flowchart TD
M["Momentum: zikzagi sondur"]
M --> A["z = grad F + beta z_onceki<br/>x+ = x - s z (hafiza)"]
M --> B["oran: (1-b)/(1+b)<br/>-> (1-sqrt b)/(1+sqrt b)"]
M --> C["ozdeger analizi:<br/>her lambda -> 2x2 R matrisi"]
M --> D["optimal: s = (2/(sqrt M + sqrt m))^2<br/>beta = oran^2"]
M --> E["kondisyon kazanci:<br/>kappa -> sqrt kappa"]
N["Nesterov: look-ahead gradyan"]
O["AdaGrad / RMSProp / Adam:<br/>gecmisi ustel biriktir"]
P["Ders 22 zikzak <- bu ders -> Ders 25 SGD"]
24 Gradient Descent’i Hızlandırmak — Momentum
Heavy ball, 2x2 özdeğer analizi, karekök hızlanması ve Nesterov
NotBölüm bilgisi
Bu ders Ders 22’nin zikzak sorununu çözer: adıma momentum (önceki yönün hafızası) ekleyerek yakınsama oranını kondisyon sayısının kareköküne indirir. Strang’in Ders 23 videosu (≈49 dk) ve OCW Lecture 23 temel alınmıştır. Okuma süresi ≈34 dk; önkoşul Ders 22 (gradient descent, kondisyon, zikzak).
24.1 Bu Derste Ne Var?
Ders 22’nin zikzak sorununu çözüyoruz. Çözüm: adıma momentum (önceki adımın hafızası) eklemek. Sonuç mucizevi: yakınsama oranı \((1-b)/(1+b)\)’den \((1-\sqrt{b})/(1+\sqrt{b})\)’ye düşer — kondisyon sayısının karekökü kadar hızlanma. Strang her şeyi gören aynı kuadratik örnekte (\(F = \tfrac{1}{2}(x^{2}+by^{2})\)) iki satırlık momentum özyinelemesini özvektör başına \(2\times 2\) bir matrise indirger ve optimal \(s, \beta\)’yı kapalı-formda okur.
Beş sonuç:
- Momentum: \(z_{k} = \nabla F(x_{k}) + \beta z_{k-1}\); \(x_{k+1} = x_{k} - s z_{k}\). Önceki yönün hafızası (\(\beta\)).
- Özdeğer analizi: her özvektörü izle → \(2\times 2\) matris \(R\); \(s\) ve \(\beta\)’yı \(R\)’nin en büyük özdeğerini tüm \(\lambda \in [m,M]\) için minimize edecek seç.
- Optimal: \(s = (2/(\sqrt{M}+\sqrt{m}))^{2}\), \(\beta = ((\sqrt{M}-\sqrt{m})/(\sqrt{M}+\sqrt{m}))^{2}\); yakınsama oranı \((\sqrt{M}-\sqrt{m})/(\sqrt{M}+\sqrt{m})\).
- Hızlanma: kondisyon \(\kappa\) yerine \(\sqrt{\kappa}\) — \(b=1/100\)’de oran \(0.98\)’den \(0.82\)’ye düşer.
- Nesterov: gradyanı kaydırılmış (look-ahead) noktada hesapla; alternatif ivmelendirme.
“…something called momentum to avoid the zigzag…” — Strang, 2:09
Şekil 24.1 dersin iskeletini gösterir: merkezdeki “zikzağı söndür” fikri iki satırlık güncelleme kuralından (hafıza), oran dönüşümünden, özvektör başına \(2\times 2\) analizden, optimal \((s, \beta)\) seçiminden ve \(\kappa \to \sqrt{\kappa}\) kondisyon kazancından dallanır; ayrı düğümlerde Nesterov’un look-ahead gradyanı, modern AdaGrad/RMSProp/Adam ailesi ve Ders 22 (zikzak) ile Ders 25 (SGD) köprüleri durur.
İpucuBuilder Notu — Hafızanın Karekök Mucizesi
Bu dersin tamamı tek bir mucizeye indirgenir: adıma önceki yönün hafızasını eklemek yakınsama oranındaki \(b\)’yi \(\sqrt{b}\) yapar. \(b = 1/100\)’de \((1-b)/(1+b) = 0.98\) (sürünür) iken \((1-\sqrt{b})/(1+\sqrt{b}) = 0.82\) (hızlı) olur — gereken adım sayısı \(\kappa\) değil \(\sqrt{\kappa}\) ile orantılıdır. ML köprüsü: derin öğrenmenin neredeyse her optimizer’ı bu hafıza terimini kullanır; Adam = momentum + adaptif adım. Strang’ın bu dersi tüm modern optimizer ailesinin matematiksel köküdür.
24.2 Zikzak Sorunu (Hatırlatma)
Ders 22’nin temel formülü: \(x_{k+1} = x_{k} - s\nabla F(x_{k})\). Kritik örnekte (\(f = \tfrac{1}{2}(x^{2} + by^{2})\), küçük \(b\)) seviye kümeleri uzun-ince elipsler. Steepest descent her adımda elipse dik iner, en içteki elipse teğet olunca durur, sonra ters yöne döner — zikzak. Yakınsama bu sayıya bağlıydı:
\[r = \frac{b - 1}{b + 1}, \qquad F_{k} = \left(\frac{1-b}{1+b}\right)^{2k} F_{0} \quad (\text{momentumsuz})\]
\(b\) küçükse (kötü kondisyon) bu oran 1’e yakın → çok yavaş. Bugünün işi: momentum terimiyle bu oranı iyileştirmek.
İpucuBuilder Notu — İsrafın Adı Zikzak
Zikzak, “en dik yön her zaman en kısa yol değildir” gerçeğinin görünür hâli (Ders 22). Steepest descent vadiyi dik açıyla geçer, ileri-geri sıçrar; vadi ekseni (asıl ilerleme yönü) boyunca neredeyse hiç gitmez. Momentum tam bu israfı düzeltir. ML köprüsü: NYU paralel kursunda KONUK Defazio’nun optimizasyon dersi de aynı resmi çizer — kötü kondisyon (\(\kappa\)) zikzak yaptırır, momentum bu salınımları söndürür.
24.3 Momentum: Önceki Adımın Hafızası
Çözüm: adıma “geçen adımı hatırlatan” bir terim ekle.
“…something called momentum to avoid the zigzag…” — Strang, 2:09
Ana sonucu önce söyleyelim (cebir sonra). Momentum, sihirli yakınsama oranını kökten değiştirir:
\[\frac{1 - b}{1 + b} \quad \longrightarrow \quad \frac{1 - \sqrt{b}}{1 + \sqrt{b}}\]
“…changes to 1 minus square root of b over 1 plus square root of b.” — Strang, 10:56
Fark devasa. \(b = 1/100\) örneğinde: momentumsuz oran \(0.99/1.01 \approx 0.98\) (1’e çok yakın, yavaş); momentumlu \(0.9/1.1 \approx 0.82\) (çok daha küçük, hızlı). \(\sqrt{b}\) ortaya çıkması, kondisyon sayısının karekökü kadar hızlanma demek.
