[0])
ax1 = fig.add_subplot(gs[1])
ax2 = fig.add_subplot(gs[2])
# ortak renk ölçeği (üç heatmap aynı skalada okunsun)
all_M = np.concatenate([X.ravel(), Lam.ravel(), Xinv.ravel()])
vmin = float(all_M.min()); vmax = float(all_M.max())
heatmap(ax0, X, title="X (özvektörler)", cmap=NAVY_CMAP, vmin=vmin, vmax=vmax, fmt="{:.2f}", fontsize=12)
heatmap(ax1, Lam, title="Λ (köşegen özdeğerler)", cmap=NAVY_CMAP, vmin=vmin, vmax=vmax, fmt="{:.2f}", fontsize=12)
heatmap(ax2, Xinv, title="X⁻¹", cmap=NAVY_CMAP, vmin=vmin, vmax=vmax, fmt="{:.2f}", fontsize=12)
# Λ köşegen vurgusu (köşegen hücrelerin çevresine çerçeve)
import matplotlib.patches as patches
for i in range(Lam.shape[0]):
ax1.add_patch(patches.Rectangle((i - 0.5, i - 0.5), 1, 1, fill=False,
edgecolor=COL_VEC3, lw=2.6, zorder=5))
# "=" işaretleri (heatmap'ler arası)
for axa, axb in [(ax0, ax1), (ax1, ax2)]:
x = 0.5 * (axa.get_position().x1 + axb.get_position().x0)
y = 0.5 * (axa.get_position().y0 + axa.get_position().y1)
fig.text(x, y, "=", ha="center", va="center", fontsize=26, color=COL_PRIMARY, fontweight="bold")
fig.text(0.5, -0.02, "Aᵏ = X Λᵏ X⁻¹: kuvvet = özdeğer kuvveti",
ha="center", va="center", fontsize=12, color=COL_TEXT, fontweight="bold")
