flowchart TD
C["SON DERS: Edelman - AD + Julia"]
C --> B1["acilis: 3x0 bos matris<br/>(rank-0 kenar-durumsuz,<br/>gecerli deger)"]
C --> B2["Julia + Swift: ML icin<br/>yeterince guclu iki dil"]
C --> B3["forward-mode AD = UCUNCU sey<br/>(ne sembolik ne sayisal):<br/>dual sayilar (deger, turev)"]
C --> B4["Babylonian sqrt + dual:<br/>turev kod degismeden"]
C --> B5["reverse-mode = backprop =<br/>(I-L)^-1 alt-ucgen cozum<br/>(backslash yeter)"]
C --> B6["BES TANIK: Karpathy + fast.ai<br/>+ NYU + Strang D27 + Edelman<br/>= reverse-mode AD"]
K1["D27 dort-tanik"]
K2["D21 Newton/Babylonian"]
K3["JAX jvp/vjp + PyTorch autograd"]
K4["KAPANIS: linear algebra<br/>is the secret to everything"]
K2 --> B4
K1 --> B6
B5 --> K3
B6 --> K4
classDef merkez fill:#1f4e79,stroke:#13243a,stroke-width:2px,color:#ffffff;
classDef dal fill:#2e75b6,stroke:#1f4e79,stroke-width:1.5px,color:#ffffff;
classDef vec fill:#ff8c42,stroke:#c25a16,stroke-width:1.5px,color:#1f2330;
classDef teal fill:#2ca6a4,stroke:#1f6f6e,stroke-width:1.5px,color:#ffffff;
class C merkez;
class B1,B2,B3,B4,B5,B6 dal;
class K1,K2 vec;
class K3,K4 teal;
35 Alan Edelman ve Julia Dili — Son Ders
Otomatik türevin üçüncü yolu, dual sayılar ve backprop’un beşinci tanığı: alt-üçgen çözüm
NotBölüm bilgisi
Kursun son dersi ve konuk dersi: konuşmacı Prof. Alan Edelman (Julia dilinin yaratıcılarından), Strang ev sahibidir (yalnız kapanış vedasında konuşur). Edelman, backpropagation’a (Ders 27) Julia diliyle yeni ve temiz bir bakış sunar: otomatik türev (AD) ne sembolik ne sayısaldır; forward-mode’da dual sayılarla, reverse-mode’da \((I-L)^{-1}\) alt-üçgen çözümle çalışır. Konuk: Alan Edelman Ders 36 videosu (≈38 dk) ve OCW Lecture 36 temel alınmıştır. Okuma süresi ≈28 dk. Önkoşul Ders 27 (backprop = ters-mod AD, dört tanık) ve Ders 21 (Newton/Babylonian karekök). Bu ders Phase 2’nin “aynı yere giden yollar” izleğini backprop’un beşinci tanığıyla kapatır.
35.1 Bu Derste Ne Var?
Kursun son dersi — konuk Prof. Alan Edelman (Julia dilinin yaratıcılarından). Ana mesaj: otomatik türev (automatic differentiation, AD) makine öğrenmesinin iş atıdır ve lineer cebir her şeyin sırrıdır. Backprop’a Phase 2’nin beşinci bakışı burada.
Altı sonuç:
- Açılış jimnastiği: satır rankı = kolon rankı ispatı sıfır matriste de çalışır (3×0 boş matris kavramı).
- Julia neden? Google’ın blogu: ML için yeterince güçlü iki dil — Julia ve Swift (Python/Java/C++/Rust elendi). “Dil matematiksel anlamda önemlidir.”
- Forward-mode AD = üçüncü bir şey: ne sembolik türev (kalkülüs tablosu) ne sayısal türev (sonlu fark). Üçüncü bir şey: dual sayılar \(D = (\text{deger},\ \text{turev})\).
- Dual sayılar + 8 satır Julia: tip tanımı + toplam/bölme kuralı (operator overloading). Babylonian \(\sqrt{x}\) algoritmasını dual sayıya uygula — türev kod yeniden yazılmadan kendiliğinden çıkar.
- Reverse-mode AD = backprop = \((I-L)^{-1}\) üçgen çözüm: skaler sinir ağının türevini lineer cebire yaz → \(dx = (I-L)^{-1} D\,dP\). Backprop aslında bir alt-üçgen sistem çözümü; “backslash zaten yapar”.
- Beşinci tanık: Edelman’ın \((I-L)^{-1}\) bakışı, Ders 27’nin dört tanığına (Karpathy micrograd + fast.ai + NYU Jacobian + Strang matris-zinciri) eklenir.
Şekil 35.1 son dersin iskeletini gösterir: merkezde Edelman’ın AD + Julia dersi, etrafında altı dal. Açılış 3×0 boş matrisle (rank-0 kenar-durum değil, geçerli değer) başlar; Julia + Swift ML için yeterince güçlü iki dildir; forward-mode AD üçüncü bir şeydir (dual sayılar, değer-türev çifti); Babylonian karekök + dual sayı türevi kod değişmeden verir; reverse-mode = backprop = \((I-L)^{-1}\) alt-üçgen çözümdür; ve beş tanık (Karpathy + fast.ai + NYU + Strang D27 + Edelman) aynı reverse-mode AD’yi söyler. Köprü düğümleri dersi öncesine ve sonrasına bağlar: D27 dört-tanık, D21 Newton/Babylonian, JAX jvp/vjp + PyTorch autograd ve kursu kapatan motto — “linear algebra is the secret to everything”.
İpucuBuilder Notu — Son Sözü Konuk Söyler
- AD = üçüncü şey: dual sayılar otomatik türevin kalbi (forward-mode); PyTorch autograd / JAX bunun (çoğunlukla reverse-mode) endüstri hali. Sembolik değil (şişme yok), sayısal değil (h seçimi/yuvarlama yok).
- Backprop = üçgen çözüm: \((I-L)^{-1}\) geri-yerine-koyma (back-substitution) = backprop; lineer cebir “geri”yi zaten içerir, tekerleği yeniden icat etme.
- Julia: tip + multiple dispatch ile “kodu yeniden yazmadan” türev (sıfır-maliyet soyutlama); kısa assembler = hızlı kod.
- Geriye köprü: Ders 27 (backprop/reverse-mode AD — dört tanık), Ders 21 (Newton/Babylonian \(\sqrt{\ }\)), Ders 6 (SVD), Ders 5 (PSD). Paralel: Karpathy micrograd
backward(), fast.ai manuel backprop, NYU vJp.
Bu kursun son dersi bir konuk dersidir; Strang sınıfı Edelman’a bırakır ve yalnız sonda veda eder. Okurken her bölümün sahibinin Edelman olduğunu, Strang’ın yalnız ev sahibi olduğunu unutma. Asıl ödül §6-7’de: backprop aslında lineer cebirin zaten bildiği bir alt-üçgen çözümdür, ve bu Phase 2’nin dört tanığına eklenen beşinci bakıştır.
35.2 1. Açılış: Sıfır Matris ve Rank
Edelman derse Strang’ın 18.06’daki bir ispatıyla başlıyor: satır rankı = kolon rankı. Strang sınıftan çıktıktan sonra Edelman’ın aklına takılan soru: bu ispat sıfır matris için de işler mi?
“…would that work for the zero matrix?” — Edelman, 0:00
Bir matrisin lineer bağımsız kolonlarını ayrı bir matrise koyarsan: tam-rank 3×3 → 3×3; rank-2 → 3×2; rank-1 → 3×1; rank-0 (sıfır matris) → 3×0 boş matris. Sonra 3×0 çarpı 0×3 = 3×3 sıfır matrisi verir. İspat hiçbir özel kenar-durum gerektirmeden işler.
