flowchart TB
M["Adim adim minimize et"]
M --> TAY["Taylor 3 terim:<br/>F + dx^T grad + (1/2) dx^T H dx"]
M --> GH["gradyan (n turev) vs<br/>Hessian (n^2/2 turev --<br/>derin ogrenmede erisilemez)"]
M --> JAC["Jacobian:<br/>gradyanin J si = Hessian"]
M --> NEW["Newton:<br/>x+ = x - J^-1 f (kok)<br/>x+ = x - H^-1 grad (min)"]
M --> YAK["yakinsama:<br/>Newton KUADRATIK,<br/>descent LINEAR"]
TAY --> GH
GH --> JAC
KON["konvekslik = anahtar kelime:<br/>kase + tek minimum"]
KES["kesisim konveks;<br/>max konveks, min degil"]
D22["Ders 22: gradient descent"]
JAC --> KON
KON --> KES
YAK --> D22
classDef center fill:#1f4e79,stroke:#163a5c,color:#ffffff,stroke-width:2px;
classDef branch fill:#2e75b6,stroke:#1f4e79,color:#ffffff,stroke-width:1px;
classDef side fill:#9dc3e6,stroke:#2e75b6,color:#11151c,stroke-width:1px;
class M center;
class TAY,GH,JAC,NEW,YAK branch;
class KON,KES,D22 side;
22 Bir Fonksiyonu Adım Adım Minimize Etmek
Taylor serisi, Newton yöntemi, yakınsama hızları ve konvekslik
NotBölüm bilgisi
Bu ders optimizasyon bloğunu (Part 6) açar — derin öğrenmenin kalbindeki “bir fonksiyonu adım adım küçült” fikrini Taylor serisi, Newton yöntemi ve konvekslik üçlüsüyle kurar: Strang’in Ders 21 videosu (≈54 dk) ve OCW Lecture 21 temel alınmıştır. Okuma süresi ≈34 dk; önkoşul Ders 20 (istatistik bloğu).
22.1 Bu Derste Ne Var?
Lineer cebir ve istatistik bloklarından sonra sıra bir sayıyı küçültmeye geliyor: bir maliyet fonksiyonu verildiğinde, onu en küçükleyen noktayı adım adım nasıl ararız? Cevap her seferinde aynı: bulunduğun noktada fonksiyonu Taylor serisiyle yaklaşıkla, o yaklaşımın minimumuna atla, tekrar et. Bu derste o döngünün araçlarını (gradyan, Hessian, Jacobian), iki ana yöntemini (Newton ve steepest descent) ve sonucu garanti eden geometrik koşulu (konvekslik) görüyoruz.
Beş sonuç:
- Taylor serisi (3 terim): \(F(x+\Delta x) \approx F(x) + (\Delta x)^{T}\nabla F + \tfrac{1}{2}(\Delta x)^{T}H(\Delta x)\); \(\nabla F\) gradyan, \(H\) Hessian (simetrik, \(n^{2}\) ikinci türev).
- Jacobian: vektör fonksiyon \(f\) için birinci türev matrisi \(J\); gradyanın Jacobian’ı = Hessian.
- Newton yöntemi: \(f = 0\) için \(x_{+} = x - J^{-1}f\); minimizasyon için \(x_{+} = x - H^{-1}\nabla F\).
- Yakınsama: Newton kuadratik (hata karelenir, çok hızlı); steepest descent linear (hata × sabit < 1).
- Konvekslik: konveks küme (iki nokta arası çizgi kümede kalır), konveks fonksiyon (grafik üstü = konveks küme); kesişim konveks, max konveks ama min değil.
“Convexity is the key word for these problems.” — Strang, 32:49
Şekil 22.1 dersin iskeletini gösterir: merkezdeki “adım adım minimize et” fikri Taylor’dan Newton’a, oradan yakınsama hızlarına ve konveksliğe dallanır; Ders 22’nin gradient descent’i ise yakınsama dalından çıkan köprü düğümüdür.
İpucuBuilder Notu — Optimizasyonun Alet Çantası
Bu dersin her satırı tek bir döngünün parçasıdır: yaklaşıkla → çöz → tekrarla. Taylor serisi yaklaşımı verir, gradyan/Hessian onun katsayılarıdır, Newton ve steepest descent çözme stratejileridir, konvekslik ise “bu döngü gerçekten dibe varır mı?” sorusunun cevabıdır. Derin öğrenmenin tüm eğitim mekanizması bu alet çantasının birinci-derece (gradyan) köşesinde yaşar — Hessian milyar parametrede erişilemez olduğu için.
22.2 Taylor Serisi: Gradyan ve Hessian
Optimizasyon, bir fonksiyonun yerel davranışını yaklaşıkla başlar.
“…three terms of a Taylor series?” — Strang, 1:44
Tek değişkende klasik üç-terim Taylor’ı çok değişkene taşı. \(x = (x_{1}, \dots, x_{n})\), \(\Delta x\) bir vektör:
\[F(x + \Delta x) \approx F(x) + (\Delta x)^{T}\nabla F + \tfrac{1}{2}(\Delta x)^{T} H\, (\Delta x)\]
Lineer terimde gradyan \(\nabla F\) (\(n\) kısmi türev vektörü); kuadratik terimde Hessian \(H\) (ikinci türev matrisi):
\[\nabla F = \left(\frac{\partial F}{\partial x_{1}}, \dots, \frac{\partial F}{\partial x_{n}}\right), \qquad H_{jk} = \frac{\partial^{2} F}{\partial x_{j}\,\partial x_{k}}\]
“…The Hessian, Hessian matrix.” — Strang, 5:19
Hessian simetriktir (karışık türevler eşit, Ders 16). \(n\) büyükse gradyan \(n\) türev, Hessian \(\sim\tfrac{1}{2}n^{2}\) türev ister — bu yüzden derin öğrenmede Hessian “erişilemez”, sadece gradyan hesaplanır (otomatik türev/backprop ile).
Şekil 22.2 bu üç terimi tek bir kesit üzerinde üst üste koyar: sabit terim noktayı, lineer terim (teğet) eğimi, kuadratik terim (parabol) eğriliği yakalar; kuadratik yaklaşım en geniş aralıkta gerçek fonksiyona yapışır.