Kod
# GD oranı (1-b)/(1+b) vs momentum oranı (1-√b)/(1+√b) aynı eksende
bs = np.linspace(0.002, 1, 400)
gd_rate = (1 - bs) / (1 + bs)
mom_rate = (1 - np.sqrt(bs)) / (1 + np.sqrt(bs))
fig, ax = plt.subplots(figsize=(7.5, 4.4))
apply_style(ax)
# Fark bölgesi hafif dolgu (GD ile momentum oranları arası)
ax.fill_between(bs, mom_rate, gd_rate, color=COL_STEEL_300, alpha=0.30, zorder=1)
# GD oranı (turuncu)
ax.plot(bs, gd_rate, color=COL_VEC3, lw=2.0,
label="GD: (1-b)/(1+b)", zorder=3)
# Momentum oranı (navy)
ax.plot(bs, mom_rate, color=COL_PRIMARY, lw=2.5,
label="momentum: (1-sqrt b)/(1+sqrt b)", zorder=3)
# b = 0.01 dikey ince çizgi + iki nokta
b1 = 0.01
ax.axvline(b1, color=COL_TEXT, lw=0.8, ls=":", alpha=0.7, zorder=2)
gd1 = (1 - b1) / (1 + b1)
mom1 = (1 - np.sqrt(b1)) / (1 + np.sqrt(b1))
ax.plot(b1, gd1, "o", color=COL_VEC3, ms=8, markeredgecolor=COL_TEXT, zorder=5)
ax.plot(b1, mom1, "o", color=COL_PRIMARY, ms=8, markeredgecolor=COL_TEXT, zorder=5)
ax.annotate(f"{gd1:.4f}", (b1, gd1), textcoords="offset points", xytext=(10, -2),
color=COL_VEC3, fontsize=9, fontweight="bold", va="center")
ax.annotate(f"{mom1:.4f}", (b1, mom1), textcoords="offset points", xytext=(10, -10),
color=COL_PRIMARY, fontsize=9, fontweight="bold", va="center")
# b = 1/9 noktaları (Egz1): GD 0.8, momentum 0.5
b2 = 1.0 / 9.0
gd2 = (1 - b2) / (1 + b2)
mom2 = (1 - np.sqrt(b2)) / (1 + np.sqrt(b2))
ax.plot(b2, gd2, "s", color=COL_VEC3, ms=8, markeredgecolor=COL_TEXT, zorder=5)
ax.plot(b2, mom2, "s", color=COL_PRIMARY, ms=8, markeredgecolor=COL_TEXT, zorder=5)
ax.annotate(f"{gd2:.1f} (Egz1)", (b2, gd2), textcoords="offset points", xytext=(10, 6),
color=COL_VEC3, fontsize=9, fontweight="bold", va="center")
ax.annotate(f"{mom2:.1f} (Egz1)", (b2, mom2), textcoords="offset points", xytext=(10, -8),
color=COL_PRIMARY, fontsize=9, fontweight="bold", va="center")
ax.set_xlabel("b (= 1/kondisyon)")
ax.set_ylabel("yakinsama orani")
ax.set_title("Karekok mucizesi: b=0.01 de 0.98 -> 0.82, b=1/9 da 0.8 -> 0.5",
color=COL_TEXT, fontsize=11, fontweight="bold")
ax.legend(loc="lower right", fontsize=9, framealpha=0.92)
plt.show()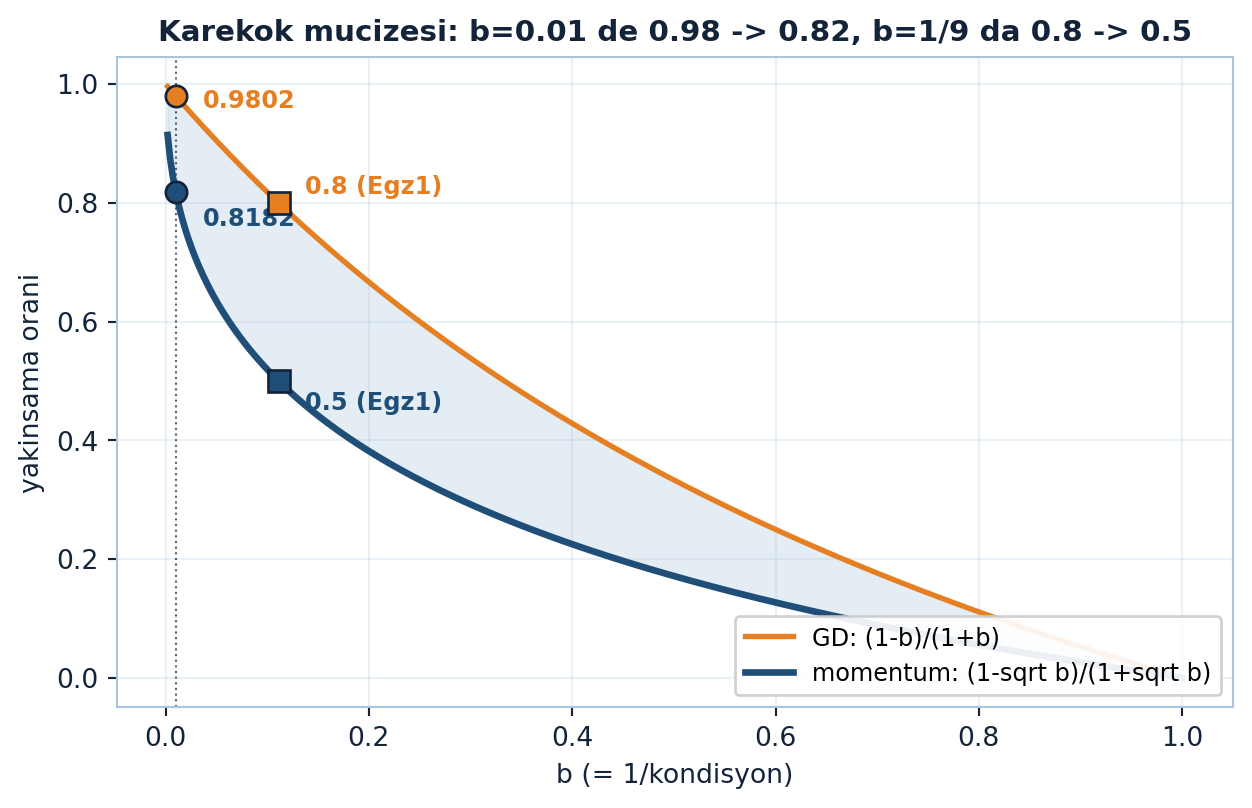
Şekil 24.2 GD ve momentum oranlarını aynı eksende kıyaslar: \(b = 1/\kappa\) küçüldükçe GD oranı \((1-b)/(1+b)\) (turuncu) yavaşça 1’e tırmanır, momentum oranı \((1-\sqrt{b})/(1+\sqrt{b})\) (navy) karekök sayesinde çok daha düşük kalır — \(b=0.01\)’de \(0.9802 \to 0.8182\), \(b=1/9\)’da (Egzersiz 1) \(0.8 \to 0.5\).
Kod
import matplotlib.pyplot as plt
import numpy as np
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10.5, 4.2))
# --- Sol: b=0.05 vadi konturları + GD zikzak + momentum süzülüş ---
xg = np.linspace(-0.15, 0.15, 150)
yg = np.linspace(-0.15, 1.1, 150)
X, Y = np.meshgrid(xg, yg)
Z = 0.5 * (X**2 + 0.05 * Y**2)
axL.contour(X, Y, Z, levels=18, cmap=NAVY_CMAP, linewidths=0.8)
p0 = np.array([0.05, 1.0])
pg = gd_plain(0.05, 2.0 / 1.05, p0, 14)
axL.plot(pg[:, 0], pg[:, 1], "o-", color=COL_VEC3, ms=4, lw=1.3, label="GD (zikzak)")
so, bo, ro = optimal_params(0.05, 1.0)
pm = momentum_gd(0.05, so, bo, p0, 14)
axL.plot(pm[:, 0], pm[:, 1], "s-", color=COL_PRIMARY, ms=4, lw=1.3, label="momentum (süzülüş)")
axL.set_xlabel("x"); axL.set_ylabel("y")
axL.set_title("Uzun-dar vadi: GD zikzaklar, momentum süzülür", fontsize=11, fontweight="bold")
axL.legend(loc="upper right", fontsize=9)
apply_style(axL)
# --- Sağ: b=0.01 F eğrileri semilogy + adım işareti ---
p0b = np.array([0.01, 1.0])
so2, bo2, _ = optimal_params(0.01, 1.0)
