flowchart TD
N["Norm (buyukluk olcusu)"] --> LP["ℓp ailesi (ℓ1/ℓ2/ℓ∞)"]
N --> KONV["konvekslik (p≥1)"]
N --> L0["ℓ0 seyreklik (norm degil)"]
N --> SNORM["S-norm (Mahalanobis elips)"]
N --> MAT["matris: ‖A‖2=σ1 / Frobenius / nukleer"]
N --> SEC["norm secimi = duzenlilestirme"]
style N fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style LP fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style MAT fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style KONV fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style SNORM fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style SEC fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style L0 fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
9 Vektör ve Matris Normları
ℓp ailesi, birim topların geometrisi, konvekslik ve üç matris normu
NotBölüm bilgisi
Video: Norms of Vectors and Matrices · OCW: MIT 18.065 Lecture 8 · Okuma süresi: ~36 dk · Eğitmen: Gilbert Strang · Önkoşul: Ders 7 (Eckart-Young, matris normlarına giriş).
9.1 Bu Derste Ne Var?
Ders 7’de üç normu Eckart-Young için tanıttık. Ders 8 normları sistematik işliyor: \(\ell^p\) ailesi, birim topların geometrisi, konvekslik ve matris normları. (Strang dersi eğlenceli bir olasılık gözlemiyle açıyor — “probability matching”: insanlar yanlı bir parada bile %75 tura tahmin eder; bu kursun konusu değil ama hoş bir kenar not.)
Üç temel fikir:
- \(\ell^p\) normları ve birim toplar — \(\ell^2\) çember, \(\ell^1\) elmas, \(\ell^\infty\) kare; konvekslik normun anahtarıdır (\(\ell^0\) ve \(p < 1\) norm değildir).
- \(\ell^1 \to\) seyreklik — kısıtlı minimizasyonda \(\ell^1\) kazananı bir köşede oturur (en çok sıfır); \(\ell^2\) (ridge) yaymaz.
- Matris normları — spektral \(\|A\|_2 = \sigma_1\) (en büyük büyütme çarpanı), Frobenius \(\sqrt{\sum \sigma_i^2}\), nükleer \(\sum \sigma_i\).
Aşağıdaki kavram haritası dersin parçalarını nasıl bağladığını gösterir (Şekil 9.1).
İpucuBuilder Notu — Büyüklüğün Dili
- Birim top geometrisi → düzenlileştirme seçimi: \(\ell^1\) elmasın köşeleri eksenlerde (Lasso, seyreklik); \(\ell^2\) çemberi yayar (ridge); \(\ell^\infty\) kutusu en kötü durum (adversarial).
- Matris 2-normu \(= \sigma_1 =\) Lipschitz sabiti: bir katmanın maksimum büyütme çarpanı; spektral normalizasyon bunu sınırlar (GAN, sağlamlık).
- Nükleer norm → düşük-rank: Srebro varsayımı — gradient descent fazla-parametreli ağlarda nükleer normu küçük çözümü seçer (implicit regularization).
- Konvekslik — norm \(=\) konveks birim top; optimizasyonun tek-minimum garantisi (Ders 5 kâse).
Tek cümle: norm bir vektör/matrisin büyüklük ölçüsüdür; hangi normu seçtiğin (\(\ell^1\) seyrek, \(\ell^2\) düzgün, nükleer düşük-rank) çözümün karakterini belirler.
9.2 1. Norm Nedir: Büyüklüğün Ölçüsü
Norm, bir vektörün, matrisin, tensörün ya da fonksiyonun büyüklüğünü ölçen bir araçtır.
“…a norm is a way to measure the size of a vector or the size of a matrix…” — Strang, 4:41
Üç temel kural: pozitiflik (\(\|v\| \geq 0\), sıfır yalnız \(v = 0\)’da), homojenlik (\(\|cv\| = |c| \cdot \|v\|\) — vektörü iki katına çıkarırsan norm da iki katına çıkar) ve üçgen eşitsizliği (\(\|v + w\| \leq \|v\| + \|w\|\)). Bu üç kuralı sağlayan her ölçü bir normdur.
İpucuBuilder Notu — Üç Kural
Norm, ML’de “ne kadar büyük/uzak” sorusunun cevabıdır: kayıp (tahmin \(-\) hedef normu), düzenlileştirme (ağırlık normu), yakınsama (gradyan normu). Hangi normu seçtiğin problemin karakterini belirler.
9.3 2. ℓp Normları (p = 1, 2, ∞)
Bir ailenin üyeleri: \(\ell^p\) normu, \(p\). kuvvetlerin toplamının \(p\). köküdür:
\[\|v\|_p = \left(|v_1|^p + |v_2|^p + \cdots + |v_n|^p\right)^{1/p}\]
Üç önemli üye:
\[\|v\|_2 = \sqrt{\textstyle\sum v_i^2}, \quad \|v\|_1 = \textstyle\sum |v_i|, \quad \|v\|_\infty = \max_i |v_i|\]
\(\ell^2\) alışılmış uzunluk, \(\ell^1\) mutlak değerlerin toplamı, \(\ell^\infty\) (\(p \to \infty\) limiti) en büyük bileşeni seçer. \(\ell^1\) özellikle önemlidir:
“…it plays a very significant part now in compressed sensing.” — Strang, 5:58
Birim topların tek bir eksende üst üste çizimi \(p\)’nin geometriyi nasıl değiştirdiğini gösterir (Şekil 9.2): \(p\) arttıkça birim top elmastan çembere, oradan kareye “şişer”.