fig.suptitle("Köşegenleştirme A = X Λ X⁻¹", color=COL_PRIMARY, fontsize=15, fontweight="bold", y=1.04)
plt.show()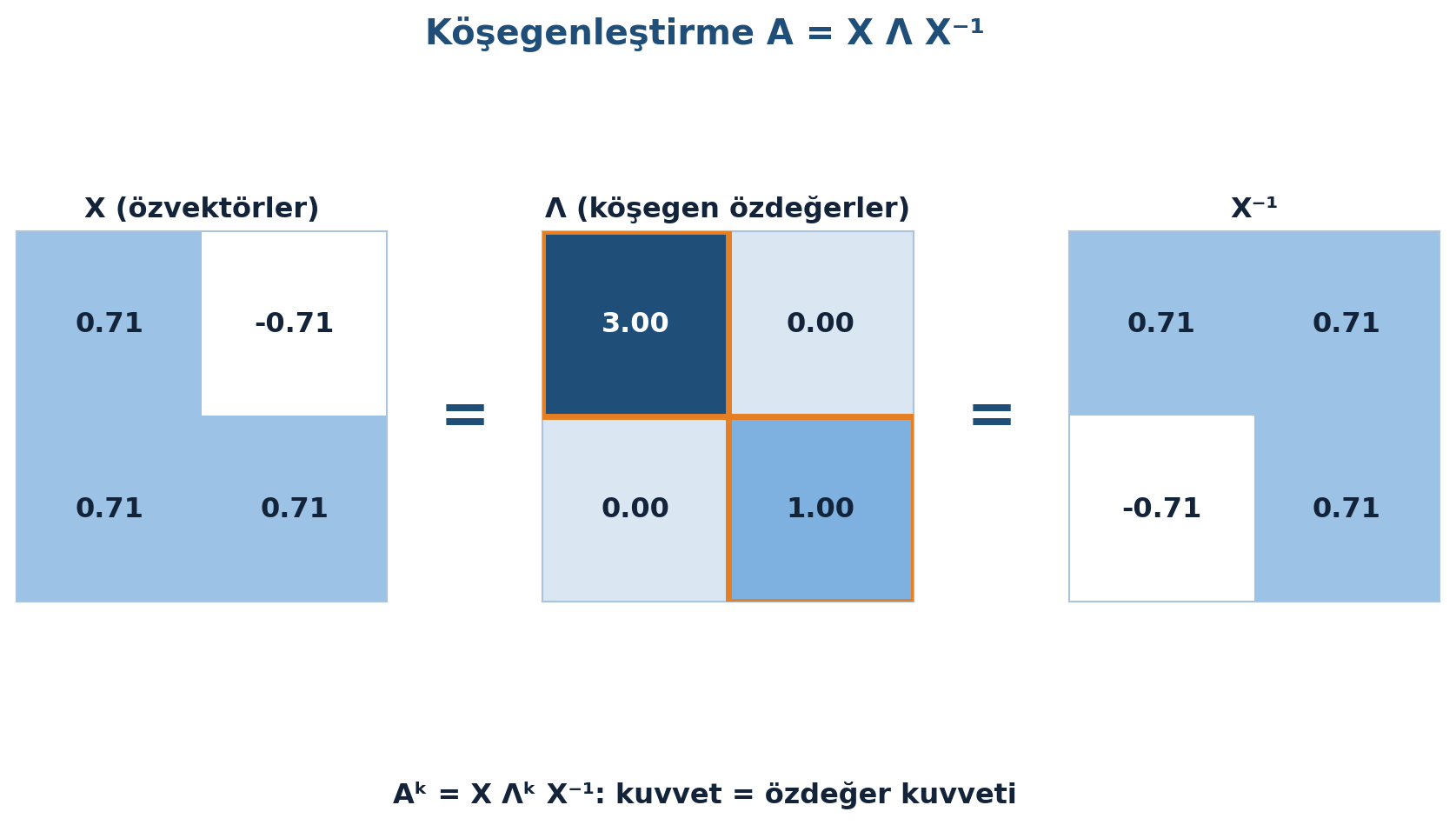
İpucuBuilder Notu — Kuvvetin Kapalı Formu
\(A = X\Lambda X^{-1}\), lineer dinamiğin kapalı formudur: \(A^{k}\)’yı doğrudan hesaplamak yerine özdeğerleri kuvvetlersin. Diyagonalleştirilemeyen (defektif) matrisler bu yüzden tehlikelidir — SVD (Ders 6) bu sorunu olmayan evrensel alternatiftir.
5.12 Spektral Teorem: S = QΛQᵀ
Matris simetrikse köşegenleştirme en güzel hâlini alır: özvektör matrisi \(X\), ortogonal bir \(Q\) olur (özvektörler ortonormal), dolayısıyla \(X^{-1} = Q^{T}\):
\[ S = Q \Lambda Q^{T}, \qquad Q^{-1} = Q^{T} \]
“…this has the name spectral theorem.” — Strang, 48:27 “…orthogonal eigenvectors, real eigenvalues.” — Strang, 48:46
Bu, Ders 2’de tanıttığımız spektral teoremin tam türetilişidir ve Ders 3’ün “simetrik → ortonormal özvektör” gözlemini kapatır. Her simetrik matris böyle görünür: gerçek özdeğerler (\(\Lambda\)) + ortonormal özvektörler (\(Q\)).
Spektral ayrışmanın geometrik anlamı Şekil 5.7’te görülüyor: ortonormal özvektörler \(q_1, q_2\) elipsin ana eksenleridir, yarı-eksen uzunlukları özdeğerlerin karekökleriyle ölçeklenir — PCA’nın tam resmi.