pm2 = momentum_gd(0.01, so2, bo2, p0b, 200)
pg2 = gd_plain(0.01, 2.0 / 1.01, p0b, 400)
Fm = np.array([F_quad(p, 0.01) for p in pm2])
Fg = np.array([F_quad(p, 0.01) for p in pg2])
axR.semilogy(np.arange(len(Fg)), Fg, "-", color=COL_VEC3, lw=1.6, label="GD")
axR.semilogy(np.arange(len(Fm)), Fm, "-", color=COL_PRIMARY, lw=1.6, label="momentum")
F0 = Fg[0]
axR.axhline(1e-6 * F0, color=COL_STEEL_300, ls="--", lw=1.0)
axR.set_xlabel("adım"); axR.set_ylabel("F")
axR.set_title("Aynı vadide F düşüşü (b=0.01)", fontsize=11, fontweight="bold")
axR.annotate("48 vs 346 adım = 7.2x (~sqrt kappa)", xy=(120, 1e-6 * F0),
xytext=(150, 1e-2 * F0), fontsize=9, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_TEAL, lw=1.0))
axR.legend(loc="upper right", fontsize=9)
apply_style(axR)
fig.suptitle("Aynı vadide iki yöntem: GD zikzaklar, momentum hafızayla süzülür — F/F0 < 1e-6: 48 vs 346 adım (7.2x)",
fontsize=11, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()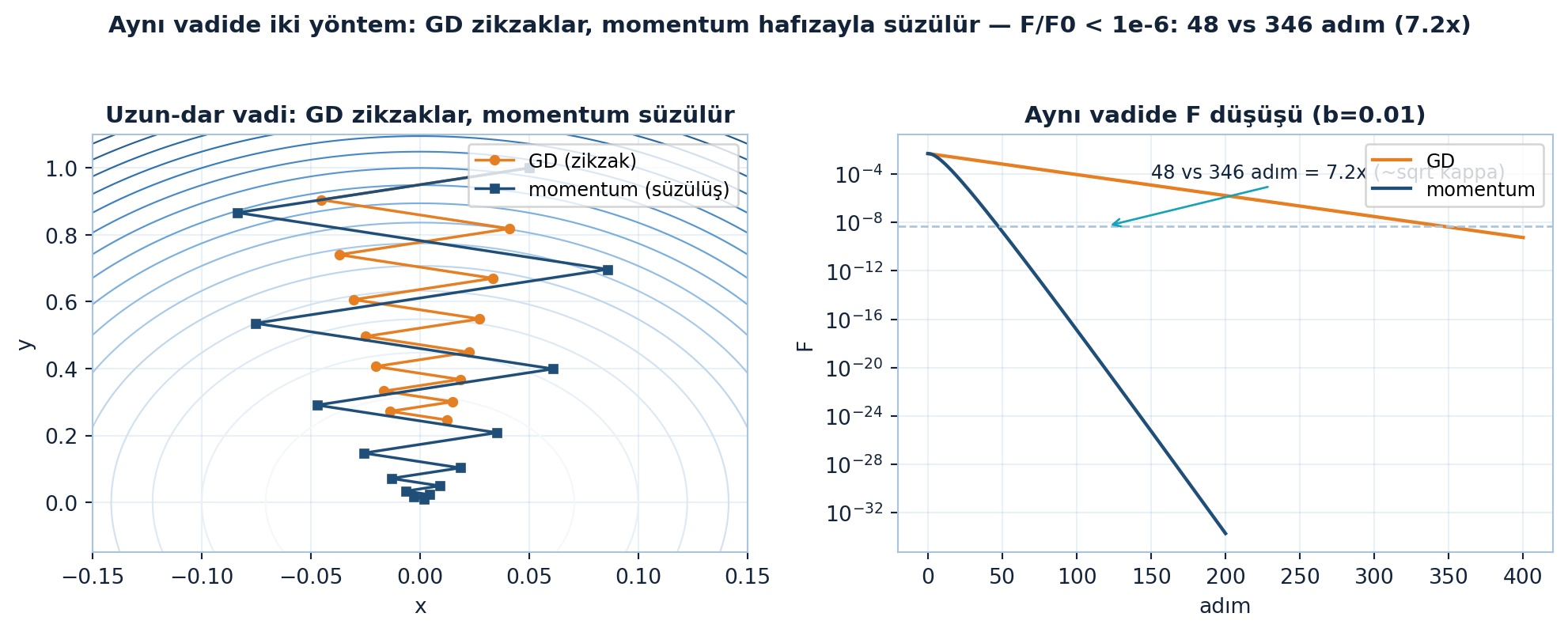
Şekil 24.3 Ders 22’nin uzun-dar vadisini geri getirir: solda \(b=0.05\)’te GD vadiyi geçen zikzak çizer (turuncu) ama momentum hafızasını kullanıp süzülerek iner (navy); sağda \(b=0.01\) kâsesinde \(F/F_{0} < 10^{-6}\) eşiğine momentum 48 adımda, GD 346 adımda ulaşır — 7.2 kat fark, \(\sqrt{\kappa}=10\) mertebesinde.
İpucuBuilder Notu — Topun Biriken Hızı
Momentum’un fizik sezgisi: yokuş aşağı yuvarlanan bir top. Top her adımda hız (velocity) biriktirir — zikzak salınımları birbirini götürür (sağa-sola), ama vadi ekseni boyunca ivme birikir (hep aynı yön). ML köprüsü: SGD + momentum derin öğrenmenin standart optimizer’ıdır; “ağır top” (heavy ball) yöntemi tam budur, \(\beta\) momentum katsayısı genelde 0.9.
24.4 Momentum Formülü
İki denklemle yaz. Bir arama yönü \(z_{k}\) tut; lider terimi gradyan, üstüne önceki yönün \(\beta\) katı (hafıza):
\[z_{k} = \nabla F(x_{k}) + \beta\, z_{k-1}, \qquad x_{k+1} = x_{k} - s\, z_{k}\]
\(\beta = 0\) olsaydı \(z_{k} = \nabla F\) olur, sıradan steepest descent’e dönerdik. \(\beta > 0\) ile her adım önceki hareketi “hatırlar” — \(z_{k}\) geçmiş gradyanların üstel-ağırlıklı toplamıdır. İki ayar parametresi: adım boyu \(s\) ve momentum katsayısı \(\beta\).
Kod
so, bo, _ = optimal_params(0.01, 1.0)
pm = momentum_gd(0.01, so, bo, np.array([0.01, 1.0]), 80)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4))
# Sol: koordinat sonumlu salinim (x bileseni, lambda=1 -> reel negatif cift ozdeger -0.818)
axL.plot(pm[:60, 0], color=COL_PRIMARY, marker="o", ms=3)
axL.axhline(0, color=COL_TEXT, lw=0.8)
axL.set_xlabel("adım")
axL.set_ylabel("koordinat (x bileşeni)")
axL.set_title("koordinat salınımlı iner (kompleks özdeğer izi)", fontsize=11, fontweight="bold")
apply_style(axL)
# Sag: F bu izde MONOTON
Fs = [F_quad(p, 0.01) for p in pm]
axR.semilogy(Fs, color=COL_TEAL, lw=2)
axR.set_xlabel("adım")
axR.set_ylabel("F (log)")
axR.set_title("[motor notu] F bu izde MONOTON — salınım koordinatta", fontsize=11, fontweight="bold")
apply_style(axR)
fig.suptitle("Heavy-ball dinamiği: kompleks özdeğerler koordinatları salındırır (|eig| = √β = 0.818), F yine monoton düşebilir", fontsize=11, fontweight="bold")
fig.tight_layout()
plt.show()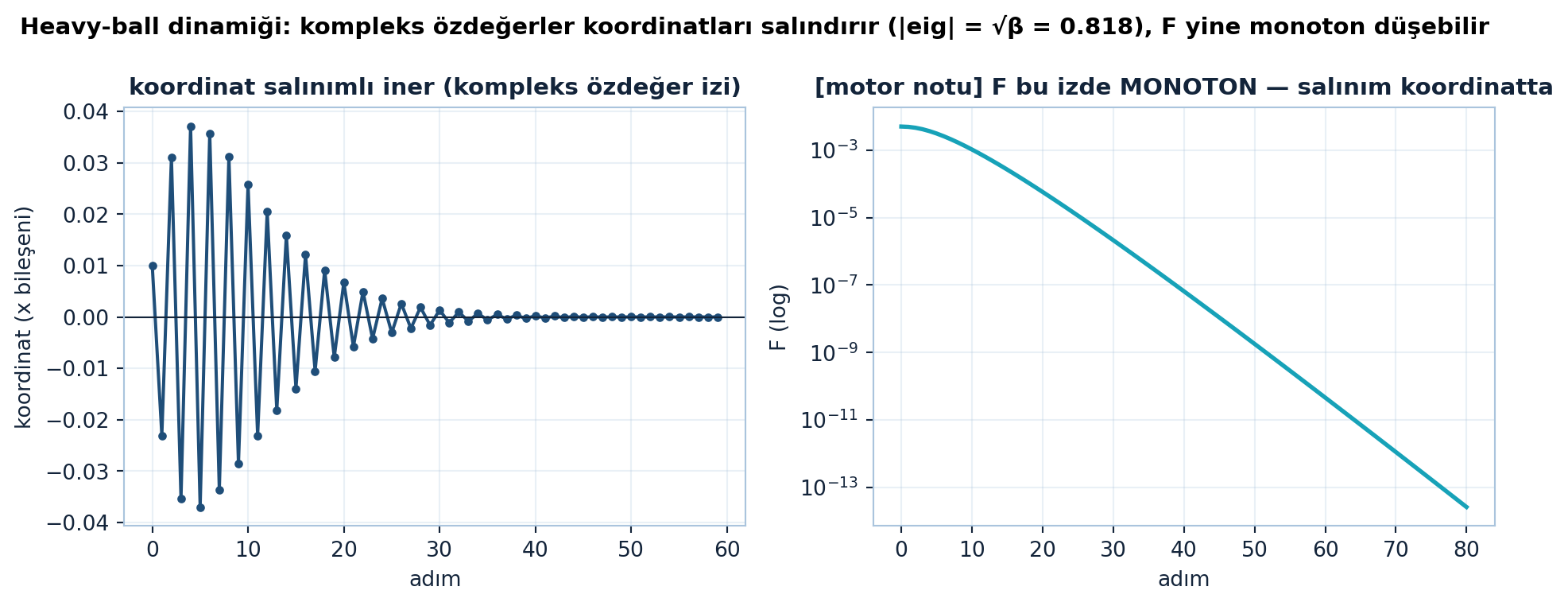
[motor notu]: Şekil 24.4 sol panelindeki koordinat 60 adımda 59 işaret değiştirir (sönümlü salınım) — heavy-ball’un kompleks eşlenik özdeğerlerinin izi (\(|\mathrm{eig}| = \sqrt{\beta} = 0.8182\)). Ama bu izde enerji \(F\) monoton düşer: salınım koordinattadır, \(F\)’de değil — “F yükselir” demek yanlış olur.