Kod
fig, ax = plt.subplots(figsize=(6.4, 6.4))
style_square_axes(ax, 1.5)
plot_pointset(ax, norm_ball(0.5), color=COL_VEC3, label="p=0.5 konveks değil", close=False)
plot_pointset(ax, norm_ball(1), color=COL_PRIMARY, label="ℓ1 elmas", close=False)
plot_pointset(ax, norm_ball(2), color=COL_ACCENT, label="ℓ2 çember", close=False)
plot_pointset(ax, norm_ball(4), color=COL_SKY_400, label="p=4", close=False)
plot_pointset(ax, norm_ball(np.inf), color=COL_PURPLE, label="ℓ∞ kare", close=False)
ax.legend(loc="upper right", fontsize=9)
ax.set_title("ℓp birim topları: p artarken elmas→çember→kare; p<1 içe çökük",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
plt.show()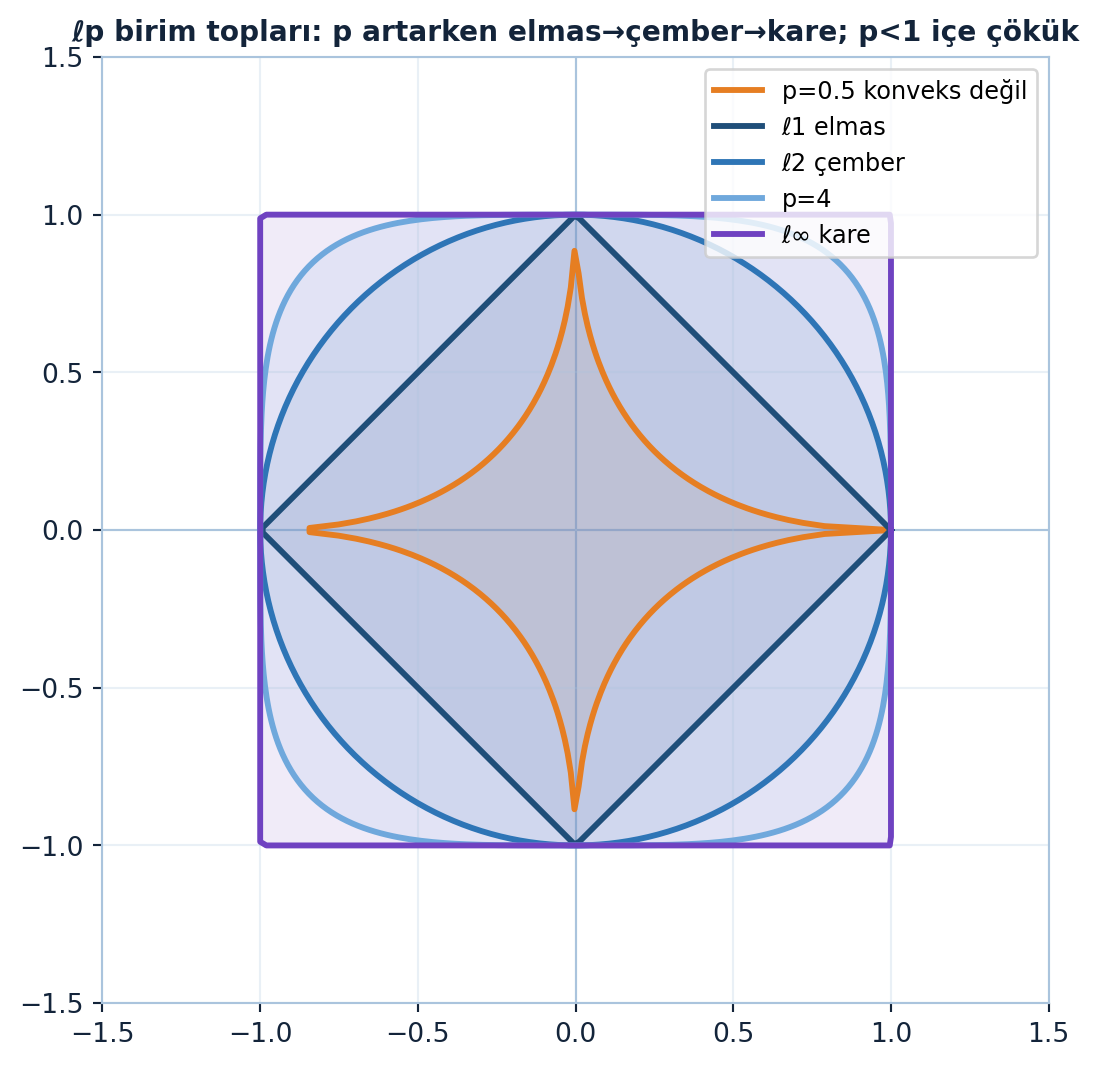
İpucuBuilder Notu — ℓp Ailesi
\(\ell^p\) ailesi ML’de farklı düzenlileştiriciler: \(\ell^2\) (ridge, ağırlık zayıflatma — düzgün küçültür), \(\ell^1\) (Lasso — seyrekleştirir), \(\ell^\infty\) (en kötü-durum, adversarial sağlamlık). \(p\) seçimi çözümün geometrisini belirler.
9.4 3. ℓ0 ve Seyreklik
Seyreklikte asıl istenen, sıfırdan-farklı bileşen sayısıdır:
\[\|v\|_0 = \#\{\, i : v_i \neq 0 \,\}\]
“…the number of non-zero components.” — Strang, 7:50
Ama bu bir norm değildir: homojenlik kuralını çiğner. \(2v\)’nin sıfırdan-farklı bileşen sayısı \(v\) ile aynıdır, yani \(\|2v\|_0 = \|v\|_0 \neq 2\|v\|_0\). Bu yüzden seyreklik problemleri pratikte \(\ell^1\) ile (en yakın gerçek norm) çözülür — \(\ell^0\)’ı doğrudan minimize etmek NP-zordur.
İpucuBuilder Notu — Sayılamayan İdeal
\(\ell^0\) “tam seyreklik” idealdir ama hesaplanamaz (kombinatoryal). \(\ell^1\), \(\ell^0\)’ın dışbükey gevşemesidir ve aynı seyrek çözümü çoğu zaman verir — compressed sensing ve Lasso’nun teorik temeli. “Norm değil ama hedef” olan \(\ell^0\), \(\ell^1\) ile yaklaşılır.
9.5 4. Birim Toplar Geometrisi
Bir normu anlamanın en iyi yolu, \(\|v\| = 1\) olan vektörleri çizmektir (birim top). 2B’de:
- \(\ell^2\): çember, \(v_1^2 + v_2^2 = 1\).
- \(\ell^1\): elmas (köşeleri eksenlerde: \((\pm 1, 0)\), \((0, \pm 1)\)), \(|v_1| + |v_2| = 1\).
- \(\ell^\infty\): kare, \(\max(|v_1|, |v_2|) = 1\).
“It’s a diamond.” — Strang, 11:26
\(p\) arttıkça şekil elmastan (\(p=1\)) çembere (\(p=2\)) oradan kareye (\(p=\infty\)) doğru “şişer” (Şekil 9.2). Köşelerin yeri kritiktir: \(\ell^1\) elmasının köşeleri eksenlerdedir — bu, seyrekliğin geometrik kaynağıdır.
İpucuBuilder Notu — Köşeler Konuşur
Birim top geometrisi, düzenlileştirmenin neden işe yaradığını gösterir: \(\ell^1\) elmasının sivri köşeleri eksenleri “yakalar” (bazı bileşenler tam sıfır), \(\ell^2\) çemberinin köşesizliği yaymaya yol açar. Bu basit resim, Lasso ile ridge’in farkını tek bakışta verir.
9.6 5. Konvekslik: Normun Anahtarı
Çember, elmas ve karenin ortak özelliği nedir? Konvekslik (dışbükeylik) — iki nokta arasındaki doğru parçası şeklin içinde kalır.
“…This is a true norm as the convex unit [ball].” — Strang, 17:09
\(p < 1\) için (örneğin \(p = 1/2\)) birim top içe çöker — konveks değildir, ve üçgen eşitsizliği bozulur, yani gerçek bir norm olmaz. \(\ell^0\) ise tamamen eksenlere büzülür (konveks değil). Demek ki “gerçek norm” ile “konveks birim top” aynı şeydir; geçerli aralık \(p \geq 1\)’dir.
Şekil 9.3 bunu yan yana gösterir: \(\ell^1\) elmasının içinde kalan doğru parçası karşısında \(p=0.5\) yıldızının dışına taşan doğru parçası.