Kod
# S = Q Λ Q^T spektral ayrışım — PCA resmi
S = np.array([[2.0, 1.0], [1.0, 2.0]])
vals, Q = eig_symmetric(S) # vals=[3,1] azalan, Q ortonormal
lam1, lam2 = vals[0], vals[1] # 3, 1
q1, q2 = Q[:, 0], Q[:, 1] # λ1=3 ekseni, λ2=1 ekseni (DİK)
fig, ax = plt.subplots(figsize=(5.4, 5.4))
style_square_axes(ax, 3.5)
# S @ birim çember = elips (accent dolgu)
circ = unit_circle()
ellipse = S @ circ
plot_pointset(ax, ellipse, color=COL_ACCENT, label="S·(birim çember) = elips", fill_alpha=0.16)
# Karşılaştırma için birim çember (gri)
ax.plot(circ[0], circ[1], color=COL_STEEL_300, lw=1.4, ls=":", label="birim çember", zorder=1)
# Ana eksenler: q·√λ — elipsin yarı-eksenleri (uzun eksen λ1=3 yönünde), DİK
a1 = q1 * np.sqrt(lam1) # navy, uzun yarı-eksen (λ1=3)
a2 = q2 * np.sqrt(lam2) # teal, kısa yarı-eksen (λ2=1)
# yön işareti: a1 her zaman ilk bileşeni pozitif olacak şekilde
if a1[0] < 0: a1 = -a1
draw_vec2d(ax, a1, color=COL_PRIMARY, lw=3.2)
draw_vec2d(ax, a2, color=COL_TEAL, lw=3.2)
ax.text(a1[0]*1.04, a1[1]*1.04, "q₁·√λ₁", color=COL_PRIMARY, fontsize=10,
fontweight="bold", ha="left", va="bottom")
ax.text(a2[0]*1.10, a2[1]*1.10 + 0.12, "q₂·√λ₂", color=COL_TEAL, fontsize=10,
fontweight="bold", ha="right", va="bottom")
# proxy çizgiler (legend için)
ax.plot([], [], color=COL_PRIMARY, lw=3.2, label="uzun eksen: q₁·√λ₁ (λ₁=3)")
ax.plot([], [], color=COL_TEAL, lw=3.2, label="kısa eksen: q₂·√λ₂ (λ₂=1)")
ax.set_title("S = Q Λ Qᵀ: ortonormal özvektörler = ana eksenler (PCA)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
ax.legend(loc="lower right", fontsize=8.0, framealpha=0.92)
plt.show()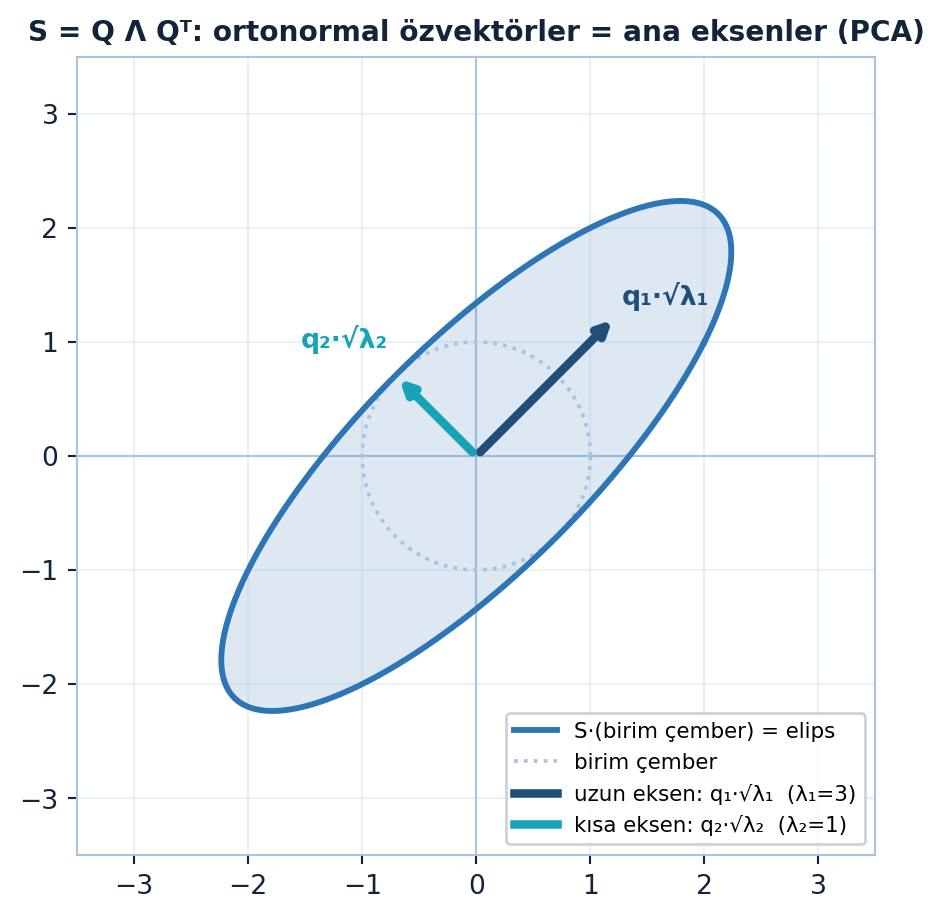
İpucuBuilder Notu — PCA’nın Matematiği
\(S = Q\Lambda Q^{T}\), PCA’nın matematiğidir: kovaryans matrisinin ortonormal özvektörleri (\(Q\)) ana bileşen eksenleri, özdeğerleri (\(\Lambda\)) o eksenlerdeki varyanslardır. Aynı ayrışım kernel PCA, spektral kümeleme (Ders 35) ve ikinci-derece optimizasyonun (Hessian) temelidir.