“…a 3 by 0 empty matrix. And that’s a concept that exists in MATLAB, and in Julia, and in Python…” — Edelman, 2:04
Kod
from matplotlib.patches import Rectangle
# Motor tanığı: 3×0 @ 0×3 = 3×3 sıfır, rank 0
Eshape, Z, zrank = empty_matrix_witness()
# rank-2 örnek matris
R = np.array([[1, 0, 1], [0, 1, 1], [1, 1, 2]], dtype=float)
fig, axes = plt.subplots(1, 3, figsize=(10.5, 3.4))
# --- Sol: rank-2 örnek matris heatmap ---
heatmap(axes[0], R, title="rank-2 -> 3x2 kolon matrisi", fmt="{:.0f}")
# --- Orta: boş matris temsili (eksen kapalı) ---
axm = axes[1]
axm.set_xlim(0, 1); axm.set_ylim(0, 1); axm.axis("off")
fx = 0.5; fw = 0.05; fy0 = 0.30; fh = 0.45
axm.add_patch(Rectangle((fx - fw / 2, fy0), fw, fh, fill=False,
edgecolor=COL_PRIMARY, linewidth=2.0))
for k in range(3):
yy = fy0 + fh * (k + 0.5) / 3.0
axm.plot([fx - fw / 2, fx + fw / 2], [yy, yy], color=COL_ACCENT, linewidth=1.4)
axm.text(0.5, 0.85, "3x0 BOS matris", ha="center", va="center",
color=COL_PRIMARY, fontsize=14, fontweight="bold")
axm.text(0.5, 0.16, "MATLAB/Julia/Python da gecerli kavram", ha="center", va="center",
color=COL_TEXT, fontsize=9)
# --- Sağ: sıfır matris heatmap (motordan Z) ---
heatmap(axes[2], Z, title="3x0 @ 0x3 = SIFIR (rank 0, motor)", fmt="{:.0f}")
fig.suptitle("Edelman acilisi: satir-rank = kolon-rank ispati sifir matriste de isler — bos matris kenar-durum degil, gecerli deger",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.93])
plt.show()
Şekil 35.2 Edelman’ın açılış jimnastiğini üç panelde gösterir. Solda rank-2 bir örnek matris: bağımsız kolonlarını ayrı bir matrise koyduğunda 3×2 bir kolon matrisi çıkar. Ortada asıl mesele — 3×0 boş matris: rank-0 (sıfır matris) durumunun temiz ifadesi, MATLAB/Julia/Python’da geçerli bir kavram. Sağda motor tanığı: bu 3×0 boş matrisi 0×3 ile çarpınca 3×3 sıfır matris çıkar, rank 0. Satır-rank = kolon-rank ispatı hiçbir özel kenar-durum gerektirmeden, sıfır matriste de işler — iyi bir tip sistemi sıfırı bir istisna değil, geçerli bir değer sayar.
İpucuBuilder Notu — Sıfırın da Hakkı Var
“Boş matris (3×0) = rank-0 durumunun temiz ifadesi” kenar-durum disiplinidir. ML köprüsü: boyut-tutarlı boş tensörler (PyTorch torch.empty(3,0)) batch/maskeleme kodunda kenar durumlarını özel-kılıf olmadan halleder — iyi bir tip sistemi sıfırı bir istisna değil, geçerli bir değer sayar.
35.3 2. Julia Neden Önemli?
Edelman’ın ilk tezi: dil matematiksel anlamda önemlidir — doğru dil, bir algoritmayı tahtadan koda çevirmekten fazlasını yapabilir.
“…the language matters in a mathematical sense.” — Edelman, 8:13
Kanıt olarak Google’ın blogunu gösteriyor: ML için yeterince güçlü dilleri eleye eleye — teknik yeterlilikte Python ve Java düşer; kullanılabilirlikte C++ ve Rust düşer — geriye Julia ve Swift kalır.
“…there really are two languages that are powerful enough to do machine learning…” — Edelman, 4:08
İkinci tezi (ve tüm kursun ruhu): lineer cebir her şeyin temelidir — “her ders lineer cebirle başlamalı”.
İpucuBuilder Notu — Dil Matematiği Taşır
“Doğru dil matematiği taşır” performans + ifade gücü argümanı. ML köprüsü: JAX (XLA derleme), Julia (LLVM + multiple dispatch), PyTorch 2.0 (torch.compile) hep “yüksek-seviye matematik + düşük-seviye hız” peşindedir. Edelman’ın asıl noktası: tip sistemi ve dispatch, türev/Jacobian gibi şeyleri kodu yeniden yazmadan verir — bu bir dil özelliğidir, eklenti kütüphane değil.
35.4 3. Forward-Mode AD: Üçüncü Bir Şey
Edelman’ın itirafı: yıllarca otomatik türevi önemsememiş — “kalkülüsü bilgisayara öğretmek” sanmış. Meğer AD üçüncü bir şeymiş — ne biri ne öteki:
“…automatic differentiation was neither the first nor the second thing… there’s actually a third thing.” — Edelman, 10:16
- Birinci (sembolik): kalkülüs tablosu (zincir/çarpım/bölüm kuralı), 18.01’in sembolik türevi. Şişer — devasa ifadeler, büyük katsayılar.
- İkinci (sayısal): sonlu fark, dy/dx ≈ (f(x+h)−f(x))/h. h çok büyükse kesme (truncation) hatası, çok küçükse yuvarlama (round-off) hatası; “iyi h”yi kimse söylemez.
- Üçüncü (AD): ne sembolik ne sayısal. Her adımda toplam/bölüm kuralını sayısal değerlerle uygular — sembolik şişme yok, h seçimi yok.
Kod
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
# ---- Sol: SEMBOLIK — ifade siser ----
axS = axes[0]
axS.axis("off")
axS.text(0.5, 0.96, "f(x) = x(x+1)(x+2)", ha="center", va="top",
fontsize=12, fontweight="bold", color=COL_TEXT, transform=axS.transAxes)
axS.text(0.5, 0.84, "f'(x) = 3x² + 6x + 2", ha="center", va="top",
fontsize=11, color=COL_PRIMARY, transform=axS.transAxes)
patlama = (
"Carpim zinciri buyudukce terim patlar:\n"
"g = x(x+1)(x+2)(x+3)(x+4)\n"
"g' = (x+1)(x+2)(x+3)(x+4)\n"
" + x(x+2)(x+3)(x+4)\n"
" + x(x+1)(x+3)(x+4)\n"
" + x(x+1)(x+2)(x+4)\n"
" + x(x+1)(x+2)(x+3)\n"
"... her carpan yeni bir uzun terim"
)
axS.text(0.5, 0.66, patlama, ha="center", va="top",
fontsize=7.5, color=COL_TEXT, family="monospace", transform=axS.transAxes)
axS.text(0.5, 0.07, "ifade SISER", ha="center", va="bottom",
fontsize=12, fontweight="bold", color=COL_VEC3, transform=axS.transAxes,