Kod
fig, axes = plt.subplots(1, 2, figsize=(9.6, 4.4))
# ---- SOL: ℓ1 (p=1) KONVEKS ----
ax = axes[0]
style_square_axes(ax, 1.3, title="ℓ1 (p=1): KONVEKS")
plot_pointset(ax, norm_ball(1), COL_PRIMARY, fill_alpha=0.15, close=False)
# iki nokta elmas üzerinde: |x|+|y|=1
A = np.array([0.7, 0.3]); B = np.array([-0.3, 0.7])
ax.scatter([A[0], B[0]], [A[1], B[1]], color=COL_PRIMARY, s=70,
zorder=5, edgecolor=COL_TEXT, linewidth=0.8)
# aralarındaki doğru parçası İÇERİDE kalır (gri)
ax.plot([A[0], B[0]], [A[1], B[1]], color=COL_TEXT, lw=2.0, ls="--",
alpha=0.8, zorder=4, label="doğru parçası içeride")
ax.legend(loc="lower left", fontsize=9, framealpha=0.9)
# ---- SAĞ: p=0.5 KONVEKS DEĞİL ----
ax = axes[1]
style_square_axes(ax, 1.3, title="p=0.5: KONVEKS DEĞİL (norm değil)")
plot_pointset(ax, norm_ball(0.5), COL_VEC3, fill_alpha=0.15, close=False)
# iki nokta yıldız üzerinde: |x|^0.5+|y|^0.5=1
A = np.array([1.0, 0.0]); B = np.array([0.0, 1.0])
ax.scatter([A[0], B[0]], [A[1], B[1]], color=COL_VEC3, s=70,
zorder=5, edgecolor=COL_TEXT, linewidth=0.8)
# doğru parçası DIŞARI taşar (orange) — üçgen eşitsizliği bozulur
ax.plot([A[0], B[0]], [A[1], B[1]], color=COL_VEC3, lw=2.4,
zorder=4, label="doğru parçası dışarı taşar")
ax.legend(loc="lower left", fontsize=9, framealpha=0.9)
fig.suptitle("Gerçek norm = konveks birim top (p≥1); p<1 üçgen eşitsizliğini bozar",
color=COL_TEXT, fontsize=12, fontweight="bold")
fig.tight_layout()
plt.show()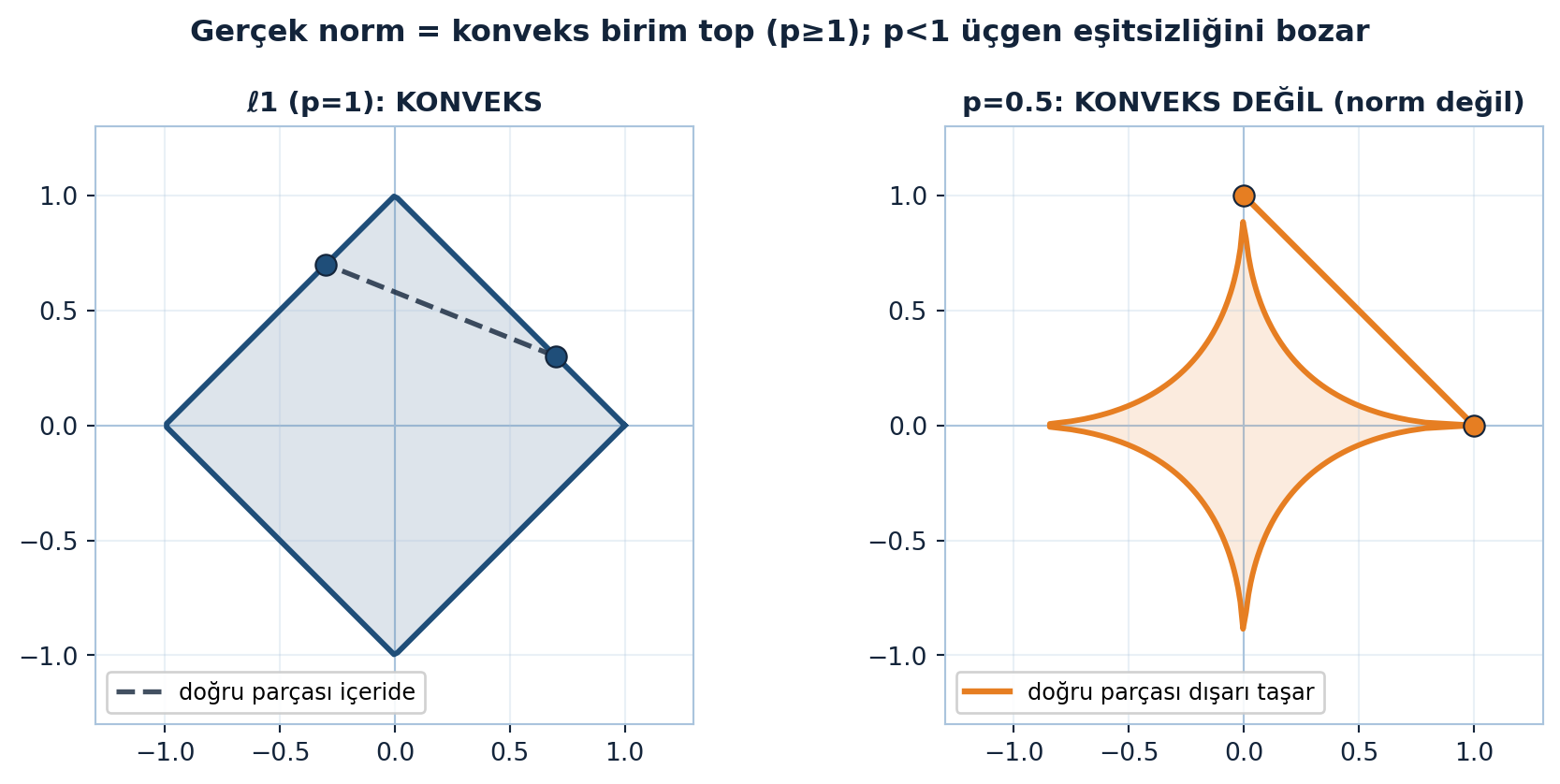
İpucuBuilder Notu — Konveks Cennet
Konvekslik, optimizasyonun cennetidir: konveks bir norm-cezası, tek bir küresel minimum garanti eder (Ders 5 kâsesi). Bu yüzden ML \(\ell^0\) (konveks değil, NP-zor) yerine \(\ell^1\) (konveks) kullanır — seyrekliği konveks bir problemle elde etmek.
9.7 6. Ağırlıklı S-Normu
Pozitif tanımlı bir \(S\) matrisi yeni bir norm tanımlar — enerjinin kareköküdür:
\[\|v\|_S = \sqrt{v^{T} S v}\]
“…The energy. That’s the energy in the vector v.” — Strang, 18:53
\(S = I\) alınca \(\ell^2\) normuna döner (çember). Farklı bir \(S\) (örneğin \(\mathrm{diag}(2, 3)\)) birim topu bir elipse dönüştürür: \(2v_1^2 + 3v_2^2 = 1\). Büyük ağırlık (3) o eksende daha az ilerlemene izin verir. Bu “ağırlıklı norm”, probleme uygun ölçekler seçmeni sağlar (Şekil 9.4).