5.13 Bu Dersin Özeti
- \(Ax = \lambda x\) — özvektör yön değiştirmez, yalnızca \(\lambda\) ile ölçeklenir.
- \(A^{k}x = \lambda^{k}x\) — kuvvetler ve fonksiyonlar özvektör tabanında önemsizleşir.
- \(\lambda = 0 \to\) tersinir değil — özvektör null uzayında.
- Özvektör bazı — \(v = \sum_i c_i x_i\); fark/diferansiyel denklemleri çözer.
- Benzer matrisler — \(B = M^{-1}AM\), aynı özdeğerler.
- \(AB\) ve \(BA\) — aynı sıfırdan-farklı özdeğerler.
- Simetrik — gerçek özdeğer, ortogonal özvektör; anti-simetrik — sanal özdeğer.
- \(\text{trace} = \sum\lambda\), \(\det = \prod\lambda\) — hızlı sağlama.
- \(A = X\Lambda X^{-1}\) — köşegenleştirme; \(A^{k} = X\Lambda^{k}X^{-1}\).
- \(S = Q\Lambda Q^{T}\) — spektral teorem (simetrik matris).
ÖnemliTek Bir Cümle
Özvektörler bir matrisin doğal eksenleridir — o eksenlerde matris yalnızca \(\lambda\) ile ölçekler; \(A = X\Lambda X^{-1}\) bunu kullanıp her kuvvet ve fonksiyonu önemsizleştirir, ve simetrik matriste eksenler ortonormal olur (\(S = Q\Lambda Q^{T}\)).
5.14 Kontrol Soruları
NotSoru 1: Aşağıdaki matrisin özdeğer ve özvektörlerini bul.
\[ A = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \]
Cevap:
\(\det(A - \lambda I) = (2-\lambda)^{2} - 1 = \lambda^{2} - 4\lambda + 3 = (\lambda-3)(\lambda-1) \to \lambda = 3, 1\).
\(\lambda = 3\): \((A - 3I)x = 0 \to (-1, 1)\) satırı → özvektör \((1, 1)\). \(\lambda = 1\): özvektör \((1, -1)\). İki özvektör diktir (\(A\) simetrik olduğu için ✓).
NotSoru 2: Aşağıdaki matrisin özdeğerlerini bul ve trace = Σλ, det = Πλ ile sağla.
\[ A = \begin{pmatrix} 4 & 1 \\ 2 & 3 \end{pmatrix} \]
Cevap:
trace \(= 4 + 3 = 7\), det \(= 4 \cdot 3 - 1 \cdot 2 = 10\). Karakteristik: \(\lambda^{2} - 7\lambda + 10 = (\lambda-5)(\lambda-2) \to \lambda = 5, 2\).