Kod
x0 = np.array([0.7, -0.4])
d = np.array([1., 1.]) / np.sqrt(2)
g = num_grad(F21, x0)
H = num_hessian(F21, x0)
ts = np.linspace(-1.5, 1.5, 200)
gercek = np.array([F21(x0 + t * d) for t in ts])
sabit = np.full_like(ts, F21(x0))
lineer = F21(x0) + ts * (d @ g)
kuadratik = F21(x0) + ts * (d @ g) + 0.5 * ts**2 * (d @ H @ d)
fig, ax = plt.subplots(figsize=(8, 4.4))
ax.plot(ts, gercek, color=COL_PRIMARY, lw=2.5, label="gerçek F")
ax.plot(ts, sabit, color="#888888", lw=1.6, linestyle="--", label="1 terim (sabit)")
ax.plot(ts, lineer, color=COL_ACCENT, lw=1.8, label="2 terim (teğet)")
ax.plot(ts, kuadratik, color=COL_VEC3, lw=2.0, label="3 terim (kuadratik)")
apply_style(ax)
ax.legend()
ax.set_xlabel("t (kesit parametresi)")
ax.set_title("Taylor üç terim: kuadratik yaklaşım en geniş aralıkta yapışır (dx yarıya inince hata ~8 kat düşer — kübik artık)", fontsize=9.5)
fig.tight_layout()
plt.show()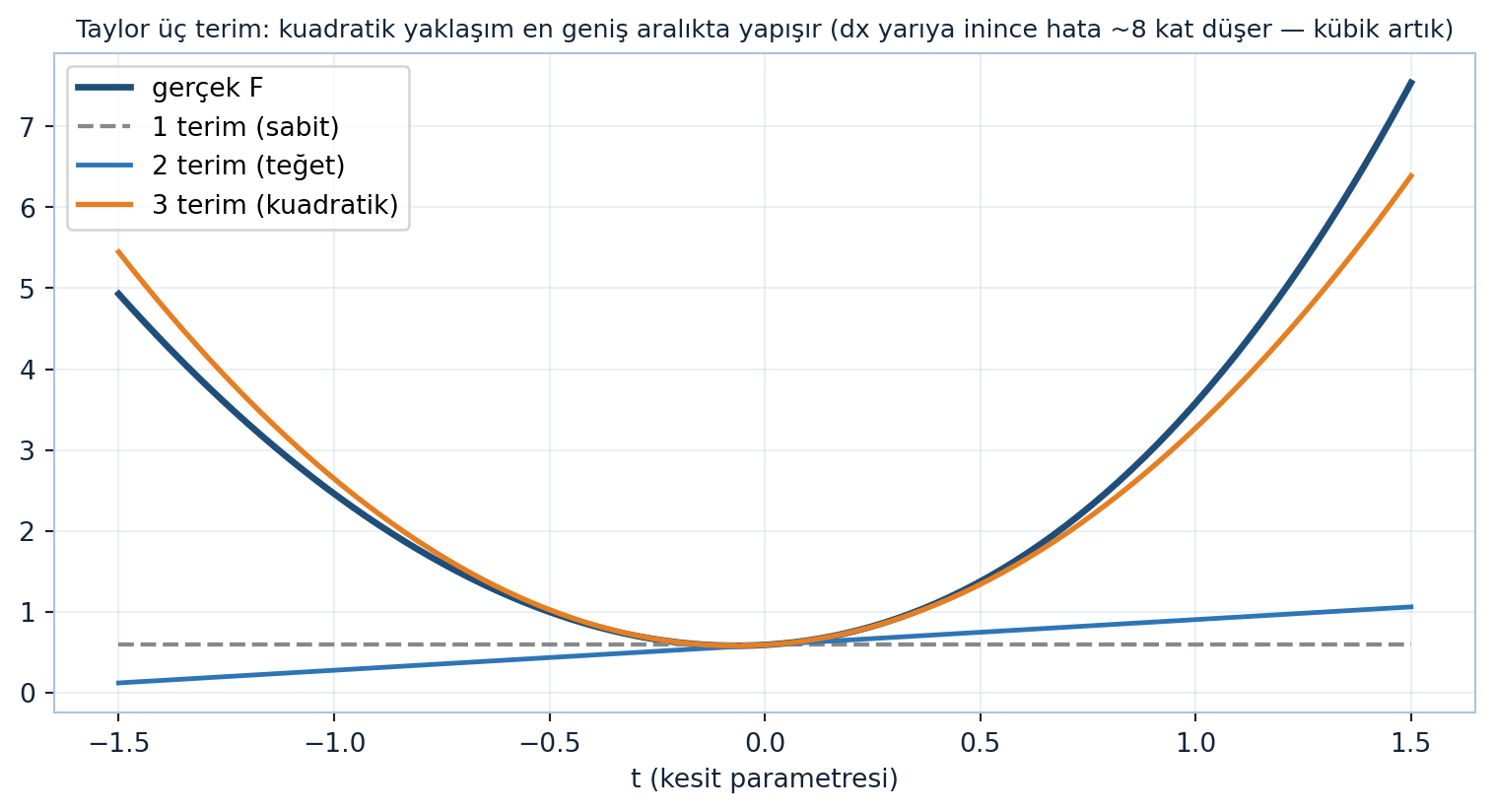
İpucuBuilder Notu — Lineer Terim Ucuz Kuadratik Pahalı
Üç-terim Taylor optimizasyonun tüm algoritmalarının temelidir: lineer terim (gradyan) → gradient descent, kuadratik terim (Hessian) → Newton. Maliyet asimetrisi belirleyicidir: gradyan \(n\) türev (ucuz), Hessian \(\sim\tfrac{1}{2}n^{2}\) türev (pahalı). ML köprüsü: \(n^{2}\) Hessian milyar-parametreli modellerde imkânsız; bu yüzden pratik derin öğrenme birinci-derece (gradyan) kalır, Hessian’a yaklaşımlar (L-BFGS, K-FAC) kullanır.
22.3 Jacobian: Vektör Fonksiyonun Türevi
Skaler \(F\) yerine vektör fonksiyon \(f = (f_{1}, \dots, f_{n})\) (\(n\) fonksiyon, \(n\) değişken). Onun Taylor açılımı:
\[f(x + \Delta x) \approx f(x) + J\,(\Delta x)\]
Buradaki birinci-türev matrisi Jacobian \(J\):
“…I’m looking for the Jacobian.” — Strang, 8:56
\[J_{jk} = \frac{\partial f_{j}}{\partial x_{k}}\]
Önemli paralellik: \(f\), gradyan \(\nabla F\)’ye karşılık gelir (ikisi de \(n\) fonksiyon/\(n\) değişken). Dolayısıyla gradyanın Jacobian’ı = Hessian (birinci türevin birinci türevi = ikinci türev). Bu, skaler ve vektör dünyaları birbirine bağlar — sayısal tanık olarak gradyanın Jacobian’ı ile doğrudan Hessian arasındaki fark merkez-fark hassasiyetinde maxdiff ~1e-4 düzeyinde kalır.
Şekil 22.7 (Egzersizler bölümünde) bu özdeşliğin somut bir Hessian örneğini gösterir: simetrik ama belirsiz bir \(H\), “gradyanın Jacobian’ı = Hessian” zincirinin sonunda konvekslik testine bağlanır.
İpucuBuilder Notu — Katman Katman Jacobian
Jacobian = çok-girişli çok-çıkışlı bir fonksiyonun türev matrisi; “gradyanın Jacobian’ı Hessian’dır” özdeşliği skaler/vektör kalkülüsü birleştirir. ML köprüsü: backprop (Ders 27) tam bir Jacobian-çarpımı zinciridir — her katman bir Jacobian, zincir kuralı bunları çarpar. PyTorch’un autograd’ı Jacobian-vektör çarpımları (JVP/VJP) hesaplar.
22.4 Newton Yöntemi: f = 0 Çözmek
\(n\) denklem \(n\) bilinmeyenli \(f(x) = 0\) sistemini çöz.
“…I’ll start with Newton’s method…” — Strang, 10:59
Taylor’ın lineer kısmını kullan: yeni nokta \(x_{k+1}\)’de \(f\) sıfır olsun istiyoruz.
\[0 = f(x_{k}) + J(x_{k})\,(x_{k+1} - x_{k})\]
\(\Delta x\)’i çöz: \(x_{k+1} - x_{k} = -J^{-1}f(x_{k})\). Yani Newton iterasyonu:
\[x_{k+1} = x_{k} - J(x_{k})^{-1}\, f(x_{k})\]
Her adımda Jacobian’ı (mevcut noktada) ters çevir, \(f\) ile çarp, çıkar. 18.02’de nadiren öğretilir ama gradyan ve Jacobian’ın büyük uygulamasıdır.
Şekil 22.3 sol paneli bu geometriyi gösterir: bir parabolde teğet doğrusunu çözüp onun \(x\)-kesişimine atlamak; sağ panel ise hatanın her adımda nasıl karelendiğini taşır (sonraki bölümdeki √9 örneğinin tanığı).
İpucuBuilder Notu — Lineerleştir Çöz Tekrarla
Newton = “lineerleştir, çöz, tekrarla.” Her adımda fonksiyonu teğet doğrusuyla değiştirir. ML köprüsü: Newton ikinci-derece optimizasyonun temeli; tam Hessian/Jacobian pahalı olduğundan pratikte yaklaşımlar (quasi-Newton: BFGS, L-BFGS) kullanılır — ters Hessian’ı gradyan farklarından tahmin eder.
22.5 Örnek: √9 Bulmak
Newton’ı somut bir tek-değişkenli örnekte gör. \(f(x) = x^{2} - 9\), \(f = 0\) çözümü \(\sqrt{9} = 3\).
“…I want to find the square root of 9.” — Strang, 14:21
Jacobian (türev) \(J = 2x\). Newton formülünü uygula ve sadeleştir:
\[x_{k+1} = x_{k} - \frac{x_{k}^{2} - 9}{2x_{k}} = \tfrac{1}{2}x_{k} + \frac{9}{2x_{k}}\]
Sağlama: \(x_{k} = 3\) ise \(x_{k+1} = \tfrac{1}{2}\cdot 3 + 9/6 = 1.5 + 1.5 = 3\) — sabit nokta, doğru kök. Bu, bilgisayarların karekök hesaplama yöntemidir (Babil yöntemi); birkaç adımda muazzam hassasiyetle yakınsar. \(x_{0}=6\)’dan başlayınca hata dizisi \(3 \to 0.75 \to 0.075 \to 9.1\mathrm{e}{-4} \to 1.4\mathrm{e}{-7}\) ilerler — her adımda doğru hane sayısı katlanır, kuadratik oran \(e_{+}/e^{2}\) teorik limit \(1/(2\sqrt{c}) = 1/6 = 0.1666\)’ya oturur.
