flowchart TD
M["Parametre sayimi + eyer noktalari"] --> YT["yapi taslari: L = n(n-1)/2, U = n(n+1)/2, Q = n(n-1)/2, S = n(n+1)/2"]
M --> KON["kontroller: LU = QR = XLX^-1 = QS = n^2 (bilgi korunur)"]
M --> SVD["SVD tam rank m: mn parametre"]
M --> RR["rank-R: R(m+n-R) -- manifold, alt-uzay degil"]
KKT["eyer kaynak 1: KKT blok [[S, A^T],[A, 0]] (Lagrange)"]
SYL["pivot isaretleri = ozdeger isaretleri (Sylvester atalet)"]
RAY["eyer kaynak 2: Rayleigh R(x) = x^T S x / x^T x -- aradaki ozdegerler eyer"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style KKT fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style SYL fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style RAY fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style YT fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style KON fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style SVD fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style RR fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
19 SVD, LU, QR ve Eyer Noktalarında Parametre Sayımı
Serbest parametre muhasebesi, KKT matrisleri ve Rayleigh bölümü
NotBölüm bilgisi
Video: MIT 18.065 — Counting Parameters in SVD, LU, QR, Saddle Points · OCW: Lecture 18 · Okuma süresi: ≈33 dk · Konuşmacı: Gilbert Strang · Önkoşul: Ders 17 (hızla azalan tekil değerler).
Bu ders lineer cebir blokunun kapanışıdır. İki konu birleşir: her matris ayrışımının kaç serbest parametre taşıdığı (muhasebe) ve eyer noktalarının iki kaynağı (KKT + Rayleigh). Buradan sonra ders 19 ile maxmin/Courant-Fischer dünyasına geçilir.
19.1 Bu Derste Ne Var?
Lineer cebir bloku kapanıyor; iki konu. İlk yarı: her matris ayrışımı (LU, QR, XΛX⁻¹, QS, UΣVᵀ) kaç serbest parametre içerir? Hepsi A’nın parametre sayısına (n² veya mn) tam tamamlanır — ayrışım bilgi kaybetmez. İkinci yarı: eyer noktaları (saddle points) nereden gelir — iki kaynak.
Beş sonuç:
- Yapı taşları: üçgensel L = ½n(n−1), U = ½n(n+1), köşegen = n, ortogonal Q = ½n(n−1), simetrik S = ½n(n+1).
- Kontroller: LU = QR = XΛX⁻¹ = QS = n²; SVD (tam rank m) = mn; rank-R matris = R(m+n−R).
- Eyer kaynağı 1 — Lagrange/KKT: kısıtlı optimizasyon → blok matris [[S, Aᵀ],[A, 0]]; belirsiz (indefinite), eyer noktası.
- Pivot işaretleri = özdeğer işaretleri: n pozitif + m negatif pivot → eyer.
- Eyer kaynağı 2 — Rayleigh bölümü: R(x) = xᵀSx/xᵀx; maks = λ₁, min = λₙ, aradaki özdeğerler eyer (Ders 19’a köprü).
“…the number of free parameters agrees with the number of parameters in A itself, like n squared.” — Strang, 0:59
Aşağıdaki kavram haritası dersin merkezini (“parametre sayımı + eyer noktaları”) ana fikirlere bağlar: yapı taşlarının serbest parametre sayıları, her ayrışımın n²’ye (SVD’nin mn’ye) oturması, rank-R matrisin R(m+n−R) parametreli bir manifold oluşturması ve eyer noktalarının iki kaynağı (KKT bloğu + Rayleigh bölümü) ile pivot/özdeğer işaret eşitliği (Şekil 19.1).
İpucuBuilder Notu — Muhasebesi Tutan Cebir
- Serbest parametre = serbestlik derecesi — bir modelin “gerçek” boyutu; Ders 17’nin “2kn sayı” saymanının sistematik hali. Etkin parametre sayısı ML’de kapasite ve aşırı-öğrenme analizinin temeli.
- KKT matrisi — kısıtlı optimizasyonun (SVM, eşitlik kısıtları) çekirdek yapısı; eyer noktası çözmek = denge bulmak.
- Eyer noktaları — derin ağ kayıp yüzeylerinde minimumdan çok eyer vardır; SGD’nin eyerlerden kaçması eğitimin kalbi.
- Geriye köprü: Ders 2 (5 ayrışım), Ders 3 (ortogonal Q), Ders 5 (pozitif tanımlı, pivot), Ders 6 (SVD), Ders 17 (parametre sayma).
Tek cümle: Her matris ayrışımı orijinal matrisle aynı sayıda serbest parametre taşır (bilgi korunur); eyer noktaları ise ya Lagrange kısıtlarının KKT blok matrisinden ya da Rayleigh bölümünün aradaki özdeğerlerinden doğar.
19.2 Fikir: Serbest Parametre Sayımı
Lineer cebir bölümünün kapanış jesti: Ders 2’nin beş ayrışımını (A = LU, QR, XΛX⁻¹, QΛQᵀ, UΣVᵀ) bir “muhasebe” testinden geçir. A genelde n² sayı içerir. Bir ayrışım hesaplandıktan sonra A’yı atabilir miyiz? Evet — bilgi ayrışımda. O hâlde ayrışımın parçalarındaki serbest parametre sayısı da n²’ye tamamlanmalı:
“…the number of free parameters agrees with the number of parameters in A itself, like n squared.” — Strang, 0:59
Bu, Strang’ın “hiçbir ders kitabında görmedim” dediği bir alıştırma — ama tüm lineer cebiri tek satıra sıkıştırır.
İpucuBuilder Notu — Bilgi Ayrışımda Saklı
“Serbest parametre = serbestlik derecesi” Ders 17’nin “2kn sayı” sayımının sistematik hâli. ML köprüsü: bir modelin etkin parametre sayısı, nominal parametre sayısından az olabilir (kısıtlar, simetriler, düşük-rank yapı). Kapasite, aşırı-öğrenme ve genelleme analizinin tamamı “kaç gerçek serbestlik derecesi?” sorusuna dayanır.
19.3 Yapı Taşları: L, U, Köşegen, Q, S
Önce parçaları say. Üçgensel matrisler:
\[L:\ \tfrac{1}{2}n(n-1), \qquad U:\ \tfrac{1}{2}n(n+1)\]
L alt-üçgensel, köşegeni hep 1 (serbest değil) → 1+2+⋯+(n−1) = ½n(n−1). U üst-üçgensel, köşegende pivotlar serbest → 1+2+⋯+n = ½n(n+1). İkisi tam n kadar farklı. Köşegen matris: n. Ortogonal Q: ilk kolon birim (n−1 serbest), ikinci kolon birim ve birinciye dik (n−2), … toplam:
\[Q:\ (n-1)+(n-2)+\cdots+0 = \tfrac{1}{2}n(n-1)\]
Simetrik S: üst üçgen + köşegen serbest, alt yarı belirli → ½n(n+1).
Aşağıdaki figür dört faktörizasyonun (LU, QR, XΛX⁻¹, QS) serbest parametre muhasebesini n=6 için gösterir; her çubuk iki parçaya ayrılır ve dördü de tam n²=36’da buluşur — sonraki bölümün kontrol sonucunu önceden görselleştirir (Şekil 19.2).