Şekil 24.4 heavy-ball dinamiğinin iki yüzünü ayırır: solda bir koordinat sönümlü salınımla iner (kompleks özdeğer izi), sağda aynı yörüngede \(F\) monoton düşer — salınım koordinatta görünür ama enerji düzenli azalır.
İpucuBuilder Notu — Geçmişin Geometrik Toplamı
\(z_{k} = \nabla F + \beta z_{k-1}\) açılırsa \(z_{k} = \nabla F_{k} + \beta\nabla F_{k-1} + \beta^{2}\nabla F_{k-2} + \dots\) — geçmiş gradyanların geometrik-ağırlıklı (\(\beta\) azalan) toplamı. ML köprüsü: PyTorch’ta momentum=0.9 tam bu \(\beta\); SGD(momentum) bu iki satırı uygular. AdaGrad/RMSProp/Adam farklı ağırlıklandırmalarla aynı “geçmişi biriktir” fikrini kullanır.
24.5 Özdeğer Analizi: 2×2 Matris R
Cebir nasıl çözülür? \(S\) simetrik olduğundan özvektörlerine ayır; her özvektörü ayrı ayrı izle — problem skalere iner (her \(\lambda\) için ayrı). Momentum özyinelemesi, \((c_{k}, d_{k})\) katsayıları için \(2\times 2\) bir matrisle çarpmaya dönüşür:
“…it’s a miracle that the algebra… you really see the value of eigenvectors.” — Strang, 9:36
\[\begin{bmatrix} c_{k+1} \\ d_{k+1} \end{bmatrix} = R \begin{bmatrix} c_{k} \\ d_{k} \end{bmatrix}, \qquad R = \begin{bmatrix} 1 - s\lambda & \beta \\ -s\lambda & \beta \end{bmatrix}\]
Her adım \(R\) ile çarpım. Yakınsama hızı \(R\)’nin özdeğerlerine bağlı (\(R^{k}\) küçülmeli). \(R\), \(\lambda\) (\(S\)’nin özdeğeri) ile \(s\) ve \(\beta\)’ya bağlı. İş: \(s\) ve \(\beta\)’yı, \(R\)’nin en büyük özdeğerini tüm \(\lambda \in [m, M]\) aralığında en küçük yapacak şekilde seç.
İpucuBuilder Notu — Her Özvektör Kendi 2x2’si
“Her özvektörü izle, problem skalere insin” Ders 4’ün köşegenleştirme gücünün doruğu: bir matris özyinelemesi, özvektör başına bağımsız \(2\times 2\) sisteme ayrışır. ML köprüsü: bu spektral analiz, optimizer’ların neden farklı özdeğer (eğrilik) yönlerinde farklı davrandığını açıklar — Adam’ın koordinat-başı adım boyu tam bu “her yön ayrı” fikrinin pratik versiyonu.
24.6 Optimal s ve β (Mucize)
İki parametreyi (\(s, \beta\)) tüm \(\lambda \in [m, M]\) için \(R\)’nin en büyük özdeğerini minimize edecek şekilde seç — şaşırtıcı derecede temiz bir çözüm çıkar (Strang’ın “mucize” dediği). \(m = \lambda_{\min}\), \(M = \lambda_{\max}\) cinsinden:
\[s_{\text{opt}} = \left(\frac{2}{\sqrt{M} + \sqrt{m}}\right)^{2}, \qquad \beta_{\text{opt}} = \left(\frac{\sqrt{M} - \sqrt{m}}{\sqrt{M} + \sqrt{m}}\right)^{2}\]
Bu seçimle \(R\)’nin özdeğerleri (yani adım-başı küçülme oranı) şu sınıra iner:
\[\text{yakinsama orani} = \frac{\sqrt{M} - \sqrt{m}}{\sqrt{M} + \sqrt{m}}\]
Örnek (\(M = 1\), \(m = b\)): \(\beta_{\text{opt}} = ((1-\sqrt{b})/(1+\sqrt{b}))^{2}\), oran \((1-\sqrt{b})/(1+\sqrt{b})\). Momentumsuz \((1-b)/(1+b)\)’nin \(\sqrt{b}\) versiyonu.
Kod
so, bo, ro = optimal_params(0.01, 1.0)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))
# --- Sol: lambda taramasi, uc beta egrisi rho(R) ---
lams = np.linspace(0.005, 1.05, 400)
rho_opt = [spectral_radius(R_matrix(l, so, bo)) for l in lams]
rho_03 = [spectral_radius(R_matrix(l, so, 0.3)) for l in lams]
rho_085 = [spectral_radius(R_matrix(l, so, 0.85)) for l in lams]
ax1.plot(lams, rho_opt, color=COL_PRIMARY, lw=2.6, label=r"$\beta=\beta_{opt}=0.6694$ (duz 0.8182)")
ax1.plot(lams, rho_03, color=COL_VEC3, lw=1.8, label=r"$\beta=0.3$ (ucta 1 i asar)")
ax1.plot(lams, rho_085, color=COL_ACCENT, lw=1.8, label=r"$\beta=0.85$")
ax1.axhline(1.0, color=COL_STEEL_300, ls="--", lw=1.2, label="iraksama siniri")
ax1.set_xlabel("lambda"); ax1.set_ylabel("spektral yaricap")
ax1.legend(fontsize=8, loc="upper center")
apply_style(ax1)
# --- Sag: kompleks duzlem ozdegerler ---
theta = np.linspace(0, 2*np.pi, 400)