Kod
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4.2))
# --- Sol: Newton geometrisi, f(x) = x^2 - 9 ---
xs = np.linspace(0, 7, 200)
ax1.plot(xs, xs**2 - 9.0, color=COL_PRIMARY, lw=2, label="f(x) = x² − 9")
ax1.axhline(0.0, color=COL_TEXT, lw=1.0, alpha=0.6)
xs9 = newton_sqrt(9.0, 6.0)
# İlk 3 Newton adımını görselleştir: x0=6, x1=3.75, x2=3.075
for k in range(3):
xk = xs9[k]
fk = xk**2 - 9.0
# teğet doğru: f(xk) + 2 xk (x - xk), x-kesişimi = sonraki iterasyon
xline = np.linspace(min(xk, xs9[k+1]) - 0.3, xk + 0.3, 50)
ax1.plot(xline, fk + 2.0*xk*(xline - xk), color=COL_VEC3, lw=1.3, alpha=0.9)
# nokta (xk, f(xk))
ax1.plot(xk, fk, "o", color=COL_VEC3, ms=7, zorder=5)
# dikey kesik çizgi (xk noktasını x-eksenine indir)
ax1.plot([xk, xk], [0.0, fk], color=COL_STEEL_300, lw=1.0, ls="--", alpha=0.8)
# x-kesişiminde küçük işaret (sonraki iterasyon)
ax1.plot(xs9[k+1], 0.0, "o", color=COL_VEC3, ms=5, alpha=0.7, zorder=5)
# kök x = 3
ax1.plot(3.0, 0.0, "o", color=COL_TEAL, ms=11, zorder=6, label="kök x = 3")
ax1.annotate("kök x = 3", xy=(3.0, 0.0), xytext=(3.4, -7.0),
color=COL_TEAL, fontsize=10, fontweight="bold")
ax1.annotate("x₀ = 6", xy=(6.0, 27.0), xytext=(5.0, 30.0), color=COL_VEC3, fontsize=9)
apply_style(ax1)
ax1.set_xlabel("x"); ax1.set_ylabel("f(x)")
ax1.set_title("Newton geometrisi: teğeti çöz, x-kesişimine atla", color=COL_TEXT, fontsize=11, fontweight="bold")
ax1.legend(loc="upper left", fontsize=8)
# --- Sağ: semilogy hata |x_k - 3| ---
errs = np.abs(xs9 - 3.0)
errs_plot = np.maximum(errs, 1e-17)
ax2.semilogy(range(len(errs_plot)), errs_plot, marker="o", ms=8, color=COL_PRIMARY, lw=1.8)
labels = ["3", "0.75", "0.075", "9.1e-4", "1.4e-7"]
# Her etiketi işaretçiden uzağa, eğrinin boş tarafına yerleştir (örtüşme yok)
offsets = [(0.10, 3.0), (0.10, 3.0), (0.12, 3.0), (-0.30, 6.0), (0.12, 5.0)]
for i, lab in enumerate(labels):
dx, fac = offsets[i]
ha = "right" if dx < 0 else "left"
ax2.annotate(lab, xy=(i, errs_plot[i]), xytext=(i + dx, errs_plot[i] * fac),
color=COL_TEXT, fontsize=8.5, fontweight="bold", ha=ha)
ax2.set_ylim(1e-17, 1e3)
ax2.annotate("kuadratik: e₊/e² → 1/6",
xy=(3.05, 1.2e-3), xytext=(5.0, 80.0),
color=COL_VEC3, fontsize=9, fontweight="bold", ha="center",
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.2))
apply_style(ax2)
ax2.set_xlabel("Newton adımı k"); ax2.set_ylabel("hata |xₖ − 3|")
ax2.set_title("Her adımda doğru hane KATLANIR", color=COL_TEXT, fontsize=11, fontweight="bold")
fig.suptitle("Newton kökü (Babil karekök): lineerleştir-çöz-tekrarla — hata KARELENIR: 3, 0.75, 0.075, 9e-4, 1e-7",
color=COL_PRIMARY, fontsize=11, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.94])
plt.show()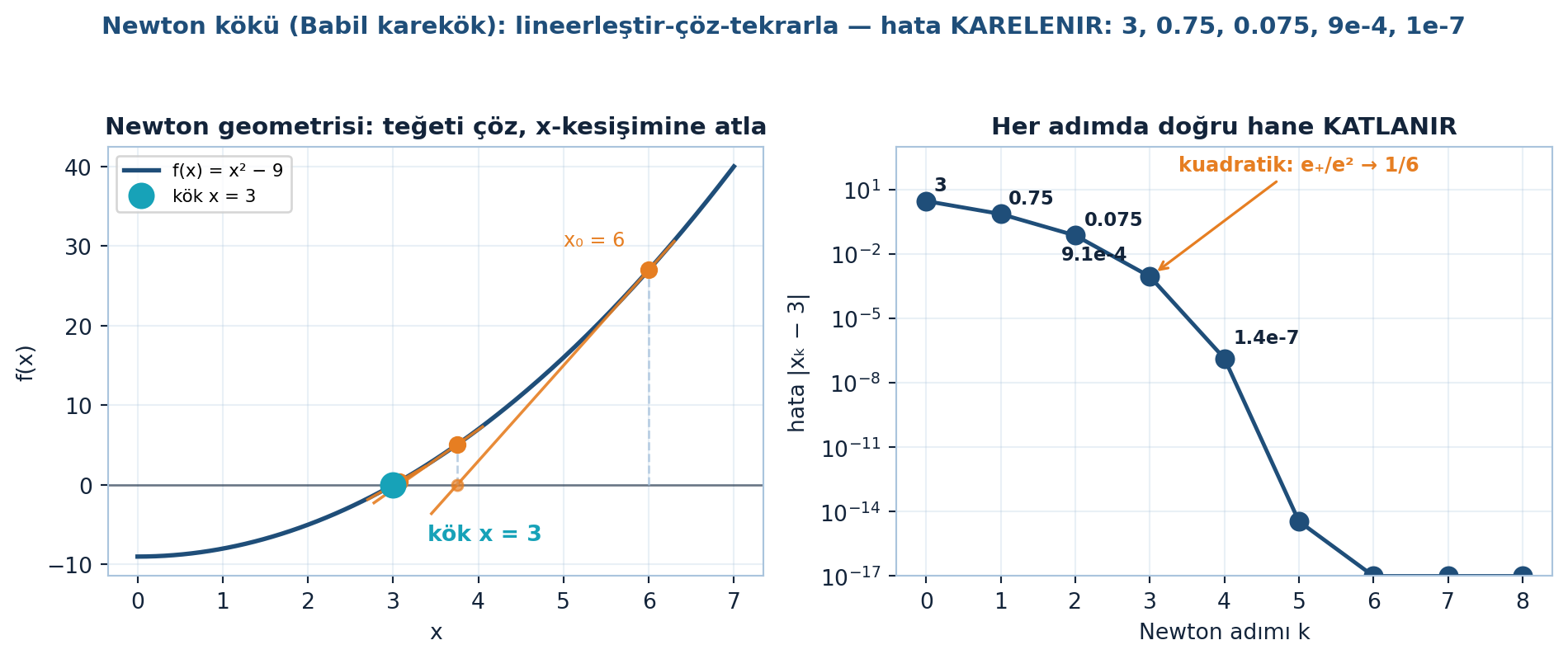
Şekil 22.3 bu örneği bütünüyle taşır: solda \(x_{0}=6 \to 3.75 \to 3.075\) teğet adımları kök \(3\)’e iner, sağda semilogy eksende hata her adımda karelenir.
İpucuBuilder Notu — Babil’den Beri Aynı Hile
\(x_{k+1} = \tfrac{1}{2}(x_{k} + 9/x_{k})\) formülü Newton’ın gücünü gösterir: \(3\)’e kuadratik yakınsar (her adımda doğru hane sayısı ikiye katlanır). ML köprüsü: aynı “tahmin et, düzelt, tekrarla” döngüsü tüm iteratif çözücülerin (ve eğitimin) kalbidir; Newton’ın hızı, ikinci-derece bilginin (eğrilik) ne kadar değerli olduğunu kanıtlar.