Kod
n = 6
L = count_L(n); U = count_U(n); Q = count_Q(n); S = count_S(n); X = count_X(n); D = count_diag(n)
n2 = n * n
# Dört faktörizasyon: her biri (alt parça navy, üst parça steel)
labels = ["LU", "QR", r"$X\Lambda X^{-1}$", "QS"]
bottoms = [L, Q, X, Q]
tops = [U, U, D, S]
bottom_names = ["L", "Q", "X", "Q"]
top_names = ["U", "R", r"$\Lambda$", "S"]
xpos = np.arange(len(labels))
fig, ax = plt.subplots(figsize=(8, 4.4))
ax.bar(xpos, bottoms, color=COL_PRIMARY, width=0.6, edgecolor=COL_WHITE, linewidth=1.2)
ax.bar(xpos, tops, bottom=bottoms, color=COL_ACCENT, width=0.6, edgecolor=COL_WHITE, linewidth=1.2)
# Parça etiketleri bar içinde
for i in range(len(labels)):
ax.text(xpos[i], bottoms[i] / 2, "{} {}".format(bottom_names[i], bottoms[i]),
ha="center", va="center", color=COL_WHITE, fontsize=11, fontweight="bold")
ax.text(xpos[i], bottoms[i] + tops[i] / 2, "{} {}".format(top_names[i], tops[i]),
ha="center", va="center", color=COL_WHITE, fontsize=11, fontweight="bold")
# n^2 = 36 yatay turuncu kesik çizgi
ax.axhline(n2, color=COL_VEC3, linestyle="--", linewidth=2.0, zorder=5)
ax.text(len(labels) - 0.5, n2 + 1.2, r"$n^2 = 36$", color=COL_VEC3, fontsize=12,
fontweight="bold", ha="right", va="bottom")
apply_style(ax)
ax.set_xticks(xpos); ax.set_xticklabels(labels, fontsize=12)
ax.set_ylabel("serbest parametre")
ax.set_ylim(0, n2 + 7)
ax.set_title("Dort ayrisim ayni hedefe oturur: LU = QR = XLX^-1 = QS = n^2 = 36 (n=6) "
"— ayrisim bilgi kaybetmez", fontsize=10.5, fontweight="bold")
fig.tight_layout()
plt.show()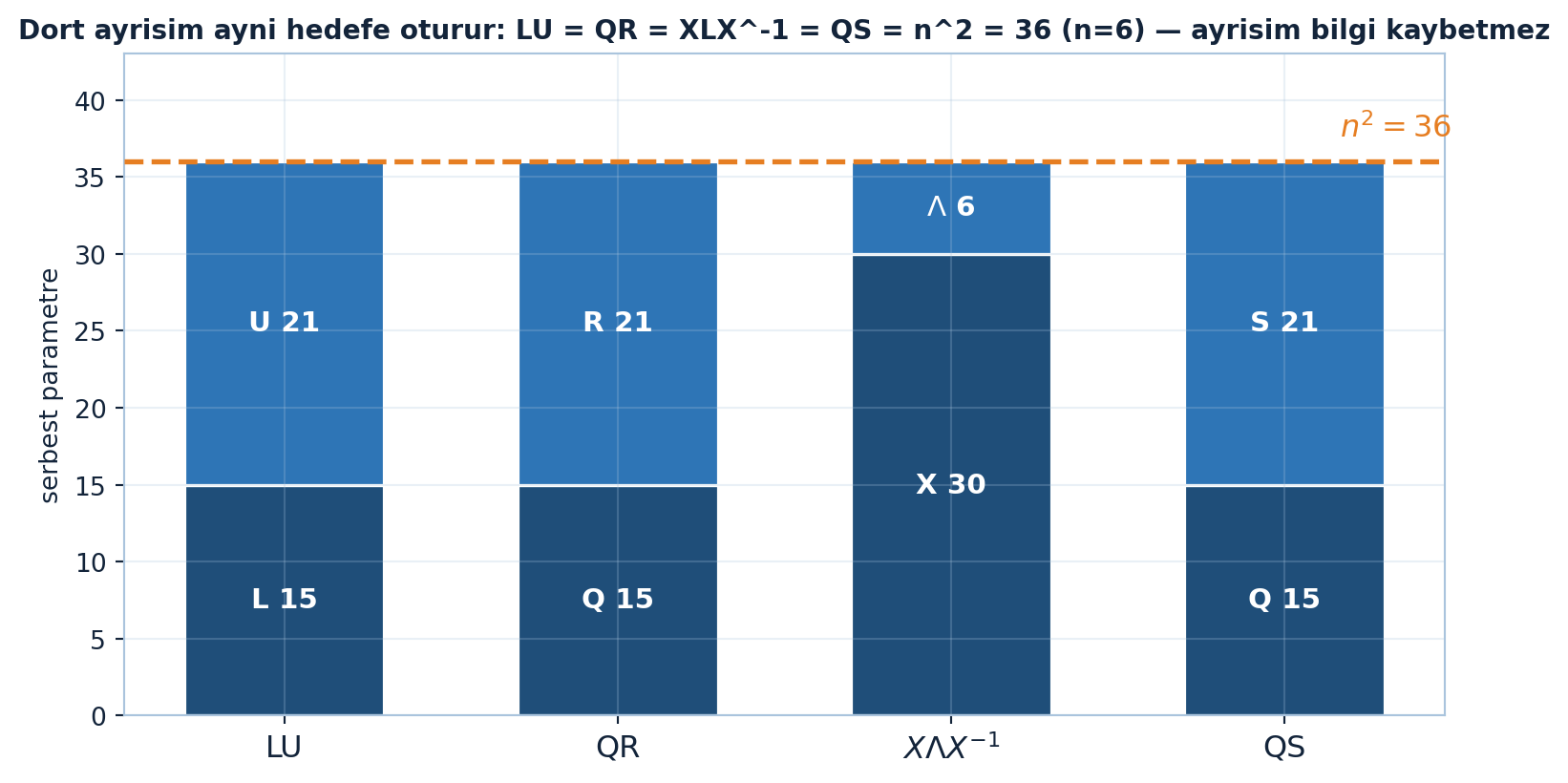
İpucuBuilder Notu — Kısıt Parametre Yer
Ortogonal matrisin n² değil sadece ½n(n−1) serbestlik derecesi olması (Ders 3) önemli: ortogonallik kısıtları parametrelerin yarısını “yer”. ML köprüsü: ortogonal/üniter ağırlık katmanları (gradyan patlamasını önler) bu yüzden daha az serbestlik taşır; Stiefel manifoldu üzerinde optimizasyon tam bu kısıtlı parametre uzayında çalışır.
19.4 Özvektör Matrisi: n² − n
Özvektör matrisi X kaç serbest parametre içerir? Her özvektör bir skalerle çarpılabilir (x özvektörse 2x de özvektör). Bir konvansiyonla her kolonun ilk bileşenini 1 yap — o zaman üst satırdaki n tane “1” sayılmaz:
\[X:\ n^{2} - n, \qquad \Lambda:\ n, \qquad X^{-1}:\ 0\]
X⁻¹ serbest değil — X tarafından belirlenir. Toplam: (n²−n) + n + 0 = n². Köşegenleştirme A = XΛX⁻¹ tam n²’ye oturur.
İpucuBuilder Notu — Yön Var Uzunluk Yok
“Özvektör ölçeklenebilir → bir serbestlik derecesi düşer” gözlemi, özvektörlerin yön taşıdığını, uzunluk taşımadığını hatırlatır. ML köprüsü: gömme (embedding) vektörlerinde de aynı belirsizlik var — ölçek/işaret çoğu zaman serbest; normalize etmek (birim uzunluk) bu fazla serbestliği sabitler.