Kod
fig, ax = plt.subplots(figsize=(6, 6))
style_square_axes(ax, 1.7)
plot_pointset(ax, norm_ball(2), COL_STEEL_300, "S=I: çember (ℓ2)", close=False)
S = np.array([[2., 0.], [0., 3.]])
plot_pointset(ax, s_norm_ellipse(S), COL_ACCENT, "S=diag(2,3): elips", close=False)
ax.legend(loc="upper right", fontsize=9)
ax.set_title("Ağırlıklı S-norm ‖v‖_S=√(vᵀSv): birim top elipse döner (Mahalanobis)",
color=COL_TEXT, fontsize=10, fontweight="bold")
plt.show()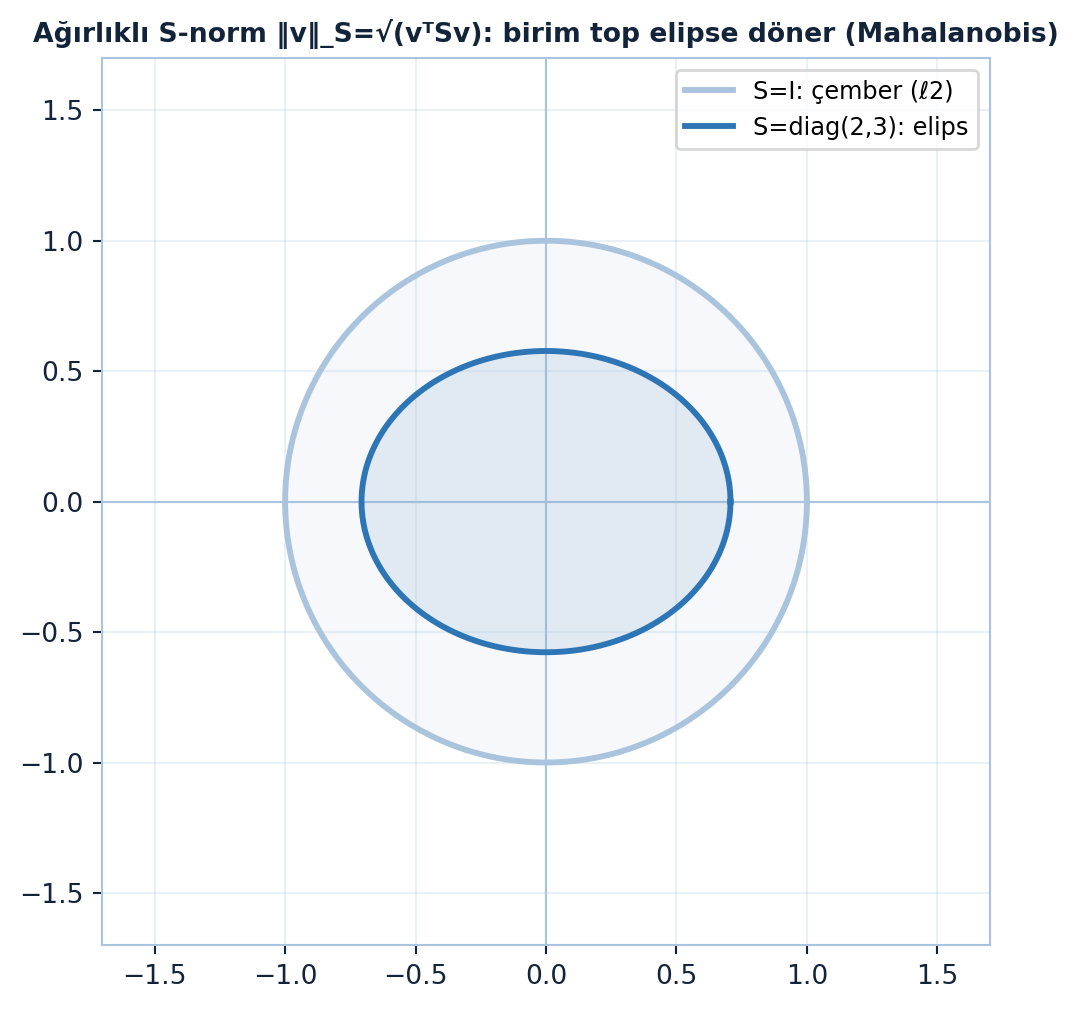
İpucuBuilder Notu — Probleme Göre Ölç
S-normu (Mahalanobis uzaklığı), istatistik ve ML’de her yerde: kovaryansın tersiyle ölçeklenmiş uzaklık, anormallik tespiti, beyazlatma. Hessian’ı \(S\) olarak almak (ikinci-derece yöntemler) kâseyi çembere çevirir — Newton/doğal gradyanın sezgisi.
9.8 7. Kısıtlı Minimizasyon: ℓ1 vs ℓ2
Temel problem: \(Ax = b\) kısıtı altında \(\|x\|\)’i minimize et. Norm seçimi sonucu kökten değiştirir. \(\ell^2\)’de buna ridge regresyon, \(\ell^1\)’de basis pursuit denir.
“…it has a famous name, basis pursuit.” — Strang, 24:02
Geometrik resim: çözümler bir doğru üzerinde. Normu (birim topu) orijinden şişir, doğruya ilk değdiği nokta kazanır. \(\ell^2\) çemberi doğruya en yakın noktada değer (dik ayak). \(\ell^1\) elması ise sivri köşesiyle değer — ve köşe eksende olduğundan kazanan bir bileşeni sıfır olan seyrek vektördür (Şekil 9.5).