ax2.plot(np.cos(theta), np.sin(theta), color=COL_STEEL_300, lw=1.0, label="birim cember")
rb = np.sqrt(bo)
ax2.plot(rb*np.cos(theta), rb*np.sin(theta), color=COL_PRIMARY, ls="--", lw=1.4, label=r"$|z|=\sqrt{\beta}$")
reals = []; imags = []
for l in lams:
ev = np.linalg.eigvals(R_matrix(l, so, bo))
reals.extend(ev.real); imags.extend(ev.imag)
ax2.scatter(reals, imags, color=COL_TEAL, s=12, zorder=3, label="R ozdegerleri")
ax2.set_aspect("equal")
ax2.set_xlabel("reel"); ax2.set_ylabel("imajiner")
ax2.legend(fontsize=8, loc="upper right")
apply_style(ax2)
fig.suptitle("Mucize: optimal (s, beta) max ozdegeri TUM lambda larda 0.8182 e sabitler; ozdegerler |z| = sqrt(beta) cemberinde", fontsize=10)
fig.tight_layout()
plt.show()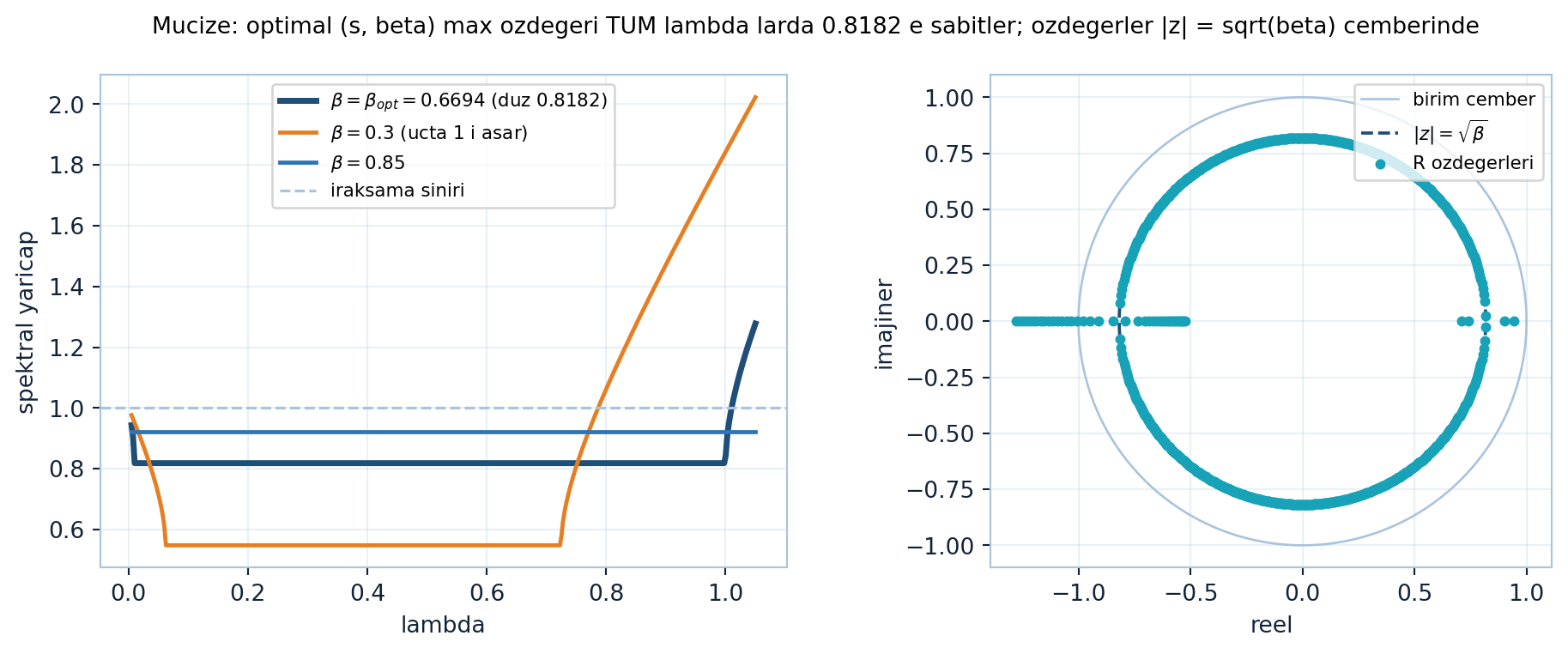
Şekil 24.5 mucizeyi spektral olarak gösterir: solda optimal \((s, \beta)\) ile \(R\)’nin maksimum özdeğeri tüm \(\lambda\) aralığında düz \(0.8182\)’ye sabitlenir (eşit-dalgalanma, çift kök), yanlış \(\beta\) ya yavaşlatır (\(\beta=0.85\), steel) ya da uçta 1’i aşıp ıraksatır (\(\beta=0.3\), turuncu); sağda özdeğerler ara \(\lambda\)’larda kompleks eşlenik olup tam \(|z| = \sqrt{\beta}\) çemberi üzerinde durur.
İpucuBuilder Notu — Polyak’ın Ağır Topu
Bu, Polyak’ın “ağır top” (heavy ball) yönteminin optimal parametreleridir. ML köprüsü: pratikte \(M\), \(m\) (Hessian özdeğerleri) bilinmez, bu yüzden \(\beta \approx 0.9\) sabit alınır ve \(s\) ayarlanır; ama teori, momentum’un neden bu kadar yardımcı olduğunu kanıtlar — kondisyon sayısı kötüleştikçe kazanç büyür.
24.7 Kondisyon Sayısı: √κ Hızlanma
Anahtar kavram kondisyon sayısı \(\kappa = \lambda_{\max}/\lambda_{\min} = M/m\) (örnekte \(1/b\)). \(\kappa\) büyükse problem zor; \(\kappa = 1\) ise (\(M = m\), $S = $ identity katı) problem trivial. Momentum’un kazancı: efektif kondisyon sayısını kareköküne indirir:
\[\kappa = \frac{M}{m} = \frac{1}{b} \quad \Longrightarrow \quad \text{momentumsuz} \sim \kappa, \quad \text{momentumlu} \sim \sqrt{\kappa}\]
\(b = 1/100\) (\(\kappa = 100\)): momentumsuz oran \(\approx (\kappa-1)/(\kappa+1) \approx 0.98\); momentumlu \(\approx (\sqrt{\kappa}-1)/(\sqrt{\kappa}+1) = 9/11 \approx 0.82\). Yakınsama için gereken adım sayısı \(\sqrt{\kappa}\) ile orantılı (\(\kappa\) değil) — büyük \(\kappa\)’da muazzam fark.
İpucuBuilder Notu — Karekök Kazancı
“\(\kappa \to \sqrt{\kappa}\)” momentum’un teorik vaadidir ve birinci-derece yöntemler için neredeyse optimaldir (Nesterov bunu kanıtladı). ML köprüsü: derin ağlarda \(\kappa\) astronomik (milyonlar); momentum olmadan eğitim pratik değil. NYU paralel kursunda KONUK Defazio momentum sönümlemesini tam bu çerçevede anlatır — batch normalization \(\kappa\)’yı küçülterek, momentum \(\sqrt{\kappa}\)’ya indirerek birlikte eğitimi mümkün kılar; ikisi de “kötü kondisyon” düşmanına karşı.
24.8 Nesterov İvmelendirmesi
Momentum’a alternatif bir hızlandırma, Rus matematikçi Nesterov’dan (makaleleri zor okunur ama içerik ciddi):
“…Nesterov’s idea.” — Strang, 42:08
Fikir benzer (önceki değeri kullan) ama bir incelikle: gradyanı mevcut noktada değil, ileriye kaydırılmış (look-ahead) bir \(y_{k}\) noktasında hesapla:
\[x_{k+1} = y_{k} - s\,\nabla F(y_{k})\]
“…the gradient is being evaluated at some different point.” — Strang, 44:09
\(y_{k}\), \(x\)’lerden bir ekstrapolasyonla (momentum yönünde bir adım ileri) elde edilir. Yani “önce momentum yönünde bak, oradaki eğimi ölç, sonra adım at.” Bu look-ahead, momentum’un aşırı-atlama (overshoot) eğilimini frenler ve aynı \(\sqrt{\kappa}\) hızlanmasını verir — birinci-derece yöntemler için optimal.