19.5 Faktorizasyon Kontrolleri: Hepsi n²
Yapı taşlarını birleştir, hepsi n²’ye toplanmalı:
\[\underbrace{\tfrac{1}{2}n(n-1)}_{L} + \underbrace{\tfrac{1}{2}n(n+1)}_{U} = n^{2}\]
\[\underbrace{\tfrac{1}{2}n(n-1)}_{Q} + \underbrace{\tfrac{1}{2}n(n+1)}_{R} = n^{2}\]
LU’da eksi artıyı götürür; QR’da Q (ortogonal) + R (üst üçgensel) yine n². Köşegenleştirme (n²−n)+n = n². Son olarak kutupsal ayrışım A = QS (ortogonal × simetrik):
“…That’s called the polar decomposition.” — Strang, 9:33
\[\underbrace{\tfrac{1}{2}n(n-1)}_{Q} + \underbrace{\tfrac{1}{2}n(n+1)}_{S} = n^{2}\]
Kutupsal ayrışım SVD’ye çok yakındır (Ders 6); bazı mühendisler SVD yerine QS hesaplamayı tercih eder. Yukarıdaki (Şekil 19.2) tam bu dört kontrolün — LU, QR, XΛX⁻¹, QS — hepsinin aynı n²’ye oturduğunu görselleştirir.
İpucuBuilder Notu — Farklı Kılık Aynı Bilgi
Her ayrışımın aynı n²’ye toplanması “ayrışım bilgi yaratmaz/yok etmez” ilkesinin niceliksel kanıtıdır — A’daki bilgi, farklı kılıklarda (L+U, Q+R, Q+S) aynen korunur. ML köprüsü: bir veriyi farklı bazlarda temsil etmek (PCA, Fourier, dalgacık) boyut/bilgi miktarını değiştirmez, sadece düzenini değiştirir — sıkıştırma ancak gerçek düşük-rank/seyreklik varsa kazanılır (Ders 17).
19.6 SVD Parametre Sayımı: mn
Şimdi dikdörtgen A (m × n, m ≤ n, tam rank m). SVD: A = UΣVᵀ, U (m×m ortogonal), Σ (m tekil değer), Vᵀ (n×n ama sadece ilk m kolonu önemli). Say:
\[\underbrace{\tfrac{1}{2}m(m-1)}_{U} + \underbrace{m}_{\Sigma} + \underbrace{mn - \tfrac{1}{2}m(m+1)}_{V} = mn\]
V’nin katkısı incelik ister: ilk m kolonu (sıfırdan farklı tekil değerlere ait) önemli, geri kalan boş-uzaydan gelir ve sayılmaz. Önemli kolonlar (n−1)+(n−2)+⋯+(n−m) = mn − ½m(m+1). Hepsi toplanınca tam mn — A’nın eleman sayısı.
İpucuBuilder Notu — Boş Uzay Sayılmaz
SVD’nin tam mn parametreye oturması, “tam rank SVD bilgi kaybetmez” anlamına gelir. ML köprüsü: bir m×n veri matrisinin gerçek bilgi içeriği mn’dir; ama tekil değerler hızla düşüyorsa (Ders 17), pratikte çok daha az parametre yeter — işte sıkıştırmanın kazancı buradan, parametre sayımı bu üst sınırı verir.
19.7 Rank-R Matris: Bir “Yüzey”
Daha ilginç soru: rank-R bir m × n matris kaç parametre içerir?
“…how many parameters are there in a rank R matrix?” — Strang, 19:30
Sıkıştırılmış SVD: U (m×R), Σ (R), Vᵀ (R×n). Say:
\[\underbrace{mR - \tfrac{1}{2}R(R+1)}_{U} + \underbrace{R}_{\Sigma} + \underbrace{nR - \tfrac{1}{2}R(R+1)}_{V} = R(m + n - R)\]
Bu sayı ilginç çünkü rank-R matrisler bir alt-uzay değildir: iki rank-R matrisin toplamı rank-2R olabilir. Matris uzayı (m×n matrisler mn-boyutlu vektör uzayı) içinde rank-R matrisler bir yüzey/manifold oluşturur — toplama altında kapalı değil, ama yerel boyutu R(m+n−R).
Aşağıdaki figür solda R(m+n−R) parametre eğrisini (m=100, n=200; R=5’te 1475 parametre = tam matrisin 13.6 kat altı, LoRA bölgesi), sağda rank-2 + rank-2 = rank-4 manifold tanığını gösterir (Şekil 19.3).
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4))
# ---- Sol panel: R(m+n-R) eğrisi (m=100, n=200) ----
m, n = 100, 200
Rs = np.arange(1, 101)
params = [rank_R_count(m, n, int(R)) for R in Rs]
axL.plot(Rs, params, color=COL_PRIMARY, lw=2)
mn = m * n # 20000
axL.axhline(mn, color=COL_VEC3, ls="--", lw=1.6)
axL.text(52, mn + 600, "tam matris: mn = 20000", color=COL_VEC3,
fontsize=9.5, fontweight="bold", ha="center", va="bottom")
# R=5 LoRA noktası
R5 = rank_R_count(m, n, 5) # 1475
axL.plot(5, R5, "o", color=COL_TEAL, markersize=11, markeredgecolor=COL_PRIMARY,
markeredgewidth=1.2, zorder=5)
axL.annotate("LoRA bölgesi: R=5 -> 1475 parametre (13.6 kat az)",
xy=(5, R5), xytext=(20, 6500), color=COL_TEXT, fontsize=9,
fontweight="bold",
arrowprops=dict(arrowstyle="->", color=COL_TEAL, lw=1.4))
axL.set_xlabel("R (rank)")
axL.set_ylabel("R(m+n-R) parametre")
axL.set_title("Rank-R parametre sayısı", color=COL_TEXT, fontsize=11, fontweight="bold")
apply_style(axL)
# ---- Sağ panel: manifold tanığı — rank-2 + rank-2 = rank-4 ----
r1, r2, r12 = rank_sum_demo() # engine ile birebir (2, 2, 4)
rngA = np.random.default_rng(5)
M1 = rngA.standard_normal((8, 2)) @ rngA.standard_normal((2, 8))
rngB = np.random.default_rng(55)
M2 = rngB.standard_normal((8, 2)) @ rngB.standard_normal((2, 8))
s1 = np.linalg.svd(M1, compute_uv=False)[:8]
s2 = np.linalg.svd(M2, compute_uv=False)[:8]
s12 = np.linalg.svd(M1 + M2, compute_uv=False)[:8]
floor = 1e-3
idx = np.arange(1, 9)
axR.semilogy(idx, np.maximum(s1, floor), "s-", color=COL_ACCENT, lw=1.6,
markersize=6, label="M1 (rank-2)")
axR.semilogy(idx, np.maximum(s2, floor), "^-", color=COL_TEAL, lw=1.6,
markersize=6, label="M2 (rank-2)")
axR.semilogy(idx, np.maximum(s12, floor), "o-", color=COL_PRIMARY, lw=2.6,
markersize=7, label="M1+M2 (rank-4)")
axR.set_xlabel("tekil değer indeksi")
axR.set_ylabel("σ (tekil değer)")
axR.set_title("σ profili: 2+2 = 4 sıfırdan-farklı", color=COL_TEXT,
fontsize=11, fontweight="bold")
axR.legend(loc="lower left", fontsize=8.5, framealpha=0.9)
apply_style(axR)
fig.suptitle("Rank-R matrisler R(m+n-R) parametreli bir MANIFOLD: alt-uzay değil — rank-2 + rank-2 = rank-4 (sağ)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
İpucuBuilder Notu — LoRA’nın Sayısı
R(m+n−R) sayısı modern ML’in kalbinde: LoRA bir n×n ağırlık güncellemesini rank-R tutarak n² yerine ~2nR parametreyle eğitir (R≪n). “Rank-R matrisler bir manifold” görüşü, düşük-rank optimizasyonun neden Öklid uzayında değil bir manifold üzerinde yapıldığını (Riemann optimizasyonu) açıklar — matris tamamlama (Ders 16 Netflix) bu manifold üzerinde arama yapar.