“The winner has the most zeros.” — Strang, 28:58
Kod
a = np.array([1., 2.]); b = 2.0
x_l1, x0, d = basis_pursuit_2d(a, b, 1)
x_l2 = basis_pursuit_2d(a, b, 2)[0]
fig, ax = plt.subplots(figsize=(6.4, 6.4))
style_square_axes(ax, 2.2)
# Kisit dogrusu a·x = b: x0 + t*d (gri kesik uzun cizgi)
ts = np.linspace(-3.0, 3.0, 2)
line = x0[:, None] + ts[None, :] * d[:, None]
ax.plot(line[0], line[1], color=COL_STEEL_300, lw=1.8, ls="--", zorder=1,
label="kısıt: a·x = b")
# Buyuyen ℓ2 cemberi (teget x_l2, eksen disi) — accent ince
plot_pointset(ax, norm_ball(2) * lp_norm(x_l2, 2), COL_ACCENT, None,
lw=1.3, fill_alpha=0.0)
# Buyuyen ℓ1 elmasi (kose x_l1, eksende) — navy ince
plot_pointset(ax, norm_ball(1) * lp_norm(x_l1, 1), COL_PRIMARY, None,
lw=1.3, fill_alpha=0.0)
# Cozum noktalari
ax.scatter([x_l2[0]], [x_l2[1]], s=90, color=COL_VEC3, zorder=5,
edgecolor=COL_TEXT, linewidth=0.8, label="ℓ2: yoğun")
ax.scatter([x_l1[0]], [x_l1[1]], s=90, color=COL_PRIMARY, zorder=5,
edgecolor=COL_TEXT, linewidth=0.8, label="ℓ1: seyrek")
ax.legend(loc="upper right", fontsize=9)
ax.set_title("Basis pursuit: ℓ1 köşede (seyrek, bir bileşen=0), ℓ2 dik ayakta (yoğun)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
plt.show()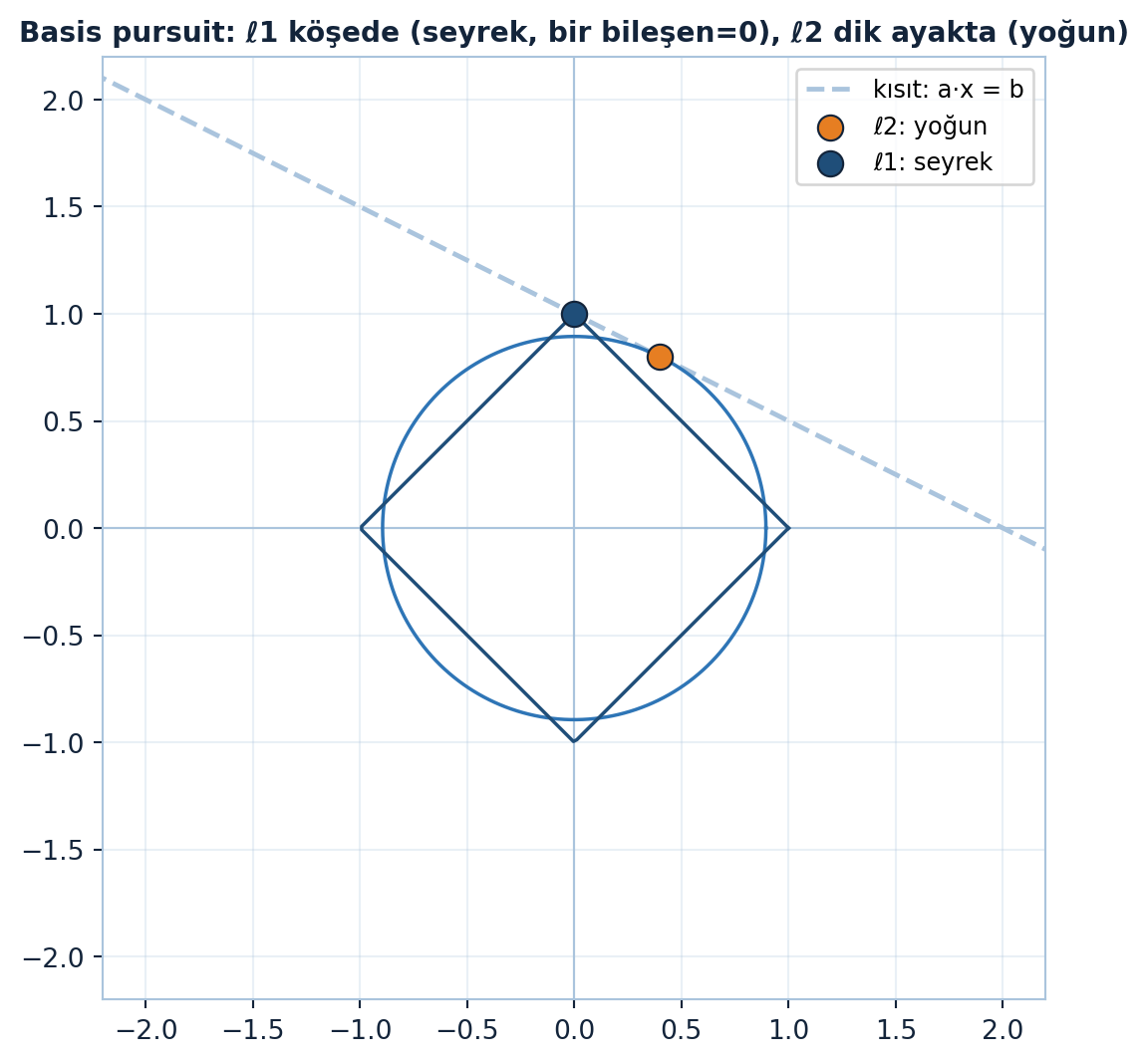
İpucuBuilder Notu — Lasso vs Ridge
Bu resim Lasso (\(\ell^1\)) ile ridge (\(\ell^2\)) farkının tamamıdır: \(\ell^1\) köşesi eksene değer → öznitelik seçimi (seyreklik); \(\ell^2\) teğeti → tüm ağırlıklar küçük ama sıfırdan farklı. Seyreklik/yorumlanabilirlik istiyorsan \(\ell^1\), düzgün küçültme istiyorsan \(\ell^2\).
9.9 8. Matris 2-Normu = σ1
Matris normu, vektör normundan türetilir: \(A\)’nın bir vektörü ne kadar “büyütebildiği” (büyütme çarpanı):
\[\|A\|_2 = \max_{x \neq 0} \frac{\|Ax\|}{\|x\|}\]
“…the answer will be the maximum blow-up.” — Strang, 34:34
En büyük büyütme çarpanı \(\sigma_1\)’dir ve onu sağlayan \(x\) birinci sağ tekil vektör \(v_1\)’dir (özvektör değil — \(A\) simetrik olmayabilir).
“…the x that has the biggest blow-up factor…” — Strang, 36:14
Yerine koy: \(x = v_1\) iken \(Av_1 = \sigma_1 u_1\), \(\|v_1\| = \|u_1\| = 1\), yani oran \(= \sigma_1\) (Şekil 9.6):
\[\|A\|_2 = \frac{\|A v_1\|}{\|v_1\|} = \frac{\|\sigma_1 u_1\|}{1} = \sigma_1\]
Kod
A = np.array([[2., 0.], [1., 2.]])