Kod
so, bo, _ = optimal_params(0.01, 1.0)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10.5, 4.2))
# --- Sol panel: ŞOK — Polyak-s NAG ıraksar, NAG kendi parametreleri yakınsar ---
nb = nesterov_gd(0.01, so, bo, np.array([0.01, 1.0]), 60)
ng = nesterov_gd(0.01, 1.0, 9.0 / 11.0, np.array([0.01, 1.0]), 200)
pm = momentum_gd(0.01, so, bo, np.array([0.01, 1.0]), 200)
nb_norm = np.linalg.norm(nb, axis=1)
ng_norm = np.linalg.norm(ng, axis=1)
pm_norm = np.linalg.norm(pm, axis=1)
axL.semilogy(nb_norm, color=COL_VEC3, lw=2.2, label="NAG + Polyak-s (ıraksar)")
axL.semilogy(ng_norm, color=COL_PRIMARY, lw=2.2, label="NAG kendi parametreleri")
axL.semilogy(pm_norm, color=COL_ACCENT, lw=1.8, ls="--", label="momentum (kıyas)")
axL.set_xlabel("adım sayısı")
axL.set_ylabel("‖p‖ (norm)")
axL.legend(loc="upper left", fontsize=8)
axL.set_title("[motor notu] parametre YONTEM-OZGU: Polyak-s NAG i IRAKSATIR (1.8e+35)",
fontsize=8.5, fontweight="bold", pad=8)
apply_style(axL)
# --- Sag panel: uc F-egrisi semilogy 400 adim ---
gd = gd_plain(0.01, 2.0 / (1.0 + 0.01), np.array([0.01, 1.0]), 400)
mm = momentum_gd(0.01, so, bo, np.array([0.01, 1.0]), 400)
ne = nesterov_gd(0.01, 1.0, 9.0 / 11.0, np.array([0.01, 1.0]), 400)
F_gd = np.array([F_quad(p, 0.01) for p in gd])
F_mm = np.array([F_quad(p, 0.01) for p in mm])
F_ne = np.array([F_quad(p, 0.01) for p in ne])
axR.semilogy(F_gd, color=COL_VEC3, lw=2.0, label="GD (346 adım)")
axR.semilogy(F_mm, color=COL_PRIMARY, lw=2.0, label="momentum (48 adım)")
axR.semilogy(F_ne, color=COL_TEAL, lw=2.0, label="NAG (88 adım)")
axR.axhline(1e-6 * F_gd[0], color="#999999", ls=":", lw=1.2, label="F/F₀ = 1e-6")
axR.annotate("346", xy=(346, F_gd[346]), xytext=(300, 1e-3),
color=COL_VEC3, fontsize=9, fontweight="bold")
axR.annotate("48", xy=(48, F_mm[48]), xytext=(48, 1e-9),
color=COL_PRIMARY, fontsize=9, fontweight="bold")
axR.annotate("88", xy=(88, F_ne[88]), xytext=(95, 1e-10),
color=COL_TEAL, fontsize=9, fontweight="bold")
axR.set_xlabel("adım sayısı")
axR.set_ylabel("F (enerji)")
axR.legend(loc="upper right", fontsize=8)
axR.set_title("uc yontem: GD 346, momentum 48, NAG 88 adim (F/F0 < 1e-6)",
fontsize=8.5, fontweight="bold", pad=8)
apply_style(axR)
fig.suptitle("Nesterov look-ahead: kendi parametreleriyle sqrt-kappa sinifi (88 adim, oran 0.907) — heavy-ball parametrelerini odunc ALMA",
fontsize=10, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.92])
plt.show()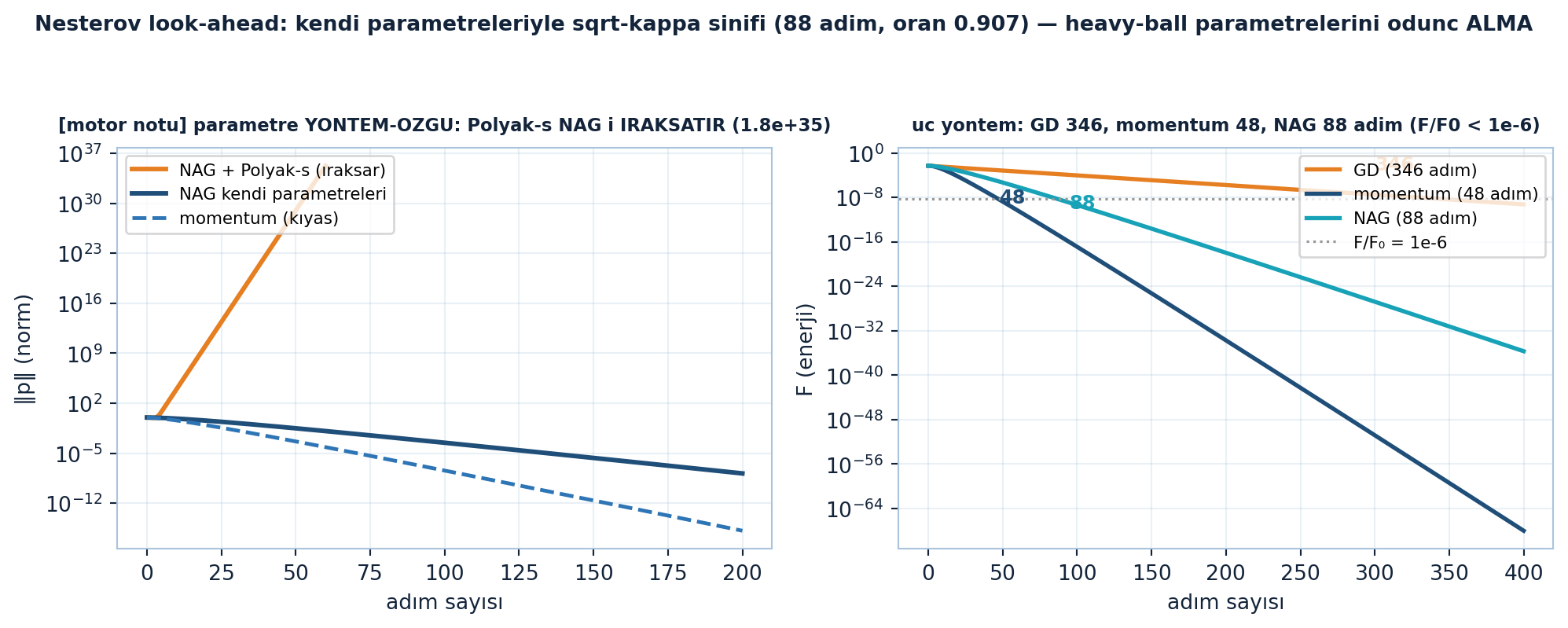
[motor notu]: heavy-ball’un optimal \(s = 3.3058\) değeri NAG’a taşınırsa yöntem ıraksar (\(\|p_{60}\| = 1.8 \times 10^{35}\)) — parametre yöntem-özgüdür, ödünç alınamaz. NAG kendi standart seçimiyle (\(s = 1/M = 1\), \(\beta = (\sqrt{\kappa}-1)/(\sqrt{\kappa}+1) = 9/11\)) 88 adımda yakınsar (empirik oran 0.9074): GD’den çok hızlı, momentum mertebesinde.
Şekil 24.6 bu yöntem-özgülüğü gösterir: solda Polyak’ın optimal \(s\)’i NAG’a taşınınca norm patlar (turuncu, ıraksar) ama NAG kendi parametreleriyle düzgün iner (navy); sağda üç yöntem yan yana — GD 346, momentum 48, NAG 88 adımda \(F/F_{0} < 10^{-6}\) eşiğine ulaşır.
İpucuBuilder Notu — Önce Bak Sonra Adım At
Nesterov’un “önce bak, sonra adım at” hilesi momentum’dan biraz daha kararlıdır (overshoot’u düzeltir). ML köprüsü: Nesterov Accelerated Gradient (NAG) PyTorch’ta nesterov=True ile mevcut; teoride birinci-derece yöntemlerin yakınsama hızının alt sınırına ulaşır — daha hızlısı (sadece gradyanla) mümkün değil.
24.9 AdaGrad, Adam ve Modern Optimizer’lar
Momentum tek bir önceki adımı (\(z_{k-1}\)) hatırlar. Modern yöntemler tüm geçmiş değerleri basit bir formülle biriktirir:
“…it goes under the names adagrad, or others.” — Strang, 41:36
AdaGrad, RMSProp, Adam: her geçmiş gradyana ayrı katsayı vermeden (o devasa iş olurdu), üstel-ağırlıklı ortalamalarla geçmişi özetler. Adam = momentum (birinci moment, geçmiş gradyan ortalaması) + adaptif adım boyu (ikinci moment, geçmiş gradyan-kare ortalaması). Her koordinata kendi efektif learning rate’ini verir — kötü kondisyona karşı momentum’dan bir adım öteye.
İpucuBuilder Notu — Momentum’dan Adam’a
Momentum → AdaGrad → RMSProp → Adam evrim çizgisi: hepsi “geçmiş gradyanları biriktir” fikrinin varyantları. ML köprüsü: Karpathy serisinde micrograd saf SGD ile başlar, nanoGPT ise AdamW kullanır — bu ders tam o geçişin teorisidir. Momentum (1. moment) zikzağı söndürür, RMSProp bileşeni (2. moment) her koordinatı ölçekleyip kondisyonu düzeltir; Adam bugün derin öğrenmenin (özellikle Transformer’ların) varsayılan optimizer’ıdır ve Strang’ın bu dersi tüm bu ailenin matematiksel kökenidir.
24.10 Bu Dersin Özeti
- Zikzak sorunu: kötü kondisyonlu (uzun-ince elips) problemde steepest descent yavaş; oran \((1-b)/(1+b) \approx 1\).
- Momentum: \(z_{k} = \nabla F(x_{k}) + \beta z_{k-1}\), \(x_{k+1} = x_{k} - s z_{k}\); önceki yönün hafızası (\(\beta\)).
- Özdeğer analizi: her özvektör → \(2\times 2\) matris \(R\); \(s, \beta\)’yı \(R\)’nin max özdeğerini tüm \(\lambda \in [m,M]\) için minimize edecek seç.
- Optimal: \(s = (2/(\sqrt{M}+\sqrt{m}))^{2}\), \(\beta = ((\sqrt{M}-\sqrt{m})/(\sqrt{M}+\sqrt{m}))^{2}\); yakınsama oranı \((\sqrt{M}-\sqrt{m})/(\sqrt{M}+\sqrt{m})\).
- √κ hızlanma: kondisyon \(\kappa = M/m\) yerine \(\sqrt{\kappa}\); oran \((1-b)/(1+b) \to (1-\sqrt{b})/(1+\sqrt{b})\).
- Nesterov: gradyanı look-ahead noktada hesapla (\(x_{k+1} = y_{k} - s\nabla F(y_{k})\)); optimal birinci-derece.
- Modern: AdaGrad/RMSProp/Adam tüm geçmişi üstel-ağırlıkla biriktirir (Adam = momentum + adaptif adım).