19.8 Eyer Noktaları: İki Kaynak
İkinci konu: eyer noktaları (saddle points). Bunlar ne maksimum ne minimumdur — ilgili matris pozitif tanımlı değildir (özdeğerleri karışık işaretli). Strang iki ana kaynak ayırt eder:
“…there are two main sources of saddle points.” — Strang, 27:08
Birincisi kısıtlı optimizasyon (Lagrange çarpanları), ikincisi Rayleigh bölümünün aradaki özdeğerleri. İkisi de derin öğrenme ve optimizasyonda her yerde.
Aşağıdaki figür 500 rastgele yönde Rayleigh bölümünün hep [λ₃, λ₁] = [1, 5] aralığında kaldığını gösterir — eyer kavramına girmeden önce sınırların kesinliğini görselleştirir; aradaki λ₂ = 3 eyeri sonraki bölümlere taşınır (Şekil 19.4).
Kod
S3 = np.diag([5., 3., 1.])
rng = np.random.default_rng(9)
rs = [rayleigh(S3, rng.standard_normal(3)) for _ in range(500)]
fig, ax = plt.subplots(figsize=(7, 4))
ax.hist(rs, bins=40, color=COL_PRIMARY, alpha=0.85)
ax.axvline(1, color=COL_VEC3, linestyle="--", linewidth=2.2)
ax.axvline(5, color=COL_VEC3, linestyle="--", linewidth=2.2)
ax.axvline(3, color=COL_TEAL, linestyle="-", linewidth=1.4)
ax.text(1, ax.get_ylim()[1]*0.92, r" $\lambda_3 = 1$ (min)", color=COL_VEC3, fontsize=10, fontweight="bold", ha="left", va="top")
ax.text(5, ax.get_ylim()[1]*0.92, r"$\lambda_1 = 5$ (maks) ", color=COL_VEC3, fontsize=10, fontweight="bold", ha="right", va="top")
ax.text(3, ax.get_ylim()[1]*0.72, r" $\lambda_2 = 3$ (eyer)", color=COL_TEAL, fontsize=10, fontweight="bold", ha="left", va="top")
apply_style(ax)
ax.set_xlabel("R(x)")
ax.set_ylabel("frekans")
ax.set_title("500 rastgele yönde R(x) = xᵀSx / xᵀx: hepsi [1, 5] içinde\n(motor: min 1.005, max 4.999) — Rayleigh sınırları kesin", fontsize=10, fontweight="bold")
plt.show()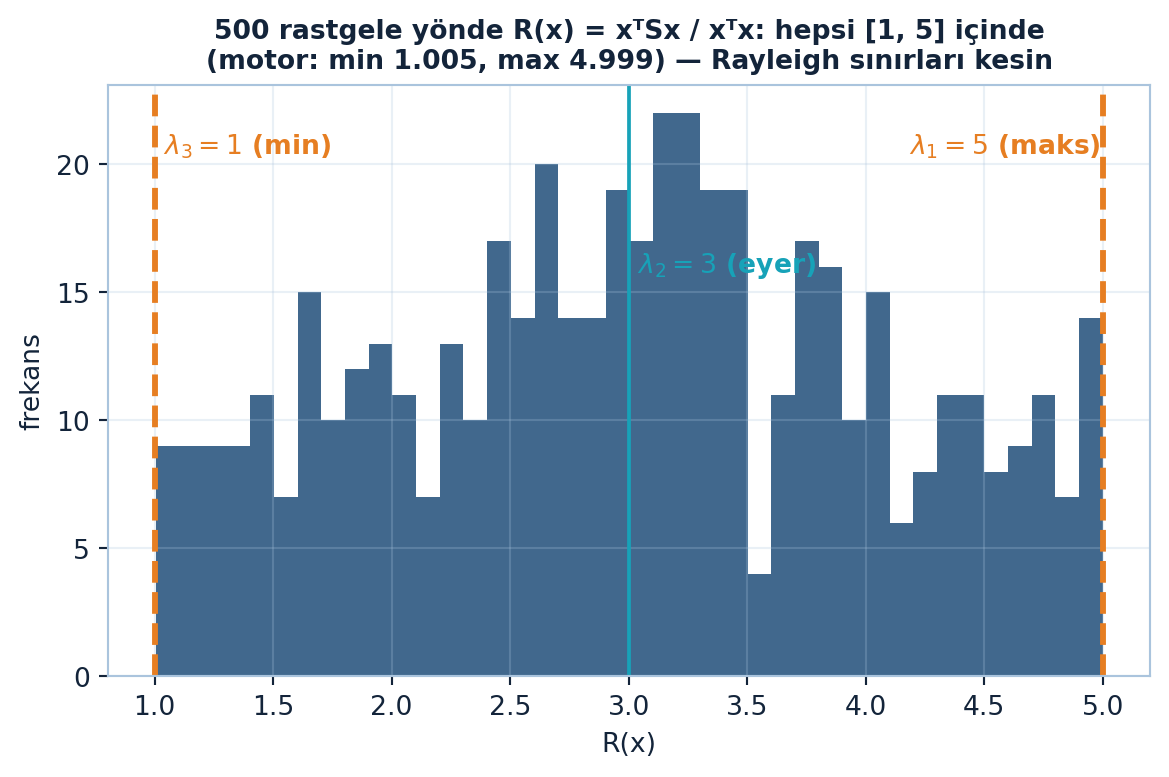
İpucuBuilder Notu — Minimum Az Eyer Çok
Eyer noktası, yüksek boyutta minimumdan çok daha yaygındır: derin ağ kayıp yüzeyinde kritik noktaların ezici çoğunluğu eyerdir, gerçek minimum azdır. ML köprüsü: SGD’nin gürültüsü eyerlerden kaçmaya yarar (Ders 25); “eyerden kaçış” modern optimizasyon teorisinin merkezî sorusudur.
19.9 Kaynak 1: Lagrange ve KKT Matrisi
Klasik kısıtlı problem: ½xᵀSx’i (S pozitif tanımlı) Ax = b kısıtı altında minimize et. Kısıt olmasa minimum sıfırdır; kısıt işi ilginçleştirir. Lagrange’ın reçetesi — m kısıt için m çarpan (λ vektörü) ekle:
\[L(x, \lambda) = \tfrac{1}{2}x^{T}Sx + \lambda^{T}(Ax - b)\]
x ve λ’ya göre türev al, sıfıra eşitle:
\[\frac{\partial L}{\partial x} = Sx + A^{T}\lambda = 0, \qquad \frac{\partial L}{\partial \lambda} = Ax - b = 0\]
İki denklemi blok matris formunda yaz:
\[\begin{bmatrix} S & A^{T} \\ A & 0 \end{bmatrix}\begin{bmatrix} x \\ \lambda \end{bmatrix} = \begin{bmatrix} 0 \\ b \end{bmatrix}\]
λ derivatifi kısıtları geri getirir. Bu blok matris, optimizasyoncuların KKT matrisi dediği şey (Karush-Kuhn-Tucker).
“…these KKT matrices…” — Strang, 36:13
Aşağıdaki figür 1D bir Lagrangian örneğini çizer: solda min x² öyle ki x = 4 kısıtlı problemi (kısıtlı min (4, 16)), sağda L(x,λ) = x² + λ(x−4) kontur haritası ve (x, λ) = (4, −8) eyer noktası — Lagrange çarpanının eyer yarattığını görselleştirir (Şekil 19.5).