22.6 Newton ile Minimizasyon
\(F(x)\)’i minimize etmek = gradyanı sıfırlamak (\(\nabla F = 0\)). Bu, “\(f = 0\)” probleminin gradyan versiyonudur: \(f\) yerine \(\nabla F\), Jacobian yerine onun Jacobian’ı (= Hessian). Newton iterasyonu:
\[x_{k+1} = x_{k} - H(x_{k})^{-1}\,\nabla F(x_{k})\]
Yani minimum ararken her adımda Hessian’ı ters çevir, gradyanla çarp, çıkar. Hessian eğriliği (kâsenin ne kadar dik büküldüğünü) bildiğinden adım yönünü ve boyunu birlikte ayarlar — gradient descent’ten çok daha akıllı, ama \(H\)’yi hesaplamak/ters almak pahalı. Kuadratik bir kâsede (örn. \(A = \mathrm{diag}(1,10)\)) Newton tek adımda merkeze (\(0,0\)) varır; kuadratik-olmayan \(F21\)’de ise \(\|\nabla F\| \to 0.0\) değerine 8 adımda iner.
Şekil 22.4 (bir sonraki bölümde) bu tek-adım davranışını steepest descent’in zikzaklı yoluyla yan yana koyar.
İpucuBuilder Notu — Eğriliği Bilen Akıllı Adım
“\(\nabla F = 0\) çözmek için Newton’ı gradyana uygula” — minimizasyon, kök bulmanın özel hâli. ML köprüsü: doğal gradyan (natural gradient) ve K-FAC, Hessian/Fisher bilgisini kullanan yaklaşık-Newton yöntemleridir; tam Newton derin ağlarda imkânsız (\(H\) milyar×milyar) ama eğrilik bilgisi optimizasyonu hızlandırır.
22.7 Yakınsama Hızları: Kuadratik vs Linear
İki yöntemin yakınsama hızı çok farklı.
“…the convergence rate for Newton’s method [will be quadratic].” — Strang, 30:35
Newton: kuadratik — hata her adımda karelenir (\(e \to e^{2}\)), yeterince yakın başlarsan süper hızlı (hane sayısı ikiye katlanır). Steepest descent (gradient descent): linear — hata her adımda bir sabitle (\(< 1\)) çarpılır; doğru matrisin tersi yerine bir sayı kullandığından süper hız beklenemez.
\[\text{Newton: } e_{k+1} \sim e_{k}^{2}, \qquad \text{steepest descent: } e_{k+1} \sim c\,e_{k}\ (c < 1)\]
Kötü-koşullu kâse \(A = \mathrm{diag}(1,10)\)’da, adım boyu \(s = 2/11\) ile steepest descent’in oranı \(e_{+}/e = 0.8182 = (\kappa - 1)/(\kappa + 1) = 9/11\) değerine BİREBİR oturur; 60 adımda hata ancak 5e-5’e iner — oysa Newton aynı kâsede tek adımda biter. Arada Levenberg-Marquardt gibi “ucuz Newton” yöntemleri var: tam Hessian’ı hesaplamaz, gradyandan görebildiği bir Hessian terimini kapar — tam ikinci-derece değil ama gradient descent’ten iyi.
Şekil 22.4 bu kıyası iki panelde tutar: solda GD konturlar üstünde zikzak çizerken Newton tek adımda merkeze atlar; sağda log-ölçekli hata GD için düz (linear) iner, Newton için tek adımda makine sıfırına çöker.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10.5, 4.2))
# --- Sol: kötü-koşullu kâse konturları + GD zikzak vs Newton tek adım ---
xg = np.linspace(-9, 9, 150); yg = np.linspace(-4, 4, 150)
XG, YG = np.meshgrid(xg, yg)
Z = 0.5 * (XG**2 + 10*YG**2)
axL.contour(XG, YG, Z, levels=25, cmap=NAVY_CMAP)
gd = gradient_descent(F_bowl, np.array([8., 3.]), s=2/11, n_iter=25, g=grad_bowl)
axL.plot(gd[:, 0], gd[:, 1], "o-", color=COL_VEC3, ms=3.5, lw=1.5, label="GD (zikzak)")
nw = newton_minimize(F_bowl, np.array([8., 3.]), n_iter=1, g=grad_bowl, Hf=hess_bowl)
axL.plot(nw[:, 0], nw[:, 1], "s-", color=COL_PRIMARY, ms=7, lw=2.5, label="Newton (TEK adım)")
axL.set_xlabel("x₁"); axL.set_ylabel("x₂")
axL.set_title("Kötü-koşullu kâse: GD zikzak vs Newton tek adım", color=COL_TEXT, fontsize=11, fontweight="bold")
axL.legend(); apply_style(axL)
# --- Sağ: yakınsama hızı — GD linear, Newton tek adımda makine sıfırı ---
gd60 = gradient_descent(F_bowl, np.array([8., 3.]), s=2/11, n_iter=60, g=grad_bowl)
errs_gd = np.linalg.norm(gd60, axis=1)
axR.semilogy(errs_gd, color=COL_VEC3, lw=2, label="GD: e₊ = 0.818·e (linear)")
axR.annotate("Newton: 1 adımda makine sıfırı", xy=(1, errs_gd.min()*1.2),
xytext=(8, errs_gd[0]*0.4), color=COL_PRIMARY, fontsize=9, fontweight="bold",
arrowprops=dict(arrowstyle="->", color=COL_PRIMARY))
axR.plot([0, 1], [errs_gd[0], 1e-13], "s-", color=COL_PRIMARY, ms=6, lw=2, label="Newton (1 adım)")
axR.set_xlabel("adım k"); axR.set_ylabel("hata ‖xₖ‖")
axR.set_title("Yakınsama: GD linear, Newton kuadratik", color=COL_TEXT, fontsize=11, fontweight="bold")
axR.legend(); apply_style(axR)
fig.suptitle("Newton vs steepest descent (kâse A=diag(1,10)): Newton 1 adım, GD 60 adımda bitmez — oran 0.8182 = (kappa-1)/(kappa+1) = 9/11 BİREBİR",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()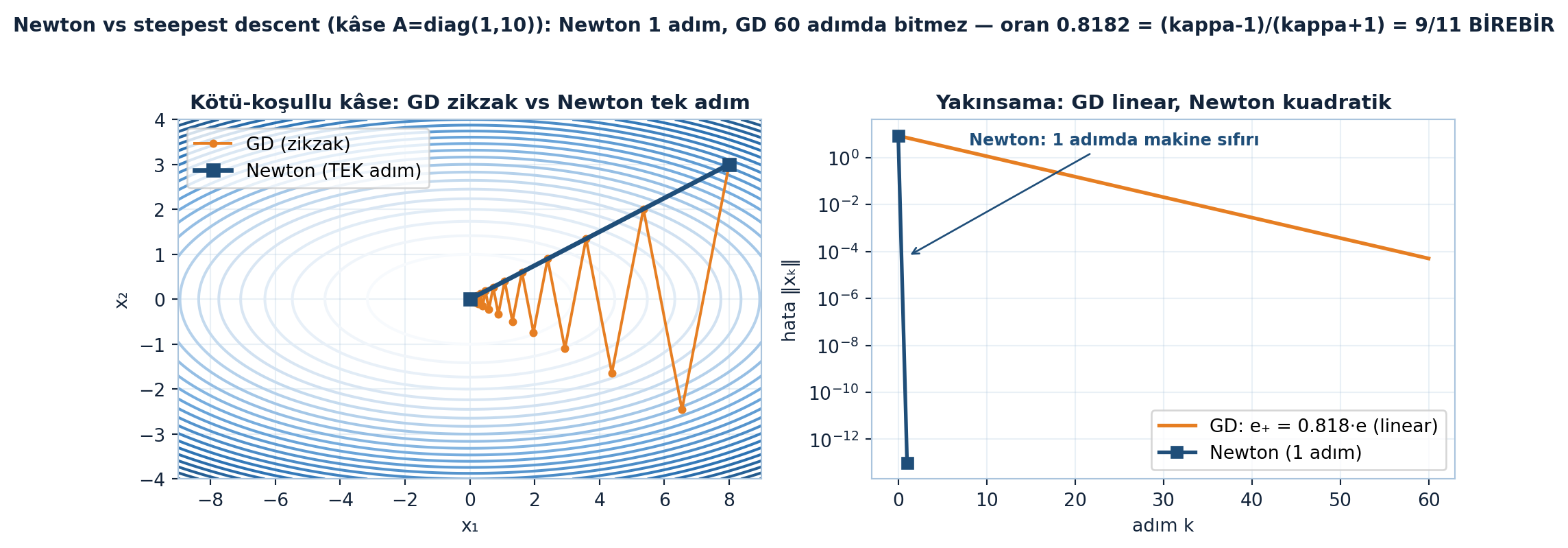
İpucuBuilder Notu — Az Pahalı Adım mı Çok Ucuz Adım mı
Kuadratik vs linear ayrımı pratikte belirleyici: Newton az adımda yakınsar ama her adım pahalı (Hessian); gradient descent çok adım ister ama her adım ucuz (sadece gradyan). ML köprüsü: derin öğrenme dev ölçekte olduğundan “çok ucuz adım” kazanır — gradient descent ve türevleri (SGD, Adam, Ders 22-25) standarttır; Levenberg-Marquardt küçük/orta problemlerde (klasik regresyon) hâlâ yaygın.