bbox=dict(boxstyle="round,pad=0.3", fc=COL_WHITE, ec=COL_VEC3, lw=1.5))
axS.set_title("1) sembolik (18.01)", color=COL_TEXT, fontsize=12, fontweight="bold")
# ---- Orta: SAYISAL — sonlu fark hatasi ----
axN = axes[1]
hs = np.logspace(-12, -1, 200)
err = np.abs(((2 + hs)**3 - (2 - hs)**3) / (2 * hs) - 12)
axN.loglog(hs, err, color=COL_PRIMARY, lw=2)
imin = int(np.argmin(err))
axN.plot(hs[imin], err[imin], "o", color=COL_VEC3, ms=9, zorder=5)
axN.annotate("buyuk h: kesme hatasi;\nkucuk h: yuvarlama —\niyi h yi kimse soylemez",
xy=(hs[imin], err[imin]), xytext=(0.05, 0.74), textcoords="axes fraction",
fontsize=8, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.4))
axN.set_xlabel("h"); axN.set_ylabel("hata")
axN.set_title("2) sonlu fark", color=COL_TEXT, fontsize=12, fontweight="bold")
apply_style(axN)
# ---- Sag: AD akisi — ucuncu sey ----
axA = axes[2]
axA.axis("off")
kutular = [
"(deger, turev) cifti",
"toplam kurali",
"carpim/bolum kurali",
"MAKINE HASSASIYETINDE turev",
]
n = len(kutular)
ys = np.linspace(0.86, 0.12, n)
for k, (txt, yk) in enumerate(zip(kutular, ys)):
son = (k == n - 1)
ec = COL_VEC3 if son else COL_PRIMARY
fc = COL_WHITE if not son else "#fdebd8"
lw = 2.2 if son else 1.6
axA.text(0.5, yk, txt, ha="center", va="center",
fontsize=9.5, fontweight="bold",
color=(COL_VEC3 if son else COL_PRIMARY),
transform=axA.transAxes,
bbox=dict(boxstyle="round,pad=0.4", fc=fc, ec=ec, lw=lw))
if k < n - 1:
ar_col = COL_VEC3 if (k == n - 2) else COL_PRIMARY
axA.annotate("", xy=(0.5, ys[k + 1] + 0.055), xytext=(0.5, yk - 0.055),
xycoords="axes fraction", textcoords="axes fraction",
arrowprops=dict(arrowstyle="-|>", color=ar_col, lw=2.0))
axA.set_title("3) AD: ucuncu sey", color=COL_TEXT, fontsize=12, fontweight="bold")
fig.suptitle("Uc yol: sembolik siser, sayisal h ye mahkum, AD ucuncu sey — kurallari SAYISAL degerlerle uygular (Edelman 10:16)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.92])
plt.show()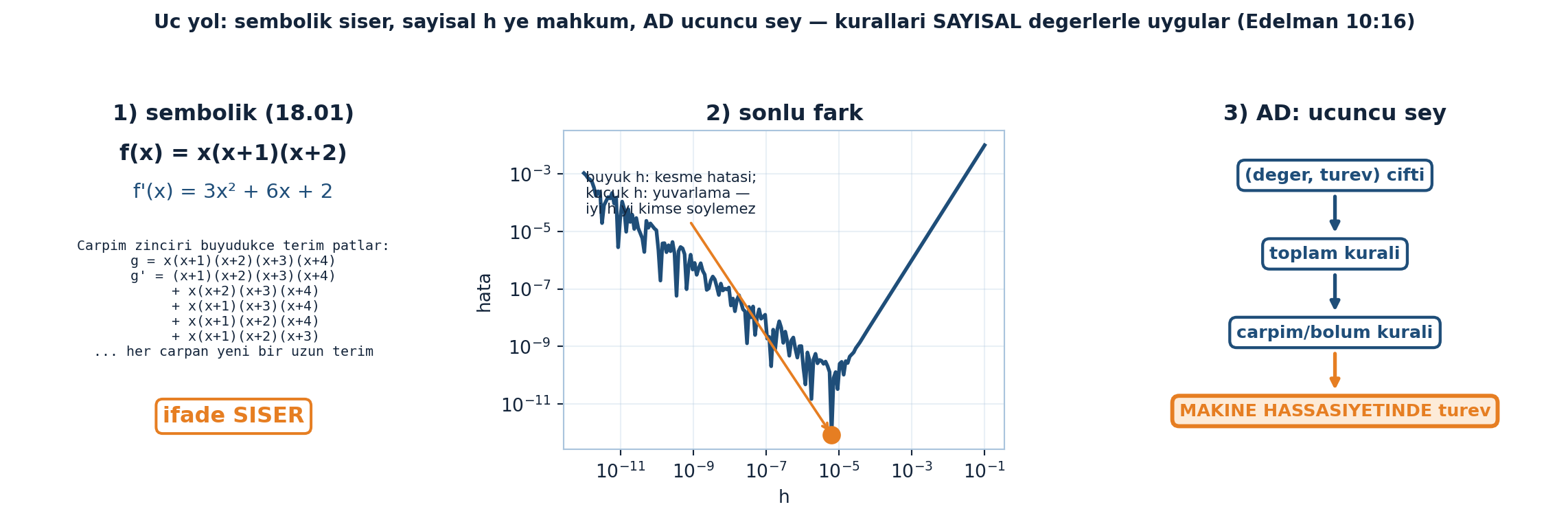
Şekil 35.3 türev almanın üç yolunu yan yana koyar. Solda sembolik (18.01): \(f(x)=x(x+1)(x+2)\) türevi küçük çarpanlarda temiz görünür, ama çarpım zinciri büyüdükçe her çarpan yeni bir uzun terim doğurur — “ifade SİŞER”. Ortada sayısal (sonlu fark): \(x^3\)’ün türev hatasının h’ye göre loglog eğrisi U biçimlidir; büyük h’de kesme, küçük h’de yuvarlama hatası baskındır, en iyi h’yi kimse önceden söyleyemez. Sağda AD = üçüncü şey: (değer, türev) çiftiyle başlayıp toplam, çarpım/bölüm kurallarını sayısal değerlerle uygulayarak makine hassasiyetinde türev verir — ne sembolik şişme ne h seçimi.
İpucuBuilder Notu — Ne Sembolik Ne Sayısal
“AD = üçüncü yol (ne sembolik ne sonlu-fark)” derin öğrenmenin temelini anlamanın anahtarı. ML köprüsü: bu, “neden PyTorch/JAX sonlu fark kullanmaz” sorusunun cevabı — AD makine hassasiyetinde tam türev verir (sonlu farkın yaklaşıklık hatası yok) ve sembolik patlama olmadan. Edelman: ML = büyük bir optimizasyon = türev al; AD bu işin iş atı.
35.5 4. Dual Sayılar: 8 Satır Julia
Nasıl? Dual sayılar ile. Bir dual sayı, bir (değer, türev) çiftidir — bir asır öncesine giden bir kavram:
\[D = (f,\ f')\]
8 satır Julia: 3 satır D tipini tanımlar (bir çift float; “sayı” gibi davranır), 5 satır toplam kuralı ile bölüm kuralını operatör aşırı-yüklemeyle (operator overloading) öğretir:
\[(f, f') + (g, g') = (f+g,\ f'+g')\]
\[\frac{(f, f')}{(g, g')} = \left(\frac{f}{g},\ \frac{g f' - f g'}{g^2}\right)\]
Şimdi sihir: Babylonian karekök algoritmasını (Newton: \(t_{k+1} = \tfrac12(t_k + x/t_k)\)) dual sayıya uygula. Kodu hiç değiştirmeden türev kendiliğinden çıkar:
“…I’m getting magically the right answer without ever [typing the derivative].” — Edelman, 18:21
Hiç \(\tfrac12 x^{-1/2}\) yazmadı, hiç sonlu fark almadı — yine de \(\sqrt{x}\)’in türevini (\(\tfrac12/\sqrt{x}\)) tam buldu. Bu sonucu (Şekil 35.4) bir sonraki bölümde işin nasıl yürüdüğünü gösterdikten sonra göreceğiz.
İpucuBuilder Notu — Sekiz Satırlık Sihir
“Dual sayı = (değer, türev) çifti + operatör aşırı-yükleme” forward-mode AD’nin tüm sırrı. ML köprüsü: bu, JAX’in jvp (Jacobian-vektör çarpımı) ve forward-mode autodiff’inin çekirdeği; ileri geçişte her sayının yanında türevini taşırsın. ε²=0 olan ikili sayı cebiriyle (a+bε) aynı: bir f fonksiyonu için f(a+bε) = f(a) + b·f’(a)·ε. Kodu yeniden yazmadan türev — bilgisayar cebiri zarafeti.
35.6 5. Forward-Mode Nasıl Çalışır?
Sihir nasıl oluyor? Kodun her satırının türevini al. Babylonian algoritmasının her satırının x’e göre türevini yazsan (toplam/bölüm kuralıyla), bu türev algoritması — yalnız +, −, ×, ÷ kullanarak — gerçek türeve yakınsar:
“…if you just take the derivatives back to your variable of every line of your code, then you can get a derivative out.” — Edelman, 22:27
Bu ne sembolik (18.01) ne sayısaldır (sonlu fark) — her adımda kuralları sayısal değerlerle uygular. Elle yazmak yerine: dual sayı tipi + operatör aşırı-yükleme, derleyicinin (Julia’nın) bunu otomatik yapmasını sağlar. Eski Fortran’da kaynak-kaynak çevirici (source-to-source) vardı; Julia’da tip + dispatch yeter.