Kod
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4.2))
# Sol: kısıtlı problem — f(x) = x^2 ve kısıt x = 4
xs = np.linspace(0, 8, 200)
ax1.plot(xs, xs**2, color=COL_PRIMARY, lw=2, label="f(x) = x^2 (s=2: (1/2) s x^2)")
ax1.axvline(4, color=COL_VEC3, ls="--", lw=2)
ax1.text(4.15, 55, "kisit: x = 4", color=COL_VEC3, fontsize=10, fontweight="bold")
ax1.plot(4, 16, marker="*", color=COL_VEC3, markersize=18, markeredgecolor=COL_TEXT, markeredgewidth=0.6, zorder=5)
ax1.annotate("kisitli min: (4, 16)", xy=(4, 16), xytext=(4.6, 24),
color=COL_TEXT, fontsize=9,
arrowprops=dict(arrowstyle="->", color=COL_TEXT, lw=1.0))
ax1.set_xlabel("x"); ax1.set_ylabel("f(x)")
ax1.set_title("kisitli problem: min x^2 oyle ki x = 4", color=COL_TEXT, fontsize=11, fontweight="bold")
ax1.legend(loc="upper left", fontsize=8)
apply_style(ax1)
# Sağ: Lagrangian L(x, lambda) kontur haritası — eyer noktası (4, -8)
xg = np.linspace(0, 8, 200)
lg = np.linspace(-16, 0, 200)
XG, LG = np.meshgrid(xg, lg, indexing="ij")
Z = lagrangian_1d(XG, LG)
cs = ax2.contour(XG, LG, Z, levels=30, cmap=NAVY_CMAP)
ax2.plot(4, -8, marker="*", color=COL_VEC3, markersize=20, markeredgecolor=COL_TEXT, markeredgewidth=0.6, zorder=5)
ax2.annotate("eyer: (x*, lambda*) = (4, -8)", xy=(4, -8), xytext=(1.2, -3.0),
color=COL_TEXT, fontsize=9, fontweight="bold",
arrowprops=dict(arrowstyle="->", color=COL_TEXT, lw=1.0))
ax2.set_xlabel("x"); ax2.set_ylabel("lambda")
ax2.set_title("Lagrangian L(x, lambda) = x^2 + lambda(x - 4)", color=COL_TEXT, fontsize=11, fontweight="bold")
apply_style(ax2)
fig.suptitle("Lagrange carpani eyer YARATIR: kisitli minimum (sol), (x, lambda) uzayinda eyer noktasi (sag) — KKT matrisi belirsiz",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.94])
plt.show()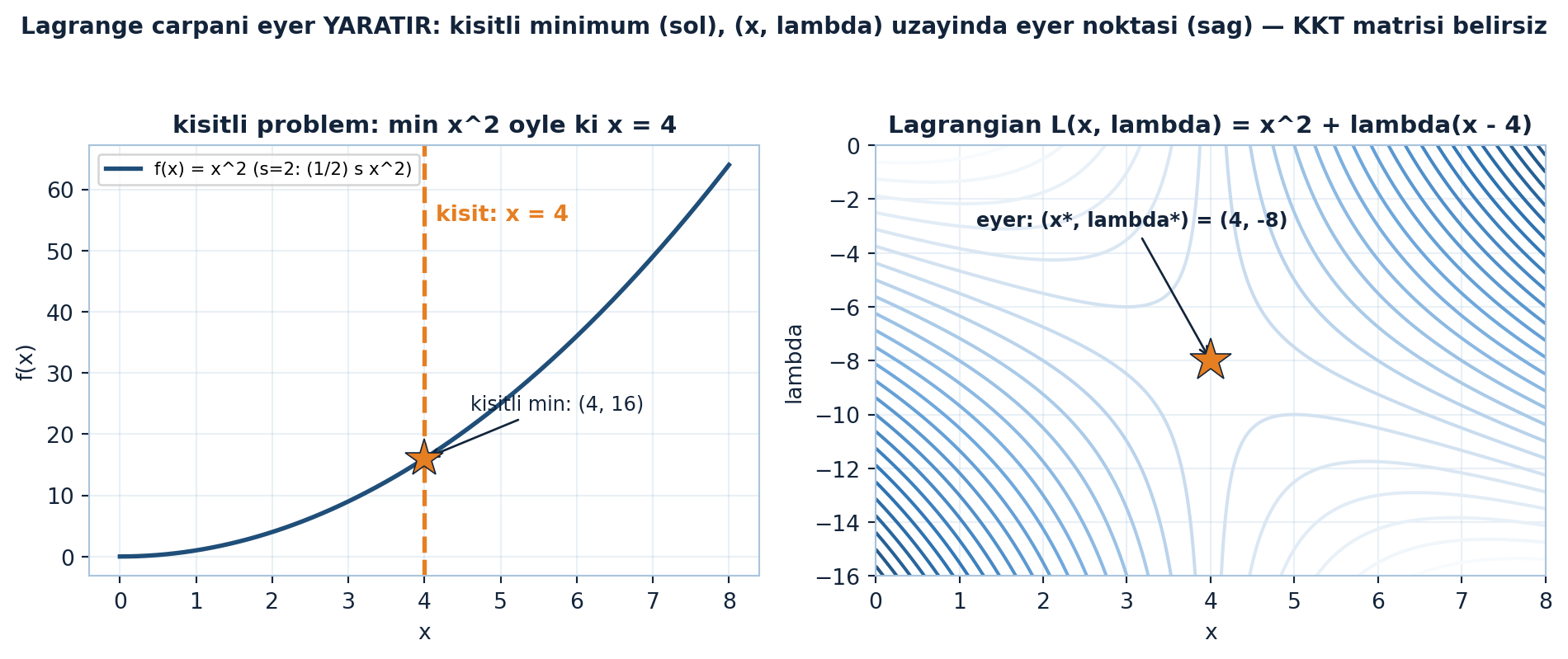
İpucuBuilder Notu — Denge Noktası Eyerdir
KKT matrisi kısıtlı optimizasyonun evrensel yapısıdır — Course 6’da (EECS) sürekli çıkar. ML köprüsü: SVM’nin dual problemi, eşitlik-kısıtlı en küçük kareler, fizik-bilgili ağlar (PINN) hep bir KKT sistemi çözer. Köşedeki sıfır blok (kısıt denklemlerinin λ’ya bağlı olmaması) bu matrisi eyer yapar — minimum değil, denge.
19.10 KKT Belirsizdir: Pivot İşaretleri = Özdeğer İşaretleri
Bu blok matris neden eyer? Köşegende sıfır blok var — bu, pozitif tanımlılığı anında bozar. Küçük örnek: [[3,1],[1,0]] determinantı negatif (−1), yani bir özdeğer artı bir özdeğer eksi. Genelde de blok eliminasyon yap: ilk n pivot S’den gelir (S pozitif tanımlı → hepsi pozitif). Sonra Schur tümleyeni:
\[\begin{bmatrix} S & A^{T} \\ A & 0 \end{bmatrix} \longrightarrow \begin{bmatrix} S & A^{T} \\ 0 & -AS^{-1}A^{T} \end{bmatrix}\]
−AS⁻¹Aᵀ negatif tanımlı → sonraki m pivot negatif. Şimdi anahtar gerçek:
“Plus and minus signs of pivots give us the plus and minus signs of the eigenvalues.” — Strang, 42:02
Simetrik matriste pivot işaretleri özdeğer işaretlerini verir (Sylvester atalet yasası). Yani KKT matrisinde n pozitif + m negatif özdeğer → kesin bir eyer noktası.
Aşağıdaki figür Egzersiz 3’ün KKT matrisi için (S = 2I, A = [1,1]) pivot işaretleri ile özdeğer işaretlerinin birebir örtüştüğünü gösterir: değerler farklı (pivotlar [2, 2, −1]) ama işaretler aynı — 2 pozitif + 1 negatif, det = −4 < 0, bir eyer (Şekil 19.6).