22.8 Konvekslik: Küme ve Fonksiyon
Optimizasyon problemlerinin anahtar kelimesi:
“Convexity is the key word for these problems.” — Strang, 32:49
İdeal problem: bir konveks fonksiyonu bir konveks küme üzerinde minimize et. Konveks küme tanımı: kümeden herhangi iki nokta al, aralarındaki çizgi tamamen kümede kalıyorsa konvekstir.
“…it stays in the set. So that’s convexity…” — Strang, 38:19
\[x_{1}, x_{2} \in K \;\Rightarrow\; t x_{1} + (1-t) x_{2} \in K \quad (0 \leq t \leq 1)\]
Üçgen konvekstir (200 kiriş testinde 0 ihlal); iki üçgenin birleşimi genelde değil — kiriş dışarı çıkar (50/200 ihlal); ama kesişimi her zaman konvekstir (iki nokta her iki kümede, çizgi her ikisinde kalır → 0/100 ihlal). Kısıt kümesi \(K\) örn. \(Ax = b\) (afin alt-uzay) olabilir. Konveks fonksiyon ise grafiğinin üstünde ve üzerindeki noktalar (epigraph) bir konveks küme oluşturuyorsa konvekstir — bir kâse şekli. İki konveks fonksiyonun maksimumu konvekstir (orta-nokta ihlali 0), ama minimumu değil (60 ihlal, max gap 0.344):
“…What about the maximum of the two functions?” — Strang, 49:05
Minimum bir “kink” (köşe) yapar, dışbükeyliği bozar; maksimum keskin köşeyi yukarı tutar, konveks kalır.
Şekil 22.5 küme tarafını gösterir: tek üçgenin kirişleri içeride kalır, birleşimde turuncu kiriş dışarı çıkar, kesişim (teal) konveks kalır. Şekil 22.6 ise fonksiyon tarafını: \(|x|\) ve \((x-1)^{2}\)’nin üst zarfı (max) düzgün konveks, alt zarfı (min) kink’lerle bozulur.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4))
# ---- Sol: tek üçgen KONVEKS (kiriş testi 0 ihlal) ----
triL = plt.Polygon(TRI1, closed=True, facecolor=COL_PRIMARY, alpha=0.25,
edgecolor=COL_PRIMARY, linewidth=1.8, zorder=2)
axL.add_patch(triL)
rng = np.random.default_rng(4)
chords = []
while len(chords) < 12:
p = rng.uniform(-1, 8, 2); q = rng.uniform(-1, 8, 2)
if in_triangle(p, TRI1) and in_triangle(q, TRI1):
chords.append((p, q))
for p, q in chords:
axL.plot([p[0], q[0]], [p[1], q[1]], color=COL_ACCENT, linewidth=0.9, alpha=0.85, zorder=3)
axL.set_xlim(-0.6, 4.6); axL.set_ylim(-0.6, 3.4)
axL.set_aspect("equal")
axL.set_title("üçgen: KONVEKS (kiriş testi 0/200 ihlal)", color=COL_TEXT, fontsize=11, fontweight="bold")
apply_style(axL)
# ---- Sağ: BİRLEŞİM konveks DEĞİL ----
triR1 = plt.Polygon(TRI1, closed=True, facecolor=COL_PRIMARY, alpha=0.20,
edgecolor=COL_PRIMARY, linewidth=1.6, zorder=2)
triR2 = plt.Polygon(TRI2, closed=True, facecolor=COL_SKY_400, alpha=0.30,
edgecolor=COL_ACCENT, linewidth=1.6, zorder=2)
axR.add_patch(triR1); axR.add_patch(triR2)
# ihlal kirişi: a TRI1 içinde, b TRI2 içinde, ortası iki kümenin DIŞINDA
# (in_triangle ile doğrulandı: a TRI1, b TRI2, kirişin iç kısmı ikisinin de dışında)
a = np.array([0.91, 2.45]); b = np.array([4.10, 3.79])
mid = 0.5 * (a + b)
axR.plot([a[0], b[0]], [a[1], b[1]], color=COL_VEC3, linewidth=2.8, zorder=5)
axR.plot(*a, "o", color=COL_PRIMARY, markersize=7, zorder=6)
axR.plot(*b, "o", color=COL_ACCENT, markersize=7, zorder=6)
axR.plot(*mid, "x", color=COL_VEC3, markersize=9, markeredgewidth=2.5, zorder=6)
# kesişim bölgesi: küçük üçgenimsi koyu teal dolgu + etiket
inter = np.array([[2.0, 1.0], [3.0, 1.0], [2.4, 1.6]])
interP = plt.Polygon(inter, closed=True, facecolor=COL_TEAL, alpha=0.85,
edgecolor=COL_TEAL, linewidth=1.0, zorder=4)
axR.add_patch(interP)
axR.annotate("kesişim: konveks", xy=(2.45, 1.2), xytext=(1.7, -0.35),