circle, ell, s1, v1, u1 = blowup(A)
fig, ax = plt.subplots(figsize=(6.4, 6.4))
style_square_axes(ax, 3)
plot_pointset(ax, circle, COL_STEEL_300, "birim çember", close=False)
plot_pointset(ax, ell, COL_ACCENT, "A·çember (elips)", close=False)
draw_vec2d(ax, v1, color=COL_VEC2, label="v1")
draw_vec2d(ax, A @ v1, color=COL_VEC1, label="Av1=σ1u1")
ax.set_title("‖A‖2 = max ‖Ax‖/‖x‖ = σ1 = en büyük büyütme (Lipschitz)",
color=COL_TEXT, fontsize=11, fontweight="bold")
ax.text(0.5, -2.78, f"σ1 = ‖A‖2 = {s1:.4f} (birim çemberi en çok büyüten yön v1)",
ha="center", va="center", fontsize=9.5, color=COL_TEXT)
ax.legend(loc="upper left", fontsize=9, framealpha=0.9)
plt.show()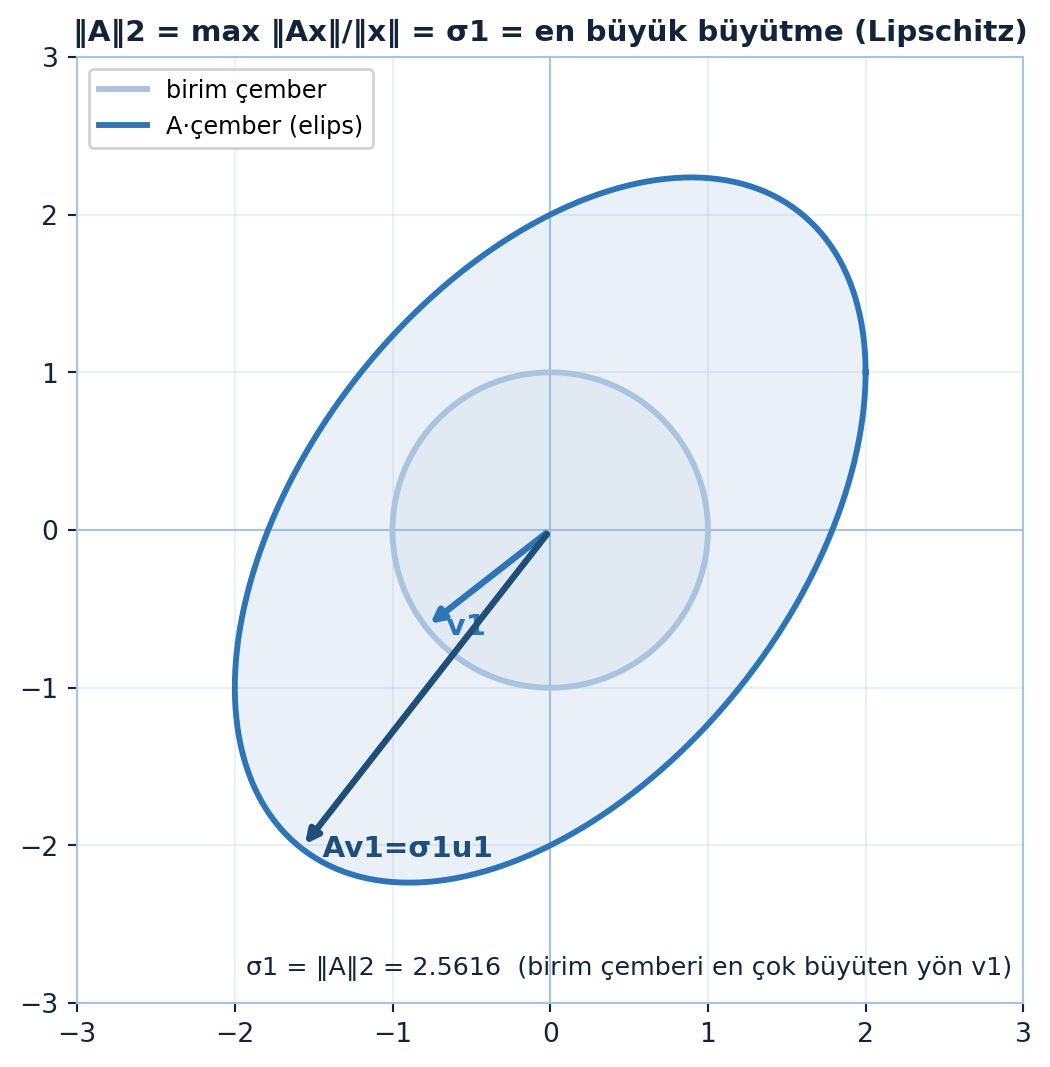
İpucuBuilder Notu — Katmanın Lipschitz’i
\(\|A\|_2 = \sigma_1\) bir katmanın Lipschitz sabiti — girdideki değişimi en fazla kaç kat büyütebileceği. Spektral normalizasyon \(\sigma_1\)’i 1’e sabitler; GAN kararlılığı, adversarial sağlamlık ve gradyan patlamasını kontrol etmenin doğrudan yolu.
9.10 9. Frobenius Normu
İkinci matris normu, matrisi uzun bir vektör gibi düşünüp tüm girdilerin karelerinin toplamının kareköküdür — ve bu, tekil değerlerin karelerinin toplamına eşittir:
\[\|A\|_F = \sqrt{\sum_{i,j} a_{ij}^2} = \sqrt{\sigma_1^2 + \sigma_2^2 + \cdots + \sigma_r^2}\]
“…the square root of the sum of the squares of all the sigmas.” — Strang, 40:58
Neden eşit? SVD’de \(A = U\Sigma V^{T}\); ortogonal \(U\) ve \(V\) Frobenius normunu değiştirmez (uzunluk korur), geriye köşegen \(\Sigma\) kalır, onun girdileri de \(\sigma\)’lardır. Üç matris normunun aynı \(\sigma\) vektöründen geldiği Şekil 9.7’da görülür.
İpucuBuilder Notu — Ucuz Büyüklük
Frobenius en yaygın matris “büyüklüğü”dür: ağırlık zayıflatma (\(\|W\|_F^2\) cezası), gradyan normu, \(\|A\|_F^2 = \mathrm{trace}(A^{T}A)\). Hesaplaması ucuz (SVD gerekmez), bu yüzden derin öğrenmede varsayılan matris düzenlileştiricisidir.
9.11 10. Nükleer Norm ve Srebro Varsayımı
Üçüncü matris normu, tekil değerlerin toplamıdır — matrisin \(\ell^1\) normu gibidir:
\[\|A\|_N = \sigma_1 + \sigma_2 + \cdots + \sigma_r\]
Hoş bir örüntü: üç matris normu, \(\sigma\) vektörünün üç normudur — spektral \(= \max \sigma\) (\(\ell^\infty\)), Frobenius \(= \sqrt{\sum \sigma^2}\) (\(\ell^2\)), nükleer \(= \sum \sigma\) (\(\ell^1\)). İndeksler matrise geçince yer değiştirir (Şekil 9.7).
Srebro’nun (derin öğrenme teorisyeni) varsayımı: fazla-parametreli ağlarda (ağırlık \(>\) örnek) birçok minimum vardır; gradient descent bunlardan nükleer normu en küçük olanı seçer.