ÖnemliTek Bir Cümle
Momentum, adıma önceki yönün hafızasını (\(\beta z_{k-1}\)) ekleyerek zikzağı söndürür ve yakınsama oranını \((1-b)/(1+b)\)’den \((1-\sqrt{b})/(1+\sqrt{b})\)’ye — kondisyon sayısının karekökü kadar — iyileştirir; Nesterov bunu look-ahead gradyanla yapar, Adam ise momentumu adaptif adım boyuyla birleştirir.
24.11 Kontrol Soruları
NotSoru 1 — Momentum terimi ve sezgisi
Soru: Momentum terimi gradient descent formülünü nasıl değiştirir ve sezgisi nedir?
Cevap: \(z_{k} = \nabla F(x_{k}) + \beta z_{k-1}\), \(x_{k+1} = x_{k} - s z_{k}\). Arama yönü \(z_{k}\), gradyana ek olarak önceki yönün \(\beta\) katını içerir (hafıza). Sezgi: yokuş aşağı yuvarlanan top — zikzak salınımlar (sağ-sol) birbirini götürür, vadi ekseni boyunca ivme (velocity) birikir. \(\beta = 0\) ise sıradan steepest descent’e döner.
NotSoru 2 — Oran iyileşmesi ve kondisyon
Soru: Momentum yakınsama oranını nasıl iyileştirir, kondisyon sayısıyla ilişkisi nedir?
Cevap: Oran \((1-b)/(1+b)\)’den \((1-\sqrt{b})/(1+\sqrt{b})\)’ye düşer. Kondisyon sayısı \(\kappa = M/m = 1/b\) cinsinden: momentumsuz hız \(\sim\kappa\), momentumlu \(\sim\sqrt{\kappa}\). Yani momentum efektif kondisyon sayısını kareköküne indirir. Büyük \(\kappa\)’da (\(b\approx 0\)) kazanç devasa: yakınsama için gereken adım sayısı \(\sqrt{\kappa}\) ile orantılı olur (\(\kappa\) yerine).
NotSoru 3 — 2×2 matris R ve özvektörler
Soru: Momentum analizinde \(2\times 2\) matris \(R\) nereden gelir, neden özvektörler kullanılır?
Cevap: \(S\) simetrik olduğundan özvektörlerine ayrılır; her özvektör ayrı izlenince problem skalere iner (her \(\lambda\) için bağımsız). Momentum özyinelemesi \((c_{k}, d_{k})\) katsayıları için \(2\times 2\) matris \(R\) ile çarpıma dönüşür. Yakınsama \(R^{k}\)’ya, yani \(R\)’nin özdeğerlerine bağlıdır. \(s, \beta\) bu özdeğerleri tüm \(\lambda \in [m,M]\) için minimize edecek seçilir — köşegenleştirme (Ders 4) problemi parçalara ayırır.
NotSoru 4 — Nesterov ile momentum farkı
Soru: Nesterov ivmelendirmesi momentum’dan nasıl farklıdır?
Cevap: Momentum gradyanı mevcut \(x_{k}\) noktasında hesaplar; Nesterov look-ahead \(y_{k}\) noktasında (momentum yönünde bir adım ileri) hesaplar: \(x_{k+1} = y_{k} - s\nabla F(y_{k})\). “Önce momentum yönünde bak, oradaki eğimi ölç, sonra adım at.” Bu, momentum’un aşırı-atlama (overshoot) eğilimini frenler ve birinci-derece yöntemler için optimal yakınsamayı verir.
24.12 Egzersizler
Oran karşılaştırması. \(b = 1/9\) için momentumsuz oran \((1-b)/(1+b)\) ve momentumlu \((1-\sqrt{b})/(1+\sqrt{b})\)’yi hesapla. Hangisi kaç kat daha küçük? Yakınsama için kabaca kaç kat daha az adım? (Motor tanığı: GD \(0.8\), momentum \(0.5\); adım çarpanı \(\log 0.5 / \log 0.8 = 3.106\times\) — bkz. Şekil 24.7.)
Momentum açılımı. \(z_{k} = \nabla F_{k} + \beta z_{k-1}\) özyinelemesini \(z_{0} = \nabla F_{0}\)’dan başlayarak \(z_{2}\)’ye kadar aç. \(z_{2}\)’nin \(\nabla F_{2}, \nabla F_{1}, \nabla F_{0}\) cinsinden (\(\beta\) ağırlıklı) ifadesini yaz. (Motor tanığı: \(z_{2} = \nabla F_{2} + \beta\nabla F_{1} + \beta^{2}\nabla F_{0}\), özyineleme = açık form, maxdiff \(\sim 10^{-15}\).)
Optimal β. \(M = 1\), \(m = 0.04\) (\(\kappa = 25\)) için \(\beta_{\text{opt}} = ((\sqrt{M}-\sqrt{m})/(\sqrt{M}+\sqrt{m}))^{2}\)’yi hesapla. (\(\sqrt{m} = 0.2\).) \(\beta\) yaklaşık kaç? Tipik derin öğrenme değeri \(0.9\) ile karşılaştır. (Motor tanığı: \(\beta_{\text{opt}} = (0.8/1.2)^{2} = 4/9 = 0.4444\); pratik sabit \(0.9\)’dan farklı, optimal \(\kappa\)’ya bağlı.)
β = 0 sınırı. Momentum formülünde \(\beta = 0\) alırsan ne olur? Yakınsama oranı \((\sqrt{M}-\sqrt{m})/(\sqrt{M}+\sqrt{m})\) hangi ifadeye döner? (İpucu: \(\beta = 0\) momentum’u kapatır, iz birebir GD’ye döner, maxdiff \(0\); oran \((1-b)/(1+b)\)’ye iner.)
(Ders 24 habercisi) Şimdiye kadar kısıtsız (veya basit kısıtlı) minimizasyon gördük. Peki amaç ve kısıtların hepsi doğrusalsa? Bir doğrusal hedefi doğrusal eşitsizlik kısıtları altında optimize etmek — köşelerde çözüm? Bir tahmin yaz — Ders 24 “lineer programlama ve iki-kişilik oyunlar” ile bu özel ama çok önemli sınıfı işliyor.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(9, 3.8))
# Sol: Egz2 — beta=0.7; z2 = grad F2 + beta grad F1 + beta^2 grad F0
beta = 0.7
weights = [1.0, beta, beta**2] # [1, 0.7, 0.49]
axL.bar([1, 2, 3], weights, color=COL_PRIMARY)
axL.set_xticks([1, 2, 3])
axL.set_xticklabels(["grad F2 (1)", "grad F1 (beta)", "grad F0 (beta^2)"], fontsize=8)
axL.set_ylabel("agirlik")
axL.set_title("Egz2: z2 acilim agirliklari (beta = 0.7)", fontsize=10, fontweight="bold")
mdiff = momentum_expansion_check(beta)
axL.annotate("ozyineleme = acik form\n(maxdiff %.0e, momentum_expansion_check)" % mdiff,