Sağlama: $5 + 2 = 7 = $ trace ✓; $5 = 10 = $ det ✓. (Bu \(A\) simetrik değil, özvektörleri dik olmayabilir.)
NotSoru 3: 90° döndürme matrisinin özdeğerleri neden gerçek değil? Hangi matris türü gerçek özdeğer garantiler?
\[ A = \begin{pmatrix} 0 & -1 \\ 1 & 0 \end{pmatrix} \]
Cevap:
\(\det(A - \lambda I) = \lambda^{2} + 1 = 0 \to \lambda = \pm i\) (sanal). Döndürme hiçbir gerçek vektörü kendi doğrultusunda bırakmaz, gerçek özvektör yoktur. \(A\) anti-simetriktir (\(A^{T} = -A\)). Simetrik matrisler (\(S = S^{T}\)) ise her zaman gerçek özdeğer ve ortonormal özvektör garantiler (Ders 3’le bağ).
NotSoru 4: Bir tekrarlı sistem vₖ = Aᵏv₀’da uzun-vadeli davranışı neden en büyük |λ| belirler?
Cevap:
\(v_0\)’ı özvektör tabanında yaz: \(v_0 = \sum_i c_i x_i\). O zaman \(v_k = A^{k}v_0 = \sum_i c_i \lambda_i^{k} x_i\). \(k\) büyüdükçe en büyük \(|\lambda|\)’lı terim diğerlerini ezer (\(\lambda_i^{k}\) oranları \(0\)’a veya \(\infty\)’a gider).
Sonuç: \(|\lambda_{\max}| > 1 \to\) patlar, \(|\lambda_{\max}| < 1 \to\) söner, \(= 1 \to\) kararlı. Power iteration tam bunu kullanır (baskın özvektöre yakınsar); RNN’lerde gradyan patlama/sönmesi ve Markov zincirinin denge dağılımı aynı ilkeye dayanır.
5.15 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. Aşağıdaki matrisin özdeğerlerini ve özvektörlerini bul. Trace ve determinant ile sağla.
\[ A = \begin{pmatrix} 5 & 4 \\ 1 & 2 \end{pmatrix} \]
Egzersiz 2. \(A = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix}\) matrisini \(A = X\Lambda X^{-1}\) olarak köşegenleştir, sonra \(A^{4}\)’ü \(X\Lambda^{4}X^{-1}\) ile hesapla (doğrudan \(A^{4}\) çarpımına gerek kalmadan).
Egzersiz 3. \(A = \text{diag}(2, 3)\) ve \(M = \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix}\) için \(B = M^{-1}AM\) hesapla. \(B\)’nin özdeğerlerinin hâlâ \(2\) ve \(3\) olduğunu (benzerlik) doğrula; özvektörlerin değiştiğini göster.
Egzersiz 4. Python ile doğrula:
import numpy as np
A = np.array([[2.0, 1.0], [1.0, 2.0]])
lam, X = np.linalg.eig(A)
print("özdeğerler:", lam) # 3, 1
print("trace =", np.trace(A), " Σλ =", lam.sum()) # eşit
print("det =", np.linalg.det(A), " Πλ =", lam.prod()) # eşit
# A = X Λ X^{-1} doğrula:
Lam = np.diag(lam)
print("A rebuild:", X @ Lam @ np.linalg.inv(X))
# A^4 = X Λ^4 X^{-1}:
print("A^4 (eig):", X @ np.diag(lam**4) @ np.linalg.inv(X))
print("A^4 (direct):", np.linalg.matrix_power(A, 4))Egzersiz 5. (Ders 5 habercisi.) Ders 5 pozitif tanımlı matrislere geçer — tüm özdeğerleri pozitif olan simetrik matrisler. Aşağıdaki simetrik matrisin özdeğerlerini bul; hepsinin pozitif olup olmadığını kontrol et (pozitif tanımlı mı?).
\[ S = \begin{pmatrix} 2 & -1 \\ -1 & 2 \end{pmatrix} \]
5.16 Sonraki Ders İçin Hazırlık
Ders 5: Pozitif Tanımlı ve Yarı-Tanımlı Matrisler
Ders 4’te simetrik matrisin gerçek özdeğerli ve ortonormal özvektörlü olduğunu gördük. Ders 5, simetrik matrislerin en güzel ailesine odaklanır: pozitif tanımlı olanlar.