“…you just give the rules and you let the computer do it.” — Edelman, 24:29
Bonus: dual sayıda Babylonian’ın assembler’ı kısadır = hızlı kod (Python’da “ekranlar dolusu” olurdu).
Kod
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11, 4.4))
# --- SOL: deger VE turev hatalarinin yakinsamasi ---
ks = range(1, 9)
vals = [babylonian(Dual(2., 1.), iters=k) for k in ks]
verr = [abs(v.f - np.sqrt(2)) for v in vals]
derr = [abs(v.fp - 1 / (2 * np.sqrt(2))) for v in vals]
ax_l.semilogy(list(ks), np.maximum(verr, 1e-17), color=COL_PRIMARY, marker="o",
label="deger hatasi |t - sqrt(2)|")
ax_l.semilogy(list(ks), np.maximum(derr, 1e-17), color=COL_VEC3, marker="s",
label="turev hatasi |t-prime - 1/(2 sqrt 2))|")
ax_l.set_xlabel("Babylonian iterasyonu")
ax_l.set_title("deger VE turev birlikte yakinsar", color=COL_TEXT, fontsize=12, fontweight="bold")
ax_l.legend(fontsize=9)
apply_style(ax_l)
# --- SAG: sonuc karti ---
ax_r.axis("off")
ax_r.text(0.5, 0.86, "babylonian(Dual(2, 1))", ha="center", va="center",
fontsize=15, fontweight="bold", color=COL_TEXT)
ax_r.text(0.5, 0.72, "= (1.414213562373, 0.353553390593)", ha="center", va="center",
fontsize=13, color=COL_PRIMARY, fontweight="bold")
ax_r.text(0.5, 0.55, "sqrt(2) dogru", ha="center", va="center", fontsize=12, color=COL_TEXT)
ax_r.text(0.5, 0.46, "1/(2 sqrt(2)) dogru", ha="center", va="center", fontsize=12, color=COL_TEXT)
ax_r.text(0.5, 0.26, "KOD DEGISMEDI — yalniz girdi tipi Dual oldu\n(operator asiri-yukleme)",
ha="center", va="center", fontsize=11, color=COL_VEC3, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.5", facecolor="#fdf0e6", edgecolor=COL_VEC3, linewidth=1.6))
ax_r.text(0.5, 0.07, "x=100 -> (10, 0.05) birebir", ha="center", va="center",
fontsize=9, color=COL_TEXT, style="italic")
fig.suptitle("Edelman in sihri: Babylonian sqrt algoritmasini dual sayiyla calistir — "
"turev kendiliginden cikar (motor 1e-12 birebir)",
fontsize=11.5, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.94])
plt.show()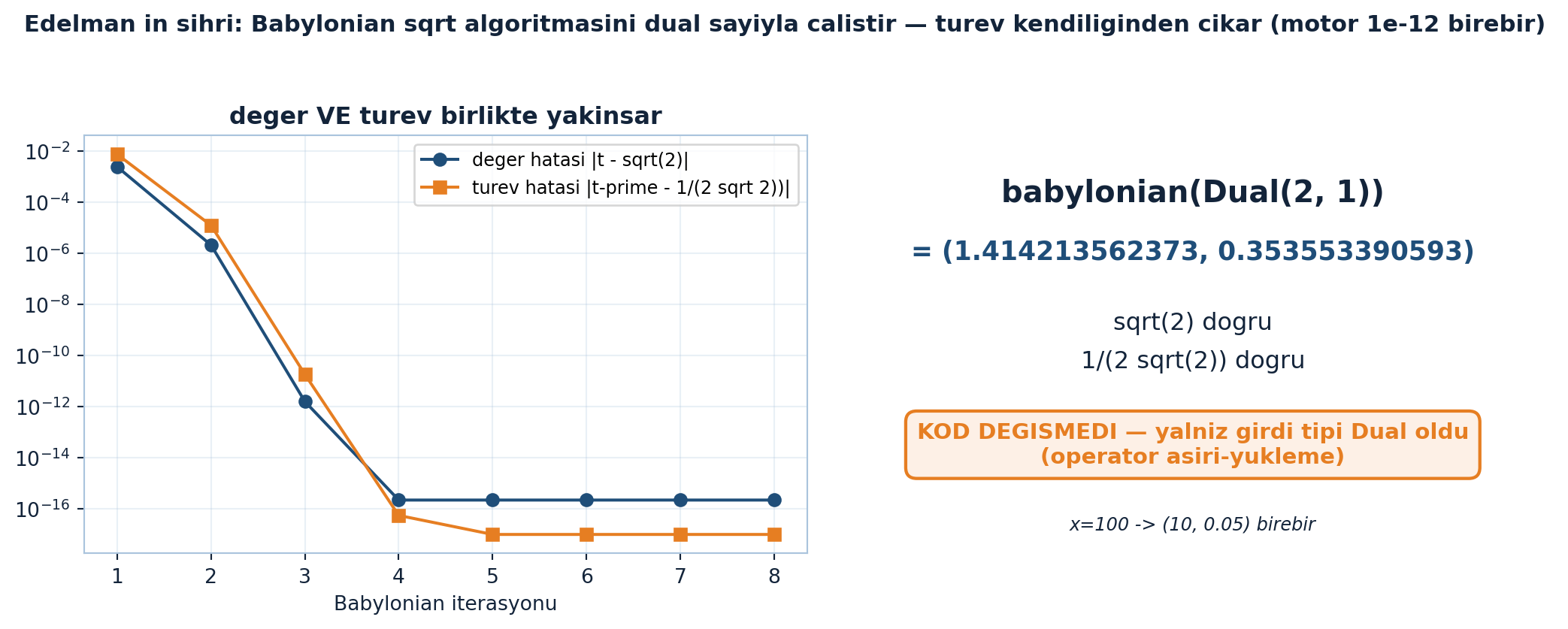
Dual olunca aynı kod hem √2 = 1.414213562373 hem türev 1/(2√2) = 0.353553390593 üretir — algoritma satırı hiç değişmedi.
Şekil 35.4 bu dersin flagship sonucudur: Babylonian karekök algoritmasını dual sayıyla çalıştırınca türev kendiliğinden çıkar. Solda değer hatası (navy daire) ve türev hatası (turuncu kare) iterasyon arttıkça birlikte makine hassasiyetine düşer — yani algoritma hem \(\sqrt{x}\)’e hem türevine aynı anda yakınsar. Sağda sonuç kartı: babylonian(Dual(2, 1)) çağrısı \((1.414213562373,\ 0.353553390593)\) verir — ilk bileşen \(\sqrt{2}\), ikinci bileşen \(1/(2\sqrt{2})\), ikisi de doğru. Anahtar nokta turuncu kutuda: KOD DEĞİŞMEDİ — yalnız girdi tipi Dual oldu (operatör aşırı-yükleme). \(x=100\) girdisi de aynı kodla \((10, 0.05)\) verir (motor 1e-12 birebir); algoritma satırına hiç dokunulmadı, yalnız sayının tipi değişti.
İpucuBuilder Notu — Her Satırın Türevini Taşı
“Forward-mode = her satırın türevini taşı, derleyici otomatikleştir” sıfır-maliyet soyutlamanın gösterisi. ML köprüsü: forward-mode AD, az girdi–çok çıktı (veya Jacobian-vektör çarpımı) durumunda verimlidir; çok-girdi (milyonlarca ağırlık, tek skaler kayıp) durumunda reverse-mode (backprop) tercih edilir — sıradaki bölüm. JAX ikisini de verir (jvp / vjp).