Kod
S2 = 2*np.eye(2); A2 = np.array([[1., 1.]]); K = kkt_matrix(S2, A2)
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(9, 3.8))
heatmap(ax0, K, "KKT = [[2I, A^T],[A, 0]]", fmt="{:.0f}")
pp, nn, pv = inertia_by_pivots(K)
ev = np.sort(np.linalg.eigvalsh(K))[::-1]
x = np.arange(1, 4)
ax1.bar(x - 0.18, pv, 0.36, color=COL_PRIMARY, label="pivotlar")
ax1.bar(x + 0.18, ev, 0.36, color=COL_VEC3, alpha=0.85, label="özdeğerler")
ax1.axhline(0, color=COL_TEXT, linewidth=0.8)
ax1.set_xticks(x)
ax1.set_xlabel("indeks")
ax1.set_ylabel("değer")
ax1.legend()
apply_style(ax1)
fig.suptitle("Sylvester atalet: pivot işaretleri = özdeğer işaretleri — 2 pozitif + 1 negatif = EYER (det = -4)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.94])
plt.show()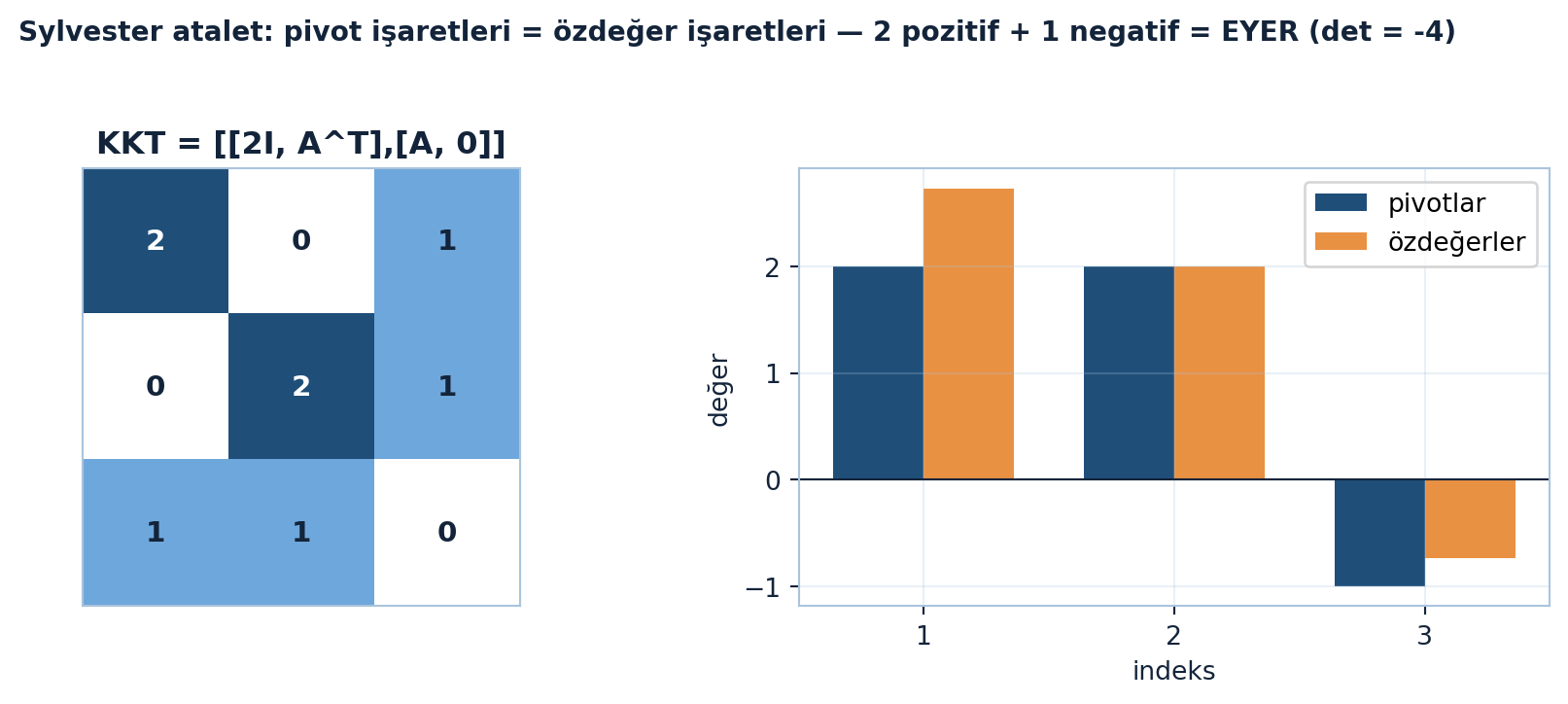
İpucuBuilder Notu — İşaretler Eliminasyondan
“Pivot işaretleri = özdeğer işaretleri” (atalet) bir matrisin tanımlılığını özdeğer hesaplamadan, sadece eliminasyonla söyler — çok ucuz bir test. ML köprüsü: bir kritik noktanın eyer mi minimum mu olduğu Hessian’ın özdeğer işaretlerine bakılarak anlaşılır; pivot/atalet testi bunu O(n³) tam özdeğer çözümü olmadan verir.
19.11 Kaynak 2: Rayleigh Bölümü
İkinci eyer kaynağı, ünlü bir orandan gelir. Simetrik S için Rayleigh bölümü:
\[R(x) = \frac{x^{T}Sx}{x^{T}x}\]
“…It’s Rayleigh quotient.” — Strang, 43:32
Maksimum değeri λ₁ (en büyük özdeğer), x = q₁’de (ilk özvektör); minimum değeri λₙ, x = qₙ’de. Herhangi bir x için R(x) bu ikisinin arasındadır: λₙ ≤ R(x) ≤ λ₁. Peki aradaki özdeğerler (λ₂, …, λₙ₋₁)?
“…those are saddle points.” — Strang, 46:22
Aradaki özvektörler R(x)’in eyer noktalarıdır: türev orada sıfır, değer özdeğere eşit, ama bazı yönlerde yukarı bazı yönlerde aşağı gider. Maksimum/minimum kolay (bir taraf), eyer zor (iki taraflı). Bu, Ders 19’un maxmin (Courant-Fischer) ilkesine doğrudan köprü.
Aşağıdaki figür solda Rayleigh bölümünü birim küre üzerinde harita olarak gösterir (maks 5 = q₁, min 1 = q₃, aradaki eyer 3 = q₂), sağda q₂ ekseninde iki yönlü davranışı kanıtlar: q₁ yönünde R 3 → 3.53 artar, q₃ yönünde 3 → 2.47 azalır — tam bir eyer (Şekil 19.7).