color=COL_TEAL, fontsize=8.5, fontweight="bold",
arrowprops=dict(arrowstyle="->", color=COL_TEAL, lw=1.2), zorder=7)
axR.set_xlim(-0.6, 6.6); axR.set_ylim(-0.8, 4.4)
axR.set_aspect("equal")
axR.set_title("BİRLEŞİM: konveks DEĞİL (50/200 ihlal)", color=COL_TEXT, fontsize=11, fontweight="bold")
apply_style(axR)
fig.suptitle("Konveks küme: iki nokta arası çizgi kümede kalır — kesişim konveksliği korur, birleşim bozar",
color=COL_PRIMARY, fontsize=12, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()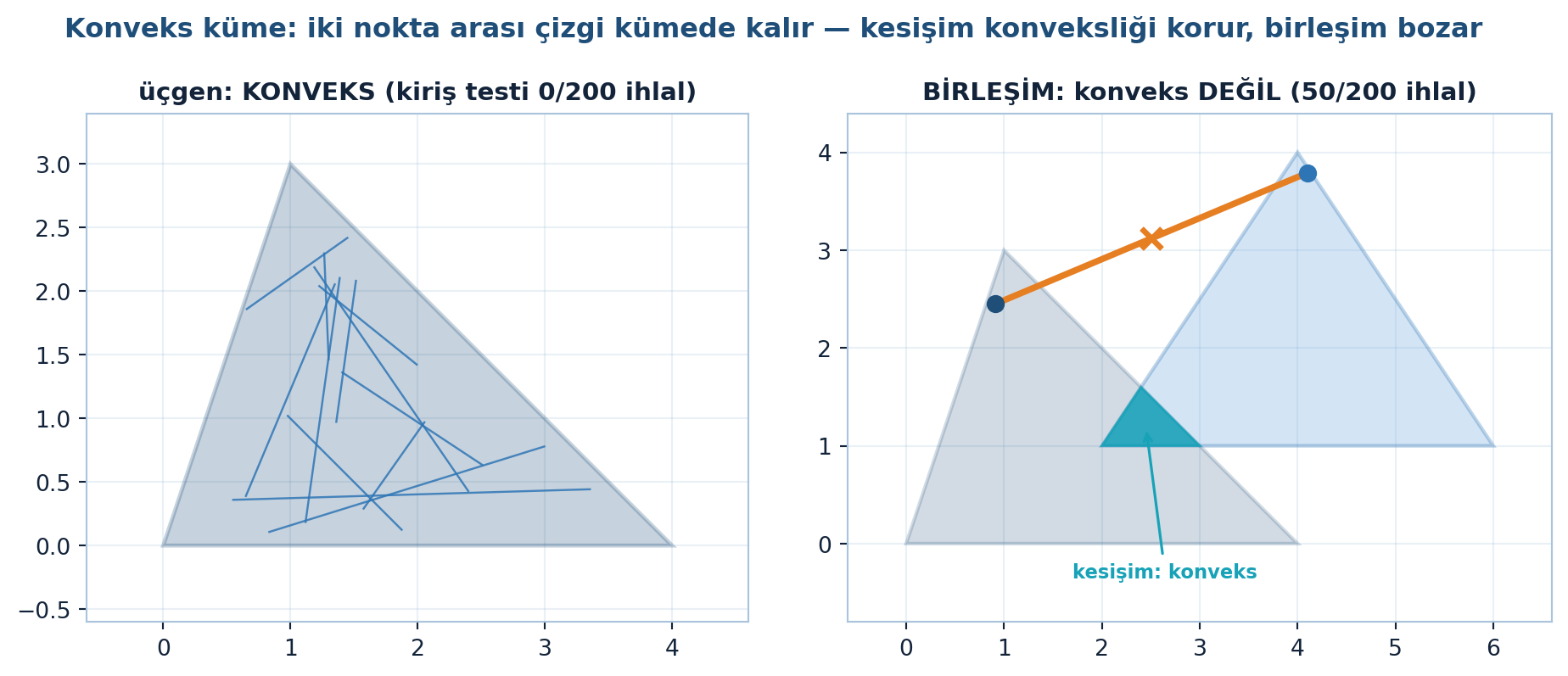
Kod
xs = np.linspace(-2, 3, 400)
f1 = np.abs(xs) # |x|
f2 = (xs - 1)**2 # (x-1)^2
fmax = np.maximum(f1, f2)
fmin = np.minimum(f1, f2)
def g_min(t):
return min(abs(t), (t - 1)**2)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4))
# --- Sol: max zarfı (KONVEKS) ---
axL.plot(xs, f1, color=COL_ACCENT, lw=1.2, label="|x|")
axL.plot(xs, f2, color=COL_SKY_400, lw=1.2, label="(x-1)^2")
axL.plot(xs, fmax, color=COL_PRIMARY, lw=2.5, label="max — KONVEKS")
axL.set_title("max: konveks (orta-nokta ihlal 0)", fontsize=11, fontweight="bold")
axL.set_xlabel("x"); axL.set_ylim(-0.5, 5.2)
axL.legend(fontsize=8, loc="upper center")
apply_style(axL)
# --- Sağ: min zarfı (konveks DEĞİL) ---
axR.plot(xs, f1, color=COL_ACCENT, lw=1.2, label="|x|")
axR.plot(xs, f2, color=COL_SKY_400, lw=1.2, label="(x-1)^2")
axR.plot(xs, fmin, color=COL_VEC3, lw=2.5, label="min — konveks DEGIL")
# kink noktaları: min eğrisinin köşeleri (f1=f2 kesişimleri + |x| köşesi x=0)
diff = f1 - f2
sign_change = np.where(np.diff(np.sign(diff)))[0]
kink_xs = list(xs[sign_change]) + [0.0]
for xk in kink_xs:
axR.plot(xk, g_min(xk), "o", color=COL_PURPLE, ms=6, zorder=5)
# orta-nokta ihlali (motor-tanıklı en kötü çift, grid linspace(-2,3,41)):
# a=0.0, b=0.75 -> mid=0.375; fonksiyon değeri kirişin ÜSTÜNDE, max gap=0.344
a, b = 0.0, 0.75
ya, yb = g_min(a), g_min(b)
mid = 0.5 * (a + b)
ymid_fn = g_min(mid) # fonksiyon değeri (kirişin ÜSTÜNDE)
ymid_chord = 0.5 * (ya + yb) # kiriş değeri
axR.plot([a, b], [ya, yb], "--", color="#888888", lw=1.4, zorder=4) # kiriş
axR.plot([a, b], [ya, yb], "o", color="#888888", ms=5, zorder=4)
axR.plot(mid, ymid_fn, "o", color=COL_VEC3, ms=7, zorder=6)
axR.annotate("", xy=(mid, ymid_fn), xytext=(mid, ymid_chord),
arrowprops=dict(arrowstyle="<->", color=COL_TEXT, lw=1.5))
axR.text(mid + 0.12, 0.5 * (ymid_fn + ymid_chord), "gap 0.34",
color=COL_TEXT, fontsize=9.5, fontweight="bold", va="center")
axR.set_title("min: konveks DEGIL (60 ihlal)", fontsize=11, fontweight="bold")
axR.set_xlabel("x"); axR.set_ylim(-0.5, 5.2)
axR.legend(fontsize=8, loc="upper center")
apply_style(axR)
fig.suptitle("Iki konveks fonksiyonun MAX i konveks, MIN i degil — kink dusbukeyligi bozar (ReLU/max-tipi yapilarin kokeni)",
fontsize=10.5, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()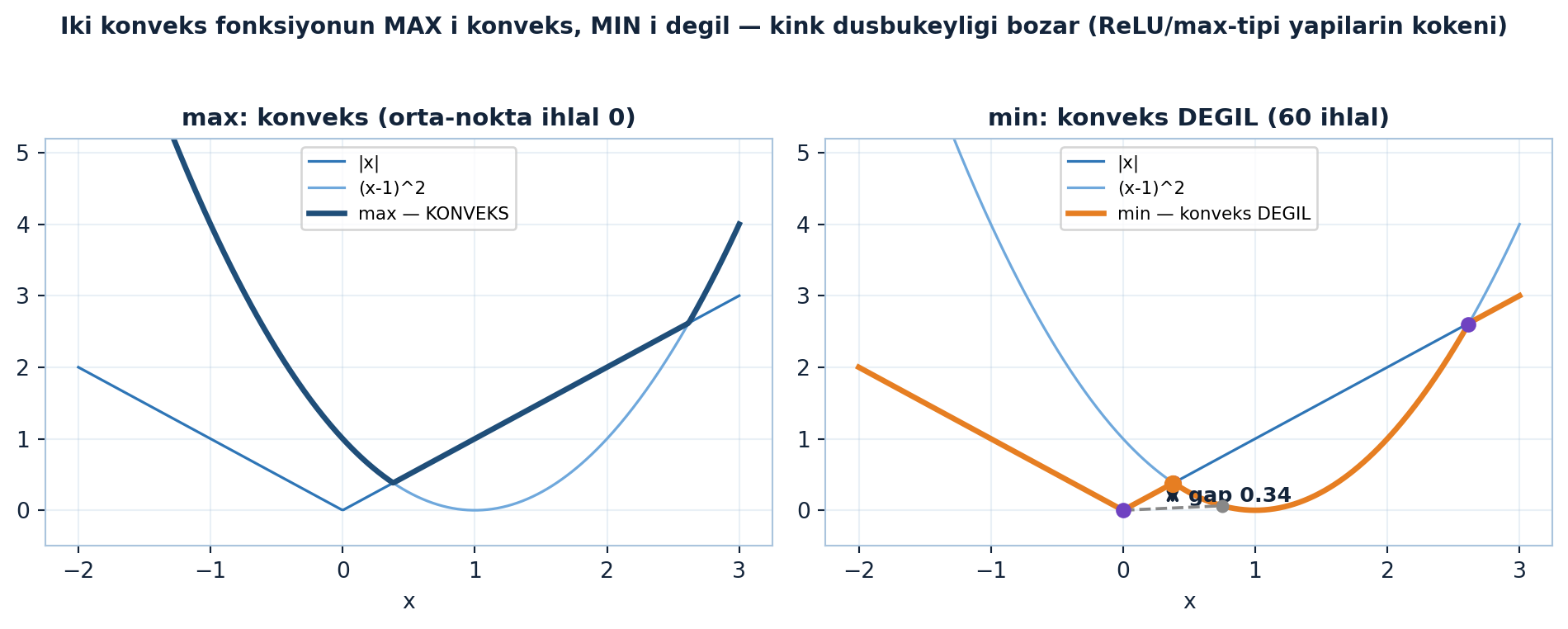
İpucuBuilder Notu — Kâse Garantisi
Konvekslik = “tek minimum + gradient descent yakınsar” garantisi. Konveks fonksiyonun testi: Hessian her yerde pozitif yarı-tanımlı (Ders 5) — kâse her yönde yukarı büker. ML köprüsü: lojistik regresyon, SVM, LASSO konvekstir (küresel optimum garantili); ama derin ağlar konveks değildir (eyer noktaları, çok minimum — Ders 19) ama yine çalışır. Yine de çalışmaları, konveks-olmayan optimizasyonun pratikteki gizemidir. “max konveks, min değil” → ReLU (max-tipi) ağların parçalı-konveks yapısının kökeni.