35.7 6. Reverse-Mode AD = Backprop = (I−L)⁻¹ Üçgen Çözüm
Edelman’ın final mücevheri: sinir ağı backprop’unun lineer-cebir özü. Skaler bir ağ düşün: ağırlık/bias \(w_i\), \(b_i\) ve
\[x_{i+1} = h(w_i x_i + b_i), \qquad h = \text{ReLU} = \max(0, t)\]
sonunda kayıp \(\tfrac12(y - x_m)^2\). Anahtar satırın türevini al; \(\delta_i = h'(w_i x_i + b_i)\) olsun:
\[dx_{i+1} = \delta_i\,(x_i\, dw_i + w_i\, dx_i + db_i)\]
Tüm bu perturbasyonları lineer cebir olarak yaz. Sonuç: bir köşegen matris (D), bir alt-üçgen matris (L) ile
\[dx = D\,dP + L\,dx \;\Longrightarrow\; (I - L)\,dx = D\,dP \;\Longrightarrow\; dx = (I - L)^{-1} D\,dP\]
“…you don’t need to do your own backpropagation. Because a simple backslash will do it for you.” — Edelman, 36:34
İşte can alıcı nokta: (I−L) alt-üçgendir; onu çözmek = geri-yerine-koyma (back-substitution) = tam olarak backprop. Lineer cebir “geri çözüm”ü zaten içerir; kendi backprop’unu elle yazmana gerek yok — bir \ (backslash) yeter. Yalnız son elemanın türevini istiyorsan \(e_n\) vektörüyle çekersin.
Kod
# === FLAGSHIP-2 (Bölüm 6): Backprop = (I-L)^-1 D dP alt-üçgen çözüm ===
w, b, x0, y = make_chain()
L, Dm, xs, deltas = edelman_LD(w, b, x0)
g_e = grad_edelman(w, b, x0, y)
g_b = grad_backprop(w, b, x0, y)
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
# --- Sol: heatmap I - L (kesin-alt-üçgen) ---
heatmap(axes[0], np.eye(4) - L, title="I - L: kesin-alt-üçgen", cmap=DIVERGE, fmt="{:.2f}")
# --- Orta: zincir şeması (eksen kapalı) ---
axc = axes[1]; axc.axis("off"); axc.set_xlim(0, 10); axc.set_ylim(0, 10)
boxes = [
(0.6, "x0"),
(2.0, "[w0,b0]\nReLU"),
(3.4, "x1"),
(4.4, "[w1,b1]\nReLU"),
(5.4, "x2"),
(6.4, "[w2,b2]\nReLU"),
(7.4, "x3"),
(8.3, "[w3,b3]\nReLU"),
(9.2, "x4"),
]
yb = 6.4
for i, (cx, lbl) in enumerate(boxes):
is_param = lbl.startswith("[")
fc = COL_BG if not is_param else COL_STEEL_300
axc.text(cx, yb, lbl, ha="center", va="center", fontsize=7.5, color=COL_TEXT,
fontweight="bold", bbox=dict(boxstyle="round,pad=0.25", fc=fc, ec=COL_PRIMARY, lw=1.0))
# ileri navy oklar
for i in range(len(boxes) - 1):
x1c = boxes[i][0]; x2c = boxes[i + 1][0]
axc.annotate("", xy=(x2c - 0.35, yb), xytext=(x1c + 0.35, yb),
arrowprops=dict(arrowstyle="->", color=COL_PRIMARY, lw=1.4))
# kayıp kutusu
axc.text(9.2, 4.4, "kayıp\n½(y-x4)²", ha="center", va="center", fontsize=7.5, color=COL_WHITE,
fontweight="bold", bbox=dict(boxstyle="round,pad=0.3", fc=COL_PRIMARY, ec=COL_PRIMARY))
axc.annotate("", xy=(9.2, 5.2), xytext=(9.2, 5.9),
arrowprops=dict(arrowstyle="->", color=COL_PRIMARY, lw=1.4))
# altta TURUNCU geri-ok zinciri
yback = 2.4
for i in range(len(boxes) - 1, 0, -1):
x1c = boxes[i][0]; x2c = boxes[i - 1][0]
axc.annotate("", xy=(x2c + 0.30, yback), xytext=(x1c - 0.30, yback),
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.6))
axc.text(5.0, 1.2, "geri-yerine-koyma = backprop (backslash yeter)",
ha="center", va="center", fontsize=8.5, color=COL_VEC3, fontweight="bold")
axc.set_title("zincir: ileri (navy) / geri (turuncu)", color=COL_TEXT, fontsize=12, fontweight="bold")
# --- Sağ: bar — 8 parametre yan-yana ---
axr = axes[2]; apply_style(axr)
idx = np.arange(8)
axr.bar(idx - 0.2, g_e, width=0.4, color=COL_PRIMARY, label="Edelman (I-L)^-1")
axr.bar(idx + 0.2, g_b, width=0.4, color=COL_VEC3, label="elle backprop")
axr.set_xticks(idx)
axr.set_xticklabels(["w0", "b0", "w1", "b1", "w2", "b2", "w3", "b3"], fontsize=9)
axr.set_ylabel("∂C/∂parametre")
axr.set_title("8 parametre gradyanı", color=COL_TEXT, fontsize=12, fontweight="bold")
axr.legend(fontsize=8, loc="best")
maxdiff = float(np.max(np.abs(g_e - g_b)))
axr.annotate("maxdiff 1.1e-16 — AYNI gradyan", xy=(0.5, 0.93), xycoords="axes fraction",
ha="center", va="top", fontsize=8.5, color=COL_TEXT, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_ACCENT, lw=1.0))
fig.suptitle("Backprop = (I-L)^-1 D dP alt-üçgen çözümü — nilpotent: (I-L)^-1 = I+L+L^2+L^3 TAM (defect 2.2e-16)",
fontsize=11, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()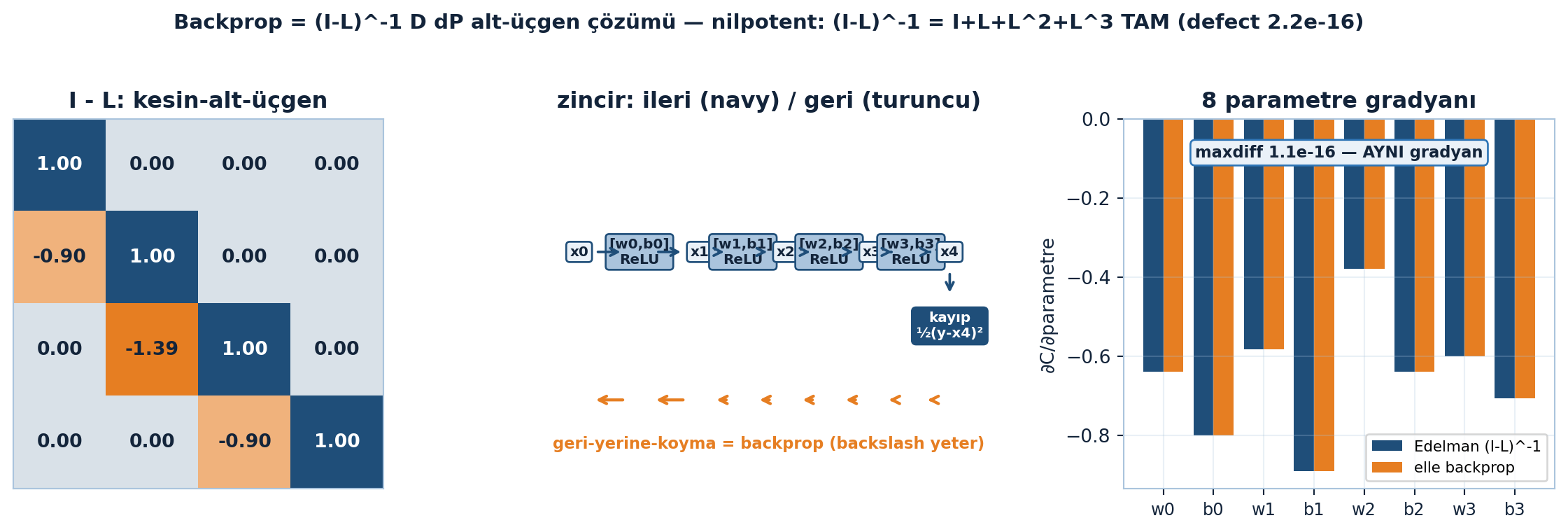
Şekil 35.5 dersin ikinci flagship’i: backprop’un \((I-L)^{-1} D\,dP\) alt-üçgen çözümü olduğunu üç panelde gösterir. Solda \(I-L\) matrisi (4×4 heatmap, diverging renk) kesin-alt-üçgendir — köşegen 1, köşegen-altında katman bağımlılığı, üst üçgen sıfır; çünkü katman \(i\)’nin türevi yalnız önceki katmanlara bağlıdır. Ortada zincir şeması: \(x_0 \to [w_0,b_0]\text{ReLU} \to x_1 \to \dots \to x_4 \to\) kayıp; navy oklar ileri geçiş, alttaki turuncu oklar geri-yerine-koyma = backprop (backslash yeter). Sağda asıl tanık: Edelman’ın \((I-L)^{-1}\) çözümü (navy) ile elle backprop (turuncu) 8 parametrenin her birinde aynı gradyanı verir — maxdiff 1.1e-16, yani makine sıfırı. Nilpotent köşesi: \(L^4 = 0\) olduğundan \((I-L)^{-1} = I + L + L^2 + L^3\) tam olur (defect 2.2e-16, Egz4).