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.2))
# --- Sol: birim kürede Rayleigh haritası ---
S3 = np.diag([5., 3., 1.])
th, ph, R = rayleigh_sphere_map(S3)
pcm = axL.pcolormesh(th, ph, R.T, cmap=NAVY_CMAP, shading="auto")
cb = fig.colorbar(pcm, ax=axL, fraction=0.046, pad=0.04)
cb.set_label("R(x)", color=COL_TEXT)
cb.ax.tick_params(colors=COL_TEXT)
# işaretler: q1 maks (θ=0, φ=π/2), q3 min (kutba yakın), q2 eyer (θ=π/2, φ=π/2)
axL.scatter([0.0], [np.pi/2], marker="*", s=320, color=COL_VEC3,
edgecolors="#7a3d00", linewidths=1.0, zorder=5)
axL.annotate("maks 5 (q1)", (0.0, np.pi/2), textcoords="offset points",
xytext=(8, 8), color=COL_VEC3, fontsize=10, fontweight="bold")
axL.scatter([0.3], [0.15], marker="*", s=320, color=COL_TEAL,
edgecolors="#0c5460", linewidths=1.0, zorder=5)
axL.annotate("min 1 (q3)", (0.3, 0.15), textcoords="offset points",
xytext=(10, 6), color=COL_TEAL, fontsize=10, fontweight="bold")
axL.scatter([np.pi/2], [np.pi/2], marker="o", s=150, facecolors=COL_WHITE,
edgecolors=COL_TEXT, linewidths=1.6, zorder=5)
axL.annotate("eyer 3 (q2)", (np.pi/2, np.pi/2), textcoords="offset points",
xytext=(8, 10), color=COL_TEXT, fontsize=10, fontweight="bold")
axL.set_xlabel("theta"); axL.set_ylabel("phi")
axL.set_title("Birim kürede R(x): maks/min/eyer", color=COL_TEXT, fontsize=11, fontweight="bold")
apply_style(axL)
# --- Sağ: q2 eyer kesitleri ---
ts, up, dn, lam = saddle_slices(S3, k=1)
axR.plot(ts, up, color=COL_PRIMARY, lw=2, label="q2 -> q1 yonu (ARTAR 3 -> 3.53)")
axR.plot(ts, dn, color=COL_VEC3, lw=2, label="q2 -> q3 yonu (AZALIR 3 -> 2.47)")
axR.axhline(3.0, color=COL_STEEL_300, ls="--", lw=1.2)
axR.axvline(0.0, color=COL_STEEL_300, ls="-", lw=0.8)
axR.set_xlabel("t (q2 + t q_komsu)"); axR.set_ylabel("R")
axR.set_title("q2 ekseninde iki yonlu davranis = eyer", color=COL_TEXT, fontsize=11, fontweight="bold")
axR.legend(loc="center left", fontsize=9, framealpha=0.9)
apply_style(axR)
fig.suptitle("Rayleigh birim kurede: maks lambda_1 = 5, min lambda_3 = 1, ARADAKI lambda_2 = 3 EYER — bir yonde artar bir yonde azalir",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.94])
plt.show()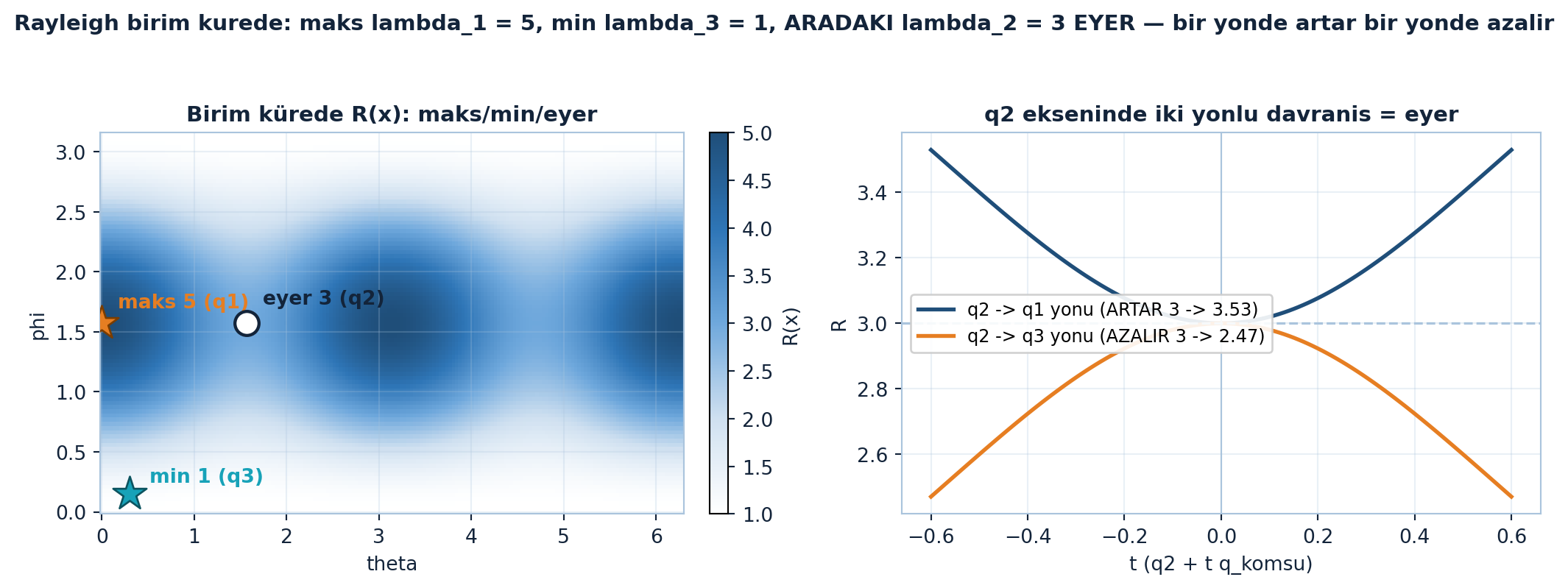
İpucuBuilder Notu — Spektrumun Motoru
Rayleigh bölümü spektral yöntemlerin motoru: en büyük/küçük özdeğeri bulmak = R(x)’i maks/min etmek (power iteration, Lanczos — Ders 11). ML köprüsü: PCA (en büyük varyans yönü = R’yi maksimize eden x), spektral kümeleme (Ders 35), ve graf Laplacian’ın Fiedler vektörü hep Rayleigh bölümü optimizasyonudur. Aradaki eyer noktaları, ara özdeğer/özvektörleri bulmanın neden zor olduğunu açıklar.
19.12 Bu Dersin Özeti
- Yapı taşları: L = ½n(n−1), U = ½n(n+1), köşegen = n, ortogonal Q = ½n(n−1), simetrik S = ½n(n+1), özvektör X = n²−n.
- Kontroller (hepsi n²): LU, QR, XΛX⁻¹, QS (kutupsal) → n². Ayrışım bilgi kaybetmez.
- SVD (tam rank m): U + Σ + V = ½m(m−1) + m + (mn − ½m(m+1)) = mn.
- Rank-R matris: R(m+n−R) parametre; matris uzayında bir manifold (alt-uzay değil).
- Eyer kaynağı 1 (KKT): ½xᵀSx, Ax=b kısıtı → Lagrangian → blok [[S, Aᵀ],[A, 0]]; köşedeki 0 → belirsiz. Pivotlar: n pozitif (S’den) + m negatif (−AS⁻¹Aᵀ’den) = eyer.
- Pivot işaretleri = özdeğer işaretleri (Sylvester atalet).
- Eyer kaynağı 2 (Rayleigh): R(x) = xᵀSx/xᵀx; maks λ₁ (q₁), min λₙ (qₙ), aradaki özdeğerler eyer noktası.
ÖnemliTek Bir Cümle
Her matris ayrışımı orijinal matrisle tam aynı sayıda serbest parametre taşır (LU/QR/QS = n², SVD = mn, rank-R = R(m+n−R)); eyer noktaları ise ya Lagrange kısıtlarının KKT blok matrisinden (n pozitif + m negatif özdeğer) ya da Rayleigh bölümünün aradaki özdeğerlerinden doğar.
19.13 Kontrol Soruları
NotSoru 1: n×n ortogonal matris Q neden n² değil ½n(n−1) serbest parametre içerir
Kolonlar birim ve birbirine dik olmalı. İlk kolon birim → n yerine n−1 serbest. İkinci kolon birim ve birinciye dik (iki kısıt) → n−2. Üçüncü → n−3, … Toplam (n−1)+(n−2)+⋯+0 = ½n(n−1). Ortogonallik kısıtları parametrelerin yaklaşık yarısını “yer”.