“…picks out the weights that minimize the nuclear norm.” — Strang, 46:00
Kod
M = np.diag([5., 3.])
s = np.array([5., 3.])
sp, fr, nu = matrix_norms(M)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4.2))
bar_values(axL, s, ["σ1", "σ2"], "σ vektoru", highlight=[0])
axR.axis("off")
lines = [
f"spektral ‖A‖2 = max σ = {sp:.0f} (σ ℓ∞)",
f"Frobenius ‖A‖F = √Σσ² = √34 ≈ {fr:.2f} (σ ℓ²)",
f"nukleer ‖A‖N = Σσ = {nu:.0f} (σ ℓ¹)",
]
axR.text(0.02, 0.5, "\n\n".join(lines), transform=axR.transAxes,
ha="left", va="center", fontsize=13, color=COL_TEXT,
fontweight="bold")
fig.suptitle("Uc matris normu = σ vektorunun uc normu (indeks yer degistirir)",
color=COL_TEXT, fontsize=12, fontweight="bold")
plt.show()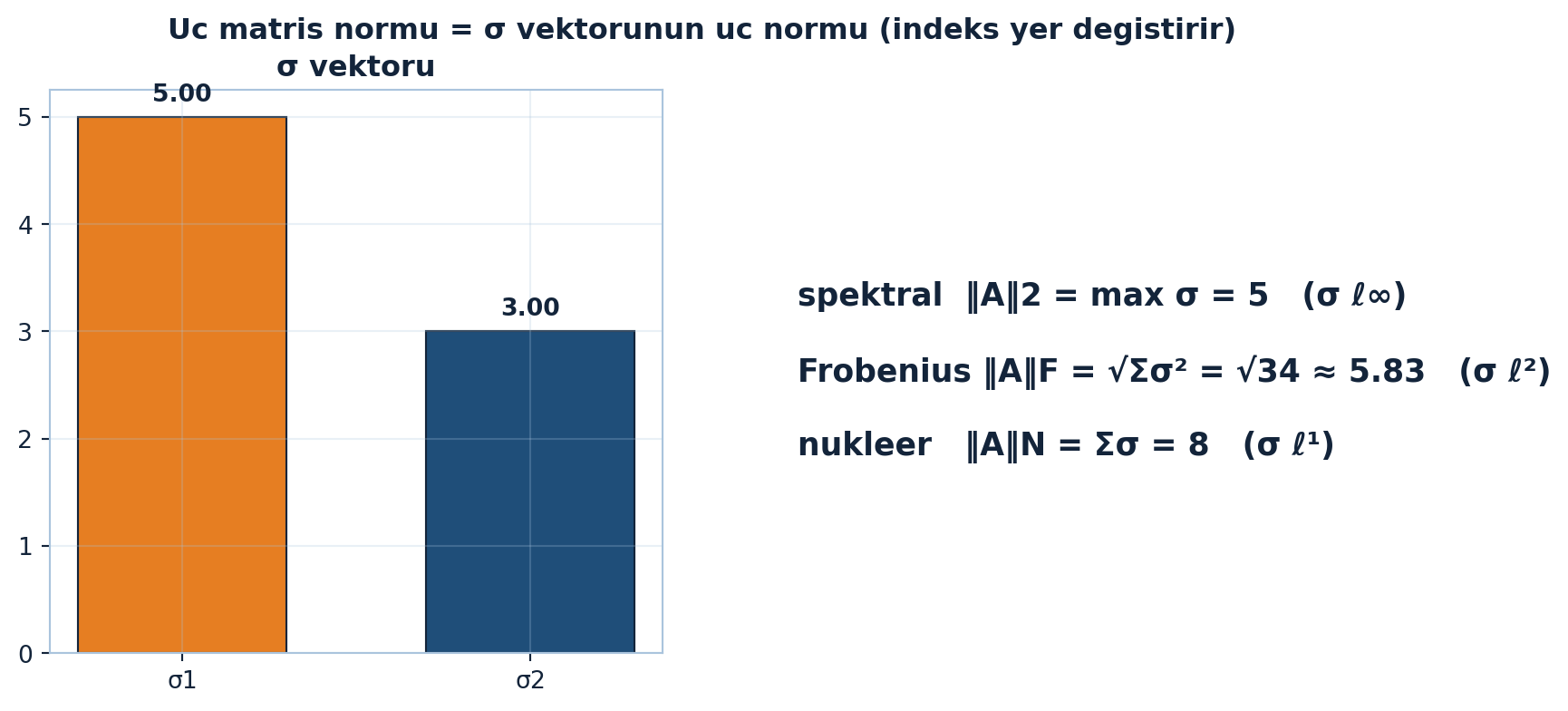
İpucuBuilder Notu — Gizli Düzenlileştirme
Nükleer norm \(=\) düşük-rank teşviki (rankın dışbükey gevşemesi): matris tamamlama (Netflix), robust PCA. Srebro varsayımı implicit regularization’ın çekirdeğidir: GD açıkça düzenlileştirme olmadan bile düşük-rank/küçük-norm çözümlere yönelir — derin öğrenmenin neden genelleştiğine dair önemli bir ipucu.
9.12 Bu Dersin Özeti
- Norm — büyüklük ölçüsü; pozitiflik + homojenlik + üçgen eşitsizliği.
- \(\ell^p\) normları — \(\ell^1\) (toplam), \(\ell^2\) (uzunluk), \(\ell^\infty\) (maksimum).
- \(\ell^0\) — sıfırdan-farklı sayısı; norm değil (homojenlik çiğnenir); seyreklik hedefi.
- Birim toplar — \(\ell^2\) çember, \(\ell^1\) elmas, \(\ell^\infty\) kare.
- Konvekslik — gerçek norm \(=\) konveks birim top; \(p < 1\) norm değildir.
- S-normu — \(\sqrt{v^{T}Sv}\); ağırlıklı, elips (Mahalanobis).
- Kısıtlı min — \(\ell^1\) seyrek köşe (basis pursuit), \(\ell^2\) ridge.
- \(\|A\|_2 = \sigma_1\) — maksimum büyütme çarpanı (Lipschitz).
- Frobenius — \(\sqrt{\sum \sigma_i^2} = \sqrt{\sum a_{ij}^2}\); en yaygın.
- Nükleer — \(\sum \sigma_i\); düşük-rank, Srebro varsayımı.
ÖnemliTek Bir Cümle
Norm bir vektör/matrisin büyüklük ölçüsüdür; birim topunun geometrisi (\(\ell^1\) elmas seyrek köşeli, \(\ell^2\) çember düzgün, nükleer düşük-rank) hangi çözümün kazanacağını belirler — bu yüzden norm seçimi ML’de düzenlileştirme kararının ta kendisidir.
9.13 Kontrol Soruları
NotSoru 1: v = (3, −4) vektörünün ℓ1, ℓ2 ve ℓ∞ normlarını hesapla.
\(\ell^2 = \sqrt{3^2 + 4^2} = \sqrt{25} = 5\) (alışılmış uzunluk). \(\ell^1 = |3| + |-4| = 7\) (mutlak toplam). \(\ell^\infty = \max(3, 4) = 4\) (en büyük bileşen). Her zaman \(\ell^\infty \leq \ell^2 \leq \ell^1\) (burada \(4 \leq 5 \leq 7\)).
NotSoru 2: Tekil değerleri σ = 5, 3 olan bir A için spektral, Frobenius ve nükleer normları hesapla. σ vektörünün hangi normlarına denk?
Spektral \(\|A\|_2 = \sigma_1 = 5\) (\(\sigma\) vektörünün \(\ell^\infty\)’u). Frobenius \(= \sqrt{25 + 9} = \sqrt{34} \approx 5.83\) (\(\sigma\)’nın \(\ell^2\)’si). Nükleer \(= 5 + 3 = 8\) (\(\sigma\)’nın \(\ell^1\)’i). Üç matris normu \(= \sigma = (5, 3)\) vektörünün \(\ell^\infty\), \(\ell^2\), \(\ell^1\) normları — indeksler yer değiştirmiş.