İpucuBuilder Notu — Backprop Dediğin Üçgen Çözüm
“Backprop = (I−L)⁻¹ alt-üçgen çözüm” Edelman’ın devrimci yeniden-çerçevelemesi. ML köprüsü: zincir kuralının ardışık (katman katman) yapısı tam bir alt-üçgen bağımlılıktır; ileri geçiş L’yi kurar, geri geçiş \((I-L)^{-1}\)’i back-substitution ile çözer. PyTorch/JAX’in reverse-mode autograd’ı tam bu üçgen çözümün otomatik halidir — Ders 27’nin matris-zinciri görüşünün en saf ifadesi.
35.8 7. Beşinci Tanık: Backprop’a Beş Bakış
Ders 27’de Phase 2’nin “aynı yere giden yollar” tezini kurmuştuk: backpropagation = reverse-mode otomatik türev, dört farklı kursta dört farklı dille anlatıldı. Edelman bugün beşinci bakışı ekliyor:
| # | Tanık / Kurs | Backprop’a bakış |
|---|---|---|
| 1 | Karpathy — Zero-to-Hero | micrograd: hesap grafiğinde geri yayılım; her düğüm yerel gradyanı zincirler |
| 2 | fast.ai — Howard | elle backprop: zincir kuralını katman katman tek tek yaz |
| 3 | NYU — LeCun | Jacobian / vektör-Jacobian çarpımı (vJp) |
| 4 | Strang — 18.065 Ders 27 | matris-zinciri kuralı: reverse mode (soldan çarpım) daha ucuz |
| 5 | Edelman — 18.065 Ders 36 | backprop = (I−L)⁻¹ alt-üçgen sistem çözümü (back-substitution) |
Beşi de aynı matematiği söyler: reverse-mode AD. Beş bakış birlikte, “tek bir gerçeğin beş dili” — Phase 2’nin bütün omurgası.
Kod
w, b, x0, y = make_chain()
g_b = grad_backprop(w, b, x0, y)
g_d = grad_dual_forward(w, b, x0, y)
g_e = grad_edelman(w, b, x0, y)
xs = np.arange(8)
xlabels = ["w0", "b0", "w1", "b1", "w2", "b2", "w3", "b3"]
ymax = max(np.max(np.abs(g_b)), np.max(np.abs(g_e))) * 1.25
ymin = min(np.min(g_b), np.min(g_e), 0.0) * 1.25
panels = [
("Karpathy: graf .backward", g_b, COL_PRIMARY, False),
("fast.ai: elle zincir", g_b, COL_PRIMARY, False),
("NYU: vJp", g_b, COL_PRIMARY, False),
("Strang: matris-zinciri (D27)", g_b, COL_PRIMARY, False),
("Edelman: (I-L)^-1", g_e, COL_VEC3, True),
]
fig, axes = plt.subplots(1, 5, figsize=(13.5, 3.6))
for ax, (title, g, col, hilite) in zip(axes, panels):
ax.bar(xs, g, color=col, width=0.7, edgecolor=COL_TEXT, linewidth=0.5)
apply_style(ax)
ax.set_ylim(ymin, ymax)
ax.set_xticks(xs); ax.set_xticklabels(xlabels, fontsize=7, rotation=90)
ax.axhline(0, color=COL_TEXT, linewidth=0.8)
ax.set_title(title, fontsize=10, fontweight="bold")
if hilite:
for sp in ax.spines.values():
sp.set_color(COL_VEC3); sp.set_linewidth(2.5)
fig.text(0.41, -0.04,
"ilk dort tanigin VEKTOR-ag kaniti D27 de (6/6 cift <= 4.4e-16); burada skaler-zincir ozleri (delta-zinciri)",
ha="center", va="top", fontsize=8, color=COL_TEXT)
fig.suptitle("BES TANIK AYNI GRADYAN: Karpathy + fast.ai + NYU + Strang (D27) + Edelman ucgen-cozum "
"(maxdiff 1.1e-16, dual-forward TAM 0.0) — tek gercek: reverse-mode AD",
fontsize=11, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0.02, 1, 0.96])
plt.show()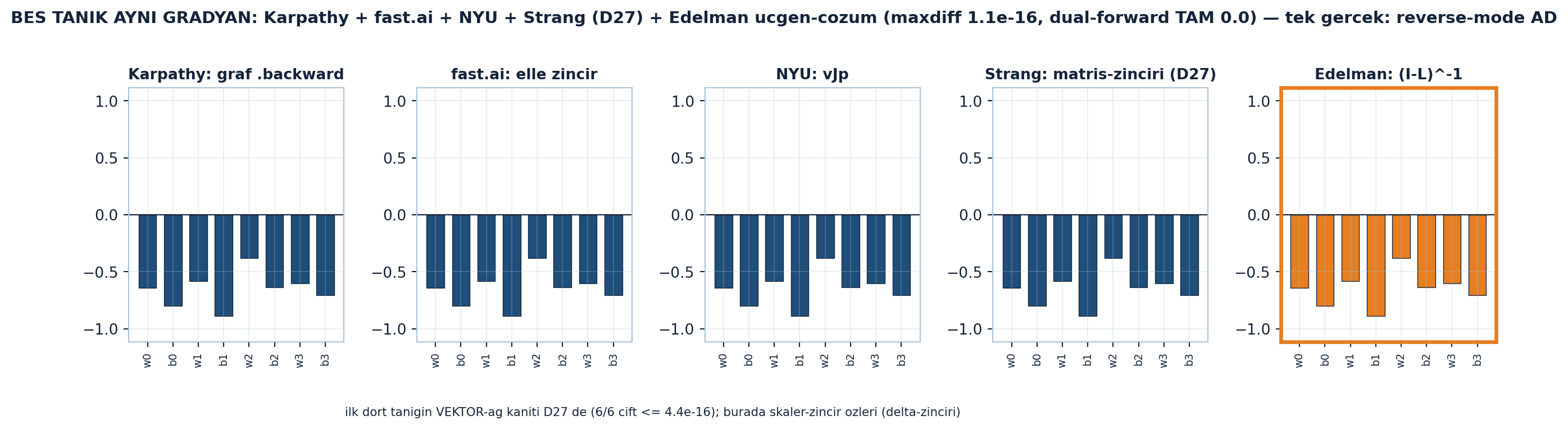
Şekil 35.6 kursun sentez flagship’i: beş tanığın aynı 8-parametreli gradyanı, aynı ölçekte beş panel. Karpathy (graf .backward), fast.ai (elle zincir), NYU (vJp) ve Strang (matris-zinciri, D27) — bu dördü skaler özde aynı \(\delta\)-zincirini hesaplar (panel başlıkları her birinin pedagojisini taşır); beşinci panel, turuncu çerçeveyle vurgulanan Edelman: \((I-L)^{-1}\). Beş bar grafiği üst üste konsa fark görünmez: Edelman üçgen-çözümü = elle backprop maxdiff 1.1e-16, dual-forward ile TAM 0.0. Dürüstlük notu altta: ilk dört tanığın vektör-ağ kanıtı Ders 27’de verildi (6/6 çift ≤ 4.4e-16); burada gösterilen skaler-zincir özleridir. Beş dil, tek gerçek: reverse-mode AD.