22.9 Bu Dersin Özeti
- Taylor (3 terim): \(F(x+\Delta x) \approx F(x) + (\Delta x)^{T}\nabla F + \tfrac{1}{2}(\Delta x)^{T}H(\Delta x)\); \(\nabla F\) gradyan, \(H\) Hessian (simetrik).
- Jacobian: vektör \(f\) için \(J_{jk} = \partial f_{j}/\partial x_{k}\); gradyanın Jacobian’ı = Hessian.
- Newton (f=0): \(x_{k+1} = x_{k} - J^{-1}f(x_{k})\). Örnek \(x^{2}-9 \to x_{k+1} = \tfrac{1}{2}x_{k} + 9/(2x_{k}) \to 3\).
- Newton (min, ∇F=0): \(x_{k+1} = x_{k} - H^{-1}\nabla F(x_{k})\).
- Yakınsama: Newton kuadratik (\(e \to e^{2}\)), steepest descent linear (\(e \to ce\), \(c<1\)); Levenberg-Marquardt = ucuz Newton.
- Konveks küme: iki nokta arası çizgi kümede kalır; kesişim konveks, birleşim genelde değil.
- Konveks fonksiyon: epigraph konveks küme (kâse); test: Hessian pozitif yarı-tanımlı; max konveks, min değil.
ÖnemliTek Bir Cümle
Bir fonksiyonu minimize etmek Taylor açılımıyla iteratif adım atmaktır — Newton ikinci-dereceyi (Hessian) kullanıp kuadratik yakınsar, gradient descent birinci-derecedir (linear); konvekslik (Hessian pozitif yarı-tanımlı, kâse) tek minimumu ve yakınsamayı garanti eder.
22.10 Kontrol Soruları
NotSoru 1 — Taylor’da gradyan ve Hessian
Soru: Çok değişkenli Taylor serisinin üç teriminde gradyan ve Hessian nerede çıkar, Hessian’ın özelliği nedir?
Cevap: \(F(x+\Delta x) \approx F(x) + (\Delta x)^{T}\nabla F + \tfrac{1}{2}(\Delta x)^{T}H(\Delta x)\). Sabit terim \(F(x)\); lineer terimde gradyan \(\nabla F\) (\(n\) kısmi türev); kuadratik terimde Hessian \(H\) (\(n^{2}\) ikinci türev). Hessian simetriktir (\(\partial^{2}F/\partial x_{j}\partial x_{k} = \partial^{2}F/\partial x_{k}\partial x_{j}\)). \(n\) büyükse gradyan \(n\) türev, Hessian \(\sim\tfrac{1}{2}n^{2}\) türev ister — derin öğrenmede Hessian erişilemez.
NotSoru 2 — Newton iterasyonu ve √9
Soru: \(f = 0\) çözmek için Newton iterasyonu nedir ve \(x^{2}-9\) örneğinde nasıl görünür?
Cevap: \(x_{k+1} = x_{k} - J(x_{k})^{-1}f(x_{k})\) (Taylor’ın lineer kısmını sıfıra eşitleyip \(\Delta x\) çözülür). \(f(x)=x^{2}-9\), \(J=2x\) için: \(x_{k+1} = x_{k} - (x_{k}^{2}-9)/(2x_{k}) = \tfrac{1}{2}x_{k} + 9/(2x_{k})\). \(x_{k}=3\)’te sabit kalır (kök). Babil karekök yöntemi; kuadratik yakınsar (her adımda hane sayısı ikiye katlanır).
NotSoru 3 — Newton vs steepest descent hızı
Soru: Newton ve steepest descent (gradient descent) yakınsama hızları nasıl farklıdır, neden?
Cevap: Newton kuadratik (\(e_{k+1} \sim e_{k}^{2}\)) — doğru ters Hessian’ı kullandığından her adımda hata karelenir, süper hızlı. Steepest descent linear (\(e_{k+1} \sim c\,e_{k}\), \(c<1\)) — doğru matrisin tersi yerine sabit bir adım kullandığından her adımda hata sadece bir oranla küçülür. Newton az ama pahalı adım, gradient descent çok ama ucuz adım.
NotSoru 4 — Konveks küme ve max/min
Soru: Konveks küme nedir, ve iki konveks fonksiyonun min’i mi yoksa max’ı mı konvekstir?
Cevap: Konveks küme: içinden alınan herhangi iki noktayı birleştiren çizgi tamamen kümede kalır. İki konveks fonksiyonun maksimumu konvekstir (keskin köşe yukarı tutulur, kâse korunur); minimumu konveks değildir (kesişimde bir kink/köşe oluşur, dışbükeylik bozulur). Konveks kümelerin kesişimi konveks, birleşimi genelde değil.
22.11 Egzersizler
Karekök Newton’ı. \(f(x) = x^{2} - 2\) için Newton formülünü yaz (\(x_{k+1} = \tfrac{1}{2}x_{k} + 1/x_{k}\)). \(x_{0} = 1\)’den başla, iki adım hesapla; \(\sqrt{2} \approx 1.41421\)’e ne kadar yaklaştın? (Motor tanığı: \(1 \to 1.5 \to 17/12 = 1.41667\); iki adım sonra hata 2.45e-3.)
Hessian sayımı. \(F(x_{1}, x_{2}, x_{3}) = x_{1}^{2} + x_{2}x_{3}\) için gradyanı ve Hessian’ı yaz. Hessian simetrik mi? Kaç bağımsız ikinci türev var?
[motor notu]: \(H\)’nin özdeğerleri {−1, 1, 2} — simetrik ama BELİRSİZ; \(F = x_{1}^{2} + x_{2}x_{3}\) konveks değildir, \(x_{2}x_{3}\) terimi eyer üretir (Ders 18-19 köprüsü).