NotSoru 2: A = UΣVᵀ (m×n, tam rank m) tam kaç parametreye toplanır ve neden
mn’ye toplanır (A’nın eleman sayısı). U (m×m ortogonal) = ½m(m−1), Σ = m, V’nin önemli ilk m kolonu = mn − ½m(m+1) (geri kalanı boş-uzaydan, sayılmaz). Toplam ½m(m−1) + m + mn − ½m(m+1) = mn. Tam rank SVD bilgi kaybetmez.
NotSoru 3: KKT matrisi [[S, Aᵀ],[A, 0]] neden pozitif tanımlı olamaz, ve özdeğer işaretleri nedir
Köşegende sıfır blok var; pozitif tanımlı bir matrisin köşegeni hep pozitif olmalı, sıfır bunu bozar. Blok eliminasyon: ilk n pivot S’den (pozitif tanımlı → pozitif), Schur tümleyeni −AS⁻¹Aᵀ negatif tanımlı → sonraki m pivot negatif. Pivot işaretleri = özdeğer işaretleri (Sylvester atalet), yani n pozitif + m negatif özdeğer → eyer noktası.
NotSoru 4: Rayleigh bölümü R(x) = xᵀSx/xᵀx’in maksimum, minimum ve eyer noktaları hangi özdeğer/özvektörlerdir
Maksimum = λ₁ (en büyük özdeğer), x = q₁ (ilk özvektör); minimum = λₙ, x = qₙ. Herhangi x için λₙ ≤ R(x) ≤ λ₁. Aradaki özdeğerler λ₂, …, λₙ₋₁ ise eyer noktalarıdır: o özvektörlerde türev sıfır ama bazı yönlerde yukarı, bazılarında aşağı gider. Bu yüzden uç (maks/min) özdeğerler kolay, ara özdeğerler zordur.
19.14 Egzersizler
Sayım kontrolü. n = 3 al. L, U, köşegen, ortogonal Q ve simetrik S için serbest parametre sayılarını hesapla. LU ve QR’ın 9 (= n²) verdiğini doğrula. (Motor: L=3, U=6, köşegen=3, Q=3, S=6 → LU = 3+6 = 9, QR = 3+6 = 9 = n².)
Rank-R formülü. 100×200 bir matris rank-5 ise R(m+n−R) formülüyle kaç parametre içerir? Tam (mn = 20000) sayıyla karşılaştır; sıkıştırma oranı nedir? (Motor: R(m+n−R) = 5·(100+200−5) = 1475 vs 20000 — oran ≈ 13.6×.)
KKT örneği. S = [[2,0],[0,2]], A = [1, 1] (tek kısıt), b = [4]. KKT blok matrisini [[S, Aᵀ],[A, 0]] yaz (3×3). Determinantının negatif olduğunu (eyer) göster. (Motor: 3×3 blok det = −4 < 0; çözüm x = [2, 2], λ = −4.)
Rayleigh sınırları. S = diag(5, 3, 1). x = [1,1,1]ᵀ için R(x) = xᵀSx/xᵀx’i hesapla. Sonucun λₙ=1 ile λ₁=5 arasında olduğunu doğrula. (Motor: R([1,1,1]) = 3 ∈ [1, 5].)
(Ders 19 habercisi) Bu derste Rayleigh bölümünün maks = λ₁, min = λₙ verdiğini gördük; aradaki özdeğerler eyerdi. Peki λ₂’yi (ikinci özdeğer) bir maks-min olarak nasıl yazarsın? Bir tahmin yaz — Ders 19 “eyer noktaları (devam) + maxmin ilkesi”ni (Courant-Fischer) işliyor; Phase 2 paralel NYU dersinin spektral graf ağı (GCN) köprüsü de orada.
19.15 Sonraki Ders İçin Hazırlık
Ders 19: Eyer Noktaları (Devam), Maxmin İlkesi. Bu dersin Rayleigh bölümü eyer noktalarını sistematikleştiririz: Courant-Fischer maxmin/minimax ilkesi her özdeğeri λₖ’yı bir maks-min olarak tanımlar. Ders 15’in interlacing’i buradan kanıtlanır. NYU paralel dersinin spektral graf evrişim ağı (GCN) köprüsü de Ders 19’da.
UyarıDers 19 Öncesi Yapılacak
Bu dersin Rayleigh bölümü sonucunu hatırla: maks = λ₁ (q₁’de), min = λₙ (qₙ’de), aradaki özdeğerler eyer. Ders 19 aradaki λ₂, …, λₙ₋₁’i sistematik bir maks-min (Courant-Fischer) olarak yazacak. Soru: λ₂’yi bir alt-uzay üzerinden maksimum, alt-uzaylar üzerinden minimum olarak nasıl tanımlarsın? Eyerin “bir yönde artar, bir yönde azalır” davranışını (Şekil 19.7) düşün — maxmin tam bunu yakalar.
19.16 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Strang (dk) |
|---|---|---|
| Serbest parametre | ayrışım = A ile aynı sayı; bilgi korunur | 0m59 |
| Yapı taşları | L = ½n(n−1), U = ½n(n+1), Q = ½n(n−1) | 2m05 |
| Özvektör matrisi | X = n²−n, Λ = n, X⁻¹ = 0 → n² | 4m09 |
| Kutupsal QS | ortogonal × simetrik = n² | 9m33 |
| Rank-R matris | R(m+n−R); matris uzayında manifold | 19m30 |
| Eyer: iki kaynak | KKT (Lagrange) + Rayleigh bölümü | 27m08 |
| KKT matrisi | [[S, Aᵀ],[A, 0]]; belirsiz (eyer) | 36m13 |
| Pivot = özdeğer işareti | n pozitif + m negatif (Sylvester atalet) | 42m02 |
| Rayleigh bölümü | R = xᵀSx/xᵀx; maks λ₁, min λₙ | 43m32 |
| Aradaki = eyer | λ₂…λₙ₋₁ eyer noktaları | 46m22 |
19.17 ML Bağlantıları Özeti
- Etkin parametre / serbestlik derecesi: modelin gerçek kapasitesi; düşük-rank/ortogonal/simetri kısıtları nominal parametreyi azaltır (aşırı-öğrenme analizi).
- LoRA / düşük-rank: rank-R matris R(m+n−R) parametre; n² yerine ~2nR ile fine-tuning; rank-R manifoldu üzerinde optimizasyon.
- KKT / kısıtlı optimizasyon: SVM dual, eşitlik-kısıtlı en küçük kareler, PINN — hepsi KKT blok sistemi çözer (eyer = denge).
- Eyer noktaları: derin ağ kayıp yüzeyinde minimumdan çok eyer var; SGD gürültüsü eyerden kaçışı sağlar (Ders 25).
- Rayleigh / spektral: PCA (maks varyans), spektral kümeleme (Ders 35), Fiedler vektörü — hepsi Rayleigh bölümü optimizasyonu.
- Pivot/atalet testi: Hessian’ın eyer mi minimum mu olduğunu özdeğer çözmeden, eliminasyon işaretleriyle anla.
- Geriye köprü: Ders 2 (5 ayrışım), Ders 3 (ortogonal Q), Ders 5 (pozitif tanımlı, pivot), Ders 6 (SVD), Ders 16 (rank-R/matris tamamlama), Ders 17 (parametre sayma).
ÖnemliAyrışımlar Korur, Eyerler Armağandır
“…the number of free parameters agrees with the number of parameters in A itself, like n squared.” — Strang, 0:59
Ayrışımlar bilgiyi farklı kılıklarda korur; eyer noktaları ise kısıtların (KKT) ve ara özdeğerlerin (Rayleigh) kaçınılmaz armağanıdır.