İpucuBuilder Notu — Beş Dil Tek Gerçek
“Beş tanık, tek gerçek: reverse-mode AD” Phase 2’nin sentez anıdır. ML köprüsü: bir kavramı beş farklı çerçeveden görmek (hesap grafiği, elle zincir, Jacobian, matris-zinciri, üçgen çözüm) onu “ezber” olmaktan çıkarıp “anlaşılmış” kılar — Karpathy’nin “kendin inşa et” felsefesinin özü. Edelman’ın katkısı belki en derini: backprop yeni bir algoritma değil, lineer cebirin zaten bildiği bir alt-üçgen çözümdür.
Şekil 35.7 ise maliyet dersini kapatır (Egz3): m=4 katmanlı skaler ağda forward-mode dual türev her parametre için ayrı geçiş ister (2m=8 geçiş, turuncu), reverse-mode tek geri geçişle yeter (navy). Sağda parametre sayısı n büyüdükçe forward maliyeti n ile doğrusal artar, reverse ~sabit kalır — milyon ağırlık + tek kayıpta backprop tek seçenektir (Ders 27’nin 1000× tanığının genel hali).
Kod
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(10, 4.2))
# Sol: bar [forward 8, reverse 1]
vals = [8, 1]
bars = ax0.bar([0, 1], vals, color=[COL_VEC3, COL_PRIMARY], width=0.6)
ax0.set_xticks([0, 1])
ax0.set_xticklabels(["forward-mode: 2m = 8 geçiş", "reverse-mode: 1 geri geçiş"], fontsize=9)
for bar, v in zip(bars, vals):
ax0.text(bar.get_x() + bar.get_width() / 2, v + 0.15, str(v),
ha="center", va="bottom", fontsize=12, fontweight="bold", color=COL_TEXT)
ax0.set_title("m=4 katman, 8 parametre", fontsize=12, fontweight="bold")
ax0.set_ylim(0, 9)
apply_style(ax0)
# Sağ: loglog forward vs reverse
ns = np.logspace(1, 6, 50)
ax1.loglog(ns, ns, color=COL_VEC3, lw=2, label="forward: n geçiş")
ax1.loglog(ns, np.ones_like(ns) * 4, color=COL_PRIMARY, lw=2, label="reverse: ~sabit (tek geri geçiş)")
ax1.legend(loc="upper left", fontsize=9)
ax1.annotate("milyon ağırlık + tek kayıp -> backprop tek seçenek\n(D27 1000x tanığının genel hali)",
xy=(1e5, 1e5), xytext=(20, 3e3), fontsize=8, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_VEC3, lw=1.2))
ax1.set_xlabel("parametre sayısı n")
apply_style(ax1)
fig.suptitle("Egz3: az girdi-çok çıktı -> forward; çok girdi-tek kayıp -> reverse. Derin öğrenme bu yüzden backprop",
fontsize=11, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()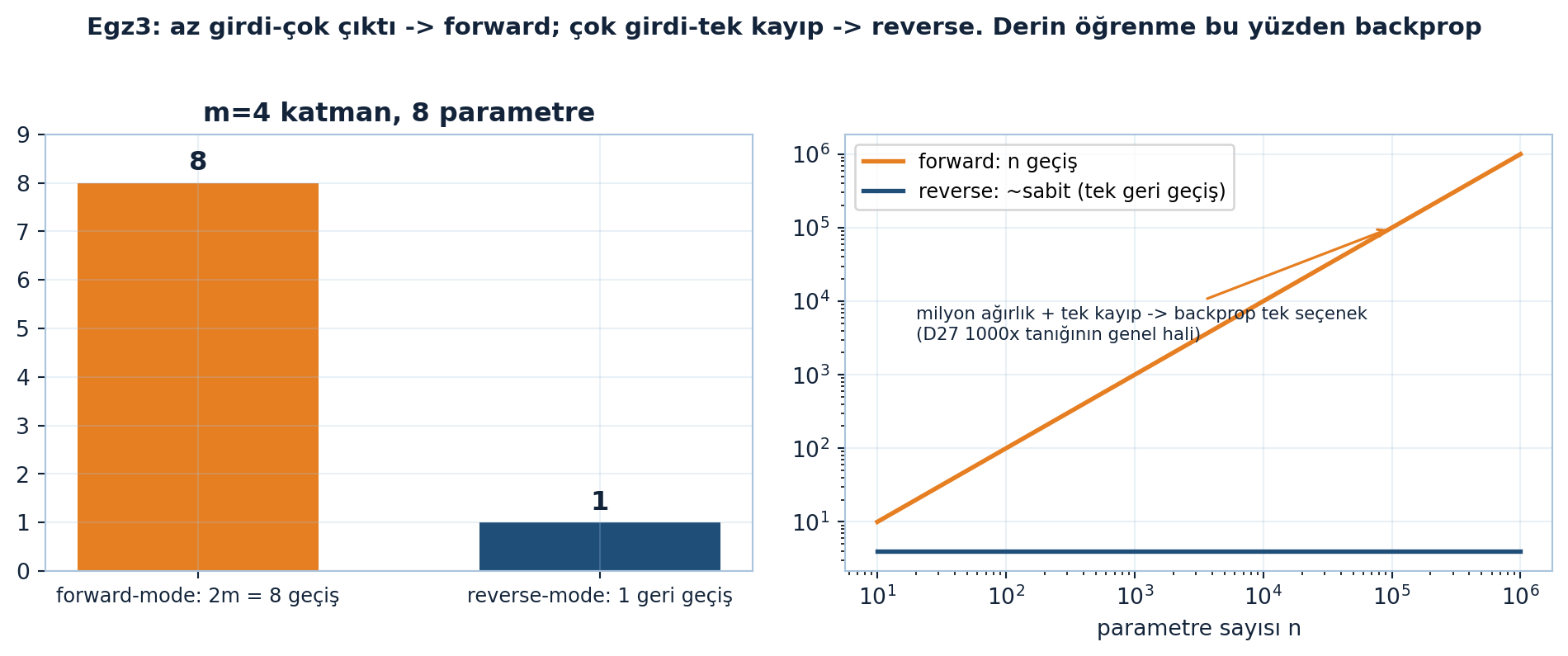
35.9 Bu Dersin Özeti
- Açılış: rank (satır=kolon) ispatı sıfır matriste de işler (3×0 boş matris).
- Julia: ML için iki güçlü dil (Julia + Swift); “dil matematiksel olarak önemli”; lineer cebir her şeyin temeli.
- Forward-mode AD: üçüncü şey (ne sembolik ne sayısal); dual sayılar D=(değer, türev), 8 satır Julia, türev kod yeniden yazılmadan çıkar.
- Reverse-mode AD = backprop: skaler ağ → \(dx=(I-L)^{-1}D\cdot dP\); backprop = alt-üçgen çözüm (back-substitution), “backslash zaten yapar”.
- Beşinci tanık: Edelman’ın \((I-L)^{-1}\) bakışı + Karpathy / fast.ai / NYU / Strang = backprop’a beş bakış, tek gerçek (reverse-mode AD).
- Kapanış mottosu: “linear algebra is the secret to everything.”
ÖnemliTek Bir Cümle
Otomatik türev ne sembolik ne sayısaldır — forward-mode’da dual sayılarla, reverse-mode’da \((I-L)^{-1}\) alt-üçgen çözümle (= backprop) türevi kod yeniden yazılmadan üretir; ve Edelman’ın bu üçgen-çözüm bakışı, Karpathy / fast.ai / NYU / Strang’ın yanında backprop’a beşinci tanıktır — hepsinin söylediği tek gerçek: reverse-mode AD.