Kod
fig, axes = plt.subplots(1, 2, figsize=(9, 3.8))
# Sol: Hessian heatmap
heatmap(axes[0], H_EGZ2, "H = [[2,0,0],[0,0,1],[0,1,0]] (simetrik)", fmt="{:.0f}")
# Sağ: özdeğer bar
ev = np.sort(np.linalg.eigvalsh(H_EGZ2))
axes[1].bar([1, 2, 3], ev, color=[COL_VEC3 if v < 0 else COL_PRIMARY for v in ev])
axes[1].axhline(0, color=COL_TEXT, linewidth=0.8)
axes[1].set_xticks([1, 2, 3])
axes[1].set_xlabel("özdeğer sırası")
axes[1].set_ylabel("özdeğer")
axes[1].set_title("Özdeğerler: {-1, 1, 2}", color=COL_TEXT, fontsize=12, fontweight="bold")
axes[1].annotate("BELİRSİZ: F = x1^2 + x2 x3\nkonveks DEĞİL (x2 x3 eyer üretir)",
xy=(1, ev[0]), xytext=(1.4, 1.4),
fontsize=9, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_STEEL_300))
apply_style(axes[1])
fig.suptitle("Egz2 gizli ders: Hessian simetrik AMA özdeğerler {-1, 1, 2} belirsiz — konvekslik testi = H pozitif yarı-tanımlı (Ders 5/18 köprüsü)",
color=COL_TEXT, fontsize=10, fontweight="bold")
fig.tight_layout()
plt.show()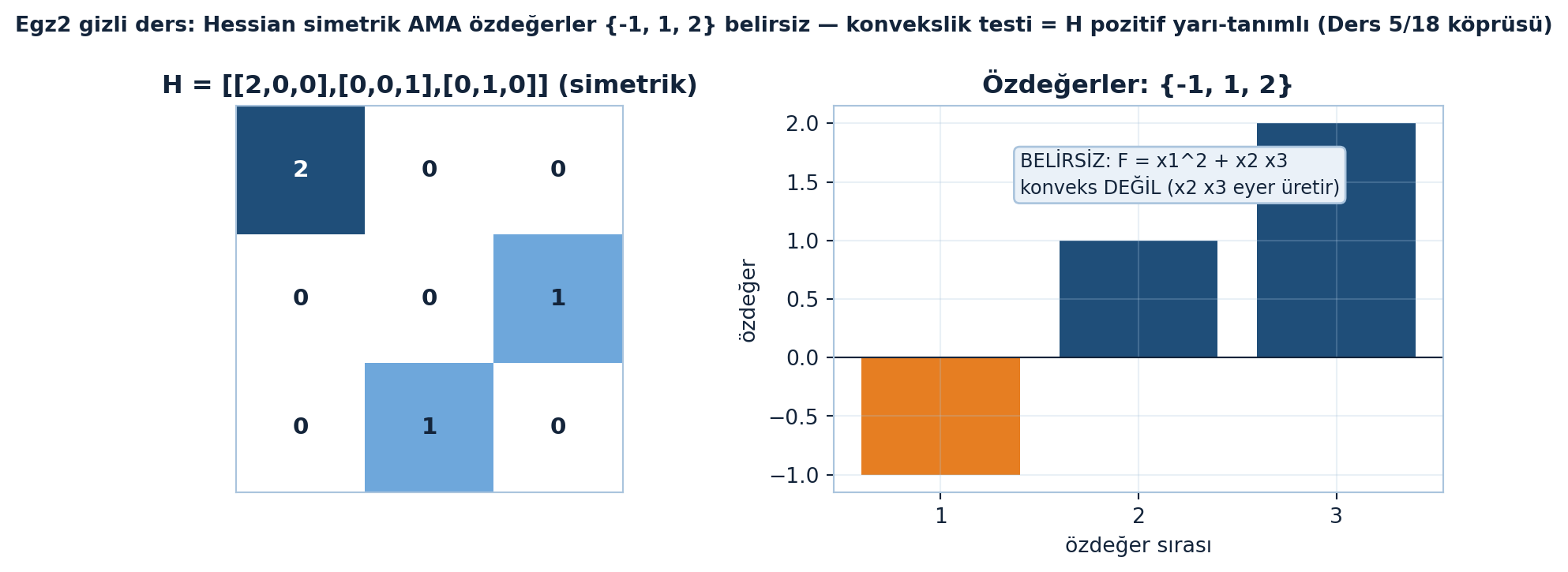
Şekil 22.7 bu egzersizin gizli dersini görselleştirir: Hessian simetrik olmasına rağmen özdeğer çubukları sıfırın iki yanına dağılır (belirsiz), yani \(F\) konveks değildir.
Newton minimizasyon. \(F(x) = \tfrac{1}{2}(x - 4)^{2}\) (tek değişken). \(H = F'' = 1\), \(\nabla F = x - 4\). Newton adımı \(x_{k+1} = x_{k} - H^{-1}\nabla F\)’i hesapla; tek adımda minimuma (\(x = 4\)) ulaştığını göster. (Kuadratik fonksiyonda Newton tek adımda biter — neden?)
Konvekslik testi. \(f(x) = x^{4}\) konveks mi? (İpucu: \(f'' = 12x^{2} \geq 0\), motor tanığı: 0 ihlal.) Peki \(f(x) = x^{3}\)? (Motor tanığı: 256 ihlal — konveks değil.) İki konveks fonksiyon \(|x|\) ve \(x^{2}\)’nin maksimumu konveks mi?
(Ders 22 habercisi) Bu derste Newton’ın hızlı ama Hessian-pahalı olduğunu gördük. Hessian’ı atıp sadece gradyanla, sabit bir adım boyuyla inersek ne olur? Adım boyu (learning rate) çok büyük/küçük olursa? Bir tahmin yaz — Ders 22 “gradient descent: minimuma doğru aşağı” ile birinci-derece optimizasyonu derinlemesine işliyor.
22.12 Sonraki Ders İçin Hazırlık
Ders 22: Gradient Descent — Minimuma Doğru Aşağı. Newton’ın pahalı Hessian’ını bırakıp en temel algoritmaya geçiş: \(x_{k+1} = x_{k} - s\nabla F(x_{k})\). Strang adım boyunu (learning rate \(s\)), yakınsama koşullarını ve kötü-koşullu (uzun-dar kâse) problemlerde zikzak davranışını işler — derin öğrenme eğitiminin çekirdeği.
UyarıHazırlık
Bu dersteki Şekil 22.4 sol panelindeki zikzak yolu zihninde tut: kötü-koşullu kâse \(A = \mathrm{diag}(1,10)\)’da steepest descent oranı \(9/11 = 0.8182\)’ydi. Ders 22 bu sayının nereden geldiğini (\(\kappa = \lambda_{\max}/\lambda_{\min}\) kondisyon sayısı, Ders 10) ve adım boyunun yakınsamayı nasıl belirlediğini açacak. Newton’ın “tek adım” lüksünü neden bıraktığımızı (milyar-parametreli \(H\)) hatırla.
22.13 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Strang (dk) |
|---|---|---|
| Taylor 3 terim | \(F(x+\Delta x) \approx F + (\Delta x)^{T}\nabla F + \tfrac{1}{2}(\Delta x)^{T}H(\Delta x)\) | 1m44 |
| Hessian | \(H_{jk} = \partial^{2}F/\partial x_{j}\partial x_{k}\); simetrik; \(\sim\tfrac{1}{2}n^{2}\) türev | 5m19 |
| Jacobian | \(J_{jk} = \partial f_{j}/\partial x_{k}\); gradyanın J’si = Hessian | 8m56 |
| Newton (f=0) | \(x_{+} = x - J^{-1}f(x)\) | 10m59 |
| √9 örneği | \(x_{+} = \tfrac{1}{2}x + 9/(2x) \to 3\) (Babil) | 14m21 |
| Newton kuadratik | \(e_{+} \sim e^{2}\); steepest descent linear \(e_{+} \sim ce\) | 30m35 |
| Konvekslik anahtar | konveks fonksiyon konveks küme üzerinde min | 32m49 |
| Konveks küme | iki nokta arası çizgi kümede kalır; kesişim konveks | 38m19 |
| max vs min | iki konveks fonk: max konveks, min değil | 49m05 |
22.14 ML Bağlantıları Özeti
- Newton vs birinci-derece: Newton kuadratik (Hessian, az/pahalı adım); derin öğrenme \(n^{2}\) Hessian’ı hesaplayamaz → gradient descent/SGD (birinci-derece, çok/ucuz adım).
- Quasi-Newton: BFGS/L-BFGS ters Hessian’ı gradyan farklarından tahmin eder; doğal gradyan/K-FAC eğrilik bilgisini yaklaşık kullanır.
- Autodiff = backprop (Ders 27): gradyan/Jacobian’ı verimli hesaplama; her katman bir Jacobian, zincir kuralı çarpar (JVP/VJP).
- Konvekslik: lojistik regresyon/SVM/LASSO konveks (küresel optimum garantili); derin ağlar konveks değil (eyer, çok minimum — Ders 19) ama yine çalışır.
- Hessian = eğrilik: kötü-koşullu (özdeğer oranı büyük) Hessian → gradient descent yavaş/zikzak (Ders 22); kondisyon sayısı (Ders 10) yakınsama hızını belirler.
- max/min konvekslik → ReLU: max-tipi (ReLU) parçalı-konveks yapı; ağların parçalı-doğrusal geometrisi.
- Geriye köprü: Ders 18-19 (Hessian, eyer noktaları), Ders 5 (pozitif yarı-tanımlı = konvekslik testi), Ders 16 (simetrik Hessian), Calculus (Taylor, türev).
ÖnemliKapanış
“Convexity is the key word for these problems.” — Strang, 32:49
Optimizasyon Taylor açılımıyla başlar; Newton eğriliği (Hessian) kullanıp hızlı yakınsar, gradient descent sadece eğimi kullanır, ve konvekslik tüm bunların tek bir minimuma varmasını garanti eder.