NotSoru 3: ℓ0 neden norm değildir? p = 1/2 neden gerçek bir norm vermez?
\(\ell^0\) (sıfırdan-farklı sayısı) homojenliği çiğner: \(\|2v\|_0 = \|v\|_0 \neq 2\|v\|_0\) (ölçeklemek sıfır sayısını değiştirmez). \(p = 1/2\)’nin birim topu konveks değildir (içe çöker), bu yüzden üçgen eşitsizliği bozulur — norm olmaz. Gerçek norm aralığı \(p \geq 1\)’dir (konveks birim top).
NotSoru 4: Seyrek öznitelik seçimi için hangi norm cezasını seçersin? Geometrik nedenini açıkla.
\(\ell^1\) (Lasso). Sebep geometrik: kısıt kümesi \(\ell^1\) elmasının sivri köşesine değer, köşeler eksenlerde olduğundan bazı bileşenler tam sıfır olur (seyrek). \(\ell^2\) çemberi köşesiz olduğundan teğet noktası genelde eksende değildir → tüm bileşenler küçük ama sıfırdan farklı (ridge). İdeal seyreklik \(\ell^0\)’dır ama hesaplanamaz; \(\ell^1\) onun dışbükey, çözülebilir vekilidir.
9.14 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. \(v = (1, -2, 2)\) için \(\ell^1\), \(\ell^2\) ve \(\ell^\infty\) normlarını hesapla. \(\ell^\infty \leq \ell^2 \leq \ell^1\) olduğunu doğrula.
Egzersiz 2. Aşağıdaki rank-1 matrisin spektral, Frobenius ve nükleer normlarını bul. (İpucu: tek bir tekil değer var.)
\[A = \begin{pmatrix} 3 & 4 \\ 0 & 0 \end{pmatrix}\]
Egzersiz 3. 2B’de \(\ell^1\), \(\ell^2\), \(\ell^\infty\) birim toplarını çiz. Hangisi diğerini içerir? (İpucu: aynı yarıçapta \(\ell^1 \subseteq \ell^2 \subseteq \ell^\infty\) mı, tersi mi?) Konveks olmayan bir “birim top” örneği ver (\(p < 1\)).
Egzersiz 4. Python ile normları keşfet:
import numpy as np
v = np.array([1.0, -2.0, 2.0])
print("ℓ1:", np.linalg.norm(v, 1), " ℓ2:", np.linalg.norm(v, 2), " ℓ∞:", np.linalg.norm(v, np.inf))
A = np.array([[3.0, 4.0], [0.0, 0.0]])
print("spektral:", np.linalg.norm(A, 2)) # σ1
print("Frobenius:", np.linalg.norm(A, 'fro'))
print("nükleer:", np.linalg.norm(A, 'nuc')) # Σσ
print("σ:", np.linalg.svd(A, compute_uv=False))Egzersiz 5. (Ders 9 habercisi.) Ders 9 least squares’in dört çözüm yolunu işler. Aşağıdaki tutarsız sistem için (3 denklem, 1 bilinmeyen) normal denklem \(A^{T}A\hat{x} = A^{T}b\)’yi kurup \(\hat{x}\)’i bul. Bu, \(\ell^2\) (en küçük kareler) çözümüdür.
\[A = \begin{pmatrix} 1 \\ 1 \\ 1 \end{pmatrix}, \quad b = \begin{pmatrix} 1 \\ 2 \\ 3 \end{pmatrix}\]
9.15 Sonraki Ders İçin Hazırlık
Ders 9: En Küçük Kareleri Çözmenin Dört Yolu
Ders 8’de normları tamamladık. Ders 9, \(Ax = b\)’nin çözümü olmadığında “en iyi” \(x\)’i bulmanın (least squares) dört farklı yolunu işler.
- Normal denklemler (\(A^{T}A\hat{x} = A^{T}b\))
- QR ile (sayısal kararlılık)
- SVD / pseudoinverse ile (en genel)
- Gram-Schmidt ve doğrudan geometri (projeksiyon)
UyarıDers 9 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (normal denklem).
- Python’da
np.linalg.lstsqile birkaç tutarsız sistemi çöz; \(\ell^2\) hatasını gözlemle. - Ana cümleyi tekrar oku: “Norm seçimi (\(\ell^1\) seyrek, \(\ell^2\) düzgün) çözümün karakterini belirler.”
9.16 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| Norm | Büyüklük ölçüsü; pozitiflik + homojenlik + üçgen | 4m41 |
| \(\ell^p\) normları | \((\sum \lvert v_i \rvert^p)^{1/p}\); \(\ell^1\), \(\ell^2\), \(\ell^\infty\) | 5m58 |
| \(\ell^0\) | Sıfırdan-farklı sayısı; norm değil (homojenlik) | 7m50 |
| Birim toplar | \(\ell^2\) çember, \(\ell^1\) elmas, \(\ell^\infty\) kare | 11m26 |
| Konvekslik | Gerçek norm \(=\) konveks birim top; \(p \geq 1\) | 17m09 |
| S-normu | \(\sqrt{v^{T}Sv}\); ağırlıklı, elips (Mahalanobis) | 18m53 |
| Kısıtlı min \(\ell^1\) | Basis pursuit; kazanan seyrek (köşe) | 24m02 |
| Matris 2-normu | Maksimum büyütme çarpanı \(= \sigma_1\) (Lipschitz) | 36m14 |
| Frobenius | \(\sqrt{\sum a_{ij}^2} = \sqrt{\sum \sigma_i^2}\); en yaygın | 40m58 |
| Nükleer norm | \(\sum \sigma_i\); düşük-rank, Srebro varsayımı | 46m00 |
9.17 ML Bağlantıları Özeti
- \(\ell^1 \to\) seyreklik → Lasso, compressed sensing, öznitelik seçimi (elmas köşesi).
- \(\ell^2 \to\) ridge → ağırlık zayıflatma; düzgün küçültür, sıfırlamaz.
- \(\ell^\infty\) → en kötü-durum, adversarial sağlamlık (kare birim top).
- \(\|A\|_2 = \sigma_1\) → Lipschitz sabiti; spektral normalizasyon (GAN, sağlamlık).
- Frobenius → ağırlık zayıflatma cezası, gradyan normu; en yaygın matris düzenlileştirmesi.
- Nükleer norm → matris tamamlama, robust PCA; implicit regularization (Srebro).
- Konvekslik → norm cezaları konveks problem verir; tek küresel minimum.
ÖnemliEğer bu dersten tek bir şey alıp gidersen
Norm bir vektör/matrisin büyüklük ölçüsüdür, ama asıl güç birim topunun geometrisindedir: \(\ell^1\) elmasının köşeleri seyreklik üretir (Lasso), \(\ell^2\) çemberi düzgün küçültür (ridge), \(\ell^\infty\) kutusu en kötü durumu ölçer. Matris tarafında \(\|A\|_2 = \sigma_1\) (Lipschitz), Frobenius \(= \sqrt{\sum \sigma_i^2}\), nükleer \(= \sum \sigma_i\) (düşük-rank). Hangi normu seçtiğin, ML’de düzenlileştirme kararının ta kendisidir.