35.10 Kontrol Soruları
NotSoru 1 — Otomatik türev neden ’üçüncü bir şey’dir; sembolik ve sayısaldan farkı ne
Sembolik türev (kalkülüs tablosu, 18.01) ifadeleri devasa büyütür (şişme). Sayısal türev (sonlu fark (f(x+h)−f(x))/h) h seçimine duyarlıdır — büyük h kesme hatası, küçük h yuvarlama hatası. AD ise üçüncü bir şeydir: her temel işlemde toplam/çarpım/bölüm kuralını sayısal değerlerle uygular. Sonuç makine hassasiyetinde tam türevdir — ne sembolik şişme ne de h kaynaklı yaklaşıklık hatası vardır.
NotSoru 2 — Dual sayı nedir; √ türevi nasıl kod yeniden yazılmadan elde edilir
Dual sayı bir (değer, türev) çiftidir: D=(f, f′). Operatörleri aşırı-yükleyerek (toplam: bileşen-bileşen; bölüm: (f/g, (gf′−fg′)/g²)) bu çiftler sayı gibi davranır. Babylonian karekök algoritmasını sayılar yerine dual sayılarla çalıştırınca, her işlem değeri yanında türevini de taşır; algoritma sonunda (√x, ½/√x) çiftini verir. Kod hiç değişmedi — yalnız girdi tipi dual sayıya çevrildi.
NotSoru 3 — Edelman’a göre backprop neyle aynıdır; (I−L) neden alt-üçgendir
Backprop, \((I-L)^{-1} D\,dP\) ile aynıdır — yani alt-üçgen bir \((I-L)\) sisteminin geri-yerine-koyma (back-substitution) çözümü. \(L\) alt-üçgendir çünkü ağdaki katman bağımlılığı ardışıktır: katman i’nin türevi yalnız önceki katmanlara bağlıdır (ileriye değil). Bu yüzden “geri çözüm” lineer cebirde zaten vardır; ayrı bir backprop kodu yazmaya gerek yoktur (bir backslash yeter).
NotSoru 4 — ‘Beş tanık’ hangileridir; ortak gerçek nedir
- Karpathy micrograd (hesap grafiğinde .backward()), (2) fast.ai elle backprop (zincir kuralı katman katman), (3) NYU Jacobian / vektör-Jacobian çarpımı, (4) Strang matris-zinciri kuralı (Ders 27), (5) Edelman \((I-L)^{-1}\) alt-üçgen çözümü (Ders 36). Beşinin de söylediği tek gerçek: reverse-mode otomatik türev. Aynı matematik, beş farklı dil.
35.11 Egzersizler
- Dual sayı aritmetiği. D=(değer, türev). (a) (3, 1) + (2, 5) toplamını bul. (b) (3, 1) · (2, 5) çarpımını, çarpım kuralı (fg, f′g + fg′) ile hesapla. (Burada (3,1), x=3 noktasında f=x, f′=1 anlamına gelir.) (Motor tanığı: toplam \((3,1)+(2,5)=\textbf{(5,6)}\); çarpım \((3,1)\cdot(2,5)=\textbf{(6,17)}\) (1·2+3·5=17); bölüm \((3,1)/(2,5)=\textbf{(1.5,\,−3.25)}\).)
- Dual ile türev. f(x)=x² fonksiyonunu dual sayıyla hesapla: girdi (3, 1) (yani x=3, dx=1). Çarpım kuralıyla x·x dual çarpımını yap; sonucun (9, 6) çıktığını ve 6 = 2x|ₓ₌₃ olduğunu doğrula. (Motor tanığı: \((3,1)\cdot(3,1)=\textbf{(9,6)}\); \(6 = 2x|_{x=3}\) ✓.)
- Forward vs reverse maliyeti. n girdili, tek skaler çıktılı (kayıp) bir fonksiyon için: forward-mode AD kaç ileri geçiş gerektirir, reverse-mode kaç? Sinir ağı eğitiminde (milyonlarca ağırlık, tek kayıp) neden reverse-mode (backprop) tercih edilir? (Motor tanığı: m=4 katmanda forward-mode dual 2m = 8 ayrı geçiş (her parametre için bir), reverse/backprop tek geri geçiş; milyon parametrede fark milyon kat — Ders 27’nin 1000× tanığının kardeşi.)
- (I−L)⁻¹ üçgen. 3-katmanlı bir zincirde L kesin-alt-üçgen 3×3 olsun. (I−L)’nin de alt-üçgen olduğunu ve (I−L)⁻¹ x = b sisteminin geri-yerine-koymayla (back-substitution) O(n²) işlemde çözüldüğünü açıkla. Bu neden “backprop bedava” anlamına gelir? (Motor tanığı: kesin-alt-üçgen L nilpotenttir (L⁴=0); bu yüzden \((I-L)^{-1} = I + L + L^2 + L^3\) tam olur (defect 2.2e-16); elle üçgen-çözüm O(n²) = np.linalg.solve birebir.)
- (Kurs sentezi — kapanış) Phase 2 boyunca backprop’u beş kez gördün: Karpathy, fast.ai, NYU, Strang (D27), Edelman (D36). Hangi bakış sana en çok “tıkladı” ve neden beşi de aynı reverse-mode AD’yi anlatıyor? Kısa bir paragraf yaz — bu, kursun kapanış refleksiyonudur.
35.12 Kurs Kapanışı (Ders 36 = Son Ders)
Bu, MIT 18.065’in son dersi. Edelman’ın ve Strang’ın veda sözleri:
“…linear algebra is the secret to everything. That’s the big message.” — Edelman, 36:34
“…I hope you guys enjoyed it. I certainly enjoyed it, as you could tell.” — Strang, kapanış
34 kayıtlı ders (OCW Lec 28-29 kayıtsız lab) tamamlandı: kolon uzayından (Ders 1) backprop’un üçgen-çözüm bakışına (Ders 36); SVD, Eckart-Young, gradyan inişi, sinir ağları, sirkülant/Fourier, evrişim, graf Laplacian. Phase 2’nin altıncı kursu burada kapanır.
35.13 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Edelman (dk) |
|---|---|---|
| Sıfır matris / rank | rank-0 → 3×0 boş matris; ispat kenar-durumsuz işler | 0m00 |
| Julia (Edelman tezi) | ML için Julia + Swift; “dil matematiksel olarak önemli” | 4m08 |
| Forward-mode AD | üçüncü şey; ne sembolik ne sayısal | 10m16 |
| Dual sayılar | D=(değer, türev); 8 satır Julia, türev bedava | 14m19 |
| Reverse-mode / backprop | \(dx = (I-L)^{-1} D\cdot dP\); alt-üçgen çözüm | 34m33 |
| Kapanış | “linear algebra is the secret to everything” | 36m34 |
35.14 ML Bağlantıları Özeti
- Forward-mode AD / dual sayılar: JAX
jvp, ileri-mod autodiff; az girdi–çok çıktı durumunda verimli. - Reverse-mode AD = backprop: PyTorch/JAX autograd; çok girdi–tek kayıp; özü \((I-L)^{-1}\) alt-üçgen çözüm.
- Julia: multiple dispatch + tip = sıfır-maliyet türev; yüksek-seviye matematik + düşük-seviye hız.
- ML = optimizasyon = türev: AD bu işin iş atı; “ML aslında tek bir min/maks problemi”.
- Beşinci tanık: backprop’a beş bakış (Karpathy micrograd + fast.ai + NYU vJp + Strang matris-zinciri + Edelman \((I-L)^{-1}\)) = reverse-mode AD.
- Geriye köprü: Ders 27 (dört tanık), Ders 21 (Newton/Babylonian \(\sqrt{\ }\)), Ders 5-6 (PSD/SVD). Paralel: Karpathy micrograd, fast.ai manuel backprop, NYU vJp, JAX/PyTorch autograd.
ÖnemliKapanış
“…linear algebra is the secret to everything.” — Edelman, 36:34
18.065 burada kapanır: kolon uzayından (Ders 1) Eckart-Young’a, gradyan inişinden backprop’a, sirkülanttan graf Laplacian’ına — ve son sözde hepsi tek bir cümleye iner: lineer cebir her şeyin sırrı. Phase 2’nin altıncı kursu tamam; backprop’un beşinci tanığıyla “aynı yere giden yollar” izleği kapandı.