xy=(2, 0.7), xytext=(2.0, 0.86), fontsize=7.5, color=COL_TEXT,
ha="center")
apply_style(axL)
# Sag: Egz3 — beta_opt(m) egrisi, M=1
ms = np.linspace(0.005, 0.5, 200)
betas = [optimal_params(m, 1.0)[1] for m in ms]
axR.plot(ms, betas, color=COL_PRIMARY, lw=2.0)
# m=0.04 noktasi: kappa=25 -> 4/9=0.4444
m_star = 0.04
b_star = optimal_params(m_star, 1.0)[1]
axR.plot([m_star], [b_star], marker="*", ms=15, color=COL_VEC3, linestyle="None", zorder=5)
axR.annotate("m=0.04 (kappa=25)\nbeta_opt = 4/9 = %.4f" % b_star,
xy=(m_star, b_star), xytext=(0.11, 0.50), fontsize=7.5, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.2))
axR.axhline(0.9, color=COL_STEEL_300, ls="--", lw=1.2)
axR.text(0.30, 0.915, "DL tipik beta = 0.9", fontsize=8, color=COL_TEXT)
axR.set_xlabel("m (= 1/kondisyon, M=1)")
axR.set_ylabel("optimal beta")
axR.set_title("Egz3: optimal beta kondisyona bagli", fontsize=10, fontweight="bold")
apply_style(axR)
fig.suptitle("Egzersiz taniklari: z_k gecmisin geometrik toplami; optimal beta kondisyona bagli (kappa=25 -> 4/9)",
fontsize=10, fontweight="bold", color=COL_TEXT)
plt.show()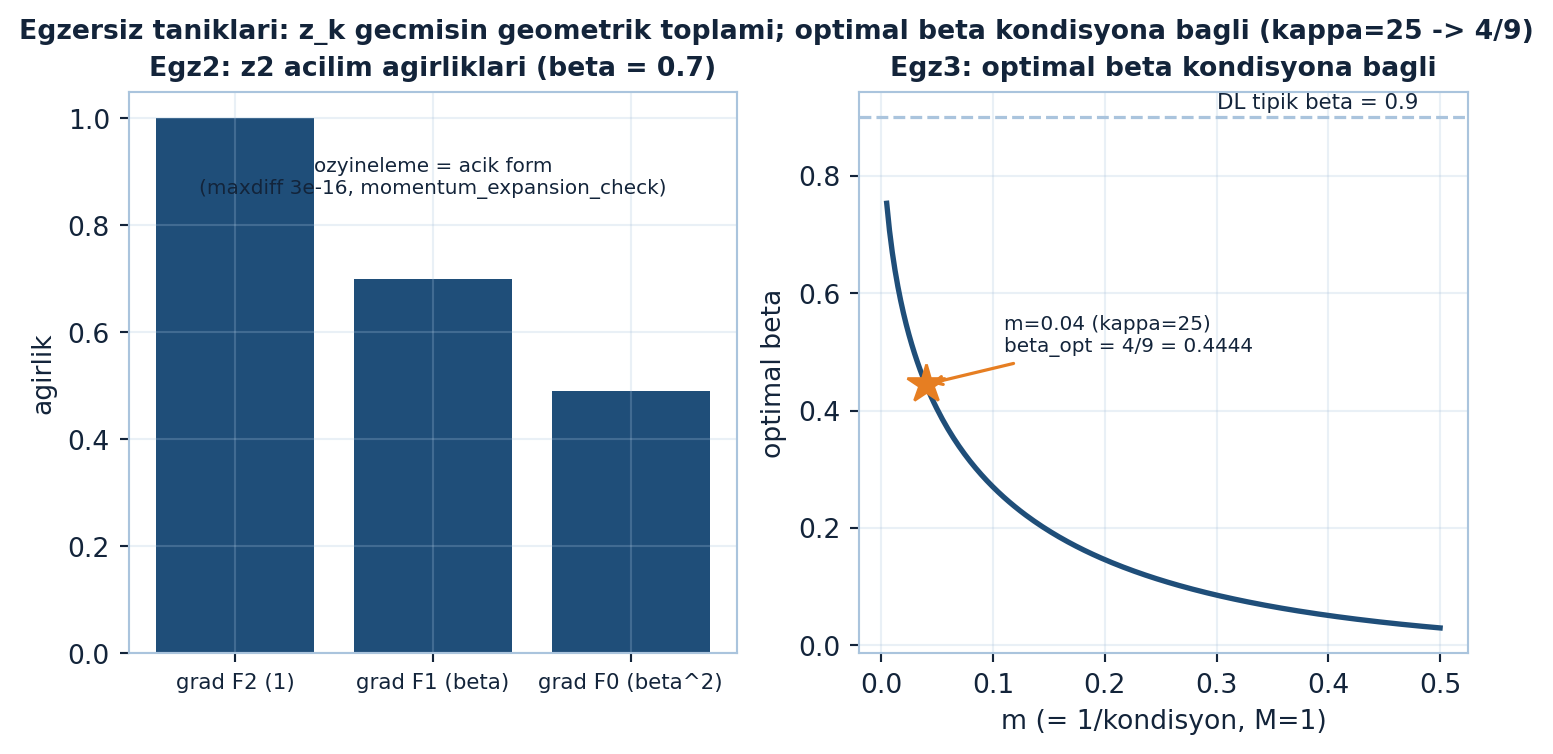
momentum_expansion_check); sağ: optimal \(\beta(m)\) eğrisi kondisyona bağlıdır — \(m=0.04\) (\(\kappa=25\)) noktasında \(\beta_{\text{opt}}=4/9=0.4444\) (turuncu yıldız), DL pratiğinin sabit \(\beta=0.9\)’undan farklı.
Şekil 24.7 iki egzersizi sayısal olarak doğrular: solda Egz2’nin açılım ağırlıkları \([1, \beta, \beta^{2}] = [1, 0.7, 0.49]\) özyinelemenin açık formla birebir eşleştiğini gösterir (maxdiff \(\sim 10^{-16}\)); sağda optimal \(\beta(m)\) eğrisi kondisyona bağlıdır — \(m = 0.04\) (\(\kappa = 25\)) noktasında \(\beta_{\text{opt}} = 4/9 = 0.4444\) (turuncu yıldız), DL pratiğinin sabit \(\beta = 0.9\)’undan farklı.
24.13 Sonraki Ders İçin Hazırlık
Ders 24: Lineer Programlama ve İki-Kişilik Oyunlar. Optimizasyonun özel ama merkezî sınıfı: doğrusal hedef + doğrusal kısıtlar. Çözüm bir köşededir (simplex yöntemi köşeden köşeye yürür). Dualite (primal-dual), ve iki-kişilik sıfır-toplamlı oyunların minimax dengesi (Ders 19 maxmin bağı) — von Neumann’ın minimax teoremi.
UyarıHazırlık
Bu dersteki Şekil 24.3 sol panelindeki süzülen momentum yörüngesini zihninde tut: kısıtsız bir kuadratiği gradyanla (artı hafıza) minimize ettik ve oran \(\sqrt{\kappa}\)’ya indi. Ders 24 ise tamamen farklı bir geometriye geçer: hedef ve kısıtların hepsi doğrusalsa minimum içte değil bir köşede olur. Ders 19’un maxmin (Courant-Fischer) fikrini hatırla — iki-kişilik oyunların minimax dengesi oraya bağlanacak.
24.14 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Strang (dk) |
|---|---|---|
| Zikzak (momentumsuz) | oran \((1-b)/(1+b) \approx 1\), yavaş | 2m09 |
| Momentum | \(z = \nabla F + \beta z_{-1}\); \(x_{+} = x - s z\) | 2m09 |
| √b mucizesi | \((1-b)/(1+b) \to (1-\sqrt{b})/(1+\sqrt{b})\) | 10m56 |
| Özvektör analizi | her \(\lambda \to 2\times 2\) \(R\); max özdeğeri minimize et | 9m36 |
| Optimal s, β | \(s = (2/(\sqrt{M}+\sqrt{m}))^{2}\), \(\beta = ((\sqrt{M}-\sqrt{m})/(\sqrt{M}+\sqrt{m}))^{2}\) | 37m00 |
| Kondisyon √κ | \(\kappa \to \sqrt{\kappa}\); adım sayısı \(\sim\sqrt{\kappa}\) | 30m50 |
| Nesterov | look-ahead: \(x_{+} = y - s\nabla F(y)\) | 42m08 |
| AdaGrad / Adam | tüm geçmişi üstel-ağırlıkla biriktir | 41m36 |
24.15 ML Bağlantıları Özeti
- SGD + momentum = standart: derin öğrenmede neredeyse her optimizer momentum kullanır (\(\beta \approx 0.9\)); zikzağı söndürür, yakınsamayı \(\sqrt{\kappa}\)’ya hızlandırır.
- Adam = momentum + adaptif: 1. moment (momentum, geçmiş gradyan) + 2. moment (RMSProp, geçmiş gradyan-kare); koordinat-başı learning rate; Transformer’ların varsayılanı.
- Nesterov (NAG): look-ahead gradyan; birinci-derece yöntemlerin optimal yakınsama hızı (PyTorch
nesterov=True). - Fizik sezgisi: momentum = yokuş aşağı yuvarlanan top, hız biriktirir; salınımlar söner, ivme birikir.
- √κ teorisi: momentum efektif kondisyonu kareköke indirir; batch norm \(\kappa\)’yı küçültür — ikisi birlikte derin ağ eğitimini mümkün kılar.
- Köşegenleştirme gücü: özvektör başına \(2\times 2\) analiz (Ders 4); Adam’ın koordinat-başı adımının teorik kökeni.
- Geriye köprü: Ders 22 (zikzak, kondisyon, oran), Ders 4 (özvektör/köşegenleştirme), Ders 10 (kondisyon sayısı \(\kappa\)), Ders 5 (pozitif tanımlı \(S\)).
ÖnemliKapanış
“…changes to 1 minus square root of b over 1 plus square root of b.” — Strang, 10:56
Momentum tek bir hafıza terimiyle kondisyon sayısını kareköküne indirir; bu küçük ekleme, gradient descent’i pratik bir algoritmadan derin öğrenmeyi mümkün kılan bir araca dönüştürür.