- Pozitif tanımlılık: tüm özdeğerler \(> 0\); eşdeğer testler (pivotlar, alt-determinantlar, \(x^{T}Sx > 0\))
- Yarı-tanımlı: özdeğerler \(\geq 0\)
- Neden ML’de kritik: kovaryans, kernel, Hessian, kayıp fonksiyonu eğriliği
UyarıDers 5 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (pozitif özdeğer kontrolü).
- Python’da
np.linalg.eigvalshile birkaç simetrik matrisin özdeğer işaretlerini incele. - Ana cümleyi tekrar oku: “Özvektörler matrisin doğal eksenleri; \(A = X\Lambda X^{-1}\).”
5.17 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| \(Ax = \lambda x\) | Özvektör yön değiştirmez, \(\lambda\) ile ölçeklenir | 1m51 |
| \(A^{k}x = \lambda^{k}x\) | Kuvvetler/fonksiyonlar özvektör tabanında kolay | 4m28 |
| \(\lambda = 0\) | Matris tersinir değil; özvektör null uzayında | 5m22 |
| Özvektör bazı | \(v = \sum_i c_i x_i\); fark/diferansiyel denklem çözer | 10m38 |
| Benzer matris | \(B = M^{-1}AM\), aynı özdeğerler | 13m56 |
| eig algoritması | \(M\)’lerle üçgensele/köşegene taşıma | 16m13 |
| \(AB\) ve \(BA\) | Aynı sıfırdan-farklı özdeğerler | 19m58 |
| Anti-simetrik | \(A^{T} = -A\); sanal özdeğerler (döndürme) | 25m51 |
| \(\text{trace} = \sum\lambda\) | Köşegen toplamı; \(\det = \prod\lambda\) | 31m03 |
| \(A = X\Lambda X^{-1}\) | Köşegenleştirme; \(A^{k} = X\Lambda^{k}X^{-1}\) | 45m39 |
| \(S = Q\Lambda Q^{T}\) | Spektral teorem (simetrik matris) | 48m27 |
5.18 ML Bağlantıları Özeti
- \(Ax = \lambda x\) → PCA; veri kovaryansının doğal eksenleri (özvektörler) ana bileşenler.
- \(A^{k}x = \lambda^{k}x\) → tekrarlı sistem kararlılığı; RNN gradyan patlama/sönmesi, power iteration, Markov dengesi.
- \(\lambda = 0\) / küçük \(\lambda\) → kötü koşullanma; ridge/Tikhonov düzenlileştirmesi (\(\lambda I\) ekleme) tam bunu giderir.
- \(AB\) ve \(BA\) aynı \(\lambda\) → Gram matrisi numarası; \(XX^{T}\) ile \(X^{T}X\)’ten küçüğünü hesapla (kernel trick, SVD).
- Trace/determinant → nuclear norm, log-det olabilirlik, Frobenius norm² \(= \text{trace}(A^{T}A)\).
- \(A = X\Lambda X^{-1}\) → lineer dinamiğin kapalı formu; defektif matris riski → SVD’ye geçiş (Ders 6).
- \(S = Q\Lambda Q^{T}\) → PCA, kernel PCA, spektral kümeleme, Hessian analizi.
ÖnemliTek bir şey alıp gideceksen
Özvektörler bir matrisin doğal eksenleridir — o eksenlerde matris döndürmez, yalnızca \(\lambda\) ile gerer. \(A = X\Lambda X^{-1}\) bu görüşü kapsüller ve her kuvvet/fonksiyon hesabını önemsizleştirir; simetrik matriste eksenler ortonormal olur (\(S = Q\Lambda Q^{T}\)), ki bu PCA’dan kararlılık analizine kadar ML’in çatısıdır.